
title
stringlengths 2
169
| diff
stringlengths 235
19.5k
| body
stringlengths 0
30.5k
| url
stringlengths 48
84
| created_at
stringlengths 20
20
| closed_at
stringlengths 20
20
| merged_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| diff_len
float64 101
3.99k
| repo_name
stringclasses 83
values | __index_level_0__
int64 15
52.7k
|
|---|---|---|---|---|---|---|---|---|---|---|
Added CodeLlama 70b model | diff --git a/g4f/models.py b/g4f/models.py
index e58ccef2ed..dd8e175d57 100644
--- a/g4f/models.py
+++ b/g4f/models.py
@@ -123,6 +123,12 @@ def __all__() -> list[str]:
best_provider = RetryProvider([HuggingChat, PerplexityLabs, DeepInfra])
)
+codellama_70b_instruct = Model(
+ name = "codellama/CodeLlama-70b-Instruct-hf",
+ base_provider = "huggingface",
+ best_provider = DeepInfra
+)
+
# Mistral
mixtral_8x7b = Model(
name = "mistralai/Mixtral-8x7B-Instruct-v0.1",
@@ -256,6 +262,7 @@ class ModelUtils:
'llama2-13b': llama2_13b,
'llama2-70b': llama2_70b,
'codellama-34b-instruct': codellama_34b_instruct,
+ 'codellama-70b-instruct': codellama_70b_instruct,
'mixtral-8x7b': mixtral_8x7b,
'mistral-7b': mistral_7b,
@@ -270,4 +277,4 @@ class ModelUtils:
'pi': pi
}
-_all_models = list(ModelUtils.convert.keys())
\ No newline at end of file
+_all_models = list(ModelUtils.convert.keys())
| https://api.github.com/repos/xtekky/gpt4free/pulls/1547 | 2024-02-04T18:51:10Z | 2024-02-05T13:47:24Z | 2024-02-05T13:47:24Z | 2024-02-14T01:28:01Z | 357 | xtekky/gpt4free | 38,171 |
|
Fixed #18110 -- Improve template cache tag documentation | diff --git a/docs/topics/cache.txt b/docs/topics/cache.txt
index 03afa86647632..d0bd9f699294d 100644
--- a/docs/topics/cache.txt
+++ b/docs/topics/cache.txt
@@ -595,7 +595,8 @@ the ``cache`` template tag. To give your template access to this tag, put
The ``{% cache %}`` template tag caches the contents of the block for a given
amount of time. It takes at least two arguments: the cache timeout, in seconds,
-and the name to give the cache fragment. For example:
+and the name to give the cache fragment. The name will be taken as is, do not
+use a variable. For example:
.. code-block:: html+django
| For me it was not clear that the fragment name cannot be a variable. I just found out by wondering about errors and having a quick look into Django's code. It should be made more clear that the second argument will not be resolved even though all the others will be (even the cache time gets resolved).
"It takes at least two arguments: the cache timeout, in seconds, and the name to give the cache fragment. For example:"
should at least be something like
"It takes at least two arguments: the cache timeout, in seconds, and the name to give the cache fragment. The name will be taken as is, do not use a variable. For example:"
https://docs.djangoproject.com/en/dev/topics/cache/#template-fragment-caching
https://code.djangoproject.com/ticket/18110
| https://api.github.com/repos/django/django/pulls/153 | 2012-06-14T14:43:06Z | 2012-08-04T19:50:42Z | 2012-08-04T19:50:42Z | 2014-06-26T08:30:28Z | 164 | django/django | 50,876 |
Fix TFDWConv() `c1 == c2` check | diff --git a/models/tf.py b/models/tf.py
index b70e3748800..3428032a0aa 100644
--- a/models/tf.py
+++ b/models/tf.py
@@ -88,10 +88,10 @@ def call(self, inputs):
class TFDWConv(keras.layers.Layer):
# Depthwise convolution
- def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ def __init__(self, c1, c2, k=1, s=1, p=None, act=True, w=None):
# ch_in, ch_out, weights, kernel, stride, padding, groups
super().__init__()
- assert g == c1 == c2, f'TFDWConv() groups={g} must equal input={c1} and output={c2} channels'
+ assert c1 == c2, f'TFDWConv() input={c1} must equal output={c2} channels'
conv = keras.layers.DepthwiseConv2D(
kernel_size=k,
strides=s,
|
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhancement of Depthwise Convolution Layer in TensorFlow Models.
### 📊 Key Changes
- Removed the `g` parameter (number of groups) from `TFDWConv` layer initializer arguments.
- Modified the assertion check to only require input channels (`c1`) to be equal to the output channels (`c2`), instead of also checking against the `g` parameter.
### 🎯 Purpose & Impact
- 🧹 Simplifies the initialization of the depthwise convolution layer by removing an unnecessary parameter.
- 🛠️ Ensures the integrity of the model by checking that the number of input channels matches the number of output channels, a requirement for depthwise convolution.
- 🔧 Reduces potential for configuration errors by removing the group check, which is not needed in depthwise convolutions as the input and output channels are naturally equal.
- 👩💻 Helps developers to work with a cleaner interface when utilizing the TFDWConv layer in their machine learning models, potentially increasing development productivity and model stability. | https://api.github.com/repos/ultralytics/yolov5/pulls/7842 | 2022-05-16T16:06:17Z | 2022-05-16T16:06:46Z | 2022-05-16T16:06:46Z | 2024-01-19T10:27:17Z | 254 | ultralytics/yolov5 | 25,521 |
Fix for #13740 | diff --git a/youtube_dl/extractor/mlb.py b/youtube_dl/extractor/mlb.py
index 59cd4b8389f..4d45f960eea 100644
--- a/youtube_dl/extractor/mlb.py
+++ b/youtube_dl/extractor/mlb.py
@@ -15,7 +15,7 @@ class MLBIE(InfoExtractor):
(?:[\da-z_-]+\.)*mlb\.com/
(?:
(?:
- (?:.*?/)?video/(?:topic/[\da-z_-]+/)?v|
+ (?:.*?/)?video/(?:topic/[\da-z_-]+/)?(?:v|.*?/c-)|
(?:
shared/video/embed/(?:embed|m-internal-embed)\.html|
(?:[^/]+/)+(?:play|index)\.jsp|
@@ -94,6 +94,10 @@ class MLBIE(InfoExtractor):
'upload_date': '20150415',
}
},
+ {
+ 'url': 'https://www.mlb.com/video/hargrove-homers-off-caldwell/c-1352023483?tid=67793694',
+ 'only_matching': True,
+ },
{
'url': 'http://m.mlb.com/shared/video/embed/embed.html?content_id=35692085&topic_id=6479266&width=400&height=224&property=mlb',
'only_matching': True,
| ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [adding new extractor tutorial](https://github.com/rg3/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/rg3/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
### In order to be accepted and merged into youtube-dl each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [ ] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Adjust `_VALID_URL` in mlb.py to fix #13740
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/13773 | 2017-07-29T23:32:08Z | 2017-08-04T15:46:55Z | 2017-08-04T15:46:55Z | 2017-08-04T15:46:55Z | 326 | ytdl-org/youtube-dl | 50,090 |
Create model card for spanbert-finetuned-squadv2 | diff --git a/model_cards/mrm8488/spanbert-finetuned-squadv2/README.md b/model_cards/mrm8488/spanbert-finetuned-squadv2/README.md
new file mode 100644
index 0000000000000..47a4cc42d8c89
--- /dev/null
+++ b/model_cards/mrm8488/spanbert-finetuned-squadv2/README.md
@@ -0,0 +1,86 @@
+---
+language: english
+thumbnail:
+---
+
+# SpanBERT (spanbert-base-cased) fine-tuned on SQuAD v2
+
+[SpanBERT](https://github.com/facebookresearch/SpanBERT) created by [Facebook Research](https://github.com/facebookresearch) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
+
+## Details of SpanBERT
+
+[SpanBERT: Improving Pre-training by Representing and Predicting Spans](https://arxiv.org/abs/1907.10529)
+
+## Details of the downstream task (Q&A) - Dataset
+
+[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
+
+| Dataset | Split | # samples |
+| -------- | ----- | --------- |
+| SQuAD2.0 | train | 130k |
+| SQuAD2.0 | eval | 12.3k |
+
+## Model training
+
+The model was trained on a Tesla P100 GPU and 25GB of RAM.
+The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py)
+
+## Results:
+
+| Metric | # Value |
+| ------ | --------- |
+| **EM** | **78.80** |
+| **F1** | **82.22** |
+
+### Raw metrics:
+
+```json
+{
+ "exact": 78.80064010780762,
+ "f1": 82.22801347271162,
+ "total": 11873,
+ "HasAns_exact": 78.74493927125506,
+ "HasAns_f1": 85.60951483831069,
+ "HasAns_total": 5928,
+ "NoAns_exact": 78.85618166526493,
+ "NoAns_f1": 78.85618166526493,
+ "NoAns_total": 5945,
+ "best_exact": 78.80064010780762,
+ "best_exact_thresh": 0.0,
+ "best_f1": 82.2280134727116,
+ "best_f1_thresh": 0.0
+}
+```
+
+## Comparison:
+
+| Model | EM | F1 score |
+| ----------------------------------------------------------------------------------------- | --------- | --------- |
+| [SpanBert official repo](https://github.com/facebookresearch/SpanBERT#pre-trained-models) | - | 83.6\* |
+| [spanbert-finetuned-squadv2](https://huggingface.co/mrm8488/spanbert-finetuned-squadv2) | **78.80** | **82.22** |
+
+## Model in action
+
+Fast usage with **pipelines**:
+
+```python
+from transformers import pipeline
+
+qa_pipeline = pipeline(
+ "question-answering",
+ model="mrm8488/spanbert-finetuned-squadv2",
+ tokenizer="mrm8488/spanbert-finetuned-squadv2"
+)
+
+qa_pipeline({
+ 'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
+ 'question': "Who has been working hard for hugginface/transformers lately?"
+
+})
+
+# Output: {'answer': 'Manuel Romero','end': 13,'score': 6.836378586818937e-09, 'start': 0}
+```
+
+> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
+
+> Made with <span style="color: #e25555;">♥</span> in Spain
| https://api.github.com/repos/huggingface/transformers/pulls/3293 | 2020-03-16T08:02:08Z | 2020-03-16T16:32:47Z | 2020-03-16T16:32:47Z | 2020-03-16T16:32:48Z | 1,044 | huggingface/transformers | 12,822 |
|
downloader.webclient: make reactor import local | diff --git a/scrapy/core/downloader/webclient.py b/scrapy/core/downloader/webclient.py
index 915cb5fe332..06cb9648978 100644
--- a/scrapy/core/downloader/webclient.py
+++ b/scrapy/core/downloader/webclient.py
@@ -3,7 +3,7 @@
from urllib.parse import urlparse, urlunparse, urldefrag
from twisted.web.http import HTTPClient
-from twisted.internet import defer, reactor
+from twisted.internet import defer
from twisted.internet.protocol import ClientFactory
from scrapy.http import Headers
@@ -170,6 +170,7 @@ def buildProtocol(self, addr):
p.followRedirect = self.followRedirect
p.afterFoundGet = self.afterFoundGet
if self.timeout:
+ from twisted.internet import reactor
timeoutCall = reactor.callLater(self.timeout, p.timeout)
self.deferred.addBoth(self._cancelTimeout, timeoutCall)
return p
| All reactor imports must be local not top level because twisted.internet.reactor import installs default reactor, and if you want to use non-default reactor like asyncio top level import will break things for you.
In my case I had a middleware imported in spider
in spider
```python
from project.middlewares.retry import CustomRetryMiddleware
```
this was importing
```
from scrapy.downloadermiddlewares import retry
```
then retry was importing
```
from scrapy.core.downloader.handlers.http11 import TunnelError
```
and http11 was importing
```
from scrapy.core.downloader.webclient import _parse
```
and webclient was importing and installing reactor. I wonder how this was not detected earlier? It should break things for people trying to be using asyncio reactor in more complex projects.
This import of reactor may be annoying for many projects because it is easy to forget and do import reactor somewhere in your scrapy middleware or somewhere else. Then you'll get an error when using asyncio, and some people will be confused they may not know where to look for source of the problem. | https://api.github.com/repos/scrapy/scrapy/pulls/5357 | 2021-12-30T12:15:31Z | 2021-12-31T10:57:12Z | 2021-12-31T10:57:12Z | 2021-12-31T10:57:26Z | 204 | scrapy/scrapy | 35,059 |
Update interpreter.py for a typo error | diff --git a/interpreter/interpreter.py b/interpreter/interpreter.py
index ea34fdf68..d7db07dbc 100644
--- a/interpreter/interpreter.py
+++ b/interpreter/interpreter.py
@@ -132,7 +132,7 @@ def cli(self):
def get_info_for_system_message(self):
"""
- Gets relevent information for the system message.
+ Gets relevant information for the system message.
"""
info = ""
| ### Describe the changes you have made:
I have fixed a typo error in interpreter.py file
### Reference any relevant issue (actually none for current PR)
None
- [x] I have performed a self-review of my code:
### I have tested the code on the following OS:
- [x] Windows
- [x] MacOS
- [x] Linux
| https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/397 | 2023-09-16T04:13:58Z | 2023-09-16T06:25:43Z | 2023-09-16T06:25:43Z | 2023-09-16T06:25:44Z | 102 | OpenInterpreter/open-interpreter | 40,810 |
Minor CF refactoring; enhance error logging for SSL cert errors | diff --git a/localstack/services/cloudformation/cloudformation_starter.py b/localstack/services/cloudformation/cloudformation_starter.py
index c4f8bfbbb21a9..cdadc7312c167 100644
--- a/localstack/services/cloudformation/cloudformation_starter.py
+++ b/localstack/services/cloudformation/cloudformation_starter.py
@@ -174,6 +174,14 @@ def update_physical_resource_id(resource):
LOG.warning('Unable to determine physical_resource_id for resource %s' % type(resource))
+def update_resource_name(resource, resource_json):
+ """ Some resources require minor fixes in their CF resource definition
+ before we can pass them on to deployment. """
+ props = resource_json['Properties'] = resource_json.get('Properties') or {}
+ if isinstance(resource, sfn_models.StateMachine) and not props.get('StateMachineName'):
+ props['StateMachineName'] = resource.name
+
+
def apply_patches():
""" Apply patches to make LocalStack seamlessly interact with the moto backend.
TODO: Eventually, these patches should be contributed to the upstream repo! """
@@ -354,13 +362,6 @@ def find_id(resource):
return resource
- def update_resource_name(resource, resource_json):
- """ Some resources require minor fixes in their CF resource definition
- before we can pass them on to deployment. """
- props = resource_json['Properties'] = resource_json.get('Properties') or {}
- if isinstance(resource, sfn_models.StateMachine) and not props.get('StateMachineName'):
- props['StateMachineName'] = resource.name
-
def update_resource_id(resource, new_id, props, region_name, stack_name, resource_map):
""" Update and fix the ID(s) of the given resource. """
diff --git a/localstack/utils/server/http2_server.py b/localstack/utils/server/http2_server.py
index 988ffe12299d6..60343a42b4555 100644
--- a/localstack/utils/server/http2_server.py
+++ b/localstack/utils/server/http2_server.py
@@ -1,5 +1,4 @@
import os
-import ssl
import asyncio
import logging
import traceback
@@ -113,13 +112,14 @@ def run_app_sync(*args, loop=None, shutdown_event=None):
try:
try:
return loop.run_until_complete(serve(app, config, **run_kwargs))
- except ssl.SSLError:
- c_exists = os.path.exists(cert_file_name)
- k_exists = os.path.exists(key_file_name)
- c_size = len(load_file(cert_file_name)) if c_exists else 0
- k_size = len(load_file(key_file_name)) if k_exists else 0
- LOG.warning('Unable to create SSL context. Cert files exist: %s %s (%sB), %s %s (%sB)' %
- (cert_file_name, c_exists, c_size, key_file_name, k_exists, k_size))
+ except Exception as e:
+ if 'SSLError' in str(e):
+ c_exists = os.path.exists(cert_file_name)
+ k_exists = os.path.exists(key_file_name)
+ c_size = len(load_file(cert_file_name)) if c_exists else 0
+ k_size = len(load_file(key_file_name)) if k_exists else 0
+ LOG.warning('Unable to create SSL context. Cert files exist: %s %s (%sB), %s %s (%sB)' %
+ (cert_file_name, c_exists, c_size, key_file_name, k_exists, k_size))
raise
finally:
try:
diff --git a/requirements.txt b/requirements.txt
index ced77277e46d4..3dae44630ef9f 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -41,7 +41,7 @@ pympler>=0.6
pyopenssl==17.5.0
python-coveralls>=2.9.1
pyyaml>=3.13,<=5.1
-quart>=0.12.0
+Quart>=0.12.0
requests>=2.20.0 #basic-lib
requests-aws4auth==0.9
sasl>=0.2.1
| Minor CF refactoring; enhance error logging for SSL cert errors | https://api.github.com/repos/localstack/localstack/pulls/2549 | 2020-06-11T23:05:17Z | 2020-06-11T23:47:14Z | 2020-06-11T23:47:14Z | 2020-06-11T23:47:20Z | 924 | localstack/localstack | 28,443 |
Contentview scripts | diff --git a/examples/custom_contentviews.py b/examples/custom_contentviews.py
new file mode 100644
index 0000000000..1a2bcb1e8d
--- /dev/null
+++ b/examples/custom_contentviews.py
@@ -0,0 +1,66 @@
+import string
+from libmproxy import script, flow, utils
+import libmproxy.contentviews as cv
+from netlib.http import Headers
+import lxml.html
+import lxml.etree
+
+
+class ViewPigLatin(cv.View):
+ name = "pig_latin_HTML"
+ prompt = ("pig latin HTML", "l")
+ content_types = ["text/html"]
+
+ def __call__(self, data, **metadata):
+ if utils.isXML(data):
+ parser = lxml.etree.HTMLParser(
+ strip_cdata=True,
+ remove_blank_text=True
+ )
+ d = lxml.html.fromstring(data, parser=parser)
+ docinfo = d.getroottree().docinfo
+
+ def piglify(src):
+ words = string.split(src)
+ ret = ''
+ for word in words:
+ idx = -1
+ while word[idx] in string.punctuation and (idx * -1) != len(word): idx -= 1
+ if word[0].lower() in 'aeiou':
+ if idx == -1: ret += word[0:] + "hay"
+ else: ret += word[0:len(word)+idx+1] + "hay" + word[idx+1:]
+ else:
+ if idx == -1: ret += word[1:] + word[0] + "ay"
+ else: ret += word[1:len(word)+idx+1] + word[0] + "ay" + word[idx+1:]
+ ret += ' '
+ return ret.strip()
+
+ def recurse(root):
+ if hasattr(root, 'text') and root.text:
+ root.text = piglify(root.text)
+ if hasattr(root, 'tail') and root.tail:
+ root.tail = piglify(root.tail)
+
+ if len(root):
+ for child in root:
+ recurse(child)
+
+ recurse(d)
+
+ s = lxml.etree.tostring(
+ d,
+ pretty_print=True,
+ doctype=docinfo.doctype
+ )
+ return "HTML", cv.format_text(s)
+
+
+pig_view = ViewPigLatin()
+
+
+def start(context, argv):
+ context.add_contentview(pig_view)
+
+
+def stop(context):
+ context.remove_contentview(pig_view)
diff --git a/libmproxy/contentviews.py b/libmproxy/contentviews.py
index 9af0803353..2f46cccafc 100644
--- a/libmproxy/contentviews.py
+++ b/libmproxy/contentviews.py
@@ -479,34 +479,9 @@ def __call__(self, data, **metadata):
return None
-views = [
- ViewAuto(),
- ViewRaw(),
- ViewHex(),
- ViewJSON(),
- ViewXML(),
- ViewWBXML(),
- ViewHTML(),
- ViewHTMLOutline(),
- ViewJavaScript(),
- ViewCSS(),
- ViewURLEncoded(),
- ViewMultipart(),
- ViewImage(),
-]
-if pyamf:
- views.append(ViewAMF())
-
-if ViewProtobuf.is_available():
- views.append(ViewProtobuf())
-
+views = []
content_types_map = {}
-for i in views:
- for ct in i.content_types:
- l = content_types_map.setdefault(ct, [])
- l.append(i)
-
-view_prompts = [i.prompt for i in views]
+view_prompts = []
def get_by_shortcut(c):
@@ -515,6 +490,58 @@ def get_by_shortcut(c):
return i
+def add(view):
+ # TODO: auto-select a different name (append an integer?)
+ for i in views:
+ if i.name == view.name:
+ raise ContentViewException("Duplicate view: " + view.name)
+
+ # TODO: the UI should auto-prompt for a replacement shortcut
+ for prompt in view_prompts:
+ if prompt[1] == view.prompt[1]:
+ raise ContentViewException("Duplicate view shortcut: " + view.prompt[1])
+
+ views.append(view)
+
+ for ct in view.content_types:
+ l = content_types_map.setdefault(ct, [])
+ l.append(view)
+
+ view_prompts.append(view.prompt)
+
+
+def remove(view):
+ for ct in view.content_types:
+ l = content_types_map.setdefault(ct, [])
+ l.remove(view)
+
+ if not len(l):
+ del content_types_map[ct]
+
+ view_prompts.remove(view.prompt)
+ views.remove(view)
+
+
+add(ViewAuto())
+add(ViewRaw())
+add(ViewHex())
+add(ViewJSON())
+add(ViewXML())
+add(ViewWBXML())
+add(ViewHTML())
+add(ViewHTMLOutline())
+add(ViewJavaScript())
+add(ViewCSS())
+add(ViewURLEncoded())
+add(ViewMultipart())
+add(ViewImage())
+
+if pyamf:
+ add(ViewAMF())
+
+if ViewProtobuf.is_available():
+ add(ViewProtobuf())
+
def get(name):
for i in views:
if i.name == name:
diff --git a/libmproxy/flow.py b/libmproxy/flow.py
index 55a4dbcfb3..3343e694f1 100644
--- a/libmproxy/flow.py
+++ b/libmproxy/flow.py
@@ -9,7 +9,7 @@
import os
import re
import urlparse
-
+import inspect
from netlib import wsgi
from netlib.exceptions import HttpException
@@ -21,6 +21,7 @@
from .protocol.http_replay import RequestReplayThread
from .protocol import Kill
from .models import ClientConnection, ServerConnection, HTTPResponse, HTTPFlow, HTTPRequest
+from . import contentviews as cv
class AppRegistry:
diff --git a/libmproxy/script.py b/libmproxy/script.py
index 9d051c129c..4da40c52f6 100644
--- a/libmproxy/script.py
+++ b/libmproxy/script.py
@@ -5,6 +5,8 @@
import shlex
import sys
+from . import contentviews as cv
+
class ScriptError(Exception):
pass
@@ -56,6 +58,12 @@ def replay_request(self, f):
def app_registry(self):
return self._master.apps
+ def add_contentview(self, view_obj):
+ cv.add(view_obj)
+
+ def remove_contentview(self, view_obj):
+ cv.remove(view_obj)
+
class Script:
"""
diff --git a/test/test_contentview.py b/test/test_contentview.py
index 9760852094..eba624a269 100644
--- a/test/test_contentview.py
+++ b/test/test_contentview.py
@@ -210,6 +210,21 @@ def test_get_content_view(self):
assert "decoded gzip" in r[0]
assert "Raw" in r[0]
+ def test_add_cv(self):
+ class TestContentView(cv.View):
+ name = "test"
+ prompt = ("t", "test")
+
+ tcv = TestContentView()
+ cv.add(tcv)
+
+ # repeated addition causes exception
+ tutils.raises(
+ ContentViewException,
+ cv.add,
+ tcv
+ )
+
if pyamf:
def test_view_amf_request():
diff --git a/test/test_custom_contentview.py b/test/test_custom_contentview.py
new file mode 100644
index 0000000000..4b5a3e53f6
--- /dev/null
+++ b/test/test_custom_contentview.py
@@ -0,0 +1,52 @@
+from libmproxy import script, flow
+import libmproxy.contentviews as cv
+from netlib.http import Headers
+
+
+def test_custom_views():
+ class ViewNoop(cv.View):
+ name = "noop"
+ prompt = ("noop", "n")
+ content_types = ["text/none"]
+
+ def __call__(self, data, **metadata):
+ return "noop", cv.format_text(data)
+
+
+ view_obj = ViewNoop()
+
+ cv.add(view_obj)
+
+ assert cv.get("noop")
+
+ r = cv.get_content_view(
+ cv.get("noop"),
+ "[1, 2, 3]",
+ headers=Headers(
+ content_type="text/plain"
+ )
+ )
+ assert "noop" in r[0]
+
+ # now try content-type matching
+ r = cv.get_content_view(
+ cv.get("Auto"),
+ "[1, 2, 3]",
+ headers=Headers(
+ content_type="text/none"
+ )
+ )
+ assert "noop" in r[0]
+
+ # now try removing the custom view
+ cv.remove(view_obj)
+ r = cv.get_content_view(
+ cv.get("Auto"),
+ "[1, 2, 3]",
+ headers=Headers(
+ content_type="text/none"
+ )
+ )
+ assert "noop" not in r[0]
+
+
diff --git a/test/test_script.py b/test/test_script.py
index 1b0e5a5b4c..8612d5f344 100644
--- a/test/test_script.py
+++ b/test/test_script.py
@@ -127,3 +127,4 @@ def test_command_parsing():
absfilepath = os.path.normcase(tutils.test_data.path("scripts/a.py"))
s = script.Script(absfilepath, fm)
assert os.path.isfile(s.args[0])
+
| Based on feedback from PR #832, simple custom content view support in scripts for mitmproxy/mitmdump.
| https://api.github.com/repos/mitmproxy/mitmproxy/pulls/833 | 2015-11-13T21:56:30Z | 2015-11-14T02:41:05Z | 2015-11-14T02:41:05Z | 2015-11-14T02:41:06Z | 2,213 | mitmproxy/mitmproxy | 27,422 |
PERF: add shortcut to Timestamp constructor | diff --git a/asv_bench/benchmarks/tslibs/timestamp.py b/asv_bench/benchmarks/tslibs/timestamp.py
index 8ebb2d8d2f35d..3ef9b814dd79e 100644
--- a/asv_bench/benchmarks/tslibs/timestamp.py
+++ b/asv_bench/benchmarks/tslibs/timestamp.py
@@ -1,12 +1,19 @@
import datetime
import dateutil
+import numpy as np
import pytz
from pandas import Timestamp
class TimestampConstruction:
+ def setup(self):
+ self.npdatetime64 = np.datetime64("2020-01-01 00:00:00")
+ self.dttime_unaware = datetime.datetime(2020, 1, 1, 0, 0, 0)
+ self.dttime_aware = datetime.datetime(2020, 1, 1, 0, 0, 0, 0, pytz.UTC)
+ self.ts = Timestamp("2020-01-01 00:00:00")
+
def time_parse_iso8601_no_tz(self):
Timestamp("2017-08-25 08:16:14")
@@ -28,6 +35,18 @@ def time_fromordinal(self):
def time_fromtimestamp(self):
Timestamp.fromtimestamp(1515448538)
+ def time_from_npdatetime64(self):
+ Timestamp(self.npdatetime64)
+
+ def time_from_datetime_unaware(self):
+ Timestamp(self.dttime_unaware)
+
+ def time_from_datetime_aware(self):
+ Timestamp(self.dttime_aware)
+
+ def time_from_pd_timestamp(self):
+ Timestamp(self.ts)
+
class TimestampProperties:
_tzs = [None, pytz.timezone("Europe/Amsterdam"), pytz.UTC, dateutil.tz.tzutc()]
diff --git a/doc/source/whatsnew/v1.1.0.rst b/doc/source/whatsnew/v1.1.0.rst
index d0cf92b60fe0d..a0e1c964dd365 100644
--- a/doc/source/whatsnew/v1.1.0.rst
+++ b/doc/source/whatsnew/v1.1.0.rst
@@ -109,7 +109,9 @@ Deprecations
Performance improvements
~~~~~~~~~~~~~~~~~~~~~~~~
+
- Performance improvement in :class:`Timedelta` constructor (:issue:`30543`)
+- Performance improvement in :class:`Timestamp` constructor (:issue:`30543`)
-
-
diff --git a/pandas/_libs/tslibs/timestamps.pyx b/pandas/_libs/tslibs/timestamps.pyx
index 36566b55e74ad..4915671aa6512 100644
--- a/pandas/_libs/tslibs/timestamps.pyx
+++ b/pandas/_libs/tslibs/timestamps.pyx
@@ -391,7 +391,18 @@ class Timestamp(_Timestamp):
# User passed tzinfo instead of tz; avoid silently ignoring
tz, tzinfo = tzinfo, None
- if isinstance(ts_input, str):
+ # GH 30543 if pd.Timestamp already passed, return it
+ # check that only ts_input is passed
+ # checking verbosely, because cython doesn't optimize
+ # list comprehensions (as of cython 0.29.x)
+ if (isinstance(ts_input, Timestamp) and freq is None and
+ tz is None and unit is None and year is None and
+ month is None and day is None and hour is None and
+ minute is None and second is None and
+ microsecond is None and nanosecond is None and
+ tzinfo is None):
+ return ts_input
+ elif isinstance(ts_input, str):
# User passed a date string to parse.
# Check that the user didn't also pass a date attribute kwarg.
if any(arg is not None for arg in _date_attributes):
diff --git a/pandas/tests/indexes/datetimes/test_constructors.py b/pandas/tests/indexes/datetimes/test_constructors.py
index b6013c3939793..68285d41bda70 100644
--- a/pandas/tests/indexes/datetimes/test_constructors.py
+++ b/pandas/tests/indexes/datetimes/test_constructors.py
@@ -957,3 +957,10 @@ def test_timedelta_constructor_identity():
expected = pd.Timedelta(np.timedelta64(1, "s"))
result = pd.Timedelta(expected)
assert result is expected
+
+
+def test_timestamp_constructor_identity():
+ # Test for #30543
+ expected = pd.Timestamp("2017-01-01T12")
+ result = pd.Timestamp(expected)
+ assert result is expected
diff --git a/pandas/tests/indexes/datetimes/test_timezones.py b/pandas/tests/indexes/datetimes/test_timezones.py
index c785eb67e5184..cd8e8c3542cce 100644
--- a/pandas/tests/indexes/datetimes/test_timezones.py
+++ b/pandas/tests/indexes/datetimes/test_timezones.py
@@ -2,7 +2,6 @@
Tests for DatetimeIndex timezone-related methods
"""
from datetime import date, datetime, time, timedelta, tzinfo
-from distutils.version import LooseVersion
import dateutil
from dateutil.tz import gettz, tzlocal
@@ -11,7 +10,6 @@
import pytz
from pandas._libs.tslibs import conversion, timezones
-from pandas.compat._optional import _get_version
import pandas.util._test_decorators as td
import pandas as pd
@@ -583,15 +581,7 @@ def test_dti_construction_ambiguous_endpoint(self, tz):
["US/Pacific", "shift_forward", "2019-03-10 03:00"],
["dateutil/US/Pacific", "shift_forward", "2019-03-10 03:00"],
["US/Pacific", "shift_backward", "2019-03-10 01:00"],
- pytest.param(
- "dateutil/US/Pacific",
- "shift_backward",
- "2019-03-10 01:00",
- marks=pytest.mark.xfail(
- LooseVersion(_get_version(dateutil)) < LooseVersion("2.7.0"),
- reason="GH 31043",
- ),
- ),
+ ["dateutil/US/Pacific", "shift_backward", "2019-03-10 01:00"],
["US/Pacific", timedelta(hours=1), "2019-03-10 03:00"],
],
)
| - [X] closes #30543
- [X] tests added 1 / passed 1
- [X] passes `black pandas`
- [X] passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
- [X] whatsnew entry
This implements a shortcut in the Timestamp constructor to cut down on processing if Timestamp is passed. We still need to check if the timezone was passed correctly. Then, if a Timestamp was passed, and there is no timezone, we just return that same Timestamp.
A test is added to check that the Timestamp is still the same object.
PR for timedelta to be added once I confirm that this is the approach we want to go with.
| https://api.github.com/repos/pandas-dev/pandas/pulls/30676 | 2020-01-04T07:19:38Z | 2020-01-26T01:03:37Z | 2020-01-26T01:03:37Z | 2020-01-27T06:55:10Z | 1,464 | pandas-dev/pandas | 45,157 |
BUG: pivot/unstack leading to too many items should raise exception | diff --git a/doc/source/whatsnew/v0.24.0.rst b/doc/source/whatsnew/v0.24.0.rst
index a84fd118061bc..5f40ca2ad3b36 100644
--- a/doc/source/whatsnew/v0.24.0.rst
+++ b/doc/source/whatsnew/v0.24.0.rst
@@ -1646,6 +1646,7 @@ Reshaping
- :meth:`DataFrame.nlargest` and :meth:`DataFrame.nsmallest` now returns the correct n values when keep != 'all' also when tied on the first columns (:issue:`22752`)
- Constructing a DataFrame with an index argument that wasn't already an instance of :class:`~pandas.core.Index` was broken (:issue:`22227`).
- Bug in :class:`DataFrame` prevented list subclasses to be used to construction (:issue:`21226`)
+- Bug in :func:`DataFrame.unstack` and :func:`DataFrame.pivot_table` returning a missleading error message when the resulting DataFrame has more elements than int32 can handle. Now, the error message is improved, pointing towards the actual problem (:issue:`20601`)
.. _whatsnew_0240.bug_fixes.sparse:
diff --git a/pandas/core/reshape/pivot.py b/pandas/core/reshape/pivot.py
index 61ac5d9ed6a2e..c7c447d18b6b1 100644
--- a/pandas/core/reshape/pivot.py
+++ b/pandas/core/reshape/pivot.py
@@ -78,8 +78,6 @@ def pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',
pass
values = list(values)
- # group by the cartesian product of the grouper
- # if we have a categorical
grouped = data.groupby(keys, observed=False)
agged = grouped.agg(aggfunc)
if dropna and isinstance(agged, ABCDataFrame) and len(agged.columns):
diff --git a/pandas/core/reshape/reshape.py b/pandas/core/reshape/reshape.py
index 70161826696c5..f436b3b92a359 100644
--- a/pandas/core/reshape/reshape.py
+++ b/pandas/core/reshape/reshape.py
@@ -109,6 +109,21 @@ def __init__(self, values, index, level=-1, value_columns=None,
self.removed_level = self.new_index_levels.pop(self.level)
self.removed_level_full = index.levels[self.level]
+ # Bug fix GH 20601
+ # If the data frame is too big, the number of unique index combination
+ # will cause int32 overflow on windows environments.
+ # We want to check and raise an error before this happens
+ num_rows = np.max([index_level.size for index_level
+ in self.new_index_levels])
+ num_columns = self.removed_level.size
+
+ # GH20601: This forces an overflow if the number of cells is too high.
+ num_cells = np.multiply(num_rows, num_columns, dtype=np.int32)
+
+ if num_rows > 0 and num_columns > 0 and num_cells <= 0:
+ raise ValueError('Unstacked DataFrame is too big, '
+ 'causing int32 overflow')
+
self._make_sorted_values_labels()
self._make_selectors()
diff --git a/pandas/tests/reshape/test_pivot.py b/pandas/tests/reshape/test_pivot.py
index e32e1999836ec..a2b5eacd873bb 100644
--- a/pandas/tests/reshape/test_pivot.py
+++ b/pandas/tests/reshape/test_pivot.py
@@ -1272,6 +1272,17 @@ def test_pivot_string_func_vs_func(self, f, f_numpy):
aggfunc=f_numpy)
tm.assert_frame_equal(result, expected)
+ @pytest.mark.slow
+ def test_pivot_number_of_levels_larger_than_int32(self):
+ # GH 20601
+ df = DataFrame({'ind1': np.arange(2 ** 16),
+ 'ind2': np.arange(2 ** 16),
+ 'count': 0})
+
+ with pytest.raises(ValueError, match='int32 overflow'):
+ df.pivot_table(index='ind1', columns='ind2',
+ values='count', aggfunc='count')
+
class TestCrosstab(object):
diff --git a/pandas/tests/test_multilevel.py b/pandas/tests/test_multilevel.py
index 6c1a2490ea76e..ce95f0f86ef7b 100644
--- a/pandas/tests/test_multilevel.py
+++ b/pandas/tests/test_multilevel.py
@@ -3,6 +3,7 @@
from warnings import catch_warnings, simplefilter
import datetime
import itertools
+
import pytest
import pytz
@@ -720,6 +721,14 @@ def test_unstack_unobserved_keys(self):
recons = result.stack()
tm.assert_frame_equal(recons, df)
+ @pytest.mark.slow
+ def test_unstack_number_of_levels_larger_than_int32(self):
+ # GH 20601
+ df = DataFrame(np.random.randn(2 ** 16, 2),
+ index=[np.arange(2 ** 16), np.arange(2 ** 16)])
+ with pytest.raises(ValueError, match='int32 overflow'):
+ df.unstack()
+
def test_stack_order_with_unsorted_levels(self):
# GH 16323
|
- [x] closes #20601
- [x] tests added / passed
- [x] passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
- [x] whatsnew entry | https://api.github.com/repos/pandas-dev/pandas/pulls/23512 | 2018-11-05T16:56:10Z | 2018-12-31T13:16:44Z | 2018-12-31T13:16:44Z | 2018-12-31T15:51:55Z | 1,237 | pandas-dev/pandas | 45,175 |
Address #1980 | diff --git a/docs/patterns/packages.rst b/docs/patterns/packages.rst
index af51717d92..1cd7797420 100644
--- a/docs/patterns/packages.rst
+++ b/docs/patterns/packages.rst
@@ -8,9 +8,9 @@ module. That is quite simple. Imagine a small application looks like
this::
/yourapplication
- /yourapplication.py
+ yourapplication.py
/static
- /style.css
+ style.css
/templates
layout.html
index.html
@@ -29,9 +29,9 @@ You should then end up with something like that::
/yourapplication
/yourapplication
- /__init__.py
+ __init__.py
/static
- /style.css
+ style.css
/templates
layout.html
index.html
@@ -41,11 +41,36 @@ You should then end up with something like that::
But how do you run your application now? The naive ``python
yourapplication/__init__.py`` will not work. Let's just say that Python
does not want modules in packages to be the startup file. But that is not
-a big problem, just add a new file called :file:`runserver.py` next to the inner
+a big problem, just add a new file called :file:`setup.py` next to the inner
:file:`yourapplication` folder with the following contents::
- from yourapplication import app
- app.run(debug=True)
+ from setuptools import setup
+
+ setup(
+ name='yourapplication',
+ packages=['yourapplication'],
+ include_package_data=True,
+ install_requires=[
+ 'flask',
+ ],
+ )
+
+In order to run the application you need to export an environment variable
+that tells Flask where to find the application instance::
+
+ export FLASK_APP=yourapplication
+
+If you are outside of the project directory make sure to provide the exact
+path to your application directory. Similiarly you can turn on "debug
+mode" with this environment variable::
+
+ export FLASK_DEBUG=true
+
+In order to install and run the application you need to issue the following
+commands::
+
+ pip install -e .
+ flask run
What did we gain from this? Now we can restructure the application a bit
into multiple modules. The only thing you have to remember is the
@@ -77,12 +102,12 @@ And this is what :file:`views.py` would look like::
You should then end up with something like that::
/yourapplication
- /runserver.py
+ setup.py
/yourapplication
- /__init__.py
- /views.py
+ __init__.py
+ views.py
/static
- /style.css
+ style.css
/templates
layout.html
index.html
| - Large apps play nicer with recommended project structure #1980
- runserver.py --> setup.py
- Run as:
pip install -e.
export FLASK_APP=yourapplication
flask run
I did not change much, one new paragraph.
<!-- Reviewable:start -->
---
This change is [<img src="https://reviewable.io/review_button.svg" height="34" align="absmiddle" alt="Reviewable"/>](https://reviewable.io/reviews/pallets/flask/2021)
<!-- Reviewable:end -->
| https://api.github.com/repos/pallets/flask/pulls/2021 | 2016-09-11T15:38:18Z | 2016-09-11T15:53:35Z | 2016-09-11T15:53:35Z | 2020-11-14T04:33:22Z | 665 | pallets/flask | 20,216 |
Fix superbooga when using regenerate | diff --git a/extensions/superbooga/script.py b/extensions/superbooga/script.py
index 5ef14d9d82..475cf1e061 100644
--- a/extensions/superbooga/script.py
+++ b/extensions/superbooga/script.py
@@ -96,7 +96,8 @@ def apply_settings(chunk_count, chunk_count_initial, time_weight):
def custom_generate_chat_prompt(user_input, state, **kwargs):
global chat_collector
- history = state['history']
+ # get history as being modified when using regenerate.
+ history = kwargs['history']
if state['mode'] == 'instruct':
results = collector.get_sorted(user_input, n_results=params['chunk_count'])
| When superbooga is active and you use regenerate, superbooga uses the history that still includes the output of the last query. This little change fixes it. I do not think that there are other side effects. | https://api.github.com/repos/oobabooga/text-generation-webui/pulls/3362 | 2023-07-30T00:51:21Z | 2023-08-09T02:26:28Z | 2023-08-09T02:26:28Z | 2023-08-09T02:51:18Z | 158 | oobabooga/text-generation-webui | 26,598 |
Fix leaderboard.json file in Hebrew translation, Resolves #3159. | diff --git a/website/public/locales/he/leaderboard.json b/website/public/locales/he/leaderboard.json
index 117c7b2296..fc8f45535a 100644
--- a/website/public/locales/he/leaderboard.json
+++ b/website/public/locales/he/leaderboard.json
@@ -9,6 +9,7 @@
"labels_simple": "תוויות (פשוטות)",
"last_updated_at": "עודכן לאחרונה ב: {{val, datetime}}",
"leaderboard": "לוח ניהול",
+ "level_progress_message": "עם סך נקודות של {{score}}, אתה הגעת לרמה {{level,number,integer}}!",
"month": "חודש",
"monthly": "חודשי",
"next": "הבא",
@@ -19,6 +20,7 @@
"prompt": "קלטים",
"rank": "דרגה",
"rankings": "דירוגים",
+ "reached_max_level": "הגעת לרמה במקסימלית, תודה על העבודה הקשה!",
"replies_assistant": "תשובות כעוזר",
"replies_prompter": "תשובות כמזין",
"reply": "תשובות",
@@ -31,6 +33,7 @@
"view_all": "הצג הכל",
"week": "שבוע",
"weekly": "שבועי",
+ "xp_progress_message": "אתה צריך עוד {{need, number, integer}} נקודות כדי להגיע לרמה הבאה!",
"your_account": "החשבון שלך",
"your_stats": "הסטטיסטיקה שלך"
}
| Added `level_progress_message`, `reached_max_level`, and `xp_progress_message` to the leaderboard.json file in the Hebrew translation. | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/3160 | 2023-05-14T16:36:40Z | 2023-05-14T18:07:20Z | 2023-05-14T18:07:20Z | 2023-05-14T18:30:37Z | 522 | LAION-AI/Open-Assistant | 36,878 |
CI: Format isort output for azure | diff --git a/ci/code_checks.sh b/ci/code_checks.sh
index ceb13c52ded9c..cfe55f1e05f71 100755
--- a/ci/code_checks.sh
+++ b/ci/code_checks.sh
@@ -105,7 +105,12 @@ if [[ -z "$CHECK" || "$CHECK" == "lint" ]]; then
# Imports - Check formatting using isort see setup.cfg for settings
MSG='Check import format using isort ' ; echo $MSG
- isort --recursive --check-only pandas asv_bench
+ ISORT_CMD="isort --recursive --check-only pandas asv_bench"
+ if [[ "$GITHUB_ACTIONS" == "true" ]]; then
+ eval $ISORT_CMD | awk '{print "##[error]" $0}'; RET=$(($RET + ${PIPESTATUS[0]}))
+ else
+ eval $ISORT_CMD
+ fi
RET=$(($RET + $?)) ; echo $MSG "DONE"
fi
| - [x] closes #27179
- [x] tests added / passed
- [x] passes `black pandas`
- [x] passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
Current behaviour on master of isort formatting:

Finishing up stale PR @https://github.com/pandas-dev/pandas/pull/27334
| https://api.github.com/repos/pandas-dev/pandas/pulls/29654 | 2019-11-16T02:59:26Z | 2019-12-06T01:10:29Z | 2019-12-06T01:10:28Z | 2019-12-25T20:27:02Z | 230 | pandas-dev/pandas | 45,550 |
Slight refactoring to allow customizing DynamoDB server startup | diff --git a/localstack/services/dynamodb/server.py b/localstack/services/dynamodb/server.py
index 2752e309d1a08..59aff5c8dc57a 100644
--- a/localstack/services/dynamodb/server.py
+++ b/localstack/services/dynamodb/server.py
@@ -100,11 +100,13 @@ def create_dynamodb_server(port=None) -> DynamodbServer:
Creates a dynamodb server from the LocalStack configuration.
"""
port = port or get_free_tcp_port()
+ ddb_data_dir = f"{config.dirs.data}/dynamodb" if config.dirs.data else None
+ return do_create_dynamodb_server(port, ddb_data_dir)
- server = DynamodbServer(port)
- if config.dirs.data:
- ddb_data_dir = "%s/dynamodb" % config.dirs.data
+def do_create_dynamodb_server(port: int, ddb_data_dir: Optional[str]) -> DynamodbServer:
+ server = DynamodbServer(port)
+ if ddb_data_dir:
mkdir(ddb_data_dir)
absolute_path = os.path.abspath(ddb_data_dir)
server.db_path = absolute_path
| DynamoDBLocal can start in [two different modes](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.UsageNotes.html). If a `dbPath` is set, DynamoDB writes its database files in that directory.
If not, it runs in `inMemory`mode with a transient state (which is what we currently do if persistence is not enabled).
Before, we were interested in having files on disk only when `DATA_DIR` was set. However, now that Pods are independent from persistence, we have a similar need. Therefore, we would just set a temporary directory to dump the database files.
As a future optimization we can investigate whether is possible to run start DynamoDBLocal `inMemory` and only ask for its content on the fly.
@whummer this is basically what we briefly discussed before. Could there be any implications that I do not see? | https://api.github.com/repos/localstack/localstack/pulls/6109 | 2022-05-20T16:00:59Z | 2022-05-21T15:29:05Z | 2022-05-21T15:29:05Z | 2022-05-21T15:29:22Z | 256 | localstack/localstack | 28,639 |
cli[patch]: copyright 2024 default | diff --git a/libs/cli/langchain_cli/integration_template/LICENSE b/libs/cli/langchain_cli/integration_template/LICENSE
index 426b65090341f3..fc0602feecdd67 100644
--- a/libs/cli/langchain_cli/integration_template/LICENSE
+++ b/libs/cli/langchain_cli/integration_template/LICENSE
@@ -1,6 +1,6 @@
MIT License
-Copyright (c) 2023 LangChain, Inc.
+Copyright (c) 2024 LangChain, Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
diff --git a/libs/cli/langchain_cli/package_template/LICENSE b/libs/cli/langchain_cli/package_template/LICENSE
index 426b65090341f3..fc0602feecdd67 100644
--- a/libs/cli/langchain_cli/package_template/LICENSE
+++ b/libs/cli/langchain_cli/package_template/LICENSE
@@ -1,6 +1,6 @@
MIT License
-Copyright (c) 2023 LangChain, Inc.
+Copyright (c) 2024 LangChain, Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
diff --git a/templates/retrieval-agent-fireworks/LICENSE b/templates/retrieval-agent-fireworks/LICENSE
index 426b65090341f3..fc0602feecdd67 100644
--- a/templates/retrieval-agent-fireworks/LICENSE
+++ b/templates/retrieval-agent-fireworks/LICENSE
@@ -1,6 +1,6 @@
MIT License
-Copyright (c) 2023 LangChain, Inc.
+Copyright (c) 2024 LangChain, Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
| https://api.github.com/repos/langchain-ai/langchain/pulls/17204 | 2024-02-07T22:51:51Z | 2024-02-07T22:52:37Z | 2024-02-07T22:52:37Z | 2024-02-07T22:56:26Z | 413 | langchain-ai/langchain | 42,832 |
|
Fix race condition when running mssql tests | diff --git a/scripts/ci/docker-compose/backend-mssql.yml b/scripts/ci/docker-compose/backend-mssql.yml
index 69b4aa5fb6e5a..7fc5540e467a0 100644
--- a/scripts/ci/docker-compose/backend-mssql.yml
+++ b/scripts/ci/docker-compose/backend-mssql.yml
@@ -49,6 +49,12 @@ services:
entrypoint:
- bash
- -c
- - opt/mssql-tools/bin/sqlcmd -S mssql -U sa -P Airflow123 -i /mssql_create_airflow_db.sql || true
+ - >
+ for i in {1..10};
+ do
+ /opt/mssql-tools/bin/sqlcmd -S mssql -U sa -P Airflow123 -i /mssql_create_airflow_db.sql &&
+ exit 0;
+ sleep 1;
+ done
volumes:
- ./mssql_create_airflow_db.sql:/mssql_create_airflow_db.sql:ro
| There is a race condition where initialization of Airlfow DB
for mssql might be executed when the server is started but it is
not yet initialized with a model db needed to create airflow db.
In such case mssql database intialization will fail as it will
not be able to obtain a locl on the `model` database. The error
in the mssqlsetup container will be similar to:
```
Msg 1807, Level 16, State 3, Server d2888dd467fe, Line 20
Could not obtain exclusive lock on database 'model'. Retry the operation later.
Msg 1802, Level 16, State 4, Server d2888dd467fe, Line 20
CREATE DATABASE failed. Some file names listed could not be created. Check related errors.
Msg 5011, Level 14, State 5, Server d2888dd467fe, Line 21
User does not have permission to alter database 'airflow', the database does not exist, or the database is not in a state that allows access checks.
Msg 5069, Level 16, State 1, Server d2888dd467fe, Line 21
ALTER DATABASE statement failed.
```
This PR alters the setup job to try to create airflow db
several times and wait a second before every retry.
<!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of existing issue, reference it using one of the following:
closes: #ISSUE
related: #ISSUE
How to write a good git commit message:
http://chris.beams.io/posts/git-commit/
-->
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information.
In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/main/UPDATING.md).
| https://api.github.com/repos/apache/airflow/pulls/19863 | 2021-11-28T16:59:25Z | 2021-11-29T11:13:41Z | 2021-11-29T11:13:41Z | 2022-07-29T20:10:11Z | 225 | apache/airflow | 14,261 |
De-Multiprocess Convert | diff --git a/plugins/convert/writer/opencv.py b/plugins/convert/writer/opencv.py
index cabd0ab652..17cafdc591 100644
--- a/plugins/convert/writer/opencv.py
+++ b/plugins/convert/writer/opencv.py
@@ -47,6 +47,7 @@ def write(self, filename, image):
logger.error("Failed to save image '%s'. Original Error: %s", filename, err)
def pre_encode(self, image):
+ """ Pre_encode the image in lib/convert.py threads as it is a LOT quicker """
logger.trace("Pre-encoding image")
image = cv2.imencode(self.extension, image, self.args)[1] # pylint: disable=no-member
return image
diff --git a/plugins/convert/writer/pillow.py b/plugins/convert/writer/pillow.py
index e207183c22..ef440f2b6c 100644
--- a/plugins/convert/writer/pillow.py
+++ b/plugins/convert/writer/pillow.py
@@ -50,6 +50,7 @@ def write(self, filename, image):
logger.error("Failed to save image '%s'. Original Error: %s", filename, err)
def pre_encode(self, image):
+ """ Pre_encode the image in lib/convert.py threads as it is a LOT quicker """
logger.trace("Pre-encoding image")
fmt = self.format_dict.get(self.config["format"], None)
fmt = self.config["format"].upper() if fmt is None else fmt
diff --git a/scripts/convert.py b/scripts/convert.py
index bd3a1632cf..cf51e73902 100644
--- a/scripts/convert.py
+++ b/scripts/convert.py
@@ -6,6 +6,7 @@
import os
import sys
from threading import Event
+from time import sleep
from cv2 import imwrite # pylint:disable=no-name-in-module
import numpy as np
@@ -16,8 +17,8 @@
from lib.convert import Converter
from lib.faces_detect import DetectedFace
from lib.gpu_stats import GPUStats
-from lib.multithreading import MultiThread, PoolProcess, total_cpus
-from lib.queue_manager import queue_manager, QueueEmpty
+from lib.multithreading import MultiThread, total_cpus
+from lib.queue_manager import queue_manager
from lib.utils import FaceswapError, get_folder, get_image_paths, hash_image_file
from plugins.extract.pipeline import Extractor
from plugins.plugin_loader import PluginLoader
@@ -32,6 +33,7 @@ def __init__(self, arguments):
self.args = arguments
Utils.set_verbosity(self.args.loglevel)
+ self.patch_threads = None
self.images = Images(self.args)
self.validate()
self.alignments = Alignments(self.args, False, self.images.is_video)
@@ -83,9 +85,8 @@ def validate(self):
if (self.args.writer == "ffmpeg" and
not self.images.is_video and
self.args.reference_video is None):
- logger.error("Output as video selected, but using frames as input. You must provide a "
- "reference video ('-ref', '--reference-video').")
- exit(1)
+ raise FaceswapError("Output as video selected, but using frames as input. You must "
+ "provide a reference video ('-ref', '--reference-video').")
output_dir = get_folder(self.args.output_dir)
logger.info("Output Directory: %s", output_dir)
@@ -93,7 +94,7 @@ def add_queues(self):
""" Add the queues for convert """
logger.debug("Adding queues. Queue size: %s", self.queue_size)
for qname in ("convert_in", "convert_out", "patch"):
- queue_manager.add_queue(qname, self.queue_size)
+ queue_manager.add_queue(qname, self.queue_size, multiprocessing_queue=False)
def process(self):
""" Process the conversion """
@@ -121,27 +122,17 @@ def convert_images(self):
logger.debug("Converting images")
save_queue = queue_manager.get_queue("convert_out")
patch_queue = queue_manager.get_queue("patch")
- completion_queue = queue_manager.get_queue("patch_completed")
- pool = PoolProcess(self.converter.process, patch_queue, save_queue,
- completion_queue=completion_queue,
- processes=self.pool_processes)
- pool.start()
- completed_count = 0
+ self.patch_threads = MultiThread(self.converter.process, patch_queue, save_queue,
+ thread_count=self.pool_processes, name="patch")
+
+ self.patch_threads.start()
while True:
self.check_thread_error()
if self.disk_io.completion_event.is_set():
logger.debug("DiskIO completion event set. Joining Pool")
break
- try:
- completed = completion_queue.get(True, 1)
- except QueueEmpty:
- continue
- completed_count += completed
- logger.debug("Total process pools completed: %s of %s", completed_count, pool.procs)
- if completed_count == pool.procs:
- logger.debug("All processes completed. Joining Pool")
- break
- pool.join()
+ sleep(1)
+ self.patch_threads.join()
logger.debug("Putting EOF")
save_queue.put("EOF")
@@ -149,7 +140,10 @@ def convert_images(self):
def check_thread_error(self):
""" Check and raise thread errors """
- for thread in (self.predictor.thread, self.disk_io.load_thread, self.disk_io.save_thread):
+ for thread in (self.predictor.thread,
+ self.disk_io.load_thread,
+ self.disk_io.save_thread,
+ self.patch_threads):
thread.check_and_raise_error()
@@ -238,15 +232,13 @@ def get_frame_ranges(self):
logger.debug("minframe: %s, maxframe: %s", minframe, maxframe)
if minframe is None or maxframe is None:
- logger.error("Frame Ranges specified, but could not determine frame numbering "
- "from filenames")
- exit(1)
+ raise FaceswapError("Frame Ranges specified, but could not determine frame numbering "
+ "from filenames")
retval = list()
for rng in self.args.frame_ranges:
if "-" not in rng:
- logger.error("Frame Ranges not specified in the correct format")
- exit(1)
+ raise FaceswapError("Frame Ranges not specified in the correct format")
start, end = rng.split("-")
retval.append((max(int(start), minframe), min(int(end), maxframe)))
logger.debug("frame ranges: %s", retval)
@@ -289,7 +281,9 @@ def add_queue(self, task):
q_name = "convert_out"
else:
q_name = task
- setattr(self, "{}_queue".format(task), queue_manager.get_queue(q_name))
+ setattr(self,
+ "{}_queue".format(task),
+ queue_manager.get_queue(q_name, multiprocessing_queue=False))
logger.debug("Added queue for task: '%s'", task)
def start_thread(self, task):
@@ -312,7 +306,7 @@ def load(self, *args): # pylint: disable=unused-argument
if self.load_queue.shutdown.is_set():
logger.debug("Load Queue: Stop signal received. Terminating")
break
- if image is None or (not image.any() and image.ndim not in ((2, 3))):
+ if image is None or (not image.any() and image.ndim not in (2, 3)):
# All black frames will return not np.any() so check dims too
logger.warning("Unable to open image. Skipping: '%s'", filename)
continue
@@ -488,8 +482,7 @@ def load_model(self):
logger.debug("Loading Model")
model_dir = get_folder(self.args.model_dir, make_folder=False)
if not model_dir:
- logger.error("%s does not exist.", self.args.model_dir)
- exit(1)
+ raise FaceswapError("{} does not exist.".format(self.args.model_dir))
trainer = self.get_trainer(model_dir)
gpus = 1 if not hasattr(self.args, "gpus") else self.args.gpus
model = PluginLoader.get_model(trainer)(model_dir, gpus, predict=True)
@@ -505,9 +498,9 @@ def get_trainer(self, model_dir):
statefile = [fname for fname in os.listdir(str(model_dir))
if fname.endswith("_state.json")]
if len(statefile) != 1:
- logger.error("There should be 1 state file in your model folder. %s were found. "
- "Specify a trainer with the '-t', '--trainer' option.", len(statefile))
- exit(1)
+ raise FaceswapError("There should be 1 state file in your model folder. {} were "
+ "found. Specify a trainer with the '-t', '--trainer' "
+ "option.".format(len(statefile)))
statefile = os.path.join(str(model_dir), statefile[0])
with open(statefile, "rb") as inp:
@@ -515,9 +508,8 @@ def get_trainer(self, model_dir):
trainer = state.get("name", None)
if not trainer:
- logger.error("Trainer name could not be read from state file. "
- "Specify a trainer with the '-t', '--trainer' option.")
- exit(1)
+ raise FaceswapError("Trainer name could not be read from state file. "
+ "Specify a trainer with the '-t', '--trainer' option.")
logger.debug("Trainer from state file: '%s'", trainer)
return trainer
@@ -702,9 +694,8 @@ def get_face_hashes(self):
face_hashes.append(hash_image_file(face))
logger.debug("Face Hashes: %s", (len(face_hashes)))
if not face_hashes:
- logger.error("Aligned directory is empty, no faces will be converted!")
- exit(1)
- elif len(face_hashes) <= len(self.input_images) / 3:
+ raise FaceswapError("Aligned directory is empty, no faces will be converted!")
+ if len(face_hashes) <= len(self.input_images) / 3:
logger.warning("Aligned directory contains far fewer images than the input "
"directory, are you sure this is the right folder?")
return face_hashes
| OpenCV and Numpy release the GIL, so it is actually faster, in many cases, to use threading rather than Multiprocess. This has the added bonus of simplifying the code.
In tests, this PR improves conversion speeds by up to 30% for OpenCV writer and up to 40% for FFMPEG writer. Other writers remain unchanged.
```
|WRITER | MP | THREADS | DIFF |
|-------|-------|---------|------|
|OpenCV | 45 | 32 | 29% |
|FFMPEG | 49 | 29 | 41% |
|Pillow | 47.5 | 47.5 | 0% |
Time in seconds for 550 images
Tested on 8 cores. Average over 3 runs
``` | https://api.github.com/repos/deepfakes/faceswap/pulls/857 | 2019-09-02T21:35:54Z | 2019-09-02T21:55:37Z | 2019-09-02T21:55:37Z | 2019-09-02T21:55:37Z | 2,281 | deepfakes/faceswap | 18,826 |
Control ds_report output | diff --git a/bin/ds_report b/bin/ds_report
index 4a31a75c2eab..e6f7b50a78b2 100755
--- a/bin/ds_report
+++ b/bin/ds_report
@@ -1,6 +1,6 @@
#!/usr/bin/env python3
-from deepspeed.env_report import main
+from deepspeed.env_report import cli_main
if __name__ == '__main__':
- main()
+ cli_main()
diff --git a/deepspeed/env_report.py b/deepspeed/env_report.py
index b14ac4464835..5ede10a678c4 100644
--- a/deepspeed/env_report.py
+++ b/deepspeed/env_report.py
@@ -1,6 +1,7 @@
import torch
import deepspeed
import subprocess
+import argparse
from .ops.op_builder import ALL_OPS
from .git_version_info import installed_ops, torch_info
from .ops import __compatible_ops__ as compatible_ops
@@ -20,7 +21,7 @@
warning = f"{YELLOW}[WARNING]{END}"
-def op_report():
+def op_report(verbose=True):
max_dots = 23
max_dots2 = 11
h = ["op name", "installed", "compatible"]
@@ -43,7 +44,7 @@ def op_report():
no = f"{YELLOW}[NO]{END}"
for op_name, builder in ALL_OPS.items():
dots = "." * (max_dots - len(op_name))
- is_compatible = OKAY if builder.is_compatible() else no
+ is_compatible = OKAY if builder.is_compatible(verbose) else no
is_installed = installed if installed_ops[op_name] else no
dots2 = '.' * ((len(h[1]) + (max_dots2 - len(h[1]))) -
(len(is_installed) - color_len))
@@ -100,10 +101,32 @@ def debug_report():
print(name, "." * (max_dots - len(name)), value)
-def main():
- op_report()
+def parse_arguments():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--hide_operator_status',
+ action='store_true',
+ help=
+ 'Suppress display of installation and compatiblity statuses of DeepSpeed operators. '
+ )
+ parser.add_argument('--hide_errors_and_warnings',
+ action='store_true',
+ help='Suppress warning and error messages.')
+ args = parser.parse_args()
+ return args
+
+
+def main(hide_operator_status=False, hide_errors_and_warnings=False):
+ if not hide_operator_status:
+ op_report(verbose=not hide_errors_and_warnings)
debug_report()
+def cli_main():
+ args = parse_arguments()
+ main(hide_operator_status=args.hide_operator_status,
+ hide_errors_and_warnings=args.hide_errors_and_warnings)
+
+
if __name__ == "__main__":
main()
diff --git a/op_builder/async_io.py b/op_builder/async_io.py
index 3860f3376106..aec7911ce96b 100644
--- a/op_builder/async_io.py
+++ b/op_builder/async_io.py
@@ -84,14 +84,14 @@ def check_for_libaio_pkg(self):
break
return found
- def is_compatible(self):
+ def is_compatible(self, verbose=True):
# Check for the existence of libaio by using distutils
# to compile and link a test program that calls io_submit,
# which is a function provided by libaio that is used in the async_io op.
# If needed, one can define -I and -L entries in CFLAGS and LDFLAGS
# respectively to specify the directories for libaio.h and libaio.so.
aio_compatible = self.has_function('io_submit', ('aio', ))
- if not aio_compatible:
+ if verbose and not aio_compatible:
self.warning(
f"{self.NAME} requires the dev libaio .so object and headers but these were not found."
)
@@ -103,4 +103,4 @@ def is_compatible(self):
self.warning(
"If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found."
)
- return super().is_compatible() and aio_compatible
+ return super().is_compatible(verbose) and aio_compatible
diff --git a/op_builder/builder.py b/op_builder/builder.py
index 5b0da34a3456..1a98e8d7b110 100644
--- a/op_builder/builder.py
+++ b/op_builder/builder.py
@@ -153,7 +153,7 @@ def cxx_args(self):
'''
return []
- def is_compatible(self):
+ def is_compatible(self, verbose=True):
'''
Check if all non-python dependencies are satisfied to build this op
'''
@@ -370,7 +370,7 @@ def load(self, verbose=True):
return self.jit_load(verbose)
def jit_load(self, verbose=True):
- if not self.is_compatible():
+ if not self.is_compatible(verbose):
raise RuntimeError(
f"Unable to JIT load the {self.name} op due to it not being compatible due to hardware/software issue."
)
@@ -482,8 +482,8 @@ def version_dependent_macros(self):
version_ge_1_5 = ['-DVERSION_GE_1_5']
return version_ge_1_1 + version_ge_1_3 + version_ge_1_5
- def is_compatible(self):
- return super().is_compatible()
+ def is_compatible(self, verbose=True):
+ return super().is_compatible(verbose)
def builder(self):
from torch.utils.cpp_extension import CUDAExtension
diff --git a/op_builder/cpu_adagrad.py b/op_builder/cpu_adagrad.py
index 6558477c094d..68fc78583960 100644
--- a/op_builder/cpu_adagrad.py
+++ b/op_builder/cpu_adagrad.py
@@ -14,7 +14,7 @@ class CPUAdagradBuilder(CUDAOpBuilder):
def __init__(self):
super().__init__(name=self.NAME)
- def is_compatible(self):
+ def is_compatible(self, verbose=True):
# Disable on Windows.
return sys.platform != "win32"
diff --git a/op_builder/cpu_adam.py b/op_builder/cpu_adam.py
index 640e244aad4c..8a58756d1fcd 100644
--- a/op_builder/cpu_adam.py
+++ b/op_builder/cpu_adam.py
@@ -14,7 +14,7 @@ class CPUAdamBuilder(CUDAOpBuilder):
def __init__(self):
super().__init__(name=self.NAME)
- def is_compatible(self):
+ def is_compatible(self, verbose=True):
# Disable on Windows.
return sys.platform != "win32"
diff --git a/op_builder/sparse_attn.py b/op_builder/sparse_attn.py
index 6f30cc84da23..a4acff6cd767 100644
--- a/op_builder/sparse_attn.py
+++ b/op_builder/sparse_attn.py
@@ -21,7 +21,7 @@ def sources(self):
def cxx_args(self):
return ['-O2', '-fopenmp']
- def is_compatible(self):
+ def is_compatible(self, verbose=True):
# Check to see if llvm and cmake are installed since they are dependencies
#required_commands = ['llvm-config|llvm-config-9', 'cmake']
#command_status = list(map(self.command_exists, required_commands))
@@ -52,4 +52,4 @@ def is_compatible(self):
f'{self.NAME} requires a torch version >= 1.5 but detected {TORCH_MAJOR}.{TORCH_MINOR}'
)
- return super().is_compatible() and torch_compatible and cuda_compatible
+ return super().is_compatible(verbose) and torch_compatible and cuda_compatible
| Add two flags to help control ds_report out:
1. --hide_operator_status
2. --hide_errors_and_warnings
Separate cli and function entry points into ds_report
Should fix #1541. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/1622 | 2021-12-08T20:10:25Z | 2021-12-09T00:29:13Z | 2021-12-09T00:29:13Z | 2023-07-07T02:40:01Z | 1,798 | microsoft/DeepSpeed | 10,188 |
[Bandcamp] Added track number for metadata (fixes issue #17266) | diff --git a/youtube_dl/extractor/bandcamp.py b/youtube_dl/extractor/bandcamp.py
index b8514734d57..bc4c5165af7 100644
--- a/youtube_dl/extractor/bandcamp.py
+++ b/youtube_dl/extractor/bandcamp.py
@@ -44,6 +44,17 @@ class BandcampIE(InfoExtractor):
'title': 'Ben Prunty - Lanius (Battle)',
'uploader': 'Ben Prunty',
},
+ }, {
+ 'url': 'https://relapsealumni.bandcamp.com/track/hail-to-fire',
+ 'info_dict': {
+ 'id': '2584466013',
+ 'ext': 'mp3',
+ 'title': 'Hail to Fire',
+ 'track_number': 5,
+ },
+ 'params': {
+ 'skip_download': True,
+ },
}]
def _real_extract(self, url):
@@ -82,6 +93,7 @@ def _real_extract(self, url):
'thumbnail': thumbnail,
'formats': formats,
'duration': float_or_none(data.get('duration')),
+ 'track_number': int_or_none(data.get('track_num')),
}
else:
raise ExtractorError('No free songs found')
| ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [adding new extractor tutorial](https://github.com/rg3/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/rg3/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into youtube-dl each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [ ] Bug fix
- [x] Improvement
- [ ] New extractor
- [ ] New feature
---
Updated the extractor for Bandcamp.com to also include the track number as part of the metadata - issue #17266.
Cheers and thank you!
Parmjit V. | https://api.github.com/repos/ytdl-org/youtube-dl/pulls/17366 | 2018-08-27T22:03:56Z | 2018-08-30T19:32:36Z | 2018-08-30T19:32:36Z | 2018-08-30T21:52:41Z | 296 | ytdl-org/youtube-dl | 50,093 |
Fix an exception when auto-casting dicts to fp16 | diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index 1fd7d7e964e8..59e1b9030431 100644
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -1694,7 +1694,7 @@ def _cast_inputs_half(self, inputs):
return inputs.__class__(new_inputs)
elif isinstance(inputs, dict):
new_inputs = {}
- for k, v in inputs:
+ for k, v in inputs.items():
new_inputs[k] = self._cast_inputs_half(v)
return new_inputs
elif hasattr(inputs, 'half'):
| Deepspeed raises an exception when using fp16 auto_cast mode with a model that takes a dictionary as input. Quick test on `0.7.3` to display what I'm talking about:
```
$ cat test.py
import torch
import deepspeed
import argparse
parser = argparse.ArgumentParser(description='Test model')
parser.add_argument('--local_rank', type=int, default=-1,
help='local rank passed from distributed launcher')
parser = deepspeed.add_config_arguments(parser)
cmd_args = parser.parse_args()
class ValueDoubler(torch.nn.Module):
def forward(self, d):
return d["value"] * 2
m = ValueDoubler()
m, _, _, _ = deepspeed.initialize(args=cmd_args, model=m)
print("Torch: ", torch.__version__)
print("DeepSpeed: ", deepspeed.__version__)
print("New value: ", m({"value": 1.0}))
$ cat ds.json
{"fp16": {"auto_cast": true, "enabled": true}, "train_batch_size": 1}
$ deepspeed test.py --deepspeed --deepspeed_config ds.json
...
Torch: 1.12.1+cu102
DeepSpeed: 0.7.3
Traceback (most recent call last):
File "test.py", line 20, in <module>
print(m({"value": 1.0}))
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1664, in forward
inputs = self._cast_inputs_half(inputs)
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1693, in _cast_inputs_half
new_inputs.append(self._cast_inputs_half(v))
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1697, in _cast_inputs_half
for k, v in inputs:
ValueError: too many values to unpack (expected 2)
```
And testing on master (I had to fuss it a little to get master to work):
```
$ deepspeed test.py --deepspeed --deepspeed_config ds.json
...
Torch: 1.12.1+cu102
DeepSpeed: 0.7.4+eed4032
Traceback (most recent call last):
File "test.py", line 20, in <module>
print(m({"value": 1.0}))
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1664, in forward
inputs = self._cast_inputs_half(inputs)
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1693, in _cast_inputs_half
new_inputs.append(self._cast_inputs_half(v))
File "/data/home/mattks/.local/share/virtualenvs/test-t-h-loqS/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1697, in _cast_inputs_half
for k, v in inputs:
ValueError: too many values to unpack (expected 2)
```
This PR fixes this:
```
$ deepspeed test.py --deepspeed --deepspeed_config ds.json
Torch: 1.12.1+cu102
DeepSpeed: 0.7.4+45d39d7
New value: 2.0
``` | https://api.github.com/repos/microsoft/DeepSpeed/pulls/2370 | 2022-09-27T23:41:34Z | 2022-09-29T20:09:37Z | 2022-09-29T20:09:37Z | 2022-09-30T01:33:52Z | 147 | microsoft/DeepSpeed | 9,979 |
Support BBC News (bbc.com/news) | diff --git a/youtube_dl/extractor/__init__.py b/youtube_dl/extractor/__init__.py
index dc1a302e69c..1a9585c9264 100644
--- a/youtube_dl/extractor/__init__.py
+++ b/youtube_dl/extractor/__init__.py
@@ -38,7 +38,7 @@
from .baidu import BaiduVideoIE
from .bambuser import BambuserIE, BambuserChannelIE
from .bandcamp import BandcampIE, BandcampAlbumIE
-from .bbccouk import BBCCoUkIE
+from .bbc import BBCCoUkIE, BBCNewsIE
from .beeg import BeegIE
from .behindkink import BehindKinkIE
from .beatportpro import BeatportProIE
diff --git a/youtube_dl/extractor/bbccouk.py b/youtube_dl/extractor/bbc.py
similarity index 69%
rename from youtube_dl/extractor/bbccouk.py
rename to youtube_dl/extractor/bbc.py
index 5825d286774..c8f285165f7 100644
--- a/youtube_dl/extractor/bbccouk.py
+++ b/youtube_dl/extractor/bbc.py
@@ -5,9 +5,11 @@
from .common import InfoExtractor
from ..utils import (
ExtractorError,
+ parse_duration,
int_or_none,
)
from ..compat import compat_HTTPError
+import re
class BBCCoUkIE(InfoExtractor):
@@ -15,6 +17,8 @@ class BBCCoUkIE(InfoExtractor):
IE_DESC = 'BBC iPlayer'
_VALID_URL = r'https?://(?:www\.)?bbc\.co\.uk/(?:(?:(?:programmes|iplayer(?:/[^/]+)?/(?:episode|playlist))/)|music/clips[/#])(?P<id>[\da-z]{8})'
+ mediaselector_url = 'http://open.live.bbc.co.uk/mediaselector/5/select/version/2.0/mediaset/pc/vpid/%s'
+
_TESTS = [
{
'url': 'http://www.bbc.co.uk/programmes/b039g8p7',
@@ -262,7 +266,7 @@ def _get_subtitles(self, media, programme_id):
def _download_media_selector(self, programme_id):
try:
media_selection = self._download_xml(
- 'http://open.live.bbc.co.uk/mediaselector/5/select/version/2.0/mediaset/pc/vpid/%s' % programme_id,
+ self.mediaselector_url % programme_id,
programme_id, 'Downloading media selection XML')
except ExtractorError as ee:
if isinstance(ee.cause, compat_HTTPError) and ee.cause.code == 403:
@@ -377,3 +381,177 @@ def _real_extract(self, url):
'formats': formats,
'subtitles': subtitles,
}
+
+
+class BBCNewsIE(BBCCoUkIE):
+ IE_NAME = 'bbc.com'
+ IE_DESC = 'BBC news'
+ _VALID_URL = r'https?://(?:www\.)?bbc\.com/.+?/(?P<id>[^/]+)$'
+
+ mediaselector_url = 'http://open.live.bbc.co.uk/mediaselector/4/mtis/stream/%s'
+
+ _TESTS = [{
+ 'url': 'http://www.bbc.com/news/world-europe-32668511',
+ 'info_dict': {
+ 'id': 'world-europe-32668511',
+ 'title': 'Russia stages massive WW2 parade despite Western boycott',
+ },
+ 'playlist_count': 2,
+ }, {
+ 'url': 'http://www.bbc.com/news/business-28299555',
+ 'info_dict': {
+ 'id': 'business-28299555',
+ 'title': 'Farnborough Airshow: Video highlights',
+ },
+ 'playlist_count': 9,
+ }, {
+ 'url': 'http://www.bbc.com/news/world-europe-32041533',
+ 'note': 'Video',
+ 'info_dict': {
+ 'id': 'p02mprgb',
+ 'ext': 'mp4',
+ 'title': 'Aerial footage showed the site of the crash in the Alps - courtesy BFM TV',
+ 'description': 'Germanwings plane crash site in aerial video - Aerial footage showed the site of the crash in the Alps - courtesy BFM TV',
+ 'duration': 47,
+ 'upload_date': '20150324',
+ 'uploader': 'BBC News',
+ },
+ 'params': {
+ 'skip_download': True,
+ }
+ }, {
+ 'url': 'http://www.bbc.com/turkce/haberler/2015/06/150615_telabyad_kentin_cogu',
+ 'note': 'Video',
+ 'info_dict': {
+ 'id': 'NA',
+ 'ext': 'mp4',
+ 'title': 'YPG: Tel Abyad\'\u0131n tamam\u0131 kontrol\xfcm\xfczde',
+ 'description': 'YPG: Tel Abyad\'\u0131n tamam\u0131 kontrol\xfcm\xfczde',
+ 'duration': 47,
+ 'upload_date': '20150615',
+ 'uploader': 'BBC News',
+ },
+ 'params': {
+ 'skip_download': True,
+ }
+ }, {
+ 'url': 'http://www.bbc.com/mundo/video_fotos/2015/06/150619_video_honduras_militares_hospitales_corrupcion_aw',
+ 'note': 'Video',
+ 'info_dict': {
+ 'id': '39275083',
+ 'ext': 'mp4',
+ 'title': 'Honduras militariza sus hospitales por nuevo esc\xe1ndalo de corrupci\xf3n',
+ 'description': 'Honduras militariza sus hospitales por nuevo esc\xe1ndalo de corrupci\xf3n',
+ 'duration': 87,
+ 'upload_date': '20150619',
+ 'uploader': 'BBC News',
+ },
+ 'params': {
+ 'skip_download': True,
+ }
+ }]
+
+ def _real_extract(self, url):
+ list_id = self._match_id(url)
+ webpage = self._download_webpage(url, list_id)
+
+ list_title = self._html_search_regex(r'<title>(.*?)(?:\s*-\s*BBC [^ ]+)?</title>', webpage, 'list title')
+
+ pubdate = self._html_search_regex(r'"datePublished":\s*"(\d+-\d+-\d+)', webpage, 'date', default=None)
+ if pubdate:
+ pubdate = pubdate.replace('-', '')
+
+ ret = []
+ jsent = []
+
+ # works with bbc.com/news/something-something-123456 articles
+ jsent = map(
+ lambda m: self._parse_json(m, list_id),
+ re.findall(r"data-media-meta='({[^']+})'", webpage)
+ )
+
+ if len(jsent) == 0:
+ # http://www.bbc.com/news/video_and_audio/international
+ # and single-video articles
+ masset = self._html_search_regex(r'mediaAssetPage\.init\(\s*({.+?}), "/', webpage, 'mediaassets', default=None)
+ if masset:
+ jmasset = self._parse_json(masset, list_id)
+ for key, val in jmasset.get('videos', {}).items():
+ for skey, sval in val.items():
+ sval['id'] = skey
+ jsent.append(sval)
+
+ if len(jsent) == 0:
+ # stubbornly generic extractor for {json with "image":{allvideoshavethis},etc}
+ # in http://www.bbc.com/news/video_and_audio/international
+ # prone to breaking if entries have sourceFiles list
+ jsent = map(
+ lambda m: self._parse_json(m, list_id),
+ re.findall(r"({[^{}]+image\":{[^}]+}[^}]+})", webpage)
+ )
+
+ if len(jsent) == 0:
+ raise ExtractorError('No video found', expected=True)
+
+ for jent in jsent:
+ programme_id = jent.get('externalId')
+ xml_url = jent.get('href')
+
+ title = jent.get('caption', '')
+ if title == '':
+ title = list_title
+
+ duration = parse_duration(jent.get('duration'))
+ description = list_title
+ if jent.get('caption', '') != '':
+ description += ' - ' + jent.get('caption')
+ thumbnail = None
+ if jent.get('image') is not None:
+ thumbnail = jent['image'].get('href')
+
+ formats = []
+ subtitles = []
+
+ if programme_id:
+ formats, subtitles = self._download_media_selector(programme_id)
+ elif jent.get('sourceFiles') is not None:
+ # mediaselector not used at
+ # http://www.bbc.com/turkce/haberler/2015/06/150615_telabyad_kentin_cogu
+ for key, val in jent['sourceFiles'].items():
+ formats.append({
+ 'ext': val.get('encoding'),
+ 'url': val.get('url'),
+ 'filesize': int(val.get('filesize')),
+ 'format_id': key
+ })
+ elif xml_url:
+ # Cheap fallback
+ # http://playlists.bbc.co.uk/news/(list_id)[ABC..]/playlist.sxml
+ xml = self._download_webpage(xml_url, programme_id, 'Downloading playlist.sxml for externalId (fallback)')
+ programme_id = self._search_regex(r'<mediator [^>]*identifier="(.+?)"', xml, 'playlist.sxml (externalId fallback)')
+ formats, subtitles = self._download_media_selector(programme_id)
+
+ if len(formats) == 0:
+ raise ExtractorError('unsupported json media entry.\n ' + str(jent) + '\n')
+
+ self._sort_formats(formats)
+
+ id = jent.get('id') if programme_id is None else programme_id
+ if id is None:
+ id = 'NA'
+
+ ret.append({
+ 'id': id,
+ 'uploader': 'BBC News',
+ 'upload_date': pubdate,
+ 'title': title,
+ 'description': description,
+ 'thumbnail': thumbnail,
+ 'duration': duration,
+ 'formats': formats,
+ 'subtitles': subtitles,
+ })
+
+ if len(ret) > 0:
+ return self.playlist_result(ret, list_id, list_title)
+ raise ExtractorError('No video found', expected=True)
| bbc.com/news uses the same mediaselector format, but a different mediaselector url, and inlined json + xml playlist.sxml methods for obtaining video ids.
_download_media_selector is mostly redundant except for the hardcoded url; perhaps it should be made a third argument?
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/6026 | 2015-06-19T06:47:09Z | 2015-07-25T14:22:21Z | 2015-07-25T14:22:21Z | 2015-07-25T14:25:31Z | 2,528 | ytdl-org/youtube-dl | 50,439 |
Refs #25136 -- Added a missing field/model in aggregation topic guide. | diff --git a/docs/topics/db/aggregation.txt b/docs/topics/db/aggregation.txt
index fbf3e51ebd2bf..310745d869b88 100644
--- a/docs/topics/db/aggregation.txt
+++ b/docs/topics/db/aggregation.txt
@@ -193,24 +193,25 @@ Combining multiple aggregations with ``annotate()`` will `yield the wrong
results <https://code.djangoproject.com/ticket/10060>`_ because joins are used
instead of subqueries:
- >>> Book.objects.first().authors.count()
+ >>> book = Book.objects.first()
+ >>> book.authors.count()
2
- >>> Book.objects.first().chapters.count()
+ >>> book.store_set.count()
3
- >>> q = Book.objects.annotate(Count('authors'), Count('chapters'))
+ >>> q = Book.objects.annotate(Count('authors'), Count('store'))
>>> q[0].authors__count
6
- >>> q[0].chapters__count
+ >>> q[0].store__count
6
For most aggregates, there is no way to avoid this problem, however, the
:class:`~django.db.models.Count` aggregate has a ``distinct`` parameter that
may help:
- >>> q = Book.objects.annotate(Count('authors', distinct=True), Count('chapters', distinct=True))
+ >>> q = Book.objects.annotate(Count('authors', distinct=True), Count('store', distinct=True))
>>> q[0].authors__count
2
- >>> q[0].chapters__count
+ >>> q[0].store__count
3
.. admonition:: If in doubt, inspect the SQL query!
| Reported on django-users: https://groups.google.com/d/topic/django-users/uSXcyWdm7q4/discussion
| https://api.github.com/repos/django/django/pulls/6524 | 2016-04-27T18:51:00Z | 2016-04-27T19:26:10Z | 2016-04-27T19:26:10Z | 2016-04-27T19:26:42Z | 378 | django/django | 51,492 |
Update config.html | diff --git a/gae_proxy/web_ui/config.html b/gae_proxy/web_ui/config.html
index 704861d5f0..4bf92b3135 100644
--- a/gae_proxy/web_ui/config.html
+++ b/gae_proxy/web_ui/config.html
@@ -8,7 +8,7 @@
<div id="public-appid-tip" class="hide">
<p>
<span color="red">{{ _( "The public appids are disabled to access videos or download files." ) }}</span>
- <a href="https://github.com/XX-net/XX-Net/wiki/Register-Google-appid" target="_blank">({{ _( "How to apply" ) }})</a>
+ <a href="https://github.com/XX-net/XX-Net/wiki/how-to-create-my-appids" target="_blank">({{ _( "How to apply" ) }})</a>
</p>
</div>
<div id="gae-appid-tip" class="hide">
| https://api.github.com/repos/XX-net/XX-Net/pulls/2850 | 2016-04-12T01:57:50Z | 2016-04-12T13:26:23Z | 2016-04-12T13:26:23Z | 2016-04-13T04:32:05Z | 219 | XX-net/XX-Net | 17,275 |
|
Added format to specify VAE filename for generated image filenames | diff --git a/modules/images.py b/modules/images.py
index a41965ab6f5..3abaf4121ae 100644
--- a/modules/images.py
+++ b/modules/images.py
@@ -21,6 +21,8 @@
from modules import sd_samplers, shared, script_callbacks, errors
from modules.shared import opts, cmd_opts
+import modules.sd_vae as sd_vae
+
LANCZOS = (Image.Resampling.LANCZOS if hasattr(Image, 'Resampling') else Image.LANCZOS)
@@ -335,6 +337,16 @@ def sanitize_filename_part(text, replace_spaces=True):
class FilenameGenerator:
+ def get_vae_filename(self): #get the name of the VAE file.
+ if sd_vae.loaded_vae_file is None:
+ return "NoneType"
+ file_name = os.path.basename(sd_vae.loaded_vae_file)
+ split_file_name = file_name.split('.')
+ if len(split_file_name) > 1 and split_file_name[0] == '':
+ return split_file_name[1] # if the first character of the filename is "." then [1] is obtained.
+ else:
+ return split_file_name[0]
+
replacements = {
'seed': lambda self: self.seed if self.seed is not None else '',
'steps': lambda self: self.p and self.p.steps,
@@ -358,6 +370,8 @@ class FilenameGenerator:
'hasprompt': lambda self, *args: self.hasprompt(*args), # accepts formats:[hasprompt<prompt1|default><prompt2>..]
'clip_skip': lambda self: opts.data["CLIP_stop_at_last_layers"],
'denoising': lambda self: self.p.denoising_strength if self.p and self.p.denoising_strength else NOTHING_AND_SKIP_PREVIOUS_TEXT,
+ 'vae_filename': lambda self: self.get_vae_filename(),
+
}
default_time_format = '%Y%m%d%H%M%S'
| Subject:.
Added format to specify VAE filename for generated image filenames
Body:.
1) Added new line 24 to import sd_vae module.
2) Added new method get_vae_filename at lines 340-349 to obtain the VAE filename to be used for image generation and further process it to extract only the filename by splitting it with a dot symbol. 3) Added a new lambda function 'vae_filename' at line 373 to handle VAE filenames.
Reason:.
A function was needed to get the VAE filename and handle it in the program.
Test:.
We tested whether we could use this new functionality to get the expected file names. The correct behaviour was confirmed for the following commonly distributed VAE files. vae-ft-mse-840000-ema-pruned.safetensors -> vae-ft-mse-840000-ema-pruned anything-v4.0.vae.pt -> anything-v4.0
ruff response:.
There were no problems with the code I added.
There was a minor configuration error in a line I did not modify, but I did not modify it as it was not relevant to this modification. Logged.
images.py:426:56: F841 [*] Local variable `_` is assigned to but never used images.py:432:43: F841 [*] Local variable `_` is assigned to but never used
Impact:.
This change makes it easier to retrieve the VAE filename used for image generation and use it in the programme.
# Please read the [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing) before submitting a pull request!
If you have a large change, pay special attention to this paragraph:
> Before making changes, if you think that your feature will result in more than 100 lines changing, find me and talk to me about the feature you are proposing. It pains me to reject the hard work someone else did, but I won't add everything to the repo, and it's better if the rejection happens before you have to waste time working on the feature.
Otherwise, after making sure you're following the rules described in wiki page, remove this section and continue on.
**Describe what this pull request is trying to achieve.**
A clear and concise description of what you're trying to accomplish with this, so your intent doesn't have to be extracted from your code.
**Additional notes and description of your changes**
More technical discussion about your changes go here, plus anything that a maintainer might have to specifically take a look at, or be wary of.
**Environment this was tested in**
List the environment you have developed / tested this on. As per the contributing page, changes should be able to work on Windows out of the box.
- OS: [e.g. Windows, Linux]
- Browser: [e.g. chrome, safari]
- Graphics card: [e.g. NVIDIA RTX 2080 8GB, AMD RX 6600 8GB]
**Screenshots or videos of your changes**
If applicable, screenshots or a video showing off your changes. If it edits an existing UI, it should ideally contain a comparison of what used to be there, before your changes were made.
This is **required** for anything that touches the user interface. | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/10655 | 2023-05-23T07:52:56Z | 2023-05-27T17:11:22Z | 2023-05-27T17:11:22Z | 2023-05-27T17:11:22Z | 443 | AUTOMATIC1111/stable-diffusion-webui | 40,310 |
fix OrderType and OrderSide | diff --git a/ts/src/base/types.ts b/ts/src/base/types.ts
index 84bd4b3295c6..3dddc4fdd525 100644
--- a/ts/src/base/types.ts
+++ b/ts/src/base/types.ts
@@ -198,6 +198,6 @@ export type IndexType = number | string;
export type Int = number;
-export type OrderSide = 'buy' | 'sell';
+export type OrderSide = 'buy' | 'sell' | string;
-export type OrderType = 'limit' | 'market';
+export type OrderType = 'limit' | 'market' | string;
| - sometimes, we support custom values like `stop_market` or `long` so these types must be more inclusive | https://api.github.com/repos/ccxt/ccxt/pulls/17712 | 2023-04-29T13:19:14Z | 2023-04-29T14:07:35Z | 2023-04-29T14:07:35Z | 2023-04-29T14:07:35Z | 139 | ccxt/ccxt | 13,002 |
Change the color for deferred status to mediumpurple | diff --git a/airflow/settings.py b/airflow/settings.py
index 140375913268d..fc2c6bbbef8e0 100644
--- a/airflow/settings.py
+++ b/airflow/settings.py
@@ -93,7 +93,7 @@
"upstream_failed": "orange",
"skipped": "pink",
"scheduled": "tan",
- "deferred": "lightseagreen",
+ "deferred": "mediumpurple",
}
diff --git a/airflow/utils/state.py b/airflow/utils/state.py
index 39e89b56a9608..99fe392627209 100644
--- a/airflow/utils/state.py
+++ b/airflow/utils/state.py
@@ -120,9 +120,9 @@ class State:
TaskInstanceState.SKIPPED: 'pink',
TaskInstanceState.REMOVED: 'lightgrey',
TaskInstanceState.SCHEDULED: 'tan',
- TaskInstanceState.SENSING: 'lightseagreen',
- TaskInstanceState.DEFERRED: 'lightseagreen',
+ TaskInstanceState.DEFERRED: 'mediumpurple',
}
+ state_color[TaskInstanceState.SENSING] = state_color[TaskInstanceState.DEFERRED]
state_color.update(STATE_COLORS) # type: ignore
@classmethod
diff --git a/docs/apache-airflow/howto/customize-ui.rst b/docs/apache-airflow/howto/customize-ui.rst
index 1d52e360c2eca..179c223417119 100644
--- a/docs/apache-airflow/howto/customize-ui.rst
+++ b/docs/apache-airflow/howto/customize-ui.rst
@@ -45,7 +45,7 @@ following steps:
"upstream_failed": "orange",
"skipped": "darkorchid",
"scheduled": "tan",
- "deferred": "lightseagreen",
+ "deferred": "mediumpurple",
}
diff --git a/tests/www/views/test_views_home.py b/tests/www/views/test_views_home.py
index 1225df7146ba9..748f5ee6b3e25 100644
--- a/tests/www/views/test_views_home.py
+++ b/tests/www/views/test_views_home.py
@@ -51,10 +51,10 @@ def test_home(capture_templates, admin_client):
check_content_in_response('DAGs', resp)
val_state_color_mapping = (
'const STATE_COLOR = {'
- '"deferred": "lightseagreen", "failed": "red", '
+ '"deferred": "mediumpurple", "failed": "red", '
'"null": "lightblue", "queued": "gray", '
'"removed": "lightgrey", "restarting": "violet", "running": "lime", '
- '"scheduled": "tan", "sensing": "lightseagreen", '
+ '"scheduled": "tan", "sensing": "mediumpurple", '
'"shutdown": "blue", "skipped": "pink", '
'"success": "green", "up_for_reschedule": "turquoise", '
'"up_for_retry": "gold", "upstream_failed": "orange"};'
| Changes the color for the deferred status to something more distinct, mediumpurple.


closes: #18245 | https://api.github.com/repos/apache/airflow/pulls/18414 | 2021-09-21T19:25:23Z | 2021-10-06T19:45:12Z | 2021-10-06T19:45:12Z | 2021-10-06T19:45:12Z | 708 | apache/airflow | 14,479 |
Update readme.md with proper dependency version | diff --git a/README.md b/README.md
index 1045189d6d63b..c02e2556fc9e7 100644
--- a/README.md
+++ b/README.md
@@ -140,7 +140,7 @@ localstack start
### Using `docker-compose`
-You can also use the `docker-compose.yml` file from the repository and use this command (currently requires `docker-compose` version 2.1+):
+You can also use the `docker-compose.yml` file from the repository and use this command (currently requires `docker-compose` version 1.9.0+):
```
docker-compose up
| The docker-compose.yml file in the root director is using the version 2.1 file spec. This requires Compose 1.9.0+. Updating readme.md to reflect this. docker-compose latest version is currently at 1.27.4
See: https://docs.docker.com/compose/compose-file/compose-versioning/#version-21
**Please refer to the contribution guidelines in the README when submitting PRs.**
| https://api.github.com/repos/localstack/localstack/pulls/3163 | 2020-10-23T18:55:34Z | 2020-10-24T09:59:17Z | 2020-10-24T09:59:17Z | 2020-10-24T09:59:17Z | 144 | localstack/localstack | 28,832 |
[polskieradio] Add thumbnails. | diff --git a/youtube_dl/extractor/polskieradio.py b/youtube_dl/extractor/polskieradio.py
index d3bebaea32f..9e7eab12edc 100644
--- a/youtube_dl/extractor/polskieradio.py
+++ b/youtube_dl/extractor/polskieradio.py
@@ -33,6 +33,7 @@ class PolskieRadioIE(InfoExtractor):
'timestamp': 1456594200,
'upload_date': '20160227',
'duration': 2364,
+ 'thumbnail': 're:^https?://static.prsa.pl/images/.*\.jpg$'
},
}],
}, {
@@ -68,6 +69,8 @@ def _real_extract(self, url):
r'(?s)<span[^>]+id="datetime2"[^>]*>(.+?)</span>',
webpage, 'timestamp', fatal=False))
+ thumbnail_url = self._og_search_thumbnail(webpage)
+
entries = []
media_urls = set()
@@ -87,6 +90,7 @@ def _real_extract(self, url):
'duration': int_or_none(media.get('length')),
'vcodec': 'none' if media.get('provider') == 'audio' else None,
'timestamp': timestamp,
+ 'thumbnail': thumbnail_url
})
title = self._og_search_title(webpage).strip()
| ### What is the purpose of your _pull request_?
- [x] Bug fix
- [ ] New extractor
- [ ] New feature
---
### Description of your _pull request_ and other information
This is a simple change to extract thumbnails from Polskie Radio auditions.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/10028 | 2016-07-07T09:31:06Z | 2016-07-08T11:36:14Z | 2016-07-08T11:36:14Z | 2016-08-25T10:08:12Z | 316 | ytdl-org/youtube-dl | 49,828 |
gh-89653: PEP 670: Convert PyUnicode_KIND() macro to function | diff --git a/Include/cpython/unicodeobject.h b/Include/cpython/unicodeobject.h
index 8c53962437b6e0..030614e263344d 100644
--- a/Include/cpython/unicodeobject.h
+++ b/Include/cpython/unicodeobject.h
@@ -242,9 +242,23 @@ enum PyUnicode_Kind {
PyUnicode_4BYTE_KIND = 4
};
-/* Return one of the PyUnicode_*_KIND values defined above. */
+// PyUnicode_KIND(): Return one of the PyUnicode_*_KIND values defined above.
+#if !defined(Py_LIMITED_API) || Py_LIMITED_API+0 < 0x030c0000
+// gh-89653: Converting this macro to a static inline function would introduce
+// new compiler warnings on "kind < PyUnicode_KIND(str)" (compare signed and
+// unsigned numbers) where kind type is an int or on
+// "unsigned int kind = PyUnicode_KIND(str)" (cast signed to unsigned).
+// Only declare the function as static inline function in the limited C API
+// version 3.12 which is stricter.
#define PyUnicode_KIND(op) \
(_PyASCIIObject_CAST(op)->state.kind)
+#else
+// Limited C API 3.12 and newer
+static inline int PyUnicode_KIND(PyObject *op) {
+ assert(PyUnicode_IS_READY(op));
+ return _PyASCIIObject_CAST(op)->state.kind;
+}
+#endif
/* Return a void pointer to the raw unicode buffer. */
static inline void* _PyUnicode_COMPACT_DATA(PyObject *op) {
diff --git a/Modules/_decimal/_decimal.c b/Modules/_decimal/_decimal.c
index 65885965ff046d..5cbddac6232487 100644
--- a/Modules/_decimal/_decimal.c
+++ b/Modules/_decimal/_decimal.c
@@ -1933,7 +1933,7 @@ is_space(enum PyUnicode_Kind kind, const void *data, Py_ssize_t pos)
Return NULL if malloc fails and an empty string if invalid characters
are found. */
static char *
-numeric_as_ascii(const PyObject *u, int strip_ws, int ignore_underscores)
+numeric_as_ascii(PyObject *u, int strip_ws, int ignore_underscores)
{
enum PyUnicode_Kind kind;
const void *data;
@@ -2047,7 +2047,7 @@ PyDecType_FromCStringExact(PyTypeObject *type, const char *s,
/* Return a new PyDecObject or a subtype from a PyUnicodeObject. */
static PyObject *
-PyDecType_FromUnicode(PyTypeObject *type, const PyObject *u,
+PyDecType_FromUnicode(PyTypeObject *type, PyObject *u,
PyObject *context)
{
PyObject *dec;
@@ -2067,7 +2067,7 @@ PyDecType_FromUnicode(PyTypeObject *type, const PyObject *u,
* conversion. If the conversion is not exact, fail with InvalidOperation.
* Allow leading and trailing whitespace in the input operand. */
static PyObject *
-PyDecType_FromUnicodeExactWS(PyTypeObject *type, const PyObject *u,
+PyDecType_FromUnicodeExactWS(PyTypeObject *type, PyObject *u,
PyObject *context)
{
PyObject *dec;
@@ -2150,7 +2150,7 @@ PyDecType_FromSsizeExact(PyTypeObject *type, mpd_ssize_t v, PyObject *context)
/* Convert from a PyLongObject. The context is not modified; flags set
during conversion are accumulated in the status parameter. */
static PyObject *
-dec_from_long(PyTypeObject *type, const PyObject *v,
+dec_from_long(PyTypeObject *type, PyObject *v,
const mpd_context_t *ctx, uint32_t *status)
{
PyObject *dec;
@@ -2201,7 +2201,7 @@ dec_from_long(PyTypeObject *type, const PyObject *v,
/* Return a new PyDecObject from a PyLongObject. Use the context for
conversion. */
static PyObject *
-PyDecType_FromLong(PyTypeObject *type, const PyObject *v, PyObject *context)
+PyDecType_FromLong(PyTypeObject *type, PyObject *v, PyObject *context)
{
PyObject *dec;
uint32_t status = 0;
@@ -2227,7 +2227,7 @@ PyDecType_FromLong(PyTypeObject *type, const PyObject *v, PyObject *context)
/* Return a new PyDecObject from a PyLongObject. Use a maximum context
for conversion. If the conversion is not exact, set InvalidOperation. */
static PyObject *
-PyDecType_FromLongExact(PyTypeObject *type, const PyObject *v,
+PyDecType_FromLongExact(PyTypeObject *type, PyObject *v,
PyObject *context)
{
PyObject *dec;
diff --git a/Objects/stringlib/eq.h b/Objects/stringlib/eq.h
index 2f2438845a629c..2eac4baf5ca9ce 100644
--- a/Objects/stringlib/eq.h
+++ b/Objects/stringlib/eq.h
@@ -6,9 +6,6 @@
Py_LOCAL_INLINE(int)
unicode_eq(PyObject *a, PyObject *b)
{
- assert(PyUnicode_Check(a));
- assert(PyUnicode_Check(b));
-
if (PyUnicode_GET_LENGTH(a) != PyUnicode_GET_LENGTH(b))
return 0;
if (PyUnicode_GET_LENGTH(a) == 0)
| In the limited C API version 3.12, PyUnicode_KIND() is now
implemented as a static inline function. Keep the macro for the
regular C API and for the limited C API version 3.11 and older to
prevent introducing new compiler warnings.
Update _decimal.c and stringlib/eq.h for PyUnicode_KIND().
<!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
gh-NNNNN: Summary of the changes made
```
Where: gh-NNNNN refers to the GitHub issue number.
Most PRs will require an issue number. Trivial changes, like fixing a typo, do not need an issue.
# Backport Pull Request title
If this is a backport PR (PR made against branches other than `main`),
please ensure that the PR title is in the following format:
```
[X.Y] <title from the original PR> (GH-NNNN)
```
Where: [X.Y] is the branch name, e.g. [3.6].
GH-NNNN refers to the PR number from `main`.
-->
| https://api.github.com/repos/python/cpython/pulls/92705 | 2022-05-12T00:33:12Z | 2022-05-13T09:49:57Z | 2022-05-13T09:49:57Z | 2022-05-16T08:04:04Z | 1,204 | python/cpython | 4,236 |
fix: check-license | diff --git a/scripts/check-license.py b/scripts/check-license.py
index 67caa30a3e3f..e5d5792d06b6 100755
--- a/scripts/check-license.py
+++ b/scripts/check-license.py
@@ -19,20 +19,24 @@ def err(s: str) -> None:
COPYRIGHT = [
- r"^\(\/\/\|#\) Copyright (c) Microsoft Corporation.$", r"^\(\/\/\|#\) SPDX-License-Identifier: Apache-2.0$",
- r"^\(\/\/\|#\) DeepSpeed Team$"
+ (r"^# Copyright (c) Microsoft Corporation.$", r"^\/\/ Copyright (c) Microsoft Corporation.$"),
+ (r"^# SPDX-License-Identifier: Apache-2.0$", r"^\/\/ SPDX-License-Identifier: Apache-2.0$"),
+ (r"^# DeepSpeed Team$", r"^\/\/ DeepSpeed Team$"),
]
success = True
failures = []
for f in sys.argv[1:]:
for copyright_line in COPYRIGHT:
- if not success:
- break
- res = subprocess.run(["git", "grep", "--quiet", "-e", copyright_line, f], capture_output=True)
+ cmd = ["git", "grep", "--quiet"]
+ for line in copyright_line:
+ cmd.extend(["-e", line])
+ cmd.append(f)
+ res = subprocess.run(cmd, capture_output=True)
if res.returncode == 1:
success = False
failures.append(f)
+ break
elif res.returncode == 2:
err(f"Error invoking grep on {', '.join(sys.argv[1:])}:")
err(res.stderr.decode("utf-8"))
| git grep on apple is currently unable to parse the regex used in the license check.
I have changed the logic in the license check script such that it works on mac and linux.
On Mac, the git grep does not work, even though the grep works:
<img width="706" alt="image" src="https://github.com/microsoft/DeepSpeed/assets/56836461/26215f5d-3a88-442d-89d4-1e136a7af519">
While remoted to a machine running Ubuntu, the git grep works:
<img width="665" alt="image" src="https://github.com/microsoft/DeepSpeed/assets/56836461/891485e3-a81d-4d6d-adc1-c4cde3af0070">
| https://api.github.com/repos/microsoft/DeepSpeed/pulls/4432 | 2023-10-01T12:35:42Z | 2023-10-03T17:27:39Z | 2023-10-03T17:27:39Z | 2023-10-03T20:32:30Z | 372 | microsoft/DeepSpeed | 10,379 |
Use win32 as platform in tox.ini | diff --git a/tox.ini b/tox.ini
index 8965b6055c6..03f638c0efa 100644
--- a/tox.ini
+++ b/tox.ini
@@ -26,8 +26,8 @@ source_paths = acme/acme certbot/certbot certbot-apache/certbot_apache certbot-c
passenv =
CERTBOT_NO_PIN
platform =
- win: win64
- posix: ^(?!.*win64).*$
+ win: win32
+ posix: ^(?!.*win32).*$
commands_pre = python {toxinidir}/tools/pipstrap.py
commands =
!cover-win: {[base]install_and_test} {[base]win_all_packages}
| This is used to match against sys.platform, which for windows is
win32 regardless of bitness | https://api.github.com/repos/certbot/certbot/pulls/9277 | 2022-04-11T18:43:19Z | 2022-04-18T21:40:46Z | 2022-04-18T21:40:46Z | 2022-04-18T21:40:47Z | 163 | certbot/certbot | 105 |
adding dora | diff --git a/README.md b/README.md
index 21bd737c..aa2ddfc1 100644
--- a/README.md
+++ b/README.md
@@ -800,6 +800,7 @@ on MNIST digits[DEEP LEARNING]
* [bqplot](https://github.com/bloomberg/bqplot) - An API for plotting in Jupyter (IPython)
* [pastalog](https://github.com/rewonc/pastalog) - Simple, realtime visualization of neural network training performance.
* [caravel](https://github.com/airbnb/caravel) - A data exploration platform designed to be visual, intuitive, and interactive.
+* [Dora](https://github.com/nathanepstein/dora) - Tools for exploratory data analysis in Python.
<a name="python-misc" />
#### Misc Scripts / iPython Notebooks / Codebases
| Adding Dora (library for exploratory data analysis in Python) to the list.
| https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/274 | 2016-05-11T02:03:01Z | 2016-05-11T14:37:10Z | 2016-05-11T14:37:10Z | 2016-05-11T14:37:14Z | 196 | josephmisiti/awesome-machine-learning | 52,304 |
New cloudsplaining tool to AWS Pentest page | diff --git a/Methodology and Resources/Cloud - AWS Pentest.md b/Methodology and Resources/Cloud - AWS Pentest.md
index e795052a1b..e20e2698a2 100644
--- a/Methodology and Resources/Cloud - AWS Pentest.md
+++ b/Methodology and Resources/Cloud - AWS Pentest.md
@@ -149,6 +149,13 @@
$ python s3-objects-check.py -p whitebox-profile -e blackbox-profile
```
+* [cloudsplaining](https://github.com/salesforce/cloudsplaining) - An AWS IAM Security Assessment tool that identifies violations of least privilege and generates a risk-prioritized report
+ ```powershell
+ $ pip3 install --user cloudsplaining
+ $ cloudsplaining download --profile myawsprofile
+ $ cloudsplaining scan --input-file default.json
+ ```
+
* [weirdAAL](https://github.com/carnal0wnage/weirdAAL/wiki) - AWS Attack Library
```powershell
python3 weirdAAL.py -m ec2_describe_instances -t demo
| https://api.github.com/repos/swisskyrepo/PayloadsAllTheThings/pulls/320 | 2021-01-12T12:02:01Z | 2021-01-12T12:42:37Z | 2021-01-12T12:42:36Z | 2021-01-12T14:04:03Z | 255 | swisskyrepo/PayloadsAllTheThings | 8,511 |
|
Add plug points for code/config initializations in LambdaExecutorPlugin | diff --git a/localstack/services/awslambda/lambda_api.py b/localstack/services/awslambda/lambda_api.py
index 2fb94d851fd28..a56fc1f24d078 100644
--- a/localstack/services/awslambda/lambda_api.py
+++ b/localstack/services/awslambda/lambda_api.py
@@ -224,14 +224,6 @@ def check_batch_size_range(source_arn, batch_size=None):
return batch_size
-def add_function_mapping(lambda_name, lambda_handler, lambda_cwd=None):
- region = LambdaRegion.get()
- arn = func_arn(lambda_name)
- lambda_details = region.lambdas[arn]
- lambda_details.versions.get(VERSION_LATEST)["Function"] = lambda_handler
- lambda_details.cwd = lambda_cwd or lambda_details.cwd
-
-
def build_mapping_obj(data) -> Dict:
mapping = {}
function_name = data["FunctionName"]
@@ -963,18 +955,21 @@ def set_archive_code(code, lambda_name, zip_file_content=None):
return tmp_dir
-def set_function_code(code, lambda_name, lambda_cwd=None):
+def set_function_code(lambda_function: LambdaFunction):
def _set_and_configure():
- lambda_handler = do_set_function_code(code, lambda_name, lambda_cwd=lambda_cwd)
- add_function_mapping(lambda_name, lambda_handler, lambda_cwd)
+ lambda_handler = do_set_function_code(lambda_function)
+ lambda_function.versions.get(VERSION_LATEST)["Function"] = lambda_handler
+ # initialize function code via plugins
+ for plugin in lambda_executors.LambdaExecutorPlugin.get_plugins():
+ plugin.init_function_code(lambda_function)
# unzipping can take some time - limit the execution time to avoid client/network timeout issues
run_for_max_seconds(25, _set_and_configure)
- return {"FunctionName": lambda_name}
+ return {"FunctionName": lambda_function.name()}
-def do_set_function_code(code, lambda_name, lambda_cwd=None):
- def generic_handler(event, context):
+def do_set_function_code(lambda_function: LambdaFunction):
+ def generic_handler(*_):
raise ClientError(
(
'Unable to find executor for Lambda function "%s". Note that '
@@ -984,15 +979,16 @@ def generic_handler(event, context):
)
region = LambdaRegion.get()
- arn = func_arn(lambda_name)
+ lambda_name = lambda_function.name()
+ arn = lambda_function.arn()
lambda_details = region.lambdas[arn]
runtime = get_lambda_runtime(lambda_details)
lambda_environment = lambda_details.envvars
handler_name = lambda_details.handler = lambda_details.handler or LAMBDA_DEFAULT_HANDLER
- code_passed = code
- code = code or lambda_details.code
- is_local_mount = code.get("S3Bucket") == config.BUCKET_MARKER_LOCAL
+ code_passed = lambda_function.code
+ is_local_mount = code_passed.get("S3Bucket") == config.BUCKET_MARKER_LOCAL
zip_file_content = None
+ lambda_cwd = lambda_function.cwd
LAMBDA_EXECUTOR.cleanup(arn)
@@ -1361,7 +1357,7 @@ def create_function():
func_details.image_config = data.get("ImageConfig", {})
func_details.tracing_config = data.get("TracingConfig", {})
func_details.set_dead_letter_config(data)
- result = set_function_code(func_details.code, lambda_name)
+ result = set_function_code(func_details)
if isinstance(result, Response):
del region.lambdas[arn]
return result
@@ -1460,13 +1456,14 @@ def update_function_code(function):
"""
region = LambdaRegion.get()
arn = func_arn(function)
- if arn not in region.lambdas:
+ func_details = region.lambdas.get(arn)
+ if not func_details:
return not_found_error("Function not found: %s" % arn)
data = json.loads(to_str(request.data))
- result = set_function_code(data, function)
+ func_details.code = data
+ result = set_function_code(func_details)
if isinstance(result, Response):
return result
- func_details = region.lambdas.get(arn)
func_details.last_modified = datetime.utcnow()
result.update(format_func_details(func_details))
if data.get("Publish"):
@@ -1558,6 +1555,10 @@ def update_function_configuration(function):
func_details = region.lambdas.get(arn)
result.update(format_func_details(func_details))
+ # initialize plugins
+ for plugin in lambda_executors.LambdaExecutorPlugin.get_plugins():
+ plugin.init_function_configuration(func_details)
+
return jsonify(result)
diff --git a/localstack/services/awslambda/lambda_executors.py b/localstack/services/awslambda/lambda_executors.py
index 80e1c95d02981..da2ab05310cc9 100644
--- a/localstack/services/awslambda/lambda_executors.py
+++ b/localstack/services/awslambda/lambda_executors.py
@@ -11,7 +11,7 @@
import time
import traceback
from multiprocessing import Process, Queue
-from typing import Any, Dict, Optional, Tuple, Union
+from typing import Any, Dict, List, Optional, Tuple, Union
from localstack import config
from localstack.services.awslambda.lambda_utils import (
@@ -145,7 +145,7 @@ def __init__(
class LambdaExecutorPlugin:
"""Plugin abstraction that allows to hook in additional functionality into the Lambda executors."""
- INSTANCES = []
+ INSTANCES: List["LambdaExecutorPlugin"] = []
def initialize(self):
"""Called once, for any active plugin to run initialization logic (e.g., downloading dependencies).
@@ -168,8 +168,16 @@ def process_result(
"""Optionally modify the result returned from the given Lambda invocation."""
return result
+ def init_function_configuration(self, lambda_function: LambdaFunction):
+ """Initialize the configuration of the given function upon creation or function update."""
+ pass
+
+ def init_function_code(self, lambda_function: LambdaFunction):
+ """Initialize the code of the given function upon creation or function update."""
+ pass
+
@classmethod
- def get_plugins(cls):
+ def get_plugins(cls) -> List["LambdaExecutorPlugin"]:
if not cls.INSTANCES:
classes = get_all_subclasses(LambdaExecutorPlugin)
cls.INSTANCES = [clazz() for clazz in classes]
diff --git a/localstack/utils/testutil.py b/localstack/utils/testutil.py
index e737c792e0be0..a96dcab3b4e4f 100644
--- a/localstack/utils/testutil.py
+++ b/localstack/utils/testutil.py
@@ -1,5 +1,6 @@
import glob
import importlib
+import io
import json
import os
import shutil
@@ -7,7 +8,7 @@
import time
import zipfile
from contextlib import contextmanager
-from typing import Dict
+from typing import Callable, Dict, List
import requests
from six import iteritems
@@ -35,14 +36,18 @@
load_file,
mkdir,
poll_condition,
+ rm_rf,
run,
save_file,
+ short_uid,
to_str,
)
ARCHIVE_DIR_PREFIX = "lambda.archive."
DEFAULT_GET_LOG_EVENTS_DELAY = 3
LAMBDA_TIMEOUT_SEC = 8
+LAMBDA_ASSETS_BUCKET_NAME = "ls-test-lambda-assets-bucket"
+MAX_LAMBDA_ARCHIVE_UPLOAD_SIZE = 50_000_000
def is_local_test_mode():
@@ -64,48 +69,63 @@ def rm_dir(dir):
shutil.rmtree(dir)
-def create_lambda_archive(script, get_content=False, libs=[], runtime=None, file_name=None):
+def create_lambda_archive(
+ script: str,
+ get_content: bool = False,
+ libs: List[str] = [],
+ runtime: str = None,
+ file_name: str = None,
+ exclude_func: Callable[[str], bool] = None,
+):
"""Utility method to create a Lambda function archive"""
runtime = runtime or LAMBDA_DEFAULT_RUNTIME
- tmp_dir = tempfile.mkdtemp(prefix=ARCHIVE_DIR_PREFIX)
- TMP_FILES.append(tmp_dir)
- file_name = file_name or get_handler_file_from_name(LAMBDA_DEFAULT_HANDLER, runtime=runtime)
- script_file = os.path.join(tmp_dir, file_name)
- if os.path.sep in script_file:
- mkdir(os.path.dirname(script_file))
- # create __init__.py files along the path to allow Python imports
- path = file_name.split(os.path.sep)
- for i in range(1, len(path)):
- save_file(os.path.join(tmp_dir, *(path[:i] + ["__init__.py"])), "")
- save_file(script_file, script)
- chmod_r(script_file, 0o777)
- # copy libs
- for lib in libs:
- paths = [lib, "%s.py" % lib]
- try:
- module = importlib.import_module(lib)
- paths.append(module.__file__)
- except Exception:
- pass
- target_dir = tmp_dir
- root_folder = os.path.join(LOCALSTACK_VENV_FOLDER, "lib/python*/site-packages")
- if lib == "localstack":
- paths = ["localstack/*.py", "localstack/utils"]
- root_folder = LOCALSTACK_ROOT_FOLDER
- target_dir = os.path.join(tmp_dir, lib)
- mkdir(target_dir)
- for path in paths:
- file_to_copy = path if path.startswith("/") else os.path.join(root_folder, path)
- for file_path in glob.glob(file_to_copy):
- name = os.path.join(target_dir, file_path.split(os.path.sep)[-1])
- if os.path.isdir(file_path):
- copy_dir(file_path, name)
- else:
- shutil.copyfile(file_path, name)
- # create zip file
- result = create_zip_file(tmp_dir, get_content=get_content)
- return result
+ with tempfile.TemporaryDirectory(prefix=ARCHIVE_DIR_PREFIX) as tmp_dir:
+ file_name = file_name or get_handler_file_from_name(LAMBDA_DEFAULT_HANDLER, runtime=runtime)
+ script_file = os.path.join(tmp_dir, file_name)
+ if os.path.sep in script_file:
+ mkdir(os.path.dirname(script_file))
+ # create __init__.py files along the path to allow Python imports
+ path = file_name.split(os.path.sep)
+ for i in range(1, len(path)):
+ save_file(os.path.join(tmp_dir, *(path[:i] + ["__init__.py"])), "")
+ save_file(script_file, script)
+ chmod_r(script_file, 0o777)
+ # copy libs
+ for lib in libs:
+ paths = [lib, "%s.py" % lib]
+ try:
+ module = importlib.import_module(lib)
+ paths.append(module.__file__)
+ except Exception:
+ pass
+ target_dir = tmp_dir
+ root_folder = os.path.join(LOCALSTACK_VENV_FOLDER, "lib/python*/site-packages")
+ if lib == "localstack":
+ paths = ["localstack/*.py", "localstack/utils"]
+ root_folder = LOCALSTACK_ROOT_FOLDER
+ target_dir = os.path.join(tmp_dir, lib)
+ mkdir(target_dir)
+ for path in paths:
+ file_to_copy = path if path.startswith("/") else os.path.join(root_folder, path)
+ for file_path in glob.glob(file_to_copy):
+ name = os.path.join(target_dir, file_path.split(os.path.sep)[-1])
+ if os.path.isdir(file_path):
+ copy_dir(file_path, name)
+ else:
+ shutil.copyfile(file_path, name)
+
+ if exclude_func:
+ for dirpath, folders, files in os.walk(tmp_dir):
+ for name in list(folders) + list(files):
+ full_name = os.path.join(dirpath, name)
+ relative = os.path.relpath(full_name, start=tmp_dir)
+ if exclude_func(relative):
+ rm_rf(full_name)
+
+ # create zip file
+ result = create_zip_file(tmp_dir, get_content=get_content)
+ return result
def delete_lambda_function(name):
@@ -125,7 +145,7 @@ def create_zip_file_python(source_path, base_dir, zip_file):
for root, dirs, files in os.walk(base_dir):
for name in files:
full_name = os.path.join(root, name)
- relative = root[len(base_dir) :].lstrip(os.path.sep)
+ relative = os.path.relpath(root, start=base_dir)
dest = os.path.join(relative, name)
zip_file.write(full_name, dest)
@@ -198,6 +218,16 @@ def create_lambda_function(
except Exception:
pass
+ lambda_code = {"ZipFile": zip_file}
+ if len(zip_file) > MAX_LAMBDA_ARCHIVE_UPLOAD_SIZE:
+ s3 = aws_stack.connect_to_service("s3")
+ aws_stack.get_or_create_bucket(LAMBDA_ASSETS_BUCKET_NAME)
+ asset_key = f"{short_uid()}.zip"
+ s3.upload_fileobj(
+ Fileobj=io.BytesIO(zip_file), Bucket=LAMBDA_ASSETS_BUCKET_NAME, Key=asset_key
+ )
+ lambda_code = {"S3Bucket": LAMBDA_ASSETS_BUCKET_NAME, "S3Key": asset_key}
+
# create function
additional_kwargs = kwargs
kwargs = {
@@ -205,7 +235,7 @@ def create_lambda_function(
"Runtime": runtime,
"Handler": handler,
"Role": LAMBDA_TEST_ROLE,
- "Code": {"ZipFile": zip_file},
+ "Code": lambda_code,
"Timeout": LAMBDA_TIMEOUT_SEC,
"Environment": dict(Variables=envvars),
"Tags": tags,
| * Add plug points for code/config initializations in LambdaExecutorPlugin
* Streamline parameters for `set_function_code(..)` functions - replacing individual args with single `LambdaFunction` arg
* Refactor `testutil.py` to deploy large Lambda zip files automatically via S3 (avoiding `RequestEntityTooLargeException`)
| https://api.github.com/repos/localstack/localstack/pulls/4540 | 2021-09-04T12:24:17Z | 2021-09-04T13:00:06Z | 2021-09-04T13:00:06Z | 2021-09-04T13:00:09Z | 3,095 | localstack/localstack | 29,095 |
Added Superhero API | diff --git a/README.md b/README.md
index 19e9522c0a..4c2cc5b0be 100644
--- a/README.md
+++ b/README.md
@@ -428,6 +428,7 @@ API | Description | Auth | HTTPS | CORS |
| [Riot Games](https://developer.riotgames.com/) | League of Legends Game Information | `apiKey` | Yes | Unknown |
| [Scryfall](https://scryfall.com/docs/api) | Magic: The Gathering database | No | Yes | Yes |
| [Steam](https://developer.valvesoftware.com/wiki/Steam_Web_API) | Steam Client Interaction | `OAuth` | Yes | Unknown |
+| [SuperHeroes](https://superheroapi.com) | All SuperHeroes and Villains data from all universes under a single API | `apiKey` | Yes | Unknown |
| [Tronald Dump](https://www.tronalddump.io/) | The dumbest things Donald Trump has ever said | No | Yes | Unknown |
| [Vainglory](https://developer.vainglorygame.com/) | Vainglory Players, Matches and Telemetry | `apiKey` | Yes | Yes |
| [Wargaming.net](https://developers.wargaming.net/) | Wargaming.net info and stats | `apiKey` | Yes | No |
| Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [X] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [X] Your additions are ordered alphabetically
- [X] Your submission has a useful description
- [X] The description does not end with punctuation
- [X] Each table column should be padded with one space on either side
- [X] You have searched the repository for any relevant issues or pull requests
- [ ] Any category you are creating has the minimum requirement of 3 items
- [X] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
| https://api.github.com/repos/public-apis/public-apis/pulls/939 | 2019-04-22T13:01:37Z | 2019-10-23T13:34:18Z | 2019-10-23T13:34:18Z | 2019-10-23T19:51:45Z | 292 | public-apis/public-apis | 35,509 |
fix insert for simple vector index | diff --git a/gpt_index/indices/vector_store/vector_indices.py b/gpt_index/indices/vector_store/vector_indices.py
index 73ef44afcbc86..f1ba5c768128d 100644
--- a/gpt_index/indices/vector_store/vector_indices.py
+++ b/gpt_index/indices/vector_store/vector_indices.py
@@ -15,6 +15,7 @@
SimpleIndexDict,
WeaviateIndexDict,
)
+from gpt_index.schema import BaseDocument
from gpt_index.embeddings.base import BaseEmbedding
from gpt_index.indices.base import DOCUMENTS_INPUT, BaseGPTIndex
from gpt_index.indices.query.base import BaseGPTIndexQuery
@@ -102,6 +103,14 @@ def __init__(
# update docstore with current struct
self._docstore.add_documents([self.index_struct], allow_update=True)
+ def _insert(self, document: BaseDocument, **insert_kwargs: Any) -> None:
+ """Insert a document."""
+ super()._insert(document, **insert_kwargs)
+ # TODO: Temporary hack to also store embeddings in index_struct
+ vector_store = cast(SimpleVectorStore, self._vector_store)
+ embedding_dict = vector_store._data.embedding_dict
+ self._index_struct.embeddings_dict = embedding_dict
+
@classmethod
def get_query_map(self) -> Dict[str, Type[BaseGPTIndexQuery]]:
"""Get query map."""
| https://api.github.com/repos/run-llama/llama_index/pulls/934 | 2023-03-28T00:09:25Z | 2023-03-28T00:18:02Z | 2023-03-28T00:18:02Z | 2023-03-28T00:18:03Z | 314 | run-llama/llama_index | 6,630 |
|
Enable select platform in Overkiz integration | diff --git a/homeassistant/components/overkiz/const.py b/homeassistant/components/overkiz/const.py
index 119f7a322624..8488103a2384 100644
--- a/homeassistant/components/overkiz/const.py
+++ b/homeassistant/components/overkiz/const.py
@@ -28,6 +28,7 @@
Platform.LOCK,
Platform.NUMBER,
Platform.SCENE,
+ Platform.SELECT,
Platform.SENSOR,
Platform.SIREN,
Platform.SWITCH,
| ## Proposed change
Not sure how this could have happened, but it seems that the Select platform has been merged, but that the constant is not present in the enabled platforms list...
## Type of change
<!--
What type of change does your PR introduce to Home Assistant?
NOTE: Please, check only 1! box!
If your PR requires multiple boxes to be checked, you'll most likely need to
split it into multiple PRs. This makes things easier and faster to code review.
-->
- [ ] Dependency upgrade
- [x] Bugfix (non-breaking change which fixes an issue)
- [ ] New integration (thank you!)
- [ ] New feature (which adds functionality to an existing integration)
- [ ] Breaking change (fix/feature causing existing functionality to break)
- [ ] Code quality improvements to existing code or addition of tests
## Additional information
<!--
Details are important, and help maintainers processing your PR.
Please be sure to fill out additional details, if applicable.
-->
- This PR fixes or closes issue: fixes #
- This PR is related to issue:
- Link to documentation pull request:
## Checklist
<!--
Put an `x` in the boxes that apply. You can also fill these out after
creating the PR. If you're unsure about any of them, don't hesitate to ask.
We're here to help! This is simply a reminder of what we are going to look
for before merging your code.
-->
- [x] The code change is tested and works locally.
- [x] Local tests pass. **Your PR cannot be merged unless tests pass**
- [x] There is no commented out code in this PR.
- [x] I have followed the [development checklist][dev-checklist]
- [x] The code has been formatted using Black (`black --fast homeassistant tests`)
- [ ] Tests have been added to verify that the new code works.
If user exposed functionality or configuration variables are added/changed:
- [ ] Documentation added/updated for [www.home-assistant.io][docs-repository]
If the code communicates with devices, web services, or third-party tools:
- [ ] The [manifest file][manifest-docs] has all fields filled out correctly.
Updated and included derived files by running: `python3 -m script.hassfest`.
- [ ] New or updated dependencies have been added to `requirements_all.txt`.
Updated by running `python3 -m script.gen_requirements_all`.
- [ ] For the updated dependencies - a link to the changelog, or at minimum a diff between library versions is added to the PR description.
- [ ] Untested files have been added to `.coveragerc`.
The integration reached or maintains the following [Integration Quality Scale][quality-scale]:
<!--
The Integration Quality Scale scores an integration on the code quality
and user experience. Each level of the quality scale consists of a list
of requirements. We highly recommend getting your integration scored!
-->
- [ ] No score or internal
- [ ] 🥈 Silver
- [ ] 🥇 Gold
- [ ] 🏆 Platinum
<!--
This project is very active and we have a high turnover of pull requests.
Unfortunately, the number of incoming pull requests is higher than what our
reviewers can review and merge so there is a long backlog of pull requests
waiting for review. You can help here!
By reviewing another pull request, you will help raise the code quality of
that pull request and the final review will be faster. This way the general
pace of pull request reviews will go up and your wait time will go down.
When picking a pull request to review, try to choose one that hasn't yet
been reviewed.
Thanks for helping out!
-->
To help with the load of incoming pull requests:
- [ ] I have reviewed two other [open pull requests][prs] in this repository.
[prs]: https://github.com/home-assistant/core/pulls?q=is%3Aopen+is%3Apr+-author%3A%40me+-draft%3Atrue+-label%3Awaiting-for-upstream+sort%3Acreated-desc+review%3Anone+-status%3Afailure
<!--
Thank you for contributing <3
Below, some useful links you could explore:
-->
[dev-checklist]: https://developers.home-assistant.io/docs/en/development_checklist.html
[manifest-docs]: https://developers.home-assistant.io/docs/en/creating_integration_manifest.html
[quality-scale]: https://developers.home-assistant.io/docs/en/next/integration_quality_scale_index.html
[docs-repository]: https://github.com/home-assistant/home-assistant.io
| https://api.github.com/repos/home-assistant/core/pulls/68995 | 2022-03-31T16:31:20Z | 2022-04-01T14:28:29Z | 2022-04-01T14:28:29Z | 2022-04-02T17:03:07Z | 119 | home-assistant/core | 38,715 |
Fixes ios_logging idempotence issue CP into 2.6 | diff --git a/lib/ansible/modules/network/ios/ios_logging.py b/lib/ansible/modules/network/ios/ios_logging.py
index 74a3bc193b837d..10923d77975557 100644
--- a/lib/ansible/modules/network/ios/ios_logging.py
+++ b/lib/ansible/modules/network/ios/ios_logging.py
@@ -121,7 +121,6 @@
import re
from copy import deepcopy
-
from ansible.module_utils.basic import AnsibleModule
from ansible.module_utils.network.common.utils import remove_default_spec, validate_ip_address
from ansible.module_utils.network.ios.ios import get_config, load_config
@@ -138,6 +137,7 @@ def validate_size(value, module):
def map_obj_to_commands(updates, module, os_version):
+ dest_group = ('console', 'monitor', 'buffered', 'on')
commands = list()
want, have = updates
for w in want:
@@ -149,23 +149,36 @@ def map_obj_to_commands(updates, module, os_version):
state = w['state']
del w['state']
+ if facility:
+ w['dest'] = 'facility'
+
if state == 'absent' and w in have:
- if dest == 'host':
- if '12.' in os_version:
- commands.append('no logging {0}'.format(name))
+ if dest:
+ if dest == 'host':
+ if '12.' in os_version:
+ commands.append('no logging {0}'.format(name))
+ else:
+ commands.append('no logging host {0}'.format(name))
+
+ elif dest in dest_group:
+ commands.append('no logging {0}'.format(dest))
+
else:
- commands.append('no logging host {0}'.format(name))
- elif dest:
- commands.append('no logging {0}'.format(dest))
- else:
- module.fail_json(msg='dest must be among console, monitor, buffered, host, on')
+ module.fail_json(msg='dest must be among console, monitor, buffered, host, on')
if facility:
commands.append('no logging facility {0}'.format(facility))
if state == 'present' and w not in have:
if facility:
- commands.append('logging facility {0}'.format(facility))
+ present = False
+
+ for entry in have:
+ if entry['dest'] == 'facility' and entry['facility'] == facility:
+ present = True
+
+ if not present:
+ commands.append('logging facility {0}'.format(facility))
if dest == 'host':
if '12.' in os_version:
@@ -177,10 +190,17 @@ def map_obj_to_commands(updates, module, os_version):
commands.append('logging on')
elif dest == 'buffered' and size:
- if level and level != 'debugging':
- commands.append('logging buffered {0} {1}'.format(size, level))
- else:
- commands.append('logging buffered {0}'.format(size))
+ present = False
+
+ for entry in have:
+ if entry['dest'] == 'buffered' and entry['size'] == size and entry['level'] == level:
+ present = True
+
+ if not present:
+ if level and level != 'debugging':
+ commands.append('logging buffered {0} {1}'.format(size, level))
+ else:
+ commands.append('logging buffered {0}'.format(size))
else:
if dest:
@@ -293,7 +313,6 @@ def map_config_to_obj(module):
'facility': parse_facility(line, dest),
'level': parse_level(line, dest)
})
-
return obj
@@ -355,7 +374,6 @@ def map_params_to_obj(module, required_if=None):
'level': module.params['level'],
'state': module.params['state']
})
-
return obj
@@ -412,5 +430,6 @@ def main():
module.exit_json(**result)
+
if __name__ == '__main__':
main()
diff --git a/test/integration/targets/ios_logging/tests/cli/basic.yaml b/test/integration/targets/ios_logging/tests/cli/basic.yaml
index 2ac13b1a2d6d2a..ced1c65d8bae69 100644
--- a/test/integration/targets/ios_logging/tests/cli/basic.yaml
+++ b/test/integration/targets/ios_logging/tests/cli/basic.yaml
@@ -99,6 +99,7 @@
- 'result.changed == true'
- '"logging buffered 8000" in result.commands'
+
- name: Change logging parameters using aggregate
ios_logging:
aggregate:
@@ -113,11 +114,42 @@
- '"logging buffered 9000" in result.commands'
- '"logging console notifications" in result.commands'
+- name: Set both logging destination and facility
+ ios_logging:
+ dest: buffered
+ facility: uucp
+ level: alerts
+ size: 4096
+ state: present
+ provider: "{{ cli }}"
+ register: result
+
+- assert:
+ that:
+ - 'result.changed == true'
+ - '"logging buffered 4096 alerts" in result.commands'
+ - '"logging facility uucp" in result.commands'
+
+- name: Set both logging destination and facility (idempotent)
+ ios_logging:
+ dest: buffered
+ facility: uucp
+ level: alerts
+ size: 4096
+ state: present
+ provider: "{{ cli }}"
+ register: result
+
+- assert:
+ that:
+ - 'result.changed == false'
+
- name: remove logging as collection tearDown
ios_logging:
aggregate:
- { dest: console, level: notifications }
- - { dest: buffered, size: 9000 }
+ - { dest: buffered, size: 4096, level: alerts }
+ - { facility: uucp }
state: absent
provider: "{{ cli }}"
register: result
@@ -127,3 +159,4 @@
- 'result.changed == true'
- '"no logging console" in result.commands'
- '"no logging buffered" in result.commands'
+ - '"no logging facility uucp" in result.commands'
| * Fixes ios_logging idempotence issue
* Added integration tests
##### SUMMARY
Fixed ios_logging idempotence issue while setting both logging destination and facility.
(PR https://github.com/ansible/ansible/pull/40701)
##### ISSUE TYPE
- Bugfix Pull Request
##### COMPONENT NAME
```
ios_logging.py
```
##### ANSIBLE VERSION
```
stable-2.6
```
| https://api.github.com/repos/ansible/ansible/pulls/40897 | 2018-05-30T15:28:54Z | 2018-05-31T17:00:43Z | 2018-05-31T17:00:43Z | 2019-05-31T15:42:56Z | 1,420 | ansible/ansible | 48,981 |
Add a rewrite directive for the .well-known location so we don't hit existing rewrites | diff --git a/certbot-nginx/certbot_nginx/http_01.py b/certbot-nginx/certbot_nginx/http_01.py
index c25081ae04e..2885e7ac0fc 100644
--- a/certbot-nginx/certbot_nginx/http_01.py
+++ b/certbot-nginx/certbot_nginx/http_01.py
@@ -191,3 +191,8 @@ def _make_or_mod_server_block(self, achall):
self.configurator.parser.add_server_directives(vhost,
location_directive, replace=False)
+
+ rewrite_directive = [['rewrite', ' ', '^(/.well-known/acme-challenge/.*)',
+ ' ', '$1', ' ', 'break']]
+ self.configurator.parser.add_server_directives(vhost,
+ rewrite_directive, replace=False, insert_at_top=True)
diff --git a/certbot-nginx/certbot_nginx/parser.py b/certbot-nginx/certbot_nginx/parser.py
index 5497f7e6360..fbd6c0ade8c 100644
--- a/certbot-nginx/certbot_nginx/parser.py
+++ b/certbot-nginx/certbot_nginx/parser.py
@@ -276,7 +276,7 @@ def has_ssl_on_directive(self, vhost):
return False
- def add_server_directives(self, vhost, directives, replace):
+ def add_server_directives(self, vhost, directives, replace, insert_at_top=False):
"""Add or replace directives in the server block identified by vhost.
This method modifies vhost to be fully consistent with the new directives.
@@ -293,10 +293,12 @@ def add_server_directives(self, vhost, directives, replace):
whose information we use to match on
:param list directives: The directives to add
:param bool replace: Whether to only replace existing directives
+ :param bool insert_at_top: True if the directives need to be inserted at the top
+ of the server block instead of the bottom
"""
self._modify_server_directives(vhost,
- functools.partial(_add_directives, directives, replace))
+ functools.partial(_add_directives, directives, replace, insert_at_top))
def remove_server_directives(self, vhost, directive_name, match_func=None):
"""Remove all directives of type directive_name.
@@ -521,7 +523,7 @@ def _is_ssl_on_directive(entry):
len(entry) == 2 and entry[0] == 'ssl' and
entry[1] == 'on')
-def _add_directives(directives, replace, block):
+def _add_directives(directives, replace, insert_at_top, block):
"""Adds or replaces directives in a config block.
When replace=False, it's an error to try and add a nonrepeatable directive that already
@@ -535,17 +537,18 @@ def _add_directives(directives, replace, block):
:param list directives: The new directives.
:param bool replace: Described above.
+ :param bool insert_at_top: Described above.
:param list block: The block to replace in
"""
for directive in directives:
- _add_directive(block, directive, replace)
+ _add_directive(block, directive, replace, insert_at_top)
if block and '\n' not in block[-1]: # could be " \n " or ["\n"] !
block.append(nginxparser.UnspacedList('\n'))
INCLUDE = 'include'
-REPEATABLE_DIRECTIVES = set(['server_name', 'listen', INCLUDE, 'location'])
+REPEATABLE_DIRECTIVES = set(['server_name', 'listen', INCLUDE, 'location', 'rewrite'])
COMMENT = ' managed by Certbot'
COMMENT_BLOCK = [' ', '#', COMMENT]
@@ -597,7 +600,7 @@ def _find_location(block, directive_name, match_func=None):
return next((index for index, line in enumerate(block) \
if line and line[0] == directive_name and (match_func is None or match_func(line))), None)
-def _add_directive(block, directive, replace):
+def _add_directive(block, directive, replace, insert_at_top):
"""Adds or replaces a single directive in a config block.
See _add_directives for more documentation.
@@ -619,7 +622,7 @@ def is_whitespace_or_comment(directive):
block[location] = directive
comment_directive(block, location)
return
- # Append directive. Fail if the name is not a repeatable directive name,
+ # Append or prepend directive. Fail if the name is not a repeatable directive name,
# and there is already a copy of that directive with a different value
# in the config file.
@@ -652,8 +655,15 @@ def can_append(loc, dir_name):
_comment_out_directive(block, included_dir_loc, directive[1])
if can_append(location, directive_name):
- block.append(directive)
- comment_directive(block, len(block) - 1)
+ if insert_at_top:
+ # Add a newline so the comment doesn't comment
+ # out existing directives
+ block.insert(0, nginxparser.UnspacedList('\n'))
+ block.insert(0, directive)
+ comment_directive(block, 0)
+ else:
+ block.append(directive)
+ comment_directive(block, len(block) - 1)
elif block[location] != directive:
raise errors.MisconfigurationError(err_fmt.format(directive, block[location]))
| Part of #5409.
Implementation as suggested by https://community.letsencrypt.org/t/help-test-certbot-apache-and-nginx-fixes-for-tls-sni-01-outage/50207/18.
Implementation currently adds a redundant `rewrite` directive every time we add a `location` block to the server block to handle a different challenge. This is not a problem, especially since this code doesn't need to be nice to look at, it just needs to be temporarily understandable by Nginx to serve the responses. On the principle of doing the minimally invasive code changes on this short notice, I contend that it's better to leave this than to write more code to dedupe the addition. | https://api.github.com/repos/certbot/certbot/pulls/5436 | 2018-01-16T23:37:49Z | 2018-01-17T16:01:45Z | 2018-01-17T16:01:45Z | 2018-01-17T16:01:45Z | 1,250 | certbot/certbot | 24 |
Add limit_to_domains to APIChain based tools | diff --git a/libs/langchain/langchain/agents/load_tools.py b/libs/langchain/langchain/agents/load_tools.py
index e464d6b7287808..60377c137d056f 100644
--- a/libs/langchain/langchain/agents/load_tools.py
+++ b/libs/langchain/langchain/agents/load_tools.py
@@ -142,7 +142,11 @@ def _get_llm_math(llm: BaseLanguageModel) -> BaseTool:
def _get_open_meteo_api(llm: BaseLanguageModel) -> BaseTool:
- chain = APIChain.from_llm_and_api_docs(llm, open_meteo_docs.OPEN_METEO_DOCS)
+ chain = APIChain.from_llm_and_api_docs(
+ llm,
+ open_meteo_docs.OPEN_METEO_DOCS,
+ limit_to_domains=["https://api.open-meteo.com/"],
+ )
return Tool(
name="Open-Meteo-API",
description="Useful for when you want to get weather information from the OpenMeteo API. The input should be a question in natural language that this API can answer.",
@@ -159,7 +163,10 @@ def _get_open_meteo_api(llm: BaseLanguageModel) -> BaseTool:
def _get_news_api(llm: BaseLanguageModel, **kwargs: Any) -> BaseTool:
news_api_key = kwargs["news_api_key"]
chain = APIChain.from_llm_and_api_docs(
- llm, news_docs.NEWS_DOCS, headers={"X-Api-Key": news_api_key}
+ llm,
+ news_docs.NEWS_DOCS,
+ headers={"X-Api-Key": news_api_key},
+ limit_to_domains=["https://newsapi.org/"],
)
return Tool(
name="News-API",
@@ -174,6 +181,7 @@ def _get_tmdb_api(llm: BaseLanguageModel, **kwargs: Any) -> BaseTool:
llm,
tmdb_docs.TMDB_DOCS,
headers={"Authorization": f"Bearer {tmdb_bearer_token}"},
+ limit_to_domains=["https://api.themoviedb.org/"],
)
return Tool(
name="TMDB-API",
@@ -188,6 +196,7 @@ def _get_podcast_api(llm: BaseLanguageModel, **kwargs: Any) -> BaseTool:
llm,
podcast_docs.PODCAST_DOCS,
headers={"X-ListenAPI-Key": listen_api_key},
+ limit_to_domains=["https://listen-api.listennotes.com/"],
)
return Tool(
name="Podcast-API",
| - **Description:** Adds `limit_to_domains` param to the APIChain based tools (open_meteo, TMDB, podcast_docs, and news_api)
- **Issue:** I didn't open an issue, but after upgrading to 0.0.328 using these tools would throw an error.
- **Dependencies:** N/A
- **Tag maintainer:** @baskaryan
**Note**: I included the trailing / simply because the docs here did https://github.com/langchain-ai/langchain/blob/fc886cc3039c2479bb13287f48fcbdb097a44c70/docs/docs/use_cases/apis.ipynb#L246 , but I checked the code and it is using `urlparse`. SoI followed the docs since it comes down to stylee. | https://api.github.com/repos/langchain-ai/langchain/pulls/13367 | 2023-11-14T20:15:54Z | 2023-11-15T03:07:16Z | 2023-11-15T03:07:16Z | 2023-11-15T03:07:17Z | 573 | langchain-ai/langchain | 43,184 |
Doc: Use ``closer.lua`` script for downloading sources | diff --git a/docs/apache-airflow/installing-from-sources.rst b/docs/apache-airflow/installing-from-sources.rst
index d5559106b5507..630e61c33d0c1 100644
--- a/docs/apache-airflow/installing-from-sources.rst
+++ b/docs/apache-airflow/installing-from-sources.rst
@@ -34,9 +34,11 @@ The packages are available at the
The |version| downloads are available at:
-* `Apache Airflow |version| sdist package <https://downloads.apache.org/airflow/|version|/apache-airflow-|version|.tar.gz>`_ (`asc <https://downloads.apache.org/airflow/|version|/apache-airflow-|version|.tar.gz.asc>`__, `sha512 <https://downloads.apache.org/airflow/|version|/apache-airflow-|version|.tar.gz.sha512>`__)
-* `Apache Airflow |version| wheel package <https://downloads.apache.org/airflow/|version|/apache_airflow-|version|-py3-none-any.whl>`_ (`asc <https://downloads.apache.org/airflow/|version|/apache_airflow-|version|-py3-none-any.whl.asc>`__, `sha512 <https://downloads.apache.org/airflow/|version|/apache_airflow-|version|-py3-none-any.whl.sha512>`__)
-* `Apache Airflow |version| sources <https://downloads.apache.org/airflow/|version|/apache-airflow-|version|-source.tar.gz>`_ (`asc <https://downloads.apache.org/airflow/|version|/apache-airflow-|version|-source.tar.gz.asc>`__, `sha512 <https://downloads.apache.org/airflow/|version|/apache-airflow-|version|-source.tar.gz.sha512>`__)
+.. jinja:: official_download_page
+
+ * `Sdist package <{{ closer_lua_url }}/apache-airflow-{{ airflow_version }}.tar.gz>`_ (`asc <{{ base_url }}/apache-airflow-{{ airflow_version }}.tar.gz.asc>`__, `sha512 <{{ base_url }}/apache-airflow-{{ airflow_version }}.tar.gz.sha512>`__)
+ * `Wheel package <{{ closer_lua_url }}/apache_airflow-{{ airflow_version }}-py3-none-any.whl>`_ (`asc <{{ base_url }}/apache_airflow-{{ airflow_version }}-py3-none-any.whl.asc>`__, `sha512 <{{ base_url }}/apache_airflow-{{ airflow_version }}-py3-none-any.whl.sha512>`__)
+ * `Sources <{{ closer_lua_url }}/apache-airflow-{{ airflow_version }}-source.tar.gz>`_ (`asc <{{ base_url }}/apache_airflow-{{ airflow_version }}-source.tar.gz.asc>`__, `sha512 <{{ base_url }}/apache-airflow-{{ airflow_version }}-source.tar.gz.sha512>`__)
If you want to install from the source code, you can download from the sources link above, it will contain
a ``INSTALL`` file containing details on how you can build and install Airflow.
diff --git a/docs/conf.py b/docs/conf.py
index 705f1a0c498f6..cebb8b1463571 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -374,6 +374,11 @@ def _get_rst_filepath_from_path(filepath: str):
'http://apache-airflow-docs.s3-website.eu-central-1.amazonaws.com/docs/apache-airflow/latest/'
)
},
+ 'official_download_page': {
+ 'base_url': f'https://downloads.apache.org/airflow/{PACKAGE_VERSION}',
+ 'closer_lua_url': f'https://www.apache.org/dyn/closer.lua/airflow/{PACKAGE_VERSION}',
+ 'airflow_version': PACKAGE_VERSION,
+ },
}
elif PACKAGE_NAME.startswith('apache-airflow-providers-'):
| - Follows first point of https://infra.apache.org/release-download-pages.html#download-page to use `https://www.apache.org/dyn/closer.lua/PROJECT/VERSION/SOURCE-RELEASE` for mirrors
- Fixes bug as the current version substitution does not work for Hyperlinks (open PR: https://github.com/adamtheturtle/sphinx-substitution-extensions/issues/178)
**Before**:

**After**:

<!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of existing issue, reference it using one of the following:
closes: #ISSUE
related: #ISSUE
How to write a good git commit message:
http://chris.beams.io/posts/git-commit/
-->
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information.
In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/main/UPDATING.md).
| https://api.github.com/repos/apache/airflow/pulls/18179 | 2021-09-12T02:00:52Z | 2021-09-12T08:58:54Z | 2021-09-12T08:58:54Z | 2021-11-22T18:42:47Z | 825 | apache/airflow | 14,432 |
fix #2600 | diff --git a/gym/envs/toy_text/frozen_lake.py b/gym/envs/toy_text/frozen_lake.py
index 90ee6a16231..6c23d759498 100644
--- a/gym/envs/toy_text/frozen_lake.py
+++ b/gym/envs/toy_text/frozen_lake.py
@@ -230,10 +230,10 @@ def reset(
def render(self, mode="human"):
desc = self.desc.tolist()
- if mode == "ansi":
- return self._render_text(desc)
- else:
+ if mode == "human":
return self._render_gui(desc)
+ else:
+ return self._render_text(desc)
def _render_gui(self, desc):
if self.window_surface is None:
| fix #2600 | https://api.github.com/repos/openai/gym/pulls/2601 | 2022-02-07T18:57:16Z | 2022-02-08T01:48:48Z | 2022-02-08T01:48:48Z | 2022-02-08T01:48:48Z | 178 | openai/gym | 5,262 |
Setup Github Action to instantiate and run a forward pass with each registered model. | diff --git a/.github/workflows/tests.yml b/.github/workflows/tests.yml
new file mode 100644
index 0000000000..68fa474167
--- /dev/null
+++ b/.github/workflows/tests.yml
@@ -0,0 +1,43 @@
+name: Python tests
+
+on:
+ push:
+ branches: [ master ]
+ pull_request:
+ branches: [ master ]
+
+jobs:
+ test:
+ name: Run tests on ${{ matrix.os }} with Python ${{ matrix.python }}
+ strategy:
+ matrix:
+ os: [ubuntu-latest, macOS-latest]
+ python: ['3.8']
+ torch: ['1.5.0']
+ torchvision: ['0.6.0']
+ runs-on: ${{ matrix.os }}
+
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python ${{ matrix.python }}
+ uses: actions/setup-python@v1
+ with:
+ python-version: ${{ matrix.python }}
+ - name: Install testing dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install pytest pytest-timeout
+ - name: Install torch on mac
+ if: startsWith(matrix.os, 'macOS')
+ run: pip install torch==${{ matrix.torch }} torchvision==${{ matrix.torchvision }}
+ - name: Install torch on ubuntu
+ if: startsWith(matrix.os, 'ubuntu')
+ run: pip install torch==${{ matrix.torch }}+cpu torchvision==${{ matrix.torchvision }}+cpu -f https://download.pytorch.org/whl/torch_stable.html
+ - name: Install requirements
+ run: |
+ if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
+ pip install scipy
+ pip install git+https://github.com/mapillary/inplace_abn.git@v1.0.11
+ - name: Run tests
+ run: |
+ pytest -vv --durations=0 ./tests
diff --git a/tests/__init__.py b/tests/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/test_inference.py b/tests/test_inference.py
new file mode 100644
index 0000000000..75b8d445b4
--- /dev/null
+++ b/tests/test_inference.py
@@ -0,0 +1,19 @@
+import pytest
+import torch
+
+from timm import list_models, create_model
+
+
+@pytest.mark.timeout(60)
+@pytest.mark.parametrize('model_name', list_models())
+@pytest.mark.parametrize('batch_size', [1])
+def test_model_forward(model_name, batch_size):
+ """Run a single forward pass with each model"""
+ model = create_model(model_name, pretrained=False)
+ model.eval()
+
+ inputs = torch.randn((batch_size, *model.default_cfg['input_size']))
+ outputs = model(inputs)
+
+ assert outputs.shape[0] == batch_size
+ assert not torch.isnan(outputs).any(), 'Output included NaNs'
| This adds a github action to run a test suite, which at the moment only instantiates each model and runs a forward pass.
Here's how that looks live: https://github.com/michalwols/pytorch-image-models/runs/651871707?check_suite_focus=true
Results include timing for each model:
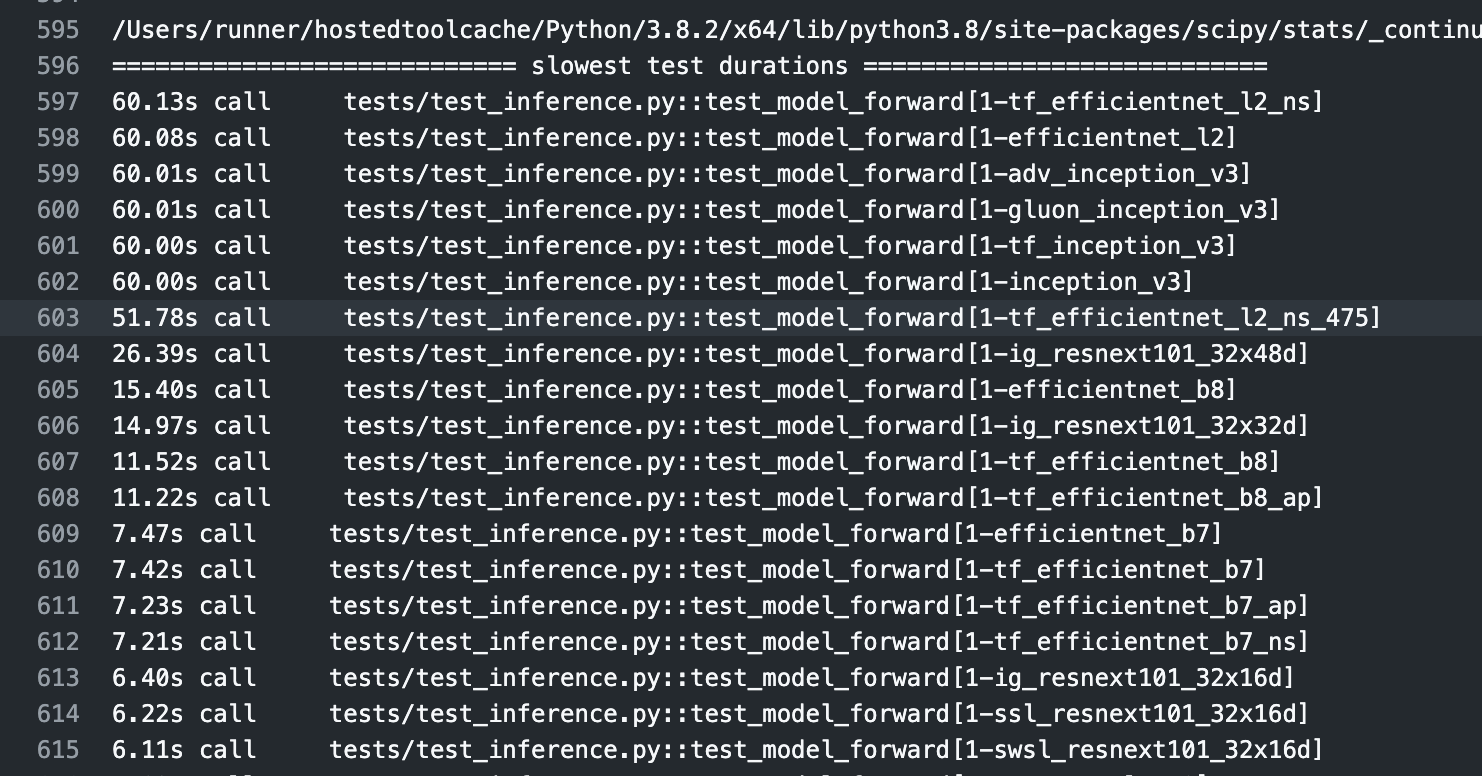
The runners are really underpowered so it might make sense to pick the smallest variant of each model class to keep the runtime of the action reasonable.
I added a timeout of 60s for each model, which they all comfortably pass on my laptop but it should probably be changed for the CI env since it will lead to flaky tests. | https://api.github.com/repos/huggingface/pytorch-image-models/pulls/143 | 2020-05-07T05:39:17Z | 2020-05-07T16:47:14Z | 2020-05-07T16:47:14Z | 2020-05-07T16:47:14Z | 721 | huggingface/pytorch-image-models | 16,347 |
Add prepending text for specific headers (h1, h2, h3) | diff --git a/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.test.tsx b/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.test.tsx
index b3bd3f0a688a..745271b16d87 100644
--- a/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.test.tsx
+++ b/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.test.tsx
@@ -188,4 +188,43 @@ describe("Heading", () => {
expect(wrapper.find("h1").text()).toEqual("hello")
expect(wrapper.find("StyledStreamlitMarkdown")).toHaveLength(0)
})
+
+ it("does not render ol block", () => {
+ const props = getHeadingProps({ body: "1) hello" })
+ const wrapper = mount(<Heading {...props} />)
+ expect(wrapper.find("h1").text()).toEqual("1) hello")
+ expect(wrapper.find("ol")).toHaveLength(0)
+ })
+
+ it("does not render ul block", () => {
+ const props = getHeadingProps({ body: "* hello" })
+ const wrapper = mount(<Heading {...props} />)
+ expect(wrapper.find("h1").text()).toEqual("* hello")
+ expect(wrapper.find("ul")).toHaveLength(0)
+ })
+
+ it("does not render blockquote with >", () => {
+ const props = getHeadingProps({ body: ">hello" })
+ const wrapper = mount(<Heading {...props} />)
+ expect(wrapper.find("h1").text()).toEqual(">hello")
+ expect(wrapper.find("blockquote")).toHaveLength(0)
+ })
+
+ it("does not render tables", () => {
+ const props = getHeadingProps({
+ body: `| Syntax | Description |
+ | ----------- | ----------- |
+ | Header | Title |
+ | Paragraph | Text |`,
+ })
+ const wrapper = mount(<Heading {...props} />)
+ expect(wrapper.find("h1").text()).toEqual(`| Syntax | Description |`)
+ expect(wrapper.find("StyledStreamlitMarkdown").text()).toEqual(
+ `| ----------- | ----------- |
+| Header | Title |
+| Paragraph | Text |
+`
+ )
+ expect(wrapper.find("table")).toHaveLength(0)
+ })
})
diff --git a/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.tsx b/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.tsx
index 69a11ed3fb1c..6799fcffb409 100644
--- a/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.tsx
+++ b/frontend/src/components/shared/StreamlitMarkdown/StreamlitMarkdown.tsx
@@ -303,6 +303,24 @@ export function LinkWithTargetBlank(props: LinkProps): ReactElement {
)
}
+function makeMarkdownHeading(tag: string, markdown: string): string {
+ switch (tag.toLowerCase()) {
+ // willhuang1997: TODO: could be refactored to Enums
+ case "h1": {
+ return `# ${markdown}`
+ }
+ case "h2": {
+ return `## ${markdown}`
+ }
+ case "h3": {
+ return `### ${markdown}`
+ }
+ default: {
+ throw new Error(`Unrecognized tag for header: ${tag}`)
+ }
+ }
+}
+
export function Heading(props: HeadingProtoProps): ReactElement {
const { width } = props
const { tag, anchor, body } = props.element
@@ -315,7 +333,7 @@ export function Heading(props: HeadingProtoProps): ReactElement {
<div className="stMarkdown" style={{ width }}>
<HeadingWithAnchor tag={tag} anchor={anchor}>
<RenderedMarkdown
- source={heading}
+ source={makeMarkdownHeading(tag, heading)}
allowHTML={false}
// this is purely an inline string
overrideComponents={{
| <!--
Before contributing (PLEASE READ!)
⚠️ If your contribution is more than a few lines of code, then prior to starting to code on it please post in the issue saying you want to volunteer, then wait for a positive response. And if there is no issue for it yet, create it first.
This helps make sure:
1. Two people aren't working on the same thing
2. This is something Streamlit's maintainers believe should be implemented/fixed
3. Any API, UI, or deeper architectural changes that need to be implemented have been fully thought through by Streamlit's maintainers
4. Your time is well spent!
More information in our wiki: https://github.com/streamlit/streamlit/wiki/Contributing
-->
## 📚 Context
Currently, I broke StreamlitMarkdown by refactoring Heading to its own component. This was done because we removed the "#" that was prepended by the backend. However, we are readding them on the frontend. I tried adding the `ReactMarkdown` prop `allowedElements` and `disallowedElements` in two separate testing scenarios and they both seem to not work.
`allowedElements` just did not print anything.
`disallowedElements` printed things but when it was introduced to disallowedElements such as `li`, it just didn't show anything.
- What kind of change does this PR introduce?
- [x] Bugfix
- [ ] Feature
- [ ] Refactoring
- [ ] Other, please describe:
## 🧠 Description of Changes
Adding a method that prepends a # or ## or ### based on the tag.
- _Add bullet points summarizing your changes here_
- [ ] This is a breaking API change
- [x] This is a visible (user-facing) change
**Revised:**
<img width="1175" alt="Screen Shot 2022-09-09 at 3 36 12 PM" src="https://user-images.githubusercontent.com/16749069/189454729-6529066e-60b9-40c7-bb0e-82aca1cd3638.png">
_Insert screenshot of your updated UI/code here_
**Current:**
<img width="973" alt="Screen Shot 2022-09-09 at 3 36 24 PM" src="https://user-images.githubusercontent.com/16749069/189454752-c806f7a2-ca4c-43ca-a178-14220c649bfd.png">
_Insert screenshot of existing UI/code here_
## 🧪 Testing Done
- [x] Screenshots included
- [x] Added/Updated unit tests
- [ ] Added/Updated e2e tests
## 🌐 References
_Does this depend on other work, documents, or tickets?_
- **Issue**: Closes #5329
---
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
| https://api.github.com/repos/streamlit/streamlit/pulls/5330 | 2022-09-09T22:36:42Z | 2022-09-13T16:02:24Z | 2022-09-13T16:02:24Z | 2023-05-26T23:34:25Z | 877 | streamlit/streamlit | 21,599 |
DOC: Remove dead link | diff --git a/doc/install.rst b/doc/install.rst
index ef9f68b73d2d9..2596476b9fef5 100644
--- a/doc/install.rst
+++ b/doc/install.rst
@@ -1,3 +1,5 @@
+.. _installation-instructions:
+
=========================
Installing `scikit-learn`
=========================
diff --git a/doc/tutorial/text_analytics/working_with_text_data.rst b/doc/tutorial/text_analytics/working_with_text_data.rst
index 3fe45fcbf597f..b7646b1b13c3b 100644
--- a/doc/tutorial/text_analytics/working_with_text_data.rst
+++ b/doc/tutorial/text_analytics/working_with_text_data.rst
@@ -27,10 +27,8 @@ Tutorial setup
To get started with this tutorial, you firstly must have the
*scikit-learn* and all of its required dependencies installed.
-Please refer to the `scikit-learn install`_ page for more information
-and for per-system instructions.
-
-.. _`scikit-learn install`: http://scikit-learn.sourceforge.net/install.html
+Please refer to the :ref:`installation instructions <installation-instructions>`
+page for more information and for per-system instructions.
The source of this tutorial can be found within your
scikit-learn folder::
| Link to installation instructions was pointed to a non-existant location.
| https://api.github.com/repos/scikit-learn/scikit-learn/pulls/3082 | 2014-04-17T19:38:44Z | 2014-04-17T21:47:00Z | 2014-04-17T21:47:00Z | 2014-06-13T12:20:29Z | 297 | scikit-learn/scikit-learn | 46,190 |
Closes #1977 | diff --git a/mitmproxy/addons/view.py b/mitmproxy/addons/view.py
index d2ab75f3fd..3a0587b054 100644
--- a/mitmproxy/addons/view.py
+++ b/mitmproxy/addons/view.py
@@ -102,7 +102,7 @@ def generate(self, f: mitmproxy.flow.Flow) -> int:
class View(collections.Sequence):
def __init__(self):
super().__init__()
- self._store = {}
+ self._store = collections.OrderedDict()
self.filter = matchall
# Should we show only marked flows?
self.show_marked = False
| Changes view._store from dict to OrderedDict | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/1988 | 2017-02-04T12:26:50Z | 2017-02-04T12:46:45Z | 2017-02-04T12:46:45Z | 2017-02-04T12:49:42Z | 145 | mitmproxy/mitmproxy | 28,110 |
Add Nantes City open data | diff --git a/README.md b/README.md
index db7325a492..bc5abfea4c 100644
--- a/README.md
+++ b/README.md
@@ -490,6 +490,8 @@ API | Description | Auth | HTTPS | CORS |
| [BCLaws](http://www.bclaws.ca/civix/template/complete/api/index.html) | Access to the laws of British Columbia | No | No | Unknown |
| [BusinessUSA](https://business.usa.gov/developer) | Authoritative information on U.S. programs, events, services and more | `apiKey` | Yes | Unknown |
| [Census.gov](https://www.census.gov/data/developers/data-sets.html) | The US Census Bureau provides various APIs and data sets on demographics and businesses | No | Yes | Unknown |
+| [City, Nantes Opendata](https://data.nantesmetropole.fr/pages/home/) | Nantes(FR) City Open Data | `apiKey` | Yes | Unknown |
+| [City, Prague Opendata](http://opendata.praha.eu/en) | Prague(CZ) City Open Data | No | No | Unknown |
| [Colorado Data Engine](http://codataengine.org/) | Formatted and geolocated Colorado public data | No | Yes | Unknown |
| [Colorado Information Marketplace](https://data.colorado.gov/) | Colorado State Government Open Data | No | Yes | Unknown |
| [Data USA](https://datausa.io/about/api/) | US Public Data | No | Yes | Unknown |
@@ -509,7 +511,6 @@ API | Description | Auth | HTTPS | CORS |
| [Open Government, New Zealand](https://www.data.govt.nz/) | New Zealand Government Open Data | No | Yes | Unknown |
| [Open Government, Taiwan](https://data.gov.tw/) | Taiwan Government Open Data | No | Yes | Unknown |
| [Open Government, USA](https://www.data.gov/) | United States Government Open Data | No | Yes | Unknown |
-| [Prague Opendata](http://opendata.praha.eu/en) | Prague City Open Data | No | No | Unknown |
| [Regulations.gov](https://regulationsgov.github.io/developers/) | Federal regulatory materials to increase understanding of the Federal rule making process | `apiKey` | Yes | Unknown |
| [Represent by Open North](https://represent.opennorth.ca/) | Find Canadian Government Representatives | No | Yes | Unknown |
| [USAspending.gov](https://api.usaspending.gov/) | US federal spending data | No | Yes | Unknown |
| Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] Your additions are ordered alphabetically
- [x] Your submission has a useful description
- [x] The description does not end with punctuation
- [x] Each table column should be padded with one space on either side
- [x] You have searched the repository for any relevant issues or pull requests
- [x] Any category you are creating has the minimum requirement of 3 items
- [x] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
| https://api.github.com/repos/public-apis/public-apis/pulls/1078 | 2019-10-07T09:42:06Z | 2019-10-07T11:11:59Z | 2019-10-07T11:11:59Z | 2019-10-07T11:12:08Z | 560 | public-apis/public-apis | 35,763 |
OS X Integration Tests Environment Setup | diff --git a/docs/contributing.rst b/docs/contributing.rst
index c6443e3b298..c746c6ae731 100644
--- a/docs/contributing.rst
+++ b/docs/contributing.rst
@@ -67,8 +67,10 @@ The following tools are there to help you:
Integration
~~~~~~~~~~~
+Mac OS X users: Run `./tests/mac-bootstrap.sh` instead of `boulder-start.sh` to
+install dependencies, configure the environment, and start boulder.
-First, install `Go`_ 1.5, libtool-ltdl, mariadb-server and
+Otherwise, install `Go`_ 1.5, libtool-ltdl, mariadb-server and
rabbitmq-server and then start Boulder_, an ACME CA server::
./tests/boulder-start.sh
diff --git a/tests/mac-bootstrap.sh b/tests/mac-bootstrap.sh
new file mode 100755
index 00000000000..66036ce566a
--- /dev/null
+++ b/tests/mac-bootstrap.sh
@@ -0,0 +1,26 @@
+#!/bin/sh
+
+#Check Homebrew
+if ! hash brew 2>/dev/null; then
+ echo "Homebrew Not Installed\nDownloading..."
+ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
+fi
+
+brew install libtool mariadb rabbitmq coreutils go
+
+mysql.server start
+
+rabbit_pid=`ps | grep rabbitmq | grep -v grep | awk '{ print $1}'`
+if [ -n "$rabbit_pid" ]; then
+ echo "RabbitMQ already running"
+else
+ rabbitmq-server &
+fi
+
+hosts_entry=`cat /etc/hosts | grep "127.0.0.1 le.wtf"`
+if [ -z "$hosts_entry" ]; then
+ echo "Adding hosts entry for le.wtf..."
+ sudo sh -c "echo 127.0.0.1 le.wtf >> /etc/hosts"
+fi
+
+./tests/boulder-start.sh
| Adds script and documentation to configure and setup environment for integration tests on OS X
| https://api.github.com/repos/certbot/certbot/pulls/883 | 2015-10-03T02:40:33Z | 2015-10-05T19:19:21Z | 2015-10-05T19:19:21Z | 2016-05-06T19:22:10Z | 468 | certbot/certbot | 3,417 |
Refactor MPS PyTorch fixes, add fix still required for PyTorch nightly builds back | diff --git a/modules/devices.py b/modules/devices.py
index 655ca1d3f3f..919048d0dec 100644
--- a/modules/devices.py
+++ b/modules/devices.py
@@ -2,6 +2,7 @@
import contextlib
import torch
from modules import errors
+from modules.sd_hijack_utils import CondFunc
from packaging import version
@@ -156,36 +157,7 @@ def test_for_nans(x, where):
raise NansException(message)
-# MPS workaround for https://github.com/pytorch/pytorch/issues/79383
-orig_tensor_to = torch.Tensor.to
-def tensor_to_fix(self, *args, **kwargs):
- if self.device.type != 'mps' and \
- ((len(args) > 0 and isinstance(args[0], torch.device) and args[0].type == 'mps') or \
- (isinstance(kwargs.get('device'), torch.device) and kwargs['device'].type == 'mps')):
- self = self.contiguous()
- return orig_tensor_to(self, *args, **kwargs)
-
-
-# MPS workaround for https://github.com/pytorch/pytorch/issues/80800
-orig_layer_norm = torch.nn.functional.layer_norm
-def layer_norm_fix(*args, **kwargs):
- if len(args) > 0 and isinstance(args[0], torch.Tensor) and args[0].device.type == 'mps':
- args = list(args)
- args[0] = args[0].contiguous()
- return orig_layer_norm(*args, **kwargs)
-
-
-# MPS workaround for https://github.com/pytorch/pytorch/issues/90532
-orig_tensor_numpy = torch.Tensor.numpy
-def numpy_fix(self, *args, **kwargs):
- if self.requires_grad:
- self = self.detach()
- return orig_tensor_numpy(self, *args, **kwargs)
-
-
# MPS workaround for https://github.com/pytorch/pytorch/issues/89784
-orig_cumsum = torch.cumsum
-orig_Tensor_cumsum = torch.Tensor.cumsum
def cumsum_fix(input, cumsum_func, *args, **kwargs):
if input.device.type == 'mps':
output_dtype = kwargs.get('dtype', input.dtype)
@@ -199,11 +171,20 @@ def cumsum_fix(input, cumsum_func, *args, **kwargs):
if has_mps():
if version.parse(torch.__version__) < version.parse("1.13"):
# PyTorch 1.13 doesn't need these fixes but unfortunately is slower and has regressions that prevent training from working
- torch.Tensor.to = tensor_to_fix
- torch.nn.functional.layer_norm = layer_norm_fix
- torch.Tensor.numpy = numpy_fix
+
+ # MPS workaround for https://github.com/pytorch/pytorch/issues/79383
+ CondFunc('torch.Tensor.to', lambda orig_func, self, *args, **kwargs: orig_func(self.contiguous(), *args, **kwargs),
+ lambda _, self, *args, **kwargs: self.device.type != 'mps' and (args and isinstance(args[0], torch.device) and args[0].type == 'mps' or isinstance(kwargs.get('device'), torch.device) and kwargs['device'].type == 'mps'))
+ # MPS workaround for https://github.com/pytorch/pytorch/issues/80800
+ CondFunc('torch.nn.functional.layer_norm', lambda orig_func, *args, **kwargs: orig_func(*([args[0].contiguous()] + list(args[1:])), **kwargs),
+ lambda _, *args, **kwargs: args and isinstance(args[0], torch.Tensor) and args[0].device.type == 'mps')
+ # MPS workaround for https://github.com/pytorch/pytorch/issues/90532
+ CondFunc('torch.Tensor.numpy', lambda orig_func, self, *args, **kwargs: orig_func(self.detach(), *args, **kwargs), lambda _, self, *args, **kwargs: self.requires_grad)
elif version.parse(torch.__version__) > version.parse("1.13.1"):
cumsum_needs_int_fix = not torch.Tensor([1,2]).to(torch.device("mps")).equal(torch.ShortTensor([1,1]).to(torch.device("mps")).cumsum(0))
cumsum_needs_bool_fix = not torch.BoolTensor([True,True]).to(device=torch.device("mps"), dtype=torch.int64).equal(torch.BoolTensor([True,False]).to(torch.device("mps")).cumsum(0))
- torch.cumsum = lambda input, *args, **kwargs: ( cumsum_fix(input, orig_cumsum, *args, **kwargs) )
- torch.Tensor.cumsum = lambda self, *args, **kwargs: ( cumsum_fix(self, orig_Tensor_cumsum, *args, **kwargs) )
+ cumsum_fix_func = lambda orig_func, input, *args, **kwargs: cumsum_fix(input, orig_func, *args, **kwargs)
+ CondFunc('torch.cumsum', cumsum_fix_func, None)
+ CondFunc('torch.Tensor.cumsum', cumsum_fix_func, None)
+ CondFunc('torch.narrow', lambda orig_func, *args, **kwargs: orig_func(*args, **kwargs).clone(), None)
+
| **Describe what this pull request is trying to achieve.**
Refactor MPS fixes to use CondFunc, and put `torch.narrow()` fix that is unfortunately still required back.
**Environment this was tested in**
- OS: macOS
- Browser: Safari
- Graphics card: M1 Max 64 GB | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/7455 | 2023-02-01T10:39:50Z | 2023-02-01T13:11:41Z | 2023-02-01T13:11:41Z | 2023-02-06T21:37:09Z | 1,135 | AUTOMATIC1111/stable-diffusion-webui | 39,711 |
Expanding tests for le-auto, adding Debian test suite | diff --git a/.travis.yml b/.travis.yml
index ed58cff076c..944c88471c2 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -66,6 +66,11 @@ matrix:
services: docker
before_install:
addons:
+ - sudo: required
+ env: TOXENV=le_auto_wheezy
+ services: docker
+ before_install:
+ addons:
- python: "2.7"
env: TOXENV=apacheconftest
sudo: required
diff --git a/letsencrypt-auto-source/Dockerfile.wheezy b/letsencrypt-auto-source/Dockerfile.wheezy
new file mode 100644
index 00000000000..f86795e08ad
--- /dev/null
+++ b/letsencrypt-auto-source/Dockerfile.wheezy
@@ -0,0 +1,31 @@
+# For running tests, build a docker image with a passwordless sudo and a trust
+# store we can manipulate.
+
+FROM debian:wheezy
+
+# Add an unprivileged user:
+RUN useradd --create-home --home-dir /home/lea --shell /bin/bash --groups sudo --uid 1000 lea
+
+# Install pip, sudo, openssl, and nose:
+RUN apt-get update && \
+ apt-get -q -y install python-pip sudo openssl && \
+ apt-get clean
+RUN pip install nose
+
+# Let that user sudo:
+RUN sed -i.bkp -e \
+ 's/%sudo\s\+ALL=(ALL\(:ALL\)\?)\s\+ALL/%sudo ALL=NOPASSWD:ALL/g' \
+ /etc/sudoers
+
+RUN mkdir -p /home/lea/certbot
+
+# Install fake testing CA:
+COPY ./tests/certs/ca/my-root-ca.crt.pem /usr/local/share/ca-certificates/
+
+# Copy code:
+COPY . /home/lea/certbot/letsencrypt-auto-source
+
+USER lea
+WORKDIR /home/lea
+
+CMD ["nosetests", "-v", "-s", "certbot/letsencrypt-auto-source/tests"]
diff --git a/tox.ini b/tox.ini
index 18fc252c8b9..426a1f707c0 100644
--- a/tox.ini
+++ b/tox.ini
@@ -137,3 +137,13 @@ commands =
whitelist_externals =
docker
passenv = DOCKER_*
+
+[testenv:le_auto_wheezy]
+# At the moment, this tests under Python 2.7 only, as only that version is
+# readily available on the Wheezy Docker image.
+commands =
+ docker build -f letsencrypt-auto-source/Dockerfile.wheezy -t lea letsencrypt-auto-source
+ docker run --rm -t -i lea
+whitelist_externals =
+ docker
+passenv = DOCKER_*
| Addresses issue #2443
Added Debian Wheezy (7) and Jessie (8)
| https://api.github.com/repos/certbot/certbot/pulls/2635 | 2016-03-10T07:45:59Z | 2016-11-10T22:01:15Z | 2016-11-10T22:01:15Z | 2016-11-10T22:03:48Z | 662 | certbot/certbot | 595 |
[Workflow] Cleanup workflow docs | diff --git a/README.rst b/README.rst
index c0e32bbf0cb55..8c04c28ee93b4 100644
--- a/README.rst
+++ b/README.rst
@@ -27,7 +27,7 @@ Ray is packaged with the following libraries for accelerating machine learning w
As well as libraries for taking ML and distributed apps to production:
- `Serve`_: Scalable and Programmable Serving
-- `Workflows`_: Fast, Durable Application Flows (alpha)
+- `Workflow`_: Fast, Durable Application Flows (alpha)
There are also many `community integrations <https://docs.ray.io/en/master/ray-libraries.html>`_ with Ray, including `Dask`_, `MARS`_, `Modin`_, `Horovod`_, `Hugging Face`_, `Scikit-learn`_, and others. Check out the `full list of Ray distributed libraries here <https://docs.ray.io/en/master/ray-libraries.html>`_.
@@ -42,7 +42,7 @@ Install Ray with: ``pip install ray``. For nightly wheels, see the
.. _`Scikit-learn`: https://docs.ray.io/en/master/joblib.html
.. _`Serve`: https://docs.ray.io/en/master/serve/index.html
.. _`Datasets`: https://docs.ray.io/en/master/data/dataset.html
-.. _`Workflows`: https://docs.ray.io/en/master/workflows/concepts.html
+.. _`Workflow`: https://docs.ray.io/en/master/workflows/concepts.html
.. _`Train`: https://docs.ray.io/en/master/train/train.html
diff --git a/doc/source/workflows/advanced.rst b/doc/source/workflows/advanced.rst
index 3ed03ae76d643..619fb03fd102d 100644
--- a/doc/source/workflows/advanced.rst
+++ b/doc/source/workflows/advanced.rst
@@ -4,7 +4,7 @@ Advanced Topics
Workflow task Checkpointing
---------------------------
-Ray Workflows provides strong fault tolerance and exactly-once execution semantics by checkpointing. However, checkpointing could be time consuming, especially when you have large inputs and outputs for workflow tasks. When exactly-once execution semantics is not required, you can skip some checkpoints to speed up your workflow.
+Ray Workflow provides strong fault tolerance and exactly-once execution semantics by checkpointing. However, checkpointing could be time consuming, especially when you have large inputs and outputs for workflow tasks. When exactly-once execution semantics is not required, you can skip some checkpoints to speed up your workflow.
We control the checkpoints by specify the checkpoint options like this:
diff --git a/doc/source/workflows/comparison.rst b/doc/source/workflows/comparison.rst
index 52ae404b2a63e..31f4e20ec475e 100644
--- a/doc/source/workflows/comparison.rst
+++ b/doc/source/workflows/comparison.rst
@@ -3,14 +3,14 @@ API Comparisons
Comparison between Ray Core APIs and Workflows
----------------------------------------------
-Workflows is built on top of Ray, and offers a mostly consistent subset of its API while providing durability. This section highlights some of the differences:
+Ray Workflow is built on top of Ray, and offers a mostly consistent subset of its API while providing durability. This section highlights some of the differences:
``func.remote`` vs ``func.bind``
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
With Ray tasks, ``func.remote`` will submit a remote task to run eagerly; ``func.bind`` will generate
a node in a DAG, it will not be executed until the DAG is been executed.
-Under the context of Ray Workflows, the execution of the DAG is deferred until ``workflow.run(dag, workflow_id=...)`` or ``workflow.run_async(dag, workflow_id=...)`` is called on the DAG.
+Under the context of Ray Workflow, the execution of the DAG is deferred until ``workflow.run(dag, workflow_id=...)`` or ``workflow.run_async(dag, workflow_id=...)`` is called on the DAG.
Specifying the workflow id allows for resuming of the workflow by its id in case of cluster failure.
Other Workflow Engines
diff --git a/doc/source/workflows/concepts.rst b/doc/source/workflows/concepts.rst
index 0135b76852497..3b891e283f7e0 100644
--- a/doc/source/workflows/concepts.rst
+++ b/doc/source/workflows/concepts.rst
@@ -1,33 +1,33 @@
.. _workflows:
-Workflows: Fast, Durable Application Flows
-==========================================
+Ray Workflow: Fast, Durable Application Flows
+=============================================
.. warning::
- Workflows is available as **alpha** in Ray 1.7+. Expect rough corners and for its APIs and storage format to change. Please file feature requests and bug reports on GitHub Issues or join the discussion on the `Ray Slack <https://forms.gle/9TSdDYUgxYs8SA9e8>`__.
+ Ray Workflow is available as **alpha** in Ray 1.7+. Expect rough corners and for its APIs and storage format to change. Please file feature requests and bug reports on GitHub Issues or join the discussion on the `Ray Slack <https://forms.gle/9TSdDYUgxYs8SA9e8>`__.
-Ray Workflows provides high-performance, *durable* application workflows using Ray tasks as the underlying execution engine. It is intended to support both large-scale workflows (e.g., ML and data pipelines) and long-running business workflows (when used together with Ray Serve).
+Ray Workflow provides high-performance, *durable* application workflows using Ray tasks as the underlying execution engine. It is intended to support both large-scale workflows (e.g., ML and data pipelines) and long-running business workflows (when used together with Ray Serve).
.. image:: workflows.svg
..
https://docs.google.com/drawings/d/113uAs-i4YjGBNxonQBC89ns5VqL3WeQHkUOWPSpeiXk/edit
-Why Workflows?
---------------
+Why Ray Workflow?
+-----------------
**Flexibility:** Combine the flexibility of Ray's dynamic task graphs with strong durability guarantees. Branch or loop conditionally based on runtime data. Use Ray distributed libraries seamlessly within workflow tasks.
-**Performance:** Workflows offers sub-second overheads for task launch and supports workflows with hundreds of thousands of tasks. Take advantage of the Ray object store to pass distributed datasets between tasks with zero-copy overhead.
+**Performance:** Ray Workflow offers sub-second overheads for task launch and supports workflows with hundreds of thousands of tasks. Take advantage of the Ray object store to pass distributed datasets between tasks with zero-copy overhead.
-**Dependency management:** Workflows leverages Ray's runtime environment feature to snapshot the code dependencies of a workflow. This enables management of workflows and virtual actors as code is upgraded over time.
+**Dependency management:** Ray Workflow leverages Ray's runtime environment feature to snapshot the code dependencies of a workflow. This enables management of workflows as code is upgraded over time.
-You might find that workflows is *lower level* compared to engines such as `AirFlow <https://www.astronomer.io/blog/airflow-ray-data-science-story>`__ (which can also run on Ray). This is because workflows focuses more on core workflow primitives as opposed to tools and integrations.
+You might find that Ray Workflow is *lower level* compared to engines such as `AirFlow <https://www.astronomer.io/blog/airflow-ray-data-science-story>`__ (which can also run on Ray). This is because Ray Workflow focuses more on core workflow primitives as opposed to tools and integrations.
Concepts
--------
-Workflows provides the *task* and *virtual actor* durable primitives, which are analogous to Ray's non-durable tasks and actors.
+Ray Workflow provides the durable *task* primitives, which are analogous to Ray's non-durable tasks.
Ray DAG
~~~~~~~
diff --git a/doc/source/workflows/events.rst b/doc/source/workflows/events.rst
index d423b08aa2eec..faea753f8779b 100644
--- a/doc/source/workflows/events.rst
+++ b/doc/source/workflows/events.rst
@@ -4,7 +4,7 @@ Events
Introduction
------------
-In order to allow an event to trigger a workflow, workflows support pluggable event systems. Using the event framework provides a few properties.
+In order to allow an event to trigger a workflow, Ray Workflow support pluggable event systems. Using the event framework provides a few properties.
1. Waits for events efficiently (without requiring a running workflow task while waiting).
2. Supports exactly-once event delivery semantics while providing fault tolerance.
diff --git a/doc/source/workflows/management.rst b/doc/source/workflows/management.rst
index 62cfa8beb392e..8b2996c3e630b 100644
--- a/doc/source/workflows/management.rst
+++ b/doc/source/workflows/management.rst
@@ -76,11 +76,11 @@ Bulk workflow management APIs
Recurring workflows
-------------------
-Ray workflows currently has no built-in job scheduler. You can however easily use any external job scheduler to interact with your Ray cluster (via :ref:`job submission <jobs-overview>` or :ref:`client connection <ray-client>`) trigger workflow runs.
+Ray Workflow currently has no built-in job scheduler. You can however easily use any external job scheduler to interact with your Ray cluster (via :ref:`job submission <jobs-overview>` or :ref:`client connection <ray-client>`) trigger workflow runs.
Storage Configuration
---------------------
-Workflows supports two types of storage backends out of the box:
+Ray Workflow supports two types of storage backends out of the box:
* Local file system: the data is stored locally. This is only for single node testing. It needs to be a NFS to work with multi-node clusters. To use local storage, specify ``ray.init(storage="/path/to/storage_dir")``.
* S3: Production users should use S3 as the storage backend. Enable S3 storage with ``ray.init(storage="s3://bucket/path")``.
@@ -91,7 +91,7 @@ If left unspecified, ``/tmp/ray/workflow_data`` will be used for temporary stora
Concurrency Control
-------------------
-Ray workflow supports concurrency control. You can support the maximum running workflows and maximum pending workflows via ``workflow.init()``
+Ray Workflow supports concurrency control. You can support the maximum running workflows and maximum pending workflows via ``workflow.init()``
before executing any workflow. ``workflow.init()`` again with a different configuration would raise an error.
For example, ``workflow.init(max_running_workflows=10, max_pending_workflows=50)`` means there will be at most 10 workflows running, 50 workflows pending.
@@ -112,5 +112,3 @@ Handling Dependencies
Ray logs the runtime environment (code and dependencies) of the workflow to storage at submission time. This ensures that the workflow can be resumed at a future time on a different Ray cluster.
You can also explicitly set the runtime environment for a particular task (e.g., specify conda environment, container image, etc.).
-
-For virtual actors, the runtime environment of the actor can be upgraded via the virtual actor management API.
diff --git a/doc/source/workflows/package-ref.rst b/doc/source/workflows/package-ref.rst
index 44a88f41ca1b0..089f76c0a7b4e 100644
--- a/doc/source/workflows/package-ref.rst
+++ b/doc/source/workflows/package-ref.rst
@@ -1,4 +1,4 @@
-Ray Workflows API
+Ray Workflow API
=================
Workflow Execution API
| Signed-off-by: Siyuan Zhuang <suquark@gmail.com>
<!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
Cherry pick #27197
## Why are these changes needed?
* Unify the component name - "Ray Workflow" instead of "workflow", "workflows", "Ray workflow", "Ray workflows", "Ray Workflows"
* Remove remaining part about virtual actors
## Related issue number
Closes #26971
## Checks
- [ ] I've signed off every commit(by using the -s flag, i.e., `git commit -s`) in this PR.
- [ ] I've run `scripts/format.sh` to lint the changes in this PR.
- [ ] I've included any doc changes needed for https://docs.ray.io/en/master/.
- [ ] I've made sure the tests are passing. Note that there might be a few flaky tests, see the recent failures at https://flakey-tests.ray.io/
- Testing Strategy
- [ ] Unit tests
- [ ] Release tests
- [ ] This PR is not tested :(
| https://api.github.com/repos/ray-project/ray/pulls/27217 | 2022-07-28T20:57:53Z | 2022-08-02T01:04:33Z | 2022-08-02T01:04:33Z | 2022-08-02T01:04:34Z | 2,569 | ray-project/ray | 19,153 |
Update nv-transformers workflow to use cu11.6 | diff --git a/.github/workflows/nv-transformers-v100.yml b/.github/workflows/nv-transformers-v100.yml
index a252c615015d..4e5a34365f52 100644
--- a/.github/workflows/nv-transformers-v100.yml
+++ b/.github/workflows/nv-transformers-v100.yml
@@ -16,7 +16,7 @@ concurrency:
jobs:
unit-tests:
- runs-on: [self-hosted, nvidia, cu111, v100]
+ runs-on: [self-hosted, nvidia, cu116, v100]
steps:
- uses: actions/checkout@v3
| - Update nv-transformers to use cuda 11.6. This also has the side effect of running on a runner using Ubuntu 20.04 which will be needed for new async_io features. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/4412 | 2023-09-27T18:18:50Z | 2023-09-27T21:11:40Z | 2023-09-27T21:11:40Z | 2023-09-27T21:11:41Z | 149 | microsoft/DeepSpeed | 10,066 |
[crunchyroll:beta] Use anonymous access instead of redirecting | diff --git a/yt_dlp/extractor/crunchyroll.py b/yt_dlp/extractor/crunchyroll.py
index d4968c13b26..141d8c5a7c1 100644
--- a/yt_dlp/extractor/crunchyroll.py
+++ b/yt_dlp/extractor/crunchyroll.py
@@ -720,15 +720,20 @@ class CrunchyrollBetaBaseIE(CrunchyrollBaseIE):
def _get_params(self, lang):
if not CrunchyrollBetaBaseIE.params:
+ if self._get_cookies(f'https://beta.crunchyroll.com/{lang}').get('etp_rt'):
+ grant_type, key = 'etp_rt_cookie', 'accountAuthClientId'
+ else:
+ grant_type, key = 'client_id', 'anonClientId'
+
initial_state, app_config = self._get_beta_embedded_json(self._download_webpage(
f'https://beta.crunchyroll.com/{lang}', None, note='Retrieving main page'), None)
api_domain = app_config['cxApiParams']['apiDomain']
- basic_token = str(base64.b64encode(('%s:' % app_config['cxApiParams']['accountAuthClientId']).encode('ascii')), 'ascii')
+
auth_response = self._download_json(
- f'{api_domain}/auth/v1/token', None, note='Authenticating with cookie',
+ f'{api_domain}/auth/v1/token', None, note=f'Authenticating with grant_type={grant_type}',
headers={
- 'Authorization': 'Basic ' + basic_token
- }, data='grant_type=etp_rt_cookie'.encode('ascii'))
+ 'Authorization': 'Basic ' + str(base64.b64encode(('%s:' % app_config['cxApiParams'][key]).encode('ascii')), 'ascii')
+ }, data=f'grant_type={grant_type}'.encode('ascii'))
policy_response = self._download_json(
f'{api_domain}/index/v2', None, note='Retrieving signed policy',
headers={
@@ -747,21 +752,6 @@ def _get_params(self, lang):
CrunchyrollBetaBaseIE.params = (api_domain, bucket, params)
return CrunchyrollBetaBaseIE.params
- def _redirect_from_beta(self, url, lang, internal_id, display_id, is_episode, iekey):
- initial_state, app_config = self._get_beta_embedded_json(self._download_webpage(url, display_id), display_id)
- content_data = initial_state['content']['byId'][internal_id]
- if is_episode:
- video_id = content_data['external_id'].split('.')[1]
- series_id = content_data['episode_metadata']['series_slug_title']
- else:
- series_id = content_data['slug_title']
- series_id = re.sub(r'-{2,}', '-', series_id)
- url = f'https://www.crunchyroll.com/{lang}{series_id}'
- if is_episode:
- url = url + f'/{display_id}-{video_id}'
- self.to_screen(f'{display_id}: Not logged in. Redirecting to non-beta site - {url}')
- return self.url_result(url, iekey, display_id)
-
class CrunchyrollBetaIE(CrunchyrollBetaBaseIE):
IE_NAME = 'crunchyroll:beta'
@@ -800,10 +790,6 @@ class CrunchyrollBetaIE(CrunchyrollBetaBaseIE):
def _real_extract(self, url):
lang, internal_id, display_id = self._match_valid_url(url).group('lang', 'id', 'display_id')
-
- if not self._get_cookies(url).get('etp_rt'):
- return self._redirect_from_beta(url, lang, internal_id, display_id, True, CrunchyrollIE.ie_key())
-
api_domain, bucket, params = self._get_params(lang)
episode_response = self._download_json(
@@ -897,10 +883,6 @@ class CrunchyrollBetaShowIE(CrunchyrollBetaBaseIE):
def _real_extract(self, url):
lang, internal_id, display_id = self._match_valid_url(url).group('lang', 'id', 'display_id')
-
- if not self._get_cookies(url).get('etp_rt'):
- return self._redirect_from_beta(url, lang, internal_id, display_id, False, CrunchyrollShowPlaylistIE.ie_key())
-
api_domain, bucket, params = self._get_params(lang)
series_response = self._download_json(
| ### Description of your *pull request* and other information
Eliminates the beta -> non-beta redirect code, due to changes in the api making it impossible. Instead, uses anonymous access to the beta api, which already works, and its momentarily used by the browser before redirect.
Closes #4692
Ran all beta tests, both with and without an `etp_rt` cookie.
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
- [ ] New extractor ([Piracy websites will not be accepted](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy))
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/4704 | 2022-08-19T03:48:14Z | 2022-08-30T16:34:13Z | 2022-08-30T16:34:13Z | 2022-08-30T19:59:43Z | 1,017 | yt-dlp/yt-dlp | 8,024 |
Update requirements.txt with tf-cpu and tf-aarch64 | diff --git a/requirements.txt b/requirements.txt
index 6313cecee57..a7c567a67ed 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -29,7 +29,7 @@ seaborn>=0.11.0
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
-# tensorflow>=2.4.1 # TFLite export
+# tensorflow>=2.4.1 # TFLite export (or tensorflow-cpu, tensorflow-aarch64)
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
|
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhanced TensorFlow compatibility for YOLOv5 TFLite export
### 📊 Key Changes
- Updated `requirements.txt` to clarify TensorFlow requirements for TFLite export.
### 🎯 Purpose & Impact
- 🎨 **Simplicity for Users**: Helps users understand that they can use different TensorFlow packages (`tensorflow-cpu`, `tensorflow-aarch64`) based on their hardware for TFLite model exports.
- ⚙️ **Flexibility**: Provides users with more options for TensorFlow installation, accommodating a variety of system architectures.
- 🚀 **Accessibility**: Makes it easier for users to export their YOLOv5 models to TFLite format, potentially expanding usage to more platforms, such as lightweight or mobile devices. | https://api.github.com/repos/ultralytics/yolov5/pulls/8807 | 2022-07-31T12:50:09Z | 2022-07-31T12:54:55Z | 2022-07-31T12:54:55Z | 2024-01-19T07:58:16Z | 172 | ultralytics/yolov5 | 24,964 |
Update xlsx arg description (xslx -> xlsx) | diff --git a/README.md b/README.md
index b71cc2bca..f480f4fd1 100644
--- a/README.md
+++ b/README.md
@@ -70,7 +70,7 @@ optional arguments:
path.
--csv Create Comma-Separated Values (CSV) File.
--xlsx Create the standard file for the modern Microsoft Excel
- spreadsheet (xslx).
+ spreadsheet (xlsx).
--site SITE_NAME Limit analysis to just the listed sites. Add multiple options to
specify more than one site.
--proxy PROXY_URL, -p PROXY_URL
diff --git a/sherlock/sherlock.py b/sherlock/sherlock.py
index a8760f2f9..fb9f52453 100644
--- a/sherlock/sherlock.py
+++ b/sherlock/sherlock.py
@@ -555,7 +555,7 @@ def main():
action="store_true",
dest="xlsx",
default=False,
- help="Create the standard file for the modern Microsoft Excel spreadsheet (xslx).",
+ help="Create the standard file for the modern Microsoft Excel spreadsheet (xlsx).",
)
parser.add_argument(
"--site",
| https://api.github.com/repos/sherlock-project/sherlock/pulls/2050 | 2024-03-15T16:58:08Z | 2024-03-15T16:59:25Z | 2024-03-15T16:59:25Z | 2024-03-15T17:00:54Z | 277 | sherlock-project/sherlock | 36,317 |
|
Maintain score order when curating sources | diff --git a/private_gpt/ui/ui.py b/private_gpt/ui/ui.py
index a4b131fe8..460f16014 100644
--- a/private_gpt/ui/ui.py
+++ b/private_gpt/ui/ui.py
@@ -44,8 +44,8 @@ class Config:
frozen = True
@staticmethod
- def curate_sources(sources: list[Chunk]) -> set["Source"]:
- curated_sources = set()
+ def curate_sources(sources: list[Chunk]) -> list["Source"]:
+ curated_sources = []
for chunk in sources:
doc_metadata = chunk.document.doc_metadata
@@ -54,7 +54,10 @@ def curate_sources(sources: list[Chunk]) -> set["Source"]:
page_label = doc_metadata.get("page_label", "-") if doc_metadata else "-"
source = Source(file=file_name, page=page_label, text=chunk.text)
- curated_sources.add(source)
+ curated_sources.append(source)
+ curated_sources = list(
+ dict.fromkeys(curated_sources).keys()
+ ) # Unique sources only
return curated_sources
| I noticed that every time after restarting PrivateGPT, the output on the screen would vary with similar queries used in "Search Files" mode even though the retrieved 'response' contained the same values that were ordered to the same scores.
After some troubleshooting, it looked like the output from the Source.curate_sources(response) function mixes up the values, which results in sources that are no longer ordered to the reponse scores.
In order to fix this, 'curated_sources' in the 'Source' class is changed from a set to a unique list to ensure that the score order is maintained and the results are consistent. | https://api.github.com/repos/zylon-ai/private-gpt/pulls/1643 | 2024-02-23T14:33:38Z | 2024-03-11T21:27:30Z | 2024-03-11T21:27:30Z | 2024-03-11T21:27:30Z | 249 | zylon-ai/private-gpt | 38,474 |
Increase unit test timeout for --coverage. | diff --git a/test/utils/shippable/units.sh b/test/utils/shippable/units.sh
index 26cbe1cabcc104..27d678745c2e99 100755
--- a/test/utils/shippable/units.sh
+++ b/test/utils/shippable/units.sh
@@ -8,7 +8,7 @@ IFS='/:' read -ra args <<< "$1"
version="${args[1]}"
if [[ "${COVERAGE:-}" == "--coverage" ]]; then
- timeout=90
+ timeout=99
else
timeout=11
fi
| ##### SUMMARY
Increase unit test timeout for --coverage.
##### ISSUE TYPE
Bugfix Pull Request
##### COMPONENT NAME
test/utils/shippable/units.sh | https://api.github.com/repos/ansible/ansible/pulls/54913 | 2019-04-05T16:33:05Z | 2019-04-05T16:43:43Z | 2019-04-05T16:43:43Z | 2019-07-25T17:24:48Z | 131 | ansible/ansible | 48,743 |
fix url encoding when validating pre-signed signature | diff --git a/localstack/services/s3/presigned_url.py b/localstack/services/s3/presigned_url.py
index faea038fee49e..f6b9bde367b15 100644
--- a/localstack/services/s3/presigned_url.py
+++ b/localstack/services/s3/presigned_url.py
@@ -282,6 +282,7 @@ def validate_presigned_url_s3(context: RequestContext) -> None:
:param context: RequestContext
"""
query_parameters = context.request.args
+ method = context.request.method
# todo: use the current User credentials instead? so it would not be set in stone??
credentials = Credentials(
access_key=TEST_AWS_ACCESS_KEY_ID,
@@ -306,13 +307,10 @@ def validate_presigned_url_s3(context: RequestContext) -> None:
auth_signer = HmacV1QueryAuthValidation(credentials=credentials, expires=expires)
- pre_signature_request = _reverse_inject_signature_hmac_v1_query(context)
-
- split = urlsplit(pre_signature_request.url)
- headers = _get_aws_request_headers(pre_signature_request.headers)
+ split_url, headers = _reverse_inject_signature_hmac_v1_query(context.request)
signature, string_to_sign = auth_signer.get_signature(
- pre_signature_request.method, split, headers, auth_path=None
+ method, split_url, headers, auth_path=None
)
# after passing through the virtual host to path proxy, the signature is parsed and `+` are replaced by space
req_signature = context.request.args.get("Signature").replace(" ", "+")
@@ -329,36 +327,20 @@ def validate_presigned_url_s3(context: RequestContext) -> None:
raise ex
-def _get_aws_request_headers(werkzeug_headers: Headers) -> HTTPHeaders:
- """
- Converts Werkzeug headers into HTTPHeaders() needed to form an AWSRequest
- :param werkzeug_headers: Werkzeug request headers
- :return: headers in HTTPHeaders format
- """
- # Werkzeug Headers can have multiple values for the same key
- # HTTPHeaders will append automatically the values when we set it to the same key multiple times
- # see https://docs.python.org/3/library/http.client.html#httpmessage-objects
- # see https://docs.python.org/3/library/email.compat32-message.html#email.message.Message.__setitem__
- headers = HTTPHeaders()
- for key, value in werkzeug_headers.items():
- headers[key] = value
-
- return headers
-
-
-def _reverse_inject_signature_hmac_v1_query(context: RequestContext) -> Request:
+def _reverse_inject_signature_hmac_v1_query(
+ request: Request,
+) -> tuple[urlparse.SplitResult, HTTPHeaders]:
"""
Reverses what does HmacV1QueryAuth._inject_signature while injecting the signature in the request.
Transforms the query string parameters in headers to recalculate the signature
see botocore.auth.HmacV1QueryAuth._inject_signature
- :param context:
- :return:
+ :param request: the original request
+ :return: tuple of a split result from the reversed request, and the reversed headers
"""
-
new_headers = {}
new_query_string_dict = {}
- for header, value in context.request.args.items():
+ for header, value in request.args.items():
header_low = header.lower()
if header_low not in HmacV1QueryAuthValidation.post_signature_headers:
new_headers[header] = value
@@ -367,7 +349,7 @@ def _reverse_inject_signature_hmac_v1_query(context: RequestContext) -> Request:
# there should not be any headers here. If there are, it means they have been added by the client
# We should verify them, they will fail the signature except if they were part of the original request
- for header, value in context.request.headers.items():
+ for header, value in request.headers.items():
header_low = header.lower()
if header_low.startswith("x-amz-") or header_low in ["content-type", "date", "content-md5"]:
new_headers[header_low] = value
@@ -375,36 +357,16 @@ def _reverse_inject_signature_hmac_v1_query(context: RequestContext) -> Request:
# rebuild the query string
new_query_string = percent_encode_sequence(new_query_string_dict)
- # easier to recreate the request, we would have to delete every cached property otherwise
- reversed_request = _create_new_request(
- request=context.request,
- headers=new_headers,
- query_string=new_query_string,
- )
+ # we need to URL encode the path, as the key needs to be urlencoded for the signature to match
+ encoded_path = urlparse.quote(request.path)
- return reversed_request
+ reversed_url = f"{request.scheme}://{request.host}{encoded_path}?{new_query_string}"
+ reversed_headers = HTTPHeaders()
+ for key, value in new_headers.items():
+ reversed_headers[key] = value
-def _create_new_request(request: Request, headers: Dict[str, str], query_string: str) -> Request:
- """
- Create a new request from an existent one, with new headers and query string
- It is easier to create a new one as the existing request has a lot of cached properties based on query_string
- We are not using the request body to generate the signature, so do not pass it to the new request
- :param request: the incoming pre-signed request
- :param headers: new headers used for signature calculation
- :param query_string: new query string for signature calculation
- :return: a new Request with passed headers and query_string
- """
- return Request(
- method=request.method,
- headers=headers,
- path=request.path,
- query_string=query_string,
- scheme=request.scheme,
- root_path=request.root_path,
- server=request.server,
- remote_addr=request.remote_addr,
- )
+ return urlsplit(reversed_url), reversed_headers
def validate_presigned_url_s3v4(context: RequestContext) -> None:
@@ -537,6 +499,8 @@ def __init__(self, context: RequestContext):
else:
self.path = self.request.path
+ # we need to URL encode the path, as the key needs to be urlencoded for the signature to match
+ self.path = urlparse.quote(self.path)
self.aws_request = self._get_aws_request()
def update_host_port(self, new_host_port: str, original_host_port: str = None):
diff --git a/tests/integration/s3/test_s3.py b/tests/integration/s3/test_s3.py
index 9cb4481b6b824..924733e04c36d 100644
--- a/tests/integration/s3/test_s3.py
+++ b/tests/integration/s3/test_s3.py
@@ -6496,6 +6496,31 @@ def test_pre_signed_url_forward_slash_bucket(
request_content = xmltodict.parse(req.content)
assert "GET\n//test-bucket" in request_content["Error"]["CanonicalRequest"]
+ @pytest.mark.parametrize(
+ "signature_version",
+ ["s3", "s3v4"],
+ )
+ def test_s3_presign_url_encoding(
+ self, aws_client, s3_bucket, signature_version, patch_s3_skip_signature_validation_false
+ ):
+ object_key = "table1-partitioned/date=2023-06-28/test.csv"
+ aws_client.s3.put_object(Key=object_key, Bucket=s3_bucket, Body="123")
+
+ s3_endpoint_path_style = _endpoint_url()
+ client = _s3_client_custom_config(
+ Config(signature_version=signature_version, s3={}),
+ endpoint_url=s3_endpoint_path_style,
+ )
+
+ url = client.generate_presigned_url(
+ "get_object",
+ Params={"Bucket": s3_bucket, "Key": object_key},
+ )
+
+ req = requests.get(url)
+ assert req.ok
+ assert req.content == b"123"
+
@staticmethod
def _get_presigned_snapshot_transformers(snapshot):
return [
| As reported by #8663, we were not properly re-URL-encoding the request path before validating the signature of the pre-signed URL.
I've made the necessary modifications into both signature types, and simplified the HMACv1 (signature type `s3`) quite a bit by not recreating a `Request` object but instead directly recreating a `SplitResult` and the new `HTTPHeaders`.
Added a test to validate the use case of the user and the fix. | https://api.github.com/repos/localstack/localstack/pulls/8664 | 2023-07-10T13:42:17Z | 2023-07-11T08:06:53Z | 2023-07-11T08:06:53Z | 2023-07-17T10:07:38Z | 1,822 | localstack/localstack | 29,086 |
Update gptv tool and save code tests | diff --git a/examples/crawl_webpage.py b/examples/crawl_webpage.py
index 7dcbf7993..2db9e407b 100644
--- a/examples/crawl_webpage.py
+++ b/examples/crawl_webpage.py
@@ -10,7 +10,7 @@
async def main():
prompt = """Get data from `paperlist` table in https://papercopilot.com/statistics/iclr-statistics/iclr-2024-statistics/,
- and save it to a csv file. paper title must include `multiagent` or `large language model`. *notice: print key data*"""
+ and save it to a csv file. paper title must include `multiagent` or `large language model`. *notice: print key variables*"""
ci = CodeInterpreter(goal=prompt, use_tools=True)
await ci.run(prompt)
diff --git a/metagpt/config2.py b/metagpt/config2.py
index d983a43c3..bc6af18c6 100644
--- a/metagpt/config2.py
+++ b/metagpt/config2.py
@@ -75,8 +75,6 @@ class Config(CLIParams, YamlModel):
iflytek_api_key: str = ""
azure_tts_subscription_key: str = ""
azure_tts_region: str = ""
- openai_vision_model: str = "gpt-4-vision-preview"
- vision_max_tokens: int = 4096
@classmethod
def from_home(cls, path):
diff --git a/metagpt/tools/libs/gpt_v_generator.py b/metagpt/tools/libs/gpt_v_generator.py
index 6953300d8..b1e8317ed 100644
--- a/metagpt/tools/libs/gpt_v_generator.py
+++ b/metagpt/tools/libs/gpt_v_generator.py
@@ -5,15 +5,13 @@
@Author : mannaandpoem
@File : gpt_v_generator.py
"""
-import base64
import os
from pathlib import Path
-import requests
-
from metagpt.const import DEFAULT_WORKSPACE_ROOT
from metagpt.tools.tool_registry import register_tool
from metagpt.tools.tool_type import ToolType
+from metagpt.utils.common import encode_image
ANALYZE_LAYOUT_PROMPT = """You are now a UI/UX, please generate layout information for this image:
@@ -43,27 +41,26 @@ class GPTvGenerator:
def __init__(self):
"""Initialize GPTvGenerator class with default values from the configuration."""
from metagpt.config2 import config
+ from metagpt.llm import LLM
- self.api_key = config.llm.api_key
- self.api_base = config.llm.base_url
- self.model = config.openai_vision_model
- self.max_tokens = config.vision_max_tokens
+ self.llm = LLM(llm_config=config.get_openai_llm())
+ self.llm.model = "gpt-4-vision-preview"
- def analyze_layout(self, image_path):
- """Analyze the layout of the given image and return the result.
+ async def analyze_layout(self, image_path: Path) -> str:
+ """Asynchronously analyze the layout of the given image and return the result.
This is a helper method to generate a layout description based on the image.
Args:
- image_path (str): Path of the image to analyze.
+ image_path (Path): Path of the image to analyze.
Returns:
str: The layout analysis result.
"""
- return self.get_result(image_path, ANALYZE_LAYOUT_PROMPT)
+ return await self.llm.aask(msg=ANALYZE_LAYOUT_PROMPT, images=[encode_image(image_path)])
- def generate_webpages(self, image_path):
- """Generate webpages including all code (HTML, CSS, and JavaScript) in one go based on the image.
+ async def generate_webpages(self, image_path: str) -> str:
+ """Asynchronously generate webpages including all code (HTML, CSS, and JavaScript) in one go based on the image.
Args:
image_path (str): The path of the image file.
@@ -71,58 +68,14 @@ def generate_webpages(self, image_path):
Returns:
str: Generated webpages content.
"""
- layout = self.analyze_layout(image_path)
+ if isinstance(image_path, str):
+ image_path = Path(image_path)
+ layout = await self.analyze_layout(image_path)
prompt = GENERATE_PROMPT + "\n\n # Context\n The layout information of the sketch image is: \n" + layout
- result = self.get_result(image_path, prompt)
- return result
-
- def get_result(self, image_path, prompt):
- """Get the result from the vision model based on the given image path and prompt.
-
- Args:
- image_path (str): Path of the image to analyze.
- prompt (str): Prompt to use for the analysis.
-
- Returns:
- str: The model's response as a string.
- """
- base64_image = self.encode_image(image_path)
- headers = {"Content-Type": "application/json", "Authorization": f"Bearer {self.api_key}"}
- payload = {
- "model": self.model,
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": prompt},
- {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}},
- ],
- }
- ],
- "max_tokens": self.max_tokens,
- }
- response = requests.post(f"{self.api_base}/chat/completions", headers=headers, json=payload)
-
- if response.status_code != 200:
- raise ValueError(f"Request failed with status {response.status_code}, {response.text}")
- else:
- return response.json()["choices"][0]["message"]["content"]
+ return await self.llm.aask(msg=prompt, images=[encode_image(image_path)])
@staticmethod
- def encode_image(image_path):
- """Encode the image at the given path to a base64 string.
-
- Args:
- image_path (str): Path of the image to encode.
-
- Returns:
- str: The base64 encoded string of the image.
- """
- with open(image_path, "rb") as image_file:
- return base64.b64encode(image_file.read()).decode("utf-8")
-
- @staticmethod
- def save_webpages(image_path, webpages) -> Path:
+ def save_webpages(image_path: str, webpages: str) -> Path:
"""Save webpages including all code (HTML, CSS, and JavaScript) at once.
Args:
@@ -132,35 +85,29 @@ def save_webpages(image_path, webpages) -> Path:
Returns:
Path: The path of the saved webpages.
"""
- # 在workspace目录下,创建一个名为下webpages的文件夹,用于存储html、css和js文件
+ # Create a folder called webpages in the workspace directory to store HTML, CSS, and JavaScript files
webpages_path = DEFAULT_WORKSPACE_ROOT / "webpages" / Path(image_path).stem
os.makedirs(webpages_path, exist_ok=True)
index_path = webpages_path / "index.html"
-
try:
index = webpages.split("```html")[1].split("```")[0]
- except IndexError:
- index = "No html code found in the result, please check your image and try again." + "\n" + webpages
-
- try:
+ style_path = None
if "styles.css" in index:
style_path = webpages_path / "styles.css"
elif "style.css" in index:
style_path = webpages_path / "style.css"
- else:
- style_path = None
style = webpages.split("```css")[1].split("```")[0] if style_path else ""
+ js_path = None
if "scripts.js" in index:
js_path = webpages_path / "scripts.js"
elif "script.js" in index:
js_path = webpages_path / "script.js"
- else:
- js_path = None
+
js = webpages.split("```javascript")[1].split("```")[0] if js_path else ""
except IndexError:
- raise ValueError("No css or js code found in the result, please check your image and try again.")
+ raise ValueError(f"No html or css or js code found in the result. \nWebpages: {webpages}")
try:
with open(index_path, "w", encoding="utf-8") as f:
diff --git a/metagpt/tools/libs/web_scraping.py b/metagpt/tools/libs/web_scraping.py
index 6fd3b9435..d01e69d09 100644
--- a/metagpt/tools/libs/web_scraping.py
+++ b/metagpt/tools/libs/web_scraping.py
@@ -4,19 +4,18 @@
@register_tool(tool_type=ToolType.WEBSCRAPING.type_name)
-async def scrape_web_playwright(url, *urls):
+async def scrape_web_playwright(url):
"""
- Scrape and save the HTML structure and inner text content of a web page using Playwright.
+ Asynchronously Scrape and save the HTML structure and inner text content of a web page using Playwright.
Args:
url (str): The main URL to fetch inner text from.
- *urls (str): Additional URLs to fetch inner text from.
Returns:
- (dict): The inner text content and html structure of the web page, key are : 'inner_text', 'html'.
+ dict: The inner text content and html structure of the web page, keys are 'inner_text', 'html'.
"""
# Create a PlaywrightWrapper instance for the Chromium browser
- web = await PlaywrightWrapper().run(url, *urls)
+ web = await PlaywrightWrapper().run(url)
# Return the inner text content of the web page
return {"inner_text": web.inner_text.strip(), "html": web.html.strip()}
diff --git a/metagpt/tools/tool_convert.py b/metagpt/tools/tool_convert.py
index 417a938e1..fc7cb9a15 100644
--- a/metagpt/tools/tool_convert.py
+++ b/metagpt/tools/tool_convert.py
@@ -15,7 +15,8 @@ def convert_code_to_tool_schema(obj, include: list[str] = []):
# method_doc = inspect.getdoc(method)
method_doc = get_class_method_docstring(obj, name)
if method_doc:
- schema["methods"][name] = docstring_to_schema(method_doc)
+ function_type = "function" if not inspect.iscoroutinefunction(method) else "async_function"
+ schema["methods"][name] = {"type": function_type, **docstring_to_schema(method_doc)}
elif inspect.isfunction(obj):
schema = {
diff --git a/tests/metagpt/tools/libs/test_gpt_v_generator.py b/tests/metagpt/tools/libs/test_gpt_v_generator.py
index d686d38ba..907006765 100644
--- a/tests/metagpt/tools/libs/test_gpt_v_generator.py
+++ b/tests/metagpt/tools/libs/test_gpt_v_generator.py
@@ -5,36 +5,81 @@
@Author : mannaandpoem
@File : test_gpt_v_generator.py
"""
+from pathlib import Path
+
import pytest
from metagpt import logs
+from metagpt.const import METAGPT_ROOT
from metagpt.tools.libs.gpt_v_generator import GPTvGenerator
@pytest.fixture
-def mock_webpages(mocker):
+def mock_webpage_filename_with_styles_and_scripts(mocker):
mock_data = """```html\n<html>\n<script src="scripts.js"></script>
-<link rel="stylesheet" href="styles.css(">\n</html>\n```\n
-```css\n.class { ... }\n```\n
-```javascript\nfunction() { ... }\n```\n"""
- mocker.patch("metagpt.tools.libs.gpt_v_generator.GPTvGenerator.generate_webpages", return_value=mock_data)
+<link rel="stylesheet" href="styles.css">\n</html>\n```\n
+```css\n/* styles.css */\n```\n
+```javascript\n// scripts.js\n```\n"""
+ mocker.patch("metagpt.provider.base_llm.BaseLLM.aask", return_value=mock_data)
+ return mocker
+
+
+@pytest.fixture
+def mock_webpage_filename_with_style_and_script(mocker):
+ mock_data = """```html\n<html>\n<script src="script.js"></script>
+<link rel="stylesheet" href="style.css">\n</html>\n```\n
+```css\n/* style.css */\n```\n
+```javascript\n// script.js\n```\n"""
+ mocker.patch("metagpt.provider.base_llm.BaseLLM.aask", return_value=mock_data)
return mocker
-def test_vision_generate_webpages(mock_webpages):
- image_path = "image.png"
+@pytest.fixture
+def mock_image_layout(mocker):
+ image_layout = "The layout information of the sketch image is ..."
+ mocker.patch("metagpt.provider.base_llm.BaseLLM.aask", return_value=image_layout)
+ return mocker
+
+
+@pytest.fixture
+def image_path():
+ return f"{METAGPT_ROOT}/docs/resources/workspace/content_rec_sys/resources/competitive_analysis.png"
+
+
+@pytest.mark.asyncio
+async def test_generate_webpages(mock_webpage_filename_with_styles_and_scripts, image_path):
generator = GPTvGenerator()
- rsp = generator.generate_webpages(image_path=image_path)
+ rsp = await generator.generate_webpages(image_path=image_path)
logs.logger.info(rsp)
assert "html" in rsp
assert "css" in rsp
assert "javascript" in rsp
-def test_save_webpages(mock_webpages):
- image_path = "image.png"
+@pytest.mark.asyncio
+async def test_save_webpages_with_styles_and_scripts(mock_webpage_filename_with_styles_and_scripts, image_path):
generator = GPTvGenerator()
- webpages = generator.generate_webpages(image_path)
+ webpages = await generator.generate_webpages(image_path)
webpages_dir = generator.save_webpages(image_path=image_path, webpages=webpages)
logs.logger.info(webpages_dir)
assert webpages_dir.exists()
+
+
+@pytest.mark.asyncio
+async def test_save_webpages_with_style_and_script(mock_webpage_filename_with_style_and_script, image_path):
+ generator = GPTvGenerator()
+ webpages = await generator.generate_webpages(image_path)
+ webpages_dir = generator.save_webpages(image_path=image_path, webpages=webpages)
+ logs.logger.info(webpages_dir)
+ assert webpages_dir.exists()
+
+
+@pytest.mark.asyncio
+async def test_analyze_layout(mock_image_layout, image_path):
+ layout = await GPTvGenerator().analyze_layout(Path(image_path))
+ logs.logger.info(layout)
+ assert layout
+
+
+if __name__ == "__main__":
+ pytest.main([__file__, "-s"])
diff --git a/tests/metagpt/utils/test_save_code.py b/tests/metagpt/utils/test_save_code.py
index 57a19049b..35ad84baf 100644
--- a/tests/metagpt/utils/test_save_code.py
+++ b/tests/metagpt/utils/test_save_code.py
@@ -41,4 +41,4 @@ async def test_save_code_file_notebook():
notebook = nbformat.read(file_path, as_version=4)
assert len(notebook.cells) > 0, "Notebook should have at least one cell"
first_cell_source = notebook.cells[0].source
- assert "print('Hello, World!')" in first_cell_source, "Notebook cell content does not match"
+ assert "print" in first_cell_source, "Notebook cell content does not match"
| https://api.github.com/repos/geekan/MetaGPT/pulls/847 | 2024-02-06T06:27:08Z | 2024-02-06T07:12:15Z | 2024-02-06T07:12:15Z | 2024-02-06T07:12:15Z | 3,600 | geekan/MetaGPT | 16,689 |
|
[3.7] bpo-32384: Skip test when _testcapi isn't available (GH-4940) | diff --git a/Lib/test/test_generators.py b/Lib/test/test_generators.py
index 7360b34023d3d8..7a21cb7e954ad5 100644
--- a/Lib/test/test_generators.py
+++ b/Lib/test/test_generators.py
@@ -9,12 +9,18 @@
from test import support
-_testcapi = support.import_module('_testcapi')
+try:
+ import _testcapi
+except ImportError:
+ _testcapi = None
# This tests to make sure that if a SIGINT arrives just before we send into a
# yield from chain, the KeyboardInterrupt is raised in the innermost
# generator (see bpo-30039).
+@unittest.skipUnless(_testcapi is not None and
+ hasattr(_testcapi, "raise_SIGINT_then_send_None"),
+ "needs _testcapi.raise_SIGINT_then_send_None")
class SignalAndYieldFromTest(unittest.TestCase):
def generator1(self):
| (cherry picked from commit 4cc3eb48e1e8289df5153db1c701cae263a1ef86)
Co-authored-by: Isaiah Peng <isaiah@users.noreply.github.com>
<!-- issue-number: bpo-32384 -->
https://bugs.python.org/issue32384
<!-- /issue-number -->
| https://api.github.com/repos/python/cpython/pulls/6891 | 2018-05-16T08:05:29Z | 2018-05-16T08:35:07Z | 2018-05-16T08:35:07Z | 2018-05-16T08:35:10Z | 225 | python/cpython | 4,111 |
Update check img | diff --git a/paddleocr.py b/paddleocr.py
index af0145b48b..96a641bb77 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -26,6 +26,9 @@
import logging
import numpy as np
from pathlib import Path
+import base64
+from io import BytesIO
+from PIL import Image
tools = importlib.import_module('.', 'tools')
ppocr = importlib.import_module('.', 'ppocr')
@@ -431,7 +434,25 @@ def check_img(img):
img, flag_gif, flag_pdf = check_and_read(image_file)
if not flag_gif and not flag_pdf:
with open(image_file, 'rb') as f:
- img = img_decode(f.read())
+ img_str = f.read()
+ img = img_decode(img_str)
+ if img is None:
+ try:
+ buf = BytesIO()
+ image = BytesIO(img_str)
+ im = Image.open(image)
+ rgb = im.convert('RGB')
+ rgb.save(buf, 'jpeg')
+ buf.seek(0)
+ image_bytes = buf.read()
+ data_base64 = str(base64.b64encode(image_bytes),
+ encoding="utf-8")
+ image_decode = base64.b64decode(data_base64)
+ img_array = np.frombuffer(image_decode, np.uint8)
+ img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
+ except:
+ logger.error("error in loading image:{}".format(image_file))
+ return None
if img is None:
logger.error("error in loading image:{}".format(image_file))
return None
| fix https://github.com/PaddlePaddle/PaddleOCR/issues/8457 | https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/8558 | 2022-12-06T12:08:26Z | 2022-12-07T01:51:54Z | 2022-12-07T01:51:54Z | 2023-08-07T06:12:35Z | 374 | PaddlePaddle/PaddleOCR | 41,861 |
Added entry for the Associated Press API | diff --git a/README.md b/README.md
index b264ef11e8..6105d1f4ce 100644
--- a/README.md
+++ b/README.md
@@ -597,6 +597,7 @@ API | Description | Auth | HTTPS | CORS |
### News
API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
+| [Associated Press](https://developer.ap.org/) | Search for news and metadata from Associated Press | `apiKey` | Yes | Unknown |
| [Chronicling America](http://chroniclingamerica.loc.gov/about/api/) | Provides access to millions of pages of historic US newspapers from the Library of Congress | No | No | Unknown |
| [Currents](https://currentsapi.services/) | Latest news published in various news sources, blogs and forums | `apiKey` | Yes | Yes |
| [Feedbin](https://github.com/feedbin/feedbin-api) | RSS reader | `OAuth` | Yes | Unknown |
| Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [X] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [X] Your additions are ordered alphabetically
- [X] Your submission has a useful description
- [X] The description does not end with punctuation
- [X] Each table column should be padded with one space on either side
- [X] You have searched the repository for any relevant issues or pull requests
- [X] Any category you are creating has the minimum requirement of 3 items
- [X] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
| https://api.github.com/repos/public-apis/public-apis/pulls/1083 | 2019-10-09T16:05:47Z | 2019-10-10T21:54:28Z | 2019-10-10T21:54:28Z | 2019-10-10T21:54:32Z | 220 | public-apis/public-apis | 36,075 |
✅ Enable tests for Python 3.11 | diff --git a/.github/workflows/test.yml b/.github/workflows/test.yml
index 3e6225db3343f..9e492c1adacf8 100644
--- a/.github/workflows/test.yml
+++ b/.github/workflows/test.yml
@@ -12,7 +12,7 @@ jobs:
runs-on: ubuntu-latest
strategy:
matrix:
- python-version: ["3.7", "3.8", "3.9", "3.10"]
+ python-version: ["3.7", "3.8", "3.9", "3.10", "3.11"]
fail-fast: false
steps:
diff --git a/pyproject.toml b/pyproject.toml
index 543ba15c1dd4f..ad088ce33527f 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -136,6 +136,11 @@ filterwarnings = [
# TODO: needed by asyncio in Python 3.9.7 https://bugs.python.org/issue45097, try to remove on 3.9.8
'ignore:The loop argument is deprecated since Python 3\.8, and scheduled for removal in Python 3\.10:DeprecationWarning:asyncio',
'ignore:starlette.middleware.wsgi is deprecated and will be removed in a future release\..*:DeprecationWarning:starlette',
+ # TODO: remove after upgrading HTTPX to a version newer than 0.23.0
+ # Including PR: https://github.com/encode/httpx/pull/2309
+ "ignore:'cgi' is deprecated:DeprecationWarning",
+ # For passlib
+ "ignore:'crypt' is deprecated and slated for removal in Python 3.13:DeprecationWarning",
# see https://trio.readthedocs.io/en/stable/history.html#trio-0-22-0-2022-09-28
"ignore:You seem to already have a custom.*:RuntimeWarning:trio",
"ignore::trio.TrioDeprecationWarning",
| ✅ Enable tests for Python 3.11
This will have to wait for a Uvloop wheel to be available. | https://api.github.com/repos/tiangolo/fastapi/pulls/4881 | 2022-05-09T16:25:50Z | 2022-11-03T12:26:48Z | 2022-11-03T12:26:48Z | 2022-11-03T12:26:49Z | 466 | tiangolo/fastapi | 23,067 |
Dont use constraints file in scheduled builds | diff --git a/.github/scripts/build_info.py b/.github/scripts/build_info.py
index 1853329b60c6..390a057ab1e4 100755
--- a/.github/scripts/build_info.py
+++ b/.github/scripts/build_info.py
@@ -89,6 +89,7 @@
class GithubEvent(enum.Enum):
PULL_REQUEST = "pull_request"
PUSH = "push"
+ SCHEDULE = "schedule"
def get_changed_files() -> List[str]:
@@ -182,6 +183,8 @@ def is_canary_build() -> bool:
For push event, we return true when the default branch is checked. In other case,
we return false.
+ For scheduled event, we always return true.
+
For other events, we return false
"""
if GITHUB_EVENT_NAME == GithubEvent.PULL_REQUEST.value:
@@ -208,8 +211,15 @@ def is_canary_build() -> bool:
)
return True
return False
+ elif GITHUB_EVENT_NAME == GithubEvent.SCHEDULE.value:
+ print(
+ "Current build is canary, "
+ f"because current github event name is {GITHUB_EVENT_NAME!r}"
+ )
+ return True
+
print(
- "Current build is canary, "
+ "Current build is NOT canary, "
f"because current github event name is {GITHUB_EVENT_NAME!r}"
)
return False
diff --git a/.github/workflows/python-versions.yml b/.github/workflows/python-versions.yml
index 5ee8c8458f24..7cea0fdaae5b 100644
--- a/.github/workflows/python-versions.yml
+++ b/.github/workflows/python-versions.yml
@@ -134,7 +134,11 @@ jobs:
contents: write
runs-on: ubuntu-latest
- if: github.repository == 'streamlit/streamlit' && github.event_name == 'push' && github.ref_name == 'develop'
+ if: |
+ github.repository == 'streamlit/streamlit' && (
+ (github.event_name == 'push' && github.ref_name == 'develop') ||
+ (github.event_name == 'schedule')
+ )
name: Upload constraints
| <!--
Before contributing (PLEASE READ!)
⚠️ If your contribution is more than a few lines of code, then prior to starting to code on it please post in the issue saying you want to volunteer, then wait for a positive response. And if there is no issue for it yet, create it first.
This helps make sure:
1. Two people aren't working on the same thing
2. This is something Streamlit's maintainers believe should be implemented/fixed
3. Any API, UI, or deeper architectural changes that need to be implemented have been fully thought through by Streamlit's maintainers
4. Your time is well spent!
More information in our wiki: https://github.com/streamlit/streamlit/wiki/Contributing
-->
## 📚 Context
Currently, the constraints files are updated when a new PR is merged into the `develop` branch.
After merging, the constraints files will be updated by scheduled builds as well, so these files will be updated at least once a day.
_Please describe the project or issue background here_
- What kind of change does this PR introduce?
- [ ] Bugfix
- [ ] Feature
- [ ] Refactoring
- [ ] Other, please describe:
## 🧠 Description of Changes
- _Add bullet points summarizing your changes here_
- [ ] This is a breaking API change
- [ ] This is a visible (user-facing) change
**Revised:**
_Insert screenshot of your updated UI/code here_
**Current:**
_Insert screenshot of existing UI/code here_
## 🧪 Testing Done
- [ ] Screenshots included
- [ ] Added/Updated unit tests
- [ ] Added/Updated e2e tests
## 🌐 References
_Does this depend on other work, documents, or tickets?_
- **Issue**: Closes #XXXX
---
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
| https://api.github.com/repos/streamlit/streamlit/pulls/6470 | 2023-04-11T07:33:20Z | 2023-04-20T10:51:58Z | 2023-04-20T10:51:58Z | 2023-10-05T19:30:17Z | 497 | streamlit/streamlit | 22,198 |
Made builder pattern much simpler by removing unnecessary class. | diff --git a/creational/builder.py b/creational/builder.py
index 71e3b12f..2c642d7a 100644
--- a/creational/builder.py
+++ b/creational/builder.py
@@ -10,10 +10,10 @@
from its actual representation (generally for abstraction).
*What does this example do?
-This particular example uses a Director to abtract the
+This particular example uses a director function to abtract the
construction of a building. The user specifies a Builder (House or
Flat) and the director specifies the methods in the order necessary
-creating a different building dependding on the specified
+creating a different building depending on the specified
specification (through the Builder class).
@author: Diogenes Augusto Fernandes Herminio <diofeher@gmail.com>
@@ -29,19 +29,11 @@
"""
-# Director
-class Director(object):
-
- def __init__(self):
- self.builder = None
-
- def construct_building(self):
- self.builder.new_building()
- self.builder.build_floor()
- self.builder.build_size()
-
- def get_building(self):
- return self.builder.building
+def construct_building(builder):
+ builder.new_building()
+ builder.build_floor()
+ builder.build_size()
+ return builder.building
# Abstract Builder
@@ -93,14 +85,9 @@ def __repr__(self):
# Client
if __name__ == "__main__":
- director = Director()
- director.builder = BuilderHouse()
- director.construct_building()
- building = director.get_building()
+ building = construct_building(BuilderHouse())
print(building)
- director.builder = BuilderFlat()
- director.construct_building()
- building = director.get_building()
+ building = construct_building(BuilderFlat())
print(building)
### OUTPUT ###
diff --git a/tests/test_builder.py b/tests/test_builder.py
index 17aeba68..533c11c9 100644
--- a/tests/test_builder.py
+++ b/tests/test_builder.py
@@ -1,16 +1,13 @@
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import unittest
-from creational.builder import Director, BuilderHouse, BuilderFlat
+from creational.builder import construct_building, BuilderHouse, BuilderFlat
class TestHouseBuilding(unittest.TestCase):
def setUp(self):
- self.director = Director()
- self.director.builder = BuilderHouse()
- self.director.construct_building()
- self.building = self.director.get_building()
+ self.building = construct_building(BuilderHouse())
def test_house_size(self):
self.assertEqual(self.building.size, 'Big')
@@ -22,10 +19,7 @@ def test_num_floor_in_house(self):
class TestFlatBuilding(unittest.TestCase):
def setUp(self):
- self.director = Director()
- self.director.builder = BuilderFlat()
- self.director.construct_building()
- self.building = self.director.get_building()
+ self.building = construct_building(BuilderFlat())
def test_house_size(self):
self.assertEqual(self.building.size, 'Small')
| This follows the motto "a class with only one method that actually does anything should be a function", with the result that using the director function requires one line of code instead of 5. | https://api.github.com/repos/faif/python-patterns/pulls/216 | 2018-02-03T13:48:49Z | 2018-02-06T18:32:29Z | 2018-02-06T18:32:29Z | 2018-02-06T18:33:44Z | 699 | faif/python-patterns | 33,678 |
[AIR][Serve] Add support for multi-modal array input | diff --git a/doc/source/serve/http-adapters.md b/doc/source/serve/http-adapters.md
index 56fb75605c4dd..129dbb77bad8a 100644
--- a/doc/source/serve/http-adapters.md
+++ b/doc/source/serve/http-adapters.md
@@ -141,6 +141,6 @@ Here is a list of adapters and please feel free to [contribute more](https://git
```{eval-rst}
.. automodule:: ray.serve.http_adapters
- :members: json_to_ndarray, image_to_ndarray, starlette_request, json_request, pandas_read_json
+ :members: json_to_ndarray, image_to_ndarray, starlette_request, json_request, pandas_read_json, json_to_multi_ndarray
```
\ No newline at end of file
diff --git a/python/ray/serve/http_adapters.py b/python/ray/serve/http_adapters.py
index 948288985ec1b..88bddd81102af 100644
--- a/python/ray/serve/http_adapters.py
+++ b/python/ray/serve/http_adapters.py
@@ -52,6 +52,12 @@ def json_to_ndarray(payload: NdArray) -> np.ndarray:
return arr
+@PublicAPI(stability="beta")
+def json_to_multi_ndarray(payload: Dict[str, NdArray]) -> Dict[str, np.ndarray]:
+ """Accepts a JSON of shape {str_key: NdArray} and converts it to dict of arrays."""
+ return {key: json_to_ndarray(arr_obj) for key, arr_obj in payload.items()}
+
+
@PublicAPI(stability="beta")
def starlette_request(
request: starlette.requests.Request,
diff --git a/python/ray/serve/model_wrappers.py b/python/ray/serve/model_wrappers.py
index 479261dfab198..815b6fea11843 100644
--- a/python/ray/serve/model_wrappers.py
+++ b/python/ray/serve/model_wrappers.py
@@ -1,3 +1,4 @@
+from collections import defaultdict
from typing import Callable, Dict, List, Optional, Tuple, Type, Union
import numpy as np
@@ -45,18 +46,73 @@ def collate_array(
def unpack(output_arr):
if isinstance(output_arr, list):
return output_arr
- assert isinstance(
- output_arr, np.ndarray
- ), f"The output should be np.ndarray but Serve got {type(output_arr)}."
- assert len(output_arr) == batch_size, (
- f"The output array should have shape of ({batch_size}, ...) "
- f"but Serve got {output_arr.shape}"
- )
+ if not isinstance(output_arr, np.ndarray):
+ raise TypeError(
+ f"The output should be np.ndarray but Serve got {type(output_arr)}."
+ )
+ if len(output_arr) != batch_size:
+ raise ValueError(
+ f"The output array should have shape of ({batch_size}, ...) "
+ f"because the input has {batch_size} entries "
+ f"but Serve got {output_arr.shape}"
+ )
return [arr.squeeze(axis=0) for arr in np.split(output_arr, batch_size, axis=0)]
return batched, unpack
+def collate_dict_array(
+ input_list: List[Dict[str, np.ndarray]]
+) -> Tuple[
+ Dict[str, np.ndarray],
+ Callable[[Dict[str, np.ndarray]], List[Dict[str, np.ndarray]]],
+]:
+ batch_size = len(input_list)
+
+ # Check all input has the same dict keys.
+ input_keys = [set(item.keys()) for item in input_list]
+ batch_has_same_keys = input_keys.count(input_keys[0]) == batch_size
+ if not batch_has_same_keys:
+ raise ValueError(
+ f"The input batch contains dictionary of different keys: {input_keys}"
+ )
+
+ # Turn list[dict[str, array]] to dict[str, List[array]]
+ key_to_list = defaultdict(list)
+ for single_dict in input_list:
+ for key, arr in single_dict.items():
+ key_to_list[key].append(arr)
+
+ # Turn dict[str, List[array]] to dict[str, array]
+ batched_dict = {}
+ unpack_dict = {}
+ for key, list_of_arr in key_to_list.items():
+ arr, unpack_func = collate_array(list_of_arr)
+ batched_dict[key] = arr
+ unpack_dict[key] = unpack_func
+
+ def unpack(output_dict: Dict[str, np.ndarray]):
+ # short circuit behavior, assume users already unpacked the output for us.
+ if isinstance(output_dict, list):
+ return output_dict
+
+ if not isinstance(output_dict, Dict):
+ raise TypeError(
+ f"The output should be a dictionary but Serve got {type(output_dict)}."
+ )
+
+ split_list_of_dict = [{} for _ in range(batch_size)]
+ for key, arr_unpack_func in unpack_dict.items():
+ arr_list = arr_unpack_func(output_dict[key])
+ # in place update each dictionary with the split array chunk.
+ for item, arr in zip(split_list_of_dict, arr_list):
+ item[key] = arr
+
+ return split_list_of_dict
+
+ return batched_dict, unpack
+
+
@require_packages(["pandas"])
def collate_dataframe(
input_list: List["pd.DataFrame"],
@@ -69,13 +125,17 @@ def collate_dataframe(
def unpack(output_df):
if isinstance(output_df, list):
return output_df
- assert isinstance(
- output_df, pd.DataFrame
- ), f"The output should be a Pandas DataFrame but Serve got {type(output_df)}"
- assert len(output_df) % batch_size == 0, (
- f"The output dataframe should have length divisible by {batch_size}, "
- f"but Serve got length {len(output_df)}."
- )
+ if not isinstance(output_df, pd.DataFrame):
+ raise TypeError(
+ "The output should be a Pandas DataFrame but Serve got "
+ f"{type(output_df)}"
+ )
+ if len(output_df) % batch_size != 0:
+ raise ValueError(
+ f"The output dataframe should have length divisible by {batch_size}, "
+ f"because the input from {batch_size} different requests "
+ f"but Serve got length {len(output_df)}."
+ )
return [df.reset_index(drop=True) for df in np.split(output_df, batch_size)]
return batched, unpack
diff --git a/python/ray/serve/tests/test_http_adapters.py b/python/ray/serve/tests/test_http_adapters.py
index bd23804f4a135..c7d661ca979df 100644
--- a/python/ray/serve/tests/test_http_adapters.py
+++ b/python/ray/serve/tests/test_http_adapters.py
@@ -8,6 +8,7 @@
from ray.serve.http_adapters import (
NdArray,
+ json_to_multi_ndarray,
json_to_ndarray,
image_to_ndarray,
pandas_read_json,
@@ -51,6 +52,12 @@ def test_json_to_ndarray():
)
+def test_json_to_multi_ndarray():
+ assert json_to_multi_ndarray(
+ {"a": NdArray(array=[1]), "b": NdArray(array=[3])}
+ ) == {"a": np.array(1), "b": np.array(3)}
+
+
def test_image_to_ndarray():
buffer = io.BytesIO()
arr = (np.random.rand(100, 100, 3) * 255).astype("uint8")
diff --git a/python/ray/serve/tests/test_model_wrappers.py b/python/ray/serve/tests/test_model_wrappers.py
index d99dbf54abf36..62d3f3f10f730 100644
--- a/python/ray/serve/tests/test_model_wrappers.py
+++ b/python/ray/serve/tests/test_model_wrappers.py
@@ -10,6 +10,7 @@
ModelWrapperDeployment,
collate_array,
collate_dataframe,
+ collate_dict_array,
)
from ray.air.checkpoint import Checkpoint
from ray.air.predictor import DataBatchType, Predictor
@@ -34,11 +35,28 @@ def test_array(self):
def test_array_error(self):
list_of_arr = [np.array([i]) for i in range(4)]
_, unpack = collate_array(list_of_arr)
- with pytest.raises(AssertionError, match="output array should have shape of"):
+ with pytest.raises(ValueError, match="output array should have shape of"):
unpack(np.arange(2))
- with pytest.raises(AssertionError, match="output should be np.ndarray but"):
+ with pytest.raises(TypeError, match="output should be np.ndarray but"):
unpack("string")
+ def test_dict_array(self):
+ list_of_dicts = [
+ {"a": np.array([1, 2]), "b": np.array(3)},
+ {"a": np.array([3, 4]), "b": np.array(4)},
+ ]
+ batched_dict = {"a": np.array([[1, 2], [3, 4]]), "b": np.array([3, 4])}
+
+ batched, unpack = collate_dict_array(list_of_dicts)
+ assert batched.keys() == batched_dict.keys()
+ for key in batched.keys():
+ assert np.array_equal(batched[key], batched_dict[key])
+
+ for original, unpacked in zip(list_of_dicts, unpack(batched)):
+ assert original.keys() == unpacked.keys()
+ for key in original.keys():
+ assert np.array_equal(original[key], unpacked[key])
+
def test_dataframe(self):
list_of_dfs = [pd.DataFrame({"a": [i, i], "b": [i, i]}) for i in range(4)]
batched_df = pd.DataFrame(
| <!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
Ray AIR's data batch type accepts no just simple array or dataframe, but also a dictionary of array. This PR adds support for that in Serve's model wrapper, as well as a new http adapter accepting that. Most code re-uses existing array implementation.
<!-- Please give a short summary of the change and the problem this solves. -->
## Related issue number
<!-- For example: "Closes #1234" -->
## Checks
- [x] I've run `scripts/format.sh` to lint the changes in this PR.
- [x] I've included any doc changes needed for https://docs.ray.io/en/master/.
- [ ] I've made sure the tests are passing. Note that there might be a few flaky tests, see the recent failures at https://flakey-tests.ray.io/
- Testing Strategy
- [x] Unit tests
- [ ] Release tests
- [ ] This PR is not tested :(
| https://api.github.com/repos/ray-project/ray/pulls/25609 | 2022-06-09T00:45:15Z | 2022-06-10T16:19:42Z | 2022-06-10T16:19:42Z | 2022-06-10T16:19:42Z | 2,217 | ray-project/ray | 19,618 |
CLN: remove unused axis kwarg from Block.putmask | diff --git a/pandas/core/generic.py b/pandas/core/generic.py
index 6a80fa3e93362..857b97f58d8a0 100644
--- a/pandas/core/generic.py
+++ b/pandas/core/generic.py
@@ -8935,9 +8935,7 @@ def _where(
# reconstruct the block manager
self._check_inplace_setting(other)
- new_data = self._mgr.putmask(
- mask=cond, new=other, align=align, axis=block_axis
- )
+ new_data = self._mgr.putmask(mask=cond, new=other, align=align)
result = self._constructor(new_data)
return self._update_inplace(result)
diff --git a/pandas/core/internals/array_manager.py b/pandas/core/internals/array_manager.py
index 99edec3c606d4..90591370c3583 100644
--- a/pandas/core/internals/array_manager.py
+++ b/pandas/core/internals/array_manager.py
@@ -343,7 +343,7 @@ def where(self, other, cond, align: bool, errors: str, axis: int) -> ArrayManage
# def setitem(self, indexer, value) -> ArrayManager:
# return self.apply_with_block("setitem", indexer=indexer, value=value)
- def putmask(self, mask, new, align: bool = True, axis: int = 0):
+ def putmask(self, mask, new, align: bool = True):
if align:
align_keys = ["new", "mask"]
@@ -356,7 +356,6 @@ def putmask(self, mask, new, align: bool = True, axis: int = 0):
align_keys=align_keys,
mask=mask,
new=new,
- axis=axis,
)
def diff(self, n: int, axis: int) -> ArrayManager:
diff --git a/pandas/core/internals/blocks.py b/pandas/core/internals/blocks.py
index 1356b9d3b2ca3..02c3340412983 100644
--- a/pandas/core/internals/blocks.py
+++ b/pandas/core/internals/blocks.py
@@ -998,7 +998,7 @@ def setitem(self, indexer, value):
block = self.make_block(values)
return block
- def putmask(self, mask, new, axis: int = 0) -> List["Block"]:
+ def putmask(self, mask, new) -> List["Block"]:
"""
putmask the data to the block; it is possible that we may create a
new dtype of block
@@ -1009,7 +1009,6 @@ def putmask(self, mask, new, axis: int = 0) -> List["Block"]:
----------
mask : np.ndarray[bool], SparseArray[bool], or BooleanArray
new : a ndarray/object
- axis : int
Returns
-------
@@ -1026,8 +1025,6 @@ def putmask(self, mask, new, axis: int = 0) -> List["Block"]:
new = self.fill_value
if self._can_hold_element(new):
- # We only get here for non-Extension Blocks, so _try_coerce_args
- # is only relevant for DatetimeBlock and TimedeltaBlock
if self.dtype.kind in ["m", "M"]:
arr = self.array_values()
arr = cast("NDArrayBackedExtensionArray", arr)
@@ -1040,14 +1037,17 @@ def putmask(self, mask, new, axis: int = 0) -> List["Block"]:
new_values = new_values.T
putmask_without_repeat(new_values, mask, new)
+ return [self]
+
+ elif not mask.any():
+ return [self]
- # maybe upcast me
- elif mask.any():
+ else:
+ # may need to upcast
if transpose:
mask = mask.T
if isinstance(new, np.ndarray):
new = new.T
- axis = new_values.ndim - axis - 1
# operate column-by-column
def f(mask, val, idx):
@@ -1074,8 +1074,6 @@ def f(mask, val, idx):
new_blocks = self.split_and_operate(mask, f, True)
return new_blocks
- return [self]
-
def coerce_to_target_dtype(self, other):
"""
coerce the current block to a dtype compat for other
@@ -1577,7 +1575,7 @@ def set_inplace(self, locs, values):
assert locs.tolist() == [0]
self.values = values
- def putmask(self, mask, new, axis: int = 0) -> List["Block"]:
+ def putmask(self, mask, new) -> List["Block"]:
"""
See Block.putmask.__doc__
"""
diff --git a/pandas/core/internals/managers.py b/pandas/core/internals/managers.py
index ad9cdcfa1b07f..8e605a906eced 100644
--- a/pandas/core/internals/managers.py
+++ b/pandas/core/internals/managers.py
@@ -564,7 +564,7 @@ def where(self, other, cond, align: bool, errors: str, axis: int) -> BlockManage
def setitem(self, indexer, value) -> BlockManager:
return self.apply("setitem", indexer=indexer, value=value)
- def putmask(self, mask, new, align: bool = True, axis: int = 0):
+ def putmask(self, mask, new, align: bool = True):
if align:
align_keys = ["new", "mask"]
@@ -577,7 +577,6 @@ def putmask(self, mask, new, align: bool = True, axis: int = 0):
align_keys=align_keys,
mask=mask,
new=new,
- axis=axis,
)
def diff(self, n: int, axis: int) -> BlockManager:
| - [ ] closes #xxxx
- [ ] tests added / passed
- [ ] Ensure all linting tests pass, see [here](https://pandas.pydata.org/pandas-docs/dev/development/contributing.html#code-standards) for how to run them
- [ ] whatsnew entry
| https://api.github.com/repos/pandas-dev/pandas/pulls/39238 | 2021-01-17T19:11:11Z | 2021-01-19T18:11:37Z | 2021-01-19T18:11:37Z | 2021-01-19T18:15:08Z | 1,355 | pandas-dev/pandas | 45,216 |
Handle binary files when scanning metadata in python 3 (#53773) - 2.7 | diff --git a/test/runner/lib/target.py b/test/runner/lib/target.py
index b363c4a0e507bc..4971c07aec3521 100644
--- a/test/runner/lib/target.py
+++ b/test/runner/lib/target.py
@@ -363,8 +363,12 @@ def analyze_integration_target_dependencies(integration_targets):
for meta_path in meta_paths:
if os.path.exists(meta_path):
- with open(meta_path, 'r') as meta_fd:
- meta_lines = meta_fd.read().splitlines()
+ with open(meta_path, 'rb') as meta_fd:
+ # try and decode the file as a utf-8 string, skip if it contains invalid chars (binary file)
+ try:
+ meta_lines = meta_fd.read().decode('utf-8').splitlines()
+ except UnicodeDecodeError:
+ continue
for meta_line in meta_lines:
if re.search(r'^ *#.*$', meta_line):
| (cherry picked from commit c2466c545bce1c89bed5ca6536376444d01f0522)
##### SUMMARY
Backport of https://github.com/ansible/ansible/pull/53773
##### ISSUE TYPE
- Bugfix Pull Request
##### COMPONENT NAME
ansible-test | https://api.github.com/repos/ansible/ansible/pulls/53784 | 2019-03-14T05:19:04Z | 2019-03-18T19:54:31Z | 2019-03-18T19:54:31Z | 2019-07-25T17:10:35Z | 214 | ansible/ansible | 49,222 |
[autoparallel] added new strategy constructor template | diff --git a/colossalai/auto_parallel/solver/op_handler/__init__.py b/colossalai/auto_parallel/solver/op_handler/__init__.py
index a0d570325fe5..486a8fe886f6 100644
--- a/colossalai/auto_parallel/solver/op_handler/__init__.py
+++ b/colossalai/auto_parallel/solver/op_handler/__init__.py
@@ -6,8 +6,9 @@
from .bcast_op_handler import BcastOpHandler
from .embedding_handler import EmbeddingHandler
from .unary_elementwise_handler import UnaryElementwiseHandler
+from .dot_handler_v2 import LinearFunctionHandler, LinearModuleHandler
__all__ = [
'OperatorHandler', 'DotHandler', 'ConvHandler', 'BatchNormHandler', 'ReshapeHandler', 'BcastOpHandler',
- 'UnaryElementwiseHandler', 'EmbeddingHandler'
+ 'UnaryElementwiseHandler', 'EmbeddingHandler', 'LinearFunctionHandler', 'LinearModuleHandler'
]
diff --git a/colossalai/auto_parallel/solver/op_handler/registry.py b/colossalai/auto_parallel/solver/op_handler/registry.py
index 51855e4bf56e..6bed842d4966 100644
--- a/colossalai/auto_parallel/solver/op_handler/registry.py
+++ b/colossalai/auto_parallel/solver/op_handler/registry.py
@@ -14,7 +14,7 @@ def wrapper(func):
return wrapper
def get(self, source):
- assert source in self.store
+ assert source in self.store, f'{source} not found in the {self.name} registry'
target = self.store[source]
return target
diff --git a/colossalai/auto_parallel/solver/sharding_strategy.py b/colossalai/auto_parallel/solver/sharding_strategy.py
index 4df2565683b5..4c1a390ce169 100644
--- a/colossalai/auto_parallel/solver/sharding_strategy.py
+++ b/colossalai/auto_parallel/solver/sharding_strategy.py
@@ -49,9 +49,10 @@ class OperationDataType(Enum):
"""
An operation can come from the argument list of an operator or the parameter list of a module.
"""
- ARG = 0
- PARAM = 1
- OUTPUT = 2
+ INPUT = 0
+ ARG = 1
+ PARAM = 2
+ OUTPUT = 3
@dataclass
diff --git a/colossalai/auto_parallel/solver/strategies_constructor.py b/colossalai/auto_parallel/solver/strategies_constructor.py
index ed3da6c8cb34..6eb843eba185 100644
--- a/colossalai/auto_parallel/solver/strategies_constructor.py
+++ b/colossalai/auto_parallel/solver/strategies_constructor.py
@@ -4,6 +4,7 @@
from colossalai.tensor.sharding_spec import ShardingSpec
from colossalai.device.device_mesh import DeviceMesh
from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.auto_parallel.solver.op_handler.registry import operator_registry
from .options import SolverOptions
from . import ShardingStrategy, StrategiesVector
from .op_handler import *
@@ -16,6 +17,8 @@
from ._utils import generate_sharding_spec, generate_resharding_costs
import builtins
+__all__ = ['StrategiesConstructor', 'StrategiesConstructor_V2']
+
class StrategiesConstructor:
"""
@@ -49,6 +52,7 @@ def remove_duplicated_strategy(self, strategies_vector):
name_checklist.append(strategy.name)
else:
remove_list.append(strategy)
+
for strategy in remove_list:
strategies_vector.remove(strategy)
@@ -394,3 +398,87 @@ def build_strategies_and_cost(self):
setattr(node, 'strategies_vector', strategies_vector)
self.leaf_strategies.append(strategies_vector)
self.strategy_map[node] = strategies_vector
+
+
+class StrategiesConstructor_V2:
+ """
+ StrategiesConstructor is used to construct the parallelization plan for the model execution.
+
+ Args:
+ graph (Graph): a Graph object used for analysis and strategy generation.
+ device_mesh (DeviceMesh): a DeviceMesh object which contains the meta information about the cluster.
+ solver_options (SolverOptions): a SolverOptions object which specifies the preferences for plan searching.
+ """
+
+ def __init__(self, graph: Graph, device_mesh: DeviceMesh, solver_options: SolverOptions):
+ self.graph = graph
+ assert graph.owning_module is not None, 'The given graph is not associated with a owning_module'
+ self.root_module = self.graph.owning_module
+ self.nodes = list(graph.nodes)
+ self.device_mesh = device_mesh
+ self.leaf_strategies = []
+ self.strategy_map = {}
+ self.solver_options = solver_options
+
+ def remove_duplicated_strategy(self, strategies_vector):
+ '''
+ In build_strategies_and_cost method, we may produce some duplicated strategies.
+ In this method, we will remove the duplicated strategies depending on the strategies name.
+ Note that this operation is in-place.
+ '''
+ name_checklist = []
+ remove_list = []
+ for strategy in strategies_vector:
+ if strategy.name not in name_checklist:
+ name_checklist.append(strategy.name)
+ else:
+ remove_list.append(strategy)
+ for strategy in remove_list:
+ strategies_vector.remove(strategy)
+
+ def build_strategies_and_cost(self):
+ """
+ This method is to build the strategy vector for each node in the computation graph.
+ """
+ for node in self.nodes:
+ strategies_vector = StrategiesVector(node)
+
+ # placeholder node
+ if node.op == 'placeholder':
+ # TODO: implement placeholder node handler
+ pass
+
+ # get_attr node
+ elif node.op == 'get_attr':
+ # TODO: implement getattr node handler
+ pass
+
+ # call_module node
+ elif node.op == 'call_module':
+ target = node.target
+ submod = self.root_module.get_submodule(target)
+ submod_type = type(submod)
+ handler = operator_registry.get(submod_type)(node, self.device_mesh, strategies_vector)
+ handler.register_strategy()
+
+ # call_function node
+ elif node.op == 'call_function':
+ target = node.target
+ handler = operator_registry.get(target)(node, self.device_mesh, strategies_vector)
+ handler.register_strategy()
+
+ # call_method node
+ elif node.op == 'call_method':
+ method = getattr(node.args[0]._meta_data.__class__, node.target)
+ handler = operator_registry.get(method)(node, self.device_mesh, strategies_vector)
+ handler.register_strategy()
+
+ # output node
+ elif node.op == 'output':
+ # TODO: implement output node handler
+ pass
+
+ self.remove_duplicated_strategy(strategies_vector)
+ setattr(node, 'strategies_vector', strategies_vector)
+ self.leaf_strategies.append(strategies_vector)
+ self.strategy_map[node] = strategies_vector
| Added the template for the new strategy constructor, it has not been implemented yet, we will come back to this part after all the node handlers are migrated to the new version. | https://api.github.com/repos/hpcaitech/ColossalAI/pulls/1661 | 2022-09-27T09:24:15Z | 2022-09-28T06:01:36Z | 2022-09-28T06:01:36Z | 2023-01-26T07:45:52Z | 1,580 | hpcaitech/ColossalAI | 11,755 |
Track st.stop usage | diff --git a/lib/streamlit/commands/execution_control.py b/lib/streamlit/commands/execution_control.py
index 52a09c37db46..90f0a67b4302 100644
--- a/lib/streamlit/commands/execution_control.py
+++ b/lib/streamlit/commands/execution_control.py
@@ -18,6 +18,7 @@
from streamlit.runtime.scriptrunner import RerunData, get_script_run_ctx
+@gather_metrics("stop")
def stop() -> None:
"""Stops execution immediately.
|
## Describe your changes
The metrics decorator works for `st.stop` with the new implementation, so it would be nice to collect usage like everything else.
---
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
| https://api.github.com/repos/streamlit/streamlit/pulls/7222 | 2023-08-22T23:23:28Z | 2023-08-23T18:17:38Z | 2023-08-23T18:17:38Z | 2023-08-23T18:17:42Z | 122 | streamlit/streamlit | 21,570 |
Bump safetensors from 0.4.0 to 0.4.1 | diff --git a/requirements.txt b/requirements.txt
index 2cfc6a3a89..3d25bfd770 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_amd.txt b/requirements_amd.txt
index ebaff9022a..e27f3016e2 100644
--- a/requirements_amd.txt
+++ b/requirements_amd.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_amd_noavx2.txt b/requirements_amd_noavx2.txt
index ed0c416723..f78832e3f3 100644
--- a/requirements_amd_noavx2.txt
+++ b/requirements_amd_noavx2.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_apple_intel.txt b/requirements_apple_intel.txt
index 9a290c512c..febb0609e6 100644
--- a/requirements_apple_intel.txt
+++ b/requirements_apple_intel.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_apple_silicon.txt b/requirements_apple_silicon.txt
index 3aa0a10604..2997c98f32 100644
--- a/requirements_apple_silicon.txt
+++ b/requirements_apple_silicon.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_cpu_only.txt b/requirements_cpu_only.txt
index 340276f894..ec0e84ffd0 100644
--- a/requirements_cpu_only.txt
+++ b/requirements_cpu_only.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_cpu_only_noavx2.txt b/requirements_cpu_only_noavx2.txt
index f2812229a9..02e51844e6 100644
--- a/requirements_cpu_only_noavx2.txt
+++ b/requirements_cpu_only_noavx2.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_noavx2.txt b/requirements_noavx2.txt
index 3ccc93636b..eeff8eb71d 100644
--- a/requirements_noavx2.txt
+++ b/requirements_noavx2.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
diff --git a/requirements_nowheels.txt b/requirements_nowheels.txt
index 48829427a4..d08204fd1c 100644
--- a/requirements_nowheels.txt
+++ b/requirements_nowheels.txt
@@ -12,7 +12,7 @@ peft==0.6.*
Pillow>=9.5.0
pyyaml
requests
-safetensors==0.4.0
+safetensors==0.4.1
scipy
sentencepiece
tensorboard
| Bumps [safetensors](https://github.com/huggingface/safetensors) from 0.4.0 to 0.4.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/huggingface/safetensors/releases">safetensors's releases</a>.</em></p>
<blockquote>
<h2>v0.4.1rc1</h2>
<h2>What's Changed</h2>
<ul>
<li>Back on dev. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/313">huggingface/safetensors#313</a></li>
<li>Clarify specification around endianness and header padding by <a href="https://github.com/akx"><code>@akx</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/306">huggingface/safetensors#306</a></li>
<li>Adding new target for m1 by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/317">huggingface/safetensors#317</a></li>
<li>Fixing macos 13 release script (by prebuilding). by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/315">huggingface/safetensors#315</a></li>
<li>Cache dir all the time. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/319">huggingface/safetensors#319</a></li>
<li>Supporting whisper conversion. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/320">huggingface/safetensors#320</a></li>
<li>add tensorshare to featured projects by <a href="https://github.com/chainyo"><code>@chainyo</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/322">huggingface/safetensors#322</a></li>
<li>Fix Bench GH action. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/323">huggingface/safetensors#323</a></li>
<li>Yaml is nice. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/325">huggingface/safetensors#325</a></li>
<li>Fixing big endian. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/327">huggingface/safetensors#327</a></li>
<li>Fixing boolean + numpy > 1.20 by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/326">huggingface/safetensors#326</a></li>
<li>Add NumPy for all backends dependencies by <a href="https://github.com/chainyo"><code>@chainyo</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/332">huggingface/safetensors#332</a></li>
<li>impl <code>View</code> for <code>TensorView</code> by <a href="https://github.com/coreylowman"><code>@coreylowman</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/329">huggingface/safetensors#329</a></li>
<li>Reworked the release script entirely by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/334">huggingface/safetensors#334</a></li>
<li>Preparing small patch release (Big Endian fix). by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/335">huggingface/safetensors#335</a></li>
<li>Temporary revert of the breaking change (keep it for 0.4.0). by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/336">huggingface/safetensors#336</a></li>
<li>Don't release rust versions on RC by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/337">huggingface/safetensors#337</a></li>
<li>Fixing release script. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/338">huggingface/safetensors#338</a></li>
<li>Python 3.8 for arm by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/339">huggingface/safetensors#339</a></li>
<li>Win64. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/342">huggingface/safetensors#342</a></li>
<li>win64 by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/343">huggingface/safetensors#343</a></li>
<li>Trying out maturin. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/344">huggingface/safetensors#344</a></li>
<li>Reduce memory allocations by <a href="https://github.com/cospectrum"><code>@cospectrum</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/350">huggingface/safetensors#350</a></li>
<li>[docs] Convert weights by <a href="https://github.com/stevhliu"><code>@stevhliu</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/345">huggingface/safetensors#345</a></li>
<li>Update types for load_model filename by <a href="https://github.com/kevinhu"><code>@kevinhu</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/356">huggingface/safetensors#356</a></li>
<li>Fixing release script for windows aarch64 and 3.12 by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/348">huggingface/safetensors#348</a></li>
<li>Minor docstring edit to flax.py by <a href="https://github.com/paulbricman"><code>@paulbricman</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/359">huggingface/safetensors#359</a></li>
<li>Stop recreating the hashmap all the time. by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/363">huggingface/safetensors#363</a></li>
<li>fix: add py.typed by <a href="https://github.com/b-kamphorst"><code>@b-kamphorst</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/365">huggingface/safetensors#365</a></li>
<li>Preparing a new release (0.4.0). by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/366">huggingface/safetensors#366</a></li>
<li>Supporting bfloat16 for tensorflow + jax (was failing because of intermediary numpy). by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/382">huggingface/safetensors#382</a></li>
<li>Fix typo by <a href="https://github.com/cccntu"><code>@cccntu</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/377">huggingface/safetensors#377</a></li>
<li>Support fp8_e4m3/fp8_e5m2 by <a href="https://github.com/Narsil"><code>@Narsil</code></a> in <a href="https://redirect.github.com/huggingface/safetensors/pull/383">huggingface/safetensors#383</a></li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/akx"><code>@akx</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/306">huggingface/safetensors#306</a></li>
<li><a href="https://github.com/chainyo"><code>@chainyo</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/322">huggingface/safetensors#322</a></li>
<li><a href="https://github.com/coreylowman"><code>@coreylowman</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/329">huggingface/safetensors#329</a></li>
<li><a href="https://github.com/cospectrum"><code>@cospectrum</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/350">huggingface/safetensors#350</a></li>
<li><a href="https://github.com/stevhliu"><code>@stevhliu</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/345">huggingface/safetensors#345</a></li>
<li><a href="https://github.com/kevinhu"><code>@kevinhu</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/356">huggingface/safetensors#356</a></li>
<li><a href="https://github.com/paulbricman"><code>@paulbricman</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/359">huggingface/safetensors#359</a></li>
<li><a href="https://github.com/b-kamphorst"><code>@b-kamphorst</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/365">huggingface/safetensors#365</a></li>
<li><a href="https://github.com/cccntu"><code>@cccntu</code></a> made their first contribution in <a href="https://redirect.github.com/huggingface/safetensors/pull/377">huggingface/safetensors#377</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/huggingface/safetensors/compare/v0.3.2...v0.4.1rc1">https://github.com/huggingface/safetensors/compare/v0.3.2...v0.4.1rc1</a></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/huggingface/safetensors/commit/cc43011eaae470d14c411b8ba243273135830ce7"><code>cc43011</code></a> New release.</li>
<li><a href="https://github.com/huggingface/safetensors/commit/9610b4fcbbcf9b242e56ec679c6d1fb1d9bdb64d"><code>9610b4f</code></a> Fix convert. (<a href="https://redirect.github.com/huggingface/safetensors/issues/390">#390</a>)</li>
<li><a href="https://github.com/huggingface/safetensors/commit/094e676b371763498a5d04a28477a7ef0fb6f6a8"><code>094e676</code></a> Adding support for Ascend NPU (<a href="https://redirect.github.com/huggingface/safetensors/issues/372">#372</a>)</li>
<li><a href="https://github.com/huggingface/safetensors/commit/829bfa8f3db33d2c36fada5d02e3d6b6ba14911d"><code>829bfa8</code></a> Ignore closed PRs to avoid spam. (<a href="https://redirect.github.com/huggingface/safetensors/issues/385">#385</a>)</li>
<li><a href="https://github.com/huggingface/safetensors/commit/179943873766cd41b955d145137670706e161716"><code>1799438</code></a> Better convert. (<a href="https://redirect.github.com/huggingface/safetensors/issues/384">#384</a>)</li>
<li><a href="https://github.com/huggingface/safetensors/commit/7faab77eb0209f6e51fb13f7c87007789fc3935b"><code>7faab77</code></a> Support fp8_e4m3/fp8_e5m2 (<a href="https://redirect.github.com/huggingface/safetensors/issues/383">#383</a>)</li>
<li><a href="https://github.com/huggingface/safetensors/commit/bfd22b312ac56f35cb8cbb129714833b19529844"><code>bfd22b3</code></a> Fix typo (<a href="https://redirect.github.com/huggingface/safetensors/issues/377">#377</a>)</li>
<li><a href="https://github.com/huggingface/safetensors/commit/9e0bc087231b0109dc35b0473347bf7019f70dfc"><code>9e0bc08</code></a> Supporting bfloat16 for tensorflow + jax (was failing because of (<a href="https://redirect.github.com/huggingface/safetensors/issues/382">#382</a>)</li>
<li>See full diff in <a href="https://github.com/huggingface/safetensors/compare/v0.4.0...v0.4.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details> | https://api.github.com/repos/oobabooga/text-generation-webui/pulls/4750 | 2023-11-27T20:05:11Z | 2023-12-04T01:50:10Z | 2023-12-04T01:50:10Z | 2023-12-04T01:50:18Z | 1,046 | oobabooga/text-generation-webui | 26,683 |
feedexport removed multispider support | diff --git a/scrapy/contrib/feedexport.py b/scrapy/contrib/feedexport.py
index 3732de87f93..bf16cd0f43c 100644
--- a/scrapy/contrib/feedexport.py
+++ b/scrapy/contrib/feedexport.py
@@ -148,7 +148,6 @@ def __init__(self, settings):
self.store_empty = settings.getbool('FEED_STORE_EMPTY')
uripar = settings['FEED_URI_PARAMS']
self._uripar = load_object(uripar) if uripar else lambda x, y: None
- self.slots = {}
@classmethod
def from_crawler(cls, crawler):
@@ -172,10 +171,10 @@ def open_spider(self, spider):
file = storage.open(spider)
exporter = self._get_exporter(file)
exporter.start_exporting()
- self.slots[spider] = SpiderSlot(file, exporter, storage, uri)
+ self.slot = SpiderSlot(file, exporter, storage, uri)
def close_spider(self, spider):
- slot = self.slots.pop(spider)
+ slot = self.slot
if not slot.itemcount and not self.store_empty:
return
slot.exporter.finish_exporting()
@@ -187,7 +186,7 @@ def close_spider(self, spider):
return d
def item_scraped(self, item, spider):
- slot = self.slots[spider]
+ slot = self.slot
slot.exporter.export_item(item)
slot.itemcount += 1
return item
| https://api.github.com/repos/scrapy/scrapy/pulls/334 | 2013-07-03T21:25:40Z | 2013-07-03T21:26:49Z | 2013-07-03T21:26:49Z | 2013-07-03T21:26:49Z | 347 | scrapy/scrapy | 34,867 |
|
Correct changelog to mention acme changes. | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 30cb4d4de12..4a8926c3c14 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -58,6 +58,7 @@ Despite us having broken lockstep, we are continuing to release new versions of
all Certbot components during releases for the time being, however, the only
package with changes other than its version number was:
+* acme
* certbot
* certbot-apache
* certbot-nginx
| We forgot to update the changelog when deprecating TLS-SNI-01 code in `acme` which was included in our release today. This fixes up the changelog entry for the last release so at least the information is right going forward.
Maybe it's time we finally automate this step... | https://api.github.com/repos/certbot/certbot/pulls/6909 | 2019-04-03T21:36:06Z | 2019-04-03T22:17:26Z | 2019-04-03T22:17:26Z | 2019-04-03T22:17:47Z | 125 | certbot/certbot | 2,760 |
Fixed github action config | diff --git a/.github/workflows/PR_CI.yml b/.github/workflows/PR_CI.yml
index dc0685af6bb3..173677b25e2d 100644
--- a/.github/workflows/PR_CI.yml
+++ b/.github/workflows/PR_CI.yml
@@ -3,6 +3,15 @@ name: Pull Request CI and Build
on: pull_request
jobs:
+ cancel_previous_workflow:
+ runs-on: ubuntu-latest
+ if: github.event.pull_request.draft == false && github.base_ref == 'main' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
+ steps:
+ - name: Cancel Previous Runs
+ uses: styfle/cancel-workflow-action@0.9.1
+ with:
+ access_token: ${{ github.token }}
+
assign_reviewer:
name: Assign Reviewer for PR
runs-on: ubuntu-latest
@@ -15,7 +24,7 @@ jobs:
build:
name: Build and Test Colossal-AI
if: ${{ always() }} && github.event.pull_request.draft == false && github.base_ref == 'main' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
- needs: [assign_reviewer]
+ needs: [cancel_previous_workflow, assign_reviewer]
runs-on: [self-hosted, gpu]
container:
image: nvcr.io/nvidia/pytorch:21.07-py3
@@ -43,8 +52,8 @@ jobs:
format_check:
name: Format Check
- if: ${{ always() }} && github.event.pull_request.draft == false && github.base_ref == 'main' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
- needs: [assign_reviewer, build]
+ if: github.event.pull_request.draft == false && github.base_ref == 'main' && github.head_ref == 'develop' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
+ needs: [build]
runs-on: ubuntu-latest
steps:
- name: Checkout repo
diff --git a/.github/workflows/close_inactive.yml b/.github/workflows/close_inactive.yml
index 66c7bd461232..988d9e3bc5ba 100644
--- a/.github/workflows/close_inactive.yml
+++ b/.github/workflows/close_inactive.yml
@@ -5,6 +5,7 @@ on:
jobs:
close-issues:
+ if: github.event.pull_request.draft == false && github.base_ref == 'main' && github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
runs-on: ubuntu-latest
permissions:
issues: write
| https://api.github.com/repos/hpcaitech/ColossalAI/pulls/205 | 2022-02-04T05:32:08Z | 2022-02-04T07:04:55Z | 2022-02-04T07:04:55Z | 2022-02-17T10:44:17Z | 624 | hpcaitech/ColossalAI | 11,205 |
|
[3.12] gh-106242: Fix path truncation in os.path.normpath (GH-106816) | diff --git a/Include/internal/pycore_fileutils.h b/Include/internal/pycore_fileutils.h
index ef6642d00f1b54..7c2b6ec0bffef5 100644
--- a/Include/internal/pycore_fileutils.h
+++ b/Include/internal/pycore_fileutils.h
@@ -252,7 +252,8 @@ extern int _Py_add_relfile(wchar_t *dirname,
const wchar_t *relfile,
size_t bufsize);
extern size_t _Py_find_basename(const wchar_t *filename);
-PyAPI_FUNC(wchar_t *) _Py_normpath(wchar_t *path, Py_ssize_t size);
+PyAPI_FUNC(wchar_t*) _Py_normpath(wchar_t *path, Py_ssize_t size);
+extern wchar_t *_Py_normpath_and_size(wchar_t *path, Py_ssize_t size, Py_ssize_t *length);
// The Windows Games API family does not provide these functions
// so provide our own implementations. Remove them in case they get added
diff --git a/Lib/test/test_genericpath.py b/Lib/test/test_genericpath.py
index 489044f8090d3b..4f311c2d498e9f 100644
--- a/Lib/test/test_genericpath.py
+++ b/Lib/test/test_genericpath.py
@@ -460,6 +460,10 @@ def test_normpath_issue5827(self):
for path in ('', '.', '/', '\\', '///foo/.//bar//'):
self.assertIsInstance(self.pathmodule.normpath(path), str)
+ def test_normpath_issue106242(self):
+ for path in ('\x00', 'foo\x00bar', '\x00\x00', '\x00foo', 'foo\x00'):
+ self.assertEqual(self.pathmodule.normpath(path), path)
+
def test_abspath_issue3426(self):
# Check that abspath returns unicode when the arg is unicode
# with both ASCII and non-ASCII cwds.
diff --git a/Misc/NEWS.d/next/Library/2023-08-14-23-11-11.gh-issue-106242.71HMym.rst b/Misc/NEWS.d/next/Library/2023-08-14-23-11-11.gh-issue-106242.71HMym.rst
new file mode 100644
index 00000000000000..44237a9f15708c
--- /dev/null
+++ b/Misc/NEWS.d/next/Library/2023-08-14-23-11-11.gh-issue-106242.71HMym.rst
@@ -0,0 +1 @@
+Fixes :func:`os.path.normpath` to handle embedded null characters without truncating the path.
diff --git a/Modules/posixmodule.c b/Modules/posixmodule.c
index 342f393b1f0f9c..b9f45c0ce5543d 100644
--- a/Modules/posixmodule.c
+++ b/Modules/posixmodule.c
@@ -5275,7 +5275,9 @@ os__path_normpath_impl(PyObject *module, PyObject *path)
if (!buffer) {
return NULL;
}
- PyObject *result = PyUnicode_FromWideChar(_Py_normpath(buffer, len), -1);
+ Py_ssize_t norm_len;
+ wchar_t *norm_path = _Py_normpath_and_size(buffer, len, &norm_len);
+ PyObject *result = PyUnicode_FromWideChar(norm_path, norm_len);
PyMem_Free(buffer);
return result;
}
diff --git a/Python/fileutils.c b/Python/fileutils.c
index f137ee936502c1..268ffa3d61a470 100644
--- a/Python/fileutils.c
+++ b/Python/fileutils.c
@@ -2377,12 +2377,14 @@ _Py_find_basename(const wchar_t *filename)
path, which will be within the original buffer. Guaranteed to not
make the path longer, and will not fail. 'size' is the length of
the path, if known. If -1, the first null character will be assumed
- to be the end of the path. */
+ to be the end of the path. 'normsize' will be set to contain the
+ length of the resulting normalized path. */
wchar_t *
-_Py_normpath(wchar_t *path, Py_ssize_t size)
+_Py_normpath_and_size(wchar_t *path, Py_ssize_t size, Py_ssize_t *normsize)
{
assert(path != NULL);
- if (!path[0] || size == 0) {
+ if ((size < 0 && !path[0]) || size == 0) {
+ *normsize = 0;
return path;
}
wchar_t *pEnd = size >= 0 ? &path[size] : NULL;
@@ -2431,11 +2433,7 @@ _Py_normpath(wchar_t *path, Py_ssize_t size)
*p2++ = lastC = *p1;
}
}
- if (sepCount) {
- minP2 = p2; // Invalid path
- } else {
- minP2 = p2 - 1; // Absolute path has SEP at minP2
- }
+ minP2 = p2 - 1;
}
#else
// Skip past two leading SEPs
@@ -2495,13 +2493,28 @@ _Py_normpath(wchar_t *path, Py_ssize_t size)
while (--p2 != minP2 && *p2 == SEP) {
*p2 = L'\0';
}
+ } else {
+ --p2;
}
+ *normsize = p2 - path + 1;
#undef SEP_OR_END
#undef IS_SEP
#undef IS_END
return path;
}
+/* In-place path normalisation. Returns the start of the normalized
+ path, which will be within the original buffer. Guaranteed to not
+ make the path longer, and will not fail. 'size' is the length of
+ the path, if known. If -1, the first null character will be assumed
+ to be the end of the path. */
+wchar_t *
+_Py_normpath(wchar_t *path, Py_ssize_t size)
+{
+ Py_ssize_t norm_length;
+ return _Py_normpath_and_size(path, size, &norm_length);
+}
+
/* Get the current directory. buflen is the buffer size in wide characters
including the null character. Decode the path from the locale encoding.
| <!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
gh-NNNNN: Summary of the changes made
```
Where: gh-NNNNN refers to the GitHub issue number.
Most PRs will require an issue number. Trivial changes, like fixing a typo, do not need an issue.
# Backport Pull Request title
If this is a backport PR (PR made against branches other than `main`),
please ensure that the PR title is in the following format:
```
[X.Y] <title from the original PR> (GH-NNNN)
```
Where: [X.Y] is the branch name, e.g. [3.6].
GH-NNNN refers to the PR number from `main`.
-->
<!-- gh-issue-number: gh-106242 -->
* Issue: gh-106242
<!-- /gh-issue-number -->
| https://api.github.com/repos/python/cpython/pulls/107981 | 2023-08-15T15:39:11Z | 2023-08-16T23:19:48Z | 2023-08-16T23:19:48Z | 2023-08-17T15:48:03Z | 1,463 | python/cpython | 3,910 |
Add more type hints | diff --git a/patterns/behavioral/publish_subscribe.py b/patterns/behavioral/publish_subscribe.py
index 760d8e7b..40aefd2e 100644
--- a/patterns/behavioral/publish_subscribe.py
+++ b/patterns/behavioral/publish_subscribe.py
@@ -5,21 +5,24 @@
"""
+from __future__ import annotations
+
+
class Provider:
- def __init__(self):
+ def __init__(self) -> None:
self.msg_queue = []
self.subscribers = {}
- def notify(self, msg):
+ def notify(self, msg: str) -> None:
self.msg_queue.append(msg)
- def subscribe(self, msg, subscriber):
+ def subscribe(self, msg: str, subscriber: Subscriber) -> None:
self.subscribers.setdefault(msg, []).append(subscriber)
- def unsubscribe(self, msg, subscriber):
+ def unsubscribe(self, msg: str, subscriber: Subscriber) -> None:
self.subscribers[msg].remove(subscriber)
- def update(self):
+ def update(self) -> None:
for msg in self.msg_queue:
for sub in self.subscribers.get(msg, []):
sub.run(msg)
@@ -27,25 +30,25 @@ def update(self):
class Publisher:
- def __init__(self, msg_center):
+ def __init__(self, msg_center: Provider) -> None:
self.provider = msg_center
- def publish(self, msg):
+ def publish(self, msg: str) -> None:
self.provider.notify(msg)
class Subscriber:
- def __init__(self, name, msg_center):
+ def __init__(self, name: str, msg_center: Provider) -> None:
self.name = name
self.provider = msg_center
- def subscribe(self, msg):
+ def subscribe(self, msg: str) -> None:
self.provider.subscribe(msg, self)
- def unsubscribe(self, msg):
+ def unsubscribe(self, msg: str) -> None:
self.provider.unsubscribe(msg, self)
- def run(self, msg):
+ def run(self, msg: str) -> None:
print(f"{self.name} got {msg}")
diff --git a/patterns/behavioral/state.py b/patterns/behavioral/state.py
index 423b749e..db4d9468 100644
--- a/patterns/behavioral/state.py
+++ b/patterns/behavioral/state.py
@@ -8,12 +8,13 @@
Implements state transitions by invoking methods from the pattern's superclass.
"""
+from __future__ import annotations
-class State:
+class State:
"""Base state. This is to share functionality"""
- def scan(self):
+ def scan(self) -> None:
"""Scan the dial to the next station"""
self.pos += 1
if self.pos == len(self.stations):
@@ -22,43 +23,42 @@ def scan(self):
class AmState(State):
- def __init__(self, radio):
+ def __init__(self, radio: Radio) -> None:
self.radio = radio
self.stations = ["1250", "1380", "1510"]
self.pos = 0
self.name = "AM"
- def toggle_amfm(self):
+ def toggle_amfm(self) -> None:
print("Switching to FM")
self.radio.state = self.radio.fmstate
class FmState(State):
- def __init__(self, radio):
+ def __init__(self, radio: Radio) -> None:
self.radio = radio
self.stations = ["81.3", "89.1", "103.9"]
self.pos = 0
self.name = "FM"
- def toggle_amfm(self):
+ def toggle_amfm(self) -> None:
print("Switching to AM")
self.radio.state = self.radio.amstate
class Radio:
-
"""A radio. It has a scan button, and an AM/FM toggle switch."""
- def __init__(self):
+ def __init__(self) -> None:
"""We have an AM state and an FM state"""
self.amstate = AmState(self)
self.fmstate = FmState(self)
self.state = self.amstate
- def toggle_amfm(self):
+ def toggle_amfm(self) -> None:
self.state.toggle_amfm()
- def scan(self):
+ def scan(self) -> None:
self.state.scan()
diff --git a/patterns/creational/borg.py b/patterns/creational/borg.py
index ab364f61..de36a23f 100644
--- a/patterns/creational/borg.py
+++ b/patterns/creational/borg.py
@@ -38,12 +38,12 @@
class Borg:
_shared_state: Dict[str, str] = {}
- def __init__(self):
+ def __init__(self) -> None:
self.__dict__ = self._shared_state
class YourBorg(Borg):
- def __init__(self, state=None):
+ def __init__(self, state: str = None) -> None:
super().__init__()
if state:
self.state = state
@@ -52,7 +52,7 @@ def __init__(self, state=None):
if not hasattr(self, "state"):
self.state = "Init"
- def __str__(self):
+ def __str__(self) -> str:
return self.state
diff --git a/patterns/creational/builder.py b/patterns/creational/builder.py
index b1f463ee..22383923 100644
--- a/patterns/creational/builder.py
+++ b/patterns/creational/builder.py
@@ -34,7 +34,7 @@ class for a building, where the initializer (__init__ method) specifies the
# Abstract Building
class Building:
- def __init__(self):
+ def __init__(self) -> None:
self.build_floor()
self.build_size()
@@ -44,24 +44,24 @@ def build_floor(self):
def build_size(self):
raise NotImplementedError
- def __repr__(self):
+ def __repr__(self) -> str:
return "Floor: {0.floor} | Size: {0.size}".format(self)
# Concrete Buildings
class House(Building):
- def build_floor(self):
+ def build_floor(self) -> None:
self.floor = "One"
- def build_size(self):
+ def build_size(self) -> None:
self.size = "Big"
class Flat(Building):
- def build_floor(self):
+ def build_floor(self) -> None:
self.floor = "More than One"
- def build_size(self):
+ def build_size(self) -> None:
self.size = "Small"
@@ -72,19 +72,19 @@ def build_size(self):
class ComplexBuilding:
- def __repr__(self):
+ def __repr__(self) -> str:
return "Floor: {0.floor} | Size: {0.size}".format(self)
class ComplexHouse(ComplexBuilding):
- def build_floor(self):
+ def build_floor(self) -> None:
self.floor = "One"
- def build_size(self):
+ def build_size(self) -> None:
self.size = "Big and fancy"
-def construct_building(cls):
+def construct_building(cls) -> Building:
building = cls()
building.build_floor()
building.build_size()
diff --git a/patterns/fundamental/delegation_pattern.py b/patterns/fundamental/delegation_pattern.py
index bdcefc9d..34e1071f 100644
--- a/patterns/fundamental/delegation_pattern.py
+++ b/patterns/fundamental/delegation_pattern.py
@@ -28,7 +28,7 @@ class Delegator:
AttributeError: 'Delegate' object has no attribute 'do_anything'
"""
- def __init__(self, delegate: Delegate):
+ def __init__(self, delegate: Delegate) -> None:
self.delegate = delegate
def __getattr__(self, name: str) -> Any | Callable:
@@ -44,7 +44,7 @@ def wrapper(*args, **kwargs):
class Delegate:
- def __init__(self):
+ def __init__(self) -> None:
self.p1 = 123
def do_something(self, something: str) -> str:
diff --git a/patterns/other/blackboard.py b/patterns/other/blackboard.py
index 49f8775f..ef48f501 100644
--- a/patterns/other/blackboard.py
+++ b/patterns/other/blackboard.py
@@ -8,13 +8,14 @@
https://en.wikipedia.org/wiki/Blackboard_system
"""
+from __future__ import annotations
import abc
import random
class Blackboard:
- def __init__(self):
+ def __init__(self) -> None:
self.experts = []
self.common_state = {
"problems": 0,
@@ -23,12 +24,12 @@ def __init__(self):
"progress": 0, # percentage, if 100 -> task is finished
}
- def add_expert(self, expert):
+ def add_expert(self, expert: AbstractExpert) -> None:
self.experts.append(expert)
class Controller:
- def __init__(self, blackboard):
+ def __init__(self, blackboard: Blackboard) -> None:
self.blackboard = blackboard
def run_loop(self):
@@ -44,7 +45,7 @@ def run_loop(self):
class AbstractExpert(metaclass=abc.ABCMeta):
- def __init__(self, blackboard):
+ def __init__(self, blackboard: Blackboard) -> None:
self.blackboard = blackboard
@property
@@ -59,10 +60,10 @@ def contribute(self):
class Student(AbstractExpert):
@property
- def is_eager_to_contribute(self):
+ def is_eager_to_contribute(self) -> bool:
return True
- def contribute(self):
+ def contribute(self) -> None:
self.blackboard.common_state["problems"] += random.randint(1, 10)
self.blackboard.common_state["suggestions"] += random.randint(1, 10)
self.blackboard.common_state["contributions"] += [self.__class__.__name__]
@@ -71,10 +72,10 @@ def contribute(self):
class Scientist(AbstractExpert):
@property
- def is_eager_to_contribute(self):
+ def is_eager_to_contribute(self) -> int:
return random.randint(0, 1)
- def contribute(self):
+ def contribute(self) -> None:
self.blackboard.common_state["problems"] += random.randint(10, 20)
self.blackboard.common_state["suggestions"] += random.randint(10, 20)
self.blackboard.common_state["contributions"] += [self.__class__.__name__]
@@ -83,10 +84,10 @@ def contribute(self):
class Professor(AbstractExpert):
@property
- def is_eager_to_contribute(self):
+ def is_eager_to_contribute(self) -> bool:
return True if self.blackboard.common_state["problems"] > 100 else False
- def contribute(self):
+ def contribute(self) -> None:
self.blackboard.common_state["problems"] += random.randint(1, 2)
self.blackboard.common_state["suggestions"] += random.randint(10, 20)
self.blackboard.common_state["contributions"] += [self.__class__.__name__]
diff --git a/patterns/structural/decorator.py b/patterns/structural/decorator.py
index 01c91b00..a32e2b06 100644
--- a/patterns/structural/decorator.py
+++ b/patterns/structural/decorator.py
@@ -28,30 +28,30 @@
class TextTag:
"""Represents a base text tag"""
- def __init__(self, text):
+ def __init__(self, text: str) -> None:
self._text = text
- def render(self):
+ def render(self) -> str:
return self._text
class BoldWrapper(TextTag):
"""Wraps a tag in <b>"""
- def __init__(self, wrapped):
+ def __init__(self, wrapped: TextTag) -> None:
self._wrapped = wrapped
- def render(self):
+ def render(self) -> str:
return f"<b>{self._wrapped.render()}</b>"
class ItalicWrapper(TextTag):
"""Wraps a tag in <i>"""
- def __init__(self, wrapped):
+ def __init__(self, wrapped: TextTag) -> None:
self._wrapped = wrapped
- def render(self):
+ def render(self) -> str:
return f"<i>{self._wrapped.render()}</i>"
diff --git a/patterns/structural/facade.py b/patterns/structural/facade.py
index 6561c6dc..f7b00be3 100644
--- a/patterns/structural/facade.py
+++ b/patterns/structural/facade.py
@@ -35,13 +35,13 @@ class CPU:
Simple CPU representation.
"""
- def freeze(self):
+ def freeze(self) -> None:
print("Freezing processor.")
- def jump(self, position):
+ def jump(self, position: str) -> None:
print("Jumping to:", position)
- def execute(self):
+ def execute(self) -> None:
print("Executing.")
@@ -50,7 +50,7 @@ class Memory:
Simple memory representation.
"""
- def load(self, position, data):
+ def load(self, position: str, data: str) -> None:
print(f"Loading from {position} data: '{data}'.")
@@ -59,7 +59,7 @@ class SolidStateDrive:
Simple solid state drive representation.
"""
- def read(self, lba, size):
+ def read(self, lba: str, size: str) -> str:
return f"Some data from sector {lba} with size {size}"
diff --git a/patterns/structural/front_controller.py b/patterns/structural/front_controller.py
index 4852208d..92f58b21 100644
--- a/patterns/structural/front_controller.py
+++ b/patterns/structural/front_controller.py
@@ -5,23 +5,27 @@
Provides a centralized entry point that controls and manages request handling.
"""
+from __future__ import annotations
+
+from typing import Any
+
class MobileView:
- def show_index_page(self):
+ def show_index_page(self) -> None:
print("Displaying mobile index page")
class TabletView:
- def show_index_page(self):
+ def show_index_page(self) -> None:
print("Displaying tablet index page")
class Dispatcher:
- def __init__(self):
+ def __init__(self) -> None:
self.mobile_view = MobileView()
self.tablet_view = TabletView()
- def dispatch(self, request):
+ def dispatch(self, request: Request) -> None:
"""
This function is used to dispatch the request based on the type of device.
If it is a mobile, then mobile view will be called and if it is a tablet,
@@ -39,10 +43,10 @@ def dispatch(self, request):
class RequestController:
"""front controller"""
- def __init__(self):
+ def __init__(self) -> None:
self.dispatcher = Dispatcher()
- def dispatch_request(self, request):
+ def dispatch_request(self, request: Any) -> None:
"""
This function takes a request object and sends it to the dispatcher.
"""
| Add type hints to multiple design pattern examples
Related to https://github.com/faif/python-patterns/issues/373 | https://api.github.com/repos/faif/python-patterns/pulls/397 | 2022-07-27T03:24:34Z | 2022-08-08T19:13:13Z | 2022-08-08T19:13:13Z | 2022-08-08T19:13:13Z | 3,589 | faif/python-patterns | 33,482 |
docs: add basic intro to certbot in user guide | diff --git a/certbot/docs/using.rst b/certbot/docs/using.rst
index 8c1a0ac548e..5f24aade0ea 100644
--- a/certbot/docs/using.rst
+++ b/certbot/docs/using.rst
@@ -21,25 +21,40 @@ The ``certbot`` script on your web server might be named ``letsencrypt`` if your
Getting certificates (and choosing plugins)
===========================================
-The Certbot client supports two types of plugins for
-obtaining and installing certificates: authenticators and installers.
-
-Authenticators are plugins used with the ``certonly`` command to obtain a certificate.
-The authenticator validates that you
-control the domain(s) you are requesting a certificate for, obtains a certificate for the specified
-domain(s), and places the certificate in the ``/etc/letsencrypt`` directory on your
-machine. The authenticator does not install the certificate (it does not edit any of your server's configuration files to serve the
-obtained certificate). If you specify multiple domains to authenticate, they will
-all be listed in a single certificate. To obtain multiple separate certificates
-you will need to run Certbot multiple times.
-
-Installers are Plugins used with the ``install`` command to install a certificate.
-These plugins can modify your webserver's configuration to
-serve your website over HTTPS using certificates obtained by certbot.
-
-Plugins that do both can be used with the ``certbot run`` command, which is the default
-when no command is specified. The ``run`` subcommand can also be used to specify
-a combination_ of distinct authenticator and installer plugins.
+Certbot helps you achieve two tasks:
+
+1. Obtaining a certificate: automatically performing the required authentication steps to prove that you control the domain(s),
+ saving the certificate to ``/etc/letsencrypt/live/`` and renewing it on a regular schedule.
+2. Optionally, installing that certificate to supported web servers (like Apache or nginx) and other kinds of servers. This is
+ done by automatically modifying the configuration of your server in order to use the certificate.
+
+To obtain a certificate and also install it, use the ``certbot run`` command (or ``certbot``, which is the same).
+
+To just obtain the certificate without installing it anywhere, the ``certbot certonly`` ("certificate only") command can be used.
+
+Some example ways to use Certbot::
+
+ # Obtain and install a certificate:
+ certbot
+
+ # Obtain a certificate but don't install it:
+ certbot certonly
+
+ # You may specify multiple domains with -d and obtain and
+ # install different certificates by running Certbot multiple times:
+ certbot certonly -d example.com -d www.example.com
+ certbot certonly -d app.example.com -d api.example.com
+
+To perform these tasks, Certbot will ask you to choose from a selection of authenticator and installer plugins. The appropriate
+choice of plugins will depend on what kind of server software you are running and plan to use your certificates with.
+
+**Authenticators** are plugins which automatically perform the required steps to prove that you control the domain names you're trying
+to request a certificate for. An authenticator is always required to obtain a certificate.
+
+**Installers** are plugins which can automatically modify your web server's configuration to serve your website over HTTPS, using the
+certificates obtained by Certbot. An installer is only required if you want Certbot to install the certificate to your web server.
+
+Some plugins are both authenticators and installers and it is possible to specify a distinct combination_ of authenticator and plugin.
=========== ==== ==== =============================================================== =============================
Plugin Auth Inst Notes Challenge types (and port)
| In the "Getting certificates (and choosing plugins)" section.
---
Fixes #8179.

| https://api.github.com/repos/certbot/certbot/pulls/8979 | 2021-08-09T07:19:41Z | 2021-08-14T00:39:12Z | 2021-08-14T00:39:12Z | 2021-08-14T00:39:12Z | 824 | certbot/certbot | 3,044 |
Fix `leading` Parameter Type In Docstring | diff --git a/rich/table.py b/rich/table.py
index 5fc5ace0b..fe4054cf1 100644
--- a/rich/table.py
+++ b/rich/table.py
@@ -54,7 +54,7 @@ class Column:
show_footer (bool, optional): Show a footer row. Defaults to False.
show_edge (bool, optional): Draw a box around the outside of the table. Defaults to True.
show_lines (bool, optional): Draw lines between every row. Defaults to False.
- leading (bool, optional): Number of blank lines between rows (precludes ``show_lines``). Defaults to 0.
+ leading (int, optional): Number of blank lines between rows (precludes ``show_lines``). Defaults to 0.
style (Union[str, Style], optional): Default style for the table. Defaults to "none".
row_styles (List[Union, str], optional): Optional list of row styles, if more than one style is given then the styles will alternate. Defaults to None.
header_style (Union[str, Style], optional): Style of the header. Defaults to "table.header".
@@ -167,7 +167,7 @@ class Table(JupyterMixin):
show_footer (bool, optional): Show a footer row. Defaults to False.
show_edge (bool, optional): Draw a box around the outside of the table. Defaults to True.
show_lines (bool, optional): Draw lines between every row. Defaults to False.
- leading (bool, optional): Number of blank lines between rows (precludes ``show_lines``). Defaults to 0.
+ leading (int, optional): Number of blank lines between rows (precludes ``show_lines``). Defaults to 0.
style (Union[str, Style], optional): Default style for the table. Defaults to "none".
row_styles (List[Union, str], optional): Optional list of row styles, if more than one style is given then the styles will alternate. Defaults to None.
header_style (Union[str, Style], optional): Style of the header. Defaults to "table.header".
| ## Type of changes
- [ ] Bug fix
- [ ] New feature
- [x] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [ ] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [ ] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [ ] I've added tests for new code.
- [x] I accept that @willmcgugan may be pedantic in the code review.
## Description
Noticed on [the docs](https://rich.readthedocs.io/en/stable/reference/table.html) that the `leading` parameter (available for the `Table` and `Column` objects), mention that this parameter is a `bool` type, although it appears to be an `int` type and has a default value of `0`.
This PR fixes the docstrings to annotate this parameter with the correct `int` type.
| https://api.github.com/repos/Textualize/rich/pulls/3276 | 2024-02-08T13:04:32Z | 2024-02-29T14:02:23Z | 2024-02-29T14:02:23Z | 2024-02-29T14:02:23Z | 454 | Textualize/rich | 48,019 |
Fix comment stating incorrect assigned variable | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index b9da55b5e..87472c593 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -10374,7 +10374,7 @@ Reuse of a member name as a local variable can also be a problem:
if (x) {
int m = 9;
// ...
- m = 99; // assign to member
+ m = 99; // assign to local variable
// ...
}
}
| https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1342 | 2019-02-23T16:14:08Z | 2019-02-26T22:27:49Z | 2019-02-26T22:27:49Z | 2019-03-09T00:23:32Z | 130 | isocpp/CppCoreGuidelines | 15,305 |
|
cabana: fix MacOS build | diff --git a/tools/cabana/mainwin.cc b/tools/cabana/mainwin.cc
index 922ea7a9e26813..9b52b6823d1ed7 100644
--- a/tools/cabana/mainwin.cc
+++ b/tools/cabana/mainwin.cc
@@ -497,8 +497,8 @@ void MainWindow::updateLoadSaveMenus() {
}
QStringList title;
- for (auto &[filename, sources] : dbc_files) {
- QString bus = dbc_files.size() == 1 ? "all" : sources.join(",");
+ for (auto &[filename, src] : dbc_files) {
+ QString bus = dbc_files.size() == 1 ? "all" : src.join(",");
title.push_back("[" + bus + "]" + QFileInfo(filename).baseName());
}
setWindowFilePath(title.join(" | "));
diff --git a/tools/cabana/util.cc b/tools/cabana/util.cc
index 4fe04a51605ef1..135c630d8a928b 100644
--- a/tools/cabana/util.cc
+++ b/tools/cabana/util.cc
@@ -1,6 +1,7 @@
#include "tools/cabana/util.h"
#include <QFontDatabase>
+#include <QHelpEvent>
#include <QPainter>
#include <QPixmapCache>
#include <QToolTip>
| Add missing include and fix shadowed variable | https://api.github.com/repos/commaai/openpilot/pulls/27950 | 2023-04-18T08:23:22Z | 2023-04-18T19:18:34Z | 2023-04-18T19:18:34Z | 2023-04-18T19:18:34Z | 304 | commaai/openpilot | 9,864 |
Fix README typo | diff --git a/README.rst b/README.rst
index fe66f8af2f9..72188608b00 100644
--- a/README.rst
+++ b/README.rst
@@ -39,4 +39,4 @@ Current Features
.. Do not modify this comment unless you know what you're doing. tag:features-end
-For extensive documentation on using and contributing to Certbot, go to https://certbot.eff.org/docs. If you would like to contribute to the project or run the latest code from git, you should read our `developer guide <https://certbot.eff.org/docs/contributing.html>`.
+For extensive documentation on using and contributing to Certbot, go to https://certbot.eff.org/docs. If you would like to contribute to the project or run the latest code from git, you should read our `developer guide <https://certbot.eff.org/docs/contributing.html>`_.
| https://api.github.com/repos/certbot/certbot/pulls/3354 | 2016-07-30T01:56:27Z | 2016-07-30T02:10:57Z | 2016-07-30T02:10:57Z | 2016-10-06T01:21:41Z | 205 | certbot/certbot | 2,945 |
|
Fix minor markup issues | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 209060b76..06c16fcfd 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -5965,6 +5965,7 @@ Here, we ignore such cases.
* [R.15: Always overload matched allocation/deallocation pairs](#Rr-pair)
* <a name="Rr-summary-smartptrs"></a> Smart pointer rule summary:
+
* [R.20: Use `unique_ptr` or `shared_ptr` to represent ownership](#Rr-owner)
* [R.21: Prefer `unique_ptr` over `shared_ptr` unless you need to share ownership](#Rr-unique)
* [R.22: Use `make_shared()` to make `shared_ptr`s](#Rr-make_shared)
@@ -6841,7 +6842,7 @@ Arithmetic rules:
* [ES.101: use unsigned types for bit manipulation](#Res-unsigned)
* [ES.102: Used signed types for arithmetic](#Res-signed)
* [ES.103: Don't overflow](#Res-overflow)
-* [ES.104: Don't underflow](#Res-overflow)
+* [ES.104: Don't underflow](#Res-underflow)
* [ES.105: Don't divide by zero](#Res-zero)
### <a name="Res-lib"></a> ES.1: Prefer the standard library to other libraries and to "handcrafted code"
@@ -8460,7 +8461,7 @@ Incrementing a value beyond a maximum value can lead to memory corruption and un
???
-### <a name="Res-overflow"></a> ES.104: Don't underflow
+### <a name="Res-underflow"></a> ES.104: Don't underflow
##### Reason
@@ -10589,7 +10590,8 @@ In many cases you can provide a stable interface by not parameterizing a base; s
##### Enforcement
* Flag virtual functions that depend on a template argument. ??? False positives
- ### <a name="Rt-array"></a> T.81: Do not mix hierarchies and arrays
+
+### <a name="Rt-array"></a> T.81: Do not mix hierarchies and arrays
##### Reason
@@ -11101,6 +11103,7 @@ Use a C++ compiler.
##### Enforcement
* Flag if using a build mode that compiles code as C.
+
* The C++ compiler will enforce that the code is valid C++ unless you use C extension options.
### <a name="Rcpl-interface"></a> CPL.3: If you must use C for interfaces, use C++ in the calling code using such interfaces
@@ -13349,7 +13352,7 @@ Alternatively, we will decide that no change is needed and delete the entry.
\[Meyers96\]: S. Meyers. More Effective C++ (Addison-Wesley, 1996).
* <a name="Meyers97"></a>
\[Meyers97\]: S. Meyers. Effective C++ (2ndEdition) (Addison-Wesley, 1997).
-* <a name="Meyers97"></a>
+* <a name="Meyers14"></a>
\[Meyers14\]: S. Meyers. Effective Modern C++ (Addison-Wesley, 2014).
* <a name="Murray93"></a>
\[Murray93\]: R. Murray. C++ Strategies and Tactics (Addison-Wesley, 1993).
| https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/264 | 2015-10-02T16:09:31Z | 2015-10-02T16:10:45Z | 2015-10-02T16:10:45Z | 2015-10-05T06:49:59Z | 809 | isocpp/CppCoreGuidelines | 15,636 |
|
New Provider 'Bestim' | diff --git a/g4f/Provider/Bestim.py b/g4f/Provider/Bestim.py
new file mode 100644
index 0000000000..312655b8a7
--- /dev/null
+++ b/g4f/Provider/Bestim.py
@@ -0,0 +1,78 @@
+from __future__ import annotations
+
+from ..typing import Messages, List, Dict
+from .base_provider import BaseProvider, CreateResult
+from uuid import uuid4
+import requests
+
+def format_prompt(messages) -> List[Dict[str, str]]:
+
+ return [{"id": str(uuid4()), "content": '\n'.join(f'{m["role"]}: {m["content"]}' for m in messages), "from": "you"}]
+
+class Bestim(BaseProvider):
+ url = "https://chatgpt.bestim.org"
+ supports_gpt_35_turbo = True
+ supports_message_history = True
+ working = True
+ supports_stream = True
+
+ @staticmethod
+ def create_completion(
+ model: str,
+ messages: Messages,
+ stream: bool,
+ proxy: str = None,
+ **kwargs
+ ) -> CreateResult:
+
+ headers = {
+ 'POST': '/chat/send2/ HTTP/3',
+ 'Host': 'chatgpt.bestim.org',
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0',
+ 'Accept': 'application/json, text/event-stream',
+ 'Accept-Language': 'en-US,en;q=0.5',
+ 'Accept-Encoding': 'gzip, deflate, br',
+ 'Referer': 'https://chatgpt.bestim.org/chat/',
+ 'Content-Type': 'application/json',
+ 'Content-Length': '109',
+ 'Origin': 'https://chatgpt.bestim.org',
+ 'Cookie': 'NpZAER=qKkRHguMIOraVbJAWpoyzGLFjZwYlm; qKkRHguMIOraVbJAWpoyzGLFjZwYlm=8ebb5ae1561bde05354de5979b52c6e1-1704058188-1704058188; NpZAER_hits=2; _csrf-front=fcf20965823c0a152ae8f9cdf15b23022bb26cdc6bf32a9d4c8bfe78dcc6b807a%3A2%3A%7Bi%3A0%3Bs%3A11%3A%22_csrf-front%22%3Bi%3A1%3Bs%3A32%3A%22a5wP6azsc7dxV8rmwAXaNsl8XS1yvW5V%22%3B%7D',
+ 'Alt-Used': 'chatgpt.bestim.org',
+ 'Connection': 'keep-alive',
+ 'Sec-Fetch-Dest': 'empty',
+ 'Sec-Fetch-Mode': 'cors',
+ 'Sec-Fetch-Site': 'same-origin',
+ 'TE': 'trailers'
+ }
+
+ data = {
+
+ "messagesHistory": format_prompt(messages),
+ "type": "chat",
+ }
+
+ response = requests.post(
+ url="https://chatgpt.bestim.org/chat/send2/",
+ headers=headers,
+ json=data,
+ proxies={"https": proxy}
+ )
+
+ response.raise_for_status()
+
+ for chunk in response.iter_lines():
+
+ if b"event: trylimit" not in chunk:
+
+ yield chunk.decode().removeprefix("data: ")
+
+
+
+
+
+
+
+
+
+
+
diff --git a/g4f/Provider/__init__.py b/g4f/Provider/__init__.py
index 4670d33116..ff7ee115b9 100644
--- a/g4f/Provider/__init__.py
+++ b/g4f/Provider/__init__.py
@@ -52,6 +52,7 @@
from .You import You
from .Yqcloud import Yqcloud
from .GeekGpt import GeekGpt
+from .Bestim import Bestim
import sys
| New BaseProvider 'Bestim' from [this comment](https://github.com/xtekky/gpt4free/issues/802#issuecomment-1873032520) | https://api.github.com/repos/xtekky/gpt4free/pulls/1416 | 2024-01-01T14:34:39Z | 2024-01-02T01:42:21Z | 2024-01-02T01:42:21Z | 2024-01-02T01:42:33Z | 1,023 | xtekky/gpt4free | 38,059 |
Removed comment on why basecamp was ever added | diff --git a/removed_sites.md b/removed_sites.md
index 233d09847..1af7a3f46 100644
--- a/removed_sites.md
+++ b/removed_sites.md
@@ -123,7 +123,6 @@ This can be detected, but it requires a different detection method.
As of 2020-02-23, all usernames are reported as not existing.
-Why was this ever added? It does not look like a social network.
```
"Basecamp": {
| Removed comment on remove_sites.md about Basecamp | https://api.github.com/repos/sherlock-project/sherlock/pulls/740 | 2020-08-30T01:30:24Z | 2020-08-30T18:52:47Z | 2020-08-30T18:52:47Z | 2020-08-30T18:52:47Z | 116 | sherlock-project/sherlock | 36,203 |
Fixed #21141 -- Update Sphinx URL | diff --git a/docs/README b/docs/README
index 05133d8917b4d..5001eef57e06d 100644
--- a/docs/README
+++ b/docs/README
@@ -14,4 +14,4 @@ To create an HTML version of the docs:
The documentation in _build/html/index.html can then be viewed in a web browser.
[1] http://docutils.sourceforge.net/rst.html
-[2] http://sphinx.pocoo.org/
+[2] http://sphinx-doc.org/
diff --git a/docs/conf.py b/docs/conf.py
index 0c35e935e6f01..3b3816f69bcdc 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -111,7 +111,7 @@ def django_release():
# branch, which is located at this URL.
intersphinx_mapping = {
'python': ('http://docs.python.org/2.7', None),
- 'sphinx': ('http://sphinx.pocoo.org/', None),
+ 'sphinx': ('http://sphinx-doc.org/', None),
'six': ('http://pythonhosted.org/six/', None),
'simplejson': ('http://simplejson.readthedocs.org/en/latest/', None),
}
diff --git a/docs/internals/contributing/writing-documentation.txt b/docs/internals/contributing/writing-documentation.txt
index 52ad7b7599e0c..e565b4d54f704 100644
--- a/docs/internals/contributing/writing-documentation.txt
+++ b/docs/internals/contributing/writing-documentation.txt
@@ -42,7 +42,7 @@ Django's documentation uses the Sphinx__ documentation system, which in turn
is based on docutils__. The basic idea is that lightly-formatted plain-text
documentation is transformed into HTML, PDF, and any other output format.
-__ http://sphinx.pocoo.org/
+__ http://sphinx-doc.org/
__ http://docutils.sourceforge.net/
To actually build the documentation locally, you'll currently need to install
@@ -141,7 +141,7 @@ Django-specific markup
Besides the `Sphinx built-in markup`__, Django's docs defines some extra
description units:
-__ http://sphinx.pocoo.org/markup/desc.html
+__ http://sphinx-doc.org/markup/desc.html
* Settings::
@@ -305,7 +305,7 @@ look better:
* Add `info field lists`__ where appropriate.
- __ http://sphinx.pocoo.org/markup/desc.html#info-field-lists
+ __ http://sphinx-doc.org/markup/desc.html#info-field-lists
* Whenever possible, use links. So, use ``:setting:`ADMIN_FOR``` instead
of ````ADMIN_FOR````.
diff --git a/docs/intro/whatsnext.txt b/docs/intro/whatsnext.txt
index 638d219afe855..e2a0c75b95a00 100644
--- a/docs/intro/whatsnext.txt
+++ b/docs/intro/whatsnext.txt
@@ -192,7 +192,7 @@ You can get a local copy of the HTML documentation following a few easy steps:
Generation of the Django documentation will work with Sphinx version 0.6
or newer, but we recommend going straight to Sphinx 1.0.2 or newer.
-__ http://sphinx.pocoo.org/
+__ http://sphinx-doc.org/
__ http://www.gnu.org/software/make/
.. _differences-between-doc-versions:
diff --git a/docs/releases/1.0-beta-2.txt b/docs/releases/1.0-beta-2.txt
index fac64d843329e..0c5225b6e1dd5 100644
--- a/docs/releases/1.0-beta-2.txt
+++ b/docs/releases/1.0-beta-2.txt
@@ -45,7 +45,7 @@ Refactored documentation
have Sphinx installed, build the HTML yourself from the
documentation files bundled with Django.
-.. _Sphinx: http://sphinx.pocoo.org/
+.. _Sphinx: http://sphinx-doc.org/
.. _online: https://docs.djangoproject.com/
Along with these new features, the Django team has also been hard at
| Updated Sphinx URL from http://sphinx.pocoo.org/ to http://sphinx-doc.org/.
| https://api.github.com/repos/django/django/pulls/1658 | 2013-09-22T17:37:19Z | 2013-09-22T17:54:36Z | 2013-09-22T17:54:36Z | 2014-06-13T00:29:21Z | 960 | django/django | 50,693 |
fix(binanceWs): fetchOpenOrdersWs symbol requirement removal | diff --git a/ts/src/pro/binance.ts b/ts/src/pro/binance.ts
index 309a69b64fb2..c64e8ceab047 100644
--- a/ts/src/pro/binance.ts
+++ b/ts/src/pro/binance.ts
@@ -1833,7 +1833,6 @@ export default class binance extends binanceRest {
* @param {object} [params] extra parameters specific to the binance api endpoint
* @returns {object[]} a list of [order structures]{@link https://docs.ccxt.com/#/?id=order-structure}
*/
- this.checkRequiredSymbol ('fetchOpenOrdersWs', symbol);
await this.loadMarkets ();
this.checkIsSpot ('fetchOpenOrdersWs', symbol);
const url = this.urls['api']['ws']['ws'];
@@ -1842,9 +1841,11 @@ export default class binance extends binanceRest {
let returnRateLimits = false;
[ returnRateLimits, params ] = this.handleOptionAndParams (params, 'fetchOrderWs', 'returnRateLimits', false);
const payload = {
- 'symbol': this.marketId (symbol),
'returnRateLimits': returnRateLimits,
};
+ if (symbol !== undefined) {
+ payload['symbol'] = this.marketId (symbol);
+ }
const message = {
'id': messageHash,
'method': 'openOrders.status',
| - fixes https://github.com/ccxt/ccxt/issues/18705
DEMO
```
p binance fetchOpenOrdersWs --sandbox
Python v3.10.9
CCXT v4.0.43
binance.fetchOpenOrdersWs()
[{'amount': 0.002,
'average': None,
'clientOrderId': 'x-R4BD3S82d59a66489401748191cf4c',
'cost': 0.0,
'datetime': '2023-07-27T10:47:12.481Z',
'fee': {'cost': None, 'currency': None, 'rate': None},
'fees': [{'cost': None, 'currency': None, 'rate': None}],
'filled': 0.0,
'id': '10011014',
'info': {'clientOrderId': 'x-R4BD3S82d59a66489401748191cf4c',
'cummulativeQuoteQty': '0.00000000',
'executedQty': '0.00000000',
'icebergQty': '0.00000000',
'isWorking': True,
'orderId': 10011014,
'orderListId': -1,
'origQty': '0.00200000',
'origQuoteOrderQty': '0.00000000',
'price': '25000.00000000',
'selfTradePreventionMode': 'NONE',
'side': 'BUY',
'status': 'NEW',
'stopPrice': '0.00000000',
'symbol': 'BTCUSDT',
'time': 1690454832481,
'timeInForce': 'GTC',
'type': 'LIMIT',
'updateTime': 1690454832481,
'workingTime': 1690454832481},
'lastTradeTimestamp': None,
'lastUpdateTimestamp': 1690454832481,
'postOnly': False,
'price': 25000.0,
'reduceOnly': None,
'remaining': 0.002,
'side': 'buy',
'status': 'open',
'stopLossPrice': None,
'stopPrice': None,
'symbol': 'BTC/USDT',
'takeProfitPrice': None,
'timeInForce': 'GTC',
'timestamp': 1690454832481,
'trades': [],
'triggerPrice': None,
'type': 'limit'}]
```
| https://api.github.com/repos/ccxt/ccxt/pulls/18706 | 2023-07-30T13:25:33Z | 2023-07-30T13:26:58Z | 2023-07-30T13:26:58Z | 2023-07-30T13:26:58Z | 312 | ccxt/ccxt | 13,221 |
Remove unused httpbin parameters | diff --git a/tests/test_requests.py b/tests/test_requests.py
index 1b05333290..dea411bfec 100644
--- a/tests/test_requests.py
+++ b/tests/test_requests.py
@@ -1400,7 +1400,7 @@ def test_transport_adapter_ordering(self):
assert 'http://' in s2.adapters
assert 'https://' in s2.adapters
- def test_session_get_adapter_prefix_matching(self, httpbin):
+ def test_session_get_adapter_prefix_matching(self):
prefix = 'https://example.com'
more_specific_prefix = prefix + '/some/path'
@@ -1418,7 +1418,7 @@ def test_session_get_adapter_prefix_matching(self, httpbin):
assert s.get_adapter(url_matching_more_specific_prefix) is more_specific_prefix_adapter
assert s.get_adapter(url_not_matching_prefix) not in (prefix_adapter, more_specific_prefix_adapter)
- def test_session_get_adapter_prefix_matching_mixed_case(self, httpbin):
+ def test_session_get_adapter_prefix_matching_mixed_case(self):
mixed_case_prefix = 'hTtPs://eXamPle.CoM/MixEd_CAse_PREfix'
url_matching_prefix = mixed_case_prefix + '/full_url'
@@ -1428,7 +1428,7 @@ def test_session_get_adapter_prefix_matching_mixed_case(self, httpbin):
assert s.get_adapter(url_matching_prefix) is my_adapter
- def test_session_get_adapter_prefix_matching_is_case_insensitive(self, httpbin):
+ def test_session_get_adapter_prefix_matching_is_case_insensitive(self):
mixed_case_prefix = 'hTtPs://eXamPle.CoM/MixEd_CAse_PREfix'
url_matching_prefix_with_different_case = 'HtTpS://exaMPLe.cOm/MiXeD_caSE_preFIX/another_url'
@@ -1795,12 +1795,12 @@ def test_session_close_proxy_clear(self, mocker):
proxies['one'].clear.assert_called_once_with()
proxies['two'].clear.assert_called_once_with()
- def test_proxy_auth(self, httpbin):
+ def test_proxy_auth(self):
adapter = HTTPAdapter()
headers = adapter.proxy_headers("http://user:pass@httpbin.org")
assert headers == {'Proxy-Authorization': 'Basic dXNlcjpwYXNz'}
- def test_proxy_auth_empty_pass(self, httpbin):
+ def test_proxy_auth_empty_pass(self):
adapter = HTTPAdapter()
headers = adapter.proxy_headers("http://user:@httpbin.org")
assert headers == {'Proxy-Authorization': 'Basic dXNlcjo='}
| httpbin is used to mock HTTP endpoints. In these methods, the parameter goes unused. | https://api.github.com/repos/psf/requests/pulls/4712 | 2018-06-26T18:32:35Z | 2018-07-18T02:39:19Z | 2018-07-18T02:39:19Z | 2021-09-02T00:07:39Z | 573 | psf/requests | 32,978 |
Fixed #34687 -- Made Apps.clear_cache() clear get_swappable_settings_name() cache. | diff --git a/AUTHORS b/AUTHORS
index 2148c64322a45..40df3589c024d 100644
--- a/AUTHORS
+++ b/AUTHORS
@@ -747,6 +747,7 @@ answer newbie questions, and generally made Django that much better:
Nicolas Lara <nicolaslara@gmail.com>
Nicolas Noé <nicolas@niconoe.eu>
Nikita Marchant <nikita.marchant@gmail.com>
+ Nikita Sobolev <mail@sobolevn.me>
Niran Babalola <niran@niran.org>
Nis Jørgensen <nis@superlativ.dk>
Nowell Strite <https://nowell.strite.org/>
diff --git a/django/apps/registry.py b/django/apps/registry.py
index 0683f3ad3ccb3..92de6075fc90a 100644
--- a/django/apps/registry.py
+++ b/django/apps/registry.py
@@ -373,6 +373,7 @@ def clear_cache(self):
This is mostly used in tests.
"""
+ self.get_swappable_settings_name.cache_clear()
# Call expire cache on each model. This will purge
# the relation tree and the fields cache.
self.get_models.cache_clear()
diff --git a/tests/apps/tests.py b/tests/apps/tests.py
index 9f989c5d9a854..ecfb70162ff26 100644
--- a/tests/apps/tests.py
+++ b/tests/apps/tests.py
@@ -197,6 +197,17 @@ def test_get_model(self):
with self.assertRaises(ValueError):
apps.get_model("admin_LogEntry")
+ @override_settings(INSTALLED_APPS=SOME_INSTALLED_APPS)
+ def test_clear_cache(self):
+ # Set cache.
+ self.assertIsNone(apps.get_swappable_settings_name("admin.LogEntry"))
+ apps.get_models()
+
+ apps.clear_cache()
+
+ self.assertEqual(apps.get_swappable_settings_name.cache_info().currsize, 0)
+ self.assertEqual(apps.get_models.cache_info().currsize, 0)
+
@override_settings(INSTALLED_APPS=["apps.apps.RelabeledAppsConfig"])
def test_relabeling(self):
self.assertEqual(apps.get_app_config("relabeled").name, "apps")
| When `django.apps.apps.clear_cache()` is called,
we now also clean the cache of `@functools.cache`
of `get_swappable_settings_name` method.
Original issue https://code.djangoproject.com/ticket/34687
Refs https://github.com/typeddjango/django-stubs/pull/1601 | https://api.github.com/repos/django/django/pulls/17029 | 2023-06-29T13:18:26Z | 2023-06-30T07:57:43Z | 2023-06-30T07:57:43Z | 2023-06-30T07:57:43Z | 507 | django/django | 51,007 |
Update Meater codeowners | diff --git a/CODEOWNERS b/CODEOWNERS
index 1b9c9bfa69d85e..424cd0d6b99835 100644
--- a/CODEOWNERS
+++ b/CODEOWNERS
@@ -588,8 +588,8 @@ build.json @home-assistant/supervisor
/homeassistant/components/matrix/ @tinloaf
/homeassistant/components/mazda/ @bdr99
/tests/components/mazda/ @bdr99
-/homeassistant/components/meater/ @Sotolotl
-/tests/components/meater/ @Sotolotl
+/homeassistant/components/meater/ @Sotolotl @emontnemery
+/tests/components/meater/ @Sotolotl @emontnemery
/homeassistant/components/media_player/ @home-assistant/core
/tests/components/media_player/ @home-assistant/core
/homeassistant/components/media_source/ @hunterjm
diff --git a/homeassistant/components/meater/manifest.json b/homeassistant/components/meater/manifest.json
index 192a534cd755e6..6df4f6939e1ca6 100644
--- a/homeassistant/components/meater/manifest.json
+++ b/homeassistant/components/meater/manifest.json
@@ -1,5 +1,5 @@
{
- "codeowners": ["@Sotolotl"],
+ "codeowners": ["@Sotolotl", "@emontnemery"],
"config_flow": true,
"documentation": "https://www.home-assistant.io/integrations/meater",
"domain": "meater",
| <!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Proposed change
<!--
Describe the big picture of your changes here to communicate to the
maintainers why we should accept this pull request. If it fixes a bug
or resolves a feature request, be sure to link to that issue in the
additional information section.
-->
Update Meater codeowners
## Type of change
<!--
What type of change does your PR introduce to Home Assistant?
NOTE: Please, check only 1! box!
If your PR requires multiple boxes to be checked, you'll most likely need to
split it into multiple PRs. This makes things easier and faster to code review.
-->
- [ ] Dependency upgrade
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New integration (thank you!)
- [ ] New feature (which adds functionality to an existing integration)
- [ ] Breaking change (fix/feature causing existing functionality to break)
- [ ] Code quality improvements to existing code or addition of tests
## Additional information
<!--
Details are important, and help maintainers processing your PR.
Please be sure to fill out additional details, if applicable.
-->
- This PR fixes or closes issue: fixes #
- This PR is related to issue:
- Link to documentation pull request:
## Checklist
<!--
Put an `x` in the boxes that apply. You can also fill these out after
creating the PR. If you're unsure about any of them, don't hesitate to ask.
We're here to help! This is simply a reminder of what we are going to look
for before merging your code.
-->
- [ ] The code change is tested and works locally.
- [ ] Local tests pass. **Your PR cannot be merged unless tests pass**
- [ ] There is no commented out code in this PR.
- [ ] I have followed the [development checklist][dev-checklist]
- [ ] The code has been formatted using Black (`black --fast homeassistant tests`)
- [ ] Tests have been added to verify that the new code works.
If user exposed functionality or configuration variables are added/changed:
- [ ] Documentation added/updated for [www.home-assistant.io][docs-repository]
If the code communicates with devices, web services, or third-party tools:
- [ ] The [manifest file][manifest-docs] has all fields filled out correctly.
Updated and included derived files by running: `python3 -m script.hassfest`.
- [ ] New or updated dependencies have been added to `requirements_all.txt`.
Updated by running `python3 -m script.gen_requirements_all`.
- [ ] For the updated dependencies - a link to the changelog, or at minimum a diff between library versions is added to the PR description.
- [ ] Untested files have been added to `.coveragerc`.
The integration reached or maintains the following [Integration Quality Scale][quality-scale]:
<!--
The Integration Quality Scale scores an integration on the code quality
and user experience. Each level of the quality scale consists of a list
of requirements. We highly recommend getting your integration scored!
-->
- [ ] No score or internal
- [ ] 🥈 Silver
- [ ] 🥇 Gold
- [ ] 🏆 Platinum
<!--
This project is very active and we have a high turnover of pull requests.
Unfortunately, the number of incoming pull requests is higher than what our
reviewers can review and merge so there is a long backlog of pull requests
waiting for review. You can help here!
By reviewing another pull request, you will help raise the code quality of
that pull request and the final review will be faster. This way the general
pace of pull request reviews will go up and your wait time will go down.
When picking a pull request to review, try to choose one that hasn't yet
been reviewed.
Thanks for helping out!
-->
To help with the load of incoming pull requests:
- [ ] I have reviewed two other [open pull requests][prs] in this repository.
[prs]: https://github.com/home-assistant/core/pulls?q=is%3Aopen+is%3Apr+-author%3A%40me+-draft%3Atrue+-label%3Awaiting-for-upstream+sort%3Acreated-desc+review%3Anone+-status%3Afailure
<!--
Thank you for contributing <3
Below, some useful links you could explore:
-->
[dev-checklist]: https://developers.home-assistant.io/docs/en/development_checklist.html
[manifest-docs]: https://developers.home-assistant.io/docs/en/creating_integration_manifest.html
[quality-scale]: https://developers.home-assistant.io/docs/en/next/integration_quality_scale_index.html
[docs-repository]: https://github.com/home-assistant/home-assistant.io
| https://api.github.com/repos/home-assistant/core/pulls/69915 | 2022-04-12T12:49:52Z | 2022-04-12T12:54:01Z | 2022-04-12T12:54:01Z | 2022-04-13T13:13:54Z | 358 | home-assistant/core | 39,492 |
fix typos | diff --git a/benchmark/RESULTS.md b/benchmark/RESULTS.md
index 200cfc2835..5e39d2e2e9 100644
--- a/benchmark/RESULTS.md
+++ b/benchmark/RESULTS.md
@@ -66,7 +66,7 @@ Uncaught ReferenceError: module is not defined
- failure mode: placeholder text
-url_shortner starts but gets the error:
+url_shortener starts but gets the error:
SQLite objects created in a thread can only be used in that same thread. The object was created in thread id 8636125824 and this is thread id 13021003776.
markdown_editor:
diff --git a/gpt_engineer/steps.py b/gpt_engineer/steps.py
index 31f0b6ef8f..503aad065e 100644
--- a/gpt_engineer/steps.py
+++ b/gpt_engineer/steps.py
@@ -181,7 +181,7 @@ def gen_entrypoint(ai, dbs):
"From this you will answer with code blocks that includes all the necessary "
"unix terminal commands to "
"a) install dependencies "
- "b) run all necessary parts of the codebase (in parallell if necessary).\n"
+ "b) run all necessary parts of the codebase (in parallel if necessary).\n"
"Do not install globally. Do not use sudo.\n"
"Do not explain the code, just give the commands.\n"
"Do not use placeholders, use example values (like . for a folder argument) "
| https://api.github.com/repos/gpt-engineer-org/gpt-engineer/pulls/359 | 2023-06-23T10:18:14Z | 2023-06-23T12:24:41Z | 2023-06-23T12:24:41Z | 2023-06-23T12:30:22Z | 341 | gpt-engineer-org/gpt-engineer | 33,252 |
|
Fix get top billionaires BROKEN file | diff --git a/DIRECTORY.md b/DIRECTORY.md
index 8d1567465fbc..bcac340f3ce2 100644
--- a/DIRECTORY.md
+++ b/DIRECTORY.md
@@ -1220,6 +1220,7 @@
* [Get Amazon Product Data](web_programming/get_amazon_product_data.py)
* [Get Imdb Top 250 Movies Csv](web_programming/get_imdb_top_250_movies_csv.py)
* [Get Imdbtop](web_programming/get_imdbtop.py)
+ * [Get Top Billionaires](web_programming/get_top_billionaires.py)
* [Get Top Hn Posts](web_programming/get_top_hn_posts.py)
* [Get User Tweets](web_programming/get_user_tweets.py)
* [Giphy](web_programming/giphy.py)
diff --git a/web_programming/get_top_billionaires.py.disabled b/web_programming/get_top_billionaires.py
similarity index 72%
rename from web_programming/get_top_billionaires.py.disabled
rename to web_programming/get_top_billionaires.py
index 6a8054e26270..6f986acb9181 100644
--- a/web_programming/get_top_billionaires.py.disabled
+++ b/web_programming/get_top_billionaires.py
@@ -3,7 +3,7 @@
This works for some of us but fails for others.
"""
-from datetime import datetime
+from datetime import UTC, datetime, timedelta
import requests
from rich import box
@@ -20,18 +20,31 @@
)
-def calculate_age(unix_date: int) -> str:
+def calculate_age(unix_date: float) -> str:
"""Calculates age from given unix time format.
Returns:
Age as string
- >>> calculate_age(-657244800000)
- '73'
- >>> calculate_age(46915200000)
- '51'
+ >>> from datetime import datetime, UTC
+ >>> years_since_create = datetime.now(tz=UTC).year - 2022
+ >>> int(calculate_age(-657244800000)) - years_since_create
+ 73
+ >>> int(calculate_age(46915200000)) - years_since_create
+ 51
"""
- birthdate = datetime.fromtimestamp(unix_date / 1000).date()
+ # Convert date from milliseconds to seconds
+ unix_date /= 1000
+
+ if unix_date < 0:
+ # Handle timestamp before epoch
+ epoch = datetime.fromtimestamp(0, tz=UTC)
+ seconds_since_epoch = (datetime.now(tz=UTC) - epoch).seconds
+ birthdate = (
+ epoch - timedelta(seconds=abs(unix_date) - seconds_since_epoch)
+ ).date()
+ else:
+ birthdate = datetime.fromtimestamp(unix_date, tz=UTC).date()
return str(
TODAY.year
- birthdate.year
| ### Describe your change:
Fixes a `get_top_billionaires` and unmarks it as disabled
* [ ] Add an algorithm?
* [x] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.
* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): "Fixes #ISSUE-NUMBER".
| https://api.github.com/repos/TheAlgorithms/Python/pulls/8970 | 2023-08-16T15:43:31Z | 2023-08-18T12:13:38Z | 2023-08-18T12:13:38Z | 2023-08-18T12:17:13Z | 654 | TheAlgorithms/Python | 29,550 |
update:pypi verison | diff --git a/setup.py b/setup.py
index 433e694d9..48b4c03d7 100644
--- a/setup.py
+++ b/setup.py
@@ -57,7 +57,7 @@ def run(self):
setup(
name="metagpt",
- version="0.6.11",
+ version="0.6.12",
description="The Multi-Agent Framework",
long_description=long_description,
long_description_content_type="text/markdown",
| **Features**
<!-- Clear and direct description of the submit features. -->
<!-- If it's a bug fix, please also paste the issue link. -->
- xx
- yy
**Feature Docs**
<!-- The RFC, tutorial, or use cases about the feature if it's a pretty big update. If not, there is no need to fill. -->
**Influence**
<!-- Tell me the impact of the new feature and I'll focus on it. -->
**Result**
<!-- The screenshot/log of unittest/running result -->
**Other**
<!-- Something else about this PR. --> | https://api.github.com/repos/geekan/MetaGPT/pulls/1158 | 2024-04-03T03:28:08Z | 2024-04-03T03:31:21Z | 2024-04-03T03:31:21Z | 2024-04-03T03:31:21Z | 109 | geekan/MetaGPT | 16,673 |
Suppress `export.run()` `TracerWarning` | diff --git a/export.py b/export.py
index 8666f3de63e..09c50baa415 100644
--- a/export.py
+++ b/export.py
@@ -16,6 +16,10 @@
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
TensorFlow.js | `tfjs` | yolov5s_web_model/
+Requirements:
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
+
Usage:
$ python path/to/export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
@@ -437,6 +441,7 @@ def run(data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
# Exports
f = [''] * 10 # exported filenames
+ warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
if 'torchscript' in include:
f[0] = export_torchscript(model, im, file, optimize)
if 'engine' in include: # TensorRT required before ONNX
@@ -509,10 +514,8 @@ def parse_opt():
def main(opt):
- with warnings.catch_warnings():
- warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
- for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
- run(**vars(opt))
+ for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
+ run(**vars(opt))
if __name__ == "__main__":
| Suppresses warnings when calling export.run() directly, not just CLI python export.py.
Also adds Requirements examples for CPU and GPU backends
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Improved model export functionality with updated requirements and reduced warning clutter.
### 📊 Key Changes
- Added dependencies installation instructions for CPU and GPU setups in the `export.py` file.
- Suppressed `torch.jit.TracerWarning` globally within the export script, rather than on each model export action.
### 🎯 Purpose & Impact
- 🛠️ **Easier Setup**: Users can now easily find dependency installation commands according to their hardware (CPU or GPU), streamlining the setup process.
- 🧹 **Cleaner Output**: Suppressing tracer warnings by default makes the output less cluttered, allowing users to focus on more important messages and reducing potential confusion from warning messages.
- ✨ **Smoother Experience**: The changes contribute to a smoother user experience when exporting models by simplifying the preparation steps and reducing visual noise during the export process. | https://api.github.com/repos/ultralytics/yolov5/pulls/6499 | 2022-02-01T22:07:04Z | 2022-02-01T22:52:51Z | 2022-02-01T22:52:51Z | 2024-01-19T13:07:57Z | 428 | ultralytics/yolov5 | 24,879 |
Assorted docs updates | diff --git a/docs/_templates/sidebarintro.html b/docs/_templates/sidebarintro.html
index 9d07a5ca78..d2ffff0d20 100644
--- a/docs/_templates/sidebarintro.html
+++ b/docs/_templates/sidebarintro.html
@@ -11,8 +11,7 @@
<p>
Requests is an elegant and simple HTTP library for Python, built for
- human beings. You are currently looking at the documentation of the
- development release.
+ human beings.
</p>
diff --git a/docs/user/advanced.rst b/docs/user/advanced.rst
index a69a1404f0..ffcb777fe6 100644
--- a/docs/user/advanced.rst
+++ b/docs/user/advanced.rst
@@ -268,6 +268,8 @@ Then, we can make a request using our Pizza Auth::
>>> requests.get('http://pizzabin.org/admin', auth=PizzaAuth('kenneth'))
<Response [200]>
+.. _streaming-requests
+
Streaming Requests
------------------
@@ -574,3 +576,19 @@ a good start would be to subclass the ``requests.adapters.BaseAdapter`` class.
.. _`described here`: http://kennethreitz.org/exposures/the-future-of-python-http
.. _`urllib3`: https://github.com/shazow/urllib3
+Blocking Or Non-Blocking?
+-------------------------
+
+With the default Transport Adapter in place, Requests does not provide any kind
+of non-blocking IO. The ``Response.content`` property will block until the
+entire response has been downloaded. If you require more granularity, the
+streaming features of the library (see :ref:`streaming-requests`) allow you to
+retrieve smaller quantities of the response at a time. However, these calls
+will still block.
+
+If you are concerned about the use of blocking IO, there are lots of projects
+out there that combine Requests with one of Python's asynchronicity frameworks.
+Two excellent examples are `grequests`_ and `requests-futures`_.
+
+.. _`grequests`: https://github.com/kennethreitz/grequests
+.. _`requests-futures`: https://github.com/ross/requests-futures
| This should resolve #1390, #1399 and #1383.
```
DOCUMENT
,,
';;
''
____ ||
; \ ||
\,---'-,-, ||
/ ( o) ||
(o )__,--'-' \ ||
,,,, ;'uuuuu'' ) ;;
\ \ \ ) ) /\//
'--' \'nnnnn' / \
\\ //'------' \
\\ // \ \
\\ // ) )
\\// | |
\\ / |
ALL THE THINGS!!!!
```
| https://api.github.com/repos/psf/requests/pulls/1413 | 2013-06-08T10:12:16Z | 2013-06-08T10:13:14Z | 2013-06-08T10:13:14Z | 2021-09-08T20:01:26Z | 499 | psf/requests | 32,212 |
Glenn space compatibility | diff --git a/gym/core.py b/gym/core.py
index 5bbb1250f48..450439f33b9 100644
--- a/gym/core.py
+++ b/gym/core.py
@@ -189,10 +189,6 @@ def compatible(self, space):
Return boolean specifying if space is compatible with this Space
(equal shape structure, ignoring bounds). None matches any Space.
"""
- # allow None to match with any space
- if space is None:
- return True
-
# compare classes
if type(self) != type(space):
return False
| https://api.github.com/repos/openai/gym/pulls/872 | 2018-02-08T21:04:06Z | 2018-02-08T21:09:29Z | 2018-02-08T21:09:29Z | 2018-02-08T21:09:29Z | 135 | openai/gym | 5,643 |
|
Delete unfinished/writesonic directory | diff --git a/unfinished/writesonic/README.md b/unfinished/writesonic/README.md
deleted file mode 100644
index a658a87c62..0000000000
--- a/unfinished/writesonic/README.md
+++ /dev/null
@@ -1,53 +0,0 @@
-### Example: `writesonic` (use like openai pypi package) <a name="example-writesonic"></a>
-
-```python
-# import writesonic
-import writesonic
-
-# create account (3-4s)
-account = writesonic.Account.create(logging = True)
-
-# with loging:
- # 2023-04-06 21:50:25 INFO __main__ -> register success : '{"id":"51aa0809-3053-44f7-922a...' (2s)
- # 2023-04-06 21:50:25 INFO __main__ -> id : '51aa0809-3053-44f7-922a-2b85d8d07edf'
- # 2023-04-06 21:50:25 INFO __main__ -> token : 'eyJhbGciOiJIUzI1NiIsInR5cCI6Ik...'
- # 2023-04-06 21:50:28 INFO __main__ -> got key : '194158c4-d249-4be0-82c6-5049e869533c' (2s)
-
-# simple completion
-response = writesonic.Completion.create(
- api_key = account.key,
- prompt = 'hello world'
-)
-
-print(response.completion.choices[0].text) # Hello! How may I assist you today?
-
-# conversation
-
-response = writesonic.Completion.create(
- api_key = account.key,
- prompt = 'what is my name ?',
- enable_memory = True,
- history_data = [
- {
- 'is_sent': True,
- 'message': 'my name is Tekky'
- },
- {
- 'is_sent': False,
- 'message': 'hello Tekky'
- }
- ]
-)
-
-print(response.completion.choices[0].text) # Your name is Tekky.
-
-# enable internet
-
-response = writesonic.Completion.create(
- api_key = account.key,
- prompt = 'who won the quatar world cup ?',
- enable_google_results = True
-)
-
-print(response.completion.choices[0].text) # Argentina won the 2022 FIFA World Cup tournament held in Qatar ...
-```
\ No newline at end of file
diff --git a/unfinished/writesonic/__init__.py b/unfinished/writesonic/__init__.py
deleted file mode 100644
index ce684912ff..0000000000
--- a/unfinished/writesonic/__init__.py
+++ /dev/null
@@ -1,163 +0,0 @@
-from random import choice
-from time import time
-
-from colorama import Fore, init;
-from names import get_first_name, get_last_name
-from requests import Session
-from requests import post
-
-init()
-
-
-class logger:
- @staticmethod
- def info(string) -> print:
- import datetime
- now = datetime.datetime.now()
- return print(
- f"{Fore.CYAN}{now.strftime('%Y-%m-%d %H:%M:%S')} {Fore.BLUE}INFO {Fore.MAGENTA}__main__ -> {Fore.RESET}{string}")
-
-
-class SonicResponse:
- class Completion:
- class Choices:
- def __init__(self, choice: dict) -> None:
- self.text = choice['text']
- self.content = self.text.encode()
- self.index = choice['index']
- self.logprobs = choice['logprobs']
- self.finish_reason = choice['finish_reason']
-
- def __repr__(self) -> str:
- return f'''<__main__.APIResponse.Completion.Choices(\n text = {self.text.encode()},\n index = {self.index},\n logprobs = {self.logprobs},\n finish_reason = {self.finish_reason})object at 0x1337>'''
-
- def __init__(self, choices: dict) -> None:
- self.choices = [self.Choices(choice) for choice in choices]
-
- class Usage:
- def __init__(self, usage_dict: dict) -> None:
- self.prompt_tokens = usage_dict['prompt_chars']
- self.completion_tokens = usage_dict['completion_chars']
- self.total_tokens = usage_dict['total_chars']
-
- def __repr__(self):
- return f'''<__main__.APIResponse.Usage(\n prompt_tokens = {self.prompt_tokens},\n completion_tokens = {self.completion_tokens},\n total_tokens = {self.total_tokens})object at 0x1337>'''
-
- def __init__(self, response_dict: dict) -> None:
- self.response_dict = response_dict
- self.id = response_dict['id']
- self.object = response_dict['object']
- self.created = response_dict['created']
- self.model = response_dict['model']
- self.completion = self.Completion(response_dict['choices'])
- self.usage = self.Usage(response_dict['usage'])
-
- def json(self) -> dict:
- return self.response_dict
-
-
-class Account:
- session = Session()
- session.headers = {
- "connection": "keep-alive",
- "sec-ch-ua": "\"Not_A Brand\";v=\"99\", \"Google Chrome\";v=\"109\", \"Chromium\";v=\"109\"",
- "accept": "application/json, text/plain, */*",
- "content-type": "application/json",
- "sec-ch-ua-mobile": "?0",
- "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
- "sec-ch-ua-platform": "\"Windows\"",
- "sec-fetch-site": "same-origin",
- "sec-fetch-mode": "cors",
- "sec-fetch-dest": "empty",
- # "accept-encoding" : "gzip, deflate, br",
- "accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
- "cookie": ""
- }
-
- @staticmethod
- def get_user():
- password = f'0opsYouGoTme@1234'
- f_name = get_first_name()
- l_name = get_last_name()
- hosts = ['gmail.com', 'protonmail.com', 'proton.me', 'outlook.com']
-
- return {
- "email": f"{f_name.lower()}.{l_name.lower()}@{choice(hosts)}",
- "password": password,
- "confirm_password": password,
- "full_name": f'{f_name} {l_name}'
- }
-
- @staticmethod
- def create(logging: bool = False):
- while True:
- try:
- user = Account.get_user()
- start = time()
- response = Account.session.post("https://app.writesonic.com/api/session-login", json=user | {
- "utmParams": "{}",
- "visitorId": "0",
- "locale": "en",
- "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
- "signInWith": "password",
- "request_type": "signup",
- })
-
- if logging:
- logger.info(f"\x1b[31mregister success\x1b[0m : '{response.text[:30]}...' ({int(time() - start)}s)")
- logger.info(f"\x1b[31mid\x1b[0m : '{response.json()['id']}'")
- logger.info(f"\x1b[31mtoken\x1b[0m : '{response.json()['token'][:30]}...'")
-
- start = time()
- response = Account.session.post("https://api.writesonic.com/v1/business/set-business-active",
- headers={"authorization": "Bearer " + response.json()['token']})
- key = response.json()["business"]["api_key"]
- if logging: logger.info(f"\x1b[31mgot key\x1b[0m : '{key}' ({int(time() - start)}s)")
-
- return Account.AccountResponse(user['email'], user['password'], key)
-
- except Exception as e:
- if logging: logger.info(f"\x1b[31merror\x1b[0m : '{e}'")
- continue
-
- class AccountResponse:
- def __init__(self, email, password, key):
- self.email = email
- self.password = password
- self.key = key
-
-
-class Completion:
- def create(
- api_key: str,
- prompt: str,
- enable_memory: bool = False,
- enable_google_results: bool = False,
- history_data: list = []) -> SonicResponse:
- response = post('https://api.writesonic.com/v2/business/content/chatsonic?engine=premium',
- headers={"X-API-KEY": api_key},
- json={
- "enable_memory": enable_memory,
- "enable_google_results": enable_google_results,
- "input_text": prompt,
- "history_data": history_data}).json()
-
- return SonicResponse({
- 'id': f'cmpl-premium-{int(time())}',
- 'object': 'text_completion',
- 'created': int(time()),
- 'model': 'premium',
-
- 'choices': [{
- 'text': response['message'],
- 'index': 0,
- 'logprobs': None,
- 'finish_reason': 'stop'
- }],
-
- 'usage': {
- 'prompt_chars': len(prompt),
- 'completion_chars': len(response['message']),
- 'total_chars': len(prompt) + len(response['message'])
- }
- })
| help deleting directory -> I am helping delete the directory of writesonic as per the takedown request. | https://api.github.com/repos/xtekky/gpt4free/pulls/292 | 2023-04-29T21:51:24Z | 2023-04-30T11:20:31Z | 2023-04-30T11:20:31Z | 2023-04-30T11:20:31Z | 2,320 | xtekky/gpt4free | 37,984 |
add test for rstrip_end() in Text class | diff --git a/tests/test_text.py b/tests/test_text.py
index 432bc4a91..9419b2fbf 100644
--- a/tests/test_text.py
+++ b/tests/test_text.py
@@ -106,6 +106,12 @@ def test_rstrip():
assert str(test) == "Hello, World!"
+def test_rstrip_end():
+ test = Text("Hello, World! ")
+ test.rstrip_end(14)
+ assert str(test) == "Hello, World! "
+
+
def test_stylize():
test = Text("Hello, World!")
test.stylize(7, 11, "bold")
| ## Type of changes
- [ ] Bug fix
- [ ] New feature
- [ ] Documentation / docstrings
- [x] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/ambv/black) with default args on new code.
- [ ] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [ ] I've added tests for new code.
- [x] I accept that @willmcgugan may be pedantic in the code review.
## Description
been looking at rich/text.py and found that tests for rstrip_end was missing, not sure why the coverage was 100% for text.py before then, now obviously is still 100% for the file.
Changed file: tests/test_text.py
Also,
1. I tried running `black . --check` but found that several other files needs reformatting, haven't pushed the reformatting changes yet, need to know your thoughts on that first:
2. Looks like you forgot to add the return type for rstrip_end() ?
https://github.com/willmcgugan/rich/blob/e9e72000c50f56654c89e119ff882e322e51ecf3/rich/text.py#L415
https://github.com/willmcgugan/rich/blob/e9e72000c50f56654c89e119ff882e322e51ecf3/rich/text.py#L411 | https://api.github.com/repos/Textualize/rich/pulls/160 | 2020-07-15T08:54:33Z | 2020-07-15T10:40:40Z | 2020-07-15T10:40:40Z | 2020-07-15T10:40:40Z | 145 | Textualize/rich | 48,239 |
Adding tests for refactored CLI | diff --git a/gpt_engineer/__init__.py b/gpt_engineer/__init__.py
index e69de29bb2..a427f9fc49 100644
--- a/gpt_engineer/__init__.py
+++ b/gpt_engineer/__init__.py
@@ -0,0 +1,8 @@
+# Adding convenience imports to the package
+from gpt_engineer.core import (
+ ai,
+ domain,
+ chat_to_files,
+ steps,
+ db,
+)
diff --git a/gpt_engineer/cli/__init__.py b/gpt_engineer/cli/__init__.py
new file mode 100644
index 0000000000..97b52d8d82
--- /dev/null
+++ b/gpt_engineer/cli/__init__.py
@@ -0,0 +1,15 @@
+"""
+gpt_engineer.cli
+-----------------
+
+The CLI package for the GPT Engineer project, providing the command line interface
+for the application.
+
+Modules:
+ - main: The primary CLI module for GPT Engineer.
+ - collect: Collect send learning data for analysis and improvement.
+ - file_selector: Selecting files using GUI and terminal-based file explorer.
+ - learning: Tools and data structures for data collection.
+
+For more specific details, refer to the docstrings within each module.
+"""
diff --git a/gpt_engineer/core/__init__.py b/gpt_engineer/core/__init__.py
index 370ba51cf7..ddbaaeefef 100644
--- a/gpt_engineer/core/__init__.py
+++ b/gpt_engineer/core/__init__.py
@@ -14,11 +14,3 @@
For more specific details, refer to the docstrings within each module.
"""
-
-from gpt_engineer.core import (
- ai,
- domain,
- chat_to_files,
- steps,
- db,
-)
diff --git a/pyproject.toml b/pyproject.toml
index c152645662..9a51f93383 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -65,7 +65,7 @@ gpt-engineer = 'gpt_engineer.cli.main:app'
ge = 'gpt_engineer.cli.main:app'
[tool.setuptools]
-packages = ["gpt_engineer"]
+packages = ["gpt_engineer", "gpt_engineer.cli", "gpt_engineer.core"]
[tool.ruff]
select = ["F", "E", "W", "I001"]
diff --git a/tests/test_install.py b/tests/test_install.py
new file mode 100644
index 0000000000..8f0d3bcce5
--- /dev/null
+++ b/tests/test_install.py
@@ -0,0 +1,60 @@
+"""
+Tests for successful import and installation of the package.
+"""
+import subprocess
+import sys
+import venv
+import shutil
+
+# Setup the test environment
+VENV_DIR = "./venv_test_installation"
+venv.create(VENV_DIR, with_pip=True)
+
+
+# Test that the package can be installed via pip
+def test_installation():
+ # Use pip from the virtual environment directly
+ pip_executable = f"{VENV_DIR}/bin/pip"
+ if sys.platform == "win32":
+ pip_executable = f"{VENV_DIR}/Scripts/pip.exe"
+
+ result = subprocess.run([pip_executable, "install", "."], capture_output=True)
+ assert result.returncode == 0, f"Install via pip failed: {result.stderr.decode()}"
+
+
+# Test that the package can be imported
+def test_import():
+ try:
+ from gpt_engineer import (
+ ai,
+ domain,
+ chat_to_files,
+ steps,
+ db,
+ )
+ except ImportError as e:
+ assert False, f"Failed to import {e.name}"
+
+
+# Test that the CLI command works
+def test_cli_execution():
+ # This assumes that after installation, `gpt-engineer` command should work.
+ result = subprocess.run(
+ args=["gpt-engineer", "--help"], capture_output=True, text=True
+ )
+ assert (
+ result.returncode == 0
+ ), f"gpt-engineer command failed with message: {result.stderr}"
+
+
+# Cleanup the test environment
+def test_cleanup():
+ shutil.rmtree(VENV_DIR)
+
+
+# Run the tests using pytest
+if __name__ == "__main__":
+ test_installation()
+ test_import()
+ test_cli_execution()
+ test_cleanup()
| Given the bug surfaced and resolved with PR #778, added tests to cover this and related cases in the future.
Created 3 tests (and cleanup utility function) in test_install.py:
* Test that the package can be installed (locally) using `pip`
* This is done in a virtual environment
* The virtual environment persists throughout the rest of the tests
* Test that all modules can be imported
* This tests only the imports of the core modules, as imports of the CLI modules is not recommended or supported (see issue #718)
* Tests that `gpt-engineer` command can be successfully run via the CLI
* This tests the bug that was resolved in PR #778 and related bugs
After test execution, the virtual environment is removed.
I could use some guidance on how to separate this PR -- which I'm raising from the `refactored-cli-tests` branch which contains only the 3 CLI-related test addition commits -- from the other PR (#778) / branch that I created to solve the bug (branch `bugfix-cli-20231009`). When I check the git log for the tests branch, I only see the 3 commits I want as part of this PR (which build on the other PR, admittedly).

I hope I've done this right! Please share any comments or guidance. | https://api.github.com/repos/gpt-engineer-org/gpt-engineer/pulls/779 | 2023-10-10T01:57:32Z | 2023-10-10T09:27:22Z | 2023-10-10T09:27:22Z | 2023-10-10T16:27:29Z | 1,035 | gpt-engineer-org/gpt-engineer | 33,132 |