
title
stringlengths 2
169
| diff
stringlengths 235
19.5k
| body
stringlengths 0
30.5k
| url
stringlengths 48
84
| created_at
stringlengths 20
20
| closed_at
stringlengths 20
20
| merged_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| diff_len
float64 101
3.99k
| repo_name
stringclasses 83
values | __index_level_0__
int64 15
52.7k
|
|---|---|---|---|---|---|---|---|---|---|---|
Embed description and URL as MP4 tags | diff --git a/youtube_dl/postprocessor/ffmpeg.py b/youtube_dl/postprocessor/ffmpeg.py
index 5b0ff32b147..faccdc43dfb 100644
--- a/youtube_dl/postprocessor/ffmpeg.py
+++ b/youtube_dl/postprocessor/ffmpeg.py
@@ -509,6 +509,10 @@ def run(self, info):
metadata['artist'] = info['uploader']
elif info.get('uploader_id') is not None:
metadata['artist'] = info['uploader_id']
+ if info.get('description') is not None:
+ metadata['description'] = info['description']
+ if info.get('webpage_url') is not None:
+ metadata['comment'] = info['webpage_url']
if not metadata:
self._downloader.to_screen('[ffmpeg] There isn\'t any metadata to add')
| Description is one of the MP4 tags honored by ffmpeg, looks like a good place to store the video description when embedding metadata. I believe the source URL is useful information to keep as well, the comment tag seems like a good place to record it.
While I don't see the description becoming long enough to significantly affect the size of the output video, it can be long and unwieldy, for example while reading mediainfo dumps. Should including it be dependant on another option in addition to --add-metadata, perhaps --add-description?
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/4745 | 2015-01-18T23:27:17Z | 2015-01-23T00:22:19Z | 2015-01-23T00:22:19Z | 2015-01-23T00:22:24Z | 188 | ytdl-org/youtube-dl | 50,607 |
rename readme.txt to markdown file | diff --git a/Assembler/README.txt b/Assembler/README.md
similarity index 96%
rename from Assembler/README.txt
rename to Assembler/README.md
index f4b8ce982d..6ca8be477b 100644
--- a/Assembler/README.txt
+++ b/Assembler/README.md
@@ -1,5 +1,5 @@
# Python-Assembler
-#WE NEED A FREE T-SHIRT
+# WE NEED A FREE T-SHIRT
This program is a simple assembler-like (intel-syntax) interpreter language. The program is written in python 2.
To start the program you will need to type
| Changed readme.txt to readme.md to see the markdown syntax that was already there. | https://api.github.com/repos/geekcomputers/Python/pulls/752 | 2020-06-24T04:02:09Z | 2020-06-27T18:06:10Z | 2020-06-27T18:06:10Z | 2020-06-27T18:06:10Z | 144 | geekcomputers/Python | 31,645 |
add icdar2015 download | diff --git a/doc/doc_ch/detection.md b/doc/doc_ch/detection.md
index 88cb197d5a..66295b2525 100644
--- a/doc/doc_ch/detection.md
+++ b/doc/doc_ch/detection.md
@@ -25,7 +25,7 @@ icdar2015数据集可以从[官网](https://rrc.cvc.uab.es/?ch=4&com=downloads)
注册完成登陆后,下载下图中红色框标出的部分,其中, `Training Set Images`下载的内容保存为`icdar_c4_train_imgs`文件夹下,`Test Set Images` 下载的内容保存为`ch4_test_images`文件夹下
<p align="center">
- <img src="../datasets/ic15_location_download.png" align="middle" width = "600"/>
+ <img src="../datasets/ic15_location_download.png" align="middle" width = "700"/>
<p align="center">
将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。另外,PaddleOCR将零散的标注文件整理成单独的标注文件
diff --git a/doc/doc_en/detection_en.md b/doc/doc_en/detection_en.md
index 03b88179ba..d3f6f3da10 100644
--- a/doc/doc_en/detection_en.md
+++ b/doc/doc_en/detection_en.md
@@ -25,7 +25,7 @@ The icdar2015 dataset contains train set which has 1000 images obtained with wea
After registering and logging in, download the part marked in the red box in the figure below. And, the content downloaded by `Training Set Images` should be saved as the folder `icdar_c4_train_imgs`, and the content downloaded by `Test Set Images` is saved as the folder `ch4_test_images`
<p align="center">
- <img src="../datasets/ic15_location_download.png" align="middle" width = "600"/>
+ <img src="../datasets/ic15_location_download.png" align="middle" width = "700"/>
<p align="center">
Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. In addition, PaddleOCR organizes many scattered annotation files into two separate annotation files for train and test respectively, which can be downloaded by wget:
| https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/3935 | 2021-09-07T03:36:48Z | 2021-09-07T03:36:54Z | 2021-09-07T03:36:54Z | 2021-09-07T03:36:55Z | 522 | PaddlePaddle/PaddleOCR | 42,350 |
|
DOC Contributing guidelines - avoid referring to tests before instructing to install pytest | diff --git a/doc/developers/contributing.rst b/doc/developers/contributing.rst
index 753c9b8e8c7f0..fc1ef95dbced0 100644
--- a/doc/developers/contributing.rst
+++ b/doc/developers/contributing.rst
@@ -247,7 +247,7 @@ how to set up your git repository:
git clone git@github.com:YourLogin/scikit-learn.git # add --depth 1 if your connection is slow
cd scikit-learn
-4. Follow steps 2-7 in :ref:`install_bleeding_edge` to build scikit-learn in
+4. Follow steps 2-6 in :ref:`install_bleeding_edge` to build scikit-learn in
development mode and return to this document.
5. Install the development dependencies:
@@ -274,9 +274,11 @@ how to set up your git repository:
upstream git@github.com:scikit-learn/scikit-learn.git (fetch)
upstream git@github.com:scikit-learn/scikit-learn.git (push)
-You should now have a working installation of scikit-learn, and your git
-repository properly configured. The next steps now describe the process of
-modifying code and submitting a PR:
+You should now have a working installation of scikit-learn, and your git repository
+properly configured. It could be useful to run some test to verify your installation.
+Please refer to :ref:`pytest_tips` for examples.
+
+The next steps now describe the process of modifying code and submitting a PR:
8. Synchronize your ``main`` branch with the ``upstream/main`` branch,
more details on `GitHub Docs <https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/syncing-a-fork>`_:
| <!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md
-->
#### What does this implement/fix? Explain your changes.
This change fixes the contributing code section in the contributing guidelines. In this section, step **4** refers to steps **2-7** in building from source. In building from source, step **7** refers to testing. The problem is that in the contributing code section, pytest is installed only in step **5**.
The fix:
1. In contributing code, step **4** now refers to steps **2-6** in building from source.
2. In contributing code, a suggestion to run tests now appears between steps 7 and 8.
#### Any other comments?
<!--
Please be aware that we are a loose team of volunteers so patience is
necessary; assistance handling other issues is very welcome. We value
all user contributions, no matter how minor they are. If we are slow to
review, either the pull request needs some benchmarking, tinkering,
convincing, etc. or more likely the reviewers are simply busy. In either
case, we ask for your understanding during the review process.
For more information, see our FAQ on this topic:
http://scikit-learn.org/dev/faq.html#why-is-my-pull-request-not-getting-any-attention.
Thanks for contributing!
-->
| https://api.github.com/repos/scikit-learn/scikit-learn/pulls/26800 | 2023-07-07T12:56:51Z | 2023-07-07T13:57:25Z | 2023-07-07T13:57:25Z | 2023-07-07T13:57:25Z | 414 | scikit-learn/scikit-learn | 45,955 |
BUG: fix timedelta floordiv with scalar float (correction of #44466) | diff --git a/pandas/core/arrays/timedeltas.py b/pandas/core/arrays/timedeltas.py
index 91e90ebdb6253..2a2e59cfda5e9 100644
--- a/pandas/core/arrays/timedeltas.py
+++ b/pandas/core/arrays/timedeltas.py
@@ -651,7 +651,7 @@ def __floordiv__(self, other):
# at this point we should only have numeric scalars; anything
# else will raise
- result = self._ndarray / other
+ result = self._ndarray // other
freq = None
if self.freq is not None:
# Note: freq gets division, not floor-division
| Follow-up on https://github.com/pandas-dev/pandas/pull/44466#discussion_r749430496
I still need to add a test that would actually catch this | https://api.github.com/repos/pandas-dev/pandas/pulls/44471 | 2021-11-15T15:33:16Z | 2021-11-18T18:59:51Z | 2021-11-18T18:59:51Z | 2021-11-18T18:59:54Z | 164 | pandas-dev/pandas | 45,493 |
Add Free Forex API | diff --git a/README.md b/README.md
index 7a1c531154..b7adc5759b 100644
--- a/README.md
+++ b/README.md
@@ -332,6 +332,7 @@ API | Description | Auth | HTTPS | CORS |
| [Exchangerate.host](https://exchangerate.host) | Free foreign exchange & crypto rates API | No | Yes | Unknown |
| [Exchangeratesapi.io](https://exchangeratesapi.io) | Exchange rates with currency conversion | `apiKey` | Yes | Yes |
| [Frankfurter](https://www.frankfurter.app/docs) | Exchange rates, currency conversion and time series | No | Yes | Yes |
+| [FreeForexAPI](https://freeforexapi.com/Home/Api) | Real-time foreign exchange rates for major currency pairs | No | Yes | No |
| [National Bank of Poland](http://api.nbp.pl/en.html) | A collection of currency exchange rates (data in XML and JSON) | No | Yes | Yes |
| [Rwanda Locations](https://rapidapi.com/victorkarangwa4/api/rwanda) | Rwanda Provences, Districts, Cities,Capital City, Sector, cells, villages and streets | No | Yes | Unknown |
| [VATComply.com](https://www.vatcomply.com/documentation) | Exchange rates, geolocation and VAT number validation | No | Yes | Yes |
| <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x] My submission has a useful description
- [x] The description does not end with punctuation
- [x] Each table column is padded with one space on either side
- [x] I have searched the repository for any relevant issues or pull requests
- [x] Any category I am creating has the minimum requirement of 3 items
- [x] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
| https://api.github.com/repos/public-apis/public-apis/pulls/2202 | 2021-10-03T16:55:33Z | 2021-10-07T21:27:08Z | 2021-10-07T21:27:08Z | 2021-10-07T21:27:09Z | 316 | public-apis/public-apis | 35,488 |
[cleanup] Misc. (for 2023-11 release) | diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index cbed8217348..c4d3e812e2e 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -40,10 +40,4 @@ Fixes #
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
-
-<!-- Do NOT edit/remove anything below this! -->
-</details><details><summary>Copilot Summary</summary>
-
-copilot:all
-
</details>
diff --git a/README.md b/README.md
index 1b92c64d6ce..8b92f827b9f 100644
--- a/README.md
+++ b/README.md
@@ -163,10 +163,10 @@ Some of yt-dlp's default options are different from that of youtube-dl and youtu
For ease of use, a few more compat options are available:
* `--compat-options all`: Use all compat options (Do NOT use)
-* `--compat-options youtube-dl`: Same as `--compat-options all,-multistreams,-playlist-match-filter`
-* `--compat-options youtube-dlc`: Same as `--compat-options all,-no-live-chat,-no-youtube-channel-redirect,-playlist-match-filter`
+* `--compat-options youtube-dl`: Same as `--compat-options all,-multistreams,-playlist-match-filter,-manifest-filesize-approx`
+* `--compat-options youtube-dlc`: Same as `--compat-options all,-no-live-chat,-no-youtube-channel-redirect,-playlist-match-filter,-manifest-filesize-approx`
* `--compat-options 2021`: Same as `--compat-options 2022,no-certifi,filename-sanitization,no-youtube-prefer-utc-upload-date`
-* `--compat-options 2022`: Same as `--compat-options playlist-match-filter,no-external-downloader-progress,prefer-legacy-http-handler`. Use this to enable all future compat options
+* `--compat-options 2022`: Same as `--compat-options playlist-match-filter,no-external-downloader-progress,prefer-legacy-http-handler,manifest-filesize-approx`. Use this to enable all future compat options
# INSTALLATION
diff --git a/devscripts/changelog_override.json b/devscripts/changelog_override.json
index fe0c82c66b0..010820295d1 100644
--- a/devscripts/changelog_override.json
+++ b/devscripts/changelog_override.json
@@ -98,5 +98,21 @@
"action": "add",
"when": "61bdf15fc7400601c3da1aa7a43917310a5bf391",
"short": "[priority] Security: [[CVE-2023-40581](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-40581)] [Prevent RCE when using `--exec` with `%q` on Windows](https://github.com/yt-dlp/yt-dlp/security/advisories/GHSA-42h4-v29r-42qg)\n - The shell escape function is now using `\"\"` instead of `\\\"`.\n - `utils.Popen` has been patched to properly quote commands."
+ },
+ {
+ "action": "change",
+ "when": "8a8b54523addf46dfd50ef599761a81bc22362e6",
+ "short": "[rh:requests] Add handler for `requests` HTTP library (#3668)\n\n\tAdds support for HTTPS proxies and persistent connections (keep-alive)",
+ "authors": ["bashonly", "coletdjnz", "Grub4K"]
+ },
+ {
+ "action": "add",
+ "when": "1d03633c5a1621b9f3a756f0a4f9dc61fab3aeaa",
+ "short": "[priority] **The release channels have been adjusted!**\n\t* [`master`](https://github.com/yt-dlp/yt-dlp-master-builds) builds are made after each push, containing the latest fixes (but also possibly bugs). This was previously the `nightly` channel.\n\t* [`nightly`](https://github.com/yt-dlp/yt-dlp-nightly-builds) builds are now made once a day, if there were any changes."
+ },
+ {
+ "action": "add",
+ "when": "f04b5bedad7b281bee9814686bba1762bae092eb",
+ "short": "[priority] Security: [[CVE-2023-46121](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-46121)] Patch [Generic Extractor MITM Vulnerability via Arbitrary Proxy Injection](https://github.com/yt-dlp/yt-dlp/security/advisories/GHSA-3ch3-jhc6-5r8x)\n\t- Disallow smuggling of arbitary `http_headers`; extractors now only use specific headers"
}
]
diff --git a/yt_dlp/extractor/la7.py b/yt_dlp/extractor/la7.py
index a3cd12b0034..f5fd24134d0 100644
--- a/yt_dlp/extractor/la7.py
+++ b/yt_dlp/extractor/la7.py
@@ -208,9 +208,9 @@ class LA7PodcastIE(LA7PodcastEpisodeIE): # XXX: Do not subclass from concrete I
'url': 'https://www.la7.it/propagandalive/podcast',
'info_dict': {
'id': 'propagandalive',
- 'title': "Propaganda Live",
+ 'title': 'Propaganda Live',
},
- 'playlist_count_min': 10,
+ 'playlist_mincount': 10,
}]
def _real_extract(self, url):
diff --git a/yt_dlp/extractor/redtube.py b/yt_dlp/extractor/redtube.py
index 49076ccd815..172c31b3969 100644
--- a/yt_dlp/extractor/redtube.py
+++ b/yt_dlp/extractor/redtube.py
@@ -39,7 +39,7 @@ class RedTubeIE(InfoExtractor):
def _real_extract(self, url):
video_id = self._match_id(url)
webpage = self._download_webpage(
- 'http://www.redtube.com/%s' % video_id, video_id)
+ f'https://www.redtube.com/{video_id}', video_id)
ERRORS = (
(('video-deleted-info', '>This video has been removed'), 'has been removed'),
diff --git a/yt_dlp/extractor/videoken.py b/yt_dlp/extractor/videoken.py
index 560b41a6d7f..eaf0cc8ae98 100644
--- a/yt_dlp/extractor/videoken.py
+++ b/yt_dlp/extractor/videoken.py
@@ -11,6 +11,7 @@
ExtractorError,
InAdvancePagedList,
int_or_none,
+ remove_start,
traverse_obj,
update_url_query,
url_or_none,
@@ -39,11 +40,11 @@ def _create_slideslive_url(self, video_url, video_id, referer):
if not video_url and not video_id:
return
elif not video_url or 'embed/sign-in' in video_url:
- video_url = f'https://slideslive.com/embed/{video_id.lstrip("slideslive-")}'
+ video_url = f'https://slideslive.com/embed/{remove_start(video_id, "slideslive-")}'
if url_or_none(referer):
return update_url_query(video_url, {
'embed_parent_url': referer,
- 'embed_container_origin': f'https://{urllib.parse.urlparse(referer).netloc}',
+ 'embed_container_origin': f'https://{urllib.parse.urlparse(referer).hostname}',
})
return video_url
@@ -57,12 +58,12 @@ def _extract_videos(self, videos, url):
video_url = video_id
ie_key = 'Youtube'
else:
- video_url = traverse_obj(video, 'embed_url', 'embeddableurl')
- if urllib.parse.urlparse(video_url).netloc == 'slideslive.com':
+ video_url = traverse_obj(video, 'embed_url', 'embeddableurl', expected_type=url_or_none)
+ if not video_url:
+ continue
+ elif urllib.parse.urlparse(video_url).hostname == 'slideslive.com':
ie_key = SlidesLiveIE
video_url = self._create_slideslive_url(video_url, video_id, url)
- if not video_url:
- continue
yield self.url_result(video_url, ie_key, video_id)
@@ -178,7 +179,7 @@ def _real_extract(self, url):
return self.url_result(
self._create_slideslive_url(None, video_id, url), SlidesLiveIE, video_id)
elif re.match(r'^[\w-]{11}$', video_id):
- self.url_result(video_id, 'Youtube', video_id)
+ return self.url_result(video_id, 'Youtube', video_id)
else:
raise ExtractorError('Unable to extract without VideoKen API response')
diff --git a/yt_dlp/extractor/youtube.py b/yt_dlp/extractor/youtube.py
index adbac8e955d..f6caf09708f 100644
--- a/yt_dlp/extractor/youtube.py
+++ b/yt_dlp/extractor/youtube.py
@@ -6687,7 +6687,7 @@ class YoutubePlaylistIE(InfoExtractor):
'uploader_url': 'https://www.youtube.com/@milan5503',
'availability': 'public',
},
- 'expected_warnings': [r'[Uu]navailable videos? (is|are|will be) hidden'],
+ 'expected_warnings': [r'[Uu]navailable videos? (is|are|will be) hidden', 'Retrying', 'Giving up'],
}, {
'url': 'http://www.youtube.com/embed/_xDOZElKyNU?list=PLsyOSbh5bs16vubvKePAQ1x3PhKavfBIl',
'playlist_mincount': 455,
diff --git a/yt_dlp/networking/_requests.py b/yt_dlp/networking/_requests.py
index fe3f60b0b3a..9fb1d75f4a3 100644
--- a/yt_dlp/networking/_requests.py
+++ b/yt_dlp/networking/_requests.py
@@ -255,7 +255,8 @@ def __init__(self, *args, **kwargs):
handler.setFormatter(logging.Formatter('requests: %(message)s'))
handler.addFilter(Urllib3LoggingFilter())
logger.addHandler(handler)
- logger.setLevel(logging.WARNING)
+ # TODO: Use a logger filter to suppress pool reuse warning instead
+ logger.setLevel(logging.ERROR)
if self.verbose:
# Setting this globally is not ideal, but is easier than hacking with urllib3.
| **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be understood. Provide as much **context and examples** as possible
-->
<details open><summary>Template</summary> <!-- OPEN is intentional -->
<!--
# PLEASE FOLLOW THE GUIDE BELOW
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes `[ ]` relevant to your *pull request* (like [x])
- Use *Preview* tab to see how your *pull request* will actually look like
-->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check all of the following options that apply:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [x] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (bashonly, coletdjnz, dirkf, gamer191, seproDev)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
- [ ] New extractor ([Piracy websites will not be accepted](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy))
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
<!-- Do NOT edit/remove anything below this! -->
</details><details><summary>Copilot Summary</summary>
<!--
copilot:all
-->
### <samp>🤖 Generated by Copilot at 31c5391</samp>
### Summary
:sparkles::warning::mute:
<!--
1. :sparkles: for the new feature that adds support for the requests library
2. :warning: for the modified test case that expects more warnings from the extractor
3. :mute: for the lowered logging level of the urllib3 logger to suppress a warning message
-->
Add support for the requests library as an alternative to urllib3, and update the YoutubePlaylistIE extractor and the changelog accordingly. Fix a logging issue with the requests library in `yt_dlp/networking/_requests.py`.
> _`requests` library_
> _new feature for youtube-dl_
> _autumn changelog cut_
### Walkthrough
* Add support for the requests HTTP library, which enables HTTPS proxies and persistent connections ([link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-323808d1d1a45be3d06ea051c76192878238cd5c25e74087fbdad00eab2c6a16R101-R106), [link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-ef5ef94777b4b7a8fd1579b2053264fb5068b9e7baf33e95c23d3541a9eab1e4L258-R259), [link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-b7b9f6790de4427214b61939432e667d95b929d07fd918b9da1a36d7996cc506L6690-R6690))
* Override the changelog entry for this feature in `changelog_override.json` ([link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-323808d1d1a45be3d06ea051c76192878238cd5c25e74087fbdad00eab2c6a16R101-R106))
* Implement a wrapper class `RequestsRH` that adapts the requests library to the request handler interface ([link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-ef5ef94777b4b7a8fd1579b2053264fb5068b9e7baf33e95c23d3541a9eab1e4L258-R259))
* Suppress a warning message from the urllib3 logger by lowering its level to ERROR ([link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-ef5ef94777b4b7a8fd1579b2053264fb5068b9e7baf33e95c23d3541a9eab1e4L258-R259))
* Update the test case for `YoutubePlaylistIE` to expect two more warnings related to unavailable videos ([link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-b7b9f6790de4427214b61939432e667d95b929d07fd918b9da1a36d7996cc506L6690-R6690))
* Reflect the new behavior of the extractor, which uses the requests library and handles unavailable videos differently ([link](https://github.com/yt-dlp/yt-dlp/pull/8510/files?diff=unified&w=0#diff-b7b9f6790de4427214b61939432e667d95b929d07fd918b9da1a36d7996cc506L6690-R6690))
</details>
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/8510 | 2023-11-03T19:19:52Z | 2023-11-14T21:40:38Z | 2023-11-14T21:40:38Z | 2023-11-14T21:47:52Z | 2,549 | yt-dlp/yt-dlp | 7,782 |
[GPT2 batch generation] Make test clearer. `do_sample=True` is not deterministic. | diff --git a/tests/test_modeling_gpt2.py b/tests/test_modeling_gpt2.py
index f7fe21e0482fd..2fd4256f6b7e6 100644
--- a/tests/test_modeling_gpt2.py
+++ b/tests/test_modeling_gpt2.py
@@ -446,7 +446,6 @@ def test_batch_generation(self):
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
- torch.manual_seed(0)
outputs = model.generate(
input_ids=inputs["input_ids"].to(torch_device),
attention_mask=inputs["attention_mask"].to(torch_device),
| # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #7745
Small fix that deleted an unnecessary line from the test
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
| https://api.github.com/repos/huggingface/transformers/pulls/7947 | 2020-10-21T16:53:08Z | 2020-10-21T17:06:24Z | 2020-10-21T17:06:23Z | 2020-10-21T17:06:24Z | 142 | huggingface/transformers | 12,789 |
poloniex error mapping | diff --git a/ts/src/poloniex.ts b/ts/src/poloniex.ts
index c049175a0bbe..d4674d1eaa9c 100644
--- a/ts/src/poloniex.ts
+++ b/ts/src/poloniex.ts
@@ -290,6 +290,7 @@ export default class poloniex extends Exchange {
'21352': BadSymbol, // Trading for this currency is frozen
'21353': PermissionDenied, // Trading for US customers is not supported
'21354': PermissionDenied, // Account needs to be verified via email before trading is enabled. Contact support
+ '21359': OrderNotFound, // { "code" : 21359, "message" : "Order was already canceled or filled." }
'21360': InvalidOrder, // { "code" : 21360, "message" : "Order size exceeds the limit.Please enter a smaller amount and try again." }
'24106': BadRequest, // Invalid market depth
'24201': ExchangeNotAvailable, // Service busy. Try again later
| https://api.github.com/repos/ccxt/ccxt/pulls/19537 | 2023-10-12T12:44:13Z | 2023-10-13T10:45:36Z | 2023-10-13T10:45:36Z | 2023-10-13T10:45:36Z | 233 | ccxt/ccxt | 13,464 |
|
Test on Python 3.8 final | diff --git a/.travis.yml b/.travis.yml
index b95e479a21..91e60a7da9 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -17,7 +17,7 @@ jobs:
- stage: test
python: '3.7'
- stage: test
- python: '3.8-dev'
+ python: '3.8'
- stage: coverage
python: '3.6'
script: codecov
| The Trove classifier is already added:
https://github.com/psf/requests/blob/fab1fd10d0b115e635b9ef1364f8444089725000/setup.py#L98
| https://api.github.com/repos/psf/requests/pulls/5243 | 2019-10-22T15:47:28Z | 2019-10-25T02:32:26Z | 2019-10-25T02:32:26Z | 2021-08-30T00:06:34Z | 119 | psf/requests | 32,557 |
Add Storj to storage APIs | diff --git a/README.md b/README.md
index ce62698c2f..1bf8b65111 100644
--- a/README.md
+++ b/README.md
@@ -329,6 +329,7 @@ API | Description | Auth | HTTPS | CORS |
| [Pastebin](https://pastebin.com/doc_api) | Plain Text Storage | `apiKey` | Yes | Unknown |
| [Pinata](https://docs.pinata.cloud/) | IPFS Pinning Services API | `apiKey` | Yes | Unknown |
| [Quip](https://quip.com/dev/automation/documentation) | File Sharing and Storage for groups | `apiKey` | Yes | Yes |
+| [Storj](https://docs.storj.io/dcs/) | Decentralized Open-Source Cloud Storage | `apiKey` | Yes | Unknown |
| [The Null Pointer](https://0x0.st) | No-bullshit file hosting and URL shortening service | No | Yes | Unknown |
| [Web3 Storage](https://web3.storage/) | File Sharing and Storage for Free with 1TB Space | `apiKey` | Yes | Yes |
| <!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x] My submission has a useful description
- [x] The description does not have more than 100 characters
- [x] The description does not end with punctuation
- [x] Each table column is padded with one space on either side
- [x] I have searched the repository for any relevant issues or pull requests
- [x] Any category I am creating has the minimum requirement of 3 items
- [x] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
| https://api.github.com/repos/public-apis/public-apis/pulls/2970 | 2021-12-22T10:33:32Z | 2021-12-23T07:05:37Z | 2021-12-23T07:05:37Z | 2021-12-23T07:05:37Z | 248 | public-apis/public-apis | 35,950 |
Add Letvcloud support, as in #422 | diff --git a/src/you_get/common.py b/src/you_get/common.py
old mode 100644
new mode 100755
index 8bfc422c78..8240680dbc
--- a/src/you_get/common.py
+++ b/src/you_get/common.py
@@ -898,7 +898,7 @@ def script_main(script_name, download, download_playlist = None):
sys.exit(1)
def url_to_module(url):
- from .extractors import netease, w56, acfun, baidu, bilibili, blip, catfun, cntv, cbs, coursera, dailymotion, dongting, douban, ehow, facebook, freesound, google, sina, ifeng, alive, instagram, iqiyi, joy, jpopsuki, khan, ku6, kugou, kuwo, letv, magisto, miomio, mixcloud, mtv81, nicovideo, pptv, qq, sohu, songtaste, soundcloud, ted, theplatform, tudou, tucao, tumblr, vid48, videobam, vimeo, vine, vk, xiami, yinyuetai, youku, youtube
+ from .extractors import netease, w56, acfun, baidu, bilibili, blip, catfun, cntv, cbs, coursera, dailymotion, dongting, douban, ehow, facebook, freesound, google, sina, ifeng, alive, instagram, iqiyi, joy, jpopsuki, khan, ku6, kugou, kuwo, letv, letvcloud, magisto, miomio, mixcloud, mtv81, nicovideo, pptv, qq, sohu, songtaste, soundcloud, ted, theplatform, tudou, tucao, tumblr, vid48, videobam, vimeo, vine, vk, xiami, yinyuetai, youku, youtube
video_host = r1(r'https?://([^/]+)/', url)
video_url = r1(r'https?://[^/]+(.*)', url)
@@ -941,6 +941,7 @@ def url_to_module(url):
'kugou': kugou,
'kuwo': kuwo,
'letv': letv,
+ 'letvcloud': letvcloud,
'magisto': magisto,
'miomio': miomio,
'mixcloud': mixcloud,
diff --git a/src/you_get/extractors/__init__.py b/src/you_get/extractors/__init__.py
old mode 100644
new mode 100755
index 98aae05f1d..8b58a43fb9
--- a/src/you_get/extractors/__init__.py
+++ b/src/you_get/extractors/__init__.py
@@ -24,6 +24,7 @@
from .kugou import *
from .kuwo import *
from .letv import *
+from .letvcloud import *
from .magisto import *
from .miomio import *
from .mixcloud import *
diff --git a/src/you_get/extractors/letvcloud.py b/src/you_get/extractors/letvcloud.py
new file mode 100755
index 0000000000..fa17e4d5e5
--- /dev/null
+++ b/src/you_get/extractors/letvcloud.py
@@ -0,0 +1,40 @@
+#!/usr/bin/env python
+
+__all__ = ['letvcloud_download', 'letvcloud_download_by_vu']
+
+from ..common import *
+import urllib.request
+import json
+import hashlib
+
+
+def letvcloud_download_by_vu(vu, title = None, output_dir = '.', merge = True, info_only = False):
+ str2Hash = 'cfflashformatjsonran0.7214574650861323uu2d8c027396ver2.1vu' + vu + 'bie^#@(%27eib58'
+ sign = hashlib.md5(str2Hash.encode('utf-8')).hexdigest()
+ request_info = urllib.request.Request('http://api.letvcloud.com/gpc.php?&sign='+sign+'&cf=flash&vu='+vu+'&ver=2.1&ran=0.7214574650861323&qr=2&format=json&uu=2d8c027396')
+ try:
+ response = urllib.request.urlopen(request_info)
+ data = response.read()
+ info = json.loads(data.decode('utf-8'))
+ if info['code'] == 0:
+ for i in info['data']['video_info']['media']:
+ type_available.append({'video_url': info['data']['video_info']['media'][i]['play_url']['main_url'], 'video_quality': int(info['data']['video_info']['media'][i]['play_url']['vtype'])})
+ url = [b64decode(sorted(type_available ,key = lambda x:x['video_quality'])[-1]['video_url'])]
+ else:
+ raise ValueError('Cannot get URL!')
+ except:
+ print('ERROR: Cannot get video URL!')
+ download_urls([url], title, ext, size, output_dir, merge = merge)
+
+
+def letvcloud_download(url, output_dir = '.', merge = True, info_only = False):
+ for i in url.split('&'):
+ if 'vu=' in i:
+ vu = i[3:]
+ if len(vu) == 0:
+ raise ValueError('Cannot get vu!')
+ letvcloud_download_by_vu(vu, title, output_dir, merge = merge, info_only = info_only)
+
+site_info = "Letvcloud"
+download = letvcloud_download
+download_playlist = playlist_not_supported('letvcloud')
\ No newline at end of file
| There's one problem with the extractor:
The main extractor is failing to send `yuntv.ltev.com` to the right extractor, `letvcloud`.
I am feeling that fixing this problem is over my ability, so I 've finished everything else, hoping someone else would like to fix it up.
Now you can call `letvcloud_download_by_vu` to download Letvcloud's video.
P.S: I have to set the file permission to 755 in order to edit them. And I am sure you would need to re-edit them later, since the bug with the main extractor is left untouched. I would not say it is not working, but the effect is lower than my expectation.
| https://api.github.com/repos/soimort/you-get/pulls/427 | 2014-10-26T15:06:36Z | 2014-10-31T08:15:28Z | 2014-10-31T08:15:28Z | 2014-10-31T08:26:48Z | 1,303 | soimort/you-get | 21,516 |
Fix multi-discrete sampling | diff --git a/gym/spaces/multi_discrete.py b/gym/spaces/multi_discrete.py
index da37ba22ddf..13fd5d59f59 100644
--- a/gym/spaces/multi_discrete.py
+++ b/gym/spaces/multi_discrete.py
@@ -35,7 +35,7 @@ def sample(self):
""" Returns a array with one sample from each discrete action space """
# For each row: round(random .* (max - min) + min, 0)
random_array = prng.np_random.rand(self.num_discrete_space)
- return [int(x) for x in np.rint(np.multiply((self.high - self.low), random_array) + self.low)]
+ return [int(x) for x in np.floor(np.multiply((self.high - self.low + 1.), random_array) + self.low)]
def contains(self, x):
return len(x) == self.num_discrete_space and (np.array(x) >= self.low).all() and (np.array(x) <= self.high).all()
| The current sampling from the MultiDiscrete space is non-uniform for any sub-space larger than two values. The code rounds the values from a float ranging between the sub-space extremes, which means that the end points only get half the space of the internal points.
eg for a space between 0 and 2, all values between 0 and 0.5 will go to 0, all the ones between 0.5 and 1.5 will map to 1 and all between 1.5 and 2 will map to 2, which means 1 gets twice the "hits" of either 0 or 2.
This one-line change fixes it by grabbing the floor of the range + 1.
Testing. Before:
```
In [4]: from gym.spaces import MultiDiscrete
In [5]: space = MultiDiscrete([[0,2]])
In [6]: from collections import defaultdict
In [7]: count = defaultdict(int)
In [8]: for r in range(1000000):
...: sample = space.sample()
...: count[sample[0]] += 1
...:
In [9]: count
Out[9]: defaultdict(<type 'int'>, {0: 249643, 1: 499561, 2: 250796})
```
After:
```
n [1]: from gym.spaces import MultiDiscrete
In [2]: from collections import defaultdict
In [3]: space = MultiDiscrete([[0,2]])
In [4]: count = defaultdict(int)
In [5]: for r in range(1000000):
...: sample = space.sample()
...: count[sample[0]] += 1
...:
In [6]: count
Out[6]: defaultdict(<type 'int'>, {0: 332802, 1: 333425, 2: 333773})
```
| https://api.github.com/repos/openai/gym/pulls/475 | 2017-01-30T01:14:26Z | 2017-01-31T00:14:18Z | 2017-01-31T00:14:18Z | 2017-01-31T00:14:42Z | 234 | openai/gym | 5,131 |
Fix prompt incorrectly set to empty when suffix is empty string | diff --git a/modules/chat.py b/modules/chat.py
index c8516c5940..5fb5523ca0 100644
--- a/modules/chat.py
+++ b/modules/chat.py
@@ -161,12 +161,14 @@ def make_prompt(messages):
prompt = instruction_template.render(messages=outer_messages)
suffix = get_generation_prompt(instruct_renderer, impersonate=False)[1]
- prompt = prompt[:-len(suffix)]
+ if len(suffix) > 0:
+ prompt = prompt[:-len(suffix)]
else:
if _continue:
suffix = get_generation_prompt(renderer, impersonate=impersonate)[1]
- prompt = prompt[:-len(suffix)]
+ if len(suffix) > 0:
+ prompt = prompt[:-len(suffix)]
else:
prefix = get_generation_prompt(renderer, impersonate=impersonate)[0]
if state['mode'] == 'chat' and not impersonate:
| While using the qwen model, I use the template from its `tokenizer_config.json`.
```
"{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|im_end|>' + '\n'}}{% endif %}{% endfor %}{% if add_generation_prompt and messages[-1]['role'] != 'assistant' %}{{ '<|im_start|>assistant\n' }}{% endif %}"
```
In this case, the `suffix` is an empty string, which len is 0.
The execution of `prompt[:-0]`, will incorrectly set the prompt to an empty string.
The conversation works fine, but use "continue" will get an error.
## Checklist:
- [x] I have read the [Contributing guidelines](https://github.com/oobabooga/text-generation-webui/wiki/Contributing-guidelines).
| https://api.github.com/repos/oobabooga/text-generation-webui/pulls/5757 | 2024-03-26T14:36:19Z | 2024-03-26T19:33:10Z | 2024-03-26T19:33:10Z | 2024-03-26T19:33:10Z | 203 | oobabooga/text-generation-webui | 26,452 |
[nrktv:series] Fix extraction | diff --git a/youtube_dl/extractor/nrk.py b/youtube_dl/extractor/nrk.py
index 5f43e692f43..60933f069c4 100644
--- a/youtube_dl/extractor/nrk.py
+++ b/youtube_dl/extractor/nrk.py
@@ -406,7 +406,7 @@ class NRKTVSerieBaseIE(InfoExtractor):
def _extract_series(self, webpage, display_id, fatal=True):
config = self._parse_json(
self._search_regex(
- (r'INITIAL_DATA_*\s*=\s*({.+?})\s*;',
+ (r'INITIAL_DATA(?:_V\d)?_*\s*=\s*({.+?})\s*;',
r'({.+?})\s*,\s*"[^"]+"\s*\)\s*</script>'),
webpage, 'config', default='{}' if not fatal else NO_DEFAULT),
display_id, fatal=False)
| ## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [adding new extractor tutorial](https://github.com/ytdl-org/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/ytdl-org/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](https://github.com/ytdl-org/youtube-dl/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into youtube-dl each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [ ] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
NRK has made a minor change to their site and downloading series no longer works. This change fixes it and `TestDownload.test_NRKTVSeason` now passes.
| https://api.github.com/repos/ytdl-org/youtube-dl/pulls/22596 | 2019-10-03T20:42:42Z | 2019-10-04T11:57:18Z | 2019-10-04T11:57:18Z | 2019-10-04T11:57:18Z | 220 | ytdl-org/youtube-dl | 50,475 |
Add setup.cfg to declare wheel as universal | diff --git a/Makefile b/Makefile
index b45647b854..adf0b8f13f 100644
--- a/Makefile
+++ b/Makefile
@@ -50,8 +50,7 @@ idna:
publish:
pip install 'twine>=1.5.0'
- python setup.py sdist
- python setup.py bdist_wheel --universal
+ python setup.py sdist bdist_wheel
twine upload dist/*
rm -fr build dist .egg requests.egg-info
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000000..2a9acf13da
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,2 @@
+[bdist_wheel]
+universal = 1
| As the project is pure Python, a built wheel should always be universal,
so define in the project globally. Can remove --universal command from
Makefile.
See:
http://pythonwheels.com/ | https://api.github.com/repos/psf/requests/pulls/4041 | 2017-05-20T14:41:02Z | 2017-05-20T15:11:12Z | 2017-05-20T15:11:12Z | 2021-09-04T00:06:46Z | 184 | psf/requests | 32,215 |
gh-100931: Test all `pickle` protocols in `test_slice` | diff --git a/Lib/test/test_json/test_attrdict.py b/Lib/test/test_json/test_attrdict.py
index 48d14f4db93c12..143ea462d310aa 100644
--- a/Lib/test/test_json/test_attrdict.py
+++ b/Lib/test/test_json/test_attrdict.py
@@ -133,7 +133,7 @@ def test_pickle(self):
cached_module = sys.modules.get('json')
sys.modules['json'] = self.json
try:
- for protocol in range(6):
+ for protocol in range(pickle.HIGHEST_PROTOCOL + 1):
kepler_ad2 = pickle.loads(pickle.dumps(kepler_ad, protocol))
self.assertEqual(kepler_ad2, kepler_ad)
self.assertEqual(type(kepler_ad2), AttrDict)
diff --git a/Lib/test/test_slice.py b/Lib/test/test_slice.py
index 4ae4142c60c8a8..c4bc8c82023d74 100644
--- a/Lib/test/test_slice.py
+++ b/Lib/test/test_slice.py
@@ -235,8 +235,10 @@ def __setitem__(self, i, k):
self.assertEqual(tmp, [(slice(1, 2), 42)])
def test_pickle(self):
+ import pickle
+
s = slice(10, 20, 3)
- for protocol in (0,1,2):
+ for protocol in range(pickle.HIGHEST_PROTOCOL + 1):
t = loads(dumps(s, protocol))
self.assertEqual(s, t)
self.assertEqual(s.indices(15), t.indices(15))
|
<!-- gh-issue-number: gh-100931 -->
* Issue: gh-100931
<!-- /gh-issue-number -->
| https://api.github.com/repos/python/cpython/pulls/100932 | 2023-01-11T08:30:46Z | 2023-01-11T09:43:46Z | 2023-01-11T09:43:45Z | 2023-01-12T10:56:51Z | 361 | python/cpython | 4,513 |
VW MQB: Volkswagen Tiguan Mk2 | diff --git a/README.md b/README.md
index a70cb6eca9e3ed..693682a32725ae 100644
--- a/README.md
+++ b/README.md
@@ -174,6 +174,7 @@ Community Maintained Cars and Features
| Subaru | Forester 2019-20 | EyeSight | Stock | 0mph | 0mph |
| Subaru | Impreza 2017-19 | EyeSight | Stock | 0mph | 0mph |
| Volkswagen| Golf 2015-19 | Driver Assistance | Stock | 0mph | 0mph |
+| Volkswagen| Tiguan 2020 | Driver Assistance | Stock | 0mph | 0mph |
<sup>1</sup>Requires an [OBD-II car harness](https://comma.ai/shop/products/comma-car-harness) and [community built ASCM harness](https://github.com/commaai/openpilot/wiki/GM#hardware). ***NOTE: disconnecting the ASCM disables Automatic Emergency Braking (AEB).*** <br />
diff --git a/selfdrive/car/volkswagen/interface.py b/selfdrive/car/volkswagen/interface.py
index 1a0755206d30ff..e57efe4756a3c7 100644
--- a/selfdrive/car/volkswagen/interface.py
+++ b/selfdrive/car/volkswagen/interface.py
@@ -62,6 +62,11 @@ def get_params(candidate, fingerprint=gen_empty_fingerprint(), car_fw=None):
ret.mass = 1500 + STD_CARGO_KG
ret.wheelbase = 2.64
+ if candidate == CAR.TIGUAN_MK2:
+ # Average of SWB and LWB variants
+ ret.mass = 1715 + STD_CARGO_KG
+ ret.wheelbase = 2.74
+
ret.centerToFront = ret.wheelbase * 0.45
ret.enableCamera = True # Stock camera detection doesn't apply to VW
diff --git a/selfdrive/car/volkswagen/values.py b/selfdrive/car/volkswagen/values.py
index 146f2690c70e02..b93796da537bc1 100644
--- a/selfdrive/car/volkswagen/values.py
+++ b/selfdrive/car/volkswagen/values.py
@@ -55,18 +55,24 @@ class CANBUS:
# FW_VERSIONS for that existing CAR.
class CAR:
- GOLF = "VOLKSWAGEN GOLF" # Chassis 5G/AU/BA/BE, Mk7 VW Golf and variants
- AUDI_A3 = "AUDI A3" # Chassis 8V/FF, Mk3 Audi A3 and variants
+ GOLF = "VOLKSWAGEN GOLF" # Chassis 5G/AU/BA/BE, Mk7 VW Golf and variants
+ TIGUAN_MK2 = "VOLKSWAGEN TIGUAN 2ND GEN" # Chassis AD/BW, Mk2 VW Tiguan and variants
+ AUDI_A3 = "AUDI A3" # Chassis 8V/FF, Mk3 Audi A3 and variants
FINGERPRINTS = {
CAR.GOLF: [{
64: 8, 134: 8, 159: 8, 173: 8, 178: 8, 253: 8, 257: 8, 260: 8, 262: 8, 264: 8, 278: 8, 279: 8, 283: 8, 286: 8, 288: 8, 289: 8, 290: 8, 294: 8, 299: 8, 302: 8, 346: 8, 385: 8, 418: 8, 427: 8, 668: 8, 679: 8, 681: 8, 695: 8, 779: 8, 780: 8, 783: 8, 792: 8, 795: 8, 804: 8, 806: 8, 807: 8, 808: 8, 809: 8, 870: 8, 896: 8, 897: 8, 898: 8, 901: 8, 917: 8, 919: 8, 927: 8, 949: 8, 958: 8, 960: 4, 981: 8, 987: 8, 988: 8, 991: 8, 997: 8, 1000: 8, 1019: 8, 1120: 8, 1122: 8, 1123: 8, 1124: 8, 1153: 8, 1162: 8, 1175: 8, 1312: 8, 1385: 8, 1413: 8, 1440: 5, 1514: 8, 1515: 8, 1520: 8, 1529: 8, 1600: 8, 1601: 8, 1603: 8, 1605: 8, 1624: 8, 1626: 8, 1629: 8, 1631: 8, 1646: 8, 1648: 8, 1712: 6, 1714: 8, 1716: 8, 1717: 8, 1719: 8, 1720: 8, 1721: 8
}],
+ CAR.TIGUAN_MK2: [{
+ 64: 8, 134: 8, 159: 8, 173: 8, 178: 8, 253: 8, 257: 8, 260: 8, 262: 8, 278: 8, 279: 8, 283: 8, 286: 8, 288: 8, 289: 8, 290: 8, 294: 8, 299: 8, 302: 8, 346: 8, 376: 8, 418: 8, 427: 8, 573: 8, 679: 8, 681: 8, 684: 8, 695: 8, 779: 8, 780: 8, 783: 8, 787: 8, 788: 8, 789: 8, 792: 8, 795: 8, 804: 8, 806: 8, 807: 8, 808: 8, 809: 8, 828: 8, 870: 8, 879: 8, 884: 8, 888: 8, 891: 8, 896: 8, 897: 8, 898: 8, 901: 8, 913: 8, 917: 8, 919: 8, 949: 8, 958: 8, 960: 4, 981: 8, 987: 8, 988: 8, 991: 8, 997: 8, 1000: 8, 1019: 8, 1122: 8, 1123: 8, 1124: 8, 1153: 8, 1156: 8, 1157: 8, 1158: 8, 1162: 8, 1175: 8, 1312: 8, 1343: 8, 1385: 8, 1413: 8, 1440: 5, 1471: 4, 1514: 8, 1515: 8, 1520: 8, 1600: 8, 1601: 8, 1603: 8, 1605: 8, 1624: 8, 1626: 8, 1629: 8, 1631: 8, 1635: 8, 1646: 8, 1648: 8, 1712: 6, 1714: 8, 1716: 8, 1717: 8, 1719: 8, 1720: 8, 1721: 8
+ }],
CAR.AUDI_A3: [{
64: 8, 134: 8, 159: 8, 173: 8, 178: 8, 253: 8, 257: 8, 260: 8, 262: 8, 278: 8, 279: 8, 283: 8, 285: 8, 286: 8, 288: 8, 289: 8, 290: 8, 294: 8, 295: 8, 299: 8, 302: 8, 346: 8, 418: 8, 427: 8, 506: 8, 679: 8, 681: 8, 695: 8, 779: 8, 780: 8, 783: 8, 787: 8, 788: 8, 789: 8, 792: 8, 802: 8, 804: 8, 806: 8, 807: 8, 808: 8, 809: 8, 846: 8, 847: 8, 870: 8, 896: 8, 897: 8, 898: 8, 901: 8, 917: 8, 919: 8, 949: 8, 958: 8, 960: 4, 981: 8, 987: 8, 988: 8, 991: 8, 997: 8, 1000: 8, 1019: 8, 1122: 8, 1123: 8, 1124: 8, 1153: 8, 1162: 8, 1175: 8, 1312: 8, 1385: 8, 1413: 8, 1440: 5, 1514: 8, 1515: 8, 1520: 8, 1600: 8, 1601: 8, 1603: 8, 1624: 8, 1629: 8, 1631: 8, 1646: 8, 1648: 8, 1712: 6, 1714: 8, 1716: 8, 1717: 8, 1719: 8, 1720: 8, 1721: 8, 1792: 8, 1872: 8, 1976: 8, 1977: 8, 1982: 8, 1985: 8
}],
}
+IGNORED_FINGERPRINTS = [CAR.TIGUAN_MK2]
+
FW_VERSIONS = {
CAR.AUDI_A3: {
(Ecu.engine, 0x7e0, None): [
@@ -101,10 +107,28 @@ class CAR:
(Ecu.fwdRadar, 0x757, None): [
b'\xf1\x875Q0907572J \xf1\x890654',
],
- }
+ },
+ CAR.TIGUAN_MK2: {
+ (Ecu.engine, 0x7e0, None): [
+ b'\xf1\x8783A907115B \xf1\x890005',
+ ],
+ (Ecu.transmission, 0x7e1, None): [
+ b'\xf1\x8709G927158DT\xf1\x893698',
+ ],
+ (Ecu.srs, 0x715, None): [
+ b'\xf1\x875Q0959655BM\xf1\x890403\xf1\x82\02316143231313500314641011750179333423100',
+ ],
+ (Ecu.eps, 0x712, None): [
+ b'\xf1\x875QM909144C \xf1\x891082\xf1\x82\00521A60804A1',
+ ],
+ (Ecu.fwdRadar, 0x757, None): [
+ b'\xf1\x872Q0907572R \xf1\x890372',
+ ],
+ },
}
DBC = {
CAR.GOLF: dbc_dict('vw_mqb_2010', None),
+ CAR.TIGUAN_MK2: dbc_dict('vw_mqb_2010', None),
CAR.AUDI_A3: dbc_dict('vw_mqb_2010', None),
}
diff --git a/selfdrive/test/test_car_models.py b/selfdrive/test/test_car_models.py
index 65e0f84f49dd2b..cf5ee1a83bb113 100755
--- a/selfdrive/test/test_car_models.py
+++ b/selfdrive/test/test_car_models.py
@@ -207,7 +207,7 @@ def get_route_log(route_name):
},
"c75a59efa0ecd502|2021-03-11--20-52-55": {
'carFingerprint': HYUNDAI.KIA_SELTOS,
- 'enableCamera': True,
+ 'enableCamera': True,
},
"5b7c365c50084530|2020-04-15--16-13-24": {
'carFingerprint': HYUNDAI.SONATA,
@@ -441,6 +441,10 @@ def get_route_log(route_name):
'carFingerprint': VOLKSWAGEN.GOLF,
'enableCamera': True,
},
+ "2cef8a0b898f331a|2021-03-25--20-13-57": {
+ 'carFingerprint': VOLKSWAGEN.TIGUAN_MK2,
+ 'enableCamera': True,
+ },
"07667b885add75fd|2021-01-23--19-48-42": {
'carFingerprint': VOLKSWAGEN.AUDI_A3,
'enableCamera': True,
| **New MQB Model**
This CAR will cover all variants of the second generation Tiguan. 2018-current in North America, 2016-current RoW.
- [x] added to README
- [x] test route added to [test_car_models](../../selfdrive/test/test_car_models.py)
- [x] route with openpilot: 2cef8a0b898f331a|2021-03-25--20-13-57
| https://api.github.com/repos/commaai/openpilot/pulls/20484 | 2021-03-26T03:59:13Z | 2021-03-26T04:48:14Z | 2021-03-26T04:48:14Z | 2021-03-26T08:05:25Z | 3,323 | commaai/openpilot | 9,163 |
[squash] zero-ckpt-cpu-issue | diff --git a/deepspeed/runtime/constants.py b/deepspeed/runtime/constants.py
index daf9ffeaadff..7892dda1a76f 100755
--- a/deepspeed/runtime/constants.py
+++ b/deepspeed/runtime/constants.py
@@ -444,3 +444,9 @@ class ValidationMode:
'''
DATALOADER_DROP_LAST = "dataloader_drop_last"
DATALOADER_DROP_LAST_DEFAULT = False
+
+#########################################
+# Optimizer checkpoint keys
+#########################################
+OPTIMIZER_STATE_DICT = "optimizer_state_dict"
+FP32_GROUPS = "fp32_groups"
diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
old mode 100755
new mode 100644
index 4ba3a2be7627..e206444efde9
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -42,9 +42,10 @@
from deepspeed.runtime.dataloader import DeepSpeedDataLoader
from deepspeed.runtime.constants import \
ROUTE_TRAIN, ROUTE_PREDICT, ROUTE_EVAL, \
- PLD_THETA, PLD_GAMMA
+ PLD_THETA, PLD_GAMMA, OPTIMIZER_STATE_DICT
from deepspeed.runtime.zero.constants import \
- ZERO_OPTIMIZATION_OPTIMIZER_STATES, ZERO_OPTIMIZATION_GRADIENTS, ZERO_OPTIMIZATION_WEIGHTS
+ ZERO_OPTIMIZATION_OPTIMIZER_STATES, ZERO_OPTIMIZATION_GRADIENTS, ZERO_OPTIMIZATION_WEIGHTS, \
+ SINGLE_PARTITION_OF_FP32_GROUPS
from deepspeed.runtime.sparse_tensor import SparseTensor
import deepspeed.runtime.lr_schedules as lr_schedules
@@ -1385,7 +1386,8 @@ def _configure_zero_optimizer(self, optimizer):
round_robin_gradients=round_robin_gradients,
has_moe_layers=self.has_moe_layers,
fp16_master_weights_and_gradients=self.fp16_master_weights_and_gradients(
- ))
+ ),
+ elastic_checkpoint=self.zero_elastic_checkpoint())
elif zero_stage == ZERO_OPTIMIZATION_WEIGHTS:
assert not self.has_moe_layers, "MoE not supported with Stage 3"
@@ -2577,10 +2579,27 @@ def _get_all_zero_checkpoints(self, load_dir, tag):
return None
zero_sd_list = []
- for ckpt_name in zero_ckpt_names:
- zero_sd_list.append(torch.load(ckpt_name, map_location="cpu"))
+ for i, ckpt_name in enumerate(zero_ckpt_names):
+ _state = None
+ # Fully load state for current rank
+ if self.zero_elastic_checkpoint() or dist.get_rank(
+ group=self.optimizer.dp_process_group) == i:
+ _state = torch.load(ckpt_name, map_location='cpu')
+ elif self.zero_optimization_stage(
+ ) <= ZERO_OPTIMIZATION_GRADIENTS and self.zero_load_from_fp32_weights():
+ # Extract fp32 groups only, otherwise throw away to prevent unnecessary CPU memory overheads
+ _state = torch.load(ckpt_name, map_location='cpu')
+ _state = {
+ OPTIMIZER_STATE_DICT: {
+ SINGLE_PARTITION_OF_FP32_GROUPS:
+ _state[OPTIMIZER_STATE_DICT][SINGLE_PARTITION_OF_FP32_GROUPS]
+ }
+ }
+ else:
+ _state = {OPTIMIZER_STATE_DICT: None}
+ zero_sd_list.append(_state)
- zero_optimizer_sd = [sd["optimizer_state_dict"] for sd in zero_sd_list]
+ zero_optimizer_sd = [sd[OPTIMIZER_STATE_DICT] for sd in zero_sd_list]
print(
f"successfully loaded {len(zero_optimizer_sd)} ZeRO state_dicts for rank {self.global_rank}"
)
diff --git a/deepspeed/runtime/fp16/fused_optimizer.py b/deepspeed/runtime/fp16/fused_optimizer.py
index 370bd9cae5c1..8b96d511a8eb 100755
--- a/deepspeed/runtime/fp16/fused_optimizer.py
+++ b/deepspeed/runtime/fp16/fused_optimizer.py
@@ -6,12 +6,12 @@
'''
import torch
-import math
from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
from deepspeed.runtime.utils import get_global_norm, get_grad_norm, CheckOverflow, get_weight_norm
from deepspeed.runtime.fp16.loss_scaler import INITIAL_LOSS_SCALE, SCALE_WINDOW, MIN_LOSS_SCALE
from deepspeed.utils import groups, logger, log_dist
+from deepspeed.runtime.constants import OPTIMIZER_STATE_DICT
import torch.distributed as dist
@@ -396,7 +396,7 @@ def state_dict(self):
state_dict['last_overflow_iter'] = self.last_overflow_iter
state_dict['scale_factor'] = self.scale_factor
state_dict['scale_window'] = self.scale_window
- state_dict['optimizer_state_dict'] = self.optimizer.state_dict()
+ state_dict[OPTIMIZER_STATE_DICT] = self.optimizer.state_dict()
state_dict['fp32_groups_flat'] = self.fp32_groups_flat
state_dict['clip_grad'] = self.clip_grad
return state_dict
@@ -431,7 +431,7 @@ def load_state_dict(self, state_dict, load_optimizer_states=True):
self.scale_factor = state_dict['scale_factor']
self.scale_window = state_dict['scale_window']
if load_optimizer_states:
- self.optimizer.load_state_dict(state_dict['optimizer_state_dict'])
+ self.optimizer.load_state_dict(state_dict[OPTIMIZER_STATE_DICT])
self.clip_grad = state_dict['clip_grad']
# At this point, the optimizer's references to the model's fp32 parameters are up to date.
# The optimizer's hyperparameters and internal buffers are also up to date.
diff --git a/deepspeed/runtime/fp16/unfused_optimizer.py b/deepspeed/runtime/fp16/unfused_optimizer.py
index d0110d5f828c..cd1c20ef4235 100755
--- a/deepspeed/runtime/fp16/unfused_optimizer.py
+++ b/deepspeed/runtime/fp16/unfused_optimizer.py
@@ -7,12 +7,12 @@
from deepspeed.moe.utils import split_params_grads_into_shared_and_expert_params
import torch
-from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
-import math
+from torch._utils import _flatten_dense_tensors
-from deepspeed.runtime.utils import get_global_norm, get_grad_norm, CheckOverflow, get_weight_norm
+from deepspeed.runtime.utils import get_global_norm, CheckOverflow, get_weight_norm
from deepspeed.runtime.fp16.loss_scaler import INITIAL_LOSS_SCALE, SCALE_WINDOW, MIN_LOSS_SCALE
from deepspeed.utils import logger
+from deepspeed.runtime.constants import OPTIMIZER_STATE_DICT
class FP16_UnfusedOptimizer(object):
@@ -332,7 +332,7 @@ def state_dict(self):
state_dict['last_overflow_iter'] = self.last_overflow_iter
state_dict['scale_factor'] = self.scale_factor
state_dict['scale_window'] = self.scale_window
- state_dict['optimizer_state_dict'] = self.optimizer.state_dict()
+ state_dict[OPTIMIZER_STATE_DICT] = self.optimizer.state_dict()
state_dict['fp32_groups'] = self.fp32_groups
return state_dict
@@ -368,7 +368,7 @@ def load_state_dict(self, state_dict, load_optimizer_states=True):
self.scale_window = state_dict['scale_window']
if load_optimizer_states:
- self.optimizer.load_state_dict(state_dict['optimizer_state_dict'])
+ self.optimizer.load_state_dict(state_dict[OPTIMIZER_STATE_DICT])
# At this point, the optimizer's references to the model's fp32 parameters are up to date.
# The optimizer's hyperparameters and internal buffers are also up to date.
# However, the fp32 master copies of the model's fp16 params stored by the optimizer are still
diff --git a/deepspeed/runtime/zero/constants.py b/deepspeed/runtime/zero/constants.py
index e3b2dfc0c68f..7ff99b25b10b 100755
--- a/deepspeed/runtime/zero/constants.py
+++ b/deepspeed/runtime/zero/constants.py
@@ -48,6 +48,8 @@
ZERO_OPTIMIZATION_STAGE_2 = 'stage_2'
ZERO_OPTIMIZATION_STAGE_3 = 'stage_3'
+SINGLE_PARTITION_OF_FP32_GROUPS = "single_partition_of_fp32_groups"
+
ZERO_OPTIMIZATION_STAGE_DEFAULT = ZERO_OPTIMIZATION_DISABLED
ZERO_OPTIMIZATION_ALLGATHER_PARTITIONS = 'allgather_partitions'
@@ -74,7 +76,7 @@
ZERO_OPTIMIZATION_LOAD_FROM_FP32_WEIGHTS_DEFAULT = True
ZERO_OPTIMIZATION_ELASTIC_CHECKPOINT = 'elastic_checkpoint'
-ZERO_OPTIMIZATION_ELASTIC_CHECKPOINT_DEFAULT = True
+ZERO_OPTIMIZATION_ELASTIC_CHECKPOINT_DEFAULT = False
ZERO_OPTIMIZATION_CPU_OFFLOAD = 'cpu_offload'
ZERO_OPTIMIZATION_CPU_OFFLOAD_DEFAULT = False
diff --git a/deepspeed/runtime/zero/stage2.py b/deepspeed/runtime/zero/stage2.py
index b995e4dd975c..604bac71f771 100755
--- a/deepspeed/runtime/zero/stage2.py
+++ b/deepspeed/runtime/zero/stage2.py
@@ -5,13 +5,9 @@
import torch
from torch.distributed.distributed_c10d import _get_global_rank
import torch.distributed as dist
-import math
from torch._six import inf
-from torch.autograd import Variable
from packaging import version as pkg_version
-import collections
-
from deepspeed.runtime.fp16.loss_scaler import LossScaler, DynamicLossScaler
from deepspeed.runtime.utils import bwc_tensor_model_parallel_rank, get_global_norm, see_memory_usage, is_model_parallel_parameter
from deepspeed.runtime.zero.config import ZERO_OPTIMIZATION_GRADIENTS
@@ -22,6 +18,8 @@
from deepspeed.moe.utils import is_moe_param
from deepspeed.git_version_info import version
+from .constants import SINGLE_PARTITION_OF_FP32_GROUPS
+
# Toggle this to true to enable correctness test
# with gradient partitioning and without
pg_correctness_test = False
@@ -107,7 +105,8 @@ def __init__(self,
partition_grads=True,
round_robin_gradients=False,
has_moe_layers=False,
- fp16_master_weights_and_gradients=False):
+ fp16_master_weights_and_gradients=False,
+ elastic_checkpoint=False):
if dist.get_rank() == 0:
logger.info(f"Reduce bucket size {reduce_bucket_size}")
@@ -118,6 +117,8 @@ def __init__(self,
# 1. maintain same user API from apex.fp16_utils
# 2. keep common stuff here in case we need to add ne552w fused optimizer later
+ self.elastic_checkpoint = elastic_checkpoint
+
# differences from apex.fp16_utils:
# - assume all model params in fp16
# - assume all params requires grad
@@ -1969,7 +1970,17 @@ def state_dict(self):
state_dict['loss_scaler'] = self.loss_scaler
state_dict['dynamic_loss_scale'] = self.dynamic_loss_scale
state_dict['overflow'] = self.overflow
- state_dict['base_optimizer_state'] = self._get_base_optimizer_state()
+
+ if self.elastic_checkpoint:
+ state_dict['base_optimizer_state'] = self._get_base_optimizer_state()
+ # Remove paddings for DP alignment to enable loading for other alignment values
+ fp32_groups_without_padding = self._get_groups_without_padding(
+ self.single_partition_of_fp32_groups)
+ state_dict[SINGLE_PARTITION_OF_FP32_GROUPS] = fp32_groups_without_padding
+ else:
+ state_dict['base_optimizer_state'] = self.optimizer.state_dict()
+ state_dict[
+ SINGLE_PARTITION_OF_FP32_GROUPS] = self.single_partition_of_fp32_groups
state_dict['zero_stage'] = ZERO_OPTIMIZATION_GRADIENTS
state_dict['partition_count'] = self.partition_count
@@ -1979,7 +1990,7 @@ def state_dict(self):
# Remove paddings for DP alignment to enable loading for other alignment values
fp32_groups_without_padding = self._get_groups_without_padding(
self.single_partition_of_fp32_groups)
- state_dict['single_partition_of_fp32_groups'] = fp32_groups_without_padding
+ state_dict[SINGLE_PARTITION_OF_FP32_GROUPS] = fp32_groups_without_padding
# if self.cpu_offload:
# state_dict_tmp = async_copy_to(state_dict,
@@ -1999,7 +2010,7 @@ def _restore_from_fp32_weights(self, all_state_dict):
for i in range(len(self.single_partition_of_fp32_groups)):
partition_id = dist.get_rank(group=self.real_dp_process_group[i])
merged_partitions = [
- sd['single_partition_of_fp32_groups'][i] for sd in all_state_dict
+ sd[SINGLE_PARTITION_OF_FP32_GROUPS][i] for sd in all_state_dict
]
if self.is_moe_group(self.optimizer.param_groups[i]):
ranks = self.get_ep_ranks()
@@ -2112,25 +2123,36 @@ def load_state_dict(self,
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
"""
+ dp_rank = dist.get_rank(group=self.dp_process_group)
# I think it should actually be ok to reload the optimizer before the model.
- self.loss_scaler = state_dict_list[0]['loss_scaler']
- self.dynamic_loss_scale = state_dict_list[0]['dynamic_loss_scale']
- self.overflow = state_dict_list[0]['overflow']
+ self.loss_scaler = state_dict_list[dp_rank]['loss_scaler']
+ self.dynamic_loss_scale = state_dict_list[dp_rank]['dynamic_loss_scale']
+ self.overflow = state_dict_list[dp_rank]['overflow']
+
+ ckpt_version = state_dict_list[dp_rank].get("ds_version", False)
+ assert ckpt_version, f"Empty ds_version! {error_str}"
+ ckpt_version = pkg_version.parse(ckpt_version)
# zero stage 1 mode
if not self.partition_gradients:
required_version = pkg_version.parse("0.3.17")
- ckpt_version = state_dict_list[0].get("ds_version", False)
error_str = f"ZeRO stage 1 changed in {required_version} and is not backwards compatible " \
"with older stage 1 checkpoints. If you'd like to load an old ZeRO-1 checkpoint " \
"please set 'legacy_stage1': true in your zero config json. This old version of " \
"stage 1 will be removed in v0.4.0."
+ assert required_version <= ckpt_version, f"Old version: {ckpt_version} {error_str}"
- assert ckpt_version, f"Empty ds_version! {error_str}"
- assert required_version <= pkg_version.parse(ckpt_version), f"Old version: {ckpt_version} {error_str}"
+ if ckpt_version < pkg_version.parse("0.5.8"):
+ # zero checkpoints before 0.5.8 defaulted to elastic enabled, must
+ # load checkpoint state using elastic logic
+ self.elastic_checkpoint = True
if load_optimizer_states:
- self._restore_base_optimizer_state(state_dict_list)
+ if self.elastic_checkpoint:
+ self._restore_base_optimizer_state(state_dict_list)
+ else:
+ self.optimizer.load_state_dict(
+ state_dict_list[dp_rank]['base_optimizer_state'])
# At this point, the optimizer's references to the model's fp32 parameters are up to date.
# The optimizer's hyperparameters and internal buffers are also up to date.
@@ -2148,8 +2170,10 @@ def load_state_dict(self,
# are guaranteed to exist, so we can just copy_() from the saved master params.
if load_from_fp32_weights:
+ # option 2 from above
self._restore_from_fp32_weights(state_dict_list)
else:
+ # option 1 from above
self._restore_from_bit16_weights()
diff --git a/deepspeed/runtime/zero/stage3.py b/deepspeed/runtime/zero/stage3.py
index 1387ced6fc8d..a86ed6003e32 100755
--- a/deepspeed/runtime/zero/stage3.py
+++ b/deepspeed/runtime/zero/stage3.py
@@ -26,6 +26,7 @@
from deepspeed.runtime.swap_tensor.partitioned_param_swapper import PartitionedParamStatus
from deepspeed.runtime.swap_tensor.partitioned_optimizer_swapper import PartitionedOptimizerSwapper
from deepspeed.runtime.swap_tensor.pipelined_optimizer_swapper import PipelinedOptimizerSwapper
+from deepspeed.runtime.constants import OPTIMIZER_STATE_DICT
# Toggle this to true to enable correctness test
# with gradient partitioning and without
@@ -3114,7 +3115,7 @@ def _rigid_state_dict(self):
state_dict['partition_count'] = self.partition_count
self._set_fp32_optimizer_param_groups()
- state_dict['optimizer_state_dict'] = self.optimizer.state_dict()
+ state_dict[OPTIMIZER_STATE_DICT] = self.optimizer.state_dict()
state_dict['fp32_flat_groups'] = self.fp32_partitioned_groups_flat
self._clear_fp32_optimizer_param_groups()
@@ -3227,7 +3228,7 @@ def _rigid_load_state_dict(self, state_dict, load_optimizer_states=True):
if load_optimizer_states:
self._set_fp32_optimizer_param_groups()
- self.optimizer.load_state_dict(state_dict['optimizer_state_dict'])
+ self.optimizer.load_state_dict(state_dict[OPTIMIZER_STATE_DICT])
self._clear_fp32_optimizer_param_groups()
# restore fp32 partitions
| https://api.github.com/repos/microsoft/DeepSpeed/pulls/1673 | 2022-01-05T21:53:51Z | 2022-01-05T21:54:01Z | 2022-01-05T21:54:01Z | 2022-01-05T21:54:02Z | 3,921 | microsoft/DeepSpeed | 10,440 |
|
Fix links and add question about branch strategies | diff --git a/exercises/git/README.md b/exercises/git/README.md
index f827096fb..1abd82f1d 100644
--- a/exercises/git/README.md
+++ b/exercises/git/README.md
@@ -4,9 +4,9 @@
|Name|Topic|Objective & Instructions|Solution|Comments|
|--------|--------|------|----|----|
-| My first Commit | Commit | [Exercise](exercises/git/commit_01.md) | [Solution](exercises/git/solutions/commit_01_solution.md) | |
-| Time to Branch | Branch | [Exercise](exercises/git/branch_01.md) | [Solution](exercises/git/solutions/branch_01_solution.md) | |
-| Squashing Commits | Commit | [Exercise](exercises/git/squashing_commits.md) | [Solution](exercises/git/solutions/squashing_commits.md) | |
+| My first Commit | Commit | [Exercise](commit_01.md) | [Solution](solutions/commit_01_solution.md) | |
+| Time to Branch | Branch | [Exercise](branch_01.md) | [Solution](solutions/branch_01_solution.md) | |
+| Squashing Commits | Commit | [Exercise](squashing_commits.md) | [Solution](solutions/squashing_commits.md) | |
## Questions
@@ -62,6 +62,18 @@ There are different ways to check whether a file is tracked or not:
### Branches
+<details>
+<summary>What's is the branch strategy (flow) you know?</summary><br><b>
+
+* Git flow
+* GitHub flow
+* Trunk based development
+* GitLab flow
+
+[Explanation](https://www.bmc.com/blogs/devops-branching-strategies/#:~:text=What%20is%20a%20branching%20strategy,used%20in%20the%20development%20process).
+
+</b></details>
+
<details>
<summary>True or False? A branch is basically a simple pointer or reference to the head of certain line of work</summary><br><b>
| https://api.github.com/repos/bregman-arie/devops-exercises/pulls/242 | 2022-05-19T02:06:39Z | 2022-05-19T06:46:40Z | 2022-05-19T06:46:40Z | 2022-05-19T06:46:40Z | 475 | bregman-arie/devops-exercises | 17,627 |
|
Fixes various button overflowing UI and compact checkbox | diff --git a/modules/ui.py b/modules/ui.py
index af6dfb213da..12fc9e6a74b 100644
--- a/modules/ui.py
+++ b/modules/ui.py
@@ -919,7 +919,7 @@ def copy_image(img):
seed, reuse_seed, subseed, reuse_subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox = create_seed_inputs('img2img')
elif category == "checkboxes":
- with FormRow(elem_id="img2img_checkboxes"):
+ with FormRow(elem_id="img2img_checkboxes", variant="compact"):
restore_faces = gr.Checkbox(label='Restore faces', value=False, visible=len(shared.face_restorers) > 1, elem_id="img2img_restore_faces")
tiling = gr.Checkbox(label='Tiling', value=False, elem_id="img2img_tiling")
diff --git a/scripts/xy_grid.py b/scripts/xy_grid.py
index 8ff315a7411..0caece091fa 100644
--- a/scripts/xy_grid.py
+++ b/scripts/xy_grid.py
@@ -307,7 +307,7 @@ def ui(self, is_img2img):
y_values = gr.Textbox(label="Y values", lines=1, elem_id=self.elem_id("y_values"))
fill_y_button = ToolButton(value=fill_values_symbol, elem_id="xy_grid_fill_y_tool_button", visible=False)
- with gr.Row(variant="compact"):
+ with gr.Row(variant="compact", elem_id="axis_options"):
draw_legend = gr.Checkbox(label='Draw legend', value=True, elem_id=self.elem_id("draw_legend"))
include_lone_images = gr.Checkbox(label='Include Separate Images', value=False, elem_id=self.elem_id("include_lone_images"))
no_fixed_seeds = gr.Checkbox(label='Keep -1 for seeds', value=False, elem_id=self.elem_id("no_fixed_seeds"))
diff --git a/style.css b/style.css
index 507acec1bc8..bf8260d7f37 100644
--- a/style.css
+++ b/style.css
@@ -589,7 +589,7 @@ canvas[key="mask"] {
/* Extensions */
-#tab_extensions table``{
+#tab_extensions table{
border-collapse: collapse;
}
@@ -718,6 +718,14 @@ footer {
margin-left: -0.8em;
}
+#img2img_copy_to_img2img, #img2img_copy_to_sketch, #img2img_copy_to_inpaint, #img2img_copy_to_inpaint_sketch{
+ margin-left: 0em;
+}
+
+#axis_options {
+ margin-left: 0em;
+}
+
.inactive{
opacity: 0.5;
}
| ## Describe what this pull request is trying to achieve.
Fixes overflow margin issues with x/y plot axis button in txt2img and img2img.
Fixes overflow margin issues in img2img with the copy to image tab buttons.
Makes the img2img_checkboxes a compact variant like txt2img, putting `Restore Faces` and `Tiling` on the same line.
Also fixes typo in `style.css` for #tab_extensions table. I didn't investigate too much but the extensions tab still seems fine.
Please also let me know if this is an actual issue that is occurring with the overflow for this one, and also #7020. I labeled the commits where I recorded the original video. These are from the very latest commits at that time, but I saw a recent PR with a screenshot from the page and that does not have these error.
Next, I am going to try and fix the css around the generate button but I have been looking at it and does seem a bit more rough.
## Original version in Firefox (taken from f2eae6127d16a80d1516d3f6245b648eeca26330)
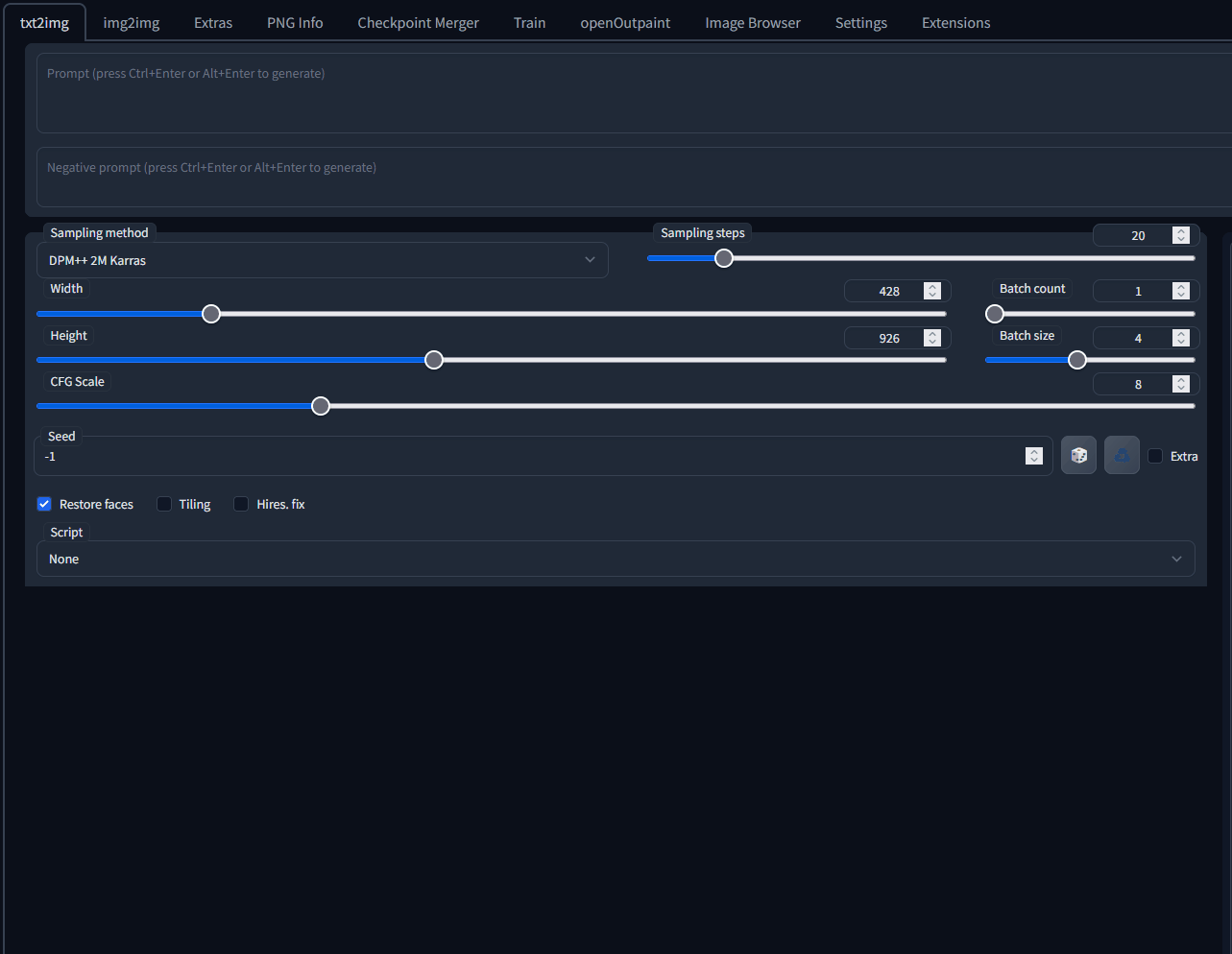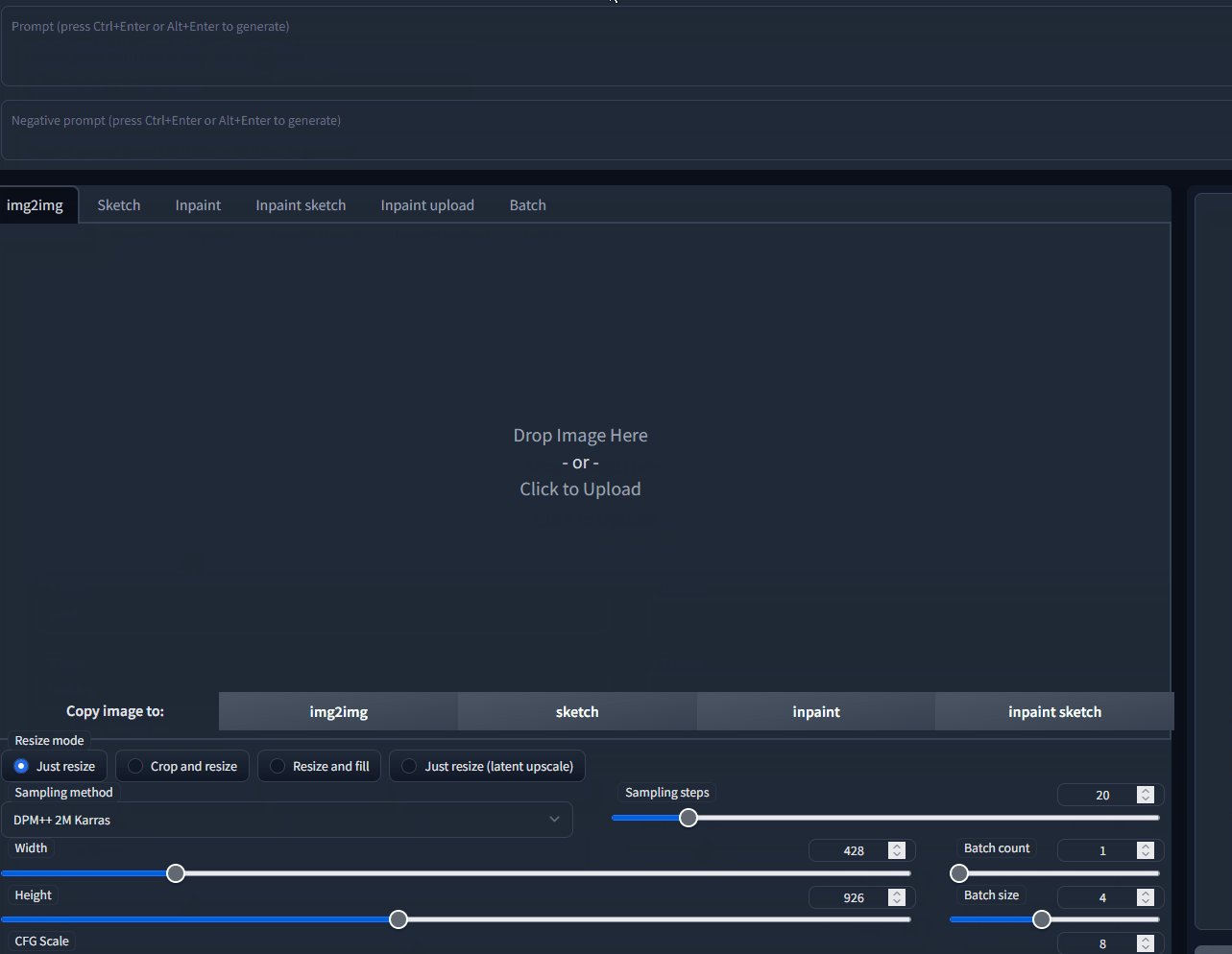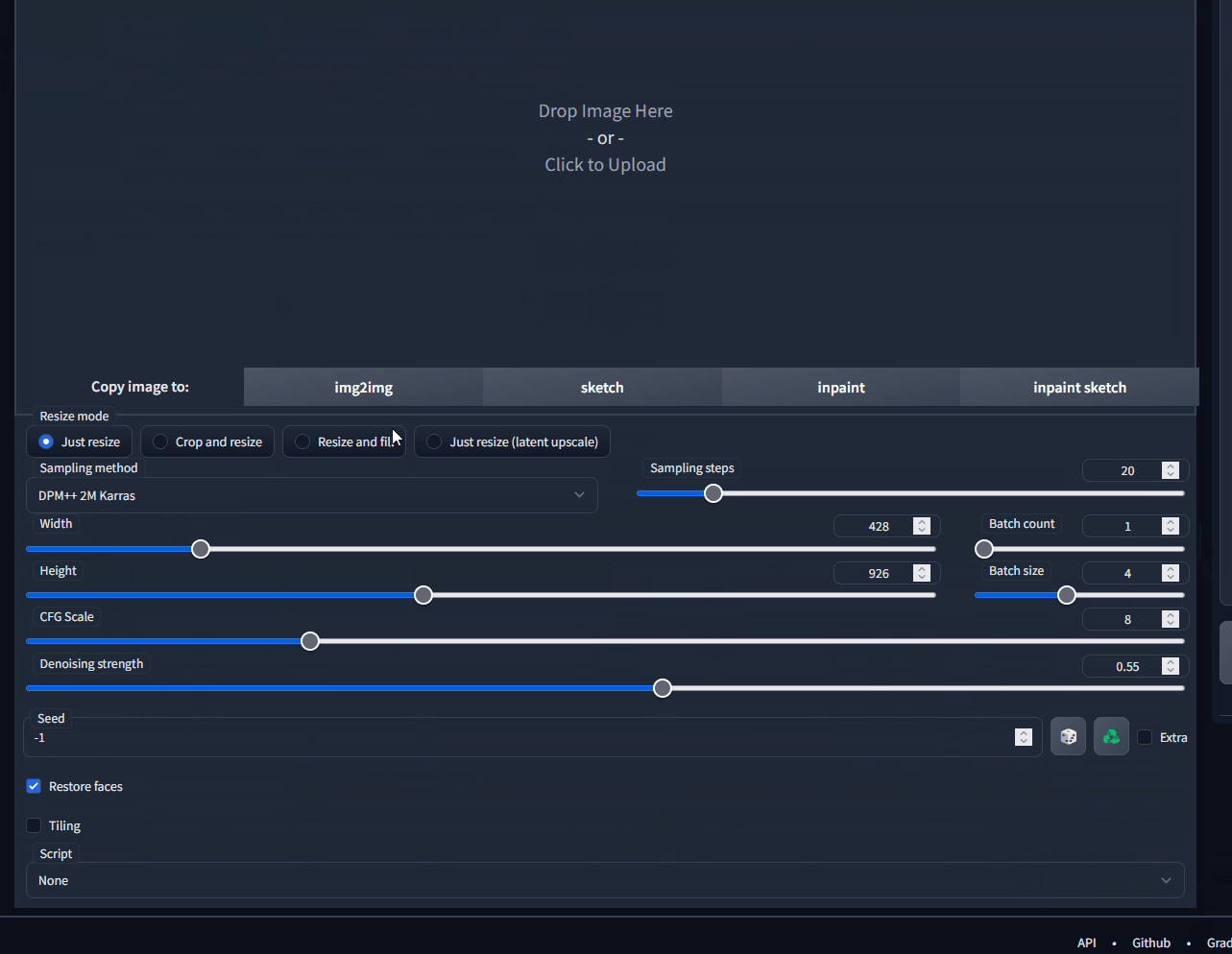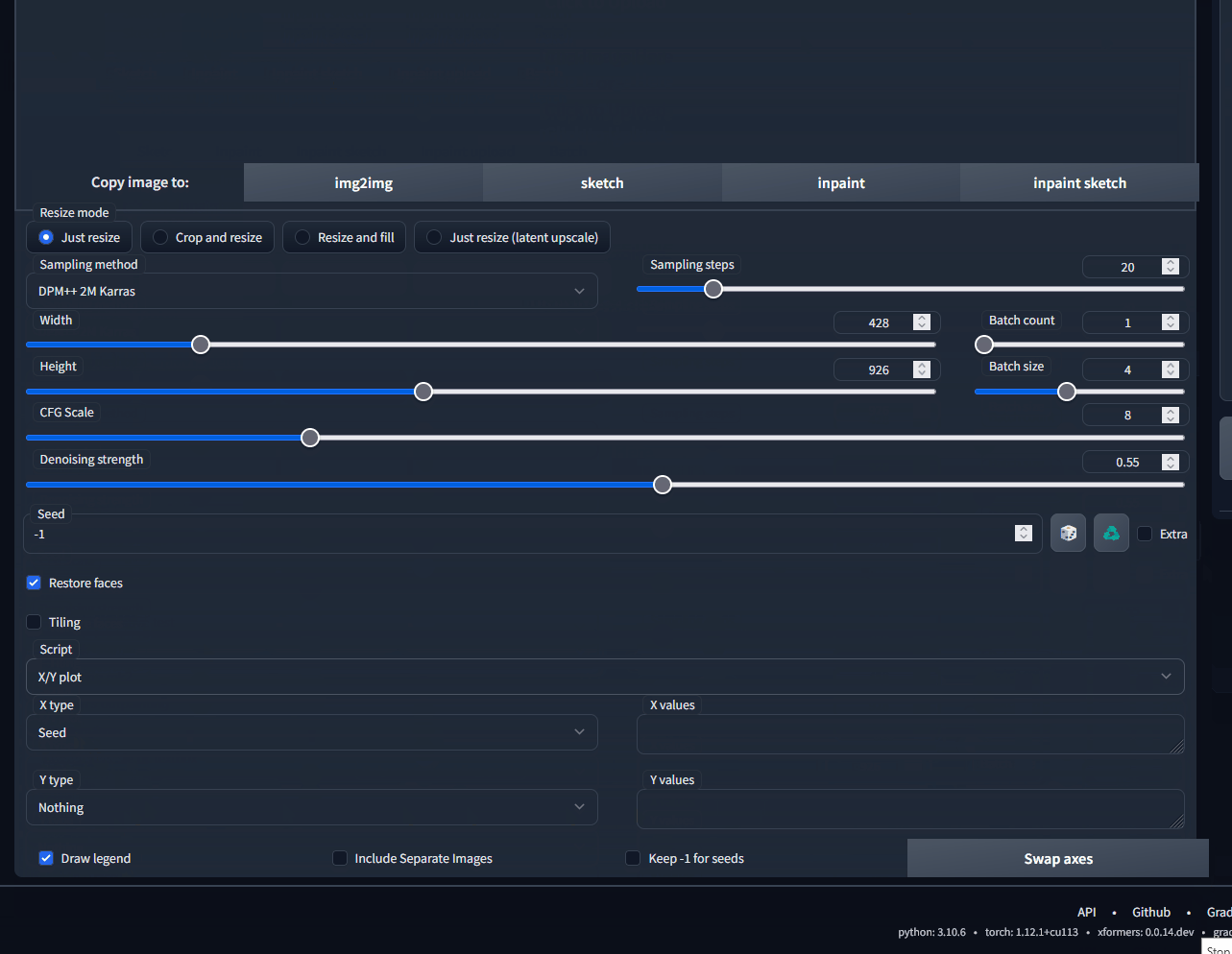
## New Version in Firefox
## Environment this was tested in
- OS: Windows
- Browser: Firefox
- Graphics card: NVIDIA GTX 1080 | https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/7031 | 2023-01-21T21:36:58Z | 2023-01-23T12:22:06Z | 2023-01-23T12:22:06Z | 2023-01-23T12:22:06Z | 617 | AUTOMATIC1111/stable-diffusion-webui | 39,889 |
[chat] correcting a few obvious typos and grammars errors | diff --git a/applications/Chat/README.md b/applications/Chat/README.md
index f0abbf0397b9..8f22084953ba 100644
--- a/applications/Chat/README.md
+++ b/applications/Chat/README.md
@@ -45,12 +45,12 @@ Coati stands for `ColossalAI Talking Intelligence`. It is the name for the modul
The Coati package provides a unified large language model framework that has implemented the following functions
- Supports comprehensive large-model training acceleration capabilities for ColossalAI, without requiring knowledge of complex distributed training algorithms
- Supervised datasets collection
-- Supervised insturcts fine-tuning
+- Supervised instructions fine-tuning
- Training reward model
- Reinforcement learning with human feedback
- Quantization inference
- Fast model deploying
-- Perfectly integration with the Hugging Face ecosystem, high degree of model customization
+- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
<div align="center">
<p align="center">
@@ -98,7 +98,7 @@ pip install .
### Supervised datasets collection
-we colllected 104K bilingual dataset of Chinese and English, and you can find the datasets in this repo
+we collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
Here is how we collected the data
@@ -188,17 +188,17 @@ if not USE_8BIT:
model.eval()
```
-**Troubleshooting**: if you get error indicating your CUDA-related libraries not found when loading 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
+**Troubleshooting**: if you get errors indicating your CUDA-related libraries are not found when loading the 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
#### 4-bit setup
-Please ensure you have downloaded HF-format model weights of LLaMA models first.
+Please ensure you have downloaded the HF-format model weights of LLaMA models first.
-Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight convertion script.
+Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight conversion scripts.
-After installing this lib, we may convert the original HF-format LLaMA model weights to 4-bit version.
+After installing this lib, we may convert the original HF-format LLaMA model weights to a 4-bit version.
```shell
CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
@@ -206,7 +206,7 @@ CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4
Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
-**Troubleshooting**: if you get error about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+**Troubleshooting**: if you get errors about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
@@ -334,7 +334,7 @@ trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
- [x] implement PPO-ptx fine-tuning
- [ ] integrate with Ray
- [ ] support more RL paradigms, like Implicit Language Q-Learning (ILQL),
-- [ ] support chain of throught by [langchain](https://github.com/hwchase17/langchain)
+- [ ] support chain-of-thought by [langchain](https://github.com/hwchase17/langchain)
### Real-time progress
You will find our progress in github project broad
| ## 📌 Checklist before creating the PR
- [x] I have created an issue for this PR for traceability
- [x] The title follows the standard format: `[doc/gemini/tensor/...]: A concise description`
- [x] I have added relevant tags if possible for us to better distinguish different PRs
## 🚨 Issue number
fixed #3337
## 📝 What does this PR do?
correcting a few obvious typos and grammars errors in the README of Chat to improve the readability.
## 💥 Checklist before requesting a review
- [x] I have linked my PR to an issue ([instruction](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
- [x] My issue clearly describes the problem/feature/proposal, with diagrams/charts/table/code if possible
- [x] I have performed a self-review of my code
- [x] I have added thorough tests.
- [x] I have added docstrings for all the functions/methods I implemented
The last two are not applicable. The check mark is to meet the requirement.
## ⭐️ Do you enjoy contributing to Colossal-AI?
- [x] 🌝 Yes, I do.
- [ ] 🌚 No, I don't.
Tell us more if you don't enjoy contributing to Colossal-AI.
| https://api.github.com/repos/hpcaitech/ColossalAI/pulls/3338 | 2023-03-30T06:07:44Z | 2023-03-30T06:18:38Z | 2023-03-30T06:18:38Z | 2023-03-30T06:18:49Z | 1,030 | hpcaitech/ColossalAI | 11,580 |
community[patch]: Release 0.0.8 | diff --git a/libs/community/pyproject.toml b/libs/community/pyproject.toml
index 47c00c013aaa2e..daf6bb3a6af39a 100644
--- a/libs/community/pyproject.toml
+++ b/libs/community/pyproject.toml
@@ -1,6 +1,6 @@
[tool.poetry]
name = "langchain-community"
-version = "0.0.7"
+version = "0.0.8"
description = "Community contributed LangChain integrations."
authors = []
license = "MIT"
| https://api.github.com/repos/langchain-ai/langchain/pulls/15481 | 2024-01-03T15:26:00Z | 2024-01-03T16:28:50Z | 2024-01-03T16:28:50Z | 2024-01-03T16:28:51Z | 120 | langchain-ai/langchain | 43,278 |
|
Remove Hardcoded Signature | diff --git a/letsencrypt/plugins/manual_test.py b/letsencrypt/plugins/manual_test.py
index 2d7c3e1e483..6b9359db1af 100644
--- a/letsencrypt/plugins/manual_test.py
+++ b/letsencrypt/plugins/manual_test.py
@@ -46,12 +46,9 @@ def test_perform_empty(self):
self.assertEqual([], self.auth.perform([]))
@mock.patch("letsencrypt.plugins.manual.sys.stdout")
- @mock.patch("letsencrypt.plugins.manual.os.urandom")
@mock.patch("acme.challenges.SimpleHTTPResponse.simple_verify")
@mock.patch("__builtin__.raw_input")
- def test_perform(self, mock_raw_input, mock_verify, mock_urandom,
- mock_stdout):
- mock_urandom.side_effect = nonrandom_urandom
+ def test_perform(self, mock_raw_input, mock_verify, mock_stdout):
mock_verify.return_value = True
resp = challenges.SimpleHTTPResponse(tls=False)
@@ -61,27 +58,7 @@ def test_perform(self, mock_raw_input, mock_verify, mock_urandom,
self.achalls[0].challb.chall, "foo.com", KEY.public_key(), 4430)
message = mock_stdout.write.mock_calls[0][1][0]
- self.assertEqual(message, """\
-Make sure your web server displays the following content at
-http://foo.com/.well-known/acme-challenge/ZXZhR3hmQURzNnBTUmIyTEF2OUlaZjE3RHQzanV4R0orUEN0OTJ3citvQQ before continuing:
-
-{"header": {"alg": "RS256", "jwk": {"e": "AQAB", "kty": "RSA", "n": "rHVztFHtH92ucFJD_N_HW9AsdRsUuHUBBBDlHwNlRd3fp580rv2-6QWE30cWgdmJS86ObRz6lUTor4R0T-3C5Q"}}, "payload": "eyJ0bHMiOiBmYWxzZSwgInRva2VuIjogIlpYWmhSM2htUVVSek5uQlRVbUl5VEVGMk9VbGFaakUzUkhRemFuVjRSMG9yVUVOME9USjNjaXR2UVEiLCAidHlwZSI6ICJzaW1wbGVIdHRwIn0", "signature": "jFPJFC-2eRyBw7Sl0wyEBhsdvRZtKk8hc6HykEPAiofZlIwdIu76u2xHqMVZWSZdpxwMNUnnawTEAqgMWFydMA"}
-
-Content-Type header MUST be set to application/jose+json.
-
-If you don\'t have HTTP server configured, you can run the following
-command on the target server (as root):
-
-mkdir -p /tmp/letsencrypt/public_html/.well-known/acme-challenge
-cd /tmp/letsencrypt/public_html
-echo -n \'{"header": {"alg": "RS256", "jwk": {"e": "AQAB", "kty": "RSA", "n": "rHVztFHtH92ucFJD_N_HW9AsdRsUuHUBBBDlHwNlRd3fp580rv2-6QWE30cWgdmJS86ObRz6lUTor4R0T-3C5Q"}}, "payload": "eyJ0bHMiOiBmYWxzZSwgInRva2VuIjogIlpYWmhSM2htUVVSek5uQlRVbUl5VEVGMk9VbGFaakUzUkhRemFuVjRSMG9yVUVOME9USjNjaXR2UVEiLCAidHlwZSI6ICJzaW1wbGVIdHRwIn0", "signature": "jFPJFC-2eRyBw7Sl0wyEBhsdvRZtKk8hc6HykEPAiofZlIwdIu76u2xHqMVZWSZdpxwMNUnnawTEAqgMWFydMA"}\' > .well-known/acme-challenge/ZXZhR3hmQURzNnBTUmIyTEF2OUlaZjE3RHQzanV4R0orUEN0OTJ3citvQQ
-# run only once per server:
-$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\
-"import BaseHTTPServer, SimpleHTTPServer; \\
-SimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {\'\': \'application/jose+json\'}; \\
-s = BaseHTTPServer.HTTPServer((\'\', 4430), SimpleHTTPServer.SimpleHTTPRequestHandler); \\
-s.serve_forever()" \n""")
- #self.assertTrue(validation in message)
+ self.assertTrue(self.achalls[0].chall.encode("token") in message)
mock_verify.return_value = False
self.assertEqual([None], self.auth.perform(self.achalls))
@@ -130,10 +107,5 @@ def test_cleanup_test_mode_kills_still_running(self, mock_killpg):
mock_killpg.assert_called_once_with(1234, signal.SIGTERM)
-def nonrandom_urandom(num_bytes):
- """Returns a string of length num_bytes"""
- return "x" * num_bytes
-
-
if __name__ == "__main__":
unittest.main() # pragma: no cover
| Recently, `tox` began failing for me locally for me due to the following error:
```
======================================================================
FAIL: test_perform (letsencrypt.plugins.manual_test.ManualAuthenticatorTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/bmw/Code/le/.tox/py27/lib/python2.7/site-packages/mock.py", line 1201, in patched
return func(*args, **keywargs)
File "/home/bmw/Code/le/letsencrypt/plugins/manual_test.py", line 83, in test_perform
s.serve_forever()" \n""")
AssertionError: 'Make sure your web server displays the following content at\nhttp://foo.com/.well-known/acme-challenge/ZXZhR3hmQURzNnBTUmIyTEF2OUlaZjE3RHQzanV4R0orUEN0OTJ3citvQQ before continuing:\n\n{"header": {"alg": "RS256", "jwk": {"e": "AQAB", "kty": "RSA", "n": "rHVztFHtH92ucFJD_N_HW9AsdRsUuHUBBBDlHwNlRd3fp580rv2-6QWE30cWgdmJS86ObRz6lUTor4R0T-3C5Q"}}, "payload": "eyJ0bHMiOiBmYWxzZSwgInRva2VuIjogIlpYWmhSM2htUVVSek5uQlRVbUl5VEVGMk9VbGFaakUzUkhRemFuVjRSMG9yVUVOME9USjNjaXR2UVEiLCAidHlwZSI6ICJzaW1wbGVIdHRwIn0", "signature": "R9SBqaLIXJ84TBT8l-QcZ8dkcOeCbJJjulQ9m9Z65LPAWpNH0lJwIW-hUrgRoDRD-Q4zyda1dOC3B4F5dQ9a4A"}\n\nContent-Type header MUST be set to application/jose+json.\n\nIf you don\'t have HTTP server configured, you can run the following\ncommand on the target server (as root):\n\nmkdir -p /tmp/letsencrypt/public_html/.well-known/acme-challenge\ncd /tmp/letsencrypt/public_html\necho -n \'{"header": {"alg": "RS256", "jwk": {"e": "AQAB", "kty": "RSA", "n": "rHVztFHtH92ucFJD_N_HW9AsdRsUuHUBBBDlHwNlRd3fp580rv2-6QWE30cWgdmJS86ObRz6lUTor4R0T-3C5Q"}}, "payload": "eyJ0bHMiOiBmYWxzZSwgInRva2VuIjogIlpYWmhSM2htUVVSek5uQlRVbUl5VEVGMk9VbGFaakUzUkhRemFuVjRSMG9yVUVOME9USjNjaXR2UVEiLCAidHlwZSI6ICJzaW1wbGVIdHRwIn0", "signature": "R9SBqaLIXJ84TBT8l-QcZ8dkcOeCbJJjulQ9m9Z65LPAWpNH0lJwIW-hUrgRoDRD-Q4zyda1dOC3B4F5dQ9a4A"}\' > .well-known/acme-challenge/ZXZhR3hmQURzNnBTUmIyTEF2OUlaZjE3RHQzanV4R0orUEN0OTJ3citvQQ\n# run only once per server:\n$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\\n"import BaseHTTPServer, SimpleHTTPServer; \\\nSimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {\'\': \'application/jose+json\'}; \\\ns = BaseHTTPServer.HTTPServer((\'\', 4430), SimpleHTTPServer.SimpleHTTPRequestHandler); \\\ns.serve_forever()" \n' != 'Make sure your web server displays the following content at\nhttp://foo.com/.well-known/acme-challenge/ZXZhR3hmQURzNnBTUmIyTEF2OUlaZjE3RHQzanV4R0orUEN0OTJ3citvQQ before continuing:\n\n{"header": {"alg": "RS256", "jwk": {"e": "AQAB", "kty": "RSA", "n": "rHVztFHtH92ucFJD_N_HW9AsdRsUuHUBBBDlHwNlRd3fp580rv2-6QWE30cWgdmJS86ObRz6lUTor4R0T-3C5Q"}}, "payload": "eyJ0bHMiOiBmYWxzZSwgInRva2VuIjogIlpYWmhSM2htUVVSek5uQlRVbUl5VEVGMk9VbGFaakUzUkhRemFuVjRSMG9yVUVOME9USjNjaXR2UVEiLCAidHlwZSI6ICJzaW1wbGVIdHRwIn0", "signature": "jFPJFC-2eRyBw7Sl0wyEBhsdvRZtKk8hc6HykEPAiofZlIwdIu76u2xHqMVZWSZdpxwMNUnnawTEAqgMWFydMA"}\n\nContent-Type header MUST be set to application/jose+json.\n\nIf you don\'t have HTTP server configured, you can run the following\ncommand on the target server (as root):\n\nmkdir -p /tmp/letsencrypt/public_html/.well-known/acme-challenge\ncd /tmp/letsencrypt/public_html\necho -n \'{"header": {"alg": "RS256", "jwk": {"e": "AQAB", "kty": "RSA", "n": "rHVztFHtH92ucFJD_N_HW9AsdRsUuHUBBBDlHwNlRd3fp580rv2-6QWE30cWgdmJS86ObRz6lUTor4R0T-3C5Q"}}, "payload": "eyJ0bHMiOiBmYWxzZSwgInRva2VuIjogIlpYWmhSM2htUVVSek5uQlRVbUl5VEVGMk9VbGFaakUzUkhRemFuVjRSMG9yVUVOME9USjNjaXR2UVEiLCAidHlwZSI6ICJzaW1wbGVIdHRwIn0", "signature": "jFPJFC-2eRyBw7Sl0wyEBhsdvRZtKk8hc6HykEPAiofZlIwdIu76u2xHqMVZWSZdpxwMNUnnawTEAqgMWFydMA"}\' > .well-known/acme-challenge/ZXZhR3hmQURzNnBTUmIyTEF2OUlaZjE3RHQzanV4R0orUEN0OTJ3citvQQ\n# run only once per server:\n$(command -v python2 || command -v python2.7 || command -v python2.6) -c \\\n"import BaseHTTPServer, SimpleHTTPServer; \\\nSimpleHTTPServer.SimpleHTTPRequestHandler.extensions_map = {\'\': \'application/jose+json\'}; \\\ns = BaseHTTPServer.HTTPServer((\'\', 4430), SimpleHTTPServer.SimpleHTTPRequestHandler); \\\ns.serve_forever()" \n'
----------------------------------------------------------------------
```
Examining the output of `strace`, some requests for `urandom` get through instead of returning the dummy value. This PR fixes this by removing the hardcoded value.
| https://api.github.com/repos/certbot/certbot/pulls/800 | 2015-09-21T22:18:35Z | 2015-09-22T20:16:31Z | 2015-09-22T20:16:31Z | 2016-05-06T19:22:28Z | 1,262 | certbot/certbot | 3,451 |
adding an action | diff --git a/metagpt/actions/detail_mining.py b/metagpt/actions/detail_mining.py
new file mode 100644
index 000000000..e29d6911b
--- /dev/null
+++ b/metagpt/actions/detail_mining.py
@@ -0,0 +1,52 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/9/12 17:45
+@Author : fisherdeng
+@File : detail_mining.py
+"""
+from metagpt.actions import Action, ActionOutput
+from metagpt.logs import logger
+
+PROMPT_TEMPLATE = """
+##TOPIC
+{topic}
+
+##RECORD
+{record}
+
+##Format example
+{format_example}
+-----
+
+Task: Refer to the "##TOPIC" (discussion objectives) and "##RECORD" (discussion records) to further inquire about the details that interest you, within a word limit of 150 words.
+Special Note 1: Your intention is solely to ask questions without endorsing or negating any individual's viewpoints.
+Special Note 2: This output should only include the topic "##OUTPUT". Do not add, remove, or modify the topic. Begin the output with '##OUTPUT', followed by an immediate line break, and then proceed to provide the content in the specified format as outlined in the "##Format example" section.
+Special Note 3: The output should be in the same language as the input.
+"""
+FORMAT_EXAMPLE = """
+
+##
+
+##OUTPUT
+...(Please provide the specific details you would like to inquire about here.)
+
+##
+
+##
+"""
+OUTPUT_MAPPING = {
+ "OUTPUT": (str, ...),
+}
+
+
+class DetailMining(Action):
+ """This class allows LLM to further mine noteworthy details based on specific "##TOPIC"(discussion topic) and "##RECORD" (discussion records), thereby deepening the discussion.
+ """
+ def __init__(self, name="", context=None, llm=None):
+ super().__init__(name, context, llm)
+
+ async def run(self, topic, record) -> ActionOutput:
+ prompt = PROMPT_TEMPLATE.format(topic=topic, record=record, format_example=FORMAT_EXAMPLE)
+ rsp = await self._aask_v1(prompt, "detail_mining", OUTPUT_MAPPING)
+ return rsp
diff --git a/tests/metagpt/actions/test_detail_mining.py b/tests/metagpt/actions/test_detail_mining.py
new file mode 100644
index 000000000..c9d5331f9
--- /dev/null
+++ b/tests/metagpt/actions/test_detail_mining.py
@@ -0,0 +1,23 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+"""
+@Time : 2023/9/13 00:26
+@Author : fisherdeng
+@File : test_detail_mining.py
+"""
+import pytest
+
+from metagpt.actions.detail_mining import DetailMining
+from metagpt.logs import logger
+
+@pytest.mark.asyncio
+async def test_detail_mining():
+ topic = "如何做一个生日蛋糕"
+ record = "我认为应该先准备好材料,然后再开始做蛋糕。"
+ detail_mining = DetailMining("detail_mining")
+ rsp = await detail_mining.run(topic=topic, record=record)
+ logger.info(f"{rsp.content=}")
+
+ assert '##OUTPUT' in rsp.content
+ assert '蛋糕' in rsp.content
+
| 增加了一个action
这个action叫detail_mining
可让LLM针对特定的”##讨论目标“和”##讨论记录“,进一步挖掘值得关注的细节,从而深化讨论。

| https://api.github.com/repos/geekan/MetaGPT/pulls/310 | 2023-09-12T14:12:29Z | 2023-09-22T05:22:39Z | 2023-09-22T05:22:39Z | 2023-09-22T05:22:39Z | 813 | geekan/MetaGPT | 16,664 |
Update Stability AI icon | diff --git a/website/src/data/team.json b/website/src/data/team.json
index f907cb151e..eda7546f73 100644
--- a/website/src/data/team.json
+++ b/website/src/data/team.json
@@ -189,7 +189,7 @@
"title": "Preemptible Compute (via LAION)",
"url": "https://stability.ai/",
"githubURL": "https://github.com/stability-ai",
- "imageURL": "https://platform.stability.ai/assets/HexagonTextLong.4501db27.png"
+ "imageURL": "https://images.squarespace-cdn.com/content/6213c340453c3f502425776e/cfbf5bc5-47d4-4f4a-b133-23bd12a7d7c2/S_AI_Favicon.png"
}
},
"groups": [
| https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2812 | 2023-04-21T18:34:26Z | 2023-04-21T18:38:14Z | 2023-04-21T18:38:14Z | 2023-04-21T18:38:15Z | 201 | LAION-AI/Open-Assistant | 37,590 |
|
Fix GitHub auth flow on inference server | diff --git a/inference/server/oasst_inference_server/routes/auth.py b/inference/server/oasst_inference_server/routes/auth.py
index 2580f9374a..98760756a1 100644
--- a/inference/server/oasst_inference_server/routes/auth.py
+++ b/inference/server/oasst_inference_server/routes/auth.py
@@ -116,7 +116,7 @@ async def callback_github(
user_response_json = await user_response.json()
try:
- github_id = user_response_json["id"]
+ github_id = str(user_response_json["id"])
github_username = user_response_json["login"]
except KeyError:
raise HTTPException(status_code=400, detail="Invalid user info response from GitHub")
| Close #2119. Unlike Discord, GitHub returns user IDs as integers in JSON, not strings. We therefore need to convert to string for the ID to be compatible with our database. | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2121 | 2023-03-19T12:58:09Z | 2023-03-19T19:13:12Z | 2023-03-19T19:13:12Z | 2023-03-19T19:13:12Z | 164 | LAION-AI/Open-Assistant | 37,568 |
Remove czmq part 1 | diff --git a/selfdrive/logcatd/SConscript b/selfdrive/logcatd/SConscript
index 7f87cbaddf423f..2646537adf773d 100644
--- a/selfdrive/logcatd/SConscript
+++ b/selfdrive/logcatd/SConscript
@@ -1,6 +1,6 @@
Import('env', 'cereal', 'messaging', 'arch')
if arch == "aarch64":
- env.Program('logcatd', 'logcatd_android.cc', LIBS=[cereal, messaging, 'cutils', 'zmq', 'czmq', 'capnp', 'kj'])
+ env.Program('logcatd', 'logcatd_android.cc', LIBS=[cereal, messaging, 'cutils', 'zmq', 'capnp', 'kj'])
else:
env.Program('logcatd', 'logcatd_systemd.cc', LIBS=[cereal, messaging, 'zmq', 'capnp', 'kj', 'systemd', 'json11'])
diff --git a/selfdrive/loggerd/SConscript b/selfdrive/loggerd/SConscript
index 2e5dae5553c738..5d59e929e3acac 100644
--- a/selfdrive/loggerd/SConscript
+++ b/selfdrive/loggerd/SConscript
@@ -1,7 +1,7 @@
Import('env', 'arch', 'cereal', 'messaging', 'common', 'visionipc')
src = ['loggerd.cc', 'logger.cc']
-libs = ['zmq', 'czmq', 'capnp', 'kj', 'z',
+libs = ['zmq', 'capnp', 'kj', 'z',
'avformat', 'avcodec', 'swscale', 'avutil',
'yuv', 'bz2', common, cereal, messaging, visionipc]
diff --git a/selfdrive/loggerd/encoder.c b/selfdrive/loggerd/encoder.c
index 721c6901e87943..5dccbeadd51f0a 100644
--- a/selfdrive/loggerd/encoder.c
+++ b/selfdrive/loggerd/encoder.c
@@ -6,8 +6,6 @@
#include <unistd.h>
#include <assert.h>
-#include <czmq.h>
-
#include <pthread.h>
#include <OMX_Component.h>
@@ -397,15 +395,6 @@ static void handle_out_buf(EncoderState *s, OMX_BUFFERHEADERTYPE *out_buf) {
memcpy(s->codec_config, buf_data, out_buf->nFilledLen);
}
- if (s->stream_sock_raw) {
- //uint64_t current_time = nanos_since_boot();
- //uint64_t diff = current_time - out_buf->nTimeStamp*1000LL;
- //double msdiff = (double) diff / 1000000.0;
- // printf("encoded latency to tsEof: %f\n", msdiff);
- zmq_send(s->stream_sock_raw, &out_buf->nTimeStamp, sizeof(out_buf->nTimeStamp), ZMQ_SNDMORE);
- zmq_send(s->stream_sock_raw, buf_data, out_buf->nFilledLen, 0);
- }
-
if (s->of) {
//printf("write %d flags 0x%x\n", out_buf->nFilledLen, out_buf->nFlags);
fwrite(buf_data, out_buf->nFilledLen, 1, s->of);
diff --git a/selfdrive/loggerd/encoder.h b/selfdrive/loggerd/encoder.h
index 18054d20d8254a..abd9d18c5308ae 100644
--- a/selfdrive/loggerd/encoder.h
+++ b/selfdrive/loggerd/encoder.h
@@ -56,15 +56,11 @@ typedef struct EncoderState {
Queue free_in;
Queue done_out;
- void *stream_sock_raw;
-
AVFormatContext *ofmt_ctx;
AVCodecContext *codec_ctx;
AVStream *out_stream;
bool remuxing;
- void *zmq_ctx;
-
bool downscale;
uint8_t *y_ptr2, *u_ptr2, *v_ptr2;
} EncoderState;
diff --git a/selfdrive/loggerd/loggerd.cc b/selfdrive/loggerd/loggerd.cc
index 5d81f5480816e4..bd151ad79dedf4 100644
--- a/selfdrive/loggerd/loggerd.cc
+++ b/selfdrive/loggerd/loggerd.cc
@@ -23,7 +23,6 @@
#include <random>
#include <ftw.h>
-#include <zmq.h>
#ifdef QCOM
#include <cutils/properties.h>
#endif
@@ -200,7 +199,7 @@ struct LoggerdState {
LoggerdState s;
#ifndef DISABLE_ENCODER
-void encoder_thread(RotateState *rotate_state, bool is_streaming, bool raw_clips, int cam_idx) {
+void encoder_thread(RotateState *rotate_state, bool raw_clips, int cam_idx) {
switch (cam_idx) {
case LOG_CAMERA_ID_DCAMERA: {
@@ -271,12 +270,6 @@ void encoder_thread(RotateState *rotate_state, bool is_streaming, bool raw_clips
}
encoder_inited = true;
- if (is_streaming) {
- encoder.zmq_ctx = zmq_ctx_new();
- encoder.stream_sock_raw = zmq_socket(encoder.zmq_ctx, ZMQ_PUB);
- assert(encoder.stream_sock_raw);
- zmq_bind(encoder.stream_sock_raw, "tcp://*:9002");
- }
}
// dont log a raw clip in the first minute
@@ -664,16 +657,6 @@ int main(int argc, char** argv) {
logger_init(&s.logger, "rlog", bytes.begin(), bytes.size(), true);
}
- bool is_streaming = false;
- bool is_logging = true;
-
- if (argc > 1 && strcmp(argv[1], "--stream") == 0) {
- is_streaming = true;
- } else if (argc > 1 && strcmp(argv[1], "--only-stream") == 0) {
- is_streaming = true;
- is_logging = false;
- }
-
s.rotate_seq_id = 0;
s.should_close = 0;
s.finish_close = 0;
@@ -681,17 +664,17 @@ int main(int argc, char** argv) {
pthread_mutex_init(&s.rotate_lock, NULL);
#ifndef DISABLE_ENCODER
// rear camera
- std::thread encoder_thread_handle(encoder_thread, &s.rotate_state[LOG_CAMERA_ID_FCAMERA], is_streaming, false, LOG_CAMERA_ID_FCAMERA);
+ std::thread encoder_thread_handle(encoder_thread, &s.rotate_state[LOG_CAMERA_ID_FCAMERA], false, LOG_CAMERA_ID_FCAMERA);
s.rotate_state[LOG_CAMERA_ID_FCAMERA].enabled = true;
// front camera
std::thread front_encoder_thread_handle;
if (record_front) {
- front_encoder_thread_handle = std::thread(encoder_thread, &s.rotate_state[LOG_CAMERA_ID_DCAMERA], false, false, LOG_CAMERA_ID_DCAMERA);
+ front_encoder_thread_handle = std::thread(encoder_thread, &s.rotate_state[LOG_CAMERA_ID_DCAMERA], false, LOG_CAMERA_ID_DCAMERA);
s.rotate_state[LOG_CAMERA_ID_DCAMERA].enabled = true;
}
#ifdef QCOM2
// wide camera
- std::thread wide_encoder_thread_handle(encoder_thread, &s.rotate_state[LOG_CAMERA_ID_ECAMERA], false, false, LOG_CAMERA_ID_ECAMERA);
+ std::thread wide_encoder_thread_handle(encoder_thread, &s.rotate_state[LOG_CAMERA_ID_ECAMERA], false, LOG_CAMERA_ID_ECAMERA);
s.rotate_state[LOG_CAMERA_ID_ECAMERA].enabled = true;
#endif
#endif
@@ -787,13 +770,11 @@ int main(int argc, char** argv) {
pthread_mutex_lock(&s.rotate_lock);
last_rotate_tms = millis_since_boot();
- // rotate the log
- if (is_logging) {
- err = logger_next(&s.logger, LOG_ROOT, s.segment_path, sizeof(s.segment_path), &s.rotate_segment);
- assert(err == 0);
- if (s.logger.part == 0) { LOGW("logging to %s", s.segment_path); }
- LOGW("rotated to %s", s.segment_path);
- }
+ err = logger_next(&s.logger, LOG_ROOT, s.segment_path, sizeof(s.segment_path), &s.rotate_segment);
+ assert(err == 0);
+ if (s.logger.part == 0) { LOGW("logging to %s", s.segment_path); }
+ LOGW("rotated to %s", s.segment_path);
+
// rotate the encoders
for (int cid=0;cid<=MAX_CAM_IDX;cid++) { s.rotate_state[cid].rotate(); }
pthread_mutex_unlock(&s.rotate_lock);
diff --git a/selfdrive/modeld/modeld.cc b/selfdrive/modeld/modeld.cc
index e2dcf69cb428b3..69d71ac2490714 100644
--- a/selfdrive/modeld/modeld.cc
+++ b/selfdrive/modeld/modeld.cc
@@ -1,6 +1,7 @@
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
+#include <unistd.h>
#include <eigen3/Eigen/Dense>
#include "common/visionbuf.h"
diff --git a/selfdrive/modeld/models/commonmodel.c b/selfdrive/modeld/models/commonmodel.c
index 0bdc61bbe32e47..c156ad39df7ea9 100644
--- a/selfdrive/modeld/models/commonmodel.c
+++ b/selfdrive/modeld/models/commonmodel.c
@@ -1,6 +1,7 @@
+#include <assert.h>
+#include <math.h>
#include "commonmodel.h"
-#include <czmq.h>
#include "common/mat.h"
#include "common/timing.h"
diff --git a/selfdrive/modeld/models/driving.h b/selfdrive/modeld/models/driving.h
index 52e7401a3b18ec..170982db11b78a 100644
--- a/selfdrive/modeld/models/driving.h
+++ b/selfdrive/modeld/models/driving.h
@@ -14,7 +14,6 @@
#include "commonmodel.h"
#include "runners/run.h"
-#include <czmq.h>
#include <memory>
#include "messaging.hpp"
diff --git a/selfdrive/modeld/visiontest.mk b/selfdrive/modeld/visiontest.mk
index f1aa7afdbaa85b..8e8f199d0c4b24 100644
--- a/selfdrive/modeld/visiontest.mk
+++ b/selfdrive/modeld/visiontest.mk
@@ -30,7 +30,6 @@ OPENCV_LIBS = -lopencv_video -lopencv_core -lopencv_imgproc
ifeq ($(UNAME_S),Darwin)
VT_LDFLAGS += $(PHONELIBS)/capnp-c/mac/lib/libcapnp_c.a \
- $(PHONELIBS)/zmq/mac/lib/libczmq.a \
$(PHONELIBS)/zmq/mac/lib/libzmq.a \
-framework OpenCL
@@ -41,7 +40,7 @@ else
VT_LDFLAGS += $(CEREAL_LIBS) \
-L/system/vendor/lib64 \
-L$(BASEDIR)/external/zmq/lib/ \
- -l:libczmq.a -l:libzmq.a \
+ -l:libzmq.a \
-lOpenCL
endif
diff --git a/selfdrive/proclogd/SConscript b/selfdrive/proclogd/SConscript
index e7677099e989c8..b80d17200d7221 100644
--- a/selfdrive/proclogd/SConscript
+++ b/selfdrive/proclogd/SConscript
@@ -1,2 +1,2 @@
Import('env', 'cereal', 'messaging')
-env.Program('proclogd.cc', LIBS=[cereal, messaging, 'pthread', 'zmq', 'czmq', 'capnp', 'kj'])
+env.Program('proclogd.cc', LIBS=[cereal, messaging, 'pthread', 'zmq', 'capnp', 'kj'])
diff --git a/selfdrive/ui/SConscript b/selfdrive/ui/SConscript
index 2207123a9777a7..55f269cb550617 100644
--- a/selfdrive/ui/SConscript
+++ b/selfdrive/ui/SConscript
@@ -1,7 +1,7 @@
Import('env', 'qt_env', 'arch', 'common', 'messaging', 'gpucommon', 'visionipc', 'cereal')
src = ['ui.cc', 'paint.cc', 'sidebar.cc', '#phonelibs/nanovg/nanovg.c']
-libs = [common, 'zmq', 'czmq', 'capnp', 'kj', 'm', cereal, messaging, gpucommon, visionipc]
+libs = [common, 'zmq', 'capnp', 'kj', 'm', cereal, messaging, gpucommon, visionipc]
if qt_env is None:
diff --git a/selfdrive/ui/test/Makefile b/selfdrive/ui/test/Makefile
index e0442db518f9d4..f321593ec3505b 100644
--- a/selfdrive/ui/test/Makefile
+++ b/selfdrive/ui/test/Makefile
@@ -14,7 +14,7 @@ CXXFLAGS = -std=c++11 -g -fPIC -O2 $(WARN_FLAGS)
ZMQ_FLAGS = -I$(PHONELIBS)/zmq/aarch64/include
ZMQ_LIBS = -L$(PHONELIBS)/zmq/aarch64/lib \
- -l:libczmq.a -l:libzmq.a \
+ -l:libzmq.a \
-lgnustl_shared
NANOVG_FLAGS = -I$(PHONELIBS)/nanovg
| Only camerad left, will be done in separate PR. | https://api.github.com/repos/commaai/openpilot/pulls/2332 | 2020-10-13T11:03:35Z | 2020-10-13T14:01:07Z | 2020-10-13T14:01:07Z | 2020-10-13T14:01:09Z | 3,156 | commaai/openpilot | 9,784 |
Add referer to "Spider error processing" log message | diff --git a/scrapy/core/scraper.py b/scrapy/core/scraper.py
index e5120ec0d2b..3409a0e7c79 100644
--- a/scrapy/core/scraper.py
+++ b/scrapy/core/scraper.py
@@ -57,6 +57,7 @@ def is_idle(self):
def needs_backout(self):
return self.active_size > self.max_active_size
+
class Scraper(object):
def __init__(self, crawler):
@@ -100,8 +101,8 @@ def finish_scraping(_):
self._scrape_next(spider, slot)
return _
dfd.addBoth(finish_scraping)
- dfd.addErrback(log.err, 'Scraper bug processing %s' % request, \
- spider=spider)
+ dfd.addErrback(
+ log.err, 'Scraper bug processing %s' % request, spider=spider)
self._scrape_next(spider, slot)
return dfd
@@ -124,13 +125,13 @@ def _scrape2(self, request_result, request, spider):
"""Handle the different cases of request's result been a Response or a
Failure"""
if not isinstance(request_result, Failure):
- return self.spidermw.scrape_response(self.call_spider, \
- request_result, request, spider)
+ return self.spidermw.scrape_response(
+ self.call_spider, request_result, request, spider)
else:
# FIXME: don't ignore errors in spider middleware
dfd = self.call_spider(request_result, request, spider)
- return dfd.addErrback(self._log_download_errors, \
- request_result, request, spider)
+ return dfd.addErrback(
+ self._log_download_errors, request_result, request, spider)
def call_spider(self, result, request, spider):
result.request = request
@@ -143,11 +144,21 @@ def handle_spider_error(self, _failure, request, response, spider):
if isinstance(exc, CloseSpider):
self.crawler.engine.close_spider(spider, exc.reason or 'cancelled')
return
- log.err(_failure, "Spider error processing %s" % request, spider=spider)
- self.signals.send_catch_log(signal=signals.spider_error, failure=_failure, response=response, \
- spider=spider)
- self.crawler.stats.inc_value("spider_exceptions/%s" % _failure.value.__class__.__name__, \
- spider=spider)
+ referer = request.headers.get('Referer')
+ log.err(
+ _failure,
+ "Spider error processing %s (referer: %s)" % (request, referer),
+ spider=spider
+ )
+ self.signals.send_catch_log(
+ signal=signals.spider_error,
+ failure=_failure, response=response,
+ spider=spider
+ )
+ self.crawler.stats.inc_value(
+ "spider_exceptions/%s" % _failure.value.__class__.__name__,
+ spider=spider
+ )
def handle_spider_output(self, result, request, response, spider):
if not result:
@@ -180,8 +191,8 @@ def _log_download_errors(self, spider_failure, download_failure, request, spider
"""Log and silence errors that come from the engine (typically download
errors that got propagated thru here)
"""
- if isinstance(download_failure, Failure) \
- and not download_failure.check(IgnoreRequest):
+ if (isinstance(download_failure, Failure) and
+ not download_failure.check(IgnoreRequest)):
if download_failure.frames:
log.err(download_failure, 'Error downloading %s' % request,
spider=spider)
@@ -204,13 +215,15 @@ def _itemproc_finished(self, output, item, response, spider):
if isinstance(ex, DropItem):
logkws = self.logformatter.dropped(item, ex, response, spider)
log.msg(spider=spider, **logkws)
- return self.signals.send_catch_log_deferred(signal=signals.item_dropped, \
- item=item, response=response, spider=spider, exception=output.value)
+ return self.signals.send_catch_log_deferred(
+ signal=signals.item_dropped, item=item, response=response,
+ spider=spider, exception=output.value)
else:
log.err(output, 'Error processing %s' % item, spider=spider)
else:
logkws = self.logformatter.scraped(output, response, spider)
log.msg(spider=spider, **logkws)
- return self.signals.send_catch_log_deferred(signal=signals.item_scraped, \
- item=output, response=response, spider=spider)
+ return self.signals.send_catch_log_deferred(
+ signal=signals.item_scraped, item=output, response=response,
+ spider=spider)
| \+ fixed some pep8 issues
Motivation: I want to be able to see response request referer in cases like this one:

Also I wonder if messages like "Spider error processing", "Error downloading" etc. should be handled by logformatter - to make it possible to override/disable them.
| https://api.github.com/repos/scrapy/scrapy/pulls/795 | 2014-07-11T13:31:48Z | 2014-10-07T22:57:48Z | 2014-10-07T22:57:48Z | 2014-10-07T22:57:48Z | 1,106 | scrapy/scrapy | 34,346 |
#432 - Moved SideMenu to component & refactored layout | diff --git a/website/src/components/Dashboard/index.ts b/website/src/components/Dashboard/index.ts
index 0b4ff49aaf..6e110534c7 100644
--- a/website/src/components/Dashboard/index.ts
+++ b/website/src/components/Dashboard/index.ts
@@ -1,3 +1,2 @@
export { LeaderboardTable } from "./LeaderboardTable";
-export { SideMenu } from "./SideMenu";
export { TaskOption } from "./TaskOption";
diff --git a/website/src/components/Layout.tsx b/website/src/components/Layout.tsx
index bf66211322..1faefcc0c6 100644
--- a/website/src/components/Layout.tsx
+++ b/website/src/components/Layout.tsx
@@ -1,9 +1,11 @@
// https://nextjs.org/docs/basic-features/layouts
import type { NextPage } from "next";
+import { FiLayout, FiMessageSquare } from "react-icons/fi";
import { Header } from "src/components/Header";
import { Footer } from "./Footer";
+import { SideMenuLayout } from "./SideMenuLayout";
export type NextPageWithLayout<P = unknown, IP = P> = NextPage<P, IP> & {
getLayout?: (page: React.ReactElement) => React.ReactNode;
@@ -28,7 +30,24 @@ export const getTransparentHeaderLayout = (page: React.ReactElement) => (
export const getDashboardLayout = (page: React.ReactElement) => (
<div className="grid grid-rows-[min-content_1fr_min-content] h-full justify-items-stretch">
<Header transparent={true} />
- {page}
+ <SideMenuLayout
+ menuButtonOptions={[
+ {
+ label: "Dashboard",
+ pathname: "/dashboard",
+ desc: "Dashboard Home",
+ icon: FiLayout,
+ },
+ {
+ label: "Messages",
+ pathname: "/messages",
+ desc: "Messages Dashboard",
+ icon: FiMessageSquare,
+ },
+ ]}
+ >
+ {page}
+ </SideMenuLayout>
</div>
);
diff --git a/website/src/components/Dashboard/SideMenu.tsx b/website/src/components/SideMenu.tsx
similarity index 77%
rename from website/src/components/Dashboard/SideMenu.tsx
rename to website/src/components/SideMenu.tsx
index 499117a289..59489e0e3c 100644
--- a/website/src/components/Dashboard/SideMenu.tsx
+++ b/website/src/components/SideMenu.tsx
@@ -1,37 +1,23 @@
import { Box, Button, Link, Text, Tooltip, useColorMode } from "@chakra-ui/react";
import { useRouter } from "next/router";
-import { FiLayout, FiSun, FiMessageSquare } from "react-icons/fi";
+import { FiSun } from "react-icons/fi";
+import { IconType } from "react-icons/lib";
import { colors } from "styles/Theme/colors";
-export function SideMenu() {
+export interface MenuButtonOption {
+ label: string;
+ pathname: string;
+ desc: string;
+ icon: IconType;
+}
+
+export interface SideMenuProps {
+ buttonOptions: MenuButtonOption[];
+}
+
+export function SideMenu(props: SideMenuProps) {
const router = useRouter();
const { colorMode, toggleColorMode } = useColorMode();
- const buttonOptions = [
- {
- label: "Dashboard",
- pathname: "/dashboard",
- desc: "Dashboard Home",
- icon: FiLayout,
- },
- {
- label: "Messages",
- pathname: "/messages",
- desc: "Messages Dashboard",
- icon: FiMessageSquare,
- },
- // {
- // label: "Leaderboard",
- // pathname: "#",
- // desc: "Public Leaderboard",
- // icon: FiAward,
- // },
- // {
- // label: "Stats",
- // pathname: "#",
- // desc: "User Statistics",
- // icon: FiBarChart2,
- // },
- ];
return (
<main className="sticky top-0 sm:h-full">
@@ -43,7 +29,7 @@ export function SideMenu() {
className="grid grid-cols-4 gap-2 sm:flex sm:flex-col sm:justify-between p-4 h-full"
>
<nav className="grid grid-cols-3 col-span-3 sm:flex sm:flex-col gap-2">
- {buttonOptions.map((item, itemIndex) => (
+ {props.buttonOptions.map((item, itemIndex) => (
<Tooltip
key={itemIndex}
fontFamily="inter"
diff --git a/website/src/components/SideMenuLayout.tsx b/website/src/components/SideMenuLayout.tsx
new file mode 100644
index 0000000000..e6c521a135
--- /dev/null
+++ b/website/src/components/SideMenuLayout.tsx
@@ -0,0 +1,23 @@
+import { Box, useColorMode } from "@chakra-ui/react";
+import { colors } from "styles/Theme/colors";
+import { SideMenu, MenuButtonOption } from "src/components/SideMenu";
+
+interface SideMenuLayoutProps {
+ menuButtonOptions: MenuButtonOption[];
+ children: React.ReactNode;
+}
+
+export const SideMenuLayout = (props: SideMenuLayoutProps) => {
+ const { colorMode } = useColorMode();
+
+ return (
+ <Box backgroundColor={colorMode === "light" ? colors.light.bg : colors.dark.bg} className="sm:overflow-hidden">
+ <Box className="sm:flex h-full gap-6">
+ <Box className="p-6 sm:pr-0">
+ <SideMenu buttonOptions={props.menuButtonOptions} />
+ </Box>
+ <Box className="flex flex-col overflow-auto p-6 sm:pl-0 gap-14">{props.children}</Box>
+ </Box>
+ </Box>
+ );
+};
diff --git a/website/src/pages/dashboard.tsx b/website/src/pages/dashboard.tsx
index 8b1f68610a..8ab4d52773 100644
--- a/website/src/pages/dashboard.tsx
+++ b/website/src/pages/dashboard.tsx
@@ -1,29 +1,17 @@
-import { Box, useColorMode } from "@chakra-ui/react";
import Head from "next/head";
import { getDashboardLayout } from "src/components/Layout";
-import { LeaderboardTable, SideMenu, TaskOption } from "src/components/Dashboard";
-import { colors } from "styles/Theme/colors";
+import { LeaderboardTable, TaskOption } from "src/components/Dashboard";
const Dashboard = () => {
- const { colorMode } = useColorMode();
return (
<>
<Head>
<title>Dashboard - Open Assistant</title>
<meta name="description" content="Chat with Open Assistant and provide feedback." />
</Head>
- <Box backgroundColor={colorMode === "light" ? colors.light.bg : colors.dark.bg} className="sm:overflow-hidden">
- <Box className="sm:flex h-full gap-6">
- <Box className="p-6 sm:pr-0">
- <SideMenu />
- </Box>
- <Box className="flex flex-col overflow-auto p-6 sm:pl-0 gap-14">
- <TaskOption />
- <LeaderboardTable />
- </Box>
- </Box>
- </Box>
+ <TaskOption />
+ <LeaderboardTable />
</>
);
};
diff --git a/website/src/pages/messages/index.tsx b/website/src/pages/messages/index.tsx
index 39430caf07..96ee19dbf5 100644
--- a/website/src/pages/messages/index.tsx
+++ b/website/src/pages/messages/index.tsx
@@ -2,15 +2,11 @@ import { Box, CircularProgress, SimpleGrid, Text, useColorModeValue } from "@cha
import Head from "next/head";
import { useState } from "react";
import useSWRImmutable from "swr/immutable";
-
import fetcher from "src/lib/fetcher";
-import { SideMenu } from "src/components/Dashboard";
import { MessageTable } from "src/components/Messages/MessageTable";
import { getDashboardLayout } from "src/components/Layout";
-import { colors } from "styles/Theme/colors";
const MessagesDashboard = () => {
- const bgColor = useColorModeValue(colors.light.bg, colors.dark.bg);
const boxBgColor = useColorModeValue("white", "gray.700");
const boxAccentColor = useColorModeValue("gray.200", "gray.900");
@@ -35,45 +31,36 @@ const MessagesDashboard = () => {
<title>Messages - Open Assistant</title>
<meta name="description" content="Chat with Open Assistant and provide feedback." />
</Head>
- <Box backgroundColor={bgColor} className="sm:overflow-hidden">
- <Box className="sm:flex h-full gap-6">
- <Box className="p-6 sm:pr-0">
- <SideMenu />
+ <SimpleGrid columns={[1, 1, 1, 2]} gap={4}>
+ <Box>
+ <Text className="text-2xl font-bold" pb="4">
+ Most recent messages
+ </Text>
+ <Box
+ backgroundColor={boxBgColor}
+ boxShadow="base"
+ dropShadow={boxAccentColor}
+ borderRadius="xl"
+ className="p-6 shadow-sm"
+ >
+ {isLoadingAll ? <CircularProgress isIndeterminate /> : <MessageTable messages={messages} />}
</Box>
- <Box className="flex flex-col overflow-auto p-6 sm:pl-0 gap-14">
- <SimpleGrid columns={[1, 1, 1, 2]} gap={4}>
- <Box>
- <Text className="text-2xl font-bold" pb="4">
- Most recent messages
- </Text>
- <Box
- backgroundColor={boxBgColor}
- boxShadow="base"
- dropShadow={boxAccentColor}
- borderRadius="xl"
- className="p-6 shadow-sm"
- >
- {isLoadingAll ? <CircularProgress isIndeterminate /> : <MessageTable messages={messages} />}
- </Box>
- </Box>
- <Box>
- <Text className="text-2xl font-bold" pb="4">
- Your most recent messages
- </Text>
- <Box
- backgroundColor={boxBgColor}
- boxShadow="base"
- dropShadow={boxAccentColor}
- borderRadius="xl"
- className="p-6 shadow-sm"
- >
- {isLoadingUser ? <CircularProgress isIndeterminate /> : <MessageTable messages={userMessages} />}
- </Box>
- </Box>
- </SimpleGrid>
+ </Box>
+ <Box>
+ <Text className="text-2xl font-bold" pb="4">
+ Your most recent messages
+ </Text>
+ <Box
+ backgroundColor={boxBgColor}
+ boxShadow="base"
+ dropShadow={boxAccentColor}
+ borderRadius="xl"
+ className="p-6 shadow-sm"
+ >
+ {isLoadingUser ? <CircularProgress isIndeterminate /> : <MessageTable messages={userMessages} />}
</Box>
</Box>
- </Box>
+ </SimpleGrid>
</>
);
};
| #432
Should complete tasks 1 & 2. Moved the `SideMenu` to it's own component & included it in the `SideMenuLayout`.
Updated `getDashboardLayout` in NextJS's Layout resolver to work with new component.
Reworked `/dashboard` and '/messages' pages to use the updated `getDashboardLayout`.
Also spotted wierd issue with colorMode flashing while switching between `/dashboard` and `/messages`. Might look into it a little bit later. | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/469 | 2023-01-07T00:55:47Z | 2023-01-07T07:03:07Z | 2023-01-07T07:03:07Z | 2023-01-07T10:51:09Z | 2,598 | LAION-AI/Open-Assistant | 36,874 |
[bug] fixed grad scaler compatibility with torch 1.8 | diff --git a/colossalai/amp/torch_amp/_grad_scaler.py b/colossalai/amp/torch_amp/_grad_scaler.py
index 48c7eb949b0b..d5e526d0c00a 100644
--- a/colossalai/amp/torch_amp/_grad_scaler.py
+++ b/colossalai/amp/torch_amp/_grad_scaler.py
@@ -12,6 +12,7 @@
import torch.distributed as dist
from colossalai.core import global_context as gpc
from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
+from packaging import version
class _MultiDeviceReplicator(object):
@@ -122,6 +123,14 @@ def __init__(self, init_scale=2.**16, growth_factor=2.0, backoff_factor=0.5, gro
else:
self._enabled = enabled
+ # check version
+ torch_version = version.parse(torch.__version__)
+ assert torch_version.major == 1
+ if torch_version.minor > 8:
+ self._higher_than_torch18 = True
+ else:
+ self._higher_than_torch18 = False
+
if self._enabled:
assert growth_factor > 1.0, "The growth factor must be > 1.0."
assert backoff_factor < 1.0, "The backoff factor must be < 1.0."
@@ -404,8 +413,12 @@ def update(self, new_scale=None):
for i in range(1, len(found_infs)):
found_inf_combined += found_infs[i]
- torch._amp_update_scale_(_scale, _growth_tracker, found_inf_combined, self._growth_factor,
- self._backoff_factor, self._growth_interval)
+ if self._higher_than_torch18:
+ torch._amp_update_scale_(_scale, _growth_tracker, found_inf_combined, self._growth_factor,
+ self._backoff_factor, self._growth_interval)
+ else:
+ self._scale = torch._amp_update_scale(_growth_tracker, _scale, found_inf_combined, self._growth_factor,
+ self._backoff_factor, self._growth_interval)
# To prepare for next iteration, clear the data collected from optimizers this iteration.
self._per_optimizer_states = defaultdict(_refresh_per_optimizer_state)
| This fixed #734 as part of the effort to tackle #733 .
The screenshot of the successful unit test is shown below.
<img width="1913" alt="Screenshot 2022-04-12 at 3 18 47 PM" src="https://user-images.githubusercontent.com/31818963/162903213-633f92fc-e532-4cac-a9b7-0855313ff283.png">
| https://api.github.com/repos/hpcaitech/ColossalAI/pulls/735 | 2022-04-12T07:16:30Z | 2022-04-12T08:04:21Z | 2022-04-12T08:04:21Z | 2022-04-12T08:04:21Z | 527 | hpcaitech/ColossalAI | 11,873 |
updated eop imports | diff --git a/active_projects/eop/birthday.py b/active_projects/eop/birthday.py
index f59f70211d..7fae9bf92c 100644
--- a/active_projects/eop/birthday.py
+++ b/active_projects/eop/birthday.py
@@ -1,19 +1,4 @@
-from helpers import *
-from mobject import Mobject
-from mobject.vectorized_mobject import *
-from animation.animation import Animation
-from animation.transform import *
-from animation.simple_animations import *
-from topics.geometry import *
-from scene import Scene
-from camera import *
-from topics.number_line import *
-from topics.three_dimensions import *
-from topics.light import *
-from topics.characters import *
-from topics.numerals import *
-
-
+from big_ol_pile_of_manim_imports import *
class Birthday(Scene):
diff --git a/active_projects/eop/histograms.py b/active_projects/eop/histograms.py
index be0ea491d2..7303155d6b 100644
--- a/active_projects/eop/histograms.py
+++ b/active_projects/eop/histograms.py
@@ -1,17 +1,4 @@
-from helpers import *
-from mobject import Mobject
-from mobject.vectorized_mobject import *
-from animation.animation import Animation
-from animation.transform import *
-from animation.simple_animations import *
-from topics.geometry import *
-from scene import Scene
-from camera import *
-from topics.number_line import *
-from topics.three_dimensions import *
-from topics.light import *
-from topics.characters import *
-from topics.numerals import *
+from big_ol_pile_of_manim_imports import *
from random import *
def text_range(start,stop,step):
diff --git a/active_projects/eop/pascal.py b/active_projects/eop/pascal.py
index b2f5f40dca..087caf6bbd 100644
--- a/active_projects/eop/pascal.py
+++ b/active_projects/eop/pascal.py
@@ -1,12 +1,4 @@
-from helpers import *
-from mobject import Mobject
-from mobject.vectorized_mobject import *
-from animation.animation import Animation
-from animation.transform import *
-from animation.simple_animations import *
-from topics.geometry import *
-from scene import Scene
-from camera import *
+from big_ol_pile_of_manim_imports import *
nb_levels = 50
| https://api.github.com/repos/3b1b/manim/pulls/187 | 2018-04-03T00:54:00Z | 2018-04-03T00:54:09Z | 2018-04-03T00:54:09Z | 2018-04-03T00:54:13Z | 510 | 3b1b/manim | 18,273 |
|
Pin the date for man pages. | diff --git a/extras/man/http.1 b/extras/man/http.1
index 7e444e004a..b72e0eb0a9 100644
--- a/extras/man/http.1
+++ b/extras/man/http.1
@@ -1,4 +1,4 @@
-.TH http 1 "2022-03-14" "HTTPie 3.1.0" "HTTPie Manual"
+.TH http 1 "2022-03-08" "HTTPie 3.1.0" "HTTPie Manual"
.SH NAME
http
.SH SYNOPSIS
diff --git a/extras/man/https.1 b/extras/man/https.1
index b81d03370c..c953e4d506 100644
--- a/extras/man/https.1
+++ b/extras/man/https.1
@@ -1,4 +1,4 @@
-.TH https 1 "2022-03-14" "HTTPie 3.1.0" "HTTPie Manual"
+.TH https 1 "2022-03-08" "HTTPie 3.1.0" "HTTPie Manual"
.SH NAME
https
.SH SYNOPSIS
diff --git a/extras/scripts/generate_man_pages.py b/extras/scripts/generate_man_pages.py
index 8f74ac1fb8..d6e7398cde 100644
--- a/extras/scripts/generate_man_pages.py
+++ b/extras/scripts/generate_man_pages.py
@@ -11,7 +11,6 @@
from httpie.output.ui.rich_utils import render_as_string
from httpie.utils import split
-LAST_EDIT_DATE = str(datetime.date.today())
# Escape certain characters so they are rendered properly on
# all terminals.
@@ -88,7 +87,7 @@ def to_man_page(program_name: str, spec: ParserSpec) -> str:
full_name='HTTPie',
program_name=program_name,
program_version=httpie.__version__,
- last_edit_date=LAST_EDIT_DATE,
+ last_edit_date=httpie.__date__,
)
builder.set_name(program_name)
diff --git a/httpie/__init__.py b/httpie/__init__.py
index 90aa2789d2..0a55bdc4b9 100644
--- a/httpie/__init__.py
+++ b/httpie/__init__.py
@@ -4,5 +4,6 @@
"""
__version__ = '3.1.0'
+__date__ = '2022-03-08'
__author__ = 'Jakub Roztocil'
__licence__ = 'BSD'
| The date for the man pages should be the same with the release date. This also improved reproducibility on the CI. | https://api.github.com/repos/httpie/cli/pulls/1326 | 2022-03-15T09:54:34Z | 2022-03-15T09:58:39Z | 2022-03-15T09:58:39Z | 2022-03-15T09:58:40Z | 580 | httpie/cli | 34,118 |
cleanup car port docs | diff --git a/selfdrive/car/README.MD b/selfdrive/car/README.MD
index 19a33085f0109f..2dcbf56059a2e3 100644
--- a/selfdrive/car/README.MD
+++ b/selfdrive/car/README.MD
@@ -1,6 +1,6 @@
# selfdrive/car
-### Checkout this blogpost for a high level overview of car ports
+### Check out this blogpost for a high level overview of car ports
https://blog.comma.ai/how-to-write-a-car-port-for-openpilot/
## Useful car porting utilities
@@ -9,7 +9,7 @@ Testing car ports in your car is very time consuming! Checkout these utilities t
### [Cabana](/tools/cabana/README.md)
-View your cars CAN signals through DBC files, which openpilot uses to parse and create messages that talk to the car.
+View your car's CAN signals through DBC files, which openpilot uses to parse and create messages that talk to the car.
Example:
```bash
@@ -18,7 +18,7 @@ Example:
### [selfdrive/debug/auto_fingerprint.py](/selfdrive/debug/auto_fingerprint.py)
-Given a route and platform, automatically inserts fw fingerprints from the platform into the correct place in values.py
+Given a route and platform, automatically inserts FW fingerprints from the platform into the correct place in values.py
Example:
```bash
| https://api.github.com/repos/commaai/openpilot/pulls/30707 | 2023-12-13T02:14:01Z | 2023-12-13T02:17:11Z | 2023-12-13T02:17:11Z | 2023-12-13T04:09:03Z | 321 | commaai/openpilot | 9,003 |
|
Reenable containerised Travis infrastructure | diff --git a/.travis.yml b/.travis.yml
index 86a0d3e7dc6..96e28b1b0d5 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -2,11 +2,12 @@ language: python
services:
- rabbitmq
+ - mariadb
# http://docs.travis-ci.com/user/ci-environment/#CI-environment-OS
# gimme has to be kept in sync with Boulder's Go version setting in .travis.yml
before_install:
- - sudo apt-get install -y mariadb-server mariadb-server-10.0
+ - 'dpkg -s libaugeas0'
- '[ "xxx$BOULDER_INTEGRATION" = "xxx" ] || eval "$(gimme 1.5.1)"'
# using separate envs with different TOXENVs creates 4x1 Travis build
@@ -31,9 +32,8 @@ branches:
- master
- /^test-.*$/
-# enable Trusty beta on travis
-sudo: required
-dist: trusty
+# container-based infrastructure
+sudo: false
addons:
# make sure simplehttp simple verification works (custom /etc/hosts)
@@ -41,6 +41,8 @@ addons:
- le.wtf
mariadb: "10.0"
apt:
+ sources:
+ - augeas
packages: # keep in sync with bootstrap/ubuntu.sh and Boulder
- python
- python-dev
| We're having builds error on the beta trusty infrastructure, so we're trying switching back.
| https://api.github.com/repos/certbot/certbot/pulls/1470 | 2015-11-11T23:51:43Z | 2015-11-12T07:51:50Z | 2015-11-12T07:51:50Z | 2016-05-06T19:22:23Z | 348 | certbot/certbot | 1,322 |
Correct Speech Event Readme | diff --git a/examples/research_projects/robust-speech-event/README.md b/examples/research_projects/robust-speech-event/README.md
index 31bdc5bff57e1..daeabbbf197f5 100644
--- a/examples/research_projects/robust-speech-event/README.md
+++ b/examples/research_projects/robust-speech-event/README.md
@@ -675,8 +675,8 @@ We are very excited to be hosting 2 days of talks from Kensho-Technologies, Mozi
Speaker | Topic | Time | Video |
|-------------|---------------------------------|------------------------|------------------------|
-| Gabriel Habayeb, Mozilla Common Voice | The Common Voice Dataset | 4h30pm - 5h00pm UTC | [](https://www.youtube.com/watch?v=ic_J7ZCROBM)
-| Changhan Wang, Meta AI Research | XLS-R: Large-Scale Cross-lingual Speech Representation Learning on 128 Languages | 5h30pm - 6h00pm UTC | [](https://www.youtube.com/watch?v=Vvn984QmAVg)
+| Gabriel Habayeb, Mozilla Common Voice | The Common Voice Dataset | 4h30pm - 5h00pm UTC | [](https://www.youtube.com/watch?v=Vvn984QmAVg)
+| Changhan Wang, Meta AI Research | XLS-R: Large-Scale Cross-lingual Speech Representation Learning on 128 Languages | 5h30pm - 6h00pm UTC | [](https://www.youtube.com/watch?v=ic_J7ZCROBM)
### Talks & Speakers
| # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Correct YouTube links
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| https://api.github.com/repos/huggingface/transformers/pulls/15226 | 2022-01-19T14:22:11Z | 2022-01-19T14:23:00Z | 2022-01-19T14:23:00Z | 2022-01-19T14:25:05Z | 444 | huggingface/transformers | 12,236 |
Refactor arrow serialization logic for custom components | diff --git a/lib/streamlit/components/v1/component_arrow.py b/lib/streamlit/components/v1/component_arrow.py
index 93ea653857e6..8fe455d62b8c 100644
--- a/lib/streamlit/components/v1/component_arrow.py
+++ b/lib/streamlit/components/v1/component_arrow.py
@@ -16,13 +16,20 @@
CustomComponent for dataframe serialization.
"""
+from __future__ import annotations
+
+from typing import Any
+
import pandas as pd
-import pyarrow as pa
-from streamlit import type_util, util
+from streamlit import type_util
+from streamlit.elements.lib import pandas_styler_utils
+from streamlit.proto.Components_pb2 import ArrowTable as ArrowTableProto
-def marshall(proto, data, default_uuid=None):
+def marshall(
+ proto: ArrowTableProto, data: Any, default_uuid: str | None = None
+) -> None:
"""Marshall data into an ArrowTable proto.
Parameters
@@ -35,251 +42,15 @@ def marshall(proto, data, default_uuid=None):
"""
if type_util.is_pandas_styler(data):
- _marshall_styler(proto, data, default_uuid)
+ pandas_styler_utils.marshall_styler(proto, data, default_uuid) # type: ignore
df = type_util.convert_anything_to_df(data)
_marshall_index(proto, df.index)
_marshall_columns(proto, df.columns)
- _marshall_data(proto, df.to_numpy())
-
-
-def _marshall_styler(proto, styler, default_uuid):
- """Marshall pandas.Styler styling data into an ArrowTable proto.
-
- Parameters
- ----------
- proto : proto.ArrowTable
- Output. The protobuf for a Streamlit ArrowTable proto.
-
- styler : pandas.Styler
- Styler holding styling data for the dataframe.
-
- default_uuid : str
- If Styler custom uuid is not provided, this value will be used.
-
- """
- # NB: UUID should be set before _compute is called.
- _marshall_uuid(proto, styler, default_uuid)
-
- # NB: We're using protected members of Styler to get styles,
- # which is non-ideal and could break if Styler's interface changes.
- styler._compute()
-
- pandas_styles = styler._translate(False, False)
-
- _marshall_caption(proto, styler)
- _marshall_styles(proto, styler, pandas_styles)
- _marshall_display_values(proto, styler.data, pandas_styles)
-
-
-def _marshall_uuid(proto, styler, default_uuid):
- """Marshall pandas.Styler UUID into an ArrowTable proto.
-
- Parameters
- ----------
- proto : proto.ArrowTable
- Output. The protobuf for a Streamlit ArrowTable proto.
-
- styler : pandas.Styler
- Styler holding styling data for the dataframe.
-
- default_uuid : str
- If Styler custom uuid is not provided, this value will be used.
-
- """
- if styler.uuid is None:
- styler.set_uuid(default_uuid)
-
- proto.styler.uuid = str(styler.uuid)
-
-
-def _marshall_caption(proto, styler):
- """Marshall pandas.Styler caption into an ArrowTable proto.
-
- Parameters
- ----------
- proto : proto.ArrowTable
- Output. The protobuf for a Streamlit ArrowTable proto.
-
- styler : pandas.Styler
- Styler holding styling data for the dataframe.
-
- """
- if styler.caption is not None:
- proto.styler.caption = styler.caption
-
-
-def _marshall_styles(proto, styler, styles):
- """Marshall pandas.Styler styles into an ArrowTable proto.
-
- Parameters
- ----------
- proto : proto.ArrowTable
- Output. The protobuf for a Streamlit ArrowTable proto.
-
- styler : pandas.Styler
- Styler holding styling data for the dataframe.
-
- styles : dict
- pandas.Styler translated styles.
-
- """
- css_rules = []
-
- if "table_styles" in styles:
- table_styles = styles["table_styles"]
- table_styles = _trim_pandas_styles(table_styles)
- for style in table_styles:
- # NB: styles in "table_styles" have a space
- # between the UUID and the selector.
- rule = _pandas_style_to_css(
- "table_styles", style, styler.uuid, separator=" "
- )
- css_rules.append(rule)
-
- if "cellstyle" in styles:
- cellstyle = styles["cellstyle"]
- cellstyle = _trim_pandas_styles(cellstyle)
- for style in cellstyle:
- rule = _pandas_style_to_css("cell_style", style, styler.uuid)
- css_rules.append(rule)
-
- if len(css_rules) > 0:
- proto.styler.styles = "\n".join(css_rules)
-
-
-def _trim_pandas_styles(styles):
- """Trim pandas styles dict.
-
- Parameters
- ----------
- styles : dict
- pandas.Styler translated styles.
-
- """
- # Filter out empty styles, as every cell will have a class
- # but the list of props may just be [['', '']].
- return [x for x in styles if any(any(y) for y in x["props"])]
-
-
-def _pandas_style_to_css(style_type, style, uuid, separator=""):
- """Convert pandas.Styler translated styles entry to CSS.
-
- Parameters
- ----------
- style : dict
- pandas.Styler translated styles entry.
-
- uuid: str
- pandas.Styler UUID.
-
- separator: str
- A string separator used between table and cell selectors.
-
- """
- declarations = []
- for css_property, css_value in style["props"]:
- declaration = css_property.strip() + ": " + css_value.strip()
- declarations.append(declaration)
-
- table_selector = "#T_" + str(uuid)
-
- # In pandas >= 1.1.0
- # translated_style["cellstyle"] has the following shape:
- # [
- # {
- # "props": [("color", " black"), ("background-color", "orange"), ("", "")],
- # "selectors": ["row0_col0"]
- # }
- # ...
- # ]
- if style_type == "table_styles":
- cell_selectors = [style["selector"]]
- else:
- cell_selectors = style["selectors"]
-
- selectors = []
- for cell_selector in cell_selectors:
- selectors.append(table_selector + separator + cell_selector)
- selector = ", ".join(selectors)
-
- declaration_block = "; ".join(declarations)
- rule_set = selector + " { " + declaration_block + " }"
-
- return rule_set
-
-
-def _marshall_display_values(proto, df, styles):
- """Marshall pandas.Styler display values into an ArrowTable proto.
-
- Parameters
- ----------
- proto : proto.ArrowTable
- Output. The protobuf for a Streamlit ArrowTable proto.
-
- df : pandas.DataFrame
- A dataframe with original values.
-
- styles : dict
- pandas.Styler translated styles.
-
- """
- new_df = _use_display_values(df, styles)
- proto.styler.display_values = _dataframe_to_pybytes(new_df)
-
-
-def _use_display_values(df, styles):
- """Create a new pandas.DataFrame where display values are used instead of original ones.
-
- Parameters
- ----------
- df : pandas.DataFrame
- A dataframe with original values.
-
- styles : dict
- pandas.Styler translated styles.
-
- """
- # (HK) TODO: Rewrite this method without using regex.
- import re
-
- # If values in a column are not of the same type, Arrow Table
- # serialization would fail. Thus, we need to cast all values
- # of the dataframe to strings before assigning them display values.
- new_df = df.astype(str)
-
- cell_selector_regex = re.compile(r"row(\d+)_col(\d+)")
- if "body" in styles:
- rows = styles["body"]
- for row in rows:
- for cell in row:
- cell_id = cell["id"]
- match = cell_selector_regex.match(cell_id)
- if match:
- r, c = map(int, match.groups())
- new_df.iat[r, c] = str(cell["display_value"])
-
- return new_df
-
+ _marshall_data(proto, df)
-def _dataframe_to_pybytes(df):
- """Convert pandas.DataFrame to pybytes.
- Parameters
- ----------
- df : pandas.DataFrame
- A dataframe to convert.
-
- """
- table = pa.Table.from_pandas(df)
- sink = pa.BufferOutputStream()
- writer = pa.RecordBatchStreamWriter(sink, table.schema)
- writer.write_table(table)
- writer.close()
- return sink.getvalue().to_pybytes()
-
-
-def _marshall_index(proto, index):
+def _marshall_index(proto: ArrowTableProto, index: pd.Index) -> None:
"""Marshall pandas.DataFrame index into an ArrowTable proto.
Parameters
@@ -287,17 +58,17 @@ def _marshall_index(proto, index):
proto : proto.ArrowTable
Output. The protobuf for a Streamlit ArrowTable proto.
- index : Index or array-like
+ index : pd.Index
Index to use for resulting frame.
Will default to RangeIndex (0, 1, 2, ..., n) if no index is provided.
"""
- index = map(util._maybe_tuple_to_list, index.values)
+ index = map(type_util.maybe_tuple_to_list, index.values)
index_df = pd.DataFrame(index)
- proto.index = _dataframe_to_pybytes(index_df)
+ proto.index = type_util.data_frame_to_bytes(index_df)
-def _marshall_columns(proto, columns):
+def _marshall_columns(proto: ArrowTableProto, columns: pd.Series) -> None:
"""Marshall pandas.DataFrame columns into an ArrowTable proto.
Parameters
@@ -305,17 +76,17 @@ def _marshall_columns(proto, columns):
proto : proto.ArrowTable
Output. The protobuf for a Streamlit ArrowTable proto.
- columns : Index or array-like
+ columns : Series
Column labels to use for resulting frame.
Will default to RangeIndex (0, 1, 2, ..., n) if no column labels are provided.
"""
- columns = map(util._maybe_tuple_to_list, columns.values)
+ columns = map(type_util.maybe_tuple_to_list, columns.values)
columns_df = pd.DataFrame(columns)
- proto.columns = _dataframe_to_pybytes(columns_df)
+ proto.columns = type_util.data_frame_to_bytes(columns_df)
-def _marshall_data(proto, data):
+def _marshall_data(proto: ArrowTableProto, df: pd.DataFrame) -> None:
"""Marshall pandas.DataFrame data into an ArrowTable proto.
Parameters
@@ -327,11 +98,10 @@ def _marshall_data(proto, data):
A dataframe to marshall.
"""
- df = pd.DataFrame(data)
- proto.data = _dataframe_to_pybytes(df)
+ proto.data = type_util.data_frame_to_bytes(df)
-def arrow_proto_to_dataframe(proto):
+def arrow_proto_to_dataframe(proto: ArrowTableProto) -> pd.DataFrame:
"""Convert ArrowTable proto to pandas.DataFrame.
Parameters
@@ -340,23 +110,10 @@ def arrow_proto_to_dataframe(proto):
Output. pandas.DataFrame
"""
- data = _pybytes_to_dataframe(proto.data)
- index = _pybytes_to_dataframe(proto.index)
- columns = _pybytes_to_dataframe(proto.columns)
+ data = type_util.bytes_to_data_frame(proto.data)
+ index = type_util.bytes_to_data_frame(proto.index)
+ columns = type_util.bytes_to_data_frame(proto.columns)
return pd.DataFrame(
data.values, index=index.values.T.tolist(), columns=columns.values.T.tolist()
)
-
-
-def _pybytes_to_dataframe(source):
- """Convert pybytes to pandas.DataFrame.
-
- Parameters
- ----------
- source : pybytes
- Will default to RangeIndex (0, 1, 2, ..., n) if no `index` or `columns` are provided.
-
- """
- reader = pa.RecordBatchStreamReader(source)
- return reader.read_pandas()
diff --git a/lib/streamlit/type_util.py b/lib/streamlit/type_util.py
index 66710de56b09..3d151f2831c8 100644
--- a/lib/streamlit/type_util.py
+++ b/lib/streamlit/type_util.py
@@ -1010,6 +1010,11 @@ def to_key(key: Optional[Key]) -> Optional[str]:
return str(key)
+def maybe_tuple_to_list(item: Any) -> Any:
+ """Convert a tuple to a list. Leave as is if it's not a tuple."""
+ return list(item) if isinstance(item, tuple) else item
+
+
def maybe_raise_label_warnings(label: Optional[str], label_visibility: Optional[str]):
if not label:
_LOGGER.warning(
diff --git a/lib/streamlit/util.py b/lib/streamlit/util.py
index 7c7192cd40e0..5f1cf64d5d1e 100644
--- a/lib/streamlit/util.py
+++ b/lib/streamlit/util.py
@@ -106,13 +106,6 @@ def _open_browser_with_command(command, url):
subprocess.Popen(cmd_line, stdout=devnull, stderr=subprocess.STDOUT)
-def _maybe_tuple_to_list(item: Any) -> Any:
- """Convert a tuple to a list. Leave as is if it's not a tuple."""
- if isinstance(item, tuple):
- return list(item)
- return item
-
-
def repr_(self: Any) -> str:
"""A clean repr for a class, excluding both values that are likely defaults,
and those explicitly default for dataclasses.
| ## Describe your changes
Refactor the arrow version of our components API to reuse the logic from our other arrow implementation. The current form had some redundant code and was missing type annotations.
---
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
| https://api.github.com/repos/streamlit/streamlit/pulls/7611 | 2023-10-26T05:36:42Z | 2023-10-26T16:34:25Z | 2023-10-26T16:34:25Z | 2024-01-23T00:23:47Z | 3,194 | streamlit/streamlit | 22,502 |
[enhance]: use opencv to rewrite morphological_open(), achieve a 40x speed increase in morphological_open opporation | diff --git a/modules/inpaint_worker.py b/modules/inpaint_worker.py
index 88ec39d6d..43a7ae23e 100644
--- a/modules/inpaint_worker.py
+++ b/modules/inpaint_worker.py
@@ -4,6 +4,7 @@
from PIL import Image, ImageFilter
from modules.util import resample_image, set_image_shape_ceil, get_image_shape_ceil
from modules.upscaler import perform_upscale
+import cv2
inpaint_head_model = None
@@ -28,19 +29,25 @@ def box_blur(x, k):
return np.array(x)
-def max33(x):
- x = Image.fromarray(x)
- x = x.filter(ImageFilter.MaxFilter(3))
- return np.array(x)
+def max_filter_opencv(x, ksize=3):
+ # Use OpenCV maximum filter
+ # Make sure the input type is int16
+ return cv2.dilate(x, np.ones((ksize, ksize), dtype=np.int16))
def morphological_open(x):
- x_int32 = np.zeros_like(x).astype(np.int32)
- x_int32[x > 127] = 256
- for _ in range(32):
- maxed = max33(x_int32) - 8
- x_int32 = np.maximum(maxed, x_int32)
- return x_int32.clip(0, 255).astype(np.uint8)
+ # Convert array to int16 type via threshold operation
+ x_int16 = np.zeros_like(x, dtype=np.int16)
+ x_int16[x > 127] = 256
+
+ for i in range(32):
+ # Use int16 type to avoid overflow
+ maxed = max_filter_opencv(x_int16, ksize=3) - 8
+ x_int16 = np.maximum(maxed, x_int16)
+
+ # Clip negative values to 0 and convert back to uint8 type
+ x_uint8 = np.clip(x_int16, 0, 255).astype(np.uint8)
+ return x_uint8
def up255(x, t=0):
| Hi~
lllyasviel,
Fooocus is an excellent work, it can generate beautiful images in both text2img and img2img tasks. However, I encountered a speed bottleneck with Fooocus when using it for inpainting/outpainting tasks. The issue was with the `morphological_open` function, which was originally written by PIL, This implementation tends to become slow as the size of the input image increased. To address this, I rewrote the function using OpenCV, achieving a 40x increase in speed for image sizes below 3K in inpainting/outpainting tasks.
The following table presents a comparation of the execution speeds for the modified of `morphological_open`, which was tested on Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz CPU and V100 GPU

| https://api.github.com/repos/lllyasviel/Fooocus/pulls/2016 | 2024-01-22T06:26:06Z | 2024-01-27T12:59:59Z | 2024-01-27T12:59:59Z | 2024-01-27T12:59:59Z | 482 | lllyasviel/Fooocus | 7,178 |
Correct some typos | diff --git a/README.md b/README.md
index e9923f9..11c575b 100644
--- a/README.md
+++ b/README.md
@@ -198,7 +198,7 @@ SyntaxError: invalid syntax
>>> a
6
->>> a, b = 6, 9 # Typcial unpacking
+>>> a, b = 6, 9 # Typical unpacking
>>> a, b
(6, 9)
>>> (a, b = 16, 19) # Oops
@@ -666,7 +666,7 @@ for i, some_dict[i] in enumerate(some_string):
1\.
```py
array = [1, 8, 15]
-# A typical generator expresion
+# A typical generator expression
gen = (x for x in array if array.count(x) > 0)
array = [2, 8, 22]
```
@@ -3070,7 +3070,7 @@ _A__variable = "Some value"
class A(object):
def some_func(self):
- return __variable # not initiatlized anywhere yet
+ return __variable # not initialized anywhere yet
```
**Output:**
@@ -3263,7 +3263,7 @@ def convert_list_to_string(l, iters):
**Output:**
```py
-# Executed in ipython shell using %timeit for better readablity of results.
+# Executed in ipython shell using %timeit for better readability of results.
# You can also use the timeit module in normal python shell/scriptm=, example usage below
# timeit.timeit('add_string_with_plus(10000)', number=1000, globals=globals())
@@ -3387,7 +3387,7 @@ Let's increase the number of iterations by a factor of 10.
46
```
- **💡 Explanation:** The `@` operator was added in Python 3.5 keeping sthe cientific community in mind. Any object can overload `__matmul__` magic method to define behavior for this operator.
+ **💡 Explanation:** The `@` operator was added in Python 3.5 keeping the scientific community in mind. Any object can overload `__matmul__` magic method to define behavior for this operator.
* From Python 3.8 onwards you can use a typical f-string syntax like `f'{some_var=}` for quick debugging. Example,
```py
@@ -3443,7 +3443,7 @@ Let's increase the number of iterations by a factor of 10.
* `int('١٢٣٤٥٦٧٨٩')` returns `123456789` in Python 3. In Python, Decimal characters include digit characters, and all characters that can be used to form decimal-radix numbers, e.g. U+0660, ARABIC-INDIC DIGIT ZERO. Here's an [interesting story](http://chris.improbable.org/2014/8/25/adventures-in-unicode-digits/) related to this behavior of Python.
-* You can seperate numeric literals with underscores (for better readablity) from Python 3 onwards.
+* You can separate numeric literals with underscores (for better readability) from Python 3 onwards.
```py
>>> six_million = 6_000_000
| Corrected a handful of typos. | https://api.github.com/repos/satwikkansal/wtfpython/pulls/157 | 2019-12-23T09:33:06Z | 2019-12-23T10:02:33Z | 2019-12-23T10:02:33Z | 2019-12-23T10:12:30Z | 736 | satwikkansal/wtfpython | 25,734 |
Update to the README | diff --git a/README.md b/README.md
index 4509bc1b4bacf..8d21b48e09103 100644
--- a/README.md
+++ b/README.md
@@ -311,7 +311,7 @@ def my_app_test():
# here goes your test logic
```
-See the example test file `tests/test_integration.py` for more details.
+See the example test file `tests/integration/test_integration.py` for more details.
## Integration with Serverless
| Updating the path to the test_integration.py in the README
**Please refer to the contribution guidelines in the README when submitting PRs.**
| https://api.github.com/repos/localstack/localstack/pulls/1405 | 2019-06-28T21:35:21Z | 2019-07-08T19:56:53Z | 2019-07-08T19:56:53Z | 2019-07-08T19:56:53Z | 114 | localstack/localstack | 28,996 |
Fix Apache unit tests on Debian | diff --git a/certbot-apache/certbot_apache/_internal/override_centos.py b/certbot-apache/certbot_apache/_internal/override_centos.py
index de5c312680c..9883bb1f10f 100644
--- a/certbot-apache/certbot_apache/_internal/override_centos.py
+++ b/certbot-apache/certbot_apache/_internal/override_centos.py
@@ -58,8 +58,13 @@ def _rhel9_or_newer(self) -> bool:
"rhel", "redhatenterpriseserver", "red hat enterprise linux server",
"scientific", "scientific linux",
]
+ # It is important that the loose version comparison below is not made
+ # if the OS is not RHEL derived. See
+ # https://github.com/certbot/certbot/issues/9481.
+ if not rhel_derived:
+ return False
at_least_v9 = util.parse_loose_version(os_version) >= util.parse_loose_version('9')
- return rhel_derived and at_least_v9
+ return at_least_v9
def _override_cmds(self) -> None:
super()._override_cmds()
diff --git a/certbot/CHANGELOG.md b/certbot/CHANGELOG.md
index b60f94eb059..177ab09261a 100644
--- a/certbot/CHANGELOG.md
+++ b/certbot/CHANGELOG.md
@@ -21,6 +21,7 @@ Certbot adheres to [Semantic Versioning](https://semver.org/).
have started erroring with `AttributeError` in Certbot v2.0.0.
- Plugin authors can find more information about Certbot 2.x compatibility
[here](https://github.com/certbot/certbot/wiki/Certbot-v2.x-Plugin-Compatibility).
+* A bug causing our certbot-apache tests to crash on some systems has been resolved.
More details about these changes can be found on our GitHub repo.
| Fixes https://github.com/certbot/certbot/issues/9481.
I poked around our other uses of this function and they seem OK to me for now, however, I opened https://github.com/certbot/certbot/issues/9489 to track the bigger refactor I think we should do here. | https://api.github.com/repos/certbot/certbot/pulls/9490 | 2022-12-01T20:13:04Z | 2022-12-01T20:27:25Z | 2022-12-01T20:27:25Z | 2022-12-01T20:27:26Z | 455 | certbot/certbot | 1,078 |
Initial implementation of the inference system | diff --git a/inference/README.md b/inference/README.md
new file mode 100644
index 0000000000..3dee94f900
--- /dev/null
+++ b/inference/README.md
@@ -0,0 +1,35 @@
+# OpenAssitant Inference
+
+Preliminary implementation of the inference engine for OpenAssistant.
+
+## Development (you'll need multiple terminals)
+
+Run a redis container (or use the one of the general docker compose file):
+
+```bash
+docker run --rm -it -p 6379:6379 redis
+```
+
+Run the inference server:
+
+```bash
+cd server
+pip install -r requirements.txt
+uvicorn main:app --reload
+```
+
+Run one (or more) workers:
+
+```bash
+cd worker
+pip install -r requirements.txt
+python __main__.py
+```
+
+Run the client:
+
+```bash
+cd text-client
+pip install -r requirements.txt
+python __main__.py
+```
diff --git a/inference/server/README.md b/inference/server/README.md
new file mode 100644
index 0000000000..a235a7e618
--- /dev/null
+++ b/inference/server/README.md
@@ -0,0 +1,10 @@
+# OpenAssistant Inference Server
+
+Workers communicate with the `/work` endpoint via Websocket. They provide their
+configuration and if a task is available, the server returns it. The worker then
+performs the task and returns the result in a streaming fashion to the server,
+also via websocket.
+
+Clients first call `/chat` to make a new chat, then add to that via
+`/chat/<id>/message`. The response is a SSE event source, which will send tokens
+as they are available.
diff --git a/inference/server/main.py b/inference/server/main.py
new file mode 100644
index 0000000000..f3ec02b13e
--- /dev/null
+++ b/inference/server/main.py
@@ -0,0 +1,193 @@
+import asyncio
+import enum
+import uuid
+
+import fastapi
+import pydantic
+import redis.asyncio as redis
+from fastapi.middleware.cors import CORSMiddleware
+from loguru import logger
+from oasst_shared.schemas import inference, protocol
+from sse_starlette.sse import EventSourceResponse
+
+app = fastapi.FastAPI()
+
+# Allow CORS
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=["*"],
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"],
+)
+
+
+class Settings(pydantic.BaseSettings):
+ redis_host: str = "localhost"
+ redis_port: int = 6379
+ redis_db: int = 0
+
+ sse_retry_timeout: int = 15000
+
+
+settings = Settings()
+
+# create async redis client
+redisClient = redis.Redis(
+ host=settings.redis_host, port=settings.redis_port, db=settings.redis_db, decode_responses=True
+)
+
+
+class CreateChatRequest(pydantic.BaseModel):
+ pass
+
+
+class CreateChatResponse(pydantic.BaseModel):
+ id: str
+
+
+class MessageRequest(pydantic.BaseModel):
+ message: str = pydantic.Field(..., repr=False)
+ model_name: str = "distilgpt2"
+ max_new_tokens: int = 100
+
+ def compatible_with(self, worker_config: inference.WorkerConfig) -> bool:
+ return self.model_name == worker_config.model_name
+
+
+class TokenResponseEvent(pydantic.BaseModel):
+ token: str
+
+
+class MessageRequestState(str, enum.Enum):
+ pending = "pending"
+ in_progress = "in_progress"
+ complete = "complete"
+
+
+class DbChatEntry(pydantic.BaseModel):
+ id: str = pydantic.Field(default_factory=lambda: str(uuid.uuid4()))
+ conversation: protocol.Conversation = pydantic.Field(default_factory=protocol.Conversation)
+ pending_message_request: MessageRequest | None = None
+ message_request_state: MessageRequestState | None = None
+
+
+# TODO: make real database
+CHATS: dict[str, DbChatEntry] = {}
+
+
+@app.post("/chat")
+async def create_chat(request: CreateChatRequest) -> CreateChatResponse:
+ """Allows a client to create a new chat."""
+ logger.info(f"Received {request}")
+ chat = DbChatEntry()
+ CHATS[chat.id] = chat
+ return CreateChatResponse(id=chat.id)
+
+
+@app.get("/chat/{id}")
+async def get_chat(id: str) -> protocol.Conversation:
+ """Allows a client to get the current state of a chat."""
+ return CHATS[id].conversation
+
+
+@app.post("/chat/{id}/message")
+async def create_message(id: str, message_request: MessageRequest, fastapi_request: fastapi.Request):
+ """Allows the client to stream the results of a request."""
+
+ chat = CHATS[id]
+ if not chat.conversation.is_prompter_turn:
+ raise fastapi.HTTPException(status_code=400, detail="Not your turn")
+ if chat.pending_message_request is not None:
+ raise fastapi.HTTPException(status_code=400, detail="Already pending")
+
+ chat.conversation.messages.append(
+ protocol.ConversationMessage(
+ text=message_request.message,
+ is_assistant=False,
+ )
+ )
+
+ chat.pending_message_request = message_request
+ chat.message_request_state = MessageRequestState.pending
+
+ async def event_generator():
+ result_data = []
+
+ try:
+ while True:
+ if await fastapi_request.is_disconnected():
+ logger.warning("Client disconnected")
+ break
+
+ item = await redisClient.blpop(chat.id, 1)
+ if item is None:
+ continue
+
+ _, response_packet_str = item
+ response_packet = inference.WorkResponsePacket.parse_raw(response_packet_str)
+ result_data.append(response_packet)
+
+ if response_packet.is_end:
+ break
+
+ yield {
+ "retry": settings.sse_retry_timeout,
+ "data": TokenResponseEvent(token=response_packet.token).json(),
+ }
+ logger.info(f"Finished streaming {chat.id} {len(result_data)=}")
+ except Exception:
+ logger.exception(f"Error streaming {chat.id}")
+
+ chat.conversation.messages.append(
+ protocol.ConversationMessage(
+ text="".join([d.token for d in result_data[:-1]]),
+ is_assistant=True,
+ )
+ )
+ chat.pending_message_request = None
+
+ return EventSourceResponse(event_generator())
+
+
+@app.websocket("/work")
+async def work(websocket: fastapi.WebSocket):
+ await websocket.accept()
+ worker_config = inference.WorkerConfig.parse_raw(await websocket.receive_text())
+ while True:
+ # find a pending task that matches the worker's config
+ # could also be implemented using task queues
+ # but general compatibility matching is tricky
+ for chat in CHATS.values():
+ if (request := chat.pending_message_request) is not None:
+ if chat.message_request_state == MessageRequestState.pending:
+ if request.compatible_with(worker_config):
+ break
+ else:
+ logger.debug("No pending tasks")
+ await asyncio.sleep(1)
+ continue
+
+ chat.message_request_state = MessageRequestState.in_progress
+
+ work_request = inference.WorkRequest(
+ conversation=chat.conversation,
+ model_name=request.model_name,
+ max_new_tokens=request.max_new_tokens,
+ )
+
+ logger.info(f"Created {work_request}")
+ try:
+ await websocket.send_text(work_request.json())
+ while True:
+ # maybe unnecessary to parse and re-serialize
+ # could just pass the raw string and mark end via empty string
+ response_packet = inference.WorkResponsePacket.parse_raw(await websocket.receive_text())
+ await redisClient.rpush(chat.id, response_packet.json())
+ if response_packet.is_end:
+ break
+ except fastapi.WebSocketException:
+ # TODO: handle this better
+ logger.exception(f"Websocket closed during handling of {chat.id}")
+
+ chat.message_request_state = MessageRequestState.complete
diff --git a/inference/server/requirements.txt b/inference/server/requirements.txt
new file mode 100644
index 0000000000..e0a00339da
--- /dev/null
+++ b/inference/server/requirements.txt
@@ -0,0 +1,6 @@
+fastapi[all]
+loguru
+pydantic
+redis
+sse-starlette
+websockets
diff --git a/inference/text-client/__main__.py b/inference/text-client/__main__.py
new file mode 100644
index 0000000000..bf1f8b029b
--- /dev/null
+++ b/inference/text-client/__main__.py
@@ -0,0 +1,40 @@
+"""Simple REPL frontend."""
+
+import json
+
+import requests
+import sseclient
+import typer
+
+app = typer.Typer()
+
+
+@app.command()
+def main(backend_url: str = "http://127.0.0.1:8000"):
+ """Simple REPL client."""
+ chat_id = requests.post(f"{backend_url}/chat", json={}).json()["id"]
+ while True:
+ message = typer.prompt("User").strip()
+
+ # wait for stream to be ready
+ # could implement a queue position indicator
+ # could be implemented with long polling
+ # but server load needs to be considered
+ response = requests.post(
+ f"{backend_url}/chat/{chat_id}/message",
+ json={"message": message},
+ stream=True,
+ headers={"Accept": "text/event-stream"},
+ )
+ response.raise_for_status()
+
+ client = sseclient.SSEClient(response)
+ print("Assistant: ", end="", flush=True)
+ for event in client.events():
+ data = json.loads(event.data)
+ print(data["token"], end="", flush=True)
+ print()
+
+
+if __name__ == "__main__":
+ app()
diff --git a/inference/text-client/requirements.txt b/inference/text-client/requirements.txt
new file mode 100644
index 0000000000..8d7bff7dd3
--- /dev/null
+++ b/inference/text-client/requirements.txt
@@ -0,0 +1,3 @@
+requests
+sseclient-py
+typer
diff --git a/inference/worker/__main__.py b/inference/worker/__main__.py
new file mode 100644
index 0000000000..ad5e5cefbc
--- /dev/null
+++ b/inference/worker/__main__.py
@@ -0,0 +1,79 @@
+import re
+import time
+
+import rel
+import torch
+import typer
+import websocket
+from loguru import logger
+from oasst_shared.schemas import inference, protocol
+from transformers import pipeline
+
+app = typer.Typer()
+
+
+@app.command()
+def main(
+ backend_url: str = "ws://localhost:8000",
+ model_name: str = "distilgpt2",
+):
+ pipe = pipeline("text-generation", model=model_name)
+
+ def on_open(ws: websocket.WebSocket):
+ worker_config = inference.WorkerConfig(model_name=model_name)
+ ws.send(worker_config.json())
+
+ def on_message(ws: websocket.WebSocket, message: str):
+ # TODO: what if this comes in, but one is already in progress?
+ # also need to think of enabling batching
+ work_request = inference.WorkRequest.parse_raw(message)
+
+ def _prepare_message(message: protocol.ConversationMessage) -> str:
+ prefix = "Assistant: " if message.is_assistant else "User: "
+ return prefix + message.text
+
+ # construct prompt
+ messages = [_prepare_message(message) for message in work_request.conversation.messages]
+
+ prompt = "\n".join(messages) + "\nAssistant:"
+
+ # TODO: replace this with incremental generation
+ torch.manual_seed(work_request.seed)
+ model_output = pipe(prompt, max_new_tokens=work_request.max_new_tokens, do_sample=True, return_full_text=False)[
+ 0
+ ]["generated_text"]
+ model_output = model_output.strip()
+
+ # fake streaming
+ split_idcs = [m.start() for m in re.finditer(r"([\w:]+)", model_output)]
+ pieces = [model_output[a:b] for a, b in zip([0] + split_idcs, split_idcs + [None])]
+ for piece in pieces:
+ if not piece:
+ continue
+ if piece.strip() in ("User:", "Assistant:"):
+ break
+ ws.send(inference.WorkResponsePacket(token=piece).json())
+ time.sleep(0.1)
+ ws.send(inference.WorkResponsePacket(is_end=True).json())
+
+ def on_error(ws: websocket.WebSocket, error: Exception):
+ logger.error(f"Connection error: {error}")
+
+ def on_close(ws: websocket.WebSocket, close_status_code: int, close_msg: str):
+ logger.warning(f"Connection closed: {close_status_code=} {close_msg=}")
+
+ ws = websocket.WebSocketApp(
+ f"{backend_url}/work",
+ on_message=on_message,
+ on_error=on_error,
+ on_close=on_close,
+ on_open=on_open,
+ )
+
+ ws.run_forever(dispatcher=rel, reconnect=5)
+ rel.signal(2, rel.abort)
+ rel.dispatch()
+
+
+if __name__ == "__main__":
+ app()
diff --git a/inference/worker/requirements.txt b/inference/worker/requirements.txt
new file mode 100644
index 0000000000..c248c6529f
--- /dev/null
+++ b/inference/worker/requirements.txt
@@ -0,0 +1,6 @@
+loguru
+rel
+torch
+transformers
+typer
+websocket-client
diff --git a/oasst-shared/oasst_shared/schemas/inference.py b/oasst-shared/oasst_shared/schemas/inference.py
new file mode 100644
index 0000000000..0acb5014aa
--- /dev/null
+++ b/oasst-shared/oasst_shared/schemas/inference.py
@@ -0,0 +1,21 @@
+import random
+
+import pydantic
+
+from . import protocol
+
+
+class WorkerConfig(pydantic.BaseModel):
+ model_name: str = "distilgpt2"
+
+
+class WorkRequest(pydantic.BaseModel):
+ conversation: protocol.Conversation = pydantic.Field(..., repr=False)
+ model_name: str = "distilgpt2"
+ max_new_tokens: int = 100
+ seed: int = pydantic.Field(default_factory=lambda: random.randint(0, 2**32 - 1))
+
+
+class WorkResponsePacket(pydantic.BaseModel):
+ token: str | None = None
+ is_end: bool = False
diff --git a/oasst-shared/oasst_shared/schemas/protocol.py b/oasst-shared/oasst_shared/schemas/protocol.py
index f2164e8f74..20bbdf9b4c 100644
--- a/oasst-shared/oasst_shared/schemas/protocol.py
+++ b/oasst-shared/oasst_shared/schemas/protocol.py
@@ -64,6 +64,18 @@ class Conversation(BaseModel):
messages: list[ConversationMessage] = []
+ def __len__(self):
+ return len(self.messages)
+
+ @property
+ def is_prompter_turn(self) -> bool:
+ if len(self) == 0:
+ return True
+ last_message = self.messages[-1]
+ if last_message.is_assistant:
+ return True
+ return False
+
class Message(ConversationMessage):
parent_id: Optional[UUID] = None
| This PR introduces:
- A server for coordination
- A minimal worker
- A text client
all building on redis lists to stream data as it is being produced | https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/869 | 2023-01-20T22:43:12Z | 2023-01-21T21:38:18Z | 2023-01-21T21:38:18Z | 2023-01-21T21:38:19Z | 3,697 | LAION-AI/Open-Assistant | 37,432 |
Fix the sequence-parallelism for the dense model architecture | diff --git a/deepspeed/runtime/config.py b/deepspeed/runtime/config.py
index c31b9671296f..9fb9eba44a38 100755
--- a/deepspeed/runtime/config.py
+++ b/deepspeed/runtime/config.py
@@ -238,8 +238,10 @@ def get_sparse_gradients_enabled(param_dict):
return get_scalar_param(param_dict, SPARSE_GRADIENTS, SPARSE_GRADIENTS_DEFAULT)
-def get_communication_data_type(param_dict):
- val = get_scalar_param(param_dict, COMMUNICATION_DATA_TYPE, COMMUNICATION_DATA_TYPE_DEFAULT)
+def get_communication_data_type(param_dict,
+ comm_type=COMMUNICATION_DATA_TYPE,
+ comm_data_type_default=COMMUNICATION_DATA_TYPE_DEFAULT):
+ val = get_scalar_param(param_dict, comm_type, comm_data_type_default)
val = val.lower() if val is not None else val
if val is None:
return val # we must determine it by other parameters
@@ -784,6 +786,8 @@ def _initialize_params(self, param_dict):
self.disable_allgather = get_disable_allgather(param_dict)
self.communication_data_type = get_communication_data_type(param_dict)
+ self.seq_parallel_communication_data_type = get_communication_data_type(
+ param_dict, SEQ_PARALLEL_COMMUNICATION_DATA_TYPE, SEQ_PARALLEL_COMMUNICATION_DATA_TYPE_DEFAULT)
self.prescale_gradients = get_prescale_gradients(param_dict)
self.gradient_predivide_factor = get_gradient_predivide_factor(param_dict)
self.sparse_gradients_enabled = get_sparse_gradients_enabled(param_dict)
diff --git a/deepspeed/runtime/constants.py b/deepspeed/runtime/constants.py
index 0bdac2557847..cc493ee007c5 100755
--- a/deepspeed/runtime/constants.py
+++ b/deepspeed/runtime/constants.py
@@ -223,6 +223,19 @@
COMMUNICATION_DATA_TYPE = "communication_data_type"
COMMUNICATION_DATA_TYPE_DEFAULT = None
+###########################################################
+# Gradient communication data type for sequence parallelism
+###########################################################
+# Supported types: ['fp16', 'bf16','fp32']
+# Default value is fp32
+# Users can configure in ds_config.json as below example:
+SEQ_PARALLEL_COMMUNICATION_DATA_TYPE_FORMAT = '''
+Optional comm data type for seq paralleism should be set as:
+"seq_parallel_communication_data_type": "fp32"
+'''
+SEQ_PARALLEL_COMMUNICATION_DATA_TYPE = "seq_parallel_comm_data_type"
+SEQ_PARALLEL_COMMUNICATION_DATA_TYPE_DEFAULT = "fp32"
+
#########################################
# Scale/predivide gradients before allreduce
#########################################
diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index d2cb93394a53..e5f9d0ec8d03 100644
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -808,6 +808,10 @@ def communication_data_type(self):
return torch.float32
+ @communication_data_type.setter
+ def communication_data_type(self, value):
+ self._config.communication_data_type = value
+
def postscale_gradients(self):
return not self._config.prescale_gradients
@@ -1114,6 +1118,9 @@ def _configure_distributed_model(self, model):
self.mp_world_size = groups._get_model_parallel_world_size()
self.expert_parallel_group = groups._get_expert_parallel_group_dict()
self.expert_data_parallel_group = groups._get_expert_data_parallel_group_dict()
+ self.sequence_parallel_size = groups._get_sequence_parallel_world_size()
+ if self.sequence_parallel_size > 1:
+ self.communication_data_type = self._config.seq_parallel_communication_data_type
if not (self.amp_enabled() or is_zero_init_model):
self._broadcast_model()
@@ -2370,7 +2377,7 @@ def _reduce_non_expert_gradients(self, grads, elements_per_buffer):
if self.pipeline_parallelism:
dp_group = self.mpu.get_data_parallel_group()
else:
- dp_group = groups._get_data_parallel_group()
+ dp_group = groups._get_sequence_data_parallel_group()
if bucket_type == SparseTensor.type():
self.sparse_allreduce_no_retain(bucket, dp_group=dp_group)
@@ -2431,9 +2438,10 @@ def sparse_allreduce(self, sparse, dp_group):
if self.postscale_gradients():
if self.gradient_average:
- values.mul_(self.gradient_predivide_factor() / dist.get_world_size(group=dp_group))
+ values.mul_(self.gradient_predivide_factor() /
+ (dist.get_world_size(group=dp_group) / float(self.sequence_parallel_size)))
else:
- values.mul_(1. / dist.get_world_size(group=dp_group))
+ values.mul_(1. / (dist.get_world_size(group=dp_group) / float(self.sequence_parallel_size)))
indices_device_list = self.sparse_all_gather(indices, dp_group)
values_device_list = self.sparse_all_gather(values, dp_group)
diff --git a/deepspeed/runtime/zero/stage3.py b/deepspeed/runtime/zero/stage3.py
index 3c5128744848..38539ba57033 100644
--- a/deepspeed/runtime/zero/stage3.py
+++ b/deepspeed/runtime/zero/stage3.py
@@ -219,6 +219,7 @@ def __init__(
self.reduce_scatter = reduce_scatter
self.dp_process_group = self.parameter_offload.dp_process_group
+ self.sequence_parallel_size = groups._get_sequence_parallel_world_size()
self.all2all_process_group = all2all_process_group
@@ -1177,7 +1178,7 @@ def __avg_scatter_contiguous_grads(self, buffer_to_reduce: Tensor) -> List[Tenso
world_sz = dist.get_world_size(self.dp_process_group)
rank = dist.get_rank(self.dp_process_group)
- buffer_to_reduce.div_(world_sz)
+ buffer_to_reduce.div_(world_sz / float(self.sequence_parallel_size))
dist.all_reduce(buffer_to_reduce, group=self.dp_process_group)
@@ -1476,7 +1477,7 @@ def allreduce_bucket(self, bucket, rank=None, log=None):
if communication_data_type != tensor.dtype:
tensor_to_allreduce = tensor.to(communication_data_type)
- tensor_to_allreduce.div_(dist.get_world_size(group=self.dp_process_group))
+ tensor_to_allreduce.div_(dist.get_world_size(group=self.dp_process_group) / float(self.sequence_parallel_size))
if rank is None:
# "All Reducing"
diff --git a/deepspeed/runtime/zero/stage_1_and_2.py b/deepspeed/runtime/zero/stage_1_and_2.py
index 32fe74b02a58..c3b4160ebf31 100755
--- a/deepspeed/runtime/zero/stage_1_and_2.py
+++ b/deepspeed/runtime/zero/stage_1_and_2.py
@@ -31,6 +31,7 @@
from deepspeed.utils import link_hp_params
from deepspeed.checkpoint import enable_universal_checkpoint
+from deepspeed.utils import groups
# Toggle this to true to enable correctness test
# with gradient partitioning and without
pg_correctness_test = False
@@ -182,7 +183,7 @@ def __init__(self,
self.device = get_accelerator().current_device_name() if not self.cpu_offload else 'cpu'
self.dp_process_group = dp_process_group
-
+ self.sequence_parallel_size = groups._get_sequence_parallel_world_size()
#expert parallel group
self.ep_process_group = expert_parallel_group
@@ -941,9 +942,10 @@ def gradient_reduction_w_predivide(self, tensor):
dist.all_reduce(tensor_to_allreduce, group=self.dp_process_group)
if self.gradient_predivide_factor != dp_world_size:
- tensor_to_allreduce.mul_(self.gradient_predivide_factor / dp_world_size)
+ tensor_to_allreduce.mul_(self.gradient_predivide_factor /
+ (dp_world_size / float(self.sequence_parallel_size)))
else:
- tensor_to_allreduce.div_(dp_world_size)
+ tensor_to_allreduce.div_(dp_world_size / float(self.sequence_parallel_size))
dist.all_reduce(tensor_to_allreduce, group=self.dp_process_group)
if self.communication_data_type != tensor.dtype and tensor is not tensor_to_allreduce:
@@ -985,7 +987,7 @@ def average_tensor(self, tensor):
if self.ipg_bucket_has_moe_params:
process_group = self.expert_dp_process_group[param.group_name] if is_moe_param(
param) else self.dp_process_group
- grad_reduc.data.div_(dist.get_world_size(group=process_group))
+ grad_reduc.data.div_(dist.get_world_size(group=process_group) / float(self.sequence_parallel_size))
partition_ids = self.param_to_partition_ids[i][param_id]
assert all([p_id < dist.get_world_size(group=process_group) for p_id in partition_ids
@@ -1025,7 +1027,7 @@ def average_tensor(self, tensor):
prev_id, prev_process_group = partition_id, process_group
if not self.ipg_bucket_has_moe_params:
- tensor.div_(dist.get_world_size(group=self.dp_process_group))
+ tensor.div_(dist.get_world_size(group=self.dp_process_group) / float(self.sequence_parallel_size))
tensor_to_reduce = tensor
if self.communication_data_type != tensor.dtype:
@@ -1395,7 +1397,7 @@ def allreduce_bucket(self, bucket, rank=None, log=None):
tensor_to_allreduce = tensor
- if pg_correctness_test:
+ if pg_correctness_test or self.sequence_parallel_size > 1:
communication_data_type = torch.float32
else:
communication_data_type = self.communication_data_type
@@ -1403,7 +1405,7 @@ def allreduce_bucket(self, bucket, rank=None, log=None):
if communication_data_type != tensor.dtype:
tensor_to_allreduce = tensor.to(communication_data_type)
- tensor_to_allreduce.div_(dist.get_world_size(group=self.dp_process_group))
+ tensor_to_allreduce.div_(dist.get_world_size(group=self.dp_process_group) / float(self.sequence_parallel_size))
if rank is None:
# "All Reducing"
| This PR fixes some convergence issues for when SP > 1.
We have seen that the gradients were lower when using SP=2 for a dense model, and by further investigation, we find that the gradients were scaled with the total world size, however, they should have been summed across the SP ranks and averaged on the DP-world. Here is the initial curve comparing grad norm of SP=1 (grey) vs SP=2 (green):

After adding the fix for scaling the gradients using the right scale, we get parity for the grad_norm, however, it keeps gradually increasing over time, and results in inferior LM validation (orange: SP1, grey: SP-2).

Fortunately, we are able to fix this by increasing the precision of the gradients before summing them up. The following curves show the LM validation loss of different cases of debugging the SP convergence issue (orange: SP1, grey: SP-2(bf16 gradient), blue: SP2(fp32 gradient)):
<img width="788" alt="image" src="https://github.com/microsoft/DeepSpeed/assets/44502768/a456d78b-d711-4476-b80b-cfa7d6a2a492">
cc: @samadejacobs @tohtana | https://api.github.com/repos/microsoft/DeepSpeed/pulls/4530 | 2023-10-17T19:24:30Z | 2023-10-25T23:57:21Z | 2023-10-25T23:57:21Z | 2023-10-26T00:34:29Z | 2,248 | microsoft/DeepSpeed | 10,081 |
[MRG] include default values in SparseCoder class doc | diff --git a/sklearn/decomposition/_dict_learning.py b/sklearn/decomposition/_dict_learning.py
index 0eb69f5b5a74c..29839157ca33f 100644
--- a/sklearn/decomposition/_dict_learning.py
+++ b/sklearn/decomposition/_dict_learning.py
@@ -952,7 +952,7 @@ class SparseCoder(SparseCodingMixin, BaseEstimator):
normalized to unit norm.
transform_algorithm : {'lasso_lars', 'lasso_cd', 'lars', 'omp', \
- 'threshold'}
+ 'threshold'}, default='omp'
Algorithm used to transform the data:
lars: uses the least angle regression method (linear_model.lars_path)
lasso_lars: uses Lars to compute the Lasso solution
@@ -963,12 +963,12 @@ class SparseCoder(SparseCodingMixin, BaseEstimator):
threshold: squashes to zero all coefficients less than alpha from
the projection ``dictionary * X'``
- transform_n_nonzero_coefs : int, ``0.1 * n_features`` by default
+ transform_n_nonzero_coefs : int, default=0.1*n_features
Number of nonzero coefficients to target in each column of the
solution. This is only used by `algorithm='lars'` and `algorithm='omp'`
and is overridden by `alpha` in the `omp` case.
- transform_alpha : float, 1. by default
+ transform_alpha : float, default=1.
If `algorithm='lasso_lars'` or `algorithm='lasso_cd'`, `alpha` is the
penalty applied to the L1 norm.
If `algorithm='threshold'`, `alpha` is the absolute value of the
@@ -977,23 +977,23 @@ class SparseCoder(SparseCodingMixin, BaseEstimator):
the reconstruction error targeted. In this case, it overrides
`n_nonzero_coefs`.
- split_sign : bool, False by default
+ split_sign : bool, default=False
Whether to split the sparse feature vector into the concatenation of
its negative part and its positive part. This can improve the
performance of downstream classifiers.
- n_jobs : int or None, optional (default=None)
+ n_jobs : int or None, default=None
Number of parallel jobs to run.
``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
``-1`` means using all processors. See :term:`Glossary <n_jobs>`
for more details.
- positive_code : bool
+ positive_code : bool, default=False
Whether to enforce positivity when finding the code.
.. versionadded:: 0.20
- transform_max_iter : int, optional (default=1000)
+ transform_max_iter : int, default=1000
Maximum number of iterations to perform if `algorithm='lasso_cd'` or
`lasso_lars`.
| This PR includes default values to the documentation of the SparseCoder class. It also changes the existing default values to the format "default=value". | https://api.github.com/repos/scikit-learn/scikit-learn/pulls/15600 | 2019-11-11T22:16:17Z | 2019-11-17T09:17:14Z | 2019-11-17T09:17:14Z | 2019-12-02T03:11:17Z | 666 | scikit-learn/scikit-learn | 46,567 |
[tune] Remove extra check | diff --git a/python/ray/tune/tune.py b/python/ray/tune/tune.py
index 7660075aabd90..ac3d9cae08bc3 100644
--- a/python/ray/tune/tune.py
+++ b/python/ray/tune/tune.py
@@ -95,10 +95,13 @@ def run_experiments(experiments,
print(runner.debug_string(max_debug=99999))
+ errored_trials = []
for trial in runner.get_trials():
- # TODO(rliaw): What about errored?
if trial.status != Trial.TERMINATED:
- raise TuneError("Trial did not complete", trial)
+ errored_trials += [trial]
+
+ if errored_trials:
+ raise TuneError("Trials did not complete", errored_trials)
wait_for_log_sync()
return runner.get_trials()
| ## What do these changes do?
Removes an extra check after all experiments have finished. Allows user to go through all results even if some trials errorred out.
@vlad17 | https://api.github.com/repos/ray-project/ray/pulls/2292 | 2018-06-22T17:47:00Z | 2018-06-29T03:23:39Z | 2018-06-29T03:23:39Z | 2018-06-29T03:23:42Z | 195 | ray-project/ray | 19,857 |
style: file-metadata word-break | diff --git a/style.css b/style.css
index e336e79df2e..bbfb7d39557 100644
--- a/style.css
+++ b/style.css
@@ -1009,6 +1009,8 @@ div.block.gradio-box.edit-user-metadata {
.edit-user-metadata .file-metadata th, .edit-user-metadata .file-metadata td{
padding: 0.3em 1em;
+ overflow-wrap: anywhere;
+ word-break: break-word;
}
.edit-user-metadata .wrap.translucent{
| ## Description
* a simple description of what you're trying to accomplish
* a summary of changes in code
* which issues it fixes, if any
## Screenshots/videos:

vs

## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I have performed a self-review of my own code
- [x] My code follows the [style guidelines](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing#code-style)
- [x] My code passes [tests](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Tests)
| https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/12837 | 2023-08-28T22:22:59Z | 2023-08-29T05:52:58Z | 2023-08-29T05:52:58Z | 2023-08-29T05:52:58Z | 118 | AUTOMATIC1111/stable-diffusion-webui | 40,130 |
[embeddings] more detailed timer | diff --git a/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py b/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py
index 5babeb009267..725daff40c7f 100644
--- a/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py
+++ b/colossalai/nn/parallel/layers/cache_embedding/cache_mgr.py
@@ -91,6 +91,7 @@ def __init__(
dtype=torch.long).fill_(sys.maxsize),
persistent=False)
self._elapsed_dict = {}
+ self._show_cache_miss = True
self._reset_comm_stats()
def _reset_comm_stats(self):
@@ -99,6 +100,9 @@ def _reset_comm_stats(self):
self._cpu_to_cuda_numel = 0
self._cuda_to_cpu_numel = 0
+ if self._show_cache_miss:
+ self._cache_miss = 0
+ self._total_cache = 0
@contextmanager
def timer(self, name):
@@ -268,6 +272,10 @@ def flush(self):
self.inverted_cached_idx.index_fill_(0, row_ids, -1)
self._cuda_available_row_num += slots.numel()
+ if self._show_cache_miss:
+ self._cache_miss = 0
+ self._total_cache = 0
+
if self._evict_strategy == EvictionStrategy.LFU:
self.freq_cnter.fill_(sys.maxsize)
assert self._cuda_available_row_num == self.cuda_row_num
@@ -275,14 +283,14 @@ def flush(self):
assert torch.all(self.cached_idx_map == -1).item()
def print_comm_stats(self):
- if self._cuda_to_cpu_numel > 0 and "3_2_2_evict_out_gpu_to_cpu_copy" in self._elapsed_dict:
- elapsed = self._elapsed_dict["3_2_2_evict_out_gpu_to_cpu_copy"]
+ if self._cuda_to_cpu_numel > 0 and "3_evict_out" in self._elapsed_dict:
+ elapsed = self._elapsed_dict["3_evict_out"]
print(
f"CUDA->CPU BWD {self._cuda_to_cpu_numel * self.elem_size_in_byte / 1e6 / elapsed} MB/s {self._cuda_to_cpu_numel / 1e6} M elem"
)
print(f'cuda_to_cpu_elapse {elapsed} sec')
- if self._cpu_to_cuda_numel > 0 and "3_4_2_evict_in_gpu_to_cpu_copy" in self._elapsed_dict:
- elapsed = self._elapsed_dict["3_4_2_evict_in_gpu_to_cpu_copy"]
+ if self._cpu_to_cuda_numel > 0 and "5_evict_in" in self._elapsed_dict:
+ elapsed = self._elapsed_dict["5_evict_in"]
print(
f"CPU->CUDA BWD {self._cpu_to_cuda_numel * self.elem_size_in_byte / 1e6 / elapsed} MB/s {self._cpu_to_cuda_numel / 1e6} M elem"
)
@@ -291,6 +299,8 @@ def print_comm_stats(self):
for k, v in self._elapsed_dict.items():
print(f'{k}: {v}')
+ print(f'cache miss ratio {self._cache_miss / self._total_cache}')
+
@torch.no_grad()
def _id_to_cached_cuda_id(self, ids: torch.Tensor) -> torch.Tensor:
"""
@@ -315,41 +325,45 @@ def prepare_ids(self, ids: torch.Tensor) -> torch.Tensor:
torch.Tensor: indices on the cuda_cached_weight.
"""
torch.cuda.synchronize()
- with self.timer("1_unique_indices") as timer:
- with record_function("(cache) get unique indices"):
- cpu_row_idxs, repeat_times = torch.unique(self.idx_map.index_select(0, ids), return_counts=True)
-
- assert len(cpu_row_idxs) <= self.cuda_row_num, \
- f"You move {len(cpu_row_idxs)} embedding rows from CPU to CUDA. " \
- f"It is larger than the capacity of the cache, which at most contains {self.cuda_row_num} rows, " \
- f"Please increase cuda_row_num or decrease the training batch size."
- self.evict_backlist = cpu_row_idxs
- torch.cuda.synchronize()
-
- # O(cache ratio)
- with self.timer("2_cpu_row_idx") as timer:
- with record_function("(cache) get cpu row idxs"):
- comm_cpu_row_idxs = cpu_row_idxs[torch.isin(cpu_row_idxs, self.cached_idx_map, invert=True)]
-
- self.num_hits_history.append(len(cpu_row_idxs) - len(comm_cpu_row_idxs))
- self.num_miss_history.append(len(comm_cpu_row_idxs))
- self.num_write_back_history.append(0)
-
- # move sure the cuda rows will not be evicted!
- with self.timer("3_prepare_rows_on_cuda") as timer:
+ with self.timer("cache_op") as gtimer:
+ # identify cpu rows to cache
+ with self.timer("1_identify_cpu_row_idxs") as timer:
+ with record_function("(cache) get unique indices"):
+ if self._evict_strategy == EvictionStrategy.LFU:
+ cpu_row_idxs, repeat_times = torch.unique(ids, return_counts=True)
+ else:
+ cpu_row_idxs, repeat_times = torch.unique(self.idx_map.index_select(0, ids), return_counts=True)
+
+ assert len(cpu_row_idxs) <= self.cuda_row_num, \
+ f"You move {len(cpu_row_idxs)} embedding rows from CPU to CUDA. " \
+ f"It is larger than the capacity of the cache, which at most contains {self.cuda_row_num} rows, " \
+ f"Please increase cuda_row_num or decrease the training batch size."
+ self.evict_backlist = cpu_row_idxs
+ tmp = torch.isin(cpu_row_idxs, self.cached_idx_map, invert=True)
+ comm_cpu_row_idxs = cpu_row_idxs[tmp]
+
+ if self._show_cache_miss:
+ self._cache_miss += torch.sum(repeat_times[tmp])
+ self._total_cache += ids.numel()
+
+ self.num_hits_history.append(len(cpu_row_idxs) - len(comm_cpu_row_idxs))
+ self.num_miss_history.append(len(comm_cpu_row_idxs))
+ self.num_write_back_history.append(0)
+
+ # move sure the cuda rows will not be evicted!
with record_function("(cache) prepare_rows_on_cuda"):
self._prepare_rows_on_cuda(comm_cpu_row_idxs)
- self.evict_backlist = torch.tensor([], device=cpu_row_idxs.device, dtype=cpu_row_idxs.dtype)
+ self.evict_backlist = torch.tensor([], device=cpu_row_idxs.device, dtype=cpu_row_idxs.dtype)
- with self.timer("4_cpu_to_gpu_row_idxs") as timer:
- with record_function("(cache) embed cpu rows idx -> cache gpu row idxs"):
- gpu_row_idxs = self._id_to_cached_cuda_id(ids)
+ with self.timer("6_update_cache") as timer:
+ with record_function("6_update_cache"):
+ gpu_row_idxs = self._id_to_cached_cuda_id(ids)
- # update for LFU.
- if self._evict_strategy == EvictionStrategy.LFU:
- unique_gpu_row_idxs = self.inverted_cached_idx[cpu_row_idxs]
- self.freq_cnter.scatter_add_(0, unique_gpu_row_idxs, repeat_times)
+ # update for LFU.
+ if self._evict_strategy == EvictionStrategy.LFU:
+ unique_gpu_row_idxs = self.inverted_cached_idx[cpu_row_idxs]
+ self.freq_cnter.scatter_add_(0, unique_gpu_row_idxs, repeat_times)
return gpu_row_idxs
@@ -377,8 +391,7 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
raise NotImplemented
if evict_num > 0:
- torch.cuda.synchronize()
- with self.timer("3_1_evict_prepare") as timer:
+ with self.timer("2_identify_cuda_row_idxs") as timer:
mask_cpu_row_idx = torch.isin(self.cached_idx_map, self.evict_backlist)
invalid_idxs = torch.nonzero(mask_cpu_row_idx).squeeze(1)
if self._evict_strategy == EvictionStrategy.DATASET:
@@ -388,7 +401,7 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
backup_idxs = self.cached_idx_map[mask_cpu_row_idx].clone()
self.cached_idx_map.index_fill_(0, invalid_idxs, -2)
- with self.timer("3_1_1_find_evict_gpu_idxs_elapsed") as timer:
+ with self.timer("2_1_find_evict_gpu_idxs") as timer:
evict_gpu_row_idxs = self._find_evict_gpu_idxs(evict_num)
# move evict out rows to cpu
@@ -401,11 +414,11 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
self.cached_idx_map.index_copy_(0, invalid_idxs, backup_idxs)
elif self._evict_strategy == EvictionStrategy.LFU:
- with self.timer("3_1_0_backup_freqs") as timer:
+ with self.timer("2_1_backup_freqs") as timer:
backup_freqs = self.freq_cnter[invalid_idxs].clone()
self.freq_cnter.index_fill_(0, invalid_idxs, sys.maxsize)
- with self.timer("3_1_1_find_evict_gpu_idxs_elapsed") as timer:
+ with self.timer("2_2_find_evict_gpu_idxs") as timer:
evict_gpu_row_idxs = self._find_evict_gpu_idxs(evict_num)
if self._async_copy:
@@ -414,12 +427,13 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
evict_out_rows_cpu = torch.empty_like(evict_out_rows_gpu, device='cpu', pin_memory=True)
with torch.cuda.stream(None):
evict_out_rows_cpu.copy_(evict_out_rows_gpu, non_blocking=True)
- with self.timer("3_1_2_find_evict_index_copy") as timer:
+
+ with self.timer("2_3_revert_freqs") as timer:
self.freq_cnter.index_copy_(0, invalid_idxs, backup_freqs)
evict_info = self.cached_idx_map[evict_gpu_row_idxs]
- with self.timer("3_2_evict_out_elapse") as timer:
+ with self.timer("3_evict_out") as timer:
if self.buffer_size > 0:
self.limit_buff_index_copyer.index_copy(0,
src_index=evict_gpu_row_idxs,
@@ -432,13 +446,13 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
if self._async_copy:
_wait_for_data(evict_out_rows_cpu, None)
else:
- with self.timer("3_2_1_evict_out_index_select") as timer:
+ with self.timer("3_1_evict_out_index_select") as timer:
evict_out_rows_cpu = self.cuda_cached_weight.view(self.cuda_row_num,
-1).index_select(0, evict_gpu_row_idxs)
- with self.timer("3_2_2_evict_out_gpu_to_cpu_copy") as timer:
+ with self.timer("3_2_evict_out_gpu_to_cpu_copy") as timer:
evict_out_rows_cpu = evict_out_rows_cpu.cpu()
- with self.timer("3_2_2_evict_out_index_select") as timer:
+ with self.timer("3_2_evict_out_cpu_copy") as timer:
self.weight.view(self.num_embeddings, -1).index_copy_(0, evict_info.cpu(), evict_out_rows_cpu)
self.cached_idx_map.index_fill_(0, evict_gpu_row_idxs, -1)
@@ -447,15 +461,15 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
self._cuda_available_row_num += evict_num
weight_size = evict_gpu_row_idxs.numel() * self.embedding_dim
- self._cuda_to_cpu_numel += weight_size
+ self._cuda_to_cpu_numel += weight_size
# print(f"evict embedding weight: {weight_size*self.elem_size_in_byte/1e6:.2f} MB")
# slots of cuda weight to evict in
- with self.timer("3_3_non_zero") as timer:
+ with self.timer("4_identify_cuda_slot") as timer:
slots = torch.nonzero(self.cached_idx_map == -1).squeeze(1)[:cpu_row_idxs.numel()]
# TODO wait for optimize
- with self.timer("3_4_evict_in_elapse") as timer:
+ with self.timer("5_evict_in") as timer:
# Here also allocate extra memory on CUDA. #cpu_row_idxs
if self.buffer_size > 0:
self.limit_buff_index_copyer.index_copy(0,
@@ -467,20 +481,20 @@ def _prepare_rows_on_cuda(self, cpu_row_idxs: torch.Tensor) -> None:
if self._async_copy:
_wait_for_data(evict_in_rows_gpu, self._memcpy_stream)
else:
- with self.timer("3_4_1_evict_in_index_select") as timer:
+ with self.timer("5_1_evict_in_index_select") as timer:
# narrow index select to a subset of self.weight
# tmp = torch.narrow(self.weight.view(self.num_embeddings, -1), 0, min(cpu_row_idxs).cpu(), max(cpu_row_idxs) - min(cpu_row_idxs) + 1)
# evict_in_rows_gpu = tmp.index_select(0, cpu_row_idxs_copy - min(cpu_row_idxs).cpu())
evict_in_rows_gpu = self.weight.view(self.num_embeddings,
-1).index_select(0, cpu_row_idxs_copy).pin_memory()
- with self.timer("3_4_2_evict_in_gpu_to_cpu_copy") as timer:
+ with self.timer("5_2_evict_in_gpu_to_cpu_copy") as timer:
evict_in_rows_gpu = evict_in_rows_gpu.cuda()
- with self.timer("3_4_3_evict_in_index_copy") as timer:
+ with self.timer("5_3_evict_in_index_copy") as timer:
self.cuda_cached_weight.view(self.cuda_row_num, -1).index_copy_(0, slots, evict_in_rows_gpu)
- with self.timer("3_5_evict_in_elapse_final") as timer:
+ with self.timer("6_update_cache") as timer:
self.cached_idx_map[slots] = cpu_row_idxs
self.inverted_cached_idx.index_copy_(0, cpu_row_idxs, slots)
if self._evict_strategy == EvictionStrategy.LFU:
| https://api.github.com/repos/hpcaitech/ColossalAI/pulls/1692 | 2022-10-12T04:00:36Z | 2022-10-12T04:01:21Z | 2022-10-12T04:01:21Z | 2022-10-12T04:01:24Z | 3,322 | hpcaitech/ColossalAI | 11,375 |
|
Include plugin info in `--debug` output | diff --git a/CHANGELOG.md b/CHANGELOG.md
index ee0a89f6d4..ecdc4f489c 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -7,6 +7,7 @@ This project adheres to [Semantic Versioning](https://semver.org/).
- Fixed duplicate keys preservation of JSON data. ([#1163](https://github.com/httpie/httpie/issues/1163))
- Added support for formatting & coloring of JSON bodies preceded by non-JSON data (e.g., an XXSI prefix). ([#1130](https://github.com/httpie/httpie/issues/1130))
+- Installed plugins are now listed in `--debug` output. ([#1165](https://github.com/httpie/httpie/issues/1165))
## [2.5.0](https://github.com/httpie/httpie/compare/2.4.0...2.5.0) (2021-09-06)
diff --git a/docs/README.md b/docs/README.md
index 8814114bf9..c578afad15 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -1200,7 +1200,6 @@ Use one of these options to control output processing:
| `--pretty=format` | Apply formatting |
| `--pretty=none` | Disables output processing. Default for redirected output |
-
Formatting has the following effects:
- HTTP headers are sorted by name.
diff --git a/httpie/core.py b/httpie/core.py
index 9c9e3ce406..c3567219be 100644
--- a/httpie/core.py
+++ b/httpie/core.py
@@ -227,6 +227,8 @@ def print_debug_info(env: Environment):
])
env.stderr.write('\n\n')
env.stderr.write(repr(env))
+ env.stderr.write('\n\n')
+ env.stderr.write(repr(plugin_manager))
env.stderr.write('\n')
diff --git a/httpie/plugins/manager.py b/httpie/plugins/manager.py
index 23acd53f8b..420fb36bf2 100644
--- a/httpie/plugins/manager.py
+++ b/httpie/plugins/manager.py
@@ -4,6 +4,7 @@
from pkg_resources import iter_entry_points
+from ..utils import repr_dict
from . import AuthPlugin, ConverterPlugin, FormatterPlugin
from .base import BasePlugin, TransportPlugin
@@ -65,5 +66,13 @@ def get_converters(self) -> List[Type[ConverterPlugin]]:
def get_transport_plugins(self) -> List[Type[TransportPlugin]]:
return self.filter(TransportPlugin)
+ def __str__(self):
+ return repr_dict({
+ 'adapters': self.get_transport_plugins(),
+ 'auth': self.get_auth_plugins(),
+ 'converters': self.get_converters(),
+ 'formatters': self.get_formatters(),
+ })
+
def __repr__(self):
- return f'<PluginManager: {list(self)}>'
+ return f'<{type(self).__name__} {self}>'
| Closes #455.
Example:
```bash
$ http --debug pie.dev/get
HTTPie 2.6.0.dev0
Requests 2.26.0
Pygments 2.10.0
Python 3.9.7+ (heads/3.9:09390c837a, Sep 22 2021, 11:36:19)
[GCC 10.3.0]
/home/tiger-222/projects/httpie/venv39/bin/python
Linux 5.10.0-8-amd64
<Environment {'colors': 256,
'config': {'default_options': ['--style=monokai']},
'config_dir': PosixPath('/home/tiger-222/.httpie'),
'devnull': <property object at 0x7f1b74dbb130>,
'is_windows': False,
'log_error': <function Environment.log_error at 0x7f1b74da9d30>,
'program_name': '__main__.py',
'stderr': <_io.TextIOWrapper name='<stderr>' mode='w' encoding='utf-8'>,
'stderr_isatty': True,
'stdin': <_io.TextIOWrapper name='<stdin>' mode='r' encoding='utf-8'>,
'stdin_encoding': 'utf-8',
'stdin_isatty': True,
'stdout': <_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>,
'stdout_encoding': 'utf-8',
'stdout_isatty': True}>
<PluginManager {'adapters': [<class 'httpie_snapdsocket.SnapdSocketTransportPlugin'>],
'auth': [<class 'httpie.plugins.builtin.BasicAuthPlugin'>,
<class 'httpie.plugins.builtin.DigestAuthPlugin'>],
'converters': [],
'formatters': [<class 'httpie.output.formatters.headers.HeadersFormatter'>,
<class 'httpie.output.formatters.json.JSONFormatter'>,
<class 'httpie.output.formatters.xml.XMLFormatter'>,
<class 'httpie.output.formatters.colors.ColorFormatter'>]}>
>>> requests.request(**{'auth': None,
'data': RequestJSONDataDict(),
'headers': {'User-Agent': b'HTTPie/2.6.0.dev0'},
'method': 'get',
'params': <generator object MultiValueOrderedDict.items at 0x7f1b742d7510>,
'url': 'http://pie.dev/get'})
HTTP/1.1 200 OK
CF-Cache-Status: DYNAMIC
CF-RAY: 69347a9b088fedbf-CDG
Connection: keep-alive
Content-Encoding: gzip
Content-Type: application/json
Date: Thu, 23 Sep 2021 14:31:50 GMT
NEL: {"success_fraction":0,"report_to":"cf-nel","max_age":604800}
Report-To: {"endpoints":[{"url":"https:\/\/a.nel.cloudflare.com\/report\/v3?s=Pi%2Bew9tk41cRrv9swQiYxozWzBIwPtMk8%2F0ZpzyYLO%2B1PEhq8%2Fk%2BqO8heSXy5JBRXsdpx%2Bw0e1RskVMsoQztEdvWywJzn0JfU4Ct2sHm6VZ2AkPN9G0pZPg7"}],"group":"cf-nel","max_age":604800}
Server: cloudflare
Transfer-Encoding: chunked
access-control-allow-credentials: true
access-control-allow-origin: *
alt-svc: h3=":443"; ma=86400, h3-29=":443"; ma=86400, h3-28=":443"; ma=86400, h3-27=":443"; ma=86400
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip",
"Cdn-Loop": "cloudflare",
"Cf-Connecting-Ip": "89.159.87.157",
"Cf-Ipcountry": "FR",
"Cf-Ray": "69347a9b088fedbf-FRA",
"Cf-Visitor": "{\"scheme\":\"http\"}",
"Connection": "Keep-Alive",
"Host": "pie.dev",
"User-Agent": "HTTPie/2.6.0.dev0"
},
"origin": "89.159.87.157",
"url": "http://pie.dev/get"
}
``` | https://api.github.com/repos/httpie/cli/pulls/1165 | 2021-09-23T14:43:10Z | 2021-09-23T15:15:15Z | 2021-09-23T15:15:14Z | 2021-09-23T15:15:15Z | 692 | httpie/cli | 33,880 |
Adding documentation for Acrobot-v1 in docs/classic_control | diff --git a/docs/classic_control/acrobot.md b/docs/classic_control/acrobot.md
new file mode 100644
index 00000000000..e4289e7f63e
--- /dev/null
+++ b/docs/classic_control/acrobot.md
@@ -0,0 +1,112 @@
+Acrobot-v1
+---
+|Title|Action Type|Action Shape|Action Values|Observation Type| Observation Shape|Observation Values|Average Total Reward|Import|
+| ----------- | -----------| ----------- | -----------|-----------| ----------- | -----------| ----------- | -----------|
+|Acrobot-v1|Discrete|(2,)|(0,1,2)| Box |(6,)|[(-1,1),(-1,1), (-1, 1), (-1, 1), (-12.567, 12.567), (-28.274, 28.274)]| |`from gym.envs.classic_control import acrobot`|
+
+---
+
+### Description
+The Acrobot system includes two joints and two links, where the joint between the two links is actuated. Initially, the
+links are hanging downwards, and the goal is to swing the end of the lower link up to a given height by applying changes
+to torque on the actuated joint (middle).
+
+
+
+
+**Image**: two blue pendulum links connected by two green joints. The joint in between the two pendulum links is acted
+upon by the agent via changes in torque. The goal is to swing the end of the outer-link to reach the target height
+(black horizontal line above system).
+
+### Action Space
+
+The action is either applying +1, 0 or -1 torque on the joint between the two pendulum links.
+
+| Num | Action |
+|-----|------------------------|
+| 0 | apply -1 torque to the joint |
+| 1 | apply 0 torque to the joint |
+| 2 | apply 1 torque to the joint |
+
+### Observation Space
+
+The observation space gives information about the two rotational joint angles `theta1` and `theta2`, as well as their
+angular velocities:
+- `theta1` is the angle of the inner link joint, where an angle of 0 indicates the first link is pointing directly
+downwards.
+- `theta2` is *relative to the angle of the first link.* An angle of 0 corresponds to having the same angle between the
+two links.
+
+The angular velocities of `theta1` and `theta2` are bounded at ±4π, and ±9π respectively.
+The observation is a `ndarray` with shape `(6,)` where the elements correspond to the following:
+
+| Num | Observation | Min | Max |
+|-----|-----------------------|----------------------|--------------------|
+| 0 | Cosine of `theta1` | -1 | 1 |
+| 1 | Sine of `theta1` | -1 | 1 |
+| 2 | Cosine of `theta2` | -1 | 1 |
+| 3 | Sine of `theta2` | -1 | 1 |
+| 4 | Angular velocity of `theta1` | ~ -12.567 (-4 * pi) | ~ 12.567 (4 * pi) |
+| 5 | Angular velocity of `theta2` | ~ -28.274 (-9 * pi) | ~ 28.274 (9 * pi) |
+
+or `[cos(theta1) sin(theta1) cos(theta2) sin(theta2) thetaDot1 thetaDot2]`. As an example, a state of
+`[1, 0, 1, 0, ..., ...]` indicates that both links are pointing downwards.
+
+### Rewards
+
+All steps that do not reach the goal (termination criteria) incur a reward of -1. Achieving the target height and
+terminating incurs a reward of 0. The reward threshold is -100.
+
+### Starting State
+
+At start, each parameter in the underlying state (`theta1`, `theta2`, and the two angular velocities) is initialized
+uniformly at random between -0.1 and 0.1. This means both links are pointing roughly downwards.
+
+### Episode Termination
+The episode terminates of one of the following occurs:
+
+1. The target height is achieved. As constructed, this occurs when
+`-cos(theta1) - cos(theta2 + theta1) > 1.0`
+2. Episode length is greater than 500 (200 for v0)
+
+### Arguments
+
+There are no arguments supported in constructing the environment. As an example:
+
+```python
+import gym
+env_name = 'Acrobot-v1'
+env = gym.make(env_name)
+```
+
+By default, the dynamics of the acrobot follow those described in Richard Sutton's book
+[Reinforcement Learning: An Introduction](http://incompleteideas.net/book/11/node4.html). However, a `book_or_nips`
+setting can be modified on the environment to change the pendulum dynamics to those described
+in [the original NeurIPS paper](https://papers.nips.cc/paper/1995/hash/8f1d43620bc6bb580df6e80b0dc05c48-Abstract.html).
+See the following note and
+the [implementation](https://github.com/openai/gym/blob/master/gym/envs/classic_control/acrobot.py) for details:
+
+> The dynamics equations were missing some terms in the NIPS paper which
+ are present in the book. R. Sutton confirmed in personal correspondence
+ that the experimental results shown in the paper and the book were
+ generated with the equations shown in the book.
+ However, there is the option to run the domain with the paper equations
+ by setting `book_or_nips = 'nips'`
+
+Continuing from the prior example:
+```python
+# To change the dynamics as described above
+env.env.book_or_nips = 'nips'
+```
+
+
+### Version History
+
+- v1: Maximum number of steps increased from 200 to 500. The observation space for v0 provided direct readings of
+`theta1` and `theta2` in radians, having a range of `[-pi, pi]`. The v1 observation space as described here provides the
+sin and cosin of each angle instead.
+- v0: Initial versions release (1.0.0) (removed from openai/gym for v1)
+
+### References
+- Sutton, R. S. (1996). Generalization in Reinforcement Learning: Successful Examples Using Sparse Coarse Coding. In D. Touretzky, M. C. Mozer, & M. Hasselmo (Eds.), Advances in Neural Information Processing Systems (Vol. 8). MIT Press. https://proceedings.neurips.cc/paper/1995/file/8f1d43620bc6bb580df6e80b0dc05c48-Paper.pdf
+- Sutton, R. S., Barto, A. G. (2018 ). Reinforcement Learning: An Introduction. The MIT Press.
diff --git a/docs/classic_control/acrobot.png b/docs/classic_control/acrobot.png
new file mode 100644
index 00000000000..78d73682890
Binary files /dev/null and b/docs/classic_control/acrobot.png differ
| Added some docs!
I noticed `Acrobot-v0` was removed rather than deprecated, I believe in [this commit](https://github.com/openai/gym/commit/5ba5cb7e2dd7fb06412b0ba26fdba14127e87bbf). In the version history I mentioned the functional changes but did not mention the change from direct angle readings to sin/cos pairings provided by the v1 observation space. Let me know if you think there's a better way to handle (there's also a stale issue on [bringing `Acrobot-v0` back](https://github.com/openai/gym/issues/353)) | https://api.github.com/repos/openai/gym/pulls/2533 | 2021-12-20T18:12:40Z | 2021-12-20T18:28:39Z | 2021-12-20T18:28:39Z | 2021-12-20T18:28:39Z | 1,674 | openai/gym | 5,569 |
import numpy for lines 544 and 545 | diff --git a/lib/model/losses.py b/lib/model/losses.py
index b54e2bc1d6..66b6873310 100644
--- a/lib/model/losses.py
+++ b/lib/model/losses.py
@@ -7,9 +7,9 @@
from __future__ import absolute_import
-
import keras.backend as K
from keras.layers import Lambda, concatenate
+import numpy as np
import tensorflow as tf
from tensorflow.contrib.distributions import Beta
@@ -541,8 +541,8 @@ def scharr_edges(image, magnitude):
kernels = [[[-1.0, -2.0, -3.0, -2.0, -1.0], [-1.0, -2.0, -6.0, -2.0, -1.0], [0.0, 0.0, 0.0, 0.0, 0.0], [1.0, 2.0, 6.0, 2.0, 1.0], [1.0, 2.0, 3.0, 2.0, 1.0]],
[[-1.0, -1.0, 0.0, 1.0, 1.0], [-2.0, -2.0, 0.0, 2.0, 2.0], [-3.0, -6.0, 0.0, 6.0, 3.0], [-2.0, -2.0, 0.0, 2.0, 2.0], [-1.0, -1.0, 0.0, 1.0, 1.0]]]
num_kernels = len(kernels)
- kernels = numpy.transpose(numpy.asarray(kernels), (1, 2, 0))
- kernels = numpy.expand_dims(kernels, -2) / numpy.sum(numpy.abs(kernels))
+ kernels = np.transpose(np.asarray(kernels), (1, 2, 0))
+ kernels = np.expand_dims(kernels, -2) / np.sum(np.abs(kernels))
kernels_tf = tf.constant(kernels, dtype=image.dtype)
kernels_tf = tf.tile(kernels_tf, [1, 1, image_shape[-1], 1], name='scharr_filters')
| [flake8](http://flake8.pycqa.org) testing of https://github.com/deepfakes/faceswap on Python 3.7.1
$ __flake8 . --count --select=E901,E999,F821,F822,F823 --show-source --statistics__
```
./lib/model/losses.py:544:15: F821 undefined name 'numpy'
kernels = numpy.transpose(numpy.asarray(kernels), (1, 2, 0))
^
./lib/model/losses.py:544:31: F821 undefined name 'numpy'
kernels = numpy.transpose(numpy.asarray(kernels), (1, 2, 0))
^
./lib/model/losses.py:545:15: F821 undefined name 'numpy'
kernels = numpy.expand_dims(kernels, -2) / numpy.sum(numpy.abs(kernels))
^
./lib/model/losses.py:545:48: F821 undefined name 'numpy'
kernels = numpy.expand_dims(kernels, -2) / numpy.sum(numpy.abs(kernels))
^
./lib/model/losses.py:545:58: F821 undefined name 'numpy'
kernels = numpy.expand_dims(kernels, -2) / numpy.sum(numpy.abs(kernels))
^
5 F821 undefined name 'numpy'
5
```
__E901,E999,F821,F822,F823__ are the "_showstopper_" [flake8](http://flake8.pycqa.org) issues that can halt the runtime with a SyntaxError, NameError, etc. These 5 are different from most other flake8 issues which are merely "style violations" -- useful for readability but they do not effect runtime safety.
* F821: undefined name `name`
* F822: undefined name `name` in `__all__`
* F823: local variable name referenced before assignment
* E901: SyntaxError or IndentationError
* E999: SyntaxError -- failed to compile a file into an Abstract Syntax Tree | https://api.github.com/repos/deepfakes/faceswap/pulls/612 | 2019-02-18T19:09:29Z | 2019-02-19T18:12:48Z | 2019-02-19T18:12:48Z | 2019-02-19T18:18:39Z | 519 | deepfakes/faceswap | 18,653 |
Refs #28459 -- Improved performance of select_related() when model is prefetched from its parent. | diff --git a/django/db/models/query.py b/django/db/models/query.py
index 0b65bb56e8141..11976611509e7 100644
--- a/django/db/models/query.py
+++ b/django/db/models/query.py
@@ -1665,21 +1665,10 @@ def __init__(self, klass_info, select, db):
]
self.reorder_for_init = None
else:
- model_init_attnames = [
- f.attname for f in klass_info['model']._meta.concrete_fields
- ]
- reorder_map = []
- for idx in select_fields:
- field = select[idx][0].target
- init_pos = model_init_attnames.index(field.attname)
- reorder_map.append((init_pos, field.attname, idx))
- reorder_map.sort()
- self.init_list = [v[1] for v in reorder_map]
- pos_list = [row_pos for _, _, row_pos in reorder_map]
-
- def reorder_for_init(row):
- return [row[row_pos] for row_pos in pos_list]
- self.reorder_for_init = reorder_for_init
+ attname_indexes = {select[idx][0].target.attname: idx for idx in select_fields}
+ model_init_attnames = (f.attname for f in klass_info['model']._meta.concrete_fields)
+ self.init_list = [attname for attname in model_init_attnames if attname in attname_indexes]
+ self.reorder_for_init = operator.itemgetter(*[attname_indexes[attname] for attname in self.init_list])
self.model_cls = klass_info['model']
self.pk_idx = self.init_list.index(self.model_cls._meta.pk.attname)
| https://code.djangoproject.com/ticket/28459
Before:
```
In [2]: %timeit for x in Human.objects.select_related('person'): pass
196 ms ± 2.05 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
After:
```
In [2]: %timeit for x in Human.objects.select_related('person'): pass
186 ms ± 1.59 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
``` | https://api.github.com/repos/django/django/pulls/8845 | 2017-08-02T07:42:31Z | 2017-08-07T23:49:41Z | 2017-08-07T23:49:41Z | 2017-08-08T04:11:29Z | 391 | django/django | 50,860 |
fix md file to avoid evaluation crash | diff --git a/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md b/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md
index 66a0f9ebf6a98..d8a4e11087301 100644
--- a/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md
+++ b/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md
@@ -349,7 +349,7 @@ def speech_file_to_array_fn(batch):
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
-inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
+inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
@@ -357,7 +357,7 @@ with torch.no_grad():
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
-print("Reference:", test_dataset["sentence"][:2])
+print("Reference:", test_dataset[:2]["sentence"])
```
| # What does this PR do?
Fix the crash due to the memory usage in the instructions for model evaluation in `FINE_TUNE_XLSR_WAV2VEC2.md`.
The original version `test_dataset["speech"][:2]` load the whole speech array into memory which is too large.
Change it to `test_dataset[:2]["speech"]` runs smoothly and much faster.
## Before submitting
- [ ] This PR improves the docs
## Who can review?
@patrickvonplaten
| https://api.github.com/repos/huggingface/transformers/pulls/10962 | 2021-03-30T10:28:12Z | 2021-03-30T18:26:23Z | 2021-03-30T18:26:23Z | 2022-05-05T10:41:55Z | 304 | huggingface/transformers | 12,363 |
Added function that checks if a string is an isogram | diff --git a/strings/is_isogram.py b/strings/is_isogram.py
new file mode 100644
index 000000000000..a9d9acc8138e
--- /dev/null
+++ b/strings/is_isogram.py
@@ -0,0 +1,30 @@
+"""
+wiki: https://en.wikipedia.org/wiki/Heterogram_(literature)#Isograms
+"""
+
+
+def is_isogram(string: str) -> bool:
+ """
+ An isogram is a word in which no letter is repeated.
+ Examples of isograms are uncopyrightable and ambidextrously.
+ >>> is_isogram('Uncopyrightable')
+ True
+ >>> is_isogram('allowance')
+ False
+ >>> is_isogram('copy1')
+ Traceback (most recent call last):
+ ...
+ ValueError: String must only contain alphabetic characters.
+ """
+ if not all(x.isalpha() for x in string):
+ raise ValueError("String must only contain alphabetic characters.")
+
+ letters = sorted(string.lower())
+ return len(letters) == len(set(letters))
+
+
+if __name__ == "__main__":
+ input_str = input("Enter a string ").strip()
+
+ isogram = is_isogram(input_str)
+ print(f"{input_str} is {'an' if isogram else 'not an'} isogram.")
| ### Describe your change:
* [x] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [ ] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [ ] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms have a URL in its comments that points to Wikipedia or other similar explanation.
* [ ] If this pull request resolves one or more open issues then the commit message contains `Fixes: #{$ISSUE_NO}`.
| https://api.github.com/repos/TheAlgorithms/Python/pulls/7608 | 2022-10-25T02:07:28Z | 2022-10-26T03:31:16Z | 2022-10-26T03:31:16Z | 2022-10-26T03:35:37Z | 312 | TheAlgorithms/Python | 30,359 |
Upgrade GitHub Actions | diff --git a/.github/workflows/lint_python.yml b/.github/workflows/lint_python.yml
index 63796567..2fd12494 100644
--- a/.github/workflows/lint_python.yml
+++ b/.github/workflows/lint_python.yml
@@ -4,8 +4,10 @@ jobs:
lint_python:
runs-on: ubuntu-latest
steps:
- - uses: actions/checkout@v2
- - uses: actions/setup-python@v2
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v4
+ with:
+ python-version: 3.x
- run: pip install --upgrade pip
- run: pip install black codespell flake8 isort mypy pytest pyupgrade tox
- run: black --check .
@@ -17,4 +19,4 @@ jobs:
- run: mypy --ignore-missing-imports . || true
- run: pytest .
- run: pytest --doctest-modules . || true
- - run: shopt -s globstar && pyupgrade --py36-plus **/*.py
+ - run: shopt -s globstar && pyupgrade --py37-plus **/*.py
diff --git a/setup.py b/setup.py
index b4d2cdf1..ec2528f4 100644
--- a/setup.py
+++ b/setup.py
@@ -12,5 +12,6 @@
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
+ "Programming Language :: Python :: 3.10",
],
)
diff --git a/tox.ini b/tox.ini
index 168e2c9d..1eca32ab 100644
--- a/tox.ini
+++ b/tox.ini
@@ -1,5 +1,5 @@
[tox]
-envlist = py38,py39,cov-report
+envlist = py38,py39,py310,cov-report
skip_missing_interpreters = true
| https://api.github.com/repos/faif/python-patterns/pulls/395 | 2022-07-18T23:10:28Z | 2022-07-19T19:56:44Z | 2022-07-19T19:56:44Z | 2022-07-19T20:18:03Z | 468 | faif/python-patterns | 33,419 |
|
fix annotation | diff --git a/face_recognition/api.py b/face_recognition/api.py
index 9df9e6e6d..e42d39e91 100644
--- a/face_recognition/api.py
+++ b/face_recognition/api.py
@@ -65,7 +65,7 @@ def face_distance(face_encodings, face_to_compare):
Given a list of face encodings, compare them to a known face encoding and get a euclidean distance
for each comparison face. The distance tells you how similar the faces are.
- :param faces: List of face encodings to compare
+ :param face_encodings: List of face encodings to compare
:param face_to_compare: A face encoding to compare against
:return: A numpy ndarray with the distance for each face in the same order as the 'faces' array
"""
| https://api.github.com/repos/ageitgey/face_recognition/pulls/1174 | 2020-07-01T07:42:42Z | 2020-09-26T14:32:41Z | 2020-09-26T14:32:40Z | 2020-09-26T14:32:41Z | 189 | ageitgey/face_recognition | 22,584 |
|
Updating autotune json default in docs. | diff --git a/csrc/lamb/fused_lamb_cuda_kernel.cu b/csrc/lamb/fused_lamb_cuda_kernel.cu
index 2cd3800e9b3a..a957eb628751 100644
--- a/csrc/lamb/fused_lamb_cuda_kernel.cu
+++ b/csrc/lamb/fused_lamb_cuda_kernel.cu
@@ -7,12 +7,12 @@
#include "ATen/TensorUtils.h"
#include "ATen/cuda/CUDAContext.h"
#include "ATen/cuda/detail/IndexUtils.cuh"
-//#include "ATen/Type.h"
+// #include "ATen/Type.h"
#include "ATen/AccumulateType.h"
#include <iostream>
-//#include <helper_functions.h>
+// #include <helper_functions.h>
#if defined(__HIP_PLATFORM_HCC__) && HIP_VERSION > 305
#include <hip/hip_cooperative_groups.h>
#else
diff --git a/docs/_pages/config-json.md b/docs/_pages/config-json.md
index 457ebc36cbb8..7a47fd53d506 100755
--- a/docs/_pages/config-json.md
+++ b/docs/_pages/config-json.md
@@ -652,8 +652,8 @@ Configuring the asynchronous I/O module for offloading parameter and optimizer s
{
"autotuning": {
"enabled": false,
- "results_dir": null,
- "exps_dir": null,
+ "results_dir": "autotuning_results",
+ "exps_dir": "autotuning_exps",
"overwrite": false,
"metric": "throughput",
"start_profile_step": 3,
@@ -678,15 +678,15 @@ Configuring the asynchronous I/O module for offloading parameter and optimizer s
<i>**results_dir**</i>: [string]
-| Description | Default |
-| -------------------------------------------------------------------------------------------------------------------------------- | ------- |
-| Path to the autotuning experiment results directory. If None, "autotuning_results" under the training script launching path is used. | `null` |
+| Description | Default |
+| ------------------------------------------------------------------------------------------------------------------------------------- | --------------------- |
+| Path to the autotuning experiment results directory. The default appears in the working directory from which Deepspeed was launched. | "autotuning_results" |
<i>**exps_dir**</i>: [string]
-| Description | Default |
-| ---------------------------------------------------------------------------------------------------------------------------------- | ------- |
-| Path to the auotuning experiment descriptions directory. If None, "autotuning_exps" under the train script launching path is used. | `null` |
+| Description | Default |
+| ---------------------------------------------------------------------------------------------------------------------------------------- | ------------------ |
+| Path to the auotuning experiment descriptions directory. The default appears in the working directory from which Deepspeed was launched. | "autotuning_exps" |
<i>**overwrite**</i>: [boolean]
| Changing the defaults listed in the docs for the autotune json from `null` to the values found in constants.py. Addresses the issues found in bug [2373](https://github.com/microsoft/DeepSpeed/issues/2473). | https://api.github.com/repos/microsoft/DeepSpeed/pulls/2476 | 2022-11-04T18:52:30Z | 2022-11-04T23:00:13Z | 2022-11-04T23:00:13Z | 2023-07-07T02:38:50Z | 651 | microsoft/DeepSpeed | 10,585 |
Refs #26464 -- Added a link to OWASP Top 10 in security topic guide. | diff --git a/docs/topics/security.txt b/docs/topics/security.txt
index 324e198410494..eb1172e7e8e32 100644
--- a/docs/topics/security.txt
+++ b/docs/topics/security.txt
@@ -273,5 +273,10 @@ security protection of the Web server, operating system and other components.
* Keep your :setting:`SECRET_KEY` a secret.
* It is a good idea to limit the accessibility of your caching system and
database using a firewall.
+* Take a look at the Open Web Application Security Project (OWASP) `Top 10
+ list`_ which identifies some common vulnerabilities in web applications. While
+ Django has tools to address some of the issues, other issues must be
+ accounted for in the design of your project.
.. _LimitRequestBody: https://httpd.apache.org/docs/2.4/mod/core.html#limitrequestbody
+.. _Top 10 list: https://www.owasp.org/index.php/Top_10_2013-Top_10
| as discussed at https://groups.google.com/d/topic/django-developers/_Z6ZufcOmps/discussion
| https://api.github.com/repos/django/django/pulls/6425 | 2016-04-06T17:04:04Z | 2016-04-09T12:10:15Z | 2016-04-09T12:10:15Z | 2016-04-09T12:23:16Z | 226 | django/django | 51,288 |
fix(tests): Another attempt to reduce flakiness of event frequency tests | diff --git a/tests/snuba/rules/conditions/test_event_frequency.py b/tests/snuba/rules/conditions/test_event_frequency.py
index c990cb03614e77..e65a1c4b506554 100644
--- a/tests/snuba/rules/conditions/test_event_frequency.py
+++ b/tests/snuba/rules/conditions/test_event_frequency.py
@@ -99,76 +99,75 @@ def test_one_week_no_events(self):
self._run_test(data=data, minutes=10080, passes=False)
def test_comparison(self):
- with freeze_time(before_now(days=1).replace(hour=12, minute=30, second=0, microsecond=0)):
- # Test data is 4 events in the current period and 2 events in the comparison period, so
- # a 100% increase.
- event = self.store_event(
- data={
- "fingerprint": ["something_random"],
- "timestamp": iso_format(before_now(minutes=1)),
- "user": {"id": uuid4().hex},
- },
- project_id=self.project.id,
- )
- self.increment(
- event,
- 3,
- timestamp=now() - timedelta(minutes=1),
- )
- self.increment(
- event,
- 2,
- timestamp=now() - timedelta(days=1, minutes=20),
- )
- data = {
- "interval": "1h",
- "value": 99,
- "comparisonType": "percent",
- "comparisonInterval": "1d",
- }
- rule = self.get_rule(data=data, rule=Rule(environment_id=None))
- self.assertPasses(rule, event)
+ # Test data is 4 events in the current period and 2 events in the comparison period, so
+ # a 100% increase.
+ event = self.store_event(
+ data={
+ "fingerprint": ["something_random"],
+ "timestamp": iso_format(before_now(minutes=1)),
+ "user": {"id": uuid4().hex},
+ },
+ project_id=self.project.id,
+ )
+ self.increment(
+ event,
+ 3,
+ timestamp=now() - timedelta(minutes=1),
+ )
+ self.increment(
+ event,
+ 2,
+ timestamp=now() - timedelta(days=1, minutes=20),
+ )
+ data = {
+ "interval": "1h",
+ "value": 99,
+ "comparisonType": "percent",
+ "comparisonInterval": "1d",
+ }
+ rule = self.get_rule(data=data, rule=Rule(environment_id=None))
+ self.assertPasses(rule, event)
- data = {
- "interval": "1h",
- "value": 101,
- "comparisonType": "percent",
- "comparisonInterval": "1d",
- }
- rule = self.get_rule(data=data, rule=Rule(environment_id=None))
- self.assertDoesNotPass(rule, event)
+ data = {
+ "interval": "1h",
+ "value": 101,
+ "comparisonType": "percent",
+ "comparisonInterval": "1d",
+ }
+ rule = self.get_rule(data=data, rule=Rule(environment_id=None))
+ self.assertDoesNotPass(rule, event)
def test_comparison_empty_comparison_period(self):
- with freeze_time(before_now(days=1).replace(hour=12, minute=30, second=0, microsecond=0)):
- # Test data is 1 event in the current period and 0 events in the comparison period. This
- # should always result in 0 and never fire.
- event = self.store_event(
- data={
- "fingerprint": ["something_random"],
- "timestamp": iso_format(before_now(minutes=1)),
- "user": {"id": uuid4().hex},
- },
- project_id=self.project.id,
- )
- data = {
- "interval": "1h",
- "value": 0,
- "comparisonType": "percent",
- "comparisonInterval": "1d",
- }
- rule = self.get_rule(data=data, rule=Rule(environment_id=None))
- self.assertDoesNotPass(rule, event)
+ # Test data is 1 event in the current period and 0 events in the comparison period. This
+ # should always result in 0 and never fire.
+ event = self.store_event(
+ data={
+ "fingerprint": ["something_random"],
+ "timestamp": iso_format(before_now(minutes=1)),
+ "user": {"id": uuid4().hex},
+ },
+ project_id=self.project.id,
+ )
+ data = {
+ "interval": "1h",
+ "value": 0,
+ "comparisonType": "percent",
+ "comparisonInterval": "1d",
+ }
+ rule = self.get_rule(data=data, rule=Rule(environment_id=None))
+ self.assertDoesNotPass(rule, event)
- data = {
- "interval": "1h",
- "value": 100,
- "comparisonType": "percent",
- "comparisonInterval": "1d",
- }
- rule = self.get_rule(data=data, rule=Rule(environment_id=None))
- self.assertDoesNotPass(rule, event)
+ data = {
+ "interval": "1h",
+ "value": 100,
+ "comparisonType": "percent",
+ "comparisonInterval": "1d",
+ }
+ rule = self.get_rule(data=data, rule=Rule(environment_id=None))
+ self.assertDoesNotPass(rule, event)
+@freeze_time((now() - timedelta(days=2)).replace(hour=12, minute=40, second=0, microsecond=0))
class EventFrequencyConditionTestCase(
FrequencyConditionMixin, StandardIntervalMixin, RuleTestCase, SnubaTestCase
):
@@ -189,7 +188,7 @@ def increment(self, event, count, environment=None, timestamp=None):
)
-@freeze_time()
+@freeze_time((now() - timedelta(days=2)).replace(hour=12, minute=40, second=0, microsecond=0))
class EventUniqueUserFrequencyConditionTestCase(
FrequencyConditionMixin,
StandardIntervalMixin,
@@ -215,16 +214,15 @@ def increment(self, event, count, environment=None, timestamp=None):
)
-@freeze_time()
+@freeze_time((now() - timedelta(days=2)).replace(hour=12, minute=40, second=0, microsecond=0))
class EventFrequencyPercentConditionTestCase(
RuleTestCase,
SnubaTestCase,
):
rule_cls = EventFrequencyPercentCondition
- def _make_sessions(self, num, minutes):
- received = time.time() - minutes * 60
- session_started = received // 60 * 60
+ def _make_sessions(self, num):
+ received = time.time()
def make_session(i):
return dict(
@@ -240,7 +238,7 @@ def make_session(i):
duration=None,
errors=0,
# The line below is crucial to spread sessions throughout the time period.
- started=session_started - (i * (minutes / 30)),
+ started=received - i,
received=received,
)
@@ -268,13 +266,12 @@ def _run_test(self, minutes, data, passes, add_events=False):
)
rule = self.get_rule(data=data, rule=Rule(environment_id=None))
environment_rule = self.get_rule(data=data, rule=Rule(environment_id=self.environment.id))
- with freeze_time(before_now(minutes=minutes)):
- if passes:
- self.assertPasses(rule, self.test_event)
- self.assertPasses(environment_rule, self.test_event)
- else:
- self.assertDoesNotPass(rule, self.test_event)
- self.assertDoesNotPass(environment_rule, self.test_event)
+ if passes:
+ self.assertPasses(rule, self.test_event)
+ self.assertPasses(environment_rule, self.test_event)
+ else:
+ self.assertDoesNotPass(rule, self.test_event)
+ self.assertDoesNotPass(environment_rule, self.test_event)
def increment(self, event, count, environment=None, timestamp=None):
data = {
@@ -294,7 +291,7 @@ def increment(self, event, count, environment=None, timestamp=None):
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_five_minutes_with_events(self):
- self._make_sessions(60, 5)
+ self._make_sessions(60)
data = {"interval": "5m", "value": 39}
self._run_test(data=data, minutes=5, passes=True, add_events=True)
data = {"interval": "5m", "value": 41}
@@ -302,7 +299,7 @@ def test_five_minutes_with_events(self):
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_ten_minutes_with_events(self):
- self._make_sessions(60, 10)
+ self._make_sessions(60)
data = {"interval": "10m", "value": 49}
self._run_test(data=data, minutes=10, passes=True, add_events=True)
data = {"interval": "10m", "value": 51}
@@ -310,7 +307,7 @@ def test_ten_minutes_with_events(self):
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_thirty_minutes_with_events(self):
- self._make_sessions(60, 30)
+ self._make_sessions(60)
data = {"interval": "30m", "value": 49}
self._run_test(data=data, minutes=30, passes=True, add_events=True)
data = {"interval": "30m", "value": 51}
@@ -318,7 +315,7 @@ def test_thirty_minutes_with_events(self):
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_one_hour_with_events(self):
- self._make_sessions(60, 60)
+ self._make_sessions(60)
data = {"interval": "1h", "value": 49}
self._run_test(data=data, minutes=60, add_events=True, passes=True)
data = {"interval": "1h", "value": 51}
@@ -326,69 +323,68 @@ def test_one_hour_with_events(self):
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_five_minutes_no_events(self):
- self._make_sessions(60, 5)
+ self._make_sessions(60)
data = {"interval": "5m", "value": 39}
self._run_test(data=data, minutes=5, passes=True, add_events=True)
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_ten_minutes_no_events(self):
- self._make_sessions(60, 10)
+ self._make_sessions(60)
data = {"interval": "10m", "value": 49}
self._run_test(data=data, minutes=10, passes=True, add_events=True)
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_thirty_minutes_no_events(self):
- self._make_sessions(60, 30)
+ self._make_sessions(60)
data = {"interval": "30m", "value": 49}
self._run_test(data=data, minutes=30, passes=True, add_events=True)
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_one_hour_no_events(self):
- self._make_sessions(60, 60)
+ self._make_sessions(60)
data = {"interval": "1h", "value": 49}
self._run_test(data=data, minutes=60, passes=False)
@patch("sentry.rules.conditions.event_frequency.MIN_SESSIONS_TO_FIRE", 1)
def test_comparison(self):
- with freeze_time(before_now(minutes=0)):
- self._make_sessions(10, 1)
- # Create sessions for previous period
- self._make_sessions(10, 60 * 24 + 20)
-
- # Test data is 2 events in the current period and 1 events in the comparison period.
- # Number of sessions is 20 in each period, so current period is 20% of sessions, prev
- # is 10%. Overall a 100% increase comparitively.
- event = self.store_event(
- data={
- "fingerprint": ["something_random"],
- "timestamp": iso_format(before_now(minutes=1)),
- },
- project_id=self.project.id,
- )
- self.increment(
- event,
- 1,
- timestamp=now() - timedelta(minutes=1),
- )
- self.increment(
- event,
- 1,
- timestamp=now() - timedelta(days=1, minutes=20),
- )
- data = {
- "interval": "1h",
- "value": 99,
- "comparisonType": "percent",
- "comparisonInterval": "1d",
- }
- rule = self.get_rule(data=data, rule=Rule(environment_id=None))
- self.assertPasses(rule, event)
+ self._make_sessions(10)
+ # Create sessions for previous period
+ self._make_sessions(10)
- data = {
- "interval": "1h",
- "value": 101,
- "comparisonType": "percent",
- "comparisonInterval": "1d",
- }
- rule = self.get_rule(data=data, rule=Rule(environment_id=None))
- self.assertDoesNotPass(rule, event)
+ # Test data is 2 events in the current period and 1 events in the comparison period.
+ # Number of sessions is 20 in each period, so current period is 20% of sessions, prev
+ # is 10%. Overall a 100% increase comparitively.
+ event = self.store_event(
+ data={
+ "fingerprint": ["something_random"],
+ "timestamp": iso_format(before_now(minutes=1)),
+ },
+ project_id=self.project.id,
+ )
+ self.increment(
+ event,
+ 1,
+ timestamp=now() - timedelta(minutes=1),
+ )
+ self.increment(
+ event,
+ 1,
+ timestamp=now() - timedelta(days=1, minutes=20),
+ )
+ data = {
+ "interval": "1h",
+ "value": 99,
+ "comparisonType": "percent",
+ "comparisonInterval": "1d",
+ }
+ rule = self.get_rule(data=data, rule=Rule(environment_id=None))
+ self.assertPasses(rule, event)
+
+ data = {
+ "interval": "1h",
+ "value": 101,
+ "comparisonType": "percent",
+ "comparisonInterval": "1d",
+ }
+ rule = self.get_rule(data=data, rule=Rule(environment_id=None))
+ self.assertDoesNotPass(rule, event)
| Fixing the date at a specific time of day and also making sure that freeze_time is used overall for
the test and not at multiple points.
Also improved how we create sessions | https://api.github.com/repos/getsentry/sentry/pulls/32580 | 2022-03-14T19:00:50Z | 2022-03-14T22:39:51Z | 2022-03-14T22:39:51Z | 2022-03-30T00:01:43Z | 3,430 | getsentry/sentry | 43,991 |
Fix grammatical errors in README.md | diff --git a/README.md b/README.md
index bcaf184146..f313156fe0 100644
--- a/README.md
+++ b/README.md
@@ -300,16 +300,16 @@ response = g4f.ChatCompletion.create(
print(f"Result:", response)
```
-### interference openai-proxy api (use with openai python package)
+### interference openai-proxy API (use with openai python package)
-#### run interference api from pypi package:
+#### run interference API from pypi package:
```py
from g4f.api import run_api
run_api()
```
-#### run interference api from repo:
+#### run interference API from repo:
If you want to use the embedding function, you need to get a Hugging Face token. You can get one at https://huggingface.co/settings/tokens make sure your role is set to write. If you have your token, just use it instead of the OpenAI api-key.
run server:
@@ -539,7 +539,7 @@ Call in your terminal the "create_provider" script:
python etc/tool/create_provider.py
```
1. Enter your name for the new provider.
-2. Copy & Paste a cURL command from your browser developer tools.
+2. Copy and paste a cURL command from your browser developer tools.
3. Let the AI create the provider for you.
4. Customize the provider according to your needs.
@@ -571,8 +571,8 @@ class HogeService(AsyncGeneratorProvider):
yield ""
```
-4. Here, you can adjust the settings, for example if the website does support streaming, set `supports_stream` to `True`...
-5. Write code to request the provider in `create_async_generator` and `yield` the response, _even if_ its a one-time response, do not hesitate to look at other providers for inspiration
+4. Here, you can adjust the settings, for example, if the website does support streaming, set `supports_stream` to `True`...
+5. Write code to request the provider in `create_async_generator` and `yield` the response, _even if_ it's a one-time response, do not hesitate to look at other providers for inspiration
6. Add the Provider Name in [g4f/provider/**init**.py](./g4f/provider/__init__.py)
```py
| I have fixed a couple of grammatical errors in the README.md file. | https://api.github.com/repos/xtekky/gpt4free/pulls/1148 | 2023-10-24T19:11:14Z | 2023-10-25T08:57:15Z | 2023-10-25T08:57:15Z | 2023-10-25T08:57:15Z | 517 | xtekky/gpt4free | 38,222 |
feat: add troubleshooting guide to bug report template again | diff --git a/.github/ISSUE_TEMPLATE/bug_report.yml b/.github/ISSUE_TEMPLATE/bug_report.yml
index 483e0de14..5b9cded68 100644
--- a/.github/ISSUE_TEMPLATE/bug_report.yml
+++ b/.github/ISSUE_TEMPLATE/bug_report.yml
@@ -21,6 +21,7 @@ body:
5. Try a fresh installation of Fooocus in a different directory - see if a clean installation solves the issue
Before making a issue report please, check that the issue hasn't been reported recently.
options:
+ - label: The issue has not been resolved by following the [troubleshooting guide](https://github.com/lllyasviel/Fooocus/blob/main/troubleshoot.md)
- label: The issue exists on a clean installation of Fooocus
- label: The issue exists in the current version of Fooocus
- label: The issue has not been reported before recently
| A few issues were popping up lately, which could have been solved by following steps in the troubleshooting guide.
This PR adds the link as checkbox to the bug report template again with the goal of better guiding users to fix their issues themselves. | https://api.github.com/repos/lllyasviel/Fooocus/pulls/2489 | 2024-03-09T13:12:02Z | 2024-03-09T13:13:16Z | 2024-03-09T13:13:16Z | 2024-03-09T13:13:16Z | 212 | lllyasviel/Fooocus | 7,041 |
Update urllib3 to a43319f | diff --git a/requests/packages/urllib3/_collections.py b/requests/packages/urllib3/_collections.py
index b35a73672e..282b8d5e05 100644
--- a/requests/packages/urllib3/_collections.py
+++ b/requests/packages/urllib3/_collections.py
@@ -5,7 +5,7 @@
# the MIT License: http://www.opensource.org/licenses/mit-license.php
from collections import MutableMapping
-from threading import Lock
+from threading import RLock
try: # Python 2.7+
from collections import OrderedDict
@@ -40,18 +40,18 @@ def __init__(self, maxsize=10, dispose_func=None):
self.dispose_func = dispose_func
self._container = self.ContainerCls()
- self._lock = Lock()
+ self.lock = RLock()
def __getitem__(self, key):
# Re-insert the item, moving it to the end of the eviction line.
- with self._lock:
+ with self.lock:
item = self._container.pop(key)
self._container[key] = item
return item
def __setitem__(self, key, value):
evicted_value = _Null
- with self._lock:
+ with self.lock:
# Possibly evict the existing value of 'key'
evicted_value = self._container.get(key, _Null)
self._container[key] = value
@@ -65,21 +65,21 @@ def __setitem__(self, key, value):
self.dispose_func(evicted_value)
def __delitem__(self, key):
- with self._lock:
+ with self.lock:
value = self._container.pop(key)
if self.dispose_func:
self.dispose_func(value)
def __len__(self):
- with self._lock:
+ with self.lock:
return len(self._container)
def __iter__(self):
raise NotImplementedError('Iteration over this class is unlikely to be threadsafe.')
def clear(self):
- with self._lock:
+ with self.lock:
# Copy pointers to all values, then wipe the mapping
# under Python 2, this copies the list of values twice :-|
values = list(self._container.values())
@@ -90,5 +90,5 @@ def clear(self):
self.dispose_func(value)
def keys(self):
- with self._lock:
+ with self.lock:
return self._container.keys()
diff --git a/requests/packages/urllib3/contrib/pyopenssl.py b/requests/packages/urllib3/contrib/pyopenssl.py
index 9829e80b60..6d0255f6c2 100644
--- a/requests/packages/urllib3/contrib/pyopenssl.py
+++ b/requests/packages/urllib3/contrib/pyopenssl.py
@@ -106,6 +106,9 @@ def __init__(self, connection, socket):
self.connection = connection
self.socket = socket
+ def fileno(self):
+ return self.socket.fileno()
+
def makefile(self, mode, bufsize=-1):
return _fileobject(self.connection, mode, bufsize)
diff --git a/requests/packages/urllib3/poolmanager.py b/requests/packages/urllib3/poolmanager.py
index 2a1aa48bf0..804f2b2fc2 100644
--- a/requests/packages/urllib3/poolmanager.py
+++ b/requests/packages/urllib3/poolmanager.py
@@ -104,15 +104,16 @@ def connection_from_host(self, host, port=None, scheme='http'):
pool_key = (scheme, host, port)
- # If the scheme, host, or port doesn't match existing open connections,
- # open a new ConnectionPool.
- pool = self.pools.get(pool_key)
- if pool:
- return pool
-
- # Make a fresh ConnectionPool of the desired type
- pool = self._new_pool(scheme, host, port)
- self.pools[pool_key] = pool
+ with self.pools.lock:
+ # If the scheme, host, or port doesn't match existing open connections,
+ # open a new ConnectionPool.
+ pool = self.pools.get(pool_key)
+ if pool:
+ return pool
+
+ # Make a fresh ConnectionPool of the desired type
+ pool = self._new_pool(scheme, host, port)
+ self.pools[pool_key] = pool
return pool
def connection_from_url(self, url):
diff --git a/requests/packages/urllib3/util.py b/requests/packages/urllib3/util.py
index f4eb5e943a..a9d30e01b4 100644
--- a/requests/packages/urllib3/util.py
+++ b/requests/packages/urllib3/util.py
@@ -113,7 +113,7 @@ def parse_url(url):
# While this code has overlap with stdlib's urlparse, it is much
# simplified for our needs and less annoying.
- # Additionally, this imeplementations does silly things to be optimal
+ # Additionally, this implementations does silly things to be optimal
# on CPython.
scheme = None
@@ -142,7 +142,8 @@ def parse_url(url):
# IPv6
if url and url[0] == '[':
- host, url = url[1:].split(']', 1)
+ host, url = url.split(']', 1)
+ host += ']'
# Port
if ':' in url:
| Includes a fix for a race condition
| https://api.github.com/repos/psf/requests/pulls/1463 | 2013-07-18T21:09:16Z | 2013-07-18T22:00:28Z | 2013-07-18T22:00:28Z | 2021-09-08T20:01:30Z | 1,247 | psf/requests | 32,771 |
Fix cupy install version detection | diff --git a/.github/workflows/nv-torch19-p40.yml b/.github/workflows/nv-torch19-p40.yml
index 0c83b3a44ef8..9d21c1506b4d 100644
--- a/.github/workflows/nv-torch19-p40.yml
+++ b/.github/workflows/nv-torch19-p40.yml
@@ -45,7 +45,7 @@ jobs:
- name: Install deepspeed
run: |
- pip install .[dev,1bit,autotuning]
+ pip install .[dev,1bit,autotuning] --no-build-isolation
ds_report
- name: Python environment
diff --git a/.github/workflows/nv-torch19-v100.yml b/.github/workflows/nv-torch19-v100.yml
index cb663b1b834d..562e961e9f3e 100644
--- a/.github/workflows/nv-torch19-v100.yml
+++ b/.github/workflows/nv-torch19-v100.yml
@@ -45,7 +45,7 @@ jobs:
- name: Install deepspeed
run: |
- pip install .[dev,1bit,autotuning]
+ pip install .[dev,1bit,autotuning] --no-build-isolation
ds_report
- name: Python environment
diff --git a/.github/workflows/setup-venv/action.yml b/.github/workflows/setup-venv/action.yml
index dacd50b8d471..1828b2ed9eef 100644
--- a/.github/workflows/setup-venv/action.yml
+++ b/.github/workflows/setup-venv/action.yml
@@ -15,6 +15,7 @@ runs:
python -m venv unit-test-venv
source ./unit-test-venv/bin/activate
python -m pip install --upgrade pip
+ pip install wheel # required after pip>=23.1
echo PATH=$PATH >> $GITHUB_ENV # Make it so venv is inherited for other steps
shell: bash
- id: print-env
diff --git a/setup.py b/setup.py
index 1c7c29663700..b032bcf362c1 100755
--- a/setup.py
+++ b/setup.py
@@ -78,7 +78,12 @@ def fetch_requirements(path):
if rocm_major <= 4:
cupy = f"cupy-rocm-{rocm_major}-{rocm_minor}"
else:
- cupy = f"cupy-cuda{''.join(map(str,installed_cuda_version()))}"
+ cuda_major_ver, cuda_minor_ver = installed_cuda_version()
+ if (cuda_major_ver < 11) or ((cuda_major_ver == 11) and (cuda_minor_ver < 3)):
+ cupy = f"cupy-cuda{cuda_major_ver}{cuda_minor_ver}"
+ else:
+ cupy = f"cupy-cuda{cuda_major_ver}x"
+
if cupy:
extras_require['1bit'].append(cupy)
extras_require['1bit_mpi'].append(cupy)
| For later versions of cuda, we would try to install a cupy version that doesn't exist. Updating our `setup.py` to match https://docs.cupy.dev/en/stable/install.html#installing-cupy-from-pypi
Also, with the recent release of pip 23.1, our setup.py will not correctly install cupy due to isolated builds being the default now. More on that here: https://github.com/pypa/pip/issues/8559
This change has further implications for installing DeepSpeed from source. We will need to rethink what we do in `setup.py` and/or require users to install with the `--no-build-isolation` option for pip | https://api.github.com/repos/microsoft/DeepSpeed/pulls/3276 | 2023-04-17T20:55:12Z | 2023-04-18T17:13:36Z | 2023-04-18T17:13:35Z | 2023-04-21T17:34:51Z | 701 | microsoft/DeepSpeed | 10,785 |
Fix "itslef" to "itself" | diff --git a/manimlib/animation/transform.py b/manimlib/animation/transform.py
index ef07090cf5..fef381848d 100644
--- a/manimlib/animation/transform.py
+++ b/manimlib/animation/transform.py
@@ -152,7 +152,7 @@ def __init__(self, method, *args, **kwargs):
method is a method of Mobject, *args are arguments for
that method. Key word arguments should be passed in
as the last arg, as a dict, since **kwargs is for
- configuration of the transform itslef
+ configuration of the transform itself
Relies on the fact that mobject methods return the mobject
"""
| I know this is trivial, but I had to fix it. | https://api.github.com/repos/3b1b/manim/pulls/1069 | 2020-05-14T19:43:47Z | 2020-05-21T03:21:11Z | 2020-05-21T03:21:10Z | 2020-05-21T03:34:34Z | 162 | 3b1b/manim | 18,170 |
Luno :: fix parse ledger | diff --git a/js/luno.js b/js/luno.js
index 1757a31921ae..0a0642ed0f50 100644
--- a/js/luno.js
+++ b/js/luno.js
@@ -977,7 +977,7 @@ module.exports = class luno extends Exchange {
let direction = undefined;
let status = undefined;
if (!Precise.stringEquals (balance_delta, '0.0')) {
- before = after - balance_delta;
+ before = Precise.stringSub (after, balance_delta);
status = 'ok';
amount = Precise.stringAbs (balance_delta);
} else if (Precise.stringLt (available_delta, '0.0')) {
| 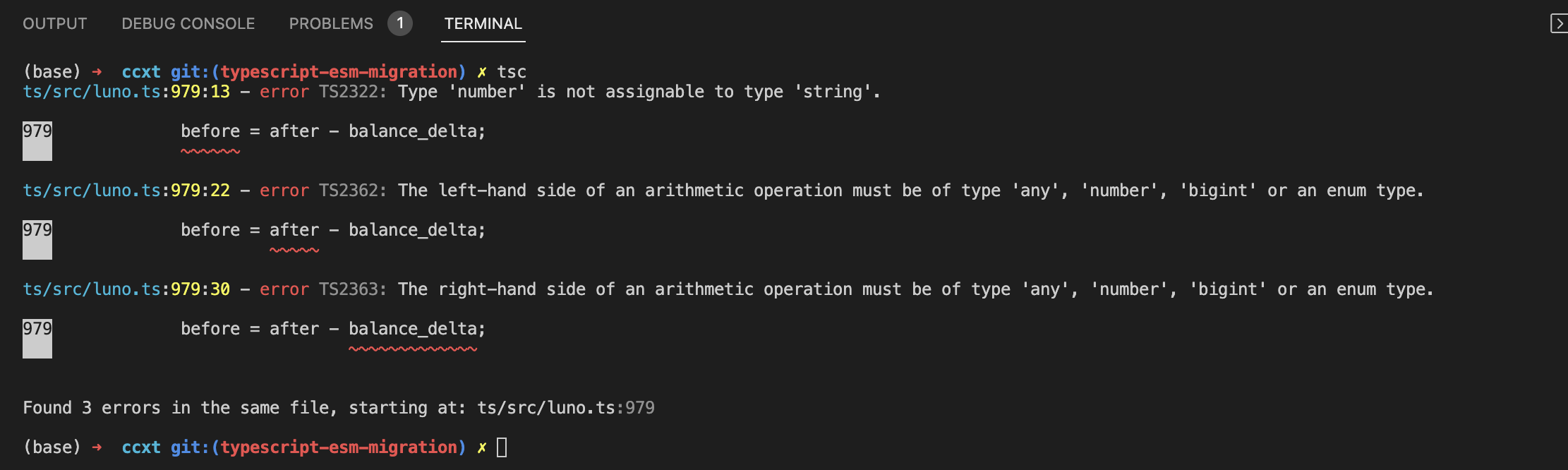
| https://api.github.com/repos/ccxt/ccxt/pulls/16178 | 2022-12-23T10:22:04Z | 2022-12-23T11:45:20Z | 2022-12-23T11:45:20Z | 2023-01-23T16:35:32Z | 157 | ccxt/ccxt | 12,948 |
Cleaned up JSON test with ambiguous DTA usage | diff --git a/pandas/tests/io/json/test_pandas.py b/pandas/tests/io/json/test_pandas.py
index 4851f4bd27a7b..9c489c7cc17ec 100644
--- a/pandas/tests/io/json/test_pandas.py
+++ b/pandas/tests/io/json/test_pandas.py
@@ -813,20 +813,11 @@ def test_series_roundtrip_simple(self, orient, numpy):
@pytest.mark.parametrize("dtype", [False, None])
@pytest.mark.parametrize("numpy", [True, False])
def test_series_roundtrip_object(self, orient, numpy, dtype):
- # TODO: see why tm.makeObjectSeries provides back DTA
- dtSeries = Series(
- [str(d) for d in self.objSeries],
- index=self.objSeries.index,
- name=self.objSeries.name,
- )
- data = dtSeries.to_json(orient=orient)
+ data = self.objSeries.to_json(orient=orient)
result = pd.read_json(
data, typ="series", orient=orient, numpy=numpy, dtype=dtype
)
- if dtype is False:
- expected = dtSeries.copy()
- else:
- expected = self.objSeries.copy()
+ expected = self.objSeries.copy()
if not numpy and PY35 and orient in ("index", "columns"):
expected = expected.sort_index()
@@ -897,6 +888,19 @@ def test_series_with_dtype(self):
expected = Series([4] * 3)
assert_series_equal(result, expected)
+ @pytest.mark.parametrize(
+ "dtype,expected",
+ [
+ (True, Series(["2000-01-01"], dtype="datetime64[ns]")),
+ (False, Series([946684800000])),
+ ],
+ )
+ def test_series_with_dtype_datetime(self, dtype, expected):
+ s = Series(["2000-01-01"], dtype="datetime64[ns]")
+ data = s.to_json()
+ result = pd.read_json(data, typ="series", dtype=dtype)
+ assert_series_equal(result, expected)
+
def test_frame_from_json_precise_float(self):
df = DataFrame([[4.56, 4.56, 4.56], [4.56, 4.56, 4.56]])
result = read_json(df.to_json(), precise_float=True)
| Follow up to #27838 enabled by #28444
I created a new test specific to the handling of DTA with `dtype=X` to provide a more logical separation of concerns | https://api.github.com/repos/pandas-dev/pandas/pulls/28502 | 2019-09-18T15:38:03Z | 2019-09-18T16:27:03Z | 2019-09-18T16:27:03Z | 2019-09-18T16:27:14Z | 528 | pandas-dev/pandas | 45,037 |
coinbase: deposit, fetchDeposit | diff --git a/ts/src/coinbase.ts b/ts/src/coinbase.ts
index 2e315cb48de0..9956e5f86ec6 100644
--- a/ts/src/coinbase.ts
+++ b/ts/src/coinbase.ts
@@ -53,6 +53,7 @@ export default class coinbase extends Exchange {
'createStopLimitOrder': true,
'createStopMarketOrder': false,
'createStopOrder': true,
+ 'deposit': true,
'editOrder': true,
'fetchAccounts': true,
'fetchBalance': true,
@@ -64,6 +65,7 @@ export default class coinbase extends Exchange {
'fetchCrossBorrowRate': false,
'fetchCrossBorrowRates': false,
'fetchCurrencies': true,
+ 'fetchDeposit': true,
'fetchDepositAddress': 'emulated',
'fetchDepositAddresses': false,
'fetchDepositAddressesByNetwork': true,
@@ -3574,6 +3576,147 @@ export default class coinbase extends Exchange {
};
}
+ async deposit (code: string, amount: number, id: string, params = {}) {
+ /**
+ * @method
+ * @name coinbase#deposit
+ * @description make a deposit
+ * @see https://docs.cloud.coinbase.com/sign-in-with-coinbase/docs/api-deposits#deposit-funds
+ * @param {string} code unified currency code
+ * @param {float} amount the amount to deposit
+ * @param {string} id the payment method id to be used for the deposit, can be retrieved from v2PrivateGetPaymentMethods
+ * @param {object} [params] extra parameters specific to the exchange API endpoint
+ * @param {string} [params.accountId] the id of the account to deposit into
+ * @returns {object} a [transaction structure]{@link https://docs.ccxt.com/#/?id=transaction-structure}
+ */
+ await this.loadMarkets ();
+ let accountId = this.safeString2 (params, 'account_id', 'accountId');
+ params = this.omit (params, [ 'account_id', 'accountId' ]);
+ if (accountId === undefined) {
+ if (code === undefined) {
+ throw new ArgumentsRequired (this.id + ' deposit() requires an account_id (or accountId) parameter OR a currency code argument');
+ }
+ accountId = await this.findAccountId (code);
+ if (accountId === undefined) {
+ throw new ExchangeError (this.id + ' deposit() could not find account id for ' + code);
+ }
+ }
+ const request = {
+ 'account_id': accountId,
+ 'amount': this.numberToString (amount),
+ 'currency': code.toUpperCase (), // need to use code in case depositing USD etc.
+ 'payment_method': id,
+ };
+ const response = await this.v2PrivatePostAccountsAccountIdDeposits (this.extend (request, params));
+ //
+ // {
+ // "data": {
+ // "id": "67e0eaec-07d7-54c4-a72c-2e92826897df",
+ // "status": "created",
+ // "payment_method": {
+ // "id": "83562370-3e5c-51db-87da-752af5ab9559",
+ // "resource": "payment_method",
+ // "resource_path": "/v2/payment-methods/83562370-3e5c-51db-87da-752af5ab9559"
+ // },
+ // "transaction": {
+ // "id": "441b9494-b3f0-5b98-b9b0-4d82c21c252a",
+ // "resource": "transaction",
+ // "resource_path": "/v2/accounts/2bbf394c-193b-5b2a-9155-3b4732659ede/transactions/441b9494-b3f0-5b98-b9b0-4d82c21c252a"
+ // },
+ // "amount": {
+ // "amount": "10.00",
+ // "currency": "USD"
+ // },
+ // "subtotal": {
+ // "amount": "10.00",
+ // "currency": "USD"
+ // },
+ // "created_at": "2015-01-31T20:49:02Z",
+ // "updated_at": "2015-02-11T16:54:02-08:00",
+ // "resource": "deposit",
+ // "resource_path": "/v2/accounts/2bbf394c-193b-5b2a-9155-3b4732659ede/deposits/67e0eaec-07d7-54c4-a72c-2e92826897df",
+ // "committed": true,
+ // "fee": {
+ // "amount": "0.00",
+ // "currency": "USD"
+ // },
+ // "payout_at": "2015-02-18T16:54:00-08:00"
+ // }
+ // }
+ //
+ const data = this.safeDict (response, 'data', {});
+ return this.parseTransaction (data);
+ }
+
+ async fetchDeposit (id: string, code: Str = undefined, params = {}) {
+ /**
+ * @method
+ * @name coinbase#fetchDeposit
+ * @description fetch information on a deposit, fiat only, for crypto transactions use fetchLedger
+ * @see https://docs.cloud.coinbase.com/sign-in-with-coinbase/docs/api-deposits#show-deposit
+ * @param {string} id deposit id
+ * @param {string} [code] unified currency code
+ * @param {object} [params] extra parameters specific to the exchange API endpoint
+ * @param {string} [params.accountId] the id of the account that the funds were deposited into
+ * @returns {object} a [transaction structure]{@link https://docs.ccxt.com/#/?id=transaction-structure}
+ */
+ await this.loadMarkets ();
+ let accountId = this.safeString2 (params, 'account_id', 'accountId');
+ params = this.omit (params, [ 'account_id', 'accountId' ]);
+ if (accountId === undefined) {
+ if (code === undefined) {
+ throw new ArgumentsRequired (this.id + ' fetchDeposit() requires an account_id (or accountId) parameter OR a currency code argument');
+ }
+ accountId = await this.findAccountId (code);
+ if (accountId === undefined) {
+ throw new ExchangeError (this.id + ' fetchDeposit() could not find account id for ' + code);
+ }
+ }
+ const request = {
+ 'account_id': accountId,
+ 'deposit_id': id,
+ };
+ const response = await this.v2PrivateGetAccountsAccountIdDepositsDepositId (this.extend (request, params));
+ //
+ // {
+ // "data": {
+ // "id": "67e0eaec-07d7-54c4-a72c-2e92826897df",
+ // "status": "completed",
+ // "payment_method": {
+ // "id": "83562370-3e5c-51db-87da-752af5ab9559",
+ // "resource": "payment_method",
+ // "resource_path": "/v2/payment-methods/83562370-3e5c-51db-87da-752af5ab9559"
+ // },
+ // "transaction": {
+ // "id": "441b9494-b3f0-5b98-b9b0-4d82c21c252a",
+ // "resource": "transaction",
+ // "resource_path": "/v2/accounts/2bbf394c-193b-5b2a-9155-3b4732659ede/transactions/441b9494-b3f0-5b98-b9b0-4d82c21c252a"
+ // },
+ // "amount": {
+ // "amount": "10.00",
+ // "currency": "USD"
+ // },
+ // "subtotal": {
+ // "amount": "10.00",
+ // "currency": "USD"
+ // },
+ // "created_at": "2015-01-31T20:49:02Z",
+ // "updated_at": "2015-02-11T16:54:02-08:00",
+ // "resource": "deposit",
+ // "resource_path": "/v2/accounts/2bbf394c-193b-5b2a-9155-3b4732659ede/deposits/67e0eaec-07d7-54c4-a72c-2e92826897df",
+ // "committed": true,
+ // "fee": {
+ // "amount": "0.00",
+ // "currency": "USD"
+ // },
+ // "payout_at": "2015-02-18T16:54:00-08:00"
+ // }
+ // }
+ //
+ const data = this.safeValue (response, 'data', {});
+ return this.parseTransaction (data);
+ }
+
sign (path, api = [], method = 'GET', params = {}, headers = undefined, body = undefined) {
const version = api[0];
const signed = api[1] === 'private';
| Added `deposit` and `fetchDeposit` methods to coinbase for fiat deposits.
closes: #21375 | https://api.github.com/repos/ccxt/ccxt/pulls/21422 | 2024-02-27T10:45:25Z | 2024-02-27T12:23:36Z | 2024-02-27T12:23:36Z | 2024-02-27T12:23:36Z | 2,261 | ccxt/ccxt | 13,153 |
✏️ Fix Pydantic examples in tutorial for Python types | diff --git a/docs_src/python_types/tutorial011.py b/docs_src/python_types/tutorial011.py
index c8634cbff505a..297a84db68ca0 100644
--- a/docs_src/python_types/tutorial011.py
+++ b/docs_src/python_types/tutorial011.py
@@ -6,7 +6,7 @@
class User(BaseModel):
id: int
- name = "John Doe"
+ name: str = "John Doe"
signup_ts: Union[datetime, None] = None
friends: List[int] = []
diff --git a/docs_src/python_types/tutorial011_py310.py b/docs_src/python_types/tutorial011_py310.py
index 7f173880f5b89..842760c60d24f 100644
--- a/docs_src/python_types/tutorial011_py310.py
+++ b/docs_src/python_types/tutorial011_py310.py
@@ -5,7 +5,7 @@
class User(BaseModel):
id: int
- name = "John Doe"
+ name: str = "John Doe"
signup_ts: datetime | None = None
friends: list[int] = []
diff --git a/docs_src/python_types/tutorial011_py39.py b/docs_src/python_types/tutorial011_py39.py
index 468496f519325..4eb40b405fe50 100644
--- a/docs_src/python_types/tutorial011_py39.py
+++ b/docs_src/python_types/tutorial011_py39.py
@@ -6,7 +6,7 @@
class User(BaseModel):
id: int
- name = "John Doe"
+ name: str = "John Doe"
signup_ts: Union[datetime, None] = None
friends: list[int] = []
| pydantic script was getting an error,
"pydantic.errors.PydanticUserError: A non-annotated attribute was detected: `name = 'John Doe'`. All model fields require a type annotation; if `name` is not meant to be a field, you may be able to resolve this error by annotating it as a `ClassVar` or updating `model_config['ignored_types']`."
fixed by adding type annotation str | https://api.github.com/repos/tiangolo/fastapi/pulls/9961 | 2023-07-28T15:54:26Z | 2023-09-02T15:56:35Z | 2023-09-02T15:56:35Z | 2023-09-02T15:56:36Z | 378 | tiangolo/fastapi | 22,912 |
Added CurrencyScoop | diff --git a/README.md b/README.md
index e0d676035b..4c6c3b6ed8 100644
--- a/README.md
+++ b/README.md
@@ -218,6 +218,7 @@ API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
| [1Forge](https://1forge.com/forex-data-api/api-documentation) | Forex currency market data | `apiKey` | Yes | Unknown |
| [Currencylayer](https://currencylayer.com/documentation) | Exchange rates and currency conversion | `apiKey` | Yes | Unknown |
+| [CurrencyScoop](https://currencyscoop.com/api-documentation) | Real-time and historical currency rates JSON API | `apiKey` | Yes | Yes |
| [Czech National Bank](https://www.cnb.cz/cs/financni_trhy/devizovy_trh/kurzy_devizoveho_trhu/denni_kurz.xml) | A collection of exchange rates | No | Yes | Unknown |
| [ExchangeRate-API](https://www.exchangerate-api.com) | Free currency conversion | No | Yes | Yes |
| [Exchangeratesapi.io](https://exchangeratesapi.io) | Exchange rates with currency conversion | No | Yes | Yes |
| Thank you for taking the time to work on a Pull Request for this project!
To ensure your PR is dealt with swiftly please check the following:
- [x] Your submissions are formatted according to the guidelines in the [contributing guide](CONTRIBUTING.md)
- [x] Your additions are ordered alphabetically
- [x] Your submission has a useful description
- [x] The description does not end with punctuation
- [x] Each table column should be padded with one space on either side
- [x] You have searched the repository for any relevant issues or pull requests
- [x] Any category you are creating has the minimum requirement of 3 items
- [x] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
| https://api.github.com/repos/public-apis/public-apis/pulls/1153 | 2020-01-20T15:22:27Z | 2021-03-26T16:46:36Z | 2021-03-26T16:46:36Z | 2021-03-26T16:46:36Z | 287 | public-apis/public-apis | 35,322 |
Fix the ECMAScript edition | diff --git a/docs/ref/request-response.txt b/docs/ref/request-response.txt
index 8ff1d14a4aaf4..64bd5960cd4c0 100644
--- a/docs/ref/request-response.txt
+++ b/docs/ref/request-response.txt
@@ -987,8 +987,8 @@ Without passing ``safe=False``, a :exc:`TypeError` will be raised.
.. warning::
- Before the `5th edition of EcmaScript
- <http://www.ecma-international.org/publications/standards/Ecma-262.htm>`_
+ Before the `5th edition of ECMAScript
+ <http://www.ecma-international.org/ecma-262/5.1/index.html#sec-11.1.4>`_
it was possible to poison the JavaScript ``Array`` constructor. For this
reason, Django does not allow passing non-dict objects to the
:class:`~django.http.JsonResponse` constructor by default. However, most
| The link goes to the ECMAScript 2015 spec, which is actually the 6th edition.
| https://api.github.com/repos/django/django/pulls/6588 | 2016-05-11T17:28:32Z | 2016-05-13T00:06:34Z | 2016-05-13T00:06:34Z | 2016-05-13T00:06:34Z | 219 | django/django | 51,628 |
[Docs] fix typos in some tokenizer docs | diff --git a/src/transformers/models/longformer/tokenization_longformer.py b/src/transformers/models/longformer/tokenization_longformer.py
index 5ff6f70afdeaf..69bc50595387d 100644
--- a/src/transformers/models/longformer/tokenization_longformer.py
+++ b/src/transformers/models/longformer/tokenization_longformer.py
@@ -124,7 +124,7 @@ class LongformerTokenizer(PreTrainedTokenizer):
>>> from transformers import LongformerTokenizer
>>> tokenizer = LongformerTokenizer.from_pretrained("allenai/longformer-base-4096")
>>> tokenizer("Hello world")['input_ids']
- [0, 31414, 232, 328, 2]
+ [0, 31414, 232, 2]
>>> tokenizer(" Hello world")['input_ids']
[0, 20920, 232, 2]
```
diff --git a/src/transformers/models/longformer/tokenization_longformer_fast.py b/src/transformers/models/longformer/tokenization_longformer_fast.py
index 5d20caf8c2dfa..dfe1b08e1458f 100644
--- a/src/transformers/models/longformer/tokenization_longformer_fast.py
+++ b/src/transformers/models/longformer/tokenization_longformer_fast.py
@@ -100,7 +100,7 @@ class LongformerTokenizerFast(PreTrainedTokenizerFast):
>>> from transformers import LongformerTokenizerFast
>>> tokenizer = LongformerTokenizerFast.from_pretrained("allenai/longformer-base-4096")
>>> tokenizer("Hello world")['input_ids']
- [0, 31414, 232, 328, 2]
+ [0, 31414, 232, 2]
>>> tokenizer(" Hello world")['input_ids']
[0, 20920, 232, 2]
```
diff --git a/src/transformers/models/roberta/tokenization_roberta.py b/src/transformers/models/roberta/tokenization_roberta.py
index d291a2f9d97a0..e8d4a751bc197 100644
--- a/src/transformers/models/roberta/tokenization_roberta.py
+++ b/src/transformers/models/roberta/tokenization_roberta.py
@@ -115,7 +115,7 @@ class RobertaTokenizer(PreTrainedTokenizer):
>>> from transformers import RobertaTokenizer
>>> tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
>>> tokenizer("Hello world")['input_ids']
- [0, 31414, 232, 328, 2]
+ [0, 31414, 232, 2]
>>> tokenizer(" Hello world")['input_ids']
[0, 20920, 232, 2]
```
diff --git a/src/transformers/models/roberta/tokenization_roberta_fast.py b/src/transformers/models/roberta/tokenization_roberta_fast.py
index 49311b3aeff9a..32cc66d750b0e 100644
--- a/src/transformers/models/roberta/tokenization_roberta_fast.py
+++ b/src/transformers/models/roberta/tokenization_roberta_fast.py
@@ -85,7 +85,7 @@ class RobertaTokenizerFast(PreTrainedTokenizerFast):
>>> from transformers import RobertaTokenizerFast
>>> tokenizer = RobertaTokenizerFast.from_pretrained("roberta-base")
>>> tokenizer("Hello world")['input_ids']
- [0, 31414, 232, 328, 2]
+ [0, 31414, 232, 2]
>>> tokenizer(" Hello world")['input_ids']
[0, 20920, 232, 2]
```
| # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fix the typos in tokenizer examples.
It would be 4 tokens. Thx
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| https://api.github.com/repos/huggingface/transformers/pulls/22256 | 2023-03-19T13:41:44Z | 2023-03-20T12:17:32Z | 2023-03-20T12:17:32Z | 2023-03-20T12:20:14Z | 855 | huggingface/transformers | 12,295 |
Remove trailing \n from texttobase64.sh | diff --git a/scripts/texttobase64.sh b/scripts/texttobase64.sh
index 791f21c..04c1feb 100755
--- a/scripts/texttobase64.sh
+++ b/scripts/texttobase64.sh
@@ -2,7 +2,7 @@ commentChar="#"
while read p; do
firstChar=${p:0:1}
if [[ "$firstChar" != "$commentChar" && "$firstChar" != "" ]] ; then
- echo $p | base64;
+ echo -n $p | base64;
else
echo $p;
fi
| Without this, all base64 strings will get a trailing \n in their encoded form
ref #86
Does _not_ update the `blns.base64.txt` file
| https://api.github.com/repos/minimaxir/big-list-of-naughty-strings/pulls/94 | 2016-02-11T09:43:08Z | 2016-02-11T15:04:01Z | 2016-02-11T15:04:01Z | 2016-05-01T15:57:15Z | 141 | minimaxir/big-list-of-naughty-strings | 4,830 |
Add Knet.jl | diff --git a/README.md b/README.md
index 1a53fca4..3eb971ca 100644
--- a/README.md
+++ b/README.md
@@ -488,6 +488,7 @@ For a list of free machine learning books available for download, go [here](http
* [ROCAnalysis](https://github.com/davidavdav/ROCAnalysis.jl) - Receiver Operating Characteristics and functions for evaluation probabilistic binary classifiers
* [GaussianMixtures] (https://github.com/davidavdav/GaussianMixtures.jl) - Large scale Gaussian Mixture Models
* [ScikitLearn] (https://github.com/cstjean/ScikitLearn.jl) - Julia implementation of the scikit-learn API
+* [Knet](https://github.com/denizyuret/Knet.jl) - Koç University Deep Learning Framework
<a name="julia-nlp" />
#### Natural Language Processing
| Add Knet.jl - Koç University Deep Learning Framework.
| https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/310 | 2016-09-06T16:58:28Z | 2016-09-09T03:01:33Z | 2016-09-09T03:01:33Z | 2016-09-09T03:01:38Z | 211 | josephmisiti/awesome-machine-learning | 52,210 |
Force color | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 4b2800e89..4b95a4790 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -5,8 +5,13 @@ All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
+
## [Unreleased]
+### Added
+
+- Add support for `FORCE_COLOR` env var https://github.com/Textualize/rich/pull/2449
+
### Fixed
- Fix NO_COLOR support on legacy Windows https://github.com/Textualize/rich/pull/2458
diff --git a/rich/console.py b/rich/console.py
index 4f4675b10..4a3ebb559 100644
--- a/rich/console.py
+++ b/rich/console.py
@@ -697,7 +697,12 @@ def __init__(
self._height = height
self._color_system: Optional[ColorSystem]
- self._force_terminal = force_terminal
+
+ if force_terminal is not None:
+ self._force_terminal = force_terminal
+ else:
+ self._force_terminal = self._environ.get("FORCE_COLOR") is not None
+
self._file = file
self.quiet = quiet
self.stderr = stderr
diff --git a/tests/test_console.py b/tests/test_console.py
index 2db88af0b..07692f198 100644
--- a/tests/test_console.py
+++ b/tests/test_console.py
@@ -895,3 +895,11 @@ def test_render_lines_height_minus_vertical_pad_is_negative():
# Ensuring that no exception is raised...
console.render_lines(Padding("hello", pad=(1, 0)), options=options)
+
+
+@mock.patch.dict(os.environ, {"FORCE_COLOR": "anything"})
+def test_force_color():
+ # Even though we use a non-tty file, the presence of FORCE_COLOR env var
+ # means is_terminal returns True.
+ console = Console(file=io.StringIO())
+ assert console.is_terminal
| ## Type of changes
- [ ] Bug fix
- [x] New feature
- [ ] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [x] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [x] I've added tests for new code.
- [x] I accept that @willmcgugan may be pedantic in the code review.
## Description
Adds support for `FORCE_COLOR` environment variable.
Presence of this variable in the environment results in `Console.force_terminal = True`.
If `FORCE_COLOR` and `NO_COLOR` are both set, `NO_COLOR` takes priority.
### `NO_COLOR = 1` only
<img width="542" alt="image" src="https://user-images.githubusercontent.com/5740731/183630837-8c4221a6-679f-487f-be5e-dcb4957db42c.png">
### `NO_COLOR = 1` and `FORCE_COLOR = 1`
<img width="489" alt="image" src="https://user-images.githubusercontent.com/5740731/183630920-a280a0eb-6d1c-4da7-9654-d7b37a5d1bee.png">
### `FORCE_COLOR = 1` only
<img width="485" alt="image" src="https://user-images.githubusercontent.com/5740731/183631049-52987368-76cc-4233-be62-5f54b71b54eb.png">
| https://api.github.com/repos/Textualize/rich/pulls/2449 | 2022-08-05T14:40:01Z | 2022-08-17T13:52:39Z | 2022-08-17T13:52:39Z | 2023-11-25T00:27:56Z | 509 | Textualize/rich | 48,334 |
Document context processors' variable functions | diff --git a/docs/templating.rst b/docs/templating.rst
index bd940b0e49..15433f2a4a 100644
--- a/docs/templating.rst
+++ b/docs/templating.rst
@@ -186,3 +186,22 @@ The context processor above makes a variable called `user` available in
the template with the value of `g.user`. This example is not very
interesting because `g` is available in templates anyways, but it gives an
idea how this works.
+
+It is also possible to inject functions that can have any number of
+arguments::
+
+ @app.context_processor
+ def price_formatter():
+ def loader(amount, currency=u'€'):
+ return u'{0:.2f}{1}.format(amount, currency)
+ return dict(format_price=loader)
+
+The above construct registers a "variable" function called
+`format_price` which can then be used in template::
+
+ {{ format_price(0.33) }}
+
+The difference from regular context processor' variables is that functions
+are evaluated upon template rendering compared to variables whose values
+are created during `app` startup . Therefore "variable" functions make it
+possible to inject dynamic data into templates.
| Document a way to use functions via context processors. The example isn't the best one, but I couldn't figure out a better one.
| https://api.github.com/repos/pallets/flask/pulls/394 | 2012-02-01T13:04:06Z | 2012-02-01T23:04:43Z | 2012-02-01T23:04:43Z | 2020-11-14T07:08:15Z | 278 | pallets/flask | 20,131 |
Correct spelling (woking -> working) | diff --git a/README.md b/README.md
index 430f8f09b..b2aa2995f 100644
--- a/README.md
+++ b/README.md
@@ -591,7 +591,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
## Internationalization
-*Libraries for woking with i18n.*
+*Libraries for working with i18n.*
* [Babel](http://babel.pocoo.org/) - An internationalization library for Python.
* [Korean](https://korean.readthedocs.org/) - A library for [Korean](http://en.wikipedia.org/wiki/Korean_language) morphology.
@@ -712,7 +712,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
## Processes and Threads
-*Libraries for woking with processes or threads*
+*Libraries for working with processes or threads*
* [multiprocessing](https://docs.python.org/2/library/multiprocessing.html) - (Python standard library) Process-based "threading" interface.
* [threading](https://docs.python.org/2/library/threading.html) - (Python standard library) Higher-level threading interface.
@@ -737,7 +737,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
## WebSocket
-*Libraries for woking with WebSocket.*
+*Libraries for working with WebSocket.*
* [AutobahnPython](https://github.com/tavendo/AutobahnPython) - WebSocket & WAMP for Python on Twisted and [asyncio](https://docs.python.org/3/library/asyncio.html).
* [WebSocket-for-Python](https://github.com/Lawouach/WebSocket-for-Python) - WebSocket client and server library for Python 2 and 3 as well as PyPy.
| https://api.github.com/repos/vinta/awesome-python/pulls/323 | 2015-03-17T04:15:30Z | 2015-03-17T04:58:58Z | 2015-03-17T04:58:58Z | 2015-03-17T05:08:15Z | 399 | vinta/awesome-python | 27,348 |
|
Add Support for Python 3.6 | diff --git a/.travis.yml b/.travis.yml
index 95984110..fd8619f9 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -9,6 +9,7 @@ python:
- "3.3"
- "3.4"
- "3.5"
+ - "3.6"
# Disabled for now since cause more pain than gain
# - "pypy"
# - "pypy3"
| Python 3.6.0 is the newest major release of the Python language, and it contains many new features and optimizations. Adding it travis CI configuration. | https://api.github.com/repos/faif/python-patterns/pulls/169 | 2017-01-07T23:12:51Z | 2017-01-09T21:33:47Z | 2017-01-09T21:33:47Z | 2017-01-09T21:33:47Z | 111 | faif/python-patterns | 33,568 |
fix doc | diff --git a/docs/sources/layers/noise.md b/docs/sources/layers/noise.md
index ef2124b7bdc..9589dc88435 100644
--- a/docs/sources/layers/noise.md
+++ b/docs/sources/layers/noise.md
@@ -2,7 +2,7 @@
## GaussianNoise
```python
-keras.layers.core.GaussianNoise(sigma)
+keras.layers.noise.GaussianNoise(sigma)
```
Apply to the input an additive zero-centred gaussian noise with standard deviation `sigma`. This is useful to mitigate overfitting (you could see it as a kind of random data augmentation). Gaussian Noise (GS) is a natural choice as corruption process for real valued inputs.
@@ -16,4 +16,4 @@ The gaussian noise is only added at training time.
- __sigma__: float, standard deviation of the noise distribution.
----
\ No newline at end of file
+---
| https://api.github.com/repos/keras-team/keras/pulls/349 | 2015-07-06T20:59:06Z | 2015-07-07T14:37:29Z | 2015-07-07T14:37:29Z | 2015-07-07T14:37:29Z | 202 | keras-team/keras | 47,092 |
|
Fix #623 | diff --git a/flask/helpers.py b/flask/helpers.py
index 6aea45c61a..e8d72bf4bf 100644
--- a/flask/helpers.py
+++ b/flask/helpers.py
@@ -247,8 +247,9 @@ def external_url_handler(error, endpoint, **values):
appctx = _app_ctx_stack.top
reqctx = _request_ctx_stack.top
if appctx is None:
- raise RuntimeError('Attempted to generate a URL with the application '
- 'context being pushed. This has to be executed ')
+ raise RuntimeError('Attempted to generate a URL without the '
+ 'application context being pushed. This has to be '
+ 'executed when application context is available.')
# If request specific information is available we have some extra
# features that support "relative" urls.
| https://api.github.com/repos/pallets/flask/pulls/630 | 2012-11-08T19:57:47Z | 2013-01-25T04:13:31Z | 2013-01-25T04:13:30Z | 2020-11-14T05:42:41Z | 188 | pallets/flask | 20,887 |
|
Only render auth method icon when it is available | diff --git a/website/src/components/UserDisplayNameCell.tsx b/website/src/components/UserDisplayNameCell.tsx
index 925df981d9..1dfa704652 100644
--- a/website/src/components/UserDisplayNameCell.tsx
+++ b/website/src/components/UserDisplayNameCell.tsx
@@ -1,6 +1,6 @@
import { Flex, Link, Tooltip } from "@chakra-ui/react";
import { Discord, Google } from "@icons-pack/react-simple-icons";
-import { Mail } from "lucide-react";
+import { Bot, Mail } from "lucide-react";
import NextLink from "next/link";
import { useHasAnyRole } from "src/hooks/auth/useHasAnyRole";
import { ROUTES } from "src/lib/routes";
@@ -12,6 +12,7 @@ const AUTH_METHOD_TO_ICON: Record<AuthMethod, JSX.Element> = {
local: <Mail size="20" />,
discord: <Discord size="20" />,
google: <Google size="20" />,
+ system: <Bot size="20" />,
};
export const UserDisplayNameCell = ({
@@ -35,7 +36,9 @@ export const UserDisplayNameCell = ({
<Link as={NextLink} href={ROUTES.ADMIN_USER_DETAIL(userId)} style={{ overflow: "hidden" }}>
{displayName}
</Link>
- <Tooltip label={`Signed in with ${authMethod}`}>{AUTH_METHOD_TO_ICON[authMethod]}</Tooltip>
+ {AUTH_METHOD_TO_ICON[authMethod] && (
+ <Tooltip label={`Signed in with ${authMethod}`}>{AUTH_METHOD_TO_ICON[authMethod]}</Tooltip>
+ )}
</>
) : (
<div style={{ overflow: "hidden" }}>{displayName}</div>
diff --git a/website/src/types/Providers.ts b/website/src/types/Providers.ts
index c316d5c5af..61eaaa1dd6 100644
--- a/website/src/types/Providers.ts
+++ b/website/src/types/Providers.ts
@@ -1 +1 @@
-export type AuthMethod = "local" | "discord" | "google";
+export type AuthMethod = "local" | "discord" | "google" | "system";
| https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/3258 | 2023-05-29T20:30:43Z | 2023-05-29T23:13:53Z | 2023-05-29T23:13:53Z | 2023-05-29T23:13:54Z | 479 | LAION-AI/Open-Assistant | 37,207 |
|
Removed unused DatabaseOperations.last_insert_id() on PostgreSQL. | diff --git a/django/db/backends/postgresql/operations.py b/django/db/backends/postgresql/operations.py
index 2cc886a76d1eb..bff8e87d6870d 100644
--- a/django/db/backends/postgresql/operations.py
+++ b/django/db/backends/postgresql/operations.py
@@ -85,13 +85,6 @@ def lookup_cast(self, lookup_type, internal_type=None):
return lookup
- def last_insert_id(self, cursor, table_name, pk_name):
- # Use pg_get_serial_sequence to get the underlying sequence name
- # from the table name and column name (available since PostgreSQL 8)
- cursor.execute("SELECT CURRVAL(pg_get_serial_sequence('%s','%s'))" % (
- self.quote_name(table_name), pk_name))
- return cursor.fetchone()[0]
-
def no_limit_value(self):
return None
| Unused since 9eb2afddfa0165d69f3e506122c2aa2b68618591. | https://api.github.com/repos/django/django/pulls/8842 | 2017-08-01T19:20:32Z | 2017-08-01T20:53:17Z | 2017-08-01T20:53:17Z | 2017-08-02T06:33:14Z | 203 | django/django | 50,707 |
sanity_check - dead code removal | diff --git a/letsencrypt/client/client.py b/letsencrypt/client/client.py
index 0f516639962..223a1ce3ac9 100644
--- a/letsencrypt/client/client.py
+++ b/letsencrypt/client/client.py
@@ -4,8 +4,6 @@
import logging
import os
import shutil
-import socket
-import string
import sys
import M2Crypto
@@ -25,11 +23,6 @@
from letsencrypt.client.apache import configurator
-# it's weird to point to ACME servers via raw IPv6 addresses, and
-# such addresses can be %SCARY in some contexts, so out of paranoia
-# let's disable them by default
-ALLOW_RAW_IPV6_SERVER = False
-
class Client(object):
"""ACME protocol client.
@@ -96,8 +89,6 @@ def obtain_certificate(self, domains, csr=None,
logging.warning("Unable to obtain a certificate, because client "
"does not have a valid auth handler.")
- sanity_check_names(domains)
-
# Request Challenges
for name in domains:
self.auth_handler.add_chall_msg(
@@ -401,47 +392,6 @@ def csr_pem_to_der(csr):
return Client.CSR(csr.file, csr_obj.as_der(), "der")
-def sanity_check_names(names):
- """Make sure host names are valid.
-
- :param list names: List of host names
-
- """
- for name in names:
- if not is_hostname_sane(name):
- logging.fatal("%r is an impossible hostname", name)
- sys.exit(81)
-
-
-def is_hostname_sane(hostname):
- """Make sure the given host name is sane.
-
- Do enough to avoid shellcode from the environment. There's
- no need to do more.
-
- :param str hostname: Host name to validate
-
- :returns: True if hostname is valid, otherwise false.
- :rtype: bool
-
- """
- # hostnames & IPv4
- allowed = string.ascii_letters + string.digits + "-."
- if all([c in allowed for c in hostname]):
- return True
-
- if not ALLOW_RAW_IPV6_SERVER:
- return False
-
- # ipv6 is messy and complicated, can contain %zoneindex etc.
- try:
- # is this a valid IPv6 address?
- socket.getaddrinfo(hostname, 443, socket.AF_INET6)
- return True
- except socket.error:
- return False
-
-
# This should be controlled by commandline parameters
def determine_authenticator():
"""Returns a valid IAuthenticator."""
diff --git a/letsencrypt/scripts/main.py b/letsencrypt/scripts/main.py
index 4dfa70764ab..20d3022f605 100755
--- a/letsencrypt/scripts/main.py
+++ b/letsencrypt/scripts/main.py
@@ -1,5 +1,9 @@
#!/usr/bin/env python
-"""Parse command line and call the appropriate functions."""
+"""Parse command line and call the appropriate functions.
+
+..todo:: Sanity check all input. Be sure to avoid shell code etc...
+
+"""
import argparse
import logging
import os
@@ -165,7 +169,6 @@ def get_all_names(installer):
"""
names = list(installer.get_all_names())
- client.sanity_check_names(names)
if not names:
logging.fatal("No domain names were found in your installation")
@@ -177,7 +180,6 @@ def get_all_names(installer):
return names
-
def read_file(filename):
"""Returns the given file's contents with universal new line support.
| This is extremely old code that doesn't quite go far enough to fully protect everything. Leaving it in makes us more likely to forget that the solution was incomplete.
I didn't want to spend the time to scrub and analyze all of the input right now so I left it as a TODO item.
| https://api.github.com/repos/certbot/certbot/pulls/208 | 2015-01-29T00:36:15Z | 2015-01-29T10:11:28Z | 2015-01-29T10:11:28Z | 2016-05-06T19:22:12Z | 817 | certbot/certbot | 652 |
Jikan API - Website + Description update | diff --git a/README.md b/README.md
index e7dfad8195..99030442ef 100644
--- a/README.md
+++ b/README.md
@@ -76,7 +76,7 @@ API | Description | Auth | HTTPS | CORS | Link |
API | Description | Auth | HTTPS | CORS | Link |
|---|---|---|---|---|---|
| AniList | Anime discovery & tracking | `OAuth` | Yes | Unknown | [Go!](https://github.com/AniList/ApiV2-GraphQL-Docs) |
-| Jikan | Unofficial MyAnimeList API | No | Yes | Yes | [Go!](https://jikan.me) |
+| Jikan | Unofficial MyAnimeList API | No | Yes | Yes | [Go!](https://jikan.moe) |
| Kitsu | Anime discovery platform | `OAuth` | Yes | Unknown | [Go!](http://docs.kitsu.apiary.io/) |
| Studio Ghibli | Resources from Studio Ghibli films | No | Yes | Unknown | [Go!](https://ghibliapi.herokuapp.com) |
| Website update from `jikan.me` to `jikan.moe`. The former domain will expire on May 12th, 18.
Also a minor change to the description.
Thanks! | https://api.github.com/repos/public-apis/public-apis/pulls/665 | 2018-05-09T16:58:56Z | 2018-05-22T20:21:18Z | 2018-05-22T20:21:18Z | 2018-05-22T20:32:54Z | 250 | public-apis/public-apis | 35,761 |
Fix crashing when editing form with random data, fix #2794 | diff --git a/mitmproxy/net/http/request.py b/mitmproxy/net/http/request.py
index 6b4041f6f2..959fdd3399 100644
--- a/mitmproxy/net/http/request.py
+++ b/mitmproxy/net/http/request.py
@@ -429,10 +429,7 @@ def constrain_encoding(self):
def _get_urlencoded_form(self):
is_valid_content_type = "application/x-www-form-urlencoded" in self.headers.get("content-type", "").lower()
if is_valid_content_type:
- try:
- return tuple(mitmproxy.net.http.url.decode(self.content.decode()))
- except ValueError:
- pass
+ return tuple(mitmproxy.net.http.url.decode(self.get_text(strict=False)))
return ()
def _set_urlencoded_form(self, form_data):
@@ -441,7 +438,7 @@ def _set_urlencoded_form(self, form_data):
This will overwrite the existing content if there is one.
"""
self.headers["content-type"] = "application/x-www-form-urlencoded"
- self.content = mitmproxy.net.http.url.encode(form_data, self.content.decode()).encode()
+ self.content = mitmproxy.net.http.url.encode(form_data, self.get_text(strict=False)).encode()
@property
def urlencoded_form(self):
diff --git a/test/mitmproxy/net/http/test_request.py b/test/mitmproxy/net/http/test_request.py
index ce49002c06..ef581a9147 100644
--- a/test/mitmproxy/net/http/test_request.py
+++ b/test/mitmproxy/net/http/test_request.py
@@ -351,10 +351,10 @@ def test_get_urlencoded_form(self):
request.headers["Content-Type"] = "application/x-www-form-urlencoded"
assert list(request.urlencoded_form.items()) == [("foobar", "baz")]
request.raw_content = b"\xFF"
- assert len(request.urlencoded_form) == 0
+ assert len(request.urlencoded_form) == 1
def test_set_urlencoded_form(self):
- request = treq()
+ request = treq(content=b"\xec\xed")
request.urlencoded_form = [('foo', 'bar'), ('rab', 'oof')]
assert request.headers["Content-Type"] == "application/x-www-form-urlencoded"
assert request.content
| Fixes #2794 | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/2868 | 2018-02-15T03:13:58Z | 2018-03-04T18:53:16Z | 2018-03-04T18:53:16Z | 2018-03-05T08:57:19Z | 496 | mitmproxy/mitmproxy | 28,302 |
Fix Typo : `openai_api_key` -> `serpapi_api_key` | diff --git a/docs/extras/modules/agents/agent_types/openai_multi_functions_agent.ipynb b/docs/extras/modules/agents/agent_types/openai_multi_functions_agent.ipynb
index 84cdad508adb55..d1dc5cdb94a801 100644
--- a/docs/extras/modules/agents/agent_types/openai_multi_functions_agent.ipynb
+++ b/docs/extras/modules/agents/agent_types/openai_multi_functions_agent.ipynb
@@ -71,7 +71,7 @@
"llm = ChatOpenAI(temperature=0, model=\"gpt-3.5-turbo-0613\")\n",
"\n",
"# Initialize the SerpAPIWrapper for search functionality\n",
- "# Replace <your_api_key> in openai_api_key=\"<your_api_key>\" with your actual SerpAPI key.\n",
+ "# Replace <your_api_key> in serpapi_api_key=\"<your_api_key>\" with your actual SerpAPI key.\n",
"search = SerpAPIWrapper()\n",
"\n",
"# Define a list of tools offered by the agent\n",
| Fixed typo in the comments Notebook. (which says `openai_api_key` for SerpAPI)
| https://api.github.com/repos/langchain-ai/langchain/pulls/10020 | 2023-08-31T04:59:56Z | 2023-08-31T07:33:13Z | 2023-08-31T07:33:13Z | 2023-09-04T03:46:52Z | 251 | langchain-ai/langchain | 43,225 |
Add domain fronting example | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 7b30846972..71a8c3ac22 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -10,6 +10,8 @@
([#5109](https://github.com/mitmproxy/mitmproxy/issues/5109), @mhils)
* Make sure that mitmproxy displays error messages on startup.
([#5225](https://github.com/mitmproxy/mitmproxy/issues/5225), @mhils)
+* Add example addon for domain fronting.
+ ([#5217](https://github.com/mitmproxy/mitmproxy/issues/5217), @randomstuff)
## 19 March 2022: mitmproxy 8.0.0
diff --git a/examples/contrib/domain_fronting.py b/examples/contrib/domain_fronting.py
new file mode 100644
index 0000000000..8ef07278ce
--- /dev/null
+++ b/examples/contrib/domain_fronting.py
@@ -0,0 +1,130 @@
+from typing import Set, Union, Dict, Optional
+import json
+from dataclasses import dataclass
+from mitmproxy import ctx
+from mitmproxy.addonmanager import Loader
+from mitmproxy.http import HTTPFlow
+
+
+"""
+This extension implements support for domain fronting.
+
+Usage:
+
+ mitmproxy -s examples/contrib/domain_fronting.py --set domainfrontingfile=./domain_fronting.json
+
+In the following basic example, www.example.com will be used for DNS requests and SNI values
+but the secret.example.com value will be used for the HTTP host header:
+
+ {
+ "mappings": [
+ {
+ "patterns": ["secret.example.com"],
+ "server": "www.example.com"
+ }
+ ]
+ }
+
+The following example demonstrates the usage of a wildcard (at the beginning of the domain name only):
+
+ {
+ "mappings": [
+ {
+ "patterns": ["*.foo.example.com"],
+ "server": "www.example.com"
+ }
+ ]
+ }
+
+In the following example, we override the HTTP host header:
+
+ {
+ "mappings": [
+ {
+ "patterns": ["foo.example"],
+ "server": "www.example.com",
+ "host": "foo.proxy.example.com"
+ }
+ ]
+ }
+
+"""
+
+
+@dataclass
+class Mapping:
+ server: Union[str, None]
+ host: Union[str, None]
+
+
+class HttpsDomainFronting:
+
+ # configurations for regular ("foo.example.com") mappings:
+ star_mappings: Dict[str, Mapping]
+
+ # Configurations for star ("*.example.com") mappings:
+ strict_mappings: Dict[str, Mapping]
+
+ def __init__(self) -> None:
+ self.strict_mappings = {}
+ self.star_mappings = {}
+
+ def _resolve_addresses(self, host: str) -> Optional[Mapping]:
+ mapping = self.strict_mappings.get(host)
+ if mapping is not None:
+ return mapping
+
+ index = 0
+ while True:
+ index = host.find(".", index)
+ if index == -1:
+ break
+ super_domain = host[(index + 1):]
+ mapping = self.star_mappings.get(super_domain)
+ if mapping is not None:
+ return mapping
+ index += 1
+
+ return None
+
+ def load(self, loader: Loader) -> None:
+ loader.add_option(
+ name="domainfrontingfile",
+ typespec=str,
+ default="./fronting.json",
+ help="Domain fronting configuration file",
+ )
+
+ def _load_configuration_file(self, filename: str) -> None:
+ config = json.load(open(filename, "rt"))
+ strict_mappings: Dict[str, Mapping] = {}
+ star_mappings: Dict[str, Mapping] = {}
+ for mapping in config["mappings"]:
+ item = Mapping(server=mapping.get("server"), host=mapping.get("host"))
+ for pattern in mapping["patterns"]:
+ if pattern.startswith("*."):
+ star_mappings[pattern[2:]] = item
+ else:
+ strict_mappings[pattern] = item
+ self.strict_mappings = strict_mappings
+ self.star_mappings = star_mappings
+
+ def configure(self, updated: Set[str]) -> None:
+ if "domainfrontingfile" in updated:
+ domain_fronting_file = ctx.options.domainfrontingfile
+ self._load_configuration_file(domain_fronting_file)
+
+ def request(self, flow: HTTPFlow) -> None:
+ if not flow.request.scheme == "https":
+ return
+ # We use the host header to dispatch the request:
+ target = flow.request.host_header
+ if target is None:
+ return
+ mapping = self._resolve_addresses(target)
+ if mapping is not None:
+ flow.request.host = mapping.server or target
+ flow.request.headers["host"] = mapping.host or target
+
+
+addons = [HttpsDomainFronting()]
| #### Description
Adds an addon which implements domain fronting.
#### Checklist
- [X] I have updated tests where applicable.
- [X] I have added an entry to the CHANGELOG.
| https://api.github.com/repos/mitmproxy/mitmproxy/pulls/5217 | 2022-03-27T20:14:48Z | 2022-03-29T16:25:01Z | 2022-03-29T16:25:00Z | 2022-03-29T16:25:01Z | 1,164 | mitmproxy/mitmproxy | 27,490 |
Only call Init Distributed if required | diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index 80b6013c9a87..422131b5437b 100755
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -131,10 +131,10 @@ def __init__(self,
dist_init_required = not dist.is_initialized()
if dist_init_required is False:
- assert (dist.is_initialized()==True), "Torch distributed not initialized. Please set dist_init_required to True or initialize before calling deepspeed.initialize()"
-
- # Initialize torch distributed if needed
- init_distributed(dist_backend=self.dist_backend)
+ assert dist.is_initialized() is True, "Torch distributed not initialized. Please set dist_init_required to True or initialize before calling deepspeed.initialize()"
+ else:
+ # Initialize torch distributed if needed
+ init_distributed(dist_backend=self.dist_backend)
self._do_args_sanity_check(args)
self._configure_with_arguments(args, mpu)
| Adds an else statement to make sure we only call `init_distributed` if required.
I added this due to running into an `mpi4py` missing requirement issue, since we do not expose the `auto_mpi_discovery` flag within the `init_distributed` function. As a result by ensuring we use the check first to see if distributed has already been initialized, we can omit calling this check. | https://api.github.com/repos/microsoft/DeepSpeed/pulls/734 | 2021-02-08T17:18:02Z | 2021-02-11T06:52:06Z | 2021-02-11T06:52:06Z | 2021-02-11T06:52:06Z | 224 | microsoft/DeepSpeed | 10,518 |
Cascade update of taskinstance to TaskMap table | diff --git a/airflow/migrations/versions/0125_2_6_2_add_onupdate_cascade_to_taskmap.py b/airflow/migrations/versions/0125_2_6_2_add_onupdate_cascade_to_taskmap.py
new file mode 100644
index 0000000000000..cdc21ddaa18df
--- /dev/null
+++ b/airflow/migrations/versions/0125_2_6_2_add_onupdate_cascade_to_taskmap.py
@@ -0,0 +1,62 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""Add ``onupdate`` cascade to ``task_map`` table
+
+Revision ID: c804e5c76e3e
+Revises: 98ae134e6fff
+Create Date: 2023-05-19 23:30:57.368617
+
+"""
+from __future__ import annotations
+
+from alembic import op
+
+# revision identifiers, used by Alembic.
+revision = "c804e5c76e3e"
+down_revision = "98ae134e6fff"
+branch_labels = None
+depends_on = None
+airflow_version = "2.6.2"
+
+
+def upgrade():
+ """Apply Add onupdate cascade to taskmap"""
+ with op.batch_alter_table("task_map") as batch_op:
+ batch_op.drop_constraint("task_map_task_instance_fkey", type_="foreignkey")
+ batch_op.create_foreign_key(
+ "task_map_task_instance_fkey",
+ "task_instance",
+ ["dag_id", "task_id", "run_id", "map_index"],
+ ["dag_id", "task_id", "run_id", "map_index"],
+ ondelete="CASCADE",
+ onupdate="CASCADE",
+ )
+
+
+def downgrade():
+ """Unapply Add onupdate cascade to taskmap"""
+ with op.batch_alter_table("task_map") as batch_op:
+ batch_op.drop_constraint("task_map_task_instance_fkey", type_="foreignkey")
+ batch_op.create_foreign_key(
+ "task_map_task_instance_fkey",
+ "task_instance",
+ ["dag_id", "task_id", "run_id", "map_index"],
+ ["dag_id", "task_id", "run_id", "map_index"],
+ ondelete="CASCADE",
+ )
diff --git a/airflow/migrations/versions/0125_2_7_0_add_index_to_task_instance_table.py b/airflow/migrations/versions/0126_2_7_0_add_index_to_task_instance_table.py
similarity index 96%
rename from airflow/migrations/versions/0125_2_7_0_add_index_to_task_instance_table.py
rename to airflow/migrations/versions/0126_2_7_0_add_index_to_task_instance_table.py
index b9a1df82fd9ff..225776119e4b5 100644
--- a/airflow/migrations/versions/0125_2_7_0_add_index_to_task_instance_table.py
+++ b/airflow/migrations/versions/0126_2_7_0_add_index_to_task_instance_table.py
@@ -19,7 +19,7 @@
"""Add index to task_instance table
Revision ID: 937cbd173ca1
-Revises: 98ae134e6fff
+Revises: c804e5c76e3e
Create Date: 2023-05-03 11:31:32.527362
"""
@@ -29,7 +29,7 @@
# revision identifiers, used by Alembic.
revision = "937cbd173ca1"
-down_revision = "98ae134e6fff"
+down_revision = "c804e5c76e3e"
branch_labels = None
depends_on = None
airflow_version = "2.7.0"
diff --git a/airflow/models/taskmap.py b/airflow/models/taskmap.py
index e7abcc1b6e0ae..9704cfb5cc9fb 100644
--- a/airflow/models/taskmap.py
+++ b/airflow/models/taskmap.py
@@ -72,6 +72,7 @@ class TaskMap(Base):
],
name="task_map_task_instance_fkey",
ondelete="CASCADE",
+ onupdate="CASCADE",
),
)
diff --git a/docs/apache-airflow/img/airflow_erd.sha256 b/docs/apache-airflow/img/airflow_erd.sha256
index 1f2c2c1f3419a..2405a400dbc83 100644
--- a/docs/apache-airflow/img/airflow_erd.sha256
+++ b/docs/apache-airflow/img/airflow_erd.sha256
@@ -1 +1 @@
-4987842fd67d29e194f1117e127d3291ba60d3fbc3e81cba75ce93884c263321
\ No newline at end of file
+2d0924c9f5c471214953113e8830b842fc45e9344ff6d67b46267cac99e2cdef
\ No newline at end of file
diff --git a/docs/apache-airflow/img/airflow_erd.svg b/docs/apache-airflow/img/airflow_erd.svg
index 8439c226f8b98..142c05dfd84b4 100644
--- a/docs/apache-airflow/img/airflow_erd.svg
+++ b/docs/apache-airflow/img/airflow_erd.svg
@@ -1225,28 +1225,28 @@
<g id="edge48" class="edge">
<title>task_instance--xcom</title>
<path fill="none" stroke="#7f7f7f" stroke-dasharray="5,2" d="M1137.01,-488.65C1161.12,-465.83 1186.07,-443.06 1210,-422 1216.27,-416.48 1222.72,-410.89 1229.27,-405.29"/>
-<text text-anchor="start" x="1219.27" y="-394.09" font-family="Times,serif" font-size="14.00">1</text>
+<text text-anchor="start" x="1198.27" y="-394.09" font-family="Times,serif" font-size="14.00">0..N</text>
<text text-anchor="start" x="1137.01" y="-477.45" font-family="Times,serif" font-size="14.00">1</text>
</g>
<!-- task_instance--xcom -->
<g id="edge49" class="edge">
<title>task_instance--xcom</title>
<path fill="none" stroke="#7f7f7f" stroke-dasharray="5,2" d="M1137.01,-506.4C1161.12,-483.83 1186.07,-461.06 1210,-440 1216.27,-434.48 1222.72,-428.89 1229.27,-423.28"/>
-<text text-anchor="start" x="1198.27" y="-412.08" font-family="Times,serif" font-size="14.00">0..N</text>
+<text text-anchor="start" x="1219.27" y="-412.08" font-family="Times,serif" font-size="14.00">1</text>
<text text-anchor="start" x="1137.01" y="-495.2" font-family="Times,serif" font-size="14.00">1</text>
</g>
<!-- task_instance--xcom -->
<g id="edge50" class="edge">
<title>task_instance--xcom</title>
<path fill="none" stroke="#7f7f7f" stroke-dasharray="5,2" d="M1137.01,-524.15C1161.12,-501.83 1186.07,-479.06 1210,-458 1216.66,-452.14 1223.53,-446.19 1230.5,-440.21"/>
-<text text-anchor="start" x="1199.5" y="-444.01" font-family="Times,serif" font-size="14.00">0..N</text>
+<text text-anchor="start" x="1220.5" y="-444.01" font-family="Times,serif" font-size="14.00">1</text>
<text text-anchor="start" x="1137.01" y="-512.95" font-family="Times,serif" font-size="14.00">1</text>
</g>
<!-- task_instance--xcom -->
<g id="edge51" class="edge">
<title>task_instance--xcom</title>
<path fill="none" stroke="#7f7f7f" stroke-dasharray="5,2" d="M1137.01,-541.9C1161.12,-519.83 1186.07,-497.06 1210,-476 1223.32,-464.28 1237.48,-452.19 1251.63,-440.12"/>
-<text text-anchor="start" x="1241.63" y="-443.92" font-family="Times,serif" font-size="14.00">1</text>
+<text text-anchor="start" x="1251.63" y="-443.92" font-family="Times,serif" font-size="14.00">0..N</text>
<text text-anchor="start" x="1137.01" y="-530.7" font-family="Times,serif" font-size="14.00">1</text>
</g>
<!-- log_template -->
diff --git a/docs/apache-airflow/migrations-ref.rst b/docs/apache-airflow/migrations-ref.rst
index 2fdc682025a07..7b09a46f8c02c 100644
--- a/docs/apache-airflow/migrations-ref.rst
+++ b/docs/apache-airflow/migrations-ref.rst
@@ -39,7 +39,9 @@ Here's the list of all the Database Migrations that are executed via when you ru
+---------------------------------+-------------------+-------------------+--------------------------------------------------------------+
| Revision ID | Revises ID | Airflow Version | Description |
+=================================+===================+===================+==============================================================+
-| ``937cbd173ca1`` (head) | ``98ae134e6fff`` | ``2.7.0`` | Add index to task_instance table |
+| ``937cbd173ca1`` (head) | ``c804e5c76e3e`` | ``2.7.0`` | Add index to task_instance table |
++---------------------------------+-------------------+-------------------+--------------------------------------------------------------+
+| ``c804e5c76e3e`` | ``98ae134e6fff`` | ``2.6.2`` | Add ``onupdate`` cascade to ``task_map`` table |
+---------------------------------+-------------------+-------------------+--------------------------------------------------------------+
| ``98ae134e6fff`` | ``6abdffdd4815`` | ``2.6.0`` | Increase length of user identifier columns in ``ab_user`` |
| | | | and ``ab_register_user`` tables |
diff --git a/tests/models/test_taskinstance.py b/tests/models/test_taskinstance.py
index 0dcfb632142de..0a20891896ac2 100644
--- a/tests/models/test_taskinstance.py
+++ b/tests/models/test_taskinstance.py
@@ -70,7 +70,7 @@
from airflow.operators.python import PythonOperator
from airflow.sensors.base import BaseSensorOperator
from airflow.sensors.python import PythonSensor
-from airflow.serialization.serialized_objects import SerializedBaseOperator
+from airflow.serialization.serialized_objects import SerializedBaseOperator, SerializedDAG
from airflow.settings import TIMEZONE
from airflow.stats import Stats
from airflow.ti_deps.dep_context import DepContext
@@ -3643,6 +3643,39 @@ def pull_something(value):
assert task_map.length == expected_length
assert task_map.keys == expected_keys
+ def test_no_error_on_changing_from_non_mapped_to_mapped(self, dag_maker, session):
+ """If a task changes from non-mapped to mapped, don't fail on integrity error."""
+ with dag_maker(dag_id="test_no_error_on_changing_from_non_mapped_to_mapped") as dag:
+
+ @dag.task()
+ def add_one(x):
+ return [x + 1]
+
+ @dag.task()
+ def add_two(x):
+ return x + 2
+
+ task1 = add_one(2)
+ add_two.expand(x=task1)
+
+ dr = dag_maker.create_dagrun()
+ ti = dr.get_task_instance(task_id="add_one")
+ ti.run()
+ assert ti.state == TaskInstanceState.SUCCESS
+ dag._remove_task("add_one")
+ with dag:
+ task1 = add_one.expand(x=[1, 2, 3]).operator
+ serialized_dag = SerializedDAG.from_dict(SerializedDAG.to_dict(dag))
+
+ dr.dag = serialized_dag
+ dr.verify_integrity(session=session)
+ ti = dr.get_task_instance(task_id="add_one")
+ assert ti.state == TaskInstanceState.REMOVED
+ dag.clear()
+ ti.refresh_from_task(task1)
+ # This should not raise an integrity error
+ dr.task_instance_scheduling_decisions()
+
class TestMappedTaskInstanceReceiveValue:
@pytest.mark.parametrize(
| Updating a taskinstance's map_index etc should cascade to the task_map table
else we would get foreign key violation error when updating a task instance from unmapped
to mapped.
closes: https://github.com/apache/airflow/issues/31431 | https://api.github.com/repos/apache/airflow/pulls/31445 | 2023-05-21T10:23:17Z | 2023-05-24T10:54:46Z | 2023-05-24T10:54:46Z | 2023-06-10T09:35:58Z | 3,253 | apache/airflow | 14,465 |
HKG: Add FW Versions for China Kia Carnival 2023 | diff --git a/docs/CARS.md b/docs/CARS.md
index ee99b7d13857a0..f9a8ac7ceec3e3 100644
--- a/docs/CARS.md
+++ b/docs/CARS.md
@@ -4,7 +4,7 @@
A supported vehicle is one that just works when you install a comma three. All supported cars provide a better experience than any stock system. Supported vehicles reference the US market unless otherwise specified.
-# 254 Supported Cars
+# 255 Supported Cars
|Make|Model|Supported Package|ACC|No ACC accel below|No ALC below|Steering Torque|Resume from stop|<a href="##"><img width=2000></a>Hardware Needed<br> |Video|
|---|---|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
@@ -107,6 +107,7 @@ A supported vehicle is one that just works when you install a comma three. All s
|Jeep|Grand Cherokee 2016-18|Adaptive Cruise Control (ACC)|Stock|0 mph|9 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 FCA connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Jeep&model=Grand Cherokee 2016-18">Buy Here</a></sub></details>|<a href="https://www.youtube.com/watch?v=eLR9o2JkuRk" target="_blank"><img height="18px" src="assets/icon-youtube.svg"></img></a>|
|Jeep|Grand Cherokee 2019-21|Adaptive Cruise Control (ACC)|Stock|0 mph|39 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 FCA connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Jeep&model=Grand Cherokee 2019-21">Buy Here</a></sub></details>|<a href="https://www.youtube.com/watch?v=jBe4lWnRSu4" target="_blank"><img height="18px" src="assets/icon-youtube.svg"></img></a>|
|Kia|Carnival 2023[<sup>6</sup>](#footnotes)|Smart Cruise Control (SCC)|Stock|0 mph|0 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 Hyundai A connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Kia&model=Carnival 2023">Buy Here</a></sub></details>||
+|Kia|Carnival (China only) 2023[<sup>6</sup>](#footnotes)|Smart Cruise Control (SCC)|Stock|0 mph|0 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 Hyundai K connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Kia&model=Carnival (China only) 2023">Buy Here</a></sub></details>||
|Kia|Ceed 2019|Smart Cruise Control (SCC)|Stock|0 mph|0 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 Hyundai E connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Kia&model=Ceed 2019">Buy Here</a></sub></details>||
|Kia|EV6 (Southeast Asia only) 2022-23[<sup>6</sup>](#footnotes)|All|openpilot available[<sup>1</sup>](#footnotes)|0 mph|0 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 Hyundai P connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Kia&model=EV6 (Southeast Asia only) 2022-23">Buy Here</a></sub></details>||
|Kia|EV6 (with HDA II) 2022-23[<sup>6</sup>](#footnotes)|Highway Driving Assist II|openpilot available[<sup>1</sup>](#footnotes)|0 mph|0 mph|[](##)|[](##)|<details><summary>View</summary><sub>- 1 Hyundai P connector<br>- 1 RJ45 cable (7 ft)<br>- 1 comma power v2<br>- 1 comma three<br>- 1 harness box<br>- 1 mount<br>- 1 right angle OBD-C cable (1.5 ft)<br><a href="https://comma.ai/shop/comma-three.html?make=Kia&model=EV6 (with HDA II) 2022-23">Buy Here</a></sub></details>||
diff --git a/selfdrive/car/hyundai/values.py b/selfdrive/car/hyundai/values.py
index 4a0e7b78802a01..607c37f2f2b90e 100644
--- a/selfdrive/car/hyundai/values.py
+++ b/selfdrive/car/hyundai/values.py
@@ -249,7 +249,7 @@ def init_make(self, CP: car.CarParams):
],
CAR.KIA_CARNIVAL_4TH_GEN: [
HyundaiCarInfo("Kia Carnival 2023", car_parts=CarParts.common([CarHarness.hyundai_a])),
- # HyundaiCarInfo("Kia Carnival (China only) 2023", car_parts=CarParts.common([CarHarness.hyundai_k]))
+ HyundaiCarInfo("Kia Carnival (China only) 2023", car_parts=CarParts.common([CarHarness.hyundai_k]))
],
# Genesis
@@ -1883,9 +1883,11 @@ def match_fw_to_car_fuzzy(live_fw_versions) -> Set[str]:
CAR.KIA_CARNIVAL_4TH_GEN: {
(Ecu.fwdCamera, 0x7c4, None): [
b'\xf1\x00KA4 MFC AT USA LHD 1.00 1.06 99210-R0000 220221',
+ b'\xf1\x00KA4CMFC AT CHN LHD 1.00 1.01 99211-I4000 210525',
],
(Ecu.fwdRadar, 0x7d0, None): [
b'\xf1\x00KA4_ SCC FHCUP 1.00 1.03 99110-R0000 ',
+ b'\xf1\x00KA4c SCC FHCUP 1.00 1.01 99110-I4000 ',
],
},
}
diff --git a/selfdrive/car/tests/routes.py b/selfdrive/car/tests/routes.py
index 3066756a5b014c..3e365991bd913a 100644
--- a/selfdrive/car/tests/routes.py
+++ b/selfdrive/car/tests/routes.py
@@ -100,6 +100,7 @@
CarTestRoute("37398f32561a23ad|2021-11-18--00-11-35", HYUNDAI.SANTA_FE_HEV_2022),
CarTestRoute("656ac0d830792fcc|2021-12-28--14-45-56", HYUNDAI.SANTA_FE_PHEV_2022, segment=1),
CarTestRoute("de59124955b921d8|2023-06-24--00-12-50", HYUNDAI.KIA_CARNIVAL_4TH_GEN),
+ CarTestRoute("409c9409979a8abc|2023-07-11--09-06-44", HYUNDAI.KIA_CARNIVAL_4TH_GEN), # Chinese model
CarTestRoute("e0e98335f3ebc58f|2021-03-07--16-38-29", HYUNDAI.KIA_CEED),
CarTestRoute("7653b2bce7bcfdaa|2020-03-04--15-34-32", HYUNDAI.KIA_OPTIMA_G4),
CarTestRoute("018654717bc93d7d|2022-09-19--23-11-10", HYUNDAI.KIA_OPTIMA_G4_FL, segment=0),
| **Checklist**
- [x] added entry to CarInfo in selfdrive/car/*/values.py and ran `selfdrive/car/docs.py` to generate new docs
- [x] test route added to [routes.py](https://github.com/commaai/openpilot/blob/master/selfdrive/car/tests/routes.py)
- [x] route with stock system: `409c9409979a8abc|2023-03-25--11-30-08`
- [x] route with openpilot: `409c9409979a8abc|2023-07-11--09-06-44`
- [x] harness type: Chinese Model: [Hyundai K](https://github.com/commaai/openpilot/wiki/Hyundai-Kia-Genesis#harness-guide)
- [x] architecture: CAN-FD
**Physical setup**
- Top port behind comma three
- comma Power <-> First Harness Box <-> comma three USB C/Right-Angle C <-> comma three
- Bottom port behind comma three
- Camera Harness <-> Second Harness Box <-> USB C/C 3.1 <-> Red Panda <-> USB A/A <-> USB A to C **OTG Adapter** <-> comma three
- Link to all physical parts during install:
- [comma three](https://comma.ai/shop/comma-three)
- [car harness kit](https://comma.ai/shop/car-harness)
- [CAN FD panda kit](https://comma.ai/shop/can-fd-panda-kit)
Thanks to the community Kia Carnival 2023 (Chinese model) owners `RTK#4465` (Discord). | https://api.github.com/repos/commaai/openpilot/pulls/28918 | 2023-07-13T17:50:05Z | 2023-07-14T00:51:59Z | 2023-07-14T00:51:59Z | 2023-07-14T00:52:34Z | 2,305 | commaai/openpilot | 9,118 |
Fix loading latest history for file names with dots | diff --git a/modules/chat.py b/modules/chat.py
index 8ddb753114..dccd20b753 100644
--- a/modules/chat.py
+++ b/modules/chat.py
@@ -510,8 +510,7 @@ def load_latest_history(state):
histories = find_all_histories(state)
if len(histories) > 0:
- unique_id = Path(histories[0]).stem
- history = load_history(unique_id, state['character_menu'], state['mode'])
+ history = load_history(histories[0], state['character_menu'], state['mode'])
else:
history = start_new_chat(state)
| ## Problem
When the most recent chat or instruct log is loaded, it fails when the file name has a dot in it. This seems to happen because `.stem` is being used twice:
https://github.com/oobabooga/text-generation-webui/blob/894e1a070067a7d9f22b032b53cdd3a3528dce53/modules/chat.py#L496 https://github.com/oobabooga/text-generation-webui/blob/894e1a070067a7d9f22b032b53cdd3a3528dce53/modules/chat.py#L513
## The fix
Remove the extra `.stem` and use the "unique id" that comes from `find_all_histories` as is.
I've tested the fix in several ways, including crazy file names and directory junctions, but I'd love to hear if I missed some important reason for why the `Path(...).stem` was there.
## Error logs
Starting up Webui, most recent history is named `This.File.Name.Has.Several.Dots.json`.
```
Traceback (most recent call last):
File "E:\webui\installer_files\env\Lib\site-packages\gradio\queueing.py", line 407, in call_prediction
output = await route_utils.call_process_api(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\gradio\route_utils.py", line 226, in call_process_api
output = await app.get_blocks().process_api(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\gradio\blocks.py", line 1550, in process_api
result = await self.call_function(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\gradio\blocks.py", line 1185, in call_function
prediction = await anyio.to_thread.run_sync(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\anyio\_backends\_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\anyio\_backends\_asyncio.py", line 807, in run
result = context.run(func, *args)
^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\installer_files\env\Lib\site-packages\gradio\utils.py", line 661, in wrapper
response = f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^
File "E:\webui\modules\chat.py", line 514, in load_latest_history
history = load_history(unique_id, state['character_menu'], state['mode'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\webui\modules\chat.py", line 524, in load_history
f = json.loads(open(p, 'rb').read())
^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: 'logs\\chat\\Ann\\This.File.Name.Has.Several.json'
```
## Checklist
- [X] I have read the [Contributing guidelines](https://github.com/oobabooga/text-generation-webui/wiki/Contributing-guidelines).
| https://api.github.com/repos/oobabooga/text-generation-webui/pulls/5162 | 2024-01-04T01:26:47Z | 2024-01-04T01:39:41Z | 2024-01-04T01:39:41Z | 2024-01-04T01:40:56Z | 140 | oobabooga/text-generation-webui | 26,820 |
[ie/zaiko] add thumbnails from event pages | diff --git a/yt_dlp/extractor/zaiko.py b/yt_dlp/extractor/zaiko.py
index 0ccacbb6aa0..2b6221da21b 100644
--- a/yt_dlp/extractor/zaiko.py
+++ b/yt_dlp/extractor/zaiko.py
@@ -9,6 +9,7 @@
traverse_obj,
try_call,
unescapeHTML,
+ url_basename,
url_or_none,
)
@@ -45,12 +46,14 @@ class ZaikoIE(ZaikoBaseIE):
'uploader_id': '454',
'uploader': 'ZAIKO ZERO',
'release_timestamp': 1583809200,
- 'thumbnail': r're:https://[a-z0-9]+.cloudfront.net/[a-z0-9_]+/[a-z0-9_]+',
+ 'thumbnail': r're:^https://[\w.-]+/\w+/\w+',
+ 'thumbnails': 'maxcount:2',
'release_date': '20200310',
'categories': ['Tech House'],
'live_status': 'was_live',
},
'params': {'skip_download': 'm3u8'},
+ 'skip': 'Your account does not have tickets to this event',
}]
def _real_extract(self, url):
@@ -83,6 +86,12 @@ def _real_extract(self, url):
if not formats:
self.raise_no_formats(msg, expected=expected)
+ thumbnail_urls = [
+ traverse_obj(player_meta, ('initial_event_info', 'poster_url')),
+ self._og_search_thumbnail(self._download_webpage(
+ f'https://zaiko.io/event/{video_id}', video_id, 'Downloading event page', fatal=False) or ''),
+ ]
+
return {
'id': video_id,
'formats': formats,
@@ -96,8 +105,8 @@ def _real_extract(self, url):
}),
**traverse_obj(player_meta, ('initial_event_info', {
'alt_title': ('title', {str}),
- 'thumbnail': ('poster_url', {url_or_none}),
})),
+ 'thumbnails': [{'url': url, 'id': url_basename(url)} for url in thumbnail_urls if url_or_none(url)]
}
| **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be understood. Provide as much **context and examples** as possible
-->
Hi.
This PR improves #7254.
This commit could not be finished without help of @c-basalt.
### Different thumbnails?
The newly added thumbnail, which is from the event page, may be the same as the one of "poster_url", but not always. I participated in a live event that has two different thumbnails before. A thumbnail was shown first and contained something like "there's a special guest coming". The second thumbnail, a few days later, replaced the first one and contained that special guest's name and photo. Fans were pleasantly surprised.
The first thumbnail I saw looks like this:

### Local test
Unfortunately, the testing URL "ZAIKO STREAMING TEST" does not seem to work anymore, so I've tested the code with my own ticket only. I don't post the url because posting a real URL might give Zaiko a chance to find the user who shared their ticket.
```JSON
{
"id": "...",
//...
"thumbnails": [
{
"url": "https://d38fgd7fmrcuct.cloudfront.net/pf_1/1_3ybh***",
"id": "1_3ybh***"
},
{
"url": "https://media.zaiko.io/pf_1/1_3ybi***",
"id": "1_3ybi***"
}
],
```
```console
> Get-FileHash *1_3yb*
Algorithm Hash Path
--------- ---- ----
SHA256 9B7*** ***
SHA256 C60*** ***
```
<details open><summary>Template</summary> <!-- OPEN is intentional -->
<!--
# PLEASE FOLLOW THE GUIDE BELOW
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes `[ ]` relevant to your *pull request* (like [x])
- Use *Preview* tab to see how your *pull request* will actually look like
-->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check all of the following options that apply:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
- [ ] New extractor ([Piracy websites will not be accepted](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy))
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
<!-- Do NOT edit/remove anything below this! -->
</details><details><summary>Copilot Summary</summary>
<!--
copilot:all
-->
### <samp>🤖 Generated by Copilot at 7ad8088</samp>
### Summary
:sparkles::hammer::mag:
<!--
1. :sparkles: - This emoji is often used to indicate a new feature or enhancement, and adding support for multiple thumbnails is a significant improvement for the zaiko extractor.
2. :hammer: - This emoji is often used to indicate a refactor or improvement of existing code, and using the `url_basename` function to generate thumbnail IDs from URLs is a more robust and consistent way of handling thumbnail metadata than relying on the order of the JSON array.
3. :mag: - This emoji is often used to indicate a bug fix or improvement of user experience, and collecting thumbnail URLs from both JSON and Open Graph data ensures that the extractor can handle different sources of thumbnail information and provide more accurate and complete results.
-->
Added support for multiple thumbnails in `zaiko.py`. Extracted thumbnail URLs from different sources and assigned them IDs based on their filenames.
> _We'll scrape the web for thumbnails, me hearties, yo ho ho_
> _We'll use the `url_basename` to name them as we go_
> _We'll fetch them from the JSON and Open Graph, you see_
> _And store them in the zaiko extractor, one, two, three_
### Walkthrough
* Import `url_basename` function from `utils` module to generate thumbnail IDs from URLs ([link](https://github.com/yt-dlp/yt-dlp/pull/8054/files?diff=unified&w=0#diff-7d130eab65fcf03eadc31278b6ba72081994079a527d403533d2ebb83dc2e854R12))
* Modify `_real_extract` function to collect two possible thumbnail URLs from `player_meta` and Open Graph tags ([link](https://github.com/yt-dlp/yt-dlp/pull/8054/files?diff=unified&w=0#diff-7d130eab65fcf03eadc31278b6ba72081994079a527d403533d2ebb83dc2e854R93-R98))
* Replace `thumbnail` field with `thumbnails` field in `info_dict`, using `url_basename` to create a list of dictionaries with `id` and `url` keys for each thumbnail ([link](https://github.com/yt-dlp/yt-dlp/pull/8054/files?diff=unified&w=0#diff-7d130eab65fcf03eadc31278b6ba72081994079a527d403533d2ebb83dc2e854L99-R113))
* Update test case to reflect the change from `thumbnail` to `thumbnails` field, and provide two expected thumbnail URLs ([link](https://github.com/yt-dlp/yt-dlp/pull/8054/files?diff=unified&w=0#diff-7d130eab65fcf03eadc31278b6ba72081994079a527d403533d2ebb83dc2e854L48-R55))
</details>
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/8054 | 2023-09-07T16:15:58Z | 2023-09-16T21:04:11Z | 2023-09-16T21:04:10Z | 2023-09-17T00:52:05Z | 511 | yt-dlp/yt-dlp | 7,925 |
Fix docstring in face_recognition.api.batch_face_locations | diff --git a/face_recognition/api.py b/face_recognition/api.py
index 5aed5ec0b..c74c5f95c 100644
--- a/face_recognition/api.py
+++ b/face_recognition/api.py
@@ -138,7 +138,7 @@ def batch_face_locations(images, number_of_times_to_upsample=1, batch_size=128):
If you are using a GPU, this can give you much faster results since the GPU
can process batches of images at once. If you aren't using a GPU, you don't need this function.
- :param img: A list of images (each as a numpy array)
+ :param images: A list of images (each as a numpy array)
:param number_of_times_to_upsample: How many times to upsample the image looking for faces. Higher numbers find smaller faces.
:param batch_size: How many images to include in each GPU processing batch.
:return: A list of tuples of found face locations in css (top, right, bottom, left) order
| In doc: parameter img fix to images as function parameter. | https://api.github.com/repos/ageitgey/face_recognition/pulls/964 | 2019-10-25T21:41:10Z | 2019-11-13T08:03:21Z | 2019-11-13T08:03:21Z | 2019-11-13T08:03:21Z | 235 | ageitgey/face_recognition | 22,561 |
Note -> Not, are -> is | diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index e0fdf3dc8..2c3c935c4 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -7091,9 +7091,9 @@ Consistent use of `override` would catch this.
##### Note
-Note every class is meant to be a base class.
+Not every class is meant to be a base class.
Most standard-library classes are examples of that (e.g., `std::vector` and `std::string` are not designed to be derived from).
-This rule are about using `final` on classes with virtual functions meant to be interfaces for a class hierarchy.
+This rule is about using `final` on classes with virtual functions meant to be interfaces for a class hierarchy.
##### Note
| https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/909 | 2017-05-01T02:33:20Z | 2017-05-01T18:07:16Z | 2017-05-01T18:07:16Z | 2017-05-02T00:27:47Z | 188 | isocpp/CppCoreGuidelines | 15,308 |
|
[ie/asobistage] Add extractor for live and archives | diff --git a/yt_dlp/extractor/_extractors.py b/yt_dlp/extractor/_extractors.py
index c7536553680..c8b364c7bc5 100644
--- a/yt_dlp/extractor/_extractors.py
+++ b/yt_dlp/extractor/_extractors.py
@@ -150,6 +150,7 @@
)
from .arnes import ArnesIE
from .asobichannel import AsobiChannelIE, AsobiChannelTagURLIE
+from .asobistage import AsobiStageIE
from .atresplayer import AtresPlayerIE
from .atscaleconf import AtScaleConfEventIE
from .atvat import ATVAtIE
diff --git a/yt_dlp/extractor/asobistage.py b/yt_dlp/extractor/asobistage.py
new file mode 100644
index 00000000000..b088a1b1321
--- /dev/null
+++ b/yt_dlp/extractor/asobistage.py
@@ -0,0 +1,154 @@
+import functools
+
+from .common import InfoExtractor
+from ..utils import str_or_none, url_or_none
+from ..utils.traversal import traverse_obj
+
+
+class AsobiStageIE(InfoExtractor):
+ IE_DESC = 'ASOBISTAGE (アソビステージ)'
+ _VALID_URL = r'https?://asobistage\.asobistore\.jp/event/(?P<id>(?P<event>\w+)/(?P<type>archive|player)/(?P<slug>\w+))(?:[?#]|$)'
+ _TESTS = [{
+ 'url': 'https://asobistage.asobistore.jp/event/315passionhour_2022summer/archive/frame',
+ 'info_dict': {
+ 'id': '315passionhour_2022summer/archive/frame',
+ 'title': '315プロダクションプレゼンツ 315パッションアワー!!!',
+ 'thumbnail': r're:^https?://[\w.-]+/\w+/\w+',
+ },
+ 'playlist_count': 1,
+ 'playlist': [{
+ 'info_dict': {
+ 'id': 'edff52f2',
+ 'ext': 'mp4',
+ 'title': '315passion_FRAME_only',
+ 'thumbnail': r're:^https?://[\w.-]+/\w+/\w+',
+ },
+ }],
+ }, {
+ 'url': 'https://asobistage.asobistore.jp/event/idolmaster_idolworld2023_goods/archive/live',
+ 'info_dict': {
+ 'id': 'idolmaster_idolworld2023_goods/archive/live',
+ 'title': 'md5:378510b6e830129d505885908bd6c576',
+ 'thumbnail': r're:^https?://[\w.-]+/\w+/\w+',
+ },
+ 'playlist_count': 1,
+ 'playlist': [{
+ 'info_dict': {
+ 'id': '3aef7110',
+ 'ext': 'mp4',
+ 'title': 'asobistore_station_1020_serverREC',
+ 'thumbnail': r're:^https?://[\w.-]+/\w+/\w+',
+ },
+ }],
+ }, {
+ 'url': 'https://asobistage.asobistore.jp/event/sidem_fclive_bpct/archive/premium_hc',
+ 'playlist_count': 4,
+ 'info_dict': {
+ 'id': 'sidem_fclive_bpct/archive/premium_hc',
+ 'title': '315 Production presents F@NTASTIC COMBINATION LIVE ~BRAINPOWER!!~/~CONNECTIME!!!!~',
+ 'thumbnail': r're:^https?://[\w.-]+/\w+/\w+',
+ },
+ }, {
+ 'url': 'https://asobistage.asobistore.jp/event/ijigenfes_utagassen/player/day1',
+ 'only_matching': True,
+ }]
+
+ _API_HOST = 'https://asobistage-api.asobistore.jp'
+ _HEADERS = {}
+ _is_logged_in = False
+
+ @functools.cached_property
+ def _owned_tickets(self):
+ owned_tickets = set()
+ if not self._is_logged_in:
+ return owned_tickets
+
+ for path, name in [
+ ('api/v1/purchase_history/list', 'ticket purchase history'),
+ ('api/v1/serialcode/list', 'redemption history'),
+ ]:
+ response = self._download_json(
+ f'{self._API_HOST}/{path}', None, f'Downloading {name}',
+ f'Unable to download {name}', expected_status=400)
+ if traverse_obj(response, ('payload', 'error_message'), 'error') == 'notlogin':
+ self._is_logged_in = False
+ break
+ owned_tickets.update(
+ traverse_obj(response, ('payload', 'value', ..., 'digital_product_id', {str_or_none})))
+
+ return owned_tickets
+
+ def _get_available_channel_id(self, channel):
+ channel_id = traverse_obj(channel, ('chennel_vspf_id', {str}))
+ if not channel_id:
+ return None
+ # if rights_type_id == 6, then 'No conditions (no login required - non-members are OK)'
+ if traverse_obj(channel, ('viewrights', lambda _, v: v['rights_type_id'] == 6)):
+ return channel_id
+ available_tickets = traverse_obj(channel, (
+ 'viewrights', ..., ('tickets', 'serialcodes'), ..., 'digital_product_id', {str_or_none}))
+ if not self._owned_tickets.intersection(available_tickets):
+ self.report_warning(
+ f'You are not a ticketholder for "{channel.get("channel_name") or channel_id}"')
+ return None
+ return channel_id
+
+ def _real_initialize(self):
+ if self._get_cookies(self._API_HOST):
+ self._is_logged_in = True
+ token = self._download_json(
+ f'{self._API_HOST}/api/v1/vspf/token', None, 'Getting token', 'Unable to get token')
+ self._HEADERS['Authorization'] = f'Bearer {token}'
+
+ def _real_extract(self, url):
+ video_id, event, type_, slug = self._match_valid_url(url).group('id', 'event', 'type', 'slug')
+ video_type = {'archive': 'archives', 'player': 'broadcasts'}[type_]
+ webpage = self._download_webpage(url, video_id)
+ event_data = traverse_obj(
+ self._search_nextjs_data(webpage, video_id, default='{}'),
+ ('props', 'pageProps', 'eventCMSData', {
+ 'title': ('event_name', {str}),
+ 'thumbnail': ('event_thumbnail_image', {url_or_none}),
+ }))
+
+ available_channels = traverse_obj(self._download_json(
+ f'https://asobistage.asobistore.jp/cdn/v101/events/{event}/{video_type}.json',
+ video_id, 'Getting channel list', 'Unable to get channel list'), (
+ video_type, lambda _, v: v['broadcast_slug'] == slug,
+ 'channels', lambda _, v: v['chennel_vspf_id'] != '00000'))
+
+ entries = []
+ for channel_id in traverse_obj(available_channels, (..., {self._get_available_channel_id})):
+ if video_type == 'archives':
+ channel_json = self._download_json(
+ f'https://survapi.channel.or.jp/proxy/v1/contents/{channel_id}/get_by_cuid', channel_id,
+ 'Getting archive channel info', 'Unable to get archive channel info', fatal=False,
+ headers=self._HEADERS)
+ channel_data = traverse_obj(channel_json, ('ex_content', {
+ 'm3u8_url': 'streaming_url',
+ 'title': 'title',
+ 'thumbnail': ('thumbnail', 'url'),
+ }))
+ else: # video_type == 'broadcasts'
+ channel_json = self._download_json(
+ f'https://survapi.channel.or.jp/ex/events/{channel_id}', channel_id,
+ 'Getting live channel info', 'Unable to get live channel info', fatal=False,
+ headers=self._HEADERS, query={'embed': 'channel'})
+ channel_data = traverse_obj(channel_json, ('data', {
+ 'm3u8_url': ('Channel', 'Custom_live_url'),
+ 'title': 'Name',
+ 'thumbnail': 'Poster_url',
+ }))
+
+ entries.append({
+ 'id': channel_id,
+ 'title': channel_data.get('title'),
+ 'formats': self._extract_m3u8_formats(channel_data.get('m3u8_url'), channel_id, fatal=False),
+ 'is_live': video_type == 'broadcasts',
+ 'thumbnail': url_or_none(channel_data.get('thumbnail')),
+ })
+
+ if not self._is_logged_in and not entries:
+ self.raise_login_required()
+
+ return self.playlist_result(entries, video_id, **event_data)
| **IMPORTANT**: PRs without the template will be CLOSED
### Description of your *pull request* and other information
<!--
Explanation of your *pull request* in arbitrary form goes here. Please **make sure the description explains the purpose and effect** of your *pull request* and is worded well enough to be understood. Provide as much **context and examples** as possible
-->
### Summary
[ASOBISTAGE (アソビステージ)](https://asobistage.asobistore.jp/) is a Japanese live-streaming platform owned by Bandai Namco Entertainment Inc.

This extractor currently does not support URLs like `https://asobistage.asobistore.jp/event/foo/rental/player/normal` (note the "rental/player").
### Note
- I didn't find the way to get the correct timestamp of an video.
- The `dict.get()` check after "`traverse_obj()`" looks not good. How do I make it better? I mean, how can I check required fields in the downloaded JSON?
<details open><summary>Template</summary> <!-- OPEN is intentional -->
<!--
# PLEASE FOLLOW THE GUIDE BELOW
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes `[ ]` relevant to your *pull request* (like [x])
- Use *Preview* tab to see how your *pull request* will actually look like
-->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check all of the following options that apply:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [ ] Fix or improvement to an extractor (Make sure to add/update tests)
- [x] New extractor ([Piracy websites will not be accepted](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy))
- [ ] Core bug fix/improvement
- [ ] New feature (It is strongly [recommended to open an issue first](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#adding-new-feature-or-making-overarching-changes))
</details>
| https://api.github.com/repos/yt-dlp/yt-dlp/pulls/8735 | 2023-12-09T10:41:39Z | 2024-04-01T22:29:14Z | 2024-04-01T22:29:14Z | 2024-04-02T01:03:03Z | 2,094 | yt-dlp/yt-dlp | 8,137 |
Remove route53 readme | diff --git a/certbot-dns-route53/MANIFEST.in b/certbot-dns-route53/MANIFEST.in
index fc62028b018..a53dbd85b22 100644
--- a/certbot-dns-route53/MANIFEST.in
+++ b/certbot-dns-route53/MANIFEST.in
@@ -1,5 +1,4 @@
include LICENSE.txt
-include README
recursive-include docs *
recursive-include tests *
global-exclude __pycache__
diff --git a/certbot-dns-route53/README.md b/certbot-dns-route53/README.md
deleted file mode 100644
index 4af66aa0068..00000000000
--- a/certbot-dns-route53/README.md
+++ /dev/null
@@ -1,35 +0,0 @@
-## Route53 plugin for Let's Encrypt client
-
-### Before you start
-
-It's expected that the root hosted zone for the domain in question already
-exists in your account.
-
-### Setup
-
-1. Create a virtual environment
-
-2. Update its pip and setuptools (`VENV/bin/pip install -U setuptools pip`)
-to avoid problems with cryptography's dependency on setuptools>=11.3.
-
-3. Make sure you have libssl-dev and libffi (or your regional equivalents)
-installed. You might have to set compiler flags to pick things up (I have to
-use `CPPFLAGS=-I/usr/local/opt/openssl/include
-LDFLAGS=-L/usr/local/opt/openssl/lib` on my macOS to pick up brew's openssl,
-for example).
-
-4. Install this package.
-
-### How to use it
-
-Make sure you have access to AWS's Route53 service, either through IAM roles or
-via `.aws/credentials`. Check out
-[sample-aws-policy.json](examples/sample-aws-policy.json) for the necessary permissions.
-
-To generate a certificate:
-```
-certbot certonly \
- -n --agree-tos --email DEVOPS@COMPANY.COM \
- --dns-route53 \
- -d MY.DOMAIN.NAME
-```
| Our route53 plugin was initially a 3rd party plugin and we took on maintenance of it ourselves in https://github.com/certbot/certbot/pull/4692. This README file came along with the plugin, but we have more complete and up-to-date documentation for the plugin at https://certbot-dns-route53.readthedocs.io/en/stable/ so I think we should delete this file in favor of that which also helps keep things consistent with our other DNS plugins.
I also deleted the reference to the file in `MANIFEST.in` which wasn't even working because it was missing the `.md` extension. | https://api.github.com/repos/certbot/certbot/pulls/8581 | 2021-01-07T00:11:19Z | 2021-01-07T07:08:16Z | 2021-01-07T07:08:16Z | 2021-01-07T07:08:17Z | 468 | certbot/certbot | 2,145 |
Add points are collinear in 3d algorithm to /maths | diff --git a/maths/points_are_collinear_3d.py b/maths/points_are_collinear_3d.py
new file mode 100644
index 000000000000..3bc0b3b9ebe5
--- /dev/null
+++ b/maths/points_are_collinear_3d.py
@@ -0,0 +1,126 @@
+"""
+Check if three points are collinear in 3D.
+
+In short, the idea is that we are able to create a triangle using three points,
+and the area of that triangle can determine if the three points are collinear or not.
+
+
+First, we create two vectors with the same initial point from the three points,
+then we will calculate the cross-product of them.
+
+The length of the cross vector is numerically equal to the area of a parallelogram.
+
+Finally, the area of the triangle is equal to half of the area of the parallelogram.
+
+Since we are only differentiating between zero and anything else,
+we can get rid of the square root when calculating the length of the vector,
+and also the division by two at the end.
+
+From a second perspective, if the two vectors are parallel and overlapping,
+we can't get a nonzero perpendicular vector,
+since there will be an infinite number of orthogonal vectors.
+
+To simplify the solution we will not calculate the length,
+but we will decide directly from the vector whether it is equal to (0, 0, 0) or not.
+
+
+Read More:
+ https://math.stackexchange.com/a/1951650
+"""
+
+Vector3d = tuple[float, float, float]
+Point3d = tuple[float, float, float]
+
+
+def create_vector(end_point1: Point3d, end_point2: Point3d) -> Vector3d:
+ """
+ Pass two points to get the vector from them in the form (x, y, z).
+
+ >>> create_vector((0, 0, 0), (1, 1, 1))
+ (1, 1, 1)
+ >>> create_vector((45, 70, 24), (47, 32, 1))
+ (2, -38, -23)
+ >>> create_vector((-14, -1, -8), (-7, 6, 4))
+ (7, 7, 12)
+ """
+ x = end_point2[0] - end_point1[0]
+ y = end_point2[1] - end_point1[1]
+ z = end_point2[2] - end_point1[2]
+ return (x, y, z)
+
+
+def get_3d_vectors_cross(ab: Vector3d, ac: Vector3d) -> Vector3d:
+ """
+ Get the cross of the two vectors AB and AC.
+
+ I used determinant of 2x2 to get the determinant of the 3x3 matrix in the process.
+
+ Read More:
+ https://en.wikipedia.org/wiki/Cross_product
+ https://en.wikipedia.org/wiki/Determinant
+
+ >>> get_3d_vectors_cross((3, 4, 7), (4, 9, 2))
+ (-55, 22, 11)
+ >>> get_3d_vectors_cross((1, 1, 1), (1, 1, 1))
+ (0, 0, 0)
+ >>> get_3d_vectors_cross((-4, 3, 0), (3, -9, -12))
+ (-36, -48, 27)
+ >>> get_3d_vectors_cross((17.67, 4.7, 6.78), (-9.5, 4.78, -19.33))
+ (-123.2594, 277.15110000000004, 129.11260000000001)
+ """
+ x = ab[1] * ac[2] - ab[2] * ac[1] # *i
+ y = (ab[0] * ac[2] - ab[2] * ac[0]) * -1 # *j
+ z = ab[0] * ac[1] - ab[1] * ac[0] # *k
+ return (x, y, z)
+
+
+def is_zero_vector(vector: Vector3d, accuracy: int) -> bool:
+ """
+ Check if vector is equal to (0, 0, 0) of not.
+
+ Sine the algorithm is very accurate, we will never get a zero vector,
+ so we need to round the vector axis,
+ because we want a result that is either True or False.
+ In other applications, we can return a float that represents the collinearity ratio.
+
+ >>> is_zero_vector((0, 0, 0), accuracy=10)
+ True
+ >>> is_zero_vector((15, 74, 32), accuracy=10)
+ False
+ >>> is_zero_vector((-15, -74, -32), accuracy=10)
+ False
+ """
+ return tuple(round(x, accuracy) for x in vector) == (0, 0, 0)
+
+
+def are_collinear(a: Point3d, b: Point3d, c: Point3d, accuracy: int = 10) -> bool:
+ """
+ Check if three points are collinear or not.
+
+ 1- Create tow vectors AB and AC.
+ 2- Get the cross vector of the tow vectors.
+ 3- Calcolate the length of the cross vector.
+ 4- If the length is zero then the points are collinear, else they are not.
+
+ The use of the accuracy parameter is explained in is_zero_vector docstring.
+
+ >>> are_collinear((4.802293498137402, 3.536233125455244, 0),
+ ... (-2.186788107953106, -9.24561398001649, 7.141509524846482),
+ ... (1.530169574640268, -2.447927606600034, 3.343487096469054))
+ True
+ >>> are_collinear((-6, -2, 6),
+ ... (6.200213806439997, -4.930157614926678, -4.482371908289856),
+ ... (-4.085171149525941, -2.459889509029438, 4.354787180795383))
+ True
+ >>> are_collinear((2.399001826862445, -2.452009976680793, 4.464656666157666),
+ ... (-3.682816335934376, 5.753788986533145, 9.490993909044244),
+ ... (1.962903518985307, 3.741415730125627, 7))
+ False
+ >>> are_collinear((1.875375340689544, -7.268426006071538, 7.358196269835993),
+ ... (-3.546599383667157, -4.630005261513976, 3.208784032924246),
+ ... (-2.564606140206386, 3.937845170672183, 7))
+ False
+ """
+ ab = create_vector(a, b)
+ ac = create_vector(a, c)
+ return is_zero_vector(get_3d_vectors_cross(ab, ac), accuracy)
| I'm not sure if /maths directory is suitable for this algorithm so if there is a better place for it please let me know in the comments.
### Describe your change:
* [x] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms have a URL in its comments that points to Wikipedia or other similar explanation.
* [ ] If this pull request resolves one or more open issues then the commit message contains `Fixes: #{$ISSUE_NO}`.
| https://api.github.com/repos/TheAlgorithms/Python/pulls/5983 | 2022-02-07T03:31:36Z | 2022-02-13T17:09:09Z | 2022-02-13T17:09:09Z | 2022-02-13T17:11:04Z | 1,710 | TheAlgorithms/Python | 29,892 |
Added a New Script To Download Spotlight Wallpapers | diff --git a/spotlight.py b/spotlight.py
new file mode 100644
index 0000000000..4e539a3aee
--- /dev/null
+++ b/spotlight.py
@@ -0,0 +1,65 @@
+""" Script To Copy Spotlight(Lockscreen) Images from Windows """
+import os
+import shutil
+import errno
+import hashlib
+from PIL import Image
+
+def md5(fname):
+ """ Function to return the MD5 Digest of a file """
+
+ hash_md5 = hashlib.md5()
+ with open(fname, "rb") as file_var:
+ for chunk in iter(lambda: file_var.read(4096), b""):
+ hash_md5.update(chunk)
+ return hash_md5.hexdigest()
+
+def make_folder(folder_name):
+ """Function to make the required folers"""
+ try:
+ os.makedirs(folder_name)
+ except OSError as exc:
+ if exc.errno == errno.EEXIST and os.path.isdir(folder_name):
+ pass
+ else:
+ print "Error! Could not create a folder"
+ raise
+
+def get_spotlight_wallpapers(target_folder):
+ """Fetches wallpapers from source folder inside AppData to the
+ newly created folders in C:\\Users\\['user.name']\\Pictures"""
+ #PATHS REQUIRED TO FETCH AND STORE WALLPAPERS
+ #Creating necessary folders
+
+ source_folder = os.environ['HOME']+"\\AppData\\Local\\Packages\\"
+ source_folder += "Microsoft.Windows.ContentDeliveryManager_cw5n1h2txyewy"
+ source_folder += "\\LocalState\\Assets"
+ spotlight_path_mobile = target_folder+"\\Mobile"
+ spotlight_path_desktop = target_folder+"\\Desktop"
+ make_folder(spotlight_path_mobile)
+ make_folder(spotlight_path_desktop)
+
+
+ #Fetching files from the source dir
+ for filename in os.listdir(source_folder):
+ filename = source_folder+"\\"+filename
+ #if size of file is less than 100 KB, ignore the file
+ if os.stat(filename).st_size > 100000:
+ #Check resolution and classify based upon the resolution of the images
+
+ #name the file equal to the MD5 of the file, so that no duplicate files are to be copied
+ img_file = Image.open(filename)
+ if img_file.size[0] >= 1080:
+ if img_file.size[0] > img_file.size[1]:
+ temp_path = spotlight_path_desktop+"\\"+md5(filename)
+ else:
+ temp_path = spotlight_path_mobile+"\\"+md5(filename)
+ #If file doesn't exist, copy the file to the new folders
+ if not os.path.exists(temp_path+".png"):
+ shutil.copy(filename, temp_path+".png")
+
+if __name__ == '__main__':
+ PATH = raw_input("Enter directory path:")
+ get_spotlight_wallpapers(PATH)
+ print "Lockscreen images have been copied to \""+PATH+"\""
+
\ No newline at end of file
| This script downloads all currently active lock screen backgrounds ( spotlight wallpapers ) into a directory that can be specified by the user. | https://api.github.com/repos/geekcomputers/Python/pulls/235 | 2017-09-22T13:55:52Z | 2017-09-30T08:12:10Z | 2017-09-30T08:12:10Z | 2017-09-30T08:12:26Z | 706 | geekcomputers/Python | 30,969 |
Add gradient_average flag support for sparse grads | diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index 476f71de2120..13d58ff11438 100644
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -2292,9 +2292,6 @@ def sparse_allreduce_bucket(self, bucket, dp_group):
return sparse_list
def sparse_allreduce(self, sparse, dp_group):
- # Pre-divide for fp16 stability
- sparse.values.mul_(1.0 / dist.get_world_size(group=dp_group))
-
original_data_type = sparse.values.dtype
if self.communication_data_type != sparse.values.dtype:
if self.communication_data_type in (torch.float16, torch.bfloat16):
@@ -2306,6 +2303,13 @@ def sparse_allreduce(self, sparse, dp_group):
indices = sparse.indices
values = sparse.values
+ if self.postscale_gradients():
+ if self.gradient_average:
+ values.mul_(self.gradient_predivide_factor() /
+ dist.get_world_size(group=dp_group))
+ else:
+ values.mul_(1. / dist.get_world_size(group=dp_group))
+
indices_device_list = self.sparse_all_gather(indices, dp_group)
values_device_list = self.sparse_all_gather(values, dp_group)
diff --git a/tests/unit/test_averaging.py b/tests/unit/test_averaging.py
new file mode 100644
index 000000000000..35c39f4257af
--- /dev/null
+++ b/tests/unit/test_averaging.py
@@ -0,0 +1,73 @@
+import torch
+import deepspeed
+from .common import distributed_test
+
+
+def test_sparse_adam(tmpdir):
+ config_dict = {"train_batch_size": 2, "steps_per_print": 1, "sparse_gradients": True}
+
+ class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.emb = torch.nn.EmbeddingBag(10, 3, mode="sum", sparse=True)
+ self.linear = torch.nn.Linear(3, 1)
+
+ def forward(self, x, offsets):
+ return self.linear(self.emb(x, offsets))
+
+ class Adam(torch.optim.Optimizer):
+ def __init__(self, dense_params, sparse_params):
+ super().__init__(dense_params + sparse_params, defaults={})
+ self.adam = torch.optim.Adam(dense_params)
+ self.adam_sparse = torch.optim.SparseAdam(sparse_params)
+
+ @torch.no_grad()
+ def step(self, closure=None):
+ loss_1 = self.adam.step(closure)
+ loss_2 = self.adam_sparse.step(closure)
+
+ if loss_1 is not None and loss_2 is not None:
+ return loss_1 + loss_2
+ return loss_1 or loss_2
+
+ def get_model_optimizer():
+ torch.manual_seed(0)
+ model = Model()
+ optimizer = Adam(list(model.linear.parameters()), list(model.emb.parameters()))
+ return model, optimizer
+
+ def get_data(device):
+ x = torch.tensor([1, 2, 4, 5, 4, 3, 2, 9], dtype=torch.long, device=device)
+ offsets = torch.tensor([0, 4], dtype=torch.long, device=device)
+ y = torch.tensor([[1.0], [0.0]], device=device)
+ return x, offsets, y
+
+ @distributed_test(world_size=2)
+ def _test():
+ model, optimizer = get_model_optimizer()
+ loss = torch.nn.BCEWithLogitsLoss()
+ engine, _, _, _ = deepspeed.initialize(model=model,
+ optimizer=optimizer,
+ config=config_dict)
+
+ x, offsets, y = get_data(engine.device)
+
+ engine.gradient_average = True
+ res = engine(x, offsets)
+ engine.backward(loss(res, y))
+
+ averaged_grads = {}
+ for k, v in engine.named_parameters():
+ grad = v.grad.to_dense() if v.grad.is_sparse else v.grad
+ averaged_grads[k] = grad
+ v.grad = None
+
+ engine.gradient_average = False
+ res = engine(x, offsets)
+ engine.backward(loss(res, y))
+
+ for k, v in engine.named_parameters():
+ grad = v.grad.to_dense() if v.grad.is_sparse else v.grad
+ assert torch.allclose(grad, averaged_grads[k] * engine.world_size)
+
+ _test()
| Added support for disabling the gradient average for sparse grads.
Logic copied from here: https://github.com/microsoft/DeepSpeed/blob/2210ebe70f68135b6b43e91323a7d96a403a2299/deepspeed/runtime/engine.py#L2172 | https://api.github.com/repos/microsoft/DeepSpeed/pulls/2188 | 2022-08-05T11:43:47Z | 2022-08-09T16:00:03Z | 2022-08-09T16:00:03Z | 2022-08-09T16:00:10Z | 1,029 | microsoft/DeepSpeed | 10,327 |
Refs #30399 -- Made assertHTMLEqual normalize character and entity references. | diff --git a/django/test/html.py b/django/test/html.py
index 8b064529b0f0c..911872bb69060 100644
--- a/django/test/html.py
+++ b/django/test/html.py
@@ -3,11 +3,14 @@
import re
from html.parser import HTMLParser
-WHITESPACE = re.compile(r'\s+')
+# ASCII whitespace is U+0009 TAB, U+000A LF, U+000C FF, U+000D CR, or U+0020
+# SPACE.
+# https://infra.spec.whatwg.org/#ascii-whitespace
+ASCII_WHITESPACE = re.compile(r'[\t\n\f\r ]+')
def normalize_whitespace(string):
- return WHITESPACE.sub(' ', string)
+ return ASCII_WHITESPACE.sub(' ', string)
class Element:
@@ -144,7 +147,7 @@ class Parser(HTMLParser):
)
def __init__(self):
- super().__init__(convert_charrefs=False)
+ super().__init__()
self.root = RootElement()
self.open_tags = []
self.element_positions = {}
@@ -202,12 +205,6 @@ def handle_endtag(self, tag):
def handle_data(self, data):
self.current.append(data)
- def handle_charref(self, name):
- self.current.append('&%s;' % name)
-
- def handle_entityref(self, name):
- self.current.append('&%s;' % name)
-
def parse_html(html):
"""
diff --git a/docs/releases/3.0.txt b/docs/releases/3.0.txt
index 2b9c5c5ea0179..335ab2c0d573e 100644
--- a/docs/releases/3.0.txt
+++ b/docs/releases/3.0.txt
@@ -246,6 +246,11 @@ Tests
* Tests and test cases to run can be selected by test name pattern using the
new :option:`test -k` option.
+* HTML comparison, as used by
+ :meth:`~django.test.SimpleTestCase.assertHTMLEqual`, now treats text, character
+ references, and entity references that refer to the same character as
+ equivalent.
+
URLs
~~~~
diff --git a/docs/topics/testing/tools.txt b/docs/topics/testing/tools.txt
index d9f508023c0cb..6d37a7421d838 100644
--- a/docs/topics/testing/tools.txt
+++ b/docs/topics/testing/tools.txt
@@ -1603,14 +1603,16 @@ your test suite.
* The ordering of attributes of an HTML element is not significant.
* Attributes without an argument are equal to attributes that equal in
name and value (see the examples).
+ * Text, character references, and entity references that refer to the same
+ character are equivalent.
The following examples are valid tests and don't raise any
``AssertionError``::
self.assertHTMLEqual(
- '<p>Hello <b>world!</p>',
+ '<p>Hello <b>'world'!</p>',
'''<p>
- Hello <b>world! </b>
+ Hello <b>'world'! </b>
</p>'''
)
self.assertHTMLEqual(
diff --git a/tests/test_utils/tests.py b/tests/test_utils/tests.py
index 69a99d47d253d..5b84bbd383fec 100644
--- a/tests/test_utils/tests.py
+++ b/tests/test_utils/tests.py
@@ -612,6 +612,31 @@ def test_attributes(self):
'<input type="text" id="id_name" />',
'<input type="password" id="id_name" />')
+ def test_normalize_refs(self):
+ pairs = [
+ (''', '''),
+ (''', "'"),
+ (''', '''),
+ (''', "'"),
+ ("'", '''),
+ ("'", '''),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ('&', '&'),
+ ]
+ for pair in pairs:
+ with self.subTest(repr(pair)):
+ self.assertHTMLEqual(*pair)
+
def test_complex_examples(self):
self.assertHTMLEqual(
"""<tr><th><label for="id_first_name">First name:</label></th>
| https://api.github.com/repos/django/django/pulls/11343 | 2019-05-08T13:29:56Z | 2019-05-09T13:55:33Z | 2019-05-09T13:55:33Z | 2019-05-09T14:00:01Z | 1,085 | django/django | 50,979 |
|
Add a GitHub workflow to close inactive issues and PRs automatically | diff --git a/.github/workflows/close-inactive-issues.yml b/.github/workflows/close-inactive-issues.yml
new file mode 100644
index 0000000000..d81b727aaa
--- /dev/null
+++ b/.github/workflows/close-inactive-issues.yml
@@ -0,0 +1,31 @@
+name: Close inactive issues
+
+on:
+ schedule:
+ - cron: "5 0 * * *"
+
+jobs:
+ close-issues:
+ runs-on: ubuntu-latest
+ permissions:
+ issues: write
+ pull-requests: write
+ steps:
+ - uses: actions/stale@v5
+ with:
+ days-before-issue-stale: 7
+ days-before-issue-close: 7
+
+ days-before-pr-stale: 7
+ days-before-pr-close: 7
+
+ stale-issue-label: "stale"
+ stale-pr-label: "stale"
+
+ stale-issue-message: "Bumping this issue because it has been open for 7 days with no activity. Closing automatically in 7 days unless it becomes active again."
+ close-issue-message: "Closing due to inactivity."
+
+ stale-pr-message: "Bumping this pull request because it has been open for 7 days with no activity. Closing automatically in 7 days unless it becomes active again."
+ close-pr-message: "Closing due to inactivity."
+
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
| Way too many issues have been piling up with their authors disappearing and never closing them. At the same time, lots of the unmerged PRs remain completely unanswered due to their sheer irrelevance. Closing both would clean up a big portion of the clutter lingering on the project's page. | https://api.github.com/repos/xtekky/gpt4free/pulls/777 | 2023-07-27T12:08:46Z | 2023-08-07T11:21:04Z | 2023-08-07T11:21:04Z | 2023-08-07T11:21:04Z | 343 | xtekky/gpt4free | 38,048 |
eventlog: Override set_focus to check for index error | diff --git a/mitmproxy/tools/console/flowlist.py b/mitmproxy/tools/console/flowlist.py
index 31d48ee3ec..044f8f05d7 100644
--- a/mitmproxy/tools/console/flowlist.py
+++ b/mitmproxy/tools/console/flowlist.py
@@ -57,6 +57,10 @@ def __init__(self, master):
self.master = master
urwid.ListBox.__init__(self, master.logbuffer)
+ def set_focus(self, index):
+ if 0 <= index < len(self.master.logbuffer):
+ super().set_focus(index)
+
def keypress(self, size, key):
key = common.shortcuts(key)
if key == "z":
| Mitmproxy crashes on pressing `g` or `G` while `eventlog` is focused and is empty. This happens due to `IndexError` in `set_focus`, so this PR just put a check by overriding it.
#### Mitmproxy version
Mitmproxy version: 3.0.0 (1.0.1dev0502-0x60b2fdfe)
Python version: 3.6.0
Platform: Linux-4.8.13-1-ARCH-x86_64-with-arch
SSL version: OpenSSL 1.0.2j 26 Sep 2016
Linux distro: arch
PS: Should I open a issue before sending PR? | https://api.github.com/repos/mitmproxy/mitmproxy/pulls/2220 | 2017-03-28T14:47:51Z | 2017-03-28T19:35:44Z | 2017-03-28T19:35:44Z | 2017-03-29T13:09:32Z | 163 | mitmproxy/mitmproxy | 28,285 |