
html_url stringlengths 51 51 | title stringlengths 6 280 | comments stringlengths 67 24.7k | body stringlengths 51 36.2k | __index_level_0__ int64 1 1.17k | comment_length int64 16 1.45k | text stringlengths 190 38.3k | embeddings list |
|---|---|---|---|---|---|---|---|
https://github.com/huggingface/datasets/issues/5437 | Can't load png dataset with 4 channel (RGBA) | Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.
| I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand.
I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand. | > Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.
>
>
I have only 1 folder that I use in the load_dataset function with the name "IMGDATA" and all my 9000 images are located... | I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand.
I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand. | Okay, I figured out what was wrong. When uploading my dataset via Google Drive, the images broke and Pillow couldn't open them. As a result, I solved the problem by downloading the ZIP archive | I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand.
I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand., it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples cou... | 337 | 77 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage
### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shu... | [
-1.1909445524215698,
-0.9180267453193665,
-0.6570744514465332,
1.3565850257873535,
-0.13932180404663086,
-1.3442559242248535,
0.1825108677148819,
-1.1079790592193604,
1.7494699954986572,
-0.7056476473808289,
0.19381839036941528,
-1.7175660133361816,
-0.045251257717609406,
-0.55962181091308... |
https://github.com/huggingface/datasets/issues/5435 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage | Also note that you are referring to an outdated documentation page: datasets 1.10.2 version
Current datasets version is 2.8.0 and the corresponding documentation page is: https://huggingface.co/docs/datasets/stream#split-dataset | ### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples cou... | 337 | 26 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage
### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shu... | [
-1.1905205249786377,
-0.9313532114028931,
-0.6946508884429932,
1.361343264579773,
-0.11745374649763107,
-1.321941614151001,
0.13184931874275208,
-1.0772746801376343,
1.7131266593933105,
-0.6895366311073303,
0.1830805540084839,
-1.7229007482528687,
-0.07875096797943115,
-0.5333200693130493,... |
https://github.com/huggingface/datasets/issues/5435 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage | Hi @albertvillanova thanks for your reply and your explaination here.
Sorry for the confusion as I'm not actually a user of your repo and I just happen to find the thread by Google (and didn't read carefully).
Great to know that and you made everything very clear now.
Thanks for your time and sorry for the co... | ### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples cou... | 337 | 63 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage
### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shu... | [
-1.239044189453125,
-0.9613012671470642,
-0.6822177171707153,
1.3689988851547241,
-0.1253994107246399,
-1.336166262626648,
0.13282009959220886,
-1.119757890701294,
1.6800132989883423,
-0.725843071937561,
0.20270109176635742,
-1.6984111070632935,
-0.028832409530878067,
-0.5352584719657898,
... |
https://github.com/huggingface/datasets/issues/5433 | Support latest Docker image in CI benchmarks | Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559; should be fixed with [v0.18.17](https://github.com/iterative/cml/releases/tag/v0.18.17).
[^1]: More or less, see https://github.com/yargs/yargs/issues/873. | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | 339 | 18 | Support latest Docker image in CI benchmarks
Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432
Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559... | [
-1.1741132736206055,
-0.9020137786865234,
-0.9337199926376343,
1.5220918655395508,
-0.0625097006559372,
-1.2240580320358276,
0.11463204026222229,
-0.9091006517410278,
1.6163134574890137,
-0.6164934635162354,
0.2926141619682312,
-1.615256428718567,
-0.07128304243087769,
-0.5232698321342468,... |
https://github.com/huggingface/datasets/issues/5433 | Support latest Docker image in CI benchmarks | Hi @0x2b3bfa0, thanks a lot for the investigation, the context about the the root cause and for fixing it!!
We are reviewing your PR to unpin the container image. | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | 339 | 29 | Support latest Docker image in CI benchmarks
Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432
Hi @0x2b3bfa0, thanks a lot for the investigation, the context about the the root cause and for fixing it!!
We are reviewing your PR... | [
-1.17626953125,
-0.9430264830589294,
-0.9038001894950867,
1.3165526390075684,
-0.3127286434173584,
-1.38706374168396,
0.17333859205245972,
-1.0670613050460815,
1.619828462600708,
-0.9278891086578369,
0.4337567985057831,
-1.6069083213806152,
0.12599827349185944,
-0.54421067237854,
-0.8060... |
https://github.com/huggingface/datasets/issues/5430 | Support Apache Beam >= 2.44.0 | Some of the shard files now have 0 number of rows.
We have opened an issue in the Apache Beam repo:
- https://github.com/apache/beam/issues/25041 | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | 340 | 23 | Support Apache Beam >= 2.44.0
Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429
Some of the shard files now have 0 number of rows.
We have opened an issue in the Apache Beam repo:
- https://github.com/apache/beam/issues/25041 | [
-1.2750862836837769,
-0.9439370036125183,
-0.8172897696495056,
1.540722370147705,
-0.22284150123596191,
-1.2459444999694824,
0.0407663993537426,
-0.8248154520988464,
1.5018937587738037,
-0.7695805430412292,
0.36583229899406433,
-1.6501755714416504,
0.011896209791302681,
-0.4887296557426452... |
https://github.com/huggingface/datasets/issues/5428 | Load/Save FAISS index using fsspec | Hi! Sure, feel free to submit a PR. Maybe if we want to be consistent with the existing API, it would be cleaner to directly add support for `fsspec` paths in `Dataset.load_faiss_index`/`Dataset.save_faiss_index` in the same manner as it was done in `Dataset.load_from_disk`/`Dataset.save_to_disk`. | ### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_faiss_index`.
### Motivation
In... | 341 | 42 | Load/Save FAISS index using fsspec
### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_... | [
-1.1222985982894897,
-0.8920488357543945,
-0.7614911198616028,
1.5106948614120483,
-0.12036654353141785,
-1.264846682548523,
0.21462397277355194,
-0.9880435466766357,
1.6212654113769531,
-0.9347405433654785,
0.3081521689891815,
-1.6232985258102417,
0.09116572141647339,
-0.6534204483032227,... |
https://github.com/huggingface/datasets/issues/5427 | Unable to download dataset id_clickbait | Thanks for reporting, @ilos-vigil.
We have transferred this issue to the corresponding dataset on the Hugging Face Hub: https://huggingface.co/datasets/id_clickbait/discussions/1 | ### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i got this XML data.
```xml
<?xml versi... | 342 | 19 | Unable to download dataset id_clickbait
### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i... | [
-1.1930586099624634,
-0.8530861139297485,
-0.6839118003845215,
1.3900913000106812,
-0.12742212414741516,
-1.2396419048309326,
0.1807224154472351,
-1.1172120571136475,
1.6125329732894897,
-0.6963998079299927,
0.2914436459541321,
-1.6744513511657715,
-0.07168597728013992,
-0.5758096575737,
... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | Hi!
`Dataset.sort` calls `df.sort_values` internally, and `df.sort_values` brings all the "sort" columns in memory, so sorting on multiple keys could be very expensive. This makes me think that maybe we can replace `df.sort_values` with `pyarrow.compute.sort_indices` - the latter can also sort on multiple keys and ... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 109 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.2507238388061523,
-0.9375834465026855,
-0.6712387204170227,
1.4547932147979736,
-0.14533424377441406,
-1.3173452615737915,
0.20516350865364075,
-1.07721745967865,
1.7774194478988647,
-0.8531342148780823,
0.33074915409088135,
-1.6261314153671265,
0.08578143268823624,
-0.6216345429420471,... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | @mariosasko If I understand the code right, using `pyarrow.compute.sort_indices` would also require changes to the `select` method if it is meant to sort multiple keys. That's because `select` only accepts 1D input for `indices`, not an iterable or similar which would be required for multiple keys unless you want some ... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 64 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.2212759256362915,
-0.9480838775634766,
-0.7015002369880676,
1.4788826704025269,
-0.10449813306331635,
-1.2614364624023438,
0.1443437933921814,
-1.0273969173431396,
1.7198460102081299,
-0.8230888247489929,
0.33712315559387207,
-1.6211422681808472,
0.12400048971176147,
-0.6231672167778015... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | @MichlF No, it doesn't require modifying select because sorting on multiple keys also returns a 1D array.
It's easier to understand with an example:
```python
>>> import pyarrow as pa
>>> import pyarrow.compute as pc
>>> table = pa.table({
... "name": ["John", "Eve", "Peter", "John"],
... "surname": ["... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 76 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.21726655960083,
-0.9191803932189941,
-0.7278240919113159,
1.4414478540420532,
-0.18655966222286224,
-1.2138382196426392,
0.1759604960680008,
-1.0843857526779175,
1.6804003715515137,
-0.7789862155914307,
0.3355465829372406,
-1.6246124505996704,
0.01778346672654152,
-0.588951587677002,
... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | Thanks for clarifying.
I can prepare a PR to address this issue. This would be my first PR here so I have a few maybe silly questions but:
- What is the preferred input type of `sort_keys` for the sort method? A sequence with name, order tuples like pyarrow's `sort_indices` requires?
- What about backwards compatabi... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 112 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.2062435150146484,
-0.955108106136322,
-0.6964579224586487,
1.4512603282928467,
-0.13979633152484894,
-1.2945438623428345,
0.1756330132484436,
-1.0331217050552368,
1.7455586194992065,
-0.8622071146965027,
0.36619484424591064,
-1.6305056810379028,
0.10075096786022186,
-0.6490331292152405,... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | I think we can have the following signature:
```python
def sort(
self,
column_names: Union[str, Sequence[str]],
reverse: Union[bool, Sequence[bool]] = False,
kind="deprecated",
null_placement: str = "last",
keep_in_memory: bool = False,
load_from_cache_fi... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 127 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.1986860036849976,
-0.9022864103317261,
-0.7445774674415588,
1.5108447074890137,
-0.14732931554317474,
-1.2305964231491089,
0.1892164647579193,
-1.0421628952026367,
1.6967023611068726,
-0.8177416920661926,
0.3498031795024872,
-1.6219446659088135,
0.08035118877887726,
-0.6614535450935364,... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | I am pretty much done with the PR. Just one clarification: `Sequence` in `arrow_dataset.py` is a custom dataclass from `features.py` instead of the `type.hinting` class `Sequence` from Python. Do you suggest using that custom `Sequence` class somehow ? Otherwise signature currently reads instead:
```Python
def so... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 119 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.206371784210205,
-0.9001083374023438,
-0.7287048697471619,
1.5281463861465454,
-0.15486183762550354,
-1.2318964004516602,
0.1660555899143219,
-1.061037540435791,
1.6927155256271362,
-0.8267017006874084,
0.31720396876335144,
-1.615334391593933,
0.09671789407730103,
-0.6464735269546509,
... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | I meant `typing.Sequence` (`datasets.Sequence` is a feature type).
Regarding `null_placement`, I think we can support both `at_start` and `at_end`, and `last` and `first` (for backward compatibility; convert internally to `at_end` and `at_start` respectively). | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 33 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.2010776996612549,
-0.9742602109909058,
-0.7009586691856384,
1.479052186012268,
-0.0717446357011795,
-1.3149577379226685,
0.18090492486953735,
-1.047257900238037,
1.756934642791748,
-0.8613452911376953,
0.36277204751968384,
-1.6430747509002686,
0.0807223990559578,
-0.6359919309616089,
... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | > I meant typing.Sequence (datasets.Sequence is a feature type).
Sorry, I actually meant `typing.Sequence` and not `type.hinting`. However, the issue is still that `dataset.Sequence` is imported in `arrow_dataset.py` so I cannot import and use `typing.Sequence` for the `sort`'s signature without overwriting the `dat... | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 119 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.2026468515396118,
-0.9789732694625854,
-0.6965401768684387,
1.44068443775177,
-0.13039067387580872,
-1.3307585716247559,
0.14831256866455078,
-1.1041706800460815,
1.7870264053344727,
-0.8782883286476135,
0.30281975865364075,
-1.668694019317627,
0.08402121812105179,
-0.5972263216972351,
... |
https://github.com/huggingface/datasets/issues/5425 | Sort on multiple keys with datasets.Dataset.sort() | You can avoid the name collision by renaming `typing.Sequence` to `Sequence_` when importing:
```python
from typing import Sequence as Sequence_
``` | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | 343 | 21 | Sort on multiple keys with datasets.Dataset.sort()
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggeste... | [
-1.2064616680145264,
-0.9316847920417786,
-0.7140529751777649,
1.5059329271316528,
-0.11384304612874985,
-1.3094804286956787,
0.12475172430276871,
-1.0355916023254395,
1.7230068445205688,
-0.8554967045783997,
0.34709468483924866,
-1.6594160795211792,
0.10467644780874252,
-0.629877567291259... |
https://github.com/huggingface/datasets/issues/5424 | When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset? | Hi! You can get a `DatasetDict` if you pass a dictionary with read instructions as follows:
```python
instructions = [
ReadInstruction(split_name="train", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="dev", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(spli... | ### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduc... | 344 | 51 | When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset?
### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict`... | [
-1.2014646530151367,
-0.9519798755645752,
-0.664831817150116,
1.4391368627548218,
-0.1864701360464096,
-1.1531896591186523,
0.17084240913391113,
-1.0244344472885132,
1.580081820487976,
-0.7707537412643433,
0.31056874990463257,
-1.6319173574447632,
-0.008924031630158424,
-0.6302415132522583... |
https://github.com/huggingface/datasets/issues/5422 | Datasets load error for saved github issues | I can confirm that the error exists!
I'm trying to read 3 parquet files locally:
```python
from datasets import load_dataset, Features, Value, ClassLabel
review_dataset = load_dataset(
"parquet",
data_files={
"train": os.path.join(sentiment_analysis_data_path, "train.parquet"),
"valida... | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset... | 345 | 95 | Datasets load error for saved github issues
### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: ... | [
-1.1963127851486206,
-0.9330918788909912,
-0.7827396392822266,
1.4344896078109741,
-0.1406930536031723,
-1.2193514108657837,
0.08512034267187119,
-1.1205116510391235,
1.6201714277267456,
-0.678076446056366,
0.23913109302520752,
-1.6713672876358032,
0.04052264243364334,
-0.5257079005241394,... |
https://github.com/huggingface/datasets/issues/5422 | Datasets load error for saved github issues | @Extremesarova I think this is a different issue, but understand using features could be a work-around.
It seems the field `closed_at` is `null` in many cases.
I've not found a way to specify only a single feature without (succesfully) specifiying the full and quite detailed set of expected features. Using this fea... | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset... | 345 | 66 | Datasets load error for saved github issues
### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: ... | [
-1.1963127851486206,
-0.9330918788909912,
-0.7827396392822266,
1.4344896078109741,
-0.1406930536031723,
-1.2193514108657837,
0.08512034267187119,
-1.1205116510391235,
1.6201714277267456,
-0.678076446056366,
0.23913109302520752,
-1.6713672876358032,
0.04052264243364334,
-0.5257079005241394,... |
https://github.com/huggingface/datasets/issues/5422 | Datasets load error for saved github issues | Found this when searching for the same error, looks like based on #3965 it's just an issue with the data. I found that changing `df = pd.DataFrame.from_records(all_issues)` to `df = pd.DataFrame.from_records(all_issues).dropna(axis=1, how='all').drop(['milestone'], axis=1)` from the fetch_issues function fixed the issu... | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset... | 345 | 65 | Datasets load error for saved github issues
### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: ... | [
-1.1963127851486206,
-0.9330918788909912,
-0.7827396392822266,
1.4344896078109741,
-0.1406930536031723,
-1.2193514108657837,
0.08512034267187119,
-1.1205116510391235,
1.6201714277267456,
-0.678076446056366,
0.23913109302520752,
-1.6713672876358032,
0.04052264243364334,
-0.5257079005241394,... |
https://github.com/huggingface/datasets/issues/5422 | Datasets load error for saved github issues | I have this same issue. I saved a dataset to disk and now I can't load it. | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset... | 345 | 17 | Datasets load error for saved github issues
### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: ... | [
-1.1963127851486206,
-0.9330918788909912,
-0.7827396392822266,
1.4344896078109741,
-0.1406930536031723,
-1.2193514108657837,
0.08512034267187119,
-1.1205116510391235,
1.6201714277267456,
-0.678076446056366,
0.23913109302520752,
-1.6713672876358032,
0.04052264243364334,
-0.5257079005241394,... |
https://github.com/huggingface/datasets/issues/5421 | Support case-insensitive Hub dataset name in load_dataset | Closing as case-insensitivity should be only for URL redirection on the Hub. In the APIs, we will only support the canonical name (https://github.com/huggingface/moon-landing/pull/2399#issuecomment-1382085611) | ### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from d... | 346 | 23 | Support case-insensitive Hub dataset name in load_dataset
### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we cou... | [
-1.1574761867523193,
-0.9057379961013794,
-0.8160881400108337,
1.4558465480804443,
-0.07727113366127014,
-1.312180995941162,
0.1407918632030487,
-0.9606278538703918,
1.6307440996170044,
-0.7902531027793884,
0.37747347354888916,
-1.7550194263458252,
0.008631757460534573,
-0.6654250621795654... |
https://github.com/huggingface/datasets/issues/5419 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator | Hi! Thanks for pointing out this inconsistency. Changing the default value at this point is probably not worth it, considering we've started discussing the state of the task API internally - we will most likely deprecate the current one and replace it with a more robust solution that relies on the `train_eval_index` fi... | ### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column... | 347 | 62 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator
### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default ... | [
-1.1833069324493408,
-0.9694234132766724,
-0.619713306427002,
1.6215074062347412,
-0.12914401292800903,
-1.279888391494751,
0.24085275828838348,
-1.0611002445220947,
1.6883082389831543,
-0.8849717378616333,
0.3013935089111328,
-1.653178334236145,
0.01117192953824997,
-0.5831577777862549,
... |
https://github.com/huggingface/datasets/issues/5419 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator | The task templates API has been deprecated (will be removed in version 3.0), so I'm closing this issue. | ### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column... | 347 | 18 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator
### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default ... | [
-1.1833069324493408,
-0.9694234132766724,
-0.619713306427002,
1.6215074062347412,
-0.12914401292800903,
-1.279888391494751,
0.24085275828838348,
-1.0611002445220947,
1.6883082389831543,
-0.8849717378616333,
0.3013935089111328,
-1.653178334236145,
0.01117192953824997,
-0.5831577777862549,
... |
https://github.com/huggingface/datasets/issues/5418 | Add ProgressBar for `to_parquet` | Thanks for your proposal, @zanussbaum. Yes, I agree that would definitely be a nice feature to have! | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | 348 | 17 | Add ProgressBar for `to_parquet`
### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help i... | [
-1.1281404495239258,
-0.9272894859313965,
-0.876679003238678,
1.5756957530975342,
-0.12682101130485535,
-1.3146666288375854,
0.21620792150497437,
-1.059373378753662,
1.6573750972747803,
-0.7932515740394592,
0.4578741490840912,
-1.5561256408691406,
0.07988949865102768,
-0.7136300802230835,
... |
https://github.com/huggingface/datasets/issues/5418 | Add ProgressBar for `to_parquet` | That would be awesome ! You can comment `#self-assign` to assign you to this issue and open a PR :) Will be happy to review | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | 348 | 25 | Add ProgressBar for `to_parquet`
### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help i... | [
-1.104288935661316,
-0.9040449857711792,
-0.8816316723823547,
1.6051945686340332,
-0.13855379819869995,
-1.3316636085510254,
0.15115419030189514,
-1.067552089691162,
1.6967405080795288,
-0.7785230875015259,
0.4231182038784027,
-1.550559639930725,
0.10968958586454391,
-0.7439088821411133,
... |
https://github.com/huggingface/datasets/issues/5414 | Sharding error with Multilingual LibriSpeech | Thanks for reporting, @Nithin-Holla.
This is a known issue for multiple datasets and we are investigating it:
- See e.g.: https://huggingface.co/datasets/ami/discussions/3 | ### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/... | 349 | 21 | Sharding error with Multilingual LibriSpeech
### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datas... | [
-1.138941764831543,
-0.8181207180023193,
-0.6920398473739624,
1.4167742729187012,
-0.001813550479710102,
-1.3891597986221313,
0.020772943273186684,
-0.9953727126121521,
1.4881454706192017,
-0.7330920696258545,
0.3880062401294708,
-1.7275402545928955,
0.11068633943796158,
-0.562932252883911... |
https://github.com/huggingface/datasets/issues/5413 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers | Hi ! Thanks for reporting :)
I managed to reproduce the hub using
```python
from datasets import concatenate_datasets, Dataset, load_from_disk
Dataset.from_dict({"a": range(9)}).save_to_disk("tmp/ds1")
ds1 = load_from_disk("tmp/ds1")
ds1 = concatenate_datasets([ds1, ds1])
Dataset.from_dict({"b": range(6)... | ### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_data... | 350 | 140 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers
### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/dataset... | [
-1.2022230625152588,
-0.933254063129425,
-0.7547227144241333,
1.3154925107955933,
-0.1193099319934845,
-1.2487061023712158,
0.14360904693603516,
-1.046956181526184,
1.5380277633666992,
-0.7598488330841064,
0.12326542288064957,
-1.6745375394821167,
-0.19994229078292847,
-0.5410534143447876,... |
https://github.com/huggingface/datasets/issues/5412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | Hi ! It fails because the dataset is already being prepared by your first run. I'd encourage you to prepare your dataset before using it for multiple trainings.
You can also specify another cache directory by passing `cache_dir=` to `load_dataset()`. | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | 351 | 40 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel
### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code... | [
-1.2141274213790894,
-0.9969725012779236,
-0.6490305066108704,
1.4509425163269043,
-0.19368737936019897,
-1.2160694599151611,
0.19137239456176758,
-1.0793054103851318,
1.5731899738311768,
-0.7488421201705933,
0.2618825137615204,
-1.631170392036438,
-0.0954568088054657,
-0.5608007311820984,... |
https://github.com/huggingface/datasets/issues/5412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | Thank you! What do you mean by prepare it beforehand? I am unclear how to conduct dataset preparation outside of using the `load_dataset` function. | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | 351 | 24 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel
### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code... | [
-1.2141274213790894,
-0.9969725012779236,
-0.6490305066108704,
1.4509425163269043,
-0.19368737936019897,
-1.2160694599151611,
0.19137239456176758,
-1.0793054103851318,
1.5731899738311768,
-0.7488421201705933,
0.2618825137615204,
-1.631170392036438,
-0.0954568088054657,
-0.5608007311820984,... |
https://github.com/huggingface/datasets/issues/5412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | You can have a separate script that does load_dataset + map + save_to_disk to save your prepared dataset somewhere. Then in your training script you can reload the dataset with load_from_disk | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | 351 | 31 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel
### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code... | [
-1.2141274213790894,
-0.9969725012779236,
-0.6490305066108704,
1.4509425163269043,
-0.19368737936019897,
-1.2160694599151611,
0.19137239456176758,
-1.0793054103851318,
1.5731899738311768,
-0.7488421201705933,
0.2618825137615204,
-1.631170392036438,
-0.0954568088054657,
-0.5608007311820984,... |
https://github.com/huggingface/datasets/issues/5412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | Thank you! I believe I was running additional map steps after loading, resulting in the cache conflict. | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | 351 | 17 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel
### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code... | [
-1.2141274213790894,
-0.9969725012779236,
-0.6490305066108704,
1.4509425163269043,
-0.19368737936019897,
-1.2160694599151611,
0.19137239456176758,
-1.0793054103851318,
1.5731899738311768,
-0.7488421201705933,
0.2618825137615204,
-1.631170392036438,
-0.0954568088054657,
-0.5608007311820984,... |
https://github.com/huggingface/datasets/issues/5408 | dataset map function could not be hash properly | Hi ! On macos I tried with
- py 3.9.11
- datasets 2.8.0
- transformers 4.25.1
- dill 0.3.4
and I was able to hash `prepare_dataset` correctly:
```python
from datasets.fingerprint import Hasher
Hasher.hash(prepare_dataset)
```
What version of transformers do you have ? Can you try to call `Hasher.hash` on ... | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_... | 352 | 64 | dataset map function could not be hash properly
### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_... | [
-1.2026370763778687,
-0.8830283284187317,
-0.6998029947280884,
1.4831172227859497,
-0.14322924613952637,
-1.1129162311553955,
0.19913989305496216,
-1.045048475265503,
1.5351014137268066,
-0.7666561603546143,
0.2680216133594513,
-1.6109470129013062,
-0.0031448248773813248,
-0.52774876356124... |
https://github.com/huggingface/datasets/issues/5408 | dataset map function could not be hash properly | Thanks for your prompt reply.
I update datasets version to 2.8.0 and the warning is gong. | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_... | 352 | 16 | dataset map function could not be hash properly
### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_... | [
-1.2026370763778687,
-0.8830283284187317,
-0.6998029947280884,
1.4831172227859497,
-0.14322924613952637,
-1.1129162311553955,
0.19913989305496216,
-1.045048475265503,
1.5351014137268066,
-0.7666561603546143,
0.2680216133594513,
-1.6109470129013062,
-0.0031448248773813248,
-0.52774876356124... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | Hi ! I just tested locally and or colab and it works fine for 2.9 on `sst2`.
Also the code that is shown in your stack trace is not present in the 2.9 source code - so I'm wondering how you installed `datasets` that could cause this ? (you can check by searching for `[0:{label_ids[-1] + 1}]` in the [2.9 codebase](ht... | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 76 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.19907546043396,
-0.9080106019973755,
-0.7455325722694397,
1.4518007040023804,
-0.1747923493385315,
-1.2968993186950684,
0.09794913232326508,
-1.1907931566238403,
1.7332526445388794,
-0.7653722167015076,
0.3084734082221985,
-1.6923916339874268,
0.04660734534263611,
-0.5048437714576721,
... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | For what it's worth, I've also gotten this error on 2.9.0, and I've tried uninstalling an reinstalling
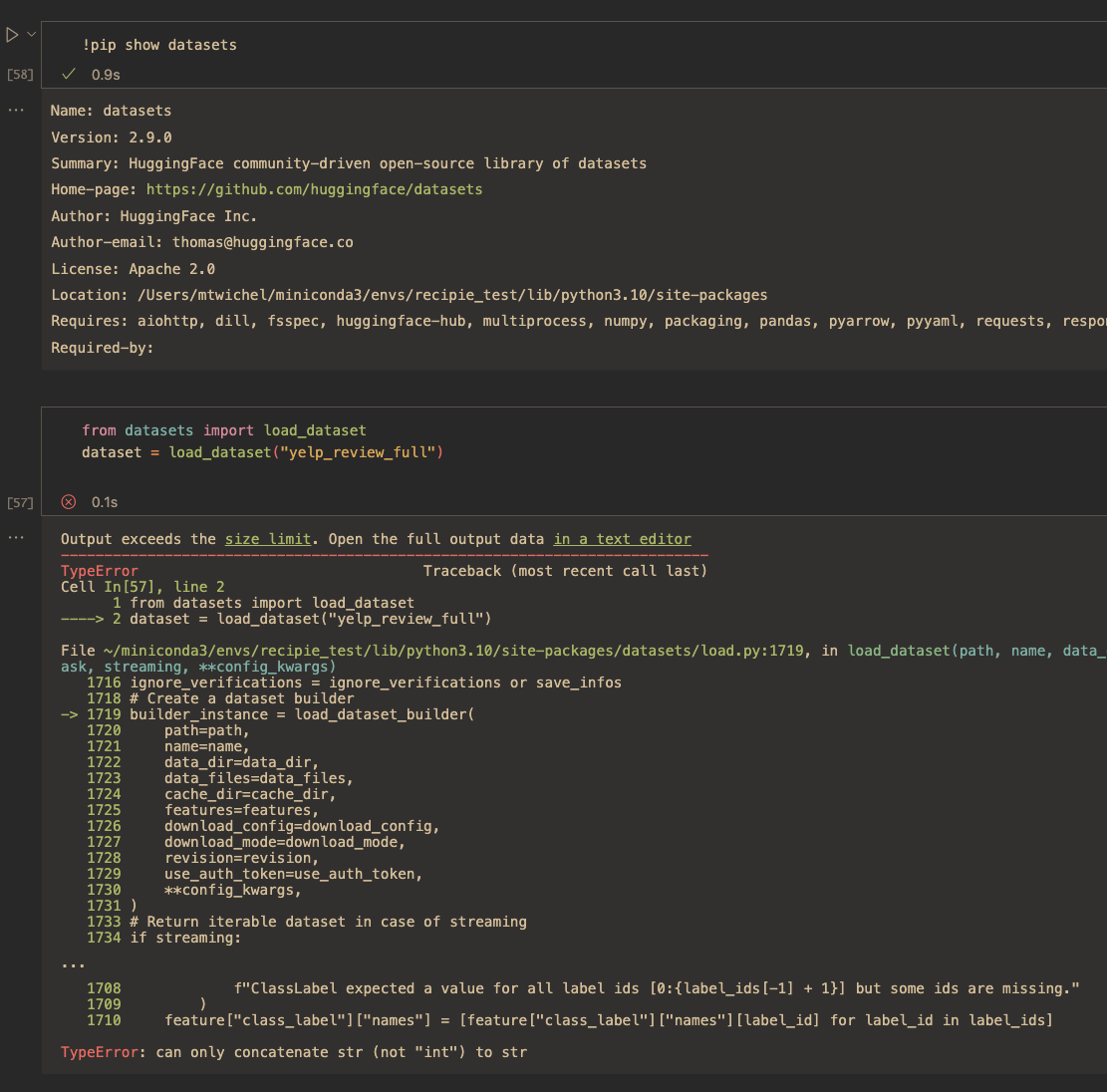
I'm very new to this package (I was following this tutorial: https://h... | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 54 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.1893925666809082,
-0.9478173851966858,
-0.7714112997055054,
1.412634253501892,
-0.15072843432426453,
-1.257697343826294,
0.09516014158725739,
-1.0975152254104614,
1.7222583293914795,
-0.7652689814567566,
0.3060447573661804,
-1.7043513059616089,
0.013540535233914852,
-0.5268344283103943,... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | @ntrpnr @mtwichel Did you install `datasets` with conda ?
I suspect that `datasets` 2.9 on conda still have this issue for some reason. When I install `datasets` with `pip` I don't have this error. | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 34 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.1625075340270996,
-0.9114705920219421,
-0.756309449672699,
1.44755220413208,
-0.1924143135547638,
-1.2859165668487549,
0.12256346642971039,
-1.187840461730957,
1.7959147691726685,
-0.7802746891975403,
0.3234862983226776,
-1.747164011001587,
0.018785636872053146,
-0.5356882214546204,
-... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | > @ntrpnr @mtwichel Did you install datasets with conda ?
I did yeah, I wonder if that's the issue | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 19 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.1661595106124878,
-0.9210278987884521,
-0.7668328881263733,
1.4417788982391357,
-0.21570250391960144,
-1.2651389837265015,
0.10105810314416885,
-1.1767208576202393,
1.7375155687332153,
-0.787563145160675,
0.3176383376121521,
-1.7452316284179688,
0.016856275498867035,
-0.5132984519004822... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | I just checked on conda at https://anaconda.org/HuggingFace/datasets/files
and everything looks fine, I got
```python
f"ClassLabel expected a value for all label ids [0:{int(label_ids[-1]) + 1}] but some ids are missing."
```
as expected in features.py line 1760 (notice the "int()") to not have the TypeError.
... | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 70 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.1509339809417725,
-0.919567346572876,
-0.776763916015625,
1.4301351308822632,
-0.14443561434745789,
-1.3198052644729614,
0.10859495401382446,
-1.1645647287368774,
1.7269237041473389,
-0.7640339732170105,
0.315082311630249,
-1.7467060089111328,
0.035089846700429916,
-0.5291357636451721,
... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | Could you also try this in your notebook ? In case your python kernel doesn't match the `pip` environment in your shell
```python
import datasets; datasets.__version__
```
and
```
!which python
```
```python
import sys; sys.executable
``` | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 37 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.1121143102645874,
-0.9188764095306396,
-0.7429848909378052,
1.4759175777435303,
-0.17823047935962677,
-1.3194260597229004,
0.14361748099327087,
-1.1888262033462524,
1.8266671895980835,
-0.8005570769309998,
0.3374331593513489,
-1.7366091012954712,
0.02338600531220436,
-0.5286593437194824... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | Mmmm, just a potential clue:
Where are you running your Python code? Is it the Spyder IDE?
I have recently seen some users reporting conflicting Python environments while using Spyder...
Maybe related:
- #5487 | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 34 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.164669394493103,
-0.9222587943077087,
-0.7590553760528564,
1.463395595550537,
-0.20731991529464722,
-1.2697645425796509,
0.071416936814785,
-1.1582248210906982,
1.7317662239074707,
-0.7659924626350403,
0.3236183822154999,
-1.733502984046936,
0.014324785210192204,
-0.5283750891685486,
... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | Other potential clue:
- Had you already imported `datasets` before pip-updating it? You should first update datasets, before importing it. Otherwise, you need to restart the kernel after updating it. | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 30 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.172698974609375,
-0.9135552048683167,
-0.7403936982154846,
1.4711757898330688,
-0.19127242267131805,
-1.3008623123168945,
0.09696647524833679,
-1.1633660793304443,
1.7608200311660767,
-0.799736499786377,
0.3188323378562927,
-1.7471706867218018,
0.02611558884382248,
-0.5236750245094299,
... |
https://github.com/huggingface/datasets/issues/5406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | I installed `datasets` with Conda using `conda install datasets` and got this issue.
Then I tried to reinstall using
`
conda install -c huggingface -c conda-forge datasets
`
The issue is now fixed. | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | 354 | 33 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ... | [
-1.1325589418411255,
-0.9141225814819336,
-0.764790415763855,
1.4390449523925781,
-0.15683706104755402,
-1.3214763402938843,
0.09748121351003647,
-1.172407865524292,
1.7872029542922974,
-0.7789129018783569,
0.33265209197998047,
-1.7489564418792725,
0.02682737447321415,
-0.5387814044952393,... |
https://github.com/huggingface/datasets/issues/5405 | size_in_bytes the same for all splits | Hi @Breakend,
Indeed, the attribute `size_in_bytes` refers to the size of the entire dataset configuration, for all splits (size of downloaded files + Arrow files), not the specific split.
This is also the case for `download_size` (downloaded files) and `dataset_size` (Arrow files).
The size of the Arrow files f... | ### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_da... | 355 | 76 | size_in_bytes the same for all splits
### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
... | [
-1.1352394819259644,
-0.796729326248169,
-0.7571126818656921,
1.434135913848877,
-0.0972394347190857,
-1.2886606454849243,
0.20292288064956665,
-1.1315603256225586,
1.7133888006210327,
-0.8233996629714966,
0.27702584862709045,
-1.6561424732208252,
-0.028486154973506927,
-0.5886371731758118... |
https://github.com/huggingface/datasets/issues/5402 | Missing state.json when creating a cloud dataset using a dataset_builder | `load_from_disk` must be used on datasets saved using `save_to_disk`: they correspond to fully serialized datasets including their state.
On the other hand, `download_and_prepare` just downloads the raw data and convert them to arrow (or parquet if you want). We are working on allowing you to reload a dataset saved ... | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_da... | 357 | 66 | Missing state.json when creating a cloud dataset using a dataset_builder
### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session... | [
-1.2194854021072388,
-0.9229915738105774,
-0.633399486541748,
1.543872594833374,
-0.1812359094619751,
-1.2233837842941284,
0.22043099999427795,
-1.0921630859375,
1.6815913915634155,
-0.8181195259094238,
0.33051154017448425,
-1.6326212882995605,
-0.0265568345785141,
-0.5852939486503601,
-... |
https://github.com/huggingface/datasets/issues/5402 | Missing state.json when creating a cloud dataset using a dataset_builder | Thanks, I'll follow that issue.
I was following the [cloud storage](https://huggingface.co/docs/datasets/filesystems) docs section and perhaps I'm missing some part of the flow; start with `load_dataset_builder` + `download_and_prepare`. You say I need an explicit `save_to_disk` but what object needs to be saved? t... | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_da... | 357 | 50 | Missing state.json when creating a cloud dataset using a dataset_builder
### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session... | [
-1.2194854021072388,
-0.9229915738105774,
-0.633399486541748,
1.543872594833374,
-0.1812359094619751,
-1.2233837842941284,
0.22043099999427795,
-1.0921630859375,
1.6815913915634155,
-0.8181195259094238,
0.33051154017448425,
-1.6326212882995605,
-0.0265568345785141,
-0.5852939486503601,
-... |
https://github.com/huggingface/datasets/issues/5402 | Missing state.json when creating a cloud dataset using a dataset_builder | Right now `load_dataset_builder` + `download_and_prepare` is to be used with tools like dask or spark, but `load_dataset` will support private cloud storage soon as well so you'll be able to reload the dataset with `datasets`.
Right now the only function that can load a dataset from a cloud storage is `load_from_dis... | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_da... | 357 | 61 | Missing state.json when creating a cloud dataset using a dataset_builder
### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session... | [
-1.2194854021072388,
-0.9229915738105774,
-0.633399486541748,
1.543872594833374,
-0.1812359094619751,
-1.2233837842941284,
0.22043099999427795,
-1.0921630859375,
1.6815913915634155,
-0.8181195259094238,
0.33051154017448425,
-1.6326212882995605,
-0.0265568345785141,
-0.5852939486503601,
-... |
https://github.com/huggingface/datasets/issues/5394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | @MFatnassi, this issue and the corresponding fix only affect our Continuous Integration testing environment.
Note that `datasets` does not depend on `spacy`. | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hoste... | 358 | 22 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_modul... | [
-1.151152491569519,
-0.8921622633934021,
-0.6899294853210449,
1.5089271068572998,
-0.10564844310283661,
-1.2708711624145508,
0.18829965591430664,
-0.9905667304992676,
1.4451483488082886,
-0.7144368886947632,
0.18018119037151337,
-1.629974365234375,
-0.14859190583229065,
-0.4965536296367645... |
https://github.com/huggingface/datasets/issues/5391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | Hey @catswithbats! Super sorry for the late reply! This is happening because there is data with label length (504) that exceeds the model's max length (448).
There are two options here:
1. Increase the model's `max_length` parameter:
```python
model.config.max_length = 512
```
2. Filter data with labels longe... | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1... | 359 | 108 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it]
Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-ev... | [
-1.2096641063690186,
-0.8761712312698364,
-0.6895792484283447,
1.4795067310333252,
-0.06263969838619232,
-1.3368308544158936,
0.07178962975740433,
-0.9243023991584778,
1.5293045043945312,
-0.7532963156700134,
0.3631325662136078,
-1.6789805889129639,
0.0257553793489933,
-0.5565799474716187,... |
https://github.com/huggingface/datasets/issues/5391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | @sanchit-gandhi Thank you for all your work on this topic.
I'm finding that changing the `max_length` value does not make this error go away. | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1... | 359 | 24 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it]
Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-ev... | [
-1.2096641063690186,
-0.8761712312698364,
-0.6895792484283447,
1.4795067310333252,
-0.06263969838619232,
-1.3368308544158936,
0.07178962975740433,
-0.9243023991584778,
1.5293045043945312,
-0.7532963156700134,
0.3631325662136078,
-1.6789805889129639,
0.0257553793489933,
-0.5565799474716187,... |
https://github.com/huggingface/datasets/issues/5390 | Error when pushing to the CI hub | Hmmm, git bisect tells me that the behavior is the same since https://github.com/huggingface/datasets/commit/67e65c90e9490810b89ee140da11fdd13c356c9c (3 Oct), i.e. https://github.com/huggingface/datasets/pull/4926 | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████... | 360 | 17 | Error when pushing to the CI hub
### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%... | [
-1.1982983350753784,
-0.9045103192329407,
-0.6958116292953491,
1.477090835571289,
-0.09118883311748505,
-1.2786083221435547,
0.10011560469865799,
-1.0638335943222046,
1.448171854019165,
-0.6696186661720276,
0.2905119061470032,
-1.6558254957199097,
-0.12557749450206757,
-0.5398754477500916,... |
https://github.com/huggingface/datasets/issues/5390 | Error when pushing to the CI hub | Maybe the current version of moonlanding in Hub CI is the issue.
I relaunched tests that were working two days ago: now they are failing. https://github.com/huggingface/datasets-server/commit/746414449cae4b311733f8a76e5b3b4ca73b38a9 for example
cc @huggingface/moon-landing | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████... | 360 | 30 | Error when pushing to the CI hub
### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%... | [
-1.1982983350753784,
-0.9045103192329407,
-0.6958116292953491,
1.477090835571289,
-0.09118883311748505,
-1.2786083221435547,
0.10011560469865799,
-1.0638335943222046,
1.448171854019165,
-0.6696186661720276,
0.2905119061470032,
-1.6558254957199097,
-0.12557749450206757,
-0.5398754477500916,... |
https://github.com/huggingface/datasets/issues/5390 | Error when pushing to the CI hub | Hi! I don't think this has anything to do with `datasets`. Hub CI seems to be the culprit - the identical failure can be found in [this](https://github.com/huggingface/datasets/pull/5389) PR (with unrelated changes) opened today. | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████... | 360 | 33 | Error when pushing to the CI hub
### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%... | [
-1.1982983350753784,
-0.9045103192329407,
-0.6958116292953491,
1.477090835571289,
-0.09118883311748505,
-1.2786083221435547,
0.10011560469865799,
-1.0638335943222046,
1.448171854019165,
-0.6696186661720276,
0.2905119061470032,
-1.6558254957199097,
-0.12557749450206757,
-0.5398754477500916,... |
https://github.com/huggingface/datasets/issues/5388 | Getting Value Error while loading a dataset.. | Hi! I can't reproduce this error locally (Mac) or in Colab. What version of `datasets` are you using? | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---... | 361 | 18 | Getting Value Error while loading a dataset..
### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom ... | [
-1.2207598686218262,
-0.8148059844970703,
-0.5596593022346497,
1.43604576587677,
0.0015513254329562187,
-1.3575323820114136,
0.09363394975662231,
-0.8919865489006042,
1.5938446521759033,
-0.777728259563446,
0.3635711371898651,
-1.6353535652160645,
0.05427566543221474,
-0.6565396189689636,
... |
https://github.com/huggingface/datasets/issues/5388 | Getting Value Error while loading a dataset.. | @valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.
Please, restart your Colab runtime and execute the install commands before importing `datasets`:
```python
!pip install datasets
!pip install zstandard
from datasets import load_dataset
ds ... | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---... | 361 | 49 | Getting Value Error while loading a dataset..
### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom ... | [
-1.2318658828735352,
-0.8209953308105469,
-0.5635695457458496,
1.4319144487380981,
0.012867887504398823,
-1.3619483709335327,
0.09219809621572495,
-0.9112747311592102,
1.611975908279419,
-0.7809149026870728,
0.36555957794189453,
-1.6345086097717285,
0.04313938692212105,
-0.6638200879096985... |
https://github.com/huggingface/datasets/issues/5388 | Getting Value Error while loading a dataset.. | > @valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.
>
> Please, restart your Colab runtime and execute the install commands before importing `datasets`:
>
> ```python
> !pip install datasets
> !pip install zstandard
>
> from datasets import... | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---... | 361 | 85 | Getting Value Error while loading a dataset..
### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom ... | [
-1.2317373752593994,
-0.8201888203620911,
-0.5662683844566345,
1.4329051971435547,
0.011797354556620121,
-1.3598886728286743,
0.09152227640151978,
-0.9091744422912598,
1.6110221147537231,
-0.7832229137420654,
0.36153727769851685,
-1.6367824077606201,
0.041485495865345,
-0.6567408442497253,... |
https://github.com/huggingface/datasets/issues/5387 | Missing documentation page : improve-performance | Hi! Our documentation builder does not support links to sections, hence the bug. This is the link it should point to https://huggingface.co/docs/datasets/v2.8.0/en/cache#improve-performance. | ### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce t... | 362 | 22 | Missing documentation page : improve-performance
### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.lo... | [
-1.1014243364334106,
-0.9106428623199463,
-0.7939819097518921,
1.4811865091323853,
-0.051111478358507156,
-1.3317861557006836,
0.023666583001613617,
-0.8950523734092712,
1.5431022644042969,
-0.7251619696617126,
0.16005802154541016,
-1.662352204322815,
-0.09296072274446487,
-0.5701299905776... |
https://github.com/huggingface/datasets/issues/5386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | Hi!
This behavior stems from the fact that we don't always embed image bytes in the underlying arrow table, which can lead to bad size estimation (we use the first 1000 table rows to [estimate](https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L4627)... | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_siz... | 363 | 101 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files
### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes... | [
-1.1633338928222656,
-0.8149734735488892,
-0.7043008804321289,
1.434211254119873,
-0.09023202210664749,
-1.3169342279434204,
0.18928304314613342,
-1.1059308052062988,
1.6641753911972046,
-0.8078272342681885,
0.33024078607559204,
-1.6406126022338867,
0.01942853070795536,
-0.6141484379768372... |
https://github.com/huggingface/datasets/issues/5385 | Is `fs=` deprecated in `load_from_disk()` as well? | Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR? | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the... | 364 | 17 | Is `fs=` deprecated in `load_from_disk()` as well?
### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/... | [
-1.1008424758911133,
-0.8759396076202393,
-0.7833763957023621,
1.4252301454544067,
-0.1309547871351242,
-1.2820782661437988,
0.19362300634384155,
-0.9829559922218323,
1.6879687309265137,
-0.769312858581543,
0.26621225476264954,
-1.6562386751174927,
-0.031870193779468536,
-0.646486639976501... |
https://github.com/huggingface/datasets/issues/5385 | Is `fs=` deprecated in `load_from_disk()` as well? | > Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR?
Yeah I can do that sometime next week. Should the storage_options be a new arg here? I’ll look around for anywhere else where fs is an arg. | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the... | 364 | 45 | Is `fs=` deprecated in `load_from_disk()` as well?
### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/... | [
-1.125098705291748,
-0.8834214210510254,
-0.7604483366012573,
1.4321540594100952,
-0.13877306878566742,
-1.2583807706832886,
0.16905181109905243,
-1.0252035856246948,
1.65404212474823,
-0.7715718150138855,
0.27621519565582275,
-1.647864818572998,
-0.040658678859472275,
-0.6162246465682983,... |
https://github.com/huggingface/datasets/issues/5383 | IterableDataset missing column_names, differs from Dataset interface | Another example is that `IterableDataset.map` does not have `fn_kwargs`, among other arguments. It makes it harder to convert code from Dataset to IterableDataset. | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.colu... | 365 | 23 | IterableDataset missing column_names, differs from Dataset interface
### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remov... | [
-1.1468578577041626,
-0.9682489633560181,
-0.7764684557914734,
1.501160740852356,
-0.1847407966852188,
-1.3009629249572754,
0.18761226534843445,
-1.0661351680755615,
1.805435061454773,
-0.8446510434150696,
0.3817614018917084,
-1.7188199758529663,
0.05701552331447601,
-0.5752741694450378,
... |
https://github.com/huggingface/datasets/issues/5383 | IterableDataset missing column_names, differs from Dataset interface | Hi! `fn_kwargs` was added to `IterableDataset.map` in `datasets 2.5.0`, so please update your installation (`pip install -U datasets`) to use it.
Regarding `column_names`, I agree we should add this property to `IterableDataset`. In the meantime, you can use `list(dataset.features.keys())` instead. | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.colu... | 365 | 40 | IterableDataset missing column_names, differs from Dataset interface
### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remov... | [
-1.143869161605835,
-0.9259105920791626,
-0.748171329498291,
1.4314974546432495,
-0.15763162076473236,
-1.3012871742248535,
0.24143864214420319,
-1.051605463027954,
1.839693546295166,
-0.8496646881103516,
0.39766421914100647,
-1.699894905090332,
0.04279761016368866,
-0.5868715047836304,
... |
https://github.com/huggingface/datasets/issues/5383 | IterableDataset missing column_names, differs from Dataset interface | Thanks! That's great news.
On Thu, Dec 22, 2022, 07:48 Mario Šaško ***@***.***> wrote:
> Hi! fn_kwargs was added to IterableDataset.map in datasets 2.5.0, so
> please update your installation (pip install -U datasets) to use it.
>
> Regarding column_names, I agree we should add this property to
> IterableDataset. In ... | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.colu... | 365 | 96 | IterableDataset missing column_names, differs from Dataset interface
### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remov... | [
-1.1667553186416626,
-0.9909883737564087,
-0.6709811687469482,
1.3800957202911377,
-0.18547743558883667,
-1.2485452890396118,
0.19360460340976715,
-1.0743534564971924,
1.750270962715149,
-0.6683366298675537,
0.2915157377719879,
-1.7066031694412231,
-0.06736880540847778,
-0.5485260486602783... |
https://github.com/huggingface/datasets/issues/5383 | IterableDataset missing column_names, differs from Dataset interface | I'm marking this issue as a "good first issue", as it makes sense to have `IterableDataset.column_names` in the API. Besides the case when `features` are `None` (e.g., `features` are `None` after `map`), in which we can also return `column_names` as `None`, adding this property should be straightforward, | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.colu... | 365 | 47 | IterableDataset missing column_names, differs from Dataset interface
### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remov... | [
-1.1084904670715332,
-0.9190534353256226,
-0.7726215124130249,
1.4612256288528442,
-0.14932122826576233,
-1.3125042915344238,
0.23134325444698334,
-1.054985761642456,
1.868650197982788,
-0.8625642657279968,
0.3928910791873932,
-1.7145966291427612,
0.0339580737054348,
-0.6022754311561584,
... |
https://github.com/huggingface/datasets/issues/5381 | Wrong URL for the_pile dataset | Hi! This error can happen if there is a local file/folder with the same name as the requested dataset. And to avoid it, rename the local file/folder.
Soon, it will be possible to explicitly request a Hub dataset as follows:https://github.com/huggingface/datasets/issues/5228#issuecomment-1313494020 | ### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message... | 366 | 40 | Wrong URL for the_pile dataset
### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name"... | [
-1.1432254314422607,
-1.2211201190948486,
-0.8732572793960571,
1.7928019762039185,
-0.32185065746307373,
-0.9648703932762146,
-0.057976171374320984,
-0.8220487833023071,
1.4992340803146362,
-0.6081598997116089,
-0.05005406215786934,
-1.7608273029327393,
-0.2303871065378189,
-0.880644738674... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | Hi! I agree `skip` can be inefficient to use in the current state.
To make it fast, we could use "statistics" stored in Parquet metadata and read only the chunks needed to form a dataset.
And thanks to the "datasets-server" project, which aims to store the Parquet versions of the Hub datasets (only the smaller d... | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 75 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2274943590164185,
-0.9124903678894043,
-0.7533583641052246,
1.467544674873352,
-0.15666110813617706,
-1.300691843032837,
0.10872672498226166,
-1.1673073768615723,
1.7051230669021606,
-0.8363287448883057,
0.3156016767024994,
-1.705657720565796,
0.07431887835264206,
-0.6132233738899231,
... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | @mariosasko do the current parquet files created by the datasets-server already have the required "statistics"? If not, please open an issue on https://github.com/huggingface/datasets-server with some details to make sure we implement it. | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 32 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2342714071273804,
-0.9034605026245117,
-0.7973090410232544,
1.4881747961044312,
-0.1418568342924118,
-1.3189365863800049,
0.11679156124591827,
-1.119535207748413,
1.722557544708252,
-0.8398538827896118,
0.3317399024963379,
-1.7266713380813599,
0.10830366611480713,
-0.6023262143135071,
... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | Yes, nothing has to be changed on the datasets-server side. What I mean by "statistics" is that we can use the "row_group" metadata embedded in a Parquet file (by default) to fetch the requested rows more efficiently. | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 37 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.245270013809204,
-0.8871921896934509,
-0.8230929374694824,
1.472529411315918,
-0.14608696103096008,
-1.3091472387313843,
0.13141018152236938,
-1.1319018602371216,
1.723118543624878,
-0.8718251585960388,
0.3581838309764862,
-1.6821587085723877,
0.14463059604167938,
-0.5820703506469727,
... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | Glad to see the feature could be of interest.
I'm sure there are many possible ways to implement this feature. I don't know enough about the datasets-server, but I guess that it is not instantaneous, in the sense that user-owned private datasets might need hours or days until they are ported to the datasets-server ... | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 82 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2383397817611694,
-0.9065281748771667,
-0.7987818121910095,
1.4999955892562866,
-0.13826140761375427,
-1.2874218225479126,
0.0928129106760025,
-1.1051973104476929,
1.7765353918075562,
-0.8670092821121216,
0.30463019013404846,
-1.7415071725845337,
0.09678739309310913,
-0.6170414686203003... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | re: statistics:
- https://arrow.apache.org/docs/python/generated/pyarrow.parquet.FileMetaData.html
- https://arrow.apache.org/docs/python/generated/pyarrow.parquet.RowGroupMetaData.html
```python
>>> import pyarrow.parquet as pq
>>> import hffs
>>> fs = hffs.HfFileSystem("glue", repo_type="dataset", revision=... | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 71 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2170804738998413,
-0.8857828378677368,
-0.710685670375824,
1.513796329498291,
-0.18721462786197662,
-1.296402931213379,
0.10488943010568619,
-1.088772177696228,
1.6562261581420898,
-0.8069204092025757,
0.3440224528312683,
-1.677908182144165,
0.03769025579094887,
-0.4935606122016907,
-... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | > user-owned private datasets might need hours or days until they are ported to the datasets-server (if at all)
private datasets are not supported yet (https://github.com/huggingface/datasets-server/issues/39) | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 26 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.236828327178955,
-0.91953045129776,
-0.816565215587616,
1.4637548923492432,
-0.10846497863531113,
-1.304808497428894,
0.08491496741771698,
-1.1008682250976562,
1.742102861404419,
-0.8288906812667847,
0.31637775897979736,
-1.714299201965332,
0.08610109984874725,
-0.5974811911582947,
-0... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | @versae `Dataset.push_to_hub` writes shards in Parquet, so this solution would also work for such datasets (immediately after the push). | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 19 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.246268391609192,
-0.8859814405441284,
-0.8050820827484131,
1.5180631875991821,
-0.1462196260690689,
-1.3354055881500244,
0.13288341462612152,
-1.1224117279052734,
1.7512195110321045,
-0.8549055457115173,
0.3242103159427643,
-1.6801427602767944,
0.1334267258644104,
-0.6327071189880371,
... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | @mariosasko that is right. However, there are still a good amount of datasets for which the shards are created manually. In our very specific case, we create medium-sized datasets (rarely over 100-200GB) of both text and audio, we prepare the shards by hand and then upload then. It would be great to have immediate acce... | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 63 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2387419939041138,
-0.9189008474349976,
-0.7748364806175232,
1.4695217609405518,
-0.12237699329853058,
-1.3122913837432861,
0.09067177772521973,
-1.123357892036438,
1.7218047380447388,
-0.8738673329353333,
0.3279164731502533,
-1.703904390335083,
0.11273796856403351,
-0.5978707671165466,
... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | From looking at Arrow's source, it seems Parquet stores metadata at the end, which means one needs to iterate over a Parquet file's data before accessing its metadata. We could mimic Dask to address this "limitation" and write metadata in a `_metadata`/`_common_metadata` file in `to_parquet`/`push_to_hub`, which we cou... | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 66 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2075860500335693,
-0.9106705784797668,
-0.7977585196495056,
1.576055645942688,
-0.13508634269237518,
-1.3018547296524048,
0.1560361087322235,
-1.1006830930709839,
1.7036341428756714,
-0.8785424828529358,
0.3370455801486969,
-1.6747663021087646,
0.08513769507408142,
-0.6540365219116211,
... |
https://github.com/huggingface/datasets/issues/5380 | Improve dataset `.skip()` speed in streaming mode | So if Parquet metadata needs to be in its own file anyway, why not implement this skipping feature by storing the example counts per shard in `dataset_infos.json`? That would allow:
- Support both private and public datasets
- Immediate access to the feature upon uploading of shards
- Use any dataset, not only those... | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | 367 | 74 | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the down... | [
-1.2239469289779663,
-0.9064879417419434,
-0.7884495258331299,
1.520706057548523,
-0.15377222001552582,
-1.3413708209991455,
0.12355312705039978,
-1.1004829406738281,
1.7480214834213257,
-0.8756932616233826,
0.34082502126693726,
-1.6941733360290527,
0.09066649526357651,
-0.6561979651451111... |
https://github.com/huggingface/datasets/issues/5378 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure | Thanks for reporting @shaoyuta. We are investigating it.
We are transferring the issue to "the_pile" Community tab on the Hub: https://huggingface.co/datasets/the_pile/discussions/4 | ### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset(... | 368 | 21 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure
### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run bel... | [
-1.213745355606079,
-0.8449054956436157,
-0.714655339717865,
1.4032294750213623,
-0.16015246510505676,
-1.2523725032806396,
0.10127006471157074,
-1.0374091863632202,
1.578595519065857,
-0.7577510476112366,
0.278439998626709,
-1.5970723628997803,
0.010846962220966816,
-0.47150227427482605,
... |
https://github.com/huggingface/datasets/issues/5374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | The data files are hosted on HF at https://huggingface.co/datasets/allenai/c4/tree/main
You have 200 runs streaming the same files in parallel. So this is probably a Hub limitation. Maybe rate limiting ? cc @julien-c
Maybe you can also try to reduce the number of HTTP requests by increasing the block size of eac... | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | 369 | 81 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
... | [
-1.2248406410217285,
-0.8955921530723572,
-0.6917340159416199,
1.4215863943099976,
-0.19765296578407288,
-1.1916404962539673,
0.06477683037519455,
-1.129605770111084,
1.6703031063079834,
-0.7351623177528381,
0.20575542747974396,
-1.600921392440796,
-0.06676789373159409,
-0.5356887578964233... |
https://github.com/huggingface/datasets/issues/5374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | you don't get an HTTP error code or something in your stack trace? Kinda hard to debug with this info | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | 369 | 20 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
... | [
-1.2248406410217285,
-0.8955921530723572,
-0.6917340159416199,
1.4215863943099976,
-0.19765296578407288,
-1.1916404962539673,
0.06477683037519455,
-1.129605770111084,
1.6703031063079834,
-0.7351623177528381,
0.20575542747974396,
-1.600921392440796,
-0.06676789373159409,
-0.5356887578964233... |
https://github.com/huggingface/datasets/issues/5374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | You could try to re-run using this `datasets` branch: [raise-err-when-disconnect](https://github.com/huggingface/datasets/compare/raise-err-when-disconnect?expand=1)
It should raise the fsspec error | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | 369 | 16 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
... | [
-1.2248406410217285,
-0.8955921530723572,
-0.6917340159416199,
1.4215863943099976,
-0.19765296578407288,
-1.1916404962539673,
0.06477683037519455,
-1.129605770111084,
1.6703031063079834,
-0.7351623177528381,
0.20575542747974396,
-1.600921392440796,
-0.06676789373159409,
-0.5356887578964233... |
https://github.com/huggingface/datasets/issues/5374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | The weird thing is that I already have it saved locally & it seems to indeed be using the cached one 🧐 ; I'm also using offline mode, so I don't think it has something to do with the Hub.
```
WARNING:datasets.load:Using the latest cached version of the module from /users/muennighoff/.cache/huggingface/modules/datase... | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | 369 | 68 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
... | [
-1.2248406410217285,
-0.8955921530723572,
-0.6917340159416199,
1.4215863943099976,
-0.19765296578407288,
-1.1916404962539673,
0.06477683037519455,
-1.129605770111084,
1.6703031063079834,
-0.7351623177528381,
0.20575542747974396,
-1.600921392440796,
-0.06676789373159409,
-0.5356887578964233... |
https://github.com/huggingface/datasets/issues/5374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | No, you passed `streaming=True` so it streams the data from the Hub.
This message just shows that you use the cached version of the `c4` **module**, aka the python script that is run to generate the examples from the raw data files.
Maybe the offline mode should also disable `fsspec`/`aiohttp` HTTP calls in `datase... | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | 369 | 60 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
... | [
-1.2248406410217285,
-0.8955921530723572,
-0.6917340159416199,
1.4215863943099976,
-0.19765296578407288,
-1.1916404962539673,
0.06477683037519455,
-1.129605770111084,
1.6703031063079834,
-0.7351623177528381,
0.20575542747974396,
-1.600921392440796,
-0.06676789373159409,
-0.5356887578964233... |
https://github.com/huggingface/datasets/issues/5374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | > This message just shows that you use the cached version of the c4 module
Ah my bad you're right about the module, but it's also using the downloaded & cached c4 dataset. There's no internet during the runs so it wouldn't work otherwise | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | 369 | 44 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
... | [
-1.2248406410217285,
-0.8955921530723572,
-0.6917340159416199,
1.4215863943099976,
-0.19765296578407288,
-1.1916404962539673,
0.06477683037519455,
-1.129605770111084,
1.6703031063079834,
-0.7351623177528381,
0.20575542747974396,
-1.600921392440796,
-0.06676789373159409,
-0.5356887578964233... |
https://github.com/huggingface/datasets/issues/5362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | Thanks for reporting, @shaoyuta.
We have checked and yes, apparently there is an issue with the server hosting the data of the "enron_emails" subset of "the_pile" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst
It seems to be down: The connection has timed out.
Please note that at the Hugging Face Hub... | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | 371 | 103 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' )
### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
 | We have transferred this issue to the corresponding dataset Community tab: https://huggingface.co/datasets/the_pile/discussions/2
Please, follow the updates there. | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:

Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | 371 | 17 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' )
### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
:
return {"concatenated_audio": [np.concatenate([audio["array"] for audio in batch["audio"]])]}
dataset = dataset.map(
mapper_function,
batched=True,
batch_size=3,
remove_columns=list(dataset.features),
)
``` | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | 372 | 26 | How concatenate `Audio` elements using batch mapping
### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# n... | [
-1.2300209999084473,
-0.908704400062561,
-0.7244388461112976,
1.4816561937332153,
-0.11995435506105423,
-1.188879132270813,
0.15715862810611725,
-1.067185878753662,
1.6922037601470947,
-0.8047590255737305,
0.3042461574077606,
-1.6780784130096436,
0.03688329458236694,
-0.6428915858268738,
... |
https://github.com/huggingface/datasets/issues/5361 | How concatenate `Audio` elements using batch mapping | Thanks for the snippet!
One more question. I wonder why those two mappers are working so different that one taking 4 sec while other taking over 1 min :
```python
%%time
def mapper_function1(batch):
# list_audio
return {
"audio": [
{
"array": np.concatenate([audi... | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | 372 | 144 | How concatenate `Audio` elements using batch mapping
### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# n... | [
-1.242618203163147,
-0.8907074928283691,
-0.7427430152893066,
1.4521963596343994,
-0.14945264160633087,
-1.1915191411972046,
0.14419618248939514,
-1.0921580791473389,
1.6813335418701172,
-0.7954922318458557,
0.30321723222732544,
-1.6631571054458618,
0.01981276646256447,
-0.6217243075370789... |
https://github.com/huggingface/datasets/issues/5361 | How concatenate `Audio` elements using batch mapping | In the first one you get a dataset with an Audio type, and in the second one you get a dataset with a sequence of floats type.
The Audio type encodes the data as WAV to save disk space, so it takes more time to create.
The Audio type is automatically inferred because you modify the column "audio" which was already ... | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | 372 | 84 | How concatenate `Audio` elements using batch mapping
### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# n... | [
-1.2529680728912354,
-0.9348393678665161,
-0.7474684119224548,
1.4107993841171265,
-0.1689836084842682,
-1.1990835666656494,
0.11322429776191711,
-1.072511911392212,
1.6957645416259766,
-0.7959940433502197,
0.2705734372138977,
-1.6895568370819092,
0.05957791954278946,
-0.6231801509857178,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | If you use huggingface trainer, you will find the trainer has wrapped a `IterableDatasetShard` to avoid duplication.
See:
https://github.com/huggingface/transformers/blob/dfd818420dcbad68e05a502495cf666d338b2bfb/src/transformers/trainer.py#L835
| As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 19 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.266662359237671,
-0.872687816619873,
-0.7881004214286804,
1.5121513605117798,
-0.12996762990951538,
-1.277140498161316,
0.08665143698453903,
-1.1018645763397217,
1.6233916282653809,
-0.735805869102478,
0.4112835228443146,
-1.6999651193618774,
0.06509319692850113,
-0.4879054129123688,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | If you want to support it by datasets natively, maybe we also need to change the code in `transformers` ? | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 20 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.3557546138763428,
-0.850594699382782,
-0.7625929117202759,
1.5348939895629883,
-0.1815050095319748,
-1.3051652908325195,
0.18186256289482117,
-1.229117751121521,
1.7325905561447144,
-0.7724425196647644,
0.3544665575027466,
-1.683726191520691,
0.09307768940925598,
-0.5063937306404114,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | Maybe something like this then ?
```python
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=rank, world_size=world_size)
```
For map-style datasets the implementation is trivial (it can simply use `.shard()`).
For iterable datasets we would need to implement a new Exa... | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 66 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.3632258176803589,
-0.9250876307487488,
-0.7467833757400513,
1.4937503337860107,
-0.14968734979629517,
-1.3493001461029053,
0.12449230998754501,
-1.1274056434631348,
1.7735309600830078,
-0.913582444190979,
0.42215946316719055,
-1.6959872245788574,
0.11669615656137466,
-0.5556533932685852... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | My plan is to skip examples by default to not end up with duplicates.
And if a dataset has a number of shards that is a factor of the world size, then I'd make it more optimized by distributing the shards evenly across nodes instead. | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 45 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.325636863708496,
-0.9164933562278748,
-0.8207869529724121,
1.4739124774932861,
-0.19144713878631592,
-1.3338234424591064,
0.09250319749116898,
-1.1914547681808472,
1.698036789894104,
-0.8442822098731995,
0.3746383786201477,
-1.744189739227295,
0.08582194894552231,
-0.49747714400291443,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | Opened a PR here: https://github.com/huggingface/datasets/pull/5369
feel free to play with it and share your feedbacks :) | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 16 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.318827509880066,
-0.9129341840744019,
-0.7674424648284912,
1.5067760944366455,
-0.1617230623960495,
-1.2709053754806519,
0.08908992260694504,
-1.1039825677871704,
1.6272544860839844,
-0.6929435729980469,
0.3575601875782013,
-1.7100776433944702,
0.030399253591895103,
-0.5237666964530945,... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | @lhoestq I add shuffle after split_dataset_by_node, duplicated data still exist.
For example, we have a directory named `mock_pretraining_data`, which has three files, `part-00000`, `part-00002`,`part-00002`.
Text in `part-00000` is like this:
{"id": 0}
{"id": 1}
{"id": 2}
{"id": 3}
{"id": 4}
{"id": 5}
{"id... | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 403 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.1243226528167725,
-0.811016857624054,
-0.8749836087226868,
1.5584391355514526,
-0.2119290977716446,
-1.1258975267410278,
0.2200663834810257,
-1.2918739318847656,
1.5447651147842407,
-0.6987407803535461,
0.4961589276790619,
-1.6239959001541138,
0.08669319748878479,
-0.5821733474731445,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | Hi ! Thanks for reporting, you need to pass `seed=` to `shuffle()` or the processes won't use the same seed to shuffle the shards order before assigning each shard to a node.
The issue is that the workers are not using the same seed to shuffle the shards before splitting the shards list by node. | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 55 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.316110610961914,
-0.8762099742889404,
-0.8423028588294983,
1.4903324842453003,
-0.1469218134880066,
-1.317747712135315,
0.1321864128112793,
-1.2471261024475098,
1.6973176002502441,
-0.8230382204055786,
0.38144439458847046,
-1.5872833728790283,
0.11481374502182007,
-0.5468330383300781,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | I have the same issue
```
ds['train'] = load_dataset(streaming=True)
ds['train'] = split_dataset_by_node(ds['train'], rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
vectorized_datasets = ds.map(
prepare_dataset,
remove_columns=raw_datasets_features,
).with_format("torch")
vect... | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 118 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.3350664377212524,
-0.9291308522224426,
-0.6569652557373047,
1.5620737075805664,
-0.2202267199754715,
-1.1483135223388672,
0.2004573792219162,
-1.1747883558273315,
1.6732017993927002,
-0.8242869973182678,
0.3046208620071411,
-1.5980899333953857,
0.05460178107023239,
-0.6136983633041382,
... |
https://github.com/huggingface/datasets/issues/5360 | IterableDataset returns duplicated data using PyTorch DDP | There are two ways an iterable dataset can be split by node:
1. if the number of shards is a factor of number of GPUs: in that case the shards are evenly distributed per GPU
2. otherwise, each GPU iterate on the data and at the end keeps 1 sample out of n(GPUs) - skipping the others.
In case 2. it's therefore poss... | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | 373 | 111 | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size... | [
-1.3229150772094727,
-0.954928994178772,
-0.834199070930481,
1.5285686254501343,
-0.26840588450431824,
-1.2820279598236084,
0.06130075454711914,
-1.1555571556091309,
1.7199827432632446,
-0.9163379669189453,
0.3741273581981659,
-1.6826754808425903,
0.1528691202402115,
-0.5496371388435364,
... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.