
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/1597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1597/comments | https://api.github.com/repos/huggingface/datasets/issues/1597/events | https://github.com/huggingface/datasets/pull/1597 | 770,276,140 | MDExOlB1bGxSZXF1ZXN0NTQyMDUwMTc5 | 1,597 | adding hate-speech-and-offensive-language | [] | closed | false | null | 1 | 2020-12-17T18:35:15Z | 2020-12-23T23:27:17Z | 2020-12-23T23:27:16Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1597/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1597.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1597",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1597.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1597"
} | true | [
"made suggested changes and opened PR https://github.com/huggingface/datasets/pull/1628"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/2240 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2240/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2240/comments | https://api.github.com/repos/huggingface/datasets/issues/2240/events | https://github.com/huggingface/datasets/pull/2240 | 862,537,856 | MDExOlB1bGxSZXF1ZXN0NjE5MDkyODc5 | 2,240 | Clarify how to load wikihow | [] | closed | false | null | 0 | 2021-04-20T08:02:58Z | 2021-04-21T09:54:57Z | 2021-04-21T09:54:57Z | null | Explain clearer how to load the dataset in the manual download instructions.
En relation with #2239. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2240/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2240/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2240.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2240",
"merged_at": "2021-04-21T09:54:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2240.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2240"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5696/comments | https://api.github.com/repos/huggingface/datasets/issues/5696/events | https://github.com/huggingface/datasets/issues/5696 | 1,651,707,008 | I_kwDODunzps5icwyA | 5,696 | Shuffle a sharded iterable dataset without seed can lead to duplicate data | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2023-04-03T09:40:03Z | 2023-04-04T14:58:18Z | 2023-04-04T14:58:18Z | null | As reported in https://github.com/huggingface/datasets/issues/5360
If `seed=None` in `.shuffle()`, shuffled datasets don't use the same shuffling seed across nodes.
Because of that, the lists of shards is not shuffled the same way across nodes, and therefore some shards may be assigned to multiple nodes instead of exactly one.
This can happen only when you have a number of shards that is a factor of the number of nodes.
The current workaround is to always set a `seed` in `.shuffle()` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5696/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5696/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5815 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5815/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5815/comments | https://api.github.com/repos/huggingface/datasets/issues/5815/events | https://github.com/huggingface/datasets/issues/5815 | 1,693,701,743 | I_kwDODunzps5k89Zv | 5,815 | Easy way to create a Kaggle dataset from a Huggingface dataset? | [] | open | false | null | 4 | 2023-05-02T21:43:33Z | 2023-07-26T16:13:31Z | null | null | I'm not sure whether this is more appropriately addressed with HuggingFace or Kaggle. I would like to somehow directly create a Kaggle dataset from a HuggingFace Dataset.
While Kaggle does provide the option to create a dataset from a URI, that URI must point to a single file. For example:
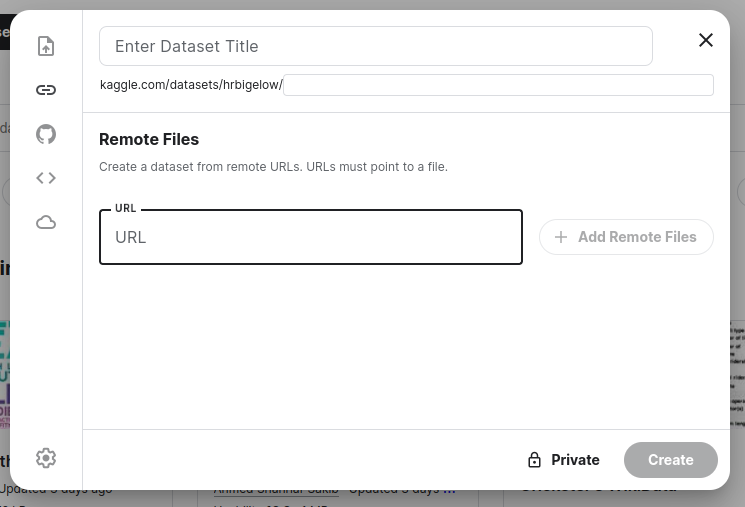
Is there some mechanism from huggingface to represent a dataset (such as that from `load_dataset('wmt14', 'de-en', split='train')` as a single file? Or, some other way to get that into a Kaggle dataset so that I can use the huggingface `datasets` module to process and consume it inside of a Kaggle notebook?
Thanks in advance!
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5815/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5815/timeline | null | null | null | null | false | [
"Hi @hrbigelow , I'm no expert for such a question so I'll ping @lhoestq from the `datasets` library (also this issue could be moved there if someone with permission can do it :) )",
"Hi ! Many datasets are made of several files, and how they are parsed often requires a python script. Because of that, datasets like wmt14 are not available as a single file on HF. Though you can create this file using `datasets`:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"wmt14\", \"de-en\", split=\"train\")\r\n\r\nds.to_json(\"wmt14-train.json\")\r\n# OR to parquet, which is compressed:\r\n# ds.to_parquet(\"wmt14-train.parquet\")\r\n```\r\n\r\nWe are also working on providing parquet exports for all datasets, but wmt14 is not supported yet (we're rolling it out for datasets <1GB first). They're usually available in the `refs/convert/parquet` branch (empty for wmt14):\r\n\r\n<img width=\"267\" alt=\"image\" src=\"https://user-images.githubusercontent.com/42851186/235878909-7339f5a4-be19-4ada-85d8-8a50d23acf35.png\">\r\n",
"also cc @nateraw for visibility on this (and cc @osanseviero too)",
"I've requested support for creating a Kaggle dataset from an imported HF dataset repo on their \"forum\" here: https://www.kaggle.com/discussions/product-feedback/427142 (upvotes appreciated 🙂)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3849 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3849/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3849/comments | https://api.github.com/repos/huggingface/datasets/issues/3849/events | https://github.com/huggingface/datasets/pull/3849 | 1,162,091,075 | PR_kwDODunzps40E6sW | 3,849 | Add "Adversarial GLUE" dataset to datasets library | [] | closed | false | null | 5 | 2022-03-08T00:47:11Z | 2022-03-28T11:17:14Z | 2022-03-28T11:12:04Z | null | Adds the Adversarial GLUE dataset: https://adversarialglue.github.io/
```python
>>> import datasets
>>> >>> datasets.load_dataset('adv_glue')
Using the latest cached version of the module from /home/jxm3/.cache/huggingface/modules/datasets_modules/datasets/adv_glue/26709a83facad2830d72d4419dd179c0be092f4ad3303ad0ebe815d0cdba5cb4 (last modified on Mon Mar 7 19:19:48 2022) since it couldn't be found locally at adv_glue., or remotely on the Hugging Face Hub.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jxm3/random/datasets/src/datasets/load.py", line 1657, in load_dataset
builder_instance = load_dataset_builder(
File "/home/jxm3/random/datasets/src/datasets/load.py", line 1510, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/jxm3/random/datasets/src/datasets/builder.py", line 1021, in __init__
super().__init__(*args, **kwargs)
File "/home/jxm3/random/datasets/src/datasets/builder.py", line 258, in __init__
self.config, self.config_id = self._create_builder_config(
File "/home/jxm3/random/datasets/src/datasets/builder.py", line 337, in _create_builder_config
raise ValueError(
ValueError: Config name is missing.
Please pick one among the available configs: ['adv_sst2', 'adv_qqp', 'adv_mnli', 'adv_mnli_mismatched', 'adv_qnli', 'adv_rte']
Example of usage:
`load_dataset('adv_glue', 'adv_sst2')`
>>> datasets.load_dataset('adv_glue', 'adv_sst2')['validation'][0]
Reusing dataset adv_glue (/home/jxm3/.cache/huggingface/datasets/adv_glue/adv_sst2/1.0.0/3719a903f606f2c96654d87b421bc01114c37084057cdccae65cd7bc24b10933)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 604.11it/s]
{'sentence': "it 's an uneven treat that bores fun at the democratic exercise while also examining its significance for those who take part .", 'label': 1, 'idx': 0}
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3849/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3849/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3849.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3849",
"merged_at": "2022-03-28T11:12:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3849.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3849"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq can you review when you have some time?",
"Hi @lhoestq -- thanks so much for your review! I just added the stuff you requested to the README.md, including an example from the dataset, the table of contents, and lots of section headers with \"More Information Needed\" below. Let me know if there's anything else I need to do!",
"Feel free to also merge `master` into your branch to get the latest updates for the tests ;)",
"thanks @lhoestq - just made all the updates you requested!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2490 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2490/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2490/comments | https://api.github.com/repos/huggingface/datasets/issues/2490/events | https://github.com/huggingface/datasets/pull/2490 | 919,571,385 | MDExOlB1bGxSZXF1ZXN0NjY4ODc4NDA3 | 2,490 | Allow latest pyarrow version | [] | closed | false | {
"closed_at": "2021-07-09T05:50:07Z",
"closed_issues": 12,
"created_at": "2021-05-31T16:13:06Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-07-08T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/5",
"id": 6808903,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/5/labels",
"node_id": "MDk6TWlsZXN0b25lNjgwODkwMw==",
"number": 5,
"open_issues": 0,
"state": "closed",
"title": "1.9",
"updated_at": "2021-07-12T14:12:00Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/5"
} | 1 | 2021-06-12T14:17:34Z | 2021-07-06T16:54:52Z | 2021-06-14T07:53:23Z | null | Allow latest pyarrow version, once that version 4.0.1 fixes the segfault bug introduced in version 4.0.0.
Close #2489. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2490/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2490/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2490.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2490",
"merged_at": "2021-06-14T07:53:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2490.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2490"
} | true | [
"i need some help with this"
] |
https://api.github.com/repos/huggingface/datasets/issues/2352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2352/comments | https://api.github.com/repos/huggingface/datasets/issues/2352/events | https://github.com/huggingface/datasets/pull/2352 | 889,810,100 | MDExOlB1bGxSZXF1ZXN0NjQyOTI4NTgz | 2,352 | Set to_json default to JSON lines | [] | closed | false | null | 2 | 2021-05-12T08:19:25Z | 2021-05-21T09:01:14Z | 2021-05-21T09:01:13Z | null | With this PR, the method `Dataset.to_json`:
- is added to the docs
- defaults to JSON lines | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2352/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2352.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2352",
"merged_at": "2021-05-21T09:01:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2352.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2352"
} | true | [
"This is perfect, @albertvillanova - thank you! Tested it to work.\r\n\r\nMight it be a good idea to document the args to `to_json`?\r\n\r\nand also even a very basic progress bar? took 10min for 8M large records for `openwebtext` so perhaps some indication of it's being alive every min or so?",
"@lhoestq I added tests for both `lines` and `orient`."
] |
https://api.github.com/repos/huggingface/datasets/issues/1540 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1540/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1540/comments | https://api.github.com/repos/huggingface/datasets/issues/1540/events | https://github.com/huggingface/datasets/pull/1540 | 765,357,702 | MDExOlB1bGxSZXF1ZXN0NTM4OTQ1NDc2 | 1,540 | added TTC4900: A Benchmark Data for Turkish Text Categorization dataset | [] | closed | false | null | 7 | 2020-12-13T12:43:33Z | 2020-12-18T10:09:01Z | 2020-12-18T10:09:01Z | null | This PR adds the TTC4900 dataset which is a Turkish Text Categorization dataset by me and @basakbuluz.
Homepage: [https://www.kaggle.com/savasy/ttc4900](https://www.kaggle.com/savasy/ttc4900)
Point of Contact: [Savaş Yıldırım](mailto:savasy@gmail.com) / @savasy
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1540/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1540/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1540.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1540",
"merged_at": "2020-12-18T10:09:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1540.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1540"
} | true | [
"@lhoestq, can you help with creating dummy_data?\r\n",
"Hi @yavuzKomecoglu did you manage to build the dummy data ?",
"> Hi @yavuzKomecoglu did you manage to build the dummy data ?\r\n\r\nHi, sorry for the return. I've created dummy_data.zip manually.",
"> Nice thank you !\r\n> \r\n> Before we merge can you fill the two sections of the dataset card I suggested ?\r\n> And also remove one remaining print statement\r\n\r\nI updated your suggestions. Thank you very much for your support.",
"I think you accidentally pushed the readme of another dataset (name_to_nation).\r\nI removed it so you have to `git pull`\r\n\r\nBecause of that I guess your changes about the ttc4900 was not included.\r\nFeel free to ping me once they're added\r\n\r\n\r\n",
"> I think you accidentally pushed the readme of another dataset (name_to_nation).\r\n> I removed it so you have to `git pull`\r\n> \r\n> Because of that I guess your changes about the ttc4900 was not included.\r\n> Feel free to ping me once they're added\r\n\r\nI did `git pull` and updated readme **ttc4900**.",
"merging since the Ci is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5089/comments | https://api.github.com/repos/huggingface/datasets/issues/5089/events | https://github.com/huggingface/datasets/issues/5089 | 1,400,788,486 | I_kwDODunzps5TflYG | 5,089 | Resume failed process | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2022-10-07T08:07:03Z | 2022-10-07T08:07:03Z | null | null | **Is your feature request related to a problem? Please describe.**
When a process (`map`, `filter`, etc.) crashes part-way through, you lose all progress.
**Describe the solution you'd like**
It would be good if the cache reflected the partial progress, so that after we restart the script, the process can restart where it left off.
**Describe alternatives you've considered**
Doing processing outside of `datasets`, by writing the dataset to json files and building a restart mechanism myself.
**Additional context**
N/A
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5089/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/893/comments | https://api.github.com/repos/huggingface/datasets/issues/893/events | https://github.com/huggingface/datasets/pull/893 | 751,703,696 | MDExOlB1bGxSZXF1ZXN0NTI4MTY4NDgx | 893 | add metrec: arabic poetry dataset | [] | closed | false | null | 10 | 2020-11-26T16:10:16Z | 2020-12-01T16:24:55Z | 2020-12-01T15:15:07Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/893/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/893.diff",
"html_url": "https://github.com/huggingface/datasets/pull/893",
"merged_at": "2020-12-01T15:15:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/893.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/893"
} | true | [
"@lhoestq removed prints and added the dataset card. ",
"@lhoestq, I want to add other datasets as well. I am not sure if it is possible to do so with the same branch. ",
"Hi @zaidalyafeai, really excited to get more Arabic coverage in the lib, thanks for your contribution!\r\n\r\nCouple of last comments:\r\n- this PR seems to modify some files that are unrelated to your dataset. Could you rebase from master? It should take care of that.\r\n- The dataset card is a good start! Can you describe the task in a few words and add more information in the Data Structure part, including listing and describing the fields? Also, if you don't know how to fill out a paragraph, or if you have some information but think more would be beneficial, please leave `[More Information Needed]` instead of `[N/A]`",
"> Hi @zaidalyafeai, really excited to get more Arabic coverage in the lib, thanks for your contribution!\r\n> \r\n> Couple of last comments:\r\n> \r\n> * this PR seems to modify some files that are unrelated to your dataset. Could you rebase from master? It should take care of that.\r\n> * The dataset card is a good start! Can you describe the task in a few words and add more information in the Data Structure part, including listing and describing the fields? Also, if you don't know how to fill out a paragraph, or if you have some information but think more would be beneficial, please leave `[More Information Needed]` instead of `[N/A]`\r\n\r\nI have no idea how some other files changed. I tried to rebase and push but this created some errors. I had to run the command \r\n`git push -u --force origin add-metrec-dataset` which might cause some problems. ",
"Feel free to create another branch/another PR without all the other changes",
"@yjernite can you explain which other files are changed because of the PR ? https://github.com/huggingface/datasets/pull/893/files only shows files related to the dataset. ",
"Right ! github is nice with us today :)",
"Looks like this one is ready to merge, thanks @zaidalyafeai !",
"@lhoestq thanks for the merge. I am not a GitHub geek. I already have another dataset to add. I'm not sure how to add another given my forked repo. Do I follow the same steps with a different checkout name ?",
"If you've followed the instructions in here : https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#start-by-preparing-your-environment\r\n\r\n(especially point 2. and the command `git remote add upstream ....`)\r\n\r\nThen you can try\r\n```\r\ngit checkout master\r\ngit fetch upstream\r\ngit rebase upstream/master\r\ngit checkout -b add-<my-new-dataset-name>\r\n```"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/4342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4342/comments | https://api.github.com/repos/huggingface/datasets/issues/4342/events | https://github.com/huggingface/datasets/pull/4342 | 1,234,743,765 | PR_kwDODunzps43woHm | 4,342 | Fix failing CI on Windows for sari and wiki_split metrics | [] | closed | false | null | 0 | 2022-05-13T05:03:38Z | 2022-05-13T05:47:42Z | 2022-05-13T05:47:42Z | null | This PR adds `sacremoses` as explicit tests dependency (required by sari and wiki_split metrics).
Before, this library was installed as a third-party dependency, but this is no longer the case for Windows.
Fix #4341. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4342/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4342.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4342",
"merged_at": "2022-05-13T05:47:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4342.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4342"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5264/comments | https://api.github.com/repos/huggingface/datasets/issues/5264/events | https://github.com/huggingface/datasets/issues/5264 | 1,455,252,906 | I_kwDODunzps5WvWWq | 5,264 | `datasets` can't read a Parquet file in Python 3.9.13 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 16 | 2022-11-18T14:44:01Z | 2023-05-07T09:52:59Z | 2022-11-22T11:18:08Z | null | ### Describe the bug
I have an error when trying to load this [dataset](https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj) (it's private but I can add you to the bigcode org). `datasets` can't read one of the parquet files in the Java subset
```python
from datasets import load_dataset
ds = load_dataset("bigcode/the-stack-dedup-pjj", data_dir="data/java", split="train", revision="v1.1.a1", use_auth_token=True)
````
```
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.
```
It seems to be an issue with new Python versions, Because it works in these two environements:
```
- `datasets` version: 2.6.1
- Platform: Linux-5.4.0-131-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
```
```
- `datasets` version: 2.6.1
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.12
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
```
But not in this:
```
- `datasets` version: 2.6.1
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
```
### Steps to reproduce the bug
Load the dataset in python 3.9.13
### Expected behavior
Load the dataset without the pyarrow error.
### Environment info
```
- `datasets` version: 2.6.1
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5264/timeline | null | completed | null | null | false | [
"Could you share the full stack trace please ?\r\n\r\n\r\nCan you also try running this code ? It can be useful to determine if the issue comes from `datasets` or `fsspec` (streaming) or `pyarrow` (parquet reading):\r\n```python\r\nds = load_dataset(\"parquet\", data_files=a_parquet_file_url, use_auth_token=True)\r\n```",
"Here's the full trace\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/loubna_huggingface_co/load.py\", line 15, in <module>\r\n ds_all = load_dataset(\"bigcode/the-stack-dedup-pjj\", data_dir=\"data/java\",use_auth_token=True, split=\"train\", revision=\"v1.1.a1\")\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1742, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 814, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 905, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 1502, in _prepare_split\r\n for key, table in logging.tqdm(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py\", line 1195, in __iter__\r\n for obj in iterable:\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py\", line 67, in _generate_tables\r\n parquet_file = pq.ParquetFile(f)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/parquet/__init__.py\", line 286, in __init__\r\n self.reader.open(\r\n File \"pyarrow/_parquet.pyx\", line 1227, in pyarrow._parquet.ParquetReader.open\r\n File \"pyarrow/error.pxi\", line 100, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.\r\n```\r\n\r\nwhen running\r\n```python\r\nds = load_dataset(\"parquet\", data_files=\"https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/blob/v1.1.a1/data/java/data_0000.parquet\", use_auth_token=True)\r\n```\r\nI get 401 error, but that's the case for the python subset too which I can load properly\r\n```\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1719, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1497, in load_dataset_builder\r\n dataset_module = dataset_module_factory(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1134, in dataset_module_factory\r\n return PackagedDatasetModuleFactory(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 707, in get_module\r\n data_files = DataFilesDict.from_local_or_remote(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 795, in from_local_or_remote\r\n DataFilesList.from_local_or_remote(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 764, in from_local_or_remote\r\n origin_metadata = _get_origin_metadata_locally_or_by_urls(data_files, use_auth_token=use_auth_token)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 710, in _get_origin_metadata_locally_or_by_urls\r\n return thread_map(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/contrib/concurrent.py\", line 94, in thread_map\r\n return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/contrib/concurrent.py\", line 76, in _executor_map\r\n return list(tqdm_class(ex.map(fn, *iterables, **map_args), **kwargs))\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py\", line 1183, in __iter__\r\n for obj in iterable:\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/_base.py\", line 609, in result_iterator\r\n yield fs.pop().result()\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/_base.py\", line 446, in result\r\n return self.__get_result()\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/_base.py\", line 391, in __get_result\r\n raise self._exception\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/thread.py\", line 58, in run\r\n result = self.fn(*self.args, **self.kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 701, in _get_single_origin_metadata_locally_or_by_urls\r\n return (request_etag(data_file, use_auth_token=use_auth_token),)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 411, in request_etag\r\n response.raise_for_status()\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/requests/models.py\", line 960, in raise_for_status\r\n raise HTTPError(http_error_msg, response=self)\r\nrequests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/blob/v1.1.a1/data/python/data_0000.parquet```",
"Can you check you used the right token ? You shouldn't get a 401 using your token",
"I checked it’s the right token, when loading the full dataset I get the error after data extraction so I can access the files. \r\n```\r\nDownloading and preparing dataset parquet/bigcode--the-stack-dedup-pjj to /home/loubna_huggingface_co/.cache/huggingface/datasets/bigcode___parquet/bigcode--the-stack-dedup-pjj-872ffac7f4bb46ca/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...\r\nDownloading data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 22.38it/s]\r\nExtracting data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 49.91it/s]\r\nTraceback (most recent call last):\r\n File \"/home/loubna_huggingface_co/load_ds.py\", line 5, in <module>\r\n ds = load_dataset(\"bigcode/the-stack-dedup-pjj\", data_dir=\"data/java\", use_auth_token=True,split=\"train\", revision=\"v1.1.a1\")\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1742, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 814, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 905, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 1502, in _prepare_split\r\n for key, table in logging.tqdm(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py\", line 1195, in __iter__\r\n for obj in iterable:\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py\", line 67, in _generate_tables\r\n parquet_file = pq.ParquetFile(f)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/parquet/__init__.py\", line 286, in __init__\r\n self.reader.open(\r\n File \"pyarrow/_parquet.pyx\", line 1227, in pyarrow._parquet.ParquetReader.open\r\n File \"pyarrow/error.pxi\", line 100, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.\r\n```\r\nCould it be that I'm using a wrong url, I just copied it from the address bar",
"The URL is wrong indeed, the right one is the one with \"resolve\" (the one you get when clicking on \"download\")- otherwise you try to download an html page ;)\r\n```\r\nhttps://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/resolve/v1.1.a1/data/java/data_0000.parquet\r\n```",
"Ah thanks! So I tried it with the first parquet file and it works, is there a way to know which parquet file was causing the issue since there are a lot of shards?",
"I think you have to try them all :/\r\n\r\nAlternatively you can add a try/catch in `parquet.py` in `datasets` to raise the name of the file that fails at doing `parquet_file = pq.ParquetFile(f)` when you run your initial code\r\n```python\r\nload_dataset(\"bigcode/the-stack-dedup-pjj\", data_dir=\"data/java\", split=\"train\", revision=\"v1.1.a1\", use_auth_token=True)\r\n```\r\nbut it will still iterate on all the files until it fails",
"Ok I will do that",
"I did find the file, and I get the same error as before \r\n```\r\nDownloading data files: 100%|███████████████████| 1/1 [00:00<00:00, 8160.12it/s]\r\nExtracting data files: 100%|████████████████████| 1/1 [00:00<00:00, 1447.81it/s]\r\n \r\n---------------------------------------------------------------------------\r\nArrowInvalid Traceback (most recent call last)\r\nInput In [22], in <cell line: 7>()\r\n 4 data_features = (data[\"train\"].features)\r\n 6 url = \"/home/loubna_huggingface_co/.cache/huggingface/datasets/downloads/93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7\"\r\n----> 7 data = load_dataset(\"parquet\", \r\n 8 data_files=url,\r\n 9 split=\"train\",\r\n 10 features=data_features,\r\n 11 use_auth_token=True)\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py:1742, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)\r\n 1739 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES\r\n 1741 # Download and prepare data\r\n-> 1742 builder_instance.download_and_prepare(\r\n 1743 download_config=download_config,\r\n 1744 download_mode=download_mode,\r\n 1745 ignore_verifications=ignore_verifications,\r\n 1746 try_from_hf_gcs=try_from_hf_gcs,\r\n 1747 use_auth_token=use_auth_token,\r\n 1748 )\r\n 1750 # Build dataset for splits\r\n 1751 keep_in_memory = (\r\n 1752 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)\r\n 1753 )\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py:814, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, storage_options, **download_and_prepare_kwargs)\r\n 808 if not downloaded_from_gcs:\r\n 809 prepare_split_kwargs = {\r\n 810 \"file_format\": file_format,\r\n 811 \"max_shard_size\": max_shard_size,\r\n 812 **download_and_prepare_kwargs,\r\n 813 }\r\n--> 814 self._download_and_prepare(\r\n 815 dl_manager=dl_manager,\r\n 816 verify_infos=verify_infos,\r\n 817 **prepare_split_kwargs,\r\n 818 **download_and_prepare_kwargs,\r\n 819 )\r\n 820 # Sync info\r\n 821 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py:905, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 901 split_dict.add(split_generator.split_info)\r\n 903 try:\r\n 904 # Prepare split will record examples associated to the split\r\n--> 905 self._prepare_split(split_generator, **prepare_split_kwargs)\r\n 906 except OSError as e:\r\n 907 raise OSError(\r\n 908 \"Cannot find data file. \"\r\n 909 + (self.manual_download_instructions or \"\")\r\n 910 + \"\\nOriginal error:\\n\"\r\n 911 + str(e)\r\n 912 ) from None\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py:1502, in ArrowBasedBuilder._prepare_split(self, split_generator, file_format, max_shard_size)\r\n 1500 total_num_examples, total_num_bytes = 0, 0\r\n 1501 try:\r\n-> 1502 for key, table in logging.tqdm(\r\n 1503 generator,\r\n 1504 unit=\" tables\",\r\n 1505 leave=False,\r\n 1506 disable=not logging.is_progress_bar_enabled(),\r\n 1507 ):\r\n 1508 if max_shard_size is not None and writer._num_bytes > max_shard_size:\r\n 1509 num_examples, num_bytes = writer.finalize()\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py:1195, in tqdm.__iter__(self)\r\n 1192 time = self._time\r\n 1194 try:\r\n-> 1195 for obj in iterable:\r\n 1196 yield obj\r\n 1197 # Update and possibly print the progressbar.\r\n 1198 # Note: does not call self.update(1) for speed optimisation.\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py:67, in Parquet._generate_tables(self, files)\r\n 65 for file_idx, file in enumerate(itertools.chain.from_iterable(files)):\r\n 66 with open(file, \"rb\") as f:\r\n---> 67 parquet_file = pq.ParquetFile(f)\r\n 68 try:\r\n 69 for batch_idx, record_batch in enumerate(\r\n 70 parquet_file.iter_batches(batch_size=self.config.batch_size, columns=self.config.columns)\r\n 71 ):\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/parquet/__init__.py:286, in ParquetFile.__init__(self, source, metadata, common_metadata, read_dictionary, memory_map, buffer_size, pre_buffer, coerce_int96_timestamp_unit, decryption_properties, thrift_string_size_limit, thrift_container_size_limit)\r\n 280 def __init__(self, source, *, metadata=None, common_metadata=None,\r\n 281 read_dictionary=None, memory_map=False, buffer_size=0,\r\n 282 pre_buffer=False, coerce_int96_timestamp_unit=None,\r\n 283 decryption_properties=None, thrift_string_size_limit=None,\r\n 284 thrift_container_size_limit=None):\r\n 285 self.reader = ParquetReader()\r\n--> 286 self.reader.open(\r\n 287 source, use_memory_map=memory_map,\r\n 288 buffer_size=buffer_size, pre_buffer=pre_buffer,\r\n 289 read_dictionary=read_dictionary, metadata=metadata,\r\n 290 coerce_int96_timestamp_unit=coerce_int96_timestamp_unit,\r\n 291 decryption_properties=decryption_properties,\r\n 292 thrift_string_size_limit=thrift_string_size_limit,\r\n 293 thrift_container_size_limit=thrift_container_size_limit,\r\n 294 )\r\n 295 self.common_metadata = common_metadata\r\n 296 self._nested_paths_by_prefix = self._build_nested_paths()\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/_parquet.pyx:1227, in pyarrow._parquet.ParquetReader.open()\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/error.pxi:100, in pyarrow.lib.check_status()\r\n\r\nArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.\r\n```",
"Can you check the JSON file associated to `/home/loubna_huggingface_co/.cache/huggingface/datasets/downloads/93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7` ? In the JSON file we can know from where it was downloaded\r\n\r\nYou can find it at `/home/loubna_huggingface_co/.cache/huggingface/datasets/downloads/93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7.json`",
"It's this file `https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/resolve/f48656daa9f3a3607dacf8b57a65810a6a7a7f73/data/java/data_0022.parquet` loading it gives the same error",
"I'm able to load it properly using\r\n```python\r\nds = load_dataset(\"parquet\", data_files=a_parquet_file_url, use_auth_token=token)\r\n```\r\n\r\nMy guess is that your download was corrupted. Please delete `93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7` and `93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7.json` locally and try again",
"That worked, thanks! But I thought if something went wrong with a download `datasets` creates new cache for all the files, that's not the case? (at some point I even changed dataset versions so it was still using that cache?)",
"Cool !\r\n\r\n> But I thought if something went wrong with a download datasets creates new cache for all the files\r\n\r\nWe don't perform integrity verifications if we don't know in advance the hash of the file to download.\r\n\r\n> at some point I even changed dataset versions so it was still using that cache?\r\n\r\n`datasets` caches the files by URL and ETag. If the content of a file changes, then the ETag changes and so it redownloads the file",
"I see, thank you!\r\n",
"I experience the same error in v 2.12.0. But found out it was due to one column from polars was a categorical dtype (related to the error from #5706. Temporarily resolved it by casting the column to str instead."
] |
https://api.github.com/repos/huggingface/datasets/issues/2314 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2314/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2314/comments | https://api.github.com/repos/huggingface/datasets/issues/2314/events | https://github.com/huggingface/datasets/pull/2314 | 875,729,271 | MDExOlB1bGxSZXF1ZXN0NjMwMDExODc4 | 2,314 | Minor refactor prepare_module | [] | closed | false | null | 2 | 2021-05-04T18:37:26Z | 2021-10-13T09:07:34Z | 2021-10-13T09:07:34Z | null | Start to refactor `prepare_module` to try to decouple functionality.
This PR does:
- extract function `_initialize_dynamic_modules_namespace_package`
- extract function `_find_module_in_github_or_s3`
- some renaming of variables
- use of f-strings | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2314/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2314/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2314.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2314",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2314.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2314"
} | true | [
"@lhoestq this is the PR that I mentioned to you, which can be considered as a first step in refactoring `prepare_module`.",
"closing in favor of #2986 "
] |
https://api.github.com/repos/huggingface/datasets/issues/1881 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1881/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1881/comments | https://api.github.com/repos/huggingface/datasets/issues/1881/events | https://github.com/huggingface/datasets/pull/1881 | 808,578,200 | MDExOlB1bGxSZXF1ZXN0NTczNTk1Nzkw | 1,881 | `list_datasets()` returns a list of strings, not objects | [] | closed | false | null | 0 | 2021-02-15T14:20:15Z | 2021-02-15T15:09:49Z | 2021-02-15T15:09:48Z | null | Here and there in the docs there is still stuff like this:
```python
>>> datasets_list = list_datasets()
>>> print(', '.join(dataset.id for dataset in datasets_list))
```
However, my understanding is that `list_datasets()` returns a list of strings rather than a list of objects. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1881/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1881/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1881.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1881",
"merged_at": "2021-02-15T15:09:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1881.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1881"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2824 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2824/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2824/comments | https://api.github.com/repos/huggingface/datasets/issues/2824/events | https://github.com/huggingface/datasets/pull/2824 | 976,394,721 | MDExOlB1bGxSZXF1ZXN0NzE3MzIyMzY5 | 2,824 | Fix defaults in cache_dir docstring in load.py | [] | closed | false | null | 0 | 2021-08-22T14:48:37Z | 2021-08-26T13:23:32Z | 2021-08-26T11:55:16Z | null | Fix defaults in the `cache_dir` docstring. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2824/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2824/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2824.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2824",
"merged_at": "2021-08-26T11:55:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2824.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2824"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3623/comments | https://api.github.com/repos/huggingface/datasets/issues/3623/events | https://github.com/huggingface/datasets/pull/3623 | 1,112,835,239 | PR_kwDODunzps4xgWig | 3,623 | Extend support for streaming datasets that use os.path.relpath | [] | closed | false | null | 0 | 2022-01-24T16:00:52Z | 2022-02-04T14:03:55Z | 2022-02-04T14:03:54Z | null | This PR extends the support in streaming mode for datasets that use `os.path.relpath`, by patching that function.
This feature will also be useful to yield the relative path of audio or image files, within an archive or parent dir.
Close #3622. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3623/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3623/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3623.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3623",
"merged_at": "2022-02-04T14:03:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3623.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3623"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4141 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4141/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4141/comments | https://api.github.com/repos/huggingface/datasets/issues/4141/events | https://github.com/huggingface/datasets/issues/4141 | 1,199,610,885 | I_kwDODunzps5HgJwF | 4,141 | Why is the dataset not visible under the dataset preview section? | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 0 | 2022-04-11T08:36:42Z | 2022-04-11T18:55:32Z | 2022-04-11T17:09:49Z | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4141/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4141/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4556/comments | https://api.github.com/repos/huggingface/datasets/issues/4556/events | https://github.com/huggingface/datasets/issues/4556 | 1,283,462,881 | I_kwDODunzps5MgBbh | 4,556 | Dataset Viewer issue for conll2003 | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 1 | 2022-06-24T08:55:18Z | 2022-06-24T09:50:39Z | 2022-06-24T09:50:39Z | null | ### Link
https://huggingface.co/datasets/conll2003/viewer/conll2003/test
### Description
Seems like a cache problem with this config / split:
```
Server error
Status code: 400
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: '/cache/modules/datasets_modules/datasets/conll2003/__init__.py'
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4556/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4556/timeline | null | completed | null | null | false | [
"Fixed, thanks."
] |
https://api.github.com/repos/huggingface/datasets/issues/3530 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3530/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3530/comments | https://api.github.com/repos/huggingface/datasets/issues/3530/events | https://github.com/huggingface/datasets/pull/3530 | 1,093,894,732 | PR_kwDODunzps4wiZCw | 3,530 | Update README.md | [] | closed | false | null | 0 | 2022-01-05T01:32:07Z | 2022-01-05T12:50:51Z | 2022-01-05T12:50:50Z | null | Removing reference to "Common Voice" in Personal and Sensitive Information section.
Adding link to license.
Correct license type in metadata. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3530/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3530/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3530.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3530",
"merged_at": "2022-01-05T12:50:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3530.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3530"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/407/comments | https://api.github.com/repos/huggingface/datasets/issues/407/events | https://github.com/huggingface/datasets/issues/407 | 658,672,736 | MDU6SXNzdWU2NTg2NzI3MzY= | 407 | MissingBeamOptions for Wikipedia 20200501.en | [] | closed | false | null | 4 | 2020-07-16T23:48:03Z | 2021-01-12T11:41:16Z | 2020-07-17T14:24:28Z | null | There may or may not be a regression for the pre-processed Wikipedia dataset. This was working fine 10 commits ago (without having Apache Beam available):
```
nlp.load_dataset('wikipedia', "20200501.en", split='train')
```
And now, having pulled master, I get:
```
Downloading and preparing dataset wikipedia/20200501.en (download: 16.99 GiB, generated: 17.07 GiB, total: 34.06 GiB) to /home/hltcoe/mgordon/.cache/huggingface/datasets/wikipedia/20200501.en/1.0.0/76b0b2747b679bb0ee7a1621e50e5a6378477add0c662668a324a5bc07d516dd...
Traceback (most recent call last):
File "scripts/download.py", line 11, in <module>
fire.Fire(download_pretrain)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 138, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 468, in _Fire
target=component.__name__)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 672, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "scripts/download.py", line 6, in download_pretrain
nlp.load_dataset('wikipedia', "20200501.en", split='train')
File "/exp/mgordon/nlp/src/nlp/load.py", line 534, in load_dataset
save_infos=save_infos,
File "/exp/mgordon/nlp/src/nlp/builder.py", line 460, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/exp/mgordon/nlp/src/nlp/builder.py", line 870, in _download_and_prepare
"\n\t`{}`".format(usage_example)
nlp.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, S
park, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.en', beam_runner='DirectRunner')`
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/407/timeline | null | completed | null | null | false | [
"Fixed. Could you try again @mitchellgordon95 ?\r\nIt was due a file not being updated on S3.\r\n\r\nWe need to make sure all the datasets scripts get updated properly @julien-c ",
"Works for me! Thanks.",
"I found the same issue with almost any language other than English. (For English, it works). Will someone need to update the file on S3 again?",
"This is because only some languages are already preprocessed (en, de, fr, it) and stored on our google storage.\r\nWe plan to have a systematic way to preprocess more wikipedia languages in the future.\r\n\r\nFor the other languages you have to process them on your side using apache beam. That's why the lib asks for a Beam runner."
] |
https://api.github.com/repos/huggingface/datasets/issues/2271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2271/comments | https://api.github.com/repos/huggingface/datasets/issues/2271/events | https://github.com/huggingface/datasets/issues/2271 | 869,002,141 | MDU6SXNzdWU4NjkwMDIxNDE= | 2,271 | Synchronize table metadata with features | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2021-04-27T15:55:13Z | 2022-06-01T17:13:21Z | 2022-06-01T17:13:21Z | null | **Is your feature request related to a problem? Please describe.**
As pointed out in this [comment](https://github.com/huggingface/datasets/pull/2145#discussion_r621326767):
> Metadata stored in the schema is just a redundant information regarding the feature types.
It is used when calling Dataset.from_file to know which feature types to use.
These metadata are stored in the schema of the pyarrow table by using `update_metadata_with_features`.
However this something that's almost never tested properly.
**Describe the solution you'd like**
We should find a way to always make sure that the metadata (in `self.data.schema.metadata`) are synced with the actual feature types (in `self.info.features`). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2271/timeline | null | completed | null | null | false | [
"See PR #2274 "
] |
https://api.github.com/repos/huggingface/datasets/issues/1300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1300/comments | https://api.github.com/repos/huggingface/datasets/issues/1300/events | https://github.com/huggingface/datasets/pull/1300 | 759,418,122 | MDExOlB1bGxSZXF1ZXN0NTM0NDI3Njk1 | 1,300 | added dutch_social | [] | closed | false | null | 1 | 2020-12-08T12:47:50Z | 2020-12-08T16:09:05Z | 2020-12-08T16:09:05Z | null | WIP
As some tests did not clear! 👎🏼 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1300/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1300",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1300"
} | true | [
"Closing this since a new pull request has been made. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3030 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3030/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3030/comments | https://api.github.com/repos/huggingface/datasets/issues/3030/events | https://github.com/huggingface/datasets/pull/3030 | 1,016,435,324 | PR_kwDODunzps4ss41W | 3,030 | Add `remove_columns` to `IterableDataset` | [] | closed | false | null | 4 | 2021-10-05T14:58:33Z | 2021-10-08T15:33:15Z | 2021-10-08T15:31:53Z | null | Fixes #2944
WIP
* Not tested yet.
* We might want to allow batched remove for efficiency.
@lhoestq Do you think it should have `batched=` and `batch_size=`? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3030/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3030/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3030.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3030",
"merged_at": "2021-10-08T15:31:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3030.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3030"
} | true | [
"Thanks ! That looks all good :)\r\n\r\nI don't think that batching would help. Indeed we're dealing with python iterators that yield elements one by one, so batched `map` needs to accumulate a batch, apply the function, and then yield examples from the batch.\r\n\r\nThough once we have parallel processing in `map`, we can reconsider it\r\n\r\nAlso feel free to check the CI failure - apparently the import of `Union` is missing",
"Thanks for the review and explaining that! \r\nOn top of what you said, I think `remove_columns` is very unlikely to be a bottleneck, so it doesn't matter anyways.",
"Thank you for reviewing! @mariosasko \r\n\r\nI wonder how the checking would work. Is there any checking present in `IterableDataset ` now? What if `.remove_columns()` is applied after some arbitrary `.map()`?",
"> I wonder how the checking would work. Is there any checking present in IterableDataset now? What if .remove_columns() is applied after some arbitrary .map()?\r\n\r\nThat's the challenge here indeed ^^ In this case it's not trivial to know the names of the columns. Feel free to open an issue so we can discuss this"
] |
https://api.github.com/repos/huggingface/datasets/issues/1757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1757/comments | https://api.github.com/repos/huggingface/datasets/issues/1757/events | https://github.com/huggingface/datasets/issues/1757 | 790,466,509 | MDU6SXNzdWU3OTA0NjY1MDk= | 1,757 | FewRel | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 5 | 2021-01-20T23:56:03Z | 2021-03-09T02:52:05Z | 2021-03-08T14:34:52Z | null | ## Adding a Dataset
- **Name:** FewRel
- **Description:** Large-Scale Supervised Few-Shot Relation Classification Dataset
- **Paper:** @inproceedings{han2018fewrel,
title={FewRel:A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation},
author={Han, Xu and Zhu, Hao and Yu, Pengfei and Wang, Ziyun and Yao, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={EMNLP},
year={2018}}
- **Data:** https://github.com/ProKil/FewRel
- **Motivation:** relationship extraction dataset that's been used by some state of the art systems that should be incorporated.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1757/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1757/timeline | null | completed | null | null | false | [
"+1",
"@dspoka Please check the following link : https://github.com/thunlp/FewRel\r\nThis link mentions two versions of the datasets. Also, this one seems to be the official link.\r\n\r\nI am assuming this is the correct link and implementing based on the same.",
"Hi @lhoestq,\r\n\r\nThis issue can be closed, I guess.",
"Yes :) closing\r\nThanks again for adding FewRel !",
"Thanks for adding this @gchhablani ! Sorry didn't see the email notifications sooner!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4764 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4764/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4764/comments | https://api.github.com/repos/huggingface/datasets/issues/4764/events | https://github.com/huggingface/datasets/pull/4764 | 1,321,295,961 | PR_kwDODunzps48RMLu | 4,764 | Update CI badge | [] | closed | false | null | 1 | 2022-07-28T18:04:20Z | 2022-07-29T11:36:37Z | 2022-07-29T11:23:51Z | null | Replace the old CircleCI badge with a new one for GH Actions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4764/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4764/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4764.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4764",
"merged_at": "2022-07-29T11:23:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4764.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4764"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1923/comments | https://api.github.com/repos/huggingface/datasets/issues/1923/events | https://github.com/huggingface/datasets/pull/1923 | 813,363,472 | MDExOlB1bGxSZXF1ZXN0NTc3NTI0MTU0 | 1,923 | Fix save_to_disk with relative path | [] | closed | false | null | 0 | 2021-02-22T10:27:19Z | 2021-02-22T11:22:44Z | 2021-02-22T11:22:43Z | null | As noticed in #1919 and #1920 the target directory was not created using `makedirs` so saving to it raises `FileNotFoundError`. For absolute paths it works but not for the good reason. This is because the target path was the same as the temporary path where in-memory data are written as an intermediary step.
I added the `makedirs` call using `fs.makedirs` in order to support remote filesystems.
I also fixed the issue with the target path being the temporary path.
I added a test case for relative paths as well for save_to_disk.
Thanks to @M-Salti for reporting and investigating | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1923/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1923.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1923",
"merged_at": "2021-02-22T11:22:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1923.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1923"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4255 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4255/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4255/comments | https://api.github.com/repos/huggingface/datasets/issues/4255/events | https://github.com/huggingface/datasets/pull/4255 | 1,221,142,899 | PR_kwDODunzps43FHgR | 4,255 | No google drive URL for pubmed_qa | [] | closed | false | null | 2 | 2022-04-29T15:55:46Z | 2022-04-29T16:24:55Z | 2022-04-29T16:18:56Z | null | I hosted the data files in https://huggingface.co/datasets/pubmed_qa. This is allowed because the data is under the MIT license.
cc @stas00 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4255/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4255/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4255.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4255",
"merged_at": "2022-04-29T16:18:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4255.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4255"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI is failing because some sections are missing in the dataset card, but this is unrelated to this PR - Merging !"
] |
https://api.github.com/repos/huggingface/datasets/issues/1179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1179/comments | https://api.github.com/repos/huggingface/datasets/issues/1179/events | https://github.com/huggingface/datasets/pull/1179 | 757,784,074 | MDExOlB1bGxSZXF1ZXN0NTMzMDk0OTYz | 1,179 | Small update to the doc: add flatten_indices in doc | [] | closed | false | null | 0 | 2020-12-05T21:30:10Z | 2020-12-07T13:42:57Z | 2020-12-07T13:42:56Z | null | Small update to the doc: add flatten_indices in doc | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1179/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1179/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1179.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1179",
"merged_at": "2020-12-07T13:42:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1179.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1179"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5837 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5837/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5837/comments | https://api.github.com/repos/huggingface/datasets/issues/5837/events | https://github.com/huggingface/datasets/issues/5837 | 1,703,019,816 | I_kwDODunzps5lggUo | 5,837 | Use DeepSpeed load myself " .csv " dataset. | [] | open | false | null | 3 | 2023-05-10T02:39:28Z | 2023-05-15T03:51:36Z | null | null | ### Describe the bug
When I use DeepSpeed train a model with my own " XXX.csv" dataset I got the follow question:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py", line 1767, in load_dataset
builder_instance = load_dataset_builder(
File "/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py", line 1498, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py", line 1217, in dataset_module_factory
raise FileNotFoundError(
FileNotFoundError: Couldn't find a dataset script at /home/fm001/hzl/Data/qa.csv/qa.csv.py or any data file in the same directory.
### Steps to reproduce the bug
my code is :
from datasets import load_dataset
mydata = load_dataset("/home/fm001/hzl/Data/qa.csv")
### Expected behavior
。。。
### Environment info
。。。 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5837/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5837/timeline | null | null | null | null | false | [
"Hi ! Doing `load_dataset(\"path/to/data.csv\")` is not supported yet, but you can do\r\n\r\n```python\r\nds = load_dataset(\"csv\", data_files=[\"path/to/data.csv\"])\r\n```",
"@lhoestq thank you.",
"The other question: \r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1767, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1498, in load_dataset_builder\r\n dataset_module = dataset_module_factory(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1127, in dataset_module_factory\r\n return PackagedDatasetModuleFactory(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 708, in get_module\r\n data_files = DataFilesDict.from_local_or_remote(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/data_files.py\", line 796, in from_local_or_remote\r\n DataFilesList.from_local_or_remote(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/data_files.py\", line 764, in from_local_or_remote\r\n data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/data_files.py\", line 362, in resolve_patterns_locally_or_by_urls\r\n for path in _resolve_single_pattern_locally(base_path, pattern, allowed_extensions):\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/data_files.py\", line 306, in _resolve_single_pattern_locally\r\n raise FileNotFoundError(error_msg)\r\nFileNotFoundError: Unable to find '/home/fm001/hzl/Data/qa/' at /\r\n>>> mydata = load_dataset(\"/home/fm001/hzl/Data/qa/\")\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1767, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1508, in load_dataset_builder\r\n builder_cls = import_main_class(dataset_module.module_path)\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 115, in import_main_class\r\n module = importlib.import_module(module_path)\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/importlib/__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 1014, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 991, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 975, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 671, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 783, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"/home/fm001/.cache/huggingface/modules/datasets_modules/datasets/qa/b8b9f481eff9d17b769b4b50f30a51da32b47c94d1af4d2bdffb9fc2c589513a/qa.py\", line 2, in <module>\r\n mydata = load_dataset(\"/home/fm001/hzl/Data/qa/\")\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1767, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/home/fm001/.conda/envs/hzl/lib/python3.8/site-packages/datasets/load.py\", line 1524, in load_dataset_builder\r\n builder_instance: DatasetBuilder = builder_cls(\r\nTypeError: 'NoneType' object is not callable\r\n\r\nAnd I follow the setting with https://huggingface.co/docs/datasets/dataset_script"
] |
https://api.github.com/repos/huggingface/datasets/issues/3832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3832/comments | https://api.github.com/repos/huggingface/datasets/issues/3832/events | https://github.com/huggingface/datasets/issues/3832 | 1,160,503,446 | I_kwDODunzps5FK-CW | 3,832 | Making Hugging Face the place to go for Graph NNs datasets | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "7AFCAA",
"default": false,
"description": "Datasets for Graph Neural Networks",
"id": 3898693527,
"name": "graph",
"node_id": "LA_kwDODunzps7oYVeX",
"url": "https://api.github.com/repos/huggingface/datasets/labels/graph"
}
] | open | false | null | 4 | 2022-03-06T03:02:58Z | 2022-03-14T07:45:38Z | null | null | Let's make Hugging Face Datasets the central hub for GNN datasets :)
**Motivation**. Datasets are currently quite scattered and an open-source central point such as the Hugging Face Hub would be ideal to support the growth of the GNN field.
What are some datasets worth integrating into the Hugging Face hub?
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Special thanks to @napoles-uach for his collaboration on identifying the first ones:
- [ ] [SNAP-Stanford OGB Datasets](https://github.com/snap-stanford/ogb).
- [ ] [SNAP-Stanford Pretrained GNNs Chemistry and Biology Datasets](https://github.com/snap-stanford/pretrain-gnns).
- [ ] [TUDatasets](https://chrsmrrs.github.io/datasets/) (A collection of benchmark datasets for graph classification and regression)
cc @osanseviero
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3832/timeline | null | null | null | null | false | [
"It will be indeed really great to add support to GNN datasets. Big :+1: for this initiative.",
"@napoles-uach identifies the [TUDatasets](https://chrsmrrs.github.io/datasets/) (A collection of benchmark datasets for graph classification and regression). \r\n\r\nAdded to the Tasks in the initial issue.",
"Thanks Omar, that is a great collection!",
"Great initiative! Let's keep this issue for these 3 datasets, but moving forward maybe let's create a new issue per dataset :rocket: great work @napoles-uach and @omarespejel!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4837 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4837/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4837/comments | https://api.github.com/repos/huggingface/datasets/issues/4837/events | https://github.com/huggingface/datasets/pull/4837 | 1,337,079,723 | PR_kwDODunzps49Fb6l | 4,837 | Add support for CSV metadata files to ImageFolder | [] | closed | false | null | 4 | 2022-08-12T11:19:18Z | 2022-08-31T12:01:27Z | 2022-08-31T11:59:07Z | null | Fix #4814 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4837/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4837/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4837.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4837",
"merged_at": "2022-08-31T11:59:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4837.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4837"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Maybe let's include this change after the refactoring from FolderBasedBuilder in #3963 to avoid dealing with too many unpleasant conflicts ?",
"@lhoestq I resolved the conflicts (AudioFolder also supports CSV metadata now). Let me know what you think.\r\n",
"@lhoestq Thanks for the suggestion! Indeed it makes more sense to use CSV as the default format in the folder-based builders."
] |
https://api.github.com/repos/huggingface/datasets/issues/4330 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4330/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4330/comments | https://api.github.com/repos/huggingface/datasets/issues/4330/events | https://github.com/huggingface/datasets/pull/4330 | 1,233,992,681 | PR_kwDODunzps43uIwm | 4,330 | Adding eval metadata to Allociné dataset | [] | closed | false | null | 0 | 2022-05-12T13:31:39Z | 2022-05-12T21:03:05Z | 2022-05-12T21:03:05Z | null | Adding eval metadata to Allociné dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4330/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4330/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4330.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4330",
"merged_at": "2022-05-12T21:03:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4330.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4330"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4314 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4314/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4314/comments | https://api.github.com/repos/huggingface/datasets/issues/4314/events | https://github.com/huggingface/datasets/pull/4314 | 1,232,326,726 | PR_kwDODunzps43oqXD | 4,314 | Catch pull error when mirroring | [] | closed | false | null | 1 | 2022-05-11T09:38:35Z | 2022-05-11T12:54:07Z | 2022-05-11T12:46:42Z | null | Catch pull errors when mirroring so that the script continues to update the other datasets.
The error will still be printed at the end of the job. In this case the job also fails, and asks to manually update the datasets that failed. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4314/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4314/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4314.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4314",
"merged_at": "2022-05-11T12:46:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4314.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4314"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/747/comments | https://api.github.com/repos/huggingface/datasets/issues/747/events | https://github.com/huggingface/datasets/pull/747 | 725,884,704 | MDExOlB1bGxSZXF1ZXN0NTA3MDQ3MDE4 | 747 | Add Quail question answering dataset | [] | closed | false | null | 0 | 2020-10-20T19:33:14Z | 2020-10-21T08:35:15Z | 2020-10-21T08:35:15Z | null | QuAIL is a multi-domain RC dataset featuring news, blogs, fiction and user stories. Each domain is represented by 200 texts, which gives us a 4-way data split. The texts are 300-350 word excerpts from CC-licensed texts that were hand-picked so as to make sense to human readers without larger context. Domain diversity mitigates the issue of possible overlap between training and test data of large pre-trained models, which the current SOTA systems are based on. For instance, BERT is trained on Wikipedia + BookCorpus, and was tested on Wikipedia-based SQuAD (Devlin, Chang, Lee, & Toutanova, 2019).
https://text-machine-lab.github.io/blog/2020/quail/ @annargrs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/747/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/747/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/747.diff",
"html_url": "https://github.com/huggingface/datasets/pull/747",
"merged_at": "2020-10-21T08:35:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/747.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/747"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/184 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/184/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/184/comments | https://api.github.com/repos/huggingface/datasets/issues/184/events | https://github.com/huggingface/datasets/pull/184 | 623,120,929 | MDExOlB1bGxSZXF1ZXN0NDIxODQ5MTQ3 | 184 | Use IndexError instead of ValueError when index out of range | [] | closed | false | null | 0 | 2020-05-22T10:43:42Z | 2020-05-28T08:31:18Z | 2020-05-28T08:31:18Z | null | **`default __iter__ needs IndexError`**.
When I want to create a wrapper of arrow dataset to adapt to fastai,
I don't know how to initialize it, so I didn't use inheritance but use object composition.
I wrote sth like this.
```
clas HF_dataset():
def __init__(self, arrow_dataset):
self.dset = arrow_dataset
def __getitem__(self, i):
return self.my_get_item(self.dset)
```
But `for sample in my_dataset:` gave me `ValueError(f"Index ({key}) outside of table length ({self._data.num_rows}).")` . This is because default `__iter__` will stop when it catched `IndexError`.
You can also see my [work](https://github.com/richardyy1188/Pretrain-MLM-and-finetune-on-GLUE-with-fastai/blob/master/GLUE_with_fastai.ipynb) that uses fastai2 to show/load batches from huggingface/nlp GLUE datasets
So I hope we can use `IndexError` instead to let other people who want to wrap it for any purpose won't be caught by this caveat.
BTW, I super appreciate your work, both transformers and nlp save my life. 💖💖💖💖💖💖💖
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/184/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/184/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/184.diff",
"html_url": "https://github.com/huggingface/datasets/pull/184",
"merged_at": "2020-05-28T08:31:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/184.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/184"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5348/comments | https://api.github.com/repos/huggingface/datasets/issues/5348/events | https://github.com/huggingface/datasets/issues/5348 | 1,486,975,626 | I_kwDODunzps5YoXKK | 5,348 | The data downloaded in the download folder of the cache does not respect `umask` | [] | open | false | null | 1 | 2022-12-09T15:46:27Z | 2022-12-09T17:21:26Z | null | null | ### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is downloaded by giving read and write permissions only to the user launching the command (and no permissions to the group). In our case, those permissions don't respect the `umask` of this user, which was `0007`.
Traceback:
```
Using custom data configuration default
Downloading and preparing dataset text_caps/default to /gpfswork/rech/cnw/commun/datasets/HuggingFaceM4___text_caps/default/1.0.0/2b9ad220cd90fcf2bfb454645bc54364711b83d6d39401ffdaf8cc40882e9141...
Downloading data files: 100%|████████████████████| 3/3 [00:00<00:00, 921.62it/s]
---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
Cell In [3], line 1
----> 1 ds = load_dataset(dataset_name)
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/load.py:1746, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1743 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1745 # Download and prepare data
-> 1746 builder_instance.download_and_prepare(
1747 download_config=download_config,
1748 download_mode=download_mode,
1749 ignore_verifications=ignore_verifications,
1750 try_from_hf_gcs=try_from_hf_gcs,
1751 use_auth_token=use_auth_token,
1752 )
1754 # Build dataset for splits
1755 keep_in_memory = (
1756 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1757 )
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
706 )
707 # Sync info
708 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:1227, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verify_infos)
1226 def _download_and_prepare(self, dl_manager, verify_infos):
-> 1227 super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:771, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
769 split_dict = SplitDict(dataset_name=self.name)
770 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 771 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
773 # Checksums verification
774 if verify_infos and dl_manager.record_checksums:
File /gpfswork/rech/cnw/commun/modules/datasets_modules/datasets/HuggingFaceM4--TextCaps/2b9ad220cd90fcf2bfb454645bc54364711b83d6d39401ffdaf8cc40882e9141/TextCaps.py:125, in TextCapsDataset._split_generators(self, dl_manager)
123 def _split_generators(self, dl_manager):
124 # urls = _URLS[self.config.name] # TODO later
--> 125 data_dir = dl_manager.download_and_extract(_URLS)
126 gen_kwargs = {
127 split_name: {
128 f"{dir_name}_path": Path(data_dir[dir_name][split_name])
(...)
133 for split_name in ["train", "val", "test"]
134 }
136 for split_name in ["train", "val", "test"]:
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:431, in DownloadManager.download_and_extract(self, url_or_urls)
415 def download_and_extract(self, url_or_urls):
416 """Download and extract given url_or_urls.
417
418 Is roughly equivalent to:
(...)
429 extracted_path(s): `str`, extracted paths of given URL(s).
430 """
--> 431 return self.extract(self.download(url_or_urls))
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:324, in DownloadManager.download(self, url_or_urls)
321 self.downloaded_paths.update(dict(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())))
323 start_time = datetime.now()
--> 324 self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
325 duration = datetime.now() - start_time
326 logger.info(f"Checksum Computation took {duration.total_seconds() // 60} min")
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:229, in DownloadManager._record_sizes_checksums(self, url_or_urls, downloaded_path_or_paths)
226 """Record size/checksum of downloaded files."""
227 for url, path in zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten()):
228 # call str to support PathLike objects
--> 229 self._recorded_sizes_checksums[str(url)] = get_size_checksum_dict(
230 path, record_checksum=self.record_checksums
231 )
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/utils/info_utils.py:82, in get_size_checksum_dict(path, record_checksum)
80 if record_checksum:
81 m = sha256()
---> 82 with open(path, "rb") as f:
83 for chunk in iter(lambda: f.read(1 << 20), b""):
84 m.update(chunk)
PermissionError: [Errno 13] Permission denied: '/gpfswork/rech/cnw/commun/datasets/downloads/1e6aa6d23190c30885194fabb193dce3874d902d7636b66315ee8aaa584e80d6'
```
### Steps to reproduce the bug
I think the following will reproduce the bug.
Given 2 users belonging to the same group with `umask` set to `0007`
- first run with User 1:
```python
from datasets import load_dataset
ds_name = "HuggingFaceM4/VQAv2"
ds = load_dataset(ds_name)
```
- then run with User 2:
```python
from datasets import load_dataset
ds_name = "HuggingFaceM4/TextCaps"
ds = load_dataset(ds_name)
```
### Expected behavior
No `PermissionError`
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-4.18.0-305.65.1.el8_4.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 7.0.0
- Pandas version: 1.4.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5348/timeline | null | null | null | null | false | [
"note, that `datasets` already did some of that umask fixing in the past and also at the hub - the recent work on the hub about the same: https://github.com/huggingface/huggingface_hub/pull/1220\r\n\r\nAlso I noticed that each file has a .json counterpart and the latter always has the correct perms:\r\n\r\n```\r\n-rw------- 1 uue59kq cnw 173M Dec 9 01:37 537596e64721e2ae3d98785b91d30fda0360c196a8224e29658ad629e7303a4d\r\n-rw-rw---- 1 uue59kq cnw 101 Dec 9 01:37 537596e64721e2ae3d98785b91d30fda0360c196a8224e29658ad629e7303a4d.json\r\n```\r\n\r\nso perhaps cheating is possible and syncing the perms between the 2 will do the trick."
] |
https://api.github.com/repos/huggingface/datasets/issues/5135 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5135/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5135/comments | https://api.github.com/repos/huggingface/datasets/issues/5135/events | https://github.com/huggingface/datasets/issues/5135 | 1,414,413,519 | I_kwDODunzps5UTjzP | 5,135 | Update docs once dataset scripts transferred to the Hub | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 0 | 2022-10-19T06:58:19Z | 2022-10-20T08:10:01Z | 2022-10-20T08:10:01Z | null | ## Describe the bug
As discussed in:
- https://github.com/huggingface/hub-docs/pull/423#pullrequestreview-1146083701
we should update our docs once dataset scripts have been transferred to the Hub (and removed from GitHub):
- #4974
Concretely:
- [x] Datasets on GitHub (legacy): https://huggingface.co/docs/datasets/main/en/share#datasets-on-github-legacy
- [x] ADD_NEW_DATASET: https://github.com/huggingface/datasets/blob/main/ADD_NEW_DATASET.md
- ...
This PR complements the work of:
- #5067
This PR is a follow-up of PRs:
- #3777
CC: @julien-c | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5135/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5135/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5369/comments | https://api.github.com/repos/huggingface/datasets/issues/5369/events | https://github.com/huggingface/datasets/pull/5369 | 1,500,622,276 | PR_kwDODunzps5Fqaj- | 5,369 | Distributed support | [] | closed | false | null | 11 | 2022-12-16T17:43:47Z | 2023-07-25T12:00:31Z | 2023-01-16T13:33:32Z | null | To split your dataset across your training nodes, you can use the new [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
```
This works for both map-style datasets and iterable datasets.
The dataset is split for the node at rank `rank` in a pool of nodes of size `world_size`.
For map-style datasets:
Each node is assigned a chunk of data, e.g. rank 0 is given the first chunk of the dataset.
For iterable datasets:
If the dataset has a number of shards that is a factor of `world_size` (i.e. if `dataset.n_shards % world_size == 0`),
then the shards are evenly assigned across the nodes, which is the most optimized.
Otherwise, each node keeps 1 example out of `world_size`, skipping the other examples.
This can also be combined with a `torch.utils.data.DataLoader` if you want each node to use multiple workers to load the data.
This also supports shuffling. At each epoch, the iterable dataset shards are reshuffled across all the nodes - you just have to call `iterable_ds.set_epoch(epoch_number)`.
TODO:
- [x] docs for usage in PyTorch
- [x] unit tests
- [x] integration tests with torch.distributed.launch
Related to https://github.com/huggingface/transformers/issues/20770
Close https://github.com/huggingface/datasets/issues/5360 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5369/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5369/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5369.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5369",
"merged_at": "2023-01-16T13:33:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5369.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5369"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright all the tests are passing - this is ready for review",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.015146 / 0.011353 (0.003793) | 0.006683 / 0.011008 (-0.004326) | 0.125994 / 0.038508 (0.087486) | 0.041345 / 0.023109 (0.018235) | 0.378609 / 0.275898 (0.102711) | 0.483139 / 0.323480 (0.159659) | 0.009669 / 0.007986 (0.001684) | 0.005143 / 0.004328 (0.000814) | 0.092015 / 0.004250 (0.087765) | 0.052728 / 0.037052 (0.015676) | 0.397166 / 0.258489 (0.138677) | 0.465820 / 0.293841 (0.171979) | 0.051025 / 0.128546 (-0.077521) | 0.018451 / 0.075646 (-0.057196) | 0.397311 / 0.419271 (-0.021960) | 0.054842 / 0.043533 (0.011309) | 0.391203 / 0.255139 (0.136064) | 0.412743 / 0.283200 (0.129543) | 0.111356 / 0.141683 (-0.030327) | 1.697526 / 1.452155 (0.245372) | 1.795017 / 1.492716 (0.302301) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.253737 / 0.018006 (0.235731) | 0.583071 / 0.000490 (0.582581) | 0.005958 / 0.000200 (0.005758) | 0.000110 / 0.000054 (0.000056) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030397 / 0.037411 (-0.007014) | 0.112242 / 0.014526 (0.097716) | 0.138807 / 0.176557 (-0.037749) | 0.209820 / 0.737135 (-0.527316) | 0.139530 / 0.296338 (-0.156808) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.574111 / 0.215209 (0.358902) | 5.623713 / 2.077655 (3.546058) | 2.416880 / 1.504120 (0.912760) | 1.951013 / 1.541195 (0.409819) | 2.124565 / 1.468490 (0.656075) | 1.268854 / 4.584777 (-3.315923) | 5.942368 / 3.745712 (2.196656) | 5.413814 / 5.269862 (0.143952) | 2.931638 / 4.565676 (-1.634038) | 0.135070 / 0.424275 (-0.289205) | 0.014290 / 0.007607 (0.006683) | 0.708384 / 0.226044 (0.482340) | 7.487994 / 2.268929 (5.219065) | 3.074210 / 55.444624 (-52.370414) | 2.380583 / 6.876477 (-4.495893) | 2.522298 / 2.142072 (0.380226) | 1.336741 / 4.805227 (-3.468486) | 0.236761 / 6.500664 (-6.263903) | 0.076592 / 0.075469 (0.001123) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.629415 / 1.841788 (-0.212373) | 19.000640 / 8.074308 (10.926332) | 21.474058 / 10.191392 (11.282666) | 0.231227 / 0.680424 (-0.449197) | 0.046213 / 0.534201 (-0.487988) | 0.565703 / 0.579283 (-0.013580) | 0.662956 / 0.434364 (0.228592) | 0.656475 / 0.540337 (0.116137) | 0.762534 / 1.386936 (-0.624402) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010952 / 0.011353 (-0.000400) | 0.006259 / 0.011008 (-0.004749) | 0.132430 / 0.038508 (0.093922) | 0.037920 / 0.023109 (0.014811) | 0.483565 / 0.275898 (0.207667) | 0.528190 / 0.323480 (0.204710) | 0.008116 / 0.007986 (0.000130) | 0.006768 / 0.004328 (0.002440) | 0.100520 / 0.004250 (0.096270) | 0.055208 / 0.037052 (0.018155) | 0.484672 / 0.258489 (0.226183) | 0.556937 / 0.293841 (0.263096) | 0.057938 / 0.128546 (-0.070609) | 0.020821 / 0.075646 (-0.054826) | 0.430735 / 0.419271 (0.011464) | 0.066317 / 0.043533 (0.022785) | 0.496652 / 0.255139 (0.241513) | 0.502004 / 0.283200 (0.218804) | 0.125403 / 0.141683 (-0.016280) | 1.833396 / 1.452155 (0.381241) | 1.974517 / 1.492716 (0.481800) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269198 / 0.018006 (0.251191) | 0.620314 / 0.000490 (0.619824) | 0.000535 / 0.000200 (0.000335) | 0.000083 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032373 / 0.037411 (-0.005039) | 0.130043 / 0.014526 (0.115517) | 0.146217 / 0.176557 (-0.030339) | 0.200187 / 0.737135 (-0.536948) | 0.152839 / 0.296338 (-0.143499) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.677478 / 0.215209 (0.462268) | 6.678856 / 2.077655 (4.601201) | 3.025870 / 1.504120 (1.521750) | 2.678196 / 1.541195 (1.137001) | 2.740640 / 1.468490 (1.272150) | 1.237163 / 4.584777 (-3.347614) | 5.752621 / 3.745712 (2.006908) | 3.170435 / 5.269862 (-2.099427) | 2.049174 / 4.565676 (-2.516502) | 0.147663 / 0.424275 (-0.276612) | 0.016107 / 0.007607 (0.008500) | 0.849666 / 0.226044 (0.623621) | 8.395212 / 2.268929 (6.126283) | 3.741120 / 55.444624 (-51.703505) | 3.102926 / 6.876477 (-3.773550) | 3.233655 / 2.142072 (1.091583) | 1.520349 / 4.805227 (-3.284878) | 0.267159 / 6.500664 (-6.233505) | 0.083646 / 0.075469 (0.008177) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.640458 / 1.841788 (-0.201330) | 19.043169 / 8.074308 (10.968861) | 22.786126 / 10.191392 (12.594734) | 0.218040 / 0.680424 (-0.462384) | 0.032948 / 0.534201 (-0.501253) | 0.569574 / 0.579283 (-0.009710) | 0.658746 / 0.434364 (0.224382) | 0.650501 / 0.540337 (0.110164) | 0.730588 / 1.386936 (-0.656348) |\n\n</details>\n</details>\n\n\n",
"just added a note :)",
"Hi @lhoestq ,\r\nCan you please throw some light on the following statement\r\n`If the dataset has a number of shards that is a factor of world_size (i.e. if dataset.n_shards % world_size == 0), then the shards are evenly assigned across the nodes, which is the most optimized. Otherwise, each node keeps 1 example out of world_size, skipping the other examples.`\r\n\r\nLet's assume I have 127 parquet files and world_size is 4. I was not able to fully comprehend the above statement\r\nWhat does this statement mean?\r\n`each node keeps 1 example out of world_size, skipping the other examples.`\r\nThank you!",
"If you have 128 parquet files, then `dataset.n_shards % world_size == 0`. In this case each worker can take care of 32 parquet files.\r\n\r\nOn the other hand if you have `dataset.n_shards % world_size != 0` (in your case 127 files), then we can't assign the same number of files to each worker. This is an issue because it may under-utilize your GPU at the end of your training since some workers will take longer to iterate on the dataset than others.\r\n\r\nTherefore in this case, all the workers take care of the 127 parquet files but workers will skip examples to not end up with duplicates. That's what \"each node keeps 1 example out of world_size, skipping the other examples\" means, and in your case it implies:\r\n- rank=0 will read the samples with idx=0, 4, 8 etc.\r\n- rank=1 will read the samples with idx=1, 5, 9 etc.\r\n- rank=2 will read the samples with idx=2, 6, 10 etc.\r\n- rank=3 will read the samples with idx=3, 7, 11 etc.",
"Thanks a lot @lhoestq , this helps!",
"Hi, in the case above, if we use `keep_in_memory=True` for `Dataset`, then we still need to read in n times the dataset if we use DDP on n GPUs (1 node), right? That means we need n times the memory. Is there any way to only load the data once, to save memory?",
"`Dataset` objects are memory mapped from disk so they use almost no RAM (only the current batch)\r\n\r\nAlso they are perfectly sharded using `split_dataset_by_node` so it's going to be read exactly once in total using DDP.\r\nYou can also achieve the same thing using a DistributedSampler in pytorch for DDP instead of using `split_dataset_by_node`.",
"Hi, please correct if I mistake anything: \r\n1. `Dataset` with `keep_in_memory=True` would explicitly pre-load the data into memory, instead of reading from disk via the memory map for every batch. The former way should be faster than the latter.\r\n2. When using DDP, before sending the `Dataset` object into `split_dataset_by_node` or incorporate it with `DistributedSampler`, every process still needs to pre-load the entire data into memory (when `keep_in_memory=True`) and then select the chunked indices from the loaded data. \r\n\r\nGenerally, the dilemma I'm facing is:\r\nSuppose we have a data around 120GB, and we want to use `DistributedLengthGroupedSampler` to optimize batching. When using DDP and `keep_in_memory=True`, every process loads 120GB which is not acceptable. For now, I turned off `keep_in_memory` and try to increase the number of workers for `DataLoader` to get better pipelining. \r\n\r\n**But is it possible to load 120GB once into 4 * A100 (which has around 4*120GB memory) and make each process read from this shared data from memory? Theoretically, maybe it should be faster?** ",
"Feel free to ask your questions on the [forum](https://discuss.huggingface.co/c/datasets/10) if you don't mind, this way the discussions may be useful to other people ;) "
] |
https://api.github.com/repos/huggingface/datasets/issues/3551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3551/comments | https://api.github.com/repos/huggingface/datasets/issues/3551/events | https://github.com/huggingface/datasets/pull/3551 | 1,096,561,111 | PR_kwDODunzps4wq_AO | 3,551 | Add more compression types for `to_json` | [] | closed | false | null | 8 | 2022-01-07T18:25:02Z | 2022-07-10T14:36:55Z | 2022-02-21T15:58:15Z | null | This PR adds `bz2`, `xz`, and `zip` (WIP) for `to_json`. I also plan to add `infer` like how `pandas` does it | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3551/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3551/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3551",
"merged_at": "2022-02-21T15:58:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3551"
} | true | [
"@lhoestq, I looked into how to compress with `zipfile` for which few methods exist, let me know which one looks good:\r\n1. create the file in normal `wb` mode and then zip it separately\r\n2. use `ZipFile.write_str` to write file into the archive. For this we'll need to change how we're writing files from `_write` method \r\n\r\nHow `pandas` handles it is that they have created a wrapper for standard library class `ZipFile` and allow the returned file-like handle to accept byte strings via `write` method instead of `write_str` (purpose was to change the name of function by creating that wrapper)",
"1. sounds not ideal since it creates an intermediary file.\r\nI like pandas' approach. Is it possible to implement 2. using the pandas class ? Or maybe we can have something similar ?",
"Definitely, @lhoestq! I've adapted that from original code and turns out it is faster than `gz` compression. Apart from that I've also added `infer` option to automatically infer compression type from `path_or_buf` given",
"One small thing, currently I'm assuming that user will provide compression extension in `path_or_buf`. Is it this also possible?\r\n`dataset.to_json(\"from_dataset.json\", compression=\"zip\")`? \r\nShould I put an `assert` to ensure the file name provided always has a compression extension?",
"Thanks !\r\n\r\n> One small thing, currently I'm assuming that user will provide compression extension in path_or_buf. Is it this also possible?\r\n>dataset.to_json(\"from_dataset.json\", compression=\"zip\")?\r\n>Should I put an assert to ensure the file name provided always has a compression extension?\r\n\r\nI think it's fine as it is right now :) No need to check the extension of the filename passed to `path_or_buf`.\r\n",
"> turns out it is faster than gz compression\r\n\r\nI think the default compression level of `gzip` is 9 in python, which is very slow. Maybe we can switch to compression level 6 instead which is faster, like the `gzip` command on unix",
"I found that `fsspec` has something that may interest you: [fsspec.open(..., compression=...)](https://filesystem-spec.readthedocs.io/en/latest/api.html#fsspec.open). I don't remember if we've already mentioned it or not\r\n\r\nIt also has `zip` if I understand correctly ! see https://github.com/fsspec/filesystem_spec/blob/master/fsspec/compression.py#L70\r\n\r\nSince `fsspec` is a dependency of `datasets` we can use all this :)\r\n\r\nLet me know if you prefer using `fsspec` instead (I haven't tested this yet to write compressed files). IMO it sounds pretty easy to use and it would make the code base simpler",
"Just tried `fsspec` but I'm not able to write compressed `zip` files :/\r\n`gzip`, `xz`, `bz2` are all working fine and it's really simple (no need for `FileWriteHandler` now!)"
] |
https://api.github.com/repos/huggingface/datasets/issues/498 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/498/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/498/comments | https://api.github.com/repos/huggingface/datasets/issues/498/events | https://github.com/huggingface/datasets/pull/498 | 677,597,479 | MDExOlB1bGxSZXF1ZXN0NDY2Njg5NTcy | 498 | dont use beam fs to save info for local cache dir | [] | closed | false | null | 0 | 2020-08-12T11:00:00Z | 2020-08-14T13:17:21Z | 2020-08-14T13:17:20Z | null | If the cache dir is local, then we shouldn't use beam's filesystem to save the dataset info
Fix #490
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/498/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/498/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/498.diff",
"html_url": "https://github.com/huggingface/datasets/pull/498",
"merged_at": "2020-08-14T13:17:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/498.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/498"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/13 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/13/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/13/comments | https://api.github.com/repos/huggingface/datasets/issues/13/events | https://github.com/huggingface/datasets/pull/13 | 604,547,951 | MDExOlB1bGxSZXF1ZXN0NDA3MTIxMjkw | 13 | [Make style] | [] | closed | false | null | 3 | 2020-04-22T08:10:06Z | 2022-10-04T09:31:51Z | 2020-04-23T13:02:22Z | null | Added Makefile and applied make style to all.
make style runs the following code:
```
style:
black --line-length 119 --target-version py35 src
isort --recursive src
```
It's the same code that is run in `transformers`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/13/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/13/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/13.diff",
"html_url": "https://github.com/huggingface/datasets/pull/13",
"merged_at": "2020-04-23T13:02:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/13.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/13"
} | true | [
"I think this can be quickly reproduced. \r\nI use `black, version 19.10b0`. \r\n\r\nWhen running: \r\n`black nlp/src/arrow_reader.py` \r\nit gives me: \r\n\r\n```\r\nerror: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST error message: invalid syntax (<unknown>, line 78)\r\nOh no! 💥 💔 💥\r\n1 file failed to reformat.\r\n```\r\n\r\nThe line in question is: \r\nhttps://github.com/huggingface/nlp/blob/6922a16705e61f9e31a365f2606090b84d49241f/src/nlp/arrow_reader.py#L78\r\n\r\nWhat is weird is that the trainer file in `transformers` has more or less the same syntax and black does not fail there: \r\nhttps://github.com/huggingface/transformers/blob/cb3c2212c79d7ff0a4a4e84c3db48371ecc1c15d/src/transformers/trainer.py#L95\r\n\r\nI googled quite a bit about black & typing hints yesterday and didn't find anything useful. \r\nAny ideas @thomwolf @julien-c @LysandreJik ?",
"> I think this can be quickly reproduced.\r\n> I use `black, version 19.10b0`.\r\n> \r\n> When running:\r\n> `black nlp/src/arrow_reader.py`\r\n> it gives me:\r\n> \r\n> ```\r\n> error: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST error message: invalid syntax (<unknown>, line 78)\r\n> Oh no! 💥 💔 💥\r\n> 1 file failed to reformat.\r\n> ```\r\n> \r\n> The line in question is:\r\n> https://github.com/huggingface/nlp/blob/6922a16705e61f9e31a365f2606090b84d49241f/src/nlp/arrow_reader.py#L78\r\n> \r\n> What is weird is that the trainer file in `transformers` has more or less the same syntax and black does not fail there:\r\n> https://github.com/huggingface/transformers/blob/cb3c2212c79d7ff0a4a4e84c3db48371ecc1c15d/src/transformers/trainer.py#L95\r\n> \r\n> I googled quite a bit about black & typing hints yesterday and didn't find anything useful.\r\n> Any ideas @thomwolf @julien-c @LysandreJik ?\r\n\r\nOk I found the problem. It was the one Julien mentioned and has nothing to do with this line. Black's error message is a bit misleading here, I guess",
"Ok, just had to remove the python 2 syntax comments `# type`. \r\n\r\nGood to merge for me now @thomwolf "
] |
https://api.github.com/repos/huggingface/datasets/issues/5285 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5285/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5285/comments | https://api.github.com/repos/huggingface/datasets/issues/5285/events | https://github.com/huggingface/datasets/pull/5285 | 1,461,521,215 | PR_kwDODunzps5DjLgG | 5,285 | Save file name in embed_storage | [] | closed | false | null | 2 | 2022-11-23T10:55:54Z | 2022-11-24T14:11:41Z | 2022-11-24T14:08:37Z | null | Having the file name is useful in case we need to check the extension of the file (e.g. mp3), or in general in case it includes some metadata information (track id, image id etc.)
Related to https://github.com/huggingface/datasets/issues/5276 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5285/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5285/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5285.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5285",
"merged_at": "2022-11-24T14:08:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5285.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5285"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I updated the tests, met le know if it sounds good to you now :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3954/comments | https://api.github.com/repos/huggingface/datasets/issues/3954/events | https://github.com/huggingface/datasets/issues/3954 | 1,172,141,664 | I_kwDODunzps5F3XZg | 3,954 | The dataset preview is not available for tdklab/Hebrew_Squad_v1.1 dataset | [] | closed | false | null | 6 | 2022-03-17T09:38:11Z | 2022-04-20T12:39:07Z | 2022-04-20T12:39:07Z | null | ## Dataset viewer issue for 'tdklab/Hebrew_Squad_v1.1'
**Link:** https://huggingface.co/api/datasets/tdklab/Hebrew_Squad_v1.1?full=true
The dataset preview is not available for this dataset.
Am I the one who added this dataset ? Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3954/timeline | null | completed | null | null | false | [
"Hi @MatanBenChorin, thanks for reporting.\r\n\r\nPlease, take into account that the preview may take some time until it properly renders (we are working to reduce this time).\r\n\r\nMaybe @severo can give more details on this.",
"Hi, \r\nThank you",
"Thanks for reporting. We are looking at it and will give updates here.",
"I imagine the dataset has been moved to https://huggingface.co/datasets/tdklab/Hebrew_Squad_v1, which still has an issue:\r\n\r\n```\r\nServer Error\r\n\r\nStatus code: 400\r\nException: NameError\r\nMessage: name 'HebrewSquad' is not defined\r\n```",
"The issue is not related to the dataset viewer but to the loading script (cc @albertvillanova @lhoestq @mariosasko)\r\n\r\n```python\r\n>>> import datasets as ds\r\n>>> hf_token = \"hf_...\" # <- required because the dataset is gated\r\n>>> d = ds.load_dataset('tdklab/Hebrew_Squad_v1', use_auth_token=hf_token)\r\n...\r\nNameError: name 'HebrewSquad' is not defined\r\n```",
"Yes indeed there is an error in [Hebrew_Squad_v1.py:L40](https://huggingface.co/datasets/tdklab/Hebrew_Squad_v1/blob/main/Hebrew_Squad_v1.py#L40)\r\n\r\nHere is the fix @MatanBenChorin :\r\n\r\n```diff\r\n- HebrewSquad(\r\n+ HebrewSquadConfig(\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/6085 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6085/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6085/comments | https://api.github.com/repos/huggingface/datasets/issues/6085/events | https://github.com/huggingface/datasets/pull/6085 | 1,824,985,188 | PR_kwDODunzps5WlAyA | 6,085 | Fix `fsspec` download | [] | open | false | null | 3 | 2023-07-27T18:54:47Z | 2023-07-27T19:06:13Z | null | null | Testing `ds = load_dataset("audiofolder", data_files="s3://datasets.huggingface.co/SpeechCommands/v0.01/v0.01_test.tar.gz", storage_options={"anon": True})` and trying to fix the issues raised by `fsspec` ...
TODO: fix
```
self.session = aiobotocore.session.AioSession(**self.kwargs)
TypeError: __init__() got an unexpected keyword argument 'hf'
```
by "preparing `storage_options`" for the `fsspec` head/get | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6085/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6085/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/6085.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6085",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6085.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6085"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006031 / 0.011353 (-0.005322) | 0.003579 / 0.011008 (-0.007429) | 0.080862 / 0.038508 (0.042354) | 0.056660 / 0.023109 (0.033551) | 0.388285 / 0.275898 (0.112387) | 0.422270 / 0.323480 (0.098790) | 0.004651 / 0.007986 (-0.003335) | 0.002895 / 0.004328 (-0.001433) | 0.062767 / 0.004250 (0.058517) | 0.046491 / 0.037052 (0.009438) | 0.389918 / 0.258489 (0.131428) | 0.434650 / 0.293841 (0.140809) | 0.027265 / 0.128546 (-0.101281) | 0.007946 / 0.075646 (-0.067701) | 0.261207 / 0.419271 (-0.158065) | 0.045057 / 0.043533 (0.001525) | 0.391977 / 0.255139 (0.136838) | 0.418525 / 0.283200 (0.135326) | 0.020705 / 0.141683 (-0.120978) | 1.459271 / 1.452155 (0.007116) | 1.516935 / 1.492716 (0.024218) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.174659 / 0.018006 (0.156653) | 0.429627 / 0.000490 (0.429137) | 0.003714 / 0.000200 (0.003514) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023255 / 0.037411 (-0.014156) | 0.073463 / 0.014526 (0.058937) | 0.083000 / 0.176557 (-0.093557) | 0.146704 / 0.737135 (-0.590431) | 0.084419 / 0.296338 (-0.211919) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.392222 / 0.215209 (0.177013) | 3.902620 / 2.077655 (1.824966) | 1.903056 / 1.504120 (0.398936) | 1.753423 / 1.541195 (0.212228) | 1.874547 / 1.468490 (0.406057) | 0.495947 / 4.584777 (-4.088829) | 3.084680 / 3.745712 (-0.661032) | 4.235064 / 5.269862 (-1.034797) | 2.626840 / 4.565676 (-1.938837) | 0.057273 / 0.424275 (-0.367002) | 0.006457 / 0.007607 (-0.001150) | 0.466018 / 0.226044 (0.239974) | 4.648264 / 2.268929 (2.379335) | 2.520293 / 55.444624 (-52.924331) | 2.339393 / 6.876477 (-4.537083) | 2.538848 / 2.142072 (0.396775) | 0.592018 / 4.805227 (-4.213210) | 0.125041 / 6.500664 (-6.375623) | 0.061038 / 0.075469 (-0.014431) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244285 / 1.841788 (-0.597503) | 18.411576 / 8.074308 (10.337268) | 13.850100 / 10.191392 (3.658708) | 0.131904 / 0.680424 (-0.548520) | 0.016824 / 0.534201 (-0.517377) | 0.328931 / 0.579283 (-0.250352) | 0.364801 / 0.434364 (-0.069563) | 0.376298 / 0.540337 (-0.164039) | 0.525045 / 1.386936 (-0.861891) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006059 / 0.011353 (-0.005294) | 0.003693 / 0.011008 (-0.007315) | 0.062982 / 0.038508 (0.024473) | 0.062155 / 0.023109 (0.039046) | 0.389467 / 0.275898 (0.113568) | 0.437046 / 0.323480 (0.113566) | 0.004823 / 0.007986 (-0.003163) | 0.002935 / 0.004328 (-0.001393) | 0.062679 / 0.004250 (0.058429) | 0.049676 / 0.037052 (0.012623) | 0.418054 / 0.258489 (0.159565) | 0.442467 / 0.293841 (0.148626) | 0.027652 / 0.128546 (-0.100895) | 0.008146 / 0.075646 (-0.067501) | 0.069414 / 0.419271 (-0.349858) | 0.042884 / 0.043533 (-0.000649) | 0.387167 / 0.255139 (0.132028) | 0.418684 / 0.283200 (0.135484) | 0.022419 / 0.141683 (-0.119264) | 1.460606 / 1.452155 (0.008451) | 1.514204 / 1.492716 (0.021487) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200523 / 0.018006 (0.182517) | 0.415970 / 0.000490 (0.415481) | 0.003202 / 0.000200 (0.003002) | 0.000069 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025836 / 0.037411 (-0.011575) | 0.078859 / 0.014526 (0.064333) | 0.088523 / 0.176557 (-0.088034) | 0.141572 / 0.737135 (-0.595563) | 0.090258 / 0.296338 (-0.206080) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.416548 / 0.215209 (0.201339) | 4.155278 / 2.077655 (2.077623) | 2.126683 / 1.504120 (0.622563) | 1.963762 / 1.541195 (0.422568) | 2.029018 / 1.468490 (0.560528) | 0.499005 / 4.584777 (-4.085772) | 3.063503 / 3.745712 (-0.682209) | 4.250800 / 5.269862 (-1.019061) | 2.642634 / 4.565676 (-1.923043) | 0.057815 / 0.424275 (-0.366460) | 0.006784 / 0.007607 (-0.000823) | 0.492481 / 0.226044 (0.266437) | 4.914306 / 2.268929 (2.645377) | 2.601582 / 55.444624 (-52.843042) | 2.337863 / 6.876477 (-4.538614) | 2.462854 / 2.142072 (0.320782) | 0.593738 / 4.805227 (-4.211489) | 0.127030 / 6.500664 (-6.373634) | 0.064206 / 0.075469 (-0.011263) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.326919 / 1.841788 (-0.514868) | 18.728929 / 8.074308 (10.654621) | 13.903681 / 10.191392 (3.712289) | 0.162670 / 0.680424 (-0.517754) | 0.016913 / 0.534201 (-0.517288) | 0.337504 / 0.579283 (-0.241779) | 0.339786 / 0.434364 (-0.094577) | 0.384955 / 0.540337 (-0.155383) | 0.514358 / 1.386936 (-0.872578) |\n\n</details>\n</details>\n\n\n",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6085). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007610 / 0.011353 (-0.003743) | 0.004616 / 0.011008 (-0.006392) | 0.100330 / 0.038508 (0.061821) | 0.084450 / 0.023109 (0.061341) | 0.386610 / 0.275898 (0.110712) | 0.418479 / 0.323480 (0.094999) | 0.006085 / 0.007986 (-0.001900) | 0.003800 / 0.004328 (-0.000529) | 0.076248 / 0.004250 (0.071997) | 0.065175 / 0.037052 (0.028122) | 0.387154 / 0.258489 (0.128665) | 0.425484 / 0.293841 (0.131643) | 0.035946 / 0.128546 (-0.092601) | 0.009901 / 0.075646 (-0.065745) | 0.343015 / 0.419271 (-0.076256) | 0.060965 / 0.043533 (0.017432) | 0.390585 / 0.255139 (0.135446) | 0.405873 / 0.283200 (0.122673) | 0.026929 / 0.141683 (-0.114754) | 1.767916 / 1.452155 (0.315761) | 1.893431 / 1.492716 (0.400715) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237888 / 0.018006 (0.219882) | 0.503949 / 0.000490 (0.503459) | 0.004769 / 0.000200 (0.004570) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031553 / 0.037411 (-0.005859) | 0.096950 / 0.014526 (0.082424) | 0.110374 / 0.176557 (-0.066183) | 0.176754 / 0.737135 (-0.560381) | 0.111703 / 0.296338 (-0.184635) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.449232 / 0.215209 (0.234023) | 4.510247 / 2.077655 (2.432592) | 2.188547 / 1.504120 (0.684427) | 2.007530 / 1.541195 (0.466335) | 2.095650 / 1.468490 (0.627160) | 0.563262 / 4.584777 (-4.021515) | 4.062412 / 3.745712 (0.316700) | 6.338350 / 5.269862 (1.068489) | 3.844669 / 4.565676 (-0.721008) | 0.064517 / 0.424275 (-0.359758) | 0.008536 / 0.007607 (0.000929) | 0.553872 / 0.226044 (0.327828) | 5.530311 / 2.268929 (3.261383) | 2.835109 / 55.444624 (-52.609516) | 2.493900 / 6.876477 (-4.382577) | 2.728412 / 2.142072 (0.586340) | 0.680161 / 4.805227 (-4.125066) | 0.155831 / 6.500664 (-6.344833) | 0.070359 / 0.075469 (-0.005110) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.504852 / 1.841788 (-0.336936) | 22.806335 / 8.074308 (14.732027) | 16.598386 / 10.191392 (6.406994) | 0.207857 / 0.680424 (-0.472566) | 0.021425 / 0.534201 (-0.512776) | 0.474069 / 0.579283 (-0.105214) | 0.472263 / 0.434364 (0.037899) | 0.542195 / 0.540337 (0.001858) | 0.782871 / 1.386936 (-0.604065) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007443 / 0.011353 (-0.003910) | 0.004465 / 0.011008 (-0.006544) | 0.076268 / 0.038508 (0.037759) | 0.086607 / 0.023109 (0.063498) | 0.443295 / 0.275898 (0.167397) | 0.472819 / 0.323480 (0.149339) | 0.005841 / 0.007986 (-0.002144) | 0.003727 / 0.004328 (-0.000602) | 0.076015 / 0.004250 (0.071765) | 0.063188 / 0.037052 (0.026136) | 0.450555 / 0.258489 (0.192066) | 0.478532 / 0.293841 (0.184691) | 0.036258 / 0.128546 (-0.092288) | 0.009869 / 0.075646 (-0.065777) | 0.083786 / 0.419271 (-0.335486) | 0.056546 / 0.043533 (0.013013) | 0.449647 / 0.255139 (0.194508) | 0.457588 / 0.283200 (0.174389) | 0.027197 / 0.141683 (-0.114486) | 1.769991 / 1.452155 (0.317836) | 1.859905 / 1.492716 (0.367189) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268637 / 0.018006 (0.250631) | 0.492860 / 0.000490 (0.492370) | 0.008574 / 0.000200 (0.008374) | 0.000140 / 0.000054 (0.000085) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037679 / 0.037411 (0.000268) | 0.108258 / 0.014526 (0.093733) | 0.117850 / 0.176557 (-0.058707) | 0.181611 / 0.737135 (-0.555524) | 0.120901 / 0.296338 (-0.175437) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.485780 / 0.215209 (0.270571) | 4.851289 / 2.077655 (2.773635) | 2.486068 / 1.504120 (0.981948) | 2.299417 / 1.541195 (0.758222) | 2.387093 / 1.468490 (0.918603) | 0.568826 / 4.584777 (-4.015951) | 4.163426 / 3.745712 (0.417713) | 6.224964 / 5.269862 (0.955102) | 3.255619 / 4.565676 (-1.310058) | 0.067081 / 0.424275 (-0.357194) | 0.009065 / 0.007607 (0.001458) | 0.580449 / 0.226044 (0.354405) | 5.786394 / 2.268929 (3.517465) | 3.057780 / 55.444624 (-52.386844) | 2.764339 / 6.876477 (-4.112138) | 2.880718 / 2.142072 (0.738645) | 0.681376 / 4.805227 (-4.123851) | 0.157858 / 6.500664 (-6.342806) | 0.072481 / 0.075469 (-0.002988) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.590704 / 1.841788 (-0.251083) | 23.141929 / 8.074308 (15.067620) | 17.001141 / 10.191392 (6.809749) | 0.203790 / 0.680424 (-0.476634) | 0.021766 / 0.534201 (-0.512435) | 0.475309 / 0.579283 (-0.103974) | 0.466448 / 0.434364 (0.032084) | 0.551470 / 0.540337 (0.011132) | 0.727876 / 1.386936 (-0.659060) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2615/comments | https://api.github.com/repos/huggingface/datasets/issues/2615/events | https://github.com/huggingface/datasets/issues/2615 | 940,794,339 | MDU6SXNzdWU5NDA3OTQzMzk= | 2,615 | Jsonlines export error | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 10 | 2021-07-09T14:02:05Z | 2021-07-09T15:29:07Z | 2021-07-09T15:28:33Z | null | ## Describe the bug
When exporting large datasets in jsonlines (c4 in my case) the created file has an error every 9999 lines: the 9999th and 10000th are concatenated, thus breaking the jsonlines format. This sounds like it is related to batching, which is by 10000 by default
## Steps to reproduce the bug
This what I'm running:
in python:
```
from datasets import load_dataset
ptb = load_dataset("ptb_text_only")
ptb["train"].to_json("ptb.jsonl")
```
then out of python:
```
head -10000 ptb.jsonl
```
## Expected results
Properly separated lines
## Actual results
The last line is a concatenation of two lines
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.1.dev0
- Platform: Linux-5.4.0-1046-gcp-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyArrow version: 4.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2615/timeline | null | completed | null | null | false | [
"Thanks for reporting @TevenLeScao! I'm having a look...",
"(not sure what just happened on the assignations sorry)",
"For some reason this happens (both `datasets` version are on master) only on Python 3.6 and not Python 3.8.",
"@TevenLeScao we are using `pandas` to serialize the dataset to JSON Lines. So it must be due to pandas. Could you please check the pandas version causing the issue?",
"@TevenLeScao I have just checked it: this was a bug in `pandas` and it was fixed in version 1.2: https://github.com/pandas-dev/pandas/pull/36898",
"Thanks ! I'm creating a PR",
"Well I though it was me who has taken on this issue... 😅 ",
"Sorry, I was also talking to teven offline so I already had the PR ready before noticing x)",
"I was also already working in my PR... Nevermind. Next time we should pay attention if there is somebody (self-)assigned to an issue and if he/she is still working on it before overtaking it... 😄 ",
"The fix is available on `master` @TevenLeScao , thanks for reporting"
] |
https://api.github.com/repos/huggingface/datasets/issues/4975 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4975/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4975/comments | https://api.github.com/repos/huggingface/datasets/issues/4975/events | https://github.com/huggingface/datasets/pull/4975 | 1,371,703,691 | PR_kwDODunzps4-4NXX | 4,975 | Add `fn_kwargs` param to `IterableDataset.map` | [] | closed | false | null | 4 | 2022-09-13T16:19:05Z | 2023-05-05T16:53:43Z | 2022-09-13T16:45:34Z | null | Add the `fn_kwargs` parameter to `IterableDataset.map`.
("Resolves" https://discuss.huggingface.co/t/how-to-use-large-image-text-datasets-in-hugging-face-hub-without-downloading-for-free/22780/3) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4975/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4975/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4975.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4975",
"merged_at": "2022-09-13T16:45:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4975.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4975"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thank you for adding this fix! \r\n\r\nWould it be possible to get `fn_kwargs` added to `IterableDatasetDict.map` as well? It looks like a very similar problem, and hopefully shouldn't be a huge change. \r\n",
"Hi @brianhill11! https://github.com/huggingface/datasets/pull/5810 adds this (opened a couple of days ago). It should be merged soon.",
"That's fantastic news, thanks @mariosasko ! I'll give it a shot once the changes are merged in. "
] |
https://api.github.com/repos/huggingface/datasets/issues/4308 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4308/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4308/comments | https://api.github.com/repos/huggingface/datasets/issues/4308/events | https://github.com/huggingface/datasets/pull/4308 | 1,231,217,783 | PR_kwDODunzps43lHdP | 4,308 | Remove unused multiprocessing args from test CLI | [] | closed | false | null | 1 | 2022-05-10T14:02:15Z | 2022-05-11T12:58:25Z | 2022-05-11T12:50:43Z | null | Multiprocessing is not used in the test CLI. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4308/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4308/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4308.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4308",
"merged_at": "2022-05-11T12:50:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4308.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4308"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/481 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/481/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/481/comments | https://api.github.com/repos/huggingface/datasets/issues/481/events | https://github.com/huggingface/datasets/pull/481 | 674,567,389 | MDExOlB1bGxSZXF1ZXN0NDY0MjM2MTA1 | 481 | Apply utf-8 encoding to all datasets | [] | closed | false | null | 6 | 2020-08-06T20:02:09Z | 2020-08-20T08:16:08Z | 2020-08-20T08:16:08Z | null | ## Description
This PR applies utf-8 encoding for all instances of `with open(...) as f` to all Python files in `datasets/`. As suggested by @thomwolf in #468 , we use regular expressions and the following function
```python
def apply_encoding_on_file_open(filepath: str):
"""Apply UTF-8 encoding for all instances where a non-binary file is opened."""
with open(filepath, 'r', encoding='utf-8') as input_file:
regexp = re.compile(r"(?!.*\b(?:encoding|rb|w|wb|w+|wb+|ab|ab+)\b)(?<=\s)(open)\((.*)\)")
input_text = input_file.read()
match = regexp.search(input_text)
if match:
output = regexp.sub(lambda m: m.group()[:-1]+', encoding="utf-8")', input_text)
with open(filepath, 'w', encoding='utf-8') as output_file:
output_file.write(output)
```
to perform the replacement.
Note:
1. I excluded all _**binary files**_ from the search since it's possible some objects are opened for which the encoding doesn't make sense. Please correct me if I'm wrong and I'll tweak the regexp accordingly
2. There were two edge cases where the regexp failed (e.g. two `open` instances on a single line), but I decided to just fix these manually in the interest of time.
3. I only applied the replacement to files in `datasets/`. Let me know if this should be extended to other places like `metrics/`
4. I have implemented a unit test that should catch missing encodings in future CI runs
Closes #468 and possibly #347 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/481/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/481/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/481.diff",
"html_url": "https://github.com/huggingface/datasets/pull/481",
"merged_at": "2020-08-20T08:16:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/481.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/481"
} | true | [
"Not sure why the AWS test is failing - perhaps I made too many concurrent CI builds 😢. Can someone please rerun the CI to check the error is not on my end?",
"I pushed an improved docstring and the unit tests now pass, which suggests the previous failure on AWS was simply a timeout error. \r\n\r\nFor some reason the docs are now failing to build, but does not seem related to my changes:\r\n```\r\nWarning, treated as error:\r\n/home/circleci/nlp/src/nlp/dataset_dict.py:docstring of nlp.DatasetDict.filter:27:Inline interpreted text or phrase reference start-string without end-string.\r\nmake: *** [Makefile:20: html] Error 2\r\n```\r\n\r\nAny ideas what's going wrong?",
"The build_doc fail has been fixed on master.\r\nIt was due to the latest update of sphinx that has some issues, so I pinned the previous version for now.",
"I noticed that you also changed the Apache Beam `open` to also use utf-8. However it doesn't have an `encoding` parameter.\r\nTherefore you should ignore lines like\r\n\r\n```python\r\nbeam.io.filesystems.FileSystems.open(filepath)\r\n```\r\n\r\nI guess you could add a rule to your regex to only include the `open` call that have a space right before it.",
"Good catch @lhoestq! Your suggestion to match on `open(...)` with a whitespace was a great idea - it allowed me to simplify the regexp considerably 😄.\r\n\r\nI fixed the Apache Beam false positives and also caught a few problems in `json.load()`, e.g.\r\n```python\r\nrelation_name_map = json.load(open(rel_info), encoding='utf-8')\r\n```\r\n\r\nI've tested that the new regexp doesn't reintroduce these false positives, so I think the PR is ready for another review.",
"Ok to merge this @lhoestq ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/3195 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3195/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3195/comments | https://api.github.com/repos/huggingface/datasets/issues/3195/events | https://github.com/huggingface/datasets/pull/3195 | 1,042,204,044 | PR_kwDODunzps4t-ZR0 | 3,195 | More robust `None` handling | [] | closed | false | null | 5 | 2021-11-02T11:15:10Z | 2021-12-09T14:27:00Z | 2021-12-09T14:26:58Z | null | PyArrow has explicit support for `null` values, so it makes sense to support Nones on our side as well.
[Colab Notebook with examples](https://colab.research.google.com/drive/1zcK8BnZYnRe3Ao2271u1T19ag9zLEiy3?usp=sharing)
Changes:
* allow None for the features types with special encoding (`ClassLabel, TranslationVariableLanguages, Value, _ArrayXD`)
* handle None in `class_encode_column` (also there is an option to stringify Nones and treat them as a class)
* support None sorting in `sort` (use pandas for that)
* handle None in align_labels_with_mapping
* support for None in ArrayXD (converts `None` to `np.nan` to align the behavior with PyArrow)
* support for None in the Audio/Image feature
* allow promotion when concatenating tables (`pa.concat_tables(table_list, promote=True)`) and `null` row/~~column~~ broadcasting similar to pandas
Additional notes:
* use `null` instead of `none` for function arguments for consistency with existing `disable_nullable`
* fixes a bug with the `update_metadata_with_features` call in `Dataset.rename_columns`
* had to update some tests, let me know if that's ok
TODO:
- [x] check how the Audio features behaves with Nones
- [x] Better None handling in `concatenate_datasets`/`add_item`
- [x] Fix formatting with Nones
- [x] Add Colab with examples
- [x] Tests
TODOs for subsequent PRs:
- Mention None handling in the docs
- Add `drop_null`/`fill_null` to `Dataset`/`DatasetDict`
Fix #3181 #3253 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3195/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3195/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3195.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3195",
"merged_at": "2021-12-09T14:26:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3195.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3195"
} | true | [
"I also created a PR regarding `disable_nullable` that must be always `False` by default, in order to always allow None values\r\nhttps://github.com/huggingface/datasets/pull/3211",
"@lhoestq I addressed your comments, added tests, did some refactoring to make the implementation cleaner and added support for `None` values in `map` transforms when the feature type is `ArrayXD` (previously, I only implemented `None` decoding).\r\n\r\nMy only concern is that during decoding `ArrayXD` arrays with `None` values will be auto-casted to `float64` to allow `np.nan` insertion and this might be unexpected if `dtype` is not `float`, so one option would be to allow `None` values only if the storage type is `float32` or `float64`. Let me know WDYT would be the most consistent behavior here.",
"Cool ! :D\r\n> My only concern is that during decoding ArrayXD arrays with None values will be auto-casted to float64 to allow np.nan insertion and this might be unexpected if dtype is not float, so one option would be to allow None values only if the storage type is float32 or float64. Let me know WDYT would be the most consistent behavior here.\r\n\r\nYes that makes sense to only fill with nan if the type is compatible",
"After some more experimenting, I think we can keep auto-cast to float because PyArrow also does it:\r\n```python\r\nimport pyarrow as pa\r\narr = pa.array([1, 2, 3, 4, None], type=pa.int32()).to_numpy(zero_copy_only=False) # None present - int32 -> float64\r\nassert arr.dtype == np.float64\r\n```\r\nAdditional changes:\r\n* fixes a bug in the `_is_zero_copy_only` implementation for the ArraXD types. Previously, `_is_zero_copy_only` would always return False for these types. Still have to see if it's possible to optimize copying of the non-extension types (`Sequence`, ...), but I plan to work on that in a separate PR.\r\n* https://github.com/huggingface/datasets/pull/2891 introduced a bug where the dtype of `ArrayXD` wouldn't be preserved due to `to_pylist` call in NumPy Formatter (`np.array(np.array(..).tolist())` doesn't necessarily preserve dtype of the initial array), so I'm also fixing that. ",
"The CI fail for windows is unrelated to this PR, merging"
] |
https://api.github.com/repos/huggingface/datasets/issues/5021 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5021/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5021/comments | https://api.github.com/repos/huggingface/datasets/issues/5021/events | https://github.com/huggingface/datasets/issues/5021 | 1,385,351,250 | I_kwDODunzps5SkshS | 5,021 | Split is inferred from filename and overrides metadata.jsonl | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | 3 | 2022-09-26T03:22:14Z | 2022-09-29T08:07:50Z | 2022-09-29T08:07:50Z | null | ## Describe the bug
Including the strings "test" or "train" anywhere in a filename causes `datasets` to infer the split and silently ignore all other files.
This behavior is documented for directory names but not filenames: https://huggingface.co/docs/datasets/image_dataset#imagefolder
## Steps to reproduce the bug
`metadata.jsonl`
```json
{"file_name": "photo of a cat.jpg", "text": "a photo of a cat"}
{"file_name": "photo of a dog.jpg", "text": "a photo of a dog"}
{"file_name": "photo of a train.jpg", "text": "a photo of a train"}
{"file_name": "photo of test tubes.jpg", "text": "a photo of test tubes"}
```
`bug.py`
```python
from datasets import load_dataset
dataset = load_dataset("dataset")
print(dataset)
# DatasetDict({
# train: Dataset({
# features: ['image', 'text'],
# num_rows: 1
# })
# test: Dataset({
# features: ['image', 'text'],
# num_rows: 1
# })
# })
for split in dataset:
for n in dataset[split]:
print(n['text'])
# a photo of a train
# a photo of test tubes
```
## Expected results
One single dataset with all four images / a warning for unused files / documentation of this behavior
## Actual results
Only the images with "test" or "train" in the name are loaded
## Environment info
- `datasets` version: 2.5.1
- Platform: macOS-12.5.1-x86_64-i386-64bit
- Python version: 3.10.4
- PyArrow version: 9.0.0
- Pandas version: 1.5.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5021/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5021/timeline | null | completed | null | null | false | [
"Hi! What's the structure of your image folder? `datasets` by default tries to infer to what split each file belongs based on directory/file names. If it's OK to load all the images inside the `dataset` folder in the `train` split, you can do the following:\r\n```python\r\ndataset = load_dataset(\"imagefolder\", data_files=\"dataset/**\")\r\n```",
"Thanks! Specifying `data_files` worked for that case.\r\n\r\nI'm new to the library, so let me try rephrasing the issue. If there's no actual bug here, sorry for the trouble.\r\n\r\nI've uploaded an example [here](https://files.catbox.moe/nfj2pd.zip) with the following files: \r\n\r\n```\r\n.\r\n├── bug.py\r\n└── imagefolder\r\n ├── test\r\n │ ├── metadata.jsonl\r\n │ ├── dog.jpg\r\n │ └── personal trainer.jpg\r\n └── train\r\n ├── metadata.jsonl\r\n ├── cat.jpg\r\n └── testing center.jpg\r\n```\r\n\r\n`bug.py`\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"imagefolder\")\r\n\r\nprint(dataset)\r\n# DatasetDict({\r\n# test: Dataset({\r\n# features: ['image', 'text'],\r\n# num_rows: 1\r\n# })\r\n# })\r\n\r\nfor split in dataset:\r\n print(\"Split:\", split)\r\n for n in dataset[split]:\r\n print(n['text'])\r\n\r\n\r\n# Split: test\r\n# testing center\r\n```\r\n\r\nAs far as I can tell, this conforms with the example given here: https://huggingface.co/docs/datasets/image_dataset#imagefolder. It appears to me that, even though `metadata.jsonl` is present, the inferred labels from the path are taking precedent. Does this sound like a bug/undocumented behavior?",
"This looks like a duplicate of https://github.com/huggingface/datasets/issues/4895 (the problem is explained in this comment: https://github.com/huggingface/datasets/issues/4895#issuecomment-1248269550).\r\n\r\nIn the meantime, you can do the following to fetch all the splits:\r\n```python\r\ndataset = load_dataset(\"imagefolder\", data_files={\"train\": \"imagefolder/train/**\", \"test\": \"imagefolder/test/**\"})\r\n```\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1062 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1062/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1062/comments | https://api.github.com/repos/huggingface/datasets/issues/1062/events | https://github.com/huggingface/datasets/pull/1062 | 756,373,187 | MDExOlB1bGxSZXF1ZXN0NTMxOTI4NDY5 | 1,062 | Add KorNLU dataset | [] | closed | false | null | 1 | 2020-12-03T16:52:39Z | 2020-12-04T11:05:19Z | 2020-12-04T11:05:19Z | null | Added Korean NLU datasets. The link to the dataset can be found [here](https://github.com/kakaobrain/KorNLUDatasets) and the paper can be found [here](https://arxiv.org/abs/2004.03289)
**Note**: The MNLI tsv file is broken, so this code currently excludes the file. Please suggest other alternative if any @lhoestq
- [x] Followed the instructions in CONTRIBUTING.md
- [x] Ran the tests successfully
- [x] Created the dummy data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1062/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1062/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1062.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1062",
"merged_at": "2020-12-04T11:05:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1062.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1062"
} | true | [
"Nice thank you !\r\nCan you regenerate the dataset_infos.json file ? Since we changed the features we must update it\r\n\r\nThen I think we'll be good to merge :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/6049 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6049/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6049/comments | https://api.github.com/repos/huggingface/datasets/issues/6049/events | https://github.com/huggingface/datasets/pull/6049 | 1,810,378,706 | PR_kwDODunzps5Vz1pd | 6,049 | Update `ruff` version in pre-commit config | [] | open | false | null | 1 | 2023-07-18T17:13:50Z | 2023-07-20T12:09:16Z | null | null | so that it corresponds to the one that is being run in CI | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6049/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6049/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6049.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6049",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6049.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6049"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6049). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/3963 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3963/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3963/comments | https://api.github.com/repos/huggingface/datasets/issues/3963/events | https://github.com/huggingface/datasets/pull/3963 | 1,173,492,562 | PR_kwDODunzps40puyZ | 3,963 | Add Audio Folder | [] | closed | false | null | 14 | 2022-03-18T11:40:09Z | 2022-06-15T16:33:19Z | 2022-06-15T16:33:19Z | null | Would resolve #3964
AudioFolder loads a .txt file with transcriptions and creates a dataset with all audiofiles in provided directory that has a transcription (independently of the directory structure) as a single split (train).
Can be loaded via:
```python
# for local dirs
dataset = load_dataset("audiofolder", data_dir="/path/to/folder", transcripts_filename="transcripts.txt")
```
```python
# for local and remote zip archives
dataset = load_dataset("audiofolder", data_files="path/to/archive/archive.zip", transcripts_filename="transcripts.txt")
```
default transcriptions filename is `transcripts.txt`. it should have the following structure:
```
audio_id_1 transcription text 1
audio_id_1 transcription text 1
```
separator is `\t`!
---
sorry for first old commits from other branch, don't know how that happened... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3963/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3963/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/3963.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3963",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3963.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3963"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3963). All of your documentation changes will be reflected on that endpoint.",
"Feel free to merge `master` into this branch to fix the CI errors related to Google Drive :)\r\n\r\nI think we can just remove the test that is based on dummy data, or make it have the `sampling_rate` parameter hardcoded in the test",
"IMO it's important to keep this loader aligned with `imagefolder`. I'm aware that the current `imagefolder` API is limiting because only labels can be inferred from the directory structure, which means it can only be used for classification and self-supervised pretraining. However, to make the loader more generic, we plan to support [metadata files](https://huggingface.slack.com/archives/C02JB9L6JKF/p1645450017434029?thread_ts=1645157416.389499&cid=C02JB9L6JKF) (will work on that this week), and in the audio case, these files can store transcripts.\r\n\r\nStreaming TAR archives (`iter_archive`) is not supported by any of the loaders currently, so we can add that in a separate PR for all of them (to keep this PR simple).\r\n\r\nWDYT?",
"> Streaming TAR archives (iter_archive) is not supported by any of the loaders currently, so we can add that in a separate PR for all of them (to keep this PR simple).\r\n\r\nYes definitely, we can see that later\r\n\r\n> to make the loader more generic, we plan to support [metadata files](https://huggingface.slack.com/archives/C02JB9L6JKF/p1645450017434029?thread_ts=1645157416.389499&cid=C02JB9L6JKF) (will work on that this week), and in the audio case, these files can store transcripts.\r\n\r\nCould you share an example of what the structure would look like in this case ?\r\n\r\nNote that for audio we ultimately should be able to load several splits at once (common voice, librispeech, etc. all have splits), unlike the current imagefolder implementation that puts everything in `train` (EDIT: I mean, when we pass `data_dir`). If we want consistency then we would need the same for imagefolder.",
"> I think we can just remove the test that is based on dummy data, or make it have the sampling_rate parameter hardcoded in the test\r\n\r\nNot sure what to do with `test_builder_class` and `test_load_dataset_offline`, I don't really want to drop these tests completely but do you think it's a good idea to hardcode builder loading like this: 🤔\r\n```\r\nif dataset_name == \"audiofolder\":\r\n builder = builder_cls(name=name, cache_dir=tmp_cache_dir, sampling_rate=16_000)\r\nelse:\r\n builder = builder_cls(name=name, cache_dir=tmp_cache_dir)\r\n```\r\n@mariosasko totally agree on that APIs should be aligned, do you think we should implement metadata support first? Or maybe we can merge this PR with explicit single transcript file and add full metadata support further.\r\n\r\nSplits support is definitely a required feature too, I think we can implement it in the future PR too. \r\n",
"btw i've found a workaround for splits generation :D\r\n\r\n```\r\nfrom datasets.data_files import DataFilesDict\r\n\r\nds = load_dataset(\r\n \"audiofolder\",\r\n data_files=DataFilesDict(\r\n {\r\n \"train\":\"../audiofolder/AudioTestSplits/train.zip\",\r\n \"test\": \"../audiofolder/AudioTestSplits/test.zip\"\r\n }\r\n ),\r\n sampling_rate=16_000\r\n)\r\n```",
"> Not sure what to do with test_builder_class and test_load_dataset_offline, I don't really want to drop these tests completely but do you think it's a good idea to hardcode builder loading like this: 🤔\r\n\r\nYes it's fine. If you you're not a fan of having such parameters directly at the core of the code you can declare a global variable `PACKAGED_MODULES_TEST_KWARGS = {\"audiofolder\": {\"sampling_rate\": 16_000}}` and do\r\n```python\r\nbuilder_kwargs = PACKAGED_MODULES_TEST_KWARGS.get(name, {})\r\nbuilder = builder_cls(name=name, cache_dir=tmp_cache_dir, **builder_kwargs)\r\n```\r\n\r\n> btw i've found a workaround for splits generation :D\r\n\r\nYes that works :) Note that you don't have to use `DataFilesDict` and you can pass a python dict directly (`DataFilesDict` is for internal usage only)",
"@lhoestq @mariosasko please take a look at the code and feel free to add your comments and discuss the potential issues\r\n \r\nafter we are satisfied with the code, I'll write the documentation ",
"@lhoestq it appeared that this PR already exists... https://github.com/huggingface/datasets/pull/3364",
"> The current problem with this loader is that it supports the ASR task by default, which could be surprising for the users thinking that this is the Image Folder counterpart for audio. To avoid this, we should support the audio classification task by default instead (we can add a template for it in this PR), where the label column is inferred from the directory structure.\r\n\r\nRight indeed, good catch. It's better to keep polishing the API rather than pushing fast something that can be confusing for users. Let's go for maximum alignment between the two then @polinaeterna ?",
"@mariosasko sorry, I didn't understand from your previous message that by aligning with the ImageFolder you mean inferring labels from directories names. Sure, that's not a problem, I can add the corresponding code. Do you also mean that in this version we should get rid of transcription file and feature and add it in the future when the metadata support https://github.com/huggingface/datasets/pull/4069 will be merged? \r\nMy understanding was that support for ASR task is more crucial than audio classification as it's more \"common\", but I would ask @anton-l and @patrickvonplaten about this. Anyway, it's not a problem to implement the classification task first, and the ASR one later. ",
"> Do you also mean that in this version we should get rid of transcription file and feature and add it in the future when the metadata support https://github.com/huggingface/datasets/pull/4069 will be merged?\r\n\r\nWe can wait for the linked PR to be merged first and then add the changes to this PR to have support for ASR from the get-go.",
"Don't follow 100% here, but as @polinaeterna said I think ASR is much more common than audio classification. Also, do you guys think a lot of users will use both the audio and image folder functionality ? Is it very important to have audio and image aligned here? Note that in Transformers while all models follow a common API, audio and vision models can be very different with respect to pre- and post-processing",
"> I think ASR is much more common than audio classification\r\n\r\nI agree, the main focus is ASR\r\n\r\n> do you guys think a lot of users will use both the audio and image folder functionality ?\r\n\r\nYup I think so, people don't just use public academic datasets right ? `imagefolder` is almost used 1k times a week, and it's just the beginning.\r\n\r\n> Is it very important to have audio and image aligned here?\r\n\r\nIf we can get some consistency for free, let's take it ^^ This way it will be easy for users to go from one modality to another, and documentation will be simpler.\r\n\r\n> Note that in Transformers while all models follow a common API, audio and vision models can be very different with respect to pre- and post-processing\r\n\r\nThat make total sense. Here this is mainly about raw data loading (before preprocessing) so we just need to make something generic, no matter what task the data is used for. Even though actually we know that ASR will be the main usage for now :p\r\n\r\nLet me know if it's clearer now or if you have other questions !"
] |
https://api.github.com/repos/huggingface/datasets/issues/2198 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2198/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2198/comments | https://api.github.com/repos/huggingface/datasets/issues/2198/events | https://github.com/huggingface/datasets/pull/2198 | 854,357,481 | MDExOlB1bGxSZXF1ZXN0NjEyMzE0MTIz | 2,198 | added file_permission in load_dataset | [] | closed | false | null | 1 | 2021-04-09T09:39:06Z | 2021-04-16T14:11:46Z | 2021-04-16T14:11:46Z | null | As discussed in #2065 I've added `file_permission` argument in `load_dataset`.
Added mainly 2 things here:
1) Permission of downloaded datasets when converted to .arrow files can be changed with argument `file_permission` argument in `load_dataset` (default is 0o644 only)
2) Incase the user uses `map` later on to generate another cache file of dataset, it ensures the permissions of newly generated file are similar to that of` *-train.arrow` file inside cache_dir for that dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2198/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2198/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2198.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2198",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2198.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2198"
} | true | [
"From offline discussions: we want to make the permissions handling consistent with `transformers`. However from discussion in https://github.com/huggingface/transformers/pull/11119 it looks like it might not be a good solution to provide this argument. Users should use umask for now, and we'll see how things evolve.\r\n\r\n@bhavitvyamalik I'm closing the PR for now if you don't mind"
] |
https://api.github.com/repos/huggingface/datasets/issues/3326 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3326/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3326/comments | https://api.github.com/repos/huggingface/datasets/issues/3326/events | https://github.com/huggingface/datasets/pull/3326 | 1,064,664,479 | PR_kwDODunzps4vEaYG | 3,326 | Fix import `datasets` on python 3.10 | [] | closed | false | null | 0 | 2021-11-26T16:10:00Z | 2021-11-26T16:31:23Z | 2021-11-26T16:31:23Z | null | In python 3.10 it's no longer possible to use `functools.wraps` on a method decorated with `classmethod`.
To fix this I inverted the order of the `inject_arrow_table_documentation` and `classmethod` decorators
Fix #3324 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3326/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3326/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3326.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3326",
"merged_at": "2021-11-26T16:31:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3326.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3326"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1165 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1165/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1165/comments | https://api.github.com/repos/huggingface/datasets/issues/1165/events | https://github.com/huggingface/datasets/pull/1165 | 757,720,226 | MDExOlB1bGxSZXF1ZXN0NTMzMDQ0NzEy | 1,165 | Add ar rest reviews | [] | closed | false | null | 8 | 2020-12-05T16:56:42Z | 2020-12-21T17:06:23Z | 2020-12-21T17:06:23Z | null | added restaurants reviews in Arabic for sentiment analysis tasks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1165/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1165/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1165.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1165",
"merged_at": "2020-12-21T17:06:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1165.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1165"
} | true | [
"Copy-pasted from the Slack discussion:\r\nthe annotation and language creators should be found , not unknown\r\nthe example should go under the \"Data Instances\" paragraph, not \"Data fields\"\r\ncan you remove the abstract from the citation and add it to the dataset description? More people will see that",
"@yjernite done! thanks for the feedback",
"@lhoestq not sure why it's failing tests now, I only changed cosmetics",
"You can ignores these errors\r\n```\r\n\r\n=========================== short test summary info ===========================\r\nFAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_ajgt_twitter_ar\r\nFAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_chr_en\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_ajgt_twitter_ar\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_chr_en\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_great_code\r\n```\r\n\r\nthey're fixed on master",
"Feel free to ping me for the final review once you managed to change to ClassLabel :) ",
"Hey @lhoestq I was able to fix it !! I think the same errors appeared on circleCI and now it's hopefully ready to be merged?",
"@lhoestq done! thanks for your review ",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/2169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2169/comments | https://api.github.com/repos/huggingface/datasets/issues/2169/events | https://github.com/huggingface/datasets/pull/2169 | 850,456,180 | MDExOlB1bGxSZXF1ZXN0NjA5MDI2ODUz | 2,169 | Updated WER metric implementation to avoid memory issues | [] | closed | false | null | 1 | 2021-04-05T15:43:20Z | 2021-04-06T15:02:58Z | 2021-04-06T15:02:58Z | null | This is in order to fix this issue:
https://github.com/huggingface/datasets/issues/2078
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2169/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2169.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2169",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2169.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2169"
} | true | [
"Hi ! Thanks for suggesting this fix \r\nUnfortunately it looks like it's already been fixed by #2111 \r\n\r\nFeel free to share your thoughts about this PR !\r\n\r\nI'm closing this one if you don't mind."
] |
https://api.github.com/repos/huggingface/datasets/issues/859 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/859/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/859/comments | https://api.github.com/repos/huggingface/datasets/issues/859/events | https://github.com/huggingface/datasets/pull/859 | 743,917,091 | MDExOlB1bGxSZXF1ZXN0NTIxNzI4MDM4 | 859 | Integrate file_lock inside the lib for better logging control | [] | closed | false | null | 0 | 2020-11-16T15:13:39Z | 2020-11-16T17:06:44Z | 2020-11-16T17:06:42Z | null | Previously the locking system of the lib was based on the file_lock package. However as noticed in #812 there were too many logs printed even when the datasets logging was set to warnings or errors.
For example
```python
import logging
logging.basicConfig(level=logging.INFO)
import datasets
datasets.set_verbosity_warning()
datasets.load_dataset("squad")
```
would still log the file lock events:
```
INFO:filelock:Lock 5737989232 acquired on /Users/quentinlhoest/.cache/huggingface/datasets/44801f118d500eff6114bfc56ab4e6def941f1eb14b70ac1ecc052e15cdac49d.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py.lock
INFO:filelock:Lock 5737989232 released on /Users/quentinlhoest/.cache/huggingface/datasets/44801f118d500eff6114bfc56ab4e6def941f1eb14b70ac1ecc052e15cdac49d.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py.lock
INFO:filelock:Lock 4393489968 acquired on /Users/quentinlhoest/.cache/huggingface/datasets/_Users_quentinlhoest_.cache_huggingface_datasets_squad_plain_text_1.0.0_1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41.lock
INFO:filelock:Lock 4393489968 released on /Users/quentinlhoest/.cache/huggingface/datasets/_Users_quentinlhoest_.cache_huggingface_datasets_squad_plain_text_1.0.0_1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41.lock
INFO:filelock:Lock 4393490808 acquired on /Users/quentinlhoest/.cache/huggingface/datasets/_Users_quentinlhoest_.cache_huggingface_datasets_squad_plain_text_1.0.0_1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41.lock
Reusing dataset squad (/Users/quentinlhoest/.cache/huggingface/datasets/squad/plain_text/1.0.0/1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41)
INFO:filelock:Lock 4393490808 released on /Users/quentinlhoest/.cache/huggingface/datasets/_Users_quentinlhoest_.cache_huggingface_datasets_squad_plain_text_1.0.0_1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41.lock
```
With the integration of file_lock in the library, the ouput is much cleaner:
```
Reusing dataset squad (/Users/quentinlhoest/.cache/huggingface/datasets/squad/plain_text/1.0.0/1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41)
```
Since the file_lock package is only a 450 lines file I think it's fine to have it inside the lib.
Fix #812 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/859/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/859/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/859.diff",
"html_url": "https://github.com/huggingface/datasets/pull/859",
"merged_at": "2020-11-16T17:06:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/859.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/859"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/201 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/201/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/201/comments | https://api.github.com/repos/huggingface/datasets/issues/201/events | https://github.com/huggingface/datasets/pull/201 | 625,235,430 | MDExOlB1bGxSZXF1ZXN0NDIzNDkzNTMw | 201 | Fix typo in README | [] | closed | false | null | 2 | 2020-05-26T22:18:21Z | 2020-05-26T23:40:31Z | 2020-05-26T23:00:56Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/201/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/201/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/201.diff",
"html_url": "https://github.com/huggingface/datasets/pull/201",
"merged_at": "2020-05-26T23:00:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/201.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/201"
} | true | [
"Amazing, @LysandreJik!",
"Really did my best!"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/2446 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2446/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2446/comments | https://api.github.com/repos/huggingface/datasets/issues/2446/events | https://github.com/huggingface/datasets/issues/2446 | 911,635,399 | MDU6SXNzdWU5MTE2MzUzOTk= | 2,446 | `yelp_polarity` is broken | [] | closed | false | null | 2 | 2021-06-04T15:44:29Z | 2021-06-04T18:56:47Z | 2021-06-04T18:56:47Z | null | 
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2446/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2446/timeline | null | completed | null | null | false | [
"```\r\nFile \"/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/streamlit/script_runner.py\", line 332, in _run_script\r\n exec(code, module.__dict__)\r\nFile \"/home/sasha/nlp-viewer/run.py\", line 233, in <module>\r\n configs = get_confs(option)\r\nFile \"/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/streamlit/caching.py\", line 604, in wrapped_func\r\n return get_or_create_cached_value()\r\nFile \"/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/streamlit/caching.py\", line 588, in get_or_create_cached_value\r\n return_value = func(*args, **kwargs)\r\nFile \"/home/sasha/nlp-viewer/run.py\", line 148, in get_confs\r\n builder_cls = nlp.load.import_main_class(module_path[0], dataset=True)\r\nFile \"/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/datasets/load.py\", line 85, in import_main_class\r\n module = importlib.import_module(module_path)\r\nFile \"/usr/lib/python3.7/importlib/__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _gcd_import\r\nFile \"<frozen importlib._bootstrap>\", line 983, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 967, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 677, in _load_unlocked\r\nFile \"<frozen importlib._bootstrap_external>\", line 728, in exec_module\r\nFile \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\nFile \"/home/sasha/.cache/huggingface/modules/datasets_modules/datasets/yelp_polarity/a770787b2526bdcbfc29ac2d9beb8e820fbc15a03afd3ebc4fb9d8529de57544/yelp_polarity.py\", line 36, in <module>\r\n from datasets.tasks import TextClassification\r\n```",
"Solved by updating the `nlpviewer`"
] |
https://api.github.com/repos/huggingface/datasets/issues/491 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/491/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/491/comments | https://api.github.com/repos/huggingface/datasets/issues/491/events | https://github.com/huggingface/datasets/issues/491 | 676,486,275 | MDU6SXNzdWU2NzY0ODYyNzU= | 491 | No 0.4.0 release on GitHub | [] | closed | false | null | 2 | 2020-08-10T23:59:57Z | 2020-08-11T16:50:07Z | 2020-08-11T16:50:07Z | null | 0.4.0 was released on PyPi, but not on GitHub. This means [the documentation](https://huggingface.co/nlp/) is still displaying from 0.3.0, and that there's no tag to easily clone the 0.4.0 version of the repo. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/491/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/491/timeline | null | completed | null | null | false | [
"I did the release on github, and updated the doc :)\r\nSorry for the delay",
"Thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/170 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/170/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/170/comments | https://api.github.com/repos/huggingface/datasets/issues/170/events | https://github.com/huggingface/datasets/pull/170 | 621,119,747 | MDExOlB1bGxSZXF1ZXN0NDIwMjMwMDIx | 170 | Rename anli dataset | [] | closed | false | null | 0 | 2020-05-19T16:26:57Z | 2020-05-20T12:23:09Z | 2020-05-20T12:23:08Z | null | What we have now as the `anli` dataset is actually the αNLI dataset from the ART challenge dataset. This name is confusing because `anli` is also the name of adversarial NLI (see [https://github.com/facebookresearch/anli](https://github.com/facebookresearch/anli)).
I renamed the current `anli` dataset by `art`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/170/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/170/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/170.diff",
"html_url": "https://github.com/huggingface/datasets/pull/170",
"merged_at": "2020-05-20T12:23:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/170.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/170"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3928/comments | https://api.github.com/repos/huggingface/datasets/issues/3928/events | https://github.com/huggingface/datasets/issues/3928 | 1,170,017,132 | I_kwDODunzps5FvQts | 3,928 | Frugal score deprecations | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-03-15T18:10:42Z | 2022-03-17T08:37:24Z | 2022-03-17T08:37:24Z | null | ## Describe the bug
The frugal score returns a really verbose output with warnings that can be easily changed.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets.load import load_metric
frugal = load_metric("frugalscore")
frugal.compute(predictions=["Do you like spinachis"], references=["Do you like spinach"])
```
## Expected results
A clear and concise description of the expected results.
```
{'scores': [0.9946]}
```
## Actual results
Specify the actual results or traceback.
```
PyTorch: setting up devices
The default value for the training argument `--report_to` will change in v5 (from all installed integrations to none). In v5, you will need to use `--report_to all` to get the same behavior as now. You should start updating your code and make this info disappear :-).
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 864.09ba/s]
Using amp half precision backend
The following columns in the test set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence2, sentence1. If sentence2, sentence1 are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message.
***** Running Prediction *****
Num examples = 1
Batch size = 64
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4644.85it/s]
{'scores': [0.9946]}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Linux-5.13.0-30-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 7.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3928/timeline | null | completed | null | null | false | [
"Hi @Ierezell, thanks for reporting.\r\n\r\nI'm making a PR to suppress those logs from the terminal. "
] |
https://api.github.com/repos/huggingface/datasets/issues/1341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1341/comments | https://api.github.com/repos/huggingface/datasets/issues/1341/events | https://github.com/huggingface/datasets/pull/1341 | 759,784,557 | MDExOlB1bGxSZXF1ZXN0NTM0NzI3MzU5 | 1,341 | added references to only data card creator to all guides | [] | closed | false | null | 0 | 2020-12-08T21:11:11Z | 2020-12-08T21:36:12Z | 2020-12-08T21:36:11Z | null | We can now use the wonderful online form for dataset cards created by @evrardts | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1341/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1341",
"merged_at": "2020-12-08T21:36:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1341"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/320 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/320/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/320/comments | https://api.github.com/repos/huggingface/datasets/issues/320/events | https://github.com/huggingface/datasets/issues/320 | 647,188,167 | MDU6SXNzdWU2NDcxODgxNjc= | 320 | Blog Authorship Corpus, Non Matching Splits Sizes Error, nlp viewer | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 2 | 2020-06-29T07:36:35Z | 2020-06-29T14:44:42Z | 2020-06-29T14:44:42Z | null | Selecting `blog_authorship_corpus` in the nlp viewer throws the following error:
```
NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='train', num_bytes=614706451, num_examples=535568, dataset_name='blog_authorship_corpus')}, {'expected': SplitInfo(name='validation', num_bytes=37500394, num_examples=31277, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='validation', num_bytes=32553710, num_examples=28521, dataset_name='blog_authorship_corpus')}]
Traceback:
File "/home/sasha/streamlit/lib/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp-viewer/run.py", line 172, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/streamlit/lib/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/streamlit/lib/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp-viewer/run.py", line 132, in get
builder_instance.download_and_prepare()
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/builder.py", line 432, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/builder.py", line 488, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/utils/info_utils.py", line 70, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
```
@srush @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/320/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/320/timeline | null | completed | null | null | false | [
"I wonder if this means downloading failed? That corpus has a really slow server.",
"This dataset seems to have a decoding problem that results in inconsistencies in the number of generated examples.\r\nSee #215.\r\nThat's why we end up with a `NonMatchingSplitsSizesError `."
] |
https://api.github.com/repos/huggingface/datasets/issues/3145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3145/comments | https://api.github.com/repos/huggingface/datasets/issues/3145/events | https://github.com/huggingface/datasets/issues/3145 | 1,033,580,009 | I_kwDODunzps49my3p | 3,145 | [when Image type will exist] provide a way to get the data as binary + filename | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 4 | 2021-10-22T13:23:49Z | 2021-12-22T11:05:37Z | 2021-12-22T11:05:36Z | null | **Is your feature request related to a problem? Please describe.**
When a dataset cell contains a value of type Image (be it from a remote URL, an Array2D/3D, or any other way to represent images), I want to be able to write the image to the disk, with the correct filename, and optionally to know its mimetype, in order to serve it on the web.
Note: this issue would apply exactly the same for the `Audio` type.
**Describe the solution you'd like**
If a "cell" has the type `Image`, provide a way to get the binary content of the file, and the filename, eg as:
```python
filename: str
data: bytes
```
**Describe alternatives you've considered**
A way to write the cell to the disk (passing a local directory), and then return the pathname, filename, and mimetype.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3145/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3145/timeline | null | completed | null | null | false | [
"@severo, maybe somehow related to this PR ?\r\n- #3129",
"@severo I'll keep that in mind.\r\n\r\nYou can track progress on the Image feature in #3163 (still in the early stage). ",
"Hi ! As discussed with @severo offline it looks like the dataset viewer already supports reading PIL images, so maybe the dataset viewer doesn't need to disable decoding after all",
"Fixed with https://github.com/huggingface/datasets/pull/3163"
] |
https://api.github.com/repos/huggingface/datasets/issues/3464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3464/comments | https://api.github.com/repos/huggingface/datasets/issues/3464/events | https://github.com/huggingface/datasets/issues/3464 | 1,085,399,097 | I_kwDODunzps5AseA5 | 3,464 | struct.error: 'i' format requires -2147483648 <= number <= 2147483647 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 2 | 2021-12-21T03:29:01Z | 2022-11-21T19:55:11Z | null | null | ## Describe the bug
A clear and concise description of what the bug is.
using latest datasets=datasets-1.16.1-py3-none-any.whl
process my own multilingual dataset by following codes, and the number of rows in all dataset is 306000, the max_length of each sentence is 256:

then I get this error:

I have seen the issue in #2134 and #2150, so I don't understand why latest repo still can't deal with big dataset.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: linux docker
- Python version: 3.6
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3464/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3464/timeline | null | null | null | null | false | [
"Hi ! Can you try setting `datasets.config.MAX_TABLE_NBYTES_FOR_PICKLING` to a smaller value than `4 << 30` (4GiB), for example `500 << 20` (500MiB) ? It should reduce the maximum size of the arrow table being pickled during multiprocessing.\r\n\r\nIf it fixes the issue, we can consider lowering the default value for everyone.",
"@lhoestq I tried that just now but didn't seem to help."
] |
https://api.github.com/repos/huggingface/datasets/issues/1091 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1091/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1091/comments | https://api.github.com/repos/huggingface/datasets/issues/1091/events | https://github.com/huggingface/datasets/pull/1091 | 756,841,254 | MDExOlB1bGxSZXF1ZXN0NTMyMzE5MDk5 | 1,091 | Add Google wellformed query dataset | [] | closed | false | null | 1 | 2020-12-04T06:25:54Z | 2020-12-06T17:43:03Z | 2020-12-06T17:43:02Z | null | This pull request will add Google wellformed_query dataset. Link of dataset is https://github.com/google-research-datasets/query-wellformedness | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1091/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1091/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1091.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1091",
"merged_at": "2020-12-06T17:43:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1091.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1091"
} | true | [
"hope this works.."
] |
https://api.github.com/repos/huggingface/datasets/issues/34 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/34/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/34/comments | https://api.github.com/repos/huggingface/datasets/issues/34/events | https://github.com/huggingface/datasets/pull/34 | 611,385,516 | MDExOlB1bGxSZXF1ZXN0NDEyNTg0OTM0 | 34 | [Tests] add slow tests | [] | closed | false | null | 0 | 2020-05-03T11:01:22Z | 2020-05-03T12:18:30Z | 2020-05-03T12:18:29Z | null | This PR adds a slow test that downloads the "real" dataset. The test is decorated as "slow" so that it will not automatically run on circle ci.
Before uploading a dataset, one should test that this test passes, manually by running
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_<your-dataset-script-name>
```
This PR should be merged after PR: #33 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/34/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/34/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/34.diff",
"html_url": "https://github.com/huggingface/datasets/pull/34",
"merged_at": "2020-05-03T12:18:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/34.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/34"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1264/comments | https://api.github.com/repos/huggingface/datasets/issues/1264/events | https://github.com/huggingface/datasets/pull/1264 | 758,686,474 | MDExOlB1bGxSZXF1ZXN0NTMzODE4MDM2 | 1,264 | enriched webnlg dataset rebase | [] | closed | false | null | 1 | 2020-12-07T17:05:45Z | 2020-12-09T17:00:29Z | 2020-12-09T17:00:27Z | null | Rebase of #1206 ! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1264/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1264",
"merged_at": "2020-12-09T17:00:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1264"
} | true | [
"I've removed the `en` within `de` and reciprocally; but I don't think I will be able to thin it more than this. (Edit: ignore the close, I missclicked !)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5287 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5287/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5287/comments | https://api.github.com/repos/huggingface/datasets/issues/5287/events | https://github.com/huggingface/datasets/pull/5287 | 1,461,971,889 | PR_kwDODunzps5Dkttf | 5,287 | Fix methods using `IterableDataset.map` that lead to `features=None` | [] | closed | false | null | 7 | 2022-11-23T15:33:25Z | 2022-11-28T15:43:14Z | 2022-11-28T12:53:22Z | null | As currently `IterableDataset.map` is setting the `info.features` to `None` every time as we don't know the output of the dataset in advance, `IterableDataset` methods such as `rename_column`, `rename_columns`, and `remove_columns`. that internally use `map` lead to the features being `None`.
This PR is related to #3888, #5245, and #5284
## ✅ Current solution
The code in this PR is basically making sure that if the features were there since the beginning and a `rename_column`/`rename_columns` happens, those are kept and the rename is applied to the `Features` too. Also, if the features were not there before applying `rename_column`, `rename_columns` or `remove_columns`, a batch is prefetched and the features are being inferred (that could potentially be part of `IterableDataset.__init__` in case the `info.features` value is `None`).
## 💡 Ideas
Some ideas were proposed in https://github.com/huggingface/datasets/issues/3888, but probably the most consistent solution even though it may take some time is to actually do the type inferencing during the `IterableDataset.__init__` in case the provided `info.features` is `None`, otherwise, we can just use the provided features.
Additionally, as mentioned at https://github.com/huggingface/datasets/issues/3888, we could also include a `features` parameter to the `map` function, but that's probably more tedious.
Also thanks to @lhoestq for sharing some ideas in both https://github.com/huggingface/datasets/issues/3888 and https://github.com/huggingface/datasets/issues/5245 :hugs: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5287/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5287/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5287.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5287",
"merged_at": "2022-11-28T12:53:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5287.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5287"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"_The documentation is not available anymore as the PR was closed or merged._",
"Maybe other options are:\r\n* Keep the `info.features` to `None` if those were initially `None`\r\n* Infer the features with pre-fetching just if the `info.features` is `None`\r\n* If the `info.features` are there, make sure that after `map` features is not `None`",
"Hi @lhoestq something that's still not clear to me is: should we infer the features always when applying a `map` if those are initially `None`, or just assume that if the features are initially `None` those should be left that way unless the user specifically sets those (or during iter)?\r\n\r\nIn this PR I'm using `from datasets.iterable_dataset import _infer_features_from_batch` to infer the features when those are `None` using pre-fetch of `self._head()`, but I'm not sure if that's the expected behavior.\r\n\r\nThanks in advance for your help!",
"Also, the PR still has some more work to do, but probably the most relevant thing to fix right now is that the `features` are being set to `None` in the functions `IterableDataset.rename_column`, `IterableDataset.rename_columns`, and `IterableDataset.remove_columns` when the `features` originally had a value. So once that's fixed maybe we can focus on improving the current `map`'s behavior, so as to avoid this from happening also when the user uses `map` directly and not through the functions mentioned above.",
"> Cool thank you ! Resolving the features can be expensive sometimes, so maybe we don't resolve the features and we can just rename/remove columns if the features are known (i.e. if they're not None). What do you think ?\r\n\r\nThanks for the feedback! Makes sense to me 👍🏻 I'll commit the comments now!",
"Already done @lhoestq, feel free to merge whenever you want! Also before merging, can you please link the following issues https://github.com/huggingface/datasets/issues/3888, https://github.com/huggingface/datasets/issues/5245, and https://github.com/huggingface/datasets/issues/5284, so that those are closed upon merge? Thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/790 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/790/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/790/comments | https://api.github.com/repos/huggingface/datasets/issues/790/events | https://github.com/huggingface/datasets/issues/790 | 734,470,197 | MDU6SXNzdWU3MzQ0NzAxOTc= | 790 | Error running pip install -e ".[dev]" on MacOS 10.13.6: faiss/python does not exist | [] | closed | false | null | 2 | 2020-11-02T12:36:35Z | 2020-11-10T14:05:02Z | 2020-11-10T14:05:02Z | null | I was following along with https://huggingface.co/docs/datasets/share_dataset.html#adding-tests-and-metadata-to-the-dataset when I ran into this error.
```sh
git clone https://github.com/huggingface/datasets
cd datasets
virtualenv venv -p python3 --system-site-packages
source venv/bin/activate
pip install -e ".[dev]"
```


Python 3.7.7
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/790/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/790/timeline | null | completed | null | null | false | [
"I saw that `faiss-cpu` 1.6.4.post2 was released recently to fix the installation on macos. It should work now",
"Closing this one.\r\nFeel free to re-open if you still have issues"
] |
https://api.github.com/repos/huggingface/datasets/issues/1307 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1307/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1307/comments | https://api.github.com/repos/huggingface/datasets/issues/1307/events | https://github.com/huggingface/datasets/pull/1307 | 759,458,835 | MDExOlB1bGxSZXF1ZXN0NTM0NDYxODc5 | 1,307 | adding capes | [] | closed | false | null | 0 | 2020-12-08T13:46:13Z | 2020-12-09T15:40:09Z | 2020-12-09T15:27:45Z | null | Adding Parallel corpus of theses and dissertation abstracts in Portuguese and English from CAPES
https://sites.google.com/view/felipe-soares/datasets#h.p_kxOR6EhHm2a6 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1307/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1307/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1307.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1307",
"merged_at": "2020-12-09T15:27:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1307.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1307"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1211 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1211/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1211/comments | https://api.github.com/repos/huggingface/datasets/issues/1211/events | https://github.com/huggingface/datasets/pull/1211 | 757,973,719 | MDExOlB1bGxSZXF1ZXN0NTMzMjMxNDY3 | 1,211 | Add large spanish corpus | [] | closed | false | null | 0 | 2020-12-06T17:06:50Z | 2020-12-09T13:36:36Z | 2020-12-09T13:36:36Z | null | Adds a collection of Spanish corpora that can be useful for pretraining language models.
Following a nice suggestion from @yjernite we provide the user with three main ways to preprocess / load either
* the whole corpus (17GB!)
* one specific sub-corpus
* the whole corpus, but return a single split. this is useful if you want to cache the whole preprocessing step once and interact with individual sub-corpora
See the dataset card for more details.
Ready for review! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1211/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1211/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1211.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1211",
"merged_at": "2020-12-09T13:36:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1211.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1211"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5813 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5813/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5813/comments | https://api.github.com/repos/huggingface/datasets/issues/5813/events | https://github.com/huggingface/datasets/pull/5813 | 1,691,908,535 | PR_kwDODunzps5Pj0_E | 5,813 | [DO-NOT-MERGE] Debug Windows issue at #3 | [] | closed | false | null | 0 | 2023-05-02T07:19:34Z | 2023-05-02T07:21:30Z | 2023-05-02T07:21:30Z | null | TBD | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5813/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5813/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5813.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5813",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5813.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5813"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/246 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/246/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/246/comments | https://api.github.com/repos/huggingface/datasets/issues/246/events | https://github.com/huggingface/datasets/issues/246 | 632,380,054 | MDU6SXNzdWU2MzIzODAwNTQ= | 246 | What is the best way to cache a dataset? | [] | closed | false | null | 2 | 2020-06-06T11:02:07Z | 2020-07-09T09:15:07Z | 2020-07-09T09:15:07Z | null | For example if I want to use streamlit with a nlp dataset:
```
@st.cache
def load_data():
return nlp.load_dataset('squad')
```
This code raises the error "uncachable object"
Right now I just fixed with a constant for my specific case:
```
@st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})
```
But I was curious to know what is the best way in general
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/246/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/246/timeline | null | completed | null | null | false | [
"Everything is already cached by default in 🤗nlp (in particular dataset\nloading and all the “map()” operations) so I don’t think you need to do any\nspecific caching in streamlit.\n\nTell us if you feel like it’s not the case.\n\nOn Sat, 6 Jun 2020 at 13:02, Fabrizio Milo <notifications@github.com> wrote:\n\n> For example if I want to use streamlit with a nlp dataset:\n>\n> @st.cache\n> def load_data():\n> return nlp.load_dataset('squad')\n>\n> This code raises the error \"uncachable object\"\n>\n> Right now I just fixed with a constant for my specific case:\n>\n> @st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})\n>\n> But I was curious to know what is the best way in general\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/issues/246>, or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHKAKO7CWGX2QY55UXLRVIO3ZANCNFSM4NV333RQ>\n> .\n>\n",
"Closing this one. Feel free to re-open if you have other questions !"
] |
https://api.github.com/repos/huggingface/datasets/issues/6068 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6068/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6068/comments | https://api.github.com/repos/huggingface/datasets/issues/6068/events | https://github.com/huggingface/datasets/pull/6068 | 1,820,106,952 | PR_kwDODunzps5WUkZi | 6,068 | fix tqdm lock deletion | [] | closed | false | null | 5 | 2023-07-25T11:17:25Z | 2023-07-25T15:29:39Z | 2023-07-25T15:17:50Z | null | related to https://github.com/huggingface/datasets/issues/6066 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6068/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6068/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6068.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6068",
"merged_at": "2023-07-25T15:17:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6068.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6068"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006573 / 0.011353 (-0.004780) | 0.004014 / 0.011008 (-0.006994) | 0.084999 / 0.038508 (0.046491) | 0.074965 / 0.023109 (0.051855) | 0.313294 / 0.275898 (0.037396) | 0.349678 / 0.323480 (0.026198) | 0.005401 / 0.007986 (-0.002585) | 0.003401 / 0.004328 (-0.000927) | 0.065363 / 0.004250 (0.061112) | 0.057159 / 0.037052 (0.020107) | 0.313260 / 0.258489 (0.054771) | 0.354654 / 0.293841 (0.060813) | 0.030895 / 0.128546 (-0.097651) | 0.008605 / 0.075646 (-0.067042) | 0.289190 / 0.419271 (-0.130081) | 0.052474 / 0.043533 (0.008942) | 0.316193 / 0.255139 (0.061054) | 0.339966 / 0.283200 (0.056767) | 0.024112 / 0.141683 (-0.117571) | 1.515606 / 1.452155 (0.063452) | 1.571428 / 1.492716 (0.078711) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203284 / 0.018006 (0.185278) | 0.452720 / 0.000490 (0.452230) | 0.003891 / 0.000200 (0.003691) | 0.000094 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028992 / 0.037411 (-0.008419) | 0.083170 / 0.014526 (0.068644) | 0.097739 / 0.176557 (-0.078817) | 0.153401 / 0.737135 (-0.583734) | 0.098628 / 0.296338 (-0.197711) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.390190 / 0.215209 (0.174981) | 3.901272 / 2.077655 (1.823617) | 1.887194 / 1.504120 (0.383074) | 1.723696 / 1.541195 (0.182501) | 1.800537 / 1.468490 (0.332047) | 0.481758 / 4.584777 (-4.103019) | 3.605098 / 3.745712 (-0.140614) | 3.304482 / 5.269862 (-1.965380) | 2.053515 / 4.565676 (-2.512161) | 0.056997 / 0.424275 (-0.367278) | 0.007347 / 0.007607 (-0.000260) | 0.461367 / 0.226044 (0.235323) | 4.606152 / 2.268929 (2.337223) | 2.470048 / 55.444624 (-52.974576) | 2.060019 / 6.876477 (-4.816458) | 2.320507 / 2.142072 (0.178435) | 0.575050 / 4.805227 (-4.230178) | 0.133030 / 6.500664 (-6.367634) | 0.061508 / 0.075469 (-0.013962) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.275430 / 1.841788 (-0.566357) | 19.725453 / 8.074308 (11.651145) | 14.396360 / 10.191392 (4.204968) | 0.157980 / 0.680424 (-0.522443) | 0.018516 / 0.534201 (-0.515685) | 0.394717 / 0.579283 (-0.184566) | 0.404948 / 0.434364 (-0.029415) | 0.474001 / 0.540337 (-0.066336) | 0.668463 / 1.386936 (-0.718474) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006697 / 0.011353 (-0.004656) | 0.004206 / 0.011008 (-0.006802) | 0.065458 / 0.038508 (0.026950) | 0.075845 / 0.023109 (0.052735) | 0.365051 / 0.275898 (0.089153) | 0.400919 / 0.323480 (0.077439) | 0.005347 / 0.007986 (-0.002638) | 0.003386 / 0.004328 (-0.000943) | 0.065398 / 0.004250 (0.061148) | 0.057320 / 0.037052 (0.020268) | 0.379161 / 0.258489 (0.120672) | 0.406892 / 0.293841 (0.113051) | 0.031986 / 0.128546 (-0.096560) | 0.008674 / 0.075646 (-0.066972) | 0.071723 / 0.419271 (-0.347549) | 0.049897 / 0.043533 (0.006364) | 0.372034 / 0.255139 (0.116895) | 0.394293 / 0.283200 (0.111094) | 0.023681 / 0.141683 (-0.118002) | 1.479793 / 1.452155 (0.027639) | 1.553105 / 1.492716 (0.060389) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.233660 / 0.018006 (0.215654) | 0.454412 / 0.000490 (0.453923) | 0.004473 / 0.000200 (0.004273) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031115 / 0.037411 (-0.006296) | 0.090541 / 0.014526 (0.076015) | 0.104363 / 0.176557 (-0.072193) | 0.161022 / 0.737135 (-0.576114) | 0.105114 / 0.296338 (-0.191225) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.427668 / 0.215209 (0.212459) | 4.263145 / 2.077655 (2.185490) | 2.247043 / 1.504120 (0.742923) | 2.082554 / 1.541195 (0.541360) | 2.170505 / 1.468490 (0.702015) | 0.491802 / 4.584777 (-4.092975) | 3.587295 / 3.745712 (-0.158417) | 3.344697 / 5.269862 (-1.925165) | 2.060529 / 4.565676 (-2.505148) | 0.057829 / 0.424275 (-0.366446) | 0.007780 / 0.007607 (0.000173) | 0.503374 / 0.226044 (0.277330) | 5.034742 / 2.268929 (2.765814) | 2.701957 / 55.444624 (-52.742667) | 2.479002 / 6.876477 (-4.397474) | 2.622055 / 2.142072 (0.479982) | 0.591363 / 4.805227 (-4.213864) | 0.133834 / 6.500664 (-6.366830) | 0.062276 / 0.075469 (-0.013193) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.338788 / 1.841788 (-0.503000) | 20.333599 / 8.074308 (12.259291) | 14.783196 / 10.191392 (4.591804) | 0.168695 / 0.680424 (-0.511729) | 0.018478 / 0.534201 (-0.515723) | 0.397398 / 0.579283 (-0.181885) | 0.409900 / 0.434364 (-0.024464) | 0.475315 / 0.540337 (-0.065023) | 0.644267 / 1.386936 (-0.742669) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007315 / 0.011353 (-0.004038) | 0.004294 / 0.011008 (-0.006714) | 0.100300 / 0.038508 (0.061792) | 0.077780 / 0.023109 (0.054670) | 0.353728 / 0.275898 (0.077830) | 0.400538 / 0.323480 (0.077058) | 0.005807 / 0.007986 (-0.002178) | 0.003649 / 0.004328 (-0.000680) | 0.077548 / 0.004250 (0.073297) | 0.058834 / 0.037052 (0.021781) | 0.352064 / 0.258489 (0.093574) | 0.399951 / 0.293841 (0.106110) | 0.036472 / 0.128546 (-0.092074) | 0.008653 / 0.075646 (-0.066994) | 0.323089 / 0.419271 (-0.096182) | 0.075127 / 0.043533 (0.031594) | 0.334412 / 0.255139 (0.079273) | 0.375718 / 0.283200 (0.092519) | 0.027915 / 0.141683 (-0.113768) | 1.698795 / 1.452155 (0.246640) | 1.781447 / 1.492716 (0.288730) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216111 / 0.018006 (0.198104) | 0.507706 / 0.000490 (0.507216) | 0.000851 / 0.000200 (0.000651) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030451 / 0.037411 (-0.006960) | 0.087488 / 0.014526 (0.072962) | 0.105094 / 0.176557 (-0.071462) | 0.168130 / 0.737135 (-0.569006) | 0.106791 / 0.296338 (-0.189547) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426291 / 0.215209 (0.211082) | 4.281046 / 2.077655 (2.203391) | 2.162268 / 1.504120 (0.658148) | 1.909503 / 1.541195 (0.368309) | 1.943165 / 1.468490 (0.474675) | 0.516667 / 4.584777 (-4.068110) | 4.113218 / 3.745712 (0.367506) | 5.931372 / 5.269862 (0.661510) | 3.563521 / 4.565676 (-1.002155) | 0.062415 / 0.424275 (-0.361860) | 0.007577 / 0.007607 (-0.000030) | 0.534588 / 0.226044 (0.308543) | 5.183490 / 2.268929 (2.914561) | 2.790662 / 55.444624 (-52.653962) | 2.258630 / 6.876477 (-4.617846) | 2.499930 / 2.142072 (0.357857) | 0.606154 / 4.805227 (-4.199073) | 0.136093 / 6.500664 (-6.364571) | 0.061151 / 0.075469 (-0.014318) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.398392 / 1.841788 (-0.443396) | 21.482150 / 8.074308 (13.407842) | 15.477336 / 10.191392 (5.285944) | 0.192878 / 0.680424 (-0.487546) | 0.021764 / 0.534201 (-0.512437) | 0.437149 / 0.579283 (-0.142134) | 0.439976 / 0.434364 (0.005612) | 0.514498 / 0.540337 (-0.025840) | 0.762642 / 1.386936 (-0.624294) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007504 / 0.011353 (-0.003849) | 0.004526 / 0.011008 (-0.006482) | 0.071008 / 0.038508 (0.032500) | 0.078305 / 0.023109 (0.055195) | 0.436160 / 0.275898 (0.160262) | 0.439048 / 0.323480 (0.115568) | 0.006061 / 0.007986 (-0.001925) | 0.003681 / 0.004328 (-0.000648) | 0.069445 / 0.004250 (0.065195) | 0.059258 / 0.037052 (0.022206) | 0.437745 / 0.258489 (0.179256) | 0.464247 / 0.293841 (0.170406) | 0.033286 / 0.128546 (-0.095260) | 0.009846 / 0.075646 (-0.065800) | 0.076330 / 0.419271 (-0.342941) | 0.051919 / 0.043533 (0.008386) | 0.432817 / 0.255139 (0.177678) | 0.426295 / 0.283200 (0.143095) | 0.029818 / 0.141683 (-0.111865) | 1.747640 / 1.452155 (0.295485) | 1.726653 / 1.492716 (0.233937) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.251253 / 0.018006 (0.233247) | 0.483394 / 0.000490 (0.482904) | 0.003992 / 0.000200 (0.003793) | 0.000096 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032180 / 0.037411 (-0.005231) | 0.095425 / 0.014526 (0.080900) | 0.105908 / 0.176557 (-0.070648) | 0.164732 / 0.737135 (-0.572403) | 0.115903 / 0.296338 (-0.180435) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469467 / 0.215209 (0.254258) | 4.633239 / 2.077655 (2.555584) | 2.517557 / 1.504120 (1.013437) | 2.352726 / 1.541195 (0.811531) | 2.314618 / 1.468490 (0.846128) | 0.548446 / 4.584777 (-4.036331) | 3.908797 / 3.745712 (0.163085) | 3.525941 / 5.269862 (-1.743921) | 2.178858 / 4.565676 (-2.386819) | 0.057614 / 0.424275 (-0.366661) | 0.008604 / 0.007607 (0.000997) | 0.554756 / 0.226044 (0.328711) | 5.325635 / 2.268929 (3.056706) | 3.014266 / 55.444624 (-52.430359) | 2.844165 / 6.876477 (-4.032312) | 2.903019 / 2.142072 (0.760947) | 0.617750 / 4.805227 (-4.187478) | 0.144259 / 6.500664 (-6.356405) | 0.065944 / 0.075469 (-0.009525) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.504625 / 1.841788 (-0.337163) | 22.400787 / 8.074308 (14.326479) | 15.223702 / 10.191392 (5.032310) | 0.213357 / 0.680424 (-0.467067) | 0.019310 / 0.534201 (-0.514891) | 0.456596 / 0.579283 (-0.122687) | 0.473811 / 0.434364 (0.039447) | 0.517800 / 0.540337 (-0.022537) | 0.792468 / 1.386936 (-0.594468) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007420 / 0.011353 (-0.003933) | 0.004502 / 0.011008 (-0.006506) | 0.097882 / 0.038508 (0.059374) | 0.079084 / 0.023109 (0.055975) | 0.361797 / 0.275898 (0.085899) | 0.416563 / 0.323480 (0.093083) | 0.006106 / 0.007986 (-0.001879) | 0.003803 / 0.004328 (-0.000526) | 0.074669 / 0.004250 (0.070418) | 0.062168 / 0.037052 (0.025116) | 0.378844 / 0.258489 (0.120355) | 0.426601 / 0.293841 (0.132760) | 0.035619 / 0.128546 (-0.092927) | 0.009686 / 0.075646 (-0.065960) | 0.336481 / 0.419271 (-0.082790) | 0.065553 / 0.043533 (0.022021) | 0.362501 / 0.255139 (0.107362) | 0.399752 / 0.283200 (0.116552) | 0.028685 / 0.141683 (-0.112998) | 1.683495 / 1.452155 (0.231340) | 1.786105 / 1.492716 (0.293388) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220792 / 0.018006 (0.202786) | 0.501936 / 0.000490 (0.501447) | 0.000389 / 0.000200 (0.000189) | 0.000057 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032180 / 0.037411 (-0.005232) | 0.093079 / 0.014526 (0.078553) | 0.107967 / 0.176557 (-0.068589) | 0.171747 / 0.737135 (-0.565389) | 0.107920 / 0.296338 (-0.188418) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444431 / 0.215209 (0.229222) | 4.454934 / 2.077655 (2.377279) | 2.140265 / 1.504120 (0.636145) | 1.960126 / 1.541195 (0.418931) | 2.049649 / 1.468490 (0.581158) | 0.557861 / 4.584777 (-4.026916) | 4.046240 / 3.745712 (0.300528) | 4.513748 / 5.269862 (-0.756114) | 2.593643 / 4.565676 (-1.972034) | 0.066795 / 0.424275 (-0.357480) | 0.008302 / 0.007607 (0.000694) | 0.535643 / 0.226044 (0.309599) | 5.299429 / 2.268929 (3.030500) | 2.656019 / 55.444624 (-52.788606) | 2.281214 / 6.876477 (-4.595263) | 2.302910 / 2.142072 (0.160837) | 0.661696 / 4.805227 (-4.143532) | 0.149787 / 6.500664 (-6.350877) | 0.069609 / 0.075469 (-0.005860) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.509842 / 1.841788 (-0.331946) | 21.717504 / 8.074308 (13.643196) | 15.825102 / 10.191392 (5.633710) | 0.168115 / 0.680424 (-0.512309) | 0.021637 / 0.534201 (-0.512564) | 0.454270 / 0.579283 (-0.125013) | 0.458531 / 0.434364 (0.024167) | 0.523052 / 0.540337 (-0.017285) | 0.711219 / 1.386936 (-0.675717) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007189 / 0.011353 (-0.004164) | 0.004437 / 0.011008 (-0.006571) | 0.075111 / 0.038508 (0.036603) | 0.079245 / 0.023109 (0.056136) | 0.423169 / 0.275898 (0.147270) | 0.455007 / 0.323480 (0.131527) | 0.006076 / 0.007986 (-0.001909) | 0.003819 / 0.004328 (-0.000509) | 0.074976 / 0.004250 (0.070726) | 0.062127 / 0.037052 (0.025075) | 0.456809 / 0.258489 (0.198320) | 0.474707 / 0.293841 (0.180867) | 0.036221 / 0.128546 (-0.092325) | 0.009428 / 0.075646 (-0.066218) | 0.082842 / 0.419271 (-0.336429) | 0.057086 / 0.043533 (0.013553) | 0.436121 / 0.255139 (0.180982) | 0.453934 / 0.283200 (0.170734) | 0.026045 / 0.141683 (-0.115638) | 1.789782 / 1.452155 (0.337627) | 1.820934 / 1.492716 (0.328218) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230790 / 0.018006 (0.212784) | 0.497987 / 0.000490 (0.497497) | 0.002775 / 0.000200 (0.002575) | 0.000093 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034418 / 0.037411 (-0.002994) | 0.105567 / 0.014526 (0.091041) | 0.113134 / 0.176557 (-0.063423) | 0.173742 / 0.737135 (-0.563394) | 0.115936 / 0.296338 (-0.180403) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.502259 / 0.215209 (0.287050) | 4.969877 / 2.077655 (2.892222) | 2.684860 / 1.504120 (1.180740) | 2.484386 / 1.541195 (0.943192) | 2.543061 / 1.468490 (1.074571) | 0.545733 / 4.584777 (-4.039044) | 4.029660 / 3.745712 (0.283948) | 5.927883 / 5.269862 (0.658021) | 3.528372 / 4.565676 (-1.037305) | 0.065957 / 0.424275 (-0.358318) | 0.008933 / 0.007607 (0.001326) | 0.601630 / 0.226044 (0.375585) | 5.825872 / 2.268929 (3.556944) | 3.230721 / 55.444624 (-52.213904) | 2.891308 / 6.876477 (-3.985169) | 3.054994 / 2.142072 (0.912922) | 0.665480 / 4.805227 (-4.139747) | 0.154815 / 6.500664 (-6.345849) | 0.072997 / 0.075469 (-0.002472) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.549892 / 1.841788 (-0.291896) | 22.337484 / 8.074308 (14.263176) | 16.308286 / 10.191392 (6.116894) | 0.189594 / 0.680424 (-0.490830) | 0.021844 / 0.534201 (-0.512357) | 0.456958 / 0.579283 (-0.122325) | 0.459957 / 0.434364 (0.025593) | 0.529014 / 0.540337 (-0.011323) | 0.700359 / 1.386936 (-0.686577) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009050 / 0.011353 (-0.002303) | 0.004968 / 0.011008 (-0.006040) | 0.114315 / 0.038508 (0.075807) | 0.084475 / 0.023109 (0.061366) | 0.426325 / 0.275898 (0.150427) | 0.457870 / 0.323480 (0.134390) | 0.007076 / 0.007986 (-0.000910) | 0.004635 / 0.004328 (0.000307) | 0.082950 / 0.004250 (0.078700) | 0.065414 / 0.037052 (0.028361) | 0.441936 / 0.258489 (0.183447) | 0.476983 / 0.293841 (0.183142) | 0.048575 / 0.128546 (-0.079972) | 0.013929 / 0.075646 (-0.061717) | 0.377498 / 0.419271 (-0.041774) | 0.081503 / 0.043533 (0.037970) | 0.426706 / 0.255139 (0.171567) | 0.460374 / 0.283200 (0.177175) | 0.046052 / 0.141683 (-0.095631) | 1.894896 / 1.452155 (0.442741) | 1.998639 / 1.492716 (0.505923) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.313267 / 0.018006 (0.295261) | 0.607501 / 0.000490 (0.607012) | 0.003369 / 0.000200 (0.003169) | 0.000102 / 0.000054 (0.000047) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032266 / 0.037411 (-0.005145) | 0.120138 / 0.014526 (0.105613) | 0.115044 / 0.176557 (-0.061513) | 0.181374 / 0.737135 (-0.555761) | 0.114681 / 0.296338 (-0.181657) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.648039 / 0.215209 (0.432830) | 6.005048 / 2.077655 (3.927394) | 2.674524 / 1.504120 (1.170404) | 2.284831 / 1.541195 (0.743637) | 2.360150 / 1.468490 (0.891660) | 0.888021 / 4.584777 (-3.696756) | 5.419840 / 3.745712 (1.674128) | 4.825816 / 5.269862 (-0.444046) | 3.140876 / 4.565676 (-1.424801) | 0.099511 / 0.424275 (-0.324764) | 0.009176 / 0.007607 (0.001569) | 0.735646 / 0.226044 (0.509602) | 7.224026 / 2.268929 (4.955097) | 3.551146 / 55.444624 (-51.893478) | 2.844374 / 6.876477 (-4.032103) | 3.145307 / 2.142072 (1.003235) | 1.077636 / 4.805227 (-3.727591) | 0.217754 / 6.500664 (-6.282910) | 0.081755 / 0.075469 (0.006286) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.670956 / 1.841788 (-0.170831) | 25.524961 / 8.074308 (17.450653) | 23.061596 / 10.191392 (12.870204) | 0.247524 / 0.680424 (-0.432899) | 0.031712 / 0.534201 (-0.502489) | 0.513049 / 0.579283 (-0.066234) | 0.614568 / 0.434364 (0.180204) | 0.574669 / 0.540337 (0.034331) | 0.816621 / 1.386936 (-0.570315) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009384 / 0.011353 (-0.001969) | 0.004959 / 0.011008 (-0.006049) | 0.084782 / 0.038508 (0.046274) | 0.098086 / 0.023109 (0.074977) | 0.544395 / 0.275898 (0.268497) | 0.585157 / 0.323480 (0.261677) | 0.006507 / 0.007986 (-0.001479) | 0.004151 / 0.004328 (-0.000178) | 0.088596 / 0.004250 (0.084345) | 0.069149 / 0.037052 (0.032097) | 0.533109 / 0.258489 (0.274620) | 0.604117 / 0.293841 (0.310276) | 0.047685 / 0.128546 (-0.080861) | 0.013651 / 0.075646 (-0.061996) | 0.096566 / 0.419271 (-0.322705) | 0.062022 / 0.043533 (0.018489) | 0.561897 / 0.255139 (0.306758) | 0.617636 / 0.283200 (0.334436) | 0.034636 / 0.141683 (-0.107047) | 1.854667 / 1.452155 (0.402512) | 1.908923 / 1.492716 (0.416207) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260633 / 0.018006 (0.242627) | 0.622268 / 0.000490 (0.621778) | 0.002116 / 0.000200 (0.001916) | 0.000101 / 0.000054 (0.000047) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035161 / 0.037411 (-0.002250) | 0.103707 / 0.014526 (0.089181) | 0.115467 / 0.176557 (-0.061090) | 0.180077 / 0.737135 (-0.557059) | 0.118871 / 0.296338 (-0.177467) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.628481 / 0.215209 (0.413271) | 6.304929 / 2.077655 (4.227275) | 3.027775 / 1.504120 (1.523655) | 2.753880 / 1.541195 (1.212686) | 2.820442 / 1.468490 (1.351952) | 0.851103 / 4.584777 (-3.733674) | 5.427383 / 3.745712 (1.681670) | 7.434310 / 5.269862 (2.164449) | 4.418790 / 4.565676 (-0.146887) | 0.101733 / 0.424275 (-0.322542) | 0.009701 / 0.007607 (0.002094) | 0.763033 / 0.226044 (0.536989) | 7.497927 / 2.268929 (5.228998) | 3.735335 / 55.444624 (-51.709290) | 3.149200 / 6.876477 (-3.727277) | 3.306214 / 2.142072 (1.164141) | 1.085440 / 4.805227 (-3.719787) | 0.207562 / 6.500664 (-6.293102) | 0.078091 / 0.075469 (0.002622) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.820097 / 1.841788 (-0.021691) | 25.525539 / 8.074308 (17.451231) | 21.874219 / 10.191392 (11.682827) | 0.228391 / 0.680424 (-0.452033) | 0.029584 / 0.534201 (-0.504617) | 0.511546 / 0.579283 (-0.067737) | 0.602719 / 0.434364 (0.168355) | 0.581874 / 0.540337 (0.041537) | 0.802861 / 1.386936 (-0.584075) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2606/comments | https://api.github.com/repos/huggingface/datasets/issues/2606/events | https://github.com/huggingface/datasets/issues/2606 | 938,763,684 | MDU6SXNzdWU5Mzg3NjM2ODQ= | 2,606 | [Metrics] addition of wiki_split metrics | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "d4c5f9",
"default": false,
"description": "Requesting to add a new metric",
"id": 2459308248,
"name": "metric request",
"node_id": "MDU6TGFiZWwyNDU5MzA4MjQ4",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20request"
}
] | closed | false | null | 1 | 2021-07-07T10:56:04Z | 2021-07-12T22:34:31Z | 2021-07-12T22:34:31Z | null | **Is your feature request related to a problem? Please describe.**
While training the model on sentence split the task in English we require to evaluate the trained model on `Exact Match`, `SARI` and `BLEU` score
like this

While training we require metrics which can give all the output
Currently, we don't have an exact match for text normalized data
**Describe the solution you'd like**
A custom metrics for wiki_split that can calculate these three values and provide it in the form of a single dictionary
For exact match, we can refer to [this](https://github.com/huggingface/transformers/blob/master/src/transformers/data/metrics/squad_metrics.py)
**Describe alternatives you've considered**
Two metrics are already present one more can be added for an exact match then we can run all three metrics in training script
#self-assign | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2606/timeline | null | completed | null | null | false | [
"#take"
] |
https://api.github.com/repos/huggingface/datasets/issues/1385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1385/comments | https://api.github.com/repos/huggingface/datasets/issues/1385/events | https://github.com/huggingface/datasets/pull/1385 | 760,351,405 | MDExOlB1bGxSZXF1ZXN0NTM1MTk3Nzk5 | 1,385 | add best2009 | [] | closed | false | null | 0 | 2020-12-09T13:56:09Z | 2020-12-14T10:59:08Z | 2020-12-14T10:59:08Z | null | `best2009` is a Thai word-tokenization dataset from encyclopedia, novels, news and articles by [NECTEC](https://www.nectec.or.th/) (148,995/2,252 lines of train/test). It was created for [BEST 2010: Word Tokenization Competition](https://thailang.nectec.or.th/archive/indexa290.html?q=node/10). The test set answers are not provided publicly. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1385/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1385.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1385",
"merged_at": "2020-12-14T10:59:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1385.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1385"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1265/comments | https://api.github.com/repos/huggingface/datasets/issues/1265/events | https://github.com/huggingface/datasets/pull/1265 | 758,687,223 | MDExOlB1bGxSZXF1ZXN0NTMzODE4NjY0 | 1,265 | Add CovidQA dataset | [] | closed | false | null | 3 | 2020-12-07T17:06:51Z | 2020-12-08T17:02:26Z | 2020-12-08T17:02:26Z | null | This PR adds CovidQA, a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle’s COVID-19 Open Research Dataset Challenge.
Link to the paper: https://arxiv.org/pdf/2004.11339.pdf
Link to the homepage: https://covidqa.ai | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1265/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1265",
"merged_at": "2020-12-08T17:02:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1265"
} | true | [
"It seems to share the same name as this dataset: https://openreview.net/forum?id=JENSKEEzsoU",
"> It seems to share the same name as this dataset: https://openreview.net/forum?id=JENSKEEzsoU\r\n\r\nyou're right it can be confusing. I'll add the organization/research group for clarity: `covid_qa_castorini`. I added the dataset you shared as `covid_qa_deepset` in another PR (#1182) ",
"Thanks for avoiding the name collision !"
] |
https://api.github.com/repos/huggingface/datasets/issues/5223 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5223/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5223/comments | https://api.github.com/repos/huggingface/datasets/issues/5223/events | https://github.com/huggingface/datasets/pull/5223 | 1,442,610,658 | PR_kwDODunzps5CjT9Z | 5,223 | Add SQL guide | [] | closed | false | null | 4 | 2022-11-09T19:10:27Z | 2022-11-15T17:40:25Z | 2022-11-15T17:40:21Z | null | This PR adapts @nateraw's awesome SQL notebook as a guide for the docs! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5223/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5223/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5223.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5223",
"merged_at": "2022-11-15T17:40:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5223.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5223"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5223). All of your documentation changes will be reflected on that endpoint.",
"I think we may want more content on this page that's not SQL related. Some of that content probably already lives in the main `load` docs page, but might be bad to remove major things like csv/pandas from there...WDYT we should do @lhoestq ?",
"Maybe the main load page can only show one example and redirect to this page for more details ?\r\n\r\nWe can do the same for pandas stuff: have one example in load, and redirect to this page for more details",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5223). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5208 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5208/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5208/comments | https://api.github.com/repos/huggingface/datasets/issues/5208/events | https://github.com/huggingface/datasets/pull/5208 | 1,438,035,707 | PR_kwDODunzps5CTyxu | 5,208 | Refactor CI hub fixtures to use monkeypatch instead of patch | [] | closed | false | null | 1 | 2022-11-07T09:25:05Z | 2022-11-08T06:51:20Z | 2022-11-08T06:49:17Z | null | Minor refactoring of CI to use `pytest` `monkeypatch` instead of `unittest` `patch`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5208/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5208/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5208.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5208",
"merged_at": "2022-11-08T06:49:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5208.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5208"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5996 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5996/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5996/comments | https://api.github.com/repos/huggingface/datasets/issues/5996/events | https://github.com/huggingface/datasets/pull/5996 | 1,779,294,374 | PR_kwDODunzps5UKP0i | 5,996 | Deprecate `use_auth_token` in favor of `token` | [] | closed | false | null | 9 | 2023-06-28T16:26:38Z | 2023-07-05T15:22:20Z | 2023-07-03T16:03:33Z | null | ... to be consistent with `transformers` and `huggingface_hub`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5996/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5996/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5996.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5996",
"merged_at": "2023-07-03T16:03:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5996.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5996"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006134 / 0.011353 (-0.005219) | 0.003816 / 0.011008 (-0.007193) | 0.098226 / 0.038508 (0.059718) | 0.036830 / 0.023109 (0.013721) | 0.314551 / 0.275898 (0.038653) | 0.372251 / 0.323480 (0.048771) | 0.004762 / 0.007986 (-0.003224) | 0.003041 / 0.004328 (-0.001287) | 0.077651 / 0.004250 (0.073401) | 0.052445 / 0.037052 (0.015393) | 0.324632 / 0.258489 (0.066143) | 0.365724 / 0.293841 (0.071883) | 0.028069 / 0.128546 (-0.100477) | 0.008444 / 0.075646 (-0.067203) | 0.312767 / 0.419271 (-0.106505) | 0.047773 / 0.043533 (0.004240) | 0.305317 / 0.255139 (0.050178) | 0.332007 / 0.283200 (0.048807) | 0.018985 / 0.141683 (-0.122698) | 1.538022 / 1.452155 (0.085868) | 1.575898 / 1.492716 (0.083182) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204780 / 0.018006 (0.186774) | 0.428125 / 0.000490 (0.427635) | 0.003454 / 0.000200 (0.003254) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025064 / 0.037411 (-0.012348) | 0.099419 / 0.014526 (0.084893) | 0.111068 / 0.176557 (-0.065489) | 0.169775 / 0.737135 (-0.567361) | 0.112067 / 0.296338 (-0.184271) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429642 / 0.215209 (0.214433) | 4.275556 / 2.077655 (2.197901) | 1.914658 / 1.504120 (0.410539) | 1.706556 / 1.541195 (0.165361) | 1.754228 / 1.468490 (0.285738) | 0.563669 / 4.584777 (-4.021108) | 3.391501 / 3.745712 (-0.354211) | 1.791517 / 5.269862 (-3.478345) | 1.030704 / 4.565676 (-3.534973) | 0.070882 / 0.424275 (-0.353393) | 0.011351 / 0.007607 (0.003744) | 0.529438 / 0.226044 (0.303394) | 5.294316 / 2.268929 (3.025387) | 2.344653 / 55.444624 (-53.099972) | 1.997468 / 6.876477 (-4.879009) | 2.108932 / 2.142072 (-0.033140) | 0.676794 / 4.805227 (-4.128433) | 0.135058 / 6.500664 (-6.365607) | 0.065857 / 0.075469 (-0.009612) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.231864 / 1.841788 (-0.609924) | 13.986694 / 8.074308 (5.912386) | 13.306600 / 10.191392 (3.115208) | 0.145520 / 0.680424 (-0.534904) | 0.016717 / 0.534201 (-0.517484) | 0.366303 / 0.579283 (-0.212980) | 0.391637 / 0.434364 (-0.042727) | 0.425445 / 0.540337 (-0.114892) | 0.507719 / 1.386936 (-0.879217) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006236 / 0.011353 (-0.005116) | 0.003766 / 0.011008 (-0.007242) | 0.076794 / 0.038508 (0.038286) | 0.037210 / 0.023109 (0.014101) | 0.378387 / 0.275898 (0.102489) | 0.425456 / 0.323480 (0.101977) | 0.004694 / 0.007986 (-0.003291) | 0.002921 / 0.004328 (-0.001407) | 0.076985 / 0.004250 (0.072735) | 0.052188 / 0.037052 (0.015136) | 0.394385 / 0.258489 (0.135896) | 0.432527 / 0.293841 (0.138686) | 0.029091 / 0.128546 (-0.099455) | 0.008364 / 0.075646 (-0.067282) | 0.082583 / 0.419271 (-0.336689) | 0.042928 / 0.043533 (-0.000605) | 0.375321 / 0.255139 (0.120182) | 0.391719 / 0.283200 (0.108519) | 0.019388 / 0.141683 (-0.122295) | 1.550644 / 1.452155 (0.098489) | 1.604882 / 1.492716 (0.112166) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236859 / 0.018006 (0.218853) | 0.418528 / 0.000490 (0.418039) | 0.000388 / 0.000200 (0.000188) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025548 / 0.037411 (-0.011863) | 0.100644 / 0.014526 (0.086118) | 0.109102 / 0.176557 (-0.067455) | 0.161694 / 0.737135 (-0.575441) | 0.112088 / 0.296338 (-0.184250) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.484128 / 0.215209 (0.268919) | 4.849952 / 2.077655 (2.772297) | 2.512769 / 1.504120 (1.008649) | 2.303295 / 1.541195 (0.762100) | 2.356699 / 1.468490 (0.888209) | 0.564181 / 4.584777 (-4.020596) | 3.421393 / 3.745712 (-0.324319) | 2.570875 / 5.269862 (-2.698987) | 1.474307 / 4.565676 (-3.091370) | 0.068035 / 0.424275 (-0.356240) | 0.011300 / 0.007607 (0.003693) | 0.587867 / 0.226044 (0.361823) | 5.862447 / 2.268929 (3.593519) | 3.004017 / 55.444624 (-52.440607) | 2.664989 / 6.876477 (-4.211488) | 2.740020 / 2.142072 (0.597948) | 0.680840 / 4.805227 (-4.124387) | 0.137001 / 6.500664 (-6.363663) | 0.068098 / 0.075469 (-0.007371) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.297362 / 1.841788 (-0.544426) | 14.207891 / 8.074308 (6.133583) | 14.087562 / 10.191392 (3.896170) | 0.149514 / 0.680424 (-0.530910) | 0.016566 / 0.534201 (-0.517635) | 0.367602 / 0.579283 (-0.211681) | 0.400692 / 0.434364 (-0.033671) | 0.432907 / 0.540337 (-0.107431) | 0.525924 / 1.386936 (-0.861012) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006223 / 0.011353 (-0.005130) | 0.003672 / 0.011008 (-0.007336) | 0.097451 / 0.038508 (0.058943) | 0.036243 / 0.023109 (0.013133) | 0.375650 / 0.275898 (0.099752) | 0.431652 / 0.323480 (0.108172) | 0.004758 / 0.007986 (-0.003227) | 0.002941 / 0.004328 (-0.001387) | 0.077383 / 0.004250 (0.073132) | 0.055342 / 0.037052 (0.018289) | 0.390335 / 0.258489 (0.131846) | 0.427867 / 0.293841 (0.134026) | 0.027619 / 0.128546 (-0.100927) | 0.008244 / 0.075646 (-0.067402) | 0.313499 / 0.419271 (-0.105773) | 0.054987 / 0.043533 (0.011454) | 0.394044 / 0.255139 (0.138905) | 0.398784 / 0.283200 (0.115584) | 0.026499 / 0.141683 (-0.115184) | 1.496907 / 1.452155 (0.044753) | 1.554465 / 1.492716 (0.061749) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.241197 / 0.018006 (0.223190) | 0.427856 / 0.000490 (0.427366) | 0.006264 / 0.000200 (0.006065) | 0.000218 / 0.000054 (0.000164) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025550 / 0.037411 (-0.011862) | 0.104426 / 0.014526 (0.089901) | 0.110310 / 0.176557 (-0.066246) | 0.173813 / 0.737135 (-0.563322) | 0.112129 / 0.296338 (-0.184209) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.458806 / 0.215209 (0.243597) | 4.576351 / 2.077655 (2.498697) | 2.265670 / 1.504120 (0.761550) | 2.073230 / 1.541195 (0.532035) | 2.135283 / 1.468490 (0.666793) | 0.562506 / 4.584777 (-4.022271) | 3.375101 / 3.745712 (-0.370611) | 1.734393 / 5.269862 (-3.535469) | 1.026622 / 4.565676 (-3.539054) | 0.068144 / 0.424275 (-0.356131) | 0.011092 / 0.007607 (0.003485) | 0.562779 / 0.226044 (0.336734) | 5.608256 / 2.268929 (3.339328) | 2.706468 / 55.444624 (-52.738157) | 2.381607 / 6.876477 (-4.494869) | 2.451027 / 2.142072 (0.308954) | 0.671590 / 4.805227 (-4.133637) | 0.135749 / 6.500664 (-6.364915) | 0.065389 / 0.075469 (-0.010080) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244806 / 1.841788 (-0.596981) | 14.042150 / 8.074308 (5.967841) | 14.246612 / 10.191392 (4.055220) | 0.134309 / 0.680424 (-0.546114) | 0.017082 / 0.534201 (-0.517119) | 0.366043 / 0.579283 (-0.213240) | 0.400748 / 0.434364 (-0.033616) | 0.425695 / 0.540337 (-0.114643) | 0.509355 / 1.386936 (-0.877581) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006134 / 0.011353 (-0.005219) | 0.003980 / 0.011008 (-0.007028) | 0.078353 / 0.038508 (0.039845) | 0.038011 / 0.023109 (0.014902) | 0.375784 / 0.275898 (0.099886) | 0.433619 / 0.323480 (0.110139) | 0.004897 / 0.007986 (-0.003088) | 0.002981 / 0.004328 (-0.001347) | 0.077362 / 0.004250 (0.073112) | 0.056108 / 0.037052 (0.019056) | 0.395984 / 0.258489 (0.137495) | 0.427397 / 0.293841 (0.133556) | 0.029325 / 0.128546 (-0.099221) | 0.008498 / 0.075646 (-0.067148) | 0.082478 / 0.419271 (-0.336794) | 0.044085 / 0.043533 (0.000552) | 0.389923 / 0.255139 (0.134784) | 0.391180 / 0.283200 (0.107980) | 0.022452 / 0.141683 (-0.119231) | 1.507758 / 1.452155 (0.055603) | 1.530459 / 1.492716 (0.037743) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230928 / 0.018006 (0.212922) | 0.408484 / 0.000490 (0.407995) | 0.000806 / 0.000200 (0.000606) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025183 / 0.037411 (-0.012228) | 0.102292 / 0.014526 (0.087766) | 0.108142 / 0.176557 (-0.068415) | 0.161172 / 0.737135 (-0.575963) | 0.114476 / 0.296338 (-0.181862) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.482978 / 0.215209 (0.267769) | 4.816103 / 2.077655 (2.738448) | 2.505567 / 1.504120 (1.001447) | 2.302598 / 1.541195 (0.761404) | 2.371238 / 1.468490 (0.902748) | 0.567467 / 4.584777 (-4.017310) | 3.363407 / 3.745712 (-0.382306) | 1.746213 / 5.269862 (-3.523649) | 1.035468 / 4.565676 (-3.530208) | 0.068431 / 0.424275 (-0.355844) | 0.011069 / 0.007607 (0.003462) | 0.598241 / 0.226044 (0.372196) | 5.953927 / 2.268929 (3.684999) | 3.007493 / 55.444624 (-52.437132) | 2.629399 / 6.876477 (-4.247078) | 2.737201 / 2.142072 (0.595129) | 0.682456 / 4.805227 (-4.122771) | 0.137613 / 6.500664 (-6.363051) | 0.067941 / 0.075469 (-0.007528) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.306015 / 1.841788 (-0.535772) | 14.359240 / 8.074308 (6.284932) | 14.187601 / 10.191392 (3.996209) | 0.138612 / 0.680424 (-0.541812) | 0.016708 / 0.534201 (-0.517493) | 0.366365 / 0.579283 (-0.212918) | 0.396982 / 0.434364 (-0.037382) | 0.426939 / 0.540337 (-0.113398) | 0.520064 / 1.386936 (-0.866872) |\n\n</details>\n</details>\n\n\n",
"They use `token` and emit a deprecation warning if `use_auth_token` is passed instead (see https://github.com/huggingface/transformers/blob/78a2b19fc84ed55c65f4bf20a901edb7ceb73c5f/src/transformers/modeling_utils.py#L1933). \r\n\r\nI think we can update the `examples` scripts after merging this PR.",
"> I think we can update the examples scripts after merging this PR.\r\n\r\nWe should do a release before updated in the examples scripts no ? That's why it's an option to not have a deprecation warning until transformers and co are updated with the `token` arg",
"> We should do a release before updated in the examples scripts no ? That's why it's an option to not have a deprecation warning until transformers and co are updated with the token arg\r\n\r\nThis would avoid the warning only for the latest `datasets` release. TBH, I don't think this is worth the hassle, considering how simple it is to remove it.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007644 / 0.011353 (-0.003709) | 0.004667 / 0.011008 (-0.006341) | 0.117347 / 0.038508 (0.078839) | 0.050620 / 0.023109 (0.027510) | 0.415402 / 0.275898 (0.139504) | 0.485898 / 0.323480 (0.162418) | 0.005848 / 0.007986 (-0.002138) | 0.003736 / 0.004328 (-0.000592) | 0.089798 / 0.004250 (0.085547) | 0.069344 / 0.037052 (0.032292) | 0.441684 / 0.258489 (0.183195) | 0.468972 / 0.293841 (0.175131) | 0.036637 / 0.128546 (-0.091909) | 0.010219 / 0.075646 (-0.065427) | 0.394293 / 0.419271 (-0.024978) | 0.061462 / 0.043533 (0.017929) | 0.409448 / 0.255139 (0.154309) | 0.431557 / 0.283200 (0.148358) | 0.027795 / 0.141683 (-0.113888) | 1.837844 / 1.452155 (0.385690) | 1.862683 / 1.492716 (0.369967) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230500 / 0.018006 (0.212494) | 0.483139 / 0.000490 (0.482649) | 0.006517 / 0.000200 (0.006317) | 0.000143 / 0.000054 (0.000088) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033152 / 0.037411 (-0.004259) | 0.133673 / 0.014526 (0.119147) | 0.143853 / 0.176557 (-0.032704) | 0.215254 / 0.737135 (-0.521882) | 0.150676 / 0.296338 (-0.145662) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.503796 / 0.215209 (0.288587) | 5.049981 / 2.077655 (2.972326) | 2.399427 / 1.504120 (0.895307) | 2.167635 / 1.541195 (0.626441) | 2.257448 / 1.468490 (0.788958) | 0.641298 / 4.584777 (-3.943479) | 4.828676 / 3.745712 (1.082964) | 4.346069 / 5.269862 (-0.923793) | 2.103890 / 4.565676 (-2.461786) | 0.079115 / 0.424275 (-0.345160) | 0.013377 / 0.007607 (0.005770) | 0.621207 / 0.226044 (0.395162) | 6.190939 / 2.268929 (3.922011) | 2.920129 / 55.444624 (-52.524495) | 2.549225 / 6.876477 (-4.327252) | 2.719221 / 2.142072 (0.577149) | 0.790949 / 4.805227 (-4.014278) | 0.172032 / 6.500664 (-6.328632) | 0.077779 / 0.075469 (0.002310) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.432572 / 1.841788 (-0.409216) | 21.000031 / 8.074308 (12.925723) | 17.555093 / 10.191392 (7.363701) | 0.166646 / 0.680424 (-0.513778) | 0.020451 / 0.534201 (-0.513750) | 0.488767 / 0.579283 (-0.090516) | 0.737036 / 0.434364 (0.302672) | 0.621694 / 0.540337 (0.081356) | 0.732074 / 1.386936 (-0.654862) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008198 / 0.011353 (-0.003155) | 0.004987 / 0.011008 (-0.006021) | 0.090714 / 0.038508 (0.052206) | 0.053379 / 0.023109 (0.030270) | 0.425199 / 0.275898 (0.149301) | 0.514036 / 0.323480 (0.190556) | 0.006043 / 0.007986 (-0.001943) | 0.003888 / 0.004328 (-0.000441) | 0.088294 / 0.004250 (0.084043) | 0.073024 / 0.037052 (0.035971) | 0.435983 / 0.258489 (0.177494) | 0.514293 / 0.293841 (0.220452) | 0.039451 / 0.128546 (-0.089095) | 0.010439 / 0.075646 (-0.065207) | 0.096885 / 0.419271 (-0.322387) | 0.060165 / 0.043533 (0.016632) | 0.421053 / 0.255139 (0.165914) | 0.455545 / 0.283200 (0.172345) | 0.027234 / 0.141683 (-0.114449) | 1.768975 / 1.452155 (0.316820) | 1.842853 / 1.492716 (0.350137) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.278940 / 0.018006 (0.260933) | 0.480709 / 0.000490 (0.480219) | 0.000436 / 0.000200 (0.000236) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034900 / 0.037411 (-0.002511) | 0.144893 / 0.014526 (0.130368) | 0.149567 / 0.176557 (-0.026989) | 0.213200 / 0.737135 (-0.523935) | 0.156735 / 0.296338 (-0.139604) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.535897 / 0.215209 (0.320687) | 5.336998 / 2.077655 (3.259343) | 2.685854 / 1.504120 (1.181734) | 2.470177 / 1.541195 (0.928983) | 2.547495 / 1.468490 (1.079004) | 0.642830 / 4.584777 (-3.941947) | 4.595866 / 3.745712 (0.850154) | 2.186696 / 5.269862 (-3.083165) | 1.317969 / 4.565676 (-3.247708) | 0.079268 / 0.424275 (-0.345007) | 0.013792 / 0.007607 (0.006185) | 0.662236 / 0.226044 (0.436192) | 6.604775 / 2.268929 (4.335847) | 3.355888 / 55.444624 (-52.088736) | 2.968911 / 6.876477 (-3.907565) | 3.121862 / 2.142072 (0.979790) | 0.794752 / 4.805227 (-4.010475) | 0.170800 / 6.500664 (-6.329864) | 0.078393 / 0.075469 (0.002924) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.601605 / 1.841788 (-0.240183) | 20.743553 / 8.074308 (12.669245) | 17.543968 / 10.191392 (7.352576) | 0.221884 / 0.680424 (-0.458540) | 0.020779 / 0.534201 (-0.513422) | 0.479677 / 0.579283 (-0.099606) | 0.516207 / 0.434364 (0.081843) | 0.564046 / 0.540337 (0.023709) | 0.711336 / 1.386936 (-0.675600) |\n\n</details>\n</details>\n\n\n",
"Yes, sounds great! Thanks",
"yup"
] |
https://api.github.com/repos/huggingface/datasets/issues/105 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/105/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/105/comments | https://api.github.com/repos/huggingface/datasets/issues/105/events | https://github.com/huggingface/datasets/pull/105 | 618,345,191 | MDExOlB1bGxSZXF1ZXN0NDE4MDg5Njgz | 105 | [New structure on AWS] Adapt paths | [] | closed | false | null | 0 | 2020-05-14T15:55:57Z | 2020-05-14T15:56:28Z | 2020-05-14T15:56:27Z | null | Some small changes so that we have the correct paths. @julien-c | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/105/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/105/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/105.diff",
"html_url": "https://github.com/huggingface/datasets/pull/105",
"merged_at": "2020-05-14T15:56:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/105.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/105"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5141 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5141/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5141/comments | https://api.github.com/repos/huggingface/datasets/issues/5141/events | https://github.com/huggingface/datasets/pull/5141 | 1,415,479,438 | PR_kwDODunzps5BIp1l | 5,141 | Raise ImportError instead of OSError | [] | closed | false | null | 2 | 2022-10-19T19:30:05Z | 2022-10-25T15:59:25Z | 2022-10-25T15:56:58Z | null | fixes #5134 : Replaced OSError with ImportError if required extraction library is not installed. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5141/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5141/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5141.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5141",
"merged_at": "2022-10-25T15:56:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5141.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5141"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks @mariosasko ,i commited the changes as you said.\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4715/comments | https://api.github.com/repos/huggingface/datasets/issues/4715/events | https://github.com/huggingface/datasets/pull/4715 | 1,309,405,980 | PR_kwDODunzps47pSui | 4,715 | Fix POS tags | [] | closed | false | null | 2 | 2022-07-19T11:52:54Z | 2022-07-19T12:54:34Z | 2022-07-19T12:41:16Z | null | We're now using `part-of-speech` and not `part-of-speech-tagging`, see discussion here: https://github.com/huggingface/datasets/commit/114c09aff2fa1519597b46fbcd5a8e0c0d3ae020#r78794777 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4715/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4715/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4715.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4715",
"merged_at": "2022-07-19T12:41:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4715.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4715"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are about missing content in the dataset cards or bad tags, and this is unrelated to this PR. Merging :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3155 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3155/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3155/comments | https://api.github.com/repos/huggingface/datasets/issues/3155/events | https://github.com/huggingface/datasets/issues/3155 | 1,034,468,757 | I_kwDODunzps49qL2V | 3,155 | Illegal instruction (core dumped) at datasets import | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-10-24T17:21:36Z | 2021-11-18T19:07:04Z | 2021-11-18T19:07:03Z | null | ## Describe the bug
I install datasets using conda and when I import datasets I get: "Illegal instruction (core dumped)"
## Steps to reproduce the bug
```
conda create --prefix path/to/env
conda activate path/to/env
conda install -c huggingface -c conda-forge datasets
# exits with output "Illegal instruction (core dumped)"
python -m datasets
```
## Environment info
When I run "datasets-cli env", I also get "Illegal instruction (core dumped)"
If I run the following commands:
```
conda create --prefix path/to/another/new/env
conda activate path/to/another/new/env
conda install -c huggingface transformers
transformers-cli env
```
Then I get:
- `transformers` version: 4.11.3
- Platform: Linux-5.4.0-67-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
Let me know what additional information you need in order to debug this issue. Thanks in advance! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3155/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3155/timeline | null | completed | null | null | false | [
"It seems to be an issue with how conda-forge is building the binaries. It works on some machines, but not a machine with AMD Opteron 8384 processors."
] |
https://api.github.com/repos/huggingface/datasets/issues/2633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2633/comments | https://api.github.com/repos/huggingface/datasets/issues/2633/events | https://github.com/huggingface/datasets/pull/2633 | 942,396,414 | MDExOlB1bGxSZXF1ZXN0Njg4MTMwOTA5 | 2,633 | Update ASR tags | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-05T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/6",
"id": 6836458,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/6/labels",
"node_id": "MDk6TWlsZXN0b25lNjgzNjQ1OA==",
"number": 6,
"open_issues": 0,
"state": "closed",
"title": "1.10",
"updated_at": "2021-07-21T15:36:49Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/6"
} | 0 | 2021-07-12T19:58:31Z | 2021-07-13T05:45:26Z | 2021-07-13T05:45:13Z | null | This PR updates the ASR tags of the 5 datasets added in #2565 following the change of task categories in #2620 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2633/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2633/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2633.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2633",
"merged_at": "2021-07-13T05:45:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2633.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2633"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1771 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1771/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1771/comments | https://api.github.com/repos/huggingface/datasets/issues/1771/events | https://github.com/huggingface/datasets/issues/1771 | 792,701,276 | MDU6SXNzdWU3OTI3MDEyNzY= | 1,771 | Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.1/datasets/csv/csv.py | [] | closed | false | null | 3 | 2021-01-24T01:53:52Z | 2021-01-24T23:06:29Z | 2021-01-24T23:06:29Z | null | Hi,
When I load_dataset from local csv files, below error happened, looks raw.githubusercontent.com was blocked by the chinese government. But why it need to download csv.py? should it include when pip install the dataset?
```
Traceback (most recent call last):
File "/home/tom/pyenv/pystory/lib/python3.6/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/home/tom/pyenv/pystory/lib/python3.6/site-packages/datasets/utils/file_utils.py", line 343, in cached_path
max_retries=download_config.max_retries,
File "/home/tom/pyenv/pystory/lib/python3.6/site-packages/datasets/utils/file_utils.py", line 617, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.1/datasets/csv/csv.py
``` | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1771/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1771/timeline | null | completed | null | null | false | [
"I temporary manually download csv.py as custom dataset loading script",
"Indeed in 1.2.1 the script to process csv file is downloaded. Starting from the next release though we include the csv processing directly in the library.\r\nSee PR #1726 \r\nWe'll do a new release soon :)",
"Thanks."
] |
https://api.github.com/repos/huggingface/datasets/issues/1830 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1830/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1830/comments | https://api.github.com/repos/huggingface/datasets/issues/1830/events | https://github.com/huggingface/datasets/issues/1830 | 802,790,075 | MDU6SXNzdWU4MDI3OTAwNzU= | 1,830 | using map on loaded Tokenizer 10x - 100x slower than default Tokenizer? | [] | open | false | null | 9 | 2021-02-06T21:00:26Z | 2021-02-24T21:56:14Z | null | null | This could total relate to me misunderstanding particular call functions, but I added words to a GPT2Tokenizer, and saved it to disk (note I'm only showing snippets but I can share more) and the map function ran much slower:
````
def save_tokenizer(original_tokenizer,text,path="simpledata/tokenizer"):
words_unique = set(text.split(" "))
for i in words_unique:
original_tokenizer.add_tokens(i)
original_tokenizer.save_pretrained(path)
tokenizer2 = GPT2Tokenizer.from_pretrained(os.path.join(experiment_path,experiment_name,"tokenizer_squad"))
train_set_baby=Dataset.from_dict({"text":[train_set["text"][0][0:50]]})
````
I then applied the dataset map function on a fairly small set of text:
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The run time for train_set_baby.map was 6 seconds, and the batch itself was 2.6 seconds
**100% 1/1 [00:02<00:00, 2.60s/ba] CPU times: user 5.96 s, sys: 36 ms, total: 5.99 s Wall time: 5.99 s**
In comparison using (even after adding additional tokens):
`
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")`
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The time is
**100% 1/1 [00:00<00:00, 34.09ba/s] CPU times: user 68.1 ms, sys: 16 µs, total: 68.1 ms Wall time: 62.9 ms**
It seems this might relate to the tokenizer save or load function, however, the issue appears to come up when I apply the loaded tokenizer to the map function.
I should also add that playing around with the amount of words I add to the tokenizer before I save it to disk and load it into memory appears to impact the time it takes to run the map function.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1830/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1830/timeline | null | null | null | null | false | [
"Hi @wumpusman \r\n`datasets` has a caching mechanism that allows to cache the results of `.map` so that when you want to re-run it later it doesn't recompute it again.\r\nSo when you do `.map`, what actually happens is:\r\n1. compute the hash used to identify your `map` for the cache\r\n2. apply your function on every batch\r\n\r\nThis can explain the time difference between your different experiments.\r\n\r\nThe hash computation time depends of how complex your function is. For a tokenizer, the hash computation scans the lists of the words in the tokenizer to identify this tokenizer. Usually it takes 2-3 seconds.\r\n\r\nAlso note that you can disable caching though using\r\n```python\r\nimport datasets\r\n\r\ndatasets.set_caching_enabled(False)\r\n```",
"Hi @lhoestq ,\r\n\r\nThanks for the reply. It's entirely possible that is the issue. Since it's a side project I won't be looking at it till later this week, but, I'll verify it by disabling caching and hopefully I'll see the same runtime. \r\n\r\nAppreciate the reference,\r\n\r\nMichael",
"I believe this is an actual issue, tokenizing a ~4GB txt file went from an hour and a half to ~10 minutes when I switched from my pre-trained tokenizer(on the same dataset) to the default gpt2 tokenizer.\r\nBoth were loaded using:\r\n```\r\nAutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)\r\n```\r\nI trained the tokenizer using ByteLevelBPETokenizer from the Tokenizers library and save it to a tokenizer.json file.\r\n\r\nI have tested the caching ideas above, changing the number of process, the TOKENIZERS_PARALLELISM env variable, keep_in_memory=True and batching with different sizes.\r\n\r\nApologies I can't really upload much code, but wanted to back up the finding and hopefully a fix/the problem can be found.\r\nI will comment back if I find a fix as well.",
"Hi @johncookds do you think this can come from one tokenizer being faster than the other one ? Can you try to compare their speed without using `datasets` just to make sure ?",
"Hi yes, I'm closing the loop here with some timings below. The issue seems to be at least somewhat/mainly with the tokenizer's themselves. Moreover legacy saves of the trainer tokenizer perform faster but differently than the new tokenizer.json saves(note nothing about the training process/adding of special tokens changed between the top two trained tokenizer tests, only the way it was saved). This is only a 3x slowdown vs like a 10x but I think the slowdown is most likely due to this.\r\n\r\n```\r\ntrained tokenizer - tokenizer.json save (same results for AutoTokenizer legacy_format=False):\r\nTokenizer time(seconds): 0.32767510414123535\r\nTokenized avg. length: 323.01\r\n\r\ntrained tokenizer - AutoTokenizer legacy_format=True:\r\nTokenizer time(seconds): 0.09258866310119629\r\nTokenized avg. length: 301.01\r\n\r\nGPT2 Tokenizer from huggingface\r\nTokenizer time(seconds): 0.1010282039642334\r\nTokenized avg. length: 461.21\r\n```",
"@lhoestq ,\r\n\r\nHi, which version of datasets has datasets.set_caching_enabled(False)? I get \r\nmodule 'datasets' has no attribute 'set_caching_enabled'. To hopefully get around this, I reran my code on a new set of data, and did so only once.\r\n\r\n@johncookds , thanks for chiming in, it looks this might be an issue of Tokenizer.\r\n\r\n**Tokenizer**: The runtime of GPT2TokenizerFast.from_pretrained(\"gpt2\") on 1000 chars is: **143 ms**\r\n**SlowTokenizer**: The runtime of a locally saved and loaded Tokenizer using the same vocab on 1000 chars is: **4.43 s**\r\n\r\nThat being said, I compared performance on the map function:\r\n\r\nRunning Tokenizer versus using it in the map function for 1000 chars goes from **141 ms** to **356 ms** \r\nRunning SlowTokenizer versus using it in the map function for 1000 chars with a single element goes from **4.43 s** to **9.76 s**\r\n\r\nI'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\n@lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nRegards,\r\n\r\nMichael",
"Thanks for the experiments @johncookds and @wumpusman ! \r\n\r\n> Hi, which version of datasets has datasets.set_caching_enabled(False)?\r\n\r\nCurrently you have to install `datasets` from source to have this feature, but this will be available in the next release in a few days.\r\n\r\n> I'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\nCould you also try with double the number of characters ? This should let us have an idea of the fixed cost (hashing) and the dynamic cost (actual tokenization, grows with the size of the input)\r\n\r\n> @lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nFeel free to post an issue on the `transformers` repo. Also I'm sure there should be related issues so you can also look for someone with the same concerns on the `transformers` repo.",
"@lhoestq,\r\n\r\nI just checked that previous run time was actually 3000 chars. I increased it to 6k chars, again, roughly double.\r\n\r\nSlowTokenizer **7.4 s** to **15.7 s**\r\nTokenizer: **276 ms** to **616 ms**\r\n\r\nI'll post this issue on Tokenizer, seems it hasn't quite been raised (albeit I noticed a similar issue that might relate).\r\n\r\nRegards,\r\n\r\nMichael",
"Hi, \r\nI'm following up here as I found my exact issue. It was with saving and re-loading the tokenizer. When I trained then processed the data without saving and reloading it, it was 10x-100x faster than when I saved and re-loaded it.\r\nBoth resulted in the exact same tokenized datasets as well. \r\nThere is additionally a bug where the older legacy tokenizer save does not preserve a learned tokenizing behavior if trained from scratch.\r\nUnderstand its not exactly Datasets related but hope it can help someone if they have the same issue.\r\nThanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3826 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3826/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3826/comments | https://api.github.com/repos/huggingface/datasets/issues/3826/events | https://github.com/huggingface/datasets/pull/3826 | 1,159,851,110 | PR_kwDODunzps4z90JU | 3,826 | Add IterableDataset.filter | [] | closed | false | null | 2 | 2022-03-04T16:57:23Z | 2022-03-09T17:23:13Z | 2022-03-09T17:23:11Z | null | _Needs https://github.com/huggingface/datasets/pull/3801 to be merged first_
I added `IterableDataset.filter` with an API that is a subset of `Dataset.filter`:
```python
def filter(self, function, batched=False, batch_size=1000, with_indices=false, input_columns=None):
```
TODO:
- [x] tests
- [x] docs
related to https://github.com/huggingface/datasets/issues/3444 and https://github.com/huggingface/datasets/issues/3753 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3826/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3826/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3826.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3826",
"merged_at": "2022-03-09T17:23:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3826.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3826"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3826). All of your documentation changes will be reflected on that endpoint.",
"Indeed ! If `batch_size` is `None` or `<=0` then the full dataset should be passed. It's been mentioned in the docs for a while but never actually implemented. We can fix that later"
] |
https://api.github.com/repos/huggingface/datasets/issues/2541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2541/comments | https://api.github.com/repos/huggingface/datasets/issues/2541/events | https://github.com/huggingface/datasets/pull/2541 | 928,529,078 | MDExOlB1bGxSZXF1ZXN0Njc2NTIwNDgx | 2,541 | update discofuse link cc @ekQ | [] | closed | false | null | 1 | 2021-06-23T18:24:58Z | 2021-06-28T14:34:51Z | 2021-06-28T14:34:50Z | null | Updating the discofuse link: https://github.com/google-research-datasets/discofuse/commit/fd4b120cb3dd19a417e7f3b5432010b574b5eeee | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2541/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2541.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2541",
"merged_at": "2021-06-28T14:34:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2541.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2541"
} | true | [
"The CI is failing because the dataset tags for `discofuse` are missing. I'm merging this PR since this is unrelated to this PR, but feel free to open another PR to add the tags here if you have some time:\r\n\r\nhttps://github.com/huggingface/datasets/blob/19408f9fab85c79b966085574cd2da3b90959179/datasets/discofuse/README.md#L1-L5\r\n\r\nThe missing tags are:\r\n```\r\n'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'pretty_name', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'\r\n```\r\nThanks again !"
] |
https://api.github.com/repos/huggingface/datasets/issues/3130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3130/comments | https://api.github.com/repos/huggingface/datasets/issues/3130/events | https://github.com/huggingface/datasets/pull/3130 | 1,032,299,417 | PR_kwDODunzps4tfBJU | 3,130 | Create SECURITY.md | [] | closed | false | null | 1 | 2021-10-21T10:03:03Z | 2021-10-21T14:33:28Z | 2021-10-21T14:31:50Z | null | To let the repository confirm feedback@huggingface.co as its security contact. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3130/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3130/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3130.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3130",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3130.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3130"
} | true | [
"Hi @zidingz, thanks for your contribution.\r\n\r\nHowever I am closing it because it is a duplicate of a previous PR:\r\n - #2958\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1358/comments | https://api.github.com/repos/huggingface/datasets/issues/1358/events | https://github.com/huggingface/datasets/pull/1358 | 760,031,131 | MDExOlB1bGxSZXF1ZXN0NTM0OTI5ODIx | 1,358 | Add spider dataset | [] | closed | false | null | 0 | 2020-12-09T06:06:18Z | 2020-12-10T15:12:31Z | 2020-12-10T15:12:31Z | null | This PR adds the Spider dataset, a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students. The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.
Dataset website: https://yale-lily.github.io/spider
Paper link: https://www.aclweb.org/anthology/D18-1425/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1358/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1358.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1358",
"merged_at": "2020-12-10T15:12:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1358.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1358"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5170 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5170/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5170/comments | https://api.github.com/repos/huggingface/datasets/issues/5170/events | https://github.com/huggingface/datasets/issues/5170 | 1,425,301,835 | I_kwDODunzps5U9GFL | 5,170 | [Caching] Deterministic hashing of torch tensors | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2022-10-27T09:15:15Z | 2022-11-02T17:18:43Z | 2022-11-02T17:18:43Z | null | Currently this fails
```python
import torch
from datasets.fingerprint import Hasher
t = torch.tensor([1.])
def func(x):
return t + x
hash1 = Hasher.hash(func)
t = torch.tensor([1.])
hash2 = Hasher.hash(func)
assert hash1 == hash2
```
Also as noticed in https://discuss.huggingface.co/t/dataset-cant-cache-models-outputs/24945, using a model in a `map` function doesn't work well with caching. Indeed the `bert-base-uncased` model has a different hash every time you reload it. Supporting torch tensors may also help in this case.
This can be fixed by registering a custom pickling functions for torch tensors - as we did for other objects such as CodeType, FunctionType and Regex in `py_utils.py` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5170/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5170/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5912 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5912/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5912/comments | https://api.github.com/repos/huggingface/datasets/issues/5912/events | https://github.com/huggingface/datasets/issues/5912 | 1,730,299,852 | I_kwDODunzps5nIkfM | 5,912 | Missing elements in `map` a batched dataset | [] | closed | false | null | 1 | 2023-05-29T08:09:19Z | 2023-07-26T15:48:15Z | 2023-07-26T15:48:15Z | null | ### Describe the bug
As outlined [here](https://discuss.huggingface.co/t/length-error-using-map-with-datasets/40969/3?u=sachin), the following collate function drops 5 out of possible 6 elements in the batch (it is 6 because out of the eight, two are bad links in laion). A reproducible [kaggle kernel ](https://www.kaggle.com/sachin/laion-hf-dataset/edit) can be found here.
The weirdest part is when inspecting the sizes of the tensors as shown below, both `tokenized_captions["input_ids"]` and `image_features` show the correct shapes. Simply the output only has one element (with the batch dimension squeezed out).
```python
class CollateFn:
def get_image(self, url):
try:
response = requests.get(url)
return Image.open(io.BytesIO(response.content)).convert("RGB")
except PIL.UnidentifiedImageError:
logger.info(f"Reading error: Could not transform f{url}")
return None
except requests.exceptions.ConnectionError:
logger.info(f"Connection error: Could not transform f{url}")
return None
def __call__(self, batch):
images = [self.get_image(url) for url in batch["url"]]
captions = [caption for caption, image in zip(batch["caption"], images) if image is not None]
images = [image for image in images if image is not None]
tokenized_captions = tokenizer(
captions,
padding="max_length",
truncation=True,
max_length=tokenizer.model_max_length,
return_tensors="pt",
)
image_features = torch.stack([torch.Tensor(feature_extractor(image)["pixel_values"][0]) for image in images])
# import pdb; pdb.set_trace()
return {"input_ids": tokenized_captions["input_ids"], "images": image_features}
collate_fn = CollateFn()
laion_ds = datasets.load_dataset("laion/laion400m", split="train", streaming=True)
laion_ds_batched = laion_ds.map(collate_fn, batched=True, batch_size=8, remove_columns=next(iter(laion_ds)).keys())
```
### Steps to reproduce the bug
A reproducible [kaggle kernel ](https://www.kaggle.com/sachin/laion-hf-dataset/edit) can be found here.
### Expected behavior
Would expect `next(iter(laion_ds_batched))` to produce two tensors of shape `(batch_size, 77)` and `batch_size, image_shape`.
### Environment info
datasets==2.12.0
python==3.10 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5912/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5912/timeline | null | completed | null | null | false | [
"Hi ! in your code batching is **only used within** `map`, to process examples in batch. The dataset itself however is not batched and returns elements one by one.\r\n\r\nTo iterate on batches, you can do\r\n```python\r\nfor batch in dataset.iter(batch_size=8):\r\n ...\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/2250 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2250/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2250/comments | https://api.github.com/repos/huggingface/datasets/issues/2250/events | https://github.com/huggingface/datasets/issues/2250 | 865,402,449 | MDU6SXNzdWU4NjU0MDI0NDk= | 2,250 | some issue in loading local txt file as Dataset for run_mlm.py | [] | closed | false | null | 2 | 2021-04-22T19:39:13Z | 2022-03-30T08:29:47Z | 2022-03-30T08:29:47Z | null | 
first of all, I tried to load 3 .txt files as a dataset (sure that the directory and permission is OK.), I face with the below error.
> FileNotFoundError: [Errno 2] No such file or directory: 'c'
by removing one of the training .txt files It's fixed and although if I put all file as training it's ok


after this, my question is how could I use this defined Dataset for run_mlm.py for from scratch pretraining.
by using --train_file path_to_train_file just can use one .txt , .csv or, .json file. I tried to set my defined Dataset as --dataset_name but the below issue occurs.
> Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/datasets/load.py", line 336, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py", line 291, in cached_path
use_auth_token=download_config.use_auth_token,
File "/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py", line 621, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/dataset/dataset.py
> During handling of the above exception, another exception occurred:
> Traceback (most recent call last):
File "run_mlm.py", line 486, in <module>
main()
File "run_mlm.py", line 242, in main
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
File "/usr/local/lib/python3.7/dist-packages/datasets/load.py", line 719, in load_dataset
use_auth_token=use_auth_token,
File "/usr/local/lib/python3.7/dist-packages/datasets/load.py", line 347, in prepare_module
combined_path, github_file_path
FileNotFoundError: Couldn't find file locally at dataset/dataset.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.6.0/datasets/dataset/dataset.py.
The file is also not present on the master branch on github.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2250/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2250/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\n1. try\r\n ```python\r\n dataset = load_dataset(\"text\", data_files={\"train\": [\"a1.txt\", \"b1.txt\"], \"test\": [\"c1.txt\"]})\r\n ```\r\n instead.\r\n\r\n Sadly, I can't reproduce the error on my machine. If the above code doesn't resolve the issue, try to update the library to the \r\n newest version (`pip install datasets --upgrade`).\r\n\r\n2. https://github.com/huggingface/transformers/blob/3ed5e97ba04ce9b24b4a7161ea74572598a4c480/examples/pytorch/language-modeling/run_mlm.py#L258-L259\r\nThis is the original code. You'll have to modify the example source to work with multiple train files. To make it easier, let's say \"|\" will act as a delimiter between files:\r\n ```python\r\n if data_args.train_file is not None:\r\n data_files[\"train\"] = data_args.train_file.split(\"|\") # + .split(\"|\")\r\n ```\r\n Then call the script as follows (**dataset_name must be None**):\r\n ```bash\r\n python run_mlm.py [... other args] --train_file a1.txt|b1.txt\r\n ```",
"i meet the same error with datasets 1.11.0, is there any insight about this?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4686/comments | https://api.github.com/repos/huggingface/datasets/issues/4686/events | https://github.com/huggingface/datasets/pull/4686 | 1,305,974,924 | PR_kwDODunzps47d8Jf | 4,686 | Align logging with Transformers (again) | [] | closed | false | null | 2 | 2022-07-15T12:24:29Z | 2023-07-11T18:29:27Z | 2023-07-11T18:29:27Z | null | Fix #2832 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4686/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/4686.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4686",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4686.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4686"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4686). All of your documentation changes will be reflected on that endpoint.",
"I wasn't aware of https://github.com/huggingface/datasets/pull/1845 before opening this PR. This issue seems much more complex now ..."
] |
https://api.github.com/repos/huggingface/datasets/issues/880 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/880/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/880/comments | https://api.github.com/repos/huggingface/datasets/issues/880/events | https://github.com/huggingface/datasets/issues/880 | 748,949,606 | MDU6SXNzdWU3NDg5NDk2MDY= | 880 | Add SQA | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 3 | 2020-11-23T16:31:55Z | 2020-12-23T13:58:24Z | 2020-12-23T13:58:23Z | null | ## Adding a Dataset
- **Name:** SQA (Sequential Question Answering) by Microsoft.
- **Description:** The SQA dataset was created to explore the task of answering sequences of inter-related questions on HTML tables. It has 6,066 sequences with 17,553 questions in total.
- **Paper:** https://www.microsoft.com/en-us/research/publication/search-based-neural-structured-learning-sequential-question-answering/
- **Data:** https://www.microsoft.com/en-us/download/details.aspx?id=54253
- **Motivation:** currently, the [Tapas](https://ai.googleblog.com/2020/04/using-neural-networks-to-find-answers.html) algorithm by Google AI is being added to the Transformers library (see https://github.com/huggingface/transformers/pull/8113). It would be great to use that model in combination with this dataset, on which it achieves SOTA results (average question accuracy of 0.71).
Note 1: this dataset actually consists of 2 types of files:
1) TSV files, containing the questions, answer coordinates and answer texts (for training, dev and test)
2) a folder of csv files, which contain the actual tabular data
Note 2: if you download the dataset straight from the download link above, then you will see that the `answer_coordinates` and `answer_text` columns are string lists of string tuples and strings respectively, which is not ideal. It would be better to make them true Python lists of tuples and strings respectively (using `ast.literal_eval`), before uploading them to the HuggingFace hub.
Adding this would be great! Then we could possibly also add [WTQ (WikiTable Questions)](https://github.com/ppasupat/WikiTableQuestions) and [TabFact (Tabular Fact Checking)](https://github.com/wenhuchen/Table-Fact-Checking) on which TAPAS also achieves state-of-the-art results. Note that the TAPAS algorithm requires these datasets to first be converted into the SQA format.
Instructions to add a new dataset can be found [here](https://huggingface.co/docs/datasets/share_dataset.html).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/880/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/880/timeline | null | completed | null | null | false | [
"I’ll take this one to test the workflow for the sprint next week cc @yjernite @lhoestq ",
"@thomwolf here's a slightly adapted version of the code from the [official Tapas repository](https://github.com/google-research/tapas/blob/master/tapas/utils/interaction_utils.py) that is used to turn the `answer_coordinates` and `answer_texts` columns into true Python lists of tuples/strings:\r\n\r\n```\r\nimport pandas as pd\r\nimport ast\r\n\r\ndata = pd.read_csv(\"/content/sqa_data/random-split-1-dev.tsv\", sep='\\t')\r\n\r\ndef _parse_answer_coordinates(answer_coordinate_str):\r\n \"\"\"Parses the answer_coordinates of a question.\r\n Args:\r\n answer_coordinate_str: A string representation of a Python list of tuple\r\n strings.\r\n For example: \"['(1, 4)','(1, 3)', ...]\"\r\n \"\"\"\r\n\r\n try:\r\n answer_coordinates = []\r\n # make a list of strings\r\n coords = ast.literal_eval(answer_coordinate_str)\r\n # parse each string as a tuple\r\n for row_index, column_index in sorted(\r\n ast.literal_eval(coord) for coord in coords):\r\n answer_coordinates.append((row_index, column_index))\r\n except SyntaxError:\r\n raise ValueError('Unable to evaluate %s' % answer_coordinate_str)\r\n \r\n return answer_coordinates\r\n\r\n\r\ndef _parse_answer_text(answer_text):\r\n \"\"\"Populates the answer_texts field of `answer` by parsing `answer_text`.\r\n Args:\r\n answer_text: A string representation of a Python list of strings.\r\n For example: \"[u'test', u'hello', ...]\"\r\n \"\"\"\r\n try:\r\n answer = []\r\n for value in ast.literal_eval(answer_text):\r\n answer.append(value)\r\n except SyntaxError:\r\n raise ValueError('Unable to evaluate %s' % answer_text)\r\n\r\n return answer\r\n\r\ndata['answer_coordinates'] = data['answer_coordinates'].apply(lambda coords_str: _parse_answer_coordinates(coords_str))\r\ndata['answer_text'] = data['answer_text'].apply(lambda txt: _parse_answer_text(txt))\r\n```\r\n\r\nHere I'm using Pandas to read in one of the TSV files (the dev set). \r\n\r\n",
"Closing since SQA was added in #1566 "
] |
https://api.github.com/repos/huggingface/datasets/issues/884 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/884/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/884/comments | https://api.github.com/repos/huggingface/datasets/issues/884/events | https://github.com/huggingface/datasets/pull/884 | 749,862,034 | MDExOlB1bGxSZXF1ZXN0NTI2NjA5MDc1 | 884 | Auto generate dummy data | [] | closed | false | null | 3 | 2020-11-24T16:31:34Z | 2020-11-26T14:18:47Z | 2020-11-26T14:18:46Z | null | When adding a new dataset to the library, dummy data creation can take some time.
To make things easier I added a command line tool that automatically generates dummy data when possible.
The tool only supports certain data files types: txt, csv, tsv, jsonl, json and xml.
Here are some examples:
```
python datasets-cli dummy_data ./datasets/snli --auto_generate
python datasets-cli dummy_data ./datasets/squad --auto_generate --json_field data
python datasets-cli dummy_data ./datasets/iwslt2017 --auto_generate --xml_tag seg --match_text_files "train*" --n_lines 15
# --xml_tag seg => each sample corresponds to a "seg" tag in the xml tree
# --match_text_files "train*" => also match text files that don't have a proper text file extension (no suffix like ".txt" for example)
# --n_lines 15 => some text files have headers so we have to use at least 15 lines
```
and here is the command usage:
```
usage: datasets-cli <command> [<args>] dummy_data [-h] [--auto_generate]
[--n_lines N_LINES]
[--json_field JSON_FIELD]
[--xml_tag XML_TAG]
[--match_text_files MATCH_TEXT_FILES]
[--keep_uncompressed]
[--cache_dir CACHE_DIR]
path_to_dataset
positional arguments:
path_to_dataset Path to the dataset (example: ./datasets/squad)
optional arguments:
-h, --help show this help message and exit
--auto_generate Try to automatically generate dummy data
--n_lines N_LINES Number of lines or samples to keep when auto-
generating dummy data
--json_field JSON_FIELD
Optional, json field to read the data from when auto-
generating dummy data. In the json data files, this
field must point to a list of samples as json objects
(ex: the 'data' field for squad-like files)
--xml_tag XML_TAG Optional, xml tag name of the samples inside the xml
files when auto-generating dummy data.
--match_text_files MATCH_TEXT_FILES
Optional, a comma separated list of file patterns that
looks for line-by-line text files other than *.txt or
*.csv. Example: --match_text_files *.label
--keep_uncompressed Don't compress the dummy data folders when auto-
generating dummy data. Useful for debugging for to do
manual adjustements before compressing.
--cache_dir CACHE_DIR
Cache directory to download and cache files when auto-
generating dummy data
```
The command generates all the necessary `dummy_data.zip` files (one per config).
How it works:
- it runs the split_generators() method of the dataset script to download the original data files
- when downloading it records a mapping between the downloaded files and the corresponding expected dummy data files paths
- then for each data file it creates the dummy data file keeping only the first samples (the strategy depends on the type of file)
- finally it compresses the dummy data folders into dummy_zip files ready for dataset tests
Let me know if that makes sense or if you have ideas to improve this tool !
I also added a unit test. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/884/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/884/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/884.diff",
"html_url": "https://github.com/huggingface/datasets/pull/884",
"merged_at": "2020-11-26T14:18:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/884.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/884"
} | true | [
"I took your comments into account.\r\nAlso now after compressing the dummy_data.zip file it runs a dummy data test (=make sure each split has at least 1 example using the dummy data)",
"I just tested the tool with some datasets and found out that it's not working for datasets that download files using `download_and_extract(file_url)` (where file_url is a `str`). That's because in that case the dummy_data.zip is not a folder but a single zipped file.\r\n\r\nI think we have to fix that or we can have unexpected behavior when a scripts calls `download_and_extract(file_url)` several times, since it would always point to the same dummy data file.\r\n\r\nSo I decided to change that to have a folder containing the dummy files instead but it breaks around 90 tests so I need to update 90 dummy data files to follow this scheme. I'll probably fix them tomorrow morning.\r\n\r\nWhat do you guys think ? Also cc @patrickvonplaten to make sure I understand things correctly",
"Ok I changed to use the dummy_data.zip content to be a folder even for single url calls to `dl_manager.download_and_extract`. Therefore the automatic dummy data generation tool works for most datasets now.\r\n\r\nTo avoid having to change all the old dummy_data.zip files I added backward compatiblity. \r\n\r\nThe only test failing is `tests/test_dataset_common.py::RemoteDatasetTest::test_load_dataset_xcopa`\r\nIt is expected to fail since I had modify its dummy data structure that was wrong. It was causing issue with backward compatibility. It will be fixed as soon as this PR is merged"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.