
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3983 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3983/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3983/comments | https://api.github.com/repos/huggingface/datasets/issues/3983/events | https://github.com/huggingface/datasets/issues/3983 | 1,175,759,412 | I_kwDODunzps5GFKo0 | 3,983 | Infinitely attempting lock | [] | closed | false | null | 1 | 2022-03-21T18:11:57Z | 2022-05-06T16:12:18Z | 2022-05-06T16:12:18Z | null | I am trying to run one of the examples of the `transformers` repo, which makes use of `datasets`.
Important to note is that I am trying to run this via a Databricks notebook, and all the files reside in the Databricks Filesystem (DBFS).
```
%sh
python /dbfs/transformers/examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /dbfs/transformers/tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate \
--log_level debug \
--cache_dir /dbfs/transformers/cache
```
All goes well until acquiring a lock --
```
03/21/2022 17:53:19 - DEBUG - datasets.utils.filelock - Attempting to acquire lock 140386484514192 on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock
03/21/2022 17:53:19 - DEBUG - datasets.utils.filelock - Lock 140386484514192 not acquired on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock, waiting 0.05 seconds ...
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Attempting to acquire lock 140386484514192 on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Lock 140386484514192 not acquired on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock, waiting 0.05 seconds ...
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Attempting to acquire lock 140386484514192 on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Lock 140386484514192 not acquired on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock, waiting 0.05 seconds ...
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Attempting to acquire lock 140386484514192 on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Lock 140386484514192 not acquired on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock, waiting 0.05 seconds ...
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Attempting to acquire lock 140386484514192 on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Lock 140386484514192 not acquired on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock, waiting 0.05 seconds ...
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Attempting to acquire lock 140386484514192 on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock
03/21/2022 17:53:20 - DEBUG - datasets.utils.filelock - Lock 140386484514192 not acquired on /dbfs/transformers/cache/_dbfs_transformers_cache_cnn_dailymail_3.0.0_3.0.0_3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234.lock, waiting 0.05 seconds ...
```
and so on.
I imagine this has to do with DBFS -- is there a way to tackle this? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3983/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3983/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting. We're using `py-filelock` as our locking mechanism.\r\n\r\nCan you try deleting the .lock file mentioned in the logs and try again ? Make sure that no other process is generating the `cnn_dailymail` dataset.\r\n\r\nIf it doesn't work, could you try to set up a lock using the latest version of `py-filelock` and see if it works ?\r\n\r\n```\r\npip install filelock\r\n```\r\nhere is a code example from the `py-filelock` documentation that you can try:\r\n```python\r\nfrom filelock import Timeout, FileLock\r\n\r\nlock = FileLock(\"high_ground.txt.lock\")\r\nwith lock:\r\n with open(\"high_ground.txt\", \"a\") as f:\r\n f.write(\"You were the chosen one.\")\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/1386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1386/comments | https://api.github.com/repos/huggingface/datasets/issues/1386/events | https://github.com/huggingface/datasets/pull/1386 | 760,365,505 | MDExOlB1bGxSZXF1ZXN0NTM1MjA5NDUx | 1,386 | Add RecipeNLG Dataset (manual download) | [] | closed | false | null | 1 | 2020-12-09T14:13:19Z | 2020-12-10T16:58:22Z | 2020-12-10T16:58:21Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1386/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1386.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1386",
"merged_at": "2020-12-10T16:58:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1386.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1386"
} | true | [
"@lhoestq yes. I asked the authors for direct link but unfortunately we need to fill a form (captcha)"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/5244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5244/comments | https://api.github.com/repos/huggingface/datasets/issues/5244/events | https://github.com/huggingface/datasets/issues/5244 | 1,450,019,225 | I_kwDODunzps5WbYmZ | 5,244 | Allow dataset streaming from private a private source when loading a dataset with a dataset loading script | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 5 | 2022-11-15T16:02:10Z | 2022-11-23T14:02:30Z | null | null | ### Feature request
Add arguments to the function _get_authentication_headers_for_url_ like custom_endpoint and custom_token in order to add flexibility when downloading files from a private source.
It should also be possible to provide these arguments from the dataset loading script, maybe giving them to the dl_manager
### Motivation
It is possible to share a dataset hosted on another platform by writing a dataset loading script. It works perfectly for publicly available resources.
For resources that require authentication, you can provide a [download_custom](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadManager) method to the download_manager.
Unfortunately, this function doesn't work with **dataset streaming**.
A solution so as to allow dataset streaming from private sources would be a more flexible _get_authentication_headers_for_url_ function.
### Your contribution
Would you be interested in this improvement ?
If so I could provide a PR. I've got something working locally, but it's not very clean, I'd need some guidance regarding integration. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5244/timeline | null | null | null | null | false | [
"Hi ! What kind of private source ? We're exploring adding support for cloud storage and URIs like s3://, gs:// etc. with authentication in the download manager",
"Hello! It's a google cloud storage, so gs://, but I'm using it with https.\r\nBeing able to provide a file system like [here](https://huggingface.co/docs/datasets/main/filesystems#load-serialized-datasets) would be even more practical indeed.\r\nI've found a quite complicated workaround which consists of monkey patching all of the functions in streaming_download_manager.py to use my own _get_authentication_headers_for_url_ . \r\n\r\nA support for this use case would be greatly appreciated!\r\n\r\nFor reference my _get_authentication_headers_for_url_ looks like this:\r\n```\r\nimport os\r\nfrom typing import Optional, Union\r\n\r\nfrom datasets import config\r\nfrom huggingface_hub import HfFolder\r\nfrom gcsfs.credentials import GoogleCredentials\r\n\r\nDEFAULT_PROJECT = os.environ.get(\"GCSFS_DEFAULT_PROJECT\", \"\")\r\naccess = \"full_control\"\r\ngcs_token = os.environ.get(\"GCS_TOKEN\")\r\n\r\n\r\ndef get_authentication_headers_for_url(url: str, use_auth_token: Optional[Union[str, bool]] = None) -> dict:\r\n \"\"\"Handle the HF authentication\"\"\"\r\n headers = {}\r\n if url.startswith(config.HF_ENDPOINT):\r\n if use_auth_token is False:\r\n token = None\r\n elif isinstance(use_auth_token, str):\r\n token = use_auth_token\r\n else:\r\n token = HfFolder.get_token()\r\n elif url.startswith(\"https://storage.googleapis.com\"):\r\n credentials = GoogleCredentials(DEFAULT_PROJECT, access, gcs_token)\r\n credentials.maybe_refresh()\r\n token = credentials.credentials.token\r\n else:\r\n token = None\r\n if token:\r\n headers[\"authorization\"] = f\"Bearer {token}\"\r\n return headers\r\n```",
"I would be a big fan of this feature! @Hubert-Bonisseur if this doesn't become a supported feature, would you mind sharing your code? Thanks!",
"> I would be a big fan of this feature! @Hubert-Bonisseur if this doesn't become a supported feature, would you mind sharing your code? Thanks!\r\n\r\nI published it here:\r\nhttps://github.com/Hubert-Bonisseur/private-dataset-hub\r\n\r\nI modified the names of a lot of functions for privacy and I don't have time to test it again so you may get import errors, but you have the code. The custom_load_dataset is the function you are interested in I think.\r\n\r\nIt relies a lot on patching, if you find a better way to do this, I'd be interested.",
"Given the amount of patching it does, this is likely to break at one point. I'd encourage you to wait for a proper support in `datasets` directly if you can wait."
] |
https://api.github.com/repos/huggingface/datasets/issues/5818 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5818/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5818/comments | https://api.github.com/repos/huggingface/datasets/issues/5818/events | https://github.com/huggingface/datasets/issues/5818 | 1,695,052,555 | I_kwDODunzps5lCHML | 5,818 | Ability to update a dataset | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 3 | 2023-05-04T01:08:13Z | 2023-05-04T20:43:39Z | null | null | ### Feature request
The ability to load a dataset, add or change something, and save it back to disk.
Maybe it's possible, but I can't work out how to do it, e.g. this fails:
```py
import datasets
dataset = datasets.load_from_disk("data/test1")
dataset = dataset.add_item({"text": "A new item"})
dataset.save_to_disk("data/test1")
```
With the error:
```
PermissionError: Tried to overwrite /mnt/c/Users/david/py/learning/mini_projects/data_sorting_and_filtering/data/test1 but a dataset can't overwrite itself.
```
### Motivation
My use case is that I want to process a dataset in a particular way but it doesn't fit in memory if I do it in one go. So I want to perform a loop and at each step in the loop, process one shard and append it to an ever-growing dataset. The code in the loop will load a dataset, add some rows, then save it again.
Maybe I'm just thinking about things incorrectly and there's a better approach. FWIW I can't use `dataset.map()` to do the task because that doesn't work with `num_proc` when adding rows, so is confined to a single process which is too slow.
The only other way I can think of is to create a new file each time, but surely that's not how people do this sort of thing.
### Your contribution
na | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5818/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5818/timeline | null | null | null | null | false | [
"This [reply](https://discuss.huggingface.co/t/how-do-i-add-things-rows-to-an-already-saved-dataset/27423) from @mariosasko on the forums may be useful :)",
"In this case, I think we can avoid the `PermissionError` by unpacking the underlying `ConcatenationTable` and saving only the newly added data blocks (in new files).",
"Thanks @stevhliu and @mariosasko , so saving to individual files then loading them later, concatenating again and saving again is the recommended way. Good to know.\r\n\r\nQuestion that I hope doesn't sound rude: is this sort of thing (processing a dataset that doesn't fit in memory) outside of `datasets`'s core area of focus? Are there other tools you would recommend to do this sort of thing that play nice with `datasets`? Or is it just that I've found myself in a niche situation that hasn't specifically been catered for?"
] |
https://api.github.com/repos/huggingface/datasets/issues/63 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/63/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/63/comments | https://api.github.com/repos/huggingface/datasets/issues/63/events | https://github.com/huggingface/datasets/pull/63 | 614,666,365 | MDExOlB1bGxSZXF1ZXN0NDE1MTczODU5 | 63 | [Dataset scripts] add all datasets scripts | [] | closed | false | null | 0 | 2020-05-08T10:50:15Z | 2020-05-08T17:39:22Z | 2020-05-08T11:34:00Z | null | As mentioned, we can have the canonical datasets in the master. For now I also want to include all the data as present on S3 to make the synchronization easier when uploading new datastes.
@mariamabarham @lhoestq @thomwolf - what do you think?
If this is ok for you, I can sync up the master with the `add_dataset` branch: https://github.com/huggingface/nlp/pull/37 so that master is up to date. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/63/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/63/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/63.diff",
"html_url": "https://github.com/huggingface/datasets/pull/63",
"merged_at": "2020-05-08T11:34:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/63.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/63"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1573/comments | https://api.github.com/repos/huggingface/datasets/issues/1573/events | https://github.com/huggingface/datasets/pull/1573 | 767,011,938 | MDExOlB1bGxSZXF1ZXN0NTM5ODYyNjcx | 1,573 | adding dataset for diplomacy detection-2 | [] | closed | false | null | 0 | 2020-12-14T23:21:37Z | 2020-12-14T23:36:57Z | 2020-12-14T23:36:57Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1573/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1573/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1573.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1573",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1573.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1573"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/2117 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2117/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2117/comments | https://api.github.com/repos/huggingface/datasets/issues/2117/events | https://github.com/huggingface/datasets/issues/2117 | 841,535,283 | MDU6SXNzdWU4NDE1MzUyODM= | 2,117 | load_metric from local "glue.py" meet error 'NoneType' object is not callable | [] | closed | false | null | 3 | 2021-03-26T02:35:22Z | 2021-08-25T21:44:05Z | 2021-03-26T02:40:26Z | null | actual_task = "mnli" if task == "mnli-mm" else task
dataset = load_dataset(path='/home/glue.py', name=actual_task)
metric = load_metric(path='/home/glue.py', name=actual_task)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-8-7ab77a465d81> in <module>
1 actual_task = "mnli" if task == "mnli-mm" else task
2 dataset = load_dataset(path='/home/jcli/glue.py', name=actual_task)
----> 3 metric = load_metric(path='/home/jcli/glue.py', name=actual_task)
~/anaconda3/envs/pytorch/lib/python3.6/site-packages/datasets/load.py in load_metric(path, config_name, process_id, num_process, cache_dir, experiment_id, keep_in_memory, download_config, download_mode, script_version, **metric_init_kwargs)
508 keep_in_memory=keep_in_memory,
509 experiment_id=experiment_id,
--> 510 **metric_init_kwargs,
511 )
512
TypeError: 'NoneType' object is not callable
Please help | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2117/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2117/timeline | null | completed | null | null | false | [
"@Frankie123421 what was the resolution to this?",
"> @Frankie123421 what was the resolution to this?\r\n\r\nuse glue_metric.py instead of glue.py in load_metric",
"thank you!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5689/comments | https://api.github.com/repos/huggingface/datasets/issues/5689/events | https://github.com/huggingface/datasets/pull/5689 | 1,648,956,349 | PR_kwDODunzps5NVMuI | 5,689 | Support streaming Beam datasets from HF GCS preprocessed data | [] | closed | false | null | 4 | 2023-03-31T08:44:24Z | 2023-04-12T05:57:55Z | 2023-04-12T05:50:31Z | null | This PR implements streaming Apache Beam datasets that are already preprocessed by us and stored in the HF Google Cloud Storage:
- natural_questions
- wiki40b
- wikipedia
This is done by streaming from the prepared Arrow files in HF Google Cloud Storage.
This will fix their corresponding dataset viewers. Related to:
- https://github.com/huggingface/datasets-server/pull/988#discussion_r1150767138
Related to:
- https://huggingface.co/datasets/natural_questions/discussions/4
- https://huggingface.co/datasets/wiki40b/discussions/2
- https://huggingface.co/datasets/wikipedia/discussions/9
CC: @severo | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5689/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5689/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5689.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5689",
"merged_at": "2023-04-12T05:50:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5689.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5689"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"wikipedia\", \"20220301.en\", split=\"train\", streaming=True); item = next(iter(ds)); item\r\nOut[2]: \r\n{'id': '12',\r\n 'url': 'https://en.wikipedia.org/wiki/Anarchism',\r\n 'title': 'Anarchism',\r\n 'text': 'Anarchism is a political philosophy and movement that is sceptical of authority and rejects all involuntary, coercive forms of hierarchy. Anarchism calls for the abolition of the state, which it holds to be unnecessary, undesirable, and harmful. As a historically left-wing movement, placed on the farthest left of the political spectrum, it is usually described alongside communalism and libertarian Marxism as the libertarian wing (libertarian socialism) of the socialist movement,...}\r\n```",
"I love your example 🏴🅰️",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007859 / 0.011353 (-0.003493) | 0.005129 / 0.011008 (-0.005879) | 0.098070 / 0.038508 (0.059562) | 0.036500 / 0.023109 (0.013391) | 0.311575 / 0.275898 (0.035677) | 0.338351 / 0.323480 (0.014872) | 0.005962 / 0.007986 (-0.002024) | 0.004060 / 0.004328 (-0.000268) | 0.072970 / 0.004250 (0.068719) | 0.049289 / 0.037052 (0.012237) | 0.310303 / 0.258489 (0.051814) | 0.347449 / 0.293841 (0.053608) | 0.046912 / 0.128546 (-0.081634) | 0.011952 / 0.075646 (-0.063694) | 0.333600 / 0.419271 (-0.085671) | 0.052700 / 0.043533 (0.009167) | 0.325486 / 0.255139 (0.070347) | 0.326920 / 0.283200 (0.043720) | 0.107683 / 0.141683 (-0.034000) | 1.416679 / 1.452155 (-0.035476) | 1.502418 / 1.492716 (0.009702) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216520 / 0.018006 (0.198514) | 0.448450 / 0.000490 (0.447960) | 0.004213 / 0.000200 (0.004013) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027081 / 0.037411 (-0.010331) | 0.110989 / 0.014526 (0.096463) | 0.116087 / 0.176557 (-0.060470) | 0.173771 / 0.737135 (-0.563364) | 0.121240 / 0.296338 (-0.175099) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399938 / 0.215209 (0.184729) | 4.017665 / 2.077655 (1.940010) | 1.782327 / 1.504120 (0.278207) | 1.612955 / 1.541195 (0.071761) | 1.698839 / 1.468490 (0.230349) | 0.706702 / 4.584777 (-3.878075) | 4.533425 / 3.745712 (0.787713) | 2.102611 / 5.269862 (-3.167250) | 1.461429 / 4.565676 (-3.104248) | 0.085719 / 0.424275 (-0.338556) | 0.012104 / 0.007607 (0.004497) | 0.507397 / 0.226044 (0.281352) | 5.061572 / 2.268929 (2.792643) | 2.272106 / 55.444624 (-53.172518) | 1.935575 / 6.876477 (-4.940901) | 2.102541 / 2.142072 (-0.039532) | 0.838395 / 4.805227 (-3.966832) | 0.168573 / 6.500664 (-6.332091) | 0.064234 / 0.075469 (-0.011235) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.190077 / 1.841788 (-0.651710) | 15.765587 / 8.074308 (7.691279) | 14.694626 / 10.191392 (4.503234) | 0.142912 / 0.680424 (-0.537512) | 0.017669 / 0.534201 (-0.516532) | 0.421502 / 0.579283 (-0.157781) | 0.452732 / 0.434364 (0.018368) | 0.497480 / 0.540337 (-0.042857) | 0.586310 / 1.386936 (-0.800626) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007629 / 0.011353 (-0.003724) | 0.005330 / 0.011008 (-0.005679) | 0.076366 / 0.038508 (0.037858) | 0.034703 / 0.023109 (0.011593) | 0.356300 / 0.275898 (0.080402) | 0.392909 / 0.323480 (0.069429) | 0.005959 / 0.007986 (-0.002026) | 0.004140 / 0.004328 (-0.000188) | 0.075289 / 0.004250 (0.071039) | 0.047880 / 0.037052 (0.010828) | 0.357289 / 0.258489 (0.098800) | 0.404554 / 0.293841 (0.110714) | 0.037182 / 0.128546 (-0.091365) | 0.012266 / 0.075646 (-0.063380) | 0.088554 / 0.419271 (-0.330718) | 0.049698 / 0.043533 (0.006165) | 0.353453 / 0.255139 (0.098314) | 0.373252 / 0.283200 (0.090052) | 0.101892 / 0.141683 (-0.039791) | 1.481534 / 1.452155 (0.029380) | 1.553818 / 1.492716 (0.061102) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229891 / 0.018006 (0.211884) | 0.452444 / 0.000490 (0.451954) | 0.000434 / 0.000200 (0.000234) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030170 / 0.037411 (-0.007241) | 0.115097 / 0.014526 (0.100571) | 0.122094 / 0.176557 (-0.054463) | 0.171352 / 0.737135 (-0.565784) | 0.128441 / 0.296338 (-0.167898) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428347 / 0.215209 (0.213138) | 4.266243 / 2.077655 (2.188588) | 2.148327 / 1.504120 (0.644207) | 1.874141 / 1.541195 (0.332946) | 1.968737 / 1.468490 (0.500246) | 0.715320 / 4.584777 (-3.869457) | 4.166097 / 3.745712 (0.420384) | 2.169550 / 5.269862 (-3.100312) | 1.377441 / 4.565676 (-3.188236) | 0.086376 / 0.424275 (-0.337899) | 0.012018 / 0.007607 (0.004411) | 0.517433 / 0.226044 (0.291388) | 5.167327 / 2.268929 (2.898398) | 2.545822 / 55.444624 (-52.898803) | 2.241726 / 6.876477 (-4.634751) | 2.327220 / 2.142072 (0.185147) | 0.841618 / 4.805227 (-3.963609) | 0.169473 / 6.500664 (-6.331191) | 0.065505 / 0.075469 (-0.009964) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.270476 / 1.841788 (-0.571312) | 17.049885 / 8.074308 (8.975577) | 14.847615 / 10.191392 (4.656223) | 0.168671 / 0.680424 (-0.511753) | 0.017564 / 0.534201 (-0.516637) | 0.424780 / 0.579283 (-0.154503) | 0.517392 / 0.434364 (0.083028) | 0.561197 / 0.540337 (0.020859) | 0.697792 / 1.386936 (-0.689144) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3122 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3122/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3122/comments | https://api.github.com/repos/huggingface/datasets/issues/3122/events | https://github.com/huggingface/datasets/issues/3122 | 1,031,787,509 | I_kwDODunzps49f9P1 | 3,122 | OSError with a custom dataset loading script | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 8 | 2021-10-20T20:08:39Z | 2021-11-23T09:55:38Z | 2021-11-23T09:55:38Z | null | ## Describe the bug
I am getting an OS error when trying to load the newly uploaded dataset classla/janes_tag. What puzzles me is that I have already uploaded a very similar dataset - classla/reldi_hr - with no issues. The loading scripts for the two datasets are almost identical and they have the same directory structure, yet I am only getting an error with janes_tag.
## Steps to reproduce the bug
```python
dataset = datasets.load_dataset('classla/janes_tag', split='validation')
```
## Expected results
Dataset correctly loaded.
## Actual results
Traceback (most recent call last):
File "C:/mypath/test.py", line 91, in <module>
load_and_print('janes_tag')
File "C:/mypath/test.py", line 32, in load_and_print
dataset = datasets.load_dataset('classla/{}'.format(ds_name), split='validation')
File "C:\mypath\venv\lib\site-packages\datasets\load.py", line 1632, in load_dataset
use_auth_token=use_auth_token,
File "C:\mypath\venv\lib\site-packages\datasets\builder.py", line 608, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "C:\mypath\venv\lib\site-packages\datasets\builder.py", line 704, in _download_and_prepare
) from None
OSError: Cannot find data file.
Original error:
[Errno 2] No such file or directory: 'C:\\mypath\\.cache\\huggingface\\datasets\\downloads\\2c9996e44bdc5af9c89bffb9e6d7a3e42fdb2f56bacab45de13b20f3032ea7ca\\data\\train_all.conllup'
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.5
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3122/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3122/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nthere is a difference in how the `data_dir` is zipped between the `classla/janes_tag` and the `classla/reldi_hr` dataset. After unzipping, for the former, the data files (`*.conllup`) are in the root directory (root -> data files), and for the latter, they are inside the `data` directory (root -> `data` -> data files).\r\n\r\nThis can be fixed by removing the `os.path.join` call in https://huggingface.co/datasets/classla/janes_tag/blob/main/janes_tag.py#L86\r\n\r\nLet me know if this works for you.",
"Hi Mario,\r\n\r\nI had already tried that before, but it didn't work. I have now recreated the `classla/janes_tag` zip file so that it also contains the `data` directory, but I am still getting the same error.",
"Hi,\r\n\r\nI just tried to download the `classla/janes_tag` dataset, and this time the zip file is extracted correctly. However, the script is now throwing the IndexError, probably due to a bug in the `_generate_examples`.\r\n\r\nLet me know if you are still getting the same error.",
"I am still getting the same error.",
"Hi, \r\n\r\ncould you try to download the dataset with a different `cache_dir` like so:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('classla/janes_tag', split='validation', cache_dir=\"path/to/different/cache/dir\")\r\n```\r\nIf this works, then most likely the cached extracted data is causing issues. This data is stored at `~/.cache/huggingface/datasets/downloads/extracted` and needs to be deleted, and then it should work (you can easily locate the directory with the path given in the `OSError` message). Additionally, I'd suggest you to update `datasets` to the newest version with:\r\n```\r\npip install -U datasets\r\n```",
"Thank you, deleting the `~/.cache/huggingface/datasets/downloads/extracted` directory helped. However, I am still having problems.\r\n\r\nThere was indeed a bug in the script that was throwing an `IndexError`, which I have now corrected (added the condition to skip the lines starting with '# text') and it is working locally, but still throws an error when I try to load the dataset from HuggingFace. I literally copied and pasted the `_generate_examples` function and ran it on the `dev_all.conllup` file, which I even re-downloaded from the repository to be certain that the files are exactly the same. I also deleted everything again just in case, but it didn't help. The code works locally, but throws an `IndexError` when loading from `datasets.`",
"Hi,\r\n\r\nDid some investigation.\r\n\r\nTo fix the dataset script on the Hub, append the following labels to the `names` list of the `upos_tags` field:\r\n```'INTJ NOUN', 'AUX PRON', 'PART ADV', 'PRON ADP', 'INTJ INTJ', 'VERB NOUN', 'NOUN AUX'```.\r\n\r\nThis step is required to avoid an error due to missing labels in the following step which is:\r\n```python\r\nload_dataset(\"classla/janes_tag\", split=\"validation\", download_mode=\"force_redownload\")\r\n```\r\nThis will generate and cache the dataset, so specifying `download_mode` will not be required anymore unless you update the script/data on the Hub.",
"It works now, thank you!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3491 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3491/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3491/comments | https://api.github.com/repos/huggingface/datasets/issues/3491/events | https://github.com/huggingface/datasets/issues/3491 | 1,089,918,018 | I_kwDODunzps5A9tRC | 3,491 | Update version of pib dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 0 | 2021-12-28T14:03:58Z | 2021-12-29T08:42:57Z | 2021-12-29T08:42:57Z | null | On the Hub we have v0, while there exists v1.3.
Related to bigscience-workshop/data_tooling#130
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3491/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3491/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/861 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/861/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/861/comments | https://api.github.com/repos/huggingface/datasets/issues/861/events | https://github.com/huggingface/datasets/issues/861 | 744,753,458 | MDU6SXNzdWU3NDQ3NTM0NTg= | 861 | Possible Bug: Small training/dataset file creates gigantic output | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | 7 | 2020-11-17T13:48:59Z | 2021-03-30T14:04:04Z | 2021-03-22T12:04:55Z | null | Hey guys,
I was trying to create a new bert model from scratch via _huggingface transformers + tokenizers + dataets_ (actually using this example script by your team: https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py). It was supposed to be a first test with a small 5 GB raw text file but I can't even end the preprocessing handled by datasets because this tiny 5 GB text file becomes more than 1 TB when processing. My system was running out of space and crashed prematurely.
I've done training from scratch via Google's bert repo in the past and I can remember that the resulting pretraining data can become quite big. But 5 GB becoming 1 TB was never the case. Is this considered normal or is it a bug?
I've used the following CMD:
`python xla_spawn.py --num_cores=8 run_mlm.py --model_type bert --config_name config.json --tokenizer_name tokenizer.json --train_file dataset_full.txt --do_train --output_dir out --max_steps 500000 --save_steps 2500 --save_total_limit 2 --prediction_loss_only --line_by_line --max_seq_length 128 --pad_to_max_length --preprocessing_num_workers 16 --per_device_train_batch_size 128 --overwrite_output_dir --debug`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/861/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/861/timeline | null | completed | null | null | false | [
"The preprocessing tokenizes the input text. Tokenization outputs `input_ids`, `attention_mask`, `token_type_ids` and `special_tokens_mask`. All those are of length`max_seq_length` because of padding. Therefore for each sample it generate 4 *`max_seq_length` integers. Currently they're all saved as int64. This is why the tokenization takes so much space.\r\n\r\nI'm sure we can optimize that though\r\nWhat do you think @sgugger ?",
"First I think we should disable padding in the dataset processing and let the data collator do it.\r\n\r\nThen I'm wondering if you need attention_mask and token_type_ids at this point ?\r\n\r\nFinally we can also specify the output feature types at this line https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py#L280 to use more optimized integer precisions for the output. Maybe something like:\r\n- input_ids: uint16 or uint32\r\n- token_type_ids: uint8 or bool\r\n- attention_mask: bool\r\n- special_tokens_mask: bool\r\n\r\nAlso IMO these changes are all on the `transformers` side. Maybe we should discuss on the `transformers` repo",
"> First I think we should disable padding in the dataset processing and let the data collator do it.\r\n\r\nNo, you can't do that on TPUs as dynamic shapes will result in a very slow training. The script can however be tweaked to use the `PaddingDataCollator` with a fixed max length instead of dynamic batching.\r\n\r\nFor the other optimizations, they can be done by changing the script directly for each user's use case. Not sure we can find something that is general enough to be in transformers or the examples script.",
"Oh yes right..\r\nDo you think that a lazy map feature on the `datasets` side could help to avoid storing padded tokenized texts then ?",
"I think I can do the tweak mentioned above with the data collator as short fix (but fully focused on v4 right now so that will be for later this week, beginning of next week :-) ).\r\nIf it doesn't hurt performance to tokenize on the fly, that would clearly be the long-term solution however!",
"> Hey guys,\r\n> \r\n> I was trying to create a new bert model from scratch via _huggingface transformers + tokenizers + dataets_ (actually using this example script by your team: https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py). It was supposed to be a first test with a small 5 GB raw text file but I can't even end the preprocessing handled by datasets because this tiny 5 GB text file becomes more than 1 TB when processing. My system was running out of space and crashed prematurely.\r\n> \r\n> I've done training from scratch via Google's bert repo in the past and I can remember that the resulting pretraining data can become quite big. But 5 GB becoming 1 TB was never the case. Is this considered normal or is it a bug?\r\n> \r\n> I've used the following CMD:\r\n> `python xla_spawn.py --num_cores=8 run_mlm.py --model_type bert --config_name config.json --tokenizer_name tokenizer.json --train_file dataset_full.txt --do_train --output_dir out --max_steps 500000 --save_steps 2500 --save_total_limit 2 --prediction_loss_only --line_by_line --max_seq_length 128 --pad_to_max_length --preprocessing_num_workers 16 --per_device_train_batch_size 128 --overwrite_output_dir --debug`\r\n\r\nIt's actually because of the parameter 'preprocessing_num_worker' when using TPU. \r\nI am also planning to have my model trained on the google TPU with a 11gb text corpus. With x8 cores enabled, each TPU core has its own dataset. When not using distributed training, the preprocessed file is about 77gb. On the opposite, if enable xla, the file produced will easily consume all my free space(more than 220gb, I think it will be, in the end, around 600gb ). \r\nSo I think that's maybe where the problem came from. \r\n\r\nIs there any possibility that all of the cores share the same preprocess dataset?\r\n\r\n@sgugger @RammMaschine ",
"Hi @NebelAI, we have optimized Datasets' disk usage in the latest release v1.5.\r\n\r\nFeel free to update your Datasets version\r\n```shell\r\npip install -U datasets\r\n```\r\nand see if it better suits your needs."
] |
https://api.github.com/repos/huggingface/datasets/issues/1143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1143/comments | https://api.github.com/repos/huggingface/datasets/issues/1143/events | https://github.com/huggingface/datasets/pull/1143 | 757,448,920 | MDExOlB1bGxSZXF1ZXN0NTMyODI0NzMx | 1,143 | Add the Winograd Schema Challenge | [] | closed | false | null | 0 | 2020-12-04T22:26:59Z | 2020-12-09T15:11:31Z | 2020-12-09T09:32:34Z | null | Adds the Winograd Schema Challenge, including configs for the more canonical wsc273 as well as wsc285 with 12 new examples.
- https://cs.nyu.edu/faculty/davise/papers/WinogradSchemas/WS.html
The data format was a bit of a nightmare but I think I got it to a workable format. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1143/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1143/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1143.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1143",
"merged_at": "2020-12-09T09:32:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1143.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1143"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5156/comments | https://api.github.com/repos/huggingface/datasets/issues/5156/events | https://github.com/huggingface/datasets/issues/5156 | 1,421,667,125 | I_kwDODunzps5UvOs1 | 5,156 | Unable to download dataset using Azure Data Lake Gen 2 | [] | closed | false | null | 2 | 2022-10-25T00:43:18Z | 2022-11-17T23:37:09Z | 2022-11-17T23:37:08Z | null | ### Describe the bug
When using the DatasetBuilder method with the credentials for the cloud storage Azure Data Lake (adl) Gen2, the following error is showed:
```
Traceback (most recent call last):
File "download_hf_dataset.py", line 143, in <module>
main()
File "download_hf_dataset.py", line 102, in main
builder.download_and_prepare(save_dir, storage_options=storage_options, max_shard_size="250MB", file_format="parquet")
File "/home/clarisses/miniconda3/envs/hf_datasets_env/lib/python3.8/site-packages/datasets/builder.py", line 671, in download_and_prepare
fs_token_paths = fsspec.get_fs_token_paths(output_dir, storage_options=storage_options)
File "/home/clarisses/miniconda3/envs/hf_datasets_env/lib/python3.8/site-packages/fsspec/core.py", line 639, in get_fs_token_paths
fs = cls(**options)
File "/home/clarisses/miniconda3/envs/hf_datasets_env/lib/python3.8/site-packages/fsspec/spec.py", line 76, in __call__
obj = super().__call__(*args, **kwargs)
TypeError: __init__() got an unexpected keyword argument 'account_name'
```
If I don't pass the storage_options argument (leave it as None), it requires the credentials used in ADL Gen 1:
`TypeError: __init__() missing 3 required positional arguments: 'tenant_id', 'client_id', and 'client_secret'`
Thus, it is not possible to download a dataset from the cloud using Azure Data Lake (adl) Gen2.
### Steps to reproduce the bug
Assuming that you have an account on Azure and at Storage Account that can be used for reproduce:
1. Create a dict with the format to connect to Azure Data Lake Gen 2
```
storage_options = {"account_name": ACCOUNT_NAME, "account_key": ACCOUNT_KEY) # gen 2 filesystem
```
2. Create a dataset builder for any HF hosted dataset
```
builder = load_dataset_builder(dataset_name)
```
3. Try to download the dataset passing the storage_options as an argument
```
save_dir = 'adl://my_save_dir'
builder.download_and_prepare(save_dir, storage_options=storage_options, max_shard_size="250MB", file_format="parquet")
```
### Expected behavior
Not seeing the error mentioned above and being able to download the dataset to the provided path on ADL
### Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5156/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5156/timeline | null | completed | null | null | false | [
"Hi ! From the `adlfs` docs, there are two filesystems you can use:\r\n> To use the Gen1 filesystem:\r\n> - known_implementations[‘adl’] = {‘class’: ‘adlfs.AzureDatalakeFileSystem’}\r\n> \r\n> To use the Gen2 filesystem:\r\n> - known_implementations[‘abfs’] = {‘class’: ‘adlfs.AzureBlobFileSystem’}\r\n\r\nIf I'm not mistaken you're using the second one - so you should use `abfs://` instead of `adl://`, and also run this at the beginning of your script:\r\n```python\r\nfrom fsspec.registry import known_implementations\r\nknown_implementations['abfs'] = {'class': 'adlfs.AzureDatalakeFileSystem'}\r\n```\r\n\r\n",
"Thank you @lhoestq . Great call.\r\nUsing the default class from `known_implementations` dict solved my problem\r\n```\r\nknown_implementations[‘abfs’] = {‘class’: ‘adlfs.AzureBlobFileSystem’}\r\n```\r\nI'm closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/2673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2673/comments | https://api.github.com/repos/huggingface/datasets/issues/2673/events | https://github.com/huggingface/datasets/pull/2673 | 947,300,008 | MDExOlB1bGxSZXF1ZXN0NjkyMzAxMTgw | 2,673 | Fix potential DuplicatedKeysError in SQuAD | [] | closed | false | null | 0 | 2021-07-19T06:08:00Z | 2021-07-19T07:08:03Z | 2021-07-19T07:08:03Z | null | DONE:
- Fix potential DiplicatedKeysError by ensuring keys are unique.
- Align examples in the docs with SQuAD code.
We should promote as a good practice, that the keys should be programmatically generated as unique, instead of read from data (which might be not unique). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2673/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2673.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2673",
"merged_at": "2021-07-19T07:08:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2673.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2673"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2160 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2160/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2160/comments | https://api.github.com/repos/huggingface/datasets/issues/2160/events | https://github.com/huggingface/datasets/issues/2160 | 849,052,921 | MDU6SXNzdWU4NDkwNTI5MjE= | 2,160 | data_args.preprocessing_num_workers almost freezes | [] | closed | false | null | 2 | 2021-04-02T07:56:13Z | 2021-04-02T10:14:32Z | 2021-04-02T10:14:31Z | null | Hi @lhoestq
I am running this code from huggingface transformers https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py
to speed up tokenization, since I am running on multiple datasets, I am using data_args.preprocessing_num_workers = 4 with opus100 corpus but this moves on till a point and then this freezes almost for sometime during tokenization steps and then this is back again, overall to me taking more time than normal case, I appreciate your advice on how I can use this option properly to speed up.
thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2160/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2160/timeline | null | completed | null | null | false | [
"Hi.\r\nI cannot always reproduce this issue, and on later runs I did not see it so far. Sometimes also I set 8 processes but I see less being showed, is this normal, here only 5 are shown for 8 being set, thanks\r\n\r\n```\r\n#3: 11%|███████████████▊ | 172/1583 [00:46<06:21, 3.70ba/s]\r\n#4: 9%|█████████████▏ | 143/1583 [00:46<07:46, 3.09ba/s]\r\n#7: 6%|█████████ | 98/1583 [00:45<11:34, 2.14ba/s]\r\n#5: 8%|███████████▍ | 124/1583 [00:46<09:03, 2.68ba/s]\r\n#6: 7%|██████████▏ \r\n```",
"closing since I cannot reproduce it again, thanks "
] |
https://api.github.com/repos/huggingface/datasets/issues/4405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4405/comments | https://api.github.com/repos/huggingface/datasets/issues/4405/events | https://github.com/huggingface/datasets/issues/4405 | 1,248,574,087 | I_kwDODunzps5Ka7qH | 4,405 | [TypeError: Couldn't cast array of type] Cannot process dataset in v2.2.2 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-05-25T18:56:43Z | 2022-06-07T14:27:20Z | 2022-06-07T14:27:20Z | null | ## Describe the bug
I am trying to process the [conll2012_ontonotesv5](https://huggingface.co/datasets/conll2012_ontonotesv5) dataset in `datasets` v2.2.2 and am running into a type error when casting the features.
## Steps to reproduce the bug
```python
import os
from typing import (
List,
Dict,
)
from collections import (
defaultdict,
)
from dataclasses import (
dataclass,
)
from datasets import (
load_dataset,
)
@dataclass
class ConllConverter:
path: str
name: str
cache_dir: str
def __post_init__(
self,
):
self.dataset = load_dataset(
path=self.path,
name=self.name,
cache_dir=self.cache_dir,
)
def convert(
self,
):
class_label = self.dataset["train"].features["sentences"][0]["named_entities"].feature
# label_set = list(set([
# label.split("-")[1] if label != "O" else label for label in class_label.names
# ]))
def prepare_chunk(token, entity):
assert len(token) == len(entity)
# Sequence length
length = len(token)
# Variable used
entity_chunk = defaultdict(list)
idx = flag = 0
# While loop
while idx < length:
if entity[idx] == "O":
flag += 1
idx += 1
else:
iob_tp, lab_tp = entity[idx].split("-")
assert iob_tp == "B"
idx += 1
while idx < length and entity[idx].startswith("I-"):
idx += 1
entity_chunk[lab_tp].append(token[flag: idx])
flag = idx
entity_chunk = dict(entity_chunk)
# for label in label_set:
# if label != "O" and label not in entity_chunk.keys():
# entity_chunk[label] = None
return entity_chunk
def prepare_features(
batch: Dict[str, List],
) -> Dict[str, List]:
sentence = [
sent for doc_sent in batch["sentences"] for sent in doc_sent
]
feature = {
"sentence": list(),
}
for sent in sentence:
token = sent["words"]
entity = class_label.int2str(sent["named_entities"])
entity_chunk = prepare_chunk(token, entity)
sent_feat = {
"token": token,
"entity": entity,
"entity_chunk": entity_chunk,
}
feature["sentence"].append(sent_feat)
return feature
column_names = self.dataset.column_names["train"]
dataset = self.dataset.map(
function=prepare_features,
with_indices=False,
batched=True,
batch_size=3,
remove_columns=column_names,
num_proc=1,
)
dataset.save_to_disk(
dataset_dict_path=os.path.join("data", self.path, self.name)
)
if __name__ == "__main__":
converter = ConllConverter(
path="conll2012_ontonotesv5",
name="english_v4",
cache_dir="cache",
)
converter.convert()
```
## Expected results
I want to use the dataset to perform NER task and to change the label list into a {Entity Type: list of spans} format.
## Actual results
<details>
<summary>Traceback</summary>
```python
Traceback (most recent call last): | 0/81 [00:00<?, ?ba/s]
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/multiprocess/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 532, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 499, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/fingerprint.py", line 458, in wrapper
out = func(self, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2751, in _map_single
writer.write_batch(batch)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_writer.py", line 503, in write_batch
arrays.append(pa.array(typed_sequence))
File "pyarrow/array.pxi", line 230, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_writer.py", line 198, in __arrow_array__
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1675, in wrapper
return func(array, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1793, in cast_array_to_feature
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1793, in <listcomp>
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1675, in wrapper
return func(array, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1844, in cast_array_to_feature
raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
TypeError: Couldn't cast array of type
struct<CARDINAL: list<item: list<item: string>>, DATE: list<item: list<item: string>>, EVENT: list<item: list<item: string>>, FAC: list<item: list<item: string>>, GPE: list<item: list<item: string>>, LANGUAGE: list<item: list<item: string>>, LAW: list<item: list<item: string>>, LOC: list<item: list<item: string>>, MONEY: list<item: list<item: string>>, NORP: list<item: list<item: string>>, ORDINAL: list<item: list<item: string>>, ORG: list<item: list<item: string>>, PERCENT: list<item: list<item: string>>, PERSON: list<item: list<item: string>>, QUANTITY: list<item: list<item: string>>, TIME: list<item: list<item: string>>, WORK_OF_ART: list<item: list<item: string>>>
to
{'CARDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'DATE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'EVENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'FAC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'GPE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LAW': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LOC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'MONEY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'NORP': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORG': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERCENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERSON': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PRODUCT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'QUANTITY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'TIME': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'WORK_OF_ART': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None)}
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home2/jiangwangyi/workspace/work/Entity/dataconverter.py", line 110, in <module>
converter.convert()
File "/home2/jiangwangyi/workspace/work/Entity/dataconverter.py", line 91, in convert
dataset = self.dataset.map(
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/dataset_dict.py", line 770, in map
{
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/dataset_dict.py", line 771, in <dictcomp>
k: dataset.map(
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2459, in map
transformed_shards[index] = async_result.get()
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/multiprocess/pool.py", line 771, in get
raise self._value
TypeError: Couldn't cast array of type
struct<CARDINAL: list<item: list<item: string>>, DATE: list<item: list<item: string>>, EVENT: list<item: list<item: string>>, FAC: list<item: list<item: string>>, GPE: list<item: list<item: string>>, LANGUAGE: list<item: list<item: string>>, LAW: list<item: list<item: string>>, LOC: list<item: list<item: string>>, MONEY: list<item: list<item: string>>, NORP: list<item: list<item: string>>, ORDINAL: list<item: list<item: string>>, ORG: list<item: list<item: string>>, PERCENT: list<item: list<item: string>>, PERSON: list<item: list<item: string>>, QUANTITY: list<item: list<item: string>>, TIME: list<item: list<item: string>>, WORK_OF_ART: list<item: list<item: string>>>
to
{'CARDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'DATE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'EVENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'FAC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'GPE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LAW': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LOC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'MONEY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'NORP': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORG': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERCENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERSON': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PRODUCT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'QUANTITY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'TIME': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'WORK_OF_ART': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None)}
```
</details>
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.2
- Platform: Ubuntu 18.04
- Python version: 3.9.7
- PyArrow version: 7.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4405/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4405/timeline | null | completed | null | null | false | [
"And if the problem is that the way I am to construct the {Entity Type: list of spans} makes entity types without any spans hard to handle, is there a better way to meet the demand? Although I have verified that to make entity types without any spans to behave like `entity_chunk[label] = [[\"\"]]` can perform normally, I still wonder if there is a more elegant way?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4359/comments | https://api.github.com/repos/huggingface/datasets/issues/4359/events | https://github.com/huggingface/datasets/pull/4359 | 1,237,149,578 | PR_kwDODunzps434Pb6 | 4,359 | Fix Version equality | [] | closed | false | null | 1 | 2022-05-16T13:19:26Z | 2022-05-24T16:25:37Z | 2022-05-24T16:17:14Z | null | I think `Version` equality should align with other similar cases in Python, like:
```python
In [1]: "a" == 5, "a" == None
Out[1]: (False, False)
In [2]: "a" != 5, "a" != None
Out[2]: (True, True)
```
With this PR, we will get:
```python
In [3]: Version("1.0.0") == 5, Version("1.0.0") == None
Out[3]: (False, False)
In [4]: Version("1.0.0") != 5, Version("1.0.0") != None
Out[4]: (True, True)
```
Note I found this issue when `doc-builder` tried to compare:
```python
if param.default != inspect._empty
```
where `param.default` is an instance of `Version`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4359/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4359.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4359",
"merged_at": "2022-05-24T16:17:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4359.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4359"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/505/comments | https://api.github.com/repos/huggingface/datasets/issues/505/events | https://github.com/huggingface/datasets/pull/505 | 678,791,400 | MDExOlB1bGxSZXF1ZXN0NDY3NjgxMjY4 | 505 | tmp_file referenced before assignment | [] | closed | false | null | 2 | 2020-08-13T23:27:33Z | 2020-08-14T13:42:46Z | 2020-08-14T13:42:46Z | null | Just learning about this library - so might've not set up all the flags correctly, but was getting this error about "tmp_file". | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/505/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/505.diff",
"html_url": "https://github.com/huggingface/datasets/pull/505",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/505.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/505"
} | true | [
"Thanks for reporting the issue ! I'm creating a new PR to fix it and add tests.\r\n(I'm doing a new PR because I know there's some other place where it needs to be fixed)",
"I'm closing this one as I created the other PR."
] |
https://api.github.com/repos/huggingface/datasets/issues/3190 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3190/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3190/comments | https://api.github.com/repos/huggingface/datasets/issues/3190/events | https://github.com/huggingface/datasets/issues/3190 | 1,041,153,631 | I_kwDODunzps4-Dr5f | 3,190 | combination of shuffle and filter results in a bug | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2021-11-01T13:07:29Z | 2021-11-02T10:50:49Z | 2021-11-02T10:50:49Z | null | ## Describe the bug
Hi,
I would like to shuffle a dataset, then filter it based on each existing label. however, the combination of `filter`, `shuffle` seems to results in a bug. In the minimal example below, as you see in the filtered results, the filtered labels are not unique, meaning filter has not worked. Any suggestions as a temporary fix is appreciated @lhoestq.
Thanks.
Best regards
Rabeeh
## Steps to reproduce the bug
```python
import numpy as np
import datasets
datasets = datasets.load_dataset('super_glue', 'rte', script_version="master")
shuffled_data = datasets["train"].shuffle(seed=42)
for label in range(2):
print("label ", label)
data = shuffled_data.filter(lambda example: int(example['label']) == label)
print("length ", len(data), np.unique(data['label']))
```
## Expected results
Filtering per label, should only return the data with that specific label.
## Actual results
As you can see, filtered data per label, has still two labels of [0, 1]
```
label 0
length 1249 [0 1]
label 1
length 1241 [0 1]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: linux
- Python version: 3.7.11
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3190/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3190/timeline | null | completed | null | null | false | [
"I cannot reproduce this on master and pyarrow==4.0.1.\r\n",
"Hi ! There was a regression in `datasets` 1.12 that introduced this bug. It has been fixed in #3019 in 1.13\r\n\r\nCan you try to update `datasets` and try again ?",
"Thanks a lot, fixes with 1.13"
] |
https://api.github.com/repos/huggingface/datasets/issues/2087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2087/comments | https://api.github.com/repos/huggingface/datasets/issues/2087/events | https://github.com/huggingface/datasets/pull/2087 | 836,587,392 | MDExOlB1bGxSZXF1ZXN0NTk3MDg4NTk2 | 2,087 | Update metadata if dataset features are modified | [] | closed | false | null | 4 | 2021-03-20T02:05:23Z | 2021-04-09T09:25:33Z | 2021-04-09T09:25:33Z | null | This PR adds a decorator that updates the dataset metadata if a previously executed transform modifies its features.
Fixes #2083
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2087/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2087",
"merged_at": "2021-04-09T09:25:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2087"
} | true | [
"@lhoestq I'll try to add a test later if you think this approach with the wrapper is good.",
"Awesome thank you !\r\nYes this approach with a wrapper is good :)",
"@lhoestq Added a test. To verify that this change fixes the problem, replace:\r\n```\r\n!pip install datasets==1.5\r\n```\r\nwith:\r\n```\r\n!pip install git+https://github.com/mariosasko/datasets-1.git@update-metadata\r\n```\r\nin the first cell of the notebook that is attached to the linked issue.\r\n\r\nThe CI failure is unrelated I think (building the docs locally doesn't throw an error).",
"The CI fail for the docs has been fixed on master.\r\nMerging :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/329/comments | https://api.github.com/repos/huggingface/datasets/issues/329/events | https://github.com/huggingface/datasets/issues/329 | 648,446,979 | MDU6SXNzdWU2NDg0NDY5Nzk= | 329 | [Bug] FileLock dependency incompatible with filesystem | [] | closed | false | null | 9 | 2020-06-30T19:45:31Z | 2022-09-08T20:58:37Z | 2020-06-30T21:33:06Z | null | I'm downloading a dataset successfully with
`load_dataset("wikitext", "wikitext-2-raw-v1")`
But when I attempt to cache it on an external volume, it hangs indefinitely:
`load_dataset("wikitext", "wikitext-2-raw-v1", cache_dir="/fsx") # /fsx is an external volume mount`
The filesystem when hanging looks like this:
```bash
/fsx
----downloads
----94be...73.lock
----wikitext
----wikitext-2-raw
----wikitext-2-raw-1.0.0.incomplete
```
It appears that on this filesystem, the FileLock object is forever stuck in its "acquire" stage. I have verified that the issue lies specifically with the `filelock` dependency:
```python
open("/fsx/hello.txt").write("hello") # succeeds
from filelock import FileLock
with FileLock("/fsx/hello.lock"):
open("/fsx/hello.txt").write("hello") # hangs indefinitely
```
Has anyone else run into this issue? I'd raise it directly on the FileLock repo, but that project appears abandoned with the last update over a year ago. Or if there's a solution that would remove the FileLock dependency from the project, I would appreciate that. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/329/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/329/timeline | null | completed | null | null | false | [
"Hi, can you give details on your environment/os/packages versions/etc?",
"Environment is Ubuntu 18.04, Python 3.7.5, nlp==0.3.0, filelock=3.0.12.\r\n\r\nThe external volume is Amazon FSx for Lustre, and it by default creates files with limited permissions. My working theory is that FileLock creates a lockfile that isn't writable, and thus there's no way to acquire it by removing the .lock file. But Python is able to create new files and write to them outside of the FileLock package.\r\n\r\nWhen I attempt to use FileLock within a Docker container by writing to `/root/.cache/hello.txt`, it succeeds. So there's some permissions issue. But it's not a Docker configuration issue; I've replicated it without Docker.\r\n```bash\r\necho \"hello world\" >> hello.txt\r\nls -l\r\n\r\n-rw-rw-r-- 1 ubuntu ubuntu 10 Jun 30 19:52 hello.txt\r\n```",
"Looks like the `flock` syscall does not work on Lustre filesystems by default: https://github.com/benediktschmitt/py-filelock/issues/67.\r\n\r\nI added the `-o flock` option when mounting the filesystem, as [described here](https://docs.aws.amazon.com/fsx/latest/LustreGuide/getting-started-step2.html), which fixed the issue.",
"Awesome, thanks a lot for sharing your fix!",
"I'm wondering if this can be revisited. In some managed environments the same person using HF cannot change the file-system mount flags, (and the organization may be unwilling to change these flags due to other concerns) but can ensure that there won't be concurrent writes, for example because HF is offline and the models/datasets were downloaded earlier. \r\n\r\nThe real fix would be to FileLock itself, which does not seem very active and seems to not deal with failed system flock calls , which would be one way to fix this, as they mention in the issue below also raised by @jarednielsen \r\n\r\nhttps://github.com/tox-dev/py-filelock/issues/67",
"> I'm wondering if this can be revisited. In some managed environments the same person using HF cannot change the file-system mount flags, (and the organization may be unwilling to change these flags due to other concerns) but can ensure that there won't be concurrent writes, for example because HF is offline and the models/datasets were downloaded earlier.\r\n\r\nI am one of those users. Is there a work around for this?\r\n",
"The machines I use have a shared FS which has the filelock problem as well as a local one that does not. Using some env vars (HF_HOME, which controls both models and datasets, and HF_DATASETS_OFFLINE) for both transformers and datasets library one can influence where these downloads happen, and whether the locks get taken. I think some of the relevant documentation is here https://huggingface.co/docs/transformers/installation#cache-setup. I do end up using different settings when I download the models and when I use them, and have to rsync the models to the local file system using a separate script. ",
"Thanks @orm011 . These filesystems are such a pain. I'll dig around, looks like setting `cache_dir` to a non-lustre filesystem works for `transformers` but not `datasets`.",
"Note I `export HF_HOME=` in the shell prior to running python (I do not use the `cache_dir` argument, I think I ran into similar issues with it, nor `HF_DATASETS_CACHE` , though maybe that works, or maybe you can set it in python prior to importing the library ), and I change no other variables. Then `datasets.load_dataset()` works without any additional flags, and they go into `HF_HOME/datasets/` and the models go into `HF_HOME/transformers/` (and the lock files are all there as well). "
] |
https://api.github.com/repos/huggingface/datasets/issues/2638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2638/comments | https://api.github.com/repos/huggingface/datasets/issues/2638/events | https://github.com/huggingface/datasets/pull/2638 | 943,484,913 | MDExOlB1bGxSZXF1ZXN0Njg5MTA5NTg1 | 2,638 | Streaming for the Json loader | [] | closed | false | null | 2 | 2021-07-13T14:37:06Z | 2021-07-16T15:59:32Z | 2021-07-16T15:59:31Z | null | It was not using `open` in the builder. Therefore `pyarrow.json.read_json` was downloading the full file to start yielding rows.
Moreover, it appeared that `pyarrow.json.read_json` was not really suited for streaming as it was downloading too much data and failing if `block_size` was not properly configured (related to #2573).
So I switched to using `open` which is extended to support reading from remote file progressively, and I removed the pyarrow json reader which was not practical.
Instead, I'm using the classical `json.loads` from the standard library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2638/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2638/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2638.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2638",
"merged_at": "2021-07-16T15:59:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2638.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2638"
} | true | [
"A note is that I think we should add a few indicator of status (as mentioned by @stas00 in #2649), probably at the (1) downloading, (2) extracting and (3) reading steps. In particular when loading many very large files it's interesting to know a bit where we are in the process.",
"I tested locally, and the builtin `json` loader is 4x slower than `pyarrow.json`. Thanks for the comment @albertvillanova !\r\n\r\nTherefore I switched back to using `pyarrow.json`, but only on the batch that is read. This way we don't have to deal with its `block_size`, and it only loads in memory one batch at a time."
] |
https://api.github.com/repos/huggingface/datasets/issues/4026 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4026/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4026/comments | https://api.github.com/repos/huggingface/datasets/issues/4026/events | https://github.com/huggingface/datasets/pull/4026 | 1,180,968,774 | PR_kwDODunzps41Btcm | 4,026 | Support streaming xtreme dataset for bucc18 config | [] | closed | false | null | 1 | 2022-03-25T16:00:40Z | 2022-03-25T16:26:50Z | 2022-03-25T16:21:52Z | null | Support streaming xtreme dataset for bucc18 config. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4026/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4026/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4026.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4026",
"merged_at": "2022-03-25T16:21:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4026.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4026"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1941/comments | https://api.github.com/repos/huggingface/datasets/issues/1941/events | https://github.com/huggingface/datasets/issues/1941 | 815,985,167 | MDU6SXNzdWU4MTU5ODUxNjc= | 1,941 | Loading of FAISS index fails for index_name = 'exact' | [] | closed | false | null | 3 | 2021-02-25T01:30:54Z | 2021-02-25T14:28:46Z | 2021-02-25T14:28:46Z | null | Hi,
It looks like loading of FAISS index now fails when using index_name = 'exact'.
For example, from the RAG [model card](https://huggingface.co/facebook/rag-token-nq?fbclid=IwAR3bTfhls5U_t9DqsX2Vzb7NhtRHxJxfQ-uwFT7VuCPMZUM2AdAlKF_qkI8#usage).
Running `transformers==4.3.2` and datasets installed from source on latest `master` branch.
```bash
(venv) sergey_mkrtchyan datasets (master) $ python
Python 3.8.6 (v3.8.6:db455296be, Sep 23 2020, 13:31:39)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
>>> tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
>>> retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
Using custom data configuration dummy.psgs_w100.nq.no_index-dummy=True,with_index=False
Reusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.no_index-dummy=True,with_index=False/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)
Using custom data configuration dummy.psgs_w100.nq.exact-50b6cda57ff32ab4
Reusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.exact-50b6cda57ff32ab4/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)
0%| | 0/10 [00:00<?, ?it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 425, in from_pretrained
return cls(
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 387, in __init__
self.init_retrieval()
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 458, in init_retrieval
self.index.init_index()
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 284, in init_index
self.dataset = load_dataset(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/load.py", line 750, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py", line 734, in as_dataset
datasets = utils.map_nested(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/utils/py_utils.py", line 195, in map_nested
return function(data_struct)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py", line 769, in _build_single_dataset
post_processed = self._post_process(ds, resources_paths)
File "/Users/sergey_mkrtchyan/.cache/huggingface/modules/datasets_modules/datasets/wiki_dpr/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb/wiki_dpr.py", line 205, in _post_process
dataset.add_faiss_index("embeddings", custom_index=index)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/arrow_dataset.py", line 2516, in add_faiss_index
super().add_faiss_index(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py", line 416, in add_faiss_index
faiss_index.add_vectors(self, column=column, train_size=train_size, faiss_verbose=faiss_verbose)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py", line 281, in add_vectors
self.faiss_index.add(vecs)
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/__init__.py", line 104, in replacement_add
self.add_c(n, swig_ptr(x))
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/swigfaiss.py", line 3263, in add
return _swigfaiss.IndexHNSW_add(self, n, x)
RuntimeError: Error in virtual void faiss::IndexHNSW::add(faiss::Index::idx_t, const float *) at /Users/runner/work/faiss-wheels/faiss-wheels/faiss/faiss/IndexHNSW.cpp:356: Error: 'is_trained' failed
>>>
```
The issue seems to be related to the scalar quantization in faiss added in this commit: 8c5220307c33f00e01c3bf7b8. Reverting it fixes the issue.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1941/timeline | null | completed | null | null | false | [
"Thanks for reporting ! I'm taking a look",
"Index training was missing, I fixed it here: https://github.com/huggingface/datasets/commit/f5986c46323583989f6ed1dabaf267854424a521\r\n\r\nCan you try again please ?",
"Works great 👍 I just put a minor comment on the commit, I think you meant to pass the `train_size` from the one obtained from the config.\r\n\r\nThanks for a quick response!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3389/comments | https://api.github.com/repos/huggingface/datasets/issues/3389/events | https://github.com/huggingface/datasets/issues/3389 | 1,072,191,865 | I_kwDODunzps4_6Fl5 | 3,389 | Add EDGAR | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 2 | 2021-12-06T14:06:11Z | 2022-10-05T10:40:22Z | null | null | ## Adding a Dataset
- **Name:** EDGAR Database
- **Description:** https://www.sec.gov/edgar/about EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system, is the primary system for companies and others submitting documents under the Securities Act of 1933, the Securities Exchange Act of 1934, the Trust Indenture Act of 1939, and the Investment Company Act of 1940. Containing millions of company and individual filings, EDGAR benefits investors, corporations, and the U.S. economy overall by increasing the efficiency, transparency, and fairness of the securities markets. The system processes about 3,000 filings per day, serves up 3,000 terabytes of data to the public annually, and accommodates 40,000 new filers per year on average. EDGAR® and EDGARLink® are registered trademarks of the SEC.
- **Data:** https://www.sec.gov/os/accessing-edgar-data
- **Motivation:** Enabling and improving FSI (Financial Services Industry) datasets to increase ease of use
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3389/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3389/timeline | null | null | null | null | false | [
"cc @juliensimon ",
"Datasets are not tracked in this repository anymore. But you can make your own dataset in the huggingface hub"
] |
https://api.github.com/repos/huggingface/datasets/issues/4224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4224/comments | https://api.github.com/repos/huggingface/datasets/issues/4224/events | https://github.com/huggingface/datasets/pull/4224 | 1,216,209,667 | PR_kwDODunzps420KX2 | 4,224 | autoeval config | [] | closed | false | null | 0 | 2022-04-26T16:35:19Z | 2022-04-26T16:36:45Z | 2022-04-26T16:36:45Z | null | add train eval index for autoeval | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4224/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4224.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4224",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4224.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4224"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/486 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/486/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/486/comments | https://api.github.com/repos/huggingface/datasets/issues/486/events | https://github.com/huggingface/datasets/issues/486 | 675,649,034 | MDU6SXNzdWU2NzU2NDkwMzQ= | 486 | Bookcorpus data contains pretokenized text | [] | closed | false | null | 8 | 2020-08-09T06:53:24Z | 2022-10-04T17:44:33Z | 2022-10-04T17:44:33Z | null | It seem that the bookcoprus data downloaded through the library was pretokenized with NLTK's Treebank tokenizer, which changes the text in incompatible ways to how, for instance, BERT's wordpiece tokenizer works. For example, "didn't" becomes "did" + "n't", and double quotes are changed to `` and '' for start and end quotes, respectively.
On my own projects, I just run the data through NLTK's TreebankWordDetokenizer to reverse the tokenization (as best as possible). I think it would be beneficial to apply this transformation directly on your remote cached copy of the dataset. If you choose to do so, I would also suggest to use my fork of NLTK that fixes several bugs in their detokenizer (I've opened a pull-request, but they've yet to respond): https://github.com/nltk/nltk/pull/2575 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/486/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/486/timeline | null | completed | null | null | false | [
"Yes indeed it looks like some `'` and spaces are missing (for example in `dont` or `didnt`).\r\nDo you know if there exist some copies without this issue ?\r\nHow would you fix this issue on the current data exactly ? I can see that the data is raw text (not tokenized) so I'm not sure I understand how you would do it. Could you provide more details ?",
"I'm afraid that I don't know how to obtain the original BookCorpus data. I believe this version came from an anonymous Google Drive link posted in another issue.\r\n\r\nGoing through the raw text in this version, it's apparent that NLTK's TreebankWordTokenizer was applied on it (I gave some examples in my original post), followed by:\r\n`' '.join(tokens)`\r\nYou can retrieve the tokenization by splitting on whitespace. You can then \"detokenize\" it with TreebankWordDetokenizer class of NLTK (though, as I suggested, use the fixed version in my repo). This will bring the text closer to its original form, but some steps of TreebankWordTokenizer are destructive, so it wouldn't be one-to-one. Something along the lines of the following should work:\r\n```\r\ntreebank_detokenizer = nltk.tokenize.treebank.TreebankWordDetokenizer()\r\ndb = nlp.load_dataset('bookcorpus', split=nlp.Split.TRAIN)\r\ndb = db.map(lambda x: treebank_detokenizer.detokenize(x['text'].split()))\r\n```\r\n\r\nRegarding other issues beyond the above, I'm afraid that I can't help with that.",
"Ok I get it, that would be very cool indeed\r\n\r\nWhat kinds of patterns the detokenizer can't retrieve ?",
"The TreebankTokenizer makes some assumptions about whitespace, parentheses, quotation marks, etc. For instance, while tokenizing the following text:\r\n```\r\nDwayne \"The Rock\" Johnson\r\n```\r\nwill result in:\r\n```\r\nDwayne `` The Rock '' Johnson\r\n```\r\nwhere the left and right quotation marks are turned into distinct symbols. Upon reconstruction, we can attach the left part to its token on the right, and respectively for the right part. However, the following texts would be tokenized exactly the same:\r\n```\r\nDwayne \" The Rock \" Johnson\r\nDwayne \" The Rock\" Johnson\r\nDwayne \" The Rock\" Johnson\r\n...\r\n```\r\nIn the above examples, the detokenizer would correct these inputs into the canonical text\r\n```\r\nDwayne \"The Rock\" Johnson\r\n```\r\nHowever, there are cases where there the solution cannot easily be inferred (at least without a true LM - this tokenizer is just a bunch of regexes). For instance, in cases where you have a fragment that contains the end of quote, but not its beginning, plus an accidental space:\r\n```\r\n... and it sounds fantastic, \" he said.\r\n```\r\nIn the above case, the tokenizer would assume that the quotes refer to the next token, and so upon detokenization it will result in the following mistake:\r\n```\r\n... and it sounds fantastic, \"he said.\r\n```\r\n\r\nWhile these are all odd edge cases (the basic assumptions do make sense), in noisy data they can occur, which is why I mentioned that the detokenizer cannot restore the original perfectly.\r\n",
"To confirm, since this is preprocessed, this was not the exact version of the Book Corpus used to actually train the models described here (particularly Distilbert)? https://huggingface.co/datasets/bookcorpus\r\n\r\nOr does this preprocessing exactly match that of the papers?",
"I believe these are just artifacts of this particular source. It might be better to crawl it again, or use another preprocessed source, as found here: https://github.com/soskek/bookcorpus ",
"Yes actually the BookCorpus on hugginface is based on [this](https://github.com/soskek/bookcorpus/issues/24#issuecomment-643933352). And I kind of regret naming it as \"BookCorpus\" instead of something like \"BookCorpusLike\".\r\n\r\nBut there is a good news ! @shawwn has replicated BookCorpus in his way, and also provided a link to download the plain text files. see [here](https://github.com/soskek/bookcorpus/issues/27). There is chance we can have a \"OpenBookCorpus\" !",
"Resolved via #856"
] |
https://api.github.com/repos/huggingface/datasets/issues/6077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6077/comments | https://api.github.com/repos/huggingface/datasets/issues/6077/events | https://github.com/huggingface/datasets/issues/6077 | 1,822,486,810 | I_kwDODunzps5soPEa | 6,077 | Mapping gets stuck at 99% | [] | open | false | null | 3 | 2023-07-26T14:00:40Z | 2023-07-27T12:19:23Z | null | null | ### Describe the bug
Hi !
I'm currently working with a large (~150GB) unnormalized dataset at work.
The dataset is available on a read-only filesystem internally, and I use a [loading script](https://huggingface.co/docs/datasets/dataset_script) to retreive it.
I want to normalize the features of the dataset, meaning I need to compute the mean and standard deviation metric for each feature of the entire dataset. I cannot load the entire dataset to RAM as it is too big, so following [this discussion on the huggingface discourse](https://discuss.huggingface.co/t/copy-columns-in-a-dataset-and-compute-statistics-for-a-column/22157) I am using a [map operation](https://huggingface.co/docs/datasets/v2.14.0/en/package_reference/main_classes#datasets.Dataset.map) to first compute the metrics and a second map operation to apply them on the dataset.
The problem lies in the second mapping, as it gets stuck at ~99%. By checking what the process does (using `htop` and `strace`) it seems to be doing a lot of I/O operations, and I'm not sure why.
Obviously, I could always normalize the dataset externally and then load it using a loading script. However, since the internal dataset is updated fairly frequently, using the library to perform normalization automatically would make it much easier for me.
### Steps to reproduce the bug
I'm able to reproduce the problem using the following scripts:
```python
# random_data.py
import datasets
import torch
_VERSION = "1.0.0"
class RandomDataset(datasets.GeneratorBasedBuilder):
def _info(self):
return datasets.DatasetInfo(
version=_VERSION,
supervised_keys=None,
features=datasets.Features(
{
"positions": datasets.Array2D(
shape=(30000, 3),
dtype="float32",
),
"normals": datasets.Array2D(
shape=(30000, 3),
dtype="float32",
),
"features": datasets.Array2D(
shape=(30000, 6),
dtype="float32",
),
"scalars": datasets.Sequence(
feature=datasets.Value("float32"),
length=20,
),
},
),
)
def _split_generators(self, dl_manager):
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN, # type: ignore
gen_kwargs={"nb_samples": 1000},
),
datasets.SplitGenerator(
name=datasets.Split.TEST, # type: ignore
gen_kwargs={"nb_samples": 100},
),
]
def _generate_examples(self, nb_samples: int):
for idx in range(nb_samples):
yield idx, {
"positions": torch.randn(30000, 3),
"normals": torch.randn(30000, 3),
"features": torch.randn(30000, 6),
"scalars": torch.randn(20),
}
```
```python
# main.py
import datasets
import torch
def apply_mean_std(
dataset: datasets.Dataset,
means: dict[str, torch.Tensor],
stds: dict[str, torch.Tensor],
) -> dict[str, torch.Tensor]:
"""Normalize the dataset using the mean and standard deviation of each feature.
Args:
dataset (`Dataset`): A huggingface dataset.
mean (`dict[str, Tensor]`): A dictionary containing the mean of each feature.
std (`dict[str, Tensor]`): A dictionary containing the standard deviation of each feature.
Returns:
dict: A dictionary containing the normalized dataset.
"""
result = {}
for key in means.keys():
# extract data from dataset
data: torch.Tensor = dataset[key] # type: ignore
# extract mean and std from dict
mean = means[key] # type: ignore
std = stds[key] # type: ignore
# normalize data
normalized_data = (data - mean) / std
result[key] = normalized_data
return result
# get dataset
ds = datasets.load_dataset(
path="random_data.py",
split="train",
).with_format("torch")
# compute mean (along last axis)
means = {key: torch.zeros(ds[key][0].shape[-1]) for key in ds.column_names}
means_sq = {key: torch.zeros(ds[key][0].shape[-1]) for key in ds.column_names}
for batch in ds.iter(batch_size=8):
for key in ds.column_names:
data = batch[key]
batch_size = data.shape[0]
data = data.reshape(-1, data.shape[-1])
means[key] += data.mean(dim=0) / len(ds) * batch_size
means_sq[key] += (data**2).mean(dim=0) / len(ds) * batch_size
# compute std (along last axis)
stds = {key: torch.sqrt(means_sq[key] - means[key] ** 2) for key in ds.column_names}
# normalize each feature of the dataset
ds_normalized = ds.map(
desc="Applying mean/std", # type: ignore
function=apply_mean_std,
batched=False,
fn_kwargs={
"means": means,
"stds": stds,
},
)
```
### Expected behavior
Using the previous scripts, the `ds_normalized` mapping completes in ~5 minutes, but any subsequent use of `ds_normalized` is really really slow, for example reapplying `apply_mean_std` to `ds_normalized` takes forever. This is very strange, I'm sure I must be missing something, but I would still expect this to be faster.
### Environment info
- `datasets` version: 2.13.1
- Platform: Linux-3.10.0-1160.66.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.12
- Huggingface_hub version: 0.15.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6077/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6077/timeline | null | null | null | null | false | [
"The `MAX_MAP_BATCH_SIZE = 1_000_000_000` hack is bad as it loads the entire dataset into RAM when performing `.map`. Instead, it's best to use `.iter(batch_size)` to iterate over the data batches and compute `mean` for each column. (`stddev` can be computed in another pass).\r\n\r\nAlso, these arrays are big, so it makes sense to reduce `batch_size`/`writer_batch_size` to avoid RAM issues and slow IO.",
"Hi @mariosasko !\r\n\r\nI agree, it's an ugly hack, but it was convenient since the resulting `mean_std` could be cached by the library. For my large dataset (which doesn't fit in RAM), I'm actually using something similar to what you suggested. I got rid of the first mapping in the above scripts and replaced it with an iterator, but the issue with the second mapping still persists.",
"Have you tried to reduce `batch_size`/`writer_batch_size` in the 2nd `.map`? Also, can you interrupt the process when it gets stuck and share the error stack trace?",
"I think `batch_size/writer_batch_size` is already at its lowest in the 2nd `.map` since `batched=False` implies `batch_size=1` and `len(ds) = 1000 = writer_batch_size`.\r\n\r\nHere is also a bunch of stack traces when I interrupted the process:\r\n\r\n<details>\r\n <summary>stack trace 1</summary>\r\n\r\n```python\r\n(pyg)[d623204@rosetta-bigviz01 stage-laurent-f]$ python src/random_scripts/uses_random_data.py \r\nFound cached dataset random_data (/local_scratch/lfainsin/.cache/huggingface/datasets/random_data/default/0.0.0/444e214e1d0e6298cfd3f2368323ec37073dc1439f618e19395b1f421c69b066)\r\nApplying mean/std: 97%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 967/1000 [00:01<00:00, 534.87 examples/s]Traceback (most recent call last): \r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3449, in _map_single\r\n writer.write(example)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 490, in write\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 263, in _cast_to_python_objects\r\n def _cast_to_python_objects(obj: Any, only_1d_for_numpy: bool, optimize_list_casting: bool) -> Tuple[Any, bool]:\r\nKeyboardInterrupt\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/gpfs_new/data/users/lfainsin/stage-laurent-f/src/random_scripts/uses_random_data.py\", line 62, in <module>\r\n ds_normalized = ds.map(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 580, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 545, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3087, in map\r\n for rank, done, content in Dataset._map_single(**dataset_kwargs):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3492, in _map_single\r\n writer.finalize()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 584, in finalize\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in <listcomp>\r\n [\r\nKeyboardInterrupt\r\n```\r\n\r\n</details>\r\n\r\n<details>\r\n <summary>stack trace 2</summary>\r\n\r\n```python\r\n(pyg)[d623204@rosetta-bigviz01 stage-laurent-f]$ python src/random_scripts/uses_random_data.py \r\nFound cached dataset random_data (/local_scratch/lfainsin/.cache/huggingface/datasets/random_data/default/0.0.0/444e214e1d0e6298cfd3f2368323ec37073dc1439f618e19395b1f421c69b066)\r\nApplying mean/std: 99%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 988/1000 [00:20<00:00, 526.19 examples/s]Applying mean/std: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊| 999/1000 [00:21<00:00, 9.66 examples/s]Traceback (most recent call last): \r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3449, in _map_single\r\n writer.write(example)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 490, in write\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 263, in _cast_to_python_objects\r\n def _cast_to_python_objects(obj: Any, only_1d_for_numpy: bool, optimize_list_casting: bool) -> Tuple[Any, bool]:\r\nKeyboardInterrupt\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/gpfs_new/data/users/lfainsin/stage-laurent-f/src/random_scripts/uses_random_data.py\", line 62, in <module>\r\n ds_normalized = ds.map(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 580, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 545, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3087, in map\r\n for rank, done, content in Dataset._map_single(**dataset_kwargs):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3492, in _map_single\r\n writer.finalize()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 584, in finalize\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 291, in _cast_to_python_objects\r\n if config.JAX_AVAILABLE and \"jax\" in sys.modules:\r\nKeyboardInterrupt\r\n```\r\n\r\n</details>\r\n\r\n<details>\r\n <summary>stack trace 3</summary>\r\n\r\n```python\r\n(pyg)[d623204@rosetta-bigviz01 stage-laurent-f]$ python src/random_scripts/uses_random_data.py \r\nFound cached dataset random_data (/local_scratch/lfainsin/.cache/huggingface/datasets/random_data/default/0.0.0/444e214e1d0e6298cfd3f2368323ec37073dc1439f618e19395b1f421c69b066)\r\nApplying mean/std: 99%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 989/1000 [00:01<00:00, 504.80 examples/s]Traceback (most recent call last): \r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3449, in _map_single\r\n writer.write(example)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 490, in write\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\nKeyboardInterrupt\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/gpfs_new/data/users/lfainsin/stage-laurent-f/src/random_scripts/uses_random_data.py\", line 62, in <module>\r\n ds_normalized = ds.map(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 580, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 545, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3087, in map\r\n for rank, done, content in Dataset._map_single(**dataset_kwargs):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3492, in _map_single\r\n writer.finalize()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 584, in finalize\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 298, in _cast_to_python_objects\r\n if obj.ndim == 0:\r\nKeyboardInterrupt\r\n```\r\n\r\n</details>\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5255 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5255/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5255/comments | https://api.github.com/repos/huggingface/datasets/issues/5255/events | https://github.com/huggingface/datasets/issues/5255 | 1,452,631,517 | I_kwDODunzps5WlWXd | 5,255 | Add a Depth Estimation dataset - DIODE / NYUDepth / KITTI | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 21 | 2022-11-17T03:22:22Z | 2022-12-17T12:20:38Z | 2022-12-17T12:20:37Z | null | ### Name
NYUDepth
### Paper
http://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
### Data
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
### Motivation
Depth estimation is an important problem in computer vision. We have a couple of Depth Estimation models on Hub as well:
* [GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)
* [DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
Would be nice to have a dataset for depth estimation. These datasets usually have three things: input image, depth map image, and depth mask (validity mask to indicate if a reading for a pixel is valid or not). Since we already have [semantic segmentation datasets on the Hub](https://huggingface.co/datasets?task_categories=task_categories:image-segmentation&sort=downloads), I don't think we need any extended utilities to support this addition.
Having this dataset would also allow us to author data preprocessing guides for depth estimation, particularly like the ones we have for other tasks ([example](https://huggingface.co/docs/datasets/image_classification)).
Ccing @osanseviero @nateraw @NielsRogge
Happy to work on adding it. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5255/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5255/timeline | null | completed | null | null | false | [
"Also cc @mariosasko and @lhoestq ",
"Cool ! Let us know if you have questions or if we can help :)\r\n\r\nI guess we'll also have to create the NYU CS Department on the Hub ?",
"> I guess we'll also have to create the NYU CS Department on the Hub ?\r\n\r\nYes, you're right! Let me add it to my profile first, and then we can transfer. Meanwhile, if it's recommended to loop the dataset author in here, let me know. \r\n\r\nAlso, the NYU Depth dataset seems big. Any example scripts for creating image datasets that I could refer? ",
"You can check the imagenet-1k one.\r\n\r\nPS: If the licenses allows it, it'b be nice to host the dataset as sharded TAR archives (like imagenet-1k) instead of the ZIP format they use:\r\n- it will make streaming much faster\r\n- ZIP compression is not well suited for images\r\n- it will allow parallel processing of the dataset (you can pass a subset of shards to each worker)\r\n\r\n> if it's recommended to loop the dataset author in here, let me know.\r\n\r\nIt's recommended indeed, you can send them an email once you have the dataset ready and invite them to the org on the Hub",
"> You can check the imagenet-1k one.\r\n\r\nWhere can I find the script? Are you referring to https://huggingface.co/docs/datasets/image_process ? Or is there anything more specific? ",
"You can find it here: https://huggingface.co/datasets/imagenet-1k/blob/main/imagenet-1k.py",
"Update: started working on it here: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2. \r\n\r\nI am facing an issue and I have detailed it here: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/discussions/1\r\n\r\nEdit: The issue is gone. \r\n\r\nHowever, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive? \r\n\r\n@lhoestq \r\n\r\n",
"A Colab Notebook demonstrating the dataset loading part: \r\n\r\nhttps://colab.research.google.com/gist/sayakpaul/aa0958c8d4ad8518d52a78f28044d871/scratchpad.ipynb\r\n\r\n@osanseviero @lhoestq \r\n\r\nI will work on a notebook to work with the dataset including data visualization.",
"@osanseviero @lhoestq things seem to work fine with the current version of the dataset [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2). Here's a notebook I developed to help with visualization: https://colab.research.google.com/drive/1K3ZU8XUPRDOYD38MQS9nreQXJYitlKSW?usp=sharing. \r\n\r\n@lhoestq I need your help with the following:\r\n\r\n> However, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive?\r\n\r\n@osanseviero @lhoestq question for you:\r\n\r\nWhere should we host the dataset? I think hosting it under hf.co/datasets (that is HF is the org) is fine as we have ImageNet-1k hosted similarly. We could then reach out to Diana Wofk (author of [Fast Depth](https://github.com/dwofk/fast-depth) and the owner of the repo on which TFDS NYU Depth V2 is based) for a review. WDYT? ",
"> However, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive?\r\n\r\nFirst you can separate the train data and the validation data.\r\n\r\nThen since the dataset is quite big, you can even shard the train split and the validation split in multiple TAR archives. Something around 16 archives for train and 4 for validation would be fine for example.\r\n\r\nAlso no need to gzip the TAR archives, the images are already compressed in png or jpeg.",
"> Then since the dataset is quite big, you can even shard the train split and the validation split in multiple TAR archives. Something around 16 archives for train and 4 for validation would be fine for example.\r\n\r\nYes, I got you. But this process seems to be manual and should be tailored for the given dataset. Do you have any script that you used to create the ImageNet-1k shards? \r\n\r\n> Also no need to gzip the TAR archives, the images are already compressed in png or jpeg.\r\n\r\nI was not going to do that. Not sure what brought it up. ",
"> Yes, I got you. But this process seems to be manual and should be tailored for the given dataset. Do you have any script that you used to create the ImageNet-1k shards?\r\n\r\nI don't, but I agree it'd be nice to have a script for that !\r\n\r\n> I was not going to do that. Not sure what brought it up.\r\n\r\nThe original dataset is gzipped for some reason",
"Oh, I am using this URL for the download: https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py#L24. ",
"> Where should we host the dataset? I think hosting it under hf.co/datasets (that is HF is the org) is fine as we have ImageNet-1k hosted similarly.\r\n\r\nMaybe you can create an org for NYU Courant (this is the institute of the lab of the main author of the dataset if I'm not mistaken), and invite the authors to join.\r\n\r\nWe don't add datasets without namespace anymore",
"Updates: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/discussions/5\r\n\r\nThe entire process (preparing multiple archives, preparing data loading script, etc.) was fun and engaging, thanks to the documentation. I believe we could work on a small blog post that would work as a reference for the future contributors following this path. What say? \r\n\r\nCc: @lhoestq @osanseviero ",
"> I believe we could work on a small blog post that would work as a reference for the future contributors following this path. What say?\r\n\r\n@polinaeterna already mentioned it would be nice to present this process for audio (it's exactly the same), I believe it can be useful to many people",
"Cool. Let's work on that after the NYU Depth Dataset is fully in on Hub (under the appropriate org). 🤗",
"@lhoestq need to discuss something while I am adding the dataset card to https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/. \r\n\r\nAs per [Papers With Code](https://paperswithcode.com/dataset/nyuv2), NYU Depth v2 is used for many different tasks:\r\n\r\n* Monocular depth estimation\r\n* Depth estimation \r\n* Semantic segmentation\r\n* Plane instance segmentation \r\n* ...\r\n\r\nSo, while writing the supported task part of the dataset card, should we focus on all these? IMO, we could focus on just depth estimation and semantic segmentation for now since we have supported models for these two. WDYT?\r\n\r\nAlso, I am getting: \r\n\r\n\r\n```\r\nremote: Your push was accepted, but with warnings:\r\nremote: - Warning: The task_ids \"depth-estimation\" is not in the official list: acceptability-classification, entity-linking-classification, fact-checking, intent-classification, multi-class-classification, multi-label-classification, multi-input-text-classification, natural-language-inference, semantic-similarity-classification, sentiment-classification, topic-classification, semantic-similarity-scoring, sentiment-scoring, sentiment-analysis, hate-speech-detection, text-scoring, named-entity-recognition, part-of-speech, parsing, lemmatization, word-sense-disambiguation, coreference-resolution, extractive-qa, open-domain-qa, closed-domain-qa, news-articles-summarization, news-articles-headline-generation, dialogue-generation, dialogue-modeling, language-modeling, text-simplification, explanation-generation, abstractive-qa, open-domain-abstractive-qa, closed-domain-qa, open-book-qa, closed-book-qa, slot-filling, masked-language-modeling, keyword-spotting, speaker-identification, audio-intent-classification, audio-emotion-recognition, audio-language-identification, multi-label-image-classification, multi-class-image-classification, face-detection, vehicle-detection, instance-segmentation, semantic-segmentation, panoptic-segmentation, image-captioning, grasping, task-planning, tabular-multi-class-classification, tabular-multi-label-classification, tabular-single-column-regression, rdf-to-text, multiple-choice-qa, multiple-choice-coreference-resolution, document-retrieval, utterance-retrieval, entity-linking-retrieval, fact-checking-retrieval, univariate-time-series-forecasting, multivariate-time-series-forecasting, visual-question-answering, document-question-answering\r\nremote: ----------------------------------------------------------\r\nremote: Please find the documentation at:\r\nremote: https://huggingface.co/docs/hub/model-cards#model-card-metadata\r\n```\r\n\r\nWhat should be the plan of action for this?\r\n\r\nCc: @osanseviero \r\n\r\n",
"> What should be the plan of action for this?\r\n\r\nWhen you merged https://github.com/huggingface/hub-docs/pull/488, there is a JS Interfaces GitHub Actions workflow that runs https://github.com/huggingface/hub-docs/actions/workflows/js-interfaces-tests.yml. It has a step called [export-task scripts](https://github.com/huggingface/hub-docs/actions/runs/3622479064/jobs/6107238948) which exports an interface you can use in `dataset`. If you look at the logs, it prints out a map. This map can replace https://github.com/huggingface/datasets/blob/main/src/datasets/utils/resources/tasks.json (tasks.json was generated with this script), which should add depth estimation\r\n",
"Thanks @osanseviero. \r\n\r\nhttps://github.com/huggingface/datasets/pull/5335",
"Closing the issue as the dataset has been successfully added: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2"
] |
https://api.github.com/repos/huggingface/datasets/issues/3800 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3800/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3800/comments | https://api.github.com/repos/huggingface/datasets/issues/3800/events | https://github.com/huggingface/datasets/pull/3800 | 1,155,620,761 | PR_kwDODunzps4zvkjA | 3,800 | Added computer vision tasks | [] | closed | false | null | 0 | 2022-03-01T17:37:46Z | 2022-03-04T07:15:55Z | 2022-03-04T07:15:55Z | null | Previous PR was in my fork so thought it'd be easier if I do it from a branch. Added computer vision task datasets according to HF tasks. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3800/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3800/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3800.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3800",
"merged_at": "2022-03-04T07:15:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3800.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3800"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4025 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4025/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4025/comments | https://api.github.com/repos/huggingface/datasets/issues/4025/events | https://github.com/huggingface/datasets/issues/4025 | 1,180,963,105 | I_kwDODunzps5GZBEh | 4,025 | Missing argument in precision/recall | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2022-03-25T15:55:52Z | 2022-03-28T09:53:06Z | 2022-03-28T09:53:06Z | null | **Is your feature request related to a problem? Please describe.**
[`sklearn.metrics.precision_score`](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html) accepts an argument `zero_division`, but it is not available in [precision Metric](https://github.com/huggingface/datasets/blob/master/metrics/precision/precision.py#L117)
Same issue is present for Recall.
**Describe the solution you'd like**
Support for **kwargs or adding a new field for `zero_division`.
**Describe alternatives you've considered**
I could filter the warnings myself, but that is not ideal.
**Additional context**
I can make the requested changes if this is approved. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4025/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4025/timeline | null | completed | null | null | false | [
"Thanks for the suggestion, @Dref360.\r\n\r\nWe are adding that argument. "
] |
https://api.github.com/repos/huggingface/datasets/issues/1343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1343/comments | https://api.github.com/repos/huggingface/datasets/issues/1343/events | https://github.com/huggingface/datasets/pull/1343 | 759,809,999 | MDExOlB1bGxSZXF1ZXN0NTM0NzQ4NTE4 | 1,343 | Add LiveQA | [] | closed | false | null | 0 | 2020-12-08T21:52:36Z | 2020-12-14T09:40:28Z | 2020-12-14T09:40:28Z | null | This PR adds LiveQA, the Chinese real-time/timeline-based QA task by [Liu et al., 2020](https://arxiv.org/pdf/2010.00526.pdf). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1343/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1343/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1343.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1343",
"merged_at": "2020-12-14T09:40:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1343.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1343"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4041 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4041/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4041/comments | https://api.github.com/repos/huggingface/datasets/issues/4041/events | https://github.com/huggingface/datasets/issues/4041 | 1,183,599,461 | I_kwDODunzps5GjEtl | 4,041 | Add support for IIIF in datasets | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2022-03-28T15:19:25Z | 2022-04-05T18:20:53Z | null | null | This is a feature request for support for IIIF in `datasets`. Apologies for the long issue. I have also used a different format to the usual feature request since I think that makes more sense but happy to use the standard template if preferred.
## What is [IIIF](https://iiif.io/)?
IIIF (International Image Interoperability Framework)
> is a set of open standards for delivering high-quality, attributed digital objects online at scale. It’s also an international community developing and implementing the IIIF APIs. IIIF is backed by a consortium of leading cultural institutions.
The tl;dr is that IIIF provides various specifications for implementing useful functionality for:
- Institutions to make available images for various use cases
- Users to have a consistent way of interacting/requesting these images
- For developers to have a common standard for developing tools for working with IIIF images that will work across all institutions that implement a particular IIIF standard (for example the image viewer for the BNF can also work for the Library of Congress if they both use IIIF).
Some institutions that various levels of support IIF include: The British Library, Internet Archive, Library of Congress, Wikidata. There are also many smaller institutions that have IIIF support. An incomplete list can be found here: https://iiif.io/guides/finding_resources/
## IIIF APIs
IIIF consists of a number of APIs which could be integrated with datasets. I think the most obvious candidate for inclusion would be the [Image API](https://iiif.io/api/image/3.0/)
### IIIF Image API
The Image API https://iiif.io/api/image/3.0/ is likely the most suitable first candidate for integration with datasets. The Image API offers a consistent protocol for requesting images via a URL:
```{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}```
A concrete example of this:
```https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/full/0/default.jpg```
As you can see the scheme offers a number of options that can be specified in the URL, for example, size. Using the example URL we return:

We can change the size to request a size of 250 by 250, this is done by changing the size from `full` to `250,250` i.e. switching the URL to `https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/250,250/0/default.jpg`

We can also request the image with max width 250, max height 250 whilst maintaining the aspect ratio using `!w,h`. i.e. change the url to `https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/!250,250/0/default.jpg`

A full overview of the options for size can be found here: https://iiif.io/api/image/3.0/#42-size
## Why would/could this be useful for datasets?
There are a few reasons why support for the IIIF Image API could be useful. Broadly the ability to have more control over how an image is returned from a server is useful for many ML workflows:
- images can be requested in the right size, this prevents having to download/stream large images when the actual desired size is much smaller
- can select a subset of an image: it is possible to select a sub-region of an image, this could be useful for example when you already have a bounding box for a subset of an image and then want to use this subset of an image for another task. For example, https://github.com/Living-with-machines/nnanno uses IIIF to request parts of a newspaper image that have been detected as 'photograph', 'illustration' etc for downstream use.
- options for quality, rotation, the format can all be encoded in the URL request.
These may become particularly useful when pre-training models on large image datasets where the cost of downloading images with 1600 pixel width when you actually want 240 has a larger impact.
## What could this look like in datasets?
I think there are various ways in which support for IIIF could potentially be included in `datasets`. These suggestions aren't fully fleshed out but hopefully, give a sense of possible approaches that match existing `datasets` methods in their approach.
### Use through datasets scripts
Loading images via URL is already supported. There are a few possible 'extras' that could be included when using IIIF. One option is to leverage the IIIF protocol in datasets scripts, i.e. the dataset script can expose the IIIF options via the dataset script:
```python
ds = load_dataset("iiif_dataset", image_size="250,250", fmt="jpg")
```
This is already possible. The approach to parsing the IIIF URLs would be left to the person creating the dataset script.
### Support through dataset scripts (with some datasets support)
This is similar to the above but `datasets` would offer some way of saying this is a iiif URL and then expose the options associated with IIIF images automatically. i.e. if you did something like:
```python
features = {"label": ClassLabel(names=['dog','cat']),
"url": datasets.IIIFURL()}
```
inside your loading script, you would automatically have exposed `size`, `fmt` etc. options when loading the dataset.
### Other possible integrations
Some other possible pseudocode ways that a user could interact with IIIF URLs:
The ability to cast to an `IIIFImage` feature type:
```
ds.cast_column('url', IIIFImage, download=False)
```
The ability to specify some options associated with IIIF urls.
```
ds = ds.set_iiif_options(column='url', size="250,250")
```
I think all of these would rely on having an `IIIFImage` feature type - this would be a little bit of a Frankenstein between a `string` and `datasets.Image`. I think most of the actual image behaviour would be exactly the same as `datasets.Image`, the difference would be that the underlying URL could be modified in various ways.
## prerequisite requirements
There are a few pre-requisites that I can anticipate. This doesn't cover a full implementation of IIIF support which would have different requirements depending on the approach taken to implementing IIIF. Some of these features would be useful independently of adding IIIF support:
### support for handling failed images loaded via a URL (or a specific IIIFImage feature).
Working with images via web requests will inevitably return the odd failed request. If these images are then requests and don't return it would be useful to have a `None` returned instead of an error. For example, when using `push_to_hub` `datasets` will try and include the image but currently fails with bad URLs.
```python
from datasets import Dataset
import datasets
urls = ['https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/!250,250/0/default.jpg']*3
urls.append("badurl.com/image.jpg")
data = {"url":urls}
ds = Dataset.from_dict(data)
ds = ds.cast_column('url', datasets.Image())
ds[3]['url']
```
returns a `FileNotFoundError`, for streaming large datasets of images using their URLs it could be useful to have `None` returned instead. This has implications for the actual training loop i.e. you now need to somehow skip those examples because of this it might not be desirable to support this.
### Caching support
Since IIIF requests images via a URL it would be great to have a way of not requesting the images multiple times. This is tracked in https://github.com/huggingface/datasets/issues/3142 and I think this would also be very desirable to have here particularly as one of the primary use cases of IIIF may be to do unsupervised pre-training on large datasets of IIIF URLs.
### Support for Parsing IIIF URLs
This gets closer to the actual implementation. Here the requirement would be some way for `datasets` to parse a URL that the users specify is an IIIF URL. An example of a Python library that does this: https://github.com/Princeton-CDH/piffle. I also have a rough version that uses `dataclasses` which I can share.
## Why it might not be worthwhile/suitable for datasets
There are some reasons that this might not be worth implementing:
- currently, IIIF is mainly used by cultural heritage organizations (museums, archives etc.) The adoption of IIIF in this sector has been growing but it's possible that adoption won't be extended to other industries which may also be a source of image data for training ML models.
- It may end up being better to leave this to the user. It would for example be possible for someone to write map functions to change an IIIF URL to the correct size etc. Adding direct support for IIIF in datasets may potentially not be worth the trouble.
- The impact of different approaches to doing image scaling can impact the downstream model's performance, see: https://twitter.com/wightmanr/status/1479528581466243073?s=20. Since different IIIF image servers may implement different approaches to resizing images this could have a downstream impact on model performance. think this is something that could be flagged to the end-user in the documentation. This probably also falls into general "gotchas" that probably aren't the `datasets` libraries' role to protect users from.
Some of the requirements outlined above would be useful for images anyway. These could be implemented prior to a final decision about whether IIIF support could/should be added to datasets.
## Suggested next steps:
I realise this is a long and slightly open-ended issue. I am happy to clarify/answer questions on IIIF and possible integrations. If the prerequisite requirements seem worth exploring/are better explored in their own issues let me know and I can open new issues for those.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4041/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4041/timeline | null | null | null | null | false | [
"Hi! Thanks for the detailed analysis of adding IIIF support. I like the idea of \"using IIIF through datasets scripts\" due to its ease of use. Another approach that I like is yielding image ids and using the `piffle` library (which offers a bit more flexibility) + `map` to download + cache images. We can handle bad URLs in `map` by returning `None`. Plus, we can add a `Dataset Preprocessing` section with the code that explains this approach to the card of such datasets. WDYT?\r\n\r\n> currently, IIIF is mainly used by cultural heritage organizations (museums, archives etc.) The adoption of IIIF in this sector has been growing but it's possible that adoption won't be extended to other industries which may also be a source of image data for training ML models.\r\n\r\nThis is why (currently) adding a new feature type would be overkill, IMO.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/6008 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6008/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6008/comments | https://api.github.com/repos/huggingface/datasets/issues/6008/events | https://github.com/huggingface/datasets/issues/6008 | 1,789,869,344 | I_kwDODunzps5qrz0g | 6,008 | Dataset.from_generator consistently freezes at ~1000 rows | [] | closed | false | null | 3 | 2023-07-05T16:06:48Z | 2023-07-10T13:46:39Z | 2023-07-10T13:46:39Z | null | ### Describe the bug
Whenever I try to create a dataset which contains images using `Dataset.from_generator`, it freezes around 996 rows. I suppose it has something to do with memory consumption, but there's more memory available. I
Somehow it worked a few times but mostly this makes the datasets library much more cumbersome to work with because generators are the easiest way to turn an existing dataset into a Hugging Face dataset.
I've let it run in the frozen state for way longer than it can possibly take to load the actual dataset.
Let me know if you have ideas how to resolve it!
### Steps to reproduce the bug
```python
from datasets import Dataset
import numpy as np
def gen():
for row in range(10000):
yield {"i": np.random.rand(512, 512, 3)}
Dataset.from_generator(gen)
# -> 90% of the time gets stuck around 1000 rows
```
### Expected behavior
Should continue and go through all the examples yielded by the generator, or at least throw an error or somehow communicate what's going on.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 12.0.1
- Pandas version: 1.5.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6008/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6008/timeline | null | completed | null | null | false | [
"By default, we write data to disk (so it can be memory-mapped) every 1000 rows/samples. You can control this with the `writer_batch_size` parameter. Also, when working with fixed-size arrays, the `ArrayXD` feature types yield better performance (e.g., in your case, `features=datasets.Features({\"i\": datasets.Array3D(shape=(512,512,3), dtype=\"float32\")})` should be faster).\r\n\r\nOur support for multi-dim arrays could be better, and we plan to improve it as part of https://github.com/huggingface/datasets/issues/5272.",
"> By default, we write data to disk (so it can be memory-mapped) every 1000 rows/samples. You can control this with the `writer_batch_size` parameter. Also, when working with fixed-size arrays, the `ArrayXD` feature types yield better performance (e.g., in your case, `features=datasets.Features({\"i\": datasets.Array3D(shape=(512,512,3), dtype=\"float32\")})` should be faster).\r\n> \r\n> Our support for multi-dim arrays could be better, and we plan to improve it as part of #5272.\r\n\r\nThanks for the explanation! The Image array was just for demonstration, I use PIL Images in practice. Does that make a difference? What's the best approach for a dataset with PIL Images as rows?",
"It's best to use the `datasets.Image()` feature type for PIL images (to save space) :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1314 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1314/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1314/comments | https://api.github.com/repos/huggingface/datasets/issues/1314/events | https://github.com/huggingface/datasets/pull/1314 | 759,541,937 | MDExOlB1bGxSZXF1ZXN0NTM0NTMwMDE5 | 1,314 | Add snips built in intents 2016 12 | [] | closed | false | null | 3 | 2020-12-08T15:30:19Z | 2020-12-14T09:59:07Z | 2020-12-14T09:59:07Z | null | This PR proposes to add the Snips.ai built in intents dataset. The first configuration added is for the intent labels only, but the dataset includes entity slots that may in future be added as alternate configurations. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1314/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1314/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1314.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1314",
"merged_at": "2020-12-14T09:59:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1314.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1314"
} | true | [
"It is not clear how to automatically add the dummy data if the source data is a more complex json format. Should I manually take a fraction of the source data and include it as dummy data?\r\n",
"Added a fraction of the real data as dummy data.",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5754/comments | https://api.github.com/repos/huggingface/datasets/issues/5754/events | https://github.com/huggingface/datasets/pull/5754 | 1,668,755,035 | PR_kwDODunzps5OWozh | 5,754 | Minor tqdm fixes | [] | closed | false | null | 2 | 2023-04-14T18:15:14Z | 2023-04-20T15:27:58Z | 2023-04-20T15:21:00Z | null | `GeneratorBasedBuilder`'s TQDM bars were not used as context managers. This PR fixes that (missed these bars in https://github.com/huggingface/datasets/pull/5560).
Also, this PR modifies the single-proc `save_to_disk` to fix the issue with the TQDM bar not accumulating the progress in the multi-shard setting (again, this bug was introduced by me in the linked PR 😎) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5754/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5754/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5754.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5754",
"merged_at": "2023-04-20T15:21:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5754.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5754"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006479 / 0.011353 (-0.004874) | 0.004592 / 0.011008 (-0.006416) | 0.097239 / 0.038508 (0.058731) | 0.028609 / 0.023109 (0.005499) | 0.309225 / 0.275898 (0.033327) | 0.340015 / 0.323480 (0.016535) | 0.004857 / 0.007986 (-0.003129) | 0.004649 / 0.004328 (0.000320) | 0.074770 / 0.004250 (0.070520) | 0.038351 / 0.037052 (0.001299) | 0.313360 / 0.258489 (0.054871) | 0.350256 / 0.293841 (0.056416) | 0.030770 / 0.128546 (-0.097776) | 0.011591 / 0.075646 (-0.064055) | 0.322444 / 0.419271 (-0.096828) | 0.043704 / 0.043533 (0.000171) | 0.311790 / 0.255139 (0.056651) | 0.339183 / 0.283200 (0.055984) | 0.088041 / 0.141683 (-0.053642) | 1.490649 / 1.452155 (0.038494) | 1.561789 / 1.492716 (0.069072) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208984 / 0.018006 (0.190978) | 0.406105 / 0.000490 (0.405616) | 0.003152 / 0.000200 (0.002952) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022622 / 0.037411 (-0.014790) | 0.095819 / 0.014526 (0.081294) | 0.105132 / 0.176557 (-0.071424) | 0.165684 / 0.737135 (-0.571451) | 0.106706 / 0.296338 (-0.189632) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426126 / 0.215209 (0.210917) | 4.233864 / 2.077655 (2.156209) | 1.918727 / 1.504120 (0.414607) | 1.729905 / 1.541195 (0.188710) | 1.760342 / 1.468490 (0.291852) | 0.695449 / 4.584777 (-3.889328) | 3.413531 / 3.745712 (-0.332181) | 1.904557 / 5.269862 (-3.365305) | 1.270604 / 4.565676 (-3.295072) | 0.083018 / 0.424275 (-0.341257) | 0.012760 / 0.007607 (0.005152) | 0.523991 / 0.226044 (0.297947) | 5.236132 / 2.268929 (2.967204) | 2.360959 / 55.444624 (-53.083665) | 1.996533 / 6.876477 (-4.879943) | 2.072934 / 2.142072 (-0.069138) | 0.804133 / 4.805227 (-4.001094) | 0.150976 / 6.500664 (-6.349688) | 0.065503 / 0.075469 (-0.009966) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.211828 / 1.841788 (-0.629960) | 13.657743 / 8.074308 (5.583435) | 13.887148 / 10.191392 (3.695756) | 0.145996 / 0.680424 (-0.534428) | 0.016562 / 0.534201 (-0.517639) | 0.380359 / 0.579283 (-0.198924) | 0.388698 / 0.434364 (-0.045666) | 0.440373 / 0.540337 (-0.099965) | 0.531753 / 1.386936 (-0.855183) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006444 / 0.011353 (-0.004909) | 0.004569 / 0.011008 (-0.006439) | 0.076239 / 0.038508 (0.037731) | 0.028462 / 0.023109 (0.005352) | 0.365540 / 0.275898 (0.089642) | 0.398242 / 0.323480 (0.074762) | 0.005785 / 0.007986 (-0.002200) | 0.003346 / 0.004328 (-0.000982) | 0.076296 / 0.004250 (0.072046) | 0.039853 / 0.037052 (0.002800) | 0.367684 / 0.258489 (0.109195) | 0.409570 / 0.293841 (0.115730) | 0.030536 / 0.128546 (-0.098010) | 0.011534 / 0.075646 (-0.064112) | 0.084962 / 0.419271 (-0.334309) | 0.042708 / 0.043533 (-0.000825) | 0.344058 / 0.255139 (0.088919) | 0.389096 / 0.283200 (0.105897) | 0.090559 / 0.141683 (-0.051124) | 1.507101 / 1.452155 (0.054946) | 1.563977 / 1.492716 (0.071260) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228740 / 0.018006 (0.210734) | 0.396890 / 0.000490 (0.396400) | 0.000392 / 0.000200 (0.000192) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025052 / 0.037411 (-0.012360) | 0.099951 / 0.014526 (0.085426) | 0.106847 / 0.176557 (-0.069710) | 0.156666 / 0.737135 (-0.580469) | 0.110344 / 0.296338 (-0.185994) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442363 / 0.215209 (0.227154) | 4.429571 / 2.077655 (2.351917) | 2.076501 / 1.504120 (0.572381) | 1.875226 / 1.541195 (0.334031) | 1.909093 / 1.468490 (0.440603) | 0.703047 / 4.584777 (-3.881730) | 3.457036 / 3.745712 (-0.288676) | 2.866648 / 5.269862 (-2.403214) | 1.524430 / 4.565676 (-3.041246) | 0.083687 / 0.424275 (-0.340588) | 0.012251 / 0.007607 (0.004643) | 0.543945 / 0.226044 (0.317901) | 5.440559 / 2.268929 (3.171630) | 2.522924 / 55.444624 (-52.921700) | 2.188770 / 6.876477 (-4.687707) | 2.249632 / 2.142072 (0.107559) | 0.813499 / 4.805227 (-3.991728) | 0.152861 / 6.500664 (-6.347803) | 0.067189 / 0.075469 (-0.008280) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.284255 / 1.841788 (-0.557533) | 14.207864 / 8.074308 (6.133556) | 14.279691 / 10.191392 (4.088299) | 0.167027 / 0.680424 (-0.513396) | 0.016455 / 0.534201 (-0.517746) | 0.380798 / 0.579283 (-0.198485) | 0.390013 / 0.434364 (-0.044351) | 0.445493 / 0.540337 (-0.094845) | 0.526278 / 1.386936 (-0.860658) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1397/comments | https://api.github.com/repos/huggingface/datasets/issues/1397/events | https://github.com/huggingface/datasets/pull/1397 | 760,467,501 | MDExOlB1bGxSZXF1ZXN0NTM1Mjk0MDgz | 1,397 | datasets card-creator link added | [] | closed | false | null | 0 | 2020-12-09T16:15:18Z | 2020-12-09T16:47:48Z | 2020-12-09T16:47:48Z | null | dataset card creator link has been added
link: https://huggingface.co/datasets/card-creator/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1397/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1397",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1397"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1621/comments | https://api.github.com/repos/huggingface/datasets/issues/1621/events | https://github.com/huggingface/datasets/pull/1621 | 772,940,417 | MDExOlB1bGxSZXF1ZXN0NTQ0MTE4MTAz | 1,621 | updated dutch_social.py for loading jsonl (lines instead of list) files | [] | closed | false | null | 0 | 2020-12-22T13:18:11Z | 2020-12-23T11:51:51Z | 2020-12-23T11:51:51Z | null | the data_loader is modified to load files on the fly. Earlier it was reading the entire file and then processing the records
Pls refer to previous PR #1321 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1621/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1621.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1621",
"merged_at": "2020-12-23T11:51:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1621.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1621"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1733/comments | https://api.github.com/repos/huggingface/datasets/issues/1733/events | https://github.com/huggingface/datasets/issues/1733 | 784,903,002 | MDU6SXNzdWU3ODQ5MDMwMDI= | 1,733 | connection issue with glue, what is the data url for glue? | [] | closed | false | null | 1 | 2021-01-13T08:37:40Z | 2021-08-04T18:13:55Z | 2021-08-04T18:13:55Z | null | Hi
my codes sometimes fails due to connection issue with glue, could you tell me how I can have the URL datasets library is trying to read GLUE from to test the machines I am working on if there is an issue on my side or not
thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1733/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1733/timeline | null | completed | null | null | false | [
"Hello @juliahane, which config of GLUE causes you trouble?\r\nThe URLs are defined in the dataset script source code: https://github.com/huggingface/datasets/blob/master/datasets/glue/glue.py"
] |
https://api.github.com/repos/huggingface/datasets/issues/1599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1599/comments | https://api.github.com/repos/huggingface/datasets/issues/1599/events | https://github.com/huggingface/datasets/pull/1599 | 770,431,389 | MDExOlB1bGxSZXF1ZXN0NTQyMTgwMzI4 | 1,599 | add Korean Sarcasm Dataset | [] | closed | false | null | 0 | 2020-12-17T22:49:56Z | 2021-09-17T16:54:32Z | 2020-12-23T17:25:59Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1599/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1599.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1599",
"merged_at": "2020-12-23T17:25:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1599.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1599"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5381/comments | https://api.github.com/repos/huggingface/datasets/issues/5381/events | https://github.com/huggingface/datasets/issues/5381 | 1,504,498,387 | I_kwDODunzps5ZrNLT | 5,381 | Wrong URL for the_pile dataset | [] | closed | false | null | 1 | 2022-12-20T12:40:14Z | 2023-02-15T16:24:57Z | 2023-02-15T16:24:57Z | null | ### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message": "Unable to resolve any data file that matches '['**']' at /storage/store/work/lgrinszt/memorization/the_pile with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'BLP', 'BMP', 'DIB', 'BUFR', 'CUR', 'PCX', 'DCX', 'DDS', 'PS', 'EPS', 'FIT', 'FITS', 'FLI', 'FLC', 'FTC', 'FTU', 'GBR', 'GIF', 'GRIB', 'H5', 'HDF', 'PNG', 'APNG', 'JP2', 'J2K', 'JPC', 'JPF', 'JPX', 'J2C', 'ICNS', 'ICO', 'IM', 'IIM', 'TIF', 'TIFF', 'JFIF', 'JPE', 'JPG', 'JPEG', 'MPG', 'MPEG', 'MSP', 'PCD', 'PXR', 'PBM', 'PGM', 'PPM', 'PNM', 'PSD', 'BW', 'RGB', 'RGBA', 'SGI', 'RAS', 'TGA', 'ICB', 'VDA', 'VST', 'WEBP', 'WMF', 'EMF', 'XBM', 'XPM', 'aiff', 'au', 'avr', 'caf', 'flac', 'htk', 'svx', 'mat4', 'mat5', 'mpc2k', 'ogg', 'paf', 'pvf', 'raw', 'rf64', 'sd2', 'sds', 'ircam', 'voc', 'w64', 'wav', 'nist', 'wavex', 'wve', 'xi', 'mp3', 'opus', 'AIFF', 'AU', 'AVR', 'CAF', 'FLAC', 'HTK', 'SVX', 'MAT4', 'MAT5', 'MPC2K', 'OGG', 'PAF', 'PVF', 'RAW', 'RF64', 'SD2', 'SDS', 'IRCAM', 'VOC', 'W64', 'WAV', 'NIST', 'WAVEX', 'WVE', 'XI', 'MP3', 'OPUS', 'zip']"
### Expected behavior
`the_pile` dataset should be dowloaded.
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-4.15.0-112-generic-x86_64-with-glibc2.27
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5381/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5381/timeline | null | completed | null | null | false | [
"Hi! This error can happen if there is a local file/folder with the same name as the requested dataset. And to avoid it, rename the local file/folder.\r\n\r\nSoon, it will be possible to explicitly request a Hub dataset as follows:https://github.com/huggingface/datasets/issues/5228#issuecomment-1313494020"
] |
https://api.github.com/repos/huggingface/datasets/issues/5753 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5753/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5753/comments | https://api.github.com/repos/huggingface/datasets/issues/5753/events | https://github.com/huggingface/datasets/issues/5753 | 1,668,659,536 | I_kwDODunzps5jdblQ | 5,753 | [IterableDatasets] Add column followed by interleave datasets gives bogus outputs | [] | closed | false | null | 1 | 2023-04-14T17:32:31Z | 2023-04-14T17:45:52Z | 2023-04-14T17:36:37Z | null | ### Describe the bug
If we add a new column to our iterable dataset using the hack described in #5752, when we then interleave datasets the new column is pinned to one value.
### Steps to reproduce the bug
What we're going to do here is:
1. Load an iterable dataset in streaming mode (`original_dataset`)
2. Add a new column to this dataset using the hack in #5752 (`modified_dataset_1`)
3. Create another new dataset by adding a column with the same key but different values (`modified_dataset_2`)
4. Interleave our new datasets (`modified_dataset_1` + `modified_dataset_2`)
5. Check the value of our newly added column (`new_column`)
```python
from datasets import load_dataset
# load an iterable dataset
original_dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# now add a new column to our streaming dataset using our hack from 5752
name = "new_column"
column = [f"new dataset 1, row {i}" for i in range(50)]
new_features = original_dataset.features.copy()
new_features[name] = new_features["file"] # I know that "file" has the right column type to match our new feature
def add_column_fn(example, idx):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: column[idx]}
modified_dataset_1 = original_dataset.map(add_column_fn, with_indices=True, features=new_features)
# now create a second modified dataset using the same trick
column = [f"new dataset 2, row {i}" for i in range(50)]
def add_column_fn(example, idx):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: column[idx]}
modified_dataset_2 = original_dataset.map(add_column_fn, with_indices=True, features=new_features)
# interleave these datasets
interleaved_dataset = interleave_datasets([modified_dataset_1, modified_dataset_2])
# now check what the value of the added column is
for i, sample in enumerate(interleaved_dataset):
print(sample["new_column"])
if i == 10:
break
```
**Print Output:**
```
new dataset 2, row 0
new dataset 2, row 0
new dataset 2, row 1
new dataset 2, row 1
new dataset 2, row 2
new dataset 2, row 2
new dataset 2, row 3
new dataset 2, row 3
new dataset 2, row 4
new dataset 2, row 4
new dataset 2, row 5
```
We see that we only get outputs from our second dataset.
### Expected behavior
We should interleave between dataset 1 and 2 and increase in row value:
```
new dataset 1, row 0
new dataset 2, row 0
new dataset 1, row 1
new dataset 2, row 1
new dataset 1, row 2
new dataset 2, row 2
...
```
### Environment info
- datasets version: 2.10.2.dev0
- Platform: Linux-4.19.0-23-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.16
- Huggingface_hub version: 0.13.3
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5753/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5753/timeline | null | completed | null | null | false | [
"Problem with the code snippet! Using global vars and functions was not a good idea with iterable datasets!\r\n\r\nIf we update to:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\noriginal_dataset = load_dataset(\"librispeech_asr\", \"clean\", split=\"validation\", streaming=True)\r\n\r\n# now add a new column to our streaming dataset using our hack\r\nname = \"new_column\"\r\ncolumn_1 = [f\"new dataset 1, row {i}\" for i in range(50)]\r\n\r\nnew_features = original_dataset.features.copy()\r\nnew_features[name] = new_features[\"file\"] # I know that \"file\" has the right column type to match our new feature\r\n\r\ndef add_column_fn_1(example, idx):\r\n if name in example:\r\n raise ValueError(f\"Error when adding {name}: column {name} is already in the dataset.\")\r\n return {name: column_1[idx]}\r\n\r\nmodified_dataset_1 = original_dataset.map(add_column_fn_1, with_indices=True, features=new_features)\r\n\r\n# now create a second modified dataset using the same trick\r\ncolumn_2 = [f\"new dataset 2, row {i}\" for i in range(50)]\r\n\r\ndef add_column_fn_2(example, idx):\r\n if name in example:\r\n raise ValueError(f\"Error when adding {name}: column {name} is already in the dataset.\")\r\n return {name: column_2[idx]}\r\n\r\nmodified_dataset_2 = original_dataset.map(add_column_fn_2, with_indices=True, features=new_features)\r\n\r\ninterleaved_dataset = interleave_datasets([modified_dataset_1, modified_dataset_2])\r\n\r\nfor i, sample in enumerate(interleaved_dataset):\r\n print(sample[\"new_column\"])\r\n if i == 10:\r\n break\r\n```\r\nwe get the correct outputs:\r\n```python\r\nnew dataset 1, row 0\r\nnew dataset 2, row 0\r\nnew dataset 1, row 1\r\nnew dataset 2, row 1\r\nnew dataset 1, row 2\r\nnew dataset 2, row 2\r\nnew dataset 1, row 3\r\nnew dataset 2, row 3\r\nnew dataset 1, row 4\r\nnew dataset 2, row 4\r\nnew dataset 1, row 5\r\n```\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5749/comments | https://api.github.com/repos/huggingface/datasets/issues/5749/events | https://github.com/huggingface/datasets/issues/5749 | 1,668,016,321 | I_kwDODunzps5ja-jB | 5,749 | AttributeError: 'Version' object has no attribute 'match' | [] | closed | false | null | 8 | 2023-04-14T10:48:06Z | 2023-06-30T11:31:17Z | 2023-04-18T12:57:08Z | null | ### Describe the bug
When I run
from datasets import load_dataset
data = load_dataset("visual_genome", 'region_descriptions_v1.2.0')
AttributeError: 'Version' object has no attribute 'match'
### Steps to reproduce the bug
from datasets import load_dataset
data = load_dataset("visual_genome", 'region_descriptions_v1.2.0')
### Expected behavior
This is error trace:
Downloading and preparing dataset visual_genome/region_descriptions_v1.2.0 to C:/Users/Acer/.cache/huggingface/datasets/visual_genome/region_descriptions_v1.2.0/1.2.0/136fe5b83f6691884566c5530313288171e053a3b33bfe3ea2e4c8b39abaf7f3...
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 data = load_dataset("visual_genome", 'region_descriptions_v1.2.0')
File ~\.conda\envs\aai\Lib\site-packages\datasets\load.py:1791, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, storage_options, **config_kwargs)
1788 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1790 # Download and prepare data
-> 1791 builder_instance.download_and_prepare(
1792 download_config=download_config,
1793 download_mode=download_mode,
1794 verification_mode=verification_mode,
1795 try_from_hf_gcs=try_from_hf_gcs,
1796 num_proc=num_proc,
1797 storage_options=storage_options,
1798 )
1800 # Build dataset for splits
1801 keep_in_memory = (
1802 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1803 )
File ~\.conda\envs\aai\Lib\site-packages\datasets\builder.py:891, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, verification_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
889 if num_proc is not None:
890 prepare_split_kwargs["num_proc"] = num_proc
--> 891 self._download_and_prepare(
892 dl_manager=dl_manager,
893 verification_mode=verification_mode,
894 **prepare_split_kwargs,
895 **download_and_prepare_kwargs,
896 )
897 # Sync info
898 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File ~\.conda\envs\aai\Lib\site-packages\datasets\builder.py:1651, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_splits_kwargs)
1650 def _download_and_prepare(self, dl_manager, verification_mode, **prepare_splits_kwargs):
-> 1651 super()._download_and_prepare(
1652 dl_manager,
1653 verification_mode,
1654 check_duplicate_keys=verification_mode == VerificationMode.BASIC_CHECKS
1655 or verification_mode == VerificationMode.ALL_CHECKS,
1656 **prepare_splits_kwargs,
1657 )
File ~\.conda\envs\aai\Lib\site-packages\datasets\builder.py:964, in DatasetBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)
962 split_dict = SplitDict(dataset_name=self.name)
963 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 964 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
966 # Checksums verification
967 if verification_mode == VerificationMode.ALL_CHECKS and dl_manager.record_checksums:
File ~\.cache\huggingface\modules\datasets_modules\datasets\visual_genome\136fe5b83f6691884566c5530313288171e053a3b33bfe3ea2e4c8b39abaf7f3\visual_genome.py:377, in VisualGenome._split_generators(self, dl_manager)
375 def _split_generators(self, dl_manager):
376 # Download image meta datas.
--> 377 image_metadatas_dir = dl_manager.download_and_extract(self.config.image_metadata_url)
378 image_metadatas_file = os.path.join(
379 image_metadatas_dir, _get_decompressed_filename_from_url(self.config.image_metadata_url)
380 )
382 # Download annotations
File ~\.cache\huggingface\modules\datasets_modules\datasets\visual_genome\136fe5b83f6691884566c5530313288171e053a3b33bfe3ea2e4c8b39abaf7f3\visual_genome.py:328, in VisualGenomeConfig.image_metadata_url(self)
326 @property
327 def image_metadata_url(self):
--> 328 if not self.version.match(_LATEST_VERSIONS["image_metadata"]):
329 logger.warning(
330 f"Latest image metadata version is {_LATEST_VERSIONS['image_metadata']}. Trying to generate a dataset of version: {self.version}. Please double check that image data are unchanged between the two versions."
331 )
332 return f"{_BASE_ANNOTATION_URL}/image_data.json.zip"
### Environment info
datasets 2.11.0
python 3.11.3 | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5749/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5749/timeline | null | completed | null | null | false | [
"I got the same error, and the official website for visual genome is down. Did you solve this problem? ",
"I am in the same situation now :( ",
"Thanks for reporting, @gulnaz-zh.\r\n\r\nI am investigating it.",
"The host server is down: https://visualgenome.org/\r\n\r\nWe are contacting the dataset authors.",
"Apart form data host server being down, there is an additional issue with the `datasets` library introduced by this PR:\r\n- #5238\r\n\r\nI am working to fix it.",
"PR that fixes the AttributeError: https://huggingface.co/datasets/visual_genome/discussions/2",
"For the issue with their data host server being down, I have opened a discussion in the \"Community\" tab of the Hub dataset: https://huggingface.co/datasets/visual_genome/discussions/3\r\nLet's continue the discussion there.",
"The authors just replied to us with their new URL: https://homes.cs.washington.edu/~ranjay/visualgenome/\r\n\r\nWe have fixed the datasets loading script, which is operative again."
] |
https://api.github.com/repos/huggingface/datasets/issues/5690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5690/comments | https://api.github.com/repos/huggingface/datasets/issues/5690/events | https://github.com/huggingface/datasets/issues/5690 | 1,649,289,883 | I_kwDODunzps5iTiqb | 5,690 | raise AttributeError(f"No {package_name} attribute {name}") AttributeError: No huggingface_hub attribute hf_api | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2023-03-31T08:22:22Z | 2023-07-21T14:21:57Z | 2023-07-21T14:21:57Z | null | ### Describe the bug
rta.sh
Traceback (most recent call last):
File "run.py", line 7, in <module>
import datasets
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/__init__.py", line 37, in <module>
from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/builder.py", line 44, in <module>
from .data_files import DataFilesDict, _sanitize_patterns
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/data_files.py", line 120, in <module>
dataset_info: huggingface_hub.hf_api.DatasetInfo,
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/huggingface_hub/__init__.py", line 290, in __getattr__
raise AttributeError(f"No {package_name} attribute {name}")
AttributeError: No huggingface_hub attribute hf_api
### Reproduction
_No response_
### Logs
```shell
Traceback (most recent call last):
File "run.py", line 7, in <module>
import datasets
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/__init__.py", line 37, in <module>
from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/builder.py", line 44, in <module>
from .data_files import DataFilesDict, _sanitize_patterns
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/data_files.py", line 120, in <module>
dataset_info: huggingface_hub.hf_api.DatasetInfo,
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/huggingface_hub/__init__.py", line 290, in __getattr__
raise AttributeError(f"No {package_name} attribute {name}")
AttributeError: No huggingface_hub attribute hf_api
```
### System info
```shell
- huggingface_hub version: 0.13.2
- Platform: Linux-5.4.0-144-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /home/appuser/.cache/huggingface/token
- Has saved token ?: False
- Configured git credential helpers:
- FastAI: N/A
- Tensorflow: N/A
- Torch: 1.7.1
- Jinja2: N/A
- Graphviz: N/A
- Pydot: N/A
- Pillow: 9.3.0
- hf_transfer: N/A
- ENDPOINT: https://huggingface.co
- HUGGINGFACE_HUB_CACHE: /home/appuser/.cache/huggingface/hub
- HUGGINGFACE_ASSETS_CACHE: /home/appuser/.cache/huggingface/assets
- HF_TOKEN_PATH: /home/appuser/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5690/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5690/timeline | null | completed | null | null | false | [
"Hi @wccccp, thanks for reporting. \r\nThat's weird since `huggingface_hub` _has_ a module called `hf_api` and you are using a recent version of it. \r\n\r\nWhich version of `datasets` are you using? And is it a bug that you experienced only recently? (cc @lhoestq can it be somehow related to the recent release of `datasets`?)\r\n\r\n~@wccccp what I can suggest you is to uninstall and reinstall completely huggingface_hub and datasets? My first guess is that there is a discrepancy somewhere in your setup 😕~",
"@wccccp Actually I have also been able to reproduce the error so it's not an issue with your setup.\r\n\r\n@huggingface/datasets I found this issue quite weird. Is this a module that is not used very often?\r\nThe problematic line is [this one](https://github.com/huggingface/datasets/blame/c33e8ce68b5000988bf6b2e4bca27ffaa469acea/src/datasets/data_files.py#L476) where `huggingface_hub.hf_api.DatasetInfo` is used. `huggingface_hub` is imported [here](https://github.com/huggingface/datasets/blame/c33e8ce68b5000988bf6b2e4bca27ffaa469acea/src/datasets/data_files.py#L6) as `import huggingface_hub`. However since modules are lazy-loaded in `hfh` you need to explicitly import them (i.e. `import huggingface_hub.hf_api`).\r\n\r\nWhat's weird is that nothing has changed for months. Datasets code seems that it didn't change for 2 years when I git-blame this part. And lazy-loading was introduced 1 year ago in `huggingface_hub`. Could it be that `data_files.py` is a file almost never used?\r\n",
"For context, I tried to run `import huggingface_hub; huggingface_hub.hf_api.DatasetInfo` in the terminal with different versions of `hfh` and I need to go back to `huggingface_hub==0.7.0` to make it work (latest is 0.13.3).",
"Before the error happens at line 120 in `data_files.py`, `datasets.filesystems.hffilesystem` is imported at the top of `data_files.py` and this file does `from huggingface_hub.hf_api import DatasetInfo` - so `huggingface_hub.hf_api` is imported. Not sure how the error could happen, what version of `datasets` are you using @wccccp ?",
"Closing due to inactivity."
] |
https://api.github.com/repos/huggingface/datasets/issues/3778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3778/comments | https://api.github.com/repos/huggingface/datasets/issues/3778/events | https://github.com/huggingface/datasets/issues/3778 | 1,147,898,946 | I_kwDODunzps5Ea4xC | 3,778 | Not be able to download dataset - "Newsroom" | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 2 | 2022-02-23T10:15:50Z | 2022-02-23T17:05:04Z | 2022-02-23T13:26:40Z | null | Hello,
I tried to download the **newsroom** dataset but it didn't work out for me. it said me to **download it manually**!
For manually, Link is also didn't work! It is sawing some ad or something!
If anybody has solved this issue please help me out or if somebody has this dataset please share your google drive link, it would be a great help!
Thanks
Darshan Tank | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3778/timeline | null | completed | null | null | false | [
"Hi @Darshan2104, thanks for reporting.\r\n\r\nPlease note that at Hugging Face we do not host the data of this dataset, but just a loading script pointing to the host of the data owners.\r\n\r\nApparently the data owners changed their data host server. After googling it, I found their new website at: https://lil.nlp.cornell.edu/newsroom/index.html\r\n- Download page: https://lil.nlp.cornell.edu/newsroom/download/index.html\r\n\r\nI'm fixing the link in our Datasets library.",
"@albertvillanova Thanks for the solution and link you made my day!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4271/comments | https://api.github.com/repos/huggingface/datasets/issues/4271/events | https://github.com/huggingface/datasets/issues/4271 | 1,224,404,403 | I_kwDODunzps5I-u2z | 4,271 | A typo in docs of datasets.disable_progress_bar | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-05-03T17:44:56Z | 2022-05-04T06:58:35Z | 2022-05-04T06:58:35Z | null | ## Describe the bug
in the docs of V2.1.0 datasets.disable_progress_bar, we should replace "enable" with "disable". | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4271/timeline | null | completed | null | null | false | [
"Hi! Thanks for catching and reporting the typo, a PR has been opened to fix it :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2706/comments | https://api.github.com/repos/huggingface/datasets/issues/2706/events | https://github.com/huggingface/datasets/pull/2706 | 950,606,561 | MDExOlB1bGxSZXF1ZXN0Njk1MTI3ODgz | 2,706 | Update BibTeX entry | [] | closed | false | null | 0 | 2021-07-22T12:29:29Z | 2021-07-22T12:43:00Z | 2021-07-22T12:43:00Z | null | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2706/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2706/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2706.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2706",
"merged_at": "2021-07-22T12:43:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2706.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2706"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2361/comments | https://api.github.com/repos/huggingface/datasets/issues/2361/events | https://github.com/huggingface/datasets/pull/2361 | 891,982,808 | MDExOlB1bGxSZXF1ZXN0NjQ0NzYzNTU4 | 2,361 | Preserve dtype for numpy/torch/tf/jax arrays | [] | closed | false | null | 6 | 2021-05-14T14:45:23Z | 2021-08-17T08:30:04Z | 2021-08-17T08:30:04Z | null | Fixes #625. This lets the user preserve the dtype of numpy array to pyarrow array which was getting lost due to conversion of numpy array -> list -> pyarrow array. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2361/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2361.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2361",
"merged_at": "2021-08-17T08:30:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2361.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2361"
} | true | [
"Hi @lhoestq, \r\nIt turns out that pyarrow `ListArray` are not recognized as list-like when we get output from `numpy_to_pyarrow_listarray`. This might cause tests to fail. If possible can we convert that `ListArray` output to list inorder for tests to pass? Under the hood it'll maintain the dtype as that of numpy array passed during input only",
"Brought down the failing tests from 7 to 4. Let me know if that part looks good. Failing tests are looking quite similar. In `test_map_torch` https://github.com/huggingface/datasets/blob/3d46bc384f811435e59e3916faa3aa20a1cf87bc/tests/test_arrow_dataset.py#L1039 and `test_map_tf`https://github.com/huggingface/datasets/blob/3d46bc384f811435e59e3916faa3aa20a1cf87bc/tests/test_arrow_dataset.py#L1056 \r\nthey're expecting `float64`. Shouldn't that be `float32` now?",
"It's normal: pytorch and tensorflow use `float32` by default, unlike numpy which uses `float64`.\r\n\r\nI think that we should always keep the precision of the original tensor (torch/tf/numpy).\r\nIt means that as it is in this PR it's fine (the precision is conserved when doing the torch/tf -> numpy conversion).\r\n\r\nThis is a breaking change but in my opinion the fact that we had Value(\"float64\") for torch.float32 tensors was an issue already.\r\n\r\nLet me know what you think. Cc @albertvillanova if you have an opinion on this\r\n\r\nIf we agree on doing this breaking change, we can just change the test. ",
"Hi @lhoestq, \r\nMerged master into this branch. Only changing the test is left for now (mentioned below) after which all tests should pass.\r\n\r\n> Brought down the failing tests from 7 to 4. Let me know if that part looks good. Failing tests are looking quite similar. In `test_map_torch`\r\n> \r\n> https://github.com/huggingface/datasets/blob/3d46bc384f811435e59e3916faa3aa20a1cf87bc/tests/test_arrow_dataset.py#L1039\r\n> \r\n> and `test_map_tf`\r\n> https://github.com/huggingface/datasets/blob/3d46bc384f811435e59e3916faa3aa20a1cf87bc/tests/test_arrow_dataset.py#L1056\r\n> \r\n> \r\n> they're expecting `float64`. Shouldn't that be `float32` now?\r\n\r\n",
"> they're expecting float64. Shouldn't that be float32 now?\r\n\r\nYes feel free to update those tests :)\r\n\r\nIt would be nice to have the same test for JAX as well",
"Added same test for for JAX too. Also, I saw that I missed changing `test_cast_to_python_objects_jax` like I did for TF and PyTorch. Finished that as well"
] |
https://api.github.com/repos/huggingface/datasets/issues/5383 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5383/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5383/comments | https://api.github.com/repos/huggingface/datasets/issues/5383/events | https://github.com/huggingface/datasets/issues/5383 | 1,507,293,968 | I_kwDODunzps5Z13sQ | 5,383 | IterableDataset missing column_names, differs from Dataset interface | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 6 | 2022-12-22T05:27:02Z | 2023-03-13T19:03:33Z | 2023-03-13T19:03:33Z | null | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.column_names` does not exist on IterableDataset. I cannot find any clear explanation on why this is not available, is it an oversight? We do have `iterable_ds.features` available.
### Steps to reproduce the bug
See above
### Expected behavior
Dataset and IterableDataset would be expected to have the same interface, with any differences noted in the documentation.
### Environment info
n/a | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5383/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5383/timeline | null | completed | null | null | false | [
"Another example is that `IterableDataset.map` does not have `fn_kwargs`, among other arguments. It makes it harder to convert code from Dataset to IterableDataset.",
"Hi! `fn_kwargs` was added to `IterableDataset.map` in `datasets 2.5.0`, so please update your installation (`pip install -U datasets`) to use it.\r\n\r\nRegarding `column_names`, I agree we should add this property to `IterableDataset`. In the meantime, you can use `list(dataset.features.keys())` instead.",
"Thanks! That's great news.\n\nOn Thu, Dec 22, 2022, 07:48 Mario Šaško ***@***.***> wrote:\n\n> Hi! fn_kwargs was added to IterableDataset.map in datasets 2.5.0, so\n> please update your installation (pip install -U datasets) to use it.\n>\n> Regarding column_names, I agree we should add this property to\n> IterableDataset. In the meantime, you can use\n> list(dataset.features.keys()) instead.\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5383#issuecomment-1362993633>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAHD6N2EQUFEOUFDW3VHSILWORZ45ANCNFSM6AAAAAATGKWVGM>\n> .\n> You are receiving this because you authored the thread.Message ID:\n> ***@***.***>\n>\n",
"I'm marking this issue as a \"good first issue\", as it makes sense to have `IterableDataset.column_names` in the API. Besides the case when `features` are `None` (e.g., `features` are `None` after `map`), in which we can also return `column_names` as `None`, adding this property should be straightforward,",
"Hi @mariosasko, I can work on this if that's ok?",
"Yes! I've assigned you the issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/6070 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6070/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6070/comments | https://api.github.com/repos/huggingface/datasets/issues/6070/events | https://github.com/huggingface/datasets/pull/6070 | 1,820,836,330 | PR_kwDODunzps5WXDLc | 6,070 | Fix Quickstart notebook link | [] | closed | false | null | 3 | 2023-07-25T17:48:37Z | 2023-07-25T18:19:01Z | 2023-07-25T18:10:16Z | null | Reported in https://github.com/huggingface/datasets/pull/5902#issuecomment-1649885621 (cc @alvarobartt) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6070/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6070/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6070.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6070",
"merged_at": "2023-07-25T18:10:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6070.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6070"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008473 / 0.011353 (-0.002880) | 0.004734 / 0.011008 (-0.006274) | 0.103895 / 0.038508 (0.065387) | 0.071838 / 0.023109 (0.048729) | 0.379949 / 0.275898 (0.104051) | 0.397375 / 0.323480 (0.073895) | 0.006695 / 0.007986 (-0.001290) | 0.004536 / 0.004328 (0.000207) | 0.076151 / 0.004250 (0.071901) | 0.058690 / 0.037052 (0.021638) | 0.379937 / 0.258489 (0.121448) | 0.411833 / 0.293841 (0.117992) | 0.046805 / 0.128546 (-0.081741) | 0.013689 / 0.075646 (-0.061958) | 0.327896 / 0.419271 (-0.091375) | 0.063873 / 0.043533 (0.020340) | 0.378451 / 0.255139 (0.123312) | 0.398725 / 0.283200 (0.115525) | 0.034961 / 0.141683 (-0.106722) | 1.604999 / 1.452155 (0.152845) | 1.748370 / 1.492716 (0.255654) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224634 / 0.018006 (0.206628) | 0.548468 / 0.000490 (0.547979) | 0.005049 / 0.000200 (0.004849) | 0.000097 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028144 / 0.037411 (-0.009267) | 0.092184 / 0.014526 (0.077659) | 0.102987 / 0.176557 (-0.073570) | 0.176987 / 0.737135 (-0.560149) | 0.103093 / 0.296338 (-0.193246) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.578410 / 0.215209 (0.363201) | 5.664781 / 2.077655 (3.587126) | 2.487763 / 1.504120 (0.983643) | 2.254213 / 1.541195 (0.713018) | 2.239693 / 1.468490 (0.771202) | 0.810380 / 4.584777 (-3.774397) | 5.036540 / 3.745712 (1.290828) | 7.064695 / 5.269862 (1.794834) | 4.215101 / 4.565676 (-0.350575) | 0.089792 / 0.424275 (-0.334483) | 0.008487 / 0.007607 (0.000879) | 0.692292 / 0.226044 (0.466248) | 6.780226 / 2.268929 (4.511297) | 3.245510 / 55.444624 (-52.199114) | 2.575984 / 6.876477 (-4.300493) | 2.747546 / 2.142072 (0.605473) | 0.956604 / 4.805227 (-3.848623) | 0.198937 / 6.500664 (-6.301727) | 0.070849 / 0.075469 (-0.004620) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.536469 / 1.841788 (-0.305319) | 21.750583 / 8.074308 (13.676275) | 20.559532 / 10.191392 (10.368140) | 0.241244 / 0.680424 (-0.439180) | 0.030078 / 0.534201 (-0.504123) | 0.462204 / 0.579283 (-0.117079) | 0.600103 / 0.434364 (0.165739) | 0.535074 / 0.540337 (-0.005264) | 0.764427 / 1.386936 (-0.622509) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009712 / 0.011353 (-0.001641) | 0.005036 / 0.011008 (-0.005972) | 0.073683 / 0.038508 (0.035175) | 0.078684 / 0.023109 (0.055574) | 0.445096 / 0.275898 (0.169198) | 0.496233 / 0.323480 (0.172754) | 0.006231 / 0.007986 (-0.001755) | 0.004720 / 0.004328 (0.000392) | 0.076444 / 0.004250 (0.072194) | 0.060932 / 0.037052 (0.023880) | 0.505727 / 0.258489 (0.247238) | 0.498702 / 0.293841 (0.204861) | 0.047115 / 0.128546 (-0.081431) | 0.014028 / 0.075646 (-0.061618) | 0.099292 / 0.419271 (-0.319980) | 0.061571 / 0.043533 (0.018038) | 0.468435 / 0.255139 (0.213296) | 0.481747 / 0.283200 (0.198547) | 0.033962 / 0.141683 (-0.107721) | 1.665397 / 1.452155 (0.213242) | 1.830488 / 1.492716 (0.337772) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268217 / 0.018006 (0.250211) | 0.555123 / 0.000490 (0.554633) | 0.000451 / 0.000200 (0.000251) | 0.000156 / 0.000054 (0.000101) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034262 / 0.037411 (-0.003150) | 0.107807 / 0.014526 (0.093281) | 0.115631 / 0.176557 (-0.060926) | 0.175914 / 0.737135 (-0.561221) | 0.118775 / 0.296338 (-0.177564) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.583260 / 0.215209 (0.368051) | 5.934976 / 2.077655 (3.857321) | 2.752304 / 1.504120 (1.248184) | 2.382746 / 1.541195 (0.841551) | 2.389402 / 1.468490 (0.920912) | 0.794213 / 4.584777 (-3.790564) | 5.215269 / 3.745712 (1.469557) | 7.083595 / 5.269862 (1.813733) | 3.776136 / 4.565676 (-0.789540) | 0.091141 / 0.424275 (-0.333135) | 0.008803 / 0.007607 (0.001196) | 0.726510 / 0.226044 (0.500465) | 6.926860 / 2.268929 (4.657931) | 3.475612 / 55.444624 (-51.969012) | 2.730237 / 6.876477 (-4.146240) | 2.879145 / 2.142072 (0.737073) | 0.959956 / 4.805227 (-3.845271) | 0.189812 / 6.500664 (-6.310852) | 0.071624 / 0.075469 (-0.003845) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.748184 / 1.841788 (-0.093603) | 23.764520 / 8.074308 (15.690212) | 19.502461 / 10.191392 (9.311069) | 0.233987 / 0.680424 (-0.446437) | 0.028116 / 0.534201 (-0.506085) | 0.478838 / 0.579283 (-0.100445) | 0.560952 / 0.434364 (0.126588) | 0.529902 / 0.540337 (-0.010435) | 0.735095 / 1.386936 (-0.651841) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006735 / 0.011353 (-0.004618) | 0.004131 / 0.011008 (-0.006878) | 0.085619 / 0.038508 (0.047111) | 0.076973 / 0.023109 (0.053864) | 0.315175 / 0.275898 (0.039277) | 0.354703 / 0.323480 (0.031223) | 0.005409 / 0.007986 (-0.002577) | 0.003438 / 0.004328 (-0.000891) | 0.064773 / 0.004250 (0.060523) | 0.056117 / 0.037052 (0.019064) | 0.313825 / 0.258489 (0.055336) | 0.354654 / 0.293841 (0.060813) | 0.031384 / 0.128546 (-0.097163) | 0.008537 / 0.075646 (-0.067109) | 0.288528 / 0.419271 (-0.130744) | 0.053036 / 0.043533 (0.009504) | 0.312213 / 0.255139 (0.057074) | 0.335952 / 0.283200 (0.052752) | 0.023165 / 0.141683 (-0.118518) | 1.497559 / 1.452155 (0.045404) | 1.561949 / 1.492716 (0.069233) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212558 / 0.018006 (0.194552) | 0.456555 / 0.000490 (0.456065) | 0.000334 / 0.000200 (0.000134) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028571 / 0.037411 (-0.008840) | 0.085154 / 0.014526 (0.070628) | 0.095961 / 0.176557 (-0.080596) | 0.153041 / 0.737135 (-0.584094) | 0.099234 / 0.296338 (-0.197105) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.381796 / 0.215209 (0.166587) | 3.806948 / 2.077655 (1.729294) | 1.829597 / 1.504120 (0.325477) | 1.659065 / 1.541195 (0.117870) | 1.738524 / 1.468490 (0.270034) | 0.483379 / 4.584777 (-4.101398) | 3.540648 / 3.745712 (-0.205064) | 3.269188 / 5.269862 (-2.000673) | 2.042113 / 4.565676 (-2.523564) | 0.056905 / 0.424275 (-0.367370) | 0.007235 / 0.007607 (-0.000373) | 0.460581 / 0.226044 (0.234537) | 4.597451 / 2.268929 (2.328522) | 2.334284 / 55.444624 (-53.110340) | 1.960026 / 6.876477 (-4.916450) | 2.172118 / 2.142072 (0.030045) | 0.576758 / 4.805227 (-4.228470) | 0.131196 / 6.500664 (-6.369468) | 0.060053 / 0.075469 (-0.015417) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289466 / 1.841788 (-0.552322) | 19.713059 / 8.074308 (11.638750) | 14.292390 / 10.191392 (4.100998) | 0.146199 / 0.680424 (-0.534225) | 0.018123 / 0.534201 (-0.516078) | 0.392492 / 0.579283 (-0.186791) | 0.416544 / 0.434364 (-0.017820) | 0.457166 / 0.540337 (-0.083171) | 0.645490 / 1.386936 (-0.741446) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006508 / 0.011353 (-0.004845) | 0.004010 / 0.011008 (-0.006998) | 0.065201 / 0.038508 (0.026693) | 0.076322 / 0.023109 (0.053213) | 0.364198 / 0.275898 (0.088300) | 0.398251 / 0.323480 (0.074771) | 0.005328 / 0.007986 (-0.002658) | 0.003298 / 0.004328 (-0.001031) | 0.064378 / 0.004250 (0.060128) | 0.056053 / 0.037052 (0.019000) | 0.365431 / 0.258489 (0.106942) | 0.402777 / 0.293841 (0.108936) | 0.031014 / 0.128546 (-0.097532) | 0.008507 / 0.075646 (-0.067140) | 0.071471 / 0.419271 (-0.347801) | 0.048300 / 0.043533 (0.004768) | 0.359700 / 0.255139 (0.104561) | 0.382244 / 0.283200 (0.099044) | 0.023783 / 0.141683 (-0.117900) | 1.517518 / 1.452155 (0.065363) | 1.569732 / 1.492716 (0.077015) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.257447 / 0.018006 (0.239440) | 0.452598 / 0.000490 (0.452109) | 0.015187 / 0.000200 (0.014987) | 0.000164 / 0.000054 (0.000109) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030958 / 0.037411 (-0.006454) | 0.090066 / 0.014526 (0.075540) | 0.101120 / 0.176557 (-0.075437) | 0.154295 / 0.737135 (-0.582840) | 0.103582 / 0.296338 (-0.192756) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415945 / 0.215209 (0.200736) | 4.146464 / 2.077655 (2.068809) | 2.121414 / 1.504120 (0.617294) | 1.956885 / 1.541195 (0.415690) | 2.047955 / 1.468490 (0.579465) | 0.486334 / 4.584777 (-4.098443) | 3.506263 / 3.745712 (-0.239449) | 4.942274 / 5.269862 (-0.327587) | 2.907836 / 4.565676 (-1.657841) | 0.057344 / 0.424275 (-0.366931) | 0.007813 / 0.007607 (0.000206) | 0.497888 / 0.226044 (0.271844) | 4.978017 / 2.268929 (2.709089) | 2.600447 / 55.444624 (-52.844177) | 2.335050 / 6.876477 (-4.541427) | 2.480373 / 2.142072 (0.338301) | 0.597954 / 4.805227 (-4.207274) | 0.134794 / 6.500664 (-6.365870) | 0.062605 / 0.075469 (-0.012864) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.344390 / 1.841788 (-0.497398) | 20.020067 / 8.074308 (11.945759) | 14.344626 / 10.191392 (4.153234) | 0.172101 / 0.680424 (-0.508322) | 0.018549 / 0.534201 (-0.515652) | 0.393589 / 0.579283 (-0.185694) | 0.438401 / 0.434364 (0.004037) | 0.463800 / 0.540337 (-0.076537) | 0.618269 / 1.386936 (-0.768667) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3898 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3898/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3898/comments | https://api.github.com/repos/huggingface/datasets/issues/3898/events | https://github.com/huggingface/datasets/pull/3898 | 1,166,778,250 | PR_kwDODunzps40UWG4 | 3,898 | Create README.md for WER metric | [] | closed | false | null | 4 | 2022-03-11T19:29:09Z | 2022-03-15T17:05:00Z | 2022-03-15T17:04:59Z | null | Proposing a draft WER metric card, @lhoestq I'm not very certain about "Values from popular papers" -- I don't know ASR very well, what do you think of the examples I found? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3898/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3898/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3898.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3898",
"merged_at": "2022-03-15T17:04:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3898.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3898"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3898). All of your documentation changes will be reflected on that endpoint.",
"For ASR you can probably ping @patrickvonplaten ",
"Ah only noticed now that ` # Values from popular papers` is from a template. @lhoestq @sashavor - not really sure if this section is useful in general really. \r\n\r\nIMO, it's more confusing/misleading than it helps. E.g. a value of 0.03 WER on a fake read-out audio dataset is not better than a WER of 0.3 on a real-world noisy, conversational audio dataset. I think the same holds true for other metrics no? I can think of very little metrics where a metric value is not dataset dependent. E.g. perplexity is super dataset dependent, summarization metrics like ROUGE as well, ...\r\n\r\nAlso, I don't really see what this section tries to achieve - is the idea here to give the reader some papers that use this metric to better understand in which context it is used? Should we maybe rename the section to `Popular papers making use of this metric` or something? \r\n\r\n",
"I put \"Values from popular papers\" as a subsection of \"Output values\" -- I hope that's a compromise that works for everyone :hugs: "
] |
https://api.github.com/repos/huggingface/datasets/issues/2972 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2972/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2972/comments | https://api.github.com/repos/huggingface/datasets/issues/2972/events | https://github.com/huggingface/datasets/issues/2972 | 1,007,808,714 | I_kwDODunzps48EfDK | 2,972 | OSError: Not enough disk space. | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2021-09-27T07:41:22Z | 2022-08-29T23:21:36Z | 2021-09-28T06:43:15Z | null | ## Describe the bug
I'm trying to download `natural_questions` dataset from the Internet, and I've specified the cache_dir which locates in a mounted disk and has enough disk space. However, even though the space is enough, the disk space checking function still reports the space of root `/` disk having no enough space.
The file system structure is like below. The root `/` has `115G` disk space available, and the `sda1` is mounted to `/mnt`, which has `1.2T` disk space available:
```
/
/mnt/sda1/path/to/args.dataset_cache_dir
```
## Steps to reproduce the bug
```python
dataset_config = DownloadConfig(
cache_dir=os.path.abspath(args.dataset_cache_dir),
resume_download=True,
)
dataset = load_dataset("natural_questions", download_config=dataset_config)
```
## Expected results
Can download the dataset without an error.
## Actual results
The following error raised:
```
OSError: Not enough disk space. Needed: 134.92 GiB (download: 41.97 GiB, generated: 92.95 GiB, post-processed: Unknown size)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Ubuntu 18.04
- Python version: 3.8.10
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2972/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2972/timeline | null | completed | null | null | false | [
"Maybe we can change the disk space calculating API from `shutil.disk_usage` to `os.statvfs` in UNIX-like system, which can provide correct results.\r\n```\r\nstatvfs = os.statvfs('path')\r\navail_space_bytes = statvfs.f_frsize * statvfs.f_bavail\r\n```",
"Hi @qqaatw, thanks for reporting.\r\n\r\nCould you please try:\r\n```python\r\ndataset = load_dataset(\"natural_questions\", cache_dir=os.path.abspath(args.dataset_cache_dir))\r\n```",
"@albertvillanova it works! Thanks for your suggestion. Is that a bug of `DownloadConfig`?",
"`DownloadConfig` only sets the location to download the files. On the other hand, `cache_dir` sets the location for both downloading and caching the data. You can find more information here: https://huggingface.co/docs/datasets/loading_datasets.html#cache-directory",
"I had encountered the same error when running a command `ds = load_dataset('food101')` in a docker container. The error I got: `OSError: Not enough disk space. Needed: 9.43 GiB (download: 4.65 GiB, generated: 4.77 GiB, post-processed: Unknown size)`\r\n\r\nIn case anyone encountered the same issue, this was my fix:\r\n\r\n```sh\r\n# starting the container (mount project directory onto /app, so that the code and data in my project directory are available in the container)\r\ndocker run -it --rm -v $(pwd):/app my-demo:latest bash\r\n```\r\n\r\n\r\n```python\r\n# other code ...\r\nds = load_dataset('food101', cache_dir=\"/app/data\") # set cache_dir to the absolute path of a directory (e.g. /app/data) that's mounted from the host (MacOS in my case) into the docker container\r\n\r\n# this assumes ./data directory exists in your project folder. If not, create it or point it to any other existing directory where you want to store the cache\r\n```\r\n\r\nThanks @albertvillanova for posting the fix above :-) "
] |
https://api.github.com/repos/huggingface/datasets/issues/2731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2731/comments | https://api.github.com/repos/huggingface/datasets/issues/2731/events | https://github.com/huggingface/datasets/pull/2731 | 956,087,452 | MDExOlB1bGxSZXF1ZXN0Njk5NzQwMjg5 | 2,731 | Adding to_tf_dataset method | [] | closed | false | null | 7 | 2021-07-29T18:10:25Z | 2021-09-16T13:50:54Z | 2021-09-16T13:50:54Z | null | Oh my **god** do not merge this yet, it's just a draft.
I've added a method (via a mixin) to the `arrow_dataset.Dataset` class that automatically converts our Dataset classes to TF Dataset classes ready for training. It hopefully has most of the features we want, including streaming from disk (no need to load the whole dataset in memory!), correct shuffling, variable-length batches to reduce compute, and correct support for unusual padding. It achieves that by calling the tokenizer `pad` method in the middle of a TF compute graph via a very hacky call to `tf.py_function`, which is heretical but seems to work.
A number of issues need to be resolved before it's ready to merge, though:
1) Is a MixIn the right way to do this? Do other classes besides `arrow_dataset.Dataset` need this method too?
2) Needs an argument to support constant-length batches for TPU training - this is easy to add and I'll do it soon.
3) Needs the user to supply the list of columns to drop from the arrow `Dataset`. Is there some automatic way to get the columns we want, or see which columns were added by the tokenizer?
4) Assumes the label column is always present and always called "label" - this is probably not great, but I'm not sure what the 'correct' thing to do here is. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2731/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2731/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2731.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2731",
"merged_at": "2021-09-16T13:50:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2731.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2731"
} | true | [
"This seems to be working reasonably well in testing, and performance is way better. `tf.py_function` has been dropped for an input generator, but I moved as much of the code as possible outside the generator to allow TF to compile it correctly. I also avoid `tf.RaggedTensor` at all costs, and do the shuffle in the dataset followed by accessing sequential chunks, instead of shuffling an index tensor. The combination of all of these gives us a more flexible data loader as well as a ~20X boost in performance compared to the first solution.",
"I made a change to the `TFFormatter` in this PR that will need some changes to the tests, so I wanted to ping @lhoestq and anyone else before I made those changes.\r\n\r\nThe key problem is that up until now the `TFFormatter` always returns `RaggedTensor`, created using the very slow `tf.ragged.constant` function. This is a big performance penalty, but it's also (imo) surprising for users - `RaggedTensor` handles tensors where one dimension has variable length. This is a good choice for tokenized datasets with variable sequence length, but it's an odd choice when the non-batch dimensions are constant, such as in image datasets, or in datasets where all samples are padded to the same length (e.g. for TPU training).\r\n\r\nThe change I made was to try to return standard `Tensor` objects instead of `RaggedTensor` when all the samples in the batch had the same shape, and if that was not the case to fall back to fast `RaggedTensor` creation with `tf.ragged.stack`, and only falling back to the very slow `tf.ragged.constant` function as a last resort. I think this will match user expectations in most cases and greatly improve performance, but it's a (very slightly) breaking change, so any feedback is welcome!",
"Also I really can't emphasize enough how slow `tf.ragged.constant` is, it's bad enough to create a data pipeline bottleneck in more or less any training setup:\r\n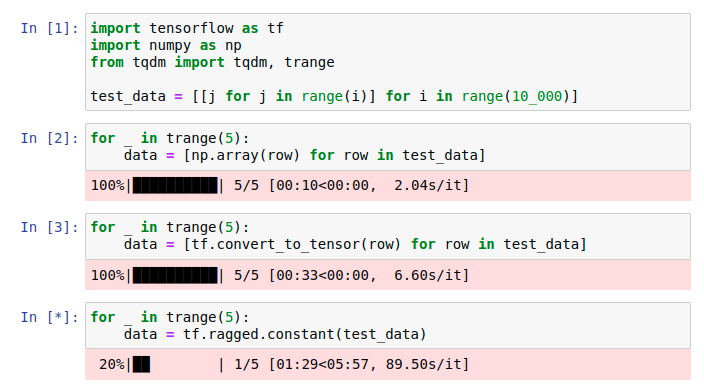\r\n",
"Hi @lhoestq, the tests have been modified and everything is passing. The Windows tests look to be failing for an unrelated reason, but other than that I'm ready to merge if you are!",
"Hi @Rocketknight1 ! Feel free to merge `master` into this branch to fix and run the full CI :)",
"@lhoestq rebased onto master and it looks good! I'm doing some testing with new notebook examples, but are you happy to merge if that looks good?",
"@lhoestq No, I'm happy to merge it as-is and add documentation afterwards!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3280/comments | https://api.github.com/repos/huggingface/datasets/issues/3280/events | https://github.com/huggingface/datasets/pull/3280 | 1,054,766,828 | PR_kwDODunzps4ulgye | 3,280 | Fix bookcorpusopen RAM usage | [] | closed | false | null | 0 | 2021-11-16T11:27:52Z | 2021-11-17T15:53:28Z | 2021-11-16T13:34:30Z | null | Each document is a full book, so the default arrow writer batch size of 10,000 is too big, and it can fill up RAM quickly before flushing the first batch on disk. I changed its batch size to 256 to use maximum 100MB of memory
Fix #3167. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3280/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3280.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3280",
"merged_at": "2021-11-16T13:34:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3280.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3280"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3845 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3845/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3845/comments | https://api.github.com/repos/huggingface/datasets/issues/3845/events | https://github.com/huggingface/datasets/pull/3845 | 1,161,739,483 | PR_kwDODunzps40DvqX | 3,845 | add RMSE and MAE metrics. | [] | closed | false | null | 6 | 2022-03-07T17:53:24Z | 2022-03-09T16:50:03Z | 2022-03-09T16:50:03Z | null | This PR adds RMSE - Root Mean Squared Error and MAE - Mean Absolute Error to the metrics API.
Both implementations are based on usage of sciket-learn.
Feature request here : Add support for continuous metrics (RMSE, MAE) [#3608](https://github.com/huggingface/datasets/issues/3608)
Please suggest any changes if required. Thank you. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3845/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3845/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3845.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3845",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3845.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3845"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3845). All of your documentation changes will be reflected on that endpoint.",
"@mariosasko I've reopened it here. Please suggest any changes if required. Thank you.",
"Thanks for suggestions. :) I have added update the KWARGS_DESCRIPTION for the missing params and also changed RMSE to MSE.\r\nWhile testing, I noticed that when the input is a list of lists, we get an error :\r\n`TypeError: float() argument must be a string or a number, not 'list'`\r\nCould you suggest the datasets.Value() attribute to support both list of floats and list of lists containing floats ?\r\n",
"Just add a new config to cover that case. You can do this by replacing the current `features` dict with:\r\n```python\r\nfeatures=datasets.Features(\r\n {\r\n \"predictions\": datasets.Sequence(datasets.Value(\"float\")),\r\n \"references\": datasets.Sequence(datasets.Value(\"float\")),\r\n }\r\n if self.config_name == \"multioutput\"\r\n else {\r\n \"predictions\": datasets.Value(\"float\"),\r\n \"references\": datasets.Value(\"float\"),\r\n }\r\n),\r\n```\r\nFeel free to suggest a better name for the config than `multioutput`",
"Also, could you please move the changes to a new branch and open a PR from there (for the 3rd time 😄) because the diff shows changes from unrelated PRs (maybe due to rebasing?).",
"Thanks for the input, I have added new config to support multi-dimensional lists and updated the examples as well.\r\n\r\nSure. Will do that and open a new PR for these changes."
] |
https://api.github.com/repos/huggingface/datasets/issues/3393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3393/comments | https://api.github.com/repos/huggingface/datasets/issues/3393/events | https://github.com/huggingface/datasets/issues/3393 | 1,073,189,777 | I_kwDODunzps4_95OR | 3,393 | Common Voice Belarusian Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] | open | false | null | 0 | 2021-12-07T10:37:02Z | 2021-12-09T15:56:03Z | null | null | ## Adding a Dataset
- **Name:** *Common Voice Belarusian Dataset*
- **Description:** *[commonvoice.mozilla.org/be](https://commonvoice.mozilla.org/be)*
- **Data:** *[commonvoice.mozilla.org/be/datasets](https://commonvoice.mozilla.org/be/datasets)*
- **Motivation:** *It has more than 7GB of data, so it will be great to have it in this package so anyone can try to train something for Belarusian language.*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3393/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3393/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5344/comments | https://api.github.com/repos/huggingface/datasets/issues/5344/events | https://github.com/huggingface/datasets/pull/5344 | 1,485,628,319 | PR_kwDODunzps5E2BPN | 5,344 | Clean up Dataset and DatasetDict | [] | closed | false | null | 1 | 2022-12-09T00:02:08Z | 2022-12-13T00:56:07Z | 2022-12-13T00:53:02Z | null | This PR cleans up the docstrings for the other half of the methods in `Dataset` and finishes `DatasetDict`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5344/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5344/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5344.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5344",
"merged_at": "2022-12-13T00:53:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5344.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5344"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5880 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5880/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5880/comments | https://api.github.com/repos/huggingface/datasets/issues/5880/events | https://github.com/huggingface/datasets/issues/5880 | 1,719,090,101 | I_kwDODunzps5mdzu1 | 5,880 | load_dataset from s3 file system through streaming can't not iterate data | [] | open | false | null | 4 | 2023-05-22T07:40:27Z | 2023-05-26T12:52:08Z | null | null | ### Describe the bug
I have a JSON file in my s3 file system(minio), I can use load_dataset to get the file link, but I can't iterate it
<img width="816" alt="image" src="https://github.com/huggingface/datasets/assets/59083384/cc0778d3-36f3-45b5-ac68-4e7c664c2ed0">
<img width="1144" alt="image" src="https://github.com/huggingface/datasets/assets/59083384/76872af3-8b3c-42ff-9f55-528c920a7af1">
we can change 4 lines to fix this bug, you can check whether it is ok for us.
<img width="941" alt="image" src="https://github.com/huggingface/datasets/assets/59083384/5a22155a-ece7-496c-8506-047e5c235cd3">
### Steps to reproduce the bug
1. storage a file in you s3 file system
2. use load_dataset to read it through streaming
3. iterate it
### Expected behavior
can iterate it successfully
### Environment info
- `datasets` version: 2.12.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.16
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5880/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5880/timeline | null | null | null | null | false | [
"This sounds related to #5281.\r\n\r\nCan you try passing `storage_options=s3_client.storage_options` instead passing it to `use_auth_token=` ?",
"I tried `storage_options` before, but it doesn't work, I checked our source code and I found that we even didn't pass this parameter to the following process. if I use `storage_options` instead of `use_auth_token`, then I also need to change another place of the code. the last line of `streaming_download_manager.py`. our code only passes the `use_auth_token` to the following handler, but does nothing to the `storage_options`\r\n<img width=\"1050\" alt=\"image\" src=\"https://github.com/huggingface/datasets/assets/59083384/5be90933-3331-4ecf-9e11-34f9852d8f92\">\r\n",
"Cloud storage support is still experimental indeed and you can expect some bugs.\r\n\r\nI think we need to pass the storage options anywhere use_auth_token is passed in indeed. Let me know if you'd be interested in contributing a fix !",
"Oh, that's great, I really like to fix it. because datasets is really useful and most of our projects need to use it, but we can store our data on the internet due to security reasons. fix it not only make our own work more efficient but also can benefit others who use it."
] |
https://api.github.com/repos/huggingface/datasets/issues/787 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/787/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/787/comments | https://api.github.com/repos/huggingface/datasets/issues/787/events | https://github.com/huggingface/datasets/pull/787 | 734,070,162 | MDExOlB1bGxSZXF1ZXN0NTEzNjk5MTQz | 787 | Adding nli_tr dataset | [] | closed | false | null | 1 | 2020-11-01T21:49:44Z | 2020-11-12T19:06:02Z | 2020-11-12T19:06:02Z | null | Hello,
In this pull request, we have implemented the necessary interface to add our recent dataset [NLI-TR](https://github.com/boun-tabi/NLI-TR). The datasets will be presented on a full paper at EMNLP 2020 this month. [[arXiv link] ](https://arxiv.org/pdf/2004.14963.pdf)
The dataset is the neural machine translation of SNLI and MultiNLI datasets into Turkish. So, we followed a similar format with the original datasets hosted in the HuggingFace datasets hub.
Our dataset is designed to be accessed as follows by following the interface of the GLUE dataset that provides multiple datasets in a single interface over the HuggingFace datasets hub.
```
from datasets import load_dataset
multinli_tr = load_dataset("nli_tr", "multinli_tr")
snli_tr = load_dataset("nli_tr", "snli_tr")
```
Thanks for your help in reviewing our pull request. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/787/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/787/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/787.diff",
"html_url": "https://github.com/huggingface/datasets/pull/787",
"merged_at": "2020-11-12T19:06:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/787.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/787"
} | true | [
"Thank you @lhoestq for the time you take to review our pull request. We appreciate your help.\r\n\r\nWe've made the changes you described. Hope that it is ready for being merged. Please let me know if you have any additional requests for revisions. "
] |
https://api.github.com/repos/huggingface/datasets/issues/4214 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4214/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4214/comments | https://api.github.com/repos/huggingface/datasets/issues/4214/events | https://github.com/huggingface/datasets/pull/4214 | 1,214,572,430 | PR_kwDODunzps42utC5 | 4,214 | Skip checksum computation in Imagefolder by default | [] | closed | false | null | 1 | 2022-04-25T14:10:41Z | 2022-05-03T15:28:32Z | 2022-05-03T15:21:29Z | null | Avoids having to set `ignore_verifications=True` in `load_dataset("imagefolder", ...)` to skip checksum verification and speed up loading.
The user can still pass `DownloadConfig(record_checksums=True)` to not skip this part. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4214/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4214/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4214.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4214",
"merged_at": "2022-05-03T15:21:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4214.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4214"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4916/comments | https://api.github.com/repos/huggingface/datasets/issues/4916/events | https://github.com/huggingface/datasets/issues/4916 | 1,357,076,940 | I_kwDODunzps5Q41nM | 4,916 | Apache Beam unable to write the downloaded wikipedia dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-08-31T09:39:25Z | 2022-08-31T10:53:19Z | 2022-08-31T10:53:19Z | null | ## Describe the bug
Hi, I am currently trying to download wikipedia dataset using
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner'). However, I end up in getting filenotfound error. I get this error for any language I try to download. It downloads the file but while saving it in hugging face cache it fails to write. This happens for any available date of any language in wikipedia dump. I had raised another issue earlier #4915 but probably was not that clear and the solution provider misunderstood my problem. Hence raising one more issue. Any help is appreciated.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner')
```
## Expected results
to load the dataset
## Actual results
I am pasting the error trace here:
Downloading builder script: 35.9kB [00:00, ?B/s]
Downloading metadata: 30.4kB [00:00, 1.94MB/s]
Using custom data configuration 20220401.aa-date=20220401,language=aa
Downloading and preparing dataset wikipedia/20220401.aa to C:\Users\Shilpa.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559...
Downloading data: 100%|████████████████████████████████████████████████████████████| 11.1k/11.1k [00:00<00:00, 712kB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.82s/it]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████| 1/1 [00:00<?, ?it/s]
Downloading data: 100%|███████████████████████████████████████████████████████████| 35.6k/35.6k [00:00<00:00, 84.3kB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.93s/it]
Traceback (most recent call last):
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1571, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "G:\Python3.7\lib\site-packages\apache_beam\io\iobase.py", line 1193, in process
self.writer = self.sink.open_writer(init_result, str(uuid.uuid4()))
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 202, in open_writer
return FileBasedSinkWriter(self, writer_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 419, in init
self.temp_handle = self.sink.open(temp_shard_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\parquetio.py", line 553, in open
self._file_handle = super().open(temp_path)
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 139, in open
temp_path, self.mime_type, self.compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filesystems.py", line 224, in create
return filesystem.create(path, mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 163, in create
return self._path_open(path, 'wb', mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 140, in _path_open
raw_file = io.open(path, mode)
FileNotFoundError: [Errno 2] No such file or directory: 'C:\Users\Shilpa\.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559.incomplete\beam-temp-wikipedia-train-880233e8287e11edaf9d3ca067f2714e\20a05238-6106-4420-a713-4eca6dd5959a.wikipedia-train'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "G:/abc/temp.py", line 32, in
beam_runner='DirectRunner')
File "G:\Python3.7\lib\site-packages\datasets\load.py", line 1751, in load_dataset
use_auth_token=use_auth_token,
File "G:\Python3.7\lib\site-packages\datasets\builder.py", line 705, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "G:\Python3.7\lib\site-packages\datasets\builder.py", line 1394, in _download_and_prepare
pipeline_results = pipeline.run()
File "G:\Python3.7\lib\site-packages\apache_beam\pipeline.py", line 574, in run
return self.runner.run_pipeline(self, self._options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\direct\direct_runner.py", line 131, in run_pipeline
return runner.run_pipeline(pipeline, options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 201, in run_pipeline
options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 212, in run_via_runner_api
return self.run_stages(stage_context, stages)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 443, in run_stages
runner_execution_context, bundle_context_manager, bundle_input)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 776, in _execute_bundle
bundle_manager))
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 1000, in _run_bundle
data_input, data_output, input_timers, expected_timer_output)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 1309, in process_bundle
result_future = self._worker_handler.control_conn.push(process_bundle_req)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\worker_handlers.py", line 380, in push
response = self.worker.do_instruction(request)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\sdk_worker.py", line 598, in do_instruction
getattr(request, request_type), request.instruction_id)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\sdk_worker.py", line 635, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 1004, in process_bundle
element.data)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 227, in process_encoded
self.output(decoded_value)
File "apache_beam\runners\worker\operations.py", line 526, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam\runners\worker\operations.py", line 528, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam\runners\worker\operations.py", line 237, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 324, in apache_beam.runners.worker.operations.GeneralPurposeConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 905, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1507, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1571, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "G:\Python3.7\lib\site-packages\apache_beam\io\iobase.py", line 1193, in process
self.writer = self.sink.open_writer(init_result, str(uuid.uuid4()))
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 202, in open_writer
return FileBasedSinkWriter(self, writer_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 419, in init
self.temp_handle = self.sink.open(temp_shard_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\parquetio.py", line 553, in open
self._file_handle = super().open(temp_path)
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 139, in open
temp_path, self.mime_type, self.compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filesystems.py", line 224, in create
return filesystem.create(path, mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 163, in create
return self._path_open(path, 'wb', mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 140, in _path_open
raw_file = io.open(path, mode)
RuntimeError: FileNotFoundError: [Errno 2] No such file or directory: 'C:\Users\Shilpa\.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559.incomplete\beam-temp-wikipedia-train-880233e8287e11edaf9d3ca067f2714e\20a05238-6106-4420-a713-4eca6dd5959a.wikipedia-train' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
## Environment info
Python: 3.7.6
Windows 10 Pro
datasets :2.4.0
apache_beam: 2.41.0
mwparserfromhell: 0.6.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4916/timeline | null | completed | null | null | false | [
"See:\r\n- #4915"
] |
https://api.github.com/repos/huggingface/datasets/issues/2708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2708/comments | https://api.github.com/repos/huggingface/datasets/issues/2708/events | https://github.com/huggingface/datasets/issues/2708 | 951,092,660 | MDU6SXNzdWU5NTEwOTI2NjA= | 2,708 | QASC: incomplete training set | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-07-22T21:59:44Z | 2021-07-23T13:30:07Z | 2021-07-23T13:30:07Z | null | ## Describe the bug
The training instances are not loaded properly.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("qasc", script_version='1.10.2')
def load_instances(split):
instances = dataset[split]
print(f"split: {split} - size: {len(instances)}")
for x in instances:
print(json.dumps(x))
load_instances('test')
load_instances('validation')
load_instances('train')
```
## results
For test and validation, we can see the examples in the output (which is good!):
```
split: test - size: 920
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Anthax", "under water", "uterus", "wombs", "two", "moles", "live", "embryo"]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "What type of birth do therian mammals have? (A) Anthax (B) under water (C) uterus (D) wombs (E) two (F) moles (G) live (H) embryo", "id": "3C44YUNSI1OBFBB8D36GODNOZN9DPA", "question": "What type of birth do therian mammals have?"}
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Corvidae", "arthropods", "birds", "backbones", "keratin", "Jurassic", "front paws", "Parakeets."]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "By what time had mouse-sized viviparous mammals evolved? (A) Corvidae (B) arthropods (C) birds (D) backbones (E) keratin (F) Jurassic (G) front paws (H) Parakeets.", "id": "3B1NLC6UGZVERVLZFT7OUYQLD1SGPZ", "question": "By what time had mouse-sized viviparous mammals evolved?"}
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Reduced friction", "causes infection", "vital to a good life", "prevents water loss", "camouflage from consumers", "Protection against predators", "spur the growth of the plant", "a smooth surface"]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "What does a plant's skin do? (A) Reduced friction (B) causes infection (C) vital to a good life (D) prevents water loss (E) camouflage from consumers (F) Protection against predators (G) spur the growth of the plant (H) a smooth surface", "id": "3QRYMNZ7FYGITFVSJET3PS0F4S0NT9", "question": "What does a plant's skin do?"}
...
```
However, only a few instances are loaded for the training split, which is not correct.
## Environment info
- `datasets` version: '1.10.2'
- Platform: MaxOS
- Python version:3.7
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2708/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2708/timeline | null | completed | null | null | false | [
"Hi @danyaljj, thanks for reporting.\r\n\r\nUnfortunately, I have not been able to reproduce your problem. My train split has 8134 examples:\r\n```ipython\r\nIn [10]: ds[\"train\"]\r\nOut[10]:\r\nDataset({\r\n features: ['id', 'question', 'choices', 'answerKey', 'fact1', 'fact2', 'combinedfact', 'formatted_question'],\r\n num_rows: 8134\r\n})\r\n\r\nIn [11]: ds[\"train\"].shape\r\nOut[11]: (8134, 8)\r\n```\r\nand the content of the last 5 examples is:\r\n```ipython\r\nIn [12]: for i in range(8129, 8134):\r\n ...: print(json.dumps(ds[\"train\"][i]))\r\n ...:\r\n{\"id\": \"3KAKFY4PGU1LGXM77JAK2700NGCI3X\", \"question\": \"Chitin can be used for protection by whom?\", \"choices\": {\"text\": [\"Fungi\", \"People\", \"Man\", \"Fish\", \"trees\", \"Dogs\", \"animal\", \"Birds\"], \"label\": [\"A\", \"B\",\r\n \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"D\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Fish scales are also composed of chitin.\", \"combinedfact\": \"Chitin can be used for prote\r\nction by fish.\", \"formatted_question\": \"Chitin can be used for protection by whom? (A) Fungi (B) People (C) Man (D) Fish (E) trees (F) Dogs (G) animal (H) Birds\"}\r\n{\"id\": \"336YQZE83VDAQVZ26HW59X51JZ9M5M\", \"question\": \"Which type of animal uses plates for protection?\", \"choices\": {\"text\": [\"squids\", \"reptiles\", \"sea urchins\", \"fish\", \"amphibians\", \"Frogs\", \"mammals\", \"salm\r\non\"], \"label\": [\"A\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"B\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Reptiles have scales or plates.\", \"combinedfact\": \"Reptiles use\r\n their plates for protection.\", \"formatted_question\": \"Which type of animal uses plates for protection? (A) squids (B) reptiles (C) sea urchins (D) fish (E) amphibians (F) Frogs (G) mammals (H) salmon\"}\r\n{\"id\": \"3WZ36BJEV3FGS66VGOOUYX0LN8GTBU\", \"question\": \"What are used for protection by fish?\", \"choices\": {\"text\": [\"scales\", \"fins\", \"streams.\", \"coral\", \"gills\", \"Collagen\", \"mussels\", \"whiskers\"], \"label\": [\"\r\nA\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"A\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Fish are backboned aquatic animals.\", \"combinedfact\": \"scales are used for prote\r\nction by fish \", \"formatted_question\": \"What are used for protection by fish? (A) scales (B) fins (C) streams. (D) coral (E) gills (F) Collagen (G) mussels (H) whiskers\"}\r\n{\"id\": \"3Z2R0DQ0JHDKFAO2706OYIXGNA4E28\", \"question\": \"What are pangolins covered in?\", \"choices\": {\"text\": [\"tunicates\", \"Echinoids\", \"shells\", \"exoskeleton\", \"blastoids\", \"barrel-shaped\", \"protection\", \"white\"\r\n], \"label\": [\"A\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"G\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Pangolins have an elongate and tapering body covered above with ov\r\nerlapping scales.\", \"combinedfact\": \"Pangolins are covered in overlapping protection.\", \"formatted_question\": \"What are pangolins covered in? (A) tunicates (B) Echinoids (C) shells (D) exoskeleton (E) blastoids\r\n (F) barrel-shaped (G) protection (H) white\"}\r\n{\"id\": \"3PMBY0YE272GIWPNWIF8IH5RBHVC9S\", \"question\": \"What are covered with protection?\", \"choices\": {\"text\": [\"apples\", \"trees\", \"coral\", \"clams\", \"roses\", \"wings\", \"hats\", \"fish\"], \"label\": [\"A\", \"B\", \"C\", \"D\r\n\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"H\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Fish are covered with scales.\", \"combinedfact\": \"Fish are covered with protection\", \"formatted_q\r\nuestion\": \"What are covered with protection? (A) apples (B) trees (C) coral (D) clams (E) roses (F) wings (G) hats (H) fish\"}\r\n```\r\n\r\nCould you please load again your dataset and print its shape, like this:\r\n```python\r\nds = load_dataset(\"qasc\", split=\"train)\r\nprint(ds.shape)\r\n```\r\nand confirm which is your output?",
"Hmm .... it must have been a mistake on my side. Sorry for the hassle! "
] |
https://api.github.com/repos/huggingface/datasets/issues/5731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5731/comments | https://api.github.com/repos/huggingface/datasets/issues/5731/events | https://github.com/huggingface/datasets/pull/5731 | 1,662,012,913 | PR_kwDODunzps5N_7Un | 5,731 | Temporarily pin fsspec | [] | closed | false | null | 2 | 2023-04-11T08:33:15Z | 2023-04-11T08:57:45Z | 2023-04-11T08:47:55Z | null | Fix #5730. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5731/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5731/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5731.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5731",
"merged_at": "2023-04-11T08:47:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5731.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5731"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009735 / 0.011353 (-0.001618) | 0.010410 / 0.011008 (-0.000598) | 0.134986 / 0.038508 (0.096478) | 0.038392 / 0.023109 (0.015283) | 0.414451 / 0.275898 (0.138553) | 0.447775 / 0.323480 (0.124295) | 0.007223 / 0.007986 (-0.000763) | 0.006373 / 0.004328 (0.002045) | 0.102631 / 0.004250 (0.098381) | 0.048516 / 0.037052 (0.011464) | 0.410179 / 0.258489 (0.151690) | 0.467773 / 0.293841 (0.173932) | 0.053163 / 0.128546 (-0.075384) | 0.019801 / 0.075646 (-0.055845) | 0.452708 / 0.419271 (0.033436) | 0.068691 / 0.043533 (0.025159) | 0.405482 / 0.255139 (0.150343) | 0.457669 / 0.283200 (0.174470) | 0.113464 / 0.141683 (-0.028219) | 1.918143 / 1.452155 (0.465988) | 2.033123 / 1.492716 (0.540407) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.274564 / 0.018006 (0.256557) | 0.608855 / 0.000490 (0.608366) | 0.006266 / 0.000200 (0.006066) | 0.000105 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033704 / 0.037411 (-0.003708) | 0.130982 / 0.014526 (0.116456) | 0.143862 / 0.176557 (-0.032694) | 0.212622 / 0.737135 (-0.524513) | 0.148899 / 0.296338 (-0.147439) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.670968 / 0.215209 (0.455759) | 6.602911 / 2.077655 (4.525256) | 2.644290 / 1.504120 (1.140171) | 2.268593 / 1.541195 (0.727399) | 2.325393 / 1.468490 (0.856903) | 1.388156 / 4.584777 (-3.196621) | 5.958569 / 3.745712 (2.212857) | 3.310756 / 5.269862 (-1.959106) | 2.390953 / 4.565676 (-2.174724) | 0.147416 / 0.424275 (-0.276859) | 0.015201 / 0.007607 (0.007594) | 0.794109 / 0.226044 (0.568064) | 7.984855 / 2.268929 (5.715926) | 3.382275 / 55.444624 (-52.062349) | 2.676102 / 6.876477 (-4.200375) | 2.846743 / 2.142072 (0.704671) | 1.467523 / 4.805227 (-3.337704) | 0.283184 / 6.500664 (-6.217480) | 0.088655 / 0.075469 (0.013186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.632765 / 1.841788 (-0.209022) | 19.102473 / 8.074308 (11.028165) | 25.632535 / 10.191392 (15.441143) | 0.255628 / 0.680424 (-0.424795) | 0.034655 / 0.534201 (-0.499546) | 0.564593 / 0.579283 (-0.014690) | 0.668339 / 0.434364 (0.233975) | 0.648414 / 0.540337 (0.108076) | 0.766735 / 1.386936 (-0.620201) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009658 / 0.011353 (-0.001695) | 0.006690 / 0.011008 (-0.004318) | 0.099151 / 0.038508 (0.060643) | 0.037092 / 0.023109 (0.013983) | 0.470354 / 0.275898 (0.194456) | 0.525863 / 0.323480 (0.202383) | 0.007593 / 0.007986 (-0.000393) | 0.006637 / 0.004328 (0.002308) | 0.098782 / 0.004250 (0.094532) | 0.058524 / 0.037052 (0.021471) | 0.502569 / 0.258489 (0.244080) | 0.526410 / 0.293841 (0.232569) | 0.059486 / 0.128546 (-0.069060) | 0.019742 / 0.075646 (-0.055904) | 0.119715 / 0.419271 (-0.299556) | 0.065269 / 0.043533 (0.021736) | 0.483327 / 0.255139 (0.228188) | 0.506148 / 0.283200 (0.222948) | 0.123178 / 0.141683 (-0.018505) | 1.916624 / 1.452155 (0.464470) | 2.051410 / 1.492716 (0.558694) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.286481 / 0.018006 (0.268475) | 0.597300 / 0.000490 (0.596810) | 0.008906 / 0.000200 (0.008706) | 0.000128 / 0.000054 (0.000074) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031406 / 0.037411 (-0.006005) | 0.146748 / 0.014526 (0.132222) | 0.152898 / 0.176557 (-0.023658) | 0.212535 / 0.737135 (-0.524600) | 0.155577 / 0.296338 (-0.140761) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.660989 / 0.215209 (0.445780) | 6.688530 / 2.077655 (4.610875) | 3.039278 / 1.504120 (1.535159) | 2.660357 / 1.541195 (1.119162) | 2.696912 / 1.468490 (1.228422) | 1.259760 / 4.584777 (-3.325017) | 5.922452 / 3.745712 (2.176740) | 5.304200 / 5.269862 (0.034338) | 2.823928 / 4.565676 (-1.741748) | 0.148118 / 0.424275 (-0.276157) | 0.015575 / 0.007607 (0.007968) | 0.794404 / 0.226044 (0.568360) | 8.233651 / 2.268929 (5.964722) | 3.777482 / 55.444624 (-51.667142) | 3.064924 / 6.876477 (-3.811552) | 3.117803 / 2.142072 (0.975731) | 1.479559 / 4.805227 (-3.325668) | 0.254070 / 6.500664 (-6.246594) | 0.086806 / 0.075469 (0.011337) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.735515 / 1.841788 (-0.106273) | 18.934157 / 8.074308 (10.859848) | 22.645248 / 10.191392 (12.453856) | 0.227073 / 0.680424 (-0.453351) | 0.030650 / 0.534201 (-0.503551) | 0.594619 / 0.579283 (0.015336) | 0.653304 / 0.434364 (0.218940) | 0.707484 / 0.540337 (0.167147) | 0.823327 / 1.386936 (-0.563610) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3736/comments | https://api.github.com/repos/huggingface/datasets/issues/3736/events | https://github.com/huggingface/datasets/pull/3736 | 1,140,134,483 | PR_kwDODunzps4y7rMR | 3,736 | Local paths in common voice | [] | closed | false | null | 2 | 2022-02-16T15:01:29Z | 2022-09-21T14:58:38Z | 2022-02-22T09:13:43Z | null | Continuation of https://github.com/huggingface/datasets/pull/3664:
- pass the `streaming` parameter to _split_generator
- update @anton-l's code to use this parameter for `common_voice`
- add a comment to explain why we use `download_and_extract` in non-streaming and `iter_archive` in streaming
Now the `common_voice` dataset has a local path back in `ds["path"]`, and this field is `None` in streaming mode.
cc @patrickvonplaten @anton-l @albertvillanova
Fix #3663. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3736/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3736.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3736",
"merged_at": "2022-02-22T09:13:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3736.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3736"
} | true | [
"I just changed to `dl_manager.is_streaming` rather than an additional parameter `streaming` that has to be handled by the DatasetBuilder class - this way the streaming logic doesn't interfere with the base builder's code.\r\n\r\nI think it's better this way, but let me know if you preferred the previous way and I can revert\r\n\r\n> But on the other hand, IMHO, I think this specific solution adds complexity to handling streaming/non-streaming, and moves this complexity to the loading script and thus to the contributors/users who want to create the loading script for their canonical/community datasets (instead of keeping it hidden form the end users).\r\n\r\nI'm down to discuss this more in the future !",
"@lhoestq good idea: much cleaner this way! That way each class has its own responsibilities without mixing around..."
] |
https://api.github.com/repos/huggingface/datasets/issues/5736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5736/comments | https://api.github.com/repos/huggingface/datasets/issues/5736/events | https://github.com/huggingface/datasets/issues/5736 | 1,662,286,061 | I_kwDODunzps5jFHjt | 5,736 | FORCE_REDOWNLOAD raises "Directory not empty" exception on second run | [] | open | false | null | 1 | 2023-04-11T11:29:15Z | 2023-04-21T15:27:40Z | null | null | ### Describe the bug
Running `load_dataset(..., download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)` twice raises a `Directory not empty` exception on the second run.
### Steps to reproduce the bug
I cannot test this on datasets v2.11.0 due to #5711, but this happens in v2.10.1.
1. Set up a script `my_dataset.py` to generate and load an offline dataset.
2. Load it with
```python
ds = datasets.load_dataset(path=/path/to/my_dataset.py,
name='toy',
data_dir=/path/to/my_dataset.py,
cache_dir=cache_dir,
download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD,
)
```
It loads fine
```
Dataset my_dataset downloaded and prepared to /path/to/cache/toy-..e05e/1.0.0/...5b4c. Subsequent calls will reuse this data.
```
3. Try to load it again with the same snippet and the splits are generated, but at the end of the loading process it raises the error
```
2023-04-11 12:10:19,965: DEBUG: open file: /path/to/cache/toy-..e05e/1.0.0/...5b4c.incomplete/dataset_info.json
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "/path/to/conda/environment/lib/python3.10/site-packages/datasets/load.py", line 1782, in load_dataset
builder_instance.download_and_prepare(
File "/path/to/conda/environment/lib/python3.10/site-packages/datasets/builder.py", line 852, in download_and_prepare
with incomplete_dir(self._output_dir) as tmp_output_dir:
File "/path/to/conda/environment/lib/python3.10/contextlib.py", line 142, in __exit__
next(self.gen)
File "/path/to/conda/environment/lib/python3.10/site-packages/datasets/builder.py", line 826, in incomplete_dir
shutil.rmtree(dirname)
File "/path/to/conda/environment/lib/python3.10/shutil.py", line 730, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File "/path/to/conda/environment/lib/python3.10/shutil.py", line 728, in rmtree
os.rmdir(path)
OSError: [Errno 39] Directory not empty: '/path/to/cache/toy-..e05e/1.0.0/...5b4c'
```
### Expected behavior
Regenerate the dataset from scratch and reload it.
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-4.18.0-483.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5736/timeline | null | null | null | null | false | [
"Hi ! I couldn't reproduce your issue :/\r\n\r\nIt seems that `shutil.rmtree` failed. It is supposed to work even if the directory is not empty, but you still end up with `OSError: [Errno 39] Directory not empty:`. Can you make sure another process is not using this directory at the same time ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/5404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5404/comments | https://api.github.com/repos/huggingface/datasets/issues/5404/events | https://github.com/huggingface/datasets/issues/5404 | 1,517,566,331 | I_kwDODunzps5adDl7 | 5,404 | Better integration of BIG-bench | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2023-01-03T15:37:57Z | 2023-02-09T20:30:26Z | null | null | ### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5404/timeline | null | null | null | null | false | [
"Hi, I made my version : https://huggingface.co/datasets/tasksource/bigbench"
] |
https://api.github.com/repos/huggingface/datasets/issues/597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/597/comments | https://api.github.com/repos/huggingface/datasets/issues/597/events | https://github.com/huggingface/datasets/issues/597 | 697,112,029 | MDU6SXNzdWU2OTcxMTIwMjk= | 597 | Indices incorrect with multiprocessing | [] | closed | false | null | 2 | 2020-09-09T19:50:56Z | 2020-09-10T11:03:37Z | 2020-09-10T11:03:37Z | null | When `num_proc` > 1, the indices argument passed to the map function is incorrect:
```python
d = load_dataset('imdb', split='test[:1%]')
def fn(x, inds):
print(inds)
return x
d.select(range(10)).map(fn, with_indices=True, batched=True)
# [0, 1]
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
d.select(range(10)).map(fn, with_indices=True, batched=True, num_proc=2)
# [0, 1]
# [0, 1]
# [0, 1, 2, 3, 4]
# [0, 1, 2, 3, 4]
```
As you can see, the subset passed to each thread is indexed from 0 to N which doesn't reflect their positions in `d`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/597/timeline | null | completed | null | null | false | [
"I fixed a bug that could cause this issue earlier today. Could you pull the latest version and try again ?",
"Still the case on master.\r\nI guess we should have an offset in the multi-procs indeed (hopefully it's enough).\r\n\r\nAlso, side note is that we should add some logging before the \"test\" to say we are testing the function otherwise its confusing for the user to see two outputs I think. Proposal (see the \"Testing the mapped function outputs:\" lines):\r\n```\r\n>>> d.select(range(10)).map(fn, with_indices=True, batched=True, num_proc=2)\r\nDone writing 10 indices in 80 bytes .\r\nDone writing 5 indices in 41 bytes .\r\nDone writing 5 indices in 41 bytes .\r\nSpawning 2 processes\r\nTesting the mapped function outputs:\r\ninds: [0, 1]\r\ninds: [0, 1]\r\nTesting finished, running the mapped function on the dataset:\r\n#0: 0%| | 0/1 [00:00<?, ?ba/s]\r\ninds: [0, 1, 2, 3, 4] inds: [0, 1, 2, 3, 4] | 0/1 [00:00<?, ?ba/s]\r\n#0: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1321.04ba/s]\r\n#1: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1841.22ba/s]\r\nConcatenating 2 shards from multiprocessing\r\nDataset(features: {'text': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=2, names=['neg', 'pos'], names_file=None, id=None)}, num_rows: 10)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/6078 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6078/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6078/comments | https://api.github.com/repos/huggingface/datasets/issues/6078/events | https://github.com/huggingface/datasets/issues/6078 | 1,822,501,472 | I_kwDODunzps5soSpg | 6,078 | resume_download with streaming=True | [] | open | false | null | 2 | 2023-07-26T14:08:22Z | 2023-07-26T21:10:40Z | null | null | ### Describe the bug
I used:
```
dataset = load_dataset(
"oscar-corpus/OSCAR-2201",
token=True,
language="fr",
streaming=True,
split="train"
)
```
Unfortunately, the server had a problem during the training process. I saved the step my training stopped at.
But how can I resume download from step 1_000_´000 without re-streaming all the first 1 million docs of the dataset?
`download_config=DownloadConfig(resume_download=True)` seems to not work with streaming=True.
### Steps to reproduce the bug
```
from datasets import load_dataset, DownloadConfig
dataset = load_dataset(
"oscar-corpus/OSCAR-2201",
token=True,
language="fr",
streaming=True, # optional
split="train",
download_config=DownloadConfig(resume_download=True)
)
# interupt the run and try to relaunch it => this restart from scratch
```
### Expected behavior
I would expect a parameter to start streaming from a given index in the dataset.
### Environment info
- `datasets` version: 2.14.0
- Platform: Linux-5.19.0-45-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.15.1
- PyArrow version: 12.0.1
- Pandas version: 2.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6078/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6078/timeline | null | null | null | null | false | [
"Currently, it's not possible to efficiently resume streaming after an error. Eventually, we plan to support this for Parquet (see https://github.com/huggingface/datasets/issues/5380). ",
"Ok thank you for your answer",
"I'm closing this as a duplicate of #5380"
] |
https://api.github.com/repos/huggingface/datasets/issues/4157 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4157/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4157/comments | https://api.github.com/repos/huggingface/datasets/issues/4157/events | https://github.com/huggingface/datasets/pull/4157 | 1,202,239,622 | PR_kwDODunzps42H2Wf | 4,157 | Fix formatting in BLEU metric card | [] | closed | false | null | 1 | 2022-04-12T18:29:51Z | 2022-04-13T14:30:25Z | 2022-04-13T14:16:34Z | null | Fix #4148 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4157/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4157/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4157.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4157",
"merged_at": "2022-04-13T14:16:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4157.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4157"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/58 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/58/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/58/comments | https://api.github.com/repos/huggingface/datasets/issues/58/events | https://github.com/huggingface/datasets/pull/58 | 614,362,308 | MDExOlB1bGxSZXF1ZXN0NDE0OTM0NTY4 | 58 | Aborted PR - Fix tests | [] | closed | false | null | 1 | 2020-05-07T21:40:19Z | 2020-05-07T21:48:01Z | 2020-05-07T21:41:27Z | null | @patrickvonplaten I've broken a bit the tests with #25 while simplifying and re-organizing the `load.py` and `download_manager.py` scripts.
I'm trying to fix them here but I have a weird error, do you think you can have a look?
```bash
(datasets) MacBook-Pro-de-Thomas:datasets thomwolf$ python -m pytest -sv ./tests/test_dataset_common.py::DatasetTest::test_builder_class_snli
============================================================================= test session starts =============================================================================
platform darwin -- Python 3.7.7, pytest-5.4.1, py-1.8.1, pluggy-0.13.1 -- /Users/thomwolf/miniconda2/envs/datasets/bin/python
cachedir: .pytest_cache
rootdir: /Users/thomwolf/Documents/GitHub/datasets
plugins: xdist-1.31.0, forked-1.1.3
collected 1 item
tests/test_dataset_common.py::DatasetTest::test_builder_class_snli ERROR
=================================================================================== ERRORS ====================================================================================
____________________________________________________________ ERROR at setup of DatasetTest.test_builder_class_snli ____________________________________________________________
file_path = <module 'tests.test_dataset_common' from '/Users/thomwolf/Documents/GitHub/datasets/tests/test_dataset_common.py'>
download_config = DownloadConfig(cache_dir=None, force_download=False, resume_download=False, local_files_only=False, proxies=None, user_agent=None, extract_compressed_file=True, force_extract=True)
download_kwargs = {}
def setup_module(file_path: str, download_config: Optional[DownloadConfig] = None, **download_kwargs,) -> DatasetBuilder:
r"""
Download/extract/cache a dataset to add to the lib from a path or url which can be:
- a path to a local directory containing the dataset processing python script
- an url to a S3 directory with a dataset processing python script
Dataset codes are cached inside the lib to allow easy import (avoid ugly sys.path tweaks)
and using cloudpickle (among other things).
Return: tuple of
the unique id associated to the dataset
the local path to the dataset
"""
if download_config is None:
download_config = DownloadConfig(**download_kwargs)
download_config.extract_compressed_file = True
download_config.force_extract = True
> name = list(filter(lambda x: x, file_path.split("/")))[-1] + ".py"
E AttributeError: module 'tests.test_dataset_common' has no attribute 'split'
src/nlp/load.py:169: AttributeError
============================================================================== warnings summary ===============================================================================
/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow_internal.py:15
/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow_internal.py:15: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
-- Docs: https://docs.pytest.org/en/latest/warnings.html
=========================================================================== short test summary info ===========================================================================
ERROR tests/test_dataset_common.py::DatasetTest::test_builder_class_snli - AttributeError: module 'tests.test_dataset_common' has no attribute 'split'
========================================================================= 1 warning, 1 error in 3.63s =========================================================================
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/58/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/58/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/58.diff",
"html_url": "https://github.com/huggingface/datasets/pull/58",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/58.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/58"
} | true | [
"Wait I messed up my branch, let me clean this."
] |
https://api.github.com/repos/huggingface/datasets/issues/3171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3171/comments | https://api.github.com/repos/huggingface/datasets/issues/3171/events | https://github.com/huggingface/datasets/issues/3171 | 1,037,728,059 | I_kwDODunzps492nk7 | 3,171 | Raise exceptions instead of using assertions for control flow | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 4 | 2021-10-27T18:26:52Z | 2021-12-23T16:40:37Z | 2021-12-23T16:40:37Z | null | Motivated by https://github.com/huggingface/transformers/issues/12789 in Transformers, one welcoming change would be replacing assertions with proper exceptions. The only type of assertions we should keep are those used as sanity checks.
Currently, there is a total of 87 files with the `assert` statements (located under `datasets` and `src/datasets`), so when working on this, to manage the PR size, only modify 4-5 files at most before submitting a PR. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3171/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3171/timeline | null | completed | null | null | false | [
"Adding the remaining tasks for this issue to help new code contributors. \r\n$ cd src/datasets && ack assert -lc \r\n- [x] commands/convert.py:1\r\n- [x] arrow_reader.py:3\r\n- [x] load.py:7\r\n- [x] utils/py_utils.py:2\r\n- [x] features/features.py:9\r\n- [x] arrow_writer.py:7\r\n- [x] search.py:6\r\n- [x] table.py:1\r\n- [x] metric.py:3\r\n- [x] tasks/image_classification.py:1\r\n- [x] arrow_dataset.py:17\r\n- [x] fingerprint.py:6\r\n- [x] io/json.py:1\r\n- [x] io/csv.py:1",
"Hi all,\r\nI am interested in taking up `fingerprint.py`, `search.py`, `arrow_writer.py` and `metric.py`. Will raise a PR soon!",
"Let me look into `arrow_dataset.py`, `table.py`, `data_files.py` & `features.py` ",
"All the tasks are completed for this issue. This can be closed. "
] |
https://api.github.com/repos/huggingface/datasets/issues/4918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4918/comments | https://api.github.com/repos/huggingface/datasets/issues/4918/events | https://github.com/huggingface/datasets/issues/4918 | 1,357,242,757 | I_kwDODunzps5Q5eGF | 4,918 | Dataset Viewer issue for pysentimiento/spanish-targeted-sentiment-headlines | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 2 | 2022-08-31T12:09:07Z | 2022-09-05T21:36:34Z | 2022-09-05T16:32:44Z | null | ### Link
https://huggingface.co/datasets/pysentimiento/spanish-targeted-sentiment-headlines
### Description
After moving the dataset from my user (`finiteautomata`) to the `pysentimiento` organization, the dataset viewer says that it doesn't exist.
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4918/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4918/timeline | null | completed | null | null | false | [
"Thanks for reporting, it's fixed now (I refreshed it manually). It's a known issue; we hope it will be fixed permanently in a few days.\r\n\r\n<img width=\"1508\" alt=\"Capture d’écran 2022-09-05 à 18 31 22\" src=\"https://user-images.githubusercontent.com/1676121/188489762-0ed86a7e-dfb3-46e8-a125-43b815a2c6f4.png\">\r\n",
"Thanks @severo! "
] |
https://api.github.com/repos/huggingface/datasets/issues/5842 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5842/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5842/comments | https://api.github.com/repos/huggingface/datasets/issues/5842/events | https://github.com/huggingface/datasets/issues/5842 | 1,705,510,602 | I_kwDODunzps5lqAbK | 5,842 | Remove columns in interable dataset | [] | closed | false | null | 3 | 2023-05-11T03:48:46Z | 2023-06-21T16:36:42Z | 2023-06-21T16:36:41Z | null | ### Feature request
Right now, remove_columns() produces a NotImplementedError for iterable style datasets
### Motivation
It would be great to have the same functionality irrespective of whether one is using an iterable or a map-style dataset
### Your contribution
hope and courage. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5842/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5842/timeline | null | completed | null | null | false | [
"Transferring this issue as it's related to the 🤗 Datasets library ",
"Hi @surya-narayanan! Could you provide some code snippet?",
"This method has been recently added to the `IterableDataset`, so you need to update the `datasets`' installation (`pip install -U datasets`) to use it."
] |
https://api.github.com/repos/huggingface/datasets/issues/2066 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2066/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2066/comments | https://api.github.com/repos/huggingface/datasets/issues/2066/events | https://github.com/huggingface/datasets/pull/2066 | 833,480,551 | MDExOlB1bGxSZXF1ZXN0NTk0NDcwMjEz | 2,066 | Fix docstring rendering of Dataset/DatasetDict.from_csv args | [] | closed | false | null | 0 | 2021-03-17T07:23:10Z | 2021-03-17T09:21:21Z | 2021-03-17T09:21:21Z | null | Fix the docstring rendering of Dataset/DatasetDict.from_csv args. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2066/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2066/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2066.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2066",
"merged_at": "2021-03-17T09:21:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2066.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2066"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1582/comments | https://api.github.com/repos/huggingface/datasets/issues/1582/events | https://github.com/huggingface/datasets/pull/1582 | 768,776,617 | MDExOlB1bGxSZXF1ZXN0NTQxMTEwODU1 | 1,582 | Adding wiki lingua dataset as new branch | [] | closed | false | null | 0 | 2020-12-16T11:53:07Z | 2020-12-17T18:06:46Z | 2020-12-17T18:06:45Z | null | Adding the dataset as new branch as advised here: #1470
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1582/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1582/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1582.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1582",
"merged_at": "2020-12-17T18:06:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1582.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1582"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1716/comments | https://api.github.com/repos/huggingface/datasets/issues/1716/events | https://github.com/huggingface/datasets/pull/1716 | 782,819,006 | MDExOlB1bGxSZXF1ZXN0NTUyMjgzNzE5 | 1,716 | Add Hatexplain Dataset | [] | closed | false | null | 0 | 2021-01-10T13:30:01Z | 2021-01-18T14:21:42Z | 2021-01-18T14:21:42Z | null | Adding Hatexplain - the first benchmark hate speech dataset covering multiple aspects of the issue | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1716/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1716.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1716",
"merged_at": "2021-01-18T14:21:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1716.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1716"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4882 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4882/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4882/comments | https://api.github.com/repos/huggingface/datasets/issues/4882/events | https://github.com/huggingface/datasets/pull/4882 | 1,348,913,665 | PR_kwDODunzps49sRtv | 4,882 | Fix language tags resource file | [] | closed | false | null | 1 | 2022-08-24T06:06:01Z | 2022-08-24T13:58:33Z | 2022-08-24T13:58:30Z | null | This PR fixes/updates/adds ALL language tags from IANA (as of 2022-08-08).
This PR also removes all BCP47 suffixes (the languages file only contains language subtags, i.e. ISO 639 1 or 2 codes; no script/region/variant suffixes). See:
- #4753 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4882/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4882/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4882.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4882",
"merged_at": "2022-08-24T13:58:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4882.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4882"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4882). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/243/comments | https://api.github.com/repos/huggingface/datasets/issues/243/events | https://github.com/huggingface/datasets/pull/243 | 631,735,848 | MDExOlB1bGxSZXF1ZXN0NDI4NTY2MTEy | 243 | Specify utf-8 encoding for GLUE | [] | closed | false | null | 1 | 2020-06-05T16:33:00Z | 2020-06-17T21:16:06Z | 2020-06-08T08:42:01Z | null | #242
This makes the GLUE-MNLI dataset readable on my machine, not sure if it's a Windows-only bug. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/243/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/243",
"merged_at": "2020-06-08T08:42:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/243"
} | true | [
"Thanks for fixing the encoding :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4762 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4762/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4762/comments | https://api.github.com/repos/huggingface/datasets/issues/4762/events | https://github.com/huggingface/datasets/pull/4762 | 1,321,261,733 | PR_kwDODunzps48RE56 | 4,762 | Improve features resolution in streaming | [] | closed | false | null | 2 | 2022-07-28T17:28:11Z | 2022-09-09T17:17:39Z | 2022-09-09T17:15:30Z | null | `IterableDataset._resolve_features` was returning the features sorted alphabetically by column name, which is not consistent with non-streaming. I changed this and used the order of columns from the data themselves. It was causing some inconsistencies in the dataset viewer as well.
I also fixed `interleave_datasets` that was not filling missing columns with None, because it was not using the columns from `IterableDataset._resolve_features`
cc @severo | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4762/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4762/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4762.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4762",
"merged_at": "2022-09-09T17:15:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4762.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4762"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Just took your comment into account @mariosasko , let me know if it's good for you now :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2235 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2235/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2235/comments | https://api.github.com/repos/huggingface/datasets/issues/2235/events | https://github.com/huggingface/datasets/pull/2235 | 861,040,716 | MDExOlB1bGxSZXF1ZXN0NjE3Nzc0NDUw | 2,235 | Update README.md | [] | closed | false | null | 0 | 2021-04-19T08:21:02Z | 2021-04-19T12:49:19Z | 2021-04-19T12:49:19Z | null | Adding relevant citations (paper accepted at AAAI 2020 & EMNLP 2020) to the benchmark | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2235/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2235/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2235.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2235",
"merged_at": "2021-04-19T12:49:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2235.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2235"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2813 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2813/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2813/comments | https://api.github.com/repos/huggingface/datasets/issues/2813/events | https://github.com/huggingface/datasets/issues/2813 | 973,470,580 | MDU6SXNzdWU5NzM0NzA1ODA= | 2,813 | Remove compression from xopen | [
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | closed | false | null | 1 | 2021-08-18T09:35:59Z | 2021-08-23T15:59:14Z | 2021-08-23T15:59:14Z | null | We implemented support for streaming with 2 requirements:
- transparent use for the end user: just needs to pass the parameter `streaming=True`
- no additional work for the contributors: previous loading scripts should also work in streaming mode with no (or minor) changes; and new loading scripts should not involve additional code to support streaming
In order to fulfill these requirements, streaming implementation patched some Python functions:
- the `open(urlpath)` function was patched with `fsspec.open(urlpath)`
- the `os.path.join(urlpath, *others)` function was patched in order to add to `urlpath` hops (`::`) and extractor protocols (`zip://`), which are required by `fsspec.open`
Recently, we implemented support for streaming all archive+compression formats: zip, tar, gz, bz2, lz4, xz, zst; tar.gz, tar.bz2,...
Under the hood, the implementation:
- passes an additional parameter `compression` to `fsspec.open`, so that it performs the decompression on the fly: `fsspec.open(urlpath, compression=...)`
Some concerns have been raised about passing the parameter `compression` to `fsspec.open`:
- https://github.com/huggingface/datasets/pull/2786#discussion_r689550254
- #2811
The main argument is that if `open` decompresses the file and afterwards we call `gzip.open` on it, that will raise an error in `oscar` dataset:
```python
gzip.open(open(urlpath
```
While this is true:
- it is not natural/usual to call `open` inside `gzip.open` (never seen this before)
- indeed, this was recently (2 months ago) coded that way in `datasets` in order to allow streaming support (with previous implementation of streaming)
In this particular case, there is a natural fix solution: #2811:
- Revert the `open` inside the `gzip.open` (change done 2 months ago): `gzip.open(open(urlpath` => `gzip.open(urlpath`
- Patch `gzip.open(urlpath` with `fsspec.open(urlpath, compression="gzip"`
Are there other issues apart from this?
Note that there is an issue just because the open inside of the gzip.open. There is no issue in the other cases where datasets loading scripts use just
- `gzip.open`
- `open` (after having called dl_manager.download_and_extract)
TODO:
- [ ] Is this really an issue? Please enumerate the `datasets` loading scripts where this is problematic.
- For the moment, there are only 3 datasets where we have an `open` inside a `gzip.open`:
- oscar (since 23 June), mc4 (since 2 July) and c4 (since 2 July)
- In the 3 datasets, the only reason to put an open inside a gzip.open was indeed to force supporting streaming
- [ ] If this is indeed an issue, which are the possible alternatives? Pros/cons? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2813/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2813/timeline | null | completed | null | null | false | [
"After discussing with @lhoestq, a reasonable alternative:\r\n- `download_manager.extract(urlpath)` adds prefixes to `urlpath` in the same way as `fsspec` does for protocols, but we implement custom prefixes for all compression formats: \r\n `bz2::http://domain.org/filename.bz2`\r\n- `xopen` parses the `urlpath` and extracts the `compression` parameter and passes it to `fsspec.open`:\r\n `fsspec.open(\"http://domain.org/filename.bz2\", compression=\"bz2\")`\r\n\r\nPros:\r\n- clean solution that continues giving support to all compression formats\r\n- no breaking change when opening non-decompressed files: if no compression-protocol-like is passed, fsspec.open does not uncompress (passes compression=None)\r\n\r\nCons:\r\n- we create a \"private\" convention for the format of `urlpath`: although similar to `fsspec` protocols, we add custom prefixes for the `compression` argument"
] |
https://api.github.com/repos/huggingface/datasets/issues/1698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1698/comments | https://api.github.com/repos/huggingface/datasets/issues/1698/events | https://github.com/huggingface/datasets/pull/1698 | 781,152,561 | MDExOlB1bGxSZXF1ZXN0NTUwOTI0ODQ3 | 1,698 | Update Coached Conv Pref DatasetCard | [] | closed | false | null | 1 | 2021-01-07T09:07:16Z | 2021-01-08T17:04:33Z | 2021-01-08T17:04:32Z | null | Update Coached Conversation Preferance DatasetCard | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1698/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1698/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1698.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1698",
"merged_at": "2021-01-08T17:04:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1698.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1698"
} | true | [
"Really cool!\r\n\r\nCan you add some task tags for `dialogue-modeling` (under `sequence-modeling`) and `parsing` (under `structured-prediction`)?"
] |
https://api.github.com/repos/huggingface/datasets/issues/3423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3423/comments | https://api.github.com/repos/huggingface/datasets/issues/3423/events | https://github.com/huggingface/datasets/issues/3423 | 1,078,049,638 | I_kwDODunzps5AQbtm | 3,423 | data duplicate when setting num_works > 1 with streaming data | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | null | 14 | 2021-12-13T03:43:17Z | 2022-12-14T16:04:22Z | 2022-12-14T16:04:22Z | null | ## Describe the bug
The data is repeated num_works times when we load_dataset with streaming and set num_works > 1 when construct dataloader
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import pandas as pd
import numpy as np
import os
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
import shutil
NUM_OF_USER = 1000000
NUM_OF_ACTION = 50000
NUM_OF_SEQUENCE = 10000
NUM_OF_FILES = 32
NUM_OF_WORKERS = 16
if __name__ == "__main__":
shutil.rmtree("./dataset")
for i in range(NUM_OF_FILES):
sequence_data = pd.DataFrame(
{
"imei": np.random.randint(1, NUM_OF_USER, size=NUM_OF_SEQUENCE),
"sequence": np.random.randint(1, NUM_OF_ACTION, size=NUM_OF_SEQUENCE)
}
)
if not os.path.exists("./dataset"):
os.makedirs("./dataset")
sequence_data.to_csv(f"./dataset/sequence_data_{i}.csv",
index=False)
dataset = load_dataset("csv",
data_files=[os.path.join("./dataset",file) for file in os.listdir("./dataset") if file.endswith(".csv")],
split="train",
streaming=True).with_format("torch")
data_loader = DataLoader(dataset,
batch_size=1024,
num_workers=NUM_OF_WORKERS)
result = pd.DataFrame()
for i, batch in tqdm(enumerate(data_loader)):
result = pd.concat([result,
pd.DataFrame(batch)],
axis=0)
result.to_csv(f"num_work_{NUM_OF_WORKERS}.csv", index=False)
```
## Expected results
data do not duplicate
## Actual results
data duplicate NUM_OF_WORKERS = 16

## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:datasets==1.14.0
- Platform:transformers==4.11.3
- Python version:3.8
- PyArrow version:
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3423/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3423/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting :)\r\n\r\nWhen using a PyTorch's data loader with `num_workers>1` and an iterable dataset, each worker streams the exact same data by default, resulting in duplicate data when iterating using the data loader.\r\n\r\nWe can probably fix this in `datasets` by checking `torch.utils.data.get_worker_info()` which gives the worker id if it happens.",
"> Hi ! Thanks for reporting :)\r\n> \r\n> When using a PyTorch's data loader with `num_workers>1` and an iterable dataset, each worker streams the exact same data by default, resulting in duplicate data when iterating using the data loader.\r\n> \r\n> We can probably fix this in `datasets` by checking `torch.utils.data.get_worker_info()` which gives the worker id if it happens.\r\nHi ! Thanks for reply\r\n\r\nDo u have some plans to fix the problem?\r\n",
"Isn’t that somehow a bug on PyTorch side? (Just asking because this behavior seems quite general and maybe not what would be intended)",
"From PyTorch's documentation [here](https://pytorch.org/docs/stable/data.html#dataset-types):\r\n\r\n> When using an IterableDataset with multi-process data loading. The same dataset object is replicated on each worker process, and thus the replicas must be configured differently to avoid duplicated data. See [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) documentations for how to achieve this.\r\n\r\nIt looks like an intended behavior from PyTorch\r\n\r\nAs suggested in the [docstring of the IterableDataset class](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset), we could pass a `worker_init_fn` to the DataLoader to fix this. It could be called `streaming_worker_init_fn` for example.\r\n\r\nHowever, while this solution works, I'm worried that many users simply don't know about this parameter and just start their training with duplicate data without knowing it. That's why I'm more in favor of integrating the check on the worker id directly in `datasets` in our implementation of `IterableDataset.__iter__`.",
"Fixed by https://github.com/huggingface/datasets/pull/4375",
"> Fixed by #4375\r\n\r\nThanks!",
"Hi there @lhoestq @cloudyuyuyu \r\nI met that problem recently, and #4375 is really useful because I finally found out I am training with duplicate data.\r\nHowever, in multi-GPU training, I'm using DDP mode and IterableDataset, which still yields duplicate data for each progress. And this is dangerous because users maybe not realize this behavior.",
"If the worker_info.id is unique per process it should work fine, could you check that they're unique ?\r\n\r\nThe code to get the worker_info in each worker is `torch.utils.data.get_worker_info()`",
"test.py\r\n```python\r\nimport json\r\nimport os\r\n\r\nimport torch\r\nfrom torch.utils.data import IterableDataset, DataLoader\r\nfrom transformers import PreTrainedTokenizer, TrainingArguments\r\n\r\nfrom common.arguments import DataTrainingArguments, ModelArguments\r\n\r\n\r\nclass MyIterableDataset(IterableDataset):\r\n def __iter__(self):\r\n worker_info = torch.utils.data.get_worker_info()\r\n print(worker_info)\r\n return iter(range(3))\r\n\r\n\r\nif __name__ == '__main__':\r\n dataset = MyIterableDataset()\r\n dataloader = DataLoader(dataset, num_workers=1)\r\n for i in dataloader:\r\n print(i)\r\n\r\n```\r\n\r\n\r\n```sh\r\n$ python3 -m torch.distributed.launch \\\r\n --nproc_per_node=2 test.py\r\nWorkerInfo(id=0, num_workers=1, seed=5545685212307804959, dataset=<__main__.MyIterableDataset object at 0x7f92648cf6a0>)\r\nWorkerInfo(id=0, num_workers=1, seed=3174108029709729025, dataset=<__main__.MyIterableDataset object at 0x7f19ab961670>)\r\ntensor([0])\r\ntensor([1])\r\ntensor([2])\r\ntensor([0])\r\ntensor([1])\r\ntensor([2])\r\n```\r\n\r\n@lhoestq they are not unique",
"It looks like a bug from pytorch no ? How can we know which data should go in which process when using DDP ?\r\n\r\nI guess we need to check `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` as well. Not fan of the design here tbh, but that's how it is",
"> It looks like a bug from pytorch no ? How can we know which data should go in which process when using DDP ?\r\n> \r\n> I guess we need to check `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` as well. Not fan of the design here tbh, but that's how it is\r\n\r\nMaybe we should document it?",
"Never mind. After reading the code, `IterableDatasetShard` has solved this problem.",
"I'm re-opening this one since I think it should be supported by `datasets` natively",
"hmm actually let me open a new issue on DDP - original post was for single node"
] |
https://api.github.com/repos/huggingface/datasets/issues/2894 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2894/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2894/comments | https://api.github.com/repos/huggingface/datasets/issues/2894/events | https://github.com/huggingface/datasets/pull/2894 | 993,375,654 | MDExOlB1bGxSZXF1ZXN0NzMxNTcxODc5 | 2,894 | Fix COUNTER dataset | [] | closed | false | null | 0 | 2021-09-10T16:07:29Z | 2021-09-10T16:27:45Z | 2021-09-10T16:27:44Z | null | Fix filename generating `FileNotFoundError`.
Related to #2866.
CC: @severo. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2894/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2894/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2894.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2894",
"merged_at": "2021-09-10T16:27:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2894.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2894"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5773/comments | https://api.github.com/repos/huggingface/datasets/issues/5773/events | https://github.com/huggingface/datasets/issues/5773 | 1,675,984,633 | I_kwDODunzps5j5X75 | 5,773 | train_dataset does not implement __len__ | [] | open | false | null | 9 | 2023-04-20T04:37:05Z | 2023-07-19T20:33:13Z | null | null | when train using data precessored by the datasets, I get follow warning and it leads to that I can not set epoch numbers:
`ValueError: The train_dataset does not implement __len__, max_steps has to be specified. The number of steps needs to be known in advance for the learning rate scheduler.` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5773/timeline | null | null | null | null | false | [
"Thanks for reporting, @v-yunbin.\r\n\r\nCould you please give more details, the steps to reproduce the bug, the complete error back trace and the environment information (`datasets-cli env`)?",
"this is a detail error info from transformers:\r\n```\r\nTraceback (most recent call last):\r\n File \"finetune.py\", line 177, in <module>\r\n whisper_finetune(traindir,devdir,outdir)\r\n File \"finetune.py\", line 161, in whisper_finetune\r\n trainer = Seq2SeqTrainer(\r\n File \"/home/ybZhang/miniconda3/envs/whister/lib/python3.8/site-packages/transformers/trainer_seq2seq.py\", line 56, in __init__\r\n super().__init__(\r\n File \"/home/ybZhang/miniconda3/envs/whister/lib/python3.8/site-packages/transformers/trainer.py\", line 567, in __init__\r\n raise ValueError(\r\nValueError: The train_dataset does not implement __len__, max_steps has to be specified. The number of steps needs to be known in advance for the learning rate scheduler.\r\n```\r\n",
"How did you create `train_dataset`? The `datasets` library does not appear in your stack trace.\r\n\r\nWe need more information in order to reproduce the issue...",
"```\r\ndef asr_dataset(traindir,devdir):\r\n we_voice = IterableDatasetDict()\r\n #we_voice[\"train\"] = load_from_disk(traindir,streaming=True)\r\n #we_voice[\"test\"]= load_from_disk(devdir,streaming=True)\r\n we_voice[\"train\"] = load_dataset(\"csv\",data_files=os.path.join(traindir,\"train.csv\"),split=\"train\",streaming=True)\r\n #print(load_dataset(\"csv\",data_files=os.path.join(traindir,\"train.csv\"),split=\"train\"))\r\n we_voice[\"test\"] = load_dataset(\"csv\",data_files=os.path.join(devdir,\"dev.csv\"), split=\"train\",streaming=True)\r\n we_voice = we_voice.remove_columns([\"id\"])\r\n we_voice = we_voice.cast_column(\"audio\", Audio(sampling_rate=16000))\r\n return we_voice\r\n\r\n```",
"As you are using iterable datasets (`streaming=True`), their length is not defined.\r\n\r\nYou should:\r\n- Either use non-iterable datasets, which have a defined length: use `DatasetDict` and not passing `streaming=True`\r\n- Or pass `args.max_steps` to the `Trainer`",
"I don't know how to give a reasonable args.max_steps...........................",
"Then you should not use streaming.",
"@albertvillanova I think @v-yunbin, myself, and others might be slightly confused about max_steps and how it differs from num_train_epochs.",
"@lkurlandski A **step** is referring to optimizer's update after back propagation, and it's associated with a batch of data. For example, if a dataset contains 64 examples and you have an overall batch size of 4, then an epoch will have 64/4=16 batches. Therefore, in one epoch, you will have 16 optimizer **steps**."
] |
https://api.github.com/repos/huggingface/datasets/issues/3202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3202/comments | https://api.github.com/repos/huggingface/datasets/issues/3202/events | https://github.com/huggingface/datasets/issues/3202 | 1,043,213,660 | I_kwDODunzps4-Li1c | 3,202 | Add mIoU metric | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2021-11-03T08:42:32Z | 2022-06-01T17:39:05Z | 2022-06-01T17:39:04Z | null | **Is your feature request related to a problem? Please describe.**
Recently, some semantic segmentation models were added to HuggingFace Transformers, including [SegFormer](https://huggingface.co/transformers/model_doc/segformer.html) and [BEiT](https://huggingface.co/transformers/model_doc/beit.html).
Semantic segmentation (which is the task of labeling every pixel of an image with a corresponding class) is typically evaluated using the Mean Intersection and Union (mIoU). Together with the upcoming Image Feature, adding this metric could be very handy when creating example scripts to fine-tune any Transformer-based model on a semantic segmentation dataset.
An implementation can be found [here](https://github.com/open-mmlab/mmsegmentation/blob/504965184c3e6bc9ec43af54237129ef21981a5f/mmseg/core/evaluation/metrics.py#L132) for instance.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3202/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3202/timeline | null | completed | null | null | false | [
"Resolved via https://github.com/huggingface/datasets/pull/3745."
] |
https://api.github.com/repos/huggingface/datasets/issues/1028 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1028/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1028/comments | https://api.github.com/repos/huggingface/datasets/issues/1028/events | https://github.com/huggingface/datasets/pull/1028 | 755,712,854 | MDExOlB1bGxSZXF1ZXN0NTMxMzc0MTYw | 1,028 | Add ASSET dataset for text simplification evaluation | [] | closed | false | null | 1 | 2020-12-03T00:28:29Z | 2020-12-17T10:03:06Z | 2020-12-03T16:34:37Z | null | Adding the ASSET dataset from https://github.com/facebookresearch/asset
One config for the simplification data, one for the human ratings of quality.
The README.md borrows from that written by @juand-r | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1028/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1028/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1028.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1028",
"merged_at": "2020-12-03T16:34:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1028.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1028"
} | true | [
"Nice, thanks @yjernite !!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3950 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3950/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3950/comments | https://api.github.com/repos/huggingface/datasets/issues/3950/events | https://github.com/huggingface/datasets/issues/3950 | 1,171,560,585 | I_kwDODunzps5F1JiJ | 3,950 | Streaming Datasets don't work with Transformers Trainer when dataloader_num_workers>1 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 1 | 2022-03-16T21:14:11Z | 2022-06-10T20:47:26Z | 2022-06-10T20:47:26Z | null | ## Describe the bug
Streaming Datasets can't be pickled, so any interaction between them and multiprocessing results in a crash.
## Steps to reproduce the bug
```python
import transformers
from transformers import Trainer, AutoModelForCausalLM, TrainingArguments
import datasets
ds = datasets.load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True).with_format("torch")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
Trainer(model, train_dataset=ds, args=TrainingArguments("out", max_steps=1000, dataloader_num_workers=4)).train()
```
## Expected results
For this code I'd expect a crash related to not having preprocessed the data, but instead we get a pickling error.
## Actual results
```
0%| | 0/1000 [00:00<?, ?it/s]Traceback (most recent call last):
File "/Users/dlwh/src/mistral/src/stream_fork_crash.py", line 7, in <module>
Trainer(model, train_dataset=ds, args=TrainingArguments("out", max_steps=1000, dataloader_num_workers=4)).train()
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/transformers/trainer.py", line 1339, in train
for step, inputs in enumerate(epoch_iterator):
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 359, in __iter__
return self._get_iterator()
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 305, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 918, in __init__
w.start()
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/process.py", line 121, in start
self._popen = self._Popen(self)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/popen_fork.py", line 19, in __init__
self._launch(process_obj)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 47, in _launch
reduction.dump(process_obj, fp)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'iterable_dataset.<locals>.TorchIterableDataset'
0%| | 0/1000 [00:00<?, ?it/s]
```
This immediate crash can be fixed by not using a local class to make the `TorchIterableDataset` (Note that you have to do with_format("torch") or you get an exception because the dataset has no len) However, any lambdas etc used as maps will also trigger this crash. A more permanent fix would be to move away from multiprocessing and instead use something like pathos or multiprocessing_on_dill (https://stackoverflow.com/questions/19984152/what-can-multiprocessing-and-dill-do-together)
Note that if you bypass this crash you get another crash. (I'll file a separate bug).
## Environment info
- `datasets` version: 2.0.0
- Platform: macOS-12.2-arm64-arm-64bit
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3950/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3950/timeline | null | completed | null | null | false | [
"Hi, thanks for reporting. This could be related to https://github.com/huggingface/datasets/issues/3148 too\r\n\r\nWe should definitely make `TorchIterableDataset` picklable by moving it in the main code instead of inside a function. If you'd like to contribute, feel free to open a Pull Request :)\r\n\r\nI'm also taking a look at your second issue, which is more technical"
] |
https://api.github.com/repos/huggingface/datasets/issues/3650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3650/comments | https://api.github.com/repos/huggingface/datasets/issues/3650/events | https://github.com/huggingface/datasets/pull/3650 | 1,118,537,429 | PR_kwDODunzps4xyr2o | 3,650 | Allow 'to_json' to run in unordered fashion in order to lower memory footprint | [] | open | false | null | 4 | 2022-01-30T13:23:19Z | 2022-07-06T15:19:50Z | null | null | I'm using `to_json(..., num_proc=num_proc, compressiong='gzip')` with `num_proc>1`. I'm having an issue where things seem to deadlock at some point. Eventually I see OOM. I'm guessing it's an issue where one process starts to take a long time for a specific batch, and so other process keep accumulating their results in memory.
In order to flush memory, I propose we use optional `imap_unordered`. This will prevent one process to block the other ones. The logical thinking is that index are rarily relevant, and in one wants to keep an index, one can still create another column and reconstruct from there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3650/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3650.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3650",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3650.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3650"
} | true | [
"Hi @thomasw21, I remember suggesting `imap_unordered` to @lhoestq at that time to speed up `to_json` further but after trying `pool_imap` on multiple datasets (>9GB) , memory utilisation was almost constant and we decided to go ahead with that only. \r\n\r\n1. Did you try this without `gzip`? Because `gzip` feature was introduced recently and I didn't check multi_proc thing with `gzip`. One thing I know is that `gzip` is slow in our implementation than `zip` (it's a WIP #3551) \r\n2. You can try reducing your batch size, this can also help in avoiding OOM errors!",
"Thanks @bhavitvyamalik ! I see. I'm not sure this PR actually fixes things for me either (I ended up reducing the num_proc/batch_size to lower it). It does allow the process to run for longer, but I think the reason why it was waiting is that one of the process crashes .... Unfortunately I was working on a setup with a low RAM/cpu core ratio. I'm actually very surprised that it doesn't change memory utilization, otherwise I don't see the purpose of `imap_unordered` existing. I think it's main purpose are when you have high variance in samples (in terms of bytes), which causes unecessary accumulation in `imap`\r\n 1. Did not try without `gzip`\r\n 2. Yeah or `num_proc`",
"Can you please try without `gzip` to see how it performs? If it works fine then we can improve `gzip` from our side (I'm already working on it)",
"I'll be busy for next few weeks on another project, will do as soon as I have some bandwidth.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3912 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3912/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3912/comments | https://api.github.com/repos/huggingface/datasets/issues/3912/events | https://github.com/huggingface/datasets/pull/3912 | 1,168,720,098 | PR_kwDODunzps40aekr | 3,912 | add draft of registering function for pandas | [] | closed | false | null | 3 | 2022-03-14T17:54:29Z | 2023-01-24T12:57:35Z | 2023-01-24T12:57:10Z | null | This PR adds a register function for `pandas`. It allows to directly push `DataFrame` objects to the hub and in return loading datasets on the hub from `DataFrame`. The motivation for this integration is to enable the vast number of `pandas` users to be able to easily push `DataFrames` to the hub.
Here is an example:
```python
import pandas as pd
from datasets import register_pandas
register_pandas()
# push to hub
df = pd.DataFrame.from_dict({"test": [1,2,3]})
df.push_to_hub("my_test")
# load from hub
df_retrieved = pd.DataFrame.load_from_hub("lvwerra/my_test")
```
It follows a similar philosophy as the `tqdm` [integration](https://github.com/tqdm/tqdm#pandas-integration). Also see [this issue](https://github.com/pandas-dev/pandas/issues/46000) on the `pandas` repository.
This is just a rough draft of what such integration could look like but I would like appreciate some feedback on this: is this something you would like to add the library and is this the way to go? cc @lhoestq @albertvillanova @julien-c | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3912/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3912/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/3912.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3912",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3912.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3912"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3912). All of your documentation changes will be reflected on that endpoint.",
"That's cool ! Though I would expect such an integration to only require `huggingface_hub`, not the full `datasets` library. \r\n Indeed if users want to use the `datasets` lib they could just to `Dataset.from_pandas(df).push_to_hub()` already. Therefore I would explore something that doesn't not necessarily requires `datasets`.\r\n\r\nFor other could storage solutions (S3, GCS, etc.), pandas allows users to pass URIs like `s3://bucket-name/path/data.csv` to the `read_xxx` and `to_xxx` (for csv, parquet, json, etc). It also support passing the **root directory** like `s3://bucket-name/dataset-dir` instead of a single file name.\r\n\r\nIn the Hugging Face Hub case, we have one dataset = one repository. We can enter pandas' paradigm by saying one dataset = one repository = one root directory. Here is what we could have:\r\n\r\n### push to Hub:\r\n```python\r\n\"\"\"\r\nDemo script for writing a pandas data frame to a CSV file on HF using fsspec-supported pandas APIs\r\n\"\"\"\r\nimport pandas as pd\r\n\r\nHF_USER = os.getenv(\"HF_USER\")\r\nHF_TOKEN = os.getenv(\"HF_TOKEN\")\r\n\r\nbooks_df = pd.DataFrame(\r\n data={\"Title\": [\"Book I\", \"Book II\", \"Book III\"], \"Price\": [56.6, 59.87, 74.54]},\r\n columns=[\"Title\", \"Price\"],\r\n)\r\n\r\ndataset_name = \"books1\"\r\n\r\nbooks_df.to_csv(\r\n f\"hf://{HF_USER}/{dataset_name}\",\r\n index=False,\r\n storage_options={\r\n \"repo_type\": \"dataset\",\r\n \"token\": HF_TOKEN,\r\n },\r\n)\r\n\r\n```\r\n\r\n### load from Hub:\r\n```python\r\n\"\"\"\r\nDemo script for reading a CSV file from HF into a pandas data frame using fsspec-supported pandas\r\nAPIs\r\n\"\"\"\r\nimport pandas as pd\r\n\r\nHF_USER = os.getenv(\"HF_USER\")\r\nHF_TOKEN = os.getenv(\"HF_TOKEN\")\r\n\r\ndataset_name = \"books1\"\r\n\r\nbooks_df = pd.read_csv(\r\n f\"hf://{HF_USER}/{dataset_name}\",\r\n storage_options={\r\n \"repo_type\": \"dataset\",\r\n \"token\": HF_TOKEN,\r\n },\r\n)\r\n\r\nprint(books_df)\r\n```\r\n\r\nAnd you could do the same with Parquet data using `read/to_parquet` or other formats. Formats like CSV, Parquet or JSON Lines would work out of the box with `datasets`. This API would also allow anyone to use Dask with the Hugging Face Hub for example.\r\n\r\nWhat do you think ?",
"I'm closing this PR as [`hffs`](https://github.com/huggingface/hffs) can now be used for reading/writing data frames from/to the Hub."
] |
https://api.github.com/repos/huggingface/datasets/issues/797 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/797/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/797/comments | https://api.github.com/repos/huggingface/datasets/issues/797/events | https://github.com/huggingface/datasets/issues/797 | 735,420,332 | MDU6SXNzdWU3MzU0MjAzMzI= | 797 | Token classification labels are strings and we don't have the list of labels | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "72f99f",
"default": false,
"description": "Discussions on the datasets",
"id": 2067401494,
"name": "Dataset discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAxNDk0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Dataset%20discussion"
}
] | closed | false | null | 4 | 2020-11-03T15:33:30Z | 2022-02-14T15:41:54Z | 2022-02-14T15:41:53Z | null | Not sure if this is an issue we want to fix or not, putting it here so it's not forgotten. Right now, in token classification datasets, the labels for NER, POS and the likes are typed as `Sequence` of `strings`, which is wrong in my opinion. These should be `Sequence` of `ClassLabel` or some types that gives easy access to the underlying labels.
The main problem for preprocessing those datasets is that the list of possible labels is not stored inside the `Dataset` object which makes converting the labels to IDs quite difficult (you either have to know the list of labels in advance or run a full pass through the dataset to get the list of labels, the `unique` method being useless with the type `Sequence[str]`). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/797/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/797/timeline | null | completed | null | null | false | [
"Indeed. Pinging @stefan-it here if he want to give an expert opinion :)",
"Related is https://github.com/huggingface/datasets/pull/636",
"Should definitely be a ClassLabel 👍 ",
"Already done."
] |
https://api.github.com/repos/huggingface/datasets/issues/482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/482/comments | https://api.github.com/repos/huggingface/datasets/issues/482/events | https://github.com/huggingface/datasets/issues/482 | 674,851,147 | MDU6SXNzdWU2NzQ4NTExNDc= | 482 | Bugs : dataset.map() is frozen on ELI5 | [] | closed | false | null | 8 | 2020-08-07T08:23:35Z | 2023-04-06T09:39:59Z | 2020-08-11T23:55:15Z | null | Hi Huggingface Team!
Thank you guys once again for this amazing repo.
I have tried to prepare ELI5 to train with T5, based on [this wonderful notebook of Suraj Patil](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb)
However, when I run `dataset.map()` on ELI5 to prepare `input_text, target_text`, `dataset.map` is **frozen** in the first hundreds examples. On the contrary, this works totally fine on SQUAD (80,000 examples). Both `nlp` version 0.3.0 and 0.4.0 cause frozen process . Also try various `pyarrow` versions from 0.16.0 / 0.17.0 / 1.0.0 also have the same frozen process.
Reproducible code can be found on [this colab notebook ](https://colab.research.google.com/drive/14wttOTv3ky74B_c0kv5WrbgQjCF2fYQk?usp=sharing), where I also show that the same mapping function works fine on SQUAD, so the problem is likely due to ELI5 somehow.
----------------------------------------
**More Info :** instead of `map`, if I run `for` loop and apply function by myself, there's no error and can finish within 10 seconds. However, `nlp dataset` is immutable (I couldn't manually assign a new key-value to `dataset `object)
I also notice that SQUAD texts are quite clean while ELI5 texts contain many special characters, not sure if this is the cause ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/482/timeline | null | completed | null | null | false | [
"This comes from an overflow in pyarrow's array.\r\nIt is stuck inside the loop that reduces the batch size to avoid the overflow.\r\nI'll take a look",
"I created a PR to fix the issue.\r\nIt was due to an overflow check that handled badly an empty list.\r\n\r\nYou can try the changes by using \r\n```\r\n!pip install git+https://github.com/huggingface/nlp.git@fix-bad-type-in-overflow-check\r\n```\r\n\r\nAlso I noticed that the first 1000 examples have an empty list in the `title_urls` field. The feature type inference in `.map` will consider it `null` because of that, and it will crash when it encounter the next example with a `title_urls` that is not empty.\r\n\r\nTherefore to fix that, what you can do for now is increase the writer batch size so that the feature inference will take into account at least one example with a non-empty `title_urls`:\r\n\r\n```python\r\n# default batch size is 1_000 and it's not enough for feature type inference because of empty lists\r\nvalid_dataset = valid_dataset.map(make_input_target, writer_batch_size=3_000) \r\n```\r\n\r\nI was able to run the frozen cell with these changes.",
"@lhoestq Perfect and thank you very much!!\r\nClose the issue.",
"@lhoestq mapping the function `make_input_target` was passed by your fixing.\r\n\r\nHowever, there is another error in the final step of `valid_dataset.map(convert_to_features, batched=True)`\r\n\r\n`ArrowInvalid: Could not convert Thepiratebay.vg with type str: converting to null type`\r\n(The [same colab notebook above with new error message](https://colab.research.google.com/drive/14wttOTv3ky74B_c0kv5WrbgQjCF2fYQk?usp=sharing#scrollTo=5sRrJ3_C8rLt))\r\n\r\nDo you have some ideas? (I am really sorry I could not debug it by myself since I never used `pyarrow` before) \r\nNote that `train_dataset.map(convert_to_features, batched=True)` can be run successfully even though train_dataset is 27x bigger than `valid_dataset` so I believe the problem lies in some field of `valid_dataset` again .",
"I got this issue too and fixed it by specifying `writer_batch_size=3_000` in `.map`.\r\nThis is because Arrow didn't expect `Thepiratebay.vg` in `title_urls `, as all previous examples have empty lists in `title_urls `",
"I am clear now . Thank so much again Quentin!",
"I'm getting a hanging `dataset.map()` when running a gradio app with `gradio` for auto-reloading instead of `python`",
"Maybe this is an issue with gradio, could you open an issue on their repo ? `Dataset.map` simply uses `multiprocess.Pool` for multiprocessing\r\n\r\nIf you interrupt the program mayeb the stack trace would give some information of where it was hanging in the code (maybe a lock somewhere ?)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3654/comments | https://api.github.com/repos/huggingface/datasets/issues/3654/events | https://github.com/huggingface/datasets/pull/3654 | 1,119,717,475 | PR_kwDODunzps4x2kiX | 3,654 | Better TQDM output | [] | closed | false | null | 1 | 2022-01-31T17:22:43Z | 2022-02-03T15:55:34Z | 2022-02-03T15:55:33Z | null | This PR does the following:
* if `dataset_infos.json` exists for a dataset, uses `num_examples` to print the total number of examples that needs to be generated (in `builder.py`)
* fixes `tqdm` + multiprocessing in Jupyter Notebook/Colab (the issue stems from this commit in the `tqdm` repo: https://github.com/tqdm/tqdm/commit/f7722edecc3010cb35cc1c923ac4850a76336f82)
* adds the missing `drop_last_batch` and `with_ranks` params to `DatasetDict.map`
* correctly computes the number of iterations in `map` and the CSV/JSON loader when `batched=True` to fix `tqdm` progress bars
* removes the `bool(logging.get_verbosity() == logging.NOTSET)` (or simplifies `bool(logging.get_verbosity() == logging.NOTSET) or not utils.is_progress_bar_enabled()` to `not utils.is_progress_bar_enabled()`) condition and uses `utils.is_progress_bar_enabled` to check if `tqdm` output is enabled (this comment from @stas00 explains why the `bool(logging.get_verbosity() == logging.NOTSET)` check is problematic: https://github.com/huggingface/transformers/issues/14889#issue-1087318463)
Fix #2630 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3654/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3654/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3654.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3654",
"merged_at": "2022-02-03T15:55:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3654.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3654"
} | true | [
"@lhoestq I've created a notebook for you to see the difference: https://colab.research.google.com/drive/1by3EqnoKvC2p-yKW4lPDGOFOZHyGVyeQ?usp=sharing.\r\n\r\nFeel free to suggest better descriptions for the progress bars. \r\n\r\nIf everything looks good, think we can merge."
] |
https://api.github.com/repos/huggingface/datasets/issues/5132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5132/comments | https://api.github.com/repos/huggingface/datasets/issues/5132/events | https://github.com/huggingface/datasets/issues/5132 | 1,413,607,306 | I_kwDODunzps5UQe-K | 5,132 | Depracate `num_proc` parameter in `DownloadManager.extract` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
},
{
"color": "DF8D62",
"default": false,
"description": "",
"id": 4614514401,
"name": "hacktoberfest",
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest"
}
] | closed | false | null | 5 | 2022-10-18T17:41:05Z | 2022-10-25T15:56:46Z | 2022-10-25T15:56:46Z | null | The `num_proc` parameter is only present in `DownloadManager.extract` but not in `StreamingDownloadManager.extract`, making it impossible to support streaming in the dataset scripts that use it (`openwebtext` and `the_pile_stack_exchange`). We can avoid this situation by deprecating this parameter and passing `DownloadConfig`'s `num_proc` to `map_nested` instead, as it's done in `DownloadManager.download`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5132/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5132/timeline | null | completed | null | null | false | [
"I can take this! #self-assign",
"#self-assign",
"@lazarust i'm already working on this issue :smile: ",
"#self-assign",
"hey @mariosasko , i made a pr for this issue. Could you please review it."
] |
https://api.github.com/repos/huggingface/datasets/issues/6037 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6037/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6037/comments | https://api.github.com/repos/huggingface/datasets/issues/6037/events | https://github.com/huggingface/datasets/issues/6037 | 1,805,887,184 | I_kwDODunzps5ro6bQ | 6,037 | Documentation links to examples are broken | [] | closed | false | null | 2 | 2023-07-15T04:54:50Z | 2023-07-17T22:35:14Z | 2023-07-17T15:10:32Z | null | ### Describe the bug
The links at the bottom of [add_dataset](https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html) to examples of specific datasets are all broken, for example
- text classification: [ag_news](https://github.com/huggingface/datasets/blob/master/datasets/ag_news/ag_news.py) (original data are in csv files)
### Steps to reproduce the bug
Click on links to examples from latest documentation
### Expected behavior
Links should be up to date - it might be more stable to link to https://huggingface.co/datasets/ag_news/blob/main/ag_news.py
### Environment info
dataset v1.2.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6037/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6037/timeline | null | completed | null | null | false | [
"These docs are outdated (version 1.2.1 is over two years old). Please refer to [this](https://huggingface.co/docs/datasets/dataset_script) version instead.\r\n\r\nInitially, we hosted datasets in this repo, but now you can find them [on the HF Hub](https://huggingface.co/datasets) (e.g. the [`ag_news`](https://huggingface.co/datasets/ag_news/blob/main/ag_news.py) script)",
"Sorry I thought I'd selected the latest version."
] |
https://api.github.com/repos/huggingface/datasets/issues/3351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3351/comments | https://api.github.com/repos/huggingface/datasets/issues/3351/events | https://github.com/huggingface/datasets/pull/3351 | 1,068,094,873 | PR_kwDODunzps4vO5AS | 3,351 | Add VCTK dataset | [] | closed | false | null | 9 | 2021-12-01T08:13:17Z | 2022-02-28T09:22:03Z | 2021-12-28T15:05:08Z | null | Fixes #1837. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3351/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3351.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3351",
"merged_at": "2021-12-28T15:05:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3351.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3351"
} | true | [
"Hello @patrickvonplaten, I hope it's okay to ping you with a (dumb) question!\r\n\r\nI've been trying to get `dl_manager.download_and_extract(_DL_URL)` to work with no avail. I verified that this is a problem on two different machines (lab server, GCP), so I doubt it's an issue with network connectivity. Here is the full trace.\r\n\r\n```\r\n(venv) (base) jaketae@jake-gpu1:~/documents/datasets$ datasets-cli test datasets/vctk --save_infos --all_configs\r\nTesting builder 'main' (1/1)\r\nDownloading and preparing dataset vctk/main to /home/jaketae/.cache/huggingface/datasets/vctk/main/0.9.2/2bfa52a93469fa9d6d4b1831c6511db5442b9f4e48620aef2bc3890d7a5268a8...\r\nTraceback (most recent call last):\r\n File \"/home/jaketae/documents/datasets/venv/bin/datasets-cli\", line 33, in <module>\r\n sys.exit(load_entry_point('datasets', 'console_scripts', 'datasets-cli')())\r\n File \"/home/jaketae/documents/datasets/src/datasets/commands/datasets_cli.py\", line 33, in main\r\n service.run()\r\n File \"/home/jaketae/documents/datasets/src/datasets/commands/test.py\", line 146, in run\r\n builder.download_and_prepare(\r\n File \"/home/jaketae/documents/datasets/src/datasets/builder.py\", line 593, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/jaketae/documents/datasets/src/datasets/builder.py\", line 659, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/home/jaketae/.cache/huggingface/modules/datasets_modules/datasets/vctk/2bfa52a93469fa9d6d4b1831c6511db5442b9f4e48620aef2bc3890d7a5268a8/vctk.py\", line 76, in _split_generators\r\n root_path = dl_manager.download_and_extract(_DL_URL)\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/download_manager.py\", line 283, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/download_manager.py\", line 195, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/py_utils.py\", line 234, in map_nested\r\n return function(data_struct)\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/download_manager.py\", line 216, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/file_utils.py\", line 298, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/file_utils.py\", line 608, in get_from_cache\r\n raise ConnectionError(f\"Couldn't reach {url}\")\r\nConnectionError: Couldn't reach https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip\r\n```\r\n\r\nOn my local, however, the URL correctly points to the download zip file. My admittedly naive guess is that the website is web-crawler or scraper proof (requiring specific headers, etc.), but I also think I might have just missed a very basic step in the process.\r\n\r\nApologies for the delayed PR, and TIA for the help!",
"Hey @jaketae, \r\n\r\nHmm, yeah I don't know really either - the link also works correctly for me when doing:\r\n\r\n```\r\nwget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip\r\n```\r\n\r\nI think however that I had a similar problem previously with Edinburgh's (`.ed.ac.uk`) websites which I solved with the following hack. Not sure if this could be the same problem here...\r\nhttps://github.com/huggingface/datasets/blob/e1104ad5d3e83f8b1571e0d6fef4fdabf0a1fde5/datasets/ami/ami.py#L364\r\n\r\n",
"The AMI dataset is stored under a different website though it seems: `\"https://groups.inf.ed.ac.uk/ami/AMICorpusMirror//amicorpus/{}/audio/{}\"`\r\n\r\nso not 100p sure if this solves the problem",
"Hi @patrickvonplaten,\r\n\r\nThanks for the feedback! Sadly, disabling multi-processing didn't cut it for me. \r\n\r\nI've been looking at VCTK code in [`torchaudio`](https://pytorch.org/audio/stable/_modules/torchaudio/datasets/vctk.html) and [`tfds`](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/audio/vctk.py). I don't think they're using a hack to accomplish this, so I'll try to look into it to see if I can pinpoint the cause. I'll keep you in the loop here. Thank you!",
"Hi @patrickvonplaten, \r\n\r\nAfter more investigation, I found that simply increasing `etag_timeout` in `get_from_cache` from 10 to 100 solved it. However, unless I'm missing something, an issue is that `etag_timeout` is basically hard-coded as a default parameter because `cached_path`, which calls `get_from_cache` has no way of modifying the default. \r\n\r\nhttps://github.com/huggingface/datasets/blob/b25ac1d62670e7b339ed552ecc37846d2abd30c7/src/datasets/utils/file_utils.py#L298-L310\r\n\r\nhttps://github.com/huggingface/datasets/blob/b25ac1d62670e7b339ed552ecc37846d2abd30c7/src/datasets/utils/file_utils.py#L497-L510\r\n\r\n\r\nI can think of two solutions.\r\n\r\n* Simply increase the default to 100\r\n* Allow `etag_timeout` to be modifiable on a per-dataset basis by integrating it to `download_config` (maybe this is already supported?)\r\n\r\nThank you!",
"I think in this case we can increase the `etag_timeout` - what do you think @lhoestq @albertvillanova ?",
"Yes let's increase it to 100 for the moment. Later we can see if it really needed to move it into `download_config` or not",
"Thanks for the feedback @patrickvonplaten @lhoestq, I'll continue working on this in that direction!",
"Hello @patrickvonplaten, VCTK is ready for review! \r\n\r\n```python\r\n>>> from datasets import load_dataset\r\n>>> ds = load_dataset(\"vctk\")\r\nUsing the latest cached version of the module from /home/lily/jt856/.cache/huggingface/modules/datasets_modules/datasets/vctk/b7aa278182de3a7aa2897cbd12c1e19f1af9840a2ead69a6d710fdbc1d2df02a (last modified on Sat Dec 25 00:47:31 2021) since it couldn't be found locally at vctk., or remotely on the Hugging Face Hub.\r\nReusing dataset vctk (/home/lily/jt856/.cache/huggingface/datasets/vctk/main/0.9.2/b7aa278182de3a7aa2897cbd12c1e19f1af9840a2ead69a6d710fdbc1d2df02a)\r\n100%|████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 198.35it/s]\r\n>>> len(ds[\"train\"])\r\n88156\r\n>>> ds[\"train\"][0]\r\n{'speaker_id': 'p225', 'audio': {'path': '/home/lily/jt856/.cache/huggingface/datasets/downloads/extracted/8ed7dad05dfffdb552a3699777442af8e8ed11e656feb277f35bf9aea448f49e/wav48_silence_trimmed/p225/p225_001_mic1.flac', 'array': array([0.00485229, 0.00689697, 0.00619507, ..., 0.00811768, 0.00836182,\r\n 0.00854492], dtype=float32), 'sampling_rate': 48000}, 'file': '/home/lily/jt856/.cache/huggingface/datasets/downloads/extracted/8ed7dad05dfffdb552a3699777442af8e8ed11e656feb277f35bf9aea448f49e/wav48_silence_trimmed/p225/p225_001_mic1.flac', 'text': 'Please call Stella.', 'text_id': '001', 'age': '23', 'gender': 'F', 'accent': 'English', 'region': 'Southern England', 'comment': ''}\r\n```\r\nA number of tests are failing on CircleCI, but from my limited knowledge they appear to be complaining about `conda` and `pip`/`wheel`-related incompatibilities. But if I'm reading them wrong and it's an issue with this PR, please let me know and I'll try to fix them.\r\n\r\nBelated merry Christmas and a happy new year!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5080 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5080/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5080/comments | https://api.github.com/repos/huggingface/datasets/issues/5080/events | https://github.com/huggingface/datasets/issues/5080 | 1,398,849,565 | I_kwDODunzps5TYMAd | 5,080 | Use hfh for caching | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2022-10-06T05:51:58Z | 2022-10-06T14:26:05Z | null | null | ## Is your feature request related to a problem?
As previously discussed in our meeting with @Wauplin and agreed on our last datasets team sync meeting, I'm investigating how `datasets` can use `hfh` for caching.
## Describe the solution you'd like
Due to the peculiarities of the `datasets` cache, I would propose adopting `hfh` caching system in stages.
First, we could easily start using `hfh` caching for:
- dataset Python scripts
- dataset READMEs
- dataset infos JSON files (now deprecated)
Second, we could also use `hfh` caching for data files downloaded from the Hub.
Further investigation is needed for:
- files downloaded from non-Hub hosts
- extracted files from downloaded archive/compressed files
- generated Arrow files
## Additional context
Docs about the `hfh` caching system:
- [Manage huggingface_hub cache-system](https://huggingface.co/docs/huggingface_hub/main/en/how-to-cache)
- [Cache-system reference](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/cache)
The `transformers` library has already adopted `hfh` for caching. See:
- huggingface/transformers#18438
- huggingface/transformers#18857
- huggingface/transformers#18966
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5080/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5080/timeline | null | null | null | null | false | [
"There is some discussion in https://github.com/huggingface/huggingface_hub/pull/1088 if it can help :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5860 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5860/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5860/comments | https://api.github.com/repos/huggingface/datasets/issues/5860/events | https://github.com/huggingface/datasets/pull/5860 | 1,709,727,460 | PR_kwDODunzps5QfojD | 5,860 | Minor tqdm optim | [] | closed | false | null | 3 | 2023-05-15T09:49:37Z | 2023-05-17T18:46:46Z | 2023-05-17T18:39:35Z | null | Don't create a tqdm progress bar when `disable_tqdm` is passed to `map_nested`.
On my side it sped up some iterable datasets by ~30% when `map_nested` is used extensively to recursively tensorize python dicts. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5860/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5860/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5860.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5860",
"merged_at": "2023-05-17T18:39:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5860.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5860"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006917 / 0.011353 (-0.004436) | 0.004803 / 0.011008 (-0.006205) | 0.097082 / 0.038508 (0.058574) | 0.035105 / 0.023109 (0.011996) | 0.325911 / 0.275898 (0.050013) | 0.371858 / 0.323480 (0.048378) | 0.006451 / 0.007986 (-0.001534) | 0.004421 / 0.004328 (0.000093) | 0.075738 / 0.004250 (0.071487) | 0.053624 / 0.037052 (0.016572) | 0.332661 / 0.258489 (0.074172) | 0.372729 / 0.293841 (0.078888) | 0.028279 / 0.128546 (-0.100267) | 0.009318 / 0.075646 (-0.066328) | 0.328505 / 0.419271 (-0.090766) | 0.066962 / 0.043533 (0.023429) | 0.316863 / 0.255139 (0.061724) | 0.344296 / 0.283200 (0.061096) | 0.120575 / 0.141683 (-0.021108) | 1.457867 / 1.452155 (0.005712) | 1.597361 / 1.492716 (0.104644) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296399 / 0.018006 (0.278392) | 0.507196 / 0.000490 (0.506706) | 0.003036 / 0.000200 (0.002836) | 0.000088 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028535 / 0.037411 (-0.008876) | 0.110566 / 0.014526 (0.096040) | 0.122078 / 0.176557 (-0.054479) | 0.182926 / 0.737135 (-0.554210) | 0.125546 / 0.296338 (-0.170792) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426952 / 0.215209 (0.211742) | 4.255608 / 2.077655 (2.177953) | 2.063865 / 1.504120 (0.559745) | 1.867198 / 1.541195 (0.326004) | 2.058236 / 1.468490 (0.589746) | 0.525885 / 4.584777 (-4.058892) | 3.723607 / 3.745712 (-0.022105) | 1.919144 / 5.269862 (-3.350718) | 1.235308 / 4.565676 (-3.330368) | 0.066423 / 0.424275 (-0.357852) | 0.012045 / 0.007607 (0.004438) | 0.528432 / 0.226044 (0.302388) | 5.268723 / 2.268929 (2.999794) | 2.504071 / 55.444624 (-52.940553) | 2.137999 / 6.876477 (-4.738477) | 2.229987 / 2.142072 (0.087914) | 0.641739 / 4.805227 (-4.163488) | 0.142635 / 6.500664 (-6.358029) | 0.065649 / 0.075469 (-0.009820) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.182710 / 1.841788 (-0.659078) | 15.339777 / 8.074308 (7.265469) | 14.722308 / 10.191392 (4.530916) | 0.145914 / 0.680424 (-0.534510) | 0.017861 / 0.534201 (-0.516340) | 0.393092 / 0.579283 (-0.186191) | 0.431179 / 0.434364 (-0.003185) | 0.485712 / 0.540337 (-0.054625) | 0.602634 / 1.386936 (-0.784302) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006792 / 0.011353 (-0.004561) | 0.005118 / 0.011008 (-0.005890) | 0.073440 / 0.038508 (0.034932) | 0.033751 / 0.023109 (0.010642) | 0.389243 / 0.275898 (0.113345) | 0.397083 / 0.323480 (0.073603) | 0.005989 / 0.007986 (-0.001997) | 0.004289 / 0.004328 (-0.000040) | 0.073228 / 0.004250 (0.068977) | 0.053490 / 0.037052 (0.016438) | 0.396070 / 0.258489 (0.137581) | 0.415134 / 0.293841 (0.121293) | 0.028649 / 0.128546 (-0.099897) | 0.009159 / 0.075646 (-0.066487) | 0.080813 / 0.419271 (-0.338458) | 0.048200 / 0.043533 (0.004667) | 0.388009 / 0.255139 (0.132870) | 0.382174 / 0.283200 (0.098975) | 0.107807 / 0.141683 (-0.033876) | 1.467276 / 1.452155 (0.015121) | 1.568091 / 1.492716 (0.075375) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.328030 / 0.018006 (0.310024) | 0.498058 / 0.000490 (0.497568) | 0.002513 / 0.000200 (0.002313) | 0.000099 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029835 / 0.037411 (-0.007576) | 0.113859 / 0.014526 (0.099333) | 0.130813 / 0.176557 (-0.045743) | 0.183646 / 0.737135 (-0.553490) | 0.136561 / 0.296338 (-0.159777) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.438901 / 0.215209 (0.223692) | 4.376426 / 2.077655 (2.298771) | 2.220932 / 1.504120 (0.716812) | 2.043585 / 1.541195 (0.502390) | 2.161383 / 1.468490 (0.692893) | 0.523224 / 4.584777 (-4.061553) | 3.730589 / 3.745712 (-0.015123) | 1.859602 / 5.269862 (-3.410260) | 1.073415 / 4.565676 (-3.492261) | 0.066363 / 0.424275 (-0.357912) | 0.012491 / 0.007607 (0.004884) | 0.542052 / 0.226044 (0.316008) | 5.426246 / 2.268929 (3.157318) | 2.673884 / 55.444624 (-52.770740) | 2.372611 / 6.876477 (-4.503865) | 2.482216 / 2.142072 (0.340143) | 0.705669 / 4.805227 (-4.099558) | 0.141075 / 6.500664 (-6.359589) | 0.065339 / 0.075469 (-0.010130) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.316403 / 1.841788 (-0.525385) | 15.832870 / 8.074308 (7.758562) | 13.307045 / 10.191392 (3.115653) | 0.147258 / 0.680424 (-0.533166) | 0.017966 / 0.534201 (-0.516235) | 0.414396 / 0.579283 (-0.164887) | 0.431801 / 0.434364 (-0.002563) | 0.465483 / 0.540337 (-0.074855) | 0.577850 / 1.386936 (-0.809086) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006368 / 0.011353 (-0.004985) | 0.004274 / 0.011008 (-0.006734) | 0.098799 / 0.038508 (0.060291) | 0.029096 / 0.023109 (0.005986) | 0.308009 / 0.275898 (0.032111) | 0.345701 / 0.323480 (0.022221) | 0.005312 / 0.007986 (-0.002674) | 0.003435 / 0.004328 (-0.000894) | 0.075912 / 0.004250 (0.071662) | 0.041993 / 0.037052 (0.004941) | 0.320075 / 0.258489 (0.061586) | 0.347506 / 0.293841 (0.053665) | 0.025456 / 0.128546 (-0.103091) | 0.008461 / 0.075646 (-0.067185) | 0.322823 / 0.419271 (-0.096448) | 0.044650 / 0.043533 (0.001117) | 0.314118 / 0.255139 (0.058979) | 0.333436 / 0.283200 (0.050237) | 0.093811 / 0.141683 (-0.047871) | 1.464464 / 1.452155 (0.012310) | 1.548098 / 1.492716 (0.055382) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.015905 / 0.018006 (-0.002101) | 0.427847 / 0.000490 (0.427357) | 0.007600 / 0.000200 (0.007400) | 0.000421 / 0.000054 (0.000366) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024530 / 0.037411 (-0.012882) | 0.099907 / 0.014526 (0.085381) | 0.107282 / 0.176557 (-0.069275) | 0.168332 / 0.737135 (-0.568804) | 0.109875 / 0.296338 (-0.186464) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.451064 / 0.215209 (0.235855) | 4.491434 / 2.077655 (2.413779) | 2.253251 / 1.504120 (0.749131) | 2.086740 / 1.541195 (0.545545) | 2.133288 / 1.468490 (0.664798) | 0.558801 / 4.584777 (-4.025976) | 3.463525 / 3.745712 (-0.282187) | 1.747657 / 5.269862 (-3.522205) | 1.005465 / 4.565676 (-3.560211) | 0.068341 / 0.424275 (-0.355934) | 0.012521 / 0.007607 (0.004914) | 0.567002 / 0.226044 (0.340957) | 5.689529 / 2.268929 (3.420601) | 2.700562 / 55.444624 (-52.744062) | 2.384888 / 6.876477 (-4.491589) | 2.503160 / 2.142072 (0.361088) | 0.667107 / 4.805227 (-4.138120) | 0.137253 / 6.500664 (-6.363412) | 0.068300 / 0.075469 (-0.007170) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.202916 / 1.841788 (-0.638872) | 14.163393 / 8.074308 (6.089085) | 14.402463 / 10.191392 (4.211071) | 0.145273 / 0.680424 (-0.535151) | 0.016996 / 0.534201 (-0.517205) | 0.363520 / 0.579283 (-0.215763) | 0.421595 / 0.434364 (-0.012769) | 0.438413 / 0.540337 (-0.101925) | 0.508615 / 1.386936 (-0.878321) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006419 / 0.011353 (-0.004934) | 0.004346 / 0.011008 (-0.006662) | 0.076356 / 0.038508 (0.037848) | 0.029370 / 0.023109 (0.006260) | 0.371046 / 0.275898 (0.095148) | 0.398279 / 0.323480 (0.074799) | 0.005258 / 0.007986 (-0.002728) | 0.003528 / 0.004328 (-0.000800) | 0.076787 / 0.004250 (0.072537) | 0.041575 / 0.037052 (0.004522) | 0.362319 / 0.258489 (0.103830) | 0.402134 / 0.293841 (0.108293) | 0.025633 / 0.128546 (-0.102913) | 0.008826 / 0.075646 (-0.066820) | 0.082380 / 0.419271 (-0.336892) | 0.041655 / 0.043533 (-0.001878) | 0.357583 / 0.255139 (0.102444) | 0.383486 / 0.283200 (0.100287) | 0.093682 / 0.141683 (-0.048001) | 1.488522 / 1.452155 (0.036367) | 1.576090 / 1.492716 (0.083373) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185556 / 0.018006 (0.167550) | 0.431345 / 0.000490 (0.430855) | 0.002290 / 0.000200 (0.002090) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026030 / 0.037411 (-0.011382) | 0.102889 / 0.014526 (0.088364) | 0.109541 / 0.176557 (-0.067015) | 0.161050 / 0.737135 (-0.576085) | 0.113525 / 0.296338 (-0.182814) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445301 / 0.215209 (0.230092) | 4.437320 / 2.077655 (2.359666) | 2.174181 / 1.504120 (0.670061) | 1.977440 / 1.541195 (0.436245) | 2.036323 / 1.468490 (0.567832) | 0.554227 / 4.584777 (-4.030550) | 3.462746 / 3.745712 (-0.282966) | 1.765257 / 5.269862 (-3.504604) | 1.014515 / 4.565676 (-3.551161) | 0.068391 / 0.424275 (-0.355884) | 0.013154 / 0.007607 (0.005546) | 0.546696 / 0.226044 (0.320652) | 5.490628 / 2.268929 (3.221699) | 2.611947 / 55.444624 (-52.832677) | 2.282659 / 6.876477 (-4.593818) | 2.333972 / 2.142072 (0.191899) | 0.663140 / 4.805227 (-4.142087) | 0.137996 / 6.500664 (-6.362668) | 0.069063 / 0.075469 (-0.006407) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.332147 / 1.841788 (-0.509641) | 14.781592 / 8.074308 (6.707284) | 13.399190 / 10.191392 (3.207798) | 0.139370 / 0.680424 (-0.541054) | 0.016742 / 0.534201 (-0.517459) | 0.364138 / 0.579283 (-0.215146) | 0.402479 / 0.434364 (-0.031885) | 0.427591 / 0.540337 (-0.112746) | 0.520864 / 1.386936 (-0.866072) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3175/comments | https://api.github.com/repos/huggingface/datasets/issues/3175/events | https://github.com/huggingface/datasets/pull/3175 | 1,038,945,271 | PR_kwDODunzps4t0bXw | 3,175 | Add docs for `to_tf_dataset` | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 2 | 2021-10-28T20:55:22Z | 2021-11-03T15:39:36Z | 2021-11-03T10:07:23Z | null | This PR adds some documentation for new features released in v1.13.0, with the main addition being `to_tf_dataset`:
- Show how to use `to_tf_dataset` in the tutorial, and move `set_format(type='tensorflow'...)` to the Process section (let me know if I'm missing anything @Rocketknight1 😅).
- Add an example for loading dataset from multiple zipped CSV files to the Load section.
- Add an example for removing columns for an `IterableDataset`.
- Add graphic for visualizing streaming. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3175/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3175.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3175",
"merged_at": "2021-11-03T10:07:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3175.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3175"
} | true | [
"This looks great, thank you!",
"Thanks !\r\n\r\nFor some reason the new GIF is 6MB, which is a bit heavy for an image on a website. The previous one was around 200KB though which is perfect. For a good experience we usually expect images to be less than 500KB - otherwise for users with poor connection it takes too long to load. Could you try to reduce its size ? Than I think we can merge :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4249 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4249/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4249/comments | https://api.github.com/repos/huggingface/datasets/issues/4249/events | https://github.com/huggingface/datasets/pull/4249 | 1,218,524,424 | PR_kwDODunzps42742y | 4,249 | Support streaming XGLUE dataset | [] | closed | false | null | 1 | 2022-04-28T10:27:23Z | 2022-05-06T08:38:21Z | 2022-04-28T16:08:03Z | null | Support streaming XGLUE dataset.
Fix #4247.
CC: @severo | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4249/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4249/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4249.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4249",
"merged_at": "2022-04-28T16:08:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4249.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4249"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.