graph LR
A{"🤗 Accelerate#32;"}
A --> B["Launching<br>Interface#32;"]
A --> C["Training Library#32;"]
A --> D["Big Model<br>Inference#32;"]
graph LR
A{"🤗 Accelerate#32;"}
A --> B["Launching<br>Interface#32;"]
A --> C["Training Library#32;"]
A --> D["Big Model<br>Inference#32;"]
Can’t I just use python do_the_thing.py?
Launching scripts in different environments is complicated:
And more!
But it doesn’t have to be:
A single command to launch with DeepSpeed, Fully Sharded Data Parallelism, across single and multi CPUs and GPUs, and to train on TPUs1 too!
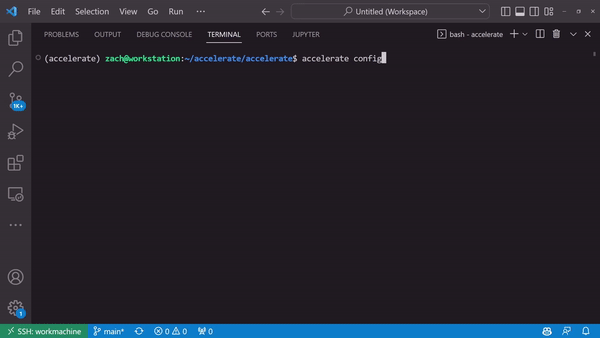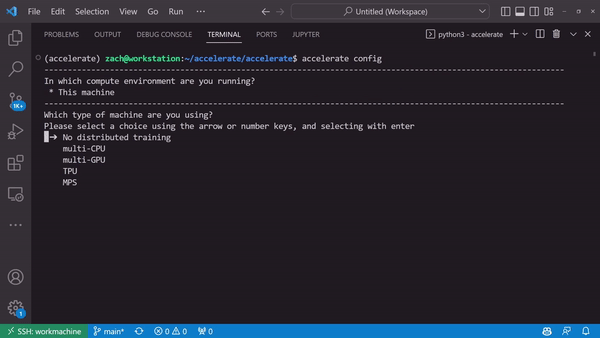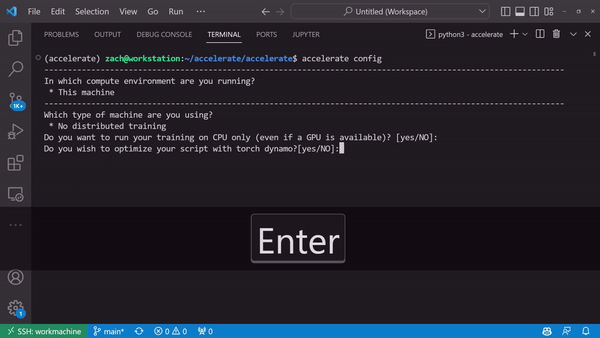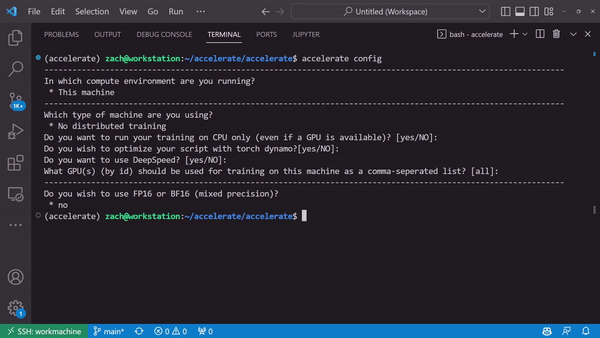
Generate a device-specific configuration through accelerate config
Or don’t. accelerate config doesn’t have to be done!
torchrun --nnodes=1 --nproc_per_node=2 script.py
accelerate launch --multi_gpu --nproc_per_node=2 script.pyA quick default configuration can be made too:
With the notebook_launcher it’s also possible to launch code directly from your Jupyter environment too!
Okay, will accelerate launch make do_the_thing.py use all my GPUs magically?
accelerate launch to launch a python script in various distributed environmentsaccelerate solves this by ensuring the same code can be ran on a CPU or GPU, multiples, and on TPUs!from accelerate import Accelerator
accelerator = Accelerator()
dataloader, model, optimizer scheduler = (
accelerator.prepare(
dataloader, model, optimizer, scheduler
)
)
for batch in dataloader:
optimizer.zero_grad()
inputs, targets = batch
# inputs = inputs.to(device)
# targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss) # loss.backward()
optimizer.step()
scheduler.step()What all happened in Accelerator.prepare?
Accelerator looked at the configurationdataloader was converted into one that can dispatch each batch onto a seperate GPUmodel was wrapped with the appropriate DDP wrapper from either torch.distributed or torch_xlaoptimizer and scheduler were both converted into an AcceleratedOptimizer and AcceleratedScheduler which knows how to handle any distributed scenario🤗 accelerate also supports automatic mixed precision.
Through a single flag to the Accelerator object when calling accelerator.backward() the mixed precision of your choosing (such as bf16 or fp16) will be applied:
Gradient accumulation in distributed setups often need extra care to ensure gradients are aligned when they need to be and the backward pass is computationally efficient.
🤗 accelerate can just easily handle this for you:
from accelerate import Accelerator
accelerator = Accelerator(gradient_accumulation_steps=4)
...
for batch in dataloader:
with accelerator.accumulate(model):
optimizer.zero_grad()
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss)
optimizer.step()
scheduler.step()ddp_model, dataloader = accelerator.prepare(model, dataloader)
for index, batch in enumerate(dataloader):
inputs, targets = batch
if index != (len(dataloader)-1) or (index % 4) != 0:
# Gradients don't sync
with accelerator.no_sync(model):
outputs = ddp_model(inputs)
loss = loss_func(outputs, targets)
accelerator.backward(loss)
else:
# Gradients finally sync
outputs = ddp_model(inputs)
loss = loss_func(outputs)
accelerator.backward(loss)Stable Diffusion taking the world by storm
As more large models were being released, Hugging Face quickly realized there must be a way to continue our decentralization of Machine Learning and have the day-to-day programmer be able to leverage these big models.
Born out of this effort by Sylvain Gugger:
🤗 Accelerate: Big Model Inference.
In PyTorch, there exists the meta device.
Super small footprint to load in huge models quickly by not loading in their weights immediatly.
As an input gets passed through each layer, we can load and unload parts of the PyTorch model quickly so that only a small portion of the big model is loaded in at a single time.
The end result? Stable Diffusion v1 can be ran on < 800mb of vRAM
Generally you start with something like so:
import torch
my_model = ModelClass(...)
state_dict = torch.load(checkpoint_file)
my_model.load_state_dict(state_dict)But this has issues:
34If a 6 billion parameter model is being loaded, each model class has a dictionary of 24GB so 48GB of vRAM is needed
We can fix step 1 by loading in an empty model skeleton at first:
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)
state_dict = torch.load(checkpoint_file)
my_model.load_state_dict(state_dict)This code will not run
It is likely that just calling my_model(x) will fail as not all tensor operations are supported on the meta device.
The next step is to have “Sharded Checkpoints” saved for your model.
Basically smaller chunks of your model weights stored that can be brought in at any particular time.
This reduces the amount of memory step 2 takes in since we can just load in a “chunk” of the model at a time, then swap it out for a new chunk through PyTorch hooks
from accelerate import init_empty_weights, load_checkpoint_and_dispatch
with init_empty_weights():
my_model = ModelClass(...)
my_model = load_checkpoint_and_dispatch(
my_model, "sharded-weights", device_map="auto"
)device_map="auto" will tell 🤗 Accelerate that it should determine where to put each layer of the model:
The transformers library combined with the Hub makes all this code wrapping much easier for you with the pipeline
A demo with diffusers & Weights and Biases