Writing a dataset loading script¶
There are two main reasons you may want to write your own dataset loading script:
you want to use local/private data files and the generic dataloader for CSV/JSON/text files (see From local files) are not enough for your use-case,
you would like to share a new dataset with the community, for instance in the HuggingFace Hub.
This chapter will explain how datasets are loaded and how you can write from scratch or adapt a dataset loading script.
Note
You can start from the template for a dataset loading script when writing a new dataset loading script. You can find this template in the templates folder on the github repository.
Here a quick general overview of the classes and method involved when generating a dataset:
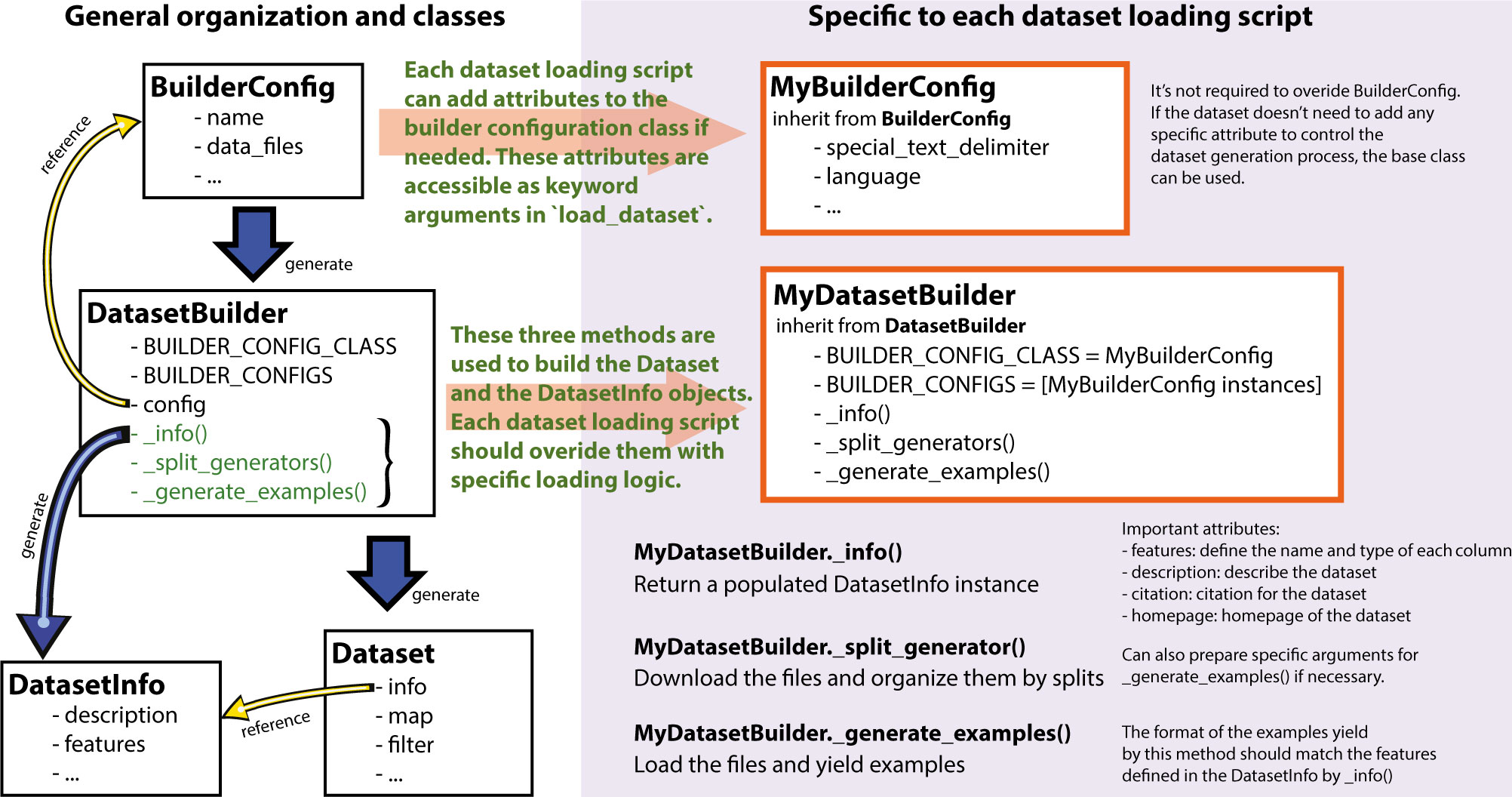
On the left is the general organization inside the library to create a datasets.Dataset instance and on the right, the elements which are specific to each dataset loading script. To create a new dataset loading script one mostly needs to specify three methods in a datasets.DatasetBuilder class:
datasets.DatasetBuilder._info()which is in charge of specifying the dataset metadata as adatasets.DatasetInfodataclass and in particular thedatasets.Featureswhich defined the names and types of each column in the dataset,datasets.DatasetBuilder._split_generator()which is in charge of downloading or retrieving the data files, organizing them by splits and defining specific arguments for the generation process if needed,datasets.DatasetBuilder._generate_examples()which is in charge of loading the files for a split and yielding examples with the format specified in thefeatures.
Optionally, the dataset loading script can define a configuration to be used by the datasets.DatasetBuilder by inheriting from datasets.BuilderConfig. Such a class allows us to customize the building process, for instance by allowing to select specific subsets of the data or specific ways to process the data when loading the dataset.
Note
Note on naming: the dataset class should be camel case, while the dataset name is its snake case equivalent (ex: class BookCorpus(datasets.GeneratorBasedBuilder) for the dataset book_corpus).
Adding dataset metadata¶
The datasets.DatasetBuilder._info() method is in charge of specifying the dataset metadata as a datasets.DatasetInfo dataclass and in particular the datasets.Features which defined the names and types of each column in the dataset. datasets.DatasetInfo has a predefined set of attributes and cannot be extended. The full list of attributes can be found in the package reference.
The most important attributes to specify are:
datasets.DatasetInfo.features: adatasets.Featuresinstance defining the name and the type of each column in the dataset and the general organization of the examples,datasets.DatasetInfo.description: astrdescribing the dataset,datasets.DatasetInfo.citation: astrcontaining the citation for the dataset in a BibTex format for inclusion in communications citing the dataset,datasets.DatasetInfo.homepage: astrcontaining an URL to an original homepage of the dataset.
Here is for instance the datasets.Dataset._info() for the SQuAD dataset for instance, which is taken from the squad dataset loading script
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=datasets.Features(
{
"id": datasets.Value("string"),
"title": datasets.Value("string"),
"context": datasets.Value("string"),
"question": datasets.Value("string"),
"answers": datasets.features.Sequence(
{"text": datasets.Value("string"), "answer_start": datasets.Value("int32"),}
),
}
),
# No default supervised_keys (as we have to pass both question
# and context as input).
supervised_keys=None,
homepage="https://rajpurkar.github.io/SQuAD-explorer/",
citation=_CITATION,
)
The datasets.Features define the structure for each examples and can define arbitrary nested objects with fields of various types. More details on the available features can be found in the guide on features Dataset features and in the package reference on datasets.Features. Many examples of features can also be found in the various dataset scripts provided on the GitHub repository and even directly inspected on the datasets viewer.
Here are the features of the SQuAD dataset for instance, which is taken from the squad dataset loading script:
datasets.Features(
{
"id": datasets.Value("string"),
"title": datasets.Value("string"),
"context": datasets.Value("string"),
"question": datasets.Value("string"),
"answers": datasets.Sequence(
{"text": datasets.Value("string"),
"answer_start": datasets.Value("int32"),
}
),
}
)
These features should be mostly self-explanatory given the above introduction. One specific behavior here is the fact that the Sequence field in "answers" is given a dictionary of sub-fields. As mentioned in the above note, in this case, this feature is actually converted into a dictionary of lists (instead of the list of dictionary that we read in the feature here). This is confirmed in the structure of the examples yielded by the generation method at the very end of the squad dataset loading script:
answer_starts = [answer["answer_start"] for answer in qa["answers"]]
answers = [answer["text"].strip() for answer in qa["answers"]]
yield id_, {
"title": title,
"context": context,
"question": question,
"id": id_,
"answers": {"answer_start": answer_starts, "text": answers,},
}
Here the "answers" is accordingly provided with a dictionary of lists and not a list of dictionary.
Let’s take another example of features from the large-scale reading comprehension dataset Race:
features=datasets.Features(
{
"article": datasets.Value("string"),
"answer": datasets.Value("string"),
"question": datasets.Value("string"),
"options": datasets.features.Sequence({"option": datasets.Value("string")})
}
)
Here is the corresponding first examples in the dataset:
>>> from datasets import load_dataset
>>> dataset = load_dataset('race', split='train')
>>> dataset[0]
{'article': 'My husband is a born shopper. He loves to look at things and to touch them. He likes to compare prices between the same items in different shops. He would never think of buying anything without looking around in several
...
sadder. When he saw me he said, "I\'m sorry, Mum. I have forgotten to buy oranges and the meat. I only remembered to buy six eggs, but I\'ve dropped three of them."',
'answer': 'C',
'question': 'The husband likes shopping because _ .',
'options': {
'option':['he has much money.',
'he likes the shops.',
'he likes to compare the prices between the same items.',
'he has nothing to do but shopping.'
]
}
}
Downloading data files and organizing splits¶
The datasets.DatasetBuilder._split_generator() method is in charge of downloading (or retrieving locally the data files), organizing them according to the splits and defining specific arguments for the generation process if needed.
This method takes as input a datasets.DownloadManager which is a utility which can be used to download files (or to retrieve them from the local filesystem if they are local files or are already in the cache) and return a list of datasets.SplitGenerator. A datasets.SplitGenerator is a simple dataclass containing the name of the split and keywords arguments to be provided to the datasets.DatasetBuilder._generate_examples() method that we detail in the next section. These arguments can be specific to each splits and typically comprise at least the local path to the data files to load for each split.
Note
Using local data files Two attributes of datasets.BuilderConfig are specifically provided to store paths to local data files if your dataset is not online but constituted by local data files. These two attributes are data_dir and data_files and can be freely used to provide a directory path or file paths. These two attributes can be set when calling datasets.load_dataset() using the associated keyword arguments, e.g. dataset = datasets.load_dataset('my_script', data_files='my_local_data_file.csv') and the values can be used in datasets.DatasetBuilder._split_generator() by accessing self.config.data_dir and self.config.data_files. See the text file loading script for a simple example using datasets.BuilderConfig.data_files.
Let’s have a look at a simple example of a datasets.DatasetBuilder._split_generator() method. We’ll take the example of the squad dataset loading script:
class Squad(datasets.GeneratorBasedBuilder):
"""SQUAD: The Stanford Question Answering Dataset. Version 1.1."""
_URL = "https://rajpurkar.github.io/SQuAD-explorer/dataset/"
_URLS = {
"train": _URL + "train-v1.1.json",
"dev": _URL + "dev-v1.1.json",
}
def _split_generators(self, dl_manager: datasets.DownloadManager) -> List[datasets.SplitGenerator]:
urls_to_download = self._URLS
downloaded_files = dl_manager.download_and_extract(urls_to_download)
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": downloaded_files["train"]}),
datasets.SplitGenerator(name=datasets.Split.VALIDATION, gen_kwargs={"filepath": downloaded_files["dev"]}),
]
As you can see this method first prepares a dict of URL to the original data files for SQuAD. This dict is then provided to the datasets.DownloadManager.download_and_extract() method which will take care of downloading or retrieving these files from the local file system and returning a object of the same type and organization (here a dictionary) with the path to the local version of the requested files. datasets.DownloadManager.download_and_extract() can take as input a single URL/path or a list or dictionary of URLs/paths and will return an object of the same structure (single URL/path, list or dictionary of URLs/paths) with the path to the local files. This method also takes care of extracting compressed tar, gzip and zip archives.
datasets.DownloadManager.download_and_extract() can download files from a large set of origins but if your data files are hosted on a special access server, it’s also possible to provide a callable which will take care of the downloading process to the DownloadManager using datasets.DownloadManager.download_custom().
Note
In addition to datasets.DownloadManager.download_and_extract() and datasets.DownloadManager.download_custom(), the datasets.DownloadManager class also provide more fine-grained control on the download and extraction process through several methods including: datasets.DownloadManager.download(), datasets.DownloadManager.extract() and datasets.DownloadManager.iter_archive(). Please refer to the package reference on datasets.DownloadManager for details on these methods.
Once the data files are downloaded, the next mission for the datasets.DatasetBuilder._split_generator() method is to prepare the datasets.SplitGenerator for each split which will be used to call the datasets.DatasetBuilder._generate_examples() method that we detail in the next session.
A datasets.SplitGenerator is a simple dataclass containing:
name(string) : the name of a split, when possible, standard split names provided indatasets.Splitcan be used:datasets.Split.TRAIN,datasets.Split.VALIDATIONanddatasets.Split.TEST,gen_kwargs(dict): keywords arguments to be provided to thedatasets.DatasetBuilder._generate_examples()method to generate the samples in this split. These arguments can be specific to each split and typically comprise at least the local path to the data files to load for each split as indicated in the above SQuAD example.
Generating the samples in each split¶
The datasets.DatasetBuilder._generate_examples() is in charge of reading the data files for a split and yielding examples with the format specified in the features set in datasets.DatasetBuilder._info().
The input arguments of datasets.DatasetBuilder._generate_examples() are defined by the gen_kwargs dictionary returned by the datasets.DatasetBuilder._split_generator() method we detailed above.
Here again, let’s take the simple example of the squad dataset loading script:
def _generate_examples(self, filepath):
"""This function returns the examples in the raw (text) form."""
logger.info("generating examples from = %s", filepath)
with open(filepath) as f:
squad = json.load(f)
for article in squad["data"]:
title = article.get("title", "").strip()
for paragraph in article["paragraphs"]:
context = paragraph["context"].strip()
for qa in paragraph["qas"]:
question = qa["question"].strip()
id_ = qa["id"]
answer_starts = [answer["answer_start"] for answer in qa["answers"]]
answers = [answer["text"].strip() for answer in qa["answers"]]
# Features currently used are "context", "question", and "answers".
# Others are extracted here for the ease of future expansions.
yield id_, {
"title": title,
"context": context,
"question": question,
"id": id_,
"answers": {"answer_start": answer_starts, "text": answers,},
}
The input argument is the filepath provided in the gen_kwargs of each datasets.SplitGenerator returned by the datasets.DatasetBuilder._split_generator() method.
The method reads and parses the inputs files and yields a tuple constituted of an id_ (can be arbitrary but should be unique (for backward compatibility with TensorFlow datasets) and an example. The example is a dictionary with the same structure and element types as the features defined in datasets.DatasetBuilder._info().
Note
Since generating a dataset is based on a python generator, then it doesn’t load all the data in memory and therefore it can handle pretty big datasets. However before being flushed to the dataset file on disk, the generated samples are stored in the ArrowWriter buffer so that they are written by batch. If your dataset’s samples take a lot of memory (with images or videos), then make sure to speficy a low value for the _writer_batch_size class attribute of the dataset builder class. We recommend to not exceed 200MB.
Specifying several dataset configurations¶
Sometimes you want to provide access to several sub-sets of your dataset, for instance if your dataset comprises several languages or is constituted of various sub-sets or if you want to provide several ways to structure examples.
This is possible by defining a specific datasets.BuilderConfig class and providing predefined instances of this class for the user to select from.
The base datasets.BuilderConfig class is very simple and only comprises the following attributes:
name(str) is the name of the dataset configuration, for instance the language name if the various configurations are specific to various languagesversionan optional version identifierdata_dir(str) can be used to store the path to a local folder containing data filesdata_files(Union[Dict, List]can be used to store paths to local data filesdescription(str) can be used to give a long description of the configuration
datasets.BuilderConfig is only used as a container of informations which can be used in the datasets.DatasetBuilder to build the dataset by being accessed in the self.config attribute of the datasets.DatasetBuilder instance.
You can sub-class the base datasets.BuilderConfig class to add additional attributes that you may want to use to control the generation of a dataset. The specific configuration class that will be used by the dataset is set in the datasets.DatasetBuilder.BUILDER_CONFIG_CLASS.
There are two ways to populate the attributes of a datasets.BuilderConfig class or sub-class:
a list of predefined
datasets.BuilderConfigclasses or sub-classes can be set in thedatasets.DatasetBuilder.BUILDER_CONFIGSattribute of the dataset. Each specific configuration can then be selected by giving itsnameasnamekeyword todatasets.load_dataset(),when calling
datasets.load_dataset(), all the keyword arguments which are not specific to thedatasets.load_dataset()method will be used to set the associated attributes of thedatasets.BuilderConfigclass and override the predefined attributes if a specific configuration was selected.
Let’s take an example adapted from the CSV files loading script.
Let’s say we would like two simple ways to load CSV files: using ',' as a delimiter (we will call this configuration 'comma') or using ';' as a delimiter (we will call this configuration 'semi-colon').
We can define a custom configuration with a delimiter attribute:
@dataclass
class CsvConfig(datasets.BuilderConfig):
"""BuilderConfig for CSV."""
delimiter: str = None
And then define several predefined configurations in the DatasetBuilder:
class Csv(datasets.ArrowBasedBuilder):
BUILDER_CONFIG_CLASS = CsvConfig
BUILDER_CONFIGS = [CsvConfig(name='comma',
description="Load CSV using ',' as a delimiter",
delimiter=','),
CsvConfig(name='semi-colon',
description="Load CSV using a semi-colon as a delimiter",
delimiter=';')]
...
def self._generate_examples(file):
with open(file) as csvfile:
data = csv.reader(csvfile, delimiter = self.config.delimiter)
for i, row in enumerate(data):
yield i, row
Here we can see how reading the CSV file can be controlled using the self.config.delimiter attribute.
The users of our dataset loading script will be able to select one or the other way to load the CSV files with the configuration names or even a totally different way by setting the delimiter attrbitute directly. For instance using commands like this:
>>> from datasets import load_dataset
>>> dataset = load_dataset('my_csv_loading_script', name='comma', data_files='my_file.csv')
>>> dataset = load_dataset('my_csv_loading_script', name='semi-colon', data_files='my_file.csv')
>>> dataset = load_dataset('my_csv_loading_script', name='comma', delimiter='\t', data_files='my_file.csv')
In the last case, the delimiter set by the configuration will be overriden by the delimiter given as argument to load_dataset.
While the configuration attributes are used in this case to control the reading/parsing of the data files, the configuration attributes can be used at any stage of the processing and in particular:
to control the
datasets.DatasetInfoattributes set in thedatasets.DatasetBuilder._info()method, for instances thefeatures,to control the files downloaded in the
datasets.DatasetBuilder._split_generator()method, for instance to select different URLs depending on alanguageattribute defined by the configuration
An example of a custom configuration class with several predefined configurations can be found in the Super-GLUE loading script which providescontrol over the various sub-dataset of the SuperGLUE benchmark through the configurations. Another example is the Wikipedia loading script which provides control over the language of the Wikipedia dataset through the configurations.
Specifying a default dataset configuration¶
When a user loads a dataset with more than one configuration, they must specify a configuration name or else a ValueError is raised. With some datasets, it may be preferable to specify a default configuration that will be loaded if a user does not specify one.
This can be done with the datasets.DatasetBuilder.DEFAULT_CONFIG_NAME attribute. By setting this attribute equal to the name of one of the dataset configurations, that config will be loaded in the case that the user does not specify a config name.
This feature is opt-in and should only be used where a default configuration makes sense for the dataset. For example, many cross-lingual datasets have a different configuration for each language. In this case, it may make sense to create an aggregate configuration which can serve as the default. This would, in effect, load all languages of the dataset by default unless the user specifies a particular language. See the Polyglot NER loading script for an example.
Testing the dataset loading script¶
Once you’re finished with creating or adapting a dataset loading script, you can try it locally by giving the path to the dataset loading script:
>>> from datasets import load_dataset
>>> dataset = load_dataset('PATH/TO/MY/SCRIPT.py')
If your dataset has several configurations or requires to be given the path to local data files, you can use the arguments of datasets.load_dataset() accordingly:
>>> from datasets import load_dataset
>>> dataset = load_dataset('PATH/TO/MY/SCRIPT.py', 'my_configuration', data_files={'train': 'my_train_file.txt', 'validation': 'my_validation_file.txt'})
Dataset scripts of reference¶
It is common to see datasets that share the same format. Therefore it is possible that there already exists a dataset script from which you can get some inspiration to help you write your own.
Here is a list of datasets of reference. Feel free to reuse parts of their code and adapt them to your case:
question-answering: squad (original data are in json)
natural language inference: snli (original data are in text files with tab separated columns)
POS/NER: conll2003 (original data are in text files with one token per line)
sentiment analysis: allocine (original data are in jsonl files)
text classification: ag_news (original data are in csv files)
translation: flores (original data come from text files - one per language)
summarization: billsum (original data are in json files)
benchmark: glue (original data are various formats)
multilingual: xquad (original data are in json)
multitask: matinf (original data need to be downloaded by the user because it requires authentificaition)