
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.12B
| node_id
stringlengths 18
32
| number
int64 1
3.68k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 2
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3678/comments | https://api.github.com/repos/huggingface/datasets/issues/3678/events | https://github.com/huggingface/datasets/pull/3678 | 1,123,402,426 | PR_kwDODunzps4yCt91 | 3,678 | Add code example in wikipedia card | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-02-03T18:09:02" | "2022-02-21T09:14:56" | "2022-02-04T13:21:39" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3678",
"html_url": "https://github.com/huggingface/datasets/pull/3678",
"diff_url": "https://github.com/huggingface/datasets/pull/3678.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3678.patch",
"merged_at": "2022-02-04T13:21:39"
} | Close #3292. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3678/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3677/comments | https://api.github.com/repos/huggingface/datasets/issues/3677/events | https://github.com/huggingface/datasets/issues/3677 | 1,123,192,866 | I_kwDODunzps5C8pAi | 3,677 | Discovery cannot be streamed anymore | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Seems like a regression from https://github.com/huggingface/datasets/pull/2843\r\n\r\nOr maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected\r\n\r\n",
"Hi @severo, thanks for reporting.\r\n\r\nSome servers do not support HTTP range requests, and those are required to stream some file formats (like ZIP in this case).\r\n\r\nLet me try to propose a workaround. "
] | "2022-02-03T15:02:03" | "2022-02-10T16:51:24" | "2022-02-10T16:51:24" | CONTRIBUTOR | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
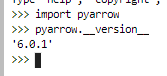
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3677/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3676/comments | https://api.github.com/repos/huggingface/datasets/issues/3676/events | https://github.com/huggingface/datasets/issues/3676 | 1,123,096,362 | I_kwDODunzps5C8Rcq | 3,676 | `None` replaced by `[]` after first batch in map | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"It looks like this is because of this behavior in pyarrow:\r\n```python\r\nimport pyarrow as pa\r\n\r\narr = pa.array([None, [0]])\r\nreconstructed_arr = pa.ListArray.from_arrays(arr.offsets, arr.values)\r\nprint(reconstructed_arr.to_pylist())\r\n# [[], [0]]\r\n```\r\n\r\nIt seems that `arr.offsets` can reconstruct the array properly, but an offsets array with null values can:\r\n```python\r\nfixed_offsets = pa.array([None, 0, 1])\r\nfixed_arr = pa.ListArray.from_arrays(fixed_offsets, arr.values)\r\nprint(fixed_arr.to_pylist())\r\n# [None, [0]]\r\n\r\nprint(arr.offsets.to_pylist())\r\n# [0, 0, 1]\r\nprint(fixed_offsets.to_pylist())\r\n# [None, 0, 1]\r\n```\r\nEDIT: this is because `arr.offsets` is not enough to reconstruct the array, we also need the validity bitmap",
"The offsets don't have nulls because they don't include the validity bitmap from `arr.buffers()[0]`, which is used to say which values are null and which values are non-null.\r\n\r\nThough the validity bitmap also seems to be wrong:\r\n```python\r\nbin(int(arr.buffers()[0].hex(), 16))\r\n# '0b10'\r\n# it should be 0b110 - 1 corresponds to non-null and 0 corresponds to null, if you take the bits in reverse order\r\n```\r\n\r\nSo apparently I can't even create the fixed offsets array using this.\r\n\r\nIf I understand correctly it's always missing the 1 on the left, so I can add it manually as a hack to fix the issue until this is fixed in pyarrow EDIT: actually it may be more complicated than that\r\n\r\nEDIT2: actuall it's right, it corresponds to the validity bitmap of the array of logical length 2. So if we use the offsets array, the values array, and this validity bitmap it should be possible to reconstruct the array properly",
"I created an issue on Apache Arrow's JIRA: https://issues.apache.org/jira/browse/ARROW-15837",
"And another one: https://issues.apache.org/jira/browse/ARROW-15839",
"FYI the behavior is the same with:\r\n- `datasets` version: 1.18.3\r\n- Platform: Linux-5.8.0-50-generic-x86_64-with-debian-bullseye-sid\r\n- Python version: 3.7.11\r\n- PyArrow version: 6.0.1\r\n\r\n\r\nbut not with:\r\n- `datasets` version: 1.8.0\r\n- Platform: Linux-4.18.0-305.40.2.el8_4.x86_64-x86_64-with-redhat-8.4-Ootpa\r\n- Python version: 3.7.11\r\n- PyArrow version: 3.0.0\r\n\r\ni.e. it outputs:\r\n```py\r\n0 [None, [0]]\r\n1 [None, [0]]\r\n2 [None, [0]]\r\n3 [None, [0]]\r\n```\r\n",
"Thanks for the insights @PaulLerner !\r\n\r\nI found a way to workaround this issue for the code example presented in this issue.\r\n\r\nNote that empty lists will still appear when you explicitly `cast` a list of lists that contain None values like [None, [0]] to a new feature type (e.g. to change the integer precision). In this case it will show a warning that it happened. If you don't cast anything, then the None values will be kept as expected.\r\n\r\nLet me know what you think !",
"Hi! I feel like I’m missing something in your answer, *what* is the workaround? Is it fixed in some `datasets` version?",
"`pa.ListArray.from_arrays` returns empty lists instead of None values. The workaround I added inside `datasets` simply consists in not using `pa.ListArray.from_arrays` :)\r\n\r\nOnce this PR [here ](https://github.com/huggingface/datasets/pull/4282)is merged, we'll release a new version of `datasets` that currectly returns the None values in the case described in this issue\r\n\r\nEDIT: released :) but let's keep this issue open because it might happen again if users change the integer precision for example"
] | "2022-02-03T13:36:48" | "2022-10-28T13:13:20" | "2022-10-28T13:13:20" | MEMBER | null | null | null | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3676/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/datasets/issues/3676/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3675/comments | https://api.github.com/repos/huggingface/datasets/issues/3675/events | https://github.com/huggingface/datasets/issues/3675 | 1,123,078,408 | I_kwDODunzps5C8NEI | 3,675 | Add CodeContests dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [
"@mariosasko Can I take this up?",
"This dataset is now available here: https://huggingface.co/datasets/deepmind/code_contests."
] | "2022-02-03T13:20:00" | "2022-07-20T11:07:05" | "2022-07-20T11:07:05" | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** CodeContests
- **Description:** CodeContests is a competitive programming dataset for machine-learning.
- **Paper:**
- **Data:** https://github.com/deepmind/code_contests
- **Motivation:** This dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3675/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3675/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3674/comments | https://api.github.com/repos/huggingface/datasets/issues/3674/events | https://github.com/huggingface/datasets/pull/3674 | 1,123,027,874 | PR_kwDODunzps4yBe17 | 3,674 | Add FrugalScore metric | {
"login": "moussaKam",
"id": 28675016,
"node_id": "MDQ6VXNlcjI4Njc1MDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/28675016?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moussaKam",
"html_url": "https://github.com/moussaKam",
"followers_url": "https://api.github.com/users/moussaKam/followers",
"following_url": "https://api.github.com/users/moussaKam/following{/other_user}",
"gists_url": "https://api.github.com/users/moussaKam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moussaKam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moussaKam/subscriptions",
"organizations_url": "https://api.github.com/users/moussaKam/orgs",
"repos_url": "https://api.github.com/users/moussaKam/repos",
"events_url": "https://api.github.com/users/moussaKam/events{/privacy}",
"received_events_url": "https://api.github.com/users/moussaKam/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq \r\n\r\nThe model used by default (`moussaKam/frugalscore_tiny_bert-base_bert-score`) is a tiny model.\r\n\r\nI still want to make one modification before merging.\r\nI would like to load the model checkpoint once. Do you think it's a good idea if I load it in `_download_and_prepare`? In this case should the model name be the `self.config_name` or another variable say `self.model_name` ? ",
"OK, I added a commit that loads the checkpoint in `_download_and_prepare`. Please let me know if it looks good. ",
"@lhoestq is everything OK to merge? ",
"I triggered the CI and it's failing, can you merge the `master` branch into yours ? It should fix the issues.\r\n\r\nAlso the doctest apparently raises an error because it outputs `{'scores': [0.6307542, 0.6449357]}` instead of `{'scores': [0.631, 0.645]}` - feel free to edit the code example in the docstring to round the scores, that should fix it",
"@lhoestq hope it's OK now"
] | "2022-02-03T12:28:52" | "2022-02-21T15:58:44" | "2022-02-21T15:58:44" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3674",
"html_url": "https://github.com/huggingface/datasets/pull/3674",
"diff_url": "https://github.com/huggingface/datasets/pull/3674.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3674.patch",
"merged_at": "2022-02-21T15:58:44"
} | This pull request add FrugalScore metric for NLG systems evaluation.
FrugalScore is a reference-based metric for NLG models evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
Paper: https://arxiv.org/abs/2110.08559?context=cs
Github: https://github.com/moussaKam/FrugalScore
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3674/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But\r\n1. maybe it's the wrong default\r\n2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).\r\n",
"Hi @severo,\r\n\r\nThanks for clarifying. \r\n\r\nI think this default is a bit counterintuitive for the user. However, this is a personal opinion that might not be general. I think it is nice to have the actual (non-encoded) labels in the viewer. On the other hand, it would be nice to match what the user sees with what they get when they download a dataset. I don't know - I can see the difficulty of choosing a default :)\r\nMaybe having non-encoded labels as a default can be useful?\r\n\r\nAnyway, I think the issue has been addressed. Thanks a lot for your super-quick answer!\r\n\r\n ",
"Thanks for the 👍 in https://github.com/huggingface/datasets/issues/3673#issuecomment-1029008349 @mariosasko @gary149 @pietrolesci, but as I proposed various solutions, it's not clear to me which you prefer. Could you write your preferences as a comment?\r\n\r\n_(note for myself: one idea per comment in the future)_",
"As I am working with seq2seq, I prefer having the label in string form rather than numeric. So the viewer is fine and the underlying dataset should be \"decoded\" (from int to str). In this way, the user does not have to search for a mapping `int -> original name` (even though is trivial to find, I reckon). Also, encoding labels is rather easy.\r\n\r\nI hope this is useful",
"I like the idea of \"0 (neutral)\". The label name can even be greyed to make it clear that it's not part of the actual item in the dataset, it's just the meaning.",
"I like @lhoestq's idea of having grayed-out labels.",
"Proposals by @gary149. Which one do you prefer? Please vote with the thumbs\r\n\r\n- 👍 \r\n\r\n \r\n\r\n- 👎 \r\n\r\n 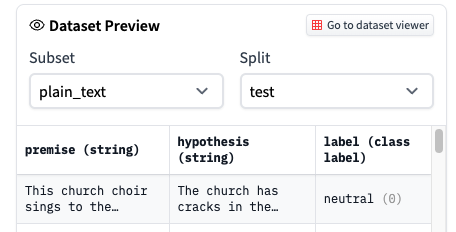\r\n\r\n",
"I like Option 1 better as it shows clearly what the user is downloading",
"Thanks! ",
"It's [live](https://huggingface.co/datasets/glue/viewer/cola/train):\r\n\r\n<img width=\"1126\" alt=\"Capture d’écran 2022-02-14 à 10 26 03\" src=\"https://user-images.githubusercontent.com/1676121/153836716-25f6205b-96af-42d8-880a-7c09cb24c420.png\">\r\n\r\nThanks all for the help to improve the UI!",
"Love it ! thanks :)"
] | "2022-02-03T12:10:43" | "2022-02-16T11:22:31" | "2022-02-11T17:01:21" | NONE | null | null | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3672/comments | https://api.github.com/repos/huggingface/datasets/issues/3672/events | https://github.com/huggingface/datasets/pull/3672 | 1,122,980,556 | PR_kwDODunzps4yBUrZ | 3,672 | Prioritize `module.builder_kwargs` over defaults in `TestCommand` | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-02-03T11:38:42" | "2022-02-04T12:37:20" | "2022-02-04T12:37:19" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3672",
"html_url": "https://github.com/huggingface/datasets/pull/3672",
"diff_url": "https://github.com/huggingface/datasets/pull/3672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3672.patch",
"merged_at": "2022-02-04T12:37:19"
} | This fixes a bug in the `TestCommand` where multiple kwargs for `name` were passed if it was set in both default and `module.builder_kwargs`. Example error:
```Python
Traceback (most recent call last):
File "create_metadata.py", line 96, in <module>
main(**vars(args))
File "create_metadata.py", line 86, in main
metadata_command.run()
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 144, in run
for j, builder in enumerate(get_builders()):
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 141, in get_builders
name=name, cache_dir=self._cache_dir, data_dir=self._data_dir, **module.builder_kwargs
TypeError: type object got multiple values for keyword argument 'name'
```
Let me know what you think. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3672/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3671/comments | https://api.github.com/repos/huggingface/datasets/issues/3671/events | https://github.com/huggingface/datasets/issues/3671 | 1,122,864,253 | I_kwDODunzps5C7Yx9 | 3,671 | Give an estimate of the dataset size in DatasetInfo | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | "2022-02-03T09:47:10" | "2022-02-03T09:47:10" | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, only part of the datasets provide `dataset_size`, `download_size`, `size_in_bytes` (and `num_bytes` and `num_examples` inside `splits`). I would want to get this information, or an estimation, for all the datasets.
**Describe the solution you'd like**
- get access to the git information for the dataset files hosted on the hub
- look at the [`Content-Length`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Length) for the files served by HTTP
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3671/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"It's a first attempt at solving https://github.com/huggingface/datasets/issues/3013.",
"I only kept these ones:\r\n```\r\n path: str,\r\n data_files: Optional[Union[Dict, List, str]] = None,\r\n download_config: Optional[DownloadConfig] = None,\r\n download_mode: Optional[GenerateMode] = None,\r\n revision: Optional[Union[str, Version]] = None,\r\n use_auth_token: Optional[Union[bool, str]] = None,\r\n **config_kwargs,\r\n```\r\n\r\nLet me know if it's better for you now !\r\n\r\n(note that there's no breaking change since the ones that are removed can be passed as config_kwargs if you really want)",
"(https://github.com/huggingface/datasets/pull/3670/commits/5636911880ea4306c27c7f5825fa3f9427ccc2b6 and https://github.com/huggingface/datasets/pull/3670/commits/07c3f0800dd34dfebb9674ad46c67a907b08ded8 -> I has forgotten to update black in my venv)"
] | "2022-02-02T22:11:56" | "2022-02-21T15:57:11" | "2022-02-21T15:57:10" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"merged_at": "2022-02-21T15:57:10"
} | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3669/comments | https://api.github.com/repos/huggingface/datasets/issues/3669/events | https://github.com/huggingface/datasets/pull/3669 | 1,122,335,622 | PR_kwDODunzps4x_OTI | 3,669 | Common voice validated partition | {
"login": "shalymin-amzn",
"id": 98762373,
"node_id": "U_kgDOBeL-hQ",
"avatar_url": "https://avatars.githubusercontent.com/u/98762373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shalymin-amzn",
"html_url": "https://github.com/shalymin-amzn",
"followers_url": "https://api.github.com/users/shalymin-amzn/followers",
"following_url": "https://api.github.com/users/shalymin-amzn/following{/other_user}",
"gists_url": "https://api.github.com/users/shalymin-amzn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shalymin-amzn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shalymin-amzn/subscriptions",
"organizations_url": "https://api.github.com/users/shalymin-amzn/orgs",
"repos_url": "https://api.github.com/users/shalymin-amzn/repos",
"events_url": "https://api.github.com/users/shalymin-amzn/events{/privacy}",
"received_events_url": "https://api.github.com/users/shalymin-amzn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @patrickvonplaten - could you please advise whether this would be a welcomed change, and if so, who I consult regarding the unit-tests?",
"I'd be happy with adding this change. @anton-l @lhoestq - what do you think?",
"Cool ! I just fixed the tests by adding a dummy `validated.tsv` file in the dummy data archive of common_voice\r\n\r\nI wonder if you should separate the train/valid/test configuration from the validated/invalidated configuration of the splits ? \r\nIn particular having `validated` along with the train/valid/test splits could be a bit weird since it comprises them. We can do that if you think it makes more sense. Otherwise it's also good as it is right now :)\r\n",
"Thanks! I think that there are 2 cases for using the validated partition: 1) trainset = {validated - dev - test}, dev and test as they come; 2) train, dev, and test sampled from validated manually with the desired ratios.\r\nIn either case, I think that it's quite a big change on the HF interface part, so could as well be taken care of in the client code. Or is it not? (In which case, what's the most compact way to implement this?)",
"What's important IMO is to let the users as much flexibility as they need - so we try to not do too much regarding splits to not constrain users. So I guess the way it is right now is ok. Can you confirm that it's ok @patrickvonplaten and that it won't break some speech training script out there ?",
"@lhoestq all split names are explicit in our example scripts, so this shouldn't break anything, feel free to merge :)\r\nI'll go ahead and add this to the official `mozilla-foundation` datasets as well ",
"Good for me! This has no real down-sides IMO and surely won't break any training scripts."
] | "2022-02-02T20:04:43" | "2022-02-08T17:26:52" | "2022-02-08T17:23:12" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3669",
"html_url": "https://github.com/huggingface/datasets/pull/3669",
"diff_url": "https://github.com/huggingface/datasets/pull/3669.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3669.patch",
"merged_at": "2022-02-08T17:23:12"
} | This patch adds access to the 'validated' partitions of CommonVoice datasets (provided by the dataset creators but not available in the HuggingFace interface yet).
As 'validated' contains significantly more data than 'train' (although it contains both test and validation, so one needs to be careful there), it can be useful to train better models where no strict comparison with the previous work is intended. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3669/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.\r\n\r\nIf you manage to share a reproducible code example that would be perfect",
"Hi,\r\n\r\nI think my team mate got this solved. Clolsing it for now and will reopen if I experience this again.\r\nThanks :) ",
"Hi @R4ZZ3,\r\n\r\nIf it is not too much of a bother, can you please help me how to resolve this error? I am exactly getting the same error where I am going as per the documentation guideline:\r\n\r\n`my_audio_dataset = my_audio_dataset.cast_column(\"audio_paths\", Audio())`\r\n\r\nwhere `\"audio_paths\"` is a dataset column (feature) having strings of absolute paths to mp3 files of the dataset.\r\n\r\n",
"I was having the same issue with this code:\r\n\r\n```\r\ndataset = dataset.map(\r\n lambda batch: {\"full_path\" : os.path.join(self.data_path, batch[\"path\"])},\r\n num_procs = 4\r\n)\r\nmy_audio_dataset = dataset.cast_column(\"full_path\", Audio(sampling_rate=16_000))\r\n```\r\n\r\nRemoving the \"num_procs\" argument fixed it somehow.\r\nUsing a mac with m1 chip",
"Hi @Hubert-Bonisseur, I think this will be fixed by https://github.com/huggingface/datasets/pull/4614"
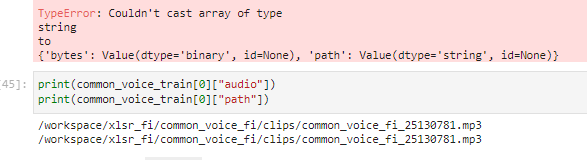
] | "2022-02-02T18:33:29" | "2022-07-19T13:36:24" | "2022-07-19T13:36:24" | NONE | null | null | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
but get error:
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3668/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3668/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Note that torchaudio is maybe less practical to use for TF or JAX users.\r\nThis is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice",
"> Note that torchaudio is maybe less practical to use for TF or JAX users. This is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice\r\n\r\n@lhoestq so maybe don't do this PR? :) if it doesn't work anyway with an opened file, only with path",
"Yes as discussed offline there seems to be issues with torchaudio on opened files. Feel free to close this PR if it's better to stick with soundfile because of that",
"We should be able to remove torchaudio, which has torch as a hard dependency, soon and use only soundfile for decoding: https://github.com/bastibe/python-soundfile/issues/252#issuecomment-1000246773 (opus + mp3 support is on the way)."
] | "2022-02-02T15:23:14" | "2022-02-04T15:29:38" | "2022-02-04T15:29:38" | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"merged_at": null
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine anyway for some reason, even with `ffmpeg` installed).
For now my current changes work with locally stored file:
```python
# download sample opus file (from MultilingualSpokenWords dataset)
!wget https://huggingface.co/datasets/polinaeterna/test_opus/resolve/main/common_voice_tt_17737010.opus
from datasets import Dataset, Audio
audio_path = "common_voice_tt_17737010.opus"
dataset = Dataset.from_dict({"audio": [audio_path]}).cast_column("audio", Audio(48000))
dataset[0]
# {'audio': {'path': 'common_voice_tt_17737010.opus',
# 'array': array([ 0.0000000e+00, 0.0000000e+00, 3.0517578e-05, ...,
# -6.1035156e-05, 6.1035156e-05, 0.0000000e+00], dtype=float32),
# 'sampling_rate': 48000}}
```
But it doesn't work when loading inside s dataset from bytes (I checked on [MultilingualSpokenWords](https://github.com/huggingface/datasets/pull/3666), the PR is a draft now, maybe the bug is somewhere there )
```python
import torchaudio
with open(audio_path, "rb") as b:
print(torchaudio.load(b))
# RuntimeError: Error loading audio file: failed to open file <in memory buffer>
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3666/comments | https://api.github.com/repos/huggingface/datasets/issues/3666/events | https://github.com/huggingface/datasets/pull/3666 | 1,122,058,894 | PR_kwDODunzps4x-ULz | 3,666 | process .opus files (for Multilingual Spoken Words) | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq I still have problems with processing `.opus` files with `soundfile` so I actually cannot fully check that it works but it should... Maybe this should be investigated in case of someone else would also have problems with that.\r\n\r\nAlso, as the data is in a private repo on the hub (before we come to a decision about audio data privacy), the needed checks cannot be done right now.",
"@lhoestq I check the data redownloading for configs sharing the same languages, you were right: the data is downloaded once for each language. But samples are generated from scratch each time. Is it a supposed behavior? ",
"> But samples are generated from scratch each time. Is it a supposed behavior?\r\n\r\nYea that's the way it works right now, because we generate one arrow file per configuration. Since changing the languages creates a new configuration, then it generates a new arrow file."
] | "2022-02-02T15:21:48" | "2022-02-22T10:04:03" | "2022-02-22T10:03:53" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3666",
"html_url": "https://github.com/huggingface/datasets/pull/3666",
"diff_url": "https://github.com/huggingface/datasets/pull/3666.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3666.patch",
"merged_at": "2022-02-22T10:03:53"
} | Opus files requires `libsndfile>=1.0.30`. Add check for this version and tests.
**outdated:**
Add [Multillingual Spoken Words dataset](https://mlcommons.org/en/multilingual-spoken-words/)
You can specify multiple languages for downloading 😌:
```python
ds = load_dataset("datasets/ml_spoken_words", languages=["ar", "tt"])
```
1. I didn't take into account that each time you pass a set of languages the data for a specific language is downloaded even if it was downloaded before (since these are custom configs like `ar+tt` and `ar+tt+br`. Maybe that wasn't a good idea?
2. The script will have to be slightly changed after merge of https://github.com/huggingface/datasets/pull/3664
2. Just can't figure out what wrong with dummy files... 😞 Maybe we should get rid of them at some point 😁 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3666/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3666/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3665/comments | https://api.github.com/repos/huggingface/datasets/issues/3665/events | https://github.com/huggingface/datasets/pull/3665 | 1,121,753,385 | PR_kwDODunzps4x9TnU | 3,665 | Fix MP3 resampling when a dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-02-02T10:31:45" | "2022-02-02T10:52:26" | "2022-02-02T10:52:26" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3665",
"html_url": "https://github.com/huggingface/datasets/pull/3665",
"diff_url": "https://github.com/huggingface/datasets/pull/3665.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3665.patch",
"merged_at": "2022-02-02T10:52:25"
} | The resampler needs to be updated if the `orig_freq` doesn't match the audio file sampling rate
Fix https://github.com/huggingface/datasets/issues/3662 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3665/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Cool thanks for giving it a try @anton-l ! \r\n\r\nWould be very much in favor of having \"real\" paths to the audio files again for non-streaming use cases. At the same time it would be nice to make the audio data loading script as understandable as possible so that the community can easily add audio datasets in the future by looking at this one as an example. Think if it's clear for a contributor how to add an audio datasets script that works for the standard non-streaming case while it is easy to extend it afterwards to a streaming dataset script, then this would be perfect",
"@anton-l @patrickvonplaten @lhoestq Is it possible somehow to provide this logic inside the library instead of a loading script so that we don't need to completely rewrite all the scripts for audio datasets and users don't have to care about two different loading approaches in the same script? 🤔 ",
"> @anton-l @patrickvonplaten @lhoestq Is it possible somehow to provide this logic inside the library instead of a loading script so that we don't need to completely rewrite all the scripts for audio datasets and users don't have to care about two different loading approaches in the same script? thinking\r\n\r\nNot sure @lhoestq - what do you think? \r\n\r\nNow that we've corrected the previous resampling bug, think this one here is of high importance. @lhoestq - what do you think how we should proceed here? ",
"> @anton-l @patrickvonplaten @lhoestq Is it possible somehow to provide this logic inside the library instead of a loading script so that we don't need to completely rewrite all the scripts for audio datasets and users don't have to care about two different loading approaches in the same script? 🤔\r\n\r\nYes let's do this :)\r\n\r\nMaybe we can change the behavior of `DownloadManager.iter_archive` back to extracting the TAR archive locally, and return an iterable of (local path, file obj). And the `StreamingDownloadManager.iter_archive` can return an iterable of (relative path inside the archive, file obj) ?\r\n\r\nIn this case, a dataset would need to have something like this:\r\n```python\r\nfor path, f in files:\r\n yield id_, {\"audio\": {\"path\": path, \"bytes\": f.read() if not is_local_file(path) else None}}\r\n```\r\n\r\nAlternatively, we can allow this if we consider that `Audio.encode_example` sets the \"bytes\" field to `None` automatically if `path` is a local path:\r\n```python\r\nfor path, f in files:\r\n yield id_, {\"audio\": {\"path\": path, \"bytes\": f.read()}}\r\n```\r\nNote that in this case the file is read for nothing though (maybe it's not a big deal ?)\r\n\r\nLet me know if it sounds good to you and what you'd prefer !",
"@lhoestq I'm very much in favor of your first aproach! With the full paths returned I think we won't even need to mess with `os.path.join` vs `\"/\".join()\"` and other local/streaming differences 👍 ",
"@lhoestq I also like the idea and favor your first approach to avoid an unnecessary read and make yielding faster.",
"Looks cool - thanks for working on this. I just feel strongly about `path` being an absolute `path` that exist and can be inspected in the non-streaming case :-) For streaming=True IMO it's absolutely fine if we only have access to the bytes",
"Hi ! I started implementing this but I noticed that returning an absolute path is breaking for many datasets that do things like\r\n```python\r\nfor path, f in files:\r\n if path.startswith(data_dir):\r\n ...\r\n```\r\nso I think I will have to add a parameter to `iter_archive` like `extract_locally=True` to avoid the breaking change, does that sound good to you ?\r\n\r\nThis makes me also think that in streaming mode it could also return a local path too, if we think that writing and deleting temporary files on-the-fly while iterating over the streaming dataset is ok.",
"@lhoestq I think it is a good idea to rollback to extracting the archives locally in non-streaming mode, as far as (as you mentioned) we do not store the bytes in the Arrow file for those cases to avoid \"doubling\" the disk space usage.\r\n\r\nOn the other hand, I don't like:\r\n- neither the possibility to avoid extracting locally in non-streaming: the behavior should be consistent; thus we always extract in non-streaming\r\n - which could be the criterium to decide whether an archive should or should not be extracted? Just because I want to make a condition on path.startswith?\r\n- nor the option to download/delete temporary files in streaming (see discussion here: https://github.com/huggingface/datasets/pull/3689#issuecomment-1032858345)\r\n\r\nUnfortunately, in order to fix the datasets that are breaking after the rollback, I would suggest fixing their scripts so that the paths are handled more robustly (considering that they can be absolute or relative).",
"I agree with Albert, fixing all of the audio datasets isn't too big of a deal (yet). I can help with those if needed :)",
"Ok cool ! I'm completely rolling it back then",
"Alright I did the rollback and now you can get local paths :)\r\nFeel free to try it out and let me know if it's good for you",
"I'll fix the CI tomorrow x)",
"Ok according to the CI there around 60+ datasets to fix",
"> fixing all of the audio datasets isn't too big of a deal (yet). I can help with those if needed :)\r\n\r\nI can help with them too :)\r\n",
"Here is the full list to keep track of things:\r\n\r\n- [x] air_dialogue\r\n- [x] id_nergrit_corpus\r\n- [ ] id_newspapers_2018\r\n- [x] imdb\r\n- [ ] indic_glue\r\n- [ ] inquisitive_qg\r\n- [x] klue\r\n- [x] lama\r\n- [x] lex_glue\r\n- [ ] lm1b\r\n- [x] amazon_polarity\r\n- [ ] mac_morpho\r\n- [ ] math_dataset\r\n- [ ] md_gender_bias\r\n- [ ] mdd\r\n- [ ] assin\r\n- [ ] atomic\r\n- [ ] babi_qa\r\n- [ ] mlqa\r\n- [ ] mocha\r\n- [ ] blended_skill_talk\r\n- [ ] capes\r\n- [ ] cbt\r\n- [ ] newsgroup\r\n- [ ] cifar10\r\n- [ ] cifar100\r\n- [ ] norec\r\n- [ ] ohsumed\r\n- [ ] code_x_glue_cc_clone_detection_poj104\r\n- [x] openslr\r\n- [ ] orange_sum\r\n- [ ] paws\r\n- [ ] paws-x\r\n- [ ] cppe-5\r\n- [ ] polyglot_ner\r\n- [ ] dbrd\r\n- [ ] empathetic_dialogues\r\n- [ ] eraser_multi_rc\r\n- [ ] flores\r\n- [ ] flue\r\n- [ ] food101\r\n- [ ] py_ast\r\n- [ ] qasc\r\n- [ ] qasper\r\n- [ ] race\r\n- [ ] reuters21578\r\n- [ ] ropes\r\n- [ ] rotten_tomatoes\r\n- [x] vivos\r\n- [ ] wi_locness\r\n- [ ] wiki_movies\r\n- [ ] wikiann\r\n- [ ] wmt20_mlqe_task1\r\n- [ ] wmt20_mlqe_task2\r\n- [ ] wmt20_mlqe_task3\r\n- [ ] scicite\r\n- [ ] xsum\r\n- [ ] scielo\r\n- [ ] scifact\r\n- [ ] setimes\r\n- [ ] social_bias_frames\r\n- [ ] sogou_news\r\n- [x] speech_commands\r\n- [ ] ted_hrlr\r\n- [ ] ted_multi\r\n- [ ] tlc\r\n- [ ] turku_ner_corpus\r\n\r\n",
"I'll do my best to fix as many as possible tomorrow :)",
"the audio datasets are fixed if I didn't forget anything :)\r\n\r\nbtw what are we gonna do with the community ones that would be broken after the fix?",
"Closing in favor of https://github.com/huggingface/datasets/pull/3736"
] | "2022-02-01T21:48:27" | "2022-02-22T09:14:06" | "2022-02-22T09:14:06" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"merged_at": null
} | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor the heck out of this PR to avoid completely copying the logic between the two generators | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
},
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
},
{
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
},
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Having talked to @lhoestq, I see that this feature is no longer supported. \r\n\r\nI really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audio files automatically, but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files - e.g. `common_voice` doesn't work anymore in a TF training script. Note this worked perfectly fine before making the change (think it was done [here](https://github.com/huggingface/datasets/pull/3290) no?)\r\n\r\nIMO, it's really important to think about a solution here and I strongly favor to make a difference here between loading a dataset in streaming mode and in non-streaming mode, so that in non-streaming mode the actual downloaded file is displayed. It's really crucial for people to be able to analyse the original files IMO when the dataset is not downloaded in streaming mode. \r\n\r\nThere are the following reasons why it is paramount to have access to the **original** audio file in my opinion (in non-streaming mode):\r\n- There are a wide variety of different libraries to load audio data with varying support on different platforms. For me it was quite clear that there is simply to single good library to load audio files for all platforms - so we have to leave the option to the user to decide which loading to use.\r\n- We had support for audio datasets a long time before streaming audio was possible. There were quite some versions where we advertised **everywhere** to load the audio from the path name (and there are many places where we still do even though it's not possible anymore). To give some examples:\r\n - Official example of TF Wav2Vec2: https://github.com/huggingface/transformers/blob/f427e750490b486944cc9be3c99834ad5cf78b57/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py#L1423 Wav2Vec2 is as important for speech as BERT is for NLP - so it's **very** important. The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment. Same goes for Flax.\r\n - The most downloaded non-nlp checkpoint: https://huggingface.co/facebook/wav2vec2-base-960h#usage has a usage example which doesn't work anymore with the current datasets implementation. I'll update this now, but we have >1000 wav2vec2 checkpoints on the Hub and we can't update all the model cards.\r\n => This is a big breaking change with no current solution. For `transformers` breaking changes are one of the biggest complaints.\r\n- Similar to this we also shouldn't assume that there is only one resampling method for Audio. I think it's good to have one offered automatically by `datasets`, but we have to leave the user the freedom to choose her/his own resampling as well. Resampling can take very different filtering windows and other parameters which are currently somewhat hardcoded in `datasets`, which users might very well want to change.\r\n\r\n\r\n=> IMO, it's a **very** big priority to again have the correct absolute path in non-streaming mode. The other solution of providing a path-like object derived from the bytes stocked in the `.array` file is not nearly as user-friendly, but better than nothing. ",
"Agree that we need to have access to the original sound files. Few days ago I was looking for these original files because I suspected there is bug in the audio resampling (confirmed in https://github.com/huggingface/datasets/issues/3662) and I want to do my own resampling to workaround the bug, which is now not possible anymore due to the unavailability of the original files.",
"@patrickvonplaten \r\n> The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing\r\n\r\nJust to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?\r\n\r\n> The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment\r\n\r\nI'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 (https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627).\r\n\r\nYour concern is reasonable, but there are situations where we can only serve bytes (see https://github.com/huggingface/datasets/pull/3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column(\"audio\", Audio(decode=False))`).\r\n",
"Related to this discussion: in https://github.com/huggingface/datasets/pull/3664#issuecomment-1031866858 I propose how we could change `iter_archive` to work for streaming and also return local paths (as it used too !). I'd love your opinions on this",
"> @patrickvonplaten\r\n> \r\n> > The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing\r\n> \r\n> Just to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?\r\n\r\nYes! \r\n\r\n> \r\n> > The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment\r\n> \r\n> I'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 ([#3667 (comment)](https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627)). \r\n> Your concern is reasonable, but there are situations where we can only serve bytes (see #3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column(\"audio\", Audio(decode=False))`).\r\n\r\nYes this might be, but I highly doubt that `soundfile` is the go-to library for audio then. @anton-l and I have tried out a bunch of different audio loading libraries (`soundfile`, `librosa`, `torchaudio`, pure `ffmpeg`, `audioread`, ...). One thing that was pretty clear to me is that there is just no \"de-facto standard\" library and they all have pros and cons. None of the libraries really supports \"batch\"-ed audio loading. Some depend on PyTorch. `torchaudio` is 100x faster (really!) than `librosa's` fallback on MP3. `torchaudio` often has problems with multi-proessing, ... Also we should keep in mind that resampling is similarly not as simple as reading a text file. It's a pretty complex signal processing transform and people very well might want to use special filters, etc...at the moment we just hard-code `torchaudio's` or `librosa's` default filter when doing resampling.\r\n\r\n=> All this to say that we **should definitely** care about whether we rely on local paths or bytes IMO. We don't want to loose all users that are forced to use `datasets` decoding or resampling or have to built a very much not intuitive way of loading bytes into a numpy array. It's much more intuitive to be able to inspect a local file. I feel pretty strongly about this and am happy to also jump on a call. Keeping libraries flexible and lean as well as exposing internals is very important IMO (this philosophy has worked quite well so far with Transformers).\r\n\r\n",
"Thanks a lot for the very detailed explanation. Now everything makes much more sense.",
"From https://github.com/huggingface/datasets/pull/3736 the Common Voice dataset now gives access to the local audio files as before",
"I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).\r\n\r\nRegardless of whether it is a breaking change, however, I don't see the other arguments.\r\n\r\n> but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files\r\n\r\nI don't exactly understand this. Why not?\r\n\r\nWhy does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?\r\n\r\nBut even if you just provide the raw bytes to TF, on TF you could just use sth like `tfio.audio.decode_mp3` or `tf.audio.decode_ogg` or `tfio.audio.decode_flac`?\r\n\r\n> There are the following reasons why it is paramount to have access to the original audio file in my opinion ...\r\n\r\nI don't really understand the arguments (despite that it maybe breaks existing code). You anyway have the original audio files but it is just embedded in the dataset? I don't really know about any library which cannot also load the audio from memory (i.e. from the dataset).\r\n\r\nBtw, on librosa being slow for decoding audio files, I saw that as well, so we have this comment RETURNN:\r\n\r\n> Don't use librosa.load which internally uses audioread which would use Gstreamer as a backend which has multiple issues:\r\n> https://github.com/beetbox/audioread/issues/62\r\n> https://github.com/beetbox/audioread/issues/63\r\n> Instead, use PySoundFile (soundfile), which is also faster. See here for discussions:\r\n> https://github.com/beetbox/audioread/issues/64\r\n> https://github.com/librosa/librosa/issues/681\r\n\r\nResampling is also a separate aspect, which is also less straightforward and with different compromises between speed and quality. So there the different tradeoffs and different implementations can make a difference.\r\n\r\nHowever, I don't see how this is related to the question whether there should be the raw bytes inside the dataset or as separate local files.\r\n",
"Thanks for your comments here @albertz - cool to get your input! \r\n\r\nAnswering a bit here between the lines:\r\n\r\n> I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).\r\n> \r\n> Regardless of whether it is a breaking change, however, I don't see the other arguments.\r\n> \r\n> > but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files\r\n> \r\n> I don't exactly understand this. Why not?\r\n\r\n> Why does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?\r\n\r\nThe problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.\r\n\r\nSo for TF and Flax it's important that users can load audio files or bytes they way the want to - this might become less important if we find (or make) a good library with few dependencies that is fast for all kinds of platforms / use cases.\r\n\r\n\r\nNow the question is whether it's better to store audio data as a path to a file or as raw bytes I guess.\\\r\nMy main arguments for storing the audio data as a path to a file is pretty much all about users experience - I don't really expect our users to understand the inner workings of datasets:\r\n\r\n- 1. It's not straightforward to know which function to use to decode it - not all `load_audio(...)` or `read_audio(...)` work on raw bytes. E.g. Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes . There are also some functions of other libraries which only work on files which would require the user to save the bytes as a file first before being able to load it.\r\n- 2. It's difficult to see which format the bytes are coming from (mp3, ogg, ...) - guess this could be remedied by adding the format to each sample though\r\n- 3. It is a bit scary IMO to see raw bytes for users. Overall, I think it's better to leave the data in it's raw form as this way it's much easier for people to play around with the audio files, less need to read docs because people don't worry about what happened to the audio files (are the bytes already resampled?)\r\n\r\nBut the argument that the audio should be loadable directly from memory is good - haven't thought about this too much. \r\nI guess it's still very much possible for the user to do this:\r\n\r\n```python\r\ndef save_as_bytes:\r\n batch[\"bytes\"] = read_in_bytes_from_file(batch[\"file\"])\\\r\n os.remove(batch[\"file\"])\r\n\r\nds = ds.map(save_as_bytes)\r\n\r\nds.save_to_disk(...)\r\n```\r\n\r\nGuess the question is more a bit about what should be the default case?",
"> The problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.\r\n\r\nBut how is this relevant for this issue here? I thought this issue here is about having the (correct) path in the dataset or having raw bytes in the dataset.\r\n\r\nHow did TF users use it at all then? Or they just do not use on-the-fly decoding? I did not even notice this problem (maybe because I had `torchaudio` installed). But what do they use instead?\r\n\r\nBut as I outlined before, they could just use `tfio.audio.decode_flac` and co, where it would be more natural if you already provide the raw bytes.\r\n\r\n> Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes\r\n\r\nI was not really familiar with `torchaudio`. It seems that they really don't provide an easy/direct API to operate on raw bytes. Which is very strange and unfortunate because as far as I can see, all the underlying backend libraries (e.g. soundfile) easily allow that. So I would say that this is the fault of `torchaudio` then. But despite, if you anyway use `torchaudio` with `soundfile` backend, why not just use `soundfile` directly. It's very simple to use and crossplatform.\r\n\r\nBut ok, now we are just discussing how to handle the on-the-fly decoding. I still think this is a separate issue and having raw bytes in the dataset instead of local files should just be fine as well.\r\n\r\n\r\n> It is a bit scary IMO to see raw bytes for users.\r\n\r\nI think nobody who writes code is scared by seeing the raw bytes content of a binary file. :)\r\n\r\n\r\n> I guess it's still very much possible for the user to do this:\r\n> \r\n> ```python\r\n> def save_as_bytes:\r\n> batch[\"bytes\"] = read_in_bytes_from_file(batch[\"file\"])\\\r\n> os.remove(batch[\"file\"])\r\n> \r\n> ds = ds.map(save_as_bytes)\r\n> \r\n> ds.save_to_disk(...)\r\n> ```\r\n\r\nIn https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this `map` is not needed anymore and `save_to_disk` could do it automatically (maybe via some option)?\r\n\r\n> Guess the question is more a bit about what should be the default case?\r\n\r\nYea this is up to you. I'm happy as long as we can get it the way we want easily and this is a well supported use case. :)\r\n",
"> In https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this map is not needed anymore and save_to_disk could do it automatically (maybe via some option)?\r\n\r\nYes! Should be super easy now see discussion here: https://github.com/rwth-i6/i6_core/issues/257#issuecomment-1105494468\r\n\r\nThanks for the super useful input :-)",
"Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2)",
"> Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2)\r\n\r\nIt appears downgrading to torchaudio 0.11.0 fixed this problem.",
"@DCNemesis, sorry which problem exactly is occuring again? Also cc @lhoestq @polinaeterna here",
"@patrickvonplaten @lhoestq @polinaeterna I was unable to load audio from Common Voice using 🤗 with the current version of torchaudio, but downgrading to torchaudio 0.11.0 fixed it. This is probably more of a torch problem than a Hugging Face problem.",
"@DCNemesis that's interesting, could you please share the error message if you still can access it? ",
"@polinaeterna I believe it is the same exact error as above. It occurs on other .mp3 sources as well, but the problem is with torchaudio > 0.11.0. I've created a short colab notebook that reproduces the error, and the fix here: https://colab.research.google.com/drive/18wsuwdHwBPN3JkcnhEtk8MUYqF9swuWZ?usp=sharing",
"Hi @DCNemesis,\r\n\r\nYour issue was slightly different from the original one in this issue page. Yours seems related to a change in the backend used by `torchaudio` (`ffmpeg` instead of `sox`). Refer to the issue page here:\r\n- #4776\r\n\r\nNormally, it should be circumvented with the patch made by @polinaeterna in:\r\n- #4923",
"I think the original issue reported here was already fixed by:\r\n- #3736\r\n\r\nOtherwise, feel free to reopen."
] | "2022-02-01T18:40:10" | "2022-09-21T15:03:09" | "2022-09-21T14:56:22" | MEMBER | null | null | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks @lhoestq for finding the reason of incorrect resampling. This issue affects all languages which have sound files with different sampling rates such as Turkish and Luganda.",
"@cahya-wirawan - do you know how many languages have different sampling rates in Common Voice? I'm quite surprised to see this for multiple languages actually",
"@cahya-wirawan, I can reproduce the problem for Common Voice 7 for Turkish. Here a script you can use:\r\n\r\n\r\n```python\r\n#!/usr/bin/env python3\r\nfrom datasets import load_dataset\r\nimport torchaudio\r\nfrom io import BytesIO\r\nfrom datasets import Audio\r\nfrom collections import Counter\r\nimport sys\r\n\r\nds_name = str(sys.argv[1])\r\nlang = str(sys.argv[2])\r\n\r\nds = load_dataset(ds_name, lang, split=\"train\", use_auth_token=True)\r\nds = ds.cast_column(\"audio\", Audio(decode=False))\r\n\r\nall_sampling_rates = []\r\n\r\n\r\ndef print_sampling_rate(x):\r\n x, sr = torchaudio.load(BytesIO(x[\"audio\"][\"bytes\"]), format=\"mp3\")\r\n all_sampling_rates.append(sr)\r\n\r\nds.map(print_sampling_rate)\r\n\r\n\r\nprint(Counter(all_sampling_rates))\r\n```\r\n\r\ncan be run with:\r\n\r\n```bash\r\npython run.py mozilla-foundation/common_voice_7_0 tr\r\n```\r\n\r\nFor CV 6.1 all samples seem to have the same audio",
"It actually shows that many more samples are in 32kHz format than it 48kHz which is unexpected. Thanks a lot for flagging! Will contact Common Voice about this as well",
"I only checked the CV 7.0 for Turkish, Luganda and Indonesian, they have audio files with difference sampling rates, and all of them are affected by this issue. Percentage of incorrect resampling as follow, Turkish: 9.1%, Luganda: 88.2% and Indonesian: 64.1%.\r\nI checked it using the original CV files. I check the original sampling rates and the length of audio array of each files and compare it with the length of audio array (and the sampling rate which is always 48kHz) from mozilla-foundation/common_voice_7_0 datasets. if the length of audio array from dataset is not equal to 48kHz/original sampling rate * length of audio array of the original audio file then it is affected,",
"Ok wow, thanks a lot for checking this - you've found a pretty big bug :sweat_smile: It seems like **a lot** more datasets are actually affected than I original thought. We'll try to solve this as soon as possible and make an announcement tomorrow."
] | "2022-02-01T17:55:04" | "2022-02-02T10:52:25" | "2022-02-02T10:52:25" | MEMBER | null | null | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with sampling_rate=32000
!wget https://file-examples-com.github.io/uploads/2017/11/file_example_MP3_700KB.mp3
import torchaudio
audio_path = "file_example_MP3_700KB.mp3"
audio_path2 = audio_path.replace(".mp3", "_resampled.mp3")
resample = torchaudio.transforms.Resample(32000, 16000) # create a new file with sampling_rate=16000
torchaudio.save(audio_path2, resample(torchaudio.load(audio_path)[0]), 16000)
```
Then we can see an issue here when decoding:
```python
from datasets import Dataset, Audio
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[0] # decode the first audio file sets the resampler orig_freq to 32000
print(dataset .features["audio"]._resampler.orig_freq)
# 32000
print(dataset[0]["audio"]["array"].shape) # here decoding is fine
# (1308096,)
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[1] # decode the second audio file sets the resampler orig_freq to 16000
print(dataset .features["audio"]._resampler.orig_freq)
# 16000
print(dataset[0]["audio"]["array"].shape) # here decoding uses orig_freq=16000 instead of 32000
# (2616192,)
```
The value of `orig_freq` doesn't change no matter what file needs to be decoded
cc @patrickvonplaten @anton-l @cahya-wirawan @albertvillanova
The issue seems to be here in `Audio.decode_mp3`:
https://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/features/audio.py#L176-L180 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3661/comments | https://api.github.com/repos/huggingface/datasets/issues/3661/events | https://github.com/huggingface/datasets/pull/3661 | 1,121,000,251 | PR_kwDODunzps4x61ad | 3,661 | Remove unnecessary 'r' arg in | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI failure is only because of the datasets is missing some sections in their cards - we can ignore that since it's unrelated to this PR"
] | "2022-02-01T17:29:27" | "2022-02-07T16:57:27" | "2022-02-07T16:02:42" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3661",
"html_url": "https://github.com/huggingface/datasets/pull/3661",
"diff_url": "https://github.com/huggingface/datasets/pull/3661.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3661.patch",
"merged_at": "2022-02-07T16:02:42"
} | Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3661/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3660/comments | https://api.github.com/repos/huggingface/datasets/issues/3660/events | https://github.com/huggingface/datasets/pull/3660 | 1,120,982,671 | PR_kwDODunzps4x6xr8 | 3,660 | Change HTTP links to HTTPS | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | "2022-02-01T17:12:51" | "2022-09-21T15:16:32" | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3660",
"html_url": "https://github.com/huggingface/datasets/pull/3660",
"diff_url": "https://github.com/huggingface/datasets/pull/3660.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3660.patch",
"merged_at": null
} | I tested the links. I also fixed some typos.
Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3660/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3660/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3659/comments | https://api.github.com/repos/huggingface/datasets/issues/3659/events | https://github.com/huggingface/datasets/issues/3659 | 1,120,913,672 | I_kwDODunzps5Cz8kI | 3,659 | push_to_hub but preview not working | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @thomas-happify, please note that the preview may take some time before rendering the data.\r\n\r\nI've seen it is already working.\r\n\r\nI close this issue. Please feel free to reopen it if the problem arises again."
] | "2022-02-01T16:23:57" | "2022-02-09T08:00:37" | "2022-02-09T08:00:37" | NONE | null | null | null | ## Dataset viewer issue for '*happifyhealth/twitter_pnn*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/happifyhealth/twitter_pnn)*
I used
```
dataset.push_to_hub("happifyhealth/twitter_pnn")
```
but the preview is not working.
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3659/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3658/comments | https://api.github.com/repos/huggingface/datasets/issues/3658/events | https://github.com/huggingface/datasets/issues/3658 | 1,120,880,395 | I_kwDODunzps5Cz0cL | 3,658 | Dataset viewer issue for *P3* | {
"login": "jeffistyping",
"id": 22351555,
"node_id": "MDQ6VXNlcjIyMzUxNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/22351555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeffistyping",
"html_url": "https://github.com/jeffistyping",
"followers_url": "https://api.github.com/users/jeffistyping/followers",
"following_url": "https://api.github.com/users/jeffistyping/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffistyping/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeffistyping/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffistyping/subscriptions",
"organizations_url": "https://api.github.com/users/jeffistyping/orgs",
"repos_url": "https://api.github.com/users/jeffistyping/repos",
"events_url": "https://api.github.com/users/jeffistyping/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeffistyping/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The error is now:\r\n\r\n```\r\nStatus code: 400\r\nException: Status400Error\r\nMessage: this dataset is not supported for now.\r\n```\r\n\r\nWe've disabled the dataset viewer for several big datasets like this one. We hope being able to reenable it soon.",
"The list of splits cannot be obtained. cc @huggingface/datasets ",
"```\r\nError code: SplitsNamesError\r\nException: SplitsNotFoundError\r\nMessage: The split names could not be parsed from the dataset config.\r\nTraceback: Traceback (most recent call last):\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 354, in get_dataset_config_info\r\n for split_generator in builder._split_generators(\r\n File \"/tmp/modules-cache/datasets_modules/datasets/bigscience--P3/12c0badfecad4564ecb8a6f81b5d0559656f269f08b13c59c93283f3a84134ba/P3.py\", line 154, in _split_generators\r\n data_dir = dl_manager.download_and_extract(_URLs)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 944, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 907, in extract\r\n urlpaths = map_nested(self._extract, path_or_paths, map_tuple=True)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 393, in map_nested\r\n mapped = [\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 394, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True, None))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in <dictcomp>\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in <dictcomp>\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 330, in _single_map_nested\r\n return function(data_struct)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 912, in _extract\r\n protocol = _get_extraction_protocol(urlpath, use_auth_token=self.download_config.use_auth_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 402, in _get_extraction_protocol\r\n return _get_extraction_protocol_with_magic_number(f)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 367, in _get_extraction_protocol_with_magic_number\r\n magic_number = f.read(MAGIC_NUMBER_MAX_LENGTH)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 574, in read\r\n return super().read(length)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/spec.py\", line 1575, in read\r\n out = self.cache._fetch(self.loc, self.loc + length)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/caching.py\", line 377, in _fetch\r\n self.cache = self.fetcher(start, bend)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 111, in wrapper\r\n return sync(self.loop, func, *args, **kwargs)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 96, in sync\r\n raise return_result\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 53, in _runner\r\n result[0] = await coro\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 616, in async_fetch_range\r\n out = await r.read()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/client_reqrep.py\", line 1036, in read\r\n self._body = await self.content.read()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 375, in read\r\n block = await self.readany()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 397, in readany\r\n await self._wait(\"readany\")\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 304, in _wait\r\n await waiter\r\n aiohttp.client_exceptions.ClientPayloadError: Response payload is not completed\r\n \r\n The above exception was the direct cause of the following exception:\r\n \r\n Traceback (most recent call last):\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 75, in get_splits_response\r\n split_full_names = get_dataset_split_full_names(dataset, hf_token)\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 35, in get_dataset_split_full_names\r\n return [\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 38, in <listcomp>\r\n for split in get_dataset_split_names(dataset, config, use_auth_token=hf_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 404, in get_dataset_split_names\r\n info = get_dataset_config_info(\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 359, in get_dataset_config_info\r\n raise SplitsNotFoundError(\"The split names could not be parsed from the dataset config.\") from err\r\n datasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.\r\n```"
] | "2022-02-01T15:57:56" | "2022-09-08T08:18:28" | null | NONE | null | null | null | ## Dataset viewer issue for '*P3*'
**Link: https://huggingface.co/datasets/bigscience/P3**
```
Status code: 400
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
```
Am I the one who added this dataset ? No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3658/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3657/comments | https://api.github.com/repos/huggingface/datasets/issues/3657/events | https://github.com/huggingface/datasets/pull/3657 | 1,120,602,620 | PR_kwDODunzps4x5f1I | 3,657 | Extend dataset builder for streaming in `get_dataset_split_names` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm impatient to see if it has an impact on the number of valid datasets for the dataset viewer. For the record, today:\r\n\r\n<img width=\"660\" alt=\"Capture d’écran 2022-02-01 à 14 32 19\" src=\"https://user-images.githubusercontent.com/1676121/151977579-b5a239d9-6662-4aeb-bfd1-eef6b8249991.png\">\r\n",
"This is now available in `datasets` 1.18.3 :)",
"I'm on it https://github.com/huggingface/datasets-preview-backend/issues/130\r\n",
"The result:\r\n<img width=\"671\" alt=\"Capture d’écran 2022-02-03 à 23 45 55\" src=\"https://user-images.githubusercontent.com/1676121/152442169-bfdac643-9a00-4901-bfa7-1d60a1679d4b.png\">\r\n\r\nNot very different. Maybe it fixed issues in the community datasets... But I'm not 100% the two states are comparable (datasets have been created, or updated, meanwhile)"
] | "2022-02-01T12:21:24" | "2022-02-03T22:49:06" | "2022-02-02T11:22:01" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3657",
"html_url": "https://github.com/huggingface/datasets/pull/3657",
"diff_url": "https://github.com/huggingface/datasets/pull/3657.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3657.patch",
"merged_at": "2022-02-02T11:22:01"
} | Currently, `get_dataset_split_names` doesn't extend a builder module to support streaming, even though it uses `StreamingDownloadManager` to download data. This PR fixes that.
To test the change, run the following:
```bash
pip install git+https://github.com/huggingface/datasets.git@fix-get_dataset_split_names-streaming
python -c "from datasets import get_dataset_split_names; print(get_dataset_split_names('facebook/multilingual_librispeech', 'german', download_mode='force_redownload', revision='137923f945552c6afdd8b60e4a7b43e3088972c1'))"
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3657/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3657/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"login": "RensDimmendaal",
"id": 9828683,
"node_id": "MDQ6VXNlcjk4Mjg2ODM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RensDimmendaal",
"html_url": "https://github.com/RensDimmendaal",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
"gists_url": "https://api.github.com/users/RensDimmendaal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RensDimmendaal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RensDimmendaal/subscriptions",
"organizations_url": "https://api.github.com/users/RensDimmendaal/orgs",
"repos_url": "https://api.github.com/users/RensDimmendaal/repos",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"received_events_url": "https://api.github.com/users/RensDimmendaal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @RensDimmendaal, \r\n\r\nI'm sorry but I can't reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset(\"subjqa\", \"electronics\")\r\nDownloading builder script: 9.15kB [00:00, 4.10MB/s] \r\nDownloading metadata: 17.7kB [00:00, 8.51MB/s] \r\nDownloading and preparing dataset subjqa/electronics (download: 10.86 MiB, generated: 3.01 MiB, post-processed: Unknown size, total: 13.86 MiB) to .../.cache/huggingface/datasets/subjqa/electronics/1.1.0/e5588f9298ff2d70686a00cc377e4bdccf4e32287459e3c6baf2dc5ab57fe7fd...\r\nDownloading data: 11.4MB [00:03, 3.50MB/s]\r\nDataset subjqa downloaded and prepared to .../.cache/huggingface/datasets/subjqa/electronics/1.1.0/e5588f9298ff2d70686a00cc377e4bdccf4e32287459e3c6baf2dc5ab57fe7fd. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 605.09it/s]\r\n\r\nIn [2]: ds\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 1295\r\n })\r\n test: Dataset({\r\n features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 358\r\n })\r\n validation: Dataset({\r\n features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 255\r\n })\r\n})\r\n```\r\n\r\nCould you please try again and see if the problem persists?\r\n\r\nIf that is the case, you can circumvent the issue by passing `ignore_verifications`:\r\n```python\r\nds = load_dataset(\"subjqa\", \"electronics\", ignore_verifications=True)",
"Thanks checking!\r\n\r\nYou're totally right. I don't know what's changed, but I'm glad it's working now!\r\n\r\n"
] | "2022-02-01T10:53:33" | "2022-02-10T10:56:59" | "2022-02-10T10:56:38" | NONE | null | null | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-2-d2857d460155> in <module>()
2 from datasets import load_dataset
3
----> 4 subjqa = load_dataset("subjqa","electronics")
3 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/lewtun/SubjQA/archive/refs/heads/master.zip']
```
## Environment info
Google colab
- `datasets` version: 1.18.2
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3655/comments | https://api.github.com/repos/huggingface/datasets/issues/3655/events | https://github.com/huggingface/datasets/issues/3655 | 1,119,801,077 | I_kwDODunzps5Cvs71 | 3,655 | Pubmed dataset not reachable | {
"login": "abhi-mosaic",
"id": 77638579,
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhi-mosaic",
"html_url": "https://github.com/abhi-mosaic",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_url": "https://api.github.com/users/abhi-mosaic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhi-mosaic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhi-mosaic/subscriptions",
"organizations_url": "https://api.github.com/users/abhi-mosaic/orgs",
"repos_url": "https://api.github.com/users/abhi-mosaic/repos",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhi-mosaic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @abhi-mosaic, thanks for reporting.\r\n\r\nI'm looking at it... ",
"also hitting this issue",
"Hey @albertvillanova, sorry to reopen this... I can confirm that on `master` branch the dataset is downloadable now but it is still broken in streaming mode:\r\n\r\n```python\r\n >>> import datasets\r\n >>> pubmed_train = datasets.load_dataset('pubmed', split='train', streaming=True)\r\n >>> next(iter(pubmed_train))\r\n```\r\n```\r\n No such file or directory: 'gzip://pubmed22n0001.xml::ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed22n0001.xml.gz'\r\n```\r\n",
"Hi @abhi-mosaic, would you mind opening another issue for this new problem?\r\n\r\nFirst issue (already solved) was a ConnectionError due to the yearly update release of PubMed: we fixed it by updating the URLs from year 2021 to year 2022.\r\n\r\nHowever this is another problem: to make pubmed streamable. Please note that NOT all our datastes are streamable: we are making streamable more and more of them... but this is an on-going process...\r\n\r\nThanks.",
"@albertvillanova \r\nWhen I tried below codes, I got the similar error\r\n\r\n```\r\n\r\ndataset=load_dataset(\"pubmed\",split=\"train\")\r\n\r\nCouldn't reach ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0601.xml.gz\r\n```",
"@y-rok you need to update `datasets`:\r\n```shell\r\npip install -U datasets\r\n```"
] | "2022-01-31T18:45:47" | "2022-12-19T19:18:10" | "2022-02-14T14:15:41" | CONTRIBUTOR | null | null | null | ## Describe the bug
Trying to use the `pubmed` dataset fails to reach / download the source files.
## Steps to reproduce the bug
```python
pubmed_train = datasets.load_dataset('pubmed', split='train')
```
## Expected results
Should begin downloading the pubmed dataset.
## Actual results
```
ConnectionError: Couldn't reach ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz (InvalidSchema("No connection adapters were found for 'ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz'"))
```
## Environment info
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3655/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3654/comments | https://api.github.com/repos/huggingface/datasets/issues/3654/events | https://github.com/huggingface/datasets/pull/3654 | 1,119,717,475 | PR_kwDODunzps4x2kiX | 3,654 | Better TQDM output | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq I've created a notebook for you to see the difference: https://colab.research.google.com/drive/1by3EqnoKvC2p-yKW4lPDGOFOZHyGVyeQ?usp=sharing.\r\n\r\nFeel free to suggest better descriptions for the progress bars. \r\n\r\nIf everything looks good, think we can merge."
] | "2022-01-31T17:22:43" | "2022-02-03T15:55:34" | "2022-02-03T15:55:33" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3654",
"html_url": "https://github.com/huggingface/datasets/pull/3654",
"diff_url": "https://github.com/huggingface/datasets/pull/3654.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3654.patch",
"merged_at": "2022-02-03T15:55:33"
} | This PR does the following:
* if `dataset_infos.json` exists for a dataset, uses `num_examples` to print the total number of examples that needs to be generated (in `builder.py`)
* fixes `tqdm` + multiprocessing in Jupyter Notebook/Colab (the issue stems from this commit in the `tqdm` repo: https://github.com/tqdm/tqdm/commit/f7722edecc3010cb35cc1c923ac4850a76336f82)
* adds the missing `drop_last_batch` and `with_ranks` params to `DatasetDict.map`
* correctly computes the number of iterations in `map` and the CSV/JSON loader when `batched=True` to fix `tqdm` progress bars
* removes the `bool(logging.get_verbosity() == logging.NOTSET)` (or simplifies `bool(logging.get_verbosity() == logging.NOTSET) or not utils.is_progress_bar_enabled()` to `not utils.is_progress_bar_enabled()`) condition and uses `utils.is_progress_bar_enabled` to check if `tqdm` output is enabled (this comment from @stas00 explains why the `bool(logging.get_verbosity() == logging.NOTSET)` check is problematic: https://github.com/huggingface/transformers/issues/14889#issue-1087318463)
Fix #2630 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3654/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3653/comments | https://api.github.com/repos/huggingface/datasets/issues/3653/events | https://github.com/huggingface/datasets/issues/3653 | 1,119,186,952 | I_kwDODunzps5CtXAI | 3,653 | `to_json` in multiprocessing fashion sometimes deadlock | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | "2022-01-31T09:35:07" | "2022-01-31T09:35:07" | null | CONTRIBUTOR | null | null | null | ## Describe the bug
`to_json` in multiprocessing fashion sometimes deadlock, instead of raising exceptions. Temporary solution is to see that it deadlocks, and then reduce the number of processes or batch size in order to reduce the memory footprint.
As @lhoestq pointed out, this might be related to https://bugs.python.org/issue22393#msg315684 where `multiprocessing` fails to raise the OOM exception. One suggested alternative is not use `concurrent.futures` instead.
## Steps to reproduce the bug
## Expected results
Script fails when one worker hits OOM, and raise appropriate error.
## Actual results
Deadlock
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.1
- Platform: Linux
- Python version: 3.8
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3653/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3652/comments | https://api.github.com/repos/huggingface/datasets/issues/3652/events | https://github.com/huggingface/datasets/pull/3652 | 1,118,808,738 | PR_kwDODunzps4xzinr | 3,652 | sp. Columbia => Colombia | {
"login": "serapio",
"id": 3781280,
"node_id": "MDQ6VXNlcjM3ODEyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3781280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/serapio",
"html_url": "https://github.com/serapio",
"followers_url": "https://api.github.com/users/serapio/followers",
"following_url": "https://api.github.com/users/serapio/following{/other_user}",
"gists_url": "https://api.github.com/users/serapio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/serapio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/serapio/subscriptions",
"organizations_url": "https://api.github.com/users/serapio/orgs",
"repos_url": "https://api.github.com/users/serapio/repos",
"events_url": "https://api.github.com/users/serapio/events{/privacy}",
"received_events_url": "https://api.github.com/users/serapio/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The original openslr site mixed both names https://openslr.org/72/ :-)",
"Yeah, I filed the issue to have it fixed there last year, but it looks like they missed a few."
] | "2022-01-31T00:41:03" | "2022-02-09T16:55:25" | "2022-01-31T08:29:07" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3652",
"html_url": "https://github.com/huggingface/datasets/pull/3652",
"diff_url": "https://github.com/huggingface/datasets/pull/3652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3652.patch",
"merged_at": "2022-01-31T08:29:07"
} | "Columbia" is various places in North America. The country is "Colombia". | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3652/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3651/comments | https://api.github.com/repos/huggingface/datasets/issues/3651/events | https://github.com/huggingface/datasets/pull/3651 | 1,118,597,647 | PR_kwDODunzps4xy3De | 3,651 | Update link in wiki_bio dataset | {
"login": "jxmorris12",
"id": 13238952,
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jxmorris12",
"html_url": "https://github.com/jxmorris12",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> all the tests pass, but I'm still not able to import the dataset\r\n\r\nSince it's not merged on `master` yet, you have to provide the path to your local `wiki_bio.py` to use it.\r\nIndeed the library downloads the dataset files from `master` if you have a dev installation of the library.\r\n\r\nI agree it would be nice to change that, and use the local dataset scripts from the `datasets` directory - it feels definitely more natural.",
"Cool, thanks for your help and I agree!"
] | "2022-01-30T16:28:54" | "2022-01-31T14:50:48" | "2022-01-31T08:38:09" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3651",
"html_url": "https://github.com/huggingface/datasets/pull/3651",
"diff_url": "https://github.com/huggingface/datasets/pull/3651.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3651.patch",
"merged_at": "2022-01-31T08:38:09"
} | Fixes #3580 and makes the wiki_bio dataset work again. I changed the link and some documentation, and all the tests pass. Thanks @lhoestq for uploading the dataset to the HuggingFace data bucket.
@lhoestq -- all the tests pass, but I'm still not able to import the dataset, as the old Google Drive link is cached somewhere:
```python
>>> from datasets import load_dataset
load_dataset("wiki_bio>>> load_dataset("wiki_bio")
Using custom data configuration default
Downloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to /home/jxm3/.cache/huggingface/datasets/wiki_bio/default/1.1.0/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...
Traceback (most recent call last):
...
File "/home/jxm3/random/datasets/src/datasets/utils/file_utils.py", line 612, in get_from_cache
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil
```
what do I have to do to invalidate the cache and actually import the dataset? It's clearly set up correctly, since the data is downloaded and processed by the tests.
As an aside, this caching-loading-scripts behavior makes for a really bad developer experience. I just wasted an hour trying to figure out where the caching was happening and how to disable it, and I don't know. All I wanted to do was update the link and submit a pull request! I recommend that you all either change this behavior (i.e. updating the link to a dataset should "just work") or document it, since I couldn't find any information about this in the contributing.md or readme or anywhere else! Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3651/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3650/comments | https://api.github.com/repos/huggingface/datasets/issues/3650/events | https://github.com/huggingface/datasets/pull/3650 | 1,118,537,429 | PR_kwDODunzps4xyr2o | 3,650 | Allow 'to_json' to run in unordered fashion in order to lower memory footprint | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @thomasw21, I remember suggesting `imap_unordered` to @lhoestq at that time to speed up `to_json` further but after trying `pool_imap` on multiple datasets (>9GB) , memory utilisation was almost constant and we decided to go ahead with that only. \r\n\r\n1. Did you try this without `gzip`? Because `gzip` feature was introduced recently and I didn't check multi_proc thing with `gzip`. One thing I know is that `gzip` is slow in our implementation than `zip` (it's a WIP #3551) \r\n2. You can try reducing your batch size, this can also help in avoiding OOM errors!",
"Thanks @bhavitvyamalik ! I see. I'm not sure this PR actually fixes things for me either (I ended up reducing the num_proc/batch_size to lower it). It does allow the process to run for longer, but I think the reason why it was waiting is that one of the process crashes .... Unfortunately I was working on a setup with a low RAM/cpu core ratio. I'm actually very surprised that it doesn't change memory utilization, otherwise I don't see the purpose of `imap_unordered` existing. I think it's main purpose are when you have high variance in samples (in terms of bytes), which causes unecessary accumulation in `imap`\r\n 1. Did not try without `gzip`\r\n 2. Yeah or `num_proc`",
"Can you please try without `gzip` to see how it performs? If it works fine then we can improve `gzip` from our side (I'm already working on it)",
"I'll be busy for next few weeks on another project, will do as soon as I have some bandwidth.\r\n"
] | "2022-01-30T13:23:19" | "2022-07-06T15:19:50" | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3650",
"html_url": "https://github.com/huggingface/datasets/pull/3650",
"diff_url": "https://github.com/huggingface/datasets/pull/3650.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3650.patch",
"merged_at": null
} | I'm using `to_json(..., num_proc=num_proc, compressiong='gzip')` with `num_proc>1`. I'm having an issue where things seem to deadlock at some point. Eventually I see OOM. I'm guessing it's an issue where one process starts to take a long time for a specific batch, and so other process keep accumulating their results in memory.
In order to flush memory, I propose we use optional `imap_unordered`. This will prevent one process to block the other ones. The logical thinking is that index are rarily relevant, and in one wants to keep an index, one can still create another column and reconstruct from there. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3650/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3649/comments | https://api.github.com/repos/huggingface/datasets/issues/3649/events | https://github.com/huggingface/datasets/issues/3649 | 1,117,502,250 | I_kwDODunzps5Cm7sq | 3,649 | Add IGLUE dataset | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608944167,
"node_id": "LA_kwDODunzps7XHB4n",
"url": "https://api.github.com/repos/huggingface/datasets/labels/multimodal",
"name": "multimodal",
"color": "19E633",
"default": false,
"description": "Multimodal datasets"
}
] | open | false | null | [] | null | [] | "2022-01-28T14:59:41" | "2022-01-28T15:02:35" | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** IGLUE
- **Description:** IGLUE brings together 4 vision-and-language tasks across 20 languages (Twitter [thread](https://twitter.com/ebugliarello/status/1487045497583976455?s=20&t=SB4LZGDhhkUW83ugcX_m5w))
- **Paper:** https://arxiv.org/abs/2201.11732
- **Data:** https://github.com/e-bug/iglue
- **Motivation:** This dataset would provide a nice example of combining the text and image features of `datasets` together for multimodal applications.
Note: the data / code are not yet visible on the GitHub repo, so I've pinged the authors for more information.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3649/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3648/comments | https://api.github.com/repos/huggingface/datasets/issues/3648/events | https://github.com/huggingface/datasets/pull/3648 | 1,117,465,505 | PR_kwDODunzps4xvXig | 3,648 | Fix Windows CI: bump python to 3.7 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-28T14:24:54" | "2022-01-28T14:40:39" | "2022-01-28T14:40:39" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3648",
"html_url": "https://github.com/huggingface/datasets/pull/3648",
"diff_url": "https://github.com/huggingface/datasets/pull/3648.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3648.patch",
"merged_at": "2022-01-28T14:40:39"
} | Python>=3.7 is needed to install `tokenizers` 0.11 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3648/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3647/comments | https://api.github.com/repos/huggingface/datasets/issues/3647/events | https://github.com/huggingface/datasets/pull/3647 | 1,117,383,675 | PR_kwDODunzps4xvGDQ | 3,647 | Fix `add_column` on datasets with indices mapping | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Sure, let's include this in today's release.",
"Cool ! The windows CI should be fixed on master now, feel free to merge :)"
] | "2022-01-28T13:06:29" | "2022-01-28T15:35:58" | "2022-01-28T15:35:58" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3647",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"merged_at": "2022-01-28T15:35:57"
} | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3647/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3646/comments | https://api.github.com/repos/huggingface/datasets/issues/3646/events | https://github.com/huggingface/datasets/pull/3646 | 1,116,544,627 | PR_kwDODunzps4xsX66 | 3,646 | Fix streaming datasets that are not reset correctly | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Works smoothly with the `transformers.Trainer` class now, thank you!"
] | "2022-01-27T17:21:02" | "2022-01-28T16:34:29" | "2022-01-28T16:34:28" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3646",
"html_url": "https://github.com/huggingface/datasets/pull/3646",
"diff_url": "https://github.com/huggingface/datasets/pull/3646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3646.patch",
"merged_at": "2022-01-28T16:34:28"
} | Streaming datasets that use `StreamingDownloadManager.iter_archive` and `StreamingDownloadManager.iter_files` had some issues. Indeed if you try to iterate over such dataset twice, then the second time it will be empty.
This is because the two methods above are generator functions. I fixed this by making them return iterables that are reset properly instead.
Close https://github.com/huggingface/datasets/issues/3645
cc @anton-l | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3646/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3645/comments | https://api.github.com/repos/huggingface/datasets/issues/3645/events | https://github.com/huggingface/datasets/issues/3645 | 1,116,541,298 | I_kwDODunzps5CjRFy | 3,645 | Streaming dataset based on dl_manager.iter_archive/iter_files are not reset correctly | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | "2022-01-27T17:17:41" | "2022-01-28T16:34:28" | "2022-01-28T16:34:28" | MEMBER | null | null | null | Hi ! When iterating over a streaming dataset once, it's not reset correctly because of some issues with `dl_manager.iter_archive` and `dl_manager.iter_files`. Indeed they are generator functions (so the iterator that is returned can be exhausted). They should be iterables instead, and be reset if we do a for loop again:
```python
from datasets import load_dataset
d = load_dataset("common_voice", "ab", split="test", streaming=True)
i = 0
for i, _ in enumerate(d):
pass
print(i) # 8
# let's do it again
i = 0
for i, _ in enumerate(d):
pass
print(i) # 0
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3645/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3644/comments | https://api.github.com/repos/huggingface/datasets/issues/3644/events | https://github.com/huggingface/datasets/issues/3644 | 1,116,519,670 | I_kwDODunzps5CjLz2 | 3,644 | Add a GROUP BY operator | {
"login": "felix-schneider",
"id": 208336,
"node_id": "MDQ6VXNlcjIwODMzNg==",
"avatar_url": "https://avatars.githubusercontent.com/u/208336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/felix-schneider",
"html_url": "https://github.com/felix-schneider",
"followers_url": "https://api.github.com/users/felix-schneider/followers",
"following_url": "https://api.github.com/users/felix-schneider/following{/other_user}",
"gists_url": "https://api.github.com/users/felix-schneider/gists{/gist_id}",
"starred_url": "https://api.github.com/users/felix-schneider/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felix-schneider/subscriptions",
"organizations_url": "https://api.github.com/users/felix-schneider/orgs",
"repos_url": "https://api.github.com/users/felix-schneider/repos",
"events_url": "https://api.github.com/users/felix-schneider/events{/privacy}",
"received_events_url": "https://api.github.com/users/felix-schneider/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Hi ! At the moment you can use `to_pandas()` to get a pandas DataFrame that supports `group_by` operations (make sure your dataset fits in memory though)\r\n\r\nWe use Arrow as a back-end for `datasets` and it doesn't have native group by (see https://github.com/apache/arrow/issues/2189) unfortunately.\r\n\r\nI just drafted what it could look like to have `group_by` in `datasets`:\r\n```python\r\nfrom datasets import concatenate_datasets\r\n\r\ndef group_by(d, col, join): \r\n \"\"\"from: https://github.com/huggingface/datasets/issues/3644\"\"\"\r\n # Get the indices of each group\r\n groups = {key: [] for key in d.unique(col)} \r\n def create_groups_indices(key, i): \r\n groups[key].append(i) \r\n d.map(create_groups_indices, with_indices=True, input_columns=col) \r\n # Get one dataset object per group\r\n groups = {key: d.select(indices) for key, indices in groups.items()} \r\n # Apply join function\r\n groups = {\r\n key: dataset_group.map(join, batched=True, batch_size=len(dataset_group), remove_columns=d.column_names)\r\n for key, dataset_group in groups.items()\r\n } \r\n # Return concatenation of all the joined groups\r\n return concatenate_datasets(groups.values())\r\n```\r\n\r\nexample of usage:\r\n```python\r\n\r\ndef join(batch): \r\n # take the batch of all the examples of a group, and return a batch with one aggregated example\r\n # (we could aggregate examples into several rows instead of one, if you want)\r\n return {\"total\": [batch[\"i\"]]} \r\n\r\nd = Dataset.from_dict({\r\n \"i\": [i for i in range(50)],\r\n \"group_key\": [i % 4 for i in range(50)],\r\n})\r\nprint(group_by(d, \"group_key\", join))\r\n# total\r\n# 0 [0, 4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48]\r\n# 1 [1, 5, 9, 13, 17, 21, 25, 29, 33, 37, 41, 45, 49]\r\n# 2 [2, 6, 10, 14, 18, 22, 26, 30, 34, 38, 42, 46]\r\n# 3 [3, 7, 11, 15, 19, 23, 27, 31, 35, 39, 43, 47]\r\n```\r\n\r\nLet me know if that helps !\r\n\r\ncc @albertvillanova @mariosasko for visibility",
"@lhoestq As of PyArrow 7.0.0, `pa.Table` has the [`group_by` method](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.group_by), so we should also consider using that function for grouping. ",
"Any update on this?",
"You can use https://github.com/mariosasko/datasets_sql by @mariosasko to go group by operations using SQL queries",
"Hi, I have a similar issue as OP but the suggested solutions do not work for my case. Basically, I process documents through a model to extract the last_hidden_state, using the \"map\" method on a Dataset object, but would like to average the result over a categorical column at the end (i.e. groupby this column).\r\n- A to_pandas() saturates the memory, although it gives me the desired result through a .groupby().apply(np.mean, axis=0) on a smaller use-case,\r\n- The solution posted on Feb 4 is much too slow,\r\n- datasets_sql seems to not like the fact that I'm averaging np.arrays.\r\nSo I'm kinda out of \"non brute force\" options... Any help appreciated",
"> Hi, I have a similar issue as OP but the suggested solutions do not work for my case. Basically, I process documents through a model to extract the last_hidden_state, using the \"map\" method on a Dataset object, but would like to average the result over a categorical column at the end (i.e. groupby this column).\r\n \r\nIf you haven't yet, you could explore using [Polars](https://www.pola.rs/) for this. It's a new DataFrame library written in Rust with Python bindings. It is Pandas like it in many ways ,but does have some biggish differences in syntax/approach so it's definitely not a drop-in replacement. \r\n\r\nPolar's also uses Arrow as a backend but also supports out-of-memory operations; in this case, it's probably easiest to write out your dataset to parquet and then use the polar's `scan_parquet` method (this will lazily read from the parquet file). The thing you get back from that is a `LazyDataFrame` i.e. nothing is loaded into memory until you specify a query and call a `collect` method. \r\n\r\nExample below of doing a groupby on a dataset which definitely wouldn't fit into memory on my machine:\r\n\r\n```\r\nfrom datasets import load_dataset\r\nimport polars as pl\r\n\r\nds = load_dataset(\"blbooks\")\r\nds['train'].to_parquet(\"test.parquet\")\r\ndf = pl.scan_parquet(\"test.parquet\")\r\ndf.groupby('date').agg([pl.count()]).collect()\r\n```\r\n\r\n>datasets_sql seems to not like the fact that I'm averaging np.arrays.\r\n\r\nI am not certain how Polars will handle this either. It does have NumPy support (https://pola-rs.github.io/polars-book/user-guide/howcani/interop/numpy.html) but I assume Polars will need to have at least enough memory in each group you want to average over so you may still end up needing more memory depending on the size of your dataset/groups. \r\n\r\n\r\n",
"Hi @davanstrien , thanks a lot, I didn't know about this library and the answer works! I need to try it on the full dataset now, but I'm hopeful. Here's what my code looks like:\r\n```\r\nlist_size = 768\r\ndf.groupby(\"date\").agg(\r\n pl.concat_list(\r\n [\r\n pl.col(\"hidden_state\")\r\n .arr.slice(n, 1)\r\n .arr.first()\r\n .mean()\r\n for n in range(0, list_size)\r\n ]\r\n ).collect()\r\n```\r\n\r\nFor some reasons, the following code was giving me a \"mean() got unexpected argument 'axis'\":\r\n```\r\ndf2 = df.groupby('date').agg(\r\n pl.col(\"hidden_state\").map(np.mean).alias(\"average_hidden_state\")\r\n).collect()\r\n\r\n```\r\n\r\nEDIT: The solution works on my large dataset, the memory does not crash and the time is reasonable, thanks a lot again!",
"@jeremylhour glad this worked for you :) ",
"I find this functionality missing in my workflow as well and the workarounds with SQL and Polars unsatisfying. Since PyArrow has exposed this functionality, I hope this soon makes it into a release. (:"
] | "2022-01-27T16:57:54" | "2023-03-14T14:45:59" | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
Using batch mapping, we can easily split examples. However, we lack an appropriate option for merging them back together by some key. Consider this example:
```python
# features:
# {
# "example_id": datasets.Value("int32"),
# "text": datasets.Value("string")
# }
ds = datasets.Dataset()
def split(examples):
sentences = [text.split(".") for text in examples["text"]]
return {
"example_id": [
example_id
for example_id, sents in zip(examples["example_id"], sentences)
for _ in sents
],
"sentence": [sent for sents in sentences for sent in sents],
"sentence_id": [i for sents in sentences for i in range(len(sents))],
}
split_ds = ds.map(split, batched=True)
def process(examples):
outputs = some_neural_network_that_works_on_sentences(examples["sentence"])
return {"outputs": outputs}
split_ds = split_ds.map(process, batched=True)
```
I have a dataset consisting of texts that I would like to process sentence by sentence in a batched way. Afterwards, I would like to put it back together as it was, merging the outputs together.
**Describe the solution you'd like**
Ideally, it would look something like this:
```python
def join(examples):
order = np.argsort(examples["sentence_id"])
text = ".".join(examples["text"][i] for i in order)
outputs = [examples["outputs"][i] for i in order]
return {"text": text, "outputs": outputs}
ds = split_ds.group_by("example_id", join)
```
**Describe alternatives you've considered**
Right now, we can do this:
```python
def merge(example):
meeting_id = example["example_id"]
parts = split_ds.filter(lambda x: x["example_id"] == meeting_id).sort("segment_no")
return {"outputs": list(parts["outputs"])}
ds = ds.map(merge)
```
Of course, we could process the dataset like this:
```python
def process(example):
outputs = some_neural_network_that_works_on_sentences(example["text"].split("."))
return {"outputs": outputs}
ds = ds.map(process, batched=True)
```
However, that does not allow using an arbitrary batch size and may lead to very inefficient use of resources if the batch size is much larger than the number of sentences in one example.
I would very much appreciate some kind of group by operator to merge examples based on the value of one column.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3644/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3644/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3643/comments | https://api.github.com/repos/huggingface/datasets/issues/3643/events | https://github.com/huggingface/datasets/pull/3643 | 1,116,417,428 | PR_kwDODunzps4xr8mX | 3,643 | Fix sem_eval_2018_task_1 download location | {
"login": "maxpel",
"id": 31095360,
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxpel",
"html_url": "https://github.com/maxpel",
"followers_url": "https://api.github.com/users/maxpel/followers",
"following_url": "https://api.github.com/users/maxpel/following{/other_user}",
"gists_url": "https://api.github.com/users/maxpel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maxpel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxpel/subscriptions",
"organizations_url": "https://api.github.com/users/maxpel/orgs",
"repos_url": "https://api.github.com/users/maxpel/repos",
"events_url": "https://api.github.com/users/maxpel/events{/privacy}",
"received_events_url": "https://api.github.com/users/maxpel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I fixed those two things, the two remaining failing checks seem to be due to some dependency missing in the tests."
] | "2022-01-27T15:45:00" | "2022-02-04T15:15:26" | "2022-02-04T15:15:26" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3643",
"html_url": "https://github.com/huggingface/datasets/pull/3643",
"diff_url": "https://github.com/huggingface/datasets/pull/3643.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3643.patch",
"merged_at": "2022-02-04T15:15:26"
} | As discussed with @lhoestq in https://github.com/huggingface/datasets/issues/3549#issuecomment-1020176931_ this is the new pull request to fix the download location. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3643/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3642/comments | https://api.github.com/repos/huggingface/datasets/issues/3642/events | https://github.com/huggingface/datasets/pull/3642 | 1,116,306,986 | PR_kwDODunzps4xrj2S | 3,642 | Fix dataset slicing with negative bounds when indices mapping is not `None` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-27T14:45:53" | "2022-01-27T18:16:23" | "2022-01-27T18:16:22" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3642",
"html_url": "https://github.com/huggingface/datasets/pull/3642",
"diff_url": "https://github.com/huggingface/datasets/pull/3642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3642.patch",
"merged_at": "2022-01-27T18:16:22"
} | Fix #3611 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3642/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3641/comments | https://api.github.com/repos/huggingface/datasets/issues/3641/events | https://github.com/huggingface/datasets/pull/3641 | 1,116,284,268 | PR_kwDODunzps4xre7C | 3,641 | Fix numpy rngs when seed is None | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-27T14:29:09" | "2022-01-27T18:16:08" | "2022-01-27T18:16:07" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3641",
"html_url": "https://github.com/huggingface/datasets/pull/3641",
"diff_url": "https://github.com/huggingface/datasets/pull/3641.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3641.patch",
"merged_at": "2022-01-27T18:16:07"
} | Fixes the NumPy RNG when `seed` is `None`.
The problem becomes obvious after reading the NumPy notes on RNG (returned by `np.random.get_state()`):
> The MT19937 state vector consists of a 624-element array of 32-bit unsigned integers plus a single integer value between 0 and 624 that indexes the current position within the main array.
`The MT19937 state vector`: the seed which we currently index, but this value stays the same for multiple rounds.
`plus a single integer value`: the `pos` value in this PR (is 624 if `seed` is set to a fixed value with `np.random.seed`, so we take the first value in the `seed` array returned by `np.random.get_state()`: https://stackoverflow.com/questions/32172054/how-can-i-retrieve-the-current-seed-of-numpys-random-number-generator)
NumPy notes: https://numpy.org/doc/stable/reference/random/bit_generators/mt19937.html
Fix #3634 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3641/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3640/comments | https://api.github.com/repos/huggingface/datasets/issues/3640/events | https://github.com/huggingface/datasets/issues/3640 | 1,116,133,769 | I_kwDODunzps5ChtmJ | 3,640 | Issues with custom dataset in Wav2Vec2 | {
"login": "peregilk",
"id": 9079808,
"node_id": "MDQ6VXNlcjkwNzk4MDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/peregilk",
"html_url": "https://github.com/peregilk",
"followers_url": "https://api.github.com/users/peregilk/followers",
"following_url": "https://api.github.com/users/peregilk/following{/other_user}",
"gists_url": "https://api.github.com/users/peregilk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/peregilk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/peregilk/subscriptions",
"organizations_url": "https://api.github.com/users/peregilk/orgs",
"repos_url": "https://api.github.com/users/peregilk/repos",
"events_url": "https://api.github.com/users/peregilk/events{/privacy}",
"received_events_url": "https://api.github.com/users/peregilk/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Closed and moved to transformers."
] | "2022-01-27T12:09:05" | "2022-01-27T12:29:48" | "2022-01-27T12:29:48" | NONE | null | null | null | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:

We are able to work around the issue, for instance by adding this check in line#222 in transformers/models/wav2vec2/modeling_wav2vec2.py:
```python
if input_length - (mask_length - 1) < num_masked_span:
num_masked_span = input_length - (mask_length - 1)
```
Interestingly, these are the variable values before the adjustment:
```
input_length=10
mask_length=10
num_masked_span=2
````
After adjusting num_masked_spin to 1, the training script runs. The issue is also fixed by setting “replace=True” in the same function.
Do you have any idea what is causing this, and how to fix this error permanently? If you do not think this is an Datasets issue, feel free to move the issue.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3640/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3639/comments | https://api.github.com/repos/huggingface/datasets/issues/3639/events | https://github.com/huggingface/datasets/issues/3639 | 1,116,021,420 | I_kwDODunzps5ChSKs | 3,639 | same value of precision, recall, f1 score at each epoch for classification task. | {
"login": "Dhanachandra",
"id": 10828657,
"node_id": "MDQ6VXNlcjEwODI4NjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/10828657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dhanachandra",
"html_url": "https://github.com/Dhanachandra",
"followers_url": "https://api.github.com/users/Dhanachandra/followers",
"following_url": "https://api.github.com/users/Dhanachandra/following{/other_user}",
"gists_url": "https://api.github.com/users/Dhanachandra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dhanachandra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dhanachandra/subscriptions",
"organizations_url": "https://api.github.com/users/Dhanachandra/orgs",
"repos_url": "https://api.github.com/users/Dhanachandra/repos",
"events_url": "https://api.github.com/users/Dhanachandra/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dhanachandra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @Dhanachandra, \r\n\r\nWe have tests for all our metrics and they work as expected: under the hood, we use scikit-learn implementations.\r\n\r\nMaybe the cause is somewhere else. For example:\r\n- Is it a binary or a multiclass or a multilabel classification? Default computation of these metrics is for binary classification; if you would like multiclass or multilabel, you should pass the corresponding parameters; see their documentation (e.g.: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html) or code below:\r\n\r\nhttps://huggingface.co/docs/datasets/using_metrics.html#computing-the-metric-scores\r\n\r\n```python\r\nIn [1]: from datasets import load_metric\r\n\r\nIn [2]: precision = load_metric(\"precision\")\r\n\r\nIn [3]: print(precision.inputs_description)\r\n\r\nArgs:\r\n predictions: Predicted labels, as returned by a model.\r\n references: Ground truth labels.\r\n labels: The set of labels to include when average != 'binary', and\r\n their order if average is None. Labels present in the data can\r\n be excluded, for example to calculate a multiclass average ignoring\r\n a majority negative class, while labels not present in the data will\r\n result in 0 components in a macro average. For multilabel targets,\r\n labels are column indices. By default, all labels in y_true and\r\n y_pred are used in sorted order.\r\n average: This parameter is required for multiclass/multilabel targets.\r\n If None, the scores for each class are returned. Otherwise, this\r\n determines the type of averaging performed on the data:\r\n binary: Only report results for the class specified by pos_label.\r\n This is applicable only if targets (y_{true,pred}) are binary.\r\n micro: Calculate metrics globally by counting the total true positives,\r\n false negatives and false positives.\r\n macro: Calculate metrics for each label, and find their unweighted mean.\r\n This does not take label imbalance into account.\r\n weighted: Calculate metrics for each label, and find their average\r\n weighted by support (the number of true instances for each label).\r\n This alters ‘macro’ to account for label imbalance; it can result\r\n in an F-score that is not between precision and recall.\r\n samples: Calculate metrics for each instance, and find their average\r\n (only meaningful for multilabel classification).\r\n sample_weight: Sample weights.\r\n\r\nReturns:\r\n precision: Precision score.\r\n\r\nExamples:\r\n\r\n >>> precision_metric = datasets.load_metric(\"precision\")\r\n >>> results = precision_metric.compute(references=[0, 1], predictions=[0, 1])\r\n >>> print(results)\r\n {'precision': 1.0}\r\n\r\n >>> predictions = [0, 2, 1, 0, 0, 1]\r\n >>> references = [0, 1, 2, 0, 1, 2]\r\n >>> results = precision_metric.compute(predictions=predictions, references=references, average='macro')\r\n >>> print(results)\r\n {'precision': 0.2222222222222222}\r\n >>> results = precision_metric.compute(predictions=predictions, references=references, average='micro')\r\n >>> print(results)\r\n {'precision': 0.3333333333333333}\r\n >>> results = precision_metric.compute(predictions=predictions, references=references, average='weighted')\r\n >>> print(results)\r\n {'precision': 0.2222222222222222}\r\n >>> results = precision_metric.compute(predictions=predictions, references=references, average=None)\r\n >>> print(results)\r\n {'precision': array([0.66666667, 0. , 0. ])}\r\n```\r\n"
] | "2022-01-27T10:14:16" | "2022-02-24T09:02:18" | "2022-02-24T09:02:17" | NONE | null | null | null | **1st Epoch:**
1/27/2022 09:30:48 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/f1/default/default_experiment-1-0.arrow.59it/s]
01/27/2022 09:30:48 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/precision/default/default_experiment-1-0.arrow
01/27/2022 09:30:49 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/recall/default/default_experiment-1-0.arrow
PRECISION: {'precision': 0.7612903225806451}
RECALL: {'recall': 0.7612903225806451}
F1: {'f1': 0.7612903225806451}
{'eval_loss': 1.4658324718475342, 'eval_accuracy': 0.7612903118133545, 'eval_runtime': 30.0054, 'eval_samples_per_second': 46.492, 'eval_steps_per_second': 46.492, 'epoch': 3.0}
**4th Epoch:**
1/27/2022 09:56:55 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/f1/default/default_experiment-1-0.arrow.92it/s]
01/27/2022 09:56:56 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/precision/default/default_experiment-1-0.arrow
01/27/2022 09:56:56 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/recall/default/default_experiment-1-0.arrow
PRECISION: {'precision': 0.7698924731182796}
RECALL: {'recall': 0.7698924731182796}
F1: {'f1': 0.7698924731182796}
## Environment info
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r /content/transformers/examples/pytorch/token-classification/requirements.txt
!pip install datasets | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3639/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3638/comments | https://api.github.com/repos/huggingface/datasets/issues/3638/events | https://github.com/huggingface/datasets/issues/3638 | 1,115,725,703 | I_kwDODunzps5CgJ-H | 3,638 | AutoTokenizer hash value got change after datasets.map | {
"login": "tshu-w",
"id": 13161779,
"node_id": "MDQ6VXNlcjEzMTYxNzc5",
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tshu-w",
"html_url": "https://github.com/tshu-w",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://api.github.com/users/tshu-w/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tshu-w/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tshu-w/subscriptions",
"organizations_url": "https://api.github.com/users/tshu-w/orgs",
"repos_url": "https://api.github.com/users/tshu-w/repos",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"received_events_url": "https://api.github.com/users/tshu-w/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"This issue was original reported at https://github.com/huggingface/transformers/issues/14931 and It seems like this issue also occur with other AutoClass like AutoFeatureExtractor.",
"Thanks for moving the issue here !\r\n\r\nI wasn't able to reproduce the issue on my env (the hashes stay the same):\r\n```\r\n- `transformers` version: 1.15.0\r\n- `tokenizers` version: 0.10.3\r\n- `datasets` version: 1.18.1\r\n- `dill` version: 0.3.4\r\n- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-debian-10.11\r\n- Python version: 3.7.10\r\n- PyArrow version: 6.0.1\r\n```\r\nHowever I was able to reproduce it on Google Colab (the hashes end up different):\r\n```\r\n- `transformers` version: 1.15.0\r\n- `tokenizers` version: 0.10.3\r\n- `datasets` version: 1.18.1\r\n- `dill` version: 0.3.4\r\n- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic\r\n- Python version: 3.7.12\r\n- PyArrow version: 3.0.0\r\n```\r\nI'll investigate why it doesn't work properly on Google Colab :)",
"I found the issue: the tokenizer has something inside it that changes.\r\n\r\nBefore the call, `tokenizer._tokenizer.truncation` is None, and after the call it changes to this for some reason:\r\n```\r\n{'max_length': 512, 'strategy': 'longest_first', 'stride': 0}\r\n```\r\n\r\nDoes anybody know why calling the tokenizer would change its state this way ? cc @Narsil @SaulLu maybe ?",
"`tokenizer.encode(..)` does not accept argument like max_length, strategy or stride.\r\n\r\nIn `tokenizers` you have to modify the tokenizer state by setting various `TruncationParams` (and/or `PaddingParams`).\r\nHowever, since this is modifying the state, you need to mutably borrow the tokenizer (a rust concept). The key principle is that there can ever be only 1 mutable borrow at a time during the span of the tokenizer lifecycle.\r\n\r\nBecause of this, if `transformers` blindly set `TruncationParams` and `PaddingParams` on every call, it would cause the tokenizer to crash (or make the various threads accessing it hang, which is not necessarily better).\r\n\r\nIn order to avoid that, we decided to handle it this way : https://github.com/huggingface/transformers/pull/12550 . \r\n\r\nWhich should explain the state of the tokenizer being modified (hence its hash).\r\n\r\nNow for a temporary solution, simply encoding once with the tokenizer should give it it's proper hash (since by default the tokenizer doesn't have this state, looks at the first encoding call, and creates it).\r\n\r\nWe could try and set these 2 dicts at initialization time, but it wouldn't work if a user modified the tokenizer state later\r\n```python\r\ntokenizer = AutoTokenizer.from_pretrained(..)\r\ntokenizer.truncation_side = \"left\"\r\n# Now we have a difference between `tokenizer._tokenizer.truncation` and `tokenizer.truncation_side`\r\n```\r\nIf we wanted to fix it correctly it would mean mapping every assignation to it's proper location on `tokenizer.{padding/truncation}`\r\n\r\nI think it's important to note that we cannot guarantee a tokenizer' hash remains the same if *any* of those parameters are modified through the `.map` function.\r\n\r\nEdit: Another option would be to override the default __hash__ function, but I don't know if there's a sound implementation that could fit.",
"Thanks a lot for the explanation !\r\nI think if we set these 2 dicts at initialization time it would be amazing already\r\n\r\nShall we open an issue in `transformers` to ask for these dictionaries to be set when the tokenizer is instantiated ?\r\n\r\n> Edit: Another option would be to override the default hash function, but I don't know if there's a sound implementation that could fit.\r\n\r\nIn `datasets` we can easily have custom hashing for objects of the other HF libraries if we want. For example we ignore the cache some tokenizers have. However in this specific case it touches parameters that may change the behavior of the tokenizer itself. I'm not sure the logic that determines how a tokenizer behaves should be in `datasets`",
"A hack we could have in the `datasets` lib would be to call the tokenizer before hashing it in order to set all its parameters correctly - but it sounds a lot like a hack and I'm not sure this can work in the long run",
"Fully agree with everything you said. \r\n\r\nI think the best course of action is creating an issue in `transformers`. I can start the work on this.\r\nI think the code changes are fairly simple. Making a sound test + not breaking other stuff might be different :D",
"It should be noted that this problem also occurs in other AutoClasses, such as AutoFeatureExtractor, so I don't think handling it in Datasets is a long-term practice either.",
"> I think the best course of action is creating an issue in `transformers`. I can start the work on this.\r\n\r\n@Narsil Hi, I reopen this issue in `transformers` https://github.com/huggingface/transformers/issues/14931",
"Here is @Narsil comment from https://github.com/huggingface/transformers/issues/14931#issuecomment-1074981569\r\n> # TL;DR\r\n> Call the function once on a dummy example beforehand will fix it.\r\n> \r\n> ```python\r\n> tokenizer(\"Some\", \"test\", truncation=True)\r\n> ```\r\n> \r\n> # Long answer\r\n> If I remember the last status, it's hard doing anything, since the call itself\r\n> \r\n> ```python\r\n> tokenizer(example[\"sentence1\"], example[\"sentence2\"], truncation=True)\r\n> ```\r\n> \r\n> will modify the tokenizer. It's the `truncation=True` that modifies the tokenizer to put it into truncation mode if you will. Calling the tokenizer once with that argument would fix the cache.\r\n> \r\n> Finding a fix that :\r\n> \r\n> * Doesn't imply a huge chunk of work on `tokenizers` (with potential loss of performance, and breaking backward compatibility)\r\n> * Doesn't imply `datasets` running a first pass of the loop\r\n> * Doesn't imply `datasets` looking at the map function itself\r\n> * Uses a sound `hash` for this object in `datasets`.\r\n> \r\n> is IIRC impossible for this use case.\r\n> \r\n> I can explain a bit more why the first option is not desirable.\r\n> \r\n> In order to \"fix\" this for tokenizers, we would need to make `tokenizer(..)` purely without side effects. This means that the \"options\" of tokenization (like `truncation` and `padding` at least) would have\r\n",
"For me this workaround only works if I don't pass the `num_proc=X` argument to `datasets.map`"
] | "2022-01-27T03:19:03" | "2022-08-26T07:47:56" | null | NONE | null | null | null | ## Describe the bug
AutoTokenizer hash value got change after datasets.map
## Steps to reproduce the bug
1. trash huggingface datasets cache
2. run the following code:
```python
from transformers import AutoTokenizer, BertTokenizer
from datasets import load_dataset
from datasets.fingerprint import Hasher
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
raw_datasets = load_dataset("glue", "mrpc")
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
```
got
```
Reusing dataset glue (/home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1112.35it/s]
f4976bb4694ebc51
3fca35a1fd4a1251
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 6.96ba/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 15.25ba/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 5.81ba/s]
d32837619b7d7d01
5fd925c82edd62b6
```
3. run raw_datasets.map(tokenize_function, batched=True) again and see some dataset are not using cache.
## Expected results
`AutoTokenizer` work like specific Tokenizer (The hash value don't change after map):
```python
from transformers import AutoTokenizer, BertTokenizer
from datasets import load_dataset
from datasets.fingerprint import Hasher
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
raw_datasets = load_dataset("glue", "mrpc")
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
```
```
Reusing dataset glue (/home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1091.22it/s]
46d4b31f54153fc7
5b8771afd8d43888
Loading cached processed dataset at /home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-6b07ff82ae9d5c51.arrow
Loading cached processed dataset at /home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-af738a6d84f3864b.arrow
Loading cached processed dataset at /home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-531d2a603ba713c1.arrow
46d4b31f54153fc7
5b8771afd8d43888
```
## Environment info
- `datasets` version: 1.18.0
- Platform: Linux-5.4.0-91-generic-x86_64-with-glibc2.27
- Python version: 3.9.7
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3638/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3638/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3637/comments | https://api.github.com/repos/huggingface/datasets/issues/3637/events | https://github.com/huggingface/datasets/issues/3637 | 1,115,526,438 | I_kwDODunzps5CfZUm | 3,637 | [TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @lewtun!\r\n \r\nThis one was tricky to debug. Initially, I tought there is a bug in the recently-added (by @lhoestq ) `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feature tpye of the `dialogue` field is `list`, which explains why you didn't get an error in earlier versions. Is there a specific reason why you use `list` instead of `Sequence` in the script? Maybe to avoid turning list of dicts to dicts of lists as it's done by `Sequence` for compatibility with TFDS or for performance reasons? If the field was `Sequence`, you would get an error in `encode_nested_example` because **the scripts yields some additional (nested) columns which are not specified in the `features` dictionary**. Previously, these additional columns would've been ignored by PyArrow (1), but now we have a check for them (2).\r\n(1) See PyArrow behavior:\r\n```\r\n>>> pa.array([{\"a\": 2, \"b\": 3}], type=pa.struct({\"a\": pa.int32()})) # pyarrow ignores the extra column\r\n-- is_valid: all not null\r\n-- child 0 type: int32\r\n [\r\n 2\r\n ]\r\n ```\r\n\r\n(2) Check:\r\nhttps://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/table.py#L1059\r\n\r\nThe fix is very simple: just add the missing columns to the _EMPTY_BELIEF_STATE list:\r\n```python\r\n_EMPTY_BELIEF_STATE.extend(['通用-产品类别', '火车-舱位档次', '通用-系列', '通用-价格区间', '通用-品牌'])\r\n```",
"Hey @mariosasko, thank you so much for figuring this one out - it certainly looks like a tricky bug 😱 ! I don't think there's a specific reason to use `list` instead of `Sequence` with the script, but I'll let the dataset creators know to see if your suggestion is acceptable.\r\n\r\nThank you again!",
"Thanks, this was indeed the fix! Would it make sense to produce a more informative error message in such cases? \r\n\r\nThe issue can be closed. \r\n\r\n"
] | "2022-01-26T21:38:02" | "2022-02-09T16:15:53" | "2022-02-09T16:15:53" | MEMBER | null | null | null | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master` too.
As far as I can tell, the dataset loading script is correct and the problematic features [here](https://huggingface.co/datasets/GEM/RiSAWOZ/blob/main/RiSAWOZ.py#L237) also look fine to me.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dset = load_dataset("GEM/RiSAWOZ")
```
## Expected results
I can load the dataset without error.
## Actual results
<details><summary>Traceback</summary>
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1083 example = self.info.features.encode_example(record)
-> 1084 writer.write(example, key)
1085 finally:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write(self, example, key, writer_batch_size)
445
--> 446 self.write_examples_on_file()
447
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
403 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 404 self.write_batch(batch_examples=batch_examples)
405 self.current_examples = []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
496 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 497 arrays.append(pa.array(typed_sequence))
498 inferred_features[col] = typed_sequence.get_inferred_type()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
204 # We only do it if trying_type is False - since this is what the user asks for.
--> 205 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
206 return out
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1064 if isinstance(feature, list):
-> 1065 return pa.ListArray.from_arrays(array.offsets, _c(array.values, feature[0]))
1066 elif isinstance(feature, Sequence):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1086 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
-> 1087 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
1088
TypeError: Couldn't cast array of type
struct<医院-3.0T MRI: string, 医院-CT: string, 医院-DSA: string, 医院-公交线路: string, 医院-区域: string, 医院-名称: string, 医院-地址: string, 医院-地铁可达: string, 医院-地铁线路: string, 医院-性质: string, 医院-挂号时间: string, 医院-电话: string, 医院-等级: string, 医院-类别: string, 医院-重点科室: string, 医院-门诊时间: string, 天气-城市: string, 天气-天气: string, 天气-日期: string, 天气-温度: string, 天气-紫外线强度: string, 天气-风力风向: string, 旅游景点-区域: string, 旅游景点-名称: string, 旅游景点-地址: string, 旅游景点-开放时间: string, 旅游景点-是否地铁直达: string, 旅游景点-景点类型: string, 旅游景点-最适合人群: string, 旅游景点-消费: string, 旅游景点-特点: string, 旅游景点-电话号码: string, 旅游景点-评分: string, 旅游景点-门票价格: string, 汽车-价格(万元): string, 汽车-倒车影像: string, 汽车-动力水平: string, 汽车-厂商: string, 汽车-发动机排量(L): string, 汽车-发动机马力(Ps): string, 汽车-名称: string, 汽车-定速巡航: string, 汽车-巡航系统: string, 汽车-座位数: string, 汽车-座椅加热: string, 汽车-座椅通风: string, 汽车-所属价格区间: string, 汽车-油耗水平: string, 汽车-环保标准: string, 汽车-级别: string, 汽车-综合油耗(L/100km): string, 汽车-能源类型: string, 汽车-车型: string, 汽车-车系: string, 汽车-车身尺寸(mm): string, 汽车-驱动方式: string, 汽车-驾驶辅助影像: string, 火车-出发地: string, 火车-出发时间: string, 火车-到达时间: string, 火车-坐席: string, 火车-日期: string, 火车-时长: string, 火车-目的地: string, 火车-票价: string, 火车-舱位档次: string, 火车-车型: string, 火车-车次信息: string, 电影-主演: string, 电影-主演名单: string, 电影-具体上映时间: string, 电影-制片国家/地区: string, 电影-导演: string, 电影-年代: string, 电影-片名: string, 电影-片长: string, 电影-类型: string, 电影-豆瓣评分: string, 电脑-CPU: string, 电脑-CPU型号: string, 电脑-产品类别: string, 电脑-价格: string, 电脑-价格区间: string, 电脑-内存容量: string, 电脑-分类: string, 电脑-品牌: string, 电脑-商品名称: string, 电脑-屏幕尺寸: string, 电脑-待机时长: string, 电脑-显卡型号: string, 电脑-显卡类别: string, 电脑-游戏性能: string, 电脑-特性: string, 电脑-硬盘容量: string, 电脑-系列: string, 电脑-系统: string, 电脑-色系: string, 电脑-裸机重量: string, 电视剧-主演: string, 电视剧-主演名单: string, 电视剧-制片国家/地区: string, 电视剧-单集片长: string, 电视剧-导演: string, 电视剧-年代: string, 电视剧-片名: string, 电视剧-类型: string, 电视剧-豆瓣评分: string, 电视剧-集数: string, 电视剧-首播时间: string, 辅导班-上课方式: string, 辅导班-上课时间: string, 辅导班-下课时间: string, 辅导班-价格: string, 辅导班-区域: string, 辅导班-年级: string, 辅导班-开始日期: string, 辅导班-教室地点: string, 辅导班-教师: string, 辅导班-教师网址: string, 辅导班-时段: string, 辅导班-校区: string, 辅导班-每周: string, 辅导班-班号: string, 辅导班-科目: string, 辅导班-结束日期: string, 辅导班-课时: string, 辅导班-课次: string, 辅导班-课程网址: string, 辅导班-难度: string, 通用-产品类别: string, 通用-价格区间: string, 通用-品牌: string, 通用-系列: string, 酒店-价位: string, 酒店-停车场: string, 酒店-区域: string, 酒店-名称: string, 酒店-地址: string, 酒店-房型: string, 酒店-房费: string, 酒店-星级: string, 酒店-电话号码: string, 酒店-评分: string, 酒店-酒店类型: string, 飞机-准点率: string, 飞机-出发地: string, 飞机-到达时间: string, 飞机-日期: string, 飞机-目的地: string, 飞机-票价: string, 飞机-航班信息: string, 飞机-舱位档次: string, 飞机-起飞时间: string, 餐厅-人均消费: string, 餐厅-价位: string, 餐厅-区域: string, 餐厅-名称: string, 餐厅-地址: string, 餐厅-推荐菜: string, 餐厅-是否地铁直达: string, 餐厅-电话号码: string, 餐厅-菜系: string, 餐厅-营业时间: string, 餐厅-评分: string>
to
{'旅游景点-名称': Value(dtype='string', id=None), '旅游景点-区域': Value(dtype='string', id=None), '旅游景点-景点类型': Value(dtype='string', id=None), '旅游景点-最适合人群': Value(dtype='string', id=None), '旅游景点-消费': Value(dtype='string', id=None), '旅游景点-是否地铁直达': Value(dtype='string', id=None), '旅游景点-门票价格': Value(dtype='string', id=None), '旅游景点-电话号码': Value(dtype='string', id=None), '旅游景点-地址': Value(dtype='string', id=None), '旅游景点-评分': Value(dtype='string', id=None), '旅游景点-开放时间': Value(dtype='string', id=None), '旅游景点-特点': Value(dtype='string', id=None), '餐厅-名称': Value(dtype='string', id=None), '餐厅-区域': Value(dtype='string', id=None), '餐厅-菜系': Value(dtype='string', id=None), '餐厅-价位': Value(dtype='string', id=None), '餐厅-是否地铁直达': Value(dtype='string', id=None), '餐厅-人均消费': Value(dtype='string', id=None), '餐厅-地址': Value(dtype='string', id=None), '餐厅-电话号码': Value(dtype='string', id=None), '餐厅-评分': Value(dtype='string', id=None), '餐厅-营业时间': Value(dtype='string', id=None), '餐厅-推荐菜': Value(dtype='string', id=None), '酒店-名称': Value(dtype='string', id=None), '酒店-区域': Value(dtype='string', id=None), '酒店-星级': Value(dtype='string', id=None), '酒店-价位': Value(dtype='string', id=None), '酒店-酒店类型': Value(dtype='string', id=None), '酒店-房型': Value(dtype='string', id=None), '酒店-停车场': Value(dtype='string', id=None), '酒店-房费': Value(dtype='string', id=None), '酒店-地址': Value(dtype='string', id=None), '酒店-电话号码': Value(dtype='string', id=None), '酒店-评分': Value(dtype='string', id=None), '电脑-品牌': Value(dtype='string', id=None), '电脑-产品类别': Value(dtype='string', id=None), '电脑-分类': Value(dtype='string', id=None), '电脑-内存容量': Value(dtype='string', id=None), '电脑-屏幕尺寸': Value(dtype='string', id=None), '电脑-CPU': Value(dtype='string', id=None), '电脑-价格区间': Value(dtype='string', id=None), '电脑-系列': Value(dtype='string', id=None), '电脑-商品名称': Value(dtype='string', id=None), '电脑-系统': Value(dtype='string', id=None), '电脑-游戏性能': Value(dtype='string', id=None), '电脑-CPU型号': Value(dtype='string', id=None), '电脑-裸机重量': Value(dtype='string', id=None), '电脑-显卡类别': Value(dtype='string', id=None), '电脑-显卡型号': Value(dtype='string', id=None), '电脑-特性': Value(dtype='string', id=None), '电脑-色系': Value(dtype='string', id=None), '电脑-待机时长': Value(dtype='string', id=None), '电脑-硬盘容量': Value(dtype='string', id=None), '电脑-价格': Value(dtype='string', id=None), '火车-出发地': Value(dtype='string', id=None), '火车-目的地': Value(dtype='string', id=None), '火车-日期': Value(dtype='string', id=None), '火车-车型': Value(dtype='string', id=None), '火车-坐席': Value(dtype='string', id=None), '火车-车次信息': Value(dtype='string', id=None), '火车-时长': Value(dtype='string', id=None), '火车-出发时间': Value(dtype='string', id=None), '火车-到达时间': Value(dtype='string', id=None), '火车-票价': Value(dtype='string', id=None), '飞机-出发地': Value(dtype='string', id=None), '飞机-目的地': Value(dtype='string', id=None), '飞机-日期': Value(dtype='string', id=None), '飞机-舱位档次': Value(dtype='string', id=None), '飞机-航班信息': Value(dtype='string', id=None), '飞机-起飞时间': Value(dtype='string', id=None), '飞机-到达时间': Value(dtype='string', id=None), '飞机-票价': Value(dtype='string', id=None), '飞机-准点率': Value(dtype='string', id=None), '天气-城市': Value(dtype='string', id=None), '天气-日期': Value(dtype='string', id=None), '天气-天气': Value(dtype='string', id=None), '天气-温度': Value(dtype='string', id=None), '天气-风力风向': Value(dtype='string', id=None), '天气-紫外线强度': Value(dtype='string', id=None), '电影-制片国家/地区': Value(dtype='string', id=None), '电影-类型': Value(dtype='string', id=None), '电影-年代': Value(dtype='string', id=None), '电影-主演': Value(dtype='string', id=None), '电影-导演': Value(dtype='string', id=None), '电影-片名': Value(dtype='string', id=None), '电影-主演名单': Value(dtype='string', id=None), '电影-具体上映时间': Value(dtype='string', id=None), '电影-片长': Value(dtype='string', id=None), '电影-豆瓣评分': Value(dtype='string', id=None), '电视剧-制片国家/地区': Value(dtype='string', id=None), '电视剧-类型': Value(dtype='string', id=None), '电视剧-年代': Value(dtype='string', id=None), '电视剧-主演': Value(dtype='string', id=None), '电视剧-导演': Value(dtype='string', id=None), '电视剧-片名': Value(dtype='string', id=None), '电视剧-主演名单': Value(dtype='string', id=None), '电视剧-首播时间': Value(dtype='string', id=None), '电视剧-集数': Value(dtype='string', id=None), '电视剧-单集片长': Value(dtype='string', id=None), '电视剧-豆瓣评分': Value(dtype='string', id=None), '辅导班-班号': Value(dtype='string', id=None), '辅导班-难度': Value(dtype='string', id=None), '辅导班-科目': Value(dtype='string', id=None), '辅导班-年级': Value(dtype='string', id=None), '辅导班-区域': Value(dtype='string', id=None), '辅导班-校区': Value(dtype='string', id=None), '辅导班-上课方式': Value(dtype='string', id=None), '辅导班-开始日期': Value(dtype='string', id=None), '辅导班-结束日期': Value(dtype='string', id=None), '辅导班-每周': Value(dtype='string', id=None), '辅导班-上课时间': Value(dtype='string', id=None), '辅导班-下课时间': Value(dtype='string', id=None), '辅导班-时段': Value(dtype='string', id=None), '辅导班-课次': Value(dtype='string', id=None), '辅导班-课时': Value(dtype='string', id=None), '辅导班-教室地点': Value(dtype='string', id=None), '辅导班-教师': Value(dtype='string', id=None), '辅导班-价格': Value(dtype='string', id=None), '辅导班-课程网址': Value(dtype='string', id=None), '辅导班-教师网址': Value(dtype='string', id=None), '汽车-名称': Value(dtype='string', id=None), '汽车-车型': Value(dtype='string', id=None), '汽车-级别': Value(dtype='string', id=None), '汽车-座位数': Value(dtype='string', id=None), '汽车-车身尺寸(mm)': Value(dtype='string', id=None), '汽车-厂商': Value(dtype='string', id=None), '汽车-能源类型': Value(dtype='string', id=None), '汽车-发动机排量(L)': Value(dtype='string', id=None), '汽车-发动机马力(Ps)': Value(dtype='string', id=None), '汽车-驱动方式': Value(dtype='string', id=None), '汽车-综合油耗(L/100km)': Value(dtype='string', id=None), '汽车-环保标准': Value(dtype='string', id=None), '汽车-驾驶辅助影像': Value(dtype='string', id=None), '汽车-巡航系统': Value(dtype='string', id=None), '汽车-价格(万元)': Value(dtype='string', id=None), '汽车-车系': Value(dtype='string', id=None), '汽车-动力水平': Value(dtype='string', id=None), '汽车-油耗水平': Value(dtype='string', id=None), '汽车-倒车影像': Value(dtype='string', id=None), '汽车-定速巡航': Value(dtype='string', id=None), '汽车-座椅加热': Value(dtype='string', id=None), '汽车-座椅通风': Value(dtype='string', id=None), '汽车-所属价格区间': Value(dtype='string', id=None), '医院-名称': Value(dtype='string', id=None), '医院-等级': Value(dtype='string', id=None), '医院-类别': Value(dtype='string', id=None), '医院-性质': Value(dtype='string', id=None), '医院-区域': Value(dtype='string', id=None), '医院-地址': Value(dtype='string', id=None), '医院-电话': Value(dtype='string', id=None), '医院-挂号时间': Value(dtype='string', id=None), '医院-门诊时间': Value(dtype='string', id=None), '医院-公交线路': Value(dtype='string', id=None), '医院-地铁可达': Value(dtype='string', id=None), '医院-地铁线路': Value(dtype='string', id=None), '医院-重点科室': Value(dtype='string', id=None), '医院-CT': Value(dtype='string', id=None), '医院-3.0T MRI': Value(dtype='string', id=None), '医院-DSA': Value(dtype='string', id=None)}
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_44306/2896005239.py in <module>
----> 1 dset = load_dataset("GEM/RiSAWOZ")
2 dset
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, script_version, **config_kwargs)
1692
1693 # Download and prepare data
-> 1694 builder_instance.download_and_prepare(
1695 download_config=download_config,
1696 download_mode=download_mode,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
593 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
594 if not downloaded_from_gcs:
--> 595 self._download_and_prepare(
596 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
597 )
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
682 try:
683 # Prepare split will record examples associated to the split
--> 684 self._prepare_split(split_generator, **prepare_split_kwargs)
685 except OSError as e:
686 raise OSError(
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1084 writer.write(example, key)
1085 finally:
-> 1086 num_examples, num_bytes = writer.finalize()
1087
1088 split_generator.split_info.num_examples = num_examples
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in finalize(self, close_stream)
525 # Re-intializing to empty list for next batch
526 self.hkey_record = []
--> 527 self.write_examples_on_file()
528 if self.pa_writer is None:
529 if self.schema:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
402 # Since current_examples contains (example, key) tuples
403 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 404 self.write_batch(batch_examples=batch_examples)
405 self.current_examples = []
406
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
495 col_try_type = try_features[col] if try_features is not None and col in try_features else None
496 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 497 arrays.append(pa.array(typed_sequence))
498 inferred_features[col] = typed_sequence.get_inferred_type()
499 schema = inferred_features.arrow_schema if self.pa_writer is None else self.schema
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
203 # Also, when trying type "string", we don't want to convert integers or floats to "string".
204 # We only do it if trying_type is False - since this is what the user asks for.
--> 205 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
206 return out
207 except (TypeError, pa.lib.ArrowInvalid) as e: # handle type errors and overflows
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1063 # feature must be either [subfeature] or Sequence(subfeature)
1064 if isinstance(feature, list):
-> 1065 return pa.ListArray.from_arrays(array.offsets, _c(array.values, feature[0]))
1066 elif isinstance(feature, Sequence):
1067 if feature.length > -1:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1085 elif not isinstance(feature, (Sequence, dict, list, tuple)):
1086 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
-> 1087 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
1088
1089
TypeError: Couldn't cast array of type
struct<医院-3.0T MRI: string, 医院-CT: string, 医院-DSA: string, 医院-公交线路: string, 医院-区域: string, 医院-名称: string, 医院-地址: string, 医院-地铁可达: string, 医院-地铁线路: string, 医院-性质: string, 医院-挂号时间: string, 医院-电话: string, 医院-等级: string, 医院-类别: string, 医院-重点科室: string, 医院-门诊时间: string, 天气-城市: string, 天气-天气: string, 天气-日期: string, 天气-温度: string, 天气-紫外线强度: string, 天气-风力风向: string, 旅游景点-区域: string, 旅游景点-名称: string, 旅游景点-地址: string, 旅游景点-开放时间: string, 旅游景点-是否地铁直达: string, 旅游景点-景点类型: string, 旅游景点-最适合人群: string, 旅游景点-消费: string, 旅游景点-特点: string, 旅游景点-电话号码: string, 旅游景点-评分: string, 旅游景点-门票价格: string, 汽车-价格(万元): string, 汽车-倒车影像: string, 汽车-动力水平: string, 汽车-厂商: string, 汽车-发动机排量(L): string, 汽车-发动机马力(Ps): string, 汽车-名称: string, 汽车-定速巡航: string, 汽车-巡航系统: string, 汽车-座位数: string, 汽车-座椅加热: string, 汽车-座椅通风: string, 汽车-所属价格区间: string, 汽车-油耗水平: string, 汽车-环保标准: string, 汽车-级别: string, 汽车-综合油耗(L/100km): string, 汽车-能源类型: string, 汽车-车型: string, 汽车-车系: string, 汽车-车身尺寸(mm): string, 汽车-驱动方式: string, 汽车-驾驶辅助影像: string, 火车-出发地: string, 火车-出发时间: string, 火车-到达时间: string, 火车-坐席: string, 火车-日期: string, 火车-时长: string, 火车-目的地: string, 火车-票价: string, 火车-舱位档次: string, 火车-车型: string, 火车-车次信息: string, 电影-主演: string, 电影-主演名单: string, 电影-具体上映时间: string, 电影-制片国家/地区: string, 电影-导演: string, 电影-年代: string, 电影-片名: string, 电影-片长: string, 电影-类型: string, 电影-豆瓣评分: string, 电脑-CPU: string, 电脑-CPU型号: string, 电脑-产品类别: string, 电脑-价格: string, 电脑-价格区间: string, 电脑-内存容量: string, 电脑-分类: string, 电脑-品牌: string, 电脑-商品名称: string, 电脑-屏幕尺寸: string, 电脑-待机时长: string, 电脑-显卡型号: string, 电脑-显卡类别: string, 电脑-游戏性能: string, 电脑-特性: string, 电脑-硬盘容量: string, 电脑-系列: string, 电脑-系统: string, 电脑-色系: string, 电脑-裸机重量: string, 电视剧-主演: string, 电视剧-主演名单: string, 电视剧-制片国家/地区: string, 电视剧-单集片长: string, 电视剧-导演: string, 电视剧-年代: string, 电视剧-片名: string, 电视剧-类型: string, 电视剧-豆瓣评分: string, 电视剧-集数: string, 电视剧-首播时间: string, 辅导班-上课方式: string, 辅导班-上课时间: string, 辅导班-下课时间: string, 辅导班-价格: string, 辅导班-区域: string, 辅导班-年级: string, 辅导班-开始日期: string, 辅导班-教室地点: string, 辅导班-教师: string, 辅导班-教师网址: string, 辅导班-时段: string, 辅导班-校区: string, 辅导班-每周: string, 辅导班-班号: string, 辅导班-科目: string, 辅导班-结束日期: string, 辅导班-课时: string, 辅导班-课次: string, 辅导班-课程网址: string, 辅导班-难度: string, 通用-产品类别: string, 通用-价格区间: string, 通用-品牌: string, 通用-系列: string, 酒店-价位: string, 酒店-停车场: string, 酒店-区域: string, 酒店-名称: string, 酒店-地址: string, 酒店-房型: string, 酒店-房费: string, 酒店-星级: string, 酒店-电话号码: string, 酒店-评分: string, 酒店-酒店类型: string, 飞机-准点率: string, 飞机-出发地: string, 飞机-到达时间: string, 飞机-日期: string, 飞机-目的地: string, 飞机-票价: string, 飞机-航班信息: string, 飞机-舱位档次: string, 飞机-起飞时间: string, 餐厅-人均消费: string, 餐厅-价位: string, 餐厅-区域: string, 餐厅-名称: string, 餐厅-地址: string, 餐厅-推荐菜: string, 餐厅-是否地铁直达: string, 餐厅-电话号码: string, 餐厅-菜系: string, 餐厅-营业时间: string, 餐厅-评分: string>
to
{'旅游景点-名称': Value(dtype='string', id=None), '旅游景点-区域': Value(dtype='string', id=None), '旅游景点-景点类型': Value(dtype='string', id=None), '旅游景点-最适合人群': Value(dtype='string', id=None), '旅游景点-消费': Value(dtype='string', id=None), '旅游景点-是否地铁直达': Value(dtype='string', id=None), '旅游景点-门票价格': Value(dtype='string', id=None), '旅游景点-电话号码': Value(dtype='string', id=None), '旅游景点-地址': Value(dtype='string', id=None), '旅游景点-评分': Value(dtype='string', id=None), '旅游景点-开放时间': Value(dtype='string', id=None), '旅游景点-特点': Value(dtype='string', id=None), '餐厅-名称': Value(dtype='string', id=None), '餐厅-区域': Value(dtype='string', id=None), '餐厅-菜系': Value(dtype='string', id=None), '餐厅-价位': Value(dtype='string', id=None), '餐厅-是否地铁直达': Value(dtype='string', id=None), '餐厅-人均消费': Value(dtype='string', id=None), '餐厅-地址': Value(dtype='string', id=None), '餐厅-电话号码': Value(dtype='string', id=None), '餐厅-评分': Value(dtype='string', id=None), '餐厅-营业时间': Value(dtype='string', id=None), '餐厅-推荐菜': Value(dtype='string', id=None), '酒店-名称': Value(dtype='string', id=None), '酒店-区域': Value(dtype='string', id=None), '酒店-星级': Value(dtype='string', id=None), '酒店-价位': Value(dtype='string', id=None), '酒店-酒店类型': Value(dtype='string', id=None), '酒店-房型': Value(dtype='string', id=None), '酒店-停车场': Value(dtype='string', id=None), '酒店-房费': Value(dtype='string', id=None), '酒店-地址': Value(dtype='string', id=None), '酒店-电话号码': Value(dtype='string', id=None), '酒店-评分': Value(dtype='string', id=None), '电脑-品牌': Value(dtype='string', id=None), '电脑-产品类别': Value(dtype='string', id=None), '电脑-分类': Value(dtype='string', id=None), '电脑-内存容量': Value(dtype='string', id=None), '电脑-屏幕尺寸': Value(dtype='string', id=None), '电脑-CPU': Value(dtype='string', id=None), '电脑-价格区间': Value(dtype='string', id=None), '电脑-系列': Value(dtype='string', id=None), '电脑-商品名称': Value(dtype='string', id=None), '电脑-系统': Value(dtype='string', id=None), '电脑-游戏性能': Value(dtype='string', id=None), '电脑-CPU型号': Value(dtype='string', id=None), '电脑-裸机重量': Value(dtype='string', id=None), '电脑-显卡类别': Value(dtype='string', id=None), '电脑-显卡型号': Value(dtype='string', id=None), '电脑-特性': Value(dtype='string', id=None), '电脑-色系': Value(dtype='string', id=None), '电脑-待机时长': Value(dtype='string', id=None), '电脑-硬盘容量': Value(dtype='string', id=None), '电脑-价格': Value(dtype='string', id=None), '火车-出发地': Value(dtype='string', id=None), '火车-目的地': Value(dtype='string', id=None), '火车-日期': Value(dtype='string', id=None), '火车-车型': Value(dtype='string', id=None), '火车-坐席': Value(dtype='string', id=None), '火车-车次信息': Value(dtype='string', id=None), '火车-时长': Value(dtype='string', id=None), '火车-出发时间': Value(dtype='string', id=None), '火车-到达时间': Value(dtype='string', id=None), '火车-票价': Value(dtype='string', id=None), '飞机-出发地': Value(dtype='string', id=None), '飞机-目的地': Value(dtype='string', id=None), '飞机-日期': Value(dtype='string', id=None), '飞机-舱位档次': Value(dtype='string', id=None), '飞机-航班信息': Value(dtype='string', id=None), '飞机-起飞时间': Value(dtype='string', id=None), '飞机-到达时间': Value(dtype='string', id=None), '飞机-票价': Value(dtype='string', id=None), '飞机-准点率': Value(dtype='string', id=None), '天气-城市': Value(dtype='string', id=None), '天气-日期': Value(dtype='string', id=None), '天气-天气': Value(dtype='string', id=None), '天气-温度': Value(dtype='string', id=None), '天气-风力风向': Value(dtype='string', id=None), '天气-紫外线强度': Value(dtype='string', id=None), '电影-制片国家/地区': Value(dtype='string', id=None), '电影-类型': Value(dtype='string', id=None), '电影-年代': Value(dtype='string', id=None), '电影-主演': Value(dtype='string', id=None), '电影-导演': Value(dtype='string', id=None), '电影-片名': Value(dtype='string', id=None), '电影-主演名单': Value(dtype='string', id=None), '电影-具体上映时间': Value(dtype='string', id=None), '电影-片长': Value(dtype='string', id=None), '电影-豆瓣评分': Value(dtype='string', id=None), '电视剧-制片国家/地区': Value(dtype='string', id=None), '电视剧-类型': Value(dtype='string', id=None), '电视剧-年代': Value(dtype='string', id=None), '电视剧-主演': Value(dtype='string', id=None), '电视剧-导演': Value(dtype='string', id=None), '电视剧-片名': Value(dtype='string', id=None), '电视剧-主演名单': Value(dtype='string', id=None), '电视剧-首播时间': Value(dtype='string', id=None), '电视剧-集数': Value(dtype='string', id=None), '电视剧-单集片长': Value(dtype='string', id=None), '电视剧-豆瓣评分': Value(dtype='string', id=None), '辅导班-班号': Value(dtype='string', id=None), '辅导班-难度': Value(dtype='string', id=None), '辅导班-科目': Value(dtype='string', id=None), '辅导班-年级': Value(dtype='string', id=None), '辅导班-区域': Value(dtype='string', id=None), '辅导班-校区': Value(dtype='string', id=None), '辅导班-上课方式': Value(dtype='string', id=None), '辅导班-开始日期': Value(dtype='string', id=None), '辅导班-结束日期': Value(dtype='string', id=None), '辅导班-每周': Value(dtype='string', id=None), '辅导班-上课时间': Value(dtype='string', id=None), '辅导班-下课时间': Value(dtype='string', id=None), '辅导班-时段': Value(dtype='string', id=None), '辅导班-课次': Value(dtype='string', id=None), '辅导班-课时': Value(dtype='string', id=None), '辅导班-教室地点': Value(dtype='string', id=None), '辅导班-教师': Value(dtype='string', id=None), '辅导班-价格': Value(dtype='string', id=None), '辅导班-课程网址': Value(dtype='string', id=None), '辅导班-教师网址': Value(dtype='string', id=None), '汽车-名称': Value(dtype='string', id=None), '汽车-车型': Value(dtype='string', id=None), '汽车-级别': Value(dtype='string', id=None), '汽车-座位数': Value(dtype='string', id=None), '汽车-车身尺寸(mm)': Value(dtype='string', id=None), '汽车-厂商': Value(dtype='string', id=None), '汽车-能源类型': Value(dtype='string', id=None), '汽车-发动机排量(L)': Value(dtype='string', id=None), '汽车-发动机马力(Ps)': Value(dtype='string', id=None), '汽车-驱动方式': Value(dtype='string', id=None), '汽车-综合油耗(L/100km)': Value(dtype='string', id=None), '汽车-环保标准': Value(dtype='string', id=None), '汽车-驾驶辅助影像': Value(dtype='string', id=None), '汽车-巡航系统': Value(dtype='string', id=None), '汽车-价格(万元)': Value(dtype='string', id=None), '汽车-车系': Value(dtype='string', id=None), '汽车-动力水平': Value(dtype='string', id=None), '汽车-油耗水平': Value(dtype='string', id=None), '汽车-倒车影像': Value(dtype='string', id=None), '汽车-定速巡航': Value(dtype='string', id=None), '汽车-座椅加热': Value(dtype='string', id=None), '汽车-座椅通风': Value(dtype='string', id=None), '汽车-所属价格区间': Value(dtype='string', id=None), '医院-名称': Value(dtype='string', id=None), '医院-等级': Value(dtype='string', id=None), '医院-类别': Value(dtype='string', id=None), '医院-性质': Value(dtype='string', id=None), '医院-区域': Value(dtype='string', id=None), '医院-地址': Value(dtype='string', id=None), '医院-电话': Value(dtype='string', id=None), '医院-挂号时间': Value(dtype='string', id=None), '医院-门诊时间': Value(dtype='string', id=None), '医院-公交线路': Value(dtype='string', id=None), '医院-地铁可达': Value(dtype='string', id=None), '医院-地铁线路': Value(dtype='string', id=None), '医院-重点科室': Value(dtype='string', id=None), '医院-CT': Value(dtype='string', id=None), '医院-3.0T MRI': Value(dtype='string', id=None), '医院-DSA': Value(dtype='string', id=None)}
```
</details>
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3636/comments | https://api.github.com/repos/huggingface/datasets/issues/3636/events | https://github.com/huggingface/datasets/pull/3636 | 1,115,362,702 | PR_kwDODunzps4xohMB | 3,636 | Update index.rst | {
"login": "VioletteLepercq",
"id": 95622912,
"node_id": "U_kgDOBbMXAA",
"avatar_url": "https://avatars.githubusercontent.com/u/95622912?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VioletteLepercq",
"html_url": "https://github.com/VioletteLepercq",
"followers_url": "https://api.github.com/users/VioletteLepercq/followers",
"following_url": "https://api.github.com/users/VioletteLepercq/following{/other_user}",
"gists_url": "https://api.github.com/users/VioletteLepercq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VioletteLepercq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VioletteLepercq/subscriptions",
"organizations_url": "https://api.github.com/users/VioletteLepercq/orgs",
"repos_url": "https://api.github.com/users/VioletteLepercq/repos",
"events_url": "https://api.github.com/users/VioletteLepercq/events{/privacy}",
"received_events_url": "https://api.github.com/users/VioletteLepercq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-26T18:43:09" | "2022-01-26T18:44:55" | "2022-01-26T18:44:54" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3636",
"html_url": "https://github.com/huggingface/datasets/pull/3636",
"diff_url": "https://github.com/huggingface/datasets/pull/3636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3636.patch",
"merged_at": "2022-01-26T18:44:54"
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3636/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3635/comments | https://api.github.com/repos/huggingface/datasets/issues/3635/events | https://github.com/huggingface/datasets/pull/3635 | 1,115,333,219 | PR_kwDODunzps4xobAe | 3,635 | Make `ted_talks_iwslt` dataset streamable | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [
"Thanks for adding this @mariosasko! It worked for me when running it with a local data file, however, when using the file on Google Drive I get the following error:\r\n```Python\r\nds = load_dataset(\"./ted_talks_iwslt\",\"eu_ca_2014\", streaming=True, split=\"train\", use_auth_token=True)\r\nnext(iter(ds))\r\n```\r\n```\r\n---------------------------------------------------------------------------\r\nClientResponseError Traceback (most recent call last)\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/implementations/http.py:383, in HTTPFileSystem._info(self, url, **kwargs)\r\n 381 try:\r\n 382 info.update(\r\n--> 383 await _file_info(\r\n 384 url,\r\n 385 size_policy=policy,\r\n 386 session=session,\r\n 387 **self.kwargs,\r\n 388 **kwargs,\r\n 389 )\r\n 390 )\r\n 391 if info.get(\"size\") is not None:\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/implementations/http.py:734, in _file_info(url, session, size_policy, **kwargs)\r\n 733 async with r:\r\n--> 734 r.raise_for_status()\r\n 736 # TODO:\r\n 737 # recognise lack of 'Accept-Ranges',\r\n 738 # or 'Accept-Ranges': 'none' (not 'bytes')\r\n 739 # to mean streaming only, no random access => return None\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/aiohttp/client_reqrep.py:1004, in ClientResponse.raise_for_status(self)\r\n 1003 self.release()\r\n-> 1004 raise ClientResponseError(\r\n 1005 self.request_info,\r\n 1006 self.history,\r\n 1007 status=self.status,\r\n 1008 message=self.reason,\r\n 1009 headers=self.headers,\r\n 1010 )\r\n\r\nClientResponseError: 403, message='Forbidden', url=URL('https://drive.google.com/u/0/uc?id=1Cz1Un9p8Xn9IpEMMrg2kXSDt0dnjxc4z&export=download&confirm=1RJz')\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nFileNotFoundError Traceback (most recent call last)\r\nInput In [9], in <module>\r\n 1 iterable = iter(ds)\r\n 2 for i in range(10):\r\n----> 3 item = next(iterable)\r\n 4 print(item['text'][:10], item['meta'])\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/datasets/iterable_dataset.py:341, in IterableDataset.__iter__(self)\r\n 340 def __iter__(self):\r\n--> 341 for key, example in self._iter():\r\n 342 if self.features:\r\n 343 # we encode the example for ClassLabel feature types for example\r\n 344 encoded_example = self.features.encode_example(example)\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/datasets/iterable_dataset.py:338, in IterableDataset._iter(self)\r\n 336 else:\r\n 337 ex_iterable = self._ex_iterable\r\n--> 338 yield from ex_iterable\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/datasets/iterable_dataset.py:78, in ExamplesIterable.__iter__(self)\r\n 77 def __iter__(self):\r\n---> 78 for key, example in self.generate_examples_fn(**self.kwargs):\r\n 79 yield key, example\r\n\r\nFile ~/.cache/huggingface/modules/datasets_modules/datasets/lm_en_ted_talks_iwslt/756148758e86e64a350f9b320744a2bd5ed5cff74f7df620763a2b5e1a45e6c6/lm_en_ted_talks_iwslt.py:118, in TedTalksIWSLT._generate_examples(self, files)\r\n 116 for _LANG in _LANG_CODES:\r\n 117 source_file_path = _YEAR_FOLDER[year] + \"/ted_\" + _LANG + _YEAR[year] + \".zip\"\r\n--> 118 for path, file in files:\r\n 119 if path.endswith(source_file_path):\r\n 120 source_talks, _ = parse_zip_file(path, file.read())\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py:596, in StreamingDownloadManager.iter_archive(self, urlpath_or_buf)\r\n 594 yield from _iter_archive(urlpath_or_buf)\r\n 595 else:\r\n--> 596 with xopen(urlpath_or_buf, \"rb\", use_auth_token=self.download_config.use_auth_token) as f:\r\n 597 yield from _iter_archive(f)\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py:296, in xopen(file, mode, use_auth_token, *args, **kwargs)\r\n 294 new_kwargs = {}\r\n 295 kwargs = {**kwargs, **new_kwargs}\r\n--> 296 file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()\r\n 297 _add_retries_to_file_obj_read_method(file_obj)\r\n 298 return file_obj\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/core.py:140, in OpenFile.open(self)\r\n 132 def open(self):\r\n 133 \"\"\"Materialise this as a real open file without context\r\n 134 \r\n 135 The file should be explicitly closed to avoid enclosed file\r\n (...)\r\n 138 been deleted; but a with-context is better style.\r\n 139 \"\"\"\r\n--> 140 out = self.__enter__()\r\n 141 closer = out.close\r\n 142 fobjects = self.fobjects.copy()[:-1]\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/core.py:103, in OpenFile.__enter__(self)\r\n 100 def __enter__(self):\r\n 101 mode = self.mode.replace(\"t\", \"\").replace(\"b\", \"\") + \"b\"\r\n--> 103 f = self.fs.open(self.path, mode=mode)\r\n 105 self.fobjects = [f]\r\n 107 if self.compression is not None:\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/spec.py:1009, in AbstractFileSystem.open(self, path, mode, block_size, cache_options, compression, **kwargs)\r\n 1007 else:\r\n 1008 ac = kwargs.pop(\"autocommit\", not self._intrans)\r\n-> 1009 f = self._open(\r\n 1010 path,\r\n 1011 mode=mode,\r\n 1012 block_size=block_size,\r\n 1013 autocommit=ac,\r\n 1014 cache_options=cache_options,\r\n 1015 **kwargs,\r\n 1016 )\r\n 1017 if compression is not None:\r\n 1018 from fsspec.compression import compr\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/implementations/http.py:343, in HTTPFileSystem._open(self, path, mode, block_size, autocommit, cache_type, cache_options, size, **kwargs)\r\n 341 kw[\"asynchronous\"] = self.asynchronous\r\n 342 kw.update(kwargs)\r\n--> 343 size = size or self.info(path, **kwargs)[\"size\"]\r\n 344 session = sync(self.loop, self.set_session)\r\n 345 if block_size and size:\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/asyn.py:91, in sync_wrapper.<locals>.wrapper(*args, **kwargs)\r\n 88 @functools.wraps(func)\r\n 89 def wrapper(*args, **kwargs):\r\n 90 self = obj or args[0]\r\n---> 91 return sync(self.loop, func, *args, **kwargs)\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/asyn.py:71, in sync(loop, func, timeout, *args, **kwargs)\r\n 69 raise FSTimeoutError from return_result\r\n 70 elif isinstance(return_result, BaseException):\r\n---> 71 raise return_result\r\n 72 else:\r\n 73 return return_result\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/asyn.py:25, in _runner(event, coro, result, timeout)\r\n 23 coro = asyncio.wait_for(coro, timeout=timeout)\r\n 24 try:\r\n---> 25 result[0] = await coro\r\n 26 except Exception as ex:\r\n 27 result[0] = ex\r\n\r\nFile ~/git/bigscience-datasets/env/lib/python3.9/site-packages/fsspec/implementations/http.py:396, in HTTPFileSystem._info(self, url, **kwargs)\r\n 393 except Exception as exc:\r\n 394 if policy == \"get\":\r\n 395 # If get failed, then raise a FileNotFoundError\r\n--> 396 raise FileNotFoundError(url) from exc\r\n 397 logger.debug(str(exc))\r\n 399 return {\"name\": url, \"size\": None, **info, \"type\": \"file\"}\r\n\r\nFileNotFoundError: https://drive.google.com/u/0/uc?id=1Cz1Un9p8Xn9IpEMMrg2kXSDt0dnjxc4z&export=download&confirm=1RJz\r\n```",
"Thanks @mariosasko.\r\n\r\nTo make this dataset streamable, we should first host the data on the Hub instead of current Google Drive. Do you know if their license allows to do so? ",
"This dataset is licensed under [cc-by-nc-4.0](https://creativecommons.org/licenses/by-nc/4.0/), so I think it should be"
] | "2022-01-26T18:07:56" | "2022-10-04T09:36:23" | "2022-10-03T09:44:47" | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3635",
"html_url": "https://github.com/huggingface/datasets/pull/3635",
"diff_url": "https://github.com/huggingface/datasets/pull/3635.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3635.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3635/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3635/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3634/comments | https://api.github.com/repos/huggingface/datasets/issues/3634/events | https://github.com/huggingface/datasets/issues/3634 | 1,115,133,279 | I_kwDODunzps5Cd5Vf | 3,634 | Dataset.shuffle(seed=None) gives fixed row permutation | {
"login": "elisno",
"id": 18127060,
"node_id": "MDQ6VXNlcjE4MTI3MDYw",
"avatar_url": "https://avatars.githubusercontent.com/u/18127060?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/elisno",
"html_url": "https://github.com/elisno",
"followers_url": "https://api.github.com/users/elisno/followers",
"following_url": "https://api.github.com/users/elisno/following{/other_user}",
"gists_url": "https://api.github.com/users/elisno/gists{/gist_id}",
"starred_url": "https://api.github.com/users/elisno/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elisno/subscriptions",
"organizations_url": "https://api.github.com/users/elisno/orgs",
"repos_url": "https://api.github.com/users/elisno/repos",
"events_url": "https://api.github.com/users/elisno/events{/privacy}",
"received_events_url": "https://api.github.com/users/elisno/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"I'm not sure if this is expected behavior.\r\n\r\nAm I supposed to work with a copy of the dataset, i.e. `shuffled_dataset = data.shuffle(seed=None)`?\r\n\r\n```diff\r\nimport datasets\r\n\r\n# Some toy example\r\ndata = datasets.Dataset.from_dict(\r\n {\"feature\": [1, 2, 3, 4, 5], \"label\": [\"a\", \"b\", \"c\", \"d\", \"e\"]}\r\n)\r\n\r\n+shuffled_data = data.shuffle(seed=None)\r\n\r\n# Doesn't work as expected\r\nprint(\"Shuffle dataset\")\r\nfor _ in range(3):\r\n+ shuffled_data = shuffled_data.shuffle(seed=None)\r\n+ print(shuffled_data[:])\r\n- print(data.shuffle(seed=None)[:])\r\n\r\n# This seems to work with pandas\r\nprint(\"\\nShuffle via pandas\")\r\nfor _ in range(3):\r\n df = data.to_pandas().sample(frac=1.0)\r\n print(datasets.Dataset.from_pandas(df, preserve_index=False)[:])\r\n\r\n```\r\n\r\nor provide a `generator` instead?\r\n\r\n```diff\r\nimport datasets\r\n+from numpy.random import default_rng\r\n\r\n# Some toy example\r\ndata = datasets.Dataset.from_dict(\r\n {\"feature\": [1, 2, 3, 4, 5], \"label\": [\"a\", \"b\", \"c\", \"d\", \"e\"]}\r\n)\r\n\r\n+rng = default_rng()\r\n\r\n# Doesn't work as expected\r\nprint(\"Shuffle dataset\")\r\nfor _ in range(3):\r\n+ print(data.shuffle(generator=rng)[:])\r\n- print(data.shuffle(seed=None)[:])\r\n\r\n# This seems to work with pandas\r\nprint(\"\\nShuffle via pandas\")\r\nfor _ in range(3):\r\n df = data.to_pandas().sample(frac=1.0)\r\n print(datasets.Dataset.from_pandas(df, preserve_index=False)[:])\r\n\r\n```",
"Hi! Thanks for reporting! Yes, this is not expected behavior. I've opened a PR with the fix."
] | "2022-01-26T15:13:08" | "2022-01-27T18:16:07" | "2022-01-27T18:16:07" | NONE | null | null | null | ## Describe the bug
Repeated attempts to `shuffle` a dataset without specifying a seed give the same results.
## Steps to reproduce the bug
```python
import datasets
# Some toy example
data = datasets.Dataset.from_dict(
{"feature": [1, 2, 3, 4, 5], "label": ["a", "b", "c", "d", "e"]}
)
# Doesn't work as expected
print("Shuffle dataset")
for _ in range(3):
print(data.shuffle(seed=None)[:])
# This seems to work with pandas
print("\nShuffle via pandas")
for _ in range(3):
df = data.to_pandas().sample(frac=1.0)
print(datasets.Dataset.from_pandas(df, preserve_index=False)[:])
```
## Expected results
I assumed that the default setting would initialize a new/random state of a `np.random.BitGenerator` (see [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=shuffle#datasets.Dataset.shuffle)).
Wouldn't that reshuffle the rows each time I call `data.shuffle()`?
## Actual results
```bash
Shuffle dataset
{'feature': [5, 1, 3, 2, 4], 'label': ['e', 'a', 'c', 'b', 'd']}
{'feature': [5, 1, 3, 2, 4], 'label': ['e', 'a', 'c', 'b', 'd']}
{'feature': [5, 1, 3, 2, 4], 'label': ['e', 'a', 'c', 'b', 'd']}
Shuffle via pandas
{'feature': [4, 2, 3, 1, 5], 'label': ['d', 'b', 'c', 'a', 'e']}
{'feature': [2, 5, 3, 4, 1], 'label': ['b', 'e', 'c', 'd', 'a']}
{'feature': [5, 2, 3, 1, 4], 'label': ['e', 'b', 'c', 'a', 'd']}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: Linux-5.13.0-27-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3634/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3633/comments | https://api.github.com/repos/huggingface/datasets/issues/3633/events | https://github.com/huggingface/datasets/pull/3633 | 1,115,040,174 | PR_kwDODunzps4xng6E | 3,633 | Mirror canonical datasets in prod | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-26T13:49:37" | "2022-01-26T13:56:21" | "2022-01-26T13:56:21" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3633",
"html_url": "https://github.com/huggingface/datasets/pull/3633",
"diff_url": "https://github.com/huggingface/datasets/pull/3633.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3633.patch",
"merged_at": "2022-01-26T13:56:21"
} | Push the datasets changes to the Hub in production by setting `HF_USE_PROD=1`
I also added a fix that makes the script ignore the json, csv, text, parquet and pandas dataset builders.
cc @SBrandeis | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3633/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3633/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3632/comments | https://api.github.com/repos/huggingface/datasets/issues/3632/events | https://github.com/huggingface/datasets/issues/3632 | 1,115,027,185 | I_kwDODunzps5Cdfbx | 3,632 | Adding CC-100: Monolingual Datasets from Web Crawl Data (Datasets links are invalid) | {
"login": "AnzorGozalishvili",
"id": 55232459,
"node_id": "MDQ6VXNlcjU1MjMyNDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/55232459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AnzorGozalishvili",
"html_url": "https://github.com/AnzorGozalishvili",
"followers_url": "https://api.github.com/users/AnzorGozalishvili/followers",
"following_url": "https://api.github.com/users/AnzorGozalishvili/following{/other_user}",
"gists_url": "https://api.github.com/users/AnzorGozalishvili/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AnzorGozalishvili/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AnzorGozalishvili/subscriptions",
"organizations_url": "https://api.github.com/users/AnzorGozalishvili/orgs",
"repos_url": "https://api.github.com/users/AnzorGozalishvili/repos",
"events_url": "https://api.github.com/users/AnzorGozalishvili/events{/privacy}",
"received_events_url": "https://api.github.com/users/AnzorGozalishvili/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @AnzorGozalishvili,\r\n\r\nMaybe their site was temporarily down, but it seems to work fine now.\r\n\r\nCould you please try again and confirm if the problem persists? ",
"Hi @albertvillanova \r\nI checked and it works. \r\nIt seems that it was really temporarily down.\r\nThanks!"
] | "2022-01-26T13:35:37" | "2022-02-10T06:58:11" | "2022-02-10T06:58:11" | CONTRIBUTOR | null | null | null | ## Describe the bug
The dataset links are no longer valid for CC-100. It seems that the website which was keeping these files are no longer accessible and therefore this dataset became unusable.
Check out the dataset [homepage](http://data.statmt.org/cc-100/) which isn't accessible.
Also the URLs for dataset file per language isn't accessible: http://data.statmt.org/cc-100/<language code here>.txt.xz (language codes: am, sr, ka, etc.)
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("cc100", "ka")
```
It throws 503 error.
## Expected results
It should successfully download and load dataset but it throws an exception because the dataset files are no longer accessible.
## Environment info
Run from google colab. Just installed the library using pip:
```!pip install -U datasets```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3632/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3631/comments | https://api.github.com/repos/huggingface/datasets/issues/3631/events | https://github.com/huggingface/datasets/issues/3631 | 1,114,833,662 | I_kwDODunzps5CcwL- | 3,631 | Labels conflict when loading a local CSV file. | {
"login": "pichljan",
"id": 8571301,
"node_id": "MDQ6VXNlcjg1NzEzMDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8571301?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pichljan",
"html_url": "https://github.com/pichljan",
"followers_url": "https://api.github.com/users/pichljan/followers",
"following_url": "https://api.github.com/users/pichljan/following{/other_user}",
"gists_url": "https://api.github.com/users/pichljan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pichljan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pichljan/subscriptions",
"organizations_url": "https://api.github.com/users/pichljan/orgs",
"repos_url": "https://api.github.com/users/pichljan/repos",
"events_url": "https://api.github.com/users/pichljan/events{/privacy}",
"received_events_url": "https://api.github.com/users/pichljan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @pichljan, thanks for reporting.\r\n\r\nThis should be fixed. I'm looking at it. "
] | "2022-01-26T10:00:33" | "2022-02-11T23:02:31" | "2022-02-11T23:02:31" | NONE | null | null | null | ## Describe the bug
I am trying to load a local CSV file with a separate file containing label names. It is successfully loaded for the first time, but when I try to load it again, there is a conflict between provided labels and the cached dataset info. Disabling caching globally and/or using `download_mode="force_redownload"` did not help.
## Steps to reproduce the bug
```python
load_dataset('csv', data_files='data/my_data.csv',
features=Features(text=Value(dtype='string'),
label=ClassLabel(names_file='data/my_data_labels.txt')))
```
`my_data.csv` file has the following structure:
```
text,label
"example1",0
"example2",1
...
```
and the `my_data_labels.txt` looks like this:
```
label1
label2
...
```
## Expected results
Successfully loaded dataset.
## Actual results
```python
File "/usr/local/lib/python3.8/site-packages/datasets/load.py", line 1706, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 766, in as_dataset
datasets = utils.map_nested(
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 261, in map_nested
mapped = [
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 262, in <listcomp>
_single_map_nested((function, obj, types, None, True))
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 797, in _build_single_dataset
ds = self._as_dataset(
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 872, in _as_dataset
return Dataset(fingerprint=fingerprint, **dataset_kwargs)
File "/usr/local/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 638, in __init__
inferred_features = Features.from_arrow_schema(arrow_table.schema)
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1242, in from_arrow_schema
return Features.from_dict(metadata["info"]["features"])
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1271, in from_dict
obj = generate_from_dict(dic)
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1076, in generate_from_dict
return {key: generate_from_dict(value) for key, value in obj.items()}
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1076, in <dictcomp>
return {key: generate_from_dict(value) for key, value in obj.items()}
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1083, in generate_from_dict
return class_type(**{k: v for k, v in obj.items() if k in field_names})
File "<string>", line 7, in __init__
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 776, in __post_init__
raise ValueError("Please provide either names or names_file but not both.")
ValueError: Please provide either names or names_file but not both.
```
## Environment info
- `datasets` version: 1.18.0
- Python version: 3.8.2
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3631/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3630/comments | https://api.github.com/repos/huggingface/datasets/issues/3630/events | https://github.com/huggingface/datasets/issues/3630 | 1,114,578,625 | I_kwDODunzps5Cbx7B | 3,630 | DuplicatedKeysError of NewsQA dataset | {
"login": "StevenTang1998",
"id": 37647985,
"node_id": "MDQ6VXNlcjM3NjQ3OTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/StevenTang1998",
"html_url": "https://github.com/StevenTang1998",
"followers_url": "https://api.github.com/users/StevenTang1998/followers",
"following_url": "https://api.github.com/users/StevenTang1998/following{/other_user}",
"gists_url": "https://api.github.com/users/StevenTang1998/gists{/gist_id}",
"starred_url": "https://api.github.com/users/StevenTang1998/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StevenTang1998/subscriptions",
"organizations_url": "https://api.github.com/users/StevenTang1998/orgs",
"repos_url": "https://api.github.com/users/StevenTang1998/repos",
"events_url": "https://api.github.com/users/StevenTang1998/events{/privacy}",
"received_events_url": "https://api.github.com/users/StevenTang1998/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm fixing it. "
] | "2022-01-26T03:05:49" | "2022-02-14T08:37:19" | "2022-02-14T08:37:19" | NONE | null | null | null | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/default to /root/.cache/huggingface/datasets/newsqa/default-data_dir=news/1.0.0/b0b23e22d94a3d352ad9d75aff2b71375264a122fae301463079ee8595e05ab9...
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 1084, in _prepare_split
writer.write(example, key)
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 442, in write
self.check_duplicate_keys()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 453, in check_duplicate_keys
raise DuplicatedKeysError(key)
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: ./cnn/stories/6a0f9c8a5d0c6e8949b37924163c92923fe5770d.story
Keys should be unique and deterministic in nature
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/datasets/load.py", line 1694, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 595, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 684, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 1086, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 524, in finalize
self.check_duplicate_keys()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 453, in check_duplicate_keys
raise DuplicatedKeysError(key)
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: ./cnn/stories/6a0f9c8a5d0c6e8949b37924163c92923fe5770d.story
Keys should be unique and deterministic in nature
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3630/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3629/comments | https://api.github.com/repos/huggingface/datasets/issues/3629/events | https://github.com/huggingface/datasets/pull/3629 | 1,113,971,575 | PR_kwDODunzps4xkCZA | 3,629 | Fix Hub repos update when there's a new release | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-25T14:39:45" | "2022-01-25T14:55:46" | "2022-01-25T14:55:46" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3629",
"html_url": "https://github.com/huggingface/datasets/pull/3629",
"diff_url": "https://github.com/huggingface/datasets/pull/3629.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3629.patch",
"merged_at": "2022-01-25T14:55:46"
} | It was not listing the full list of datasets correctly
cc @SBrandeis this is why it failed for 1.18.0
We should be good now ! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3629/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3629/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3628/comments | https://api.github.com/repos/huggingface/datasets/issues/3628/events | https://github.com/huggingface/datasets/issues/3628 | 1,113,930,644 | I_kwDODunzps5CZTuU | 3,628 | Dataset Card Creator drops information for "Additional Information" Section | {
"login": "dennlinger",
"id": 26013491,
"node_id": "MDQ6VXNlcjI2MDEzNDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/26013491?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dennlinger",
"html_url": "https://github.com/dennlinger",
"followers_url": "https://api.github.com/users/dennlinger/followers",
"following_url": "https://api.github.com/users/dennlinger/following{/other_user}",
"gists_url": "https://api.github.com/users/dennlinger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dennlinger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dennlinger/subscriptions",
"organizations_url": "https://api.github.com/users/dennlinger/orgs",
"repos_url": "https://api.github.com/users/dennlinger/repos",
"events_url": "https://api.github.com/users/dennlinger/events{/privacy}",
"received_events_url": "https://api.github.com/users/dennlinger/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | "2022-01-25T14:06:17" | "2022-01-25T14:09:01" | null | NONE | null | null | null | First of all, the card creator is a great addition and really helpful for streamlining dataset cards!
## Describe the bug
I encountered an inconvenient bug when entering "Additional Information" in the react app, which drops already entered text when switching to a previous section, and then back again to "Additional Information". I was able to reproduce the issue in both Firefox and Chrome, so I suspect a problem with the React logic that doesn't expect users to switch back in the final section.
Edit: I'm also not sure whether this is the right place to open the bug report on, since it's not clear to me which particular project it belongs to, or where I could find associated source code.
## Steps to reproduce the bug
1. Navigate to the Section "Additional Information" in the [dataset card creator](https://huggingface.co/datasets/card-creator/)
2. Enter text in an arbitrary field, e.g., "Dataset Curators".
3. Switch back to a previous section, like "Dataset Creation".
4. When switching back again to "Additional Information", the text has been deleted.
Notably, this behavior can be reproduced again and again, it's not just problematic for the first "switch-back" from Additional Information.
## Expected results
For step 4, the previously entered information should still be present in the boxes, similar to the behavior to all other sections (switching back there works as expected)
## Actual results
The text boxes are empty again, and previously entered text got deleted.
## Environment info
- `datasets` version: N/A
- Platform: Firefox 96.0 / Chrome 97.0
- Python version: N/A
- PyArrow version: N/A
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3628/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3628/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3627/comments | https://api.github.com/repos/huggingface/datasets/issues/3627/events | https://github.com/huggingface/datasets/pull/3627 | 1,113,556,837 | PR_kwDODunzps4xitGe | 3,627 | Fix host URL in The Pile datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"We should also update the `bookcorpusopen` download url (see #3561) , no? ",
"For `the_pile_openwebtext2` and `the_pile_stack_exchange` I did not regenerate the JSON files, but instead I just changed the download_checksums URL. ",
"Seems like the mystic URL is now broken and the original should be used. ",
"Also if I git clone and edit the repo or reset it before this PR it is still trying to pull using mystic? Why is this? "
] | "2022-01-25T08:11:28" | "2022-07-20T20:54:42" | "2022-02-14T08:40:58" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3627",
"html_url": "https://github.com/huggingface/datasets/pull/3627",
"diff_url": "https://github.com/huggingface/datasets/pull/3627.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3627.patch",
"merged_at": "2022-02-14T08:40:58"
} | This PR fixes the host URL in The Pile datasets, once they have mirrored their data in another server.
Fix #3626. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3627/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3626/comments | https://api.github.com/repos/huggingface/datasets/issues/3626/events | https://github.com/huggingface/datasets/issues/3626 | 1,113,534,436 | I_kwDODunzps5CXy_k | 3,626 | The Pile cannot connect to host | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | "2022-01-25T07:43:33" | "2022-02-14T08:40:58" | "2022-02-14T08:40:58" | MEMBER | null | null | null | ## Describe the bug
The Pile had issues with their previous host server and have mirrored its content to another server.
The new URL server should be updated.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3626/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3625/comments | https://api.github.com/repos/huggingface/datasets/issues/3625/events | https://github.com/huggingface/datasets/issues/3625 | 1,113,017,522 | I_kwDODunzps5CV0yy | 3,625 | Add a metadata field for when source data was produced | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"A question to the datasets maintainers: is there a policy about how the set of allowed metadata fields is maintained and expanded?\r\n\r\nMetadata are very important, but defining the standard is always a struggle between allowing exhaustivity without being too complex. Archivists have Dublin Core, open data has https://frictionlessdata.io/, geo has ISO 19139 and INSPIRE, etc. and it's always a mess! I'm not sure we want to dig too much into it, but I'm curious to know if there has been some work on the metadata standard.",
"> Metadata are very important, but defining the standard is always a struggle between allowing exhaustivity without being too complex. Archivists have Dublin Core, open data has [frictionlessdata.io](https://frictionlessdata.io/), geo has ISO 19139 and INSPIRE, etc. and it's always a mess! I'm not sure we want to dig too much into it, but I'm curious to know if there has been some work on the metadata standard.\r\n\r\n\r\nI thought this is a potential issue with adding this field since it might be hard to define what is general enough to be useful for most data vs what becomes very domain-specific. Potentially adding one extra field leads to more and more fields in the future. \r\n\r\nAnother issue is that there are some metadata standards around data i.e. [datacite](https://schema.datacite.org/meta/kernel-4.4/), but not many aimed explicitly at ML data afaik. Some of the discussions around metadata for ML are also more focused on versioning/managing data in production environments. My thinking is that here, some reference to the time of production would also often be tracked/relevant, i.e. for triggering model training, so having this information available in the hub would also help address this use case. ",
"Adding a relevant paper related to this topic: [TimeLMs: Diachronic Language Models from Twitter](https://arxiv.org/abs/2202.03829)\r\n\r\n",
"Related: https://github.com/huggingface/datasets/issues/3877",
"Also related: the [Data Catalog Vocabulary - DCAT](https://www.w3.org/TR/vocab-dcat/) standard will be discussed in a new Working Group at the W3C: https://www.w3.org/2022/06/dx-wg-charter.html"
] | "2022-01-24T18:52:39" | "2022-06-28T13:54:49" | null | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
The current problem is that information about when source data was produced is not easily visible. Though there are a variety of metadata fields available in the dataset viewer, time period information is not included. This feature request suggests making metadata relating to the time that the underlying *source* data was produced more prominent and outlines why this specific information is of particular importance, both in domain-specific historic research and more broadly.
**Describe the solution you'd like**
There are a variety of metadata fields exposed in the dataset viewer (license, task categories, etc.) These fields make this metadata more prominent both for human users and as potentially machine-actionable information (for example, through the API). I would propose to add a metadata field that says when some underlying data was produced. For example, a dataset would be labelled as being produced between `1800-1900`.
**Describe alternatives you've considered**
This information is sometimes available in the Datacard or a paper describing the dataset. However, it's often not that easy to identify or extract this information, particularly if you want to use this field as a filter to identify relevant datasets.
**Additional context**
I believe this feature is relevant for a number of reasons:
- Increasingly, there is an interest in using historical data for training language models (for example, https://huggingface.co/dbmdz/bert-base-historic-dutch-cased), and datasets to support this task (for example, https://huggingface.co/datasets/bnl_newspapers). For these datasets, indicating the time periods covered is particularly relevant.
- More broadly, time is likely a common source of domain drift. Datasets of movie reviews from the 90s may not work well for recent movie reviews. As the documentation and long-term management of ML data become more of a priority, quickly understanding the time when the underlying text (or other data types) is arguably more important.
- time-series data: datasets are adding more support for time series data. Again, the periods covered might be particularly relevant here.
**open questions**
- I think some of my points above apply not only to the underlying data but also to annotations. As a result, there could also be an argument for encoding this information somewhere. However, I would argue (but could be persuaded otherwise) that this is probably less important for filtering. This type of context is already addressed in the datasheets template and often requires more narrative to discuss.
- what level of granularity would make sense for this? e.g. assigning a decade, century or year?
- how to encode this information? What formatting makes sense
- what specific time to encode; a data range? (mean, modal, min, max value?)
This is a slightly amorphous feature request - I would be happy to discuss further/try and propose a more concrete solution if this seems like something that could be worth considering. I realise this might also touch on other parts of the 🤗 hubs ecosystem. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3625/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3623/comments | https://api.github.com/repos/huggingface/datasets/issues/3623/events | https://github.com/huggingface/datasets/pull/3623 | 1,112,835,239 | PR_kwDODunzps4xgWig | 3,623 | Extend support for streaming datasets that use os.path.relpath | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-24T16:00:52" | "2022-02-04T14:03:55" | "2022-02-04T14:03:54" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3623",
"html_url": "https://github.com/huggingface/datasets/pull/3623",
"diff_url": "https://github.com/huggingface/datasets/pull/3623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3623.patch",
"merged_at": "2022-02-04T14:03:54"
} | This PR extends the support in streaming mode for datasets that use `os.path.relpath`, by patching that function.
This feature will also be useful to yield the relative path of audio or image files, within an archive or parent dir.
Close #3622. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3623/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3622/comments | https://api.github.com/repos/huggingface/datasets/issues/3622/events | https://github.com/huggingface/datasets/issues/3622 | 1,112,831,661 | I_kwDODunzps5CVHat | 3,622 | Extend support for streaming datasets that use os.path.relpath | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | "2022-01-24T15:58:23" | "2022-02-04T14:03:54" | "2022-02-04T14:03:54" | MEMBER | null | null | null | Extend support for streaming datasets that use `os.path.relpath`.
This feature will also be useful to yield the relative path of audio or image files.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3622/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3621/comments | https://api.github.com/repos/huggingface/datasets/issues/3621/events | https://github.com/huggingface/datasets/issues/3621 | 1,112,720,434 | I_kwDODunzps5CUsQy | 3,621 | Consider adding `ipywidgets` as a dependency. | {
"login": "koaning",
"id": 1019791,
"node_id": "MDQ6VXNlcjEwMTk3OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1019791?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koaning",
"html_url": "https://github.com/koaning",
"followers_url": "https://api.github.com/users/koaning/followers",
"following_url": "https://api.github.com/users/koaning/following{/other_user}",
"gists_url": "https://api.github.com/users/koaning/gists{/gist_id}",
"starred_url": "https://api.github.com/users/koaning/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koaning/subscriptions",
"organizations_url": "https://api.github.com/users/koaning/orgs",
"repos_url": "https://api.github.com/users/koaning/repos",
"events_url": "https://api.github.com/users/koaning/events{/privacy}",
"received_events_url": "https://api.github.com/users/koaning/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! We use `tqdm` to display progress bars, so I suggest you open this issue in their repo.",
"It depends on how you use `tqdm`, no? \r\n\r\nDoesn't this library import via; \r\n\r\n```\r\nfrom tqdm.notebook import tqdm\r\n```",
"Hi! Sorry for the late reply. We import `tqdm` as `from tqdm.auto import tqdm`, which should be equal to `from tqdm.notebook import tqdm` in Jupyter.",
"Any objection if I make a PR that checks if the widgets library is installed beforehand? "
] | "2022-01-24T14:27:11" | "2022-02-24T09:04:36" | "2022-02-24T09:04:36" | NONE | null | null | null | When I install `datasets` in a fresh virtualenv with jupyterlab I always see this error.
```
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
```
It's a bit of a nuisance, because I need to run shut down the jupyterlab server in order to install the required dependency. Might it be an option to just include it as a dependency here? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3621/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3620/comments | https://api.github.com/repos/huggingface/datasets/issues/3620/events | https://github.com/huggingface/datasets/pull/3620 | 1,112,677,252 | PR_kwDODunzps4xf1J3 | 3,620 | Add Fon language tag | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-24T13:52:26" | "2022-02-04T14:04:36" | "2022-02-04T14:04:35" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3620",
"html_url": "https://github.com/huggingface/datasets/pull/3620",
"diff_url": "https://github.com/huggingface/datasets/pull/3620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3620.patch",
"merged_at": "2022-02-04T14:04:35"
} | Add Fon language tag to resources. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3620/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3619/comments | https://api.github.com/repos/huggingface/datasets/issues/3619/events | https://github.com/huggingface/datasets/pull/3619 | 1,112,611,415 | PR_kwDODunzps4xfnCQ | 3,619 | fix meta in mls | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Feel free to merge @polinaeterna as soon as you got an approval from either @lhoestq , @albertvillanova or @mariosasko"
] | "2022-01-24T12:54:38" | "2022-01-24T20:53:22" | "2022-01-24T20:53:22" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3619",
"html_url": "https://github.com/huggingface/datasets/pull/3619",
"diff_url": "https://github.com/huggingface/datasets/pull/3619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3619.patch",
"merged_at": "2022-01-24T20:53:21"
} | `monolingual` value of `m ultilinguality` param in yaml meta was changed to `multilingual` :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3619/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3618/comments | https://api.github.com/repos/huggingface/datasets/issues/3618/events | https://github.com/huggingface/datasets/issues/3618 | 1,112,123,365 | I_kwDODunzps5CSafl | 3,618 | TIMIT Dataset not working with GPU | {
"login": "TheSeamau5",
"id": 3227869,
"node_id": "MDQ6VXNlcjMyMjc4Njk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3227869?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheSeamau5",
"html_url": "https://github.com/TheSeamau5",
"followers_url": "https://api.github.com/users/TheSeamau5/followers",
"following_url": "https://api.github.com/users/TheSeamau5/following{/other_user}",
"gists_url": "https://api.github.com/users/TheSeamau5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TheSeamau5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheSeamau5/subscriptions",
"organizations_url": "https://api.github.com/users/TheSeamau5/orgs",
"repos_url": "https://api.github.com/users/TheSeamau5/repos",
"events_url": "https://api.github.com/users/TheSeamau5/events{/privacy}",
"received_events_url": "https://api.github.com/users/TheSeamau5/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! I think you should avoid calling `timit_train['audio']`. Indeed by doing so you're **loading all the audio column in memory**. This is problematic in your case because the TIMIT dataset is huge.\r\n\r\nIf you want to access the audio data of some samples, you should do this instead `timit_train[:10][\"train\"]` for example.\r\n\r\nOther than that, I'm not sure why you get a `TypeError: string indices must be integers`, do you have a code snippet that reproduces the issue that you can share here ?",
"I get the same error when I try to do `timit_train[0]` or really any indexing into the whole thing. \r\n\r\nReally, that IS the code snippet that reproduces the issue. If you index into other fields like 'file' or whatever, it works. As soon as one of the fields you're looking into is 'audio', you get that issue. It's a weird issue and I suspect it's Sagemaker/environment related, maybe the mix of libraries and dependencies are not good. \r\n\r\n\r\nExample code snippet with issue. \r\n```python\r\nfrom datasets import load_dataset\r\n\r\ntimit_train = load_dataset('timit_asr', split='train')\r\nprint(timit_train[0])\r\n```",
"Ok I see ! From the error you got, it looks like the `value` encoded in the arrow file of the TIMIT dataset you loaded is a string instead of a dictionary with keys \"path\" and \"bytes\" but we don't support this since 1.18\r\n\r\nCan you try regenerating the dataset with `load_dataset('timit_asr', download_mode=\"force_redownload\")` please ? I think it should fix the issue."
] | "2022-01-24T03:26:03" | "2023-07-25T15:20:20" | "2023-07-25T15:20:20" | NONE | null | null | null | ## Describe the bug
I am working trying to use the TIMIT dataset in order to fine-tune Wav2Vec2 model and I am unable to load the "audio" column from the dataset when working with a GPU.
I am working on Amazon Sagemaker Studio, on the Python 3 (PyTorch 1.8 Python 3.6 GPU Optimized) environment, with a single ml.g4dn.xlarge instance (corresponds to a Tesla T4 GPU).
I don't know if the issue is GPU related or Python environment related because everything works when I work off of the CPU Optimized environment with a non-GPU instance. My code also works on Google Colab with a GPU instance.
This issue is blocking because I cannot get the 'audio' column in any way due to this error, which means that I can't pass it to any functions. I later use the dataset.map function and that is where I originally noticed this error.
## Steps to reproduce the bug
```python
from datasets import load_dataset
timit_train = load_dataset('timit_asr', split='train')
print(timit_train['audio'])
```
## Expected results
Expected to see inside the 'audio' column, which contains an 'array' nested field with the array data I actually need.
## Actual results
Traceback
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-ceeac555e921> in <module>
----> 1 timit_train['audio']
/opt/conda/lib/python3.6/site-packages/datasets/arrow_dataset.py in __getitem__(self, key)
1917 """Can be used to index columns (by string names) or rows (by integer index or iterable of indices or bools)."""
1918 return self._getitem(
-> 1919 key,
1920 )
1921
/opt/conda/lib/python3.6/site-packages/datasets/arrow_dataset.py in _getitem(self, key, decoded, **kwargs)
1902 pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)
1903 formatted_output = format_table(
-> 1904 pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
1905 )
1906 return formatted_output
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in format_table(table, key, formatter, format_columns, output_all_columns)
529 python_formatter = PythonFormatter(features=None)
530 if format_columns is None:
--> 531 return formatter(pa_table, query_type=query_type)
532 elif query_type == "column":
533 if key in format_columns:
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in __call__(self, pa_table, query_type)
280 return self.format_row(pa_table)
281 elif query_type == "column":
--> 282 return self.format_column(pa_table)
283 elif query_type == "batch":
284 return self.format_batch(pa_table)
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in format_column(self, pa_table)
315 column = self.python_arrow_extractor().extract_column(pa_table)
316 if self.decoded:
--> 317 column = self.python_features_decoder.decode_column(column, pa_table.column_names[0])
318 return column
319
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in decode_column(self, column, column_name)
221
222 def decode_column(self, column: list, column_name: str) -> list:
--> 223 return self.features.decode_column(column, column_name) if self.features else column
224
225 def decode_batch(self, batch: dict) -> dict:
/opt/conda/lib/python3.6/site-packages/datasets/features/features.py in decode_column(self, column, column_name)
1337 return (
1338 [self[column_name].decode_example(value) if value is not None else None for value in column]
-> 1339 if self._column_requires_decoding[column_name]
1340 else column
1341 )
/opt/conda/lib/python3.6/site-packages/datasets/features/features.py in <listcomp>(.0)
1336 """
1337 return (
-> 1338 [self[column_name].decode_example(value) if value is not None else None for value in column]
1339 if self._column_requires_decoding[column_name]
1340 else column
/opt/conda/lib/python3.6/site-packages/datasets/features/audio.py in decode_example(self, value)
85 dict
86 """
---> 87 path, file = (value["path"], BytesIO(value["bytes"])) if value["bytes"] is not None else (value["path"], None)
88 if path is None and file is None:
89 raise ValueError(f"An audio sample should have one of 'path' or 'bytes' but both are None in {value}.")
TypeError: string indices must be integers
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: Linux-4.14.256-197.484.amzn2.x86_64-x86_64-with-debian-buster-sid
- Python version: 3.6.13
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3618/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3617/comments | https://api.github.com/repos/huggingface/datasets/issues/3617/events | https://github.com/huggingface/datasets/pull/3617 | 1,111,938,691 | PR_kwDODunzps4xdb8K | 3,617 | PR for the CFPB Consumer Complaints dataset | {
"login": "kayvane1",
"id": 42403093,
"node_id": "MDQ6VXNlcjQyNDAzMDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/42403093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kayvane1",
"html_url": "https://github.com/kayvane1",
"followers_url": "https://api.github.com/users/kayvane1/followers",
"following_url": "https://api.github.com/users/kayvane1/following{/other_user}",
"gists_url": "https://api.github.com/users/kayvane1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kayvane1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kayvane1/subscriptions",
"organizations_url": "https://api.github.com/users/kayvane1/orgs",
"repos_url": "https://api.github.com/users/kayvane1/repos",
"events_url": "https://api.github.com/users/kayvane1/events{/privacy}",
"received_events_url": "https://api.github.com/users/kayvane1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> Nice ! Thanks for adding this dataset :)\n> \n> \n> \n> I left a few comments:\n\nThanks!\n\nI'd be interested in contributing to the core codebase - I had to go down the custom loading approach because I couldn't pull this dataset in using the load_dataset() method. Using either the json or csv files available for this dataset as it was erroring. \n\nI'll rerun it and share the errors and try debug",
"Hey @lhoestq ,\r\n\r\nWhen I use this dataset as part of my project, I'm using this method\r\n\r\n`text_dataset = text_dataset['train'].train_test_split(test_size=0.2)`\r\n\r\nto create a train and test split as this dataset doesn't have one. \r\n\r\nCan I add this directly in the script itself somehow, or is it better to give users the flexibility to slice and split their datasets after loading?",
"> I'd be interested in contributing to the core codebase - I had to go down the custom loading approach because I couldn't pull this dataset in using the load_dataset() method. Using either the json or csv files available for this dataset as it was erroring.\r\n>\r\n> I'll rerun it and share the errors and try debug\r\n\r\nCool ! Let me know if you have questions or if I can help :)\r\n\r\n> Can I add this directly in the script itself somehow, or is it better to give users the flexibility to slice and split their datasets after loading?\r\n\r\nUsually we let the users the flexibility to split the datasets themselves (unless the dataset is already split, or if there is already a standard way to split it in the papers that use it)",
"Thanks Quentin!\r\nAll okay to merge now?",
"Thanks for the feedback Quentin and Mario - implemented all changes :)\r\n\r\n",
"Hey @lhoestq / @mariosasko \r\nAny other changes required to merge? 🤗",
"Hi ! Thanks and sorry for the late response \r\n\r\nIt looks very good ! The CI is still failing because it can't file the dummy_data.zip file, you can fix that by moving `datasets/consumer-finance-complaints/dummy/1.0.0/dummy_data.zip` to `datasets/consumer-finance-complaints/dummy/0.0.0/dummy_data.zip` and it should be all good !",
"@lhoestq - hopefully that should do it!\r\n"
] | "2022-01-23T17:47:12" | "2022-02-07T21:08:31" | "2022-02-07T21:08:31" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3617",
"html_url": "https://github.com/huggingface/datasets/pull/3617",
"diff_url": "https://github.com/huggingface/datasets/pull/3617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3617.patch",
"merged_at": "2022-02-07T21:08:31"
} | Think I followed all the steps but please let me know if anything needs changing or any improvements I can make to the code quality | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3617/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3617/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3616/comments | https://api.github.com/repos/huggingface/datasets/issues/3616/events | https://github.com/huggingface/datasets/pull/3616 | 1,111,587,861 | PR_kwDODunzps4xcZMD | 3,616 | Make streamable the BnL Historical Newspapers dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-22T14:52:36" | "2022-02-04T14:05:23" | "2022-02-04T14:05:21" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3616",
"html_url": "https://github.com/huggingface/datasets/pull/3616",
"diff_url": "https://github.com/huggingface/datasets/pull/3616.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3616.patch",
"merged_at": "2022-02-04T14:05:21"
} | I've refactored the code in order to make the dataset streamable and to avoid it takes too long:
- I've used `iter_files`
Close #3615 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3616/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3616/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3615/comments | https://api.github.com/repos/huggingface/datasets/issues/3615/events | https://github.com/huggingface/datasets/issues/3615 | 1,111,576,876 | I_kwDODunzps5CQVEs | 3,615 | Dataset BnL Historical Newspapers does not work in streaming mode | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"@albertvillanova let me know if there is anything I can do to help with this. I had a quick look at the code again and though I could try the following changes:\r\n- use `download` instead of `download_and_extract`\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bnl_newspapers/bnl_newspapers.py#L136\r\n- swith to using `iter_archive` to loop through downloaded data to replace\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bnl_newspapers/bnl_newspapers.py#L159\r\n\r\nLet me know if it's useful for me to try and make those changes. ",
"Thanks @davanstrien.\r\n\r\nI have already been working on it so that it can be used in the BigScience workshop.\r\n\r\nI agree that the `rglob()` is not efficient in this case.\r\n\r\nI tried different solutions without success:\r\n- `iter_archive` cannot be used in this case because it does not support ZIP files yet\r\n\r\nFinally I have used `iter_files()`.",
"I see this is fixed now 🙂. I also picked up a few other tips from your redactors so hopefully my next attempts will support streaming from the start. "
] | "2022-01-22T14:12:59" | "2022-02-04T14:05:21" | "2022-02-04T14:05:21" | MEMBER | null | null | null | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3615/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3614/comments | https://api.github.com/repos/huggingface/datasets/issues/3614/events | https://github.com/huggingface/datasets/pull/3614 | 1,110,736,657 | PR_kwDODunzps4xZdCe | 3,614 | Minor fixes | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-21T17:48:44" | "2022-01-24T12:45:49" | "2022-01-24T12:45:49" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3614",
"html_url": "https://github.com/huggingface/datasets/pull/3614",
"diff_url": "https://github.com/huggingface/datasets/pull/3614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3614.patch",
"merged_at": "2022-01-24T12:45:49"
} | This PR:
* adds "desc" to the `ignore_kwargs` list in `Dataset.filter`
* fixes the default value of `id` in `DatasetDict.prepare_for_task` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3614/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3614/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3613/comments | https://api.github.com/repos/huggingface/datasets/issues/3613/events | https://github.com/huggingface/datasets/issues/3613 | 1,110,684,015 | I_kwDODunzps5CM7Fv | 3,613 | Files not updating in dataset viewer | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/abidlabs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abidlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abidlabs/subscriptions",
"organizations_url": "https://api.github.com/users/abidlabs/orgs",
"repos_url": "https://api.github.com/users/abidlabs/repos",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"received_events_url": "https://api.github.com/users/abidlabs/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Yes. The jobs queue is full right now, following an upgrade... Back to normality in the next hours hopefully. I'll look at your datasets to be sure the dataset viewer works as expected on them.",
"Should have been fixed now."
] | "2022-01-21T16:47:20" | "2022-01-22T08:13:13" | "2022-01-22T08:13:13" | MEMBER | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:**
Some examples:
* https://huggingface.co/datasets/abidlabs/crowdsourced-speech4
* https://huggingface.co/datasets/abidlabs/test-audio-13
*short description of the issue*
It seems that the dataset viewer is reading a cached version of the dataset and it is not updating to reflect new files that are added to the dataset. I get this error:
Am I the one who added this dataset? Yes | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3613/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3613/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3612/comments | https://api.github.com/repos/huggingface/datasets/issues/3612/events | https://github.com/huggingface/datasets/pull/3612 | 1,110,506,466 | PR_kwDODunzps4xYsvS | 3,612 | wikifix | {
"login": "apergo-ai",
"id": 68908804,
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apergo-ai",
"html_url": "https://github.com/apergo-ai",
"followers_url": "https://api.github.com/users/apergo-ai/followers",
"following_url": "https://api.github.com/users/apergo-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/apergo-ai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apergo-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apergo-ai/subscriptions",
"organizations_url": "https://api.github.com/users/apergo-ai/orgs",
"repos_url": "https://api.github.com/users/apergo-ai/repos",
"events_url": "https://api.github.com/users/apergo-ai/events{/privacy}",
"received_events_url": "https://api.github.com/users/apergo-ai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"tests fail because of dataset_infos.json isn't updated. Unfortunately, I cannot get the datasets-cli locally to execute without error. Would need to troubleshoot, what's missing. Maybe someone else can pick up the stick. ",
"Hi ! If we change the default date to the latest one, users won't be able to load the \"big\" languages like english anymore, because it requires an Apache Beam runtime to process them. On the contrary, the old data 20200501 has been processed by Hugging Face so that users don't need to run Apache Beam stuff.\r\n\r\nTherefore I'm in favor of not changing the default date until we have processed the latest versions of wikipedia.\r\n\r\nUsers that want to load other languages or that can use Apache Beam can still pass the `language` and `date` parameter to `load_dataset` if they want anyway:\r\n```python\r\nload_dataset(\"wikipedia\", language=\"fr\", date=\"20220120\")\r\n```",
"in that case you can close the PR",
"Ok thanks !\r\n\r\n(oh I I just noticed that the dataset card is missing the documentation regarding the language and date parameters, let me add it)"
] | "2022-01-21T14:05:11" | "2022-02-03T17:58:16" | "2022-02-03T17:58:16" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3612",
"html_url": "https://github.com/huggingface/datasets/pull/3612",
"diff_url": "https://github.com/huggingface/datasets/pull/3612.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3612.patch",
"merged_at": null
} | This should get the wikipedia dataloading script back up and running - at least I hope so (tested with language ff and ii) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3612/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3611/comments | https://api.github.com/repos/huggingface/datasets/issues/3611/events | https://github.com/huggingface/datasets/issues/3611 | 1,110,399,096 | I_kwDODunzps5CL1h4 | 3,611 | Indexing bug after dataset.select() | {
"login": "kamalkraj",
"id": 17096858,
"node_id": "MDQ6VXNlcjE3MDk2ODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalkraj",
"html_url": "https://github.com/kamalkraj",
"followers_url": "https://api.github.com/users/kamalkraj/followers",
"following_url": "https://api.github.com/users/kamalkraj/following{/other_user}",
"gists_url": "https://api.github.com/users/kamalkraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamalkraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamalkraj/subscriptions",
"organizations_url": "https://api.github.com/users/kamalkraj/orgs",
"repos_url": "https://api.github.com/users/kamalkraj/repos",
"events_url": "https://api.github.com/users/kamalkraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamalkraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi! Thanks for reporting! I've opened a PR with the fix."
] | "2022-01-21T12:09:30" | "2022-01-27T18:16:22" | "2022-01-27T18:16:22" | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Dataset indexing is not working as expected after `dataset.select(range(100))`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import datasets
task_to_keys = {
"cola": ("sentence", None),
"mnli": ("premise", "hypothesis"),
"mrpc": ("sentence1", "sentence2"),
"qnli": ("question", "sentence"),
"qqp": ("question1", "question2"),
"rte": ("sentence1", "sentence2"),
"sst2": ("sentence", None),
"stsb": ("sentence1", "sentence2"),
"wnli": ("sentence1", "sentence2"),
}
task_name = "sst2"
raw_datasets = datasets.load_dataset("glue", task_name)
train_dataset = raw_datasets["train"]
print("before select: ",train_dataset[-2:])
# before select: {'sentence': ['a patient viewer ', 'this new jangle of noise , mayhem and stupidity must be a serious contender for the title . '], 'label': [1, 0], 'idx': [67347, 67348]}
train_dataset = train_dataset.select(range(100))
print("after select: ",train_dataset[-2:])
# after select: {'sentence': [], 'label': [], 'idx': []}
```
link to colab: https://colab.research.google.com/drive/1LngeRC9f0jE7eSQ4Kh1cIeb411lRXQD-?usp=sharing
## Expected results
A clear and concise description of the expected results.
showing 98, 99 index data
## Actual results
Specify the actual results or traceback.
empty
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3611/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3610/comments | https://api.github.com/repos/huggingface/datasets/issues/3610/events | https://github.com/huggingface/datasets/issues/3610 | 1,109,777,314 | I_kwDODunzps5CJdui | 3,610 | Checksum error when trying to load amazon_review dataset | {
"login": "rifoag",
"id": 32415171,
"node_id": "MDQ6VXNlcjMyNDE1MTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/32415171?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rifoag",
"html_url": "https://github.com/rifoag",
"followers_url": "https://api.github.com/users/rifoag/followers",
"following_url": "https://api.github.com/users/rifoag/following{/other_user}",
"gists_url": "https://api.github.com/users/rifoag/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rifoag/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rifoag/subscriptions",
"organizations_url": "https://api.github.com/users/rifoag/orgs",
"repos_url": "https://api.github.com/users/rifoag/repos",
"events_url": "https://api.github.com/users/rifoag/events{/privacy}",
"received_events_url": "https://api.github.com/users/rifoag/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"It is solved now"
] | "2022-01-20T21:20:32" | "2022-01-21T13:22:31" | "2022-01-21T13:22:31" | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
I am getting the issue when trying to load dataset using
```
dataset = load_dataset("amazon_polarity")
```
## Expected results
dataset loaded
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-3-b4758ba980ae> in <module>()
----> 1 dataset = load_dataset("amazon_polarity")
2 dataset.set_format(type='pandas')
3 content_series = dataset['train']['content']
4 label_series = dataset['train']['label']
5 df = pd.concat([content_series, label_series], axis=1)
3 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?id=0Bz8a_Dbh9QhbaW12WVVZS2drcnM&export=download']
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Google colab
- Python version: 3.7.12 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3610/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3609/comments | https://api.github.com/repos/huggingface/datasets/issues/3609/events | https://github.com/huggingface/datasets/pull/3609 | 1,109,579,112 | PR_kwDODunzps4xVrsG | 3,609 | Fixes to pubmed dataset download function | {
"login": "spacemanidol",
"id": 3886120,
"node_id": "MDQ6VXNlcjM4ODYxMjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3886120?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spacemanidol",
"html_url": "https://github.com/spacemanidol",
"followers_url": "https://api.github.com/users/spacemanidol/followers",
"following_url": "https://api.github.com/users/spacemanidol/following{/other_user}",
"gists_url": "https://api.github.com/users/spacemanidol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spacemanidol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spacemanidol/subscriptions",
"organizations_url": "https://api.github.com/users/spacemanidol/orgs",
"repos_url": "https://api.github.com/users/spacemanidol/repos",
"events_url": "https://api.github.com/users/spacemanidol/events{/privacy}",
"received_events_url": "https://api.github.com/users/spacemanidol/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! I think we can simply add a new configuration for the 2022 data instead of replacing them.\r\nYou can add the new configuration here:\r\n```python\r\n BUILDER_CONFIGS = [\r\n datasets.BuilderConfig(name=\"2021\", description=\"The 2021 annual record\", version=datasets.Version(\"1.0.0\")),\r\n datasets.BuilderConfig(name=\"2022\", description=\"The 2022 annual record\", version=datasets.Version(\"1.0.0\")),\r\n ]\r\n```\r\n\r\nAnd we can have the URLs for these two versions this way:\r\n```python\r\n_URLs = {\r\n \"2021\": f\"ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n{i:04d}.xml.gz\" for i in range(1, 1063)],\r\n \"2022\": f\"ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed22n{i:04d}.xml.gz\" for i in range(1, 1114)]\r\n}\r\n```\r\nand depending on the configuration name (you can get it with `self.config.name`) we can pick the URLs of 2021 or the ones of 2022 and pass them to the `dl_manager` in `_split_generators`\r\n\r\nFeel free to ping me if you have questions or if I can help !",
"Hi @spacemanidol, thanks for your contribution.\r\n\r\nThe update of the PubMed dataset URL (besides the update of the corresponding metadata and the dummy data) was already merged to master branch in this other PR:\r\n- #3692 \r\n\r\nI'm closing this PR then.\r\n\r\n@lhoestq please take into account that 2021 data is no longer accessible: every year PubMed releases the baseline data (containing all previous data until that year) and from that on, they release daily updates. ",
"> @lhoestq please take into account that 2021 data is no longer accessible: every year PubMed releases the baseline data (containing all previous data until that year) and from that on, they release daily updates.\r\n\r\nOh ok I didn't know, thanks"
] | "2022-01-20T17:31:35" | "2022-03-03T16:18:52" | "2022-03-03T14:23:35" | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3609",
"html_url": "https://github.com/huggingface/datasets/pull/3609",
"diff_url": "https://github.com/huggingface/datasets/pull/3609.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3609.patch",
"merged_at": null
} | Pubmed has updated its settings for 2022 and thus existing download script does not work. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3609/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3608/comments | https://api.github.com/repos/huggingface/datasets/issues/3608/events | https://github.com/huggingface/datasets/issues/3608 | 1,109,310,981 | I_kwDODunzps5CHr4F | 3,608 | Add support for continuous metrics (RMSE, MAE) | {
"login": "ck37",
"id": 50770,
"node_id": "MDQ6VXNlcjUwNzcw",
"avatar_url": "https://avatars.githubusercontent.com/u/50770?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ck37",
"html_url": "https://github.com/ck37",
"followers_url": "https://api.github.com/users/ck37/followers",
"following_url": "https://api.github.com/users/ck37/following{/other_user}",
"gists_url": "https://api.github.com/users/ck37/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ck37/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ck37/subscriptions",
"organizations_url": "https://api.github.com/users/ck37/orgs",
"repos_url": "https://api.github.com/users/ck37/repos",
"events_url": "https://api.github.com/users/ck37/events{/privacy}",
"received_events_url": "https://api.github.com/users/ck37/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | closed | false | null | [] | null | [
"Hey @ck37 \r\n\r\nYou can always use a custom metric as explained [in this guide from HF](https://huggingface.co/docs/datasets/master/loading_metrics.html#using-a-custom-metric-script).\r\n\r\nIf this issue needs to be contributed to (for enhancing the metric API) I think [this link](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_absolute_error.html) would be helpful for the `MAE` metric.",
"You can use a local metric script just by providing its path instead of the usual shortcut name ",
"#self-assign I have starting working on this issue to enhance the metric API."
] | "2022-01-20T13:35:36" | "2022-03-09T17:18:20" | "2022-03-09T17:18:20" | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
I am uploading our dataset and models for the "Constructing interval measures" method we've developed, which uses item response theory to convert multiple discrete labels into a continuous spectrum for hate speech. Once we have this outcome our NLP models conduct regression rather than classification, so binary metrics are not relevant. The only continuous metrics available at https://huggingface.co/metrics are pearson & spearman correlation, which don't ensure that the prediction is on the same scale as the outcome.
**Describe the solution you'd like**
I would like to be able to tag our models on the Hub with the following metrics:
- RMSE
- MAE
**Describe alternatives you've considered**
I don't know if there are any alternatives.
**Additional context**
Our preprint is available here: https://arxiv.org/abs/2009.10277 . We are making it available for use in Jigsaw's Toxic Severity Rating Kaggle competition: https://www.kaggle.com/c/jigsaw-toxic-severity-rating/overview . I have our first model uploaded to the Hub at https://huggingface.co/ucberkeley-dlab/hate-measure-roberta-large
Thanks,
Chris
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3608/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3607/comments | https://api.github.com/repos/huggingface/datasets/issues/3607/events | https://github.com/huggingface/datasets/pull/3607 | 1,109,218,370 | PR_kwDODunzps4xUgrR | 3,607 | Add MIT Scene Parsing Benchmark | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-20T12:03:07" | "2022-02-18T12:51:01" | "2022-02-18T12:51:00" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3607",
"html_url": "https://github.com/huggingface/datasets/pull/3607",
"diff_url": "https://github.com/huggingface/datasets/pull/3607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3607.patch",
"merged_at": "2022-02-18T12:51:00"
} | Add MIT Scene Parsing Benchmark (a subset of ADE20k).
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3606/comments | https://api.github.com/repos/huggingface/datasets/issues/3606/events | https://github.com/huggingface/datasets/issues/3606 | 1,108,918,701 | I_kwDODunzps5CGMGt | 3,606 | audio column not saved correctly after resampling | {
"login": "laphang",
"id": 24724502,
"node_id": "MDQ6VXNlcjI0NzI0NTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/24724502?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/laphang",
"html_url": "https://github.com/laphang",
"followers_url": "https://api.github.com/users/laphang/followers",
"following_url": "https://api.github.com/users/laphang/following{/other_user}",
"gists_url": "https://api.github.com/users/laphang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/laphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/laphang/subscriptions",
"organizations_url": "https://api.github.com/users/laphang/orgs",
"repos_url": "https://api.github.com/users/laphang/repos",
"events_url": "https://api.github.com/users/laphang/events{/privacy}",
"received_events_url": "https://api.github.com/users/laphang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! We just released a new version of `datasets` that should fix this.\r\n\r\nI tested resampling and using save/load_from_disk afterwards and it seems to be fixed now",
"Hi @lhoestq, \r\n\r\nJust tested the latest datasets version, and confirming that this is fixed for me. \r\n\r\nThanks!",
"Also, just an FYI, data that I had saved (with save_to_disk) previously from common voice using datasets==1.17.0 now give the error below when loading (with load_from disk) using datasets==1.18.0. \r\n\r\nHowever, when starting fresh using load_dataset, then doing the resampling, the save/load_from disk worked fine. \r\n\r\n```\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<timed exec> in <module>\r\n\r\n/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_from_disk(dataset_path, fs, keep_in_memory)\r\n 1747 return Dataset.load_from_disk(dataset_path, fs, keep_in_memory=keep_in_memory)\r\n 1748 elif fs.isfile(Path(dest_dataset_path, config.DATASETDICT_JSON_FILENAME).as_posix()):\r\n-> 1749 return DatasetDict.load_from_disk(dataset_path, fs, keep_in_memory=keep_in_memory)\r\n 1750 else:\r\n 1751 raise FileNotFoundError(\r\n\r\n/opt/conda/lib/python3.7/site-packages/datasets/dataset_dict.py in load_from_disk(dataset_dict_path, fs, keep_in_memory)\r\n 769 else Path(dest_dataset_dict_path, k).as_posix()\r\n 770 )\r\n--> 771 dataset_dict[k] = Dataset.load_from_disk(dataset_dict_split_path, fs, keep_in_memory=keep_in_memory)\r\n 772 return dataset_dict\r\n 773 \r\n\r\n/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py in load_from_disk(dataset_path, fs, keep_in_memory)\r\n 1118 info=dataset_info,\r\n 1119 split=split,\r\n-> 1120 fingerprint=state[\"_fingerprint\"],\r\n 1121 )\r\n 1122 \r\n\r\n/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py in __init__(self, arrow_table, info, split, indices_table, fingerprint)\r\n 655 if self.info.features.type != inferred_features.type:\r\n 656 raise ValueError(\r\n--> 657 f\"External features info don't match the dataset:\\nGot\\n{self.info.features}\\nwith type\\n{self.info.features.type}\\n\\nbut expected something like\\n{inferred_features}\\nwith type\\n{inferred_features.type}\"\r\n 658 )\r\n 659 \r\n\r\nValueError: External features info don't match the dataset:\r\nGot\r\n{'accent': Value(dtype='string', id=None), 'age': Value(dtype='string', id=None), 'audio': Audio(sampling_rate=48000, mono=True, id=None), 'client_id': Value(dtype='string', id=None), 'down_votes': Value(dtype='int64', id=None), 'gender': Value(dtype='string', id=None), 'locale': Value(dtype='string', id=None), 'path': Value(dtype='string', id=None), 'segment': Value(dtype='string', id=None), 'sentence': Value(dtype='string', id=None), 'up_votes': Value(dtype='int64', id=None)}\r\nwith type\r\nstruct<accent: string, age: string, audio: struct<bytes: binary, path: string>, client_id: string, down_votes: int64, gender: string, locale: string, path: string, segment: string, sentence: string, up_votes: int64>\r\n\r\nbut expected something like\r\n{'accent': Value(dtype='string', id=None), 'age': Value(dtype='string', id=None), 'audio': {'path': Value(dtype='string', id=None), 'bytes': Value(dtype='binary', id=None)}, 'client_id': Value(dtype='string', id=None), 'down_votes': Value(dtype='int64', id=None), 'gender': Value(dtype='string', id=None), 'locale': Value(dtype='string', id=None), 'path': Value(dtype='string', id=None), 'segment': Value(dtype='string', id=None), 'sentence': Value(dtype='string', id=None), 'up_votes': Value(dtype='int64', id=None)}\r\nwith type\r\nstruct<accent: string, age: string, audio: struct<path: string, bytes: binary>, client_id: string, down_votes: int64, gender: string, locale: string, path: string, segment: string, sentence: string, up_votes: int64> \r\n```"
] | "2022-01-20T06:37:10" | "2022-01-23T01:41:01" | "2022-01-23T01:24:14" | NONE | null | null | null | ## Describe the bug
After resampling the audio column, saving with save_to_disk doesn't seem to save with the correct type.
## Steps to reproduce the bug
- load a subset of common voice dataset (48Khz)
- resample audio column to 16Khz
- save with save_to_disk()
- load with load_from_disk()
## Expected results
I expected that after saving the data, and then loading it back in, the audio column has the correct dataset.Audio type (i.e. same as before saving it)
{'accent': Value(dtype='string', id=None),
'age': Value(dtype='string', id=None),
'audio': Audio(sampling_rate=16000, mono=True, _storage_dtype='string', id=None),
'client_id': Value(dtype='string', id=None),
'down_votes': Value(dtype='int64', id=None),
'gender': Value(dtype='string', id=None),
'locale': Value(dtype='string', id=None),
'path': Value(dtype='string', id=None),
'segment': Value(dtype='string', id=None),
'sentence': Value(dtype='string', id=None),
'up_votes': Value(dtype='int64', id=None)}
## Actual results
Audio column does not have the right type
{'accent': Value(dtype='string', id=None),
'age': Value(dtype='string', id=None),
'audio': {'bytes': Value(dtype='binary', id=None),
'path': Value(dtype='string', id=None)},
'client_id': Value(dtype='string', id=None),
'down_votes': Value(dtype='int64', id=None),
'gender': Value(dtype='string', id=None),
'locale': Value(dtype='string', id=None),
'path': Value(dtype='string', id=None),
'segment': Value(dtype='string', id=None),
'sentence': Value(dtype='string', id=None),
'up_votes': Value(dtype='int64', id=None)}
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: linux
- Python version:
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3606/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3605/comments | https://api.github.com/repos/huggingface/datasets/issues/3605/events | https://github.com/huggingface/datasets/pull/3605 | 1,108,738,561 | PR_kwDODunzps4xS9rX | 3,605 | Adding Turkic X-WMT evaluation set for machine translation | {
"login": "mirzakhalov",
"id": 26018417,
"node_id": "MDQ6VXNlcjI2MDE4NDE3",
"avatar_url": "https://avatars.githubusercontent.com/u/26018417?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mirzakhalov",
"html_url": "https://github.com/mirzakhalov",
"followers_url": "https://api.github.com/users/mirzakhalov/followers",
"following_url": "https://api.github.com/users/mirzakhalov/following{/other_user}",
"gists_url": "https://api.github.com/users/mirzakhalov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mirzakhalov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mirzakhalov/subscriptions",
"organizations_url": "https://api.github.com/users/mirzakhalov/orgs",
"repos_url": "https://api.github.com/users/mirzakhalov/repos",
"events_url": "https://api.github.com/users/mirzakhalov/events{/privacy}",
"received_events_url": "https://api.github.com/users/mirzakhalov/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"hi! Thank you for all the comments! I believe I addressed them all. Let me know if there is anything else",
"Hi there! I was wondering if there is anything else to change before this can be merged",
"@lhoestq Hi! Just a gentle reminder about the steps to merge this one! ",
"Thanks for the heads up ! I think I fixed the last issue with the YAML tags",
"The CI failure is unrelated to this PR and fixed on master, let's merge :)\r\n\r\nThanks a lot !"
] | "2022-01-20T01:40:29" | "2022-01-31T09:50:57" | "2022-01-31T09:50:57" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3605",
"html_url": "https://github.com/huggingface/datasets/pull/3605",
"diff_url": "https://github.com/huggingface/datasets/pull/3605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3605.patch",
"merged_at": "2022-01-31T09:50:57"
} | This dataset is a human-translated evaluation set for MT crowdsourced and provided by the [Turkic Interlingua ](turkic-interlingua.org) community. It contains eval sets for 8 Turkic languages covering 88 language directions. Languages being covered are:
Azerbaijani (az)
Bashkir (ba)
English (en)
Karakalpak (kaa)
Kazakh (kk)
Kirghiz (ky)
Russian (ru)
Turkish (tr)
Sakha (sah)
Uzbek (uz)
More info about the corpus is here: [https://github.com/turkic-interlingua/til-mt/tree/master/xwmt](https://github.com/turkic-interlingua/til-mt/tree/master/xwmt)
A paper describing the test set is here: [https://arxiv.org/abs/2109.04593](https://arxiv.org/abs/2109.04593)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3604/comments | https://api.github.com/repos/huggingface/datasets/issues/3604/events | https://github.com/huggingface/datasets/issues/3604 | 1,108,477,316 | I_kwDODunzps5CEgWE | 3,604 | Dataset Viewer not showing Previews for Private Datasets | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/abidlabs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abidlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abidlabs/subscriptions",
"organizations_url": "https://api.github.com/users/abidlabs/orgs",
"repos_url": "https://api.github.com/users/abidlabs/repos",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"received_events_url": "https://api.github.com/users/abidlabs/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Sure, it's on the roadmap.",
"Closing in favor of https://github.com/huggingface/datasets-server/issues/39."
] | "2022-01-19T19:29:26" | "2022-09-26T08:04:43" | "2022-09-26T08:04:43" | MEMBER | null | null | null | ## Dataset viewer issue for 'abidlabs/test-audio-13'
It seems that the dataset viewer does not show previews for `private` datasets, even for the user who's private dataset it is. See [1] for example. If I change the visibility to public, then it does show, but it would be useful to have the viewer even for private datasets.
**Link:**
[1] https://huggingface.co/datasets/abidlabs/test-audio-13
**Am I the one who added this dataset?**
Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3604/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3603/comments | https://api.github.com/repos/huggingface/datasets/issues/3603/events | https://github.com/huggingface/datasets/pull/3603 | 1,108,392,141 | PR_kwDODunzps4xR1ih | 3,603 | Add British Library books dataset | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for all the help and suggestions\r\n\r\n> Since the dataset has a very specific structure it might not be that easy so feel free to ping me if you have questions or if I can help !\r\n\r\nI did get a little stuck here! So far I have created directories for each config i.e:\r\n\r\n`datasets/datasets/blbooks/dummy/1700_1799/1.0.2/dummy_data.zip` \r\n\r\nI have then added two examples of the `jsonl.gz` files that are in the underlying dataset to each dummy_data directory.This fails the test using local files. \r\n\r\nSince \r\n\r\n```python\r\ndef _generate_examples(self, data_dirs):\r\n```\r\n\r\ntakes as input `data_dirs` which is a list of `iter_dirs` do I need to put the dummy files inside another directory? i.e. \r\n\r\n`datasets/datasets/blbooks/dummy/1700_1799/1.0.2/dummy_data/1700/00.jsonl.gz` \r\n\r\n\r\n ",
"I think I managed to create the dummy data :)\r\n\r\nI think everything is good now, if you don't have other changes to do, please mark your PR as \"ready for review\" and ping me!",
"> I think I managed to create the dummy data :)\r\n\r\nThanks so much for that!\r\n\r\n> I think everything is good now, if you don't have other changes to do, please mark your PR as \"ready for review\" and ping me!\r\n\r\nThink it is ready to merge from my end @lhoestq. ",
"The CI failure on windows is unrelated to your PR and fixed on `master`, we can ignore it"
] | "2022-01-19T17:53:05" | "2022-01-31T17:22:51" | "2022-01-31T17:01:49" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3603",
"html_url": "https://github.com/huggingface/datasets/pull/3603",
"diff_url": "https://github.com/huggingface/datasets/pull/3603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3603.patch",
"merged_at": "2022-01-31T17:01:49"
} | This pull request adds a dataset of text from digitised (primarily 19th Century) books from the British Library. This collection has previously been used for training language models, e.g. https://github.com/dbmdz/clef-hipe/blob/main/hlms.md. It would be nice to make this dataset more accessible for others to use through datasets.
This is still a WIP but I wanted to get some initial feedback in particular; I wanted to check:
- I am handling the use of `iter_archive` correctly - I intend to ensure that `dl_manager.download` gets the complete list of URLs to download upfront, so the progress bar knows how much is left to download and then to pass through the `gen_kwargs` a list of downloaded zip archives wrapped in `iter_archive`. I am unsure if there is a more elegant approach for this?
- the number of configs: I have aimed to keep this limited - there are a lot of URLs covering the entire dataset, but I have tried to base the configs on what I believe the majority of people will want to they are not presented with too many options - I am happy to hear suggestions for changing this
If there are other glaring omissions or mistakes, I'd be happy to hear them. If this approach seems sensible in general, I will finish all the remaining TODOs, generate dummy_data, etc.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3603/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3603/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3602/comments | https://api.github.com/repos/huggingface/datasets/issues/3602/events | https://github.com/huggingface/datasets/pull/3602 | 1,108,247,870 | PR_kwDODunzps4xRXVm | 3,602 | Update url for conll2003 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi. lhoestq \r\n\r\n\r\nWhat is the solution for it?\r\nyou can see it is still doesn't work here.\r\nhttps://colab.research.google.com/drive/1l52FGWuSaOaGYchit4CbmtUSuzNDx_Ok?usp=sharing\r\nThank you.\r\n",
"For now you can specify `load_dataset(..., revision=\"master\")` to use the fix on `master`.\r\n\r\nWe'll also do a new release of `datasets` tomorrow I think"
] | "2022-01-19T15:35:04" | "2022-01-20T16:23:03" | "2022-01-19T15:43:53" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3602",
"html_url": "https://github.com/huggingface/datasets/pull/3602",
"diff_url": "https://github.com/huggingface/datasets/pull/3602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3602.patch",
"merged_at": "2022-01-19T15:43:53"
} | Following https://github.com/huggingface/datasets/issues/3582 I'm changing the download URL of the conll2003 data files, since the previous host doesn't have the authorization to redistribute the data | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3602/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3602/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3601/comments | https://api.github.com/repos/huggingface/datasets/issues/3601/events | https://github.com/huggingface/datasets/pull/3601 | 1,108,207,131 | PR_kwDODunzps4xROtF | 3,601 | Add conll2003 licensing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-19T15:00:41" | "2022-01-19T17:17:28" | "2022-01-19T17:17:28" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3601",
"html_url": "https://github.com/huggingface/datasets/pull/3601",
"diff_url": "https://github.com/huggingface/datasets/pull/3601.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3601.patch",
"merged_at": "2022-01-19T17:17:28"
} | Following https://github.com/huggingface/datasets/issues/3582, this PR updates the licensing section of the CoNLL2003 dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3601/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3600/comments | https://api.github.com/repos/huggingface/datasets/issues/3600/events | https://github.com/huggingface/datasets/pull/3600 | 1,108,131,878 | PR_kwDODunzps4xQ-vt | 3,600 | Use old url for conll2003 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-19T13:56:49" | "2022-01-19T14:16:28" | "2022-01-19T14:16:28" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3600",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"merged_at": "2022-01-19T14:16:28"
} | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3600/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"login": "ThGouzias",
"id": 59422506,
"node_id": "MDQ6VXNlcjU5NDIyNTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ThGouzias",
"html_url": "https://github.com/ThGouzias",
"followers_url": "https://api.github.com/users/ThGouzias/followers",
"following_url": "https://api.github.com/users/ThGouzias/following{/other_user}",
"gists_url": "https://api.github.com/users/ThGouzias/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ThGouzias/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ThGouzias/subscriptions",
"organizations_url": "https://api.github.com/users/ThGouzias/orgs",
"repos_url": "https://api.github.com/users/ThGouzias/repos",
"events_url": "https://api.github.com/users/ThGouzias/events{/privacy}",
"received_events_url": "https://api.github.com/users/ThGouzias/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"similar #3611 "
] | "2022-01-19T13:36:50" | "2022-01-28T15:35:57" | "2022-01-28T15:35:57" | NONE | null | null | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousand rows, create a new dataset with these and also add a new column to it:
> dataset2 = dataset.select(list(range(1000)))
> final_dataset = dataset2.add_column('colB', list(range(1000)))
This gives an error
>ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
So it looks like even though it is a dataset with 1000 rows, it "remembers" the shape of the one it was sliced from.
## Actual results
```
ArrowInvalid Traceback (most recent call last)
<ipython-input-138-e806860f3ce3> in <module>
----> 1 final_dataset = dataset2.add_column('colB', list(range(1000)))
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
468 }
469 # apply actual function
--> 470 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
471 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
472 # re-apply format to the output
~/.local/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
404 # Call actual function
405
--> 406 out = func(self, *args, **kwargs)
407
408 # Update fingerprint of in-place transforms + update in-place history of transforms
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in add_column(self, name, column, new_fingerprint)
3343 column_table = InMemoryTable.from_pydict({name: column})
3344 # Concatenate tables horizontally
-> 3345 table = ConcatenationTable.from_tables([self._data, column_table], axis=1)
3346 # Update features
3347 info = self.info.copy()
~/.local/lib/python3.8/site-packages/datasets/table.py in from_tables(cls, tables, axis)
729 table_blocks = to_blocks(table)
730 blocks = _extend_blocks(blocks, table_blocks, axis=axis)
--> 731 return cls.from_blocks(blocks)
732
733 @property
~/.local/lib/python3.8/site-packages/datasets/table.py in from_blocks(cls, blocks)
668 @classmethod
669 def from_blocks(cls, blocks: TableBlockContainer) -> "ConcatenationTable":
--> 670 blocks = cls._consolidate_blocks(blocks)
671 if isinstance(blocks, TableBlock):
672 table = blocks
~/.local/lib/python3.8/site-packages/datasets/table.py in _consolidate_blocks(cls, blocks)
664 return cls._merge_blocks(blocks, axis=0)
665 else:
--> 666 return cls._merge_blocks(blocks)
667
668 @classmethod
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
647 for is_in_memory, block_group in groupby(blocks, key=lambda x: isinstance(x, InMemoryTable)):
648 if is_in_memory:
--> 649 block_group = [InMemoryTable(cls._concat_blocks(list(block_group), axis=axis))]
650 merged_blocks += list(block_group)
651 else: # both
~/.local/lib/python3.8/site-packages/datasets/table.py in _concat_blocks(blocks, axis)
626 else:
627 for name, col in zip(table.column_names, table.columns):
--> 628 pa_table = pa_table.append_column(name, col)
629 return pa_table
630 else:
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.append_column()
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.add_column()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
```
A solution provided by @mariosasko is to use `dataset2.flatten_indices()` after the `select()` and before attempting to add the new column:
> dataset = Dataset.from_dict({'colA': list(range(2000))})
> dataset2 = dataset.select(list(range(1000)))
> dataset2 = dataset2.flatten_indices()
> final_dataset = dataset2.add_column('colB', list(range(1000)))
which works.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.13.2 (note: also checked with version 1.17.0, still the same error)
- Platform: Ubuntu 20.04.3
- Python version: 3.8.10
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3598/comments | https://api.github.com/repos/huggingface/datasets/issues/3598/events | https://github.com/huggingface/datasets/issues/3598 | 1,108,107,199 | I_kwDODunzps5CDF-_ | 3,598 | Readme info not being parsed to show on Dataset card page | {
"login": "davidcanovas",
"id": 79796807,
"node_id": "MDQ6VXNlcjc5Nzk2ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/79796807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidcanovas",
"html_url": "https://github.com/davidcanovas",
"followers_url": "https://api.github.com/users/davidcanovas/followers",
"following_url": "https://api.github.com/users/davidcanovas/following{/other_user}",
"gists_url": "https://api.github.com/users/davidcanovas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davidcanovas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidcanovas/subscriptions",
"organizations_url": "https://api.github.com/users/davidcanovas/orgs",
"repos_url": "https://api.github.com/users/davidcanovas/repos",
"events_url": "https://api.github.com/users/davidcanovas/events{/privacy}",
"received_events_url": "https://api.github.com/users/davidcanovas/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"i suspect a markdown parsing error, @severo do you want to take a quick look at it when you have some time?",
"# Problem\r\nThe issue seems to coming from the front matter of the README\r\n```---\r\nannotations_creators:\r\n- no-annotation\r\nlanguage_creators:\r\n- machine-generated\r\nlanguages:\r\n- 'ca'\r\n- 'de'\r\nlicenses:\r\n- cc-by-4.0\r\nmultilinguality:\r\n- translation\r\npretty_name: Catalan-German aligned corpora to train NMT systems.\r\nsize_categories:\r\n- \"1M<n<10M\" \r\nsource_datasets:\r\n- extended|tilde_model\r\ntask_categories:\r\n- machine-translation\r\ntask_ids:\r\n- machine-translation\r\n---\r\n``` \r\n# Solution\r\nThe fix is to correctly style the README as explained [here](https://huggingface.co/docs/datasets/v1.12.0/dataset_card.html). I have also correctly parsed the font matter as shown below:\r\n```\r\n---\r\nannotations_creators: []\r\nlanguage_creators: [machine-generated]\r\nlanguages: ['ca', 'de']\r\nlicenses: []\r\nmultilinguality:\r\n- multilingual\r\npretty_name: 'Catalan-German aligned corpora to train NMT systems.'\r\nsize_categories: \r\n- 1M<n<10M\r\nsource_datasets: ['extended|tilde_model']\r\ntask_categories: ['machine-translation']\r\ntask_ids: ['machine-translation']\r\n---\r\n```\r\nYou can find the README for a sample dataset [here](https://huggingface.co/datasets/ritwikraha/Test)",
"Thank you. It finally worked implementing your changes and leaving a white line between title and text in the description.",
"Thanks, if this solves your issue, can you please close it?"
] | "2022-01-19T13:32:29" | "2022-01-21T10:20:01" | "2022-01-21T10:20:01" | NONE | null | null | null | ## Describe the bug
The info contained in the README.md file is not being shown in the dataset main page. Basic info and table of contents are properly formatted in the README.
## Steps to reproduce the bug
# Sample code to reproduce the bug
The README file is this one: https://huggingface.co/datasets/softcatala/Tilde-MODEL-Catalan/blob/main/README.md
## Expected results
README info should appear in the Dataset card page.
## Actual results
Nothing is shown. However, labels are parsed and shown successfully.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3598/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3598/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3597/comments | https://api.github.com/repos/huggingface/datasets/issues/3597/events | https://github.com/huggingface/datasets/issues/3597 | 1,108,092,864 | I_kwDODunzps5CDCfA | 3,597 | ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content | {
"login": "amitkml",
"id": 49492030,
"node_id": "MDQ6VXNlcjQ5NDkyMDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/49492030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amitkml",
"html_url": "https://github.com/amitkml",
"followers_url": "https://api.github.com/users/amitkml/followers",
"following_url": "https://api.github.com/users/amitkml/following{/other_user}",
"gists_url": "https://api.github.com/users/amitkml/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amitkml/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amitkml/subscriptions",
"organizations_url": "https://api.github.com/users/amitkml/orgs",
"repos_url": "https://api.github.com/users/amitkml/repos",
"events_url": "https://api.github.com/users/amitkml/events{/privacy}",
"received_events_url": "https://api.github.com/users/amitkml/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! The `cd` command in Jupyer/Colab needs to start with `%`, so this should work:\r\n```\r\n!git clone https://github.com/huggingface/datasets.git\r\n%cd datasets\r\n!pip install -e \".[streaming]\"\r\n```",
"thanks @mariosasko i had the same mistake and your solution is what was needed"
] | "2022-01-19T13:19:28" | "2022-08-05T12:35:51" | "2022-02-14T08:46:34" | NONE | null | null | null | ## Bug
The install of streaming dataset is giving following error.
## Steps to reproduce the bug
```python
! git clone https://github.com/huggingface/datasets.git
! cd datasets
! pip install -e ".[streaming]"
```
## Actual results
Cloning into 'datasets'...
remote: Enumerating objects: 50816, done.
remote: Counting objects: 100% (2356/2356), done.
remote: Compressing objects: 100% (1606/1606), done.
remote: Total 50816 (delta 834), reused 1741 (delta 525), pack-reused 48460
Receiving objects: 100% (50816/50816), 72.47 MiB | 27.68 MiB/s, done.
Resolving deltas: 100% (22541/22541), done.
Checking out files: 100% (6722/6722), done.
ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3597/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3596/comments | https://api.github.com/repos/huggingface/datasets/issues/3596/events | https://github.com/huggingface/datasets/issues/3596 | 1,107,345,338 | I_kwDODunzps5CAL-6 | 3,596 | Loss of cast `Image` feature on certain dataset method | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start working on the `push_to_hub` support for the `Image`/`Audio` feature.",
"> Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start working on the `push_to_hub` support for the `Image`/`Audio` feature.\r\n\r\nThanks, I'll keep an eye out for #3575 getting merged. I managed to use `push_to_hub` sucesfully with images when they were loaded via `map` - something like `ds.map(lambda example: {\"img\": load_image_function(example['fname']})`, this only pushed the images to the hub if the `load_image_function` return a PIL Image without the filename attribute though. I guess this might often be the prefered behaviour though. \r\n",
"Hi ! We merged the PR and did a release of `datasets` that includes the changes. Can you try updating `datasets` and try again ?",
"> Hi ! We merged the PR and did a release of `datasets` that includes the changes. Can you try updating `datasets` and try again ?\r\n\r\nThanks for checking. There is no longer an error when calling `select` but it appears the cast value isn't preserved. Before `select`\r\n\r\n```python\r\ndataset.features\r\n{'url': Image(id=None)}\r\n```\r\n\r\nafter select:\r\n```\r\n{'url': Value(dtype='string', id=None)}\r\n```\r\n\r\nUpdated Colab example [here](https://colab.research.google.com/gist/davanstrien/4e88f55a3675c279b5c2f64299ae5c6f/potential_casting_bug.ipynb) ",
"Hmmm, if I re-run your google colab I'm getting the right type at the end:\r\n```\r\nsample.features\r\n# {'url': Image(id=None)}\r\n```",
"Appolgies - I've just run again and also got this output. I have also sucesfully used the `push_to_hub` method. I think this is fixed now so will close this issue. ",
"Fixed in #3575 "
] | "2022-01-18T20:44:01" | "2022-01-21T18:07:28" | "2022-01-21T18:07:28" | MEMBER | null | null | null | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a dataset which has had a column cast to an `Image`.
I suspect this might be related to https://github.com/huggingface/datasets/pull/3556 but I don't believe that pull request fixes this issue.
## Steps to reproduce the bug
An example of casting a url to an image followed by using the `select` method:
```python
from datasets import Dataset
from datasets import features
url = "https://cf.ltkcdn.net/cats/images/std-lg/246866-1200x816-grey-white-kitten.webp"
data_dict = {"url": [url]*2}
dataset = Dataset.from_dict(data_dict)
dataset = dataset.cast_column('url',features.Image())
sample = dataset.select([1])
```
[example notebook](https://gist.github.com/davanstrien/06e53f4383c28ae77ce1b30d0eaf0d70#file-potential_casting_bug-ipynb)
## Expected results
The cast value is maintained when further methods are applied to the dataset.
## Actual results
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-12-47f393bc2d0d> in <module>()
----> 1 sample = dataset.select([1])
4 frames
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
487 }
488 # apply actual function
--> 489 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
490 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
491 # re-apply format to the output
/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
409 # Call actual function
410
--> 411 out = func(self, *args, **kwargs)
412
413 # Update fingerprint of in-place transforms + update in-place history of transforms
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in select(self, indices, keep_in_memory, indices_cache_file_name, writer_batch_size, new_fingerprint)
2772 )
2773 else:
-> 2774 return self._new_dataset_with_indices(indices_buffer=buf_writer.getvalue(), fingerprint=new_fingerprint)
2775
2776 @transmit_format
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in _new_dataset_with_indices(self, indices_cache_file_name, indices_buffer, fingerprint)
2688 split=self.split,
2689 indices_table=indices_table,
-> 2690 fingerprint=fingerprint,
2691 )
2692
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in __init__(self, arrow_table, info, split, indices_table, fingerprint)
664 if self.info.features.type != inferred_features.type:
665 raise ValueError(
--> 666 f"External features info don't match the dataset:\nGot\n{self.info.features}\nwith type\n{self.info.features.type}\n\nbut expected something like\n{inferred_features}\nwith type\n{inferred_features.type}"
667 )
668
ValueError: External features info don't match the dataset:
Got
{'url': Image(id=None)}
with type
struct<url: extension<arrow.py_extension_type<ImageExtensionType>>>
but expected something like
{'url': Value(dtype='string', id=None)}
with type
struct<url: string>
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.1.dev0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3596/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3595/comments | https://api.github.com/repos/huggingface/datasets/issues/3595/events | https://github.com/huggingface/datasets/pull/3595 | 1,107,260,527 | PR_kwDODunzps4xOIxH | 3,595 | Add ImageNet toy datasets from fastai | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [
"Thanks for your contribution, @mariosasko. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2022-01-18T19:03:35" | "2022-09-30T14:39:35" | "2022-09-30T14:39:35" | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"merged_at": null
} | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3595/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3594/comments | https://api.github.com/repos/huggingface/datasets/issues/3594/events | https://github.com/huggingface/datasets/pull/3594 | 1,107,174,619 | PR_kwDODunzps4xN3Kk | 3,594 | fix multiple language downloading in mC4 | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI failure is unrelated to your PR and fixed on master, merging :)"
] | "2022-01-18T17:25:19" | "2022-01-19T11:22:57" | "2022-01-18T19:10:22" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3594",
"html_url": "https://github.com/huggingface/datasets/pull/3594",
"diff_url": "https://github.com/huggingface/datasets/pull/3594.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3594.patch",
"merged_at": "2022-01-18T19:10:22"
} | If we try to access multiple languages of the [mC4 dataset](https://github.com/huggingface/datasets/tree/master/datasets/mc4), it will throw an error. For example, if we do
```python
mc4_subset_two_langs = load_dataset("mc4", languages=["st", "su"])
```
we got
```
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/multilingual/c4-st+su.tfrecord-00000-of-00002.json.gz
```
Now it should work. Check it (from the root dir of a project):
```python
mc4_subset_two_langs = load_dataset("./datasets/mc4/", languages=["st", "su"])
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3594/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3593/comments | https://api.github.com/repos/huggingface/datasets/issues/3593/events | https://github.com/huggingface/datasets/pull/3593 | 1,107,070,852 | PR_kwDODunzps4xNhTu | 3,593 | Update README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"repos_url": "https://api.github.com/users/borgr/repos",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-18T15:52:16" | "2022-01-20T17:14:53" | "2022-01-20T17:14:53" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3593",
"html_url": "https://github.com/huggingface/datasets/pull/3593",
"diff_url": "https://github.com/huggingface/datasets/pull/3593.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3593.patch",
"merged_at": "2022-01-20T17:14:52"
} | Towards license of Tweet Eval parts | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3593/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3593/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3592/comments | https://api.github.com/repos/huggingface/datasets/issues/3592/events | https://github.com/huggingface/datasets/pull/3592 | 1,107,026,723 | PR_kwDODunzps4xNYIW | 3,592 | Add QuickDraw dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-01-18T15:13:39" | "2022-06-09T10:04:54" | "2022-06-09T09:56:13" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3592",
"html_url": "https://github.com/huggingface/datasets/pull/3592",
"diff_url": "https://github.com/huggingface/datasets/pull/3592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3592.patch",
"merged_at": "2022-06-09T09:56:13"
} | Add the QuickDraw dataset.
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3592/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3591/comments | https://api.github.com/repos/huggingface/datasets/issues/3591/events | https://github.com/huggingface/datasets/pull/3591 | 1,106,928,613 | PR_kwDODunzps4xNDoB | 3,591 | Add support for time, date, duration, and decimal dtypes | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Is there a dataset which uses these four datatypes for tests purposes?\r\n",
"@severo Not yet. I'll let you know if that changes."
] | "2022-01-18T13:46:05" | "2022-01-31T18:29:34" | "2022-01-20T17:37:33" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3591",
"html_url": "https://github.com/huggingface/datasets/pull/3591",
"diff_url": "https://github.com/huggingface/datasets/pull/3591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3591.patch",
"merged_at": "2022-01-20T17:37:33"
} | Add support for the pyarrow time (maps to `datetime.time` in python), date (maps to `datetime.time` in python), duration (maps to `datetime.timedelta` in python), and decimal (maps to `decimal.decimal` in python) dtypes. This should be helpful when writing scripts for time-series datasets. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3591/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3590/comments | https://api.github.com/repos/huggingface/datasets/issues/3590/events | https://github.com/huggingface/datasets/pull/3590 | 1,106,784,860 | PR_kwDODunzps4xMlGg | 3,590 | Update ANLI README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"repos_url": "https://api.github.com/users/borgr/repos",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-18T11:22:53" | "2022-01-20T16:58:41" | "2022-01-20T16:58:41" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3590",
"html_url": "https://github.com/huggingface/datasets/pull/3590",
"diff_url": "https://github.com/huggingface/datasets/pull/3590.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3590.patch",
"merged_at": "2022-01-20T16:58:41"
} | Update license and little things concerning ANLI | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3590/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3590/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3589/comments | https://api.github.com/repos/huggingface/datasets/issues/3589/events | https://github.com/huggingface/datasets/pull/3589 | 1,106,766,114 | PR_kwDODunzps4xMhGp | 3,589 | Pin torchmetrics to fix the COMET test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-18T11:03:49" | "2022-01-18T11:04:56" | "2022-01-18T11:04:55" | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3589",
"html_url": "https://github.com/huggingface/datasets/pull/3589",
"diff_url": "https://github.com/huggingface/datasets/pull/3589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3589.patch",
"merged_at": "2022-01-18T11:04:55"
} | Torchmetrics 0.7.0 got released and has issues with `transformers` (see https://github.com/PyTorchLightning/metrics/issues/770)
I'm pinning it to 0.6.0 in the CI, since 0.7.0 makes the COMET metric test fail. COMET requires torchmetrics==0.6.0 anyway. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3589/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3588/comments | https://api.github.com/repos/huggingface/datasets/issues/3588/events | https://github.com/huggingface/datasets/pull/3588 | 1,106,749,000 | PR_kwDODunzps4xMdiC | 3,588 | Update HellaSwag README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"repos_url": "https://api.github.com/users/borgr/repos",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | "2022-01-18T10:46:15" | "2022-01-20T16:57:43" | "2022-01-20T16:57:43" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3588",
"html_url": "https://github.com/huggingface/datasets/pull/3588",
"diff_url": "https://github.com/huggingface/datasets/pull/3588.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3588.patch",
"merged_at": "2022-01-20T16:57:43"
} | Adding information from the git repo and paper that were missing | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3588/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3588/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3587/comments | https://api.github.com/repos/huggingface/datasets/issues/3587/events | https://github.com/huggingface/datasets/issues/3587 | 1,106,719,182 | I_kwDODunzps5B9zHO | 3,587 | No module named 'fsspec.archive' | {
"login": "shuuchen",
"id": 13246825,
"node_id": "MDQ6VXNlcjEzMjQ2ODI1",
"avatar_url": "https://avatars.githubusercontent.com/u/13246825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shuuchen",
"html_url": "https://github.com/shuuchen",
"followers_url": "https://api.github.com/users/shuuchen/followers",
"following_url": "https://api.github.com/users/shuuchen/following{/other_user}",
"gists_url": "https://api.github.com/users/shuuchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shuuchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shuuchen/subscriptions",
"organizations_url": "https://api.github.com/users/shuuchen/orgs",
"repos_url": "https://api.github.com/users/shuuchen/repos",
"events_url": "https://api.github.com/users/shuuchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/shuuchen/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | "2022-01-18T10:17:01" | "2022-08-11T09:57:54" | "2022-01-18T10:33:10" | NONE | null | null | null | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 61, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/arrow_writer.py", line 28, in <module>
from .features import (
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/features/__init__.py", line 2, in <module>
from .audio import Audio
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/features/audio.py", line 7, in <module>
from ..utils.streaming_download_manager import xopen
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 18, in <module>
from ..filesystems import COMPRESSION_FILESYSTEMS
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/filesystems/__init__.py", line 6, in <module>
from . import compression
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/filesystems/compression.py", line 5, in <module>
from fsspec.archive import AbstractArchiveFileSystem
ModuleNotFoundError: No module named 'fsspec.archive'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3587/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3587/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3586/comments | https://api.github.com/repos/huggingface/datasets/issues/3586/events | https://github.com/huggingface/datasets/issues/3586 | 1,106,455,672 | I_kwDODunzps5B8yx4 | 3,586 | Revisit `enable/disable_` toggle function prefix | {
"login": "jaketae",
"id": 25360440,
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaketae",
"html_url": "https://github.com/jaketae",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https://api.github.com/users/jaketae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jaketae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaketae/subscriptions",
"organizations_url": "https://api.github.com/users/jaketae/orgs",
"repos_url": "https://api.github.com/users/jaketae/repos",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"received_events_url": "https://api.github.com/users/jaketae/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | "2022-01-18T04:09:55" | "2022-03-14T15:01:08" | "2022-03-14T15:01:08" | CONTRIBUTOR | null | null | null | As discussed in https://github.com/huggingface/transformers/pull/15167, we should revisit the `enable/disable_` toggle function prefix, potentially in favor of `set_enabled_`. Concretely, this translates to
- De-deprecating `disable_progress_bar()`
- Adding `enable_progress_bar()`
- On the caching side, adding `enable_caching` and `disable_caching`
Additional decisions have to be made with regards to the existing `set_enabled_X` functions; that is, whether to keep them as is or deprecate them in favor of the aforementioned functions.
cc @mariosasko @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3586/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3586/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3585/comments | https://api.github.com/repos/huggingface/datasets/issues/3585/events | https://github.com/huggingface/datasets/issues/3585 | 1,105,821,470 | I_kwDODunzps5B6X8e | 3,585 | Datasets streaming + map doesn't work for `Audio` | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate",
"name": "duplicate",
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
},
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"This seems related to https://github.com/huggingface/datasets/issues/3505."
] | "2022-01-17T12:55:42" | "2022-01-20T13:28:00" | "2022-01-20T13:28:00" | MEMBER | null | null | null | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")
def map_fn(batch):
print("audio keys", batch["audio"].keys())
batch["audio"] = batch["audio"]["array"][:100]
return batch
ds = ds.map(map_fn)
sample = next(iter(ds))
```
I think the audio is somehow decoded before `.map(...)` is actually called.
## Expected results
IMO, the above code snippet should work.
## Actual results
```bash
audio keys dict_keys(['path', 'bytes'])
Traceback (most recent call last):
File "./run_audio.py", line 15, in <module>
sample = next(iter(ds))
File "/home/patrick/python_bin/datasets/iterable_dataset.py", line 341, in __iter__
for key, example in self._iter():
File "/home/patrick/python_bin/datasets/iterable_dataset.py", line 338, in _iter
yield from ex_iterable
File "/home/patrick/python_bin/datasets/iterable_dataset.py", line 192, in __iter__
yield key, self.function(example)
File "./run_audio.py", line 9, in map_fn
batch["input"] = batch["audio"]["array"][:100]
KeyError: 'array'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.1.dev0
- Platform: Linux-5.3.0-64-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3585/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3584/comments | https://api.github.com/repos/huggingface/datasets/issues/3584/events | https://github.com/huggingface/datasets/issues/3584 | 1,105,231,768 | I_kwDODunzps5B4H-Y | 3,584 | https://huggingface.co/datasets/huggingface/transformers-metadata | {
"login": "ecankirkic",
"id": 37082592,
"node_id": "MDQ6VXNlcjM3MDgyNTky",
"avatar_url": "https://avatars.githubusercontent.com/u/37082592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ecankirkic",
"html_url": "https://github.com/ecankirkic",
"followers_url": "https://api.github.com/users/ecankirkic/followers",
"following_url": "https://api.github.com/users/ecankirkic/following{/other_user}",
"gists_url": "https://api.github.com/users/ecankirkic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ecankirkic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ecankirkic/subscriptions",
"organizations_url": "https://api.github.com/users/ecankirkic/orgs",
"repos_url": "https://api.github.com/users/ecankirkic/repos",
"events_url": "https://api.github.com/users/ecankirkic/events{/privacy}",
"received_events_url": "https://api.github.com/users/ecankirkic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [] | "2022-01-17T00:18:14" | "2022-02-14T08:51:27" | "2022-02-14T08:51:27" | NONE | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3584/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | {
"login": "omarespejel",
"id": 4755430,
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omarespejel",
"html_url": "https://github.com/omarespejel",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision",
"name": "vision",
"color": "bfdadc",
"default": false,
"description": "Vision datasets"
}
] | open | false | {
"login": "pri1311",
"id": 64613009,
"node_id": "MDQ6VXNlcjY0NjEzMDA5",
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pri1311",
"html_url": "https://github.com/pri1311",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists_url": "https://api.github.com/users/pri1311/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pri1311/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pri1311/subscriptions",
"organizations_url": "https://api.github.com/users/pri1311/orgs",
"repos_url": "https://api.github.com/users/pri1311/repos",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"received_events_url": "https://api.github.com/users/pri1311/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "pri1311",
"id": 64613009,
"node_id": "MDQ6VXNlcjY0NjEzMDA5",
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pri1311",
"html_url": "https://github.com/pri1311",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists_url": "https://api.github.com/users/pri1311/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pri1311/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pri1311/subscriptions",
"organizations_url": "https://api.github.com/users/pri1311/orgs",
"repos_url": "https://api.github.com/users/pri1311/repos",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"received_events_url": "https://api.github.com/users/pri1311/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hello! I have recently been involved with a medical image segmentation project myself and was going through the `The Medical Segmentation Decathlon Dataset` as well. \r\nI haven't yet had experience adding datasets to this repository yet but would love to get started. Should I take this issue?\r\nIf yes, I've got two questions -\r\n1. There are 10 different datasets available, so are all datasets to be added in a single PR, or one at a time? \r\n2. Since it's a competition, masks for the test-set are not available. How is that to be tackled? Sorry if it's a silly question, I have recently started exploring `datasets`.",
"Hi! Sure, feel free to take this issue. You can self-assign the issue by commenting `#self-assign`.\r\n\r\nTo answer your questions:\r\n1. It makes the most sense to add each one as a separate config, so one dataset script with 10 configs in a single PR.\r\n2. Just set masks in the test set to `None`.\r\n\r\nNote that the images/masks in this dataset are in NIfTI format, which our `Image` feature currently doesn't support, so I think it's best to yield the paths to the images/masks in the script and add a preprocessing section to the card where we explain how to load/process the images/masks with `nibabel` (I can help with that). \r\n\r\n",
"> Note that the images/masks in this dataset are in NIfTI format, which our `Image` feature currently doesn't support, so I think it's best to yield the paths to the images/masks in the script and add a preprocessing section to the card where we explain how to load/process the images/masks with `nibabel` (I can help with that).\r\n\r\nGotcha, thanks. Will start working on the issue and let you know in case of any doubt.",
"#self-assign",
"This is great! There is a first model on the HUb that uses this dataset! https://huggingface.co/MONAI/example_spleen_segmentation"
] | "2022-01-16T21:42:25" | "2022-03-18T10:44:42" | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:** [link to the dataset paper if available](https://arxiv.org/abs/2106.05735)
- **Data:** http://medicaldecathlon.com/
- **Motivation:** Hugging Face seeks to democratize ML for society. One of the growing niches within ML is the ML + Medicine community. Key data sets will help increase the supply of HF resources for starting an initial community.
(cc @osanseviero @abidlabs )
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3582/comments | https://api.github.com/repos/huggingface/datasets/issues/3582/events | https://github.com/huggingface/datasets/issues/3582 | 1,104,877,303 | I_kwDODunzps5B2xb3 | 3,582 | conll 2003 dataset source url is no longer valid | {
"login": "rcanand",
"id": 303900,
"node_id": "MDQ6VXNlcjMwMzkwMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/303900?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rcanand",
"html_url": "https://github.com/rcanand",
"followers_url": "https://api.github.com/users/rcanand/followers",
"following_url": "https://api.github.com/users/rcanand/following{/other_user}",
"gists_url": "https://api.github.com/users/rcanand/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rcanand/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcanand/subscriptions",
"organizations_url": "https://api.github.com/users/rcanand/orgs",
"repos_url": "https://api.github.com/users/rcanand/repos",
"events_url": "https://api.github.com/users/rcanand/events{/privacy}",
"received_events_url": "https://api.github.com/users/rcanand/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"I came to open the same issue.",
"Thanks for reporting !\r\n\r\nI pushed a temporary fix on `master` that uses an URL from a previous commit to access the dataset for now, until we have a better solution",
"I changed the URL again to use another host, the fix is available on `master` and we'll probably do a new release of `datasets` tomorrow.\r\n\r\nIn the meantime, feel free to do `load_dataset(..., revision=\"master\")` to use the fixed script",
"We just released a new version of `datasets` with a working URL. Feel free to update `datasets` and try again :)",
"Hello! Unfortunately, this URL does not work for me. \r\nCould you please tell me how I can solve the problem?\r\n\r\n`>>> from datasets import load_dataset\r\n>>> dataset = load_dataset(\"conll2003\")\r\nDownloading and preparing dataset conll2003/conll2003 (download: 4.63 MiB, generated: 9.78 MiB, post-processed: Unknown size, total: 14.41 MiB) to /home/dafedo/.cache/huggingface/datasets/conll2003/conll2003/1.0.0/40e7cb6bcc374f7c349c83acd1e9352a4f09474eb691f64f364ee62eb65d0ca6...\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/load.py\", line 745, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/builder.py\", line 574, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/builder.py\", line 630, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/home/dafedo/.cache/huggingface/modules/datasets_modules/datasets/conll2003/40e7cb6bcc374f7c349c83acd1e9352a4f09474eb691f64f364ee62eb65d0ca6/conll2003.py\", line 196, in _split_generators\r\n downloaded_files = dl_manager.download_and_extract(urls_to_download)\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/download_manager.py\", line 287, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/download_manager.py\", line 195, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 203, in map_nested\r\n mapped = [\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 204, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 142, in _single_map_nested\r\n return function(data_struct)\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/download_manager.py\", line 218, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/file_utils.py\", line 281, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/dafedo/efficient-task-transfer/venv/lib/python3.8/site-packages/datasets/utils/file_utils.py\", line 621, in get_from_cache\r\n raise FileNotFoundError(\"Couldn't find file at {}\".format(url))\r\nFileNotFoundError: Couldn't find file at https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt\r\n`\r\n\r\nI receive the same error when I run \"itrain run_configs/conll2003.json\" from https://github.com/adapter-hub/efficient-task-transfer\r\n\r\nThank you very much in advance!\r\n\r\nRegards, \r\nDaria\r\n",
"Can you try updating `datasets` and try again ?\r\n```\r\npip install -U datasets\r\n```",
"@lhoestq Thank you very much for your answer! \r\n\r\nIt works this way, but for my research I need datasets==1.6.3 or closest to it because otherwise the other package would not work as it is built on this version.\r\nDo you have any other suggestion? I would really appreciate it. Maybe which version of the datasets is without hard-coded link but closest to 1.6.3\r\n",
"No problem, I have solved it. \r\nThank you anyway.",
"Out of curiosity, which package has the `datasets==1.6.3` requirement ?"
] | "2022-01-15T23:04:17" | "2022-07-20T13:06:40" | "2022-01-21T16:57:32" | NONE | null | null | null | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual results
It is looking for the dataset at `https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt` but it was removed from there yesterday (see [commit](https://github.com/davidsbatista/NER-datasets/commit/9d8f45cc7331569af8eb3422bbe1c97cbebd5690) that removed the file and related [issue](https://github.com/davidsbatista/NER-datasets/issues/8)).
- We should replace this with an alternate valid location.
- this is being referenced in the huggingface course chapter 7 [colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/chapter7/section2_pt.ipynb), which is also broken.
```python
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-27c956bec93c> in <module>()
1 from datasets import load_dataset
2
----> 3 raw_datasets = load_dataset("conll2003")
11 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries, use_auth_token, ignore_url_params)
610 )
611 elif response is not None and response.status_code == 404:
--> 612 raise FileNotFoundError(f"Couldn't find file at {url}")
613 _raise_if_offline_mode_is_enabled(f"Tried to reach {url}")
614 if head_error is not None:
FileNotFoundError: Couldn't find file at https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform:
- Python version:
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3582/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 5,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3582/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3581/comments | https://api.github.com/repos/huggingface/datasets/issues/3581/events | https://github.com/huggingface/datasets/issues/3581 | 1,104,857,822 | I_kwDODunzps5B2sre | 3,581 | Unable to create a dataset from a parquet file in S3 | {
"login": "regCode",
"id": 18012903,
"node_id": "MDQ6VXNlcjE4MDEyOTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/18012903?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/regCode",
"html_url": "https://github.com/regCode",
"followers_url": "https://api.github.com/users/regCode/followers",
"following_url": "https://api.github.com/users/regCode/following{/other_user}",
"gists_url": "https://api.github.com/users/regCode/gists{/gist_id}",
"starred_url": "https://api.github.com/users/regCode/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/regCode/subscriptions",
"organizations_url": "https://api.github.com/users/regCode/orgs",
"repos_url": "https://api.github.com/users/regCode/repos",
"events_url": "https://api.github.com/users/regCode/events{/privacy}",
"received_events_url": "https://api.github.com/users/regCode/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Hi ! Currently it only works with local paths, file-like objects are not supported yet"
] | "2022-01-15T21:34:16" | "2022-02-14T08:52:57" | null | NONE | null | null | null | ## Describe the bug
Trying to create a dataset from a parquet file in S3.
## Steps to reproduce the bug
```python
import s3fs
from datasets import Dataset
s3 = s3fs.S3FileSystem(anon=False)
with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
dataset = Dataset.from_parquet(s3file)
```
## Expected results
A new Dataset object
## Actual results
```AttributeError: 'S3File' object has no attribute 'decode'```
```
AttributeError Traceback (most recent call last)
<command-2452877612515691> in <module>
5
6 with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
----> 7 dataset = Dataset.from_parquet(s3file)
/databricks/python/lib/python3.8/site-packages/datasets/arrow_dataset.py in from_parquet(path_or_paths, split, features, cache_dir, keep_in_memory, columns, **kwargs)
907 from .io.parquet import ParquetDatasetReader
908
--> 909 return ParquetDatasetReader(
910 path_or_paths,
911 split=split,
/databricks/python/lib/python3.8/site-packages/datasets/io/parquet.py in __init__(self, path_or_paths, split, features, cache_dir, keep_in_memory, **kwargs)
28 path_or_paths = path_or_paths if isinstance(path_or_paths, dict) else {self.split: path_or_paths}
29 hash = _PACKAGED_DATASETS_MODULES["parquet"][1]
---> 30 self.builder = Parquet(
31 cache_dir=cache_dir,
32 data_files=path_or_paths,
/databricks/python/lib/python3.8/site-packages/datasets/builder.py in __init__(self, cache_dir, name, hash, base_path, info, features, use_auth_token, namespace, data_files, data_dir, **config_kwargs)
246
247 if data_files is not None and not isinstance(data_files, DataFilesDict):
--> 248 data_files = DataFilesDict.from_local_or_remote(
249 sanitize_patterns(data_files), base_path=base_path, use_auth_token=use_auth_token
250 )
/databricks/python/lib/python3.8/site-packages/datasets/data_files.py in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)
576 for key, patterns_for_key in patterns.items():
577 out[key] = (
--> 578 DataFilesList.from_local_or_remote(
579 patterns_for_key,
580 base_path=base_path,
/databricks/python/lib/python3.8/site-packages/datasets/data_files.py in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)
544 ) -> "DataFilesList":
545 base_path = base_path if base_path is not None else str(Path().resolve())
--> 546 data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
547 origin_metadata = _get_origin_metadata_locally_or_by_urls(data_files, use_auth_token=use_auth_token)
548 return cls(data_files, origin_metadata)
/databricks/python/lib/python3.8/site-packages/datasets/data_files.py in resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
191 data_files = []
192 for pattern in patterns:
--> 193 if is_remote_url(pattern):
194 data_files.append(Url(pattern))
195 else:
/databricks/python/lib/python3.8/site-packages/datasets/utils/file_utils.py in is_remote_url(url_or_filename)
115
116 def is_remote_url(url_or_filename: str) -> bool:
--> 117 parsed = urlparse(url_or_filename)
118 return parsed.scheme in ("http", "https", "s3", "gs", "hdfs", "ftp")
119
/usr/lib/python3.8/urllib/parse.py in urlparse(url, scheme, allow_fragments)
370 Note that we don't break the components up in smaller bits
371 (e.g. netloc is a single string) and we don't expand % escapes."""
--> 372 url, scheme, _coerce_result = _coerce_args(url, scheme)
373 splitresult = urlsplit(url, scheme, allow_fragments)
374 scheme, netloc, url, query, fragment = splitresult
/usr/lib/python3.8/urllib/parse.py in _coerce_args(*args)
122 if str_input:
123 return args + (_noop,)
--> 124 return _decode_args(args) + (_encode_result,)
125
126 # Result objects are more helpful than simple tuples
/usr/lib/python3.8/urllib/parse.py in _decode_args(args, encoding, errors)
106 def _decode_args(args, encoding=_implicit_encoding,
107 errors=_implicit_errors):
--> 108 return tuple(x.decode(encoding, errors) if x else '' for x in args)
109
110 def _coerce_args(*args):
/usr/lib/python3.8/urllib/parse.py in <genexpr>(.0)
106 def _decode_args(args, encoding=_implicit_encoding,
107 errors=_implicit_errors):
--> 108 return tuple(x.decode(encoding, errors) if x else '' for x in args)
109
110 def _coerce_args(*args):
AttributeError: 'S3File' object has no attribute 'decode'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Ubuntu 20.04.3 LTS
- Python version: 3.8.10
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3581/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3581/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_url": "https://api.github.com/users/tuhinjubcse/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuhinjubcse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuhinjubcse/subscriptions",
"organizations_url": "https://api.github.com/users/tuhinjubcse/orgs",
"repos_url": "https://api.github.com/users/tuhinjubcse/repos",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuhinjubcse/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to /home/jxm3/.cache/huggingface/datasets/wiki_bio/default/1.1.0/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/load.py\", line 1694, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/builder.py\", line 595, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/builder.py\", line 662, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/home/jxm3/.cache/huggingface/modules/datasets_modules/datasets/wiki_bio/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9/wiki_bio.py\", line 125, in _split_generators\r\n data_dir = dl_manager.download_and_extract(my_urls)\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 308, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 196, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 251, in map_nested\r\n return function(data_struct)\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 217, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 298, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 612, in get_from_cache\r\n raise FileNotFoundError(f\"Couldn't find file at {url}\")\r\nFileNotFoundError: Couldn't find file at https://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil\r\n>>>\r\n```\r\n",
"@alejandrocros and @lhoestq - you added the wiki_bio dataset in #1173. It doesn't work anymore. Can you take a look at this?",
"And if something is wrong with Google Drive, you could try to download (and collate and unzip) from here: https://github.com/DavidGrangier/wikipedia-biography-dataset",
"Hi ! Thanks for reporting. I've downloaded the data and concatenated them into a zip file available here: https://huggingface.co/datasets/wiki_bio/tree/main/data\r\n\r\nI guess we can update the dataset script to use this zip file now :)"
] | "2022-01-15T10:04:33" | "2022-01-31T08:38:09" | "2022-01-31T08:38:09" | NONE | null | null | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
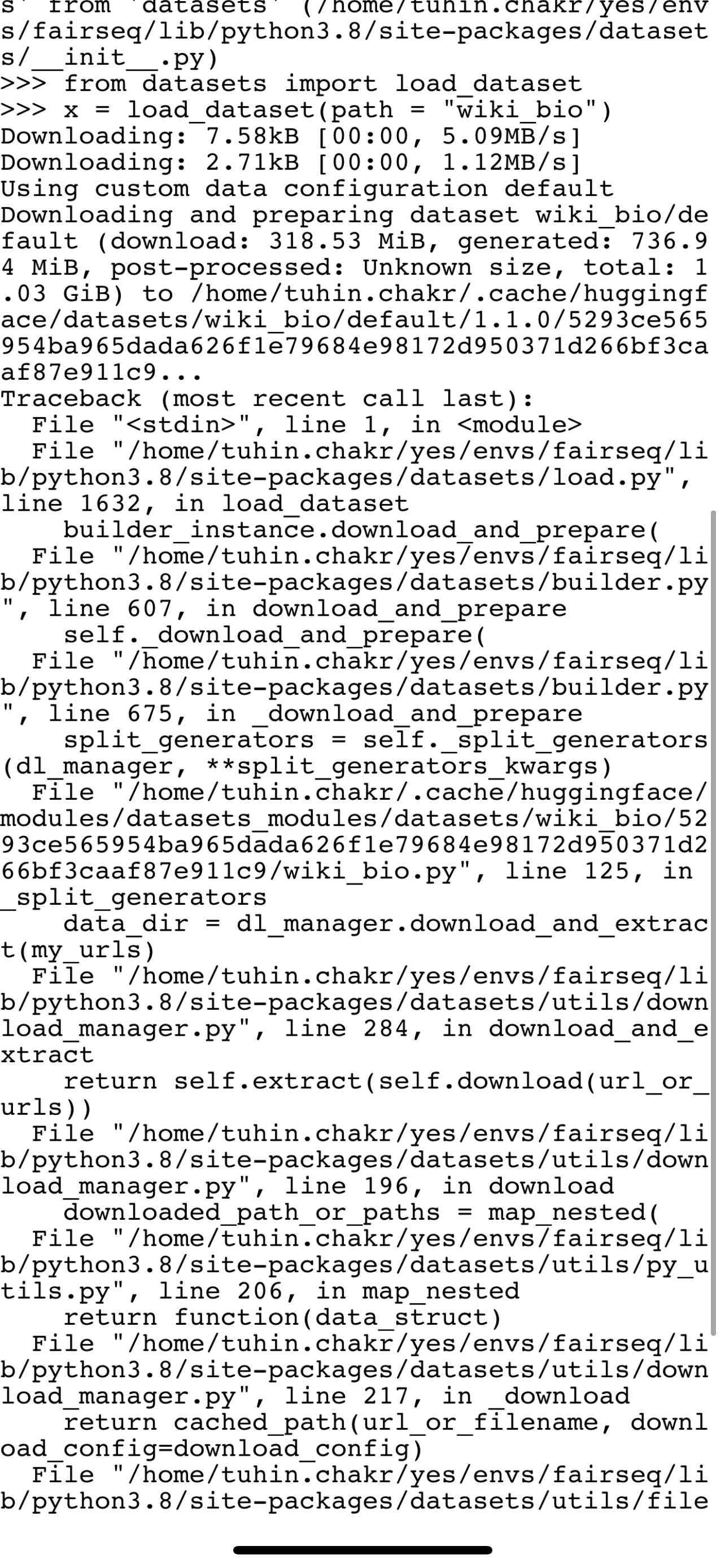
a | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3580/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3580/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3579 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3579/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3579/comments | https://api.github.com/repos/huggingface/datasets/issues/3579/events | https://github.com/huggingface/datasets/pull/3579 | 1,103,451,118 | PR_kwDODunzps4xBmY4 | 3,579 | Add Text2log Dataset | {
"login": "apergo-ai",
"id": 68908804,
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apergo-ai",
"html_url": "https://github.com/apergo-ai",
"followers_url": "https://api.github.com/users/apergo-ai/followers",
"following_url": "https://api.github.com/users/apergo-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/apergo-ai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apergo-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apergo-ai/subscriptions",
"organizations_url": "https://api.github.com/users/apergo-ai/orgs",
"repos_url": "https://api.github.com/users/apergo-ai/repos",
"events_url": "https://api.github.com/users/apergo-ai/events{/privacy}",
"received_events_url": "https://api.github.com/users/apergo-ai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI fails are unrelated to your PR and fixed on master, I think we can merge now !"
] | "2022-01-14T10:45:01" | "2022-01-20T17:09:44" | "2022-01-20T17:09:44" | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3579",
"html_url": "https://github.com/huggingface/datasets/pull/3579",
"diff_url": "https://github.com/huggingface/datasets/pull/3579.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3579.patch",
"merged_at": "2022-01-20T17:09:44"
} | Adding the text2log dataset used for training FOL sentence translating models | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3579/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3579/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3578/comments | https://api.github.com/repos/huggingface/datasets/issues/3578/events | https://github.com/huggingface/datasets/issues/3578 | 1,103,403,287 | I_kwDODunzps5BxJkX | 3,578 | label information get lost after parquet serialization | {
"login": "Tudyx",
"id": 56633664,
"node_id": "MDQ6VXNlcjU2NjMzNjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/56633664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tudyx",
"html_url": "https://github.com/Tudyx",
"followers_url": "https://api.github.com/users/Tudyx/followers",
"following_url": "https://api.github.com/users/Tudyx/following{/other_user}",
"gists_url": "https://api.github.com/users/Tudyx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Tudyx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tudyx/subscriptions",
"organizations_url": "https://api.github.com/users/Tudyx/orgs",
"repos_url": "https://api.github.com/users/Tudyx/repos",
"events_url": "https://api.github.com/users/Tudyx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Tudyx/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! We did a release of `datasets` today that may fix this issue. Can you try updating `datasets` and trying again ?\r\n\r\nEDIT: the issue is still there actually\r\n\r\nI think we can fix that by storing the Features in the parquet schema metadata, and then reload them when loading the parquet file",
"This info is stored in the Parquet schema metadata as of https://github.com/huggingface/datasets/pull/5516"
] | "2022-01-14T10:10:38" | "2023-07-25T15:44:53" | "2023-07-25T15:44:53" | NONE | null | null | null | ## Describe the bug
In *dataset_info.json* file, information about the label get lost after the dataset serialization.
## Steps to reproduce the bug
```python
from datasets import load_dataset
# normal save
dataset = load_dataset('glue', 'sst2', split='train')
dataset.save_to_disk("normal_save")
# save after parquet serialization
dataset.to_parquet("glue-sst2-train.parquet")
dataset = load_dataset("parquet", data_files='glue-sst2-train.parquet')
dataset.save_to_disk("save_after_parquet")
```
## Expected results
I expected to keep label information in *dataset_info.json* file even after parquet serialization
## Actual results
In the normal serialization i got
```json
"label": {
"num_classes": 2,
"names": [
"negative",
"positive"
],
"names_file": null,
"id": null,
"_type": "ClassLabel"
},
```
And after parquet serialization i got
```json
"label": {
"dtype": "int64",
"id": null,
"_type": "Value"
},
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: ubuntu 20.04
- Python version: 3.8.10
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | completed | false |