
id
stringlengths 30
32
| content
stringlengths 139
2.8k
|
|---|---|
codereview_new_python_data_8750
|
class Y: ...
LL = typing.Iterable[str]
""",
runtime="""
- from typing import Iterable, Dict, List
K = Dict[str, str]
L = Dict[int, int]
KK = Iterable[str]
```suggestion
from typing import Iterable, Dict
```
class Y: ...
LL = typing.Iterable[str]
""",
runtime="""
+ from typing import Iterable, Dict
K = Dict[str, str]
L = Dict[int, int]
KK = Iterable[str]
|
codereview_new_python_data_8751
|
def verify_typealias(
):
runtime_module = "typing"
runtime_fullname = f"{runtime_module}.{runtime_name}"
- if re.match(fr"_?{re.escape(stub_origin.fullname)}", runtime_fullname):
# Okay, we're probably fine.
return
Should be fullmatch? Or is that intentional?
def verify_typealias(
):
runtime_module = "typing"
runtime_fullname = f"{runtime_module}.{runtime_name}"
+ if re.fullmatch(fr"_?{re.escape(stub_origin.fullname)}", runtime_fullname):
# Okay, we're probably fine.
return
|
codereview_new_python_data_8752
|
def expand_type_by_instance(typ: Type, instance: Instance) -> Type:
else:
variables: Dict[TypeVarId, Type] = {}
if instance.type.has_type_var_tuple_type:
- import mypy.constraints
assert instance.type.type_var_tuple_prefix is not None
assert instance.type.type_var_tuple_suffix is not None
Is this import unused?
def expand_type_by_instance(typ: Type, instance: Instance) -> Type:
else:
variables: Dict[TypeVarId, Type] = {}
if instance.type.has_type_var_tuple_type:
assert instance.type.type_var_tuple_prefix is not None
assert instance.type.type_var_tuple_suffix is not None
|
codereview_new_python_data_8753
|
from typing import TypeVar, Optional, Tuple, Sequence
from mypy.types import Instance, UnpackType, ProperType, get_proper_type, Type
-"""Helpers for interacting with type var tuples."""
def find_unpack_in_list(items: Sequence[Type]) -> Optional[int]:
unpack_index: Optional[int] = None
for i, item in enumerate(items):
Style nit: move docstring to top of file.
+"""Helpers for interacting with type var tuples."""
+
from typing import TypeVar, Optional, Tuple, Sequence
from mypy.types import Instance, UnpackType, ProperType, get_proper_type, Type
+
def find_unpack_in_list(items: Sequence[Type]) -> Optional[int]:
unpack_index: Optional[int] = None
for i, item in enumerate(items):
|
codereview_new_python_data_8754
|
def visit_ClassDef(self, n: ast27.ClassDef) -> ClassDef:
cdef.line = n.lineno + len(n.decorator_list)
cdef.column = n.col_offset
cdef.end_line = n.lineno
- cdef.end_column = n.col_offset
self.class_and_function_stack.pop()
return cdef
Shouldn't this be None for consistency with `fastparse.py`?
def visit_ClassDef(self, n: ast27.ClassDef) -> ClassDef:
cdef.line = n.lineno + len(n.decorator_list)
cdef.column = n.col_offset
cdef.end_line = n.lineno
+ cdef.end_column = None
self.class_and_function_stack.pop()
return cdef
|
codereview_new_python_data_8755
|
def set_line(self,
end_column: Optional[int] = None) -> None:
super().set_line(target, column, end_line, end_column)
for arg in self.arguments:
- arg.set_line(
- self.line, self.column, self.end_line, end_column)
def is_dynamic(self) -> bool:
return self.type is None
```suggestion
arg.set_line(self.line, self.column, self.end_line, end_column)
```
Formatting
def set_line(self,
end_column: Optional[int] = None) -> None:
super().set_line(target, column, end_line, end_column)
for arg in self.arguments:
+ arg.set_line(self.line, self.column, self.end_line, end_column)
def is_dynamic(self) -> bool:
return self.type is None
|
codereview_new_python_data_8761
|
def get_portability_package_data():
'pytest-xdist>=2.5.0,<3',
'pytest-timeout>=2.1.0,<3',
'scikit-learn>=0.20.0',
- 'tensorflow>=1.0.0',
'sqlalchemy>=1.3,<2.0',
'psycopg2-binary>=2.8.5,<3.0.0',
'testcontainers[mysql]>=3.0.3,<4.0.0',
(drive-by comment): let's not depend on a large dependency like this by default. you can see how we deal with sklearn/pytorch in similar circumstances.
def get_portability_package_data():
'pytest-xdist>=2.5.0,<3',
'pytest-timeout>=2.1.0,<3',
'scikit-learn>=0.20.0',
'sqlalchemy>=1.3,<2.0',
'psycopg2-binary>=2.8.5,<3.0.0',
'testcontainers[mysql]>=3.0.3,<4.0.0',
|
codereview_new_python_data_8765
|
def validate_transform(transform_id):
"Bad coder for input of %s: %s" % (transform_id, input_coder))
if output_coder.spec.urn != common_urns.coders.KV.urn:
raise ValueError(
- "Bad coder for output of %s: %s" % (transform_id, input_coder))
output_values_coder = pipeline_proto.components.coders[
output_coder.component_coder_ids[1]]
if (input_coder.component_coder_ids[0] !=
```suggestion
"Bad coder for output of %s: %s" % (transform_id, output_coder))
```
def validate_transform(transform_id):
"Bad coder for input of %s: %s" % (transform_id, input_coder))
if output_coder.spec.urn != common_urns.coders.KV.urn:
raise ValueError(
+ "Bad coder for output of %s: %s" % (transform_id, output_coder))
output_values_coder = pipeline_proto.components.coders[
output_coder.component_coder_ids[1]]
if (input_coder.component_coder_ids[0] !=
|
codereview_new_python_data_8766
|
def run(
model_class = models.resnet152
model_params = {'num_classes': 1000}
- class PytorchModelHandlerTensorWithBatchSize(PytorchModelHandlerTensor):
- def batch_elements_kwargs(self):
- return {'min_batch_size': 10, 'max_batch_size': 100}
-
# In this example we pass keyed inputs to RunInference transform.
# Therefore, we use KeyedModelHandler wrapper over PytorchModelHandler.
model_handler = KeyedModelHandler(
- PytorchModelHandlerTensorWithBatchSize(
state_dict_path=known_args.model_path,
model_class=model_class,
model_params=model_params,
- device=device))
pipeline = test_pipeline
if not test_pipeline:
Can we use the batch config options now?
def run(
model_class = models.resnet152
model_params = {'num_classes': 1000}
# In this example we pass keyed inputs to RunInference transform.
# Therefore, we use KeyedModelHandler wrapper over PytorchModelHandler.
model_handler = KeyedModelHandler(
+ PytorchModelHandlerTensor(
state_dict_path=known_args.model_path,
model_class=model_class,
model_params=model_params,
+ device=device,
+ min_batch_size=10,
+ max_batch_size=100))
pipeline = test_pipeline
if not test_pipeline:
|
codereview_new_python_data_8767
|
--interval=10
--num_workers=5
--requirements_file=apache_beam/ml/inference/torch_tests_requirements.txt
- --topic=<pubusb_topic>
--file_pattern=<glob_pattern>
file_pattern is path(can contain glob characters), which will be passed to
```suggestion
--topic=<pubsub_topic>
```
Looks like this one got missed
--interval=10
--num_workers=5
--requirements_file=apache_beam/ml/inference/torch_tests_requirements.txt
+ --topic=<pubsub_topic>
--file_pattern=<glob_pattern>
file_pattern is path(can contain glob characters), which will be passed to
|
codereview_new_python_data_8768
|
def __init__(
during RunInference. Defaults to default_numpy_inference_fn.
**Supported Versions:** RunInference APIs in Apache Beam have been tested
- with Tensorflow 2.11.
"""
self._model_uri = model_uri
self._model_type = model_type
```suggestion
with Tensorflow 2.9, 2.10, and 2.11.
```
def __init__(
during RunInference. Defaults to default_numpy_inference_fn.
**Supported Versions:** RunInference APIs in Apache Beam have been tested
+ with Tensorflow 2.9, 2.10, 2.11.
"""
self._model_uri = model_uri
self._model_type = model_type
|
codereview_new_python_data_8773
|
def update_model_path(self, model_path: Optional[str] = None):
"""Update the model paths produced by side inputs."""
pass
- def validate_constructor_args(self):
- """
- Validate arguments passed to the ModelHandler constructor.
- """
- raise NotImplementedError
-
class KeyedModelHandler(Generic[KeyT, ExampleT, PredictionT, ModelT],
ModelHandler[Tuple[KeyT, ExampleT],
Sorry for not seeing this earlier, but do we actually get anything out of this being part of the base class? We're never going to call it from the base and its implementation will always be subclass dependent
def update_model_path(self, model_path: Optional[str] = None):
"""Update the model paths produced by side inputs."""
pass
class KeyedModelHandler(Generic[KeyT, ExampleT, PredictionT, ModelT],
ModelHandler[Tuple[KeyT, ExampleT],
|
codereview_new_python_data_8774
|
def _verify_descriptor_created_in_a_compatible_env(process_bundle_descriptor):
# type: (beam_fn_api_pb2.ProcessBundleDescriptor) -> None
runtime_sdk = environments.sdk_base_version_capability()
- for _, t in process_bundle_descriptor.transforms.items():
env = process_bundle_descriptor.environments[t.environment_id]
for c in env.capabilities:
if (c.startswith(environments.SDK_VERSION_CAPABILITY_PREFIX) and
You can also do `for t in process_bundle_descriptor.transforms.values()`
def _verify_descriptor_created_in_a_compatible_env(process_bundle_descriptor):
# type: (beam_fn_api_pb2.ProcessBundleDescriptor) -> None
runtime_sdk = environments.sdk_base_version_capability()
+ for t in process_bundle_descriptor.transforms.values():
env = process_bundle_descriptor.environments[t.environment_id]
for c in env.capabilities:
if (c.startswith(environments.SDK_VERSION_CAPABILITY_PREFIX) and
|
codereview_new_python_data_8776
|
def add_module_properties(module, data, filter_method):
"now_datetime",
"get_timestamp",
"get_eta",
- "get_system_timezone",
- "convert_utc_to_system_timezone",
"now",
"nowdate",
"today",
this might break all the server scripts - let's not merge the other pr for now
or we can even keep the aliases ...(?)
basically: `get_time_zone = get_system_timezone` in the `data.py` file
def add_module_properties(module, data, filter_method):
"now_datetime",
"get_timestamp",
"get_eta",
+ "get_time_zone",
+ "convert_utc_to_user_timezone",
"now",
"nowdate",
"today",
|
codereview_new_python_data_8778
|
def test_enqueue_call(self):
mock_enqueue_call.assert_called_once_with(
execute_job,
- on_success=None,
- on_failure=None,
timeout=300,
kwargs={
"site": frappe.local.site,
This test is failing, mostly because on_success and on_failure don't exist on stable branches.
(we need to remove them entirely tbh)
def test_enqueue_call(self):
mock_enqueue_call.assert_called_once_with(
execute_job,
timeout=300,
kwargs={
"site": frappe.local.site,
|
codereview_new_python_data_8779
|
def execute(
result = self.build_and_run()
- if with_comment_count and with_comment_count != "0" and not as_list and self.doctype:
self.add_comment_count(result)
if save_user_settings:
maybe use sbool here?
```suggestion
if sbool(with_comment_count) and not as_list and self.doctype:
```
def execute(
result = self.build_and_run()
+ if sbool(with_comment_count) and not as_list and self.doctype:
self.add_comment_count(result)
if save_user_settings:
|
codereview_new_python_data_8781
|
def execute(
self.user_settings = json.loads(user_settings)
if is_virtual_doctype(self.doctype):
- from frappe.model.virtual_doctype import get_controller
controller = get_controller(self.doctype)
self.parse_args()
```suggestion
from frappe.model.base_document import get_controller
```
def execute(
self.user_settings = json.loads(user_settings)
if is_virtual_doctype(self.doctype):
+ from frappe.model.base_document import get_controller
controller = get_controller(self.doctype)
self.parse_args()
|
codereview_new_python_data_8782
|
def import_controller(doctype):
from frappe.model.document import Document
from frappe.utils.nestedset import NestedSet
if doctype not in DOCTYPES_FOR_DOCTYPE:
meta = frappe.get_meta(doctype)
if meta.custom:
return NestedSet if meta.get("is_tree") else Document
module_name = meta.module
- else:
- module_name = "Core"
-
module_path = None
class_overrides = frappe.get_hooks("override_doctype_class")
if class_overrides and class_overrides.get(doctype):
I'm guessing meta is used because we cant club the 2 db calls we were doing before (we could use a `select *` query and check the value of is_tree) as we'll get `None` if any column is missing? - this shouldn't be a problem for all the recent versions as `is_tree` exists in them.
This change does have a impact on standard doctype controllers tho.

We should probably look into updating our patch tests with starting with v12 rather than v10 - until then this seems good enough.
def import_controller(doctype):
from frappe.model.document import Document
from frappe.utils.nestedset import NestedSet
+ module_name = "Core"
if doctype not in DOCTYPES_FOR_DOCTYPE:
meta = frappe.get_meta(doctype)
if meta.custom:
return NestedSet if meta.get("is_tree") else Document
module_name = meta.module
module_path = None
class_overrides = frappe.get_hooks("override_doctype_class")
if class_overrides and class_overrides.get(doctype):
|
codereview_new_python_data_8783
|
def migrate(verbose=True, skip_failing=False, skip_search_index=False):
def run_before_migrate_hooks():
for app in frappe.get_installed_apps():
- frappe.db.begin()
try:
for fn in frappe.get_hooks("before_migrate", app_name=app):
frappe.get_attr(fn)()
This can be removed.
def migrate(verbose=True, skip_failing=False, skip_search_index=False):
def run_before_migrate_hooks():
for app in frappe.get_installed_apps():
try:
for fn in frappe.get_hooks("before_migrate", app_name=app):
frappe.get_attr(fn)()
|
codereview_new_python_data_8784
|
def validate_duplicate_entry(self):
def set_file_name(self):
if not self.file_name and not self.file_url:
- frappe.throw(_("No `file` or `file_url` field found in form-data"))
elif not self.file_name and self.file_url:
self.file_name = self.file_url.split("/")[-1]
else:
```suggestion
frappe.throw(_("Fields `file_name` or `file_url` must be set for File", exc=frappe.MandatoryError)
```
def validate_duplicate_entry(self):
def set_file_name(self):
if not self.file_name and not self.file_url:
+ frappe.throw(_("Fields `file_name` or `file_url` must be set for File", exc=frappe.MandatoryError)
elif not self.file_name and self.file_url:
self.file_name = self.file_url.split("/")[-1]
else:
|
codereview_new_python_data_8785
|
def validate_duplicate_entry(self):
def set_file_name(self):
if not self.file_name and not self.file_url:
- frappe.throw(_("Fields `file_name` or `file_url` must be set for File", exc=frappe.MandatoryError)
elif not self.file_name and self.file_url:
self.file_name = self.file_url.split("/")[-1]
else:
```suggestion
frappe.throw(_("Fields `file_name` or `file_url` must be set for File"), exc=frappe.MandatoryError)
```
def validate_duplicate_entry(self):
def set_file_name(self):
if not self.file_name and not self.file_url:
+ frappe.throw(_("Fields `file_name` or `file_url` must be set for File"), exc=frappe.MandatoryError)
elif not self.file_name and self.file_url:
self.file_name = self.file_url.split("/")[-1]
else:
|
codereview_new_python_data_8786
|
class Database:
STANDARD_VARCHAR_COLUMNS = ("name", "owner", "modified_by")
DEFAULT_COLUMNS = ["name", "creation", "modified", "modified_by", "owner", "docstatus", "idx"]
CHILD_TABLE_COLUMNS = ("parent", "parenttype", "parentfield")
- MAX_WRITES_PER_TRANSACTION = 20_000
# NOTE:
# FOR MARIADB - using no cache - as during backup, if the sequence was used in anyform,
hey, this isn't a bug. We intentionally bumped this number.
You can fix he docstring if required.
class Database:
STANDARD_VARCHAR_COLUMNS = ("name", "owner", "modified_by")
DEFAULT_COLUMNS = ["name", "creation", "modified", "modified_by", "owner", "docstatus", "idx"]
CHILD_TABLE_COLUMNS = ("parent", "parenttype", "parentfield")
+ MAX_WRITES_PER_TRANSACTION = 200_000
# NOTE:
# FOR MARIADB - using no cache - as during backup, if the sequence was used in anyform,
|
codereview_new_python_data_8787
|
def setup_group_by(data):
frappe.throw(_("Invalid aggregate function"))
if frappe.db.has_column(data.aggregate_on_doctype, data.aggregate_on_field):
- column = f"`tab{data.aggregate_on_doctype}`.`{data.aggregate_on_field}`"
- aggregate_function = data.aggregate_function
-
- data.fields.append(f"{aggregate_function}({column}) AS _aggregate_column")
- if data.aggregate_on_field:
- data.fields.append(column)
- data.group_by += f", {column}"
else:
raise_invalid_field(data.aggregate_on_field)
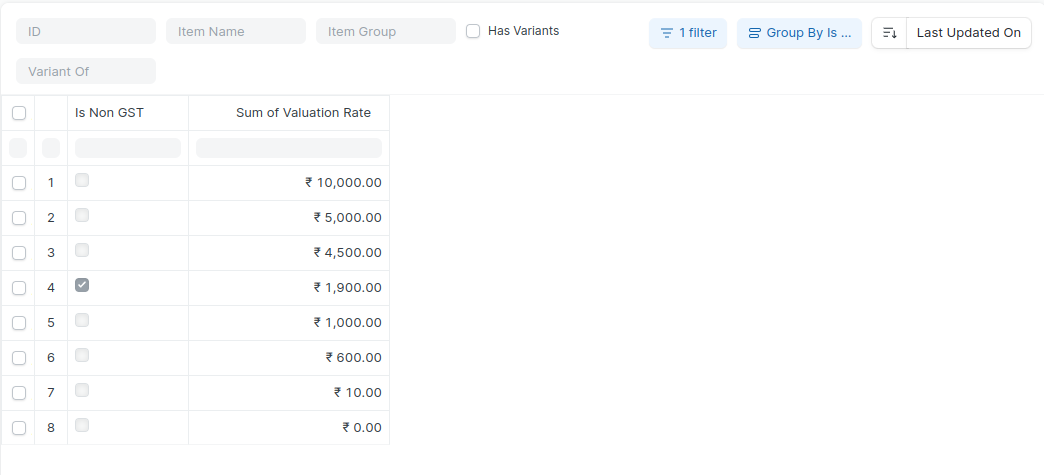
This line seems to be causing an issue.
### Before
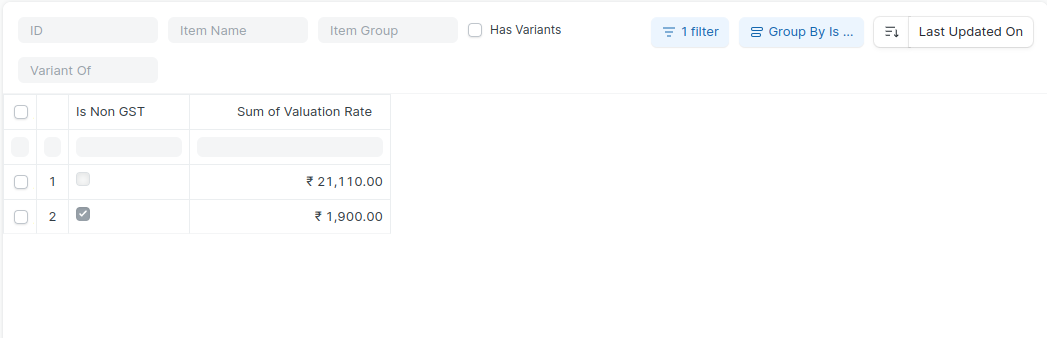
### After
def setup_group_by(data):
frappe.throw(_("Invalid aggregate function"))
if frappe.db.has_column(data.aggregate_on_doctype, data.aggregate_on_field):
+ data.fields.append(
+ f"{data.aggregate_function}(`tab{data.aggregate_on_doctype}`.`{data.aggregate_on_field}`) AS _aggregate_column"
+ )
else:
raise_invalid_field(data.aggregate_on_field)
|
codereview_new_python_data_8788
|
def get_valid_dict(
if ignore_nulls and d[fieldname] is None:
del d[fieldname]
- if not is_virtual_field and field_value is _DOC_DELETED_ATTR:
del d[fieldname]
return d
could be unified as one `if` block
def get_valid_dict(
if ignore_nulls and d[fieldname] is None:
del d[fieldname]
+ elif not is_virtual_field and field_value is _DOC_DELETED_ATTR:
del d[fieldname]
return d
|
codereview_new_python_data_8789
|
def get_high_permlevel_fields(self):
return self.high_permlevel_fields
- def get_permlevel_read_fields(self, parenttype=None, *, user=None):
- """Build list of fields with read perm level and all the higher perm levels defined."""
- if not hasattr(self, "permlevel_read_fields"):
- self.permlevel_read_fields = []
permlevel_access = set(self.get_permlevel_access("read", parenttype, user=user))
for df in self.get_fieldnames_with_value(with_field_meta=True):
if df.permlevel in permlevel_access:
- self.permlevel_read_fields.append(df)
- return self.permlevel_read_fields
def get_permlevel_access(self, permission_type="read", parenttype=None, *, user=None):
has_access_to = []
Perhaps this could be a **set** of **fieldnames**?
- faster lookup
- we only seem to be using fieldnames anyway
def get_high_permlevel_fields(self):
return self.high_permlevel_fields
+ def get_permitted_fieldnames(self, parenttype=None, *, user=None):
+ """Build list of `fieldname` with read perm level and all the higher perm levels defined."""
+ if not hasattr(self, "permitted_fieldnames"):
+ self.permitted_fieldnames = []
permlevel_access = set(self.get_permlevel_access("read", parenttype, user=user))
for df in self.get_fieldnames_with_value(with_field_meta=True):
if df.permlevel in permlevel_access:
+ self.permitted_fieldnames.append(df.fieldname)
+ return self.permitted_fieldnames
def get_permlevel_access(self, permission_type="read", parenttype=None, *, user=None):
has_access_to = []
|
codereview_new_python_data_8791
|
def inner(*args, **kwargs):
frappe.flags["has_permission_check_logs"] = []
result = func(*args, **kwargs)
self_perm_check = True if not kwargs.get("user") else kwargs.get("user") == frappe.session.user
- raise_exception = kwargs.get("raise_exception") is not False
# print only if access denied
# and if user is checking his own permission
```suggestion
raise_exception = kwargs.get("raise_exception", True)
```
even more simpler :)
`not False` is essentially `True` (when comparing with boolean expression)
def inner(*args, **kwargs):
frappe.flags["has_permission_check_logs"] = []
result = func(*args, **kwargs)
self_perm_check = True if not kwargs.get("user") else kwargs.get("user") == frappe.session.user
+ raise_exception = kwargs.get("raise_exception", True)
# print only if access denied
# and if user is checking his own permission
|
codereview_new_python_data_8792
|
def get_info_via_oauth(
def login_oauth_user(
data: dict | str,
- *,
provider: str | None = None,
- state: dict | str,
generate_login_token: bool = False,
):
# json.loads data and state
reverted this.
saw some usages hence thought might be better to not break it in v14
https://sourcegraph.com/search?q=context:global+login_oauth_user%28&patternType=standard&sm=1
def get_info_via_oauth(
def login_oauth_user(
data: dict | str,
provider: str | None = None,
+ state: dict | str | None = None,
+ email_id: str | None = None,
+ key: str | None = None,
generate_login_token: bool = False,
):
# json.loads data and state
|
codereview_new_python_data_8793
|
def can_subscribe_doc(doctype, docname):
@frappe.whitelist(allow_guest=True)
-<<<<<<< HEAD
-def can_subscribe_list(doctype):
-=======
def can_subscribe_doctype(doctype: str) -> bool:
->>>>>>> c960382667 (fix(socketio)!: Event list_update > doctype_subscribe)
from frappe.exceptions import PermissionError
if not frappe.has_permission(user=frappe.session.user, doctype=doctype, ptype="read"):
```suggestion
def can_subscribe_doctype(doctype: str) -> bool:
```
def can_subscribe_doc(doctype, docname):
@frappe.whitelist(allow_guest=True)
def can_subscribe_doctype(doctype: str) -> bool:
from frappe.exceptions import PermissionError
if not frappe.has_permission(user=frappe.session.user, doctype=doctype, ptype="read"):
|
codereview_new_python_data_8794
|
def can_subscribe_doc(doctype, docname):
@frappe.whitelist(allow_guest=True)
-<<<<<<< HEAD
-def can_subscribe_list(doctype):
-=======
def can_subscribe_doctype(doctype: str) -> bool:
->>>>>>> c960382667 (fix(socketio)!: Event list_update > doctype_subscribe)
from frappe.exceptions import PermissionError
if not frappe.has_permission(user=frappe.session.user, doctype=doctype, ptype="read"):
```suggestion
def can_subscribe_doctype(doctype: str) -> bool:
```
def can_subscribe_doc(doctype, docname):
@frappe.whitelist(allow_guest=True)
def can_subscribe_doctype(doctype: str) -> bool:
from frappe.exceptions import PermissionError
if not frappe.has_permission(user=frappe.session.user, doctype=doctype, ptype="read"):
|
codereview_new_python_data_8795
|
def get_email(data: dict) -> str:
return data.get("email") or data.get("upn") or data.get("unique_name")
-def redirect_post_login(desk_user: bool, redirect_to: str | None = None, provider: str = None):
frappe.local.response["type"] = "redirect"
if not redirect_to:
```suggestion
def redirect_post_login(desk_user: bool, redirect_to: str | None = None, provider: str | None = None):
```
def get_email(data: dict) -> str:
return data.get("email") or data.get("upn") or data.get("unique_name")
+def redirect_post_login(
+ desk_user: bool, redirect_to: str | None = None, provider: str | None = None
+):
frappe.local.response["type"] = "redirect"
if not redirect_to:
|
codereview_new_python_data_8796
|
def get_email(data: dict) -> str:
return data.get("email") or data.get("upn") or data.get("unique_name")
-def redirect_post_login(desk_user: bool, redirect_to: str | None = None, provider: str = None):
frappe.local.response["type"] = "redirect"
if not redirect_to:
this might error out if provider is not present?
`None` compared with `str` (?)
def get_email(data: dict) -> str:
return data.get("email") or data.get("upn") or data.get("unique_name")
+def redirect_post_login(
+ desk_user: bool, redirect_to: str | None = None, provider: str | None = None
+):
frappe.local.response["type"] = "redirect"
if not redirect_to:
|
codereview_new_python_data_8798
|
def get_web_form_module(doc):
@frappe.whitelist(allow_guest=True)
@rate_limit(key="web_form", limit=5, seconds=60, methods=["POST"])
-<<<<<<< HEAD
-def accept(web_form, data, docname=None, for_payment=False):
-=======
-def accept(web_form, data):
->>>>>>> d7f4540132 (chore: consider docname via data)
"""Save the web form"""
data = frappe._dict(json.loads(data))
for_payment = frappe.parse_json(for_payment)
```suggestion
def accept(web_form, data, for_payment=False):
```
def get_web_form_module(doc):
@frappe.whitelist(allow_guest=True)
@rate_limit(key="web_form", limit=5, seconds=60, methods=["POST"])
+def accept(web_form, data, for_payment=False):
"""Save the web form"""
data = frappe._dict(json.loads(data))
for_payment = frappe.parse_json(for_payment)
|
codereview_new_python_data_8800
|
def get_attached_images(doctype: str, names: list[str]) -> frappe._dict:
@frappe.whitelist()
-def get_files_in_folder(folder: str, start: int | str = 0, page_length: int | str = 20) -> dict:
- start = cint(start)
- page_length = cint(page_length)
-
attachment_folder = frappe.db.get_value(
"File",
"Home/Attachments",
This is all because of `x-url-form-encoded`?
Should we assume and cast in such cases?
def get_attached_images(doctype: str, names: list[str]) -> frappe._dict:
@frappe.whitelist()
+def get_files_in_folder(folder: str, start: int = 0, page_length: int = 20) -> dict:
attachment_folder = frappe.db.get_value(
"File",
"Home/Attachments",
|
codereview_new_python_data_8801
|
def get_perm_info(role):
@frappe.whitelist(allow_guest=True)
def update_password(
- new_password: str, logout_all_sessions: int | bool = 0, key: str = None, old_password: str = None
):
"""Update password for the current user.
```suggestion
new_password: str, logout_all_sessions: bool = 0, key: str = None, old_password: str = None
```
This should work too now? (Based on PR description of new behaviour)
def get_perm_info(role):
@frappe.whitelist(allow_guest=True)
def update_password(
+ new_password: str, logout_all_sessions: int = 0, key: str = None, old_password: str = None
):
"""Update password for the current user.
|
codereview_new_python_data_8803
|
def test_validate_whitelisted_api(self):
whitelisted_fn = next(x for x in frappe.whitelisted if x.__annotations__)
bad_params = (object(),) * len(signature(whitelisted_fn).parameters)
- with self.assertRaisesRegex(TypeError, self.ERR_REGEX):
whitelisted_fn(*bad_params)
def test_validate_whitelisted_doc_method(self):
report = frappe.get_last_doc("Report")
- with self.assertRaisesRegex(TypeError, self.ERR_REGEX):
report.toggle_disable(["disable"])
current_value = report.disabled
```suggestion
with self.assertRaisesRegex(frappe.FrappeTypeError, self.ERR_REGEX):
```
def test_validate_whitelisted_api(self):
whitelisted_fn = next(x for x in frappe.whitelisted if x.__annotations__)
bad_params = (object(),) * len(signature(whitelisted_fn).parameters)
+ with self.assertRaisesRegex(frappe.FrappeTypeError, self.ERR_REGEX):
whitelisted_fn(*bad_params)
def test_validate_whitelisted_doc_method(self):
report = frappe.get_last_doc("Report")
+ with self.assertRaisesRegex(frappe.FrappeTypeError, self.ERR_REGEX):
report.toggle_disable(["disable"])
current_value = report.disabled
|
codereview_new_python_data_8805
|
def _is_query(field):
_raise_exception()
for field in self.fields:
- lower_field = field.lower()
if SUB_QUERY_PATTERN.match(field):
- if field[0] == "(":
subquery_token = lower_field[1:].lstrip().split(" ", 1)[0]
if subquery_token in blacklisted_keywords:
_raise_exception()
```suggestion
lower_field = field.lower().strip()
```
def _is_query(field):
_raise_exception()
for field in self.fields:
+ lower_field = field.lower().strip()
if SUB_QUERY_PATTERN.match(field):
+ if lower_field[0] == "(":
subquery_token = lower_field[1:].lstrip().split(" ", 1)[0]
if subquery_token in blacklisted_keywords:
_raise_exception()
|
codereview_new_python_data_8806
|
def _is_query(field):
_raise_exception()
for field in self.fields:
- lower_field = field.lower()
if SUB_QUERY_PATTERN.match(field):
- if field[0] == "(":
subquery_token = lower_field[1:].lstrip().split(" ", 1)[0]
if subquery_token in blacklisted_keywords:
_raise_exception()
```suggestion
if lower_field[0] == "(":
```
def _is_query(field):
_raise_exception()
for field in self.fields:
+ lower_field = field.lower().strip()
if SUB_QUERY_PATTERN.match(field):
+ if lower_field[0] == "(":
subquery_token = lower_field[1:].lstrip().split(" ", 1)[0]
if subquery_token in blacklisted_keywords:
_raise_exception()
|
codereview_new_python_data_8807
|
def start_worker(
if os.environ.get("CI"):
setup_loghandlers("ERROR")
- WorkerKlass = Worker
- if strategy and strategy in DEQUEUE_STRATEGIES:
- WorkerKlass = DEQUEUE_STRATEGIES[strategy]
with Connection(redis_connection):
logging_level = "INFO"
```suggestion
WorkerKlass = DEQUEUE_STRATEGIES.get(strategy, Worker)
```

def start_worker(
if os.environ.get("CI"):
setup_loghandlers("ERROR")
+ WorkerKlass = DEQUEUE_STRATEGIES.get(strategy, Worker)
with Connection(redis_connection):
logging_level = "INFO"
|
codereview_new_python_data_8808
|
def start_scheduler():
"--strategy",
required=False,
type=click.Choice(["round_robbin", "random"]),
- help="dequeuing strategy to use.",
)
def start_worker(
queue, quiet=False, rq_username=None, rq_password=None, burst=False, strategy=None
```suggestion
help="Dequeuing strategy to use.",
```
def start_scheduler():
"--strategy",
required=False,
type=click.Choice(["round_robbin", "random"]),
+ help="Dequeuing strategy to use",
)
def start_worker(
queue, quiet=False, rq_username=None, rq_password=None, burst=False, strategy=None
|
codereview_new_python_data_8809
|
def get_print(
doc=None,
output=None,
no_letterhead=0,
- letterhead=None,
password=None,
pdf_options=None,
):
"""Get Print Format for given document.
can we move the param after `pdf_options`? - might break some code which specifies arguments by position
def get_print(
doc=None,
output=None,
no_letterhead=0,
password=None,
pdf_options=None,
+ letterhead=None,
):
"""Get Print Format for given document.
|
codereview_new_python_data_8810
|
def can_render(self):
return True
def render(self):
- action = "/login?redirect-to={}".format(frappe.request.path)
frappe.local.message_title = _("Not Permitted")
frappe.local.response["context"] = dict(
indicator_color="red", primary_action=action, primary_label=_("Login"), fullpage=True
```suggestion
action = f"/login?redirect-to={frappe.request.path}"
```
def can_render(self):
return True
def render(self):
+ action = f"/login?redirect-to={frappe.request.path}"
frappe.local.message_title = _("Not Permitted")
frappe.local.response["context"] = dict(
indicator_color="red", primary_action=action, primary_label=_("Login"), fullpage=True
|
codereview_new_python_data_8811
|
def get_link_options(web_form_name, doctype, allow_read_on_all_link_options=Fals
return "\n".join([doc.value for doc in link_options])
else:
- raise frappe.PermissionError(f"You don't have permission to access the {doctype} DocType.")
```suggestion
raise frappe.PermissionError(_("You don't have permission to access the {0} DocType.").format(doctype))
```
def get_link_options(web_form_name, doctype, allow_read_on_all_link_options=Fals
return "\n".join([doc.value for doc in link_options])
else:
+ raise frappe.PermissionError(_("You don't have permission to access the {0} DocType.").format(doctype))
|
codereview_new_python_data_8813
|
def mark_as_read(docname):
@frappe.whitelist()
def trigger_indicator_hide():
- frappe.publish_realtime("indicator_hide", user=frappe.session.user, after_commit=True)
def set_notifications_as_unseen(user):
```suggestion
frappe.publish_realtime("indicator_hide", user=frappe.session.user)
```
This might not trigger a commit. Similar problem in other `after_commit=True`
def mark_as_read(docname):
@frappe.whitelist()
def trigger_indicator_hide():
+ frappe.publish_realtime("indicator_hide", user=frappe.session.user)
def set_notifications_as_unseen(user):
|
codereview_new_python_data_8814
|
def logger(
)
-def log_error(message=None, title=None):
"""Log error to Error Log"""
- if title is None:
- title = _("Error")
# AI ALERT:
# the title and message may be swapped
```suggestion
def log_error(message=None, title="Error"):
"""Log error to Error Log"""
```
I think we shouldn't translate while logging errors ever. Logging should be as simple as possible to avoid failures from dependency logging has.
This is why we removed translation wrappers in error logs in v14.
def logger(
)
+def log_error(message=None, title="Error"):
"""Log error to Error Log"""
# AI ALERT:
# the title and message may be swapped
|
codereview_new_python_data_8815
|
def load_doc_before_save(self):
return
try:
- self._doc_before_save = frappe.get_doc(self.doctype, self.name)
except frappe.DoesNotExistError:
frappe.clear_last_message()
```suggestion
self._doc_before_save = frappe.get_doc(self.doctype, self.name, for_update=True)
```
def load_doc_before_save(self):
return
try:
+ self._doc_before_save = frappe.get_doc(self.doctype, self.name, for_update=True)
except frappe.DoesNotExistError:
frappe.clear_last_message()
|
codereview_new_python_data_8816
|
def delete_doc(doctype, name):
"""
if frappe.is_table(doctype):
- parenttype, parent, parentfield = frappe.db.get_value(
- doctype, name, ["parenttype", "parent", "parentfield"]
- )
parent = frappe.get_doc(parenttype, parent)
for row in parent.get(parentfield):
if row.name == name:
This branch should also implement "ignore_missing" behaviour?
def delete_doc(doctype, name):
"""
if frappe.is_table(doctype):
+ values = frappe.db.get_value(doctype, name, ["parenttype", "parent", "parentfield"])
+ if not values:
+ raise frappe.DoesNotExistError
+ parenttype, parent, parentfield = values
parent = frappe.get_doc(parenttype, parent)
for row in parent.get(parentfield):
if row.name == name:
|
codereview_new_python_data_8820
|
def resolve_class(*classes):
if classes is False:
return ""
- if isinstance(classes, str):
- return classes
-
if isinstance(classes, (list, tuple)):
return " ".join(resolve_class(c) for c in classes).strip()
this is useless now? :thinking:
def resolve_class(*classes):
if classes is False:
return ""
if isinstance(classes, (list, tuple)):
return " ".join(resolve_class(c) for c in classes).strip()
|
codereview_new_python_data_8824
|
def execute():
"item_type": "Action",
"action": "frappe.ui.toolbar.redirectToUrl()",
"is_standard": 1,
"idx": 3,
},
)
should be optional
def execute():
"item_type": "Action",
"action": "frappe.ui.toolbar.redirectToUrl()",
"is_standard": 1,
+ "hidden": 1,
"idx": 3,
},
)
|
codereview_new_python_data_8826
|
def savedocs(doc, action):
# action
doc.docstatus = {"Save": 0, "Submit": 1, "Update": 1, "Cancel": 2}[action]
-
if doc.docstatus == 1:
- if doc.bg_submit and doc.is_submittable:
doc.queue_action("submit", timeout=4000)
else:
doc.submit()
else:
- if doc.bg_submit and doc.is_submittable:
- doc.queue_action("save", timeout=4000)
- else:
- doc.save()
# update recent documents
run_onload(doc)
These properties are of `doc.meta` and not document itself.
doc.meta contains the metaclass for a document
def savedocs(doc, action):
# action
doc.docstatus = {"Save": 0, "Submit": 1, "Update": 1, "Cancel": 2}[action]
if doc.docstatus == 1:
+ if doc.meta.submit_in_background and doc.meta.is_submittable:
doc.queue_action("submit", timeout=4000)
else:
doc.submit()
else:
+ doc.save()
# update recent documents
run_onload(doc)
|
codereview_new_python_data_8828
|
def savedocs(doc, action):
if (
action == "Submit"
and doc.meta.queue_in_background
- and doc.meta.is_submittable
and not is_scheduler_inactive()
):
queue_submission(doc, action)
```suggestion
```
while this works this makes it hard for any other person looking into this. they will easily mistake this as being an additional unnecessary check and remove it, which will cause problems.
please make sure the validation exist in `doctype.py` as well as `customize_form.py`.
def savedocs(doc, action):
if (
action == "Submit"
and doc.meta.queue_in_background
and not is_scheduler_inactive()
):
queue_submission(doc, action)
|
codereview_new_python_data_8831
|
def get_workspace_sidebar_items():
filters = {
"restrict_to_domain": ["in", frappe.get_active_domains()],
- "ifnull(module, '')": ("not in", blocked_modules)
}
if has_access:
Can't reproduce. An empty list always adds `ifnull` for me. Try `run=0` to see generated query.
def get_workspace_sidebar_items():
filters = {
"restrict_to_domain": ["in", frappe.get_active_domains()],
+ "module": ["not in", blocked_modules],
}
if has_access:
|
codereview_new_python_data_8833
|
EmptyQueryValues = object()
FallBackDateTimeStr = "0001-01-01 00:00:00.000000"
-nested_set_hierarchy = (
- "ancestors of",
- "descendants of",
- "not ancestors of",
- "not descendants of",
- )
def is_query_type(query: str, query_type: str | tuple[str]) -> bool:
return query.lstrip().split(maxsplit=1)[0].lower().startswith(query_type)
format this like other global variables? much consistent that way
also, maybe run pre-commit :P
EmptyQueryValues = object()
FallBackDateTimeStr = "0001-01-01 00:00:00.000000"
+NESTED_SET_HIERARCHY = (
+ "ancestors of",
+ "descendants of",
+ "not ancestors of",
+ "not descendants of",
+)
+
def is_query_type(query: str, query_type: str | tuple[str]) -> bool:
return query.lstrip().split(maxsplit=1)[0].lower().startswith(query_type)
|
codereview_new_python_data_8834
|
def test_implicit_join_query(self):
),
)
- self.assertEqual(
- frappe.qb.engine.get_query(
- "Note",
- filters={"name": "Test Note Title"},
- fields=["name", "`tabNote Seen By`.`docstatus`", "`tabNote Seen By`.`user`"],
- ).run(as_dict=1),
- frappe.get_list(
- "Note",
- filters={"name": "Test Note Title"},
- fields=["name", "`tabNote Seen By`.`docstatus`", "`tabNote Seen By`.`user`"],
- ),
)
are there any tests for nested set support in qb?
def test_implicit_join_query(self):
),
)
+ @run_only_if(db_type_is.MARIADB)
+ def test_comment_stripping(self):
+ self.assertNotIn(
+ "email", frappe.qb.engine.get_query("User", fields=["name", "#email"], filters={}).get_sql()
)
|
codereview_new_python_data_8835
|
def get_context(context):
context["title"] = "Login"
context["provider_logins"] = []
context["disable_signup"] = frappe.utils.cint(frappe.get_website_settings("disable_signup"))
- context["disable_user_pass_login"] = frappe.utils.cint(frappe.get_system_settings("disable_user_pass_login"))
context["logo"] = frappe.get_website_settings("app_logo") or frappe.get_hooks("app_logo_url")[-1]
context["app_name"] = (
frappe.get_website_settings("app_name") or frappe.get_system_settings("app_name") or _("Frappe")
Based on first impression it looks like this checkbox just removes user/pass section from login page. However, one can very easily log in by sending a POST request. We should disable that too with same settings.
```javascript
fetch("http://site", {
"headers": {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "en-GB,en;q=0.9",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"x-frappe-cmd": "login",
"x-requested-with": "XMLHttpRequest"
},
"body": "cmd=login&usr=Administrator&pwd=admin&device=desktop",
"method": "POST",
});
```
def get_context(context):
context["title"] = "Login"
context["provider_logins"] = []
context["disable_signup"] = frappe.utils.cint(frappe.get_website_settings("disable_signup"))
+ context["disable_user_pass_login"] = frappe.utils.cint(
+ frappe.get_system_settings("disable_user_pass_login")
+ )
context["logo"] = frappe.get_website_settings("app_logo") or frappe.get_hooks("app_logo_url")[-1]
context["app_name"] = (
frappe.get_website_settings("app_name") or frappe.get_system_settings("app_name") or _("Frappe")
|
codereview_new_python_data_8837
|
def validate(self):
)
)
if self.use_ssl:
- self.use_starttls = None
test = imaplib.IMAP4_SSL(self.email_server, port=get_port(self))
else:
test = imaplib.IMAP4(self.email_server, port=get_port(self))
```suggestion
self.use_starttls = 0
```
def validate(self):
)
)
if self.use_ssl:
+ self.use_starttls = 0
test = imaplib.IMAP4_SSL(self.email_server, port=get_port(self))
else:
test = imaplib.IMAP4(self.email_server, port=get_port(self))
|
codereview_new_python_data_8838
|
def validate(self):
# if self.enable_incoming and not self.append_to:
# frappe.throw(_("Append To is mandatory for incoming mails"))
if (
not self.awaiting_password
and not frappe.local.flags.in_install
and not frappe.local.flags.in_patch
):
if self.password or self.smtp_server in ("127.0.0.1", "localhost"):
if self.enable_incoming:
- self.use_starttls = cint(self.use_imap and self.use_starttls and not self.use_ssl)
self.get_incoming_server()
self.no_failed = 0
maybe move this to L86?
def validate(self):
# if self.enable_incoming and not self.append_to:
# frappe.throw(_("Append To is mandatory for incoming mails"))
+ self.use_starttls = cint(self.use_imap and self.use_starttls and not self.use_ssl)
+
if (
not self.awaiting_password
and not frappe.local.flags.in_install
and not frappe.local.flags.in_patch
):
if self.password or self.smtp_server in ("127.0.0.1", "localhost"):
if self.enable_incoming:
self.get_incoming_server()
self.no_failed = 0
|
codereview_new_python_data_8839
|
def get_jloader():
apps = frappe.get_hooks("template_apps")
if not apps:
- apps = list(reversed(frappe.local.flags.web_pages_apps or frappe.get_installed_apps()))
if "frappe" not in apps:
apps.append("frappe")
This is being done instead of `apps.reverse` because we do NOT want to mutate the original object.
def get_jloader():
apps = frappe.get_hooks("template_apps")
if not apps:
+ apps = list(
+ reversed(frappe.local.flags.web_pages_apps or frappe.get_installed_apps(_ensure_on_bench=True))
+ )
if "frappe" not in apps:
apps.append("frappe")
|
codereview_new_python_data_8840
|
def update_event_in_google_calendar(doc, method=None):
)
# if add_video_conferencing enabled or disabled during update, overwrite
- frappe.db.set_value("Event", doc.name, {"google_meet_link": event.get("hangoutLink")})
doc.notify_update()
frappe.msgprint(_("Event Synced with Google Calendar."))
can we put `update_modified=False` over here?
def update_event_in_google_calendar(doc, method=None):
)
# if add_video_conferencing enabled or disabled during update, overwrite
+ frappe.db.set_value(
+ "Event",
+ doc.name,
+ {"google_meet_link": event.get("hangoutLink")},
+ update_modified=False,
+ )
doc.notify_update()
frappe.msgprint(_("Event Synced with Google Calendar."))
|
codereview_new_python_data_8842
|
def validate(self):
if self.sync_with_google_calendar and not self.google_calendar:
frappe.throw(_("Select Google Calendar to which event should be synced."))
- if not self.sync_with_google_calendar or self.event_category not in [
- "Event",
- "Meeting",
- "Other",
- ]:
- self.add_video_conferencing = False
def on_update(self):
self.sync_communication()
let `add_video_conferencing` show on all event categories? - we show the `sync_with_google_calendar` checkbox by default anyway (?)
```suggestion
if not self.sync_with_google_calendar:
self.add_video_conferencing = 0
```
def validate(self):
if self.sync_with_google_calendar and not self.google_calendar:
frappe.throw(_("Select Google Calendar to which event should be synced."))
+ if not self.sync_with_google_calendar:
+ self.add_video_conferencing = 0
def on_update(self):
self.sync_communication()
|
codereview_new_python_data_8843
|
def set_field_order(doctype, field_order):
# save to update
frappe.get_doc("DocType", doctype).save()
-
- frappe.db.commit()
-
frappe.clear_cache(doctype=doctype)
commit is not needed (?) 🤔 - `POST` request by default.
def set_field_order(doctype, field_order):
# save to update
frappe.get_doc("DocType", doctype).save()
frappe.clear_cache(doctype=doctype)
|
codereview_new_python_data_8844
|
def search_widget(
v
for v in values
if re.search(f"{re.escape(txt)}.*", _(v.name if as_dict else v[0]), re.IGNORECASE)
- or re.search(f"{_(re.escape(txt))}.*", _(v.name if as_dict else v[0]), re.IGNORECASE)
)
# Sorting the values array so that relevant results always come first
Not sure if this line is helpful / needed. What's the intended effect?
def search_widget(
v
for v in values
if re.search(f"{re.escape(txt)}.*", _(v.name if as_dict else v[0]), re.IGNORECASE)
)
# Sorting the values array so that relevant results always come first
|
codereview_new_python_data_8845
|
from frappe.utils import cast_fieldtype, cint, cstr, flt, now, sanitize_html, strip_html
from frappe.utils.html_utils import unescape_html
-max_positive_value = {"smallint": 2**15-1, "int": 2**31-1, "bigint": 2**63-1}
DOCTYPE_TABLE_FIELDS = [
_dict(fieldname="fields", options="DocField"),
```suggestion
max_positive_value = {"smallint": 2**15 - 1, "int": 2**31 - 1, "bigint": 2**63 - 1}
```
Setup autoformatter!
from frappe.utils import cast_fieldtype, cint, cstr, flt, now, sanitize_html, strip_html
from frappe.utils.html_utils import unescape_html
+max_positive_value = {"smallint": 2**15 - 1, "int": 2**31 - 1, "bigint": 2**63 - 1}
DOCTYPE_TABLE_FIELDS = [
_dict(fieldname="fields", options="DocField"),
|
codereview_new_python_data_8846
|
def extract_messages_from_javascript_code(code: str) -> list[tuple[int, str, str
return messages
-def extract_javascript(code, keywords=("__"), options=None):
"""Extract messages from JavaScript source code.
This is a modified version of babel's JS parser. Reused under BSD license.
tuples be like that 😅
```suggestion
def extract_javascript(code, keywords=("__",), options=None):
```
def extract_messages_from_javascript_code(code: str) -> list[tuple[int, str, str
return messages
+def extract_javascript(code, keywords=("__",), options=None):
"""Extract messages from JavaScript source code.
This is a modified version of babel's JS parser. Reused under BSD license.
|
codereview_new_python_data_8847
|
def only_for(roles: list[str] | tuple[str] | str, message=False):
roles = (roles,)
if not set(roles).intersection(get_roles()):
- if message:
- msgprint(
- _("This action is only allowed for {}").format(bold(", ".join(roles))),
- _("Not Permitted"),
- )
- raise PermissionError
def get_domain_data(module):
I know you didn't make the change now but looking at this, I wonder if telling people which roles are permitted is really ok
Should we instead just say they don't have permission to access this - and maybe hint at roles while we're at it? 🤔
With the current message, I have translation concerns too. Wonder if this easily translates to other languages maintaining grammar & clarity.
---
Also, `frappe.throw`
def only_for(roles: list[str] | tuple[str] | str, message=False):
roles = (roles,)
if not set(roles).intersection(get_roles()):
+ if not message:
+ raise PermissionError
+
+ throw(
+ _("This action is only allowed for {}").format(bold(", ".join(roles))),
+ PermissionError,
+ _("Not Permitted"),
+ )
def get_domain_data(module):
|
codereview_new_python_data_8849
|
get_title,
get_title_html,
)
-from frappe.desk.reportview import is_virtual_doctype
from frappe.exceptions import ImplicitCommitError
from frappe.model.document import Document
from frappe.utils import get_fullname
Simplify import path? Will improve runtime sanity a wee bit IMO
```suggestion
from frappe.model.utils import is_virtual_doctype
```
get_title,
get_title_html,
)
+from frappe.model.utils import is_virtual_doctype
from frappe.exceptions import ImplicitCommitError
from frappe.model.document import Document
from frappe.utils import get_fullname
|
codereview_new_python_data_8850
|
def run_post_save_methods(self):
self.clear_cache()
- if not hasattr(self.flags, "notify_update") or self.flags.notify_update == True:
self.notify_update()
update_global_search(self)
```suggestion
if not hasattr(self.flags, "notify_update") or self.flags.notify_update:
```
def run_post_save_methods(self):
self.clear_cache()
+ if not hasattr(self.flags, "notify_update") or self.flags.notify_update:
self.notify_update()
update_global_search(self)
|
codereview_new_python_data_8851
|
def is_query_type(query: str, query_type: str | tuple[str]) -> bool:
return query.lstrip().split(maxsplit=1)[0].lower().startswith(query_type)
-def table_from_string(table: str) -> "DocType":
- table_name = table.split("`", maxsplit=1)[1].split(".")[0][3:]
- if "`" in table_name:
- return frappe.qb.DocType(table_name=table_name.replace("`", ""))
- else:
- return frappe.qb.DocType(table_name=table_name)
-
-
def is_function_object(field: str) -> bool:
return getattr(field, "__module__", None) == "pypika.functions" or isinstance(field, Function)
this will very likely fail if the `table` doesn't have "`" in it.
since after splitting by "`", we're selecting the 2nd element.
<img width="284" alt="Screenshot 2022-08-17 at 12 20 38 AM" src="https://user-images.githubusercontent.com/32034600/184956793-317c5e81-2536-453d-b287-88ba2a1dacf3.png">
#
Also, that branching is not needed. just this should be fine (i think):
```py
return frappe.qb.DocType(table_name=table_name.replace("`", ""))
```
def is_query_type(query: str, query_type: str | tuple[str]) -> bool:
return query.lstrip().split(maxsplit=1)[0].lower().startswith(query_type)
def is_function_object(field: str) -> bool:
return getattr(field, "__module__", None) == "pypika.functions" or isinstance(field, Function)
|
codereview_new_python_data_8852
|
def get_users(doctype, name):
return frappe.db.get_all(
"DocShare",
fields=[
- "name", # Don't understant the need for pseudocolumns here, don't know why get_all supports it?
"user",
"read",
"write",
maybe remove this comment (?) 😅
def get_users(doctype, name):
return frappe.db.get_all(
"DocShare",
fields=[
+ "name",
"user",
"read",
"write",
|
codereview_new_python_data_8853
|
def is_query_type(query: str, query_type: str | tuple[str]) -> bool:
return query.lstrip().split(maxsplit=1)[0].lower().startswith(query_type)
-def is_function_object(field: str) -> bool:
return getattr(field, "__module__", None) == "pypika.functions" or isinstance(field, Function)
```suggestion
def is_pypika_function_object(field: str) -> bool:
```
better in terms of recognition (?) 🤔
def is_query_type(query: str, query_type: str | tuple[str]) -> bool:
return query.lstrip().split(maxsplit=1)[0].lower().startswith(query_type)
+def is_pypika_function_object(field: str) -> bool:
return getattr(field, "__module__", None) == "pypika.functions" or isinstance(field, Function)
|
codereview_new_python_data_8854
|
from sphinx.testing import comparer
from sphinx.testing.path import path
def _init_console(locale_dir=sphinx.locale._LOCALE_DIR, catalog='sphinx'):
"""Monkeypatch ``init_console`` to skip its action.
Perhaps:
```suggestion
def _init_console(
locale_dir = sphinx.locale._LOCALE_DIR,
catalog = 'sphinx',
):
"""Monkeypatch ``init_console``
return NullTranslations(), False
sphinx.locale.init_console = _init_console
```
from sphinx.testing import comparer
from sphinx.testing.path import path
+
def _init_console(locale_dir=sphinx.locale._LOCALE_DIR, catalog='sphinx'):
"""Monkeypatch ``init_console`` to skip its action.
|
codereview_new_python_data_8855
|
def iswrappedcoroutine(obj: Any) -> bool:
return hasattr(obj, '__wrapped__')
obj = unwrap_all(obj, stop=iswrappedcoroutine)
- # check obj.__code__ because iscoroutinefunction() crashes for custom method-like
- # objects (see https://github.com/sphinx-doc/sphinx/issues/6605)
- return hasattr(obj, '__code__') and inspect.iscoroutinefunction(obj)
def isproperty(obj: Any) -> bool:
```suggestion
return inspect.iscoroutinefunction(obj)
```
def iswrappedcoroutine(obj: Any) -> bool:
return hasattr(obj, '__wrapped__')
obj = unwrap_all(obj, stop=iswrappedcoroutine)
+ return inspect.iscoroutinefunction(obj)
def isproperty(obj: Any) -> bool:
|
codereview_new_python_data_8856
|
class DocstringStripSignatureMixin(DocstringSignatureMixin):
"""
def format_signature(self, **kwargs: Any) -> str:
if (
- self.args is None and
- self.config.autodoc_docstring_signature # type: ignore[attr-defined]
):
# only act if a signature is not explicitly given already, and if
# the feature is enabled
```suggestion
self.args is None
and self.config.autodoc_docstring_signature # type: ignore[attr-defined]
```
class DocstringStripSignatureMixin(DocstringSignatureMixin):
"""
def format_signature(self, **kwargs: Any) -> str:
if (
+ self.args is None
+ and self.config.autodoc_docstring_signature # type: ignore[attr-defined]
):
# only act if a signature is not explicitly given already, and if
# the feature is enabled
|
codereview_new_python_data_8857
|
class DocstringStripSignatureMixin(DocstringSignatureMixin):
"""
def format_signature(self, **kwargs: Any) -> str:
if (
- self.args is None and
- self.config.autodoc_docstring_signature # type: ignore[attr-defined]
):
# only act if a signature is not explicitly given already, and if
# the feature is enabled
```suggestion
and self.config.autodoc_docstring_signature # type: ignore # NoQA: W503
```
class DocstringStripSignatureMixin(DocstringSignatureMixin):
"""
def format_signature(self, **kwargs: Any) -> str:
if (
+ self.args is None
+ and self.config.autodoc_docstring_signature # type: ignore[attr-defined]
):
# only act if a signature is not explicitly given already, and if
# the feature is enabled
|
codereview_new_python_data_8858
|
def make_xrefs(self, rolename: str, domain: str, target: str,
innernode: Type[TextlikeNode] = nodes.emphasis,
contnode: Node = None, env: BuildEnvironment = None,
inliner: Inliner = None, location: Node = None) -> List[Node]:
- delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)'
delims_re = re.compile(delims)
sub_targets = re.split(delims, target)
```suggestion
delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)' # NoQA: E275, E501
```
def make_xrefs(self, rolename: str, domain: str, target: str,
innernode: Type[TextlikeNode] = nodes.emphasis,
contnode: Node = None, env: BuildEnvironment = None,
inliner: Inliner = None, location: Node = None) -> List[Node]:
+ delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)' # NoQA: E275, E501
delims_re = re.compile(delims)
sub_targets = re.split(delims, target)
|
codereview_new_python_data_8859
|
def make_xrefs(self, rolename: str, domain: str, target: str,
innernode: Type[TextlikeNode] = nodes.emphasis,
contnode: Node = None, env: BuildEnvironment = None,
inliner: Inliner = None, location: Node = None) -> List[Node]:
- delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)' # NoQA: E275, E501
delims_re = re.compile(delims)
sub_targets = re.split(delims, target)
```suggestion
delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)'
```
def make_xrefs(self, rolename: str, domain: str, target: str,
innernode: Type[TextlikeNode] = nodes.emphasis,
contnode: Node = None, env: BuildEnvironment = None,
inliner: Inliner = None, location: Node = None) -> List[Node]:
+ delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)'
delims_re = re.compile(delims)
sub_targets = re.split(delims, target)
|
codereview_new_python_data_8860
|
def make_xrefs(self, rolename: str, domain: str, target: str,
innernode: Type[TextlikeNode] = nodes.emphasis,
contnode: Node = None, env: BuildEnvironment = None,
inliner: Inliner = None, location: Node = None) -> List[Node]:
- delims = r'(\s*[\[\]\(\),](?:\s*or|of\s)?\s*|\s+or|of\s+|\s*\|\s*|\.\.\.)'
delims_re = re.compile(delims)
sub_targets = re.split(delims, target)
Does this fix the whitespace problems?
```suggestion
delims = r'(\s*[\[\]\(\),](?:\s*o[rf]\s)?\s*|\s+o[rf]\s+|\s*\|\s*|\.\.\.)'
```
def make_xrefs(self, rolename: str, domain: str, target: str,
innernode: Type[TextlikeNode] = nodes.emphasis,
contnode: Node = None, env: BuildEnvironment = None,
inliner: Inliner = None, location: Node = None) -> List[Node]:
+ delims = r'(\s*[\[\]\(\),](?:\s*o[rf]\s)?\s*|\s+o[rf]\s+|\s*\|\s*|\.\.\.)'
delims_re = re.compile(delims)
sub_targets = re.split(delims, target)
|
codereview_new_python_data_8861
|
def __init__(self, app: "Sphinx", env: BuildEnvironment = None) -> None:
# ... is passed by SphinxComponentRegistry.create_builder to not show two warnings.
warnings.warn("The 'env' argument to Builder will be required from Sphinx 7.",
RemovedInSphinx70Warning, stacklevel=2)
- self.env = Optional[BuildEnvironment] # type: ignore[assignment]
self.events: EventManager = app.events
self.config: Config = app.config
self.tags: Tags = app.tags
```suggestion
self.env: Optional[BuildEnvironment] = None # type: ignore[assignment]
```
def __init__(self, app: "Sphinx", env: BuildEnvironment = None) -> None:
# ... is passed by SphinxComponentRegistry.create_builder to not show two warnings.
warnings.warn("The 'env' argument to Builder will be required from Sphinx 7.",
RemovedInSphinx70Warning, stacklevel=2)
+ self.env: Optional[BuildEnvironment] = None # type: ignore[assignment]
self.events: EventManager = app.events
self.config: Config = app.config
self.tags: Tags = app.tags
|
codereview_new_python_data_8862
|
def __init__(self, app: "Sphinx", env: BuildEnvironment = None) -> None:
# ... is passed by SphinxComponentRegistry.create_builder to not show two warnings.
warnings.warn("The 'env' argument to Builder will be required from Sphinx 7.",
RemovedInSphinx70Warning, stacklevel=2)
- self.env: Optional[BuildEnvironment] = None # type: ignore[assignment]
self.events: EventManager = app.events
self.config: Config = app.config
self.tags: Tags = app.tags
```suggestion
self.env = None # type: ignore[assignment]
```
def __init__(self, app: "Sphinx", env: BuildEnvironment = None) -> None:
# ... is passed by SphinxComponentRegistry.create_builder to not show two warnings.
warnings.warn("The 'env' argument to Builder will be required from Sphinx 7.",
RemovedInSphinx70Warning, stacklevel=2)
+ self.env = None # type: ignore[assignment]
self.events: EventManager = app.events
self.config: Config = app.config
self.tags: Tags = app.tags
|
codereview_new_python_data_8863
|
def __init__(self, app: "Sphinx", env: BuildEnvironment = None) -> None:
# ... is passed by SphinxComponentRegistry.create_builder to not show two warnings.
warnings.warn("The 'env' argument to Builder will be required from Sphinx 7.",
RemovedInSphinx70Warning, stacklevel=2)
- self.env = None # type: ignore[assignment]
self.events: EventManager = app.events
self.config: Config = app.config
self.tags: Tags = app.tags
```suggestion
self.env = None
```
def __init__(self, app: "Sphinx", env: BuildEnvironment = None) -> None:
# ... is passed by SphinxComponentRegistry.create_builder to not show two warnings.
warnings.warn("The 'env' argument to Builder will be required from Sphinx 7.",
RemovedInSphinx70Warning, stacklevel=2)
+ self.env = None
self.events: EventManager = app.events
self.config: Config = app.config
self.tags: Tags = app.tags
|
codereview_new_python_data_8864
|
def get_filename_for_node(self, node: Node, docname: str) -> str:
filename = relpath(node.source, self.env.srcdir)\
.rsplit(':docstring of ', maxsplit=1)[0]
except Exception:
- filename = self.env.doc2path(docname, base=False)
return filename
@staticmethod
The `base` keyword is no longer needed.
```suggestion
filename = self.env.doc2path(docname, False)
```
def get_filename_for_node(self, node: Node, docname: str) -> str:
filename = relpath(node.source, self.env.srcdir)\
.rsplit(':docstring of ', maxsplit=1)[0]
except Exception:
+ filename = self.env.doc2path(docname, False)
return filename
@staticmethod
|
codereview_new_python_data_8865
|
def setup_resource_paths(app: Sphinx, pagename: str, templatename: str,
pathto = context.get('pathto')
# favicon_url
- favicon = context.get('favicon_url')
- if favicon and not isurl(favicon):
- context['favicon_url'] = pathto('_static/' + favicon, resource=True)
# logo_url
- logo = context.get('logo_url')
- if logo and not isurl(logo):
- context['logo_url'] = pathto('_static/' + logo, resource=True)
def validate_math_renderer(app: Sphinx) -> None:
It's better to call this variable as `favicon_url`.
```suggestion
favicon_url = context.get('favicon_url')
if favicon_url and not isurl(favicon_url):
context['favicon_url'] = pathto('_static/' + favicon_url, resource=True)
```
def setup_resource_paths(app: Sphinx, pagename: str, templatename: str,
pathto = context.get('pathto')
# favicon_url
+ favicon_url = context.get('favicon_url')
+ if favicon_url and not isurl(favicon_url):
+ context['favicon_url'] = pathto('_static/' + favicon_url, resource=True)
# logo_url
+ logo_url = context.get('logo_url')
+ if logo_url and not isurl(logo_url):
+ context['logo_url'] = pathto('_static/' + logo_url, resource=True)
def validate_math_renderer(app: Sphinx) -> None:
|
codereview_new_python_data_8866
|
def setup_resource_paths(app: Sphinx, pagename: str, templatename: str,
pathto = context.get('pathto')
# favicon_url
- favicon = context.get('favicon_url')
- if favicon and not isurl(favicon):
- context['favicon_url'] = pathto('_static/' + favicon, resource=True)
# logo_url
- logo = context.get('logo_url')
- if logo and not isurl(logo):
- context['logo_url'] = pathto('_static/' + logo, resource=True)
def validate_math_renderer(app: Sphinx) -> None:
This is also.
```suggestion
logo_url = context.get('logo_url')
if logo_url and not isurl(logo_url):
context['logo_url'] = pathto('_static/' + logo_url, resource=True)
```
def setup_resource_paths(app: Sphinx, pagename: str, templatename: str,
pathto = context.get('pathto')
# favicon_url
+ favicon_url = context.get('favicon_url')
+ if favicon_url and not isurl(favicon_url):
+ context['favicon_url'] = pathto('_static/' + favicon_url, resource=True)
# logo_url
+ logo_url = context.get('logo_url')
+ if logo_url and not isurl(logo_url):
+ context['logo_url'] = pathto('_static/' + logo_url, resource=True)
def validate_math_renderer(app: Sphinx) -> None:
|
codereview_new_python_data_8867
|
def is_simple_tuple(value: ast.AST) -> bool:
return "%s[%s]" % (self.visit(node.value), self.visit(node.slice))
def visit_UnaryOp(self, node: ast.UnaryOp) -> str:
if not isinstance(node.op, ast.Not):
return "%s%s" % (self.visit(node.op), self.visit(node.operand))
return "%s %s" % (self.visit(node.op), self.visit(node.operand))
`ast.UnaryOp` is one of `UAdd`, `USub`, `Invert` or `Not` per [the docs](https://docs.python.org/3/library/ast.html#ast.UnaryOp) -- for `+`, `-`, and `~` we don't want a space, but for `not` we do.
A
def is_simple_tuple(value: ast.AST) -> bool:
return "%s[%s]" % (self.visit(node.value), self.visit(node.slice))
def visit_UnaryOp(self, node: ast.UnaryOp) -> str:
+ # UnaryOp is one of {UAdd, USub, Invert, Not}. Only Not needs a space.
if not isinstance(node.op, ast.Not):
return "%s%s" % (self.visit(node.op), self.visit(node.operand))
return "%s %s" % (self.visit(node.op), self.visit(node.operand))
|
codereview_new_python_data_8868
|
def is_simple_tuple(value: ast.AST) -> bool:
def visit_UnaryOp(self, node: ast.UnaryOp) -> str:
# UnaryOp is one of {UAdd, USub, Invert, Not}. Only Not needs a space.
- if not isinstance(node.op, ast.Not):
- return "%s%s" % (self.visit(node.op), self.visit(node.operand))
- return "%s %s" % (self.visit(node.op), self.visit(node.operand))
def visit_Tuple(self, node: ast.Tuple) -> str:
if len(node.elts) == 0:
I consider `ast.Not` is a special case. So it would be better to check it first.
```suggestion
# UnaryOp is one of {UAdd, USub, Invert, Not}. Only Not needs a space.
if isinstance(node.op, ast.Not):
return "%s %s" % (self.visit(node.op), self.visit(node.operand))
else:
return "%s%s" % (self.visit(node.op), self.visit(node.operand))
```
def is_simple_tuple(value: ast.AST) -> bool:
def visit_UnaryOp(self, node: ast.UnaryOp) -> str:
# UnaryOp is one of {UAdd, USub, Invert, Not}. Only Not needs a space.
+ if isinstance(node.op, ast.Not):
+ return "%s %s" % (self.visit(node.op), self.visit(node.operand))
+ return "%s%s" % (self.visit(node.op), self.visit(node.operand))
def visit_Tuple(self, node: ast.Tuple) -> str:
if len(node.elts) == 0:
|
codereview_new_python_data_8869
|
def is_simple_tuple(value: ast.AST) -> bool:
return "%s[%s]" % (self.visit(node.value), self.visit(node.slice))
def visit_UnaryOp(self, node: ast.UnaryOp) -> str:
- # UnaryOp is one of {UAdd, USub, Invert, Not}. Only Not needs a space.
if isinstance(node.op, ast.Not):
return "%s %s" % (self.visit(node.op), self.visit(node.operand))
return "%s%s" % (self.visit(node.op), self.visit(node.operand))
I think adding examples here makes the comment clearer:
```suggestion
# UnaryOp is one of {UAdd, USub, Invert, Not}, which correspond
# respectively to `+x`, `-x`, `~x`, and `not x`. Only Not needs a space.
```
def is_simple_tuple(value: ast.AST) -> bool:
return "%s[%s]" % (self.visit(node.value), self.visit(node.slice))
def visit_UnaryOp(self, node: ast.UnaryOp) -> str:
+ # UnaryOp is one of {UAdd, USub, Invert, Not}, which refer to ``+x``,
+ # ``-x``, ``~x``, and ``not x``. Only Not needs a space.
if isinstance(node.op, ast.Not):
return "%s %s" % (self.visit(node.op), self.visit(node.operand))
return "%s%s" % (self.visit(node.op), self.visit(node.operand))
|
codereview_new_python_data_8870
|
def visit_Attribute(self, node: ast.Attribute) -> str:
return "%s.%s" % (self.visit(node.value), node.attr)
def visit_BinOp(self, node: ast.BinOp) -> str:
- # Special case ``**`` to now have surrounding spaces.
if isinstance(node.op, ast.Pow):
return "".join(map(self.visit, (node.left, node.op, node.right)))
return " ".join(self.visit(e) for e in [node.left, node.op, node.right])
```suggestion
# Special case ``**`` to not have surrounding spaces.
```
def visit_Attribute(self, node: ast.Attribute) -> str:
return "%s.%s" % (self.visit(node.value), node.attr)
def visit_BinOp(self, node: ast.BinOp) -> str:
+ # Special case ``**`` to not have surrounding spaces.
if isinstance(node.op, ast.Pow):
return "".join(map(self.visit, (node.left, node.op, node.right)))
return " ".join(self.visit(e) for e in [node.left, node.op, node.right])
|
codereview_new_python_data_8871
|
def create_builder(self, app: "Sphinx", name: str,
f"'env'argument. Report this bug to the developers of your custom builder, "
f"this is likely not a issue with Sphinx. The 'env' argument will be required "
f"from Sphinx 7.", RemovedInSphinx70Warning, stacklevel=2)
- return self.builders[name](app)
def add_domain(self, domain: Type[Domain], override: bool = False) -> None:
logger.debug('[app] adding domain: %r', domain)
* The new code never calls `set_environment()`. As a result, custom builders will get crashed because the env object is None.
* This will also cause another warning on `Builder.__init__()`. The users will see warnings twice or more.
Please be careful to changing the API. I believe Sphinx is not only an application but also a framework. So I consider this is a mix of refactoring and API changing. Is it intended?
def create_builder(self, app: "Sphinx", name: str,
f"'env'argument. Report this bug to the developers of your custom builder, "
f"this is likely not a issue with Sphinx. The 'env' argument will be required "
f"from Sphinx 7.", RemovedInSphinx70Warning, stacklevel=2)
+ builder = self.builders[name](app, env=...)
+ if env is not None:
+ builder.set_environment(env)
+ return builder
def add_domain(self, domain: Type[Domain], override: bool = False) -> None:
logger.debug('[app] adding domain: %r', domain)
|
codereview_new_python_data_9020
|
special = ['n', 't', '\\', '"', '\'', '7', 'r']
DEFAULT_LIMIT = 100
DEFAULT_PAGE_SIZE = 100
-
class AlertSeverity(Enum):
UNKNOWN = 0
```suggestion
DEFAULT_STARTING_PAGE_NUMBER = 1
```
special = ['n', 't', '\\', '"', '\'', '7', 'r']
DEFAULT_LIMIT = 100
DEFAULT_PAGE_SIZE = 100
+DEFAULT_STARTING_PAGE_NUMBER = 1
class AlertSeverity(Enum):
UNKNOWN = 0
|
codereview_new_python_data_9021
|
def normalize_scan_data(scan_data: dict) -> dict:
include_none=True,
)
- if "duration" in scan_data:
result["TotalTime"] = readable_duration_time(scan_data["duration"])
else:
If duration is present but is empty, this will also raise an error. This should cover both cases.
```suggestion
if scan_data.get("duration"):
result["TotalTime"] = readable_duration_time(scan_data["duration"])
```
def normalize_scan_data(scan_data: dict) -> dict:
include_none=True,
)
+ if scan_data.get("duration"):
result["TotalTime"] = readable_duration_time(scan_data["duration"])
else:
|
codereview_new_python_data_9022
|
def main():
dt: str = args.get('dt')
pollingCommand = args.get('pollingCommand')
pollingCommandArgName = args.get('pollingCommandArgName')
- tag = demisto.getArg('tag')
- playbookId = f' playbookId="{args.get("playbookId")}"' if args.get("playbookId") else ''
- interval = int(demisto.getArg('interval'))
- timeout = int(demisto.getArg('timeout'))
args_names = args.get('additionalPollingCommandArgNames').strip() \
if args.get('additionalPollingCommandArgNames') else None
```suggestion
playbookId = f' playbookId="{args.get("playbookId", "")}"'
```
def main():
dt: str = args.get('dt')
pollingCommand = args.get('pollingCommand')
pollingCommandArgName = args.get('pollingCommandArgName')
+ tag = args.get('tag')
+ playbookId = f' playbookId="{args.get("playbookId", "")}"'
+ interval = int(args.get('interval'))
+ timeout = int(args.get('timeout'))
args_names = args.get('additionalPollingCommandArgNames').strip() \
if args.get('additionalPollingCommandArgNames') else None
|
codereview_new_python_data_9023
|
def main():
dt: str = args.get('dt')
pollingCommand = args.get('pollingCommand')
pollingCommandArgName = args.get('pollingCommandArgName')
- tag = demisto.getArg('tag')
- playbookId = f' playbookId="{args.get("playbookId")}"' if args.get("playbookId") else ''
- interval = int(demisto.getArg('interval'))
- timeout = int(demisto.getArg('timeout'))
args_names = args.get('additionalPollingCommandArgNames').strip() \
if args.get('additionalPollingCommandArgNames') else None
```suggestion
tag = args.get('tag')
```
Use in ALL!
def main():
dt: str = args.get('dt')
pollingCommand = args.get('pollingCommand')
pollingCommandArgName = args.get('pollingCommandArgName')
+ tag = args.get('tag')
+ playbookId = f' playbookId="{args.get("playbookId", "")}"'
+ interval = int(args.get('interval'))
+ timeout = int(args.get('timeout'))
args_names = args.get('additionalPollingCommandArgNames').strip() \
if args.get('additionalPollingCommandArgNames') else None
|
codereview_new_python_data_9024
|
class IndicatorsSearcher:
:param limit: the current upper limit of the search (can be updated after init)
:type sort: ``List[Dict]``
- :param sort: Array of sort params in order of importance. Item structure: {"field": string, "asc": boolean}
:return: No data returned
:rtype: ``None``
```suggestion
:param sort: An array of sort params ordered by importance. Item structure: {"field": string, "asc": boolean}
```
class IndicatorsSearcher:
:param limit: the current upper limit of the search (can be updated after init)
:type sort: ``List[Dict]``
+ :param sort: An array of sort params ordered by importance. Item structure: {"field": string, "asc": boolean}
:return: No data returned
:rtype: ``None``
|
codereview_new_python_data_9025
|
def handle_bulk_update_string_query_arguments(
Args:
argument (Tuple[str, str]): a tuple containing the argument name and value.
Raises:
DemistoException: if the filter or update argument is not a json array.
filter_valid_input_example and update_valid_input_example are missing in the docstring.
def handle_bulk_update_string_query_arguments(
Args:
argument (Tuple[str, str]): a tuple containing the argument name and value.
+ filter_valid_input_example (str): a string representing a valid filter argument.
+ update_valid_input_example (str): a string representing a valid update argument.
Raises:
DemistoException: if the filter or update argument is not a json array.
|
codereview_new_python_data_9026
|
from CommonServerPython import *
import traceback
-import urllib3
# Disable insecure warnings
import urllib3
urllib3.disable_warnings()
'''CLIENT CLASS'''
duplicate, no?
from CommonServerPython import *
import traceback
# Disable insecure warnings
import urllib3
urllib3.disable_warnings()
+
'''CLIENT CLASS'''
|
codereview_new_python_data_9097
|
"<pre>"
" <tt>{0}</tt>"
"</pre>"
- "doesn't have the <tt>spyder-kernels{1}</tt> module installed. Without this "
- "module is not possible for Spyder to create a console for you.<br><br>"
"You can install it by activating your environment (if necessary) and "
- "running in a system terminal:"
"<pre>"
" <tt>{2}</tt>"
"</pre>"
```suggestion
"doesn't have <tt>spyder-kernels</tt> version <tt>{1}</tt> installed. "
"Without this module and specific version is not possible for Spyder to "
"create a console for you.<br><br>"
"You can install it by activating your environment (if necessary) and "
"then running in a system terminal:"
```
"<pre>"
" <tt>{0}</tt>"
"</pre>"
+ "doesn't have <tt>spyder-kernels</tt> version <tt>{1}</tt> installed. "
+ "Without this module and specific version is not possible for Spyder to "
+ "create a console for you.<br><br>"
"You can install it by activating your environment (if necessary) and "
+ "then running in a system terminal:"
"<pre>"
" <tt>{2}</tt>"
"</pre>"
|
codereview_new_python_data_9098
|
class KernelHandler(QObject):
"""
_shutdown_thread_list = []
- _shutdown_thread_list_lock = Lock()
"""List of running shutdown threads"""
def __init__(
self,
connection_file,
```suggestion
_shutdown_thread_list = []
"""List of running shutdown threads"""
_shutdown_thread_list_lock = Lock()
"""
Lock to add threads to _shutdown_thread_list or clear that list.
"""
```
class KernelHandler(QObject):
"""
_shutdown_thread_list = []
"""List of running shutdown threads"""
+ _shutdown_thread_list_lock = Lock()
+ """
+ Lock to add threads to _shutdown_thread_list or clear that list.
+ """
+
def __init__(
self,
connection_file,
|
codereview_new_python_data_9099
|
get_home_dir, get_conf_path, get_module_path, running_in_ci)
from spyder.config.manager import CONF
from spyder.dependencies import DEPENDENCIES
-from spyder.plugins.debugger.api import (
- DebuggerWidgetActions)
from spyder.plugins.externalconsole.api import ExtConsoleShConfiguration
from spyder.plugins.help.widgets import ObjectComboBox
from spyder.plugins.help.tests.test_plugin import check_text
```suggestion
from spyder.plugins.debugger.api import DebuggerWidgetActions
```
get_home_dir, get_conf_path, get_module_path, running_in_ci)
from spyder.config.manager import CONF
from spyder.dependencies import DEPENDENCIES
+from spyder.plugins.debugger.api import DebuggerWidgetActions
from spyder.plugins.externalconsole.api import ExtConsoleShConfiguration
from spyder.plugins.help.widgets import ObjectComboBox
from spyder.plugins.help.tests.test_plugin import check_text
|
codereview_new_python_data_9100
|
class SelectionContextModificator:
class ExtraAction:
- Advance = "advance"
\ No newline at end of file
```suggestion
Advance = "advance"
```
class SelectionContextModificator:
class ExtraAction:
\ No newline at end of file
+ Advance = "advance"
|
codereview_new_python_data_9101
|
class IPythonConsolePyConfiguration(TypedDict):
# then it will use an empty one.
console_namespace: bool
- # If not None, then the console will use an alternative run method.
run_method: NotRequired[str]
```suggestion
# If not None, then the console will use an alternative run method
# (e.g. `runfile`, `debugfile` or `debugcell`).
```
class IPythonConsolePyConfiguration(TypedDict):
# then it will use an empty one.
console_namespace: bool
+ # If not None, then the console will use an alternative run method
+ # (e.g. `runfile`, `debugfile` or `debugcell`).
run_method: NotRequired[str]
|
codereview_new_python_data_9102
|
def get_run_configuration_per_context(
after gathering the run configuration input. Else, no action needs
to take place.
context_modificator: Optional[str]
- str describing how to alter the context.
- e.g. run selection <from line>
re_run: bool
If True, then the requested configuration should correspond to the
last executed configuration for the given context.
```suggestion
str describing how to alter the context, e.g. run selection
<from line>.
```
def get_run_configuration_per_context(
after gathering the run configuration input. Else, no action needs
to take place.
context_modificator: Optional[str]
+ str describing how to alter the context, e.g. run selection
+ <from line>.
re_run: bool
If True, then the requested configuration should correspond to the
last executed configuration for the given context.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.