
id
stringlengths 30
32
| content
stringlengths 139
2.8k
|
|---|---|
codereview_new_python_data_10767
|
if pandas.__version__ != __pandas_version__:
warnings.warn(
- f"The pandas version installed {pandas.__version__} does not match the supported pandas version in"
- + f" Modin {__pandas_version__}. This may cause undesired side effects!"
)
with warnings.catch_warnings():
```suggestion
f"The pandas version installed ({pandas.__version__}) does not match the supported pandas version in"
+ f" Modin ({__pandas_version__}). This may cause undesired side effects!"
```
I like it with braces more
if pandas.__version__ != __pandas_version__:
warnings.warn(
+ f"The pandas version installed ({pandas.__version__}) does not match the supported pandas version in"
+ + f" Modin ({__pandas_version__}). This may cause undesired side effects!"
)
with warnings.catch_warnings():
|
codereview_new_python_data_10768
|
def pivot_table(
margins_name="All",
observed=False,
sort=True,
-): # noqa: PR01, RT01, D200
- """
- Create a spreadsheet-style pivot table as a DataFrame.
- """
if not isinstance(data, DataFrame):
raise ValueError(
"can not create pivot table with instance of type {}".format(type(data))
do we need these `noqa`-s and docstring given we inherit the doc?
def pivot_table(
margins_name="All",
observed=False,
sort=True,
+):
if not isinstance(data, DataFrame):
raise ValueError(
"can not create pivot table with instance of type {}".format(type(data))
|
codereview_new_python_data_10769
|
_doc_default_io_method = """
{summary} using pandas.
For parameters description please refer to pandas API.
Returns
-------
{returns}
?
```suggestion
For parameters description please refer to pandas API.
Returns
```
_doc_default_io_method = """
{summary} using pandas.
For parameters description please refer to pandas API.
+
Returns
-------
{returns}
|
codereview_new_python_data_10770
|
def make_distribution(self):
long_description=long_description,
long_description_content_type="text/markdown",
install_requires=[
- f"pandas==1.5.2",
"packaging",
"numpy>=1.18.5",
"fsspec",
```suggestion
"pandas==1.5.2",
```
def make_distribution(self):
long_description=long_description,
long_description_content_type="text/markdown",
install_requires=[
+ "pandas==1.5.2",
"packaging",
"numpy>=1.18.5",
"fsspec",
|
codereview_new_python_data_10771
|
try:
from dfsql import sql_query as dfsql_query
import dfsql.extensions # noqa: F401
except ImportError:
warnings.warn(
## Unused import
Import of 'dfsql' is not used.
[Show more details](https://github.com/modin-project/modin/security/code-scanning/432)
try:
from dfsql import sql_query as dfsql_query
+
+ # This import is required to inject the DataFrame.sql() method.
import dfsql.extensions # noqa: F401
except ImportError:
warnings.warn(
|
codereview_new_python_data_10772
|
try:
from dfsql import sql_query as dfsql_query
import dfsql.extensions # noqa: F401
except ImportError:
warnings.warn(
Can we put a comment here that this import adds sql method to DataFrame?
try:
from dfsql import sql_query as dfsql_query
+
+ # This import is required to inject the DataFrame.sql() method.
import dfsql.extensions # noqa: F401
except ImportError:
warnings.warn(
|
codereview_new_python_data_10773
|
def query(sql: str, *args, **kwargs) -> pd.DataFrame:
"""
- Execute SQL query using either hdk_query or dfsql.
Parameters
----------
```suggestion
Execute SQL query using either HDK engine or dfsql.
```
def query(sql: str, *args, **kwargs) -> pd.DataFrame:
"""
+ Execute SQL query using either HDK engine or dfsql.
Parameters
----------
|
codereview_new_python_data_10927
|
def ParseFileObject(self, parser_mediator, file_object, **kwargs):
event_data = LocateDatabaseEvent()
event_data.path = directory_header.path
- event_data.contents = contents
event_data.written_time = posix_time.PosixTimeInNanoseconds(
timestamp=timestamp)
`= contents or None`
def ParseFileObject(self, parser_mediator, file_object, **kwargs):
event_data = LocateDatabaseEvent()
event_data.path = directory_header.path
+ event_data.contents = contents or None
event_data.written_time = posix_time.PosixTimeInNanoseconds(
timestamp=timestamp)
|
codereview_new_python_data_10928
|
class LocateDatabaseEvent(events.EventData):
Attributes:
entries (list[str]): contents of the locate database (updatedb) entry.
- path: path of the locate database (updatedb) entry.
written_time (dfdatetime.DateTimeValues): entry written date and time.
"""
`path:` => `path (str):`
class LocateDatabaseEvent(events.EventData):
Attributes:
entries (list[str]): contents of the locate database (updatedb) entry.
+ path (str): path of the locate database (updatedb) entry.
written_time (dfdatetime.DateTimeValues): entry written date and time.
"""
|
codereview_new_python_data_10929
|
from plaso.containers import events
from plaso.containers import time_events
-from plaso.lib import errors
from plaso.lib import definitions
from plaso.parsers import manager
from plaso.parsers import text_parser
style nit: make import order alphabetical
from plaso.containers import events
from plaso.containers import time_events
from plaso.lib import definitions
+from plaso.lib import errors
from plaso.parsers import manager
from plaso.parsers import text_parser
|
codereview_new_python_data_10930
|
from plaso.parsers import opera
from plaso.parsers import pe
from plaso.parsers import plist
-from plaso.parsers import postgresql
from plaso.parsers import pls_recall
from plaso.parsers import recycler
from plaso.parsers import safari_cookies
from plaso.parsers import sccm
move this below pls_recall so it's in order
from plaso.parsers import opera
from plaso.parsers import pe
from plaso.parsers import plist
+
from plaso.parsers import pls_recall
+from plaso.parsers import postgresql
from plaso.parsers import recycler
from plaso.parsers import safari_cookies
from plaso.parsers import sccm
|
codereview_new_python_data_10931
|
from plaso.parsers import opera
from plaso.parsers import pe
from plaso.parsers import plist
-
from plaso.parsers import pls_recall
from plaso.parsers import postgresql
from plaso.parsers import recycler
i think you missed clearing this line.
from plaso.parsers import opera
from plaso.parsers import pe
from plaso.parsers import plist
from plaso.parsers import pls_recall
from plaso.parsers import postgresql
from plaso.parsers import recycler
|
codereview_new_python_data_10932
|
def ParseRecord(self, parser_mediator, key, structure):
event_data.log_line = log_line.lstrip().rstrip()
time_zone_string = self._GetValueFromStructure(structure, 'time_zone')
try:
time_zone = pytz.timezone(time_zone_string)
except pytz.UnknownTimeZoneError:
- if time_zone_string in self._PSQL_TIME_ZONE_MAPPING:
- time_zone = pytz.timezone(
- self._PSQL_TIME_ZONE_MAPPING[time_zone_string])
- else:
- parser_mediator.ProduceExtractionWarning(
- 'unsupported time zone: {0!s}'.format(time_zone_string))
- return
time_elements_structure = self._GetValueFromStructure(
structure, 'date_time')
I opt:
```
time_zone_string = self._GetValueFromStructure(structure, 'time_zone')
time_zone_string = self._PSQL_TIME_ZONE_MAPPING.get(
time_zone_string, time_zone_string)
try:
time_zone = pytz.timezone(time_zone_string)
except pytz.UnknownTimeZoneError:
parser_mediator.ProduceExtractionWarning(
'unsupported time zone: {0!s}'.format(time_zone_string))
return
```
def ParseRecord(self, parser_mediator, key, structure):
event_data.log_line = log_line.lstrip().rstrip()
time_zone_string = self._GetValueFromStructure(structure, 'time_zone')
+ time_zone_string = self._PSQL_TIME_ZONE_MAPPING.get(
+ time_zone_string, time_zone_string)
try:
time_zone = pytz.timezone(time_zone_string)
except pytz.UnknownTimeZoneError:
+ parser_mediator.ProduceExtractionWarning(
+ 'unsupported time zone: {0!s}'.format(time_zone_string))
+ return
time_elements_structure = self._GetValueFromStructure(
structure, 'date_time')
|
codereview_new_python_data_10933
|
def testProcess(self):
expected_event_values = {
'date_time': '2020-04-12 13:55:51',
- 'desc': 'com.apple.mobilecal'
- }
self.CheckEventValues(storage_writer, events[0], expected_event_values)
style nit: put the closing bracket on the same line
def testProcess(self):
expected_event_values = {
'date_time': '2020-04-12 13:55:51',
+ 'desc': 'com.apple.mobilecal'}
self.CheckEventValues(storage_writer, events[0], expected_event_values)
|
codereview_new_python_data_10937
|
def _process(self, element, key=None):
cats = list(hvds.data.dtypes[column].categories)
except TypeError:
# Issue #5619, cudf.core.index.StringIndex is not iterable.
- cats = list(hvds.data.dtypes[column].categories.values_host)
if cats == ['__UNKNOWN_CATEGORIES__']:
cats = list(hvds.data[column].cat.as_known().categories)
else:
```suggestion
cats = list(hvds.data.dtypes[column].categories.to_pandas())
```
I like this more because it could be used for other DataFrame libraries if needed. An example is `polars` which have the same method.
https://pola-rs.github.io/polars/py-polars/html/reference/dataframe/api/polars.DataFrame.to_pandas.html
def _process(self, element, key=None):
cats = list(hvds.data.dtypes[column].categories)
except TypeError:
# Issue #5619, cudf.core.index.StringIndex is not iterable.
+ cats = list(hvds.data.dtypes[column].categories.to_pandas())
if cats == ['__UNKNOWN_CATEGORIES__']:
cats = list(hvds.data[column].cat.as_known().categories)
else:
|
codereview_new_python_data_10938
|
def test_pickle(self):
def test_dataset_transform_by_spatial_select_expr_index_not_0_based():
"""Ensure 'spatial_select' expression works when index not zero-based.
-
Use 'spatial_select' defined by four nodes to select index 104, 105.
Apply expression to dataset.transform to generate new 'flag' column where True
for the two indexes."""
```suggestion
df = pd.DataFrame({"a": [7, 3, 0.5, 2, 1, 1], "b": [3, 4, 3, 2, 2, 1]}, index=list(range(101, 107)))
```
def test_pickle(self):
def test_dataset_transform_by_spatial_select_expr_index_not_0_based():
"""Ensure 'spatial_select' expression works when index not zero-based.
Use 'spatial_select' defined by four nodes to select index 104, 105.
Apply expression to dataset.transform to generate new 'flag' column where True
for the two indexes."""
|
codereview_new_python_data_10939
|
class Empty(Dimensioned, Composable):
group = param.String(default='Empty')
- def __init__(self, **params) -> None:
super().__init__(None, **params)
We have not started adding type hints to HoloViews. I'm in favor but that should be a project level decision.
```suggestion
def __init__(self, **params):
```
class Empty(Dimensioned, Composable):
group = param.String(default='Empty')
+ def __init__(self, **params):
super().__init__(None, **params)
|
codereview_new_python_data_10940
|
def spatial_select_columnar(xvals, yvals, geometry):
# Dask not compatible with above assignment statement.
# To circumvent, create a Series, fill in geom_mask values,
# and use mask() method to fill in values.
geom_mask_expanded = pd.Series(False, index=mask.index)
geom_mask_expanded[np.where(mask)[0]] = geom_mask
mask = mask.mask(mask, geom_mask_expanded)
return mask
I don't see any problem in changing the variable name `mask` to make this line clearer.
def spatial_select_columnar(xvals, yvals, geometry):
# Dask not compatible with above assignment statement.
# To circumvent, create a Series, fill in geom_mask values,
# and use mask() method to fill in values.
+ # mask() does not preserve the dtype of the original Series,
+ # and needs to be reset after the operation.
geom_mask_expanded = pd.Series(False, index=mask.index)
geom_mask_expanded[np.where(mask)[0]] = geom_mask
+ meta_orig = mask._meta
mask = mask.mask(mask, geom_mask_expanded)
+ mask._meta = meta_orig
return mask
|
codereview_new_python_data_10941
|
def help(obj, visualization=True, ansi=True, backend=None,
pydoc.help(obj)
-del io, os, rcfile, warnings
```suggestion
del os, rcfile, warnings
```
def help(obj, visualization=True, ansi=True, backend=None,
pydoc.help(obj)
+del os, rcfile, warnings
|
codereview_new_python_data_10942
|
def __call__(self, *args, **opts): # noqa (dummy signature)
if '_pyodide' in sys.modules:
from .pyodide import pyodide_extension, in_jupyterlite
if not in_jupyterlite():
extension = pyodide_extension
del pyodide_extension, in_jupyterlite
Maybe add a comment to say in jupyterlite the normal extension works just fine?
def __call__(self, *args, **opts): # noqa (dummy signature)
if '_pyodide' in sys.modules:
from .pyodide import pyodide_extension, in_jupyterlite
+ # The notebook_extension is needed inside jupyterlite,
+ # so the override is only done if we are not inside jupyterlite.
if not in_jupyterlite():
extension = pyodide_extension
del pyodide_extension, in_jupyterlite
|
codereview_new_python_data_10943
|
def test_colorbar_opts_title(self):
y,x = np.mgrid[-5:5, -5:5] * 0.1
z=np.sin(x**2+y**2)
scatter = Scatter3D((x.flat,y.flat,z.flat)).opts(colorbar=True, colorbar_opts={"title": "some-title"})
- plot = plotly_renderer.get_plot(scatter)
state = self._get_plot_state(scatter)
assert state['layout']['scene']['zaxis']['title']=="some-title"
\ No newline at end of file
This one fails. I simply cannot find the title anywhere in the `fig`. But I can see in my notebook that it works. I need help to finalize these tests.
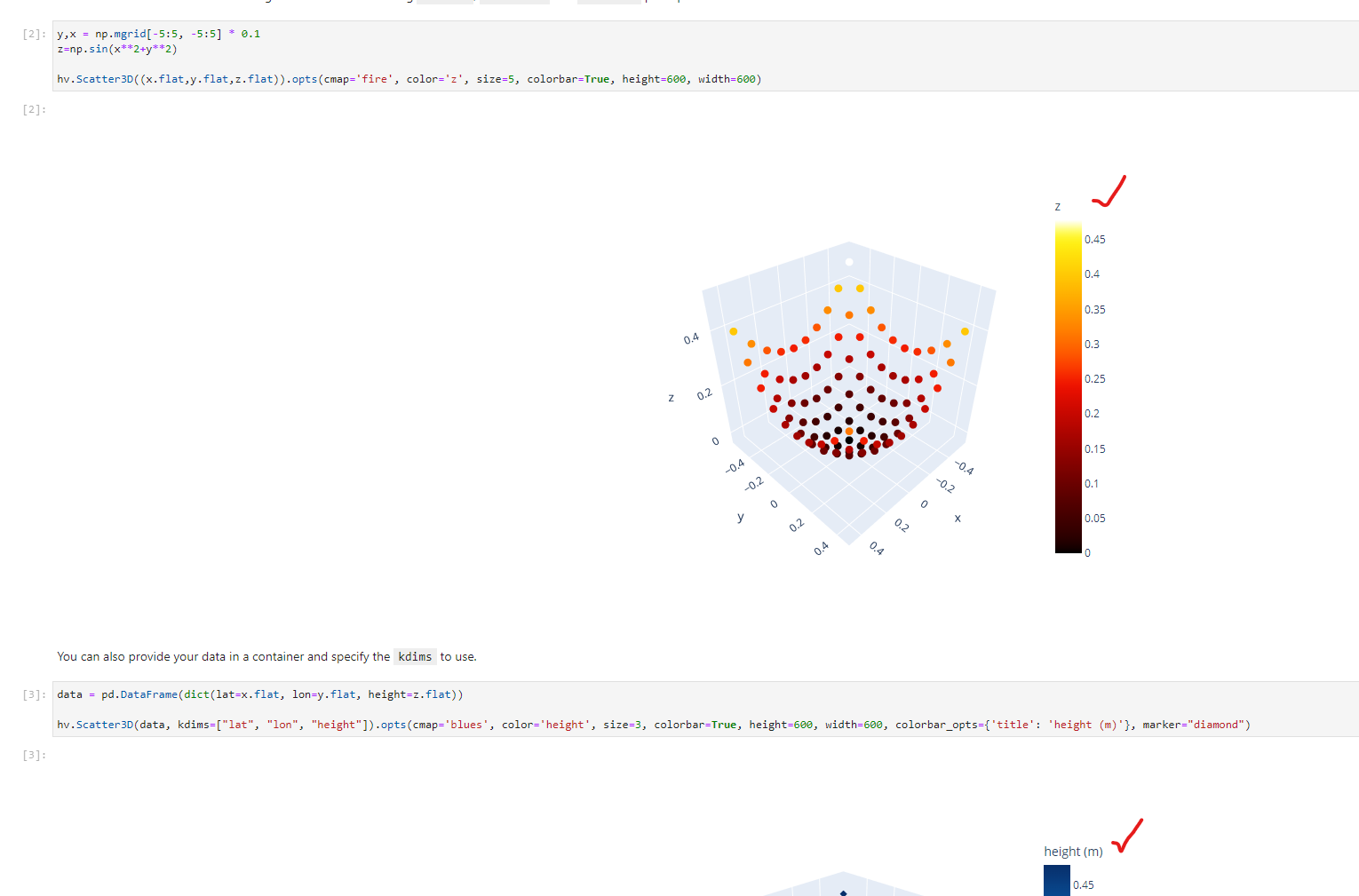
def test_colorbar_opts_title(self):
y,x = np.mgrid[-5:5, -5:5] * 0.1
z=np.sin(x**2+y**2)
scatter = Scatter3D((x.flat,y.flat,z.flat)).opts(colorbar=True, colorbar_opts={"title": "some-title"})
state = self._get_plot_state(scatter)
assert state['layout']['scene']['zaxis']['title']=="some-title"
\ No newline at end of file
|
codereview_new_python_data_10944
|
def _update_ranges(self, element, ranges):
plot.width, plot.height = None, None
else:
plot.aspect_ratio = 1./aspect
- elif not (fixed_height and fixed_width): # Bokeh 2.0 suport
# Should mirror the previous if-statement
# with the exception of plot.width -> plot.plot_width
# and plot.height -> plot.plot_height.
```suggestion
elif not (fixed_height and fixed_width): # Bokeh 2.x support
```
def _update_ranges(self, element, ranges):
plot.width, plot.height = None, None
else:
plot.aspect_ratio = 1./aspect
+ elif not (fixed_height and fixed_width): # Bokeh 2.x support
# Should mirror the previous if-statement
# with the exception of plot.width -> plot.plot_width
# and plot.height -> plot.plot_height.
|
codereview_new_python_data_11039
|
def fini_expression(
ir = setgen.scoped_set(ir, ctx=ctx)
# Compile any triggers that were triggered by the query
- ir_triggers = triggers.compile_triggers(
- ast_visitor.find_children(ir, irast.MutatingStmt), ctx=ctx)
# Collect all of the expressions stored in various side sets
# that can make it into the output, so that we can make sure
Do we have any idea how slow those traversals are? Any reason not to collect pending triggers in context as you make DML IR?
def fini_expression(
ir = setgen.scoped_set(ir, ctx=ctx)
# Compile any triggers that were triggered by the query
+ ir_triggers = triggers.compile_triggers(ctx.env.dml_stmts, ctx=ctx)
# Collect all of the expressions stored in various side sets
# that can make it into the output, so that we can make sure
|
codereview_new_python_data_11040
|
class Ptr(Base):
class Splat(Base):
depth: int
type: typing.Optional[TypeExpr] = None
intersection: typing.Optional[TypeIntersection] = None
```suggestion
class Splat(Base):
# Path element referring to all properties and links of an object
depth: int
```
class Ptr(Base):
class Splat(Base):
+ """Represents a splat operation (expansion to all props/links) in shapes"""
+
+ #: Expansion depth
depth: int
+ #: Source type expression, e.g in Type.**
type: typing.Optional[TypeExpr] = None
+ #: Type intersection on the source which would result
+ #: in polymorphic expansion, e.g. [is Type].**
intersection: typing.Optional[TypeIntersection] = None
|
codereview_new_python_data_11041
|
"cast": ("CAST", RESERVED_KEYWORD),
"catalog": ("CATALOG_P", UNRESERVED_KEYWORD),
"chain": ("CHAIN", UNRESERVED_KEYWORD),
- "char": ("CHAR_P", TYPE_FUNC_NAME_KEYWORD),
"character": ("CHARACTER", COL_NAME_KEYWORD),
"characteristics": ("CHARACTERISTICS", UNRESERVED_KEYWORD),
"check": ("CHECK", RESERVED_KEYWORD),
I'm not quite sure this is the best fix. Maybe we should special-case `"char"` in codegen instead?
"cast": ("CAST", RESERVED_KEYWORD),
"catalog": ("CATALOG_P", UNRESERVED_KEYWORD),
"chain": ("CHAIN", UNRESERVED_KEYWORD),
+ "char": ("CHAR_P", COL_NAME_KEYWORD),
"character": ("CHARACTER", COL_NAME_KEYWORD),
"characteristics": ("CHARACTERISTICS", UNRESERVED_KEYWORD),
"check": ("CHECK", RESERVED_KEYWORD),
|
codereview_new_python_data_11042
|
def parse_search_path(search_path_str: str) -> list[str]:
options = pg_resolver.Options(
current_user='edgedb',
current_database='edgedb',
**args
)
resolved = pg_resolver.resolve(stmt, schema, options)
@fantix Can you hook in actual data here? Is this easy enough?
def parse_search_path(search_path_str: str) -> list[str]:
options = pg_resolver.Options(
current_user='edgedb',
current_database='edgedb',
+ current_query=query_str,
**args
)
resolved = pg_resolver.resolve(stmt, schema, options)
|
codereview_new_python_data_11043
|
async def test_sql_static_eval(self):
res = await self.squery_values('select current_schema;')
self.assertEqual(res, [['public']])
- await self.scon.execute("set search_path to blah")
- res = await self.squery_values("select current_schema")
- self.assertEqual(res, [['blah']])
-
await self.squery_values('set search_path to blah;')
res = await self.squery_values('select current_schema;')
- # self.assertEqual(res, [['blah']])
await self.squery_values('set search_path to blah,foo;')
res = await self.squery_values('select current_schema;')
- # self.assertEqual(res, [['blah']])
res = await self.squery_values('select current_catalog;')
self.assertEqual(res, [['postgres']])
Ah this is failing because of the compile cache ... the previous `select current_schema;` is cached as the statically compiled `select 'public'...` thing and will keep working that way. I'm thinking maybe we could inject the values in the I/O server instead of the compiler, or we'll have to disable the compile cache when it is statically evaluated (a `cachable` flag somewhere?).
async def test_sql_static_eval(self):
res = await self.squery_values('select current_schema;')
self.assertEqual(res, [['public']])
await self.squery_values('set search_path to blah;')
res = await self.squery_values('select current_schema;')
+ self.assertEqual(res, [['blah']])
await self.squery_values('set search_path to blah,foo;')
res = await self.squery_values('select current_schema;')
+ self.assertEqual(res, [['blah']])
res = await self.squery_values('select current_catalog;')
self.assertEqual(res, [['postgres']])
|
codereview_new_python_data_11044
|
def _build_a_expr(n: Node, c: Context) -> pgast.BaseExpr:
def _build_func_call(n: Node, c: Context) -> pgast.FuncCall:
n = _unwrap(n, "FuncCall")
- name = tuple(_list(n, c, "funcname", _build_str)) # type: tuple[str, ...]
- if name == ('set_config',) or name == ('pg_catalog', 'set_config'):
- raise PSqlUnsupportedError(n)
return pgast.FuncCall(
- name=name,
args=_maybe_list(n, c, "args", _build_base_expr) or [],
agg_order=_maybe_list(n, c, "aggOrder", _build_sort_by),
agg_filter=_maybe(n, c, "aggFilter", _build_base_expr),
This is not really the best place to throw this error.
Consider moving this to here: https://github.com/edgedb/edgedb/blob/master/edb/pgsql/resolver/expr.py#L263-L265
def _build_a_expr(n: Node, c: Context) -> pgast.BaseExpr:
def _build_func_call(n: Node, c: Context) -> pgast.FuncCall:
n = _unwrap(n, "FuncCall")
return pgast.FuncCall(
+ name=tuple(_list(n, c, "funcname", _build_str)),
args=_maybe_list(n, c, "args", _build_base_expr) or [],
agg_order=_maybe_list(n, c, "aggOrder", _build_sort_by),
agg_filter=_maybe(n, c, "aggFilter", _build_base_expr),
|
codereview_new_python_data_11045
|
def contains_set_of_op(ir: irast.Base) -> bool:
flt = (lambda n: any(x == ft.TypeModifier.SetOfType
for x in n.params_typemods))
return bool(ast.find_children(ir, irast.Call, flt, terminate_early=True))
-
-
-class PointerCollectorVisitor(ast.NodeVisitor):
- collected: List[irast.Pointer]
-
- def __init__(self) -> None:
- super().__init__()
- self.collected = []
-
- def visit_Pointer(self, pointer: irast.Pointer) -> None:
- self.collected.append(pointer)
-
-
-def collect_pointers(expr: irast.Base) -> List[irast.Pointer]:
- """Walk over AST and collect all irast.Pointers"""
- visitor = PointerCollectorVisitor()
- visitor.visit(expr)
- return visitor.collected
I think you can use `find_children` instead of defining a visitor.
(And at that point, it's probably best just to inline the call to `find_children`)
def contains_set_of_op(ir: irast.Base) -> bool:
flt = (lambda n: any(x == ft.TypeModifier.SetOfType
for x in n.params_typemods))
return bool(ast.find_children(ir, irast.Call, flt, terminate_early=True))
|
codereview_new_python_data_11046
|
def node_visit(self, node: base.AST) -> None:
return visitor(node)
def visit_indented(
- self, node: base.AST, indent: bool = False, nest: bool = False
) -> None:
if nest:
self.write("(")
Should indent be true by default?
def node_visit(self, node: base.AST) -> None:
return visitor(node)
def visit_indented(
+ self, node: base.AST, indent: bool = True, nest: bool = False
) -> None:
if nest:
self.write("(")
|
codereview_new_python_data_11047
|
def copyfrom(self, other):
self.type = other.type
-class SubLinkType(enum.IntEnum):
- pass
- pass
- pass
- pass
-
-
class SubLink(ImmutableBaseExpr):
"""Subselect appearing in an expression."""
Maybe just one `pass`.
def copyfrom(self, other):
self.type = other.type
class SubLink(ImmutableBaseExpr):
"""Subselect appearing in an expression."""
|
codereview_new_python_data_11048
|
def _cmd_tree_from_ast(
if getattr(astnode, 'declared_overloaded', False):
cmd.set_attribute_value('declared_overloaded', True)
else:
- # This is an abstract propery/link
if cmd.get_attribute_value('default') is not None:
typ = cls.get_schema_metaclass().get_schema_class_displayname()
raise errors.SchemaDefinitionError(
```suggestion
# This is an abstract property/link
```
def _cmd_tree_from_ast(
if getattr(astnode, 'declared_overloaded', False):
cmd.set_attribute_value('declared_overloaded', True)
else:
+ # This is an abstract property/link
if cmd.get_attribute_value('default') is not None:
typ = cls.get_schema_metaclass().get_schema_class_displayname()
raise errors.SchemaDefinitionError(
|
codereview_new_python_data_11049
|
def compile_cast(
ctx=ctx,
)
if new_stype.is_enum(ctx.env.schema):
objctx = ctx.env.options.schema_object_context
if objctx in (s_constr.Constraint, s_indexes.Index):
Add a comment why
def compile_cast(
ctx=ctx,
)
+ # Constraints and indexes require an immutable expression, but pg cast is
+ # only stable. In this specific case, we use cast wrapper function that
+ # is declared to be immutable.
if new_stype.is_enum(ctx.env.schema):
objctx = ctx.env.options.schema_object_context
if objctx in (s_constr.Constraint, s_indexes.Index):
|
codereview_new_python_data_11050
|
def _maybe(
return None
-def _ident(t: T) -> Any:
return t
I'd drop the `T` and just make it `object` or `Any`. Not much point in having a type param only used once.
def _maybe(
return None
+def _ident(t: Any) -> Any:
return t
|
codereview_new_python_data_11051
|
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
-exclude_patterns = ['guides/deployment/heroku.rst']
# The reST default role (used for this markup: `text`) to use for all
# documents.
The correct way is to mark the rest file as `:orphan:`
<img width="823" alt="CleanShot 2022-12-01 at 10 51 54@2x" src="https://user-images.githubusercontent.com/239003/205135981-f9e0b9a7-809d-47ce-8249-064f992350ca.png">
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
+exclude_patterns = []
# The reST default role (used for this markup: `text`) to use for all
# documents.
|
codereview_new_python_data_11052
|
def _reset_schema(
current_tx = ctx.state.current_tx()
schema = current_tx.get_schema(ctx.compiler_state.std_schema)
- current_tx.start_migration()
-
empty_schema = s_schema.ChainedSchema(
ctx.compiler_state.std_schema,
s_schema.FlatSchema(),
Hm, does this get cleaned up somewhere?
def _reset_schema(
current_tx = ctx.state.current_tx()
schema = current_tx.get_schema(ctx.compiler_state.std_schema)
empty_schema = s_schema.ChainedSchema(
ctx.compiler_state.std_schema,
s_schema.FlatSchema(),
|
codereview_new_python_data_11053
|
def _validate_default_auth_method(
'database. May be used with or without `--bootstrap-only`.'),
click.option(
'--bootstrap-script', type=PathPath(), metavar="PATH",
- envvar="EDGEDB_SERVER_BOOTSTRAP_SCRIPT",
help='run the script when initializing the database. '
'Script run by default user within default database. '
'May be used with or without `--bootstrap-only`.'),
For consistency, we should add `--bootstrap-command-file` instead of `--bootstrap-script` for consistency with other `_FILE`
```suggestion
envvar="EDGEDB_SERVER_BOOTSTRAP_COMMAND_FILE",
```
def _validate_default_auth_method(
'database. May be used with or without `--bootstrap-only`.'),
click.option(
'--bootstrap-script', type=PathPath(), metavar="PATH",
+ envvar="EDGEDB_SERVER_BOOTSTRAP_COMMAND_FILE",
help='run the script when initializing the database. '
'Script run by default user within default database. '
'May be used with or without `--bootstrap-only`.'),
|
codereview_new_python_data_11054
|
def object_type_to_python_type(
pytype = scalar_type_to_python_type(ptype, schema)
ptr_card: qltypes.SchemaCardinality = p.get_cardinality(schema)
- try:
is_multi = ptr_card.is_multi()
- except ValueError:
raise UnsupportedExpressionError()
if is_multi:
Probably just do a `not is_known()` check instead?
def object_type_to_python_type(
pytype = scalar_type_to_python_type(ptype, schema)
ptr_card: qltypes.SchemaCardinality = p.get_cardinality(schema)
+ if ptr_card.is_known():
is_multi = ptr_card.is_multi()
+ else:
raise UnsupportedExpressionError()
if is_multi:
|
codereview_new_python_data_11055
|
async def squery_values(self, query):
res = await self.squery(query)
return [list(r.values()) for r in res]
- def assertShape(self, res, rows, cols, column_names=None):
self.assertEqual(len(res), rows)
if rows > 0:
self.assertEqual(len(res[0]), cols)
Add a docstring for this
I would also say call it `assert_shape`, except that `assertShape` matches other assert methods. Your call.
async def squery_values(self, query):
res = await self.squery(query)
return [list(r.values()) for r in res]
+ def assert_shape(self, res, rows, cols, column_names=None):
+ """
+ Fail if query result does not confront the specified shape, defined in
+ terms of:
+ - number of rows,
+ - number of columns (not checked if there are not rows)
+ - column names.
+ """
+
self.assertEqual(len(res), rows)
if rows > 0:
self.assertEqual(len(res[0]), cols)
|
codereview_new_python_data_11056
|
def _lookup_column(
elif len(name) == 2:
# look for the column in the specific table
- tab_name = name[0]
- col_name = name[1]
try:
table = _lookup_table(cast(str, tab_name), ctx)
`tab_name, col_name = name`
def _lookup_column(
elif len(name) == 2:
# look for the column in the specific table
+ tab_name, col_name = name
try:
table = _lookup_table(cast(str, tab_name), ctx)
|
codereview_new_python_data_11057
|
def prepare_patch(
# We need to delete all the support views and recreate them at the end
support_view_commands = metaschema.get_support_views(
reflschema, backend_params)
- for cv in support_view_commands:
dv = dbops.DropView(
cv.view.name,
- cascade=True,
conditions=[dbops.ViewExists(cv.view.name)],
)
dv.generate(preblock)
Any way we can avoid `cascade` here? It's pretty dangerous and can reach into parts that we didn't anticipate, hide bugs etc.
def prepare_patch(
# We need to delete all the support views and recreate them at the end
support_view_commands = metaschema.get_support_views(
reflschema, backend_params)
+ for cv in reversed(list(support_view_commands)):
dv = dbops.DropView(
cv.view.name,
conditions=[dbops.ViewExists(cv.view.name)],
)
dv.generate(preblock)
|
codereview_new_python_data_11058
|
def reduce_CreateQualifiedComputableLink(self, *kids):
#
# Access Policies
#
-sdl_commands_block('CreateAccessPolicy', SetField, SetAnnotation)
class AccessPolicyDeclarationBlock(Nonterm):
nit: Probably better to keep this expanded
def reduce_CreateQualifiedComputableLink(self, *kids):
#
# Access Policies
#
+sdl_commands_block(
+ 'CreateAccessPolicy',
+ SetField,
+ SetAnnotation
+)
class AccessPolicyDeclarationBlock(Nonterm):
|
codereview_new_python_data_11059
|
-from setuptools import setup, Extension
-from Cython.Build import cythonize
-
-import os.path
-
-libpg_query = os.path.join('.', 'libpg_query')
-
-extensions = cythonize([
- Extension('pypg_query.parser',
- ['pypg_query/parser.pyx'],
- libraries=['pg_query'],
- include_dirs=[libpg_query],
- library_dirs=[libpg_query])
-])
-
-setup(name='pypg_query',
- packages=['pypg_query'],
- ext_modules=extensions)
Move this to main `setup.py`.
|
codereview_new_python_data_11060
|
from typing import Optional
Please add our standard copyright comment to all new .py files.
+#
+# This source file is part of the EdgeDB open source project.
+#
+# Copyright 2010-present MagicStack Inc. and the EdgeDB authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+
from typing import Optional
|
codereview_new_python_data_11061
|
async def _bootstrap(ctx: BootstrapContext) -> None:
schema = s_schema.FlatSchema()
schema = await _init_defaults(schema, compiler, tpl_ctx.conn)
- if backend_params.has_create_database:
- await conn.sql_execute(
- b"ANALYZE",
- )
finally:
if in_dev_mode:
Use `tpl_ctx.conn`, we still want `ANALYZE` on single-db backends.
async def _bootstrap(ctx: BootstrapContext) -> None:
schema = s_schema.FlatSchema()
schema = await _init_defaults(schema, compiler, tpl_ctx.conn)
+ await tpl_ctx.conn.sql_execute(b"ANALYZE")
finally:
if in_dev_mode:
|
codereview_new_python_data_11062
|
def resolve_envvar_value(self, ctx: click.Context):
_server_options = [
click.option(
'-D', '--data-dir', type=PathPath(),
- envvar="EDGEDB_SERVER_DATADIR",
help='database cluster directory'),
click.option(
'--postgres-dsn', type=str, hidden=True,
```suggestion
envvar="EDGEDB_SERVER_DATADIR", cls=EnvvarResolver,
```
def resolve_envvar_value(self, ctx: click.Context):
_server_options = [
click.option(
'-D', '--data-dir', type=PathPath(),
+ envvar="EDGEDB_SERVER_DATADIR", cls=EnvvarResolver,
help='database cluster directory'),
click.option(
'--postgres-dsn', type=str, hidden=True,
|
codereview_new_python_data_11063
|
def prepare_patch(
if kind == 'sql':
return (patch, update), (), schema
# EdgeQL patches need to be compiled.
current_block = dbops.PLTopBlock()
std_plans = []
`assert` here that `kind` is `edgeql`?
def prepare_patch(
if kind == 'sql':
return (patch, update), (), schema
+ assert kind == 'edgeql'
+
# EdgeQL patches need to be compiled.
current_block = dbops.PLTopBlock()
std_plans = []
|
codereview_new_python_data_11064
|
def _compile_ql_query(
options=self._get_compile_options(ctx),
)
- if ir.cardinality.is_single():
- if ir.cardinality.can_be_zero():
- result_cardinality = enums.Cardinality.AT_MOST_ONE
- else:
- result_cardinality = enums.Cardinality.ONE
- else:
- if ir.cardinality.can_be_zero():
- result_cardinality = enums.Cardinality.MANY
- else:
- result_cardinality = enums.Cardinality.AT_LEAST_ONE
- if ctx.expected_cardinality_one:
- raise errors.ResultCardinalityMismatchError(
- f'the query has cardinality {result_cardinality.name} '
- f'which does not match the expected cardinality ONE')
sql_text, argmap = pg_compiler.compile_ir_to_sql(
ir,
I would factor this into a classmethod on the enum similarly to how we convert between cardinality representations elsewhere:
```
@classmethod
def from_ir_value(
cls,
card: ir.Cardinality
) -> Cardinality:
...
```
then, use the new helper from other such open-coded conversion places (e.g. `cardinality_from_ptr`)
def _compile_ql_query(
options=self._get_compile_options(ctx),
)
+ if ir.cardinality.is_multi() and ctx.expected_cardinality_one:
+ raise errors.ResultCardinalityMismatchError(
+ f'the query has cardinality {ir.cardinality.name} '
+ f'which does not match the expected cardinality ONE')
+ result_cardinality = enums.Cardinality.from_ir_value(ir.cardinality)
sql_text, argmap = pg_compiler.compile_ir_to_sql(
ir,
|
codereview_new_python_data_11065
|
class Cardinality(enum.Enum):
@classmethod
def from_ir_value(cls, card: ir.Cardinality) -> Cardinality:
- if card == ir.Cardinality.AT_MOST_ONE:
return Cardinality.AT_MOST_ONE
- elif card == ir.Cardinality.ONE:
return Cardinality.ONE
- elif card == ir.Cardinality.MANY:
return Cardinality.MANY
- elif card == ir.Cardinality.AT_LEAST_ONE:
return Cardinality.AT_LEAST_ONE
else:
raise ValueError(
Use `is` to test for enum (https://docs.python.org/3/library/enum.html#comparisons)
```suggestion
if card is ir.Cardinality.AT_MOST_ONE:
```
class Cardinality(enum.Enum):
@classmethod
def from_ir_value(cls, card: ir.Cardinality) -> Cardinality:
+ if card is ir.Cardinality.AT_MOST_ONE:
return Cardinality.AT_MOST_ONE
+ elif card is ir.Cardinality.ONE:
return Cardinality.ONE
+ elif card is ir.Cardinality.MANY:
return Cardinality.MANY
+ elif card is ir.Cardinality.AT_LEAST_ONE:
return Cardinality.AT_LEAST_ONE
else:
raise ValueError(
|
codereview_new_python_data_11066
|
async def _start_servers(
# Fail if none of the servers can be started, except when the admin
# server on a UNIX domain socket will be started.
- if not servers and not (admin and port):
raise StartupError("could not create any listen sockets")
addrs = []
```suggestion
if not servers and (not admin or port == 0):
```
async def _start_servers(
# Fail if none of the servers can be started, except when the admin
# server on a UNIX domain socket will be started.
+ if not servers and (not admin or port == 0):
raise StartupError("could not create any listen sockets")
addrs = []
|
codereview_new_python_data_11067
|
async def _start_servers(
if fut.result() is not None
})
- if not servers and not (admin and port):
raise StartupError("could not create any listen sockets")
addrs = []
Please add a short comment here.
async def _start_servers(
if fut.result() is not None
})
+ # Fail if none of the servers can be started, except when the admin
+ # server on a UNIX domain socket will be started.
+ if not servers and (not admin or port == 0):
raise StartupError("could not create any listen sockets")
addrs = []
|
codereview_new_python_data_11068
|
def _normalize_view_ptr_expr(
else:
msg = f'cannot assign to {ptrcls_sn.name}'
if id_access and not ctx.env.options.allow_user_specified_id:
- hint = 'config setting allow_user_specified_id must be enabled'
else:
hint = None
```suggestion
hint = 'consider enabling the "allow_user_specified_id" configuration parameter to allow setting custom object ids'
```
def _normalize_view_ptr_expr(
else:
msg = f'cannot assign to {ptrcls_sn.name}'
if id_access and not ctx.env.options.allow_user_specified_id:
+ hint = 'consider enabling the "allow_user_specified_id" configuration parameter to allow setting custom object ids'
else:
hint = None
|
codereview_new_python_data_11069
|
# Increment this whenever the database layout or stdlib changes.
-EDGEDB_CATALOG_VERSION = 2022_07_25_00_00
EDGEDB_MAJOR_VERSION = 3
```suggestion
EDGEDB_CATALOG_VERSION = 2022_07_26_00_00
```
# Increment this whenever the database layout or stdlib changes.
+EDGEDB_CATALOG_VERSION = 2022_07_26_00_00
EDGEDB_MAJOR_VERSION = 3
|
codereview_new_python_data_11070
|
def _parse_computable(
and target.is_view(expression.irast.schema)
):
raise errors.UnsupportedFeatureError(
- f'including a shape on schema-defined computed pointers '
f'is not yet supported',
context=self.source_context,
)
We tend to avoid using "pointer" in user-facing messages and documentation, so let's spell "properties" or "links" depending on what is being defined.
def _parse_computable(
and target.is_view(expression.irast.schema)
):
raise errors.UnsupportedFeatureError(
+ f'including a shape on schema-defined computed links '
f'is not yet supported',
context=self.source_context,
)
|
codereview_new_python_data_11071
|
def extend_path(
orig_ptrcls = ptrcls
- # For view ptrclses, find the place where the pointer is "really"
- # defined that is, either its schema definition site or where it
- # last had a expression defining it.
- #
# This makes it so that views don't change path ids unless they are
# introducing some computation.
- while (
- ptrcls.get_is_derived(ctx.env.schema)
- and not ptrcls.get_defined_here(ctx.env.schema)
- and (bases := ptrcls.get_bases(ctx.env.schema).objects(ctx.env.schema))
- and len(bases) == 1
- and bases[0].get_source(ctx.env.schema)
- ):
- ptrcls = bases[0]
path_id = pathctx.extend_path_id(
src_path_id,
Hmm, this reminds me of `get_nearest_non_derived_parent()`. Perhaps this should be formulated as a method on `Pointer` as well? `get_nearest_defined()` or something.
def extend_path(
orig_ptrcls = ptrcls
+ # Find the pointer definition site.
# This makes it so that views don't change path ids unless they are
# introducing some computation.
+ ptrcls = ptrcls.get_nearest_defined(ctx.env.schema)
path_id = pathctx.extend_path_id(
src_path_id,
|
codereview_new_python_data_11448
|
"""Approximate Kendall's Tau-b Metric."""
import tensorflow as tf
-from keras.metrics import Metric
from tensorflow_addons.utils.types import AcceptableDTypes
from typeguard import typechecked
We need to import Keras from TF
"""Approximate Kendall's Tau-b Metric."""
import tensorflow as tf
+from tensorflow.keras.metrics import Metric
from tensorflow_addons.utils.types import AcceptableDTypes
from typeguard import typechecked
|
codereview_new_python_data_11488
|
from test_utils import compare_pipelines
from sequences_test_utils import (ArgData, ArgDesc, ArgCb, ParamsProvider, get_video_input_cases,
sequence_suite_helper)
-from nose.plugins.attrib import attr
test_data_root = os.environ['DALI_EXTRA_PATH']
## Unused import
Import of 'attr' is not used.
[Show more details](https://github.com/NVIDIA/DALI/security/code-scanning/627)
from test_utils import compare_pipelines
from sequences_test_utils import (ArgData, ArgDesc, ArgCb, ParamsProvider, get_video_input_cases,
sequence_suite_helper)
test_data_root = os.environ['DALI_EXTRA_PATH']
|
codereview_new_python_data_11489
|
def _discover_autoserialize(module, visited):
ret = []
try:
module_members = inspect.getmembers(module)
- except ModuleNotFoundError as e:
# If any module can't be inspected, DALI will not be able to find the @autoserialize
# anyway. We can just skip this module.
return ret
Can you add a simple test with `import xyz` inside?
def _discover_autoserialize(module, visited):
ret = []
try:
module_members = inspect.getmembers(module)
+ except ModuleNotFoundError:
# If any module can't be inspected, DALI will not be able to find the @autoserialize
# anyway. We can just skip this module.
return ret
|
codereview_new_python_data_11490
|
def naive_hist_pipe():
img, _ = fn.readers.file(files=test_file_list)
# The naive_histogram accepts single-channels image, thus we conert the image to Grayscale.
- img = fn.decoders.image(img, n_bins=24, device='mixed', output_type=DALIImageType.GRAY)
img = img.gpu()
- img = fn.naive_histogram(img)
return img
```suggestion
img = fn.decoders.image(img, device='mixed', output_type=DALIImageType.GRAY)
img = img.gpu()
img = fn.naive_histogram(img, n_bins=24)
```
def naive_hist_pipe():
img, _ = fn.readers.file(files=test_file_list)
# The naive_histogram accepts single-channels image, thus we conert the image to Grayscale.
+ img = fn.decoders.image(img, device='mixed', output_type=DALIImageType.GRAY)
img = img.gpu()
+ img = fn.naive_histogram(img, n_bins=24)
return img
|
codereview_new_python_data_11491
|
def check_env_compatibility():
raise SkipTest()
if cuda.runtime.get_version() > cuda.driver.driver.get_version():
raise SkipTest()
- if '.'.join(str(i) for i in cuda.driver.driver.get_version()) >= LooseVersion('12.0') and \
LooseVersion(numba.__version__) < LooseVersion('0.56.4'):
raise SkipTest()
Should the `'.'.join(str(i) for i in cuda.driver.driver.get_version())` be wrapped in LooseVersion as well?
I am a bit wear about `str >= LooseVersion` comparison operator - if you swap arguments order it would be certain that LooseVersion's one is selected.
def check_env_compatibility():
raise SkipTest()
if cuda.runtime.get_version() > cuda.driver.driver.get_version():
raise SkipTest()
+ drv_ver_str = '.'.join(str(i) for i in cuda.driver.driver.get_version())
+ if LooseVersion(drv_ver_str) >= LooseVersion('12.0') and \
LooseVersion(numba.__version__) < LooseVersion('0.56.4'):
raise SkipTest()
|
codereview_new_python_data_11492
|
def __str__(self):
__repr__ = __str__
- def __hash__(self) -> int:
- return hash(str(self) + str(self.source))
-
# Note: Regardless of whether we want the cpu or gpu version
# of a tensor, we keep the source argument the same so that
# the pipeline can backtrack through the user-defined graph
that's unique, right?
def __str__(self):
__repr__ = __str__
# Note: Regardless of whether we want the cpu or gpu version
# of a tensor, we keep the source argument the same so that
# the pipeline can backtrack through the user-defined graph
|
codereview_new_python_data_11493
|
def conditional_split_merge_reinterpret_pipe(dtype, layout, shape):
input = fn.external_source(
source=[[np.full((10, 10, 3), 42, dtype=np.int32) for _ in range(batch_size)]], cycle=True)
pred = fn.external_source(
- source=[[np.array(i % 2 == 0, dtype=np.bool_) for i in range(batch_size)]], cycle=True)
true_branch, false_branch = fn._conditional.split(input, predicate=pred)
false_changed = fn.reinterpret(false_branch, dtype=dtype, layout=layout, shape=shape)
return fn._conditional.merge(true_branch, false_changed, predicate=pred)
https://numpy.org/devdocs/release/1.20.0-notes.html#using-the-aliases-of-builtin-types-like-np-int-is-deprecated
According to this, we can just use `bool` directly:
```suggestion
source=[[np.array(i % 2 == 0, dtype=bool) for i in range(batch_size)]], cycle=True)
```
And it gives the same results:
```
>>> x = numpy.array(1, dtype=bool)
>>> y = numpy.array(1, dtype=numpy.bool_)
>>> x.dtype
dtype('bool')
>>> y.dtype
dtype('bool')
>>> x
array(True)
>>> y
array(True)
```
def conditional_split_merge_reinterpret_pipe(dtype, layout, shape):
input = fn.external_source(
source=[[np.full((10, 10, 3), 42, dtype=np.int32) for _ in range(batch_size)]], cycle=True)
pred = fn.external_source(
+ source=[[np.array(i % 2 == 0, dtype=bool) for i in range(batch_size)]], cycle=True)
true_branch, false_branch = fn._conditional.split(input, predicate=pred)
false_changed = fn.reinterpret(false_branch, dtype=dtype, layout=layout, shape=shape)
return fn._conditional.merge(true_branch, false_changed, predicate=pred)
|
codereview_new_python_data_11494
|
def filter_pipeline(max_batch_size, inputs, device):
fill_value_bacthes = [list(fvs) for _, _, fvs in batches]
@pipeline_def
- def piepline():
samples = fn.external_source(source=sample_batches, layout="HWC")
filters = fn.external_source(source=filter_batches)
fill_values = fn.external_source(source=fill_value_bacthes)
return fn.experimental.filter(samples.gpu(), filters, fill_values, border="constant")
- return piepline(batch_size=max_batch_size, num_threads=4, device_id=0)
def sample_gen():
rng = np.random.default_rng(seed=101)
```suggestion
def pipeline():
```
def filter_pipeline(max_batch_size, inputs, device):
fill_value_bacthes = [list(fvs) for _, _, fvs in batches]
@pipeline_def
+ def pipeline():
samples = fn.external_source(source=sample_batches, layout="HWC")
filters = fn.external_source(source=filter_batches)
fill_values = fn.external_source(source=fill_value_bacthes)
return fn.experimental.filter(samples.gpu(), filters, fill_values, border="constant")
+ return pipeline(batch_size=max_batch_size, num_threads=4, device_id=0)
def sample_gen():
rng = np.random.default_rng(seed=101)
|
codereview_new_python_data_11495
|
def decoder_pipe(data_path, device, use_fast_idct=False):
test_data_root = get_dali_extra_path()
good_path = 'db/single'
misnamed_path = 'db/single/missnamed'
-test_good_path = {'jpeg', 'mixed', 'png', 'pnm', 'bmp', 'jpeg2k', 'webp'}
-test_misnamed_path = {'jpeg', 'png', 'pnm', 'bmp'}
def run_decode(data_path, batch, device, threads):
Why did you remove the tiff?
def decoder_pipe(data_path, device, use_fast_idct=False):
test_data_root = get_dali_extra_path()
good_path = 'db/single'
misnamed_path = 'db/single/missnamed'
+test_good_path = {'jpeg', 'mixed', 'png', 'tiff', 'pnm', 'bmp', 'jpeg2k', 'webp'}
+test_misnamed_path = {'jpeg', 'png', 'tiff', 'pnm', 'bmp'}
def run_decode(data_path, batch, device, threads):
|
codereview_new_python_data_11496
|
def _measure_time(func, n_iterations=30):
start = time.perf_counter()
func()
stop = time.perf_counter()
- times.append(stop - start)
return np.mean(np.array(times))
@staticmethod
shouldn't you append *inside* the loop? Otherwise you are only counting the last iteration. And the mean is just that one value
def _measure_time(func, n_iterations=30):
start = time.perf_counter()
func()
stop = time.perf_counter()
+ times.append(stop - start)
return np.mean(np.array(times))
@staticmethod
|
codereview_new_python_data_11497
|
def test_fail_conditional_split_merge():
base = (
"Divergent data found in different branches of conditional operation. All paths in "
"conditional operation are merged into one batch which must have consistent type, "
- "dimensionality, layout and other metadata. Found distinct "
)
yield check_fail_conditional_split_merge, types.UINT32, None, None, base + "types*"
yield check_fail_conditional_split_merge, None, "HWC", None, base + "layouts*"
Small hint. Now that we have `nose2`, you can write the tests without abusing the generators. I believe implementation using `@param` would be way better. Like here: https://github.com/NVIDIA/DALI/pull/4379/files?show-viewed-files=true&file-filters%5B%5D=#diff-9d4f5c833015a5d47d5c41f94b79bd93651bc9e75c3e8debb52aab2d6faa97c9R119
I've used it with `unittest.TestCase` class, but I guess it works with `test_` functions as well.
def test_fail_conditional_split_merge():
base = (
"Divergent data found in different branches of conditional operation. All paths in "
"conditional operation are merged into one batch which must have consistent type, "
+ "number of dimensions, layout and other metadata. Found distinct "
)
yield check_fail_conditional_split_merge, types.UINT32, None, None, base + "types*"
yield check_fail_conditional_split_merge, None, "HWC", None, base + "layouts*"
|
codereview_new_python_data_11498
|
def test_fail_conditional_split_merge():
base = (
"Divergent data found in different branches of conditional operation. All paths in "
"conditional operation are merged into one batch which must have consistent type, "
- "dimensionality, layout and other metadata. Found distinct "
)
yield check_fail_conditional_split_merge, types.UINT32, None, None, base + "types*"
yield check_fail_conditional_split_merge, None, "HWC", None, base + "layouts*"
How about also adding a test, where there is no split, but split&merge is? Like `predicate=[True]*batch_size`
def test_fail_conditional_split_merge():
base = (
"Divergent data found in different branches of conditional operation. All paths in "
"conditional operation are merged into one batch which must have consistent type, "
+ "number of dimensions, layout and other metadata. Found distinct "
)
yield check_fail_conditional_split_merge, types.UINT32, None, None, base + "types*"
yield check_fail_conditional_split_merge, None, "HWC", None, base + "layouts*"
|
codereview_new_python_data_11499
|
def deprecation_warning(what):
deprecation_warning("DALI support for Python 3.10 is experimental and some functionalities "
"may not work.")
- if __cuda_version__ < 102:
- deprecation_warning("DALI 1.3 is the last official release that supports CUDA 10.0. "
- "The next release will support only 10.2 from 10.x familly. "
- "Please update your environment to CUDA version 10.2 or newer.")
- if __cuda_version__ < 110:
deprecation_warning(
"DALI plans to drop the support for CUDA 10.2 in the upcoming releases. "
"Please update your CUDA toolkit.")
Oh, so actually for 102 build it says `__cuda_version__ = 10289`
def deprecation_warning(what):
deprecation_warning("DALI support for Python 3.10 is experimental and some functionalities "
"may not work.")
+ if int(str(__cuda_version__)[:3]) < 102:
+ deprecation_warning("DALI 1.3 was the last official release that supports CUDA 10.0. "
+ "Please update your CUDA toolkit ")
+ if int(str(__cuda_version__)[:2]) < 11:
deprecation_warning(
"DALI plans to drop the support for CUDA 10.2 in the upcoming releases. "
"Please update your CUDA toolkit.")
|
codereview_new_python_data_11500
|
import random
from functools import partial
from nvidia.dali.pipeline import Pipeline
-import nose_utils
test_data_root = os.environ['DALI_EXTRA_PATH']
images_dir = os.path.join(test_data_root, 'db', 'single', 'jpeg')
Is this needed?
import random
from functools import partial
from nvidia.dali.pipeline import Pipeline
test_data_root = os.environ['DALI_EXTRA_PATH']
images_dir = os.path.join(test_data_root, 'db', 'single', 'jpeg')
|
codereview_new_python_data_11501
|
def run_decode(data_path, batch, device, threads):
pipe.build()
iters = math.ceil(pipe.epoch_size("Reader") / batch)
for iter in range(iters):
- print("Iteration", iter + 1, "/", iters)
pipe.run()
remove this print?
def run_decode(data_path, batch, device, threads):
pipe.build()
iters = math.ceil(pipe.epoch_size("Reader") / batch)
for iter in range(iters):
pipe.run()
|
codereview_new_python_data_11502
|
def close(a, b):
absdiff = a - b if b < a else b - a
- return absdiff < 1e-5 or absdiff < abs(a) + abs(b) * 1e-6
def analyze_frame(image, channel_dim):
```suggestion
if isinstance(a, np.float32):
return np.isclose(a, b)
absdiff = a - b if b < a else b - a
return absdiff <= 1
```
def close(a, b):
+ if isinstance(a, np.float32):
+ return np.isclose(a, b)
absdiff = a - b if b < a else b - a
+ return absdiff <= 1
def analyze_frame(image, channel_dim):
|
codereview_new_python_data_11503
|
def test_operator_coord_flip():
layout_shape_values.append(("xy", (0, 2)))
for layout, shape in layout_shape_values:
for center_x, center_y, center_z in [(0.5, 0.5, 0.5), (0.0, 1.0, -0.5)]:
- yield check_operator_coord_flip, device, batch_size, layout, \
- shape, center_x, center_y, center_z
This file was temporarily copied before to the new dir to run it with `nose2` in CI.
This is why there are some apparent changes to it. In fact, this is just a copy of the latest version for this file.
def test_operator_coord_flip():
layout_shape_values.append(("xy", (0, 2)))
for layout, shape in layout_shape_values:
for center_x, center_y, center_z in [(0.5, 0.5, 0.5), (0.0, 1.0, -0.5)]:
+ yield (check_operator_coord_flip, device, batch_size, layout,
+ shape, center_x, center_y, center_z)
|
codereview_new_python_data_11504
|
def test_operator_coord_flip():
layout_shape_values.append(("xy", (0, 2)))
for layout, shape in layout_shape_values:
for center_x, center_y, center_z in [(0.5, 0.5, 0.5), (0.0, 1.0, -0.5)]:
- yield check_operator_coord_flip, device, batch_size, layout, \
- shape, center_x, center_y, center_z
Nitpick:
```suggestion
yield (check_operator_coord_flip, device, batch_size, layout, shapee
center_x, center_y, center_z)
```
def test_operator_coord_flip():
layout_shape_values.append(("xy", (0, 2)))
for layout, shape in layout_shape_values:
for center_x, center_y, center_z in [(0.5, 0.5, 0.5), (0.0, 1.0, -0.5)]:
+ yield (check_operator_coord_flip, device, batch_size, layout,
+ shape, center_x, center_y, center_z)
|
codereview_new_python_data_11505
|
def main(_):
assert FLAGS.image_dir, "`image_dir` missing."
assert (FLAGS.image_info_file or
FLAGS.object_annotations_file or
- FLAGS.caption_annotations_file, "All annotation files are " "missing.")
if FLAGS.image_info_file:
image_info_file = FLAGS.image_info_file
elif FLAGS.object_annotations_file:
```suggestion
FLAGS.caption_annotations_file, "All annotation files are missing.")
```
def main(_):
assert FLAGS.image_dir, "`image_dir` missing."
assert (FLAGS.image_info_file or
FLAGS.object_annotations_file or
+ FLAGS.caption_annotations_file, "All annotation files are missing.")
if FLAGS.image_info_file:
image_info_file = FLAGS.image_info_file
elif FLAGS.object_annotations_file:
|
codereview_new_python_data_11506
|
def main(_):
assert FLAGS.image_dir, "`image_dir` missing."
assert (FLAGS.image_info_file or
FLAGS.object_annotations_file or
- FLAGS.caption_annotations_file, "All annotation files are " "missing.")
if FLAGS.image_info_file:
image_info_file = FLAGS.image_info_file
elif FLAGS.object_annotations_file:
```suggestion
FLAGS.caption_annotations_file, "All annotation files are missing.")
```
def main(_):
assert FLAGS.image_dir, "`image_dir` missing."
assert (FLAGS.image_info_file or
FLAGS.object_annotations_file or
+ FLAGS.caption_annotations_file, "All annotation files are missing.")
if FLAGS.image_info_file:
image_info_file = FLAGS.image_info_file
elif FLAGS.object_annotations_file:
|
codereview_new_python_data_11507
|
class ShmMessageDesc(Structure):
`num_bytes` : unsigned long long int
Size in bytes of the serialized message
"""
- _fields = ("worker_id", "i"), ("shm_chunk_id", "i"), ("shm_capacity", "Q"), \
- ("offset", "Q"), ("num_bytes", "Q")
class WorkerArgs:
I think the following reads better (check that it passes flake8)
```suggestion
_fields = (
("worker_id", "i"),
("shm_chunk_id", "i"),
("shm_capacity", "Q"),
("offset", "Q"), ("num_bytes", "Q")
)
```
class ShmMessageDesc(Structure):
`num_bytes` : unsigned long long int
Size in bytes of the serialized message
"""
+ _fields = (("worker_id", "i"),
+ ("shm_chunk_id", "i"),
+ ("shm_capacity", "Q"),
+ ("offset", "Q"), ("num_bytes", "Q"))
class WorkerArgs:
|
codereview_new_python_data_11508
|
def _discover_autoserialize(module, visited):
def invoke_autoserialize(head_module, filename):
"""
- Perform the autoserialization of a function marked by :meth:`nvidia.dali.plugin.triton.autoserialize`.
Assuming, that user marked a function with ``@autoserialize`` decorator, the
- ``invoke_autoserialize`` is a utility function, which will actually perform the autoserialization.
- It discovers the ``@autoserialize`` function in a module tree denoted by provided ``head_module``
- and saves the serialized DALI pipeline to the file in the ``filename`` path.
Only one ``@autoserialize`` function may exist in a given module tree.
:param head_module: Module, denoting the model tree in which the decorated function shall exist.
:param filename: Path to the file, where the output of serialization will be saved.
- """ # noqa W505
autoserialize_functions = _discover_autoserialize(head_module, visited=[])
if len(autoserialize_functions) > 1:
raise RuntimeError(
Is the `flake8` prompting `W505` here? I've ran it on my side and didn't see such check being false. These are what I've got on `autoserialize.py` file:
```
dali/python/nvidia/dali/_utils/autoserialize.py:49:101: E501 line too long (106 > 100 characters)
dali/python/nvidia/dali/_utils/autoserialize.py:52:101: E501 line too long (102 > 100 characters)
dali/python/nvidia/dali/_utils/autoserialize.py:53:101: E501 line too long (101 > 100 characters)
dali/python/nvidia/dali/_utils/autoserialize.py:68:13: F541 f-string is missing placeholder
```
def _discover_autoserialize(module, visited):
def invoke_autoserialize(head_module, filename):
"""
+ Perform the autoserialization of a function marked by
+ :meth:`nvidia.dali.plugin.triton.autoserialize`.
Assuming, that user marked a function with ``@autoserialize`` decorator, the
+ ``invoke_autoserialize`` is a utility function, which will actually perform
+ the autoserialization.
+ It discovers the ``@autoserialize`` function in a module tree denoted by provided
+ ``head_module`` and saves the serialized DALI pipeline to the file in the ``filename`` path.
Only one ``@autoserialize`` function may exist in a given module tree.
:param head_module: Module, denoting the model tree in which the decorated function shall exist.
:param filename: Path to the file, where the output of serialization will be saved.
+ """
autoserialize_functions = _discover_autoserialize(head_module, visited=[])
if len(autoserialize_functions) > 1:
raise RuntimeError(
|
codereview_new_python_data_11509
|
def autoserialize(dali_pipeline):
"""
Decorator, that marks a DALI pipeline (represented by :meth:`nvidia.dali.pipeline_def`) for
- autoserialization in [DALI Backend's](https://github.com/triton-inference-server/dali_backend#dali-triton-backend) model repository.
For details about the autoserialization feature, please refer to the
- [DALI Backend documentation](https://github.com/triton-inference-server/dali_backend#autoserialization).
Only a ``pipeline_def`` can be decorated with ``autoserialize``.
Only one ``pipeline_def`` may be decorated with ``autoserialize`` in a given program.
To perform autoserialization, please refer to :meth:`nvidia.dali._utils.invoke_autoserialize`.
- For more information about Triton, please refer to [Triton documentation](https://github.com/triton-inference-server/server#triton-inference-server).
:param dali_pipeline: DALI Python model definition (``pipeline_def``).
- """ # noqa W505
if not getattr(dali_pipeline, "_is_pipeline_def", False):
raise TypeError("Only `@pipeline_def` can be decorated with `@triton.autoserialize`.")
dali_pipeline._is_autoserialize = True
How about just breaking the lines, that are too long? This shouldn't be rendering incorrectly after such change.
def autoserialize(dali_pipeline):
"""
Decorator, that marks a DALI pipeline (represented by :meth:`nvidia.dali.pipeline_def`) for
+ autoserialization in [DALI Backend's]
+ (https://github.com/triton-inference-server/dali_backend#dali-triton-backend) model repository.
For details about the autoserialization feature, please refer to the
+ [DALI Backend documentation]
+ (https://github.com/triton-inference-server/dali_backend#autoserialization).
Only a ``pipeline_def`` can be decorated with ``autoserialize``.
Only one ``pipeline_def`` may be decorated with ``autoserialize`` in a given program.
To perform autoserialization, please refer to :meth:`nvidia.dali._utils.invoke_autoserialize`.
+ For more information about Triton, please refer to
+ [Triton documentation]
+ (https://github.com/triton-inference-server/server#triton-inference-server).
:param dali_pipeline: DALI Python model definition (``pipeline_def``).
+ """
if not getattr(dali_pipeline, "_is_pipeline_def", False):
raise TypeError("Only `@pipeline_def` can be decorated with `@triton.autoserialize`.")
dali_pipeline._is_autoserialize = True
|
codereview_new_python_data_11510
|
def get(self, num_samples=1, predicate=None) -> Optional[List[MSG_CLASS]]:
was specified and it evaluated to False after waiting on empty queue.
The call returns None iff the queue was closed.
predicate : a parameterless callable
- Used for double-checking if the item should really be taken after waiting on empty queue.
- """ # noqa W501
if self.is_closed:
return
with self.cv_not_empty: # equivalent to `with self.lock`
My run of `flake8` didn't show `W501` violation. I suppose you meant `E501`, but in this case I'd like to ask, that you apply the suitable line breaks instead of turning off the check.
def get(self, num_samples=1, predicate=None) -> Optional[List[MSG_CLASS]]:
was specified and it evaluated to False after waiting on empty queue.
The call returns None iff the queue was closed.
predicate : a parameterless callable
+ Used for double-checking if the item should really be taken after waiting on empty
+ queue.
+ """
if self.is_closed:
return
with self.cv_not_empty: # equivalent to `with self.lock`
|
codereview_new_python_data_11511
|
def open_shm(self, handle):
assert self._shm_chunk is None
try:
self._shm_chunk = shared_mem.SharedMem.open(handle, self.capacity)
- except ValueError:
if handle >= 0:
os.close(handle)
raise
```suggestion
except: # noqa: E722
```
def open_shm(self, handle):
assert self._shm_chunk is None
try:
self._shm_chunk = shared_mem.SharedMem.open(handle, self.capacity)
+ except: # noqa: E722
if handle >= 0:
os.close(handle)
raise
|
codereview_new_python_data_11512
|
def name_to_sphinx(self):
class OpReference:
- def __init__(self, operator, docstring, order = None):
self.operator = operator
self.docstring = docstring
self.order = 1000000 if order is None else order
Unfortunately, Python has infinite integers and sorting by key (instead of compare function).
def name_to_sphinx(self):
class OpReference:
+ def __init__(self, operator, docstring, order=None):
self.operator = operator
self.docstring = docstring
self.order = 1000000 if order is None else order
|
codereview_new_python_data_11513
|
def name_to_sphinx(self):
class OpReference:
- def __init__(self, operator, docstring, order = None):
self.operator = operator
self.docstring = docstring
self.order = 1000000 if order is None else order
```suggestion
def __init__(self, operator, docstring, order=None):
```
def name_to_sphinx(self):
class OpReference:
+ def __init__(self, operator, docstring, order=None):
self.operator = operator
self.docstring = docstring
self.order = 1000000 if order is None else order
|
codereview_new_python_data_11514
|
def run_tf_with_dali_external_source(dev, es_args, ed_dev, dtype, *_):
run_tf_dataset_graph(
dev,
get_pipeline_desc=get_external_source_pipe(es_args, dtype, ed_dev),
- to_dataset=external_source_to_tf_dataset, to_stop_iter=True)
@with_setup(skip_inputs_for_incompatible_tf)
```suggestion
to_dataset=external_source_to_tf_dataset,
to_stop_iter=True)
```
def run_tf_with_dali_external_source(dev, es_args, ed_dev, dtype, *_):
run_tf_dataset_graph(
dev,
get_pipeline_desc=get_external_source_pipe(es_args, dtype, ed_dev),
+ to_dataset=external_source_to_tf_dataset,
+ to_stop_iter=True)
@with_setup(skip_inputs_for_incompatible_tf)
|
codereview_new_python_data_11515
|
# See the License for the specific language governing permissions and
# limitations under the License.
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.fn as fn
`# noqa` - this import has a side effect and is required for Python 3.10
# See the License for the specific language governing permissions and
# limitations under the License.
+import nose_utils # noqa: F401
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.fn as fn
|
codereview_new_python_data_11516
|
def _compare_to_cv_distortion(in_img, out_img, q, no):
decoded_img = cv2.cvtColor(decoded_img_bgr, cv2.COLOR_BGR2RGB)
diff = cv2.absdiff(out_img, decoded_img)
- diff_in_range = np.average(
- diff) < 5, f"Absolute difference with the reference is too big: {np.average(diff)}"
if dump_images or (dump_broken and not diff_in_range):
i, j = no
```suggestion
diff_in_range = np.average(diff) < 5"
```
def _compare_to_cv_distortion(in_img, out_img, q, no):
decoded_img = cv2.cvtColor(decoded_img_bgr, cv2.COLOR_BGR2RGB)
diff = cv2.absdiff(out_img, decoded_img)
+ diff_in_range = np.average(diff) < 5
if dump_images or (dump_broken and not diff_in_range):
i, j = no
|
codereview_new_python_data_11517
|
def test_operator_erase_with_out_of_bounds_roi_coords():
axis_names = "HW"
anchor_arg = (4, 10, 10, 4)
shape_arg = (40, 50, 50, 40)
- anchor_norm_arg = (
- 4 / 60.0, 10 / 80.0, 2000, 2000, 10 / 60.0, 4 / 80.0
- ) # second region is completely out of bounds
shape_norm_arg = (40 / 60.0, 50 / 80.0, 200, 200, 50 / 60.0, 40 / 80.0)
yield (check_operator_erase_with_normalized_coords,
device, batch_size,
Personal preference: I'd put the comment in the previous line and keep the tuple definition in one line
def test_operator_erase_with_out_of_bounds_roi_coords():
axis_names = "HW"
anchor_arg = (4, 10, 10, 4)
shape_arg = (40, 50, 50, 40)
+ # second region is completely out of bounds
+ anchor_norm_arg = (4 / 60.0, 10 / 80.0, 2000, 2000, 10 / 60.0, 4 / 80.0)
shape_norm_arg = (40 / 60.0, 50 / 80.0, 200, 200, 50 / 60.0, 40 / 80.0)
yield (check_operator_erase_with_normalized_coords,
device, batch_size,
|
codereview_new_python_data_11518
|
from nose_utils import assert_raises
from segmentation_test_utils import make_batch_select_masks
-from test_dali_cpu_only_utils import pipeline_arithm_ops_cpu, setup_test_nemo_asr_reader_cpu, \
- setup_test_numpy_reader_cpu
from test_detection_pipeline import coco_anchors
from test_utils import get_dali_extra_path, get_files, module_functions
from webdataset_base import generate_temp_index_file as generate_temp_wds_index
data_root = get_dali_extra_path()
images_dir = os.path.join(data_root, 'db', 'single', 'jpeg')
audio_files = get_files(os.path.join('db', 'audio', 'wav'), 'wav')
Total nitpick but consider:
```suggestion
from test_dali_cpu_only_utils import pipeline_arithm_ops_cpu, setup_test_nemo_asr_reader_cpu, \
setup_test_numpy_reader_cpu
```
```suggestion
from test_dali_cpu_only_utils import (pipeline_arithm_ops_cpu, setup_test_nemo_asr_reader_cpu,
setup_test_numpy_reader_cpu)
```
from nose_utils import assert_raises
from segmentation_test_utils import make_batch_select_masks
+from test_dali_cpu_only_utils import (pipeline_arithm_ops_cpu, setup_test_nemo_asr_reader_cpu,
+ setup_test_numpy_reader_cpu)
from test_detection_pipeline import coco_anchors
from test_utils import get_dali_extra_path, get_files, module_functions
from webdataset_base import generate_temp_index_file as generate_temp_wds_index
+
data_root = get_dali_extra_path()
images_dir = os.path.join(data_root, 'db', 'single', 'jpeg')
audio_files = get_files(os.path.join('db', 'audio', 'wav'), 'wav')
|
codereview_new_python_data_11519
|
def dali_type_to_np(dtype):
def bricon_ref(input, brightness, brightness_shift, contrast, contrast_center, out_dtype):
output_range = max_range(out_dtype)
- output = brightness_shift * output_range + brightness * (contrast_center + contrast *
- (input - contrast_center))
return convert_sat(output, out_dtype)
Invalid line break on binary operator (https://peps.python.org/pep-0008/#should-a-line-break-before-or-after-a-binary-operator):
```suggestion
output = (brightness_shift * output_range
+ brightness * (contrast_center + contrast * (input - contrast_center)))
```
def dali_type_to_np(dtype):
def bricon_ref(input, brightness, brightness_shift, contrast, contrast_center, out_dtype):
output_range = max_range(out_dtype)
+ output = (brightness_shift * output_range
+ + brightness * (contrast_center + contrast * (input - contrast_center)))
return convert_sat(output, out_dtype)
|
codereview_new_python_data_11520
|
def test_api_fw_check1(iter_type, data_definition):
pipe.run]:
try:
method()
- assert (False)
except RuntimeError:
- assert (True)
# disable check
pipe.enable_api_check(False)
for method in [pipe.schedule_run, pipe.share_outputs, pipe.release_outputs, pipe.outputs,
pipe.run]:
try:
method()
- assert (True)
except RuntimeError:
assert (False)
yield check, iter_type
```suggestion
assert False
```
def test_api_fw_check1(iter_type, data_definition):
pipe.run]:
try:
method()
+ assert False
except RuntimeError:
+ pass
# disable check
pipe.enable_api_check(False)
for method in [pipe.schedule_run, pipe.share_outputs, pipe.release_outputs, pipe.outputs,
pipe.run]:
try:
method()
except RuntimeError:
assert (False)
yield check, iter_type
|
codereview_new_python_data_11557
|
def get_normal_upgrade_frequency(conf=__conf__):
return conf.get_int("Debug.AutoUpdateNormalFrequency", 24 * 60 * 60)
def get_firewall_rules_log_period(conf=__conf__):
"""
Determine the frequency to perform the periodic operation of logging firewall rules.
This is not needed as we have only requested version agent version update path and don't need to control to disable or enable it
def get_normal_upgrade_frequency(conf=__conf__):
return conf.get_int("Debug.AutoUpdateNormalFrequency", 24 * 60 * 60)
+def get_enable_ga_versioning(conf=__conf__):
+ """
+ If True, the agent uses GA Versioning for auto-updating the agent vs automatically auto-updating to the highest version.
+ NOTE: This option is experimental and may be removed in later versions of the Agent.
+ """
+ return conf.get_switch("Debug.EnableGAVersioning", True)
+
+
def get_firewall_rules_log_period(conf=__conf__):
"""
Determine the frequency to perform the periodic operation of logging firewall rules.
|
codereview_new_python_data_11558
|
def load_conf_from_file(conf_file_path, conf=__conf__):
"Debug.CgroupCheckPeriod": 300,
"Debug.AgentCpuQuota": 50,
"Debug.AgentCpuThrottledTimeThreshold": 120,
- "Debug.AgentMemoryQuota": 31457280,
"Debug.EtpCollectionPeriod": 300,
"Debug.AutoUpdateHotfixFrequency": 14400,
"Debug.AutoUpdateNormalFrequency": 86400,
can we use the same notation as below? (30 * 1024 ** 2)
def load_conf_from_file(conf_file_path, conf=__conf__):
"Debug.CgroupCheckPeriod": 300,
"Debug.AgentCpuQuota": 50,
"Debug.AgentCpuThrottledTimeThreshold": 120,
+ "Debug.AgentMemoryQuota": 30 * 1024 ** 2,
"Debug.EtpCollectionPeriod": 300,
"Debug.AutoUpdateHotfixFrequency": 14400,
"Debug.AutoUpdateNormalFrequency": 86400,
|
codereview_new_python_data_11559
|
def _is_orphaned(self):
def _load_agents(self):
path = os.path.join(conf.get_lib_dir(), "{0}-*".format(AGENT_NAME))
- return [GuestAgent(is_fast_track_goal_state=self._goal_state.extensions_goal_state.source == GoalStateSource.FastTrack, path=agent_dir)
for agent_dir in glob.iglob(path) if os.path.isdir(agent_dir)]
def _partition(self):
Class GuestAgent actually downloads the agent packages. That download still needs to be refactored into the common download logic. For the moment, this sets up the x-ms-verify-from-artifacts-blob header
def _is_orphaned(self):
def _load_agents(self):
path = os.path.join(conf.get_lib_dir(), "{0}-*".format(AGENT_NAME))
+ is_fast_track_goal_state = None if self._goal_state is None else self._goal_state.extensions_goal_state.source == GoalStateSource.FastTrack
+ return [GuestAgent(is_fast_track_goal_state=is_fast_track_goal_state, path=agent_dir)
for agent_dir in glob.iglob(path) if os.path.isdir(agent_dir)]
def _partition(self):
|
codereview_new_python_data_11560
|
def get_used_and_available_system_memory():
"""
used_mem = available_mem = 0
free_cmd = ["free", "-b"]
- try:
- memory = shellutil.run_command(free_cmd)
- for line in memory.split("\n"):
- if ALL_MEMS_REGEX.match(line):
- mems = line.split()
- used_mem = int(mems[2])
- available_mem = int(mems[6]) # see "man free" for a description of these fields
- except CommandError as e:
- logger.warn("Cannot get the memory table. {0} failed: {1}", ustr(free_cmd), ustr(e))
return used_mem/(1024 ** 2), available_mem/(1024 ** 2)
def get_nic_state(self, as_string=False):
if this fails continuously we would be producing a warning on each period
you can let the exception bubble up and handle it on the caller (the periodic task), which can log the error once (until it succeeds again).
def get_used_and_available_system_memory():
"""
used_mem = available_mem = 0
free_cmd = ["free", "-b"]
+ memory = shellutil.run_command(free_cmd)
+ for line in memory.split("\n"):
+ if ALL_MEMS_REGEX.match(line):
+ mems = line.split()
+ used_mem = int(mems[2])
+ available_mem = int(mems[6]) # see "man free" for a description of these fields
return used_mem/(1024 ** 2), available_mem/(1024 ** 2)
def get_nic_state(self, as_string=False):
|
codereview_new_python_data_11580
|
def invoke(self, invocation_context: ApiInvocationContext):
try:
object = s3.get_object(Bucket=bucket, Key=object_key)
except s3.exceptions.NoSuchKey:
- msg = "Object %s not found" % object_key
LOG.debug(msg)
return make_error_response(msg, 404)
nit: f'string here.
def invoke(self, invocation_context: ApiInvocationContext):
try:
object = s3.get_object(Bucket=bucket, Key=object_key)
except s3.exceptions.NoSuchKey:
+ msg = f"Object {object_key} not found"
LOG.debug(msg)
return make_error_response(msg, 404)
|
codereview_new_python_data_11581
|
def register(self, subclasses=False):
def _pickle(self, pickler, obj: _T):
state = self.get_state(obj)
- # this is a builtin.Certificate which cannot be pickled, but can be restored from data inside the CertBundle
self.prepare(obj, state)
return pickler.save_reduce(self._unpickle, (state,), obj=obj)
nit: is this comment relevant in the context here? (probably a copy/pasta..?)
def register(self, subclasses=False):
def _pickle(self, pickler, obj: _T):
state = self.get_state(obj)
self.prepare(obj, state)
return pickler.save_reduce(self._unpickle, (state,), obj=obj)
|
codereview_new_python_data_11582
|
def test_cfn_with_multiple_route_table_associations(ec2_client, deploy_cfn_templ
assert subnet2["PrivateDnsNameOptionsOnLaunch"]["HostnameType"] == "ip-name"
@pytest.mark.skip_snapshot_verify(paths=["$..DriftInformation", "$..Metadata"])
def test_internet_gateway_ref_and_attr(deploy_cfn_template, cfn_client, snapshot):
stack = deploy_cfn_template(
Since we're using snapshots here I guess this was also executed against AWS and can be marked as such? (`aws_validated`)
def test_cfn_with_multiple_route_table_associations(ec2_client, deploy_cfn_templ
assert subnet2["PrivateDnsNameOptionsOnLaunch"]["HostnameType"] == "ip-name"
+@pytest.mark.aws_validated
@pytest.mark.skip_snapshot_verify(paths=["$..DriftInformation", "$..Metadata"])
def test_internet_gateway_ref_and_attr(deploy_cfn_template, cfn_client, snapshot):
stack = deploy_cfn_template(
|
codereview_new_python_data_11583
|
def start_lambda(port=None, asynchronous=False):
endpoint=handle_lambda_url_invocation,
)
- if not config.LAMBDA_EXECUTOR:
- default_mode = get_default_executor_mode()
- LOG.debug("No executor set. Lambda falling back to default executor mode: %s", default_mode)
- log.event("lambda:config", version="v1", default_executor_mode=default_mode)
# print a warning if we're not running in Docker but using Docker based LAMBDA_EXECUTOR
if "docker" in lambda_utils.get_executor_mode() and not config.is_in_docker and not is_linux():
should we maybe log this in any case? i know we're already tracking the config.LAMBDA_EXECUTOR variable through the config variables. but this seems more consistent to me.
```suggestion
log.event("lambda:config", version="v1", executor_mode=config.LAMBDA_EXECUTOR, default_executor_mode=get_default_executor_mode())
```
def start_lambda(port=None, asynchronous=False):
endpoint=handle_lambda_url_invocation,
)
+ log.event(
+ "lambda:config",
+ version="v1",
+ executor_mode=config.LAMBDA_EXECUTOR,
+ default_executor_mode=get_default_executor_mode(),
+ )
# print a warning if we're not running in Docker but using Docker based LAMBDA_EXECUTOR
if "docker" in lambda_utils.get_executor_mode() and not config.is_in_docker and not is_linux():
|
codereview_new_python_data_11584
|
def fetch_state(self, stack_name, resources):
# TODO: change the signature to pass in a Stack instance (instead of stack_name and resources)
def update_resource(self, new_resource, stack_name, resources):
"""Update the deployment of this resource, using the updated properties (implemented by subclasses)."""
- # TODO: evaluate if we can add a generic implementation here, using "update" parameters from
- # get_deploy_templates() responses, and based on checking whether resource attributes have changed
- pass
def is_updatable(self) -> bool:
return type(self).update_resource != GenericBaseModel.update_resource
We could alternatively also raise a NotImplementedError and catch that in the deployer but this should work fine as well :thinking:
def fetch_state(self, stack_name, resources):
# TODO: change the signature to pass in a Stack instance (instead of stack_name and resources)
def update_resource(self, new_resource, stack_name, resources):
"""Update the deployment of this resource, using the updated properties (implemented by subclasses)."""
+ raise NotImplementedError
def is_updatable(self) -> bool:
return type(self).update_resource != GenericBaseModel.update_resource
|
codereview_new_python_data_11585
|
def create_launch_template(
status_code=400,
)
- result = call_moto(context)
- return result
@handler("ModifyLaunchTemplate", expand=False)
def modify_launch_template(
Please create a `InvalidLaunchTemplateNameError` exception. See my previous note.
def create_launch_template(
status_code=400,
)
+ return call_moto(context)
@handler("ModifyLaunchTemplate", expand=False)
def modify_launch_template(
|
codereview_new_python_data_11586
|
def test_modify_launch_template(self, ec2_client, create_launch_template, id_typ
launch_template_result = create_launch_template(f"template-with-versions-{short_uid()}")
template = launch_template_result["LaunchTemplate"]
- # call the API identifying the template wither by `LaunchTemplateId` or `LaunchTemplateName`
kwargs = (
{"LaunchTemplateId": template["LaunchTemplateId"]}
if (id_type == "id")
nit: `wither` -> `either`
def test_modify_launch_template(self, ec2_client, create_launch_template, id_typ
launch_template_result = create_launch_template(f"template-with-versions-{short_uid()}")
template = launch_template_result["LaunchTemplate"]
+ # call the API identifying the template either by `LaunchTemplateId` or `LaunchTemplateName`
kwargs = (
{"LaunchTemplateId": template["LaunchTemplateId"]}
if (id_type == "id")
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.