
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.09B
| node_id
stringlengths 18
32
| number
int64 1
3.5k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
list | created_at
int64 1,587B
1,641B
| updated_at
int64 1,587B
1,641B
| closed_at
int64 1,587B
1,641B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/266
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/266/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/266/comments
|
https://api.github.com/repos/huggingface/datasets/issues/266/events
|
https://github.com/huggingface/datasets/pull/266
| 637,156,392 |
MDExOlB1bGxSZXF1ZXN0NDMzMTk1NDgw
| 266 |
Add sort, shuffle, test_train_split and select methods
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Nice !\r\n\r\nAlso it looks like we can have a train_test_split method for free:\r\n```python\r\ntrain_indices, test_indices = train_test_split(range(len(dataset)))\r\ntrain = dataset.sort(indices=train_indices)\r\ntest = dataset.sort(indices=test_indices)\r\n```\r\n\r\nand a shuffling method for free:\r\n```python\r\nshuffled_indices = shuffle(range(len(dataset)))\r\nshuffled_dataset = dataset.sort(indices=shuffled_indices)\r\n```\r\n\r\nMaybe we can have a specific API for train_test_split and shuffle. They are two features asked quite often (see #147, #166)",
"Ok, I think this one is ready to merge.\r\n\r\n@patrickvonplaten @jplu @mariamabarham @joeddav @n1t0 @julien-c you may want to give it a look, it adds a bunch of methods to reorder/split/select rows in a dataset:\r\n- `dataset.select(indices)`: Create a new dataset with rows selected following the list/array of indices (which can have a different size than the dataset and contain duplicated indices, the only constrain is that all the integers in the list must be smaller than the dataset size, otherwise we're indexing outside the dataset...)\r\n- `dataset.sort(column_name)`: sort a dataset according to a column (has to be a column with a numpy compatible type)\r\n- `dataset.shuffle(seed)`: shuffle a dataset rows\r\n- `dataset.train_test_split(test_size, train_size)`: Return a dictionary with two random train and test subsets (`train` and `test` ``Dataset`` splits)\r\n\r\nAll these methods are **not** in-place which means they return new ``Dataset``, which is the default behavior in the library.",
"> Might be a solution to put 0.25 and 0.75 as default values for respectively `test_size` and `train_size`. WDYT?\r\n\r\nAccording to sklearn documentation, it is indeed set to 0.25 and 0.75 if both `test_size` and `train_size` are None.\r\nLet me add it.",
"I think we're good to go now :) @joeddav @thomwolf @jplu "
] | 1,591,892,540,000 | 1,592,497,405,000 | 1,592,497,404,000 |
MEMBER
| null |
Add a bunch of methods to reorder/split/select rows in a dataset:
- `dataset.select(indices)`: Create a new dataset with rows selected following the list/array of indices (which can have a different size than the dataset and contain duplicated indices, the only constrain is that all the integers in the list must be smaller than the dataset size, otherwise we're indexing outside the dataset...)
- `dataset.sort(column_name)`: sort a dataset according to a column (has to be a column with a numpy compatible type)
- `dataset.shuffle(seed)`: shuffle a dataset rows
- `dataset.train_test_split(test_size, train_size)`: Return a dictionary with two random train and test subsets (`train` and `test` ``Dataset`` splits)
All these methods are **not** in-place which means they return new ``Dataset``.
This is the default behavior in the library.
Fix #147 #166 #259
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/266/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/266/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/266",
"html_url": "https://github.com/huggingface/datasets/pull/266",
"diff_url": "https://github.com/huggingface/datasets/pull/266.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/266.patch",
"merged_at": 1592497403000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/265
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/265/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/265/comments
|
https://api.github.com/repos/huggingface/datasets/issues/265/events
|
https://github.com/huggingface/datasets/pull/265
| 637,139,220 |
MDExOlB1bGxSZXF1ZXN0NDMzMTgxNDMz
| 265 |
Add pyarrow warning colab
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,591,891,071,000 | 1,596,392,076,000 | 1,591,949,656,000 |
MEMBER
| null |
When a user installs `nlp` on google colab, then google colab doesn't update pyarrow, and the runtime needs to be restarted to use the updated version of pyarrow.
This is an issue because `nlp` requires the updated version to work correctly.
In this PR I added en error that is shown to the user in google colab if the user tries to `import nlp` without having restarted the runtime. The error tells the user to restart the runtime.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/265/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/265/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/265",
"html_url": "https://github.com/huggingface/datasets/pull/265",
"diff_url": "https://github.com/huggingface/datasets/pull/265.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/265.patch",
"merged_at": 1591949656000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/264
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/264/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/264/comments
|
https://api.github.com/repos/huggingface/datasets/issues/264/events
|
https://github.com/huggingface/datasets/pull/264
| 637,106,170 |
MDExOlB1bGxSZXF1ZXN0NDMzMTU0ODQ4
| 264 |
Fix small issues creating dataset
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,591,888,816,000 | 1,591,949,757,000 | 1,591,949,756,000 |
MEMBER
| null |
Fix many small issues mentioned in #249:
- don't force to install apache beam for commands
- fix None cache dir when using `dl_manager.download_custom`
- added new extras in `setup.py` named `dev` that contains tests and quality dependencies
- mock dataset sizes when running tests with dummy data
- add a note about the naming convention of datasets (camel case - snake case) in CONTRIBUTING.md
This should help users create their datasets.
Next step is the `add_dataset.md` docs :)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/264/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/264/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/264",
"html_url": "https://github.com/huggingface/datasets/pull/264",
"diff_url": "https://github.com/huggingface/datasets/pull/264.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/264.patch",
"merged_at": 1591949756000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/263
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/263/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/263/comments
|
https://api.github.com/repos/huggingface/datasets/issues/263/events
|
https://github.com/huggingface/datasets/issues/263
| 637,028,015 |
MDU6SXNzdWU2MzcwMjgwMTU=
| 263 |
[Feature request] Support for external modality for language datasets
|
{
"login": "aleSuglia",
"id": 1479733,
"node_id": "MDQ6VXNlcjE0Nzk3MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aleSuglia",
"html_url": "https://github.com/aleSuglia",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "https://api.github.com/users/aleSuglia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aleSuglia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aleSuglia/subscriptions",
"organizations_url": "https://api.github.com/users/aleSuglia/orgs",
"repos_url": "https://api.github.com/users/aleSuglia/repos",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"received_events_url": "https://api.github.com/users/aleSuglia/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 2067400324,
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion",
"name": "generic discussion",
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library"
}
] |
open
| false | null |
[] | null |
[
"Thanks a lot, @aleSuglia for the very detailed and introductive feature request.\r\nIt seems like we could build something pretty useful here indeed.\r\n\r\nOne of the questions here is that Arrow doesn't have built-in support for generic \"tensors\" in records but there might be ways to do that in a clean way. We'll probably try to tackle this during the summer.",
"I was looking into Facebook MMF and apparently they decided to use LMDB to store additional features associated with every example: https://github.com/facebookresearch/mmf/blob/master/mmf/datasets/databases/features_database.py\r\n\r\n",
"I saw the Mozilla common_voice dataset in model hub, which has mp3 audio recordings as part it. It's use predominantly maybe in ASR and TTS, but dataset is a Language + Voice Dataset similar to @aleSuglia's point about Language + Vision. \r\n\r\nhttps://huggingface.co/datasets/common_voice",
"Hey @thomwolf, are there any updates on this? I would love to contribute if possible!\r\n\r\nThanks, \r\nAlessandro ",
"Hi @aleSuglia :) In today's new release 1.17 of `datasets` we introduce a new feature type `Image` that allows to store images directly in a dataset, next to text features and labels for example. There is also an `Audio` feature type, for datasets containing audio data. For tensors there are `Array2D`, `Array3D`, etc. feature types\r\n\r\nNote that both Image and Audio feature types take care of decoding the images/audio data if needed. The returned images are PIL images, and the audio signals are decoded as numpy arrays.\r\n\r\nAnd `datasets` also leverage end-to-end zero copy from the arrow data for all of them, for maximum speed :)"
] | 1,591,882,938,000 | 1,640,105,946,000 | null |
CONTRIBUTOR
| null |
# Background
In recent years many researchers have advocated that learning meanings from text-based only datasets is just like asking a human to "learn to speak by listening to the radio" [[E. Bender and A. Koller,2020](https://openreview.net/forum?id=GKTvAcb12b), [Y. Bisk et. al, 2020](https://arxiv.org/abs/2004.10151)]. Therefore, the importance of multi-modal datasets for the NLP community is of paramount importance for next-generation models. For this reason, I raised a [concern](https://github.com/huggingface/nlp/pull/236#issuecomment-639832029) related to the best way to integrate external features in NLP datasets (e.g., visual features associated with an image, audio features associated with a recording, etc.). This would be of great importance for a more systematic way of representing data for ML models that are learning from multi-modal data.
# Language + Vision
## Use case
Typically, people working on Language+Vision tasks, have a reference dataset (either in JSON or JSONL format) and for each example, they have an identifier that specifies the reference image. For a practical example, you can refer to the [GQA](https://cs.stanford.edu/people/dorarad/gqa/download.html#seconddown) dataset.
Currently, images are represented by either pooling-based features (average pooling of ResNet or VGGNet features, see [DeVries et.al, 2017](https://arxiv.org/abs/1611.08481), [Shekhar et.al, 2019](https://www.aclweb.org/anthology/N19-1265.pdf)) where you have a single vector for every image. Another option is to use a set of feature maps for every image extracted from a specific layer of a CNN (see [Xu et.al, 2015](https://arxiv.org/abs/1502.03044)). A more recent option, especially with large-scale multi-modal transformers [Li et. al, 2019](https://arxiv.org/abs/1908.03557), is to use FastRCNN features.
For all these types of features, people use one of the following formats:
1. [HD5F](https://pypi.org/project/h5py/)
2. [NumPy](https://numpy.org/doc/stable/reference/generated/numpy.savez.html)
3. [LMDB](https://lmdb.readthedocs.io/en/release/)
## Implementation considerations
I was thinking about possible ways of implementing this feature. As mentioned above, depending on the model, different visual features can be used. This step usually relies on another model (say ResNet-101) that is used to generate the visual features for each image used in the dataset. Typically, this step is done in a separate script that completes the feature generation procedure. The usual processing steps for these datasets are the following:
1. Download dataset
2. Download images associated with the dataset
3. Write a script that generates the visual features for every image and store them in a specific file
4. Create a DataLoader that maps the visual features to the corresponding language example
In my personal projects, I've decided to ignore HD5F because it doesn't have out-of-the-box support for multi-processing (see this PyTorch [issue](https://github.com/pytorch/pytorch/issues/11929)). I've been successfully using a NumPy compressed file for each image so that I can store any sort of information in it.
For ease of use of all these Language+Vision datasets, it would be really handy to have a way to associate the visual features with the text and store them in an efficient way. That's why I immediately thought about the HuggingFace NLP backend based on Apache Arrow. The assumption here is that the external modality will be mapped to a N-dimensional tensor so easily represented by a NumPy array.
Looking forward to hearing your thoughts about it!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/263/reactions",
"total_count": 23,
"+1": 18,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 4
}
|
https://api.github.com/repos/huggingface/datasets/issues/263/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/262
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/262/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/262/comments
|
https://api.github.com/repos/huggingface/datasets/issues/262/events
|
https://github.com/huggingface/datasets/pull/262
| 636,702,849 |
MDExOlB1bGxSZXF1ZXN0NDMyODI3Mzcz
| 262 |
Add new dataset ANLI Round 1
|
{
"login": "easonnie",
"id": 11016329,
"node_id": "MDQ6VXNlcjExMDE2MzI5",
"avatar_url": "https://avatars.githubusercontent.com/u/11016329?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/easonnie",
"html_url": "https://github.com/easonnie",
"followers_url": "https://api.github.com/users/easonnie/followers",
"following_url": "https://api.github.com/users/easonnie/following{/other_user}",
"gists_url": "https://api.github.com/users/easonnie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/easonnie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/easonnie/subscriptions",
"organizations_url": "https://api.github.com/users/easonnie/orgs",
"repos_url": "https://api.github.com/users/easonnie/repos",
"events_url": "https://api.github.com/users/easonnie/events{/privacy}",
"received_events_url": "https://api.github.com/users/easonnie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hello ! Thanks for adding this one :)\r\n\r\nThis looks great, you just have to do the last steps to make the CI pass.\r\nI can see that two things are missing:\r\n1. the dummy data that is used to test that the script is working as expected\r\n2. the json file with all the infos about the dataset\r\n\r\nYou can see the steps to help you create the dummy data and generate the dataset_infos.json file right [here](https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset)"
] | 1,591,848,897,000 | 1,591,999,383,000 | 1,591,999,383,000 |
CONTRIBUTOR
| null |
Adding new dataset [ANLI](https://github.com/facebookresearch/anli/).
I'm not familiar with how to add new dataset. Let me know if there is any issue. I only include round 1 data here. There will be round 2, round 3 and more in the future with potentially different format. I think it will be better to separate them.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/262/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/262/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/262",
"html_url": "https://github.com/huggingface/datasets/pull/262",
"diff_url": "https://github.com/huggingface/datasets/pull/262.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/262.patch",
"merged_at": null
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/261
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/261/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/261/comments
|
https://api.github.com/repos/huggingface/datasets/issues/261/events
|
https://github.com/huggingface/datasets/issues/261
| 636,372,380 |
MDU6SXNzdWU2MzYzNzIzODA=
| 261 |
Downloading dataset error with pyarrow.lib.RecordBatch
|
{
"login": "cuent",
"id": 5248968,
"node_id": "MDQ6VXNlcjUyNDg5Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5248968?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cuent",
"html_url": "https://github.com/cuent",
"followers_url": "https://api.github.com/users/cuent/followers",
"following_url": "https://api.github.com/users/cuent/following{/other_user}",
"gists_url": "https://api.github.com/users/cuent/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cuent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cuent/subscriptions",
"organizations_url": "https://api.github.com/users/cuent/orgs",
"repos_url": "https://api.github.com/users/cuent/repos",
"events_url": "https://api.github.com/users/cuent/events{/privacy}",
"received_events_url": "https://api.github.com/users/cuent/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:\r\n```\r\nWARNING: The following packages were previously imported in this runtime:\r\n [pyarrow]\r\nYou must restart the runtime in order to use newly installed versions.\r\n```\r\nYou just have to restart the runtime and it should be fine.\r\nIf you don't restart, then it breaks like in your message.",
"Yeah, that worked! Thanks :) "
] | 1,591,805,059,000 | 1,591,886,112,000 | 1,591,886,112,000 |
NONE
| null |
I am trying to download `sentiment140` and I have the following error
```
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
418 verify_infos = not save_infos and not ignore_verifications
419 self._download_and_prepare(
--> 420 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
421 )
422 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
472 try:
473 # Prepare split will record examples associated to the split
--> 474 self._prepare_split(split_generator, **prepare_split_kwargs)
475 except OSError:
476 raise OSError("Cannot find data file. " + (self.MANUAL_DOWNLOAD_INSTRUCTIONS or ""))
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _prepare_split(self, split_generator)
652 for key, record in utils.tqdm(generator, unit=" examples", total=split_info.num_examples, leave=False):
653 example = self.info.features.encode_example(record)
--> 654 writer.write(example)
655 num_examples, num_bytes = writer.finalize()
656
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write(self, example, writer_batch_size)
143 self._build_writer(pa_table=pa.Table.from_pydict(example))
144 if writer_batch_size is not None and len(self.current_rows) >= writer_batch_size:
--> 145 self.write_on_file()
146
147 def write_batch(
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write_on_file(self)
127 else:
128 # All good
--> 129 self._write_array_on_file(pa_array)
130 self.current_rows = []
131
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in _write_array_on_file(self, pa_array)
96 def _write_array_on_file(self, pa_array):
97 """Write a PyArrow Array"""
---> 98 pa_batch = pa.RecordBatch.from_struct_array(pa_array)
99 self._num_bytes += pa_array.nbytes
100 self.pa_writer.write_batch(pa_batch)
AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
```
I installed the last version and ran the following command:
```python
import nlp
sentiment140 = nlp.load_dataset('sentiment140', cache_dir='/content')
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/261/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/261/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/260
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/260/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/260/comments
|
https://api.github.com/repos/huggingface/datasets/issues/260/events
|
https://github.com/huggingface/datasets/pull/260
| 636,261,118 |
MDExOlB1bGxSZXF1ZXN0NDMyNDY3NDM5
| 260 |
Consistency fixes
|
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,591,796,682,000 | 1,591,871,677,000 | 1,591,871,676,000 |
MEMBER
| null |
A few bugs I've found while hacking
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/260/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/260/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/260",
"html_url": "https://github.com/huggingface/datasets/pull/260",
"diff_url": "https://github.com/huggingface/datasets/pull/260.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/260.patch",
"merged_at": 1591871676000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/259
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/259/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/259/comments
|
https://api.github.com/repos/huggingface/datasets/issues/259/events
|
https://github.com/huggingface/datasets/issues/259
| 636,239,529 |
MDU6SXNzdWU2MzYyMzk1Mjk=
| 259 |
documentation missing how to split a dataset
|
{
"login": "fotisj",
"id": 2873355,
"node_id": "MDQ6VXNlcjI4NzMzNTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/2873355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fotisj",
"html_url": "https://github.com/fotisj",
"followers_url": "https://api.github.com/users/fotisj/followers",
"following_url": "https://api.github.com/users/fotisj/following{/other_user}",
"gists_url": "https://api.github.com/users/fotisj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fotisj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fotisj/subscriptions",
"organizations_url": "https://api.github.com/users/fotisj/orgs",
"repos_url": "https://api.github.com/users/fotisj/repos",
"events_url": "https://api.github.com/users/fotisj/events{/privacy}",
"received_events_url": "https://api.github.com/users/fotisj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"this seems to work for my specific problem:\r\n\r\n`self.train_ds, self.test_ds, self.val_ds = map(_prepare_ds, ('train', 'test[:25%]+test[50%:75%]', 'test[75%:]'))`",
"Currently you can indeed split a dataset using `ds_test = nlp.load_dataset('imdb, split='test[:5000]')` (works also with percentages).\r\n\r\nHowever right now we don't have a way to shuffle a dataset but we are thinking about it in the discussion in #166. Feel free to share your thoughts about it.\r\n\r\nOne trick that you can do until we have a better solution is to shuffle and split the indices of your dataset:\r\n```python\r\nimport nlp\r\nfrom sklearn.model_selection import train_test_split\r\n\r\nimdb = nlp.load_dataset('imbd', split='test')\r\ntest_indices, val_indices = train_test_split(range(len(imdb)))\r\n```\r\n\r\nand then to iterate each split:\r\n```python\r\nfor i in test_indices:\r\n example = imdb[i]\r\n ...\r\n```\r\n",
"I added a small guide [here](https://github.com/huggingface/nlp/tree/master/docs/splits.md) that explains how to split a dataset. It is very similar to the tensorflow datasets guide, as we kept the same logic.",
"Thanks a lot, the new explanation is very helpful!\r\n\r\nAbout using train_test_split from sklearn: I stumbled across the [same error message as this user ](https://github.com/huggingface/nlp/issues/147 )and thought it can't be used at the moment in this context. Will check it out again.\r\n\r\nOne of the problems is how to shuffle very large datasets, which don't fit into the memory. Well, one strategy could be shuffling data in sections. But in a case where the data is sorted by the labels you have to swap larger sections first. \r\n",
"We added a way to shuffle datasets (shuffle the indices and then reorder to make a new dataset).\r\nYou can do `shuffled_dset = dataset.shuffle(seed=my_seed)`. It shuffles the whole dataset.\r\nThere is also `dataset.train_test_split()` which if very handy (with the same signature as sklearn).\r\n\r\nClosing this issue as we added the docs for splits and tools to split datasets. Thanks again for your feedback !"
] | 1,591,795,093,000 | 1,592,518,824,000 | 1,592,518,824,000 |
NONE
| null |
I am trying to understand how to split a dataset ( as arrow_dataset).
I know I can do something like this to access a split which is already in the original dataset :
`ds_test = nlp.load_dataset('imdb, split='test') `
But how can I split ds_test into a test and a validation set (without reading the data into memory and keeping the arrow_dataset as container)?
I guess it has something to do with the module split :-) but there is no real documentation in the code but only a reference to a longer description:
> See the [guide on splits](https://github.com/huggingface/nlp/tree/master/docs/splits.md) for more information.
But the guide seems to be missing.
To clarify: I know that this has been modelled after the dataset of tensorflow and that some of the documentation there can be used [like this one](https://www.tensorflow.org/datasets/splits). But to come back to the example above: I cannot simply split the testset doing this:
`ds_test = nlp.load_dataset('imdb, split='test'[:5000]) `
`ds_val = nlp.load_dataset('imdb, split='test'[5000:])`
because the imdb test data is sorted by class (probably not a good idea anyway)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/259/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/259/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/258
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/258/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/258/comments
|
https://api.github.com/repos/huggingface/datasets/issues/258/events
|
https://github.com/huggingface/datasets/issues/258
| 635,859,525 |
MDU6SXNzdWU2MzU4NTk1MjU=
| 258 |
Why is dataset after tokenization far more larger than the orginal one ?
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hi ! This is because `.map` added the new column `input_ids` to the dataset, and so all the other columns were kept. Therefore the dataset size increased a lot.\r\n If you want to only keep the `input_ids` column, you can stash the other ones by specifying `remove_columns=[\"title\", \"text\"]` in the arguments of `.map`",
"Hi ! Thanks for your reply.\r\n\r\nBut since size of `input_ids` < size of `text`, I am wondering why\r\nsize of `input_ids` + `text` > 2x the size of `text` 🤔",
"Hard to tell... This is probably related to the way apache arrow compresses lists of integers, that may be different from the compression of strings.",
"Thanks for your point. 😀, It might be answer.\r\nSince this is hard to know, I'll close this issue.\r\nBut if somebody knows more details, please comment below ~ 😁"
] | 1,591,752,427,000 | 1,591,793,194,000 | 1,591,793,194,000 |
CONTRIBUTOR
| null |
I tokenize wiki dataset by `map` and cache the results.
```
def tokenize_tfm(example):
example['input_ids'] = hf_fast_tokenizer.convert_tokens_to_ids(hf_fast_tokenizer.tokenize(example['text']))
return example
wiki = nlp.load_dataset('wikipedia', '20200501.en', cache_dir=cache_dir)['train']
wiki.map(tokenize_tfm, cache_file_name=cache_dir/"wikipedia/20200501.en/1.0.0/tokenized_wiki.arrow")
```
and when I see their size
```
ls -l --block-size=M
17460M wikipedia-train.arrow
47511M tokenized_wiki.arrow
```
The tokenized one is over 2x size of original one.
Is there something I did wrong ?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/258/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/258/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/257
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/257/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/257/comments
|
https://api.github.com/repos/huggingface/datasets/issues/257/events
|
https://github.com/huggingface/datasets/issues/257
| 635,620,979 |
MDU6SXNzdWU2MzU2MjA5Nzk=
| 257 |
Tokenizer pickling issue fix not landed in `nlp` yet?
|
{
"login": "sarahwie",
"id": 8027676,
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sarahwie",
"html_url": "https://github.com/sarahwie",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Yes, the new release of tokenizers solves this and should be out soon.\r\nIn the meantime, you can install it with `pip install tokenizers==0.8.0-dev2`",
"If others run into this issue, a quick fix is to use python 3.6 instead of 3.7+. Serialization differences between the 3rd party `dataclasses` package for 3.6 and the built in `dataclasses` in 3.7+ cause the issue.\r\n\r\nProbably a dumb fix, but it works for me."
] | 1,591,722,754,000 | 1,591,825,532,000 | 1,591,723,613,000 |
NONE
| null |
Unless I recreate an arrow_dataset from my loaded nlp dataset myself (which I think does not use the cache by default), I get the following error when applying the map function:
```
dataset = nlp.load_dataset('cos_e')
tokenizer = GPT2TokenizerFast.from_pretrained('gpt2', cache_dir=cache_dir)
for split in dataset.keys():
dataset[split].map(lambda x: some_function(x, tokenizer))
```
```
06/09/2020 10:09:19 - INFO - nlp.builder - Constructing Dataset for split train[:10], from /home/sarahw/.cache/huggingface/datasets/cos_e/default/0.0.1
Traceback (most recent call last):
File "generation/input_to_label_and_rationale.py", line 390, in <module>
main()
File "generation/input_to_label_and_rationale.py", line 263, in main
dataset[split] = dataset[split].map(lambda x: input_to_explanation_plus_label(x, tokenizer, max_length, datasource=data_args.task_name, wt5=(model_class=='t5'), expl_only=model_args.rationale_only), batched=False)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/arrow_dataset.py", line 522, in map
cache_file_name = self._get_cache_file_path(function, cache_kwargs)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/arrow_dataset.py", line 381, in _get_cache_file_path
function_bytes = dumps(function)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/utils/py_utils.py", line 257, in dumps
dump(obj, file)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/utils/py_utils.py", line 250, in dump
Pickler(file).dump(obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 445, in dump
StockPickler.dump(self, obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 485, in dump
self.save(obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 1410, in save_function
pickler.save_reduce(_create_function, (obj.__code__,
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 690, in save_reduce
save(args)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 899, in save_tuple
save(element)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 899, in save_tuple
save(element)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 1147, in save_cell
pickler.save_reduce(_create_cell, (f,), obj=obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 690, in save_reduce
save(args)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 884, in save_tuple
save(element)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 601, in save
self.save_reduce(obj=obj, *rv)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 715, in save_reduce
save(state)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 912, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 969, in save_dict
self._batch_setitems(obj.items())
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 995, in _batch_setitems
save(v)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 601, in save
self.save_reduce(obj=obj, *rv)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 715, in save_reduce
save(state)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 912, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 969, in save_dict
self._batch_setitems(obj.items())
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 995, in _batch_setitems
save(v)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 576, in save
rv = reduce(self.proto)
TypeError: cannot pickle 'Tokenizer' object
```
Fix seems to be in the tokenizers [`0.8.0.dev1 pre-release`](https://github.com/huggingface/tokenizers/issues/87), which I can't install with any package managers.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/257/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/257/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/256
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/256/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/256/comments
|
https://api.github.com/repos/huggingface/datasets/issues/256/events
|
https://github.com/huggingface/datasets/issues/256
| 635,596,295 |
MDU6SXNzdWU2MzU1OTYyOTU=
| 256 |
[Feature request] Add a feature to dataset
|
{
"login": "sarahwie",
"id": 8027676,
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sarahwie",
"html_url": "https://github.com/sarahwie",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Do you have an example of what you would like to do? (you can just add a field in the output of the unction you give to map and this will add this field in the output table)",
"Given another source of data loaded in, I want to pre-add it to the dataset so that it aligns with the indices of the arrow dataset prior to performing map.\r\n\r\nE.g. \r\n```\r\nnew_info = list of length dataset['train']\r\n\r\ndataset['train'] = dataset['train'].map(lambda x: some_function(x, new_info[index of x]))\r\n\r\ndef some_function(x, new_info_x):\r\n # adds new_info[index of x] as a field to x\r\n x['new_info'] = new_info_x\r\n return x\r\n```\r\nI was thinking to instead create a new field in the arrow dataset so that instance x contains all the necessary information when map function is applied (since I don't have index information to pass to map function).",
"This is what I have so far: \r\n\r\n```\r\nimport pyarrow as pa\r\nfrom nlp.arrow_dataset import Dataset\r\n\r\naug_dataset = dataset['train'][:]\r\naug_dataset['new_info'] = new_info\r\n\r\n#reformat as arrow-table\r\nschema = dataset['train'].schema\r\n\r\n# this line doesn't work:\r\nschema.append(pa.field('new_info', pa.int32()))\r\n\r\ntable = pa.Table.from_pydict(\r\n aug_dataset,\r\n schema=schema\r\n)\r\ndataset['train'] = Dataset(table) \r\n```",
"Maybe you can use `with_indices`?\r\n\r\n```python\r\nnew_info = list of length dataset['train']\r\n\r\ndef some_function(indice, x):\r\n # adds new_info[index of x] as a field to x\r\n x['new_info'] = new_info_x[indice]\r\n return x\r\n\r\ndataset['train'] = dataset['train'].map(some_function, with_indices=True)\r\n```",
"Oh great. That should work. I missed that in the documentation- thanks :) "
] | 1,591,720,692,000 | 1,591,721,502,000 | 1,591,721,502,000 |
NONE
| null |
Is there a straightforward way to add a field to the arrow_dataset, prior to performing map?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/256/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/256/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/255
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/255/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/255/comments
|
https://api.github.com/repos/huggingface/datasets/issues/255/events
|
https://github.com/huggingface/datasets/pull/255
| 635,300,822 |
MDExOlB1bGxSZXF1ZXN0NDMxNjg3MDM0
| 255 |
Add dataset/piaf
|
{
"login": "RachelKer",
"id": 36986299,
"node_id": "MDQ6VXNlcjM2OTg2Mjk5",
"avatar_url": "https://avatars.githubusercontent.com/u/36986299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RachelKer",
"html_url": "https://github.com/RachelKer",
"followers_url": "https://api.github.com/users/RachelKer/followers",
"following_url": "https://api.github.com/users/RachelKer/following{/other_user}",
"gists_url": "https://api.github.com/users/RachelKer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RachelKer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RachelKer/subscriptions",
"organizations_url": "https://api.github.com/users/RachelKer/orgs",
"repos_url": "https://api.github.com/users/RachelKer/repos",
"events_url": "https://api.github.com/users/RachelKer/events{/privacy}",
"received_events_url": "https://api.github.com/users/RachelKer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Very nice !"
] | 1,591,697,761,000 | 1,591,950,687,000 | 1,591,950,687,000 |
CONTRIBUTOR
| null |
Small SQuAD-like French QA dataset [PIAF](https://www.aclweb.org/anthology/2020.lrec-1.673.pdf)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/255/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/255/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/255",
"html_url": "https://github.com/huggingface/datasets/pull/255",
"diff_url": "https://github.com/huggingface/datasets/pull/255.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/255.patch",
"merged_at": 1591950687000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/254
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/254/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/254/comments
|
https://api.github.com/repos/huggingface/datasets/issues/254/events
|
https://github.com/huggingface/datasets/issues/254
| 635,057,568 |
MDU6SXNzdWU2MzUwNTc1Njg=
| 254 |
[Feature request] Be able to remove a specific sample of the dataset
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Oh yes you can now do that with the `dataset.filter()` method that was added in #214 "
] | 1,591,669,333,000 | 1,591,692,098,000 | 1,591,692,098,000 |
NONE
| null |
As mentioned in #117, it's currently not possible to remove a sample of the dataset.
But it is a important use case : After applying some preprocessing, some samples might be empty for example. We should be able to remove these samples from the dataset, or at least mark them as `removed` so when iterating the dataset, we don't iterate these samples.
I think it should be a feature. What do you think ?
---
Any work-around in the meantime ?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/254/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/254/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/253
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/253/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/253/comments
|
https://api.github.com/repos/huggingface/datasets/issues/253/events
|
https://github.com/huggingface/datasets/pull/253
| 634,791,939 |
MDExOlB1bGxSZXF1ZXN0NDMxMjgwOTYz
| 253 |
add flue dataset
|
{
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The dummy data file was wrong. I only fixed it for the book config. Even though the tests are all green here, this should also be fixed for all other configs. Could you take a look there @mariamabarham ? ",
"Hi @mariamabarham \r\n\r\nFLUE can indeed become a very interesting benchmark for french NLP !\r\nUnfortunately, it seems that we've both been working on adding it to the repo...\r\nI was going to open a pull request before I came across yours.\r\nI didn't want to open a duplicate, that's why I'm commenting here (I hope it's not rude).\r\n\r\nWhen I look at your code there is one issue that jump out at me: for both `vsd` and `nsd`, the labels are missing. I believe this is more a data issue, as they were not kept in the cleaned dataframes of #223. I think the *word sense disambiguation* task was a bit misunderstood. \r\n\r\nMaybe you should directly use the data provided by FLUE for these ?",
"Hi @TheophileBlard thanks for pointing this out. I will give a look at it or maybe if you already done it you can update this PR. Also I haven't added yet the parsing datasets, I submited a request to get access to them. If you already have them, you can also add them.",
"Hi,\r\n\r\nAs @TheophileBlard pointed out, the labels for the vsd and nsd stains are missing.\r\n\r\nFor the wsd, it is my mistake, I added the files containing the labels on the drive.\r\nThere is still the join to do between the files that I didn't have time to do. It can be done after importing the two files, however if you wish to have a single dataframe already containing all the information, I could do it but only when I have free time because I have a lot of work at the moment at INSERM with the covid.\r\n\r\nFor the nsd, I've downloaded the files at https://zenodo.org/record/3549806, and if you do the same you'll see that they don't contain any labels.\r\nIn the files, you can see that some words have a WN code. I don't know what it corresponds to. On the FLUE github, they say to use the disambiguate tool (https://github.com/getalp/disambiguate) but I don't understand what he's doing.\r\n\r\n@mariamabarham for the parsing datasets, I have them in my possession. What it does that I haven't shared them is that they are licensed and you have to make a request to their creators. They give them away very easily for research purposes. For another use, you have to ask a commercial licence. All this means that if the data is freely available on your librairy, their licence and their application form are no longer of interest, which is why I did not add them.\r\nAfterwards, maybe the authors will change their policies and decide to make the data freely available through your librairy",
"@mariamabarham @lbourdois, Yea I don't think we can had the parsing datasets without asking the authors permission first. I also hope they'll change their policy.\r\n\r\nRegarding `vsd` and `nsd`, if I understand well the task, the labels are \"word senses\" and the goal is to find the correct word sense for each ambiguous word. For `vsd` there is one ambiguous verb per sentence, and the labels we manually annotated with \"wiktionary senses\". For `nsd`, there are multiple ambiguous word per sentence, and the labels are WordNet Princeton Identifiers (hence the WN tag). This dataset was translated in french & automatically aligned.\r\n\r\nImo, for these 2 datasets, each example should be made of:\r\n- a list of string tokens (the words of the sentence)\r\n- a list of string labels (the word senses or 'O' when the word is not ambiguous.\r\n\r\nIn fact, for `vsd` it could be even simpler, with a single string label (as there is only one ambiguous verb), + some \"idx\" feature to indicate the location of the ambiguous verb.\r\n\r\nUnfortunately, I cannot update your PR as I'm not a maintainer of the project. Maybe we could work together on a fork ? Here's [mine](https://github.com/TheophileBlard/nlp/commits/flue-benchmark).\r\n",
"Hi\r\n\r\nAny news about this PR ?\r\nBecause thinking back FLUE basically offers only two new datasets : those for the Word Sense Disambiguation task (vsd and nsd).\r\n\r\nWouldn't it be more clever to make separate PRs to add the datasets of the other tasks which are multi-lingual (and therefore can be used for other languages) ?\r\n\r\nXNLI being already present on your library, there would only be PAWS-X (datasets and bibtex available here : https://github.com/google-research-datasets/paws/tree/master/pawsx) and the Webis-CLS-10 dataset (dataset : https://zenodo.org/record/3251672#.XvCXN-d8taQ and bibtex : https://zenodo.org/record/3251672/export/hx#.XvCXZ-d8taQ) to do.\r\n\r\nAnd next for the FLUE benchmark, all you would have to do would be to use your own library by making an nlp.load_dataset() (for example nlp.load_dataset('xnli') which is already present in your library) for each of the datasets of the benchmark tasks and to keep only the 'fr' data.\r\n\r\n\r\n\r\nAlso @mariamabarham , did you get any feedback for the parsing task dataset request?\r\nIn case of refusal from the authors, there are other datasets in French to perform this task and in this case, I would open a new topic\r\n",
"Hi @lbourdois ,\r\nPAWS-X is also present in the lib, it's part of `xtreme` dataset, so it can be loaded by `nlp.load_dataset('xtreme', 'PAWS-X.fr')` for the french version.\r\nI think the parsing and the Word Sense Disambiguation task datasets are the only missing in the lib now. \r\nI did not get a feedback yet for the parsing dataset.\r\n",
"By the way, @TheophileBlard I commented some days ago in your fork. It would be great if you can maybe open a new PR with your code or if you have a better way to make it available to others for review.",
"> By the way, @TheophileBlard I commented some days ago in your fork. It would be great if you can maybe open a new PR with your code or if you have a better way to make it available to others for review.\r\n\r\nYea sorry, missed that! I think @lbourdois has a point, it helps no one to have the same dataset in multiple places. I will try to find some time to adapt the code of my fork and open PRs for `Webis-CLS-10` and `nsd`/`vsd`. Maybe we should group `nsd`/`vsd` together ?",
"Shall we close this PR then ? @mariamabarham @TheophileBlard @lbourdois "
] | 1,591,636,269,000 | 1,594,885,859,000 | 1,594,885,859,000 |
CONTRIBUTOR
| null |
This PR add the Flue dataset as requested in this issue #223 . @lbourdois made a detailed description in that issue.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/253/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/253/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/253",
"html_url": "https://github.com/huggingface/datasets/pull/253",
"diff_url": "https://github.com/huggingface/datasets/pull/253.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/253.patch",
"merged_at": null
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/252
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/252/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/252/comments
|
https://api.github.com/repos/huggingface/datasets/issues/252/events
|
https://github.com/huggingface/datasets/issues/252
| 634,563,239 |
MDU6SXNzdWU2MzQ1NjMyMzk=
| 252 |
NonMatchingSplitsSizesError error when reading the IMDB dataset
|
{
"login": "antmarakis",
"id": 17463361,
"node_id": "MDQ6VXNlcjE3NDYzMzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antmarakis",
"html_url": "https://github.com/antmarakis",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url": "https://api.github.com/users/antmarakis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antmarakis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antmarakis/subscriptions",
"organizations_url": "https://api.github.com/users/antmarakis/orgs",
"repos_url": "https://api.github.com/users/antmarakis/repos",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"received_events_url": "https://api.github.com/users/antmarakis/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I just tried on my side and I didn't encounter your problem.\r\nApparently the script doesn't generate all the examples on your side.\r\n\r\nCan you provide the version of `nlp` you're using ?\r\nCan you try to clear your cache and re-run the code ?",
"I updated it, that was it, thanks!",
"Hello, I am facing the same problem... how do you clear the huggingface cache?",
"Hi ! The cache is at ~/.cache/huggingface\r\nYou can just delete this folder if needed :)"
] | 1,591,619,184,000 | 1,630,077,658,000 | 1,591,624,886,000 |
NONE
| null |
Hi!
I am trying to load the `imdb` dataset with this line:
`dataset = nlp.load_dataset('imdb', data_dir='/A/PATH', cache_dir='/A/PATH')`
but I am getting the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/load.py", line 517, in load_dataset
save_infos=save_infos,
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/builder.py", line 363, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/builder.py", line 421, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/utils/info_utils.py", line 70, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=33442202, num_examples=25000, dataset_name='imdb'), 'recorded': SplitInfo(name='train', num_bytes=5929447, num_examples=4537, dataset_name='imdb')}, {'expected': SplitInfo(name='unsupervised', num_bytes=67125548, num_examples=50000, dataset_name='imdb'), 'recorded': SplitInfo(name='unsupervised', num_bytes=0, num_examples=0, dataset_name='imdb')}]
```
Am I overlooking something? Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/252/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/252/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/251
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/251/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/251/comments
|
https://api.github.com/repos/huggingface/datasets/issues/251/events
|
https://github.com/huggingface/datasets/pull/251
| 634,544,977 |
MDExOlB1bGxSZXF1ZXN0NDMxMDgwMDkw
| 251 |
Better access to all dataset information
|
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,591,617,410,000 | 1,591,949,580,000 | 1,591,949,578,000 |
MEMBER
| null |
Moves all the dataset info down one level from `dataset.info.XXX` to `dataset.XXX`
This way it's easier to access `dataset.feature['label']` for instance
Also, add the original split instructions used to create the dataset in `dataset.split`
Ex:
```
from nlp import load_dataset
stsb = load_dataset('glue', name='stsb', split='train')
stsb.split
>>> NamedSplit('train')
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/251/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/251/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/251",
"html_url": "https://github.com/huggingface/datasets/pull/251",
"diff_url": "https://github.com/huggingface/datasets/pull/251.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/251.patch",
"merged_at": 1591949578000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/250
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/250/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/250/comments
|
https://api.github.com/repos/huggingface/datasets/issues/250/events
|
https://github.com/huggingface/datasets/pull/250
| 634,416,751 |
MDExOlB1bGxSZXF1ZXN0NDMwOTcyMzg4
| 250 |
Remove checksum download in c4
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Commenting again in case [previous thread](https://github.com/huggingface/nlp/pull/233) was inactive.\r\n\r\n@lhoestq I am facing `IsADirectoryError` while downloading with this command.\r\nCan you pls look into it & help me.\r\nI'm using version 0.4.0 of `nlp`.\r\n\r\n```\r\ndataset = load_dataset(\"c4\", 'en', data_dir='.', beam_runner='DirectRunner')\r\n```\r\n\r\nHere's the complete stack trace.\r\n\r\n```\r\nDownloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/devops/.cache/huggingface/datasets/c4/en/2.3.0/096df5a27756d51957c959a2499453e60a08154971fceb017bbb29f54b11bef7...\r\n\r\n---------------------------------------------------------------------------\r\nIsADirectoryError Traceback (most recent call last)\r\n<ipython-input-11-f622e6705e03> in <module>\r\n----> 1 dataset = load_dataset(\"c4\", 'en', data_dir='.', beam_runner='DirectRunner')\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)\r\n 547 # Download and prepare data\r\n 548 builder_instance.download_and_prepare(\r\n--> 549 download_config=download_config, download_mode=download_mode, ignore_verifications=ignore_verifications,\r\n 550 )\r\n 551 \r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)\r\n 461 if not downloaded_from_gcs:\r\n 462 self._download_and_prepare(\r\n--> 463 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n 464 )\r\n 465 # Sync info\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos)\r\n 964 pipeline = beam_utils.BeamPipeline(runner=beam_runner, options=beam_options,)\r\n 965 super(BeamBasedBuilder, self)._download_and_prepare(\r\n--> 966 dl_manager, verify_infos=False, pipeline=pipeline,\r\n 967 ) # TODO handle verify_infos in beam datasets\r\n 968 # Run pipeline\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 516 split_dict = SplitDict(dataset_name=self.name)\r\n 517 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)\r\n--> 518 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n 519 # Checksums verification\r\n 520 if verify_infos:\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/datasets/c4/096df5a27756d51957c959a2499453e60a08154971fceb017bbb29f54b11bef7/c4.py in _split_generators(self, dl_manager, pipeline)\r\n 187 if self.config.realnewslike:\r\n 188 files_to_download[\"realnews_domains\"] = _REALNEWS_DOMAINS_URL\r\n--> 189 file_paths = dl_manager.download_and_extract(files_to_download)\r\n 190 \r\n 191 if self.config.webtextlike:\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in download_and_extract(self, url_or_urls)\r\n 218 extracted_path(s): `str`, extracted paths of given URL(s).\r\n 219 \"\"\"\r\n--> 220 return self.extract(self.download(url_or_urls))\r\n 221 \r\n 222 def get_recorded_sizes_checksums(self):\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in download(self, url_or_urls)\r\n 156 lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,\r\n 157 )\r\n--> 158 self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)\r\n 159 return downloaded_path_or_paths\r\n 160 \r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in _record_sizes_checksums(self, url_or_urls, downloaded_path_or_paths)\r\n 106 flattened_downloaded_path_or_paths = flatten_nested(downloaded_path_or_paths)\r\n 107 for url, path in zip(flattened_urls_or_urls, flattened_downloaded_path_or_paths):\r\n--> 108 self._recorded_sizes_checksums[url] = get_size_checksum_dict(path)\r\n 109 \r\n 110 def download_custom(self, url_or_urls, custom_download):\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/info_utils.py in get_size_checksum_dict(path)\r\n 77 \"\"\"Compute the file size and the sha256 checksum of a file\"\"\"\r\n 78 m = sha256()\r\n---> 79 with open(path, \"rb\") as f:\r\n 80 for chunk in iter(lambda: f.read(1 << 20), b\"\"):\r\n 81 m.update(chunk)\r\n\r\nIsADirectoryError: [Errno 21] Is a directory: '/'\r\n\r\n```\r\n\r\nCan anyone please try to see what I am doing wrong or is this a bug?"
] | 1,591,607,580,000 | 1,598,339,096,000 | 1,591,607,819,000 |
MEMBER
| null |
There was a line from the original tfds script that was still there and causing issues when loading the c4 script. This one should fix #233 and allow anyone to load the c4 script to generate the dataset
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/250/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/250/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/250",
"html_url": "https://github.com/huggingface/datasets/pull/250",
"diff_url": "https://github.com/huggingface/datasets/pull/250.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/250.patch",
"merged_at": 1591607819000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/249
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/249/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/249/comments
|
https://api.github.com/repos/huggingface/datasets/issues/249/events
|
https://github.com/huggingface/datasets/issues/249
| 633,393,443 |
MDU6SXNzdWU2MzMzOTM0NDM=
| 249 |
[Dataset created] some critical small issues when I was creating a dataset
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Thanks for noticing all these :) They should be easy to fix indeed",
"Alright I think I fixed all the problems you mentioned. Thanks again, that will be useful for many people.\r\nThere is still more work needed for point 7. but we plan to have some nice docs soon."
] | 1,591,534,734,000 | 1,591,950,531,000 | 1,591,950,531,000 |
CONTRIBUTOR
| null |
Hi, I successfully created a dataset and has made a pr #248.
But I have encountered several problems when I was creating it, and those should be easy to fix.
1. Not found dataset_info.json
should be fixed by #241 , eager to wait it be merged.
2. Forced to install `apach_beam`
If we should install it, then it might be better to include it in the pakcage dependency or specified in `CONTRIBUTING.md`
```
Traceback (most recent call last):
File "nlp-cli", line 10, in <module>
from nlp.commands.run_beam import RunBeamCommand
File "/home/yisiang/nlp/src/nlp/commands/run_beam.py", line 6, in <module>
import apache_beam as beam
ModuleNotFoundError: No module named 'apache_beam'
```
3. `cached_dir` is `None`
```
File "/home/yisiang/nlp/src/nlp/datasets/bookscorpus/aea0bd5142d26df645a8fce23d6110bb95ecb81772bb2a1f29012e329191962c/bookscorpus.py", line 88, in _split_generators
downloaded_path_or_paths = dl_manager.download_custom(_GDRIVE_FILE_ID, download_file_from_google_drive)
File "/home/yisiang/nlp/src/nlp/utils/download_manager.py", line 128, in download_custom
downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)
File "/home/yisiang/nlp/src/nlp/utils/py_utils.py", line 172, in map_nested
return function(data_struct)
File "/home/yisiang/nlp/src/nlp/utils/download_manager.py", line 126, in url_to_downloaded_path
return os.path.join(self._download_config.cache_dir, hash_url_to_filename(url))
File "/home/yisiang/miniconda3/envs/nlppr/lib/python3.7/posixpath.py", line 80, in join
a = os.fspath(a)
```
This is because this line
https://github.com/huggingface/nlp/blob/2e0a8639a79b1abc848cff5c669094d40bba0f63/src/nlp/commands/test.py#L30-L32
And I add `--cache_dir="...."` to `python nlp-cli test datasets/<your-dataset-folder> --save_infos --all_configs` in the doc, finally I could pass this error.
But it seems to ignore my arg and use `/home/yisiang/.cache/huggingface/datasets/bookscorpus/plain_text/1.0.0` as cahe_dir
4. There is no `pytest`
So maybe in the doc we should specify a step to install pytest
5. Not enough capacity in my `/tmp`
When run test for dummy data, I don't know why it ask me for 5.6g to download something,
```
def download_and_prepare
...
if not utils.has_sufficient_disk_space(self.info.size_in_bytes or 0, directory=self._cache_dir_root):
raise IOError(
"Not enough disk space. Needed: {} (download: {}, generated: {})".format(
utils.size_str(self.info.size_in_bytes or 0),
utils.size_str(self.info.download_size or 0),
> utils.size_str(self.info.dataset_size or 0),
)
)
E OSError: Not enough disk space. Needed: 5.62 GiB (download: 1.10 GiB, generated: 4.52 GiB)
```
I add a `processed_temp_dir="some/dir"; raw_temp_dir="another/dir"` to 71, and the test passed
https://github.com/huggingface/nlp/blob/a67a6c422dece904b65d18af65f0e024e839dbe8/tests/test_dataset_common.py#L70-L72
I suggest we can create tmp dir under the `/home/user/tmp` but not `/tmp`, because take our lab server for example, everyone use `/tmp` thus it has not much capacity. Or at least we can improve error message, so the user know is what directory has no space and how many has it lefted. Or we could do both.
6. name of datasets
I was surprised by the dataset name `books_corpus`, and didn't know it is from `class BooksCorpus(nlp.GeneratorBasedBuilder)` . I change it to `Bookscorpus` afterwards. I think this point shold be also on the doc.
7. More thorough doc to how to create `dataset.py`
I believe there will be.
**Feel free to close this issue** if you think these are solved.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/249/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/249/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/248
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/248/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/248/comments
|
https://api.github.com/repos/huggingface/datasets/issues/248/events
|
https://github.com/huggingface/datasets/pull/248
| 633,390,427 |
MDExOlB1bGxSZXF1ZXN0NDMwMDQ0MzU0
| 248 |
add Toronto BooksCorpus
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks for adding this one !\r\n\r\nAbout the three points you mentioned:\r\n1. I think the `toronto_books_corpus` branch can be removed @mariamabarham ? \r\n2. You can use the download manager to download from google drive. For you case you can just do something like \r\n```python\r\nURL = \"https://drive.google.com/uc?export=download&id=16KCjV9z_FHm8LgZw05RSuk4EsAWPOP_z\"\r\n...\r\narch_path = dl_manager.download_and_extract(URL)\r\n```\r\nAlso this is is an unofficial host of the dataset, we should probably host it ourselves if we can.\r\n3. Not sure about the copyright here, but I maybe @thomwolf has better insights about it. ",
"Yes it can be removed",
"I just downloaded the file and put it on gs. The public url is\r\nhttps://storage.googleapis.com/huggingface-nlp/datasets/toronto_books_corpus/bookcorpus.tar.bz2\r\n\r\nCould you try to change the url to this one and heck that everything is ok ?",
"In `books.py`\r\n```\r\nURL = \"https://storage.googleapis.com/huggingface-nlp/datasets/toronto_books_corpus/bookcorpus.tar.bz2\"\r\n```\r\n```\r\nPython 3.7.6 (default, Jan 8 2020, 19:59:22) \r\n[GCC 7.3.0] :: Anaconda, Inc. on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> from nlp import load_dataset\r\n>>> book = load_dataset(\"nlp/datasets/bookscorpus/books.py\", cache_dir='~/tmp')\r\nDownloading and preparing dataset bookscorpus/plain_text (download: 1.10 GiB, generated: 4.52 GiB, total: 5.62 GiB) to /home/yisiang/tmp/bookscorpus/plain_text/1.0.0...\r\nDownloading: 100%|███████████████████████████████████████████████████████████| 1.18G/1.18G [00:39<00:00, 30.0MB/s]\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/yisiang/nlp/src/nlp/load.py\", line 520, in load_dataset\r\n save_infos=save_infos,\r\n File \"/home/yisiang/nlp/src/nlp/builder.py\", line 420, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/home/yisiang/nlp/src/nlp/builder.py\", line 460, in _download_and_prepare\r\n verify_checksums(self.info.download_checksums, dl_manager.get_recorded_sizes_checksums())\r\n File \"/home/yisiang/nlp/src/nlp/utils/info_utils.py\", line 31, in verify_checksums\r\n raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))\r\nnlp.utils.info_utils.ExpectedMoreDownloadedFiles: {'16KCjV9z_FHm8LgZw05RSuk4EsAWPOP_z'}\r\n>>>\r\n```\r\n\r\nBTW, I notice the path `huggingface-nlp/datasets/toronto_books_corpus`, does it mean I have to change folder name \"bookscorpus\" to \"toronto_books_corpus\"",
"> In `books.py`\r\n> \r\n> ```\r\n> URL = \"https://storage.googleapis.com/huggingface-nlp/datasets/toronto_books_corpus/bookcorpus.tar.bz2\"\r\n> ```\r\n> \r\n> ```\r\n> Python 3.7.6 (default, Jan 8 2020, 19:59:22) \r\n> [GCC 7.3.0] :: Anaconda, Inc. on linux\r\n> Type \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n> >>> from nlp import load_dataset\r\n> >>> book = load_dataset(\"nlp/datasets/bookscorpus/books.py\", cache_dir='~/tmp')\r\n> Downloading and preparing dataset bookscorpus/plain_text (download: 1.10 GiB, generated: 4.52 GiB, total: 5.62 GiB) to /home/yisiang/tmp/bookscorpus/plain_text/1.0.0...\r\n> Downloading: 100%|███████████████████████████████████████████████████████████| 1.18G/1.18G [00:39<00:00, 30.0MB/s]\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/home/yisiang/nlp/src/nlp/load.py\", line 520, in load_dataset\r\n> save_infos=save_infos,\r\n> File \"/home/yisiang/nlp/src/nlp/builder.py\", line 420, in download_and_prepare\r\n> dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n> File \"/home/yisiang/nlp/src/nlp/builder.py\", line 460, in _download_and_prepare\r\n> verify_checksums(self.info.download_checksums, dl_manager.get_recorded_sizes_checksums())\r\n> File \"/home/yisiang/nlp/src/nlp/utils/info_utils.py\", line 31, in verify_checksums\r\n> raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))\r\n> nlp.utils.info_utils.ExpectedMoreDownloadedFiles: {'16KCjV9z_FHm8LgZw05RSuk4EsAWPOP_z'}\r\n> >>>\r\n> ```\r\n> \r\n> BTW, I notice the path `huggingface-nlp/datasets/toronto_books_corpus`, does it mean I have to change folder name \"bookscorpus\" to \"toronto_books_corpus\"\r\n\r\nLet me change the url to match \"bookscorpus\", so that you don't have to change anything. Good catch.\r\n\r\nAbout the error you're getting: you just have to remove the `dataset_infos.json` and regenerate it",
"The new url is https://storage.googleapis.com/huggingface-nlp/datasets/bookscorpus/bookcorpus.tar.bz2",
"Hi, I found I made a mistake. I found the ELECTRA paper refer it as \"BooksCorpus\", but actually it is caleld \"BookCorpus\", according to the original paper. Sorry, I should have checked the original paper .\r\n\r\nCan you do me a favor and change the url path to ` https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2` ?",
"Yep I'm doing it right now. Could you please rename all the references to `bookscorpus` and `BooksCorpus` to `book_corpus` and `BookCorpus` (with the right casing) ?",
"Thank you @lhoestq ,\r\nJust to confirm it fits your naming convention\r\n* make the file path `book_corpus/book_corpus.py` ?\r\n* make `class Bookscorpus(nlp.GeneratorBasedBuilder)` -> `BookCorpus` (which make cache folder name `book_corpus` and user use `load_dataset('book_corpus')`) ?\r\n(Cuz I found \"HellaSwag\" dataset is named \"nlp/datasets/hellaswag\" and `class Hellaswag` )",
"Oh yea you're right about the Hellaswag example. We should keep the \"_\" symbol to replace spaces. As there are no space in BookCorpus, what we should do here is use:\r\n- class name: 'Bookcorpus'\r\n- script name: `bookcorpus/bookcorpus.py`\r\n- use url https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2\r\nAnd therefore the dataset name will be `bookcorpus`\r\n\r\nDon't forget to regenerate the `dataset_infos.json` and we'll be good :D ",
"Awesome thanks :)"
] | 1,591,534,496,000 | 1,591,951,503,000 | 1,591,951,502,000 |
CONTRIBUTOR
| null |
1. I knew there is a branch `toronto_books_corpus`
- After I downloaded it, I found it is all non-english, and only have one row.
- It seems that it cites the wrong paper
- according to papar using it, it is called `BooksCorpus` but not `TornotoBooksCorpus`
2. It use a text mirror in google drive
- `bookscorpus.py` include a function `download_file_from_google_drive` , maybe you will want to put it elsewhere.
- text mirror is found in this [comment on the issue](https://github.com/soskek/bookcorpus/issues/24#issuecomment-556024973), and it said to have the same statistics as the one in the paper.
- You may want to download it and put it on your gs in case of it disappears someday.
3. Copyright ?
The paper has said
> **The BookCorpus Dataset.** In order to train our sentence similarity model we collected a corpus of 11,038 books ***from the web***. These are __**free books written by yet unpublished authors**__. We only included books that had more than 20K words in order to filter out perhaps noisier shorter stories. The dataset has books in 16 different genres, e.g., Romance (2,865 books), Fantasy (1,479), Science fiction (786), Teen (430), etc. Table 2 highlights the summary statistics of our book corpus.
and we have changed the form (not books), so I don't think it should have that problems. Or we can state that use it at your own risk or only for academic use. I know @thomwolf should know these things more.
This should solved #131
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/248/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/248/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/248",
"html_url": "https://github.com/huggingface/datasets/pull/248",
"diff_url": "https://github.com/huggingface/datasets/pull/248.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/248.patch",
"merged_at": 1591951502000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/247
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/247/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/247/comments
|
https://api.github.com/repos/huggingface/datasets/issues/247/events
|
https://github.com/huggingface/datasets/pull/247
| 632,380,078 |
MDExOlB1bGxSZXF1ZXN0NDI5MTMwMzQ2
| 247 |
Make all dataset downloads deterministic by applying `sorted` to glob and os.listdir
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"That's great!\r\n\r\nI think it would be nice to test \"deterministic-ness\" of datasets in CI if we can do it (should be left for future PR of course)\r\n\r\nHere is a possibility (maybe there are other ways to do it): given that we may soon have efficient and large-scale hashing (cf our discussion on versioning/tracability), we could incorporate a hash of the final Arrow Dataset to the `dataset.json` file and have a test on it as well as CI on a diversity of platform to test the hash (Win/Mac/Linux + various python/env).\r\nWhat do you think @lhoestq @patrickvonplaten?",
"> That's great!\r\n> \r\n> I think it would be nice to test \"deterministic-ness\" of datasets in CI if we can do it (should be left for future PR of course)\r\n> \r\n> Here is a possibility (maybe there are other ways to do it): given that we may soon have efficient and large-scale hashing (cf our discussion on versioning/tracability), we could incorporate a hash of the final Arrow Dataset to the `dataset.json` file and have a test on it as well as CI on a diversity of platform to test the hash (Win/Mac/Linux + various python/env).\r\n> What do you think @lhoestq @patrickvonplaten?\r\n\r\nI think that's a great idea! The test should be a `RUN_SLOW` test, since it takes a considerable amount of time to download the dataset and generate the examples, but I think we should add some kind of hash test for each dataset.",
"Really nice!!"
] | 1,591,441,330,000 | 1,591,607,896,000 | 1,591,607,894,000 |
MEMBER
| null |
This PR makes all datasets loading deterministic by applying `sorted()` to all `glob.glob` and `os.listdir` statements.
Are there other "non-deterministic" functions apart from `glob.glob()` and `os.listdir()` that you can think of @thomwolf @lhoestq @mariamabarham @jplu ?
**Important**
It does break backward compatibility for these datasets because
1. When loading the complete dataset the order in which the examples are saved is different now
2. When loading only part of a split, the examples themselves might be different.
@patrickvonplaten - the nlp / longformer notebook has to be updated since the examples might now be different
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/247/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/247/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/247",
"html_url": "https://github.com/huggingface/datasets/pull/247",
"diff_url": "https://github.com/huggingface/datasets/pull/247.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/247.patch",
"merged_at": 1591607894000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/246
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/246/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/246/comments
|
https://api.github.com/repos/huggingface/datasets/issues/246/events
|
https://github.com/huggingface/datasets/issues/246
| 632,380,054 |
MDU6SXNzdWU2MzIzODAwNTQ=
| 246 |
What is the best way to cache a dataset?
|
{
"login": "Mistobaan",
"id": 112599,
"node_id": "MDQ6VXNlcjExMjU5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/112599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mistobaan",
"html_url": "https://github.com/Mistobaan",
"followers_url": "https://api.github.com/users/Mistobaan/followers",
"following_url": "https://api.github.com/users/Mistobaan/following{/other_user}",
"gists_url": "https://api.github.com/users/Mistobaan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mistobaan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mistobaan/subscriptions",
"organizations_url": "https://api.github.com/users/Mistobaan/orgs",
"repos_url": "https://api.github.com/users/Mistobaan/repos",
"events_url": "https://api.github.com/users/Mistobaan/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mistobaan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Everything is already cached by default in 🤗nlp (in particular dataset\nloading and all the “map()” operations) so I don’t think you need to do any\nspecific caching in streamlit.\n\nTell us if you feel like it’s not the case.\n\nOn Sat, 6 Jun 2020 at 13:02, Fabrizio Milo <notifications@github.com> wrote:\n\n> For example if I want to use streamlit with a nlp dataset:\n>\n> @st.cache\n> def load_data():\n> return nlp.load_dataset('squad')\n>\n> This code raises the error \"uncachable object\"\n>\n> Right now I just fixed with a constant for my specific case:\n>\n> @st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})\n>\n> But I was curious to know what is the best way in general\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/issues/246>, or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHKAKO7CWGX2QY55UXLRVIO3ZANCNFSM4NV333RQ>\n> .\n>\n",
"Closing this one. Feel free to re-open if you have other questions !"
] | 1,591,441,327,000 | 1,594,286,107,000 | 1,594,286,107,000 |
NONE
| null |
For example if I want to use streamlit with a nlp dataset:
```
@st.cache
def load_data():
return nlp.load_dataset('squad')
```
This code raises the error "uncachable object"
Right now I just fixed with a constant for my specific case:
```
@st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})
```
But I was curious to know what is the best way in general
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/246/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/246/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/245
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/245/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/245/comments
|
https://api.github.com/repos/huggingface/datasets/issues/245/events
|
https://github.com/huggingface/datasets/issues/245
| 631,985,108 |
MDU6SXNzdWU2MzE5ODUxMDg=
| 245 |
SST-2 test labels are all -1
|
{
"login": "jxmorris12",
"id": 13238952,
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jxmorris12",
"html_url": "https://github.com/jxmorris12",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"this also happened to me with `nlp.load_dataset('glue', 'mnli')`",
"Yes, this is because the test sets for glue are hidden so the labels are\nnot publicly available. You can read the glue paper for more details.\n\nOn Sat, 6 Jun 2020 at 18:16, Jack Morris <notifications@github.com> wrote:\n\n> this also happened to me with nlp.load_datasets('glue', 'mnli')\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/issues/245#issuecomment-640083980>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHMVQD2EDX2HTZUXG5DRVJTWRANCNFSM4NVG3AKQ>\n> .\n>\n",
"Thanks @thomwolf!",
"@thomwolf shouldn't this be visible in the .info and/or in the .features?",
"It should be in the datasets card (the README.md and on the hub) in my opinion. What do you think @yjernite?",
"I checked both before I got to looking at issues, so that would be fine as well.\r\n\r\nSome additional thoughts on this: Is there a specific reason why the \"test\" split even has a \"label\" column if it isn't tagged. Shouldn't there just not be any. Seems more transparent",
"I'm a little confused with the data size.\r\n`sst2` dataset is referenced to `Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank` and the link of the dataset in the paper is https://nlp.stanford.edu/sentiment/index.html which is often shown in GLUE/SST2 reference.\r\nFrom the original data, the standard train/dev/test splits split is 6920/872/1821 for binary classification. \r\nWhy in GLUE/SST2 the train/dev/test split is 67,349/872/1,821 ? \r\n\r\n",
"> I'm a little confused with the data size.\r\n> `sst2` dataset is referenced to `Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank` and the link of the dataset in the paper is https://nlp.stanford.edu/sentiment/index.html which is often shown in GLUE/SST2 reference.\r\n> From the original data, the standard train/dev/test splits split is 6920/872/1821 for binary classification.\r\n> Why in GLUE/SST2 the train/dev/test split is 67,349/872/1,821 ?\r\n\r\nHave you figured out this problem? AFAIK, the original sst-2 dataset is totally different from the GLUE/sst-2. Do you think so?",
"@yc1999 Sorry, I didn't solve this conflict. In the end, I just use a local data file provided by the previous work I followed(for consistent comparison), not use `datasets` package.\r\n\r\nRelated information: https://github.com/thunlp/OpenAttack/issues/146#issuecomment-766323571",
"@yc1999 I find that the original SST-2 dataset (6,920/872/1,821) can be loaded from https://huggingface.co/datasets/gpt3mix/sst2 or built with SST data and the scripts in https://github.com/prrao87/fine-grained-sentiment/tree/master/data/sst.\r\nThe GLUE/SST-2 dataset (67,349/872/1,821) should be a completely different version.\r\n"
] | 1,591,393,302,000 | 1,638,924,452,000 | 1,591,462,601,000 |
CONTRIBUTOR
| null |
I'm trying to test a model on the SST-2 task, but all the labels I see in the test set are -1.
```
>>> import nlp
>>> glue = nlp.load_dataset('glue', 'sst2')
>>> glue
{'train': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 67349), 'validation': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 872), 'test': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 1821)}
>>> list(l['label'] for l in glue['test'])
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/245/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/245/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/244
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/244/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/244/comments
|
https://api.github.com/repos/huggingface/datasets/issues/244/events
|
https://github.com/huggingface/datasets/pull/244
| 631,869,155 |
MDExOlB1bGxSZXF1ZXN0NDI4NjgxMTcx
| 244 |
Add Allociné Dataset
|
{
"login": "TheophileBlard",
"id": 37028092,
"node_id": "MDQ6VXNlcjM3MDI4MDky",
"avatar_url": "https://avatars.githubusercontent.com/u/37028092?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheophileBlard",
"html_url": "https://github.com/TheophileBlard",
"followers_url": "https://api.github.com/users/TheophileBlard/followers",
"following_url": "https://api.github.com/users/TheophileBlard/following{/other_user}",
"gists_url": "https://api.github.com/users/TheophileBlard/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TheophileBlard/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheophileBlard/subscriptions",
"organizations_url": "https://api.github.com/users/TheophileBlard/orgs",
"repos_url": "https://api.github.com/users/TheophileBlard/repos",
"events_url": "https://api.github.com/users/TheophileBlard/events{/privacy}",
"received_events_url": "https://api.github.com/users/TheophileBlard/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"great work @TheophileBlard ",
"LGTM, thanks a lot for adding dummy data tests :-) Was it difficult to create the correct dummy data folder? ",
"It was pretty easy actually. Documentation is on point !"
] | 1,591,384,766,000 | 1,591,861,646,000 | 1,591,861,646,000 |
CONTRIBUTOR
| null |
This is a french binary sentiment classification dataset, which was used to train this model: https://huggingface.co/tblard/tf-allocine.
Basically, it's a french "IMDB" dataset, with more reviews.
More info on [this repo](https://github.com/TheophileBlard/french-sentiment-analysis-with-bert).
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/244/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/244/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/244",
"html_url": "https://github.com/huggingface/datasets/pull/244",
"diff_url": "https://github.com/huggingface/datasets/pull/244.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/244.patch",
"merged_at": 1591861646000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/243
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/243/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/243/comments
|
https://api.github.com/repos/huggingface/datasets/issues/243/events
|
https://github.com/huggingface/datasets/pull/243
| 631,735,848 |
MDExOlB1bGxSZXF1ZXN0NDI4NTY2MTEy
| 243 |
Specify utf-8 encoding for GLUE
|
{
"login": "patpizio",
"id": 15801338,
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patpizio",
"html_url": "https://github.com/patpizio",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"repos_url": "https://api.github.com/users/patpizio/repos",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks for fixing the encoding :)"
] | 1,591,374,780,000 | 1,592,428,566,000 | 1,591,605,721,000 |
CONTRIBUTOR
| null |
#242
This makes the GLUE-MNLI dataset readable on my machine, not sure if it's a Windows-only bug.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/243/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/243/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/243",
"html_url": "https://github.com/huggingface/datasets/pull/243",
"diff_url": "https://github.com/huggingface/datasets/pull/243.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/243.patch",
"merged_at": 1591605721000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/242
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/242/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/242/comments
|
https://api.github.com/repos/huggingface/datasets/issues/242/events
|
https://github.com/huggingface/datasets/issues/242
| 631,733,683 |
MDU6SXNzdWU2MzE3MzM2ODM=
| 242 |
UnicodeDecodeError when downloading GLUE-MNLI
|
{
"login": "patpizio",
"id": 15801338,
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patpizio",
"html_url": "https://github.com/patpizio",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"repos_url": "https://api.github.com/users/patpizio/repos",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It should be good now, thanks for noticing and fixing it ! I would say that it was because you are on windows but not 100% sure",
"On Windows Python supports Unicode almost everywhere, but one of the notable exceptions is open() where it uses the locale encoding schema. So platform independent python scripts would always set the encoding='utf-8' in calls to open explicitly. \r\nIn the meantime: since Python 3.7 Windows users can set the default encoding for everything including open() to Unicode by setting this environment variable: set PYTHONUTF8=1 (details can be found in [PEP 540](https://www.python.org/dev/peps/pep-0540/))\r\n\r\nFor me this fixed the problem described by the OP."
] | 1,591,374,601,000 | 1,591,718,807,000 | 1,591,605,903,000 |
CONTRIBUTOR
| null |
When I run
```python
dataset = nlp.load_dataset('glue', 'mnli')
```
I get an encoding error (could it be because I'm using Windows?) :
```python
# Lots of error log lines later...
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\std.py in __iter__(self)
1128 try:
-> 1129 for obj in iterable:
1130 yield obj
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\glue\5256cc2368cf84497abef1f1a5f66648522d5854b225162148cb8fc78a5a91cc\glue.py in _generate_examples(self, data_file, split, mrpc_files)
529
--> 530 for n, row in enumerate(reader):
531 if is_cola_non_test:
~\Miniconda3\envs\nlp\lib\csv.py in __next__(self)
110 self.fieldnames
--> 111 row = next(self.reader)
112 self.line_num = self.reader.line_num
~\Miniconda3\envs\nlp\lib\encodings\cp1252.py in decode(self, input, final)
22 def decode(self, input, final=False):
---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]
24
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 6744: character maps to <undefined>
```
Anyway this can be solved by specifying to decode in UTF when reading the csv file. I am proposing a PR if that's okay.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/242/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/242/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/241
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/241/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/241/comments
|
https://api.github.com/repos/huggingface/datasets/issues/241/events
|
https://github.com/huggingface/datasets/pull/241
| 631,703,079 |
MDExOlB1bGxSZXF1ZXN0NDI4NTQwMDM0
| 241 |
Fix empty cache dir
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Looks great! Will this change force all cached datasets to be redownloaded? But even if it does, it shoud not be a big problem, I think",
"> Looks great! Will this change force all cached datasets to be redownloaded? But even if it does, it shoud not be a big problem, I think\r\n\r\nNo it shouldn't force to redownload"
] | 1,591,371,922,000 | 1,591,605,333,000 | 1,591,605,331,000 |
MEMBER
| null |
If the cache dir of a dataset is empty, the dataset fails to load and throws a FileNotFounfError. We could end up with empty cache dir because there was a line in the code that created the cache dir without using a temp dir. Using a temp dir is useful as it gets renamed to the real cache dir only if the full process is successful.
So I removed this bad line, and I also reordered things a bit to make sure that we always use a temp dir. I also added warning if we still end up with empty cache dirs in the future.
This should fix #239
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/241/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/241/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/241",
"html_url": "https://github.com/huggingface/datasets/pull/241",
"diff_url": "https://github.com/huggingface/datasets/pull/241.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/241.patch",
"merged_at": 1591605331000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/240
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/240/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/240/comments
|
https://api.github.com/repos/huggingface/datasets/issues/240/events
|
https://github.com/huggingface/datasets/issues/240
| 631,434,677 |
MDU6SXNzdWU2MzE0MzQ2Nzc=
| 240 |
Deterministic dataset loading
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Yes good point !",
"I think using `sorted(glob.glob())` would actually solve this problem. Can you think of other reasons why dataset loading might not be deterministic? @mariamabarham @yjernite @lhoestq @thomwolf . \r\n\r\nI can do a sweep through the dataset scripts and fix the glob.glob() if you guys are ok with it",
"I'm pretty sure it would solve the problem too.\r\n\r\nThe only other dataset that is not deterministic right now is `blog_authorship_corpus` (see #215) but this is a problem related to string encodings.",
"I think we should do the same also for `os.list_dir`"
] | 1,591,347,806,000 | 1,591,607,894,000 | 1,591,607,894,000 |
MEMBER
| null |
When calling:
```python
import nlp
dataset = nlp.load_dataset("trivia_qa", split="validation[:1%]")
```
the resulting dataset is not deterministic over different google colabs.
After talking to @thomwolf, I suspect the reason to be the use of `glob.glob` in line:
https://github.com/huggingface/nlp/blob/2e0a8639a79b1abc848cff5c669094d40bba0f63/datasets/trivia_qa/trivia_qa.py#L180
which seems to return an ordering of files that depends on the filesystem:
https://stackoverflow.com/questions/6773584/how-is-pythons-glob-glob-ordered
I think we should go through all the dataset scripts and make sure to have deterministic behavior.
A simple solution for `glob.glob()` would be to just replace it with `sorted(glob.glob())` to have everything sorted by name.
What do you think @lhoestq?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/240/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/240/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/239
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/239/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/239/comments
|
https://api.github.com/repos/huggingface/datasets/issues/239/events
|
https://github.com/huggingface/datasets/issues/239
| 631,340,440 |
MDU6SXNzdWU2MzEzNDA0NDA=
| 239 |
[Creating new dataset] Not found dataset_info.json
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"I think you can just `rm` this directory and it should be good :)",
"@lhoestq - this seems to happen quite often (already the 2nd issue). Can we maybe delete this automatically?",
"Yes I have an idea of what's going on. I'm sure I can fix that",
"Hi, I rebase my local copy to `fix-empty-cache-dir`, and try to run again `python nlp-cli test datasets/bookcorpus --save_infos --all_configs`.\r\n\r\nI got this, \r\n```\r\nTraceback (most recent call last):\r\n File \"nlp-cli\", line 10, in <module>\r\n from nlp.commands.run_beam import RunBeamCommand\r\n File \"/home/yisiang/nlp/src/nlp/commands/run_beam.py\", line 6, in <module>\r\n import apache_beam as beam\r\nModuleNotFoundError: No module named 'apache_beam'\r\n```\r\nAnd after I installed it. I got this\r\n```\r\nFile \"/home/yisiang/nlp/src/nlp/datasets/bookcorpus/aea0bd5142d26df645a8fce23d6110bb95ecb81772bb2a1f29012e329191962c/bookcorpus.py\", line 88, in _split_generators\r\n downloaded_path_or_paths = dl_manager.download_custom(_GDRIVE_FILE_ID, download_file_from_google_drive)\r\n File \"/home/yisiang/nlp/src/nlp/utils/download_manager.py\", line 128, in download_custom\r\n downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)\r\n File \"/home/yisiang/nlp/src/nlp/utils/py_utils.py\", line 172, in map_nested\r\n return function(data_struct)\r\n File \"/home/yisiang/nlp/src/nlp/utils/download_manager.py\", line 126, in url_to_downloaded_path\r\n return os.path.join(self._download_config.cache_dir, hash_url_to_filename(url))\r\n File \"/home/yisiang/miniconda3/envs/nlppr/lib/python3.7/posixpath.py\", line 80, in join\r\n a = os.fspath(a)\r\n```\r\nThe problem is when I print `self._download_config.cache_dir` using pdb, it is `None`.\r\n\r\nDid I miss something ? Or can you provide a workaround first so I can keep testing my script ?",
"I'll close this issue because I brings more reports in another issue #249 ."
] | 1,591,337,704,000 | 1,591,534,864,000 | 1,591,534,864,000 |
CONTRIBUTOR
| null |
Hi, I am trying to create Toronto Book Corpus. #131
I ran
`~/nlp % python nlp-cli test datasets/bookcorpus --save_infos --all_configs`
but this doesn't create `dataset_info.json` and try to use it
```
INFO:nlp.load:Checking datasets/bookcorpus/bookcorpus.py for additional imports.
INFO:filelock:Lock 139795325778640 acquired on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.load:Found main folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus
INFO:nlp.load:Found specific version folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9
INFO:nlp.load:Found script file from datasets/bookcorpus/bookcorpus.py to /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.py
INFO:nlp.load:Couldn't find dataset infos file at datasets/bookcorpus/dataset_infos.json
INFO:nlp.load:Found metadata file for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.json
INFO:filelock:Lock 139795325778640 released on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.builder:Overwrite dataset info from restored data version.
INFO:nlp.info:Loading Dataset info from /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0
Traceback (most recent call last):
File "nlp-cli", line 37, in <module>
service.run()
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/commands/test.py", line 78, in run
builders.append(builder_cls(name=config.name, data_dir=self._data_dir))
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/dataset_info.json'
```
btw, `ls /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/` show me nothing is in the directory.
I have also pushed the script to my fork [bookcorpus.py](https://github.com/richardyy1188/nlp/blob/bookcorpusdev/datasets/bookcorpus/bookcorpus.py).
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/239/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/239/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/238
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/238/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/238/comments
|
https://api.github.com/repos/huggingface/datasets/issues/238/events
|
https://github.com/huggingface/datasets/issues/238
| 631,260,143 |
MDU6SXNzdWU2MzEyNjAxNDM=
| 238 |
[Metric] Bertscore : Warning : Empty candidate sentence; Setting recall to be 0.
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067393914,
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug",
"name": "metric bug",
"color": "25b21e",
"default": false,
"description": "A bug in a metric script"
}
] |
closed
| false | null |
[] | null |
[
"This print statement comes from the official implementation of bert_score (see [here](https://github.com/Tiiiger/bert_score/blob/master/bert_score/utils.py#L343)). The warning shows up only if the attention mask outputs no candidate.\r\nRight now we want to only use official code for metrics to have fair evaluations, so I'm not sure we can do anything about it. Maybe you can try to create an issue on their [repo](https://github.com/Tiiiger/bert_score) ?"
] | 1,591,323,287,000 | 1,593,450,619,000 | 1,593,450,619,000 |
NONE
| null |
When running BERT-Score, I'm meeting this warning :
> Warning: Empty candidate sentence; Setting recall to be 0.
Code :
```
import nlp
metric = nlp.load_metric("bertscore")
scores = metric.compute(["swag", "swags"], ["swags", "totally something different"], lang="en", device=0)
```
---
**What am I doing wrong / How can I hide this warning ?**
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/238/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/238/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/237
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/237/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/237/comments
|
https://api.github.com/repos/huggingface/datasets/issues/237/events
|
https://github.com/huggingface/datasets/issues/237
| 631,199,940 |
MDU6SXNzdWU2MzExOTk5NDA=
| 237 |
Can't download MultiNLI
|
{
"login": "patpizio",
"id": 15801338,
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patpizio",
"html_url": "https://github.com/patpizio",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"repos_url": "https://api.github.com/users/patpizio/repos",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"You should use `load_dataset('glue', 'mnli')`",
"Thanks! I thought I had to use the same code displayed in the live viewer:\r\n```python\r\n!pip install nlp\r\nfrom nlp import load_dataset\r\ndataset = load_dataset('multi_nli', 'plain_text')\r\n```\r\nYour suggestion works, even if then I got a different issue (#242). ",
"Glad it helps !\nThough I am not one of hf team, but maybe you should close this issue first."
] | 1,591,311,921,000 | 1,591,440,694,000 | 1,591,440,694,000 |
CONTRIBUTOR
| null |
When I try to download MultiNLI with
```python
dataset = load_dataset('multi_nli')
```
I get this long error:
```python
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-13-3b11f6be4cb9> in <module>
1 # Load a dataset and print the first examples in the training set
2 # nli_dataset = nlp.load_dataset('multi_nli')
----> 3 dataset = load_dataset('multi_nli')
4 # nli_dataset = nlp.load_dataset('multi_nli', split='validation_matched[:10%]')
5 # print(nli_dataset['train'][0])
~\Miniconda3\envs\nlp\lib\site-packages\nlp\load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
514
515 # Download and prepare data
--> 516 builder_instance.download_and_prepare(
517 download_config=download_config,
518 download_mode=download_mode,
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
417 with utils.temporary_assignment(self, "_cache_dir", tmp_data_dir):
418 verify_infos = not save_infos and not ignore_verifications
--> 419 self._download_and_prepare(
420 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
421 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
455 split_dict = SplitDict(dataset_name=self.name)
456 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 457 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
458 # Checksums verification
459 if verify_infos:
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\multi_nli\60774175381b9f3f1e6ae1028229e3cdb270d50379f45b9f2c01008f50f09e6b\multi_nli.py in _split_generators(self, dl_manager)
99 def _split_generators(self, dl_manager):
100
--> 101 downloaded_dir = dl_manager.download_and_extract(
102 "http://storage.googleapis.com/tfds-data/downloads/multi_nli/multinli_1.0.zip"
103 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in download_and_extract(self, url_or_urls)
214 extracted_path(s): `str`, extracted paths of given URL(s).
215 """
--> 216 return self.extract(self.download(url_or_urls))
217
218 def get_recorded_sizes_checksums(self):
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in extract(self, path_or_paths)
194 path_or_paths.
195 """
--> 196 return map_nested(
197 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
198 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\py_utils.py in map_nested(function, data_struct, dict_only, map_tuple)
168 return tuple(mapped)
169 # Singleton
--> 170 return function(data_struct)
171
172
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in <lambda>(path)
195 """
196 return map_nested(
--> 197 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
198 )
199
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
231 if is_zipfile(output_path):
232 with ZipFile(output_path, "r") as zip_file:
--> 233 zip_file.extractall(output_path_extracted)
234 zip_file.close()
235 elif tarfile.is_tarfile(output_path):
~\Miniconda3\envs\nlp\lib\zipfile.py in extractall(self, path, members, pwd)
1644
1645 for zipinfo in members:
-> 1646 self._extract_member(zipinfo, path, pwd)
1647
1648 @classmethod
~\Miniconda3\envs\nlp\lib\zipfile.py in _extract_member(self, member, targetpath, pwd)
1698
1699 with self.open(member, pwd=pwd) as source, \
-> 1700 open(targetpath, "wb") as target:
1701 shutil.copyfileobj(source, target)
1702
OSError: [Errno 22] Invalid argument: 'C:\\Users\\Python\\.cache\\huggingface\\datasets\\3e12413b8ec69f22dfcfd54a79d1ba9e7aac2e18e334bbb6b81cca64fd16bffc\\multinli_1.0\\Icon\r'
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/237/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/237/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/236
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/236/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/236/comments
|
https://api.github.com/repos/huggingface/datasets/issues/236/events
|
https://github.com/huggingface/datasets/pull/236
| 631,099,875 |
MDExOlB1bGxSZXF1ZXN0NDI4MDUwNzI4
| 236 |
CompGuessWhat?! dataset
|
{
"login": "aleSuglia",
"id": 1479733,
"node_id": "MDQ6VXNlcjE0Nzk3MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aleSuglia",
"html_url": "https://github.com/aleSuglia",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "https://api.github.com/users/aleSuglia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aleSuglia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aleSuglia/subscriptions",
"organizations_url": "https://api.github.com/users/aleSuglia/orgs",
"repos_url": "https://api.github.com/users/aleSuglia/repos",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"received_events_url": "https://api.github.com/users/aleSuglia/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hi @aleSuglia, thanks for this great PR. Indeed you can have both datasets in one file. You need to add a config class which will allows you to specify the different subdataset names and then you will be able to load them as follow.\r\nnlp.load_dataset(\"compguesswhat\", \"compguesswhat-gameplay\") \r\nnlp.load_dataset(\"compguesswhat\", \"compguesswhat-zs-gameplay\").\r\n\r\nMaybe you can refer to this file https://github.com/huggingface/nlp/blob/master/datasets/discofuse/discofuse.py",
"@mariamabarham Thanks for your suggestions. I've followed your advice and integrated the additional dataset using another `DatasetConfig` class. It looks like all tests passed. What do you think?",
"great @aleSuglia. I requested an additional review from @thomwolf @lhoestq and @patrickvonplaten @jplu . You can merge it after an approval from one of them",
"Looks great! Thanks for adding the dummy data :-) ",
"Not sure whether it's the most appropriate place but I'll ask another design question. For Vision+Language dataset, is very common to have visual features associated with each example. At the moment, for instance, I'm only integrating the image identifier so that people can later on lookup the image features during training. Do you recommend this approach or do you think it should be done in a different way?\r\n\r\nThank you for your answer!",
"Hi @aleSuglia your remark on the visual features is a good point.\r\n\r\nWe haven't started to dive deeply into how CV datasets are usually structured (cc @sgugger)\r\n\r\nDo you have a pointer to how visual features are currently loaded and accessed by people using GuessCompWhat? ",
"@thomwolf As far as I know, people using Language+Vision tasks they typically have their reference dataset (either in JSON or JSONL format) and for each example in it they have an identifier that specifies the reference image. Currently, images are represented by either pooling-based visual features (average pooling of ResNet or VGGNet features, see [DeVries et.al, 2017](https://arxiv.org/abs/1611.08481), [Shekhar et.al, 2019](https://www.aclweb.org/anthology/N19-1265.pdf)) where you have a single vector for every image. Another option is to use a set of feature maps for every image extracted from a specific layer of a CNN (see [Xu et.al, 2015](https://arxiv.org/abs/1502.03044)). A more common and recent option, especially with large-scale multi-modal transformers [Li et. al, 2019](https://arxiv.org/abs/1908.03557), is to use FastRCNN features. \r\n\r\nFor all these types of features, people use either HD5F or NumPy compressed representations. In my personal projects, I've ditched altogether HD5F because it doesn't have out-of-the-box support for multi-processing (unless you have an ad-hoc installation of it). I've been successfully using a NumPy compressed file for each image so that I can store any sort of information in it (see [numpy.savez](https://numpy.org/doc/stable/reference/generated/numpy.savez.html)). However, I believe that Apache Arrow would be a really good fit for this type of features. \r\n\r\nLooking forward to hearing your thoughts about it!",
"Awesome work on this one thanks :)",
"@thomwolf I was thinking that I should create an issue regarding the visual features so that we can keep track of it for future work. I think it would be great to have it in NLP and I'll be happy to contribute. Let me know what you think :) "
] | 1,591,299,950,000 | 1,591,868,622,000 | 1,591,861,521,000 |
CONTRIBUTOR
| null |
Hello,
Thanks for the amazing library that you put together. I'm Alessandro Suglia, the first author of CompGuessWhat?!, a recently released dataset for grounded language learning accepted to ACL 2020 ([https://compguesswhat.github.io](https://compguesswhat.github.io)).
This pull-request adds the CompGuessWhat?! splits that have been extracted from the original dataset. This is only part of our evaluation framework because there is also an additional split of the dataset that has a completely different set of games. I didn't integrate it yet because I didn't know what would be the best practice in this case. Let me clarify the scenario.
In our paper, we have a main dataset (let's call it `compguesswhat-gameplay`) and a zero-shot dataset (let's call it `compguesswhat-zs-gameplay`). In the current code of the pull-request, I have only integrated `compguesswhat-gameplay`. I was thinking that it would be nice to have the `compguesswhat-zs-gameplay` in the same dataset class by simply specifying some particular option to the `nlp.load_dataset()` factory. For instance:
```python
cgw = nlp.load_dataset("compguesswhat")
cgw_zs = nlp.load_dataset("compguesswhat", zero_shot=True)
```
The other option would be to have a separate dataset class. Any preferences?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/236/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/236/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/236",
"html_url": "https://github.com/huggingface/datasets/pull/236",
"diff_url": "https://github.com/huggingface/datasets/pull/236.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/236.patch",
"merged_at": 1591861521000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/235
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/235/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/235/comments
|
https://api.github.com/repos/huggingface/datasets/issues/235/events
|
https://github.com/huggingface/datasets/pull/235
| 630,952,297 |
MDExOlB1bGxSZXF1ZXN0NDI3OTM1MjQ0
| 235 |
Add experimental datasets
|
{
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I think it would be nicer to not create a new folder `datasets_experimental` , but just put your datasets also into the folder `datasets` for the following reasons:\r\n\r\n- From my point of view, the datasets are not very different from the other datasets (assuming that we soon have C4, and the beam datasets) so I don't see why we require a new dataset folder\r\n\r\n- I'm not a big fan of adding a boolean flag to the `load_dataset()` function that basically switches between folder names on S3. The user has to know whether a dataset script is experimental or not. User installing nlp with pip won't see that there are folders called `datasets` and `datasets_experimental`\r\n\r\n- If we do this just to bypass the test, I think a good solution could be: For all tests that are too complicated to be currently tested with the testing framework, we can add a class variable called `do_test = False` to the dataset builder class and a default `do_test = True` to the abstract dataset class and skip all tests that have that variable in the dataset test framework similar to what is done to beam datasets: https://github.com/huggingface/nlp/blob/2e0a8639a79b1abc848cff5c669094d40bba0f63/tests/test_dataset_common.py#L79 \r\nWe can also print a warning for all dataset tests having `do_test = False`. This variable would only concern testing and we would not have a problem removing it at a later stage IMO.\r\n\r\n- This way the datascripts are backward compatible and can be used with earlier versions of `nlp` (not that this matters too much atm) \r\n\r\nWhat is your opinion on this @lhoestq @thomwolf ?",
"Very cool to have add those datasets :)\r\nI understand that making the dummy data for this case is not fun. I'm sure we'll be able to add them soon. For now it's still interesting to have them in the library, even if we can't test all the code with dummy data.\r\n\r\nI like the idea of the `do_tests=False` class variable. \r\nHowever it would be cool to test at least that we can load the module and instantiate the builder (only ignore the dummy data test for now). In that case a better name could be `test_dummy_data=False` or something like that.\r\n\r\nIf we want to be picky we can also add a warning in `_download_and_prepare` to tell the user that datasets with `test_dummy_data=False` are still experimental.",
"Yeah I really like the idea of a partial test.\r\n\r\nMy main concern with the class variable is visibility, but having a warning would help with that. Maybe even get the user to agree > \"are you sure you want to go ahead?\"",
"> Very cool to have add those datasets :)\r\n> I understand that making the dummy data for this case is not fun. I'm sure we'll be able to add them soon. For now it's still interesting to have them in the library, even if we can't test all the code with dummy data.\r\n> \r\n> I like the idea of the `do_tests=False` class variable.\r\n> However it would be cool to test at least that we can load the module and instantiate the builder (only ignore the dummy data test for now). In that case a better name could be `test_dummy_data=False` or something like that.\r\n> \r\n> If we want to be picky we can also add a warning in `_download_and_prepare` to tell the user that datasets with `test_dummy_data=False` are still experimental.\r\n\r\n`test_dummy_data=False` sounds good to me!",
"There we go: added a `test_dummy_data` class variable that is `False` by default for the `BeamBasedBuilder` and `True` for everyone else (except the new `explainlikeimfive` and `wiki_snippets`)\r\n\r\nNote that `wiki_snippets` should become obsolete as soon as @lhoestq adds in the `IndexedDataset` class",
"Great! LGTM!"
] | 1,591,286,096,000 | 1,591,976,335,000 | 1,591,976,335,000 |
MEMBER
| null |
## Adding an *experimental datasets* folder
After using the 🤗nlp library for some time, I find that while it makes it super easy to create new memory-mapped datasets with lots of cool utilities, a lot of what I want to do doesn't work well with the current `MockDownloader` based testing paradigm, making it hard to share my work with the community.
My suggestion would be to add a **datasets\_experimental** folder so we can start making these new datasets public without having to completely re-think testing for every single one. We would allow contributors to submit dataset PRs in this folder, but require an explanation for why the current testing suite doesn't work for them. We can then aggregate the feedback and periodically see what's missing from the current tests.
I have added a **datasets\_experimental** folder to the repository and S3 bucket with two initial datasets: ELI5 (explainlikeimfive) and a Wikipedia Snippets dataset to support indexing (wiki\_snippets)
### ELI5
#### Dataset description
This allows people to download the [ELI5: Long Form Question Answering](https://arxiv.org/abs/1907.09190) dataset, along with two variants based on the r/askscience and r/AskHistorians. Full Reddit dumps for each month are downloaded from [pushshift](https://files.pushshift.io/reddit/), filtered for submissions and comments from the desired subreddits, then deleted one at a time to save space. The resulting dataset is split into a training, validation, and test dataset for r/explainlikeimfive, r/askscience, and r/AskHistorians respectively, where each item is a question along with all of its high scoring answers.
#### Issues with the current testing
1. the list of files to be downloaded is not pre-defined, but rather determined by parsing an index web page at run time. This is necessary as the name and compression type of the dump files changes from month to month as the pushshift website is maintained. Currently, the dummy folder requires the user to know which files will be downloaded.
2. to save time, the script works on the compressed files using the corresponding python packages rather than first running `download\_and\_extract` then filtering the extracted files.
### Wikipedia Snippets
#### Dataset description
This script creates a *snippets* version of a source Wikipedia dataset: each article is split into passages of fixed length which can then be indexed using ElasticSearch or a dense indexer. The script currently handles all **wikipedia** and **wiki40b** source datasets, and allows the user to choose the passage length and how much overlap they want across passages. In addition to the passage text, each snippet also has the article title, list of titles of sections covered by the text, and information to map the passage back to the initial dataset at the paragraph and character level.
#### Issues with the current testing
1. The DatasetBuilder needs to call `nlp.load_dataset()`. Currently, testing is not recursive (the test doesn't know where to find the dummy data for the source dataset)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/235/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/235/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/235",
"html_url": "https://github.com/huggingface/datasets/pull/235",
"diff_url": "https://github.com/huggingface/datasets/pull/235.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/235.patch",
"merged_at": 1591976335000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/234
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/234/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/234/comments
|
https://api.github.com/repos/huggingface/datasets/issues/234/events
|
https://github.com/huggingface/datasets/issues/234
| 630,534,427 |
MDU6SXNzdWU2MzA1MzQ0Mjc=
| 234 |
Huggingface NLP, Uploading custom dataset
|
{
"login": "Nouman97",
"id": 42269506,
"node_id": "MDQ6VXNlcjQyMjY5NTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nouman97",
"html_url": "https://github.com/Nouman97",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "https://api.github.com/users/Nouman97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nouman97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nouman97/subscriptions",
"organizations_url": "https://api.github.com/users/Nouman97/orgs",
"repos_url": "https://api.github.com/users/Nouman97/repos",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nouman97/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"What do you mean 'custom' ? You may want to elaborate on it when ask a question.\r\n\r\nAnyway, there are two things you may interested\r\n`nlp.Dataset.from_file` and `load_dataset(..., cache_dir=)`",
"To load a dataset you need to have a script that defines the format of the examples, the splits and the way to generate examples. As your dataset has the same format of squad, you can just copy the squad script (see the [datasets](https://github.com/huggingface/nlp/tree/master/datasets) forlder) and just replace the url to load the data to your local or remote path.\r\n\r\nThen what you can do is `load_dataset(<path/to/your/script>)`",
"Also if you want to upload your script, you should be able to use the `nlp-cli`.\r\n\r\nUnfortunately the upload feature was not shipped in the latest version 0.2.0. so right now you can either clone the repo to use it or wait for the next release. We will add some docs to explain how to upload datasets.\r\n",
"Since the latest release 0.2.1 you can use \r\n```bash\r\nnlp-cli upload_dataset <path/to/dataset>\r\n```\r\nwhere `<path/to/dataset>` is a path to a folder containing your script (ex: `squad.py`).\r\nThis will upload the script under your namespace on our S3.\r\n\r\nOptionally the folder can also contain `dataset_infos.json` generated using\r\n```bash\r\nnlp-cli test <path/to/dataset> --all_configs --save_infos\r\n```\r\n\r\nThen you should be able to do\r\n```python\r\nnlp.load_dataset(\"my_namespace/dataset_name\")\r\n```"
] | 1,591,250,346,000 | 1,594,028,006,000 | 1,594,028,006,000 |
NONE
| null |
Hello,
Does anyone know how we can call our custom dataset using the nlp.load command? Let's say that I have a dataset based on the same format as that of squad-v1.1, how am I supposed to load it using huggingface nlp.
Thank you!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/234/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/234/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/233
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/233/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/233/comments
|
https://api.github.com/repos/huggingface/datasets/issues/233/events
|
https://github.com/huggingface/datasets/issues/233
| 630,432,132 |
MDU6SXNzdWU2MzA0MzIxMzI=
| 233 |
Fail to download c4 english corpus
|
{
"login": "donggyukimc",
"id": 16605764,
"node_id": "MDQ6VXNlcjE2NjA1NzY0",
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/donggyukimc",
"html_url": "https://github.com/donggyukimc",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_url": "https://api.github.com/users/donggyukimc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/donggyukimc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donggyukimc/subscriptions",
"organizations_url": "https://api.github.com/users/donggyukimc/orgs",
"repos_url": "https://api.github.com/users/donggyukimc/repos",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"received_events_url": "https://api.github.com/users/donggyukimc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hello ! Thanks for noticing this bug, let me fix that.\r\n\r\nAlso for information, as specified in the changelog of the latest release, C4 currently needs to have a runtime for apache beam to work on. Apache beam is used to process this very big dataset and it can work on dataflow, spark, flink, apex, etc. You can find more info on beam datasets [here](https://github.com/huggingface/nlp/blob/master/docs/beam_dataset.md).\r\n\r\nOur goal in the future is to make available an already-processed version of C4 (as we do for wikipedia for example) so that users without apache beam runtimes can load it.",
"@lhoestq I am facing `IsADirectoryError` while downloading with this command.\r\nCan you pls look into it & help me.\r\nI'm using version 0.4.0 of `nlp`.\r\n\r\n```\r\ndataset = load_dataset(\"c4\", 'en', data_dir='.', beam_runner='DirectRunner')\r\n```\r\n\r\nHere's the complete stack trace.\r\n\r\n```\r\nDownloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/devops/.cache/huggingface/datasets/c4/en/2.3.0/096df5a27756d51957c959a2499453e60a08154971fceb017bbb29f54b11bef7...\r\n\r\n---------------------------------------------------------------------------\r\nIsADirectoryError Traceback (most recent call last)\r\n<ipython-input-11-f622e6705e03> in <module>\r\n----> 1 dataset = load_dataset(\"c4\", 'en', data_dir='.', beam_runner='DirectRunner')\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)\r\n 547 # Download and prepare data\r\n 548 builder_instance.download_and_prepare(\r\n--> 549 download_config=download_config, download_mode=download_mode, ignore_verifications=ignore_verifications,\r\n 550 )\r\n 551 \r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)\r\n 461 if not downloaded_from_gcs:\r\n 462 self._download_and_prepare(\r\n--> 463 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n 464 )\r\n 465 # Sync info\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos)\r\n 964 pipeline = beam_utils.BeamPipeline(runner=beam_runner, options=beam_options,)\r\n 965 super(BeamBasedBuilder, self)._download_and_prepare(\r\n--> 966 dl_manager, verify_infos=False, pipeline=pipeline,\r\n 967 ) # TODO handle verify_infos in beam datasets\r\n 968 # Run pipeline\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 516 split_dict = SplitDict(dataset_name=self.name)\r\n 517 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)\r\n--> 518 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n 519 # Checksums verification\r\n 520 if verify_infos:\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/datasets/c4/096df5a27756d51957c959a2499453e60a08154971fceb017bbb29f54b11bef7/c4.py in _split_generators(self, dl_manager, pipeline)\r\n 187 if self.config.realnewslike:\r\n 188 files_to_download[\"realnews_domains\"] = _REALNEWS_DOMAINS_URL\r\n--> 189 file_paths = dl_manager.download_and_extract(files_to_download)\r\n 190 \r\n 191 if self.config.webtextlike:\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in download_and_extract(self, url_or_urls)\r\n 218 extracted_path(s): `str`, extracted paths of given URL(s).\r\n 219 \"\"\"\r\n--> 220 return self.extract(self.download(url_or_urls))\r\n 221 \r\n 222 def get_recorded_sizes_checksums(self):\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in download(self, url_or_urls)\r\n 156 lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,\r\n 157 )\r\n--> 158 self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)\r\n 159 return downloaded_path_or_paths\r\n 160 \r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in _record_sizes_checksums(self, url_or_urls, downloaded_path_or_paths)\r\n 106 flattened_downloaded_path_or_paths = flatten_nested(downloaded_path_or_paths)\r\n 107 for url, path in zip(flattened_urls_or_urls, flattened_downloaded_path_or_paths):\r\n--> 108 self._recorded_sizes_checksums[url] = get_size_checksum_dict(path)\r\n 109 \r\n 110 def download_custom(self, url_or_urls, custom_download):\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/info_utils.py in get_size_checksum_dict(path)\r\n 77 \"\"\"Compute the file size and the sha256 checksum of a file\"\"\"\r\n 78 m = sha256()\r\n---> 79 with open(path, \"rb\") as f:\r\n 80 for chunk in iter(lambda: f.read(1 << 20), b\"\"):\r\n 81 m.update(chunk)\r\n\r\nIsADirectoryError: [Errno 21] Is a directory: '/'\r\n\r\n```\r\n\r\nCan anyone please try to see what I am doing wrong or is this a bug?",
"I have the same problem as @prashant-kikani",
"Looks like a bug in the dataset script, can you open an issue ?",
"I see the same issue as @prashant-kikani. I'm using `datasets` version 1.2.0 to download C4."
] | 1,591,232,798,000 | 1,610,090,252,000 | 1,591,607,819,000 |
NONE
| null |
i run following code to download c4 English corpus.
```
dataset = nlp.load_dataset('c4', 'en', beam_runner='DirectRunner'
, data_dir='/mypath')
```
and i met failure as follows
```
Downloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/adam/.cache/huggingface/datasets/c4/en/2.3.0...
Traceback (most recent call last):
File "download_corpus.py", line 38, in <module>
, data_dir='/home/adam/data/corpus/en/c4')
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/load.py", line 520, in load_dataset
save_infos=save_infos,
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 420, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 816, in _download_and_prepare
dl_manager, verify_infos=False, pipeline=pipeline,
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 457, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/datasets/c4/f545de9f63300d8d02a6795e2eb34e140c47e62a803f572ac5599e170ee66ecc/c4.py", line 175, in _split_generators
dl_manager.download_checksums(_CHECKSUMS_URL)
AttributeError: 'DownloadManager' object has no attribute 'download_checksums
```
can i get any advice?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/233/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/233/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/232
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/232/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/232/comments
|
https://api.github.com/repos/huggingface/datasets/issues/232/events
|
https://github.com/huggingface/datasets/pull/232
| 630,029,568 |
MDExOlB1bGxSZXF1ZXN0NDI3MjI5NDcy
| 232 |
Nlp cli fix endpoints
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"LGTM 👍 "
] | 1,591,193,439,000 | 1,591,606,978,000 | 1,591,606,977,000 |
MEMBER
| null |
With this PR users will be able to upload their own datasets and metrics.
As mentioned in #181, I had to use the new endpoints and revert the use of dataclasses (just in case we have changes in the API in the future).
We now distinguish commands for datasets and commands for metrics:
```bash
nlp-cli upload_dataset <path/to/dataset>
nlp-cli upload_metric <path/to/metric>
nlp-cli s3_datasets {rm, ls}
nlp-cli s3_metrics {rm, ls}
```
Does it sound good to you @julien-c @thomwolf ?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/232/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/232/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/232",
"html_url": "https://github.com/huggingface/datasets/pull/232",
"diff_url": "https://github.com/huggingface/datasets/pull/232.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/232.patch",
"merged_at": 1591606977000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/231
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/231/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/231/comments
|
https://api.github.com/repos/huggingface/datasets/issues/231/events
|
https://github.com/huggingface/datasets/pull/231
| 629,988,694 |
MDExOlB1bGxSZXF1ZXN0NDI3MTk3MTcz
| 231 |
Add .download to MockDownloadManager
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,591,190,400,000 | 1,591,194,356,000 | 1,591,194,355,000 |
MEMBER
| null |
One method from the DownloadManager was missing and some users couldn't run the tests because of that.
@yjernite
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/231/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/231/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/231",
"html_url": "https://github.com/huggingface/datasets/pull/231",
"diff_url": "https://github.com/huggingface/datasets/pull/231.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/231.patch",
"merged_at": 1591194354000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/230
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/230/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/230/comments
|
https://api.github.com/repos/huggingface/datasets/issues/230/events
|
https://github.com/huggingface/datasets/pull/230
| 629,983,684 |
MDExOlB1bGxSZXF1ZXN0NDI3MTkzMTQ0
| 230 |
Don't force to install apache beam for wikipedia dataset
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,591,189,987,000 | 1,591,194,849,000 | 1,591,194,847,000 |
MEMBER
| null |
As pointed out in #227, we shouldn't force users to install apache beam if the processed dataset can be downloaded. I moved the imports of some datasets to avoid this problem
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/230/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/230/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/230",
"html_url": "https://github.com/huggingface/datasets/pull/230",
"diff_url": "https://github.com/huggingface/datasets/pull/230.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/230.patch",
"merged_at": 1591194847000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/229
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/229/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/229/comments
|
https://api.github.com/repos/huggingface/datasets/issues/229/events
|
https://github.com/huggingface/datasets/pull/229
| 629,956,490 |
MDExOlB1bGxSZXF1ZXN0NDI3MTcxMzc5
| 229 |
Rename dataset_infos.json to dataset_info.json
|
{
"login": "aswin-giridhar",
"id": 11817160,
"node_id": "MDQ6VXNlcjExODE3MTYw",
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aswin-giridhar",
"html_url": "https://github.com/aswin-giridhar",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
"gists_url": "https://api.github.com/users/aswin-giridhar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aswin-giridhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aswin-giridhar/subscriptions",
"organizations_url": "https://api.github.com/users/aswin-giridhar/orgs",
"repos_url": "https://api.github.com/users/aswin-giridhar/repos",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"received_events_url": "https://api.github.com/users/aswin-giridhar/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"\r\nThis was actually the right name. `dataset_infos.json` is used to have the infos of all the dataset configurations.\r\n\r\nOn the other hand `dataset_info.json` (without 's') is a cache file with the info of one specific configuration.\r\n\r\nTo fix #228, we probably just have to clear and reload the nlp-viewer cache."
] | 1,591,187,504,000 | 1,591,188,774,000 | 1,591,188,513,000 |
NONE
| null |
As the file required for the viewing in the live nlp viewer is named as dataset_info.json
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/229/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/229/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/229",
"html_url": "https://github.com/huggingface/datasets/pull/229",
"diff_url": "https://github.com/huggingface/datasets/pull/229.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/229.patch",
"merged_at": null
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/228
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/228/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/228/comments
|
https://api.github.com/repos/huggingface/datasets/issues/228/events
|
https://github.com/huggingface/datasets/issues/228
| 629,952,402 |
MDU6SXNzdWU2Mjk5NTI0MDI=
| 228 |
Not able to access the XNLI dataset
|
{
"login": "aswin-giridhar",
"id": 11817160,
"node_id": "MDQ6VXNlcjExODE3MTYw",
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aswin-giridhar",
"html_url": "https://github.com/aswin-giridhar",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
"gists_url": "https://api.github.com/users/aswin-giridhar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aswin-giridhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aswin-giridhar/subscriptions",
"organizations_url": "https://api.github.com/users/aswin-giridhar/orgs",
"repos_url": "https://api.github.com/users/aswin-giridhar/repos",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"received_events_url": "https://api.github.com/users/aswin-giridhar/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2107841032,
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer",
"name": "nlp-viewer",
"color": "94203D",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "srush",
"id": 35882,
"node_id": "MDQ6VXNlcjM1ODgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/srush",
"html_url": "https://github.com/srush",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"organizations_url": "https://api.github.com/users/srush/orgs",
"repos_url": "https://api.github.com/users/srush/repos",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"received_events_url": "https://api.github.com/users/srush/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "srush",
"id": 35882,
"node_id": "MDQ6VXNlcjM1ODgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/srush",
"html_url": "https://github.com/srush",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"organizations_url": "https://api.github.com/users/srush/orgs",
"repos_url": "https://api.github.com/users/srush/repos",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"received_events_url": "https://api.github.com/users/srush/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Added pull request to change the name of the file from dataset_infos.json to dataset_info.json",
"Thanks for reporting this bug !\r\nAs it seems to be just a cache problem, I closed your PR.\r\nI think we might just need to clear and reload the `xnli` cache @srush ? ",
"Update: The dataset_info.json error is gone, but we have a new one instead:\r\n```\r\nConnectionError: Couldn't reach https://www.nyu.edu/projects/bowman/xnli/XNLI-1.0.zip\r\n```\r\nI am not able to reproduce on my side unfortunately. Any idea @srush ?",
"xnli is now properly shown in the viewer.\r\nClosing this one."
] | 1,591,187,114,000 | 1,595,007,862,000 | 1,595,007,862,000 |
NONE
| null |
When I try to access the XNLI dataset, I get the following error. The option of plain_text get selected automatically and then I get the following error.
```
FileNotFoundError: [Errno 2] No such file or directory: '/home/sasha/.cache/huggingface/datasets/xnli/plain_text/1.0.0/dataset_info.json'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp_viewer/run.py", line 86, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp_viewer/run.py", line 72, in get
builder_instance = builder_cls(name=conf)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
```
Is it possible to see if the dataset_info.json is correctly placed?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/228/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/228/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/227
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/227/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/227/comments
|
https://api.github.com/repos/huggingface/datasets/issues/227/events
|
https://github.com/huggingface/datasets/issues/227
| 629,845,704 |
MDU6SXNzdWU2Mjk4NDU3MDQ=
| 227 |
Should we still have to force to install apache_beam to download wikipedia ?
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Thanks for your message 😊 \r\nIndeed users shouldn't have to install those dependencies",
"Got it, feel free to close this issue when you think it’s resolved.",
"It should be good now :)"
] | 1,591,176,800,000 | 1,591,197,941,000 | 1,591,197,941,000 |
CONTRIBUTOR
| null |
Hi, first thanks to @lhoestq 's revolutionary work, I successfully downloaded processed wikipedia according to the doc. 😍😍😍
But at the first try, it tell me to install `apache_beam` and `mwparserfromhell`, which I thought wouldn't be used according to #204 , it was kind of confusing me at that time.
Maybe we should not force users to install these ? Or we just add them to`nlp`'s dependency ?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/227/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/227/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/226
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/226/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/226/comments
|
https://api.github.com/repos/huggingface/datasets/issues/226/events
|
https://github.com/huggingface/datasets/pull/226
| 628,344,520 |
MDExOlB1bGxSZXF1ZXN0NDI1OTA0MjEz
| 226 |
add BlendedSkillTalk dataset
|
{
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Awesome :D"
] | 1,591,008,885,000 | 1,591,195,043,000 | 1,591,195,042,000 |
CONTRIBUTOR
| null |
This PR add the BlendedSkillTalk dataset, which is used to fine tune the blenderbot.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/226/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/226/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/226",
"html_url": "https://github.com/huggingface/datasets/pull/226",
"diff_url": "https://github.com/huggingface/datasets/pull/226.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/226.patch",
"merged_at": 1591195042000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/225
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/225/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/225/comments
|
https://api.github.com/repos/huggingface/datasets/issues/225/events
|
https://github.com/huggingface/datasets/issues/225
| 628,083,366 |
MDU6SXNzdWU2MjgwODMzNjY=
| 225 |
[ROUGE] Different scores with `files2rouge`
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067400959,
"node_id": "MDU6TGFiZWwyMDY3NDAwOTU5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Metric%20discussion",
"name": "Metric discussion",
"color": "d722e8",
"default": false,
"description": "Discussions on the metrics"
}
] |
closed
| false |
{
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"@Colanim unfortunately there are different implementations of the ROUGE metric floating around online which yield different results, and we had to chose one for the package :) We ended up including the one from the google-research repository, which does minimal post-processing before computing the P/R/F scores. If I recall correctly, files2rouge relies on the Perl, script, which among other things normalizes all numbers to a special token: in the case you presented, this should account for a good chunk of the difference.\r\n\r\nWe may end up adding in more versions of the metric, but probably not for a while (@lhoestq correct me if I'm wrong). However, feel free to take a stab at adding it in yourself and submitting a PR if you're interested!",
"Thank you for your kind answer.\r\n\r\nAs a side question : Isn't it better to have a package that normalize more ?\r\n\r\nI understand to idea of having a package that does minimal post-processing for transparency.\r\n\r\nBut it means that people using different architecture (with different tokenizers for example) will have difference in ROUGE scores even if their predictions are actually similar. \r\nThe goal of `nlp` is to have _one package to rule them all_, right ?\r\n\r\nI will look into it but I'm not sure I have the required skill for this ^^ ",
"You're right, there's a pretty interesting trade-off here between robustness and sensitivity :) The flip side of your argument is that we also still want the metric to be sensitive to model mistakes. How we think about number normalization for example has evolved a fair bit since the Perl script was written: at the time, ROUGE was used mostly to evaluate short-medium text summarization systems, where there were only a few numbers in the input and it was assumed that the most popular methods in use at the time would get those right. However, as your example showcases, that assumption does not hold any more, and we do want to be able to penalize a model that generates a wrong numerical value.\r\n\r\nAlso, we think that abstracting away tokenization differences is the role of the model/tokenizer: if you use the 🤗Tokenizers library for example, it will handle that for you ;)\r\n\r\nFinally, there is a lot of active research on developing model-powered metrics that are both more sensitive and more robust than ROUGE. Check out for example BERTscore, which is implemented in this library!"
] | 1,590,972,636,000 | 1,591,198,038,000 | 1,591,198,038,000 |
NONE
| null |
It seems that the ROUGE score of `nlp` is lower than the one of `files2rouge`.
Here is a self-contained notebook to reproduce both scores : https://colab.research.google.com/drive/14EyAXValB6UzKY9x4rs_T3pyL7alpw_F?usp=sharing
---
`nlp` : (Only mid F-scores)
>rouge1 0.33508031962733364
rouge2 0.14574333776191592
rougeL 0.2321187823256159
`files2rouge` :
>Running ROUGE...
===========================
1 ROUGE-1 Average_R: 0.48873 (95%-conf.int. 0.41192 - 0.56339)
1 ROUGE-1 Average_P: 0.29010 (95%-conf.int. 0.23605 - 0.34445)
1 ROUGE-1 Average_F: 0.34761 (95%-conf.int. 0.29479 - 0.39871)
===========================
1 ROUGE-2 Average_R: 0.20280 (95%-conf.int. 0.14969 - 0.26244)
1 ROUGE-2 Average_P: 0.12772 (95%-conf.int. 0.08603 - 0.17752)
1 ROUGE-2 Average_F: 0.14798 (95%-conf.int. 0.10517 - 0.19240)
===========================
1 ROUGE-L Average_R: 0.32960 (95%-conf.int. 0.26501 - 0.39676)
1 ROUGE-L Average_P: 0.19880 (95%-conf.int. 0.15257 - 0.25136)
1 ROUGE-L Average_F: 0.23619 (95%-conf.int. 0.19073 - 0.28663)
---
When using longer predictions/gold, the difference is bigger.
**How can I reproduce same score as `files2rouge` ?**
@lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/225/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/225/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/224
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/224/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/224/comments
|
https://api.github.com/repos/huggingface/datasets/issues/224/events
|
https://github.com/huggingface/datasets/issues/224
| 627,791,693 |
MDU6SXNzdWU2Mjc3OTE2OTM=
| 224 |
[Feature Request/Help] BLEURT model -> PyTorch
|
{
"login": "adamwlev",
"id": 6889910,
"node_id": "MDQ6VXNlcjY4ODk5MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6889910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adamwlev",
"html_url": "https://github.com/adamwlev",
"followers_url": "https://api.github.com/users/adamwlev/followers",
"following_url": "https://api.github.com/users/adamwlev/following{/other_user}",
"gists_url": "https://api.github.com/users/adamwlev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adamwlev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adamwlev/subscriptions",
"organizations_url": "https://api.github.com/users/adamwlev/orgs",
"repos_url": "https://api.github.com/users/adamwlev/repos",
"events_url": "https://api.github.com/users/adamwlev/events{/privacy}",
"received_events_url": "https://api.github.com/users/adamwlev/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
closed
| false |
{
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Is there any update on this? \r\n\r\nThanks!",
"Hitting this error when using bleurt with PyTorch ...\r\n\r\n```\r\nUnrecognizedFlagError: Unknown command line flag 'f'\r\n```\r\n... and I'm assuming because it was built for TF specifically. Is there a way to use this metric in PyTorch?",
"We currently provide a wrapper on the TensorFlow implementation: https://huggingface.co/metrics/bleurt\r\n\r\nWe have long term plans to better handle model-based metrics, but they probably won't be implemented right away\r\n\r\n@adamwlev it would still be cool to add the BLEURT checkpoints to the transformers repo if you're interested, but that would best be discussed there :) \r\n\r\nclosing for now",
"Hi there. We ran into the same problem this year (converting BLEURT to PyTorch) and thanks to @adamwlev found his colab notebook which didn't work but served as a good starting point. Finally, we **made it work** by doing just two simple conceptual fixes: \r\n\r\n1. Transposing 'kernel' layers instead of 'dense' ones when copying params from the original model;\r\n2. Taking pooler_output as a cls_state in forward function of the BleurtModel class.\r\n\r\nPlus few minor syntactical fixes for the outdated parts. The result is still not exactly the same, but is very close to the expected one (1.0483 vs 1.0474).\r\n\r\nFind the fixed version here (fixes are commented): https://colab.research.google.com/drive/1KsCUkFW45d5_ROSv2aHtXgeBa2Z98r03?usp=sharing \r\n"
] | 1,590,863,440,000 | 1,630,594,937,000 | 1,609,754,012,000 |
NONE
| null |
Hi, I am interested in porting google research's new BLEURT learned metric to PyTorch (because I wish to do something experimental with language generation and backpropping through BLEURT). I noticed that you guys don't have it yet so I am partly just asking if you plan to add it (@thomwolf said you want to do so on Twitter).
I had a go of just like manually using the checkpoint that they publish which includes the weights. It seems like the architecture is exactly aligned with the out-of-the-box BertModel in transformers just with a single linear layer on top of the CLS embedding. I loaded all the weights to the PyTorch model but I am not able to get the same numbers as the BLEURT package's python api. Here is my colab notebook where I tried https://colab.research.google.com/drive/1Bfced531EvQP_CpFvxwxNl25Pj6ptylY?usp=sharing . If you have any pointers on what might be going wrong that would be much appreciated!
Thank you muchly!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/224/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/224/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/223
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/223/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/223/comments
|
https://api.github.com/repos/huggingface/datasets/issues/223/events
|
https://github.com/huggingface/datasets/issues/223
| 627,683,386 |
MDU6SXNzdWU2Mjc2ODMzODY=
| 223 |
[Feature request] Add FLUE dataset
|
{
"login": "lbourdois",
"id": 58078086,
"node_id": "MDQ6VXNlcjU4MDc4MDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/58078086?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lbourdois",
"html_url": "https://github.com/lbourdois",
"followers_url": "https://api.github.com/users/lbourdois/followers",
"following_url": "https://api.github.com/users/lbourdois/following{/other_user}",
"gists_url": "https://api.github.com/users/lbourdois/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lbourdois/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lbourdois/subscriptions",
"organizations_url": "https://api.github.com/users/lbourdois/orgs",
"repos_url": "https://api.github.com/users/lbourdois/repos",
"events_url": "https://api.github.com/users/lbourdois/events{/privacy}",
"received_events_url": "https://api.github.com/users/lbourdois/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] |
closed
| false | null |
[] | null |
[
"Hi @lbourdois, yes please share it with us",
"@mariamabarham \r\nI put all the datasets on this drive: https://1drv.ms/u/s!Ao2Rcpiny7RFinDypq7w-LbXcsx9?e=iVsEDh\r\n\r\n\r\nSome information : \r\n• For FLUE, the quote used is\r\n\r\n> @misc{le2019flaubert,\r\n> title={FlauBERT: Unsupervised Language Model Pre-training for French},\r\n> author={Hang Le and Loïc Vial and Jibril Frej and Vincent Segonne and Maximin Coavoux and Benjamin Lecouteux and Alexandre Allauzen and Benoît Crabbé and Laurent Besacier and Didier Schwab},\r\n> year={2019},\r\n> eprint={1912.05372},\r\n> archivePrefix={arXiv},\r\n> primaryClass={cs.CL}\r\n> }\r\n\r\n• The Github repo of FLUE is avaible here : https://github.com/getalp/Flaubert/tree/master/flue\r\n\r\n\r\n\r\nInformation related to the different tasks of FLUE : \r\n\r\n**1. Classification**\r\nThree dataframes are available: \r\n- Book\r\n- DVD\r\n- Music\r\nFor each of these dataframes is available a set of training and test data, and a third one containing unlabelled data.\r\n\r\nCitation : \r\n>@dataset{prettenhofer_peter_2010_3251672,\r\n author = {Prettenhofer, Peter and\r\n Stein, Benno},\r\n title = {{Webis Cross-Lingual Sentiment Dataset 2010 (Webis- \r\n CLS-10)}},\r\n month = jul,\r\n year = 2010,\r\n publisher = {Zenodo},\r\n doi = {10.5281/zenodo.3251672},\r\n url = {https://doi.org/10.5281/zenodo.3251672}\r\n}\r\n\r\n\r\n**2. Paraphrasing** \r\nFrench part of the PAWS-X dataset (https://github.com/google-research-datasets/paws).\r\nThree dataframes are available: \r\n- train\r\n- dev\r\n- test \r\n\r\nCitation : \r\n> @InProceedings{pawsx2019emnlp,\r\n> title = {{PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification}},\r\n> author = {Yang, Yinfei and Zhang, Yuan and Tar, Chris and Baldridge, Jason},\r\n> booktitle = {Proc. of EMNLP},\r\n> year = {2019}\r\n> }\r\n\r\n\r\n\r\n**3. Natural Language Inference**\r\nFrench part of the XNLI dataset (https://github.com/facebookresearch/XNLI).\r\nThree dataframes are available: \r\n- train\r\n- dev\r\n- test \r\n\r\nFor the dev and test datasets, extra columns compared to the train dataset were available so I left them in the dataframe (I didn't know if these columns could be useful for other tasks or not). \r\nIn the context of the FLUE benchmark, only the columns gold_label, sentence1 and sentence2 are useful.\r\n\r\n\r\nCitation : \r\n\r\n> @InProceedings{conneau2018xnli,\r\n> author = \"Conneau, Alexis\r\n> and Rinott, Ruty\r\n> and Lample, Guillaume\r\n> and Williams, Adina\r\n> and Bowman, Samuel R.\r\n> and Schwenk, Holger\r\n> and Stoyanov, Veselin\",\r\n> title = \"XNLI: Evaluating Cross-lingual Sentence Representations\",\r\n> booktitle = \"Proceedings of the 2018 Conference on Empirical Methods\r\n> in Natural Language Processing\",\r\n> year = \"2018\",\r\n> publisher = \"Association for Computational Linguistics\",\r\n> location = \"Brussels, Belgium\",\r\n\r\n\r\n**4. Parsing**\r\nThe dataset used by the FLUE authors for this task is not freely available.\r\nUsers of your library will therefore not be able to access it.\r\nNevertheless, I think maybe it is useful to add a link to the site where to request this dataframe: http://ftb.linguist.univ-paris-diderot.fr/telecharger.php?langue=en \r\n(personally it was sent to me less than 48 hours after I requested it).\r\n\r\n\r\n**5. Word Sense Disambiguation Tasks**\r\n5.1 Verb Sense Disambiguation\r\n\r\nTwo dataframes are available: train and test\r\nFor both dataframes, 4 columns are available: document, sentence, lemma and word.\r\nI created the document column thinking that there were several documents in the dataset but afterwards it turns out that there were not: several sentences but only one document. It's up to you to keep it or not when importing these two dataframes.\r\n\r\nThe sentence column is used to determine to which sentence the word in the word column belongs. It is in the form of a dictionary {'id': 'd000.s001', 'idx': '1'}. I thought for a while to keep only the idx because the id doesn't matter any more information. Nevertheless for the test dataset, the dictionary has an extra value indicating the source of the sentence. I don't know if it's useful or not, that's why I left the dictionary just in case. The user is free to do what he wants with it.\r\n\r\nCitation : \r\n\r\n> Segonne, V., Candito, M., and Crabb ́e, B. (2019). Usingwiktionary as a resource for wsd: the case of frenchverbs. InProceedings of the 13th International Confer-ence on Computational Semantics-Long Papers, pages259–270\r\n\r\n5.2 Noun Sense Disambiguation\r\nTwo dataframes are available: 2 train and 1 test\r\n\r\nI confess I didn't fully understand the procedure for this task.\r\n\r\nCitation : \r\n\r\n> @dataset{loic_vial_2019_3549806,\r\n> author = {Loïc Vial},\r\n> title = {{French Word Sense Disambiguation with Princeton \r\n> WordNet Identifiers}},\r\n> month = nov,\r\n> year = 2019,\r\n> publisher = {Zenodo},\r\n> version = {1.0},\r\n> doi = {10.5281/zenodo.3549806},\r\n> url = {https://doi.org/10.5281/zenodo.3549806}\r\n> }\r\n\r\nFinally, additional information about FLUE is available in the FlauBERT publication : \r\nhttps://arxiv.org/abs/1912.05372 (p. 4).\r\n\r\n\r\nHoping to have provided you with everything you need to add this benchmark :) \r\n",
"https://github.com/huggingface/datasets/pull/943"
] | 1,590,828,735,000 | 1,607,002,773,000 | 1,607,002,773,000 |
NONE
| null |
Hi,
I think it would be interesting to add the FLUE dataset for francophones or anyone wishing to work on French.
In other requests, I read that you are already working on some datasets, and I was wondering if FLUE was planned.
If it is not the case, I can provide each of the cleaned FLUE datasets (in the form of a directly exploitable dataset rather than in the original xml formats which require additional processing, with the French part for cases where the dataset is based on a multilingual dataframe, etc.).
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/223/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/223/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/222
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/222/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/222/comments
|
https://api.github.com/repos/huggingface/datasets/issues/222/events
|
https://github.com/huggingface/datasets/issues/222
| 627,586,690 |
MDU6SXNzdWU2Mjc1ODY2OTA=
| 222 |
Colab Notebook breaks when downloading the squad dataset
|
{
"login": "carlos-aguayo",
"id": 338917,
"node_id": "MDQ6VXNlcjMzODkxNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/338917?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/carlos-aguayo",
"html_url": "https://github.com/carlos-aguayo",
"followers_url": "https://api.github.com/users/carlos-aguayo/followers",
"following_url": "https://api.github.com/users/carlos-aguayo/following{/other_user}",
"gists_url": "https://api.github.com/users/carlos-aguayo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/carlos-aguayo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/carlos-aguayo/subscriptions",
"organizations_url": "https://api.github.com/users/carlos-aguayo/orgs",
"repos_url": "https://api.github.com/users/carlos-aguayo/repos",
"events_url": "https://api.github.com/users/carlos-aguayo/events{/privacy}",
"received_events_url": "https://api.github.com/users/carlos-aguayo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The notebook forces version 0.1.0. If I use the latest, things work, I'll run the whole notebook and create a PR.\r\n\r\nBut in the meantime, this issue gets fixed by changing:\r\n`!pip install nlp==0.1.0`\r\nto\r\n`!pip install nlp`",
"It still breaks very near the end\r\n\r\n\r\n",
"When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:\r\n```\r\nWARNING: The following packages were previously imported in this runtime:\r\n [pyarrow]\r\nYou must restart the runtime in order to use newly installed versions.\r\n```\r\nYou just have to restart the runtime and it should be fine.\r\nIf you don't restart, then it breaks like in your first message ",
"Thanks for reporting the second one ! We'll update the notebook to fix this one :)",
"This trick from @thomwolf seems to be the most reliable solution to fix this colab notebook issue:\r\n\r\n```python\r\n# install nlp\r\n!pip install -qq nlp==0.2.0\r\n\r\n# Make sure that we have a recent version of pyarrow in the session before we continue - otherwise reboot Colab to activate it\r\nimport pyarrow\r\nif int(pyarrow.__version__.split('.')[1]) < 16:\r\n import os\r\n os.kill(os.getpid(), 9)\r\n```",
"The second part got fixed here: 2cbc656d6fc4b18ce57eac070baec05b31180d39\r\n\r\nThanks! I'm then closing this issue."
] | 1,590,792,959,000 | 1,591,230,065,000 | 1,591,230,065,000 |
NONE
| null |
When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
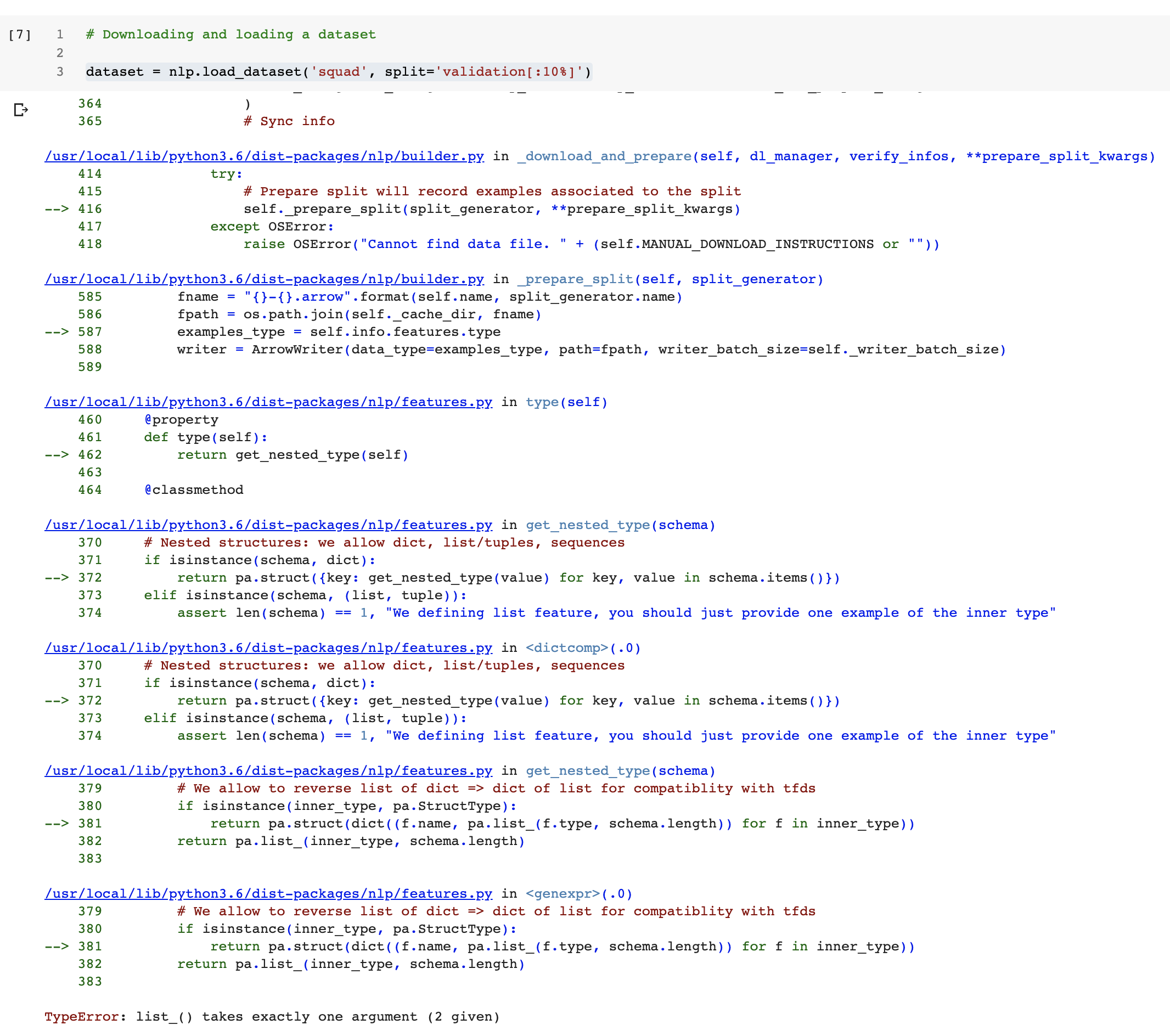
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/222/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/222/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/221
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/221/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/221/comments
|
https://api.github.com/repos/huggingface/datasets/issues/221/events
|
https://github.com/huggingface/datasets/pull/221
| 627,300,648 |
MDExOlB1bGxSZXF1ZXN0NDI1MTI5OTc0
| 221 |
Fix tests/test_dataset_common.py
|
{
"login": "tayciryahmed",
"id": 13635495,
"node_id": "MDQ6VXNlcjEzNjM1NDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/13635495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tayciryahmed",
"html_url": "https://github.com/tayciryahmed",
"followers_url": "https://api.github.com/users/tayciryahmed/followers",
"following_url": "https://api.github.com/users/tayciryahmed/following{/other_user}",
"gists_url": "https://api.github.com/users/tayciryahmed/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tayciryahmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tayciryahmed/subscriptions",
"organizations_url": "https://api.github.com/users/tayciryahmed/orgs",
"repos_url": "https://api.github.com/users/tayciryahmed/repos",
"events_url": "https://api.github.com/users/tayciryahmed/events{/privacy}",
"received_events_url": "https://api.github.com/users/tayciryahmed/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks ! Good catch :)\r\n\r\nTo fix the CI you can do:\r\n1 - rebase from master\r\n2 - then run `make style` as specified in [CONTRIBUTING.md](https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md) ?"
] | 1,590,761,535,000 | 1,591,014,042,000 | 1,590,764,543,000 |
CONTRIBUTOR
| null |
When I run the command `RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_arcd` while working on #220. I get the error ` unexpected keyword argument "'download_and_prepare_kwargs'"` at the level of `load_dataset`. Indeed, this [function](https://github.com/huggingface/nlp/blob/master/src/nlp/load.py#L441) no longer has the argument `download_and_prepare_kwargs` but rather `download_config`. So here I change the tests accordingly.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/221/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/221/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/221",
"html_url": "https://github.com/huggingface/datasets/pull/221",
"diff_url": "https://github.com/huggingface/datasets/pull/221.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/221.patch",
"merged_at": 1590764543000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/220
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/220/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/220/comments
|
https://api.github.com/repos/huggingface/datasets/issues/220/events
|
https://github.com/huggingface/datasets/pull/220
| 627,280,683 |
MDExOlB1bGxSZXF1ZXN0NDI1MTEzMzEy
| 220 |
dataset_arcd
|
{
"login": "tayciryahmed",
"id": 13635495,
"node_id": "MDQ6VXNlcjEzNjM1NDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/13635495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tayciryahmed",
"html_url": "https://github.com/tayciryahmed",
"followers_url": "https://api.github.com/users/tayciryahmed/followers",
"following_url": "https://api.github.com/users/tayciryahmed/following{/other_user}",
"gists_url": "https://api.github.com/users/tayciryahmed/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tayciryahmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tayciryahmed/subscriptions",
"organizations_url": "https://api.github.com/users/tayciryahmed/orgs",
"repos_url": "https://api.github.com/users/tayciryahmed/repos",
"events_url": "https://api.github.com/users/tayciryahmed/events{/privacy}",
"received_events_url": "https://api.github.com/users/tayciryahmed/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"you can rebase from master to fix the CI error :)",
"Awesome !"
] | 1,590,760,010,000 | 1,590,764,320,000 | 1,590,764,241,000 |
CONTRIBUTOR
| null |
Added Arabic Reading Comprehension Dataset (ARCD): https://arxiv.org/abs/1906.05394
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/220/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/220/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/220",
"html_url": "https://github.com/huggingface/datasets/pull/220",
"diff_url": "https://github.com/huggingface/datasets/pull/220.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/220.patch",
"merged_at": 1590764241000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/219
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/219/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/219/comments
|
https://api.github.com/repos/huggingface/datasets/issues/219/events
|
https://github.com/huggingface/datasets/pull/219
| 627,235,893 |
MDExOlB1bGxSZXF1ZXN0NDI1MDc2NjQx
| 219 |
force mwparserfromhell as third party
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,755,597,000 | 1,590,759,013,000 | 1,590,759,012,000 |
MEMBER
| null |
This should fix your env because you had `mwparserfromhell ` as a first party for `isort` @patrickvonplaten
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/219/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/219/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/219",
"html_url": "https://github.com/huggingface/datasets/pull/219",
"diff_url": "https://github.com/huggingface/datasets/pull/219.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/219.patch",
"merged_at": 1590759012000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/218
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/218/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/218/comments
|
https://api.github.com/repos/huggingface/datasets/issues/218/events
|
https://github.com/huggingface/datasets/pull/218
| 627,173,407 |
MDExOlB1bGxSZXF1ZXN0NDI1MDI2NzEz
| 218 |
Add Natual Questions and C4 scripts
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,748,830,000 | 1,590,755,461,000 | 1,590,755,460,000 |
MEMBER
| null |
Scripts are ready !
However they are not processed nor directly available from gcp yet.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/218/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/218/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/218",
"html_url": "https://github.com/huggingface/datasets/pull/218",
"diff_url": "https://github.com/huggingface/datasets/pull/218.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/218.patch",
"merged_at": 1590755460000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/217
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/217/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/217/comments
|
https://api.github.com/repos/huggingface/datasets/issues/217/events
|
https://github.com/huggingface/datasets/issues/217
| 627,128,403 |
MDU6SXNzdWU2MjcxMjg0MDM=
| 217 |
Multi-task dataset mixing
|
{
"login": "ghomasHudson",
"id": 13795113,
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghomasHudson",
"html_url": "https://github.com/ghomasHudson",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 2067400324,
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion",
"name": "generic discussion",
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library"
}
] |
open
| false | null |
[] | null |
[
"I like this feature! I think the first question we should decide on is how to convert all datasets into the same format. In T5, the authors decided to format every dataset into a text-to-text format. If the dataset had \"multiple\" inputs like MNLI, the inputs were concatenated. So in MNLI the input:\r\n\r\n> - **Hypothesis**: The St. Louis Cardinals have always won.\r\n> \r\n> - **Premise**: yeah well losing is i mean i’m i’m originally from Saint Louis and Saint Louis Cardinals when they were there were uh a mostly a losing team but \r\n\r\nwas flattened to a single input:\r\n\r\n> mnli hypothesis: The St. Louis Cardinals have always won. premise:\r\n> yeah well losing is i mean i’m i’m originally from Saint Louis and Saint Louis Cardinals\r\n> when they were there were uh a mostly a losing team but.\r\n\r\nThis flattening is actually a very simple operation in `nlp` already. You would just need to do the following:\r\n\r\n```python \r\ndef flatten_inputs(example):\r\n return {\"input\": \"mnli hypothesis: \" + example['hypothesis'] + \" premise: \" + example['premise']}\r\n\r\nt5_ready_mnli_ds = mnli_ds.map(flatten_inputs, remove_columns=[<all columns except output>])\r\n```\r\n\r\nSo I guess converting the datasets into the same format can be left to the user for now. \r\nThen the question is how we can merge the datasets. I would probably be in favor of a simple \r\n\r\n```python \r\ndataset.add()\r\n```\r\n\r\nfunction that checks if the dataset is of the same format and if yes merges the two datasets. Finally, how should the sampling be implemented? **Examples-proportional mixing** corresponds to just merging the datasets and shuffling. For the other two sampling approaches we would need some higher-level features, maybe even a `dataset.sample()` function for merged datasets. \r\n\r\nWhat are your thoughts on this @thomwolf @lhoestq @ghomasHudson @enzoampil ?",
"I agree that we should leave the flattening of the dataset to the user for now. Especially because although the T5 framing seems obvious, there are slight variations on how the T5 authors do it in comparison to other approaches such as gpt-3 and decaNLP.\r\n\r\nIn terms of sampling, Examples-proportional mixing does seem the simplest to implement so would probably be a good starting point.\r\n\r\nTemperature-scaled mixing would probably most useful, offering flexibility as it can simulate the other 2 methods by setting the temperature parameter. There is a [relevant part of the T5 repo](https://github.com/google-research/text-to-text-transfer-transformer/blob/03c94165a7d52e4f7230e5944a0541d8c5710788/t5/data/utils.py#L889-L1118) which should help with implementation.\r\n\r\nAccording to the T5 authors, equal-mixing performs worst. Among the other two methods, tuning the K value (the artificial dataset size limit) has a large impact.\r\n",
"I agree with going with temperature-scaled mixing for its flexibility!\r\n\r\nFor the function that combines the datasets, I also find `dataset.add()` okay while also considering that users may want it to be easy to combine a list of say 10 data sources in one go.\r\n\r\n`dataset.sample()` should also be good. By the looks of it, we're planning to have as main parameters: `temperature`, and `K`.\r\n\r\nOn converting the datasets to the same format, I agree that we can leave these to the users for now. But, I do imagine it'd be an awesome feature for the future to have this automatically handled, based on a chosen *approach* to formatting :smile: \r\n\r\nE.g. T5, GPT-3, decaNLP, original raw formatting, or a contributed way of formatting in text-to-text. ",
"This is an interesting discussion indeed and it would be nice to make multi-task easier.\r\n\r\nProbably the best would be to have a new type of dataset especially designed for that in order to easily combine and sample from the multiple datasets.\r\n\r\nThis way we could probably handle the combination of datasets with differing schemas as well (unlike T5).",
"@thomwolf Are you suggesting making a wrapper class which can take existing datasets as arguments and do all the required sampling/combining, to present the same interface as a normal dataset?\r\n\r\nThat doesn't seem too complicated to implement.\r\n",
"I guess we're looking at the end user writing something like:\r\n``` python\r\nds = nlp.load_dataset('multitask-t5',datasets=[\"squad\",\"cnn_dm\",...], k=1000, t=2.0)\r\n```\r\nUsing the t5 method of combining here (or this could be a function passed in as an arg) \r\n\r\nPassing kwargs to each 'sub-dataset' might become tricky.",
"From thinking upon @thomwolf 's suggestion, I've started experimenting:\r\n```python\r\nclass MultitaskDataset(DatasetBuilder):\r\n def __init__(self, *args, **kwargs):\r\n super(MultitaskDataset, self).__init__(*args, **kwargs)\r\n self._datasets = kwargs.get(\"datasets\")\r\n\r\n def _info(self):\r\n return nlp.DatasetInfo(\r\n description=_DESCRIPTION,\r\n features=nlp.Features({\r\n \"source\": nlp.Value(\"string\"),\r\n \"target\": nlp.Sequence(nlp.Value(\"string\"))\r\n })\r\n )\r\n\r\n def _get_common_splits(self):\r\n '''Finds the common splits present in all self._datasets'''\r\n min_set = None\r\n for dataset in self._datasets:\r\n if min_set != None:\r\n min_set.intersection(set(dataset.keys()))\r\n else:\r\n min_set = set(dataset.keys())\r\n return min_set\r\n\r\n....\r\n\r\n# Maybe this?:\r\nsquad = nlp.load_dataset(\"squad\")\r\ncnn_dm = nlp.load_dataset(\"cnn_dailymail\",\"3.0.0\")\r\nmultitask_dataset = nlp.load_dataset(\r\n 'multitask_dataset',\r\n datasets=[squad,cnn_dailymail], \r\n k=1000, \r\n t=2.0\r\n)\r\n\r\n```\r\n\r\nDoes anyone know what methods of `MultitaskDataset` I would need to implement? Maybe `as_dataset` and `download_and_prepare`? Most of these should be just calling the methods of the sub-datasets. \r\n\r\nI'm assuming DatasetBuilder is better than the more specific `GeneratorBasedBuilder`, `BeamBasedBuilder`, etc....\r\n\r\nOne of the other problems is that the dataset size is unknown till you construct it (as you can pick the sub-datasets). Am hoping not to need to make changes to `nlp.load_dataset` just for this class.\r\n\r\nI'd appreciate it if anyone more familiar with nlp's internal workings could tell me if I'm on the right track!",
"I think I would probably go for a `MultiDataset` wrapper around a list of `Dataset`.\r\n\r\nI'm not sure we need to give it `k` and `t` parameters at creation, it can maybe be something along the lines of:\r\n```python\r\nsquad = nlp.load_dataset(\"squad\")\r\ncnn_dm = nlp.load_dataset(\"cnn_dailymail\",\"3.0.0\")\r\n\r\nmultitask_dataset = nlp.MultiDataset(squad, cnn_dm)\r\n\r\nbatch = multitask_dataset.sample(10, temperature=2.0, k=1000)\r\n```\r\n\r\nThe first proof-of-concept for multi-task datasets could definitely require that the provided datasets have the same name/type for columns (if needed you easily rename/cast a column prior to instantiating the `MultiDataset`).\r\n\r\nIt's good to think about it for some time though and don't overfit too much on the T5 examples (in particular for the ways/kwargs for sampling among datasets).",
"The problem with changing `k` and `t` per sampling is that you'd have to somehow remember which examples you'd already returned while re-weighting the remaining examples based on the new `k` and `t`values. It seems possible but complicated (I can't really see a reason why you'd want to change the weighting of datasets after you constructed the multidataset).\r\n\r\nWouldn't it be convenient if it implemented the dataset interface? Then if someone has code using a single nlp dataset, they can replace it with a multitask combination of more datasets without having to change other code. We would at least need to be able to pass it into a `DataLoader`.\r\n\r\n",
"A very janky (but working) implementation of `multitask_dataset.sample()` could be something like this:\r\n```python\r\nimport nlp\r\nimport torch\r\n\r\nclass MultiDataset():\r\n def __init__(self, *args, temperature=2.0, k=1000, maximum=None, scale=1):\r\n self.datasets = args\r\n self._dataloaders = {}\r\n for split in self._get_common_splits():\r\n split_datasets = [ds[split] for ds in self.datasets]\r\n mixing_rates = self._calc_mixing_rates(split_datasets,temperature, k, maximum, scale)\r\n weights = []\r\n for i in range(len(self.datasets)):\r\n weights += [mixing_rates[i]]*len(self.datasets[i][split])\r\n self._dataloaders[split] = torch.utils.data.DataLoader(torch.utils.data.ConcatDataset(split_datasets),\r\n sampler=torch.utils.data.sampler.WeightedRandomSampler(\r\n num_samples=len(weights),\r\n weights = weights,\r\n replacement=True),\r\n shuffle=False)\r\n\r\n def _get_common_splits(self):\r\n '''Finds the common splits present in all self.datasets'''\r\n min_set = None\r\n for dataset in self.datasets:\r\n if min_set != None:\r\n min_set.intersection(set(dataset.keys()))\r\n else:\r\n min_set = set(dataset.keys())\r\n return min_set\r\n\r\n\r\n def _calc_mixing_rates(self,datasets, temperature=2.0, k=1000, maximum=None, scale=1):\r\n '''Work out the weighting of each dataset based on t and k'''\r\n mixing_rates = []\r\n for dataset in datasets:\r\n rate = len(dataset)\r\n rate *= scale\r\n if maximum:\r\n rate = min(rate, maximum)\r\n if temperature != 1.0:\r\n rate = rate ** (1.0/temperature)\r\n mixing_rates.append(rate)\r\n return mixing_rates\r\n\r\n def sample(self,n,split):\r\n batch = []\r\n for example in self._dataloaders[split]:\r\n batch.append(example)\r\n n -= 1\r\n if n == 0:\r\n return batch\r\n\r\n\r\ndef flatten(dataset,flatten_fn):\r\n for k in dataset.keys():\r\n if isinstance(dataset[k],nlp.Dataset):\r\n dataset[k] = dataset[k].map(flatten_fn,remove_columns=dataset[k].column_names)\r\n\r\n# Squad\r\ndef flatten_squad(example):\r\n return {\"source\": \"squad context: \" + example['context'] + \" question: \" + example['question'],\"target\":example[\"answers\"][\"text\"]}\r\nsquad = nlp.load_dataset(\"squad\")\r\nflatten(squad,flatten_squad)\r\n\r\n# CNN_DM\r\ndef flatten_cnn_dm(example):\r\n return {\"source\": \"cnn_dm: \" + example['article'],\"target\":[example[\"highlights\"]]}\r\ncnn_dm = nlp.load_dataset(\"cnn_dailymail\", \"3.0.0\")\r\nflatten(cnn_dm,flatten_cnn_dm)\r\n\r\nmultitask_dataset = MultiDataset(squad, cnn_dm)\r\nbatch = multitask_dataset.sample(100,\"train\")\r\n```\r\n\r\nThere's definitely a more sensible way than embedding `DataLoader`s inside. ",
"There is an interesting related investigation by @zphang here https://colab.research.google.com/github/zphang/zphang.github.io/blob/master/files/notebooks/Multi_task_Training_with_Transformers_NLP.ipynb",
"Good spot! Here are my thoughts:\r\n\r\n- Aside: Adding `MultitaskModel` to transformers might be a thing to raise - even though having task-specific heads has become unfashionable in recent times in favour of text-to-text type models.\r\n- Adding the task name as an extra field also seems useful for these kind of models which have task-specific heads\r\n- There is some validation of our approach that the user should be expected to `map` datasets into a common form.\r\n- The size-proportional sampling (also called \"Examples-proportional mixing\") used here doesn't perform too badly in the T5 paper (it's comparable to temperature-scaled mixing in many cases but less flexible. This is only reasonable with a `K` maximum size parameter to prevent very large datasets dominating). This might be good for a first prototype using:\r\n ```python\r\n def __iter__(self):\r\n \"\"\"\r\n For each batch, sample a task, and yield a batch from the respective\r\n task Dataloader.\r\n\r\n We use size-proportional sampling, but you could easily modify this\r\n to sample from some-other distribution.\r\n \"\"\"\r\n task_choice_list = []\r\n for i, task_name in enumerate(self.task_name_list):\r\n task_choice_list += [i] * self.num_batches_dict[task_name]\r\n task_choice_list = np.array(task_choice_list)\r\n np.random.shuffle(task_choice_list)\r\n\r\n dataloader_iter_dict = {\r\n task_name: iter(dataloader) \r\n for task_name, dataloader in self.dataloader_dict.items()\r\n }\r\n for task_choice in task_choice_list:\r\n task_name = self.task_name_list[task_choice]\r\n yield next(dataloader_iter_dict[task_name]) \r\n ```\r\n We'd just need to pull samples from the raw datasets and not from `DataLoader`s for each task. We can assume the user has done `dataset.shuffle()` if they want to.\r\n\r\n Other sampling methods can later be implemented by changing how the `task_choice_list` is generated. This should allow more flexibility and not tie us to specific methods for sampling among datasets.\r\n",
"Another thought: Multitasking over benchmarks (represented as Meta-datasets in nlp) is probably a common use case. Would be nice to pass an entire benchmark to our `MultiDataset` wrapper rather than having to pass individual components.",
"Here's a fully working implementation based on the `__iter__` function of @zphang.\r\n\r\n- I've generated the task choice list in the constructor as it allows us to index into the MultiDataset just like a normal dataset. I'm changing `task_choice_list` into a list of `(dataset_idx, example_idx)` so each entry references a unique dataset example. The shuffling has to be done before this as we don't want to shuffle within each task (we assume this is done by the user if this is what they intend).\r\n- I'm slightly concerned this list could become very large if many large datasets were used. Can't see a way round it at the moment though.\r\n- I've used `task.info.builder_name` as the dataset name. Not sure if this is correct.\r\n- I'd love to add some of the other `Dataset` methods (map, slicing by column, etc...). Would be great to implement the whole interface so a single dataset can be simply replaced by this.\r\n- This does everything on the individual example-level. If some application required batches all from a single task in turn we can't really do that.\r\n\r\n```python\r\nimport nlp\r\nimport numpy as np\r\n\r\nclass MultiDataset:\r\n def __init__(self,tasks):\r\n self.tasks = tasks\r\n\r\n # Create random order of tasks\r\n # Using size-proportional sampling\r\n task_choice_list = []\r\n for i, task in enumerate(self.tasks):\r\n task_choice_list += [i] * len(task)\r\n task_choice_list = np.array(task_choice_list)\r\n np.random.shuffle(task_choice_list)\r\n\r\n # Add index into each dataset\r\n # - We don't want to shuffle within each task\r\n counters = {}\r\n self.task_choice_list = []\r\n for i in range(len(task_choice_list)):\r\n idx = counters.get(task_choice_list[i],0)\r\n self.task_choice_list.append((task_choice_list[i],idx))\r\n counters[task_choice_list[i]] = idx + 1\r\n\r\n\r\n def __len__(self):\r\n return np.sum([len(t) for t in self.tasks])\r\n\r\n def __repr__(self):\r\n task_str = \", \".join([str(t) for t in self.tasks])\r\n return f\"MultiDataset(tasks: {task_str})\"\r\n\r\n def __getitem__(self,key):\r\n if isinstance(key, int):\r\n task_idx, example_idx = self.task_choice_list[key]\r\n task = self.tasks[task_idx]\r\n example = task[example_idx]\r\n example[\"task_name\"] = task.info.builder_name\r\n return example\r\n elif isinstance(key, slice):\r\n raise NotImplementedError()\r\n\r\n def __iter__(self):\r\n for i in range(len(self)):\r\n yield self[i]\r\n\r\n\r\ndef load_multitask(*datasets):\r\n '''Create multitask datasets per split'''\r\n\r\n def _get_common_splits(datasets):\r\n '''Finds the common splits present in all self.datasets'''\r\n min_set = None\r\n for dataset in datasets:\r\n if min_set != None:\r\n min_set.intersection(set(dataset.keys()))\r\n else:\r\n min_set = set(dataset.keys())\r\n return min_set\r\n\r\n common_splits = _get_common_splits(datasets)\r\n out = {}\r\n for split in common_splits:\r\n out[split] = MultiDataset([d[split] for d in datasets])\r\n return out\r\n\r\n\r\n##########################################\r\n# Dataset Flattening\r\n\r\ndef flatten(dataset,flatten_fn):\r\n for k in dataset.keys():\r\n if isinstance(dataset[k],nlp.Dataset):\r\n dataset[k] = dataset[k].map(flatten_fn,remove_columns=dataset[k].column_names)\r\n\r\n# Squad\r\ndef flatten_squad(example):\r\n return {\"source\": \"squad context: \" + example['context'] + \" question: \" + example['question'],\r\n \"target\":example[\"answers\"][\"text\"]}\r\nsquad = nlp.load_dataset(\"squad\")\r\nflatten(squad,flatten_squad)\r\n\r\n# CNN_DM\r\ndef flatten_cnn_dm(example):\r\n return {\"source\": \"cnn_dm: \" + example['article'],\"target\":[example[\"highlights\"]]}\r\ncnn_dm = nlp.load_dataset(\"cnn_dailymail\", \"3.0.0\")\r\nflatten(cnn_dm,flatten_cnn_dm)\r\n\r\n#############################################\r\n\r\nmtds = load_multitask(squad,cnn_dm)\r\n\r\nfor example in mtds[\"train\"]:\r\n print(example[\"task_name\"],example[\"target\"])\r\n```\r\nLet me know if you have any thoughts. I've started using this in some of my projects and it seems to work. If people are happy with the general approach for a first version, I can make a pull request.",
"Hey! Happy to jump into the discussion here. I'm still getting familiar with bits of this code, but the reasons I sampled over data loaders rather than datasets is 1) ensuring that each sampled batch corresponds to only 1 task (in case of different inputs formats/downstream models) and 2) potentially having different batch sizes per task (e.g. some tasks have very long/short inputs). How are you currently dealing with these in your PR?",
"The short answer is - I'm not! Everything is currently on a per-example basis. It would be fairly simple to add a `batch_size` argument which would ensure that every `batch_size` examples come from the same task. That should suit most use-cases (unless you wanted to ensure batches all came from the same task and apply something like `SortishSampler` on each task first)\r\n\r\nYour notebook was really inspiring by the way - thanks!",
"@zphang is having different batch sizes per task actually helpful? Would be interesting to know as it's not something I've come across as a technique used by any MTL papers.",
"mt-dnn's [batcher.py](https://github.com/namisan/mt-dnn/blob/master/mt_dnn/batcher.py) might be worth looking at.",
"> @zphang is having different batch sizes per task actually helpful? Would be interesting to know as it's not something I've come across as a technique used by any MTL papers.\r\n\r\nI think having different batch sizes per task is particularly helpful in some scenarios where each task has different amount of data. For example, the problem I'm currently facing is one task has tens of thousands of samples while one task has a couple hundreds. I think in this case different batch size could help. But if using the same batch size is a lot simpler to implement, I guess it makes sense to go with that.",
"I think that instead of proportional to size sampling you should specify weights or probabilities for drawing a batch from each dataset. We should also ensure that the smaller datasets are repeated so that the encoder layer doesn't overtrain on the largest dataset.",
"Are there any references for people doing different batch sizes per task in the literature? I've only seen constant batch sizes with differing numbers of batches for each task which seems sufficient to prevent the impact of large datasets (Read 3.5.3 of the [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) for example).\r\n\r\n",
"Hi,\r\nregarding building T5 dataset , I think we can use datasets https://github.com/huggingface/datasets and then need something similar to tf.data.experimental.sample_from_datasets, do you know if similar functionality exist in pytorch? Which can sample multiple datasets with the given rates. thanks. "
] | 1,590,744,146,000 | 1,603,701,993,000 | null |
CONTRIBUTOR
| null |
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sample from tasks proportionally to their dataset size
- **Equal mixing** - sample uniformly from each task
- **Temperature-scaled mixing** - The generalized approach used by multilingual BERT which uses a temperature T, where the mixing rate of each task is raised to the power 1/T and renormalized. When T=1 this is equivalent to equal mixing, and becomes closer to equal mixing with increasing T.
Following this discussion https://github.com/huggingface/transformers/issues/4340 in [transformers](https://github.com/huggingface/transformers), @enzoampil suggested that the `nlp` library might be a better place for this functionality.
Some method for combining datasets could be implemented ,e.g.
```
dataset = nlp.load_multitask(['squad','imdb','cnn_dm'], temperature=2.0, ...)
```
We would need a few additions:
- Method of identifying the tasks - how can we support adding a string to each task as an identifier: e.g. 'summarisation: '?
- Method of combining the metrics - a standard approach is to use the specific metric for each task and add them together for a combined score.
It would be great to support common use cases such as pretraining on the GLUE benchmark before fine-tuning on each GLUE task in turn.
I'm willing to write bits/most of this I just need some guidance on the interface and other library details so I can integrate it properly.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/217/reactions",
"total_count": 9,
"+1": 9,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/217/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/216
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/216/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/216/comments
|
https://api.github.com/repos/huggingface/datasets/issues/216/events
|
https://github.com/huggingface/datasets/issues/216
| 626,896,890 |
MDU6SXNzdWU2MjY4OTY4OTA=
| 216 |
❓ How to get ROUGE-2 with the ROUGE metric ?
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"ROUGE-1 and ROUGE-L shouldn't return the same thing. This is weird",
"For the rouge2 metric you can do\r\n\r\n```python\r\nrouge = nlp.load_metric('rouge')\r\nwith open(\"pred.txt\") as p, open(\"ref.txt\") as g:\r\n for lp, lg in zip(p, g):\r\n rouge.add(lp, lg)\r\nscore = rouge.compute(rouge_types=[\"rouge2\"])\r\n```\r\n\r\nNote that I just did a PR to have both `.add` and `.add_batch` for metrics, that's why now this is `rouge.add(lp, lg)` and not `rouge.add([lp], [lg])`",
"Well I just tested with the official script and both rouge1 and rougeL return exactly the same thing for the input you gave, so this is actually fine ^^\r\n\r\nI hope it helped :)"
] | 1,590,709,652,000 | 1,590,969,875,000 | 1,590,969,875,000 |
NONE
| null |
I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.add([lp], [lg])
score = rouge.compute()
```
then : _(print only the F-score for readability)_
```python
for k, s in score.items():
print(k, s.mid.fmeasure)
```
It gives :
>rouge1 0.7915168355671788
rougeL 0.7915168355671788
---
**How can I get the ROUGE-2 score ?**
Also, it's seems weird that ROUGE-1 and ROUGE-L scores are the same. Did I made a mistake ?
@lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/216/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/216/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/215
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/215/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/215/comments
|
https://api.github.com/repos/huggingface/datasets/issues/215/events
|
https://github.com/huggingface/datasets/issues/215
| 626,867,879 |
MDU6SXNzdWU2MjY4Njc4Nzk=
| 215 |
NonMatchingSplitsSizesError when loading blog_authorship_corpus
|
{
"login": "cedricconol",
"id": 52105365,
"node_id": "MDQ6VXNlcjUyMTA1MzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/52105365?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cedricconol",
"html_url": "https://github.com/cedricconol",
"followers_url": "https://api.github.com/users/cedricconol/followers",
"following_url": "https://api.github.com/users/cedricconol/following{/other_user}",
"gists_url": "https://api.github.com/users/cedricconol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cedricconol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cedricconol/subscriptions",
"organizations_url": "https://api.github.com/users/cedricconol/orgs",
"repos_url": "https://api.github.com/users/cedricconol/repos",
"events_url": "https://api.github.com/users/cedricconol/events{/privacy}",
"received_events_url": "https://api.github.com/users/cedricconol/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] |
open
| false | null |
[] | null |
[
"I just ran it on colab and got this\r\n```\r\n[{'expected': SplitInfo(name='train', num_bytes=610252351, num_examples=532812,\r\ndataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='train',\r\nnum_bytes=611607465, num_examples=533285, dataset_name='blog_authorship_corpus')},\r\n{'expected': SplitInfo(name='validation', num_bytes=37500394, num_examples=31277,\r\ndataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='validation',\r\nnum_bytes=35652716, num_examples=30804, dataset_name='blog_authorship_corpus')}]\r\n```\r\nwhich is different from the `dataset_infos.json` and also different from yours.\r\n\r\nIt looks like the script for generating examples is not consistent",
"The files provided by the authors are corrupted and the script seems to ignore the xml files that can't be decoded (it does `try:... except UnicodeDecodeError`). Maybe depending of the environment some files can be opened and some others don't but not sure why",
"Feel free to do `ignore_verifications=True` for now... The verifications only include a check on the checksums of the downloaded files, and a check on the number of examples in each splits.",
"I'm getting this same issue when loading the `imdb` corpus via `dataset = load_dataset(\"imdb\")`. When I try `ignore_verifications=True`, no examples are read into the `train` portion of the dataset. ",
"> I'm getting this same issue when loading the `imdb` corpus via `dataset = load_dataset(\"imdb\")`. When I try `ignore_verifications=True`, no examples are read into the `train` portion of the dataset.\r\n\r\nWhen the checksums don't match, it may mean that the file you downloaded is corrupted. In this case you can try to load the dataset again `load_dataset(\"imdb\", download_mode=\"force_redownload\")`\r\n\r\nAlso I just checked on my side and it worked fine:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"imdb\")\r\nprint(len(dataset[\"train\"]))\r\n# 25000\r\n```\r\n\r\nLet me know if redownloading fixes your issue @EmilyAlsentzer .\r\nIf not, feel free to open a separate issue.",
"It doesn't seem to fix the problem. I'll open a separate issue. Thanks. ",
"I wasn't aware of the \"force_redownload\" option and manually removed the '/home/me/.cache/huggingface/datasets/' dir, this worked for me (dataset 'cnn_dailymail')",
"Yes I think this might not be documented well enough. Let’s add it to the doc @lhoestq @SBrandeis.\r\nAnd everything on how to control the cache behavior better (removing, overriding, changing the path, etc)"
] | 1,590,706,519,000 | 1,609,969,023,000 | null |
NONE
| null |
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded': SplitInfo(name='train', num_bytes=616473500, num_examples=536323,
dataset_name='blog_authorship_corpus')}, {'expected': SplitInfo(name='validation',
num_bytes=37500394, num_examples=31277, dataset_name='blog_authorship_corpus'),
'recorded': SplitInfo(name='validation', num_bytes=30786661, num_examples=27766,
dataset_name='blog_authorship_corpus')}]
```
Upon checking it seems like there is a disparity between the information in `datasets/blog_authorship_corpus/dataset_infos.json` and what was downloaded. Although I can get away with this by passing `ignore_verifications=True` in `load_dataset`, I'm thinking doing so might give problems later on.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/215/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/215/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/214
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/214/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/214/comments
|
https://api.github.com/repos/huggingface/datasets/issues/214/events
|
https://github.com/huggingface/datasets/pull/214
| 626,641,549 |
MDExOlB1bGxSZXF1ZXN0NDI0NTk1NjIx
| 214 |
[arrow_dataset.py] add new filter function
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I agree that a `.filter` method would be VERY useful and appreciated. I'm not a big fan of using `flatten_nested` as it completely breaks down the structure of the example and it may create bugs. Right now I think it may not work for nested structures. Maybe there's a simpler way that we've not figured out yet.",
"Instead of flattening everything and rebuilding the example, maybe we can try to access the examples like this:\r\n```python\r\nfor i in range(num_examples):\r\n example = map_nested(lambda x: x[i], batch)\r\n # ... then test to keep it or not\r\n```",
"> Instead of flattening everything and rebuilding the example, maybe we can try to access the examples like this:\r\n> \r\n> ```python\r\n> for i in range(num_examples):\r\n> example = map_nested(lambda x: x[i], batch)\r\n> # ... then test to keep it or not\r\n> ```\r\n\r\nAwesome I'll check it out :-) ",
"> Instead of flattening everything and rebuilding the example, maybe we can try to access the examples like this:\r\n> \r\n> ```python\r\n> for i in range(num_examples):\r\n> example = map_nested(lambda x: x[i], batch)\r\n> # ... then test to keep it or not\r\n> ```\r\n\r\nAwesome this function is definitely much nicer!",
"Actually I just realized that `map_nested` might not work either as it applies the function at the very last list of the structure. However we can imagine that a single example has also a list in its structure:\r\n```python\r\none_example = {\r\n \"title\": \"blabla\",\r\n \"paragraphs\": [\r\n \"p1\", \"p2\", ...\r\n ]\r\n}\r\n```",
"We'll probably have to take into account the `dset._data.schema` to extract the examples from the batch.",
"> Actually I just realized that `map_nested` might not work either as it applies the function at the very last list of the structure. However we can imagine that a single example has also a list in its structure:\r\n> \r\n> ```python\r\n> one_example = {\r\n> \"title\": \"blabla\",\r\n> \"paragraphs\": [\r\n> \"p1\", \"p2\", ...\r\n> ]\r\n> }\r\n> ```\r\n\r\nThey both work. I'm using it on trivia_qa which is pretty nested. If you use the option `dict_only=True` I think it's fine.",
"> We'll probably have to take into account the `dset._data.schema` to extract the examples from the batch.\r\n\r\nWhy? ",
"Actually it's fine. I guess this is going to be yet another thing to be unit-tested just to make sure ^^",
"Yes, I will need to add tests and documentation! \r\n@thomwolf - would a function like this be ok? It abstracts `.map()` a bit which might be hard to understand. ",
"I tried on some datasets with nested structure and it works fine ! Great work :D \r\n",
"Awesome :-), I will add documentation and some simple unittests",
"Ok merging!"
] | 1,590,682,900,000 | 1,590,752,609,000 | 1,590,751,940,000 |
MEMBER
| null |
The `.map()` function is super useful, but can IMO a bit tedious when filtering certain examples.
I think, filtering out examples is also a very common operation people would like to perform on datasets.
This PR is a proposal to add a `.filter()` function in the same spirit than the `.map()` function.
Here is a sample code you can play around with:
```python
ds = nlp.load_dataset("squad", split="validation[:10%]")
def remove_under_idx_5(example, idx):
return idx < 5
def only_keep_examples_with_is_in_context(example):
return "is" in example["context"]
result_keep_only_first_5 = ds.filter(remove_under_idx_5, with_indices=True, load_from_cache_file=False)
result_keep_examples_with_is_in_context = ds.filter(only_keep_examples_with_is_in_context, load_from_cache_file=False)
print("Original number of examples: {}".format(len(ds)))
print("First five examples number of examples: {}".format(len(result_keep_only_first_5)))
print("Is in context examples number of examples: {}".format(len(result_keep_examples_with_is_in_context)))
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/214/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/214/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/214",
"html_url": "https://github.com/huggingface/datasets/pull/214",
"diff_url": "https://github.com/huggingface/datasets/pull/214.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/214.patch",
"merged_at": 1590751940000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/213
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/213/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/213/comments
|
https://api.github.com/repos/huggingface/datasets/issues/213/events
|
https://github.com/huggingface/datasets/pull/213
| 626,587,995 |
MDExOlB1bGxSZXF1ZXN0NDI0NTUxODE3
| 213 |
better message if missing beam options
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,678,417,000 | 1,590,745,877,000 | 1,590,745,876,000 |
MEMBER
| null |
WDYT @yjernite ?
For example:
```python
dataset = nlp.load_dataset('wikipedia', '20200501.aa')
```
Raises:
```
MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.aa', beam_runner='DirectRunner')`
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/213/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/213/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/213",
"html_url": "https://github.com/huggingface/datasets/pull/213",
"diff_url": "https://github.com/huggingface/datasets/pull/213.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/213.patch",
"merged_at": 1590745876000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/212
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/212/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/212/comments
|
https://api.github.com/repos/huggingface/datasets/issues/212/events
|
https://github.com/huggingface/datasets/pull/212
| 626,580,198 |
MDExOlB1bGxSZXF1ZXN0NDI0NTQ1NjAy
| 212 |
have 'add' and 'add_batch' for metrics
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,677,807,000 | 1,590,748,865,000 | 1,590,748,864,000 |
MEMBER
| null |
This should fix #116
Previously the `.add` method of metrics expected a batch of examples.
Now `.add` expects one prediction/reference and `.add_batch` expects a batch.
I think it is more coherent with the way the ArrowWriter works.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/212/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/212",
"html_url": "https://github.com/huggingface/datasets/pull/212",
"diff_url": "https://github.com/huggingface/datasets/pull/212.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/212.patch",
"merged_at": 1590748864000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/211
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/211/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/211/comments
|
https://api.github.com/repos/huggingface/datasets/issues/211/events
|
https://github.com/huggingface/datasets/issues/211
| 626,565,994 |
MDU6SXNzdWU2MjY1NjU5OTQ=
| 211 |
[Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
closed
| false |
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Here the full error trace:\r\n\r\n```\r\nArrowInvalid Traceback (most recent call last)\r\n<ipython-input-1-7aaf3f011358> in <module>\r\n 1 import nlp\r\n 2 ds = nlp.load_dataset(\"trivia_qa\", \"rc\", split=\"validation[:1%]\") # this might take 2.3 min to download but it's cached afterwards...\r\n----> 3 ds.map(lambda x: x, load_from_cache_file=False)\r\n\r\n~/python_bin/nlp/arrow_dataset.py in map(self, function, with_indices, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, arrow_schema, disable_nullable)\r\n 549\r\n 550 if update_data:\r\n--> 551 writer.finalize() # close_stream=bool(buf_writer is None)) # We only close if we are writing in a file\r\n 552\r\n 553 # Create new Dataset from buffer or file\r\n\r\n~/python_bin/nlp/arrow_writer.py in finalize(self, close_stream)\r\n 182 def finalize(self, close_stream=True):\r\n 183 if self.pa_writer is not None:\r\n--> 184 self.write_on_file()\r\n 185 self.pa_writer.close()\r\n 186 if close_stream:\r\n\r\n~/python_bin/nlp/arrow_writer.py in write_on_file(self)\r\n 104 \"\"\"\r\n 105 if self.current_rows:\r\n--> 106 pa_array = pa.array(self.current_rows, type=self._type)\r\n 107 first_example = pa.array(self.current_rows[0:1], type=self._type)[0]\r\n 108 # Sanity check\r\n\r\n~/hugging_face/venv_3.7/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib.array()\r\n\r\n~/hugging_face/venv_3.7/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib._sequence_to_array()\r\n\r\n~/hugging_face/venv_3.7/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowInvalid: Could not convert TagMe with type str: converting to null type\r\n```",
"Actually thinking a bit more about it, it's probably a data sample that is not correct in `trivia_qa`. But I'm a bit surprised though that we managed to write it in .arrow format and now cannot write it anymore after an \"identity\" mapping.",
"I don't have this error :x",
"Interesting, maybe I have a very old cache of trivia_qa...thanks for checking",
"I'm running it right now on colab to double check",
"Actually, I know what the problem is...I'm quite sure it's a bug. Here we take some test inputs: https://github.com/huggingface/nlp/blob/0e0ef12c14d2175e0b0bd7d8aa814b09e2cd7e1f/src/nlp/arrow_dataset.py#L472\r\n\r\nIt might be that in the test inputs, a `Sequence` type value is an emtpy list. So in my case I have `ds[0][\"entity_pages'][\"wiki_context\"] = []`. => this leads to an `arrow_schema` equal to `null` for `[\"entity_pages'][\"wiki_context\"]` => see line: https://github.com/huggingface/nlp/blob/0e0ef12c14d2175e0b0bd7d8aa814b09e2cd7e1f/src/nlp/arrow_dataset.py#L501 instead of list of string which it should for other examples. \r\n\r\nGuess it's an edge case, but it can happen.",
"Good point, I think the schema should be infered at the writing stage where we have a `writer_batch_size` number of examples (typically 10k) so it's even less likely to run into this scenario."
] | 1,590,676,694,000 | 1,595,499,316,000 | 1,595,499,316,000 |
MEMBER
| null |
Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=False)
```
triggers a `ArrowInvalid: Could not convert TagMe with type str: converting to null type` error.
On the other hand if we remove a certain column of `trivia_qa` which seems responsible for the bug, it works:
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, remove_columns=["entity_pages"], load_from_cache_file=False)
```
. Seems quite hard to debug what's going on here... @lhoestq @thomwolf - do you have a good first guess what the problem could be?
**Note** BTW: I think this could be a good test to check that the datasets work correctly: Take a tiny portion of the dataset and check that it can be written correctly.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/211/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/211/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/210
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/210/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/210/comments
|
https://api.github.com/repos/huggingface/datasets/issues/210/events
|
https://github.com/huggingface/datasets/pull/210
| 626,504,243 |
MDExOlB1bGxSZXF1ZXN0NDI0NDgyNDgz
| 210 |
fix xnli metric kwargs description
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,672,104,000 | 1,590,672,131,000 | 1,590,672,130,000 |
MEMBER
| null |
The text was wrong as noticed in #202
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/210/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/210/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/210",
"html_url": "https://github.com/huggingface/datasets/pull/210",
"diff_url": "https://github.com/huggingface/datasets/pull/210.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/210.patch",
"merged_at": 1590672130000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/209
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/209/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/209/comments
|
https://api.github.com/repos/huggingface/datasets/issues/209/events
|
https://github.com/huggingface/datasets/pull/209
| 626,405,849 |
MDExOlB1bGxSZXF1ZXN0NDI0NDAwOTc4
| 209 |
Add a Google Drive exception for small files
|
{
"login": "airKlizz",
"id": 25703835,
"node_id": "MDQ6VXNlcjI1NzAzODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/25703835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/airKlizz",
"html_url": "https://github.com/airKlizz",
"followers_url": "https://api.github.com/users/airKlizz/followers",
"following_url": "https://api.github.com/users/airKlizz/following{/other_user}",
"gists_url": "https://api.github.com/users/airKlizz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/airKlizz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/airKlizz/subscriptions",
"organizations_url": "https://api.github.com/users/airKlizz/orgs",
"repos_url": "https://api.github.com/users/airKlizz/repos",
"events_url": "https://api.github.com/users/airKlizz/events{/privacy}",
"received_events_url": "https://api.github.com/users/airKlizz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Can you run the style formatting tools to pass the code quality test?\r\n\r\nYou can find all the details in CONTRIBUTING.md: https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-contribute-to-nlp",
"Nice ! ",
"``make style`` done! Thanks for the approvals."
] | 1,590,662,417,000 | 1,590,678,904,000 | 1,590,678,904,000 |
CONTRIBUTOR
| null |
I tried to use the ``nlp`` library to load personnal datasets. I mainly copy-paste the code for ``multi-news`` dataset because my files are stored on Google Drive.
One of my dataset is small (< 25Mo) so it can be verified by Drive without asking the authorization to the user. This makes the download starts directly.
Currently the ``nlp`` raises a error: ``ConnectionError: Couldn't reach https://drive.google.com/uc?export=download&id=1DGnbUY9zwiThTdgUvVTSAvSVHoloCgun`` while the url is working. So I just add a new exception as you have already done for ``firebasestorage.googleapis.com`` :
```
elif (response.status_code == 400 and "firebasestorage.googleapis.com" in url) or (response.status_code == 405 and "drive.google.com" in url)
```
I make an example of the error that you can run on [](https://colab.research.google.com/drive/1ae_JJ9uvUt-9GBh0uGZhjbF5aXkl-BPv?usp=sharing)
I avoid the error by adding an exception but there is maybe a proper way to do it.
Many thanks :hugs:
Best,
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/209/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/209/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/209",
"html_url": "https://github.com/huggingface/datasets/pull/209",
"diff_url": "https://github.com/huggingface/datasets/pull/209.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/209.patch",
"merged_at": 1590678904000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/208
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/208/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/208/comments
|
https://api.github.com/repos/huggingface/datasets/issues/208/events
|
https://github.com/huggingface/datasets/pull/208
| 626,398,519 |
MDExOlB1bGxSZXF1ZXN0NDI0Mzk0ODIx
| 208 |
[Dummy data] insert config name instead of config
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,661,699,000 | 1,590,670,081,000 | 1,590,670,080,000 |
MEMBER
| null |
Thanks @yjernite for letting me know. in the dummy data command the config name shuold be passed to the dataset builder and not the config itself.
Also, @lhoestq fixed small import bug introduced by beam command I think.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/208/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/208",
"html_url": "https://github.com/huggingface/datasets/pull/208",
"diff_url": "https://github.com/huggingface/datasets/pull/208.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/208.patch",
"merged_at": 1590670080000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/207
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/207/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/207/comments
|
https://api.github.com/repos/huggingface/datasets/issues/207/events
|
https://github.com/huggingface/datasets/issues/207
| 625,932,200 |
MDU6SXNzdWU2MjU5MzIyMDA=
| 207 |
Remove test set from NLP viewer
|
{
"login": "chrisdonahue",
"id": 748399,
"node_id": "MDQ6VXNlcjc0ODM5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/748399?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chrisdonahue",
"html_url": "https://github.com/chrisdonahue",
"followers_url": "https://api.github.com/users/chrisdonahue/followers",
"following_url": "https://api.github.com/users/chrisdonahue/following{/other_user}",
"gists_url": "https://api.github.com/users/chrisdonahue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chrisdonahue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chrisdonahue/subscriptions",
"organizations_url": "https://api.github.com/users/chrisdonahue/orgs",
"repos_url": "https://api.github.com/users/chrisdonahue/repos",
"events_url": "https://api.github.com/users/chrisdonahue/events{/privacy}",
"received_events_url": "https://api.github.com/users/chrisdonahue/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2107841032,
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer",
"name": "nlp-viewer",
"color": "94203D",
"default": false,
"description": ""
}
] |
open
| false | null |
[] | null |
[
"~is the viewer also open source?~\r\n[is a streamlit app!](https://docs.streamlit.io/en/latest/getting_started.html)",
"Appears that [two thirds of those polled on Twitter](https://twitter.com/srush_nlp/status/1265734497632477185) are in favor of _some_ mechanism for averting eyeballs from the test data."
] | 1,590,604,327,000 | 1,591,198,147,000 | null |
NONE
| null |
While the new [NLP viewer](https://huggingface.co/nlp/viewer/) is a great tool, I think it would be best to outright remove the option of looking at the test sets. At the very least, a warning should be displayed to users before showing the test set. Newcomers to the field might not be aware of best practices, and small things like this can help increase awareness.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/207/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/207/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/206
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/206/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/206/comments
|
https://api.github.com/repos/huggingface/datasets/issues/206/events
|
https://github.com/huggingface/datasets/issues/206
| 625,842,989 |
MDU6SXNzdWU2MjU4NDI5ODk=
| 206 |
[Question] Combine 2 datasets which have the same columns
|
{
"login": "airKlizz",
"id": 25703835,
"node_id": "MDQ6VXNlcjI1NzAzODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/25703835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/airKlizz",
"html_url": "https://github.com/airKlizz",
"followers_url": "https://api.github.com/users/airKlizz/followers",
"following_url": "https://api.github.com/users/airKlizz/following{/other_user}",
"gists_url": "https://api.github.com/users/airKlizz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/airKlizz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/airKlizz/subscriptions",
"organizations_url": "https://api.github.com/users/airKlizz/orgs",
"repos_url": "https://api.github.com/users/airKlizz/repos",
"events_url": "https://api.github.com/users/airKlizz/events{/privacy}",
"received_events_url": "https://api.github.com/users/airKlizz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"We are thinking about ways to combine datasets for T5 in #217, feel free to share your thoughts about this.",
"Ok great! I will look at it. Thanks"
] | 1,590,596,752,000 | 1,591,780,274,000 | 1,591,780,274,000 |
CONTRIBUTOR
| null |
Hi,
I am using ``nlp`` to load personal datasets. I created summarization datasets in multi-languages based on wikinews. I have one dataset for english and one for german (french is getting to be ready as well). I want to keep these datasets independent because they need different pre-processing (add different task-specific prefixes for T5 : *summarize:* for english and *zusammenfassen:* for german)
My issue is that I want to train T5 on the combined english and german datasets to see if it improves results. So I would like to combine 2 datasets (which have the same columns) to make one and train T5 on it. I was wondering if there is a proper way to do it? I assume that it can be done by combining all examples of each dataset but maybe you have a better solution.
Hoping this is clear enough,
Thanks a lot 😊
Best
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/206/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/206/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/205
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/205/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/205/comments
|
https://api.github.com/repos/huggingface/datasets/issues/205/events
|
https://github.com/huggingface/datasets/pull/205
| 625,839,335 |
MDExOlB1bGxSZXF1ZXN0NDIzOTY2ODE1
| 205 |
Better arrow dataset iter
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,596,421,000 | 1,590,597,598,000 | 1,590,597,596,000 |
MEMBER
| null |
I tried to play around with `tf.data.Dataset.from_generator` and I found out that the `__iter__` that we have for `nlp.arrow_dataset.Dataset` ignores the format that has been set (torch or tensorflow).
With these changes I should be able to come up with a `tf.data.Dataset` that uses lazy loading, as asked in #193.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/205/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/205/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/205",
"html_url": "https://github.com/huggingface/datasets/pull/205",
"diff_url": "https://github.com/huggingface/datasets/pull/205.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/205.patch",
"merged_at": 1590597596000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/204
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/204/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/204/comments
|
https://api.github.com/repos/huggingface/datasets/issues/204/events
|
https://github.com/huggingface/datasets/pull/204
| 625,655,849 |
MDExOlB1bGxSZXF1ZXN0NDIzODE5MTQw
| 204 |
Add Dataflow support + Wikipedia + Wiki40b
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,582,769,000 | 1,590,653,435,000 | 1,590,653,434,000 |
MEMBER
| null |
# Add Dataflow support + Wikipedia + Wiki40b
## Support datasets processing with Apache Beam
Some datasets are too big to be processed on a single machine, for example: wikipedia, wiki40b, etc. Apache Beam allows to process datasets on many execution engines like Dataflow, Spark, Flink, etc.
To process such datasets with Beam, I added a command to run beam pipelines `nlp-cli run_beam path/to/dataset/script`. Then I used it to process the english + french wikipedia, and the english of wiki40b.
The processed arrow files are on GCS and are the result of a Dataflow job.
I added a markdown documentation file in `docs` that explains how to use it properly.
## Load already processed datasets
Now that we have those datasets already processed, I made it possible to load datasets that are already processed. You can do `load_dataset('wikipedia', '20200501.en')` and it will download the processed files from the Hugging Face GCS directly into the user's cache and be ready to use !
The Wikipedia dataset was already asked in #187 and this PR should soon allow to add Natural Questions as asked in #129
## Other changes in the code
To make things work, I had to do a few adjustments:
- add a `ship_files_with_pipeline` method to the `DownloadManager`. This is because beam pipelines can be run in the cloud and therefore need to have access to your downloaded data. I used it in the wikipedia script:
```python
if not pipeline.is_local():
downloaded_files = dl_manager.ship_files_with_pipeline(downloaded_files, pipeline)
```
- add parquet to arrow conversion. This is because the output of beam pipelines are parquet files so we need to convert them to arrow and have the arrow files on GCS
- add a test script with a dummy beam dataset
- minor adjustments to allow read/write operations on remote files using `apache_beam.io.filesystems.FileSystems` if we want (it can be connected to gcp, s3, hdfs, etc...)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/204/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/204",
"html_url": "https://github.com/huggingface/datasets/pull/204",
"diff_url": "https://github.com/huggingface/datasets/pull/204.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/204.patch",
"merged_at": 1590653434000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/203
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/203/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/203/comments
|
https://api.github.com/repos/huggingface/datasets/issues/203/events
|
https://github.com/huggingface/datasets/pull/203
| 625,515,488 |
MDExOlB1bGxSZXF1ZXN0NDIzNzEyMTQ3
| 203 |
Raise an error if no config name for datasets like glue
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,570,238,000 | 1,590,597,639,000 | 1,590,597,638,000 |
MEMBER
| null |
Some datasets like glue (see #130) and scientific_papers (see #197) have many configs.
For example for glue there are cola, sst2, mrpc etc.
Currently if a user does `load_dataset('glue')`, then Cola is loaded by default and it can be confusing. Instead, we should raise an error to let the user know that he has to pick one of the available configs (as proposed in #152). For example for glue, the message looks like:
```
ValueError: Config name is missing.
Please pick one among the available configs: ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']
Example of usage:
`load_dataset('glue', 'cola')`
```
The error is raised if the config name is missing and if there are >=2 possible configs.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/203/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/203/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/203",
"html_url": "https://github.com/huggingface/datasets/pull/203",
"diff_url": "https://github.com/huggingface/datasets/pull/203.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/203.patch",
"merged_at": 1590597638000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/202
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/202/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/202/comments
|
https://api.github.com/repos/huggingface/datasets/issues/202/events
|
https://github.com/huggingface/datasets/issues/202
| 625,493,983 |
MDU6SXNzdWU2MjU0OTM5ODM=
| 202 |
Mistaken `_KWARGS_DESCRIPTION` for XNLI metric
|
{
"login": "phiyodr",
"id": 33572125,
"node_id": "MDQ6VXNlcjMzNTcyMTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/33572125?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/phiyodr",
"html_url": "https://github.com/phiyodr",
"followers_url": "https://api.github.com/users/phiyodr/followers",
"following_url": "https://api.github.com/users/phiyodr/following{/other_user}",
"gists_url": "https://api.github.com/users/phiyodr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/phiyodr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phiyodr/subscriptions",
"organizations_url": "https://api.github.com/users/phiyodr/orgs",
"repos_url": "https://api.github.com/users/phiyodr/repos",
"events_url": "https://api.github.com/users/phiyodr/events{/privacy}",
"received_events_url": "https://api.github.com/users/phiyodr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Indeed, good catch ! thanks\r\nFixing it right now"
] | 1,590,568,482,000 | 1,590,672,156,000 | 1,590,672,156,000 |
NONE
| null |
Hi!
The [`_KWARGS_DESCRIPTION`](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/xnli/xnli.py#L45) for the XNLI metric uses `Args` and `Returns` text from [BLEU](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/bleu/bleu.py#L58) metric:
```
_KWARGS_DESCRIPTION = """
Computes XNLI score which is just simple accuracy.
Args:
predictions: list of translations to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
max_order: Maximum n-gram order to use when computing BLEU score.
smooth: Whether or not to apply Lin et al. 2004 smoothing.
Returns:
'bleu': bleu score,
'precisions': geometric mean of n-gram precisions,
'brevity_penalty': brevity penalty,
'length_ratio': ratio of lengths,
'translation_length': translation_length,
'reference_length': reference_length
"""
```
But it should be something like:
```
_KWARGS_DESCRIPTION = """
Computes XNLI score which is just simple accuracy.
Args:
predictions: Predicted labels.
references: Ground truth labels.
Returns:
'accuracy': accuracy
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/202/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/202/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/201
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/201/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/201/comments
|
https://api.github.com/repos/huggingface/datasets/issues/201/events
|
https://github.com/huggingface/datasets/pull/201
| 625,235,430 |
MDExOlB1bGxSZXF1ZXN0NDIzNDkzNTMw
| 201 |
Fix typo in README
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Amazing, @LysandreJik!",
"Really did my best!"
] | 1,590,531,501,000 | 1,590,536,431,000 | 1,590,534,056,000 |
MEMBER
| null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/201/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/201/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/201",
"html_url": "https://github.com/huggingface/datasets/pull/201",
"diff_url": "https://github.com/huggingface/datasets/pull/201.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/201.patch",
"merged_at": 1590534056000
}
| true |
|
https://api.github.com/repos/huggingface/datasets/issues/200
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/200/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/200/comments
|
https://api.github.com/repos/huggingface/datasets/issues/200/events
|
https://github.com/huggingface/datasets/pull/200
| 625,226,638 |
MDExOlB1bGxSZXF1ZXN0NDIzNDg2NTM0
| 200 |
[ArrowWriter] Set schema at first write example
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Good point!\r\n\r\nI guess we could add this to `write_batch` as well (before using `self._schema` in the first line of this method)?"
] | 1,590,530,388,000 | 1,590,570,474,000 | 1,590,570,473,000 |
MEMBER
| null |
Right now if the schema was not specified when instantiating `ArrowWriter`, then it could be set with the first `write_table` for example (it calls `self._build_writer()` to do so).
I noticed that it was not done if the first example is added via `.write`, so I added it for coherence.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/200/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/200/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/200",
"html_url": "https://github.com/huggingface/datasets/pull/200",
"diff_url": "https://github.com/huggingface/datasets/pull/200.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/200.patch",
"merged_at": 1590570473000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/199
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/199/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/199/comments
|
https://api.github.com/repos/huggingface/datasets/issues/199/events
|
https://github.com/huggingface/datasets/pull/199
| 625,217,440 |
MDExOlB1bGxSZXF1ZXN0NDIzNDc4ODIx
| 199 |
Fix GermEval 2014 dataset infos
|
{
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hopefully. this also fixes the dataset view on https://huggingface.co/nlp/viewer/ :)",
"Oh good catch ! This should fix it indeed"
] | 1,590,529,304,000 | 1,590,529,824,000 | 1,590,529,824,000 |
CONTRIBUTOR
| null |
Hi,
this PR just removes the `dataset_info.json` file and adds a newly generated `dataset_infos.json` file.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/199/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/199/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/199",
"html_url": "https://github.com/huggingface/datasets/pull/199",
"diff_url": "https://github.com/huggingface/datasets/pull/199.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/199.patch",
"merged_at": 1590529824000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/198
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/198/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/198/comments
|
https://api.github.com/repos/huggingface/datasets/issues/198/events
|
https://github.com/huggingface/datasets/issues/198
| 625,200,627 |
MDU6SXNzdWU2MjUyMDA2Mjc=
| 198 |
Index outside of table length
|
{
"login": "casajarm",
"id": 305717,
"node_id": "MDQ6VXNlcjMwNTcxNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/305717?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/casajarm",
"html_url": "https://github.com/casajarm",
"followers_url": "https://api.github.com/users/casajarm/followers",
"following_url": "https://api.github.com/users/casajarm/following{/other_user}",
"gists_url": "https://api.github.com/users/casajarm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/casajarm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/casajarm/subscriptions",
"organizations_url": "https://api.github.com/users/casajarm/orgs",
"repos_url": "https://api.github.com/users/casajarm/repos",
"events_url": "https://api.github.com/users/casajarm/events{/privacy}",
"received_events_url": "https://api.github.com/users/casajarm/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Sounds like something related to the nlp viewer @srush ",
"Fixed. "
] | 1,590,527,380,000 | 1,590,533,029,000 | 1,590,533,029,000 |
NONE
| null |
The offset input box warns of numbers larger than a limit (like 2000) but then the errors start at a smaller value than that limit (like 1955).
> ValueError: Index (2000) outside of table length (2000).
> Traceback:
> File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
> exec(code, module.__dict__)
> File "/home/sasha/nlp_viewer/run.py", line 116, in <module>
> v = d[item][k]
> File "/home/sasha/.local/lib/python3.7/site-packages/nlp/arrow_dataset.py", line 338, in __getitem__
> output_all_columns=self._output_all_columns,
> File "/home/sasha/.local/lib/python3.7/site-packages/nlp/arrow_dataset.py", line 290, in _getitem
> raise ValueError(f"Index ({key}) outside of table length ({self._data.num_rows}).")
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/198/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/198/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/197
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/197/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/197/comments
|
https://api.github.com/repos/huggingface/datasets/issues/197/events
|
https://github.com/huggingface/datasets/issues/197
| 624,966,904 |
MDU6SXNzdWU2MjQ5NjY5MDQ=
| 197 |
Scientific Papers only downloading Pubmed
|
{
"login": "antmarakis",
"id": 17463361,
"node_id": "MDQ6VXNlcjE3NDYzMzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antmarakis",
"html_url": "https://github.com/antmarakis",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url": "https://api.github.com/users/antmarakis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antmarakis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antmarakis/subscriptions",
"organizations_url": "https://api.github.com/users/antmarakis/orgs",
"repos_url": "https://api.github.com/users/antmarakis/repos",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"received_events_url": "https://api.github.com/users/antmarakis/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hi so there are indeed two configurations in the datasets as you can see [here](https://github.com/huggingface/nlp/blob/master/datasets/scientific_papers/scientific_papers.py#L81-L82).\r\n\r\nYou can load either one with:\r\n```python\r\ndataset = nlp.load_dataset('scientific_papers', 'pubmed')\r\ndataset = nlp.load_dataset('scientific_papers', 'arxiv')\r\n```\r\n\r\nThis issues is actually related to a similar user-experience issue with GLUE. When several configurations are available and the first configuration is loaded by default (see issue #152 and #130), it seems to be unexpected for users.\r\n\r\nI think we should maybe raise a (very explicit) error when there are several configurations available and the user doesn't specify one.\r\n\r\nWhat do you think @lhoestq @patrickvonplaten @mariamabarham ?",
"Yes, it looks like the right thing to do ",
"Now if you don't specify which part you want, it raises an error:\r\n```\r\nValueError: Config name is missing.\r\nPlease pick one among the available configs: ['pubmed', 'arxiv']\r\nExample of usage:\r\n\t`load_dataset('scientific_papers', 'pubmed')`\r\n```"
] | 1,590,506,327,000 | 1,590,653,968,000 | 1,590,653,968,000 |
NONE
| null |
Hi!
I have been playing around with this module, and I am a bit confused about the `scientific_papers` dataset. I thought that it would download two separate datasets, arxiv and pubmed. But when I run the following:
```
dataset = nlp.load_dataset('scientific_papers', data_dir='.', cache_dir='.')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5.05k/5.05k [00:00<00:00, 2.66MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.90k/4.90k [00:00<00:00, 2.42MB/s]
Downloading and preparing dataset scientific_papers/pubmed (download: 4.20 GiB, generated: 2.33 GiB, total: 6.53 GiB) to ./scientific_papers/pubmed/1.1.1...
Downloading: 3.62GB [00:40, 90.5MB/s]
Downloading: 880MB [00:08, 101MB/s]
Dataset scientific_papers downloaded and prepared to ./scientific_papers/pubmed/1.1.1. Subsequent calls will reuse this data.
```
only a pubmed folder is created. There doesn't seem to be something for arxiv. Are these two datasets merged? Or have I misunderstood something?
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/197/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/197/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/196
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/196/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/196/comments
|
https://api.github.com/repos/huggingface/datasets/issues/196/events
|
https://github.com/huggingface/datasets/pull/196
| 624,901,266 |
MDExOlB1bGxSZXF1ZXN0NDIzMjIwMjIw
| 196 |
Check invalid config name
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I think that's not related to the config name but the filenames in the dummy data. Mostly it occurs with files downloaded from drive. In that case the dummy file name is extracted from the google drive link and it corresponds to what comes after `https://drive.google.com/`\r\n\r\n",
"> I think that's not related to the config name but the filenames in the dummy data. Mostly it occurs with files downloaded from drive. In that case the dummy file name is extracted from the google drive link and it corresponds to what comes after `https://drive.google.com/`\r\n\r\nThe filenames of the dummy data are now encoded (see #173). So this is not a problem anymore.\r\n\r\nThe problem here is different and comes from the directory names where we save the arrow files (basically `dataset_name/config_name/version`). In this case we could have invalid directory names because of the config name\r\n",
"Okay great then.",
"I like the method, but I'm wondering whether it should just be a test method instead of a `__post_init__` function. From a logical point of view the only reason this error would be thrown is because of an invalid config name introduced when creating the dataset script / adding a new dataset => so I think it might be better to write a simple test for this in `test_dataset_common.py`...what do you think @lhoestq ?",
"`test_dataset_common.py` only tests canonical datasets no ? What if users wants to create their own script ?",
"> `test_dataset_common.py` only tests canonical datasets no ? What if users wants to create their own script ?\r\n\r\nIt tests all dataset that can be loaded either locally or on AWS (which includes all non-canonical datasets as well)...by their own script you mean like a private dataset script that they don't want to be public? I guess even then they could locally run the test functions to check...",
"We could have a bunch of simple consistency tests that run before uploading with the CLI (without loading data if we don't want to force the user to have dummy data)?",
"Let's say someone want to create his own private script. As the script is not meant to be shared, it's not going to be placed in `/datasets` right ? Maybe the script is going to be inside another project. If I'm not wrong in this case the `test_dataset_common.py` is not going to test his script.\r\n\r\nRaising an error in the post init is a sanity check that would tell the user immediately what's wrong.\r\nThe error is raised if he tried to load the script or if he uses `nlp-cli test`",
"> Let's say someone want to create his own private script. As the script is not meant to be shared, it's not going to be placed in `/datasets` right ? Maybe the script is going to be inside another project. If I'm not wrong in this case the `test_dataset_common.py` is not going to test his script.\r\n> \r\n> Raising an error in the post init is a sanity check that would tell the user immediately what's wrong.\r\n> The error is raised if he tried to load the script or if he uses `nlp-cli test`\r\n\r\nOK, fair point! I'm good with this then :-) ",
"I'm fine with this as well (even though I understand what you meant @patrickvonplaten, we can still change it later if needed)",
"> We could have a bunch of simple consistency tests that run before uploading with the CLI (without loading data if we don't want to force the user to have dummy data)?\r\n\r\nYes! I guess that's a big question whether we should force the user to add dummy data. It's probably too tedious for the user...so when uploading to circle ci should we just check \r\n- 1) All configs can be instantiated (if there are any)\r\n- 2) The BuilderClass can be instantiated ... \r\n- 3) ... maybe some more\r\n\r\nand maybe suggest to the user to add dummy data using the dummy data command?",
"I really like that we have a test with dummy data for canonical datasets. This is insurance that they'll keep working in the long run. \r\n\r\nOn the other hand I understand that we will probably not force this practice for scripts uploaded on S3 by a user under his namespace (non-canonical), as it is tedious. As I understand right now the test is done for all the datasets on aws, even the non-canonical ? We should think about different tests for non-canonical datasets.\r\n\r\nI also like the idea of a simple consistency test !",
"Merging this one for now, we can think about the test for non-canonical datasets later"
] | 1,590,501,171,000 | 1,590,527,096,000 | 1,590,527,095,000 |
MEMBER
| null |
As said in #194, we should raise an error if the config name has bad characters.
Bad characters are those that are not allowed for directory names on windows.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/196/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/196/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/196",
"html_url": "https://github.com/huggingface/datasets/pull/196",
"diff_url": "https://github.com/huggingface/datasets/pull/196.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/196.patch",
"merged_at": 1590527095000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/195
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/195/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/195/comments
|
https://api.github.com/repos/huggingface/datasets/issues/195/events
|
https://github.com/huggingface/datasets/pull/195
| 624,858,686 |
MDExOlB1bGxSZXF1ZXN0NDIzMTg1NTAy
| 195 |
[Dummy data command] add new case to command
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"@lhoestq - tiny change in the dummy data command, should be good to merge."
] | 1,590,497,447,000 | 1,590,503,908,000 | 1,590,503,907,000 |
MEMBER
| null |
Qanta: #194 introduces a case that was not noticed before. This change in code helps community users to have an easier time creating the dummy data.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/195/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/195/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/195",
"html_url": "https://github.com/huggingface/datasets/pull/195",
"diff_url": "https://github.com/huggingface/datasets/pull/195.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/195.patch",
"merged_at": 1590503907000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/194
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/194/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/194/comments
|
https://api.github.com/repos/huggingface/datasets/issues/194/events
|
https://github.com/huggingface/datasets/pull/194
| 624,854,897 |
MDExOlB1bGxSZXF1ZXN0NDIzMTgyNDM5
| 194 |
Add Dataset: Qanta
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"@lhoestq - the config name is rather special here: *E.g.* `mode=first,char_skip=25`. It includes `=` and `,` - will that be a problem for windows folders, you think? \r\n\r\nApart from that good to merge for me.",
"It's ok to have `=` and `,`.\r\nWindows doesn't like things like `?`, `:`, `/` etc.\r\n\r\nI'll add some lines to raise an error if the config name is invalid.",
"Thanks for fixing things up! I'm curious to take a look at the zip files now to know the format for future reference."
] | 1,590,497,075,000 | 1,590,512,297,000 | 1,590,498,980,000 |
MEMBER
| null |
Fixes dummy data for #169 @EntilZha
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/194/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/194/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/194",
"html_url": "https://github.com/huggingface/datasets/pull/194",
"diff_url": "https://github.com/huggingface/datasets/pull/194.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/194.patch",
"merged_at": 1590498980000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/193
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/193/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/193/comments
|
https://api.github.com/repos/huggingface/datasets/issues/193/events
|
https://github.com/huggingface/datasets/issues/193
| 624,655,558 |
MDU6SXNzdWU2MjQ2NTU1NTg=
| 193 |
[Tensorflow] Use something else than `from_tensor_slices()`
|
{
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"I guess we can use `tf.data.Dataset.from_generator` instead. I'll give it a try.",
"Is `tf.data.Dataset.from_generator` working on TPU ?",
"`from_generator` is not working on TPU, I met the following error :\r\n\r\n```\r\nFile \"/usr/local/lib/python3.6/contextlib.py\", line 88, in __exit__\r\n next(self.gen)\r\n File \"/home/usr/.venv/bart/lib/python3.6/site-packages/tensorflow_core/python/eager/context.py\", line 1900, in execution_mode\r\n executor_new.wait()\r\n File \"/home/usr/.venv/bart/lib/python3.6/site-packages/tensorflow_core/python/eager/executor.py\", line 67, in wait\r\n pywrap_tensorflow.TFE_ExecutorWaitForAllPendingNodes(self._handle)\r\ntensorflow.python.framework.errors_impl.NotFoundError: No registered 'PyFunc' OpKernel for 'CPU' devices compatible with node {{node PyFunc}}\r\n . Registered: <no registered kernels>\r\n\r\n [[PyFunc]]\r\n```\r\n\r\n---\r\n\r\n@lhoestq It seems you merged some changes that allow lazy-loading. **Can you give an example of how to use ?** Maybe the Colab notebook should be updated with this method as well.",
"Could you send me the code you used to run create the dataset using `.from_generator` ? What version of tensorflow are you using ?",
"I'm using TF2.2\r\n\r\nHere is my code :\r\n```\r\nimport nlp\r\nfrom transformers import BartTokenizer\r\n\r\ntokenizer = BartTokenizer.from_pretrained('bart-large')\r\n\r\ndef encode(sample):\r\n article_inputs = tokenizer.encode_plus(sample[\"article\"], max_length=tokenizer.model_max_length, pad_to_max_length=True)\r\n summary_inputs = tokenizer.encode_plus(sample[\"highlights\"], max_length=tokenizer.model_max_length, pad_to_max_length=True)\r\n\r\n article_inputs.update({\"lm_labels\": summary_inputs['input_ids']})\r\n return article_inputs\r\n\r\ncnn_dm = nlp.load_dataset('cnn_dailymail', '3.0.0', split='test')\r\ncnn_dm = cnn_dm.map(encode)\r\n\r\ndef gen():\r\n for sample in cnn_dm:\r\n s = {}\r\n s['input_ids'] = sample['input_ids']\r\n s['attention_mask'] = sample['attention_mask']\r\n s['lm_labels'] = sample['lm_labels']\r\n yield s\r\n\r\ndataset = tf.data.Dataset.from_generator(gen, output_types={k: tf.int32 for k in ['input_ids', 'attention_mask', 'lm_labels']}, output_shapes={k: tf.TensorShape([tokenizer.model_max_length]) for k in ['input_ids', 'attention_mask', 'lm_labels']}\r\n```",
"Apparently we'll have to wait for the next tensorflow release to use `.from_generator` and TPU. See https://github.com/tensorflow/tensorflow/issues/34346#issuecomment-598262489",
"Fixed by https://github.com/huggingface/datasets/pull/339"
] | 1,590,477,554,000 | 1,603,812,491,000 | 1,603,812,491,000 |
NONE
| null |
In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x] for x in columns[:3]}
labels = {"output_1": train_tf_dataset["start_positions"]}
labels["output_2"] = train_tf_dataset["end_positions"]
tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
```
But according to [official tensorflow documentation](https://www.tensorflow.org/guide/data#consuming_numpy_arrays), this will load the entire dataset to memory.
**This defeats one purpose of this library, which is lazy loading.**
Is there any other way to load the `nlp` dataset into TF dataset lazily ?
---
For example, is it possible to use [Arrow dataset](https://www.tensorflow.org/io/api_docs/python/tfio/arrow/ArrowDataset) ? If yes, is there any code example ?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/193/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/193/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/192
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/192/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/192/comments
|
https://api.github.com/repos/huggingface/datasets/issues/192/events
|
https://github.com/huggingface/datasets/issues/192
| 624,397,592 |
MDU6SXNzdWU2MjQzOTc1OTI=
| 192 |
[Question] Create Apache Arrow dataset from raw text file
|
{
"login": "mrm8488",
"id": 3653789,
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mrm8488",
"html_url": "https://github.com/mrm8488",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"We store every dataset in the Arrow format. This is convenient as it supports nested types and memory mapping. If you are curious feel free to check the [pyarrow documentation](https://arrow.apache.org/docs/python/)\r\n\r\nYou can use this library to load your covid papers by creating a dataset script. You can find inspiration from the ones we've already written in `/datasets`. Here is a link to the steps to [add a dataset](https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset)",
"Hello @mrm8488 and @lhoestq \r\n\r\nIs there a way to convert a dataset to Apache arrow format (locally/personal use) & use it before sending it to hugging face?\r\n\r\nThanks :)",
"> Is there a way to convert a dataset to Apache arrow format (locally/personal use) & use it before sending it to hugging face?\r\n\r\nSure, to get a dataset in arrow format you can either:\r\n- [load from local files (txt, json, csv)](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#from-local-files)\r\n- OR [load from python data (dict, pandas)](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#from-in-memory-data)\r\n- OR [create your own dataset script](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#using-a-custom-dataset-loading-script)\r\n",
"> > Is there a way to convert a dataset to Apache arrow format (locally/personal use) & use it before sending it to hugging face?\r\n> \r\n> Sure, to get a dataset in arrow format you can either:\r\n> \r\n> * [load from local files (txt, json, csv)](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#from-local-files)\r\n> \r\n> * OR [load from python data (dict, pandas)](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#from-in-memory-data)\r\n> \r\n> * OR [create your own dataset script](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#using-a-custom-dataset-loading-script)\r\n\r\nLinks were broken. \r\n\r\nUpdated links provided as below\r\n- [load from local files (txt, json, csv)](https://huggingface.co/docs/datasets/loading_datasets.html#from-local-or-remote-files)\r\n- [load from python data (dict, pandas)](https://huggingface.co/docs/datasets/loading_datasets.html#from-in-memory-data)\r\n- [create your own dataset script](https://huggingface.co/docs/datasets/loading_datasets.html#using-a-custom-dataset-loading-script)\r\n"
] | 1,590,424,967,000 | 1,639,791,934,000 | 1,603,812,022,000 |
NONE
| null |
Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT like) or any guide?
Is the worth of send it to you and add it to the NLP library?
Thanks, Manu
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/192/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/191
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/191/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/191/comments
|
https://api.github.com/repos/huggingface/datasets/issues/191/events
|
https://github.com/huggingface/datasets/pull/191
| 624,394,936 |
MDExOlB1bGxSZXF1ZXN0NDIyODI3MDMy
| 191 |
[Squad es] add dataset_infos
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,424,552,000 | 1,590,424,799,000 | 1,590,424,798,000 |
MEMBER
| null |
@mariamabarham - was still about to upload this. Should have waited with my comment a bit more :D
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/191/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/191",
"html_url": "https://github.com/huggingface/datasets/pull/191",
"diff_url": "https://github.com/huggingface/datasets/pull/191.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/191.patch",
"merged_at": 1590424798000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/190
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/190/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/190/comments
|
https://api.github.com/repos/huggingface/datasets/issues/190/events
|
https://github.com/huggingface/datasets/pull/190
| 624,124,600 |
MDExOlB1bGxSZXF1ZXN0NDIyNjA4NzAw
| 190 |
add squad Spanish v1 and v2
|
{
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Nice ! :) \r\nCan we group them into one dataset with two versions, instead of having two datasets ?",
"Yes sure, I can use the version as config name",
"@lhoestq can you check? I grouped them",
"Awesome :) feel free to merge after fixing the test in the CI",
"@mariamabarham - feel free to merge when you're ready. I only checked the dummy files. I did not run the SLOW tests. "
] | 1,590,394,120,000 | 1,590,424,126,000 | 1,590,424,125,000 |
CONTRIBUTOR
| null |
This PR add the Spanish Squad versions 1 and 2 datasets.
Fixes #164
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/190/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/190/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/190",
"html_url": "https://github.com/huggingface/datasets/pull/190",
"diff_url": "https://github.com/huggingface/datasets/pull/190.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/190.patch",
"merged_at": 1590424125000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/189
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/189/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/189/comments
|
https://api.github.com/repos/huggingface/datasets/issues/189/events
|
https://github.com/huggingface/datasets/issues/189
| 624,048,881 |
MDU6SXNzdWU2MjQwNDg4ODE=
| 189 |
[Question] BERT-style multiple choice formatting
|
{
"login": "sarahwie",
"id": 8027676,
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sarahwie",
"html_url": "https://github.com/sarahwie",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hi @sarahwie, can you details this a little more?\r\n\r\nI'm not sure I understand what you refer to and what you mean when you say \"Previously, this was done by passing a list of InputFeatures to the dataloader instead of a list of InputFeature\"",
"I think I've resolved it. For others' reference: to convert from using the [`MultipleChoiceDataset` class](https://github.com/huggingface/transformers/blob/a34a9896ac2a4a33ff9cd805c76eed914c8d8965/examples/multiple-choice/utils_multiple_choice.py#L82)/[`run_multiple_choice.py`](https://github.com/huggingface/transformers/blob/a34a9896ac2a4a33ff9cd805c76eed914c8d8965/examples/multiple-choice/run_multiple_choice.py) script in Huggingface Transformers, I've done the following for hellaswag:\r\n\r\n1. converted the `convert_examples_to_features()` function to only take one input and return a dictionary rather than a list:\r\n```\r\ndef convert_examples_to_features(example, tokenizer, max_length):\r\n\r\n choices_inputs = defaultdict(list)\r\n for ending_idx, ending in enumerate(example['endings']['ending']):\r\n text_a = example['ctx']\r\n text_b = ending\r\n\r\n inputs = tokenizer.encode_plus(\r\n text_a,\r\n text_b,\r\n add_special_tokens=True,\r\n max_length=max_length,\r\n pad_to_max_length=True,\r\n return_overflowing_tokens=True,\r\n )\r\n if \"num_truncated_tokens\" in inputs and inputs[\"num_truncated_tokens\"] > 0:\r\n logger.info(\r\n \"Attention! you are cropping tokens (swag task is ok). \"\r\n \"If you are training ARC and RACE and you are poping question + options,\"\r\n \"you need to try to use a bigger max seq length!\"\r\n )\r\n\r\n for key in inputs:\r\n choices_inputs[key].append(inputs[key])\r\n \r\n choices_inputs['label'] = int(example['label'])\r\n\r\n return choices_inputs\r\n```\r\n2. apply this directly (instance-wise) to dataset, convert dataset to torch tensors. Dataset is then ready to be passed to `Trainer` instance.\r\n\r\n```\r\ndataset['train'] = dataset['train'].map(lambda x: convert_examples_to_features(x, tokenizer, max_length), batched=False)\r\ncolumns = ['input_ids', 'token_type_ids', 'attention_mask', 'label']\r\ndataset['train'].set_format(type='torch', columns=columns)\r\n```"
] | 1,590,383,465,000 | 1,590,431,908,000 | 1,590,431,908,000 |
NONE
| null |
Hello, I am wondering what the equivalent formatting of a dataset should be to allow for multiple-choice answering prediction, BERT-style. Previously, this was done by passing a list of `InputFeatures` to the dataloader instead of a list of `InputFeature`, where `InputFeatures` contained lists of length equal to the number of answer choices in the MCQ instead of single items. I'm a bit confused on what the output of my feature conversion function should be when using `dataset.map()` to ensure similar behavior.
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/189/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/188
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/188/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/188/comments
|
https://api.github.com/repos/huggingface/datasets/issues/188/events
|
https://github.com/huggingface/datasets/issues/188
| 623,890,430 |
MDU6SXNzdWU2MjM4OTA0MzA=
| 188 |
When will the remaining math_dataset modules be added as dataset objects
|
{
"login": "tylerroost",
"id": 31251196,
"node_id": "MDQ6VXNlcjMxMjUxMTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/31251196?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tylerroost",
"html_url": "https://github.com/tylerroost",
"followers_url": "https://api.github.com/users/tylerroost/followers",
"following_url": "https://api.github.com/users/tylerroost/following{/other_user}",
"gists_url": "https://api.github.com/users/tylerroost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tylerroost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tylerroost/subscriptions",
"organizations_url": "https://api.github.com/users/tylerroost/orgs",
"repos_url": "https://api.github.com/users/tylerroost/repos",
"events_url": "https://api.github.com/users/tylerroost/events{/privacy}",
"received_events_url": "https://api.github.com/users/tylerroost/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"On a similar note it would be nice to differentiate between train-easy, train-medium, and train-hard",
"Hi @tylerroost, we don't have a timeline for this at the moment.\r\nIf you want to give it a look we would be happy to review a PR on it.\r\nAlso, the library is one week old so everything is quite barebones, in particular the doc.\r\nYou should expect some bumps on the road.\r\n\r\nTo get you started, you can check the datasets scripts in the `./datasets` folder on the repo and find the one on math_datasets that will need to be modified. Then you should check the original repository on the math_dataset to see where the other files to download are located and what is the expected format for the various parts of the dataset.\r\n\r\nTo get a general overview on how datasets scripts are written and used, you can read the nice tutorial on how to add a new dataset for TensorFlow Dataset [here](https://www.tensorflow.org/datasets/add_dataset), our API is not exactly identical but it can give you a high-level overview.",
"Thanks I'll give it a look"
] | 1,590,335,212,000 | 1,590,346,428,000 | 1,590,346,428,000 |
NONE
| null |
Currently only the algebra_linear_1d is supported. Is there a timeline for making the other modules supported. If no timeline is established, how can I help?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/188/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/188/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/187
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/187/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/187/comments
|
https://api.github.com/repos/huggingface/datasets/issues/187/events
|
https://github.com/huggingface/datasets/issues/187
| 623,627,800 |
MDU6SXNzdWU2MjM2Mjc4MDA=
| 187 |
[Question] How to load wikipedia ? Beam runner ?
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"I have seen that somebody is hard working on easierly loadable wikipedia. #129 \r\nMaybe I should wait a few days for that version ?",
"Yes we (well @lhoestq) are very actively working on this."
] | 1,590,229,132,000 | 1,590,365,522,000 | 1,590,365,522,000 |
CONTRIBUTOR
| null |
When `nlp.load_dataset('wikipedia')`, I got
* `WARNING:nlp.builder:Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided. Please pass a nlp.DownloadConfig(beam_runner=...) object to the builder.download_and_prepare(download_config=...) method. Default values will be used.`
* `AttributeError: 'NoneType' object has no attribute 'size'`
Could somebody tell me what should I do ?
# Env
On Colab,
```
git clone https://github.com/huggingface/nlp
cd nlp
pip install -q .
```
```
%pip install -q apache_beam mwparserfromhell
-> ERROR: pydrive 1.3.1 has requirement oauth2client>=4.0.0, but you'll have oauth2client 3.0.0 which is incompatible.
ERROR: google-api-python-client 1.7.12 has requirement httplib2<1dev,>=0.17.0, but you'll have httplib2 0.12.0 which is incompatible.
ERROR: chainer 6.5.0 has requirement typing-extensions<=3.6.6, but you'll have typing-extensions 3.7.4.2 which is incompatible.
```
```
pip install -q apache-beam[interactive]
ERROR: google-colab 1.0.0 has requirement ipython~=5.5.0, but you'll have ipython 5.10.0 which is incompatible.
```
# The whole message
```
WARNING:nlp.builder:Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided. Please pass a nlp.DownloadConfig(beam_runner=...) object to the builder.download_and_prepare(download_config=...) method. Default values will be used.
Downloading and preparing dataset wikipedia/20200501.aa (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/wikipedia/20200501.aa/1.0.0...
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner.process()
44 frames
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker.invoke_process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window()
/usr/local/lib/python3.6/dist-packages/apache_beam/io/iobase.py in process(self, element, init_result)
1081 writer.write(e)
-> 1082 return [window.TimestampedValue(writer.close(), timestamp.MAX_TIMESTAMP)]
1083
/usr/local/lib/python3.6/dist-packages/apache_beam/io/filebasedsink.py in close(self)
422 def close(self):
--> 423 self.sink.close(self.temp_handle)
424 return self.temp_shard_path
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in close(self, writer)
537 if len(self._buffer[0]) > 0:
--> 538 self._flush_buffer()
539 if self._record_batches_byte_size > 0:
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in _flush_buffer(self)
569 for b in x.buffers():
--> 570 size = size + b.size
571 self._record_batches_byte_size = self._record_batches_byte_size + size
AttributeError: 'NoneType' object has no attribute 'size'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
<ipython-input-9-340aabccefff> in <module>()
----> 1 dset = nlp.load_dataset('wikipedia')
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
370 verify_infos = not save_infos and not ignore_verifications
371 self._download_and_prepare(
--> 372 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
373 )
374 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos)
770 with beam.Pipeline(runner=beam_runner, options=beam_options,) as pipeline:
771 super(BeamBasedBuilder, self)._download_and_prepare(
--> 772 dl_manager, pipeline=pipeline, verify_infos=False
773 ) # TODO{beam} verify infos
774
/usr/local/lib/python3.6/dist-packages/apache_beam/pipeline.py in __exit__(self, exc_type, exc_val, exc_tb)
501 def __exit__(self, exc_type, exc_val, exc_tb):
502 if not exc_type:
--> 503 self.run().wait_until_finish()
504
505 def visit(self, visitor):
/usr/local/lib/python3.6/dist-packages/apache_beam/pipeline.py in run(self, test_runner_api)
481 return Pipeline.from_runner_api(
482 self.to_runner_api(use_fake_coders=True), self.runner,
--> 483 self._options).run(False)
484
485 if self._options.view_as(TypeOptions).runtime_type_check:
/usr/local/lib/python3.6/dist-packages/apache_beam/pipeline.py in run(self, test_runner_api)
494 finally:
495 shutil.rmtree(tmpdir)
--> 496 return self.runner.run_pipeline(self, self._options)
497
498 def __enter__(self):
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/direct/direct_runner.py in run_pipeline(self, pipeline, options)
128 runner = BundleBasedDirectRunner()
129
--> 130 return runner.run_pipeline(pipeline, options)
131
132
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in run_pipeline(self, pipeline, options)
553
554 self._latest_run_result = self.run_via_runner_api(
--> 555 pipeline.to_runner_api(default_environment=self._default_environment))
556 return self._latest_run_result
557
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in run_via_runner_api(self, pipeline_proto)
563 # TODO(pabloem, BEAM-7514): Create a watermark manager (that has access to
564 # the teststream (if any), and all the stages).
--> 565 return self.run_stages(stage_context, stages)
566
567 @contextlib.contextmanager
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in run_stages(self, stage_context, stages)
704 stage,
705 pcoll_buffers,
--> 706 stage_context.safe_coders)
707 metrics_by_stage[stage.name] = stage_results.process_bundle.metrics
708 monitoring_infos_by_stage[stage.name] = (
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in _run_stage(self, worker_handler_factory, pipeline_components, stage, pcoll_buffers, safe_coders)
1071 cache_token_generator=cache_token_generator)
1072
-> 1073 result, splits = bundle_manager.process_bundle(data_input, data_output)
1074
1075 def input_for(transform_id, input_id):
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in process_bundle(self, inputs, expected_outputs)
2332
2333 with UnboundedThreadPoolExecutor() as executor:
-> 2334 for result, split_result in executor.map(execute, part_inputs):
2335
2336 split_result_list += split_result
/usr/lib/python3.6/concurrent/futures/_base.py in result_iterator()
584 # Careful not to keep a reference to the popped future
585 if timeout is None:
--> 586 yield fs.pop().result()
587 else:
588 yield fs.pop().result(end_time - time.monotonic())
/usr/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)
430 raise CancelledError()
431 elif self._state == FINISHED:
--> 432 return self.__get_result()
433 else:
434 raise TimeoutError()
/usr/lib/python3.6/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
--> 384 raise self._exception
385 else:
386 return self._result
/usr/local/lib/python3.6/dist-packages/apache_beam/utils/thread_pool_executor.py in run(self)
42 # If the future wasn't cancelled, then attempt to execute it.
43 try:
---> 44 self._future.set_result(self._fn(*self._fn_args, **self._fn_kwargs))
45 except BaseException as exc:
46 # Even though Python 2 futures library has #set_exection(),
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in execute(part_map)
2329 self._registered,
2330 cache_token_generator=self._cache_token_generator)
-> 2331 return bundle_manager.process_bundle(part_map, expected_outputs)
2332
2333 with UnboundedThreadPoolExecutor() as executor:
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in process_bundle(self, inputs, expected_outputs)
2243 process_bundle_descriptor_id=self._bundle_descriptor.id,
2244 cache_tokens=[next(self._cache_token_generator)]))
-> 2245 result_future = self._worker_handler.control_conn.push(process_bundle_req)
2246
2247 split_results = [] # type: List[beam_fn_api_pb2.ProcessBundleSplitResponse]
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in push(self, request)
1557 self._uid_counter += 1
1558 request.instruction_id = 'control_%s' % self._uid_counter
-> 1559 response = self.worker.do_instruction(request)
1560 return ControlFuture(request.instruction_id, response)
1561
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/sdk_worker.py in do_instruction(self, request)
413 # E.g. if register is set, this will call self.register(request.register))
414 return getattr(self, request_type)(
--> 415 getattr(request, request_type), request.instruction_id)
416 else:
417 raise NotImplementedError
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/sdk_worker.py in process_bundle(self, request, instruction_id)
448 with self.maybe_profile(instruction_id):
449 delayed_applications, requests_finalization = (
--> 450 bundle_processor.process_bundle(instruction_id))
451 monitoring_infos = bundle_processor.monitoring_infos()
452 monitoring_infos.extend(self.state_cache_metrics_fn())
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/bundle_processor.py in process_bundle(self, instruction_id)
837 for data in data_channel.input_elements(instruction_id,
838 expected_transforms):
--> 839 input_op_by_transform_id[data.transform_id].process_encoded(data.data)
840
841 # Finish all operations.
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/bundle_processor.py in process_encoded(self, encoded_windowed_values)
214 decoded_value = self.windowed_coder_impl.decode_from_stream(
215 input_stream, True)
--> 216 self.output(decoded_value)
217
218 def try_split(self, fraction_of_remainder, total_buffer_size):
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.Operation.output()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.Operation.output()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.SingletonConsumerSet.receive()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.DoOperation.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.DoOperation.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner._reraise_augmented()
/usr/local/lib/python3.6/dist-packages/future/utils/__init__.py in raise_with_traceback(exc, traceback)
417 if traceback == Ellipsis:
418 _, _, traceback = sys.exc_info()
--> 419 raise exc.with_traceback(traceback)
420
421 else:
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker.invoke_process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window()
/usr/local/lib/python3.6/dist-packages/apache_beam/io/iobase.py in process(self, element, init_result)
1080 for e in bundle[1]: # values
1081 writer.write(e)
-> 1082 return [window.TimestampedValue(writer.close(), timestamp.MAX_TIMESTAMP)]
1083
1084
/usr/local/lib/python3.6/dist-packages/apache_beam/io/filebasedsink.py in close(self)
421
422 def close(self):
--> 423 self.sink.close(self.temp_handle)
424 return self.temp_shard_path
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in close(self, writer)
536 def close(self, writer):
537 if len(self._buffer[0]) > 0:
--> 538 self._flush_buffer()
539 if self._record_batches_byte_size > 0:
540 self._write_batches(writer)
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in _flush_buffer(self)
568 for x in arrays:
569 for b in x.buffers():
--> 570 size = size + b.size
571 self._record_batches_byte_size = self._record_batches_byte_size + size
AttributeError: 'NoneType' object has no attribute 'size' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/187/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/187/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/186
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/186/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/186/comments
|
https://api.github.com/repos/huggingface/datasets/issues/186/events
|
https://github.com/huggingface/datasets/issues/186
| 623,595,180 |
MDU6SXNzdWU2MjM1OTUxODA=
| 186 |
Weird-ish: Not creating unique caches for different phases
|
{
"login": "zphang",
"id": 1668462,
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zphang",
"html_url": "https://github.com/zphang",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"repos_url": "https://api.github.com/users/zphang/repos",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Looks like a duplicate of #120.\r\nThis is already fixed on master. We'll do a new release on pypi soon",
"Good catch, it looks fixed.\r\n"
] | 1,590,216,058,000 | 1,590,265,338,000 | 1,590,265,337,000 |
NONE
| null |
Sample code:
```python
import nlp
dataset = nlp.load_dataset('boolq')
def func1(x):
return x
def func2(x):
return None
train_output = dataset["train"].map(func1)
valid_output = dataset["validation"].map(func1)
print()
print(len(train_output), len(valid_output))
# Output: 9427 9427
```
The map method in both cases seem to be pointing to the same cache, so the latter call based on the validation data will return the processed train data cache.
What's weird is that the following doesn't seem to be an issue:
```python
train_output = dataset["train"].map(func2)
valid_output = dataset["validation"].map(func2)
print()
print(len(train_output), len(valid_output))
# 9427 3270
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/186/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/185
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/185/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/185/comments
|
https://api.github.com/repos/huggingface/datasets/issues/185/events
|
https://github.com/huggingface/datasets/pull/185
| 623,172,484 |
MDExOlB1bGxSZXF1ZXN0NDIxODkxNjY2
| 185 |
[Commands] In-detail instructions to create dummy data folder
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"awesome !"
] | 1,590,150,385,000 | 1,590,156,395,000 | 1,590,156,394,000 |
MEMBER
| null |
### Dummy data command
This PR adds a new command `python nlp-cli dummy_data <path_to_dataset_folder>` that gives in-detail instructions on how to add the dummy data files.
It would be great if you can try it out by moving the current dummy_data folder of any dataset in `./datasets` with `mv datasets/<dataset_script>/dummy_data datasets/<dataset_name>/dummy_data_copy` and running the command `python nlp-cli dummy_data ./datasets/<dataset_name>` to see if you like the instructions.
### CONTRIBUTING.md
Also the CONTRIBUTING.md is made cleaner including a new section on "How to add a dataset".
### Current PRs
It would be nice if we can try out if this command helps current PRs, *e.g.* #169 to add a dataset. I comment on those PRs.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/185/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/185/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/185",
"html_url": "https://github.com/huggingface/datasets/pull/185",
"diff_url": "https://github.com/huggingface/datasets/pull/185.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/185.patch",
"merged_at": 1590156394000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/184
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/184/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/184/comments
|
https://api.github.com/repos/huggingface/datasets/issues/184/events
|
https://github.com/huggingface/datasets/pull/184
| 623,120,929 |
MDExOlB1bGxSZXF1ZXN0NDIxODQ5MTQ3
| 184 |
Use IndexError instead of ValueError when index out of range
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,144,222,000 | 1,590,654,678,000 | 1,590,654,678,000 |
CONTRIBUTOR
| null |
**`default __iter__ needs IndexError`**.
When I want to create a wrapper of arrow dataset to adapt to fastai,
I don't know how to initialize it, so I didn't use inheritance but use object composition.
I wrote sth like this.
```
clas HF_dataset():
def __init__(self, arrow_dataset):
self.dset = arrow_dataset
def __getitem__(self, i):
return self.my_get_item(self.dset)
```
But `for sample in my_dataset:` gave me `ValueError(f"Index ({key}) outside of table length ({self._data.num_rows}).")` . This is because default `__iter__` will stop when it catched `IndexError`.
You can also see my [work](https://github.com/richardyy1188/Pretrain-MLM-and-finetune-on-GLUE-with-fastai/blob/master/GLUE_with_fastai.ipynb) that uses fastai2 to show/load batches from huggingface/nlp GLUE datasets
So I hope we can use `IndexError` instead to let other people who want to wrap it for any purpose won't be caught by this caveat.
BTW, I super appreciate your work, both transformers and nlp save my life. 💖💖💖💖💖💖💖
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/184/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/184/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/184",
"html_url": "https://github.com/huggingface/datasets/pull/184",
"diff_url": "https://github.com/huggingface/datasets/pull/184.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/184.patch",
"merged_at": 1590654678000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/183
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/183/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/183/comments
|
https://api.github.com/repos/huggingface/datasets/issues/183/events
|
https://github.com/huggingface/datasets/issues/183
| 623,054,270 |
MDU6SXNzdWU2MjMwNTQyNzA=
| 183 |
[Bug] labels of glue/ax are all -1
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"This is the test set given by the Glue benchmark. The labels are not provided, and therefore set to -1.",
"Ah, yeah. Why it didn’t occur to me. 😂\nThank you for your comment."
] | 1,590,137,016,000 | 1,590,185,645,000 | 1,590,185,645,000 |
CONTRIBUTOR
| null |
```
ax = nlp.load_dataset('glue', 'ax')
for i in range(30): print(ax['test'][i]['label'], end=', ')
```
```
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/183/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/183/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/182
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/182/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/182/comments
|
https://api.github.com/repos/huggingface/datasets/issues/182/events
|
https://github.com/huggingface/datasets/pull/182
| 622,646,770 |
MDExOlB1bGxSZXF1ZXN0NDIxNDcxMjg4
| 182 |
Update newsroom.py
|
{
"login": "yoavartzi",
"id": 3289873,
"node_id": "MDQ6VXNlcjMyODk4NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3289873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yoavartzi",
"html_url": "https://github.com/yoavartzi",
"followers_url": "https://api.github.com/users/yoavartzi/followers",
"following_url": "https://api.github.com/users/yoavartzi/following{/other_user}",
"gists_url": "https://api.github.com/users/yoavartzi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yoavartzi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yoavartzi/subscriptions",
"organizations_url": "https://api.github.com/users/yoavartzi/orgs",
"repos_url": "https://api.github.com/users/yoavartzi/repos",
"events_url": "https://api.github.com/users/yoavartzi/events{/privacy}",
"received_events_url": "https://api.github.com/users/yoavartzi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | null |
[] | 1,590,080,863,000 | 1,590,165,503,000 | 1,590,165,503,000 |
CONTRIBUTOR
| null |
Updated the URL for Newsroom download so it's more robust to future changes.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/182/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/182",
"html_url": "https://github.com/huggingface/datasets/pull/182",
"diff_url": "https://github.com/huggingface/datasets/pull/182.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/182.patch",
"merged_at": 1590165503000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/181
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/181/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/181/comments
|
https://api.github.com/repos/huggingface/datasets/issues/181/events
|
https://github.com/huggingface/datasets/issues/181
| 622,634,420 |
MDU6SXNzdWU2MjI2MzQ0MjA=
| 181 |
Cannot upload my own dataset
|
{
"login": "korakot",
"id": 3155646,
"node_id": "MDQ6VXNlcjMxNTU2NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/3155646?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/korakot",
"html_url": "https://github.com/korakot",
"followers_url": "https://api.github.com/users/korakot/followers",
"following_url": "https://api.github.com/users/korakot/following{/other_user}",
"gists_url": "https://api.github.com/users/korakot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/korakot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/korakot/subscriptions",
"organizations_url": "https://api.github.com/users/korakot/orgs",
"repos_url": "https://api.github.com/users/korakot/repos",
"events_url": "https://api.github.com/users/korakot/events{/privacy}",
"received_events_url": "https://api.github.com/users/korakot/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"It's my misunderstanding. I cannot just upload a csv. I need to write a dataset loading script too.",
"I now try with the sample `datasets/csv` folder. \r\n\r\n nlp-cli upload csv\r\n\r\nThe error is still the same\r\n\r\n```\r\n2020-05-21 17:20:56.394659: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\r\nAbout to upload file /content/csv/csv.py to S3 under filename csv/csv.py and namespace korakot\r\nAbout to upload file /content/csv/dummy/0.0.0/dummy_data.zip to S3 under filename csv/dummy/0.0.0/dummy_data.zip and namespace korakot\r\nProceed? [Y/n] y\r\nUploading... This might take a while if files are large\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/nlp-cli\", line 33, in <module>\r\n service.run()\r\n File \"/usr/local/lib/python3.6/dist-packages/nlp/commands/user.py\", line 234, in run\r\n token=token, filename=filename, filepath=filepath, organization=self.args.organization\r\n File \"/usr/local/lib/python3.6/dist-packages/nlp/hf_api.py\", line 141, in presign_and_upload\r\n urls = self.presign(token, filename=filename, organization=organization)\r\n File \"/usr/local/lib/python3.6/dist-packages/nlp/hf_api.py\", line 132, in presign\r\n return PresignedUrl(**d)\r\nTypeError: __init__() got an unexpected keyword argument 'cdn'\r\n```\r\n",
"We haven't tested the dataset upload feature yet cc @julien-c \r\nThis is on our short/mid-term roadmap though",
"Even if I fix the `TypeError: __init__() got an unexpected keyword argument 'cdn'` error, it looks like it still uploads to `https://s3.amazonaws.com/models.huggingface.co/bert/<namespace>/<dataset_name>` instead of `https://s3.amazonaws.com/datasets.huggingface.co/nlp/<namespace>/<dataset_name>`",
"@lhoestq The endpoints in https://github.com/huggingface/nlp/blob/master/src/nlp/hf_api.py should be (depending on the type of file):\r\n```\r\nPOST /api/datasets/presign\r\nGET /api/datasets/listObjs\r\nDELETE /api/datasets/deleteObj\r\nPOST /api/metrics/presign \r\nGET /api/metrics/listObjs\r\nDELETE /api/metrics/deleteObj\r\n```\r\n\r\nIn addition to this, @thomwolf cleaned up the objects with dataclasses but you should revert this and re-align to the hf_api that's in this branch of transformers: https://github.com/huggingface/transformers/pull/4632 (so that potential new JSON attributes in the API output don't break existing versions of any library)",
"New commands are\r\n```\r\nnlp-cli upload_dataset <path/to/dataset>\r\nnlp-cli upload_metric <path/to/metric>\r\nnlp-cli s3_datasets {rm, ls}\r\nnlp-cli s3_metrics {rm, ls}\r\n```\r\nClosing this issue."
] | 1,590,079,552,000 | 1,592,518,482,000 | 1,592,518,482,000 |
NONE
| null |
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
But I got this error.
```
2020-05-21 16:33:52.722464: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
About to upload file /content/ttc/ttc_freq_extra.csv to S3 under filename ttc/ttc_freq_extra.csv and namespace korakot
Proceed? [Y/n] y
Uploading... This might take a while if files are large
Traceback (most recent call last):
File "/usr/local/bin/nlp-cli", line 33, in <module>
service.run()
File "/usr/local/lib/python3.6/dist-packages/nlp/commands/user.py", line 234, in run
token=token, filename=filename, filepath=filepath, organization=self.args.organization
File "/usr/local/lib/python3.6/dist-packages/nlp/hf_api.py", line 141, in presign_and_upload
urls = self.presign(token, filename=filename, organization=organization)
File "/usr/local/lib/python3.6/dist-packages/nlp/hf_api.py", line 132, in presign
return PresignedUrl(**d)
TypeError: __init__() got an unexpected keyword argument 'cdn'
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/181/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/180
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/180/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/180/comments
|
https://api.github.com/repos/huggingface/datasets/issues/180/events
|
https://github.com/huggingface/datasets/pull/180
| 622,556,861 |
MDExOlB1bGxSZXF1ZXN0NDIxMzk5Nzg2
| 180 |
Add hall of fame
|
{
"login": "clmnt",
"id": 821155,
"node_id": "MDQ6VXNlcjgyMTE1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/821155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clmnt",
"html_url": "https://github.com/clmnt",
"followers_url": "https://api.github.com/users/clmnt/followers",
"following_url": "https://api.github.com/users/clmnt/following{/other_user}",
"gists_url": "https://api.github.com/users/clmnt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clmnt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clmnt/subscriptions",
"organizations_url": "https://api.github.com/users/clmnt/orgs",
"repos_url": "https://api.github.com/users/clmnt/repos",
"events_url": "https://api.github.com/users/clmnt/events{/privacy}",
"received_events_url": "https://api.github.com/users/clmnt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,590,072,828,000 | 1,590,165,316,000 | 1,590,165,314,000 |
MEMBER
| null |
powered by https://github.com/sourcerer-io/hall-of-fame
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/180/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/180/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/180",
"html_url": "https://github.com/huggingface/datasets/pull/180",
"diff_url": "https://github.com/huggingface/datasets/pull/180.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/180.patch",
"merged_at": 1590165314000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/179
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/179/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/179/comments
|
https://api.github.com/repos/huggingface/datasets/issues/179/events
|
https://github.com/huggingface/datasets/issues/179
| 622,525,410 |
MDU6SXNzdWU2MjI1MjU0MTA=
| 179 |
[Feature request] separate split name and split instructions
|
{
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"If your dataset is a collection of sub-datasets, you should probably consider having one config per sub-dataset. For example for Glue, we have sst2, mnli etc.\r\nIf you want to have multiple train sets (for example one per stage). The easiest solution would be to name them `nlp.Split(\"train_stage1\")`, `nlp.Split(\"train_stage2\")`, etc. or something like that.",
"Thanks for the tip! I ended up setting up three different versions of the dataset with their own configs.\r\n\r\nfor the named splits, I was trying with `nlp.Split(\"train-stage1\")`, which fails. Changing to `nlp.Split(\"train_stage1\")` works :) I looked for examples of what works in the code comments, it may be worth adding some examples of valid/invalid names in there?"
] | 1,590,070,251,000 | 1,590,154,268,000 | 1,590,154,267,000 |
MEMBER
| null |
Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was built in stages, adding new examples at each stage
Would it be possible to have two separate fields in the Split class, a name /instruction and a unique ID that is used as the key in the builder's split_dict ?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/179/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/178
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/178/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/178/comments
|
https://api.github.com/repos/huggingface/datasets/issues/178/events
|
https://github.com/huggingface/datasets/pull/178
| 621,979,849 |
MDExOlB1bGxSZXF1ZXN0NDIwOTMyMDI5
| 178 |
[Manual data] improve error message for manual data in general
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,589,998,245,000 | 1,589,998,732,000 | 1,589,998,730,000 |
MEMBER
| null |
`nlp.load("xsum")` now leads to the following error message:

I guess the manual download instructions for `xsum` can also be improved.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/178/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/178",
"html_url": "https://github.com/huggingface/datasets/pull/178",
"diff_url": "https://github.com/huggingface/datasets/pull/178.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/178.patch",
"merged_at": 1589998730000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/177
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/177/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/177/comments
|
https://api.github.com/repos/huggingface/datasets/issues/177/events
|
https://github.com/huggingface/datasets/pull/177
| 621,975,368 |
MDExOlB1bGxSZXF1ZXN0NDIwOTI4MzE0
| 177 |
Xsum manual download instruction
|
{
"login": "mariamabarham",
"id": 38249783,
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariamabarham",
"html_url": "https://github.com/mariamabarham",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,589,997,761,000 | 1,589,998,610,000 | 1,589,998,609,000 |
CONTRIBUTOR
| null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/177/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/177",
"html_url": "https://github.com/huggingface/datasets/pull/177",
"diff_url": "https://github.com/huggingface/datasets/pull/177.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/177.patch",
"merged_at": 1589998609000
}
| true |
|
https://api.github.com/repos/huggingface/datasets/issues/176
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/176/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/176/comments
|
https://api.github.com/repos/huggingface/datasets/issues/176/events
|
https://github.com/huggingface/datasets/pull/176
| 621,934,638 |
MDExOlB1bGxSZXF1ZXN0NDIwODkzNDky
| 176 |
[Tests] Refactor MockDownloadManager
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,589,994,456,000 | 1,589,998,639,000 | 1,589,998,638,000 |
MEMBER
| null |
Clean mock download manager class.
The print function was not of much help I think.
We should think about adding a command that creates the dummy folder structure for the user.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/176/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/176/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/176",
"html_url": "https://github.com/huggingface/datasets/pull/176",
"diff_url": "https://github.com/huggingface/datasets/pull/176.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/176.patch",
"merged_at": 1589998638000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/175
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/175/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/175/comments
|
https://api.github.com/repos/huggingface/datasets/issues/175/events
|
https://github.com/huggingface/datasets/issues/175
| 621,929,428 |
MDU6SXNzdWU2MjE5Mjk0Mjg=
| 175 |
[Manual data dir] Error message: nlp.load_dataset('xsum') -> TypeError
|
{
"login": "sshleifer",
"id": 6045025,
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sshleifer",
"html_url": "https://github.com/sshleifer",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,589,994,032,000 | 1,589,998,730,000 | 1,589,998,730,000 |
MEMBER
| null |
v 0.1.0 from pip
```python
import nlp
xsum = nlp.load_dataset('xsum')
```
Issue is `dl_manager.manual_dir`is `None`
```python
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-42-8a32f066f3bd> in <module>
----> 1 xsum = nlp.load_dataset('xsum')
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
515 download_mode=download_mode,
516 ignore_verifications=ignore_verifications,
--> 517 save_infos=save_infos,
518 )
519
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
361 verify_infos = not save_infos and not ignore_verifications
362 self._download_and_prepare(
--> 363 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
364 )
365 # Sync info
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
397 split_dict = SplitDict(dataset_name=self.name)
398 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 399 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
400 # Checksums verification
401 if verify_infos:
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/datasets/xsum/5c5fca23aaaa469b7a1c6f095cf12f90d7ab99bcc0d86f689a74fd62634a1472/xsum.py in _split_generators(self, dl_manager)
102 with open(dl_path, "r") as json_file:
103 split_ids = json.load(json_file)
--> 104 downloaded_path = os.path.join(dl_manager.manual_dir, "xsum-extracts-from-downloads")
105 return [
106 nlp.SplitGenerator(
~/miniconda3/envs/nb/lib/python3.7/posixpath.py in join(a, *p)
78 will be discarded. An empty last part will result in a path that
79 ends with a separator."""
---> 80 a = os.fspath(a)
81 sep = _get_sep(a)
82 path = a
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/175/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/174
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/174/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/174/comments
|
https://api.github.com/repos/huggingface/datasets/issues/174/events
|
https://github.com/huggingface/datasets/issues/174
| 621,928,403 |
MDU6SXNzdWU2MjE5Mjg0MDM=
| 174 |
nlp.load_dataset('xsum') -> TypeError
|
{
"login": "sshleifer",
"id": 6045025,
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sshleifer",
"html_url": "https://github.com/sshleifer",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,589,993,949,000 | 1,589,996,626,000 | 1,589,996,626,000 |
MEMBER
| null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/174/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/174/timeline
| null | null | null | false |
|
https://api.github.com/repos/huggingface/datasets/issues/173
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/173/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/173/comments
|
https://api.github.com/repos/huggingface/datasets/issues/173/events
|
https://github.com/huggingface/datasets/pull/173
| 621,764,932 |
MDExOlB1bGxSZXF1ZXN0NDIwNzUyNzQy
| 173 |
Rm extracted test dirs
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Thanks for cleaning up the extracted dummy data folders! Instead of changing the file_utils we could also just put these folders under `.gitignore` (or maybe already done?).",
"Awesome! I guess you might have to add the changes for the MockDLManager now in a different file though because of my last PR - sorry!"
] | 1,589,981,448,000 | 1,590,165,276,000 | 1,590,165,275,000 |
MEMBER
| null |
All the dummy data used for tests were duplicated. For each dataset, we had one zip file but also its extracted directory. I removed all these directories
Furthermore instead of extracting next to the dummy_data.zip file, we extract in the temp `cached_dir` used for tests, so that all the extracted directories get removed after testing.
Finally there was a bug in the `mock_download_manager` that would let it create directories with invalid names, as in #172. I fixed that by encoding url arguments. I had to rename the dummy data for `scientific_papers` and `cnn_dailymail` (the aws tests don't pass for those 2 in this PR, but they will once aws will be synced, as the local ones do)
Let me know if it sounds good to you @patrickvonplaten . I'm still not entirely familiar with the mock downloader
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/173/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/173/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/173",
"html_url": "https://github.com/huggingface/datasets/pull/173",
"diff_url": "https://github.com/huggingface/datasets/pull/173.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/173.patch",
"merged_at": 1590165275000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/172
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/172/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/172/comments
|
https://api.github.com/repos/huggingface/datasets/issues/172/events
|
https://github.com/huggingface/datasets/issues/172
| 621,377,386 |
MDU6SXNzdWU2MjEzNzczODY=
| 172 |
Clone not working on Windows environment
|
{
"login": "codehunk628",
"id": 51091425,
"node_id": "MDQ6VXNlcjUxMDkxNDI1",
"avatar_url": "https://avatars.githubusercontent.com/u/51091425?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codehunk628",
"html_url": "https://github.com/codehunk628",
"followers_url": "https://api.github.com/users/codehunk628/followers",
"following_url": "https://api.github.com/users/codehunk628/following{/other_user}",
"gists_url": "https://api.github.com/users/codehunk628/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codehunk628/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codehunk628/subscriptions",
"organizations_url": "https://api.github.com/users/codehunk628/orgs",
"repos_url": "https://api.github.com/users/codehunk628/repos",
"events_url": "https://api.github.com/users/codehunk628/events{/privacy}",
"received_events_url": "https://api.github.com/users/codehunk628/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Should be fixed on master now :)",
"Thanks @lhoestq 👍 Now I can uninstall WSL and get back to work with windows.🙂"
] | 1,589,935,514,000 | 1,590,238,153,000 | 1,590,233,272,000 |
CONTRIBUTOR
| null |
Cloning in a windows environment is not working because of use of special character '?' in folder name ..
Please consider changing the folder name ....
Reference to folder -
nlp/datasets/cnn_dailymail/dummy/3.0.0/3.0.0/dummy_data-zip-extracted/dummy_data/uc?export=download&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs/dailymail/stories/
error log:
fatal: cannot create directory at 'datasets/cnn_dailymail/dummy/3.0.0/3.0.0/dummy_data-zip-extracted/dummy_data/uc?export=download&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs': Invalid argument
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/172/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/172/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/171
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/171/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/171/comments
|
https://api.github.com/repos/huggingface/datasets/issues/171/events
|
https://github.com/huggingface/datasets/pull/171
| 621,199,128 |
MDExOlB1bGxSZXF1ZXN0NDIwMjk0ODM0
| 171 |
fix squad metric format
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"One thing for SQuAD is that I wanted to be able to use the SQuAD dataset directly in the metrics and I'm not sure it will be possible with this format.\r\n\r\n(maybe it's not really possible in general though)",
"This is kinda related to one thing I had in mind which is that we may want to be able to dump our model predictions in a `Dataset` as well so that we don't keep them in memory (and we can export them in a nice format later as well when we will have a serialization formats).\r\n\r\nMaybe this is overkill though, I haven't fully wraped my head around this.",
"I'm also perfectly fine with merging this PR in the current state and working on a larger scope later.",
"This is the format needed to run the official script directly. The format of the squad dataset is different from the input of the metric. \r\n\r\n> One thing for SQuAD is that I wanted to be able to use the SQuAD dataset directly in the metrics and I'm not sure it will be possible with this format.\r\n> \r\n> (maybe it's not really possible in general though)\r\n\r\nOk I see. I'll try to use the same format",
"Ok with this update I changed the format to fit the squad dataset format.\r\nNow you can do:\r\n```python\r\nsquad_dset = nlp.load_dataset(\"squad\")\r\nsquad_metric = nlp.load_metric(\"/Users/quentinlhoest/Desktop/hf/nlp-bis/metrics/squad\")\r\npredictions = [\r\n {\"id\": v[\"id\"], \"prediction_text\": v[\"answers\"][\"text\"][0]} # take first possible answer\r\n for v in squad_dset[\"validation\"]\r\n]\r\nsquad_metric.compute(predictions, squad_dset[\"validation\"])\r\n```"
] | 1,589,913,456,000 | 1,590,154,610,000 | 1,590,154,608,000 |
MEMBER
| null |
The format of the squad metric was wrong.
This should fix #143
I tested with
```python3
predictions = [
{'id': '56be4db0acb8001400a502ec', 'prediction_text': 'Denver Broncos'}
]
references = [
{'answers': [{'text': 'Denver Broncos'}], 'id': '56be4db0acb8001400a502ec'}
]
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/171/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/171/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/171",
"html_url": "https://github.com/huggingface/datasets/pull/171",
"diff_url": "https://github.com/huggingface/datasets/pull/171.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/171.patch",
"merged_at": 1590154608000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/170
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/170/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/170/comments
|
https://api.github.com/repos/huggingface/datasets/issues/170/events
|
https://github.com/huggingface/datasets/pull/170
| 621,119,747 |
MDExOlB1bGxSZXF1ZXN0NDIwMjMwMDIx
| 170 |
Rename anli dataset
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 1,589,905,617,000 | 1,589,977,389,000 | 1,589,977,388,000 |
MEMBER
| null |
What we have now as the `anli` dataset is actually the αNLI dataset from the ART challenge dataset. This name is confusing because `anli` is also the name of adversarial NLI (see [https://github.com/facebookresearch/anli](https://github.com/facebookresearch/anli)).
I renamed the current `anli` dataset by `art`.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/170/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/170/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/170",
"html_url": "https://github.com/huggingface/datasets/pull/170",
"diff_url": "https://github.com/huggingface/datasets/pull/170.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/170.patch",
"merged_at": 1589977387000
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/169
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/169/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/169/comments
|
https://api.github.com/repos/huggingface/datasets/issues/169/events
|
https://github.com/huggingface/datasets/pull/169
| 621,099,682 |
MDExOlB1bGxSZXF1ZXN0NDIwMjE1NDkw
| 169 |
Adding Qanta (Quizbowl) Dataset
|
{
"login": "EntilZha",
"id": 1382460,
"node_id": "MDQ6VXNlcjEzODI0NjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1382460?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/EntilZha",
"html_url": "https://github.com/EntilZha",
"followers_url": "https://api.github.com/users/EntilZha/followers",
"following_url": "https://api.github.com/users/EntilZha/following{/other_user}",
"gists_url": "https://api.github.com/users/EntilZha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/EntilZha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EntilZha/subscriptions",
"organizations_url": "https://api.github.com/users/EntilZha/orgs",
"repos_url": "https://api.github.com/users/EntilZha/repos",
"events_url": "https://api.github.com/users/EntilZha/events{/privacy}",
"received_events_url": "https://api.github.com/users/EntilZha/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Hi @EntilZha - sorry for waiting so long until taking action here. We created a new command and a new recipe of how to add dummy_data. Can you maybe rebase to `master` as explained in 7. of https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-contribute-to-nlp and check that your dummy data is correct following the instructions here: https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset ? \r\n\r\nIf the tests described in 5. of https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset pass we can merge the PR :-) ",
"I updated to the most recent master and followed the steps, but still having the similar error where it can't find the correct file since the path to the directory is given, rather than the individual files within them. This still something wrong about how I'm inputting the data or how the tests are reading it?",
"It's the dummy_data structure. You actually have to call the dummy data file name `dummy_data` (not .json anything). So there should not be a `dummy_data` folder but for each config only a `dummy_data` which contains your json dummy data. Can you maybe try once more - if it doesn't work I do it for you :-). ",
"Would that work if there are multiple files? In my case, I'm including something similar to squad 1.0/2.0 where we have the main dataset + an additional challenge set in different files. Would I have the zip decompress to two files in that case?",
"This dataset was actually a special case. It helped us improve the dummy data instructions :-), see #195 .Close this PR and merge #194."
] | 1,589,904,181,000 | 1,590,497,551,000 | 1,590,497,551,000 |
CONTRIBUTOR
| null |
This PR adds the qanta question answering datasets from [Quizbowl: The Case for Incremental Question Answering](https://arxiv.org/abs/1904.04792) and [Trick Me If You Can: Human-in-the-loop Generation of Adversarial Question Answering Examples](https://www.aclweb.org/anthology/Q19-1029/) (adversarial fold)
This partially continues a discussion around fixing dummy data from https://github.com/huggingface/nlp/issues/161
I ran the following code to double check that it works and did some sanity checks on the output. The majority of the code itself is from our `allennlp` version of the dataset reader.
```python
import nlp
# Default is full question
data = nlp.load_dataset('./datasets/qanta')
# Four configs
# Primarily useful for training
data = nlp.load_dataset('./datasets/qanta', 'mode=sentences,char_skip=25')
# Primarily used in evaluation
data = nlp.load_dataset('./datasets/qanta', 'mode=first,char_skip=25')
data = nlp.load_dataset('./datasets/qanta', 'mode=full,char_skip=25')
# Primarily useful in evaluation and "live" play
data = nlp.load_dataset('./datasets/qanta', 'mode=runs,char_skip=25')
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/169/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/169/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/169",
"html_url": "https://github.com/huggingface/datasets/pull/169",
"diff_url": "https://github.com/huggingface/datasets/pull/169.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/169.patch",
"merged_at": null
}
| true |
https://api.github.com/repos/huggingface/datasets/issues/168
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/168/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/168/comments
|
https://api.github.com/repos/huggingface/datasets/issues/168/events
|
https://github.com/huggingface/datasets/issues/168
| 620,959,819 |
MDU6SXNzdWU2MjA5NTk4MTk=
| 168 |
Loading 'wikitext' dataset fails
|
{
"login": "itay1itzhak",
"id": 25987633,
"node_id": "MDQ6VXNlcjI1OTg3NjMz",
"avatar_url": "https://avatars.githubusercontent.com/u/25987633?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/itay1itzhak",
"html_url": "https://github.com/itay1itzhak",
"followers_url": "https://api.github.com/users/itay1itzhak/followers",
"following_url": "https://api.github.com/users/itay1itzhak/following{/other_user}",
"gists_url": "https://api.github.com/users/itay1itzhak/gists{/gist_id}",
"starred_url": "https://api.github.com/users/itay1itzhak/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itay1itzhak/subscriptions",
"organizations_url": "https://api.github.com/users/itay1itzhak/orgs",
"repos_url": "https://api.github.com/users/itay1itzhak/repos",
"events_url": "https://api.github.com/users/itay1itzhak/events{/privacy}",
"received_events_url": "https://api.github.com/users/itay1itzhak/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Hi, make sure you have a recent version of pyarrow.\r\n\r\nAre you using it in Google Colab? In this case, this error is probably the same as #128",
"Thanks!\r\n\r\nYes I'm using Google Colab, it seems like a duplicate then.",
"Closing as it is a duplicate",
"Hi,\r\nThe squad bug seems to be fixed, but the loading of the 'wikitext' still suffers from this problem (on Colab with pyarrow=0.17.1).",
"When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:\r\n```\r\nWARNING: The following packages were previously imported in this runtime:\r\n [pyarrow]\r\nYou must restart the runtime in order to use newly installed versions.\r\n```\r\nYou just have to restart the runtime and it should be fine.",
"That was it, thanks!"
] | 1,589,893,469,000 | 1,590,529,612,000 | 1,590,529,612,000 |
NONE
| null |
Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-17-d5d9df94b13c> in <module>()
11
12 # Load a dataset and print the first examples in the training set
---> 13 wikitext_dataset = nlp.load_dataset('wikitext')
14 print(wikitext_dataset['train'][0])
6 frames
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
363 verify_infos = not save_infos and not ignore_verifications
364 self._download_and_prepare(
--> 365 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
366 )
367 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
416 try:
417 # Prepare split will record examples associated to the split
--> 418 self._prepare_split(split_generator, **prepare_split_kwargs)
419 except OSError:
420 raise OSError("Cannot find data file. " + (self.MANUAL_DOWNLOAD_INSTRUCTIONS or ""))
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _prepare_split(self, split_generator)
594 example = self.info.features.encode_example(record)
595 writer.write(example)
--> 596 num_examples, num_bytes = writer.finalize()
597
598 assert num_examples == num_examples, f"Expected to write {split_info.num_examples} but wrote {num_examples}"
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in finalize(self, close_stream)
173 def finalize(self, close_stream=True):
174 if self.pa_writer is not None:
--> 175 self.write_on_file()
176 self.pa_writer.close()
177 if close_stream:
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write_on_file(self)
124 else:
125 # All good
--> 126 self._write_array_on_file(pa_array)
127 self.current_rows = []
128
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in _write_array_on_file(self, pa_array)
93 def _write_array_on_file(self, pa_array):
94 """Write a PyArrow Array"""
---> 95 pa_batch = pa.RecordBatch.from_struct_array(pa_array)
96 self._num_bytes += pa_array.nbytes
97 self.pa_writer.write_batch(pa_batch)
AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/168/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/168/timeline
| null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/167
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/167/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/167/comments
|
https://api.github.com/repos/huggingface/datasets/issues/167/events
|
https://github.com/huggingface/datasets/pull/167
| 620,908,786 |
MDExOlB1bGxSZXF1ZXN0NDIwMDY0NDMw
| 167 |
[Tests] refactor tests
|
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Nice !"
] | 1,589,888,612,000 | 1,589,905,032,000 | 1,589,905,030,000 |
MEMBER
| null |
This PR separates AWS and Local tests to remove these ugly statements in the script:
```python
if "/" not in dataset_name:
logging.info("Skip {} because it is a canonical dataset")
return
```
To run a `aws` test, one should now run the following command:
```python
pytest -s tests/test_dataset_common.py::AWSDatasetTest::test_builder_class_wmt14
```
The same `local` test, can be run with:
```python
pytest -s tests/test_dataset_common.py::LocalDatasetTest::test_builder_class_wmt14
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/167/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/167/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/167",
"html_url": "https://github.com/huggingface/datasets/pull/167",
"diff_url": "https://github.com/huggingface/datasets/pull/167.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/167.patch",
"merged_at": 1589905030000
}
| true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.