
instance_id
stringlengths 13
37
| text
stringlengths 2.59k
1.94M
| repo
stringclasses 35
values | base_commit
stringlengths 40
40
| problem_statement
stringlengths 10
256k
| hints_text
stringlengths 0
908k
| created_at
stringlengths 20
20
| patch
stringlengths 18
101M
| test_patch
stringclasses 1
value | version
stringclasses 1
value | FAIL_TO_PASS
stringclasses 1
value | PASS_TO_PASS
stringclasses 1
value | environment_setup_commit
stringclasses 1
value |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
ipython__ipython-7819
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inspect requests inside a function call should be smarter about what they inspect.
Previously, `func(a, b, <shift-tab>` would give information on `func`, now it gives information on `b`, which is not especially helpful.
This is because we removed logic from the frontend to make it more language agnostic, and we have not yet reimplemented that on the frontend. For 3.1, we should make it at least as smart as 2.x was. The quicky and dirty approach would be a regex; the proper way is tokenising the code.
Ping @mwaskom who brought this up on the mailing list.
</issue>
<code>
[start of README.rst]
1 .. image:: https://img.shields.io/coveralls/ipython/ipython.svg
2 :target: https://coveralls.io/r/ipython/ipython?branch=master
3
4 .. image:: https://img.shields.io/pypi/dm/IPython.svg
5 :target: https://pypi.python.org/pypi/ipython
6
7 .. image:: https://img.shields.io/pypi/v/IPython.svg
8 :target: https://pypi.python.org/pypi/ipython
9
10 .. image:: https://img.shields.io/travis/ipython/ipython.svg
11 :target: https://travis-ci.org/ipython/ipython
12
13
14 ===========================================
15 IPython: Productive Interactive Computing
16 ===========================================
17
18 Overview
19 ========
20
21 Welcome to IPython. Our full documentation is available on `our website
22 <http://ipython.org/documentation.html>`_; if you downloaded a built source
23 distribution the ``docs/source`` directory contains the plaintext version of
24 these manuals. If you have Sphinx installed, you can build them by typing
25 ``cd docs; make html`` for local browsing.
26
27
28 Dependencies and supported Python versions
29 ==========================================
30
31 For full details, see the installation section of the manual. The basic parts
32 of IPython only need the Python standard library, but much of its more advanced
33 functionality requires extra packages.
34
35 Officially, IPython requires Python version 2.7, or 3.3 and above.
36 IPython 1.x is the last IPython version to support Python 2.6 and 3.2.
37
38
39 Instant running
40 ===============
41
42 You can run IPython from this directory without even installing it system-wide
43 by typing at the terminal::
44
45 $ python -m IPython
46
47
48 Development installation
49 ========================
50
51 If you want to hack on certain parts, e.g. the IPython notebook, in a clean
52 environment (such as a virtualenv) you can use ``pip`` to grab the necessary
53 dependencies quickly::
54
55 $ git clone --recursive https://github.com/ipython/ipython.git
56 $ cd ipython
57 $ pip install -e ".[notebook]" --user
58
59 This installs the necessary packages and symlinks IPython into your current
60 environment so that you can work on your local repo copy and run it from anywhere::
61
62 $ ipython notebook
63
64 The same process applies for other parts, such as the qtconsole (the
65 ``extras_require`` attribute in the setup.py file lists all the possibilities).
66
67 Git Hooks and Submodules
68 ************************
69
70 IPython now uses git submodules to ship its javascript dependencies.
71 If you run IPython from git master, you may need to update submodules once in a while with::
72
73 $ git submodule update
74
75 or::
76
77 $ python setup.py submodule
78
79 We have some git hooks for helping keep your submodules always in sync,
80 see our ``git-hooks`` directory for more info.
81
[end of README.rst]
[start of IPython/utils/tokenutil.py]
1 """Token-related utilities"""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 from __future__ import absolute_import, print_function
7
8 from collections import namedtuple
9 from io import StringIO
10 from keyword import iskeyword
11
12 from . import tokenize2
13 from .py3compat import cast_unicode_py2
14
15 Token = namedtuple('Token', ['token', 'text', 'start', 'end', 'line'])
16
17 def generate_tokens(readline):
18 """wrap generate_tokens to catch EOF errors"""
19 try:
20 for token in tokenize2.generate_tokens(readline):
21 yield token
22 except tokenize2.TokenError:
23 # catch EOF error
24 return
25
26 def line_at_cursor(cell, cursor_pos=0):
27 """Return the line in a cell at a given cursor position
28
29 Used for calling line-based APIs that don't support multi-line input, yet.
30
31 Parameters
32 ----------
33
34 cell: text
35 multiline block of text
36 cursor_pos: integer
37 the cursor position
38
39 Returns
40 -------
41
42 (line, offset): (text, integer)
43 The line with the current cursor, and the character offset of the start of the line.
44 """
45 offset = 0
46 lines = cell.splitlines(True)
47 for line in lines:
48 next_offset = offset + len(line)
49 if next_offset >= cursor_pos:
50 break
51 offset = next_offset
52 else:
53 line = ""
54 return (line, offset)
55
56 def token_at_cursor(cell, cursor_pos=0):
57 """Get the token at a given cursor
58
59 Used for introspection.
60
61 Parameters
62 ----------
63
64 cell : unicode
65 A block of Python code
66 cursor_pos : int
67 The location of the cursor in the block where the token should be found
68 """
69 cell = cast_unicode_py2(cell)
70 names = []
71 tokens = []
72 offset = 0
73 for tup in generate_tokens(StringIO(cell).readline):
74
75 tok = Token(*tup)
76
77 # token, text, start, end, line = tup
78 start_col = tok.start[1]
79 end_col = tok.end[1]
80 # allow '|foo' to find 'foo' at the beginning of a line
81 boundary = cursor_pos + 1 if start_col == 0 else cursor_pos
82 if offset + start_col >= boundary:
83 # current token starts after the cursor,
84 # don't consume it
85 break
86
87 if tok.token == tokenize2.NAME and not iskeyword(tok.text):
88 if names and tokens and tokens[-1].token == tokenize2.OP and tokens[-1].text == '.':
89 names[-1] = "%s.%s" % (names[-1], tok.text)
90 else:
91 names.append(tok.text)
92 elif tok.token == tokenize2.OP:
93 if tok.text == '=' and names:
94 # don't inspect the lhs of an assignment
95 names.pop(-1)
96
97 if offset + end_col > cursor_pos:
98 # we found the cursor, stop reading
99 break
100
101 tokens.append(tok)
102 if tok.token == tokenize2.NEWLINE:
103 offset += len(tok.line)
104
105 if names:
106 return names[-1]
107 else:
108 return ''
109
110
111
[end of IPython/utils/tokenutil.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
ipython/ipython
|
92333e1084ea0d6ff91b55434555e741d2274dc7
|
Inspect requests inside a function call should be smarter about what they inspect.
Previously, `func(a, b, <shift-tab>` would give information on `func`, now it gives information on `b`, which is not especially helpful.
This is because we removed logic from the frontend to make it more language agnostic, and we have not yet reimplemented that on the frontend. For 3.1, we should make it at least as smart as 2.x was. The quicky and dirty approach would be a regex; the proper way is tokenising the code.
Ping @mwaskom who brought this up on the mailing list.
|
Thanks! I don't actually know how to _use_ any of these packages, so I rely on what IPython tells me they'll do :)
Should note here too that the help also seems to be displaying the `__repr__` for, at least, pandas DataFrames slightly differently in 3.0.rc1, which yields a help popup that is garbled and hides the important bits.
The dataframe reprs sounds like a separate thing - can you file an issue for it? Preferably with screenshots? Thanks.
Done: #7817
More related to this issue:
While implementing a smarter inspector, it would be _great_ if it would work across line breaks. I'm constantly getting bitten by trying to do
``` python
complex_function(some_arg, another_arg, data_frame.some_transformation(),
a_kwarg=a_value, <shift-TAB>
```
And having it not work.
This did not work on the 2.x series either, AFAICT, but if the inspector is going to be reimplemented it would be awesome if it could be added.
If there's smart, tokenising logic to determine what you're inspecting, there's no reason it shouldn't handle multiple lines. Making it smart enough for that might not be a 3.1 thing, though.
|
2015-02-19T20:14:23Z
|
<patch>
diff --git a/IPython/utils/tokenutil.py b/IPython/utils/tokenutil.py
--- a/IPython/utils/tokenutil.py
+++ b/IPython/utils/tokenutil.py
@@ -58,6 +58,9 @@ def token_at_cursor(cell, cursor_pos=0):
Used for introspection.
+ Function calls are prioritized, so the token for the callable will be returned
+ if the cursor is anywhere inside the call.
+
Parameters
----------
@@ -70,6 +73,7 @@ def token_at_cursor(cell, cursor_pos=0):
names = []
tokens = []
offset = 0
+ call_names = []
for tup in generate_tokens(StringIO(cell).readline):
tok = Token(*tup)
@@ -93,6 +97,11 @@ def token_at_cursor(cell, cursor_pos=0):
if tok.text == '=' and names:
# don't inspect the lhs of an assignment
names.pop(-1)
+ if tok.text == '(' and names:
+ # if we are inside a function call, inspect the function
+ call_names.append(names[-1])
+ elif tok.text == ')' and call_names:
+ call_names.pop(-1)
if offset + end_col > cursor_pos:
# we found the cursor, stop reading
@@ -102,7 +111,9 @@ def token_at_cursor(cell, cursor_pos=0):
if tok.token == tokenize2.NEWLINE:
offset += len(tok.line)
- if names:
+ if call_names:
+ return call_names[-1]
+ elif names:
return names[-1]
else:
return ''
</patch>
|
[]
|
[]
| |||
docker__compose-2878
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Merge build args when using multiple compose files (or when extending services)
Based on the behavior of `environment` and `labels`, as well as `build.image`, `build.context` etc, I would also expect `build.args` to be merged, instead of being replaced.
To give an example:
## Input
**docker-compose.yml:**
``` yaml
version: "2"
services:
my_service:
build:
context: my-app
args:
SOME_VARIABLE: "42"
```
**docker-compose.override.yml:**
``` yaml
version: "2"
services:
my_service:
build:
args:
HTTP_PROXY: http://proxy.somewhere:80
HTTPS_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
```
**my-app/Dockerfile**
``` Dockerfile
# Just needed to be able to use `build:`
FROM busybox:latest
ARG SOME_VARIABLE=xyz
RUN echo "$SOME_VARIABLE" > /etc/example
```
## Current Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Expected Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
SOME_VARIABLE: 42 # Note the merged variable here
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Version Information
``` bash
$ docker-compose version
docker-compose version 1.6.0, build cdb920a
docker-py version: 1.7.0
CPython version: 2.7.11
OpenSSL version: OpenSSL 1.0.2d 9 Jul 2015
```
# Implementation proposal
I mainly want to get clarification on what the desired behavior is, so that I can possibly help implementing it, maybe even for `1.6.1`.
Personally, I'd like the behavior to be to merge the `build.args` key (as outlined above), for a couple of reasons:
- Principle of least surprise/consistency with `environment`, `labels`, `ports` and so on.
- It enables scenarios like the one outlined above, where the images require some transient configuration to build, in addition to other build variables which actually have an influence on the final image.
The scenario that one wants to replace all build args at once is not very likely IMO; why would you define base build variables in the first place if you're going to replace them anyway?
# Alternative behavior: Output a warning
If the behavior should stay the same as it is now, i.e. to fully replaced the `build.args` keys, then `docker-compose` should at least output a warning IMO. It took me some time to figure out that `docker-compose` was ignoring the build args in the base `docker-compose.yml` file.
</issue>
<code>
[start of README.md]
1 Docker Compose
2 ==============
3 
4
5 Compose is a tool for defining and running multi-container Docker applications.
6 With Compose, you use a Compose file to configure your application's services.
7 Then, using a single command, you create and start all the services
8 from your configuration. To learn more about all the features of Compose
9 see [the list of features](https://github.com/docker/compose/blob/release/docs/overview.md#features).
10
11 Compose is great for development, testing, and staging environments, as well as
12 CI workflows. You can learn more about each case in
13 [Common Use Cases](https://github.com/docker/compose/blob/release/docs/overview.md#common-use-cases).
14
15 Using Compose is basically a three-step process.
16
17 1. Define your app's environment with a `Dockerfile` so it can be
18 reproduced anywhere.
19 2. Define the services that make up your app in `docker-compose.yml` so
20 they can be run together in an isolated environment:
21 3. Lastly, run `docker-compose up` and Compose will start and run your entire app.
22
23 A `docker-compose.yml` looks like this:
24
25 web:
26 build: .
27 ports:
28 - "5000:5000"
29 volumes:
30 - .:/code
31 links:
32 - redis
33 redis:
34 image: redis
35
36 For more information about the Compose file, see the
37 [Compose file reference](https://github.com/docker/compose/blob/release/docs/compose-file.md)
38
39 Compose has commands for managing the whole lifecycle of your application:
40
41 * Start, stop and rebuild services
42 * View the status of running services
43 * Stream the log output of running services
44 * Run a one-off command on a service
45
46 Installation and documentation
47 ------------------------------
48
49 - Full documentation is available on [Docker's website](https://docs.docker.com/compose/).
50 - If you have any questions, you can talk in real-time with other developers in the #docker-compose IRC channel on Freenode. [Click here to join using IRCCloud.](https://www.irccloud.com/invite?hostname=irc.freenode.net&channel=%23docker-compose)
51 - Code repository for Compose is on [Github](https://github.com/docker/compose)
52 - If you find any problems please fill out an [issue](https://github.com/docker/compose/issues/new)
53
54 Contributing
55 ------------
56
57 [](http://jenkins.dockerproject.org/job/Compose%20Master/)
58
59 Want to help build Compose? Check out our [contributing documentation](https://github.com/docker/compose/blob/master/CONTRIBUTING.md).
60
61 Releasing
62 ---------
63
64 Releases are built by maintainers, following an outline of the [release process](https://github.com/docker/compose/blob/master/project/RELEASE-PROCESS.md).
65
[end of README.md]
[start of compose/config/config.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import codecs
5 import functools
6 import logging
7 import operator
8 import os
9 import string
10 import sys
11 from collections import namedtuple
12
13 import six
14 import yaml
15 from cached_property import cached_property
16
17 from ..const import COMPOSEFILE_V1 as V1
18 from ..const import COMPOSEFILE_V2_0 as V2_0
19 from .errors import CircularReference
20 from .errors import ComposeFileNotFound
21 from .errors import ConfigurationError
22 from .errors import VERSION_EXPLANATION
23 from .interpolation import interpolate_environment_variables
24 from .sort_services import get_container_name_from_network_mode
25 from .sort_services import get_service_name_from_network_mode
26 from .sort_services import sort_service_dicts
27 from .types import parse_extra_hosts
28 from .types import parse_restart_spec
29 from .types import ServiceLink
30 from .types import VolumeFromSpec
31 from .types import VolumeSpec
32 from .validation import match_named_volumes
33 from .validation import validate_against_fields_schema
34 from .validation import validate_against_service_schema
35 from .validation import validate_depends_on
36 from .validation import validate_extends_file_path
37 from .validation import validate_network_mode
38 from .validation import validate_top_level_object
39 from .validation import validate_top_level_service_objects
40 from .validation import validate_ulimits
41
42
43 DOCKER_CONFIG_KEYS = [
44 'cap_add',
45 'cap_drop',
46 'cgroup_parent',
47 'command',
48 'cpu_quota',
49 'cpu_shares',
50 'cpuset',
51 'detach',
52 'devices',
53 'dns',
54 'dns_search',
55 'domainname',
56 'entrypoint',
57 'env_file',
58 'environment',
59 'extra_hosts',
60 'hostname',
61 'image',
62 'ipc',
63 'labels',
64 'links',
65 'mac_address',
66 'mem_limit',
67 'memswap_limit',
68 'net',
69 'pid',
70 'ports',
71 'privileged',
72 'read_only',
73 'restart',
74 'security_opt',
75 'stdin_open',
76 'stop_signal',
77 'tty',
78 'user',
79 'volume_driver',
80 'volumes',
81 'volumes_from',
82 'working_dir',
83 ]
84
85 ALLOWED_KEYS = DOCKER_CONFIG_KEYS + [
86 'build',
87 'container_name',
88 'dockerfile',
89 'logging',
90 'network_mode',
91 ]
92
93 DOCKER_VALID_URL_PREFIXES = (
94 'http://',
95 'https://',
96 'git://',
97 'github.com/',
98 'git@',
99 )
100
101 SUPPORTED_FILENAMES = [
102 'docker-compose.yml',
103 'docker-compose.yaml',
104 ]
105
106 DEFAULT_OVERRIDE_FILENAME = 'docker-compose.override.yml'
107
108
109 log = logging.getLogger(__name__)
110
111
112 class ConfigDetails(namedtuple('_ConfigDetails', 'working_dir config_files')):
113 """
114 :param working_dir: the directory to use for relative paths in the config
115 :type working_dir: string
116 :param config_files: list of configuration files to load
117 :type config_files: list of :class:`ConfigFile`
118 """
119
120
121 class ConfigFile(namedtuple('_ConfigFile', 'filename config')):
122 """
123 :param filename: filename of the config file
124 :type filename: string
125 :param config: contents of the config file
126 :type config: :class:`dict`
127 """
128
129 @classmethod
130 def from_filename(cls, filename):
131 return cls(filename, load_yaml(filename))
132
133 @cached_property
134 def version(self):
135 if 'version' not in self.config:
136 return V1
137
138 version = self.config['version']
139
140 if isinstance(version, dict):
141 log.warn('Unexpected type for "version" key in "{}". Assuming '
142 '"version" is the name of a service, and defaulting to '
143 'Compose file version 1.'.format(self.filename))
144 return V1
145
146 if not isinstance(version, six.string_types):
147 raise ConfigurationError(
148 'Version in "{}" is invalid - it should be a string.'
149 .format(self.filename))
150
151 if version == '1':
152 raise ConfigurationError(
153 'Version in "{}" is invalid. {}'
154 .format(self.filename, VERSION_EXPLANATION))
155
156 if version == '2':
157 version = V2_0
158
159 if version != V2_0:
160 raise ConfigurationError(
161 'Version in "{}" is unsupported. {}'
162 .format(self.filename, VERSION_EXPLANATION))
163
164 return version
165
166 def get_service(self, name):
167 return self.get_service_dicts()[name]
168
169 def get_service_dicts(self):
170 return self.config if self.version == V1 else self.config.get('services', {})
171
172 def get_volumes(self):
173 return {} if self.version == V1 else self.config.get('volumes', {})
174
175 def get_networks(self):
176 return {} if self.version == V1 else self.config.get('networks', {})
177
178
179 class Config(namedtuple('_Config', 'version services volumes networks')):
180 """
181 :param version: configuration version
182 :type version: int
183 :param services: List of service description dictionaries
184 :type services: :class:`list`
185 :param volumes: Dictionary mapping volume names to description dictionaries
186 :type volumes: :class:`dict`
187 :param networks: Dictionary mapping network names to description dictionaries
188 :type networks: :class:`dict`
189 """
190
191
192 class ServiceConfig(namedtuple('_ServiceConfig', 'working_dir filename name config')):
193
194 @classmethod
195 def with_abs_paths(cls, working_dir, filename, name, config):
196 if not working_dir:
197 raise ValueError("No working_dir for ServiceConfig.")
198
199 return cls(
200 os.path.abspath(working_dir),
201 os.path.abspath(filename) if filename else filename,
202 name,
203 config)
204
205
206 def find(base_dir, filenames):
207 if filenames == ['-']:
208 return ConfigDetails(
209 os.getcwd(),
210 [ConfigFile(None, yaml.safe_load(sys.stdin))])
211
212 if filenames:
213 filenames = [os.path.join(base_dir, f) for f in filenames]
214 else:
215 filenames = get_default_config_files(base_dir)
216
217 log.debug("Using configuration files: {}".format(",".join(filenames)))
218 return ConfigDetails(
219 os.path.dirname(filenames[0]),
220 [ConfigFile.from_filename(f) for f in filenames])
221
222
223 def validate_config_version(config_files):
224 main_file = config_files[0]
225 validate_top_level_object(main_file)
226 for next_file in config_files[1:]:
227 validate_top_level_object(next_file)
228
229 if main_file.version != next_file.version:
230 raise ConfigurationError(
231 "Version mismatch: file {0} specifies version {1} but "
232 "extension file {2} uses version {3}".format(
233 main_file.filename,
234 main_file.version,
235 next_file.filename,
236 next_file.version))
237
238
239 def get_default_config_files(base_dir):
240 (candidates, path) = find_candidates_in_parent_dirs(SUPPORTED_FILENAMES, base_dir)
241
242 if not candidates:
243 raise ComposeFileNotFound(SUPPORTED_FILENAMES)
244
245 winner = candidates[0]
246
247 if len(candidates) > 1:
248 log.warn("Found multiple config files with supported names: %s", ", ".join(candidates))
249 log.warn("Using %s\n", winner)
250
251 return [os.path.join(path, winner)] + get_default_override_file(path)
252
253
254 def get_default_override_file(path):
255 override_filename = os.path.join(path, DEFAULT_OVERRIDE_FILENAME)
256 return [override_filename] if os.path.exists(override_filename) else []
257
258
259 def find_candidates_in_parent_dirs(filenames, path):
260 """
261 Given a directory path to start, looks for filenames in the
262 directory, and then each parent directory successively,
263 until found.
264
265 Returns tuple (candidates, path).
266 """
267 candidates = [filename for filename in filenames
268 if os.path.exists(os.path.join(path, filename))]
269
270 if not candidates:
271 parent_dir = os.path.join(path, '..')
272 if os.path.abspath(parent_dir) != os.path.abspath(path):
273 return find_candidates_in_parent_dirs(filenames, parent_dir)
274
275 return (candidates, path)
276
277
278 def load(config_details):
279 """Load the configuration from a working directory and a list of
280 configuration files. Files are loaded in order, and merged on top
281 of each other to create the final configuration.
282
283 Return a fully interpolated, extended and validated configuration.
284 """
285 validate_config_version(config_details.config_files)
286
287 processed_files = [
288 process_config_file(config_file)
289 for config_file in config_details.config_files
290 ]
291 config_details = config_details._replace(config_files=processed_files)
292
293 main_file = config_details.config_files[0]
294 volumes = load_mapping(config_details.config_files, 'get_volumes', 'Volume')
295 networks = load_mapping(config_details.config_files, 'get_networks', 'Network')
296 service_dicts = load_services(
297 config_details.working_dir,
298 main_file,
299 [file.get_service_dicts() for file in config_details.config_files])
300
301 if main_file.version != V1:
302 for service_dict in service_dicts:
303 match_named_volumes(service_dict, volumes)
304
305 return Config(main_file.version, service_dicts, volumes, networks)
306
307
308 def load_mapping(config_files, get_func, entity_type):
309 mapping = {}
310
311 for config_file in config_files:
312 for name, config in getattr(config_file, get_func)().items():
313 mapping[name] = config or {}
314 if not config:
315 continue
316
317 external = config.get('external')
318 if external:
319 if len(config.keys()) > 1:
320 raise ConfigurationError(
321 '{} {} declared as external but specifies'
322 ' additional attributes ({}). '.format(
323 entity_type,
324 name,
325 ', '.join([k for k in config.keys() if k != 'external'])
326 )
327 )
328 if isinstance(external, dict):
329 config['external_name'] = external.get('name')
330 else:
331 config['external_name'] = name
332
333 mapping[name] = config
334
335 return mapping
336
337
338 def load_services(working_dir, config_file, service_configs):
339 def build_service(service_name, service_dict, service_names):
340 service_config = ServiceConfig.with_abs_paths(
341 working_dir,
342 config_file.filename,
343 service_name,
344 service_dict)
345 resolver = ServiceExtendsResolver(service_config, config_file)
346 service_dict = process_service(resolver.run())
347
348 service_config = service_config._replace(config=service_dict)
349 validate_service(service_config, service_names, config_file.version)
350 service_dict = finalize_service(
351 service_config,
352 service_names,
353 config_file.version)
354 return service_dict
355
356 def build_services(service_config):
357 service_names = service_config.keys()
358 return sort_service_dicts([
359 build_service(name, service_dict, service_names)
360 for name, service_dict in service_config.items()
361 ])
362
363 def merge_services(base, override):
364 all_service_names = set(base) | set(override)
365 return {
366 name: merge_service_dicts_from_files(
367 base.get(name, {}),
368 override.get(name, {}),
369 config_file.version)
370 for name in all_service_names
371 }
372
373 service_config = service_configs[0]
374 for next_config in service_configs[1:]:
375 service_config = merge_services(service_config, next_config)
376
377 return build_services(service_config)
378
379
380 def process_config_file(config_file, service_name=None):
381 service_dicts = config_file.get_service_dicts()
382 validate_top_level_service_objects(config_file.filename, service_dicts)
383
384 interpolated_config = interpolate_environment_variables(service_dicts, 'service')
385
386 if config_file.version == V2_0:
387 processed_config = dict(config_file.config)
388 processed_config['services'] = services = interpolated_config
389 processed_config['volumes'] = interpolate_environment_variables(
390 config_file.get_volumes(), 'volume')
391 processed_config['networks'] = interpolate_environment_variables(
392 config_file.get_networks(), 'network')
393
394 if config_file.version == V1:
395 processed_config = services = interpolated_config
396
397 config_file = config_file._replace(config=processed_config)
398 validate_against_fields_schema(config_file)
399
400 if service_name and service_name not in services:
401 raise ConfigurationError(
402 "Cannot extend service '{}' in {}: Service not found".format(
403 service_name, config_file.filename))
404
405 return config_file
406
407
408 class ServiceExtendsResolver(object):
409 def __init__(self, service_config, config_file, already_seen=None):
410 self.service_config = service_config
411 self.working_dir = service_config.working_dir
412 self.already_seen = already_seen or []
413 self.config_file = config_file
414
415 @property
416 def signature(self):
417 return self.service_config.filename, self.service_config.name
418
419 def detect_cycle(self):
420 if self.signature in self.already_seen:
421 raise CircularReference(self.already_seen + [self.signature])
422
423 def run(self):
424 self.detect_cycle()
425
426 if 'extends' in self.service_config.config:
427 service_dict = self.resolve_extends(*self.validate_and_construct_extends())
428 return self.service_config._replace(config=service_dict)
429
430 return self.service_config
431
432 def validate_and_construct_extends(self):
433 extends = self.service_config.config['extends']
434 if not isinstance(extends, dict):
435 extends = {'service': extends}
436
437 config_path = self.get_extended_config_path(extends)
438 service_name = extends['service']
439
440 extends_file = ConfigFile.from_filename(config_path)
441 validate_config_version([self.config_file, extends_file])
442 extended_file = process_config_file(
443 extends_file,
444 service_name=service_name)
445 service_config = extended_file.get_service(service_name)
446
447 return config_path, service_config, service_name
448
449 def resolve_extends(self, extended_config_path, service_dict, service_name):
450 resolver = ServiceExtendsResolver(
451 ServiceConfig.with_abs_paths(
452 os.path.dirname(extended_config_path),
453 extended_config_path,
454 service_name,
455 service_dict),
456 self.config_file,
457 already_seen=self.already_seen + [self.signature])
458
459 service_config = resolver.run()
460 other_service_dict = process_service(service_config)
461 validate_extended_service_dict(
462 other_service_dict,
463 extended_config_path,
464 service_name)
465
466 return merge_service_dicts(
467 other_service_dict,
468 self.service_config.config,
469 self.config_file.version)
470
471 def get_extended_config_path(self, extends_options):
472 """Service we are extending either has a value for 'file' set, which we
473 need to obtain a full path too or we are extending from a service
474 defined in our own file.
475 """
476 filename = self.service_config.filename
477 validate_extends_file_path(
478 self.service_config.name,
479 extends_options,
480 filename)
481 if 'file' in extends_options:
482 return expand_path(self.working_dir, extends_options['file'])
483 return filename
484
485
486 def resolve_environment(service_dict):
487 """Unpack any environment variables from an env_file, if set.
488 Interpolate environment values if set.
489 """
490 env = {}
491 for env_file in service_dict.get('env_file', []):
492 env.update(env_vars_from_file(env_file))
493
494 env.update(parse_environment(service_dict.get('environment')))
495 return dict(filter(None, (resolve_env_var(k, v) for k, v in six.iteritems(env))))
496
497
498 def resolve_build_args(build):
499 args = parse_build_arguments(build.get('args'))
500 return dict(filter(None, (resolve_env_var(k, v) for k, v in six.iteritems(args))))
501
502
503 def validate_extended_service_dict(service_dict, filename, service):
504 error_prefix = "Cannot extend service '%s' in %s:" % (service, filename)
505
506 if 'links' in service_dict:
507 raise ConfigurationError(
508 "%s services with 'links' cannot be extended" % error_prefix)
509
510 if 'volumes_from' in service_dict:
511 raise ConfigurationError(
512 "%s services with 'volumes_from' cannot be extended" % error_prefix)
513
514 if 'net' in service_dict:
515 if get_container_name_from_network_mode(service_dict['net']):
516 raise ConfigurationError(
517 "%s services with 'net: container' cannot be extended" % error_prefix)
518
519 if 'network_mode' in service_dict:
520 if get_service_name_from_network_mode(service_dict['network_mode']):
521 raise ConfigurationError(
522 "%s services with 'network_mode: service' cannot be extended" % error_prefix)
523
524 if 'depends_on' in service_dict:
525 raise ConfigurationError(
526 "%s services with 'depends_on' cannot be extended" % error_prefix)
527
528
529 def validate_service(service_config, service_names, version):
530 service_dict, service_name = service_config.config, service_config.name
531 validate_against_service_schema(service_dict, service_name, version)
532 validate_paths(service_dict)
533
534 validate_ulimits(service_config)
535 validate_network_mode(service_config, service_names)
536 validate_depends_on(service_config, service_names)
537
538 if not service_dict.get('image') and has_uppercase(service_name):
539 raise ConfigurationError(
540 "Service '{name}' contains uppercase characters which are not valid "
541 "as part of an image name. Either use a lowercase service name or "
542 "use the `image` field to set a custom name for the service image."
543 .format(name=service_name))
544
545
546 def process_service(service_config):
547 working_dir = service_config.working_dir
548 service_dict = dict(service_config.config)
549
550 if 'env_file' in service_dict:
551 service_dict['env_file'] = [
552 expand_path(working_dir, path)
553 for path in to_list(service_dict['env_file'])
554 ]
555
556 if 'build' in service_dict:
557 if isinstance(service_dict['build'], six.string_types):
558 service_dict['build'] = resolve_build_path(working_dir, service_dict['build'])
559 elif isinstance(service_dict['build'], dict) and 'context' in service_dict['build']:
560 path = service_dict['build']['context']
561 service_dict['build']['context'] = resolve_build_path(working_dir, path)
562
563 if 'volumes' in service_dict and service_dict.get('volume_driver') is None:
564 service_dict['volumes'] = resolve_volume_paths(working_dir, service_dict)
565
566 if 'labels' in service_dict:
567 service_dict['labels'] = parse_labels(service_dict['labels'])
568
569 if 'extra_hosts' in service_dict:
570 service_dict['extra_hosts'] = parse_extra_hosts(service_dict['extra_hosts'])
571
572 for field in ['dns', 'dns_search']:
573 if field in service_dict:
574 service_dict[field] = to_list(service_dict[field])
575
576 return service_dict
577
578
579 def finalize_service(service_config, service_names, version):
580 service_dict = dict(service_config.config)
581
582 if 'environment' in service_dict or 'env_file' in service_dict:
583 service_dict['environment'] = resolve_environment(service_dict)
584 service_dict.pop('env_file', None)
585
586 if 'volumes_from' in service_dict:
587 service_dict['volumes_from'] = [
588 VolumeFromSpec.parse(vf, service_names, version)
589 for vf in service_dict['volumes_from']
590 ]
591
592 if 'volumes' in service_dict:
593 service_dict['volumes'] = [
594 VolumeSpec.parse(v) for v in service_dict['volumes']]
595
596 if 'net' in service_dict:
597 network_mode = service_dict.pop('net')
598 container_name = get_container_name_from_network_mode(network_mode)
599 if container_name and container_name in service_names:
600 service_dict['network_mode'] = 'service:{}'.format(container_name)
601 else:
602 service_dict['network_mode'] = network_mode
603
604 if 'restart' in service_dict:
605 service_dict['restart'] = parse_restart_spec(service_dict['restart'])
606
607 normalize_build(service_dict, service_config.working_dir)
608
609 service_dict['name'] = service_config.name
610 return normalize_v1_service_format(service_dict)
611
612
613 def normalize_v1_service_format(service_dict):
614 if 'log_driver' in service_dict or 'log_opt' in service_dict:
615 if 'logging' not in service_dict:
616 service_dict['logging'] = {}
617 if 'log_driver' in service_dict:
618 service_dict['logging']['driver'] = service_dict['log_driver']
619 del service_dict['log_driver']
620 if 'log_opt' in service_dict:
621 service_dict['logging']['options'] = service_dict['log_opt']
622 del service_dict['log_opt']
623
624 if 'dockerfile' in service_dict:
625 service_dict['build'] = service_dict.get('build', {})
626 service_dict['build'].update({
627 'dockerfile': service_dict.pop('dockerfile')
628 })
629
630 return service_dict
631
632
633 def merge_service_dicts_from_files(base, override, version):
634 """When merging services from multiple files we need to merge the `extends`
635 field. This is not handled by `merge_service_dicts()` which is used to
636 perform the `extends`.
637 """
638 new_service = merge_service_dicts(base, override, version)
639 if 'extends' in override:
640 new_service['extends'] = override['extends']
641 elif 'extends' in base:
642 new_service['extends'] = base['extends']
643 return new_service
644
645
646 class MergeDict(dict):
647 """A dict-like object responsible for merging two dicts into one."""
648
649 def __init__(self, base, override):
650 self.base = base
651 self.override = override
652
653 def needs_merge(self, field):
654 return field in self.base or field in self.override
655
656 def merge_field(self, field, merge_func, default=None):
657 if not self.needs_merge(field):
658 return
659
660 self[field] = merge_func(
661 self.base.get(field, default),
662 self.override.get(field, default))
663
664 def merge_mapping(self, field, parse_func):
665 if not self.needs_merge(field):
666 return
667
668 self[field] = parse_func(self.base.get(field))
669 self[field].update(parse_func(self.override.get(field)))
670
671 def merge_sequence(self, field, parse_func):
672 def parse_sequence_func(seq):
673 return to_mapping((parse_func(item) for item in seq), 'merge_field')
674
675 if not self.needs_merge(field):
676 return
677
678 merged = parse_sequence_func(self.base.get(field, []))
679 merged.update(parse_sequence_func(self.override.get(field, [])))
680 self[field] = [item.repr() for item in merged.values()]
681
682 def merge_scalar(self, field):
683 if self.needs_merge(field):
684 self[field] = self.override.get(field, self.base.get(field))
685
686
687 def merge_service_dicts(base, override, version):
688 md = MergeDict(base, override)
689
690 md.merge_mapping('environment', parse_environment)
691 md.merge_mapping('labels', parse_labels)
692 md.merge_mapping('ulimits', parse_ulimits)
693 md.merge_sequence('links', ServiceLink.parse)
694
695 for field in ['volumes', 'devices']:
696 md.merge_field(field, merge_path_mappings)
697
698 for field in [
699 'depends_on',
700 'expose',
701 'external_links',
702 'networks',
703 'ports',
704 'volumes_from',
705 ]:
706 md.merge_field(field, operator.add, default=[])
707
708 for field in ['dns', 'dns_search', 'env_file']:
709 md.merge_field(field, merge_list_or_string)
710
711 for field in set(ALLOWED_KEYS) - set(md):
712 md.merge_scalar(field)
713
714 if version == V1:
715 legacy_v1_merge_image_or_build(md, base, override)
716 else:
717 merge_build(md, base, override)
718
719 return dict(md)
720
721
722 def merge_build(output, base, override):
723 build = {}
724
725 if 'build' in base:
726 if isinstance(base['build'], six.string_types):
727 build['context'] = base['build']
728 else:
729 build.update(base['build'])
730
731 if 'build' in override:
732 if isinstance(override['build'], six.string_types):
733 build['context'] = override['build']
734 else:
735 build.update(override['build'])
736
737 if build:
738 output['build'] = build
739
740
741 def legacy_v1_merge_image_or_build(output, base, override):
742 output.pop('image', None)
743 output.pop('build', None)
744 if 'image' in override:
745 output['image'] = override['image']
746 elif 'build' in override:
747 output['build'] = override['build']
748 elif 'image' in base:
749 output['image'] = base['image']
750 elif 'build' in base:
751 output['build'] = base['build']
752
753
754 def merge_environment(base, override):
755 env = parse_environment(base)
756 env.update(parse_environment(override))
757 return env
758
759
760 def split_env(env):
761 if isinstance(env, six.binary_type):
762 env = env.decode('utf-8', 'replace')
763 if '=' in env:
764 return env.split('=', 1)
765 else:
766 return env, None
767
768
769 def split_label(label):
770 if '=' in label:
771 return label.split('=', 1)
772 else:
773 return label, ''
774
775
776 def parse_dict_or_list(split_func, type_name, arguments):
777 if not arguments:
778 return {}
779
780 if isinstance(arguments, list):
781 return dict(split_func(e) for e in arguments)
782
783 if isinstance(arguments, dict):
784 return dict(arguments)
785
786 raise ConfigurationError(
787 "%s \"%s\" must be a list or mapping," %
788 (type_name, arguments)
789 )
790
791
792 parse_build_arguments = functools.partial(parse_dict_or_list, split_env, 'build arguments')
793 parse_environment = functools.partial(parse_dict_or_list, split_env, 'environment')
794 parse_labels = functools.partial(parse_dict_or_list, split_label, 'labels')
795
796
797 def parse_ulimits(ulimits):
798 if not ulimits:
799 return {}
800
801 if isinstance(ulimits, dict):
802 return dict(ulimits)
803
804
805 def resolve_env_var(key, val):
806 if val is not None:
807 return key, val
808 elif key in os.environ:
809 return key, os.environ[key]
810 else:
811 return ()
812
813
814 def env_vars_from_file(filename):
815 """
816 Read in a line delimited file of environment variables.
817 """
818 if not os.path.exists(filename):
819 raise ConfigurationError("Couldn't find env file: %s" % filename)
820 env = {}
821 for line in codecs.open(filename, 'r', 'utf-8'):
822 line = line.strip()
823 if line and not line.startswith('#'):
824 k, v = split_env(line)
825 env[k] = v
826 return env
827
828
829 def resolve_volume_paths(working_dir, service_dict):
830 return [
831 resolve_volume_path(working_dir, volume)
832 for volume in service_dict['volumes']
833 ]
834
835
836 def resolve_volume_path(working_dir, volume):
837 container_path, host_path = split_path_mapping(volume)
838
839 if host_path is not None:
840 if host_path.startswith('.'):
841 host_path = expand_path(working_dir, host_path)
842 host_path = os.path.expanduser(host_path)
843 return u"{}:{}".format(host_path, container_path)
844 else:
845 return container_path
846
847
848 def normalize_build(service_dict, working_dir):
849
850 if 'build' in service_dict:
851 build = {}
852 # Shortcut where specifying a string is treated as the build context
853 if isinstance(service_dict['build'], six.string_types):
854 build['context'] = service_dict.pop('build')
855 else:
856 build.update(service_dict['build'])
857 if 'args' in build:
858 build['args'] = resolve_build_args(build)
859
860 service_dict['build'] = build
861
862
863 def resolve_build_path(working_dir, build_path):
864 if is_url(build_path):
865 return build_path
866 return expand_path(working_dir, build_path)
867
868
869 def is_url(build_path):
870 return build_path.startswith(DOCKER_VALID_URL_PREFIXES)
871
872
873 def validate_paths(service_dict):
874 if 'build' in service_dict:
875 build = service_dict.get('build', {})
876
877 if isinstance(build, six.string_types):
878 build_path = build
879 elif isinstance(build, dict) and 'context' in build:
880 build_path = build['context']
881
882 if (
883 not is_url(build_path) and
884 (not os.path.exists(build_path) or not os.access(build_path, os.R_OK))
885 ):
886 raise ConfigurationError(
887 "build path %s either does not exist, is not accessible, "
888 "or is not a valid URL." % build_path)
889
890
891 def merge_path_mappings(base, override):
892 d = dict_from_path_mappings(base)
893 d.update(dict_from_path_mappings(override))
894 return path_mappings_from_dict(d)
895
896
897 def dict_from_path_mappings(path_mappings):
898 if path_mappings:
899 return dict(split_path_mapping(v) for v in path_mappings)
900 else:
901 return {}
902
903
904 def path_mappings_from_dict(d):
905 return [join_path_mapping(v) for v in d.items()]
906
907
908 def split_path_mapping(volume_path):
909 """
910 Ascertain if the volume_path contains a host path as well as a container
911 path. Using splitdrive so windows absolute paths won't cause issues with
912 splitting on ':'.
913 """
914 # splitdrive has limitations when it comes to relative paths, so when it's
915 # relative, handle special case to set the drive to ''
916 if volume_path.startswith('.') or volume_path.startswith('~'):
917 drive, volume_config = '', volume_path
918 else:
919 drive, volume_config = os.path.splitdrive(volume_path)
920
921 if ':' in volume_config:
922 (host, container) = volume_config.split(':', 1)
923 return (container, drive + host)
924 else:
925 return (volume_path, None)
926
927
928 def join_path_mapping(pair):
929 (container, host) = pair
930 if host is None:
931 return container
932 else:
933 return ":".join((host, container))
934
935
936 def expand_path(working_dir, path):
937 return os.path.abspath(os.path.join(working_dir, os.path.expanduser(path)))
938
939
940 def merge_list_or_string(base, override):
941 return to_list(base) + to_list(override)
942
943
944 def to_list(value):
945 if value is None:
946 return []
947 elif isinstance(value, six.string_types):
948 return [value]
949 else:
950 return value
951
952
953 def to_mapping(sequence, key_field):
954 return {getattr(item, key_field): item for item in sequence}
955
956
957 def has_uppercase(name):
958 return any(char in string.ascii_uppercase for char in name)
959
960
961 def load_yaml(filename):
962 try:
963 with open(filename, 'r') as fh:
964 return yaml.safe_load(fh)
965 except (IOError, yaml.YAMLError) as e:
966 error_name = getattr(e, '__module__', '') + '.' + e.__class__.__name__
967 raise ConfigurationError(u"{}: {}".format(error_name, e))
968
[end of compose/config/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
docker/compose
|
7b5bad6050e337ca41d8f1a0e80b44787534e92f
|
Merge build args when using multiple compose files (or when extending services)
Based on the behavior of `environment` and `labels`, as well as `build.image`, `build.context` etc, I would also expect `build.args` to be merged, instead of being replaced.
To give an example:
## Input
**docker-compose.yml:**
``` yaml
version: "2"
services:
my_service:
build:
context: my-app
args:
SOME_VARIABLE: "42"
```
**docker-compose.override.yml:**
``` yaml
version: "2"
services:
my_service:
build:
args:
HTTP_PROXY: http://proxy.somewhere:80
HTTPS_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
```
**my-app/Dockerfile**
``` Dockerfile
# Just needed to be able to use `build:`
FROM busybox:latest
ARG SOME_VARIABLE=xyz
RUN echo "$SOME_VARIABLE" > /etc/example
```
## Current Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Expected Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
SOME_VARIABLE: 42 # Note the merged variable here
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Version Information
``` bash
$ docker-compose version
docker-compose version 1.6.0, build cdb920a
docker-py version: 1.7.0
CPython version: 2.7.11
OpenSSL version: OpenSSL 1.0.2d 9 Jul 2015
```
# Implementation proposal
I mainly want to get clarification on what the desired behavior is, so that I can possibly help implementing it, maybe even for `1.6.1`.
Personally, I'd like the behavior to be to merge the `build.args` key (as outlined above), for a couple of reasons:
- Principle of least surprise/consistency with `environment`, `labels`, `ports` and so on.
- It enables scenarios like the one outlined above, where the images require some transient configuration to build, in addition to other build variables which actually have an influence on the final image.
The scenario that one wants to replace all build args at once is not very likely IMO; why would you define base build variables in the first place if you're going to replace them anyway?
# Alternative behavior: Output a warning
If the behavior should stay the same as it is now, i.e. to fully replaced the `build.args` keys, then `docker-compose` should at least output a warning IMO. It took me some time to figure out that `docker-compose` was ignoring the build args in the base `docker-compose.yml` file.
|
I think we should merge build args. It was probably just overlooked since this is the first time we have nested configuration that we actually want to merge (other nested config like `logging` is not merged by design, because changing one option likely invalidates the rest).
I think the implementation would be to use the new `MergeDict()` object in `merge_build()`. Currently we just use `update()`.
A PR for this would be great!
I'm going to pick this up since it can be fixed at the same time as #2874
|
2016-02-10T18:55:23Z
|
<patch>
diff --git a/compose/config/config.py b/compose/config/config.py
--- a/compose/config/config.py
+++ b/compose/config/config.py
@@ -713,29 +713,24 @@ def merge_service_dicts(base, override, version):
if version == V1:
legacy_v1_merge_image_or_build(md, base, override)
- else:
- merge_build(md, base, override)
+ elif md.needs_merge('build'):
+ md['build'] = merge_build(md, base, override)
return dict(md)
def merge_build(output, base, override):
- build = {}
-
- if 'build' in base:
- if isinstance(base['build'], six.string_types):
- build['context'] = base['build']
- else:
- build.update(base['build'])
-
- if 'build' in override:
- if isinstance(override['build'], six.string_types):
- build['context'] = override['build']
- else:
- build.update(override['build'])
-
- if build:
- output['build'] = build
+ def to_dict(service):
+ build_config = service.get('build', {})
+ if isinstance(build_config, six.string_types):
+ return {'context': build_config}
+ return build_config
+
+ md = MergeDict(to_dict(base), to_dict(override))
+ md.merge_scalar('context')
+ md.merge_scalar('dockerfile')
+ md.merge_mapping('args', parse_build_arguments)
+ return dict(md)
def legacy_v1_merge_image_or_build(output, base, override):
</patch>
|
[]
|
[]
| |||
ipython__ipython-13417
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add line number to error messages
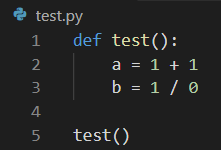
As suggested in #13169, it adds line number to error messages, in order to make them more friendly.
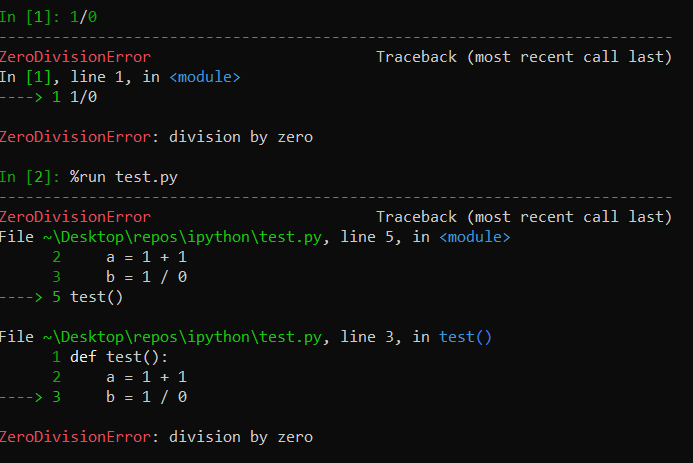
That was the file used in the test
</issue>
<code>
[start of README.rst]
1 .. image:: https://codecov.io/github/ipython/ipython/coverage.svg?branch=master
2 :target: https://codecov.io/github/ipython/ipython?branch=master
3
4 .. image:: https://img.shields.io/pypi/v/IPython.svg
5 :target: https://pypi.python.org/pypi/ipython
6
7 .. image:: https://github.com/ipython/ipython/actions/workflows/test.yml/badge.svg
8 :target: https://github.com/ipython/ipython/actions/workflows/test.yml)
9
10 .. image:: https://www.codetriage.com/ipython/ipython/badges/users.svg
11 :target: https://www.codetriage.com/ipython/ipython/
12
13 .. image:: https://raster.shields.io/badge/Follows-NEP29-brightgreen.png
14 :target: https://numpy.org/neps/nep-0029-deprecation_policy.html
15
16
17 ===========================================
18 IPython: Productive Interactive Computing
19 ===========================================
20
21 Overview
22 ========
23
24 Welcome to IPython. Our full documentation is available on `ipython.readthedocs.io
25 <https://ipython.readthedocs.io/en/stable/>`_ and contains information on how to install, use, and
26 contribute to the project.
27 IPython (Interactive Python) is a command shell for interactive computing in multiple programming languages, originally developed for the Python programming language, that offers introspection, rich media, shell syntax, tab completion, and history.
28
29 **IPython versions and Python Support**
30
31 Starting with IPython 7.10, IPython follows `NEP 29 <https://numpy.org/neps/nep-0029-deprecation_policy.html>`_
32
33 **IPython 7.17+** requires Python version 3.7 and above.
34
35 **IPython 7.10+** requires Python version 3.6 and above.
36
37 **IPython 7.0** requires Python version 3.5 and above.
38
39 **IPython 6.x** requires Python version 3.3 and above.
40
41 **IPython 5.x LTS** is the compatible release for Python 2.7.
42 If you require Python 2 support, you **must** use IPython 5.x LTS. Please
43 update your project configurations and requirements as necessary.
44
45
46 The Notebook, Qt console and a number of other pieces are now parts of *Jupyter*.
47 See the `Jupyter installation docs <https://jupyter.readthedocs.io/en/latest/install.html>`__
48 if you want to use these.
49
50 Main features of IPython
51 ========================
52 Comprehensive object introspection.
53
54 Input history, persistent across sessions.
55
56 Caching of output results during a session with automatically generated references.
57
58 Extensible tab completion, with support by default for completion of python variables and keywords, filenames and function keywords.
59
60 Extensible system of ‘magic’ commands for controlling the environment and performing many tasks related to IPython or the operating system.
61
62 A rich configuration system with easy switching between different setups (simpler than changing $PYTHONSTARTUP environment variables every time).
63
64 Session logging and reloading.
65
66 Extensible syntax processing for special purpose situations.
67
68 Access to the system shell with user-extensible alias system.
69
70 Easily embeddable in other Python programs and GUIs.
71
72 Integrated access to the pdb debugger and the Python profiler.
73
74
75 Development and Instant running
76 ===============================
77
78 You can find the latest version of the development documentation on `readthedocs
79 <https://ipython.readthedocs.io/en/latest/>`_.
80
81 You can run IPython from this directory without even installing it system-wide
82 by typing at the terminal::
83
84 $ python -m IPython
85
86 Or see the `development installation docs
87 <https://ipython.readthedocs.io/en/latest/install/install.html#installing-the-development-version>`_
88 for the latest revision on read the docs.
89
90 Documentation and installation instructions for older version of IPython can be
91 found on the `IPython website <https://ipython.org/documentation.html>`_
92
93
94
95 IPython requires Python version 3 or above
96 ==========================================
97
98 Starting with version 6.0, IPython does not support Python 2.7, 3.0, 3.1, or
99 3.2.
100
101 For a version compatible with Python 2.7, please install the 5.x LTS Long Term
102 Support version.
103
104 If you are encountering this error message you are likely trying to install or
105 use IPython from source. You need to checkout the remote 5.x branch. If you are
106 using git the following should work::
107
108 $ git fetch origin
109 $ git checkout 5.x
110
111 If you encounter this error message with a regular install of IPython, then you
112 likely need to update your package manager, for example if you are using `pip`
113 check the version of pip with::
114
115 $ pip --version
116
117 You will need to update pip to the version 9.0.1 or greater. If you are not using
118 pip, please inquiry with the maintainers of the package for your package
119 manager.
120
121 For more information see one of our blog posts:
122
123 https://blog.jupyter.org/release-of-ipython-5-0-8ce60b8d2e8e
124
125 As well as the following Pull-Request for discussion:
126
127 https://github.com/ipython/ipython/pull/9900
128
129 This error does also occur if you are invoking ``setup.py`` directly – which you
130 should not – or are using ``easy_install`` If this is the case, use ``pip
131 install .`` instead of ``setup.py install`` , and ``pip install -e .`` instead
132 of ``setup.py develop`` If you are depending on IPython as a dependency you may
133 also want to have a conditional dependency on IPython depending on the Python
134 version::
135
136 install_req = ['ipython']
137 if sys.version_info[0] < 3 and 'bdist_wheel' not in sys.argv:
138 install_req.remove('ipython')
139 install_req.append('ipython<6')
140
141 setup(
142 ...
143 install_requires=install_req
144 )
145
146 Alternatives to IPython
147 =======================
148
149 IPython may not be to your taste; if that's the case there might be similar
150 project that you might want to use:
151
152 - The classic Python REPL.
153 - `bpython <https://bpython-interpreter.org/>`_
154 - `mypython <https://www.asmeurer.com/mypython/>`_
155 - `ptpython and ptipython <https://pypi.org/project/ptpython/>`_
156 - `Xonsh <https://xon.sh/>`_
157
158 Ignoring commits with git blame.ignoreRevsFile
159 ==============================================
160
161 As of git 2.23, it is possible to make formatting changes without breaking
162 ``git blame``. See the `git documentation
163 <https://git-scm.com/docs/git-config#Documentation/git-config.txt-blameignoreRevsFile>`_
164 for more details.
165
166 To use this feature you must:
167
168 - Install git >= 2.23
169 - Configure your local git repo by running:
170 - POSIX: ``tools\configure-git-blame-ignore-revs.sh``
171 - Windows: ``tools\configure-git-blame-ignore-revs.bat``
172
[end of README.rst]
[start of IPython/core/ultratb.py]
1 # -*- coding: utf-8 -*-
2 """
3 Verbose and colourful traceback formatting.
4
5 **ColorTB**
6
7 I've always found it a bit hard to visually parse tracebacks in Python. The
8 ColorTB class is a solution to that problem. It colors the different parts of a
9 traceback in a manner similar to what you would expect from a syntax-highlighting
10 text editor.
11
12 Installation instructions for ColorTB::
13
14 import sys,ultratb
15 sys.excepthook = ultratb.ColorTB()
16
17 **VerboseTB**
18
19 I've also included a port of Ka-Ping Yee's "cgitb.py" that produces all kinds
20 of useful info when a traceback occurs. Ping originally had it spit out HTML
21 and intended it for CGI programmers, but why should they have all the fun? I
22 altered it to spit out colored text to the terminal. It's a bit overwhelming,
23 but kind of neat, and maybe useful for long-running programs that you believe
24 are bug-free. If a crash *does* occur in that type of program you want details.
25 Give it a shot--you'll love it or you'll hate it.
26
27 .. note::
28
29 The Verbose mode prints the variables currently visible where the exception
30 happened (shortening their strings if too long). This can potentially be
31 very slow, if you happen to have a huge data structure whose string
32 representation is complex to compute. Your computer may appear to freeze for
33 a while with cpu usage at 100%. If this occurs, you can cancel the traceback
34 with Ctrl-C (maybe hitting it more than once).
35
36 If you encounter this kind of situation often, you may want to use the
37 Verbose_novars mode instead of the regular Verbose, which avoids formatting
38 variables (but otherwise includes the information and context given by
39 Verbose).
40
41 .. note::
42
43 The verbose mode print all variables in the stack, which means it can
44 potentially leak sensitive information like access keys, or unencrypted
45 password.
46
47 Installation instructions for VerboseTB::
48
49 import sys,ultratb
50 sys.excepthook = ultratb.VerboseTB()
51
52 Note: Much of the code in this module was lifted verbatim from the standard
53 library module 'traceback.py' and Ka-Ping Yee's 'cgitb.py'.
54
55 Color schemes
56 -------------
57
58 The colors are defined in the class TBTools through the use of the
59 ColorSchemeTable class. Currently the following exist:
60
61 - NoColor: allows all of this module to be used in any terminal (the color
62 escapes are just dummy blank strings).
63
64 - Linux: is meant to look good in a terminal like the Linux console (black
65 or very dark background).
66
67 - LightBG: similar to Linux but swaps dark/light colors to be more readable
68 in light background terminals.
69
70 - Neutral: a neutral color scheme that should be readable on both light and
71 dark background
72
73 You can implement other color schemes easily, the syntax is fairly
74 self-explanatory. Please send back new schemes you develop to the author for
75 possible inclusion in future releases.
76
77 Inheritance diagram:
78
79 .. inheritance-diagram:: IPython.core.ultratb
80 :parts: 3
81 """
82
83 #*****************************************************************************
84 # Copyright (C) 2001 Nathaniel Gray <n8gray@caltech.edu>
85 # Copyright (C) 2001-2004 Fernando Perez <fperez@colorado.edu>
86 #
87 # Distributed under the terms of the BSD License. The full license is in
88 # the file COPYING, distributed as part of this software.
89 #*****************************************************************************
90
91
92 import inspect
93 import linecache
94 import pydoc
95 import sys
96 import time
97 import traceback
98
99 import stack_data
100 from pygments.formatters.terminal256 import Terminal256Formatter
101 from pygments.styles import get_style_by_name
102
103 # IPython's own modules
104 from IPython import get_ipython
105 from IPython.core import debugger
106 from IPython.core.display_trap import DisplayTrap
107 from IPython.core.excolors import exception_colors
108 from IPython.utils import path as util_path
109 from IPython.utils import py3compat
110 from IPython.utils.terminal import get_terminal_size
111
112 import IPython.utils.colorable as colorable
113
114 # Globals
115 # amount of space to put line numbers before verbose tracebacks
116 INDENT_SIZE = 8
117
118 # Default color scheme. This is used, for example, by the traceback
119 # formatter. When running in an actual IPython instance, the user's rc.colors
120 # value is used, but having a module global makes this functionality available
121 # to users of ultratb who are NOT running inside ipython.
122 DEFAULT_SCHEME = 'NoColor'
123
124 # ---------------------------------------------------------------------------
125 # Code begins
126
127 # Helper function -- largely belongs to VerboseTB, but we need the same
128 # functionality to produce a pseudo verbose TB for SyntaxErrors, so that they
129 # can be recognized properly by ipython.el's py-traceback-line-re
130 # (SyntaxErrors have to be treated specially because they have no traceback)
131
132
133 def _format_traceback_lines(lines, Colors, has_colors, lvals):
134 """
135 Format tracebacks lines with pointing arrow, leading numbers...
136
137 Parameters
138 ----------
139 lines : list[Line]
140 Colors
141 ColorScheme used.
142 lvals : str
143 Values of local variables, already colored, to inject just after the error line.
144 """
145 numbers_width = INDENT_SIZE - 1
146 res = []
147
148 for stack_line in lines:
149 if stack_line is stack_data.LINE_GAP:
150 res.append('%s (...)%s\n' % (Colors.linenoEm, Colors.Normal))
151 continue
152
153 line = stack_line.render(pygmented=has_colors).rstrip('\n') + '\n'
154 lineno = stack_line.lineno
155 if stack_line.is_current:
156 # This is the line with the error
157 pad = numbers_width - len(str(lineno))
158 num = '%s%s' % (debugger.make_arrow(pad), str(lineno))
159 start_color = Colors.linenoEm
160 else:
161 num = '%*s' % (numbers_width, lineno)
162 start_color = Colors.lineno
163
164 line = '%s%s%s %s' % (start_color, num, Colors.Normal, line)
165
166 res.append(line)
167 if lvals and stack_line.is_current:
168 res.append(lvals + '\n')
169 return res
170
171
172 def _format_filename(file, ColorFilename, ColorNormal):
173 """
174 Format filename lines with `In [n]` if it's the nth code cell or `File *.py` if it's a module.
175
176 Parameters
177 ----------
178 file : str
179 ColorFilename
180 ColorScheme's filename coloring to be used.
181 ColorNormal
182 ColorScheme's normal coloring to be used.
183 """
184 ipinst = get_ipython()
185
186 if ipinst is not None and file in ipinst.compile._filename_map:
187 file = "[%s]" % ipinst.compile._filename_map[file]
188 tpl_link = "Input %sIn %%s%s" % (ColorFilename, ColorNormal)
189 else:
190 file = util_path.compress_user(
191 py3compat.cast_unicode(file, util_path.fs_encoding)
192 )
193 tpl_link = "File %s%%s%s" % (ColorFilename, ColorNormal)
194
195 return tpl_link % file
196
197 #---------------------------------------------------------------------------
198 # Module classes
199 class TBTools(colorable.Colorable):
200 """Basic tools used by all traceback printer classes."""
201
202 # Number of frames to skip when reporting tracebacks
203 tb_offset = 0
204
205 def __init__(self, color_scheme='NoColor', call_pdb=False, ostream=None, parent=None, config=None):
206 # Whether to call the interactive pdb debugger after printing
207 # tracebacks or not
208 super(TBTools, self).__init__(parent=parent, config=config)
209 self.call_pdb = call_pdb
210
211 # Output stream to write to. Note that we store the original value in
212 # a private attribute and then make the public ostream a property, so
213 # that we can delay accessing sys.stdout until runtime. The way
214 # things are written now, the sys.stdout object is dynamically managed
215 # so a reference to it should NEVER be stored statically. This
216 # property approach confines this detail to a single location, and all
217 # subclasses can simply access self.ostream for writing.
218 self._ostream = ostream
219
220 # Create color table
221 self.color_scheme_table = exception_colors()
222
223 self.set_colors(color_scheme)
224 self.old_scheme = color_scheme # save initial value for toggles
225
226 if call_pdb:
227 self.pdb = debugger.Pdb()
228 else:
229 self.pdb = None
230
231 def _get_ostream(self):
232 """Output stream that exceptions are written to.
233
234 Valid values are:
235
236 - None: the default, which means that IPython will dynamically resolve
237 to sys.stdout. This ensures compatibility with most tools, including
238 Windows (where plain stdout doesn't recognize ANSI escapes).
239
240 - Any object with 'write' and 'flush' attributes.
241 """
242 return sys.stdout if self._ostream is None else self._ostream
243
244 def _set_ostream(self, val):
245 assert val is None or (hasattr(val, 'write') and hasattr(val, 'flush'))
246 self._ostream = val
247
248 ostream = property(_get_ostream, _set_ostream)
249
250 def get_parts_of_chained_exception(self, evalue):
251 def get_chained_exception(exception_value):
252 cause = getattr(exception_value, '__cause__', None)
253 if cause:
254 return cause
255 if getattr(exception_value, '__suppress_context__', False):
256 return None
257 return getattr(exception_value, '__context__', None)
258
259 chained_evalue = get_chained_exception(evalue)
260
261 if chained_evalue:
262 return chained_evalue.__class__, chained_evalue, chained_evalue.__traceback__
263
264 def prepare_chained_exception_message(self, cause):
265 direct_cause = "\nThe above exception was the direct cause of the following exception:\n"
266 exception_during_handling = "\nDuring handling of the above exception, another exception occurred:\n"
267
268 if cause:
269 message = [[direct_cause]]
270 else:
271 message = [[exception_during_handling]]
272 return message
273
274 @property
275 def has_colors(self):
276 return self.color_scheme_table.active_scheme_name.lower() != "nocolor"
277
278 def set_colors(self, *args, **kw):
279 """Shorthand access to the color table scheme selector method."""
280
281 # Set own color table
282 self.color_scheme_table.set_active_scheme(*args, **kw)
283 # for convenience, set Colors to the active scheme
284 self.Colors = self.color_scheme_table.active_colors
285 # Also set colors of debugger
286 if hasattr(self, 'pdb') and self.pdb is not None:
287 self.pdb.set_colors(*args, **kw)
288
289 def color_toggle(self):
290 """Toggle between the currently active color scheme and NoColor."""
291
292 if self.color_scheme_table.active_scheme_name == 'NoColor':
293 self.color_scheme_table.set_active_scheme(self.old_scheme)
294 self.Colors = self.color_scheme_table.active_colors
295 else:
296 self.old_scheme = self.color_scheme_table.active_scheme_name
297 self.color_scheme_table.set_active_scheme('NoColor')
298 self.Colors = self.color_scheme_table.active_colors
299
300 def stb2text(self, stb):
301 """Convert a structured traceback (a list) to a string."""
302 return '\n'.join(stb)
303
304 def text(self, etype, value, tb, tb_offset=None, context=5):
305 """Return formatted traceback.
306
307 Subclasses may override this if they add extra arguments.
308 """
309 tb_list = self.structured_traceback(etype, value, tb,
310 tb_offset, context)
311 return self.stb2text(tb_list)
312
313 def structured_traceback(self, etype, evalue, tb, tb_offset=None,
314 context=5, mode=None):
315 """Return a list of traceback frames.
316
317 Must be implemented by each class.
318 """
319 raise NotImplementedError()
320
321
322 #---------------------------------------------------------------------------
323 class ListTB(TBTools):
324 """Print traceback information from a traceback list, with optional color.
325
326 Calling requires 3 arguments: (etype, evalue, elist)
327 as would be obtained by::
328
329 etype, evalue, tb = sys.exc_info()
330 if tb:
331 elist = traceback.extract_tb(tb)
332 else:
333 elist = None
334
335 It can thus be used by programs which need to process the traceback before
336 printing (such as console replacements based on the code module from the
337 standard library).
338
339 Because they are meant to be called without a full traceback (only a
340 list), instances of this class can't call the interactive pdb debugger."""
341
342 def __init__(self, color_scheme='NoColor', call_pdb=False, ostream=None, parent=None, config=None):
343 TBTools.__init__(self, color_scheme=color_scheme, call_pdb=call_pdb,
344 ostream=ostream, parent=parent,config=config)
345
346 def __call__(self, etype, value, elist):
347 self.ostream.flush()
348 self.ostream.write(self.text(etype, value, elist))
349 self.ostream.write('\n')
350
351 def _extract_tb(self, tb):
352 if tb:
353 return traceback.extract_tb(tb)
354 else:
355 return None
356
357 def structured_traceback(self, etype, evalue, etb=None, tb_offset=None,
358 context=5):
359 """Return a color formatted string with the traceback info.
360
361 Parameters
362 ----------
363 etype : exception type
364 Type of the exception raised.
365 evalue : object
366 Data stored in the exception
367 etb : object
368 If list: List of frames, see class docstring for details.
369 If Traceback: Traceback of the exception.
370 tb_offset : int, optional
371 Number of frames in the traceback to skip. If not given, the
372 instance evalue is used (set in constructor).
373 context : int, optional
374 Number of lines of context information to print.
375
376 Returns
377 -------
378 String with formatted exception.
379 """
380 # This is a workaround to get chained_exc_ids in recursive calls
381 # etb should not be a tuple if structured_traceback is not recursive
382 if isinstance(etb, tuple):
383 etb, chained_exc_ids = etb
384 else:
385 chained_exc_ids = set()
386
387 if isinstance(etb, list):
388 elist = etb
389 elif etb is not None:
390 elist = self._extract_tb(etb)
391 else:
392 elist = []
393 tb_offset = self.tb_offset if tb_offset is None else tb_offset
394 Colors = self.Colors
395 out_list = []
396 if elist:
397
398 if tb_offset and len(elist) > tb_offset:
399 elist = elist[tb_offset:]
400
401 out_list.append('Traceback %s(most recent call last)%s:' %
402 (Colors.normalEm, Colors.Normal) + '\n')
403 out_list.extend(self._format_list(elist))
404 # The exception info should be a single entry in the list.
405 lines = ''.join(self._format_exception_only(etype, evalue))
406 out_list.append(lines)
407
408 exception = self.get_parts_of_chained_exception(evalue)
409
410 if exception and not id(exception[1]) in chained_exc_ids:
411 chained_exception_message = self.prepare_chained_exception_message(
412 evalue.__cause__)[0]
413 etype, evalue, etb = exception
414 # Trace exception to avoid infinite 'cause' loop
415 chained_exc_ids.add(id(exception[1]))
416 chained_exceptions_tb_offset = 0
417 out_list = (
418 self.structured_traceback(
419 etype, evalue, (etb, chained_exc_ids),
420 chained_exceptions_tb_offset, context)
421 + chained_exception_message
422 + out_list)
423
424 return out_list
425
426 def _format_list(self, extracted_list):
427 """Format a list of traceback entry tuples for printing.
428
429 Given a list of tuples as returned by extract_tb() or
430 extract_stack(), return a list of strings ready for printing.
431 Each string in the resulting list corresponds to the item with the
432 same index in the argument list. Each string ends in a newline;
433 the strings may contain internal newlines as well, for those items
434 whose source text line is not None.
435
436 Lifted almost verbatim from traceback.py
437 """
438
439 Colors = self.Colors
440 list = []
441 for filename, lineno, name, line in extracted_list[:-1]:
442 item = " %s, line %s%d%s, in %s%s%s\n" % (
443 _format_filename(filename, Colors.filename, Colors.Normal),
444 Colors.lineno,
445 lineno,
446 Colors.Normal,
447 Colors.name,
448 name,
449 Colors.Normal,
450 )
451 if line:
452 item += ' %s\n' % line.strip()
453 list.append(item)
454 # Emphasize the last entry
455 filename, lineno, name, line = extracted_list[-1]
456 item = "%s %s, line %s%d%s, in %s%s%s%s\n" % (
457 Colors.normalEm,
458 _format_filename(filename, Colors.filenameEm, Colors.normalEm),
459 Colors.linenoEm,
460 lineno,
461 Colors.normalEm,
462 Colors.nameEm,
463 name,
464 Colors.normalEm,
465 Colors.Normal,
466 )
467 if line:
468 item += '%s %s%s\n' % (Colors.line, line.strip(),
469 Colors.Normal)
470 list.append(item)
471 return list
472
473 def _format_exception_only(self, etype, value):
474 """Format the exception part of a traceback.
475
476 The arguments are the exception type and value such as given by
477 sys.exc_info()[:2]. The return value is a list of strings, each ending
478 in a newline. Normally, the list contains a single string; however,
479 for SyntaxError exceptions, it contains several lines that (when
480 printed) display detailed information about where the syntax error
481 occurred. The message indicating which exception occurred is the
482 always last string in the list.
483
484 Also lifted nearly verbatim from traceback.py
485 """
486 have_filedata = False
487 Colors = self.Colors
488 list = []
489 stype = py3compat.cast_unicode(Colors.excName + etype.__name__ + Colors.Normal)
490 if value is None:
491 # Not sure if this can still happen in Python 2.6 and above
492 list.append(stype + '\n')
493 else:
494 if issubclass(etype, SyntaxError):
495 have_filedata = True
496 if not value.filename: value.filename = "<string>"
497 if value.lineno:
498 lineno = value.lineno
499 textline = linecache.getline(value.filename, value.lineno)
500 else:
501 lineno = "unknown"
502 textline = ""
503 list.append(
504 "%s %s, line %s%s%s\n"
505 % (
506 Colors.normalEm,
507 _format_filename(
508 value.filename, Colors.filenameEm, Colors.normalEm
509 ),
510 Colors.linenoEm,
511 lineno,
512 Colors.Normal,
513 )
514 )
515 if textline == "":
516 textline = py3compat.cast_unicode(value.text, "utf-8")
517
518 if textline is not None:
519 i = 0
520 while i < len(textline) and textline[i].isspace():
521 i += 1
522 list.append('%s %s%s\n' % (Colors.line,
523 textline.strip(),
524 Colors.Normal))
525 if value.offset is not None:
526 s = ' '
527 for c in textline[i:value.offset - 1]:
528 if c.isspace():
529 s += c
530 else:
531 s += ' '
532 list.append('%s%s^%s\n' % (Colors.caret, s,
533 Colors.Normal))
534
535 try:
536 s = value.msg
537 except Exception:
538 s = self._some_str(value)
539 if s:
540 list.append('%s%s:%s %s\n' % (stype, Colors.excName,
541 Colors.Normal, s))
542 else:
543 list.append('%s\n' % stype)
544
545 # sync with user hooks
546 if have_filedata:
547 ipinst = get_ipython()
548 if ipinst is not None:
549 ipinst.hooks.synchronize_with_editor(value.filename, value.lineno, 0)
550
551 return list
552
553 def get_exception_only(self, etype, value):
554 """Only print the exception type and message, without a traceback.
555
556 Parameters
557 ----------
558 etype : exception type
559 value : exception value
560 """
561 return ListTB.structured_traceback(self, etype, value)
562
563 def show_exception_only(self, etype, evalue):
564 """Only print the exception type and message, without a traceback.
565
566 Parameters
567 ----------
568 etype : exception type
569 evalue : exception value
570 """
571 # This method needs to use __call__ from *this* class, not the one from
572 # a subclass whose signature or behavior may be different
573 ostream = self.ostream
574 ostream.flush()
575 ostream.write('\n'.join(self.get_exception_only(etype, evalue)))
576 ostream.flush()
577
578 def _some_str(self, value):
579 # Lifted from traceback.py
580 try:
581 return py3compat.cast_unicode(str(value))
582 except:
583 return u'<unprintable %s object>' % type(value).__name__
584
585
586 #----------------------------------------------------------------------------
587 class VerboseTB(TBTools):
588 """A port of Ka-Ping Yee's cgitb.py module that outputs color text instead
589 of HTML. Requires inspect and pydoc. Crazy, man.
590
591 Modified version which optionally strips the topmost entries from the
592 traceback, to be used with alternate interpreters (because their own code
593 would appear in the traceback)."""
594
595 def __init__(self, color_scheme='Linux', call_pdb=False, ostream=None,
596 tb_offset=0, long_header=False, include_vars=True,
597 check_cache=None, debugger_cls = None,
598 parent=None, config=None):
599 """Specify traceback offset, headers and color scheme.
600
601 Define how many frames to drop from the tracebacks. Calling it with
602 tb_offset=1 allows use of this handler in interpreters which will have
603 their own code at the top of the traceback (VerboseTB will first
604 remove that frame before printing the traceback info)."""
605 TBTools.__init__(self, color_scheme=color_scheme, call_pdb=call_pdb,
606 ostream=ostream, parent=parent, config=config)
607 self.tb_offset = tb_offset
608 self.long_header = long_header
609 self.include_vars = include_vars
610 # By default we use linecache.checkcache, but the user can provide a
611 # different check_cache implementation. This is used by the IPython
612 # kernel to provide tracebacks for interactive code that is cached,
613 # by a compiler instance that flushes the linecache but preserves its
614 # own code cache.
615 if check_cache is None:
616 check_cache = linecache.checkcache
617 self.check_cache = check_cache
618
619 self.debugger_cls = debugger_cls or debugger.Pdb
620 self.skip_hidden = True
621
622 def format_record(self, frame_info):
623 """Format a single stack frame"""
624 Colors = self.Colors # just a shorthand + quicker name lookup
625 ColorsNormal = Colors.Normal # used a lot
626
627 if isinstance(frame_info, stack_data.RepeatedFrames):
628 return ' %s[... skipping similar frames: %s]%s\n' % (
629 Colors.excName, frame_info.description, ColorsNormal)
630
631 indent = ' ' * INDENT_SIZE
632 em_normal = '%s\n%s%s' % (Colors.valEm, indent, ColorsNormal)
633 tpl_call = 'in %s%%s%s%%s%s' % (Colors.vName, Colors.valEm,
634 ColorsNormal)
635 tpl_call_fail = 'in %s%%s%s(***failed resolving arguments***)%s' % \
636 (Colors.vName, Colors.valEm, ColorsNormal)
637 tpl_name_val = '%%s %s= %%s%s' % (Colors.valEm, ColorsNormal)
638
639 link = _format_filename(frame_info.filename, Colors.filenameEm, ColorsNormal)
640 args, varargs, varkw, locals_ = inspect.getargvalues(frame_info.frame)
641
642 func = frame_info.executing.code_qualname()
643 if func == '<module>':
644 call = tpl_call % (func, '')
645 else:
646 # Decide whether to include variable details or not
647 var_repr = eqrepr if self.include_vars else nullrepr
648 try:
649 call = tpl_call % (func, inspect.formatargvalues(args,
650 varargs, varkw,
651 locals_, formatvalue=var_repr))
652 except KeyError:
653 # This happens in situations like errors inside generator
654 # expressions, where local variables are listed in the
655 # line, but can't be extracted from the frame. I'm not
656 # 100% sure this isn't actually a bug in inspect itself,
657 # but since there's no info for us to compute with, the
658 # best we can do is report the failure and move on. Here
659 # we must *not* call any traceback construction again,
660 # because that would mess up use of %debug later on. So we
661 # simply report the failure and move on. The only
662 # limitation will be that this frame won't have locals
663 # listed in the call signature. Quite subtle problem...
664 # I can't think of a good way to validate this in a unit
665 # test, but running a script consisting of:
666 # dict( (k,v.strip()) for (k,v) in range(10) )
667 # will illustrate the error, if this exception catch is
668 # disabled.
669 call = tpl_call_fail % func
670
671 lvals = ''
672 lvals_list = []
673 if self.include_vars:
674 try:
675 # we likely want to fix stackdata at some point, but
676 # still need a workaround.
677 fibp = frame_info.variables_in_executing_piece
678 for var in fibp:
679 lvals_list.append(tpl_name_val % (var.name, repr(var.value)))
680 except Exception:
681 lvals_list.append(
682 "Exception trying to inspect frame. No more locals available."
683 )
684 if lvals_list:
685 lvals = '%s%s' % (indent, em_normal.join(lvals_list))
686
687 result = "%s, %s\n" % (link, call)
688
689 result += ''.join(_format_traceback_lines(frame_info.lines, Colors, self.has_colors, lvals))
690 return result
691
692 def prepare_header(self, etype, long_version=False):
693 colors = self.Colors # just a shorthand + quicker name lookup
694 colorsnormal = colors.Normal # used a lot
695 exc = '%s%s%s' % (colors.excName, etype, colorsnormal)
696 width = min(75, get_terminal_size()[0])
697 if long_version:
698 # Header with the exception type, python version, and date
699 pyver = 'Python ' + sys.version.split()[0] + ': ' + sys.executable
700 date = time.ctime(time.time())
701
702 head = '%s%s%s\n%s%s%s\n%s' % (colors.topline, '-' * width, colorsnormal,
703 exc, ' ' * (width - len(str(etype)) - len(pyver)),
704 pyver, date.rjust(width) )
705 head += "\nA problem occurred executing Python code. Here is the sequence of function" \
706 "\ncalls leading up to the error, with the most recent (innermost) call last."
707 else:
708 # Simplified header
709 head = '%s%s' % (exc, 'Traceback (most recent call last)'. \
710 rjust(width - len(str(etype))) )
711
712 return head
713
714 def format_exception(self, etype, evalue):
715 colors = self.Colors # just a shorthand + quicker name lookup
716 colorsnormal = colors.Normal # used a lot
717 # Get (safely) a string form of the exception info
718 try:
719 etype_str, evalue_str = map(str, (etype, evalue))
720 except:
721 # User exception is improperly defined.
722 etype, evalue = str, sys.exc_info()[:2]
723 etype_str, evalue_str = map(str, (etype, evalue))
724 # ... and format it
725 return ['%s%s%s: %s' % (colors.excName, etype_str,
726 colorsnormal, py3compat.cast_unicode(evalue_str))]
727
728 def format_exception_as_a_whole(self, etype, evalue, etb, number_of_lines_of_context, tb_offset):
729 """Formats the header, traceback and exception message for a single exception.
730
731 This may be called multiple times by Python 3 exception chaining
732 (PEP 3134).
733 """
734 # some locals
735 orig_etype = etype
736 try:
737 etype = etype.__name__
738 except AttributeError:
739 pass
740
741 tb_offset = self.tb_offset if tb_offset is None else tb_offset
742 head = self.prepare_header(etype, self.long_header)
743 records = self.get_records(etb, number_of_lines_of_context, tb_offset)
744
745 frames = []
746 skipped = 0
747 lastrecord = len(records) - 1
748 for i, r in enumerate(records):
749 if not isinstance(r, stack_data.RepeatedFrames) and self.skip_hidden:
750 if r.frame.f_locals.get("__tracebackhide__", 0) and i != lastrecord:
751 skipped += 1
752 continue
753 if skipped:
754 Colors = self.Colors # just a shorthand + quicker name lookup
755 ColorsNormal = Colors.Normal # used a lot
756 frames.append(
757 " %s[... skipping hidden %s frame]%s\n"
758 % (Colors.excName, skipped, ColorsNormal)
759 )
760 skipped = 0
761 frames.append(self.format_record(r))
762 if skipped:
763 Colors = self.Colors # just a shorthand + quicker name lookup
764 ColorsNormal = Colors.Normal # used a lot
765 frames.append(
766 " %s[... skipping hidden %s frame]%s\n"
767 % (Colors.excName, skipped, ColorsNormal)
768 )
769
770 formatted_exception = self.format_exception(etype, evalue)
771 if records:
772 frame_info = records[-1]
773 ipinst = get_ipython()
774 if ipinst is not None:
775 ipinst.hooks.synchronize_with_editor(frame_info.filename, frame_info.lineno, 0)
776
777 return [[head] + frames + [''.join(formatted_exception[0])]]
778
779 def get_records(self, etb, number_of_lines_of_context, tb_offset):
780 context = number_of_lines_of_context - 1
781 after = context // 2
782 before = context - after
783 if self.has_colors:
784 style = get_style_by_name('default')
785 style = stack_data.style_with_executing_node(style, 'bg:#00005f')
786 formatter = Terminal256Formatter(style=style)
787 else:
788 formatter = None
789 options = stack_data.Options(
790 before=before,
791 after=after,
792 pygments_formatter=formatter,
793 )
794 return list(stack_data.FrameInfo.stack_data(etb, options=options))[tb_offset:]
795
796 def structured_traceback(self, etype, evalue, etb, tb_offset=None,
797 number_of_lines_of_context=5):
798 """Return a nice text document describing the traceback."""
799
800 formatted_exception = self.format_exception_as_a_whole(etype, evalue, etb, number_of_lines_of_context,
801 tb_offset)
802
803 colors = self.Colors # just a shorthand + quicker name lookup
804 colorsnormal = colors.Normal # used a lot
805 head = '%s%s%s' % (colors.topline, '-' * min(75, get_terminal_size()[0]), colorsnormal)
806 structured_traceback_parts = [head]
807 chained_exceptions_tb_offset = 0
808 lines_of_context = 3
809 formatted_exceptions = formatted_exception
810 exception = self.get_parts_of_chained_exception(evalue)
811 if exception:
812 formatted_exceptions += self.prepare_chained_exception_message(evalue.__cause__)
813 etype, evalue, etb = exception
814 else:
815 evalue = None
816 chained_exc_ids = set()
817 while evalue:
818 formatted_exceptions += self.format_exception_as_a_whole(etype, evalue, etb, lines_of_context,
819 chained_exceptions_tb_offset)
820 exception = self.get_parts_of_chained_exception(evalue)
821
822 if exception and not id(exception[1]) in chained_exc_ids:
823 chained_exc_ids.add(id(exception[1])) # trace exception to avoid infinite 'cause' loop
824 formatted_exceptions += self.prepare_chained_exception_message(evalue.__cause__)
825 etype, evalue, etb = exception
826 else:
827 evalue = None
828
829 # we want to see exceptions in a reversed order:
830 # the first exception should be on top
831 for formatted_exception in reversed(formatted_exceptions):
832 structured_traceback_parts += formatted_exception
833
834 return structured_traceback_parts
835
836 def debugger(self, force=False):
837 """Call up the pdb debugger if desired, always clean up the tb
838 reference.
839
840 Keywords:
841
842 - force(False): by default, this routine checks the instance call_pdb
843 flag and does not actually invoke the debugger if the flag is false.
844 The 'force' option forces the debugger to activate even if the flag
845 is false.
846
847 If the call_pdb flag is set, the pdb interactive debugger is
848 invoked. In all cases, the self.tb reference to the current traceback
849 is deleted to prevent lingering references which hamper memory
850 management.
851
852 Note that each call to pdb() does an 'import readline', so if your app
853 requires a special setup for the readline completers, you'll have to
854 fix that by hand after invoking the exception handler."""
855
856 if force or self.call_pdb:
857 if self.pdb is None:
858 self.pdb = self.debugger_cls()
859 # the system displayhook may have changed, restore the original
860 # for pdb
861 display_trap = DisplayTrap(hook=sys.__displayhook__)
862 with display_trap:
863 self.pdb.reset()
864 # Find the right frame so we don't pop up inside ipython itself
865 if hasattr(self, 'tb') and self.tb is not None:
866 etb = self.tb
867 else:
868 etb = self.tb = sys.last_traceback
869 while self.tb is not None and self.tb.tb_next is not None:
870 self.tb = self.tb.tb_next
871 if etb and etb.tb_next:
872 etb = etb.tb_next
873 self.pdb.botframe = etb.tb_frame
874 self.pdb.interaction(None, etb)
875
876 if hasattr(self, 'tb'):
877 del self.tb
878
879 def handler(self, info=None):
880 (etype, evalue, etb) = info or sys.exc_info()
881 self.tb = etb
882 ostream = self.ostream
883 ostream.flush()
884 ostream.write(self.text(etype, evalue, etb))
885 ostream.write('\n')
886 ostream.flush()
887
888 # Changed so an instance can just be called as VerboseTB_inst() and print
889 # out the right info on its own.
890 def __call__(self, etype=None, evalue=None, etb=None):
891 """This hook can replace sys.excepthook (for Python 2.1 or higher)."""
892 if etb is None:
893 self.handler()
894 else:
895 self.handler((etype, evalue, etb))
896 try:
897 self.debugger()
898 except KeyboardInterrupt:
899 print("\nKeyboardInterrupt")
900
901
902 #----------------------------------------------------------------------------
903 class FormattedTB(VerboseTB, ListTB):
904 """Subclass ListTB but allow calling with a traceback.
905
906 It can thus be used as a sys.excepthook for Python > 2.1.
907
908 Also adds 'Context' and 'Verbose' modes, not available in ListTB.
909
910 Allows a tb_offset to be specified. This is useful for situations where
911 one needs to remove a number of topmost frames from the traceback (such as
912 occurs with python programs that themselves execute other python code,
913 like Python shells). """
914
915 def __init__(self, mode='Plain', color_scheme='Linux', call_pdb=False,
916 ostream=None,
917 tb_offset=0, long_header=False, include_vars=False,
918 check_cache=None, debugger_cls=None,
919 parent=None, config=None):
920
921 # NEVER change the order of this list. Put new modes at the end:
922 self.valid_modes = ['Plain', 'Context', 'Verbose', 'Minimal']
923 self.verbose_modes = self.valid_modes[1:3]
924
925 VerboseTB.__init__(self, color_scheme=color_scheme, call_pdb=call_pdb,
926 ostream=ostream, tb_offset=tb_offset,
927 long_header=long_header, include_vars=include_vars,
928 check_cache=check_cache, debugger_cls=debugger_cls,
929 parent=parent, config=config)
930
931 # Different types of tracebacks are joined with different separators to
932 # form a single string. They are taken from this dict
933 self._join_chars = dict(Plain='', Context='\n', Verbose='\n',
934 Minimal='')
935 # set_mode also sets the tb_join_char attribute
936 self.set_mode(mode)
937
938 def structured_traceback(self, etype, value, tb, tb_offset=None, number_of_lines_of_context=5):
939 tb_offset = self.tb_offset if tb_offset is None else tb_offset
940 mode = self.mode
941 if mode in self.verbose_modes:
942 # Verbose modes need a full traceback
943 return VerboseTB.structured_traceback(
944 self, etype, value, tb, tb_offset, number_of_lines_of_context
945 )
946 elif mode == 'Minimal':
947 return ListTB.get_exception_only(self, etype, value)
948 else:
949 # We must check the source cache because otherwise we can print
950 # out-of-date source code.
951 self.check_cache()
952 # Now we can extract and format the exception
953 return ListTB.structured_traceback(
954 self, etype, value, tb, tb_offset, number_of_lines_of_context
955 )
956
957 def stb2text(self, stb):
958 """Convert a structured traceback (a list) to a string."""
959 return self.tb_join_char.join(stb)
960
961
962 def set_mode(self, mode=None):
963 """Switch to the desired mode.
964
965 If mode is not specified, cycles through the available modes."""
966
967 if not mode:
968 new_idx = (self.valid_modes.index(self.mode) + 1 ) % \
969 len(self.valid_modes)
970 self.mode = self.valid_modes[new_idx]
971 elif mode not in self.valid_modes:
972 raise ValueError('Unrecognized mode in FormattedTB: <' + mode + '>\n'
973 'Valid modes: ' + str(self.valid_modes))
974 else:
975 self.mode = mode
976 # include variable details only in 'Verbose' mode
977 self.include_vars = (self.mode == self.valid_modes[2])
978 # Set the join character for generating text tracebacks
979 self.tb_join_char = self._join_chars[self.mode]
980
981 # some convenient shortcuts
982 def plain(self):
983 self.set_mode(self.valid_modes[0])
984
985 def context(self):
986 self.set_mode(self.valid_modes[1])
987
988 def verbose(self):
989 self.set_mode(self.valid_modes[2])
990
991 def minimal(self):
992 self.set_mode(self.valid_modes[3])
993
994
995 #----------------------------------------------------------------------------
996 class AutoFormattedTB(FormattedTB):
997 """A traceback printer which can be called on the fly.
998
999 It will find out about exceptions by itself.
1000
1001 A brief example::
1002
1003 AutoTB = AutoFormattedTB(mode = 'Verbose',color_scheme='Linux')
1004 try:
1005 ...
1006 except:
1007 AutoTB() # or AutoTB(out=logfile) where logfile is an open file object
1008 """
1009
1010 def __call__(self, etype=None, evalue=None, etb=None,
1011 out=None, tb_offset=None):
1012 """Print out a formatted exception traceback.
1013
1014 Optional arguments:
1015 - out: an open file-like object to direct output to.
1016
1017 - tb_offset: the number of frames to skip over in the stack, on a
1018 per-call basis (this overrides temporarily the instance's tb_offset
1019 given at initialization time."""
1020
1021 if out is None:
1022 out = self.ostream
1023 out.flush()
1024 out.write(self.text(etype, evalue, etb, tb_offset))
1025 out.write('\n')
1026 out.flush()
1027 # FIXME: we should remove the auto pdb behavior from here and leave
1028 # that to the clients.
1029 try:
1030 self.debugger()
1031 except KeyboardInterrupt:
1032 print("\nKeyboardInterrupt")
1033
1034 def structured_traceback(self, etype=None, value=None, tb=None,
1035 tb_offset=None, number_of_lines_of_context=5):
1036 if etype is None:
1037 etype, value, tb = sys.exc_info()
1038 if isinstance(tb, tuple):
1039 # tb is a tuple if this is a chained exception.
1040 self.tb = tb[0]
1041 else:
1042 self.tb = tb
1043 return FormattedTB.structured_traceback(
1044 self, etype, value, tb, tb_offset, number_of_lines_of_context)
1045
1046
1047 #---------------------------------------------------------------------------
1048
1049 # A simple class to preserve Nathan's original functionality.
1050 class ColorTB(FormattedTB):
1051 """Shorthand to initialize a FormattedTB in Linux colors mode."""
1052
1053 def __init__(self, color_scheme='Linux', call_pdb=0, **kwargs):
1054 FormattedTB.__init__(self, color_scheme=color_scheme,
1055 call_pdb=call_pdb, **kwargs)
1056
1057
1058 class SyntaxTB(ListTB):
1059 """Extension which holds some state: the last exception value"""
1060
1061 def __init__(self, color_scheme='NoColor', parent=None, config=None):
1062 ListTB.__init__(self, color_scheme, parent=parent, config=config)
1063 self.last_syntax_error = None
1064
1065 def __call__(self, etype, value, elist):
1066 self.last_syntax_error = value
1067
1068 ListTB.__call__(self, etype, value, elist)
1069
1070 def structured_traceback(self, etype, value, elist, tb_offset=None,
1071 context=5):
1072 # If the source file has been edited, the line in the syntax error can
1073 # be wrong (retrieved from an outdated cache). This replaces it with
1074 # the current value.
1075 if isinstance(value, SyntaxError) \
1076 and isinstance(value.filename, str) \
1077 and isinstance(value.lineno, int):
1078 linecache.checkcache(value.filename)
1079 newtext = linecache.getline(value.filename, value.lineno)
1080 if newtext:
1081 value.text = newtext
1082 self.last_syntax_error = value
1083 return super(SyntaxTB, self).structured_traceback(etype, value, elist,
1084 tb_offset=tb_offset, context=context)
1085
1086 def clear_err_state(self):
1087 """Return the current error state and clear it"""
1088 e = self.last_syntax_error
1089 self.last_syntax_error = None
1090 return e
1091
1092 def stb2text(self, stb):
1093 """Convert a structured traceback (a list) to a string."""
1094 return ''.join(stb)
1095
1096
1097 # some internal-use functions
1098 def text_repr(value):
1099 """Hopefully pretty robust repr equivalent."""
1100 # this is pretty horrible but should always return *something*
1101 try:
1102 return pydoc.text.repr(value)
1103 except KeyboardInterrupt:
1104 raise
1105 except:
1106 try:
1107 return repr(value)
1108 except KeyboardInterrupt:
1109 raise
1110 except:
1111 try:
1112 # all still in an except block so we catch
1113 # getattr raising
1114 name = getattr(value, '__name__', None)
1115 if name:
1116 # ick, recursion
1117 return text_repr(name)
1118 klass = getattr(value, '__class__', None)
1119 if klass:
1120 return '%s instance' % text_repr(klass)
1121 except KeyboardInterrupt:
1122 raise
1123 except:
1124 return 'UNRECOVERABLE REPR FAILURE'
1125
1126
1127 def eqrepr(value, repr=text_repr):
1128 return '=%s' % repr(value)
1129
1130
1131 def nullrepr(value, repr=text_repr):
1132 return ''
1133
[end of IPython/core/ultratb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
ipython/ipython
|
1d7bb78d04ac5cb8698adb70b2b76528a1b2a0f1
|
Add line number to error messages
As suggested in #13169, it adds line number to error messages, in order to make them more friendly.

That was the file used in the test

|
2021-12-24T12:16:30Z
|
<patch>
diff --git a/IPython/core/ultratb.py b/IPython/core/ultratb.py
--- a/IPython/core/ultratb.py
+++ b/IPython/core/ultratb.py
@@ -169,7 +169,7 @@ def _format_traceback_lines(lines, Colors, has_colors, lvals):
return res
-def _format_filename(file, ColorFilename, ColorNormal):
+def _format_filename(file, ColorFilename, ColorNormal, *, lineno=None):
"""
Format filename lines with `In [n]` if it's the nth code cell or `File *.py` if it's a module.
@@ -185,14 +185,17 @@ def _format_filename(file, ColorFilename, ColorNormal):
if ipinst is not None and file in ipinst.compile._filename_map:
file = "[%s]" % ipinst.compile._filename_map[file]
- tpl_link = "Input %sIn %%s%s" % (ColorFilename, ColorNormal)
+ tpl_link = f"Input {ColorFilename}In {{file}}{ColorNormal}"
else:
file = util_path.compress_user(
py3compat.cast_unicode(file, util_path.fs_encoding)
)
- tpl_link = "File %s%%s%s" % (ColorFilename, ColorNormal)
+ if lineno is None:
+ tpl_link = f"File {ColorFilename}{{file}}{ColorNormal}"
+ else:
+ tpl_link = f"File {ColorFilename}{{file}}:{{lineno}}{ColorNormal}"
- return tpl_link % file
+ return tpl_link.format(file=file, lineno=lineno)
#---------------------------------------------------------------------------
# Module classes
@@ -439,11 +442,10 @@ def _format_list(self, extracted_list):
Colors = self.Colors
list = []
for filename, lineno, name, line in extracted_list[:-1]:
- item = " %s, line %s%d%s, in %s%s%s\n" % (
- _format_filename(filename, Colors.filename, Colors.Normal),
- Colors.lineno,
- lineno,
- Colors.Normal,
+ item = " %s in %s%s%s\n" % (
+ _format_filename(
+ filename, Colors.filename, Colors.Normal, lineno=lineno
+ ),
Colors.name,
name,
Colors.Normal,
@@ -453,12 +455,11 @@ def _format_list(self, extracted_list):
list.append(item)
# Emphasize the last entry
filename, lineno, name, line = extracted_list[-1]
- item = "%s %s, line %s%d%s, in %s%s%s%s\n" % (
- Colors.normalEm,
- _format_filename(filename, Colors.filenameEm, Colors.normalEm),
- Colors.linenoEm,
- lineno,
+ item = "%s %s in %s%s%s%s\n" % (
Colors.normalEm,
+ _format_filename(
+ filename, Colors.filenameEm, Colors.normalEm, lineno=lineno
+ ),
Colors.nameEm,
name,
Colors.normalEm,
@@ -501,14 +502,15 @@ def _format_exception_only(self, etype, value):
lineno = "unknown"
textline = ""
list.append(
- "%s %s, line %s%s%s\n"
+ "%s %s%s\n"
% (
Colors.normalEm,
_format_filename(
- value.filename, Colors.filenameEm, Colors.normalEm
+ value.filename,
+ Colors.filenameEm,
+ Colors.normalEm,
+ lineno=(None if lineno == "unknown" else lineno),
),
- Colors.linenoEm,
- lineno,
Colors.Normal,
)
)
@@ -628,27 +630,35 @@ def format_record(self, frame_info):
return ' %s[... skipping similar frames: %s]%s\n' % (
Colors.excName, frame_info.description, ColorsNormal)
- indent = ' ' * INDENT_SIZE
- em_normal = '%s\n%s%s' % (Colors.valEm, indent, ColorsNormal)
- tpl_call = 'in %s%%s%s%%s%s' % (Colors.vName, Colors.valEm,
- ColorsNormal)
- tpl_call_fail = 'in %s%%s%s(***failed resolving arguments***)%s' % \
- (Colors.vName, Colors.valEm, ColorsNormal)
- tpl_name_val = '%%s %s= %%s%s' % (Colors.valEm, ColorsNormal)
+ indent = " " * INDENT_SIZE
+ em_normal = "%s\n%s%s" % (Colors.valEm, indent, ColorsNormal)
+ tpl_call = f"in {Colors.vName}{{file}}{Colors.valEm}{{scope}}{ColorsNormal}"
+ tpl_call_fail = "in %s%%s%s(***failed resolving arguments***)%s" % (
+ Colors.vName,
+ Colors.valEm,
+ ColorsNormal,
+ )
+ tpl_name_val = "%%s %s= %%s%s" % (Colors.valEm, ColorsNormal)
- link = _format_filename(frame_info.filename, Colors.filenameEm, ColorsNormal)
+ link = _format_filename(
+ frame_info.filename,
+ Colors.filenameEm,
+ ColorsNormal,
+ lineno=frame_info.lineno,
+ )
args, varargs, varkw, locals_ = inspect.getargvalues(frame_info.frame)
func = frame_info.executing.code_qualname()
- if func == '<module>':
- call = tpl_call % (func, '')
+ if func == "<module>":
+ call = tpl_call.format(file=func, scope="")
else:
# Decide whether to include variable details or not
var_repr = eqrepr if self.include_vars else nullrepr
try:
- call = tpl_call % (func, inspect.formatargvalues(args,
- varargs, varkw,
- locals_, formatvalue=var_repr))
+ scope = inspect.formatargvalues(
+ args, varargs, varkw, locals_, formatvalue=var_repr
+ )
+ call = tpl_call.format(file=func, scope=scope)
except KeyError:
# This happens in situations like errors inside generator
# expressions, where local variables are listed in the
</patch>
|
[]
|
[]
| ||||
conda__conda-5359
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
conda should exec to non-conda subcommands, not subprocess
</issue>
<code>
[start of README.rst]
1 .. NOTE: This file serves both as the README on GitHub and the index.html for
2 conda.pydata.org. If you update this file, be sure to cd to the web
3 directory and run ``make html; make live``
4
5 .. image:: https://s3.amazonaws.com/conda-dev/conda_logo.svg
6 :alt: Conda Logo
7
8 ----------------------------------------
9
10 .. image:: https://img.shields.io/travis/conda/conda/4.4.x.svg?maxAge=900&label=Linux%20%26%20MacOS
11 :target: https://travis-ci.org/conda/conda
12 :alt: Linux & MacOS tests (Travis)
13
14 .. image:: https://img.shields.io/appveyor/ci/ContinuumAnalyticsFOSS/conda/4.4.x.svg?maxAge=900&label=Windows
15 :target: https://ci.appveyor.com/project/ContinuumAnalyticsFOSS/conda
16 :alt: Windows tests (Appveyor)
17
18 .. image:: https://img.shields.io/codecov/c/github/conda/conda/4.4.x.svg?label=coverage
19 :alt: Codecov Status
20 :target: https://codecov.io/gh/conda/conda/branch/4.4.x
21
22 .. image:: https://img.shields.io/github/release/conda/conda.svg
23 :alt: latest release version
24 :target: https://github.com/conda/conda/releases
25
26 |
27
28 .. image:: https://s3.amazonaws.com/conda-dev/conda-announce-signup-button.svg
29 :alt: Join the Conda Announcment List
30 :target: http://conda.pydata.org/docs/announcements.html
31
32 |
33
34 Conda is a cross-platform, language-agnostic binary package manager. It is the
35 package manager used by `Anaconda
36 <http://docs.continuum.io/anaconda/index.html>`_ installations, but it may be
37 used for other systems as well. Conda makes environments first-class
38 citizens, making it easy to create independent environments even for C
39 libraries. Conda is written entirely in Python, and is BSD licensed open
40 source.
41
42 Conda is enhanced by organizations, tools, and repositories created and managed by
43 the amazing members of the conda community. Some of them can be found
44 `here <https://github.com/conda/conda/wiki/Conda-Community>`_.
45
46
47 Installation
48 ------------
49
50 Conda is a part of the `Anaconda distribution <https://store.continuum.io/cshop/anaconda/>`_. You can also download a
51 minimal installation that only includes conda and its dependencies, called
52 `Miniconda <http://conda.pydata.org/miniconda.html>`_.
53
54
55 Getting Started
56 ---------------
57
58 If you install Anaconda, you will already have hundreds of packages
59 installed. You can see what packages are installed by running
60
61 .. code-block:: bash
62
63 $ conda list
64
65 to see all the packages that are available, use
66
67 .. code-block:: bash
68
69 $ conda search
70
71 and to install a package, use
72
73 .. code-block:: bash
74
75 $ conda install <package-name>
76
77
78 The real power of conda comes from its ability to manage environments. In
79 conda, an environment can be thought of as a completely separate installation.
80 Conda installs packages into environments efficiently using `hard links
81 <http://en.wikipedia.org/wiki/Hard_links>`_ by default when it is possible, so
82 environments are space efficient, and take seconds to create.
83
84 The default environment, which ``conda`` itself is installed into is called
85 ``root``. To create another environment, use the ``conda create``
86 command. For instance, to create an environment with the IPython notebook and
87 NumPy 1.6, which is older than the version that comes with Anaconda by
88 default, you would run
89
90 .. code-block:: bash
91
92 $ conda create -n numpy16 ipython-notebook numpy=1.6
93
94 This creates an environment called ``numpy16`` with the latest version of
95 the IPython notebook, NumPy 1.6, and their dependencies.
96
97 We can now activate this environment, use
98
99 .. code-block:: bash
100
101 # On Linux and Mac OS X
102 $ source activate numpy16
103
104 # On Windows
105 > activate numpy16
106
107 This puts the bin directory of the ``numpy16`` environment in the front of the
108 ``PATH``, and sets it as the default environment for all subsequent conda commands.
109
110 To go back to the root environment, use
111
112 .. code-block:: bash
113
114 # On Linux and Mac OS X
115 $ source deactivate
116
117 # On Windows
118 > deactivate
119
120
121 Building Your Own Packages
122 --------------------------
123
124 You can easily build your own packages for conda, and upload them
125 to `anaconda.org <https://anaconda.org>`_, a free service for hosting
126 packages for conda, as well as other package managers.
127 To build a package, create a recipe.
128 See http://github.com/conda/conda-recipes for many example recipes, and
129 http://docs.continuum.io/conda/build.html for documentation on how to build
130 recipes.
131
132 To upload to anaconda.org, create an account. Then, install the
133 anaconda-client and login
134
135 .. code-block:: bash
136
137 $ conda install anaconda-client
138 $ anaconda login
139
140 Then, after you build your recipe
141
142 .. code-block:: bash
143
144 $ conda build <recipe-dir>
145
146 you will be prompted to upload to anaconda.org.
147
148 To add your anaconda.org channel, or the channel of others to conda so
149 that ``conda install`` will find and install their packages, run
150
151 .. code-block:: bash
152
153 $ conda config --add channels https://conda.anaconda.org/username
154
155 (replacing ``username`` with the user name of the person whose channel you want
156 to add).
157
158 Getting Help
159 ------------
160
161 The documentation for conda is at http://conda.pydata.org/docs/. You can
162 subscribe to the `conda mailing list
163 <https://groups.google.com/a/continuum.io/forum/#!forum/conda>`_. The source
164 code and issue tracker for conda are on `GitHub <https://github.com/conda/conda>`_.
165
166 Contributing
167 ------------
168
169 Contributions to conda are welcome. Just fork the GitHub repository and send a
170 pull request.
171
172 To develop on conda, the easiest way is to use a development build. This can be
173 accomplished as follows:
174
175 * clone the conda git repository to a computer with conda already installed
176 * navigate to the root directory of the git clone
177 * run ``$CONDA/bin/python setup.py develop`` where ``$CONDA`` is the path to your
178 miniconda installation
179
180 Note building a development file requires git to be installed.
181
182 To undo this, run ``$CONDA/bin/python setup.py develop -u``. Note that if you
183 used a python other than ``$CONDA/bin/python`` to install, you may have to manually
184 delete the conda executable. For example, on OS X, if you use a homebrew python
185 located at ``/usr/local/bin/python``, then you'll need to ``rm /usr/local/bin/conda``
186 so that ``which -a conda`` lists first your miniconda installation.
187
188 If you are worried about breaking your conda installation, you can install a
189 separate instance of `Miniconda <http://conda.pydata.org/miniconda.html>`_ and
190 work off it. This is also the only way to test conda in both Python 2 and
191 Python 3, as conda can only be installed into a root environment.
192
193 To run the tests, set up a testing environment by running
194
195 * ``$CONDA/bin/python -m pip install -r utils/requirements-test.txt``.
196 * ``$CONDA/bin/python utils/setup-testing.py develop``
197
198 and then running ``py.test`` in the conda directory. You can also run tests using the
199 Makefile by running ``make unit``, ``make smoketest`` (a single integration test), or
200 ``make integration``. The tests are also run by various CI systems when you make a
201 pull request.
202
[end of README.rst]
[start of conda/cli/conda_argparse.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from argparse import (ArgumentParser as ArgumentParserBase, RawDescriptionHelpFormatter, SUPPRESS,
5 _CountAction, _HelpAction)
6 import os
7 import sys
8
9 from ..base.context import context
10 from ..common.constants import NULL
11
12
13 class ArgumentParser(ArgumentParserBase):
14 def __init__(self, *args, **kwargs):
15 if not kwargs.get('formatter_class'):
16 kwargs['formatter_class'] = RawDescriptionHelpFormatter
17 if 'add_help' not in kwargs:
18 add_custom_help = True
19 kwargs['add_help'] = False
20 else:
21 add_custom_help = False
22 super(ArgumentParser, self).__init__(*args, **kwargs)
23
24 if add_custom_help:
25 add_parser_help(self)
26
27 if self.description:
28 self.description += "\n\nOptions:\n"
29
30 def _get_action_from_name(self, name):
31 """Given a name, get the Action instance registered with this parser.
32 If only it were made available in the ArgumentError object. It is
33 passed as it's first arg...
34 """
35 container = self._actions
36 if name is None:
37 return None
38 for action in container:
39 if '/'.join(action.option_strings) == name:
40 return action
41 elif action.metavar == name:
42 return action
43 elif action.dest == name:
44 return action
45
46 def error(self, message):
47 import re
48 import subprocess
49 from .find_commands import find_executable
50
51 exc = sys.exc_info()[1]
52 if exc:
53 # this is incredibly lame, but argparse stupidly does not expose
54 # reasonable hooks for customizing error handling
55 if hasattr(exc, 'argument_name'):
56 argument = self._get_action_from_name(exc.argument_name)
57 else:
58 argument = None
59 if argument and argument.dest == "cmd":
60 m = re.compile(r"invalid choice: '([\w\-]+)'").match(exc.message)
61 if m:
62 cmd = m.group(1)
63 executable = find_executable('conda-' + cmd)
64 if not executable:
65 from ..exceptions import CommandNotFoundError
66 raise CommandNotFoundError(cmd)
67
68 args = [find_executable('conda-' + cmd)]
69 args.extend(sys.argv[2:])
70 p = subprocess.Popen(args)
71 try:
72 p.communicate()
73 except KeyboardInterrupt:
74 p.wait()
75 finally:
76 sys.exit(p.returncode)
77
78 super(ArgumentParser, self).error(message)
79
80 def print_help(self):
81 super(ArgumentParser, self).print_help()
82
83 if self.prog == 'conda' and sys.argv[1:] in ([], ['help'], ['-h'], ['--help']):
84 print("""
85 other commands, such as "conda build", are avaialble when additional conda
86 packages (e.g. conda-build) are installed
87 """)
88
89
90 class NullCountAction(_CountAction):
91
92 @staticmethod
93 def _ensure_value(namespace, name, value):
94 if getattr(namespace, name, NULL) in (NULL, None):
95 setattr(namespace, name, value)
96 return getattr(namespace, name)
97
98 def __call__(self, parser, namespace, values, option_string=None):
99 new_count = self._ensure_value(namespace, self.dest, 0) + 1
100 setattr(namespace, self.dest, new_count)
101
102
103 def add_parser_create_install_update(p):
104 add_parser_yes(p)
105 p.add_argument(
106 '-f', "--force",
107 action="store_true",
108 default=NULL,
109 help="Force install (even when package already installed), "
110 "implies --no-deps.",
111 )
112 add_parser_pscheck(p)
113 # Add the file kwarg. We don't use {action="store", nargs='*'} as we don't
114 # want to gobble up all arguments after --file.
115 p.add_argument(
116 "--file",
117 default=[],
118 action='append',
119 help="Read package versions from the given file. Repeated file "
120 "specifications can be passed (e.g. --file=file1 --file=file2).",
121 )
122 add_parser_known(p)
123 p.add_argument(
124 "--no-deps",
125 action="store_true",
126 help="Do not install dependencies.",
127 )
128 p.add_argument(
129 "--only-deps",
130 action="store_true",
131 help="Only install dependencies.",
132 )
133 p.add_argument(
134 '-m', "--mkdir",
135 action="store_true",
136 help="Create the environment directory if necessary.",
137 )
138 add_parser_use_index_cache(p)
139 add_parser_use_local(p)
140 add_parser_offline(p)
141 add_parser_no_pin(p)
142 add_parser_channels(p)
143 add_parser_prefix(p)
144 add_parser_quiet(p)
145 add_parser_copy(p)
146 add_parser_insecure(p)
147 p.add_argument(
148 "--alt-hint",
149 action="store_true",
150 default=False,
151 help="Use an alternate algorithm to generate an unsatisfiability hint.")
152 p.add_argument(
153 "--update-dependencies", "--update-deps",
154 action="store_true",
155 dest="update_deps",
156 default=NULL,
157 help="Update dependencies (default: %s)." % context.update_dependencies,
158 )
159 p.add_argument(
160 "--no-update-dependencies", "--no-update-deps",
161 action="store_false",
162 dest="update_deps",
163 default=NULL,
164 help="Don't update dependencies (default: %s)." % (not context.update_dependencies,),
165 )
166 p.add_argument(
167 "--channel-priority", "--channel-pri", "--chan-pri",
168 action="store_true",
169 dest="channel_priority",
170 default=NULL,
171 help="Channel priority takes precedence over package version (default: %s). "
172 "Note: This feature is in beta and may change in a future release."
173 "" % (context.channel_priority,)
174 )
175 p.add_argument(
176 "--no-channel-priority", "--no-channel-pri", "--no-chan-pri",
177 action="store_false",
178 dest="channel_priority",
179 default=NULL,
180 help="Package version takes precedence over channel priority (default: %s). "
181 "Note: This feature is in beta and may change in a future release."
182 "" % (not context.channel_priority,)
183 )
184 p.add_argument(
185 "--clobber",
186 action="store_true",
187 default=NULL,
188 help="Allow clobbering of overlapping file paths within packages, "
189 "and suppress related warnings.",
190 )
191 add_parser_show_channel_urls(p)
192
193 if 'update' in p.prog:
194 # I don't know if p.prog is the correct thing to use here but it's the
195 # only thing that seemed to contain the command name
196 p.add_argument(
197 'packages',
198 metavar='package_spec',
199 action="store",
200 nargs='*',
201 help="Packages to update in the conda environment.",
202 )
203 else: # create or install
204 # Same as above except the completer is not only installed packages
205 p.add_argument(
206 'packages',
207 metavar='package_spec',
208 action="store",
209 nargs='*',
210 help="Packages to install into the conda environment.",
211 )
212
213
214 def add_parser_pscheck(p):
215 p.add_argument(
216 "--force-pscheck",
217 action="store_true",
218 help=("No-op. Included for backwards compatibility (deprecated)."
219 if context.platform == 'win' else SUPPRESS)
220 )
221
222
223 def add_parser_use_local(p):
224 p.add_argument(
225 "--use-local",
226 action="store_true",
227 default=False,
228 help="Use locally built packages.",
229 )
230
231
232 def add_parser_offline(p):
233 p.add_argument(
234 "--offline",
235 action='store_true',
236 default=NULL,
237 help="Offline mode, don't connect to the Internet.",
238 )
239
240
241 def add_parser_no_pin(p):
242 p.add_argument(
243 "--no-pin",
244 action="store_false",
245 dest='respect_pinned',
246 default=NULL,
247 help="Ignore pinned file.",
248 )
249
250
251 def add_parser_show_channel_urls(p):
252 p.add_argument(
253 "--show-channel-urls",
254 action="store_true",
255 dest="show_channel_urls",
256 default=NULL,
257 help="Show channel urls (default: %s)." % context.show_channel_urls,
258 )
259 p.add_argument(
260 "--no-show-channel-urls",
261 action="store_false",
262 dest="show_channel_urls",
263 help="Don't show channel urls.",
264 )
265
266
267 def add_parser_copy(p):
268 p.add_argument(
269 '--copy',
270 action="store_true",
271 default=NULL,
272 help="Install all packages using copies instead of hard- or soft-linking."
273 )
274
275
276 def add_parser_help(p):
277 """
278 So we can use consistent capitalization and periods in the help. You must
279 use the add_help=False argument to ArgumentParser or add_parser to use
280 this. Add this first to be consistent with the default argparse output.
281
282 """
283 p.add_argument(
284 '-h', '--help',
285 action=_HelpAction,
286 help="Show this help message and exit.",
287 )
288
289
290 def add_parser_prefix(p):
291 npgroup = p.add_mutually_exclusive_group()
292 npgroup.add_argument(
293 '-n', "--name",
294 action="store",
295 help="Name of environment (in %s)." % os.pathsep.join(context.envs_dirs),
296 metavar="ENVIRONMENT",
297 )
298 npgroup.add_argument(
299 '-p', "--prefix",
300 action="store",
301 help="Full path to environment prefix (default: %s)." % context.default_prefix,
302 metavar='PATH',
303 )
304
305
306 def add_parser_yes(p):
307 p.add_argument(
308 "-y", "--yes",
309 action="store_true",
310 default=NULL,
311 help="Do not ask for confirmation.",
312 )
313 p.add_argument(
314 "--dry-run",
315 action="store_true",
316 help="Only display what would have been done.",
317 )
318
319
320 def add_parser_json(p):
321 p.add_argument(
322 "--json",
323 action="store_true",
324 default=NULL,
325 help="Report all output as json. Suitable for using conda programmatically."
326 )
327 p.add_argument(
328 "--debug",
329 action="store_true",
330 default=NULL,
331 help="Show debug output.",
332 )
333 p.add_argument(
334 "--verbose", "-v",
335 action=NullCountAction,
336 help="Use once for info, twice for debug, three times for trace.",
337 dest="verbosity",
338 default=NULL,
339 )
340
341
342 def add_parser_quiet(p):
343 p.add_argument(
344 '-q', "--quiet",
345 action="store_true",
346 default=NULL,
347 help="Do not display progress bar.",
348 )
349
350
351 def add_parser_channels(p):
352 p.add_argument(
353 '-c', '--channel',
354 dest='channel', # apparently conda-build uses this; someday rename to channels are remove context.channels alias to channel # NOQA
355 # TODO: if you ever change 'channel' to 'channels', make sure you modify the context.channels property accordingly # NOQA
356 action="append",
357 help="""Additional channel to search for packages. These are URLs searched in the order
358 they are given (including file:// for local directories). Then, the defaults
359 or channels from .condarc are searched (unless --override-channels is given). You can use
360 'defaults' to get the default packages for conda, and 'system' to get the system
361 packages, which also takes .condarc into account. You can also use any name and the
362 .condarc channel_alias value will be prepended. The default channel_alias
363 is http://conda.anaconda.org/.""",
364 )
365 p.add_argument(
366 "--override-channels",
367 action="store_true",
368 help="""Do not search default or .condarc channels. Requires --channel.""",
369 )
370
371
372 def add_parser_known(p):
373 p.add_argument(
374 "--unknown",
375 action="store_true",
376 default=False,
377 dest='unknown',
378 help=SUPPRESS,
379 )
380
381
382 def add_parser_use_index_cache(p):
383 p.add_argument(
384 "-C", "--use-index-cache",
385 action="store_true",
386 default=False,
387 help="Use cache of channel index files, even if it has expired.",
388 )
389
390
391 def add_parser_insecure(p):
392 p.add_argument(
393 "-k", "--insecure",
394 action="store_false",
395 default=NULL,
396 help="Allow conda to perform \"insecure\" SSL connections and transfers."
397 "Equivalent to setting 'ssl_verify' to 'false'."
398 )
399
[end of conda/cli/conda_argparse.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
conda/conda
|
98c6d80f3299edf775b495f90651d558248d2cf8
|
conda should exec to non-conda subcommands, not subprocess
|
2017-05-18T13:17:36Z
|
<patch>
diff --git a/conda/cli/conda_argparse.py b/conda/cli/conda_argparse.py
--- a/conda/cli/conda_argparse.py
+++ b/conda/cli/conda_argparse.py
@@ -45,7 +45,6 @@ def _get_action_from_name(self, name):
def error(self, message):
import re
- import subprocess
from .find_commands import find_executable
exc = sys.exc_info()[1]
@@ -57,7 +56,7 @@ def error(self, message):
else:
argument = None
if argument and argument.dest == "cmd":
- m = re.compile(r"invalid choice: '([\w\-]+)'").match(exc.message)
+ m = re.compile(r"invalid choice: u?'([\w\-]+)'").match(exc.message)
if m:
cmd = m.group(1)
executable = find_executable('conda-' + cmd)
@@ -67,13 +66,7 @@ def error(self, message):
args = [find_executable('conda-' + cmd)]
args.extend(sys.argv[2:])
- p = subprocess.Popen(args)
- try:
- p.communicate()
- except KeyboardInterrupt:
- p.wait()
- finally:
- sys.exit(p.returncode)
+ os.execv(args[0], args)
super(ArgumentParser, self).error(message)
</patch>
|
[]
|
[]
| ||||
pandas-dev__pandas-9743
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[] (__getitem__) boolean indexing assignment bug with nans
See repro below:
``` python
import pandas as pd
import numpy as np
temp = pd.Series(np.random.randn(10))
temp[3:6] = np.nan
temp[8] = np.nan
nan_index = np.isnan(temp)
# this works
temp1 = temp.copy()
temp1[nan_index] = [99, 99, 99, 99]
temp1[nan_index]
3 99
4 99
5 99
8 99
dtype: float64
# this doesn't - values look like they're being assigned in a different order?
temp2 = temp.copy()
temp2[nan_index] = [99, 99, 99, np.nan]
3 NaN
4 99
5 99
8 99
dtype: float64
# ... but it works properly when using .loc
temp2 = temp.copy()
temp2.loc[nan_index] = [99, 99, 99, np.nan]
3 99
4 99
5 99
8 NaN
dtype: float64
```
output of show_versions():
```
INSTALLED VERSIONS
------------------
commit: None
python: 2.7.9.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 60 Stepping 3, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.16.0
nose: 1.3.4
Cython: 0.21.2
numpy: 1.9.2
scipy: 0.14.0
statsmodels: 0.5.0
IPython: 3.0.0
sphinx: 1.2.3
patsy: 0.2.1
dateutil: 2.4.1
pytz: 2015.2
bottleneck: 0.8.0
tables: 3.1.1
numexpr: 2.3.1
matplotlib: 1.4.0
openpyxl: 2.0.2
xlrd: 0.9.3
xlwt: 0.7.5
xlsxwriter: 0.6.6
lxml: 3.4.2
bs4: 4.3.2
html5lib: 0.999
httplib2: 0.8
apiclient: None
sqlalchemy: 0.9.8
pymysql: None
psycopg2: None
```
</issue>
<code>
[start of README.md]
1 # pandas: powerful Python data analysis toolkit
2
3 
4
5 ## What is it
6
7 **pandas** is a Python package providing fast, flexible, and expressive data
8 structures designed to make working with "relational" or "labeled" data both
9 easy and intuitive. It aims to be the fundamental high-level building block for
10 doing practical, **real world** data analysis in Python. Additionally, it has
11 the broader goal of becoming **the most powerful and flexible open source data
12 analysis / manipulation tool available in any language**. It is already well on
13 its way toward this goal.
14
15 ## Main Features
16 Here are just a few of the things that pandas does well:
17
18 - Easy handling of [**missing data**][missing-data] (represented as
19 `NaN`) in floating point as well as non-floating point data
20 - Size mutability: columns can be [**inserted and
21 deleted**][insertion-deletion] from DataFrame and higher dimensional
22 objects
23 - Automatic and explicit [**data alignment**][alignment]: objects can
24 be explicitly aligned to a set of labels, or the user can simply
25 ignore the labels and let `Series`, `DataFrame`, etc. automatically
26 align the data for you in computations
27 - Powerful, flexible [**group by**][groupby] functionality to perform
28 split-apply-combine operations on data sets, for both aggregating
29 and transforming data
30 - Make it [**easy to convert**][conversion] ragged,
31 differently-indexed data in other Python and NumPy data structures
32 into DataFrame objects
33 - Intelligent label-based [**slicing**][slicing], [**fancy
34 indexing**][fancy-indexing], and [**subsetting**][subsetting] of
35 large data sets
36 - Intuitive [**merging**][merging] and [**joining**][joining] data
37 sets
38 - Flexible [**reshaping**][reshape] and [**pivoting**][pivot-table] of
39 data sets
40 - [**Hierarchical**][mi] labeling of axes (possible to have multiple
41 labels per tick)
42 - Robust IO tools for loading data from [**flat files**][flat-files]
43 (CSV and delimited), [**Excel files**][excel], [**databases**][db],
44 and saving/loading data from the ultrafast [**HDF5 format**][hdfstore]
45 - [**Time series**][timeseries]-specific functionality: date range
46 generation and frequency conversion, moving window statistics,
47 moving window linear regressions, date shifting and lagging, etc.
48
49
50 [missing-data]: http://pandas.pydata.org/pandas-docs/stable/missing_data.html#working-with-missing-data
51 [insertion-deletion]: http://pandas.pydata.org/pandas-docs/stable/dsintro.html#column-selection-addition-deletion
52 [alignment]: http://pandas.pydata.org/pandas-docs/stable/dsintro.html?highlight=alignment#intro-to-data-structures
53 [groupby]: http://pandas.pydata.org/pandas-docs/stable/groupby.html#group-by-split-apply-combine
54 [conversion]: http://pandas.pydata.org/pandas-docs/stable/dsintro.html#dataframe
55 [slicing]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#slicing-ranges
56 [fancy-indexing]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#advanced-indexing-with-ix
57 [subsetting]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#boolean-indexing
58 [merging]: http://pandas.pydata.org/pandas-docs/stable/merging.html#database-style-dataframe-joining-merging
59 [joining]: http://pandas.pydata.org/pandas-docs/stable/merging.html#joining-on-index
60 [reshape]: http://pandas.pydata.org/pandas-docs/stable/reshaping.html#reshaping-and-pivot-tables
61 [pivot-table]: http://pandas.pydata.org/pandas-docs/stable/reshaping.html#pivot-tables-and-cross-tabulations
62 [mi]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#hierarchical-indexing-multiindex
63 [flat-files]: http://pandas.pydata.org/pandas-docs/stable/io.html#csv-text-files
64 [excel]: http://pandas.pydata.org/pandas-docs/stable/io.html#excel-files
65 [db]: http://pandas.pydata.org/pandas-docs/stable/io.html#sql-queries
66 [hdfstore]: http://pandas.pydata.org/pandas-docs/stable/io.html#hdf5-pytables
67 [timeseries]: http://pandas.pydata.org/pandas-docs/stable/timeseries.html#time-series-date-functionality
68
69 ## Where to get it
70 The source code is currently hosted on GitHub at:
71 http://github.com/pydata/pandas
72
73 Binary installers for the latest released version are available at the Python
74 package index
75
76 http://pypi.python.org/pypi/pandas/
77
78 And via `easy_install`:
79
80 ```sh
81 easy_install pandas
82 ```
83
84 or `pip`:
85
86 ```sh
87 pip install pandas
88 ```
89
90 or `conda`:
91
92 ```sh
93 conda install pandas
94 ```
95
96 ## Dependencies
97 - [NumPy](http://www.numpy.org): 1.7.0 or higher
98 - [python-dateutil](http://labix.org/python-dateutil): 1.5 or higher
99 - [pytz](http://pytz.sourceforge.net)
100 - Needed for time zone support with ``pandas.date_range``
101
102 ### Highly Recommended Dependencies
103 - [numexpr](https://github.com/pydata/numexpr)
104 - Needed to accelerate some expression evaluation operations
105 - Required by PyTables
106 - [bottleneck](http://berkeleyanalytics.com/bottleneck)
107 - Needed to accelerate certain numerical operations
108
109 ### Optional dependencies
110 - [Cython](http://www.cython.org): Only necessary to build development version. Version 0.17.1 or higher.
111 - [SciPy](http://www.scipy.org): miscellaneous statistical functions
112 - [PyTables](http://www.pytables.org): necessary for HDF5-based storage
113 - [SQLAlchemy](http://www.sqlalchemy.org): for SQL database support. Version 0.8.1 or higher recommended.
114 - [matplotlib](http://matplotlib.sourceforge.net/): for plotting
115 - [statsmodels](http://statsmodels.sourceforge.net/)
116 - Needed for parts of `pandas.stats`
117 - For Excel I/O:
118 - [xlrd/xlwt](http://www.python-excel.org/)
119 - Excel reading (xlrd) and writing (xlwt)
120 - [openpyxl](http://packages.python.org/openpyxl/)
121 - openpyxl version 1.6.1 or higher, but lower than 2.0.0, for
122 writing .xlsx files
123 - xlrd >= 0.9.0
124 - [XlsxWriter](https://pypi.python.org/pypi/XlsxWriter)
125 - Alternative Excel writer.
126 - [Google bq Command Line Tool](https://developers.google.com/bigquery/bq-command-line-tool/)
127 - Needed for `pandas.io.gbq`
128 - [boto](https://pypi.python.org/pypi/boto): necessary for Amazon S3 access.
129 - One of the following combinations of libraries is needed to use the
130 top-level [`pandas.read_html`][read-html-docs] function:
131 - [BeautifulSoup4][BeautifulSoup4] and [html5lib][html5lib] (Any
132 recent version of [html5lib][html5lib] is okay.)
133 - [BeautifulSoup4][BeautifulSoup4] and [lxml][lxml]
134 - [BeautifulSoup4][BeautifulSoup4] and [html5lib][html5lib] and [lxml][lxml]
135 - Only [lxml][lxml], although see [HTML reading gotchas][html-gotchas]
136 for reasons as to why you should probably **not** take this approach.
137
138 #### Notes about HTML parsing libraries
139 - If you install [BeautifulSoup4][BeautifulSoup4] you must install
140 either [lxml][lxml] or [html5lib][html5lib] or both.
141 `pandas.read_html` will **not** work with *only* `BeautifulSoup4`
142 installed.
143 - You are strongly encouraged to read [HTML reading
144 gotchas][html-gotchas]. It explains issues surrounding the
145 installation and usage of the above three libraries.
146 - You may need to install an older version of
147 [BeautifulSoup4][BeautifulSoup4]:
148 - Versions 4.2.1, 4.1.3 and 4.0.2 have been confirmed for 64 and
149 32-bit Ubuntu/Debian
150 - Additionally, if you're using [Anaconda][Anaconda] you should
151 definitely read [the gotchas about HTML parsing][html-gotchas]
152 libraries
153 - If you're on a system with `apt-get` you can do
154
155 ```sh
156 sudo apt-get build-dep python-lxml
157 ```
158
159 to get the necessary dependencies for installation of [lxml][lxml].
160 This will prevent further headaches down the line.
161
162 [html5lib]: https://github.com/html5lib/html5lib-python "html5lib"
163 [BeautifulSoup4]: http://www.crummy.com/software/BeautifulSoup "BeautifulSoup4"
164 [lxml]: http://lxml.de
165 [Anaconda]: https://store.continuum.io/cshop/anaconda
166 [NumPy]: http://numpy.scipy.org/
167 [html-gotchas]: http://pandas.pydata.org/pandas-docs/stable/gotchas.html#html-table-parsing
168 [read-html-docs]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.io.html.read_html.html#pandas.io.html.read_html
169
170 ## Installation from sources
171 To install pandas from source you need Cython in addition to the normal
172 dependencies above. Cython can be installed from pypi:
173
174 ```sh
175 pip install cython
176 ```
177
178 In the `pandas` directory (same one where you found this file after
179 cloning the git repo), execute:
180
181 ```sh
182 python setup.py install
183 ```
184
185 or for installing in [development mode](http://www.pip-installer.org/en/latest/usage.html):
186
187 ```sh
188 python setup.py develop
189 ```
190
191 Alternatively, you can use `pip` if you want all the dependencies pulled
192 in automatically (the `-e` option is for installing it in [development
193 mode](http://www.pip-installer.org/en/latest/usage.html)):
194
195 ```sh
196 pip install -e .
197 ```
198
199 On Windows, you will need to install MinGW and execute:
200
201 ```sh
202 python setup.py build --compiler=mingw32
203 python setup.py install
204 ```
205
206 See http://pandas.pydata.org/ for more information.
207
208 ## License
209 BSD
210
211 ## Documentation
212 The official documentation is hosted on PyData.org: http://pandas.pydata.org/
213
214 The Sphinx documentation should provide a good starting point for learning how
215 to use the library. Expect the docs to continue to expand as time goes on.
216
217 ## Background
218 Work on ``pandas`` started at AQR (a quantitative hedge fund) in 2008 and
219 has been under active development since then.
220
221 ## Discussion and Development
222 Since pandas development is related to a number of other scientific
223 Python projects, questions are welcome on the scipy-user mailing
224 list. Specialized discussions or design issues should take place on
225 the PyData mailing list / Google group:
226
227 https://groups.google.com/forum/#!forum/pydata
228
[end of README.md]
[start of doc/source/whatsnew/v0.16.1.txt]
1 .. _whatsnew_0161:
2
3 v0.16.1 (April ??, 2015)
4 ------------------------
5
6 This is a minor bug-fix release from 0.16.0 and includes a a large number of
7 bug fixes along several new features, enhancements, and performance improvements.
8 We recommend that all users upgrade to this version.
9
10 .. contents:: What's new in v0.16.1
11 :local:
12 :backlinks: none
13
14
15 .. _whatsnew_0161.enhancements:
16
17 Enhancements
18 ~~~~~~~~~~~~
19
20
21
22
23
24
25 .. _whatsnew_0161.api:
26
27 API changes
28 ~~~~~~~~~~~
29
30
31
32
33
34
35 - Add support for separating years and quarters using dashes, for
36 example 2014-Q1. (:issue:`9688`)
37
38 .. _whatsnew_0161.performance:
39
40 Performance Improvements
41 ~~~~~~~~~~~~~~~~~~~~~~~~
42
43
44
45
46
47
48 .. _whatsnew_0161.bug_fixes:
49
50 Bug Fixes
51 ~~~~~~~~~
52
53
54
55
56
57 - Bug in ``transform`` causing length mismatch when null entries were present and a fast aggregator was being used (:issue:`9697`)
58
59
60
61
62
63
64
65
66 - Bug in ``Series.quantile`` on empty Series of type ``Datetime`` or ``Timedelta`` (:issue:`9675`)
67
[end of doc/source/whatsnew/v0.16.1.txt]
[start of pandas/core/common.py]
1 """
2 Misc tools for implementing data structures
3 """
4
5 import re
6 import collections
7 import numbers
8 import codecs
9 import csv
10 import types
11 from datetime import datetime, timedelta
12 from functools import partial
13
14 from numpy.lib.format import read_array, write_array
15 import numpy as np
16
17 import pandas as pd
18 import pandas.algos as algos
19 import pandas.lib as lib
20 import pandas.tslib as tslib
21 from pandas import compat
22 from pandas.compat import StringIO, BytesIO, range, long, u, zip, map, string_types
23
24 from pandas.core.config import get_option
25
26 class PandasError(Exception):
27 pass
28
29
30 class SettingWithCopyError(ValueError):
31 pass
32
33
34 class SettingWithCopyWarning(Warning):
35 pass
36
37
38 class AmbiguousIndexError(PandasError, KeyError):
39 pass
40
41
42 _POSSIBLY_CAST_DTYPES = set([np.dtype(t).name
43 for t in ['O', 'int8',
44 'uint8', 'int16', 'uint16', 'int32',
45 'uint32', 'int64', 'uint64']])
46
47 _NS_DTYPE = np.dtype('M8[ns]')
48 _TD_DTYPE = np.dtype('m8[ns]')
49 _INT64_DTYPE = np.dtype(np.int64)
50 _DATELIKE_DTYPES = set([np.dtype(t) for t in ['M8[ns]', '<M8[ns]', '>M8[ns]',
51 'm8[ns]', '<m8[ns]', '>m8[ns]']])
52 _int8_max = np.iinfo(np.int8).max
53 _int16_max = np.iinfo(np.int16).max
54 _int32_max = np.iinfo(np.int32).max
55
56 # define abstract base classes to enable isinstance type checking on our
57 # objects
58 def create_pandas_abc_type(name, attr, comp):
59 @classmethod
60 def _check(cls, inst):
61 return getattr(inst, attr, '_typ') in comp
62 dct = dict(__instancecheck__=_check,
63 __subclasscheck__=_check)
64 meta = type("ABCBase", (type,), dct)
65 return meta(name, tuple(), dct)
66
67
68 ABCIndex = create_pandas_abc_type("ABCIndex", "_typ", ("index",))
69 ABCInt64Index = create_pandas_abc_type("ABCInt64Index", "_typ", ("int64index",))
70 ABCFloat64Index = create_pandas_abc_type("ABCFloat64Index", "_typ", ("float64index",))
71 ABCMultiIndex = create_pandas_abc_type("ABCMultiIndex", "_typ", ("multiindex",))
72 ABCDatetimeIndex = create_pandas_abc_type("ABCDatetimeIndex", "_typ", ("datetimeindex",))
73 ABCTimedeltaIndex = create_pandas_abc_type("ABCTimedeltaIndex", "_typ", ("timedeltaindex",))
74 ABCPeriodIndex = create_pandas_abc_type("ABCPeriodIndex", "_typ", ("periodindex",))
75 ABCSeries = create_pandas_abc_type("ABCSeries", "_typ", ("series",))
76 ABCDataFrame = create_pandas_abc_type("ABCDataFrame", "_typ", ("dataframe",))
77 ABCPanel = create_pandas_abc_type("ABCPanel", "_typ", ("panel",))
78 ABCSparseSeries = create_pandas_abc_type("ABCSparseSeries", "_subtyp",
79 ('sparse_series',
80 'sparse_time_series'))
81 ABCSparseArray = create_pandas_abc_type("ABCSparseArray", "_subtyp",
82 ('sparse_array', 'sparse_series'))
83 ABCCategorical = create_pandas_abc_type("ABCCategorical","_typ",("categorical"))
84 ABCPeriod = create_pandas_abc_type("ABCPeriod", "_typ", ("period",))
85
86 class _ABCGeneric(type):
87
88 def __instancecheck__(cls, inst):
89 return hasattr(inst, "_data")
90
91
92 ABCGeneric = _ABCGeneric("ABCGeneric", tuple(), {})
93
94
95 def bind_method(cls, name, func):
96 """Bind a method to class, python 2 and python 3 compatible.
97
98 Parameters
99 ----------
100
101 cls : type
102 class to receive bound method
103 name : basestring
104 name of method on class instance
105 func : function
106 function to be bound as method
107
108
109 Returns
110 -------
111 None
112 """
113 # only python 2 has bound/unbound method issue
114 if not compat.PY3:
115 setattr(cls, name, types.MethodType(func, None, cls))
116 else:
117 setattr(cls, name, func)
118
119 class CategoricalDtypeType(type):
120 """
121 the type of CategoricalDtype, this metaclass determines subclass ability
122 """
123 def __init__(cls, name, bases, attrs):
124 pass
125
126 class CategoricalDtype(object):
127 __meta__ = CategoricalDtypeType
128 """
129 A np.dtype duck-typed class, suitable for holding a custom categorical dtype.
130
131 THIS IS NOT A REAL NUMPY DTYPE, but essentially a sub-class of np.object
132 """
133 name = 'category'
134 names = None
135 type = CategoricalDtypeType
136 subdtype = None
137 kind = 'O'
138 str = '|O08'
139 num = 100
140 shape = tuple()
141 itemsize = 8
142 base = np.dtype('O')
143 isbuiltin = 0
144 isnative = 0
145
146 def __unicode__(self):
147 return self.name
148
149 def __str__(self):
150 """
151 Return a string representation for a particular Object
152
153 Invoked by str(df) in both py2/py3.
154 Yields Bytestring in Py2, Unicode String in py3.
155 """
156
157 if compat.PY3:
158 return self.__unicode__()
159 return self.__bytes__()
160
161 def __bytes__(self):
162 """
163 Return a string representation for a particular object.
164
165 Invoked by bytes(obj) in py3 only.
166 Yields a bytestring in both py2/py3.
167 """
168 from pandas.core.config import get_option
169
170 encoding = get_option("display.encoding")
171 return self.__unicode__().encode(encoding, 'replace')
172
173 def __repr__(self):
174 """
175 Return a string representation for a particular object.
176
177 Yields Bytestring in Py2, Unicode String in py3.
178 """
179 return str(self)
180
181 def __hash__(self):
182 # make myself hashable
183 return hash(str(self))
184
185 def __eq__(self, other):
186 if isinstance(other, compat.string_types):
187 return other == self.name
188
189 return isinstance(other, CategoricalDtype)
190
191 def isnull(obj):
192 """Detect missing values (NaN in numeric arrays, None/NaN in object arrays)
193
194 Parameters
195 ----------
196 arr : ndarray or object value
197 Object to check for null-ness
198
199 Returns
200 -------
201 isnulled : array-like of bool or bool
202 Array or bool indicating whether an object is null or if an array is
203 given which of the element is null.
204
205 See also
206 --------
207 pandas.notnull: boolean inverse of pandas.isnull
208 """
209 return _isnull(obj)
210
211
212 def _isnull_new(obj):
213 if lib.isscalar(obj):
214 return lib.checknull(obj)
215 # hack (for now) because MI registers as ndarray
216 elif isinstance(obj, pd.MultiIndex):
217 raise NotImplementedError("isnull is not defined for MultiIndex")
218 elif isinstance(obj, (ABCSeries, np.ndarray, pd.Index)):
219 return _isnull_ndarraylike(obj)
220 elif isinstance(obj, ABCGeneric):
221 return obj._constructor(obj._data.isnull(func=isnull))
222 elif isinstance(obj, list) or hasattr(obj, '__array__'):
223 return _isnull_ndarraylike(np.asarray(obj))
224 else:
225 return obj is None
226
227
228 def _isnull_old(obj):
229 """Detect missing values. Treat None, NaN, INF, -INF as null.
230
231 Parameters
232 ----------
233 arr: ndarray or object value
234
235 Returns
236 -------
237 boolean ndarray or boolean
238 """
239 if lib.isscalar(obj):
240 return lib.checknull_old(obj)
241 # hack (for now) because MI registers as ndarray
242 elif isinstance(obj, pd.MultiIndex):
243 raise NotImplementedError("isnull is not defined for MultiIndex")
244 elif isinstance(obj, (ABCSeries, np.ndarray, pd.Index)):
245 return _isnull_ndarraylike_old(obj)
246 elif isinstance(obj, ABCGeneric):
247 return obj._constructor(obj._data.isnull(func=_isnull_old))
248 elif isinstance(obj, list) or hasattr(obj, '__array__'):
249 return _isnull_ndarraylike_old(np.asarray(obj))
250 else:
251 return obj is None
252
253 _isnull = _isnull_new
254
255
256 def _use_inf_as_null(key):
257 """Option change callback for null/inf behaviour
258 Choose which replacement for numpy.isnan / -numpy.isfinite is used.
259
260 Parameters
261 ----------
262 flag: bool
263 True means treat None, NaN, INF, -INF as null (old way),
264 False means None and NaN are null, but INF, -INF are not null
265 (new way).
266
267 Notes
268 -----
269 This approach to setting global module values is discussed and
270 approved here:
271
272 * http://stackoverflow.com/questions/4859217/
273 programmatically-creating-variables-in-python/4859312#4859312
274 """
275 flag = get_option(key)
276 if flag:
277 globals()['_isnull'] = _isnull_old
278 else:
279 globals()['_isnull'] = _isnull_new
280
281
282 def _isnull_ndarraylike(obj):
283
284 values = getattr(obj, 'values', obj)
285 dtype = values.dtype
286
287 if dtype.kind in ('O', 'S', 'U'):
288 if is_categorical_dtype(values):
289 from pandas import Categorical
290 if not isinstance(values, Categorical):
291 values = values.values
292 result = values.isnull()
293 else:
294
295 # Working around NumPy ticket 1542
296 shape = values.shape
297
298 if dtype.kind in ('S', 'U'):
299 result = np.zeros(values.shape, dtype=bool)
300 else:
301 result = np.empty(shape, dtype=bool)
302 vec = lib.isnullobj(values.ravel())
303 result[...] = vec.reshape(shape)
304
305 elif is_datetimelike(obj):
306 # this is the NaT pattern
307 result = values.view('i8') == tslib.iNaT
308 else:
309 result = np.isnan(values)
310
311 # box
312 if isinstance(obj, ABCSeries):
313 from pandas import Series
314 result = Series(result, index=obj.index, name=obj.name, copy=False)
315
316 return result
317
318 def _isnull_ndarraylike_old(obj):
319 values = getattr(obj, 'values', obj)
320 dtype = values.dtype
321
322 if dtype.kind in ('O', 'S', 'U'):
323 # Working around NumPy ticket 1542
324 shape = values.shape
325
326 if values.dtype.kind in ('S', 'U'):
327 result = np.zeros(values.shape, dtype=bool)
328 else:
329 result = np.empty(shape, dtype=bool)
330 vec = lib.isnullobj_old(values.ravel())
331 result[:] = vec.reshape(shape)
332
333 elif dtype in _DATELIKE_DTYPES:
334 # this is the NaT pattern
335 result = values.view('i8') == tslib.iNaT
336 else:
337 result = ~np.isfinite(values)
338
339 # box
340 if isinstance(obj, ABCSeries):
341 from pandas import Series
342 result = Series(result, index=obj.index, name=obj.name, copy=False)
343
344 return result
345
346
347 def notnull(obj):
348 """Replacement for numpy.isfinite / -numpy.isnan which is suitable for use
349 on object arrays.
350
351 Parameters
352 ----------
353 arr : ndarray or object value
354 Object to check for *not*-null-ness
355
356 Returns
357 -------
358 isnulled : array-like of bool or bool
359 Array or bool indicating whether an object is *not* null or if an array
360 is given which of the element is *not* null.
361
362 See also
363 --------
364 pandas.isnull : boolean inverse of pandas.notnull
365 """
366 res = isnull(obj)
367 if np.isscalar(res):
368 return not res
369 return ~res
370
371 def is_null_datelike_scalar(other):
372 """ test whether the object is a null datelike, e.g. Nat
373 but guard against passing a non-scalar """
374 if other is pd.NaT or other is None:
375 return True
376 elif np.isscalar(other):
377
378 # a timedelta
379 if hasattr(other,'dtype'):
380 return other.view('i8') == tslib.iNaT
381 elif is_integer(other) and other == tslib.iNaT:
382 return True
383 return isnull(other)
384 return False
385
386 def array_equivalent(left, right, strict_nan=False):
387 """
388 True if two arrays, left and right, have equal non-NaN elements, and NaNs in
389 corresponding locations. False otherwise. It is assumed that left and right
390 are NumPy arrays of the same dtype. The behavior of this function
391 (particularly with respect to NaNs) is not defined if the dtypes are
392 different.
393
394 Parameters
395 ----------
396 left, right : ndarrays
397 strict_nan : bool, default False
398 If True, consider NaN and None to be different.
399
400 Returns
401 -------
402 b : bool
403 Returns True if the arrays are equivalent.
404
405 Examples
406 --------
407 >>> array_equivalent(
408 ... np.array([1, 2, np.nan]),
409 ... np.array([1, 2, np.nan]))
410 True
411 >>> array_equivalent(
412 ... np.array([1, np.nan, 2]),
413 ... np.array([1, 2, np.nan]))
414 False
415 """
416
417 left, right = np.asarray(left), np.asarray(right)
418 if left.shape != right.shape: return False
419
420 # Object arrays can contain None, NaN and NaT.
421 if issubclass(left.dtype.type, np.object_) or issubclass(right.dtype.type, np.object_):
422
423 if not strict_nan:
424 # pd.isnull considers NaN and None to be equivalent.
425 return lib.array_equivalent_object(_ensure_object(left.ravel()),
426 _ensure_object(right.ravel()))
427
428 for left_value, right_value in zip(left, right):
429 if left_value is tslib.NaT and right_value is not tslib.NaT:
430 return False
431
432 elif isinstance(left_value, float) and np.isnan(left_value):
433 if not isinstance(right_value, float) or not np.isnan(right_value):
434 return False
435 else:
436 if left_value != right_value:
437 return False
438 return True
439
440 # NaNs can occur in float and complex arrays.
441 if issubclass(left.dtype.type, (np.floating, np.complexfloating)):
442 return ((left == right) | (np.isnan(left) & np.isnan(right))).all()
443
444 # NaNs cannot occur otherwise.
445 return np.array_equal(left, right)
446
447 def _iterable_not_string(x):
448 return (isinstance(x, collections.Iterable) and
449 not isinstance(x, compat.string_types))
450
451
452 def flatten(l):
453 """Flatten an arbitrarily nested sequence.
454
455 Parameters
456 ----------
457 l : sequence
458 The non string sequence to flatten
459
460 Notes
461 -----
462 This doesn't consider strings sequences.
463
464 Returns
465 -------
466 flattened : generator
467 """
468 for el in l:
469 if _iterable_not_string(el):
470 for s in flatten(el):
471 yield s
472 else:
473 yield el
474
475
476 def mask_missing(arr, values_to_mask):
477 """
478 Return a masking array of same size/shape as arr
479 with entries equaling any member of values_to_mask set to True
480 """
481 if not isinstance(values_to_mask, (list, np.ndarray)):
482 values_to_mask = [values_to_mask]
483
484 try:
485 values_to_mask = np.array(values_to_mask, dtype=arr.dtype)
486 except Exception:
487 values_to_mask = np.array(values_to_mask, dtype=object)
488
489 na_mask = isnull(values_to_mask)
490 nonna = values_to_mask[~na_mask]
491
492 mask = None
493 for x in nonna:
494 if mask is None:
495 mask = arr == x
496
497 # if x is a string and arr is not, then we get False and we must
498 # expand the mask to size arr.shape
499 if np.isscalar(mask):
500 mask = np.zeros(arr.shape, dtype=bool)
501 else:
502 mask |= arr == x
503
504 if na_mask.any():
505 if mask is None:
506 mask = isnull(arr)
507 else:
508 mask |= isnull(arr)
509
510 return mask
511
512
513 def _pickle_array(arr):
514 arr = arr.view(np.ndarray)
515
516 buf = BytesIO()
517 write_array(buf, arr)
518
519 return buf.getvalue()
520
521
522 def _unpickle_array(bytes):
523 arr = read_array(BytesIO(bytes))
524
525 # All datetimes should be stored as M8[ns]. When unpickling with
526 # numpy1.6, it will read these as M8[us]. So this ensures all
527 # datetime64 types are read as MS[ns]
528 if is_datetime64_dtype(arr):
529 arr = arr.view(_NS_DTYPE)
530
531 return arr
532
533
534 def _view_wrapper(f, arr_dtype=None, out_dtype=None, fill_wrap=None):
535 def wrapper(arr, indexer, out, fill_value=np.nan):
536 if arr_dtype is not None:
537 arr = arr.view(arr_dtype)
538 if out_dtype is not None:
539 out = out.view(out_dtype)
540 if fill_wrap is not None:
541 fill_value = fill_wrap(fill_value)
542 f(arr, indexer, out, fill_value=fill_value)
543 return wrapper
544
545
546 def _convert_wrapper(f, conv_dtype):
547 def wrapper(arr, indexer, out, fill_value=np.nan):
548 arr = arr.astype(conv_dtype)
549 f(arr, indexer, out, fill_value=fill_value)
550 return wrapper
551
552
553 def _take_2d_multi_generic(arr, indexer, out, fill_value, mask_info):
554 # this is not ideal, performance-wise, but it's better than raising
555 # an exception (best to optimize in Cython to avoid getting here)
556 row_idx, col_idx = indexer
557 if mask_info is not None:
558 (row_mask, col_mask), (row_needs, col_needs) = mask_info
559 else:
560 row_mask = row_idx == -1
561 col_mask = col_idx == -1
562 row_needs = row_mask.any()
563 col_needs = col_mask.any()
564 if fill_value is not None:
565 if row_needs:
566 out[row_mask, :] = fill_value
567 if col_needs:
568 out[:, col_mask] = fill_value
569 for i in range(len(row_idx)):
570 u_ = row_idx[i]
571 for j in range(len(col_idx)):
572 v = col_idx[j]
573 out[i, j] = arr[u_, v]
574
575
576 def _take_nd_generic(arr, indexer, out, axis, fill_value, mask_info):
577 if mask_info is not None:
578 mask, needs_masking = mask_info
579 else:
580 mask = indexer == -1
581 needs_masking = mask.any()
582 if arr.dtype != out.dtype:
583 arr = arr.astype(out.dtype)
584 if arr.shape[axis] > 0:
585 arr.take(_ensure_platform_int(indexer), axis=axis, out=out)
586 if needs_masking:
587 outindexer = [slice(None)] * arr.ndim
588 outindexer[axis] = mask
589 out[tuple(outindexer)] = fill_value
590
591
592 _take_1d_dict = {
593 ('int8', 'int8'): algos.take_1d_int8_int8,
594 ('int8', 'int32'): algos.take_1d_int8_int32,
595 ('int8', 'int64'): algos.take_1d_int8_int64,
596 ('int8', 'float64'): algos.take_1d_int8_float64,
597 ('int16', 'int16'): algos.take_1d_int16_int16,
598 ('int16', 'int32'): algos.take_1d_int16_int32,
599 ('int16', 'int64'): algos.take_1d_int16_int64,
600 ('int16', 'float64'): algos.take_1d_int16_float64,
601 ('int32', 'int32'): algos.take_1d_int32_int32,
602 ('int32', 'int64'): algos.take_1d_int32_int64,
603 ('int32', 'float64'): algos.take_1d_int32_float64,
604 ('int64', 'int64'): algos.take_1d_int64_int64,
605 ('int64', 'float64'): algos.take_1d_int64_float64,
606 ('float32', 'float32'): algos.take_1d_float32_float32,
607 ('float32', 'float64'): algos.take_1d_float32_float64,
608 ('float64', 'float64'): algos.take_1d_float64_float64,
609 ('object', 'object'): algos.take_1d_object_object,
610 ('bool', 'bool'):
611 _view_wrapper(algos.take_1d_bool_bool, np.uint8, np.uint8),
612 ('bool', 'object'):
613 _view_wrapper(algos.take_1d_bool_object, np.uint8, None),
614 ('datetime64[ns]', 'datetime64[ns]'):
615 _view_wrapper(algos.take_1d_int64_int64, np.int64, np.int64, np.int64)
616 }
617
618
619 _take_2d_axis0_dict = {
620 ('int8', 'int8'): algos.take_2d_axis0_int8_int8,
621 ('int8', 'int32'): algos.take_2d_axis0_int8_int32,
622 ('int8', 'int64'): algos.take_2d_axis0_int8_int64,
623 ('int8', 'float64'): algos.take_2d_axis0_int8_float64,
624 ('int16', 'int16'): algos.take_2d_axis0_int16_int16,
625 ('int16', 'int32'): algos.take_2d_axis0_int16_int32,
626 ('int16', 'int64'): algos.take_2d_axis0_int16_int64,
627 ('int16', 'float64'): algos.take_2d_axis0_int16_float64,
628 ('int32', 'int32'): algos.take_2d_axis0_int32_int32,
629 ('int32', 'int64'): algos.take_2d_axis0_int32_int64,
630 ('int32', 'float64'): algos.take_2d_axis0_int32_float64,
631 ('int64', 'int64'): algos.take_2d_axis0_int64_int64,
632 ('int64', 'float64'): algos.take_2d_axis0_int64_float64,
633 ('float32', 'float32'): algos.take_2d_axis0_float32_float32,
634 ('float32', 'float64'): algos.take_2d_axis0_float32_float64,
635 ('float64', 'float64'): algos.take_2d_axis0_float64_float64,
636 ('object', 'object'): algos.take_2d_axis0_object_object,
637 ('bool', 'bool'):
638 _view_wrapper(algos.take_2d_axis0_bool_bool, np.uint8, np.uint8),
639 ('bool', 'object'):
640 _view_wrapper(algos.take_2d_axis0_bool_object, np.uint8, None),
641 ('datetime64[ns]', 'datetime64[ns]'):
642 _view_wrapper(algos.take_2d_axis0_int64_int64, np.int64, np.int64,
643 fill_wrap=np.int64)
644 }
645
646
647 _take_2d_axis1_dict = {
648 ('int8', 'int8'): algos.take_2d_axis1_int8_int8,
649 ('int8', 'int32'): algos.take_2d_axis1_int8_int32,
650 ('int8', 'int64'): algos.take_2d_axis1_int8_int64,
651 ('int8', 'float64'): algos.take_2d_axis1_int8_float64,
652 ('int16', 'int16'): algos.take_2d_axis1_int16_int16,
653 ('int16', 'int32'): algos.take_2d_axis1_int16_int32,
654 ('int16', 'int64'): algos.take_2d_axis1_int16_int64,
655 ('int16', 'float64'): algos.take_2d_axis1_int16_float64,
656 ('int32', 'int32'): algos.take_2d_axis1_int32_int32,
657 ('int32', 'int64'): algos.take_2d_axis1_int32_int64,
658 ('int32', 'float64'): algos.take_2d_axis1_int32_float64,
659 ('int64', 'int64'): algos.take_2d_axis1_int64_int64,
660 ('int64', 'float64'): algos.take_2d_axis1_int64_float64,
661 ('float32', 'float32'): algos.take_2d_axis1_float32_float32,
662 ('float32', 'float64'): algos.take_2d_axis1_float32_float64,
663 ('float64', 'float64'): algos.take_2d_axis1_float64_float64,
664 ('object', 'object'): algos.take_2d_axis1_object_object,
665 ('bool', 'bool'):
666 _view_wrapper(algos.take_2d_axis1_bool_bool, np.uint8, np.uint8),
667 ('bool', 'object'):
668 _view_wrapper(algos.take_2d_axis1_bool_object, np.uint8, None),
669 ('datetime64[ns]', 'datetime64[ns]'):
670 _view_wrapper(algos.take_2d_axis1_int64_int64, np.int64, np.int64,
671 fill_wrap=np.int64)
672 }
673
674
675 _take_2d_multi_dict = {
676 ('int8', 'int8'): algos.take_2d_multi_int8_int8,
677 ('int8', 'int32'): algos.take_2d_multi_int8_int32,
678 ('int8', 'int64'): algos.take_2d_multi_int8_int64,
679 ('int8', 'float64'): algos.take_2d_multi_int8_float64,
680 ('int16', 'int16'): algos.take_2d_multi_int16_int16,
681 ('int16', 'int32'): algos.take_2d_multi_int16_int32,
682 ('int16', 'int64'): algos.take_2d_multi_int16_int64,
683 ('int16', 'float64'): algos.take_2d_multi_int16_float64,
684 ('int32', 'int32'): algos.take_2d_multi_int32_int32,
685 ('int32', 'int64'): algos.take_2d_multi_int32_int64,
686 ('int32', 'float64'): algos.take_2d_multi_int32_float64,
687 ('int64', 'int64'): algos.take_2d_multi_int64_int64,
688 ('int64', 'float64'): algos.take_2d_multi_int64_float64,
689 ('float32', 'float32'): algos.take_2d_multi_float32_float32,
690 ('float32', 'float64'): algos.take_2d_multi_float32_float64,
691 ('float64', 'float64'): algos.take_2d_multi_float64_float64,
692 ('object', 'object'): algos.take_2d_multi_object_object,
693 ('bool', 'bool'):
694 _view_wrapper(algos.take_2d_multi_bool_bool, np.uint8, np.uint8),
695 ('bool', 'object'):
696 _view_wrapper(algos.take_2d_multi_bool_object, np.uint8, None),
697 ('datetime64[ns]', 'datetime64[ns]'):
698 _view_wrapper(algos.take_2d_multi_int64_int64, np.int64, np.int64,
699 fill_wrap=np.int64)
700 }
701
702
703 def _get_take_nd_function(ndim, arr_dtype, out_dtype, axis=0, mask_info=None):
704 if ndim <= 2:
705 tup = (arr_dtype.name, out_dtype.name)
706 if ndim == 1:
707 func = _take_1d_dict.get(tup, None)
708 elif ndim == 2:
709 if axis == 0:
710 func = _take_2d_axis0_dict.get(tup, None)
711 else:
712 func = _take_2d_axis1_dict.get(tup, None)
713 if func is not None:
714 return func
715
716 tup = (out_dtype.name, out_dtype.name)
717 if ndim == 1:
718 func = _take_1d_dict.get(tup, None)
719 elif ndim == 2:
720 if axis == 0:
721 func = _take_2d_axis0_dict.get(tup, None)
722 else:
723 func = _take_2d_axis1_dict.get(tup, None)
724 if func is not None:
725 func = _convert_wrapper(func, out_dtype)
726 return func
727
728 def func(arr, indexer, out, fill_value=np.nan):
729 indexer = _ensure_int64(indexer)
730 _take_nd_generic(arr, indexer, out, axis=axis,
731 fill_value=fill_value, mask_info=mask_info)
732 return func
733
734
735 def take_nd(arr, indexer, axis=0, out=None, fill_value=np.nan,
736 mask_info=None, allow_fill=True):
737 """
738 Specialized Cython take which sets NaN values in one pass
739
740 Parameters
741 ----------
742 arr : ndarray
743 Input array
744 indexer : ndarray
745 1-D array of indices to take, subarrays corresponding to -1 value
746 indicies are filed with fill_value
747 axis : int, default 0
748 Axis to take from
749 out : ndarray or None, default None
750 Optional output array, must be appropriate type to hold input and
751 fill_value together, if indexer has any -1 value entries; call
752 common._maybe_promote to determine this type for any fill_value
753 fill_value : any, default np.nan
754 Fill value to replace -1 values with
755 mask_info : tuple of (ndarray, boolean)
756 If provided, value should correspond to:
757 (indexer != -1, (indexer != -1).any())
758 If not provided, it will be computed internally if necessary
759 allow_fill : boolean, default True
760 If False, indexer is assumed to contain no -1 values so no filling
761 will be done. This short-circuits computation of a mask. Result is
762 undefined if allow_fill == False and -1 is present in indexer.
763 """
764 if indexer is None:
765 indexer = np.arange(arr.shape[axis], dtype=np.int64)
766 dtype, fill_value = arr.dtype, arr.dtype.type()
767 else:
768 indexer = _ensure_int64(indexer)
769 if not allow_fill:
770 dtype, fill_value = arr.dtype, arr.dtype.type()
771 mask_info = None, False
772 else:
773 # check for promotion based on types only (do this first because
774 # it's faster than computing a mask)
775 dtype, fill_value = _maybe_promote(arr.dtype, fill_value)
776 if dtype != arr.dtype and (out is None or out.dtype != dtype):
777 # check if promotion is actually required based on indexer
778 if mask_info is not None:
779 mask, needs_masking = mask_info
780 else:
781 mask = indexer == -1
782 needs_masking = mask.any()
783 mask_info = mask, needs_masking
784 if needs_masking:
785 if out is not None and out.dtype != dtype:
786 raise TypeError('Incompatible type for fill_value')
787 else:
788 # if not, then depromote, set fill_value to dummy
789 # (it won't be used but we don't want the cython code
790 # to crash when trying to cast it to dtype)
791 dtype, fill_value = arr.dtype, arr.dtype.type()
792
793 flip_order = False
794 if arr.ndim == 2:
795 if arr.flags.f_contiguous:
796 flip_order = True
797
798 if flip_order:
799 arr = arr.T
800 axis = arr.ndim - axis - 1
801 if out is not None:
802 out = out.T
803
804 # at this point, it's guaranteed that dtype can hold both the arr values
805 # and the fill_value
806 if out is None:
807 out_shape = list(arr.shape)
808 out_shape[axis] = len(indexer)
809 out_shape = tuple(out_shape)
810 if arr.flags.f_contiguous and axis == arr.ndim - 1:
811 # minor tweak that can make an order-of-magnitude difference
812 # for dataframes initialized directly from 2-d ndarrays
813 # (s.t. df.values is c-contiguous and df._data.blocks[0] is its
814 # f-contiguous transpose)
815 out = np.empty(out_shape, dtype=dtype, order='F')
816 else:
817 out = np.empty(out_shape, dtype=dtype)
818
819 func = _get_take_nd_function(arr.ndim, arr.dtype, out.dtype,
820 axis=axis, mask_info=mask_info)
821
822 indexer = _ensure_int64(indexer)
823 func(arr, indexer, out, fill_value)
824
825 if flip_order:
826 out = out.T
827 return out
828
829
830 take_1d = take_nd
831
832
833 def take_2d_multi(arr, indexer, out=None, fill_value=np.nan,
834 mask_info=None, allow_fill=True):
835 """
836 Specialized Cython take which sets NaN values in one pass
837 """
838 if indexer is None or (indexer[0] is None and indexer[1] is None):
839 row_idx = np.arange(arr.shape[0], dtype=np.int64)
840 col_idx = np.arange(arr.shape[1], dtype=np.int64)
841 indexer = row_idx, col_idx
842 dtype, fill_value = arr.dtype, arr.dtype.type()
843 else:
844 row_idx, col_idx = indexer
845 if row_idx is None:
846 row_idx = np.arange(arr.shape[0], dtype=np.int64)
847 else:
848 row_idx = _ensure_int64(row_idx)
849 if col_idx is None:
850 col_idx = np.arange(arr.shape[1], dtype=np.int64)
851 else:
852 col_idx = _ensure_int64(col_idx)
853 indexer = row_idx, col_idx
854 if not allow_fill:
855 dtype, fill_value = arr.dtype, arr.dtype.type()
856 mask_info = None, False
857 else:
858 # check for promotion based on types only (do this first because
859 # it's faster than computing a mask)
860 dtype, fill_value = _maybe_promote(arr.dtype, fill_value)
861 if dtype != arr.dtype and (out is None or out.dtype != dtype):
862 # check if promotion is actually required based on indexer
863 if mask_info is not None:
864 (row_mask, col_mask), (row_needs, col_needs) = mask_info
865 else:
866 row_mask = row_idx == -1
867 col_mask = col_idx == -1
868 row_needs = row_mask.any()
869 col_needs = col_mask.any()
870 mask_info = (row_mask, col_mask), (row_needs, col_needs)
871 if row_needs or col_needs:
872 if out is not None and out.dtype != dtype:
873 raise TypeError('Incompatible type for fill_value')
874 else:
875 # if not, then depromote, set fill_value to dummy
876 # (it won't be used but we don't want the cython code
877 # to crash when trying to cast it to dtype)
878 dtype, fill_value = arr.dtype, arr.dtype.type()
879
880 # at this point, it's guaranteed that dtype can hold both the arr values
881 # and the fill_value
882 if out is None:
883 out_shape = len(row_idx), len(col_idx)
884 out = np.empty(out_shape, dtype=dtype)
885
886 func = _take_2d_multi_dict.get((arr.dtype.name, out.dtype.name), None)
887 if func is None and arr.dtype != out.dtype:
888 func = _take_2d_multi_dict.get((out.dtype.name, out.dtype.name), None)
889 if func is not None:
890 func = _convert_wrapper(func, out.dtype)
891 if func is None:
892 def func(arr, indexer, out, fill_value=np.nan):
893 _take_2d_multi_generic(arr, indexer, out,
894 fill_value=fill_value, mask_info=mask_info)
895 func(arr, indexer, out=out, fill_value=fill_value)
896 return out
897
898 _diff_special = {
899 'float64': algos.diff_2d_float64,
900 'float32': algos.diff_2d_float32,
901 'int64': algos.diff_2d_int64,
902 'int32': algos.diff_2d_int32,
903 'int16': algos.diff_2d_int16,
904 'int8': algos.diff_2d_int8,
905 }
906
907 def diff(arr, n, axis=0):
908 """ difference of n between self,
909 analagoust to s-s.shift(n) """
910
911 n = int(n)
912 na = np.nan
913 dtype = arr.dtype
914 is_timedelta = False
915 if needs_i8_conversion(arr):
916 dtype = np.float64
917 arr = arr.view('i8')
918 na = tslib.iNaT
919 is_timedelta = True
920 elif issubclass(dtype.type, np.integer):
921 dtype = np.float64
922 elif issubclass(dtype.type, np.bool_):
923 dtype = np.object_
924
925 dtype = np.dtype(dtype)
926 out_arr = np.empty(arr.shape, dtype=dtype)
927
928 na_indexer = [slice(None)] * arr.ndim
929 na_indexer[axis] = slice(None, n) if n >= 0 else slice(n, None)
930 out_arr[tuple(na_indexer)] = na
931
932 if arr.ndim == 2 and arr.dtype.name in _diff_special:
933 f = _diff_special[arr.dtype.name]
934 f(arr, out_arr, n, axis)
935 else:
936 res_indexer = [slice(None)] * arr.ndim
937 res_indexer[axis] = slice(n, None) if n >= 0 else slice(None, n)
938 res_indexer = tuple(res_indexer)
939
940 lag_indexer = [slice(None)] * arr.ndim
941 lag_indexer[axis] = slice(None, -n) if n > 0 else slice(-n, None)
942 lag_indexer = tuple(lag_indexer)
943
944 # need to make sure that we account for na for datelike/timedelta
945 # we don't actually want to subtract these i8 numbers
946 if is_timedelta:
947 res = arr[res_indexer]
948 lag = arr[lag_indexer]
949
950 mask = (arr[res_indexer] == na) | (arr[lag_indexer] == na)
951 if mask.any():
952 res = res.copy()
953 res[mask] = 0
954 lag = lag.copy()
955 lag[mask] = 0
956
957 result = res - lag
958 result[mask] = na
959 out_arr[res_indexer] = result
960 else:
961 out_arr[res_indexer] = arr[res_indexer] - arr[lag_indexer]
962
963 if is_timedelta:
964 from pandas import TimedeltaIndex
965 out_arr = TimedeltaIndex(out_arr.ravel().astype('int64')).asi8.reshape(out_arr.shape).astype('timedelta64[ns]')
966
967 return out_arr
968
969 def _coerce_indexer_dtype(indexer, categories):
970 """ coerce the indexer input array to the smallest dtype possible """
971 l = len(categories)
972 if l < _int8_max:
973 return _ensure_int8(indexer)
974 elif l < _int16_max:
975 return _ensure_int16(indexer)
976 elif l < _int32_max:
977 return _ensure_int32(indexer)
978 return _ensure_int64(indexer)
979
980 def _coerce_to_dtypes(result, dtypes):
981 """ given a dtypes and a result set, coerce the result elements to the
982 dtypes
983 """
984 if len(result) != len(dtypes):
985 raise AssertionError("_coerce_to_dtypes requires equal len arrays")
986
987 from pandas.tseries.timedeltas import _coerce_scalar_to_timedelta_type
988
989 def conv(r, dtype):
990 try:
991 if isnull(r):
992 pass
993 elif dtype == _NS_DTYPE:
994 r = lib.Timestamp(r)
995 elif dtype == _TD_DTYPE:
996 r = _coerce_scalar_to_timedelta_type(r)
997 elif dtype == np.bool_:
998 # messy. non 0/1 integers do not get converted.
999 if is_integer(r) and r not in [0,1]:
1000 return int(r)
1001 r = bool(r)
1002 elif dtype.kind == 'f':
1003 r = float(r)
1004 elif dtype.kind == 'i':
1005 r = int(r)
1006 except:
1007 pass
1008
1009 return r
1010
1011 return [conv(r, dtype) for r, dtype in zip(result, dtypes)]
1012
1013
1014 def _infer_fill_value(val):
1015 """
1016 infer the fill value for the nan/NaT from the provided scalar/ndarray/list-like
1017 if we are a NaT, return the correct dtyped element to provide proper block construction
1018
1019 """
1020
1021 if not is_list_like(val):
1022 val = [val]
1023 val = np.array(val,copy=False)
1024 if is_datetimelike(val):
1025 return np.array('NaT',dtype=val.dtype)
1026 elif is_object_dtype(val.dtype):
1027 dtype = lib.infer_dtype(_ensure_object(val))
1028 if dtype in ['datetime','datetime64']:
1029 return np.array('NaT',dtype=_NS_DTYPE)
1030 elif dtype in ['timedelta','timedelta64']:
1031 return np.array('NaT',dtype=_TD_DTYPE)
1032 return np.nan
1033
1034
1035 def _infer_dtype_from_scalar(val):
1036 """ interpret the dtype from a scalar, upcast floats and ints
1037 return the new value and the dtype """
1038
1039 dtype = np.object_
1040
1041 # a 1-element ndarray
1042 if isinstance(val, np.ndarray):
1043 if val.ndim != 0:
1044 raise ValueError(
1045 "invalid ndarray passed to _infer_dtype_from_scalar")
1046
1047 dtype = val.dtype
1048 val = val.item()
1049
1050 elif isinstance(val, compat.string_types):
1051
1052 # If we create an empty array using a string to infer
1053 # the dtype, NumPy will only allocate one character per entry
1054 # so this is kind of bad. Alternately we could use np.repeat
1055 # instead of np.empty (but then you still don't want things
1056 # coming out as np.str_!
1057
1058 dtype = np.object_
1059
1060 elif isinstance(val, (np.datetime64, datetime)) and getattr(val,'tz',None) is None:
1061 val = lib.Timestamp(val).value
1062 dtype = np.dtype('M8[ns]')
1063
1064 elif isinstance(val, (np.timedelta64, timedelta)):
1065 val = tslib.convert_to_timedelta(val,'ns')
1066 dtype = np.dtype('m8[ns]')
1067
1068 elif is_bool(val):
1069 dtype = np.bool_
1070
1071 # provide implicity upcast on scalars
1072 elif is_integer(val):
1073 dtype = np.int64
1074
1075 elif is_float(val):
1076 dtype = np.float64
1077
1078 elif is_complex(val):
1079 dtype = np.complex_
1080
1081 return dtype, val
1082
1083
1084 def _maybe_cast_scalar(dtype, value):
1085 """ if we a scalar value and are casting to a dtype that needs nan -> NaT
1086 conversion
1087 """
1088 if np.isscalar(value) and dtype in _DATELIKE_DTYPES and isnull(value):
1089 return tslib.iNaT
1090 return value
1091
1092
1093 def _maybe_promote(dtype, fill_value=np.nan):
1094
1095 # if we passed an array here, determine the fill value by dtype
1096 if isinstance(fill_value, np.ndarray):
1097 if issubclass(fill_value.dtype.type, (np.datetime64, np.timedelta64)):
1098 fill_value = tslib.iNaT
1099 else:
1100
1101 # we need to change to object type as our
1102 # fill_value is of object type
1103 if fill_value.dtype == np.object_:
1104 dtype = np.dtype(np.object_)
1105 fill_value = np.nan
1106
1107 # returns tuple of (dtype, fill_value)
1108 if issubclass(dtype.type, (np.datetime64, np.timedelta64)):
1109 # for now: refuse to upcast datetime64
1110 # (this is because datetime64 will not implicitly upconvert
1111 # to object correctly as of numpy 1.6.1)
1112 if isnull(fill_value):
1113 fill_value = tslib.iNaT
1114 else:
1115 if issubclass(dtype.type, np.datetime64):
1116 try:
1117 fill_value = lib.Timestamp(fill_value).value
1118 except:
1119 # the proper thing to do here would probably be to upcast
1120 # to object (but numpy 1.6.1 doesn't do this properly)
1121 fill_value = tslib.iNaT
1122 else:
1123 fill_value = tslib.iNaT
1124 elif is_float(fill_value):
1125 if issubclass(dtype.type, np.bool_):
1126 dtype = np.object_
1127 elif issubclass(dtype.type, np.integer):
1128 dtype = np.float64
1129 elif is_bool(fill_value):
1130 if not issubclass(dtype.type, np.bool_):
1131 dtype = np.object_
1132 elif is_integer(fill_value):
1133 if issubclass(dtype.type, np.bool_):
1134 dtype = np.object_
1135 elif issubclass(dtype.type, np.integer):
1136 # upcast to prevent overflow
1137 arr = np.asarray(fill_value)
1138 if arr != arr.astype(dtype):
1139 dtype = arr.dtype
1140 elif is_complex(fill_value):
1141 if issubclass(dtype.type, np.bool_):
1142 dtype = np.object_
1143 elif issubclass(dtype.type, (np.integer, np.floating)):
1144 dtype = np.complex128
1145 else:
1146 dtype = np.object_
1147
1148 # in case we have a string that looked like a number
1149 if is_categorical_dtype(dtype):
1150 dtype = dtype
1151 elif issubclass(np.dtype(dtype).type, compat.string_types):
1152 dtype = np.object_
1153
1154 return dtype, fill_value
1155
1156
1157 def _maybe_upcast_putmask(result, mask, other, dtype=None, change=None):
1158 """ a safe version of put mask that (potentially upcasts the result
1159 return the result
1160 if change is not None, then MUTATE the change (and change the dtype)
1161 return a changed flag
1162 """
1163
1164 if mask.any():
1165
1166 other = _maybe_cast_scalar(result.dtype, other)
1167
1168 def changeit():
1169
1170 # try to directly set by expanding our array to full
1171 # length of the boolean
1172 try:
1173 om = other[mask]
1174 om_at = om.astype(result.dtype)
1175 if (om == om_at).all():
1176 new_other = result.values.copy()
1177 new_other[mask] = om_at
1178 result[:] = new_other
1179 return result, False
1180 except:
1181 pass
1182
1183 # we are forced to change the dtype of the result as the input
1184 # isn't compatible
1185 r, fill_value = _maybe_upcast(
1186 result, fill_value=other, dtype=dtype, copy=True)
1187 np.putmask(r, mask, other)
1188
1189 # we need to actually change the dtype here
1190 if change is not None:
1191
1192 # if we are trying to do something unsafe
1193 # like put a bigger dtype in a smaller one, use the smaller one
1194 # pragma: no cover
1195 if change.dtype.itemsize < r.dtype.itemsize:
1196 raise AssertionError(
1197 "cannot change dtype of input to smaller size")
1198 change.dtype = r.dtype
1199 change[:] = r
1200
1201 return r, True
1202
1203 # we want to decide whether putmask will work
1204 # if we have nans in the False portion of our mask then we need to
1205 # upcast (possibily) otherwise we DON't want to upcast (e.g. if we are
1206 # have values, say integers in the success portion then its ok to not
1207 # upcast)
1208 new_dtype, fill_value = _maybe_promote(result.dtype, other)
1209 if new_dtype != result.dtype:
1210
1211 # we have a scalar or len 0 ndarray
1212 # and its nan and we are changing some values
1213 if (np.isscalar(other) or
1214 (isinstance(other, np.ndarray) and other.ndim < 1)):
1215 if isnull(other):
1216 return changeit()
1217
1218 # we have an ndarray and the masking has nans in it
1219 else:
1220
1221 if isnull(other[mask]).any():
1222 return changeit()
1223
1224 try:
1225 np.putmask(result, mask, other)
1226 except:
1227 return changeit()
1228
1229 return result, False
1230
1231
1232 def _maybe_upcast(values, fill_value=np.nan, dtype=None, copy=False):
1233 """ provide explict type promotion and coercion
1234
1235 Parameters
1236 ----------
1237 values : the ndarray that we want to maybe upcast
1238 fill_value : what we want to fill with
1239 dtype : if None, then use the dtype of the values, else coerce to this type
1240 copy : if True always make a copy even if no upcast is required
1241 """
1242
1243 if dtype is None:
1244 dtype = values.dtype
1245 new_dtype, fill_value = _maybe_promote(dtype, fill_value)
1246 if new_dtype != values.dtype:
1247 values = values.astype(new_dtype)
1248 elif copy:
1249 values = values.copy()
1250 return values, fill_value
1251
1252
1253 def _possibly_cast_item(obj, item, dtype):
1254 chunk = obj[item]
1255
1256 if chunk.values.dtype != dtype:
1257 if dtype in (np.object_, np.bool_):
1258 obj[item] = chunk.astype(np.object_)
1259 elif not issubclass(dtype, (np.integer, np.bool_)): # pragma: no cover
1260 raise ValueError("Unexpected dtype encountered: %s" % dtype)
1261
1262
1263 def _possibly_downcast_to_dtype(result, dtype):
1264 """ try to cast to the specified dtype (e.g. convert back to bool/int
1265 or could be an astype of float64->float32
1266 """
1267
1268 if np.isscalar(result):
1269 return result
1270
1271 trans = lambda x: x
1272 if isinstance(dtype, compat.string_types):
1273 if dtype == 'infer':
1274 inferred_type = lib.infer_dtype(_ensure_object(result.ravel()))
1275 if inferred_type == 'boolean':
1276 dtype = 'bool'
1277 elif inferred_type == 'integer':
1278 dtype = 'int64'
1279 elif inferred_type == 'datetime64':
1280 dtype = 'datetime64[ns]'
1281 elif inferred_type == 'timedelta64':
1282 dtype = 'timedelta64[ns]'
1283
1284 # try to upcast here
1285 elif inferred_type == 'floating':
1286 dtype = 'int64'
1287 if issubclass(result.dtype.type, np.number):
1288 trans = lambda x: x.round()
1289
1290 else:
1291 dtype = 'object'
1292
1293 if isinstance(dtype, compat.string_types):
1294 dtype = np.dtype(dtype)
1295
1296 try:
1297
1298 # don't allow upcasts here (except if empty)
1299 if dtype.kind == result.dtype.kind:
1300 if result.dtype.itemsize <= dtype.itemsize and np.prod(result.shape):
1301 return result
1302
1303 if issubclass(dtype.type, np.floating):
1304 return result.astype(dtype)
1305 elif dtype == np.bool_ or issubclass(dtype.type, np.integer):
1306
1307 # if we don't have any elements, just astype it
1308 if not np.prod(result.shape):
1309 return trans(result).astype(dtype)
1310
1311 # do a test on the first element, if it fails then we are done
1312 r = result.ravel()
1313 arr = np.array([r[0]])
1314 if not np.allclose(arr, trans(arr).astype(dtype)):
1315 return result
1316
1317 # a comparable, e.g. a Decimal may slip in here
1318 elif not isinstance(r[0], (np.integer, np.floating, np.bool, int,
1319 float, bool)):
1320 return result
1321
1322 if (issubclass(result.dtype.type, (np.object_, np.number)) and
1323 notnull(result).all()):
1324 new_result = trans(result).astype(dtype)
1325 try:
1326 if np.allclose(new_result, result):
1327 return new_result
1328 except:
1329
1330 # comparison of an object dtype with a number type could
1331 # hit here
1332 if (new_result == result).all():
1333 return new_result
1334
1335 # a datetimelike
1336 elif dtype.kind in ['M','m'] and result.dtype.kind in ['i']:
1337 try:
1338 result = result.astype(dtype)
1339 except:
1340 pass
1341
1342 except:
1343 pass
1344
1345 return result
1346
1347
1348 def _maybe_convert_string_to_object(values):
1349 """
1350 Convert string-like and string-like array to convert object dtype.
1351 This is to avoid numpy to handle the array as str dtype.
1352 """
1353 if isinstance(values, string_types):
1354 values = np.array([values], dtype=object)
1355 elif (isinstance(values, np.ndarray) and
1356 issubclass(values.dtype.type, (np.string_, np.unicode_))):
1357 values = values.astype(object)
1358 return values
1359
1360
1361 def _lcd_dtypes(a_dtype, b_dtype):
1362 """ return the lcd dtype to hold these types """
1363
1364 if is_datetime64_dtype(a_dtype) or is_datetime64_dtype(b_dtype):
1365 return _NS_DTYPE
1366 elif is_timedelta64_dtype(a_dtype) or is_timedelta64_dtype(b_dtype):
1367 return _TD_DTYPE
1368 elif is_complex_dtype(a_dtype):
1369 if is_complex_dtype(b_dtype):
1370 return a_dtype
1371 return np.float64
1372 elif is_integer_dtype(a_dtype):
1373 if is_integer_dtype(b_dtype):
1374 if a_dtype.itemsize == b_dtype.itemsize:
1375 return a_dtype
1376 return np.int64
1377 return np.float64
1378 elif is_float_dtype(a_dtype):
1379 if is_float_dtype(b_dtype):
1380 if a_dtype.itemsize == b_dtype.itemsize:
1381 return a_dtype
1382 else:
1383 return np.float64
1384 elif is_integer(b_dtype):
1385 return np.float64
1386 return np.object
1387
1388
1389 def _fill_zeros(result, x, y, name, fill):
1390 """
1391 if this is a reversed op, then flip x,y
1392
1393 if we have an integer value (or array in y)
1394 and we have 0's, fill them with the fill,
1395 return the result
1396
1397 mask the nan's from x
1398 """
1399
1400 if fill is None or is_float_dtype(result):
1401 return result
1402
1403 if name.startswith(('r', '__r')):
1404 x,y = y,x
1405
1406 if np.isscalar(y):
1407 y = np.array(y)
1408
1409 if is_integer_dtype(y):
1410
1411 if (y == 0).any():
1412
1413 # GH 7325, mask and nans must be broadcastable (also: PR 9308)
1414 # Raveling and then reshaping makes np.putmask faster
1415 mask = ((y == 0) & ~np.isnan(result)).ravel()
1416
1417 shape = result.shape
1418 result = result.astype('float64', copy=False).ravel()
1419
1420 np.putmask(result, mask, fill)
1421
1422 # if we have a fill of inf, then sign it correctly
1423 # (GH 6178 and PR 9308)
1424 if np.isinf(fill):
1425 signs = np.sign(y if name.startswith(('r', '__r')) else x)
1426 negative_inf_mask = (signs.ravel() < 0) & mask
1427 np.putmask(result, negative_inf_mask, -fill)
1428
1429 if "floordiv" in name: # (PR 9308)
1430 nan_mask = ((y == 0) & (x == 0)).ravel()
1431 np.putmask(result, nan_mask, np.nan)
1432
1433 result = result.reshape(shape)
1434
1435 return result
1436
1437
1438 def _interp_wrapper(f, wrap_dtype, na_override=None):
1439 def wrapper(arr, mask, limit=None):
1440 view = arr.view(wrap_dtype)
1441 f(view, mask, limit=limit)
1442 return wrapper
1443
1444
1445 _pad_1d_datetime = _interp_wrapper(algos.pad_inplace_int64, np.int64)
1446 _pad_2d_datetime = _interp_wrapper(algos.pad_2d_inplace_int64, np.int64)
1447 _backfill_1d_datetime = _interp_wrapper(algos.backfill_inplace_int64,
1448 np.int64)
1449 _backfill_2d_datetime = _interp_wrapper(algos.backfill_2d_inplace_int64,
1450 np.int64)
1451
1452
1453 def pad_1d(values, limit=None, mask=None, dtype=None):
1454
1455 if dtype is None:
1456 dtype = values.dtype
1457 _method = None
1458 if is_float_dtype(values):
1459 _method = getattr(algos, 'pad_inplace_%s' % dtype.name, None)
1460 elif dtype in _DATELIKE_DTYPES or is_datetime64_dtype(values):
1461 _method = _pad_1d_datetime
1462 elif is_integer_dtype(values):
1463 values = _ensure_float64(values)
1464 _method = algos.pad_inplace_float64
1465 elif values.dtype == np.object_:
1466 _method = algos.pad_inplace_object
1467
1468 if _method is None:
1469 raise ValueError('Invalid dtype for pad_1d [%s]' % dtype.name)
1470
1471 if mask is None:
1472 mask = isnull(values)
1473 mask = mask.view(np.uint8)
1474 _method(values, mask, limit=limit)
1475 return values
1476
1477
1478 def backfill_1d(values, limit=None, mask=None, dtype=None):
1479
1480 if dtype is None:
1481 dtype = values.dtype
1482 _method = None
1483 if is_float_dtype(values):
1484 _method = getattr(algos, 'backfill_inplace_%s' % dtype.name, None)
1485 elif dtype in _DATELIKE_DTYPES or is_datetime64_dtype(values):
1486 _method = _backfill_1d_datetime
1487 elif is_integer_dtype(values):
1488 values = _ensure_float64(values)
1489 _method = algos.backfill_inplace_float64
1490 elif values.dtype == np.object_:
1491 _method = algos.backfill_inplace_object
1492
1493 if _method is None:
1494 raise ValueError('Invalid dtype for backfill_1d [%s]' % dtype.name)
1495
1496 if mask is None:
1497 mask = isnull(values)
1498 mask = mask.view(np.uint8)
1499
1500 _method(values, mask, limit=limit)
1501 return values
1502
1503
1504 def pad_2d(values, limit=None, mask=None, dtype=None):
1505
1506 if dtype is None:
1507 dtype = values.dtype
1508 _method = None
1509 if is_float_dtype(values):
1510 _method = getattr(algos, 'pad_2d_inplace_%s' % dtype.name, None)
1511 elif dtype in _DATELIKE_DTYPES or is_datetime64_dtype(values):
1512 _method = _pad_2d_datetime
1513 elif is_integer_dtype(values):
1514 values = _ensure_float64(values)
1515 _method = algos.pad_2d_inplace_float64
1516 elif values.dtype == np.object_:
1517 _method = algos.pad_2d_inplace_object
1518
1519 if _method is None:
1520 raise ValueError('Invalid dtype for pad_2d [%s]' % dtype.name)
1521
1522 if mask is None:
1523 mask = isnull(values)
1524 mask = mask.view(np.uint8)
1525
1526 if np.all(values.shape):
1527 _method(values, mask, limit=limit)
1528 else:
1529 # for test coverage
1530 pass
1531 return values
1532
1533
1534 def backfill_2d(values, limit=None, mask=None, dtype=None):
1535
1536 if dtype is None:
1537 dtype = values.dtype
1538 _method = None
1539 if is_float_dtype(values):
1540 _method = getattr(algos, 'backfill_2d_inplace_%s' % dtype.name, None)
1541 elif dtype in _DATELIKE_DTYPES or is_datetime64_dtype(values):
1542 _method = _backfill_2d_datetime
1543 elif is_integer_dtype(values):
1544 values = _ensure_float64(values)
1545 _method = algos.backfill_2d_inplace_float64
1546 elif values.dtype == np.object_:
1547 _method = algos.backfill_2d_inplace_object
1548
1549 if _method is None:
1550 raise ValueError('Invalid dtype for backfill_2d [%s]' % dtype.name)
1551
1552 if mask is None:
1553 mask = isnull(values)
1554 mask = mask.view(np.uint8)
1555
1556 if np.all(values.shape):
1557 _method(values, mask, limit=limit)
1558 else:
1559 # for test coverage
1560 pass
1561 return values
1562
1563
1564 def _clean_interp_method(method, order=None):
1565 valid = ['linear', 'time', 'index', 'values', 'nearest', 'zero', 'slinear',
1566 'quadratic', 'cubic', 'barycentric', 'polynomial',
1567 'krogh', 'piecewise_polynomial',
1568 'pchip', 'spline']
1569 if method in ('spline', 'polynomial') and order is None:
1570 raise ValueError("You must specify the order of the spline or "
1571 "polynomial.")
1572 if method not in valid:
1573 raise ValueError("method must be one of {0}."
1574 "Got '{1}' instead.".format(valid, method))
1575 return method
1576
1577
1578 def interpolate_1d(xvalues, yvalues, method='linear', limit=None,
1579 fill_value=None, bounds_error=False, order=None):
1580 """
1581 Logic for the 1-d interpolation. The result should be 1-d, inputs
1582 xvalues and yvalues will each be 1-d arrays of the same length.
1583
1584 Bounds_error is currently hardcoded to False since non-scipy ones don't
1585 take it as an argumnet.
1586 """
1587 # Treat the original, non-scipy methods first.
1588
1589 invalid = isnull(yvalues)
1590 valid = ~invalid
1591
1592 valid_y = yvalues[valid]
1593 valid_x = xvalues[valid]
1594 new_x = xvalues[invalid]
1595
1596 if method == 'time':
1597 if not getattr(xvalues, 'is_all_dates', None):
1598 # if not issubclass(xvalues.dtype.type, np.datetime64):
1599 raise ValueError('time-weighted interpolation only works '
1600 'on Series or DataFrames with a '
1601 'DatetimeIndex')
1602 method = 'values'
1603
1604 def _interp_limit(invalid, limit):
1605 """mask off values that won't be filled since they exceed the limit"""
1606 all_nans = np.where(invalid)[0]
1607 if all_nans.size == 0: # no nans anyway
1608 return []
1609 violate = [invalid[x:x + limit + 1] for x in all_nans]
1610 violate = np.array([x.all() & (x.size > limit) for x in violate])
1611 return all_nans[violate] + limit
1612
1613 xvalues = getattr(xvalues, 'values', xvalues)
1614 yvalues = getattr(yvalues, 'values', yvalues)
1615
1616 if limit:
1617 violate_limit = _interp_limit(invalid, limit)
1618 if valid.any():
1619 firstIndex = valid.argmax()
1620 valid = valid[firstIndex:]
1621 invalid = invalid[firstIndex:]
1622 result = yvalues.copy()
1623 if valid.all():
1624 return yvalues
1625 else:
1626 # have to call np.array(xvalues) since xvalues could be an Index
1627 # which cant be mutated
1628 result = np.empty_like(np.array(xvalues), dtype=np.float64)
1629 result.fill(np.nan)
1630 return result
1631
1632 if method in ['linear', 'time', 'index', 'values']:
1633 if method in ('values', 'index'):
1634 inds = np.asarray(xvalues)
1635 # hack for DatetimeIndex, #1646
1636 if issubclass(inds.dtype.type, np.datetime64):
1637 inds = inds.view(np.int64)
1638
1639 if inds.dtype == np.object_:
1640 inds = lib.maybe_convert_objects(inds)
1641 else:
1642 inds = xvalues
1643
1644 inds = inds[firstIndex:]
1645
1646 result[firstIndex:][invalid] = np.interp(inds[invalid], inds[valid],
1647 yvalues[firstIndex:][valid])
1648
1649 if limit:
1650 result[violate_limit] = np.nan
1651 return result
1652
1653 sp_methods = ['nearest', 'zero', 'slinear', 'quadratic', 'cubic',
1654 'barycentric', 'krogh', 'spline', 'polynomial',
1655 'piecewise_polynomial', 'pchip']
1656 if method in sp_methods:
1657 new_x = new_x[firstIndex:]
1658 xvalues = xvalues[firstIndex:]
1659
1660 result[firstIndex:][invalid] = _interpolate_scipy_wrapper(
1661 valid_x, valid_y, new_x, method=method, fill_value=fill_value,
1662 bounds_error=bounds_error, order=order)
1663 if limit:
1664 result[violate_limit] = np.nan
1665 return result
1666
1667
1668 def _interpolate_scipy_wrapper(x, y, new_x, method, fill_value=None,
1669 bounds_error=False, order=None):
1670 """
1671 passed off to scipy.interpolate.interp1d. method is scipy's kind.
1672 Returns an array interpolated at new_x. Add any new methods to
1673 the list in _clean_interp_method
1674 """
1675 try:
1676 from scipy import interpolate
1677 from pandas import DatetimeIndex
1678 except ImportError:
1679 raise ImportError('{0} interpolation requires Scipy'.format(method))
1680
1681 new_x = np.asarray(new_x)
1682
1683 # ignores some kwargs that could be passed along.
1684 alt_methods = {
1685 'barycentric': interpolate.barycentric_interpolate,
1686 'krogh': interpolate.krogh_interpolate,
1687 'piecewise_polynomial': interpolate.piecewise_polynomial_interpolate,
1688 }
1689
1690 if getattr(x, 'is_all_dates', False):
1691 # GH 5975, scipy.interp1d can't hande datetime64s
1692 x, new_x = x.values.astype('i8'), new_x.astype('i8')
1693
1694 try:
1695 alt_methods['pchip'] = interpolate.pchip_interpolate
1696 except AttributeError:
1697 if method == 'pchip':
1698 raise ImportError("Your version of scipy does not support "
1699 "PCHIP interpolation.")
1700
1701 interp1d_methods = ['nearest', 'zero', 'slinear', 'quadratic', 'cubic',
1702 'polynomial']
1703 if method in interp1d_methods:
1704 if method == 'polynomial':
1705 method = order
1706 terp = interpolate.interp1d(x, y, kind=method, fill_value=fill_value,
1707 bounds_error=bounds_error)
1708 new_y = terp(new_x)
1709 elif method == 'spline':
1710 terp = interpolate.UnivariateSpline(x, y, k=order)
1711 new_y = terp(new_x)
1712 else:
1713 # GH 7295: need to be able to write for some reason
1714 # in some circumstances: check all three
1715 if not x.flags.writeable:
1716 x = x.copy()
1717 if not y.flags.writeable:
1718 y = y.copy()
1719 if not new_x.flags.writeable:
1720 new_x = new_x.copy()
1721 method = alt_methods[method]
1722 new_y = method(x, y, new_x)
1723 return new_y
1724
1725
1726 def interpolate_2d(values, method='pad', axis=0, limit=None, fill_value=None, dtype=None):
1727 """ perform an actual interpolation of values, values will be make 2-d if
1728 needed fills inplace, returns the result
1729 """
1730
1731 transf = (lambda x: x) if axis == 0 else (lambda x: x.T)
1732
1733 # reshape a 1 dim if needed
1734 ndim = values.ndim
1735 if values.ndim == 1:
1736 if axis != 0: # pragma: no cover
1737 raise AssertionError("cannot interpolate on a ndim == 1 with "
1738 "axis != 0")
1739 values = values.reshape(tuple((1,) + values.shape))
1740
1741 if fill_value is None:
1742 mask = None
1743 else: # todo create faster fill func without masking
1744 mask = mask_missing(transf(values), fill_value)
1745
1746 method = _clean_fill_method(method)
1747 if method == 'pad':
1748 values = transf(pad_2d(transf(values), limit=limit, mask=mask, dtype=dtype))
1749 else:
1750 values = transf(backfill_2d(transf(values), limit=limit, mask=mask, dtype=dtype))
1751
1752 # reshape back
1753 if ndim == 1:
1754 values = values[0]
1755
1756 return values
1757
1758
1759 def _consensus_name_attr(objs):
1760 name = objs[0].name
1761 for obj in objs[1:]:
1762 if obj.name != name:
1763 return None
1764 return name
1765
1766
1767 _fill_methods = {'pad': pad_1d, 'backfill': backfill_1d}
1768
1769
1770 def _get_fill_func(method):
1771 method = _clean_fill_method(method)
1772 return _fill_methods[method]
1773
1774
1775 #----------------------------------------------------------------------
1776 # Lots of little utilities
1777
1778 def _validate_date_like_dtype(dtype):
1779 try:
1780 typ = np.datetime_data(dtype)[0]
1781 except ValueError as e:
1782 raise TypeError('%s' % e)
1783 if typ != 'generic' and typ != 'ns':
1784 raise ValueError('%r is too specific of a frequency, try passing %r'
1785 % (dtype.name, dtype.type.__name__))
1786
1787
1788 def _invalidate_string_dtypes(dtype_set):
1789 """Change string like dtypes to object for ``DataFrame.select_dtypes()``."""
1790 non_string_dtypes = dtype_set - _string_dtypes
1791 if non_string_dtypes != dtype_set:
1792 raise TypeError("string dtypes are not allowed, use 'object' instead")
1793
1794
1795 def _get_dtype_from_object(dtype):
1796 """Get a numpy dtype.type-style object.
1797
1798 Notes
1799 -----
1800 If nothing can be found, returns ``object``.
1801 """
1802 # type object from a dtype
1803 if isinstance(dtype, type) and issubclass(dtype, np.generic):
1804 return dtype
1805 elif isinstance(dtype, np.dtype): # dtype object
1806 try:
1807 _validate_date_like_dtype(dtype)
1808 except TypeError:
1809 # should still pass if we don't have a datelike
1810 pass
1811 return dtype.type
1812 elif isinstance(dtype, compat.string_types):
1813 if dtype == 'datetime' or dtype == 'timedelta':
1814 dtype += '64'
1815 elif dtype == 'category':
1816 return CategoricalDtypeType
1817 try:
1818 return _get_dtype_from_object(getattr(np, dtype))
1819 except AttributeError:
1820 # handles cases like _get_dtype(int)
1821 # i.e., python objects that are valid dtypes (unlike user-defined
1822 # types, in general)
1823 pass
1824 return _get_dtype_from_object(np.dtype(dtype))
1825
1826
1827 def _get_info_slice(obj, indexer):
1828 """Slice the info axis of `obj` with `indexer`."""
1829 if not hasattr(obj, '_info_axis_number'):
1830 raise TypeError('object of type %r has no info axis' %
1831 type(obj).__name__)
1832 slices = [slice(None)] * obj.ndim
1833 slices[obj._info_axis_number] = indexer
1834 return tuple(slices)
1835
1836
1837 def _maybe_box(indexer, values, obj, key):
1838
1839 # if we have multiples coming back, box em
1840 if isinstance(values, np.ndarray):
1841 return obj[indexer.get_loc(key)]
1842
1843 # return the value
1844 return values
1845
1846
1847 def _maybe_box_datetimelike(value):
1848 # turn a datetime like into a Timestamp/timedelta as needed
1849
1850 if isinstance(value, np.datetime64):
1851 value = tslib.Timestamp(value)
1852 elif isinstance(value, np.timedelta64):
1853 value = tslib.Timedelta(value)
1854
1855 return value
1856
1857 _values_from_object = lib.values_from_object
1858
1859 def _possibly_convert_objects(values, convert_dates=True,
1860 convert_numeric=True,
1861 convert_timedeltas=True):
1862 """ if we have an object dtype, try to coerce dates and/or numbers """
1863
1864 # if we have passed in a list or scalar
1865 if isinstance(values, (list, tuple)):
1866 values = np.array(values, dtype=np.object_)
1867 if not hasattr(values, 'dtype'):
1868 values = np.array([values], dtype=np.object_)
1869
1870 # convert dates
1871 if convert_dates and values.dtype == np.object_:
1872
1873 # we take an aggressive stance and convert to datetime64[ns]
1874 if convert_dates == 'coerce':
1875 new_values = _possibly_cast_to_datetime(
1876 values, 'M8[ns]', coerce=True)
1877
1878 # if we are all nans then leave me alone
1879 if not isnull(new_values).all():
1880 values = new_values
1881
1882 else:
1883 values = lib.maybe_convert_objects(
1884 values, convert_datetime=convert_dates)
1885
1886 # convert timedeltas
1887 if convert_timedeltas and values.dtype == np.object_:
1888
1889 if convert_timedeltas == 'coerce':
1890 from pandas.tseries.timedeltas import to_timedelta
1891 values = to_timedelta(values, coerce=True)
1892
1893 # if we are all nans then leave me alone
1894 if not isnull(new_values).all():
1895 values = new_values
1896
1897 else:
1898 values = lib.maybe_convert_objects(
1899 values, convert_timedelta=convert_timedeltas)
1900
1901 # convert to numeric
1902 if values.dtype == np.object_:
1903 if convert_numeric:
1904 try:
1905 new_values = lib.maybe_convert_numeric(
1906 values, set(), coerce_numeric=True)
1907
1908 # if we are all nans then leave me alone
1909 if not isnull(new_values).all():
1910 values = new_values
1911
1912 except:
1913 pass
1914 else:
1915
1916 # soft-conversion
1917 values = lib.maybe_convert_objects(values)
1918
1919 return values
1920
1921
1922 def _possibly_castable(arr):
1923 # return False to force a non-fastpath
1924
1925 # check datetime64[ns]/timedelta64[ns] are valid
1926 # otherwise try to coerce
1927 kind = arr.dtype.kind
1928 if kind == 'M' or kind == 'm':
1929 return arr.dtype in _DATELIKE_DTYPES
1930
1931 return arr.dtype.name not in _POSSIBLY_CAST_DTYPES
1932
1933
1934 def _possibly_convert_platform(values):
1935 """ try to do platform conversion, allow ndarray or list here """
1936
1937 if isinstance(values, (list, tuple)):
1938 values = lib.list_to_object_array(values)
1939 if getattr(values, 'dtype', None) == np.object_:
1940 if hasattr(values, 'values'):
1941 values = values.values
1942 values = lib.maybe_convert_objects(values)
1943
1944 return values
1945
1946
1947 def _possibly_cast_to_datetime(value, dtype, coerce=False):
1948 """ try to cast the array/value to a datetimelike dtype, converting float
1949 nan to iNaT
1950 """
1951 from pandas.tseries.timedeltas import to_timedelta
1952 from pandas.tseries.tools import to_datetime
1953
1954 if dtype is not None:
1955 if isinstance(dtype, compat.string_types):
1956 dtype = np.dtype(dtype)
1957
1958 is_datetime64 = is_datetime64_dtype(dtype)
1959 is_timedelta64 = is_timedelta64_dtype(dtype)
1960
1961 if is_datetime64 or is_timedelta64:
1962
1963 # force the dtype if needed
1964 if is_datetime64 and dtype != _NS_DTYPE:
1965 if dtype.name == 'datetime64[ns]':
1966 dtype = _NS_DTYPE
1967 else:
1968 raise TypeError(
1969 "cannot convert datetimelike to dtype [%s]" % dtype)
1970 elif is_timedelta64 and dtype != _TD_DTYPE:
1971 if dtype.name == 'timedelta64[ns]':
1972 dtype = _TD_DTYPE
1973 else:
1974 raise TypeError(
1975 "cannot convert timedeltalike to dtype [%s]" % dtype)
1976
1977 if np.isscalar(value):
1978 if value == tslib.iNaT or isnull(value):
1979 value = tslib.iNaT
1980 else:
1981 value = np.array(value,copy=False)
1982
1983 # have a scalar array-like (e.g. NaT)
1984 if value.ndim == 0:
1985 value = tslib.iNaT
1986
1987 # we have an array of datetime or timedeltas & nulls
1988 elif np.prod(value.shape) and value.dtype != dtype:
1989 try:
1990 if is_datetime64:
1991 value = to_datetime(value, coerce=coerce).values
1992 elif is_timedelta64:
1993 value = to_timedelta(value, coerce=coerce).values
1994 except (AttributeError, ValueError):
1995 pass
1996
1997 else:
1998
1999 is_array = isinstance(value, np.ndarray)
2000
2001 # catch a datetime/timedelta that is not of ns variety
2002 # and no coercion specified
2003 if is_array and value.dtype.kind in ['M', 'm']:
2004 dtype = value.dtype
2005
2006 if dtype.kind == 'M' and dtype != _NS_DTYPE:
2007 value = value.astype(_NS_DTYPE)
2008
2009 elif dtype.kind == 'm' and dtype != _TD_DTYPE:
2010 value = to_timedelta(value)
2011
2012 # only do this if we have an array and the dtype of the array is not
2013 # setup already we are not an integer/object, so don't bother with this
2014 # conversion
2015 elif not (is_array and not (issubclass(value.dtype.type, np.integer) or
2016 value.dtype == np.object_)):
2017 value = _possibly_infer_to_datetimelike(value)
2018
2019 return value
2020
2021
2022 def _possibly_infer_to_datetimelike(value, convert_dates=False):
2023 """
2024 we might have a array (or single object) that is datetime like,
2025 and no dtype is passed don't change the value unless we find a
2026 datetime/timedelta set
2027
2028 this is pretty strict in that a datetime/timedelta is REQUIRED
2029 in addition to possible nulls/string likes
2030
2031 ONLY strings are NOT datetimelike
2032
2033 Parameters
2034 ----------
2035 value : np.array
2036 convert_dates : boolean, default False
2037 if True try really hard to convert dates (such as datetime.date), other
2038 leave inferred dtype 'date' alone
2039
2040 """
2041
2042 v = value
2043 if not is_list_like(v):
2044 v = [v]
2045 v = np.array(v,copy=False)
2046 shape = v.shape
2047 if not v.ndim == 1:
2048 v = v.ravel()
2049
2050 if len(v):
2051
2052 def _try_datetime(v):
2053 # safe coerce to datetime64
2054 try:
2055 return tslib.array_to_datetime(v, raise_=True).reshape(shape)
2056 except:
2057 return v
2058
2059 def _try_timedelta(v):
2060 # safe coerce to timedelta64
2061
2062 # will try first with a string & object conversion
2063 from pandas.tseries.timedeltas import to_timedelta
2064 try:
2065 return to_timedelta(v).values.reshape(shape)
2066 except:
2067 return v
2068
2069 # do a quick inference for perf
2070 sample = v[:min(3,len(v))]
2071 inferred_type = lib.infer_dtype(sample)
2072
2073 if inferred_type in ['datetime', 'datetime64'] or (convert_dates and inferred_type in ['date']):
2074 value = _try_datetime(v).reshape(shape)
2075 elif inferred_type in ['timedelta', 'timedelta64']:
2076 value = _try_timedelta(v).reshape(shape)
2077
2078 # its possible to have nulls intermixed within the datetime or timedelta
2079 # these will in general have an inferred_type of 'mixed', so have to try
2080 # both datetime and timedelta
2081
2082 # try timedelta first to avoid spurious datetime conversions
2083 # e.g. '00:00:01' is a timedelta but technically is also a datetime
2084 elif inferred_type in ['mixed']:
2085
2086 if lib.is_possible_datetimelike_array(_ensure_object(v)):
2087 value = _try_timedelta(v).reshape(shape)
2088 if lib.infer_dtype(value) in ['mixed']:
2089 value = _try_datetime(v).reshape(shape)
2090
2091 return value
2092
2093
2094 def is_bool_indexer(key):
2095 if isinstance(key, (ABCSeries, np.ndarray)):
2096 if key.dtype == np.object_:
2097 key = np.asarray(_values_from_object(key))
2098
2099 if not lib.is_bool_array(key):
2100 if isnull(key).any():
2101 raise ValueError('cannot index with vector containing '
2102 'NA / NaN values')
2103 return False
2104 return True
2105 elif key.dtype == np.bool_:
2106 return True
2107 elif isinstance(key, list):
2108 try:
2109 arr = np.asarray(key)
2110 return arr.dtype == np.bool_ and len(arr) == len(key)
2111 except TypeError: # pragma: no cover
2112 return False
2113
2114 return False
2115
2116
2117 def _default_index(n):
2118 from pandas.core.index import Int64Index
2119 values = np.arange(n, dtype=np.int64)
2120 result = Int64Index(values,name=None)
2121 result.is_unique = True
2122 return result
2123
2124
2125 def ensure_float(arr):
2126 if issubclass(arr.dtype.type, (np.integer, np.bool_)):
2127 arr = arr.astype(float)
2128 return arr
2129
2130
2131 def _mut_exclusive(**kwargs):
2132 item1, item2 = kwargs.items()
2133 label1, val1 = item1
2134 label2, val2 = item2
2135 if val1 is not None and val2 is not None:
2136 raise TypeError('mutually exclusive arguments: %r and %r' %
2137 (label1, label2))
2138 elif val1 is not None:
2139 return val1
2140 else:
2141 return val2
2142
2143
2144 def _any_none(*args):
2145 for arg in args:
2146 if arg is None:
2147 return True
2148 return False
2149
2150
2151 def _all_not_none(*args):
2152 for arg in args:
2153 if arg is None:
2154 return False
2155 return True
2156
2157
2158 def _try_sort(iterable):
2159 listed = list(iterable)
2160 try:
2161 return sorted(listed)
2162 except Exception:
2163 return listed
2164
2165
2166 def _count_not_none(*args):
2167 return sum(x is not None for x in args)
2168
2169 #------------------------------------------------------------------------------
2170 # miscellaneous python tools
2171
2172
2173
2174
2175 def adjoin(space, *lists):
2176 """
2177 Glues together two sets of strings using the amount of space requested.
2178 The idea is to prettify.
2179 """
2180 out_lines = []
2181 newLists = []
2182 lengths = [max(map(len, x)) + space for x in lists[:-1]]
2183
2184 # not the last one
2185 lengths.append(max(map(len, lists[-1])))
2186
2187 maxLen = max(map(len, lists))
2188 for i, lst in enumerate(lists):
2189 nl = [x.ljust(lengths[i]) for x in lst]
2190 nl.extend([' ' * lengths[i]] * (maxLen - len(lst)))
2191 newLists.append(nl)
2192 toJoin = zip(*newLists)
2193 for lines in toJoin:
2194 out_lines.append(_join_unicode(lines))
2195 return _join_unicode(out_lines, sep='\n')
2196
2197
2198 def _join_unicode(lines, sep=''):
2199 try:
2200 return sep.join(lines)
2201 except UnicodeDecodeError:
2202 sep = compat.text_type(sep)
2203 return sep.join([x.decode('utf-8') if isinstance(x, str) else x
2204 for x in lines])
2205
2206
2207 def iterpairs(seq):
2208 """
2209 Parameters
2210 ----------
2211 seq: sequence
2212
2213 Returns
2214 -------
2215 iterator returning overlapping pairs of elements
2216
2217 Examples
2218 --------
2219 >>> list(iterpairs([1, 2, 3, 4]))
2220 [(1, 2), (2, 3), (3, 4)]
2221 """
2222 # input may not be sliceable
2223 seq_it = iter(seq)
2224 seq_it_next = iter(seq)
2225 next(seq_it_next)
2226
2227 return zip(seq_it, seq_it_next)
2228
2229
2230 def split_ranges(mask):
2231 """ Generates tuples of ranges which cover all True value in mask
2232
2233 >>> list(split_ranges([1,0,0,1,0]))
2234 [(0, 1), (3, 4)]
2235 """
2236 ranges = [(0, len(mask))]
2237
2238 for pos, val in enumerate(mask):
2239 if not val: # this pos should be ommited, split off the prefix range
2240 r = ranges.pop()
2241 if pos > r[0]: # yield non-zero range
2242 yield (r[0], pos)
2243 if pos + 1 < len(mask): # save the rest for processing
2244 ranges.append((pos + 1, len(mask)))
2245 if ranges:
2246 yield ranges[-1]
2247
2248
2249 def indent(string, spaces=4):
2250 dent = ' ' * spaces
2251 return '\n'.join([dent + x for x in string.split('\n')])
2252
2253
2254 def banner(message):
2255 """
2256 Return 80-char width message declaration with = bars on top and bottom.
2257 """
2258 bar = '=' * 80
2259 return '%s\n%s\n%s' % (bar, message, bar)
2260
2261
2262 def _long_prod(vals):
2263 result = long(1)
2264 for x in vals:
2265 result *= x
2266 return result
2267
2268
2269 class groupby(dict):
2270
2271 """
2272 A simple groupby different from the one in itertools.
2273
2274 Does not require the sequence elements to be sorted by keys,
2275 however it is slower.
2276 """
2277
2278 def __init__(self, seq, key=lambda x: x):
2279 for value in seq:
2280 k = key(value)
2281 self.setdefault(k, []).append(value)
2282 try:
2283 __iter__ = dict.iteritems
2284 except AttributeError: # pragma: no cover
2285 # Python 3
2286 def __iter__(self):
2287 return iter(dict.items(self))
2288
2289
2290 def map_indices_py(arr):
2291 """
2292 Returns a dictionary with (element, index) pairs for each element in the
2293 given array/list
2294 """
2295 return dict([(x, i) for i, x in enumerate(arr)])
2296
2297
2298 def union(*seqs):
2299 result = set([])
2300 for seq in seqs:
2301 if not isinstance(seq, set):
2302 seq = set(seq)
2303 result |= seq
2304 return type(seqs[0])(list(result))
2305
2306
2307 def difference(a, b):
2308 return type(a)(list(set(a) - set(b)))
2309
2310
2311 def intersection(*seqs):
2312 result = set(seqs[0])
2313 for seq in seqs:
2314 if not isinstance(seq, set):
2315 seq = set(seq)
2316 result &= seq
2317 return type(seqs[0])(list(result))
2318
2319
2320 def _asarray_tuplesafe(values, dtype=None):
2321 from pandas.core.index import Index
2322
2323 if not (isinstance(values, (list, tuple))
2324 or hasattr(values, '__array__')):
2325 values = list(values)
2326 elif isinstance(values, Index):
2327 return values.values
2328
2329 if isinstance(values, list) and dtype in [np.object_, object]:
2330 return lib.list_to_object_array(values)
2331
2332 result = np.asarray(values, dtype=dtype)
2333
2334 if issubclass(result.dtype.type, compat.string_types):
2335 result = np.asarray(values, dtype=object)
2336
2337 if result.ndim == 2:
2338 if isinstance(values, list):
2339 return lib.list_to_object_array(values)
2340 else:
2341 # Making a 1D array that safely contains tuples is a bit tricky
2342 # in numpy, leading to the following
2343 try:
2344 result = np.empty(len(values), dtype=object)
2345 result[:] = values
2346 except ValueError:
2347 # we have a list-of-list
2348 result[:] = [tuple(x) for x in values]
2349
2350 return result
2351
2352
2353 def _index_labels_to_array(labels):
2354 if isinstance(labels, (compat.string_types, tuple)):
2355 labels = [labels]
2356
2357 if not isinstance(labels, (list, np.ndarray)):
2358 try:
2359 labels = list(labels)
2360 except TypeError: # non-iterable
2361 labels = [labels]
2362
2363 labels = _asarray_tuplesafe(labels)
2364
2365 return labels
2366
2367
2368 def _maybe_make_list(obj):
2369 if obj is not None and not isinstance(obj, (tuple, list)):
2370 return [obj]
2371 return obj
2372
2373 ########################
2374 ##### TYPE TESTING #####
2375 ########################
2376
2377 is_bool = lib.is_bool
2378
2379
2380 is_integer = lib.is_integer
2381
2382
2383 is_float = lib.is_float
2384
2385
2386 is_complex = lib.is_complex
2387
2388
2389 def is_iterator(obj):
2390 # python 3 generators have __next__ instead of next
2391 return hasattr(obj, 'next') or hasattr(obj, '__next__')
2392
2393
2394 def is_number(obj):
2395 return isinstance(obj, (numbers.Number, np.number))
2396
2397 def is_period_arraylike(arr):
2398 """ return if we are period arraylike / PeriodIndex """
2399 if isinstance(arr, pd.PeriodIndex):
2400 return True
2401 elif isinstance(arr, (np.ndarray, ABCSeries)):
2402 return arr.dtype == object and lib.infer_dtype(arr) == 'period'
2403 return getattr(arr, 'inferred_type', None) == 'period'
2404
2405 def is_datetime_arraylike(arr):
2406 """ return if we are datetime arraylike / DatetimeIndex """
2407 if isinstance(arr, pd.DatetimeIndex):
2408 return True
2409 elif isinstance(arr, (np.ndarray, ABCSeries)):
2410 return arr.dtype == object and lib.infer_dtype(arr) == 'datetime'
2411 return getattr(arr, 'inferred_type', None) == 'datetime'
2412
2413 def is_datetimelike(arr):
2414 return arr.dtype in _DATELIKE_DTYPES or isinstance(arr, ABCPeriodIndex)
2415
2416 def _coerce_to_dtype(dtype):
2417 """ coerce a string / np.dtype to a dtype """
2418 if is_categorical_dtype(dtype):
2419 dtype = CategoricalDtype()
2420 else:
2421 dtype = np.dtype(dtype)
2422 return dtype
2423
2424 def _get_dtype(arr_or_dtype):
2425 if isinstance(arr_or_dtype, np.dtype):
2426 return arr_or_dtype
2427 elif isinstance(arr_or_dtype, type):
2428 return np.dtype(arr_or_dtype)
2429 elif isinstance(arr_or_dtype, CategoricalDtype):
2430 return CategoricalDtype()
2431 return arr_or_dtype.dtype
2432
2433
2434 def _get_dtype_type(arr_or_dtype):
2435 if isinstance(arr_or_dtype, np.dtype):
2436 return arr_or_dtype.type
2437 elif isinstance(arr_or_dtype, type):
2438 return np.dtype(arr_or_dtype).type
2439 elif isinstance(arr_or_dtype, CategoricalDtype):
2440 return CategoricalDtypeType
2441 return arr_or_dtype.dtype.type
2442
2443
2444 def is_any_int_dtype(arr_or_dtype):
2445 tipo = _get_dtype_type(arr_or_dtype)
2446 return issubclass(tipo, np.integer)
2447
2448
2449 def is_integer_dtype(arr_or_dtype):
2450 tipo = _get_dtype_type(arr_or_dtype)
2451 return (issubclass(tipo, np.integer) and
2452 not issubclass(tipo, (np.datetime64, np.timedelta64)))
2453
2454
2455 def is_int_or_datetime_dtype(arr_or_dtype):
2456 tipo = _get_dtype_type(arr_or_dtype)
2457 return (issubclass(tipo, np.integer) or
2458 issubclass(tipo, (np.datetime64, np.timedelta64)))
2459
2460
2461 def is_datetime64_dtype(arr_or_dtype):
2462 tipo = _get_dtype_type(arr_or_dtype)
2463 return issubclass(tipo, np.datetime64)
2464
2465
2466 def is_datetime64_ns_dtype(arr_or_dtype):
2467 tipo = _get_dtype(arr_or_dtype)
2468 return tipo == _NS_DTYPE
2469
2470 def is_timedelta64_dtype(arr_or_dtype):
2471 tipo = _get_dtype_type(arr_or_dtype)
2472 return issubclass(tipo, np.timedelta64)
2473
2474
2475 def is_timedelta64_ns_dtype(arr_or_dtype):
2476 tipo = _get_dtype_type(arr_or_dtype)
2477 return tipo == _TD_DTYPE
2478
2479
2480 def is_datetime_or_timedelta_dtype(arr_or_dtype):
2481 tipo = _get_dtype_type(arr_or_dtype)
2482 return issubclass(tipo, (np.datetime64, np.timedelta64))
2483
2484
2485 needs_i8_conversion = is_datetime_or_timedelta_dtype
2486
2487 def i8_boxer(arr_or_dtype):
2488 """ return the scalar boxer for the dtype """
2489 if is_datetime64_dtype(arr_or_dtype):
2490 return lib.Timestamp
2491 elif is_timedelta64_dtype(arr_or_dtype):
2492 return lambda x: lib.Timedelta(x,unit='ns')
2493 raise ValueError("cannot find a scalar boxer for {0}".format(arr_or_dtype))
2494
2495 def is_numeric_dtype(arr_or_dtype):
2496 tipo = _get_dtype_type(arr_or_dtype)
2497 return (issubclass(tipo, (np.number, np.bool_))
2498 and not issubclass(tipo, (np.datetime64, np.timedelta64)))
2499
2500
2501 def is_float_dtype(arr_or_dtype):
2502 tipo = _get_dtype_type(arr_or_dtype)
2503 return issubclass(tipo, np.floating)
2504
2505
2506 def is_floating_dtype(arr_or_dtype):
2507 tipo = _get_dtype_type(arr_or_dtype)
2508 return isinstance(tipo, np.floating)
2509
2510
2511 def is_bool_dtype(arr_or_dtype):
2512 tipo = _get_dtype_type(arr_or_dtype)
2513 return issubclass(tipo, np.bool_)
2514
2515 def is_categorical(array):
2516 """ return if we are a categorical possibility """
2517 return isinstance(array, ABCCategorical) or isinstance(array.dtype, CategoricalDtype)
2518
2519 def is_categorical_dtype(arr_or_dtype):
2520 if hasattr(arr_or_dtype,'dtype'):
2521 arr_or_dtype = arr_or_dtype.dtype
2522
2523 if isinstance(arr_or_dtype, CategoricalDtype):
2524 return True
2525 try:
2526 return arr_or_dtype == 'category'
2527 except:
2528 return False
2529
2530 def is_complex_dtype(arr_or_dtype):
2531 tipo = _get_dtype_type(arr_or_dtype)
2532 return issubclass(tipo, np.complexfloating)
2533
2534
2535 def is_object_dtype(arr_or_dtype):
2536 tipo = _get_dtype_type(arr_or_dtype)
2537 return issubclass(tipo, np.object_)
2538
2539
2540 def is_re(obj):
2541 return isinstance(obj, re._pattern_type)
2542
2543
2544 def is_re_compilable(obj):
2545 try:
2546 re.compile(obj)
2547 except TypeError:
2548 return False
2549 else:
2550 return True
2551
2552
2553 def is_list_like(arg):
2554 return (hasattr(arg, '__iter__') and
2555 not isinstance(arg, compat.string_and_binary_types))
2556
2557 def is_null_slice(obj):
2558 return (isinstance(obj, slice) and obj.start is None and
2559 obj.stop is None and obj.step is None)
2560
2561
2562 def is_hashable(arg):
2563 """Return True if hash(arg) will succeed, False otherwise.
2564
2565 Some types will pass a test against collections.Hashable but fail when they
2566 are actually hashed with hash().
2567
2568 Distinguish between these and other types by trying the call to hash() and
2569 seeing if they raise TypeError.
2570
2571 Examples
2572 --------
2573 >>> a = ([],)
2574 >>> isinstance(a, collections.Hashable)
2575 True
2576 >>> is_hashable(a)
2577 False
2578 """
2579 # unfortunately, we can't use isinstance(arg, collections.Hashable), which
2580 # can be faster than calling hash, because numpy scalars on Python 3 fail
2581 # this test
2582
2583 # reconsider this decision once this numpy bug is fixed:
2584 # https://github.com/numpy/numpy/issues/5562
2585
2586 try:
2587 hash(arg)
2588 except TypeError:
2589 return False
2590 else:
2591 return True
2592
2593
2594 def is_sequence(x):
2595 try:
2596 iter(x)
2597 len(x) # it has a length
2598 return not isinstance(x, compat.string_and_binary_types)
2599 except (TypeError, AttributeError):
2600 return False
2601
2602
2603 def _get_callable_name(obj):
2604 # typical case has name
2605 if hasattr(obj, '__name__'):
2606 return getattr(obj, '__name__')
2607 # some objects don't; could recurse
2608 if isinstance(obj, partial):
2609 return _get_callable_name(obj.func)
2610 # fall back to class name
2611 if hasattr(obj, '__call__'):
2612 return obj.__class__.__name__
2613 # everything failed (probably because the argument
2614 # wasn't actually callable); we return None
2615 # instead of the empty string in this case to allow
2616 # distinguishing between no name and a name of ''
2617 return None
2618
2619 _string_dtypes = frozenset(map(_get_dtype_from_object, (compat.binary_type,
2620 compat.text_type)))
2621
2622
2623 _ensure_float64 = algos.ensure_float64
2624 _ensure_float32 = algos.ensure_float32
2625 _ensure_int64 = algos.ensure_int64
2626 _ensure_int32 = algos.ensure_int32
2627 _ensure_int16 = algos.ensure_int16
2628 _ensure_int8 = algos.ensure_int8
2629 _ensure_platform_int = algos.ensure_platform_int
2630 _ensure_object = algos.ensure_object
2631
2632
2633 def _astype_nansafe(arr, dtype, copy=True):
2634 """ return a view if copy is False, but
2635 need to be very careful as the result shape could change! """
2636 if not isinstance(dtype, np.dtype):
2637 dtype = _coerce_to_dtype(dtype)
2638
2639 if is_datetime64_dtype(arr):
2640 if dtype == object:
2641 return tslib.ints_to_pydatetime(arr.view(np.int64))
2642 elif dtype == np.int64:
2643 return arr.view(dtype)
2644 elif dtype != _NS_DTYPE:
2645 raise TypeError("cannot astype a datetimelike from [%s] to [%s]" %
2646 (arr.dtype, dtype))
2647 return arr.astype(_NS_DTYPE)
2648 elif is_timedelta64_dtype(arr):
2649 if dtype == np.int64:
2650 return arr.view(dtype)
2651 elif dtype == object:
2652 return tslib.ints_to_pytimedelta(arr.view(np.int64))
2653
2654 # in py3, timedelta64[ns] are int64
2655 elif ((compat.PY3 and dtype not in [_INT64_DTYPE, _TD_DTYPE]) or
2656 (not compat.PY3 and dtype != _TD_DTYPE)):
2657
2658 # allow frequency conversions
2659 if dtype.kind == 'm':
2660 mask = isnull(arr)
2661 result = arr.astype(dtype).astype(np.float64)
2662 result[mask] = np.nan
2663 return result
2664
2665 raise TypeError("cannot astype a timedelta from [%s] to [%s]" %
2666 (arr.dtype, dtype))
2667
2668 return arr.astype(_TD_DTYPE)
2669 elif (np.issubdtype(arr.dtype, np.floating) and
2670 np.issubdtype(dtype, np.integer)):
2671
2672 if np.isnan(arr).any():
2673 raise ValueError('Cannot convert NA to integer')
2674 elif arr.dtype == np.object_ and np.issubdtype(dtype.type, np.integer):
2675 # work around NumPy brokenness, #1987
2676 return lib.astype_intsafe(arr.ravel(), dtype).reshape(arr.shape)
2677 elif issubclass(dtype.type, compat.text_type):
2678 # in Py3 that's str, in Py2 that's unicode
2679 return lib.astype_unicode(arr.ravel()).reshape(arr.shape)
2680 elif issubclass(dtype.type, compat.string_types):
2681 return lib.astype_str(arr.ravel()).reshape(arr.shape)
2682
2683 if copy:
2684 return arr.astype(dtype)
2685 return arr.view(dtype)
2686
2687
2688 def _clean_fill_method(method, allow_nearest=False):
2689 if method is None:
2690 return None
2691 method = method.lower()
2692 if method == 'ffill':
2693 method = 'pad'
2694 if method == 'bfill':
2695 method = 'backfill'
2696
2697 valid_methods = ['pad', 'backfill']
2698 expecting = 'pad (ffill) or backfill (bfill)'
2699 if allow_nearest:
2700 valid_methods.append('nearest')
2701 expecting = 'pad (ffill), backfill (bfill) or nearest'
2702 if method not in valid_methods:
2703 msg = ('Invalid fill method. Expecting %s. Got %s'
2704 % (expecting, method))
2705 raise ValueError(msg)
2706 return method
2707
2708
2709 def _clean_reindex_fill_method(method):
2710 return _clean_fill_method(method, allow_nearest=True)
2711
2712
2713 def _all_none(*args):
2714 for arg in args:
2715 if arg is not None:
2716 return False
2717 return True
2718
2719
2720 class UTF8Recoder:
2721
2722 """
2723 Iterator that reads an encoded stream and reencodes the input to UTF-8
2724 """
2725
2726 def __init__(self, f, encoding):
2727 self.reader = codecs.getreader(encoding)(f)
2728
2729 def __iter__(self):
2730 return self
2731
2732 def read(self, bytes=-1):
2733 return self.reader.read(bytes).encode('utf-8')
2734
2735 def readline(self):
2736 return self.reader.readline().encode('utf-8')
2737
2738 def next(self):
2739 return next(self.reader).encode("utf-8")
2740
2741 # Python 3 iterator
2742 __next__ = next
2743
2744
2745 def _get_handle(path, mode, encoding=None, compression=None):
2746 """Gets file handle for given path and mode.
2747 NOTE: Under Python 3.2, getting a compressed file handle means reading in
2748 the entire file, decompressing it and decoding it to ``str`` all at once
2749 and then wrapping it in a StringIO.
2750 """
2751 if compression is not None:
2752 if encoding is not None and not compat.PY3:
2753 msg = 'encoding + compression not yet supported in Python 2'
2754 raise ValueError(msg)
2755
2756 if compression == 'gzip':
2757 import gzip
2758 f = gzip.GzipFile(path, 'rb')
2759 elif compression == 'bz2':
2760 import bz2
2761
2762 f = bz2.BZ2File(path, 'rb')
2763 else:
2764 raise ValueError('Unrecognized compression type: %s' %
2765 compression)
2766 if compat.PY3_2:
2767 # gzip and bz2 don't work with TextIOWrapper in 3.2
2768 encoding = encoding or get_option('display.encoding')
2769 f = StringIO(f.read().decode(encoding))
2770 elif compat.PY3:
2771 from io import TextIOWrapper
2772 f = TextIOWrapper(f, encoding=encoding)
2773 return f
2774 else:
2775 if compat.PY3:
2776 if encoding:
2777 f = open(path, mode, encoding=encoding)
2778 else:
2779 f = open(path, mode, errors='replace')
2780 else:
2781 f = open(path, mode)
2782
2783 return f
2784
2785
2786 if compat.PY3: # pragma: no cover
2787 def UnicodeReader(f, dialect=csv.excel, encoding="utf-8", **kwds):
2788 # ignore encoding
2789 return csv.reader(f, dialect=dialect, **kwds)
2790
2791 def UnicodeWriter(f, dialect=csv.excel, encoding="utf-8", **kwds):
2792 return csv.writer(f, dialect=dialect, **kwds)
2793 else:
2794 class UnicodeReader:
2795
2796 """
2797 A CSV reader which will iterate over lines in the CSV file "f",
2798 which is encoded in the given encoding.
2799
2800 On Python 3, this is replaced (below) by csv.reader, which handles
2801 unicode.
2802 """
2803
2804 def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
2805 f = UTF8Recoder(f, encoding)
2806 self.reader = csv.reader(f, dialect=dialect, **kwds)
2807
2808 def next(self):
2809 row = next(self.reader)
2810 return [compat.text_type(s, "utf-8") for s in row]
2811
2812 # python 3 iterator
2813 __next__ = next
2814
2815 def __iter__(self): # pragma: no cover
2816 return self
2817
2818 class UnicodeWriter:
2819
2820 """
2821 A CSV writer which will write rows to CSV file "f",
2822 which is encoded in the given encoding.
2823 """
2824
2825 def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
2826 # Redirect output to a queue
2827 self.queue = StringIO()
2828 self.writer = csv.writer(self.queue, dialect=dialect, **kwds)
2829 self.stream = f
2830 self.encoder = codecs.getincrementalencoder(encoding)()
2831 self.quoting = kwds.get("quoting", None)
2832
2833 def writerow(self, row):
2834 def _check_as_is(x):
2835 return (self.quoting == csv.QUOTE_NONNUMERIC and
2836 is_number(x)) or isinstance(x, str)
2837
2838 row = [x if _check_as_is(x)
2839 else pprint_thing(x).encode('utf-8') for x in row]
2840
2841 self.writer.writerow([s for s in row])
2842 # Fetch UTF-8 output from the queue ...
2843 data = self.queue.getvalue()
2844 data = data.decode("utf-8")
2845 # ... and reencode it into the target encoding
2846 data = self.encoder.encode(data)
2847 # write to the target stream
2848 self.stream.write(data)
2849 # empty queue
2850 self.queue.truncate(0)
2851
2852 def writerows(self, rows):
2853 def _check_as_is(x):
2854 return (self.quoting == csv.QUOTE_NONNUMERIC and
2855 is_number(x)) or isinstance(x, str)
2856
2857 for i, row in enumerate(rows):
2858 rows[i] = [x if _check_as_is(x)
2859 else pprint_thing(x).encode('utf-8') for x in row]
2860
2861 self.writer.writerows([[s for s in row] for row in rows])
2862 # Fetch UTF-8 output from the queue ...
2863 data = self.queue.getvalue()
2864 data = data.decode("utf-8")
2865 # ... and reencode it into the target encoding
2866 data = self.encoder.encode(data)
2867 # write to the target stream
2868 self.stream.write(data)
2869 # empty queue
2870 self.queue.truncate(0)
2871
2872
2873 def get_dtype_kinds(l):
2874 """
2875 Parameters
2876 ----------
2877 l : list of arrays
2878
2879 Returns
2880 -------
2881 a set of kinds that exist in this list of arrays
2882 """
2883
2884 typs = set()
2885 for arr in l:
2886
2887 dtype = arr.dtype
2888 if is_categorical_dtype(dtype):
2889 typ = 'category'
2890 elif isinstance(arr, ABCSparseArray):
2891 typ = 'sparse'
2892 elif is_datetime64_dtype(dtype):
2893 typ = 'datetime'
2894 elif is_timedelta64_dtype(dtype):
2895 typ = 'timedelta'
2896 elif is_object_dtype(dtype):
2897 typ = 'object'
2898 elif is_bool_dtype(dtype):
2899 typ = 'bool'
2900 else:
2901 typ = dtype.kind
2902 typs.add(typ)
2903 return typs
2904
2905 def _concat_compat(to_concat, axis=0):
2906 """
2907 provide concatenation of an array of arrays each of which is a single
2908 'normalized' dtypes (in that for example, if its object, then it is a non-datetimelike
2909 provde a combined dtype for the resulting array the preserves the overall dtype if possible)
2910
2911 Parameters
2912 ----------
2913 to_concat : array of arrays
2914 axis : axis to provide concatenation
2915
2916 Returns
2917 -------
2918 a single array, preserving the combined dtypes
2919 """
2920
2921 # filter empty arrays
2922 # 1-d dtypes always are included here
2923 def is_nonempty(x):
2924 try:
2925 return x.shape[axis] > 0
2926 except Exception:
2927 return True
2928 nonempty = [x for x in to_concat if is_nonempty(x)]
2929
2930 # If all arrays are empty, there's nothing to convert, just short-cut to
2931 # the concatenation, #3121.
2932 #
2933 # Creating an empty array directly is tempting, but the winnings would be
2934 # marginal given that it would still require shape & dtype calculation and
2935 # np.concatenate which has them both implemented is compiled.
2936
2937 typs = get_dtype_kinds(to_concat)
2938
2939 # these are mandated to handle empties as well
2940 if 'datetime' in typs or 'timedelta' in typs:
2941 from pandas.tseries.common import _concat_compat
2942 return _concat_compat(to_concat, axis=axis)
2943
2944 elif 'sparse' in typs:
2945 from pandas.sparse.array import _concat_compat
2946 return _concat_compat(to_concat, axis=axis)
2947
2948 elif 'category' in typs:
2949 from pandas.core.categorical import _concat_compat
2950 return _concat_compat(to_concat, axis=axis)
2951
2952 if not nonempty:
2953
2954 # we have all empties, but may need to coerce the result dtype to object if we
2955 # have non-numeric type operands (numpy would otherwise cast this to float)
2956 typs = get_dtype_kinds(to_concat)
2957 if len(typs) != 1:
2958
2959 if not len(typs-set(['i','u','f'])) or not len(typs-set(['bool','i','u'])):
2960 # let numpy coerce
2961 pass
2962 else:
2963 # coerce to object
2964 to_concat = [ x.astype('object') for x in to_concat ]
2965
2966 return np.concatenate(to_concat,axis=axis)
2967
2968 def _where_compat(mask, arr1, arr2):
2969 if arr1.dtype == _NS_DTYPE and arr2.dtype == _NS_DTYPE:
2970 new_vals = np.where(mask, arr1.view('i8'), arr2.view('i8'))
2971 return new_vals.view(_NS_DTYPE)
2972
2973 import pandas.tslib as tslib
2974 if arr1.dtype == _NS_DTYPE:
2975 arr1 = tslib.ints_to_pydatetime(arr1.view('i8'))
2976 if arr2.dtype == _NS_DTYPE:
2977 arr2 = tslib.ints_to_pydatetime(arr2.view('i8'))
2978
2979 return np.where(mask, arr1, arr2)
2980
2981
2982 def sentinel_factory():
2983 class Sentinel(object):
2984 pass
2985
2986 return Sentinel()
2987
2988
2989 def in_interactive_session():
2990 """ check if we're running in an interactive shell
2991
2992 returns True if running under python/ipython interactive shell
2993 """
2994 def check_main():
2995 import __main__ as main
2996 return (not hasattr(main, '__file__') or
2997 get_option('mode.sim_interactive'))
2998
2999 try:
3000 return __IPYTHON__ or check_main()
3001 except:
3002 return check_main()
3003
3004
3005 def in_qtconsole():
3006 """
3007 check if we're inside an IPython qtconsole
3008
3009 DEPRECATED: This is no longer needed, or working, in IPython 3 and above.
3010 """
3011 try:
3012 ip = get_ipython()
3013 front_end = (
3014 ip.config.get('KernelApp', {}).get('parent_appname', "") or
3015 ip.config.get('IPKernelApp', {}).get('parent_appname', "")
3016 )
3017 if 'qtconsole' in front_end.lower():
3018 return True
3019 except:
3020 return False
3021 return False
3022
3023
3024 def in_ipnb():
3025 """
3026 check if we're inside an IPython Notebook
3027
3028 DEPRECATED: This is no longer used in pandas, and won't work in IPython 3
3029 and above.
3030 """
3031 try:
3032 ip = get_ipython()
3033 front_end = (
3034 ip.config.get('KernelApp', {}).get('parent_appname', "") or
3035 ip.config.get('IPKernelApp', {}).get('parent_appname', "")
3036 )
3037 if 'notebook' in front_end.lower():
3038 return True
3039 except:
3040 return False
3041 return False
3042
3043
3044 def in_ipython_frontend():
3045 """
3046 check if we're inside an an IPython zmq frontend
3047 """
3048 try:
3049 ip = get_ipython()
3050 return 'zmq' in str(type(ip)).lower()
3051 except:
3052 pass
3053
3054 return False
3055
3056 # Unicode consolidation
3057 # ---------------------
3058 #
3059 # pprinting utility functions for generating Unicode text or
3060 # bytes(3.x)/str(2.x) representations of objects.
3061 # Try to use these as much as possible rather then rolling your own.
3062 #
3063 # When to use
3064 # -----------
3065 #
3066 # 1) If you're writing code internal to pandas (no I/O directly involved),
3067 # use pprint_thing().
3068 #
3069 # It will always return unicode text which can handled by other
3070 # parts of the package without breakage.
3071 #
3072 # 2) If you need to send something to the console, use console_encode().
3073 #
3074 # console_encode() should (hopefully) choose the right encoding for you
3075 # based on the encoding set in option "display.encoding"
3076 #
3077 # 3) if you need to write something out to file, use
3078 # pprint_thing_encoded(encoding).
3079 #
3080 # If no encoding is specified, it defaults to utf-8. Since encoding pure
3081 # ascii with utf-8 is a no-op you can safely use the default utf-8 if you're
3082 # working with straight ascii.
3083
3084
3085 def _pprint_seq(seq, _nest_lvl=0, **kwds):
3086 """
3087 internal. pprinter for iterables. you should probably use pprint_thing()
3088 rather then calling this directly.
3089
3090 bounds length of printed sequence, depending on options
3091 """
3092 if isinstance(seq, set):
3093 fmt = u("set([%s])")
3094 else:
3095 fmt = u("[%s]") if hasattr(seq, '__setitem__') else u("(%s)")
3096
3097 nitems = get_option("max_seq_items") or len(seq)
3098
3099 s = iter(seq)
3100 r = []
3101 for i in range(min(nitems, len(seq))): # handle sets, no slicing
3102 r.append(pprint_thing(next(s), _nest_lvl + 1, **kwds))
3103 body = ", ".join(r)
3104
3105 if nitems < len(seq):
3106 body += ", ..."
3107 elif isinstance(seq, tuple) and len(seq) == 1:
3108 body += ','
3109
3110 return fmt % body
3111
3112
3113 def _pprint_dict(seq, _nest_lvl=0, **kwds):
3114 """
3115 internal. pprinter for iterables. you should probably use pprint_thing()
3116 rather then calling this directly.
3117 """
3118 fmt = u("{%s}")
3119 pairs = []
3120
3121 pfmt = u("%s: %s")
3122
3123 nitems = get_option("max_seq_items") or len(seq)
3124
3125 for k, v in list(seq.items())[:nitems]:
3126 pairs.append(pfmt % (pprint_thing(k, _nest_lvl + 1, **kwds),
3127 pprint_thing(v, _nest_lvl + 1, **kwds)))
3128
3129 if nitems < len(seq):
3130 return fmt % (", ".join(pairs) + ", ...")
3131 else:
3132 return fmt % ", ".join(pairs)
3133
3134
3135 def pprint_thing(thing, _nest_lvl=0, escape_chars=None, default_escapes=False,
3136 quote_strings=False):
3137 """
3138 This function is the sanctioned way of converting objects
3139 to a unicode representation.
3140
3141 properly handles nested sequences containing unicode strings
3142 (unicode(object) does not)
3143
3144 Parameters
3145 ----------
3146 thing : anything to be formatted
3147 _nest_lvl : internal use only. pprint_thing() is mutually-recursive
3148 with pprint_sequence, this argument is used to keep track of the
3149 current nesting level, and limit it.
3150 escape_chars : list or dict, optional
3151 Characters to escape. If a dict is passed the values are the
3152 replacements
3153 default_escapes : bool, default False
3154 Whether the input escape characters replaces or adds to the defaults
3155
3156 Returns
3157 -------
3158 result - unicode object on py2, str on py3. Always Unicode.
3159
3160 """
3161 def as_escaped_unicode(thing, escape_chars=escape_chars):
3162 # Unicode is fine, else we try to decode using utf-8 and 'replace'
3163 # if that's not it either, we have no way of knowing and the user
3164 # should deal with it himself.
3165
3166 try:
3167 result = compat.text_type(thing) # we should try this first
3168 except UnicodeDecodeError:
3169 # either utf-8 or we replace errors
3170 result = str(thing).decode('utf-8', "replace")
3171
3172 translate = {'\t': r'\t',
3173 '\n': r'\n',
3174 '\r': r'\r',
3175 }
3176 if isinstance(escape_chars, dict):
3177 if default_escapes:
3178 translate.update(escape_chars)
3179 else:
3180 translate = escape_chars
3181 escape_chars = list(escape_chars.keys())
3182 else:
3183 escape_chars = escape_chars or tuple()
3184 for c in escape_chars:
3185 result = result.replace(c, translate[c])
3186
3187 return compat.text_type(result)
3188
3189 if (compat.PY3 and hasattr(thing, '__next__')) or hasattr(thing, 'next'):
3190 return compat.text_type(thing)
3191 elif (isinstance(thing, dict) and
3192 _nest_lvl < get_option("display.pprint_nest_depth")):
3193 result = _pprint_dict(thing, _nest_lvl, quote_strings=True)
3194 elif is_sequence(thing) and _nest_lvl < \
3195 get_option("display.pprint_nest_depth"):
3196 result = _pprint_seq(thing, _nest_lvl, escape_chars=escape_chars,
3197 quote_strings=quote_strings)
3198 elif isinstance(thing, compat.string_types) and quote_strings:
3199 if compat.PY3:
3200 fmt = "'%s'"
3201 else:
3202 fmt = "u'%s'"
3203 result = fmt % as_escaped_unicode(thing)
3204 else:
3205 result = as_escaped_unicode(thing)
3206
3207 return compat.text_type(result) # always unicode
3208
3209
3210 def pprint_thing_encoded(object, encoding='utf-8', errors='replace', **kwds):
3211 value = pprint_thing(object) # get unicode representation of object
3212 return value.encode(encoding, errors, **kwds)
3213
3214
3215 def console_encode(object, **kwds):
3216 """
3217 this is the sanctioned way to prepare something for
3218 sending *to the console*, it delegates to pprint_thing() to get
3219 a unicode representation of the object relies on the global encoding
3220 set in display.encoding. Use this everywhere
3221 where you output to the console.
3222 """
3223 return pprint_thing_encoded(object,
3224 get_option("display.encoding"))
3225
3226
3227 def load(path): # TODO remove in 0.13
3228 """
3229 Load pickled pandas object (or any other pickled object) from the specified
3230 file path
3231
3232 Warning: Loading pickled data received from untrusted sources can be
3233 unsafe. See: http://docs.python.org/2.7/library/pickle.html
3234
3235 Parameters
3236 ----------
3237 path : string
3238 File path
3239
3240 Returns
3241 -------
3242 unpickled : type of object stored in file
3243 """
3244 import warnings
3245 warnings.warn("load is deprecated, use read_pickle", FutureWarning)
3246 from pandas.io.pickle import read_pickle
3247 return read_pickle(path)
3248
3249
3250 def save(obj, path): # TODO remove in 0.13
3251 """
3252 Pickle (serialize) object to input file path
3253
3254 Parameters
3255 ----------
3256 obj : any object
3257 path : string
3258 File path
3259 """
3260 import warnings
3261 warnings.warn("save is deprecated, use obj.to_pickle", FutureWarning)
3262 from pandas.io.pickle import to_pickle
3263 return to_pickle(obj, path)
3264
3265
3266 def _maybe_match_name(a, b):
3267 a_name = getattr(a, 'name', None)
3268 b_name = getattr(b, 'name', None)
3269 if a_name == b_name:
3270 return a_name
3271 return None
3272
[end of pandas/core/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
pandas-dev/pandas
|
8d2818e32d0bbb50e183ccb5724c391e4f604670
|
[] (__getitem__) boolean indexing assignment bug with nans
See repro below:
``` python
import pandas as pd
import numpy as np
temp = pd.Series(np.random.randn(10))
temp[3:6] = np.nan
temp[8] = np.nan
nan_index = np.isnan(temp)
# this works
temp1 = temp.copy()
temp1[nan_index] = [99, 99, 99, 99]
temp1[nan_index]
3 99
4 99
5 99
8 99
dtype: float64
# this doesn't - values look like they're being assigned in a different order?
temp2 = temp.copy()
temp2[nan_index] = [99, 99, 99, np.nan]
3 NaN
4 99
5 99
8 99
dtype: float64
# ... but it works properly when using .loc
temp2 = temp.copy()
temp2.loc[nan_index] = [99, 99, 99, np.nan]
3 99
4 99
5 99
8 NaN
dtype: float64
```
output of show_versions():
```
INSTALLED VERSIONS
------------------
commit: None
python: 2.7.9.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 60 Stepping 3, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.16.0
nose: 1.3.4
Cython: 0.21.2
numpy: 1.9.2
scipy: 0.14.0
statsmodels: 0.5.0
IPython: 3.0.0
sphinx: 1.2.3
patsy: 0.2.1
dateutil: 2.4.1
pytz: 2015.2
bottleneck: 0.8.0
tables: 3.1.1
numexpr: 2.3.1
matplotlib: 1.4.0
openpyxl: 2.0.2
xlrd: 0.9.3
xlwt: 0.7.5
xlsxwriter: 0.6.6
lxml: 3.4.2
bs4: 4.3.2
html5lib: 0.999
httplib2: 0.8
apiclient: None
sqlalchemy: 0.9.8
pymysql: None
psycopg2: None
```
|
2015-03-28T14:08:51Z
|
<patch>
diff --git a/doc/source/whatsnew/v0.16.1.txt b/doc/source/whatsnew/v0.16.1.txt
--- a/doc/source/whatsnew/v0.16.1.txt
+++ b/doc/source/whatsnew/v0.16.1.txt
@@ -64,3 +64,4 @@ Bug Fixes
- Bug in ``Series.quantile`` on empty Series of type ``Datetime`` or ``Timedelta`` (:issue:`9675`)
+- Bug in ``where`` causing incorrect results when upcasting was required (:issue:`9731`)
diff --git a/pandas/core/common.py b/pandas/core/common.py
--- a/pandas/core/common.py
+++ b/pandas/core/common.py
@@ -1081,15 +1081,6 @@ def _infer_dtype_from_scalar(val):
return dtype, val
-def _maybe_cast_scalar(dtype, value):
- """ if we a scalar value and are casting to a dtype that needs nan -> NaT
- conversion
- """
- if np.isscalar(value) and dtype in _DATELIKE_DTYPES and isnull(value):
- return tslib.iNaT
- return value
-
-
def _maybe_promote(dtype, fill_value=np.nan):
# if we passed an array here, determine the fill value by dtype
@@ -1154,16 +1145,39 @@ def _maybe_promote(dtype, fill_value=np.nan):
return dtype, fill_value
-def _maybe_upcast_putmask(result, mask, other, dtype=None, change=None):
- """ a safe version of put mask that (potentially upcasts the result
- return the result
- if change is not None, then MUTATE the change (and change the dtype)
- return a changed flag
+def _maybe_upcast_putmask(result, mask, other):
"""
+ A safe version of putmask that potentially upcasts the result
- if mask.any():
+ Parameters
+ ----------
+ result : ndarray
+ The destination array. This will be mutated in-place if no upcasting is
+ necessary.
+ mask : boolean ndarray
+ other : ndarray or scalar
+ The source array or value
- other = _maybe_cast_scalar(result.dtype, other)
+ Returns
+ -------
+ result : ndarray
+ changed : boolean
+ Set to true if the result array was upcasted
+ """
+
+ if mask.any():
+ # Two conversions for date-like dtypes that can't be done automatically
+ # in np.place:
+ # NaN -> NaT
+ # integer or integer array -> date-like array
+ if result.dtype in _DATELIKE_DTYPES:
+ if lib.isscalar(other):
+ if isnull(other):
+ other = tslib.iNaT
+ elif is_integer(other):
+ other = np.array(other, dtype=result.dtype)
+ elif is_integer_dtype(other):
+ other = np.array(other, dtype=result.dtype)
def changeit():
@@ -1173,39 +1187,26 @@ def changeit():
om = other[mask]
om_at = om.astype(result.dtype)
if (om == om_at).all():
- new_other = result.values.copy()
- new_other[mask] = om_at
- result[:] = new_other
+ new_result = result.values.copy()
+ new_result[mask] = om_at
+ result[:] = new_result
return result, False
except:
pass
# we are forced to change the dtype of the result as the input
# isn't compatible
- r, fill_value = _maybe_upcast(
- result, fill_value=other, dtype=dtype, copy=True)
- np.putmask(r, mask, other)
-
- # we need to actually change the dtype here
- if change is not None:
-
- # if we are trying to do something unsafe
- # like put a bigger dtype in a smaller one, use the smaller one
- # pragma: no cover
- if change.dtype.itemsize < r.dtype.itemsize:
- raise AssertionError(
- "cannot change dtype of input to smaller size")
- change.dtype = r.dtype
- change[:] = r
+ r, _ = _maybe_upcast(result, fill_value=other, copy=True)
+ np.place(r, mask, other)
return r, True
- # we want to decide whether putmask will work
+ # we want to decide whether place will work
# if we have nans in the False portion of our mask then we need to
- # upcast (possibily) otherwise we DON't want to upcast (e.g. if we are
- # have values, say integers in the success portion then its ok to not
+ # upcast (possibly), otherwise we DON't want to upcast (e.g. if we
+ # have values, say integers, in the success portion then it's ok to not
# upcast)
- new_dtype, fill_value = _maybe_promote(result.dtype, other)
+ new_dtype, _ = _maybe_promote(result.dtype, other)
if new_dtype != result.dtype:
# we have a scalar or len 0 ndarray
@@ -1222,7 +1223,7 @@ def changeit():
return changeit()
try:
- np.putmask(result, mask, other)
+ np.place(result, mask, other)
except:
return changeit()
</patch>
|
[]
|
[]
| ||||
conan-io__conan-5547
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
build_requirements is ignored
I have A package, which build_requires B package. And C package requires A, build_requires B. When I execute "conan install" for C, conan will skip B. If I remove requires A, conan will not skip B. What I want is conan will install A and B. Any help you can provide would be great.
Thanks
To help us debug your issue please explain:
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
</issue>
<code>
[start of README.rst]
1 |Logo|
2
3 Conan
4 =====
5
6 Decentralized, open-source (MIT), C/C++ package manager.
7
8 - Homepage: https://conan.io/
9 - Github: https://github.com/conan-io/conan
10 - Docs: https://docs.conan.io/en/latest/
11 - Slack: https://cpplang.now.sh/ (#conan channel)
12 - Twitter: https://twitter.com/conan_io
13
14
15 Conan is a package manager for C and C++ developers:
16
17 - It is fully decentralized. Users can host their packages in their servers, privately. Integrates with Artifactory and Bintray.
18 - Portable. Works across all platforms, including Linux, OSX, Windows (with native and first class support, WSL, MinGW),
19 Solaris, FreeBSD, embedded and cross compiling, docker, WSL
20 - Manage binaries. It is able to create, upload and download binaries for any configuration and platform,
21 even cross-compiling, saving lots of time in development and continuous integration. The binary compatibility
22 can be configured and customized. Manage all your artifacts in exactly the same way in all platforms.
23 - Integrates with any build system, including any propietary and custom one. Provides tested support for major build systems
24 (CMake, MSBuild, Makefiles, Meson, etc).
25 - Extensible: Its python based recipes, together with extensions points allows for a great power and flexibility.
26 - Large and active community, specially in Github (https://github.com/conan-io/conan) and Slack (https://cpplang.now.sh/ #conan channel).
27 This community also create and maintains packages in Conan-center and Bincrafters repositories in Bintray.
28 - Stable. Used in production by many companies, since 1.0 there is a committment not to break package recipes and documented behavior.
29
30
31
32 +------------------------+-------------------------+-------------------------+-------------------------+
33 | **master** | **develop** | **Coverage** | **Code Climate** |
34 +========================+=========================+=========================+=========================+
35 | |Build Status Master| | |Build Status Develop| | |Develop coverage| | |Develop climate| |
36 +------------------------+-------------------------+-------------------------+-------------------------+
37
38
39 Setup
40 =====
41
42 Please read https://docs.conan.io/en/latest/installation.html
43
44 From binaries
45 -------------
46
47 We have installers for `most platforms here <http://conan.io>`__ but you
48 can run **conan** from sources if you want.
49
50 From pip
51 --------
52
53 Conan is compatible with Python 2 and Python 3.
54
55 - Install pip following `pip docs`_.
56 - Install conan:
57
58 .. code-block:: bash
59
60 $ pip install conan
61
62 You can also use `test.pypi.org <https://test.pypi.org/project/conan/#history>`_ repository to install development (non-stable) Conan versions:
63
64
65 .. code-block:: bash
66
67 $ pip install --index-url https://test.pypi.org/simple/ conan
68
69
70 From Homebrew (OSx)
71 -------------------
72
73 - Install Homebrew following `brew homepage`_.
74
75 .. code-block:: bash
76
77 $ brew update
78 $ brew install conan
79
80 From source
81 -----------
82
83 You can run **conan** client and server in Windows, MacOS, and Linux.
84
85 - **Install pip following** `pip docs`_.
86
87 - **Clone conan repository:**
88
89 .. code-block:: bash
90
91 $ git clone https://github.com/conan-io/conan.git
92
93 - **Install in editable mode**
94
95 .. code-block:: bash
96
97 $ cd conan && sudo pip install -e .
98
99 If you are in Windows, using ``sudo`` is not required.
100
101 - **You are ready, try to run conan:**
102
103 .. code-block::
104
105 $ conan --help
106
107 Consumer commands
108 install Installs the requirements specified in a conanfile (.py or .txt).
109 config Manages configuration. Edits the conan.conf or installs config files.
110 get Gets a file or list a directory of a given reference or package.
111 info Gets information about the dependency graph of a recipe.
112 search Searches package recipes and binaries in the local cache or in a remote.
113 Creator commands
114 new Creates a new package recipe template with a 'conanfile.py'.
115 create Builds a binary package for recipe (conanfile.py) located in current dir.
116 upload Uploads a recipe and binary packages to a remote.
117 export Copies the recipe (conanfile.py & associated files) to your local cache.
118 export-pkg Exports a recipe & creates a package with given files calling 'package'.
119 test Test a package, consuming it with a conanfile recipe with a test() method.
120 Package development commands
121 source Calls your local conanfile.py 'source()' method.
122 build Calls your local conanfile.py 'build()' method.
123 package Calls your local conanfile.py 'package()' method.
124 Misc commands
125 profile Lists profiles in the '.conan/profiles' folder, or shows profile details.
126 remote Manages the remote list and the package recipes associated to a remote.
127 user Authenticates against a remote with user/pass, caching the auth token.
128 imports Calls your local conanfile.py or conanfile.txt 'imports' method.
129 copy Copies conan recipes and packages to another user/channel.
130 remove Removes packages or binaries matching pattern from local cache or remote.
131 alias Creates and exports an 'alias recipe'.
132 download Downloads recipe and binaries to the local cache, without using settings.
133
134 Conan commands. Type "conan <command> -h" for help
135
136 Contributing to the project
137 ===========================
138
139 Feedback and contribution is always welcome in this project.
140 Please read our `contributing guide <https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md>`_.
141
142 Running the tests
143 =================
144
145 Using tox
146 ---------
147
148 .. code-block:: bash
149
150 $ tox
151
152 It will install the needed requirements and launch `nose` skipping some heavy and slow test.
153 If you want to run the full test suite:
154
155 .. code-block:: bash
156
157 $ tox -e full
158
159 Without tox
160 -----------
161
162 **Install python requirements**
163
164 .. code-block:: bash
165
166 $ pip install -r conans/requirements.txt
167 $ pip install -r conans/requirements_server.txt
168 $ pip install -r conans/requirements_dev.txt
169
170
171 Only in OSX:
172
173 .. code-block:: bash
174
175 $ pip install -r conans/requirements_osx.txt # You can omit this one if not running OSX
176
177
178 If you are not Windows and you are not using a python virtual environment, you will need to run these
179 commands using `sudo`.
180
181 Before you can run the tests, you need to set a few environment variables first.
182
183 .. code-block:: bash
184
185 $ export PYTHONPATH=$PYTHONPATH:$(pwd)
186
187 On Windows it would be (while being in the conan root directory):
188
189 .. code-block:: bash
190
191 $ set PYTHONPATH=.
192
193 Ensure that your ``cmake`` has version 2.8 or later. You can see the
194 version with the following command:
195
196 .. code-block:: bash
197
198 $ cmake --version
199
200 The appropriate values of ``CONAN_COMPILER`` and ``CONAN_COMPILER_VERSION`` depend on your
201 operating system and your requirements.
202
203 These should work for the GCC from ``build-essential`` on Ubuntu 14.04:
204
205 .. code-block:: bash
206
207 $ export CONAN_COMPILER=gcc
208 $ export CONAN_COMPILER_VERSION=4.8
209
210 These should work for OS X:
211
212 .. code-block:: bash
213
214 $ export CONAN_COMPILER=clang
215 $ export CONAN_COMPILER_VERSION=3.5
216
217 Finally, there are some tests that use conan to package Go-lang
218 libraries, so you might **need to install go-lang** in your computer and
219 add it to the path.
220
221 You can run the actual tests like this:
222
223 .. code-block:: bash
224
225 $ nosetests .
226
227
228 There are a couple of test attributes defined, as ``slow``, or ``golang`` that you can use
229 to filter the tests, and do not execute them:
230
231 .. code-block:: bash
232
233 $ nosetests . -a !golang
234
235 A few minutes later it should print ``OK``:
236
237 .. code-block:: bash
238
239 ............................................................................................
240 ----------------------------------------------------------------------
241 Ran 146 tests in 50.993s
242
243 OK
244
245 To run specific tests, you can specify the test name too, something like:
246
247 .. code-block:: bash
248
249 $ nosetests conans.test.command.config_install_test:ConfigInstallTest.install_file_test --nocapture
250
251 The ``--nocapture`` argument can be useful to see some output that otherwise is captured by nosetests.
252
253 License
254 -------
255
256 `MIT LICENSE <./LICENSE.md>`__
257
258 .. |Build Status Master| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/master
259 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/master
260
261 .. |Build Status Develop| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/develop
262 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/develop
263
264 .. |Master coverage| image:: https://codecov.io/gh/conan-io/conan/branch/master/graph/badge.svg
265 :target: https://codecov.io/gh/conan-io/conan/branch/master
266
267 .. |Develop coverage| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graph/badge.svg
268 :target: https://codecov.io/gh/conan-io/conan/branch/develop
269
270 .. |Coverage graph| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graphs/tree.svg
271 :height: 50px
272 :width: 50 px
273 :alt: Conan develop coverage
274
275 .. |Develop climate| image:: https://api.codeclimate.com/v1/badges/081b53e570d5220b34e4/maintainability.svg
276 :target: https://codeclimate.com/github/conan-io/conan/maintainability
277
278 .. |Logo| image:: https://conan.io/img/jfrog_conan_logo.png
279
280
281 .. _`pip docs`: https://pip.pypa.io/en/stable/installing/
282
283 .. _`brew homepage`: http://brew.sh/
284
[end of README.rst]
[start of conans/client/graph/graph_binaries.py]
1 import os
2
3 from conans.client.graph.graph import (BINARY_BUILD, BINARY_CACHE, BINARY_DOWNLOAD, BINARY_MISSING,
4 BINARY_SKIP, BINARY_UPDATE,
5 RECIPE_EDITABLE, BINARY_EDITABLE,
6 RECIPE_CONSUMER, RECIPE_VIRTUAL)
7 from conans.errors import NoRemoteAvailable, NotFoundException, \
8 conanfile_exception_formatter
9 from conans.model.info import ConanInfo, PACKAGE_ID_UNKNOWN
10 from conans.model.manifest import FileTreeManifest
11 from conans.model.ref import PackageReference
12 from conans.util.files import is_dirty, rmdir
13
14
15 class GraphBinariesAnalyzer(object):
16
17 def __init__(self, cache, output, remote_manager):
18 self._cache = cache
19 self._out = output
20 self._remote_manager = remote_manager
21
22 def _check_update(self, upstream_manifest, package_folder, output, node):
23 read_manifest = FileTreeManifest.load(package_folder)
24 if upstream_manifest != read_manifest:
25 if upstream_manifest.time > read_manifest.time:
26 output.warn("Current package is older than remote upstream one")
27 node.update_manifest = upstream_manifest
28 return True
29 else:
30 output.warn("Current package is newer than remote upstream one")
31
32 def _evaluate_node(self, node, build_mode, update, evaluated_nodes, remotes):
33 assert node.binary is None, "Node.binary should be None"
34 assert node.package_id is not None, "Node.package_id shouldn't be None"
35 assert node.prev is None, "Node.prev should be None"
36
37 if node.package_id == PACKAGE_ID_UNKNOWN:
38 node.binary = BINARY_MISSING
39 return
40
41 ref, conanfile = node.ref, node.conanfile
42 pref = node.pref
43 # If it has lock
44 locked = node.graph_lock_node
45 if locked and locked.pref.id == node.package_id:
46 pref = locked.pref # Keep the locked with PREV
47 else:
48 assert node.prev is None, "Non locked node shouldn't have PREV in evaluate_node"
49 pref = PackageReference(ref, node.package_id)
50
51 # Check that this same reference hasn't already been checked
52 previous_nodes = evaluated_nodes.get(pref)
53 if previous_nodes:
54 previous_nodes.append(node)
55 previous_node = previous_nodes[0]
56 node.binary = previous_node.binary
57 node.binary_remote = previous_node.binary_remote
58 node.prev = previous_node.prev
59 return
60 evaluated_nodes[pref] = [node]
61
62 output = conanfile.output
63
64 if node.recipe == RECIPE_EDITABLE:
65 node.binary = BINARY_EDITABLE
66 # TODO: PREV?
67 return
68
69 with_deps_to_build = False
70 # For cascade mode, we need to check also the "modified" status of the lockfile if exists
71 # modified nodes have already been built, so they shouldn't be built again
72 if build_mode.cascade and not (node.graph_lock_node and node.graph_lock_node.modified):
73 for dep in node.dependencies:
74 dep_node = dep.dst
75 if (dep_node.binary == BINARY_BUILD or
76 (dep_node.graph_lock_node and dep_node.graph_lock_node.modified)):
77 with_deps_to_build = True
78 break
79 if build_mode.forced(conanfile, ref, with_deps_to_build):
80 output.info('Forced build from source')
81 node.binary = BINARY_BUILD
82 node.prev = None
83 return
84
85 package_folder = self._cache.package_layout(pref.ref,
86 short_paths=conanfile.short_paths).package(pref)
87
88 # Check if dirty, to remove it
89 with self._cache.package_layout(pref.ref).package_lock(pref):
90 assert node.recipe != RECIPE_EDITABLE, "Editable package shouldn't reach this code"
91 if is_dirty(package_folder):
92 output.warn("Package is corrupted, removing folder: %s" % package_folder)
93 rmdir(package_folder) # Do not remove if it is EDITABLE
94
95 if self._cache.config.revisions_enabled:
96 metadata = self._cache.package_layout(pref.ref).load_metadata()
97 rec_rev = metadata.packages[pref.id].recipe_revision
98 if rec_rev and rec_rev != node.ref.revision:
99 output.warn("The package {} doesn't belong "
100 "to the installed recipe revision, removing folder".format(pref))
101 rmdir(package_folder)
102
103 remote = remotes.selected
104 if not remote:
105 # If the remote_name is not given, follow the binary remote, or
106 # the recipe remote
107 # If it is defined it won't iterate (might change in conan2.0)
108 metadata = self._cache.package_layout(pref.ref).load_metadata()
109 remote_name = metadata.packages[pref.id].remote or metadata.recipe.remote
110 remote = remotes.get(remote_name)
111
112 if os.path.exists(package_folder):
113 if update:
114 if remote:
115 try:
116 tmp = self._remote_manager.get_package_manifest(pref, remote)
117 upstream_manifest, pref = tmp
118 except NotFoundException:
119 output.warn("Can't update, no package in remote")
120 except NoRemoteAvailable:
121 output.warn("Can't update, no remote defined")
122 else:
123 if self._check_update(upstream_manifest, package_folder, output, node):
124 node.binary = BINARY_UPDATE
125 node.prev = pref.revision # With revision
126 if build_mode.outdated:
127 info, pref = self._remote_manager.get_package_info(pref, remote)
128 package_hash = info.recipe_hash
129 elif remotes:
130 pass
131 else:
132 output.warn("Can't update, no remote defined")
133 if not node.binary:
134 node.binary = BINARY_CACHE
135 metadata = self._cache.package_layout(pref.ref).load_metadata()
136 node.prev = metadata.packages[pref.id].revision
137 assert node.prev, "PREV for %s is None: %s" % (str(pref), metadata.dumps())
138 package_hash = ConanInfo.load_from_package(package_folder).recipe_hash
139
140 else: # Binary does NOT exist locally
141 remote_info = None
142 if remote:
143 try:
144 remote_info, pref = self._remote_manager.get_package_info(pref, remote)
145 except NotFoundException:
146 pass
147 except Exception:
148 conanfile.output.error("Error downloading binary package: '{}'".format(pref))
149 raise
150
151 # If the "remote" came from the registry but the user didn't specified the -r, with
152 # revisions iterate all remotes
153
154 if not remote or (not remote_info and self._cache.config.revisions_enabled):
155 for r in remotes.values():
156 try:
157 remote_info, pref = self._remote_manager.get_package_info(pref, r)
158 except NotFoundException:
159 pass
160 else:
161 if remote_info:
162 remote = r
163 break
164
165 if remote_info:
166 node.binary = BINARY_DOWNLOAD
167 node.prev = pref.revision
168 package_hash = remote_info.recipe_hash
169 else:
170 if build_mode.allowed(conanfile):
171 node.binary = BINARY_BUILD
172 else:
173 node.binary = BINARY_MISSING
174 node.prev = None
175
176 if build_mode.outdated:
177 if node.binary in (BINARY_CACHE, BINARY_DOWNLOAD, BINARY_UPDATE):
178 local_recipe_hash = self._cache.package_layout(ref).recipe_manifest().summary_hash
179 if local_recipe_hash != package_hash:
180 output.info("Outdated package!")
181 node.binary = BINARY_BUILD
182 node.prev = None
183 else:
184 output.info("Package is up to date")
185
186 node.binary_remote = remote
187
188 @staticmethod
189 def _compute_package_id(node, default_package_id_mode):
190 conanfile = node.conanfile
191 neighbors = node.neighbors()
192 direct_reqs = [] # of PackageReference
193 indirect_reqs = set() # of PackageReference, avoid duplicates
194 for neighbor in neighbors:
195 ref, nconan = neighbor.ref, neighbor.conanfile
196 direct_reqs.append(neighbor.pref)
197 indirect_reqs.update(nconan.info.requires.refs())
198 conanfile.options.propagate_downstream(ref, nconan.info.full_options)
199 # Might be never used, but update original requirement, just in case
200 conanfile.requires[ref.name].ref = ref
201
202 # Make sure not duplicated
203 indirect_reqs.difference_update(direct_reqs)
204 # There might be options that are not upstream, backup them, might be
205 # for build-requires
206 conanfile.build_requires_options = conanfile.options.values
207 conanfile.options.clear_unused(indirect_reqs.union(direct_reqs))
208 conanfile.options.freeze()
209
210 conanfile.info = ConanInfo.create(conanfile.settings.values,
211 conanfile.options.values,
212 direct_reqs,
213 indirect_reqs,
214 default_package_id_mode=default_package_id_mode)
215
216 # Once we are done, call package_id() to narrow and change possible values
217 with conanfile_exception_formatter(str(conanfile), "package_id"):
218 conanfile.package_id()
219
220 info = conanfile.info
221 node.package_id = info.package_id()
222
223 def _handle_private(self, node):
224 if node.binary in (BINARY_CACHE, BINARY_DOWNLOAD, BINARY_UPDATE, BINARY_SKIP):
225 private_neighbours = node.private_neighbors()
226 for neigh in private_neighbours:
227 if not neigh.private:
228 continue
229 # Current closure contains own node to be skipped
230 for n in neigh.public_closure.values():
231 if n.private:
232 n.binary = BINARY_SKIP
233 self._handle_private(n)
234
235 def evaluate_graph(self, deps_graph, build_mode, update, remotes):
236 default_package_id_mode = self._cache.config.default_package_id_mode
237 evaluated = deps_graph.evaluated
238 for node in deps_graph.ordered_iterate():
239 self._compute_package_id(node, default_package_id_mode)
240 if node.recipe in (RECIPE_CONSUMER, RECIPE_VIRTUAL):
241 continue
242 self._evaluate_node(node, build_mode, update, evaluated, remotes)
243 self._handle_private(node)
244
[end of conans/client/graph/graph_binaries.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
conan-io/conan
|
56a5b42691907598535ff9e61ac8eac0fb251305
|
build_requirements is ignored
I have A package, which build_requires B package. And C package requires A, build_requires B. When I execute "conan install" for C, conan will skip B. If I remove requires A, conan will not skip B. What I want is conan will install A and B. Any help you can provide would be great.
Thanks
To help us debug your issue please explain:
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
|
Hi @xyz1001
I am trying to reproduce your case, but so far no success. Please check the following test, that is passing:
```python
class BuildRequiresTest(unittest.TestCase):
def test_consumer(self):
# https://github.com/conan-io/conan/issues/5425
t = TestClient()
t.save({"conanfile.py": str(TestConanFile("ToolB", "0.1"))})
t.run("create . ToolB/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibA", "0.1",
build_requires=["ToolB/0.1@user/testing"]))})
t.run("create . LibA/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibC", "0.1",
requires=["LibA/0.1@user/testing"],
build_requires=["ToolB/0.1@user/testing"]))})
t.run("install .")
self.assertIn("ToolB/0.1@user/testing from local cache", t.out)
```
As you can see, the build require to ToolB is not being skipped. Could you please double check it? Maybe a more complete and reproducible case would help. Thanks!
I am sorry, LibA is private_requires ToolB. I modified the test case:
```
class BuildRequiresTest(unittest.TestCase):
def test_consumer(self):
# https://github.com/conan-io/conan/issues/5425
t = TestClient()
t.save({"conanfile.py": str(TestConanFile("ToolB", "0.1"))})
t.run("create . ToolB/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibA", "0.1",
private_requires=[("ToolB/0.1@user/testing")]))})
t.run("create . LibA/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibC", "0.1",
requires=[
"LibA/0.1@user/testing"],
build_requires=["ToolB/0.1@user/testing"]))})
t.run("install .")
self.assertIn("ToolB/0.1@user/testing from local cache", t.out)
```
I try the test case and it is passed. However, In my project `XXX`, it did print `ToolB/0.1@user/testing from local cache`, but the conanbuildinfo.txt has not any info about the `ToolB`. Here is the `conan install` output:
```
conanfile.py (XXX/None@None/None): Installing package
Requirements
catch2/2.4.2@bincrafters/stable from 'conan-local' - Cache
fmt/5.2.1@bincrafters/stable from 'conan-local' - Cache
xxx_logger/1.2.13@screenshare/stable from 'conan-local' - Cache
spdlog/1.2.1@bincrafters/stable from 'conan-local' - Cache
Packages
catch2/2.4.2@bincrafters/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Skip
fmt/5.2.1@bincrafters/stable:038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec - Cache
xxx_logger/1.2.13@screenshare/stable:aa971e8736e335273eb99282f27319bdaa20df9d - Cache
spdlog/1.2.1@bincrafters/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Cache
Build requirements
catch2/2.4.2@bincrafters/stable from 'conan-local' - Cache
Build requirements packages
catch2/2.4.2@bincrafters/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Skip
fmt/5.2.1@bincrafters/stable: Already installed!
spdlog/1.2.1@bincrafters/stable: Already installed!
xxx_logger/1.2.13@screenshare/stable: Already installed!
```
catch2 -> ToolB
xxx_logger -> LibA
XXX -> LibC
here is the conanbuildinfo.txt.
```
[includedirs]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/include
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/include
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/include
[libdirs]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/lib
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/lib
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/lib
[bindirs]
[resdirs]
[builddirs]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/
[libs]
xxx_logger
pthread
fmtd
[defines]
SPDLOG_FMT_EXTERNAL
[cppflags]
[cxxflags]
[cflags]
[sharedlinkflags]
[exelinkflags]
[sysroot]
[includedirs_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/include
[libdirs_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/lib
[bindirs_xxx_logger]
[resdirs_xxx_logger]
[builddirs_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/
[libs_xxx_logger]
xxx_logger
pthread
[defines_xxx_logger]
[cppflags_xxx_logger]
[cxxflags_xxx_logger]
[cflags_xxx_logger]
[sharedlinkflags_xxx_logger]
[exelinkflags_xxx_logger]
[sysroot_xxx_logger]
[rootpath_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d
[includedirs_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/include
[libdirs_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/lib
[bindirs_spdlog]
[resdirs_spdlog]
[builddirs_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/
[libs_spdlog]
pthread
[defines_spdlog]
SPDLOG_FMT_EXTERNAL
[cppflags_spdlog]
[cxxflags_spdlog]
[cflags_spdlog]
[sharedlinkflags_spdlog]
[exelinkflags_spdlog]
[sysroot_spdlog]
[rootpath_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9
[includedirs_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/include
[libdirs_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/lib
[bindirs_fmt]
[resdirs_fmt]
[builddirs_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/
[libs_fmt]
fmtd
[defines_fmt]
[cppflags_fmt]
[cxxflags_fmt]
[cflags_fmt]
[sharedlinkflags_fmt]
[exelinkflags_fmt]
[sysroot_fmt]
[rootpath_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec
[USER_xxx_logger]
[USER_spdlog]
[USER_fmt]
[ENV_xxx_logger]
[ENV_spdlog]
[ENV_fmt]
```
Confirmed this is an unfortunate bug, coming from a mixture of build-requirements and private requirements. It seems not trivial, it would take some time to fix.
In the meanwhile, I would strongly suggest to reconsider the usage of ``private`` requirements. We are discouraging its use (as you can see they are barely documented), should be only for some extreme cases, like needing to wrap 2 different versions of the same library. What would be the case of ``private`` requirement of ``catch`` library?
|
2019-07-29T07:06:58Z
|
<patch>
diff --git a/conans/client/graph/graph_binaries.py b/conans/client/graph/graph_binaries.py
--- a/conans/client/graph/graph_binaries.py
+++ b/conans/client/graph/graph_binaries.py
@@ -39,7 +39,6 @@ def _evaluate_node(self, node, build_mode, update, evaluated_nodes, remotes):
return
ref, conanfile = node.ref, node.conanfile
- pref = node.pref
# If it has lock
locked = node.graph_lock_node
if locked and locked.pref.id == node.package_id:
@@ -53,7 +52,13 @@ def _evaluate_node(self, node, build_mode, update, evaluated_nodes, remotes):
if previous_nodes:
previous_nodes.append(node)
previous_node = previous_nodes[0]
- node.binary = previous_node.binary
+ # The previous node might have been skipped, but current one not necessarily
+ # keep the original node.binary value (before being skipped), and if it will be
+ # defined as SKIP again by self._handle_private(node) if it is really private
+ if previous_node.binary == BINARY_SKIP:
+ node.binary = previous_node.binary_non_skip
+ else:
+ node.binary = previous_node.binary
node.binary_remote = previous_node.binary_remote
node.prev = previous_node.prev
return
@@ -229,6 +234,8 @@ def _handle_private(self, node):
# Current closure contains own node to be skipped
for n in neigh.public_closure.values():
if n.private:
+ # store the binary origin before being overwritten by SKIP
+ n.binary_non_skip = n.binary
n.binary = BINARY_SKIP
self._handle_private(n)
</patch>
|
[]
|
[]
| |||
PrefectHQ__prefect-2646
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement Depth-First Execution with Mapping
Currently each "level" of a mapped pipeline is executed before proceeding to the next level. This is undesirable especially for pipelines where it's important that each "branch" of the pipeline finish as quickly as possible.
To implement DFE, we'll need to rearrange two things:
- how mapped work gets submitted (it should start being submitted from the Flow Runner not the Task Runner)
- in order to submit work to Dask and let Dask handle the DFE scheduling, we'll want to refactor how we walk the DAG and wait to determine the width of a pipeline before we submit it (because mapping is fully dynamic we can only ascertain this width at runtime)
We'll need to be vigilant about:
- performance
- retries
- result handling
</issue>
<code>
[start of README.md]
1 <p align="center" style="margin-bottom:40px;">
2 <img src="https://uploads-ssl.webflow.com/5ba446b0e783e26d5a2f2382/5c942c9ca934ec5c88588297_primary-color-vertical.svg" height=350 style="max-height: 350px;">
3 </p>
4
5 <p align="center">
6 <a href=https://circleci.com/gh/PrefectHQ/prefect/tree/master>
7 <img src="https://circleci.com/gh/PrefectHQ/prefect/tree/master.svg?style=shield&circle-token=28689a55edc3c373486aaa5f11a1af3e5fc53344">
8 </a>
9
10 <a href="https://codecov.io/gh/PrefectHQ/prefect">
11 <img src="https://codecov.io/gh/PrefectHQ/prefect/branch/master/graph/badge.svg" />
12 </a>
13
14 <a href=https://github.com/ambv/black>
15 <img src="https://img.shields.io/badge/code%20style-black-000000.svg">
16 </a>
17
18 <a href="https://pypi.org/project/prefect/">
19 <img src="https://img.shields.io/pypi/dm/prefect.svg?color=%2327B1FF&label=installs&logoColor=%234D606E">
20 </a>
21
22 <a href="https://hub.docker.com/r/prefecthq/prefect">
23 <img src="https://img.shields.io/docker/pulls/prefecthq/prefect.svg?color=%2327B1FF&logoColor=%234D606E">
24 </a>
25
26 <a href="https://join.slack.com/t/prefect-community/shared_invite/enQtODQ3MTA2MjI4OTgyLTliYjEyYzljNTc2OThlMDE4YmViYzk3NDU4Y2EzMWZiODM0NmU3NjM0NjIyNWY0MGIxOGQzODMxNDMxYWYyOTE">
27 <img src="https://prefect-slackin.herokuapp.com/badge.svg">
28 </a>
29
30 </p>
31
32 ## Hello, world! 👋
33
34 We've rebuilt data engineering for the data science era.
35
36 Prefect is a new workflow management system, designed for modern infrastructure and powered by the open-source Prefect Core workflow engine. Users organize `Tasks` into `Flows`, and Prefect takes care of the rest.
37
38 Read the [docs](https://docs.prefect.io); get the [code](#installation); ask us [anything](https://join.slack.com/t/prefect-community/shared_invite/enQtODQ3MTA2MjI4OTgyLTliYjEyYzljNTc2OThlMDE4YmViYzk3NDU4Y2EzMWZiODM0NmU3NjM0NjIyNWY0MGIxOGQzODMxNDMxYWYyOTE)!
39
40 ### Welcome to Workflows
41
42 Prefect's Pythonic API should feel familiar for newcomers. Mark functions as tasks and call them on each other to build up a flow.
43
44 ```python
45 from prefect import task, Flow, Parameter
46
47
48 @task(log_stdout=True)
49 def say_hello(name):
50 print("Hello, {}!".format(name))
51
52
53 with Flow("My First Flow") as flow:
54 name = Parameter('name')
55 say_hello(name)
56
57
58 flow.run(name='world') # "Hello, world!"
59 flow.run(name='Marvin') # "Hello, Marvin!"
60 ```
61
62 For more detail, please see the [Core docs](https://docs.prefect.io/core/)
63
64 ### UI and Server
65
66 <p align="center" style="margin-bottom:40px;">
67 <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/orchestration/ui/dashboard-overview.png" height=440 style="max-height: 440px;">
68 </p>
69
70 In addition to the [Prefect Cloud](https://www.prefect.io/cloud) platform, Prefect includes an open-source server and UI for orchestrating and managing flows. The local server stores flow metadata in a Postgres database and exposes a GraphQL API.
71
72 Before running the server for the first time, run `prefect backend server` to configure Prefect for local orchestration. Please note the server requires [Docker](https://www.docker.com/) and [Docker Compose](https://docs.docker.com/compose/install/) to be running.
73
74 To start the server, UI, and all required infrastructure, run:
75
76 ```
77 prefect server start
78 ```
79
80 Once all components are running, you can view the UI by visiting [http://localhost:8080](http://localhost:8080).
81
82 Please note that executing flows from the server requires at least one Prefect Agent to be running: `prefect agent start`.
83
84 Finally, to register any flow with the server, call `flow.register()`. For more detail, please see the [orchestration docs](https://docs.prefect.io/orchestration/).
85
86 ## "...Prefect?"
87
88 From the Latin _praefectus_, meaning "one who is in charge", a prefect is an official who oversees a domain and makes sure that the rules are followed. Similarly, Prefect is responsible for making sure that workflows execute properly.
89
90 It also happens to be the name of a roving researcher for that wholly remarkable book, _The Hitchhiker's Guide to the Galaxy_.
91
92 ## Integrations
93
94 Thanks to Prefect's growing task library and deep ecosystem integrations, building data applications is easier than ever.
95
96 Something missing? Open a [feature request](https://github.com/PrefectHQ/prefect/issues/new/choose) or [contribute a PR](https://docs.prefect.io/core/development/overview.html)! Prefect was designed to make adding new functionality extremely easy, whether you build on top of the open-source package or maintain an internal task library for your team.
97
98 ### Task Library
99
100 | | | | | |
101 | :---: | :---: | :---: | :---: | :---: |
102 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/airtable.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Airtable</p>](https://docs.prefect.io/core/task_library/airtable.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/aws.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>AWS</p>](https://docs.prefect.io/core/task_library/aws.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/azure.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Azure</p>](https://docs.prefect.io/core/task_library/azure.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/azure_ml.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Azure ML</p>](https://docs.prefect.io/core/task_library/azureml.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/dbt.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>DBT</p>](https://docs.prefect.io/core/task_library/dbt.html) |
103 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/docker.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Docker</p>](https://docs.prefect.io/core/task_library/docker.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/dropbox.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Dropbox</p>](https://docs.prefect.io/core/task_library/dropbox.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/email.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Email</p>](https://docs.prefect.io/core/task_library/email.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/google_cloud.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Google Cloud</p>](https://docs.prefect.io/core/task_library/gcp.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/github.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>GitHub</p>](https://docs.prefect.io/core/task_library/github.html) |
104 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/jira.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Jira</p>](https://docs.prefect.io/core/task_library/jira.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/kubernetes.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Kubernetes</p>](https://docs.prefect.io/core/task_library/kubernetes.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/postgres.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>PostgreSQL</p>](https://docs.prefect.io/core/task_library/postgres.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/python.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Python</p>](https://docs.prefect.io/core/task_library/function.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/pushbullet.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Pushbullet</p>](https://docs.prefect.io/core/task_library/pushbullet.html) |
105 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/redis.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Redis</p>](https://docs.prefect.io/core/task_library/redis.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/rss.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>RSS</p>](https://docs.prefect.io/core/task_library/rss.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/shell.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Shell</p>](https://docs.prefect.io/core/task_library/shell.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/slack.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Slack</p>](https://docs.prefect.io/core/task_library/slack.html)| <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/snowflake.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Snowflake</p>](https://docs.prefect.io/core/task_library/snowflake.html) |
106 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/spacy.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>SpaCy</p>](https://docs.prefect.io/core/task_library/spacy.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/sqlite.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>SQLite</p>](https://docs.prefect.io/core/task_library/sqlite.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/twitter.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Twitter</p>](https://docs.prefect.io/core/task_library/twitter.html) |
107
108 ### Deployment & Execution
109
110 | | | | | |
111 | :---: | :---: | :---: | :---: | :---: |
112 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/azure.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Azure</p>](https://azure.microsoft.com/en-us/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/aws.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>AWS</p>](https://aws.amazon.com/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/dask.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Dask</p>](https://dask.org/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/docker.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Docker</p>](https://www.docker.com/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/google_cloud.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Google Cloud</p>](https://cloud.google.com/)
113 <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/kubernetes.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Kubernetes</p>](https://kubernetes.io/) | | | | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/shell.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Universal Deploy</p>](https://medium.com/the-prefect-blog/introducing-prefect-universal-deploy-7992283e5911)
114
115 ## Resources
116
117 Prefect provides a variety of resources to help guide you to a successful outcome.
118
119 We are committed to ensuring a positive environment, and all interactions are governed by our [Code of Conduct](https://docs.prefect.io/core/code_of_conduct.html).
120
121 ### Documentation
122
123 Prefect's documentation -- including concepts, tutorials, and a full API reference -- is always available at [docs.prefect.io](https://docs.prefect.io).
124
125 Instructions for contributing to documentation can be found in the [development guide](https://docs.prefect.io/core/development/documentation.html).
126
127 ### Slack Community
128
129 Join our [Slack](https://join.slack.com/t/prefect-community/shared_invite/enQtODQ3MTA2MjI4OTgyLTliYjEyYzljNTc2OThlMDE4YmViYzk3NDU4Y2EzMWZiODM0NmU3NjM0NjIyNWY0MGIxOGQzODMxNDMxYWYyOTE) to chat about Prefect, ask questions, and share tips.
130
131 ### Blog
132
133 Visit the [Prefect Blog](https://medium.com/the-prefect-blog) for updates and insights from the Prefect team.
134
135 ### Support
136
137 Prefect offers a variety of community and premium [support options](https://www.prefect.io/support) for users of both Prefect Core and Prefect Cloud.
138
139 ### Contributing
140
141 Read about Prefect's [community](https://docs.prefect.io/core/community.html) or dive in to the [development guides](https://docs.prefect.io/core/development/overview.html) for information about contributions, documentation, code style, and testing.
142
143 ## Installation
144
145 ### Requirements
146
147 Prefect requires Python 3.6+. If you're new to Python, we recommend installing the [Anaconda distribution](https://www.anaconda.com/distribution/).
148
149 ### Latest Release
150
151 To install Prefect, run:
152
153 ```bash
154 pip install prefect
155 ```
156
157 or, if you prefer to use `conda`:
158
159 ```bash
160 conda install -c conda-forge prefect
161 ```
162
163 or `pipenv`:
164
165 ```bash
166 pipenv install --pre prefect
167 ```
168
169 ### Bleeding Edge
170
171 For development or just to try out the latest features, you may want to install Prefect directly from source.
172
173 Please note that the master branch of Prefect is not guaranteed to be compatible with Prefect Cloud or the local server.
174
175 ```bash
176 git clone https://github.com/PrefectHQ/prefect.git
177 pip install ./prefect
178 ```
179
180 ## License
181
182 Prefect is variously licensed under the [Apache Software License Version 2.0](https://www.apache.org/licenses/LICENSE-2.0) or the [Prefect Community License](https://www.prefect.io/legal/prefect-community-license).
183
184 All code except the `/server` directory is Apache 2.0-licensed unless otherwise noted. The `/server` directory is licensed under the Prefect Community License.
185
[end of README.md]
[start of src/prefect/engine/cloud/task_runner.py]
1 import datetime
2 import time
3 from typing import Any, Callable, Dict, Iterable, Optional, Tuple
4
5 import pendulum
6
7 import prefect
8 from prefect.client import Client
9 from prefect.core import Edge, Task
10 from prefect.engine.result import Result
11 from prefect.engine.runner import ENDRUN, call_state_handlers
12 from prefect.engine.state import (
13 Cached,
14 ClientFailed,
15 Failed,
16 Mapped,
17 Queued,
18 Retrying,
19 State,
20 )
21 from prefect.engine.task_runner import TaskRunner, TaskRunnerInitializeResult
22 from prefect.utilities.executors import tail_recursive
23 from prefect.utilities.graphql import with_args
24
25
26 class CloudTaskRunner(TaskRunner):
27 """
28 TaskRunners handle the execution of Tasks and determine the State of a Task
29 before, during and after the Task is run.
30
31 In particular, through the TaskRunner you can specify the states of any upstream dependencies,
32 and what state the Task should be initialized with.
33
34 Args:
35 - task (Task): the Task to be run / executed
36 - state_handlers (Iterable[Callable], optional): A list of state change handlers
37 that will be called whenever the task changes state, providing an
38 opportunity to inspect or modify the new state. The handler
39 will be passed the task runner instance, the old (prior) state, and the new
40 (current) state, with the following signature: `state_handler(TaskRunner, old_state, new_state) -> State`;
41 If multiple functions are passed, then the `new_state` argument will be the
42 result of the previous handler.
43 - result (Result, optional): the result instance used to retrieve and store task results during execution;
44 if not provided, will default to the one on the provided Task
45 - default_result (Result, optional): the fallback result type to use for retrieving and storing state results
46 during execution (to be used on upstream inputs if they don't provide their own results)
47 """
48
49 def __init__(
50 self,
51 task: Task,
52 state_handlers: Iterable[Callable] = None,
53 result: Result = None,
54 default_result: Result = None,
55 ) -> None:
56 self.client = Client()
57 super().__init__(
58 task=task,
59 state_handlers=state_handlers,
60 result=result,
61 default_result=default_result,
62 )
63
64 def _heartbeat(self) -> bool:
65 try:
66 task_run_id = self.task_run_id # type: str
67 self.heartbeat_cmd = ["prefect", "heartbeat", "task-run", "-i", task_run_id]
68 self.client.update_task_run_heartbeat(task_run_id)
69
70 # use empty string for testing purposes
71 flow_run_id = prefect.context.get("flow_run_id", "") # type: str
72 query = {
73 "query": {
74 with_args("flow_run_by_pk", {"id": flow_run_id}): {
75 "flow": {"settings": True},
76 }
77 }
78 }
79 flow_run = self.client.graphql(query).data.flow_run_by_pk
80 if not flow_run.flow.settings.get("heartbeat_enabled", True):
81 return False
82 return True
83 except Exception as exc:
84 self.logger.exception(
85 "Heartbeat failed for Task '{}'".format(self.task.name)
86 )
87 return False
88
89 def call_runner_target_handlers(self, old_state: State, new_state: State) -> State:
90 """
91 A special state handler that the TaskRunner uses to call its task's state handlers.
92 This method is called as part of the base Runner's `handle_state_change()` method.
93
94 Args:
95 - old_state (State): the old (previous) state
96 - new_state (State): the new (current) state
97
98 Returns:
99 - State: the new state
100 """
101 raise_on_exception = prefect.context.get("raise_on_exception", False)
102
103 try:
104 new_state = super().call_runner_target_handlers(
105 old_state=old_state, new_state=new_state
106 )
107 except Exception as exc:
108 msg = "Exception raised while calling state handlers: {}".format(repr(exc))
109 self.logger.exception(msg)
110 if raise_on_exception:
111 raise exc
112 new_state = Failed(msg, result=exc)
113
114 task_run_id = prefect.context.get("task_run_id")
115 version = prefect.context.get("task_run_version")
116
117 try:
118 cloud_state = new_state
119 state = self.client.set_task_run_state(
120 task_run_id=task_run_id,
121 version=version,
122 state=cloud_state,
123 cache_for=self.task.cache_for,
124 )
125 except Exception as exc:
126 self.logger.exception(
127 "Failed to set task state with error: {}".format(repr(exc))
128 )
129 raise ENDRUN(state=ClientFailed(state=new_state))
130
131 if state.is_queued():
132 state.state = old_state # type: ignore
133 raise ENDRUN(state=state)
134
135 if version is not None:
136 prefect.context.update(task_run_version=version + 1) # type: ignore
137
138 return new_state
139
140 def initialize_run( # type: ignore
141 self, state: Optional[State], context: Dict[str, Any]
142 ) -> TaskRunnerInitializeResult:
143 """
144 Initializes the Task run by initializing state and context appropriately.
145
146 Args:
147 - state (Optional[State]): the initial state of the run
148 - context (Dict[str, Any]): the context to be updated with relevant information
149
150 Returns:
151 - tuple: a tuple of the updated state, context, and upstream_states objects
152 """
153
154 # if the map_index is not None, this is a dynamic task and we need to load
155 # task run info for it
156 map_index = context.get("map_index")
157 if map_index not in [-1, None]:
158 try:
159 task_run_info = self.client.get_task_run_info(
160 flow_run_id=context.get("flow_run_id", ""),
161 task_id=context.get("task_id", ""),
162 map_index=map_index,
163 )
164
165 # if state was provided, keep it; otherwise use the one from db
166 state = state or task_run_info.state # type: ignore
167 context.update(
168 task_run_id=task_run_info.id, # type: ignore
169 task_run_version=task_run_info.version, # type: ignore
170 )
171 except Exception as exc:
172 self.logger.exception(
173 "Failed to retrieve task state with error: {}".format(repr(exc))
174 )
175 if state is None:
176 state = Failed(
177 message="Could not retrieve state from Prefect Cloud",
178 result=exc,
179 )
180 raise ENDRUN(state=state)
181
182 # we assign this so it can be shared with heartbeat thread
183 self.task_run_id = context.get("task_run_id", "") # type: str
184 context.update(checkpointing=True)
185
186 return super().initialize_run(state=state, context=context)
187
188 @call_state_handlers
189 def check_task_is_cached(self, state: State, inputs: Dict[str, Result]) -> State:
190 """
191 Checks if task is cached in the DB and whether any of the caches are still valid.
192
193 Args:
194 - state (State): the current state of this task
195 - inputs (Dict[str, Result]): a dictionary of inputs whose keys correspond
196 to the task's `run()` arguments.
197
198 Returns:
199 - State: the state of the task after running the check
200
201 Raises:
202 - ENDRUN: if the task is not ready to run
203 """
204 if state.is_cached() is True:
205 assert isinstance(state, Cached) # mypy assert
206 sanitized_inputs = {key: res.value for key, res in inputs.items()}
207 if self.task.cache_validator(
208 state, sanitized_inputs, prefect.context.get("parameters")
209 ):
210 state = state.load_result(self.result)
211 return state
212
213 if self.task.cache_for is not None:
214 oldest_valid_cache = datetime.datetime.utcnow() - self.task.cache_for
215 cached_states = self.client.get_latest_cached_states(
216 task_id=prefect.context.get("task_id", ""),
217 cache_key=self.task.cache_key,
218 created_after=oldest_valid_cache,
219 )
220
221 if not cached_states:
222 self.logger.debug(
223 "Task '{name}': can't use cache because no Cached states were found".format(
224 name=prefect.context.get("task_full_name", self.task.name)
225 )
226 )
227 else:
228 self.logger.debug(
229 "Task '{name}': {num} candidate cached states were found".format(
230 name=prefect.context.get("task_full_name", self.task.name),
231 num=len(cached_states),
232 )
233 )
234
235 for candidate_state in cached_states:
236 assert isinstance(candidate_state, Cached) # mypy assert
237 candidate_state.load_cached_results(inputs)
238 sanitized_inputs = {key: res.value for key, res in inputs.items()}
239 if self.task.cache_validator(
240 candidate_state, sanitized_inputs, prefect.context.get("parameters")
241 ):
242 return candidate_state.load_result(self.result)
243
244 self.logger.debug(
245 "Task '{name}': can't use cache because no candidate Cached states "
246 "were valid".format(
247 name=prefect.context.get("task_full_name", self.task.name)
248 )
249 )
250
251 return state
252
253 def load_results(
254 self, state: State, upstream_states: Dict[Edge, State]
255 ) -> Tuple[State, Dict[Edge, State]]:
256 """
257 Given the task's current state and upstream states, populates all relevant result objects for this task run.
258
259 Args:
260 - state (State): the task's current state.
261 - upstream_states (Dict[Edge, State]): the upstream state_handlers
262
263 Returns:
264 - Tuple[State, dict]: a tuple of (state, upstream_states)
265
266 """
267 upstream_results = {}
268
269 try:
270 for edge, upstream_state in upstream_states.items():
271 upstream_states[edge] = upstream_state.load_result(
272 edge.upstream_task.result or self.default_result
273 )
274 if edge.key is not None:
275 upstream_results[edge.key] = (
276 edge.upstream_task.result or self.default_result
277 )
278
279 state.load_cached_results(upstream_results)
280 return state, upstream_states
281 except Exception as exc:
282 new_state = Failed(
283 message=f"Failed to retrieve task results: {exc}", result=exc
284 )
285 final_state = self.handle_state_change(old_state=state, new_state=new_state)
286 raise ENDRUN(final_state)
287
288 def get_task_inputs(
289 self, state: State, upstream_states: Dict[Edge, State]
290 ) -> Dict[str, Result]:
291 """
292 Given the task's current state and upstream states, generates the inputs for this task.
293 Upstream state result values are used. If the current state has `cached_inputs`, they
294 will override any upstream values.
295
296 Args:
297 - state (State): the task's current state.
298 - upstream_states (Dict[Edge, State]): the upstream state_handlers
299
300 Returns:
301 - Dict[str, Result]: the task inputs
302
303 """
304 task_inputs = super().get_task_inputs(state, upstream_states)
305
306 try:
307 ## for mapped tasks, we need to take extra steps to store the cached_inputs;
308 ## this is because in the event of a retry we don't want to have to load the
309 ## entire upstream array that is being mapped over, instead we need store the
310 ## individual pieces of data separately for more efficient retries
311 map_index = prefect.context.get("map_index")
312 if map_index not in [-1, None]:
313 for edge, upstream_state in upstream_states.items():
314 if (
315 edge.key
316 and edge.mapped
317 and edge.upstream_task.checkpoint is not False
318 ):
319 try:
320 task_inputs[edge.key] = task_inputs[edge.key].write( # type: ignore
321 task_inputs[edge.key].value,
322 filename=f"{edge.key}-{map_index}",
323 **prefect.context,
324 )
325 except NotImplementedError:
326 pass
327 except Exception as exc:
328 new_state = Failed(
329 message=f"Failed to save inputs for mapped task: {exc}", result=exc
330 )
331 final_state = self.handle_state_change(old_state=state, new_state=new_state)
332 raise ENDRUN(final_state)
333
334 return task_inputs
335
336 @tail_recursive
337 def run(
338 self,
339 state: State = None,
340 upstream_states: Dict[Edge, State] = None,
341 context: Dict[str, Any] = None,
342 executor: "prefect.engine.executors.Executor" = None,
343 ) -> State:
344 """
345 The main endpoint for TaskRunners. Calling this method will conditionally execute
346 `self.task.run` with any provided inputs, assuming the upstream dependencies are in a
347 state which allow this Task to run. Additionally, this method will wait and perform Task retries
348 which are scheduled for <= 1 minute in the future.
349
350 Args:
351 - state (State, optional): initial `State` to begin task run from;
352 defaults to `Pending()`
353 - upstream_states (Dict[Edge, State]): a dictionary
354 representing the states of any tasks upstream of this one. The keys of the
355 dictionary should correspond to the edges leading to the task.
356 - context (dict, optional): prefect Context to use for execution
357 - executor (Executor, optional): executor to use when performing
358 computation; defaults to the executor specified in your prefect configuration
359
360 Returns:
361 - `State` object representing the final post-run state of the Task
362 """
363 context = context or {}
364 end_state = super().run(
365 state=state,
366 upstream_states=upstream_states,
367 context=context,
368 executor=executor,
369 )
370 while (end_state.is_retrying() or end_state.is_queued()) and (
371 end_state.start_time <= pendulum.now("utc").add(minutes=10) # type: ignore
372 ):
373 assert isinstance(end_state, (Retrying, Queued))
374 naptime = max(
375 (end_state.start_time - pendulum.now("utc")).total_seconds(), 0
376 )
377 time.sleep(naptime)
378
379 # currently required as context has reset to its original state
380 task_run_info = self.client.get_task_run_info(
381 flow_run_id=context.get("flow_run_id", ""),
382 task_id=context.get("task_id", ""),
383 map_index=context.get("map_index"),
384 )
385 context.update(task_run_version=task_run_info.version) # type: ignore
386
387 end_state = super().run(
388 state=end_state,
389 upstream_states=upstream_states,
390 context=context,
391 executor=executor,
392 )
393 return end_state
394
[end of src/prefect/engine/cloud/task_runner.py]
[start of src/prefect/engine/executors/__init__.py]
1 """
2 Prefect Executors implement the logic for how Tasks are run. The standard interface
3 for an Executor consists of the following methods:
4
5 - `submit(fn, *args, **kwargs)`: submit `fn(*args, **kwargs)` for execution;
6 note that this function is (in general) non-blocking, meaning that `executor.submit(...)`
7 will _immediately_ return a future-like object regardless of whether `fn(*args, **kwargs)`
8 has completed running
9 - `wait(object)`: resolves any objects returned by `executor.submit` to
10 their values; this function _will_ block until execution of `object` is complete
11 - `map(fn, *args, upstream_states, **kwargs)`: submit function to be mapped
12 over based on the edge information contained in `upstream_states`. Any "mapped" Edge
13 will be converted into multiple function submissions, one for each value of the upstream mapped tasks.
14
15 Currently, the available executor options are:
16
17 - `LocalExecutor`: the no frills, straightforward executor - great for debugging;
18 tasks are executed immediately upon being called by `executor.submit()`.Note
19 that the `LocalExecutor` is not capable of parallelism. Currently the default executor.
20 - `LocalDaskExecutor`: an executor that runs on `dask` primitives with a
21 configurable dask scheduler.
22 - `DaskExecutor`: the most feature-rich of the executors, this executor runs
23 on `dask.distributed` and has support for multiprocessing, multithreading, and distributed execution.
24
25 Which executor you choose depends on whether you intend to use things like parallelism
26 of task execution.
27
28 The key difference between the `LocalDaskExecutor` and the `DaskExecutor` is the choice
29 of scheduler. The `LocalDaskExecutor` is configurable to use
30 [any number of schedulers](https://docs.dask.org/en/latest/scheduler-overview.html) while the
31 `DaskExecutor` uses the [distributed scheduler](https://docs.dask.org/en/latest/scheduling.html).
32 This means that the `LocalDaskExecutor` can help achieve some multithreading / multiprocessing
33 however it does not provide as many distributed features as the `DaskExecutor`.
34
35 """
36 import prefect
37 from prefect.engine.executors.base import Executor
38 from prefect.engine.executors.dask import DaskExecutor, LocalDaskExecutor
39 from prefect.engine.executors.local import LocalExecutor
40 from prefect.engine.executors.sync import SynchronousExecutor
41
[end of src/prefect/engine/executors/__init__.py]
[start of src/prefect/engine/executors/base.py]
1 import uuid
2 from contextlib import contextmanager
3 from typing import Any, Callable, Iterator, List
4
5 from prefect.utilities.executors import timeout_handler
6
7
8 class Executor:
9 """
10 Base Executor class that all other executors inherit from.
11 """
12
13 timeout_handler = staticmethod(timeout_handler)
14
15 def __init__(self) -> None:
16 self.executor_id = type(self).__name__ + ": " + str(uuid.uuid4())
17
18 def __repr__(self) -> str:
19 return "<Executor: {}>".format(type(self).__name__)
20
21 @contextmanager
22 def start(self) -> Iterator[None]:
23 """
24 Context manager for initializing execution.
25
26 Any initialization this executor needs to perform should be done in this
27 context manager, and torn down after yielding.
28 """
29 yield
30
31 def map(self, fn: Callable, *args: Any) -> List[Any]:
32 """
33 Submit a function to be mapped over its iterable arguments.
34
35 Args:
36 - fn (Callable): function that is being submitted for execution
37 - *args (Any): arguments that the function will be mapped over
38
39 Returns:
40 - List[Any]: the result of computating the function over the arguments
41
42 """
43 raise NotImplementedError()
44
45 def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> Any:
46 """
47 Submit a function to the executor for execution. Returns a future-like object.
48
49 Args:
50 - fn (Callable): function that is being submitted for execution
51 - *args (Any): arguments to be passed to `fn`
52 - **kwargs (Any): keyword arguments to be passed to `fn`
53
54 Returns:
55 - Any: a future-like object
56 """
57 raise NotImplementedError()
58
59 def wait(self, futures: Any) -> Any:
60 """
61 Resolves futures to their values. Blocks until the future is complete.
62
63 Args:
64 - futures (Any): iterable of futures to compute
65
66 Returns:
67 - Any: an iterable of resolved futures
68 """
69 raise NotImplementedError()
70
[end of src/prefect/engine/executors/base.py]
[start of src/prefect/engine/executors/dask.py]
1 import logging
2 import uuid
3 import warnings
4 from contextlib import contextmanager
5 from typing import TYPE_CHECKING, Any, Callable, Iterator, List, Union
6
7 from prefect import context
8 from prefect.engine.executors.base import Executor
9 from prefect.utilities.importtools import import_object
10
11 if TYPE_CHECKING:
12 import dask
13 from distributed import Future
14
15
16 # XXX: remove when deprecation of DaskExecutor kwargs is done
17 _valid_client_kwargs = {
18 "timeout",
19 "set_as_default",
20 "scheduler_file",
21 "security",
22 "name",
23 "direct_to_workers",
24 "heartbeat_interval",
25 }
26
27
28 class DaskExecutor(Executor):
29 """
30 An executor that runs all functions using the `dask.distributed` scheduler.
31
32 By default a temporary `distributed.LocalCluster` is created (and
33 subsequently torn down) within the `start()` contextmanager. To use a
34 different cluster class (e.g.
35 [`dask_kubernetes.KubeCluster`](https://kubernetes.dask.org/)), you can
36 specify `cluster_class`/`cluster_kwargs`.
37
38 Alternatively, if you already have a dask cluster running, you can provide
39 the address of the scheduler via the `address` kwarg.
40
41 Note that if you have tasks with tags of the form `"dask-resource:KEY=NUM"`
42 they will be parsed and passed as
43 [Worker Resources](https://distributed.dask.org/en/latest/resources.html)
44 of the form `{"KEY": float(NUM)}` to the Dask Scheduler.
45
46 Args:
47 - address (string, optional): address of a currently running dask
48 scheduler; if one is not provided, a temporary cluster will be
49 created in `executor.start()`. Defaults to `None`.
50 - cluster_class (string or callable, optional): the cluster class to use
51 when creating a temporary dask cluster. Can be either the full
52 class name (e.g. `"distributed.LocalCluster"`), or the class itself.
53 - cluster_kwargs (dict, optional): addtional kwargs to pass to the
54 `cluster_class` when creating a temporary dask cluster.
55 - adapt_kwargs (dict, optional): additional kwargs to pass to ``cluster.adapt`
56 when creating a temporary dask cluster. Note that adaptive scaling
57 is only enabled if `adapt_kwargs` are provided.
58 - client_kwargs (dict, optional): additional kwargs to use when creating a
59 [`dask.distributed.Client`](https://distributed.dask.org/en/latest/api.html#client).
60 - debug (bool, optional): When running with a local cluster, setting
61 `debug=True` will increase dask's logging level, providing
62 potentially useful debug info. Defaults to the `debug` value in
63 your Prefect configuration.
64 - **kwargs: DEPRECATED
65
66 Example:
67
68 Using a temporary local dask cluster:
69
70 ```python
71 executor = DaskExecutor()
72 ```
73
74 Using a temporary cluster running elsewhere. Any Dask cluster class should
75 work, here we use [dask-cloudprovider](https://cloudprovider.dask.org):
76
77 ```python
78 executor = DaskExecutor(
79 cluster_class="dask_cloudprovider.FargateCluster",
80 cluster_kwargs={
81 "image": "prefecthq/prefect:latest",
82 "n_workers": 5,
83 ...
84 },
85 )
86 ```
87
88 Connecting to an existing dask cluster
89
90 ```python
91 executor = DaskExecutor(address="192.0.2.255:8786")
92 ```
93 """
94
95 def __init__(
96 self,
97 address: str = None,
98 cluster_class: Union[str, Callable] = None,
99 cluster_kwargs: dict = None,
100 adapt_kwargs: dict = None,
101 client_kwargs: dict = None,
102 debug: bool = None,
103 **kwargs: Any
104 ):
105 if address is None:
106 address = context.config.engine.executor.dask.address or None
107 # XXX: deprecated
108 if address == "local":
109 warnings.warn(
110 "`address='local'` is deprecated. To use a local cluster, leave the "
111 "`address` field empty."
112 )
113 address = None
114
115 # XXX: deprecated
116 local_processes = kwargs.pop("local_processes", None)
117 if local_processes is None:
118 local_processes = context.config.engine.executor.dask.get(
119 "local_processes", None
120 )
121 if local_processes is not None:
122 warnings.warn(
123 "`local_processes` is deprecated, please use "
124 "`cluster_kwargs={'processes': local_processes}`. The default is "
125 "now `local_processes=True`."
126 )
127
128 if address is not None:
129 if cluster_class is not None or cluster_kwargs is not None:
130 raise ValueError(
131 "Cannot specify `address` and `cluster_class`/`cluster_kwargs`"
132 )
133 else:
134 if cluster_class is None:
135 cluster_class = context.config.engine.executor.dask.cluster_class
136 if isinstance(cluster_class, str):
137 cluster_class = import_object(cluster_class)
138 if cluster_kwargs is None:
139 cluster_kwargs = {}
140 else:
141 cluster_kwargs = cluster_kwargs.copy()
142
143 from distributed.deploy.local import LocalCluster
144
145 if cluster_class == LocalCluster:
146 if debug is None:
147 debug = context.config.debug
148 cluster_kwargs.setdefault(
149 "silence_logs", logging.CRITICAL if not debug else logging.WARNING
150 )
151 if local_processes is not None:
152 cluster_kwargs.setdefault("processes", local_processes)
153 for_cluster = set(kwargs).difference(_valid_client_kwargs)
154 if for_cluster:
155 warnings.warn(
156 "Forwarding executor kwargs to `LocalCluster` is now handled by the "
157 "`cluster_kwargs` parameter, please update accordingly"
158 )
159 for k in for_cluster:
160 cluster_kwargs[k] = kwargs.pop(k)
161
162 if adapt_kwargs is None:
163 adapt_kwargs = {}
164
165 if client_kwargs is None:
166 client_kwargs = {}
167 if kwargs:
168 warnings.warn(
169 "Forwarding executor kwargs to `Client` is now handled by the "
170 "`client_kwargs` parameter, please update accordingly"
171 )
172 client_kwargs.update(kwargs)
173
174 self.address = address
175 self.is_started = False
176 self.cluster_class = cluster_class
177 self.cluster_kwargs = cluster_kwargs
178 self.adapt_kwargs = adapt_kwargs
179 self.client_kwargs = client_kwargs
180
181 super().__init__()
182
183 @contextmanager
184 def start(self) -> Iterator[None]:
185 """
186 Context manager for initializing execution.
187
188 Creates a `dask.distributed.Client` and yields it.
189 """
190 # import dask client here to decrease our import times
191 from distributed import Client
192
193 try:
194 if self.address is not None:
195 with Client(self.address, **self.client_kwargs) as client:
196 self.client = client
197 self.is_started = True
198 yield self.client
199 else:
200 with self.cluster_class(**self.cluster_kwargs) as cluster: # type: ignore
201 if self.adapt_kwargs:
202 cluster.adapt(**self.adapt_kwargs)
203 with Client(cluster, **self.client_kwargs) as client:
204 self.client = client
205 self.is_started = True
206 yield self.client
207 finally:
208 self.client = None
209 self.is_started = False
210
211 def _prep_dask_kwargs(self) -> dict:
212 dask_kwargs = {"pure": False} # type: dict
213
214 # set a key for the dask scheduler UI
215 if context.get("task_full_name"):
216 key = "{}-{}".format(context.get("task_full_name", ""), str(uuid.uuid4()))
217 dask_kwargs.update(key=key)
218
219 # infer from context if dask resources are being utilized
220 dask_resource_tags = [
221 tag
222 for tag in context.get("task_tags", [])
223 if tag.lower().startswith("dask-resource")
224 ]
225 if dask_resource_tags:
226 resources = {}
227 for tag in dask_resource_tags:
228 prefix, val = tag.split("=")
229 resources.update({prefix.split(":")[1]: float(val)})
230 dask_kwargs.update(resources=resources)
231
232 return dask_kwargs
233
234 def __getstate__(self) -> dict:
235 state = self.__dict__.copy()
236 if "client" in state:
237 del state["client"]
238 return state
239
240 def __setstate__(self, state: dict) -> None:
241 self.__dict__.update(state)
242
243 def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> "Future":
244 """
245 Submit a function to the executor for execution. Returns a Future object.
246
247 Args:
248 - fn (Callable): function that is being submitted for execution
249 - *args (Any): arguments to be passed to `fn`
250 - **kwargs (Any): keyword arguments to be passed to `fn`
251
252 Returns:
253 - Future: a Future-like object that represents the computation of `fn(*args, **kwargs)`
254 """
255 # import dask functions here to decrease our import times
256 from distributed import fire_and_forget, worker_client
257
258 dask_kwargs = self._prep_dask_kwargs()
259 kwargs.update(dask_kwargs)
260
261 if self.is_started and hasattr(self, "client"):
262 future = self.client.submit(fn, *args, **kwargs)
263 elif self.is_started:
264 with worker_client(separate_thread=True) as client:
265 future = client.submit(fn, *args, **kwargs)
266 else:
267 raise ValueError("This executor has not been started.")
268
269 fire_and_forget(future)
270 return future
271
272 def map(self, fn: Callable, *args: Any, **kwargs: Any) -> List["Future"]:
273 """
274 Submit a function to be mapped over its iterable arguments.
275
276 Args:
277 - fn (Callable): function that is being submitted for execution
278 - *args (Any): arguments that the function will be mapped over
279 - **kwargs (Any): additional keyword arguments that will be passed to the Dask Client
280
281 Returns:
282 - List[Future]: a list of Future-like objects that represent each computation of
283 fn(*a), where a = zip(*args)[i]
284
285 """
286 if not args:
287 return []
288
289 # import dask functions here to decrease our import times
290 from distributed import fire_and_forget, worker_client
291
292 dask_kwargs = self._prep_dask_kwargs()
293 kwargs.update(dask_kwargs)
294
295 if self.is_started and hasattr(self, "client"):
296 futures = self.client.map(fn, *args, **kwargs)
297 elif self.is_started:
298 with worker_client(separate_thread=True) as client:
299 futures = client.map(fn, *args, **kwargs)
300 return client.gather(futures)
301 else:
302 raise ValueError("This executor has not been started.")
303
304 fire_and_forget(futures)
305 return futures
306
307 def wait(self, futures: Any) -> Any:
308 """
309 Resolves the Future objects to their values. Blocks until the computation is complete.
310
311 Args:
312 - futures (Any): single or iterable of future-like objects to compute
313
314 Returns:
315 - Any: an iterable of resolved futures with similar shape to the input
316 """
317 # import dask functions here to decrease our import times
318 from distributed import worker_client
319
320 if self.is_started and hasattr(self, "client"):
321 return self.client.gather(futures)
322 elif self.is_started:
323 with worker_client(separate_thread=True) as client:
324 return client.gather(futures)
325 else:
326 raise ValueError("This executor has not been started.")
327
328
329 class LocalDaskExecutor(Executor):
330 """
331 An executor that runs all functions locally using `dask` and a configurable dask scheduler. Note that
332 this executor is known to occasionally run tasks twice when using multi-level mapping.
333
334 Prefect's mapping feature will not work in conjunction with setting `scheduler="processes"`.
335
336 Args:
337 - scheduler (str): The local dask scheduler to use; common options are "synchronous", "threads" and "processes". Defaults to "threads".
338 - **kwargs (Any): Additional keyword arguments to pass to dask config
339 """
340
341 def __init__(self, scheduler: str = "threads", **kwargs: Any):
342 self.scheduler = scheduler
343 self.kwargs = kwargs
344 super().__init__()
345
346 @contextmanager
347 def start(self) -> Iterator:
348 """
349 Context manager for initializing execution.
350
351 Configures `dask` and yields the `dask.config` contextmanager.
352 """
353 # import dask here to reduce prefect import times
354 import dask
355
356 with dask.config.set(scheduler=self.scheduler, **self.kwargs) as cfg:
357 yield cfg
358
359 def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> "dask.delayed":
360 """
361 Submit a function to the executor for execution. Returns a `dask.delayed` object.
362
363 Args:
364 - fn (Callable): function that is being submitted for execution
365 - *args (Any): arguments to be passed to `fn`
366 - **kwargs (Any): keyword arguments to be passed to `fn`
367
368 Returns:
369 - dask.delayed: a `dask.delayed` object that represents the computation of `fn(*args, **kwargs)`
370 """
371 # import dask here to reduce prefect import times
372 import dask
373
374 return dask.delayed(fn)(*args, **kwargs)
375
376 def map(self, fn: Callable, *args: Any) -> List["dask.delayed"]:
377 """
378 Submit a function to be mapped over its iterable arguments.
379
380 Args:
381 - fn (Callable): function that is being submitted for execution
382 - *args (Any): arguments that the function will be mapped over
383
384 Returns:
385 - List[dask.delayed]: the result of computating the function over the arguments
386
387 """
388 if self.scheduler == "processes":
389 raise RuntimeError(
390 "LocalDaskExecutor cannot map if scheduler='processes'. Please set to either 'synchronous' or 'threads'."
391 )
392
393 results = []
394 for args_i in zip(*args):
395 results.append(self.submit(fn, *args_i))
396 return results
397
398 def wait(self, futures: Any) -> Any:
399 """
400 Resolves a `dask.delayed` object to its values. Blocks until the computation is complete.
401
402 Args:
403 - futures (Any): iterable of `dask.delayed` objects to compute
404
405 Returns:
406 - Any: an iterable of resolved futures
407 """
408 # import dask here to reduce prefect import times
409 import dask
410
411 with dask.config.set(scheduler=self.scheduler, **self.kwargs):
412 return dask.compute(futures)[0]
413
[end of src/prefect/engine/executors/dask.py]
[start of src/prefect/engine/executors/local.py]
1 from typing import Any, Callable, List
2
3 from prefect.engine.executors.base import Executor
4
5
6 class LocalExecutor(Executor):
7 """
8 An executor that runs all functions synchronously and immediately in
9 the main thread. To be used mainly for debugging purposes.
10 """
11
12 def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> Any:
13 """
14 Submit a function to the executor for execution. Returns the result of the computation.
15
16 Args:
17 - fn (Callable): function that is being submitted for execution
18 - *args (Any): arguments to be passed to `fn`
19 - **kwargs (Any): keyword arguments to be passed to `fn`
20
21 Returns:
22 - Any: the result of `fn(*args, **kwargs)`
23 """
24 return fn(*args, **kwargs)
25
26 def map(self, fn: Callable, *args: Any) -> List[Any]:
27 """
28 Submit a function to be mapped over its iterable arguments.
29
30 Args:
31 - fn (Callable): function that is being submitted for execution
32 - *args (Any): arguments that the function will be mapped over
33
34 Returns:
35 - List[Any]: the result of computating the function over the arguments
36
37 """
38 results = []
39 for args_i in zip(*args):
40 results.append(fn(*args_i))
41 return results
42
43 def wait(self, futures: Any) -> Any:
44 """
45 Returns the results of the provided futures.
46
47 Args:
48 - futures (Any): objects to wait on
49
50 Returns:
51 - Any: whatever `futures` were provided
52 """
53 return futures
54
[end of src/prefect/engine/executors/local.py]
[start of src/prefect/engine/flow_runner.py]
1 from typing import (
2 Any,
3 Callable,
4 Dict,
5 Iterable,
6 NamedTuple,
7 Optional,
8 Set,
9 Union,
10 )
11
12 import pendulum
13
14 import prefect
15 from prefect.core import Edge, Flow, Task
16 from prefect.engine.result import Result
17 from prefect.engine.results import ConstantResult
18 from prefect.engine.runner import ENDRUN, Runner, call_state_handlers
19 from prefect.engine.state import (
20 Cancelled,
21 Failed,
22 Mapped,
23 Pending,
24 Retrying,
25 Running,
26 Scheduled,
27 State,
28 Success,
29 )
30 from prefect.utilities.collections import flatten_seq
31 from prefect.utilities.executors import run_with_heartbeat
32
33 FlowRunnerInitializeResult = NamedTuple(
34 "FlowRunnerInitializeResult",
35 [
36 ("state", State),
37 ("task_states", Dict[Task, State]),
38 ("context", Dict[str, Any]),
39 ("task_contexts", Dict[Task, Dict[str, Any]]),
40 ],
41 )
42
43
44 class FlowRunner(Runner):
45 """
46 FlowRunners handle the execution of Flows and determine the State of a Flow
47 before, during and after the Flow is run.
48
49 In particular, through the FlowRunner you can specify which tasks should be
50 the first tasks to run, which tasks should be returned after the Flow is finished,
51 and what states each task should be initialized with.
52
53 Args:
54 - flow (Flow): the `Flow` to be run
55 - task_runner_cls (TaskRunner, optional): The class used for running
56 individual Tasks. Defaults to [TaskRunner](task_runner.html)
57 - state_handlers (Iterable[Callable], optional): A list of state change handlers
58 that will be called whenever the flow changes state, providing an
59 opportunity to inspect or modify the new state. The handler
60 will be passed the flow runner instance, the old (prior) state, and the new
61 (current) state, with the following signature:
62 `state_handler(fr: FlowRunner, old_state: State, new_state: State) -> Optional[State]`
63 If multiple functions are passed, then the `new_state` argument will be the
64 result of the previous handler.
65
66 Note: new FlowRunners are initialized within the call to `Flow.run()` and in general,
67 this is the endpoint through which FlowRunners will be interacted with most frequently.
68
69 Example:
70 ```python
71 @task
72 def say_hello():
73 print('hello')
74
75 with Flow("My Flow") as f:
76 say_hello()
77
78 fr = FlowRunner(flow=f)
79 flow_state = fr.run()
80 ```
81 """
82
83 def __init__(
84 self,
85 flow: Flow,
86 task_runner_cls: type = None,
87 state_handlers: Iterable[Callable] = None,
88 ):
89 self.context = prefect.context.to_dict()
90 self.flow = flow
91 if task_runner_cls is None:
92 task_runner_cls = prefect.engine.get_default_task_runner_class()
93 self.task_runner_cls = task_runner_cls
94 super().__init__(state_handlers=state_handlers)
95
96 def __repr__(self) -> str:
97 return "<{}: {}>".format(type(self).__name__, self.flow.name)
98
99 def call_runner_target_handlers(self, old_state: State, new_state: State) -> State:
100 """
101 A special state handler that the FlowRunner uses to call its flow's state handlers.
102 This method is called as part of the base Runner's `handle_state_change()` method.
103
104 Args:
105 - old_state (State): the old (previous) state
106 - new_state (State): the new (current) state
107
108 Returns:
109 - State: the new state
110 """
111 self.logger.debug(
112 "Flow '{name}': Handling state change from {old} to {new}".format(
113 name=self.flow.name,
114 old=type(old_state).__name__,
115 new=type(new_state).__name__,
116 )
117 )
118 for handler in self.flow.state_handlers:
119 new_state = handler(self.flow, old_state, new_state) or new_state
120
121 return new_state
122
123 def initialize_run( # type: ignore
124 self,
125 state: Optional[State],
126 task_states: Dict[Task, State],
127 context: Dict[str, Any],
128 task_contexts: Dict[Task, Dict[str, Any]],
129 parameters: Dict[str, Any],
130 ) -> FlowRunnerInitializeResult:
131 """
132 Initializes the Task run by initializing state and context appropriately.
133
134 If the provided state is a Submitted state, the state it wraps is extracted.
135
136 Args:
137 - state (Optional[State]): the initial state of the run
138 - task_states (Dict[Task, State]): a dictionary of any initial task states
139 - context (Dict[str, Any], optional): prefect.Context to use for execution
140 to use for each Task run
141 - task_contexts (Dict[Task, Dict[str, Any]], optional): contexts that will be provided to each task
142 - parameters(dict): the parameter values for the run
143
144 Returns:
145 - NamedTuple: a tuple of initialized objects:
146 `(state, task_states, context, task_contexts)`
147 """
148
149 # overwrite context parameters one-by-one
150 if parameters:
151 context_params = context.setdefault("parameters", {})
152 for param, value in parameters.items():
153 context_params[param] = value
154
155 context.update(flow_name=self.flow.name)
156 context.setdefault("scheduled_start_time", pendulum.now("utc"))
157
158 # add various formatted dates to context
159 now = pendulum.now("utc")
160 dates = {
161 "date": now,
162 "today": now.strftime("%Y-%m-%d"),
163 "yesterday": now.add(days=-1).strftime("%Y-%m-%d"),
164 "tomorrow": now.add(days=1).strftime("%Y-%m-%d"),
165 "today_nodash": now.strftime("%Y%m%d"),
166 "yesterday_nodash": now.add(days=-1).strftime("%Y%m%d"),
167 "tomorrow_nodash": now.add(days=1).strftime("%Y%m%d"),
168 }
169 for key, val in dates.items():
170 context.setdefault(key, val)
171
172 for task in self.flow.tasks:
173 task_contexts.setdefault(task, {}).update(
174 task_name=task.name, task_slug=task.slug
175 )
176 state, context = super().initialize_run(state=state, context=context)
177 return FlowRunnerInitializeResult(
178 state=state,
179 task_states=task_states,
180 context=context,
181 task_contexts=task_contexts,
182 )
183
184 def run(
185 self,
186 state: State = None,
187 task_states: Dict[Task, State] = None,
188 return_tasks: Iterable[Task] = None,
189 parameters: Dict[str, Any] = None,
190 task_runner_state_handlers: Iterable[Callable] = None,
191 executor: "prefect.engine.executors.Executor" = None,
192 context: Dict[str, Any] = None,
193 task_contexts: Dict[Task, Dict[str, Any]] = None,
194 ) -> State:
195 """
196 The main endpoint for FlowRunners. Calling this method will perform all
197 computations contained within the Flow and return the final state of the Flow.
198
199 Args:
200 - state (State, optional): starting state for the Flow. Defaults to
201 `Pending`
202 - task_states (dict, optional): dictionary of task states to begin
203 computation with, with keys being Tasks and values their corresponding state
204 - return_tasks ([Task], optional): list of Tasks to include in the
205 final returned Flow state. Defaults to `None`
206 - parameters (dict, optional): dictionary of any needed Parameter
207 values, with keys being strings representing Parameter names and values being
208 their corresponding values
209 - task_runner_state_handlers (Iterable[Callable], optional): A list of state change
210 handlers that will be provided to the task_runner, and called whenever a task changes
211 state.
212 - executor (Executor, optional): executor to use when performing
213 computation; defaults to the executor specified in your prefect configuration
214 - context (Dict[str, Any], optional): prefect.Context to use for execution
215 to use for each Task run
216 - task_contexts (Dict[Task, Dict[str, Any]], optional): contexts that will be provided to each task
217
218 Returns:
219 - State: `State` representing the final post-run state of the `Flow`.
220
221 """
222
223 self.logger.info("Beginning Flow run for '{}'".format(self.flow.name))
224
225 # make copies to avoid modifying user inputs
226 task_states = dict(task_states or {})
227 context = dict(context or {})
228 task_contexts = dict(task_contexts or {})
229 parameters = dict(parameters or {})
230 if executor is None:
231 executor = prefect.engine.get_default_executor_class()()
232
233 try:
234 state, task_states, context, task_contexts = self.initialize_run(
235 state=state,
236 task_states=task_states,
237 context=context,
238 task_contexts=task_contexts,
239 parameters=parameters,
240 )
241
242 with prefect.context(context):
243 state = self.check_flow_is_pending_or_running(state)
244 state = self.check_flow_reached_start_time(state)
245 state = self.set_flow_to_running(state)
246 state = self.get_flow_run_state(
247 state,
248 task_states=task_states,
249 task_contexts=task_contexts,
250 return_tasks=return_tasks,
251 task_runner_state_handlers=task_runner_state_handlers,
252 executor=executor,
253 )
254
255 except ENDRUN as exc:
256 state = exc.state
257
258 except KeyboardInterrupt:
259 self.logger.debug("Interrupt signal raised, cancelling Flow run.")
260 state = Cancelled(message="Interrupt signal raised, cancelling flow run.")
261
262 # All other exceptions are trapped and turned into Failed states
263 except Exception as exc:
264 self.logger.exception(
265 "Unexpected error while running flow: {}".format(repr(exc))
266 )
267 if prefect.context.get("raise_on_exception"):
268 raise exc
269 new_state = Failed(
270 message="Unexpected error while running flow: {}".format(repr(exc)),
271 result=exc,
272 )
273 state = self.handle_state_change(state or Pending(), new_state)
274
275 return state
276
277 @call_state_handlers
278 def check_flow_reached_start_time(self, state: State) -> State:
279 """
280 Checks if the Flow is in a Scheduled state and, if it is, ensures that the scheduled
281 time has been reached.
282
283 Args:
284 - state (State): the current state of this Flow
285
286 Returns:
287 - State: the state of the flow after performing the check
288
289 Raises:
290 - ENDRUN: if the flow is Scheduled with a future scheduled time
291 """
292 if isinstance(state, Scheduled):
293 if state.start_time and state.start_time > pendulum.now("utc"):
294 self.logger.debug(
295 "Flow '{name}': start_time has not been reached; ending run.".format(
296 name=self.flow.name
297 )
298 )
299 raise ENDRUN(state)
300 return state
301
302 @call_state_handlers
303 def check_flow_is_pending_or_running(self, state: State) -> State:
304 """
305 Checks if the flow is in either a Pending state or Running state. Either are valid
306 starting points (because we allow simultaneous runs of the same flow run).
307
308 Args:
309 - state (State): the current state of this flow
310
311 Returns:
312 - State: the state of the flow after running the check
313
314 Raises:
315 - ENDRUN: if the flow is not pending or running
316 """
317
318 # the flow run is already finished
319 if state.is_finished() is True:
320 self.logger.info("Flow run has already finished.")
321 raise ENDRUN(state)
322
323 # the flow run must be either pending or running (possibly redundant with above)
324 elif not (state.is_pending() or state.is_running()):
325 self.logger.info("Flow is not ready to run.")
326 raise ENDRUN(state)
327
328 return state
329
330 @call_state_handlers
331 def set_flow_to_running(self, state: State) -> State:
332 """
333 Puts Pending flows in a Running state; leaves Running flows Running.
334
335 Args:
336 - state (State): the current state of this flow
337
338 Returns:
339 - State: the state of the flow after running the check
340
341 Raises:
342 - ENDRUN: if the flow is not pending or running
343 """
344 if state.is_pending():
345 self.logger.info("Starting flow run.")
346 return Running(message="Running flow.")
347 elif state.is_running():
348 return state
349 else:
350 raise ENDRUN(state)
351
352 @run_with_heartbeat
353 @call_state_handlers
354 def get_flow_run_state(
355 self,
356 state: State,
357 task_states: Dict[Task, State],
358 task_contexts: Dict[Task, Dict[str, Any]],
359 return_tasks: Set[Task],
360 task_runner_state_handlers: Iterable[Callable],
361 executor: "prefect.engine.executors.base.Executor",
362 ) -> State:
363 """
364 Runs the flow.
365
366 Args:
367 - state (State): starting state for the Flow. Defaults to
368 `Pending`
369 - task_states (dict): dictionary of task states to begin
370 computation with, with keys being Tasks and values their corresponding state
371 - task_contexts (Dict[Task, Dict[str, Any]]): contexts that will be provided to each task
372 - return_tasks ([Task], optional): list of Tasks to include in the
373 final returned Flow state. Defaults to `None`
374 - task_runner_state_handlers (Iterable[Callable]): A list of state change
375 handlers that will be provided to the task_runner, and called whenever a task changes
376 state.
377 - executor (Executor): executor to use when performing
378 computation; defaults to the executor provided in your prefect configuration
379
380 Returns:
381 - State: `State` representing the final post-run state of the `Flow`.
382
383 """
384
385 if not state.is_running():
386 self.logger.info("Flow is not in a Running state.")
387 raise ENDRUN(state)
388
389 if return_tasks is None:
390 return_tasks = set()
391 if set(return_tasks).difference(self.flow.tasks):
392 raise ValueError("Some tasks in return_tasks were not found in the flow.")
393
394 # -- process each task in order
395
396 with executor.start():
397
398 for task in self.flow.sorted_tasks():
399
400 task_state = task_states.get(task)
401 if task_state is None and isinstance(
402 task, prefect.tasks.core.constants.Constant
403 ):
404 task_states[task] = task_state = Success(result=task.value)
405
406 # if the state is finished, don't run the task, just use the provided state
407 if (
408 isinstance(task_state, State)
409 and task_state.is_finished()
410 and not task_state.is_cached()
411 and not task_state.is_mapped()
412 ):
413 continue
414
415 upstream_states = {} # type: Dict[Edge, Union[State, Iterable]]
416
417 # -- process each edge to the task
418 for edge in self.flow.edges_to(task):
419 upstream_states[edge] = task_states.get(
420 edge.upstream_task, Pending(message="Task state not available.")
421 )
422
423 # augment edges with upstream constants
424 for key, val in self.flow.constants[task].items():
425 edge = Edge(
426 upstream_task=prefect.tasks.core.constants.Constant(val),
427 downstream_task=task,
428 key=key,
429 )
430 upstream_states[edge] = Success(
431 "Auto-generated constant value",
432 result=ConstantResult(value=val),
433 )
434
435 # -- run the task
436
437 with prefect.context(task_full_name=task.name, task_tags=task.tags):
438 task_states[task] = executor.submit(
439 self.run_task,
440 task=task,
441 state=task_state,
442 upstream_states=upstream_states,
443 context=dict(prefect.context, **task_contexts.get(task, {})),
444 task_runner_state_handlers=task_runner_state_handlers,
445 executor=executor,
446 )
447
448 # ---------------------------------------------
449 # Collect results
450 # ---------------------------------------------
451
452 # terminal tasks determine if the flow is finished
453 terminal_tasks = self.flow.terminal_tasks()
454
455 # reference tasks determine flow state
456 reference_tasks = self.flow.reference_tasks()
457
458 # wait until all terminal tasks are finished
459 final_tasks = terminal_tasks.union(reference_tasks).union(return_tasks)
460 final_states = executor.wait(
461 {
462 t: task_states.get(t, Pending("Task not evaluated by FlowRunner."))
463 for t in final_tasks
464 }
465 )
466
467 # also wait for any children of Mapped tasks to finish, and add them
468 # to the dictionary to determine flow state
469 all_final_states = final_states.copy()
470 for t, s in list(final_states.items()):
471 if s.is_mapped():
472 s.map_states = executor.wait(s.map_states)
473 s.result = [ms.result for ms in s.map_states]
474 all_final_states[t] = s.map_states
475
476 assert isinstance(final_states, dict)
477
478 key_states = set(flatten_seq([all_final_states[t] for t in reference_tasks]))
479 terminal_states = set(
480 flatten_seq([all_final_states[t] for t in terminal_tasks])
481 )
482 return_states = {t: final_states[t] for t in return_tasks}
483
484 state = self.determine_final_state(
485 state=state,
486 key_states=key_states,
487 return_states=return_states,
488 terminal_states=terminal_states,
489 )
490
491 return state
492
493 def determine_final_state(
494 self,
495 state: State,
496 key_states: Set[State],
497 return_states: Dict[Task, State],
498 terminal_states: Set[State],
499 ) -> State:
500 """
501 Implements the logic for determining the final state of the flow run.
502
503 Args:
504 - state (State): the current state of the Flow
505 - key_states (Set[State]): the states which will determine the success / failure of the flow run
506 - return_states (Dict[Task, State]): states to return as results
507 - terminal_states (Set[State]): the states of the terminal tasks for this flow
508
509 Returns:
510 - State: the final state of the flow run
511 """
512 # check that the flow is finished
513 if not all(s.is_finished() for s in terminal_states):
514 self.logger.info("Flow run RUNNING: terminal tasks are incomplete.")
515 state.result = return_states
516
517 # check if any key task failed
518 elif any(s.is_failed() for s in key_states):
519 self.logger.info("Flow run FAILED: some reference tasks failed.")
520 state = Failed(message="Some reference tasks failed.", result=return_states)
521
522 # check if all reference tasks succeeded
523 elif all(s.is_successful() for s in key_states):
524 self.logger.info("Flow run SUCCESS: all reference tasks succeeded")
525 state = Success(
526 message="All reference tasks succeeded.", result=return_states
527 )
528
529 # check for any unanticipated state that is finished but neither success nor failed
530 else:
531 self.logger.info("Flow run SUCCESS: no reference tasks failed")
532 state = Success(message="No reference tasks failed.", result=return_states)
533
534 return state
535
536 def run_task(
537 self,
538 task: Task,
539 state: State,
540 upstream_states: Dict[Edge, State],
541 context: Dict[str, Any],
542 task_runner_state_handlers: Iterable[Callable],
543 executor: "prefect.engine.executors.Executor",
544 ) -> State:
545 """
546
547 Runs a specific task. This method is intended to be called by submitting it to
548 an executor.
549
550 Args:
551 - task (Task): the task to run
552 - state (State): starting state for the Flow. Defaults to
553 `Pending`
554 - upstream_states (Dict[Edge, State]): dictionary of upstream states
555 - context (Dict[str, Any]): a context dictionary for the task run
556 - task_runner_state_handlers (Iterable[Callable]): A list of state change
557 handlers that will be provided to the task_runner, and called whenever a task changes
558 state.
559 - executor (Executor): executor to use when performing
560 computation; defaults to the executor provided in your prefect configuration
561
562 Returns:
563 - State: `State` representing the final post-run state of the `Flow`.
564
565 """
566 with prefect.context(self.context):
567 default_result = task.result or self.flow.result
568 task_runner = self.task_runner_cls(
569 task=task,
570 state_handlers=task_runner_state_handlers,
571 result=default_result or Result(),
572 default_result=self.flow.result,
573 )
574
575 # if this task reduces over a mapped state, make sure its children have finished
576 for edge, upstream_state in upstream_states.items():
577
578 # if the upstream state is Mapped, wait until its results are all available
579 if not edge.mapped and upstream_state.is_mapped():
580 assert isinstance(upstream_state, Mapped) # mypy assert
581 upstream_state.map_states = executor.wait(upstream_state.map_states)
582 upstream_state.result = [
583 s.result for s in upstream_state.map_states
584 ]
585
586 return task_runner.run(
587 state=state,
588 upstream_states=upstream_states,
589 context=context,
590 executor=executor,
591 )
592
[end of src/prefect/engine/flow_runner.py]
[start of src/prefect/engine/task_runner.py]
1 import copy
2 from contextlib import redirect_stdout
3 import itertools
4 import json
5 from typing import (
6 Any,
7 Callable,
8 Dict,
9 Iterable,
10 List,
11 NamedTuple,
12 Optional,
13 Set,
14 Tuple,
15 )
16
17 import pendulum
18
19 import prefect
20 from prefect import config
21 from prefect.core import Edge, Task
22 from prefect.engine import signals
23 from prefect.engine.result import NoResult, Result
24 from prefect.engine.results import PrefectResult
25 from prefect.engine.runner import ENDRUN, Runner, call_state_handlers
26 from prefect.engine.state import (
27 Cached,
28 Cancelled,
29 Failed,
30 Looped,
31 Mapped,
32 Paused,
33 Pending,
34 Resume,
35 Retrying,
36 Running,
37 Scheduled,
38 Skipped,
39 State,
40 Submitted,
41 Success,
42 TimedOut,
43 TriggerFailed,
44 )
45 from prefect.utilities.executors import (
46 RecursiveCall,
47 run_with_heartbeat,
48 tail_recursive,
49 )
50
51
52 TaskRunnerInitializeResult = NamedTuple(
53 "TaskRunnerInitializeResult", [("state", State), ("context", Dict[str, Any])]
54 )
55
56
57 class TaskRunner(Runner):
58 """
59 TaskRunners handle the execution of Tasks and determine the State of a Task
60 before, during and after the Task is run.
61
62 In particular, through the TaskRunner you can specify the states of any upstream dependencies
63 and what state the Task should be initialized with.
64
65 Args:
66 - task (Task): the Task to be run / executed
67 - state_handlers (Iterable[Callable], optional): A list of state change handlers
68 that will be called whenever the task changes state, providing an
69 opportunity to inspect or modify the new state. The handler
70 will be passed the task runner instance, the old (prior) state, and the new
71 (current) state, with the following signature: `state_handler(TaskRunner, old_state, new_state) -> Optional[State]`;
72 If multiple functions are passed, then the `new_state` argument will be the
73 result of the previous handler.
74 - result (Result, optional): the result type to use for retrieving and storing state results
75 during execution (if the Task doesn't already have one)
76 - default_result (Result, optional): the fallback result type to use for retrieving and storing state results
77 during execution (to be used on upstream inputs if they don't provide their own results)
78 """
79
80 def __init__(
81 self,
82 task: Task,
83 state_handlers: Iterable[Callable] = None,
84 result: Result = None,
85 default_result: Result = None,
86 ):
87 self.context = prefect.context.to_dict()
88 self.task = task
89
90 # if the result was provided off the parent Flow object
91 # we want to use the task's target as the target location
92 if task.result:
93 self.result = task.result
94 else:
95 self.result = Result().copy() if result is None else result.copy()
96 if self.task.target:
97 self.result.location = self.task.target
98 self.default_result = default_result or Result()
99 super().__init__(state_handlers=state_handlers)
100
101 def __repr__(self) -> str:
102 return "<{}: {}>".format(type(self).__name__, self.task.name)
103
104 def call_runner_target_handlers(self, old_state: State, new_state: State) -> State:
105 """
106 A special state handler that the TaskRunner uses to call its task's state handlers.
107 This method is called as part of the base Runner's `handle_state_change()` method.
108
109 Args:
110 - old_state (State): the old (previous) state
111 - new_state (State): the new (current) state
112
113 Returns:
114 - State: the new state
115 """
116 self.logger.debug(
117 "Task '{name}': Handling state change from {old} to {new}".format(
118 name=prefect.context.get("task_full_name", self.task.name),
119 old=type(old_state).__name__,
120 new=type(new_state).__name__,
121 )
122 )
123 for handler in self.task.state_handlers:
124 new_state = handler(self.task, old_state, new_state) or new_state
125
126 return new_state
127
128 def initialize_run( # type: ignore
129 self, state: Optional[State], context: Dict[str, Any]
130 ) -> TaskRunnerInitializeResult:
131 """
132 Initializes the Task run by initializing state and context appropriately.
133
134 If the task is being retried, then we retrieve the run count from the initial Retry
135 state. Otherwise, we assume the run count is 1. The run count is stored in context as
136 task_run_count.
137
138 Also, if the task is being resumed through a `Resume` state, updates context to have `resume=True`.
139
140 Args:
141 - state (Optional[State]): the initial state of the run
142 - context (Dict[str, Any]): the context to be updated with relevant information
143
144 Returns:
145 - tuple: a tuple of the updated state, context, upstream_states, and inputs objects
146 """
147 state, context = super().initialize_run(state=state, context=context)
148
149 if isinstance(state, Retrying):
150 run_count = state.run_count + 1
151 else:
152 run_count = state.context.get("task_run_count", 1)
153
154 if isinstance(state, Resume):
155 context.update(resume=True)
156
157 if "_loop_count" in state.cached_inputs: # type: ignore
158 loop_result = state.cached_inputs.pop("_loop_result")
159 if loop_result.value is None and loop_result.location is not None:
160 loop_result_value = self.result.read(loop_result.location).value
161 else:
162 loop_result_value = loop_result.value
163 loop_context = {
164 "task_loop_count": json.loads(
165 state.cached_inputs.pop( # type: ignore
166 "_loop_count"
167 ).location
168 ), # type: ignore
169 "task_loop_result": loop_result_value,
170 }
171 context.update(loop_context)
172
173 context.update(
174 task_run_count=run_count,
175 task_name=self.task.name,
176 task_tags=self.task.tags,
177 task_slug=self.task.slug,
178 )
179 context.setdefault("checkpointing", config.flows.checkpointing)
180
181 map_index = context.get("map_index", None)
182 if isinstance(map_index, int) and context.get("task_full_name"):
183 context.update(
184 logger=prefect.utilities.logging.get_logger(
185 context.get("task_full_name")
186 )
187 )
188 else:
189 context.update(logger=self.task.logger)
190
191 return TaskRunnerInitializeResult(state=state, context=context)
192
193 @tail_recursive
194 def run(
195 self,
196 state: State = None,
197 upstream_states: Dict[Edge, State] = None,
198 context: Dict[str, Any] = None,
199 executor: "prefect.engine.executors.Executor" = None,
200 ) -> State:
201 """
202 The main endpoint for TaskRunners. Calling this method will conditionally execute
203 `self.task.run` with any provided inputs, assuming the upstream dependencies are in a
204 state which allow this Task to run.
205
206 Args:
207 - state (State, optional): initial `State` to begin task run from;
208 defaults to `Pending()`
209 - upstream_states (Dict[Edge, State]): a dictionary
210 representing the states of any tasks upstream of this one. The keys of the
211 dictionary should correspond to the edges leading to the task.
212 - context (dict, optional): prefect Context to use for execution
213 - executor (Executor, optional): executor to use when performing
214 computation; defaults to the executor specified in your prefect configuration
215
216 Returns:
217 - `State` object representing the final post-run state of the Task
218 """
219 upstream_states = upstream_states or {}
220 context = context or {}
221 map_index = context.setdefault("map_index", None)
222 context["task_full_name"] = "{name}{index}".format(
223 name=self.task.name,
224 index=("" if map_index is None else "[{}]".format(map_index)),
225 )
226
227 if executor is None:
228 executor = prefect.engine.get_default_executor_class()()
229
230 # if mapped is true, this task run is going to generate a Mapped state. It won't
231 # actually run, but rather spawn children tasks to map over its inputs. We
232 # detect this case by checking for:
233 # - upstream edges that are `mapped`
234 # - no `map_index` (which indicates that this is the child task, not the parent)
235 mapped = any([e.mapped for e in upstream_states]) and map_index is None
236 task_inputs = {} # type: Dict[str, Any]
237
238 try:
239 # initialize the run
240 state, context = self.initialize_run(state, context)
241
242 # run state transformation pipeline
243 with prefect.context(context):
244
245 if prefect.context.get("task_loop_count") is None:
246 self.logger.info(
247 "Task '{name}': Starting task run...".format(
248 name=context["task_full_name"]
249 )
250 )
251
252 # check to make sure the task is in a pending state
253 state = self.check_task_is_ready(state)
254
255 # check if the task has reached its scheduled time
256 state = self.check_task_reached_start_time(state)
257
258 # Tasks never run if the upstream tasks haven't finished
259 state = self.check_upstream_finished(
260 state, upstream_states=upstream_states
261 )
262
263 # check if any upstream tasks skipped (and if we need to skip)
264 state = self.check_upstream_skipped(
265 state, upstream_states=upstream_states
266 )
267
268 # populate / hydrate all result objects
269 state, upstream_states = self.load_results(
270 state=state, upstream_states=upstream_states
271 )
272
273 # if the task is mapped, process the mapped children and exit
274 if mapped:
275 state = self.run_mapped_task(
276 state=state,
277 upstream_states=upstream_states,
278 context=context,
279 executor=executor,
280 )
281
282 state = self.wait_for_mapped_task(state=state, executor=executor)
283
284 self.logger.debug(
285 "Task '{name}': task has been mapped; ending run.".format(
286 name=context["task_full_name"]
287 )
288 )
289 raise ENDRUN(state)
290
291 # retrieve task inputs from upstream and also explicitly passed inputs
292 task_inputs = self.get_task_inputs(
293 state=state, upstream_states=upstream_states
294 )
295
296 if self.task.target:
297 # check to see if there is a Result at the task's target
298 state = self.check_target(state, inputs=task_inputs)
299 else:
300 # check to see if the task has a cached result
301 state = self.check_task_is_cached(state, inputs=task_inputs)
302
303 # check if the task's trigger passes
304 # triggers can raise Pauses, which require task_inputs to be available for caching
305 # so we run this after the previous step
306 state = self.check_task_trigger(state, upstream_states=upstream_states)
307
308 # set the task state to running
309 state = self.set_task_to_running(state, inputs=task_inputs)
310
311 # run the task
312 state = self.get_task_run_state(
313 state, inputs=task_inputs, timeout_handler=executor.timeout_handler
314 )
315
316 # cache the output, if appropriate
317 state = self.cache_result(state, inputs=task_inputs)
318
319 # check if the task needs to be retried
320 state = self.check_for_retry(state, inputs=task_inputs)
321
322 state = self.check_task_is_looping(
323 state,
324 inputs=task_inputs,
325 upstream_states=upstream_states,
326 context=context,
327 executor=executor,
328 )
329
330 # for pending signals, including retries and pauses we need to make sure the
331 # task_inputs are set
332 except (ENDRUN, signals.PrefectStateSignal) as exc:
333 exc.state.cached_inputs = task_inputs or {}
334 state = exc.state
335 except RecursiveCall as exc:
336 raise exc
337
338 except Exception as exc:
339 msg = "Task '{name}': unexpected error while running task: {exc}".format(
340 name=context["task_full_name"], exc=repr(exc)
341 )
342 self.logger.exception(msg)
343 state = Failed(message=msg, result=exc, cached_inputs=task_inputs)
344 if prefect.context.get("raise_on_exception"):
345 raise exc
346
347 # to prevent excessive repetition of this log
348 # since looping relies on recursively calling self.run
349 # TODO: figure out a way to only log this one single time instead of twice
350 if prefect.context.get("task_loop_count") is None:
351 # wrapping this final log in prefect.context(context) ensures
352 # that any run-context, including task-run-ids, are respected
353 with prefect.context(context):
354 self.logger.info(
355 "Task '{name}': finished task run for task with final state: '{state}'".format(
356 name=context["task_full_name"], state=type(state).__name__
357 )
358 )
359
360 return state
361
362 @call_state_handlers
363 def check_upstream_finished(
364 self, state: State, upstream_states: Dict[Edge, State]
365 ) -> State:
366 """
367 Checks if the upstream tasks have all finshed.
368
369 Args:
370 - state (State): the current state of this task
371 - upstream_states (Dict[Edge, Union[State, List[State]]]): the upstream states
372
373 Returns:
374 - State: the state of the task after running the check
375
376 Raises:
377 - ENDRUN: if upstream tasks are not finished.
378 """
379 all_states = set() # type: Set[State]
380 for edge, upstream_state in upstream_states.items():
381 # if the upstream state is Mapped, and this task is also mapped,
382 # we want each individual child to determine if it should
383 # proceed or not based on its upstream parent in the mapping
384 if isinstance(upstream_state, Mapped) and not edge.mapped:
385 all_states.update(upstream_state.map_states)
386 else:
387 all_states.add(upstream_state)
388
389 if not all(s.is_finished() for s in all_states):
390 self.logger.debug(
391 "Task '{name}': not all upstream states are finished; ending run.".format(
392 name=prefect.context.get("task_full_name", self.task.name)
393 )
394 )
395 raise ENDRUN(state)
396 return state
397
398 @call_state_handlers
399 def check_upstream_skipped(
400 self, state: State, upstream_states: Dict[Edge, State]
401 ) -> State:
402 """
403 Checks if any of the upstream tasks have skipped.
404
405 Args:
406 - state (State): the current state of this task
407 - upstream_states (Dict[Edge, State]): the upstream states
408
409 Returns:
410 - State: the state of the task after running the check
411 """
412
413 all_states = set() # type: Set[State]
414 for edge, upstream_state in upstream_states.items():
415
416 # if the upstream state is Mapped, and this task is also mapped,
417 # we want each individual child to determine if it should
418 # skip or not based on its upstream parent in the mapping
419 if isinstance(upstream_state, Mapped) and not edge.mapped:
420 all_states.update(upstream_state.map_states)
421 else:
422 all_states.add(upstream_state)
423
424 if self.task.skip_on_upstream_skip and any(s.is_skipped() for s in all_states):
425 self.logger.debug(
426 "Task '{name}': Upstream states were skipped; ending run.".format(
427 name=prefect.context.get("task_full_name", self.task.name)
428 )
429 )
430 raise ENDRUN(
431 state=Skipped(
432 message=(
433 "Upstream task was skipped; if this was not the intended "
434 "behavior, consider changing `skip_on_upstream_skip=False` "
435 "for this task."
436 )
437 )
438 )
439 return state
440
441 @call_state_handlers
442 def check_task_trigger(
443 self, state: State, upstream_states: Dict[Edge, State]
444 ) -> State:
445 """
446 Checks if the task's trigger function passes.
447
448 Args:
449 - state (State): the current state of this task
450 - upstream_states (Dict[Edge, Union[State, List[State]]]): the upstream states
451
452 Returns:
453 - State: the state of the task after running the check
454
455 Raises:
456 - ENDRUN: if the trigger raises an error
457 """
458 try:
459 if not self.task.trigger(upstream_states):
460 raise signals.TRIGGERFAIL(message="Trigger failed")
461
462 except signals.PrefectStateSignal as exc:
463
464 self.logger.debug(
465 "Task '{name}': {signal} signal raised during execution.".format(
466 name=prefect.context.get("task_full_name", self.task.name),
467 signal=type(exc).__name__,
468 )
469 )
470 if prefect.context.get("raise_on_exception"):
471 raise exc
472 raise ENDRUN(exc.state)
473
474 # Exceptions are trapped and turned into TriggerFailed states
475 except Exception as exc:
476 self.logger.exception(
477 "Task '{name}': unexpected error while evaluating task trigger: {exc}".format(
478 exc=repr(exc),
479 name=prefect.context.get("task_full_name", self.task.name),
480 )
481 )
482 if prefect.context.get("raise_on_exception"):
483 raise exc
484 raise ENDRUN(
485 TriggerFailed(
486 "Unexpected error while checking task trigger: {}".format(
487 repr(exc)
488 ),
489 result=exc,
490 )
491 )
492
493 return state
494
495 @call_state_handlers
496 def check_task_is_ready(self, state: State) -> State:
497 """
498 Checks to make sure the task is ready to run (Pending or Mapped).
499
500 Args:
501 - state (State): the current state of this task
502
503 Returns:
504 - State: the state of the task after running the check
505
506 Raises:
507 - ENDRUN: if the task is not ready to run
508 """
509
510 # the task is ready
511 if state.is_pending():
512 return state
513
514 # the task is mapped, in which case we still proceed so that the children tasks
515 # are generated (note that if the children tasks)
516 elif state.is_mapped():
517 self.logger.debug(
518 "Task '{name}': task is mapped, but run will proceed so children are generated.".format(
519 name=prefect.context.get("task_full_name", self.task.name)
520 )
521 )
522 return state
523
524 # this task is already running
525 elif state.is_running():
526 self.logger.debug(
527 "Task '{name}': task is already running.".format(
528 name=prefect.context.get("task_full_name", self.task.name)
529 )
530 )
531 raise ENDRUN(state)
532
533 elif state.is_cached():
534 return state
535
536 # this task is already finished
537 elif state.is_finished():
538 self.logger.debug(
539 "Task '{name}': task is already finished.".format(
540 name=prefect.context.get("task_full_name", self.task.name)
541 )
542 )
543 raise ENDRUN(state)
544
545 # this task is not pending
546 else:
547 self.logger.debug(
548 "Task '{name}' is not ready to run or state was unrecognized ({state}).".format(
549 name=prefect.context.get("task_full_name", self.task.name),
550 state=state,
551 )
552 )
553 raise ENDRUN(state)
554
555 @call_state_handlers
556 def check_task_reached_start_time(self, state: State) -> State:
557 """
558 Checks if a task is in a Scheduled state and, if it is, ensures that the scheduled
559 time has been reached. Note: Scheduled states include Retry states. Scheduled
560 states with no start time (`start_time = None`) are never considered ready;
561 they must be manually placed in another state.
562
563 Args:
564 - state (State): the current state of this task
565
566 Returns:
567 - State: the state of the task after performing the check
568
569 Raises:
570 - ENDRUN: if the task is Scheduled with a future scheduled time
571 """
572 if isinstance(state, Scheduled):
573 # handle case where no start_time is set
574 if state.start_time is None:
575 self.logger.debug(
576 "Task '{name}' is scheduled without a known start_time; ending run.".format(
577 name=prefect.context.get("task_full_name", self.task.name)
578 )
579 )
580 raise ENDRUN(state)
581
582 # handle case where start time is in the future
583 elif state.start_time and state.start_time > pendulum.now("utc"):
584 self.logger.debug(
585 "Task '{name}': start_time has not been reached; ending run.".format(
586 name=prefect.context.get("task_full_name", self.task.name)
587 )
588 )
589 raise ENDRUN(state)
590
591 return state
592
593 def get_task_inputs(
594 self, state: State, upstream_states: Dict[Edge, State]
595 ) -> Dict[str, Result]:
596 """
597 Given the task's current state and upstream states, generates the inputs for this task.
598 Upstream state result values are used. If the current state has `cached_inputs`, they
599 will override any upstream values.
600
601 Args:
602 - state (State): the task's current state.
603 - upstream_states (Dict[Edge, State]): the upstream state_handlers
604
605 Returns:
606 - Dict[str, Result]: the task inputs
607
608 """
609 task_inputs = {} # type: Dict[str, Result]
610
611 for edge, upstream_state in upstream_states.items():
612 # construct task inputs
613 if edge.key is not None:
614 task_inputs[edge.key] = upstream_state._result # type: ignore
615
616 if state.is_pending() and state.cached_inputs:
617 task_inputs.update(
618 {
619 k: r
620 for k, r in state.cached_inputs.items()
621 if task_inputs.get(k, NoResult) == NoResult
622 }
623 )
624
625 return task_inputs
626
627 def load_results(
628 self, state: State, upstream_states: Dict[Edge, State]
629 ) -> Tuple[State, Dict[Edge, State]]:
630 """
631 Given the task's current state and upstream states, populates all relevant result objects for this task run.
632
633 Args:
634 - state (State): the task's current state.
635 - upstream_states (Dict[Edge, State]): the upstream state_handlers
636
637 Returns:
638 - Tuple[State, dict]: a tuple of (state, upstream_states)
639
640 """
641 return state, upstream_states
642
643 @call_state_handlers
644 def check_target(self, state: State, inputs: Dict[str, Result]) -> State:
645 """
646 Checks if a Result exists at the task's target.
647
648 Args:
649 - state (State): the current state of this task
650 - inputs (Dict[str, Result]): a dictionary of inputs whose keys correspond
651 to the task's `run()` arguments.
652
653 Returns:
654 - State: the state of the task after running the check
655 """
656 result = self.result
657 target = self.task.target
658
659 if result and target:
660 if result.exists(target, **prefect.context):
661 new_res = result.read(target.format(**prefect.context))
662 cached_state = Cached(
663 result=new_res,
664 cached_inputs=inputs,
665 cached_result_expiration=None,
666 cached_parameters=prefect.context.get("parameters"),
667 message=f"Result found at task target {target}",
668 )
669 return cached_state
670
671 return state
672
673 @call_state_handlers
674 def check_task_is_cached(self, state: State, inputs: Dict[str, Result]) -> State:
675 """
676 Checks if task is cached and whether the cache is still valid.
677
678 Args:
679 - state (State): the current state of this task
680 - inputs (Dict[str, Result]): a dictionary of inputs whose keys correspond
681 to the task's `run()` arguments.
682
683 Returns:
684 - State: the state of the task after running the check
685
686 Raises:
687 - ENDRUN: if the task is not ready to run
688 """
689 if state.is_cached():
690 assert isinstance(state, Cached) # mypy assert
691 sanitized_inputs = {key: res.value for key, res in inputs.items()}
692 if self.task.cache_validator(
693 state, sanitized_inputs, prefect.context.get("parameters")
694 ):
695 return state
696 else:
697 state = Pending("Cache was invalid; ready to run.")
698
699 if self.task.cache_for is not None:
700 candidate_states = []
701 if prefect.context.get("caches"):
702 candidate_states = prefect.context.caches.get(
703 self.task.cache_key or self.task.name, []
704 )
705 sanitized_inputs = {key: res.value for key, res in inputs.items()}
706 for candidate in candidate_states:
707 if self.task.cache_validator(
708 candidate, sanitized_inputs, prefect.context.get("parameters")
709 ):
710 return candidate
711
712 if self.task.cache_for is not None:
713 self.logger.warning(
714 "Task '{name}': can't use cache because it "
715 "is now invalid".format(
716 name=prefect.context.get("task_full_name", self.task.name)
717 )
718 )
719 return state or Pending("Cache was invalid; ready to run.")
720
721 def run_mapped_task(
722 self,
723 state: State,
724 upstream_states: Dict[Edge, State],
725 context: Dict[str, Any],
726 executor: "prefect.engine.executors.Executor",
727 ) -> State:
728 """
729 If the task is being mapped, submits children tasks for execution. Returns a `Mapped` state.
730
731 Args:
732 - state (State): the current task state
733 - upstream_states (Dict[Edge, State]): the upstream states
734 - context (dict, optional): prefect Context to use for execution
735 - executor (Executor): executor to use when performing computation
736
737 Returns:
738 - State: the state of the task after running the check
739
740 Raises:
741 - ENDRUN: if the current state is not `Running`
742 """
743
744 map_upstream_states = []
745
746 # we don't know how long the iterables are, but we want to iterate until we reach
747 # the end of the shortest one
748 counter = itertools.count()
749
750 # infinite loop, if upstream_states has any entries
751 while True and upstream_states:
752 i = next(counter)
753 states = {}
754
755 try:
756
757 for edge, upstream_state in upstream_states.items():
758
759 # if the edge is not mapped over, then we take its state
760 if not edge.mapped:
761 states[edge] = upstream_state
762
763 # if the edge is mapped and the upstream state is Mapped, then we are mapping
764 # over a mapped task. In this case, we take the appropriately-indexed upstream
765 # state from the upstream tasks's `Mapped.map_states` array.
766 # Note that these "states" might actually be futures at this time; we aren't
767 # blocking until they finish.
768 elif edge.mapped and upstream_state.is_mapped():
769 states[edge] = upstream_state.map_states[i] # type: ignore
770
771 # Otherwise, we are mapping over the result of a "vanilla" task. In this
772 # case, we create a copy of the upstream state but set the result to the
773 # appropriately-indexed item from the upstream task's `State.result`
774 # array.
775 else:
776 states[edge] = copy.copy(upstream_state)
777
778 # if the current state is already Mapped, then we might be executing
779 # a re-run of the mapping pipeline. In that case, the upstream states
780 # might not have `result` attributes (as any required results could be
781 # in the `cached_inputs` attribute of one of the child states).
782 # Therefore, we only try to get a result if EITHER this task's
783 # state is not already mapped OR the upstream result is not None.
784 if not state.is_mapped() or upstream_state._result != NoResult:
785 if not hasattr(upstream_state.result, "__getitem__"):
786 raise TypeError(
787 "Cannot map over unsubscriptable object of type {t}: {preview}...".format(
788 t=type(upstream_state.result),
789 preview=repr(upstream_state.result)[:10],
790 )
791 )
792 upstream_result = upstream_state._result.from_value( # type: ignore
793 upstream_state.result[i]
794 )
795 states[edge].result = upstream_result
796 elif state.is_mapped():
797 if i >= len(state.map_states): # type: ignore
798 raise IndexError()
799
800 # only add this iteration if we made it through all iterables
801 map_upstream_states.append(states)
802
803 # index error means we reached the end of the shortest iterable
804 except IndexError:
805 break
806
807 def run_fn(
808 state: State, map_index: int, upstream_states: Dict[Edge, State]
809 ) -> State:
810 map_context = context.copy()
811 map_context.update(map_index=map_index)
812 with prefect.context(self.context):
813 return self.run(
814 upstream_states=upstream_states,
815 # if we set the state here, then it will not be processed by `initialize_run()`
816 state=state,
817 context=map_context,
818 executor=executor,
819 )
820
821 # generate initial states, if available
822 if isinstance(state, Mapped):
823 initial_states = list(state.map_states) # type: List[Optional[State]]
824 else:
825 initial_states = []
826 initial_states.extend([None] * (len(map_upstream_states) - len(initial_states)))
827
828 current_state = Mapped(
829 message="Preparing to submit {} mapped tasks.".format(len(initial_states)),
830 map_states=initial_states, # type: ignore
831 )
832 state = self.handle_state_change(old_state=state, new_state=current_state)
833 if state is not current_state:
834 return state
835
836 # map over the initial states, a counter representing the map_index, and also the mapped upstream states
837 map_states = executor.map(
838 run_fn, initial_states, range(len(map_upstream_states)), map_upstream_states
839 )
840
841 self.logger.debug(
842 "{} mapped tasks submitted for execution.".format(len(map_states))
843 )
844 new_state = Mapped(
845 message="Mapped tasks submitted for execution.", map_states=map_states
846 )
847 return self.handle_state_change(old_state=state, new_state=new_state)
848
849 @call_state_handlers
850 def wait_for_mapped_task(
851 self, state: State, executor: "prefect.engine.executors.Executor"
852 ) -> State:
853 """
854 Blocks until a mapped state's children have finished running.
855
856 Args:
857 - state (State): the current `Mapped` state
858 - executor (Executor): the run's executor
859
860 Returns:
861 - State: the new state
862 """
863 if state.is_mapped():
864 assert isinstance(state, Mapped) # mypy assert
865 state.map_states = executor.wait(state.map_states)
866 return state
867
868 @call_state_handlers
869 def set_task_to_running(self, state: State, inputs: Dict[str, Result]) -> State:
870 """
871 Sets the task to running
872
873 Args:
874 - state (State): the current state of this task
875 - inputs (Dict[str, Result]): a dictionary of inputs whose keys correspond
876 to the task's `run()` arguments.
877
878 Returns:
879 - State: the state of the task after running the check
880
881 Raises:
882 - ENDRUN: if the task is not ready to run
883 """
884 if not state.is_pending():
885 self.logger.debug(
886 "Task '{name}': can't set state to Running because it "
887 "isn't Pending; ending run.".format(
888 name=prefect.context.get("task_full_name", self.task.name)
889 )
890 )
891 raise ENDRUN(state)
892
893 new_state = Running(message="Starting task run.", cached_inputs=inputs)
894 return new_state
895
896 @run_with_heartbeat
897 @call_state_handlers
898 def get_task_run_state(
899 self,
900 state: State,
901 inputs: Dict[str, Result],
902 timeout_handler: Optional[Callable] = None,
903 ) -> State:
904 """
905 Runs the task and traps any signals or errors it raises.
906 Also checkpoints the result of a successful task, if `task.checkpoint` is `True`.
907
908 Args:
909 - state (State): the current state of this task
910 - inputs (Dict[str, Result], optional): a dictionary of inputs whose keys correspond
911 to the task's `run()` arguments.
912 - timeout_handler (Callable, optional): function for timing out
913 task execution, with call signature `handler(fn, *args, **kwargs)`. Defaults to
914 `prefect.utilities.executors.timeout_handler`
915
916 Returns:
917 - State: the state of the task after running the check
918
919 Raises:
920 - signals.PAUSE: if the task raises PAUSE
921 - ENDRUN: if the task is not ready to run
922 """
923 if not state.is_running():
924 self.logger.debug(
925 "Task '{name}': can't run task because it's not in a "
926 "Running state; ending run.".format(
927 name=prefect.context.get("task_full_name", self.task.name)
928 )
929 )
930
931 raise ENDRUN(state)
932
933 value = None
934 try:
935 self.logger.debug(
936 "Task '{name}': Calling task.run() method...".format(
937 name=prefect.context.get("task_full_name", self.task.name)
938 )
939 )
940 timeout_handler = (
941 timeout_handler or prefect.utilities.executors.timeout_handler
942 )
943 raw_inputs = {k: r.value for k, r in inputs.items()}
944
945 if getattr(self.task, "log_stdout", False):
946 with redirect_stdout(prefect.utilities.logging.RedirectToLog(self.logger)): # type: ignore
947 value = timeout_handler(
948 self.task.run, timeout=self.task.timeout, **raw_inputs
949 )
950 else:
951 value = timeout_handler(
952 self.task.run, timeout=self.task.timeout, **raw_inputs
953 )
954
955 except KeyboardInterrupt:
956 self.logger.debug("Interrupt signal raised, cancelling task run.")
957 state = Cancelled(message="Interrupt signal raised, cancelling task run.")
958 return state
959
960 # inform user of timeout
961 except TimeoutError as exc:
962 if prefect.context.get("raise_on_exception"):
963 raise exc
964 state = TimedOut(
965 "Task timed out during execution.", result=exc, cached_inputs=inputs
966 )
967 return state
968
969 except signals.LOOP as exc:
970 new_state = exc.state
971 assert isinstance(new_state, Looped)
972 new_state.result = self.result.from_value(value=new_state.result)
973 new_state.cached_inputs = inputs
974 new_state.message = exc.state.message or "Task is looping ({})".format(
975 new_state.loop_count
976 )
977 return new_state
978
979 ## checkpoint tasks if a result is present, except for when the user has opted out by disabling checkpointing
980 if (
981 prefect.context.get("checkpointing") is True
982 and self.task.checkpoint is not False
983 and value is not None
984 ):
985 try:
986 result = self.result.write(value, filename="output", **prefect.context)
987 except NotImplementedError:
988 result = self.result.from_value(value=value)
989 else:
990 result = self.result.from_value(value=value)
991
992 state = Success(
993 result=result, message="Task run succeeded.", cached_inputs=inputs
994 )
995 return state
996
997 @call_state_handlers
998 def cache_result(self, state: State, inputs: Dict[str, Result]) -> State:
999 """
1000 Caches the result of a successful task, if appropriate. Alternatively,
1001 if the task is failed, caches the inputs.
1002
1003 Tasks are cached if:
1004 - task.cache_for is not None
1005 - the task state is Successful
1006 - the task state is not Skipped (which is a subclass of Successful)
1007
1008 Args:
1009 - state (State): the current state of this task
1010 - inputs (Dict[str, Result], optional): a dictionary of inputs whose keys correspond
1011 to the task's `run()` arguments.
1012
1013 Returns:
1014 - State: the state of the task after running the check
1015
1016 """
1017 state.cached_inputs = inputs
1018
1019 if (
1020 state.is_successful()
1021 and not state.is_skipped()
1022 and self.task.cache_for is not None
1023 ):
1024 expiration = pendulum.now("utc") + self.task.cache_for
1025 cached_state = Cached(
1026 result=state._result,
1027 cached_inputs=inputs,
1028 cached_result_expiration=expiration,
1029 cached_parameters=prefect.context.get("parameters"),
1030 message=state.message,
1031 )
1032 return cached_state
1033
1034 return state
1035
1036 @call_state_handlers
1037 def check_for_retry(self, state: State, inputs: Dict[str, Result]) -> State:
1038 """
1039 Checks to see if a FAILED task should be retried.
1040
1041 Args:
1042 - state (State): the current state of this task
1043 - inputs (Dict[str, Result], optional): a dictionary of inputs whose keys correspond
1044 to the task's `run()` arguments.
1045
1046 Returns:
1047 - State: the state of the task after running the check
1048 """
1049 if state.is_failed():
1050 run_count = prefect.context.get("task_run_count", 1)
1051 if prefect.context.get("task_loop_count") is not None:
1052
1053 loop_result = self.result.from_value(
1054 value=prefect.context.get("task_loop_result")
1055 )
1056
1057 ## checkpoint tasks if a result is present, except for when the user has opted out by disabling checkpointing
1058 if (
1059 prefect.context.get("checkpointing") is True
1060 and self.task.checkpoint is not False
1061 and loop_result.value is not None
1062 ):
1063 try:
1064 value = prefect.context.get("task_loop_result")
1065 loop_result = self.result.write(
1066 value, filename="output", **prefect.context
1067 )
1068 except NotImplementedError:
1069 pass
1070
1071 loop_context = {
1072 "_loop_count": PrefectResult(
1073 location=json.dumps(prefect.context["task_loop_count"]),
1074 ),
1075 "_loop_result": loop_result,
1076 }
1077 inputs.update(loop_context)
1078 if run_count <= self.task.max_retries:
1079 start_time = pendulum.now("utc") + self.task.retry_delay
1080 msg = "Retrying Task (after attempt {n} of {m})".format(
1081 n=run_count, m=self.task.max_retries + 1
1082 )
1083 retry_state = Retrying(
1084 start_time=start_time,
1085 cached_inputs=inputs,
1086 message=msg,
1087 run_count=run_count,
1088 )
1089 return retry_state
1090
1091 return state
1092
1093 def check_task_is_looping(
1094 self,
1095 state: State,
1096 inputs: Dict[str, Result] = None,
1097 upstream_states: Dict[Edge, State] = None,
1098 context: Dict[str, Any] = None,
1099 executor: "prefect.engine.executors.Executor" = None,
1100 ) -> State:
1101 """
1102 Checks to see if the task is in a `Looped` state and if so, rerun the pipeline with an incremeneted `loop_count`.
1103
1104 Args:
1105 - state (State, optional): initial `State` to begin task run from;
1106 defaults to `Pending()`
1107 - inputs (Dict[str, Result], optional): a dictionary of inputs whose keys correspond
1108 to the task's `run()` arguments.
1109 - upstream_states (Dict[Edge, State]): a dictionary
1110 representing the states of any tasks upstream of this one. The keys of the
1111 dictionary should correspond to the edges leading to the task.
1112 - context (dict, optional): prefect Context to use for execution
1113 - executor (Executor, optional): executor to use when performing
1114 computation; defaults to the executor specified in your prefect configuration
1115
1116 Returns:
1117 - `State` object representing the final post-run state of the Task
1118 """
1119 if state.is_looped():
1120 assert isinstance(state, Looped) # mypy assert
1121 assert isinstance(context, dict) # mypy assert
1122 msg = "Looping task (on loop index {})".format(state.loop_count)
1123 context.update(
1124 {
1125 "task_loop_result": state.result,
1126 "task_loop_count": state.loop_count + 1,
1127 }
1128 )
1129 context.update(task_run_version=prefect.context.get("task_run_version"))
1130 new_state = Pending(message=msg, cached_inputs=inputs)
1131 raise RecursiveCall(
1132 self.run,
1133 self,
1134 new_state,
1135 upstream_states=upstream_states,
1136 context=context,
1137 executor=executor,
1138 )
1139
1140 return state
1141
[end of src/prefect/engine/task_runner.py]
[start of src/prefect/utilities/executors.py]
1 import multiprocessing
2 import os
3 import signal
4 import subprocess
5 import sys
6 import threading
7 import warnings
8 from concurrent.futures import ThreadPoolExecutor
9 from concurrent.futures import TimeoutError as FutureTimeout
10 from functools import wraps
11 from typing import TYPE_CHECKING, Any, Callable, List, Union
12
13 import prefect
14
15 if TYPE_CHECKING:
16 import prefect.engine.runner
17 import prefect.engine.state
18 from prefect.engine.state import State # pylint: disable=W0611
19
20 StateList = Union["State", List["State"]]
21
22
23 def run_with_heartbeat(
24 runner_method: Callable[..., "prefect.engine.state.State"]
25 ) -> Callable[..., "prefect.engine.state.State"]:
26 """
27 Utility decorator for running class methods with a heartbeat. The class should implement
28 `self._heartbeat` with no arguments.
29 """
30
31 @wraps(runner_method)
32 def inner(
33 self: "prefect.engine.runner.Runner", *args: Any, **kwargs: Any
34 ) -> "prefect.engine.state.State":
35 try:
36 p = None
37 try:
38 if self._heartbeat():
39 # we use Popen + a prefect CLI for a few reasons:
40 # - using threads would interfere with the task; for example, a task
41 # which does not release the GIL would prevent the heartbeat thread from
42 # firing
43 # - using multiprocessing.Process would release the GIL but a subprocess
44 # cannot be spawned from a deamonic subprocess, and Dask sometimes will
45 # submit tasks to run within daemonic subprocesses
46 current_env = dict(os.environ).copy()
47 auth_token = prefect.context.config.cloud.get("auth_token")
48 api_url = prefect.context.config.cloud.get("api")
49 current_env.setdefault("PREFECT__CLOUD__AUTH_TOKEN", auth_token)
50 current_env.setdefault("PREFECT__CLOUD__API", api_url)
51 clean_env = {k: v for k, v in current_env.items() if v is not None}
52 p = subprocess.Popen(
53 self.heartbeat_cmd,
54 env=clean_env,
55 stdout=subprocess.DEVNULL,
56 stderr=subprocess.DEVNULL,
57 )
58 except Exception as exc:
59 self.logger.exception(
60 "Heartbeat failed to start. This could result in a zombie run."
61 )
62 return runner_method(self, *args, **kwargs)
63 finally:
64 if p is not None:
65 exit_code = p.poll()
66 if exit_code is not None:
67 msg = "Heartbeat process died with exit code {}".format(exit_code)
68 self.logger.error(msg)
69 p.kill()
70
71 return inner
72
73
74 def main_thread_timeout(
75 fn: Callable, *args: Any, timeout: int = None, **kwargs: Any
76 ) -> Any:
77 """
78 Helper function for implementing timeouts on function executions.
79 Implemented by setting a `signal` alarm on a timer. Must be run in the main thread.
80 Args:
81 - fn (callable): the function to execute
82 - *args (Any): arguments to pass to the function
83 - timeout (int): the length of time to allow for
84 execution before raising a `TimeoutError`, represented as an integer in seconds
85 - **kwargs (Any): keyword arguments to pass to the function
86 Returns:
87 - the result of `f(*args, **kwargs)`
88 Raises:
89 - TimeoutError: if function execution exceeds the allowed timeout
90 - ValueError: if run from outside the main thread
91 """
92
93 if timeout is None:
94 return fn(*args, **kwargs)
95
96 def error_handler(signum, frame): # type: ignore
97 raise TimeoutError("Execution timed out.")
98
99 try:
100 signal.signal(signal.SIGALRM, error_handler)
101 signal.alarm(timeout)
102 return fn(*args, **kwargs)
103 finally:
104 signal.alarm(0)
105
106
107 def multiprocessing_timeout(
108 fn: Callable, *args: Any, timeout: int = None, **kwargs: Any
109 ) -> Any:
110 """
111 Helper function for implementing timeouts on function executions.
112 Implemented by spawning a new multiprocess.Process() and joining with timeout.
113 Args:
114 - fn (callable): the function to execute
115 - *args (Any): arguments to pass to the function
116 - timeout (int): the length of time to allow for
117 execution before raising a `TimeoutError`, represented as an integer in seconds
118 - **kwargs (Any): keyword arguments to pass to the function
119 Returns:
120 - the result of `f(*args, **kwargs)`
121 Raises:
122 - AssertionError: if run from a daemonic process
123 - TimeoutError: if function execution exceeds the allowed timeout
124 """
125
126 if timeout is None:
127 return fn(*args, **kwargs)
128
129 def retrieve_value(
130 *args: Any, _container: multiprocessing.Queue, _ctx_dict: dict, **kwargs: Any
131 ) -> None:
132 """Puts the return value in a multiprocessing-safe container"""
133 try:
134 with prefect.context(_ctx_dict):
135 val = fn(*args, **kwargs)
136 _container.put(val)
137 except Exception as exc:
138 _container.put(exc)
139
140 q = multiprocessing.Queue() # type: multiprocessing.Queue
141 kwargs["_container"] = q
142 kwargs["_ctx_dict"] = prefect.context.to_dict()
143 p = multiprocessing.Process(target=retrieve_value, args=args, kwargs=kwargs)
144 p.start()
145 p.join(timeout)
146 p.terminate()
147 if not q.empty():
148 res = q.get()
149 if isinstance(res, Exception):
150 raise res
151 return res
152 else:
153 raise TimeoutError("Execution timed out.")
154
155
156 def timeout_handler(
157 fn: Callable, *args: Any, timeout: int = None, **kwargs: Any
158 ) -> Any:
159 """
160 Helper function for implementing timeouts on function executions.
161
162 The exact implementation varies depending on whether this function is being run
163 in the main thread or a non-daemonic subprocess. If this is run from a daemonic subprocess or on Windows,
164 the task is run in a `ThreadPoolExecutor` and only a soft timeout is enforced, meaning
165 a `TimeoutError` is raised at the appropriate time but the task continues running in the background.
166
167 Args:
168 - fn (callable): the function to execute
169 - *args (Any): arguments to pass to the function
170 - timeout (int): the length of time to allow for
171 execution before raising a `TimeoutError`, represented as an integer in seconds
172 - **kwargs (Any): keyword arguments to pass to the function
173
174 Returns:
175 - the result of `f(*args, **kwargs)`
176
177 Raises:
178 - TimeoutError: if function execution exceeds the allowed timeout
179 """
180 # if no timeout, just run the function
181 if timeout is None:
182 return fn(*args, **kwargs)
183
184 # if we are running the main thread, use a signal to stop execution at the appropriate time;
185 # else if we are running in a non-daemonic process, spawn a subprocess to kill at the appropriate time
186 if not sys.platform.startswith("win"):
187 if threading.current_thread() is threading.main_thread():
188 return main_thread_timeout(fn, *args, timeout=timeout, **kwargs)
189 elif multiprocessing.current_process().daemon is False:
190 return multiprocessing_timeout(fn, *args, timeout=timeout, **kwargs)
191
192 msg = (
193 "This task is running in a daemonic subprocess; "
194 "consequently Prefect can only enforce a soft timeout limit, i.e., "
195 "if your Task reaches its timeout limit it will enter a TimedOut state "
196 "but continue running in the background."
197 )
198 else:
199 msg = (
200 "This task is running on Windows; "
201 "consequently Prefect can only enforce a soft timeout limit, i.e., "
202 "if your Task reaches its timeout limit it will enter a TimedOut state "
203 "but continue running in the background."
204 )
205
206 warnings.warn(msg)
207 executor = ThreadPoolExecutor()
208
209 def run_with_ctx(*args: Any, _ctx_dict: dict, **kwargs: Any) -> Any:
210 with prefect.context(_ctx_dict):
211 return fn(*args, **kwargs)
212
213 fut = executor.submit(
214 run_with_ctx, *args, _ctx_dict=prefect.context.to_dict(), **kwargs
215 )
216
217 try:
218 return fut.result(timeout=timeout)
219 except FutureTimeout:
220 raise TimeoutError("Execution timed out.")
221
222
223 class RecursiveCall(Exception):
224 def __init__(self, func: Callable, *args: Any, **kwargs: Any):
225 self.func = func
226 self.args = args
227 self.kwargs = kwargs
228
229
230 def tail_recursive(func: Callable) -> Callable:
231 """
232 Helper function to facilitate tail recursion of the wrapped function.
233
234 This allows for recursion with unlimited depth since a stack is not allocated for
235 each "nested" call. Note: instead of calling the target function in question, a
236 `RecursiveCall` exception must be raised instead.
237
238 Args:
239 - fn (callable): the function to execute
240
241 Returns:
242 - the result of `f(*args, **kwargs)`
243
244 Raises:
245 - RecursionError: if a recursive "call" (raised exception) is made with a function that is
246 not decorated with `tail_recursive` decorator.
247 """
248
249 @wraps(func)
250 def wrapper(*args: Any, **kwargs: Any) -> Any:
251 while True:
252 try:
253 return func(*args, **kwargs)
254 except RecursiveCall as exc:
255 try:
256 call_func = getattr(exc.func, "__wrapped_func__")
257 except AttributeError:
258 raise RecursionError(
259 "function has not been wrapped to provide tail recursion (func={})".format(
260 exc.func
261 )
262 )
263
264 # there may be multiple nested recursive calls, we should only respond to calls for the
265 # wrapped function explicitly, otherwise allow the call to continue to propagate
266 if call_func != func:
267 raise exc
268 args = exc.args
269 kwargs = exc.kwargs
270 continue
271
272 setattr(wrapper, "__wrapped_func__", func)
273 return wrapper
274
[end of src/prefect/utilities/executors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
PrefectHQ/prefect
|
35aa1de018a983cf972c9c30a77159ac7f2de18d
|
Implement Depth-First Execution with Mapping
Currently each "level" of a mapped pipeline is executed before proceeding to the next level. This is undesirable especially for pipelines where it's important that each "branch" of the pipeline finish as quickly as possible.
To implement DFE, we'll need to rearrange two things:
- how mapped work gets submitted (it should start being submitted from the Flow Runner not the Task Runner)
- in order to submit work to Dask and let Dask handle the DFE scheduling, we'll want to refactor how we walk the DAG and wait to determine the width of a pipeline before we submit it (because mapping is fully dynamic we can only ascertain this width at runtime)
We'll need to be vigilant about:
- performance
- retries
- result handling
|
2020-05-24T02:51:51Z
|
<patch>
diff --git a/src/prefect/engine/cloud/task_runner.py b/src/prefect/engine/cloud/task_runner.py
--- a/src/prefect/engine/cloud/task_runner.py
+++ b/src/prefect/engine/cloud/task_runner.py
@@ -339,7 +339,7 @@ def run(
state: State = None,
upstream_states: Dict[Edge, State] = None,
context: Dict[str, Any] = None,
- executor: "prefect.engine.executors.Executor" = None,
+ is_mapped_parent: bool = False,
) -> State:
"""
The main endpoint for TaskRunners. Calling this method will conditionally execute
@@ -354,8 +354,8 @@ def run(
representing the states of any tasks upstream of this one. The keys of the
dictionary should correspond to the edges leading to the task.
- context (dict, optional): prefect Context to use for execution
- - executor (Executor, optional): executor to use when performing
- computation; defaults to the executor specified in your prefect configuration
+ - is_mapped_parent (bool): a boolean indicating whether this task run is the run of a parent
+ mapped task
Returns:
- `State` object representing the final post-run state of the Task
@@ -365,7 +365,7 @@ def run(
state=state,
upstream_states=upstream_states,
context=context,
- executor=executor,
+ is_mapped_parent=is_mapped_parent,
)
while (end_state.is_retrying() or end_state.is_queued()) and (
end_state.start_time <= pendulum.now("utc").add(minutes=10) # type: ignore
@@ -388,6 +388,6 @@ def run(
state=end_state,
upstream_states=upstream_states,
context=context,
- executor=executor,
+ is_mapped_parent=is_mapped_parent,
)
return end_state
diff --git a/src/prefect/engine/executors/__init__.py b/src/prefect/engine/executors/__init__.py
--- a/src/prefect/engine/executors/__init__.py
+++ b/src/prefect/engine/executors/__init__.py
@@ -8,9 +8,6 @@
has completed running
- `wait(object)`: resolves any objects returned by `executor.submit` to
their values; this function _will_ block until execution of `object` is complete
-- `map(fn, *args, upstream_states, **kwargs)`: submit function to be mapped
- over based on the edge information contained in `upstream_states`. Any "mapped" Edge
- will be converted into multiple function submissions, one for each value of the upstream mapped tasks.
Currently, the available executor options are:
diff --git a/src/prefect/engine/executors/base.py b/src/prefect/engine/executors/base.py
--- a/src/prefect/engine/executors/base.py
+++ b/src/prefect/engine/executors/base.py
@@ -1,8 +1,6 @@
import uuid
from contextlib import contextmanager
-from typing import Any, Callable, Iterator, List
-
-from prefect.utilities.executors import timeout_handler
+from typing import Any, Callable, Iterator
class Executor:
@@ -10,8 +8,6 @@ class Executor:
Base Executor class that all other executors inherit from.
"""
- timeout_handler = staticmethod(timeout_handler)
-
def __init__(self) -> None:
self.executor_id = type(self).__name__ + ": " + str(uuid.uuid4())
@@ -28,20 +24,6 @@ def start(self) -> Iterator[None]:
"""
yield
- def map(self, fn: Callable, *args: Any) -> List[Any]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
-
- Returns:
- - List[Any]: the result of computating the function over the arguments
-
- """
- raise NotImplementedError()
-
def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> Any:
"""
Submit a function to the executor for execution. Returns a future-like object.
diff --git a/src/prefect/engine/executors/dask.py b/src/prefect/engine/executors/dask.py
--- a/src/prefect/engine/executors/dask.py
+++ b/src/prefect/engine/executors/dask.py
@@ -2,7 +2,7 @@
import uuid
import warnings
from contextlib import contextmanager
-from typing import TYPE_CHECKING, Any, Callable, Iterator, List, Union
+from typing import Any, Callable, Iterator, TYPE_CHECKING, Union
from prefect import context
from prefect.engine.executors.base import Executor
@@ -63,8 +63,6 @@ class name (e.g. `"distributed.LocalCluster"`), or the class itself.
your Prefect configuration.
- **kwargs: DEPRECATED
- Example:
-
Using a temporary local dask cluster:
```python
@@ -269,41 +267,6 @@ def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> "Future":
fire_and_forget(future)
return future
- def map(self, fn: Callable, *args: Any, **kwargs: Any) -> List["Future"]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
- - **kwargs (Any): additional keyword arguments that will be passed to the Dask Client
-
- Returns:
- - List[Future]: a list of Future-like objects that represent each computation of
- fn(*a), where a = zip(*args)[i]
-
- """
- if not args:
- return []
-
- # import dask functions here to decrease our import times
- from distributed import fire_and_forget, worker_client
-
- dask_kwargs = self._prep_dask_kwargs()
- kwargs.update(dask_kwargs)
-
- if self.is_started and hasattr(self, "client"):
- futures = self.client.map(fn, *args, **kwargs)
- elif self.is_started:
- with worker_client(separate_thread=True) as client:
- futures = client.map(fn, *args, **kwargs)
- return client.gather(futures)
- else:
- raise ValueError("This executor has not been started.")
-
- fire_and_forget(futures)
- return futures
-
def wait(self, futures: Any) -> Any:
"""
Resolves the Future objects to their values. Blocks until the computation is complete.
@@ -331,8 +294,6 @@ class LocalDaskExecutor(Executor):
An executor that runs all functions locally using `dask` and a configurable dask scheduler. Note that
this executor is known to occasionally run tasks twice when using multi-level mapping.
- Prefect's mapping feature will not work in conjunction with setting `scheduler="processes"`.
-
Args:
- scheduler (str): The local dask scheduler to use; common options are "synchronous", "threads" and "processes". Defaults to "threads".
- **kwargs (Any): Additional keyword arguments to pass to dask config
@@ -373,28 +334,6 @@ def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> "dask.delayed":
return dask.delayed(fn)(*args, **kwargs)
- def map(self, fn: Callable, *args: Any) -> List["dask.delayed"]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
-
- Returns:
- - List[dask.delayed]: the result of computating the function over the arguments
-
- """
- if self.scheduler == "processes":
- raise RuntimeError(
- "LocalDaskExecutor cannot map if scheduler='processes'. Please set to either 'synchronous' or 'threads'."
- )
-
- results = []
- for args_i in zip(*args):
- results.append(self.submit(fn, *args_i))
- return results
-
def wait(self, futures: Any) -> Any:
"""
Resolves a `dask.delayed` object to its values. Blocks until the computation is complete.
diff --git a/src/prefect/engine/executors/local.py b/src/prefect/engine/executors/local.py
--- a/src/prefect/engine/executors/local.py
+++ b/src/prefect/engine/executors/local.py
@@ -1,4 +1,4 @@
-from typing import Any, Callable, List
+from typing import Any, Callable
from prefect.engine.executors.base import Executor
@@ -23,23 +23,6 @@ def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> Any:
"""
return fn(*args, **kwargs)
- def map(self, fn: Callable, *args: Any) -> List[Any]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
-
- Returns:
- - List[Any]: the result of computating the function over the arguments
-
- """
- results = []
- for args_i in zip(*args):
- results.append(fn(*args_i))
- return results
-
def wait(self, futures: Any) -> Any:
"""
Returns the results of the provided futures.
diff --git a/src/prefect/engine/flow_runner.py b/src/prefect/engine/flow_runner.py
--- a/src/prefect/engine/flow_runner.py
+++ b/src/prefect/engine/flow_runner.py
@@ -10,7 +10,6 @@
)
import pendulum
-
import prefect
from prefect.core import Edge, Flow, Task
from prefect.engine.result import Result
@@ -28,7 +27,10 @@
Success,
)
from prefect.utilities.collections import flatten_seq
-from prefect.utilities.executors import run_with_heartbeat
+from prefect.utilities.executors import (
+ run_with_heartbeat,
+ prepare_upstream_states_for_mapping,
+)
FlowRunnerInitializeResult = NamedTuple(
"FlowRunnerInitializeResult",
@@ -381,6 +383,11 @@ def get_flow_run_state(
- State: `State` representing the final post-run state of the `Flow`.
"""
+ # this dictionary is used for tracking the states of "children" mapped tasks;
+ # when running on Dask, we want to avoid serializing futures, so instead
+ # of storing child task states in the `map_states` attribute we instead store
+ # in this dictionary and only after they are resolved do we attach them to the Mapped state
+ mapped_children = dict() # type: Dict[Task, list]
if not state.is_running():
self.logger.info("Flow is not in a Running state.")
@@ -396,14 +403,19 @@ def get_flow_run_state(
with executor.start():
for task in self.flow.sorted_tasks():
-
task_state = task_states.get(task)
+
+ # if a task is a constant task, we already know its return value
+ # no need to use up resources by running it through a task runner
if task_state is None and isinstance(
task, prefect.tasks.core.constants.Constant
):
task_states[task] = task_state = Success(result=task.value)
# if the state is finished, don't run the task, just use the provided state
+ # if the state is cached / mapped, we still want to run the task runner pipeline steps
+ # to either ensure the cache is still valid / or to recreate the mapped pipeline for
+ # possible retries
if (
isinstance(task_state, State)
and task_state.is_finished()
@@ -412,7 +424,12 @@ def get_flow_run_state(
):
continue
- upstream_states = {} # type: Dict[Edge, Union[State, Iterable]]
+ upstream_states = {} # type: Dict[Edge, State]
+
+ # this dictionary is used exclusively for "reduce" tasks
+ # in particular we store the states / futures corresponding to
+ # the upstream children, and if running on Dask, let Dask resolve them at the appropriate time
+ upstream_mapped_states = {} # type: Dict[Edge, list]
# -- process each edge to the task
for edge in self.flow.edges_to(task):
@@ -420,6 +437,13 @@ def get_flow_run_state(
edge.upstream_task, Pending(message="Task state not available.")
)
+ # this checks whether the task is a "reduce" task for a mapped pipeline
+ # and if so, collects the appropriate upstream children
+ if not edge.mapped and isinstance(upstream_states[edge], Mapped):
+ upstream_mapped_states[edge] = mapped_children.get(
+ edge.upstream_task, []
+ )
+
# augment edges with upstream constants
for key, val in self.flow.constants[task].items():
edge = Edge(
@@ -432,9 +456,80 @@ def get_flow_run_state(
result=ConstantResult(value=val),
)
- # -- run the task
+ # handle mapped tasks
+ if any([edge.mapped for edge in upstream_states.keys()]):
- with prefect.context(task_full_name=task.name, task_tags=task.tags):
+ ## wait on upstream states to determine the width of the pipeline
+ ## this is the key to depth-first execution
+ upstream_states.update(
+ executor.wait(
+ {e: state for e, state in upstream_states.items()}
+ )
+ )
+
+ ## we submit the task to the task runner to determine if
+ ## we can proceed with mapping - if the new task state is not a Mapped
+ ## state then we don't proceed
+ task_states[task] = executor.wait(
+ executor.submit(
+ self.run_task,
+ task=task,
+ state=task_state, # original state
+ upstream_states=upstream_states,
+ context=dict(
+ prefect.context, **task_contexts.get(task, {})
+ ),
+ task_runner_state_handlers=task_runner_state_handlers,
+ upstream_mapped_states=upstream_mapped_states,
+ is_mapped_parent=True,
+ )
+ )
+
+ ## either way, we should now have enough resolved states to restructure
+ ## the upstream states into a list of upstream state dictionaries to iterate over
+ list_of_upstream_states = prepare_upstream_states_for_mapping(
+ task_states[task], upstream_states, mapped_children
+ )
+
+ submitted_states = []
+
+ for idx, states in enumerate(list_of_upstream_states):
+ ## if we are on a future rerun of a partially complete flow run,
+ ## there might be mapped children in a retrying state; this check
+ ## looks into the current task state's map_states for such info
+ if (
+ isinstance(task_state, Mapped)
+ and len(task_state.map_states) >= idx + 1
+ ):
+ current_state = task_state.map_states[
+ idx
+ ] # type: Optional[State]
+ elif isinstance(task_state, Mapped):
+ current_state = None
+ else:
+ current_state = task_state
+
+ ## this is where each child is submitted for actual work
+ submitted_states.append(
+ executor.submit(
+ self.run_task,
+ task=task,
+ state=current_state,
+ upstream_states=states,
+ context=dict(
+ prefect.context,
+ **task_contexts.get(task, {}),
+ map_index=idx,
+ ),
+ task_runner_state_handlers=task_runner_state_handlers,
+ upstream_mapped_states=upstream_mapped_states,
+ )
+ )
+ if isinstance(task_states.get(task), Mapped):
+ mapped_children[task] = submitted_states # type: ignore
+
+ # -- run the task
+ else:
task_states[task] = executor.submit(
self.run_task,
task=task,
@@ -442,7 +537,7 @@ def get_flow_run_state(
upstream_states=upstream_states,
context=dict(prefect.context, **task_contexts.get(task, {})),
task_runner_state_handlers=task_runner_state_handlers,
- executor=executor,
+ upstream_mapped_states=upstream_mapped_states,
)
# ---------------------------------------------
@@ -469,7 +564,9 @@ def get_flow_run_state(
all_final_states = final_states.copy()
for t, s in list(final_states.items()):
if s.is_mapped():
- s.map_states = executor.wait(s.map_states)
+ # ensure we wait for any mapped children to complete
+ if t in mapped_children:
+ s.map_states = executor.wait(mapped_children[t])
s.result = [ms.result for ms in s.map_states]
all_final_states[t] = s.map_states
@@ -540,7 +637,8 @@ def run_task(
upstream_states: Dict[Edge, State],
context: Dict[str, Any],
task_runner_state_handlers: Iterable[Callable],
- executor: "prefect.engine.executors.Executor",
+ is_mapped_parent: bool = False,
+ upstream_mapped_states: Dict[Edge, list] = None,
) -> State:
"""
@@ -556,13 +654,17 @@ def run_task(
- task_runner_state_handlers (Iterable[Callable]): A list of state change
handlers that will be provided to the task_runner, and called whenever a task changes
state.
- - executor (Executor): executor to use when performing
- computation; defaults to the executor provided in your prefect configuration
+ - is_mapped_parent (bool): a boolean indicating whether this task run is the run of a parent
+ mapped task
+ - upstream_mapped_states (Dict[Edge, list]): dictionary of upstream states corresponding to
+ mapped children dependencies
Returns:
- State: `State` representing the final post-run state of the `Flow`.
"""
+ upstream_mapped_states = upstream_mapped_states or {}
+
with prefect.context(self.context):
default_result = task.result or self.flow.result
task_runner = self.task_runner_cls(
@@ -578,7 +680,9 @@ def run_task(
# if the upstream state is Mapped, wait until its results are all available
if not edge.mapped and upstream_state.is_mapped():
assert isinstance(upstream_state, Mapped) # mypy assert
- upstream_state.map_states = executor.wait(upstream_state.map_states)
+ upstream_state.map_states = upstream_mapped_states.get(
+ edge, upstream_state.map_states
+ )
upstream_state.result = [
s.result for s in upstream_state.map_states
]
@@ -587,5 +691,5 @@ def run_task(
state=state,
upstream_states=upstream_states,
context=context,
- executor=executor,
+ is_mapped_parent=is_mapped_parent,
)
diff --git a/src/prefect/engine/task_runner.py b/src/prefect/engine/task_runner.py
--- a/src/prefect/engine/task_runner.py
+++ b/src/prefect/engine/task_runner.py
@@ -1,6 +1,4 @@
-import copy
from contextlib import redirect_stdout
-import itertools
import json
from typing import (
Any,
@@ -196,7 +194,7 @@ def run(
state: State = None,
upstream_states: Dict[Edge, State] = None,
context: Dict[str, Any] = None,
- executor: "prefect.engine.executors.Executor" = None,
+ is_mapped_parent: bool = False,
) -> State:
"""
The main endpoint for TaskRunners. Calling this method will conditionally execute
@@ -210,8 +208,8 @@ def run(
representing the states of any tasks upstream of this one. The keys of the
dictionary should correspond to the edges leading to the task.
- context (dict, optional): prefect Context to use for execution
- - executor (Executor, optional): executor to use when performing
- computation; defaults to the executor specified in your prefect configuration
+ - is_mapped_parent (bool): a boolean indicating whether this task run is the run of a parent
+ mapped task
Returns:
- `State` object representing the final post-run state of the Task
@@ -224,15 +222,6 @@ def run(
index=("" if map_index is None else "[{}]".format(map_index)),
)
- if executor is None:
- executor = prefect.engine.get_default_executor_class()()
-
- # if mapped is true, this task run is going to generate a Mapped state. It won't
- # actually run, but rather spawn children tasks to map over its inputs. We
- # detect this case by checking for:
- # - upstream edges that are `mapped`
- # - no `map_index` (which indicates that this is the child task, not the parent)
- mapped = any([e.mapped for e in upstream_states]) and map_index is None
task_inputs = {} # type: Dict[str, Any]
try:
@@ -270,29 +259,16 @@ def run(
state=state, upstream_states=upstream_states
)
- # if the task is mapped, process the mapped children and exit
- if mapped:
- state = self.run_mapped_task(
- state=state,
- upstream_states=upstream_states,
- context=context,
- executor=executor,
- )
-
- state = self.wait_for_mapped_task(state=state, executor=executor)
-
- self.logger.debug(
- "Task '{name}': task has been mapped; ending run.".format(
- name=context["task_full_name"]
- )
- )
- raise ENDRUN(state)
-
# retrieve task inputs from upstream and also explicitly passed inputs
task_inputs = self.get_task_inputs(
state=state, upstream_states=upstream_states
)
+ if is_mapped_parent:
+ state = self.check_task_ready_to_map(
+ state, upstream_states=upstream_states
+ )
+
if self.task.target:
# check to see if there is a Result at the task's target
state = self.check_target(state, inputs=task_inputs)
@@ -309,9 +285,7 @@ def run(
state = self.set_task_to_running(state, inputs=task_inputs)
# run the task
- state = self.get_task_run_state(
- state, inputs=task_inputs, timeout_handler=executor.timeout_handler
- )
+ state = self.get_task_run_state(state, inputs=task_inputs)
# cache the output, if appropriate
state = self.cache_result(state, inputs=task_inputs)
@@ -324,7 +298,6 @@ def run(
inputs=task_inputs,
upstream_states=upstream_states,
context=context,
- executor=executor,
)
# for pending signals, including retries and pauses we need to make sure the
@@ -438,6 +411,45 @@ def check_upstream_skipped(
)
return state
+ @call_state_handlers
+ def check_task_ready_to_map(
+ self, state: State, upstream_states: Dict[Edge, State]
+ ) -> State:
+ """
+ Checks if the parent task is ready to proceed with mapping.
+
+ Args:
+ - state (State): the current state of this task
+ - upstream_states (Dict[Edge, Union[State, List[State]]]): the upstream states
+
+ Raises:
+ - ENDRUN: either way, we dont continue past this point
+ """
+ if state.is_mapped():
+ raise ENDRUN(state)
+
+ ## we can't map if there are no success states with iterables upstream
+ if upstream_states and not any(
+ [
+ edge.mapped and state.is_successful()
+ for edge, state in upstream_states.items()
+ ]
+ ):
+ new_state = Failed("No upstream states can be mapped over.") # type: State
+ raise ENDRUN(new_state)
+ elif not all(
+ [
+ hasattr(state.result, "__getitem__")
+ for edge, state in upstream_states.items()
+ if state.is_successful() and not state.is_mapped() and edge.mapped
+ ]
+ ):
+ new_state = Failed("No upstream states can be mapped over.")
+ raise ENDRUN(new_state)
+ else:
+ new_state = Mapped("Ready to proceed with mapping.")
+ raise ENDRUN(new_state)
+
@call_state_handlers
def check_task_trigger(
self, state: State, upstream_states: Dict[Edge, State]
@@ -718,153 +730,6 @@ def check_task_is_cached(self, state: State, inputs: Dict[str, Result]) -> State
)
return state or Pending("Cache was invalid; ready to run.")
- def run_mapped_task(
- self,
- state: State,
- upstream_states: Dict[Edge, State],
- context: Dict[str, Any],
- executor: "prefect.engine.executors.Executor",
- ) -> State:
- """
- If the task is being mapped, submits children tasks for execution. Returns a `Mapped` state.
-
- Args:
- - state (State): the current task state
- - upstream_states (Dict[Edge, State]): the upstream states
- - context (dict, optional): prefect Context to use for execution
- - executor (Executor): executor to use when performing computation
-
- Returns:
- - State: the state of the task after running the check
-
- Raises:
- - ENDRUN: if the current state is not `Running`
- """
-
- map_upstream_states = []
-
- # we don't know how long the iterables are, but we want to iterate until we reach
- # the end of the shortest one
- counter = itertools.count()
-
- # infinite loop, if upstream_states has any entries
- while True and upstream_states:
- i = next(counter)
- states = {}
-
- try:
-
- for edge, upstream_state in upstream_states.items():
-
- # if the edge is not mapped over, then we take its state
- if not edge.mapped:
- states[edge] = upstream_state
-
- # if the edge is mapped and the upstream state is Mapped, then we are mapping
- # over a mapped task. In this case, we take the appropriately-indexed upstream
- # state from the upstream tasks's `Mapped.map_states` array.
- # Note that these "states" might actually be futures at this time; we aren't
- # blocking until they finish.
- elif edge.mapped and upstream_state.is_mapped():
- states[edge] = upstream_state.map_states[i] # type: ignore
-
- # Otherwise, we are mapping over the result of a "vanilla" task. In this
- # case, we create a copy of the upstream state but set the result to the
- # appropriately-indexed item from the upstream task's `State.result`
- # array.
- else:
- states[edge] = copy.copy(upstream_state)
-
- # if the current state is already Mapped, then we might be executing
- # a re-run of the mapping pipeline. In that case, the upstream states
- # might not have `result` attributes (as any required results could be
- # in the `cached_inputs` attribute of one of the child states).
- # Therefore, we only try to get a result if EITHER this task's
- # state is not already mapped OR the upstream result is not None.
- if not state.is_mapped() or upstream_state._result != NoResult:
- if not hasattr(upstream_state.result, "__getitem__"):
- raise TypeError(
- "Cannot map over unsubscriptable object of type {t}: {preview}...".format(
- t=type(upstream_state.result),
- preview=repr(upstream_state.result)[:10],
- )
- )
- upstream_result = upstream_state._result.from_value( # type: ignore
- upstream_state.result[i]
- )
- states[edge].result = upstream_result
- elif state.is_mapped():
- if i >= len(state.map_states): # type: ignore
- raise IndexError()
-
- # only add this iteration if we made it through all iterables
- map_upstream_states.append(states)
-
- # index error means we reached the end of the shortest iterable
- except IndexError:
- break
-
- def run_fn(
- state: State, map_index: int, upstream_states: Dict[Edge, State]
- ) -> State:
- map_context = context.copy()
- map_context.update(map_index=map_index)
- with prefect.context(self.context):
- return self.run(
- upstream_states=upstream_states,
- # if we set the state here, then it will not be processed by `initialize_run()`
- state=state,
- context=map_context,
- executor=executor,
- )
-
- # generate initial states, if available
- if isinstance(state, Mapped):
- initial_states = list(state.map_states) # type: List[Optional[State]]
- else:
- initial_states = []
- initial_states.extend([None] * (len(map_upstream_states) - len(initial_states)))
-
- current_state = Mapped(
- message="Preparing to submit {} mapped tasks.".format(len(initial_states)),
- map_states=initial_states, # type: ignore
- )
- state = self.handle_state_change(old_state=state, new_state=current_state)
- if state is not current_state:
- return state
-
- # map over the initial states, a counter representing the map_index, and also the mapped upstream states
- map_states = executor.map(
- run_fn, initial_states, range(len(map_upstream_states)), map_upstream_states
- )
-
- self.logger.debug(
- "{} mapped tasks submitted for execution.".format(len(map_states))
- )
- new_state = Mapped(
- message="Mapped tasks submitted for execution.", map_states=map_states
- )
- return self.handle_state_change(old_state=state, new_state=new_state)
-
- @call_state_handlers
- def wait_for_mapped_task(
- self, state: State, executor: "prefect.engine.executors.Executor"
- ) -> State:
- """
- Blocks until a mapped state's children have finished running.
-
- Args:
- - state (State): the current `Mapped` state
- - executor (Executor): the run's executor
-
- Returns:
- - State: the new state
- """
- if state.is_mapped():
- assert isinstance(state, Mapped) # mypy assert
- state.map_states = executor.wait(state.map_states)
- return state
-
@call_state_handlers
def set_task_to_running(self, state: State, inputs: Dict[str, Result]) -> State:
"""
@@ -895,12 +760,7 @@ def set_task_to_running(self, state: State, inputs: Dict[str, Result]) -> State:
@run_with_heartbeat
@call_state_handlers
- def get_task_run_state(
- self,
- state: State,
- inputs: Dict[str, Result],
- timeout_handler: Optional[Callable] = None,
- ) -> State:
+ def get_task_run_state(self, state: State, inputs: Dict[str, Result],) -> State:
"""
Runs the task and traps any signals or errors it raises.
Also checkpoints the result of a successful task, if `task.checkpoint` is `True`.
@@ -909,9 +769,6 @@ def get_task_run_state(
- state (State): the current state of this task
- inputs (Dict[str, Result], optional): a dictionary of inputs whose keys correspond
to the task's `run()` arguments.
- - timeout_handler (Callable, optional): function for timing out
- task execution, with call signature `handler(fn, *args, **kwargs)`. Defaults to
- `prefect.utilities.executors.timeout_handler`
Returns:
- State: the state of the task after running the check
@@ -937,9 +794,7 @@ def get_task_run_state(
name=prefect.context.get("task_full_name", self.task.name)
)
)
- timeout_handler = (
- timeout_handler or prefect.utilities.executors.timeout_handler
- )
+ timeout_handler = prefect.utilities.executors.timeout_handler
raw_inputs = {k: r.value for k, r in inputs.items()}
if getattr(self.task, "log_stdout", False):
@@ -1096,7 +951,6 @@ def check_task_is_looping(
inputs: Dict[str, Result] = None,
upstream_states: Dict[Edge, State] = None,
context: Dict[str, Any] = None,
- executor: "prefect.engine.executors.Executor" = None,
) -> State:
"""
Checks to see if the task is in a `Looped` state and if so, rerun the pipeline with an incremeneted `loop_count`.
@@ -1110,8 +964,6 @@ def check_task_is_looping(
representing the states of any tasks upstream of this one. The keys of the
dictionary should correspond to the edges leading to the task.
- context (dict, optional): prefect Context to use for execution
- - executor (Executor, optional): executor to use when performing
- computation; defaults to the executor specified in your prefect configuration
Returns:
- `State` object representing the final post-run state of the Task
@@ -1134,7 +986,6 @@ def check_task_is_looping(
new_state,
upstream_states=upstream_states,
context=context,
- executor=executor,
)
return state
diff --git a/src/prefect/utilities/executors.py b/src/prefect/utilities/executors.py
--- a/src/prefect/utilities/executors.py
+++ b/src/prefect/utilities/executors.py
@@ -1,3 +1,5 @@
+import copy
+import itertools
import multiprocessing
import os
import signal
@@ -8,13 +10,15 @@
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import TimeoutError as FutureTimeout
from functools import wraps
-from typing import TYPE_CHECKING, Any, Callable, List, Union
+from typing import TYPE_CHECKING, Any, Callable, Dict, List, Union
import prefect
if TYPE_CHECKING:
import prefect.engine.runner
import prefect.engine.state
+ from prefect.core.edge import Edge # pylint: disable=W0611
+ from prefect.core.task import Task # pylint: disable=W0611
from prefect.engine.state import State # pylint: disable=W0611
StateList = Union["State", List["State"]]
@@ -271,3 +275,99 @@ def wrapper(*args: Any, **kwargs: Any) -> Any:
setattr(wrapper, "__wrapped_func__", func)
return wrapper
+
+
+def prepare_upstream_states_for_mapping(
+ state: "State",
+ upstream_states: Dict["Edge", "State"],
+ mapped_children: Dict["Task", list],
+) -> list:
+ """
+ If the task is being mapped, submits children tasks for execution. Returns a `Mapped` state.
+
+ Args:
+ - state (State): the parent task's current state
+ - upstream_states (Dict[Edge, State]): the upstream states to this task
+ - mapped_children (Dict[Task, List[State]]): any mapped children upstream of this task
+
+ Returns:
+ - List: a restructured list of upstream states correponding to each new mapped child task
+ """
+
+ ## if the current state is failed / skipped or otherwise
+ ## in a state that signifies we should not continue with mapping,
+ ## we return an empty list
+ if state.is_pending() or state.is_failed() or state.is_skipped():
+ return []
+
+ map_upstream_states = []
+
+ # we don't know how long the iterables are, but we want to iterate until we reach
+ # the end of the shortest one
+ counter = itertools.count()
+
+ # infinite loop, if upstream_states has any entries
+ while True and upstream_states:
+ i = next(counter)
+ states = {}
+
+ try:
+
+ for edge, upstream_state in upstream_states.items():
+
+ # ensure we are working with populated result objects
+ if edge.key in state.cached_inputs:
+ upstream_state._result = state.cached_inputs[edge.key]
+
+ # if the edge is not mapped over, then we take its state
+ if not edge.mapped:
+ states[edge] = upstream_state
+
+ # if the edge is mapped and the upstream state is Mapped, then we are mapping
+ # over a mapped task. In this case, we take the appropriately-indexed upstream
+ # state from the upstream tasks's `Mapped.map_states` array.
+ # Note that these "states" might actually be futures at this time; we aren't
+ # blocking until they finish.
+ elif edge.mapped and upstream_state.is_mapped():
+ states[edge] = mapped_children[edge.upstream_task][i] # type: ignore
+
+ # Otherwise, we are mapping over the result of a "vanilla" task. In this
+ # case, we create a copy of the upstream state but set the result to the
+ # appropriately-indexed item from the upstream task's `State.result`
+ # array.
+ else:
+ states[edge] = copy.copy(upstream_state)
+
+ # if the current state is already Mapped, then we might be executing
+ # a re-run of the mapping pipeline. In that case, the upstream states
+ # might not have `result` attributes (as any required results could be
+ # in the `cached_inputs` attribute of one of the child states).
+ # Therefore, we only try to get a result if EITHER this task's
+ # state is not already mapped OR the upstream result is not None.
+ if (
+ not state.is_mapped()
+ or upstream_state._result != prefect.engine.result.NoResult
+ ):
+ if not hasattr(upstream_state.result, "__getitem__"):
+ raise TypeError(
+ "Cannot map over unsubscriptable object of type {t}: {preview}...".format(
+ t=type(upstream_state.result),
+ preview=repr(upstream_state.result)[:10],
+ )
+ )
+ upstream_result = upstream_state._result.from_value( # type: ignore
+ upstream_state.result[i]
+ )
+ states[edge].result = upstream_result
+ elif state.is_mapped():
+ if i >= len(state.map_states): # type: ignore
+ raise IndexError()
+
+ # only add this iteration if we made it through all iterables
+ map_upstream_states.append(states)
+
+ # index error means we reached the end of the shortest iterable
+ except IndexError:
+ break
+
+ return map_upstream_states
</patch>
|
[]
|
[]
| ||||
googleapis__google-cloud-python-3156
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Language: support mention type in Entity.mentions.
[Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type.
Furthermore, this change should add mention_type information to the mention documentation.
</issue>
<code>
[start of README.rst]
1 Google Cloud Python Client
2 ==========================
3
4 Python idiomatic client for `Google Cloud Platform`_ services.
5
6 .. _Google Cloud Platform: https://cloud.google.com/
7
8 |pypi| |circleci| |build| |appveyor| |coverage| |versions|
9
10 - `Homepage`_
11 - `API Documentation`_
12 - `Read The Docs Documentation`_
13
14 .. _Homepage: https://googlecloudplatform.github.io/google-cloud-python/
15 .. _API Documentation: https://googlecloudplatform.github.io/google-cloud-python/stable/
16 .. _Read The Docs Documentation: https://google-cloud-python.readthedocs.io/en/latest/
17
18 This client library has **beta** support for the following Google
19 Cloud Platform services:
20
21 - `Google BigQuery`_ (`BigQuery README`_)
22 - `Google Cloud Datastore`_ (`Datastore README`_)
23 - `Stackdriver Logging`_ (`Logging README`_)
24 - `Google Cloud Storage`_ (`Storage README`_)
25 - `Google Cloud Vision`_ (`Vision README`_)
26
27 **Beta** indicates that the client library for a particular service is
28 mostly stable and is being prepared for release. Issues and requests
29 against beta libraries are addressed with a higher priority.
30
31 This client library has **alpha** support for the following Google
32 Cloud Platform services:
33
34 - `Google Cloud Pub/Sub`_ (`Pub/Sub README`_)
35 - `Google Cloud Resource Manager`_ (`Resource Manager README`_)
36 - `Stackdriver Monitoring`_ (`Monitoring README`_)
37 - `Google Cloud Bigtable`_ (`Bigtable README`_)
38 - `Google Cloud DNS`_ (`DNS README`_)
39 - `Stackdriver Error Reporting`_ (`Error Reporting README`_)
40 - `Google Cloud Natural Language`_ (`Natural Language README`_)
41 - `Google Cloud Translation`_ (`Translation README`_)
42 - `Google Cloud Speech`_ (`Speech README`_)
43 - `Google Cloud Bigtable - HappyBase`_ (`HappyBase README`_)
44 - `Google Cloud Runtime Configuration`_ (`Runtime Config README`_)
45 - `Cloud Spanner`_ (`Cloud Spanner README`_)
46
47 **Alpha** indicates that the client library for a particular service is
48 still a work-in-progress and is more likely to get backwards-incompatible
49 updates. See `versioning`_ for more details.
50
51 .. _Google Cloud Datastore: https://pypi.python.org/pypi/google-cloud-datastore
52 .. _Datastore README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/datastore
53 .. _Google Cloud Storage: https://pypi.python.org/pypi/google-cloud-storage
54 .. _Storage README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/storage
55 .. _Google Cloud Pub/Sub: https://pypi.python.org/pypi/google-cloud-pubsub
56 .. _Pub/Sub README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/pubsub
57 .. _Google BigQuery: https://pypi.python.org/pypi/google-cloud-bigquery
58 .. _BigQuery README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/bigquery
59 .. _Google Cloud Resource Manager: https://pypi.python.org/pypi/google-cloud-resource-manager
60 .. _Resource Manager README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/resource_manager
61 .. _Stackdriver Logging: https://pypi.python.org/pypi/google-cloud-logging
62 .. _Logging README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/logging
63 .. _Stackdriver Monitoring: https://pypi.python.org/pypi/google-cloud-monitoring
64 .. _Monitoring README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/monitoring
65 .. _Google Cloud Bigtable: https://pypi.python.org/pypi/google-cloud-bigtable
66 .. _Bigtable README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/bigtable
67 .. _Google Cloud DNS: https://pypi.python.org/pypi/google-cloud-dns
68 .. _DNS README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/dns
69 .. _Stackdriver Error Reporting: https://pypi.python.org/pypi/google-cloud-error-reporting
70 .. _Error Reporting README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/error_reporting
71 .. _Google Cloud Natural Language: https://pypi.python.org/pypi/google-cloud-language
72 .. _Natural Language README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/language
73 .. _Google Cloud Translation: https://pypi.python.org/pypi/google-cloud-translate
74 .. _Translation README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/translate
75 .. _Google Cloud Speech: https://pypi.python.org/pypi/google-cloud-speech
76 .. _Speech README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/speech
77 .. _Google Cloud Vision: https://pypi.python.org/pypi/google-cloud-vision
78 .. _Vision README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/vision
79 .. _Google Cloud Bigtable - HappyBase: https://pypi.python.org/pypi/google-cloud-happybase/
80 .. _HappyBase README: https://github.com/GoogleCloudPlatform/google-cloud-python-happybase
81 .. _Google Cloud Runtime Configuration: https://cloud.google.com/deployment-manager/runtime-configurator/
82 .. _Runtime Config README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/runtimeconfig
83 .. _Cloud Spanner: https://cloud.google.com/spanner/
84 .. _Cloud Spanner README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/spanner
85 .. _versioning: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst#versioning
86
87 If you need support for other Google APIs, check out the
88 `Google APIs Python Client library`_.
89
90 .. _Google APIs Python Client library: https://github.com/google/google-api-python-client
91
92 Quick Start
93 -----------
94
95 .. code-block:: console
96
97 $ pip install --upgrade google-cloud
98
99 Example Applications
100 --------------------
101
102 - `getting-started-python`_ - A sample and `tutorial`_ that demonstrates how to build a complete web application using Cloud Datastore, Cloud Storage, and Cloud Pub/Sub and deploy it to Google App Engine or Google Compute Engine.
103 - `google-cloud-python-expenses-demo`_ - A sample expenses demo using Cloud Datastore and Cloud Storage
104
105 .. _getting-started-python: https://github.com/GoogleCloudPlatform/getting-started-python
106 .. _tutorial: https://cloud.google.com/python
107 .. _google-cloud-python-expenses-demo: https://github.com/GoogleCloudPlatform/google-cloud-python-expenses-demo
108
109 Authentication
110 --------------
111
112 With ``google-cloud-python`` we try to make authentication as painless as possible.
113 Check out the `Authentication section`_ in our documentation to learn more.
114 You may also find the `authentication document`_ shared by all the
115 ``google-cloud-*`` libraries to be helpful.
116
117 .. _Authentication section: https://google-cloud-python.readthedocs.io/en/latest/google-cloud-auth.html
118 .. _authentication document: https://github.com/GoogleCloudPlatform/gcloud-common/tree/master/authentication
119
120 Contributing
121 ------------
122
123 Contributions to this library are always welcome and highly encouraged.
124
125 See `CONTRIBUTING`_ for more information on how to get started.
126
127 .. _CONTRIBUTING: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst
128
129 Community
130 ---------
131
132 Google Cloud Platform Python developers hang out in `Slack`_ in the ``#python``
133 channel, click here to `get an invitation`_.
134
135
136 .. _Slack: https://googlecloud-community.slack.com
137 .. _get an invitation: https://gcp-slack.appspot.com/
138
139 License
140 -------
141
142 Apache 2.0 - See `LICENSE`_ for more information.
143
144 .. _LICENSE: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/LICENSE
145
146 .. |build| image:: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python.svg?branch=master
147 :target: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python
148 .. |circleci| image:: https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python.svg?style=shield
149 :target: https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python
150 .. |appveyor| image:: https://ci.appveyor.com/api/projects/status/github/googlecloudplatform/google-cloud-python?branch=master&svg=true
151 :target: https://ci.appveyor.com/project/GoogleCloudPlatform/google-cloud-python
152 .. |coverage| image:: https://coveralls.io/repos/GoogleCloudPlatform/google-cloud-python/badge.svg?branch=master
153 :target: https://coveralls.io/r/GoogleCloudPlatform/google-cloud-python?branch=master
154 .. |pypi| image:: https://img.shields.io/pypi/v/google-cloud.svg
155 :target: https://pypi.python.org/pypi/google-cloud
156 .. |versions| image:: https://img.shields.io/pypi/pyversions/google-cloud.svg
157 :target: https://pypi.python.org/pypi/google-cloud
158
[end of README.rst]
[start of language/google/cloud/language/entity.py]
1 # Copyright 2016-2017 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Definition for Google Cloud Natural Language API entities.
16
17 An entity is used to describe a proper name extracted from text.
18 """
19
20
21 class EntityType(object):
22 """List of possible entity types."""
23
24 UNKNOWN = 'UNKNOWN'
25 """Unknown entity type."""
26
27 PERSON = 'PERSON'
28 """Person entity type."""
29
30 LOCATION = 'LOCATION'
31 """Location entity type."""
32
33 ORGANIZATION = 'ORGANIZATION'
34 """Organization entity type."""
35
36 EVENT = 'EVENT'
37 """Event entity type."""
38
39 WORK_OF_ART = 'WORK_OF_ART'
40 """Work of art entity type."""
41
42 CONSUMER_GOOD = 'CONSUMER_GOOD'
43 """Consumer good entity type."""
44
45 OTHER = 'OTHER'
46 """Other entity type (i.e. known but not classified)."""
47
48
49 class Entity(object):
50 """A Google Cloud Natural Language API entity.
51
52 Represents a phrase in text that is a known entity, such as a person,
53 an organization, or location. The API associates information, such as
54 salience and mentions, with entities.
55
56 .. _Entity message: https://cloud.google.com/natural-language/\
57 reference/rest/v1/Entity
58 .. _EntityType enum: https://cloud.google.com/natural-language/\
59 reference/rest/v1/Entity#Type
60
61 See `Entity message`_.
62
63 :type name: str
64 :param name: The name / phrase identified as the entity.
65
66 :type entity_type: str
67 :param entity_type: The type of the entity. See `EntityType enum`_.
68
69 :type metadata: dict
70 :param metadata: The metadata associated with the entity.
71 Wikipedia URLs and Knowledge Graph MIDs are
72 provided, if available. The associated keys are
73 "wikipedia_url" and "mid", respectively.
74
75 :type salience: float
76 :param salience: The prominence of the entity / phrase within the text
77 containing it.
78
79 :type mentions: list
80 :param mentions: List of strings that mention the entity.
81 """
82
83 def __init__(self, name, entity_type, metadata, salience, mentions):
84 self.name = name
85 self.entity_type = entity_type
86 self.metadata = metadata
87 self.salience = salience
88 self.mentions = mentions
89
90 @classmethod
91 def from_api_repr(cls, payload):
92 """Convert an Entity from the JSON API into an :class:`Entity`.
93
94 :param payload: dict
95 :type payload: The value from the backend.
96
97 :rtype: :class:`Entity`
98 :returns: The entity parsed from the API representation.
99 """
100 name = payload['name']
101 entity_type = payload['type']
102 metadata = payload['metadata']
103 salience = payload['salience']
104 mentions = [value['text']['content']
105 for value in payload['mentions']]
106 return cls(name, entity_type, metadata, salience, mentions)
107
[end of language/google/cloud/language/entity.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
googleapis/google-cloud-python
|
ebb77fb029efc65273890cb17c4aa62f99d54607
|
Language: support mention type in Entity.mentions.
[Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type.
Furthermore, this change should add mention_type information to the mention documentation.
|
Adding the release blocking tag; this is a beta blocker.
|
2017-03-16T16:21:51Z
|
<patch>
diff --git a/language/google/cloud/language/entity.py b/language/google/cloud/language/entity.py
--- a/language/google/cloud/language/entity.py
+++ b/language/google/cloud/language/entity.py
@@ -46,6 +46,80 @@ class EntityType(object):
"""Other entity type (i.e. known but not classified)."""
+class MentionType(object):
+ """List of possible mention types."""
+
+ TYPE_UNKNOWN = 'TYPE_UNKNOWN'
+ """Unknown mention type"""
+
+ PROPER = 'PROPER'
+ """Proper name"""
+
+ COMMON = 'COMMON'
+ """Common noun (or noun compound)"""
+
+
+class Mention(object):
+ """A Google Cloud Natural Language API mention.
+
+ Represents a mention for an entity in the text. Currently, proper noun
+ mentions are supported.
+ """
+ def __init__(self, text, mention_type):
+ self.text = text
+ self.mention_type = mention_type
+
+ def __str__(self):
+ return str(self.text)
+
+ @classmethod
+ def from_api_repr(cls, payload):
+ """Convert a Mention from the JSON API into an :class:`Mention`.
+
+ :param payload: dict
+ :type payload: The value from the backend.
+
+ :rtype: :class:`Mention`
+ :returns: The mention parsed from the API representation.
+ """
+ text = TextSpan.from_api_repr(payload['text'])
+ mention_type = payload['type']
+ return cls(text, mention_type)
+
+
+class TextSpan(object):
+ """A span of text from Google Cloud Natural Language API.
+
+ Represents a word or phrase of text, as well as its offset
+ from the original document.
+ """
+ def __init__(self, content, begin_offset):
+ self.content = content
+ self.begin_offset = begin_offset
+
+ def __str__(self):
+ """Return the string representation of this TextSpan.
+
+ :rtype: str
+ :returns: The text content
+ """
+ return self.content
+
+ @classmethod
+ def from_api_repr(cls, payload):
+ """Convert a TextSpan from the JSON API into an :class:`TextSpan`.
+
+ :param payload: dict
+ :type payload: The value from the backend.
+
+ :rtype: :class:`TextSpan`
+ :returns: The text span parsed from the API representation.
+ """
+ content = payload['content']
+ begin_offset = payload['beginOffset']
+ return cls(content=content, begin_offset=begin_offset)
+
+
class Entity(object):
"""A Google Cloud Natural Language API entity.
@@ -101,6 +175,5 @@ def from_api_repr(cls, payload):
entity_type = payload['type']
metadata = payload['metadata']
salience = payload['salience']
- mentions = [value['text']['content']
- for value in payload['mentions']]
+ mentions = [Mention.from_api_repr(val) for val in payload['mentions']]
return cls(name, entity_type, metadata, salience, mentions)
</patch>
|
[]
|
[]
| |||
conan-io__conan-4003
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GNU Make generator
https://github.com/solvingj/conan-make_generator/blob/master/conanfile.py by @solvingj is almost it.
I agree it could be built-in.
Can use conditional:
```
ifneq ($(USE_CONAN),)
INC_PATHS += $(CONAN_INC_PATHS)
LD_PATHS += $(CONAN_LIB_PATHS)
LD_LIBS += $(CONAN_LIBS)
CXXFLAGS += $(CONAN_CPP_FLAGS)
CFLAGS += $(CONAN_CFLAGS)
DEFINES += $(CONAN_DEFINES)
LDFLAGS_SHARED += $(CONAN_SHAREDLINKFLAGS)
LDFLAGS_EXE += $(CONAN_EXELINKFLAGS)
C_SRCS += $(CONAN_C_SRCS)
CXX_SRCS += $(CONAN_CXX_SRCS)
endif
```
</issue>
<code>
[start of README.rst]
1 Conan
2 =====
3
4 A distributed, open-source, C/C++ package manager.
5
6 +------------------------+-------------------------+
7 | **master** | **develop** |
8 +========================+=========================+
9 | |Build Status Master| | |Build Status Develop| |
10 +------------------------+-------------------------+
11
12
13 +------------------------+---------------------------+---------------------------------------------+
14 | **Coverage master** | **Coverage develop** | **Coverage graph** |
15 +========================+===========================+=============================================+
16 | |Master coverage| | |Develop coverage| | |Coverage graph| |
17 +------------------------+---------------------------+---------------------------------------------+
18
19
20 Setup
21 ======
22
23 From binaries
24 -------------
25
26 We have installers for `most platforms here <http://conan.io>`__ but you
27 can run **conan** from sources if you want.
28
29 From pip
30 --------
31
32 Conan is compatible with Python 2 and Python 3.
33
34 - Install pip following `pip docs`_.
35 - Install conan:
36
37 .. code-block:: bash
38
39 $ pip install conan
40
41 From Homebrew (OSx)
42 -------------------
43
44 - Install Homebrew following `brew homepage`_.
45
46 .. code-block:: bash
47
48 $ brew update
49 $ brew install conan
50
51 From source
52 -----------
53
54 You can run **conan** client and server in Windows, MacOS, and Linux.
55
56 - **Install pip following** `pip docs`_.
57
58 - **Clone conan repository:**
59
60 .. code-block:: bash
61
62 $ git clone https://github.com/conan-io/conan.git
63
64 - **Install in editable mode**
65
66 .. code-block:: bash
67
68 $ cd conan && sudo pip install -e .
69
70 If you are in Windows, using ``sudo`` is not required.
71
72 - **You are ready, try to run conan:**
73
74 .. code-block::
75
76 $ conan --help
77
78 Consumer commands
79 install Installs the requirements specified in a conanfile (.py or .txt).
80 config Manages configuration. Edits the conan.conf or installs config files.
81 get Gets a file or list a directory of a given reference or package.
82 info Gets information about the dependency graph of a recipe.
83 search Searches package recipes and binaries in the local cache or in a remote.
84 Creator commands
85 new Creates a new package recipe template with a 'conanfile.py'.
86 create Builds a binary package for recipe (conanfile.py) located in current dir.
87 upload Uploads a recipe and binary packages to a remote.
88 export Copies the recipe (conanfile.py & associated files) to your local cache.
89 export-pkg Exports a recipe & creates a package with given files calling 'package'.
90 test Test a package, consuming it with a conanfile recipe with a test() method.
91 Package development commands
92 source Calls your local conanfile.py 'source()' method.
93 build Calls your local conanfile.py 'build()' method.
94 package Calls your local conanfile.py 'package()' method.
95 Misc commands
96 profile Lists profiles in the '.conan/profiles' folder, or shows profile details.
97 remote Manages the remote list and the package recipes associated to a remote.
98 user Authenticates against a remote with user/pass, caching the auth token.
99 imports Calls your local conanfile.py or conanfile.txt 'imports' method.
100 copy Copies conan recipes and packages to another user/channel.
101 remove Removes packages or binaries matching pattern from local cache or remote.
102 alias Creates and exports an 'alias recipe'.
103 download Downloads recipe and binaries to the local cache, without using settings.
104
105 Conan commands. Type "conan <command> -h" for help
106
107 Running the tests
108 =================
109
110 **Install python requirements**
111
112 .. code-block:: bash
113
114 $ pip install -r conans/requirements.txt
115 $ pip install -r conans/requirements_server.txt
116 $ pip install -r conans/requirements_dev.txt
117
118
119 Only in OSX:
120
121
122 .. code-block:: bash
123
124 $ pip install -r conans/requirements_osx.txt # You can omit this one if not running OSX
125
126
127 If you are not Windows and you are not using a python virtual environment, you will need to run these
128 commands using `sudo`.
129
130 Before you can run the tests, you need to set a few environment variables first.
131
132 .. code-block:: bash
133
134 $ export PYTHONPATH=$PYTHONPATH:$(pwd)
135
136 On Windows it would be (while being in the conan root directory):
137
138 .. code-block:: bash
139
140 $ set PYTHONPATH=.
141
142 Ensure that your ``cmake`` has version 2.8 or later. You can see the
143 version with the following command:
144
145 .. code-block:: bash
146
147 $ cmake --version
148
149 The appropriate values of ``CONAN_COMPILER`` and ``CONAN_COMPILER_VERSION`` depend on your
150 operating system and your requirements.
151
152 These should work for the GCC from ``build-essential`` on Ubuntu 14.04:
153
154 .. code-block:: bash
155
156 $ export CONAN_COMPILER=gcc
157 $ export CONAN_COMPILER_VERSION=4.8
158
159 These should work for OS X:
160
161 .. code-block:: bash
162
163 $ export CONAN_COMPILER=clang
164 $ export CONAN_COMPILER_VERSION=3.5
165
166 Finally, there are some tests that use conan to package Go-lang
167 libraries, so you might **need to install go-lang** in your computer and
168 add it to the path.
169
170 You can run the actual tests like this:
171
172 .. code-block:: bash
173
174 $ nosetests .
175
176
177 There are a couple of test attributes defined, as ``slow``, or ``golang`` that you can use
178 to filter the tests, and do not execute them:
179
180 .. code-block:: bash
181
182 $ nosetests . -a !golang
183
184 A few minutes later it should print ``OK``:
185
186 .. code-block:: bash
187
188 ............................................................................................
189 ----------------------------------------------------------------------
190 Ran 146 tests in 50.993s
191
192 OK
193
194 To run specific tests, you can specify the test name too, something like:
195
196 .. code-block:: bash
197
198 $ nosetests conans.test.command.config_install_test:ConfigInstallTest.install_file_test --nocapture
199
200 The ``--nocapture`` argument can be useful to see some output that otherwise is captured by nosetests.
201
202 License
203 -------
204
205 `MIT LICENSE <./LICENSE.md>`__
206
207 .. |Build Status Master| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/master
208 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/master
209
210 .. |Build Status Develop| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/develop
211 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/develop
212
213 .. |Master coverage| image:: https://codecov.io/gh/conan-io/conan/branch/master/graph/badge.svg
214 :target: https://codecov.io/gh/conan-io/conan/branch/master
215
216 .. |Develop coverage| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graph/badge.svg
217 :target: https://codecov.io/gh/conan-io/conan/branch/develop
218
219 .. |Coverage graph| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graphs/tree.svg
220 :height: 50px
221 :width: 50 px
222 :alt: Conan develop coverage
223
224 .. _`pip docs`: https://pip.pypa.io/en/stable/installing/
225
226 .. _`brew homepage`: http://brew.sh/
227
[end of README.rst]
[start of conans/client/generators/__init__.py]
1 from os.path import join
2
3 from conans.client.generators.cmake_find_package import CMakeFindPackageGenerator
4 from conans.client.generators.compiler_args import CompilerArgsGenerator
5 from conans.client.generators.pkg_config import PkgConfigGenerator
6 from conans.errors import ConanException
7 from conans.util.files import save, normalize
8
9 from .virtualrunenv import VirtualRunEnvGenerator
10 from .text import TXTGenerator
11 from .gcc import GCCGenerator
12 from .cmake import CMakeGenerator
13 from .cmake_paths import CMakePathsGenerator
14 from .cmake_multi import CMakeMultiGenerator
15 from .qmake import QmakeGenerator
16 from .qbs import QbsGenerator
17 from .scons import SConsGenerator
18 from .visualstudio import VisualStudioGenerator
19 from .visualstudio_multi import VisualStudioMultiGenerator
20 from .visualstudiolegacy import VisualStudioLegacyGenerator
21 from .xcode import XCodeGenerator
22 from .ycm import YouCompleteMeGenerator
23 from .virtualenv import VirtualEnvGenerator
24 from .virtualbuildenv import VirtualBuildEnvGenerator
25 from .boostbuild import BoostBuildGenerator
26 from .json_generator import JsonGenerator
27 import traceback
28 from conans.util.env_reader import get_env
29 from .b2 import B2Generator
30 from .premake import PremakeGenerator
31
32
33 class _GeneratorManager(object):
34 def __init__(self):
35 self._generators = {}
36
37 def add(self, name, generator_class):
38 if name not in self._generators:
39 self._generators[name] = generator_class
40
41 @property
42 def available(self):
43 return list(self._generators.keys())
44
45 def __contains__(self, name):
46 return name in self._generators
47
48 def __getitem__(self, key):
49 return self._generators[key]
50
51
52 registered_generators = _GeneratorManager()
53
54 registered_generators.add("txt", TXTGenerator)
55 registered_generators.add("gcc", GCCGenerator)
56 registered_generators.add("compiler_args", CompilerArgsGenerator)
57 registered_generators.add("cmake", CMakeGenerator)
58 registered_generators.add("cmake_multi", CMakeMultiGenerator)
59 registered_generators.add("cmake_paths", CMakePathsGenerator)
60 registered_generators.add("cmake_find_package", CMakeFindPackageGenerator)
61 registered_generators.add("qmake", QmakeGenerator)
62 registered_generators.add("qbs", QbsGenerator)
63 registered_generators.add("scons", SConsGenerator)
64 registered_generators.add("visual_studio", VisualStudioGenerator)
65 registered_generators.add("visual_studio_multi", VisualStudioMultiGenerator)
66 registered_generators.add("visual_studio_legacy", VisualStudioLegacyGenerator)
67 registered_generators.add("xcode", XCodeGenerator)
68 registered_generators.add("ycm", YouCompleteMeGenerator)
69 registered_generators.add("virtualenv", VirtualEnvGenerator)
70 registered_generators.add("virtualbuildenv", VirtualBuildEnvGenerator)
71 registered_generators.add("virtualrunenv", VirtualRunEnvGenerator)
72 registered_generators.add("boost-build", BoostBuildGenerator)
73 registered_generators.add("pkg_config", PkgConfigGenerator)
74 registered_generators.add("json", JsonGenerator)
75 registered_generators.add("b2", B2Generator)
76 registered_generators.add("premake", PremakeGenerator)
77
78
79 def write_generators(conanfile, path, output):
80 """ produces auxiliary files, required to build a project or a package.
81 """
82 for generator_name in conanfile.generators:
83 try:
84 generator_class = registered_generators[generator_name]
85 except KeyError:
86 raise ConanException("Invalid generator '%s'. Available types: %s" %
87 (generator_name, ", ".join(registered_generators.available)))
88 try:
89 generator = generator_class(conanfile)
90 except TypeError:
91 # To allow old-style generator packages to work (e.g. premake)
92 output.warn("Generator %s failed with new __init__(), trying old one")
93 generator = generator_class(conanfile.deps_cpp_info, conanfile.cpp_info)
94
95 try:
96 generator.output_path = path
97 content = generator.content
98 if isinstance(content, dict):
99 if generator.filename:
100 output.warn("Generator %s is multifile. Property 'filename' not used"
101 % (generator_name,))
102 for k, v in content.items():
103 v = normalize(v)
104 output.info("Generator %s created %s" % (generator_name, k))
105 save(join(path, k), v, only_if_modified=True)
106 else:
107 content = normalize(content)
108 output.info("Generator %s created %s" % (generator_name, generator.filename))
109 save(join(path, generator.filename), content, only_if_modified=True)
110 except Exception as e:
111 if get_env("CONAN_VERBOSE_TRACEBACK", False):
112 output.error(traceback.format_exc())
113 output.error("Generator %s(file:%s) failed\n%s"
114 % (generator_name, generator.filename, str(e)))
115 raise ConanException(e)
116
[end of conans/client/generators/__init__.py]
[start of conans/client/generators/premake.py]
1 from conans.model import Generator
2 from conans.paths import BUILD_INFO_PREMAKE
3
4
5 class PremakeDeps(object):
6 def __init__(self, deps_cpp_info):
7 self.include_paths = ",\n".join('"%s"' % p.replace("\\", "/")
8 for p in deps_cpp_info.include_paths)
9 self.lib_paths = ",\n".join('"%s"' % p.replace("\\", "/")
10 for p in deps_cpp_info.lib_paths)
11 self.bin_paths = ",\n".join('"%s"' % p.replace("\\", "/")
12 for p in deps_cpp_info.bin_paths)
13 self.libs = ", ".join('"%s"' % p for p in deps_cpp_info.libs)
14 self.defines = ", ".join('"%s"' % p for p in deps_cpp_info.defines)
15 self.cppflags = ", ".join('"%s"' % p for p in deps_cpp_info.cppflags)
16 self.cflags = ", ".join('"%s"' % p for p in deps_cpp_info.cflags)
17 self.sharedlinkflags = ", ".join('"%s"' % p for p in deps_cpp_info.sharedlinkflags)
18 self.exelinkflags = ", ".join('"%s"' % p for p in deps_cpp_info.exelinkflags)
19
20 self.rootpath = "%s" % deps_cpp_info.rootpath.replace("\\", "/")
21
22
23 class PremakeGenerator(Generator):
24 @property
25 def filename(self):
26 return BUILD_INFO_PREMAKE
27
28 @property
29 def content(self):
30 deps = PremakeDeps(self.deps_build_info)
31
32 template = ('conan_includedirs{dep} = {{{deps.include_paths}}}\n'
33 'conan_libdirs{dep} = {{{deps.lib_paths}}}\n'
34 'conan_bindirs{dep} = {{{deps.bin_paths}}}\n'
35 'conan_libs{dep} = {{{deps.libs}}}\n'
36 'conan_cppdefines{dep} = {{{deps.defines}}}\n'
37 'conan_cppflags{dep} = {{{deps.cppflags}}}\n'
38 'conan_cflags{dep} = {{{deps.cflags}}}\n'
39 'conan_sharedlinkflags{dep} = {{{deps.sharedlinkflags}}}\n'
40 'conan_exelinkflags{dep} = {{{deps.exelinkflags}}}\n')
41
42 sections = ["#!lua"]
43 all_flags = template.format(dep="", deps=deps)
44 sections.append(all_flags)
45 template_deps = template + 'conan_rootpath{dep} = "{deps.rootpath}"\n'
46
47 for dep_name, dep_cpp_info in self.deps_build_info.dependencies:
48 deps = PremakeDeps(dep_cpp_info)
49 dep_name = dep_name.replace("-", "_")
50 dep_flags = template_deps.format(dep="_" + dep_name, deps=deps)
51 sections.append(dep_flags)
52
53 return "\n".join(sections)
54
[end of conans/client/generators/premake.py]
[start of conans/paths.py]
1 import os
2 from conans.model.ref import ConanFileReference, PackageReference
3 from os.path import join, normpath
4 import platform
5 from conans.errors import ConanException
6 from conans.util.files import rmdir
7
8
9 if platform.system() == "Windows":
10 from conans.util.windows import path_shortener, rm_conandir, conan_expand_user
11 else:
12 def path_shortener(x, _):
13 return x
14 conan_expand_user = os.path.expanduser
15 rm_conandir = rmdir
16
17
18 EXPORT_FOLDER = "export"
19 EXPORT_SRC_FOLDER = "export_source"
20 SRC_FOLDER = "source"
21 BUILD_FOLDER = "build"
22 PACKAGES_FOLDER = "package"
23 SYSTEM_REQS_FOLDER = "system_reqs"
24
25
26 CONANFILE = 'conanfile.py'
27 CONANFILE_TXT = "conanfile.txt"
28 CONAN_MANIFEST = "conanmanifest.txt"
29 BUILD_INFO = 'conanbuildinfo.txt'
30 BUILD_INFO_GCC = 'conanbuildinfo.gcc'
31 BUILD_INFO_COMPILER_ARGS = 'conanbuildinfo.args'
32 BUILD_INFO_CMAKE = 'conanbuildinfo.cmake'
33 BUILD_INFO_QMAKE = 'conanbuildinfo.pri'
34 BUILD_INFO_QBS = 'conanbuildinfo.qbs'
35 BUILD_INFO_VISUAL_STUDIO = 'conanbuildinfo.props'
36 BUILD_INFO_XCODE = 'conanbuildinfo.xcconfig'
37 BUILD_INFO_PREMAKE = 'conanbuildinfo.lua'
38 CONANINFO = "conaninfo.txt"
39 CONANENV = "conanenv.txt"
40 SYSTEM_REQS = "system_reqs.txt"
41 PUT_HEADERS = "artifacts.properties"
42 SCM_FOLDER = "scm_folder.txt"
43 PACKAGE_METADATA = "metadata.json"
44
45 PACKAGE_TGZ_NAME = "conan_package.tgz"
46 EXPORT_TGZ_NAME = "conan_export.tgz"
47 EXPORT_SOURCES_TGZ_NAME = "conan_sources.tgz"
48 EXPORT_SOURCES_DIR_OLD = ".c_src"
49
50 RUN_LOG_NAME = "conan_run.log"
51 DEFAULT_PROFILE_NAME = "default"
52
53
54 def get_conan_user_home():
55 user_home = os.getenv("CONAN_USER_HOME", "~")
56 tmp = conan_expand_user(user_home)
57 if not os.path.isabs(tmp):
58 raise Exception("Invalid CONAN_USER_HOME value '%s', "
59 "please specify an absolute or path starting with ~/ "
60 "(relative to user home)" % tmp)
61 return os.path.abspath(tmp)
62
63
64 def is_case_insensitive_os():
65 system = platform.system()
66 return system != "Linux" and system != "FreeBSD" and system != "SunOS"
67
68
69 if is_case_insensitive_os():
70 def check_ref_case(conan_reference, conan_folder, store_folder):
71 if not os.path.exists(conan_folder): # If it doesn't exist, not a problem
72 return
73 # If exists, lets check path
74 tmp = store_folder
75 for part in conan_reference.dir_repr().split("/"):
76 items = os.listdir(tmp)
77 if part not in items:
78 offending = ""
79 for item in items:
80 if item.lower() == part.lower():
81 offending = item
82 break
83 raise ConanException("Requested '%s' but found case incompatible '%s'\n"
84 "Case insensitive filesystem can't manage this"
85 % (str(conan_reference), offending))
86 tmp = os.path.normpath(tmp + os.sep + part)
87 else:
88 def check_ref_case(conan_reference, conan_folder, store_folder): # @UnusedVariable
89 pass
90
91
92 class SimplePaths(object):
93 """
94 Generate Conan paths. Handles the conan domain path logic. NO DISK ACCESS, just
95 path logic responsability
96 """
97 def __init__(self, store_folder):
98 self._store_folder = store_folder
99
100 @property
101 def store(self):
102 return self._store_folder
103
104 def conan(self, conan_reference):
105 """ the base folder for this package reference, for each ConanFileReference
106 """
107 assert isinstance(conan_reference, ConanFileReference)
108 return normpath(join(self._store_folder, conan_reference.dir_repr()))
109
110 def export(self, conan_reference):
111 assert isinstance(conan_reference, ConanFileReference)
112 return normpath(join(self.conan(conan_reference), EXPORT_FOLDER))
113
114 def export_sources(self, conan_reference, short_paths=False):
115 assert isinstance(conan_reference, ConanFileReference)
116 p = normpath(join(self.conan(conan_reference), EXPORT_SRC_FOLDER))
117 return path_shortener(p, short_paths)
118
119 def source(self, conan_reference, short_paths=False):
120 assert isinstance(conan_reference, ConanFileReference)
121 p = normpath(join(self.conan(conan_reference), SRC_FOLDER))
122 return path_shortener(p, short_paths)
123
124 def conanfile(self, conan_reference):
125 export = self.export(conan_reference)
126 check_ref_case(conan_reference, export, self.store)
127 return normpath(join(export, CONANFILE))
128
129 def builds(self, conan_reference):
130 assert isinstance(conan_reference, ConanFileReference)
131 return normpath(join(self.conan(conan_reference), BUILD_FOLDER))
132
133 def build(self, package_reference, short_paths=False):
134 assert isinstance(package_reference, PackageReference)
135 p = normpath(join(self.conan(package_reference.conan), BUILD_FOLDER,
136 package_reference.package_id))
137 return path_shortener(p, short_paths)
138
139 def system_reqs(self, conan_reference):
140 assert isinstance(conan_reference, ConanFileReference)
141 return normpath(join(self.conan(conan_reference), SYSTEM_REQS_FOLDER, SYSTEM_REQS))
142
143 def system_reqs_package(self, package_reference):
144 assert isinstance(package_reference, PackageReference)
145 return normpath(join(self.conan(package_reference.conan), SYSTEM_REQS_FOLDER,
146 package_reference.package_id, SYSTEM_REQS))
147
148 def packages(self, conan_reference):
149 assert isinstance(conan_reference, ConanFileReference)
150 return normpath(join(self.conan(conan_reference), PACKAGES_FOLDER))
151
152 def package(self, package_reference, short_paths=False):
153 assert isinstance(package_reference, PackageReference)
154 p = normpath(join(self.conan(package_reference.conan), PACKAGES_FOLDER,
155 package_reference.package_id))
156 return path_shortener(p, short_paths)
157
158 def scm_folder(self, conan_reference):
159 return normpath(join(self.conan(conan_reference), SCM_FOLDER))
160
161 def package_metadata(self, conan_reference):
162 return normpath(join(self.conan(conan_reference), PACKAGE_METADATA))
163
[end of conans/paths.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
conan-io/conan
|
4486c5d6ca77e979ac0a991b964a86cdf26e95d2
|
GNU Make generator
https://github.com/solvingj/conan-make_generator/blob/master/conanfile.py by @solvingj is almost it.
I agree it could be built-in.
Can use conditional:
```
ifneq ($(USE_CONAN),)
INC_PATHS += $(CONAN_INC_PATHS)
LD_PATHS += $(CONAN_LIB_PATHS)
LD_LIBS += $(CONAN_LIBS)
CXXFLAGS += $(CONAN_CPP_FLAGS)
CFLAGS += $(CONAN_CFLAGS)
DEFINES += $(CONAN_DEFINES)
LDFLAGS_SHARED += $(CONAN_SHAREDLINKFLAGS)
LDFLAGS_EXE += $(CONAN_EXELINKFLAGS)
C_SRCS += $(CONAN_C_SRCS)
CXX_SRCS += $(CONAN_CXX_SRCS)
endif
```
|
Labeled as high because the invest should be minimal.
|
2018-11-26T17:02:07Z
|
<patch>
diff --git a/conans/client/generators/__init__.py b/conans/client/generators/__init__.py
--- a/conans/client/generators/__init__.py
+++ b/conans/client/generators/__init__.py
@@ -28,6 +28,7 @@
from conans.util.env_reader import get_env
from .b2 import B2Generator
from .premake import PremakeGenerator
+from .make import MakeGenerator
class _GeneratorManager(object):
@@ -74,6 +75,7 @@ def __getitem__(self, key):
registered_generators.add("json", JsonGenerator)
registered_generators.add("b2", B2Generator)
registered_generators.add("premake", PremakeGenerator)
+registered_generators.add("make", MakeGenerator)
def write_generators(conanfile, path, output):
diff --git a/conans/client/generators/make.py b/conans/client/generators/make.py
new file mode 100644
--- /dev/null
+++ b/conans/client/generators/make.py
@@ -0,0 +1,109 @@
+from conans.model import Generator
+from conans.paths import BUILD_INFO_MAKE
+
+
+class MakeGenerator(Generator):
+
+ def __init__(self, conanfile):
+ Generator.__init__(self, conanfile)
+ self.makefile_newline = "\n"
+ self.makefile_line_continuation = " \\\n"
+ self.assignment_if_absent = " ?= "
+ self.assignment_append = " += "
+
+ @property
+ def filename(self):
+ return BUILD_INFO_MAKE
+
+ @property
+ def content(self):
+
+ content = [
+ "#-------------------------------------------------------------------#",
+ "# Makefile variables from Conan Dependencies #",
+ "#-------------------------------------------------------------------#",
+ "",
+ ]
+
+ for line_as_list in self.create_deps_content():
+ content.append("".join(line_as_list))
+
+ content.append("#-------------------------------------------------------------------#")
+ content.append(self.makefile_newline)
+ return self.makefile_newline.join(content)
+
+ def create_deps_content(self):
+ deps_content = self.create_content_from_deps()
+ deps_content.extend(self.create_combined_content())
+ return deps_content
+
+ def create_content_from_deps(self):
+ content = []
+ for pkg_name, cpp_info in self.deps_build_info.dependencies:
+ content.extend(self.create_content_from_dep(pkg_name, cpp_info))
+ return content
+
+ def create_content_from_dep(self, pkg_name, cpp_info):
+
+ vars_info = [("ROOT", self.assignment_if_absent, [cpp_info.rootpath]),
+ ("SYSROOT", self.assignment_if_absent, [cpp_info.sysroot]),
+ ("INCLUDE_PATHS", self.assignment_append, cpp_info.include_paths),
+ ("LIB_PATHS", self.assignment_append, cpp_info.lib_paths),
+ ("BIN_PATHS", self.assignment_append, cpp_info.bin_paths),
+ ("BUILD_PATHS", self.assignment_append, cpp_info.build_paths),
+ ("RES_PATHS", self.assignment_append, cpp_info.res_paths),
+ ("LIBS", self.assignment_append, cpp_info.libs),
+ ("DEFINES", self.assignment_append, cpp_info.defines),
+ ("CFLAGS", self.assignment_append, cpp_info.cflags),
+ ("CPPFLAGS", self.assignment_append, cpp_info.cppflags),
+ ("SHAREDLINKFLAGS", self.assignment_append, cpp_info.sharedlinkflags),
+ ("EXELINKFLAGS", self.assignment_append, cpp_info.exelinkflags)]
+
+ return [self.create_makefile_var_pkg(var_name, pkg_name, operator, info)
+ for var_name, operator, info in vars_info]
+
+ def create_combined_content(self):
+ content = []
+ for var_name in self.all_dep_vars():
+ content.append(self.create_makefile_var_global(var_name, self.assignment_append,
+ self.create_combined_var_list(var_name)))
+ return content
+
+ def create_combined_var_list(self, var_name):
+ make_vars = []
+ for pkg_name, _ in self.deps_build_info.dependencies:
+ pkg_var = self.create_makefile_var_name_pkg(var_name, pkg_name)
+ make_vars.append("$({pkg_var})".format(pkg_var=pkg_var))
+ return make_vars
+
+ def create_makefile_var_global(self, var_name, operator, values):
+ make_var = [self.create_makefile_var_name_global(var_name)]
+ make_var.extend(self.create_makefile_var_common(operator, values))
+ return make_var
+
+ def create_makefile_var_pkg(self, var_name, pkg_name, operator, values):
+ make_var = [self.create_makefile_var_name_pkg(var_name, pkg_name)]
+ make_var.extend(self.create_makefile_var_common(operator, values))
+ return make_var
+
+ def create_makefile_var_common(self, operator, values):
+ return [operator, self.makefile_line_continuation, self.create_makefile_var_value(values),
+ self.makefile_newline]
+
+ @staticmethod
+ def create_makefile_var_name_global(var_name):
+ return "CONAN_{var}".format(var=var_name).upper()
+
+ @staticmethod
+ def create_makefile_var_name_pkg(var_name, pkg_name):
+ return "CONAN_{var}_{lib}".format(var=var_name, lib=pkg_name).upper()
+
+ def create_makefile_var_value(self, values):
+ formatted_values = [value.replace("\\", "/") for value in values]
+ return self.makefile_line_continuation.join(formatted_values)
+
+ @staticmethod
+ def all_dep_vars():
+ return ["rootpath", "sysroot", "include_paths", "lib_paths", "bin_paths", "build_paths",
+ "res_paths", "libs", "defines", "cflags", "cppflags", "sharedlinkflags",
+ "exelinkflags"]
diff --git a/conans/client/generators/premake.py b/conans/client/generators/premake.py
--- a/conans/client/generators/premake.py
+++ b/conans/client/generators/premake.py
@@ -3,6 +3,7 @@
class PremakeDeps(object):
+
def __init__(self, deps_cpp_info):
self.include_paths = ",\n".join('"%s"' % p.replace("\\", "/")
for p in deps_cpp_info.include_paths)
diff --git a/conans/paths.py b/conans/paths.py
--- a/conans/paths.py
+++ b/conans/paths.py
@@ -35,6 +35,7 @@ def path_shortener(x, _):
BUILD_INFO_VISUAL_STUDIO = 'conanbuildinfo.props'
BUILD_INFO_XCODE = 'conanbuildinfo.xcconfig'
BUILD_INFO_PREMAKE = 'conanbuildinfo.lua'
+BUILD_INFO_MAKE = 'conanbuildinfo.mak'
CONANINFO = "conaninfo.txt"
CONANENV = "conanenv.txt"
SYSTEM_REQS = "system_reqs.txt"
</patch>
|
[]
|
[]
| |||
pypa__pip-7289
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip 19.3 doesn't send client certificate
**Ubuntu 18.04 virtual environment**
* pip version: 19.3
* Python version: 3.6.8
* OS: Ubuntu 18.04.3 LTS
We have a private Pypi server hosted with [pypicloud](https://pypicloud.readthedocs.io/en/latest/index.html). We use client certificates to authenticate users for downloading/uploading packages.
**Description**
pip 19.3 doesn't seem to send our client certificates so authentication fails and packages cannot be installed:
`WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<our package name>/
`
I captured some of the SSL traffic from pip install in Wireshark and the client certificate option is there in the SSL handshake, but the certificates length is 0 with pip 19.3:
In 19.2.1, the length is non-zero and Wireshark shows the client certificate I expect.
**Expected behavior**
We should not get an SSL error if our client certificates and CA certificates are not expired. I have checked our server logs there don't appear to be any errors there with our certificates.
If I downgrade to pip 19.2.1 or 19.2.3 in my virtual environment, then the SSL error goes away.
I also checked with the `openssl s_client` that a handshake succeeded with the same client certificate:
```
openssl s_client -connect <my server> -cert <cert> -key <key> -state
CONNECTED(00000005)
SSL_connect:before SSL initialization
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS read server hello
depth=2 O = Digital Signature Trust Co., CN = DST Root CA X3
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3
verify return:1
depth=0 CN = <my server>
verify return:1
SSL_connect:SSLv3/TLS read server certificate
SSL_connect:SSLv3/TLS read server key exchange
SSL_connect:SSLv3/TLS read server certificate request
SSL_connect:SSLv3/TLS read server done
SSL_connect:SSLv3/TLS write client certificate
...
SSL handshake has read 4268 bytes and written 1546 bytes
Verification: OK
---
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES256-GCM-SHA384
Session-ID:
```
**How to Reproduce**
1. Setup pip.conf or command-line arguments to use client certificate
2. pip install <package>
3. sslv3 alert handshake failure occurs
**Output**
```
pip install <my package>
Looking in indexes: https://pypi.org/simple/, https://<my server>/simple/
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
```
</issue>
<code>
[start of README.rst]
1 pip - The Python Package Installer
2 ==================================
3
4 .. image:: https://img.shields.io/pypi/v/pip.svg
5 :target: https://pypi.org/project/pip/
6
7 .. image:: https://readthedocs.org/projects/pip/badge/?version=latest
8 :target: https://pip.pypa.io/en/latest
9
10 pip is the `package installer`_ for Python. You can use pip to install packages from the `Python Package Index`_ and other indexes.
11
12 Please take a look at our documentation for how to install and use pip:
13
14 * `Installation`_
15 * `Usage`_
16
17 Updates are released regularly, with a new version every 3 months. More details can be found in our documentation:
18
19 * `Release notes`_
20 * `Release process`_
21
22 If you find bugs, need help, or want to talk to the developers please use our mailing lists or chat rooms:
23
24 * `Issue tracking`_
25 * `Discourse channel`_
26 * `User IRC`_
27
28 If you want to get involved head over to GitHub to get the source code, look at our development documentation and feel free to jump on the developer mailing lists and chat rooms:
29
30 * `GitHub page`_
31 * `Dev documentation`_
32 * `Dev mailing list`_
33 * `Dev IRC`_
34
35 Code of Conduct
36 ---------------
37
38 Everyone interacting in the pip project's codebases, issue trackers, chat
39 rooms, and mailing lists is expected to follow the `PyPA Code of Conduct`_.
40
41 .. _package installer: https://packaging.python.org/en/latest/current/
42 .. _Python Package Index: https://pypi.org
43 .. _Installation: https://pip.pypa.io/en/stable/installing.html
44 .. _Usage: https://pip.pypa.io/en/stable/
45 .. _Release notes: https://pip.pypa.io/en/stable/news.html
46 .. _Release process: https://pip.pypa.io/en/latest/development/release-process/
47 .. _GitHub page: https://github.com/pypa/pip
48 .. _Dev documentation: https://pip.pypa.io/en/latest/development
49 .. _Issue tracking: https://github.com/pypa/pip/issues
50 .. _Discourse channel: https://discuss.python.org/c/packaging
51 .. _Dev mailing list: https://groups.google.com/forum/#!forum/pypa-dev
52 .. _User IRC: https://webchat.freenode.net/?channels=%23pypa
53 .. _Dev IRC: https://webchat.freenode.net/?channels=%23pypa-dev
54 .. _PyPA Code of Conduct: https://www.pypa.io/en/latest/code-of-conduct/
55
[end of README.rst]
[start of src/pip/_internal/network/session.py]
1 """PipSession and supporting code, containing all pip-specific
2 network request configuration and behavior.
3 """
4
5 # The following comment should be removed at some point in the future.
6 # mypy: disallow-untyped-defs=False
7
8 import email.utils
9 import json
10 import logging
11 import mimetypes
12 import os
13 import platform
14 import sys
15 import warnings
16
17 from pip._vendor import requests, six, urllib3
18 from pip._vendor.cachecontrol import CacheControlAdapter
19 from pip._vendor.requests.adapters import BaseAdapter, HTTPAdapter
20 from pip._vendor.requests.models import Response
21 from pip._vendor.requests.structures import CaseInsensitiveDict
22 from pip._vendor.six.moves.urllib import parse as urllib_parse
23 from pip._vendor.urllib3.exceptions import InsecureRequestWarning
24
25 from pip import __version__
26 from pip._internal.network.auth import MultiDomainBasicAuth
27 from pip._internal.network.cache import SafeFileCache
28 # Import ssl from compat so the initial import occurs in only one place.
29 from pip._internal.utils.compat import HAS_TLS, ipaddress, ssl
30 from pip._internal.utils.filesystem import check_path_owner
31 from pip._internal.utils.glibc import libc_ver
32 from pip._internal.utils.misc import (
33 build_url_from_netloc,
34 get_installed_version,
35 parse_netloc,
36 )
37 from pip._internal.utils.typing import MYPY_CHECK_RUNNING
38 from pip._internal.utils.urls import url_to_path
39
40 if MYPY_CHECK_RUNNING:
41 from typing import (
42 Iterator, List, Optional, Tuple, Union,
43 )
44
45 from pip._internal.models.link import Link
46
47 SecureOrigin = Tuple[str, str, Optional[Union[int, str]]]
48
49
50 logger = logging.getLogger(__name__)
51
52
53 # Ignore warning raised when using --trusted-host.
54 warnings.filterwarnings("ignore", category=InsecureRequestWarning)
55
56
57 SECURE_ORIGINS = [
58 # protocol, hostname, port
59 # Taken from Chrome's list of secure origins (See: http://bit.ly/1qrySKC)
60 ("https", "*", "*"),
61 ("*", "localhost", "*"),
62 ("*", "127.0.0.0/8", "*"),
63 ("*", "::1/128", "*"),
64 ("file", "*", None),
65 # ssh is always secure.
66 ("ssh", "*", "*"),
67 ] # type: List[SecureOrigin]
68
69
70 # These are environment variables present when running under various
71 # CI systems. For each variable, some CI systems that use the variable
72 # are indicated. The collection was chosen so that for each of a number
73 # of popular systems, at least one of the environment variables is used.
74 # This list is used to provide some indication of and lower bound for
75 # CI traffic to PyPI. Thus, it is okay if the list is not comprehensive.
76 # For more background, see: https://github.com/pypa/pip/issues/5499
77 CI_ENVIRONMENT_VARIABLES = (
78 # Azure Pipelines
79 'BUILD_BUILDID',
80 # Jenkins
81 'BUILD_ID',
82 # AppVeyor, CircleCI, Codeship, Gitlab CI, Shippable, Travis CI
83 'CI',
84 # Explicit environment variable.
85 'PIP_IS_CI',
86 )
87
88
89 def looks_like_ci():
90 # type: () -> bool
91 """
92 Return whether it looks like pip is running under CI.
93 """
94 # We don't use the method of checking for a tty (e.g. using isatty())
95 # because some CI systems mimic a tty (e.g. Travis CI). Thus that
96 # method doesn't provide definitive information in either direction.
97 return any(name in os.environ for name in CI_ENVIRONMENT_VARIABLES)
98
99
100 def user_agent():
101 """
102 Return a string representing the user agent.
103 """
104 data = {
105 "installer": {"name": "pip", "version": __version__},
106 "python": platform.python_version(),
107 "implementation": {
108 "name": platform.python_implementation(),
109 },
110 }
111
112 if data["implementation"]["name"] == 'CPython':
113 data["implementation"]["version"] = platform.python_version()
114 elif data["implementation"]["name"] == 'PyPy':
115 if sys.pypy_version_info.releaselevel == 'final':
116 pypy_version_info = sys.pypy_version_info[:3]
117 else:
118 pypy_version_info = sys.pypy_version_info
119 data["implementation"]["version"] = ".".join(
120 [str(x) for x in pypy_version_info]
121 )
122 elif data["implementation"]["name"] == 'Jython':
123 # Complete Guess
124 data["implementation"]["version"] = platform.python_version()
125 elif data["implementation"]["name"] == 'IronPython':
126 # Complete Guess
127 data["implementation"]["version"] = platform.python_version()
128
129 if sys.platform.startswith("linux"):
130 from pip._vendor import distro
131 distro_infos = dict(filter(
132 lambda x: x[1],
133 zip(["name", "version", "id"], distro.linux_distribution()),
134 ))
135 libc = dict(filter(
136 lambda x: x[1],
137 zip(["lib", "version"], libc_ver()),
138 ))
139 if libc:
140 distro_infos["libc"] = libc
141 if distro_infos:
142 data["distro"] = distro_infos
143
144 if sys.platform.startswith("darwin") and platform.mac_ver()[0]:
145 data["distro"] = {"name": "macOS", "version": platform.mac_ver()[0]}
146
147 if platform.system():
148 data.setdefault("system", {})["name"] = platform.system()
149
150 if platform.release():
151 data.setdefault("system", {})["release"] = platform.release()
152
153 if platform.machine():
154 data["cpu"] = platform.machine()
155
156 if HAS_TLS:
157 data["openssl_version"] = ssl.OPENSSL_VERSION
158
159 setuptools_version = get_installed_version("setuptools")
160 if setuptools_version is not None:
161 data["setuptools_version"] = setuptools_version
162
163 # Use None rather than False so as not to give the impression that
164 # pip knows it is not being run under CI. Rather, it is a null or
165 # inconclusive result. Also, we include some value rather than no
166 # value to make it easier to know that the check has been run.
167 data["ci"] = True if looks_like_ci() else None
168
169 user_data = os.environ.get("PIP_USER_AGENT_USER_DATA")
170 if user_data is not None:
171 data["user_data"] = user_data
172
173 return "{data[installer][name]}/{data[installer][version]} {json}".format(
174 data=data,
175 json=json.dumps(data, separators=(",", ":"), sort_keys=True),
176 )
177
178
179 class LocalFSAdapter(BaseAdapter):
180
181 def send(self, request, stream=None, timeout=None, verify=None, cert=None,
182 proxies=None):
183 pathname = url_to_path(request.url)
184
185 resp = Response()
186 resp.status_code = 200
187 resp.url = request.url
188
189 try:
190 stats = os.stat(pathname)
191 except OSError as exc:
192 resp.status_code = 404
193 resp.raw = exc
194 else:
195 modified = email.utils.formatdate(stats.st_mtime, usegmt=True)
196 content_type = mimetypes.guess_type(pathname)[0] or "text/plain"
197 resp.headers = CaseInsensitiveDict({
198 "Content-Type": content_type,
199 "Content-Length": stats.st_size,
200 "Last-Modified": modified,
201 })
202
203 resp.raw = open(pathname, "rb")
204 resp.close = resp.raw.close
205
206 return resp
207
208 def close(self):
209 pass
210
211
212 class InsecureHTTPAdapter(HTTPAdapter):
213
214 def cert_verify(self, conn, url, verify, cert):
215 conn.cert_reqs = 'CERT_NONE'
216 conn.ca_certs = None
217
218
219 class PipSession(requests.Session):
220
221 timeout = None # type: Optional[int]
222
223 def __init__(self, *args, **kwargs):
224 """
225 :param trusted_hosts: Domains not to emit warnings for when not using
226 HTTPS.
227 """
228 retries = kwargs.pop("retries", 0)
229 cache = kwargs.pop("cache", None)
230 trusted_hosts = kwargs.pop("trusted_hosts", []) # type: List[str]
231 index_urls = kwargs.pop("index_urls", None)
232
233 super(PipSession, self).__init__(*args, **kwargs)
234
235 # Namespace the attribute with "pip_" just in case to prevent
236 # possible conflicts with the base class.
237 self.pip_trusted_origins = [] # type: List[Tuple[str, Optional[int]]]
238
239 # Attach our User Agent to the request
240 self.headers["User-Agent"] = user_agent()
241
242 # Attach our Authentication handler to the session
243 self.auth = MultiDomainBasicAuth(index_urls=index_urls)
244
245 # Create our urllib3.Retry instance which will allow us to customize
246 # how we handle retries.
247 retries = urllib3.Retry(
248 # Set the total number of retries that a particular request can
249 # have.
250 total=retries,
251
252 # A 503 error from PyPI typically means that the Fastly -> Origin
253 # connection got interrupted in some way. A 503 error in general
254 # is typically considered a transient error so we'll go ahead and
255 # retry it.
256 # A 500 may indicate transient error in Amazon S3
257 # A 520 or 527 - may indicate transient error in CloudFlare
258 status_forcelist=[500, 503, 520, 527],
259
260 # Add a small amount of back off between failed requests in
261 # order to prevent hammering the service.
262 backoff_factor=0.25,
263 )
264
265 # Check to ensure that the directory containing our cache directory
266 # is owned by the user current executing pip. If it does not exist
267 # we will check the parent directory until we find one that does exist.
268 if cache and not check_path_owner(cache):
269 logger.warning(
270 "The directory '%s' or its parent directory is not owned by "
271 "the current user and the cache has been disabled. Please "
272 "check the permissions and owner of that directory. If "
273 "executing pip with sudo, you may want sudo's -H flag.",
274 cache,
275 )
276 cache = None
277
278 # We want to _only_ cache responses on securely fetched origins. We do
279 # this because we can't validate the response of an insecurely fetched
280 # origin, and we don't want someone to be able to poison the cache and
281 # require manual eviction from the cache to fix it.
282 if cache:
283 secure_adapter = CacheControlAdapter(
284 cache=SafeFileCache(cache),
285 max_retries=retries,
286 )
287 else:
288 secure_adapter = HTTPAdapter(max_retries=retries)
289
290 # Our Insecure HTTPAdapter disables HTTPS validation. It does not
291 # support caching (see above) so we'll use it for all http:// URLs as
292 # well as any https:// host that we've marked as ignoring TLS errors
293 # for.
294 insecure_adapter = InsecureHTTPAdapter(max_retries=retries)
295 # Save this for later use in add_insecure_host().
296 self._insecure_adapter = insecure_adapter
297
298 self.mount("https://", secure_adapter)
299 self.mount("http://", insecure_adapter)
300
301 # Enable file:// urls
302 self.mount("file://", LocalFSAdapter())
303
304 for host in trusted_hosts:
305 self.add_trusted_host(host, suppress_logging=True)
306
307 def add_trusted_host(self, host, source=None, suppress_logging=False):
308 # type: (str, Optional[str], bool) -> None
309 """
310 :param host: It is okay to provide a host that has previously been
311 added.
312 :param source: An optional source string, for logging where the host
313 string came from.
314 """
315 if not suppress_logging:
316 msg = 'adding trusted host: {!r}'.format(host)
317 if source is not None:
318 msg += ' (from {})'.format(source)
319 logger.info(msg)
320
321 host_port = parse_netloc(host)
322 if host_port not in self.pip_trusted_origins:
323 self.pip_trusted_origins.append(host_port)
324
325 self.mount(build_url_from_netloc(host) + '/', self._insecure_adapter)
326 if not host_port[1]:
327 # Mount wildcard ports for the same host.
328 self.mount(
329 build_url_from_netloc(host) + ':',
330 self._insecure_adapter
331 )
332
333 def iter_secure_origins(self):
334 # type: () -> Iterator[SecureOrigin]
335 for secure_origin in SECURE_ORIGINS:
336 yield secure_origin
337 for host, port in self.pip_trusted_origins:
338 yield ('*', host, '*' if port is None else port)
339
340 def is_secure_origin(self, location):
341 # type: (Link) -> bool
342 # Determine if this url used a secure transport mechanism
343 parsed = urllib_parse.urlparse(str(location))
344 origin_protocol, origin_host, origin_port = (
345 parsed.scheme, parsed.hostname, parsed.port,
346 )
347
348 # The protocol to use to see if the protocol matches.
349 # Don't count the repository type as part of the protocol: in
350 # cases such as "git+ssh", only use "ssh". (I.e., Only verify against
351 # the last scheme.)
352 origin_protocol = origin_protocol.rsplit('+', 1)[-1]
353
354 # Determine if our origin is a secure origin by looking through our
355 # hardcoded list of secure origins, as well as any additional ones
356 # configured on this PackageFinder instance.
357 for secure_origin in self.iter_secure_origins():
358 secure_protocol, secure_host, secure_port = secure_origin
359 if origin_protocol != secure_protocol and secure_protocol != "*":
360 continue
361
362 try:
363 # We need to do this decode dance to ensure that we have a
364 # unicode object, even on Python 2.x.
365 addr = ipaddress.ip_address(
366 origin_host
367 if (
368 isinstance(origin_host, six.text_type) or
369 origin_host is None
370 )
371 else origin_host.decode("utf8")
372 )
373 network = ipaddress.ip_network(
374 secure_host
375 if isinstance(secure_host, six.text_type)
376 # setting secure_host to proper Union[bytes, str]
377 # creates problems in other places
378 else secure_host.decode("utf8") # type: ignore
379 )
380 except ValueError:
381 # We don't have both a valid address or a valid network, so
382 # we'll check this origin against hostnames.
383 if (
384 origin_host and
385 origin_host.lower() != secure_host.lower() and
386 secure_host != "*"
387 ):
388 continue
389 else:
390 # We have a valid address and network, so see if the address
391 # is contained within the network.
392 if addr not in network:
393 continue
394
395 # Check to see if the port matches.
396 if (
397 origin_port != secure_port and
398 secure_port != "*" and
399 secure_port is not None
400 ):
401 continue
402
403 # If we've gotten here, then this origin matches the current
404 # secure origin and we should return True
405 return True
406
407 # If we've gotten to this point, then the origin isn't secure and we
408 # will not accept it as a valid location to search. We will however
409 # log a warning that we are ignoring it.
410 logger.warning(
411 "The repository located at %s is not a trusted or secure host and "
412 "is being ignored. If this repository is available via HTTPS we "
413 "recommend you use HTTPS instead, otherwise you may silence "
414 "this warning and allow it anyway with '--trusted-host %s'.",
415 origin_host,
416 origin_host,
417 )
418
419 return False
420
421 def request(self, method, url, *args, **kwargs):
422 # Allow setting a default timeout on a session
423 kwargs.setdefault("timeout", self.timeout)
424
425 # Dispatch the actual request
426 return super(PipSession, self).request(method, url, *args, **kwargs)
427
[end of src/pip/_internal/network/session.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
pypa/pip
|
44c8caccd4a39d6230666bca637157dfc78b95ea
|
pip 19.3 doesn't send client certificate
**Ubuntu 18.04 virtual environment**
* pip version: 19.3
* Python version: 3.6.8
* OS: Ubuntu 18.04.3 LTS
We have a private Pypi server hosted with [pypicloud](https://pypicloud.readthedocs.io/en/latest/index.html). We use client certificates to authenticate users for downloading/uploading packages.
**Description**
pip 19.3 doesn't seem to send our client certificates so authentication fails and packages cannot be installed:
`WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<our package name>/
`
I captured some of the SSL traffic from pip install in Wireshark and the client certificate option is there in the SSL handshake, but the certificates length is 0 with pip 19.3:

In 19.2.1, the length is non-zero and Wireshark shows the client certificate I expect.
**Expected behavior**
We should not get an SSL error if our client certificates and CA certificates are not expired. I have checked our server logs there don't appear to be any errors there with our certificates.
If I downgrade to pip 19.2.1 or 19.2.3 in my virtual environment, then the SSL error goes away.
I also checked with the `openssl s_client` that a handshake succeeded with the same client certificate:
```
openssl s_client -connect <my server> -cert <cert> -key <key> -state
CONNECTED(00000005)
SSL_connect:before SSL initialization
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS read server hello
depth=2 O = Digital Signature Trust Co., CN = DST Root CA X3
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3
verify return:1
depth=0 CN = <my server>
verify return:1
SSL_connect:SSLv3/TLS read server certificate
SSL_connect:SSLv3/TLS read server key exchange
SSL_connect:SSLv3/TLS read server certificate request
SSL_connect:SSLv3/TLS read server done
SSL_connect:SSLv3/TLS write client certificate
...
SSL handshake has read 4268 bytes and written 1546 bytes
Verification: OK
---
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES256-GCM-SHA384
Session-ID:
```
**How to Reproduce**
1. Setup pip.conf or command-line arguments to use client certificate
2. pip install <package>
3. sslv3 alert handshake failure occurs
**Output**
```
pip install <my package>
Looking in indexes: https://pypi.org/simple/, https://<my server>/simple/
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
```
|
I cannot reproduce this (Ubuntu 18.04.2, Python 3.6.7) with
<details>
<summary><strong>repro.sh</strong></summary>
```
#!/bin/sh
trap "exit" INT TERM
trap "kill 0" EXIT
set -e
cd "$(mktemp -d)"
openssl req -new -x509 -nodes \
-out cert.pem -keyout cert.pem \
-addext 'subjectAltName = IP:127.0.0.1' \
-subj '/CN=127.0.0.1'
cat <<EOF > server.py
import socket
import ssl
import sys
from pathlib import Path
cert = sys.argv[1]
context = ssl.SSLContext(ssl.PROTOCOL_TLS_SERVER)
context.load_cert_chain(cert, cert)
context.load_verify_locations(cafile=cert)
context.verify_mode = ssl.CERT_REQUIRED
with socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) as sock:
sock.bind(('127.0.0.1', 0))
sock.listen(1)
_, port = sock.getsockname()
Path('port.txt').write_text(str(port), encoding='utf-8')
with context.wrap_socket(sock, server_side=True) as ssock:
while True:
conn, addr = ssock.accept()
cert = conn.getpeercert()
print(cert)
conn.write(b'HTTP/1.1 400 Bad Request\r\n\r\n')
conn.close()
EOF
PYTHON="${PYTHON:-python}"
"$PYTHON" -V
"$PYTHON" -m venv venv
venv/bin/python server.py cert.pem &
sleep 1
venv/bin/python -m pip install --upgrade pip==19.2.3
echo "- Old pip ------------------------------"
venv/bin/python -m pip -V
venv/bin/python -m pip install \
--ignore-installed \
--disable-pip-version-check \
--index-url https://127.0.0.1:$(cat port.txt) \
--cert cert.pem \
--client-cert cert.pem \
pip || true
venv/bin/python -m pip install --upgrade pip
echo "- New pip ------------------------------"
venv/bin/python -m pip -V
pip install \
--ignore-installed \
--disable-pip-version-check \
--index-url https://127.0.0.1:$(cat port.txt) \
--cert cert.pem \
--client-cert cert.pem \
pip
```
</details>
My output is
<details>
<summary><strong>Output</strong></summary>
```
$ PYTHON=~/.pyenv/versions/3.6.7/bin/python ./repro.sh
Generating a RSA private key
................................................................+++++
.......+++++
writing new private key to 'cert.pem'
-----
Python 3.6.7
Collecting pip==19.2.3
Using cached https://files.pythonhosted.org/packages/30/db/9e38760b32e3e7f40cce46dd5fb107b8c73840df38f0046d8e6514e675a1/pip-19.2.3-py2.py3-none-any.whl
Installing collected packages: pip
Found existing installation: pip 10.0.1
Uninstalling pip-10.0.1:
Successfully uninstalled pip-10.0.1
Successfully installed pip-19.2.3
You are using pip version 19.2.3, however version 19.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
- Old pip ------------------------------
pip 19.2.3 from /tmp/user/1000/tmp.ZqHiG62cpt/venv/lib/python3.6/site-packages/pip (python 3.6)
Looking in indexes: https://127.0.0.1:55649
Collecting pip
{'subject': ((('commonName', '127.0.0.1'),),), 'issuer': ((('commonName', '127.0.0.1'),),), 'version': 3, 'serialNumber': '5D7B2701E9D3E0E8A9E6CA66AEC3849D3BE826CD', 'notBefore': 'Oct 15 01:55:59 2019 GMT', 'notAfter': 'Nov 14 01:55:59 2019 GMT', 'subjectAltName': (('IP Address', '127.0.0.1'),)}
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
Collecting pip
Using cached https://files.pythonhosted.org/packages/4a/08/6ca123073af4ebc4c5488a5bc8a010ac57aa39ce4d3c8a931ad504de4185/pip-19.3-py2.py3-none-any.whl
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Successfully uninstalled pip-19.2.3
Successfully installed pip-19.3
- New pip ------------------------------
pip 19.3 from /tmp/user/1000/tmp.ZqHiG62cpt/venv/lib/python3.6/site-packages/pip (python 3.6)
Looking in indexes: https://127.0.0.1:55649
Collecting pip
{'subject': ((('commonName', '127.0.0.1'),),), 'issuer': ((('commonName', '127.0.0.1'),),), 'version': 3, 'serialNumber': '5D7B2701E9D3E0E8A9E6CA66AEC3849D3BE826CD', 'notBefore': 'Oct 15 01:55:59 2019 GMT', 'notAfter': 'Nov 14 01:55:59 2019 GMT', 'subjectAltName': (('IP Address', '127.0.0.1'),)}
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
```
</details>
Notice in the second instance (with pip 19.3) that the server is still tracing the peer (pip) certificate.
How are you configuring the client cert for pip? Command line, configuration file, or environment variable?
Can you try shaping `repro.sh` from above into something self-contained that demonstrates your issue?
We're using ~/.pip/pip.conf to specify the client certificates. I modified your `repo.sh` and was not able to reproduce the problem using our client + server certificates and a fake SSL server (instead of the python one, I wanted to disable TLS 1.3 so I could see the certificates being sent in Wireshark):
`openssl s_server -accept 8999 -www -cert server.pem -key server.key -CAfile ca-cert.pem -no_tls1_3 -Verify 1`
It's a bit hard to produce something self-contained since we've got a Letsencrypt certificate tied to our own domain and a private PKI infrastructure for the client certificates.
It's looking like it might be an issue when the client certificate bundle is specified in pip.conf, specifying on the command-line seemed to work fine in 19.3. I'll try and come up with a new repro script that simulates this.
You may also run in a container so as not to clobber any existing configuration.
Ok, I think I have a container + script that reproduces the issue. It sets up its own CA and server/client certificates so it should be self-contained. I ran tshark in the Docker container and verified that when pip 19.3 talks to a dummy openssl server acting as pypi.org on the loopback interface, it doesn't send the client cert.
It has something to do with the `trusted-host` parameter in /root/.pip/pip.conf. With that commented out, there's no error. In the output below, some of the output from the openssl s_server process is mixed in with the script output (showing no client certificate sent).
<details>
<summary>Dockerfile</summary>
```
FROM python:3.8.0-slim-buster
COPY repro.sh /root
COPY pip.conf /root/.pip/pip.conf
WORKDIR /root
```
</details>
<details>
<summary>pip.conf</summary>
```
[global]
index-url = https://127.0.0.1:8999
trusted-host = 127.0.0.1
client-cert = /root/pip.client.bundle.pem
```
</details>
<details>
<summary>repro.sh</summary>
```bash
#!/bin/sh
trap "exit" INT TERM
trap "kill 0" EXIT
set -e
# CA + server cert
openssl genrsa -des3 -out ca.key -passout pass:notsecure 2048
openssl req -x509 -new -nodes -key ca.key -sha256 -days 1825 -addext "keyUsage = cRLSign, digitalSignature, keyCertSign" -out ca.pem -subj "/CN=Fake Root CA" -passin pass:notsecure
openssl genrsa -out pip.local.key 2048
openssl req -new -key pip.local.key -out pip.local.csr -subj "/CN=127.0.0.1"
cat << EOF > pip.local.ext
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
IP.1 = 127.0.0.1
EOF
openssl x509 -req -in pip.local.csr -CA ca.pem -CAkey ca.key -CAcreateserial \
-out pip.local.pem -days 1825 -sha256 -extfile pip.local.ext -passin pass:notsecure
cat << EOF > pip.client.ext
keyUsage = digitalSignature
extendedKeyUsage = clientAuth
EOF
# client cert
openssl genrsa -out pip.client.key 2048
openssl req -new -key pip.client.key -out pip.client.csr -subj "/CN=pip install"
openssl x509 -req -in pip.client.csr -CA ca.pem -CAkey ca.key -CAcreateserial \
-out pip.client.pem -days 1825 -sha256 -extfile pip.client.ext -passin pass:notsecure
# create key + cert bundle for pip install
cat pip.client.key pip.client.pem > pip.client.bundle.pem
PYTHON="${PYTHON:-python3}"
"$PYTHON" -V
"$PYTHON" -m venv venv
openssl s_server -accept 8999 -www -cert pip.local.pem -key pip.local.key -CAfile ca.pem -no_tls1_3 -Verify 1 &
sleep 1
venv/bin/python -m pip install --index-url https://pypi.org/simple/ --upgrade pip==19.2.3
echo "- Old pip ------------------------------"
venv/bin/python -m pip -V
venv/bin/python -m pip install \
--ignore-installed \
--disable-pip-version-check \
--cert /root/ca.pem \
pip || true
echo "Upgrading pip --------------------------"
venv/bin/python -m pip install --index-url https://pypi.org/simple/ --upgrade pip
echo "- New pip ------------------------------"
venv/bin/python -m pip -V
pip install \
--ignore-installed \
--disable-pip-version-check \
--cert ca.pem \
pip
```
</details>
<details>
<summary>Usage</summary>
```bash
docker build -t pip-debug -f Dockerfile .
docker run -it pip-debug bash
root@6d0a40c1179c:~# ./repro.sh
```
</details>
<details>
<summary>Output</summary>
```
root@0e1127dd4124:~# ./repro.sh
Generating RSA private key, 2048 bit long modulus (2 primes)
.......................+++++
..........+++++
e is 65537 (0x010001)
Generating RSA private key, 2048 bit long modulus (2 primes)
...................................+++++
......................................................................................................................+++++
e is 65537 (0x010001)
Signature ok
subject=CN = 127.0.0.1
Getting CA Private Key
Generating RSA private key, 2048 bit long modulus (2 primes)
........................................+++++
.......................+++++
e is 65537 (0x010001)
Signature ok
subject=CN = pip install
Getting CA Private Key
Python 3.8.0
verify depth is 1, must return a certificate
Using default temp DH parameters
ACCEPT
Looking in indexes: https://pypi.org/simple/
Requirement already up-to-date: pip==19.2.3 in ./venv/lib/python3.8/site-packages (19.2.3)
WARNING: You are using pip version 19.2.3, however version 19.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
- Old pip ------------------------------
pip 19.2.3 from /root/venv/lib/python3.8/site-packages/pip (python 3.8)
Looking in indexes: https://127.0.0.1:8999
Collecting pip
depth=1 CN = Fake Root CA
verify return:1
depth=0 CN = pip install
verify return:1
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
Upgrading pip --------------------------
Looking in indexes: https://pypi.org/simple/
Collecting pip
Downloading https://files.pythonhosted.org/packages/4a/08/6ca123073af4ebc4c5488a5bc8a010ac57aa39ce4d3c8a931ad504de4185/pip-19.3-py2.py3-none-any.whl (1.4MB)
|████████████████████████████████| 1.4MB 3.7MB/s
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Successfully uninstalled pip-19.2.3
Successfully installed pip-19.3
- New pip ------------------------------
pip 19.3 from /root/venv/lib/python3.8/site-packages/pip (python 3.8)
Looking in indexes: https://127.0.0.1:8999
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
Could not fetch URL https://127.0.0.1:8999/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='127.0.0.1', port=8999): Max retries exceeded with url: /pip/ (Caused by SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))) - skipping
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
```
</details>
Nice, thanks.
I bisected and it looks like the issue was introduced in 3f9136f. Previously the "trusted host" parameter with https URLs was only being applied for index URLs that did not have a port specified. As of 19.3 we assume that an unspecified port means the port is a wildcard. That change in conjunction with your configuration may have uncovered a bug in our `InsecureHTTPAdapter` [here](https://github.com/pypa/pip/blob/8c50c8a9bc8579886fa787a631dc15d4b503a8ac/src/pip/_internal/network/session.py#L214-L216) - we aren't doing anything with the `cert` parameter.
If I'm not missing something, I think we should be doing something like
```python
super(InsecureHTTPAdapter, self).cert_verify(conn=conn, url=url, verify=False, cert=cert)
```
to get the correct behavior (from [here](https://github.com/psf/requests/blob/67a7b2e8336951d527e223429672354989384197/requests/adapters.py#L241-L253)).
In your particular case is it possible to drop the trusted-host parameter since it wasn't being applied in previous versions?
Yeah, we can drop `trusted-host` for now. Most people have just reverted to pip 19.2.3
Thanks @surry for a well designed reproducer and @chrahunt for figuring out a potential root cause! :)
|
2019-11-03T18:18:36Z
|
<patch>
diff --git a/src/pip/_internal/network/session.py b/src/pip/_internal/network/session.py
--- a/src/pip/_internal/network/session.py
+++ b/src/pip/_internal/network/session.py
@@ -212,8 +212,9 @@ def close(self):
class InsecureHTTPAdapter(HTTPAdapter):
def cert_verify(self, conn, url, verify, cert):
- conn.cert_reqs = 'CERT_NONE'
- conn.ca_certs = None
+ super(InsecureHTTPAdapter, self).cert_verify(
+ conn=conn, url=url, verify=False, cert=cert
+ )
class PipSession(requests.Session):
</patch>
|
[]
|
[]
| |||
Lightning-AI__lightning-941
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support stepping options for lr scheduler
Currently schedulers get called every epoch. Sometimes though, we want them to be called every step.
Proposal 1:
Allow configure_optimizers to return this:
```python
return Adam, {'scheduler': LRScheduler, 'interval': 'batch|epoch'}
```
@ethanwharris @Borda thoughts? any simpler more general way of doing this? i think this dict can eventually have more options if we need to.
@srush
</issue>
<code>
[start of README.md]
1 <div align="center">
2
3 
4
5 # PyTorch Lightning
6
7 **The lightweight PyTorch wrapper for ML researchers. Scale your models. Write less boilerplate.**
8
9
10 [](https://badge.fury.io/py/pytorch-lightning)
11 [](https://pepy.tech/project/pytorch-lightning)
12 [](https://github.com/PytorchLightning/pytorch-lightning/tree/master/tests#running-coverage)
13 [](https://www.codefactor.io/repository/github/pytorchlightning/pytorch-lightning)
14
15 [](https://pytorch-lightning.readthedocs.io/en/latest/)
16 [](https://join.slack.com/t/pytorch-lightning/shared_invite/enQtODU5ODIyNTUzODQwLTFkMDg5Mzc1MDBmNjEzMDgxOTVmYTdhYjA1MDdmODUyOTg2OGQ1ZWZkYTQzODhhNzdhZDA3YmNhMDhlMDY4YzQ)
17 [](https://github.com/PytorchLightning/pytorch-lightning/blob/master/LICENSE)
18 [](https://shields.io/)
19
20 <!--
21 removed until codecov badge isn't empy. likely a config error showing nothing on master.
22 [](https://codecov.io/gh/Borda/pytorch-lightning)
23 -->
24 </div>
25
26 ---
27 ## Continuous Integration
28 <center>
29
30 | System / PyTorch Version | 1.1 | 1.2 | 1.3 | 1.4 |
31 | :---: | :---: | :---: | :---: | :---: |
32 | Linux py3.6 | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) |
33 | Linux py3.7 |  | <center>—</center> | <center>—</center> |  |
34 | OSX py3.6 |  | <center>—</center> | <center>—</center> |  |
35 | OSX py3.7 |  | <center>—</center> | <center>—</center> |  |
36 | Windows py3.6 |  | <center>—</center> | <center>—</center> |  |
37 | Windows py3.7 |  | <center>—</center> | <center>—</center> |  |
38
39 </center>
40
41 Simple installation from PyPI
42 ```bash
43 pip install pytorch-lightning
44 ```
45
46 ## Docs
47 - [master](https://pytorch-lightning.readthedocs.io/en/latest)
48 - [0.6.0](https://pytorch-lightning.readthedocs.io/en/0.6.0/)
49 - [0.5.3.2](https://pytorch-lightning.readthedocs.io/en/0.5.3.2/)
50
51 ## Demo
52 [Copy and run this COLAB!](https://colab.research.google.com/drive/1F_RNcHzTfFuQf-LeKvSlud6x7jXYkG31#scrollTo=HOk9c4_35FKg)
53
54 ## What is it?
55 Lightning is a way to organize your PyTorch code to decouple the science code from the engineering. It's more of a style-guide than a framework.
56
57 By refactoring your code, we can automate most of the non-research code. Lightning guarantees tested, correct, modern best practices for the automated parts.
58
59 Here's an example of how to organize PyTorch code into the LightningModule.
60
61 
62
63 - If you are a researcher, Lightning is infinitely flexible, you can modify everything down to the way .backward is called or distributed is set up.
64 - If you are a scientist or production team, lightning is very simple to use with best practice defaults.
65
66 ## What does lightning control for me?
67
68 Everything in Blue!
69 This is how lightning separates the science (red) from the engineering (blue).
70
71 
72
73 ## How much effort is it to convert?
74 You're probably tired of switching frameworks at this point. But it is a very quick process to refactor into the Lightning format (ie: hours). [Check out this tutorial](https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09).
75
76 ## What are the differences with PyTorch?
77 If you're wondering what you gain out of refactoring your PyTorch code, [read this comparison!](https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09)
78
79 ## Starting a new project?
80 [Use our seed-project aimed at reproducibility!](https://github.com/PytorchLightning/pytorch-lightning-conference-seed)
81
82 ## Why do I want to use lightning?
83 Every research project starts the same, a model, a training loop, validation loop, etc. As your research advances, you're likely to need distributed training, 16-bit precision, checkpointing, gradient accumulation, etc.
84
85 Lightning sets up all the boilerplate state-of-the-art training for you so you can focus on the research.
86
87 ---
88
89 ## README Table of Contents
90 - [How do I use it](https://github.com/PytorchLightning/pytorch-lightning#how-do-i-do-use-it)
91 - [What lightning automates](https://github.com/PytorchLightning/pytorch-lightning#what-does-lightning-control-for-me)
92 - [Tensorboard integration](https://github.com/PytorchLightning/pytorch-lightning#tensorboard)
93 - [Lightning features](https://github.com/PytorchLightning/pytorch-lightning#lightning-automates-all-of-the-following-each-is-also-configurable)
94 - [Examples](https://github.com/PytorchLightning/pytorch-lightning#examples)
95 - [Tutorials](https://github.com/PytorchLightning/pytorch-lightning#tutorials)
96 - [Asking for help](https://github.com/PytorchLightning/pytorch-lightning#asking-for-help)
97 - [Contributing](https://github.com/PytorchLightning/pytorch-lightning/blob/master/.github/CONTRIBUTING.md)
98 - [Bleeding edge install](https://github.com/PytorchLightning/pytorch-lightning#bleeding-edge)
99 - [Lightning Design Principles](https://github.com/PytorchLightning/pytorch-lightning#lightning-design-principles)
100 - [Lightning team](https://github.com/PytorchLightning/pytorch-lightning#lightning-team)
101 - [FAQ](https://github.com/PytorchLightning/pytorch-lightning#faq)
102
103 ---
104
105 ## How do I do use it?
106 Think about Lightning as refactoring your research code instead of using a new framework. The research code goes into a [LightningModule](https://pytorch-lightning.rtfd.io/en/latest/lightning-module.html) which you fit using a Trainer.
107
108 The LightningModule defines a *system* such as seq-2-seq, GAN, etc... It can ALSO define a simple classifier such as the example below.
109
110 To use lightning do 2 things:
111 1. [Define a LightningModule](https://pytorch-lightning.rtfd.io/en/latest/lightning-module.html)
112 **WARNING:** This syntax is for version 0.5.0+ where abbreviations were removed.
113 ```python
114 import os
115
116 import torch
117 from torch.nn import functional as F
118 from torch.utils.data import DataLoader
119 from torchvision.datasets import MNIST
120 from torchvision import transforms
121
122 import pytorch_lightning as pl
123
124 class CoolSystem(pl.LightningModule):
125
126 def __init__(self):
127 super(CoolSystem, self).__init__()
128 # not the best model...
129 self.l1 = torch.nn.Linear(28 * 28, 10)
130
131 def forward(self, x):
132 return torch.relu(self.l1(x.view(x.size(0), -1)))
133
134 def training_step(self, batch, batch_idx):
135 # REQUIRED
136 x, y = batch
137 y_hat = self.forward(x)
138 loss = F.cross_entropy(y_hat, y)
139 tensorboard_logs = {'train_loss': loss}
140 return {'loss': loss, 'log': tensorboard_logs}
141
142 def validation_step(self, batch, batch_idx):
143 # OPTIONAL
144 x, y = batch
145 y_hat = self.forward(x)
146 return {'val_loss': F.cross_entropy(y_hat, y)}
147
148 def validation_end(self, outputs):
149 # OPTIONAL
150 avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
151 tensorboard_logs = {'val_loss': avg_loss}
152 return {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
153
154 def test_step(self, batch, batch_idx):
155 # OPTIONAL
156 x, y = batch
157 y_hat = self.forward(x)
158 return {'test_loss': F.cross_entropy(y_hat, y)}
159
160 def test_end(self, outputs):
161 # OPTIONAL
162 avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean()
163 tensorboard_logs = {'test_loss': avg_loss}
164 return {'avg_test_loss': avg_loss, 'log': tensorboard_logs}
165
166 def configure_optimizers(self):
167 # REQUIRED
168 # can return multiple optimizers and learning_rate schedulers
169 # (LBFGS it is automatically supported, no need for closure function)
170 return torch.optim.Adam(self.parameters(), lr=0.02)
171
172 @pl.data_loader
173 def train_dataloader(self):
174 # REQUIRED
175 return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)
176
177 @pl.data_loader
178 def val_dataloader(self):
179 # OPTIONAL
180 return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)
181
182 @pl.data_loader
183 def test_dataloader(self):
184 # OPTIONAL
185 return DataLoader(MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor()), batch_size=32)
186 ```
187 2. Fit with a [trainer](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.html)
188 ```python
189 from pytorch_lightning import Trainer
190
191 model = CoolSystem()
192
193 # most basic trainer, uses good defaults
194 trainer = Trainer()
195 trainer.fit(model)
196 ```
197
198 Trainer sets up a tensorboard logger, early stopping and checkpointing by default (you can modify all of them or
199 use something other than tensorboard).
200
201 Here are more advanced examples
202 ```python
203 # train on cpu using only 10% of the data (for demo purposes)
204 trainer = Trainer(max_epochs=1, train_percent_check=0.1)
205
206 # train on 4 gpus (lightning chooses GPUs for you)
207 # trainer = Trainer(max_epochs=1, gpus=4, distributed_backend='ddp')
208
209 # train on 4 gpus (you choose GPUs)
210 # trainer = Trainer(max_epochs=1, gpus=[0, 1, 3, 7], distributed_backend='ddp')
211
212 # train on 32 gpus across 4 nodes (make sure to submit appropriate SLURM job)
213 # trainer = Trainer(max_epochs=1, gpus=8, num_gpu_nodes=4, distributed_backend='ddp')
214
215 # train (1 epoch only here for demo)
216 trainer.fit(model)
217
218 # view tensorboard logs
219 logging.info(f'View tensorboard logs by running\ntensorboard --logdir {os.getcwd()}')
220 logging.info('and going to http://localhost:6006 on your browser')
221 ```
222
223 When you're all done you can even run the test set separately.
224 ```python
225 trainer.test()
226 ```
227
228 **Could be as complex as seq-2-seq + attention**
229
230 ```python
231 # define what happens for training here
232 def training_step(self, batch, batch_idx):
233 x, y = batch
234
235 # define your own forward and loss calculation
236 hidden_states = self.encoder(x)
237
238 # even as complex as a seq-2-seq + attn model
239 # (this is just a toy, non-working example to illustrate)
240 start_token = '<SOS>'
241 last_hidden = torch.zeros(...)
242 loss = 0
243 for step in range(max_seq_len):
244 attn_context = self.attention_nn(hidden_states, start_token)
245 pred = self.decoder(start_token, attn_context, last_hidden)
246 last_hidden = pred
247 pred = self.predict_nn(pred)
248 loss += self.loss(last_hidden, y[step])
249
250 #toy example as well
251 loss = loss / max_seq_len
252 return {'loss': loss}
253 ```
254
255 **Or as basic as CNN image classification**
256
257 ```python
258 # define what happens for validation here
259 def validation_step(self, batch, batch_idx):
260 x, y = batch
261
262 # or as basic as a CNN classification
263 out = self.forward(x)
264 loss = my_loss(out, y)
265 return {'loss': loss}
266 ```
267
268 **And you also decide how to collate the output of all validation steps**
269
270 ```python
271 def validation_end(self, outputs):
272 """
273 Called at the end of validation to aggregate outputs
274 :param outputs: list of individual outputs of each validation step
275 :return:
276 """
277 val_loss_mean = 0
278 val_acc_mean = 0
279 for output in outputs:
280 val_loss_mean += output['val_loss']
281 val_acc_mean += output['val_acc']
282
283 val_loss_mean /= len(outputs)
284 val_acc_mean /= len(outputs)
285 logs = {'val_loss': val_loss_mean.item(), 'val_acc': val_acc_mean.item()}
286 result = {'log': logs}
287 return result
288 ```
289
290 ## Tensorboard
291 Lightning is fully integrated with tensorboard, MLFlow and supports any logging module.
292
293 
294
295 Lightning also adds a text column with all the hyperparameters for this experiment.
296
297 
298
299 ## Lightning automates all of the following ([each is also configurable](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.html)):
300
301
302 - [Running grid search on a cluster](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.distrib_data_parallel.html)
303 - [Fast dev run](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.utilities.debugging.html)
304 - [Logging](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.loggers.html)
305 - [Implement Your Own Distributed (DDP) training](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.core.lightning.html#pytorch_lightning.core.lightning.LightningModule.configure_ddp)
306 - [Multi-GPU & Multi-node](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.distrib_parts.html)
307 - [Training loop](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.training_loop.html)
308 - [Hooks](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.core.hooks.html)
309 - [Configure optimizers](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.core.lightning.html#pytorch_lightning.core.lightning.LightningModule.configure_optimizers)
310 - [Validations](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.evaluation_loop.html)
311 - [Model saving & Restoring training session](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.training_io.html)
312
313
314 ## Examples
315 - [GAN](https://github.com/PytorchLightning/pytorch-lightning/tree/master/pl_examples/domain_templates/gan.py)
316 - [MNIST](https://github.com/PytorchLightning/pytorch-lightning/tree/master/pl_examples/basic_examples)
317 - [Other projects using Lightning](https://github.com/PytorchLightning/pytorch-lightning/network/dependents?package_id=UGFja2FnZS0zNzE3NDU4OTM%3D)
318 - [Multi-node](https://github.com/PytorchLightning/pytorch-lightning/tree/master/pl_examples/multi_node_examples)
319
320 ## Tutorials
321 - [Basic Lightning use](https://towardsdatascience.com/supercharge-your-ai-research-with-pytorch-lightning-337948a99eec)
322 - [9 key speed features in Pytorch-Lightning](https://towardsdatascience.com/9-tips-for-training-lightning-fast-neural-networks-in-pytorch-8e63a502f565)
323 - [SLURM, multi-node training with Lightning](https://towardsdatascience.com/trivial-multi-node-training-with-pytorch-lightning-ff75dfb809bd)
324
325 ---
326
327 ## Asking for help
328 Welcome to the Lightning community!
329
330 If you have any questions, feel free to:
331 1. [read the docs](https://pytorch-lightning.rtfd.io/en/latest/).
332 2. [Search through the issues](https://github.com/PytorchLightning/pytorch-lightning/issues?utf8=%E2%9C%93&q=my++question).
333 3. [Ask on stackoverflow](https://stackoverflow.com/questions/ask?guided=false) with the tag pytorch-lightning.
334
335 If no one replies to you quickly enough, feel free to post the stackoverflow link to our Gitter chat!
336
337 To chat with the rest of us visit our [gitter channel](https://gitter.im/PyTorch-Lightning/community)!
338
339 ---
340 ## FAQ
341 **How do I use Lightning for rapid research?**
342 [Here's a walk-through](https://pytorch-lightning.rtfd.io/en/latest/)
343
344 **Why was Lightning created?**
345 Lightning has 3 goals in mind:
346 1. Maximal flexibility while abstracting out the common boilerplate across research projects.
347 2. Reproducibility. If all projects use the LightningModule template, it will be much much easier to understand what's going on and where to look! It will also mean every implementation follows a standard format.
348 3. Democratizing PyTorch power user features. Distributed training? 16-bit? know you need them but don't want to take the time to implement? All good... these come built into Lightning.
349
350 **How does Lightning compare with Ignite and fast.ai?**
351 [Here's a thorough comparison](https://medium.com/@_willfalcon/pytorch-lightning-vs-pytorch-ignite-vs-fast-ai-61dc7480ad8a).
352
353 **Is this another library I have to learn?**
354 Nope! We use pure Pytorch everywhere and don't add unecessary abstractions!
355
356 **Are there plans to support Python 2?**
357 Nope.
358
359 **Are there plans to support virtualenv?**
360 Nope. Please use anaconda or miniconda.
361
362 **Which PyTorch versions do you support?**
363 - **PyTorch 1.1.0**
364 ```bash
365 # install pytorch 1.1.0 using the official instructions
366
367 # install test-tube 0.6.7.6 which supports 1.1.0
368 pip install test-tube==0.6.7.6
369
370 # install latest Lightning version without upgrading deps
371 pip install -U --no-deps pytorch-lightning
372 ```
373 - **PyTorch 1.2.0, 1.3.0,**
374 Install via pip as normal
375
376 ## Custom installation
377
378 ### Bleeding edge
379
380 If you can't wait for the next release, install the most up to date code with:
381 * using GIT (locally clone whole repo with full history)
382 ```bash
383 pip install git+https://github.com/PytorchLightning/pytorch-lightning.git@master --upgrade
384 ```
385 * using instant zip (last state of the repo without git history)
386 ```bash
387 pip install https://github.com/PytorchLightning/pytorch-lightning/archive/master.zip --upgrade
388 ```
389
390 ### Any release installation
391
392 You can also install any past release `0.X.Y` from this repository:
393 ```bash
394 pip install https://github.com/PytorchLightning/pytorch-lightning/archive/0.X.Y.zip --upgrade
395 ```
396
397 ### Lightning team
398
399 #### Leads
400 - William Falcon [(williamFalcon)](https://github.com/williamFalcon) (Lightning founder)
401 - Jirka Borovec [(Borda)](https://github.com/Borda) (-_-)
402 - Ethan Harris [(ethanwharris)](https://github.com/ethanwharris) (Torchbearer founder)
403 - Matthew Painter [(MattPainter01)](https://github.com/MattPainter01) (Torchbearer founder)
404
405 #### Core Maintainers
406
407 - Nick Eggert [(neggert)](https://github.com/neggert)
408 - Jeremy Jordan [(jeremyjordan)](https://github.com/jeremyjordan)
409 - Jeff Ling [(jeffling)](https://github.com/jeffling)
410 - Tullie Murrell [(tullie)](https://github.com/tullie)
411
412 ## Bibtex
413 If you want to cite the framework feel free to use this (but only if you loved it 😊):
414 ```
415 @misc{Falcon2019,
416 author = {Falcon, W.A. et al.},
417 title = {PyTorch Lightning},
418 year = {2019},
419 publisher = {GitHub},
420 journal = {GitHub repository},
421 howpublished = {\url{https://github.com/PytorchLightning/pytorch-lightning}}
422 }
423 ```
424
[end of README.md]
[start of pytorch_lightning/core/lightning.py]
1 import collections
2 import inspect
3 import logging as log
4 import os
5 import warnings
6 from abc import ABC, abstractmethod
7 from argparse import Namespace
8 from typing import Any, Callable, Dict, Optional, Union
9
10 import torch
11 import torch.distributed as dist
12 from torch.optim import Adam
13
14 from pytorch_lightning.core.decorators import data_loader
15 from pytorch_lightning.core.grads import GradInformation
16 from pytorch_lightning.core.hooks import ModelHooks
17 from pytorch_lightning.core.saving import ModelIO, load_hparams_from_tags_csv
18 from pytorch_lightning.core.memory import ModelSummary
19 from pytorch_lightning.overrides.data_parallel import LightningDistributedDataParallel
20 from pytorch_lightning.utilities.debugging import MisconfigurationException
21
22 try:
23 import torch_xla.core.xla_model as xm
24 XLA_AVAILABLE = True
25
26 except ImportError:
27 XLA_AVAILABLE = False
28
29
30 class LightningModule(ABC, GradInformation, ModelIO, ModelHooks):
31
32 def __init__(self, *args, **kwargs):
33 super(LightningModule, self).__init__(*args, **kwargs)
34
35 #: Current dtype
36 self.dtype = torch.FloatTensor
37
38 self.exp_save_path = None
39
40 #: The current epoch
41 self.current_epoch = 0
42
43 #: Total training batches seen across all epochs
44 self.global_step = 0
45
46 self.loaded_optimizer_states_dict = {}
47
48 #: Pointer to the trainer object
49 self.trainer = None
50
51 #: Pointer to the logger object
52 self.logger = None
53 self.example_input_array = None
54
55 #: True if your model is currently running on GPUs.
56 #: Useful to set flags around the LightningModule for different CPU vs GPU behavior.
57 self.on_gpu = False
58
59 #: True if using dp
60 self.use_dp = False
61
62 #: True if using ddp
63 self.use_ddp = False
64
65 #: True if using ddp2
66 self.use_ddp2 = False
67
68 #: True if using amp
69 self.use_amp = False
70
71 self.hparams = None
72
73 def print(self, *args, **kwargs):
74 r"""
75 Prints only from process 0. Use this in any distributed mode to log only once
76
77 Args:
78 x (object): The thing to print
79
80 Example
81 -------
82
83 .. code-block:: python
84
85 # example if we were using this model as a feature extractor
86 def forward(self, x):
87 self.print(x, 'in loader')
88
89 """
90 if self.trainer.proc_rank == 0:
91 log.info(*args, **kwargs)
92
93 @abstractmethod
94 def forward(self, *args, **kwargs):
95 r"""
96 Same as torch.nn.Module.forward(), however in Lightning you want this to define
97 the operations you want to use for prediction (ie: on a server or as a feature extractor).
98
99 Normally you'd call self.forward() from your training_step() method. This makes it easy to write a complex
100 system for training with the outputs you'd want in a prediction setting.
101
102 Args:
103 x (tensor): Whatever you decide to define in the forward method
104
105 Return:
106 Predicted output
107
108 Example
109 -------
110
111 .. code-block:: python
112
113 # example if we were using this model as a feature extractor
114 def forward(self, x):
115 feature_maps = self.convnet(x)
116 return feature_maps
117
118 def training_step(self, batch, batch_idx):
119 x, y = batch
120 feature_maps = self.forward(x)
121 logits = self.classifier(feature_maps)
122
123 # ...
124 return loss
125
126 # splitting it this way allows model to be used a feature extractor
127 model = MyModelAbove()
128
129 inputs = server.get_request()
130 results = model(inputs)
131 server.write_results(results)
132
133 # -------------
134 # This is in stark contrast to torch.nn.Module where normally you would have this:
135 def forward(self, batch):
136 x, y = batch
137 feature_maps = self.convnet(x)
138 logits = self.classifier(feature_maps)
139 return logits
140
141 """
142
143 def training_step(self, *args, **kwargs):
144 r"""return loss, dict with metrics for tqdm
145
146 Args:
147 batch (torch.nn.Tensor | (Tensor, Tensor) | [Tensor, Tensor]): The output of your dataloader.
148 A tensor, tuple or list
149 batch_idx (int): Integer displaying index of this batch
150 optimizer_idx (int): If using multiple optimizers, this argument will also be present.
151 hiddens(:`Tensor <https://pytorch.org/docs/stable/tensors.html>`_): Passed in if truncated_bptt_steps > 0.
152
153 :param
154
155 :return: dict with loss key and optional log, progress keys
156 if implementing training_step, return whatever you need in that step:
157
158 - loss -> tensor scalar [REQUIRED]
159 - progress_bar -> Dict for progress bar display. Must have only tensors
160 - log -> Dict of metrics to add to logger. Must have only tensors (no images, etc)
161
162 In this step you'd normally do the forward pass and calculate the loss for a batch.
163 You can also do fancier things like multiple forward passes or something specific to your model.
164
165 Example
166 -------
167
168 .. code-block:: python
169
170 def training_step(self, batch, batch_idx):
171 x, y, z = batch
172
173 # implement your own
174 out = self.forward(x)
175 loss = self.loss(out, x)
176
177 logger_logs = {'training_loss': loss} # optional (MUST ALL BE TENSORS)
178
179 # if using TestTubeLogger or TensorBoardLogger you can nest scalars
180 logger_logs = {'losses': logger_logs} # optional (MUST ALL BE TENSORS)
181
182 output = {
183 'loss': loss, # required
184 'progress_bar': {'training_loss': loss}, # optional (MUST ALL BE TENSORS)
185 'log': logger_logs
186 }
187
188 # return a dict
189 return output
190
191 If you define multiple optimizers, this step will also be called with an additional `optimizer_idx` param.
192
193 .. code-block:: python
194
195 # Multiple optimizers (ie: GANs)
196 def training_step(self, batch, batch_idx, optimizer_idx):
197 if optimizer_idx == 0:
198 # do training_step with encoder
199 if optimizer_idx == 1:
200 # do training_step with decoder
201
202
203 If you add truncated back propagation through time you will also get an additional
204 argument with the hidden states of the previous step.
205
206 .. code-block:: python
207
208 # Truncated back-propagation through time
209 def training_step(self, batch, batch_idx, hiddens):
210 # hiddens are the hiddens from the previous truncated backprop step
211 ...
212 out, hiddens = self.lstm(data, hiddens)
213 ...
214
215 return {
216 "loss": ...,
217 "hiddens": hiddens # remember to detach() this
218 }
219
220 You can also return a -1 instead of a dict to stop the current loop. This is useful
221 if you want to break out of the current training epoch early.
222 """
223
224 def training_end(self, *args, **kwargs):
225 """return loss, dict with metrics for tqdm
226
227 :param outputs: What you return in `training_step`.
228 :return dict: dictionary with loss key and optional log, progress keys:
229 - loss -> tensor scalar [REQUIRED]
230 - progress_bar -> Dict for progress bar display. Must have only tensors
231 - log -> Dict of metrics to add to logger. Must have only tensors (no images, etc)
232
233 In certain cases (dp, ddp2), you might want to use all outputs of every process to do something.
234 For instance, if using negative samples, you could run a batch via dp and use ALL the outputs
235 for a single softmax across the full batch (ie: the denominator would use the full batch).
236
237 In this case you should define training_end to perform those calculations.
238
239 Example
240 -------
241
242 .. code-block:: python
243
244 # WITHOUT training_end
245 # if used in DP or DDP2, this batch is 1/num_gpus large
246 def training_step(self, batch, batch_idx):
247 # batch is 1/num_gpus big
248 x, y = batch
249
250 out = self.forward(x)
251 loss = self.softmax(out)
252 loss = nce_loss(loss)
253 return {'loss': loss}
254
255 # --------------
256 # with training_end to do softmax over the full batch
257 def training_step(self, batch, batch_idx):
258 # batch is 1/num_gpus big
259 x, y = batch
260
261 out = self.forward(x)
262 return {'out': out}
263
264 def training_end(self, outputs):
265 # this out is now the full size of the batch
266 out = outputs['out']
267
268 # this softmax now uses the full batch size
269 loss = self.softmax(out)
270 loss = nce_loss(loss)
271 return {'loss': loss}
272
273 .. note:: see the `multi-gpu guide for more details <multi_gpu.rst#caveats>`_.
274
275 If you define multiple optimizers, this step will also be called with an additional `optimizer_idx` param.
276
277 .. code-block:: python
278
279 # Multiple optimizers (ie: GANs)
280 def training_step(self, batch, batch_idx, optimizer_idx):
281 if optimizer_idx == 0:
282 # do training_step with encoder
283 if optimizer_idx == 1:
284 # do training_step with decoder
285
286 If you add truncated back propagation through time you will also get an additional argument
287 with the hidden states of the previous step.
288
289 .. code-block:: python
290
291 # Truncated back-propagation through time
292 def training_step(self, batch, batch_idx, hiddens):
293 # hiddens are the hiddens from the previous truncated backprop step
294
295 You can also return a -1 instead of a dict to stop the current loop. This is useful if you want to
296 break out of the current training epoch early.
297 """
298
299 def validation_step(self, *args, **kwargs):
300 r"""
301
302 This is the validation loop. It is called for each batch of the validation set.
303 Whatever is returned from here will be passed in as a list on validation_end.
304 In this step you'd normally generate examples or calculate anything of interest such as accuracy.
305
306 Args:
307 batch (torch.nn.Tensor | (Tensor, Tensor) | [Tensor, Tensor]): The output of your dataloader.
308 A tensor, tuple or list
309 batch_idx (int): The index of this batch
310 dataloader_idx (int): The index of the dataloader that produced this batch (only if multiple
311 val datasets used)
312
313 Return:
314 Dict or OrderedDict - passed to the validation_end step
315
316 .. code-block:: python
317
318 # if you have one val dataloader:
319 def validation_step(self, batch, batch_idx)
320
321 # if you have multiple val dataloaders:
322 def validation_step(self, batch, batch_idx, dataloader_idxdx)
323
324 Example
325 -------
326
327 .. code-block:: python
328
329 # CASE 1: A single validation dataset
330 def validation_step(self, batch, batch_idx):
331 x, y = batch
332
333 # implement your own
334 out = self.forward(x)
335 loss = self.loss(out, y)
336
337 # log 6 example images
338 # or generated text... or whatever
339 sample_imgs = x[:6]
340 grid = torchvision.utils.make_grid(sample_imgs)
341 self.logger.experiment.add_image('example_images', grid, 0)
342
343 # calculate acc
344 labels_hat = torch.argmax(out, dim=1)
345 val_acc = torch.sum(y == labels_hat).item() / (len(y) * 1.0)
346
347 # all optional...
348 # return whatever you need for the collation function validation_end
349 output = OrderedDict({
350 'val_loss': loss_val,
351 'val_acc': torch.tensor(val_acc), # everything must be a tensor
352 })
353
354 # return an optional dict
355 return output
356
357 If you pass in multiple validation datasets, validation_step will have an additional argument.
358
359 .. code-block:: python
360
361 # CASE 2: multiple validation datasets
362 def validation_step(self, batch, batch_idx, dataset_idx):
363 # dataset_idx tells you which dataset this is.
364
365 .. note:: If you don't need to validate you don't need to implement this method.
366
367 .. note:: When the validation_step is called, the model has been put in eval mode and PyTorch gradients
368 have been disabled. At the end of validation, model goes back to training mode and gradients are enabled.
369 """
370
371 def test_step(self, *args, **kwargs):
372 """return whatever outputs will need to be aggregated in test_end
373 :param batch: The output of your dataloader. A tensor, tuple or list
374 :param int batch_idx: Integer displaying which batch this is
375 :param int dataloader_idx: Integer displaying which dataloader this is (only if multiple test datasets used)
376 :return dict: Dict or OrderedDict with metrics to display in progress bar. All keys must be tensors.
377
378 .. code-block:: python
379
380 # if you have one test dataloader:
381 def test_step(self, batch, batch_idx)
382
383 # if you have multiple test dataloaders:
384 def test_step(self, batch, batch_idx, dataloader_idxdx)
385
386
387 **OPTIONAL**
388 If you don't need to test you don't need to implement this method.
389 In this step you'd normally generate examples or
390 calculate anything of interest such as accuracy.
391
392 When the validation_step is called, the model has been put in eval mode
393 and PyTorch gradients have been disabled.
394 At the end of validation, model goes back to training mode and gradients are enabled.
395
396 The dict you return here will be available in the `test_end` method.
397
398 This function is used when you execute `trainer.test()`.
399
400 Example
401 -------
402
403 .. code-block:: python
404
405 # CASE 1: A single test dataset
406 def test_step(self, batch, batch_idx):
407 x, y = batch
408
409 # implement your own
410 out = self.forward(x)
411 loss = self.loss(out, y)
412
413 # calculate acc
414 labels_hat = torch.argmax(out, dim=1)
415 test_acc = torch.sum(y == labels_hat).item() / (len(y) * 1.0)
416
417 # all optional...
418 # return whatever you need for the collation function test_end
419 output = OrderedDict({
420 'test_loss': loss_test,
421 'test_acc': torch.tensor(test_acc), # everything must be a tensor
422 })
423
424 # return an optional dict
425 return output
426
427
428 If you pass in multiple test datasets, `test_step` will have an additional argument.
429
430 .. code-block:: python
431
432 # CASE 2: multiple test datasets
433 def test_step(self, batch, batch_idx, dataset_idx):
434 # dataset_idx tells you which dataset this is.
435
436
437 The `dataset_idx` corresponds to the order of datasets returned in `test_dataloader`.
438 """
439
440 def validation_end(self, outputs):
441 """Outputs has the appended output after each validation step.
442
443 :param outputs: List of outputs you defined in validation_step, or if there are multiple dataloaders,
444 a list containing a list of outputs for each dataloader
445 :return dict: Dictionary or OrderedDict with optional:
446 progress_bar -> Dict for progress bar display. Must have only tensors
447 log -> Dict of metrics to add to logger. Must have only tensors (no images, etc)
448
449 If you didn't define a validation_step, this won't be called.
450 Called at the end of the validation loop with the outputs of validation_step.
451
452 The outputs here are strictly for the progress bar.
453 If you don't need to display anything, don't return anything.
454 Any keys present in 'log', 'progress_bar' or the rest of the dictionary
455 are available for callbacks to access. If you want to manually set current step, you can specify it with
456 'step' key in the 'log' Dict.
457
458 Example
459 -------
460
461 With a single dataloader
462
463 .. code-block:: python
464
465 def validation_end(self, outputs):
466 val_loss_mean = 0
467 val_acc_mean = 0
468 for output in outputs:
469 val_loss_mean += output['val_loss']
470 val_acc_mean += output['val_acc']
471
472 val_loss_mean /= len(outputs)
473 val_acc_mean /= len(outputs)
474 tqdm_dict = {'val_loss': val_loss_mean.item(), 'val_acc': val_acc_mean.item()}
475
476 # show val_loss and val_acc in progress bar but only log val_loss
477 results = {
478 'progress_bar': tqdm_dict,
479 'log': {'val_loss': val_loss_mean.item()}
480 }
481 return results
482
483 With multiple dataloaders, `outputs` will be a list of lists. The outer list contains
484 one entry per dataloader, while the inner list contains the individual outputs of
485 each validation step for that dataloader.
486
487 .. code-block:: python
488
489 def validation_end(self, outputs):
490 val_loss_mean = 0
491 val_acc_mean = 0
492 i = 0
493 for dataloader_outputs in outputs:
494 for output in dataloader_outputs:
495 val_loss_mean += output['val_loss']
496 val_acc_mean += output['val_acc']
497 i += 1
498
499 val_loss_mean /= i
500 val_acc_mean /= i
501 tqdm_dict = {'val_loss': val_loss_mean.item(), 'val_acc': val_acc_mean.item()}
502
503 # show val_loss and val_acc in progress bar but only log val_loss
504 results = {
505 'progress_bar': tqdm_dict,
506 'log': {'val_loss': val_loss_mean.item(), 'step': self.current_epoch}
507 }
508 return results
509
510 """
511
512 def test_end(self, outputs):
513 """Outputs has the appended output after each test step.
514
515 :param outputs: List of outputs you defined in test_step, or if there are multiple dataloaders,
516 a list containing a list of outputs for each dataloader
517 :return dict: Dict of OrderedDict with metrics to display in progress bar
518
519 If you didn't define a test_step, this won't be called.
520 Called at the end of the test step with the output of each test_step.
521 The outputs here are strictly for the progress bar.
522 If you don't need to display anything, don't return anything.
523
524 Example
525 -------
526
527 .. code-block:: python
528
529 def test_end(self, outputs):
530 test_loss_mean = 0
531 test_acc_mean = 0
532 for output in outputs:
533 test_loss_mean += output['test_loss']
534 test_acc_mean += output['test_acc']
535
536 test_loss_mean /= len(outputs)
537 test_acc_mean /= len(outputs)
538 tqdm_dict = {'test_loss': test_loss_mean.item(), 'test_acc': test_acc_mean.item()}
539
540 # show test_loss and test_acc in progress bar but only log test_loss
541 results = {
542 'progress_bar': tqdm_dict,
543 'log': {'test_loss': val_loss_mean.item()}
544 }
545 return results
546
547 With multiple dataloaders, `outputs` will be a list of lists. The outer list contains
548 one entry per dataloader, while the inner list contains the individual outputs of
549 each validation step for that dataloader.
550
551 .. code-block:: python
552
553 def test_end(self, outputs):
554 test_loss_mean = 0
555 test_acc_mean = 0
556 i = 0
557 for dataloader_outputs in outputs:
558 for output in dataloader_outputs:
559 test_loss_mean += output['test_loss']
560 test_acc_mean += output['test_acc']
561 i += 1
562
563 test_loss_mean /= i
564 test_acc_mean /= i
565 tqdm_dict = {'test_loss': test_loss_mean.item(), 'test_acc': test_acc_mean.item()}
566
567 # show test_loss and test_acc in progress bar but only log test_loss
568 results = {
569 'progress_bar': tqdm_dict,
570 'log': {'test_loss': val_loss_mean.item()}
571 }
572 return results
573
574 """
575
576 def configure_ddp(self, model, device_ids):
577 r"""
578
579 Override to init DDP in your own way or with your own wrapper.
580 The only requirements are that:
581
582 1. On a validation batch the call goes to model.validation_step.
583 2. On a training batch the call goes to model.training_step.
584 3. On a testing batch, the call goes to model.test_step
585
586 Args:
587 model (:class:`.LightningModule`): the LightningModule currently being optimized
588 device_ids (list): the list of GPU ids
589
590 Return:
591 DDP wrapped model
592
593 Example
594 -------
595 .. code-block:: python
596
597 # default implementation used in Trainer
598 def configure_ddp(self, model, device_ids):
599 # Lightning DDP simply routes to test_step, val_step, etc...
600 model = LightningDistributedDataParallel(
601 model,
602 device_ids=device_ids,
603 find_unused_parameters=True
604 )
605 return model
606
607
608 """
609 model = LightningDistributedDataParallel(
610 model,
611 device_ids=device_ids,
612 find_unused_parameters=True
613 )
614 return model
615
616 def init_ddp_connection(self, proc_rank, world_size):
617 r"""
618
619 Override to define your custom way of setting up a distributed environment.
620
621 Lightning's implementation uses env:// init by default and sets the first node as root.
622
623 Args:
624 proc_rank (int): The current process rank within the node.
625 world_size (int): Number of GPUs being use across all nodes. (num_nodes*nb_gpu_nodes).
626 Example
627 -------
628 .. code-block:: python
629
630 def init_ddp_connection(self):
631 # use slurm job id for the port number
632 # guarantees unique ports across jobs from same grid search
633 try:
634 # use the last 4 numbers in the job id as the id
635 default_port = os.environ['SLURM_JOB_ID']
636 default_port = default_port[-4:]
637
638 # all ports should be in the 10k+ range
639 default_port = int(default_port) + 15000
640
641 except Exception as e:
642 default_port = 12910
643
644 # if user gave a port number, use that one instead
645 try:
646 default_port = os.environ['MASTER_PORT']
647 except Exception:
648 os.environ['MASTER_PORT'] = str(default_port)
649
650 # figure out the root node addr
651 try:
652 root_node = os.environ['SLURM_NODELIST'].split(' ')[0]
653 except Exception:
654 root_node = '127.0.0.2'
655
656 root_node = self.trainer.resolve_root_node_address(root_node)
657 os.environ['MASTER_ADDR'] = root_node
658 dist.init_process_group(
659 'nccl',
660 rank=self.proc_rank,
661 world_size=self.world_size
662 )
663
664 """
665 # use slurm job id for the port number
666 # guarantees unique ports across jobs from same grid search
667 try:
668 # use the last 4 numbers in the job id as the id
669 default_port = os.environ['SLURM_JOB_ID']
670 default_port = default_port[-4:]
671
672 # all ports should be in the 10k+ range
673 default_port = int(default_port) + 15000
674
675 except Exception:
676 default_port = 12910
677
678 # if user gave a port number, use that one instead
679 try:
680 default_port = os.environ['MASTER_PORT']
681 except Exception:
682 os.environ['MASTER_PORT'] = str(default_port)
683
684 # figure out the root node addr
685 try:
686 root_node = os.environ['SLURM_NODELIST'].split(' ')[0]
687 except Exception:
688 root_node = '127.0.0.2'
689
690 root_node = self.trainer.resolve_root_node_address(root_node)
691 os.environ['MASTER_ADDR'] = root_node
692 dist.init_process_group('nccl', rank=proc_rank, world_size=world_size)
693
694 def configure_apex(self, amp, model, optimizers, amp_level):
695 r"""
696 Override to init AMP your own way
697 Must return a model and list of optimizers
698
699 Args:
700 amp (object): pointer to amp library object
701 model (:class:`.LightningModule`): pointer to current lightningModule
702 optimizers (list): list of optimizers passed in configure_optimizers()
703 amp_level (str): AMP mode chosen ('O1', 'O2', etc...)
704
705 Return:
706 Apex wrapped model and optimizers
707
708 Example
709 -------
710 .. code-block:: python
711
712 # Default implementation used by Trainer.
713 def configure_apex(self, amp, model, optimizers, amp_level):
714 model, optimizers = amp.initialize(
715 model, optimizers, opt_level=amp_level,
716 )
717
718 return model, optimizers
719 """
720 model, optimizers = amp.initialize(
721 model, optimizers, opt_level=amp_level,
722 )
723
724 return model, optimizers
725
726 def configure_optimizers(self):
727 r"""
728 This is where you choose what optimizers and learning-rate schedulers to use in your optimization.
729 Normally you'd need one. But in the case of GANs or something more esoteric you might have multiple.
730
731 If you don't define this method Lightning will automatically use Adam(lr=1e-3)
732
733 Return: any of these 3 options:
734 - Single optimizer
735 - List or Tuple - List of optimizers
736 - Two lists - The first list has multiple optimizers, the second a list of learning-rate schedulers
737
738 Example
739 -------
740
741 .. code-block:: python
742
743 # most cases (default if not defined)
744 def configure_optimizers(self):
745 opt = Adam(self.parameters(), lr=1e-3)
746 return opt
747
748 # multiple optimizer case (eg: GAN)
749 def configure_optimizers(self):
750 generator_opt = Adam(self.model_gen.parameters(), lr=0.01)
751 disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02)
752 return generator_opt, disriminator_opt
753
754 # example with learning_rate schedulers
755 def configure_optimizers(self):
756 generator_opt = Adam(self.model_gen.parameters(), lr=0.01)
757 disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02)
758 discriminator_sched = CosineAnnealing(discriminator_opt, T_max=10)
759 return [generator_opt, disriminator_opt], [discriminator_sched]
760
761 .. note:: Lightning calls .backward() and .step() on each optimizer and learning rate scheduler as needed.
762
763 .. note:: If you use 16-bit precision (use_amp=True), Lightning will automatically
764 handle the optimizers for you.
765
766 .. note:: If you use multiple optimizers, training_step will have an additional `optimizer_idx` parameter.
767
768 .. note:: If you use LBFGS lightning handles the closure function automatically for you
769
770 .. note:: If you use multiple optimizers, gradients will be calculated only
771 for the parameters of current optimizer at each training step.
772
773 .. note:: If you need to control how often those optimizers step or override the default .step() schedule,
774 override the `optimizer_step` hook.
775
776
777 """
778 return Adam(self.parameters(), lr=1e-3)
779
780 def optimizer_step(self, epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
781 r"""
782
783 Override this method to adjust the default way the Trainer calls each optimizer. By default, Lightning
784 calls .step() and zero_grad() as shown in the example once per optimizer.
785
786 Args:
787 epoch (int): Current epoch
788 batch_idx (int): Index of current batch
789 optimizer (torch.nn.Optimizer): A PyTorch optimizer
790 optimizer_idx (int): If you used multiple optimizers this indexes into that list
791 second_order_closure (int): closure for second order methods
792
793 Example
794 -------
795 .. code-block:: python
796
797 # DEFAULT
798 def optimizer_step(self, current_epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
799 optimizer.step()
800 optimizer.zero_grad()
801
802 # Alternating schedule for optimizer steps (ie: GANs)
803 def optimizer_step(self, current_epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
804 # update generator opt every 2 steps
805 if optimizer_idx == 0:
806 if batch_idx % 2 == 0 :
807 optimizer.step()
808 optimizer.zero_grad()
809
810 # update discriminator opt every 4 steps
811 if optimizer_idx == 1:
812 if batch_idx % 4 == 0 :
813 optimizer.step()
814 optimizer.zero_grad()
815
816 # ...
817 # add as many optimizers as you want
818
819
820 Here's another example showing how to use this for more advanced things such as learning-rate warm-up:
821
822 .. code-block:: python
823
824 # learning rate warm-up
825 def optimizer_step(self, current_epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
826 # warm up lr
827 if self.trainer.global_step < 500:
828 lr_scale = min(1., float(self.trainer.global_step + 1) / 500.)
829 for pg in optimizer.param_groups:
830 pg['lr'] = lr_scale * self.hparams.learning_rate
831
832 # update params
833 optimizer.step()
834 optimizer.zero_grad()
835
836 """
837 if self.trainer.use_tpu and XLA_AVAILABLE:
838 xm.optimizer_step(optimizer)
839 elif isinstance(optimizer, torch.optim.LBFGS):
840 optimizer.step(second_order_closure)
841 else:
842 optimizer.step()
843
844 # clear gradients
845 optimizer.zero_grad()
846
847 def tbptt_split_batch(self, batch, split_size):
848 r"""
849
850 When using truncated backpropagation through time, each batch must be split along the time dimension.
851 Lightning handles this by default, but for custom behavior override this function.
852
853 Args:
854 batch (torch.nn.Tensor): Current batch
855 split_size (int): How big the split is
856
857 Return:
858 list of batch splits. Each split will be passed to forward_step to enable truncated
859 back propagation through time. The default implementation splits root level Tensors and
860 Sequences at dim=1 (i.e. time dim). It assumes that each time dim is the same length.
861
862 Example
863 -------
864 .. code-block:: python
865
866 def tbptt_split_batch(self, batch, split_size):
867 splits = []
868 for t in range(0, time_dims[0], split_size):
869 batch_split = []
870 for i, x in enumerate(batch):
871 if isinstance(x, torch.Tensor):
872 split_x = x[:, t:t + split_size]
873 elif isinstance(x, collections.Sequence):
874 split_x = [None] * len(x)
875 for batch_idx in range(len(x)):
876 split_x[batch_idx] = x[batch_idx][t:t + split_size]
877
878 batch_split.append(split_x)
879
880 splits.append(batch_split)
881
882 return splits
883
884 .. note:: Called in the training loop after on_batch_start if `truncated_bptt_steps > 0`.
885 Each returned batch split is passed separately to training_step(...).
886
887 """
888 time_dims = [len(x[0]) for x in batch if isinstance(x, (torch.Tensor, collections.Sequence))]
889 assert len(time_dims) >= 1, "Unable to determine batch time dimension"
890 assert all(x == time_dims[0] for x in time_dims), "Batch time dimension length is ambiguous"
891
892 splits = []
893 for t in range(0, time_dims[0], split_size):
894 batch_split = []
895 for i, x in enumerate(batch):
896 if isinstance(x, torch.Tensor):
897 split_x = x[:, t:t + split_size]
898 elif isinstance(x, collections.Sequence):
899 split_x = [None] * len(x)
900 for batch_idx in range(len(x)):
901 split_x[batch_idx] = x[batch_idx][t:t + split_size]
902
903 batch_split.append(split_x)
904
905 splits.append(batch_split)
906
907 return splits
908
909 def prepare_data(self):
910 """Use this to download and prepare data.
911 In distributed (GPU, TPU), this will only be called once
912
913 :return: PyTorch DataLoader
914
915 This is called before requesting the dataloaders
916
917 .. code-block:: python
918
919 model.prepare_data()
920 model.train_dataloader()
921 model.val_dataloader()
922 model.test_dataloader()
923
924 Example
925 -------
926
927 .. code-block:: python
928
929 def prepare_data(self):
930 download_imagenet()
931 clean_imagenet()
932 cache_imagenet()
933 """
934 return None
935
936 def train_dataloader(self):
937 """Implement a PyTorch DataLoader
938
939 :return: PyTorch DataLoader
940
941 Return a dataloader. It will not be called every epoch unless you set
942 ```Trainer(reload_dataloaders_every_epoch=True)```.
943
944 It's recommended that all data downloads and preparation happen in prepare_data().
945
946 .. note:: Lightning adds the correct sampler for distributed and arbitrary hardware. No need to set yourself.
947
948 - .fit()
949 - ...
950 - prepare_data()
951 - train_dataloader
952
953 Example
954 -------
955
956 .. code-block:: python
957
958 def train_dataloader(self):
959 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
960 dataset = MNIST(root='/path/to/mnist/', train=True, transform=transform, download=True)
961 loader = torch.utils.data.DataLoader(
962 dataset=dataset,
963 batch_size=self.hparams.batch_size,
964 shuffle=True
965 )
966 return loader
967
968 """
969 return None
970
971 @data_loader
972 def tng_dataloader(self): # todo: remove in v0.8.0
973 """Implement a PyTorch DataLoader.
974
975 .. warning:: Deprecated in v0.5.0. use train_dataloader instead.
976 """
977 output = self.train_dataloader()
978 warnings.warn("`tng_dataloader` has been renamed to `train_dataloader` since v0.5.0."
979 " and this method will be removed in v0.8.0", DeprecationWarning)
980 return output
981
982 def test_dataloader(self):
983 r"""
984
985 Return a dataloader. It will not be called every epoch unless you set
986 ```Trainer(reload_dataloaders_every_epoch=True)```.
987
988 It's recommended that all data downloads and preparation happen in prepare_data().
989
990 - .fit()
991 - ...
992 - prepare_data()
993 - train_dataloader
994 - val_dataloader
995 - test_dataloader
996
997 .. note:: Lightning adds the correct sampler for distributed and arbitrary hardware. No need to set yourself.
998
999 Return:
1000 PyTorch DataLoader
1001
1002 Example
1003 -------
1004
1005 .. code-block:: python
1006
1007 def test_dataloader(self):
1008 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
1009 dataset = MNIST(root='/path/to/mnist/', train=False, transform=transform, download=True)
1010 loader = torch.utils.data.DataLoader(
1011 dataset=dataset,
1012 batch_size=self.hparams.batch_size,
1013 shuffle=True
1014 )
1015
1016 return loader
1017
1018 .. note:: If you don't need a test dataset and a test_step, you don't need to implement this method.
1019
1020 .. note:: If you want to change the data during every epoch DON'T use the data_loader decorator.
1021
1022 """
1023 return None
1024
1025 def val_dataloader(self):
1026 r"""
1027
1028 Return a dataloader. It will not be called every epoch unless you set
1029 ```Trainer(reload_dataloaders_every_epoch=True)```.
1030
1031 It's recommended that all data downloads and preparation happen in prepare_data().
1032
1033 - .fit()
1034 - ...
1035 - prepare_data()
1036 - train_dataloader
1037 - val_dataloader
1038
1039 .. note:: Lightning adds the correct sampler for distributed and arbitrary hardware No need to set yourself.
1040
1041 Return:
1042 PyTorch DataLoader
1043
1044 Example
1045 -------
1046
1047 .. code-block:: python
1048
1049 def val_dataloader(self):
1050 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
1051 dataset = MNIST(root='/path/to/mnist/', train=False, transform=transform, download=True)
1052 loader = torch.utils.data.DataLoader(
1053 dataset=dataset,
1054 batch_size=self.hparams.batch_size,
1055 shuffle=True
1056 )
1057
1058 return loader
1059
1060 # can also return multiple dataloaders
1061 def val_dataloader(self):
1062 return [loader_a, loader_b, ..., loader_n]
1063
1064 Example
1065 -------
1066
1067 .. code-block:: python
1068
1069 @pl.data_loader
1070 def val_dataloader(self):
1071 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
1072 dataset = MNIST(root='/path/to/mnist/', train=False, transform=transform, download=True)
1073 loader = torch.utils.data.DataLoader(
1074 dataset=dataset,
1075 batch_size=self.hparams.batch_size,
1076 shuffle=True
1077 )
1078
1079 return loader
1080
1081 # can also return multiple dataloaders
1082 @pl.data_loader
1083 def val_dataloader(self):
1084 return [loader_a, loader_b, ..., loader_n]
1085
1086 .. note:: If you don't need a validation dataset and a validation_step, you don't need to implement this method.
1087
1088 .. note:: If you want to change the data during every epoch DON'T use the data_loader decorator.
1089
1090 .. note:: In the case where you return multiple `val_dataloaders`, the `validation_step`
1091 will have an argument `dataset_idx` which matches the order here.
1092 """
1093 return None
1094
1095 @classmethod
1096 def load_from_metrics(cls, weights_path, tags_csv, map_location=None):
1097 r"""
1098 Warning:
1099 Deprecated in version 0.7.0.
1100 You should use `load_from_checkpoint` instead.
1101 Will be removed in v0.9.0.
1102 """
1103 warnings.warn(
1104 "`load_from_metrics` method has been unified with `load_from_checkpoint` in v0.7.0."
1105 " The deprecated method will be removed in v0.9.0.", DeprecationWarning
1106 )
1107 return cls.load_from_checkpoint(weights_path, tags_csv=tags_csv, map_location=map_location)
1108
1109 @classmethod
1110 def load_from_checkpoint(
1111 cls,
1112 checkpoint_path: str,
1113 map_location: Optional[Union[Dict[str, str], str, torch.device, int, Callable]] = None,
1114 tags_csv: Optional[str] = None,
1115 ) -> 'LightningModule':
1116 r"""
1117
1118 Primary way of loading model from a checkpoint. When Lightning saves a checkpoint
1119 it stores the hyperparameters in the checkpoint if you initialized your LightningModule
1120 with an argument called `hparams` which is a Namespace (output of using argparse
1121 to parse command line arguments).
1122
1123 Example
1124 -------
1125 .. code-block:: python
1126
1127 from argparse import Namespace
1128 hparams = Namespace(**{'learning_rate': 0.1})
1129
1130 model = MyModel(hparams)
1131
1132 class MyModel(LightningModule):
1133 def __init__(self, hparams):
1134 self.learning_rate = hparams.learning_rate
1135
1136 Args:
1137 checkpoint_path: Path to checkpoint.
1138 map_location:
1139 If your checkpoint saved a GPU model and you now load on CPUs
1140 or a different number of GPUs, use this to map to the new setup.
1141 The behaviour is the same as in
1142 `torch.load <https://pytorch.org/docs/stable/torch.html#torch.load>`_.
1143 tags_csv: Optional path to a .csv file with two columns (key, value)
1144 as in this example::
1145
1146 key,value
1147 drop_prob,0.2
1148 batch_size,32
1149
1150 You most likely won't need this since Lightning will always save the hyperparameters
1151 to the checkpoint.
1152 However, if your checkpoint weights don't have the hyperparameters saved,
1153 use this method to pass in a .csv file with the hparams you'd like to use.
1154 These will be converted into a argparse.Namespace and passed into your
1155 LightningModule for use.
1156
1157 Return:
1158 LightningModule with loaded weights and hyperparameters (if available).
1159
1160 Example
1161 -------
1162 .. code-block:: python
1163
1164 # load weights without mapping ...
1165 MyLightningModule.load_from_checkpoint('path/to/checkpoint.ckpt')
1166
1167 # or load weights mapping all weights from GPU 1 to GPU 0 ...
1168 map_location = {'cuda:1':'cuda:0'}
1169 MyLightningModule.load_from_checkpoint(
1170 'path/to/checkpoint.ckpt',
1171 map_location=map_location
1172 )
1173
1174 # or load weights and hyperparameters from separate files.
1175 MyLightningModule.load_from_checkpoint(
1176 'path/to/checkpoint.ckpt',
1177 tags_csv='/path/to/hparams_file.csv'
1178 )
1179
1180 # predict
1181 pretrained_model.eval()
1182 pretrained_model.freeze()
1183 y_hat = pretrained_model(x)
1184 """
1185 if map_location is not None:
1186 checkpoint = torch.load(checkpoint_path, map_location=map_location)
1187 else:
1188 checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
1189
1190 if tags_csv is not None:
1191 # add the hparams from csv file to checkpoint
1192 hparams = load_hparams_from_tags_csv(tags_csv)
1193 hparams.__setattr__('on_gpu', False)
1194 checkpoint['hparams'] = vars(hparams)
1195
1196 model = cls._load_model_state(checkpoint)
1197 return model
1198
1199 @classmethod
1200 def _load_model_state(cls, checkpoint):
1201 cls_takes_hparams = 'hparams' in inspect.signature(cls.__init__).parameters
1202 ckpt_hparams = checkpoint.get('hparams')
1203
1204 if cls_takes_hparams:
1205 if ckpt_hparams is not None:
1206 is_namespace = checkpoint.get('hparams_type') == 'namespace'
1207 hparams = Namespace(**ckpt_hparams) if is_namespace else ckpt_hparams
1208 else:
1209 warnings.warn(
1210 f"Checkpoint does not contain hyperparameters but {cls.__name__}'s __init__ contains"
1211 " argument 'hparams'. Will pass in an empty Namespace instead."
1212 " Did you forget to store your model hyperparameters in self.hparams?"
1213 )
1214 hparams = Namespace()
1215 else: # The user's LightningModule does not define a hparams argument
1216 if ckpt_hparams is None:
1217 hparams = None
1218 else:
1219 raise MisconfigurationException(
1220 f"Checkpoint contains hyperparameters but {cls.__name__}'s __init__ is missing the"
1221 " argument 'hparams'. Are you loading the correct checkpoint?"
1222 )
1223
1224 # load the state_dict on the model automatically
1225 model_args = [hparams] if hparams else []
1226 model = cls(*model_args)
1227 model.load_state_dict(checkpoint['state_dict'])
1228
1229 # give model a chance to load something
1230 model.on_load_checkpoint(checkpoint)
1231
1232 return model
1233
1234 def summarize(self, mode):
1235 model_summary = ModelSummary(self, mode=mode)
1236 log.info('\n' + model_summary.__str__())
1237
1238 def freeze(self):
1239 r"""
1240 Freeze all params for inference
1241
1242 Example
1243 -------
1244 .. code-block:: python
1245
1246 model = MyLightningModule(...)
1247 model.freeze()
1248
1249 """
1250 for param in self.parameters():
1251 param.requires_grad = False
1252
1253 self.eval()
1254
1255 def unfreeze(self):
1256 """Unfreeze all params for training.
1257
1258 .. code-block:: python
1259
1260 model = MyLightningModule(...)
1261 model.unfreeze()
1262
1263 """
1264 for param in self.parameters():
1265 param.requires_grad = True
1266
1267 self.train()
1268
1269 def on_load_checkpoint(self, checkpoint):
1270 r"""
1271 Called by lightning to restore your model.
1272 If you saved something with **on_save_checkpoint** this is your chance to restore this.
1273
1274 Args:
1275 checkpoint (dict): Loaded checkpoint
1276
1277
1278 Example
1279 -------
1280
1281 .. code-block:: python
1282
1283 def on_load_checkpoint(self, checkpoint):
1284 # 99% of the time you don't need to implement this method
1285 self.something_cool_i_want_to_save = checkpoint['something_cool_i_want_to_save']
1286
1287 .. note:: Lighting auto-restores global step, epoch, and all training state including amp scaling.
1288 No need for you to restore anything regarding training.
1289 """
1290
1291 def on_save_checkpoint(self, checkpoint):
1292 r"""
1293
1294 Called by lightning when saving a checkpoint to give you a chance to store anything else you
1295 might want to save
1296
1297 Args:
1298 checkpoint (dic): Checkpoint to be saved
1299
1300 Example
1301 -------
1302
1303 .. code-block:: python
1304
1305 def on_save_checkpoint(self, checkpoint):
1306 # 99% of use cases you don't need to implement this method
1307 checkpoint['something_cool_i_want_to_save'] = my_cool_pickable_object
1308
1309 .. note:: Lighting saves all aspects of training (epoch, global step, etc...) including amp scaling. No need
1310 for you to store anything about training.
1311
1312 """
1313
1314 def get_tqdm_dict(self):
1315 r"""
1316 Additional items to be displayed in the progress bar.
1317
1318 Return:
1319 Dictionary with the items to be displayed in the progress bar.
1320 """
1321 tqdm_dict = {
1322 'loss': '{:.3f}'.format(self.trainer.avg_loss)
1323 }
1324
1325 if self.trainer.truncated_bptt_steps is not None:
1326 tqdm_dict['split_idx'] = self.trainer.split_idx
1327
1328 if self.trainer.logger is not None and self.trainer.logger.version is not None:
1329 tqdm_dict['v_num'] = self.trainer.logger.version
1330
1331 return tqdm_dict
1332
[end of pytorch_lightning/core/lightning.py]
[start of pytorch_lightning/trainer/trainer.py]
1 import os
2 import sys
3 import warnings
4 import logging as log
5 from typing import Union, Optional, List, Dict, Tuple, Iterable
6 from argparse import ArgumentParser
7
8 import torch
9 import torch.distributed as dist
10 import torch.multiprocessing as mp
11 from torch.utils.data import DataLoader
12 from tqdm.auto import tqdm
13 from torch.optim.optimizer import Optimizer
14
15 from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
16 from pytorch_lightning.loggers import LightningLoggerBase
17 from pytorch_lightning.profiler.profiler import BaseProfiler
18 from pytorch_lightning.trainer.auto_mix_precision import TrainerAMPMixin
19 from pytorch_lightning.trainer.callback_config import TrainerCallbackConfigMixin
20 from pytorch_lightning.trainer.data_loading import TrainerDataLoadingMixin
21 from pytorch_lightning.trainer.distrib_data_parallel import TrainerDDPMixin
22 from pytorch_lightning.trainer.distrib_parts import (
23 TrainerDPMixin,
24 parse_gpu_ids,
25 determine_root_gpu_device
26 )
27 from pytorch_lightning.core.lightning import LightningModule
28 from pytorch_lightning.trainer.evaluation_loop import TrainerEvaluationLoopMixin
29 from pytorch_lightning.trainer.logging import TrainerLoggingMixin
30 from pytorch_lightning.trainer.model_hooks import TrainerModelHooksMixin
31 from pytorch_lightning.trainer.training_io import TrainerIOMixin
32 from pytorch_lightning.trainer.training_loop import TrainerTrainLoopMixin
33 from pytorch_lightning.trainer.training_tricks import TrainerTrainingTricksMixin
34 from pytorch_lightning.trainer.callback_hook import TrainerCallbackHookMixin
35 from pytorch_lightning.utilities.debugging import MisconfigurationException
36 from pytorch_lightning.profiler import Profiler, PassThroughProfiler
37 from pytorch_lightning.callbacks import Callback
38
39
40 try:
41 from apex import amp
42 except ImportError:
43 APEX_AVAILABLE = False
44 else:
45 APEX_AVAILABLE = True
46
47 try:
48 import torch_xla
49 import torch_xla.core.xla_model as xm
50 import torch_xla.distributed.xla_multiprocessing as xmp
51 except ImportError:
52 XLA_AVAILABLE = False
53 else:
54 XLA_AVAILABLE = True
55
56
57 class Trainer(TrainerIOMixin,
58 TrainerDPMixin,
59 TrainerDDPMixin,
60 TrainerLoggingMixin,
61 TrainerModelHooksMixin,
62 TrainerTrainingTricksMixin,
63 TrainerDataLoadingMixin,
64 TrainerAMPMixin,
65 TrainerEvaluationLoopMixin,
66 TrainerTrainLoopMixin,
67 TrainerCallbackConfigMixin,
68 TrainerCallbackHookMixin
69 ):
70
71 def __init__(
72 self,
73 logger: Union[LightningLoggerBase, Iterable[LightningLoggerBase], bool] = True,
74 checkpoint_callback: Union[ModelCheckpoint, bool] = True,
75 early_stop_callback: Optional[Union[EarlyStopping, bool]] = False,
76 callbacks: List[Callback] = [],
77 default_save_path: Optional[str] = None,
78 gradient_clip_val: float = 0,
79 gradient_clip=None, # backward compatible, todo: remove in v0.8.0
80 process_position: int = 0,
81 nb_gpu_nodes=None, # backward compatible, todo: remove in v0.8.0
82 num_nodes: int = 1,
83 gpus: Optional[Union[List[int], str, int]] = None,
84 num_tpu_cores: Optional[int] = None,
85 log_gpu_memory: Optional[str] = None,
86 show_progress_bar: bool = True,
87 progress_bar_refresh_rate: int = 50,
88 overfit_pct: float = 0.0,
89 track_grad_norm: int = -1,
90 check_val_every_n_epoch: int = 1,
91 fast_dev_run: bool = False,
92 accumulate_grad_batches: Union[int, Dict[int, int], List[list]] = 1,
93 max_nb_epochs=None, # backward compatible, todo: remove in v0.8.0
94 min_nb_epochs=None, # backward compatible, todo: remove in v0.8.0
95 max_epochs: int = 1000,
96 min_epochs: int = 1,
97 max_steps: Optional[int] = None,
98 min_steps: Optional[int] = None,
99 train_percent_check: float = 1.0,
100 val_percent_check: float = 1.0,
101 test_percent_check: float = 1.0,
102 val_check_interval: float = 1.0,
103 log_save_interval: int = 100,
104 row_log_interval: int = 10,
105 add_row_log_interval=None, # backward compatible, todo: remove in v0.8.0
106 distributed_backend: Optional[str] = None,
107 use_amp=False, # backward compatible, todo: remove in v0.8.0
108 precision: int = 32,
109 print_nan_grads: bool = False,
110 weights_summary: str = 'full',
111 weights_save_path: Optional[str] = None,
112 amp_level: str = 'O1',
113 nb_sanity_val_steps=None, # backward compatible, todo: remove in v0.8.0
114 num_sanity_val_steps: int = 5,
115 truncated_bptt_steps: Optional[int] = None,
116 resume_from_checkpoint: Optional[str] = None,
117 profiler: Optional[BaseProfiler] = None,
118 benchmark: bool = False,
119 reload_dataloaders_every_epoch: bool = False,
120 **kwargs
121 ):
122 r"""
123
124 Customize every aspect of training via flags
125
126 Args:
127 logger: Logger (or iterable collection of loggers) for experiment tracking.
128 Example::
129
130 from pytorch_lightning.loggers import TensorBoardLogger
131
132 # default logger used by trainer
133 logger = TensorBoardLogger(
134 save_dir=os.getcwd(),
135 version=self.slurm_job_id,
136 name='lightning_logs'
137 )
138
139 Trainer(logger=logger)
140
141 checkpoint_callback: Callback for checkpointing.
142 Example::
143
144 from pytorch_lightning.callbacks import ModelCheckpoint
145
146 # default used by the Trainer
147 checkpoint_callback = ModelCheckpoint(
148 filepath=os.getcwd(),
149 save_best_only=True,
150 verbose=True,
151 monitor='val_loss',
152 mode='min',
153 prefix=''
154 )
155
156 trainer = Trainer(checkpoint_callback=checkpoint_callback)
157
158 early_stop_callback (:class:`pytorch_lightning.callbacks.EarlyStopping`):
159 Callback for early stopping.
160 If set to ``True``, then a default callback monitoring ``'val_loss'`` is created.
161 Will raise an error if ``'val_loss'`` is not found.
162 If set to ``False``, then early stopping will be disabled.
163 If set to ``None``, then the default callback monitoring ``'val_loss'`` is created.
164 If ``'val_loss'`` is not found will work as if early stopping is disabled.
165 Default: ``None``.
166 Example::
167
168 from pytorch_lightning.callbacks import EarlyStopping
169
170 # default used by the Trainer
171 early_stop_callback = EarlyStopping(
172 monitor='val_loss',
173 patience=3,
174 strict=False,
175 verbose=False,
176 mode='min'
177 )
178
179 trainer = Trainer(early_stop_callback=early_stop_callback)
180
181 callbacks: Add a list of callbacks.
182 Example::
183 from pytorch_lightning.callbacks import Callback
184 class PrintCallback(Callback):
185 def on_train_start(self):
186 print("Training is started!")
187 def on_train_end(self):
188 print(f"Training is done. The logs are: {self.trainer.logs}")
189 # a list of callbacks
190 callbacks = [PrintCallback()]
191 trainer = Trainer(callbacks=callbacks)
192
193 default_save_path: Default path for logs and weights when no logger/ckpt_callback passed
194 Example::
195
196 # default used by the Trainer
197 trainer = Trainer(default_save_path=os.getcwd())
198
199 gradient_clip_val: 0 means don't clip.
200 Example::
201
202 # default used by the Trainer
203 trainer = Trainer(gradient_clip_val=0.0)
204
205 gradient_clip:
206 .. warning: .. deprecated:: 0.5.0
207 Use `gradient_clip_val` instead. Will remove 0.8.0.
208
209 process_position: orders the tqdm bar when running multiple models on same machine.
210 Example::
211
212 # default used by the Trainer
213 trainer = Trainer(process_position=0)
214
215 num_nodes: number of GPU nodes for distributed training.
216 Example::
217
218 # default used by the Trainer
219 trainer = Trainer(num_nodes=1)
220
221 # to train on 8 nodes
222 trainer = Trainer(num_nodes=8)
223
224 nb_gpu_nodes:
225 ..warning:: .. deprecated:: 0.5.0
226 Use `num_nodes` instead. Will remove 0.8.0.
227
228 gpus: Which GPUs to train on.
229 Example::
230
231 # default used by the Trainer (ie: train on CPU)
232 trainer = Trainer(gpus=None)
233
234 # int: train on 2 gpus
235 trainer = Trainer(gpus=2)
236
237 # list: train on GPUs 1, 4 (by bus ordering)
238 trainer = Trainer(gpus=[1, 4])
239 trainer = Trainer(gpus='1, 4') # equivalent
240
241 # -1: train on all gpus
242 trainer = Trainer(gpus=-1)
243 trainer = Trainer(gpus='-1') # equivalent
244
245 # combine with num_nodes to train on multiple GPUs across nodes
246 trainer = Trainer(gpus=2, num_nodes=4) # uses 8 gpus in total
247
248 num_tpu_cores: How many TPU cores to train on (1 or 8).
249 A single TPU v2 or v3 has 8 cores. A TPU pod has
250 up to 2048 cores. A slice of a POD means you get as many cores
251 as you request.
252
253 You MUST use DistributedDataSampler with your dataloader for this
254 to work. Your effective batch size is batch_size * total tpu cores.
255
256 This parameter can be either 1 or 8.
257
258 Example::
259
260 # your_trainer_file.py
261
262 # default used by the Trainer (ie: train on CPU)
263 trainer = Trainer(num_tpu_cores=None)
264
265 # int: train on a single core
266 trainer = Trainer(num_tpu_cores=1)
267
268 # int: train on all cores few cores
269 trainer = Trainer(num_tpu_cores=8)
270
271 # for 8+ cores must submit via xla script with
272 # a max of 8 cores specified. The XLA script
273 # will duplicate script onto each TPU in the POD
274 trainer = Trainer(num_tpu_cores=8)
275
276 # -1: train on all available TPUs
277 trainer = Trainer(num_tpu_cores=-1)
278
279 To train on more than 8 cores (ie: a POD),
280 submit this script using the xla_dist script.
281
282 Example::
283
284 $ python -m torch_xla.distributed.xla_dist
285 --tpu=$TPU_POD_NAME
286 --conda-env=torch-xla-nightly
287 --env=XLA_USE_BF16=1
288 -- python your_trainer_file.py
289
290 log_gpu_memory: None, 'min_max', 'all'. Might slow performance
291 because it uses the output of nvidia-smi.
292 Example::
293
294 # default used by the Trainer
295 trainer = Trainer(log_gpu_memory=None)
296
297 # log all the GPUs (on master node only)
298 trainer = Trainer(log_gpu_memory='all')
299
300 # log only the min and max memory on the master node
301 trainer = Trainer(log_gpu_memory='min_max')
302
303 show_progress_bar: If true shows tqdm progress bar
304 Example::
305
306 # default used by the Trainer
307 trainer = Trainer(show_progress_bar=True)
308
309 progress_bar_refresh_rate: How often to refresh progress bar (in steps)
310
311 overfit_pct: uses this much data of all datasets.
312 Example::
313
314 # default used by the Trainer
315 trainer = Trainer(overfit_pct=0.0)
316
317 # use only 1% of the train, test, val datasets
318 trainer = Trainer(overfit_pct=0.01)
319
320 track_grad_norm: -1 no tracking. Otherwise tracks that norm
321 Example::
322
323 # default used by the Trainer
324 trainer = Trainer(track_grad_norm=-1)
325
326 # track the 2-norm
327 trainer = Trainer(track_grad_norm=2)
328
329 check_val_every_n_epoch: Check val every n train epochs.
330 Example::
331
332 # default used by the Trainer
333 trainer = Trainer(check_val_every_n_epoch=1)
334
335 # run val loop every 10 training epochs
336 trainer = Trainer(check_val_every_n_epoch=10)
337
338 fast_dev_run: runs 1 batch of train, test and val to find any bugs (ie: a sort of unit test).
339 Example::
340
341 # default used by the Trainer
342 trainer = Trainer(fast_dev_run=False)
343
344 # runs 1 train, val, test batch and program ends
345 trainer = Trainer(fast_dev_run=True)
346
347 accumulate_grad_batches: Accumulates grads every k batches or as set up in the dict.
348 Example::
349
350 # default used by the Trainer (no accumulation)
351 trainer = Trainer(accumulate_grad_batches=1)
352
353 # accumulate every 4 batches (effective batch size is batch*4)
354 trainer = Trainer(accumulate_grad_batches=4)
355
356 # no accumulation for epochs 1-4. accumulate 3 for epochs 5-10. accumulate 20 after that
357 trainer = Trainer(accumulate_grad_batches={5: 3, 10: 20})
358
359 max_epochs: Stop training once this number of epochs is reached.
360 Example::
361
362 # default used by the Trainer
363 trainer = Trainer(max_epochs=1000)
364
365 max_nb_epochs:
366 .. warning:: .. deprecated:: 0.5.0
367 Use `max_epochs` instead. Will remove 0.8.0.
368
369 min_epochs: Force training for at least these many epochs
370 Example::
371
372 # default used by the Trainer
373 trainer = Trainer(min_epochs=1)
374
375 min_nb_epochs:
376 .. warning:: .. deprecated:: 0.5.0
377 Use `min_nb_epochs` instead. Will remove 0.8.0.
378
379 max_steps: Stop training after this number of steps. Disabled by default (None).
380 Training will stop if max_steps or max_epochs have reached (earliest).
381 Example::
382
383 # Stop after 100 steps
384 trainer = Trainer(max_steps=100)
385
386 min_steps: Force training for at least these number of steps. Disabled by default (None).
387 Trainer will train model for at least min_steps or min_epochs (latest).
388 Example::
389
390 # Run at least for 100 steps (disable min_epochs)
391 trainer = Trainer(min_steps=100, min_epochs=0)
392
393 train_percent_check: How much of training dataset to check.
394 Useful when debugging or testing something that happens at the end of an epoch.
395 Example::
396
397 # default used by the Trainer
398 trainer = Trainer(train_percent_check=1.0)
399
400 # run through only 25% of the training set each epoch
401 trainer = Trainer(train_percent_check=0.25)
402
403 val_percent_check: How much of validation dataset to check.
404 Useful when debugging or testing something that happens at the end of an epoch.
405 Example::
406
407 # default used by the Trainer
408 trainer = Trainer(val_percent_check=1.0)
409
410 # run through only 25% of the validation set each epoch
411 trainer = Trainer(val_percent_check=0.25)
412
413 test_percent_check: How much of test dataset to check.
414 Useful when debugging or testing something that happens at the end of an epoch.
415 Example::
416
417 # default used by the Trainer
418 trainer = Trainer(test_percent_check=1.0)
419
420 # run through only 25% of the test set each epoch
421 trainer = Trainer(test_percent_check=0.25)
422
423 val_check_interval: How often within one training epoch to check the validation set
424 If float, % of tng epoch. If int, check every n batch
425 Example::
426
427 # default used by the Trainer
428 trainer = Trainer(val_check_interval=1.0)
429
430 # check validation set 4 times during a training epoch
431 trainer = Trainer(val_check_interval=0.25)
432
433 # check validation set every 1000 training batches
434 # use this when using iterableDataset and your dataset has no length
435 # (ie: production cases with streaming data)
436 trainer = Trainer(val_check_interval=1000)
437
438 log_save_interval: Writes logs to disk this often
439 Example::
440
441 # default used by the Trainer
442 trainer = Trainer(log_save_interval=100)
443
444 row_log_interval: How often to add logging rows (does not write to disk)
445 Example::
446
447 # default used by the Trainer
448 trainer = Trainer(row_log_interval=10)
449
450 add_row_log_interval:
451 .. warning:: .. deprecated:: 0.5.0
452 Use `row_log_interval` instead. Will remove 0.8.0.
453
454 distributed_backend: The distributed backend to use.
455 Options: 'dp', 'ddp', 'ddp2'.
456 Example::
457
458 # default used by the Trainer
459 trainer = Trainer(distributed_backend=None)
460
461 # dp = DataParallel (split a batch onto k gpus on same machine).
462 trainer = Trainer(gpus=2, distributed_backend='dp')
463
464 # ddp = DistributedDataParallel
465 # Each gpu trains by itself on a subset of the data.
466 # Gradients sync across all gpus and all machines.
467 trainer = Trainer(gpus=2, num_nodes=2, distributed_backend='ddp')
468
469 # ddp2 = DistributedDataParallel + dp
470 # behaves like dp on every node
471 # syncs gradients across nodes like ddp
472 # useful for things like increasing the number of negative samples
473 trainer = Trainer(gpus=2, num_nodes=2, distributed_backend='ddp2')
474
475 use_amp:
476 .. warning:: .. deprecated:: 0.6.1
477 Use `precision` instead. Will remove 0.8.0.
478
479 precision: Full precision (32), half precision (16).
480 Can be used on CPU, GPU or TPUs.
481
482 If used on TPU will use torch.bfloat16 but tensor printing
483 will still show torch.float32.
484
485 Example::
486
487 # default used by the Trainer
488 trainer = Trainer(precision=32)
489
490 # 16-bit precision
491 trainer = Trainer(precision=16)
492
493 # one day
494 trainer = Trainer(precision=8|4|2)
495
496 print_nan_grads: Prints gradients with nan values
497 Example::
498
499 # default used by the Trainer
500 trainer = Trainer(print_nan_grads=False)
501
502 weights_summary: Prints a summary of the weights when training begins.
503 Options: 'full', 'top', None.
504 Example::
505
506 # default used by the Trainer (ie: print all weights)
507 trainer = Trainer(weights_summary='full')
508
509 # print only the top level modules
510 trainer = Trainer(weights_summary='top')
511
512 # don't print a summary
513 trainer = Trainer(weights_summary=None)
514
515 weights_save_path: Where to save weights if specified.
516 Example::
517
518 # default used by the Trainer
519 trainer = Trainer(weights_save_path=os.getcwd())
520
521 # save to your custom path
522 trainer = Trainer(weights_save_path='my/path')
523
524 # if checkpoint callback used, then overrides the weights path
525 # **NOTE: this saves weights to some/path NOT my/path
526 checkpoint_callback = ModelCheckpoint(filepath='some/path')
527 trainer = Trainer(
528 checkpoint_callback=checkpoint_callback,
529 weights_save_path='my/path'
530 )
531
532 amp_level: The optimization level to use (O1, O2, etc...).
533 Check nvidia docs for level (https://nvidia.github.io/apex/amp.html#opt-levels)
534 Example::
535
536 # default used by the Trainer
537 trainer = Trainer(amp_level='O1')
538
539 num_sanity_val_steps: Sanity check runs n batches of val before starting the training routine.
540 This catches any bugs in your validation without having to wait for the first validation check.
541 The Trainer uses 5 steps by default. Turn it off or modify it here.
542 Example::
543
544 # default used by the Trainer
545 trainer = Trainer(num_sanity_val_steps=5)
546
547 # turn it off
548 trainer = Trainer(num_sanity_val_steps=0)
549
550 nb_sanity_val_steps:
551 .. warning:: .. deprecated:: 0.5.0
552 Use `num_sanity_val_steps` instead. Will remove 0.8.0.
553
554 truncated_bptt_steps: Truncated back prop breaks performs backprop every k steps of
555 a much longer sequence If this is enabled, your batches will automatically get truncated
556 and the trainer will apply Truncated Backprop to it. Make sure your batches have a sequence
557 dimension. (`Williams et al. "An efficient gradient-based algorithm for on-line training of
558 recurrent network trajectories."
559 <http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.56.7941&rep=rep1&type=pdf>`_)
560 Example::
561
562 # default used by the Trainer (ie: disabled)
563 trainer = Trainer(truncated_bptt_steps=None)
564
565 # backprop every 5 steps in a batch
566 trainer = Trainer(truncated_bptt_steps=5)
567
568
569 Lightning takes care to split your batch along the time-dimension.
570
571 .. note:: If you need to modify how the batch is split,
572 override :meth:`pytorch_lightning.core.LightningModule.tbptt_split_batch`.
573
574 .. note:: Using this feature requires updating your LightningModule's
575 :meth:`pytorch_lightning.core.LightningModule.training_step` to include a `hiddens` arg.
576
577 resume_from_checkpoint: To resume training from a specific checkpoint pass in the path here.k
578 Example::
579
580 # default used by the Trainer
581 trainer = Trainer(resume_from_checkpoint=None)
582
583 # resume from a specific checkpoint
584 trainer = Trainer(resume_from_checkpoint='some/path/to/my_checkpoint.ckpt')
585 profiler: To profile individual steps during training and assist in
586 identifying bottlenecks.
587 Example::
588
589 from pytorch_lightning.profiler import Profiler, AdvancedProfiler
590
591 # default used by the Trainer
592 trainer = Trainer(profiler=None)
593
594 # to profile standard training events
595 trainer = Trainer(profiler=True)
596
597 # equivalent to profiler=True
598 profiler = Profiler()
599 trainer = Trainer(profiler=profiler)
600
601 # advanced profiler for function-level stats
602 profiler = AdvancedProfiler()
603 trainer = Trainer(profiler=profiler)
604 reload_dataloaders_every_epoch: Set to True to reload dataloaders every epoch
605
606 benchmark (bool): If true enables cudnn.benchmark.
607 This flag is likely to increase the speed of your system if your
608 input sizes don't change. However, if it does, then it will likely
609 make your system slower.
610
611 The speedup comes from allowing the cudnn auto-tuner to find the best
612 algorithm for the hardware `[see discussion here]
613 <https://discuss.pytorch.org/t/what-does-torch-backends-cudnn-benchmark-do/5936>`_.
614
615 .. warning:: Following arguments become deprecated and they will be removed in v0.8.0:
616
617 - `nb_sanity_val_steps`
618
619 """
620
621 # Init callbacks
622 self.callbacks = callbacks
623 self.on_init_start()
624
625 # benchmarking
626 self.benchmark = benchmark
627 if benchmark:
628 torch.backends.cudnn.benchmark = True
629
630 # Transfer params
631 # Backward compatibility
632 self.num_nodes = num_nodes
633 if nb_gpu_nodes is not None:
634 warnings.warn("`nb_gpu_nodes` has renamed to `num_nodes` since v0.5.0"
635 " and this method will be removed in v0.8.0", DeprecationWarning)
636 if not num_nodes: # in case you did not set the proper value
637 num_nodes = nb_gpu_nodes
638 self.num_gpu_nodes = num_nodes
639 self.log_gpu_memory = log_gpu_memory
640
641 # Backward compatibility
642 if gradient_clip is not None:
643 warnings.warn("`gradient_clip` has renamed to `gradient_clip_val` since v0.5.0"
644 " and this method will be removed in v0.8.0", DeprecationWarning)
645 if not gradient_clip_val: # in case you did not set the proper value
646 gradient_clip_val = gradient_clip
647 self.gradient_clip_val = gradient_clip_val
648
649 self.reload_dataloaders_every_epoch = reload_dataloaders_every_epoch
650 self.progress_bar_refresh_rate = progress_bar_refresh_rate
651 self.check_val_every_n_epoch = check_val_every_n_epoch
652 self.track_grad_norm = track_grad_norm
653 self.on_gpu = True if (gpus and torch.cuda.is_available()) else False
654
655 # tpu config
656 self.on_tpu = num_tpu_cores is not None
657 self.num_tpu_cores = num_tpu_cores
658 assert num_tpu_cores in [1, 8, None], 'num_tpu_cores can only be 1 or 8'
659
660 self.process_position = process_position
661 self.weights_summary = weights_summary
662
663 # Backward compatibility
664 if max_nb_epochs is not None:
665 warnings.warn("`max_nb_epochs` has renamed to `max_epochs` since v0.5.0"
666 " and this method will be removed in v0.8.0", DeprecationWarning)
667 if not max_epochs: # in case you did not set the proper value
668 max_epochs = max_nb_epochs
669 self.max_epochs = max_epochs
670
671 # Backward compatibility
672 if min_nb_epochs is not None:
673 warnings.warn("`min_nb_epochs` has renamed to `min_epochs` since v0.5.0"
674 " and this method will be removed in v0.8.0", DeprecationWarning)
675 if not min_epochs: # in case you did not set the proper value
676 min_epochs = min_nb_epochs
677 self.min_epochs = min_epochs
678
679 self.max_steps = max_steps
680 self.min_steps = min_steps
681
682 # Backward compatibility
683 if nb_sanity_val_steps is not None:
684 warnings.warn("`nb_sanity_val_steps` has renamed to `num_sanity_val_steps` since v0.5.0"
685 " and this method will be removed in v0.8.0", DeprecationWarning)
686 if not num_sanity_val_steps: # in case you did not set the proper value
687 num_sanity_val_steps = nb_sanity_val_steps
688
689 self.num_sanity_val_steps = num_sanity_val_steps
690 self.print_nan_grads = print_nan_grads
691 self.truncated_bptt_steps = truncated_bptt_steps
692 self.resume_from_checkpoint = resume_from_checkpoint
693 self.shown_warnings = set()
694
695 self.fast_dev_run = fast_dev_run
696 if self.fast_dev_run:
697 self.num_sanity_val_steps = 1
698 self.max_epochs = 1
699 m = '''
700 Running in fast_dev_run mode: will run a full train,
701 val loop using a single batch
702 '''
703 log.info(m)
704
705 # set default save path if user didn't provide one
706 self.default_save_path = default_save_path
707 if self.default_save_path is None:
708 self.default_save_path = os.getcwd()
709
710 # training bookeeping
711 self.total_batch_idx = 0
712 self.running_loss = []
713 self.avg_loss = 0
714 self.batch_idx = 0
715 self.tqdm_metrics = {}
716 self.callback_metrics = {}
717 self.num_val_batches = 0
718 self.num_training_batches = 0
719 self.num_test_batches = 0
720 self.train_dataloader = None
721 self.test_dataloaders = None
722 self.val_dataloaders = None
723
724 # training state
725 self.model = None
726 self.testing = False
727 self.disable_validation = False
728 self.lr_schedulers = []
729 self.optimizers = None
730 self.global_step = 0
731 self.current_epoch = 0
732 self.total_batches = 0
733
734 # configure logger
735 self.configure_logger(logger)
736
737 # configure profiler
738 if profiler is True:
739 profiler = Profiler()
740 self.profiler = profiler or PassThroughProfiler()
741
742 # configure early stop callback
743 # creates a default one if none passed in
744 self.configure_early_stopping(early_stop_callback)
745
746 self.reduce_lr_on_plateau_scheduler = None
747
748 # configure checkpoint callback
749 self.checkpoint_callback = checkpoint_callback
750 self.weights_save_path = weights_save_path
751
752 # accumulated grads
753 self.accumulate_grad_batches = accumulate_grad_batches
754 self.configure_accumulated_gradients(accumulate_grad_batches)
755
756 # allow int, string and gpu list
757 self.gpus = gpus
758 self.data_parallel_device_ids = parse_gpu_ids(self.gpus)
759 self.root_gpu = determine_root_gpu_device(self.data_parallel_device_ids)
760
761 # tpu state flags
762 self.use_tpu = False
763 self.tpu_local_core_rank = None
764 self.tpu_global_core_rank = None
765
766 # distributed backend choice
767 self.use_ddp = False
768 self.use_ddp2 = False
769 self.use_dp = False
770 self.single_gpu = False
771 self.distributed_backend = distributed_backend
772 self.set_distributed_mode(distributed_backend, num_nodes)
773
774 # override dist backend when using tpus
775 if self.on_tpu:
776 self.init_tpu()
777 self.current_tpu_idx = None
778
779 # init flags for SLURM+ddp to work
780 self.proc_rank = 0
781 self.world_size = 1
782 self.node_rank = 0
783 self.configure_slurm_ddp(num_nodes)
784
785 # nvidia setup
786 self.set_nvidia_flags(self.is_slurm_managing_tasks, self.data_parallel_device_ids)
787
788 # can't init progress bar here because starting a new process
789 # means the progress_bar won't survive pickling
790 self.show_progress_bar = show_progress_bar
791
792 # logging
793 self.log_save_interval = log_save_interval
794 self.val_check_interval = val_check_interval
795
796 # backward compatibility
797 if add_row_log_interval is not None:
798 warnings.warn("`add_row_log_interval` has renamed to `row_log_interval` since v0.5.0"
799 " and this method will be removed in v0.8.0", DeprecationWarning)
800 if not row_log_interval: # in case you did not set the proper value
801 row_log_interval = add_row_log_interval
802 self.row_log_interval = row_log_interval
803
804 # how much of the data to use
805 self.overfit_pct = overfit_pct
806 self.determine_data_use_amount(train_percent_check, val_percent_check,
807 test_percent_check, overfit_pct)
808
809 # 16 bit mixed precision training using apex
810 self.amp_level = amp_level
811 self.precision = precision
812
813 assert self.precision in (16, 32), 'only 32 or 16 bit precision supported'
814
815 if self.precision == 16 and num_tpu_cores is None:
816 use_amp = True
817 self.init_amp(use_amp)
818
819 # Callback system
820 self.on_init_end()
821
822 @property
823 def slurm_job_id(self) -> int:
824 try:
825 job_id = os.environ['SLURM_JOB_ID']
826 job_id = int(job_id)
827 except Exception:
828 job_id = None
829 return job_id
830
831 @classmethod
832 def default_attributes(cls):
833 return vars(cls())
834
835 @classmethod
836 def add_argparse_args(cls, parent_parser: ArgumentParser) -> ArgumentParser:
837 """Extend existing argparse by default `Trainer` attributes."""
838 parser = ArgumentParser(parents=[parent_parser])
839
840 trainer_default_params = Trainer.default_attributes()
841
842 for arg in trainer_default_params:
843 parser.add_argument('--{0}'.format(arg), default=trainer_default_params[arg], dest=arg)
844
845 return parser
846
847 @classmethod
848 def from_argparse_args(cls, args):
849
850 params = vars(args)
851 return cls(**params)
852
853 def __parse_gpu_ids(self, gpus):
854 """Parse GPUs id.
855
856 :param list|str|int gpus: input GPU ids
857 :return list(int):
858 """
859 # if gpus = -1 then use all available devices
860 # otherwise, split the string using commas
861 if gpus is not None:
862 if isinstance(gpus, list):
863 gpus = gpus
864 elif isinstance(gpus, str):
865 if gpus == '-1':
866 gpus = list(range(0, torch.cuda.device_count()))
867 else:
868 gpus = [int(x.strip()) for x in gpus.split(',')]
869 elif isinstance(gpus, int):
870 gpus = gpus
871 else:
872 raise ValueError('`gpus` has to be a string, int or list of ints')
873
874 return gpus
875
876 def __set_root_gpu(self, gpus):
877 if gpus is None:
878 return None
879
880 # set root gpu
881 root_gpu = 0
882 if isinstance(gpus, list):
883 root_gpu = gpus[0]
884
885 return root_gpu
886
887 @property
888 def num_gpus(self) -> int:
889 gpus = self.data_parallel_device_ids
890 if gpus is None:
891 return 0
892 return len(gpus)
893
894 @property
895 def data_parallel(self) -> bool:
896 return self.use_dp or self.use_ddp or self.use_ddp2
897
898 @property
899 def training_tqdm_dict(self) -> dict:
900 """Read-only for tqdm metrics.
901 :return:
902 """
903 ref_model = self.model if not self.data_parallel else self.model.module
904
905 return dict(**ref_model.get_tqdm_dict(), **self.tqdm_metrics)
906
907 @property
908 def tng_tqdm_dic(self):
909 """Read-only for tqdm metrics.
910
911 :return: dictionary
912
913 .. warning:: .. deprecated:: 0.5.0
914 Use `training_tqdm_dict` instead. Will remove 0.8.0.
915 """
916 warnings.warn("`tng_tqdm_dic` has renamed to `training_tqdm_dict` since v0.5.0"
917 " and this method will be removed in v0.8.0", DeprecationWarning)
918 return self.training_tqdm_dict
919
920 # -----------------------------
921 # MODEL TRAINING
922 # -----------------------------
923 def fit(
924 self,
925 model: LightningModule,
926 train_dataloader: Optional[DataLoader] = None,
927 val_dataloaders: Optional[DataLoader] = None,
928 test_dataloaders: Optional[DataLoader] = None
929 ):
930 r"""
931 Runs the full optimization routine.
932
933 Args:
934 model: Model to fit.
935
936 train_dataloader: A Pytorch
937 DataLoader with training samples. If the model has
938 a predefined train_dataloader method this will be skipped.
939
940 val_dataloaders: Either a single
941 Pytorch Dataloader or a list of them, specifying validation samples.
942 If the model has a predefined val_dataloaders method this will be skipped
943
944 test_dataloaders: Either a single
945 Pytorch Dataloader or a list of them, specifying validation samples.
946 If the model has a predefined test_dataloaders method this will be skipped
947
948 Example::
949
950 # Option 1,
951 # Define the train_dataloader(), test_dataloader() and val_dataloader() fxs
952 # in the lightningModule
953 # RECOMMENDED FOR MOST RESEARCH AND APPLICATIONS TO MAINTAIN READABILITY
954 trainer = Trainer()
955 model = LightningModule()
956 trainer.fit(model)
957
958 # Option 2
959 # in production cases we might want to pass different datasets to the same model
960 # Recommended for PRODUCTION SYSTEMS
961 train, val, test = DataLoader(...), DataLoader(...), DataLoader(...)
962 trainer = Trainer()
963 model = LightningModule()
964 trainer.fit(model, train_dataloader=train,
965 val_dataloader=val, test_dataloader=test)
966
967 # Option 1 & 2 can be mixed, for example the training set can be
968 # defined as part of the model, and validation/test can then be
969 # feed to .fit()
970
971 """
972 # bind logger
973 model.logger = self.logger
974
975 # set up the passed in dataloaders (if needed)
976 self.__set_fit_dataloaders(model, train_dataloader, val_dataloaders, test_dataloaders)
977
978 # route to appropriate start method
979 # when using multi-node or DDP within a node start each module in a separate process
980 if self.use_ddp2:
981 task = int(os.environ['SLURM_LOCALID'])
982 self.ddp_train(task, model)
983
984 elif self.use_ddp:
985 if self.is_slurm_managing_tasks:
986 task = int(os.environ['SLURM_LOCALID'])
987 self.ddp_train(task, model)
988 else:
989 self.__set_random_port()
990
991 # track for predict
992 self.model = model
993
994 # train
995 mp.spawn(self.ddp_train, nprocs=self.num_gpus, args=(model,))
996
997 # load weights if not interrupted
998 self.load_spawn_weights(model)
999 self.model = model
1000
1001 # 1 gpu or dp option triggers training using DP module
1002 # easier to avoid NCCL issues
1003 elif self.use_dp:
1004 self.dp_train(model)
1005
1006 elif self.single_gpu:
1007 self.single_gpu_train(model)
1008
1009 elif self.use_tpu:
1010 log.info(f'training on {self.num_tpu_cores} TPU cores')
1011
1012 # COLAB_GPU is an env var available by default in Colab environments.
1013 start_method = 'fork' if os.getenv('COLAB_GPU') else 'spawn'
1014
1015 # track for predict
1016 self.model = model
1017
1018 # train
1019 xmp.spawn(self.tpu_train, args=(model,), nprocs=self.num_tpu_cores, start_method=start_method)
1020
1021 # load weights if not interrupted
1022 self.load_spawn_weights(model)
1023 self.model = model
1024
1025 # ON CPU
1026 else:
1027 # run through amp wrapper
1028 if self.use_amp:
1029 raise MisconfigurationException('amp + cpu is not supported. Please use a GPU option')
1030
1031 # CHOOSE OPTIMIZER
1032 # allow for lr schedulers as well
1033 self.optimizers, self.lr_schedulers = self.init_optimizers(model.configure_optimizers())
1034
1035 self.run_pretrain_routine(model)
1036
1037 # return 1 when finished
1038 # used for testing or when we need to know that training succeeded
1039 return 1
1040
1041 def __set_random_port(self):
1042 """
1043 When running DDP NOT managed by SLURM, the ports might collide
1044 :return:
1045 """
1046 try:
1047 default_port = os.environ['MASTER_PORT']
1048 except Exception:
1049 import random
1050 default_port = random.randint(10000, 19000)
1051 os.environ['MASTER_PORT'] = str(default_port)
1052
1053 def __set_fit_dataloaders(self, model, train_dataloader, val_dataloaders, test_dataloaders):
1054 # when dataloader is passed via fit, patch the train_dataloader
1055 # functions to overwrite with these implementations
1056 if train_dataloader is not None:
1057 if not self.is_overriden('training_step', model):
1058 m = 'You called .fit() with a train_dataloader but did not define training_step()'
1059 raise MisconfigurationException(m)
1060
1061 model.train_dataloader = _PatchDataLoader(train_dataloader)
1062
1063 if val_dataloaders is not None:
1064 if not self.is_overriden('validation_step', model):
1065 m = 'You called .fit() with a val_dataloaders but did not define validation_step()'
1066 raise MisconfigurationException(m)
1067
1068 model.val_dataloader = _PatchDataLoader(val_dataloaders)
1069
1070 if test_dataloaders is not None:
1071 if not self.is_overriden('test_step', model):
1072 m = 'You called .fit() with a test_dataloaders but did not define test_step()'
1073 raise MisconfigurationException(m)
1074
1075 model.test_dataloader = _PatchDataLoader(test_dataloaders)
1076
1077 def init_optimizers(
1078 self,
1079 optimizers: Union[Optimizer, Tuple[List, List], List[Optimizer], Tuple[Optimizer]]
1080 ) -> Tuple[List, List]:
1081
1082 # single optimizer
1083 if isinstance(optimizers, Optimizer):
1084 return [optimizers], []
1085
1086 # two lists
1087 if len(optimizers) == 2 and isinstance(optimizers[0], list):
1088 optimizers, lr_schedulers = optimizers
1089 lr_schedulers, self.reduce_lr_on_plateau_scheduler = self.configure_schedulers(lr_schedulers)
1090 return optimizers, lr_schedulers
1091
1092 # single list or tuple
1093 if isinstance(optimizers, (list, tuple)):
1094 return optimizers, []
1095
1096 def configure_schedulers(self, schedulers: list):
1097 for i, scheduler in enumerate(schedulers):
1098 if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
1099 reduce_lr_on_plateau_scheduler = schedulers.pop(i)
1100 return schedulers, reduce_lr_on_plateau_scheduler
1101 return schedulers, None
1102
1103 def run_pretrain_routine(self, model: LightningModule):
1104 """Sanity check a few things before starting actual training.
1105
1106 Args:
1107 model: The model to run sanity test on.
1108 """
1109 ref_model = model
1110 if self.data_parallel:
1111 ref_model = model.module
1112
1113 # give model convenience properties
1114 ref_model.trainer = self
1115
1116 # set local properties on the model
1117 self.copy_trainer_model_properties(ref_model)
1118
1119 # log hyper-parameters
1120 if self.logger is not None:
1121 # save exp to get started
1122 if hasattr(ref_model, "hparams"):
1123 self.logger.log_hyperparams(ref_model.hparams)
1124
1125 self.logger.save()
1126
1127 if self.use_ddp or self.use_ddp2:
1128 dist.barrier()
1129
1130 # wait for all models to restore weights
1131 if self.on_tpu and XLA_AVAILABLE:
1132 # wait for all processes to catch up
1133 torch_xla.core.xla_model.rendezvous("pl.Trainer.run_pretrain_routine")
1134
1135 # register auto-resubmit when on SLURM
1136 self.register_slurm_signal_handlers()
1137
1138 # print model summary
1139 # TODO: remove self.testing condition because model.summarize() is wiping out the weights
1140 if self.proc_rank == 0 and self.weights_summary is not None and not self.testing:
1141 if self.weights_summary in ['full', 'top']:
1142 ref_model.summarize(mode=self.weights_summary)
1143 else:
1144 m = "weights_summary can be None, 'full' or 'top'"
1145 raise MisconfigurationException(m)
1146
1147 # track model now.
1148 # if cluster resets state, the model will update with the saved weights
1149 self.model = model
1150
1151 # set up checkpoint callback
1152 self.configure_checkpoint_callback()
1153
1154 # restore training and model before hpc call
1155 self.restore_weights(model)
1156
1157 # download the data and do whatever transforms we need
1158 self.call_prepare_data(ref_model)
1159
1160 # when testing requested only run test and return
1161 if self.testing:
1162 # only load test dataloader for testing
1163 # self.reset_test_dataloader(ref_model)
1164 self.run_evaluation(test_mode=True)
1165 return
1166
1167 # check if we should run validation during training
1168 self.disable_validation = not self.is_overriden('validation_step') and not self.fast_dev_run
1169
1170 # run tiny validation (if validation defined)
1171 # to make sure program won't crash during val
1172 ref_model.on_sanity_check_start()
1173 if not self.disable_validation and self.num_sanity_val_steps > 0:
1174 self.reset_val_dataloader(ref_model)
1175 # init progress bars for validation sanity check
1176 pbar = tqdm(desc='Validation sanity check',
1177 total=self.num_sanity_val_steps * len(self.val_dataloaders),
1178 leave=False, position=2 * self.process_position,
1179 disable=not self.show_progress_bar, dynamic_ncols=True)
1180 self.main_progress_bar = pbar
1181 # dummy validation progress bar
1182 self.val_progress_bar = tqdm(disable=True)
1183
1184 eval_results = self.evaluate(model,
1185 self.val_dataloaders,
1186 self.num_sanity_val_steps,
1187 False)
1188 _, _, _, callback_metrics, _ = self.process_output(eval_results)
1189
1190 # close progress bars
1191 self.main_progress_bar.close()
1192 self.val_progress_bar.close()
1193
1194 if self.enable_early_stop:
1195 self.early_stop_callback.check_metrics(callback_metrics)
1196
1197 # init progress bar
1198 pbar = tqdm(leave=True, position=2 * self.process_position,
1199 disable=not self.show_progress_bar, dynamic_ncols=True,
1200 file=sys.stdout)
1201 self.main_progress_bar = pbar
1202
1203 # clear cache before training
1204 if self.on_gpu:
1205 torch.cuda.empty_cache()
1206
1207 # CORE TRAINING LOOP
1208 self.train()
1209
1210 def test(self, model: Optional[LightningModule] = None):
1211 r"""
1212
1213 Separates from fit to make sure you never run on your test set until you want to.
1214
1215 Args:
1216 model (:class:`.LightningModule`): The model to test.
1217
1218 Example::
1219
1220 # Option 1
1221 # run test after fitting
1222 trainer = Trainer()
1223 model = LightningModule()
1224
1225 trainer.fit()
1226 trainer.test()
1227
1228 # Option 2
1229 # run test from a loaded model
1230 model = LightningModule.load_from_checkpoint('path/to/checkpoint.ckpt')
1231 trainer = Trainer()
1232 trainer.test(model)
1233 """
1234
1235 self.testing = True
1236 if model is not None:
1237 self.model = model
1238 self.fit(model)
1239 elif self.use_ddp or self.use_tpu:
1240 # attempt to load weights from a spawn
1241 path = os.path.join(self.default_save_path, '__temp_weight_ddp_end.ckpt')
1242 test_model = self.model
1243 if os.path.exists(path):
1244 test_model = self.load_spawn_weights(self.model)
1245
1246 self.fit(test_model)
1247 else:
1248 self.run_evaluation(test_mode=True)
1249
1250
1251 class _PatchDataLoader(object):
1252 r'''
1253 Callable object for patching dataloaders passed into trainer.fit().
1254 Use this class to override model.*_dataloader() and be pickle-compatible.
1255
1256 Args:
1257 dataloader: Dataloader object to return when called.
1258 '''
1259 def __init__(self, dataloader: Union[List[DataLoader], DataLoader]):
1260 self.dataloader = dataloader
1261
1262 def __call__(self) -> Union[List[DataLoader], DataLoader]:
1263 return self.dataloader
1264
1265
1266 def _set_dataloader(model, dataloader, attribute):
1267 r'''
1268 Check dataloaders passed to .fit() method if they are pytorch DataLoader
1269 objects and whether or not we should overright the corresponding dataloader
1270 in the model
1271
1272 Args:
1273 model (LightningModule): The model to check
1274
1275 dataloader: If a pytorch dataloader (or a list of pytorch dataloaders)
1276 is passed, it will be incorporate into the model as model.attribute.
1277 If attribute alreay exist it will warn the userpass. If not a
1278 dataloader will throw an error
1279
1280 attribute (str): The attribute to save the dataloader under
1281
1282 '''
1283 # Check if attribute comes directly from base class or
1284 # derived in user subclass
1285 if LightningModule.__qualname__ in getattr(model, attribute).__qualname__:
1286 # Val and test should be list of dataloaders
1287 dataloader = dataloader if attribute == 'train_dataloader' or \
1288 (attribute != 'train_dataloader' and isinstance(dataloader, list)) else [dataloader]
1289
1290 # Check we are given valid dataloaders
1291 is_dataloader = isinstance(dataloader, torch.utils.data.DataLoader)
1292 is_dataloader_list = isinstance(dataloader, list)
1293 valid_loaders = None
1294 if is_dataloader_list:
1295 valid_loaders = all(isinstance(d, torch.utils.data.DataLoader) for d in dataloader)
1296 if is_dataloader or is_dataloader_list and valid_loaders:
1297
1298 # Overwrite abstract methods
1299 def dl():
1300 return dataloader
1301 dl.__name__ = attribute
1302 setattr(model, attribute, dl)
1303
1304 elif dataloader and dataloader != [None]:
1305 raise ValueError(f'`{attribute}` needs to be an instance of '
1306 '`torch.utils.data.DataLoader` or a list of '
1307 'DataLoaders, instead got %r`' % dataloader)
1308
1309 elif dataloader: # if default (None) is passed, do not warn the user
1310 warnings.warn(f'Model has predefined `{attribute}`,'
1311 f' will skip `{attribute}={dataloader}` passed to fit method.')
1312
[end of pytorch_lightning/trainer/trainer.py]
[start of pytorch_lightning/trainer/training_io.py]
1 import logging as log
2 import os
3 import re
4 import signal
5 import warnings
6 from abc import ABC
7 from argparse import Namespace
8 from subprocess import call
9 from typing import Union
10
11 import torch
12 import torch.distributed as dist
13
14 from pytorch_lightning.core.lightning import LightningModule
15 from pytorch_lightning.loggers import LightningLoggerBase
16 from pytorch_lightning.overrides.data_parallel import (
17 LightningDistributedDataParallel,
18 LightningDataParallel,
19 )
20
21 try:
22 import torch_xla
23 import torch_xla.core.xla_model as xm
24 import torch_xla.distributed.xla_multiprocessing as xmp
25 except ImportError:
26 XLA_AVAILABLE = False
27 else:
28 XLA_AVAILABLE = True
29
30
31 class TrainerIOMixin(ABC):
32
33 # this is just a summary on variables used in this abstract class,
34 # the proper values/initialisation should be done in child class
35 model: LightningModule
36 on_gpu: bool
37 root_gpu: ...
38 resume_from_checkpoint: ...
39 use_ddp: bool
40 use_ddp2: bool
41 checkpoint_callback: ...
42 proc_rank: int
43 weights_save_path: str
44 logger: Union[LightningLoggerBase, bool]
45 early_stop_callback: ...
46 lr_schedulers: ...
47 optimizers: ...
48 on_tpu: bool
49 num_training_batches: int
50 accumulate_grad_batches: int
51
52 def get_model(self):
53 is_dp_module = isinstance(self.model, (LightningDistributedDataParallel,
54 LightningDataParallel))
55 model = self.model.module if is_dp_module else self.model
56 return model
57
58 # --------------------
59 # CHECK-POINTING
60 # --------------------
61 def restore_weights(self, model):
62 """
63 We attempt to restore weights in this order:
64 1. HPC weights.
65 2. if no HPC weights restore checkpoint_path weights
66 3. otherwise don't restore weights
67
68 :param model:
69 :return:
70 """
71 # clear cache before restore
72 if self.on_gpu:
73 torch.cuda.empty_cache()
74
75 # if script called from hpc resubmit, load weights
76 did_restore_hpc_weights = self.restore_hpc_weights_if_needed(model)
77
78 # clear cache after restore
79 if self.on_gpu:
80 torch.cuda.empty_cache()
81
82 if not did_restore_hpc_weights:
83 if self.resume_from_checkpoint is not None:
84 self.restore(self.resume_from_checkpoint, on_gpu=self.on_gpu)
85
86 # wait for all models to restore weights
87 if self.use_ddp or self.use_ddp2:
88 # wait for all processes to catch up
89 dist.barrier()
90
91 # wait for all models to restore weights
92 if self.on_tpu and XLA_AVAILABLE:
93 # wait for all processes to catch up
94 torch_xla.core.xla_model.rendezvous("pl.TrainerIOMixin.restore_weights")
95
96 # clear cache after restore
97 if self.on_gpu:
98 torch.cuda.empty_cache()
99
100 # --------------------
101 # HPC SIGNAL HANDLING
102 # --------------------
103 def register_slurm_signal_handlers(self):
104 # see if we're using slurm (not interactive)
105 on_slurm = False
106 try:
107 job_name = os.environ['SLURM_JOB_NAME']
108 if job_name != 'bash':
109 on_slurm = True
110 except Exception as e:
111 pass
112
113 if on_slurm:
114 log.info('Set SLURM handle signals.')
115 signal.signal(signal.SIGUSR1, self.sig_handler)
116 signal.signal(signal.SIGTERM, self.term_handler)
117
118 def sig_handler(self, signum, frame):
119 if self.proc_rank == 0:
120 # save weights
121 log.info('handling SIGUSR1')
122 self.hpc_save(self.weights_save_path, self.logger)
123
124 # find job id
125 job_id = os.environ['SLURM_JOB_ID']
126 cmd = 'scontrol requeue {}'.format(job_id)
127
128 # requeue job
129 log.info(f'requeing job {job_id}...')
130 result = call(cmd, shell=True)
131
132 # print result text
133 if result == 0:
134 log.info(f'requeued exp {job_id}')
135 else:
136 log.info('requeue failed...')
137
138 # close experiment to avoid issues
139 self.logger.close()
140
141 def term_handler(self, signum, frame):
142 # save
143 log.info("bypassing sigterm")
144
145 # --------------------
146 # MODEL SAVE CHECKPOINT
147 # --------------------
148 def _atomic_save(self, checkpoint, filepath):
149 """Saves a checkpoint atomically, avoiding the creation of incomplete checkpoints.
150
151 This will create a temporary checkpoint with a suffix of ``.part``, then copy it to the final location once
152 saving is finished.
153
154 Args:
155 checkpoint (object): The object to save.
156 Built to be used with the ``dump_checkpoint`` method, but can deal with anything which ``torch.save``
157 accepts.
158 filepath (str|pathlib.Path): The path to which the checkpoint will be saved.
159 This points to the file that the checkpoint will be stored in.
160 """
161 tmp_path = str(filepath) + ".part"
162 torch.save(checkpoint, tmp_path)
163 os.replace(tmp_path, filepath)
164
165 def save_checkpoint(self, filepath):
166 checkpoint = self.dump_checkpoint()
167
168 if self.proc_rank == 0:
169 # do the actual save
170 try:
171 self._atomic_save(checkpoint, filepath)
172 except AttributeError:
173 if 'hparams' in checkpoint:
174 del checkpoint['hparams']
175
176 self._atomic_save(checkpoint, filepath)
177
178 def restore(self, checkpoint_path, on_gpu):
179 """
180 Restore training state from checkpoint.
181 Also restores all training state like:
182 - epoch
183 - callbacks
184 - schedulers
185 - optimizer
186 :param checkpoint_path:
187 :param on_gpu:
188
189 :return:
190 """
191
192 # if on_gpu:
193 # checkpoint = torch.load(checkpoint_path)
194 # else:
195 # load on CPU first
196 checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
197
198 # load model state
199 model = self.get_model()
200
201 # load the state_dict on the model automatically
202 model.load_state_dict(checkpoint['state_dict'])
203 if on_gpu:
204 model.cuda(self.root_gpu)
205
206 # load training state (affects trainer only)
207 self.restore_training_state(checkpoint)
208
209 def dump_checkpoint(self):
210 checkpoint = {
211 'epoch': self.current_epoch + 1,
212 'global_step': self.global_step + 1,
213 }
214
215 if self.checkpoint_callback is not None and self.checkpoint_callback is not False:
216 checkpoint['checkpoint_callback_best'] = self.checkpoint_callback.best
217
218 if self.early_stop_callback is not None and self.checkpoint_callback is not False:
219 checkpoint['early_stop_callback_wait'] = self.early_stop_callback.wait
220 checkpoint['early_stop_callback_patience'] = self.early_stop_callback.patience
221
222 # save optimizers
223 optimizer_states = []
224 for i, optimizer in enumerate(self.optimizers):
225 optimizer_states.append(optimizer.state_dict())
226
227 checkpoint['optimizer_states'] = optimizer_states
228
229 # save lr schedulers
230 lr_schedulers = []
231 for i, scheduler in enumerate(self.lr_schedulers):
232 lr_schedulers.append(scheduler.state_dict())
233
234 checkpoint['lr_schedulers'] = lr_schedulers
235
236 # add the hparams and state_dict from the model
237 model = self.get_model()
238
239 checkpoint['state_dict'] = model.state_dict()
240
241 if hasattr(model, "hparams"):
242 is_namespace = isinstance(model.hparams, Namespace)
243 checkpoint['hparams'] = vars(model.hparams) if is_namespace else model.hparams
244 checkpoint['hparams_type'] = 'namespace' if is_namespace else 'dict'
245 else:
246 warnings.warn(
247 "Did not find hyperparameters at model.hparams. Saving checkpoint without"
248 " hyperparameters"
249 )
250
251 # give the model a chance to add a few things
252 model.on_save_checkpoint(checkpoint)
253
254 return checkpoint
255
256 # --------------------
257 # HPC IO
258 # --------------------
259 def restore_hpc_weights_if_needed(self, model):
260 """
261 If there is a set of hpc weights, use as signal to restore model
262 :param model:
263 :return:
264 """
265 did_restore = False
266
267 # look for hpc weights
268 folderpath = self.weights_save_path
269 if os.path.exists(folderpath):
270 files = os.listdir(folderpath)
271 hpc_weight_paths = [x for x in files if 'hpc_ckpt' in x]
272
273 # if hpc weights exist restore model
274 if len(hpc_weight_paths) > 0:
275 self.hpc_load(folderpath, self.on_gpu)
276 did_restore = True
277 return did_restore
278
279 def restore_training_state(self, checkpoint):
280 """
281 Restore trainer state.
282 Model will get its change to update
283 :param checkpoint:
284 :return:
285 """
286 if self.checkpoint_callback is not None and self.checkpoint_callback is not False:
287 self.checkpoint_callback.best = checkpoint['checkpoint_callback_best']
288
289 if self.early_stop_callback is not None and self.early_stop_callback is not False:
290 self.early_stop_callback.wait = checkpoint['early_stop_callback_wait']
291 self.early_stop_callback.patience = checkpoint['early_stop_callback_patience']
292
293 self.global_step = checkpoint['global_step']
294 self.current_epoch = checkpoint['epoch']
295
296 # Division deals with global step stepping once per accumulated batch
297 # Inequality deals with different global step for odd vs even num_training_batches
298 n_accum = 1 if self.accumulate_grad_batches is None else self.accumulate_grad_batches
299 expected_steps = self.num_training_batches / n_accum
300 if self.num_training_batches != 0 and self.global_step % expected_steps > 1:
301 warnings.warn(
302 "You're resuming from a checkpoint that ended mid-epoch. "
303 "This can cause unreliable results if further training is done, "
304 "consider using an end of epoch checkpoint. "
305 )
306
307 # restore the optimizers
308 optimizer_states = checkpoint['optimizer_states']
309 for optimizer, opt_state in zip(self.optimizers, optimizer_states):
310 optimizer.load_state_dict(opt_state)
311
312 # move optimizer to GPU 1 weight at a time
313 # avoids OOM
314 if self.root_gpu is not None:
315 for state in optimizer.state.values():
316 for k, v in state.items():
317 if isinstance(v, torch.Tensor):
318 state[k] = v.cuda(self.root_gpu)
319
320 # restore the lr schedulers
321 lr_schedulers = checkpoint['lr_schedulers']
322 for scheduler, lrs_state in zip(self.lr_schedulers, lr_schedulers):
323 scheduler.load_state_dict(lrs_state)
324
325 # ----------------------------------
326 # PRIVATE OPS
327 # ----------------------------------
328 def hpc_save(self, folderpath: str, logger):
329 # make sure the checkpoint folder exists
330 os.makedirs(folderpath, exist_ok=True)
331
332 # save logger to make sure we get all the metrics
333 logger.save()
334
335 ckpt_number = self.max_ckpt_in_folder(folderpath) + 1
336
337 if not os.path.exists(folderpath):
338 os.makedirs(folderpath, exist_ok=True)
339 filepath = os.path.join(folderpath, f'hpc_ckpt_{ckpt_number}.ckpt')
340
341 # give model a chance to do something on hpc_save
342 model = self.get_model()
343 checkpoint = self.dump_checkpoint()
344
345 model.on_hpc_save(checkpoint)
346
347 # do the actual save
348 # TODO: fix for anything with multiprocess DP, DDP, DDP2
349 try:
350 self._atomic_save(checkpoint, filepath)
351 except AttributeError:
352 if 'hparams' in checkpoint:
353 del checkpoint['hparams']
354
355 self._atomic_save(checkpoint, filepath)
356
357 return filepath
358
359 def hpc_load(self, folderpath, on_gpu):
360 filepath = '{}/hpc_ckpt_{}.ckpt'.format(folderpath, self.max_ckpt_in_folder(folderpath))
361
362 # load on CPU first
363 checkpoint = torch.load(filepath, map_location=lambda storage, loc: storage)
364
365 # load model state
366 model = self.get_model()
367
368 # load the state_dict on the model automatically
369 model.load_state_dict(checkpoint['state_dict'])
370
371 if self.root_gpu is not None:
372 model.cuda(self.root_gpu)
373
374 # load training state (affects trainer only)
375 self.restore_training_state(checkpoint)
376
377 # call model hook
378 model.on_hpc_load(checkpoint)
379
380 log.info(f'restored hpc model from: {filepath}')
381
382 def max_ckpt_in_folder(self, path, name_key='ckpt_'):
383 files = os.listdir(path)
384 files = [x for x in files if name_key in x]
385 if len(files) == 0:
386 return 0
387
388 ckpt_vs = []
389 for name in files:
390 name = name.split(name_key)[-1]
391 name = re.sub('[^0-9]', '', name)
392 ckpt_vs.append(int(name))
393
394 return max(ckpt_vs)
395
[end of pytorch_lightning/trainer/training_io.py]
[start of pytorch_lightning/trainer/training_loop.py]
1 """
2 The lightning training loop handles everything except the actual computations of your model.
3 To decide what will happen in your training loop, define the `training_step` function.
4
5 Below are all the things lightning automates for you in the training loop.
6
7 Accumulated gradients
8 ---------------------
9
10 Accumulated gradients runs K small batches of size N before doing a backwards pass.
11 The effect is a large effective batch size of size KxN.
12
13 .. code-block:: python
14
15 # DEFAULT (ie: no accumulated grads)
16 trainer = Trainer(accumulate_grad_batches=1)
17
18 Force training for min or max epochs
19 ------------------------------------
20
21 It can be useful to force training for a minimum number of epochs or limit to a max number
22
23 .. code-block:: python
24
25 # DEFAULT
26 trainer = Trainer(min_epochs=1, max_epochs=1000)
27
28 Force disable early stop
29 ------------------------
30
31 To disable early stopping pass None to the early_stop_callback
32
33 .. code-block:: python
34
35 # DEFAULT
36 trainer = Trainer(early_stop_callback=None)
37
38 Gradient Clipping
39 -----------------
40
41 Gradient clipping may be enabled to avoid exploding gradients.
42 Specifically, this will `clip the gradient norm computed over all model parameters
43 `together <https://pytorch.org/docs/stable/nn.html#torch.nn.utils.clip_grad_norm_>`_.
44
45 .. code-block:: python
46
47 # DEFAULT (ie: don't clip)
48 trainer = Trainer(gradient_clip_val=0)
49
50 # clip gradients with norm above 0.5
51 trainer = Trainer(gradient_clip_val=0.5)
52
53 Inspect gradient norms
54 ----------------------
55
56 Looking at grad norms can help you figure out where training might be going wrong.
57
58 .. code-block:: python
59
60 # DEFAULT (-1 doesn't track norms)
61 trainer = Trainer(track_grad_norm=-1)
62
63 # track the LP norm (P=2 here)
64 trainer = Trainer(track_grad_norm=2)
65
66 Set how much of the training set to check
67 -----------------------------------------
68
69 If you don't want to check 100% of the training set (for debugging or if it's huge), set this flag.
70
71 train_percent_check will be overwritten by overfit_pct if `overfit_pct > 0`
72
73 .. code-block:: python
74
75 # DEFAULT
76 trainer = Trainer(train_percent_check=1.0)
77
78 # check 10% only
79 trainer = Trainer(train_percent_check=0.1)
80
81 Packed sequences as inputs
82 --------------------------
83
84 When using PackedSequence, do 2 things:
85 1. return either a padded tensor in dataset or a list of variable length tensors
86 in the dataloader collate_fn (example above shows the list implementation).
87 2. Pack the sequence in forward or training and validation steps depending on use case.
88
89 .. code-block:: python
90
91 # For use in dataloader
92 def collate_fn(batch):
93 x = [item[0] for item in batch]
94 y = [item[1] for item in batch]
95 return x, y
96
97 # In module
98 def training_step(self, batch, batch_idx):
99 x = rnn.pack_sequence(batch[0], enforce_sorted=False)
100 y = rnn.pack_sequence(batch[1], enforce_sorted=False)
101
102
103 Truncated Backpropagation Through Time
104 --------------------------------------
105
106 There are times when multiple backwards passes are needed for each batch.
107 For example, it may save memory to use Truncated Backpropagation Through Time when training RNNs.
108
109 When this flag is enabled each batch is split into sequences of size truncated_bptt_steps
110 and passed to training_step(...) separately. A default splitting function is provided,
111 however, you can override it for more flexibility. See `tbptt_split_batch`.
112
113 .. code-block:: python
114
115 # DEFAULT (single backwards pass per batch)
116 trainer = Trainer(truncated_bptt_steps=None)
117
118 # (split batch into sequences of size 2)
119 trainer = Trainer(truncated_bptt_steps=2)
120
121
122 """
123
124 from typing import Callable
125
126 import copy
127 import warnings
128 import logging as log
129 from abc import ABC, abstractmethod
130 from typing import Union, List
131
132 import numpy as np
133 from torch.utils.data import DataLoader
134
135 from pytorch_lightning.core.lightning import LightningModule
136 from pytorch_lightning.loggers import LightningLoggerBase
137 from pytorch_lightning.utilities.debugging import MisconfigurationException
138 from pytorch_lightning.callbacks.base import Callback
139
140 try:
141 from apex import amp
142 except ImportError:
143 APEX_AVAILABLE = False
144 else:
145 APEX_AVAILABLE = True
146
147 try:
148 import torch_xla.distributed.parallel_loader as xla_pl
149 import torch_xla.core.xla_model as xm
150 except ImportError:
151 XLA_AVAILABLE = False
152 else:
153 XLA_AVAILABLE = True
154
155
156 class TrainerTrainLoopMixin(ABC):
157
158 # this is just a summary on variables used in this abstract class,
159 # the proper values/initialisation should be done in child class
160 max_epochs: int
161 min_epochs: int
162 use_ddp: bool
163 use_dp: bool
164 use_ddp2: bool
165 single_gpu: bool
166 use_tpu: bool
167 data_parallel_device_ids: ...
168 check_val_every_n_epoch: ...
169 num_training_batches: int
170 val_check_batch: ...
171 num_val_batches: int
172 disable_validation: bool
173 fast_dev_run: ...
174 main_progress_bar: ...
175 accumulation_scheduler: ...
176 lr_schedulers: ...
177 enable_early_stop: ...
178 early_stop_callback: ...
179 callback_metrics: ...
180 logger: Union[LightningLoggerBase, bool]
181 global_step: int
182 testing: bool
183 log_save_interval: float
184 proc_rank: int
185 row_log_interval: float
186 total_batches: int
187 truncated_bptt_steps: ...
188 optimizers: ...
189 accumulate_grad_batches: int
190 use_amp: bool
191 print_nan_grads: ...
192 track_grad_norm: ...
193 model: LightningModule
194 running_loss: ...
195 training_tqdm_dict: ...
196 reduce_lr_on_plateau_scheduler: ...
197 profiler: ...
198 batch_idx: int
199 precision: ...
200 train_dataloader: DataLoader
201 reload_dataloaders_every_epoch: bool
202 progress_bar_refresh_rate: ...
203 max_steps: int
204 max_steps: int
205 total_batch_idx: int
206 checkpoint_callback: ...
207
208 # Callback system
209 callbacks: List[Callback]
210 on_train_start: Callable
211 on_train_end: Callable
212 on_batch_start: Callable
213 on_batch_end: Callable
214 on_epoch_start: Callable
215 on_epoch_end: Callable
216 on_validation_end: Callable
217
218 @property
219 def max_nb_epochs(self):
220 """
221 .. warning:: `max_nb_epochs` is deprecated and will be removed in v0.8.0, use `max_epochs` instead.
222 """
223 warnings.warn("`max_nb_epochs` is deprecated and will be removed in "
224 "v0.8.0, use `max_epochs` instead.", DeprecationWarning)
225 return self.max_epochs
226
227 @property
228 def min_nb_epochs(self):
229 """
230 .. warning:: `min_nb_epochs` is deprecated and will be removed in v0.8.0, use `min_epochs` instead.
231 """
232 warnings.warn("`min_nb_epochs` is deprecated and will be removed in "
233 "v0.8.0, use `min_epochs` instead.", DeprecationWarning)
234 return self.min_epochs
235
236 @abstractmethod
237 def get_model(self):
238 """Warning: this is just empty shell for code implemented in other class."""
239
240 @abstractmethod
241 def is_function_implemented(self, *args):
242 """Warning: this is just empty shell for code implemented in other class."""
243
244 @abstractmethod
245 def is_infinite_dataloader(self, *args):
246 """Warning: this is just empty shell for code implemented in other class."""
247
248 @abstractmethod
249 def run_evaluation(self, *args):
250 """Warning: this is just empty shell for code implemented in other class."""
251
252 @abstractmethod
253 def transfer_batch_to_gpu(self, *args):
254 """Warning: this is just empty shell for code implemented in other class."""
255
256 @abstractmethod
257 def transfer_batch_to_tpu(self, *args):
258 """Warning: this is just empty shell for code implemented in other class."""
259
260 @abstractmethod
261 def clip_gradients(self):
262 """Warning: this is just empty shell for code implemented in other class."""
263
264 @abstractmethod
265 def print_nan_gradients(self):
266 """Warning: this is just empty shell for code implemented in other class."""
267
268 @abstractmethod
269 def is_overriden(self, *args):
270 """Warning: this is just empty shell for code implemented in other class."""
271
272 @abstractmethod
273 def add_tqdm_metrics(self, *args):
274 """Warning: this is just empty shell for code implemented in other class."""
275
276 @abstractmethod
277 def log_metrics(self, *args):
278 """Warning: this is just empty shell for code implemented in other class."""
279
280 @abstractmethod
281 def process_output(self, *args):
282 """Warning: this is just empty shell for code implemented in other class."""
283
284 @abstractmethod
285 def reset_train_dataloader(self, *args):
286 """Warning: this is just empty shell for code implemented in other class."""
287
288 @abstractmethod
289 def reset_val_dataloader(self, model):
290 """Warning: this is just empty shell for code implemented in other class."""
291
292 @abstractmethod
293 def has_arg(self, *args):
294 """Warning: this is just empty shell for code implemented in other class."""
295
296 def train(self):
297 warnings.warn('Displayed epoch numbers in the progress bar start from "1" until v0.6.x,'
298 ' but will start from "0" in v0.8.0.', DeprecationWarning)
299
300 # get model
301 model = self.get_model()
302
303 # load data
304 self.reset_train_dataloader(model)
305 self.reset_val_dataloader(model)
306
307 # Train start events
308 with self.profiler.profile('on_train_start'):
309 # callbacks
310 self.on_train_start()
311 # initialize early stop callback
312 if self.early_stop_callback is not None:
313 self.early_stop_callback.on_train_start(self, self.get_model())
314 # model hooks
315 model.on_train_start()
316
317 try:
318 # run all epochs
319 for epoch in range(self.current_epoch, self.max_epochs):
320 # set seed for distributed sampler (enables shuffling for each epoch)
321 if self.use_ddp \
322 and hasattr(self.train_dataloader.sampler, 'set_epoch'):
323 self.train_dataloader.sampler.set_epoch(epoch)
324
325 # update training progress in trainer and model
326 model.current_epoch = epoch
327 self.current_epoch = epoch
328
329 total_val_batches = 0
330 is_val_epoch = False
331 if not self.disable_validation:
332 # val can be checked multiple times in epoch
333 is_val_epoch = (self.current_epoch + 1) % self.check_val_every_n_epoch == 0
334 val_checks_per_epoch = self.num_training_batches // self.val_check_batch
335 val_checks_per_epoch = val_checks_per_epoch if is_val_epoch else 0
336 total_val_batches = self.num_val_batches * val_checks_per_epoch
337
338 # total batches includes multiple val checks
339 self.total_batches = self.num_training_batches + total_val_batches
340 self.batch_loss_value = 0 # accumulated grads
341
342 if self.fast_dev_run:
343 # limit the number of batches to 2 (1 train and 1 val) in fast_dev_run
344 num_iterations = 2
345 elif self.is_infinite_dataloader(self.train_dataloader):
346 # for infinite train loader, the progress bar never ends
347 num_iterations = None
348 else:
349 num_iterations = self.total_batches
350
351 # reset progress bar
352 # .reset() doesn't work on disabled progress bar so we should check
353 if not self.main_progress_bar.disable:
354 self.main_progress_bar.reset(num_iterations)
355 desc = f'Epoch {epoch + 1}' if not self.is_infinite_dataloader(self.train_dataloader) else ''
356 self.main_progress_bar.set_description(desc)
357
358 # -----------------
359 # RUN TNG EPOCH
360 # -----------------
361 self.run_training_epoch()
362
363 # update LR schedulers
364 if self.lr_schedulers is not None:
365 for lr_scheduler in self.lr_schedulers:
366 lr_scheduler.step()
367 if self.reduce_lr_on_plateau_scheduler is not None:
368 val_loss = self.callback_metrics.get('val_loss')
369 if val_loss is None:
370 avail_metrics = ','.join(list(self.callback_metrics.keys()))
371 m = f'ReduceLROnPlateau conditioned on metric val_loss ' \
372 f'which is not available. Available metrics are: {avail_metrics}'
373 raise MisconfigurationException(m)
374 self.reduce_lr_on_plateau_scheduler.step(val_loss)
375
376 if self.max_steps and self.max_steps == self.global_step:
377 self.run_training_teardown()
378 return
379
380 # early stopping
381 met_min_epochs = epoch >= self.min_epochs - 1
382 met_min_steps = self.global_step >= self.min_steps if self.min_steps else True
383
384 # TODO wrap this logic into the callback
385 if self.enable_early_stop and not self.disable_validation and is_val_epoch:
386 if ((met_min_epochs and met_min_steps) or self.fast_dev_run):
387 should_stop = self.early_stop_callback.on_epoch_end(self, self.get_model())
388 # stop training
389 stop = should_stop and met_min_epochs
390 if stop:
391 self.run_training_teardown()
392 return
393
394 self.run_training_teardown()
395
396 except KeyboardInterrupt:
397 log.info('Detected KeyboardInterrupt, attempting graceful shutdown...')
398 self.run_training_teardown()
399
400 def run_training_epoch(self):
401
402 # Epoch start events
403 with self.profiler.profile('on_epoch_start'):
404 # callbacks
405 self.on_epoch_start()
406 # changing gradient according accumulation_scheduler
407 self.accumulation_scheduler.on_epoch_start(self, self.get_model())
408 # model hooks
409 if self.is_function_implemented('on_epoch_start'):
410 self.get_model().on_epoch_start()
411
412 # reset train dataloader
413 if self.reload_dataloaders_every_epoch:
414 self.reset_train_dataloader(self.get_model())
415
416 # track local dataloader so TPU can wrap each epoch
417 train_dataloader = self.train_dataloader
418
419 # on TPU we have to wrap it under the ParallelLoader
420 if self.use_tpu:
421 device = xm.xla_device()
422 train_dataloader = xla_pl.ParallelLoader(train_dataloader, [device])
423 train_dataloader = train_dataloader.per_device_loader(device)
424
425 # run epoch
426 for batch_idx, batch in self.profiler.profile_iterable(
427 enumerate(train_dataloader), "get_train_batch"
428 ):
429 # stop epoch if we limited the number of training batches
430 if batch_idx >= self.num_training_batches:
431 break
432
433 self.batch_idx = batch_idx
434
435 model = self.get_model()
436 model.global_step = self.global_step
437
438 # ---------------
439 # RUN TRAIN STEP
440 # ---------------
441 output = self.run_training_batch(batch, batch_idx)
442 batch_result, grad_norm_dic, batch_step_metrics = output
443
444 # when returning -1 from train_step, we end epoch early
445 early_stop_epoch = batch_result == -1
446
447 # ---------------
448 # RUN VAL STEP
449 # ---------------
450 is_val_check_batch = (batch_idx + 1) % self.val_check_batch == 0
451 can_check_epoch = (self.current_epoch + 1) % self.check_val_every_n_epoch == 0
452 should_check_val = not self.disable_validation and can_check_epoch
453 should_check_val = should_check_val and (is_val_check_batch or early_stop_epoch)
454
455 # fast_dev_run always forces val checking after train batch
456 if self.fast_dev_run or should_check_val:
457 self.run_evaluation(test_mode=self.testing)
458
459 # when logs should be saved
460 should_save_log = (batch_idx + 1) % self.log_save_interval == 0 or early_stop_epoch
461 if should_save_log or self.fast_dev_run:
462 if self.proc_rank == 0 and self.logger is not None:
463 self.logger.save()
464
465 # when metrics should be logged
466 should_log_metrics = batch_idx % self.row_log_interval == 0 or early_stop_epoch
467 if should_log_metrics or self.fast_dev_run:
468 # logs user requested information to logger
469 self.log_metrics(batch_step_metrics, grad_norm_dic)
470
471 # ---------------
472 # CHECKPOINTING, EARLY STOPPING
473 # ---------------
474 # save checkpoint even when no test or val step are defined
475 train_step_only = not self.is_overriden('validation_step')
476 if self.fast_dev_run or should_check_val or train_step_only:
477 self.call_checkpoint_callback()
478
479 if self.enable_early_stop:
480 self.early_stop_callback.check_metrics(self.callback_metrics)
481
482 # progress global step according to grads progress
483 if (self.batch_idx + 1) % self.accumulate_grad_batches == 0:
484 self.global_step += 1
485 self.total_batch_idx += 1
486
487 # max steps reached, end training
488 if self.max_steps is not None and self.max_steps == self.global_step:
489 break
490
491 # end epoch early
492 # stop when the flag is changed or we've gone past the amount
493 # requested in the batches
494 if early_stop_epoch or self.fast_dev_run:
495 break
496
497 # Epoch end events
498 with self.profiler.profile('on_epoch_end'):
499 # callbacks
500 self.on_epoch_end()
501 # model hooks
502 if self.is_function_implemented('on_epoch_end'):
503 self.get_model().on_epoch_end()
504
505 def run_training_batch(self, batch, batch_idx):
506 # track grad norms
507 grad_norm_dic = {}
508
509 # track all metrics for callbacks
510 all_callback_metrics = []
511
512 # track metrics to log
513 all_log_metrics = []
514
515 if batch is None:
516 return 0, grad_norm_dic, {}
517
518 # Batch start events
519 with self.profiler.profile('on_batch_start'):
520 # callbacks
521 self.on_batch_start()
522 # hooks
523 if self.is_function_implemented('on_batch_start'):
524 response = self.get_model().on_batch_start(batch)
525 if response == -1:
526 return -1, grad_norm_dic, {}
527
528 splits = [batch]
529 if self.truncated_bptt_steps is not None:
530 model_ref = self.get_model()
531 with self.profiler.profile('tbptt_split_batch'):
532 splits = model_ref.tbptt_split_batch(batch, self.truncated_bptt_steps)
533
534 self.hiddens = None
535 for split_idx, split_batch in enumerate(splits):
536 self.split_idx = split_idx
537
538 # call training_step once per optimizer
539 for opt_idx, optimizer in enumerate(self.optimizers):
540 # make sure only the gradients of the current optimizer's paramaters are calculated
541 # in the training step to prevent dangling gradients in multiple-optimizer setup.
542 if len(self.optimizers) > 1:
543 for param in self.get_model().parameters():
544 param.requires_grad = False
545 for group in optimizer.param_groups:
546 for param in group['params']:
547 param.requires_grad = True
548
549 # wrap the forward step in a closure so second order methods work
550 def optimizer_closure():
551 # forward pass
552 with self.profiler.profile('model_forward'):
553 output = self.training_forward(
554 split_batch, batch_idx, opt_idx, self.hiddens)
555
556 closure_loss = output[0]
557 progress_bar_metrics = output[1]
558 log_metrics = output[2]
559 callback_metrics = output[3]
560 self.hiddens = output[4]
561
562 # accumulate loss
563 # (if accumulate_grad_batches = 1 no effect)
564 closure_loss = closure_loss / self.accumulate_grad_batches
565
566 # backward pass
567 model_ref = self.get_model()
568 with self.profiler.profile('model_backward'):
569 model_ref.backward(self, closure_loss, optimizer, opt_idx)
570
571 # track metrics for callbacks
572 all_callback_metrics.append(callback_metrics)
573
574 # track progress bar metrics
575 self.add_tqdm_metrics(progress_bar_metrics)
576 all_log_metrics.append(log_metrics)
577
578 # insert after step hook
579 if self.is_function_implemented('on_after_backward'):
580 model_ref = self.get_model()
581 with self.profiler.profile('on_after_backward'):
582 model_ref.on_after_backward()
583
584 return closure_loss
585
586 # calculate loss
587 loss = optimizer_closure()
588
589 # nan grads
590 if self.print_nan_grads:
591 self.print_nan_gradients()
592
593 # track total loss for logging (avoid mem leaks)
594 self.batch_loss_value += loss.item()
595
596 # gradient update with accumulated gradients
597 if (self.batch_idx + 1) % self.accumulate_grad_batches == 0:
598
599 # track gradient norms when requested
600 if batch_idx % self.row_log_interval == 0:
601 if self.track_grad_norm > 0:
602 model = self.get_model()
603 grad_norm_dic = model.grad_norm(
604 self.track_grad_norm)
605
606 # clip gradients
607 self.clip_gradients()
608
609 # calls .step(), .zero_grad()
610 # override function to modify this behavior
611 model = self.get_model()
612 with self.profiler.profile('optimizer_step'):
613 model.optimizer_step(self.current_epoch, batch_idx,
614 optimizer, opt_idx, optimizer_closure)
615
616 # calculate running loss for display
617 self.running_loss.append(self.batch_loss_value)
618 self.batch_loss_value = 0
619 self.avg_loss = np.mean(self.running_loss[-100:])
620
621 # Batch end events
622 with self.profiler.profile('on_batch_end'):
623 # callbacks
624 self.on_batch_end()
625 # model hooks
626 if self.is_function_implemented('on_batch_end'):
627 self.get_model().on_batch_end()
628
629 # update progress bar
630 if batch_idx % self.progress_bar_refresh_rate == 0:
631 self.main_progress_bar.update(self.progress_bar_refresh_rate)
632 self.main_progress_bar.set_postfix(**self.training_tqdm_dict)
633
634 # collapse all metrics into one dict
635 all_log_metrics = {k: v for d in all_log_metrics for k, v in d.items()}
636
637 # track all metrics for callbacks
638 self.callback_metrics.update({k: v for d in all_callback_metrics for k, v in d.items()})
639
640 return 0, grad_norm_dic, all_log_metrics
641
642 def run_training_teardown(self):
643 self.main_progress_bar.close()
644
645 # Train end events
646 with self.profiler.profile('on_train_end'):
647 # callbacks
648 self.on_train_end()
649 # model hooks
650 if self.is_function_implemented('on_train_end'):
651 self.get_model().on_train_end()
652
653 if self.logger is not None:
654 self.logger.finalize("success")
655
656 # summarize profile results
657 self.profiler.describe()
658
659 def training_forward(self, batch, batch_idx, opt_idx, hiddens):
660 """
661 Handle forward for each training case (distributed, single gpu, etc...)
662 :param batch:
663 :param batch_idx:
664 :return:
665 """
666 # ---------------
667 # FORWARD
668 # ---------------
669 # enable not needing to add opt_idx to training_step
670 args = [batch, batch_idx]
671
672 if len(self.optimizers) > 1:
673 if self.has_arg('training_step', 'optimizer_idx'):
674 args.append(opt_idx)
675 else:
676 raise ValueError(
677 f'Your LightningModule defines {len(self.optimizers)} optimizers but '
678 f'training_step is missing the "optimizer_idx" argument.'
679 )
680
681 # pass hiddens if using tbptt
682 if self.truncated_bptt_steps is not None:
683 args.append(hiddens)
684
685 # distributed forward
686 if self.use_ddp or self.use_ddp2 or self.use_dp:
687 output = self.model(*args)
688
689 # single GPU forward
690 elif self.single_gpu:
691 gpu_id = 0
692 if isinstance(self.data_parallel_device_ids, list):
693 gpu_id = self.data_parallel_device_ids[0]
694 batch = self.transfer_batch_to_gpu(copy.copy(batch), gpu_id)
695 args[0] = batch
696 output = self.model.training_step(*args)
697
698 # TPU support
699 elif self.use_tpu:
700 batch = self.transfer_batch_to_tpu(copy.copy(batch))
701 args[0] = batch
702 output = self.model.training_step(*args)
703
704 # CPU forward
705 else:
706 output = self.model.training_step(*args)
707
708 # allow any mode to define training_end
709 if self.is_overriden('training_end'):
710 model_ref = self.get_model()
711 with self.profiler.profile('training_end'):
712 output = model_ref.training_end(output)
713
714 # format and reduce outputs accordingly
715 output = self.process_output(output, train=True)
716
717 return output
718
719 def call_checkpoint_callback(self):
720 if self.checkpoint_callback is not None:
721 self.checkpoint_callback.on_validation_end(self, self.get_model())
722 self.on_validation_end()
723
[end of pytorch_lightning/trainer/training_loop.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
Lightning-AI/lightning
|
bcb45d906d5f378a30461d513728cad34fc647ce
|
Support stepping options for lr scheduler
Currently schedulers get called every epoch. Sometimes though, we want them to be called every step.
Proposal 1:
Allow configure_optimizers to return this:
```python
return Adam, {'scheduler': LRScheduler, 'interval': 'batch|epoch'}
```
@ethanwharris @Borda thoughts? any simpler more general way of doing this? i think this dict can eventually have more options if we need to.
@srush
|
2020-02-25T15:48:00Z
|
<patch>
diff --git a/pytorch_lightning/core/lightning.py b/pytorch_lightning/core/lightning.py
--- a/pytorch_lightning/core/lightning.py
+++ b/pytorch_lightning/core/lightning.py
@@ -758,6 +758,15 @@ def configure_optimizers(self):
discriminator_sched = CosineAnnealing(discriminator_opt, T_max=10)
return [generator_opt, disriminator_opt], [discriminator_sched]
+ # example with step-based learning_rate schedulers
+ def configure_optimizers(self):
+ gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
+ dis_opt = Adam(self.model_disc.parameters(), lr=0.02)
+ gen_sched = {'scheduler': ExponentialLR(gen_opt, 0.99),
+ 'interval': 'step'} # called after each training step
+ dis_sched = CosineAnnealing(discriminator_opt, T_max=10) # called after each epoch
+ return [gen_opt, dis_opt], [gen_sched, dis_sched]
+
.. note:: Lightning calls .backward() and .step() on each optimizer and learning rate scheduler as needed.
.. note:: If you use 16-bit precision (use_amp=True), Lightning will automatically
@@ -773,6 +782,8 @@ def configure_optimizers(self):
.. note:: If you need to control how often those optimizers step or override the default .step() schedule,
override the `optimizer_step` hook.
+ .. note:: If you only want to call a learning rate schduler every `x` step or epoch,
+ you can input this as 'frequency' key: dict(scheduler=lr_schudler, interval='step' or 'epoch', frequency=x)
"""
return Adam(self.parameters(), lr=1e-3)
diff --git a/pytorch_lightning/trainer/trainer.py b/pytorch_lightning/trainer/trainer.py
--- a/pytorch_lightning/trainer/trainer.py
+++ b/pytorch_lightning/trainer/trainer.py
@@ -6,6 +6,7 @@
from argparse import ArgumentParser
import torch
+from torch import optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.utils.data import DataLoader
@@ -743,8 +744,6 @@ def on_train_end(self):
# creates a default one if none passed in
self.configure_early_stopping(early_stop_callback)
- self.reduce_lr_on_plateau_scheduler = None
-
# configure checkpoint callback
self.checkpoint_callback = checkpoint_callback
self.weights_save_path = weights_save_path
@@ -1079,26 +1078,56 @@ def init_optimizers(
optimizers: Union[Optimizer, Tuple[List, List], List[Optimizer], Tuple[Optimizer]]
) -> Tuple[List, List]:
- # single optimizer
+ # single output, single optimizer
if isinstance(optimizers, Optimizer):
return [optimizers], []
- # two lists
- if len(optimizers) == 2 and isinstance(optimizers[0], list):
+ # two lists, optimizer + lr schedulers
+ elif len(optimizers) == 2 and isinstance(optimizers[0], list):
optimizers, lr_schedulers = optimizers
- lr_schedulers, self.reduce_lr_on_plateau_scheduler = self.configure_schedulers(lr_schedulers)
+ lr_schedulers = self.configure_schedulers(lr_schedulers)
return optimizers, lr_schedulers
- # single list or tuple
- if isinstance(optimizers, (list, tuple)):
+ # single list or tuple, multiple optimizer
+ elif isinstance(optimizers, (list, tuple)):
return optimizers, []
+ # unknown configuration
+ else:
+ raise ValueError('Unknown configuration for model optimizers. Output'
+ 'from model.configure_optimizers() should either be:'
+ '* single output, single torch.optim.Optimizer'
+ '* single output, list of torch.optim.Optimizer'
+ '* two outputs, first being a list of torch.optim.Optimizer',
+ 'second being a list of torch.optim.lr_scheduler')
+
def configure_schedulers(self, schedulers: list):
- for i, scheduler in enumerate(schedulers):
- if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
- reduce_lr_on_plateau_scheduler = schedulers.pop(i)
- return schedulers, reduce_lr_on_plateau_scheduler
- return schedulers, None
+ # Convert each scheduler into dict sturcture with relevant information
+ lr_schedulers = []
+ default_config = {'interval': 'epoch', # default every epoch
+ 'frequency': 1, # default every epoch/batch
+ 'reduce_on_plateau': False, # most often not ReduceLROnPlateau scheduler
+ 'monitor': 'val_loss'} # default value to monitor for ReduceLROnPlateau
+ for scheduler in schedulers:
+ if isinstance(scheduler, dict):
+ if 'scheduler' not in scheduler:
+ raise ValueError(f'Lr scheduler should have key `scheduler`',
+ ' with item being a lr scheduler')
+ scheduler['reduce_on_plateau'] = \
+ isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau)
+
+ lr_schedulers.append({**default_config, **scheduler})
+
+ elif isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau):
+ lr_schedulers.append({**default_config, 'scheduler': scheduler,
+ 'reduce_on_plateau': True})
+
+ elif isinstance(scheduler, optim.lr_scheduler._LRScheduler):
+ lr_schedulers.append({**default_config, 'scheduler': scheduler})
+ else:
+ raise ValueError(f'Input {scheduler} to lr schedulers '
+ 'is a invalid input.')
+ return lr_schedulers
def run_pretrain_routine(self, model: LightningModule):
"""Sanity check a few things before starting actual training.
diff --git a/pytorch_lightning/trainer/training_io.py b/pytorch_lightning/trainer/training_io.py
--- a/pytorch_lightning/trainer/training_io.py
+++ b/pytorch_lightning/trainer/training_io.py
@@ -1,3 +1,94 @@
+"""
+Lightning can automate saving and loading checkpoints
+=====================================================
+
+Checkpointing is enabled by default to the current working directory.
+To change the checkpoint path pass in::
+
+ Trainer(default_save_path='/your/path/to/save/checkpoints')
+
+
+To modify the behavior of checkpointing pass in your own callback.
+
+.. code-block:: python
+
+ from pytorch_lightning.callbacks import ModelCheckpoint
+
+ # DEFAULTS used by the Trainer
+ checkpoint_callback = ModelCheckpoint(
+ filepath=os.getcwd(),
+ save_best_only=True,
+ verbose=True,
+ monitor='val_loss',
+ mode='min',
+ prefix=''
+ )
+
+ trainer = Trainer(checkpoint_callback=checkpoint_callback)
+
+
+Restoring training session
+--------------------------
+
+You might want to not only load a model but also continue training it. Use this method to
+restore the trainer state as well. This will continue from the epoch and global step you last left off.
+However, the dataloaders will start from the first batch again (if you shuffled it shouldn't matter).
+
+Lightning will restore the session if you pass a logger with the same version and there's a saved checkpoint.
+
+.. code-block:: python
+
+ from pytorch_lightning import Trainer
+ from pytorch_lightning.loggers import TestTubeLogger
+
+ logger = TestTubeLogger(
+ save_dir='./savepath',
+ version=1 # An existing version with a saved checkpoint
+ )
+ trainer = Trainer(
+ logger=logger,
+ default_save_path='./savepath'
+ )
+
+ # this fit call loads model weights and trainer state
+ # the trainer continues seamlessly from where you left off
+ # without having to do anything else.
+ trainer.fit(model)
+
+
+The trainer restores:
+
+- global_step
+- current_epoch
+- All optimizers
+- All lr_schedulers
+- Model weights
+
+You can even change the logic of your model as long as the weights and "architecture" of
+the system isn't different. If you add a layer, for instance, it might not work.
+
+At a rough level, here's what happens inside Trainer :py:mod:`pytorch_lightning.base_module.model_saving.py`:
+
+.. code-block:: python
+
+ self.global_step = checkpoint['global_step']
+ self.current_epoch = checkpoint['epoch']
+
+ # restore the optimizers
+ optimizer_states = checkpoint['optimizer_states']
+ for optimizer, opt_state in zip(self.optimizers, optimizer_states):
+ optimizer.load_state_dict(opt_state)
+
+ # restore the lr schedulers
+ lr_schedulers = checkpoint['lr_schedulers']
+ for scheduler, lrs_state in zip(self.lr_schedulers, lr_schedulers):
+ scheduler['scheduler'].load_state_dict(lrs_state)
+
+ # uses the model you passed into trainer
+ model.load_state_dict(checkpoint['state_dict'])
+
+"""
+
import logging as log
import os
import re
@@ -228,8 +319,8 @@ def dump_checkpoint(self):
# save lr schedulers
lr_schedulers = []
- for i, scheduler in enumerate(self.lr_schedulers):
- lr_schedulers.append(scheduler.state_dict())
+ for scheduler in self.lr_schedulers:
+ lr_schedulers.append(scheduler['scheduler'].state_dict())
checkpoint['lr_schedulers'] = lr_schedulers
@@ -320,7 +411,7 @@ def restore_training_state(self, checkpoint):
# restore the lr schedulers
lr_schedulers = checkpoint['lr_schedulers']
for scheduler, lrs_state in zip(self.lr_schedulers, lr_schedulers):
- scheduler.load_state_dict(lrs_state)
+ scheduler['scheduler'].load_state_dict(lrs_state)
# ----------------------------------
# PRIVATE OPS
diff --git a/pytorch_lightning/trainer/training_loop.py b/pytorch_lightning/trainer/training_loop.py
--- a/pytorch_lightning/trainer/training_loop.py
+++ b/pytorch_lightning/trainer/training_loop.py
@@ -361,17 +361,7 @@ def train(self):
self.run_training_epoch()
# update LR schedulers
- if self.lr_schedulers is not None:
- for lr_scheduler in self.lr_schedulers:
- lr_scheduler.step()
- if self.reduce_lr_on_plateau_scheduler is not None:
- val_loss = self.callback_metrics.get('val_loss')
- if val_loss is None:
- avail_metrics = ','.join(list(self.callback_metrics.keys()))
- m = f'ReduceLROnPlateau conditioned on metric val_loss ' \
- f'which is not available. Available metrics are: {avail_metrics}'
- raise MisconfigurationException(m)
- self.reduce_lr_on_plateau_scheduler.step(val_loss)
+ self.update_learning_rates(interval='epoch')
if self.max_steps and self.max_steps == self.global_step:
self.run_training_teardown()
@@ -444,6 +434,9 @@ def run_training_epoch(self):
# when returning -1 from train_step, we end epoch early
early_stop_epoch = batch_result == -1
+ # update lr
+ self.update_learning_rates(interval='step')
+
# ---------------
# RUN VAL STEP
# ---------------
@@ -716,6 +709,34 @@ def training_forward(self, batch, batch_idx, opt_idx, hiddens):
return output
+ def update_learning_rates(self, interval):
+ ''' Update learning rates
+ Args:
+ interval (str): either 'epoch' or 'step'.
+ '''
+ if not self.lr_schedulers:
+ return
+
+ for lr_scheduler in self.lr_schedulers:
+ current_idx = self.batch_idx if interval == 'step' else self.current_epoch
+ current_idx += 1 # account for both batch and epoch starts from 0
+ # Take step if call to update_learning_rates matches the interval key and
+ # the current step modulo the schedulers frequency is zero
+ if lr_scheduler['interval'] == interval and current_idx % lr_scheduler['frequency'] == 0:
+ # If instance of ReduceLROnPlateau, we need to pass validation loss
+ if lr_scheduler['reduce_on_plateau']:
+ monitor_key = lr_scheduler['monitor']
+ monitor_val = self.callback_metrics.get(monitor_key)
+ if monitor_val is None:
+ avail_metrics = ','.join(list(self.callback_metrics.keys()))
+ m = f'ReduceLROnPlateau conditioned on metric {monitor_key} ' \
+ f'which is not available. Available metrics are: {avail_metrics}. ' \
+ 'Condition can be set using `monitor` key in lr scheduler dict'
+ raise MisconfigurationException(m)
+ lr_scheduler['scheduler'].step(monitor_val)
+ else:
+ lr_scheduler['scheduler'].step()
+
def call_checkpoint_callback(self):
if self.checkpoint_callback is not None:
self.checkpoint_callback.on_validation_end(self, self.get_model())
</patch>
|
[]
|
[]
| ||||
PrefectHQ__prefect-1386
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`auth login` CLI check needs token required query
## Description
`prefect auth login` runs a graphql query to verify the token provided is valid. The current query is `query { hello }` and this query does not require authentication. This query needs to be updated to one which requires authentication (which is every other query, let's just find the smallest one)
## Expected Behavior
If the token is invalid it should elevate an error to the user
## Reproduction
Query the API with `query { hello }` without a token and it will still work.
## Environment
N/A
</issue>
<code>
[start of README.md]
1 <p align="center" style="margin-bottom:40px;">
2 <img src="https://uploads-ssl.webflow.com/5ba446b0e783e26d5a2f2382/5c942c9ca934ec5c88588297_primary-color-vertical.svg" height=350 style="max-height: 350px;">
3 </p>
4
5 <p align="center">
6 <a href=https://circleci.com/gh/PrefectHQ/prefect/tree/master>
7 <img src="https://circleci.com/gh/PrefectHQ/prefect/tree/master.svg?style=shield&circle-token=28689a55edc3c373486aaa5f11a1af3e5fc53344">
8 </a>
9
10 <a href="https://codecov.io/gh/PrefectHQ/prefect">
11 <img src="https://codecov.io/gh/PrefectHQ/prefect/branch/master/graph/badge.svg" />
12 </a>
13
14 <a href=https://github.com/ambv/black>
15 <img src="https://img.shields.io/badge/code%20style-black-000000.svg">
16 </a>
17
18 <a href="https://pypi.org/project/prefect/">
19 <img src="https://img.shields.io/pypi/dm/prefect.svg?color=%2327B1FF&label=installs&logoColor=%234D606E">
20 </a>
21
22 <a href="https://hub.docker.com/r/prefecthq/prefect">
23 <img src="https://img.shields.io/docker/pulls/prefecthq/prefect.svg?color=%2327B1FF&logoColor=%234D606E">
24 </a>
25
26 <a href="https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU">
27 <img src="https://img.shields.io/static/v1.svg?label=chat&message=on%20slack&color=27b1ff&style=flat">
28 </a>
29
30 </p>
31
32 ## Hello, world! 👋
33
34 We've rebuilt data engineering for the data science era.
35
36 Prefect is a new workflow management system, designed for modern infrastructure and powered by the open-source Prefect Core workflow engine. Users organize `Tasks` into `Flows`, and Prefect takes care of the rest.
37
38 Read the [docs](https://docs.prefect.io); get the [code](#installation); ask us [anything](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU)!
39
40 ```python
41 from prefect import task, Flow
42
43
44 @task
45 def say_hello():
46 print("Hello, world!")
47
48
49 with Flow("My First Flow") as flow:
50 say_hello()
51
52
53 flow.run() # "Hello, world!"
54 ```
55
56 ## Docs
57
58 Prefect's documentation -- including concepts, tutorials, and a full API reference -- is always available at [docs.prefect.io](https://docs.prefect.io).
59
60 ## Contributing
61
62 Read about Prefect's [community](https://docs.prefect.io/guide/welcome/community.html) or dive in to the [development guides](https://docs.prefect.io/guide/development/overview.html) for information about contributions, documentation, code style, and testing.
63
64 Join our [Slack](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) to chat about Prefect, ask questions, and share tips.
65
66 Prefect is committed to ensuring a positive environment. All interactions are governed by our [Code of Conduct](https://docs.prefect.io/guide/welcome/code_of_conduct.html).
67
68 ## "...Prefect?"
69
70 From the Latin _praefectus_, meaning "one who is in charge", a prefect is an official who oversees a domain and makes sure that the rules are followed. Similarly, Prefect is responsible for making sure that workflows execute properly.
71
72 It also happens to be the name of a roving researcher for that wholly remarkable book, _The Hitchhiker's Guide to the Galaxy_.
73
74 ## Installation
75
76 ### Requirements
77
78 Prefect requires Python 3.5.2+.
79
80 ### Install latest release
81
82 Using `pip`:
83
84 ```bash
85 pip install prefect
86 ```
87
88 or `conda`:
89
90 ```bash
91 conda install -c conda-forge prefect
92 ```
93
94 or `pipenv`:
95 ```
96 pipenv install --pre prefect
97 ```
98
99 ### Install bleeding edge
100
101 ```bash
102 git clone https://github.com/PrefectHQ/prefect.git
103 pip install ./prefect
104 ```
105
106 ## License
107
108 Prefect is licensed under the Apache Software License version 2.0.
109
[end of README.md]
[start of src/prefect/cli/auth.py]
1 import click
2
3 from prefect import Client, config
4 from prefect.utilities.exceptions import AuthorizationError, ClientError
5
6
7 @click.group(hidden=True)
8 def auth():
9 """
10 Handle Prefect Cloud authorization.
11
12 \b
13 Usage:
14 $ prefect auth [COMMAND]
15
16 \b
17 Arguments:
18 login Login to Prefect Cloud
19
20 \b
21 Examples:
22 $ prefect auth login --token MY_TOKEN
23 """
24 pass
25
26
27 @auth.command(hidden=True)
28 @click.option(
29 "--token", "-t", required=True, help="A Prefect Cloud API token.", hidden=True
30 )
31 def login(token):
32 """
33 Login to Prefect Cloud with an api token to use for Cloud communication.
34
35 \b
36 Options:
37 --token, -t TEXT A Prefect Cloud api token [required]
38 """
39
40 if config.cloud.auth_token:
41 click.confirm(
42 "Prefect Cloud API token already set in config. Do you want to override?",
43 default=True,
44 )
45
46 client = Client()
47 client.login(api_token=token)
48
49 # Verify login obtained a valid api token
50 try:
51 client.graphql(query={"query": "hello"})
52 except AuthorizationError:
53 click.secho(
54 "Error attempting to use Prefect API token {}".format(token), fg="red"
55 )
56 return
57 except ClientError:
58 click.secho("Error attempting to communicate with Prefect Cloud", fg="red")
59 return
60
61 click.secho("Login successful", fg="green")
62
[end of src/prefect/cli/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
PrefectHQ/prefect
|
e92d10977339e7cf230471804bf471db2f6ace7d
|
`auth login` CLI check needs token required query
## Description
`prefect auth login` runs a graphql query to verify the token provided is valid. The current query is `query { hello }` and this query does not require authentication. This query needs to be updated to one which requires authentication (which is every other query, let's just find the smallest one)
## Expected Behavior
If the token is invalid it should elevate an error to the user
## Reproduction
Query the API with `query { hello }` without a token and it will still work.
## Environment
N/A
|
2019-08-21T17:00:45Z
|
<patch>
diff --git a/src/prefect/cli/auth.py b/src/prefect/cli/auth.py
--- a/src/prefect/cli/auth.py
+++ b/src/prefect/cli/auth.py
@@ -37,10 +37,11 @@ def login(token):
--token, -t TEXT A Prefect Cloud api token [required]
"""
- if config.cloud.auth_token:
+ if config.cloud.get("auth_token"):
click.confirm(
"Prefect Cloud API token already set in config. Do you want to override?",
default=True,
+ abort=True,
)
client = Client()
@@ -48,7 +49,7 @@ def login(token):
# Verify login obtained a valid api token
try:
- client.graphql(query={"query": "hello"})
+ client.graphql(query={"query": {"tenant": "id"}})
except AuthorizationError:
click.secho(
"Error attempting to use Prefect API token {}".format(token), fg="red"
</patch>
|
[]
|
[]
| ||||
pandas-dev__pandas-34877
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: s3 reads from public buckets not working
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest version of pandas.
- [ ] (optional) I have confirmed this bug exists on the master branch of pandas.
---
#### Code Sample
```python
# Your code here
import pandas as pd
df = pd.read_csv("s3://nyc-tlc/trip data/yellow_tripdata_2019-01.csv")
```
<details>
<summary> Error stack trace </summary>
<pre>
Traceback (most recent call last):
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 33, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
botocore.exceptions.NoCredentialsError: Unable to locate credentials
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f
return _read(filepath_or_buffer, kwds)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 431, in _read
filepath_or_buffer, encoding, compression
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/common.py", line 212, in get_filepath_or_buffer
filepath_or_buffer, encoding=encoding, compression=compression, mode=mode
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 52, in get_filepath_or_buffer
file, _fs = get_file_and_filesystem(filepath_or_buffer, mode=mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 42, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
</pre>
</details>
#### Problem description
Reading directly from s3 public buckets (without manually configuring the `anon` parameter via s3fs) is broken with pandas 1.0.4 (worked with 1.0.3).
Looks like reading from public buckets requires `anon=True` while creating the filesystem. This 22cf0f5dfcfbddd5506fdaf260e485bff1b88ef1 seems to have introduced the issue, where `anon=False` is passed when the `noCredentialsError` is encountered.
#### Output of ``pd.show_versions()``
<details>
INSTALLED VERSIONS
------------------
commit : None
python : 3.7.7.final.0
python-bits : 64
OS : Linux
OS-release : 4.15.0-55-generic
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 1.0.4
numpy : 1.18.1
pytz : 2020.1
dateutil : 2.8.1
pip : 20.0.2
setuptools : 47.1.1.post20200604
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fastparquet : None
gcsfs : None
lxml.etree : None
matplotlib : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
pyarrow : 0.15.1
pytables : None
pytest : None
pyxlsb : None
s3fs : 0.4.2
scipy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlwt : None
xlsxwriter : None
numba : None
</details>
</issue>
<code>
[start of README.md]
1 <div align="center">
2 <img src="https://dev.pandas.io/static/img/pandas.svg"><br>
3 </div>
4
5 -----------------
6
7 # pandas: powerful Python data analysis toolkit
8 [](https://pypi.org/project/pandas/)
9 [](https://anaconda.org/anaconda/pandas/)
10 [](https://doi.org/10.5281/zenodo.3509134)
11 [](https://pypi.org/project/pandas/)
12 [](https://github.com/pandas-dev/pandas/blob/master/LICENSE)
13 [](https://travis-ci.org/pandas-dev/pandas)
14 [](https://dev.azure.com/pandas-dev/pandas/_build/latest?definitionId=1&branch=master)
15 [](https://codecov.io/gh/pandas-dev/pandas)
16 [](https://pandas.pydata.org)
17 [](https://gitter.im/pydata/pandas)
18 [](https://numfocus.org)
19 [](https://github.com/psf/black)
20
21 ## What is it?
22
23 **pandas** is a Python package that provides fast, flexible, and expressive data
24 structures designed to make working with "relational" or "labeled" data both
25 easy and intuitive. It aims to be the fundamental high-level building block for
26 doing practical, **real world** data analysis in Python. Additionally, it has
27 the broader goal of becoming **the most powerful and flexible open source data
28 analysis / manipulation tool available in any language**. It is already well on
29 its way towards this goal.
30
31 ## Main Features
32 Here are just a few of the things that pandas does well:
33
34 - Easy handling of [**missing data**][missing-data] (represented as
35 `NaN`) in floating point as well as non-floating point data
36 - Size mutability: columns can be [**inserted and
37 deleted**][insertion-deletion] from DataFrame and higher dimensional
38 objects
39 - Automatic and explicit [**data alignment**][alignment]: objects can
40 be explicitly aligned to a set of labels, or the user can simply
41 ignore the labels and let `Series`, `DataFrame`, etc. automatically
42 align the data for you in computations
43 - Powerful, flexible [**group by**][groupby] functionality to perform
44 split-apply-combine operations on data sets, for both aggregating
45 and transforming data
46 - Make it [**easy to convert**][conversion] ragged,
47 differently-indexed data in other Python and NumPy data structures
48 into DataFrame objects
49 - Intelligent label-based [**slicing**][slicing], [**fancy
50 indexing**][fancy-indexing], and [**subsetting**][subsetting] of
51 large data sets
52 - Intuitive [**merging**][merging] and [**joining**][joining] data
53 sets
54 - Flexible [**reshaping**][reshape] and [**pivoting**][pivot-table] of
55 data sets
56 - [**Hierarchical**][mi] labeling of axes (possible to have multiple
57 labels per tick)
58 - Robust IO tools for loading data from [**flat files**][flat-files]
59 (CSV and delimited), [**Excel files**][excel], [**databases**][db],
60 and saving/loading data from the ultrafast [**HDF5 format**][hdfstore]
61 - [**Time series**][timeseries]-specific functionality: date range
62 generation and frequency conversion, moving window statistics,
63 date shifting and lagging.
64
65
66 [missing-data]: https://pandas.pydata.org/pandas-docs/stable/missing_data.html#working-with-missing-data
67 [insertion-deletion]: https://pandas.pydata.org/pandas-docs/stable/dsintro.html#column-selection-addition-deletion
68 [alignment]: https://pandas.pydata.org/pandas-docs/stable/dsintro.html?highlight=alignment#intro-to-data-structures
69 [groupby]: https://pandas.pydata.org/pandas-docs/stable/groupby.html#group-by-split-apply-combine
70 [conversion]: https://pandas.pydata.org/pandas-docs/stable/dsintro.html#dataframe
71 [slicing]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#slicing-ranges
72 [fancy-indexing]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#advanced-indexing-with-ix
73 [subsetting]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#boolean-indexing
74 [merging]: https://pandas.pydata.org/pandas-docs/stable/merging.html#database-style-dataframe-joining-merging
75 [joining]: https://pandas.pydata.org/pandas-docs/stable/merging.html#joining-on-index
76 [reshape]: https://pandas.pydata.org/pandas-docs/stable/reshaping.html#reshaping-and-pivot-tables
77 [pivot-table]: https://pandas.pydata.org/pandas-docs/stable/reshaping.html#pivot-tables-and-cross-tabulations
78 [mi]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#hierarchical-indexing-multiindex
79 [flat-files]: https://pandas.pydata.org/pandas-docs/stable/io.html#csv-text-files
80 [excel]: https://pandas.pydata.org/pandas-docs/stable/io.html#excel-files
81 [db]: https://pandas.pydata.org/pandas-docs/stable/io.html#sql-queries
82 [hdfstore]: https://pandas.pydata.org/pandas-docs/stable/io.html#hdf5-pytables
83 [timeseries]: https://pandas.pydata.org/pandas-docs/stable/timeseries.html#time-series-date-functionality
84
85 ## Where to get it
86 The source code is currently hosted on GitHub at:
87 https://github.com/pandas-dev/pandas
88
89 Binary installers for the latest released version are available at the [Python
90 package index](https://pypi.org/project/pandas) and on conda.
91
92 ```sh
93 # conda
94 conda install pandas
95 ```
96
97 ```sh
98 # or PyPI
99 pip install pandas
100 ```
101
102 ## Dependencies
103 - [NumPy](https://www.numpy.org)
104 - [python-dateutil](https://labix.org/python-dateutil)
105 - [pytz](https://pythonhosted.org/pytz)
106
107 See the [full installation instructions](https://pandas.pydata.org/pandas-docs/stable/install.html#dependencies) for minimum supported versions of required, recommended and optional dependencies.
108
109 ## Installation from sources
110 To install pandas from source you need Cython in addition to the normal
111 dependencies above. Cython can be installed from pypi:
112
113 ```sh
114 pip install cython
115 ```
116
117 In the `pandas` directory (same one where you found this file after
118 cloning the git repo), execute:
119
120 ```sh
121 python setup.py install
122 ```
123
124 or for installing in [development mode](https://pip.pypa.io/en/latest/reference/pip_install.html#editable-installs):
125
126
127 ```sh
128 python -m pip install -e . --no-build-isolation --no-use-pep517
129 ```
130
131 If you have `make`, you can also use `make develop` to run the same command.
132
133 or alternatively
134
135 ```sh
136 python setup.py develop
137 ```
138
139 See the full instructions for [installing from source](https://pandas.pydata.org/pandas-docs/stable/install.html#installing-from-source).
140
141 ## License
142 [BSD 3](LICENSE)
143
144 ## Documentation
145 The official documentation is hosted on PyData.org: https://pandas.pydata.org/pandas-docs/stable
146
147 ## Background
148 Work on ``pandas`` started at AQR (a quantitative hedge fund) in 2008 and
149 has been under active development since then.
150
151 ## Getting Help
152
153 For usage questions, the best place to go to is [StackOverflow](https://stackoverflow.com/questions/tagged/pandas).
154 Further, general questions and discussions can also take place on the [pydata mailing list](https://groups.google.com/forum/?fromgroups#!forum/pydata).
155
156 ## Discussion and Development
157 Most development discussions take place on github in this repo. Further, the [pandas-dev mailing list](https://mail.python.org/mailman/listinfo/pandas-dev) can also be used for specialized discussions or design issues, and a [Gitter channel](https://gitter.im/pydata/pandas) is available for quick development related questions.
158
159 ## Contributing to pandas [](https://www.codetriage.com/pandas-dev/pandas)
160
161 All contributions, bug reports, bug fixes, documentation improvements, enhancements, and ideas are welcome.
162
163 A detailed overview on how to contribute can be found in the **[contributing guide](https://pandas.pydata.org/docs/dev/development/contributing.html)**. There is also an [overview](.github/CONTRIBUTING.md) on GitHub.
164
165 If you are simply looking to start working with the pandas codebase, navigate to the [GitHub "issues" tab](https://github.com/pandas-dev/pandas/issues) and start looking through interesting issues. There are a number of issues listed under [Docs](https://github.com/pandas-dev/pandas/issues?labels=Docs&sort=updated&state=open) and [good first issue](https://github.com/pandas-dev/pandas/issues?labels=good+first+issue&sort=updated&state=open) where you could start out.
166
167 You can also triage issues which may include reproducing bug reports, or asking for vital information such as version numbers or reproduction instructions. If you would like to start triaging issues, one easy way to get started is to [subscribe to pandas on CodeTriage](https://www.codetriage.com/pandas-dev/pandas).
168
169 Or maybe through using pandas you have an idea of your own or are looking for something in the documentation and thinking ‘this can be improved’...you can do something about it!
170
171 Feel free to ask questions on the [mailing list](https://groups.google.com/forum/?fromgroups#!forum/pydata) or on [Gitter](https://gitter.im/pydata/pandas).
172
173 As contributors and maintainers to this project, you are expected to abide by pandas' code of conduct. More information can be found at: [Contributor Code of Conduct](https://github.com/pandas-dev/pandas/blob/master/.github/CODE_OF_CONDUCT.md)
174
[end of README.md]
[start of pandas/io/common.py]
1 """Common IO api utilities"""
2
3 import bz2
4 from collections import abc
5 import gzip
6 from io import BufferedIOBase, BytesIO, RawIOBase
7 import mmap
8 import os
9 import pathlib
10 from typing import (
11 IO,
12 TYPE_CHECKING,
13 Any,
14 AnyStr,
15 Dict,
16 List,
17 Mapping,
18 Optional,
19 Tuple,
20 Type,
21 Union,
22 )
23 from urllib.parse import (
24 urljoin,
25 urlparse as parse_url,
26 uses_netloc,
27 uses_params,
28 uses_relative,
29 )
30 import zipfile
31
32 from pandas._typing import FilePathOrBuffer
33 from pandas.compat import _get_lzma_file, _import_lzma
34 from pandas.compat._optional import import_optional_dependency
35
36 from pandas.core.dtypes.common import is_file_like
37
38 lzma = _import_lzma()
39
40
41 _VALID_URLS = set(uses_relative + uses_netloc + uses_params)
42 _VALID_URLS.discard("")
43
44
45 if TYPE_CHECKING:
46 from io import IOBase # noqa: F401
47
48
49 def is_url(url) -> bool:
50 """
51 Check to see if a URL has a valid protocol.
52
53 Parameters
54 ----------
55 url : str or unicode
56
57 Returns
58 -------
59 isurl : bool
60 If `url` has a valid protocol return True otherwise False.
61 """
62 if not isinstance(url, str):
63 return False
64 return parse_url(url).scheme in _VALID_URLS
65
66
67 def _expand_user(
68 filepath_or_buffer: FilePathOrBuffer[AnyStr],
69 ) -> FilePathOrBuffer[AnyStr]:
70 """
71 Return the argument with an initial component of ~ or ~user
72 replaced by that user's home directory.
73
74 Parameters
75 ----------
76 filepath_or_buffer : object to be converted if possible
77
78 Returns
79 -------
80 expanded_filepath_or_buffer : an expanded filepath or the
81 input if not expandable
82 """
83 if isinstance(filepath_or_buffer, str):
84 return os.path.expanduser(filepath_or_buffer)
85 return filepath_or_buffer
86
87
88 def validate_header_arg(header) -> None:
89 if isinstance(header, bool):
90 raise TypeError(
91 "Passing a bool to header is invalid. Use header=None for no header or "
92 "header=int or list-like of ints to specify "
93 "the row(s) making up the column names"
94 )
95
96
97 def stringify_path(
98 filepath_or_buffer: FilePathOrBuffer[AnyStr],
99 ) -> FilePathOrBuffer[AnyStr]:
100 """
101 Attempt to convert a path-like object to a string.
102
103 Parameters
104 ----------
105 filepath_or_buffer : object to be converted
106
107 Returns
108 -------
109 str_filepath_or_buffer : maybe a string version of the object
110
111 Notes
112 -----
113 Objects supporting the fspath protocol (python 3.6+) are coerced
114 according to its __fspath__ method.
115
116 For backwards compatibility with older pythons, pathlib.Path and
117 py.path objects are specially coerced.
118
119 Any other object is passed through unchanged, which includes bytes,
120 strings, buffers, or anything else that's not even path-like.
121 """
122 if hasattr(filepath_or_buffer, "__fspath__"):
123 # https://github.com/python/mypy/issues/1424
124 return filepath_or_buffer.__fspath__() # type: ignore
125 elif isinstance(filepath_or_buffer, pathlib.Path):
126 return str(filepath_or_buffer)
127 return _expand_user(filepath_or_buffer)
128
129
130 def urlopen(*args, **kwargs):
131 """
132 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
133 the stdlib.
134 """
135 import urllib.request
136
137 return urllib.request.urlopen(*args, **kwargs)
138
139
140 def is_fsspec_url(url: FilePathOrBuffer) -> bool:
141 """
142 Returns true if the given URL looks like
143 something fsspec can handle
144 """
145 return (
146 isinstance(url, str)
147 and "://" in url
148 and not url.startswith(("http://", "https://"))
149 )
150
151
152 def get_filepath_or_buffer(
153 filepath_or_buffer: FilePathOrBuffer,
154 encoding: Optional[str] = None,
155 compression: Optional[str] = None,
156 mode: Optional[str] = None,
157 storage_options: Optional[Dict[str, Any]] = None,
158 ):
159 """
160 If the filepath_or_buffer is a url, translate and return the buffer.
161 Otherwise passthrough.
162
163 Parameters
164 ----------
165 filepath_or_buffer : a url, filepath (str, py.path.local or pathlib.Path),
166 or buffer
167 compression : {{'gzip', 'bz2', 'zip', 'xz', None}}, optional
168 encoding : the encoding to use to decode bytes, default is 'utf-8'
169 mode : str, optional
170 storage_options: dict, optional
171 passed on to fsspec, if using it; this is not yet accessed by the public API
172
173 Returns
174 -------
175 Tuple[FilePathOrBuffer, str, str, bool]
176 Tuple containing the filepath or buffer, the encoding, the compression
177 and should_close.
178 """
179 filepath_or_buffer = stringify_path(filepath_or_buffer)
180
181 if isinstance(filepath_or_buffer, str) and is_url(filepath_or_buffer):
182 # TODO: fsspec can also handle HTTP via requests, but leaving this unchanged
183 req = urlopen(filepath_or_buffer)
184 content_encoding = req.headers.get("Content-Encoding", None)
185 if content_encoding == "gzip":
186 # Override compression based on Content-Encoding header
187 compression = "gzip"
188 reader = BytesIO(req.read())
189 req.close()
190 return reader, encoding, compression, True
191
192 if is_fsspec_url(filepath_or_buffer):
193 assert isinstance(
194 filepath_or_buffer, str
195 ) # just to appease mypy for this branch
196 # two special-case s3-like protocols; these have special meaning in Hadoop,
197 # but are equivalent to just "s3" from fsspec's point of view
198 # cc #11071
199 if filepath_or_buffer.startswith("s3a://"):
200 filepath_or_buffer = filepath_or_buffer.replace("s3a://", "s3://")
201 if filepath_or_buffer.startswith("s3n://"):
202 filepath_or_buffer = filepath_or_buffer.replace("s3n://", "s3://")
203 fsspec = import_optional_dependency("fsspec")
204
205 file_obj = fsspec.open(
206 filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
207 ).open()
208 return file_obj, encoding, compression, True
209
210 if isinstance(filepath_or_buffer, (str, bytes, mmap.mmap)):
211 return _expand_user(filepath_or_buffer), None, compression, False
212
213 if not is_file_like(filepath_or_buffer):
214 msg = f"Invalid file path or buffer object type: {type(filepath_or_buffer)}"
215 raise ValueError(msg)
216
217 return filepath_or_buffer, None, compression, False
218
219
220 def file_path_to_url(path: str) -> str:
221 """
222 converts an absolute native path to a FILE URL.
223
224 Parameters
225 ----------
226 path : a path in native format
227
228 Returns
229 -------
230 a valid FILE URL
231 """
232 # lazify expensive import (~30ms)
233 from urllib.request import pathname2url
234
235 return urljoin("file:", pathname2url(path))
236
237
238 _compression_to_extension = {"gzip": ".gz", "bz2": ".bz2", "zip": ".zip", "xz": ".xz"}
239
240
241 def get_compression_method(
242 compression: Optional[Union[str, Mapping[str, str]]]
243 ) -> Tuple[Optional[str], Dict[str, str]]:
244 """
245 Simplifies a compression argument to a compression method string and
246 a mapping containing additional arguments.
247
248 Parameters
249 ----------
250 compression : str or mapping
251 If string, specifies the compression method. If mapping, value at key
252 'method' specifies compression method.
253
254 Returns
255 -------
256 tuple of ({compression method}, Optional[str]
257 {compression arguments}, Dict[str, str])
258
259 Raises
260 ------
261 ValueError on mapping missing 'method' key
262 """
263 if isinstance(compression, Mapping):
264 compression_args = dict(compression)
265 try:
266 compression = compression_args.pop("method")
267 except KeyError as err:
268 raise ValueError("If mapping, compression must have key 'method'") from err
269 else:
270 compression_args = {}
271 return compression, compression_args
272
273
274 def infer_compression(
275 filepath_or_buffer: FilePathOrBuffer, compression: Optional[str]
276 ) -> Optional[str]:
277 """
278 Get the compression method for filepath_or_buffer. If compression='infer',
279 the inferred compression method is returned. Otherwise, the input
280 compression method is returned unchanged, unless it's invalid, in which
281 case an error is raised.
282
283 Parameters
284 ----------
285 filepath_or_buffer : str or file handle
286 File path or object.
287 compression : {'infer', 'gzip', 'bz2', 'zip', 'xz', None}
288 If 'infer' and `filepath_or_buffer` is path-like, then detect
289 compression from the following extensions: '.gz', '.bz2', '.zip',
290 or '.xz' (otherwise no compression).
291
292 Returns
293 -------
294 string or None
295
296 Raises
297 ------
298 ValueError on invalid compression specified.
299 """
300 # No compression has been explicitly specified
301 if compression is None:
302 return None
303
304 # Infer compression
305 if compression == "infer":
306 # Convert all path types (e.g. pathlib.Path) to strings
307 filepath_or_buffer = stringify_path(filepath_or_buffer)
308 if not isinstance(filepath_or_buffer, str):
309 # Cannot infer compression of a buffer, assume no compression
310 return None
311
312 # Infer compression from the filename/URL extension
313 for compression, extension in _compression_to_extension.items():
314 if filepath_or_buffer.endswith(extension):
315 return compression
316 return None
317
318 # Compression has been specified. Check that it's valid
319 if compression in _compression_to_extension:
320 return compression
321
322 msg = f"Unrecognized compression type: {compression}"
323 valid = ["infer", None] + sorted(_compression_to_extension)
324 msg += f"\nValid compression types are {valid}"
325 raise ValueError(msg)
326
327
328 def get_handle(
329 path_or_buf,
330 mode: str,
331 encoding=None,
332 compression: Optional[Union[str, Mapping[str, Any]]] = None,
333 memory_map: bool = False,
334 is_text: bool = True,
335 errors=None,
336 ):
337 """
338 Get file handle for given path/buffer and mode.
339
340 Parameters
341 ----------
342 path_or_buf : str or file handle
343 File path or object.
344 mode : str
345 Mode to open path_or_buf with.
346 encoding : str or None
347 Encoding to use.
348 compression : str or dict, default None
349 If string, specifies compression mode. If dict, value at key 'method'
350 specifies compression mode. Compression mode must be one of {'infer',
351 'gzip', 'bz2', 'zip', 'xz', None}. If compression mode is 'infer'
352 and `filepath_or_buffer` is path-like, then detect compression from
353 the following extensions: '.gz', '.bz2', '.zip', or '.xz' (otherwise
354 no compression). If dict and compression mode is one of
355 {'zip', 'gzip', 'bz2'}, or inferred as one of the above,
356 other entries passed as additional compression options.
357
358 .. versionchanged:: 1.0.0
359
360 May now be a dict with key 'method' as compression mode
361 and other keys as compression options if compression
362 mode is 'zip'.
363
364 .. versionchanged:: 1.1.0
365
366 Passing compression options as keys in dict is now
367 supported for compression modes 'gzip' and 'bz2' as well as 'zip'.
368
369 memory_map : boolean, default False
370 See parsers._parser_params for more information.
371 is_text : boolean, default True
372 whether file/buffer is in text format (csv, json, etc.), or in binary
373 mode (pickle, etc.).
374 errors : str, default 'strict'
375 Specifies how encoding and decoding errors are to be handled.
376 See the errors argument for :func:`open` for a full list
377 of options.
378
379 .. versionadded:: 1.1.0
380
381 Returns
382 -------
383 f : file-like
384 A file-like object.
385 handles : list of file-like objects
386 A list of file-like object that were opened in this function.
387 """
388 need_text_wrapping: Tuple[Type["IOBase"], ...]
389 try:
390 from s3fs import S3File
391
392 need_text_wrapping = (BufferedIOBase, RawIOBase, S3File)
393 except ImportError:
394 need_text_wrapping = (BufferedIOBase, RawIOBase)
395
396 handles: List[IO] = list()
397 f = path_or_buf
398
399 # Convert pathlib.Path/py.path.local or string
400 path_or_buf = stringify_path(path_or_buf)
401 is_path = isinstance(path_or_buf, str)
402
403 compression, compression_args = get_compression_method(compression)
404 if is_path:
405 compression = infer_compression(path_or_buf, compression)
406
407 if compression:
408
409 # GH33398 the type ignores here seem related to mypy issue #5382;
410 # it may be possible to remove them once that is resolved.
411
412 # GZ Compression
413 if compression == "gzip":
414 if is_path:
415 f = gzip.open(
416 path_or_buf, mode, **compression_args # type: ignore
417 )
418 else:
419 f = gzip.GzipFile(
420 fileobj=path_or_buf, **compression_args # type: ignore
421 )
422
423 # BZ Compression
424 elif compression == "bz2":
425 if is_path:
426 f = bz2.BZ2File(
427 path_or_buf, mode, **compression_args # type: ignore
428 )
429 else:
430 f = bz2.BZ2File(path_or_buf, **compression_args) # type: ignore
431
432 # ZIP Compression
433 elif compression == "zip":
434 zf = _BytesZipFile(path_or_buf, mode, **compression_args)
435 # Ensure the container is closed as well.
436 handles.append(zf)
437 if zf.mode == "w":
438 f = zf
439 elif zf.mode == "r":
440 zip_names = zf.namelist()
441 if len(zip_names) == 1:
442 f = zf.open(zip_names.pop())
443 elif len(zip_names) == 0:
444 raise ValueError(f"Zero files found in ZIP file {path_or_buf}")
445 else:
446 raise ValueError(
447 "Multiple files found in ZIP file. "
448 f"Only one file per ZIP: {zip_names}"
449 )
450
451 # XZ Compression
452 elif compression == "xz":
453 f = _get_lzma_file(lzma)(path_or_buf, mode)
454
455 # Unrecognized Compression
456 else:
457 msg = f"Unrecognized compression type: {compression}"
458 raise ValueError(msg)
459
460 handles.append(f)
461
462 elif is_path:
463 if encoding:
464 # Encoding
465 f = open(path_or_buf, mode, encoding=encoding, errors=errors, newline="")
466 elif is_text:
467 # No explicit encoding
468 f = open(path_or_buf, mode, errors="replace", newline="")
469 else:
470 # Binary mode
471 f = open(path_or_buf, mode)
472 handles.append(f)
473
474 # Convert BytesIO or file objects passed with an encoding
475 if is_text and (compression or isinstance(f, need_text_wrapping)):
476 from io import TextIOWrapper
477
478 g = TextIOWrapper(f, encoding=encoding, errors=errors, newline="")
479 if not isinstance(f, (BufferedIOBase, RawIOBase)):
480 handles.append(g)
481 f = g
482
483 if memory_map and hasattr(f, "fileno"):
484 try:
485 wrapped = _MMapWrapper(f)
486 f.close()
487 f = wrapped
488 except Exception:
489 # we catch any errors that may have occurred
490 # because that is consistent with the lower-level
491 # functionality of the C engine (pd.read_csv), so
492 # leave the file handler as is then
493 pass
494
495 return f, handles
496
497
498 class _BytesZipFile(zipfile.ZipFile, BytesIO): # type: ignore
499 """
500 Wrapper for standard library class ZipFile and allow the returned file-like
501 handle to accept byte strings via `write` method.
502
503 BytesIO provides attributes of file-like object and ZipFile.writestr writes
504 bytes strings into a member of the archive.
505 """
506
507 # GH 17778
508 def __init__(
509 self,
510 file: FilePathOrBuffer,
511 mode: str,
512 archive_name: Optional[str] = None,
513 **kwargs,
514 ):
515 if mode in ["wb", "rb"]:
516 mode = mode.replace("b", "")
517 self.archive_name = archive_name
518 super().__init__(file, mode, zipfile.ZIP_DEFLATED, **kwargs)
519
520 def write(self, data):
521 archive_name = self.filename
522 if self.archive_name is not None:
523 archive_name = self.archive_name
524 super().writestr(archive_name, data)
525
526 @property
527 def closed(self):
528 return self.fp is None
529
530
531 class _MMapWrapper(abc.Iterator):
532 """
533 Wrapper for the Python's mmap class so that it can be properly read in
534 by Python's csv.reader class.
535
536 Parameters
537 ----------
538 f : file object
539 File object to be mapped onto memory. Must support the 'fileno'
540 method or have an equivalent attribute
541
542 """
543
544 def __init__(self, f: IO):
545 self.mmap = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
546
547 def __getattr__(self, name: str):
548 return getattr(self.mmap, name)
549
550 def __iter__(self) -> "_MMapWrapper":
551 return self
552
553 def __next__(self) -> str:
554 newbytes = self.mmap.readline()
555
556 # readline returns bytes, not str, but Python's CSV reader
557 # expects str, so convert the output to str before continuing
558 newline = newbytes.decode("utf-8")
559
560 # mmap doesn't raise if reading past the allocated
561 # data but instead returns an empty string, so raise
562 # if that is returned
563 if newline == "":
564 raise StopIteration
565 return newline
566
[end of pandas/io/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
pandas-dev/pandas
|
b0468aa45f3912d6f8823d1cd418af34ffdcd2b1
|
BUG: s3 reads from public buckets not working
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest version of pandas.
- [ ] (optional) I have confirmed this bug exists on the master branch of pandas.
---
#### Code Sample
```python
# Your code here
import pandas as pd
df = pd.read_csv("s3://nyc-tlc/trip data/yellow_tripdata_2019-01.csv")
```
<details>
<summary> Error stack trace </summary>
<pre>
Traceback (most recent call last):
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 33, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
botocore.exceptions.NoCredentialsError: Unable to locate credentials
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f
return _read(filepath_or_buffer, kwds)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 431, in _read
filepath_or_buffer, encoding, compression
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/common.py", line 212, in get_filepath_or_buffer
filepath_or_buffer, encoding=encoding, compression=compression, mode=mode
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 52, in get_filepath_or_buffer
file, _fs = get_file_and_filesystem(filepath_or_buffer, mode=mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 42, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
</pre>
</details>
#### Problem description
Reading directly from s3 public buckets (without manually configuring the `anon` parameter via s3fs) is broken with pandas 1.0.4 (worked with 1.0.3).
Looks like reading from public buckets requires `anon=True` while creating the filesystem. This 22cf0f5dfcfbddd5506fdaf260e485bff1b88ef1 seems to have introduced the issue, where `anon=False` is passed when the `noCredentialsError` is encountered.
#### Output of ``pd.show_versions()``
<details>
INSTALLED VERSIONS
------------------
commit : None
python : 3.7.7.final.0
python-bits : 64
OS : Linux
OS-release : 4.15.0-55-generic
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 1.0.4
numpy : 1.18.1
pytz : 2020.1
dateutil : 2.8.1
pip : 20.0.2
setuptools : 47.1.1.post20200604
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fastparquet : None
gcsfs : None
lxml.etree : None
matplotlib : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
pyarrow : 0.15.1
pytables : None
pytest : None
pyxlsb : None
s3fs : 0.4.2
scipy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlwt : None
xlsxwriter : None
numba : None
</details>
|
@ayushdg thanks for the report!
cc @simonjayhawkins @alimcmaster1 for 1.0.5, it might be safer to revert https://github.com/pandas-dev/pandas/pull/33632, and then target the fixes (like https://github.com/pandas-dev/pandas/pull/34500) to master
Agree @jorisvandenbossche - do you want me to open a PR to revert #33632 on 1.0.x branch? Apologies for this change it didn’t go as planned. I’ll check why our test cases didn’t catch the above!
> do you want me to open a PR to revert #33632 on 1.0.x branch?
Yes, that sounds good
> Apologies for this change it didn’t go as planned.
No, no, nobody of us had foreseen the breakages ;)
Can't seem to reproduce this using moto... Potentially related: https://github.com/dask/s3fs/blob/master/s3fs/tests/test_s3fs.py#L1089
(I can repo locally using the s3 URL above - if I remove AWS Creds from my environment)
The fix for this to target 1.1 is to set ‘anon=True’ in S3FileSystem https://github.com/pandas-dev/pandas/pull/33632/files#diff-a37b395bed03f0404dec864a4529c97dR41
I’ll wait as we are moving to fsspec which gets rid of this logic https://github.com/pandas-dev/pandas/pull/34266 - but we should definitely trying using moto to test this.
Can anyone summarize the status here?
1.0.3: worked
1.0.4: broken
master: broken?
master+https://github.com/pandas-dev/pandas/pull/34266: broken?
Do we have a plan in place to restore this? IIUC the old way was to
1. try with the default (which I think looks up keys based on env vars)
2. If we get an error, retry with `anon=True`
Yep, it broke in 1.0.4, and will be fixed in 1.0.5 by reverting the patch that broke it.
That means that master is still broken, and thus we first need to write a test for it, and check whether #34266 actually fixes it already, or otherwise still fix it differently.
The old way was indeed to try with `anon=True` if it first failed. I suppose we can "simply" restore that logic? (in case it's not automatically fixed with fsspec)
Thanks
> in case it's not automatically fixed with fsspec
It's not. So we'll need to do that explicitly. Long-term we might want to get away from this logic by asking users to do `read_csv(..., storage_options={"requester_pays": False})`. But for 1.1 we'll want to restore the old implicit retry behavior if possible.
|
2020-06-19T23:07:29Z
|
<patch>
diff --git a/pandas/io/common.py b/pandas/io/common.py
--- a/pandas/io/common.py
+++ b/pandas/io/common.py
@@ -202,9 +202,37 @@ def get_filepath_or_buffer(
filepath_or_buffer = filepath_or_buffer.replace("s3n://", "s3://")
fsspec = import_optional_dependency("fsspec")
- file_obj = fsspec.open(
- filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
- ).open()
+ # If botocore is installed we fallback to reading with anon=True
+ # to allow reads from public buckets
+ err_types_to_retry_with_anon: List[Any] = []
+ try:
+ import_optional_dependency("botocore")
+ from botocore.exceptions import ClientError, NoCredentialsError
+
+ err_types_to_retry_with_anon = [
+ ClientError,
+ NoCredentialsError,
+ PermissionError,
+ ]
+ except ImportError:
+ pass
+
+ try:
+ file_obj = fsspec.open(
+ filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
+ ).open()
+ # GH 34626 Reads from Public Buckets without Credentials needs anon=True
+ except tuple(err_types_to_retry_with_anon):
+ if storage_options is None:
+ storage_options = {"anon": True}
+ else:
+ # don't mutate user input.
+ storage_options = dict(storage_options)
+ storage_options["anon"] = True
+ file_obj = fsspec.open(
+ filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
+ ).open()
+
return file_obj, encoding, compression, True
if isinstance(filepath_or_buffer, (str, bytes, mmap.mmap)):
</patch>
|
[]
|
[]
| |||
Qiskit__qiskit-9386
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DAGCircuitError: 'bit mapping invalid
### Informations
- **Qiskit: 0.39.2**:
- **Python: 3.10.9**:
- **Mac**:
### What is the current behavior?
I'm implementing quantum half adder on Jupyter Notebook.
When I try running my circuit on the simulator "qasm_simulator", Jupyter said
DAGCircuitError: 'bit mapping invalid: expected 4, got 8'
here is the code I've written. The error occurs on the last line of the third code.
```
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute, Aer
#SUM
X = QuantumRegister(1, "in |X⟩")
Y = QuantumRegister(1, "in |Y⟩")
sum_out = QuantumRegister(1, "out SUM |0⟩")
SUM = QuantumCircuit(X, Y, sum_out, name='SUM')
SUM.cx(1, 2)
SUM.cx(0, 2)
fig = SUM.draw('mpl', True)
SUM = SUM.to_instruction()
fig
```
```
#half_adder
cout = QuantumRegister(1, 'out Carry |0⟩')
c = ClassicalRegister(4)
hadder = QuantumCircuit(X,Y,sum_out,cout,c)
hadder.ccx(X,Y,cout)
hadder.append(SUM,[0,1,2])
show = hadder.draw("mpl",True)
hadder = hadder.to_instruction()
show
```
```
#testing half_adder
qu = QuantumRegister(4)
cl = ClassicalRegister(4)
circ = QuantumCircuit(qu,cl)
circ.x(qu[0])
circ.x(qu[1])
circ.append(hadder,[0,1,2,3])
for i in range(0,4):
circ.measure(qu[i],cl[i])
circ.draw("mpl",True)
print(execute(circ,Aer.get_backend('qasm_simulator'), shots = 1).result().get_counts())
```
### What is the expected behavior?
I don't totally understand the error. I hope to troubleshoot to see the result.
### Suggested solutions
</issue>
<code>
[start of README.md]
1 # Qiskit Terra
2 [](https://opensource.org/licenses/Apache-2.0)<!--- long-description-skip-begin -->[](https://github.com/Qiskit/qiskit-terra/releases)[](https://pypi.org/project/qiskit-terra/)[](https://coveralls.io/github/Qiskit/qiskit-terra?branch=main)[](https://rust-lang.github.io/rfcs/2495-min-rust-version.html)<!--- long-description-skip-end -->
3
4 **Qiskit** is an open-source framework for working with noisy quantum computers at the level of pulses, circuits, and algorithms.
5
6 This library is the core component of Qiskit, **Terra**, which contains the building blocks for creating
7 and working with quantum circuits, programs, and algorithms. It also contains a compiler that supports
8 different quantum computers and a common interface for running programs on different quantum computer architectures.
9
10 For more details on how to use Qiskit you can refer to the documentation located here:
11
12 https://qiskit.org/documentation/
13
14
15 ## Installation
16
17 We encourage installing Qiskit via ``pip``. The following command installs the core Qiskit components, including Terra.
18
19 ```bash
20 pip install qiskit
21 ```
22
23 Pip will handle all dependencies automatically and you will always install the latest (and well-tested) version.
24
25 To install from source, follow the instructions in the [documentation](https://qiskit.org/documentation/contributing_to_qiskit.html#install-install-from-source-label).
26
27 ## Creating Your First Quantum Program in Qiskit Terra
28
29 Now that Qiskit is installed, it's time to begin working with Qiskit. To do this
30 we create a `QuantumCircuit` object to define a basic quantum program.
31
32 ```python
33 from qiskit import QuantumCircuit
34 qc = QuantumCircuit(2, 2)
35 qc.h(0)
36 qc.cx(0, 1)
37 qc.measure([0,1], [0,1])
38 ```
39
40 This simple example makes an entangled state, also called a [Bell state](https://qiskit.org/textbook/ch-gates/multiple-qubits-entangled-states.html#3.2-Entangled-States-).
41
42 Once you've made your first quantum circuit, you can then simulate it.
43 To do this, first we need to compile your circuit for the target backend we're going to run
44 on. In this case we are leveraging the built-in `BasicAer` simulator. However, this
45 simulator is primarily for testing and is limited in performance and functionality (as the name
46 implies). You should consider more sophisticated simulators, such as [`qiskit-aer`](https://github.com/Qiskit/qiskit-aer/),
47 for any real simulation work.
48
49 ```python
50 from qiskit import transpile
51 from qiskit.providers.basicaer import QasmSimulatorPy
52 backend_sim = QasmSimulatorPy()
53 transpiled_qc = transpile(qc, backend_sim)
54 ```
55
56 After compiling the circuit we can then run this on the ``backend`` object with:
57
58 ```python
59 result = backend_sim.run(transpiled_qc).result()
60 print(result.get_counts(qc))
61 ```
62
63 The output from this execution will look similar to this:
64
65 ```python
66 {'00': 513, '11': 511}
67 ```
68
69 For further examples of using Qiskit you can look at the example scripts in **examples/python**. You can start with
70 [using_qiskit_terra_level_0.py](examples/python/using_qiskit_terra_level_0.py) and working up in the levels. Also
71 you can refer to the tutorials in the documentation here:
72
73 https://qiskit.org/documentation/tutorials.html
74
75
76 ### Executing your code on a real quantum chip
77
78 You can also use Qiskit to execute your code on a **real quantum processor**.
79 Qiskit provides an abstraction layer that lets users run quantum circuits on hardware from any
80 vendor that provides an interface to their systems through Qiskit. Using these ``providers`` you can run any Qiskit code against
81 real quantum computers. Some examples of published provider packages for running on real hardware are:
82
83 * https://github.com/Qiskit/qiskit-ibmq-provider
84 * https://github.com/Qiskit-Partners/qiskit-ionq
85 * https://github.com/Qiskit-Partners/qiskit-aqt-provider
86 * https://github.com/qiskit-community/qiskit-braket-provider
87 * https://github.com/qiskit-community/qiskit-quantinuum-provider
88 * https://github.com/rigetti/qiskit-rigetti
89
90 <!-- This is not an exhasutive list, and if you maintain a provider package please feel free to open a PR to add new providers -->
91
92 You can refer to the documentation of these packages for further instructions
93 on how to get access and use these systems.
94
95 ## Contribution Guidelines
96
97 If you'd like to contribute to Qiskit Terra, please take a look at our
98 [contribution guidelines](CONTRIBUTING.md). This project adheres to Qiskit's [code of conduct](CODE_OF_CONDUCT.md). By participating, you are expected to uphold this code.
99
100 We use [GitHub issues](https://github.com/Qiskit/qiskit-terra/issues) for tracking requests and bugs. Please
101 [join the Qiskit Slack community](https://qisk.it/join-slack)
102 and use our [Qiskit Slack channel](https://qiskit.slack.com) for discussion and simple questions.
103 For questions that are more suited for a forum we use the `qiskit` tag in the [Stack Exchange](https://quantumcomputing.stackexchange.com/questions/tagged/qiskit).
104
105 ## Next Steps
106
107 Now you're set up and ready to check out some of the other examples from our
108 [Qiskit Tutorials](https://github.com/Qiskit/qiskit-tutorials) repository.
109
110 ## Authors and Citation
111
112 Qiskit Terra is the work of [many people](https://github.com/Qiskit/qiskit-terra/graphs/contributors) who contribute
113 to the project at different levels. If you use Qiskit, please cite as per the included [BibTeX file](https://github.com/Qiskit/qiskit/blob/master/Qiskit.bib).
114
115 ## Changelog and Release Notes
116
117 The changelog for a particular release is dynamically generated and gets
118 written to the release page on Github for each release. For example, you can
119 find the page for the `0.9.0` release here:
120
121 https://github.com/Qiskit/qiskit-terra/releases/tag/0.9.0
122
123 The changelog for the current release can be found in the releases tab:
124 [](https://github.com/Qiskit/qiskit-terra/releases)
125 The changelog provides a quick overview of notable changes for a given
126 release.
127
128 Additionally, as part of each release detailed release notes are written to
129 document in detail what has changed as part of a release. This includes any
130 documentation on potential breaking changes on upgrade and new features.
131 For example, you can find the release notes for the `0.9.0` release in the
132 Qiskit documentation here:
133
134 https://qiskit.org/documentation/release_notes.html#terra-0-9
135
136 ## License
137
138 [Apache License 2.0](LICENSE.txt)
139
[end of README.md]
[start of qiskit/circuit/instruction.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """
14 A generic quantum instruction.
15
16 Instructions can be implementable on hardware (u, cx, etc.) or in simulation
17 (snapshot, noise, etc.).
18
19 Instructions can be unitary (a.k.a Gate) or non-unitary.
20
21 Instructions are identified by the following:
22
23 name: A string to identify the type of instruction.
24 Used to request a specific instruction on the backend, or in visualizing circuits.
25
26 num_qubits, num_clbits: dimensions of the instruction.
27
28 params: List of parameters to specialize a specific instruction instance.
29
30 Instructions do not have any context about where they are in a circuit (which qubits/clbits).
31 The circuit itself keeps this context.
32 """
33
34 import copy
35 from itertools import zip_longest
36 from typing import List
37
38 import numpy
39
40 from qiskit.circuit.exceptions import CircuitError
41 from qiskit.circuit.quantumregister import QuantumRegister
42 from qiskit.circuit.classicalregister import ClassicalRegister, Clbit
43 from qiskit.qasm.exceptions import QasmError
44 from qiskit.qobj.qasm_qobj import QasmQobjInstruction
45 from qiskit.circuit.parameter import ParameterExpression
46 from qiskit.circuit.operation import Operation
47 from .tools import pi_check
48
49 _CUTOFF_PRECISION = 1e-10
50
51
52 class Instruction(Operation):
53 """Generic quantum instruction."""
54
55 # Class attribute to treat like barrier for transpiler, unroller, drawer
56 # NOTE: Using this attribute may change in the future (See issue # 5811)
57 _directive = False
58
59 def __init__(self, name, num_qubits, num_clbits, params, duration=None, unit="dt", label=None):
60 """Create a new instruction.
61
62 Args:
63 name (str): instruction name
64 num_qubits (int): instruction's qubit width
65 num_clbits (int): instruction's clbit width
66 params (list[int|float|complex|str|ndarray|list|ParameterExpression]):
67 list of parameters
68 duration (int or float): instruction's duration. it must be integer if ``unit`` is 'dt'
69 unit (str): time unit of duration
70 label (str or None): An optional label for identifying the instruction.
71
72 Raises:
73 CircuitError: when the register is not in the correct format.
74 TypeError: when the optional label is provided, but it is not a string.
75 """
76 if not isinstance(num_qubits, int) or not isinstance(num_clbits, int):
77 raise CircuitError("num_qubits and num_clbits must be integer.")
78 if num_qubits < 0 or num_clbits < 0:
79 raise CircuitError(
80 "bad instruction dimensions: %d qubits, %d clbits." % num_qubits, num_clbits
81 )
82 self._name = name
83 self._num_qubits = num_qubits
84 self._num_clbits = num_clbits
85
86 self._params = [] # a list of gate params stored
87 # Custom instruction label
88 # NOTE: The conditional statement checking if the `_label` attribute is
89 # already set is a temporary work around that can be removed after
90 # the next stable qiskit-aer release
91 if not hasattr(self, "_label"):
92 if label is not None and not isinstance(label, str):
93 raise TypeError("label expects a string or None")
94 self._label = label
95 # tuple (ClassicalRegister, int), tuple (Clbit, bool) or tuple (Clbit, int)
96 # when the instruction has a conditional ("if")
97 self.condition = None
98 # list of instructions (and their contexts) that this instruction is composed of
99 # empty definition means opaque or fundamental instruction
100 self._definition = None
101
102 self._duration = duration
103 self._unit = unit
104
105 self.params = params # must be at last (other properties may be required for validation)
106
107 def __eq__(self, other):
108 """Two instructions are the same if they have the same name,
109 same dimensions, and same params.
110
111 Args:
112 other (instruction): other instruction
113
114 Returns:
115 bool: are self and other equal.
116 """
117 if (
118 type(self) is not type(other)
119 or self.name != other.name
120 or self.num_qubits != other.num_qubits
121 or self.num_clbits != other.num_clbits
122 or self.definition != other.definition
123 ):
124 return False
125
126 for self_param, other_param in zip_longest(self.params, other.params):
127 try:
128 if self_param == other_param:
129 continue
130 except ValueError:
131 pass
132
133 try:
134 self_asarray = numpy.asarray(self_param)
135 other_asarray = numpy.asarray(other_param)
136 if numpy.shape(self_asarray) == numpy.shape(other_asarray) and numpy.allclose(
137 self_param, other_param, atol=_CUTOFF_PRECISION, rtol=0
138 ):
139 continue
140 except (ValueError, TypeError):
141 pass
142
143 try:
144 if numpy.isclose(
145 float(self_param), float(other_param), atol=_CUTOFF_PRECISION, rtol=0
146 ):
147 continue
148 except TypeError:
149 pass
150
151 return False
152
153 return True
154
155 def __repr__(self) -> str:
156 """Generates a representation of the Intruction object instance
157 Returns:
158 str: A representation of the Instruction instance with the name,
159 number of qubits, classical bits and params( if any )
160 """
161 return "Instruction(name='{}', num_qubits={}, num_clbits={}, params={})".format(
162 self.name, self.num_qubits, self.num_clbits, self.params
163 )
164
165 def soft_compare(self, other: "Instruction") -> bool:
166 """
167 Soft comparison between gates. Their names, number of qubits, and classical
168 bit numbers must match. The number of parameters must match. Each parameter
169 is compared. If one is a ParameterExpression then it is not taken into
170 account.
171
172 Args:
173 other (instruction): other instruction.
174
175 Returns:
176 bool: are self and other equal up to parameter expressions.
177 """
178 if (
179 self.name != other.name
180 or other.num_qubits != other.num_qubits
181 or other.num_clbits != other.num_clbits
182 or len(self.params) != len(other.params)
183 ):
184 return False
185
186 for self_param, other_param in zip_longest(self.params, other.params):
187 if isinstance(self_param, ParameterExpression) or isinstance(
188 other_param, ParameterExpression
189 ):
190 continue
191 if isinstance(self_param, numpy.ndarray) and isinstance(other_param, numpy.ndarray):
192 if numpy.shape(self_param) == numpy.shape(other_param) and numpy.allclose(
193 self_param, other_param, atol=_CUTOFF_PRECISION
194 ):
195 continue
196 else:
197 try:
198 if numpy.isclose(self_param, other_param, atol=_CUTOFF_PRECISION):
199 continue
200 except TypeError:
201 pass
202
203 return False
204
205 return True
206
207 def _define(self):
208 """Populates self.definition with a decomposition of this gate."""
209 pass
210
211 @property
212 def params(self):
213 """return instruction params."""
214 return self._params
215
216 @params.setter
217 def params(self, parameters):
218 self._params = []
219 for single_param in parameters:
220 if isinstance(single_param, ParameterExpression):
221 self._params.append(single_param)
222 else:
223 self._params.append(self.validate_parameter(single_param))
224
225 def validate_parameter(self, parameter):
226 """Instruction parameters has no validation or normalization."""
227 return parameter
228
229 def is_parameterized(self):
230 """Return True .IFF. instruction is parameterized else False"""
231 return any(
232 isinstance(param, ParameterExpression) and param.parameters for param in self.params
233 )
234
235 @property
236 def definition(self):
237 """Return definition in terms of other basic gates."""
238 if self._definition is None:
239 self._define()
240 return self._definition
241
242 @definition.setter
243 def definition(self, array):
244 """Set gate representation"""
245 self._definition = array
246
247 @property
248 def decompositions(self):
249 """Get the decompositions of the instruction from the SessionEquivalenceLibrary."""
250 # pylint: disable=cyclic-import
251 from qiskit.circuit.equivalence_library import SessionEquivalenceLibrary as sel
252
253 return sel.get_entry(self)
254
255 @decompositions.setter
256 def decompositions(self, decompositions):
257 """Set the decompositions of the instruction from the SessionEquivalenceLibrary."""
258 # pylint: disable=cyclic-import
259 from qiskit.circuit.equivalence_library import SessionEquivalenceLibrary as sel
260
261 sel.set_entry(self, decompositions)
262
263 def add_decomposition(self, decomposition):
264 """Add a decomposition of the instruction to the SessionEquivalenceLibrary."""
265 # pylint: disable=cyclic-import
266 from qiskit.circuit.equivalence_library import SessionEquivalenceLibrary as sel
267
268 sel.add_equivalence(self, decomposition)
269
270 @property
271 def duration(self):
272 """Get the duration."""
273 return self._duration
274
275 @duration.setter
276 def duration(self, duration):
277 """Set the duration."""
278 self._duration = duration
279
280 @property
281 def unit(self):
282 """Get the time unit of duration."""
283 return self._unit
284
285 @unit.setter
286 def unit(self, unit):
287 """Set the time unit of duration."""
288 self._unit = unit
289
290 def assemble(self):
291 """Assemble a QasmQobjInstruction"""
292 instruction = QasmQobjInstruction(name=self.name)
293 # Evaluate parameters
294 if self.params:
295 params = [x.evalf(x) if hasattr(x, "evalf") else x for x in self.params]
296 instruction.params = params
297 # Add placeholder for qarg and carg params
298 if self.num_qubits:
299 instruction.qubits = list(range(self.num_qubits))
300 if self.num_clbits:
301 instruction.memory = list(range(self.num_clbits))
302 # Add label if defined
303 if self.label:
304 instruction.label = self.label
305 # Add condition parameters for assembler. This is needed to convert
306 # to a qobj conditional instruction at assemble time and after
307 # conversion will be deleted by the assembler.
308 if self.condition:
309 instruction._condition = self.condition
310 return instruction
311
312 @property
313 def label(self) -> str:
314 """Return instruction label"""
315 return self._label
316
317 @label.setter
318 def label(self, name: str):
319 """Set instruction label to name
320
321 Args:
322 name (str or None): label to assign instruction
323
324 Raises:
325 TypeError: name is not string or None.
326 """
327 if isinstance(name, (str, type(None))):
328 self._label = name
329 else:
330 raise TypeError("label expects a string or None")
331
332 def reverse_ops(self):
333 """For a composite instruction, reverse the order of sub-instructions.
334
335 This is done by recursively reversing all sub-instructions.
336 It does not invert any gate.
337
338 Returns:
339 qiskit.circuit.Instruction: a new instruction with
340 sub-instructions reversed.
341 """
342 if not self._definition:
343 return self.copy()
344
345 reverse_inst = self.copy(name=self.name + "_reverse")
346 reversed_definition = self._definition.copy_empty_like()
347 for inst in reversed(self._definition):
348 reversed_definition.append(inst.operation.reverse_ops(), inst.qubits, inst.clbits)
349 reverse_inst.definition = reversed_definition
350 return reverse_inst
351
352 def inverse(self):
353 """Invert this instruction.
354
355 If the instruction is composite (i.e. has a definition),
356 then its definition will be recursively inverted.
357
358 Special instructions inheriting from Instruction can
359 implement their own inverse (e.g. T and Tdg, Barrier, etc.)
360
361 Returns:
362 qiskit.circuit.Instruction: a fresh instruction for the inverse
363
364 Raises:
365 CircuitError: if the instruction is not composite
366 and an inverse has not been implemented for it.
367 """
368 if self.definition is None:
369 raise CircuitError("inverse() not implemented for %s." % self.name)
370
371 from qiskit.circuit import Gate # pylint: disable=cyclic-import
372
373 if self.name.endswith("_dg"):
374 name = self.name[:-3]
375 else:
376 name = self.name + "_dg"
377 if self.num_clbits:
378 inverse_gate = Instruction(
379 name=name,
380 num_qubits=self.num_qubits,
381 num_clbits=self.num_clbits,
382 params=self.params.copy(),
383 )
384
385 else:
386 inverse_gate = Gate(name=name, num_qubits=self.num_qubits, params=self.params.copy())
387
388 inverse_definition = self._definition.copy_empty_like()
389 inverse_definition.global_phase = -inverse_definition.global_phase
390 for inst in reversed(self._definition):
391 inverse_definition._append(inst.operation.inverse(), inst.qubits, inst.clbits)
392 inverse_gate.definition = inverse_definition
393 return inverse_gate
394
395 def c_if(self, classical, val):
396 """Set a classical equality condition on this instruction between the register or cbit
397 ``classical`` and value ``val``.
398
399 .. note::
400
401 This is a setter method, not an additive one. Calling this multiple times will silently
402 override any previously set condition; it does not stack.
403 """
404 if not isinstance(classical, (ClassicalRegister, Clbit)):
405 raise CircuitError("c_if must be used with a classical register or classical bit")
406 if val < 0:
407 raise CircuitError("condition value should be non-negative")
408 if isinstance(classical, Clbit):
409 # Casting the conditional value as Boolean when
410 # the classical condition is on a classical bit.
411 val = bool(val)
412 self.condition = (classical, val)
413 return self
414
415 def copy(self, name=None):
416 """
417 Copy of the instruction.
418
419 Args:
420 name (str): name to be given to the copied circuit, if ``None`` then the name stays the same.
421
422 Returns:
423 qiskit.circuit.Instruction: a copy of the current instruction, with the name updated if it
424 was provided
425 """
426 cpy = self.__deepcopy__()
427
428 if name:
429 cpy.name = name
430 return cpy
431
432 def __deepcopy__(self, _memo=None):
433 cpy = copy.copy(self)
434 cpy._params = copy.copy(self._params)
435 if self._definition:
436 cpy._definition = copy.deepcopy(self._definition, _memo)
437 return cpy
438
439 def _qasmif(self, string):
440 """Print an if statement if needed."""
441 if self.condition is None:
442 return string
443 if not isinstance(self.condition[0], ClassicalRegister):
444 raise QasmError(
445 "OpenQASM 2 can only condition on registers, but got '{self.condition[0]}'"
446 )
447 return "if(%s==%d) " % (self.condition[0].name, self.condition[1]) + string
448
449 def qasm(self):
450 """Return a default OpenQASM string for the instruction.
451
452 Derived instructions may override this to print in a
453 different format (e.g. measure q[0] -> c[0];).
454 """
455 name_param = self.name
456 if self.params:
457 name_param = "{}({})".format(
458 name_param,
459 ",".join([pi_check(i, output="qasm", eps=1e-12) for i in self.params]),
460 )
461
462 return self._qasmif(name_param)
463
464 def broadcast_arguments(self, qargs, cargs):
465 """
466 Validation of the arguments.
467
468 Args:
469 qargs (List): List of quantum bit arguments.
470 cargs (List): List of classical bit arguments.
471
472 Yields:
473 Tuple(List, List): A tuple with single arguments.
474
475 Raises:
476 CircuitError: If the input is not valid. For example, the number of
477 arguments does not match the gate expectation.
478 """
479 if len(qargs) != self.num_qubits:
480 raise CircuitError(
481 f"The amount of qubit arguments {len(qargs)} does not match"
482 f" the instruction expectation ({self.num_qubits})."
483 )
484
485 # [[q[0], q[1]], [c[0], c[1]]] -> [q[0], c[0]], [q[1], c[1]]
486 flat_qargs = [qarg for sublist in qargs for qarg in sublist]
487 flat_cargs = [carg for sublist in cargs for carg in sublist]
488 yield flat_qargs, flat_cargs
489
490 def _return_repeat(self, exponent):
491 return Instruction(
492 name=f"{self.name}*{exponent}",
493 num_qubits=self.num_qubits,
494 num_clbits=self.num_clbits,
495 params=self.params,
496 )
497
498 def repeat(self, n):
499 """Creates an instruction with `gate` repeated `n` amount of times.
500
501 Args:
502 n (int): Number of times to repeat the instruction
503
504 Returns:
505 qiskit.circuit.Instruction: Containing the definition.
506
507 Raises:
508 CircuitError: If n < 1.
509 """
510 if int(n) != n or n < 1:
511 raise CircuitError("Repeat can only be called with strictly positive integer.")
512
513 n = int(n)
514
515 instruction = self._return_repeat(n)
516 qargs = [] if self.num_qubits == 0 else QuantumRegister(self.num_qubits, "q")
517 cargs = [] if self.num_clbits == 0 else ClassicalRegister(self.num_clbits, "c")
518
519 if instruction.definition is None:
520 # pylint: disable=cyclic-import
521 from qiskit.circuit import QuantumCircuit, CircuitInstruction
522
523 qc = QuantumCircuit()
524 if qargs:
525 qc.add_register(qargs)
526 if cargs:
527 qc.add_register(cargs)
528 circuit_instruction = CircuitInstruction(self, qargs, cargs)
529 for _ in [None] * n:
530 qc._append(circuit_instruction)
531 instruction.definition = qc
532 return instruction
533
534 @property
535 def condition_bits(self) -> List[Clbit]:
536 """Get Clbits in condition."""
537 if self.condition is None:
538 return []
539 if isinstance(self.condition[0], Clbit):
540 return [self.condition[0]]
541 else: # ClassicalRegister
542 return list(self.condition[0])
543
544 @property
545 def name(self):
546 """Return the name."""
547 return self._name
548
549 @name.setter
550 def name(self, name):
551 """Set the name."""
552 self._name = name
553
554 @property
555 def num_qubits(self):
556 """Return the number of qubits."""
557 return self._num_qubits
558
559 @num_qubits.setter
560 def num_qubits(self, num_qubits):
561 """Set num_qubits."""
562 self._num_qubits = num_qubits
563
564 @property
565 def num_clbits(self):
566 """Return the number of clbits."""
567 return self._num_clbits
568
569 @num_clbits.setter
570 def num_clbits(self, num_clbits):
571 """Set num_clbits."""
572 self._num_clbits = num_clbits
573
[end of qiskit/circuit/instruction.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
Qiskit/qiskit
|
3ab57152c1d7e0eb572eb298f6fa922299492586
|
DAGCircuitError: 'bit mapping invalid
### Informations
- **Qiskit: 0.39.2**:
- **Python: 3.10.9**:
- **Mac**:
### What is the current behavior?
I'm implementing quantum half adder on Jupyter Notebook.
When I try running my circuit on the simulator "qasm_simulator", Jupyter said
DAGCircuitError: 'bit mapping invalid: expected 4, got 8'
here is the code I've written. The error occurs on the last line of the third code.
```
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute, Aer
#SUM
X = QuantumRegister(1, "in |X⟩")
Y = QuantumRegister(1, "in |Y⟩")
sum_out = QuantumRegister(1, "out SUM |0⟩")
SUM = QuantumCircuit(X, Y, sum_out, name='SUM')
SUM.cx(1, 2)
SUM.cx(0, 2)
fig = SUM.draw('mpl', True)
SUM = SUM.to_instruction()
fig
```
```
#half_adder
cout = QuantumRegister(1, 'out Carry |0⟩')
c = ClassicalRegister(4)
hadder = QuantumCircuit(X,Y,sum_out,cout,c)
hadder.ccx(X,Y,cout)
hadder.append(SUM,[0,1,2])
show = hadder.draw("mpl",True)
hadder = hadder.to_instruction()
show
```
```
#testing half_adder
qu = QuantumRegister(4)
cl = ClassicalRegister(4)
circ = QuantumCircuit(qu,cl)
circ.x(qu[0])
circ.x(qu[1])
circ.append(hadder,[0,1,2,3])
for i in range(0,4):
circ.measure(qu[i],cl[i])
circ.draw("mpl",True)
print(execute(circ,Aer.get_backend('qasm_simulator'), shots = 1).result().get_counts())
```
### What is the expected behavior?
I don't totally understand the error. I hope to troubleshoot to see the result.
### Suggested solutions
|
Your immediate problem is that the line
```python
circ.append(hadder, [0, 1, 2, 3])
```
doesn't include any classical arguments to apply `hadder` to, but it expects 4 (though they're not used). Perhaps you either meant not to have the `ClassicalRegister` `c` in `hadder`, or you meant to write the above line as
```python
circ.append(hadder, [0, 1, 2, 3], [0, 1, 2, 3])
```
On our side, the `append` call I pulled out should have raised an error. I'm not certain why it didn't, but it definitely looks like a bug that it didn't.
|
2023-01-18T12:43:42Z
|
<patch>
diff --git a/qiskit/circuit/instruction.py b/qiskit/circuit/instruction.py
--- a/qiskit/circuit/instruction.py
+++ b/qiskit/circuit/instruction.py
@@ -481,6 +481,11 @@ def broadcast_arguments(self, qargs, cargs):
f"The amount of qubit arguments {len(qargs)} does not match"
f" the instruction expectation ({self.num_qubits})."
)
+ if len(cargs) != self.num_clbits:
+ raise CircuitError(
+ f"The amount of clbit arguments {len(cargs)} does not match"
+ f" the instruction expectation ({self.num_clbits})."
+ )
# [[q[0], q[1]], [c[0], c[1]]] -> [q[0], c[0]], [q[1], c[1]]
flat_qargs = [qarg for sublist in qargs for qarg in sublist]
</patch>
|
[]
|
[]
| |||
docker__compose-3056
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pyinstaller has issues with signals
There's a bunch of history in #1040 and #2055.
We've tried multiple implementations of signal handlers, but each has their own set of issues, but **ONLY** when run from the frozen binary created by pyinstaller.
It looks like there is a very old issue in pyinstaller around this: https://github.com/pyinstaller/pyinstaller/issues/208
These problems can manifest in three ways:
- a `thread.error` when a signal interrupts a thread lock
- the signal handlers being completely ignored and raising a `KeynoardInterupt` instead
- the signal handlers being registered but the try/except to handle the except is skipped (this could be caused by the signal firing multiple times for a single `ctrl-c`, but I can't really verify that's what is happening)
</issue>
<code>
[start of README.md]
1 Docker Compose
2 ==============
3 
4
5 Compose is a tool for defining and running multi-container Docker applications.
6 With Compose, you use a Compose file to configure your application's services.
7 Then, using a single command, you create and start all the services
8 from your configuration. To learn more about all the features of Compose
9 see [the list of features](https://github.com/docker/compose/blob/release/docs/overview.md#features).
10
11 Compose is great for development, testing, and staging environments, as well as
12 CI workflows. You can learn more about each case in
13 [Common Use Cases](https://github.com/docker/compose/blob/release/docs/overview.md#common-use-cases).
14
15 Using Compose is basically a three-step process.
16
17 1. Define your app's environment with a `Dockerfile` so it can be
18 reproduced anywhere.
19 2. Define the services that make up your app in `docker-compose.yml` so
20 they can be run together in an isolated environment:
21 3. Lastly, run `docker-compose up` and Compose will start and run your entire app.
22
23 A `docker-compose.yml` looks like this:
24
25 web:
26 build: .
27 ports:
28 - "5000:5000"
29 volumes:
30 - .:/code
31 links:
32 - redis
33 redis:
34 image: redis
35
36 For more information about the Compose file, see the
37 [Compose file reference](https://github.com/docker/compose/blob/release/docs/compose-file.md)
38
39 Compose has commands for managing the whole lifecycle of your application:
40
41 * Start, stop and rebuild services
42 * View the status of running services
43 * Stream the log output of running services
44 * Run a one-off command on a service
45
46 Installation and documentation
47 ------------------------------
48
49 - Full documentation is available on [Docker's website](https://docs.docker.com/compose/).
50 - If you have any questions, you can talk in real-time with other developers in the #docker-compose IRC channel on Freenode. [Click here to join using IRCCloud.](https://www.irccloud.com/invite?hostname=irc.freenode.net&channel=%23docker-compose)
51 - Code repository for Compose is on [Github](https://github.com/docker/compose)
52 - If you find any problems please fill out an [issue](https://github.com/docker/compose/issues/new)
53
54 Contributing
55 ------------
56
57 [](http://jenkins.dockerproject.org/job/Compose%20Master/)
58
59 Want to help build Compose? Check out our [contributing documentation](https://github.com/docker/compose/blob/master/CONTRIBUTING.md).
60
61 Releasing
62 ---------
63
64 Releases are built by maintainers, following an outline of the [release process](https://github.com/docker/compose/blob/master/project/RELEASE-PROCESS.md).
65
[end of README.md]
[start of compose/cli/main.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 import contextlib
6 import json
7 import logging
8 import re
9 import sys
10 from inspect import getdoc
11 from operator import attrgetter
12
13 from docker.errors import APIError
14 from requests.exceptions import ReadTimeout
15
16 from . import signals
17 from .. import __version__
18 from ..config import config
19 from ..config import ConfigurationError
20 from ..config import parse_environment
21 from ..config.serialize import serialize_config
22 from ..const import API_VERSION_TO_ENGINE_VERSION
23 from ..const import DEFAULT_TIMEOUT
24 from ..const import HTTP_TIMEOUT
25 from ..const import IS_WINDOWS_PLATFORM
26 from ..progress_stream import StreamOutputError
27 from ..project import NoSuchService
28 from ..service import BuildError
29 from ..service import ConvergenceStrategy
30 from ..service import ImageType
31 from ..service import NeedsBuildError
32 from .command import friendly_error_message
33 from .command import get_config_path_from_options
34 from .command import project_from_options
35 from .docopt_command import DocoptCommand
36 from .docopt_command import NoSuchCommand
37 from .errors import UserError
38 from .formatter import ConsoleWarningFormatter
39 from .formatter import Formatter
40 from .log_printer import LogPrinter
41 from .utils import get_version_info
42 from .utils import yesno
43
44
45 if not IS_WINDOWS_PLATFORM:
46 from dockerpty.pty import PseudoTerminal, RunOperation, ExecOperation
47
48 log = logging.getLogger(__name__)
49 console_handler = logging.StreamHandler(sys.stderr)
50
51
52 def main():
53 setup_logging()
54 try:
55 command = TopLevelCommand()
56 command.sys_dispatch()
57 except KeyboardInterrupt:
58 log.error("Aborting.")
59 sys.exit(1)
60 except (UserError, NoSuchService, ConfigurationError) as e:
61 log.error(e.msg)
62 sys.exit(1)
63 except NoSuchCommand as e:
64 commands = "\n".join(parse_doc_section("commands:", getdoc(e.supercommand)))
65 log.error("No such command: %s\n\n%s", e.command, commands)
66 sys.exit(1)
67 except APIError as e:
68 log_api_error(e)
69 sys.exit(1)
70 except BuildError as e:
71 log.error("Service '%s' failed to build: %s" % (e.service.name, e.reason))
72 sys.exit(1)
73 except StreamOutputError as e:
74 log.error(e)
75 sys.exit(1)
76 except NeedsBuildError as e:
77 log.error("Service '%s' needs to be built, but --no-build was passed." % e.service.name)
78 sys.exit(1)
79 except ReadTimeout as e:
80 log.error(
81 "An HTTP request took too long to complete. Retry with --verbose to "
82 "obtain debug information.\n"
83 "If you encounter this issue regularly because of slow network "
84 "conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher "
85 "value (current value: %s)." % HTTP_TIMEOUT
86 )
87 sys.exit(1)
88
89
90 def log_api_error(e):
91 if 'client is newer than server' in e.explanation:
92 # we need JSON formatted errors. In the meantime...
93 # TODO: fix this by refactoring project dispatch
94 # http://github.com/docker/compose/pull/2832#commitcomment-15923800
95 client_version = e.explanation.split('client API version: ')[1].split(',')[0]
96 log.error(
97 "The engine version is lesser than the minimum required by "
98 "compose. Your current project requires a Docker Engine of "
99 "version {version} or superior.".format(
100 version=API_VERSION_TO_ENGINE_VERSION[client_version]
101 ))
102 else:
103 log.error(e.explanation)
104
105
106 def setup_logging():
107 root_logger = logging.getLogger()
108 root_logger.addHandler(console_handler)
109 root_logger.setLevel(logging.DEBUG)
110
111 # Disable requests logging
112 logging.getLogger("requests").propagate = False
113
114
115 def setup_console_handler(handler, verbose):
116 if handler.stream.isatty():
117 format_class = ConsoleWarningFormatter
118 else:
119 format_class = logging.Formatter
120
121 if verbose:
122 handler.setFormatter(format_class('%(name)s.%(funcName)s: %(message)s'))
123 handler.setLevel(logging.DEBUG)
124 else:
125 handler.setFormatter(format_class())
126 handler.setLevel(logging.INFO)
127
128
129 # stolen from docopt master
130 def parse_doc_section(name, source):
131 pattern = re.compile('^([^\n]*' + name + '[^\n]*\n?(?:[ \t].*?(?:\n|$))*)',
132 re.IGNORECASE | re.MULTILINE)
133 return [s.strip() for s in pattern.findall(source)]
134
135
136 class TopLevelCommand(DocoptCommand):
137 """Define and run multi-container applications with Docker.
138
139 Usage:
140 docker-compose [-f=<arg>...] [options] [COMMAND] [ARGS...]
141 docker-compose -h|--help
142
143 Options:
144 -f, --file FILE Specify an alternate compose file (default: docker-compose.yml)
145 -p, --project-name NAME Specify an alternate project name (default: directory name)
146 --verbose Show more output
147 -v, --version Print version and exit
148
149 Commands:
150 build Build or rebuild services
151 config Validate and view the compose file
152 create Create services
153 down Stop and remove containers, networks, images, and volumes
154 events Receive real time events from containers
155 exec Execute a command in a running container
156 help Get help on a command
157 kill Kill containers
158 logs View output from containers
159 pause Pause services
160 port Print the public port for a port binding
161 ps List containers
162 pull Pulls service images
163 restart Restart services
164 rm Remove stopped containers
165 run Run a one-off command
166 scale Set number of containers for a service
167 start Start services
168 stop Stop services
169 unpause Unpause services
170 up Create and start containers
171 version Show the Docker-Compose version information
172 """
173 base_dir = '.'
174
175 def docopt_options(self):
176 options = super(TopLevelCommand, self).docopt_options()
177 options['version'] = get_version_info('compose')
178 return options
179
180 def perform_command(self, options, handler, command_options):
181 setup_console_handler(console_handler, options.get('--verbose'))
182
183 if options['COMMAND'] in ('help', 'version'):
184 # Skip looking up the compose file.
185 handler(None, command_options)
186 return
187
188 if options['COMMAND'] == 'config':
189 handler(options, command_options)
190 return
191
192 project = project_from_options(self.base_dir, options)
193 with friendly_error_message():
194 handler(project, command_options)
195
196 def build(self, project, options):
197 """
198 Build or rebuild services.
199
200 Services are built once and then tagged as `project_service`,
201 e.g. `composetest_db`. If you change a service's `Dockerfile` or the
202 contents of its build directory, you can run `docker-compose build` to rebuild it.
203
204 Usage: build [options] [SERVICE...]
205
206 Options:
207 --force-rm Always remove intermediate containers.
208 --no-cache Do not use cache when building the image.
209 --pull Always attempt to pull a newer version of the image.
210 """
211 project.build(
212 service_names=options['SERVICE'],
213 no_cache=bool(options.get('--no-cache', False)),
214 pull=bool(options.get('--pull', False)),
215 force_rm=bool(options.get('--force-rm', False)))
216
217 def config(self, config_options, options):
218 """
219 Validate and view the compose file.
220
221 Usage: config [options]
222
223 Options:
224 -q, --quiet Only validate the configuration, don't print
225 anything.
226 --services Print the service names, one per line.
227
228 """
229 config_path = get_config_path_from_options(config_options)
230 compose_config = config.load(config.find(self.base_dir, config_path))
231
232 if options['--quiet']:
233 return
234
235 if options['--services']:
236 print('\n'.join(service['name'] for service in compose_config.services))
237 return
238
239 print(serialize_config(compose_config))
240
241 def create(self, project, options):
242 """
243 Creates containers for a service.
244
245 Usage: create [options] [SERVICE...]
246
247 Options:
248 --force-recreate Recreate containers even if their configuration and
249 image haven't changed. Incompatible with --no-recreate.
250 --no-recreate If containers already exist, don't recreate them.
251 Incompatible with --force-recreate.
252 --no-build Don't build an image, even if it's missing
253 """
254 service_names = options['SERVICE']
255
256 project.create(
257 service_names=service_names,
258 strategy=convergence_strategy_from_opts(options),
259 do_build=not options['--no-build']
260 )
261
262 def down(self, project, options):
263 """
264 Stop containers and remove containers, networks, volumes, and images
265 created by `up`. Only containers and networks are removed by default.
266
267 Usage: down [options]
268
269 Options:
270 --rmi type Remove images, type may be one of: 'all' to remove
271 all images, or 'local' to remove only images that
272 don't have an custom name set by the `image` field
273 -v, --volumes Remove data volumes
274 """
275 image_type = image_type_from_opt('--rmi', options['--rmi'])
276 project.down(image_type, options['--volumes'])
277
278 def events(self, project, options):
279 """
280 Receive real time events from containers.
281
282 Usage: events [options] [SERVICE...]
283
284 Options:
285 --json Output events as a stream of json objects
286 """
287 def format_event(event):
288 attributes = ["%s=%s" % item for item in event['attributes'].items()]
289 return ("{time} {type} {action} {id} ({attrs})").format(
290 attrs=", ".join(sorted(attributes)),
291 **event)
292
293 def json_format_event(event):
294 event['time'] = event['time'].isoformat()
295 return json.dumps(event)
296
297 for event in project.events():
298 formatter = json_format_event if options['--json'] else format_event
299 print(formatter(event))
300 sys.stdout.flush()
301
302 def exec_command(self, project, options):
303 """
304 Execute a command in a running container
305
306 Usage: exec [options] SERVICE COMMAND [ARGS...]
307
308 Options:
309 -d Detached mode: Run command in the background.
310 --privileged Give extended privileges to the process.
311 --user USER Run the command as this user.
312 -T Disable pseudo-tty allocation. By default `docker-compose exec`
313 allocates a TTY.
314 --index=index index of the container if there are multiple
315 instances of a service [default: 1]
316 """
317 index = int(options.get('--index'))
318 service = project.get_service(options['SERVICE'])
319 try:
320 container = service.get_container(number=index)
321 except ValueError as e:
322 raise UserError(str(e))
323 command = [options['COMMAND']] + options['ARGS']
324 tty = not options["-T"]
325
326 create_exec_options = {
327 "privileged": options["--privileged"],
328 "user": options["--user"],
329 "tty": tty,
330 "stdin": tty,
331 }
332
333 exec_id = container.create_exec(command, **create_exec_options)
334
335 if options['-d']:
336 container.start_exec(exec_id, tty=tty)
337 return
338
339 signals.set_signal_handler_to_shutdown()
340 try:
341 operation = ExecOperation(
342 project.client,
343 exec_id,
344 interactive=tty,
345 )
346 pty = PseudoTerminal(project.client, operation)
347 pty.start()
348 except signals.ShutdownException:
349 log.info("received shutdown exception: closing")
350 exit_code = project.client.exec_inspect(exec_id).get("ExitCode")
351 sys.exit(exit_code)
352
353 def help(self, project, options):
354 """
355 Get help on a command.
356
357 Usage: help COMMAND
358 """
359 handler = self.get_handler(options['COMMAND'])
360 raise SystemExit(getdoc(handler))
361
362 def kill(self, project, options):
363 """
364 Force stop service containers.
365
366 Usage: kill [options] [SERVICE...]
367
368 Options:
369 -s SIGNAL SIGNAL to send to the container.
370 Default signal is SIGKILL.
371 """
372 signal = options.get('-s', 'SIGKILL')
373
374 project.kill(service_names=options['SERVICE'], signal=signal)
375
376 def logs(self, project, options):
377 """
378 View output from containers.
379
380 Usage: logs [options] [SERVICE...]
381
382 Options:
383 --no-color Produce monochrome output.
384 """
385 containers = project.containers(service_names=options['SERVICE'], stopped=True)
386
387 monochrome = options['--no-color']
388 print("Attaching to", list_containers(containers))
389 LogPrinter(containers, monochrome=monochrome).run()
390
391 def pause(self, project, options):
392 """
393 Pause services.
394
395 Usage: pause [SERVICE...]
396 """
397 containers = project.pause(service_names=options['SERVICE'])
398 exit_if(not containers, 'No containers to pause', 1)
399
400 def port(self, project, options):
401 """
402 Print the public port for a port binding.
403
404 Usage: port [options] SERVICE PRIVATE_PORT
405
406 Options:
407 --protocol=proto tcp or udp [default: tcp]
408 --index=index index of the container if there are multiple
409 instances of a service [default: 1]
410 """
411 index = int(options.get('--index'))
412 service = project.get_service(options['SERVICE'])
413 try:
414 container = service.get_container(number=index)
415 except ValueError as e:
416 raise UserError(str(e))
417 print(container.get_local_port(
418 options['PRIVATE_PORT'],
419 protocol=options.get('--protocol') or 'tcp') or '')
420
421 def ps(self, project, options):
422 """
423 List containers.
424
425 Usage: ps [options] [SERVICE...]
426
427 Options:
428 -q Only display IDs
429 """
430 containers = sorted(
431 project.containers(service_names=options['SERVICE'], stopped=True) +
432 project.containers(service_names=options['SERVICE'], one_off=True),
433 key=attrgetter('name'))
434
435 if options['-q']:
436 for container in containers:
437 print(container.id)
438 else:
439 headers = [
440 'Name',
441 'Command',
442 'State',
443 'Ports',
444 ]
445 rows = []
446 for container in containers:
447 command = container.human_readable_command
448 if len(command) > 30:
449 command = '%s ...' % command[:26]
450 rows.append([
451 container.name,
452 command,
453 container.human_readable_state,
454 container.human_readable_ports,
455 ])
456 print(Formatter().table(headers, rows))
457
458 def pull(self, project, options):
459 """
460 Pulls images for services.
461
462 Usage: pull [options] [SERVICE...]
463
464 Options:
465 --ignore-pull-failures Pull what it can and ignores images with pull failures.
466 """
467 project.pull(
468 service_names=options['SERVICE'],
469 ignore_pull_failures=options.get('--ignore-pull-failures')
470 )
471
472 def rm(self, project, options):
473 """
474 Remove stopped service containers.
475
476 By default, volumes attached to containers will not be removed. You can see all
477 volumes with `docker volume ls`.
478
479 Any data which is not in a volume will be lost.
480
481 Usage: rm [options] [SERVICE...]
482
483 Options:
484 -f, --force Don't ask to confirm removal
485 -v Remove volumes associated with containers
486 """
487 all_containers = project.containers(service_names=options['SERVICE'], stopped=True)
488 stopped_containers = [c for c in all_containers if not c.is_running]
489
490 if len(stopped_containers) > 0:
491 print("Going to remove", list_containers(stopped_containers))
492 if options.get('--force') \
493 or yesno("Are you sure? [yN] ", default=False):
494 project.remove_stopped(
495 service_names=options['SERVICE'],
496 v=options.get('-v', False)
497 )
498 else:
499 print("No stopped containers")
500
501 def run(self, project, options):
502 """
503 Run a one-off command on a service.
504
505 For example:
506
507 $ docker-compose run web python manage.py shell
508
509 By default, linked services will be started, unless they are already
510 running. If you do not want to start linked services, use
511 `docker-compose run --no-deps SERVICE COMMAND [ARGS...]`.
512
513 Usage: run [options] [-p PORT...] [-e KEY=VAL...] SERVICE [COMMAND] [ARGS...]
514
515 Options:
516 -d Detached mode: Run container in the background, print
517 new container name.
518 --name NAME Assign a name to the container
519 --entrypoint CMD Override the entrypoint of the image.
520 -e KEY=VAL Set an environment variable (can be used multiple times)
521 -u, --user="" Run as specified username or uid
522 --no-deps Don't start linked services.
523 --rm Remove container after run. Ignored in detached mode.
524 -p, --publish=[] Publish a container's port(s) to the host
525 --service-ports Run command with the service's ports enabled and mapped
526 to the host.
527 -T Disable pseudo-tty allocation. By default `docker-compose run`
528 allocates a TTY.
529 """
530 service = project.get_service(options['SERVICE'])
531 detach = options['-d']
532
533 if IS_WINDOWS_PLATFORM and not detach:
534 raise UserError(
535 "Interactive mode is not yet supported on Windows.\n"
536 "Please pass the -d flag when using `docker-compose run`."
537 )
538
539 if options['COMMAND']:
540 command = [options['COMMAND']] + options['ARGS']
541 else:
542 command = service.options.get('command')
543
544 container_options = {
545 'command': command,
546 'tty': not (detach or options['-T'] or not sys.stdin.isatty()),
547 'stdin_open': not detach,
548 'detach': detach,
549 }
550
551 if options['-e']:
552 container_options['environment'] = parse_environment(options['-e'])
553
554 if options['--entrypoint']:
555 container_options['entrypoint'] = options.get('--entrypoint')
556
557 if options['--rm']:
558 container_options['restart'] = None
559
560 if options['--user']:
561 container_options['user'] = options.get('--user')
562
563 if not options['--service-ports']:
564 container_options['ports'] = []
565
566 if options['--publish']:
567 container_options['ports'] = options.get('--publish')
568
569 if options['--publish'] and options['--service-ports']:
570 raise UserError(
571 'Service port mapping and manual port mapping '
572 'can not be used togather'
573 )
574
575 if options['--name']:
576 container_options['name'] = options['--name']
577
578 run_one_off_container(container_options, project, service, options)
579
580 def scale(self, project, options):
581 """
582 Set number of containers to run for a service.
583
584 Numbers are specified in the form `service=num` as arguments.
585 For example:
586
587 $ docker-compose scale web=2 worker=3
588
589 Usage: scale [options] [SERVICE=NUM...]
590
591 Options:
592 -t, --timeout TIMEOUT Specify a shutdown timeout in seconds.
593 (default: 10)
594 """
595 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
596
597 for s in options['SERVICE=NUM']:
598 if '=' not in s:
599 raise UserError('Arguments to scale should be in the form service=num')
600 service_name, num = s.split('=', 1)
601 try:
602 num = int(num)
603 except ValueError:
604 raise UserError('Number of containers for service "%s" is not a '
605 'number' % service_name)
606 project.get_service(service_name).scale(num, timeout=timeout)
607
608 def start(self, project, options):
609 """
610 Start existing containers.
611
612 Usage: start [SERVICE...]
613 """
614 containers = project.start(service_names=options['SERVICE'])
615 exit_if(not containers, 'No containers to start', 1)
616
617 def stop(self, project, options):
618 """
619 Stop running containers without removing them.
620
621 They can be started again with `docker-compose start`.
622
623 Usage: stop [options] [SERVICE...]
624
625 Options:
626 -t, --timeout TIMEOUT Specify a shutdown timeout in seconds.
627 (default: 10)
628 """
629 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
630 project.stop(service_names=options['SERVICE'], timeout=timeout)
631
632 def restart(self, project, options):
633 """
634 Restart running containers.
635
636 Usage: restart [options] [SERVICE...]
637
638 Options:
639 -t, --timeout TIMEOUT Specify a shutdown timeout in seconds.
640 (default: 10)
641 """
642 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
643 containers = project.restart(service_names=options['SERVICE'], timeout=timeout)
644 exit_if(not containers, 'No containers to restart', 1)
645
646 def unpause(self, project, options):
647 """
648 Unpause services.
649
650 Usage: unpause [SERVICE...]
651 """
652 containers = project.unpause(service_names=options['SERVICE'])
653 exit_if(not containers, 'No containers to unpause', 1)
654
655 def up(self, project, options):
656 """
657 Builds, (re)creates, starts, and attaches to containers for a service.
658
659 Unless they are already running, this command also starts any linked services.
660
661 The `docker-compose up` command aggregates the output of each container. When
662 the command exits, all containers are stopped. Running `docker-compose up -d`
663 starts the containers in the background and leaves them running.
664
665 If there are existing containers for a service, and the service's configuration
666 or image was changed after the container's creation, `docker-compose up` picks
667 up the changes by stopping and recreating the containers (preserving mounted
668 volumes). To prevent Compose from picking up changes, use the `--no-recreate`
669 flag.
670
671 If you want to force Compose to stop and recreate all containers, use the
672 `--force-recreate` flag.
673
674 Usage: up [options] [SERVICE...]
675
676 Options:
677 -d Detached mode: Run containers in the background,
678 print new container names.
679 Incompatible with --abort-on-container-exit.
680 --no-color Produce monochrome output.
681 --no-deps Don't start linked services.
682 --force-recreate Recreate containers even if their configuration
683 and image haven't changed.
684 Incompatible with --no-recreate.
685 --no-recreate If containers already exist, don't recreate them.
686 Incompatible with --force-recreate.
687 --no-build Don't build an image, even if it's missing
688 --abort-on-container-exit Stops all containers if any container was stopped.
689 Incompatible with -d.
690 -t, --timeout TIMEOUT Use this timeout in seconds for container shutdown
691 when attached or when containers are already
692 running. (default: 10)
693 """
694 monochrome = options['--no-color']
695 start_deps = not options['--no-deps']
696 cascade_stop = options['--abort-on-container-exit']
697 service_names = options['SERVICE']
698 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
699 detached = options.get('-d')
700
701 if detached and cascade_stop:
702 raise UserError("--abort-on-container-exit and -d cannot be combined.")
703
704 with up_shutdown_context(project, service_names, timeout, detached):
705 to_attach = project.up(
706 service_names=service_names,
707 start_deps=start_deps,
708 strategy=convergence_strategy_from_opts(options),
709 do_build=not options['--no-build'],
710 timeout=timeout,
711 detached=detached)
712
713 if detached:
714 return
715 log_printer = build_log_printer(to_attach, service_names, monochrome, cascade_stop)
716 print("Attaching to", list_containers(log_printer.containers))
717 log_printer.run()
718
719 if cascade_stop:
720 print("Aborting on container exit...")
721 project.stop(service_names=service_names, timeout=timeout)
722
723 def version(self, project, options):
724 """
725 Show version informations
726
727 Usage: version [--short]
728
729 Options:
730 --short Shows only Compose's version number.
731 """
732 if options['--short']:
733 print(__version__)
734 else:
735 print(get_version_info('full'))
736
737
738 def convergence_strategy_from_opts(options):
739 no_recreate = options['--no-recreate']
740 force_recreate = options['--force-recreate']
741 if force_recreate and no_recreate:
742 raise UserError("--force-recreate and --no-recreate cannot be combined.")
743
744 if force_recreate:
745 return ConvergenceStrategy.always
746
747 if no_recreate:
748 return ConvergenceStrategy.never
749
750 return ConvergenceStrategy.changed
751
752
753 def image_type_from_opt(flag, value):
754 if not value:
755 return ImageType.none
756 try:
757 return ImageType[value]
758 except KeyError:
759 raise UserError("%s flag must be one of: all, local" % flag)
760
761
762 def run_one_off_container(container_options, project, service, options):
763 if not options['--no-deps']:
764 deps = service.get_dependency_names()
765 if deps:
766 project.up(
767 service_names=deps,
768 start_deps=True,
769 strategy=ConvergenceStrategy.never)
770
771 project.initialize()
772
773 container = service.create_container(
774 quiet=True,
775 one_off=True,
776 **container_options)
777
778 if options['-d']:
779 service.start_container(container)
780 print(container.name)
781 return
782
783 def remove_container(force=False):
784 if options['--rm']:
785 project.client.remove_container(container.id, force=True)
786
787 signals.set_signal_handler_to_shutdown()
788 try:
789 try:
790 operation = RunOperation(
791 project.client,
792 container.id,
793 interactive=not options['-T'],
794 logs=False,
795 )
796 pty = PseudoTerminal(project.client, operation)
797 sockets = pty.sockets()
798 service.start_container(container)
799 pty.start(sockets)
800 exit_code = container.wait()
801 except signals.ShutdownException:
802 project.client.stop(container.id)
803 exit_code = 1
804 except signals.ShutdownException:
805 project.client.kill(container.id)
806 remove_container(force=True)
807 sys.exit(2)
808
809 remove_container()
810 sys.exit(exit_code)
811
812
813 def build_log_printer(containers, service_names, monochrome, cascade_stop):
814 if service_names:
815 containers = [
816 container
817 for container in containers if container.service in service_names
818 ]
819 return LogPrinter(containers, monochrome=monochrome, cascade_stop=cascade_stop)
820
821
822 @contextlib.contextmanager
823 def up_shutdown_context(project, service_names, timeout, detached):
824 if detached:
825 yield
826 return
827
828 signals.set_signal_handler_to_shutdown()
829 try:
830 try:
831 yield
832 except signals.ShutdownException:
833 print("Gracefully stopping... (press Ctrl+C again to force)")
834 project.stop(service_names=service_names, timeout=timeout)
835 except signals.ShutdownException:
836 project.kill(service_names=service_names)
837 sys.exit(2)
838
839
840 def list_containers(containers):
841 return ", ".join(c.name for c in containers)
842
843
844 def exit_if(condition, message, exit_code):
845 if condition:
846 log.error(message)
847 raise SystemExit(exit_code)
848
[end of compose/cli/main.py]
[start of compose/cli/multiplexer.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 from threading import Thread
5
6 from six.moves import _thread as thread
7
8 try:
9 from Queue import Queue, Empty
10 except ImportError:
11 from queue import Queue, Empty # Python 3.x
12
13
14 STOP = object()
15
16
17 class Multiplexer(object):
18 """
19 Create a single iterator from several iterators by running all of them in
20 parallel and yielding results as they come in.
21 """
22
23 def __init__(self, iterators, cascade_stop=False):
24 self.iterators = iterators
25 self.cascade_stop = cascade_stop
26 self._num_running = len(iterators)
27 self.queue = Queue()
28
29 def loop(self):
30 self._init_readers()
31
32 while self._num_running > 0:
33 try:
34 item, exception = self.queue.get(timeout=0.1)
35
36 if exception:
37 raise exception
38
39 if item is STOP:
40 if self.cascade_stop is True:
41 break
42 else:
43 self._num_running -= 1
44 else:
45 yield item
46 except Empty:
47 pass
48 # See https://github.com/docker/compose/issues/189
49 except thread.error:
50 raise KeyboardInterrupt()
51
52 def _init_readers(self):
53 for iterator in self.iterators:
54 t = Thread(target=_enqueue_output, args=(iterator, self.queue))
55 t.daemon = True
56 t.start()
57
58
59 def _enqueue_output(iterator, queue):
60 try:
61 for item in iterator:
62 queue.put((item, None))
63 queue.put((STOP, None))
64 except Exception as e:
65 queue.put((None, e))
66
[end of compose/cli/multiplexer.py]
[start of compose/parallel.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import operator
5 import sys
6 from threading import Thread
7
8 from docker.errors import APIError
9 from six.moves.queue import Empty
10 from six.moves.queue import Queue
11
12 from compose.utils import get_output_stream
13
14
15 def perform_operation(func, arg, callback, index):
16 try:
17 callback((index, func(arg)))
18 except Exception as e:
19 callback((index, e))
20
21
22 def parallel_execute(objects, func, index_func, msg):
23 """For a given list of objects, call the callable passing in the first
24 object we give it.
25 """
26 objects = list(objects)
27 stream = get_output_stream(sys.stderr)
28 writer = ParallelStreamWriter(stream, msg)
29
30 for obj in objects:
31 writer.initialize(index_func(obj))
32
33 q = Queue()
34
35 # TODO: limit the number of threads #1828
36 for obj in objects:
37 t = Thread(
38 target=perform_operation,
39 args=(func, obj, q.put, index_func(obj)))
40 t.daemon = True
41 t.start()
42
43 done = 0
44 errors = {}
45
46 while done < len(objects):
47 try:
48 msg_index, result = q.get(timeout=1)
49 except Empty:
50 continue
51
52 if isinstance(result, APIError):
53 errors[msg_index] = "error", result.explanation
54 writer.write(msg_index, 'error')
55 elif isinstance(result, Exception):
56 errors[msg_index] = "unexpected_exception", result
57 else:
58 writer.write(msg_index, 'done')
59 done += 1
60
61 if not errors:
62 return
63
64 stream.write("\n")
65 for msg_index, (result, error) in errors.items():
66 stream.write("ERROR: for {} {} \n".format(msg_index, error))
67 if result == 'unexpected_exception':
68 raise error
69
70
71 class ParallelStreamWriter(object):
72 """Write out messages for operations happening in parallel.
73
74 Each operation has it's own line, and ANSI code characters are used
75 to jump to the correct line, and write over the line.
76 """
77
78 def __init__(self, stream, msg):
79 self.stream = stream
80 self.msg = msg
81 self.lines = []
82
83 def initialize(self, obj_index):
84 self.lines.append(obj_index)
85 self.stream.write("{} {} ... \r\n".format(self.msg, obj_index))
86 self.stream.flush()
87
88 def write(self, obj_index, status):
89 position = self.lines.index(obj_index)
90 diff = len(self.lines) - position
91 # move up
92 self.stream.write("%c[%dA" % (27, diff))
93 # erase
94 self.stream.write("%c[2K\r" % 27)
95 self.stream.write("{} {} ... {}\r".format(self.msg, obj_index, status))
96 # move back down
97 self.stream.write("%c[%dB" % (27, diff))
98 self.stream.flush()
99
100
101 def parallel_operation(containers, operation, options, message):
102 parallel_execute(
103 containers,
104 operator.methodcaller(operation, **options),
105 operator.attrgetter('name'),
106 message)
107
108
109 def parallel_remove(containers, options):
110 stopped_containers = [c for c in containers if not c.is_running]
111 parallel_operation(stopped_containers, 'remove', options, 'Removing')
112
113
114 def parallel_stop(containers, options):
115 parallel_operation(containers, 'stop', options, 'Stopping')
116
117
118 def parallel_start(containers, options):
119 parallel_operation(containers, 'start', options, 'Starting')
120
121
122 def parallel_pause(containers, options):
123 parallel_operation(containers, 'pause', options, 'Pausing')
124
125
126 def parallel_unpause(containers, options):
127 parallel_operation(containers, 'unpause', options, 'Unpausing')
128
129
130 def parallel_kill(containers, options):
131 parallel_operation(containers, 'kill', options, 'Killing')
132
133
134 def parallel_restart(containers, options):
135 parallel_operation(containers, 'restart', options, 'Restarting')
136
[end of compose/parallel.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
docker/compose
|
768460483089f2f712f32eb859c95d1ba30fdc0e
|
Pyinstaller has issues with signals
There's a bunch of history in #1040 and #2055.
We've tried multiple implementations of signal handlers, but each has their own set of issues, but **ONLY** when run from the frozen binary created by pyinstaller.
It looks like there is a very old issue in pyinstaller around this: https://github.com/pyinstaller/pyinstaller/issues/208
These problems can manifest in three ways:
- a `thread.error` when a signal interrupts a thread lock
- the signal handlers being completely ignored and raising a `KeynoardInterupt` instead
- the signal handlers being registered but the try/except to handle the except is skipped (this could be caused by the signal firing multiple times for a single `ctrl-c`, but I can't really verify that's what is happening)
|
https://github.com/pyinstaller/pyinstaller/pull/1822 seems to fix it!
We could run my patched version to build the binaries if they don't want to accept the patch upstream. I'll prepare a PR so it can be tested on OSX.
It looks like the windows branch uses a completely different function, so there should be no impact on windows.
Having just upgraded to 1.6.1, I'm now hitting this most of the time. It's an irregular behaviour: sometimes CTRL-C stops the container, some times it aborts. Quite an annoying bug, leaving containers running in the background when I wasn't aware of it!
|
2016-03-01T21:46:06Z
|
<patch>
diff --git a/compose/cli/main.py b/compose/cli/main.py
--- a/compose/cli/main.py
+++ b/compose/cli/main.py
@@ -54,7 +54,7 @@ def main():
try:
command = TopLevelCommand()
command.sys_dispatch()
- except KeyboardInterrupt:
+ except (KeyboardInterrupt, signals.ShutdownException):
log.error("Aborting.")
sys.exit(1)
except (UserError, NoSuchService, ConfigurationError) as e:
diff --git a/compose/cli/multiplexer.py b/compose/cli/multiplexer.py
--- a/compose/cli/multiplexer.py
+++ b/compose/cli/multiplexer.py
@@ -10,6 +10,7 @@
except ImportError:
from queue import Queue, Empty # Python 3.x
+from compose.cli.signals import ShutdownException
STOP = object()
@@ -47,7 +48,7 @@ def loop(self):
pass
# See https://github.com/docker/compose/issues/189
except thread.error:
- raise KeyboardInterrupt()
+ raise ShutdownException()
def _init_readers(self):
for iterator in self.iterators:
diff --git a/compose/parallel.py b/compose/parallel.py
--- a/compose/parallel.py
+++ b/compose/parallel.py
@@ -6,9 +6,11 @@
from threading import Thread
from docker.errors import APIError
+from six.moves import _thread as thread
from six.moves.queue import Empty
from six.moves.queue import Queue
+from compose.cli.signals import ShutdownException
from compose.utils import get_output_stream
@@ -26,19 +28,7 @@ def parallel_execute(objects, func, index_func, msg):
objects = list(objects)
stream = get_output_stream(sys.stderr)
writer = ParallelStreamWriter(stream, msg)
-
- for obj in objects:
- writer.initialize(index_func(obj))
-
- q = Queue()
-
- # TODO: limit the number of threads #1828
- for obj in objects:
- t = Thread(
- target=perform_operation,
- args=(func, obj, q.put, index_func(obj)))
- t.daemon = True
- t.start()
+ q = setup_queue(writer, objects, func, index_func)
done = 0
errors = {}
@@ -48,6 +38,9 @@ def parallel_execute(objects, func, index_func, msg):
msg_index, result = q.get(timeout=1)
except Empty:
continue
+ # See https://github.com/docker/compose/issues/189
+ except thread.error:
+ raise ShutdownException()
if isinstance(result, APIError):
errors[msg_index] = "error", result.explanation
@@ -68,6 +61,23 @@ def parallel_execute(objects, func, index_func, msg):
raise error
+def setup_queue(writer, objects, func, index_func):
+ for obj in objects:
+ writer.initialize(index_func(obj))
+
+ q = Queue()
+
+ # TODO: limit the number of threads #1828
+ for obj in objects:
+ t = Thread(
+ target=perform_operation,
+ args=(func, obj, q.put, index_func(obj)))
+ t.daemon = True
+ t.start()
+
+ return q
+
+
class ParallelStreamWriter(object):
"""Write out messages for operations happening in parallel.
</patch>
|
[]
|
[]
| |||
googleapis__google-cloud-python-10162
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BigQuery: raise a `TypeError` if a dictionary is passed to `insert_rows_json`
**Is your feature request related to a problem? Please describe.**
If I want to only insert a single row at a time into a table, it's easy to accidentally try something like:
```python
json_row = {"col1": "hello", "col2": "world"}
errors = client.insert_rows_json(
table,
json_row
)
```
This results in a `400 BadRequest` error from the API, because it expects a list of rows, not a single row.
**Describe the solution you'd like**
It's difficult to debug this situation from the API response, so it'd be better if we raised a client-side error for passing in the wrong type for `json_rows`.
**Describe alternatives you've considered**
Leave as-is and request a better server-side message. This may be difficult to do, as the error happens at a level above BigQuery, which translates JSON to Protobuf for internal use.
**Additional context**
This issue was encountered by a customer engineer, and it took me a bit of debugging to figure out the actual issue. I expect other customers will encounter this problem as well.
</issue>
<code>
[start of README.rst]
1 Google Cloud Python Client
2 ==========================
3
4 Python idiomatic clients for `Google Cloud Platform`_ services.
5
6 .. _Google Cloud Platform: https://cloud.google.com/
7
8 **Heads up**! These libraries are supported on App Engine standard's `Python 3 runtime`_ but are *not* supported on App Engine's `Python 2 runtime`_.
9
10 .. _Python 3 runtime: https://cloud.google.com/appengine/docs/standard/python3
11 .. _Python 2 runtime: https://cloud.google.com/appengine/docs/standard/python
12
13 General Availability
14 --------------------
15
16 **GA** (general availability) indicates that the client library for a
17 particular service is stable, and that the code surface will not change in
18 backwards-incompatible ways unless either absolutely necessary (e.g. because
19 of critical security issues) or with an extensive deprecation period.
20 Issues and requests against GA libraries are addressed with the highest
21 priority.
22
23 .. note::
24
25 Sub-components of GA libraries explicitly marked as beta in the
26 import path (e.g. ``google.cloud.language_v1beta2``) should be considered
27 to be beta.
28
29 The following client libraries have **GA** support:
30
31 - `Google BigQuery`_ (`BigQuery README`_, `BigQuery Documentation`_)
32 - `Google Cloud Bigtable`_ (`Bigtable README`_, `Bigtable Documentation`_)
33 - `Google Cloud Datastore`_ (`Datastore README`_, `Datastore Documentation`_)
34 - `Google Cloud KMS`_ (`KMS README`_, `KMS Documentation`_)
35 - `Google Cloud Natural Language`_ (`Natural Language README`_, `Natural Language Documentation`_)
36 - `Google Cloud Pub/Sub`_ (`Pub/Sub README`_, `Pub/Sub Documentation`_)
37 - `Google Cloud Scheduler`_ (`Scheduler README`_, `Scheduler Documentation`_)
38 - `Google Cloud Spanner`_ (`Spanner README`_, `Spanner Documentation`_)
39 - `Google Cloud Speech to Text`_ (`Speech to Text README`_, `Speech to Text Documentation`_)
40 - `Google Cloud Storage`_ (`Storage README`_, `Storage Documentation`_)
41 - `Google Cloud Tasks`_ (`Tasks README`_, `Tasks Documentation`_)
42 - `Google Cloud Translation`_ (`Translation README`_, `Translation Documentation`_)
43 - `Stackdriver Logging`_ (`Logging README`_, `Logging Documentation`_)
44
45 .. _Google BigQuery: https://pypi.org/project/google-cloud-bigquery/
46 .. _BigQuery README: https://github.com/googleapis/google-cloud-python/tree/master/bigquery
47 .. _BigQuery Documentation: https://googleapis.dev/python/bigquery/latest
48
49 .. _Google Cloud Bigtable: https://pypi.org/project/google-cloud-bigtable/
50 .. _Bigtable README: https://github.com/googleapis/google-cloud-python/tree/master/bigtable
51 .. _Bigtable Documentation: https://googleapis.dev/python/bigtable/latest
52
53 .. _Google Cloud Datastore: https://pypi.org/project/google-cloud-datastore/
54 .. _Datastore README: https://github.com/googleapis/google-cloud-python/tree/master/datastore
55 .. _Datastore Documentation: https://googleapis.dev/python/datastore/latest
56
57 .. _Google Cloud KMS: https://pypi.org/project/google-cloud-kms/
58 .. _KMS README: https://github.com/googleapis/google-cloud-python/tree/master/kms
59 .. _KMS Documentation: https://googleapis.dev/python/cloudkms/latest
60
61 .. _Google Cloud Natural Language: https://pypi.org/project/google-cloud-language/
62 .. _Natural Language README: https://github.com/googleapis/google-cloud-python/tree/master/language
63 .. _Natural Language Documentation: https://googleapis.dev/python/language/latest
64
65 .. _Google Cloud Pub/Sub: https://pypi.org/project/google-cloud-pubsub/
66 .. _Pub/Sub README: https://github.com/googleapis/google-cloud-python/tree/master/pubsub
67 .. _Pub/Sub Documentation: https://googleapis.dev/python/pubsub/latest
68
69 .. _Google Cloud Spanner: https://pypi.org/project/google-cloud-spanner
70 .. _Spanner README: https://github.com/googleapis/google-cloud-python/tree/master/spanner
71 .. _Spanner Documentation: https://googleapis.dev/python/spanner/latest
72
73 .. _Google Cloud Speech to Text: https://pypi.org/project/google-cloud-speech/
74 .. _Speech to Text README: https://github.com/googleapis/google-cloud-python/tree/master/speech
75 .. _Speech to Text Documentation: https://googleapis.dev/python/speech/latest
76
77 .. _Google Cloud Storage: https://pypi.org/project/google-cloud-storage/
78 .. _Storage README: https://github.com/googleapis/google-cloud-python/tree/master/storage
79 .. _Storage Documentation: https://googleapis.dev/python/storage/latest
80
81 .. _Google Cloud Tasks: https://pypi.org/project/google-cloud-tasks/
82 .. _Tasks README: https://github.com/googleapis/google-cloud-python/tree/master/tasks
83 .. _Tasks Documentation: https://googleapis.dev/python/cloudtasks/latest
84
85 .. _Google Cloud Translation: https://pypi.org/project/google-cloud-translate/
86 .. _Translation README: https://github.com/googleapis/google-cloud-python/tree/master/translate
87 .. _Translation Documentation: https://googleapis.dev/python/translation/latest
88
89 .. _Google Cloud Scheduler: https://pypi.org/project/google-cloud-scheduler/
90 .. _Scheduler README: https://github.com/googleapis/google-cloud-python/tree/master/scheduler
91 .. _Scheduler Documentation: https://googleapis.dev/python/cloudscheduler/latest
92
93 .. _Stackdriver Logging: https://pypi.org/project/google-cloud-logging/
94 .. _Logging README: https://github.com/googleapis/google-cloud-python/tree/master/logging
95 .. _Logging Documentation: https://googleapis.dev/python/logging/latest
96
97 Beta Support
98 ------------
99
100 **Beta** indicates that the client library for a particular service is
101 mostly stable and is being prepared for release. Issues and requests
102 against beta libraries are addressed with a higher priority.
103
104 The following client libraries have **beta** support:
105
106 - `Google Cloud Billing Budgets`_ (`Billing Budgets README`_, `Billing Budgets Documentation`_)
107 - `Google Cloud Data Catalog`_ (`Data Catalog README`_, `Data Catalog Documentation`_)
108 - `Google Cloud Firestore`_ (`Firestore README`_, `Firestore Documentation`_)
109 - `Google Cloud Video Intelligence`_ (`Video Intelligence README`_, `Video Intelligence Documentation`_)
110 - `Google Cloud Vision`_ (`Vision README`_, `Vision Documentation`_)
111
112 .. _Google Cloud Billing Budgets: https://pypi.org/project/google-cloud-billing-budgets/
113 .. _Billing Budgets README: https://github.com/googleapis/google-cloud-python/tree/master/billingbudgets
114 .. _Billing Budgets Documentation: https://googleapis.dev/python/billingbudgets/latest
115
116 .. _Google Cloud Data Catalog: https://pypi.org/project/google-cloud-datacatalog/
117 .. _Data Catalog README: https://github.com/googleapis/google-cloud-python/tree/master/datacatalog
118 .. _Data Catalog Documentation: https://googleapis.dev/python/datacatalog/latest
119
120 .. _Google Cloud Firestore: https://pypi.org/project/google-cloud-firestore/
121 .. _Firestore README: https://github.com/googleapis/google-cloud-python/tree/master/firestore
122 .. _Firestore Documentation: https://googleapis.dev/python/firestore/latest
123
124 .. _Google Cloud Video Intelligence: https://pypi.org/project/google-cloud-videointelligence
125 .. _Video Intelligence README: https://github.com/googleapis/google-cloud-python/tree/master/videointelligence
126 .. _Video Intelligence Documentation: https://googleapis.dev/python/videointelligence/latest
127
128 .. _Google Cloud Vision: https://pypi.org/project/google-cloud-vision/
129 .. _Vision README: https://github.com/googleapis/google-cloud-python/tree/master/vision
130 .. _Vision Documentation: https://googleapis.dev/python/vision/latest
131
132
133 Alpha Support
134 -------------
135
136 **Alpha** indicates that the client library for a particular service is
137 still a work-in-progress and is more likely to get backwards-incompatible
138 updates. See `versioning`_ for more details.
139
140 The following client libraries have **alpha** support:
141
142 - `Google Cloud Asset`_ (`Asset README`_, `Asset Documentation`_)
143 - `Google Cloud AutoML`_ (`AutoML README`_, `AutoML Documentation`_)
144 - `Google BigQuery Data Transfer`_ (`BigQuery Data Transfer README`_, `BigQuery Documentation`_)
145 - `Google Cloud Bigtable - HappyBase`_ (`HappyBase README`_, `HappyBase Documentation`_)
146 - `Google Cloud Build`_ (`Cloud Build README`_, `Cloud Build Documentation`_)
147 - `Google Cloud Container`_ (`Container README`_, `Container Documentation`_)
148 - `Google Cloud Container Analysis`_ (`Container Analysis README`_, `Container Analysis Documentation`_)
149 - `Google Cloud Dataproc`_ (`Dataproc README`_, `Dataproc Documentation`_)
150 - `Google Cloud DLP`_ (`DLP README`_, `DLP Documentation`_)
151 - `Google Cloud DNS`_ (`DNS README`_, `DNS Documentation`_)
152 - `Google Cloud IoT`_ (`IoT README`_, `IoT Documentation`_)
153 - `Google Cloud Memorystore for Redis`_ (`Redis README`_, `Redis Documentation`_)
154 - `Google Cloud Recommender`_ (`Recommender README`_, `Recommender Documentation`_)
155 - `Google Cloud Resource Manager`_ (`Resource Manager README`_, `Resource Manager Documentation`_)
156 - `Google Cloud Runtime Configuration`_ (`Runtime Config README`_, `Runtime Config Documentation`_)
157 - `Google Cloud Security Scanner`_ (`Security Scanner README`_ , `Security Scanner Documentation`_)
158 - `Google Cloud Trace`_ (`Trace README`_, `Trace Documentation`_)
159 - `Google Cloud Text-to-Speech`_ (`Text-to-Speech README`_, `Text-to-Speech Documentation`_)
160 - `Grafeas`_ (`Grafeas README`_, `Grafeas Documentation`_)
161 - `Stackdriver Error Reporting`_ (`Error Reporting README`_, `Error Reporting Documentation`_)
162 - `Stackdriver Monitoring`_ (`Monitoring README`_, `Monitoring Documentation`_)
163
164 .. _Google Cloud Asset: https://pypi.org/project/google-cloud-asset/
165 .. _Asset README: https://github.com/googleapis/google-cloud-python/blob/master/asset
166 .. _Asset Documentation: https://googleapis.dev/python/cloudasset/latest
167
168 .. _Google Cloud AutoML: https://pypi.org/project/google-cloud-automl/
169 .. _AutoML README: https://github.com/googleapis/google-cloud-python/blob/master/automl
170 .. _AutoML Documentation: https://googleapis.dev/python/automl/latest
171
172 .. _Google BigQuery Data Transfer: https://pypi.org/project/google-cloud-bigquery-datatransfer/
173 .. _BigQuery Data Transfer README: https://github.com/googleapis/google-cloud-python/tree/master/bigquery_datatransfer
174 .. _BigQuery Documentation: https://googleapis.dev/python/bigquery/latest
175
176 .. _Google Cloud Bigtable - HappyBase: https://pypi.org/project/google-cloud-happybase/
177 .. _HappyBase README: https://github.com/googleapis/google-cloud-python-happybase
178 .. _HappyBase Documentation: https://google-cloud-python-happybase.readthedocs.io/en/latest/
179
180 .. _Google Cloud Build: https://pypi.org/project/google-cloud-build/
181 .. _Cloud Build README: https://github.com/googleapis/google-cloud-python/cloudbuild
182 .. _Cloud Build Documentation: https://googleapis.dev/python/cloudbuild/latest
183
184 .. _Google Cloud Container: https://pypi.org/project/google-cloud-container/
185 .. _Container README: https://github.com/googleapis/google-cloud-python/tree/master/container
186 .. _Container Documentation: https://googleapis.dev/python/container/latest
187
188 .. _Google Cloud Container Analysis: https://pypi.org/project/google-cloud-containeranalysis/
189 .. _Container Analysis README: https://github.com/googleapis/google-cloud-python/tree/master/containeranalysis
190 .. _Container Analysis Documentation: https://googleapis.dev/python/containeranalysis/latest
191
192 .. _Google Cloud Dataproc: https://pypi.org/project/google-cloud-dataproc/
193 .. _Dataproc README: https://github.com/googleapis/google-cloud-python/tree/master/dataproc
194 .. _Dataproc Documentation: https://googleapis.dev/python/dataproc/latest
195
196 .. _Google Cloud DLP: https://pypi.org/project/google-cloud-dlp/
197 .. _DLP README: https://github.com/googleapis/google-cloud-python/tree/master/dlp
198 .. _DLP Documentation: https://googleapis.dev/python/dlp/latest
199
200 .. _Google Cloud DNS: https://pypi.org/project/google-cloud-dns/
201 .. _DNS README: https://github.com/googleapis/google-cloud-python/tree/master/dns
202 .. _DNS Documentation: https://googleapis.dev/python/dns/latest
203
204 .. _Google Cloud IoT: https://pypi.org/project/google-cloud-iot/
205 .. _IoT README: https://github.com/googleapis/google-cloud-python/tree/master/iot
206 .. _IoT Documentation: https://googleapis.dev/python/cloudiot/latest
207
208 .. _Google Cloud Memorystore for Redis: https://pypi.org/project/google-cloud-redis/
209 .. _Redis README: https://github.com/googleapis/google-cloud-python/tree/master/redis
210 .. _Redis Documentation: https://googleapis.dev/python/redis/latest
211
212 .. _Google Cloud Recommender: https://pypi.org/project/google-cloud-recommender/
213 .. _Recommender README: https://github.com/googleapis/google-cloud-python/tree/master/recommender
214 .. _Recommender Documentation: https://googleapis.dev/python/recommender/latest
215
216 .. _Google Cloud Resource Manager: https://pypi.org/project/google-cloud-resource-manager/
217 .. _Resource Manager README: https://github.com/googleapis/google-cloud-python/tree/master/resource_manager
218 .. _Resource Manager Documentation: https://googleapis.dev/python/cloudresourcemanager/latest
219
220 .. _Google Cloud Runtime Configuration: https://pypi.org/project/google-cloud-runtimeconfig/
221 .. _Runtime Config README: https://github.com/googleapis/google-cloud-python/tree/master/runtimeconfig
222 .. _Runtime Config Documentation: https://googleapis.dev/python/runtimeconfig/latest
223
224 .. _Google Cloud Security Scanner: https://pypi.org/project/google-cloud-websecurityscanner/
225 .. _Security Scanner README: https://github.com/googleapis/google-cloud-python/blob/master/websecurityscanner
226 .. _Security Scanner Documentation: https://googleapis.dev/python/websecurityscanner/latest
227
228 .. _Google Cloud Text-to-Speech: https://pypi.org/project/google-cloud-texttospeech/
229 .. _Text-to-Speech README: https://github.com/googleapis/google-cloud-python/tree/master/texttospeech
230 .. _Text-to-Speech Documentation: https://googleapis.dev/python/texttospeech/latest
231
232 .. _Google Cloud Trace: https://pypi.org/project/google-cloud-trace/
233 .. _Trace README: https://github.com/googleapis/google-cloud-python/tree/master/trace
234 .. _Trace Documentation: https://googleapis.dev/python/cloudtrace/latest
235
236 .. _Grafeas: https://pypi.org/project/grafeas/
237 .. _Grafeas README: https://github.com/googleapis/google-cloud-python/tree/master/grafeas
238 .. _Grafeas Documentation: https://googleapis.dev/python/grafeas/latest
239
240 .. _Stackdriver Error Reporting: https://pypi.org/project/google-cloud-error-reporting/
241 .. _Error Reporting README: https://github.com/googleapis/google-cloud-python/tree/master/error_reporting
242 .. _Error Reporting Documentation: https://googleapis.dev/python/clouderrorreporting/latest
243
244 .. _Stackdriver Monitoring: https://pypi.org/project/google-cloud-monitoring/
245 .. _Monitoring README: https://github.com/googleapis/google-cloud-python/tree/master/monitoring
246 .. _Monitoring Documentation: https://googleapis.dev/python/monitoring/latest
247
248 .. _versioning: https://github.com/googleapis/google-cloud-python/blob/master/CONTRIBUTING.rst#versioning
249
250 If you need support for other Google APIs, check out the
251 `Google APIs Python Client library`_.
252
253 .. _Google APIs Python Client library: https://github.com/google/google-api-python-client
254
255
256 Example Applications
257 --------------------
258
259 - `getting-started-python`_ - A sample and `tutorial`_ that demonstrates how to build a complete web application using Cloud Datastore, Cloud Storage, and Cloud Pub/Sub and deploy it to Google App Engine or Google Compute Engine.
260 - `google-cloud-python-expenses-demo`_ - A sample expenses demo using Cloud Datastore and Cloud Storage
261
262 .. _getting-started-python: https://github.com/GoogleCloudPlatform/getting-started-python
263 .. _tutorial: https://cloud.google.com/python
264 .. _google-cloud-python-expenses-demo: https://github.com/GoogleCloudPlatform/google-cloud-python-expenses-demo
265
266
267 Authentication
268 --------------
269
270 With ``google-cloud-python`` we try to make authentication as painless as possible.
271 Check out the `Authentication section`_ in our documentation to learn more.
272 You may also find the `authentication document`_ shared by all the
273 ``google-cloud-*`` libraries to be helpful.
274
275 .. _Authentication section: https://googleapis.dev/python/google-api-core/latest/auth.html
276 .. _authentication document: https://github.com/googleapis/google-cloud-common/tree/master/authentication
277
278 Contributing
279 ------------
280
281 Contributions to this library are always welcome and highly encouraged.
282
283 See the `CONTRIBUTING doc`_ for more information on how to get started.
284
285 .. _CONTRIBUTING doc: https://github.com/googleapis/google-cloud-python/blob/master/CONTRIBUTING.rst
286
287
288 Community
289 ---------
290
291 Google Cloud Platform Python developers hang out in `Slack`_ in the ``#python``
292 channel, click here to `get an invitation`_.
293
294 .. _Slack: https://googlecloud-community.slack.com
295 .. _get an invitation: https://gcp-slack.appspot.com/
296
297
298 License
299 -------
300
301 Apache 2.0 - See `the LICENSE`_ for more information.
302
303 .. _the LICENSE: https://github.com/googleapis/google-cloud-python/blob/master/LICENSE
304
[end of README.rst]
[start of bigquery/google/cloud/bigquery/client.py]
1 # Copyright 2015 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Client for interacting with the Google BigQuery API."""
16
17 from __future__ import absolute_import
18 from __future__ import division
19
20 try:
21 from collections import abc as collections_abc
22 except ImportError: # Python 2.7
23 import collections as collections_abc
24
25 import concurrent.futures
26 import copy
27 import functools
28 import gzip
29 import io
30 import itertools
31 import json
32 import math
33 import os
34 import tempfile
35 import uuid
36 import warnings
37
38 try:
39 import pyarrow
40 except ImportError: # pragma: NO COVER
41 pyarrow = None
42 import six
43
44 from google import resumable_media
45 from google.resumable_media.requests import MultipartUpload
46 from google.resumable_media.requests import ResumableUpload
47
48 import google.api_core.client_options
49 import google.api_core.exceptions
50 from google.api_core import page_iterator
51 from google.auth.transport.requests import TimeoutGuard
52 import google.cloud._helpers
53 from google.cloud import exceptions
54 from google.cloud.client import ClientWithProject
55
56 from google.cloud.bigquery._helpers import _record_field_to_json
57 from google.cloud.bigquery._helpers import _str_or_none
58 from google.cloud.bigquery._helpers import _verify_job_config_type
59 from google.cloud.bigquery._http import Connection
60 from google.cloud.bigquery import _pandas_helpers
61 from google.cloud.bigquery.dataset import Dataset
62 from google.cloud.bigquery.dataset import DatasetListItem
63 from google.cloud.bigquery.dataset import DatasetReference
64 from google.cloud.bigquery import job
65 from google.cloud.bigquery.model import Model
66 from google.cloud.bigquery.model import ModelReference
67 from google.cloud.bigquery.query import _QueryResults
68 from google.cloud.bigquery.retry import DEFAULT_RETRY
69 from google.cloud.bigquery.routine import Routine
70 from google.cloud.bigquery.routine import RoutineReference
71 from google.cloud.bigquery.schema import SchemaField
72 from google.cloud.bigquery.table import _table_arg_to_table
73 from google.cloud.bigquery.table import _table_arg_to_table_ref
74 from google.cloud.bigquery.table import Table
75 from google.cloud.bigquery.table import TableListItem
76 from google.cloud.bigquery.table import TableReference
77 from google.cloud.bigquery.table import RowIterator
78
79
80 _DEFAULT_CHUNKSIZE = 1048576 # 1024 * 1024 B = 1 MB
81 _MAX_MULTIPART_SIZE = 5 * 1024 * 1024
82 _DEFAULT_NUM_RETRIES = 6
83 _BASE_UPLOAD_TEMPLATE = (
84 u"https://bigquery.googleapis.com/upload/bigquery/v2/projects/"
85 u"{project}/jobs?uploadType="
86 )
87 _MULTIPART_URL_TEMPLATE = _BASE_UPLOAD_TEMPLATE + u"multipart"
88 _RESUMABLE_URL_TEMPLATE = _BASE_UPLOAD_TEMPLATE + u"resumable"
89 _GENERIC_CONTENT_TYPE = u"*/*"
90 _READ_LESS_THAN_SIZE = (
91 "Size {:d} was specified but the file-like object only had " "{:d} bytes remaining."
92 )
93 _NEED_TABLE_ARGUMENT = (
94 "The table argument should be a table ID string, Table, or TableReference"
95 )
96
97
98 class Project(object):
99 """Wrapper for resource describing a BigQuery project.
100
101 Args:
102 project_id (str): Opaque ID of the project
103
104 numeric_id (int): Numeric ID of the project
105
106 friendly_name (str): Display name of the project
107 """
108
109 def __init__(self, project_id, numeric_id, friendly_name):
110 self.project_id = project_id
111 self.numeric_id = numeric_id
112 self.friendly_name = friendly_name
113
114 @classmethod
115 def from_api_repr(cls, resource):
116 """Factory: construct an instance from a resource dict."""
117 return cls(resource["id"], resource["numericId"], resource["friendlyName"])
118
119
120 class Client(ClientWithProject):
121 """Client to bundle configuration needed for API requests.
122
123 Args:
124 project (str):
125 Project ID for the project which the client acts on behalf of.
126 Will be passed when creating a dataset / job. If not passed,
127 falls back to the default inferred from the environment.
128 credentials (google.auth.credentials.Credentials):
129 (Optional) The OAuth2 Credentials to use for this client. If not
130 passed (and if no ``_http`` object is passed), falls back to the
131 default inferred from the environment.
132 _http (requests.Session):
133 (Optional) HTTP object to make requests. Can be any object that
134 defines ``request()`` with the same interface as
135 :meth:`requests.Session.request`. If not passed, an ``_http``
136 object is created that is bound to the ``credentials`` for the
137 current object.
138 This parameter should be considered private, and could change in
139 the future.
140 location (str):
141 (Optional) Default location for jobs / datasets / tables.
142 default_query_job_config (google.cloud.bigquery.job.QueryJobConfig):
143 (Optional) Default ``QueryJobConfig``.
144 Will be merged into job configs passed into the ``query`` method.
145 client_info (google.api_core.client_info.ClientInfo):
146 The client info used to send a user-agent string along with API
147 requests. If ``None``, then default info will be used. Generally,
148 you only need to set this if you're developing your own library
149 or partner tool.
150 client_options (Union[google.api_core.client_options.ClientOptions, Dict]):
151 (Optional) Client options used to set user options on the client.
152 API Endpoint should be set through client_options.
153
154 Raises:
155 google.auth.exceptions.DefaultCredentialsError:
156 Raised if ``credentials`` is not specified and the library fails
157 to acquire default credentials.
158 """
159
160 SCOPE = (
161 "https://www.googleapis.com/auth/bigquery",
162 "https://www.googleapis.com/auth/cloud-platform",
163 )
164 """The scopes required for authenticating as a BigQuery consumer."""
165
166 def __init__(
167 self,
168 project=None,
169 credentials=None,
170 _http=None,
171 location=None,
172 default_query_job_config=None,
173 client_info=None,
174 client_options=None,
175 ):
176 super(Client, self).__init__(
177 project=project, credentials=credentials, _http=_http
178 )
179
180 kw_args = {"client_info": client_info}
181 if client_options:
182 if type(client_options) == dict:
183 client_options = google.api_core.client_options.from_dict(
184 client_options
185 )
186 if client_options.api_endpoint:
187 api_endpoint = client_options.api_endpoint
188 kw_args["api_endpoint"] = api_endpoint
189
190 self._connection = Connection(self, **kw_args)
191 self._location = location
192 self._default_query_job_config = copy.deepcopy(default_query_job_config)
193
194 @property
195 def location(self):
196 """Default location for jobs / datasets / tables."""
197 return self._location
198
199 def close(self):
200 """Close the underlying transport objects, releasing system resources.
201
202 .. note::
203
204 The client instance can be used for making additional requests even
205 after closing, in which case the underlying connections are
206 automatically re-created.
207 """
208 self._http._auth_request.session.close()
209 self._http.close()
210
211 def get_service_account_email(
212 self, project=None, retry=DEFAULT_RETRY, timeout=None
213 ):
214 """Get the email address of the project's BigQuery service account
215
216 Note:
217 This is the service account that BigQuery uses to manage tables
218 encrypted by a key in KMS.
219
220 Args:
221 project (str, optional):
222 Project ID to use for retreiving service account email.
223 Defaults to the client's project.
224 retry (Optional[google.api_core.retry.Retry]): How to retry the RPC.
225 timeout (Optional[float]):
226 The number of seconds to wait for the underlying HTTP transport
227 before using ``retry``.
228
229 Returns:
230 str: service account email address
231
232 Example:
233
234 >>> from google.cloud import bigquery
235 >>> client = bigquery.Client()
236 >>> client.get_service_account_email()
237 my_service_account@my-project.iam.gserviceaccount.com
238
239 """
240 if project is None:
241 project = self.project
242 path = "/projects/%s/serviceAccount" % (project,)
243
244 api_response = self._call_api(retry, method="GET", path=path, timeout=timeout)
245 return api_response["email"]
246
247 def list_projects(
248 self, max_results=None, page_token=None, retry=DEFAULT_RETRY, timeout=None
249 ):
250 """List projects for the project associated with this client.
251
252 See
253 https://cloud.google.com/bigquery/docs/reference/rest/v2/projects/list
254
255 Args:
256 max_results (int):
257 (Optional) maximum number of projects to return,
258 If not passed, defaults to a value set by the API.
259
260 page_token (str):
261 (Optional) Token representing a cursor into the projects. If
262 not passed, the API will return the first page of projects.
263 The token marks the beginning of the iterator to be returned
264 and the value of the ``page_token`` can be accessed at
265 ``next_page_token`` of the
266 :class:`~google.api_core.page_iterator.HTTPIterator`.
267
268 retry (google.api_core.retry.Retry): (Optional) How to retry the RPC.
269
270 timeout (Optional[float]):
271 The number of seconds to wait for the underlying HTTP transport
272 before using ``retry``.
273
274 Returns:
275 google.api_core.page_iterator.Iterator:
276 Iterator of :class:`~google.cloud.bigquery.client.Project`
277 accessible to the current client.
278 """
279 return page_iterator.HTTPIterator(
280 client=self,
281 api_request=functools.partial(self._call_api, retry, timeout=timeout),
282 path="/projects",
283 item_to_value=_item_to_project,
284 items_key="projects",
285 page_token=page_token,
286 max_results=max_results,
287 )
288
289 def list_datasets(
290 self,
291 project=None,
292 include_all=False,
293 filter=None,
294 max_results=None,
295 page_token=None,
296 retry=DEFAULT_RETRY,
297 timeout=None,
298 ):
299 """List datasets for the project associated with this client.
300
301 See
302 https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/list
303
304 Args:
305 project (str):
306 Optional. Project ID to use for retreiving datasets. Defaults
307 to the client's project.
308 include_all (bool):
309 Optional. True if results include hidden datasets. Defaults
310 to False.
311 filter (str):
312 Optional. An expression for filtering the results by label.
313 For syntax, see
314 https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/list#body.QUERY_PARAMETERS.filter
315 max_results (int):
316 Optional. Maximum number of datasets to return.
317 page_token (str):
318 Optional. Token representing a cursor into the datasets. If
319 not passed, the API will return the first page of datasets.
320 The token marks the beginning of the iterator to be returned
321 and the value of the ``page_token`` can be accessed at
322 ``next_page_token`` of the
323 :class:`~google.api_core.page_iterator.HTTPIterator`.
324 retry (google.api_core.retry.Retry):
325 Optional. How to retry the RPC.
326 timeout (Optional[float]):
327 The number of seconds to wait for the underlying HTTP transport
328 before using ``retry``.
329
330 Returns:
331 google.api_core.page_iterator.Iterator:
332 Iterator of :class:`~google.cloud.bigquery.dataset.DatasetListItem`.
333 associated with the project.
334 """
335 extra_params = {}
336 if project is None:
337 project = self.project
338 if include_all:
339 extra_params["all"] = True
340 if filter:
341 # TODO: consider supporting a dict of label -> value for filter,
342 # and converting it into a string here.
343 extra_params["filter"] = filter
344 path = "/projects/%s/datasets" % (project,)
345 return page_iterator.HTTPIterator(
346 client=self,
347 api_request=functools.partial(self._call_api, retry, timeout=timeout),
348 path=path,
349 item_to_value=_item_to_dataset,
350 items_key="datasets",
351 page_token=page_token,
352 max_results=max_results,
353 extra_params=extra_params,
354 )
355
356 def dataset(self, dataset_id, project=None):
357 """Construct a reference to a dataset.
358
359 Args:
360 dataset_id (str): ID of the dataset.
361
362 project (str):
363 (Optional) project ID for the dataset (defaults to
364 the project of the client).
365
366 Returns:
367 google.cloud.bigquery.dataset.DatasetReference:
368 a new ``DatasetReference`` instance.
369 """
370 if project is None:
371 project = self.project
372
373 return DatasetReference(project, dataset_id)
374
375 def _create_bqstorage_client(self):
376 """Create a BigQuery Storage API client using this client's credentials.
377
378 Returns:
379 google.cloud.bigquery_storage_v1beta1.BigQueryStorageClient:
380 A BigQuery Storage API client.
381 """
382 from google.cloud import bigquery_storage_v1beta1
383
384 return bigquery_storage_v1beta1.BigQueryStorageClient(
385 credentials=self._credentials
386 )
387
388 def create_dataset(
389 self, dataset, exists_ok=False, retry=DEFAULT_RETRY, timeout=None
390 ):
391 """API call: create the dataset via a POST request.
392
393 See
394 https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/insert
395
396 Args:
397 dataset (Union[ \
398 google.cloud.bigquery.dataset.Dataset, \
399 google.cloud.bigquery.dataset.DatasetReference, \
400 str, \
401 ]):
402 A :class:`~google.cloud.bigquery.dataset.Dataset` to create.
403 If ``dataset`` is a reference, an empty dataset is created
404 with the specified ID and client's default location.
405 exists_ok (bool):
406 Defaults to ``False``. If ``True``, ignore "already exists"
407 errors when creating the dataset.
408 retry (google.api_core.retry.Retry):
409 Optional. How to retry the RPC.
410 timeout (Optional[float]):
411 The number of seconds to wait for the underlying HTTP transport
412 before using ``retry``.
413
414 Returns:
415 google.cloud.bigquery.dataset.Dataset:
416 A new ``Dataset`` returned from the API.
417
418 Example:
419
420 >>> from google.cloud import bigquery
421 >>> client = bigquery.Client()
422 >>> dataset = bigquery.Dataset(client.dataset('my_dataset'))
423 >>> dataset = client.create_dataset(dataset)
424
425 """
426 if isinstance(dataset, str):
427 dataset = DatasetReference.from_string(
428 dataset, default_project=self.project
429 )
430 if isinstance(dataset, DatasetReference):
431 dataset = Dataset(dataset)
432
433 path = "/projects/%s/datasets" % (dataset.project,)
434
435 data = dataset.to_api_repr()
436 if data.get("location") is None and self.location is not None:
437 data["location"] = self.location
438
439 try:
440 api_response = self._call_api(
441 retry, method="POST", path=path, data=data, timeout=timeout
442 )
443 return Dataset.from_api_repr(api_response)
444 except google.api_core.exceptions.Conflict:
445 if not exists_ok:
446 raise
447 return self.get_dataset(dataset.reference, retry=retry)
448
449 def create_routine(
450 self, routine, exists_ok=False, retry=DEFAULT_RETRY, timeout=None
451 ):
452 """[Beta] Create a routine via a POST request.
453
454 See
455 https://cloud.google.com/bigquery/docs/reference/rest/v2/routines/insert
456
457 Args:
458 routine (google.cloud.bigquery.routine.Routine):
459 A :class:`~google.cloud.bigquery.routine.Routine` to create.
460 The dataset that the routine belongs to must already exist.
461 exists_ok (bool):
462 Defaults to ``False``. If ``True``, ignore "already exists"
463 errors when creating the routine.
464 retry (google.api_core.retry.Retry):
465 Optional. How to retry the RPC.
466 timeout (Optional[float]):
467 The number of seconds to wait for the underlying HTTP transport
468 before using ``retry``.
469
470 Returns:
471 google.cloud.bigquery.routine.Routine:
472 A new ``Routine`` returned from the service.
473 """
474 reference = routine.reference
475 path = "/projects/{}/datasets/{}/routines".format(
476 reference.project, reference.dataset_id
477 )
478 resource = routine.to_api_repr()
479 try:
480 api_response = self._call_api(
481 retry, method="POST", path=path, data=resource, timeout=timeout
482 )
483 return Routine.from_api_repr(api_response)
484 except google.api_core.exceptions.Conflict:
485 if not exists_ok:
486 raise
487 return self.get_routine(routine.reference, retry=retry)
488
489 def create_table(self, table, exists_ok=False, retry=DEFAULT_RETRY, timeout=None):
490 """API call: create a table via a PUT request
491
492 See
493 https://cloud.google.com/bigquery/docs/reference/rest/v2/tables/insert
494
495 Args:
496 table (Union[ \
497 google.cloud.bigquery.table.Table, \
498 google.cloud.bigquery.table.TableReference, \
499 str, \
500 ]):
501 A :class:`~google.cloud.bigquery.table.Table` to create.
502 If ``table`` is a reference, an empty table is created
503 with the specified ID. The dataset that the table belongs to
504 must already exist.
505 exists_ok (bool):
506 Defaults to ``False``. If ``True``, ignore "already exists"
507 errors when creating the table.
508 retry (google.api_core.retry.Retry):
509 Optional. How to retry the RPC.
510 timeout (Optional[float]):
511 The number of seconds to wait for the underlying HTTP transport
512 before using ``retry``.
513
514 Returns:
515 google.cloud.bigquery.table.Table:
516 A new ``Table`` returned from the service.
517 """
518 table = _table_arg_to_table(table, default_project=self.project)
519
520 path = "/projects/%s/datasets/%s/tables" % (table.project, table.dataset_id)
521 data = table.to_api_repr()
522 try:
523 api_response = self._call_api(
524 retry, method="POST", path=path, data=data, timeout=timeout
525 )
526 return Table.from_api_repr(api_response)
527 except google.api_core.exceptions.Conflict:
528 if not exists_ok:
529 raise
530 return self.get_table(table.reference, retry=retry)
531
532 def _call_api(self, retry, **kwargs):
533 call = functools.partial(self._connection.api_request, **kwargs)
534 if retry:
535 call = retry(call)
536 return call()
537
538 def get_dataset(self, dataset_ref, retry=DEFAULT_RETRY, timeout=None):
539 """Fetch the dataset referenced by ``dataset_ref``
540
541 Args:
542 dataset_ref (Union[ \
543 google.cloud.bigquery.dataset.DatasetReference, \
544 str, \
545 ]):
546 A reference to the dataset to fetch from the BigQuery API.
547 If a string is passed in, this method attempts to create a
548 dataset reference from a string using
549 :func:`~google.cloud.bigquery.dataset.DatasetReference.from_string`.
550 retry (google.api_core.retry.Retry):
551 (Optional) How to retry the RPC.
552 timeout (Optional[float]):
553 The number of seconds to wait for the underlying HTTP transport
554 before using ``retry``.
555
556 Returns:
557 google.cloud.bigquery.dataset.Dataset:
558 A ``Dataset`` instance.
559 """
560 if isinstance(dataset_ref, str):
561 dataset_ref = DatasetReference.from_string(
562 dataset_ref, default_project=self.project
563 )
564
565 api_response = self._call_api(
566 retry, method="GET", path=dataset_ref.path, timeout=timeout
567 )
568 return Dataset.from_api_repr(api_response)
569
570 def get_model(self, model_ref, retry=DEFAULT_RETRY, timeout=None):
571 """[Beta] Fetch the model referenced by ``model_ref``.
572
573 Args:
574 model_ref (Union[ \
575 google.cloud.bigquery.model.ModelReference, \
576 str, \
577 ]):
578 A reference to the model to fetch from the BigQuery API.
579 If a string is passed in, this method attempts to create a
580 model reference from a string using
581 :func:`google.cloud.bigquery.model.ModelReference.from_string`.
582 retry (google.api_core.retry.Retry):
583 (Optional) How to retry the RPC.
584 timeout (Optional[float]):
585 The number of seconds to wait for the underlying HTTP transport
586 before using ``retry``.
587
588 Returns:
589 google.cloud.bigquery.model.Model: A ``Model`` instance.
590 """
591 if isinstance(model_ref, str):
592 model_ref = ModelReference.from_string(
593 model_ref, default_project=self.project
594 )
595
596 api_response = self._call_api(
597 retry, method="GET", path=model_ref.path, timeout=timeout
598 )
599 return Model.from_api_repr(api_response)
600
601 def get_routine(self, routine_ref, retry=DEFAULT_RETRY, timeout=None):
602 """[Beta] Get the routine referenced by ``routine_ref``.
603
604 Args:
605 routine_ref (Union[ \
606 google.cloud.bigquery.routine.Routine, \
607 google.cloud.bigquery.routine.RoutineReference, \
608 str, \
609 ]):
610 A reference to the routine to fetch from the BigQuery API. If
611 a string is passed in, this method attempts to create a
612 reference from a string using
613 :func:`google.cloud.bigquery.routine.RoutineReference.from_string`.
614 retry (google.api_core.retry.Retry):
615 (Optional) How to retry the API call.
616 timeout (Optional[float]):
617 The number of seconds to wait for the underlying HTTP transport
618 before using ``retry``.
619
620 Returns:
621 google.cloud.bigquery.routine.Routine:
622 A ``Routine`` instance.
623 """
624 if isinstance(routine_ref, str):
625 routine_ref = RoutineReference.from_string(
626 routine_ref, default_project=self.project
627 )
628
629 api_response = self._call_api(
630 retry, method="GET", path=routine_ref.path, timeout=timeout
631 )
632 return Routine.from_api_repr(api_response)
633
634 def get_table(self, table, retry=DEFAULT_RETRY, timeout=None):
635 """Fetch the table referenced by ``table``.
636
637 Args:
638 table (Union[ \
639 google.cloud.bigquery.table.Table, \
640 google.cloud.bigquery.table.TableReference, \
641 str, \
642 ]):
643 A reference to the table to fetch from the BigQuery API.
644 If a string is passed in, this method attempts to create a
645 table reference from a string using
646 :func:`google.cloud.bigquery.table.TableReference.from_string`.
647 retry (google.api_core.retry.Retry):
648 (Optional) How to retry the RPC.
649 timeout (Optional[float]):
650 The number of seconds to wait for the underlying HTTP transport
651 before using ``retry``.
652
653 Returns:
654 google.cloud.bigquery.table.Table:
655 A ``Table`` instance.
656 """
657 table_ref = _table_arg_to_table_ref(table, default_project=self.project)
658 api_response = self._call_api(
659 retry, method="GET", path=table_ref.path, timeout=timeout
660 )
661 return Table.from_api_repr(api_response)
662
663 def update_dataset(self, dataset, fields, retry=DEFAULT_RETRY, timeout=None):
664 """Change some fields of a dataset.
665
666 Use ``fields`` to specify which fields to update. At least one field
667 must be provided. If a field is listed in ``fields`` and is ``None`` in
668 ``dataset``, it will be deleted.
669
670 If ``dataset.etag`` is not ``None``, the update will only
671 succeed if the dataset on the server has the same ETag. Thus
672 reading a dataset with ``get_dataset``, changing its fields,
673 and then passing it to ``update_dataset`` will ensure that the changes
674 will only be saved if no modifications to the dataset occurred
675 since the read.
676
677 Args:
678 dataset (google.cloud.bigquery.dataset.Dataset):
679 The dataset to update.
680 fields (Sequence[str]):
681 The properties of ``dataset`` to change (e.g. "friendly_name").
682 retry (google.api_core.retry.Retry, optional):
683 How to retry the RPC.
684 timeout (Optional[float]):
685 The number of seconds to wait for the underlying HTTP transport
686 before using ``retry``.
687
688 Returns:
689 google.cloud.bigquery.dataset.Dataset:
690 The modified ``Dataset`` instance.
691 """
692 partial = dataset._build_resource(fields)
693 if dataset.etag is not None:
694 headers = {"If-Match": dataset.etag}
695 else:
696 headers = None
697 api_response = self._call_api(
698 retry,
699 method="PATCH",
700 path=dataset.path,
701 data=partial,
702 headers=headers,
703 timeout=timeout,
704 )
705 return Dataset.from_api_repr(api_response)
706
707 def update_model(self, model, fields, retry=DEFAULT_RETRY, timeout=None):
708 """[Beta] Change some fields of a model.
709
710 Use ``fields`` to specify which fields to update. At least one field
711 must be provided. If a field is listed in ``fields`` and is ``None``
712 in ``model``, the field value will be deleted.
713
714 If ``model.etag`` is not ``None``, the update will only succeed if
715 the model on the server has the same ETag. Thus reading a model with
716 ``get_model``, changing its fields, and then passing it to
717 ``update_model`` will ensure that the changes will only be saved if
718 no modifications to the model occurred since the read.
719
720 Args:
721 model (google.cloud.bigquery.model.Model): The model to update.
722 fields (Sequence[str]):
723 The fields of ``model`` to change, spelled as the Model
724 properties (e.g. "friendly_name").
725 retry (google.api_core.retry.Retry):
726 (Optional) A description of how to retry the API call.
727 timeout (Optional[float]):
728 The number of seconds to wait for the underlying HTTP transport
729 before using ``retry``.
730
731 Returns:
732 google.cloud.bigquery.model.Model:
733 The model resource returned from the API call.
734 """
735 partial = model._build_resource(fields)
736 if model.etag:
737 headers = {"If-Match": model.etag}
738 else:
739 headers = None
740 api_response = self._call_api(
741 retry,
742 method="PATCH",
743 path=model.path,
744 data=partial,
745 headers=headers,
746 timeout=timeout,
747 )
748 return Model.from_api_repr(api_response)
749
750 def update_routine(self, routine, fields, retry=DEFAULT_RETRY, timeout=None):
751 """[Beta] Change some fields of a routine.
752
753 Use ``fields`` to specify which fields to update. At least one field
754 must be provided. If a field is listed in ``fields`` and is ``None``
755 in ``routine``, the field value will be deleted.
756
757 .. warning::
758 During beta, partial updates are not supported. You must provide
759 all fields in the resource.
760
761 If :attr:`~google.cloud.bigquery.routine.Routine.etag` is not
762 ``None``, the update will only succeed if the resource on the server
763 has the same ETag. Thus reading a routine with
764 :func:`~google.cloud.bigquery.client.Client.get_routine`, changing
765 its fields, and then passing it to this method will ensure that the
766 changes will only be saved if no modifications to the resource
767 occurred since the read.
768
769 Args:
770 routine (google.cloud.bigquery.routine.Routine): The routine to update.
771 fields (Sequence[str]):
772 The fields of ``routine`` to change, spelled as the
773 :class:`~google.cloud.bigquery.routine.Routine` properties
774 (e.g. ``type_``).
775 retry (google.api_core.retry.Retry):
776 (Optional) A description of how to retry the API call.
777 timeout (Optional[float]):
778 The number of seconds to wait for the underlying HTTP transport
779 before using ``retry``.
780
781 Returns:
782 google.cloud.bigquery.routine.Routine:
783 The routine resource returned from the API call.
784 """
785 partial = routine._build_resource(fields)
786 if routine.etag:
787 headers = {"If-Match": routine.etag}
788 else:
789 headers = None
790
791 # TODO: remove when routines update supports partial requests.
792 partial["routineReference"] = routine.reference.to_api_repr()
793
794 api_response = self._call_api(
795 retry,
796 method="PUT",
797 path=routine.path,
798 data=partial,
799 headers=headers,
800 timeout=timeout,
801 )
802 return Routine.from_api_repr(api_response)
803
804 def update_table(self, table, fields, retry=DEFAULT_RETRY, timeout=None):
805 """Change some fields of a table.
806
807 Use ``fields`` to specify which fields to update. At least one field
808 must be provided. If a field is listed in ``fields`` and is ``None``
809 in ``table``, the field value will be deleted.
810
811 If ``table.etag`` is not ``None``, the update will only succeed if
812 the table on the server has the same ETag. Thus reading a table with
813 ``get_table``, changing its fields, and then passing it to
814 ``update_table`` will ensure that the changes will only be saved if
815 no modifications to the table occurred since the read.
816
817 Args:
818 table (google.cloud.bigquery.table.Table): The table to update.
819 fields (Sequence[str]):
820 The fields of ``table`` to change, spelled as the Table
821 properties (e.g. "friendly_name").
822 retry (google.api_core.retry.Retry):
823 (Optional) A description of how to retry the API call.
824 timeout (Optional[float]):
825 The number of seconds to wait for the underlying HTTP transport
826 before using ``retry``.
827
828 Returns:
829 google.cloud.bigquery.table.Table:
830 The table resource returned from the API call.
831 """
832 partial = table._build_resource(fields)
833 if table.etag is not None:
834 headers = {"If-Match": table.etag}
835 else:
836 headers = None
837 api_response = self._call_api(
838 retry,
839 method="PATCH",
840 path=table.path,
841 data=partial,
842 headers=headers,
843 timeout=timeout,
844 )
845 return Table.from_api_repr(api_response)
846
847 def list_models(
848 self,
849 dataset,
850 max_results=None,
851 page_token=None,
852 retry=DEFAULT_RETRY,
853 timeout=None,
854 ):
855 """[Beta] List models in the dataset.
856
857 See
858 https://cloud.google.com/bigquery/docs/reference/rest/v2/models/list
859
860 Args:
861 dataset (Union[ \
862 google.cloud.bigquery.dataset.Dataset, \
863 google.cloud.bigquery.dataset.DatasetReference, \
864 str, \
865 ]):
866 A reference to the dataset whose models to list from the
867 BigQuery API. If a string is passed in, this method attempts
868 to create a dataset reference from a string using
869 :func:`google.cloud.bigquery.dataset.DatasetReference.from_string`.
870 max_results (int):
871 (Optional) Maximum number of models to return. If not passed,
872 defaults to a value set by the API.
873 page_token (str):
874 (Optional) Token representing a cursor into the models. If
875 not passed, the API will return the first page of models. The
876 token marks the beginning of the iterator to be returned and
877 the value of the ``page_token`` can be accessed at
878 ``next_page_token`` of the
879 :class:`~google.api_core.page_iterator.HTTPIterator`.
880 retry (google.api_core.retry.Retry):
881 (Optional) How to retry the RPC.
882 timeout (Optional[float]):
883 The number of seconds to wait for the underlying HTTP transport
884 before using ``retry``.
885
886 Returns:
887 google.api_core.page_iterator.Iterator:
888 Iterator of
889 :class:`~google.cloud.bigquery.model.Model` contained
890 within the requested dataset.
891 """
892 if isinstance(dataset, str):
893 dataset = DatasetReference.from_string(
894 dataset, default_project=self.project
895 )
896
897 if not isinstance(dataset, (Dataset, DatasetReference)):
898 raise TypeError("dataset must be a Dataset, DatasetReference, or string")
899
900 path = "%s/models" % dataset.path
901 result = page_iterator.HTTPIterator(
902 client=self,
903 api_request=functools.partial(self._call_api, retry, timeout=timeout),
904 path=path,
905 item_to_value=_item_to_model,
906 items_key="models",
907 page_token=page_token,
908 max_results=max_results,
909 )
910 result.dataset = dataset
911 return result
912
913 def list_routines(
914 self,
915 dataset,
916 max_results=None,
917 page_token=None,
918 retry=DEFAULT_RETRY,
919 timeout=None,
920 ):
921 """[Beta] List routines in the dataset.
922
923 See
924 https://cloud.google.com/bigquery/docs/reference/rest/v2/routines/list
925
926 Args:
927 dataset (Union[ \
928 google.cloud.bigquery.dataset.Dataset, \
929 google.cloud.bigquery.dataset.DatasetReference, \
930 str, \
931 ]):
932 A reference to the dataset whose routines to list from the
933 BigQuery API. If a string is passed in, this method attempts
934 to create a dataset reference from a string using
935 :func:`google.cloud.bigquery.dataset.DatasetReference.from_string`.
936 max_results (int):
937 (Optional) Maximum number of routines to return. If not passed,
938 defaults to a value set by the API.
939 page_token (str):
940 (Optional) Token representing a cursor into the routines. If
941 not passed, the API will return the first page of routines. The
942 token marks the beginning of the iterator to be returned and
943 the value of the ``page_token`` can be accessed at
944 ``next_page_token`` of the
945 :class:`~google.api_core.page_iterator.HTTPIterator`.
946 retry (google.api_core.retry.Retry):
947 (Optional) How to retry the RPC.
948 timeout (Optional[float]):
949 The number of seconds to wait for the underlying HTTP transport
950 before using ``retry``.
951
952 Returns:
953 google.api_core.page_iterator.Iterator:
954 Iterator of all
955 :class:`~google.cloud.bigquery.routine.Routine`s contained
956 within the requested dataset, limited by ``max_results``.
957 """
958 if isinstance(dataset, str):
959 dataset = DatasetReference.from_string(
960 dataset, default_project=self.project
961 )
962
963 if not isinstance(dataset, (Dataset, DatasetReference)):
964 raise TypeError("dataset must be a Dataset, DatasetReference, or string")
965
966 path = "{}/routines".format(dataset.path)
967 result = page_iterator.HTTPIterator(
968 client=self,
969 api_request=functools.partial(self._call_api, retry, timeout=timeout),
970 path=path,
971 item_to_value=_item_to_routine,
972 items_key="routines",
973 page_token=page_token,
974 max_results=max_results,
975 )
976 result.dataset = dataset
977 return result
978
979 def list_tables(
980 self,
981 dataset,
982 max_results=None,
983 page_token=None,
984 retry=DEFAULT_RETRY,
985 timeout=None,
986 ):
987 """List tables in the dataset.
988
989 See
990 https://cloud.google.com/bigquery/docs/reference/rest/v2/tables/list
991
992 Args:
993 dataset (Union[ \
994 google.cloud.bigquery.dataset.Dataset, \
995 google.cloud.bigquery.dataset.DatasetReference, \
996 str, \
997 ]):
998 A reference to the dataset whose tables to list from the
999 BigQuery API. If a string is passed in, this method attempts
1000 to create a dataset reference from a string using
1001 :func:`google.cloud.bigquery.dataset.DatasetReference.from_string`.
1002 max_results (int):
1003 (Optional) Maximum number of tables to return. If not passed,
1004 defaults to a value set by the API.
1005 page_token (str):
1006 (Optional) Token representing a cursor into the tables. If
1007 not passed, the API will return the first page of tables. The
1008 token marks the beginning of the iterator to be returned and
1009 the value of the ``page_token`` can be accessed at
1010 ``next_page_token`` of the
1011 :class:`~google.api_core.page_iterator.HTTPIterator`.
1012 retry (google.api_core.retry.Retry):
1013 (Optional) How to retry the RPC.
1014 timeout (Optional[float]):
1015 The number of seconds to wait for the underlying HTTP transport
1016 before using ``retry``.
1017
1018 Returns:
1019 google.api_core.page_iterator.Iterator:
1020 Iterator of
1021 :class:`~google.cloud.bigquery.table.TableListItem` contained
1022 within the requested dataset.
1023 """
1024 if isinstance(dataset, str):
1025 dataset = DatasetReference.from_string(
1026 dataset, default_project=self.project
1027 )
1028
1029 if not isinstance(dataset, (Dataset, DatasetReference)):
1030 raise TypeError("dataset must be a Dataset, DatasetReference, or string")
1031
1032 path = "%s/tables" % dataset.path
1033 result = page_iterator.HTTPIterator(
1034 client=self,
1035 api_request=functools.partial(self._call_api, retry, timeout=timeout),
1036 path=path,
1037 item_to_value=_item_to_table,
1038 items_key="tables",
1039 page_token=page_token,
1040 max_results=max_results,
1041 )
1042 result.dataset = dataset
1043 return result
1044
1045 def delete_dataset(
1046 self,
1047 dataset,
1048 delete_contents=False,
1049 retry=DEFAULT_RETRY,
1050 timeout=None,
1051 not_found_ok=False,
1052 ):
1053 """Delete a dataset.
1054
1055 See
1056 https://cloud.google.com/bigquery/docs/reference/rest/v2/datasets/delete
1057
1058 Args
1059 dataset (Union[ \
1060 google.cloud.bigquery.dataset.Dataset, \
1061 google.cloud.bigquery.dataset.DatasetReference, \
1062 str, \
1063 ]):
1064 A reference to the dataset to delete. If a string is passed
1065 in, this method attempts to create a dataset reference from a
1066 string using
1067 :func:`google.cloud.bigquery.dataset.DatasetReference.from_string`.
1068 delete_contents (boolean):
1069 (Optional) If True, delete all the tables in the dataset. If
1070 False and the dataset contains tables, the request will fail.
1071 Default is False.
1072 retry (google.api_core.retry.Retry):
1073 (Optional) How to retry the RPC.
1074 timeout (Optional[float]):
1075 The number of seconds to wait for the underlying HTTP transport
1076 before using ``retry``.
1077 not_found_ok (bool):
1078 Defaults to ``False``. If ``True``, ignore "not found" errors
1079 when deleting the dataset.
1080 """
1081 if isinstance(dataset, str):
1082 dataset = DatasetReference.from_string(
1083 dataset, default_project=self.project
1084 )
1085
1086 if not isinstance(dataset, (Dataset, DatasetReference)):
1087 raise TypeError("dataset must be a Dataset or a DatasetReference")
1088
1089 params = {}
1090 if delete_contents:
1091 params["deleteContents"] = "true"
1092
1093 try:
1094 self._call_api(
1095 retry,
1096 method="DELETE",
1097 path=dataset.path,
1098 query_params=params,
1099 timeout=timeout,
1100 )
1101 except google.api_core.exceptions.NotFound:
1102 if not not_found_ok:
1103 raise
1104
1105 def delete_model(
1106 self, model, retry=DEFAULT_RETRY, timeout=None, not_found_ok=False
1107 ):
1108 """[Beta] Delete a model
1109
1110 See
1111 https://cloud.google.com/bigquery/docs/reference/rest/v2/models/delete
1112
1113 Args:
1114 model (Union[ \
1115 google.cloud.bigquery.model.Model, \
1116 google.cloud.bigquery.model.ModelReference, \
1117 str, \
1118 ]):
1119 A reference to the model to delete. If a string is passed in,
1120 this method attempts to create a model reference from a
1121 string using
1122 :func:`google.cloud.bigquery.model.ModelReference.from_string`.
1123 retry (google.api_core.retry.Retry):
1124 (Optional) How to retry the RPC.
1125 timeout (Optional[float]):
1126 The number of seconds to wait for the underlying HTTP transport
1127 before using ``retry``.
1128 not_found_ok (bool):
1129 Defaults to ``False``. If ``True``, ignore "not found" errors
1130 when deleting the model.
1131 """
1132 if isinstance(model, str):
1133 model = ModelReference.from_string(model, default_project=self.project)
1134
1135 if not isinstance(model, (Model, ModelReference)):
1136 raise TypeError("model must be a Model or a ModelReference")
1137
1138 try:
1139 self._call_api(retry, method="DELETE", path=model.path, timeout=timeout)
1140 except google.api_core.exceptions.NotFound:
1141 if not not_found_ok:
1142 raise
1143
1144 def delete_routine(
1145 self, routine, retry=DEFAULT_RETRY, timeout=None, not_found_ok=False
1146 ):
1147 """[Beta] Delete a routine.
1148
1149 See
1150 https://cloud.google.com/bigquery/docs/reference/rest/v2/routines/delete
1151
1152 Args:
1153 model (Union[ \
1154 google.cloud.bigquery.routine.Routine, \
1155 google.cloud.bigquery.routine.RoutineReference, \
1156 str, \
1157 ]):
1158 A reference to the routine to delete. If a string is passed
1159 in, this method attempts to create a routine reference from a
1160 string using
1161 :func:`google.cloud.bigquery.routine.RoutineReference.from_string`.
1162 retry (google.api_core.retry.Retry):
1163 (Optional) How to retry the RPC.
1164 timeout (Optional[float]):
1165 The number of seconds to wait for the underlying HTTP transport
1166 before using ``retry``.
1167 not_found_ok (bool):
1168 Defaults to ``False``. If ``True``, ignore "not found" errors
1169 when deleting the routine.
1170 """
1171 if isinstance(routine, str):
1172 routine = RoutineReference.from_string(
1173 routine, default_project=self.project
1174 )
1175
1176 if not isinstance(routine, (Routine, RoutineReference)):
1177 raise TypeError("routine must be a Routine or a RoutineReference")
1178
1179 try:
1180 self._call_api(retry, method="DELETE", path=routine.path, timeout=timeout)
1181 except google.api_core.exceptions.NotFound:
1182 if not not_found_ok:
1183 raise
1184
1185 def delete_table(
1186 self, table, retry=DEFAULT_RETRY, timeout=None, not_found_ok=False
1187 ):
1188 """Delete a table
1189
1190 See
1191 https://cloud.google.com/bigquery/docs/reference/rest/v2/tables/delete
1192
1193 Args:
1194 table (Union[ \
1195 google.cloud.bigquery.table.Table, \
1196 google.cloud.bigquery.table.TableReference, \
1197 str, \
1198 ]):
1199 A reference to the table to delete. If a string is passed in,
1200 this method attempts to create a table reference from a
1201 string using
1202 :func:`google.cloud.bigquery.table.TableReference.from_string`.
1203 retry (google.api_core.retry.Retry):
1204 (Optional) How to retry the RPC.
1205 timeout (Optional[float]):
1206 The number of seconds to wait for the underlying HTTP transport
1207 before using ``retry``.
1208 not_found_ok (bool):
1209 Defaults to ``False``. If ``True``, ignore "not found" errors
1210 when deleting the table.
1211 """
1212 table = _table_arg_to_table_ref(table, default_project=self.project)
1213 if not isinstance(table, TableReference):
1214 raise TypeError("Unable to get TableReference for table '{}'".format(table))
1215
1216 try:
1217 self._call_api(retry, method="DELETE", path=table.path, timeout=timeout)
1218 except google.api_core.exceptions.NotFound:
1219 if not not_found_ok:
1220 raise
1221
1222 def _get_query_results(
1223 self, job_id, retry, project=None, timeout_ms=None, location=None, timeout=None,
1224 ):
1225 """Get the query results object for a query job.
1226
1227 Arguments:
1228 job_id (str): Name of the query job.
1229 retry (google.api_core.retry.Retry):
1230 (Optional) How to retry the RPC.
1231 project (str):
1232 (Optional) project ID for the query job (defaults to the
1233 project of the client).
1234 timeout_ms (int):
1235 (Optional) number of milliseconds the the API call should
1236 wait for the query to complete before the request times out.
1237 location (str): Location of the query job.
1238 timeout (Optional[float]):
1239 The number of seconds to wait for the underlying HTTP transport
1240 before using ``retry``.
1241
1242 Returns:
1243 google.cloud.bigquery.query._QueryResults:
1244 A new ``_QueryResults`` instance.
1245 """
1246
1247 extra_params = {"maxResults": 0}
1248
1249 if project is None:
1250 project = self.project
1251
1252 if timeout_ms is not None:
1253 extra_params["timeoutMs"] = timeout_ms
1254
1255 if location is None:
1256 location = self.location
1257
1258 if location is not None:
1259 extra_params["location"] = location
1260
1261 path = "/projects/{}/queries/{}".format(project, job_id)
1262
1263 # This call is typically made in a polling loop that checks whether the
1264 # job is complete (from QueryJob.done(), called ultimately from
1265 # QueryJob.result()). So we don't need to poll here.
1266 resource = self._call_api(
1267 retry, method="GET", path=path, query_params=extra_params, timeout=timeout
1268 )
1269 return _QueryResults.from_api_repr(resource)
1270
1271 def job_from_resource(self, resource):
1272 """Detect correct job type from resource and instantiate.
1273
1274 Args:
1275 resource (Dict): one job resource from API response
1276
1277 Returns:
1278 Union[ \
1279 google.cloud.bigquery.job.LoadJob, \
1280 google.cloud.bigquery.job.CopyJob, \
1281 google.cloud.bigquery.job.ExtractJob, \
1282 google.cloud.bigquery.job.QueryJob \
1283 ]:
1284 The job instance, constructed via the resource.
1285 """
1286 config = resource.get("configuration", {})
1287 if "load" in config:
1288 return job.LoadJob.from_api_repr(resource, self)
1289 elif "copy" in config:
1290 return job.CopyJob.from_api_repr(resource, self)
1291 elif "extract" in config:
1292 return job.ExtractJob.from_api_repr(resource, self)
1293 elif "query" in config:
1294 return job.QueryJob.from_api_repr(resource, self)
1295 return job.UnknownJob.from_api_repr(resource, self)
1296
1297 def get_job(
1298 self, job_id, project=None, location=None, retry=DEFAULT_RETRY, timeout=None
1299 ):
1300 """Fetch a job for the project associated with this client.
1301
1302 See
1303 https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs/get
1304
1305 Arguments:
1306 job_id (str): Unique job identifier.
1307
1308 Keyword Arguments:
1309 project (str):
1310 (Optional) ID of the project which ownsthe job (defaults to
1311 the client's project).
1312 location (str): Location where the job was run.
1313 retry (google.api_core.retry.Retry):
1314 (Optional) How to retry the RPC.
1315 timeout (Optional[float]):
1316 The number of seconds to wait for the underlying HTTP transport
1317 before using ``retry``.
1318
1319 Returns:
1320 Union[ \
1321 google.cloud.bigquery.job.LoadJob, \
1322 google.cloud.bigquery.job.CopyJob, \
1323 google.cloud.bigquery.job.ExtractJob, \
1324 google.cloud.bigquery.job.QueryJob \
1325 ]:
1326 Job instance, based on the resource returned by the API.
1327 """
1328 extra_params = {"projection": "full"}
1329
1330 if project is None:
1331 project = self.project
1332
1333 if location is None:
1334 location = self.location
1335
1336 if location is not None:
1337 extra_params["location"] = location
1338
1339 path = "/projects/{}/jobs/{}".format(project, job_id)
1340
1341 resource = self._call_api(
1342 retry, method="GET", path=path, query_params=extra_params, timeout=timeout
1343 )
1344
1345 return self.job_from_resource(resource)
1346
1347 def cancel_job(
1348 self, job_id, project=None, location=None, retry=DEFAULT_RETRY, timeout=None
1349 ):
1350 """Attempt to cancel a job from a job ID.
1351
1352 See
1353 https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs/cancel
1354
1355 Args:
1356 job_id (str): Unique job identifier.
1357
1358 Keyword Arguments:
1359 project (str):
1360 (Optional) ID of the project which owns the job (defaults to
1361 the client's project).
1362 location (str): Location where the job was run.
1363 retry (google.api_core.retry.Retry):
1364 (Optional) How to retry the RPC.
1365 timeout (Optional[float]):
1366 The number of seconds to wait for the underlying HTTP transport
1367 before using ``retry``.
1368
1369 Returns:
1370 Union[ \
1371 google.cloud.bigquery.job.LoadJob, \
1372 google.cloud.bigquery.job.CopyJob, \
1373 google.cloud.bigquery.job.ExtractJob, \
1374 google.cloud.bigquery.job.QueryJob, \
1375 ]:
1376 Job instance, based on the resource returned by the API.
1377 """
1378 extra_params = {"projection": "full"}
1379
1380 if project is None:
1381 project = self.project
1382
1383 if location is None:
1384 location = self.location
1385
1386 if location is not None:
1387 extra_params["location"] = location
1388
1389 path = "/projects/{}/jobs/{}/cancel".format(project, job_id)
1390
1391 resource = self._call_api(
1392 retry, method="POST", path=path, query_params=extra_params, timeout=timeout
1393 )
1394
1395 return self.job_from_resource(resource["job"])
1396
1397 def list_jobs(
1398 self,
1399 project=None,
1400 parent_job=None,
1401 max_results=None,
1402 page_token=None,
1403 all_users=None,
1404 state_filter=None,
1405 retry=DEFAULT_RETRY,
1406 timeout=None,
1407 min_creation_time=None,
1408 max_creation_time=None,
1409 ):
1410 """List jobs for the project associated with this client.
1411
1412 See
1413 https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs/list
1414
1415 Args:
1416 project (Optional[str]):
1417 Project ID to use for retreiving datasets. Defaults
1418 to the client's project.
1419 parent_job (Optional[Union[ \
1420 google.cloud.bigquery.job._AsyncJob, \
1421 str, \
1422 ]]):
1423 If set, retrieve only child jobs of the specified parent.
1424 max_results (Optional[int]):
1425 Maximum number of jobs to return.
1426 page_token (Optional[str]):
1427 Opaque marker for the next "page" of jobs. If not
1428 passed, the API will return the first page of jobs. The token
1429 marks the beginning of the iterator to be returned and the
1430 value of the ``page_token`` can be accessed at
1431 ``next_page_token`` of
1432 :class:`~google.api_core.page_iterator.HTTPIterator`.
1433 all_users (Optional[bool]):
1434 If true, include jobs owned by all users in the project.
1435 Defaults to :data:`False`.
1436 state_filter (Optional[str]):
1437 If set, include only jobs matching the given state. One of:
1438 * ``"done"``
1439 * ``"pending"``
1440 * ``"running"``
1441 retry (Optional[google.api_core.retry.Retry]):
1442 How to retry the RPC.
1443 timeout (Optional[float]):
1444 The number of seconds to wait for the underlying HTTP transport
1445 before using ``retry``.
1446 min_creation_time (Optional[datetime.datetime]):
1447 Min value for job creation time. If set, only jobs created
1448 after or at this timestamp are returned. If the datetime has
1449 no time zone assumes UTC time.
1450 max_creation_time (Optional[datetime.datetime]):
1451 Max value for job creation time. If set, only jobs created
1452 before or at this timestamp are returned. If the datetime has
1453 no time zone assumes UTC time.
1454
1455 Returns:
1456 google.api_core.page_iterator.Iterator:
1457 Iterable of job instances.
1458 """
1459 if isinstance(parent_job, job._AsyncJob):
1460 parent_job = parent_job.job_id
1461
1462 extra_params = {
1463 "allUsers": all_users,
1464 "stateFilter": state_filter,
1465 "minCreationTime": _str_or_none(
1466 google.cloud._helpers._millis_from_datetime(min_creation_time)
1467 ),
1468 "maxCreationTime": _str_or_none(
1469 google.cloud._helpers._millis_from_datetime(max_creation_time)
1470 ),
1471 "projection": "full",
1472 "parentJobId": parent_job,
1473 }
1474
1475 extra_params = {
1476 param: value for param, value in extra_params.items() if value is not None
1477 }
1478
1479 if project is None:
1480 project = self.project
1481
1482 path = "/projects/%s/jobs" % (project,)
1483 return page_iterator.HTTPIterator(
1484 client=self,
1485 api_request=functools.partial(self._call_api, retry, timeout=timeout),
1486 path=path,
1487 item_to_value=_item_to_job,
1488 items_key="jobs",
1489 page_token=page_token,
1490 max_results=max_results,
1491 extra_params=extra_params,
1492 )
1493
1494 def load_table_from_uri(
1495 self,
1496 source_uris,
1497 destination,
1498 job_id=None,
1499 job_id_prefix=None,
1500 location=None,
1501 project=None,
1502 job_config=None,
1503 retry=DEFAULT_RETRY,
1504 timeout=None,
1505 ):
1506 """Starts a job for loading data into a table from CloudStorage.
1507
1508 See
1509 https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#jobconfigurationload
1510
1511 Arguments:
1512 source_uris (Union[str, Sequence[str]]):
1513 URIs of data files to be loaded; in format
1514 ``gs://<bucket_name>/<object_name_or_glob>``.
1515 destination (Union[ \
1516 google.cloud.bigquery.table.Table, \
1517 google.cloud.bigquery.table.TableReference, \
1518 str, \
1519 ]):
1520 Table into which data is to be loaded. If a string is passed
1521 in, this method attempts to create a table reference from a
1522 string using
1523 :func:`google.cloud.bigquery.table.TableReference.from_string`.
1524
1525 Keyword Arguments:
1526 job_id (str): (Optional) Name of the job.
1527 job_id_prefix (str):
1528 (Optional) the user-provided prefix for a randomly generated
1529 job ID. This parameter will be ignored if a ``job_id`` is
1530 also given.
1531 location (str):
1532 Location where to run the job. Must match the location of the
1533 destination table.
1534 project (str):
1535 Project ID of the project of where to run the job. Defaults
1536 to the client's project.
1537 job_config (google.cloud.bigquery.job.LoadJobConfig):
1538 (Optional) Extra configuration options for the job.
1539 retry (google.api_core.retry.Retry):
1540 (Optional) How to retry the RPC.
1541 timeout (Optional[float]):
1542 The number of seconds to wait for the underlying HTTP transport
1543 before using ``retry``.
1544
1545 Returns:
1546 google.cloud.bigquery.job.LoadJob: A new load job.
1547
1548 Raises:
1549 TypeError:
1550 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.LoadJobConfig`
1551 class.
1552 """
1553 job_id = _make_job_id(job_id, job_id_prefix)
1554
1555 if project is None:
1556 project = self.project
1557
1558 if location is None:
1559 location = self.location
1560
1561 job_ref = job._JobReference(job_id, project=project, location=location)
1562
1563 if isinstance(source_uris, six.string_types):
1564 source_uris = [source_uris]
1565
1566 destination = _table_arg_to_table_ref(destination, default_project=self.project)
1567
1568 if job_config:
1569 job_config = copy.deepcopy(job_config)
1570 _verify_job_config_type(job_config, google.cloud.bigquery.job.LoadJobConfig)
1571
1572 load_job = job.LoadJob(job_ref, source_uris, destination, self, job_config)
1573 load_job._begin(retry=retry, timeout=timeout)
1574
1575 return load_job
1576
1577 def load_table_from_file(
1578 self,
1579 file_obj,
1580 destination,
1581 rewind=False,
1582 size=None,
1583 num_retries=_DEFAULT_NUM_RETRIES,
1584 job_id=None,
1585 job_id_prefix=None,
1586 location=None,
1587 project=None,
1588 job_config=None,
1589 ):
1590 """Upload the contents of this table from a file-like object.
1591
1592 Similar to :meth:`load_table_from_uri`, this method creates, starts and
1593 returns a :class:`~google.cloud.bigquery.job.LoadJob`.
1594
1595 Arguments:
1596 file_obj (file): A file handle opened in binary mode for reading.
1597 destination (Union[ \
1598 google.cloud.bigquery.table.Table, \
1599 google.cloud.bigquery.table.TableReference, \
1600 str, \
1601 ]):
1602 Table into which data is to be loaded. If a string is passed
1603 in, this method attempts to create a table reference from a
1604 string using
1605 :func:`google.cloud.bigquery.table.TableReference.from_string`.
1606
1607 Keyword Arguments:
1608 rewind (bool):
1609 If True, seek to the beginning of the file handle before
1610 reading the file.
1611 size (int):
1612 The number of bytes to read from the file handle. If size is
1613 ``None`` or large, resumable upload will be used. Otherwise,
1614 multipart upload will be used.
1615 num_retries (int): Number of upload retries. Defaults to 6.
1616 job_id (str): (Optional) Name of the job.
1617 job_id_prefix (str):
1618 (Optional) the user-provided prefix for a randomly generated
1619 job ID. This parameter will be ignored if a ``job_id`` is
1620 also given.
1621 location (str):
1622 Location where to run the job. Must match the location of the
1623 destination table.
1624 project (str):
1625 Project ID of the project of where to run the job. Defaults
1626 to the client's project.
1627 job_config (google.cloud.bigquery.job.LoadJobConfig):
1628 (Optional) Extra configuration options for the job.
1629
1630 Returns:
1631 google.cloud.bigquery.job.LoadJob: A new load job.
1632
1633 Raises:
1634 ValueError:
1635 If ``size`` is not passed in and can not be determined, or if
1636 the ``file_obj`` can be detected to be a file opened in text
1637 mode.
1638
1639 TypeError:
1640 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.LoadJobConfig`
1641 class.
1642 """
1643 job_id = _make_job_id(job_id, job_id_prefix)
1644
1645 if project is None:
1646 project = self.project
1647
1648 if location is None:
1649 location = self.location
1650
1651 destination = _table_arg_to_table_ref(destination, default_project=self.project)
1652 job_ref = job._JobReference(job_id, project=project, location=location)
1653 if job_config:
1654 job_config = copy.deepcopy(job_config)
1655 _verify_job_config_type(job_config, google.cloud.bigquery.job.LoadJobConfig)
1656 load_job = job.LoadJob(job_ref, None, destination, self, job_config)
1657 job_resource = load_job.to_api_repr()
1658
1659 if rewind:
1660 file_obj.seek(0, os.SEEK_SET)
1661
1662 _check_mode(file_obj)
1663
1664 try:
1665 if size is None or size >= _MAX_MULTIPART_SIZE:
1666 response = self._do_resumable_upload(
1667 file_obj, job_resource, num_retries
1668 )
1669 else:
1670 response = self._do_multipart_upload(
1671 file_obj, job_resource, size, num_retries
1672 )
1673 except resumable_media.InvalidResponse as exc:
1674 raise exceptions.from_http_response(exc.response)
1675
1676 return self.job_from_resource(response.json())
1677
1678 def load_table_from_dataframe(
1679 self,
1680 dataframe,
1681 destination,
1682 num_retries=_DEFAULT_NUM_RETRIES,
1683 job_id=None,
1684 job_id_prefix=None,
1685 location=None,
1686 project=None,
1687 job_config=None,
1688 parquet_compression="snappy",
1689 ):
1690 """Upload the contents of a table from a pandas DataFrame.
1691
1692 Similar to :meth:`load_table_from_uri`, this method creates, starts and
1693 returns a :class:`~google.cloud.bigquery.job.LoadJob`.
1694
1695 Arguments:
1696 dataframe (pandas.DataFrame):
1697 A :class:`~pandas.DataFrame` containing the data to load.
1698 destination (google.cloud.bigquery.table.TableReference):
1699 The destination table to use for loading the data. If it is an
1700 existing table, the schema of the :class:`~pandas.DataFrame`
1701 must match the schema of the destination table. If the table
1702 does not yet exist, the schema is inferred from the
1703 :class:`~pandas.DataFrame`.
1704
1705 If a string is passed in, this method attempts to create a
1706 table reference from a string using
1707 :func:`google.cloud.bigquery.table.TableReference.from_string`.
1708
1709 Keyword Arguments:
1710 num_retries (Optional[int]): Number of upload retries.
1711 job_id (Optional[str]): Name of the job.
1712 job_id_prefix (Optional[str]):
1713 The user-provided prefix for a randomly generated
1714 job ID. This parameter will be ignored if a ``job_id`` is
1715 also given.
1716 location (str):
1717 Location where to run the job. Must match the location of the
1718 destination table.
1719 project (Optional[str]):
1720 Project ID of the project of where to run the job. Defaults
1721 to the client's project.
1722 job_config (Optional[google.cloud.bigquery.job.LoadJobConfig]):
1723 Extra configuration options for the job.
1724
1725 To override the default pandas data type conversions, supply
1726 a value for
1727 :attr:`~google.cloud.bigquery.job.LoadJobConfig.schema` with
1728 column names matching those of the dataframe. The BigQuery
1729 schema is used to determine the correct data type conversion.
1730 Indexes are not loaded. Requires the :mod:`pyarrow` library.
1731 parquet_compression (str):
1732 [Beta] The compression method to use if intermittently
1733 serializing ``dataframe`` to a parquet file.
1734
1735 If ``pyarrow`` and job config schema are used, the argument
1736 is directly passed as the ``compression`` argument to the
1737 underlying ``pyarrow.parquet.write_table()`` method (the
1738 default value "snappy" gets converted to uppercase).
1739 https://arrow.apache.org/docs/python/generated/pyarrow.parquet.write_table.html#pyarrow-parquet-write-table
1740
1741 If either ``pyarrow`` or job config schema are missing, the
1742 argument is directly passed as the ``compression`` argument
1743 to the underlying ``DataFrame.to_parquet()`` method.
1744 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_parquet.html#pandas.DataFrame.to_parquet
1745
1746 Returns:
1747 google.cloud.bigquery.job.LoadJob: A new load job.
1748
1749 Raises:
1750 ImportError:
1751 If a usable parquet engine cannot be found. This method
1752 requires :mod:`pyarrow` or :mod:`fastparquet` to be
1753 installed.
1754 TypeError:
1755 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.LoadJobConfig`
1756 class.
1757 """
1758 job_id = _make_job_id(job_id, job_id_prefix)
1759
1760 if job_config:
1761 _verify_job_config_type(job_config, google.cloud.bigquery.job.LoadJobConfig)
1762 # Make a copy so that the job config isn't modified in-place.
1763 job_config_properties = copy.deepcopy(job_config._properties)
1764 job_config = job.LoadJobConfig()
1765 job_config._properties = job_config_properties
1766
1767 else:
1768 job_config = job.LoadJobConfig()
1769
1770 job_config.source_format = job.SourceFormat.PARQUET
1771
1772 if location is None:
1773 location = self.location
1774
1775 # If table schema is not provided, we try to fetch the existing table
1776 # schema, and check if dataframe schema is compatible with it - except
1777 # for WRITE_TRUNCATE jobs, the existing schema does not matter then.
1778 if (
1779 not job_config.schema
1780 and job_config.write_disposition != job.WriteDisposition.WRITE_TRUNCATE
1781 ):
1782 try:
1783 table = self.get_table(destination)
1784 except google.api_core.exceptions.NotFound:
1785 table = None
1786 else:
1787 columns_and_indexes = frozenset(
1788 name
1789 for name, _ in _pandas_helpers.list_columns_and_indexes(dataframe)
1790 )
1791 # schema fields not present in the dataframe are not needed
1792 job_config.schema = [
1793 field for field in table.schema if field.name in columns_and_indexes
1794 ]
1795
1796 job_config.schema = _pandas_helpers.dataframe_to_bq_schema(
1797 dataframe, job_config.schema
1798 )
1799
1800 if not job_config.schema:
1801 # the schema could not be fully detected
1802 warnings.warn(
1803 "Schema could not be detected for all columns. Loading from a "
1804 "dataframe without a schema will be deprecated in the future, "
1805 "please provide a schema.",
1806 PendingDeprecationWarning,
1807 stacklevel=2,
1808 )
1809
1810 tmpfd, tmppath = tempfile.mkstemp(suffix="_job_{}.parquet".format(job_id[:8]))
1811 os.close(tmpfd)
1812
1813 try:
1814 if pyarrow and job_config.schema:
1815 if parquet_compression == "snappy": # adjust the default value
1816 parquet_compression = parquet_compression.upper()
1817
1818 _pandas_helpers.dataframe_to_parquet(
1819 dataframe,
1820 job_config.schema,
1821 tmppath,
1822 parquet_compression=parquet_compression,
1823 )
1824 else:
1825 if job_config.schema:
1826 warnings.warn(
1827 "job_config.schema is set, but not used to assist in "
1828 "identifying correct types for data serialization. "
1829 "Please install the pyarrow package.",
1830 PendingDeprecationWarning,
1831 stacklevel=2,
1832 )
1833
1834 dataframe.to_parquet(tmppath, compression=parquet_compression)
1835
1836 with open(tmppath, "rb") as parquet_file:
1837 return self.load_table_from_file(
1838 parquet_file,
1839 destination,
1840 num_retries=num_retries,
1841 rewind=True,
1842 job_id=job_id,
1843 job_id_prefix=job_id_prefix,
1844 location=location,
1845 project=project,
1846 job_config=job_config,
1847 )
1848
1849 finally:
1850 os.remove(tmppath)
1851
1852 def load_table_from_json(
1853 self,
1854 json_rows,
1855 destination,
1856 num_retries=_DEFAULT_NUM_RETRIES,
1857 job_id=None,
1858 job_id_prefix=None,
1859 location=None,
1860 project=None,
1861 job_config=None,
1862 ):
1863 """Upload the contents of a table from a JSON string or dict.
1864
1865 Args:
1866 json_rows (Iterable[Dict[str, Any]]):
1867 Row data to be inserted. Keys must match the table schema fields
1868 and values must be JSON-compatible representations.
1869
1870 .. note::
1871
1872 If your data is already a newline-delimited JSON string,
1873 it is best to wrap it into a file-like object and pass it
1874 to :meth:`~google.cloud.bigquery.client.Client.load_table_from_file`::
1875
1876 import io
1877 from google.cloud import bigquery
1878
1879 data = u'{"foo": "bar"}'
1880 data_as_file = io.StringIO(data)
1881
1882 client = bigquery.Client()
1883 client.load_table_from_file(data_as_file, ...)
1884
1885 destination (Union[ \
1886 google.cloud.bigquery.table.Table, \
1887 google.cloud.bigquery.table.TableReference, \
1888 str, \
1889 ]):
1890 Table into which data is to be loaded. If a string is passed
1891 in, this method attempts to create a table reference from a
1892 string using
1893 :func:`google.cloud.bigquery.table.TableReference.from_string`.
1894
1895 Keyword Arguments:
1896 num_retries (Optional[int]): Number of upload retries.
1897 job_id (str): (Optional) Name of the job.
1898 job_id_prefix (str):
1899 (Optional) the user-provided prefix for a randomly generated
1900 job ID. This parameter will be ignored if a ``job_id`` is
1901 also given.
1902 location (str):
1903 Location where to run the job. Must match the location of the
1904 destination table.
1905 project (str):
1906 Project ID of the project of where to run the job. Defaults
1907 to the client's project.
1908 job_config (google.cloud.bigquery.job.LoadJobConfig):
1909 (Optional) Extra configuration options for the job. The
1910 ``source_format`` setting is always set to
1911 :attr:`~google.cloud.bigquery.job.SourceFormat.NEWLINE_DELIMITED_JSON`.
1912
1913 Returns:
1914 google.cloud.bigquery.job.LoadJob: A new load job.
1915
1916 Raises:
1917 TypeError:
1918 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.LoadJobConfig`
1919 class.
1920 """
1921 job_id = _make_job_id(job_id, job_id_prefix)
1922
1923 if job_config:
1924 _verify_job_config_type(job_config, google.cloud.bigquery.job.LoadJobConfig)
1925 # Make a copy so that the job config isn't modified in-place.
1926 job_config = copy.deepcopy(job_config)
1927 else:
1928 job_config = job.LoadJobConfig()
1929
1930 job_config.source_format = job.SourceFormat.NEWLINE_DELIMITED_JSON
1931
1932 if job_config.schema is None:
1933 job_config.autodetect = True
1934
1935 if project is None:
1936 project = self.project
1937
1938 if location is None:
1939 location = self.location
1940
1941 destination = _table_arg_to_table_ref(destination, default_project=self.project)
1942
1943 data_str = u"\n".join(json.dumps(item) for item in json_rows)
1944 data_file = io.BytesIO(data_str.encode())
1945
1946 return self.load_table_from_file(
1947 data_file,
1948 destination,
1949 num_retries=num_retries,
1950 job_id=job_id,
1951 job_id_prefix=job_id_prefix,
1952 location=location,
1953 project=project,
1954 job_config=job_config,
1955 )
1956
1957 def _do_resumable_upload(self, stream, metadata, num_retries):
1958 """Perform a resumable upload.
1959
1960 Args:
1961 stream (IO[bytes]): A bytes IO object open for reading.
1962
1963 metadata (Dict): The metadata associated with the upload.
1964
1965 num_retries (int):
1966 Number of upload retries. (Deprecated: This
1967 argument will be removed in a future release.)
1968
1969 Returns:
1970 requests.Response:
1971 The "200 OK" response object returned after the final chunk
1972 is uploaded.
1973 """
1974 upload, transport = self._initiate_resumable_upload(
1975 stream, metadata, num_retries
1976 )
1977
1978 while not upload.finished:
1979 response = upload.transmit_next_chunk(transport)
1980
1981 return response
1982
1983 def _initiate_resumable_upload(self, stream, metadata, num_retries):
1984 """Initiate a resumable upload.
1985
1986 Args:
1987 stream (IO[bytes]): A bytes IO object open for reading.
1988
1989 metadata (Dict): The metadata associated with the upload.
1990
1991 num_retries (int):
1992 Number of upload retries. (Deprecated: This
1993 argument will be removed in a future release.)
1994
1995 Returns:
1996 Tuple:
1997 Pair of
1998
1999 * The :class:`~google.resumable_media.requests.ResumableUpload`
2000 that was created
2001 * The ``transport`` used to initiate the upload.
2002 """
2003 chunk_size = _DEFAULT_CHUNKSIZE
2004 transport = self._http
2005 headers = _get_upload_headers(self._connection.user_agent)
2006 upload_url = _RESUMABLE_URL_TEMPLATE.format(project=self.project)
2007 # TODO: modify ResumableUpload to take a retry.Retry object
2008 # that it can use for the initial RPC.
2009 upload = ResumableUpload(upload_url, chunk_size, headers=headers)
2010
2011 if num_retries is not None:
2012 upload._retry_strategy = resumable_media.RetryStrategy(
2013 max_retries=num_retries
2014 )
2015
2016 upload.initiate(
2017 transport, stream, metadata, _GENERIC_CONTENT_TYPE, stream_final=False
2018 )
2019
2020 return upload, transport
2021
2022 def _do_multipart_upload(self, stream, metadata, size, num_retries):
2023 """Perform a multipart upload.
2024
2025 Args:
2026 stream (IO[bytes]): A bytes IO object open for reading.
2027
2028 metadata (Dict): The metadata associated with the upload.
2029
2030 size (int):
2031 The number of bytes to be uploaded (which will be read
2032 from ``stream``). If not provided, the upload will be
2033 concluded once ``stream`` is exhausted (or :data:`None`).
2034
2035 num_retries (int):
2036 Number of upload retries. (Deprecated: This
2037 argument will be removed in a future release.)
2038
2039 Returns:
2040 requests.Response:
2041 The "200 OK" response object returned after the multipart
2042 upload request.
2043
2044 Raises:
2045 ValueError:
2046 if the ``stream`` has fewer than ``size``
2047 bytes remaining.
2048 """
2049 data = stream.read(size)
2050 if len(data) < size:
2051 msg = _READ_LESS_THAN_SIZE.format(size, len(data))
2052 raise ValueError(msg)
2053
2054 headers = _get_upload_headers(self._connection.user_agent)
2055
2056 upload_url = _MULTIPART_URL_TEMPLATE.format(project=self.project)
2057 upload = MultipartUpload(upload_url, headers=headers)
2058
2059 if num_retries is not None:
2060 upload._retry_strategy = resumable_media.RetryStrategy(
2061 max_retries=num_retries
2062 )
2063
2064 response = upload.transmit(self._http, data, metadata, _GENERIC_CONTENT_TYPE)
2065
2066 return response
2067
2068 def copy_table(
2069 self,
2070 sources,
2071 destination,
2072 job_id=None,
2073 job_id_prefix=None,
2074 location=None,
2075 project=None,
2076 job_config=None,
2077 retry=DEFAULT_RETRY,
2078 timeout=None,
2079 ):
2080 """Copy one or more tables to another table.
2081
2082 See
2083 https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#jobconfigurationtablecopy
2084
2085 Args:
2086 sources (Union[ \
2087 google.cloud.bigquery.table.Table, \
2088 google.cloud.bigquery.table.TableReference, \
2089 str, \
2090 Sequence[ \
2091 Union[ \
2092 google.cloud.bigquery.table.Table, \
2093 google.cloud.bigquery.table.TableReference, \
2094 str, \
2095 ] \
2096 ], \
2097 ]):
2098 Table or tables to be copied.
2099 destination (Union[ \
2100 google.cloud.bigquery.table.Table, \
2101 google.cloud.bigquery.table.TableReference, \
2102 str, \
2103 ]):
2104 Table into which data is to be copied.
2105
2106 Keyword Arguments:
2107 job_id (str): (Optional) The ID of the job.
2108 job_id_prefix (str)
2109 (Optional) the user-provided prefix for a randomly generated
2110 job ID. This parameter will be ignored if a ``job_id`` is
2111 also given.
2112 location (str):
2113 Location where to run the job. Must match the location of any
2114 source table as well as the destination table.
2115 project (str):
2116 Project ID of the project of where to run the job. Defaults
2117 to the client's project.
2118 job_config (google.cloud.bigquery.job.CopyJobConfig):
2119 (Optional) Extra configuration options for the job.
2120 retry (google.api_core.retry.Retry):
2121 (Optional) How to retry the RPC.
2122 timeout (Optional[float]):
2123 The number of seconds to wait for the underlying HTTP transport
2124 before using ``retry``.
2125
2126 Returns:
2127 google.cloud.bigquery.job.CopyJob: A new copy job instance.
2128
2129 Raises:
2130 TypeError:
2131 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.CopyJobConfig`
2132 class.
2133 """
2134 job_id = _make_job_id(job_id, job_id_prefix)
2135
2136 if project is None:
2137 project = self.project
2138
2139 if location is None:
2140 location = self.location
2141
2142 job_ref = job._JobReference(job_id, project=project, location=location)
2143
2144 # sources can be one of many different input types. (string, Table,
2145 # TableReference, or a sequence of any of those.) Convert them all to a
2146 # list of TableReferences.
2147 #
2148 # _table_arg_to_table_ref leaves lists unmodified.
2149 sources = _table_arg_to_table_ref(sources, default_project=self.project)
2150
2151 if not isinstance(sources, collections_abc.Sequence):
2152 sources = [sources]
2153
2154 sources = [
2155 _table_arg_to_table_ref(source, default_project=self.project)
2156 for source in sources
2157 ]
2158
2159 destination = _table_arg_to_table_ref(destination, default_project=self.project)
2160
2161 if job_config:
2162 _verify_job_config_type(job_config, google.cloud.bigquery.job.CopyJobConfig)
2163 job_config = copy.deepcopy(job_config)
2164
2165 copy_job = job.CopyJob(
2166 job_ref, sources, destination, client=self, job_config=job_config
2167 )
2168 copy_job._begin(retry=retry, timeout=timeout)
2169
2170 return copy_job
2171
2172 def extract_table(
2173 self,
2174 source,
2175 destination_uris,
2176 job_id=None,
2177 job_id_prefix=None,
2178 location=None,
2179 project=None,
2180 job_config=None,
2181 retry=DEFAULT_RETRY,
2182 timeout=None,
2183 ):
2184 """Start a job to extract a table into Cloud Storage files.
2185
2186 See
2187 https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#jobconfigurationextract
2188
2189 Args:
2190 source (Union[ \
2191 google.cloud.bigquery.table.Table, \
2192 google.cloud.bigquery.table.TableReference, \
2193 src, \
2194 ]):
2195 Table to be extracted.
2196 destination_uris (Union[str, Sequence[str]]):
2197 URIs of Cloud Storage file(s) into which table data is to be
2198 extracted; in format
2199 ``gs://<bucket_name>/<object_name_or_glob>``.
2200
2201 Keyword Arguments:
2202 job_id (str): (Optional) The ID of the job.
2203 job_id_prefix (str)
2204 (Optional) the user-provided prefix for a randomly generated
2205 job ID. This parameter will be ignored if a ``job_id`` is
2206 also given.
2207 location (str):
2208 Location where to run the job. Must match the location of the
2209 source table.
2210 project (str):
2211 Project ID of the project of where to run the job. Defaults
2212 to the client's project.
2213 job_config (google.cloud.bigquery.job.ExtractJobConfig):
2214 (Optional) Extra configuration options for the job.
2215 retry (google.api_core.retry.Retry):
2216 (Optional) How to retry the RPC.
2217 timeout (Optional[float]):
2218 The number of seconds to wait for the underlying HTTP transport
2219 before using ``retry``.
2220 Args:
2221 source (google.cloud.bigquery.table.TableReference): table to be extracted.
2222
2223 Returns:
2224 google.cloud.bigquery.job.ExtractJob: A new extract job instance.
2225
2226 Raises:
2227 TypeError:
2228 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.ExtractJobConfig`
2229 class.
2230 """
2231 job_id = _make_job_id(job_id, job_id_prefix)
2232
2233 if project is None:
2234 project = self.project
2235
2236 if location is None:
2237 location = self.location
2238
2239 job_ref = job._JobReference(job_id, project=project, location=location)
2240 source = _table_arg_to_table_ref(source, default_project=self.project)
2241
2242 if isinstance(destination_uris, six.string_types):
2243 destination_uris = [destination_uris]
2244
2245 if job_config:
2246 _verify_job_config_type(
2247 job_config, google.cloud.bigquery.job.ExtractJobConfig
2248 )
2249 job_config = copy.deepcopy(job_config)
2250
2251 extract_job = job.ExtractJob(
2252 job_ref, source, destination_uris, client=self, job_config=job_config
2253 )
2254 extract_job._begin(retry=retry, timeout=timeout)
2255
2256 return extract_job
2257
2258 def query(
2259 self,
2260 query,
2261 job_config=None,
2262 job_id=None,
2263 job_id_prefix=None,
2264 location=None,
2265 project=None,
2266 retry=DEFAULT_RETRY,
2267 timeout=None,
2268 ):
2269 """Run a SQL query.
2270
2271 See
2272 https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#jobconfigurationquery
2273
2274 Args:
2275 query (str):
2276 SQL query to be executed. Defaults to the standard SQL
2277 dialect. Use the ``job_config`` parameter to change dialects.
2278
2279 Keyword Arguments:
2280 job_config (google.cloud.bigquery.job.QueryJobConfig):
2281 (Optional) Extra configuration options for the job.
2282 To override any options that were previously set in
2283 the ``default_query_job_config`` given to the
2284 ``Client`` constructor, manually set those options to ``None``,
2285 or whatever value is preferred.
2286 job_id (str): (Optional) ID to use for the query job.
2287 job_id_prefix (str):
2288 (Optional) The prefix to use for a randomly generated job ID.
2289 This parameter will be ignored if a ``job_id`` is also given.
2290 location (str):
2291 Location where to run the job. Must match the location of the
2292 any table used in the query as well as the destination table.
2293 project (str):
2294 Project ID of the project of where to run the job. Defaults
2295 to the client's project.
2296 retry (google.api_core.retry.Retry):
2297 (Optional) How to retry the RPC.
2298 timeout (Optional[float]):
2299 The number of seconds to wait for the underlying HTTP transport
2300 before using ``retry``.
2301
2302 Returns:
2303 google.cloud.bigquery.job.QueryJob: A new query job instance.
2304
2305 Raises:
2306 TypeError:
2307 If ``job_config`` is not an instance of :class:`~google.cloud.bigquery.job.QueryJobConfig`
2308 class.
2309 """
2310 job_id = _make_job_id(job_id, job_id_prefix)
2311
2312 if project is None:
2313 project = self.project
2314
2315 if location is None:
2316 location = self.location
2317
2318 job_config = copy.deepcopy(job_config)
2319
2320 if self._default_query_job_config:
2321 if job_config:
2322 _verify_job_config_type(
2323 job_config, google.cloud.bigquery.job.QueryJobConfig
2324 )
2325 # anything that's not defined on the incoming
2326 # that is in the default,
2327 # should be filled in with the default
2328 # the incoming therefore has precedence
2329 job_config = job_config._fill_from_default(
2330 self._default_query_job_config
2331 )
2332 else:
2333 _verify_job_config_type(
2334 self._default_query_job_config,
2335 google.cloud.bigquery.job.QueryJobConfig,
2336 )
2337 job_config = copy.deepcopy(self._default_query_job_config)
2338
2339 job_ref = job._JobReference(job_id, project=project, location=location)
2340 query_job = job.QueryJob(job_ref, query, client=self, job_config=job_config)
2341 query_job._begin(retry=retry, timeout=timeout)
2342
2343 return query_job
2344
2345 def insert_rows(self, table, rows, selected_fields=None, **kwargs):
2346 """Insert rows into a table via the streaming API.
2347
2348 See
2349 https://cloud.google.com/bigquery/docs/reference/rest/v2/tabledata/insertAll
2350
2351 Args:
2352 table (Union[ \
2353 google.cloud.bigquery.table.Table, \
2354 google.cloud.bigquery.table.TableReference, \
2355 str, \
2356 ]):
2357 The destination table for the row data, or a reference to it.
2358 rows (Union[Sequence[Tuple], Sequence[dict]]):
2359 Row data to be inserted. If a list of tuples is given, each
2360 tuple should contain data for each schema field on the
2361 current table and in the same order as the schema fields. If
2362 a list of dictionaries is given, the keys must include all
2363 required fields in the schema. Keys which do not correspond
2364 to a field in the schema are ignored.
2365 selected_fields (Sequence[google.cloud.bigquery.schema.SchemaField]):
2366 The fields to return. Required if ``table`` is a
2367 :class:`~google.cloud.bigquery.table.TableReference`.
2368 kwargs (Dict):
2369 Keyword arguments to
2370 :meth:`~google.cloud.bigquery.client.Client.insert_rows_json`.
2371
2372 Returns:
2373 Sequence[Mappings]:
2374 One mapping per row with insert errors: the "index" key
2375 identifies the row, and the "errors" key contains a list of
2376 the mappings describing one or more problems with the row.
2377
2378 Raises:
2379 ValueError: if table's schema is not set
2380 """
2381 table = _table_arg_to_table(table, default_project=self.project)
2382
2383 if not isinstance(table, Table):
2384 raise TypeError(_NEED_TABLE_ARGUMENT)
2385
2386 schema = table.schema
2387
2388 # selected_fields can override the table schema.
2389 if selected_fields is not None:
2390 schema = selected_fields
2391
2392 if len(schema) == 0:
2393 raise ValueError(
2394 (
2395 "Could not determine schema for table '{}'. Call client.get_table() "
2396 "or pass in a list of schema fields to the selected_fields argument."
2397 ).format(table)
2398 )
2399
2400 json_rows = [_record_field_to_json(schema, row) for row in rows]
2401
2402 return self.insert_rows_json(table, json_rows, **kwargs)
2403
2404 def insert_rows_from_dataframe(
2405 self, table, dataframe, selected_fields=None, chunk_size=500, **kwargs
2406 ):
2407 """Insert rows into a table from a dataframe via the streaming API.
2408
2409 Args:
2410 table (Union[ \
2411 google.cloud.bigquery.table.Table, \
2412 google.cloud.bigquery.table.TableReference, \
2413 str, \
2414 ]):
2415 The destination table for the row data, or a reference to it.
2416 dataframe (pandas.DataFrame):
2417 A :class:`~pandas.DataFrame` containing the data to load.
2418 selected_fields (Sequence[google.cloud.bigquery.schema.SchemaField]):
2419 The fields to return. Required if ``table`` is a
2420 :class:`~google.cloud.bigquery.table.TableReference`.
2421 chunk_size (int):
2422 The number of rows to stream in a single chunk. Must be positive.
2423 kwargs (Dict):
2424 Keyword arguments to
2425 :meth:`~google.cloud.bigquery.client.Client.insert_rows_json`.
2426
2427 Returns:
2428 Sequence[Sequence[Mappings]]:
2429 A list with insert errors for each insert chunk. Each element
2430 is a list containing one mapping per row with insert errors:
2431 the "index" key identifies the row, and the "errors" key
2432 contains a list of the mappings describing one or more problems
2433 with the row.
2434
2435 Raises:
2436 ValueError: if table's schema is not set
2437 """
2438 insert_results = []
2439
2440 chunk_count = int(math.ceil(len(dataframe) / chunk_size))
2441 rows_iter = (
2442 dict(six.moves.zip(dataframe.columns, row))
2443 for row in dataframe.itertuples(index=False, name=None)
2444 )
2445
2446 for _ in range(chunk_count):
2447 rows_chunk = itertools.islice(rows_iter, chunk_size)
2448 result = self.insert_rows(table, rows_chunk, selected_fields, **kwargs)
2449 insert_results.append(result)
2450
2451 return insert_results
2452
2453 def insert_rows_json(
2454 self,
2455 table,
2456 json_rows,
2457 row_ids=None,
2458 skip_invalid_rows=None,
2459 ignore_unknown_values=None,
2460 template_suffix=None,
2461 retry=DEFAULT_RETRY,
2462 timeout=None,
2463 ):
2464 """Insert rows into a table without applying local type conversions.
2465
2466 See
2467 https://cloud.google.com/bigquery/docs/reference/rest/v2/tabledata/insertAll
2468
2469 Args:
2470 table (Union[ \
2471 google.cloud.bigquery.table.Table \
2472 google.cloud.bigquery.table.TableReference, \
2473 str \
2474 ]):
2475 The destination table for the row data, or a reference to it.
2476 json_rows (Sequence[Dict]):
2477 Row data to be inserted. Keys must match the table schema fields
2478 and values must be JSON-compatible representations.
2479 row_ids (Optional[Sequence[Optional[str]]]):
2480 Unique IDs, one per row being inserted. An ID can also be
2481 ``None``, indicating that an explicit insert ID should **not**
2482 be used for that row. If the argument is omitted altogether,
2483 unique IDs are created automatically.
2484 skip_invalid_rows (Optional[bool]):
2485 Insert all valid rows of a request, even if invalid rows exist.
2486 The default value is ``False``, which causes the entire request
2487 to fail if any invalid rows exist.
2488 ignore_unknown_values (Optional[bool]):
2489 Accept rows that contain values that do not match the schema.
2490 The unknown values are ignored. Default is ``False``, which
2491 treats unknown values as errors.
2492 template_suffix (Optional[str]):
2493 Treat ``name`` as a template table and provide a suffix.
2494 BigQuery will create the table ``<name> + <template_suffix>``
2495 based on the schema of the template table. See
2496 https://cloud.google.com/bigquery/streaming-data-into-bigquery#template-tables
2497 retry (Optional[google.api_core.retry.Retry]):
2498 How to retry the RPC.
2499 timeout (Optional[float]):
2500 The number of seconds to wait for the underlying HTTP transport
2501 before using ``retry``.
2502
2503 Returns:
2504 Sequence[Mappings]:
2505 One mapping per row with insert errors: the "index" key
2506 identifies the row, and the "errors" key contains a list of
2507 the mappings describing one or more problems with the row.
2508 """
2509 # Convert table to just a reference because unlike insert_rows,
2510 # insert_rows_json doesn't need the table schema. It's not doing any
2511 # type conversions.
2512 table = _table_arg_to_table_ref(table, default_project=self.project)
2513 rows_info = []
2514 data = {"rows": rows_info}
2515
2516 for index, row in enumerate(json_rows):
2517 info = {"json": row}
2518 if row_ids is not None:
2519 info["insertId"] = row_ids[index]
2520 else:
2521 info["insertId"] = str(uuid.uuid4())
2522 rows_info.append(info)
2523
2524 if skip_invalid_rows is not None:
2525 data["skipInvalidRows"] = skip_invalid_rows
2526
2527 if ignore_unknown_values is not None:
2528 data["ignoreUnknownValues"] = ignore_unknown_values
2529
2530 if template_suffix is not None:
2531 data["templateSuffix"] = template_suffix
2532
2533 # We can always retry, because every row has an insert ID.
2534 response = self._call_api(
2535 retry,
2536 method="POST",
2537 path="%s/insertAll" % table.path,
2538 data=data,
2539 timeout=timeout,
2540 )
2541 errors = []
2542
2543 for error in response.get("insertErrors", ()):
2544 errors.append({"index": int(error["index"]), "errors": error["errors"]})
2545
2546 return errors
2547
2548 def list_partitions(self, table, retry=DEFAULT_RETRY, timeout=None):
2549 """List the partitions in a table.
2550
2551 Args:
2552 table (Union[ \
2553 google.cloud.bigquery.table.Table, \
2554 google.cloud.bigquery.table.TableReference, \
2555 str, \
2556 ]):
2557 The table or reference from which to get partition info
2558 retry (google.api_core.retry.Retry):
2559 (Optional) How to retry the RPC.
2560 timeout (Optional[float]):
2561 The number of seconds to wait for the underlying HTTP transport
2562 before using ``retry``.
2563 If multiple requests are made under the hood, ``timeout`` is
2564 interpreted as the approximate total time of **all** requests.
2565
2566 Returns:
2567 List[str]:
2568 A list of the partition ids present in the partitioned table
2569 """
2570 table = _table_arg_to_table_ref(table, default_project=self.project)
2571
2572 with TimeoutGuard(
2573 timeout, timeout_error_type=concurrent.futures.TimeoutError
2574 ) as guard:
2575 meta_table = self.get_table(
2576 TableReference(
2577 self.dataset(table.dataset_id, project=table.project),
2578 "%s$__PARTITIONS_SUMMARY__" % table.table_id,
2579 ),
2580 retry=retry,
2581 timeout=timeout,
2582 )
2583 timeout = guard.remaining_timeout
2584
2585 subset = [col for col in meta_table.schema if col.name == "partition_id"]
2586 return [
2587 row[0]
2588 for row in self.list_rows(
2589 meta_table, selected_fields=subset, retry=retry, timeout=timeout
2590 )
2591 ]
2592
2593 def list_rows(
2594 self,
2595 table,
2596 selected_fields=None,
2597 max_results=None,
2598 page_token=None,
2599 start_index=None,
2600 page_size=None,
2601 retry=DEFAULT_RETRY,
2602 timeout=None,
2603 ):
2604 """List the rows of the table.
2605
2606 See
2607 https://cloud.google.com/bigquery/docs/reference/rest/v2/tabledata/list
2608
2609 .. note::
2610
2611 This method assumes that the provided schema is up-to-date with the
2612 schema as defined on the back-end: if the two schemas are not
2613 identical, the values returned may be incomplete. To ensure that the
2614 local copy of the schema is up-to-date, call ``client.get_table``.
2615
2616 Args:
2617 table (Union[ \
2618 google.cloud.bigquery.table.Table, \
2619 google.cloud.bigquery.table.TableListItem, \
2620 google.cloud.bigquery.table.TableReference, \
2621 str, \
2622 ]):
2623 The table to list, or a reference to it. When the table
2624 object does not contain a schema and ``selected_fields`` is
2625 not supplied, this method calls ``get_table`` to fetch the
2626 table schema.
2627 selected_fields (Sequence[google.cloud.bigquery.schema.SchemaField]):
2628 The fields to return. If not supplied, data for all columns
2629 are downloaded.
2630 max_results (int):
2631 (Optional) maximum number of rows to return.
2632 page_token (str):
2633 (Optional) Token representing a cursor into the table's rows.
2634 If not passed, the API will return the first page of the
2635 rows. The token marks the beginning of the iterator to be
2636 returned and the value of the ``page_token`` can be accessed
2637 at ``next_page_token`` of the
2638 :class:`~google.cloud.bigquery.table.RowIterator`.
2639 start_index (int):
2640 (Optional) The zero-based index of the starting row to read.
2641 page_size (int):
2642 Optional. The maximum number of rows in each page of results
2643 from this request. Non-positive values are ignored. Defaults
2644 to a sensible value set by the API.
2645 retry (google.api_core.retry.Retry):
2646 (Optional) How to retry the RPC.
2647 timeout (Optional[float]):
2648 The number of seconds to wait for the underlying HTTP transport
2649 before using ``retry``.
2650 If multiple requests are made under the hood, ``timeout`` is
2651 interpreted as the approximate total time of **all** requests.
2652
2653 Returns:
2654 google.cloud.bigquery.table.RowIterator:
2655 Iterator of row data
2656 :class:`~google.cloud.bigquery.table.Row`-s. During each
2657 page, the iterator will have the ``total_rows`` attribute
2658 set, which counts the total number of rows **in the table**
2659 (this is distinct from the total number of rows in the
2660 current page: ``iterator.page.num_items``).
2661 """
2662 table = _table_arg_to_table(table, default_project=self.project)
2663
2664 if not isinstance(table, Table):
2665 raise TypeError(_NEED_TABLE_ARGUMENT)
2666
2667 schema = table.schema
2668
2669 # selected_fields can override the table schema.
2670 if selected_fields is not None:
2671 schema = selected_fields
2672
2673 # No schema, but no selected_fields. Assume the developer wants all
2674 # columns, so get the table resource for them rather than failing.
2675 elif len(schema) == 0:
2676 with TimeoutGuard(
2677 timeout, timeout_error_type=concurrent.futures.TimeoutError
2678 ) as guard:
2679 table = self.get_table(table.reference, retry=retry, timeout=timeout)
2680 timeout = guard.remaining_timeout
2681 schema = table.schema
2682
2683 params = {}
2684 if selected_fields is not None:
2685 params["selectedFields"] = ",".join(field.name for field in selected_fields)
2686 if start_index is not None:
2687 params["startIndex"] = start_index
2688
2689 row_iterator = RowIterator(
2690 client=self,
2691 api_request=functools.partial(self._call_api, retry, timeout=timeout),
2692 path="%s/data" % (table.path,),
2693 schema=schema,
2694 page_token=page_token,
2695 max_results=max_results,
2696 page_size=page_size,
2697 extra_params=params,
2698 table=table,
2699 # Pass in selected_fields separately from schema so that full
2700 # tables can be fetched without a column filter.
2701 selected_fields=selected_fields,
2702 )
2703 return row_iterator
2704
2705 def _schema_from_json_file_object(self, file_obj):
2706 """Helper function for schema_from_json that takes a
2707 file object that describes a table schema.
2708
2709 Returns:
2710 List of schema field objects.
2711 """
2712 json_data = json.load(file_obj)
2713 return [SchemaField.from_api_repr(field) for field in json_data]
2714
2715 def _schema_to_json_file_object(self, schema_list, file_obj):
2716 """Helper function for schema_to_json that takes a schema list and file
2717 object and writes the schema list to the file object with json.dump
2718 """
2719 json.dump(schema_list, file_obj, indent=2, sort_keys=True)
2720
2721 def schema_from_json(self, file_or_path):
2722 """Takes a file object or file path that contains json that describes
2723 a table schema.
2724
2725 Returns:
2726 List of schema field objects.
2727 """
2728 if isinstance(file_or_path, io.IOBase):
2729 return self._schema_from_json_file_object(file_or_path)
2730
2731 with open(file_or_path) as file_obj:
2732 return self._schema_from_json_file_object(file_obj)
2733
2734 def schema_to_json(self, schema_list, destination):
2735 """Takes a list of schema field objects.
2736
2737 Serializes the list of schema field objects as json to a file.
2738
2739 Destination is a file path or a file object.
2740 """
2741 json_schema_list = [f.to_api_repr() for f in schema_list]
2742
2743 if isinstance(destination, io.IOBase):
2744 return self._schema_to_json_file_object(json_schema_list, destination)
2745
2746 with open(destination, mode="w") as file_obj:
2747 return self._schema_to_json_file_object(json_schema_list, file_obj)
2748
2749
2750 # pylint: disable=unused-argument
2751 def _item_to_project(iterator, resource):
2752 """Convert a JSON project to the native object.
2753
2754 Args:
2755 iterator (google.api_core.page_iterator.Iterator): The iterator that is currently in use.
2756
2757 resource (Dict): An item to be converted to a project.
2758
2759 Returns:
2760 google.cloud.bigquery.client.Project: The next project in the page.
2761 """
2762 return Project.from_api_repr(resource)
2763
2764
2765 # pylint: enable=unused-argument
2766
2767
2768 def _item_to_dataset(iterator, resource):
2769 """Convert a JSON dataset to the native object.
2770
2771 Args:
2772 iterator (google.api_core.page_iterator.Iterator): The iterator that is currently in use.
2773
2774 resource (Dict): An item to be converted to a dataset.
2775
2776 Returns:
2777 google.cloud.bigquery.dataset.DatasetListItem: The next dataset in the page.
2778 """
2779 return DatasetListItem(resource)
2780
2781
2782 def _item_to_job(iterator, resource):
2783 """Convert a JSON job to the native object.
2784
2785 Args:
2786 iterator (google.api_core.page_iterator.Iterator): The iterator that is currently in use.
2787
2788 resource (Dict): An item to be converted to a job.
2789
2790 Returns:
2791 job instance: The next job in the page.
2792 """
2793 return iterator.client.job_from_resource(resource)
2794
2795
2796 def _item_to_model(iterator, resource):
2797 """Convert a JSON model to the native object.
2798
2799 Args:
2800 iterator (google.api_core.page_iterator.Iterator):
2801 The iterator that is currently in use.
2802 resource (Dict): An item to be converted to a model.
2803
2804 Returns:
2805 google.cloud.bigquery.model.Model: The next model in the page.
2806 """
2807 return Model.from_api_repr(resource)
2808
2809
2810 def _item_to_routine(iterator, resource):
2811 """Convert a JSON model to the native object.
2812
2813 Args:
2814 iterator (google.api_core.page_iterator.Iterator):
2815 The iterator that is currently in use.
2816 resource (Dict): An item to be converted to a routine.
2817
2818 Returns:
2819 google.cloud.bigquery.routine.Routine: The next routine in the page.
2820 """
2821 return Routine.from_api_repr(resource)
2822
2823
2824 def _item_to_table(iterator, resource):
2825 """Convert a JSON table to the native object.
2826
2827 Args:
2828 iterator (google.api_core.page_iterator.Iterator): The iterator that is currently in use.
2829
2830 resource (Dict): An item to be converted to a table.
2831
2832 Returns:
2833 google.cloud.bigquery.table.Table: The next table in the page.
2834 """
2835 return TableListItem(resource)
2836
2837
2838 def _make_job_id(job_id, prefix=None):
2839 """Construct an ID for a new job.
2840
2841 Args:
2842 job_id (Optional[str]): the user-provided job ID.
2843
2844 prefix (Optional[str]): the user-provided prefix for a job ID.
2845
2846 Returns:
2847 str: A job ID
2848 """
2849 if job_id is not None:
2850 return job_id
2851 elif prefix is not None:
2852 return str(prefix) + str(uuid.uuid4())
2853 else:
2854 return str(uuid.uuid4())
2855
2856
2857 def _check_mode(stream):
2858 """Check that a stream was opened in read-binary mode.
2859
2860 Args:
2861 stream (IO[bytes]): A bytes IO object open for reading.
2862
2863 Raises:
2864 ValueError:
2865 if the ``stream.mode`` is a valid attribute
2866 and is not among ``rb``, ``r+b`` or ``rb+``.
2867 """
2868 mode = getattr(stream, "mode", None)
2869
2870 if isinstance(stream, gzip.GzipFile):
2871 if mode != gzip.READ:
2872 raise ValueError(
2873 "Cannot upload gzip files opened in write mode: use "
2874 "gzip.GzipFile(filename, mode='rb')"
2875 )
2876 else:
2877 if mode is not None and mode not in ("rb", "r+b", "rb+"):
2878 raise ValueError(
2879 "Cannot upload files opened in text mode: use "
2880 "open(filename, mode='rb') or open(filename, mode='r+b')"
2881 )
2882
2883
2884 def _get_upload_headers(user_agent):
2885 """Get the headers for an upload request.
2886
2887 Args:
2888 user_agent (str): The user-agent for requests.
2889
2890 Returns:
2891 Dict: The headers to be used for the request.
2892 """
2893 return {
2894 "Accept": "application/json",
2895 "Accept-Encoding": "gzip, deflate",
2896 "User-Agent": user_agent,
2897 "content-type": "application/json",
2898 }
2899
[end of bigquery/google/cloud/bigquery/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
googleapis/google-cloud-python
|
b492bdcc2d288022b5c81e90aea993432eec078a
|
BigQuery: raise a `TypeError` if a dictionary is passed to `insert_rows_json`
**Is your feature request related to a problem? Please describe.**
If I want to only insert a single row at a time into a table, it's easy to accidentally try something like:
```python
json_row = {"col1": "hello", "col2": "world"}
errors = client.insert_rows_json(
table,
json_row
)
```
This results in a `400 BadRequest` error from the API, because it expects a list of rows, not a single row.
**Describe the solution you'd like**
It's difficult to debug this situation from the API response, so it'd be better if we raised a client-side error for passing in the wrong type for `json_rows`.
**Describe alternatives you've considered**
Leave as-is and request a better server-side message. This may be difficult to do, as the error happens at a level above BigQuery, which translates JSON to Protobuf for internal use.
**Additional context**
This issue was encountered by a customer engineer, and it took me a bit of debugging to figure out the actual issue. I expect other customers will encounter this problem as well.
|
2020-01-16T13:04:56Z
|
<patch>
diff --git a/bigquery/google/cloud/bigquery/client.py b/bigquery/google/cloud/bigquery/client.py
--- a/bigquery/google/cloud/bigquery/client.py
+++ b/bigquery/google/cloud/bigquery/client.py
@@ -2506,6 +2506,8 @@ def insert_rows_json(
identifies the row, and the "errors" key contains a list of
the mappings describing one or more problems with the row.
"""
+ if not isinstance(json_rows, collections_abc.Sequence):
+ raise TypeError("json_rows argument should be a sequence of dicts")
# Convert table to just a reference because unlike insert_rows,
# insert_rows_json doesn't need the table schema. It's not doing any
# type conversions.
</patch>
|
[]
|
[]
| ||||
numpy__numpy-14074
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NumPy 1.17 RC fails to compile with Intel C Compile 2016
<!-- Please describe the issue in detail here, and fill in the fields below -->
Compiling NumPy 1.17.0rc2 sources with Intel C Compiler 2016, which does not yet implement `__builtin_cpu_supports("avx512f")` fails with compilation error:
```
icc: numpy/core/src/umath/cpuid.c
numpy/core/src/umath/cpuid.c(63): catastrophic error: invalid use of '__builtin_cpu_supports'
compilation aborted for numpy/core/src/umath/cpuid.c (code 1)
```
Recent Intel C compiler (2019) proceeds just fine.
There is config test to probe compiler for support of `__builtin_cpu_supports`, but the the test does not discriminate between supported arguments.
</issue>
<code>
[start of README.md]
1 # <img alt="NumPy" src="https://cdn.rawgit.com/numpy/numpy/master/branding/icons/numpylogo.svg" height="60">
2
3 [](
4 https://travis-ci.org/numpy/numpy)
5 [](
6 https://ci.appveyor.com/project/charris/numpy)
7 [](
8 https://dev.azure.com/numpy/numpy/_build/latest?definitionId=5)
9 [](
10 https://codecov.io/gh/numpy/numpy)
11
12 NumPy is the fundamental package needed for scientific computing with Python.
13
14 - **Website:** https://www.numpy.org
15 - **Documentation:** http://docs.scipy.org/
16 - **Mailing list:** https://mail.python.org/mailman/listinfo/numpy-discussion
17 - **Source code:** https://github.com/numpy/numpy
18 - **Contributing:** https://www.numpy.org/devdocs/dev/index.html
19 - **Bug reports:** https://github.com/numpy/numpy/issues
20 - **Report a security vulnerability:** https://tidelift.com/docs/security
21
22 It provides:
23
24 - a powerful N-dimensional array object
25 - sophisticated (broadcasting) functions
26 - tools for integrating C/C++ and Fortran code
27 - useful linear algebra, Fourier transform, and random number capabilities
28
29 Testing:
30
31 - NumPy versions ≥ 1.15 require `pytest`
32 - NumPy versions < 1.15 require `nose`
33
34 Tests can then be run after installation with:
35
36 python -c 'import numpy; numpy.test()'
37
38
39 Call for Contributions
40 ----------------------
41
42 NumPy appreciates help from a wide range of different backgrounds.
43 Work such as high level documentation or website improvements are valuable
44 and we would like to grow our team with people filling these roles.
45 Small improvements or fixes are always appreciated and issues labeled as easy
46 may be a good starting point.
47 If you are considering larger contributions outside the traditional coding work,
48 please contact us through the mailing list.
49
50
51 [](https://numfocus.org)
52
[end of README.md]
[start of numpy/core/setup_common.py]
1 from __future__ import division, absolute_import, print_function
2
3 # Code common to build tools
4 import sys
5 import warnings
6 import copy
7 import binascii
8
9 from numpy.distutils.misc_util import mingw32
10
11
12 #-------------------
13 # Versioning support
14 #-------------------
15 # How to change C_API_VERSION ?
16 # - increase C_API_VERSION value
17 # - record the hash for the new C API with the script cversions.py
18 # and add the hash to cversions.txt
19 # The hash values are used to remind developers when the C API number was not
20 # updated - generates a MismatchCAPIWarning warning which is turned into an
21 # exception for released version.
22
23 # Binary compatibility version number. This number is increased whenever the
24 # C-API is changed such that binary compatibility is broken, i.e. whenever a
25 # recompile of extension modules is needed.
26 C_ABI_VERSION = 0x01000009
27
28 # Minor API version. This number is increased whenever a change is made to the
29 # C-API -- whether it breaks binary compatibility or not. Some changes, such
30 # as adding a function pointer to the end of the function table, can be made
31 # without breaking binary compatibility. In this case, only the C_API_VERSION
32 # (*not* C_ABI_VERSION) would be increased. Whenever binary compatibility is
33 # broken, both C_API_VERSION and C_ABI_VERSION should be increased.
34 #
35 # 0x00000008 - 1.7.x
36 # 0x00000009 - 1.8.x
37 # 0x00000009 - 1.9.x
38 # 0x0000000a - 1.10.x
39 # 0x0000000a - 1.11.x
40 # 0x0000000a - 1.12.x
41 # 0x0000000b - 1.13.x
42 # 0x0000000c - 1.14.x
43 # 0x0000000c - 1.15.x
44 # 0x0000000d - 1.16.x
45 C_API_VERSION = 0x0000000d
46
47 class MismatchCAPIWarning(Warning):
48 pass
49
50 def is_released(config):
51 """Return True if a released version of numpy is detected."""
52 from distutils.version import LooseVersion
53
54 v = config.get_version('../version.py')
55 if v is None:
56 raise ValueError("Could not get version")
57 pv = LooseVersion(vstring=v).version
58 if len(pv) > 3:
59 return False
60 return True
61
62 def get_api_versions(apiversion, codegen_dir):
63 """
64 Return current C API checksum and the recorded checksum.
65
66 Return current C API checksum and the recorded checksum for the given
67 version of the C API version.
68
69 """
70 # Compute the hash of the current API as defined in the .txt files in
71 # code_generators
72 sys.path.insert(0, codegen_dir)
73 try:
74 m = __import__('genapi')
75 numpy_api = __import__('numpy_api')
76 curapi_hash = m.fullapi_hash(numpy_api.full_api)
77 apis_hash = m.get_versions_hash()
78 finally:
79 del sys.path[0]
80
81 return curapi_hash, apis_hash[apiversion]
82
83 def check_api_version(apiversion, codegen_dir):
84 """Emits a MismatchCAPIWarning if the C API version needs updating."""
85 curapi_hash, api_hash = get_api_versions(apiversion, codegen_dir)
86
87 # If different hash, it means that the api .txt files in
88 # codegen_dir have been updated without the API version being
89 # updated. Any modification in those .txt files should be reflected
90 # in the api and eventually abi versions.
91 # To compute the checksum of the current API, use
92 # code_generators/cversions.py script
93 if not curapi_hash == api_hash:
94 msg = ("API mismatch detected, the C API version "
95 "numbers have to be updated. Current C api version is %d, "
96 "with checksum %s, but recorded checksum for C API version %d in "
97 "codegen_dir/cversions.txt is %s. If functions were added in the "
98 "C API, you have to update C_API_VERSION in %s."
99 )
100 warnings.warn(msg % (apiversion, curapi_hash, apiversion, api_hash,
101 __file__),
102 MismatchCAPIWarning, stacklevel=2)
103 # Mandatory functions: if not found, fail the build
104 MANDATORY_FUNCS = ["sin", "cos", "tan", "sinh", "cosh", "tanh", "fabs",
105 "floor", "ceil", "sqrt", "log10", "log", "exp", "asin",
106 "acos", "atan", "fmod", 'modf', 'frexp', 'ldexp']
107
108 # Standard functions which may not be available and for which we have a
109 # replacement implementation. Note that some of these are C99 functions.
110 OPTIONAL_STDFUNCS = ["expm1", "log1p", "acosh", "asinh", "atanh",
111 "rint", "trunc", "exp2", "log2", "hypot", "atan2", "pow",
112 "copysign", "nextafter", "ftello", "fseeko",
113 "strtoll", "strtoull", "cbrt", "strtold_l", "fallocate",
114 "backtrace", "madvise"]
115
116
117 OPTIONAL_HEADERS = [
118 # sse headers only enabled automatically on amd64/x32 builds
119 "xmmintrin.h", # SSE
120 "emmintrin.h", # SSE2
121 "immintrin.h", # AVX
122 "features.h", # for glibc version linux
123 "xlocale.h", # see GH#8367
124 "dlfcn.h", # dladdr
125 "sys/mman.h", #madvise
126 ]
127
128 # optional gcc compiler builtins and their call arguments and optional a
129 # required header and definition name (HAVE_ prepended)
130 # call arguments are required as the compiler will do strict signature checking
131 OPTIONAL_INTRINSICS = [("__builtin_isnan", '5.'),
132 ("__builtin_isinf", '5.'),
133 ("__builtin_isfinite", '5.'),
134 ("__builtin_bswap32", '5u'),
135 ("__builtin_bswap64", '5u'),
136 ("__builtin_expect", '5, 0'),
137 ("__builtin_mul_overflow", '5, 5, (int*)5'),
138 # broken on OSX 10.11, make sure its not optimized away
139 ("volatile int r = __builtin_cpu_supports", '"sse"',
140 "stdio.h", "__BUILTIN_CPU_SUPPORTS"),
141 # MMX only needed for icc, but some clangs don't have it
142 ("_m_from_int64", '0', "emmintrin.h"),
143 ("_mm_load_ps", '(float*)0', "xmmintrin.h"), # SSE
144 ("_mm_prefetch", '(float*)0, _MM_HINT_NTA',
145 "xmmintrin.h"), # SSE
146 ("_mm_load_pd", '(double*)0', "emmintrin.h"), # SSE2
147 ("__builtin_prefetch", "(float*)0, 0, 3"),
148 # check that the linker can handle avx
149 ("__asm__ volatile", '"vpand %xmm1, %xmm2, %xmm3"',
150 "stdio.h", "LINK_AVX"),
151 ("__asm__ volatile", '"vpand %ymm1, %ymm2, %ymm3"',
152 "stdio.h", "LINK_AVX2"),
153 ("__asm__ volatile", '"vpaddd %zmm1, %zmm2, %zmm3"',
154 "stdio.h", "LINK_AVX512F"),
155 ("__asm__ volatile", '"xgetbv"', "stdio.h", "XGETBV"),
156 ]
157
158 # function attributes
159 # tested via "int %s %s(void *);" % (attribute, name)
160 # function name will be converted to HAVE_<upper-case-name> preprocessor macro
161 OPTIONAL_FUNCTION_ATTRIBUTES = [('__attribute__((optimize("unroll-loops")))',
162 'attribute_optimize_unroll_loops'),
163 ('__attribute__((optimize("O3")))',
164 'attribute_optimize_opt_3'),
165 ('__attribute__((nonnull (1)))',
166 'attribute_nonnull'),
167 ('__attribute__((target ("avx")))',
168 'attribute_target_avx'),
169 ('__attribute__((target ("avx2")))',
170 'attribute_target_avx2'),
171 ('__attribute__((target ("avx512f")))',
172 'attribute_target_avx512f'),
173 ]
174
175 # function attributes with intrinsics
176 # To ensure your compiler can compile avx intrinsics with just the attributes
177 # gcc 4.8.4 support attributes but not with intrisics
178 # tested via "#include<%s> int %s %s(void *){code; return 0;};" % (header, attribute, name, code)
179 # function name will be converted to HAVE_<upper-case-name> preprocessor macro
180 OPTIONAL_FUNCTION_ATTRIBUTES_WITH_INTRINSICS = [('__attribute__((target("avx2")))',
181 'attribute_target_avx2_with_intrinsics',
182 '__m256 temp = _mm256_set1_ps(1.0)',
183 'immintrin.h'),
184 ('__attribute__((target("avx512f")))',
185 'attribute_target_avx512f_with_intrinsics',
186 '__m512 temp = _mm512_set1_ps(1.0)',
187 'immintrin.h'),
188 ]
189
190 # variable attributes tested via "int %s a" % attribute
191 OPTIONAL_VARIABLE_ATTRIBUTES = ["__thread", "__declspec(thread)"]
192
193 # Subset of OPTIONAL_STDFUNCS which may already have HAVE_* defined by Python.h
194 OPTIONAL_STDFUNCS_MAYBE = [
195 "expm1", "log1p", "acosh", "atanh", "asinh", "hypot", "copysign",
196 "ftello", "fseeko"
197 ]
198
199 # C99 functions: float and long double versions
200 C99_FUNCS = [
201 "sin", "cos", "tan", "sinh", "cosh", "tanh", "fabs", "floor", "ceil",
202 "rint", "trunc", "sqrt", "log10", "log", "log1p", "exp", "expm1",
203 "asin", "acos", "atan", "asinh", "acosh", "atanh", "hypot", "atan2",
204 "pow", "fmod", "modf", 'frexp', 'ldexp', "exp2", "log2", "copysign",
205 "nextafter", "cbrt"
206 ]
207 C99_FUNCS_SINGLE = [f + 'f' for f in C99_FUNCS]
208 C99_FUNCS_EXTENDED = [f + 'l' for f in C99_FUNCS]
209 C99_COMPLEX_TYPES = [
210 'complex double', 'complex float', 'complex long double'
211 ]
212 C99_COMPLEX_FUNCS = [
213 "cabs", "cacos", "cacosh", "carg", "casin", "casinh", "catan",
214 "catanh", "ccos", "ccosh", "cexp", "cimag", "clog", "conj", "cpow",
215 "cproj", "creal", "csin", "csinh", "csqrt", "ctan", "ctanh"
216 ]
217
218 def fname2def(name):
219 return "HAVE_%s" % name.upper()
220
221 def sym2def(symbol):
222 define = symbol.replace(' ', '')
223 return define.upper()
224
225 def type2def(symbol):
226 define = symbol.replace(' ', '_')
227 return define.upper()
228
229 # Code to detect long double representation taken from MPFR m4 macro
230 def check_long_double_representation(cmd):
231 cmd._check_compiler()
232 body = LONG_DOUBLE_REPRESENTATION_SRC % {'type': 'long double'}
233
234 # Disable whole program optimization (the default on vs2015, with python 3.5+)
235 # which generates intermediary object files and prevents checking the
236 # float representation.
237 if sys.platform == "win32" and not mingw32():
238 try:
239 cmd.compiler.compile_options.remove("/GL")
240 except (AttributeError, ValueError):
241 pass
242
243 # Disable multi-file interprocedural optimization in the Intel compiler on Linux
244 # which generates intermediary object files and prevents checking the
245 # float representation.
246 elif (sys.platform != "win32"
247 and cmd.compiler.compiler_type.startswith('intel')
248 and '-ipo' in cmd.compiler.cc_exe):
249 newcompiler = cmd.compiler.cc_exe.replace(' -ipo', '')
250 cmd.compiler.set_executables(
251 compiler=newcompiler,
252 compiler_so=newcompiler,
253 compiler_cxx=newcompiler,
254 linker_exe=newcompiler,
255 linker_so=newcompiler + ' -shared'
256 )
257
258 # We need to use _compile because we need the object filename
259 src, obj = cmd._compile(body, None, None, 'c')
260 try:
261 ltype = long_double_representation(pyod(obj))
262 return ltype
263 except ValueError:
264 # try linking to support CC="gcc -flto" or icc -ipo
265 # struct needs to be volatile so it isn't optimized away
266 body = body.replace('struct', 'volatile struct')
267 body += "int main(void) { return 0; }\n"
268 src, obj = cmd._compile(body, None, None, 'c')
269 cmd.temp_files.append("_configtest")
270 cmd.compiler.link_executable([obj], "_configtest")
271 ltype = long_double_representation(pyod("_configtest"))
272 return ltype
273 finally:
274 cmd._clean()
275
276 LONG_DOUBLE_REPRESENTATION_SRC = r"""
277 /* "before" is 16 bytes to ensure there's no padding between it and "x".
278 * We're not expecting any "long double" bigger than 16 bytes or with
279 * alignment requirements stricter than 16 bytes. */
280 typedef %(type)s test_type;
281
282 struct {
283 char before[16];
284 test_type x;
285 char after[8];
286 } foo = {
287 { '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0',
288 '\001', '\043', '\105', '\147', '\211', '\253', '\315', '\357' },
289 -123456789.0,
290 { '\376', '\334', '\272', '\230', '\166', '\124', '\062', '\020' }
291 };
292 """
293
294 def pyod(filename):
295 """Python implementation of the od UNIX utility (od -b, more exactly).
296
297 Parameters
298 ----------
299 filename : str
300 name of the file to get the dump from.
301
302 Returns
303 -------
304 out : seq
305 list of lines of od output
306
307 Note
308 ----
309 We only implement enough to get the necessary information for long double
310 representation, this is not intended as a compatible replacement for od.
311 """
312 def _pyod2():
313 out = []
314
315 with open(filename, 'rb') as fid:
316 yo = [int(oct(int(binascii.b2a_hex(o), 16))) for o in fid.read()]
317 for i in range(0, len(yo), 16):
318 line = ['%07d' % int(oct(i))]
319 line.extend(['%03d' % c for c in yo[i:i+16]])
320 out.append(" ".join(line))
321 return out
322
323 def _pyod3():
324 out = []
325
326 with open(filename, 'rb') as fid:
327 yo2 = [oct(o)[2:] for o in fid.read()]
328 for i in range(0, len(yo2), 16):
329 line = ['%07d' % int(oct(i)[2:])]
330 line.extend(['%03d' % int(c) for c in yo2[i:i+16]])
331 out.append(" ".join(line))
332 return out
333
334 if sys.version_info[0] < 3:
335 return _pyod2()
336 else:
337 return _pyod3()
338
339 _BEFORE_SEQ = ['000', '000', '000', '000', '000', '000', '000', '000',
340 '001', '043', '105', '147', '211', '253', '315', '357']
341 _AFTER_SEQ = ['376', '334', '272', '230', '166', '124', '062', '020']
342
343 _IEEE_DOUBLE_BE = ['301', '235', '157', '064', '124', '000', '000', '000']
344 _IEEE_DOUBLE_LE = _IEEE_DOUBLE_BE[::-1]
345 _INTEL_EXTENDED_12B = ['000', '000', '000', '000', '240', '242', '171', '353',
346 '031', '300', '000', '000']
347 _INTEL_EXTENDED_16B = ['000', '000', '000', '000', '240', '242', '171', '353',
348 '031', '300', '000', '000', '000', '000', '000', '000']
349 _MOTOROLA_EXTENDED_12B = ['300', '031', '000', '000', '353', '171',
350 '242', '240', '000', '000', '000', '000']
351 _IEEE_QUAD_PREC_BE = ['300', '031', '326', '363', '105', '100', '000', '000',
352 '000', '000', '000', '000', '000', '000', '000', '000']
353 _IEEE_QUAD_PREC_LE = _IEEE_QUAD_PREC_BE[::-1]
354 _IBM_DOUBLE_DOUBLE_BE = (['301', '235', '157', '064', '124', '000', '000', '000'] +
355 ['000'] * 8)
356 _IBM_DOUBLE_DOUBLE_LE = (['000', '000', '000', '124', '064', '157', '235', '301'] +
357 ['000'] * 8)
358
359 def long_double_representation(lines):
360 """Given a binary dump as given by GNU od -b, look for long double
361 representation."""
362
363 # Read contains a list of 32 items, each item is a byte (in octal
364 # representation, as a string). We 'slide' over the output until read is of
365 # the form before_seq + content + after_sequence, where content is the long double
366 # representation:
367 # - content is 12 bytes: 80 bits Intel representation
368 # - content is 16 bytes: 80 bits Intel representation (64 bits) or quad precision
369 # - content is 8 bytes: same as double (not implemented yet)
370 read = [''] * 32
371 saw = None
372 for line in lines:
373 # we skip the first word, as od -b output an index at the beginning of
374 # each line
375 for w in line.split()[1:]:
376 read.pop(0)
377 read.append(w)
378
379 # If the end of read is equal to the after_sequence, read contains
380 # the long double
381 if read[-8:] == _AFTER_SEQ:
382 saw = copy.copy(read)
383 # if the content was 12 bytes, we only have 32 - 8 - 12 = 12
384 # "before" bytes. In other words the first 4 "before" bytes went
385 # past the sliding window.
386 if read[:12] == _BEFORE_SEQ[4:]:
387 if read[12:-8] == _INTEL_EXTENDED_12B:
388 return 'INTEL_EXTENDED_12_BYTES_LE'
389 if read[12:-8] == _MOTOROLA_EXTENDED_12B:
390 return 'MOTOROLA_EXTENDED_12_BYTES_BE'
391 # if the content was 16 bytes, we are left with 32-8-16 = 16
392 # "before" bytes, so 8 went past the sliding window.
393 elif read[:8] == _BEFORE_SEQ[8:]:
394 if read[8:-8] == _INTEL_EXTENDED_16B:
395 return 'INTEL_EXTENDED_16_BYTES_LE'
396 elif read[8:-8] == _IEEE_QUAD_PREC_BE:
397 return 'IEEE_QUAD_BE'
398 elif read[8:-8] == _IEEE_QUAD_PREC_LE:
399 return 'IEEE_QUAD_LE'
400 elif read[8:-8] == _IBM_DOUBLE_DOUBLE_LE:
401 return 'IBM_DOUBLE_DOUBLE_LE'
402 elif read[8:-8] == _IBM_DOUBLE_DOUBLE_BE:
403 return 'IBM_DOUBLE_DOUBLE_BE'
404 # if the content was 8 bytes, left with 32-8-8 = 16 bytes
405 elif read[:16] == _BEFORE_SEQ:
406 if read[16:-8] == _IEEE_DOUBLE_LE:
407 return 'IEEE_DOUBLE_LE'
408 elif read[16:-8] == _IEEE_DOUBLE_BE:
409 return 'IEEE_DOUBLE_BE'
410
411 if saw is not None:
412 raise ValueError("Unrecognized format (%s)" % saw)
413 else:
414 # We never detected the after_sequence
415 raise ValueError("Could not lock sequences (%s)" % saw)
416
[end of numpy/core/setup_common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
|
numpy/numpy
|
ab87388a76c0afca4eb1159ab0ed232d502a8378
|
NumPy 1.17 RC fails to compile with Intel C Compile 2016
<!-- Please describe the issue in detail here, and fill in the fields below -->
Compiling NumPy 1.17.0rc2 sources with Intel C Compiler 2016, which does not yet implement `__builtin_cpu_supports("avx512f")` fails with compilation error:
```
icc: numpy/core/src/umath/cpuid.c
numpy/core/src/umath/cpuid.c(63): catastrophic error: invalid use of '__builtin_cpu_supports'
compilation aborted for numpy/core/src/umath/cpuid.c (code 1)
```
Recent Intel C compiler (2019) proceeds just fine.
There is config test to probe compiler for support of `__builtin_cpu_supports`, but the the test does not discriminate between supported arguments.
|
@mattip This is the issue with 1.17 sources and older compiler that I mentioned at the sprint.
To reproduce I did:
1. `conda create -n b_np117 -c defaults --override-channels python setuptools cython pip pytest mkl-devel`
2. `git clone http://github.com/numpy/numpy.git --branch maintenance/1.17.x numpy_src`
3. `conda activate b_np117`
4. Edit `site.cfg`. So that
```
(b_np117) [16:15:03 vmlin numpy_src_tmp]$ cat site.cfg
[mkl]
library_dirs = /tmp/miniconda/envs/b_np117/lib
include_dirs = /tmp/miniconda/envs/b_np117/include
lapack_libs = mkl_rt
mkl_libs = mkl_rt
```
5. Check compiler version:
```
(b_np117) [17:02:25 vmlin numpy_src_tmp]$ icc --version
icc (ICC) 16.0.3 20160415
Copyright (C) 1985-2016 Intel Corporation. All rights reserved.
```
6. Execute `CFLAGS="-DNDEBUG -I$PREFIX/include $CFLAGS" python setup.py config_cc --compiler=intelem config_fc --fcompiler=intelem build --force build_ext --inplace`
It seems we need someone with that compiler to test and fix this.
I definitely volunteer for testing and fixing it, but I would appreciate some guidance as what to try tweaking and where.
Pinging @r-devulap, maybe you can have a look/know something? It seems he wrote (or modified it and is also at Intel – albeit a very different part).
@oleksandr-pavlyk could you try this fix from my branch https://github.com/r-devulap/numpy/tree/avx512-cpuid and let me know if that fixes your problem. If it does, I can submit a PR.
never mind, created a PR with a simpler fix.
|
2019-07-21T14:28:45Z
|
<patch>
diff --git a/numpy/core/setup_common.py b/numpy/core/setup_common.py
--- a/numpy/core/setup_common.py
+++ b/numpy/core/setup_common.py
@@ -138,6 +138,8 @@ def check_api_version(apiversion, codegen_dir):
# broken on OSX 10.11, make sure its not optimized away
("volatile int r = __builtin_cpu_supports", '"sse"',
"stdio.h", "__BUILTIN_CPU_SUPPORTS"),
+ ("volatile int r = __builtin_cpu_supports", '"avx512f"',
+ "stdio.h", "__BUILTIN_CPU_SUPPORTS_AVX512F"),
# MMX only needed for icc, but some clangs don't have it
("_m_from_int64", '0', "emmintrin.h"),
("_mm_load_ps", '(float*)0', "xmmintrin.h"), # SSE
</patch>
|
[]
|
[]
|
Subsets and Splits
Filtered Test Data by Commit
Retrieves a limited number of records from the 'test' dataset where the 'base_commit' starts with '1018f9f', providing basic filtering but minimal insight.