
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.1B
| node_id
stringlengths 18
32
| number
int64 1
3.54k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
int64 1,587B
1,642B
| updated_at
int64 1,587B
1,642B
| closed_at
int64 1,587B
1,641B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3442/comments | https://api.github.com/repos/huggingface/datasets/issues/3442/events | https://github.com/huggingface/datasets/pull/3442 | 1,081,862,747 | PR_kwDODunzps4v7oBZ | 3,442 | Extend text to support yielding lines, paragraphs or documents | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The parameter can also be named `split_by` with values \"line\", \"paragraph\" or \"document\" (no 's' at the end)",
"> The parameter can also be named `split_by` with values \"line\", \"paragraph\" or \"document\" (no 's' at the end)\r\n\r\n@lhoestq @mariosasko I would avoid the term `split` in this context and keep it only for \"train\", \"validation\" and \"test\" splits.\r\n- https://huggingface.co/docs/datasets/process.html#split\r\n > datasets.Dataset.train_test_split() creates train and test splits, if your dataset doesn’t already have them.\r\n- https://huggingface.co/docs/datasets/process.html#process-multiple-splits\r\n > Many datasets have splits that you can process simultaneously with datasets.DatasetDict.map().\r\n\r\nPlease note that in the documentation, one of the terms more frequently used in this context is **\"row\"**:\r\n- https://huggingface.co/docs/datasets/access.html#features-and-columns\r\n > A dataset is a table of rows and typed columns.\r\n\r\n > Return the number of rows and columns with the following standard attributes:\r\n > dataset.num_columns\r\n > 4\r\n > dataset.num_rows\r\n > 3668\r\n\r\n- https://huggingface.co/docs/datasets/access.html#rows-slices-batches-and-columns\r\n > Get several rows of your dataset at a time with slice notation or a list of indices:\r\n- https://huggingface.co/docs/datasets/process.html#map\r\n > This function can even create new rows and columns.\r\n\r\nOther of the terms more frequently used in the docs (in the code as well) is **\"example\"**:\r\n- https://huggingface.co/docs/datasets/process.html#map\r\n > It allows you to apply a processing function to each example in a dataset, independently or in batches.\r\n- https://huggingface.co/docs/datasets/process.html#batch-processing\r\n > datasets.Dataset.map() also supports working with batches of examples.\r\n- https://huggingface.co/docs/datasets/process.html#split-long-examples\r\n > When your examples are too long, you may want to split them\r\n- https://huggingface.co/docs/datasets/process.html#data-augmentation\r\n > With batch processing, you can even augment your dataset with additional examples.\r\n\r\nLess frequently used: **\"item\"**:\r\n- https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.add_item\r\n > Add item to Dataset.\r\n\r\nOther term used in the docs (although less frequently) is **\"sample\"**. The advantage of this word is that it is also a verb, so we can use the parameter: \"sample_by\" (if you insist on using a verb instead of a noun).\r\n\r\nIn summary, these proposals:\r\n- config.row\r\n- config.example\r\n- config.item\r\n- config.sample\r\n- config.sample_by",
"I like `sample_by`. Another idea I had was `separate_by`.\r\n\r\nIt could also be `sampling`, `sampling_method`, `separation_method`.\r\n\r\nNot a big fan of the proposed nouns alone since they are very generic, that's why I tried to have something more specific.\r\n\r\nI also agree that we actually should avoid `split` to avoid any confusion",
"Thanks for the analysis of the used terms. I also like `sample_by` (`separate_by` is good too).",
"Thank you !! :D "
] | 1,639,639,997,000 | 1,640,019,550,000 | 1,640,018,358,000 | MEMBER | null | Add `config.row` option to `text` module to allow yielding lines (default, current case), paragraphs or documents.
Feel free to comment on the name of the config parameter `row`:
- Currently, the docs state datasets are made of rows and columns
- Other names I considered: `example`, `item` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3442/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3442",
"html_url": "https://github.com/huggingface/datasets/pull/3442",
"diff_url": "https://github.com/huggingface/datasets/pull/3442.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3442.patch",
"merged_at": 1640018358000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3441/comments | https://api.github.com/repos/huggingface/datasets/issues/3441/events | https://github.com/huggingface/datasets/issues/3441 | 1,081,571,784 | I_kwDODunzps5Ad3nI | 3,441 | Add QuALITY dataset | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"I'll take this one if no one hasn't yet!"
] | 1,639,607,179,000 | 1,640,704,625,000 | null | MEMBER | null | ## Adding a Dataset
- **Name:** QuALITY
- **Description:** A challenging question answering with very long contexts (Twitter [thread](https://twitter.com/sleepinyourhat/status/1471225421794529281?s=20))
- **Paper:** No ArXiv link yet, but draft is [here](https://github.com/nyu-mll/quality/blob/main/quality_preprint.pdf)
- **Data:** GitHub repo [here](https://github.com/nyu-mll/quality)
- **Motivation:** This dataset would serve as a nice way to benchmark long-range Transformer models like BigBird, Longformer and their descendants. In particular, it would be very interesting to see how the S4 model fares on this given it's impressive performance on the Long Range Arena
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3441/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3441/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3440/comments | https://api.github.com/repos/huggingface/datasets/issues/3440/events | https://github.com/huggingface/datasets/issues/3440 | 1,081,528,426 | I_kwDODunzps5AdtBq | 3,440 | datasets keeps reading from cached files, although I disabled it | {
"login": "dorost1234",
"id": 79165106,
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorost1234",
"html_url": "https://github.com/dorost1234",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! What version of `datasets` are you using ? Can you also provide the logs you get before it raises the error ?"
] | 1,639,603,582,000 | 1,639,668,747,000 | null | NONE | null | ## Describe the bug
Hi,
I am trying to avoid dataset library using cached files, I get the following bug when this tried to read the cached files. I tried to do the followings:
```
from datasets import set_caching_enabled
set_caching_enabled(False)
```
also force redownlaod:
```
download_mode='force_redownload'
```
but none worked so far, this is on a cluster and on some of the machines this reads from the cached files, I really appreciate any idea on how to fully remove caching @lhoestq
many thanks
```
File "run_clm.py", line 496, in <module>
main()
File "run_clm.py", line 419, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 943, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/transformers/trainer.py", line 1445, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 172, in evaluate
output = self.eval_loop(
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 241, in eval_loop
metrics = self.compute_pet_metrics(eval_datasets, model, self.extra_info[metric_key_prefix], task=task)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 268, in compute_pet_metrics
centroids = self._compute_per_token_train_centroids(model, task=task)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 353, in _compute_per_token_train_centroids
data = get_label_samples(self.get_per_task_train_dataset(task), label)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 350, in get_label_samples
return dataset.filter(lambda example: int(example['labels']) == label)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 470, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/fingerprint.py", line 406, in wrapper
out = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2519, in filter
indices = self.map(
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2036, in map
return self._map_single(
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 503, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 470, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/fingerprint.py", line 406, in wrapper
out = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2248, in _map_single
return Dataset.from_file(cache_file_name, info=info, split=self.split)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 654, in from_file
return cls(
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 593, in __init__
self.info.features = self.info.features.reorder_fields_as(inferred_features)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/features/features.py", line 1092, in reorder_fields_as
return Features(recursive_reorder(self, other))
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/features/features.py", line 1081, in recursive_reorder
raise ValueError(f"Keys mismatch: between {source} and {target}" + stack_position)
ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'candidates_ids': Sequence(feature=Value(dtype='null', id=None), length=-1, id=None), 'labels': Value(dtype='int64', id=None), 'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None), 'input_ids': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None), 'extra_fields': {}, 'task': Value(dtype='string', id=None)}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: linux
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3440/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3440/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3439/comments | https://api.github.com/repos/huggingface/datasets/issues/3439/events | https://github.com/huggingface/datasets/pull/3439 | 1,081,389,723 | PR_kwDODunzps4v6Hxs | 3,439 | Add `cast_column` to `IterableDataset` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Awesome thanks a lot @mariosasko "
] | 1,639,594,845,000 | 1,639,670,120,000 | 1,639,670,119,000 | CONTRIBUTOR | null | Closes #3369.
cc: @patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3439/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3439/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3439",
"html_url": "https://github.com/huggingface/datasets/pull/3439",
"diff_url": "https://github.com/huggingface/datasets/pull/3439.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3439.patch",
"merged_at": 1639670119000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3438 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3438/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3438/comments | https://api.github.com/repos/huggingface/datasets/issues/3438/events | https://github.com/huggingface/datasets/pull/3438 | 1,081,302,203 | PR_kwDODunzps4v52Va | 3,438 | Update supported versions of Python in setup.py | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,589,412,000 | 1,640,010,133,000 | 1,640,010,132,000 | CONTRIBUTOR | null | Update the list of supported versions of Python in `setup.py` to keep the PyPI project description updated. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3438/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3438",
"html_url": "https://github.com/huggingface/datasets/pull/3438",
"diff_url": "https://github.com/huggingface/datasets/pull/3438.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3438.patch",
"merged_at": 1640010132000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3437/comments | https://api.github.com/repos/huggingface/datasets/issues/3437/events | https://github.com/huggingface/datasets/pull/3437 | 1,081,247,889 | PR_kwDODunzps4v5qzI | 3,437 | Update BLEURT hyperlink | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"seems like a very very low-prio improvement :)",
"@albertvillanova thanks for the feedback! I removed the formatting altogether since I think this is a bit simpler tor read than non-rendered Markdown"
] | 1,639,586,087,000 | 1,639,747,706,000 | 1,639,747,705,000 | MEMBER | null | The description of BLEURT on the hf.co website has a strange use of URL hyperlinking. This PR attempts to fix this, although I am not 100% sure Markdown syntax is allowed on the frontend or not.

| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3437/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3437/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3437",
"html_url": "https://github.com/huggingface/datasets/pull/3437",
"diff_url": "https://github.com/huggingface/datasets/pull/3437.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3437.patch",
"merged_at": 1639747705000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3436 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3436/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3436/comments | https://api.github.com/repos/huggingface/datasets/issues/3436/events | https://github.com/huggingface/datasets/pull/3436 | 1,081,068,139 | PR_kwDODunzps4v5FE3 | 3,436 | Add the OneStopQa dataset | {
"login": "scaperex",
"id": 28459495,
"node_id": "MDQ6VXNlcjI4NDU5NDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/28459495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/scaperex",
"html_url": "https://github.com/scaperex",
"followers_url": "https://api.github.com/users/scaperex/followers",
"following_url": "https://api.github.com/users/scaperex/following{/other_user}",
"gists_url": "https://api.github.com/users/scaperex/gists{/gist_id}",
"starred_url": "https://api.github.com/users/scaperex/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/scaperex/subscriptions",
"organizations_url": "https://api.github.com/users/scaperex/orgs",
"repos_url": "https://api.github.com/users/scaperex/repos",
"events_url": "https://api.github.com/users/scaperex/events{/privacy}",
"received_events_url": "https://api.github.com/users/scaperex/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,576,411,000 | 1,639,751,520,000 | 1,639,747,529,000 | CONTRIBUTOR | null | Adding OneStopQA, a multiple choice reading comprehension dataset annotated according to the STARC (Structured Annotations for Reading Comprehension) scheme. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3436/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3436/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3436",
"html_url": "https://github.com/huggingface/datasets/pull/3436",
"diff_url": "https://github.com/huggingface/datasets/pull/3436.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3436.patch",
"merged_at": 1639747529000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3435 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3435/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3435/comments | https://api.github.com/repos/huggingface/datasets/issues/3435/events | https://github.com/huggingface/datasets/pull/3435 | 1,081,043,756 | PR_kwDODunzps4v4_-0 | 3,435 | Improve Wikipedia Loading Script | {
"login": "geohci",
"id": 45494522,
"node_id": "MDQ6VXNlcjQ1NDk0NTIy",
"avatar_url": "https://avatars.githubusercontent.com/u/45494522?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/geohci",
"html_url": "https://github.com/geohci",
"followers_url": "https://api.github.com/users/geohci/followers",
"following_url": "https://api.github.com/users/geohci/following{/other_user}",
"gists_url": "https://api.github.com/users/geohci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/geohci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/geohci/subscriptions",
"organizations_url": "https://api.github.com/users/geohci/orgs",
"repos_url": "https://api.github.com/users/geohci/repos",
"events_url": "https://api.github.com/users/geohci/events{/privacy}",
"received_events_url": "https://api.github.com/users/geohci/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"I wanted to flag a change from since we discussed this: I initially wrote a function for using the Wikimedia APIs to collect namespace aliases, but decided that adding in more http requests to the script wasn't a great idea so instead used that code to build a static list that I just added directly to the code.\r\n\r\nAlso, an FYI that python library dependencies weren't working on my local end so I wasn't able to directly test the code. I tested a copy with the problematic elements stripped (beam etc.) that worked fine, but someone with a working local copy may want to test just to make sure I didn't accidentally break anything.",
"Also, while I would argue more strongly for some of the changes in this code, they are five distinct changes so not so hard to remove one or two if other folks think they aren't worth the overhead etc."
] | 1,639,575,006,000 | 1,639,575,420,000 | null | NONE | null | * More structured approach to detecting redirects
* Remove redundant template filter code (covered by strip_code)
* Add language-specific lists of additional media namespace aliases for filtering
* Add language-specific lists of category namespace aliases for new link text cleaning step
* Remove magic words (parser directions like __TOC__ that occasionally occur in text)
Fix #3400
With support from @albertvillanova
CC @yjernite | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3435/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3435",
"html_url": "https://github.com/huggingface/datasets/pull/3435",
"diff_url": "https://github.com/huggingface/datasets/pull/3435.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3435.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3434/comments | https://api.github.com/repos/huggingface/datasets/issues/3434/events | https://github.com/huggingface/datasets/issues/3434 | 1,080,917,446 | I_kwDODunzps5AbX3G | 3,434 | Add The People's Speech | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech",
"name": "speech",
"color": "d93f0b",
"default": false,
"description": ""
}
] | open | false | null | [] | null | [] | 1,639,567,281,000 | 1,639,567,281,000 | null | CONTRIBUTOR | null | ## Adding a Dataset
- **Name:** The People's Speech
- **Description:** a massive English-language dataset of audio transcriptions of full sentences.
- **Paper:** https://openreview.net/pdf?id=R8CwidgJ0yT
- **Data:** https://mlcommons.org/en/peoples-speech/
- **Motivation:** With over 30,000 hours of speech, this dataset is the largest and most diverse freely available English speech recognition corpus today.
[The article](https://thegradient.pub/new-datasets-to-democratize-speech-recognition-technology-2/) which may be useful when working on the dataset.
cc: @anton-l
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3434/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3434/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3433/comments | https://api.github.com/repos/huggingface/datasets/issues/3433/events | https://github.com/huggingface/datasets/issues/3433 | 1,080,910,724 | I_kwDODunzps5AbWOE | 3,433 | Add Multilingual Spoken Words dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech",
"name": "speech",
"color": "d93f0b",
"default": false,
"description": ""
}
] | open | false | null | [] | null | [] | 1,639,566,884,000 | 1,639,566,884,000 | null | MEMBER | null | ## Adding a Dataset
- **Name:** Multilingual Spoken Words
- **Description:** Multilingual Spoken Words Corpus is a large and growing audio dataset of spoken words in 50 languages for academic research and commercial applications in keyword spotting and spoken term search, licensed under CC-BY 4.0. The dataset contains more than 340,000 keywords, totaling 23.4 million 1-second spoken examples (over 6,000 hours).
Read more: https://mlcommons.org/en/news/spoken-words-blog/
- **Paper:** https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/fe131d7f5a6b38b23cc967316c13dae2-Paper-round2.pdf
- **Data:** https://mlcommons.org/en/multilingual-spoken-words/
- **Motivation:**
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3433/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3433/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3432 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3432/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3432/comments | https://api.github.com/repos/huggingface/datasets/issues/3432/events | https://github.com/huggingface/datasets/pull/3432 | 1,079,910,769 | PR_kwDODunzps4v1NGS | 3,432 | Correctly indent builder config in dataset script docs | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,496,387,000 | 1,639,503,317,000 | 1,639,503,317,000 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3432/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3432/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3432",
"html_url": "https://github.com/huggingface/datasets/pull/3432",
"diff_url": "https://github.com/huggingface/datasets/pull/3432.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3432.patch",
"merged_at": 1639503317000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3431/comments | https://api.github.com/repos/huggingface/datasets/issues/3431/events | https://github.com/huggingface/datasets/issues/3431 | 1,079,866,083 | I_kwDODunzps5AXXLj | 3,431 | Unable to resolve any data file after loading once | {
"login": "Fischer-love-fish",
"id": 84694183,
"node_id": "MDQ6VXNlcjg0Njk0MTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/84694183?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Fischer-love-fish",
"html_url": "https://github.com/Fischer-love-fish",
"followers_url": "https://api.github.com/users/Fischer-love-fish/followers",
"following_url": "https://api.github.com/users/Fischer-love-fish/following{/other_user}",
"gists_url": "https://api.github.com/users/Fischer-love-fish/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Fischer-love-fish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Fischer-love-fish/subscriptions",
"organizations_url": "https://api.github.com/users/Fischer-love-fish/orgs",
"repos_url": "https://api.github.com/users/Fischer-love-fish/repos",
"events_url": "https://api.github.com/users/Fischer-love-fish/events{/privacy}",
"received_events_url": "https://api.github.com/users/Fischer-love-fish/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi ! `load_dataset` accepts as input either a local dataset directory or a dataset name from the Hugging Face Hub.\r\n\r\nSo here you are getting this error the second time because it tries to load the local `wiki_dpr` directory, instead of `wiki_dpr` from the Hub. It doesn't work since it's a **cache** directory, not a **dataset** directory in itself.\r\n\r\nTo fix that you can use another cache directory like `cache_dir=\"/data2/whr/lzy/open_domain_data/retrieval/cache\"`",
"thx a lot"
] | 1,639,494,135,000 | 1,640,084,526,000 | null | NONE | null | when I rerun my program, it occurs this error
" Unable to resolve any data file that matches '['**train*']' at /data2/whr/lzy/open_domain_data/retrieval/wiki_dpr with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'zip']", so how could i deal with this problem?
thx.
And below is my code .

| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3431/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3431/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3430/comments | https://api.github.com/repos/huggingface/datasets/issues/3430/events | https://github.com/huggingface/datasets/pull/3430 | 1,079,811,124 | PR_kwDODunzps4v033w | 3,430 | Make decoding of Audio and Image feature optional | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Closing this PR for now due to https://github.com/huggingface/datasets/issues/3145#issuecomment-993664104.",
"Okay, after some more thinking, I'm re-opening this PR for three reasons:\r\n* This feature will allow us to remove the `image_file_path`/`audio_file_path` columns in our vision/audio datasets. Currently, it makes sense to keep those columns because it's not obvious how to access the underlying path information of the Image/Audio feature. However, if the user is not aware and does `dataset[0][\"image_file_path\"]` on our vision/audio datasets, this will be costly because the image/audio file data has to be decoded first (stored in `dataset[0][\"image\"]`/`dataset[0][\"audio\"]`)\r\n* In CV, we often work with the so-called \"half life\" datasets (RedCaps, WIT, ...) that only provide image URLs and not actual image data, and some of these image URLs even go down. Our solution to this problem is to give a note on how to efficiently download the image data using `map` in the datasets cards of such datasets. This feature will remove the need for a separate `image_url` column of type `Value(\"string\")` in such datasets. Instead, we will be able to use the `image` column of type `Image()` (the image feature knows how to decode image URLs using `xopen`), disable decoding and use `requests.get` for download, which I expect to be faster than `xopen`.\r\n* This feature should help us in implementing `push_to_hub` for the Image/Audio where we transfer actual image/audio data and not paths",
"> This feature will allow us to remove the image_file_path/audio_file_path columns in our vision/audio datasets. Currently, it makes sense to keep those columns because it's not obvious how to access the underlying path information of the Image/Audio feature. However, if the user is not aware and does dataset[0][\"image_file_path\"] on our vision/audio datasets, this will be costly because the image/audio file data has to be decoded first (stored in dataset[0][\"image\"]/dataset[0][\"audio\"])\r\n\r\nThat makes sense !\r\n\r\n> Instead, we will be able to use the image column of type Image() (the image feature knows how to decode image URLs using xopen), disable decoding and use requests.get for download, which I expect to be faster than xopen.\r\n\r\nI feel like it's a bit convoluted compared to having the `image_url` column as string, and say to users to `map` using `requests.get` with `image_url`.\r\n\r\nMoreover I'm not 100% sure that we should have `Image` features with both local paths and URLs, since this behavior is a bit hidden the users and they don't give the same performance at all.\r\n\r\n> This feature should help us in implementing push_to_hub for the Image/Audio where we transfer actual image/audio data and not paths\r\n\r\nCool !",
"Thanks, @lhoestq.\r\n\r\n> I feel like it's a bit convoluted compared to having the image_url column as string, and say to users to map using requests.get with image_url.\r\n\r\nYes, that makes sense. \r\n\r\n>Moreover I'm not 100% sure that we should have Image features with both local paths and URLs, since this behavior is a bit hidden the users and they don't give the same performance at all.\r\n\r\nDo you mean we should remove support for URLs in the Image feature? Because this is what we get for free by adding support for streaming (by using `xopen` instead of `open`) and this is also what the Audio feature does.",
"> Do you mean we should remove support for URLs in the Image feature? Because this is what we get for free by adding support for streaming (by using xopen instead of open) and this is also what the Audio feature does.\r\n\r\nI think it might not be ideal to have URLs in an `Image` type column for a dataset in **non-streaming** mode, since you'd expect to have everything locally. But for a streaming dataset it must use `xopen` indeed",
"Yes, I agree. Let's have the `image_url` columns as `Value(\"string\")` + a note with the map function to download images for local datasets and a note with `cast_column` (which is requested in https://github.com/huggingface/datasets/issues/3369) for streamed datasets (`ds.cast_column(\"image_url\", Image())`)."
] | 1,639,491,308,000 | 1,639,589,074,000 | null | CONTRIBUTOR | null | Add the `decode` argument (`True` by default) to the `Audio` and the `Image` feature to make it possible to toggle on/off decoding of these features.
Even though we've discussed that on Slack, I'm not removing the `_storage_dtype` argument of the Audio feature in this PR to avoid breaking the Audio feature tests. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3430/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3430/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3430",
"html_url": "https://github.com/huggingface/datasets/pull/3430",
"diff_url": "https://github.com/huggingface/datasets/pull/3430.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3430.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3429/comments | https://api.github.com/repos/huggingface/datasets/issues/3429/events | https://github.com/huggingface/datasets/pull/3429 | 1,078,902,390 | PR_kwDODunzps4vx1gp | 3,429 | Make cast cacheable (again) on Windows | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,423,922,000 | 1,639,492,791,000 | 1,639,492,790,000 | CONTRIBUTOR | null | `cast` currently emits the following warning when called on Windows:
```
Parameter 'function'=<function Dataset.cast.<locals>.<lambda> at 0x000001C930571EA0> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting
and caching to work. If you reuse this transform, the caching mechanism will consider it to be different
from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
```
It seems like the issue stems from the `config.PYARROW_VERSION` object not being serializable on Windows (tested with `dumps(lambda: config.PYARROW_VERSION)`), so I'm fixing this by capturing `config.PYARROW_VERSION.major` before the lambda definition. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3429/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3429/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3429",
"html_url": "https://github.com/huggingface/datasets/pull/3429",
"diff_url": "https://github.com/huggingface/datasets/pull/3429.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3429.patch",
"merged_at": 1639492790000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3428/comments | https://api.github.com/repos/huggingface/datasets/issues/3428/events | https://github.com/huggingface/datasets/pull/3428 | 1,078,863,468 | PR_kwDODunzps4vxtNT | 3,428 | Clean squad dummy data | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,421,189,000 | 1,639,421,870,000 | 1,639,421,870,000 | MEMBER | null | Some unused files were remaining, this PR removes them. We just need to keep the dummy_data.zip file | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3428/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3428",
"html_url": "https://github.com/huggingface/datasets/pull/3428",
"diff_url": "https://github.com/huggingface/datasets/pull/3428.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3428.patch",
"merged_at": 1639421870000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3427 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3427/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3427/comments | https://api.github.com/repos/huggingface/datasets/issues/3427/events | https://github.com/huggingface/datasets/pull/3427 | 1,078,782,159 | PR_kwDODunzps4vxb_y | 3,427 | Add The Pile Enron Emails subset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,415,656,000 | 1,639,503,059,000 | 1,639,503,057,000 | MEMBER | null | Add:
- Enron Emails subset of The Pile: "enron_emails" config
Close bigscience-workshop/data_tooling#310.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3427/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3427/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3427",
"html_url": "https://github.com/huggingface/datasets/pull/3427",
"diff_url": "https://github.com/huggingface/datasets/pull/3427.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3427.patch",
"merged_at": 1639503055000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3426/comments | https://api.github.com/repos/huggingface/datasets/issues/3426/events | https://github.com/huggingface/datasets/pull/3426 | 1,078,670,031 | PR_kwDODunzps4vxEN5 | 3,426 | Update disaster_response_messages download urls (+ add validation split) | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,409,412,000 | 1,639,492,710,000 | 1,639,492,709,000 | CONTRIBUTOR | null | Fixes #3240, fixes #3416 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3426/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3426/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3426",
"html_url": "https://github.com/huggingface/datasets/pull/3426",
"diff_url": "https://github.com/huggingface/datasets/pull/3426.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3426.patch",
"merged_at": 1639492709000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3425/comments | https://api.github.com/repos/huggingface/datasets/issues/3425/events | https://github.com/huggingface/datasets/issues/3425 | 1,078,598,140 | I_kwDODunzps5AShn8 | 3,425 | Getting configs names takes too long | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"maybe related to https://github.com/huggingface/datasets/issues/2859\r\n",
"It looks like it's currently calling `HfFileSystem.ls()` ~8 times at the root and for each subdirectory:\r\n- \"\"\r\n- \"en.noblocklist\"\r\n- \"en.noclean\"\r\n- \"en\"\r\n- \"multilingual\"\r\n- \"realnewslike\"\r\n\r\nCurrently `ls` is slow because it iterates on all the files inside the repository.\r\n\r\nAn easy optimization would be to cache the result of each call to `ls`.\r\nWe can also optimize `ls` by using a tree structure per directory instead of a list of all the files.\r\n",
"ok\r\n"
] | 1,639,405,677,000 | 1,639,407,213,000 | null | CONTRIBUTOR | null |
## Steps to reproduce the bug
```python
from datasets import get_dataset_config_names
get_dataset_config_names("allenai/c4")
```
## Expected results
I would expect to get the answer quickly, at least in less than 10s
## Actual results
It takes about 45s on my environment
## Environment info
- `datasets` version: 1.16.1
- Platform: Linux-5.11.0-1022-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 4.0.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3425/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3424/comments | https://api.github.com/repos/huggingface/datasets/issues/3424/events | https://github.com/huggingface/datasets/pull/3424 | 1,078,543,625 | PR_kwDODunzps4vwpNt | 3,424 | Add RedCaps dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Cool ! If you want you can include `dataset_infos.json` but only for the main configurations. That's what we do for example for translation datasets when there are too many configs"
] | 1,639,402,693,000 | 1,641,392,539,000 | null | CONTRIBUTOR | null | Add the RedCaps dataset. I'm not adding the generated `dataset_infos.json` file for now due to its size (11 MB).
TODOs:
- [x] dummy data
- [x] dataset card
Close #3316 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3424/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3424/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3424",
"html_url": "https://github.com/huggingface/datasets/pull/3424",
"diff_url": "https://github.com/huggingface/datasets/pull/3424.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3424.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3423/comments | https://api.github.com/repos/huggingface/datasets/issues/3423/events | https://github.com/huggingface/datasets/issues/3423 | 1,078,049,638 | I_kwDODunzps5AQbtm | 3,423 | data duplicate when setting num_works > 1 with streaming data | {
"login": "cloudyuyuyu",
"id": 16486492,
"node_id": "MDQ6VXNlcjE2NDg2NDky",
"avatar_url": "https://avatars.githubusercontent.com/u/16486492?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cloudyuyuyu",
"html_url": "https://github.com/cloudyuyuyu",
"followers_url": "https://api.github.com/users/cloudyuyuyu/followers",
"following_url": "https://api.github.com/users/cloudyuyuyu/following{/other_user}",
"gists_url": "https://api.github.com/users/cloudyuyuyu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cloudyuyuyu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cloudyuyuyu/subscriptions",
"organizations_url": "https://api.github.com/users/cloudyuyuyu/orgs",
"repos_url": "https://api.github.com/users/cloudyuyuyu/repos",
"events_url": "https://api.github.com/users/cloudyuyuyu/events{/privacy}",
"received_events_url": "https://api.github.com/users/cloudyuyuyu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3287858981,
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming",
"name": "streaming",
"color": "fef2c0",
"default": false,
"description": ""
}
] | open | false | null | [] | null | [
"Hi ! Thanks for reporting :)\r\n\r\nWhen using a PyTorch's data loader with `num_workers>1` and an iterable dataset, each worker streams the exact same data by default, resulting in duplicate data when iterating using the data loader.\r\n\r\nWe can probably fix this in `datasets` by checking `torch.utils.data.get_worker_info()` which gives the worker id if it happens.",
"> Hi ! Thanks for reporting :)\r\n> \r\n> When using a PyTorch's data loader with `num_workers>1` and an iterable dataset, each worker streams the exact same data by default, resulting in duplicate data when iterating using the data loader.\r\n> \r\n> We can probably fix this in `datasets` by checking `torch.utils.data.get_worker_info()` which gives the worker id if it happens.\r\nHi ! Thanks for reply\r\n\r\nDo u have some plans to fix the problem?\r\n",
"Isn’t that somehow a bug on PyTorch side? (Just asking because this behavior seems quite general and maybe not what would be intended)",
"From PyTorch's documentation [here](https://pytorch.org/docs/stable/data.html#dataset-types):\r\n\r\n> When using an IterableDataset with multi-process data loading. The same dataset object is replicated on each worker process, and thus the replicas must be configured differently to avoid duplicated data. See [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) documentations for how to achieve this.\r\n\r\nIt looks like an intended behavior from PyTorch\r\n\r\nAs suggested in the [docstring of the IterableDataset class](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset), we could pass a `worker_init_fn` to the DataLoader to fix this. It could be called `streaming_worker_init_fn` for example.\r\n\r\nHowever, while this solution works, I'm worried that many users simply don't know about this parameter and just start their training with duplicate data without knowing it. That's why I'm more in favor of integrating the check on the worker id directly in `datasets` in our implementation of `IterableDataset.__iter__`."
] | 1,639,366,997,000 | 1,639,479,210,000 | null | NONE | null | ## Describe the bug
The data is repeated num_works times when we load_dataset with streaming and set num_works > 1 when construct dataloader
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import pandas as pd
import numpy as np
import os
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
import shutil
NUM_OF_USER = 1000000
NUM_OF_ACTION = 50000
NUM_OF_SEQUENCE = 10000
NUM_OF_FILES = 32
NUM_OF_WORKERS = 16
if __name__ == "__main__":
shutil.rmtree("./dataset")
for i in range(NUM_OF_FILES):
sequence_data = pd.DataFrame(
{
"imei": np.random.randint(1, NUM_OF_USER, size=NUM_OF_SEQUENCE),
"sequence": np.random.randint(1, NUM_OF_ACTION, size=NUM_OF_SEQUENCE)
}
)
if not os.path.exists("./dataset"):
os.makedirs("./dataset")
sequence_data.to_csv(f"./dataset/sequence_data_{i}.csv",
index=False)
dataset = load_dataset("csv",
data_files=[os.path.join("./dataset",file) for file in os.listdir("./dataset") if file.endswith(".csv")],
split="train",
streaming=True).with_format("torch")
data_loader = DataLoader(dataset,
batch_size=1024,
num_workers=NUM_OF_WORKERS)
result = pd.DataFrame()
for i, batch in tqdm(enumerate(data_loader)):
result = pd.concat([result,
pd.DataFrame(batch)],
axis=0)
result.to_csv(f"num_work_{NUM_OF_WORKERS}.csv", index=False)
```
## Expected results
data do not duplicate
## Actual results
data duplicate NUM_OF_WORKERS = 16

## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:datasets==1.14.0
- Platform:transformers==4.11.3
- Python version:3.8
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3423/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3423/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3422 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3422/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3422/comments | https://api.github.com/repos/huggingface/datasets/issues/3422/events | https://github.com/huggingface/datasets/issues/3422 | 1,078,022,619 | I_kwDODunzps5AQVHb | 3,422 | Error about load_metric | {
"login": "jiacheng-ye",
"id": 30772464,
"node_id": "MDQ6VXNlcjMwNzcyNDY0",
"avatar_url": "https://avatars.githubusercontent.com/u/30772464?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jiacheng-ye",
"html_url": "https://github.com/jiacheng-ye",
"followers_url": "https://api.github.com/users/jiacheng-ye/followers",
"following_url": "https://api.github.com/users/jiacheng-ye/following{/other_user}",
"gists_url": "https://api.github.com/users/jiacheng-ye/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jiacheng-ye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiacheng-ye/subscriptions",
"organizations_url": "https://api.github.com/users/jiacheng-ye/orgs",
"repos_url": "https://api.github.com/users/jiacheng-ye/repos",
"events_url": "https://api.github.com/users/jiacheng-ye/events{/privacy}",
"received_events_url": "https://api.github.com/users/jiacheng-ye/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! I wasn't able to reproduce your error.\r\n\r\nCan you try to clear your cache at `~/.cache/huggingface/modules` and try again ?"
] | 1,639,363,791,000 | 1,639,507,463,000 | null | NONE | null | ## Describe the bug
File "/opt/conda/lib/python3.8/site-packages/datasets/load.py", line 1371, in load_metric
metric = metric_cls(
TypeError: 'NoneType' object is not callable
## Steps to reproduce the bug
```python
metric = load_metric("glue", "sst2")
```
## Environment info
- `datasets` version: 1.16.1
- Platform: Linux-4.15.0-161-generic-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3422/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3422/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3421/comments | https://api.github.com/repos/huggingface/datasets/issues/3421/events | https://github.com/huggingface/datasets/pull/3421 | 1,077,966,571 | PR_kwDODunzps4vuvJK | 3,421 | Adding mMARCO dataset | {
"login": "lhbonifacio",
"id": 17603035,
"node_id": "MDQ6VXNlcjE3NjAzMDM1",
"avatar_url": "https://avatars.githubusercontent.com/u/17603035?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhbonifacio",
"html_url": "https://github.com/lhbonifacio",
"followers_url": "https://api.github.com/users/lhbonifacio/followers",
"following_url": "https://api.github.com/users/lhbonifacio/following{/other_user}",
"gists_url": "https://api.github.com/users/lhbonifacio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhbonifacio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhbonifacio/subscriptions",
"organizations_url": "https://api.github.com/users/lhbonifacio/orgs",
"repos_url": "https://api.github.com/users/lhbonifacio/repos",
"events_url": "https://api.github.com/users/lhbonifacio/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhbonifacio/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @albertvillanova we've made a major overhaul of the loading script including all configurations we're making available. Could you please review it again?",
"@albertvillanova :ping_pong: "
] | 1,639,357,003,000 | 1,641,209,015,000 | null | NONE | null | Adding mMARCO (v1.1) to HF datasets. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3421/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3421/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3421",
"html_url": "https://github.com/huggingface/datasets/pull/3421",
"diff_url": "https://github.com/huggingface/datasets/pull/3421.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3421.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3420/comments | https://api.github.com/repos/huggingface/datasets/issues/3420/events | https://github.com/huggingface/datasets/pull/3420 | 1,077,913,468 | PR_kwDODunzps4vukyD | 3,420 | Add eli5_category dataset | {
"login": "jingshenSN2",
"id": 40377373,
"node_id": "MDQ6VXNlcjQwMzc3Mzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/40377373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jingshenSN2",
"html_url": "https://github.com/jingshenSN2",
"followers_url": "https://api.github.com/users/jingshenSN2/followers",
"following_url": "https://api.github.com/users/jingshenSN2/following{/other_user}",
"gists_url": "https://api.github.com/users/jingshenSN2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jingshenSN2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jingshenSN2/subscriptions",
"organizations_url": "https://api.github.com/users/jingshenSN2/orgs",
"repos_url": "https://api.github.com/users/jingshenSN2/repos",
"events_url": "https://api.github.com/users/jingshenSN2/events{/privacy}",
"received_events_url": "https://api.github.com/users/jingshenSN2/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> Thanks a lot for adding this dataset ! Good job with the dataset card and the dataset scripts - they're really good :)\r\n> \r\n> I just added minor changes\r\n\r\nThanks for fixing typos!"
] | 1,639,344,645,000 | 1,639,504,383,000 | 1,639,504,382,000 | CONTRIBUTOR | null | This pull request adds a categorized Long-form question answering dataset `ELI5_Category`. It's a new variant of the [ELI5](https://huggingface.co/datasets/eli5) dataset that uses the Reddit tags to alleviate the training/validation overlapping in the origin ELI5 dataset.
A [report](https://celeritasml.netlify.app/posts/2021-12-01-eli5c/)(Section 2) on this dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3420/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3420/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3420",
"html_url": "https://github.com/huggingface/datasets/pull/3420",
"diff_url": "https://github.com/huggingface/datasets/pull/3420.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3420.patch",
"merged_at": 1639504382000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3419/comments | https://api.github.com/repos/huggingface/datasets/issues/3419/events | https://github.com/huggingface/datasets/issues/3419 | 1,077,350,974 | I_kwDODunzps5ANxI- | 3,419 | `.to_json` is extremely slow after `.select` | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "https://api.github.com/users/eladsegal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladsegal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladsegal/subscriptions",
"organizations_url": "https://api.github.com/users/eladsegal/orgs",
"repos_url": "https://api.github.com/users/eladsegal/repos",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladsegal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! It's slower indeed because a datasets on which `select`/`shard`/`train_test_split`/`shuffle` has been called has to do additional steps to retrieve the data of the dataset table in the right order.\r\n\r\nIndeed, if you call `dataset.select([0, 5, 10])`, the underlying table of the dataset is not altered to keep the examples at index 0, 5, and 10. Instead, an indices mapping is added on top of the table, that says that the first example is at index 0, the second at index 5 and the last one at index 10.\r\n\r\nTherefore accessing the examples of the dataset is slower because of the additional step that uses the indices mapping.\r\n\r\nThe step that takes the most time is to query the dataset table from a list of indices here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/047dc756ed20fbf06e6bcaf910464aba0e20610a/src/datasets/formatting/formatting.py#L61-L63\r\n\r\nIn your case it can be made significantly faster by checking if the indices are contiguous. If they're contiguous, we could pass a python `slice` or `range` instead of a list of integers to `_query_table`. This way `_query_table` will do only one lookup to get the queried batch instead of `batch_size` lookups.\r\n\r\nGiven that calling `select` with contiguous indices is a common use case I'm in favor of implementing such an optimization :)\r\nLet me know what you think",
"Hi, thanks for the response!\r\nI still don't understand why it is so much slower than iterating and saving:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\noriginal = load_dataset(\"squad\", split=\"train\")\r\noriginal.to_json(\"from_original.json\") # Takes 0 seconds\r\n\r\nselected_subset1 = original.select([i for i in range(len(original))])\r\nselected_subset1.to_json(\"from_select1.json\") # Takes 99 seconds\r\n\r\nselected_subset2 = original.select([i for i in range(int(len(original) / 2))])\r\nselected_subset2.to_json(\"from_select2.json\") # Takes 47 seconds\r\n\r\nselected_subset3 = original.select([i for i in range(len(original)) if i % 2 == 0])\r\nselected_subset3.to_json(\"from_select3.json\") # Takes 49 seconds\r\n\r\nimport json\r\nimport time\r\ndef fast_to_json(dataset, path):\r\n start = time.time()\r\n with open(path, mode=\"w\") as f:\r\n for example in dataset:\r\n f.write(json.dumps(example, separators=(',', ':')) + \"\\n\")\r\n end = time.time()\r\n print(f\"Saved {len(dataset)} examples to {path} in {end - start} seconds.\")\r\n\r\nfast_to_json(original, \"from_original_fast.json\")\r\nfast_to_json(selected_subset1, \"from_select1_fast.json\")\r\nfast_to_json(selected_subset2, \"from_select2_fast.json\")\r\nfast_to_json(selected_subset3, \"from_select3_fast.json\")\r\n```\r\n```\r\nSaved 87599 examples to from_original_fast.json in 8 seconds.\r\nSaved 87599 examples to from_select1_fast.json in 10 seconds.\r\nSaved 43799 examples to from_select2_fast.json in 6 seconds.\r\nSaved 43800 examples to from_select3_fast.json in 5 seconds.\r\n```",
"There are slight differences between what you're doing and what `to_json` is actually doing.\r\nIn particular `to_json` currently converts batches of rows (as an arrow table) to a pandas dataframe, and then to JSON Lines. From your benchmark it looks like it's faster if we don't use pandas.\r\n\r\nThanks for investigating, I think we can optimize `to_json` significantly thanks to your test.",
"Thanks for your observations, @eladsegal! I spent some time with this and tried different approaches. Turns out that https://github.com/huggingface/datasets/blob/bb13373637b1acc55f8a468a8927a56cf4732230/src/datasets/io/json.py#L100 is giving the problem when we use `to_json` after `select`. This is when `indices` parameter in `query_table` is not `None` (if it is `None` then `to_json` should work as expected)\r\n\r\nIn order to circumvent this problem, I found out instead of doing Arrow Table -> Pandas-> JSON we can directly go to JSON by using `to_pydict()` which is a little slower than the current approach but at least `select` works properly now. Lmk what you guys think of it @lhoestq, @eladsegal?",
"Sounds good to me ! Feel free to also share your benchmarks for reference @bhavitvyamalik ",
"Posting it in @eladsegal's format:\r\n\r\nFor `squad`:\r\nSaving examples using current `to_json` in 3.63 secs\r\nSaving examples to `from_select1_fast.json` in 5.00 secs\r\nSaving examples to `from_select2_fast.json` in 2.45 secs\r\nSaving examples to `from_select3_fast.json` in 2.50 secs\r\n\r\nFor `squad_v2`:\r\nSaving examples using current `to_json` in 5.26 secs\r\nSaving examples to `from_select1_fast.json` in 7.54 secs\r\nSaving examples to `from_select2_fast.json` in 3.80 secs\r\nSaving examples to `from_select3_fast.json` in 3.67 secs"
] | 1,639,186,591,000 | 1,640,101,747,000 | null | CONTRIBUTOR | null | ## Describe the bug
Saving a dataset to JSON with `to_json` is extremely slow after using `.select` on the original dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
original = load_dataset("squad", split="train")
original.to_json("from_original.json") # Takes 0 seconds
selected_subset1 = original.select([i for i in range(len(original))])
selected_subset1.to_json("from_select1.json") # Takes 212 seconds
selected_subset2 = original.select([i for i in range(int(len(original) / 2))])
selected_subset2.to_json("from_select2.json") # Takes 90 seconds
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: master (https://github.com/huggingface/datasets/commit/6090f3cfb5c819f441dd4a4bb635e037c875b044)
- Platform: Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.27
- Python version: 3.9.7
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3419/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3419/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3418/comments | https://api.github.com/repos/huggingface/datasets/issues/3418/events | https://github.com/huggingface/datasets/pull/3418 | 1,077,053,296 | PR_kwDODunzps4vsHMK | 3,418 | Add Wikisource dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,639,155,884,000 | 1,639,669,549,000 | null | MEMBER | null | Add loading script for Wikisource dataset.
Fix #3399.
CC: @geohci, @yjernite | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3418/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3418/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3418",
"html_url": "https://github.com/huggingface/datasets/pull/3418",
"diff_url": "https://github.com/huggingface/datasets/pull/3418.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3418.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3417 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3417/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3417/comments | https://api.github.com/repos/huggingface/datasets/issues/3417/events | https://github.com/huggingface/datasets/pull/3417 | 1,076,943,343 | PR_kwDODunzps4vrwd7 | 3,417 | Fix type of bridge field in QED | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,148,841,000 | 1,639,492,746,000 | 1,639,492,745,000 | CONTRIBUTOR | null | Use `Value("string")` instead of `Value("bool")` for the feature type of the `"bridge"` field in the QED dataset. If the value is `False`, set to `None`.
The following paragraph in the QED repo explains the purpose of this field:
>Each annotation in referential_equalities is a pair of spans, the question_reference and the sentence_reference, corresponding to an entity mention in the question and the selected_sentence respectively. As described in the paper, sentence_references can be "bridged in", in which case they do not correspond with any actual span in the selected_sentence. Hence, sentence_reference spans contain an additional field, bridge, which is a prepositional phrase when a reference is bridged, and is False otherwise. Prepositional phrases serve to link bridged references to an anchoring phrase in the selected_sentence. In the case a sentence_reference is bridged, the start and end, as well as the span string, map to such an anchoring phrase in the selected_sentence.
Fix #3346
cc @VictorSanh | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3417/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3417/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3417",
"html_url": "https://github.com/huggingface/datasets/pull/3417",
"diff_url": "https://github.com/huggingface/datasets/pull/3417.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3417.patch",
"merged_at": 1639492745000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3416 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3416/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3416/comments | https://api.github.com/repos/huggingface/datasets/issues/3416/events | https://github.com/huggingface/datasets/issues/3416 | 1,076,868,771 | I_kwDODunzps5AL7aj | 3,416 | disaster_response_messages unavailable | {
"login": "sacdallago",
"id": 6240943,
"node_id": "MDQ6VXNlcjYyNDA5NDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6240943?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sacdallago",
"html_url": "https://github.com/sacdallago",
"followers_url": "https://api.github.com/users/sacdallago/followers",
"following_url": "https://api.github.com/users/sacdallago/following{/other_user}",
"gists_url": "https://api.github.com/users/sacdallago/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sacdallago/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sacdallago/subscriptions",
"organizations_url": "https://api.github.com/users/sacdallago/orgs",
"repos_url": "https://api.github.com/users/sacdallago/repos",
"events_url": "https://api.github.com/users/sacdallago/events{/privacy}",
"received_events_url": "https://api.github.com/users/sacdallago/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Hi, thanks for reporting! This is a duplicate of https://github.com/huggingface/datasets/issues/3240. We are working on a fix.\r\n\r\n"
] | 1,639,144,157,000 | 1,639,492,709,000 | 1,639,492,709,000 | NONE | null | ## Dataset viewer issue for '* disaster_response_messages*'
**Link:** https://huggingface.co/datasets/disaster_response_messages
Dataset unavailable. Link dead: https://datasets.appen.com/appen_datasets/disaster_response_data/disaster_response_messages_training.csv
Am I the one who added this dataset ?No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3416/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3416/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3415/comments | https://api.github.com/repos/huggingface/datasets/issues/3415/events | https://github.com/huggingface/datasets/issues/3415 | 1,076,472,534 | I_kwDODunzps5AKarW | 3,415 | Non-deterministic tests: CI tests randomly fail | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"I think it might come from two different issues:\r\n1. Google Drive is an unreliable host, mainly because of quota limitations\r\n2. the staging environment can sometimes raise some errors\r\n\r\nFor Google Drive tests we could set up some retries with backup URLs if necessary I guess.\r\nFor staging on the other hand, I guess we can investigate what causes this and discuss with the back-end team"
] | 1,639,116,539,000 | 1,639,490,479,000 | null | MEMBER | null | ## Describe the bug
Some CI tests fail randomly.
1. In https://github.com/huggingface/datasets/pull/3375/commits/c10275fe36085601cb7bdb9daee9a8f1fc734f48, there were 3 failing tests, only on Linux:
```
=========================== short test summary info ============================
FAILED tests/test_streaming_download_manager.py::test_streaming_dl_manager_get_extraction_protocol[https://drive.google.com/uc?export=download&id=1k92sUfpHxKq8PXWRr7Y5aNHXwOCNUmqh-zip]
FAILED tests/test_streaming_download_manager.py::test_streaming_gg_drive - Fi...
FAILED tests/test_streaming_download_manager.py::test_streaming_gg_drive_zipped
= 3 failed, 3553 passed, 2950 skipped, 2 xfailed, 1 xpassed, 125 warnings in 192.79s (0:03:12) =
```
2. After re-running the CI (without any change in the code) in https://github.com/huggingface/datasets/pull/3375/commits/57bfe1f342cd3c59d2510b992d5f06a0761eb147, there was only 1 failing test (one on Linux and a different one on Windows):
- On Linux:
```
=========================== short test summary info ============================
FAILED tests/test_streaming_download_manager.py::test_streaming_gg_drive_zipped
= 1 failed, 3555 passed, 2950 skipped, 2 xfailed, 1 xpassed, 125 warnings in 199.76s (0:03:19) =
```
- On Windows:
```
=========================== short test summary info ===========================
FAILED tests/test_load.py::test_load_dataset_builder_for_community_dataset_without_script
= 1 failed, 3551 passed, 2954 skipped, 2 xfailed, 1 xpassed, 121 warnings in 478.58s (0:07:58) =
```
The test `tests/test_streaming_download_manager.py::test_streaming_gg_drive_zipped` passes locally.
3. After re-running again the CI (without any change in the code) in https://github.com/huggingface/datasets/pull/3375/commits/39f32f2119cf91b86867216bb5c356c586503c6a, ALL the tests passed.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3415/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3415/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3414/comments | https://api.github.com/repos/huggingface/datasets/issues/3414/events | https://github.com/huggingface/datasets/pull/3414 | 1,076,028,998 | PR_kwDODunzps4voyaq | 3,414 | Skip None encoding (line deleted by accident in #3195) | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,084,653,000 | 1,639,134,003,000 | 1,639,134,002,000 | CONTRIBUTOR | null | Return the line deleted by accident in #3195 while [resolving merge conflicts](https://github.com/huggingface/datasets/pull/3195/commits/8b0ed15be08559056b817836a07d47acda0c4510).
Fix #3181 (finally :))
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3414/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3414/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3414",
"html_url": "https://github.com/huggingface/datasets/pull/3414",
"diff_url": "https://github.com/huggingface/datasets/pull/3414.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3414.patch",
"merged_at": 1639134002000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3413/comments | https://api.github.com/repos/huggingface/datasets/issues/3413/events | https://github.com/huggingface/datasets/pull/3413 | 1,075,854,325 | PR_kwDODunzps4voNZv | 3,413 | Add WIDER FACE dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,639,073,018,000 | 1,641,311,035,000 | null | CONTRIBUTOR | null | Adds the WIDER FACE face detection benchmark.
TODOs:
* [x] dataset card
* [x] dummy data | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3413/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3413/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3413",
"html_url": "https://github.com/huggingface/datasets/pull/3413",
"diff_url": "https://github.com/huggingface/datasets/pull/3413.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3413.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3412/comments | https://api.github.com/repos/huggingface/datasets/issues/3412/events | https://github.com/huggingface/datasets/pull/3412 | 1,075,846,368 | PR_kwDODunzps4voLs4 | 3,412 | Fix flaky test again for s3 serialization | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,072,481,000 | 1,639,072,852,000 | 1,639,072,852,000 | MEMBER | null | Following https://github.com/huggingface/datasets/pull/3388 that wasn't enough (see CI error [here](https://app.circleci.com/pipelines/github/huggingface/datasets/9080/workflows/b971fb27-ff20-4220-9416-c19acdfdf6f4/jobs/55985)) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3412/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3412/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3412",
"html_url": "https://github.com/huggingface/datasets/pull/3412",
"diff_url": "https://github.com/huggingface/datasets/pull/3412.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3412.patch",
"merged_at": 1639072852000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3411/comments | https://api.github.com/repos/huggingface/datasets/issues/3411/events | https://github.com/huggingface/datasets/issues/3411 | 1,075,846,272 | I_kwDODunzps5AIByA | 3,411 | [chinese wwm] load_datasets behavior not as expected when using run_mlm_wwm.py script | {
"login": "hyusterr",
"id": 52968111,
"node_id": "MDQ6VXNlcjUyOTY4MTEx",
"avatar_url": "https://avatars.githubusercontent.com/u/52968111?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hyusterr",
"html_url": "https://github.com/hyusterr",
"followers_url": "https://api.github.com/users/hyusterr/followers",
"following_url": "https://api.github.com/users/hyusterr/following{/other_user}",
"gists_url": "https://api.github.com/users/hyusterr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hyusterr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hyusterr/subscriptions",
"organizations_url": "https://api.github.com/users/hyusterr/orgs",
"repos_url": "https://api.github.com/users/hyusterr/repos",
"events_url": "https://api.github.com/users/hyusterr/events{/privacy}",
"received_events_url": "https://api.github.com/users/hyusterr/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"@LysandreJik not so sure who to @\r\nCould you help?",
"Hi @hyusterr, I believe it is @wlhgtc from https://github.com/huggingface/transformers/pull/9887"
] | 1,639,072,475,000 | 1,640,172,093,000 | null | NONE | null | ## Describe the bug
Model I am using (Bert, XLNet ...): bert-base-chinese
The problem arises when using:
* [https://github.com/huggingface/transformers/blob/master/examples/research_projects/mlm_wwm/run_mlm_wwm.py] the official example scripts: `rum_mlm_wwm.py`
The tasks I am working on is: pretraining whole word masking with my own dataset and ref.json file
I tried follow the run_mlm_wwm.py procedure to do whole word masking on pretraining task. my file is in .txt form, where one line represents one sample, with `9,264,784` chinese lines in total. the ref.json file is also contains 9,264,784 lines of whole word masking reference data for my chinese corpus. but when I try to adapt the run_mlm_wwm.py script, it shows that somehow after
`datasets["train"] = load_dataset(...`
`len(datasets["train"])` returns `9,265,365`
then, after `tokenized_datasets = datasets.map(...`
`len(tokenized_datasets["train"])` returns `9,265,279`
I'm really confused and tried to trace code by myself but can't know what happened after a week trial.
I want to know what happened in the `load_dataset()` function and `datasets.map` here and how did I get more lines of data than I input. so I'm here to ask.
## To reproduce
Sorry that I can't provide my data here since it did not belong to me. but I'm sure I remove the blank lines.
## Expected behavior
I expect the code run as it should. but the AssertionError in line 167 keeps raise as the line of reference json and datasets['train'] differs.
Thanks for your patient reading!
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: Linux-5.4.0-91-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3411/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3410/comments | https://api.github.com/repos/huggingface/datasets/issues/3410/events | https://github.com/huggingface/datasets/pull/3410 | 1,075,815,415 | PR_kwDODunzps4voFG7 | 3,410 | Fix dependencies conflicts in Windows CI after conda update to 4.11 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,070,351,000 | 1,639,071,380,000 | 1,639,071,379,000 | MEMBER | null | For some reason the CI wasn't using python 3.6 but python 3.7 after the update to conda 4.11 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3410/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3410/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3410",
"html_url": "https://github.com/huggingface/datasets/pull/3410",
"diff_url": "https://github.com/huggingface/datasets/pull/3410.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3410.patch",
"merged_at": 1639071379000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3409/comments | https://api.github.com/repos/huggingface/datasets/issues/3409/events | https://github.com/huggingface/datasets/pull/3409 | 1,075,684,593 | PR_kwDODunzps4vnpU0 | 3,409 | Pass new_fingerprint in multiprocessing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,639,062,720,000 | 1,639,071,524,000 | 1,639,071,523,000 | MEMBER | null | Following https://github.com/huggingface/datasets/pull/3045
Currently one can pass `new_fingerprint` to `.map()` to use a custom fingerprint instead of the one computed by hashing the map transform. However it's ignored if `num_proc>1`.
In this PR I fixed that by passing `new_fingerprint` to `._map_single()` when `num_proc>1`.
More specifically, `new_fingerprint` with a suffix based on the process `rank` is passed, so that each process has a different `new_fingerprint`
cc @TevenLeScao @vlievin | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3409/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3409/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3409",
"html_url": "https://github.com/huggingface/datasets/pull/3409",
"diff_url": "https://github.com/huggingface/datasets/pull/3409.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3409.patch",
"merged_at": 1639071523000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3408/comments | https://api.github.com/repos/huggingface/datasets/issues/3408/events | https://github.com/huggingface/datasets/issues/3408 | 1,075,642,915 | I_kwDODunzps5AHQIj | 3,408 | Typo in Dataset viewer error message | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Fixed, thanks\r\n<img width=\"661\" alt=\"Capture d’écran 2021-12-22 à 12 02 30\" src=\"https://user-images.githubusercontent.com/1676121/147082881-cf700e8d-0511-4431-b214-d6cf8137db10.png\">\r\n"
] | 1,639,060,442,000 | 1,640,170,973,000 | 1,640,170,973,000 | MEMBER | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
When creating an empty dataset repo, the Dataset Preview provides a helpful message that no files were found. There is a tiny typo in that message: "ressource" should be "resource"

Am I the one who added this dataset ?
N/A
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3408/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3408/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3407/comments | https://api.github.com/repos/huggingface/datasets/issues/3407/events | https://github.com/huggingface/datasets/pull/3407 | 1,074,502,225 | PR_kwDODunzps4vjyrB | 3,407 | Use max number of data files to infer module | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Cool thanks :) Feel free to merge if it's all good for you"
] | 1,638,975,523,000 | 1,639,501,722,000 | 1,639,501,722,000 | MEMBER | null | When inferring the module for datasets without script, set a maximum number of iterations over data files.
This PR fixes the issue of taking too long when hundred of data files present.
Please, feel free to agree on both numbers:
```
# Datasets without script
DATA_FILES_MAX_NUMBER = 10
ARCHIVED_DATA_FILES_MAX_NUMBER = 5
```
Fix #3404. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3407/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3407/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3407",
"html_url": "https://github.com/huggingface/datasets/pull/3407",
"diff_url": "https://github.com/huggingface/datasets/pull/3407.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3407.patch",
"merged_at": 1639501721000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3406/comments | https://api.github.com/repos/huggingface/datasets/issues/3406/events | https://github.com/huggingface/datasets/pull/3406 | 1,074,366,050 | PR_kwDODunzps4vjV21 | 3,406 | Fix module inference for archive with a directory | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,967,152,000 | 1,638,968,610,000 | 1,638,968,609,000 | MEMBER | null | Fix module inference for an archive file that contains files within a directory.
Fix #3405. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3406/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3406/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3406",
"html_url": "https://github.com/huggingface/datasets/pull/3406",
"diff_url": "https://github.com/huggingface/datasets/pull/3406.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3406.patch",
"merged_at": 1638968608000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3405/comments | https://api.github.com/repos/huggingface/datasets/issues/3405/events | https://github.com/huggingface/datasets/issues/3405 | 1,074,360,362 | I_kwDODunzps5ACXAq | 3,405 | ZIP format inference does not work when files located in a dir inside the archive | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,966,735,000 | 1,638,968,609,000 | 1,638,968,609,000 | MEMBER | null | ## Describe the bug
When a zipped file contains archived files within a directory, the function `infer_module_for_data_files_in_archives` does not work.
It only works for files located in the root directory of the ZIP file.
## Steps to reproduce the bug
```python
infer_module_for_data_files_in_archives(["path/to/zip/file.zip"], False)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3405/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3404/comments | https://api.github.com/repos/huggingface/datasets/issues/3404/events | https://github.com/huggingface/datasets/issues/3404 | 1,073,657,561 | I_kwDODunzps4__rbZ | 3,404 | Optimize ZIP format inference | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,902,689,000 | 1,639,501,721,000 | 1,639,501,721,000 | MEMBER | null | **Is your feature request related to a problem? Please describe.**
When hundreds of ZIP files are present in a dataset, format inference takes too long.
See: https://github.com/bigscience-workshop/data_tooling/issues/232#issuecomment-986685497
**Describe the solution you'd like**
Iterate over a maximum number of files.
CC: @lhoestq
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3404/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3404/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3403/comments | https://api.github.com/repos/huggingface/datasets/issues/3403/events | https://github.com/huggingface/datasets/issues/3403 | 1,073,622,120 | I_kwDODunzps4__ixo | 3,403 | Cannot import name 'maybe_sync' | {
"login": "KMFODA",
"id": 35491698,
"node_id": "MDQ6VXNlcjM1NDkxNjk4",
"avatar_url": "https://avatars.githubusercontent.com/u/35491698?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KMFODA",
"html_url": "https://github.com/KMFODA",
"followers_url": "https://api.github.com/users/KMFODA/followers",
"following_url": "https://api.github.com/users/KMFODA/following{/other_user}",
"gists_url": "https://api.github.com/users/KMFODA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KMFODA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KMFODA/subscriptions",
"organizations_url": "https://api.github.com/users/KMFODA/orgs",
"repos_url": "https://api.github.com/users/KMFODA/repos",
"events_url": "https://api.github.com/users/KMFODA/events{/privacy}",
"received_events_url": "https://api.github.com/users/KMFODA/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! Can you try updating `fsspec` ? The minimum version is `2021.05.0`",
"hey @lhoestq. I'm using `fsspec-2021.11.1` but still getting that error.",
"Maybe this discussion can help:\r\n\r\nhttps://github.com/fsspec/filesystem_spec/issues/597#issuecomment-958646964",
"Thanks @lhoestq. Downgrading `fsspec and s3fs` to `2021.10` fixed this issue!"
] | 1,638,899,879,000 | 1,639,724,435,000 | 1,639,724,435,000 | CONTRIBUTOR | null | ## Describe the bug
Cannot seem to import datasets when running run_summarizer.py script on a VM set up on ovhcloud
## Steps to reproduce the bug
```python
from datasets import load_dataset
```
## Expected results
No error
## Actual results
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/lib/python3.7/site-packages/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 48, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_writer.py", line 27, in <module>
from .features import (
File "/opt/conda/lib/python3.7/site-packages/datasets/features/__init__.py", line 2, in <module>
from .audio import Audio
File "/opt/conda/lib/python3.7/site-packages/datasets/features/audio.py", line 8, in <module>
from ..utils.streaming_download_manager import xopen
File "/opt/conda/lib/python3.7/site-packages/datasets/utils/streaming_download_manager.py", line 16, in <module>
from ..filesystems import COMPRESSION_FILESYSTEMS
File "/opt/conda/lib/python3.7/site-packages/datasets/filesystems/__init__.py", line 13, in <module>
from .s3filesystem import S3FileSystem # noqa: F401
File "/opt/conda/lib/python3.7/site-packages/datasets/filesystems/s3filesystem.py", line 1, in <module>
import s3fs
File "/opt/conda/lib/python3.7/site-packages/s3fs/__init__.py", line 1, in <module>
from .core import S3FileSystem, S3File
File "/opt/conda/lib/python3.7/site-packages/s3fs/core.py", line 11, in <module>
from fsspec.asyn import AsyncFileSystem, sync, sync_wrapper, maybe_sync
ImportError: cannot import name 'maybe_sync' from 'fsspec.asyn' (/opt/conda/lib/python3.7/site-packages/fsspec/asyn.py)
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.0
- Platform: OVH Cloud Tesla V100 Machine
- Python version: 3.7.9
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3403/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3403/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3402/comments | https://api.github.com/repos/huggingface/datasets/issues/3402/events | https://github.com/huggingface/datasets/pull/3402 | 1,073,614,815 | PR_kwDODunzps4vg5Ff | 3,402 | More robust first elem check in encode/cast example | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,899,296,000 | 1,638,968,536,000 | 1,638,968,535,000 | CONTRIBUTOR | null | Fix #3306 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3402/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3402/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3402",
"html_url": "https://github.com/huggingface/datasets/pull/3402",
"diff_url": "https://github.com/huggingface/datasets/pull/3402.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3402.patch",
"merged_at": 1638968535000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3401/comments | https://api.github.com/repos/huggingface/datasets/issues/3401/events | https://github.com/huggingface/datasets/issues/3401 | 1,073,603,508 | I_kwDODunzps4__eO0 | 3,401 | Add Wikimedia pre-processed datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,638,898,399,000 | 1,638,899,017,000 | null | MEMBER | null | ## Adding a Dataset
- **Name:** Add pre-processed data to:
- *wikimedia/wikipedia*: https://huggingface.co/datasets/wikimedia/wikipedia
- *wikimedia/wikisource*: https://huggingface.co/datasets/wikimedia/wikisource
- **Description:** Add pre-processed data to the Hub for all languages
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** This will be very useful for the NLP community, as the pre-processing has a high cost for lot of researchers (both in computation and in knowledge)
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
CC: @geohci, @yjernite | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3401/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3400/comments | https://api.github.com/repos/huggingface/datasets/issues/3400/events | https://github.com/huggingface/datasets/issues/3400 | 1,073,600,382 | I_kwDODunzps4__dd- | 3,400 | Improve Wikipedia loading script | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"Thanks! See https://public.paws.wmcloud.org/User:Isaac_(WMF)/HuggingFace%20Wikipedia%20Processing.ipynb for more implementation details / some data around the overhead induced by adding the extra preprocessing steps (stripping link prefixes and magic words)"
] | 1,638,898,165,000 | 1,638,908,751,000 | null | MEMBER | null | As reported by @geohci, the "wikipedia" processing/loading script could be improved by some additional small suggested processing functions:
- _extract_content(filepath):
- Replace .startswith("#redirect") with more structured approach: if elem.find(f"./{namespace}redirect") is None: continue
- _parse_and_clean_wikicode(raw_content, parser):
- Remove rm_template from cleaning -- this is redundant with .strip_code() from mwparserformhell
- Build a language-specific list of namespace prefixes to filter out per below get_namespace_prefixes
- Optional: strip prefixes like categories -- e.g., Category:Towns in Tianjin becomes Towns in Tianjin
- Optional: strip magic words
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3400/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3400/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3399/comments | https://api.github.com/repos/huggingface/datasets/issues/3399/events | https://github.com/huggingface/datasets/issues/3399 | 1,073,593,861 | I_kwDODunzps4__b4F | 3,399 | Add Wikisource dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"See notebook by @geohci: https://public.paws.wmcloud.org/User:Isaac_(WMF)/HuggingFace%20Wikisource%20Processing.ipynb"
] | 1,638,897,691,000 | 1,639,157,186,000 | null | MEMBER | null | ## Adding a Dataset
- **Name:** *wikisource*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** Additional high quality textual data, besides Wikipedia.
Add loading script as "canonical" dataset (as it is the case for ""wikipedia").
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
CC: @geohci, @yjernite | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3399/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3398/comments | https://api.github.com/repos/huggingface/datasets/issues/3398/events | https://github.com/huggingface/datasets/issues/3398 | 1,073,590,384 | I_kwDODunzps4__bBw | 3,398 | Add URL field to Wikimedia dataset instances: wikipedia,... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,638,897,447,000 | 1,638,898,092,000 | null | MEMBER | null | As reported by @geohci, once we will host pre-processed data in the Hub, we should add the full URL to data instances (new field "url") in order to conform to proper attribution from license requirement. See, e.g.: https://fair-trec.github.io/docs/Fair_Ranking_2021_Participant_Instructions.pdf#subsection.3.2
This should be done for all pre-processed datasets under "wikimedia" org in the Hub: https://huggingface.co/wikimedia
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3398/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3398/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3397/comments | https://api.github.com/repos/huggingface/datasets/issues/3397/events | https://github.com/huggingface/datasets/pull/3397 | 1,073,502,444 | PR_kwDODunzps4vgh1U | 3,397 | add BNL processed newspapers | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"\r\n> Also, maybe calling the dataset as \"bnl_historical_newspapers\" and setting \"processed\" as one configuration name?\r\n\r\nThis sounds like a good idea but my only question around this is how easy it would be to use the same approach for processing the other newspaper collections [https://data.bnl.lu/data/historical-newspapers/](). \r\n\r\nFor example, the \"BIG DATA PACK\" is `257GB` of ALTO XML. This format is slightly more annoying to process because the metadata and text are contained in different files but the bigger issue might be that processing this XML using the Python XML libraries will probably be quite slow? I had thought for those larger datasets it might be more appropriate to use the Beam datasets? I don't have any experience using Beam so I'm not sure what that would involve and there is a reason to not include it in a dataset script alongside a non Beam dataset? \r\n\r\nIf there isn't an issue with potentially later adding other datasets (which may require Beam) into the same script I'll add one config for the processed version now which leaves open the option for later adding the other datasets. If this makes sense I'll also change the name as you suggest. \r\n\r\nThere is another dataset that could be a good candidate for inclusion here is the \"Monograph Text pack\" which is also processed into a simpler XML format however as the name suggests this isn't newspapers so might be confusing to include under a 'newspapers' script. One option would be to put everything under a `BNL` collection but it might be better to keep the monographs separate if they are added as a dataset so a single script doesn't end up including too much variety of content types? \r\n\r\n\r\n\r\n",
"> My initial idea was to contribute the script also as \"community\" datasets (instead of canonical), i.e. in this case, pushing the script to the repo [huggingface.co/datasets/bigscience-catalogue-data/bnl_historical_newspapers](https://huggingface.co/datasets/bigscience-catalogue-data/bnl_historical_newspapers)\r\n\r\nSorry to respond to this late - happy for this to go in the community datasets. I think it would be nice to include in the canonical datasets at some point but since there is less urgency with this I could try and first work on improving the Datacard before doing that (i.e. make this a draft PR) - let me know if you think that makes more sense? \r\n\r\n\r\n",
"> My initial idea was to contribute the script also as \"community\" datasets (instead of canonical), i.e. in this case, pushing the script to the repo https://huggingface.co/datasets/bigscience-catalogue-data/bnl_historical_newspapers\r\n> One of the advantages is that no dummy data is required, so the addition can be made faster\r\n> On the other hand, one disadvantage is that contributions cannot be made through PRs\r\n> Therefore, we should use the Issue page for discussions, reviews, decisions,...\r\n\r\nSure we can use the issues to discuss/review community datasets. Maybe let's have an issue template for that ?\r\nFor this dataset in particular I'll let @albertvillanova decide whether it's best as community dataset or not. IMO both are fine :)\r\n\r\n> I had thought for those larger datasets it might be more appropriate to use the Beam datasets? I don't have any experience using Beam so I'm not sure what that would involve and there is a reason to not include it in a dataset script alongside a non Beam dataset?\r\n\r\nBeam is nice to process a dataset once and for all and store the resulting processed data on the Hugging Face Hub or elsewhere. However for big datasets it must run on a distributed processing runtime like Google DataFlow, which is often inconvenient for many users. We've been using it though for datasets like Wikipedia and sharing the processed data in a GCS bucket.\r\n\r\nSo feel free to use the tools you like to process the datasets, but in the end I think we just need to host the processed data in a convenient format on the Hugging Face Hub to share it with the community. The processing script you used can also be shared with the community for reproducibility and documentation. But maybe @albertvillanova already has something in mind",
"> > My initial idea was to contribute the script also as \"community\" datasets (instead of canonical), i.e. in this case, pushing the script to the repo [huggingface.co/datasets/bigscience-catalogue-data/bnl_historical_newspapers](https://huggingface.co/datasets/bigscience-catalogue-data/bnl_historical_newspapers)\r\n> > One of the advantages is that no dummy data is required, so the addition can be made faster\r\n> > On the other hand, one disadvantage is that contributions cannot be made through PRs\r\n> > Therefore, we should use the Issue page for discussions, reviews, decisions,...\r\n> \r\n> Sure we can use the issues to discuss/review community datasets. Maybe let's have an issue template for that ? For this dataset in particular I'll let @albertvillanova decide whether it's best as community dataset or not. IMO both are fine :)\r\n\r\nThanks, I'll hold off and let @albertvillanova decide best place for this. \r\n\r\n> > I had thought for those larger datasets it might be more appropriate to use the Beam datasets? I don't have any experience using Beam so I'm not sure what that would involve and there is a reason to not include it in a dataset script alongside a non Beam dataset?\r\n> \r\n> Beam is nice to process a dataset once and for all and store the resulting processed data on the Hugging Face Hub or elsewhere. However for big datasets it must run on a distributed processing runtime like Google DataFlow, which is often inconvenient for many users. We've been using it though for datasets like Wikipedia and sharing the processed data in a GCS bucket.\r\n> \r\n> So feel free to use the tools you like to process the datasets, but in the end I think we just need to host the processed data in a convenient format on the Hugging Face Hub to share it with the community. The processing script you used can also be shared with the community for reproducibility and documentation. But maybe @albertvillanova already has something in mind\r\n\r\nThat's useful, my own 2 cents are that it would make sense to do as @albertvillanova suggested and:-\r\n\r\n- rename the dataset to 'bnl_newspapers' \r\n- make the 'processed dataset' a config \r\n\r\nI won't try and include all the other datasets now but this leaves open the option of adding those later. The actual ALTO processing should be okay to do but I think it makes sense to do this as a one-off process and make the plain text + some associated metadata available elsewere so the dataset script can be kept simple and the processing doesn't get done multiple times. \r\n\r\n@albertvillanova if that sounds okay I'll update pull request to include those changes. \r\n",
"@albertvillanova I've now created a config (currently with only one option) and renamed the dataset. This should keep the option to add other configs based on different bnl newspapers in the future. \r\n"
] | 1,638,891,801,000 | 1,641,486,031,000 | null | CONTRIBUTOR | null | This pull request adds the BNL's [processed newspaper collections](https://data.bnl.lu/data/historical-newspapers/) as a dataset. This is partly done to support BigScience see: https://github.com/bigscience-workshop/data_tooling/issues/192.
The Datacard is more sparse than I would like but I plan to make a separate pull request to try and make this more complete at a later date.
I had to manually add the `dummy_data` but I believe I've done this correctly (the tests pass locally).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3397/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3397/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3397",
"html_url": "https://github.com/huggingface/datasets/pull/3397",
"diff_url": "https://github.com/huggingface/datasets/pull/3397.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3397.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3396/comments | https://api.github.com/repos/huggingface/datasets/issues/3396/events | https://github.com/huggingface/datasets/issues/3396 | 1,073,467,183 | I_kwDODunzps4_-88v | 3,396 | Install Audio dependencies to support audio decoding | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | [
"https://huggingface.co/datasets/projecte-aina/parlament_parla -> works (but we still have to show an audio player)\r\n\r\nhttps://huggingface.co/datasets/openslr -> another issue: `Message: [Errno 2] No such file or directory: '/home/hf/datasets-preview-backend/zip:/asr_javanese/data/00/00004fe6aa.flac'`"
] | 1,638,889,896,000 | 1,640,170,747,000 | null | MEMBER | null | ## Dataset viewer issue for '*openslr*', '*projecte-aina/parlament_parla*'
**Link:** *https://huggingface.co/datasets/openslr*
**Link:** *https://huggingface.co/datasets/projecte-aina/parlament_parla*
Error:
```
Status code: 400
Exception: ImportError
Message: To support decoding audio files, please install 'librosa'.
```
Am I the one who added this dataset ? Yes-No
- openslr: No
- projecte-aina/parlament_parla: Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3396/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3395/comments | https://api.github.com/repos/huggingface/datasets/issues/3395/events | https://github.com/huggingface/datasets/pull/3395 | 1,073,432,650 | PR_kwDODunzps4vgTKG | 3,395 | Fix formatting in IterableDataset.map docs | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,888,061,000 | 1,638,958,293,000 | 1,638,958,293,000 | CONTRIBUTOR | null | Fix formatting in the recently added `Map` section of the streaming docs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3395/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3395/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3395",
"html_url": "https://github.com/huggingface/datasets/pull/3395",
"diff_url": "https://github.com/huggingface/datasets/pull/3395.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3395.patch",
"merged_at": 1638958292000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3394/comments | https://api.github.com/repos/huggingface/datasets/issues/3394/events | https://github.com/huggingface/datasets/issues/3394 | 1,073,396,308 | I_kwDODunzps4_-rpU | 3,394 | Preserve all feature types when saving a dataset on the Hub with `push_to_hub` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"According to this [comment in the forum](https://discuss.huggingface.co/t/save-datasetdict-to-huggingface-hub/12075/8?u=lhoestq), using `push_to_hub` on a dataset with `ClassLabel` can also make the feature simply disappear when it's reloaded !",
"Maybe we can also fix https://github.com/huggingface/datasets/issues/3035 while working on this because, as pointed out in my initial post, `save_to_disk` also saves the `dataset_info.json` file."
] | 1,638,886,110,000 | 1,640,106,009,000 | 1,640,106,009,000 | CONTRIBUTOR | null | Currently, if one of the dataset features is of type `ClassLabel`, saving the dataset with `push_to_hub` and reloading the dataset with `load_dataset` will return the feature of type `Value`. To fix this, we should do something similar to `save_to_disk` (which correctly preserves the types) and not only push the parquet files in `push_to_hub`, but also the dataset `info` (stored in a JSON file). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3394/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3394/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3393/comments | https://api.github.com/repos/huggingface/datasets/issues/3393/events | https://github.com/huggingface/datasets/issues/3393 | 1,073,189,777 | I_kwDODunzps4_95OR | 3,393 | Common Voice Belarusian Dataset | {
"login": "wiedymi",
"id": 42713027,
"node_id": "MDQ6VXNlcjQyNzEzMDI3",
"avatar_url": "https://avatars.githubusercontent.com/u/42713027?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wiedymi",
"html_url": "https://github.com/wiedymi",
"followers_url": "https://api.github.com/users/wiedymi/followers",
"following_url": "https://api.github.com/users/wiedymi/following{/other_user}",
"gists_url": "https://api.github.com/users/wiedymi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wiedymi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wiedymi/subscriptions",
"organizations_url": "https://api.github.com/users/wiedymi/orgs",
"repos_url": "https://api.github.com/users/wiedymi/repos",
"events_url": "https://api.github.com/users/wiedymi/events{/privacy}",
"received_events_url": "https://api.github.com/users/wiedymi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech",
"name": "speech",
"color": "d93f0b",
"default": false,
"description": ""
}
] | open | false | null | [] | null | [] | 1,638,873,422,000 | 1,639,065,363,000 | null | NONE | null | ## Adding a Dataset
- **Name:** *Common Voice Belarusian Dataset*
- **Description:** *[commonvoice.mozilla.org/be](https://commonvoice.mozilla.org/be)*
- **Data:** *[commonvoice.mozilla.org/be/datasets](https://commonvoice.mozilla.org/be/datasets)*
- **Motivation:** *It has more than 7GB of data, so it will be great to have it in this package so anyone can try to train something for Belarusian language.*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3393/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3393/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3392/comments | https://api.github.com/repos/huggingface/datasets/issues/3392/events | https://github.com/huggingface/datasets/issues/3392 | 1,073,073,408 | I_kwDODunzps4_9c0A | 3,392 | Dataset viewer issue for `dansbecker/hackernews_hiring_posts` | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"This issue was fixed by me calling `all_datasets.push_to_hub(\"hackernews_hiring_posts\")`.\r\n\r\nThe previous problems were from calling `all_datasets.save_to_disk` and then pushing with `my_repo.git_add` and `my_repo.push_to_hub`.\r\n"
] | 1,638,866,461,000 | 1,638,885,868,000 | 1,638,885,868,000 | CONTRIBUTOR | null | ## Dataset viewer issue for `dansbecker/hackernews_hiring_posts`
**Link:** https://huggingface.co/datasets/dansbecker/hackernews_hiring_posts
*short description of the issue*
Dataset preview not showing for uploaded DatasetDict. See https://discuss.huggingface.co/t/dataset-preview-not-showing-for-uploaded-datasetdict/12603
Am I the one who added this dataset ?
No -> @dansbecker | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3392/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3392/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3391/comments | https://api.github.com/repos/huggingface/datasets/issues/3391/events | https://github.com/huggingface/datasets/issues/3391 | 1,072,849,055 | I_kwDODunzps4_8mCf | 3,391 | method to select columns | {
"login": "cccntu",
"id": 31893406,
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cccntu",
"html_url": "https://github.com/cccntu",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"repos_url": "https://api.github.com/users/cccntu/repos",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"duplicate of #2655"
] | 1,638,845,059,000 | 1,638,845,127,000 | 1,638,845,127,000 | CONTRIBUTOR | null | **Is your feature request related to a problem? Please describe.**
* There is currently no way to select some columns of a dataset. In pandas, one can use `df[['col1', 'col2']]` to select columns, but in `datasets`, it results in error.
**Describe the solution you'd like**
* A new method that can be used to create a new dataset with only a list of specified columns.
**Describe alternatives you've considered**
`.remove_columns(self, columns: Union[str, List[str]], inverse: bool = False)`
Or
`.select(self, indices: Iterable = None, columns: List[str] = None)`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3391/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3391/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3390/comments | https://api.github.com/repos/huggingface/datasets/issues/3390/events | https://github.com/huggingface/datasets/issues/3390 | 1,072,462,456 | I_kwDODunzps4_7Hp4 | 3,390 | Loading dataset throws "KeyError: 'Field "builder_name" does not exist in table schema'" | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Got solved it with push_to_hub, closing"
] | 1,638,814,969,000 | 1,638,822,125,000 | 1,638,822,125,000 | NONE | null | ## Describe the bug
I have prepared dataset to datasets and now I am trying to load it back Finnish-NLP/voxpopuli_fi
I get "KeyError: 'Field "builder_name" does not exist in table schema'"
My dataset folder and files should be like @patrickvonplaten has here https://huggingface.co/datasets/flax-community/german-common-voice-processed
How my voxpopuli dataset looks like:

Part of the processing (path column is the absolute path to audio files)
```
def add_audio_column(example):
example['audio'] = example['path']
return example
voxpopuli = voxpopuli.map(add_audio_column)
voxpopuli.cast_column("audio", Audio())
voxpopuli["audio"] <-- to my knowledge this does load the local files and prepares those arrays
voxpopuli = voxpopuli.cast_column("audio", Audio(sampling_rate=16_000)) resampling 16kHz
```
I have then saved it to disk_
`voxpopuli.save_to_disk('/asr_disk/datasets_processed_new/voxpopuli')`
and made folder structure same as @patrickvonplaten
I also get same error while trying to load_dataset from his repo:

## Steps to reproduce the bug
```python
dataset = load_dataset("Finnish-NLP/voxpopuli_fi")
```
## Expected results
Dataset is loaded correctly and looks like in the first picture
## Actual results
Loading throws keyError:
KeyError: 'Field "builder_name" does not exist in table schema'
Resources I have been trying to follow:
https://huggingface.co/docs/datasets/audio_process.html
https://huggingface.co/docs/datasets/share_dataset.html
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.2.dev0
- Platform: Ubuntu 20.04.2 LTS
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3390/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3390/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3389/comments | https://api.github.com/repos/huggingface/datasets/issues/3389/events | https://github.com/huggingface/datasets/issues/3389 | 1,072,191,865 | I_kwDODunzps4_6Fl5 | 3,389 | Add EDGAR | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"cc @juliensimon "
] | 1,638,799,571,000 | 1,638,799,581,000 | null | MEMBER | null | ## Adding a Dataset
- **Name:** EDGAR Database
- **Description:** https://www.sec.gov/edgar/about EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system, is the primary system for companies and others submitting documents under the Securities Act of 1933, the Securities Exchange Act of 1934, the Trust Indenture Act of 1939, and the Investment Company Act of 1940. Containing millions of company and individual filings, EDGAR benefits investors, corporations, and the U.S. economy overall by increasing the efficiency, transparency, and fairness of the securities markets. The system processes about 3,000 filings per day, serves up 3,000 terabytes of data to the public annually, and accommodates 40,000 new filers per year on average. EDGAR® and EDGARLink® are registered trademarks of the SEC.
- **Data:** https://www.sec.gov/os/accessing-edgar-data
- **Motivation:** Enabling and improving FSI (Financial Services Industry) datasets to increase ease of use
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3389/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3389/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3388/comments | https://api.github.com/repos/huggingface/datasets/issues/3388/events | https://github.com/huggingface/datasets/pull/3388 | 1,072,022,021 | PR_kwDODunzps4vbnyY | 3,388 | Fix flaky test of the temporary directory used by load_from_disk | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"CI failed because of a server error - merging"
] | 1,638,788,971,000 | 1,638,789,903,000 | 1,638,789,889,000 | MEMBER | null | The test is flaky, here is an example of random CI failure:
https://github.com/huggingface/datasets/commit/73ed6615b4b3eb74d5311684f7b9e05cdb76c989
I fixed that by not checking the content of the random part of the temporary directory name | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3388/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3388/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3388",
"html_url": "https://github.com/huggingface/datasets/pull/3388",
"diff_url": "https://github.com/huggingface/datasets/pull/3388.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3388.patch",
"merged_at": 1638789889000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3387/comments | https://api.github.com/repos/huggingface/datasets/issues/3387/events | https://github.com/huggingface/datasets/pull/3387 | 1,071,836,456 | PR_kwDODunzps4vbAyC | 3,387 | Create Language Modeling task | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,777,367,000 | 1,639,761,508,000 | 1,639,761,507,000 | MEMBER | null | Create Language Modeling task to be able to specify the input "text" column in a dataset.
This can be useful for datasets which are not exclusively used for language modeling and have more than one column:
- for text classification datasets (with columns "review" and "rating", for example), the Language Modeling task can be used to specify the "text" column ("review" in this case).
TODO:
- [ ] Add the LanguageModeling task to all dataset scripts which can be used for language modeling | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3387/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3387/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3387",
"html_url": "https://github.com/huggingface/datasets/pull/3387",
"diff_url": "https://github.com/huggingface/datasets/pull/3387.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3387.patch",
"merged_at": 1639761507000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3386/comments | https://api.github.com/repos/huggingface/datasets/issues/3386/events | https://github.com/huggingface/datasets/pull/3386 | 1,071,813,141 | PR_kwDODunzps4va7-2 | 3,386 | Fix typos in dataset cards | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,775,240,000 | 1,638,783,055,000 | 1,638,783,054,000 | MEMBER | null | This PR:
- Fix typos in dataset cards
- Fix Papers With Code ID for:
- Bilingual Corpus of Arabic-English Parallel Tweets
- Tweets Hate Speech Detection
- Add pretty name tags | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3386/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3386/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3386",
"html_url": "https://github.com/huggingface/datasets/pull/3386",
"diff_url": "https://github.com/huggingface/datasets/pull/3386.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3386.patch",
"merged_at": 1638783054000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3385/comments | https://api.github.com/repos/huggingface/datasets/issues/3385/events | https://github.com/huggingface/datasets/issues/3385 | 1,071,742,310 | I_kwDODunzps4_4X1m | 3,385 | None batched `with_transform`, `set_transform` | {
"login": "cccntu",
"id": 31893406,
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cccntu",
"html_url": "https://github.com/cccntu",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"repos_url": "https://api.github.com/users/cccntu/repos",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Hi ! Thanks for the suggestion :)\r\nIt makes sense to me, and it can surely be implemented by wrapping the user's function to make it a batched function. However I'm not a big fan of the inconsistency it would create with `map`: `with_transform` is batched by default while `map` isn't.\r\n\r\nIs there something you would like to contribute ? I can give you some pointers if you want"
] | 1,638,768,054,000 | 1,639,491,858,000 | null | CONTRIBUTOR | null | **Is your feature request related to a problem? Please describe.**
A `torch.utils.data.Dataset.__getitem__` operates on a single example.
But 🤗 `Datasets.with_transform` doesn't seem to allow non-batched transform.
**Describe the solution you'd like**
Have a `batched=True` argument in `Datasets.with_transform`
**Describe alternatives you've considered**
* Convert a non-batched transform function to batched one myself.
* Wrap a 🤗 Dataset with torch Dataset, and add a `__getitem__`. 🙄
* Have `lazy=False` in `Dataset.map`, and returns a `LazyDataset` if `lazy=True`. This way the same `map` interface can be used, and existing code can be updated with one argument change. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3385/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3385/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3384/comments | https://api.github.com/repos/huggingface/datasets/issues/3384/events | https://github.com/huggingface/datasets/pull/3384 | 1,071,594,165 | PR_kwDODunzps4vaNwL | 3,384 | Adding mMARCO dataset | {
"login": "lhbonifacio",
"id": 17603035,
"node_id": "MDQ6VXNlcjE3NjAzMDM1",
"avatar_url": "https://avatars.githubusercontent.com/u/17603035?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhbonifacio",
"html_url": "https://github.com/lhbonifacio",
"followers_url": "https://api.github.com/users/lhbonifacio/followers",
"following_url": "https://api.github.com/users/lhbonifacio/following{/other_user}",
"gists_url": "https://api.github.com/users/lhbonifacio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhbonifacio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhbonifacio/subscriptions",
"organizations_url": "https://api.github.com/users/lhbonifacio/orgs",
"repos_url": "https://api.github.com/users/lhbonifacio/repos",
"events_url": "https://api.github.com/users/lhbonifacio/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhbonifacio/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,748,751,000 | 1,639,322,856,000 | 1,639,322,856,000 | NONE | null | We are adding mMARCO dataset to HuggingFace datasets repo.
This way, all the languages covered in the translation are available in a easy way. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3384/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3384/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3384",
"html_url": "https://github.com/huggingface/datasets/pull/3384",
"diff_url": "https://github.com/huggingface/datasets/pull/3384.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3384.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3383 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3383/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3383/comments | https://api.github.com/repos/huggingface/datasets/issues/3383/events | https://github.com/huggingface/datasets/pull/3383 | 1,071,551,884 | PR_kwDODunzps4vaFpm | 3,383 | add Georgian data in cc100. | {
"login": "AnzorGozalishvili",
"id": 55232459,
"node_id": "MDQ6VXNlcjU1MjMyNDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/55232459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AnzorGozalishvili",
"html_url": "https://github.com/AnzorGozalishvili",
"followers_url": "https://api.github.com/users/AnzorGozalishvili/followers",
"following_url": "https://api.github.com/users/AnzorGozalishvili/following{/other_user}",
"gists_url": "https://api.github.com/users/AnzorGozalishvili/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AnzorGozalishvili/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AnzorGozalishvili/subscriptions",
"organizations_url": "https://api.github.com/users/AnzorGozalishvili/orgs",
"repos_url": "https://api.github.com/users/AnzorGozalishvili/repos",
"events_url": "https://api.github.com/users/AnzorGozalishvili/events{/privacy}",
"received_events_url": "https://api.github.com/users/AnzorGozalishvili/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,736,689,000 | 1,639,492,643,000 | 1,639,492,642,000 | CONTRIBUTOR | null | update cc100 dataset to support loading Georgian (ka) data which is originally available in CC100 dataset source.
All tests are passed.
Dummy data generated.
metadata generated. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3383/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3383/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3383",
"html_url": "https://github.com/huggingface/datasets/pull/3383",
"diff_url": "https://github.com/huggingface/datasets/pull/3383.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3383.patch",
"merged_at": 1639492642000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3382/comments | https://api.github.com/repos/huggingface/datasets/issues/3382/events | https://github.com/huggingface/datasets/pull/3382 | 1,071,293,299 | PR_kwDODunzps4vZT2K | 3,382 | #3337 Add typing overloads to Dataset.__getitem__ for mypy | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"repos_url": "https://api.github.com/users/Dref360/repos",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Locally the `make quality` passes with the same dependencies. I would suggest upgrading flake8. (I can take care of it in another PR)\r\ncc @lhoestq ",
"Thank you for fixing flake8! I think we are ready to merge then. "
] | 1,638,651,289,000 | 1,639,477,735,000 | 1,639,477,735,000 | CONTRIBUTOR | null | Add typing overloads to Dataset.__getitem__ for mypy
Fixes #3337
**Iterable**
Iterable from `collections` cannot have a type, so you can't do `Iterable[int]` for example. `typing` has a Generic version that builds upon the one from `collections`.
**Flake8**
I had to add `# noqa: F811`, this is a bug from Flake8.
datasets uses flake8==3.7.9 which released in October 2019 if I update flake8 (4.0.1), I no longer get these errors, but I did not want to make the update without your approval. (It also triggers other errors like no args in f-strings.) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3382/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3382/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3382",
"html_url": "https://github.com/huggingface/datasets/pull/3382",
"diff_url": "https://github.com/huggingface/datasets/pull/3382.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3382.patch",
"merged_at": 1639477734000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3381/comments | https://api.github.com/repos/huggingface/datasets/issues/3381/events | https://github.com/huggingface/datasets/issues/3381 | 1,071,283,879 | I_kwDODunzps4_2n6n | 3,381 | Unable to load audio_features from common_voice dataset | {
"login": "ashu5644",
"id": 8268102,
"node_id": "MDQ6VXNlcjgyNjgxMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8268102?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashu5644",
"html_url": "https://github.com/ashu5644",
"followers_url": "https://api.github.com/users/ashu5644/followers",
"following_url": "https://api.github.com/users/ashu5644/following{/other_user}",
"gists_url": "https://api.github.com/users/ashu5644/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ashu5644/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ashu5644/subscriptions",
"organizations_url": "https://api.github.com/users/ashu5644/orgs",
"repos_url": "https://api.github.com/users/ashu5644/repos",
"events_url": "https://api.github.com/users/ashu5644/events{/privacy}",
"received_events_url": "https://api.github.com/users/ashu5644/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! Feel free to access `batch[\"audio\"][\"array\"]` and `batch[\"audio\"][\"sampling_rate\"]` instead\r\n\r\n`datasets` 1.16 introduced some changes in `common_voice` and now the `path` field is no longer a path to a local file (but rather the path to the file in the archive it's extracted from)",
"Thanks for the information. It works.",
"Cool ! Closing this issue then"
] | 1,638,647,951,000 | 1,638,813,162,000 | 1,638,813,162,000 | NONE | null | ## Describe the bug
I am not able to load audio features from common_voice dataset
## Steps to reproduce the bug
```
from datasets import load_dataset
import torchaudio
test_dataset = load_dataset("common_voice", "hi", split="test[:2%]")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
```
## Expected results
This piece of code should return test_dataset after loading audio features.
## Actual results
Reusing dataset common_voice (/home/jovyan/.cache/huggingface/datasets/common_voice/hi/6.1.0/b879a355caa529b11f2249400b61cadd0d9433f334d5c60f8c7216ccedfecfe1)
/opt/conda/lib/python3.7/site-packages/transformers/configuration_utils.py:341: UserWarning: Passing `gradient_checkpointing` to a config initialization is deprecated and will be removed in v5 Transformers. Using `model.gradient_checkpointing_enable()` instead, or if you are using the `Trainer` API, pass `gradient_checkpointing=True` in your `TrainingArguments`.
"Passing `gradient_checkpointing` to a config initialization is deprecated and will be removed in v5 "
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
0%| | 0/3 [00:00<?, ?ex/s]formats: can't open input file `common_voice_hi_23795358.mp3': No such file or directory
0%| | 0/3 [00:00<?, ?ex/s]
Traceback (most recent call last):
File "demo_file.py", line 23, in <module>
test_dataset = test_dataset.map(speech_file_to_array_fn)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2036, in map
desc=desc,
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 518, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 485, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py", line 411, in wrapper
out = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2368, in _map_single
example = apply_function_on_filtered_inputs(example, i, offset=offset)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2277, in apply_function_on_filtered_inputs
processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1978, in decorated
result = f(decorated_item, *args, **kwargs)
File "demo_file.py", line 19, in speech_file_to_array_fn
speech_array, sampling_rate = torchaudio.load(batch["path"])
File "/opt/conda/lib/python3.7/site-packages/torchaudio/backend/sox_io_backend.py", line 154, in load
filepath, frame_offset, num_frames, normalize, channels_first, format)
RuntimeError: Error loading audio file: failed to open file common_voice_hi_23795358.mp3
## Environment info
- `datasets` version: 1.16.1
- Platform: Linux-4.14.243 with-debian-bullseye-sid
- Python version: 3.7.9
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3381/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3381/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3380/comments | https://api.github.com/repos/huggingface/datasets/issues/3380/events | https://github.com/huggingface/datasets/issues/3380 | 1,071,166,270 | I_kwDODunzps4_2LM- | 3,380 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,609,513,000 | 1,638,609,513,000 | null | MEMBER | null | Thanks to all of you, `datasets` will pass 11.5k stars :star2: this week!
If you have a couple of minutes and want to participate in shaping the future of the ecosystem, please share your thoughts:
[**hf.co/oss-survey**](https://hf.co/oss-survey)
(please reply in the above feedback form rather than to this thread)
Thank you all on behalf of the HuggingFace team! 🤗 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3380/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3380/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3379/comments | https://api.github.com/repos/huggingface/datasets/issues/3379/events | https://github.com/huggingface/datasets/pull/3379 | 1,071,079,146 | PR_kwDODunzps4vYr7K | 3,379 | iter_archive on zipfiles with better compression type check | {
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://api.github.com/users/Mehdi2402/followers",
"following_url": "https://api.github.com/users/Mehdi2402/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehdi2402/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehdi2402/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehdi2402/subscriptions",
"organizations_url": "https://api.github.com/users/Mehdi2402/orgs",
"repos_url": "https://api.github.com/users/Mehdi2402/repos",
"events_url": "https://api.github.com/users/Mehdi2402/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehdi2402/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hello @lhoestq, thank you for your answer.\r\n\r\nI don't use pytest a lot so I think I might need some help on it :) but I tried some tests for `streaming_download_manager.py` only. I don't know how to test `download_manager.py` since we need to use local files.\r\n\r\n# Comments : \r\n* In **download_manager.py** I removed some unnecessary imports after the simplification of `_get_extraction_protocol_local`.\r\n* In **streaming_download_manager** I moved the raised Error as suggested.\r\n \r\n### I also started some tests on `StreamingDownloadManager()` :\r\n* Used an existing zipfile url and added a new one that has a folder and many files : \r\n```python\r\nTEST_GG_DRIVE_ZIPPED_URL = \"https://drive.google.com/uc?export=download&id=1k92sUfpHxKq8PXWRr7Y5aNHXwOCNUmqh\"\r\nTEST_GG_DRIVE2_ZIPPED_URL = \"https://drive.google.com/uc?export=download&id=1X4jyUBBbShyCRfD-vCO1ZvfqFXP3NEeU\"\r\n``` \r\n* **For now is being tested :**\r\n * Return type of the function : should be tuple\r\n * Files names\r\n * Files content\r\n * Added an `xfail` test for the gzip file, because I get a `zipfile.BadZipFile exception`.\r\n\r\n\r\n * And lastly, changed the test for `_get_extraction_protocol_throws` since it was moved to `_extract` : \r\n ```diff\r\n@pytest.mark.xfail(raises=NotImplementedError)\r\ndef test_streaming_dl_manager_get_extraction_protocol_throws(urlpath):\r\n- _get_extraction_protocol(urlpath)\r\n\r\n@pytest.mark.xfail(raises=NotImplementedError)\r\ndef test_streaming_dl_manager_get_extraction_protocol_throws(urlpath):\r\n+ StreamingDownloadManager()._extract(urlpath)\r\n```\r\n\r\n\r\n"
] | 1,638,579,888,000 | 1,639,410,829,000 | null | CONTRIBUTOR | null | Hello @lhoestq , thank you for your detailed answer on previous PR !
I made this new PR because I misused git on the previous one #3347.
Related issue #3272.
# Comments :
* For extension check I used the `_get_extraction_protocol` function in **download_manager.py** with a slight change and called it `_get_extraction_protocol_local`:
**I removed this part :**
```python
elif path.endswith(".tar.gz") or path.endswith(".tgz"):
raise NotImplementedError(
f"Extraction protocol for TAR archives like '{urlpath}' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead."
)
```
**And also changed :**
```diff
- extension = path.split(".")[-1]
+ extension = "tar" if path.endswith(".tar.gz") else path.split(".")[-1]
```
The reason for this is a compression like **.tar.gz** will be considered a **.gz** which is handled with **zipfile**, though **tar.gz** can only be opened using **tarfile**.
Please tell me if there's anything to change.
# Tasks :
- [x] download_manager.py
- [x] streaming_download_manager.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3379/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3379/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3379",
"html_url": "https://github.com/huggingface/datasets/pull/3379",
"diff_url": "https://github.com/huggingface/datasets/pull/3379.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3379.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3378/comments | https://api.github.com/repos/huggingface/datasets/issues/3378/events | https://github.com/huggingface/datasets/pull/3378 | 1,070,580,126 | PR_kwDODunzps4vXF1D | 3,378 | Add The Pile subsets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,537,294,000 | 1,639,073,485,000 | 1,639,073,483,000 | MEMBER | null | Add The Pile subsets:
- pubmed
- ubuntu_irc
- europarl
- hacker_news
- nih_exporter
Close bigscience-workshop/data_tooling#301.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3378/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3378/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3378",
"html_url": "https://github.com/huggingface/datasets/pull/3378",
"diff_url": "https://github.com/huggingface/datasets/pull/3378.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3378.patch",
"merged_at": 1639073483000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3377/comments | https://api.github.com/repos/huggingface/datasets/issues/3377/events | https://github.com/huggingface/datasets/pull/3377 | 1,070,562,907 | PR_kwDODunzps4vXCHn | 3,377 | COCO 🥥 on the 🤗 Hub? | {
"login": "merveenoyan",
"id": 53175384,
"node_id": "MDQ6VXNlcjUzMTc1Mzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/merveenoyan",
"html_url": "https://github.com/merveenoyan",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_url": "https://api.github.com/users/merveenoyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/merveenoyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/merveenoyan/subscriptions",
"organizations_url": "https://api.github.com/users/merveenoyan/orgs",
"repos_url": "https://api.github.com/users/merveenoyan/repos",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/merveenoyan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@mariosasko I fixed couple of bugs",
"TO-DO: \r\n- [x] Add unlabeled 2017 splits, train and validation splits of 2015\r\n- [x] Add Class Labels as list instead",
"@mariosasko added fine & coarse grained labels, will fix the bugs (currently getting set up with VM, my internet is too slow to run the tests and download the data 🥲)",
"migrated to here https://github.com/huggingface/datasets/tree/coco"
] | 1,638,536,127,000 | 1,640,009,641,000 | 1,640,009,640,000 | CONTRIBUTOR | null | This is a draft PR since I ran into few small problems.
I referred to this TFDS code: https://github.com/tensorflow/datasets/blob/2538a08c184d53b37bfcf52cc21dd382572a88f4/tensorflow_datasets/object_detection/coco.py
cc: @mariosasko | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3377/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3377/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3377",
"html_url": "https://github.com/huggingface/datasets/pull/3377",
"diff_url": "https://github.com/huggingface/datasets/pull/3377.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3377.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3376/comments | https://api.github.com/repos/huggingface/datasets/issues/3376/events | https://github.com/huggingface/datasets/pull/3376 | 1,070,522,979 | PR_kwDODunzps4vW5sB | 3,376 | Update clue benchmark | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI error is due to missing tags in the CLUE dataset card - merging !"
] | 1,638,533,161,000 | 1,638,972,882,000 | 1,638,972,881,000 | CONTRIBUTOR | null | Fix #3374 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3376/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3376/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3376",
"html_url": "https://github.com/huggingface/datasets/pull/3376",
"diff_url": "https://github.com/huggingface/datasets/pull/3376.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3376.patch",
"merged_at": 1638972881000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3375/comments | https://api.github.com/repos/huggingface/datasets/issues/3375/events | https://github.com/huggingface/datasets/pull/3375 | 1,070,454,913 | PR_kwDODunzps4vWrXz | 3,375 | Support streaming zipped dataset repo by passing only repo name | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I just tested and I think this only opens one file ? If there are several files in the ZIP, only the first one is opened. To open several files from a ZIP, one has to call `open` several times.\r\n\r\nWhat about updating the CSV loader to make it `download_and_extract` zip files, and open each extracted file ?",
"I have implemented the glob of ZIP files in the packaged modules:\r\n- csv\r\n- json\r\n- text",
"Also for streaming and non-streaming.",
"In https://github.com/huggingface/datasets/pull/3375/commits/c10275fe36085601cb7bdb9daee9a8f1fc734f48, there were 3 failing tests, only on Linux:\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_streaming_download_manager.py::test_streaming_dl_manager_get_extraction_protocol[https://drive.google.com/uc?export=download&id=1k92sUfpHxKq8PXWRr7Y5aNHXwOCNUmqh-zip]\r\nFAILED tests/test_streaming_download_manager.py::test_streaming_gg_drive - Fi...\r\nFAILED tests/test_streaming_download_manager.py::test_streaming_gg_drive_zipped\r\n= 3 failed, 3553 passed, 2950 skipped, 2 xfailed, 1 xpassed, 125 warnings in 192.79s (0:03:12) =\r\n```\r\n\r\nAfter re-running the CI in https://github.com/huggingface/datasets/pull/3375/commits/57bfe1f342cd3c59d2510b992d5f06a0761eb147, there was only 1 failing test:\r\n- On Linux:\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_streaming_download_manager.py::test_streaming_gg_drive_zipped\r\n= 1 failed, 3555 passed, 2950 skipped, 2 xfailed, 1 xpassed, 125 warnings in 199.76s (0:03:19) =\r\n```\r\n- On Windows:\r\n```\r\n=========================== short test summary info ===========================\r\nFAILED tests/test_load.py::test_load_dataset_builder_for_community_dataset_without_script\r\n= 1 failed, 3551 passed, 2954 skipped, 2 xfailed, 1 xpassed, 121 warnings in 478.58s (0:07:58) =\r\n```\r\n\r\nThe test `tests/test_streaming_download_manager.py::test_streaming_gg_drive_zipped` passes locally.\r\n\r\nI guess the issue is caused by those tests and has nothing to do with this PR.",
"@lhoestq my final proposed solution:\r\n- I have added the method `iter_files` to DownloadManager and StreamingDownloadManager\r\n- I use this in modules: \"csv\", \"json\", \"text\"\r\n- I test for CSV/JSONL/TXT zipped (and non-zipped) files, both in streaming and non-streaming modes",
"> Note that at one point we might consider switching to using `iter_archive` for ZIP files in the json/text/csv loaders since it should be faster.\r\n\r\nAs far as the functionality is kept... ;)"
] | 1,638,528,185,000 | 1,639,677,812,000 | 1,639,677,811,000 | MEMBER | null | Proposed solution:
- I have added the method `iter_files` to DownloadManager and StreamingDownloadManager
- I use this in modules: "csv", "json", "text"
- I test for CSV/JSONL/TXT zipped (and non-zipped) files, both in streaming and non-streaming modes
Fix #3373. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3375/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3375/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3375",
"html_url": "https://github.com/huggingface/datasets/pull/3375",
"diff_url": "https://github.com/huggingface/datasets/pull/3375.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3375.patch",
"merged_at": 1639677811000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3374/comments | https://api.github.com/repos/huggingface/datasets/issues/3374/events | https://github.com/huggingface/datasets/issues/3374 | 1,070,426,462 | I_kwDODunzps4_zWle | 3,374 | NonMatchingChecksumError for the CLUE:cluewsc2020, chid, c3 and tnews | {
"login": "Namco0816",
"id": 34687537,
"node_id": "MDQ6VXNlcjM0Njg3NTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/34687537?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Namco0816",
"html_url": "https://github.com/Namco0816",
"followers_url": "https://api.github.com/users/Namco0816/followers",
"following_url": "https://api.github.com/users/Namco0816/following{/other_user}",
"gists_url": "https://api.github.com/users/Namco0816/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Namco0816/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Namco0816/subscriptions",
"organizations_url": "https://api.github.com/users/Namco0816/orgs",
"repos_url": "https://api.github.com/users/Namco0816/repos",
"events_url": "https://api.github.com/users/Namco0816/events{/privacy}",
"received_events_url": "https://api.github.com/users/Namco0816/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Seems like the issue still exists,:\r\n`Downloading and preparing dataset clue/chid (download: 127.15 MiB, generated: 259.71 MiB, post-processed: Unknown size, total: 386.86 MiB) to /mnt/cache/tanhaochen/.cache/huggingface/datasets/clue/chid/1.0.0/e55b490cb7809dcd8db31b9a87119f2e2ec87cdc060da8a9ac070b070ca3e379...\r\nTraceback (most recent call last):\r\n File \"/mnt/cache/tanhaochen/PromptCLUE/test_datasets.py\", line 3, in <module>\r\n cluewsc2020 = datasets.load_dataset(\"clue\",\"chid\")\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/load.py\", line 1667, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/builder.py\", line 593, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/builder.py\", line 663, in _download_and_prepare\r\n verify_checksums(\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/utils/info_utils.py\", line 40, in verify_checksums\r\n raise NonMatchingChecksumError(error_msg + str(bad_urls))\r\ndatasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://storage.googleapis.com/cluebenchmark/tasks/chid_public.zip']\r\n`",
"Hi,\r\n\r\nthe fix hasn't been merged yet (it should be merged early next week)."
] | 1,638,526,254,000 | 1,638,972,881,000 | 1,638,972,881,000 | NONE | null | Hi, it seems like there are updates in cluewsc2020, chid, c3 and tnews, since i could not load them due to the checksum error. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3374/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3374/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3373/comments | https://api.github.com/repos/huggingface/datasets/issues/3373/events | https://github.com/huggingface/datasets/issues/3373 | 1,070,406,391 | I_kwDODunzps4_zRr3 | 3,373 | Support streaming zipped CSV dataset repo by passing only repo name | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,524,904,000 | 1,639,677,811,000 | 1,639,677,811,000 | MEMBER | null | Given a community 🤗 dataset repository containing only a zipped CSV file (only raw data, no loading script), I would like to load it in streaming mode without passing `data_files`:
```
ds_name = "bigscience-catalogue-data/vietnamese_poetry_from_fsoft_ai_lab"
ds = load_dataset(ds_name, split="train", streaming=True, use_auth_token=True)
item = next(iter(ds))
```
Currently, it gives a `FileNotFoundError` because there is no glob (no "\*" after "zip://": "zip://*") in the passed URL:
```
'zip://::https://huggingface.co/datasets/bigscience-catalogue-data/vietnamese_poetry_from_fsoft_ai_lab/resolve/e5d45f1bd9a8a798cc14f0a45ebc1ce91907c792/poems_dataset.zip'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3373/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3373/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3372/comments | https://api.github.com/repos/huggingface/datasets/issues/3372/events | https://github.com/huggingface/datasets/issues/3372 | 1,069,948,178 | I_kwDODunzps4_xh0S | 3,372 | [SEO improvement] Add Dataset Metadata to make datasets indexable | {
"login": "cakiki",
"id": 3664563,
"node_id": "MDQ6VXNlcjM2NjQ1NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cakiki",
"html_url": "https://github.com/cakiki",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://api.github.com/users/cakiki/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cakiki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cakiki/subscriptions",
"organizations_url": "https://api.github.com/users/cakiki/orgs",
"repos_url": "https://api.github.com/users/cakiki/repos",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"received_events_url": "https://api.github.com/users/cakiki/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,638,476,467,000 | 1,638,476,467,000 | null | NONE | null | Some people who host datasets on github seem to include a table of metadata at the end of their README.md to make the dataset indexable by [Google Dataset Search](https://datasetsearch.research.google.com/) (See [here](https://github.com/google-research/google-research/tree/master/goemotions#dataset-metadata) and [here](https://github.com/cvdfoundation/google-landmark#dataset-metadata)). This could be a useful addition to canonical datasets; perhaps even community datasets.
I'll include a screenshot (as opposed to markdown) as an example so as not to have a github issue indexed as a dataset:
> 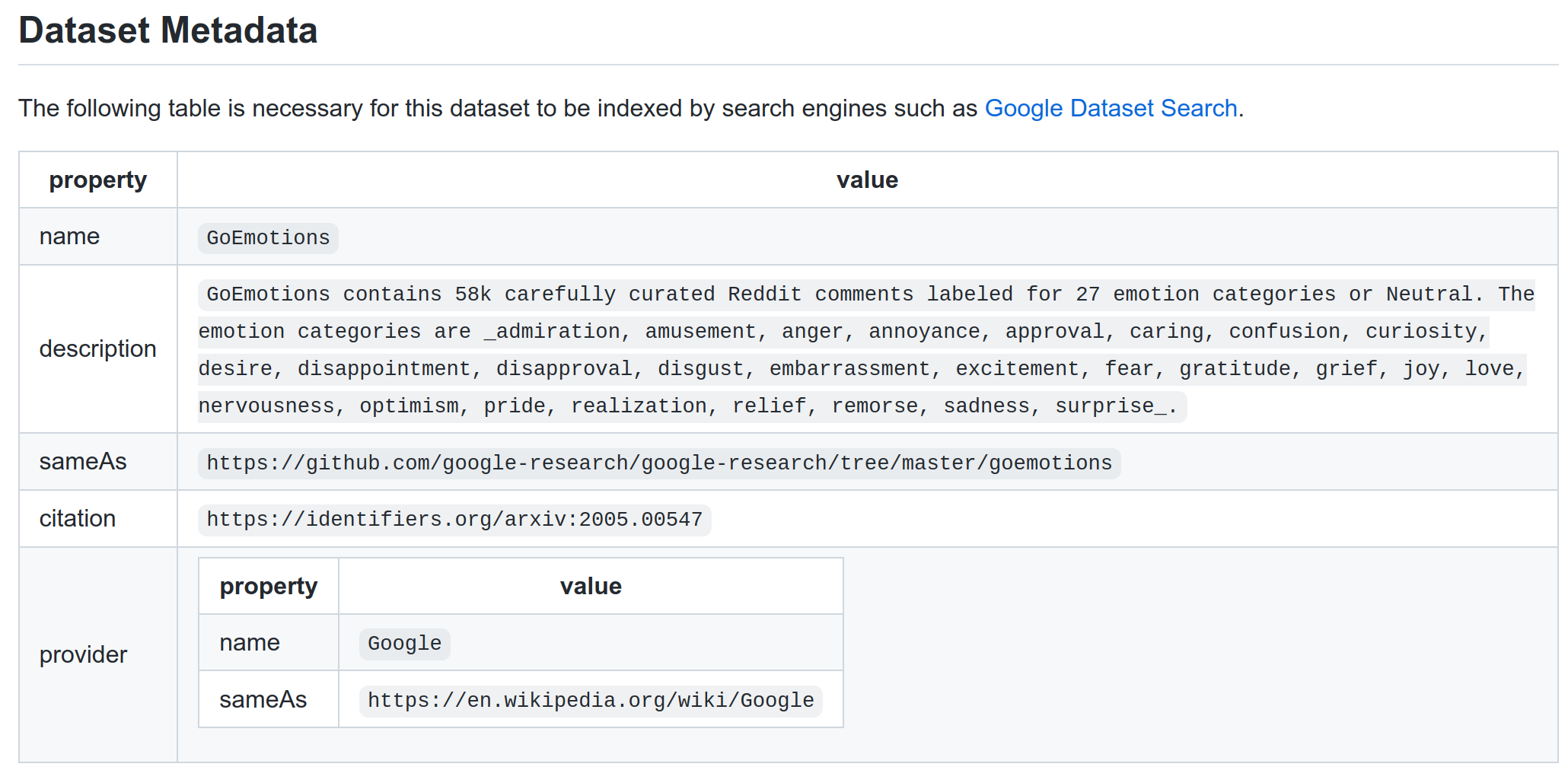
**_PS: It might very well be the case that this is already covered by some other markdown magic I'm not aware of._**
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3372/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3372/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3371/comments | https://api.github.com/repos/huggingface/datasets/issues/3371/events | https://github.com/huggingface/datasets/pull/3371 | 1,069,821,335 | PR_kwDODunzps4vUnbp | 3,371 | New: Americas NLI dataset | {
"login": "fdschmidt93",
"id": 39233597,
"node_id": "MDQ6VXNlcjM5MjMzNTk3",
"avatar_url": "https://avatars.githubusercontent.com/u/39233597?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fdschmidt93",
"html_url": "https://github.com/fdschmidt93",
"followers_url": "https://api.github.com/users/fdschmidt93/followers",
"following_url": "https://api.github.com/users/fdschmidt93/following{/other_user}",
"gists_url": "https://api.github.com/users/fdschmidt93/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fdschmidt93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fdschmidt93/subscriptions",
"organizations_url": "https://api.github.com/users/fdschmidt93/orgs",
"repos_url": "https://api.github.com/users/fdschmidt93/repos",
"events_url": "https://api.github.com/users/fdschmidt93/events{/privacy}",
"received_events_url": "https://api.github.com/users/fdschmidt93/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,467,099,000 | 1,638,971,892,000 | 1,638,971,891,000 | CONTRIBUTOR | null | This PR adds the [Americas NLI](https://arxiv.org/abs/2104.08726) dataset, extension of XNLI to 10 low-resource indigenous languages spoken in the Americas: Ashaninka, Aymara, Bribri, Guarani, Nahuatl, Otomi, Quechua, Raramuri, Shipibo-Konibo, and Wixarika.
One odd thing (not sure) is that I had to set
`datasets-cli dummy_data ./datasets/americas_nli/ --auto_generate --n_lines 7500`
`n_lines` very large to successfully generate the dummy files for all the subsets. Happy to get some guidance here.
Otherwise, I hope everything is in order :)
e: missed a step, onto fixing the tests
e2: there you go -- hope it's ok to have added more languages with their ISO codes to `languages.json`, need those tests to pass :laughing: | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3371/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3371/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3371",
"html_url": "https://github.com/huggingface/datasets/pull/3371",
"diff_url": "https://github.com/huggingface/datasets/pull/3371.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3371.patch",
"merged_at": 1638971891000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3370 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3370/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3370/comments | https://api.github.com/repos/huggingface/datasets/issues/3370/events | https://github.com/huggingface/datasets/pull/3370 | 1,069,735,423 | PR_kwDODunzps4vUVA3 | 3,370 | Document a training loop for streaming dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,461,820,000 | 1,638,538,475,000 | 1,638,538,474,000 | MEMBER | null | I added some docs about streaming dataset. In particular I added two subsections:
- one on how to use `map` for preprocessing
- one on how to use a streaming dataset in a pytorch training loop
cc @patrickvonplaten @stevhliu if you have some comments
cc @Rocketknight1 later we can add the one for TF and I might need your help ^^' | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3370/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3370/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3370",
"html_url": "https://github.com/huggingface/datasets/pull/3370",
"diff_url": "https://github.com/huggingface/datasets/pull/3370.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3370.patch",
"merged_at": 1638538474000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3369/comments | https://api.github.com/repos/huggingface/datasets/issues/3369/events | https://github.com/huggingface/datasets/issues/3369 | 1,069,587,674 | I_kwDODunzps4_wJza | 3,369 | [Audio] Allow resampling for audio datasets in streaming mode | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
},
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"This requires implementing `cast_column` for iterable datasets, it could be a very nice addition !\r\n\r\n<s>It can also be useful to be able to disable the audio/image decoding for the dataset viewer (see PR https://github.com/huggingface/datasets/pull/3430) cc @severo </s>\r\nEDIT: actually following https://github.com/huggingface/datasets/issues/3145 the dataset viewer might not need it anymore",
"Just to clarify a bit. This feature is **always** needed when using the common voice dataset in streaming mode. So I think it's quite important"
] | 1,638,453,897,000 | 1,639,670,119,000 | 1,639,670,119,000 | MEMBER | null | Many audio datasets like Common Voice always need to be resampled. This can very easily be done in non-streaming mode as follows:
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "ab", split="test")
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
```
However in streaming mode it fails currently:
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "ab", split="test", streaming=True)
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
```
with the following error:
```
AttributeError: 'IterableDataset' object has no attribute 'cast_column'
```
It would be great if we could add such a feature (I'm not 100% sure though how complex this would be) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3369/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3369/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3368/comments | https://api.github.com/repos/huggingface/datasets/issues/3368/events | https://github.com/huggingface/datasets/pull/3368 | 1,069,403,624 | PR_kwDODunzps4vTObo | 3,368 | Fix dict source_datasets tagset validator | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,442,340,000 | 1,638,460,118,000 | 1,638,460,117,000 | MEMBER | null | Currently, the `source_datasets` tag validation does not support passing a dict with configuration keys.
This PR:
- Extends `tagset_validator` to support regex tags
- Uses `tagset_validator` to validate dict `source_datasets` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3368/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3368/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3368",
"html_url": "https://github.com/huggingface/datasets/pull/3368",
"diff_url": "https://github.com/huggingface/datasets/pull/3368.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3368.patch",
"merged_at": 1638460117000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3367/comments | https://api.github.com/repos/huggingface/datasets/issues/3367/events | https://github.com/huggingface/datasets/pull/3367 | 1,069,241,274 | PR_kwDODunzps4vSsfk | 3,367 | Fix typo in other-structured-to-text task tag | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,432,147,000 | 1,638,461,234,000 | 1,638,461,233,000 | MEMBER | null | Fix typo in task tag:
- `other-stuctured-to-text` (before)
- `other-structured-to-text` (now) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3367/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3367/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3367",
"html_url": "https://github.com/huggingface/datasets/pull/3367",
"diff_url": "https://github.com/huggingface/datasets/pull/3367.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3367.patch",
"merged_at": 1638461233000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3366/comments | https://api.github.com/repos/huggingface/datasets/issues/3366/events | https://github.com/huggingface/datasets/issues/3366 | 1,069,214,022 | I_kwDODunzps4_uulG | 3,366 | Add multimodal datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,429,844,000 | 1,638,430,413,000 | null | MEMBER | null | Epic issue to track the addition of multimodal datasets:
- [ ] #2526
- [ ] #1842
- [ ] #1810
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
@VictorSanh feel free to add and sort by priority any interesting dataset. I have added the multimodal dataset requests which were already present as issues. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3366/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/3366/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3365/comments | https://api.github.com/repos/huggingface/datasets/issues/3365/events | https://github.com/huggingface/datasets/issues/3365 | 1,069,195,887 | I_kwDODunzps4_uqJv | 3,365 | Add task tags for multimodal datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,638,428,300,000 | 1,638,430,389,000 | null | MEMBER | null | ## **Is your feature request related to a problem? Please describe.**
Currently, task tags are either exclusively related to text or speech processing:
- https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/tasks.json
## **Describe the solution you'd like**
We should also add tasks related to:
- multimodality
- image
- video
CC: @VictorSanh @lewtun @lhoestq @merveenoyan @SBrandeis | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3365/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3365/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3364/comments | https://api.github.com/repos/huggingface/datasets/issues/3364/events | https://github.com/huggingface/datasets/pull/3364 | 1,068,851,196 | PR_kwDODunzps4vRaxq | 3,364 | Use the Audio feature in the AutomaticSpeechRecognition template | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,391,346,000 | 1,638,449,170,000 | null | CONTRIBUTOR | null | This updates the ASR template and all supported datasets to use the `Audio` feature | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3364/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3364/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3364",
"html_url": "https://github.com/huggingface/datasets/pull/3364",
"diff_url": "https://github.com/huggingface/datasets/pull/3364.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3364.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3363/comments | https://api.github.com/repos/huggingface/datasets/issues/3363/events | https://github.com/huggingface/datasets/pull/3363 | 1,068,824,340 | PR_kwDODunzps4vRVCl | 3,363 | Update URL of Jeopardy! dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing this PR in favor of #3266."
] | 1,638,389,290,000 | 1,638,534,901,000 | 1,638,534,901,000 | CONTRIBUTOR | null | Updates the URL of the Jeopardy! dataset.
Fix #3361 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3363/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3363/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3363",
"html_url": "https://github.com/huggingface/datasets/pull/3363",
"diff_url": "https://github.com/huggingface/datasets/pull/3363.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3363.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3362/comments | https://api.github.com/repos/huggingface/datasets/issues/3362/events | https://github.com/huggingface/datasets/pull/3362 | 1,068,809,768 | PR_kwDODunzps4vRR2r | 3,362 | Adapt image datasets | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This PR can be merged after #3163 is merged (this PR is pretty big because I was working on the forked branch).\r\n\r\n@lhoestq @albertvillanova Could you please take a look at the changes in `src/datasets/utils/streaming_download_manager.py`? These changes were required to support streaming of the `cats_vs_dogs` and the `beans` datasets.",
"The CI failures are due to the missing fields in the README files.",
"and thanks for adding support for Path.name and Path.parent for streaming :)"
] | 1,638,388,321,000 | 1,639,075,062,000 | 1,639,075,061,000 | CONTRIBUTOR | null | This PR:
* adapts the ImageClassification template to use the new Image feature
* adapts the following datasets to use the new Image feature:
* beans (+ fixes streaming)
* cast_vs_dogs (+ fixes streaming)
* cifar10
* cifar100
* fashion_mnist
* mnist
* head_qa
cc @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3362/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3362/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3362",
"html_url": "https://github.com/huggingface/datasets/pull/3362",
"diff_url": "https://github.com/huggingface/datasets/pull/3362.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3362.patch",
"merged_at": 1639075061000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3361/comments | https://api.github.com/repos/huggingface/datasets/issues/3361/events | https://github.com/huggingface/datasets/issues/3361 | 1,068,736,268 | I_kwDODunzps4_s58M | 3,361 | Jeopardy _URL access denied | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Just a side note: duplicate #3264"
] | 1,638,382,893,000 | 1,639,227,023,000 | 1,638,789,391,000 | CONTRIBUTOR | null | ## Describe the bug
http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz returns Access Denied now.
However, https://drive.google.com/file/d/0BwT5wj_P7BKXb2hfM3d2RHU1ckE/view?usp=sharing from the original Reddit post https://www.reddit.com/r/datasets/comments/1uyd0t/200000_jeopardy_questions_in_a_json_file/ may work.
## Steps to reproduce the bug
```shell
> python
Python 3.7.12 (default, Sep 5 2021, 08:34:29)
[Clang 11.0.3 (clang-1103.0.32.62)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
```
```python
>>> from datasets import load_dataset
>>> load_dataset("jeopardy")
```
## Expected results
The download completes.
## Actual results
```shell
Downloading: 4.18kB [00:00, 1.60MB/s]
Downloading: 2.03kB [00:00, 1.04MB/s]
Using custom data configuration default
Downloading and preparing dataset jeopardy/default (download: 12.13 MiB, generated: 34.46 MiB, post-processed: Unknown size, total: 46.59 MiB) to /Users/mike/.cache/huggingface/datasets/jeopardy/default/0.1.0/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/load.py", line 1632, in load_dataset
use_auth_token=use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 608, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/mike/.cache/huggingface/modules/datasets_modules/datasets/jeopardy/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810/jeopardy.py", line 72, in _split_generators
filepath = dl_manager.download_and_extract(_DATA_URL)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 197, in download
download_func, url_or_urls, map_tuple=True, num_proc=download_config.num_proc, disable_tqdm=False
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 197, in map_nested
return function(data_struct)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 305, in cached_path
use_auth_token=download_config.use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
---
```shell
> curl http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
```xml
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>70Y9R36XNPEQXMGV</RequestId><HostId>G6F5AK4qo7JdaEdKGMtS0P6gdLPeFOdEfSEfvTOZEfk9km0/jAfp08QLfKSTFFj1oWIKoAoBehM=</HostId></Error>
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14.0
- Platform: macOS Catalina 10.15.7
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3361/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3361/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3360/comments | https://api.github.com/repos/huggingface/datasets/issues/3360/events | https://github.com/huggingface/datasets/pull/3360 | 1,068,724,697 | PR_kwDODunzps4vQ_16 | 3,360 | Add The Pile USPTO subset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,382,085,000 | 1,638,531,929,000 | 1,638,531,928,000 | MEMBER | null | Add:
- USPTO subset of The Pile: "uspto" config
Close bigscience-workshop/data_tooling#297.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3360/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3360/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3360",
"html_url": "https://github.com/huggingface/datasets/pull/3360",
"diff_url": "https://github.com/huggingface/datasets/pull/3360.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3360.patch",
"merged_at": 1638531927000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3359/comments | https://api.github.com/repos/huggingface/datasets/issues/3359/events | https://github.com/huggingface/datasets/pull/3359 | 1,068,638,213 | PR_kwDODunzps4vQtI0 | 3,359 | Add The Pile Free Law subset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@albertvillanova Is there a specific reason you’re adding the Pile under “the” instead of under “pile”? That does not appear to be consistent with other datasets.",
"Hi @StellaAthena,\r\n\r\nI asked myself the same question, but at the end I decided to be consistent with previously added Pile subsets:\r\n- #2817\r\n\r\nI guess the reason is to stress that the definite article is always used before the name of the dataset (your site says: \"The Pile. An 800GB Dataset of Diverse Text for Language Modeling\"). Other datasets are not usually preceded by the definite article, like \"the SQuAD\" or \"the GLUE\" or \"the Common Voice\"...\r\n\r\nCC: @lhoestq ",
"> I guess the reason is to stress that the definite article is always used before the name of the dataset (your site says: \"The Pile. An 800GB Dataset of Diverse Text for Language Modeling\").\r\n\r\nYes that's because of this that it starts with \"the\""
] | 1,638,377,164,000 | 1,638,785,537,000 | 1,638,379,844,000 | MEMBER | null | Add:
- Free Law subset of The Pile: "free_law" config
Close bigscience-workshop/data_tooling#75.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3359/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3359/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3359",
"html_url": "https://github.com/huggingface/datasets/pull/3359",
"diff_url": "https://github.com/huggingface/datasets/pull/3359.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3359.patch",
"merged_at": 1638379843000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3358/comments | https://api.github.com/repos/huggingface/datasets/issues/3358/events | https://github.com/huggingface/datasets/issues/3358 | 1,068,623,216 | I_kwDODunzps4_seVw | 3,358 | add new field, and get errors | {
"login": "yanllearnn",
"id": 38966558,
"node_id": "MDQ6VXNlcjM4OTY2NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yanllearnn",
"html_url": "https://github.com/yanllearnn",
"followers_url": "https://api.github.com/users/yanllearnn/followers",
"following_url": "https://api.github.com/users/yanllearnn/following{/other_user}",
"gists_url": "https://api.github.com/users/yanllearnn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yanllearnn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yanllearnn/subscriptions",
"organizations_url": "https://api.github.com/users/yanllearnn/orgs",
"repos_url": "https://api.github.com/users/yanllearnn/repos",
"events_url": "https://api.github.com/users/yanllearnn/events{/privacy}",
"received_events_url": "https://api.github.com/users/yanllearnn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi, \r\n\r\ncould you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests? ",
"> Hi,\r\n> \r\n> could you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests?\r\n\r\nok."
] | 1,638,376,538,000 | 1,638,411,982,000 | 1,638,411,982,000 | NONE | null | after adding new field **tokenized_examples["example_id"]**, and get errors below,
I think it is due to changing data to tensor, and **tokenized_examples["example_id"]** is string list
**all fields**
```
***************** train_dataset 1: Dataset({
features: ['attention_mask', 'end_positions', 'example_id', 'input_ids', 'start_positions', 'token_type_ids'],
num_rows: 87714
})
```
**Errors**
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 705, in convert_to_tensors
tensor = as_tensor(value)
ValueError: too many dimensions 'str'
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3358/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3358/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3357/comments | https://api.github.com/repos/huggingface/datasets/issues/3357/events | https://github.com/huggingface/datasets/pull/3357 | 1,068,607,382 | PR_kwDODunzps4vQmcL | 3,357 | Update README.md | {
"login": "apergo-ai",
"id": 68908804,
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apergo-ai",
"html_url": "https://github.com/apergo-ai",
"followers_url": "https://api.github.com/users/apergo-ai/followers",
"following_url": "https://api.github.com/users/apergo-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/apergo-ai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apergo-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apergo-ai/subscriptions",
"organizations_url": "https://api.github.com/users/apergo-ai/orgs",
"repos_url": "https://api.github.com/users/apergo-ai/repos",
"events_url": "https://api.github.com/users/apergo-ai/events{/privacy}",
"received_events_url": "https://api.github.com/users/apergo-ai/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,375,646,000 | 1,638,375,646,000 | null | CONTRIBUTOR | null | After having worked a bit with the dataset.
As far as I know, it is solely in English (en-US). There are only a few mails in Spanish, French or German (less than a dozen I would estimate). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3357/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3357/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3357",
"html_url": "https://github.com/huggingface/datasets/pull/3357",
"diff_url": "https://github.com/huggingface/datasets/pull/3357.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3357.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3356/comments | https://api.github.com/repos/huggingface/datasets/issues/3356/events | https://github.com/huggingface/datasets/pull/3356 | 1,068,503,932 | PR_kwDODunzps4vQQLD | 3,356 | to_tf_dataset() refactor | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Also, please don't merge yet - I need to make sure all the code samples and notebooks have a collate_fn specified, since we're removing the ability for this method to work without one!",
"Hi @lhoestq @mariosasko, the other PRs this was depending on in Transformers and huggingface/notebooks are now merged, so this is ready to go. Do you want to take one more look at it, or are you happy at this point?",
"The documentation for the method is fine, it doesn't need to be changed, but the tutorial notebook definitely looks a little out of date. Let me see what I can do!",
"@lhoestq I rewrote the last bit of the notebook - let me know what you think!",
"Cool thank you ! It's much nicer that what we had :)\r\n\r\nI also spotted other things I'd like to update in the notebook (especially the beginning) but it can be fixed later"
] | 1,638,370,470,000 | 1,639,045,613,000 | 1,639,045,613,000 | CONTRIBUTOR | null | This is the promised cleanup to `to_tf_dataset()` now that the course is out of the way! The main changes are:
- A collator is always required (there was way too much hackiness making things like labels work without it)
- Lots of cleanup and a lot of code moved to `_get_output_signature`
- Should now handle it gracefully when the data collator adds unexpected columns | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3356/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 3,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3356/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3356",
"html_url": "https://github.com/huggingface/datasets/pull/3356",
"diff_url": "https://github.com/huggingface/datasets/pull/3356.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3356.patch",
"merged_at": 1639045613000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3355/comments | https://api.github.com/repos/huggingface/datasets/issues/3355/events | https://github.com/huggingface/datasets/pull/3355 | 1,068,468,573 | PR_kwDODunzps4vQIoy | 3,355 | Extend support for streaming datasets that use pd.read_excel | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"TODO in the future: https://github.com/huggingface/datasets/pull/3355#discussion_r761138011\r\n- If we finally find a use case where the `pd.read_excel()` can work in streaming mode (using fsspec), that is, without using the `.read()`, I propose to try this first, catch the ValueError and then try with `.read`, but all implemented in `xpandas_read_excel`. "
] | 1,638,368,563,000 | 1,639,725,859,000 | 1,639,725,858,000 | MEMBER | null | This PR fixes error:
```
ValueError: Cannot seek streaming HTTP file
```
CC: @severo | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3355/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3355/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3355",
"html_url": "https://github.com/huggingface/datasets/pull/3355",
"diff_url": "https://github.com/huggingface/datasets/pull/3355.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3355.patch",
"merged_at": 1639725858000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3354/comments | https://api.github.com/repos/huggingface/datasets/issues/3354/events | https://github.com/huggingface/datasets/pull/3354 | 1,068,307,271 | PR_kwDODunzps4vPl9d | 3,354 | Remove duplicate name from dataset cards | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,359,140,000 | 1,638,364,470,000 | 1,638,364,469,000 | MEMBER | null | Remove duplicate name from dataset card for:
- ajgt_twitter_ar
- emotone_ar | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3354/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3354/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3354",
"html_url": "https://github.com/huggingface/datasets/pull/3354",
"diff_url": "https://github.com/huggingface/datasets/pull/3354.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3354.patch",
"merged_at": 1638364469000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3353/comments | https://api.github.com/repos/huggingface/datasets/issues/3353/events | https://github.com/huggingface/datasets/issues/3353 | 1,068,173,783 | I_kwDODunzps4_qwnX | 3,353 | add one field "example_id", but I can't see it in the "comput_loss" function | {
"login": "yanllearnn",
"id": 38966558,
"node_id": "MDQ6VXNlcjM4OTY2NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yanllearnn",
"html_url": "https://github.com/yanllearnn",
"followers_url": "https://api.github.com/users/yanllearnn/followers",
"following_url": "https://api.github.com/users/yanllearnn/following{/other_user}",
"gists_url": "https://api.github.com/users/yanllearnn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yanllearnn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yanllearnn/subscriptions",
"organizations_url": "https://api.github.com/users/yanllearnn/orgs",
"repos_url": "https://api.github.com/users/yanllearnn/repos",
"events_url": "https://api.github.com/users/yanllearnn/events{/privacy}",
"received_events_url": "https://api.github.com/users/yanllearnn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! Your function looks fine, I used to map `squad` locally and it indeed added the `example_id` field correctly.\r\n\r\nHowever I think that in the `compute_loss` method only a subset of the fields are available: the model inputs. Since `example_id` is not a model input (it's not passed as a parameter to the model), the data loader doesn't need to return it by default.\r\n\r\nHowever you can disable this behavior by setting `remove_unused_columns` to `False` to your training arguments. In this case in `compute_loss` you will get the full item with all the fields.\r\n\r\nNote that since the model doesn't take `example_id` as input, you will have to remove it from the inputs when `model(**inputs)` is called",
"Hi, I have set **args.remove_unused_columns=False** and **training_args.remove_unused_columns=False**, but the field doesn't been contained yet.\r\n```\r\ndef main():\r\n argp = HfArgumentParser(TrainingArguments)\r\n # The HfArgumentParser object collects command-line arguments into an object (and provides default values for unspecified arguments).\r\n # In particular, TrainingArguments has several keys that you'll need/want to specify (when you call run.py from the command line):\r\n # --do_train\r\n # When included, this argument tells the script to train a model.\r\n # See docstrings for \"--task\" and \"--dataset\" for how the training dataset is selected.\r\n # --do_eval\r\n # When included, this argument tells the script to evaluate the trained/loaded model on the validation split of the selected dataset.\r\n # --per_device_train_batch_size <int, default=8>\r\n # This is the training batch size.\r\n # If you're running on GPU, you should try to make this as large as you can without getting CUDA out-of-memory errors.\r\n # For reference, with --max_length=128 and the default ELECTRA-small model, a batch size of 32 should fit in 4gb of GPU memory.\r\n # --num_train_epochs <float, default=3.0>\r\n # How many passes to do through the training data.\r\n # --output_dir <path>\r\n # Where to put the trained model checkpoint(s) and any eval predictions.\r\n # *This argument is required*.\r\n\r\n argp.add_argument('--model', type=str,\r\n default='google/electra-small-discriminator',\r\n help=\"\"\"This argument specifies the base model to fine-tune.\r\n This should either be a HuggingFace model ID (see https://huggingface.co/models)\r\n or a path to a saved model checkpoint (a folder containing config.json and pytorch_model.bin).\"\"\")\r\n argp.add_argument('--task', type=str, choices=['nli', 'qa'], required=True,\r\n help=\"\"\"This argument specifies which task to train/evaluate on.\r\n Pass \"nli\" for natural language inference or \"qa\" for question answering.\r\n By default, \"nli\" will use the SNLI dataset, and \"qa\" will use the SQuAD dataset.\"\"\")\r\n argp.add_argument('--dataset', type=str, default=None,\r\n help=\"\"\"This argument overrides the default dataset used for the specified task.\"\"\")\r\n argp.add_argument('--max_length', type=int, default=128,\r\n help=\"\"\"This argument limits the maximum sequence length used during training/evaluation.\r\n Shorter sequence lengths need less memory and computation time, but some examples may end up getting truncated.\"\"\")\r\n argp.add_argument('--max_train_samples', type=int, default=None,\r\n help='Limit the number of examples to train on.')\r\n argp.add_argument('--max_eval_samples', type=int, default=None,\r\n help='Limit the number of examples to evaluate on.')\r\n\r\n argp.remove_unused_columns = False\r\n training_args, args = argp.parse_args_into_dataclasses()\r\n args.remove_unused_columns=False\r\n training_args.remove_unused_columns=False\r\n```\r\n\r\n\r\n```\r\n**************** train_dataset: Dataset({\r\n features: ['id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 87599\r\n})\r\n\r\n\r\n**************** train_dataset_featurized: Dataset({\r\n features: ['attention_mask', 'end_positions', 'input_ids', 'start_positions', 'token_type_ids'],\r\n num_rows: 87714\r\n})\r\n```",
"Hi, I print the value, all are set to False, but don't work.\r\n```\r\n********************* training_args: TrainingArguments(\r\n_n_gpu=1,\r\nadafactor=False,\r\nadam_beta1=0.9,\r\nadam_beta2=0.999,\r\nadam_epsilon=1e-08,\r\ndataloader_drop_last=False,\r\ndataloader_num_workers=0,\r\ndataloader_pin_memory=True,\r\nddp_find_unused_parameters=None,\r\ndebug=[],\r\ndeepspeed=None,\r\ndisable_tqdm=False,\r\ndo_eval=False,\r\ndo_predict=False,\r\ndo_train=True,\r\neval_accumulation_steps=None,\r\neval_steps=None,\r\nevaluation_strategy=IntervalStrategy.NO,\r\nfp16=False,\r\nfp16_backend=auto,\r\nfp16_full_eval=False,\r\nfp16_opt_level=O1,\r\ngradient_accumulation_steps=1,\r\ngreater_is_better=None,\r\ngroup_by_length=False,\r\nignore_data_skip=False,\r\nlabel_names=None,\r\nlabel_smoothing_factor=0.0,\r\nlearning_rate=5e-05,\r\nlength_column_name=length,\r\nload_best_model_at_end=False,\r\nlocal_rank=-1,\r\nlog_level=-1,\r\nlog_level_replica=-1,\r\nlog_on_each_node=True,\r\nlogging_dir=./re_trained_model/runs/Dec01_14-15-08_399b9290604c,\r\nlogging_first_step=False,\r\nlogging_steps=500,\r\nlogging_strategy=IntervalStrategy.STEPS,\r\nlr_scheduler_type=SchedulerType.LINEAR,\r\nmax_grad_norm=1.0,\r\nmax_steps=-1,\r\nmetric_for_best_model=None,\r\nmp_parameters=,\r\nno_cuda=False,\r\nnum_train_epochs=3.0,\r\noutput_dir=./re_trained_model,\r\noverwrite_output_dir=False,\r\npast_index=-1,\r\nper_device_eval_batch_size=8,\r\nper_device_train_batch_size=8,\r\nprediction_loss_only=False,\r\npush_to_hub=False,\r\npush_to_hub_model_id=re_trained_model,\r\npush_to_hub_organization=None,\r\npush_to_hub_token=None,\r\nremove_unused_columns=False,\r\nreport_to=['tensorboard'],\r\nresume_from_checkpoint=None,\r\nrun_name=./re_trained_model,\r\nsave_on_each_node=False,\r\nsave_steps=500,\r\nsave_strategy=IntervalStrategy.STEPS,\r\nsave_total_limit=None,\r\nseed=42,\r\nsharded_ddp=[],\r\nskip_memory_metrics=True,\r\ntpu_metrics_debug=False,\r\ntpu_num_cores=None,\r\nuse_legacy_prediction_loop=False,\r\nwarmup_ratio=0.0,\r\nwarmup_steps=0,\r\nweight_decay=0.0,\r\n)\r\n```\r\n```\r\n********************* args: Namespace(dataset='squad', max_eval_samples=None, max_length=128, max_train_samples=None, model='google/electra-small-discriminator', remove_unused_columns=False, task='qa')\r\n2021-12-01 14:15:10,048 - WARNING - datasets.builder - Reusing dataset squad (/root/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\r\nSome weights of the model checkpoint at google/electra-small-discriminator were not used when initializing ElectraForQuestionAnswering: ['discriminator_predictions.dense_prediction.weight', 'discriminator_predictions.dense_prediction.bias', 'discriminator_predictions.dense.weight', 'discriminator_predictions.dense.bias']\r\n- This IS expected if you are initializing ElectraForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\r\n- This IS NOT expected if you are initializing ElectraForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\r\nSome weights of ElectraForQuestionAnswering were not initialized from the model checkpoint at google/electra-small-discriminator and are newly initialized: ['qa_outputs.bias', 'qa_outputs.weight']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\nPreprocessing data... (this takes a little bit, should only happen once per dataset)\r\n```",
"Hmmm, it might be because the default data collator removes all the fields with `string` type:\r\n\r\nhttps://github.com/huggingface/transformers/blob/4c0dd199c8305903564c2edeae23d294edd4b321/src/transformers/data/data_collator.py#L107-L112\r\n\r\nI guess you also need a custom data collator that doesn't remove them.",
"can you give a tutorial about how to do this?",
"I overwrite **get_train_dataloader**, and remove **_remove_unused_columns**, but it doesn't work.\r\n\r\n```\r\n def get_train_dataloader(self) -> DataLoader:\r\n \"\"\"\r\n Returns the training :class:`~torch.utils.data.DataLoader`.\r\n\r\n Will use no sampler if :obj:`self.train_dataset` does not implement :obj:`__len__`, a random sampler (adapted\r\n to distributed training if necessary) otherwise.\r\n\r\n Subclass and override this method if you want to inject some custom behavior.\r\n \"\"\"\r\n if self.train_dataset is None:\r\n raise ValueError(\"Trainer: training requires a train_dataset.\")\r\n\r\n train_dataset = self.train_dataset\r\n # if is_datasets_available() and isinstance(train_dataset, datasets.Dataset):\r\n # train_dataset = self._remove_unused_columns(train_dataset, description=\"training\")\r\n\r\n if isinstance(train_dataset, torch.utils.data.IterableDataset):\r\n if self.args.world_size > 1:\r\n train_dataset = IterableDatasetShard(\r\n train_dataset,\r\n batch_size=self.args.train_batch_size,\r\n drop_last=self.args.dataloader_drop_last,\r\n num_processes=self.args.world_size,\r\n process_index=self.args.process_index,\r\n )\r\n\r\n return DataLoader(\r\n train_dataset,\r\n batch_size=self.args.train_batch_size,\r\n collate_fn=self.data_collator,\r\n num_workers=self.args.dataloader_num_workers,\r\n pin_memory=self.args.dataloader_pin_memory,\r\n )\r\n\r\n train_sampler = self._get_train_sampler()\r\n\r\n return DataLoader(\r\n train_dataset,\r\n batch_size=self.args.train_batch_size,\r\n sampler=train_sampler,\r\n collate_fn=self.data_collator,\r\n drop_last=self.args.dataloader_drop_last,\r\n num_workers=self.args.dataloader_num_workers,\r\n pin_memory=self.args.dataloader_pin_memory,\r\n )\r\n```",
"Hi, it works now, thank you.\r\n1. **args.remove_unused_columns=False** and **training_args.remove_unused_columns=False**\r\n2. overwrite **get_train_dataloader**, and remove **_remove_unused_columns**\r\n3. add new fields, and can be got in **inputs**. "
] | 1,638,351,309,000 | 1,638,374,559,000 | 1,638,374,559,000 | NONE | null | Hi, I add one field **example_id**, but I can't see it in the **comput_loss** function, how can I do this? below is the information of inputs
```
*********************** inputs: {'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]], device='cuda:0'), 'end_positions': tensor([ 25, 97, 93, 44, 25, 112, 109, 134], device='cuda:0'), 'input_ids': tensor([[ 101, 2054, 2390, ..., 0, 0, 0],
[ 101, 2054, 2515, ..., 0, 0, 0],
[ 101, 2054, 2106, ..., 0, 0, 0],
...,
[ 101, 2339, 2001, ..., 0, 0, 0],
[ 101, 2054, 2515, ..., 0, 0, 0],
[ 101, 2054, 2003, ..., 0, 0, 0]], device='cuda:0'), 'start_positions': tensor([ 20, 90, 89, 41, 25, 96, 106, 132], device='cuda:0'), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], device='cuda:0')}
```
```
# This function preprocesses a question answering dataset, tokenizing the question and context text
# and finding the right offsets for the answer spans in the tokenized context (to use as labels).
# Adapted from https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_qa.py
def prepare_train_dataset_qa(examples, tokenizer, max_seq_length=None):
questions = [q.lstrip() for q in examples["question"]]
max_seq_length = tokenizer.model_max_length
# tokenize both questions and the corresponding context
# if the context length is longer than max_length, we split it to several
# chunks of max_length
tokenized_examples = tokenizer(
questions,
examples["context"],
truncation="only_second",
max_length=max_seq_length,
stride=min(max_seq_length // 2, 128),
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length"
)
# Since one example might give us several features if it has a long context,
# we need a map from a feature to its corresponding example.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The offset mappings will give us a map from token to character position
# in the original context. This will help us compute the start_positions
# and end_positions to get the final answer string.
offset_mapping = tokenized_examples.pop("offset_mapping")
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
tokenized_examples["example_id"] = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
# We will label features not containing the answer the index of the CLS token.
cls_index = input_ids.index(tokenizer.cls_token_id)
sequence_ids = tokenized_examples.sequence_ids(i)
# from the feature idx to sample idx
sample_index = sample_mapping[i]
# get the answer for a feature
answers = examples["answers"][sample_index]
tokenized_examples["example_id"].append(examples["id"][sample_index])
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# Start/end character index of the answer in the text.
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and
offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and \
offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(
token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
```
_Originally posted by @yanllearnn in https://github.com/huggingface/datasets/issues/3333#issuecomment-983457161_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3353/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3353/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3352/comments | https://api.github.com/repos/huggingface/datasets/issues/3352/events | https://github.com/huggingface/datasets/pull/3352 | 1,068,102,994 | PR_kwDODunzps4vO6uZ | 3,352 | Make LABR dataset streamable | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,346,947,000 | 1,638,355,742,000 | 1,638,355,741,000 | MEMBER | null | Fix LABR dataset to make it streamable.
Related to: #3350. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3352/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3352/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3352",
"html_url": "https://github.com/huggingface/datasets/pull/3352",
"diff_url": "https://github.com/huggingface/datasets/pull/3352.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3352.patch",
"merged_at": 1638355741000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3351/comments | https://api.github.com/repos/huggingface/datasets/issues/3351/events | https://github.com/huggingface/datasets/pull/3351 | 1,068,094,873 | PR_kwDODunzps4vO5AS | 3,351 | Add VCTK dataset | {
"login": "jaketae",
"id": 25360440,
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaketae",
"html_url": "https://github.com/jaketae",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https://api.github.com/users/jaketae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jaketae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaketae/subscriptions",
"organizations_url": "https://api.github.com/users/jaketae/orgs",
"repos_url": "https://api.github.com/users/jaketae/repos",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"received_events_url": "https://api.github.com/users/jaketae/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hello @patrickvonplaten, I hope it's okay to ping you with a (dumb) question!\r\n\r\nI've been trying to get `dl_manager.download_and_extract(_DL_URL)` to work with no avail. I verified that this is a problem on two different machines (lab server, GCP), so I doubt it's an issue with network connectivity. Here is the full trace.\r\n\r\n```\r\n(venv) (base) jaketae@jake-gpu1:~/documents/datasets$ datasets-cli test datasets/vctk --save_infos --all_configs\r\nTesting builder 'main' (1/1)\r\nDownloading and preparing dataset vctk/main to /home/jaketae/.cache/huggingface/datasets/vctk/main/0.9.2/2bfa52a93469fa9d6d4b1831c6511db5442b9f4e48620aef2bc3890d7a5268a8...\r\nTraceback (most recent call last):\r\n File \"/home/jaketae/documents/datasets/venv/bin/datasets-cli\", line 33, in <module>\r\n sys.exit(load_entry_point('datasets', 'console_scripts', 'datasets-cli')())\r\n File \"/home/jaketae/documents/datasets/src/datasets/commands/datasets_cli.py\", line 33, in main\r\n service.run()\r\n File \"/home/jaketae/documents/datasets/src/datasets/commands/test.py\", line 146, in run\r\n builder.download_and_prepare(\r\n File \"/home/jaketae/documents/datasets/src/datasets/builder.py\", line 593, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/jaketae/documents/datasets/src/datasets/builder.py\", line 659, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/home/jaketae/.cache/huggingface/modules/datasets_modules/datasets/vctk/2bfa52a93469fa9d6d4b1831c6511db5442b9f4e48620aef2bc3890d7a5268a8/vctk.py\", line 76, in _split_generators\r\n root_path = dl_manager.download_and_extract(_DL_URL)\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/download_manager.py\", line 283, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/download_manager.py\", line 195, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/py_utils.py\", line 234, in map_nested\r\n return function(data_struct)\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/download_manager.py\", line 216, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/file_utils.py\", line 298, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/jaketae/documents/datasets/src/datasets/utils/file_utils.py\", line 608, in get_from_cache\r\n raise ConnectionError(f\"Couldn't reach {url}\")\r\nConnectionError: Couldn't reach https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip\r\n```\r\n\r\nOn my local, however, the URL correctly points to the download zip file. My admittedly naive guess is that the website is web-crawler or scraper proof (requiring specific headers, etc.), but I also think I might have just missed a very basic step in the process.\r\n\r\nApologies for the delayed PR, and TIA for the help!",
"Hey @jaketae, \r\n\r\nHmm, yeah I don't know really either - the link also works correctly for me when doing:\r\n\r\n```\r\nwget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip\r\n```\r\n\r\nI think however that I had a similar problem previously with Edinburgh's (`.ed.ac.uk`) websites which I solved with the following hack. Not sure if this could be the same problem here...\r\nhttps://github.com/huggingface/datasets/blob/e1104ad5d3e83f8b1571e0d6fef4fdabf0a1fde5/datasets/ami/ami.py#L364\r\n\r\n",
"The AMI dataset is stored under a different website though it seems: `\"https://groups.inf.ed.ac.uk/ami/AMICorpusMirror//amicorpus/{}/audio/{}\"`\r\n\r\nso not 100p sure if this solves the problem",
"Hi @patrickvonplaten,\r\n\r\nThanks for the feedback! Sadly, disabling multi-processing didn't cut it for me. \r\n\r\nI've been looking at VCTK code in [`torchaudio`](https://pytorch.org/audio/stable/_modules/torchaudio/datasets/vctk.html) and [`tfds`](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/audio/vctk.py). I don't think they're using a hack to accomplish this, so I'll try to look into it to see if I can pinpoint the cause. I'll keep you in the loop here. Thank you!",
"Hi @patrickvonplaten, \r\n\r\nAfter more investigation, I found that simply increasing `etag_timeout` in `get_from_cache` from 10 to 100 solved it. However, unless I'm missing something, an issue is that `etag_timeout` is basically hard-coded as a default parameter because `cached_path`, which calls `get_from_cache` has no way of modifying the default. \r\n\r\nhttps://github.com/huggingface/datasets/blob/b25ac1d62670e7b339ed552ecc37846d2abd30c7/src/datasets/utils/file_utils.py#L298-L310\r\n\r\nhttps://github.com/huggingface/datasets/blob/b25ac1d62670e7b339ed552ecc37846d2abd30c7/src/datasets/utils/file_utils.py#L497-L510\r\n\r\n\r\nI can think of two solutions.\r\n\r\n* Simply increase the default to 100\r\n* Allow `etag_timeout` to be modifiable on a per-dataset basis by integrating it to `download_config` (maybe this is already supported?)\r\n\r\nThank you!",
"I think in this case we can increase the `etag_timeout` - what do you think @lhoestq @albertvillanova ?",
"Yes let's increase it to 100 for the moment. Later we can see if it really needed to move it into `download_config` or not",
"Thanks for the feedback @patrickvonplaten @lhoestq, I'll continue working on this in that direction!",
"Hello @patrickvonplaten, VCTK is ready for review! \r\n\r\n```python\r\n>>> from datasets import load_dataset\r\n>>> ds = load_dataset(\"vctk\")\r\nUsing the latest cached version of the module from /home/lily/jt856/.cache/huggingface/modules/datasets_modules/datasets/vctk/b7aa278182de3a7aa2897cbd12c1e19f1af9840a2ead69a6d710fdbc1d2df02a (last modified on Sat Dec 25 00:47:31 2021) since it couldn't be found locally at vctk., or remotely on the Hugging Face Hub.\r\nReusing dataset vctk (/home/lily/jt856/.cache/huggingface/datasets/vctk/main/0.9.2/b7aa278182de3a7aa2897cbd12c1e19f1af9840a2ead69a6d710fdbc1d2df02a)\r\n100%|████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 198.35it/s]\r\n>>> len(ds[\"train\"])\r\n88156\r\n>>> ds[\"train\"][0]\r\n{'speaker_id': 'p225', 'audio': {'path': '/home/lily/jt856/.cache/huggingface/datasets/downloads/extracted/8ed7dad05dfffdb552a3699777442af8e8ed11e656feb277f35bf9aea448f49e/wav48_silence_trimmed/p225/p225_001_mic1.flac', 'array': array([0.00485229, 0.00689697, 0.00619507, ..., 0.00811768, 0.00836182,\r\n 0.00854492], dtype=float32), 'sampling_rate': 48000}, 'file': '/home/lily/jt856/.cache/huggingface/datasets/downloads/extracted/8ed7dad05dfffdb552a3699777442af8e8ed11e656feb277f35bf9aea448f49e/wav48_silence_trimmed/p225/p225_001_mic1.flac', 'text': 'Please call Stella.', 'text_id': '001', 'age': '23', 'gender': 'F', 'accent': 'English', 'region': 'Southern England', 'comment': ''}\r\n```\r\nA number of tests are failing on CircleCI, but from my limited knowledge they appear to be complaining about `conda` and `pip`/`wheel`-related incompatibilities. But if I'm reading them wrong and it's an issue with this PR, please let me know and I'll try to fix them.\r\n\r\nBelated merry Christmas and a happy new year!"
] | 1,638,346,397,000 | 1,640,704,320,000 | 1,640,703,908,000 | CONTRIBUTOR | null | Fixes #1837. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3351/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3351/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3351",
"html_url": "https://github.com/huggingface/datasets/pull/3351",
"diff_url": "https://github.com/huggingface/datasets/pull/3351.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3351.patch",
"merged_at": 1640703907000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3350/comments | https://api.github.com/repos/huggingface/datasets/issues/3350/events | https://github.com/huggingface/datasets/pull/3350 | 1,068,078,160 | PR_kwDODunzps4vO1aj | 3,350 | Avoid content-encoding issue while streaming datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,345,408,000 | 1,638,346,501,000 | 1,638,346,500,000 | MEMBER | null | This PR will fix streaming of datasets served with gzip content-encoding:
```
ClientPayloadError: 400, message='Can not decode content-encoding: gzip'
```
Fix #2918.
CC: @severo | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3350/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3350/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3350",
"html_url": "https://github.com/huggingface/datasets/pull/3350",
"diff_url": "https://github.com/huggingface/datasets/pull/3350.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3350.patch",
"merged_at": 1638346500000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3349/comments | https://api.github.com/repos/huggingface/datasets/issues/3349/events | https://github.com/huggingface/datasets/pull/3349 | 1,067,853,601 | PR_kwDODunzps4vOF-s | 3,349 | raise exception instead of using assertions. | {
"login": "manisnesan",
"id": 153142,
"node_id": "MDQ6VXNlcjE1MzE0Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/153142?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manisnesan",
"html_url": "https://github.com/manisnesan",
"followers_url": "https://api.github.com/users/manisnesan/followers",
"following_url": "https://api.github.com/users/manisnesan/following{/other_user}",
"gists_url": "https://api.github.com/users/manisnesan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/manisnesan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manisnesan/subscriptions",
"organizations_url": "https://api.github.com/users/manisnesan/orgs",
"repos_url": "https://api.github.com/users/manisnesan/repos",
"events_url": "https://api.github.com/users/manisnesan/events{/privacy}",
"received_events_url": "https://api.github.com/users/manisnesan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@mariosasko - Thanks for the review & suggestions. Updated as per the suggestions. ",
"@mariosasko - Hello, Are there any additional changes required from my end??. Wondering if this PR can be merged or still pending on additional steps.",
"@mariosasko - The approved changes in the PR now has conflicts with the master branch. Would you like me to resolve the conflicts??. Let me know. ",
"@mariosasko @lhoestq - Gentle reminder about my previous question. ",
"Hi ! Thanks for the heads up :)\r\nI just resolved the conflicts, it should be alright now",
"Merging, thanks for the help @manisnesan !"
] | 1,638,322,671,000 | 1,640,016,447,000 | 1,640,016,447,000 | CONTRIBUTOR | null | fix for the remaining files https://github.com/huggingface/datasets/issues/3171 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3349/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3349/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3349",
"html_url": "https://github.com/huggingface/datasets/pull/3349",
"diff_url": "https://github.com/huggingface/datasets/pull/3349.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3349.patch",
"merged_at": 1640016447000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3348/comments | https://api.github.com/repos/huggingface/datasets/issues/3348/events | https://github.com/huggingface/datasets/pull/3348 | 1,067,831,113 | PR_kwDODunzps4vOBOQ | 3,348 | BLEURT: Match key names to correspond with filename | {
"login": "jaehlee",
"id": 11873078,
"node_id": "MDQ6VXNlcjExODczMDc4",
"avatar_url": "https://avatars.githubusercontent.com/u/11873078?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaehlee",
"html_url": "https://github.com/jaehlee",
"followers_url": "https://api.github.com/users/jaehlee/followers",
"following_url": "https://api.github.com/users/jaehlee/following{/other_user}",
"gists_url": "https://api.github.com/users/jaehlee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jaehlee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaehlee/subscriptions",
"organizations_url": "https://api.github.com/users/jaehlee/orgs",
"repos_url": "https://api.github.com/users/jaehlee/repos",
"events_url": "https://api.github.com/users/jaehlee/events{/privacy}",
"received_events_url": "https://api.github.com/users/jaehlee/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for the suggestion! I think the current checked-in `CHECKPOINT_URLS` is already not working. I believe anyone who tried using the new ckpts (`BLEURT-20-X`) can't unless this fix is in. The zip file from bleurt side unzips to directory name matching the filename (capitalized for new ones). For example without current changes I'd get the following error\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nAssertionError Traceback (most recent call last)\r\n<ipython-input-5-f6832fe20f84> in <module>()\r\n 1 predictions = [\"hello there\", \"general kenobi\"]\r\n 2 references = [\"hello there\", \"general kenobi\"]\r\n----> 3 bleurt = datasets.load_metric(\"bleurt\", \"bleurt-20\")\r\n 4 results = bleurt.compute(predictions=predictions, references=references)\r\n\r\n4 frames\r\n/usr/local/lib/python3.7/dist-packages/bleurt/checkpoint.py in read_bleurt_config(path)\r\n 84 \"\"\"Reads and checks config file from a BLEURT checkpoint.\"\"\"\r\n 85 assert tf.io.gfile.exists(path), \\\r\n---> 86 \"Could not find BLEURT checkpoint {}\".format(path)\r\n 87 config_path = os.path.join(path, CONFIG_FILE)\r\n 88 assert tf.io.gfile.exists(config_path), \\\r\n\r\nAssertionError: Could not find BLEURT checkpoint /root/.cache/huggingface/metrics/bleurt/bleurt-20/downloads/extracted/e34c60f1a05394ecda54e253a10413ca7b5d59f9a23f3cc73258c6b78ffa2f50/bleurt-20\r\n```\r\ninspecting specified path I see that directory name is `BLEURT-20` instead of `bleurt-20`. \r\nOther solution similar to your suggestion is meddle with `dl_manager.download_and_extract` to unzip to paths with lowering all the paths but I imagine this will affect other parts of the library. ",
"Indeed, good catch ! Your solution that fixes `CHECKPOINT_URLS ` is simple and works well, thanks :)\r\n\r\nFurthermore to avoid breaking changes though we could also keep the support for the lowercase one:\r\n```python\r\n if self.config_name.lower() in CHECKPOINT_URLS:\r\n checkpoint_name = self.config_name.lower()\r\n elif self.config_name.upper() in CHECKPOINT_URLS:\r\n checkpoint_name = self.config_name.upper()\r\n else:\r\n raise KeyError(\r\n f\"{self.config_name} model not found. You should supply the name of a model checkpoint for bleurt in {CHECKPOINT_URLS.keys()}\"\r\n )\r\n```\r\nand then we can use `checkpoint_name` instead of `self.config_name` to download and instantiate the model:\r\n```python\r\n model_path = dl_manager.download_and_extract(CHECKPOINT_URLS[checkpoint_name])\r\n self.scorer = score.BleurtScorer(os.path.join(model_path, checkpoint_name))\r\n```\r\n\r\nPlease let me know if that sounds reasonable to you !",
"Thanks for the suggestion! I believe your suggestion should work to make keys case insensitive. Changes are committed to the PR now. "
] | 1,638,320,478,000 | 1,638,893,217,000 | 1,638,893,217,000 | CONTRIBUTOR | null | In order to properly locate downloaded ckpt files key name needs to match filename. Correcting change introduced in #3235 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3348/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3348/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3348",
"html_url": "https://github.com/huggingface/datasets/pull/3348",
"diff_url": "https://github.com/huggingface/datasets/pull/3348.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3348.patch",
"merged_at": 1638893217000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3347/comments | https://api.github.com/repos/huggingface/datasets/issues/3347/events | https://github.com/huggingface/datasets/pull/3347 | 1,067,738,902 | PR_kwDODunzps4vNthw | 3,347 | iter_archive for zip files | {
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://api.github.com/users/Mehdi2402/followers",
"following_url": "https://api.github.com/users/Mehdi2402/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehdi2402/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehdi2402/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehdi2402/subscriptions",
"organizations_url": "https://api.github.com/users/Mehdi2402/orgs",
"repos_url": "https://api.github.com/users/Mehdi2402/repos",
"events_url": "https://api.github.com/users/Mehdi2402/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehdi2402/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"And also don't always try streaming with Google Drive - it can have issues because of how Google Drive works (with quotas, restrictions, etc.) and it can indeed cause `BlockSizeError`.\r\n\r\nFeel free to host your test data elsewhere, such as in a dataset repository on https://huggingface.co (see [here](https://huggingface.co/docs/datasets/upload_dataset.html#upload-your-files) for a tutorial on how to upload files)"
] | 1,638,311,657,000 | 1,638,577,342,000 | 1,638,577,331,000 | CONTRIBUTOR | null | * In this PR, I added the option to iterate through zipfiles for `download_manager.py` only.
* Next PR will be the same applied to `streaming_download_manager.py`.
* Related issue #3272.
## Comments :
* There is no `.isreg()` equivalent in zipfile library to check if file is Regular so I used `.is_dir()` instead to skip directories.
* For now I got `streaming_download_manager.py` working for local zip files, but not for urls. I get the following error when I test it on an archive in google drive, so still working on it. `BlockSizeError: Got more bytes so far (>2112) than requested (22)`
## Tasks :
- [x] download_manager.py
- [ ] streaming_download_manager.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3347/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3347/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3347",
"html_url": "https://github.com/huggingface/datasets/pull/3347",
"diff_url": "https://github.com/huggingface/datasets/pull/3347.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3347.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3346/comments | https://api.github.com/repos/huggingface/datasets/issues/3346/events | https://github.com/huggingface/datasets/issues/3346 | 1,067,632,365 | I_kwDODunzps4_osbt | 3,346 | Failed to convert `string` with pyarrow for QED since 1.15.0 | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Scratch that, probably the old and incompatible usage of dataset builder from promptsource.",
"Actually, re-opening this issue cause the error persists\r\n\r\n```python\r\n>>> load_dataset(\"qed\")\r\nDownloading and preparing dataset qed/qed (download: 13.43 MiB, generated: 9.70 MiB, post-processed: Unknown size, total: 23.14 MiB) to /home/victor_huggingface_co/.cache/huggingface/datasets/qed/qed/1.0.0/47d8b6f033393aa520a8402d4baf2d6bdc1b2fbde3dc156e595d2ef34caf7d75...\r\n100%|███████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 2228.64it/s]\r\nTraceback (most recent call last): \r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/load.py\", line 1669, in load_dataset\r\n use_auth_token=use_auth_token,\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/builder.py\", line 594, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/builder.py\", line 681, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/builder.py\", line 1083, in _prepare_split\r\n num_examples, num_bytes = writer.finalize()\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/arrow_writer.py\", line 468, in finalize\r\n self.write_examples_on_file()\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/arrow_writer.py\", line 339, in write_examples_on_file\r\n pa_array = pa.array(typed_sequence)\r\n File \"pyarrow/array.pxi\", line 229, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/arrow_writer.py\", line 125, in __arrow_array__\r\n out = pa.array(cast_to_python_objects(self.data, only_1d_for_numpy=True), type=type)\r\n File \"pyarrow/array.pxi\", line 315, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 143, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 99, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Could not convert 'in' with type str: tried to convert to boolean\r\n```\r\n\r\nEnvironment (datasets and pyarrow):\r\n\r\n```bash\r\n(promptsource) victor_huggingface_co@victor-dev:~/promptsource$ datasets-cli env\r\n\r\nCopy-and-paste the text below in your GitHub issue.\r\n\r\n- `datasets` version: 1.16.1\r\n- Platform: Linux-5.0.0-1020-gcp-x86_64-with-debian-buster-sid\r\n- Python version: 3.7.11\r\n- PyArrow version: 6.0.1\r\n```\r\n```bash\r\n(promptsource) victor_huggingface_co@victor-dev:~/promptsource$ pip show pyarrow\r\nName: pyarrow\r\nVersion: 6.0.1\r\nSummary: Python library for Apache Arrow\r\nHome-page: https://arrow.apache.org/\r\nAuthor: \r\nAuthor-email: \r\nLicense: Apache License, Version 2.0\r\nLocation: /home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages\r\nRequires: numpy\r\nRequired-by: streamlit, datasets\r\n```"
] | 1,638,303,102,000 | 1,639,492,745,000 | 1,639,492,745,000 | CONTRIBUTOR | null | ## Describe the bug
Loading QED was fine until 1.15.0.
related: bigscience-workshop/promptsource#659, bigscience-workshop/promptsource#670
Not sure where the root cause is, but here are some candidates:
- #3158
- #3120
- #3196
- #2891
## Steps to reproduce the bug
```python
load_dataset("qed")
```
## Expected results
Loading completed.
## Actual results
```shell
ArrowInvalid: Could not convert in with type str: tried to convert to boolean
Traceback:
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/script_runner.py", line 354, in _run_script
exec(code, module.__dict__)
File "/Users/s0s0cr3/Documents/GitHub/promptsource/promptsource/app.py", line 260, in <module>
dataset = get_dataset(dataset_key, str(conf_option.name) if conf_option else None)
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/caching.py", line 543, in wrapped_func
return get_or_create_cached_value()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/caching.py", line 527, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/Users/s0s0cr3/Documents/GitHub/promptsource/promptsource/utils.py", line 49, in get_dataset
builder_instance.download_and_prepare()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 1106, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 456, in finalize
self.write_examples_on_file()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 325, in write_examples_on_file
pa_array = pa.array(typed_sequence)
File "pyarrow/array.pxi", line 222, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 121, in __arrow_array__
out = pa.array(cast_to_python_objects(self.data, only_1d_for_numpy=True), type=type)
File "pyarrow/array.pxi", line 305, in pyarrow.lib.array
File "pyarrow/array.pxi", line 39, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.0, 1.16.1
- Platform: macOS 1.15.7 or above
- Python version: 3.7.12 and 3.9
- PyArrow version: 3.0.0, 5.0.0, 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3346/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3346/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3345/comments | https://api.github.com/repos/huggingface/datasets/issues/3345/events | https://github.com/huggingface/datasets/issues/3345 | 1,067,622,951 | I_kwDODunzps4_oqIn | 3,345 | Failed to download species_800 from Google Drive zip file | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthe dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?",
"> Hi,\r\n> \r\n> the dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?\r\n\r\nI have tried that many times with both load_dataset() and a browser almost simultaneously. The browser always works for me while load_dataset() fails.",
"@mariosasko \r\n> the dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?\r\n\r\nI've tried yet again just a moment ago. This time I realize that, the step `(... post-processed: Unknown size, total: 20.89 MiB) to /Users/mike/.cache/huggingface/datasets/species800/species_800/1.0.0/532167f0bb8fbc0d77d6d03c4fd642c8c55527b9c5f2b1da77f3d00b0e559976...` and the one after seem unstable. If I want to retry, I will have to delete it (and probably other cache lock files). It **_sometimes_** works.\r\n\r\nBut I didn't try `download_mode=\"force_redownload\"` yet.\r\n\r\nAnyway, I suppose this isn't really a pressing issue for the time being, so I'm going to close this. Thank you.\r\n\r\n"
] | 1,638,302,428,000 | 1,638,381,195,000 | 1,638,381,195,000 | CONTRIBUTOR | null | ## Describe the bug
One can manually download the zip file on Google Drive, but `load_dataset()` cannot.
related: #3248
## Steps to reproduce the bug
```shell
> python
Python 3.7.12 (default, Sep 5 2021, 08:34:29)
[Clang 11.0.3 (clang-1103.0.32.62)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
```
```python
>>> from datasets import load_dataset
>>> s800 = load_dataset("species_800")
```
## Expected results
species_800 downloaded.
## Actual results
```shell
Downloading: 5.68kB [00:00, 1.22MB/s]
Downloading: 2.70kB [00:00, 691kB/s]
Downloading and preparing dataset species800/species_800 (download: 17.36 MiB, generated: 3.53 MiB, post-processed: Unknown size, total: 20.89 MiB) to /Users/mike/.cache/huggingface/datasets/species800/species_800/1.0.0/532167f0bb8fbc0d77d6d03c4fd642c8c55527b9c5f2b1da77f3d00b0e559976...
0%| | 0/1 [00:00<?, ?it/s]Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/load.py", line 1632, in load_dataset
use_auth_token=use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 608, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/mike/.cache/huggingface/modules/datasets_modules/datasets/species_800/532167f0bb8fbc0d77d6d03c4fd642c8c55527b9c5f2b1da77f3d00b0e559976/species_800.py", line 104, in _split_generators
downloaded_files = dl_manager.download_and_extract(urls_to_download)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 197, in download
download_func, url_or_urls, map_tuple=True, num_proc=download_config.num_proc, disable_tqdm=False
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 209, in map_nested
for obj in utils.tqdm(iterable, disable=disable_tqdm)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 209, in <listcomp>
for obj in utils.tqdm(iterable, disable=disable_tqdm)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 143, in _single_map_nested
return function(data_struct)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 305, in cached_path
use_auth_token=download_config.use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://drive.google.com/u/0/uc?id=1OletxmPYNkz2ltOr9pyT0b0iBtUWxslh&export=download/
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14,0 1.15.0, 1.16.1
- Platform: macOS Catalina 10.15.7
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3345/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3345/timeline | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3344/comments | https://api.github.com/repos/huggingface/datasets/issues/3344/events | https://github.com/huggingface/datasets/pull/3344 | 1,067,567,603 | PR_kwDODunzps4vNJwd | 3,344 | Add ArrayXD docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,298,411,000 | 1,638,389,763,000 | 1,638,387,332,000 | CONTRIBUTOR | null | Documents support for dynamic first dimension in `ArrayXD` from #2891, and explain the `ArrayXD` feature in general.
Let me know if I'm missing anything @lhoestq :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3344/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3344/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3344",
"html_url": "https://github.com/huggingface/datasets/pull/3344",
"diff_url": "https://github.com/huggingface/datasets/pull/3344.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3344.patch",
"merged_at": 1638387332000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/3343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3343/comments | https://api.github.com/repos/huggingface/datasets/issues/3343/events | https://github.com/huggingface/datasets/pull/3343 | 1,067,505,507 | PR_kwDODunzps4vM8yB | 3,343 | Better error message when download fails | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,293,930,000 | 1,638,358,079,000 | 1,638,358,078,000 | MEMBER | null | From our discussions in https://github.com/huggingface/datasets/issues/3269 and https://github.com/huggingface/datasets/issues/3282 it would be nice to have better messages if a download fails.
In particular the error now shows:
- the error from the HEAD request if there's one
- otherwise the response code of the HEAD request
I also added an error to tell users to pass `use_auth_token` when the Hugging Face Hub returns 401 (Unauthorized).
While paying around with this I also fixed a minor issue with the `force_download` parameter that was not always taken into account | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3343/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3343/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3343",
"html_url": "https://github.com/huggingface/datasets/pull/3343",
"diff_url": "https://github.com/huggingface/datasets/pull/3343.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3343.patch",
"merged_at": 1638358078000
} | true |