
source
stringclasses 40
values | file_type
stringclasses 1
value | chunk
stringlengths 3
512
| id
int64 0
1.5k
|
|---|---|---|---|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Defaults to None.
license (`str`, *optional*):
License of this model. Example: apache-2.0 or any license from
https://huggingface.co/docs/hub/repositories-licenses. Defaults to None.
license_name (`str`, *optional*):
Name of the license of this model. Defaults to None. To be used in conjunction with `license_link`.
Common licenses (Apache-2.0, MIT, CC-BY-SA-4.0) do not need a name. In that case, use `license` instead.
license_link (`str`, *optional*): | 800 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | license_link (`str`, *optional*):
Link to the license of this model. Defaults to None. To be used in conjunction with `license_name`.
Common licenses (Apache-2.0, MIT, CC-BY-SA-4.0) do not need a link. In that case, use `license` instead.
metrics (`List[str]`, *optional*):
List of metrics used to evaluate this model. Should be a metric name that can be found
at https://hf.co/metrics. Example: 'accuracy'. Defaults to None.
model_name (`str`, *optional*):
A name for this model. It is used along with | 801 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | model_name (`str`, *optional*):
A name for this model. It is used along with
`eval_results` to construct the `model-index` within the card's metadata. The name
you supply here is what will be used on PapersWithCode's leaderboards. If None is provided
then the repo name is used as a default. Defaults to None.
pipeline_tag (`str`, *optional*):
The pipeline tag associated with the model. Example: "text-classification".
tags (`List[str]`, *optional*): | 802 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | The pipeline tag associated with the model. Example: "text-classification".
tags (`List[str]`, *optional*):
List of tags to add to your model that can be used when filtering on the Hugging
Face Hub. Defaults to None.
ignore_metadata_errors (`str`):
If True, errors while parsing the metadata section will be ignored. Some information might be lost during
the process. Use it at your own risk.
kwargs (`dict`, *optional*):
Additional metadata that will be added to the model card. Defaults to None. | 803 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Example:
```python
>>> from huggingface_hub import ModelCardData
>>> card_data = ModelCardData(
... language="en",
... license="mit",
... library_name="timm",
... tags=['image-classification', 'resnet'],
... )
>>> card_data.to_dict()
{'language': 'en', 'license': 'mit', 'library_name': 'timm', 'tags': ['image-classification', 'resnet']}
```
``` | 804 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Dataset cards are also known as Data Cards in the ML Community. | 805 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | No docstring found for huggingface_hub.DatasetCard | 806 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Dataset Card Metadata that is used by Hugging Face Hub when included at the top of your README.md | 807 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Args:
language (`List[str]`, *optional*):
Language of dataset's data or metadata. It must be an ISO 639-1, 639-2 or
639-3 code (two/three letters), or a special value like "code", "multilingual".
license (`Union[str, List[str]]`, *optional*):
License(s) of this dataset. Example: apache-2.0 or any license from
https://huggingface.co/docs/hub/repositories-licenses.
annotations_creators (`Union[str, List[str]]`, *optional*):
How the annotations for the dataset were created. | 808 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | annotations_creators (`Union[str, List[str]]`, *optional*):
How the annotations for the dataset were created.
Options are: 'found', 'crowdsourced', 'expert-generated', 'machine-generated', 'no-annotation', 'other'.
language_creators (`Union[str, List[str]]`, *optional*):
How the text-based data in the dataset was created.
Options are: 'found', 'crowdsourced', 'expert-generated', 'machine-generated', 'other'
multilinguality (`Union[str, List[str]]`, *optional*):
Whether the dataset is multilingual. | 809 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | multilinguality (`Union[str, List[str]]`, *optional*):
Whether the dataset is multilingual.
Options are: 'monolingual', 'multilingual', 'translation', 'other'.
size_categories (`Union[str, List[str]]`, *optional*):
The number of examples in the dataset. Options are: 'n<1K', '1K<n<10K', '10K<n<100K',
'100K<n<1M', '1M<n<10M', '10M<n<100M', '100M<n<1B', '1B<n<10B', '10B<n<100B', '100B<n<1T', 'n>1T', and 'other'.
source_datasets (`List[str]]`, *optional*): | 810 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | source_datasets (`List[str]]`, *optional*):
Indicates whether the dataset is an original dataset or extended from another existing dataset.
Options are: 'original' and 'extended'.
task_categories (`Union[str, List[str]]`, *optional*):
What categories of task does the dataset support?
task_ids (`Union[str, List[str]]`, *optional*):
What specific tasks does the dataset support?
paperswithcode_id (`str`, *optional*):
ID of the dataset on PapersWithCode.
pretty_name (`str`, *optional*): | 811 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | paperswithcode_id (`str`, *optional*):
ID of the dataset on PapersWithCode.
pretty_name (`str`, *optional*):
A more human-readable name for the dataset. (ex. "Cats vs. Dogs")
train_eval_index (`Dict`, *optional*):
A dictionary that describes the necessary spec for doing evaluation on the Hub.
If not provided, it will be gathered from the 'train-eval-index' key of the kwargs.
config_names (`Union[str, List[str]]`, *optional*):
A list of the available dataset configs for the dataset.
``` | 812 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | No docstring found for huggingface_hub.SpaceCard | 813 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Space Card Metadata that is used by Hugging Face Hub when included at the top of your README.md
To get an exhaustive reference of Spaces configuration, please visit https://huggingface.co/docs/hub/spaces-config-reference#spaces-configuration-reference. | 814 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Args:
title (`str`, *optional*)
Title of the Space.
sdk (`str`, *optional*)
SDK of the Space (one of `gradio`, `streamlit`, `docker`, or `static`).
sdk_version (`str`, *optional*)
Version of the used SDK (if Gradio/Streamlit sdk).
python_version (`str`, *optional*)
Python version used in the Space (if Gradio/Streamlit sdk).
app_file (`str`, *optional*)
Path to your main application file (which contains either gradio or streamlit Python code, or static html code). | 815 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Path to your main application file (which contains either gradio or streamlit Python code, or static html code).
Path is relative to the root of the repository.
app_port (`str`, *optional*)
Port on which your application is running. Used only if sdk is `docker`.
license (`str`, *optional*)
License of this model. Example: apache-2.0 or any license from
https://huggingface.co/docs/hub/repositories-licenses.
duplicated_from (`str`, *optional*)
ID of the original Space if this is a duplicated Space. | 816 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | duplicated_from (`str`, *optional*)
ID of the original Space if this is a duplicated Space.
models (List[`str`], *optional*)
List of models related to this Space. Should be a dataset ID found on https://hf.co/models.
datasets (`List[str]`, *optional*)
List of datasets related to this Space. Should be a dataset ID found on https://hf.co/datasets.
tags (`List[str]`, *optional*)
List of tags to add to your Space that can be used when filtering on the Hub.
ignore_metadata_errors (`str`): | 817 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | List of tags to add to your Space that can be used when filtering on the Hub.
ignore_metadata_errors (`str`):
If True, errors while parsing the metadata section will be ignored. Some information might be lost during
the process. Use it at your own risk.
kwargs (`dict`, *optional*):
Additional metadata that will be added to the space card. | 818 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Example:
```python
>>> from huggingface_hub import SpaceCardData
>>> card_data = SpaceCardData(
... title="Dreambooth Training",
... license="mit",
... sdk="gradio",
... duplicated_from="multimodalart/dreambooth-training"
... )
>>> card_data.to_dict()
{'title': 'Dreambooth Training', 'sdk': 'gradio', 'license': 'mit', 'duplicated_from': 'multimodalart/dreambooth-training'}
```
``` | 819 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Flattened representation of individual evaluation results found in model-index of Model Cards.
For more information on the model-index spec, see https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1. | 820 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Args:
task_type (`str`):
The task identifier. Example: "image-classification".
dataset_type (`str`):
The dataset identifier. Example: "common_voice". Use dataset id from https://hf.co/datasets.
dataset_name (`str`):
A pretty name for the dataset. Example: "Common Voice (French)".
metric_type (`str`):
The metric identifier. Example: "wer". Use metric id from https://hf.co/metrics.
metric_value (`Any`):
The metric value. Example: 0.9 or "20.0 ± 1.2".
task_name (`str`, *optional*): | 821 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | metric_value (`Any`):
The metric value. Example: 0.9 or "20.0 ± 1.2".
task_name (`str`, *optional*):
A pretty name for the task. Example: "Speech Recognition".
dataset_config (`str`, *optional*):
The name of the dataset configuration used in `load_dataset()`.
Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info:
https://hf.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
dataset_split (`str`, *optional*): | 822 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | https://hf.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
dataset_split (`str`, *optional*):
The split used in `load_dataset()`. Example: "test".
dataset_revision (`str`, *optional*):
The revision (AKA Git Sha) of the dataset used in `load_dataset()`.
Example: 5503434ddd753f426f4b38109466949a1217c2bb
dataset_args (`Dict[str, Any]`, *optional*):
The arguments passed during `Metric.compute()`. Example for `bleu`: `{"max_order": 4}`
metric_name (`str`, *optional*): | 823 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | The arguments passed during `Metric.compute()`. Example for `bleu`: `{"max_order": 4}`
metric_name (`str`, *optional*):
A pretty name for the metric. Example: "Test WER".
metric_config (`str`, *optional*):
The name of the metric configuration used in `load_metric()`.
Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`.
See the `datasets` docs for more info: https://huggingface.co/docs/datasets/v2.1.0/en/loading#load-configurations
metric_args (`Dict[str, Any]`, *optional*): | 824 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | metric_args (`Dict[str, Any]`, *optional*):
The arguments passed during `Metric.compute()`. Example for `bleu`: max_order: 4
verified (`bool`, *optional*):
Indicates whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not. Automatically computed by Hugging Face, do not set.
verify_token (`str`, *optional*): | 825 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | verify_token (`str`, *optional*):
A JSON Web Token that is used to verify whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not.
source_name (`str`, *optional*):
The name of the source of the evaluation result. Example: "Open LLM Leaderboard".
source_url (`str`, *optional*):
The URL of the source of the evaluation result. Example: "https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard".
``` | 826 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Takes in a model index and returns the model name and a list of `huggingface_hub.EvalResult` objects.
A detailed spec of the model index can be found here:
https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
Args:
model_index (`List[Dict[str, Any]]`):
A model index data structure, likely coming from a README.md file on the
Hugging Face Hub. | 827 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Returns:
model_name (`str`):
The name of the model as found in the model index. This is used as the
identifier for the model on leaderboards like PapersWithCode.
eval_results (`List[EvalResult]`):
A list of `huggingface_hub.EvalResult` objects containing the metrics
reported in the provided model_index. | 828 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Example:
```python
>>> from huggingface_hub.repocard_data import model_index_to_eval_results
>>> # Define a minimal model index
>>> model_index = [
... {
... "name": "my-cool-model",
... "results": [
... {
... "task": {
... "type": "image-classification"
... },
... "dataset": {
... "type": "beans",
... "name": "Beans"
... }, | 829 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ... "type": "beans",
... "name": "Beans"
... },
... "metrics": [
... {
... "type": "accuracy",
... "value": 0.9
... }
... ]
... }
... ]
... }
... ]
>>> model_name, eval_results = model_index_to_eval_results(model_index)
>>> model_name
'my-cool-model'
>>> eval_results[0].task_type
'image-classification' | 830 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | >>> model_name
'my-cool-model'
>>> eval_results[0].task_type
'image-classification'
>>> eval_results[0].metric_type
'accuracy'
```
``` | 831 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Takes in given model name and list of `huggingface_hub.EvalResult` and returns a
valid model-index that will be compatible with the format expected by the
Hugging Face Hub.
Args:
model_name (`str`):
Name of the model (ex. "my-cool-model"). This is used as the identifier
for the model on leaderboards like PapersWithCode.
eval_results (`List[EvalResult]`):
List of `huggingface_hub.EvalResult` objects containing the metrics to be
reported in the model-index. | 832 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Returns:
model_index (`List[Dict[str, Any]]`): The eval_results converted to a model-index. | 833 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Example:
```python
>>> from huggingface_hub.repocard_data import eval_results_to_model_index, EvalResult
>>> # Define minimal eval_results
>>> eval_results = [
... EvalResult(
... task_type="image-classification", # Required
... dataset_type="beans", # Required
... dataset_name="Beans", # Required
... metric_type="accuracy", # Required
... metric_value=0.9, # Required
... )
... ]
>>> eval_results_to_model_index("my-cool-model", eval_results) | 834 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ... metric_value=0.9, # Required
... )
... ]
>>> eval_results_to_model_index("my-cool-model", eval_results)
[{'name': 'my-cool-model', 'results': [{'task': {'type': 'image-classification'}, 'dataset': {'name': 'Beans', 'type': 'beans'}, 'metrics': [{'type': 'accuracy', 'value': 0.9}]}]}]
```
``` | 835 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Creates a metadata dict with the result from a model evaluated on a dataset. | 836 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Args:
model_pretty_name (`str`):
The name of the model in natural language.
task_pretty_name (`str`):
The name of a task in natural language.
task_id (`str`):
Example: automatic-speech-recognition. A task id.
metrics_pretty_name (`str`):
A name for the metric in natural language. Example: Test WER.
metrics_id (`str`):
Example: wer. A metric id from https://hf.co/metrics.
metrics_value (`Any`):
The value from the metric. Example: 20.0 or "20.0 ± 1.2".
dataset_pretty_name (`str`): | 837 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | metrics_value (`Any`):
The value from the metric. Example: 20.0 or "20.0 ± 1.2".
dataset_pretty_name (`str`):
The name of the dataset in natural language.
dataset_id (`str`):
Example: common_voice. A dataset id from https://hf.co/datasets.
metrics_config (`str`, *optional*):
The name of the metric configuration used in `load_metric()`.
Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`.
metrics_verified (`bool`, *optional*, defaults to `False`): | 838 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | metrics_verified (`bool`, *optional*, defaults to `False`):
Indicates whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not. Automatically computed by Hugging Face, do not set.
dataset_config (`str`, *optional*):
Example: fr. The name of the dataset configuration used in `load_dataset()`.
dataset_split (`str`, *optional*):
Example: test. The name of the dataset split used in `load_dataset()`. | 839 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | dataset_split (`str`, *optional*):
Example: test. The name of the dataset split used in `load_dataset()`.
dataset_revision (`str`, *optional*):
Example: 5503434ddd753f426f4b38109466949a1217c2bb. The name of the dataset dataset revision
used in `load_dataset()`.
metrics_verification_token (`bool`, *optional*):
A JSON Web Token that is used to verify whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not. | 840 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Returns:
`dict`: a metadata dict with the result from a model evaluated on a dataset. | 841 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Example:
```python
>>> from huggingface_hub import metadata_eval_result
>>> results = metadata_eval_result(
... model_pretty_name="RoBERTa fine-tuned on ReactionGIF",
... task_pretty_name="Text Classification",
... task_id="text-classification",
... metrics_pretty_name="Accuracy",
... metrics_id="accuracy",
... metrics_value=0.2662102282047272,
... dataset_pretty_name="ReactionJPEG",
... dataset_id="julien-c/reactionjpeg", | 842 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ... dataset_pretty_name="ReactionJPEG",
... dataset_id="julien-c/reactionjpeg",
... dataset_config="default",
... dataset_split="test",
... )
>>> results == {
... 'model-index': [
... {
... 'name': 'RoBERTa fine-tuned on ReactionGIF',
... 'results': [
... {
... 'task': {
... 'type': 'text-classification',
... 'name': 'Text Classification' | 843 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ... 'type': 'text-classification',
... 'name': 'Text Classification'
... },
... 'dataset': {
... 'name': 'ReactionJPEG',
... 'type': 'julien-c/reactionjpeg',
... 'config': 'default',
... 'split': 'test'
... },
... 'metrics': [
... { | 844 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ... },
... 'metrics': [
... {
... 'type': 'accuracy',
... 'value': 0.2662102282047272,
... 'name': 'Accuracy',
... 'verified': False
... }
... ]
... }
... ]
... }
... ]
... }
True
```
``` | 845 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ```python
Updates the metadata in the README.md of a repository on the Hugging Face Hub.
If the README.md file doesn't exist yet, a new one is created with metadata and an
the default ModelCard or DatasetCard template. For `space` repo, an error is thrown
as a Space cannot exist without a `README.md` file. | 846 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Args:
repo_id (`str`):
The name of the repository.
metadata (`dict`):
A dictionary containing the metadata to be updated.
repo_type (`str`, *optional*):
Set to `"dataset"` or `"space"` if updating to a dataset or space,
`None` or `"model"` if updating to a model. Default is `None`.
overwrite (`bool`, *optional*, defaults to `False`):
If set to `True` an existing field can be overwritten, otherwise
attempting to overwrite an existing field will cause an error.
token (`str`, *optional*): | 847 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | attempting to overwrite an existing field will cause an error.
token (`str`, *optional*):
The Hugging Face authentication token.
commit_message (`str`, *optional*):
The summary / title / first line of the generated commit. Defaults to
`f"Update metadata with huggingface_hub"`
commit_description (`str` *optional*)
The description of the generated commit
revision (`str`, *optional*):
The git revision to commit from. Defaults to the head of the
`"main"` branch.
create_pr (`boolean`, *optional*): | 848 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | The git revision to commit from. Defaults to the head of the
`"main"` branch.
create_pr (`boolean`, *optional*):
Whether or not to create a Pull Request from `revision` with that commit.
Defaults to `False`.
parent_commit (`str`, *optional*):
The OID / SHA of the parent commit, as a hexadecimal string. Shorthands (7 first characters) are also supported.
If specified and `create_pr` is `False`, the commit will fail if `revision` does not point to `parent_commit`. | 849 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | If specified and `create_pr` is `False`, the commit will fail if `revision` does not point to `parent_commit`.
If specified and `create_pr` is `True`, the pull request will be created from `parent_commit`.
Specifying `parent_commit` ensures the repo has not changed before committing the changes, and can be
especially useful if the repo is updated / committed to concurrently.
Returns:
`str`: URL of the commit which updated the card metadata. | 850 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | Example:
```python
>>> from huggingface_hub import metadata_update
>>> metadata = {'model-index': [{'name': 'RoBERTa fine-tuned on ReactionGIF',
... 'results': [{'dataset': {'name': 'ReactionGIF',
... 'type': 'julien-c/reactiongif'},
... 'metrics': [{'name': 'Recall',
... 'type': 'recall',
... 'value': 0.7762102282047272}], | 851 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md | .md | ... 'value': 0.7762102282047272}],
... 'task': {'name': 'Text Classification',
... 'type': 'text-classification'}}]}]}
>>> url = metadata_update("hf-internal-testing/reactiongif-roberta-card", metadata)
```
``` | 852 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | Inference Endpoints provides a secure production solution to easily deploy any `transformers`, `sentence-transformers`, and `diffusers` models on a dedicated and autoscaling infrastructure managed by Hugging Face. An Inference Endpoint is built from a model from the [Hub](https://huggingface.co/models). | 853 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | In this guide, we will learn how to programmatically manage Inference Endpoints with `huggingface_hub`. For more information about the Inference Endpoints product itself, check out its [official documentation](https://huggingface.co/docs/inference-endpoints/index). | 854 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | This guide assumes `huggingface_hub` is correctly installed and that your machine is logged in. Check out the [Quick Start guide](https://huggingface.co/docs/huggingface_hub/quick-start#quickstart) if that's not the case yet. The minimal version supporting Inference Endpoints API is `v0.19.0`. | 855 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | The first step is to create an Inference Endpoint using [`create_inference_endpoint`]:
```py
>>> from huggingface_hub import create_inference_endpoint | 856 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | >>> endpoint = create_inference_endpoint(
... "my-endpoint-name",
... repository="gpt2",
... framework="pytorch",
... task="text-generation",
... accelerator="cpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="x2",
... instance_type="intel-icl"
... )
``` | 857 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | In this example, we created a `protected` Inference Endpoint named `"my-endpoint-name"`, to serve [gpt2](https://huggingface.co/gpt2) for `text-generation`. A `protected` Inference Endpoint means your token is required to access the API. We also need to provide additional information to configure the hardware requirements, such as vendor, region, accelerator, instance type, and size. You can check out the list of available resources | 858 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | requirements, such as vendor, region, accelerator, instance type, and size. You can check out the list of available resources [here](https://api.endpoints.huggingface.cloud/#/v2%3A%3Aprovider/list_vendors). Alternatively, you can create an Inference Endpoint manually using the [Web interface](https://ui.endpoints.huggingface.co/new) for convenience. Refer to this [guide](https://huggingface.co/docs/inference-endpoints/guides/advanced) for details on advanced settings and their usage. | 859 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | The value returned by [`create_inference_endpoint`] is an [`InferenceEndpoint`] object:
```py
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
```
It's a dataclass that holds information about the endpoint. You can access important attributes such as `name`, `repository`, `status`, `task`, `created_at`, `updated_at`, etc. If you need it, you can also access the raw response from the server with `endpoint.raw`. | 860 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | Once your Inference Endpoint is created, you can find it on your [personal dashboard](https://ui.endpoints.huggingface.co/).
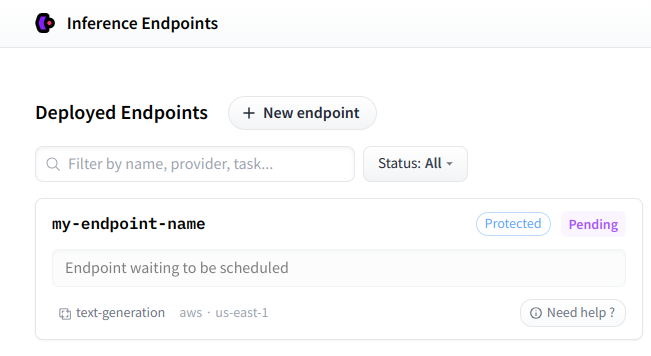 | 861 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | By default the Inference Endpoint is built from a docker image provided by Hugging Face. However, it is possible to specify any docker image using the `custom_image` parameter. A common use case is to run LLMs using the [text-generation-inference](https://github.com/huggingface/text-generation-inference) framework. This can be done like this:
```python
# Start an Inference Endpoint running Zephyr-7b-beta on TGI
>>> from huggingface_hub import create_inference_endpoint | 862 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ```python
# Start an Inference Endpoint running Zephyr-7b-beta on TGI
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "aws-zephyr-7b-beta-0486",
... repository="HuggingFaceH4/zephyr-7b-beta",
... framework="pytorch",
... task="text-generation",
... accelerator="gpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="x1",
... instance_type="nvidia-a10g",
... custom_image={ | 863 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ... type="protected",
... instance_size="x1",
... instance_type="nvidia-a10g",
... custom_image={
... "health_route": "/health",
... "env": {
... "MAX_BATCH_PREFILL_TOKENS": "2048",
... "MAX_INPUT_LENGTH": "1024",
... "MAX_TOTAL_TOKENS": "1512",
... "MODEL_ID": "/repository"
... },
... "url": "ghcr.io/huggingface/text-generation-inference:1.1.0",
... },
... )
``` | 864 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ... },
... "url": "ghcr.io/huggingface/text-generation-inference:1.1.0",
... },
... )
```
The value to pass as `custom_image` is a dictionary containing a url to the docker container and configuration to run it. For more details about it, checkout the [Swagger documentation](https://api.endpoints.huggingface.cloud/#/v2%3A%3Aendpoint/create_endpoint). | 865 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | In some cases, you might need to manage Inference Endpoints you created previously. If you know the name, you can fetch it using [`get_inference_endpoint`], which returns an [`InferenceEndpoint`] object. Alternatively, you can use [`list_inference_endpoints`] to retrieve a list of all Inference Endpoints. Both methods accept an optional `namespace` parameter. You can set the `namespace` to any organization you are a part of. Otherwise, it defaults to your username.
```py | 866 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ```py
>>> from huggingface_hub import get_inference_endpoint, list_inference_endpoints | 867 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Get one
>>> get_inference_endpoint("my-endpoint-name")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# List all endpoints from an organization
>>> list_inference_endpoints(namespace="huggingface")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...] | 868 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # List all endpoints from all organizations the user belongs to
>>> list_inference_endpoints(namespace="*")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]
``` | 869 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | In the rest of this guide, we will assume that we have a [`InferenceEndpoint`] object called `endpoint`. You might have noticed that the endpoint has a `status` attribute of type [`InferenceEndpointStatus`]. When the Inference Endpoint is deployed and accessible, the status should be `"running"` and the `url` attribute is set:
```py
>>> endpoint | 870 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ```py
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
``` | 871 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ```
Before reaching a `"running"` state, the Inference Endpoint typically goes through an `"initializing"` or `"pending"` phase. You can fetch the new state of the endpoint by running [`~InferenceEndpoint.fetch`]. Like every other method from [`InferenceEndpoint`] that makes a request to the server, the internal attributes of `endpoint` are mutated in place:
```py
>>> endpoint.fetch()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
``` | 872 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
```
Instead of fetching the Inference Endpoint status while waiting for it to run, you can directly call [`~InferenceEndpoint.wait`]. This helper takes as input a `timeout` and a `fetch_every` parameter (in seconds) and will block the thread until the Inference Endpoint is deployed. Default values are respectively `None` (no timeout) and `5` seconds.
```py
# Pending endpoint
>>> endpoint | 873 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ```py
# Pending endpoint
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None) | 874 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Wait 10s => raises a InferenceEndpointTimeoutError
>>> endpoint.wait(timeout=10)
raise InferenceEndpointTimeoutError("Timeout while waiting for Inference Endpoint to be deployed.")
huggingface_hub._inference_endpoints.InferenceEndpointTimeoutError: Timeout while waiting for Inference Endpoint to be deployed. | 875 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Wait more
>>> endpoint.wait()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
```
If `timeout` is set and the Inference Endpoint takes too much time to load, a [`InferenceEndpointTimeoutError`] timeout error is raised. | 876 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | Once your Inference Endpoint is up and running, you can finally run inference on it!
[`InferenceEndpoint`] has two properties `client` and `async_client` returning respectively an [`InferenceClient`] and an [`AsyncInferenceClient`] objects.
```py
# Run text_generation task:
>>> endpoint.client.text_generation("I am")
' not a fan of the idea of a "big-budget" movie. I think it\'s a' | 877 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Or in an asyncio context:
>>> await endpoint.async_client.text_generation("I am")
```
If the Inference Endpoint is not running, an [`InferenceEndpointError`] exception is raised:
```py
>>> endpoint.client
huggingface_hub._inference_endpoints.InferenceEndpointError: Cannot create a client for this Inference Endpoint as it is not yet deployed. Please wait for the Inference Endpoint to be deployed using `endpoint.wait()` and try again.
``` | 878 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | ```
For more details about how to use the [`InferenceClient`], check out the [Inference guide](../guides/inference). | 879 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | Now that we saw how to create an Inference Endpoint and run inference on it, let's see how to manage its lifecycle.
<Tip> | 880 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | In this section, we will see methods like [`~InferenceEndpoint.pause`], [`~InferenceEndpoint.resume`], [`~InferenceEndpoint.scale_to_zero`], [`~InferenceEndpoint.update`] and [`~InferenceEndpoint.delete`]. All of those methods are aliases added to [`InferenceEndpoint`] for convenience. If you prefer, you can also use the generic methods defined in `HfApi`: [`pause_inference_endpoint`], [`resume_inference_endpoint`], [`scale_to_zero_inference_endpoint`], [`update_inference_endpoint`], and | 881 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | [`resume_inference_endpoint`], [`scale_to_zero_inference_endpoint`], [`update_inference_endpoint`], and [`delete_inference_endpoint`]. | 882 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | </Tip> | 883 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | To reduce costs when your Inference Endpoint is not in use, you can choose to either pause it using [`~InferenceEndpoint.pause`] or scale it to zero using [`~InferenceEndpoint.scale_to_zero`].
<Tip> | 884 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | <Tip>
An Inference Endpoint that is *paused* or *scaled to zero* doesn't cost anything. The difference between those two is that a *paused* endpoint needs to be explicitly *resumed* using [`~InferenceEndpoint.resume`]. On the contrary, a *scaled to zero* endpoint will automatically start if an inference call is made to it, with an additional cold start delay. An Inference Endpoint can also be configured to scale to zero automatically after a certain period of inactivity.
</Tip>
```py | 885 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | </Tip>
```py
# Pause and resume endpoint
>>> endpoint.pause()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='paused', url=None)
>>> endpoint.resume()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
>>> endpoint.wait().client.text_generation(...)
... | 886 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Scale to zero
>>> endpoint.scale_to_zero()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='scaledToZero', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
# Endpoint is not 'running' but still has a URL and will restart on first call.
``` | 887 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | In some cases, you might also want to update your Inference Endpoint without creating a new one. You can either update the hosted model or the hardware requirements to run the model. You can do this using [`~InferenceEndpoint.update`]:
```py
# Change target model
>>> endpoint.update(repository="gpt2-large")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None) | 888 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Update number of replicas
>>> endpoint.update(min_replica=2, max_replica=6)
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update to larger instance
>>> endpoint.update(accelerator="cpu", instance_size="x4", instance_type="intel-icl")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
``` | 889 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | Finally if you won't use the Inference Endpoint anymore, you can simply call [`~InferenceEndpoint.delete()`].
<Tip warning={true}>
This is a non-revertible action that will completely remove the endpoint, including its configuration, logs and usage metrics. You cannot restore a deleted Inference Endpoint.
</Tip> | 890 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | A typical use case of Inference Endpoints is to process a batch of jobs at once to limit the infrastructure costs. You can automate this process using what we saw in this guide:
```py
>>> import asyncio
>>> from huggingface_hub import create_inference_endpoint
# Start endpoint + wait until initialized
>>> endpoint = create_inference_endpoint(name="batch-endpoint",...).wait()
# Run inference
>>> client = endpoint.client
>>> results = [client.text_generation(...) for job in jobs] | 891 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Run inference
>>> client = endpoint.client
>>> results = [client.text_generation(...) for job in jobs]
# Or with asyncio
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()
```
Or if your Inference Endpoint already exists and is paused:
```py
>>> import asyncio
>>> from huggingface_hub import get_inference_endpoint | 892 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md | .md | # Get endpoint + wait until initialized
>>> endpoint = get_inference_endpoint("batch-endpoint").resume().wait()
# Run inference
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()
``` | 893 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md | .md | <!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 894 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md | .md | Inference is the process of using a trained model to make predictions on new data. As this process can be compute-intensive,
running on a dedicated server can be an interesting option. The `huggingface_hub` library provides an easy way to call a
service that runs inference for hosted models. There are several services you can connect to:
- [Inference API](https://huggingface.co/docs/api-inference/index): a service that allows you to run accelerated inference | 895 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md | .md | - [Inference API](https://huggingface.co/docs/api-inference/index): a service that allows you to run accelerated inference
on Hugging Face's infrastructure for free. This service is a fast way to get started, test different models, and
prototype AI products.
- [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index): a product to easily deploy models to production.
Inference is run by Hugging Face in a dedicated, fully managed infrastructure on a cloud provider of your choice. | 896 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md | .md | Inference is run by Hugging Face in a dedicated, fully managed infrastructure on a cloud provider of your choice.
These services can be called with the [`InferenceClient`] object. It acts as a replacement for the legacy
[`InferenceApi`] client, adding specific support for tasks and handling inference on both
[Inference API](https://huggingface.co/docs/api-inference/index) and [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index). | 897 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md | .md | Learn how to migrate to the new client in the [Legacy InferenceAPI client](#legacy-inferenceapi-client) section.
<Tip>
[`InferenceClient`] is a Python client making HTTP calls to our APIs. If you want to make the HTTP calls directly using
your preferred tool (curl, postman,...), please refer to the [Inference API](https://huggingface.co/docs/api-inference/index)
or to the [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) documentation pages. | 898 |
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md | .md | or to the [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) documentation pages.
For web development, a [JS client](https://huggingface.co/docs/huggingface.js/inference/README) has been released.
If you are interested in game development, you might have a look at our [C# project](https://github.com/huggingface/unity-api).
</Tip> | 899 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.