
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
listlengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
katanaml/sparrow
|
computer-vision
| 54 |
Getting Errors while running sparrow.sh under llm
|
I already installed all dependencies, Looks like there are some version conflicts.
FYI: I'm running it on Linux(Ubuntu 22.04.1)
Issues: ModuleNotFoundError: No module named 'tenacity.asyncio'
|
closed
|
2024-06-17T11:01:41Z
|
2024-06-18T10:53:23Z
|
https://github.com/katanaml/sparrow/issues/54
|
[] |
sanjay-nit
| 3 |
custom-components/pyscript
|
jupyter
| 484 |
@state_trigger does not trigger on climate domain, attribute changes
|
In general, there appears to be a hit or miss state trigger situation with the climate domain.
For instance, the following
`@state_trigger('climate.my_thermostat.hvac_action')`
does not trigger on `hvac_action` but only on `hvac_mode` changes.
to workaround that, I tried adding a watch:
`@state_trigger('climate.my_thermostat.hvac_action', watch=['climate.my_thermostat.hvac_action'])`
which made it trigger on the `hvac_action` attribute but the value/old_value I get, are both from the `hvac_mode`.
meaning, inside the trigger I have to explicitly get the value of the climate attribute `hvac_action`.
Another problem that I could not work around easily this time, was trigger on the climate `current_temperature` attribute.
Even with a watch, I can't get it to trigger. It only triggers for `hvac_action` changes.
Example:
`@state_trigger('climate.my_thermostat.current_temperature', watch=['climate.my_thermostat.current_temperature'])`
This one, just does not want to trigger on current temperature changes. It triggers on `hvac_mode` changes, instead.
Same thing, even with the `*`, like so:
`@state_trigger('climate.my_thermostat.*', watch=['climate.my_thermostat.*'])`
It will only trigger again, on `hvac_mode` changes and NOT on `current_temperature` changes.
My more involved workaround, was making a service with pyscript, that gets called by a HA "native" trigger on the `current_temperature` attribute changes, so that I can capture changes to that attribute. But that now has created a tightly coupled service/function to a HA trigger, which is not ideal. My pyscripts should be standalone.
Thank you.
|
open
|
2023-07-08T19:43:06Z
|
2024-10-22T22:13:28Z
|
https://github.com/custom-components/pyscript/issues/484
|
[] |
antokara
| 1 |
Lightning-AI/pytorch-lightning
|
deep-learning
| 19,989 |
TransformerEnginePrecision _convert_layers(module) fails for FSDP zero2/zero3
|
### Bug description
`TransformerEnginePrecision.convert_module` function seems to not work for the the FSDP-wrapped model.
### What version are you seeing the problem on?
master
### How to reproduce the bug
```python
model = FSDP(
model,
sharding_strategy=sharding_strategy,
auto_wrap_policy=custom_wrap_policy,
device_id=local_rank,
use_orig_params=True,
device_mesh=mesh,
)
te_precision = TransformerEnginePrecision(weights_dtype=torch.bfloat16, replace_layers=True)
self.model = te_precision.convert_module(self.model)
```
### Error messages and logs
```
[rank1]: self.model = te_precision.convert_module(self.model)
[rank1]: _convert_layers(module)
[rank1]: File "/usr/local/lib/python3.10/dist-packages/lightning/fabric/plugins/precision/transformer_engine.py", line 165, in _convert_layers
[rank1]: replacement.weight.data = child.weight.data.clone()
[rank1]: RuntimeError: Attempted to call `variable.set_data(tensor)`, but `variable` and `tensor` have incompatible tensor type.
```
### More info
I actually see it for pytorch-lightning==2.3.0
|
open
|
2024-06-18T14:08:00Z
|
2024-06-18T14:08:56Z
|
https://github.com/Lightning-AI/pytorch-lightning/issues/19989
|
[
"bug",
"needs triage",
"ver: 2.2.x"
] |
wprazuch
| 0 |
twopirllc/pandas-ta
|
pandas
| 890 |
wrong NaN import
|
in momentum squeeze_pro
there should be
from numpy import nan as npNaN
not from numpy import Nan as npNaN
|
closed
|
2025-02-22T09:52:54Z
|
2025-02-22T18:59:15Z
|
https://github.com/twopirllc/pandas-ta/issues/890
|
[
"bug",
"duplicate"
] |
kkr007007
| 1 |
jupyterlab/jupyter-ai
|
jupyter
| 833 |
We have Github Copilot license and we want to use this model provider on Jupyter AI
|
### Proposed Solution
We don´t see in the list of model providers : https://jupyter-ai.readthedocs.io/en/latest/users/index.html#model-providers , the GithHUb Copilot solution, Are you going to integrate this model provider?
Thanks.
|
open
|
2024-06-14T10:24:16Z
|
2024-07-30T22:56:55Z
|
https://github.com/jupyterlab/jupyter-ai/issues/833
|
[
"enhancement",
"status:Blocked"
] |
japineda3
| 2 |
jacobgil/pytorch-grad-cam
|
computer-vision
| 193 |
Gradients are: 'NoneType' object has no attribute 'shape'
|
Hi, thank you for providing an open-source implementation for your work. I am trying to build on top of it to visualize my Resnet-18 encoder for the Image captioning task. It is an encoder-decoder architecture with a resnet-18 encoder and an RNN decoder. Below is my code for reproducibility.
```python
from pytorch_grad_cam import GradCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM, EigenCAM, FullGrad
from pytorch_grad_cam.utils.image import show_cam_on_image
from model import EncoderCNN, DecoderRNN
class CaptioningModelOutputWrapper(torch.nn.Module):
def __init__(self, embedding, gloves):
super(CaptioningModelOutputWrapper, self).__init__()
self.embedding_size = 300
self.embed_size = 512
self.embedding = embedding
self.gloves = gloves
self.hidden_size = 512
self.vocab_size = len(data_loader.dataset.vocab)
self.encoder = EncoderCNN(self.embed_size,self.embedding_size+18)
self.decoder = DecoderRNN(self.embedding_size, self.embed_size, self.hidden_size, self.vocab_size)
def forward(self, x):
features = self.encoder(x, self.embedding)
outputs = self.decoder(features, self.gloves)
return outputs
class CaptionModelOutputTarget:
def __init__(self, index, category):
self.index = index
self.category = category
def __call__(self, model_output):
print(model_output.shape)
return model_output[self.index, self.category]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
it=iter(data_loader)
input_tensor, embedding, gloves, caption, string_caption, entity_name, path = next(it)
input_tensor, embedding, gloves = input_tensor.to(device), embedding.to(device), gloves.to(device)
model = CaptioningModelOutputWrapper(embedding, gloves)
model.to(device)
outputs = model.forward(input_tensor)
print(outputs.shape)
target_layers = [model.encoder.resnet[:-2]]
# Note: input_tensor can be a batch tensor with several images!
# Construct the CAM object once, and then re-use it on many images:
cam = GradCAM(model=model, target_layers=target_layers, use_cuda=True)
targets = [CaptionModelOutputTarget(10,caption[0,10])]
cam.model = model.train()
# You can also pass aug_smooth=True and eigen_smooth=True, to apply smoothing.
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)
# In this example grayscale_cam has only one image in the batch:
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
```
Error Stack:
```python
torch.Size([1, 100, 31480])
torch.Size([100, 31480])
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/tmp/ipykernel_86959/3158658298.py in <module>
13 cam.model = model.train()
14 # You can also pass aug_smooth=True and eigen_smooth=True, to apply smoothing.
---> 15 grayscale_cam = cam(input_tensor=input_tensor, targets=targets)
16
17 # In this example grayscale_cam has only one image in the batch:
~/anaconda3/envs/fake/lib/python3.9/site-packages/pytorch_grad_cam/base_cam.py in __call__(self, input_tensor, targets, aug_smooth, eigen_smooth)
182 input_tensor, targets, eigen_smooth)
183
--> 184 return self.forward(input_tensor,
185 targets, eigen_smooth)
186
~/anaconda3/envs/fake/lib/python3.9/site-packages/pytorch_grad_cam/base_cam.py in forward(self, input_tensor, targets, eigen_smooth)
91 # use all conv layers for example, all Batchnorm layers,
92 # or something else.
---> 93 cam_per_layer = self.compute_cam_per_layer(input_tensor,
94 targets,
95 eigen_smooth)
~/anaconda3/envs/fake/lib/python3.9/site-packages/pytorch_grad_cam/base_cam.py in compute_cam_per_layer(self, input_tensor, targets, eigen_smooth)
123 layer_grads = grads_list[i]
124
--> 125 cam = self.get_cam_image(input_tensor,
126 target_layer,
127 targets,
~/anaconda3/envs/fake/lib/python3.9/site-packages/pytorch_grad_cam/base_cam.py in get_cam_image(self, input_tensor, target_layer, targets, activations, grads, eigen_smooth)
48 eigen_smooth: bool = False) -> np.ndarray:
49
---> 50 weights = self.get_cam_weights(input_tensor,
51 target_layer,
52 targets,
~/anaconda3/envs/fake/lib/python3.9/site-packages/pytorch_grad_cam/grad_cam.py in get_cam_weights(self, input_tensor, target_layer, target_category, activations, grads)
20 activations,
21 grads):
---> 22 return np.mean(grads, axis=(2, 3))
AttributeError: 'NoneType' object has no attribute 'shape'
```
I add the line ```python cam.model=model.train()``` to the training script in order to allow backpropagation in the RNN otherwise it throws cuDNN error that RNN backward cannot be called outside train mode. Solving that error leads to this. It would really help if you can help debug why this issue occurs in first place.
|
closed
|
2022-01-11T11:17:02Z
|
2022-01-11T14:47:10Z
|
https://github.com/jacobgil/pytorch-grad-cam/issues/193
|
[] |
Anurag14
| 1 |
pytest-dev/pytest-django
|
pytest
| 1,144 |
do not require DJANGO_SETTINGS_MODULE when running pytest help
|
Is it really necessary to require seting `DJANGO_SETTINGS_MODULE` only to display help?
I run my tests using `tox`, and `DJANGO_SETTINGS_MODULE` is being set there.
Sometimes I just need to quickly run `pytest help` just to see some syntax.
Does the output of `pytest help` depend on my currently configured settings?
My current output:
```
$ pytest --help
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "H:\python\django-pytest\.venv\Scripts\pytest.exe\__main__.py", line 7, in <module>
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 201, in console_main
code = main()
^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 156, in main
config = _prepareconfig(args, plugins)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 341, in _prepareconfig
config = pluginmanager.hook.pytest_cmdline_parse(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_hooks.py", line 513, in __call__
return self._hookexec(self.name, self._hookimpls.copy(), kwargs, firstresult)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_manager.py", line 120, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 139, in _multicall
raise exception.with_traceback(exception.__traceback__)
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 122, in _multicall
teardown.throw(exception) # type: ignore[union-attr]
^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\helpconfig.py", line 105, in pytest_cmdline_parse
config = yield
^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 103, in _multicall
res = hook_impl.function(*args)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 1140, in pytest_cmdline_parse
self.parse(args)
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 1490, in parse
self._preparse(args, addopts=addopts)
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 1394, in _preparse
self.hook.pytest_load_initial_conftests(
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_hooks.py", line 513, in __call__
return self._hookexec(self.name, self._hookimpls.copy(), kwargs, firstresult)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_manager.py", line 120, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 139, in _multicall
raise exception.with_traceback(exception.__traceback__)
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 122, in _multicall
teardown.throw(exception) # type: ignore[union-attr]
^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\warnings.py", line 151, in pytest_load_initial_conftests
return (yield)
^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 122, in _multicall
teardown.throw(exception) # type: ignore[union-attr]
^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\capture.py", line 154, in pytest_load_initial_conftests
yield
File "H:\python\django-pytest\.venv\Lib\site-packages\pluggy\_callers.py", line 103, in _multicall
res = hook_impl.function(*args)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 1218, in pytest_load_initial_conftests
self.pluginmanager._set_initial_conftests(
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 581, in _set_initial_conftests
self._try_load_conftest(
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 619, in _try_load_conftest
self._loadconftestmodules(
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 659, in _loadconftestmodules
mod = self._importconftest(
^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 735, in _importconftest
self.consider_conftest(mod, registration_name=conftestpath_plugin_name)
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 816, in consider_conftest
self.register(conftestmodule, name=registration_name)
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 512, in register
self.consider_module(plugin)
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 824, in consider_module
self._import_plugin_specs(getattr(mod, "pytest_plugins", []))
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 831, in _import_plugin_specs
self.import_plugin(import_spec)
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\config\__init__.py", line 858, in import_plugin
__import__(importspec)
File "<frozen importlib._bootstrap>", line 1176, in _find_and_load
File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "H:\python\django-pytest\.venv\Lib\site-packages\_pytest\assertion\rewrite.py", line 174, in exec_module
exec(co, module.__dict__)
File "h:\python\django-pytest\test_fixtures.py", line 11, in <module>
from django_pytest_app.models import (
File "H:\python\django-pytest\django_pytest_app\models.py", line 5, in <module>
class Foo(models.Model):
File "H:\python\django-pytest\.venv\Lib\site-packages\django\db\models\base.py", line 129, in __new__
app_config = apps.get_containing_app_config(module)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\python\django-pytest\.venv\Lib\site-packages\django\apps\registry.py", line 260, in get_containing_app_config
self.check_apps_ready()
File "H:\python\django-pytest\.venv\Lib\site-packages\django\apps\registry.py", line 137, in check_apps_ready
settings.INSTALLED_APPS
File "H:\python\django-pytest\.venv\Lib\site-packages\django\conf\__init__.py", line 81, in __getattr__
self._setup(name)
File "H:\python\django-pytest\.venv\Lib\site-packages\django\conf\__init__.py", line 61, in _setup
raise ImproperlyConfigured(
django.core.exceptions.ImproperlyConfigured: Requested setting INSTALLED_APPS, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings.
```
|
closed
|
2024-09-04T08:48:47Z
|
2024-09-04T12:20:33Z
|
https://github.com/pytest-dev/pytest-django/issues/1144
|
[] |
piotr-kubiak
| 4 |
deepfakes/faceswap
|
machine-learning
| 439 |
Secondary masks/artifacts/blur in converted images, even thou secondary aligned images have been deleted
|
running latest github version.
|
closed
|
2018-06-21T15:01:37Z
|
2018-07-18T05:37:14Z
|
https://github.com/deepfakes/faceswap/issues/439
|
[] |
minersday
| 4 |
tqdm/tqdm
|
pandas
| 1,185 |
Throw a warning for `tqdm(enumerate(...))`
|
It would be helpful to warn people know they use `tqdm(enumerate(...))` instead of `enumerate(tqdm(...))`.
It can be detected like this:
```
>>> a = [1,2,3]
>>> b = enumerate(a)
>>> isinstance(b, enumerate)
True
```
|
open
|
2021-06-15T14:00:42Z
|
2021-07-29T11:04:38Z
|
https://github.com/tqdm/tqdm/issues/1185
|
[
"help wanted 🙏",
"p4-enhancement-future 🧨"
] |
cccntu
| 0 |
neuml/txtai
|
nlp
| 541 |
Encoding using multiple-GPUs
|
I am doing this task where I am recommending products based on their reviews. To do that I am using your library and when I am creating the index, what I would like to know is whether there is a way to utilize several GPUs. Because the time it takes to encode the review text is huge and I have a multiGPU environment.
Also the task also expects explanations and I would also like to know can the same be done when I execute the explain method.
Thank you.
|
closed
|
2023-09-01T07:21:20Z
|
2024-12-22T01:32:13Z
|
https://github.com/neuml/txtai/issues/541
|
[] |
DenuwanClouda
| 7 |
nolar/kopf
|
asyncio
| 143 |
[PR] Die properly: fast and with no remnants
|
> <a href="https://github.com/nolar"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> A pull request by [nolar](https://github.com/nolar) at _2019-07-10 15:42:31+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/pull/143
>
When an operator gets SIGINT (Ctrl+C) or SIGTERM (in pods), it exits immediately, with no extra waits for anything.
This also improves its behaviour in PyCharm, where the operator can now be stopped and restarted in one click (previously required double-stopping).
> Issue : #142
> Requires: https://github.com/hjacobs/pykube/pull/31
## Description
### Watch-stream termination
`pykube-ng`, `kubernetes`, `requests`, and any other synchronous client libraries use the streaming responses of the built-in `urllib3` and `http` for watching over the k8s-events.
These streaming requests/responses can be closed when a chunk/line is yielded to the consumer, the control flow is returned to the caller, and the streaming socket itself is idling. E.g., for `requests`: https://2.python-requests.org/en/master/user/advanced/#streaming-requests
However, if nothing happens on the k8s-event stream (i.e. no k8s resources are added/modified/deleted), the streaming response spends most of its time in the blocking `read()` operation on a socket. It can remain there for long time — minutes, hours — until some data arrives on the socket.
If the streaming response runs in a thread, while the main thread is used for an asyncio event-loop, such stream cannot be closed/cancelled/terminated (because of the blocking `read()`). This, in turn, makes the application to hang on exit, holding its pod from restarting, since the thread is not finished until the `read()` call is finished.
There is no easy way to terminate the blocking `read()` operation on a socket. The only way is a dirty hack with the OS-level process signals, which interrupt the I/O operations on low (libc&co) level.
This hack can be done only from the main thread (because signal handlers can be set only from the main thread — a Python's limitation), and therefore is only suitable for the runnable application rather than for a library.
In `kopf run`, we can be sure that the event-loop and its asyncio tasks run in the main thread. In case of explicit task orchestration, we can assume that the operator developers do the same, but warn if they don't.
This PR:
* Moves the streaming watch-requests into their dedicated threads (instead of the asyncio thread-pool executors for every `next()` call).
* These dedicated threads are tracked in each `watch_objs()` call, and are interrupted when the watch-stream exits for any reason (an error, generator-exit, task cancellation, etc).
### Tasks cancellation
Beside of the stream termination, this PR improves the way how the tasks are orchestrated in an event-loop, so that they are cancelled properly, and have some minimal time for graceful exit (e.g. cleanups). This is used, for example, by the peering `disappear()` call to remove self from the peering object (previously, this call was cancelled on start, and therefore never actually executed).
Also, the sub-tasks of the root tasks are tracked and also cancelled. For example, the scheduled workers, handlers, all shielded tasks, and generally anything that is not produced by `create_tasks()`, but runs in the loop. This guarantees, that when `run()` exits, it leaves nothing behind.
## Types of Changes
- Bug fix (non-breaking change which fixes an issue)
- Refactor/improvements
## Review
_List of tasks the reviewer must do to review the PR_
- [ ] Tests
- [ ] Documentation
---
> <a href="https://github.com/nolar"><img align="left" height="30" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> Commented by [nolar](https://github.com/nolar) at _2019-07-16 10:33:52+00:00_
>
Closed in favour of separate #147 #148 #149 #152 — one per fix.
|
closed
|
2020-08-18T19:57:19Z
|
2020-08-23T20:47:32Z
|
https://github.com/nolar/kopf/issues/143
|
[
"bug",
"archive"
] |
kopf-archiver[bot]
| 0 |
kynan/nbstripout
|
jupyter
| 86 |
Allowlist metadata fields to keep
|
By far the most requested feature is adding extra metadata fields to strip (#58 #72 #78 #85). A more scalable approach would be using a (configurable) list of metadata fields to keep.
|
open
|
2018-08-14T10:53:46Z
|
2025-01-20T10:40:30Z
|
https://github.com/kynan/nbstripout/issues/86
|
[
"type:enhancement",
"help wanted"
] |
kynan
| 5 |
vitalik/django-ninja
|
django
| 569 |
[BUG] Incorrect storing url_name to URLconf
|
In case that you have two endpoints with same url, but different `url_name` param, django will store only last name in URLconf for reverse matching.
Example:
We have companies_list endpoint and company_create endpoint with the same url '/' but different methods (GET and POST).
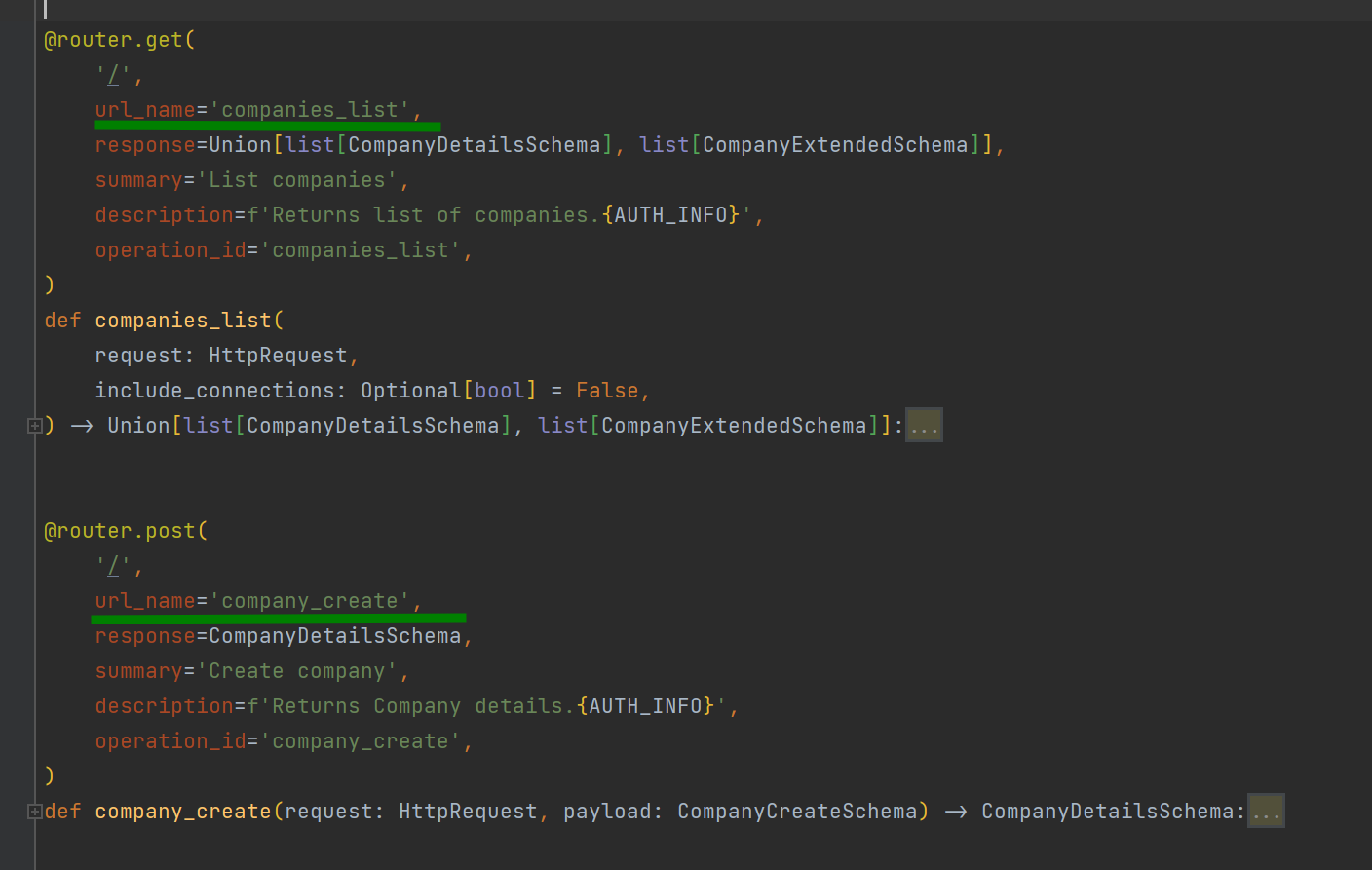
And only second name appears in URLconf list.
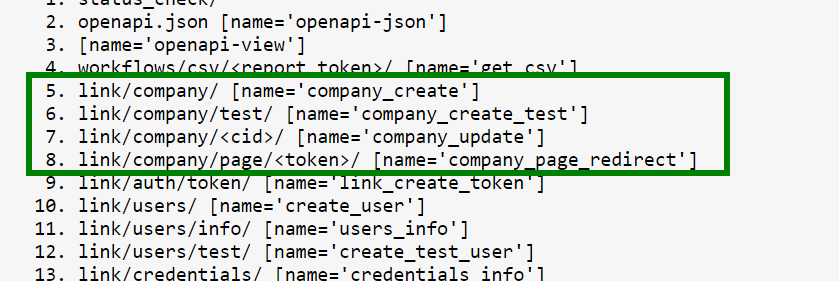
So if we try make reverse match `reverse('api:companies_list ')` - NoReverseMatch exception will be raised.
**Versions (please complete the following information):**
- Python version: 3.9
- Django version: 3.2.15
- Django-Ninja version: 0.18.0
|
closed
|
2022-09-16T12:27:34Z
|
2022-09-16T12:33:54Z
|
https://github.com/vitalik/django-ninja/issues/569
|
[] |
denis-manakov-cndt
| 1 |
dask/dask
|
scikit-learn
| 11,809 |
module 'dask.dataframe.multi' has no attribute 'concat'
|
<!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiable Examples https://stackoverflow.com/help/mcve
Bug reports that follow these guidelines are easier to diagnose, and so are often handled much more quickly.
-->
**Describe the issue**:
I am trying to run the first examle code from https://xgboost.readthedocs.io/en/stable/tutorials/dask.html
and get following error
```shell
Traceback (most recent call last):
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 244, in dconcat
return concat(value)
^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/compat.py", line 164, in concat
raise TypeError("Unknown type.")
^^^^^^^^^^^^^^^^^
TypeError: Unknown type.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/liao/LeoGit/NEU_courses/a.py", line 20, in <module>
output = dxgb.train(
^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/core.py", line 726, in inner_f
return func(**kwargs)
^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 1088, in train
return client.sync(
^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/distributed/utils.py", line 363, in sync
return sync(
^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/distributed/utils.py", line 439, in sync
raise error
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/distributed/utils.py", line 413, in f
result = yield future
^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/tornado/gen.py", line 766, in run
value = future.result()
^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 1024, in _train_async
result = await map_worker_partitions(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 549, in map_worker_partitions
result = await client.compute(fut).result()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/distributed/client.py", line 409, in _result
raise exc.with_traceback(tb)
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 533, in <lambda>
lambda *args, **kwargs: [func(*args, **kwargs)],
^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 979, in dispatched_train
Xy, evals = _get_dmatrices(
^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 921, in _get_dmatrices
Xy = _dmatrix_from_list_of_parts(**train_ref, nthread=n_threads)
^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 828, in _dmatrix_from_list_of_parts
return _create_dmatrix(**kwargs)
^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 810, in _create_dmatrix
v = concat_or_none(value)
^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 805, in concat_or_none
return dconcat(data)
^^^^^^^^^^^^^^^^^
File "/Users/liao/miniconda3/envs/boost3/lib/python3.11/site-packages/xgboost/dask/__init__.py", line 246, in dconcat
return dd.multi.concat(list(value), axis=0)
^^^^^^^^^^^^^^^^^
AttributeError: module 'dask.dataframe.multi' has no attribute 'concat'
```
**Minimal Complete Verifiable Example**:
```python
from xgboost import dask as dxgb
import dask.array as da
import dask.distributed
if __name__ == "__main__":
cluster = dask.distributed.LocalCluster()
client = dask.distributed.Client(cluster)
# X and y must be Dask dataframes or arrays
num_obs = 1e5
num_features = 20
X = da.random.random(size=(num_obs, num_features), chunks=(1000, num_features))
y = da.random.random(size=(num_obs, 1), chunks=(1000, 1))
dtrain = dxgb.DaskDMatrix(client, X, y)
# or
# dtrain = dxgb.DaskQuantileDMatrix(client, X, y)
output = dxgb.train(
client,
{"verbosity": 2, "tree_method": "hist", "objective": "reg:squarederror"},
dtrain,
num_boost_round=4,
evals=[(dtrain, "train")],
)
```
**Anything else we need to know?**:
I create a new conda env, and only install neccessary packages
**Environment**:
- Dask version: 2025.2.0
- Python version: 3.11
- Operating System: mac M3
- Install method (conda, pip, source): conda
- xgboost version: 2.1.4
|
closed
|
2025-03-05T01:50:56Z
|
2025-03-05T10:58:26Z
|
https://github.com/dask/dask/issues/11809
|
[
"needs triage"
] |
Leo-AO-99
| 1 |
biosustain/potion
|
sqlalchemy
| 57 |
Enhancement: Optionally make use of SQLAlchemy joinedloads in `instances` queries
|
Depending on how ones' relationships are configured in SQLAlchemy, adding `.options(joinedload("relationship_name"))` to the query can substantially reduce the number of queries executed.
I've prototyped this a bit for our code, relationship set ups, and on Postgres, and would be happy to share that snippet or start a preliminary PR. Unfortunately, I'm not 100% sure how well this generates to different model specifications, DB backends, etc.
|
open
|
2015-12-30T20:17:01Z
|
2016-01-01T21:06:34Z
|
https://github.com/biosustain/potion/issues/57
|
[] |
boydgreenfield
| 2 |
2noise/ChatTTS
|
python
| 238 |
【分享】几个还不错的音色分享给大家
|
https://ixo96gpj4vq.feishu.cn/wiki/SjiZwNSuUin9fukZh23cIMBOnge?from=from_copylink
|
closed
|
2024-06-03T16:40:32Z
|
2024-07-01T10:12:39Z
|
https://github.com/2noise/ChatTTS/issues/238
|
[
"ad"
] |
QuantumDriver
| 7 |
pyjanitor-devs/pyjanitor
|
pandas
| 1,102 |
improvement suggestions for conditional_join
|
- [x] allow selection/renaming of final columns within the function
- [x] implement a numba alternative, for hopefully faster processing
- [x] improve performance for left and right joins
|
closed
|
2022-05-11T23:06:42Z
|
2022-11-03T20:03:11Z
|
https://github.com/pyjanitor-devs/pyjanitor/issues/1102
|
[] |
samukweku
| 1 |
replicate/cog
|
tensorflow
| 1,303 |
the server sometimes just hang, can't receive request or process the request
|
i 'm using the cog python interface, and i deploy a model on virtual machine with ubuntu os
the server is running successfully at the beginning. but after a long time could be days or a cuple of hours, when the server process plenty of http requests, suddenly the server can't receive any request.
if i use postman to send a post request, there will be no logs. and if i use curl to send a health-check request, there will be nothing output. but the port is still occupied and the server process still exists.
and sometimes the server suddenly can't process any request. if i send a request, the cog log will be like this:
```python
{"prediction_id": "dcb630a2-f1d1-4d60-b05d-28918f087478", "logger": "cog.server.runner", "timestamp": "2023-09-14T02:58:10.318314Z", "severity": "INFO", "message": "starting prediction"}
```
and after the starting prediction log, there will be no more logs, and server hang. even i print something in predict function, there will be no logs.
could anyone give me some advices?
|
open
|
2023-09-14T03:14:14Z
|
2023-09-14T03:14:14Z
|
https://github.com/replicate/cog/issues/1303
|
[] |
zhangvia
| 0 |
thtrieu/darkflow
|
tensorflow
| 495 |
Please verify correct format of detection in Json
|
I am getting this as result in json file.
[{"topleft": {"y": 376, "x": 1073}, "confidence": 0.6, "bottomright": {"y": 419, "x": 1135}, "label": "0"}, {"topleft": {"y": 562, "x": 755}, "confidence": 0.62, "bottomright": {"y": 605, "x": 826}, "label": "0"},
{"topleft": {"y": 562, "x": 857}, "confidence": 0.61, "bottomright": {"y": 605, "x": 932}, "label": "0"}]
Is above is the correct format of result.
In Readme file of this repo the format shown for detection is below which i different from what I am getting:
[{"label":"person", "confidence": 0.56, "topleft": {"x": 184, "y": 101}, "bottomright": {"x": 274, "y": 382}},
{"label": "dog", "confidence": 0.32, "topleft": {"x": 71, "y": 263}, "bottomright": {"x": 193, "y": 353}},
{"label": "horse", "confidence": 0.76, "topleft": {"x": 412, "y": 109}, "bottomright": {"x": 592,"y": 337}}]
Any help will be appreciated.
|
closed
|
2017-12-31T09:30:47Z
|
2017-12-31T11:20:27Z
|
https://github.com/thtrieu/darkflow/issues/495
|
[] |
gangooteli
| 1 |
benbusby/whoogle-search
|
flask
| 1,089 |
[QUESTION] Persistency of custom theme when using Docker(-compose)
|
Hi,
since a few days now im using this awesome application.
I had a look at the documentation and was wondering why there is no volume-mount in the docker-compose file to keep all settings persistent
I understand that it is possible to set 90% of all settings as env-var, but i could not figure out how to make e.g. a custom theme persistent
After each server-reboot, the default settings/theme is present again
Is there a single file holding all of these settings to be able to mount this file/folder to a docker-volume?
Thanks in advance
|
closed
|
2023-10-23T16:49:47Z
|
2023-10-25T14:18:25Z
|
https://github.com/benbusby/whoogle-search/issues/1089
|
[
"question"
] |
SHU-red
| 2 |
plotly/dash-table
|
plotly
| 717 |
Objects are not valid as a React child (found: object with keys {id, full_name}). If you meant to render a collection of children, use an array instead.
|
Code
```python
app.layout = html.Div(children=[
html.H1('Dashboard', className='text-center'),
dash_table.DataTable(
id='preventions',
columns=[{"name": col, "id": col} for col in df.columns],
data=df.to_dict('records')
)
])
```
```
Objects are not valid as a React child (found: object with keys {id, full_name}). If you meant to render a collection of children, use an array instead.
in div (created by t)
in t (created by t)
in td (created by t)
in t (created by t)
in tr (created by t)
in tbody (created by t)
in table (created by t)
in div (created by t)
in div (created by t)
in div (created by t)
in div (created by t)
in div (created by t)
in t (created by t)
in t (created by t)
in t (created by t)
in Suspense (created by t)
in t (created by CheckedComponent)
in CheckedComponent (created by TreeContainer)
in UnconnectedComponentErrorBoundary (created by Connect(UnconnectedComponentErrorBoundary))
in Connect(UnconnectedComponentErrorBoundary) (created by TreeContainer)
in TreeContainer (created by Connect(TreeContainer))
in Connect(TreeContainer) (created by TreeContainer)
in div (created by u)
in u (created by CheckedComponent)
in CheckedComponent (created by TreeContainer)
in UnconnectedComponentErrorBoundary (created by Connect(UnconnectedComponentErrorBoundary))
in Connect(UnconnectedComponentErrorBoundary) (created by TreeContainer)
in TreeContainer (created by Connect(TreeContainer))
in Connect(TreeContainer) (created by UnconnectedContainer)
in div (created by UnconnectedGlobalErrorContainer)
in div (created by GlobalErrorOverlay)
in div (created by GlobalErrorOverlay)
in GlobalErrorOverlay (created by DebugMenu)
in div (created by DebugMenu)
in DebugMenu (created by UnconnectedGlobalErrorContainer)
in div (created by UnconnectedGlobalErrorContainer)
in UnconnectedGlobalErrorContainer (created by Connect(UnconnectedGlobalErrorContainer))
in Connect(UnconnectedGlobalErrorContainer) (created by UnconnectedContainer)
in UnconnectedContainer (created by Connect(UnconnectedContainer))
in Connect(UnconnectedContainer) (created by UnconnectedAppContainer)
in UnconnectedAppContainer (created by Connect(UnconnectedAppContainer))
in Connect(UnconnectedAppContainer) (created by AppProvider)
in Provider (created by AppProvider)
in AppProvider
```
```
(This error originated from the built-in JavaScript code that runs Dash apps. Click to see the full stack trace or open your browser's console.)
invariant@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:49:15
throwOnInvalidObjectType@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:11968:14
reconcileChildFibers@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:12742:31
reconcileChildren@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:14537:28
updateHostComponent@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:14998:20
beginWork@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:15784:14
performUnitOfWork@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:19447:12
workLoop@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:19487:24
renderRoot@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:19570:15
performWorkOnRoot@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:20477:17
performWork@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:20389:24
performSyncWork@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:20363:14
requestWork@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:20232:5
retryTimedOutBoundary@http://localhost:8050/_dash-component-suites/dash_renderer/react-dom@16.v1_2_2m1583518104.8.6.js:19924:18
wrapped@http://localhost:8050/_dash-component-suites/dash_renderer/react@16.v1_2_2m1583518104.8.6.js:1353:34
```
|
closed
|
2020-03-06T19:35:01Z
|
2020-03-06T20:06:10Z
|
https://github.com/plotly/dash-table/issues/717
|
[] |
e0ff
| 1 |
pydantic/pydantic-ai
|
pydantic
| 1,082 |
Cannot upload images to gemini
|
### Initial Checks
- [x] I confirm that I'm using the latest version of Pydantic AI
### Description
Hi, i have been trying to upload an image to gemini mode gemini-2.0-flash-thinking-exp-01-21 which accepts multimodal image.
However when I try to upload the image which has a file extension it seems to break. It works fine if there is some url on the internet which has an image but the URL does not have file extension.
below is the attached response
```
pydantic_ai.exceptions.ModelHTTPError: status_code: 400, model_name: gemini-2.0-flash-thinking-exp-01-21, body: {
"error": {
"code": 400,
"message": "Request contains an invalid argument.",
"status": "INVALID_ARGUMENT"
}
}
```
### Example Code
```Python
import os
import io
import base64
from dotenv import load_dotenv
from pydantic_ai.models.gemini import GeminiModel
from pydantic_ai.agent import Agent
from pydantic_ai.messages import ImageUrl
from PIL import Image
load_dotenv(override=True)
llm = GeminiModel(os.getenv('MODEL'))
pydantic_agent = Agent(
model=llm,
system_prompt="You are an helpful agent for reading and extracting data from images and pdfs."
)
def image_to_byte_string(image: Image.Image) -> str:
img_byte_arr = io.BytesIO()
image.save(img_byte_arr, format='PNG') # or 'JPEG', etc.
img_byte_arr = img_byte_arr.getvalue()
return base64.b64encode(img_byte_arr).decode('utf-8')
def main():
image = Image.open("./fuzzy-bunnies.png")
formatted_image=image_to_byte_string(image)
input = [
"What is this image of?",
# ImageUrl(f'data:{image.get_format_mimetype()};base64,{formatted_image}'),
ImageUrl(url='https://hatrabbits.com/wp-content/uploads/2017/01/random.png')
]
response = pydantic_agent.run_sync(input)
print(response.data)
if __name__ == "__main__":
main()
```
### Python, Pydantic AI & LLM client version
```Text
python: 3.9.6
pydantic_core: 2.27.2
pydantic_ai: 0.0.36
```
|
open
|
2025-03-08T21:08:41Z
|
2025-03-10T10:29:56Z
|
https://github.com/pydantic/pydantic-ai/issues/1082
|
[
"need confirmation"
] |
Atoo35
| 6 |
fastapi/sqlmodel
|
pydantic
| 356 |
Support discriminated union
|
### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I already read and followed all the tutorial in the docs and didn't find an answer.
- [X] I already checked if it is not related to SQLModel but to [Pydantic](https://github.com/samuelcolvin/pydantic).
- [X] I already checked if it is not related to SQLModel but to [SQLAlchemy](https://github.com/sqlalchemy/sqlalchemy).
### Commit to Help
- [ ] I commit to help with one of those options 👆
### Example Code
```python
from typing import Literal, Union, Optional
from sqlmodel import SQLModel, Field
class Bar(SQLModel):
class_type: Literal["bar"] = "bar"
name: str
class Foo(SQLModel):
class_type: Literal["foo"] = "foo"
name: str
id: Optional[int]
class FooBar(SQLModel, table=True):
id: int = Field(default=None, primary_key=True)
data: Union[Foo, Bar] = Field(discriminator="class_type")
```
### Description
* No support for Pydantic 1.9's implementation of discriminated union
### Wanted Solution
Would like to have support for discriminated union in SQLModel-classes
### Wanted Code
```python
from typing import Literal, Union, Optional
from sqlmodel import SQLModel, Field
class Bar(SQLModel):
class_type: Literal["bar"] = "bar"
name: str
class Foo(SQLModel):
class_type: Literal["foo"] = "foo"
name: str
id: Optional[int]
class FooBar(SQLModel, table=True):
id: int = Field(default=None, primary_key=True)
data: Union[Foo, Bar] = Field(discriminator="class_type")
```
### Alternatives
_No response_
### Operating System
Linux
### Operating System Details
_No response_
### SQLModel Version
0.0.6
### Python Version
3.10.4
### Additional Context
Pydantic has added support for discrimated unions, something I use in my project with Pydantic + SQLAlchemy.
I want to switch to SQLModel, but cannot switch before discriminated unions
|
closed
|
2022-06-07T12:50:05Z
|
2023-11-06T00:10:07Z
|
https://github.com/fastapi/sqlmodel/issues/356
|
[
"feature",
"answered"
] |
wholmen
| 3 |
SALib/SALib
|
numpy
| 614 |
`extract_group_names()` and associated methods can be simplified
|
These methods can now be replaced with variations of `pd.unique()` and `np.unique()`
|
closed
|
2024-04-19T13:13:25Z
|
2024-04-21T01:56:45Z
|
https://github.com/SALib/SALib/issues/614
|
[
"clean up/maintenance"
] |
ConnectedSystems
| 0 |
deepspeedai/DeepSpeed
|
pytorch
| 6,994 |
[BUG] loading model error
|
**Describe the bug**
I use 8 * A100-80GB GPUs to fine-tune a 72B model, but when it loads 16/37 safetensor, it always been shutdown for no reasons without any hints!
The error is as follows:
```
Loading checkpoint Shards"43%16/37 [19:49<25:57,74.18s/it]
Sending process4029695 closing signal SIGTERK
failad (edtcote: -5) lcalrank:5
```
I use zero-3 and acclerate to launch my script. The command I use is `accelerate launch --config_file xxx --gpu_ids 0,1,2,3,4,5,6,7 xxx.py`.
The deepspeed file is as follows:
```
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"sub_group_size": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": "auto"
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
**Expected behavior**
I think it should load all of safetensors, what's more, during the loading process, I notice that gpu memory is still 0.
**Screenshots**
<img width="1392" alt="Image" src="https://github.com/user-attachments/assets/9da6fc2c-d842-4a77-8f9c-6d14fa6f74c3" />
**System info (please complete the following information):**
- OS: Ubuntu 18.04
- GPU count and types: 8*A100-80GB
- Python version 3.12
|
open
|
2025-02-03T08:03:14Z
|
2025-02-03T08:03:14Z
|
https://github.com/deepspeedai/DeepSpeed/issues/6994
|
[
"bug",
"training"
] |
tengwang0318
| 0 |
mirumee/ariadne-codegen
|
graphql
| 350 |
10x memory increase from v0.13 -> v0.14
|
We measured the Ariadne generated module after upgrading to v0.14, and we realize memory of the module increased from 400MB -> 4GB after upgrading from v0.13 to v0.14.
We would like to use ClientForwardRefs in v0.14, but the memory increase between v0.13 and v0.14 is untenable.
Any ideas what might be causing this and how to avoid this?
Verified on python 3.9 and 3.10 and 3.11 and 3.12
|
closed
|
2025-02-03T21:43:11Z
|
2025-02-11T16:59:56Z
|
https://github.com/mirumee/ariadne-codegen/issues/350
|
[] |
eltontian
| 3 |
jupyter-book/jupyter-book
|
jupyter
| 2,181 |
README - outdated section?
|
is this section outdated and can be deleted from README.md?
https://github.com/jupyter-book/jupyter-book/blob/47d2481c8ddc427ee8c9d1bbb24a4d57cc0a8fbd/README.md?plain=1#L21-L25
|
closed
|
2024-07-29T18:34:22Z
|
2024-08-29T22:27:54Z
|
https://github.com/jupyter-book/jupyter-book/issues/2181
|
[] |
VladimirFokow
| 2 |
jacobgil/pytorch-grad-cam
|
computer-vision
| 364 |
Possibly inverted heatmaps for Score-CAM for YOLOv5
|
Hi @jacobgil , I'm working on applying Score-CAM on YOLOv5 by implementing the `YOLOBoxScoreTarget` class (so this issue is closely related with #242). There are several issues I want to iron out before making a PR (e.g. YOLOv5 returns parseable `Detection` objects only when the input is _not_ a Torch tensor - see https://github.com/ultralytics/yolov5/issues/6726 - and my workaround is ad-hoc atm), but in my current implementation I find that the resulting heatmaps are inverted, e.g.:
Outputs for dog & cat example, unnormalized (L)/normalized (R):
 
Also observed similar trends with other images like the 5-dogs example. My `YOLOBoxScoreTarget` is as follows, it is essentially identical to [FasterRCNNBoxScoreTarget](https://github.com/jacobgil/pytorch-grad-cam/blob/2183a9cbc1bd5fc1d8e134b4f3318c3b6db5671f/pytorch_grad_cam/utils/model_targets.py#L69), except it leverages `parse_detections` from the YOLOv5 notebook:
```
class YOLOBoxScoreTarget:
""" For every original detected bounding box specified in "bounding boxes",
assign a score on how the current bounding boxes match it,
1. In IOU
2. In the classification score.
If there is not a large enough overlap, or the category changed,
assign a score of 0.
The total score is the sum of all the box scores.
"""
def __init__(self, labels, bounding_boxes, iou_threshold=0.5):
self.labels = labels
self.bounding_boxes = bounding_boxes
self.iou_threshold = iou_threshold
def __call__(self, model_outputs):
boxes, colors, categories, names, confidences = parse_detections(model_outputs)
boxes = torch.Tensor(boxes)
output = torch.Tensor([0])
if torch.cuda.is_available():
output = output.cuda()
boxes = boxes.cuda()
if len(boxes) == 0:
return output
for box, label in zip(self.bounding_boxes, self.labels):
box = torch.Tensor(box[None, :])
if torch.cuda.is_available():
box = box.cuda()
ious = torchvision.ops.box_iou(box, boxes)
index = ious.argmax()
if ious[0, index] > self.iou_threshold and categories[index] == label:
score = ious[0, index] + confidences[index]
output = output + score
return output
```
I also slightly altered `get_cam_weights` in [score_cam.py](https://github.com/jacobgil/pytorch-grad-cam/blob/master/pytorch_grad_cam/score_cam.py) to make it play nice with numpy inputs instead of torch tensors.
```
import torch
import tqdm
from .base_cam import BaseCAM
import numpy as np
class ScoreCAM(BaseCAM):
def __init__(
self,
model,
target_layers,
use_cuda=False,
reshape_transform=None):
super(ScoreCAM, self).__init__(model,
target_layers,
use_cuda,
reshape_transform=reshape_transform,
uses_gradients=False)
if len(target_layers) > 0:
print("Warning: You are using ScoreCAM with target layers, "
"however ScoreCAM will ignore them.")
def get_cam_weights(self,
input_tensor,
target_layer,
targets,
activations,
grads):
with torch.no_grad():
upsample = torch.nn.UpsamplingBilinear2d(
size=input_tensor.shape[-2:])
activation_tensor = torch.from_numpy(activations)
if self.cuda:
activation_tensor = activation_tensor.cuda()
upsampled = upsample(activation_tensor)
maxs = upsampled.view(upsampled.size(0),
upsampled.size(1), -1).max(dim=-1)[0]
mins = upsampled.view(upsampled.size(0),
upsampled.size(1), -1).min(dim=-1)[0]
maxs, mins = maxs[:, :, None, None], mins[:, :, None, None]
upsampled = (upsampled - mins) / (maxs - mins)
input_tensors = input_tensor[:, None,
:, :] * upsampled[:, :, None, :, :]
if hasattr(self, "batch_size"):
BATCH_SIZE = self.batch_size
else:
BATCH_SIZE = 16
scores = []
for target, tensor in zip(targets, input_tensors):
for i in tqdm.tqdm(range(0, tensor.size(0), BATCH_SIZE)):
batch = tensor[i: i + BATCH_SIZE, :]
# TODO: current solution to handle the issues with torch inputs, improve
batch = list(batch.numpy())
batch = [np.swapaxes((elt * 255).astype(np.uint8), 0, -1) for elt in batch]
outs = [self.model(b) for b in batch]
outputs = [target(o).cpu().item() for o in outs]
scores.extend(outputs)
scores = torch.Tensor(scores)
scores = scores.view(activations.shape[0], activations.shape[1])
weights = torch.nn.Softmax(dim=-1)(scores).numpy()
return weights
```
To me the implementations seem correct, and therefore I am not able to address why the resulting heatmaps seem inverted. Any ideas? I'd be happy to make a branch with a reproducible example to debug and potentially extend it to a PR. Please let me know.
|
open
|
2022-11-17T12:13:34Z
|
2023-11-08T15:38:48Z
|
https://github.com/jacobgil/pytorch-grad-cam/issues/364
|
[] |
semihcanturk
| 3 |
ageitgey/face_recognition
|
python
| 624 |
How to increase the size of a detected rectangle in python?
|
* face_recognition version: latest version
* Python version: 3.7
* Operating System: Kali Linux
### Description
How to increase the size of a detected rectangle, for example, I want to crop 3x4 photo of detected faces
### What I Did
First I thought it needs to increase the top&bottom position but then it breaks the accuracy of face detection and images are not face-centered. after that, I searched about that and found OpenCV version which can add padding to the detected rectangle. Are you have the same function that can add padding and space to the detected rectangle?
```
from PIL import Image
import face_recognition
image = face_recognition.load_image_file(importLocation)
face_locations = face_recognition.face_locations(image)
i = 0
for face_location in face_locations:
top, right, bottom, left = face_location
face_image = image[top:bottom, left:right]
pil_img = Image.fromarray(face_image)
pil_img.save("%s/face-{}.jpg".format(i) % (exportLocation))
i += 1
```
|
closed
|
2018-09-19T13:53:13Z
|
2018-09-23T14:59:24Z
|
https://github.com/ageitgey/face_recognition/issues/624
|
[] |
hasanparasteh
| 1 |
onnx/onnx
|
deep-learning
| 6,425 |
Inconsistency in LSTM's operator description and backend testcases?
|
# Ask a Question
### Question
In the [LSTM's operator description](https://onnx.ai/onnx/operators/onnx__LSTM.html#inputs), there are 3 optional outputs(`Y, Y_h, Y_c`). But in the [testcases](https://github.com/onnx/onnx/blob/main/onnx/backend/test/case/node/lstm.py), there are only 2 outputs(looks like `Y, Y_h`). Is this something deliberate?
### Further information
- Relevant Area: operators
- Is this issue related to a specific model?
**Model name**: LSTM
**Model opset**: all
|
open
|
2024-10-03T20:48:13Z
|
2024-10-21T09:13:40Z
|
https://github.com/onnx/onnx/issues/6425
|
[
"question"
] |
knwng
| 1 |
marcomusy/vedo
|
numpy
| 430 |
Color aberations
|
Hey,
I am using [BrainRender](https://github.com/brainglobe/brainrender) for visualisation of neuro-related data.
I have been using a function to slice some parts of the 3D objects however I get some aberations.
After discussing with Fede Claudi, he mentionned that the problem could be probably using vedo.
I am attached here an example. Any idea how to solve that?
Thanks a lot !!

|
closed
|
2021-07-20T13:30:10Z
|
2021-08-28T10:53:24Z
|
https://github.com/marcomusy/vedo/issues/430
|
[] |
MathieuBo
| 6 |
ivy-llc/ivy
|
pytorch
| 28,628 |
Fix Frontend Failing Test: torch - activations.tensorflow.keras.activations.relu
|
To-do List: https://github.com/unifyai/ivy/issues/27498
|
closed
|
2024-03-17T23:57:34Z
|
2024-03-25T12:47:11Z
|
https://github.com/ivy-llc/ivy/issues/28628
|
[
"Sub Task"
] |
ZJay07
| 0 |
nerfstudio-project/nerfstudio
|
computer-vision
| 3,541 |
Error running command: colmap vocab_tree_matcher --database_path during ns-process-data
|
Given an input of 20 images in a folder located in /vulcanscratch/aidris12/nerfstudio/data/nerfstudio/unprocessed_monkey/, I am trying to run ns-process-data. I am running the following:
`ns-process-data images --data /vulcanscratch/aidris12/nerfstudio/data/nerfstudio/unprocessed_monkey/ --output-dir /vulcanscratch/aidris12/nerfstudio/data/nerfstudio/processed_monkey/
`
However, I am currently running into this problem:
<img width="1440" alt="Screen Shot 2024-12-04 at 10 48 06 PM" src="https://github.com/user-attachments/assets/7aba065a-0397-4ab7-98e4-8b5fb6f0e68a">
I don't know why this is occurring. I have tried running COLMAP before in another directory, where I ran
`ns-process-data images --data /vulcanscratch/aidris12/nerfstudio/data/nerfstudio/unprocessed_teapot/ --output-dir /vulcanscratch/aidris12/nerfstudio/data/nerfstudio/processed_teapot/`
The result was the following. Not good, but at least it ran:
<img width="1440" alt="Screen Shot 2024-12-04 at 10 51 31 PM" src="https://github.com/user-attachments/assets/5ba64237-a505-4fcc-b099-4e2eaa7d6065">
They are both folders of png images that COLMAP processes that are even in the same superfolder (/vulcanscratch/aidris12/nerfstudio/data/nerfstudio), but it is freaking out in one folder versus the other.
Is there perhaps a problem with pathing? You may have noticed that I had a folder named nerfstudio/data/nerfstudio, which seems like poor practice. However, I am confused why the pathing to one folder was fine when the other was not.
|
open
|
2024-12-05T03:55:25Z
|
2024-12-05T03:55:25Z
|
https://github.com/nerfstudio-project/nerfstudio/issues/3541
|
[] |
aidris823
| 0 |
huggingface/datasets
|
deep-learning
| 6,990 |
Problematic rank after calling `split_dataset_by_node` twice
|
### Describe the bug
I'm trying to split `IterableDataset` by `split_dataset_by_node`.
But when doing split on a already split dataset, the resulting `rank` is greater than `world_size`.
### Steps to reproduce the bug
Here is the minimal code for reproduction:
```py
>>> from datasets import load_dataset
>>> from datasets.distributed import split_dataset_by_node
>>> dataset = load_dataset('fla-hub/slimpajama-test', split='train', streaming=True)
>>> dataset = split_dataset_by_node(dataset, 1, 32)
>>> dataset._distributed
DistributedConfig(rank=1, world_size=32)
>>> dataset = split_dataset_by_node(dataset, 1, 15)
>>> dataset._distributed
DistributedConfig(rank=481, world_size=480)
```
As you can see, the second rank 481 > 480, which is problematic.
### Expected behavior
I think this error comes from this line @lhoestq
https://github.com/huggingface/datasets/blob/a6ccf944e42c1a84de81bf326accab9999b86c90/src/datasets/iterable_dataset.py#L2943-L2944
We may need to obtain the rank first. Then the above code gives
```py
>>> dataset._distributed
DistributedConfig(rank=16, world_size=480)
```
### Environment info
datasets==2.20.0
|
closed
|
2024-06-21T14:25:26Z
|
2024-06-25T16:19:19Z
|
https://github.com/huggingface/datasets/issues/6990
|
[] |
yzhangcs
| 1 |
schemathesis/schemathesis
|
pytest
| 2,355 |
[FEATURE] Negative tests for GraphQL
|
### Checklist
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [x] I am using the latest version of Schemathesis
### Describe the bug
I try to generate negative tests, however it doesn't work.
### To Reproduce
```python
import schemathesis
from hypothesis import settings
from schemathesis import DataGenerationMethod
f = open("schema.graphql")
schema = schemathesis.graphql.from_file(f, data_generation_methods=[DataGenerationMethod.negative])
@schema.parametrize()
@settings(max_examples=10)
def test_api(case):
print(case.body)
```
Minimal API schema causing this issue:
```
schema {
query: Query
mutation: Mutation
}
type Query {
hello: String
user(id: Int!): String
}
type Mutation {
createUser(name: String!, age: Int!): String
}
```
### Expected behavior
I was expecting negative tests, but clearly these are just ordinary.
```
{
user(id: 0)
}
```
```
mutation {
createUser(name: "", age: 0) {
age
}
}
```
### Environment
```
- OS: MacOS Ventura
- Python version: 3.12
- Schemathesis version: 3.32.2
```
|
open
|
2024-07-18T11:01:47Z
|
2024-07-18T11:10:13Z
|
https://github.com/schemathesis/schemathesis/issues/2355
|
[
"Priority: Medium",
"Type: Feature",
"Specification: GraphQL",
"Difficulty: Hard"
] |
antonchuvashow
| 1 |
ansible/ansible
|
python
| 84,074 |
Expose more timeout-related context in `ansible-test`
|
### Summary
So sometimes our CI gets stuck on a single task for so long that it gets killed after a 50-minute timeout. And there wouldn't be any context regarding what was the state of processes at that point.
Here's an example: https://dev.azure.com/ansible/ansible/_build/results?buildId=125233&view=logs&j=decc2f6c-caaf-5327-9dc2-edc5c3d85ed8&t=c5b61780-1e0c-5015-76da-ae0f2062a595&l=11894. Following the source code is just a guessing game. My guess is that the file system access is slow somewhere since `assert` does templating, but I'm pretty sure I won't be able to reproduce it w/o knowing where to look more precisely.
### Issue Type
Bug Report
### Component Name
ansible-test
### Ansible Version
```
stable-2.15
```
### Configuration
```console
N/A
```
### OS / Environment
alpine container @ azure pipelines
### Steps to Reproduce
N/A
### Expected Results
There should be more info printed out.
I think the signal handler @ https://github.com/ansible/ansible/blob/f1f0d9bd5355de5b45b894a9adf649abb2f97df5/test/lib/ansible_test/_internal/timeout.py#L115-L119 should attempt retrieving more context to show us.
What occurred to me was that maybe it could call `py-spy` and perhaps integrate [the stdlib `faulthandler`](https://docs.python.org/3/library/faulthandler.html#dumping-the-traceback-on-a-user-signal).
cc @mattclay any other ideas?
### Actual Results
```console
No useful context that would provide any clues regarding what's happening beyond the timestamps that vaguely point to the action plugin that's hanging:
15:14 TASK [assert] ******************************************************************
15:14 ok: [localhost] => {
15:14 "changed": false,
15:14 "msg": "All assertions passed"
15:14 }
15:14
15:14 TASK [Less than 1] *************************************************************
15:15 Pausing for 1 seconds
15:15 ok: [localhost] => {"changed": false, "delta": 1, "echo": true, "rc": 0, "start": "2024-10-08 07:20:03.109197", "stderr": "", "stdout": "Paused for 1.0 seconds", "stop": "2024-10-08 07:20:04.112144", "user_input": ""}
15:15
15:15 TASK [assert] ******************************************************************
50:10
50:10 NOTICE: Killed command to avoid an orphaned child process during handling of an unexpected exception.
50:10 Run command with stdout: docker exec -i ansible-test-controller-fNcVkXOj sh -c 'tar cf - -C /root/ansible/test --exclude .tmp results | gzip'
50:10 Run command with stdin: tar oxzf - -C /__w/1/ansible/test
50:10 FATAL: Tests aborted after exceeding the 50 minute time limit.
50:10 Run command: docker stop --time 0 ansible-test-controller-fNcVkXOj
50:10 Run command: docker rm ansible-test-controller-fNcVkXOj
50:11 Run command: docker stop --time 0 48cbf6f96fc859d835848038445a1164ddfe08ea7695b68f39636c8cb6693599
50:11 Run command: docker rm 48cbf6f96fc859d835848038445a1164ddfe08ea7695b68f39636c8cb6693599
##[error]Bash exited with code '1'.
Finishing: Run Tests
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
|
open
|
2024-10-08T13:24:55Z
|
2025-01-21T15:43:38Z
|
https://github.com/ansible/ansible/issues/84074
|
[
"bug"
] |
webknjaz
| 4 |
junyanz/pytorch-CycleGAN-and-pix2pix
|
pytorch
| 1,608 |
wandb & visdom question
|
I used visdom and wandb to record the training process.But steps is not the same,For visdom ,it's xaxis have 200 epochs,but in wandb have 1200 steps.Why is there such a problem.
|
open
|
2023-11-01T02:49:01Z
|
2023-12-22T11:12:37Z
|
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1608
|
[] |
xia-QQ
| 1 |
kizniche/Mycodo
|
automation
| 678 |
7.6.3 Test Email Not Sending
|
Mycodo Issue Report: 7.6.3
Problem Description:
While using the test email alert system I noticed that none of the emails showed up in my inbox despite saying that the email was sent successfully. I have filled in all of the SMTP account information and have enabled the POP and IMAP stuff on the gmail account.
|
closed
|
2019-08-06T23:38:11Z
|
2023-11-08T20:21:03Z
|
https://github.com/kizniche/Mycodo/issues/678
|
[] |
wllyng
| 4 |
autogluon/autogluon
|
scikit-learn
| 4,561 |
[MultiModal] Need to add supported loss functions in AutoMM
|
### Describe the issue linked to the documentation
Users need to understand the list of supported loss functions for their problem type in our doc, specifically at [here](https://auto.gluon.ai/stable/tutorials/multimodal/advanced_topics/customization.html#optimization)
### Suggest a potential alternative/fix
_No response_
|
open
|
2024-10-18T19:56:44Z
|
2024-11-26T21:42:57Z
|
https://github.com/autogluon/autogluon/issues/4561
|
[
"API & Doc",
"Needs Triage",
"module: multimodal"
] |
tonyhoo
| 2 |
FactoryBoy/factory_boy
|
django
| 776 |
Add Dynamodb ORM Factory
|
#### The problem
I haven't found support for creating a factory with the Dynamodb ORM [pynamodb](https://github.com/pynamodb/PynamoDB). Sometimes I use a django-supported ORM for which the `DjangoModelFactory` works great, and sometimes I need a NoSQL DB.
#### Proposed solution
I assume this would include implementing the `base.Factory` interface, though I'm pretty unfamiliar with what's under the hood of factory_boy.
Edit: ORM (Object Relational Mapping) for a NoSQL DB is a misnomer :-P ONSQLM (Object NoSQL Mapping) would be more appropriate
|
open
|
2020-08-28T15:46:34Z
|
2022-01-25T12:57:30Z
|
https://github.com/FactoryBoy/factory_boy/issues/776
|
[
"Feature",
"DesignDecision"
] |
ezbc
| 6 |
yt-dlp/yt-dlp
|
python
| 11,871 |
[telegram:embed] Extractor telegram:embed returned nothing
|
### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting that yt-dlp is broken on a **supported** site
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#video-url-contains-an-ampersand--and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)
- [X] I've searched [known issues](https://github.com/yt-dlp/yt-dlp/issues/3766) and the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues **including closed ones**. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required
### Region
Russia
### Provide a description that is worded well enough to be understood
Unable to download audio or videos messages from telegram
### Provide verbose output that clearly demonstrates the problem
- [X] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)
- [ ] If using API, add `'verbose': True` to `YoutubeDL` params instead
- [X] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below
### Complete Verbose Output
```shell
[debug] Command-line config: ['-vU', '--verbose', 'https://t.me/trsch/4068']
[debug] Encodings: locale cp1251, fs utf-8, pref cp1251, out utf-8, error utf-8, screen utf-8
[debug] yt-dlp version stable@2024.12.13 from yt-dlp/yt-dlp [542166962] (win_exe)
[debug] Python 3.10.11 (CPython AMD64 64bit) - Windows-10-10.0.17763-SP0 (OpenSSL 1.1.1t 7 Feb 2023)
[debug] exe versions: ffmpeg 6.0-full_build-www.gyan.dev (setts), ffprobe 6.0-full_build-www.gyan.dev
[debug] Optional libraries: Cryptodome-3.21.0, brotli-1.1.0, certifi-2024.08.30, curl_cffi-0.5.10, mutagen-1.47.0, requests-2.32.3, sqlite3-3.40.1, urllib3-2.2.3, websockets-14.1
[debug] Proxy map: {}
[debug] Request Handlers: urllib, requests, websockets, curl_cffi
[debug] Loaded 1837 extractors
[debug] Fetching release info: https://api.github.com/repos/yt-dlp/yt-dlp/releases/latest
Latest version: stable@2024.12.13 from yt-dlp/yt-dlp
yt-dlp is up to date (stable@2024.12.13 from yt-dlp/yt-dlp)
[telegram:embed] Extracting URL: https://t.me/trsch/4068
[telegram:embed] 4068: Downloading embed frame
WARNING: Extractor telegram:embed returned nothing; please report this issue on https://github.com/yt-dlp/yt-dlp/issues?q= , filling out the appropriate issue template. Confirm you are on the latest version using yt-dlp -U
```
|
open
|
2024-12-22T06:01:58Z
|
2024-12-24T11:53:28Z
|
https://github.com/yt-dlp/yt-dlp/issues/11871
|
[
"site-bug",
"patch-available"
] |
k0zyrev
| 5 |
microsoft/nni
|
machine-learning
| 5,766 |
TypeError: 'Tensor' object is not a mapping
|
**Describe the issue**:
Upon running the following code to compress and speed up the YOLOv5 model using NNI's pruning and speedup techniques.:
```
import torch
from nni.common.concrete_trace_utils import concrete_trace
from nni.compression.pruning import L1NormPruner
from nni.compression.utils import auto_set_denpendency_group_ids
from nni.compression.speedup import ModelSpeedup
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu')
model(torch.rand([1, 3, 640, 640]))
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d'],
'exclude_op_names_re': ['model.model.model.24.*'], # this layer is detector head
}]
config_list = auto_set_denpendency_group_ids(model, config_list, torch.rand([1, 3, 640, 640]))
pruner = L1NormPruner(model, config_list)
masked_model, masks = pruner.compress()
pruner.unwrap_model()
graph_module = concrete_trace(model, (torch.rand([1, 3, 640, 640])))
ModelSpeedup(model, torch.rand([1, 3, 640, 640]), masks, graph_module=graph_module).speedup_model()
model(torch.rand([1, 3, 640, 640]))
```
The observed error:
```
/usr/local/lib/python3.10/dist-packages/nni/compression/speedup/utils.py:32: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
_register_pytree_node(immutable_dict, _idict_flatten, _idict_unflatten)
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:254: UserWarning: <class 'torch.fx.immutable_collections.immutable_dict'> is already registered as pytree node. Overwriting the previous registration.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/nni/compression/speedup/utils.py:33: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
_register_pytree_node(immutable_list, _ilist_flatten, _ilist_unflatten)
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:254: UserWarning: <class 'torch.fx.immutable_collections.immutable_list'> is already registered as pytree node. Overwriting the previous registration.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torch/hub.py:294: UserWarning: You are about to download and run code from an untrusted repository. In a future release, this won't be allowed. To add the repository to your trusted list, change the command to {calling_fn}(..., trust_repo=False) and a command prompt will appear asking for an explicit confirmation of trust, or load(..., trust_repo=True), which will assume that the prompt is to be answered with 'yes'. You can also use load(..., trust_repo='check') which will only prompt for confirmation if the repo is not already trusted. This will eventually be the default behaviour
warnings.warn(
Downloading: "https://github.com/ultralytics/yolov5/zipball/master" to /root/.cache/torch/hub/master.zip
requirements: Ultralytics requirement ['gitpython>=3.1.30'] not found, attempting AutoUpdate...
Collecting gitpython>=3.1.30
Downloading GitPython-3.1.42-py3-none-any.whl (195 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 195.4/195.4 kB 2.1 MB/s eta 0:00:00
Collecting gitdb<5,>=4.0.1 (from gitpython>=3.1.30)
Downloading gitdb-4.0.11-py3-none-any.whl (62 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 62.7/62.7 kB 20.4 MB/s eta 0:00:00
Collecting smmap<6,>=3.0.1 (from gitdb<5,>=4.0.1->gitpython>=3.1.30)
Downloading smmap-5.0.1-py3-none-any.whl (24 kB)
Installing collected packages: smmap, gitdb, gitpython
Successfully installed gitdb-4.0.11 gitpython-3.1.42 smmap-5.0.1
requirements: AutoUpdate success ✅ 6.3s, installed 1 package: ['gitpython>=3.1.30']
requirements: ⚠️ Restart runtime or rerun command for updates to take effect
YOLOv5 🚀 2024-3-25 Python-3.10.12 torch-2.2.1+cu121 CPU
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt...
100%|██████████| 14.1M/14.1M [00:00<00:00, 134MB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
Adding AutoShape...
/root/.cache/torch/hub/ultralytics_yolov5_master/models/yolo.py:100: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
/root/.cache/torch/hub/ultralytics_yolov5_master/models/yolo.py:100: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
/root/.cache/torch/hub/ultralytics_yolov5_master/models/yolo.py:100: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
/root/.cache/torch/hub/ultralytics_yolov5_master/models/yolo.py:100: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-3-667814b03cd6>](https://localhost:8080/#) in <cell line: 24>()
22 pruner.unwrap_model()
23
---> 24 graph_module = concrete_trace(model, (torch.rand([1, 3, 640, 640])))
25 ModelSpeedup(model, torch.rand([1, 3, 640, 640]), masks, graph_module=graph_module).speedup_model()
26
1 frames
[/usr/local/lib/python3.10/dist-packages/nni/common/concrete_trace_utils/concrete_tracer.py](https://localhost:8080/#) in trace(self, root, autowrap_modules, autowrap_leaf_function, autowrap_leaf_class, leaf_module, fake_middle_class, concrete_args, use_operator_patch, operator_patch_backlist, forward_function_name)
677 else:
678 kv_default = {k: v for k, v in zip(args[-len(defaults):], defaults)}
--> 679 concrete_args = {
680 **concrete_args,
681 **{n: kv_default[n] for n in args if n not in concrete_args}
TypeError: 'Tensor' object is not a mapping
```
**Environment**:
- NNI version: 3.0
- Training service (local|remote|pai|aml|etc): remote
- Client OS:
- Server OS (for remote mode only): Google Colab
- Python version: 3.10.12
- PyTorch/TensorFlow version: 2.2.1+cu121
- Is conda/virtualenv/venv used?: No
- Is running in Docker?: No
**Configuration**:
- Experiment config (remember to remove secrets!):
- Search space:
**Log message**:
- nnimanager.log:
- dispatcher.log:
- nnictl stdout and stderr:
<!--
Where can you find the log files:
LOG: https://github.com/microsoft/nni/blob/master/docs/en_US/Tutorial/HowToDebug.md#experiment-root-director
STDOUT/STDERR: https://nni.readthedocs.io/en/stable/reference/nnictl.html#nnictl-log-stdout
-->
**How to reproduce it?**:
|
open
|
2024-03-25T00:29:17Z
|
2024-03-25T00:29:17Z
|
https://github.com/microsoft/nni/issues/5766
|
[] |
AKSHILMY
| 0 |
encode/databases
|
asyncio
| 214 |
Common interface for each backends Record/RowProxy
|
Current implementation has different class for each Row/Record/RowProxy.
Any chance a common interface can be used / monkey patched into each of these so they behave more similarly.
Something as simple as:
```py
from typing import Mapping
row = await database.fetch_one(query)
isinstance(row, Mapping)
# returns True for Postgres but False for SQLite
```
Also the `__str__` and `__repr__` have a vastly different look.
The postgres `Record` class has neither a `__str__` nor a `__repr__` (PR for `__str__` done that returns what looks like a standard python dict / Mapping)
But when you get a RowProxy from sqlite it looks like a tuple. This is surprising because `RowProxy` has `item()`, `keys()`, `values()`. Shouldn't it look more like a mapping in `__str__`?
I haven't investigated mysql yet.
|
open
|
2020-06-02T16:18:25Z
|
2020-06-02T16:18:25Z
|
https://github.com/encode/databases/issues/214
|
[] |
skewty
| 0 |
junyanz/pytorch-CycleGAN-and-pix2pix
|
pytorch
| 1,515 |
can find the results of combine_A_and_B.py
|
Why combine_A_and_B.py can only combine the same picture? Once i put different photos in two folder A and B, the code is still working shown nothing wrong but there isn't any results in the folder_AB
|
open
|
2022-12-02T12:09:46Z
|
2023-01-12T07:15:45Z
|
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1515
|
[] |
1987521
| 3 |
matplotlib/mplfinance
|
matplotlib
| 96 |
fill_between()
|
In the past I've used pyplot's fill_between() to shade the area between upper and lower Bollinger Bands for example.
Can this be done now with mpf?
|
closed
|
2020-04-14T17:39:47Z
|
2020-06-07T23:40:50Z
|
https://github.com/matplotlib/mplfinance/issues/96
|
[
"enhancement",
"released"
] |
tmcguire65
| 6 |
Avaiga/taipy
|
data-visualization
| 1,948 |
[🐛 BUG] scenario_selector visual element has inactive edit button
|
### What went wrong? 🤔
I'm trying out the scenario_selector visual element. I'm working with Taipy develop, I pulled and installed it in a new env yesterday. The editing button doesn't seem to work.
When I click on "Add Scenario", it works, overall it looks fine.
But the edit button (the little pencil) is grayed out (I can see it, and when I hover over it, it says "Edit Scenario"). When I click on it, it triggers the on_change function but doesn't open the edition panel.
### Expected Behavior
The edit button should be clickable, and open the edit pane.
### Steps to Reproduce Issue
Here is a sample, but I think any `scenario_selector` has the problem.
```
tgb.scenario_selector(
value="{None}",
show_pins=True,
on_creation=add_scenario,
on_change=run_scenario,
)
```
### Screenshots

### Runtime Environment
Windows 10, I used Python 12 within Anaconda, Taipy develop
### Browsers
Brave
### OS
Windows
### Version of Taipy
develop (4)
### Additional Context
```bash
I can't select the pencil button, so there are no logs or errors either.
```
### Acceptance Criteria
- [ ] Ensure new code is unit tested, and check code coverage is at least 90%.
- [ ] Create related issue in taipy-doc for documentation and Release Notes.
### Code of Conduct
- [X] I have checked the [existing issues](https://github.com/Avaiga/taipy/issues?q=is%3Aissue+).
- [ ] I am willing to work on this issue (optional)
|
closed
|
2024-10-07T11:17:09Z
|
2024-10-08T15:42:05Z
|
https://github.com/Avaiga/taipy/issues/1948
|
[
"Core",
"🟥 Priority: Critical",
"💥Malfunction",
"📝Release Notes",
"GUI: Front-End"
] |
enarroied
| 3 |
Neoteroi/BlackSheep
|
asyncio
| 425 |
add Python 3.12 support
|
In python3.12, datetime.utcnow() has been issued a deprecation warning:
datetime.utcnow() is deprecated and scheduled for "
"removal in a future version. Instead, Use timezone-aware "
"objects to represent datetimes in UTC: "
"datetime.datetime.now(datetime.UTC).
and
Then in setuptools, there is such a warning:
`Use of pkg_resources is deprecated in favor of importlib.resources, importlib.metadata and their backports (importlib_resources, importlib_metadata). Some useful APIs are also provided by packaging (e.g. requirements and version parsing). Users should refrain from new usage of pkg_resources and should work to port to importlib-based solutions.`
I think we should adapt to them
|
closed
|
2023-10-23T10:21:08Z
|
2023-11-03T22:23:47Z
|
https://github.com/Neoteroi/BlackSheep/issues/425
|
[] |
bymoye
| 2 |
sczhou/CodeFormer
|
pytorch
| 355 |
Scene image training
|
If I retrain the model on real scene images, can Codeformer perform inpainting on images of natural scenes? For example, the Imagenet data set
|
open
|
2024-02-29T06:18:10Z
|
2024-02-29T06:18:10Z
|
https://github.com/sczhou/CodeFormer/issues/355
|
[] |
duxiangcheng
| 0 |
chatanywhere/GPT_API_free
|
api
| 297 |
付费API,无法使用claude3.5
|
**Describe the bug 描述bug**
付费购买了API,但无法使用claude3.5 模型。
接口为:https://api.chatanywhere.tech/v1/chat/completions
以及接口:https://api.chatanywhere.tech

**To Reproduce 复现方法**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Screenshots 截图**

**Tools or Programming Language 使用的工具或编程语言**
使用lobechat。
**Additional context 其他内容**
|
closed
|
2024-09-22T04:46:13Z
|
2024-09-22T05:16:08Z
|
https://github.com/chatanywhere/GPT_API_free/issues/297
|
[] |
Flyingpen
| 1 |
huggingface/diffusers
|
deep-learning
| 10,963 |
cannot import name 'AutoencoderKLWan' from 'diffusers'
|
### Describe the bug
ImportError: cannot import name 'AutoencoderKLWan' from 'diffusers' (/usr/local/lib/python3.10/dist-packages/diffusers/__init__.py)
### Reproduction
from diffusers import AutoencoderKLWan, WanPipeline
### Logs
```shell
```
### System Info
diffusers-0.32.2,linux,python3.10
### Who can help?
_No response_
|
closed
|
2025-03-04T12:51:41Z
|
2025-03-04T13:03:13Z
|
https://github.com/huggingface/diffusers/issues/10963
|
[
"bug"
] |
spawner1145
| 3 |
robotframework/robotframework
|
automation
| 4,442 |
Robot cannot find chrome driver in PATH
|
Seems like Robot is completely broken for me. I have used webdrivermanager (the command line tool) to download the latest webdriver for chrome on windows. I have added this executable's parent bin folder to the path. I have restarted the terminals that run the robot command. I have googled forever on this issue. This feels like a super blocking P0 bug. Feels like Robot Framework is willfully ignoring the path/driver.




(RobotSelenium) C:\Users\Alex\PycharmProjects\RobotSelenium>robot firstRobot.robot
==============================================================================
firstRobot :: My First Test This test will Verify Google
==============================================================================
Open Google & Verify Google
DevTools listening on ws://127.0.0.1:60982/devtools/browser/102de287-77a8-4cf1-a65c-444076a55a18
Open Google & Verify Google | FAIL |
SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 91
Current browser version is 104.0.5112.101 with binary path C:\Program Files\Google\Chrome\Application\chrome.exe
Stacktrace:
Backtrace:
Ordinal0 [0x005E3733+2504499]
Ordinal0 [0x0057C401+2081793]
Ordinal0 [0x00482628+1058344]
Ordinal0 [0x004A071A+1181466]
Ordinal0 [0x0049C58C+1164684]
Ordinal0 [0x00499DC3+1154499]
Ordinal0 [0x004C9B82+1350530]
Ordinal0 [0x004C97DA+1349594]
Ordinal0 [0x004C5D4B+1334603]
Ordinal0 [0x004A22B4+1188532]
Ordinal0 [0x004A3149+1192265]
GetHandleVerifier [0x0075FB8C+1512252]
GetHandleVerifier [0x0080B0DF+2214031]
GetHandleVerifier [0x00664BC3+484211]
GetHandleVerifier [0x00663E69+480793]
Ordinal0 [0x0058218D+2105741]
Ordinal0 [0x005866E8+2123496]
Ordinal0 [0x00586827+2123815]
Ordinal0 [0x0058FB73+2161523]
BaseThreadInitThunk [0x7673FA29+25]
RtlGetAppContainerNamedObjectPath [0x771A7A9E+286]
RtlGetAppContainerNamedObjectPath [0x771A7A6E+238]
------------------------------------------------------------------------------
firstRobot :: My First Test This test will Verify Google | FAIL |
1 test, 0 passed, 1 failed
==============================================================================
Output: C:\Users\Alex\PycharmProjects\RobotSelenium\output.xml
Log: C:\Users\Alex\PycharmProjects\RobotSelenium\log.html
Report: C:\Users\Alex\PycharmProjects\RobotSelenium\report.html
|
closed
|
2022-08-22T07:09:55Z
|
2022-08-22T07:24:26Z
|
https://github.com/robotframework/robotframework/issues/4442
|
[] |
openSourceBugs
| 1 |
PokeAPI/pokeapi
|
api
| 469 |
pokemon data has wrong ID
|
<!--# PLEASE READ BEFORE CREATING ISSUE
Thanks for contributing to the PokéAPI project. To make sure we're effective, please check the following:
- Make sure your issue hasn't already been submitted on the issues tab. (It has search functionality!)
- If your issue is one of outdated API data, please note that we get our data from [veekun](https://github.com/veekun/pokedex/) without modifying it. If they are not up to date either, please look for or create an issue there. Otherwise, feel free to create an issue here.
- Provide a clear description of the issue.
- Provide a clear description of the steps to reproduce.
- Provide a clear description of the expected behaviour.
Thank you!-->
Hello!
I noticed a small bug, where getting a pokemon by name has the wrong ID in the data returned. Heres a example:
```json
{
baby_trigger_item: null,
chain: {
evolution_details: [],
evolves_to: [ [Object] ],
is_baby: false,
species: {
name: 'aron',
url: 'https://pokeapi.co/api/v2/pokemon-species/304/'
}
},
id: 151
}
```
For this, i searched for Mew. Searching for the evolutions of Mew shouldnt return Aron.
|
closed
|
2020-01-05T02:33:09Z
|
2020-02-15T21:40:52Z
|
https://github.com/PokeAPI/pokeapi/issues/469
|
[] |
0xf0xx0
| 3 |
aminalaee/sqladmin
|
sqlalchemy
| 886 |
custom action in example not working
|
### Checklist
- [x] The bug is reproducible against the latest release or `master`.
- [x] There are no similar issues or pull requests to fix it yet.
### Describe the bug
In example https://aminalaee.dev/sqladmin/configurations/#custom-action
function get_object_for_edit is called with param pk
but definition waits for request object:
`async def get_object_for_edit(self, request: Request)`
and it looks for for path_param 'pk' in request not 'pks'
### Steps to reproduce the bug
Use example in https://aminalaee.dev/sqladmin/configurations/#custom-action
### Expected behavior
_No response_
### Actual behavior
Error
### Debugging material
_No response_
### Environment
any/3.12/last
### Additional context
_No response_
|
open
|
2025-02-26T14:01:31Z
|
2025-03-11T17:40:43Z
|
https://github.com/aminalaee/sqladmin/issues/886
|
[] |
akudryav
| 3 |
ipython/ipython
|
jupyter
| 13,904 |
logger in ipython does not return prompt
|
When using the logging module in a separate thread IPython, the debug or info printed messages do not cause the terminal to create a new prompt. Instead, I have to manually press enter to get the prompt and continue typing. This issue occurs even when the logger is configured to use sys.stderr or sys.stdout as the output stream. The issue persists even when the flush=True option is used.
My way of dealing with this now is to add a `print("")` after each debug statement, but that does not work in debugs originating in imported libraries.
This issue has been observed with Python 3.9 and IPython version IPython 8.5.
|
open
|
2023-01-26T01:41:56Z
|
2023-01-29T20:43:47Z
|
https://github.com/ipython/ipython/issues/13904
|
[] |
mahdi-b
| 1 |
hankcs/HanLP
|
nlp
| 798 |
HanLP进行文本转汉语拼音时需要优化
|
用HanLP的用户目前多为做语音识别相关,目前HanLP对汉字转汉语拼音的支持仅限汉字。
但是通常情况下,用户输入的文本并不能确定是中文还是英文,那么,在这种场景中应该支持的是:如果是中文,那么就转成汉语拼音,如果不是那么就保留。
|
closed
|
2018-04-19T04:55:35Z
|
2018-04-19T18:25:41Z
|
https://github.com/hankcs/HanLP/issues/798
|
[
"invalid"
] |
isblwang
| 1 |
vaexio/vaex
|
data-science
| 2,153 |
[BUG-REPORT] Filtering breaks negative indexing
|
**Description**
The following code
```
import pandas as pd
import vaex
p_df = pd.DataFrame({"A": ["abc"] * 100})
df = vaex.from_pandas(p_df)
f_df = df[df["A"] == "abc"]
f_df[99] # Works fine.
f_df[-1] # Throws an error (same for any negative number).
```
throws
```
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Input In [3], in <cell line: 6>()
3 f_df = df[df["A"] == "abc"]
5 f_df[99] # Works fine.
----> 6 f_df[-1]
File ~/mambaforge/envs/tmp_env/lib/python3.9/site-packages/vaex/dataframe.py:5337, in DataFrame.__getitem__(self, item)
5335 if isinstance(item, int):
5336 names = self.get_column_names()
-> 5337 return [self.evaluate(name, item, item+1, array_type='python')[0] for name in names]
5338 elif isinstance(item, six.string_types):
5339 if hasattr(self, item) and isinstance(getattr(self, item), Expression):
File ~/mambaforge/envs/tmp_env/lib/python3.9/site-packages/vaex/dataframe.py:5337, in <listcomp>(.0)
5335 if isinstance(item, int):
5336 names = self.get_column_names()
-> 5337 return [self.evaluate(name, item, item+1, array_type='python')[0] for name in names]
5338 elif isinstance(item, six.string_types):
5339 if hasattr(self, item) and isinstance(getattr(self, item), Expression):
File ~/mambaforge/envs/tmp_env/lib/python3.9/site-packages/vaex/dataframe.py:3090, in DataFrame.evaluate(self, expression, i1, i2, out, selection, filtered, array_type, parallel, chunk_size, progress)
3088 return self.evaluate_iterator(expression, s1=i1, s2=i2, out=out, selection=selection, filtered=filtered, array_type=array_type, parallel=parallel, chunk_size=chunk_size, progress=progress)
3089 else:
-> 3090 return self._evaluate_implementation(expression, i1=i1, i2=i2, out=out, selection=selection, filtered=filtered, array_type=array_type, parallel=parallel, chunk_size=chunk_size, progress=progress)
File ~/mambaforge/envs/tmp_env/lib/python3.9/site-packages/vaex/dataframe.py:6362, in DataFrameLocal._evaluate_implementation(self, expression, i1, i2, out, selection, filtered, array_type, parallel, chunk_size, raw, progress)
6360 mask = self._selection_masks[FILTER_SELECTION_NAME]
6361 i1, i2 = mask.indices(i1, i2-1)
-> 6362 assert i1 != -1
6363 i2 += 1
6364 # TODO: performance: can we collapse the two trims in one?
AssertionError:
```
**Software information**
- Vaex version (`import vaex; vaex.__version__)`: `{'vaex-core': '4.9.2', 'vaex-viz': '0.5.2', 'vaex-hdf5': '0.12.2', 'vaex-server': '0.8.1', 'vaex-astro': '0.9.1', 'vaex-jupyter': '0.8.0', 'vaex-ml': '0.17.0'}`
- Vaex was installed via: `mamba install -c conda-forge vaex`
- OS: macOS Monterey, Version 12.4
**Additional information**
No additional information to add.
|
closed
|
2022-08-05T08:03:03Z
|
2022-08-31T09:58:43Z
|
https://github.com/vaexio/vaex/issues/2153
|
[
"bug"
] |
karotchykau
| 5 |
encode/apistar
|
api
| 353 |
Feature request: datetime.date and datetime.datetime query/form param parsing
|
The following doesn't work, but likely should:
```python
import datetime
def some_endpoint(before: datetime.datetime):
pass
```
Attempting to call this endpoint produces the following:
<details>
```
Traceback (most recent call last):
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/components/dependency.py", line 114, in run_all
func_steps = self._steps_cache[func]
KeyError: <function compute_state at 0x10baf0a60>
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/gunicorn/workers/sync.py", line 135, in handle
self.handle_request(listener, req, client, addr)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/gunicorn/workers/sync.py", line 176, in handle_request
respiter = self.wsgi(environ, resp.start_response)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/frameworks/wsgi.py", line 134, in __call__
response = self.http_injector.run_all(funcs, state=state)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/components/dependency.py", line 141, in run_all
ret = step.func(**kwargs)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/frameworks/wsgi.py", line 130, in __call__
response = self.http_injector.run_all(funcs, state=state)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/components/dependency.py", line 116, in run_all
func_steps = self._create_steps(func)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/components/dependency.py", line 247, in _create_steps
key, provider_func = self._resolve_parameter(param, func)
File "/Users/owen/Development/grimoire.ca/cadastre/.venv/lib/python3.6/site-packages/apistar/components/dependency.py", line 208, in _resolve_parameter
raise exceptions.CouldNotResolveDependency(msg)
apistar.exceptions.CouldNotResolveDependency: Injector could not resolve parameter before:datetime.datetime=None
```
</details>
It's not 100% clear what the right parsing behaviour here is; I'm partial to ISO8601 or to using [dateparser](https://dateparser.readthedocs.io/en/latest/), personally, but any pre-fab format would work.
Looking at the code and features, I _think_ this is independent of support for datetimes at the schema level.
Workaround:
```python
import datetime
def some_endpoint(before):
before = datetime.datetime.strptime(before, SOME_FORMAT)
...
```
|
closed
|
2017-11-04T02:44:45Z
|
2018-03-13T10:47:04Z
|
https://github.com/encode/apistar/issues/353
|
[] |
ojacobson
| 9 |
zihangdai/xlnet
|
nlp
| 211 |
with tf.variable_scope(scope, 'sequnece_summary', reuse=reuse):
|
Typo in word sequence in modeling.py:699
```
with tf.variable_scope(scope, 'sequnece_summary', reuse=reuse):
```
|
open
|
2019-08-13T21:48:22Z
|
2019-08-13T21:48:42Z
|
https://github.com/zihangdai/xlnet/issues/211
|
[] |
pertschuk
| 0 |
quasarstream/python-ffmpeg-video-streaming
|
dash
| 77 |
flask api + redis and mariadb backend queue + multithreading
|
That would be great if you add flask api job as convertor with support of multithreading , redis and mariadb as backend queue.
we send file via POST curl command to the server and the server create a directory for each video and put all ts file into it. the out put of directory will be save into database. concurreny of job would be awsome .
|
closed
|
2022-03-09T21:48:16Z
|
2022-03-11T14:29:46Z
|
https://github.com/quasarstream/python-ffmpeg-video-streaming/issues/77
|
[] |
rfakit
| 1 |
babysor/MockingBird
|
pytorch
| 717 |
!python demo_toolbox.py -d.\samples缺少模块
|
配置环境一切正常,使用Google的colab
但在最后一句话的时候报错

|
closed
|
2022-08-20T07:52:47Z
|
2022-08-21T03:11:41Z
|
https://github.com/babysor/MockingBird/issues/717
|
[] |
GTohne
| 1 |
hankcs/HanLP
|
nlp
| 1,135 |
依存关系拆分与官网不一致
|
注意事项
请确认下列注意事项:
我已仔细阅读下列文档,都没有找到答案:
首页文档
wiki
常见问题
我已经通过Google和issue区检索功能搜索了我的问题,也没有找到答案。
我明白开源社区是出于兴趣爱好聚集起来的自由社区,不承担任何责任或义务。我会礼貌发言,向每一个帮助我的人表示感谢。
我在此括号内输入x打钩,代表上述事项确认完毕。
**版本号**
当前最新版本号是:1.7.2
我使用的版本是:1.7.2
**我的问题**
依存关系拆分最新版与官网预览不一致
复现问题
步骤
触发代码
String chineseSentence = “你爸叫什么?”;
CoNLLSentence sentence = HanLP.parseDependency(chineseSentence);
System.out.println(sentence);
List<WordRelate> wordRelateList = new ArrayList<WordRelate>();
// 可以方便地遍历它
for (CoNLLWord word : sentence) {
System.out.printf("%s --(%s)--> %s\n", word.LEMMA, word.DEPREL, word.HEAD.LEMMA);
WordRelate wordRelate = new WordRelate();
wordRelate.setCont(word.LEMMA);
wordRelate.setId(word.ID);
wordRelate.setParent(word.HEAD.ID);
wordRelate.setRelate(RelateEnum.getEnumByKey(word.DEPREL).getRelateTag());
wordRelate.setPos(word.POSTAG);
wordRelateList.add(wordRelate);
}
期望输出
1 你 你 r r _ 2 定中关系 _ _
2 爸 爸 n n _ 0 主谓关系 _ _
3 叫 叫 v v _ 2 核心关系 _ _
4 什么 什么 r r _ 3 动宾关系 _ _
5 ? ? wp w _ 3 标点符号 _ _
make
实际输出
1 你 你 r r _ 2 主谓关系 _ _
2 爸 爸 v v _ 0 核心关系 _ _
3 叫 叫 v v _ 2 并列关系 _ _
4 什么 什么 r r _ 3 动宾关系 _ _
5 ? ? wp w _ 3 标点符号 _ _
|
closed
|
2019-03-28T02:50:24Z
|
2019-03-29T03:37:19Z
|
https://github.com/hankcs/HanLP/issues/1135
|
[] |
humingxinghxs
| 1 |
littlecodersh/ItChat
|
api
| 889 |
iOS 7.0.9 和 android 7.0.10 开始支持的“引用”
|
有人分析吗?谢谢
|
open
|
2019-12-23T11:16:01Z
|
2019-12-23T12:10:04Z
|
https://github.com/littlecodersh/ItChat/issues/889
|
[] |
coronin
| 0 |
google-research/bert
|
tensorflow
| 919 |
TF2 version of BERT multilingual on TF Hub
|
As the title says the multilingual model is available in https://tfhub.dev/google/bert_multi_cased_L-12_H-768_A-12/1 but there's no TF2 version.
Everything else seems to have been converted so this is probably just an oversight. Is there an ETA?
|
open
|
2019-11-14T13:11:13Z
|
2020-02-27T09:17:05Z
|
https://github.com/google-research/bert/issues/919
|
[] |
grofte
| 1 |
iterative/dvc
|
machine-learning
| 10,114 |
DVCX datasets
|
closed
|
2023-11-28T03:06:07Z
|
2024-02-26T15:43:40Z
|
https://github.com/iterative/dvc/issues/10114
|
[
"p1-important"
] |
skshetry
| 16 |
|
gradio-app/gradio
|
python
| 10,465 |
Lite: Graphs drawn with Plotly are no longer displayed
|
### Describe the bug
Since 1/29/2025 (or 1/25/2025 ), graphs drawn with Plotly and gr.Plot() have not been displayed.
But last week they were displayed without any problems.
I tried specifying the previous version like this.
`<head>`
`<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite@5.10.0/dist/lite.js"></script>`
`<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite@5.10.0/dist/lite.css" />`
`</head>`
However, the problem still remains.
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Screenshot
Yesterday

When launched on January 24th

### System Info
```shell
Lite version 5.10.0, 5.12.0, 5.13.0, 5.13.1
```
### Severity
I can work around it
|
closed
|
2025-01-30T00:48:29Z
|
2025-01-30T01:59:08Z
|
https://github.com/gradio-app/gradio/issues/10465
|
[
"bug"
] |
maruyamanemaru
| 1 |
huggingface/pytorch-image-models
|
pytorch
| 1,302 |
[FEATURE] Add ViT GSAM
|
Is your feature request related to a problem? Please describe.
ViT GSAM checkpoint have been released in https://console.cloud.google.com/storage/browser/vit_models/gsam
|
closed
|
2022-06-13T14:53:24Z
|
2023-02-08T23:50:18Z
|
https://github.com/huggingface/pytorch-image-models/issues/1302
|
[
"enhancement"
] |
banda-larga
| 3 |
ultralytics/yolov5
|
machine-learning
| 12,674 |
KeyError: 'train'
|
### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Transferred 308/362 items from yolov5\weights\yolov5s.pt
Traceback (most recent call last):
File "yolov5/train.py", line 542, in <module>
train(hyp, opt, device, tb_writer)
File "yolov5/train.py", line 100, in train
train_path = data_dict['train']
KeyError: 'train'
### Additional
_No response_
|
closed
|
2024-01-27T10:18:24Z
|
2024-10-20T19:38:19Z
|
https://github.com/ultralytics/yolov5/issues/12674
|
[
"question",
"Stale"
] |
2ljz
| 3 |
zihangdai/xlnet
|
nlp
| 223 |
Condition at data_utils.py line 369 always True?
|
https://github.com/zihangdai/xlnet/blob/5cd50bc451436e188a8e7fea15358d5a8c916b72/data_utils.py#L358-L373
At line 369, I think beg won't change and this condition is somehow useless while considering line 360 and it will be always True. So am I make some mistakes? I hope someone could help me with this. Thanks.
|
open
|
2019-08-31T07:35:54Z
|
2019-08-31T07:40:55Z
|
https://github.com/zihangdai/xlnet/issues/223
|
[] |
fangwch
| 1 |
huggingface/datasets
|
tensorflow
| 6,699 |
`Dataset` unexpected changed dict data and may cause error
|
### Describe the bug
Will unexpected get keys with `None` value in the parsed json dict.
### Steps to reproduce the bug
```jsonl test.jsonl
{"id": 0, "indexs": {"-1": [0, 10]}}
{"id": 1, "indexs": {"-1": [0, 10]}}
```
```python
dataset = Dataset.from_json('.test.jsonl')
print(dataset[0])
```
Result:
```
{'id': 0, 'indexs': {'-1': [...], '-2': None, '-3': None, '-4': None, '-5': None, '-6': None, '-7': None, '-8': None, '-9': None, ...}}
```
Those keys with `None` value will unexpected appear in the dict.
### Expected behavior
Result should be
```
{'id': 0, 'indexs': {'-1': [0, 10]}}
```
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-6.5.0-14-generic-x86_64-with-glibc2.35
- Python version: 3.11.6
- `huggingface_hub` version: 0.20.2
- PyArrow version: 14.0.2
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0
|
open
|
2024-02-28T05:30:10Z
|
2024-02-28T19:14:36Z
|
https://github.com/huggingface/datasets/issues/6699
|
[] |
scruel
| 2 |
graphql-python/graphene
|
graphql
| 761 |
how to fix Int type limit -2147483648(MIN_INT) ~ 2147483647(MAX_INT)
|
How to fix the limit of Int type limit range -2147483648(MIN_INT) ~ 2147483647(MAX_INT). Defined in file [scalars.py](https://github.com/graphql-python/graphene/blob/master/graphene/types/scalars.py).
|
closed
|
2018-06-08T11:49:33Z
|
2019-03-16T17:33:39Z
|
https://github.com/graphql-python/graphene/issues/761
|
[] |
wahello
| 3 |
man-group/arctic
|
pandas
| 359 |
AttributeError : set_quota
|
#### Arctic Version
```
Arctic 1.26.0
```
#### Arctic Store
```
VersionStore
```
#### Platform and version
Windows , Python 2.7.12
#### Description of problem and/or code sample that reproduces the issue
`from arctic import Arctic`
`store = Arctic('LOCALHOST')`
`lib = store['library_main']`
`lib.set_quota(20 * 1024 * 1024 * 1024)`
When inserting data into arctic I got a "full quota warning" so tried to set my quota higher. However, I get "AttributeError: 'VersionStore' object has no attribute 'set_quota' " when trying to set quota. How should I set the quota then ? I'm pretty sure I did this before and it used to work.
|
closed
|
2017-05-19T14:46:42Z
|
2017-05-19T14:52:41Z
|
https://github.com/man-group/arctic/issues/359
|
[] |
TheTradingWarrior
| 1 |
flasgger/flasgger
|
api
| 591 |
Flasgger Reports Errors on Apache Server but Works Fine on Local
|
Hi there, I was working on a local Windows machine with flask==2.3.2, flask-restful==0.3.10, and flasgger==0.9.7.1. My flasgger initializes in `create_app()` as `Swagger(app)`. And each endpoint with `@swag_from({path_to_a_yml_dir})`. This worked fine on my local machine, no error showed up. However, after I deployed on my Apache server with the same libraries versions, it showed me the following page

This page persisted after I deleted all `swag_from` and deleted the entire yml directory. Might you have any ideas why? Any help is appreciated.
Thanks.
|
open
|
2023-08-18T19:07:20Z
|
2023-08-18T19:07:20Z
|
https://github.com/flasgger/flasgger/issues/591
|
[] |
Hongwei-W
| 0 |
openapi-generators/openapi-python-client
|
rest-api
| 378 |
Allow `id` and `type` as model attributes
|
**Describe the bug**
If a schema is defined with `id` as a property, it is translated to `id_` in the generated code.
I believe this was done to fix a security vulnerability, but if we allow `id` only as model attributes (and not as variables), that doesn't seem like it would be an issue.
This is a big usability concern for us at Benchling because almost all of our models have an `id`, and it increases the onboarding cost for new users of our SDK to have to learn to use `id_`.
**To Reproduce**
Example spec snippet:
```
DnaSequence:
type: object
additionalProperties: false
properties:
id:
type: string
```
**Expected behavior**
Properties that are keywords/reserved words should not be altered, if possible.
**OpenAPI Spec File**
**Desktop (please complete the following information):**
- OS: [e.g. macOS 10.15.1]
- Python Version: [e.g. 3.8.0]
- openapi-python-client version [e.g. 0.1.0]
**Additional context**
Add any other context about the problem here.
|
closed
|
2021-04-07T13:29:46Z
|
2021-05-03T14:58:38Z
|
https://github.com/openapi-generators/openapi-python-client/issues/378
|
[
"🐞bug"
] |
forest-benchling
| 4 |
WZMIAOMIAO/deep-learning-for-image-processing
|
deep-learning
| 387 |
如何将标签中原来的数据根据目标的类别索引信息进行填充
|
作者您好,我运行了fcn。但是我在标签处理这一块不是很懂,我想请问您,原来标签的数据并不是从0-类别数,但是在代码中训练过程,计算损失函数,计算混淆矩阵时,label内的值都是对应类别数的索引值,我想请问这一块是怎么实现的。然后我自己的数据集并没有pascal_voc_classes.json这样的文件,我是不是需要自己创建一个这样的文件??求回复,感谢
|
closed
|
2021-10-29T05:37:10Z
|
2021-11-01T02:40:00Z
|
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/387
|
[] |
liul-ing
| 1 |
AntonOsika/gpt-engineer
|
python
| 522 |
How exactly to answer clarifications?
|
When being asked for clarifications, I write something like:
```
1. Do this1 / that1
2. Do this2 / that2
etc...
```
Yet, I just get the clarifications listed again. The tutorial video shows only one clarification being needed at a time, so how do I address a whole list of clarifications. Using current stable build.
|
closed
|
2023-07-09T19:25:05Z
|
2023-07-09T19:28:13Z
|
https://github.com/AntonOsika/gpt-engineer/issues/522
|
[] |
lazyarse
| 1 |
huggingface/datasets
|
machine-learning
| 7,470 |
Is it possible to shard a single-sharded IterableDataset?
|
I thought https://github.com/huggingface/datasets/pull/7252 might be applicable but looking at it maybe not.
Say we have a process, eg. a database query, that can return data in slightly different order each time. So, the initial query needs to be run by a single thread (not to mention running multiple times incurs more cost too). But the results are also big enough that we don't want to materialize it entirely and instead stream it with an IterableDataset.
But after we have the results we want to split it up across workers to parallelize processing.
Is something like this possible to do?
Here's a failed attempt. The end result should be that each of the shards has unique data, but unfortunately with this attempt the generator gets run once in each shard and the results end up with duplicates...
```
import random
import datasets
def gen():
print('RUNNING GENERATOR!')
items = list(range(10))
random.shuffle(items)
yield from items
ds = datasets.IterableDataset.from_generator(gen)
print('dataset contents:')
for item in ds:
print(item)
print()
print('dataset contents (2):')
for item in ds:
print(item)
print()
num_shards = 3
def sharded(shard_id):
for i, example in enumerate(ds):
if i % num_shards in shard_id:
yield example
ds1 = datasets.IterableDataset.from_generator(
sharded, gen_kwargs={'shard_id': list(range(num_shards))}
)
for shard in range(num_shards):
print('shard', shard)
for item in ds1.shard(num_shards, shard):
print(item)
```
|
open
|
2025-03-21T04:33:37Z
|
2025-03-21T04:33:37Z
|
https://github.com/huggingface/datasets/issues/7470
|
[] |
jonathanasdf
| 0 |
aiortc/aiortc
|
asyncio
| 431 |
State never changes from "checking" when using iOS browsers
|
I developed an app using aiortc in which browsers can connect to to send messages through data channels. It works fine using chrome in both android and macos, but when I try to connect with a browser on an iPhone (both safari and chrome), the ICE connection state never leaves the "checking" state. Below I have the logs produced by the app using aiortc. If anyone has any idea why this happens it would be really helpful.
```
DEBUG:ice:Connection(0) protocol(0) connection_made(<_SelectorDatagramTransport fd=11 read=idle write=<idle, bufsize=0>>)
DEBUG:ice:Connection(0) protocol(1) connection_made(<_SelectorDatagramTransport fd=12 read=idle write=<idle, bufsize=0>>)
DEBUG:ice:Connection(0) protocol(2) connection_made(<_SelectorDatagramTransport fd=13 read=idle write=<idle, bufsize=0>>)
DEBUG:ice:Connection(0) protocol(3) connection_made(<_SelectorDatagramTransport fd=14 read=idle write=<idle, bufsize=0>>)
DEBUG:ice:Connection(0) protocol(4) connection_made(<_SelectorDatagramTransport fd=15 read=idle write=<idle, bufsize=0>>)
DEBUG:ice:Connection(0) protocol(5) connection_made(<_SelectorDatagramTransport fd=16 read=idle write=<idle, bufsize=0>>)
DEBUG:ice:Connection(0) protocol(0) > ('66.102.1.127', 19302) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xa5\x0fq\xa8q\xd6\x95FQ\xc6\x03F')
DEBUG:ice:Connection(0) protocol(3) > ('66.102.1.127', 19302) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'(\xb2?\x17\x98\xe0=\xf7\x18\x94un')
DEBUG:ice:Connection(0) protocol(3) < ('66.102.1.127', 19302) Message(message_method=Method.BINDING, message_class=Class.RESPONSE, transaction_id=b'(\xb2?\x17\x98\xe0=\xf7\x18\x94un')
DEBUG:ice:Connection(0) protocol(0) < ('66.102.1.127', 19302) Message(message_method=Method.BINDING, message_class=Class.RESPONSE, transaction_id=b'\xa5\x0fq\xa8q\xd6\x95FQ\xc6\x03F')
DEBUG:turn:turn/udp connection_made(<_SelectorDatagramTransport fd=17 read=idle write=<idle, bufsize=0>>)
DEBUG:turn:turn/udp > ('relay.backups.cz', 3478) Message(message_method=Method.ALLOCATE, message_class=Class.REQUEST, transaction_id=b'\x84\xd1=\x0f\xc6\x9bg\xa1\x08!\xfe\x1b')
DEBUG:turn:turn/udp < ('2a06:9280::130', 3478, 0, 0) Message(message_method=Method.ALLOCATE, message_class=Class.ERROR, transaction_id=b'\x84\xd1=\x0f\xc6\x9bg\xa1\x08!\xfe\x1b')
DEBUG:turn:turn/udp > ('relay.backups.cz', 3478) Message(message_method=Method.ALLOCATE, message_class=Class.REQUEST, transaction_id=b'c\x87,\x14\xd2\xa0\xf7\xaac\xd25+')
DEBUG:turn:turn/udp < ('2a06:9280::130', 3478, 0, 0) Message(message_method=Method.ALLOCATE, message_class=Class.RESPONSE, transaction_id=b'c\x87,\x14\xd2\xa0\xf7\xaac\xd25+')
INFO:turn:TURN allocation created ('81.201.60.130', 38150)
DEBUG:ice:Connection(0) protocol(6) connection_made(<aioice.turn.TurnTransport object at 0x1199da4f0>)
DEBUG:ice:controlled - new -> checking
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('94.62.240.219', 61647)) State.FROZEN -> State.WAITING
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('94.62.240.219', 61647)) State.FROZEN -> State.WAITING
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('81.201.60.130', 34854)) State.FROZEN -> State.WAITING
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('94.62.240.219', 61647)) State.FROZEN -> State.WAITING
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('94.62.240.219', 61647)) State.WAITING -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(0) > ('94.62.240.219', 61647) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'P+P\x92\xe2#Me\xe9\xb3\x03&')
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('94.62.240.219', 61647)) State.WAITING -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(3) > ('94.62.240.219', 61647) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xb2m\xb0k\xcf\xd6+\t\xa4p,\x89')
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('81.201.60.130', 34854)) State.WAITING -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('94.62.240.219', 61647)) State.WAITING -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(6) > ('94.62.240.219', 61647) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xd2\x0e\xae\xa2\xbd\n\x05l\xd7\xb6\xbb\xfe')
DEBUG:turn:turn/udp > ('relay.backups.cz', 3478) Message(message_method=Method.CHANNEL_BIND, message_class=Class.REQUEST, transaction_id=b'\xcbm\xe1\x93\xe0\x92_\xd0E\x02kY')
DEBUG:ice:Connection(0) protocol(3) < ('192.168.1.111', 61647) Message(message_method=Method.BINDING, message_class=Class.RESPONSE, transaction_id=b'\xb2m\xb0k\xcf\xd6+\t\xa4p,\x89')
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('94.62.240.219', 61647)) failed : source address mismatch
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('94.62.240.219', 61647)) State.IN_PROGRESS -> State.FAILED
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('81.201.60.130', 34854)) State.FROZEN -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('81.201.60.130', 46715)) State.FROZEN -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:turn:turn/udp < ('2a06:9280::130', 3478, 0, 0) Message(message_method=Method.CHANNEL_BIND, message_class=Class.RESPONSE, transaction_id=b'\xcbm\xe1\x93\xe0\x92_\xd0E\x02kY')
INFO:turn:TURN channel bound 16384 ('94.62.240.219', 61647)
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('81.201.60.130', 46715)) State.FROZEN -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('81.201.60.130', 34854)) State.FROZEN -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:turn:turn/udp > ('relay.backups.cz', 3478) Message(message_method=Method.CHANNEL_BIND, message_class=Class.REQUEST, transaction_id=b'\x9a"\xb7\x11\x9c\x02\x86\xaf\xe05\xe4l')
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('81.201.60.130', 46715)) State.FROZEN -> State.IN_PROGRESS
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
DEBUG:turn:turn/udp > ('relay.backups.cz', 3478) Message(message_method=Method.CHANNEL_BIND, message_class=Class.REQUEST, transaction_id=b':\xefy\xeb\xbc\xa5b@\xcd\n\xb9\x94')
DEBUG:ice:Connection(0) protocol(0) < ('192.168.1.111', 61647) Message(message_method=Method.BINDING, message_class=Class.RESPONSE, transaction_id=b'P+P\x92\xe2#Me\xe9\xb3\x03&')
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('94.62.240.219', 61647)) failed : source address mismatch
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('94.62.240.219', 61647)) State.IN_PROGRESS -> State.FAILED
DEBUG:turn:turn/udp < ('2a06:9280::130', 3478, 0, 0) Message(message_method=Method.CHANNEL_BIND, message_class=Class.RESPONSE, transaction_id=b'\x9a"\xb7\x11\x9c\x02\x86\xaf\xe05\xe4l')
INFO:turn:TURN channel bound 16385 ('81.201.60.130', 34854)
DEBUG:turn:turn/udp < ('2a06:9280::130', 3478, 0, 0) Message(message_method=Method.CHANNEL_BIND, message_class=Class.RESPONSE, transaction_id=b':\xefy\xeb\xbc\xa5b@\xcd\n\xb9\x94')
INFO:turn:TURN channel bound 16386 ('81.201.60.130', 46715)
DEBUG:ice:Connection(0) protocol(6) < ('94.62.240.219', 61647) Message(message_method=Method.BINDING, message_class=Class.RESPONSE, transaction_id=b'\xd2\x0e\xae\xa2\xbd\n\x05l\xd7\xb6\xbb\xfe')
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('94.62.240.219', 61647)) State.IN_PROGRESS -> State.SUCCEEDED
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'T=\xc8\xdd$\xd5R9t\xa3[\x1d')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x90\\\xdeIDd\x15\xe7\xc3\x8e\xbb\x86')
DEBUG:ice:Connection(0) protocol(0) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\x8eM\xfe\xe7\x82G\xf3\x11\xfb\x110x')
DEBUG:ice:Connection(0) protocol(3) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'oO\xb9\x01Q\xa7\xb7\xdc6\xc9\xb0\x9f')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 34854) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'\xc7\xbe\xd1b\xb5|\t\xba\xf9Z\xb9\xbd')
DEBUG:ice:Connection(0) protocol(6) > ('81.201.60.130', 46715) Message(message_method=Method.BINDING, message_class=Class.REQUEST, transaction_id=b'C\xed\xcb\xc1a\r\xc9]\x98\xa4:K')
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('81.201.60.130', 34854)) State.IN_PROGRESS -> State.FAILED
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('81.201.60.130', 34854)) State.IN_PROGRESS -> State.FAILED
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.161', 54873) -> ('81.201.60.130', 46715)) State.IN_PROGRESS -> State.FAILED
INFO:ice:Connection(0) Check CandidatePair(('192.168.1.162', 62304) -> ('81.201.60.130', 46715)) State.IN_PROGRESS -> State.FAILED
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('81.201.60.130', 34854)) State.IN_PROGRESS -> State.FAILED
INFO:ice:Connection(0) Check CandidatePair(('81.201.60.130', 38150) -> ('81.201.60.130', 46715)) State.IN_PROGRESS -> State.FAILED
```
|
closed
|
2020-11-05T10:07:44Z
|
2020-11-05T15:11:43Z
|
https://github.com/aiortc/aiortc/issues/431
|
[] |
Guerra04
| 1 |
strnad/CrewAI-Studio
|
streamlit
| 70 |
add the new claude-3-7-sonnet
|
Is it possible to add to llms.py the new "claude-3-7-sonnet-20250219" ?
|
closed
|
2025-03-13T09:40:02Z
|
2025-03-13T09:51:26Z
|
https://github.com/strnad/CrewAI-Studio/issues/70
|
[] |
Tazzzounet
| 1 |
modin-project/modin
|
pandas
| 6,906 |
Update to pandas 2.2.*
|
closed
|
2024-02-02T17:55:15Z
|
2024-02-09T21:31:16Z
|
https://github.com/modin-project/modin/issues/6906
|
[
"new feature/request 💬",
"dependencies 🔗",
"P1"
] |
anmyachev
| 0 |
|
CorentinJ/Real-Time-Voice-Cloning
|
deep-learning
| 446 |
Catch NoBackendError exception and tell user to install ffmpeg
|
Despite instructions to install ffmpeg in README.md (#414), people still skip it and get audioread's NoBackendError whenever trying to load mp3s. The exception is confusing to the end user and we get a lot of questions about it.
* The error message looks like this: https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/386#issue-646643932
* What people need to do to resolve it is this: https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/431#issuecomment-660647785
Here are some options for dealing with it, sorted in ascending order of preference.
### Option 1: Catch it when it occurs
This would make a nice starter issue for someone who is just getting started with python:
In demo_cli.py and demo_toolbox.py,
1. Use try/except around librosa.load()
* [Lines 132-138 of demo_cli.py](https://github.com/CorentinJ/Real-Time-Voice-Cloning/blob/054f16ecc186d8d4fa280a890a67418e6b9667a8/demo_cli.py#L132-L138)
* [Lines 153-156 of toolbox/\_\_init\_\_.py](https://github.com/CorentinJ/Real-Time-Voice-Cloning/blob/054f16ecc186d8d4fa280a890a67418e6b9667a8/toolbox/__init__.py#L153-L156)
2. Catch the NoBackendError exception (this will require you to import NoBackendError from audioread.exceptions)
3. Print a helpful error message instructing the user to install ffmpeg for mp3 support.
### Option 2: Test for mp3 support as toolbox is loaded
This is a little more advanced, but I think this is preferred.
1. As the toolbox is opened, or when demo_cli.py is started, we either use librosa.load() or audioread.audio_open() on a sample mp3 file to test the capability.
2. If we catch NoBackendError we nag the user and tell them to either install ffmpeg, or rerun the toolbox with `--no_mp3_support`
3. The `--no_mp3_support` flag disallows loading of mp3s when one is selected, preventing NoBackendError from being encountered.
### Option 3: Check for ffmpeg backend as toolbox is loaded
Although other backends are able to open mp3, we can force a check for Windows users to see if they followed the instructions and installed ffmpeg. Then do the same nag as option 2 if not detected.
audioread.ffdec.available() can test for ffmpeg availability: [audioread/ffdec.py](https://github.com/beetbox/audioread/blob/master/audioread/ffdec.py)
Take a look at [audioread/\_\_init\_\_.py](https://github.com/beetbox/audioread/blob/master/audioread/__init__.py) and see how it raises NoBackendError. The code is extremely simple.
### Option 4: Contribute to audioread to make the error message more descriptive
https://github.com/beetbox/audioread/issues/104
|
closed
|
2020-07-24T06:19:07Z
|
2020-09-05T07:49:06Z
|
https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/446
|
[
"good first issue"
] |
ghost
| 2 |
grillazz/fastapi-sqlalchemy-asyncpg
|
sqlalchemy
| 61 |
add ruff as code base linter
|
closed
|
2022-11-04T09:28:29Z
|
2022-11-13T10:58:08Z
|
https://github.com/grillazz/fastapi-sqlalchemy-asyncpg/issues/61
|
[] |
grillazz
| 0 |
|
gradio-app/gradio
|
deep-learning
| 10,336 |
Monitoring API endpoints return 404
|
### Describe the bug
Monitoring API endpoints returns 404 whether `enable_monitoring` is `None` or `True`.
Both `http://127.0.0.1:7860/monitoring/` and `http://127.0.0.1:7860/monitoring/KLQKZLCAxSABsioTJ2LMtQ` return 404 and
`json
{
"detail": "Not Found"
}
`
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
import time
def slow_function(x):
time.sleep(2) # Simulate a long-running process
return x * 2
with gr.Blocks() as demo:
inp = gr.Number(label="Input")
out = gr.Number(label="Output")
btn = gr.Button("Run")
btn.click(fn=slow_function, inputs=inp, outputs=out)
demo.launch(enable_monitoring=True)
```
### Screenshot

### Logs
_No response_
### System Info
```shell
Gradio Environment Information:
------------------------------
Operating System: Both Windows and Linux
gradio version: Both 5.10.0 and 5.12.0
gradio_client version: 1.5.4
------------------------------------------------
gradio dependencies in your environment:
aiofiles: 23.2.1
anyio: 4.7.0
audioop-lts is not installed.
fastapi: 0.115.6
ffmpy: 0.4.0
gradio-client==1.5.4 is not installed.
httpx: 0.28.1
huggingface-hub: 0.26.5
jinja2: 3.1.4
markupsafe: 2.1.5
numpy: 1.23.5
orjson: 3.10.12
packaging: 24.2
pandas: 2.2.3
pillow: 10.4.0
pydantic: 2.10.3
pydub: 0.25.1
python-multipart: 0.0.19
pyyaml: 6.0.2
ruff: 0.8.2
safehttpx: 0.1.6
semantic-version: 2.10.0
starlette: 0.41.3
tomlkit: 0.12.0
typer: 0.15.1
typing-extensions: 4.12.2
urllib3: 2.2.3
uvicorn: 0.32.1
authlib; extra == 'oauth' is not installed.
itsdangerous; extra == 'oauth' is not installed.
gradio_client dependencies in your environment:
fsspec: 2024.10.0
httpx: 0.28.1
huggingface-hub: 0.26.5
packaging: 24.2
typing-extensions: 4.12.2
websockets: 12.0
```
### Severity
I can work around it
|
open
|
2025-01-11T16:27:29Z
|
2025-03-03T23:33:43Z
|
https://github.com/gradio-app/gradio/issues/10336
|
[
"bug",
"Regression"
] |
libokj
| 1 |
AutoGPTQ/AutoGPTQ
|
nlp
| 699 |
Buffers in Marlin setting
|
Hi @Qubitium and @fxmarty,
I want to access weights and qzeros in marlin QuantLinear, like QuantLinear in exllamav2. Could you please guide me on how to access these buffers in the marlin setting? How are they stored in the B buffer? I want to dequantize them using the functions provided in the script of the qlinear marlin
Thanks.
|
closed
|
2024-06-27T14:26:22Z
|
2024-06-29T22:45:15Z
|
https://github.com/AutoGPTQ/AutoGPTQ/issues/699
|
[] |
yaldashbz
| 0 |
sloria/TextBlob
|
nlp
| 173 |
ModuleNotFoundError: No module named '_sqlite3'
|
Hello,
I'm migrating my script from my Mac to a AWS Linux instance. I upgraded the AWS instance to Python 3.6 before importing packages, including textbook. Now I get this error and cannot find where it's coming from. I'm not the greatest python programmer, but I did have it running perfectly on my Mac before installing it on AWS.
Here's the entire Traceback:
Traceback (most recent call last):
File "wikiparser20170801.py", line 8, in <module>
from textblob import TextBlob
File "/usr/local/lib/python3.6/site-packages/textblob/__init__.py", line 9, in <module>
from .blob import TextBlob, Word, Sentence, Blobber, WordList
File "/usr/local/lib/python3.6/site-packages/textblob/blob.py", line 28, in <module>
import nltk
File "/usr/local/lib/python3.6/site-packages/nltk/__init__.py", line 137, in <module>
from nltk.stem import *
File "/usr/local/lib/python3.6/site-packages/nltk/stem/__init__.py", line 29, in <module>
from nltk.stem.snowball import SnowballStemmer
File "/usr/local/lib/python3.6/site-packages/nltk/stem/snowball.py", line 26, in <module>
from nltk.corpus import stopwords
File "/usr/local/lib/python3.6/site-packages/nltk/corpus/__init__.py", line 66, in <module>
from nltk.corpus.reader import *
File "/usr/local/lib/python3.6/site-packages/nltk/corpus/reader/__init__.py", line 105, in <module>
from nltk.corpus.reader.panlex_lite import *
File "/usr/local/lib/python3.6/site-packages/nltk/corpus/reader/panlex_lite.py", line 15, in <module>
import sqlite3
File "/usr/local/lib/python3.6/sqlite3/__init__.py", line 23, in <module>
from sqlite3.dbapi2 import *
File "/usr/local/lib/python3.6/sqlite3/dbapi2.py", line 27, in <module>
from _sqlite3 import *
ModuleNotFoundError: No module named '_sqlite3
|
closed
|
2017-08-08T15:11:09Z
|
2021-12-09T17:27:59Z
|
https://github.com/sloria/TextBlob/issues/173
|
[] |
arnieadm35
| 17 |
sinaptik-ai/pandas-ai
|
data-science
| 1,150 |
Column MultiIndex support
|
### 🚀 The feature
At the moment I'm unable to use an Agent with a DataFrame that has MultiIndex columns, I would like to be able to do this.
### Motivation, pitch
MultiIndex DataFrames let the user organise data in a more meaningful way, which can also guide the Agent towards better answers.
### Alternatives
Flattening the MultiIndex into a simple Index
### Additional context
Here's the error I get when I try to query a SmartDataframe with a MultiIndex columns attribute.
```
Traceback (most recent call last):
File "../site-packages/pandasai/pipelines/chat/generate_chat_pipeline.py", line 307, in run
output = (self.code_generation_pipeline | self.code_execution_pipeline).run(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "../site-packages/pandasai/pipelines/pipeline.py", line 137, in run
raise e
File "../site-packages/pandasai/pipelines/pipeline.py", line 101, in run
step_output = logic.execute(
^^^^^^^^^^^^^^
File "../site-packages/pandasai/pipelines/chat/cache_lookup.py", line 36, in execute
pipeline_context.cache.get_cache_key(pipeline_context)
File "../site-packages/pandasai/helpers/cache.py", line 100, in get_cache_key
cache_key += str(df.column_hash)
^^^^^^^^^^^^^^
File "../site-packages/pandasai/connectors/pandas.py", line 131, in column_hash
columns_str = "".join(self.pandas_df.columns)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: sequence item 0: expected str instance, tuple found
```
|
closed
|
2024-05-08T16:05:42Z
|
2024-08-14T16:04:44Z
|
https://github.com/sinaptik-ai/pandas-ai/issues/1150
|
[] |
iAbadia
| 0 |
nonebot/nonebot2
|
fastapi
| 2,881 |
Plugin: Minecraft查服
|
### PyPI 项目名
nonebot-plugin-mccheck
### 插件 import 包名
nonebot_plugin_mccheck
### 标签
[{"label":"Minecraft","color":"#ea5252"},{"label":"i18n","color":"#39c5bb"}]
### 插件配置项
_No Response_
|
closed
|
2024-08-14T09:19:56Z
|
2024-08-22T14:35:07Z
|
https://github.com/nonebot/nonebot2/issues/2881
|
[
"Plugin"
] |
molanp
| 13 |
taverntesting/tavern
|
pytest
| 847 |
Unable to use external function in MQTT publish
|
I tried using an external function in a MQTT publish request, and the function wasn't getting evaluated.
My request looks like this:
```
- id: publish_thing_1
name: Publish thing 1
mqtt_publish:
topic: &ping_topic '/device/123/ping'
qos: 1
json:
$ext:
function: utils.testing_utils:my_function
thing_1: abc
mqtt_response:
topic: *ping_topic
json:
header: test
thing_1: abc
timeout: 5
qos: 1
```
It looks like the line below in [request.py](https://github.com/taverntesting/tavern/blob/master/tavern/_plugins/mqtt/request.py)
```
update_from_ext(publish_args, ["json"], test_block_config)
```
should be
```
update_from_ext(publish_args, ["payload"], test_block_config)
```
instead, since publish_args looks like this:
```
{'topic': '/device/123/ping', 'qos': 1, 'payload': '{"$ext": {"function": "utils.testing_utils:my_function"}, "thing_1": "abc"}'}
```
Note that the `payload` value is a string, which prevents external function evaluation even after I do the `update_from_ext` change. Before I go down the rabbit hole too much, I wanted to confirm that I've configured the request properly, and that this feature is expected to work after this [PR](https://github.com/taverntesting/tavern/pull/620).
|
closed
|
2023-02-15T06:59:04Z
|
2023-02-16T21:06:26Z
|
https://github.com/taverntesting/tavern/issues/847
|
[] |
samunnat
| 3 |
Netflix/metaflow
|
data-science
| 2,198 |
Why the workflow end step cannot be the end of split node
|
I have a workflow with two steps before the end step
```
from metaflow import FlowSpec, step
class LinearFlow(FlowSpec):
@step
def start(self):
self.my_var = 'hello world'
self.next(self.a, self.b)
@step
def a(self):
print('the data artifact is: %s' % self.my_var)
self.next(self.end)
@step
def b(self):
print('test b')
self.next(self.end)
@step
def end(self):
print('the data artifact is still: %s' % self.my_var)
if __name__ == '__main__':
LinearFlow()
```
When I use it to create a workflow, the following error occurs
```
Validating your flow...
Validity checker found an issue:
Step end reached before a split started at step(s) a, b were joined. Add a join step before end.
```
I think the end step should be able to support multiple upstream steps. I read the documentation of metaflow and did not find an explanation of this design. My workflow runs on argo-workflow. Are there any other considerations for this limitation?
|
open
|
2025-01-07T07:32:15Z
|
2025-01-07T07:32:15Z
|
https://github.com/Netflix/metaflow/issues/2198
|
[] |
EveT0n
| 0 |
tflearn/tflearn
|
tensorflow
| 243 |
Typing Err in Titanic Tutorial
|
def download_dataset(filename='titanic_dataset.csv', work_directory='./'):
...
if not os.path.exists(filepath):
print('Downloading MNIST...')
...
'MNIST' should be 'titanic_dataset'
|
closed
|
2016-07-29T06:12:57Z
|
2016-07-30T19:50:14Z
|
https://github.com/tflearn/tflearn/issues/243
|
[] |
forhonourlx
| 0 |
unionai-oss/pandera
|
pandas
| 1,029 |
Add support for tags
|
**Is your feature request related to a problem? Please describe.**
Pandera schemas currently do not allow for attaching user-defined tags to it at the component level (columns, indexes) of a schema. This additional metadata would allow for operations on the schema, such as selecting subsets of schema columns based on those tags.
**Describe the solution you'd like**
Add a `tags` kwarg for all schema component objects and the SchemaModel equivalents: `pa.Column`, `pa.Index`, and `pa.Field`. Pandera will not have any opinions about what the tag is, it could be any object that implements the `__eq__` method so that membership to a set of tags can be evaluated.
### User-facing API
Then, the user-facing API for this would look something like:
```python
schema = pa.DataFrameSchema(
{
"cont1": pa.Column(
int,
checks=pa.Check(lambda x: 0 <= len(x) <= 100, element_wise=True),
tags=["numeric"],
),
"cont2": pa.Column(int, tags=["numeric"]),
"cat1": pa.Column(int, tags=["numeric"]),
"binary": pa.Column(int, tags=["binary"]),
},
strict="filter",
)
# equivalent SchemaModel would be
class Schema(pa.SchemaModel):
cont1: pa.typing.Series[int] = pa.Field(tags=["numeric"])
... # and so on
```
### Imperative API
```python
# add tags to columns (maybe support regex)
schema.add_tags({"cont*": "numeric"}) # support regex pattern matching on columns
schema.add_tags({"cat*": "categorical"})
schema.add_tags(["cont1", "cont2"], tags=["numeric"]) # support updating multiple fields (column/index) by name
```
### Schema Tranformations Based on Tags
```python
# select columns by tags
schema.select_by_tags("numeric") == pa.DataFrameSchema(
{
"cont1": pa.Column(int),
"cont2": pa.Column(int),
},
)
# or select multiple tags
schema.select_by_tags(["numeric", "binary"])
```
**Describe alternatives you've considered**
Users can extend the `DataFramSchema` class on their own to implement this functionality.
**Additional context**
Chatted with @marcromeyn about this feature so that he can integration [NVTabular](https://github.com/NVIDIA-Merlin/NVTabular) with pandera.
|
open
|
2022-11-21T17:23:19Z
|
2023-04-17T18:05:59Z
|
https://github.com/unionai-oss/pandera/issues/1029
|
[
"enhancement",
"help wanted"
] |
cosmicBboy
| 2 |
deepset-ai/haystack
|
nlp
| 8,598 |
Move `SentenceSplitter` into utils
|
Move the `SentenceSplitter` currently packed into the [NLTKDocumentSplitter](https://github.com/deepset-ai/haystack/blob/main/haystack/components/preprocessors/nltk_document_splitter.py#L384) into another file so that it can be easily reused.
In this way, it can later be reused by any component that wants to implement some splitting/chunking technique that needs to rely on a robust sentence detection algorithm.
|
closed
|
2024-12-03T10:21:49Z
|
2024-12-04T09:44:37Z
|
https://github.com/deepset-ai/haystack/issues/8598
|
[] |
davidsbatista
| 0 |
yunjey/pytorch-tutorial
|
deep-learning
| 106 |
No dashboards are active for the current data set.
|
It succeed at the first time, and when I run the program the second time, the page show nothing but "No dashboards are active for the current data set...." after opening the page.
|
closed
|
2018-04-12T13:41:09Z
|
2018-06-22T17:54:32Z
|
https://github.com/yunjey/pytorch-tutorial/issues/106
|
[] |
Jane233
| 2 |
stanfordnlp/stanza
|
nlp
| 1,042 |
Avoid downloading resources file on every function call
|
I am using lemmatization from Stanza (1.4.0). To disable the warning and send only critical messages to the console, I am using the following config
```
import warnings
warnings.filterwarnings('ignore')
import sys
logging.disable(sys.maxsize)
logger = logging.getLogger()
logger.setLevel(logging.CRITICAL)
```
While doing lemmatization, I receive the message below which says that it is downloading file "resources_1.4.0.json" on every call. This further increases the total runtime. How can I avoid this.
> Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/main/resources_1.4.0.json: 154kB [00:00, 612k Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/main/resources_1.4.0.json: 154kB [00:00, 603kB/s]
> Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/main/resources_1.4.0.json: 154kB [00:00, 648k Downloading https://raw.githubusercontent.com/stanfordnlp/stanza-resources/main/resources_1.4.0.json: 154kB [00:00, 634kB/s]
Lemmatization function
```
def lemmatize_text(text):
import stanza
nlp = stanza.Pipeline(lang='en', processors='tokenize, mwt, pos, lemma')
doc = nlp(text)
word_lemma = [sent.words[0].lemma for sent in doc.sentences]
return word_lemma[0]
```
|
closed
|
2022-05-31T11:03:17Z
|
2022-10-11T07:38:48Z
|
https://github.com/stanfordnlp/stanza/issues/1042
|
[
"question",
"stale"
] |
jmohit13
| 6 |
dask/dask
|
pandas
| 11,753 |
`ValueError: cannot broadcast shape` in `Array.__setitem__` with boolean mask
|
**Describe the issue**:
After https://github.com/dask/dask/pull/11728, `Array.__setitem__` with a boolean mass fails with a `ValueError`
**Minimal Complete Verifiable Example**:
```python
import dask.array as da
a = da.random.uniform(size=10)
mask = a > 0.5
a[mask] = a
```
that raises:
```pytb
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[3], line 6
4 a = da.random.uniform(size=10)
5 mask = a > 0.5
----> 6 a[mask] = a
File ~/gh/dask/dask/dask/array/core.py:1973, in Array.__setitem__(self, key, value)
1967 # If value has ndim > 0, they must be broadcastable to self.shape[idx].
1968 # This raises when the bool mask causes the size to become unknown,
1969 # e.g. this is valid in numpy but raises here:
1970 # x = da.array([1,2,3])
1971 # x[da.array([True, True, False])] = [4, 5]
1972 if value.ndim:
-> 1973 value = broadcast_to(value, self[key].shape)
1975 y = where(key, value, self)
1976 # FIXME does any backend allow mixed ops vs. numpy?
1977 # If yes, is it wise to let them change the meta?
File ~/gh/dask/dask/dask/array/core.py:5241, in broadcast_to(x, shape, chunks, meta)
5237 ndim_new = len(shape) - x.ndim
5238 if ndim_new < 0 or any(
5239 new != old for new, old in zip(shape[ndim_new:], x.shape) if old != 1
5240 ):
-> 5241 raise ValueError(f"cannot broadcast shape {x.shape} to shape {shape}")
5243 if chunks is None:
5244 chunks = tuple((s,) for s in shape[:ndim_new]) + tuple(
5245 bd if old > 1 else (new,)
5246 for bd, old, new in zip(x.chunks, x.shape, shape[ndim_new:])
5247 )
ValueError: cannot broadcast shape (10,) to shape (nan,)
```
**Anything else we need to know?**:
That snippet worked prior to #11728. https://github.com/dask/dask-ml/issues/1012 is a downstream failure in dask-ml from this.
**Environment**:
- Dask version:
- Python version:
- Operating System:
- Install method (conda, pip, source):
|
open
|
2025-02-17T16:01:52Z
|
2025-03-20T00:23:40Z
|
https://github.com/dask/dask/issues/11753
|
[
"array",
"bug"
] |
TomAugspurger
| 6 |
eriklindernoren/ML-From-Scratch
|
deep-learning
| 71 |
may be a bug with activation_functions.py
|
the Class Softmax function gradient may be should return x * (p-1)
|
closed
|
2019-12-22T11:22:32Z
|
2019-12-22T11:56:01Z
|
https://github.com/eriklindernoren/ML-From-Scratch/issues/71
|
[] |
zhouchiji
| 0 |
unit8co/darts
|
data-science
| 2,540 |
historical_forecasts consuming huge memory
|
Does the historical_forecasts function require a large amount of memory?
```
backtest_results = model.historical_forecasts(
series=train_series,
past_covariates=cov,
forecast_horizon=4,
num_samples=100,
last_points_only=False,
fit_kwargs={'val_series': val_series, 'val_past_covariates': cov},
verbose=False,
retrain=True)
```
When I run this program, it takes a significant amount of time, and the memory usage gradually increases until it eventually crashes.
I’m running a global model on 100 time series ( a list of 100 time series) , each with an average length of 500 timesteps.
I have 16GB of memory available.
Are there any optimizations or settings that can be applied to reduce memory consumption for the historical_forecasts function?
|
closed
|
2024-09-24T14:48:06Z
|
2024-10-03T07:26:48Z
|
https://github.com/unit8co/darts/issues/2540
|
[
"question"
] |
Manohar0077
| 3 |
microsoft/qlib
|
machine-learning
| 1,892 |
data collector for PIT is not working
|
## 🐛 Bug Description
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. Follow the example to download PIT data.
`python collector.py download_data --source_dir ~/.qlib/stock_data/source/pit --start 2000-01-01 --end 2020-01-01 --interval quarterly`
1. Get this error
```
Traceback (most recent call last):
File "E:\Git\qlib\scripts\data_collector\pit\collector.py", line 261, in <module>
fire.Fire(Run)
File "C:\veighna_studio\lib\site-packages\fire\core.py", line 135, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "C:\veighna_studio\lib\site-packages\fire\core.py", line 468, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File "C:\veighna_studio\lib\site-packages\fire\core.py", line 684, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "E:\Git\qlib\scripts\data_collector\base.py", line 402, in download_data
_class(
File "E:\Git\qlib\scripts\data_collector\pit\collector.py", line 69, in __init__
super().__init__(
File "E:\Git\qlib\scripts\data_collector\base.py", line 80, in __init__
self.instrument_list = sorted(set(self.get_instrument_list()))
File "E:\Git\qlib\scripts\data_collector\pit\collector.py", line 83, in get_instrument_list
symbols = get_hs_stock_symbols()
File "E:\Git\qlib\scripts\data_collector\utils.py", line 235, in get_hs_stock_symbols
symbols |= _get_symbol()
File "E:\Git\qlib\scripts\data_collector\utils.py", line 219, in _get_symbol
raise ValueError("The complete list of stocks is not available.")
ValueError: The complete list of stocks is not available.
(pit)
```
## Expected Behavior
No error occurs and we fetch the data successfully.
## Screenshot
<!-- A screenshot of the error message or anything shouldn't appear-->
## Environment
**Note**: User could run `cd scripts && python collect_info.py all` under project directory to get system information
and paste them here directly.
- Qlib version:
- Python version:
- OS (`Windows`, `Linux`, `MacOS`): Windows
- Commit number (optional, please provide it if you are using the dev version):
## Additional Notes
The possible problem is that [this API](https://github.com/microsoft/qlib/blob/main/scripts/data_collector/utils.py#L205) is not returning the full list of 5000+ symbols, but only part of it.
If we want the full list, it must be sourced from somewhere else.
<!-- Add any other information about the problem here. -->
|
open
|
2025-03-06T10:04:38Z
|
2025-03-06T10:05:01Z
|
https://github.com/microsoft/qlib/issues/1892
|
[
"bug"
] |
hlstwizard
| 0 |
seleniumbase/SeleniumBase
|
web-scraping
| 2,886 |
Cannot bypass the check box of the CF of this website
|
This is where the iframe is located:
<
<img width="454" alt="Screenshot 2024-06-30 at 15 00 00" src="https://github.com/seleniumbase/SeleniumBase/assets/64100264/1345a547-2d96-4f11-a72f-03fb9c7671d1">
This is the website:
<img width="746" alt="Screenshot 2024-06-30 at 15 03 37" src="https://github.com/seleniumbase/SeleniumBase/assets/64100264/851eeb1c-11ff-4465-81ae-2cedc71ac3d0">
I am having a problem bypassing this CF checkbox in this website. I am using the newly updated functions. When the browser opens the newly updated uc_click() method which is now handled by uc_gui_handle_cf() does not work. What can I do to get through this? The iframe located in this id="cf-chl-widget-om6tb". My code structure looks like this :
```
with SB(uc=True, test=True, rtf=True,incognito=True, agent=agent, headless=False) as sb:
sb.driver.uc_open_with_disconnect(url, 6)
# sb.scroll_to("iframe")
sb.uc_gui_handle_cf("#cf-chl-widget-om6tb iframe")
sb.set_messenger_theme(location="bottom_center")
sb.post_message("SeleniumBase wasn't detected!")
```
Exception I am getting :
```
urllib3.exceptions.NewConnectionError: <urllib3.connection.HTTPConnection object at 0x111201e40>: Failed to establish a new connection: [Errno 61] Connection refused
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/Users/orbiszeus/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher/../../debugpy/__main__.py", line 39, in <module>
cli.main()
File "/Users/orbiszeus/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 430, in main
run()
File "/Users/orbiszeus/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 284, in run_file
runpy.run_path(target, run_name="__main__")
File "/Users/orbiszeus/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 321, in run_path
return _run_module_code(code, init_globals, run_name,
File "/Users/orbiszeus/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 135, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "/Users/orbiszeus/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 124, in _run_code
exec(code, run_globals)
File "/Users/orbiszeus/metro_analyst/menu_crawler.py", line 570, in <module>
main()
File "/Users/orbiszeus/metro_analyst/menu_crawler.py", line 545, in main
sb.uc_gui_handle_cf("#cf-chl-widget-om6tb iframe")
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/seleniumbase/core/browser_launcher.py", line 4031, in <lambda>
lambda *args, **kwargs: uc_gui_handle_cf(
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/seleniumbase/core/browser_launcher.py", line 653, in uc_gui_handle_cf
source = driver.get_page_source()
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/seleniumbase/core/sb_driver.py", line 50, in get_page_source
return self.driver.page_source
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/seleniumbase/undetected/__init__.py", line 330, in __getattribute__
return super().__getattribute__(item)
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/selenium/webdriver/remote/webdriver.py", line 455, in page_source
return self.execute(Command.GET_PAGE_SOURCE)["value"]
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/selenium/webdriver/remote/webdriver.py", line 352, in execute
response = self.command_executor.execute(driver_command, params)
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/selenium/webdriver/remote/remote_connection.py", line 302, in execute
return self._request(command_info[0], url, body=data)
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/selenium/webdriver/remote/remote_connection.py", line 322, in _request
response = self._conn.request(method, url, body=body, headers=headers)
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/_request_methods.py", line 136, in request
return self.request_encode_url(
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/_request_methods.py", line 183, in request_encode_url
return self.urlopen(method, url, **extra_kw)
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/poolmanager.py", line 444, in urlopen
response = conn.urlopen(method, u.request_uri, **kw)
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/connectionpool.py", line 877, in urlopen
return self.urlopen(
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/connectionpool.py", line 877, in urlopen
return self.urlopen(
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/connectionpool.py", line 877, in urlopen
return self.urlopen(
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/connectionpool.py", line 847, in urlopen
retries = retries.increment(
File "/Users/orbiszeus/metro_analyst/myenv/lib/python3.10/site-packages/urllib3/util/retry.py", line 515, in increment
raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='localhost', port=53964): Max retries exceeded with url: /session/33d97a286c7d6d58961e0ec9b48dcc5f/source (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x111201e40>: Failed to establish a new connection: [Errno 61] Connection refused'))
```
|
closed
|
2024-06-30T13:02:14Z
|
2024-06-30T15:26:08Z
|
https://github.com/seleniumbase/SeleniumBase/issues/2886
|
[
"question",
"can't reproduce",
"UC Mode / CDP Mode"
] |
Orbiszeus
| 7 |
amidaware/tacticalrmm
|
django
| 2,021 |
[UI Tweeks] Add more info to the automation policies for checks
|
**Is your feature request related to a problem? Please describe.**
currently it is impossible to have a global overview of how each check has been set or if any would be in the need of tweeking without going into each check individualy
**Describe the solution you'd like**
make each parameter of each check available in individual collumns
**Additional context**

|
open
|
2024-10-04T10:52:13Z
|
2024-10-22T07:21:25Z
|
https://github.com/amidaware/tacticalrmm/issues/2021
|
[] |
P6g9YHK6
| 2 |
JaidedAI/EasyOCR
|
deep-learning
| 614 |
ModuleNotFoundError: No module named 'easyocr'
|
Hey,
I tried every method to install easyocr. I installed PyTorch without GPU
`pip3 install torch torchvision torchaudio`
and then I tried `pip install easyocr` but still I got an error, afterwards from one of the solved issues I tried
`pip uninstall easyocr`
`pip install git+git://github.com/jaidedai/easyocr.git` but still unable to import easyocr.
And also firstly when I run the command `pip uninstall easyocr`, it showed me **WARNING: Skipping easyocr as it is not installed.**
@rkcosmos please help through this problem
|
closed
|
2021-12-09T06:57:13Z
|
2022-08-07T05:01:26Z
|
https://github.com/JaidedAI/EasyOCR/issues/614
|
[] |
harshitkd
| 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.