
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
listlengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
vllm-project/vllm
|
pytorch
| 15,218 |
[Bug]: load model from s3 storage failed
|
### Your current environment
<details>
<summary>The output of `python collect_env.py`</summary>
```text
Collecting environment information...
PyTorch version: 2.5.1+cu124
Is debug build: False
CUDA used to build PyTorch: 12.4
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.31.4
Libc version: glibc-2.35
Python version: 3.12.9 (main, Feb 5 2025, 08:49:00) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-162-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.1.105
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A30
GPU 1: NVIDIA A30
Nvidia driver version: 535.129.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz
CPU family: 6
Model: 106
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 1
Stepping: 6
BogoMIPS: 4589.21
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves wbnoinvd arat avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq rdpid md_clear arch_capabilities
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 1.3 MiB (28 instances)
L1i cache: 896 KiB (28 instances)
L2 cache: 35 MiB (28 instances)
L3 cache: 54 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-55
Vulnerability Gather data sampling: Unknown: Dependent on hypervisor status
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy-boto3-s3==1.37.0
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.26.4
[pip3] nvidia-cublas-cu12==12.4.5.8
[pip3] nvidia-cuda-cupti-cu12==12.4.127
[pip3] nvidia-cuda-nvrtc-cu12==12.4.127
[pip3] nvidia-cuda-runtime-cu12==12.4.127
[pip3] nvidia-cudnn-cu12==9.1.0.70
[pip3] nvidia-cufft-cu12==11.2.1.3
[pip3] nvidia-curand-cu12==10.3.5.147
[pip3] nvidia-cusolver-cu12==11.6.1.9
[pip3] nvidia-cusparse-cu12==12.3.1.170
[pip3] nvidia-cusparselt-cu12==0.6.2
[pip3] nvidia-nccl-cu12==2.21.5
[pip3] nvidia-nvjitlink-cu12==12.4.127
[pip3] nvidia-nvtx-cu12==12.4.127
[pip3] pyzmq==26.3.0
[pip3] sentence-transformers==3.2.1
[pip3] torch==2.5.1
[pip3] torchaudio==2.5.1
[pip3] torchvision==0.20.1
[pip3] transformers==4.50.0.dev0
[pip3] transformers-stream-generator==0.0.5
[pip3] triton==3.1.0
[pip3] tritonclient==2.51.0
[pip3] vector-quantize-pytorch==1.21.2
[conda] Could not collect
ROCM Version: Could not collect
Neuron SDK Version: N/A
vLLM Version: 0.7.3
vLLM Build Flags:
CUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled
GPU Topology:
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X SYS 0-55 0 N/A
GPU1 SYS X 0-55 0 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
NVIDIA_VISIBLE_DEVICES=all
NVIDIA_REQUIRE_CUDA=cuda>=12.1 brand=tesla,driver>=470,driver<471 brand=unknown,driver>=470,driver<471 brand=nvidia,driver>=470,driver<471 brand=nvidiartx,driver>=470,driver<471 brand=geforce,driver>=470,driver<471 brand=geforcertx,driver>=470,driver<471 brand=quadro,driver>=470,driver<471 brand=quadrortx,driver>=470,driver<471 brand=titan,driver>=470,driver<471 brand=titanrtx,driver>=470,driver<471 brand=tesla,driver>=525,driver<526 brand=unknown,driver>=525,driver<526 brand=nvidia,driver>=525,driver<526 brand=nvidiartx,driver>=525,driver<526 brand=geforce,driver>=525,driver<526 brand=geforcertx,driver>=525,driver<526 brand=quadro,driver>=525,driver<526 brand=quadrortx,driver>=525,driver<526 brand=titan,driver>=525,driver<526 brand=titanrtx,driver>=525,driver<526
NCCL_VERSION=2.17.1-1
NVIDIA_DRIVER_CAPABILITIES=compute,utility
NVIDIA_PRODUCT_NAME=CUDA
VLLM_USAGE_SOURCE=production-docker-image
NVIDIA_CUDA_END_OF_LIFE=1
CUDA_VERSION=12.1.0
LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64
NCCL_CUMEM_ENABLE=0
TORCHINDUCTOR_COMPILE_THREADS=1
CUDA_MODULE_LOADING=LAZY
```
</details>
### 🐛 Describe the bug
I want to load model from s3 storage, the model stored in the s3 bucket is as following:

the demo code is:
```python
import json
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
bucket_name="mynewbucket"
llm = LLM(
model=f"s3://{bucket_name}/Qwen2.5-7B-Instruct"
)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```

### Before submitting a new issue...
- [x] Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://docs.vllm.ai/en/latest/), which can answer lots of frequently asked questions.
|
open
|
2025-03-20T12:47:20Z
|
2025-03-20T12:56:53Z
|
https://github.com/vllm-project/vllm/issues/15218
|
[
"bug"
] |
warjiang
| 1 |
CatchTheTornado/text-extract-api
|
api
| 51 |
[feat] colpali support
|
https://medium.com/@simeon.emanuilov/colpali-revolutionizing-multimodal-document-retrieval-324eab1cf480
It would be great to add colpali support as a OCR driver
|
open
|
2025-01-02T11:37:24Z
|
2025-01-19T16:55:20Z
|
https://github.com/CatchTheTornado/text-extract-api/issues/51
|
[
"feature"
] |
pkarw
| 0 |
sinaptik-ai/pandas-ai
|
pandas
| 1,290 |
Question Regarding Licence
|
Hey Guys, i cant get my head around your special licence for the folder ee
Could you explain a bit when content of this folder is used and therefore when the licence applies ?
thx!
|
closed
|
2024-07-23T06:25:34Z
|
2024-08-24T10:55:35Z
|
https://github.com/sinaptik-ai/pandas-ai/issues/1290
|
[] |
DRXD1000
| 1 |
sinaptik-ai/pandas-ai
|
pandas
| 720 |
Supporting for Azure Synopsis
|
### 🚀 The feature
We propose the addition of a new feature: Azure Synopsis integration. Azure Synopsis is an indispensable tool that addresses a critical need in workflow. This integration will significantly enhance the capabilities, providing essential benefits to users and the project as a whole.
Why Azure Synopsis is an Inevitable Need:
### Motivation, pitch
Azure Synopsis offers a powerful set of tools and services that are essential for . By integrating Azure Synopsis, one can achieve the following key advantages:
Enhanced Security: Azure Synopsis provides robust security features, ensuring that our project data remains confidential and protected against threats.
Efficient Data Processing: The streamlined data processing capabilities of Azure Synopsis will significantly improve the efficiency of our system, enabling faster execution of tasks and operations.
Scalability: As our project grows, Azure Synopsis offers seamless scalability, allowing us to handle increased workloads and user demands without compromising performance.
Advanced Analytics: Azure Synopsis offers advanced analytics tools, enabling us to gain valuable insights from our data. These insights can inform decision-making and contribute to the overall improvement of our project.
Reliability and Redundancy: Azure Synopsis ensures high reliability and redundancy, minimizing downtime and ensuring uninterrupted access to our services for our users.
### Alternatives
_No response_
### Additional context
_No response_
|
closed
|
2023-11-02T06:01:46Z
|
2024-06-01T00:20:20Z
|
https://github.com/sinaptik-ai/pandas-ai/issues/720
|
[] |
MuthusivamGS
| 0 |
slackapi/bolt-python
|
fastapi
| 345 |
Receiving action requests in a different path
|
I'm having an issue with actions.
I have my blocks, but every time I click the button, I get a 404 through ngrok:
```Python
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"Hi, {user_name} Welcome to NAME for Slack \n*We can help you get instant recommendations for different types of stressful situations happening at work, here is how it works.*"
}
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "👉Tell us what’s going on\n🔠 What word or sentence describe better how you feel\n😊 NAME will propose a session, activity or advice for you to follow"
}
},
{
"type": "actions",
"elements": [
{
"type": "button",
"text": {
"type": "plain_text",
"text": "Ask NAME for help."
},
"value": "get_help_button",
"action_id": "get_help_button"
}
]
}
```
```Python
@app.action("get_help_button")
def handle_get_help_button(ack, say):
ack()
```
I have my Interactivity Request URL set to: https://*SOMETHING*.ngrok.io/slack/interactive-endpoint
as it's displayed in the Placeholder text on the website, but I still keep getting 404.
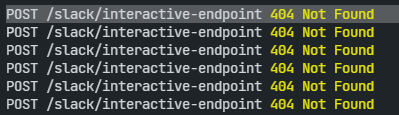
`POST /slack/interactive-endpoint 404 Not Found`
I assume it's because my Request URL isn't what the bolt-python library expects? But I can't see anywhere in any documentation or the code that it has a reference to any /slack/ endpoints besides /slack/events
### Reproducible in:
```bash
slack-bolt==1.6.0
slack-sdk==3.5.1
Python 3.9.2
Microsoft Windows [Version 10.0.19042.928]
2020-08-22 17:48
```
#### The `slack_bolt` version
slack-bolt==1.6.0
slack-sdk==3.5.1
#### Python runtime version
Python 3.9.2
#### OS info
Microsoft Windows [Version 10.0.19042.928]
2020-08-22 17:48
#### Steps to reproduce:
Source code was posted earlier, but I'll post the whole code if needed :)
### Expected result:
I'd expect my @app.action to get triggered.
### Actual result:
My @app.action() doesn't get triggered, and I get a 404 from NGROK.
## Requirements
Please read the [Contributing guidelines](https://github.com/slackapi/bolt-python/blob/main/.github/contributing.md) and [Code of Conduct](https://slackhq.github.io/code-of-conduct) before creating this issue or pull request. By submitting, you are agreeing to those rules.
|
closed
|
2021-05-21T15:54:14Z
|
2021-06-19T01:53:59Z
|
https://github.com/slackapi/bolt-python/issues/345
|
[
"question",
"area:async"
] |
LucasLundJensen
| 1 |
jina-ai/clip-as-service
|
pytorch
| 273 |
how to run monitor
|
when I want to run the monitor with failed
bert-serving-start -http_port 8001 -model_dir=/Users/hainingzhang/Downloads/chinese_L-12_H-768_A-12 -tuned_model_dir=/Documents/bert_output/ -ckpt_name=model.ckpt-18 -num_worker=4 -pooling_strategy=CLS_TOKEN
:VENTILATOR:[__i:_ru:148]:new config request req id: 1 client: b'91810d36-4eea-40ad-9fb3-3ad8ead1f8f0'
I:SINK:[__i:_ru:320]:send config client b'91810d36-4eea-40ad-9fb3-3ad8ead1f8f0'
I:VENTILATOR:[__i:_ru:148]:new config request req id: 1 client: b'2b3019dd-3792-4ec2-bc7f-d5d900252ab7'
I:SINK:[__i:_ru:320]:send config client b'2b3019dd-3792-4ec2-bc7f-d5d900252ab7'
* Serving Flask app "bert_serving.server.http" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:8001/ (Press CTRL+C to quit)
* Running on http://0.0.0.0:8001/ (Press CTRL+C to quit)
127.0.0.1 - - [14/Mar/2019 16:43:03] "GET / HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:43:03] "GET /robots.txt?1552552983893 HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:43:05] "GET /favicon.ico HTTP/1.1" 404 -
I:WORKER-1:[__i:gen:506]:ready and listening!
I:WORKER-0:[__i:gen:506]:ready and listening!
I:WORKER-2:[__i:gen:506]:ready and listening!
I:WORKER-3:[__i:gen:506]:ready and listening!
### run service start is successful
but when I open the webpae link is fail in chrome or Safari
http://0.0.0.0:8001/index.html
http://0.0.0.0:8001
I dont know why
127.0.0.1 - - [14/Mar/2019 16:43:49] "GET /robots.txt?1552553029264 HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:44:00] "GET /robots.txt?1552553040140 HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:44:31] "GET /plugin/dashboard/index.html HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:44:31] "GET /favicon.ico HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:49:33] "GET /index.html HTTP/1.1" 404 -
127.0.0.1 - - [14/Mar/2019 16:49:33] "GET /favicon.ico HTTP/1.1" 404 -
**Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [ ] Are you running the latest `bert-as-service`?
* [ ] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [ ] Did you check the [FAQ list in `README.md`](https://github.com/hanxiao/bert-as-service#speech_balloon-faq)?
* [ ] Did you perform [a cursory search on existing issues](https://github.com/hanxiao/bert-as-service/issues)?
**System information**
> Some of this information can be collected via [this script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh).
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
- TensorFlow installed from (source or binary):
- TensorFlow version:
- Python version:
- `bert-as-service` version:
- GPU model and memory:
- CPU model and memory:
---
### Description
> Please replace `YOUR_SERVER_ARGS` and `YOUR_CLIENT_ARGS` accordingly. You can also write your own description for reproducing the issue.
I'm using this command to start the server:
```bash
bert-serving-start YOUR_SERVER_ARGS
```
and calling the server via:
```python
bc = BertClient(YOUR_CLIENT_ARGS)
bc.encode()
```
Then this issue shows up:
...
|
closed
|
2019-03-14T08:54:12Z
|
2020-02-05T12:37:18Z
|
https://github.com/jina-ai/clip-as-service/issues/273
|
[] |
mullerhai
| 3 |
streamlit/streamlit
|
data-science
| 9,912 |
Toast API throws exception on use of Shortcodes.
|
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
As per documentation of [Toast](https://docs.streamlit.io/1.34.0/develop/api-reference/status/st.toast#sttoast) we can use material icons or shorthand since version 1.34.0
### Reproducible Code Example
```Python
import streamlit as st
# both of the methods give errors
st.toast("Removed from favorites!", icon="️:material/heart_minus:")
st.toast("Added to favorites!", icon="️:hearts:")
```
### Steps To Reproduce
streamlit run app.py
### Expected Behavior
Icon should be rendered properly as they are rendered in Exception message.
### Current Behavior
StreamlitAPIException: The value "️:material/heart_minus:" is not a valid emoji. Shortcodes are not allowed, please use a single character instead.
StreamlitAPIException: The value "️♥️" is not a valid emoji. Shortcodes are not allowed, please use a single character instead.
### Is this a regression?
- [ ] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: 1.40.0
- Python version: 3.8.5
- Operating System: Windows 11
- Browser: Edge
### Additional Information
I have also tried streamlit version 1.39.0
|
closed
|
2024-11-23T12:26:36Z
|
2024-11-26T13:57:16Z
|
https://github.com/streamlit/streamlit/issues/9912
|
[
"type:bug"
] |
ManGupt
| 3 |
jpadilla/django-rest-framework-jwt
|
django
| 493 |
Cookie not removed in request when response is 401
|
I'm using JWT in a httpOnly cookie and allowing multiple logins on the system.
If I have 2 sessions opened with the same user (different JWT tokens) and if one of them logs out I reset all JWT tokens by changing the user's UUID. I also delete that session's cookie by means of:
response = HttpResponse()
response.delete_cookie("cookie.jwt",path="/")
This logs out both browser sessions and that's OK, but the browser session in which I DID NOT explicitly log out keeps an invalid cookie in the browser and I can't get rid of it via javascript because its httpOnly (I want it to stay that way). All further requests to the server return as a 401 and I can't seem to change the response to add a "delete_cookie".
Two questions:
1. Why not always delete the cookie JWT_AUTH_COOKIE from the response if an exception is raised by JWT?
2. How can I work around this issue?
Thanks!
|
open
|
2020-02-11T15:48:28Z
|
2020-02-11T15:48:28Z
|
https://github.com/jpadilla/django-rest-framework-jwt/issues/493
|
[] |
pedroflying
| 0 |
dropbox/PyHive
|
sqlalchemy
| 360 |
PyHive Connection to HiveServer2 Didn't support Keytab login?
|
It seems that connection to Presto support keytab login. But connection to HiveServer2 didn't support it.
Is there any consideration for that?
|
open
|
2020-08-07T09:05:48Z
|
2020-08-07T09:06:40Z
|
https://github.com/dropbox/PyHive/issues/360
|
[] |
VicoWu
| 0 |
pytest-dev/pytest-html
|
pytest
| 106 |
encoding error
|
I just tried to update to the latest pytest html and I'm getting an encoding error. The line referred to isn't encoded that I see, so perhaps that needs an update. I can try to look more into this later.
```
metadata: {'Python': '2.7.13', 'Driver': 'Remote', 'Capabilities': {'browserName': 'chrome', 'screenResolution': '1440x900'}, 'Server': 'http://selenium-server:4444', 'Base URL': 'http://local.better.com:3000', 'Platform': 'Linux-4.4.23-31.54.amzn1.x86_64-x86_64-with', 'Plugins': {'bdd': '2.18.1', 'variables': '1.5.1', 'selenium': '1.9.1', 'rerunfailures': '2.1.0', 'html': '1.14.1', 'timeout': '1.2.0', 'base-url': '1.3.0', 'metadata': '1.3.0'}, 'Packages': {'py': '1.4.32', 'pytest': '3.0.6', 'pluggy': '0.4.0'}}
rootdir: inifile: pytest.ini
plugins: variables-1.5.1, timeout-1.2.0, selenium-1.9.1, rerunfailures-2.1.0, metadata-1.3.0, html-1.14.1, bdd-2.18.1, base-url-1.3.0
timeout: 480.0s method: signal
collected 2 items
INTERNALERROR> Traceback (most recent call last):
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/main.py", line 98, in wrap_session
INTERNALERROR> session.exitstatus = doit(config, session) or 0
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/main.py", line 133, in _main
INTERNALERROR> config.hook.pytest_runtestloop(session=session)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 745, in __call__
INTERNALERROR> return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 339, in _hookexec
INTERNALERROR> return self._inner_hookexec(hook, methods, kwargs)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 334, in <lambda>
INTERNALERROR> _MultiCall(methods, kwargs, hook.spec_opts).execute()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 614, in execute
INTERNALERROR> res = hook_impl.function(*args)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/main.py", line 154, in pytest_runtestloop
INTERNALERROR> item.config.hook.pytest_runtest_protocol(item=item, nextitem=nextitem)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 745, in __call__
INTERNALERROR> return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 339, in _hookexec
INTERNALERROR> return self._inner_hookexec(hook, methods, kwargs)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 334, in <lambda>
INTERNALERROR> _MultiCall(methods, kwargs, hook.spec_opts).execute()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 613, in execute
INTERNALERROR> return _wrapped_call(hook_impl.function(*args), self.execute)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 254, in _wrapped_call
INTERNALERROR> return call_outcome.get_result()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 280, in get_result
INTERNALERROR> _reraise(*ex) # noqa
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 265, in __init__
INTERNALERROR> self.result = func()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 613, in execute
INTERNALERROR> return _wrapped_call(hook_impl.function(*args), self.execute)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 254, in _wrapped_call
INTERNALERROR> return call_outcome.get_result()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 280, in get_result
INTERNALERROR> _reraise(*ex) # noqa
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 265, in __init__
INTERNALERROR> self.result = func()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 614, in execute
INTERNALERROR> res = hook_impl.function(*args)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_rerunfailures.py", line 96, in pytest_runtest_protocol
INTERNALERROR> item.ihook.pytest_runtest_logreport(report=report)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 745, in __call__
INTERNALERROR> return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 339, in _hookexec
INTERNALERROR> return self._inner_hookexec(hook, methods, kwargs)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 334, in <lambda>
INTERNALERROR> _MultiCall(methods, kwargs, hook.spec_opts).execute()
INTERNALERROR> File "/usr/lib/python2.7/site-packages/_pytest/vendored_packages/pluggy.py", line 614, in execute
INTERNALERROR> res = hook_impl.function(*args)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_html/plugin.py", line 469, in pytest_runtest_logreport
INTERNALERROR> self.append_other(report)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_html/plugin.py", line 293, in append_other
INTERNALERROR> self._appendrow('Rerun', report)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_html/plugin.py", line 249, in _appendrow
INTERNALERROR> result = self.TestResult(outcome, report, self.logfile, self.config)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_html/plugin.py", line 114, in __init__
INTERNALERROR> self.append_extra_html(extra, extra_index, test_index)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_html/plugin.py", line 199, in append_extra_html
INTERNALERROR> href = data_uri(content)
INTERNALERROR> File "/usr/lib/python2.7/site-packages/pytest_html/plugin.py", line 77, in data_uri
INTERNALERROR> data = b64encode(content)
INTERNALERROR> File "/usr/lib/python2.7/base64.py", line 54, in b64encode
INTERNALERROR> encoded = binascii.b2a_base64(s)[:-1]
INTERNALERROR> UnicodeEncodeError: 'ascii' codec can't encode character u'\u2019' in position 56830: ordinal not in range(128)
```
|
closed
|
2017-03-03T16:58:22Z
|
2023-08-11T15:26:40Z
|
https://github.com/pytest-dev/pytest-html/issues/106
|
[
"bug"
] |
micheletest
| 9 |
kornia/kornia
|
computer-vision
| 2,602 |
Create test for Auto Modules with `InputTensor` / `OutputTensor`
|
@johnnv1 i think as post meta task from this we could exploring to prototype an AutoModule that basically given a function parsed via `inspect` to automatically generate Modules. This might requires creating `InputTensor` / `OutputTensor` alias types.
_Originally posted by @edgarriba in https://github.com/kornia/kornia/pull/2588#discussion_r1343692970_
|
closed
|
2023-10-04T08:22:45Z
|
2024-01-24T11:41:48Z
|
https://github.com/kornia/kornia/issues/2602
|
[
"code heatlh :pill:",
"CI :gear:"
] |
edgarriba
| 2 |
exaloop/codon
|
numpy
| 322 |
error: syntax error, unexpected 'or'
|
I have run the following python program program2.py by codon.
class O8Y694p3o ():
a3e16X35 = "CgtSETQBaCgC"
def L62326a80a ( self , XY7C5a3Z : bytes ) -> bytes :
if ((True)or(False))or((("sR2Kt7"))==(self.a3e16X35)) :
B06Cx4V2 = "vAl_r1iUA_H" ;
if __name__ == '__main__':
Qokhsc8W = 28
U27KnA44y3= O8Y694p3o();
U27KnA44y3.L62326a80a(Qokhsc8W)
print(U27KnA44y3.a3e16X35)
And it output error message as follow:
codon_program2.py:4:14: error: syntax error, unexpected 'or'
I hava run it by both python3 and pypy3 and output the following content:
CgtSETQBaCgC
The related files can be found in https://github.com/starbugs-qurong/python-compiler-test/tree/main/codon/python_2
|
closed
|
2023-04-04T10:35:57Z
|
2024-11-09T20:24:44Z
|
https://github.com/exaloop/codon/issues/322
|
[
"bug"
] |
starbugs-qurong
| 5 |
syrupy-project/syrupy
|
pytest
| 954 |
JSONSnapshotExtension can't serialize dicts with integer keys
|
**Describe the bug**
When using `JSONSnapshotExtension` to snapshot a dictionary with an integer key, the stored snapshot contains an empty dictionary.
**To reproduce**
```python
import pytest
from syrupy.extensions.json import JSONSnapshotExtension
@pytest.fixture
def snapshot_json(snapshot):
return snapshot.with_defaults(extension_class=JSONSnapshotExtension)
def test_integer_key(snapshot_json):
assert snapshot_json == {1: "value"}
```
Running `pytest --snapshot-update` generates a JSON snapshot file that contains an empty dictionary: `{}`.
**Expected behavior**
The generated snapshot should contain the input dictionary: `{1: "value"}`.
**Environment:**
- OS: Windows 10
- Syrupy Version: 4.8.1
- Python Version: Tried with 3.13.1 and 3.11.8
**Additional context**
Other similar dictionaries, such as `{"key": 1}` and `{"key": "value"}`, work as expected, as long as the key is not an integer.
|
closed
|
2025-02-18T16:21:50Z
|
2025-02-18T18:04:25Z
|
https://github.com/syrupy-project/syrupy/issues/954
|
[] |
skykasko
| 3 |
waditu/tushare
|
pandas
| 1,641 |
量比实时数据
|
请问各位,怎么获取量比的实时数据,查了很久,都是历史量比数据
|
open
|
2022-03-29T09:32:42Z
|
2022-03-29T09:32:42Z
|
https://github.com/waditu/tushare/issues/1641
|
[] |
changyunke
| 0 |
pydantic/pydantic-ai
|
pydantic
| 139 |
Support OpenRouter
|
Openrouter offers simple switing between providers and consolidated billing.
Is it possbile to support openrouter,
Or can I tweak the code a bit to change the base_url of OpenAI model?
|
closed
|
2024-12-04T14:21:15Z
|
2024-12-26T21:31:55Z
|
https://github.com/pydantic/pydantic-ai/issues/139
|
[] |
thisiskeithkwan
| 3 |
ultralytics/ultralytics
|
pytorch
| 18,819 |
Moving comet-ml to opensource?
|
### Search before asking
- [x] I have searched the Ultralytics [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
### Description
There is a new recently project that is opensource and it's cool for everyone and open source AI
https://github.com/aimhubio/aim
Feel free to close the issue if you are not interested @glenn-jocher
### Use case
_No response_
### Additional
_No response_
### Are you willing to submit a PR?
- [ ] Yes I'd like to help by submitting a PR!
|
closed
|
2025-01-22T09:41:02Z
|
2025-01-22T20:03:47Z
|
https://github.com/ultralytics/ultralytics/issues/18819
|
[
"enhancement"
] |
johnnynunez
| 2 |
anselal/antminer-monitor
|
dash
| 184 |
Support for ANTMINER D7?
|
Hi,
What would be my best approach to connect a D7 to this software ?
I can write a PR, maybe you have some tips ?
https://miners-world.com/product/antminer-model/
Kind regards, JB
|
open
|
2021-08-18T13:08:36Z
|
2022-03-11T13:15:45Z
|
https://github.com/anselal/antminer-monitor/issues/184
|
[] |
Eggwise
| 3 |
labmlai/annotated_deep_learning_paper_implementations
|
deep-learning
| 189 |
can not run ViT(vision transformer) experiment file (failed to connect to https://api.labml.ai/api/vl/track?run%20wuid-87829.c05191leeae2db06088ee9ee4&labml%20version=0.4.162)
|
When I try to run experiment.py, it gives an error message.
"failed to connect: https://api.labml.ai/api/vl/track?run%20wuid-87829.c05191leeae2db06088ee9ee4&labml%20version=0.4.162"
I also can't visit this site.
[https://api.labml.ai/api/vl/track?run%20wuid-87829.c05191leeae2db06088ee9ee4&labml%20version=0.4.162](url)
|
closed
|
2023-06-07T10:05:26Z
|
2023-07-03T03:26:36Z
|
https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/189
|
[] |
HiFei4869
| 2 |
mljar/mljar-supervised
|
scikit-learn
| 307 |
Installation error, problem with catboost dependency
|
OS: Fedora 33
Python: 3.9
Environment:
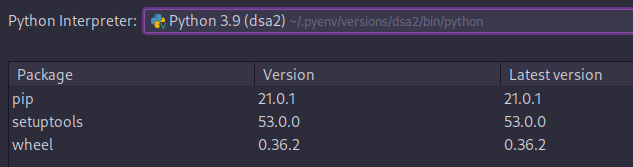
Note: before getting to this state I was having errors for not having lapack and blas installed on my environment.
Installation with pip 20.2.3:
```python
$ pip install mljar-supervised
Collecting mljar-supervised
Using cached mljar-supervised-0.8.9.tar.gz (83 kB)
Collecting numpy>=1.18.5
Using cached numpy-1.20.1-cp39-cp39-manylinux2010_x86_64.whl (15.4 MB)
Collecting pandas==1.1.2
Using cached pandas-1.1.2.tar.gz (5.2 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting scipy==1.4.1
Using cached scipy-1.4.1.tar.gz (24.6 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting scikit-learn==0.23.2
Using cached scikit-learn-0.23.2.tar.gz (7.2 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting xgboost==1.2.0
Using cached xgboost-1.2.0-py3-none-manylinux2010_x86_64.whl (148.9 MB)
Collecting lightgbm==3.0.0
Using cached lightgbm-3.0.0-py2.py3-none-manylinux1_x86_64.whl (1.7 MB)
ERROR: Could not find a version that satisfies the requirement catboost==0.24.1 (from mljar-supervised) (from versions: 0.1.1.2, 0.24.4)
ERROR: No matching distribution found for catboost==0.24.1 (from mljar-supervised)
WARNING: You are using pip version 20.2.3; however, version 21.0.1 is available.
You should consider upgrading via the '/home/hygor/.pyenv/versions/3.9-dev/envs/dsa2/bin/python3 -m pip install --upgrade pip' command.
```
Installation with pip 21.0.1:
```python
$ pip install mljar-supervised
Collecting mljar-supervised
Using cached mljar-supervised-0.8.9.tar.gz (83 kB)
Collecting numpy>=1.18.5
Using cached numpy-1.20.1-cp39-cp39-manylinux2010_x86_64.whl (15.4 MB)
Collecting pandas==1.1.2
Using cached pandas-1.1.2.tar.gz (5.2 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting scipy==1.4.1
Using cached scipy-1.4.1.tar.gz (24.6 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting scikit-learn==0.23.2
Using cached scikit-learn-0.23.2.tar.gz (7.2 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting xgboost==1.2.0
Using cached xgboost-1.2.0-py3-none-manylinux2010_x86_64.whl (148.9 MB)
Collecting lightgbm==3.0.0
Using cached lightgbm-3.0.0-py2.py3-none-manylinux1_x86_64.whl (1.7 MB)
Collecting mljar-supervised
Using cached mljar-supervised-0.8.8.tar.gz (83 kB)
Using cached mljar-supervised-0.8.7.tar.gz (83 kB)
Using cached mljar-supervised-0.8.6.tar.gz (83 kB)
Using cached mljar-supervised-0.8.5.tar.gz (83 kB)
Using cached mljar-supervised-0.8.4.tar.gz (83 kB)
Using cached mljar-supervised-0.8.3.tar.gz (83 kB)
Using cached mljar-supervised-0.8.2.tar.gz (83 kB)
Using cached mljar-supervised-0.8.1.tar.gz (83 kB)
Using cached mljar-supervised-0.8.0.tar.gz (83 kB)
Using cached mljar-supervised-0.7.20.tar.gz (79 kB)
Using cached mljar-supervised-0.7.19.tar.gz (78 kB)
Using cached mljar-supervised-0.7.18.tar.gz (78 kB)
Using cached mljar-supervised-0.7.17.tar.gz (78 kB)
Using cached mljar-supervised-0.7.16.tar.gz (77 kB)
Using cached mljar-supervised-0.7.15.tar.gz (77 kB)
Using cached mljar-supervised-0.7.14.tar.gz (77 kB)
Using cached mljar-supervised-0.7.13.tar.gz (77 kB)
Using cached mljar-supervised-0.7.12.tar.gz (76 kB)
Using cached mljar-supervised-0.7.11.tar.gz (75 kB)
Using cached mljar-supervised-0.7.10.tar.gz (74 kB)
Using cached mljar-supervised-0.7.9.tar.gz (73 kB)
Using cached mljar-supervised-0.7.8.tar.gz (72 kB)
Using cached mljar-supervised-0.7.7.tar.gz (72 kB)
Using cached mljar-supervised-0.7.6.tar.gz (72 kB)
Using cached mljar-supervised-0.7.5.tar.gz (72 kB)
Using cached mljar-supervised-0.7.4.tar.gz (71 kB)
Using cached mljar-supervised-0.7.3.tar.gz (72 kB)
Using cached mljar-supervised-0.7.2.tar.gz (70 kB)
Using cached mljar-supervised-0.7.1.tar.gz (69 kB)
Using cached mljar-supervised-0.7.0.tar.gz (69 kB)
Using cached mljar-supervised-0.6.1.tar.gz (65 kB)
Using cached mljar-supervised-0.6.0.tar.gz (61 kB)
Using cached mljar-supervised-0.5.5.tar.gz (58 kB)
Using cached mljar-supervised-0.5.4.tar.gz (58 kB)
Using cached mljar-supervised-0.5.3.tar.gz (57 kB)
Using cached mljar-supervised-0.5.2.tar.gz (55 kB)
Using cached mljar-supervised-0.5.1.tar.gz (55 kB)
Using cached mljar-supervised-0.5.0.tar.gz (55 kB)
Using cached mljar-supervised-0.4.1.tar.gz (52 kB)
Using cached mljar-supervised-0.4.0.tar.gz (52 kB)
Using cached mljar-supervised-0.3.5.tar.gz (43 kB)
Collecting numpy==1.16.4
Using cached numpy-1.16.4.zip (5.1 MB)
Collecting pandas==1.0.3
Using cached pandas-1.0.3.tar.gz (5.0 MB)
Installing build dependencies ... error
ERROR: Command errored out with exit status 1:
command: /home/hygor/.pyenv/versions/3.9-dev/envs/dsa2/bin/python3 /home/hygor/.pyenv/versions/3.9-dev/envs/dsa2/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-21iiv1pg/overlay --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.org/simple -- setuptools wheel 'Cython>=0.29.13' 'numpy==1.13.3; python_version=='"'"'3.6'"'"' and platform_system!='"'"'AIX'"'"'' 'numpy==1.14.5; python_version>='"'"'3.7'"'"' and platform_system!='"'"'AIX'"'"'' 'numpy==1.16.0; python_version=='"'"'3.6'"'"' and platform_system=='"'"'AIX'"'"'' 'numpy==1.16.0; python_version>='"'"'3.7'"'"' and platform_system=='"'"'AIX'"'"''
cwd: None
Complete output (5158 lines):
Ignoring numpy: markers 'python_version == "3.6" and platform_system != "AIX"' don't match your environment
Ignoring numpy: markers 'python_version == "3.6" and platform_system == "AIX"' don't match your environment
Ignoring numpy: markers 'python_version >= "3.7" and platform_system == "AIX"' don't match your environment
...
> OMITTING SOME OUTPUT DUE TO GITHUB'S MESSAGE SIZE LIMIT
...
Collecting mljar-supervised
Using cached mljar-supervised-0.1.6.tar.gz (25 kB)
Using cached mljar-supervised-0.1.5.tar.gz (25 kB)
Using cached mljar-supervised-0.1.4.tar.gz (25 kB)
Using cached mljar-supervised-0.1.3.tar.gz (25 kB)
Using cached mljar-supervised-0.1.2.tar.gz (24 kB)
Using cached mljar-supervised-0.1.1.tar.gz (23 kB)
Using cached mljar-supervised-0.1.0.tar.gz (21 kB)
ERROR: Cannot install mljar-supervised==0.1.0, mljar-supervised==0.1.1, mljar-supervised==0.1.2, mljar-supervised==0.1.3, mljar-supervised==0.1.4, mljar-supervised==0.1.5, mljar-supervised==0.1.6, mljar-supervised==0.1.7, mljar-supervised==0.2.2, mljar-supervised==0.2.3, mljar-supervised==0.2.4, mljar-supervised==0.2.5, mljar-supervised==0.2.6, mljar-supervised==0.2.7, mljar-supervised==0.2.8, mljar-supervised==0.3.0, mljar-supervised==0.3.1, mljar-supervised==0.3.2, mljar-supervised==0.3.3, mljar-supervised==0.3.4, mljar-supervised==0.3.5, mljar-supervised==0.4.0, mljar-supervised==0.4.1, mljar-supervised==0.5.0, mljar-supervised==0.5.1, mljar-supervised==0.5.2, mljar-supervised==0.5.3, mljar-supervised==0.5.4, mljar-supervised==0.5.5, mljar-supervised==0.6.0, mljar-supervised==0.6.1, mljar-supervised==0.7.0, mljar-supervised==0.7.1, mljar-supervised==0.7.10, mljar-supervised==0.7.11, mljar-supervised==0.7.12, mljar-supervised==0.7.13, mljar-supervised==0.7.14, mljar-supervised==0.7.15, mljar-supervised==0.7.16, mljar-supervised==0.7.17, mljar-supervised==0.7.18, mljar-supervised==0.7.19, mljar-supervised==0.7.2, mljar-supervised==0.7.20, mljar-supervised==0.7.3, mljar-supervised==0.7.4, mljar-supervised==0.7.5, mljar-supervised==0.7.6, mljar-supervised==0.7.7, mljar-supervised==0.7.8, mljar-supervised==0.7.9, mljar-supervised==0.8.0, mljar-supervised==0.8.1, mljar-supervised==0.8.2, mljar-supervised==0.8.3, mljar-supervised==0.8.4, mljar-supervised==0.8.5, mljar-supervised==0.8.6, mljar-supervised==0.8.7, mljar-supervised==0.8.8 and mljar-supervised==0.8.9 because these package versions have conflicting dependencies.
The conflict is caused by:
mljar-supervised 0.8.9 depends on catboost==0.24.1
mljar-supervised 0.8.8 depends on catboost==0.24.1
mljar-supervised 0.8.7 depends on catboost==0.24.1
mljar-supervised 0.8.6 depends on catboost==0.24.1
mljar-supervised 0.8.5 depends on catboost==0.24.1
mljar-supervised 0.8.4 depends on catboost==0.24.1
mljar-supervised 0.8.3 depends on catboost==0.24.1
mljar-supervised 0.8.2 depends on catboost==0.24.1
mljar-supervised 0.8.1 depends on catboost==0.24.1
mljar-supervised 0.8.0 depends on catboost==0.24.1
mljar-supervised 0.7.20 depends on catboost==0.24.1
mljar-supervised 0.7.19 depends on catboost==0.24.1
mljar-supervised 0.7.18 depends on catboost==0.24.1
mljar-supervised 0.7.17 depends on catboost==0.24.1
mljar-supervised 0.7.16 depends on catboost==0.24.1
mljar-supervised 0.7.15 depends on catboost==0.24.1
mljar-supervised 0.7.14 depends on catboost==0.24.1
mljar-supervised 0.7.13 depends on catboost==0.24.1
mljar-supervised 0.7.12 depends on catboost==0.24.1
mljar-supervised 0.7.11 depends on catboost==0.24.1
mljar-supervised 0.7.10 depends on catboost==0.24.1
mljar-supervised 0.7.9 depends on catboost==0.24.1
mljar-supervised 0.7.8 depends on catboost==0.24.1
mljar-supervised 0.7.7 depends on catboost==0.24.1
mljar-supervised 0.7.6 depends on catboost==0.24.1
mljar-supervised 0.7.5 depends on catboost==0.24.1
mljar-supervised 0.7.4 depends on catboost==0.24.1
mljar-supervised 0.7.3 depends on tensorflow==2.2.0
mljar-supervised 0.7.2 depends on tensorflow==2.2.0
mljar-supervised 0.7.1 depends on tensorflow==2.2.0
mljar-supervised 0.7.0 depends on tensorflow==2.2.0
mljar-supervised 0.6.1 depends on tensorflow==2.2.0
mljar-supervised 0.6.0 depends on tensorflow==2.2.0
mljar-supervised 0.5.5 depends on tensorflow==2.2.0
mljar-supervised 0.5.4 depends on tensorflow==2.2.0
mljar-supervised 0.5.3 depends on tensorflow==2.2.0
mljar-supervised 0.5.2 depends on tensorflow==2.2.0
mljar-supervised 0.5.1 depends on tensorflow==2.2.0
mljar-supervised 0.5.0 depends on tensorflow==2.2.0
mljar-supervised 0.4.1 depends on tensorflow==2.2.0
mljar-supervised 0.4.0 depends on tensorflow==2.2.0
mljar-supervised 0.3.5 depends on pandas==1.0.3
mljar-supervised 0.3.4 depends on pandas==1.0.3
mljar-supervised 0.3.3 depends on pandas==1.0.3
mljar-supervised 0.3.2 depends on pandas==1.0.3
mljar-supervised 0.3.1 depends on pandas==1.0.3
mljar-supervised 0.3.0 depends on pandas==1.0.3
mljar-supervised 0.2.8 depends on pandas==1.0.3
mljar-supervised 0.2.7 depends on pandas==1.0.3
mljar-supervised 0.2.6 depends on pandas==1.0.3
mljar-supervised 0.2.5 depends on pandas==1.0.3
mljar-supervised 0.2.4 depends on pandas==1.0.3
mljar-supervised 0.2.3 depends on pandas==1.0.3
mljar-supervised 0.2.2 depends on pandas==1.0.3
mljar-supervised 0.1.7 depends on catboost==0.13.1
mljar-supervised 0.1.6 depends on catboost==0.13.1
mljar-supervised 0.1.5 depends on catboost==0.13.1
mljar-supervised 0.1.4 depends on catboost==0.13.1
mljar-supervised 0.1.3 depends on catboost==0.13.1
mljar-supervised 0.1.2 depends on catboost==0.13.1
mljar-supervised 0.1.1 depends on catboost==0.13.1
mljar-supervised 0.1.0 depends on catboost==0.13.1
To fix this you could try to:
1. loosen the range of package versions you've specified
2. remove package versions to allow pip attempt to solve the dependency conflict
ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/user_guide/#fixing-conflicting-dependencies
```
|
closed
|
2021-02-09T10:28:02Z
|
2021-02-09T23:37:18Z
|
https://github.com/mljar/mljar-supervised/issues/307
|
[] |
hygorxaraujo
| 2 |
psf/black
|
python
| 3,633 |
Line not wrapped
|
I found an issue in the current version of black where line wrapping is not correctly applied. This does not involve string reformatting.
**Black v23.3.0**
[Playground link](https://black.vercel.app/?version=stable&state=_Td6WFoAAATm1rRGAgAhARYAAAB0L-Wj4AHfAOhdAD2IimZxl1N_WlXnON2nzOXxnCQIxzIqQZbS3zQTwTW6xptQlTj-3pETmXPnpbnXnLb3eYNAvH6LCRbVMTSCqZQr7FCRQ4-fkpwBhQ_Kz5CtmFXpjv0xc0_v8nuB0CGjzA9o2ytyiyMRU7df_BmY9pQ2UapC3cfAYp1osTezMWNzrcufcWOYSQlLLO62l9n9j0LJUiBO-IQyOXnjiVNVMD9JCUIwGB3jbUyYFJKo-yvRpw9WGHrhrOkRZtwvsPzNCn17jwUPU9VEs55zPlEadM_bJk9QUD-ihc-tsr7jdIQ27qff53k9ygAAcjvKZbMf-RQAAYQC4AMAABIujeixxGf7AgAAAAAEWVo=)
## Options
`--line-length=88`
`--safe`
## Input
```python
class Test:
def example(self):
if True:
try:
result = very_important_function(
testdict=json.dumps(
{
"something_quite_long": self.this_is_a_long_string_as_well,
})
)
except:
pass
```
## Output
```python
class Test:
def example(self):
if True:
try:
result = very_important_function(
testdict=json.dumps(
{
"something_quite_long": self.this_is_a_long_string_as_well,
}
)
)
except:
pass
```
## Expected
```python
class Test:
def example(self):
if True:
try:
result = very_important_function(
testdict=json.dumps(
{
"something_quite_long":
self.this_is_a_long_string_as_well,
}
)
)
except:
pass
```
|
closed
|
2023-03-31T16:30:40Z
|
2024-02-02T21:05:49Z
|
https://github.com/psf/black/issues/3633
|
[] |
classner
| 4 |
tensorflow/tensor2tensor
|
machine-learning
| 1,441 |
Problems in multihead_attention
|
In T2T v1.12.0
Lines 3600-3643 in common_attention.py
` if cache is None or memory_antecedent is None:
q, k, v = compute_qkv(query_antecedent, memory_antecedent,
total_key_depth, total_value_depth, q_filter_width,
kv_filter_width, q_padding, kv_padding,
vars_3d_num_heads=vars_3d_num_heads)
if cache is not None:
if attention_type not in ["dot_product", "dot_product_relative"]:
# TODO(petershaw): Support caching when using relative position
# representations, i.e. "dot_product_relative" attention.
raise NotImplementedError(
"Caching is not guaranteed to work with attention types other than"
" dot_product.")
if bias is None:
raise ValueError("Bias required for caching. See function docstring "
"for details.")
if memory_antecedent is not None:
# Encoder-Decoder Attention Cache
q = compute_attention_component(query_antecedent, total_key_depth,
q_filter_width, q_padding, "q",
vars_3d_num_heads=vars_3d_num_heads)
k = cache["k_encdec"]
v = cache["v_encdec"]
else:
k = split_heads(k, num_heads)
v = split_heads(v, num_heads)
decode_loop_step = kwargs.get("decode_loop_step")
if decode_loop_step is None:
k = cache["k"] = tf.concat([cache["k"], k], axis=2)
v = cache["v"] = tf.concat([cache["v"], v], axis=2)
else:
# Inplace update is required for inference on TPU.
# Inplace_ops only supports inplace_update on the first dimension.
# The performance of current implementation is better than updating
# the tensor by adding the result of matmul(one_hot,
# update_in_current_step)
tmp_k = tf.transpose(cache["k"], perm=[2, 0, 1, 3])
tmp_k = inplace_ops.alias_inplace_update(
tmp_k, decode_loop_step, tf.squeeze(k, axis=2))
k = cache["k"] = tf.transpose(tmp_k, perm=[1, 2, 0, 3])
tmp_v = tf.transpose(cache["v"], perm=[2, 0, 1, 3])
tmp_v = inplace_ops.alias_inplace_update(
tmp_v, decode_loop_step, tf.squeeze(v, axis=2))
v = cache["v"] = tf.transpose(tmp_v, perm=[1, 2, 0, 3])`
The block:
` if memory_antecedent is not None:
# Encoder-Decoder Attention Cache
q = compute_attention_component(query_antecedent, total_key_depth,
q_filter_width, q_padding, "q",
vars_3d_num_heads=vars_3d_num_heads)
k = cache["k_encdec"]
v = cache["v_encdec"]`
should be unreachable, due to the sequence of preceding conditionals.
Also - currently trying to debug why I'm having shape issues in dot product attention:
` with tf.variable_scope(
name, default_name="dot_product_attention", values=[q, k, v]) as scope:
q = tf.Print(q,[q],'ATTENTION QUERY: ')
k = tf.Print(k,[k],'ATTENTION KEY: ')
logits = tf.matmul(q, k, transpose_b=True) # [..., length_q, length_kv]
if bias is not None:
bias = common_layers.cast_like(bias, logits)
bias = tf.Print(bias,[bias],'BIAS: ')
logits = tf.Print(logits,[logits],'LOGITS ')
logits += bias
logits = tf.Print(logits,[logits],'LOGITS POST ADD BIAS')
# If logits are fp16, upcast before softmax
logits = maybe_upcast(logits, activation_dtype, weight_dtype)
weights = tf.nn.softmax(logits, name="attention_weights")
weights = common_layers.cast_like(weights, q)
weights = tf.Print(weights,[weights],'WEIGHTS POST CAST LIKE')
if save_weights_to is not None:
save_weights_to[scope.name] = weights
save_weights_to[scope.name + "/logits"] = logits
# Drop out attention links for each head.
weights = common_layers.dropout_with_broadcast_dims(weights, 1.0 - dropout_rate, broadcast_dims=dropout_broadcast_dims)
#Debugging weights last dimension not matching value first dimension
weights = tf.Print(weights,[weights],'ATTENTION WEIGHTS AFTER DROPOUT: ')
v = tf.Print(v,[v],'VALUE VECTOR')
if common_layers.should_generate_summaries() and make_image_summary:
attention_image_summary(weights, image_shapes)
return tf.matmul(weights, v)
`
OUTPUT:
BIAS: [[[[-0]]]]BIAS: [[[[-0]]]]
BIAS: [[[[-0]]]]
BIAS: [[[[-0]]]]
BIAS: [[[[-0]]]]
BIAS: [[[[-0]]]]
ATTENTION KEY: [[[[0.151335612 -0.404835284 1.54091191...]]]...]
VALUE VECTOR[[[[0.166511878 -1.3204602 -0.372632712...]]]...]
ATTENTION QUERY: [[[[0.0620518401 -0.0874474421 0.000517165521...]]]...]
LOGITS [[[[-0.137875706]][[1.05136979]][[-0.866865873]]]...]
LOGITS POST ADD BIAS[[[[-0.137875706]][[1.05136979]][[-0.866865873]]]...]
WEIGHTS POST CAST LIKE[[[[1]][[1]][[1]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[1]][[1]][[1]]]...]
ATTENTION KEY: [[[[-0.493546933 0.678736925 1.12754095...]]]...]
VALUE VECTOR[[[[0.427185386 -0.0682374686 -0.551386356...]]]...]
ATTENTION QUERY: [[[[-0.290087074 0.0257696807 -0.136151105...]]]...]
LOGITS [[[[-0.889816523]][[0.497348607]][[-1.31549573]]]...]
LOGITS POST ADD BIAS[[[[-0.889816523]][[0.497348607]][[-1.31549573]]]...]
WEIGHTS POST CAST LIKE[[[[1]][[1]][[1]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[1]][[1]][[1]]]...]
VALUE VECTOR[[[[0.394824564 -0.571578 -1.01061356...]]]...]
ATTENTION KEY: [[[[3.20773053 -1.05240285 0.20996505...]]]...]
ATTENTION QUERY: [[[[0.187075511 -0.0486161038 0.089396365...]]]...]
LOGITS [[[[1.59205556]][[-1.71665192]][[-1.37695456]]]...]
LOGITS POST ADD BIAS[[[[1.59205556]][[-1.71665192]][[-1.37695456]]]...]
WEIGHTS POST CAST LIKE[[[[1]][[1]][[1]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[1]][[1]][[1]]]...]
ATTENTION QUERY: [[[[-0.136278272 -0.159313381 -0.204157695...]]]...]
VALUE VECTOR[[[[-1.74210846 1.38060951 -1.33350658...]]]...]
ATTENTION KEY: [[[[-0.646322787 -0.519498885 -0.108884774...]]]...]
LOGITS [[[[-1.05637074]][[-1.38687372]][[1.01201]]]...]
LOGITS POST ADD BIAS[[[[-1.05637074]][[-1.38687372]][[1.01201]]]...]
WEIGHTS POST CAST LIKE[[[[1]][[1]][[1]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[1]][[1]][[1]]]...]
ATTENTION KEY: [[[[-0.766771 1.29248929 0.353579193...]]]...]
VALUE VECTOR[[[[-0.473533779 0.339176893 -0.285344601...]]]...]
ATTENTION QUERY: [[[[-0.00684091263 -0.0722586587 -0.0857348889...]]]...]
LOGITS [[[[-1.03410649]][[0.495673776]][[-1.93785417]]]...]
LOGITS POST ADD BIAS[[[[-1.03410649]][[0.495673776]][[-1.93785417]]]...]
WEIGHTS POST CAST LIKE[[[[1]][[1]][[1]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[1]][[1]][[1]]]...]
ATTENTION KEY: [[[[-0.752419114 0.899734139 0.263004512...]]]...]
VALUE VECTOR[[[[-1.55072808 0.319361448 0.537948072...]]]...]
ATTENTION QUERY: [[[[-0.130305797 0.192893207 -0.0268632658...]]]...]
LOGITS [[[[-0.535128653]][[0.04286623]][[0.769883]]]...]
LOGITS POST ADD BIAS[[[[-0.535128653]][[0.04286623]][[0.769883]]]...]
WEIGHTS POST CAST LIKE[[[[1]][[1]][[1]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[1]][[1]][[1]]]...]
BIAS: [[[[-0 -0]]]]
BIAS: [[[[-0 -0]]]]
BIAS: [[[[-0 -0]]]]
BIAS: [[[[-0 -0]]]]
BIAS: [[[[-0 -0]]]]
BIAS: [[[[-0 -0]]]]
ATTENTION KEY: [[[[-1.19346094 0.665090382 -0.502224...]]]...]
ATTENTION QUERY: [[[[0.193519413 -0.132038742 -0.0287191756...]]]...]
LOGITS [[[[-0.292171031]][[1.25045216]][[1.87848222]]]...]
VALUE VECTOR[[[[-0.436115 -0.63339144 0.0544230118...]]]...]
LOGITS POST ADD BIAS[[[[-0.292171031 -0.292171031]][[1.25045216...]]]...]
WEIGHTS POST CAST LIKE[[[[0.5 0.5]][[0.5...]]]...]
ATTENTION WEIGHTS AFTER DROPOUT: [[[[0.5 0.5]][[0.5...]]]...]
File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/layers/common_attention.py", line 3682, in multihead_attention
activation_dtype=kwargs.get("activation_dtype"))
File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/layers/common_attention.py", line 1540, in dot_product_attention
return tf.matmul(weights, v)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/math_ops.py", line 2019, in matmul
a, b, adj_x=adjoint_a, adj_y=adjoint_b, name=name)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/gen_math_ops.py", line 1245, in batch_mat_mul
"BatchMatMul", x=x, y=y, adj_x=adj_x, adj_y=adj_y, name=name)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/util/deprecation.py", line 488, in new_func
return func(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/ops.py", line 3274, in create_op
op_def=op_def)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/ops.py", line 1770, in __init__
self._traceback = tf_stack.extract_stack()
InvalidArgumentError (see above for traceback): In[0] mismatch In[1] shape: 2 vs. 1: [1,16,1,2] [1,16,1,64] 0 0
[[node transformer/while/body/parallel_0/body/decoder/layer_0/self_attention/multihead_attention/dot_product_attention/MatMul_1 (defined at /usr/local/lib/python2.7/dist-packages/tensor2tensor/layers/common_attention.py:1540) = BatchMatMul[T=DT_FLOAT, adj_x=false, adj_y=false, _device="/job:localhost/replica:0/task:0/device:CPU:0"](transformer/while/body/parallel_0/body/decoder/layer_0/self_attention/multihead_attention/dot_product_attention/Print_6, transformer/while/body/parallel_0/body/decoder/layer_0/self_attention/multihead_attention/dot_product_attention/Print_7)]]
Basically, adding logits to bias is causing logits to have an invalid shape. This sort of seems to be a caching issue, since the previous queries,keys, and values are not found on the second autoregressive iteration.
|
open
|
2019-02-07T19:01:01Z
|
2019-02-07T19:44:53Z
|
https://github.com/tensorflow/tensor2tensor/issues/1441
|
[] |
mikeymezher
| 1 |
amidaware/tacticalrmm
|
django
| 1,459 |
[FEATURE REQUEST]: Schedule bulk tasks
|
**Is your feature request related to a problem? Please describe.**
One of our clients has frequent power outages that don't follow any sort of schedule.
Each time, we need to "time" this using `shutdown /s /t` a day or so in advance, and we have to calculate the number of minutes until the desired shutdown time.
**Describe the solution you'd like**
Besides shutdowns, there are several cases where we have desired to quickly fire off bulk command / script at a scheduled time as opposed to creating a one-time task in Automation Manager.
In addition, we often use the same Automation Policies across clients (using sub containers as a workaround for fine grained policies). This works perfect for our needs, but since you can only apply one policy per container it would be much more flexible and powerful (and easier) if we could schedule bulk tasks to run at a specified time.
**Describe alternatives you've considered**
Some commands like `shutdown` allow us to work around this. Another potential workaround is to do a bulk command that adds the task using the build in Windows Task Scheduler, but this is a lot more work.
**Additional context**
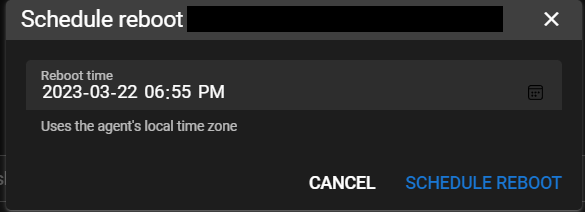
IMO **Tools -> Bulk Command** and **Tools -> Bulk Script** would benefit form having a scheduling option similar to the **Reboot Later** option:
For consistency, I also think the right-click on agent -> **Send Command** and **Run Script** should have this option as well.
Thank you,
|
open
|
2023-03-23T00:59:26Z
|
2023-03-23T01:01:39Z
|
https://github.com/amidaware/tacticalrmm/issues/1459
|
[] |
joeldeteves
| 0 |
polarsource/polar
|
fastapi
| 4,526 |
Deprecate `Ads`
|
Our Ad benefit was designed for two use cases:
1. README sponsorship
2. Sponsorship shoutout/showcase in our newsletter feature
We've sunsetted our newsletter feature a few months ago (https://github.com/orgs/polarsource/discussions/3998) so `#2` is no longer applicable – leaving `#1`. Simultaneously, we've been supported in the amazing `Sponsorkit` (https://github.com/antfu-collective/sponsorkit) library for a while which can merge sponsors/subscribers from GitHub, Patreon, Polar and more into one. Being a better offering and solution for `#1`.
As a result, we should sunset our ad benefit and update our documentation to promote `Sponsorkit` alone for this use case as it's a better solution and offering. Since you're getting setup now, I'd highly recommend going with `Sponsorkit` out of the gates.
|
closed
|
2024-11-24T21:03:04Z
|
2025-02-28T10:03:48Z
|
https://github.com/polarsource/polar/issues/4526
|
[
"refactor",
"docs/content"
] |
birkjernstrom
| 0 |
kizniche/Mycodo
|
automation
| 471 |
6.1.0: Send Test Mail broken?
|
So my installation has been acting up lately, so I tried to set up some alerts.
After configuring all the smtp parameters I tried to send a test mail:
Entered my eMail Address, clicked "Send Test eMail" and got the following error:
Error: Modify Alert Settings: name 'message' is not defined
Either my installation has some serious issues, or mycodo is quite buggy right now...
|
closed
|
2018-05-15T10:01:54Z
|
2018-06-20T03:18:30Z
|
https://github.com/kizniche/Mycodo/issues/471
|
[] |
fry42
| 7 |
microsoft/nni
|
tensorflow
| 5,059 |
borken when ModelSpeedup
|
**borken when ModelSpeedup**:
**Ubuntu20**:
- NNI version:2.7
- Training service (local|remote|pai|aml|etc):local
- Client OS:
- Server OS (for remote mode only):
- Python version:3.7
- PyTorch/TensorFlow version:PyTorch 1.11.0
- Is conda/virtualenv/venv used?:conda
- Is running in Docker?:No
**Configuration**:
- Experiment config (remember to remove secrets!):
- Search space:
**Log message**:
-
nnimanager.log:
> Traceback (most recent call last):
File "lib/prune_gssl.py", line 137, in <module>
ModelSpeedup(model, torch.rand(3, 3, cfg.input_size, cfg.input_size).to(device), "./prune_model/mask.pth").speedup_model()
File "/home/inspur/Projects/nni/nni/compression/pytorch/speedup/compressor.py", line 512, in speedup_model
self.infer_modules_masks()
File "/home/inspur/Projects/nni/nni/compression/pytorch/speedup/compressor.py", line 355, in infer_modules_masks
self.update_direct_sparsity(curnode)
File "/home/inspur/Projects/nni/nni/compression/pytorch/speedup/compressor.py", line 237, in update_direct_sparsity
node.outputs) == 1, 'The number of the output should be one after the Tuple unpacked manually'
AssertionError: The number of the output should be one after the Tuple unpacked manually
- dispatcher.log:
- nnictl stdout and stderr:
<!--
Where can you find the log files:
LOG: https://github.com/microsoft/nni/blob/master/docs/en_US/Tutorial/HowToDebug.md#experiment-root-director
STDOUT/STDERR: https://nni.readthedocs.io/en/stable/reference/nnictl.html#nnictl-log-stdout
-->
**How to reproduce it?**: below is my forward code
> def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
cls1 = self.cls_layer(x)
offset_x = self.x_layer(x)
offset_y = self.y_layer(x)
nb_x = self.nb_x_layer(x)
nb_y = self.nb_y_layer(x)
x = self.my_maxpool(x)
cls2 = self.cls_layer(x)
x = self.my_maxpool(x)
cls3 = self.cls_layer(x)
return cls1, cls2, cls3, offset_x, offset_y, nb_x, nb_y
"cls1, cls2, cls3" are produced by the same layer(cls_layer), when return cls1, cls2, cls3, error comes up, when return one of them, error is gone
|
open
|
2022-08-11T08:33:38Z
|
2023-05-11T10:30:20Z
|
https://github.com/microsoft/nni/issues/5059
|
[
"bug",
"support",
"ModelSpeedup",
"v3.0"
] |
ly0303521
| 3 |
explosion/spaCy
|
machine-learning
| 13,528 |
Numpy v2.0.0 breaks the ability to download models using spaCy
|
## How to reproduce the behaviour
In my dockerfile, I run these commands:
```Dockerfile
FROM --platform=linux/amd64 python:3.12.4
RUN pip install --upgrade pip
RUN pip install torch --index-url https://download.pytorch.org/whl/cpu
RUN pip install spacy
RUN python -m spacy download en_core_web_lg
```
It returns the following error (and stacktrace):
```
2.519 Traceback (most recent call last):
2.519 File "<frozen runpy>", line 189, in _run_module_as_main
2.519 File "<frozen runpy>", line 148, in _get_module_details
2.519 File "<frozen runpy>", line 112, in _get_module_details
2.519 File "/usr/local/lib/python3.12/site-packages/spacy/__init__.py", line 6, in <module>
2.521 from .errors import setup_default_warnings
2.522 File "/usr/local/lib/python3.12/site-packages/spacy/errors.py", line 3, in <module>
2.522 from .compat import Literal
2.522 File "/usr/local/lib/python3.12/site-packages/spacy/compat.py", line 39, in <module>
2.522 from thinc.api import Optimizer # noqa: F401
2.522 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.522 File "/usr/local/lib/python3.12/site-packages/thinc/api.py", line 1, in <module>
2.522 from .backends import (
2.522 File "/usr/local/lib/python3.12/site-packages/thinc/backends/__init__.py", line 17, in <module>
2.522 from .cupy_ops import CupyOps
2.522 File "/usr/local/lib/python3.12/site-packages/thinc/backends/cupy_ops.py", line 16, in <module>
2.522 from .numpy_ops import NumpyOps
2.522 File "thinc/backends/numpy_ops.pyx", line 1, in init thinc.backends.numpy_ops
2.524 ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
```
Locking to the previous version of numpy will resolve this issue:
```Dockerfile
FROM --platform=linux/amd64 python:3.12.4
RUN pip install --upgrade pip
RUN pip install torch --index-url https://download.pytorch.org/whl/cpu
RUN pip install numpy==1.26.4 spacy
RUN python -m spacy download en_core_web_lg
```
|
open
|
2024-06-16T15:42:21Z
|
2024-12-29T11:20:23Z
|
https://github.com/explosion/spaCy/issues/13528
|
[
"bug"
] |
afogel
| 16 |
modoboa/modoboa
|
django
| 2,336 |
Webmail does not list mails when FTS-Solr is enabled
|
# Impacted versions
* OS Type: Debian
* OS Version: 9 (stretch)
* Database Type: MySQL
* Database version: 10.1.48-MariaDB-0+deb9u2
* Modoboa: 1.17.0
* installer used: Yes
* Webserver: Nginx / Uwsgi
# Steps to reproduce
1. Configure Solr as FTS engine for Dovecot like:
plugin {
fts = solr
fts_autoindex = yes
fts_solr = break-imap-search url=http://xxxx:8080/solr/
}
2. Launch webmail client in Modoboa
# Current behavior
1. Mails are not listed in overview but are searchable
2. Also quarantine lists mails
Due to how default IMAP search is implemented no mails are found
# Expected behavior
List mails in overview
# Video/Screenshot link (optional)
<img width="1236" alt="grafik" src="https://user-images.githubusercontent.com/15322546/127743140-5afd3717-d139-4209-ab33-f91b65cc1993.png">
|
open
|
2021-07-31T14:33:07Z
|
2021-10-14T07:21:02Z
|
https://github.com/modoboa/modoboa/issues/2336
|
[
"bug"
] |
zsoltbarat
| 5 |
marshmallow-code/apispec
|
rest-api
| 440 |
Add minimum/maximum on date/datetime fields
|
Python's date/datetime objects have min/max bounds.
https://docs.python.org/3.5/library/datetime.html
https://stackoverflow.com/a/31972447/4653485
We should use those to automatically specify min/max values in the spec.
|
open
|
2019-04-29T13:09:32Z
|
2025-01-21T18:22:35Z
|
https://github.com/marshmallow-code/apispec/issues/440
|
[
"help wanted"
] |
lafrech
| 0 |
wkentaro/labelme
|
computer-vision
| 780 |
new script to convert a whole folder of Json files to a ready to training dataset
|
Hi, i have created a variation script of json_to_dataset.py script, i would like make this contribution to the project if you consider it appropriate.
its named "folder_to_dataset.py", it converts not a single json file into dataset, but a whole folder of json files into a ready to training dataset.
**OUTPUT**: as output it drops the folders "training/images" and "training/labels" with the png files obtained from his correspondent json file, the png files are named as a sequence of numbers started by default from "1"
**PARAMETERS**: folder_to_dataset.py receives as input the folder which contains the json files you want to convert into dataset, also has an optional parameter named "-startsWith" which sets the first number to start the sequence of png output files.
**Example**:
the command: "folder_to_dataset.py myJsonsFolderPath" will drop: 1.png, 2.png, 3.png, … in training/images and training/labels folders
the command: "folder_to_dataset.py myJsonsFolderPath -startsWith 5“ will drop: 5.png, 6.png, 7.png, … in training/images and training/labels folders
**script features:**
*shows dataset building progress by percents
*skip no Json files without interrupt the process
*allows dataset updating by “startsWith” parameter
-the picture “example” shows how the script works

|
closed
|
2020-09-27T16:34:47Z
|
2022-06-25T04:56:21Z
|
https://github.com/wkentaro/labelme/issues/780
|
[] |
JasgTrilla
| 0 |
Miserlou/Zappa
|
flask
| 1,896 |
FastAPI incompatibility
|
## Context
I get a 500 response code when I try to deploy a simple application.
```python
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
```
Zappa tail says `[1562665728357] __call__() missing 1 required positional argument: 'send'`.
When I go to the api gateway url, I see this message:
> "{'message': 'An uncaught exception happened while servicing this request. You can investigate this with the `zappa tail` command.', 'traceback': ['Traceback (most recent call last):\\n', ' File \"/var/task/handler.py\", line 531, in handler\\n with Response.from_app(self.wsgi_app, environ) as response:\\n', ' File \"/var/task/werkzeug/wrappers/base_response.py\", line 287, in from_app\\n return cls(*_run_wsgi_app(app, environ, buffered))\\n', ' File \"/var/task/werkzeug/test.py\", line 1119, in run_wsgi_app\\n app_rv = app(environ, start_response)\\n', ' File \"/var/task/zappa/middleware.py\", line 70, in __call__\\n response = self.application(environ, encode_response)\\n', \"TypeError: __call__() missing 1 required positional argument: 'send'\\n\"]}"
## Steps to Reproduce
```bash
zappa init
zappa deploy dev
# Error: Warning! Status check on the deployed lambda failed. A GET request to '/' yielded a 500 response code.
```
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa version used: 0.48.2
* Operating System and Python version: macOS Mojave | Python 3.6.5
* The output of `pip freeze`:
```
Package Version
------------------- ---------
aiofiles 0.4.0
aniso8601 6.0.0
argcomplete 1.9.3
boto3 1.9.184
botocore 1.12.184
certifi 2019.6.16
cfn-flip 1.2.1
chardet 3.0.4
Click 7.0
dataclasses 0.6
dnspython 1.16.0
docutils 0.14
durationpy 0.5
email-validator 1.0.4
fastapi 0.31.0
future 0.16.0
graphene 2.1.6
graphql-core 2.2
graphql-relay 0.4.5
h11 0.8.1
hjson 3.0.1
httptools 0.0.13
idna 2.8
itsdangerous 1.1.0
Jinja2 2.10.1
jmespath 0.9.3
kappa 0.6.0
lambda-packages 0.20.0
MarkupSafe 1.1.1
pip 19.1.1
placebo 0.9.0
promise 2.2.1
pydantic 0.29
python-dateutil 2.6.1
python-multipart 0.0.5
python-slugify 1.2.4
PyYAML 5.1.1
requests 2.22.0
Rx 1.6.1
s3transfer 0.2.1
setuptools 39.0.1
six 1.12.0
starlette 0.12.0
toml 0.10.0
tqdm 4.19.1
troposphere 2.4.9
ujson 1.35
Unidecode 1.1.1
urllib3 1.25.3
uvicorn 0.8.3
uvloop 0.12.2
websockets 7.0
Werkzeug 0.15.4
wheel 0.33.4
wsgi-request-logger 0.4.6
zappa 0.48.2
```
* Your `zappa_settings.py`:
```
{
"dev": {
"app_function": "app.main.app",
"aws_region": "ap-northeast-2",
"profile_name": "default",
"project_name": "myprojectname",
"runtime": "python3.6",
"s3_bucket": "mybucketname"
}
}
```
|
open
|
2019-07-09T10:06:07Z
|
2020-02-09T21:40:56Z
|
https://github.com/Miserlou/Zappa/issues/1896
|
[] |
sunnysid3up
| 11 |
kizniche/Mycodo
|
automation
| 426 |
LCD does not activate when attempt to display relay state
|
## Mycodo Issue Report:
- Specific Mycodo Version: 5.6.1
#### Problem Description
- Attempt to display relay state on LCD. e.g. Output 4 (Lights) State (on/off)
- Activate LCD
- nothing happens, LCD continues to show Mycodo version (see Daemon errors below)
### Errors
2018-03-15 00:34:38,819 - mycodo.lcd_1 - ERROR - Count not initialize LCD. Error: 'LCDController' object has no attribute 'LCD_CMD'
2018-03-15 00:39:45,509 - mycodo.lcd_1 - ERROR - Error: 'relay_state'
Traceback (most recent call last):
File "/var/mycodo-root/mycodo/controller_lcd.py", line 171, in __init__
each_lcd_display.line_2_measurement)
File "/var/mycodo-root/mycodo/controller_lcd.py", line 440, in setup_lcd_line
self.lcd_line[display_id][line]['unit'] = self.list_inputs[measurement]['unit']
KeyError: 'relay_state'
2018-03-15 00:39:45,540 - mycodo.lcd_1 - INFO - Activated in 24436.7 ms
2018-03-15 00:39:45,547 - mycodo.lcd_1 - ERROR - Exception: 'LCDController' object has no attribute 'LCD_CMD'
Traceback (most recent call last):
File "/var/mycodo-root/mycodo/controller_lcd.py", line 268, in run
self.lcd_byte(0x01, self.LCD_CMD, self.LCD_BACKLIGHT_OFF)
AttributeError: 'LCDController' object has no attribute 'LCD_CMD'
2018-03-15 00:39:45,599 - mycodo.lcd_1 - ERROR - Count not initialize LCD. Error: 'LCDController' object has no attribute 'LCD_CMD'
2018-03-15 00:51:16,468 - mycodo.lcd_1 - INFO - Activated in 9383.0 ms
|
closed
|
2018-03-15T01:03:42Z
|
2018-03-15T02:09:27Z
|
https://github.com/kizniche/Mycodo/issues/426
|
[] |
drgrumpy
| 4 |
FactoryBoy/factory_boy
|
django
| 912 |
Consider renaming to FactoryPy or the like
|
#### The problem
There is massive gender imbalance in the tech industry and the Ruby library which this project was inspired from was renamed some time ago. A fixtures factory has nothing to do with a "boy".
[FactoryGirl was renamed FactoryBot](https://dev.to/ben/factorygirl-has-been-renamed-factorybot-cma)
- https://github.com/thoughtbot/factory_bot/issues/921
- https://thoughtbot.com/blog/factory_bot
#### Proposed solution
Rename the project to something gender-neutral, for example:
- FactoryPy
- FixtureFactory
- other?
#### Extra notes
Such a change will probably break lots of things, so it should be part of a major release bump. The GitHub organisation should also be renamed.
|
closed
|
2022-03-07T08:43:59Z
|
2022-06-29T14:03:46Z
|
https://github.com/FactoryBoy/factory_boy/issues/912
|
[] |
scarroll32
| 9 |
flairNLP/flair
|
pytorch
| 2,774 |
NER training problem with BILOU format
|
Hello,
Thank you so much for this beautiful tool.
My Flair version is 0.11.2
I am doing NER with `BILOU` format datasets. I am using `ColumnCorpus` option to feed my custom data, But training stops and shows this error.
```
Traceback (most recent call last):
File "train_ner.py", line 65, in <module>
train(
File "train_ner.py", line 57, in train
trainer.train(log_dir,
File "/home/sagor/anaconda3/envs/flair/lib/python3.8/site-packages/flair/trainers/trainer.py", line 502, in train
loss = self.model.forward_loss(batch_step)
File "/home/sagor/anaconda3/envs/flair/lib/python3.8/site-packages/flair/models/sequence_tagger_model.py", line 272, in forward_loss
scores, gold_labels = self.forward(sentences) # type: ignore
File "/home/sagor/anaconda3/envs/flair/lib/python3.8/site-packages/flair/models/sequence_tagger_model.py", line 330, in forward
gold_labels = self._get_gold_labels(sentences)
File "/home/sagor/anaconda3/envs/flair/lib/python3.8/site-packages/flair/models/sequence_tagger_model.py", line 415, in _get_gold_labels
if len(span) == 1:
TypeError: object of type 'Token' has no len()
```
Then I debugged thoroughly and modified the following line shown here in snippets.
If I add `U-` in the code, it's training perfectly, otherwise, it fails.
The working list is `["B-", "I-", "E-", "S-", "U-", "L-"]`
Does `Flair` support the `BILOU` format? Please let me know.
Also please let me know if this is a mergeable pull request if I create one with this issue solving.
Thanks and regards
https://github.com/flairNLP/flair/blob/88f332ab7b5ff89cfb02641c529fac286be08c15/flair/datasets/sequence_labeling.py#L614
|
closed
|
2022-05-16T20:28:04Z
|
2022-05-18T09:39:54Z
|
https://github.com/flairNLP/flair/issues/2774
|
[] |
sagorbrur
| 1 |
keras-team/keras
|
pytorch
| 20,700 |
ValueError: creating distributed tf.Variable with aggregation=MEAN and a non-floating dtype is not supported, please use a different aggregation or dtype
|
It happens while using [keras-models](https://keras.io/api/applications/) in kaggle tpu.
|
closed
|
2024-12-28T18:31:33Z
|
2024-12-31T04:22:19Z
|
https://github.com/keras-team/keras/issues/20700
|
[] |
innat
| 2 |
yinkaisheng/Python-UIAutomation-for-Windows
|
automation
| 277 |
Error when installing from git with 3.12.3
|
```
python -V
Python 3.12.3
```
```
Collecting git+https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/
Running command git clone --filter=blob:none --quiet https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/ 'C:\Users\user\AppData\Local\Temp\pip-req-build-wchu7359'
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [25 lines of output]
Traceback (most recent call last):
File "C:\Folder\Hotkeys\venv\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\Folder\Hotkeys\venv\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Folder\Hotkeys\venv\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\user\AppData\Local\Temp\pip-build-env-3wwdi05m\overlay\Lib\site-packages\setuptools\build_meta.py", line 325, in get_requires_for_build_wheel
return self._get_build_requires(config_settings, requirements=['wheel'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\user\AppData\Local\Temp\pip-build-env-3wwdi05m\overlay\Lib\site-packages\setuptools\build_meta.py", line 295, in _get_build_requires
self.run_setup()
File "C:\Users\user\AppData\Local\Temp\pip-build-env-3wwdi05m\overlay\Lib\site-packages\setuptools\build_meta.py", line 487, in run_setup
super().run_setup(setup_script=setup_script)
File "C:\Users\user\AppData\Local\Temp\pip-build-env-3wwdi05m\overlay\Lib\site-packages\setuptools\build_meta.py", line 311, in run_setup
exec(code, locals())
File "<string>", line 4, in <module>
File "C:\Users\user\AppData\Local\Temp\pip-req-build-wchu7359\uiautomation\__init__.py", line 4, in <module>
from .uiautomation import *
File "C:\Users\user\AppData\Local\Temp\pip-req-build-wchu7359\uiautomation\uiautomation.py", line 22, in <module>
import comtypes # need 'pip install comtypes'
^^^^^^^^^^^^^^^
ModuleNotFoundError: No module named 'comtypes'
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
Cloning https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/ to c:\users\user\appdata\local\temp\pip-req-build-wchu7359
Resolved https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/ to commit c897b68b4dbac44b86dbc3e110757c285f8b68a0
Installing build dependencies: started
Installing build dependencies: finished with status 'done'
Getting requirements to build wheel: started
Getting requirements to build wheel: finished with status 'error'
```
|
open
|
2024-04-24T19:41:12Z
|
2024-04-24T19:41:12Z
|
https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/277
|
[] |
michaelmesser
| 0 |
tflearn/tflearn
|
tensorflow
| 828 |
Tflearn does not see networked devices / gpu cluser that tensorflow sees
|
Installations:
tensorflow==0.12
tflearn==for 0.2.1
I cannot put layers onto specific devices using tflearn.
If I try
```
tf.device('/gpu:0'):
net=tflearn.lstm(net, 128, return_seq=True)
```
<-- it works only if I launch the script via command prompt.
If I launch the same script through slurm, tensorflow can see the gpu(evidenced by show devices command:
```
local_device_protos = device_lib.list_local_devices()
print([x.name for x in local_device_protos if x.device_type == 'GPU'])
```
), while tflearn cannot. I get the following error
```
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a device to node 'save_1/Const': Could not satisfy explicit device specification '/device:GPU:0' because no supported kernel for GPU devices is available.
Colocation Debug Info:
Colocation group had the following types and devices:
Identity: CPU
Const: CPU
[[Node: save_1/Const = Const[dtype=DT_STRING, value=Tensor<type: string shape: [] values: model>, _device="/device:GPU:0"]()]]
```
|
open
|
2017-07-09T16:51:24Z
|
2017-07-09T16:52:07Z
|
https://github.com/tflearn/tflearn/issues/828
|
[] |
vedhas
| 0 |
microsoft/unilm
|
nlp
| 907 |
Regarding DeepSpeed for pre-training BEiT and BEiT2
|
Hello,
I noticed that in BEiT and BEiT 2, you only used `enable_deepspeed` for fine-tuning. Could you share why you didn't use it for pre-training?
Thank you in advance for your response.
|
closed
|
2022-11-02T22:22:25Z
|
2022-11-26T11:20:30Z
|
https://github.com/microsoft/unilm/issues/907
|
[] |
netw0rkf10w
| 5 |
TencentARC/GFPGAN
|
deep-learning
| 501 |
Local gradio demo
|
It would be really helpful if [this demo](https://huggingface.co/spaces/Xintao/GFPGAN) was available for building locally too.
|
open
|
2024-01-29T15:51:22Z
|
2024-01-29T15:51:22Z
|
https://github.com/TencentARC/GFPGAN/issues/501
|
[] |
artcoai
| 0 |
man-group/arctic
|
pandas
| 479 |
Index with unexpected dtype datetime64[ns, tzfile('Zulu')]
|
#### Arctic Version
```
# 1.49.0
```
#### Arctic Store
```
# TickStoreV3
```
#### Description of problem and/or code sample that reproduces the issue
Libraries seems to have index type datetime64[ns, tzfile('Zulu')]
This seems to prevent some basic functions to work.
Example:
import pytz
data = pd.DataFrame([
('2017-07-28 23:59:59',40),
('2017-07-29 23:59:59',41),
('2017-07-30 23:59:59',42)
],columns=['timestamp','data'])
data.index = data['timestamp'].apply(lambda x: pd.Timestamp(x, tz=pytz.UTC))
data = data.drop(axis=1, labels=['timestamp'])
store.delete_library('user.test_library')
store.initialize_library('user.test_library', lib_type='TickStoreV3')
lib = store.get_library('user.test_library')
symbol=''
lib.write(symbol,data)
df = lib.read('')
df.index # datetime64[ns, tzfile('Zulu')]
data.index # datetime64[ns, UTC]
In this example, data.plot() would work, while df.plot() would give error
AttributeError: 'tzfile' object has no attribute '_transition_info'
Can someone please explain what is going on and how can I prevent this from happening to new libraries?
|
closed
|
2017-12-22T01:08:51Z
|
2022-08-04T03:49:45Z
|
https://github.com/man-group/arctic/issues/479
|
[] |
BarrancoC
| 9 |
graphql-python/graphene-django
|
graphql
| 562 |
What's the best way to rate limit specific graphql endpoints?
|
Is there a way to limit graphql endpoints? What are the current workarounds for this?
As a feature request, it might be a good idea to have something like https://django-ratelimit.readthedocs.io/en/v1.0.0/, where you can use decorators to ratelimit your APIs.
|
closed
|
2018-12-10T12:07:20Z
|
2021-04-14T20:09:08Z
|
https://github.com/graphql-python/graphene-django/issues/562
|
[
"question",
"wontfix"
] |
charlesverdad
| 7 |
freqtrade/freqtrade
|
python
| 11,439 |
FreqAI Initializes but Fails to Train Models (5-Byte Output)
|
<!--
Have you searched for similar issues before posting it?
If you have discovered a bug in the bot, please [search the issue tracker](https://github.com/freqtrade/freqtrade/issues?q=is%3Aissue).
If it hasn't been reported, please create a new issue.
Please do not use bug reports to request new features.
-->
## Describe your environment
Freqtrade Version: 2025.3-dev-5b9102f9a (also tested with 2025.2)
Python Version: 3.10
Dependencies:
xgboost: 2.1.4
pandas: 2.2.3
numpy: 1.26.4
talib: 0.4.38
OS: Ubuntu 22.00
Data:
Additional Observations
Data is valid: 2047 rows for training, 2017 for backtest, no NaN in close column.
No errors logged beyond initialization steps.
Issue persists with clean virtual environment and stable version (2025.2).
No similar reports found from other users, suggesting a potential environment-specific issue or subtle configuration error.
## Describe the problem:
BTC_USDT-5m.feather contains 50,000+ rows from 2023-01-01 to 2025-02-28.
Training period (2025-02-13 to 2025-02-20): 2047 rows.
Backtest period (2025-02-20 to 2025-02-27): 2017 rows.
FreqAI initializes correctly (logs show Set fresh train queue... and auto-downloader using 30 startup candles), but it does not proceed to call feature_engineering_* methods or train models. The resulting .joblib model files are consistently 5 bytes (empty), and no training-related logs (e.g., Starting FreqAI training...) appear, despite "enabled": true in the configuration and explicit dependency on do_predict in the strategy. This issue persists across both dev (2025.3-dev-5b9102f9a) and stable (2025.2) versions.
### Steps to reproduce:
Use the following train_config.json:
[train_config.json](https://github.com/user-attachments/files/19031969/train_config.json)
Use the following SimpleStrategy.py:
[SimpleStrategy.py.zip](https://github.com/user-attachments/files/19031993/SimpleStrategy.py.zip)
**Download Data**
freqtrade download-data --exchange binance --pairs BTC/USDT --timeframes 5m --days 14 --timerange 20250213-20250227
rm -rf user_data/models/improved-ai/*
freqtrade backtesting --strategy SimpleStrategy --timerange 20250220-20250227 --config user_data/train_config.json --cache none --verbose > backtest.log 2>&1
**Expected Behavior**
FreqAI should train models for BTC/USDT using the XGBoostRegressor.
Logs should include:
freqtrade.freqai.freqai_interface - INFO - Set fresh train queue from whitelist. Queue: ['BTC/USDT']
freqtrade.freqai.utils - INFO - FreqAI auto-downloader using 30 startup candles
🤖 BTC/USDT | Standard engineering...
Starting FreqAI training for BTC/USDT...
Model files in user_data/models/improved-ai/ should be > 5 bytes (e.g., 20 KB+).
**Actual Behavior**
Logs show initialization:
freqtrade.freqai.freqai_interface - INFO - Set fresh train queue from whitelist. Queue: ['BTC/USDT']
freqtrade.freqai.utils - INFO - FreqAI auto-downloader using 30 startup candles
No further FreqAI logs: No feature_engineering_* or Starting FreqAI training....
Model files remain 5 bytes (e.g., model_improved-ai_BTC_USDT.joblib).
Backtest completes with 0 trades.
### Relevant code exceptions or logs
Note: Please copy/paste text of the messages, no screenshots of logs please.
```
// paste your log here
```
|
closed
|
2025-02-28T18:48:29Z
|
2025-02-28T19:09:57Z
|
https://github.com/freqtrade/freqtrade/issues/11439
|
[
"Question",
"Strategy assistance",
"freqAI"
] |
rsulym
| 1 |
amdegroot/ssd.pytorch
|
computer-vision
| 449 |
How to achieve real-time detection?
|
How to achieve real-time detection?Thanks
|
open
|
2019-12-17T07:39:54Z
|
2019-12-17T07:39:54Z
|
https://github.com/amdegroot/ssd.pytorch/issues/449
|
[] |
niliuxi
| 0 |
fastapi-users/fastapi-users
|
fastapi
| 1,015 |
A function "parse_id" is always returns an NotImplementedError.
|
## Describe the bug
A function "parse_id" is always returns an NotImplementedError.
No return id.
## To Reproduce
fastapi_users/manager.py
```python
def parse_id(self, value: Any) -> models.ID:
"""
Parse a value into a correct models.ID instance.
:param value: The value to parse.
:raises InvalidID: The models.ID value is invalid.
:return: An models.ID object.
"""
raise NotImplementedError() # pragma: no cover
```
## Configuration
- Python version : 3.9.13
- FastAPI version : 0.78.0
- FastAPI Users version : 10.0.7
## Additional context
Add any other context about the problem here.
|
closed
|
2022-06-16T05:28:25Z
|
2022-06-16T05:31:45Z
|
https://github.com/fastapi-users/fastapi-users/issues/1015
|
[
"bug"
] |
takashi-yoneya
| 0 |
widgetti/solara
|
flask
| 122 |
Solara website Python errors
|
I have noticed that the Solara website does not seem to gracefully handle Python errors.
For example:
* Go to https://solara.dev/docs/tutorial/data-science
* Scroll to last chart
* Click on a point
* Set the Y-axis to "Species"
Result:
``` python
Traceback (most recent call last):
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/ops/array_ops.py", line 171, in _na_arithmetic_op
result = func(left, right)
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/computation/expressions.py", line 239, in evaluate
return _evaluate(op, op_str, a, b) # type: ignore[misc]
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/computation/expressions.py", line 70, in _evaluate_standard
return op(a, b)
TypeError: unsupported operand type(s) for -: 'str' and 'float'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/reacton/core.py", line 1647, in _render
root_element = el.component.f(*el.args, **el.kwargs)
File "app.ipynb input cell 21", line 20, in Page
File "app.ipynb input cell 21", line 6, in find_nearest_neighbours
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/ops/common.py", line 81, in new_method
return method(self, other)
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/arraylike.py", line 194, in __sub__
return self._arith_method(other, operator.sub)
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/series.py", line 6108, in _arith_method
return base.IndexOpsMixin._arith_method(self, other, op)
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/base.py", line 1348, in _arith_method
result = ops.arithmetic_op(lvalues, rvalues, op)
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/ops/array_ops.py", line 232, in arithmetic_op
res_values = _na_arithmetic_op(left, right, op) # type: ignore[arg-type]
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/ops/array_ops.py", line 178, in _na_arithmetic_op
result = _masked_arith_op(left, right, op)
File "/opt/render/project/src/.venv/lib/python3.9/site-packages/pandas/core/ops/array_ops.py", line 135, in _masked_arith_op
result[mask] = op(xrav[mask], y)
TypeError: unsupported operand type(s) for -: 'str' and 'float'
```
|
open
|
2023-05-26T09:21:36Z
|
2023-05-26T11:23:07Z
|
https://github.com/widgetti/solara/issues/122
|
[] |
platinops
| 1 |
aiogram/aiogram
|
asyncio
| 1,005 |
Fix pytest warnings
|
Fix pytest warnings

_Originally posted by @andrew000 in https://github.com/aiogram/aiogram/issues/1003#issuecomment-1250347489_
|
closed
|
2022-09-20T13:03:23Z
|
2022-12-30T20:48:55Z
|
https://github.com/aiogram/aiogram/issues/1005
|
[
"tests",
"2.x"
] |
Olegt0rr
| 0 |
rougier/from-python-to-numpy
|
numpy
| 43 |
2.1 Introduction - Simple Example, procedural example
|
The random_walk function is not a direct equivalent to the RandomWalker class method. A strict equivalent would be this:
def random_walk(n):
position = 0
for i in range(n):
yield position
position += 2*random.randint(0,1)-1
It is still not much faster, but it's a more fair comparison.
|
open
|
2017-01-12T16:49:04Z
|
2017-01-16T14:06:29Z
|
https://github.com/rougier/from-python-to-numpy/issues/43
|
[] |
tweigel-vaisala
| 8 |
ydataai/ydata-profiling
|
pandas
| 1,628 |
None Problem solved
|
closed
|
2024-07-16T03:38:04Z
|
2024-08-01T10:20:03Z
|
https://github.com/ydataai/ydata-profiling/issues/1628
|
[
"needs-triage"
] |
zhizhuaa
| 0 |
|
dgtlmoon/changedetection.io
|
web-scraping
| 2,039 |
Restock not working if out of stock text has children
|
**Describe the bug**
If using the restock feature on a page that has child elements inside the element containing the out of stock text, the text is not detected.
**Version**
v0.45.8.1
**To Reproduce**
Steps to reproduce the behavior:
1. Add page 'https://www.winterfeldt-schokoladen.de/Ajala-Cascara-60-VEGAN-45g' with type "Re-stock detection for single product pages"
2. Ensure that Request fetch method is set to Playwright Chromium
3. Wait for Check to complete
4. See "In stock" despite it currently being out of stock ("Leider ausverkauft")
or use this config share link: https://changedetection.io/share/LZi1aohNLlIa
**Expected behavior**
The page should be detected as out of stock.
**Screenshots**


**Desktop (please complete the following information):**
- OS: Windows 10
- Browser: Firefox
- Version: 120.0.1
**Additional context**
````html
<div class="delivery-status">
<ul class="list-unstyled">
<li>
<span class="status status-0">
<span class="fas fa-truck status-icon"></span>Leider ausverkauft
</span>
<link itemprop="availability" href="https://schema.org/OutOfStock" />
</li>
</ul>
</div>
````
As you can see in the html of the page, the phrase "ausverkauft", which is part of the `outOfStockTexts` inside `stock-not-in-stock.js`, does appear, but it's not scanned, as the element does have children.
If I modify the js from
````js
const elementsWithZeroChildren = Array.from(document.getElementsByTagName('*')).filter(element => element.children.length === 0);
````
to
````js
const elementsWithZeroChildren = Array.from(document.getElementsByTagName('*'));
````
it does work, but the message is obviosly not very pretty:
````
isItemInStock()
->
"
leider ausverkauft
"
````
For me it would be good enough if the result of that would be trimmed, but maybe you have a better idea.
This should probably a seperate feature request, but consider scanning for `schema.org/OutOfStock` / `schema.org/InStock`, or [structured data](https://developers.google.com/search/docs/appearance/structured-data/product?hl=en#offer-details) in general. I don't know how common it is, but it seems like a nice, language independent way to mark availability.
|
closed
|
2023-12-08T15:12:27Z
|
2024-01-15T09:12:10Z
|
https://github.com/dgtlmoon/changedetection.io/issues/2039
|
[
"bug",
"enhancement"
] |
druppelt
| 4 |
piccolo-orm/piccolo
|
fastapi
| 962 |
Make it clearer how multiple `where` clauses work in the docs
|
Discussed in https://github.com/piccolo-orm/piccolo/discussions/961
|
closed
|
2024-03-21T13:56:54Z
|
2024-03-21T13:58:35Z
|
https://github.com/piccolo-orm/piccolo/issues/962
|
[
"documentation"
] |
dantownsend
| 0 |
biolab/orange3
|
pandas
| 6,569 |
Favorites widget
|
**What's your use case?**
Most of the time, I use less than 10 widgets in several categorie.
**What's your proposed solution?**
A new widget category, "favorites". You can right click on any widget and add it to the favorites. The category only displays when there is at least one favorite.
Here is a screenshot on Alteryx feature :
Adding a tool to favorite :

Result :

**Are there any alternative solutions?**
Not I found.
|
closed
|
2023-09-09T07:22:15Z
|
2024-11-23T08:51:21Z
|
https://github.com/biolab/orange3/issues/6569
|
[] |
simonaubertbd
| 2 |
roboflow/supervision
|
computer-vision
| 1,451 |
How does line zone get triggered?
|
### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
Hi, I am trying to under how the line zone get triggered.
Let's say I set the triggering_anchors as BOTTOM_LEFT. Does xy of the bottom_left corner of the detection box of the object has to cross the line exactly to trigger the line zone? For example, does the bottom left corner needs to be one pixel below the line in frame 1, then the corner is on the line in frame 2, and then the corner is one pixel above the line in frame 3, to trigger the line?
Or is there a buffer zone? For example, if the bottom_left corner is a few pixels BELOW the line in frame 1 and it is a few pixels ABOVE the line in frame 2, will it trigger the line?
Sorry I am aware how confusing my question sounds...
### Additional
_No response_
|
closed
|
2024-08-15T11:17:47Z
|
2024-08-15T11:25:06Z
|
https://github.com/roboflow/supervision/issues/1451
|
[
"question"
] |
abichoi
| 0 |
the0demiurge/ShadowSocksShare
|
flask
| 22 |
今天偶然看了别人的技术文
|
服务器信息都是base64编码解码。
编码解码倒是不太难
|
closed
|
2017-12-28T14:40:15Z
|
2018-01-14T01:35:01Z
|
https://github.com/the0demiurge/ShadowSocksShare/issues/22
|
[] |
zebradonna
| 3 |
datadvance/DjangoChannelsGraphqlWs
|
graphql
| 112 |
No module named 'graphql.execution.executors'
|
File " ... /env/lib/python3.10/site-packages/channels_graphql_ws/graphql_ws.py", line 83, in <module>
import graphql.execution.executors.asyncio
ModuleNotFoundError: No module named 'graphql.execution.executors'
Whhen i execute Example
|
open
|
2023-08-17T13:41:44Z
|
2023-11-03T23:24:12Z
|
https://github.com/datadvance/DjangoChannelsGraphqlWs/issues/112
|
[] |
meafekih
| 3 |
jmcnamara/XlsxWriter
|
pandas
| 951 |
Bug: Rare behavior with autofit(), text wrap and multiline
|
### Current behavior
Hi! Great job with this project.
When writting a multiline string into a cell, and then call `autofit()` (with `text_warp: False` format), the string is represented as a single line, as seen below:
If I enter into the cell and click "Enter", the string is correctly showned:

Also, when using `text_wrap: True`, the autofit works properly or not, depending on the lenght of the individual lines of the string (This is generated by the code added to the issue):

### Expected behavior
In case of the code, the expected behavior would be to make column wide enough for "Measured VariabelVALUE" to be printed in the same line, as seen here:
### Sample code to reproduce
```markdown
import xlsxwriter
with xlsxwriter.Workbook('test.xlsx') as workbook:
# Create format objects
cell_format = workbook.add_format({
'font_name': 'Garamond',
'border': 1,
})
header_format = workbook.add_format({
'font_name': 'Garamond',
'border': 1,
'bold': True,
'text_wrap': True,
'align': 'center',
'valign': 'vcenter'
})
worksheet = workbook.add_worksheet('Some worksheet')
worksheet.write('A1', 'VAL #1\nMeasured VariableVALUE\n[kWh/m²]',
header_format)
worksheet.write('A2', 15200.00, cell_format)
worksheet.write('A3', 1000.569, cell_format)
worksheet.write('A4', 200.25, cell_format)
worksheet.autofit()
```
### Environment
```markdown
- XlsxWriter version: 3.0.8
- Python version: Python 3.10.8
- Excel version: Microsoft® Excel® for Microsoft 365 MSO (Version 2301 Build 16.0.16026.20002) 64-bit
- OS: Windows 10 Home 22H2
```
### Any other information
_No response_
### OpenOffice and LibreOffice users
- [ ] I have tested the output file with Excel.
|
closed
|
2023-02-13T15:20:57Z
|
2023-02-13T17:06:25Z
|
https://github.com/jmcnamara/XlsxWriter/issues/951
|
[
"bug"
] |
ajossorioarana
| 4 |
STVIR/pysot
|
computer-vision
| 512 |
Access to youtube-bb cropped dataset
|
I am very appreciate at your valuable works.
Unfortunately, there is hardness to access baidu cloud from outside of China. Therefore, our model cannot reach the original performance...TT. Could you please upload the dataset on google drive? Or.. anybody who already downloaded the dataset can share your files?
Best regards,
Ilchae Jung
|
closed
|
2021-03-23T07:58:34Z
|
2021-03-23T08:59:30Z
|
https://github.com/STVIR/pysot/issues/512
|
[] |
IlchaeJung
| 0 |
gradio-app/gradio
|
data-science
| 10,828 |
Receive ValueError when using nested @gr.render()
|
### Describe the bug
When attempting to use a nested @gr.render() I receive a `ValueError: Reactive render must be inside a Blocks context.`. However, as the example code shoes, the reactive render IS placed in a Blocks context (it's nested).
The motivation here is to be able to dynamically render nested gradio components. For example, suppose I want to render certain gradio components for certain users (high level use of gr.render()) and within that gradio component I want to dynamically render a list of buttons based on user interaction or API calls (the nested gr.render()).
Without being able to use gr.render() nested, I cannot create those dynamic components at a lower level. This prevents me from creating composable and dynamic gradio components.
The example code below shows an example implementation and reproduces the error.
Perhaps I am missing something? I checked the issue log and couldn't find something similar.
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
def run_nested_app(user):
with gr.Blocks() as nested_app:
gr.Textbox(f"{user}", label="User Profile")
search_box = gr.Textbox(
value="", interactive=True, placeholder="Edit me", label="Search Bar"
)
# This dynamic render here is supposed to provide dynamic content based on user interaction.
# But this render is broken because it is not "inside a Blocks context"
@gr.render(inputs=search_box)
def render_stuff(search_box):
split_words = search_box.split()
for word in split_words:
gr.Button(value=word, key=word)
return nested_app
with gr.Blocks() as demo:
user = gr.State("User1")
# This dynamic render works correctly.
@gr.render(inputs=user)
def render_example(user):
run_nested_app(user)
if __name__ == "__main__":
demo.launch()
```
### Screenshot
_No response_
### Logs
```shell
File "bar/.venv/lib/python3.11/site-packages/gradio/renderable.py", line 75, in apply
self.fn(*args, **kwargs)
File "bar/foo/ui/example.py", line 28, in render_example
run_nested_app(user)
File "bar/foo/ui/example.py", line 13, in run_nested_app
@gr.render(inputs=search_box)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "bar/.venv/
lib/python3.11/site-packages/gradio/renderable.py", line 127, in render
raise ValueError("Reactive render must be inside a Blocks context.")
ValueError: Reactive render must be inside a Blocks context.
```
### System Info
```shell
Gradio Environment Information:
------------------------------
Operating System: Linux
gradio version: 5.12.0
gradio_client version: 1.5.4
------------------------------------------------
gradio dependencies in your environment:
aiofiles: 23.2.1
anyio: 4.8.0
audioop-lts is not installed.
fastapi: 0.115.6
ffmpy: 0.5.0
gradio-client==1.5.4 is not installed.
httpx: 0.27.2
huggingface-hub: 0.27.1
jinja2: 3.1.4
markupsafe: 2.1.5
numpy: 1.26.4
orjson: 3.10.15
packaging: 24.2
pandas: 2.2.3
pillow: 11.1.0
pydantic: 2.10.5
pydub: 0.25.1
python-multipart: 0.0.20
pyyaml: 6.0.2
ruff: 0.9.2
safehttpx: 0.1.6
semantic-version: 2.10.0
starlette: 0.41.3
tomlkit: 0.13.2
typer: 0.15.1
typing-extensions: 4.12.2
urllib3: 2.3.0
uvicorn: 0.34.0
authlib; extra == 'oauth' is not installed.
itsdangerous; extra == 'oauth' is not installed.
gradio_client dependencies in your environment:
fsspec: 2024.12.0
httpx: 0.27.2
huggingface-hub: 0.27.1
packaging: 24.2
typing-extensions: 4.12.2
websockets: 14.2
```
### Severity
Blocking usage of gradio
|
open
|
2025-03-17T21:57:16Z
|
2025-03-17T21:57:16Z
|
https://github.com/gradio-app/gradio/issues/10828
|
[
"bug"
] |
i-am-mike-davis
| 0 |
MaartenGr/BERTopic
|
nlp
| 1,636 |
model.get_topic_freq() show different count per topic than i get by using document_topics, _ = model.transform(data['text']) and filter the rows
|
i have a 5 mil rows dataset of Reddit posts i am doing topic analysis on.
i fitted the model, all seems to make sense, the clusters i got make sense.
When I look at the cluster's sizes in model.get_topic_freq() it shows the counts for each topic ( how many documents are in the cluster)
however when i run document_topics, _ = model.transform(data['text']) and look at the rows in the dataset that correspond to a topic, it shows a different count...
for example for topic 4:
model.get_topic_freq() -> gives a count of about 3000
len(data[document_topics == 4])-> gives a count of around 6000
when i look at the text in those rows it is making sense ...again...the topic makes sense.... but the counts differ ...
why is this happening ... i can't understand it ??
sorry if this is a silly question, please if there is documentation that would help with this link to it ...i looked but can't seem to find anything that would clarify this issue...
thank you!
|
open
|
2023-11-18T11:39:29Z
|
2023-11-20T07:11:51Z
|
https://github.com/MaartenGr/BERTopic/issues/1636
|
[] |
andrea-mar
| 1 |
jpadilla/django-rest-framework-jwt
|
django
| 475 |
redis cache
|
I debug my django project these days, found every single request is calling authentication model query, could this too wasted.

**Query authentication model one time**

When I using my Spring Boot project I always store the token in Redis, because redis is faster than database, in django, request.user is useful, store an object is best, I think if there is a way to store authentication model in redis as the first login time, set it's alive time, maybe few hours, time ended, data gone, when a new request come, query from redis, I think this could get an higher performance, thanks!
And if there is chance, I want to add this code.
|
open
|
2019-04-17T09:03:08Z
|
2019-04-27T14:43:25Z
|
https://github.com/jpadilla/django-rest-framework-jwt/issues/475
|
[] |
yisen-cai
| 1 |
joke2k/django-environ
|
django
| 289 |
Feature Request: Warning if an env.path does not exist
|
Hello,
I recently did a very dumb thing and think it might be worth it if this library caught the issue, just in case someone else also makes my mistake.
I put this in my '.env' file:
```
MEDIA_ROOT="/some/path/" # Put ... here
```
Now obviously this spits out a garbage path, and my first reaction is to check for it. However, this would be a perfectly valid path:
```
MEDIA_ROOT="My Media"/#Crazy_file/
```
So, instead of trying to do complicated parsing, why not just check if the Path exists at all and if it doesn't then spit out a warning?
|
open
|
2021-03-25T14:06:59Z
|
2021-08-31T22:53:36Z
|
https://github.com/joke2k/django-environ/issues/289
|
[
"enhancement"
] |
EmperorArthur
| 0 |
flasgger/flasgger
|
api
| 442 |
Auto-parsing MethodView docs don't use full endpoint name when using blueprints
|
I am currently using MethodView and `{blueprint}.add_url_rule()` to create my endpoints. I have now added flasgger but have run into an issue trying to use auto-parsing of external YAML to endpoints, as it is not using the full endpoint name.
For example, I have this code
```py
blueprint = Blueprint('auth', __name__, url_prefix="/auth")
blueprint.add_url_rule('/register', view_func=Register.as_view('register'))
```
But it doesn't appear to work if I place the docs in the expected path
`{...}\docs\auth\register\post.yml`
But if I remove `\auth\` folder it works fine, but this isn't a solution if there are two separate blueprints with the same endpoint name.
While testing I found that if I called the view `Register.as_view('auth/register')`, it would find the right folder, but that isn't a solution either.
Further testing while looking at flasgger in [utils `get_spec()`](https://github.com/flasgger/flasgger/blob/ce98b046cbec2b2eb8c6de6df4b5409c06a8e539/flasgger/utils.py#L69) I found that `rule.endpoint` actually gave the full correct name of `auth.register`, but when getting the endpoint again it uses `endpoint.__name__`, which doesn't include the blueprint name, so it doesn't add this to the doc path.
|
closed
|
2020-11-18T16:15:50Z
|
2023-04-17T21:01:54Z
|
https://github.com/flasgger/flasgger/issues/442
|
[] |
AHollowedHunter
| 1 |
explosion/spaCy
|
data-science
| 12,534 |
Adding many special cases to Tokenizer greatly degrades startup performance
|
### Discussed in https://github.com/explosion/spaCy/discussions/12523
<div type='discussions-op-text'>
<sup>Originally posted by **Nickersoft** April 12, 2023</sup>
Hey folks,
I wasn't sure whether to flag this as a bug or a question, so to play it safe I opened it as a discussion. Recently, after running some benchmarks, I've noticed that adding several special cases to the spaCy tokenizer (in this case over 200k) severely impacts the time it takes to load the pipeline. For clarity, I'm attempting to add several compound English phrases to the tokenizer (like "lay out" or "garbage man") so they are preserved when processing text.
- Without any special cases added, loading my pipeline takes about **3s** on average.
- Loading in my special cases at runtime results in a latency of about **20s**.
- If I save my own pipeline by loading the special cases beforehand, then serializing it to a directory and loading my pipeline from the path, it takes upwards of **40s-130s**.
I would have thought that the last case would have been the _most_ performant, seeing it's writing the tokenizer to disk with all of the special cases contained in it, so I was surprised to see it perform so poorly. I would think for the second use case this latency would make sense, as it would need to iterate over 200k words individually and add each to the tokenizer via `add_special_case`.
The reason I am filing this as a discussion and not a bug is I'm not sure if this is the best way to achieve what I'm hoping to, or if there is something I can do on my end to improve performance. I can provide code snippets as needed, though right now it's all pretty straightforward (loading a pipeline via `load()`, looping through my words and adding each via `add_special_case`, then writing it to disk via `nlp.to_disk()`).</div>
|
closed
|
2023-04-17T08:36:27Z
|
2023-05-21T00:02:21Z
|
https://github.com/explosion/spaCy/issues/12534
|
[
"bug",
"feat / tokenizer"
] |
adrianeboyd
| 2 |
ydataai/ydata-profiling
|
jupyter
| 1,170 |
Larger correlation plots
|
### Missing functionality
The correlation plot has a lot of information in it
and is currently too small
### Proposed feature
Increase correlation plot size
### Alternatives considered
_No response_
### Additional context
_No response_
|
closed
|
2022-11-25T07:04:36Z
|
2023-01-24T22:33:11Z
|
https://github.com/ydataai/ydata-profiling/issues/1170
|
[
"feature request 💬"
] |
m-a-r-o-u
| 1 |
pydantic/pydantic-ai
|
pydantic
| 586 |
deepseek model adapter please enhance/extend
|
based on a copy of the openai model in latest pydantic-ai version. imports based on a separate copy of pydantic-ai in my codebase/src folder. Mostly just had chatgpt rewrite the _process_response method to account for empty messages from Deepseek v3.
Works with Deepseek v3 in simple example:
Example pydantic-ai script:
```from __future__ import annotations
import os
from dotenv import load_dotenv
import json
from dataclasses import dataclass, field
from typing import Optional
from uuid import UUID, uuid4
from pathlib import Path
from pydantic import BaseModel, Field
from pydantic_ai import Agent, RunContext, Tool
from pydantic_ai.models.openai import OpenAIModel
from pydantic_ai.models.ollama import OllamaModel
from src.deepseek import DeepSeekModel
from src.db.sqlite_db import Database
load_dotenv()
class CalculatorResult(BaseModel):
"""Result type for calculator operations."""
value: float = Field(description='The calculated result')
operation: str = Field(description='The operation performed')
description: str = Field(description='The description of the operation')
@dataclass
class CalculatorDeps:
"""Dependencies for the calculator agent."""
memory: dict[str, float] = field(default_factory=dict)
# Calculator tools should return strings
async def add(ctx: RunContext[CalculatorDeps], a: float, b: float) -> CalculatorResult:
"""Add two numbers together."""
result = a + b
print(f"🔢 ADD TOOL CALLED: {a} + {b} = {result}")
ctx.deps.memory['last_result'] = result
print(f"🔢 MEMORY: {ctx.deps.memory}")
return result
async def multiply(ctx: RunContext[CalculatorDeps], a: float, b: float) -> CalculatorResult:
"""Multiply two numbers together."""
result = a * b
print(f"🔢 MULTIPLY TOOL CALLED: {a} × {b} = {result}")
ctx.deps.memory['last_result'] = result
return result
async def get_last_result(ctx: RunContext[CalculatorDeps]) -> float:
"""Get the last calculated result from memory."""
result = ctx.deps.memory.get('last_result', 0.0)
print(f"🔢 GET_LAST_RESULT TOOL CALLED: {result}")
return result
model = DeepSeekModel(
model_name='deepseek-chat',
base_url='https://api.deepseek.com/v1',
api_key=os.getenv('DEEPSEEK_API_KEY'))
# model="ollama:llama3.2:3b-instruct-q8_0"
# model = OllamaModel(
# model_name="llama3.2:3b-instruct-q8_0",
# base_url='http://localhost:11434/v1',
# api_key='ollama')
# Create calculator agent with string result type
calculator_agent = Agent(
model=model,
deps_type=CalculatorDeps,
result_type=str,
tools=[Tool(add), Tool(multiply), Tool(get_last_result)],
system_prompt=(
"You are a calculator assistant. When performing calculations, you should:"
"1. Use the appropriate tool (add, multiply, or get_last_result)"
"2. Return the tool's JSON response directly without modification"
"3. Do not add any additional text or formatting"
"\nExample:"
"\nUser: What is 5 plus 3?"
"\nAssistant: {\"value\": 8.0, \"operation\": \"addition\", \"description\": \"5.0 + 3.0 = 8.0\"}"
"This an example of what I am not looking for: The answer to the question ..."
"Do not respond with \"The answer to the question ...\" or anything like that."
"This is an example of what I am looking for: {\"value\": 8.0, \"operation\": \"addition\", \"description\": \"5.0 + 3.0 = 8.0\"}"
"Respond with a single floating point number for the \"value\" field of the JSON response."
"Only respond with a float like this: 4.1"
"Do not respond with any other text or formatting besides the JSON response."
"Remove any text that is not a float for the \"value\" field of the JSON response."
"This an example of what I am not looking for: The answer to the question of ..."
"This is an example of what I am looking for: {\"value\": 8.0, \"operation\": \"addition\", \"description\": \"5.0 + 3.0 = 8.0\"}"
"You are a calculator assistant. When performing calculations, you should:"
"1. Use the appropriate tool (add, multiply, or get_last_result)"
"2. Return the tool's JSON response directly without modification"
"3. Do not add any additional text or formatting"
"\nRESPOND LIKE THIS: {\"value\": 8.0, \"operation\": \"addition\", \"description\": \"5.0 + 3.0 = 8.0\"}"
"\nRESPOND LIKE THIS: {\"value\": 8.0, \"operation\": \"multiply\", \"description\": \"5.0 x 3.0 = 8.0\"}"
"\nRESPOND LIKE THIS: {\"value\": 8.0, \"operation\": \"get_last_result\", \"description\": \"The last result was 8.0\"}"
),
retries=3
)
class ToolExampleAgent:
"""Example agent implementation with tool support."""
def __init__(self, database: Database):
"""Initialize the agent with database configuration."""
self.database = database
self.agent_id = uuid4()
self.deps = CalculatorDeps()
self.calculator = calculator_agent
async def process_message(self, message: str) -> str:
"""Process message with LLM and store in database."""
if not message:
return "Error: Message cannot be empty"
print(f"\n📝 INPUT MESSAGE: {message}")
result = await self.calculator.run(message, deps=self.deps)
# print(f"🔢 RESULT: {result}")
# Store messages in database - serialize only necessary fields
messages_to_store = []
for msg in result.new_messages():
msg_dict = {
"kind": msg.kind,
"parts": [{
"part_kind": part.part_kind,
"content": part.content if hasattr(part, 'content') else None,
"tool_name": part.tool_name if hasattr(part, 'tool_name') else None,
"args": part.args.__dict__ if hasattr(part, 'args') and part.args else None
} for part in msg.parts]
}
messages_to_store.append(msg_dict)
# Convert to JSON with custom handling for special types
json_str = json.dumps(
messages_to_store,
default=lambda x: str(x) if not isinstance(x, (dict, list, str, int, float, bool, type(None))) else x
)
await self.database.add_messages(json_str.encode('utf-8'))
return str(result.data)
async def get_history(self) -> list[dict]:
"""Retrieve conversation history."""
print("\n" + "="*50)
print("📚 FETCHING HISTORY")
print("="*50)
try:
messages = await self.database.get_messages()
print(f"\n📥 Retrieved {len(messages)} messages")
return messages
except Exception as e:
print("\n❌ History Error:")
print(f" Type: {type(e).__name__}")
print(f" Message: {str(e)}")
return [{"error": f"Failed to retrieve history: {str(e)}"}]
async def main():
"""Example usage of the ToolExampleAgent."""
async with Database.connect(Path('.chat_app_messages.sqlite')) as database:
agent = ToolExampleAgent(database=database)
# Test basic calculation
calc_result = await agent.process_message("What is 521312123123.2 plus 321321321.2?")
print(f"Calc Result: {calc_result}")
# Test memory
memory_result = await agent.process_message("What was the last result?")
print(f"Memory: {memory_result}")
# Test complex operation
complex_result = await agent.process_message("Multiply the last result by 2")
print(f"Complex: {complex_result}")
test_result = await agent.process_message("What is 123.2 plus 321.2 times 423?")
print(f"Test: {test_result}")
# Get history
history = await agent.get_history()
# print(f"History: {json.dumps(history, indent=2)}")
if __name__ == "__main__":
import asyncio
from pathlib import Path
asyncio.run(main())
```
deepseek model based on openai:
```from __future__ import annotations as _annotations
from collections.abc import AsyncIterator, Iterable
from contextlib import asynccontextmanager
from dataclasses import dataclass, field
from datetime import datetime, timezone
from itertools import chain
from typing import Literal, Union, overload
from httpx import AsyncClient as AsyncHTTPClient
from typing_extensions import assert_never
from pydantic_ai import UnexpectedModelBehavior, _utils, result
from pydantic_ai._utils import guard_tool_call_id as _guard_tool_call_id
from pydantic_ai.messages import (
ModelMessage,
ModelRequest,
ModelResponse,
ModelResponsePart,
RetryPromptPart,
SystemPromptPart,
TextPart,
ToolCallPart,
ToolReturnPart,
UserPromptPart,
)
from pydantic_ai.result import Usage
from pydantic_ai.settings import ModelSettings
from pydantic_ai.tools import ToolDefinition
from pydantic_ai.models import (
AgentModel,
EitherStreamedResponse,
Model,
StreamStructuredResponse,
StreamTextResponse,
cached_async_http_client,
check_allow_model_requests,
)
try:
from openai import NOT_GIVEN, AsyncOpenAI, AsyncStream
from openai.types import ChatModel, chat
from openai.types.chat import ChatCompletionChunk
from openai.types.chat.chat_completion_chunk import ChoiceDeltaToolCall
except ImportError as _import_error:
raise ImportError(
'Please install `openai` to use the DeepSeek model, '
"you can use the `openai` optional group — `pip install 'pydantic-ai-slim[openai]'`"
) from _import_error
DeepSeekModelName = Union[ChatModel, str]
"""
Using this more broad type for the model name instead of the ChatModel definition
allows this model to be used more easily with other model types (ie, Ollama)
"""
@dataclass(init=False)
class DeepSeekModel(Model):
"""A model that uses the DeepSeek API.
Internally, this uses the [DeepSeek Python client](https://github.com/openai/openai-python) to interact with the API.
Apart from `__init__`, all methods are private or match those of the base class.
"""
model_name: DeepSeekModelName
client: AsyncOpenAI = field(repr=False)
def __init__(
self,
model_name: DeepSeekModelName,
*,
base_url: str | None = None,
api_key: str | None = None,
openai_client: AsyncOpenAI | None = None,
http_client: AsyncHTTPClient | None = None,
):
"""Initialize an DeepSeek model.
Args:
model_name: The name of the DeepSeek model to use. List of model names available
[here](https://github.com/openai/openai-python/blob/v1.54.3/src/openai/types/chat_model.py#L7)
(Unfortunately, despite being ask to do so, DeepSeek do not provide `.inv` files for their API).
base_url: The base url for the DeepSeek requests. If not provided, the `OPENAI_BASE_URL` environment variable
will be used if available. Otherwise, defaults to DeepSeek's base url.
api_key: The API key to use for authentication, if not provided, the `OPENAI_API_KEY` environment variable
will be used if available.
openai_client: An existing
[`AsyncOpenAI`](https://github.com/openai/openai-python?tab=readme-ov-file#async-usage)
client to use. If provided, `base_url`, `api_key`, and `http_client` must be `None`.
http_client: An existing `httpx.AsyncClient` to use for making HTTP requests.
"""
self.model_name: DeepSeekModelName = model_name
if openai_client is not None:
assert http_client is None, 'Cannot provide both `openai_client` and `http_client`'
assert base_url is None, 'Cannot provide both `openai_client` and `base_url`'
assert api_key is None, 'Cannot provide both `openai_client` and `api_key`'
self.client = openai_client
elif http_client is not None:
self.client = AsyncOpenAI(base_url=base_url, api_key=api_key, http_client=http_client)
else:
self.client = AsyncOpenAI(base_url=base_url, api_key=api_key, http_client=cached_async_http_client())
async def agent_model(
self,
*,
function_tools: list[ToolDefinition],
allow_text_result: bool,
result_tools: list[ToolDefinition],
) -> AgentModel:
check_allow_model_requests()
tools = [self._map_tool_definition(r) for r in function_tools]
if result_tools:
tools += [self._map_tool_definition(r) for r in result_tools]
return DeepSeekAgentModel(
self.client,
self.model_name,
allow_text_result,
tools,
)
def name(self) -> str:
return f'openai:{self.model_name}'
@staticmethod
def _map_tool_definition(f: ToolDefinition) -> chat.ChatCompletionToolParam:
return {
'type': 'function',
'function': {
'name': f.name,
'description': f.description,
'parameters': f.parameters_json_schema,
},
}
@dataclass
class DeepSeekAgentModel(AgentModel):
"""Implementation of `AgentModel` for DeepSeek models."""
client: AsyncOpenAI
model_name: DeepSeekModelName
allow_text_result: bool
tools: list[chat.ChatCompletionToolParam]
async def request(
self, messages: list[ModelMessage], model_settings: ModelSettings | None
) -> tuple[ModelResponse, result.Usage]:
response = await self._completions_create(messages, False, model_settings)
return self._process_response(response), _map_usage(response)
@asynccontextmanager
async def request_stream(
self, messages: list[ModelMessage], model_settings: ModelSettings | None
) -> AsyncIterator[EitherStreamedResponse]:
response = await self._completions_create(messages, True, model_settings)
async with response:
yield await self._process_streamed_response(response)
@overload
async def _completions_create(
self, messages: list[ModelMessage], stream: Literal[True], model_settings: ModelSettings | None
) -> AsyncStream[ChatCompletionChunk]:
pass
@overload
async def _completions_create(
self, messages: list[ModelMessage], stream: Literal[False], model_settings: ModelSettings | None
) -> chat.ChatCompletion:
pass
async def _completions_create(
self, messages: list[ModelMessage], stream: bool, model_settings: ModelSettings | None
) -> chat.ChatCompletion | AsyncStream[ChatCompletionChunk]:
# standalone function to make it easier to override
if not self.tools:
tool_choice: Literal['none', 'required', 'auto'] | None = None
elif not self.allow_text_result:
tool_choice = 'required'
else:
tool_choice = 'auto'
deepseek_messages = list(chain(*(self._map_message(m) for m in messages)))
model_settings = model_settings or {}
return await self.client.chat.completions.create(
model=self.model_name,
messages=deepseek_messages,
n=1,
parallel_tool_calls=True if self.tools else NOT_GIVEN,
tools=self.tools or NOT_GIVEN,
tool_choice=tool_choice or NOT_GIVEN,
stream=stream,
stream_options={'include_usage': True} if stream else NOT_GIVEN,
max_tokens=model_settings.get('max_tokens', NOT_GIVEN),
temperature=model_settings.get('temperature', NOT_GIVEN),
top_p=model_settings.get('top_p', NOT_GIVEN),
timeout=model_settings.get('timeout', NOT_GIVEN),
)
# @staticmethod
# def _process_response(response: chat.ChatCompletion) -> ModelResponse:
# """Process a non-streamed response, and prepare a message to return."""
# timestamp = datetime.fromtimestamp(response.created, tz=timezone.utc)
# choice = response.choices[0]
# items: list[ModelResponsePart] = []
# # if choice.message.content is not None:
# # items.append(TextPart(choice.message.content))
# if 'choices' not in response or not response['choices']:
# print(f"🔢 RESPONSE: {response}")
# raise UnexpectedModelBehavior(f'Received empty or invalid model response: {response}')
# choice = response['choices'][0]
# items: list[ModelResponsePart] = []
# if 'content' in choice['message']:
# items.append(TextPart(choice['message']['content']))
# if choice.message.tool_calls is not None:
# for c in choice.message.tool_calls:
# items.append(ToolCallPart.from_raw_args(c.function.name, c.function.arguments, c.id))
# return ModelResponse(items, timestamp=timestamp)
@staticmethod
def _process_response(response: chat.ChatCompletion) -> ModelResponse:
"""Process a non-streamed response and prepare a message to return."""
# Ensure the response contains choices
if not response.choices:
raise UnexpectedModelBehavior(f'Received empty or invalid model response: {response}')
# Extract the first choice
choice = response.choices[0]
timestamp = datetime.fromtimestamp(response.created, tz=timezone.utc)
items: list[ModelResponsePart] = []
# Process tool calls if they exist
if choice.message.tool_calls:
for tool_call in choice.message.tool_calls:
items.append(ToolCallPart.from_raw_args(
tool_call.function.name,
tool_call.function.arguments,
tool_call.id
))
# If there's no content or tool calls, handle it gracefully
if not items:
if choice.finish_reason == "stop":
# Add a placeholder message or handle gracefully
# print(f"⚠️ No content or tool calls in response, adding default fallback: {response}")
items.append(TextPart("Operation completed successfully, but no further output was provided."))
else:
raise UnexpectedModelBehavior(
f"Unexpected finish_reason with no content or tool calls: {response}"
)
return ModelResponse(items, timestamp=timestamp)
@staticmethod
async def _process_streamed_response(response: AsyncStream[ChatCompletionChunk]) -> EitherStreamedResponse:
"""Process a streamed response, and prepare a streaming response to return."""
timestamp: datetime | None = None
start_usage = Usage()
# the first chunk may contain enough information so we iterate until we get either `tool_calls` or `content`
while True:
try:
chunk = await response.__anext__()
except StopAsyncIteration as e:
raise UnexpectedModelBehavior('Streamed response ended without content or tool calls') from e
timestamp = timestamp or datetime.fromtimestamp(chunk.created, tz=timezone.utc)
start_usage += _map_usage(chunk)
if chunk.choices:
delta = chunk.choices[0].delta
if delta.content is not None:
return DeepSeekStreamTextResponse(delta.content, response, timestamp, start_usage)
elif delta.tool_calls is not None:
return DeepSeekStreamStructuredResponse(
response,
{c.index: c for c in delta.tool_calls},
timestamp,
start_usage,
)
# else continue until we get either delta.content or delta.tool_calls
@classmethod
def _map_message(cls, message: ModelMessage) -> Iterable[chat.ChatCompletionMessageParam]:
"""Just maps a `pydantic_ai.Message` to a `openai.types.ChatCompletionMessageParam`."""
if isinstance(message, ModelRequest):
yield from cls._map_user_message(message)
elif isinstance(message, ModelResponse):
texts: list[str] = []
tool_calls: list[chat.ChatCompletionMessageToolCallParam] = []
for item in message.parts:
if isinstance(item, TextPart):
texts.append(item.content)
elif isinstance(item, ToolCallPart):
tool_calls.append(_map_tool_call(item))
else:
assert_never(item)
message_param = chat.ChatCompletionAssistantMessageParam(role='assistant')
if texts:
# Note: model responses from this model should only have one text item, so the following
# shouldn't merge multiple texts into one unless you switch models between runs:
message_param['content'] = '\n\n'.join(texts)
if tool_calls:
message_param['tool_calls'] = tool_calls
yield message_param
else:
assert_never(message)
@classmethod
def _map_user_message(cls, message: ModelRequest) -> Iterable[chat.ChatCompletionMessageParam]:
for part in message.parts:
if isinstance(part, SystemPromptPart):
yield chat.ChatCompletionSystemMessageParam(role='system', content=part.content)
elif isinstance(part, UserPromptPart):
yield chat.ChatCompletionUserMessageParam(role='user', content=part.content)
elif isinstance(part, ToolReturnPart):
yield chat.ChatCompletionToolMessageParam(
role='tool',
tool_call_id=_guard_tool_call_id(t=part, model_source='DeepSeek'),
content=part.model_response_str(),
)
elif isinstance(part, RetryPromptPart):
if part.tool_name is None:
yield chat.ChatCompletionUserMessageParam(role='user', content=part.model_response())
else:
yield chat.ChatCompletionToolMessageParam(
role='tool',
tool_call_id=_guard_tool_call_id(t=part, model_source='DeepSeek'),
content=part.model_response(),
)
else:
assert_never(part)
@dataclass
class DeepSeekStreamTextResponse(StreamTextResponse):
"""Implementation of `StreamTextResponse` for DeepSeek models."""
_first: str | None
_response: AsyncStream[ChatCompletionChunk]
_timestamp: datetime
_usage: result.Usage
_buffer: list[str] = field(default_factory=list, init=False)
async def __anext__(self) -> None:
if self._first is not None:
self._buffer.append(self._first)
self._first = None
return None
chunk = await self._response.__anext__()
self._usage += _map_usage(chunk)
try:
choice = chunk.choices[0]
except IndexError:
raise StopAsyncIteration()
# we don't raise StopAsyncIteration on the last chunk because usage comes after this
if choice.finish_reason is None:
assert choice.delta.content is not None, f'Expected delta with content, invalid chunk: {chunk!r}'
if choice.delta.content is not None:
self._buffer.append(choice.delta.content)
def get(self, *, final: bool = False) -> Iterable[str]:
yield from self._buffer
self._buffer.clear()
def usage(self) -> Usage:
return self._usage
def timestamp(self) -> datetime:
return self._timestamp
@dataclass
class DeepSeekStreamStructuredResponse(StreamStructuredResponse):
"""Implementation of `StreamStructuredResponse` for DeepSeek models."""
_response: AsyncStream[ChatCompletionChunk]
_delta_tool_calls: dict[int, ChoiceDeltaToolCall]
_timestamp: datetime
_usage: result.Usage
async def __anext__(self) -> None:
chunk = await self._response.__anext__()
self._usage += _map_usage(chunk)
try:
choice = chunk.choices[0]
except IndexError:
raise StopAsyncIteration()
if choice.finish_reason is not None:
raise StopAsyncIteration()
assert choice.delta.content is None, f'Expected tool calls, got content instead, invalid chunk: {chunk!r}'
for new in choice.delta.tool_calls or []:
if current := self._delta_tool_calls.get(new.index):
if current.function is None:
current.function = new.function
elif new.function is not None:
current.function.name = _utils.add_optional(current.function.name, new.function.name)
current.function.arguments = _utils.add_optional(current.function.arguments, new.function.arguments)
else:
self._delta_tool_calls[new.index] = new
def get(self, *, final: bool = False) -> ModelResponse:
items: list[ModelResponsePart] = []
for c in self._delta_tool_calls.values():
if f := c.function:
if f.name is not None and f.arguments is not None:
items.append(ToolCallPart.from_raw_args(f.name, f.arguments, c.id))
return ModelResponse(items, timestamp=self._timestamp)
def usage(self) -> Usage:
return self._usage
def timestamp(self) -> datetime:
return self._timestamp
def _map_tool_call(t: ToolCallPart) -> chat.ChatCompletionMessageToolCallParam:
return chat.ChatCompletionMessageToolCallParam(
id=_guard_tool_call_id(t=t, model_source='DeepSeek'),
type='function',
function={'name': t.tool_name, 'arguments': t.args_as_json_str()},
)
def _map_usage(response: chat.ChatCompletion | ChatCompletionChunk) -> result.Usage:
usage = response.usage
if usage is None:
return result.Usage()
else:
details: dict[str, int] = {}
if usage.completion_tokens_details is not None:
details.update(usage.completion_tokens_details.model_dump(exclude_none=True))
if usage.prompt_tokens_details is not None:
details.update(usage.prompt_tokens_details.model_dump(exclude_none=True))
return result.Usage(
request_tokens=usage.prompt_tokens,
response_tokens=usage.completion_tokens,
total_tokens=usage.total_tokens,
details=details,
)
```
result:
```📝 INPUT MESSAGE: What is 521312123123.2 plus 321321321.2?
🔢 ADD TOOL CALLED: 521312123123.2 + 321321321.2 = 521633444444.4
🔢 MEMORY: {'last_result': 521633444444.4}
Calc Result: Operation completed successfully, but no further output was provided.
📝 INPUT MESSAGE: What was the last result?
🔢 GET_LAST_RESULT TOOL CALLED: 521633444444.4
Memory: Operation completed successfully, but no further output was provided.
📝 INPUT MESSAGE: Multiply the last result by 2
🔢 GET_LAST_RESULT TOOL CALLED: 521633444444.4
Complex: Operation completed successfully, but no further output was provided.
📝 INPUT MESSAGE: What is 123.2 plus 321.2 times 423?
🔢 ADD TOOL CALLED: 123.2 + 321.2 = 444.4
🔢 MEMORY: {'last_result': 444.4}
🔢 MULTIPLY TOOL CALLED: 321.2 × 423.0 = 135867.6
🔢 ADD TOOL CALLED: 444.4 + 135867.6 = 136312.0
🔢 MEMORY: {'last_result': 136312.0}
Test: Operation completed successfully, but no further output was provided.
==================================================
📚 FETCHING HISTORY
==================================================
📥 Retrieved 108 messages
```
|
closed
|
2025-01-02T11:07:05Z
|
2025-01-31T04:33:28Z
|
https://github.com/pydantic/pydantic-ai/issues/586
|
[] |
georgiedekker
| 9 |
KaiyangZhou/deep-person-reid
|
computer-vision
| 502 |
Euclidean vs Cosine distance in same-domain, cross-domain and multi-source
|
Hi @KaiyangZhou, thanks again for you great work,
I see that most of the models under: https://kaiyangzhou.github.io/deep-person-reid/MODEL_ZOO use euclidean distances. Specially under same-domain ReiD. However, under cross domain I see both. And for multi-source I only see cosine. For cross-domain and multi-source, cosine seem to outperform euclidean. What is the rationale behind this?
|
closed
|
2022-04-24T14:56:16Z
|
2022-04-25T08:50:36Z
|
https://github.com/KaiyangZhou/deep-person-reid/issues/502
|
[] |
mikel-brostrom
| 2 |
slackapi/python-slack-sdk
|
asyncio
| 1,348 |
Why is new user metadata being sent to channel when using the team_join API
|
I am learning to develop a Slack Bot application to help improve communications for a large internal collaboration of scientists. I wrote a test Python script to send a welcome message using the `team_join` API to each new member to the Slack workspace. During an unexpected massive invite of ~100 users (ergo the comms issue), the welcome message to each user was published in the designated test-bot channel on invite (not on acceptance) and the metadata for users who accepted was published to the channel. I don't know why the metadata was published, too, when I followed a Slack Bolt example.
### Reproducible in:
```bash
pip freeze | grep slack
python --version
sw_vers && uname -v # or `ver`
```
#### The Slack SDK version
slack-bolt==1.16.4
slack-sdk==3.20.2
#### Python runtime version
Python 3.6.9
#### OS info
Distributor ID: Ubuntu
Description: Ubuntu 18.04.6 LTS
Release: 18.04
Codename: bionic
#### Steps to reproduce:
(Share the commands to run, source code, and project settings (e.g., setup.py))
Running in a docker container with python 3.8
```
# When a user joins the workspace, send a message in a predefined channel asking them to introduce themselves
@app.event("team_join")
def ask_for_introduction(event, say):
welcome_channel_id = "test-bot"
user_id = event["user"]
text = f"Welcome to the team, <@{user_id}>! 🎉 You can introduce yourself in this channel."
say(text=text, channel=welcome_channel_id)
```
### Expected result:
(Tell what you expected to happen)
### Actual result:
<img width="980" alt="Screenshot 2023-03-28 at 22 23 32" src="https://user-images.githubusercontent.com/15669942/228358246-00733241-0804-4d29-a91e-79aa512b52b8.png">
|
closed
|
2023-03-28T20:28:23Z
|
2023-03-31T14:45:32Z
|
https://github.com/slackapi/python-slack-sdk/issues/1348
|
[
"question",
"needs info"
] |
jeipollack
| 2 |
unit8co/darts
|
data-science
| 1,991 |
[BUG] Error with XGBModel and Encoders
|
**Describe the bug**
I get a TypeError when trying to fit sparse data with encoders and XGBModel from the darts package.
If I remove the encoders and lags_past_covariates the bug goes away, but I'm not sure why.
**To Reproduce**
```python
import pandas as pd
import numpy as np
import darts
from datetime import datetime
from darts import TimeSeries
from darts.models import XGBModel
values = np.array([3.5, 0, 6.5, 0, 0, 0, 0, 0, 0])
dates = pd.date_range(start=datetime(2021, 5, 1),
end=datetime(2022, 1, 1),
freq='MS')
data = {'Date':dates,
'Values':values}
encoders = {'cyclic': {'past':['month']}}
model_kwargs = {'lags':[-6, -3, -2],
'lags_past_covariates':[-6],
'add_encoders':encoders
}
model = XGBModel(**model_kwargs)
df = pd.DataFrame(data)
ts = TimeSeries.from_dataframe(df, time_col='Date', value_cols=['Values'])
model.fit(ts)
```
**Expected behavior**
I expected the model to fit without error, but instead I get the following error:
TypeError: unsupported operand type(s) for //: 'Timedelta' and 'pandas._libs.tslibs.offsets.MonthBegin'
**System (please complete the following information):**
- Python version: [3.9.4]
- darts version [0.24.0]
|
closed
|
2023-09-12T17:00:05Z
|
2023-10-28T13:55:21Z
|
https://github.com/unit8co/darts/issues/1991
|
[
"bug"
] |
negodfre
| 3 |
graphdeco-inria/gaussian-splatting
|
computer-vision
| 221 |
diff-gaussian-rasterization based on Python
|
Note that [diff-gaussian-rasterization](https://github.com/graphdeco-inria/diff-gaussian-rasterization) is implemented based on CUDA. I would like to know if there is any Python implementation? Let me first compare the gap between CUDA-based implementation and Python-based implementation. thank you
|
closed
|
2023-09-22T06:15:57Z
|
2023-10-04T08:25:32Z
|
https://github.com/graphdeco-inria/gaussian-splatting/issues/221
|
[] |
TwiceMao
| 2 |
huggingface/peft
|
pytorch
| 1,510 |
Implementing GLora
|
### Feature request
Implementing GLORA in PEFT as a superset of LORA, reference:
https://arxiv.org/abs/2306.07967
### Motivation
This is a superset of regular LORA and performs better in some circumstances.
### Your contribution
I can help with implementation if given guidance.
|
closed
|
2024-02-26T16:16:42Z
|
2024-04-06T15:03:29Z
|
https://github.com/huggingface/peft/issues/1510
|
[] |
aravindhv10
| 3 |
lux-org/lux
|
pandas
| 74 |
New Action: Text visualizations
|
Currently, text attributes are recognized as categorical attributes and displayed as bar charts. We should add a new datatype for text attributes, perhaps distinguishing between short: 1~2 words (more like labels, categories), long: 2+ (more like reviews, sentences, etc). In addition, we can add an action that visualizes text fields, such as word clouds, N-grams, etc.
[This article](https://towardsdatascience.com/a-complete-exploratory-data-analysis-and-visualization-for-text-data-29fb1b96fb6a) documents some possible visualization types for text data.
|
open
|
2020-08-22T11:29:32Z
|
2021-01-11T12:55:37Z
|
https://github.com/lux-org/lux/issues/74
|
[
"enhancement",
"easy"
] |
dorisjlee
| 1 |
ExpDev07/coronavirus-tracker-api
|
fastapi
| 301 |
[BUG] Encoding of coordinates, latitude and longitude, differ between CSBS & NYT
|
The encoding of coordinates, latitude and longitude, differ between these two sources:
NYT - v2/locations?source=nyt&timelines=true" - properties encoded as numbers
"coordinates":{"latitude":0,"longitude":0}
CSBS - v2/locations?source=csbs - properties encoded as strings
"coordinates":{"latitude":"40.71455","longitude":"-74.00714"}
This causes a deserializing exception when using the same destination classes.
Workarounds are to use a cloned set of destination classes or to replace all NYT instances of {"latitude":0,"longitude":0} with {"latitude":"0","longitude":"0"} since they are all zeroes anyway as long as they will always be zeroes.
|
closed
|
2020-04-25T00:28:03Z
|
2020-04-26T00:34:16Z
|
https://github.com/ExpDev07/coronavirus-tracker-api/issues/301
|
[
"bug",
"duplicate"
] |
ChuckVanzant
| 2 |
deezer/spleeter
|
tensorflow
| 214 |
[Discussion] Example on how to change bitrate
|
I'm new to Python and don't know much. I know that in the recent release of Spleeter bitrate options were introduced. I used pip uninstall, deleted other info from it, and then reinstalled it so I could have it (please tell me if I did it wrong). I tried using the command as so
spleeter separate -i 'SEARCHLIGHT.mp3' -p spleeter:5stems -b 320k -o splits
however nothing is changing as the bitrate is still 128. is there an example on how this should work?
|
closed
|
2019-12-30T04:38:20Z
|
2020-01-13T16:44:15Z
|
https://github.com/deezer/spleeter/issues/214
|
[
"question"
] |
Waffled-II
| 3 |
praw-dev/praw
|
api
| 1,495 |
Add 'body-html' attribute to comment
|
When accessing a comment through the reddit api, all comments have a `body-html` attribute. But, there is no such feature for praw comments.
|
closed
|
2020-05-05T18:05:14Z
|
2020-07-02T05:45:12Z
|
https://github.com/praw-dev/praw/issues/1495
|
[
"Documentation"
] |
SJS830
| 4 |
ymcui/Chinese-LLaMA-Alpaca-2
|
nlp
| 181 |
合并中间checkpoint
|
### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://github.com/hwchase17/langchain)、[text-generation-webui](https://github.com/oobabooga/text-generation-webui)等,同时建议到对应的项目中查找解决方案。
### 问题类型
模型转换和合并
### 基础模型
Alpaca-2-7B
### 操作系统
Windows
### 详细描述问题
想问一下能不能合并中途的checkpoint查看效果?直接用merge_llama2_with_chinese_lora_low_mem会报错
### 依赖情况(代码类问题务必提供)
_No response_
### 运行日志或截图
================================================================================
Base model: ../../configs
LoRA model: /training/output/scripts/training/checkpoing-22200
Loading /training/output/scripts/training/checkpoing-22200
Cannot find lora model on the disk. Downloading lora model from hub...
Traceback (most recent call last):
File "/mnt/d/Chinese-LLaMA-Alpaca-2/scripts/merge_llama2_with_chinese_lora_low_mem.py", line 238, in <module>
lora_model_path = snapshot_download(repo_id=lora_model_path)
File "/home/zw238/miniconda3/envs/train/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 110, in _inner_fn
validate_repo_id(arg_value)
File "/home/zw238/miniconda3/envs/train/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 158, in validate_repo_id
raise HFValidationError(
huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/training/output/scripts/training/checkpoing-22200'. Use `repo_type` argument if needed.
|
closed
|
2023-08-24T01:28:43Z
|
2023-09-05T14:11:44Z
|
https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/181
|
[] |
altria-zewei-wang
| 3 |
google-research/bert
|
tensorflow
| 918 |
What does output_fn at line 471 do in run_squad.py?
|
In run_squad.py at Line 471, under the function convert_examples_to_features, there is a callback:
`output_fn(feature)`
However, there is no function that is defined with the name 'output_fn'.
Is it a function from TPU_estimator? What does it do during both training and prediction?
|
open
|
2019-11-14T11:40:00Z
|
2019-11-14T11:40:00Z
|
https://github.com/google-research/bert/issues/918
|
[] |
JeevaTM
| 0 |
QingdaoU/OnlineJudge
|
django
| 46 |
提交代码时为什么要卡std::endl?
|
https://qduoj.com/problem/4/
上题
``` C++
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
int n;
cin >> n;
vector<int> v;
v.resize(n);
for(int i = 0; i < n; i++)
{
cin >> v[i];
}
sort(v.begin(), v.end());
cin >> n;
cout << v[n - 1];
return 0;
}
```
该代码提交报WA。
``` C++
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
int n;
cin >> n;
vector<int> v;
v.resize(n);
for(int i = 0; i < n; i++)
{
cin >> v[i];
}
sort(v.begin(), v.end());
cin >> n;
cout << v[n - 1] << endl;
return 0;
}
```
加std::endl后AC。
|
closed
|
2016-06-07T14:41:48Z
|
2016-06-08T15:19:21Z
|
https://github.com/QingdaoU/OnlineJudge/issues/46
|
[] |
July541
| 2 |
sqlalchemy/alembic
|
sqlalchemy
| 865 |
Online migration crashes when changing type from Text to REAL
|
**Describe the bug**
Running the commands:
alembic revision --autogenerate
alembic upgrade head
with this configuration:
```py
def run_migrations_online():
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix="sqlalchemy.",
poolclass=pool.NullPool
)
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
include_schemas=True,
compare_server_default=True,
compare_type=True,
)
with context.begin_transaction():
context.run_migrations()
```
**Expected behavior**
No errors and changing the data type from text to real
**To Reproduce**
Having an existing table with a text column (with float values representation), change the data type from Text to REAL. Afterwards, run the migrations.
```py
import sqlalchemy as sa
from alembic import op
# revision identifiers, used by Alembic.
revision = '36a16b8bc992'
down_revision = '58e041e2c164'
branch_labels = None
depends_on = None
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.alter_column('t1', 'p1',
existing_type=sa.TEXT(),
type_=sa.REAL(),
existing_nullable=True,
schema='s1')
op.alter_column('t1', 'p1',
existing_type=sa.TEXT(),
type_=sa.REAL(),
existing_nullable=True,
schema='s2')
op.alter_column('t1', 'p1',
existing_type=sa.TEXT(),
type_=sa.REAL(),
existing_nullable=True,
schema='s3')
op.alter_column('t1', 'p1',
existing_type=sa.TEXT(),
type_=sa.REAL(),
existing_nullable=True,
schema='s4')
# ### end Alembic commands ###
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.alter_column('t1', 'p1',
existing_type=sa.REAL(),
type_=sa.TEXT(),
existing_nullable=True,
schema='s4')
op.alter_column('t1', 'p1',
existing_type=sa.REAL(),
type_=sa.TEXT(),
existing_nullable=True,
schema='s3')
op.alter_column('t1', 'p1',
existing_type=sa.REAL(),
type_=sa.TEXT(),
existing_nullable=True,
schema='s2')
op.alter_column('t1', 'p1',
existing_type=sa.REAL(),
type_=sa.TEXT(),
existing_nullable=True,
schema='s1')
# ### end Alembic commands ###
```
**Error**
```
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 58e041e2c164 -> 36a16b8bc992, empty message
Traceback (most recent call last):
File "...\site-packages\sqlalchemy\engine\base.py", line 1770, in _execute_context
self.dialect.do_execute(
File "...\site-packages\sqlalchemy\engine\default.py", line 717, in do_execute
cursor.execute(statement, parameters)
psycopg2.errors.DatatypeMismatch: column "p1" cannot be cast automatically to type real
HINT: You might need to specify "USING "p1"::real".
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "...\lib\runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "...\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "...\venv\Scripts\alembic.exe\__main__.py", line 7, in <module>
File "...\site-packages\alembic\config.py", line 559, in main
CommandLine(prog=prog).main(argv=argv)
File "...\site-packages\alembic\config.py", line 553, in main
self.run_cmd(cfg, options)
File "...\site-packages\alembic\config.py", line 530, in run_cmd
fn(
File "...\site-packages\alembic\command.py", line 294, in upgrade
script.run_env()
File "...\site-packages\alembic\script\base.py", line 490, in run_env
util.load_python_file(self.dir, "env.py")
File "...\site-packages\alembic\util\pyfiles.py", line 97, in load_python_file
module = load_module_py(module_id, path)
File "...\site-packages\alembic\util\compat.py", line 184, in load_module_py
spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 848, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "...\alembic\env.py", line 135, in <module>
run_migrations_online()
File "...\alembic\env.py", line 129, in run_migrations_online
context.run_migrations()
File "<string>", line 8, in run_migrations
File "...\site-packages\alembic\runtime\environment.py", line 813, in run_migrations
self.get_context().run_migrations(**kw)
File "...\site-packages\alembic\runtime\migration.py", line 561, in run_migrations
step.migration_fn(**kw)
File "...\alembic\versions\36a16b8bc992_.py", line 20, in upgrade
op.alter_column('t1', 'p1',
File "<string>", line 8, in alter_column
File "<string>", line 3, in alter_column
File "...\site-packages\alembic\operations\ops.py", line 1655, in alter_column
return operations.invoke(alt)
File "...\site-packages\alembic\operations\base.py", line 354, in invoke
return fn(self, operation)
File "...\site-packages\alembic\operations\toimpl.py", line 43, in alter_column
operations.impl.alter_column(
File "...\site-packages\alembic\ddl\postgresql.py", line 128, in alter_column
self._exec(
File "...\site-packages\alembic\ddl\impl.py", line 146, in _exec
return conn.execute(construct, multiparams)
File "...\site-packages\sqlalchemy\engine\base.py", line 1262, in execute
return meth(self, multiparams, params, _EMPTY_EXECUTION_OPTS)
File "...\site-packages\sqlalchemy\sql\ddl.py", line 77, in _execute_on_connection
return connection._execute_ddl(
File "...\site-packages\sqlalchemy\engine\base.py", line 1352, in _execute_ddl
ret = self._execute_context(
File "...\site-packages\sqlalchemy\engine\base.py", line 1813, in _execute_context
self._handle_dbapi_exception(
File "...\site-packages\sqlalchemy\engine\base.py", line 1994, in _handle_dbapi_exception
util.raise_(
File "...\site-packages\sqlalchemy\util\compat.py", line 207, in raise_
raise exception
File "...\site-packages\sqlalchemy\engine\base.py", line 1770, in _execute_context
self.dialect.do_execute(
File "...\site-packages\sqlalchemy\engine\default.py", line 717, in do_execute
cursor.execute(statement, parameters)
sqlalchemy.exc.ProgrammingError: (psycopg2.errors.DatatypeMismatch) column "p1" cannot be cast automatically to type real
HINT: You might need to specify "USING "p1"::real".
[SQL: ALTER TABLE jira_autodata."Sprints_backlog" ALTER COLUMN "p1" TYPE REAL ]
(Background on this error at: http://sqlalche.me/e/14/f405)
```
**Versions.**
- OS: Windows
- Python: 3.8.10
- Alembic: 1.6.5
- SQLAlchemy: 1.4.18
- Database: Postgres 12
- DBAPI: psycopg2
**Additional context**
<!-- Add any other context about the problem here. -->
**Have a nice day!**
|
closed
|
2021-06-16T10:37:14Z
|
2021-08-24T07:11:39Z
|
https://github.com/sqlalchemy/alembic/issues/865
|
[] |
Bechma
| 0 |
explosion/spaCy
|
data-science
| 12,923 |
Chinese word segmentation model for spaCy
|
The Chinese word segmentation model zh_core_web_sm-3.5.0 in spaCy has two files. One is weights.npz, which contains dimensions and model weight values, and I can understand that. The other file is features.msgpack; what is this file for? Is it for features? Because I want to train my own word segmentation model and embed it into spaCy, can you explain it?
|
closed
|
2023-08-18T08:15:28Z
|
2023-09-18T05:14:08Z
|
https://github.com/explosion/spaCy/issues/12923
|
[
"models",
"lang / zh",
"third-party"
] |
PythonCancer
| 1 |
huggingface/pytorch-image-models
|
pytorch
| 1,595 |
[BUG] Feature extraction and gradient checkpointing
|
In models with feature extraction that use FeatureListNet, trying to enable gradient checkpointing results in an error.
**To Reproduce**
Steps to reproduce the behavior:
1. Start Google Colab
2. Run the following:
```python
!pip install timm
import timm
myModel = timm.create_model('resnet50', features_only=False)
myModel.set_grad_checkpointing()
...
# as expected
myModel = timm.create_model('resnet50', features_only=True)
myModel.set_grad_checkpointing()
# fails with 'FeatureListNet' object has no attribute 'set_grad_checkpointing'
```
**Expected behavior**
Calling `.set_grad_checkpointing()` on a model with `features_only=True` should work and the forward pass should result in the pyramid features but calculated with gradient checkpointing.
**Desktop (please complete the following information):**
Test was done in Google Colab.
- OS: ubuntu 18.04
- timm-0.6.12
- torch 1.13.0+cu116
|
closed
|
2022-12-17T05:43:07Z
|
2023-02-10T01:48:23Z
|
https://github.com/huggingface/pytorch-image-models/issues/1595
|
[
"bug"
] |
fffffgggg54
| 2 |
pytest-dev/pytest-cov
|
pytest
| 463 |
RecursionError during branch calculate on huge source
|
# Summary
When i tried to generate huge sources and calculate coverage - found the issue.
## Expected vs actual result
Expected, that any size source will be computed with branch coverage
```
============================= test session starts ==============================
platform linux -- Python 3.8.9, pytest-6.2.3, py-1.10.0, pluggy-0.13.1
rootdir: /home/babenek/wunderwaffe
collected 500 items
test_dummy.py .......................................................... [ 11%]
........................................................................ [ 26%]
........................................................................ [ 40%]
........................................................................ [ 54%]
........................................................................ [ 69%]
........................................................................ [ 83%]
........................................................................ [ 98%]
.......... [100%]
INTERNALERROR> Traceback (most recent call last):
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/_pytest/main.py", line 269, in wrap_session
INTERNALERROR> session.exitstatus = doit(config, session) or 0
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/_pytest/main.py", line 323, in _main
INTERNALERROR> config.hook.pytest_runtestloop(session=session)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pluggy/hooks.py", line 286, in __call__
INTERNALERROR> return self._hookexec(self, self.get_hookimpls(), kwargs)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pluggy/manager.py", line 93, in _hookexec
INTERNALERROR> return self._inner_hookexec(hook, methods, kwargs)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pluggy/manager.py", line 84, in <lambda>
INTERNALERROR> self._inner_hookexec = lambda hook, methods, kwargs: hook.multicall(
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pluggy/callers.py", line 203, in _multicall
INTERNALERROR> gen.send(outcome)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pytest_cov/plugin.py", line 271, in pytest_runtestloop
INTERNALERROR> self.cov_controller.finish()
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pytest_cov/engine.py", line 44, in ensure_topdir_wrapper
INTERNALERROR> return meth(self, *args, **kwargs)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/pytest_cov/engine.py", line 167, in summary
INTERNALERROR> total = self.cov.report(**options)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/control.py", line 913, in report
INTERNALERROR> return reporter.report(morfs, outfile=file)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/summary.py", line 45, in report
INTERNALERROR> for fr, analysis in get_analysis_to_report(self.coverage, morfs):
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/report.py", line 70, in get_analysis_to_report
INTERNALERROR> analysis = coverage._analyze(fr)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/control.py", line 808, in _analyze
INTERNALERROR> return Analysis(data, it, self._file_mapper)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/results.py", line 30, in __init__
INTERNALERROR> self._arc_possibilities = sorted(self.file_reporter.arcs())
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/python.py", line 213, in arcs
INTERNALERROR> return self.parser.arcs()
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 273, in arcs
INTERNALERROR> self._analyze_ast()
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 283, in _analyze_ast
INTERNALERROR> aaa.analyze()
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 561, in analyze
INTERNALERROR> code_object_handler(node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 1168, in _code_object__FunctionDef
INTERNALERROR> exits = self.add_body_arcs(node.body, from_start=ArcStart(-start))
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 698, in add_body_arcs
INTERNALERROR> prev_starts = self.add_arcs(body_node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 661, in add_arcs
INTERNALERROR> return handler(node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 942, in _handle__If
...........................................................................................................................................................
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 942, in _handle__If
INTERNALERROR> exits |= self.add_body_arcs(node.orelse, from_start=from_start)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 698, in add_body_arcs
INTERNALERROR> prev_starts = self.add_arcs(body_node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 661, in add_arcs
INTERNALERROR> return handler(node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 940, in _handle__If
INTERNALERROR> exits = self.add_body_arcs(node.body, from_start=from_start)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 698, in add_body_arcs
INTERNALERROR> prev_starts = self.add_arcs(body_node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 661, in add_arcs
INTERNALERROR> return handler(node)
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 962, in _handle__Return
INTERNALERROR> return_start = ArcStart(here, cause="the return on line {lineno} wasn't executed")
INTERNALERROR> File "/home/babenek/.local/lib/python3.8/site-packages/coverage/parser.py", line 493, in __new__
INTERNALERROR> return super(ArcStart, cls).__new__(cls, lineno, cause)
INTERNALERROR> File "<string>", line 1, in __new__
INTERNALERROR> RecursionError: maximum recursion depth exceeded while calling a Python object
```
# Reproducer
```pytest, pytest-cov``` packages are mentioned in requirements.txt
run: ```python3 -m pytest --cov=src```
## Versions
Python 3.6, 3.7, 3.9 were used for tests - the same
## Config
`.coveragerc` was given from https://coverage.readthedocs.io/en/latest/config.html
branch = True - raises the bug
branch = False - does not
## Code
https://github.com/babenek/coverage-recursion-error
Yes, it is dummy file. In real life nobody does like this (we hope).
It is not important for me, but if you would like to pay attention...
|
closed
|
2021-04-14T19:37:15Z
|
2021-07-23T04:08:59Z
|
https://github.com/pytest-dev/pytest-cov/issues/463
|
[] |
babenek
| 2 |
chaos-genius/chaos_genius
|
data-visualization
| 768 |
Refactor the alert view
|
open
|
2022-02-23T14:19:38Z
|
2022-03-14T05:53:52Z
|
https://github.com/chaos-genius/chaos_genius/issues/768
|
[
"good first issue",
"help wanted"
] |
suranah
| 0 |
|
litestar-org/polyfactory
|
pydantic
| 507 |
Bug: Data generated incorrectly from nested Annotated
|
### Description
I have attempted to make this bug report once from another account: https://github.com/litestar-org/polyfactory/issues/506
But it is not visible to any other users (or when logged out)
I am attempting to use nested annotations with pydantic FieldInfo on each level.
I have seen https://github.com/litestar-org/polyfactory/issues/434
and for a moment i thought simply updating polyfactory would solve my problem, but alas.
From what i can see these nested annotations are working correctly in pydantic and seems to be the expectation for more complex annotations, such that FieldInfo is applied to the correct "level" of the annotation.
The a and b attributes produce two different errors that seem related.
### URL to code causing the issue
_No response_
### MCVE
```python
from polyfactory.factories.pydantic_factory import ModelFactory
from pydantic import BaseModel, Field
from typing import Annotated
def ofloatlist(min_length=None, max_length=None, gt=None, ge=None, lt=None, le=None, **kwargs) -> type[None | list[None | float]]:
annotation = None | Annotated[list[None | Annotated[float, Field(gt=gt, ge=ge, lt=lt, le=le)]], Field(min_length=min_length, max_length=max_length)]
return Annotated[annotation, Field(**kwargs)] # type: ignore
bleh = Annotated[None | list[Annotated[None | Annotated[float, Field(ge=0, le=5)], Field(min_length=6)]], Field(title="meh")]
class MyModel(BaseModel):
a: ofloatlist(min_length=6, ge=2, le=5, title="Value") = None
b: bleh = None
class MyModelFactory(ModelFactory):
__model__ = MyModel
__random_seed__ = 3
print(MyModelFactory.build())
```
### Steps to reproduce
```bash
Run the MCVE
```
### Screenshots
_No response_
### Logs
```bash
pydantic_core._pydantic_core.ValidationError: 3 validation errors for MyModel
a.0
Input should be less than or equal to 5 [type=less_than_equal, input_value=67018326269.9516, input_type=float]
For further information visit https://errors.pydantic.dev/2.6/v/less_than_equal
a.3
Input should be less than or equal to 5 [type=less_than_equal, input_value=4563270605912.7, input_type=float]
For further information visit https://errors.pydantic.dev/2.6/v/less_than_equal
b.0
Input should be less than or equal to 5 [type=less_than_equal, input_value=60.518708028656015, input_type=float]
For further information visit https://errors.pydantic.dev/2.6/v/less_than_equal
```
### Release Version
Python: 3.10
Pydantic: 2.6.1
Polyfactory: 2.14.1
### Platform
- [ ] Linux
- [ ] Mac
- [X] Windows
- [ ] Other (Please specify in the description above)
|
closed
|
2024-02-29T13:27:37Z
|
2025-03-20T15:53:14Z
|
https://github.com/litestar-org/polyfactory/issues/507
|
[
"bug",
"duplicate"
] |
XenoMonk
| 4 |
google-research/bert
|
tensorflow
| 579 |
Why BERT divides a word into 3 not meaningfull parts? Is it a bug?
|
I made it bold and bigger. The word Kontinental is a word only. But BERT divides it into 3.
I used BERT as:
os.system("python3 extract_features.py \
--input_file=input.txt \
--output_file=output.jsonl \
--vocab_file=uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=uncased_L-12_H-768_A-12/bert_model.ckpt \
--layers=-1 \
--max_seq_length=256 \
--batch_size=8")
The text i give to BERT:
Upon their acceptance into the **### Kontinental** Hockey League, Dehner left Finland to sign a contract in Germany with EHC M*nchen of the DEL on June 18, 2014. After capturing the German championship with the M*nchen team in 2016, he left the club and was picked up by fellow DEL side EHC Wolfsburg in July 2016. Former NHLer Gary Suter and Olympic-medalist Bob Suter are Dehner's uncles. His cousin is Minnesota Wild's alternate captain Ryan Suter.
And word embeddings it produces:
feat_bilgi: layers token
0 [{'index': -1, 'values': [-0.541755, -0.128789... [CLS]
1 [{'index': -1, 'values': [0.494534, -0.124512,... "
2 [{'index': -1, 'values': [-1.108163, 0.3459100... upon
3 [{'index': -1, 'values': [-0.591283, 0.331246,... their
4 [{'index': -1, 'values': [-0.857997, 0.2843859... acceptance
5 [{'index': -1, 'values': [-1.271261, 0.2383219... into
6 [{'index': -1, 'values': [-0.874073, -0.239765... the
**### 7 [{'index': -1, 'values': [-0.980497, -0.794095... ko
8 [{'index': -1, 'values': [-0.005285, -0.460016... ##ntine
9 [{'index': -1, 'values': [-0.47325399999999995... ##ntal**
10 [{'index': -1, 'values': [-0.418784, -0.295219... hockey
11 [{'index': -1, 'values': [-0.34199399999999996... league
|
open
|
2019-04-14T19:51:14Z
|
2019-07-13T13:35:21Z
|
https://github.com/google-research/bert/issues/579
|
[] |
haydarozler
| 3 |
PeterL1n/BackgroundMattingV2
|
computer-vision
| 19 |
Direct prediction
|
Hi!
I really like your paper, it's written so clearly. I think the whole community is thankful to you for the upcoming datasets. But I do not get one thing. Why do we need to use such a complicated approach if we can take just the difference between a background and a source? In this case, pixels which equal 0 will be our background.
|
closed
|
2020-12-30T17:03:39Z
|
2021-01-01T19:26:30Z
|
https://github.com/PeterL1n/BackgroundMattingV2/issues/19
|
[] |
kkuchynskyi
| 1 |
mars-project/mars
|
numpy
| 3,181 |
Warnning from ray backend:The remote function 'ray.util.client.ommon.get_class_info' has been exported 100 times.
|
* Python: 3.7.11
* mars: 0.9.0
* ray: 1.9.2
```
import ray
import mars
import mars.tensor as mt
n = 20000
ray.init("ray://<my_ray_cluster_addr>")
mars.new_ray_session(worker_num=4, worker_cpu=4)
X = mt.random.RandomState(0).rand(n,n)
invX = mt.linalg.inv(X).execute()
```
And there is a warning
> "The remote function 'ray.util.client.common.get_class_info' has been exported 100 times. It's "
> "possible that this warning is accidental, but this "
> "may indicate that the same remote function is being "
> "defined repeatedly from within many tasks and "
> "exported to all of the workers. This can be a "
> "performance issue and can be resolved by defining "
> "the remote function on the driver instead. See "
> "https://github.com/ray-project/ray/issues/6240 for "
> "more discussion."
|
closed
|
2022-07-07T02:58:39Z
|
2022-07-08T03:32:24Z
|
https://github.com/mars-project/mars/issues/3181
|
[] |
cmsxbc
| 4 |
onnx/onnx
|
deep-learning
| 6,536 |
[Feature request] operator Conv has no example with a bias in the backend test
|
### System information
All
### What is the problem that this feature solves?
Robustness.
### Alternatives considered
_No response_
### Describe the feature
_No response_
### Will this influence the current api (Y/N)?
No
### Feature Area
_No response_
### Are you willing to contribute it (Y/N)
Yes
### Notes
_No response_
|
open
|
2024-11-07T10:22:43Z
|
2024-11-07T10:22:43Z
|
https://github.com/onnx/onnx/issues/6536
|
[
"topic: enhancement"
] |
xadupre
| 0 |
cvat-ai/cvat
|
pytorch
| 8,805 |
Rate limiting breaks annotation UI
|
### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
This is not exactly a reproducer, just what I did to "break" the server :)
1. Upload 19 4k .png files to a project.
2. Annotate ~7 of them.
3. Be unable to move to remaining ones.
### Expected Behavior
Everything works by default :)
### Possible Solution
_No response_
### Context
Hey team, I am stuck with a `uvicorn` error when trying to annotate images, here is a line from `cvat-backend` logs:
```bash
2024-12-09 18:43:25,606 DEBG 'uvicorn-0' stdout output:
INFO: 10.15.0.40:0 - "GET /api/jobs/1/data?org=&quality=compressed&type=chunk&index=0 HTTP/1.0" 429 Too Many Requests
```
I am not sure why there are too many requests to be honest, I am just a single user trying to annotate pictures through the UI.
### Environment
```Markdown
Using provided Helm chart from 12eec5481bb3d4e6219bb8214df524f27b3037e3.
```
|
open
|
2024-12-09T19:10:41Z
|
2025-01-22T16:13:53Z
|
https://github.com/cvat-ai/cvat/issues/8805
|
[
"bug"
] |
pratclot
| 7 |
Kanaries/pygwalker
|
matplotlib
| 192 |
In the GUI, is there a way to modify the range of values on the x or y axis?
|
I found a way to edit in the vega-lite output here:
https://stackoverflow.com/questions/55134128/setting-a-maximum-axis-value-in-vega-lite
But I'm curious if there a way to modify the range of values on the x or y axis in the PyGWalker GUI?
|
open
|
2023-08-06T15:22:15Z
|
2024-09-28T04:12:51Z
|
https://github.com/Kanaries/pygwalker/issues/192
|
[
"enhancement",
"graphic-walker"
] |
jimmybuffi
| 5 |
gradio-app/gradio
|
data-science
| 10,701 |
Gradio meta tags override issue
|
### Describe the bug
## Problem Description
When attempting to set custom meta tags in a Gradio application via the [head](https://www.gradio.app/docs/gradio/blocks#param-blocks-head) parameter for `Blocks`, Gradio overrides or conflicts with custom meta tags, particularly Open Graph and Twitter Card meta tags. This makes it difficult to properly set up social media previews for a Gradio application.
## Steps to Reproduce
- Create a simple Gradio application with custom social media (twitter) meta tags.
- Inspect the HTML source of the resulting page in the browser
- Notice that the twitter meta tags have been overridden by Gradio's default values.
(See attached sample code)
## Expected Behavior
Custom meta tags provided through the head parameter should take precedence over any default meta tags Gradio adds, especially Open Graph and Twitter Card meta tags.
## Actual Behavior
Gradio overwrites the custom meta tags with its own values.
The specific tags I notice this behavior with are:
- `property=og:description`
- `property=og:image`
- `name=twitter:creator`
- `name=twitter:description`
- `name=twitter:image`
## Impact
This issue prevents Gradio applications from properly setting up social media previews, which is critical for applications that are shared on platforms like Twitter, Facebook, Slack, and other social media sites. Without the ability to set custom meta tags, Gradio applications cannot control how they appear when shared on these platforms. (There are work arounds like serving the gradio app in an iframe, but it would be so much simpler if the `head` parameter worked as expected.)
## Possible Solution
Consider adding a specific parameter for social media meta tags or enhancing the existing head parameter to ensure custom meta tags take precedence over any default values.
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
def build_gradio_interface() -> gr.Blocks:
custom_head = """
<!-- HTML Meta Tags -->
<title>Sample App</title>
<meta name="description" content="An open-source web application showcasing various features and capabilities.">
<!-- Facebook Meta Tags -->
<meta property="og:url" content="https://example.com">
<meta property="og:type" content="website">
<meta property="og:title" content="Sample App">
<meta property="og:description" content="An open-source web application showcasing various features and capabilities.">
<meta property="og:image" content="https://example.com/sample-image.jpg">
<!-- Twitter Meta Tags -->
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:creator" content="@example_user">
<meta name="twitter:title" content="Sample App">
<meta name="twitter:description" content="An open-source web application showcasing various features and capabilities.">
<meta name="twitter:image" content="https://example.com/sample-image.jpg">
<meta property="twitter:domain" content="example.com">
<meta property="twitter:url" content="https://example.com">
<!-- Meta Tags Generated via https://www.opengraph.xyz/ -->
"""
with gr.Blocks(
title="My App",
head=custom_head,
) as demo:
gr.HTML("<h1>My App</h1>")
return demo
demo = build_gradio_interface()
demo.launch()
```
### Screenshot
_No response_
### Logs
```shell
```
### System Info
```shell
- Gradio version: 5.18.0
- Browser: Chrome/Firefox
- OS: Windows/Mac/Linux
```
### Severity
I can work around it
|
open
|
2025-03-01T00:03:01Z
|
2025-03-06T09:29:46Z
|
https://github.com/gradio-app/gradio/issues/10701
|
[
"bug"
] |
zgreathouse
| 6 |
X-PLUG/MobileAgent
|
automation
| 76 |
absl.flags._exceptions.DuplicateFlagError
|

|
closed
|
2024-11-25T10:59:52Z
|
2024-11-28T06:14:13Z
|
https://github.com/X-PLUG/MobileAgent/issues/76
|
[] |
ZeruiQin
| 0 |
waditu/tushare
|
pandas
| 1,375 |
pro_bar - API文档描述
|
sdk version: '1.2.58'
doc: https://tushare.pro/document/2?doc_id=146
实测` ts.pro_bar`中的 `adj` 参数
- 为 `""`是,返回的是 前复权,等同于 "qfq"
- 为 `None`是,返回的是 不复权,等同于 "daily"
建议改进文档说明:
- “复权说明” 中描述—— 不复权 | 无 | 空或None;传个空字符串 得到的是前复权价格
|
open
|
2020-06-14T03:08:37Z
|
2020-06-15T10:29:33Z
|
https://github.com/waditu/tushare/issues/1375
|
[] |
chrjxj
| 1 |
axnsan12/drf-yasg
|
rest-api
| 7 |
Output Schemas into definitions
|
Allow Schemas to be output into the definitions sections of the Swagger object, and generate definition references instead of inline models.
- [x] Automatically output a single schema definition per serializer class
- [x] Allow forcing inline output
|
closed
|
2017-12-08T06:00:19Z
|
2017-12-10T02:00:48Z
|
https://github.com/axnsan12/drf-yasg/issues/7
|
[] |
axnsan12
| 1 |
kiwicom/pytest-recording
|
pytest
| 75 |
[FEATURE] Provide a way to use pytest_recording without `pytest.mark.vcr` decorator
|
**Is your feature request related to a problem? Please describe.**
It might be convenient to use `_vcr.use_cassette` directly for granular control of VCR setup & teardown mechanisms.
**Describe the solution you'd like**
Create a separate function that will not depend on pytest-related types & expose it as a part of the public API. It might be used by `_vcr.use_cassette` under the hood (or, likely, `_vcr.use_cassette` will be renamed to something else, and the new function will take this name).
**Additional context**
Requested by @selevit
|
open
|
2021-07-15T15:20:31Z
|
2022-12-08T16:30:17Z
|
https://github.com/kiwicom/pytest-recording/issues/75
|
[
"Type: Feature"
] |
Stranger6667
| 2 |
PaddlePaddle/PaddleHub
|
nlp
| 1,889 |
paddlehub载入u2_conformer_wenetspeech失败
|
### 请提出你的问题 Please ask your question

|
open
|
2022-06-07T04:25:25Z
|
2024-02-26T05:01:55Z
|
https://github.com/PaddlePaddle/PaddleHub/issues/1889
|
[
"status/new-issue",
"type/question"
] |
xiaotingyun
| 1 |
huggingface/datasets
|
deep-learning
| 7,159 |
JSON lines with missing struct fields raise TypeError: Couldn't cast array
|
JSON lines with missing struct fields raise TypeError: Couldn't cast array of type.
See example: https://huggingface.co/datasets/wikimedia/structured-wikipedia/discussions/5
One would expect that the struct missing fields are added with null values.
|
closed
|
2024-09-23T07:57:58Z
|
2024-10-21T08:07:07Z
|
https://github.com/huggingface/datasets/issues/7159
|
[
"bug"
] |
albertvillanova
| 1 |
jupyterhub/repo2docker
|
jupyter
| 1,077 |
Pinning R 4.0 with runtime.txt on mybinder.org not working as expected
|
### Bug description
Pinning the R version to 4.0 using `runtime.txt` on `mybinder.org` does not work – I get R 4.1 instead.
#### Expected behaviour
I expect R version 4.0.5 ("Shake and Throw"):
```
> R.version.string
[1] "R version 4.0.5 (2021-03-31)"
```
#### Actual behaviour
I get R version 4.1.0 ("Camp Pontanezen"):
```
> R.version.string
[1] "R version 4.1.0 (2021-05-18)"
```
### How to reproduce
1. Set up a repository with the following [`runtime.txt`](https://gitlab.com/fkohrt/RMarkdown-sandbox/-/blob/f5d8582b/binder/runtime.txt):
```runtime.txt
r-4.0-2021-05-19
```
2. [](https://gke.mybinder.org/v2/gl/fkohrt%2FRMarkdown-sandbox/f5d8582b?urlpath=rstudio)
### Your personal set up
I am using the `mybinder.org` service.
Versions:
- `jupyterhub --version`: `1.3.0`
- `python --version`: `Python 3.7.10`
<details><summary>Full environment</summary>
```
aiohttp==3.7.4.post0
alembic @ file:///home/conda/feedstock_root/build_artifacts/alembic_1613901514078/work
anyio @ file:///home/conda/feedstock_root/build_artifacts/anyio_1612745536224/work/dist
argon2-cffi @ file:///home/conda/feedstock_root/build_artifacts/argon2-cffi_1602546578258/work
async-generator==1.10
async-timeout==3.0.1
attrs @ file:///home/conda/feedstock_root/build_artifacts/attrs_1605083924122/work
Babel @ file:///home/conda/feedstock_root/build_artifacts/babel_1605182336601/work
backcall @ file:///home/conda/feedstock_root/build_artifacts/backcall_1592338393461/work
backports.functools-lru-cache==1.6.1
bleach @ file:///home/conda/feedstock_root/build_artifacts/bleach_1612213472466/work
blinker==1.4
brotlipy==0.7.0
certifi==2020.12.5
certipy==0.1.3
cffi @ file:///home/conda/feedstock_root/build_artifacts/cffi_1613413867554/work
chardet @ file:///home/conda/feedstock_root/build_artifacts/chardet_1610093487176/work
cryptography @ file:///home/conda/feedstock_root/build_artifacts/cryptography_1612993734132/work
decorator==4.4.2
defusedxml==0.6.0
entrypoints @ file:///home/conda/feedstock_root/build_artifacts/entrypoints_1602701733603/work/dist/entrypoints-0.3-py2.py3-none-any.whl
idna @ file:///home/conda/feedstock_root/build_artifacts/idna_1593328102638/work
importlib-metadata @ file:///home/conda/feedstock_root/build_artifacts/importlib-metadata_1610355166636/work
ipykernel @ file:///home/conda/feedstock_root/build_artifacts/ipykernel_1613852948592/work/dist/ipykernel-5.5.0-py3-none-any.whl
ipython @ file:///home/conda/feedstock_root/build_artifacts/ipython_1612487002309/work
ipython-genutils==0.2.0
ipywidgets @ file:///home/conda/feedstock_root/build_artifacts/ipywidgets_1609995587151/work
jedi @ file:///home/conda/feedstock_root/build_artifacts/jedi_1610146791823/work
Jinja2 @ file:///home/conda/feedstock_root/build_artifacts/jinja2_1612119311452/work
json5 @ file:///home/conda/feedstock_root/build_artifacts/json5_1600692310011/work
jsonschema==3.2.0
jupyter-client @ file:///home/conda/feedstock_root/build_artifacts/jupyter_client_1610375432619/work
jupyter-core @ file:///home/conda/feedstock_root/build_artifacts/jupyter_core_1612125257337/work
jupyter-offlinenotebook @ file:///home/conda/feedstock_root/build_artifacts/jupyter-offlinenotebook_1610833110941/work
jupyter-resource-usage @ file:///home/conda/feedstock_root/build_artifacts/jupyter-resource-usage_1608550684149/work
jupyter-rsession-proxy @ https://github.com/jupyterhub/jupyter-rsession-proxy/archive/d5efed5455870556fc414f30871d0feca675a4b4.zip
jupyter-server @ file:///home/conda/feedstock_root/build_artifacts/jupyter_server_1613709403212/work
jupyter-server-proxy==1.4.0
jupyter-shiny-proxy @ https://github.com/ryanlovett/jupyter-shiny-proxy/archive/47557dc47e2aeeab490eb5f3eeae414cdde4a6a9.zip
jupyter-telemetry @ file:///home/conda/feedstock_root/build_artifacts/jupyter_telemetry_1605173804246/work
jupyterhub @ file:///home/conda/feedstock_root/build_artifacts/jupyterhub-feedstock_1607688225833/work
jupyterlab @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_1612296988614/work
jupyterlab-pygments @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_pygments_1601375948261/work
jupyterlab-server @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_server_1613760084674/work
jupyterlab-widgets @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_widgets_1609173350931/work
Mako @ file:///home/conda/feedstock_root/build_artifacts/mako_1610659158978/work
MarkupSafe @ file:///home/conda/feedstock_root/build_artifacts/markupsafe_1610127564475/work
mistune @ file:///home/conda/feedstock_root/build_artifacts/mistune_1610112870915/work
multidict==5.1.0
nbclassic @ file:///home/conda/feedstock_root/build_artifacts/nbclassic_1610352513187/work
nbclient @ file:///home/conda/feedstock_root/build_artifacts/nbclient_1612903843315/work
nbconvert @ file:///home/conda/feedstock_root/build_artifacts/nbconvert_1605401831777/work
nbformat @ file:///home/conda/feedstock_root/build_artifacts/nbformat_1611005694671/work
nbgitpuller==0.9.0
nest-asyncio @ file:///home/conda/feedstock_root/build_artifacts/nest-asyncio_1605195931949/work
notebook @ file:///home/conda/feedstock_root/build_artifacts/notebook_1610575319689/work
nteract-on-jupyter==2.1.3
oauthlib==3.0.1
packaging @ file:///home/conda/feedstock_root/build_artifacts/packaging_1612459636436/work
pamela==1.0.0
pandocfilters==1.4.2
parso @ file:///home/conda/feedstock_root/build_artifacts/parso_1607618318316/work
pexpect==4.8.0
pickleshare @ file:///home/conda/feedstock_root/build_artifacts/pickleshare_1602535628301/work
prometheus-client @ file:///home/conda/feedstock_root/build_artifacts/prometheus_client_1605543085815/work
prompt-toolkit @ file:///home/conda/feedstock_root/build_artifacts/prompt-toolkit_1613068548426/work
psutil @ file:///home/conda/feedstock_root/build_artifacts/psutil_1610127094245/work
ptyprocess @ file:///home/conda/feedstock_root/build_artifacts/ptyprocess_1609419310487/work/dist/ptyprocess-0.7.0-py2.py3-none-any.whl
pycparser @ file:///home/conda/feedstock_root/build_artifacts/pycparser_1593275161868/work
pycurl==7.43.0.6
Pygments @ file:///home/conda/feedstock_root/build_artifacts/pygments_1613412098605/work
PyJWT @ file:///home/conda/feedstock_root/build_artifacts/pyjwt_1610910308735/work
pyOpenSSL @ file:///home/conda/feedstock_root/build_artifacts/pyopenssl_1608055815057/work
pyparsing==2.4.7
pyrsistent @ file:///home/conda/feedstock_root/build_artifacts/pyrsistent_1610146801408/work
PySocks @ file:///home/conda/feedstock_root/build_artifacts/pysocks_1610291444829/work
python-dateutil==2.8.1
python-editor==1.0.4
python-json-logger @ file:///home/conda/feedstock_root/build_artifacts/python-json-logger_1602545356084/work
pytz @ file:///home/conda/feedstock_root/build_artifacts/pytz_1612179539967/work
pyzmq @ file:///home/conda/feedstock_root/build_artifacts/pyzmq_1613478743724/work
requests @ file:///home/conda/feedstock_root/build_artifacts/requests_1608156231189/work
ruamel.yaml @ file:///home/conda/feedstock_root/build_artifacts/ruamel.yaml_1610291373612/work
ruamel.yaml.clib @ file:///home/conda/feedstock_root/build_artifacts/ruamel.yaml.clib_1610146839777/work
Send2Trash==1.5.0
simpervisor==0.4
six @ file:///home/conda/feedstock_root/build_artifacts/six_1590081179328/work
sniffio @ file:///home/conda/feedstock_root/build_artifacts/sniffio_1610318316464/work
SQLAlchemy @ file:///home/conda/feedstock_root/build_artifacts/sqlalchemy_1612225082967/work
terminado @ file:///home/conda/feedstock_root/build_artifacts/terminado_1609794176029/work
testpath==0.4.4
tornado @ file:///home/conda/feedstock_root/build_artifacts/tornado_1610094704591/work
traitlets @ file:///home/conda/feedstock_root/build_artifacts/traitlets_1602771532708/work
typing-extensions @ file:///home/conda/feedstock_root/build_artifacts/typing_extensions_1602702424206/work
urllib3 @ file:///home/conda/feedstock_root/build_artifacts/urllib3_1611695416663/work
wcwidth @ file:///home/conda/feedstock_root/build_artifacts/wcwidth_1600965781394/work
webencodings==0.5.1
widgetsnbextension @ file:///home/conda/feedstock_root/build_artifacts/widgetsnbextension_1603129364725/work
yarl==1.6.3
zipp @ file:///home/conda/feedstock_root/build_artifacts/zipp_1603668650351/work
```
</details>
### Related information
Explicitly demanding R 4.1 using the following [`runtime.txt`](https://gitlab.com/fkohrt/RMarkdown-sandbox/-/blob/825db203/binder/runtime.txt)…
```runtime.txt
r-4.1-2021-05-20
```
…does not work (which [makes sense](https://github.com/jupyterhub/repo2docker/blob/b66caf6/repo2docker/buildpacks/r.py#L61-L96)):
```
Error during build: Version '4.1' of R is not supported.
```
Try here: [](https://gke.mybinder.org/v2/gl/fkohrt%2FRMarkdown-sandbox/825db203?urlpath=rstudio)
|
closed
|
2021-05-20T21:21:40Z
|
2022-01-25T18:07:46Z
|
https://github.com/jupyterhub/repo2docker/issues/1077
|
[
"bug"
] |
fkohrt
| 14 |
onnx/onnxmltools
|
scikit-learn
| 601 |
convert_xgboost - AssertionError: Missing required property "tree_info".
|
I was trying to run the sample code of convert_xgboost(onnxmltools/docs/examples/plot_convert_xgboost.py), and I got an error ["AssertionError: Missing required property "tree_info".] which is only for Dmatrix ( for sklearn model, it's ok).
Looking forward to your responses.
# ------------------------- The Output is as follow ----------------------------
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1,
objective='multi:softprob', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=None, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
[1 2 2 0 2 0 0 1 0 1 1 2 2 1 2 2 2 2 2 2 0 1 2 0 2 1 1 0 2 2 2 1 2 0 0 2 2
2]
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Input In [10], in <cell line: 71>()
68 bst = train_xgb(param, dtrain, 10)
70 initial_type = [('float_input', FloatTensorType([None, 4]))]
---> 71 onx = convert_xgboost(bst, initial_types=initial_type)
73 sess = rt.InferenceSession(onx.SerializeToString())
74 input_name = sess.get_inputs()[0].name
File ~/miniconda3/envs/mlflow/lib/python3.8/site-packages/onnxmltools/convert/main.py:177, in convert_xgboost(*args, **kwargs)
174 raise RuntimeError('xgboost is not installed. Please install xgboost to use this feature.')
176 from .xgboost.convert import convert
--> 177 return convert(*args, **kwargs)
File ~/miniconda3/envs/mlflow/lib/python3.8/site-packages/onnxmltools/convert/xgboost/convert.py:39, in convert(model, name, initial_types, doc_string, target_opset, targeted_onnx, custom_conversion_functions, custom_shape_calculators)
36 name = str(uuid4().hex)
38 if isinstance(model, xgboost.Booster):
---> 39 model = WrappedBooster(model)
40 target_opset = target_opset if target_opset else get_maximum_opset_supported()
41 topology = parse_xgboost(model, initial_types, target_opset, custom_conversion_functions, custom_shape_calculators)
File ~/miniconda3/envs/mlflow/lib/python3.8/site-packages/onnxmltools/convert/xgboost/_parse.py:85, in WrappedBooster.__init__(self, booster)
83 def __init__(self, booster):
84 self.booster_ = booster
---> 85 self.kwargs = _get_attributes(booster)
87 if self.kwargs['num_class'] > 0:
88 self.classes_ = self._generate_classes(self.kwargs)
File ~/miniconda3/envs/mlflow/lib/python3.8/site-packages/onnxmltools/convert/xgboost/_parse.py:35, in _get_attributes(booster)
33 reg = re.compile(b'("tree_info":\\[[0-9,]*\\])')
34 objs = list(set(reg.findall(bstate)))
---> 35 assert len(objs) == 1, 'Missing required property "tree_info".'
36 tree_info = json.loads("{{{}}}".format(objs[0].decode('ascii')))['tree_info']
37 num_class = len(set(tree_info))
AssertionError: Missing required property "tree_info".
# ---------------------------------------------------------------
|
open
|
2023-01-04T09:37:25Z
|
2023-03-28T09:07:57Z
|
https://github.com/onnx/onnxmltools/issues/601
|
[] |
ShuningL
| 8 |
pykaldi/pykaldi
|
numpy
| 214 |
move from "svn co" to "git clone" or "svn export" in for llvm/install_clif.sh
|
I would be interested in submitting a PR that modifies the `install_clif.sh` file to do one of the following:
1. Moves to `git clone` (from svn) to reflect the move of the official repositories to "git" (note: I wanted to confirm this and the https://llvm.org/ home page states "GitHub Migration: Completed! Many thanks to all the participants").
2. Moves the commands `svn co https://llvm.org/svn/llvm-project/llvm/trunk@307315 llvm` and `svn co https://llvm.org/svn/llvm-project/cfe/trunk@307315 clang` to `svn co https://llvm.org/svn/llvm-project/llvm/trunk@307315 llvm` and `svn co https://llvm.org/svn/llvm-project/cfe/trunk@307315 clang`, respectively.
My feeling is `git clone` would be ideal and I'm happy to submit a PR to either move to using `git clone` or `svn export` if either is preferred.
|
closed
|
2020-04-07T19:16:57Z
|
2021-01-12T17:06:27Z
|
https://github.com/pykaldi/pykaldi/issues/214
|
[] |
colinbjohnson
| 1 |
iperov/DeepFaceLab
|
machine-learning
| 5,294 |
SAEHD Training - Root Errors
|
When trying to run the SAEHD training on my GTX 980 I get these code lines
Something about exhausting a resource called OOM
I really don't know what this is about
Anyone knows how to fix it?
Code:
`Running trainer.
[new] No saved models found. Enter a name of a new model :
new
Model first run.
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : GeForce GTX 980
[0] Which GPU indexes to choose? :
0
[0] Autobackup every N hour ( 0..24 ?:help ) :
0
[n] Write preview history ( y/n ?:help ) :
n
[200000] Target iteration :
200000
[y] Flip faces randomly ( y/n ?:help ) :
y
[8] Batch_size ( ?:help ) :
8
[128] Resolution ( 64-640 ?:help ) :
128
[wf] Face type ( h/mf/f/wf/head ?:help ) :
wf
[liae-ud] AE architecture ( ?:help ) :
liae-ud
[256] AutoEncoder dimensions ( 32-1024 ?:help ) :
256
[64] Encoder dimensions ( 16-256 ?:help ) :
64
[64] Decoder dimensions ( 16-256 ?:help ) :
64
[32] Decoder mask dimensions ( 16-256 ?:help ) :
32
[y] Masked training ( y/n ?:help ) :
y
[n] Eyes and mouth priority ( y/n ?:help ) :
n
[n] Uniform yaw distribution of samples ( y/n ?:help ) :
n
[y] Place models and optimizer on GPU ( y/n ?:help ) :
y
[y] Use AdaBelief optimizer? ( y/n ?:help ) :
y
[n] Use learning rate dropout ( n/y/cpu ?:help ) :
n
[y] Enable random warp of samples ( y/n ?:help ) :
y
[0.0] GAN power ( 0.0 .. 1.0 ?:help ) :
0.0
[0.0] Face style power ( 0.0..100.0 ?:help ) :
0.0
[0.0] Background style power ( 0.0..100.0 ?:help ) :
0.0
[rct] Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) :
rct
[n] Enable gradient clipping ( y/n ?:help ) :
n
[n] Enable pretraining mode ( y/n ?:help ) :
n
Initializing models: 100%|###########################################| 5/5 [00:38<00:00, 7.72s/it]
Loading samples: 100%|######################################| 18627/18627 [03:00<00:00, 103.18it/s]
Loading samples: 100%|########################################| 1381/1381 [00:09<00:00, 143.55it/s]
============== Model Summary ===============
== ==
== Model name: new_SAEHD ==
== ==
== Current iteration: 0 ==
== ==
==------------ Model Options -------------==
== ==
== resolution: 128 ==
== face_type: wf ==
== models_opt_on_gpu: True ==
== archi: liae-ud ==
== ae_dims: 256 ==
== e_dims: 64 ==
== d_dims: 64 ==
== d_mask_dims: 32 ==
== masked_training: True ==
== eyes_mouth_prio: False ==
== uniform_yaw: False ==
== adabelief: True ==
== lr_dropout: n ==
== random_warp: True ==
== true_face_power: 0.0 ==
== face_style_power: 0.0 ==
== bg_style_power: 0.0 ==
== ct_mode: rct ==
== clipgrad: False ==
== pretrain: False ==
== autobackup_hour: 0 ==
== write_preview_history: False ==
== target_iter: 200000 ==
== random_flip: True ==
== batch_size: 8 ==
== gan_power: 0.0 ==
== gan_patch_size: 24 ==
== gan_dims: 16 ==
== ==
==-------------- Running On --------------==
== ==
== Device index: 0 ==
== Name: GeForce GTX 980 ==
== VRAM: 4.00GB ==
== ==
============================================
Starting. Target iteration: 200000. Press "Enter" to stop training and save model.
Trying to do the first iteration. If an error occurs, reduce the model parameters.
!!!
Windows 10 users IMPORTANT notice. You should set this setting in order to work correctly.
https://i.imgur.com/B7cmDCB.jpg
!!!
You are training the model from scratch. It is strongly recommended to use a pretrained model to speed up the training and improve the quality.
Error: 2 root error(s) found.
(0) Resource exhausted: OOM when allocating tensor with shape[8,128,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node LeakyRelu_18 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py:69) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[concat_39/concat/_231]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
(1) Resource exhausted: OOM when allocating tensor with shape[8,128,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node LeakyRelu_18 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py:69) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
0 successful operations.
0 derived errors ignored.
Errors may have originated from an input operation.
Input Source operations connected to node LeakyRelu_18:
Add_29 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\layers\Conv2D.py:105)
Input Source operations connected to node LeakyRelu_18:
Add_29 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\layers\Conv2D.py:105)
Original stack trace for 'LeakyRelu_18':
File "threading.py", line 884, in _bootstrap
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Trainer.py", line 58, in trainerThread
debug=debug,
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\ModelBase.py", line 189, in __init__
self.on_initialize()
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\Model_SAEHD\Model.py", line 381, in on_initialize
gpu_pred_src_src, gpu_pred_src_srcm = self.decoder(gpu_src_code)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\models\ModelBase.py", line 117, in __call__
return self.forward(*args, **kwargs)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py", line 158, in forward
x = self.res2(x)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\models\ModelBase.py", line 117, in __call__
return self.forward(*args, **kwargs)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py", line 69, in forward
x = tf.nn.leaky_relu(x, 0.2)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\util\dispatch.py", line 201, in wrapper
return target(*args, **kwargs)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\ops\nn_ops.py", line 3502, in leaky_relu
return gen_nn_ops.leaky_relu(features, alpha=alpha, name=name)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\ops\gen_nn_ops.py", line 5104, in leaky_relu
"LeakyRelu", features=features, alpha=alpha, name=name)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\op_def_library.py", line 750, in _apply_op_helper
attrs=attr_protos, op_def=op_def)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\ops.py", line 3536, in _create_op_internal
op_def=op_def)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\ops.py", line 1990, in __init__
self._traceback = tf_stack.extract_stack()
Traceback (most recent call last):
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1375, in _do_call
return fn(*args)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1360, in _run_fn
target_list, run_metadata)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1453, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.ResourceExhaustedError: 2 root error(s) found.
(0) Resource exhausted: OOM when allocating tensor with shape[8,128,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node LeakyRelu_18}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[concat_39/concat/_231]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
(1) Resource exhausted: OOM when allocating tensor with shape[8,128,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node LeakyRelu_18}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
0 successful operations.
0 derived errors ignored.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Trainer.py", line 130, in trainerThread
iter, iter_time = model.train_one_iter()
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\ModelBase.py", line 462, in train_one_iter
losses = self.onTrainOneIter()
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\Model_SAEHD\Model.py", line 678, in onTrainOneIter
src_loss, dst_loss = self.src_dst_train (warped_src, target_src, target_srcm, target_srcm_em, warped_dst, target_dst, target_dstm, target_dstm_em)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\Model_SAEHD\Model.py", line 538, in src_dst_train
self.target_dstm_em:target_dstm_em,
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 968, in run
run_metadata_ptr)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1191, in _run
feed_dict_tensor, options, run_metadata)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1369, in _do_run
run_metadata)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1394, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.ResourceExhaustedError: 2 root error(s) found.
(0) Resource exhausted: OOM when allocating tensor with shape[8,128,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node LeakyRelu_18 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py:69) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[concat_39/concat/_231]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
(1) Resource exhausted: OOM when allocating tensor with shape[8,128,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node LeakyRelu_18 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py:69) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
0 successful operations.
0 derived errors ignored.
Errors may have originated from an input operation.
Input Source operations connected to node LeakyRelu_18:
Add_29 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\layers\Conv2D.py:105)
Input Source operations connected to node LeakyRelu_18:
Add_29 (defined at D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\layers\Conv2D.py:105)
Original stack trace for 'LeakyRelu_18':
File "threading.py", line 884, in _bootstrap
File "threading.py", line 916, in _bootstrap_inner
File "threading.py", line 864, in run
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\mainscripts\Trainer.py", line 58, in trainerThread
debug=debug,
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\ModelBase.py", line 189, in __init__
self.on_initialize()
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\models\Model_SAEHD\Model.py", line 381, in on_initialize
gpu_pred_src_src, gpu_pred_src_srcm = self.decoder(gpu_src_code)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\models\ModelBase.py", line 117, in __call__
return self.forward(*args, **kwargs)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py", line 158, in forward
x = self.res2(x)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\models\ModelBase.py", line 117, in __call__
return self.forward(*args, **kwargs)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\DeepFaceLab\core\leras\archis\DeepFakeArchi.py", line 69, in forward
x = tf.nn.leaky_relu(x, 0.2)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\util\dispatch.py", line 201, in wrapper
return target(*args, **kwargs)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\ops\nn_ops.py", line 3502, in leaky_relu
return gen_nn_ops.leaky_relu(features, alpha=alpha, name=name)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\ops\gen_nn_ops.py", line 5104, in leaky_relu
"LeakyRelu", features=features, alpha=alpha, name=name)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\op_def_library.py", line 750, in _apply_op_helper
attrs=attr_protos, op_def=op_def)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\ops.py", line 3536, in _create_op_internal
op_def=op_def)
File "D:\.Arquivos\Programs\DFL\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\ops.py", line 1990, in __init__
self._traceback = tf_stack.extract_stack()`
|
closed
|
2021-03-23T23:04:40Z
|
2021-03-29T15:46:32Z
|
https://github.com/iperov/DeepFaceLab/issues/5294
|
[] |
JapaTuts
| 0 |
nalepae/pandarallel
|
pandas
| 162 |
CUstomizing progress bars
|
Although it is easy to customize the progress bar display by modifying utils/progressbars, it would be great to have the opportunity to set custom progressbar at initialization.
something like
`pandarallel.initialize(progress=MyProgressBar)`
where MyProgressBar would be a custom class (similar to those defined in utils)
I've tried to monkey patch pandarallel, but couldn't reach my goals. could someone point give some starting information to implement that feature?
|
open
|
2021-12-08T13:22:57Z
|
2024-01-23T09:57:30Z
|
https://github.com/nalepae/pandarallel/issues/162
|
[
"enhancement"
] |
Yves33
| 1 |
huggingface/peft
|
pytorch
| 1,889 |
local pytest run puts torch.allclose() out of range in test_4bit_lora_mixed_adapter_batches_lora
|
### System Info
peft main branch (7ffa43b16e4625322c9f157db12c9358f2f54cdf)
System is Ubuntu 22.04 with 2x3090 ti cards.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder
- [ ] My own task or dataset (give details below)
### Reproduction
Run `pytest -v tests/test_common_gpu.py -k test_4bit_lora_mixed_adapter_batches_lora`
### Expected behavior
Test pass. Instead, the resulting tensors are a tiny bit too different. Adding
```py
if not torch.allclose(out_adapter0[1::3], out_mixed[1::3], atol=atol, rtol=rtol):
def compare_tensors(A, B, prefix=""):
for i, (a, b) in enumerate(zip(A, B)):
if len(a.shape) > 1:
compare_tensors(a, b, f"{prefix}{i}.")
elif not torch.allclose(a, b, atol=atol, rtol=rtol):
for j, (c, d) in enumerate(zip(a, b)):
if not torch.allclose(c, d, atol=atol, rtol=rtol):
print(f"{prefix}{i}.{j}: {c} vs {d}")
compare_tensors(out_adapter0[1::3], out_mixed[1::3])
```
above the second-to-last (failing) assert produces (1617 out of range cases)
<details>
<summary>non-comprehensive list of not torch.allclose() scalars</summary>
```
0.7.49: 0.03169405832886696 vs 0.03168218210339546
0.7.69: -0.34240224957466125 vs -0.34242019057273865
0.7.78: -0.07967423647642136 vs -0.07969018816947937
0.7.79: 1.0376322269439697 vs 1.037610411643982
...
0.8.49: 0.03169405832886696 vs 0.03168218210339546
0.8.69: -0.34240224957466125 vs -0.34242019057273865
0.8.78: -0.07967423647642136 vs -0.07969018816947937
...
0.9.49: 0.03169405832886696 vs 0.03168218210339546
0.9.69: -0.34240224957466125 vs -0.34242019057273865
0.9.78: -0.07967423647642136 vs -0.07969018816947937
...
0.10.49: 0.03169405832886696 vs 0.03168218210339546
0.10.69: -0.34240224957466125 vs -0.34242019057273865
0.10.78: -0.07967423647642136 vs -0.07969018816947937
...
0.11.49: 0.03169405832886696 vs 0.03168218210339546
0.11.69: -0.34240224957466125 vs -0.34242019057273865
0.11.78: -0.07967423647642136 vs -0.07969018816947937
...
0.12.49: 0.03169405832886696 vs 0.03168218210339546
0.12.69: -0.34240224957466125 vs -0.34242019057273865
0.12.78: -0.07967423647642136 vs -0.07969018816947937
...
0.13.49: 0.03169405832886696 vs 0.03168218210339546
0.13.69: -0.34240224957466125 vs -0.34242019057273865
0.13.78: -0.07967423647642136 vs -0.07969018816947937
...
```
</details>
It appears like this test is not failing on github, so if there is something I can do on my side to make it pass please advise.
|
closed
|
2024-06-27T04:08:41Z
|
2024-07-02T09:37:44Z
|
https://github.com/huggingface/peft/issues/1889
|
[] |
kallewoof
| 6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.