
path
stringlengths 9
135
| content
stringlengths 8
143k
|
|---|---|
qdrant-landing/content/documentation/concepts/payload.md | ---
title: Payload
weight: 40
aliases:
- ../payload
---
# Payload
One of the significant features of Qdrant is the ability to store additional information along with vectors.
This information is called `payload` in Qdrant terminology.
Qdrant allows you to store any information that can be represented using JSON.
Here is an example of a typical payload:
```json
{
"name": "jacket",
"colors": ["red", "blue"],
"count": 10,
"price": 11.99,
"locations": [
{
"lon": 52.5200,
"lat": 13.4050
}
],
"reviews": [
{
"user": "alice",
"score": 4
},
{
"user": "bob",
"score": 5
}
]
}
```
## Payload types
In addition to storing payloads, Qdrant also allows you search based on certain kinds of values.
This feature is implemented as additional filters during the search and will enable you to incorporate custom logic on top of semantic similarity.
During the filtering, Qdrant will check the conditions over those values that match the type of the filtering condition. If the stored value type does not fit the filtering condition - it will be considered not satisfied.
For example, you will get an empty output if you apply the [range condition](../filtering/#range) on the string data.
However, arrays (multiple values of the same type) are treated a little bit different. When we apply a filter to an array, it will succeed if at least one of the values inside the array meets the condition.
The filtering process is discussed in detail in the section [Filtering](../filtering/).
Let's look at the data types that Qdrant supports for searching:
### Integer
`integer` - 64-bit integer in the range from `-9223372036854775808` to `9223372036854775807`.
Example of single and multiple `integer` values:
```json
{
"count": 10,
"sizes": [35, 36, 38]
}
```
### Float
`float` - 64-bit floating point number.
Example of single and multiple `float` values:
```json
{
"price": 11.99,
"ratings": [9.1, 9.2, 9.4]
}
```
### Bool
Bool - binary value. Equals to `true` or `false`.
Example of single and multiple `bool` values:
```json
{
"is_delivered": true,
"responses": [false, false, true, false]
}
```
### Keyword
`keyword` - string value.
Example of single and multiple `keyword` values:
```json
{
"name": "Alice",
"friends": [
"bob",
"eva",
"jack"
]
}
```
### Geo
`geo` is used to represent geographical coordinates.
Example of single and multiple `geo` values:
```json
{
"location": {
"lon": 52.5200,
"lat": 13.4050
},
"cities": [
{
"lon": 51.5072,
"lat": 0.1276
},
{
"lon": 40.7128,
"lat": 74.0060
}
]
}
```
Coordinate should be described as an object containing two fields: `lon` - for longitude, and `lat` - for latitude.
### Datetime
*Available as of v1.8.0*
`datetime` - date and time in [RFC 3339] format.
See the following examples of single and multiple `datetime` values:
```json
{
"created_at": "2023-02-08T10:49:00Z",
"updated_at": [
"2023-02-08T13:52:00Z",
"2023-02-21T21:23:00Z"
]
}
```
The following formats are supported:
- `"2023-02-08T10:49:00Z"` ([RFC 3339], UTC)
- `"2023-02-08T11:49:00+01:00"` ([RFC 3339], with timezone)
- `"2023-02-08T10:49:00"` (without timezone, UTC is assumed)
- `"2023-02-08T10:49"` (without timezone and seconds)
- `"2023-02-08"` (only date, midnight is assumed)
Notes about the format:
- `T` can be replaced with a space.
- The `T` and `Z` symbols are case-insensitive.
- UTC is always assumed when the timezone is not specified.
- Timezone can have the following formats: `±HH:MM`, `±HHMM`, `±HH`, or `Z`.
- Seconds can have up to 6 decimals, so the finest granularity for `datetime` is microseconds.
[RFC 3339]: https://datatracker.ietf.org/doc/html/rfc3339#section-5.6
## Create point with payload
REST API ([Schema](https://api.qdrant.tech/api-reference/points/upsert-points))
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"vector": [0.05, 0.61, 0.76, 0.74],
"payload": {"city": "Berlin", "price": 1.99}
},
{
"id": 2,
"vector": [0.19, 0.81, 0.75, 0.11],
"payload": {"city": ["Berlin", "London"], "price": 1.99}
},
{
"id": 3,
"vector": [0.36, 0.55, 0.47, 0.94],
"payload": {"city": ["Berlin", "Moscow"], "price": [1.99, 2.99]}
}
]
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector=[0.05, 0.61, 0.76, 0.74],
payload={
"city": "Berlin",
"price": 1.99,
},
),
models.PointStruct(
id=2,
vector=[0.19, 0.81, 0.75, 0.11],
payload={
"city": ["Berlin", "London"],
"price": 1.99,
},
),
models.PointStruct(
id=3,
vector=[0.36, 0.55, 0.47, 0.94],
payload={
"city": ["Berlin", "Moscow"],
"price": [1.99, 2.99],
},
),
],
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.upsert("{collection_name}", {
points: [
{
id: 1,
vector: [0.05, 0.61, 0.76, 0.74],
payload: {
city: "Berlin",
price: 1.99,
},
},
{
id: 2,
vector: [0.19, 0.81, 0.75, 0.11],
payload: {
city: ["Berlin", "London"],
price: 1.99,
},
},
{
id: 3,
vector: [0.36, 0.55, 0.47, 0.94],
payload: {
city: ["Berlin", "Moscow"],
price: [1.99, 2.99],
},
},
],
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::PointStruct};
use serde_json::json;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
let points = vec![
PointStruct::new(
1,
vec![0.05, 0.61, 0.76, 0.74],
json!(
{"city": "Berlin", "price": 1.99}
)
.try_into()
.unwrap(),
),
PointStruct::new(
2,
vec![0.19, 0.81, 0.75, 0.11],
json!(
{"city": ["Berlin", "London"]}
)
.try_into()
.unwrap(),
),
PointStruct::new(
3,
vec![0.36, 0.55, 0.47, 0.94],
json!(
{"city": ["Berlin", "Moscow"], "price": [1.99, 2.99]}
)
.try_into()
.unwrap(),
),
];
client
.upsert_points("{collection_name}".to_string(), None, points, None)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(0.05f, 0.61f, 0.76f, 0.74f))
.putAllPayload(Map.of("city", value("Berlin"), "price", value(1.99)))
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(vectors(0.19f, 0.81f, 0.75f, 0.11f))
.putAllPayload(
Map.of("city", list(List.of(value("Berlin"), value("London")))))
.build(),
PointStruct.newBuilder()
.setId(id(3))
.setVectors(vectors(0.36f, 0.55f, 0.47f, 0.94f))
.putAllPayload(
Map.of(
"city",
list(List.of(value("Berlin"), value("London"))),
"price",
list(List.of(value(1.99), value(2.99)))))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new PointStruct
{
Id = 1,
Vectors = new[] { 0.05f, 0.61f, 0.76f, 0.74f },
Payload = { ["city"] = "Berlin", ["price"] = 1.99 }
},
new PointStruct
{
Id = 2,
Vectors = new[] { 0.19f, 0.81f, 0.75f, 0.11f },
Payload = { ["city"] = new[] { "Berlin", "London" } }
},
new PointStruct
{
Id = 3,
Vectors = new[] { 0.36f, 0.55f, 0.47f, 0.94f },
Payload =
{
["city"] = new[] { "Berlin", "Moscow" },
["price"] = new Value
{
ListValue = new ListValue { Values = { new Value[] { 1.99, 2.99 } } }
}
}
}
}
);
```
## Update payload
### Set payload
Set only the given payload values on a point.
REST API ([Schema](https://api.qdrant.tech/api-reference/points/set-payload)):
```http
POST /collections/{collection_name}/points/payload
{
"payload": {
"property1": "string",
"property2": "string"
},
"points": [
0, 3, 100
]
}
```
```python
client.set_payload(
collection_name="{collection_name}",
payload={
"property1": "string",
"property2": "string",
},
points=[0, 3, 10],
)
```
```typescript
client.setPayload("{collection_name}", {
payload: {
property1: "string",
property2: "string",
},
points: [0, 3, 10],
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, PointsIdsList, PointsSelector,
};
use serde_json::json;
client
.set_payload_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(PointsIdsList {
ids: vec![0.into(), 3.into(), 10.into()],
})),
},
json!({
"property1": "string",
"property2": "string",
})
.try_into()
.unwrap(),
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
client
.setPayloadAsync(
"{collection_name}",
Map.of("property1", value("string"), "property2", value("string")),
List.of(id(0), id(3), id(10)),
true,
null,
null)
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SetPayloadAsync(
collectionName: "{collection_name}",
payload: new Dictionary<string, Value> { { "property1", "string" }, { "property2", "string" } },
ids: new ulong[] { 0, 3, 10 }
);
```
You don't need to know the ids of the points you want to modify. The alternative
is to use filters.
```http
POST /collections/{collection_name}/points/payload
{
"payload": {
"property1": "string",
"property2": "string"
},
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
}
}
```
```python
client.set_payload(
collection_name="{collection_name}",
payload={
"property1": "string",
"property2": "string",
},
points=models.Filter(
must=[
models.FieldCondition(
key="color",
match=models.MatchValue(value="red"),
),
],
),
)
```
```typescript
client.setPayload("{collection_name}", {
payload: {
property1: "string",
property2: "string",
},
filter: {
must: [
{
key: "color",
match: {
value: "red",
},
},
],
},
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, Condition, Filter, PointsSelector,
};
use serde_json::json;
client
.set_payload_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Filter(Filter::must([
Condition::matches("color", "red".to_string()),
]))),
},
json!({
"property1": "string",
"property2": "string",
})
.try_into()
.unwrap(),
None,
)
.await?;
```
```java
import java.util.Map;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import static io.qdrant.client.ValueFactory.value;
client
.setPayloadAsync(
"{collection_name}",
Map.of("property1", value("string"), "property2", value("string")),
Filter.newBuilder().addMust(matchKeyword("color", "red")).build(),
true,
null,
null)
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.SetPayloadAsync(
collectionName: "{collection_name}",
payload: new Dictionary<string, Value> { { "property1", "string" }, { "property2", "string" } },
filter: MatchKeyword("color", "red")
);
```
_Available as of v1.8.0_
It is possible to modify only a specific key of the payload by using the `key` parameter.
For instance, given the following payload JSON object on a point:
```json
{
"property1": {
"nested_property": "foo",
},
"property2": {
"nested_property": "bar",
}
}
```
You can modify the `nested_property` of `property1` with the following request:
```http
POST /collections/{collection_name}/points/payload
{
"payload": {
"nested_property": "qux",
},
"key": "property1",
"points": [1]
}
```
Resulting in the following payload:
```json
{
"property1": {
"nested_property": "qux",
},
"property2": {
"nested_property": "bar",
}
}
```
### Overwrite payload
Fully replace any existing payload with the given one.
REST API ([Schema](https://api.qdrant.tech/api-reference/points/overwrite-payload)):
```http
PUT /collections/{collection_name}/points/payload
{
"payload": {
"property1": "string",
"property2": "string"
},
"points": [
0, 3, 100
]
}
```
```python
client.overwrite_payload(
collection_name="{collection_name}",
payload={
"property1": "string",
"property2": "string",
},
points=[0, 3, 10],
)
```
```typescript
client.overwritePayload("{collection_name}", {
payload: {
property1: "string",
property2: "string",
},
points: [0, 3, 10],
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, PointsIdsList, PointsSelector,
};
use serde_json::json;
client
.overwrite_payload_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(PointsIdsList {
ids: vec![0.into(), 3.into(), 10.into()],
})),
},
json!({
"property1": "string",
"property2": "string",
})
.try_into()
.unwrap(),
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
client
.overwritePayloadAsync(
"{collection_name}",
Map.of("property1", value("string"), "property2", value("string")),
List.of(id(0), id(3), id(10)),
true,
null,
null)
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.OverwritePayloadAsync(
collectionName: "{collection_name}",
payload: new Dictionary<string, Value> { { "property1", "string" }, { "property2", "string" } },
ids: new ulong[] { 0, 3, 10 }
);
```
Like [set payload](#set-payload), you don't need to know the ids of the points
you want to modify. The alternative is to use filters.
### Clear payload
This method removes all payload keys from specified points
REST API ([Schema](https://api.qdrant.tech/api-reference/points/clear-payload)):
```http
POST /collections/{collection_name}/points/payload/clear
{
"points": [0, 3, 100]
}
```
```python
client.clear_payload(
collection_name="{collection_name}",
points_selector=[0, 3, 100],
)
```
```typescript
client.clearPayload("{collection_name}", {
points: [0, 3, 100],
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, PointsIdsList, PointsSelector,
};
client
.clear_payload(
"{collection_name}",
None,
Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(PointsIdsList {
ids: vec![0.into(), 3.into(), 100.into()],
})),
}),
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
client
.clearPayloadAsync("{collection_name}", List.of(id(0), id(3), id(100)), true, null, null)
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.ClearPayloadAsync(collectionName: "{collection_name}", ids: new ulong[] { 0, 3, 100 });
```
<aside role="status">
You can also use <code>models.FilterSelector</code> to remove the points matching given filter criteria, instead of providing the ids.
</aside>
### Delete payload keys
Delete specific payload keys from points.
REST API ([Schema](https://api.qdrant.tech/api-reference/points/delete-payload)):
```http
POST /collections/{collection_name}/points/payload/delete
{
"keys": ["color", "price"],
"points": [0, 3, 100]
}
```
```python
client.delete_payload(
collection_name="{collection_name}",
keys=["color", "price"],
points=[0, 3, 100],
)
```
```typescript
client.deletePayload("{collection_name}", {
keys: ["color", "price"],
points: [0, 3, 100],
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, PointsIdsList, PointsSelector,
};
client
.delete_payload_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(PointsIdsList {
ids: vec![0.into(), 3.into(), 100.into()],
})),
},
vec!["color".to_string(), "price".to_string()],
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
client
.deletePayloadAsync(
"{collection_name}",
List.of("color", "price"),
List.of(id(0), id(3), id(100)),
true,
null,
null)
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.DeletePayloadAsync(
collectionName: "{collection_name}",
keys: ["color", "price"],
ids: new ulong[] { 0, 3, 100 }
);
```
Alternatively, you can use filters to delete payload keys from the points.
```http
POST /collections/{collection_name}/points/payload/delete
{
"keys": ["color", "price"],
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
}
}
```
```python
client.delete_payload(
collection_name="{collection_name}",
keys=["color", "price"],
points=models.Filter(
must=[
models.FieldCondition(
key="color",
match=models.MatchValue(value="red"),
),
],
),
)
```
```typescript
client.deletePayload("{collection_name}", {
keys: ["color", "price"],
filter: {
must: [
{
key: "color",
match: {
value: "red",
},
},
],
},
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, Condition, Filter, PointsSelector,
};
client
.delete_payload_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Filter(Filter::must([
Condition::matches("color", "red".to_string()),
]))),
},
vec!["color".to_string(), "price".to_string()],
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.ConditionFactory.matchKeyword;
client
.deletePayloadAsync(
"{collection_name}",
List.of("color", "price"),
Filter.newBuilder().addMust(matchKeyword("color", "red")).build(),
true,
null,
null)
.get();
```
```csharp
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.DeletePayloadAsync(
collectionName: "{collection_name}",
keys: ["color", "price"],
filter: MatchKeyword("color", "red")
);
```
## Payload indexing
To search more efficiently with filters, Qdrant allows you to create indexes for payload fields by specifying the name and type of field it is intended to be.
The indexed fields also affect the vector index. See [Indexing](../indexing/) for details.
In practice, we recommend creating an index on those fields that could potentially constrain the results the most.
For example, using an index for the object ID will be much more efficient, being unique for each record, than an index by its color, which has only a few possible values.
In compound queries involving multiple fields, Qdrant will attempt to use the most restrictive index first.
To create index for the field, you can use the following:
REST API ([Schema](https://api.qdrant.tech/api-reference/indexes/create-field-index))
```http
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": "keyword"
}
```
```python
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema="keyword",
)
```
```typescript
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: "keyword",
});
```
```rust
use qdrant_client::qdrant::FieldType;
client
.create_field_index(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Keyword,
None,
None,
)
.await?;
```
```java
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
client.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Keyword,
null,
true,
null,
null);
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index"
);
```
The index usage flag is displayed in the payload schema with the [collection info API](https://api.qdrant.tech/api-reference/collections/get-collection).
Payload schema example:
```json
{
"payload_schema": {
"property1": {
"data_type": "keyword"
},
"property2": {
"data_type": "integer"
}
}
}
```
|
qdrant-landing/content/documentation/concepts/points.md | ---
title: Points
weight: 40
aliases:
- ../points
---
# Points
The points are the central entity that Qdrant operates with.
A point is a record consisting of a vector and an optional [payload](../payload/).
You can search among the points grouped in one [collection](../collections/) based on vector similarity.
This procedure is described in more detail in the [search](../search/) and [filtering](../filtering/) sections.
This section explains how to create and manage vectors.
Any point modification operation is asynchronous and takes place in 2 steps.
At the first stage, the operation is written to the Write-ahead-log.
After this moment, the service will not lose the data, even if the machine loses power supply.
## Awaiting result
If the API is called with the `&wait=false` parameter, or if it is not explicitly specified, the client will receive an acknowledgment of receiving data:
```json
{
"result": {
"operation_id": 123,
"status": "acknowledged"
},
"status": "ok",
"time": 0.000206061
}
```
This response does not mean that the data is available for retrieval yet. This
uses a form of eventual consistency. It may take a short amount of time before it
is actually processed as updating the collection happens in the background. In
fact, it is possible that such request eventually fails.
If inserting a lot of vectors, we also recommend using asynchronous requests to take advantage of pipelining.
If the logic of your application requires a guarantee that the vector will be available for searching immediately after the API responds, then use the flag `?wait=true`.
In this case, the API will return the result only after the operation is finished:
```json
{
"result": {
"operation_id": 0,
"status": "completed"
},
"status": "ok",
"time": 0.000206061
}
```
## Point IDs
Qdrant supports using both `64-bit unsigned integers` and `UUID` as identifiers for points.
Examples of UUID string representations:
- simple: `936DA01F9ABD4d9d80C702AF85C822A8`
- hyphenated: `550e8400-e29b-41d4-a716-446655440000`
- urn: `urn:uuid:F9168C5E-CEB2-4faa-B6BF-329BF39FA1E4`
That means that in every request UUID string could be used instead of numerical id.
Example:
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": "5c56c793-69f3-4fbf-87e6-c4bf54c28c26",
"payload": {"color": "red"},
"vector": [0.9, 0.1, 0.1]
}
]
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id="5c56c793-69f3-4fbf-87e6-c4bf54c28c26",
payload={
"color": "red",
},
vector=[0.9, 0.1, 0.1],
),
],
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.upsert("{collection_name}", {
points: [
{
id: "5c56c793-69f3-4fbf-87e6-c4bf54c28c26",
payload: {
color: "red",
},
vector: [0.9, 0.1, 0.1],
},
],
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::PointStruct};
use serde_json::json;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.upsert_points_blocking(
"{collection_name}".to_string(),
None,
vec![PointStruct::new(
"5c56c793-69f3-4fbf-87e6-c4bf54c28c26".to_string(),
vec![0.05, 0.61, 0.76, 0.74],
json!(
{"color": "Red"}
)
.try_into()
.unwrap(),
)],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import java.util.UUID;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(UUID.fromString("5c56c793-69f3-4fbf-87e6-c4bf54c28c26")))
.setVectors(vectors(0.05f, 0.61f, 0.76f, 0.74f))
.putAllPayload(Map.of("color", value("Red")))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = Guid.Parse("5c56c793-69f3-4fbf-87e6-c4bf54c28c26"),
Vectors = new[] { 0.05f, 0.61f, 0.76f, 0.74f },
Payload = { ["city"] = "red" }
}
}
);
```
and
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"payload": {"color": "red"},
"vector": [0.9, 0.1, 0.1]
}
]
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
payload={
"color": "red",
},
vector=[0.9, 0.1, 0.1],
),
],
)
```
```typescript
client.upsert("{collection_name}", {
points: [
{
id: 1,
payload: {
color: "red",
},
vector: [0.9, 0.1, 0.1],
},
],
});
```
```rust
use qdrant_client::qdrant::PointStruct;
use serde_json::json;
client
.upsert_points_blocking(
1,
None,
vec![PointStruct::new(
"5c56c793-69f3-4fbf-87e6-c4bf54c28c26".to_string(),
vec![0.05, 0.61, 0.76, 0.74],
json!(
{"color": "Red"}
)
.try_into()
.unwrap(),
)],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(0.05f, 0.61f, 0.76f, 0.74f))
.putAllPayload(Map.of("color", value("Red")))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new[] { 0.05f, 0.61f, 0.76f, 0.74f },
Payload = { ["city"] = "red" }
}
}
);
```
are both possible.
## Upload points
To optimize performance, Qdrant supports batch loading of points. I.e., you can load several points into the service in one API call.
Batching allows you to minimize the overhead of creating a network connection.
The Qdrant API supports two ways of creating batches - record-oriented and column-oriented.
Internally, these options do not differ and are made only for the convenience of interaction.
Create points with batch:
```http
PUT /collections/{collection_name}/points
{
"batch": {
"ids": [1, 2, 3],
"payloads": [
{"color": "red"},
{"color": "green"},
{"color": "blue"}
],
"vectors": [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9]
]
}
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=models.Batch(
ids=[1, 2, 3],
payloads=[
{"color": "red"},
{"color": "green"},
{"color": "blue"},
],
vectors=[
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9],
],
),
)
```
```typescript
client.upsert("{collection_name}", {
batch: {
ids: [1, 2, 3],
payloads: [{ color: "red" }, { color: "green" }, { color: "blue" }],
vectors: [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9],
],
},
});
```
or record-oriented equivalent:
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"payload": {"color": "red"},
"vector": [0.9, 0.1, 0.1]
},
{
"id": 2,
"payload": {"color": "green"},
"vector": [0.1, 0.9, 0.1]
},
{
"id": 3,
"payload": {"color": "blue"},
"vector": [0.1, 0.1, 0.9]
}
]
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
payload={
"color": "red",
},
vector=[0.9, 0.1, 0.1],
),
models.PointStruct(
id=2,
payload={
"color": "green",
},
vector=[0.1, 0.9, 0.1],
),
models.PointStruct(
id=3,
payload={
"color": "blue",
},
vector=[0.1, 0.1, 0.9],
),
],
)
```
```typescript
client.upsert("{collection_name}", {
points: [
{
id: 1,
payload: { color: "red" },
vector: [0.9, 0.1, 0.1],
},
{
id: 2,
payload: { color: "green" },
vector: [0.1, 0.9, 0.1],
},
{
id: 3,
payload: { color: "blue" },
vector: [0.1, 0.1, 0.9],
},
],
});
```
```rust
use qdrant_client::qdrant::PointStruct;
use serde_json::json;
client
.upsert_points_batch_blocking(
"{collection_name}".to_string(),
None,
vec![
PointStruct::new(
1,
vec![0.9, 0.1, 0.1],
json!(
{"color": "red"}
)
.try_into()
.unwrap(),
),
PointStruct::new(
2,
vec![0.1, 0.9, 0.1],
json!(
{"color": "green"}
)
.try_into()
.unwrap(),
),
PointStruct::new(
3,
vec![0.1, 0.1, 0.9],
json!(
{"color": "blue"}
)
.try_into()
.unwrap(),
),
],
None,
100,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(0.9f, 0.1f, 0.1f))
.putAllPayload(Map.of("color", value("red")))
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(vectors(0.1f, 0.9f, 0.1f))
.putAllPayload(Map.of("color", value("green")))
.build(),
PointStruct.newBuilder()
.setId(id(3))
.setVectors(vectors(0.1f, 0.1f, 0.9f))
.putAllPayload(Map.of("color", value("blue")))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new[] { 0.9f, 0.1f, 0.1f },
Payload = { ["city"] = "red" }
},
new()
{
Id = 2,
Vectors = new[] { 0.1f, 0.9f, 0.1f },
Payload = { ["city"] = "green" }
},
new()
{
Id = 3,
Vectors = new[] { 0.1f, 0.1f, 0.9f },
Payload = { ["city"] = "blue" }
}
}
);
```
The Python client has additional features for loading points, which include:
- Parallelization
- A retry mechanism
- Lazy batching support
For example, you can read your data directly from hard drives, to avoid storing all data in RAM. You can use these
features with the `upload_collection` and `upload_points` methods.
Similar to the basic upsert API, these methods support both record-oriented and column-oriented formats.
<aside role="status">
<code>upload_points</code> is available as of v1.7.1. It has replaced <code>upload_records</code> which is now deprecated.
</aside>
Column-oriented format:
```python
client.upload_collection(
collection_name="{collection_name}",
ids=[1, 2],
payload=[
{"color": "red"},
{"color": "green"},
],
vectors=[
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
],
parallel=4,
max_retries=3,
)
```
<aside role="status">
If <code>ids</code> are not provided, Qdrant Client will generate them automatically as random UUIDs.
</aside>
Record-oriented format:
```python
client.upload_points(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
payload={
"color": "red",
},
vector=[0.9, 0.1, 0.1],
),
models.PointStruct(
id=2,
payload={
"color": "green",
},
vector=[0.1, 0.9, 0.1],
),
],
parallel=4,
max_retries=3,
)
```
All APIs in Qdrant, including point loading, are idempotent.
It means that executing the same method several times in a row is equivalent to a single execution.
In this case, it means that points with the same id will be overwritten when re-uploaded.
Idempotence property is useful if you use, for example, a message queue that doesn't provide an exactly-ones guarantee.
Even with such a system, Qdrant ensures data consistency.
[_Available as of v0.10.0_](#create-vector-name)
If the collection was created with multiple vectors, each vector data can be provided using the vector's name:
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"vector": {
"image": [0.9, 0.1, 0.1, 0.2],
"text": [0.4, 0.7, 0.1, 0.8, 0.1, 0.1, 0.9, 0.2]
}
},
{
"id": 2,
"vector": {
"image": [0.2, 0.1, 0.3, 0.9],
"text": [0.5, 0.2, 0.7, 0.4, 0.7, 0.2, 0.3, 0.9]
}
}
]
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector={
"image": [0.9, 0.1, 0.1, 0.2],
"text": [0.4, 0.7, 0.1, 0.8, 0.1, 0.1, 0.9, 0.2],
},
),
models.PointStruct(
id=2,
vector={
"image": [0.2, 0.1, 0.3, 0.9],
"text": [0.5, 0.2, 0.7, 0.4, 0.7, 0.2, 0.3, 0.9],
},
),
],
)
```
```typescript
client.upsert("{collection_name}", {
points: [
{
id: 1,
vector: {
image: [0.9, 0.1, 0.1, 0.2],
text: [0.4, 0.7, 0.1, 0.8, 0.1, 0.1, 0.9, 0.2],
},
},
{
id: 2,
vector: {
image: [0.2, 0.1, 0.3, 0.9],
text: [0.5, 0.2, 0.7, 0.4, 0.7, 0.2, 0.3, 0.9],
},
},
],
});
```
```rust
use qdrant_client::qdrant::PointStruct;
use std::collections::HashMap;
client
.upsert_points_blocking(
"{collection_name}".to_string(),
None,
vec![
PointStruct::new(
1,
HashMap::from([
("image".to_string(), vec![0.9, 0.1, 0.1, 0.2]),
(
"text".to_string(),
vec![0.4, 0.7, 0.1, 0.8, 0.1, 0.1, 0.9, 0.2],
),
]),
HashMap::new().into(),
),
PointStruct::new(
2,
HashMap::from([
("image".to_string(), vec![0.2, 0.1, 0.3, 0.9]),
(
"text".to_string(),
vec![0.5, 0.2, 0.7, 0.4, 0.7, 0.2, 0.3, 0.9],
),
]),
HashMap::new().into(),
),
],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.VectorFactory.vector;
import static io.qdrant.client.VectorsFactory.namedVectors;
import io.qdrant.client.grpc.Points.PointStruct;
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(
namedVectors(
Map.of(
"image",
vector(List.of(0.9f, 0.1f, 0.1f, 0.2f)),
"text",
vector(List.of(0.4f, 0.7f, 0.1f, 0.8f, 0.1f, 0.1f, 0.9f, 0.2f)))))
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(
namedVectors(
Map.of(
"image",
List.of(0.2f, 0.1f, 0.3f, 0.9f),
"text",
List.of(0.5f, 0.2f, 0.7f, 0.4f, 0.7f, 0.2f, 0.3f, 0.9f))))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new Dictionary<string, float[]>
{
["image"] = [0.9f, 0.1f, 0.1f, 0.2f],
["text"] = [0.4f, 0.7f, 0.1f, 0.8f, 0.1f, 0.1f, 0.9f, 0.2f]
}
},
new()
{
Id = 2,
Vectors = new Dictionary<string, float[]>
{
["image"] = [0.2f, 0.1f, 0.3f, 0.9f],
["text"] = [0.5f, 0.2f, 0.7f, 0.4f, 0.7f, 0.2f, 0.3f, 0.9f]
}
}
}
);
```
_Available as of v1.2.0_
Named vectors are optional. When uploading points, some vectors may be omitted.
For example, you can upload one point with only the `image` vector and a second
one with only the `text` vector.
When uploading a point with an existing ID, the existing point is deleted first,
then it is inserted with just the specified vectors. In other words, the entire
point is replaced, and any unspecified vectors are set to null. To keep existing
vectors unchanged and only update specified vectors, see [update vectors](#update-vectors).
_Available as of v1.7.0_
Points can contain dense and sparse vectors.
A sparse vector is an array in which most of the elements have a value of zero.
It is possible to take advantage of this property to have an optimized representation, for this reason they have a different shape than dense vectors.
They are represented as a list of `(index, value)` pairs, where `index` is an integer and `value` is a floating point number. The `index` is the position of the non-zero value in the vector. The `values` is the value of the non-zero element.
For example, the following vector:
```
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 2.0, 0.0, 0.0]
```
can be represented as a sparse vector:
```
[(6, 1.0), (7, 2.0)]
```
Qdrant uses the following JSON representation throughout its APIs.
```json
{
"indices": [6, 7],
"values": [1.0, 2.0]
}
```
The `indices` and `values` arrays must have the same length.
And the `indices` must be unique.
If the `indices` are not sorted, Qdrant will sort them internally so you may not rely on the order of the elements.
Sparse vectors must be named and can be uploaded in the same way as dense vectors.
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"vector": {
"text": {
"indices": [6, 7],
"values": [1.0, 2.0]
}
}
},
{
"id": 2,
"vector": {
"text": {
"indices": [1, 1, 2, 3, 4, 5],
"values": [0.1, 0.2, 0.3, 0.4, 0.5]
}
}
}
]
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector={
"text": models.SparseVector(
indices=[6, 7],
values=[1.0, 2.0],
)
},
),
models.PointStruct(
id=2,
vector={
"text": models.SparseVector(
indices=[1, 2, 3, 4, 5],
values=[0.1, 0.2, 0.3, 0.4, 0.5],
)
},
),
],
)
```
```typescript
client.upsert("{collection_name}", {
points: [
{
id: 1,
vector: {
text: {
indices: [6, 7],
values: [1.0, 2.0],
},
},
},
{
id: 2,
vector: {
text: {
indices: [1, 2, 3, 4, 5],
values: [0.1, 0.2, 0.3, 0.4, 0.5],
},
},
},
],
});
```
```rust
use qdrant_client::qdrant::{PointStruct, Vector};
use std::collections::HashMap;
client
.upsert_points_blocking(
"{collection_name}".to_string(),
vec![
PointStruct::new(
1,
HashMap::from([
(
"text".to_string(),
Vector::from(
(vec![6, 7], vec![1.0, 2.0])
),
),
]),
HashMap::new().into(),
),
PointStruct::new(
2,
HashMap::from([
(
"text".to_string(),
Vector::from(
(vec![1, 2, 3, 4, 5], vec![0.1, 0.2, 0.3, 0.4, 0.5])
),
),
]),
HashMap::new().into(),
),
],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.VectorFactory.vector;
import io.qdrant.client.grpc.Points.NamedVectors;
import io.qdrant.client.grpc.Points.PointStruct;
import io.qdrant.client.grpc.Points.Vectors;
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(
Vectors.newBuilder()
.setVectors(
NamedVectors.newBuilder()
.putAllVectors(
Map.of(
"text", vector(List.of(1.0f, 2.0f), List.of(6, 7))))
.build())
.build())
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(
Vectors.newBuilder()
.setVectors(
NamedVectors.newBuilder()
.putAllVectors(
Map.of(
"text",
vector(
List.of(0.1f, 0.2f, 0.3f, 0.4f, 0.5f),
List.of(1, 2, 3, 4, 5))))
.build())
.build())
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new Dictionary<string, Vector> { ["text"] = ([1.0f, 2.0f], [6, 7]) }
},
new()
{
Id = 2,
Vectors = new Dictionary<string, Vector>
{
["text"] = ([0.1f, 0.2f, 0.3f, 0.4f, 0.5f], [1, 2, 3, 4, 5])
}
}
}
);
```
## Modify points
To change a point, you can modify its vectors or its payload. There are several
ways to do this.
### Update vectors
_Available as of v1.2.0_
This method updates the specified vectors on the given points. Unspecified
vectors are kept unchanged. All given points must exist.
REST API ([Schema](https://api.qdrant.tech/api-reference/points/update-vectors)):
```http
PUT /collections/{collection_name}/points/vectors
{
"points": [
{
"id": 1,
"vector": {
"image": [0.1, 0.2, 0.3, 0.4]
}
},
{
"id": 2,
"vector": {
"text": [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
}
}
]
}
```
```python
client.update_vectors(
collection_name="{collection_name}",
points=[
models.PointVectors(
id=1,
vector={
"image": [0.1, 0.2, 0.3, 0.4],
},
),
models.PointVectors(
id=2,
vector={
"text": [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2],
},
),
],
)
```
```typescript
client.updateVectors("{collection_name}", {
points: [
{
id: 1,
vector: {
image: [0.1, 0.2, 0.3, 0.4],
},
},
{
id: 2,
vector: {
text: [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2],
},
},
],
});
```
```rust
use qdrant_client::qdrant::PointVectors;
use std::collections::HashMap;
client
.update_vectors_blocking(
"{collection_name}",
None,
&[
PointVectors {
id: Some(1.into()),
vectors: Some(
HashMap::from([("image".to_string(), vec![0.1, 0.2, 0.3, 0.4])]).into(),
),
},
PointVectors {
id: Some(2.into()),
vectors: Some(
HashMap::from([(
"text".to_string(),
vec![0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2],
)])
.into(),
),
},
],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.VectorFactory.vector;
import static io.qdrant.client.VectorsFactory.namedVectors;
client
.updateVectorsAsync(
"{collection_name}",
List.of(
PointVectors.newBuilder()
.setId(id(1))
.setVectors(namedVectors(Map.of("image", vector(List.of(0.1f, 0.2f, 0.3f, 0.4f)))))
.build(),
PointVectors.newBuilder()
.setId(id(2))
.setVectors(
namedVectors(
Map.of(
"text", vector(List.of(0.9f, 0.8f, 0.7f, 0.6f, 0.5f, 0.4f, 0.3f, 0.2f)))))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpdateVectorsAsync(
collectionName: "{collection_name}",
points: new List<PointVectors>
{
new() { Id = 1, Vectors = ("image", new float[] { 0.1f, 0.2f, 0.3f, 0.4f }) },
new()
{
Id = 2,
Vectors = ("text", new float[] { 0.9f, 0.8f, 0.7f, 0.6f, 0.5f, 0.4f, 0.3f, 0.2f })
}
}
);
```
To update points and replace all of its vectors, see [uploading
points](#upload-points).
### Delete vectors
_Available as of v1.2.0_
This method deletes just the specified vectors from the given points. Other
vectors are kept unchanged. Points are never deleted.
REST API ([Schema](https://api.qdrant.tech/api-reference/points/delete-vectors)):
```http
POST /collections/{collection_name}/points/vectors/delete
{
"points": [0, 3, 100],
"vectors": ["text", "image"]
}
```
```python
client.delete_vectors(
collection_name="{collection_name}",
points=[0, 3, 100],
vectors=["text", "image"],
)
```
```typescript
client.deleteVectors("{collection_name}", {
points: [0, 3, 10],
vectors: ["text", "image"],
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, PointsIdsList, PointsSelector, VectorsSelector,
};
client
.delete_vectors_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(PointsIdsList {
ids: vec![0.into(), 3.into(), 10.into()],
})),
},
&VectorsSelector {
names: vec!["text".into(), "image".into()],
},
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
client
.deleteVectorsAsync(
"{collection_name}", List.of("text", "image"), List.of(id(0), id(3), id(10)))
.get();
```
To delete entire points, see [deleting points](#delete-points).
### Update payload
Learn how to modify the payload of a point in the [Payload](../payload/#update-payload) section.
## Delete points
REST API ([Schema](https://api.qdrant.tech/api-reference/points/delete-points)):
```http
POST /collections/{collection_name}/points/delete
{
"points": [0, 3, 100]
}
```
```python
client.delete(
collection_name="{collection_name}",
points_selector=models.PointIdsList(
points=[0, 3, 100],
),
)
```
```typescript
client.delete("{collection_name}", {
points: [0, 3, 100],
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, PointsIdsList, PointsSelector,
};
client
.delete_points_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(PointsIdsList {
ids: vec![0.into(), 3.into(), 100.into()],
})),
},
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
client.deleteAsync("{collection_name}", List.of(id(0), id(3), id(100)));
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.DeleteAsync(collectionName: "{collection_name}", ids: [0, 3, 100]);
```
Alternative way to specify which points to remove is to use filter.
```http
POST /collections/{collection_name}/points/delete
{
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
}
}
```
```python
client.delete(
collection_name="{collection_name}",
points_selector=models.FilterSelector(
filter=models.Filter(
must=[
models.FieldCondition(
key="color",
match=models.MatchValue(value="red"),
),
],
)
),
)
```
```typescript
client.delete("{collection_name}", {
filter: {
must: [
{
key: "color",
match: {
value: "red",
},
},
],
},
});
```
```rust
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf, Condition, Filter, PointsSelector,
};
client
.delete_points_blocking(
"{collection_name}",
None,
&PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Filter(Filter::must([
Condition::matches("color", "red".to_string()),
]))),
},
None,
)
.await?;
```
```java
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.grpc.Points.Filter;
client
.deleteAsync(
"{collection_name}",
Filter.newBuilder().addMust(matchKeyword("color", "red")).build())
.get();
```
```csharp
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.DeleteAsync(collectionName: "{collection_name}", filter: MatchKeyword("color", "red"));
```
This example removes all points with `{ "color": "red" }` from the collection.
## Retrieve points
There is a method for retrieving points by their ids.
REST API ([Schema](https://api.qdrant.tech/api-reference/points/get-points)):
```http
POST /collections/{collection_name}/points
{
"ids": [0, 3, 100]
}
```
```python
client.retrieve(
collection_name="{collection_name}",
ids=[0, 3, 100],
)
```
```typescript
client.retrieve("{collection_name}", {
ids: [0, 3, 100],
});
```
```rust
client
.get_points(
"{collection_name}",
None,
&[0.into(), 30.into(), 100.into()],
Some(false),
Some(false),
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
client
.retrieveAsync("{collection_name}", List.of(id(0), id(30), id(100)), false, false, null)
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.RetrieveAsync(
collectionName: "{collection_name}",
ids: [0, 30, 100],
withPayload: false,
withVectors: false
);
```
This method has additional parameters `with_vectors` and `with_payload`.
Using these parameters, you can select parts of the point you want as a result.
Excluding helps you not to waste traffic transmitting useless data.
The single point can also be retrieved via the API:
REST API ([Schema](https://api.qdrant.tech/api-reference/points/get-point)):
```http
GET /collections/{collection_name}/points/{point_id}
```
<!--
Python client:
```python
```
-->
## Scroll points
Sometimes it might be necessary to get all stored points without knowing ids, or iterate over points that correspond to a filter.
REST API ([Schema](https://api.qdrant.tech/master/api-reference/search/scroll-points)):
```http
POST /collections/{collection_name}/points/scroll
{
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
},
"limit": 1,
"with_payload": true,
"with_vector": false
}
```
```python
client.scroll(
collection_name="{collection_name}",
scroll_filter=models.Filter(
must=[
models.FieldCondition(key="color", match=models.MatchValue(value="red")),
]
),
limit=1,
with_payload=True,
with_vectors=False,
)
```
```typescript
client.scroll("{collection_name}", {
filter: {
must: [
{
key: "color",
match: {
value: "red",
},
},
],
},
limit: 1,
with_payload: true,
with_vector: false,
});
```
```rust
use qdrant_client::qdrant::{Condition, Filter, ScrollPoints};
client
.scroll(&ScrollPoints {
collection_name: "{collection_name}".to_string(),
filter: Some(Filter::must([Condition::matches(
"color",
"red".to_string(),
)])),
limit: Some(1),
with_payload: Some(true.into()),
with_vectors: Some(false.into()),
..Default::default()
})
.await?;
```
```java
import static io.qdrant.client.ConditionFactory.matchKeyword;
import static io.qdrant.client.WithPayloadSelectorFactory.enable;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.ScrollPoints;
client
.scrollAsync(
ScrollPoints.newBuilder()
.setCollectionName("{collection_name}")
.setFilter(Filter.newBuilder().addMust(matchKeyword("color", "red")).build())
.setLimit(1)
.setWithPayload(enable(true))
.build())
.get();
```
```csharp
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.ScrollAsync(
collectionName: "{collection_name}",
filter: MatchKeyword("color", "red"),
limit: 1,
payloadSelector: true
);
```
Returns all point with `color` = `red`.
```json
{
"result": {
"next_page_offset": 1,
"points": [
{
"id": 0,
"payload": {
"color": "red"
}
}
]
},
"status": "ok",
"time": 0.0001
}
```
The Scroll API will return all points that match the filter in a page-by-page manner.
All resulting points are sorted by ID. To query the next page it is necessary to specify the largest seen ID in the `offset` field.
For convenience, this ID is also returned in the field `next_page_offset`.
If the value of the `next_page_offset` field is `null` - the last page is reached.
### Order points by payload key
_Available as of v1.8.0_
When using the [`scroll`](#scroll-points) API, you can sort the results by payload key. For example, you can retrieve points in chronological order if your payloads have a `"timestamp"` field, as is shown from the example below:
<aside role="status">Without an appropriate index, payload-based ordering would create too much load on the system for each request. Qdrant therefore requires a payload index which supports <a href=/documentation/concepts/indexing/#payload-index target="_blank">Range filtering conditions</a> on the field used for <code>order_by</code></aside>
```http
POST /collections/{collection_name}/points/scroll
{
"limit": 15,
"order_by": "timestamp", // <-- this!
}
```
```python
client.scroll(
collection_name="{collection_name}",
limit=15,
order_by="timestamp", # <-- this!
)
```
```typescript
client.scroll("{collection_name}", {
limit: 15,
order_by: "timestamp", // <-- this!
});
```
```rust
use qdrant_client::qdrant::{Condition, Filter, ScrollPoints, OrderBy};
client
.scroll(&ScrollPoints {
collection_name: "{collection_name}".to_string(),
limit: Some(15),
order_by: Some(OrderBy {
key: "timestamp".to_string(), // <-- this!
..Default::default(),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.grpc.Points.OrderBy;
import io.qdrant.client.grpc.Points.ScrollPoints;
client.scrollAsync(ScrollPoints.newBuilder()
.setCollectionName("{collection_name}")
.setLimit(15)
.setOrderBy(OrderBy.newBuilder().setKey("timestamp").build())
.build()).get();
```
```csharp
await client.ScrollAsync("{collection_name}", limit: 15, orderBy: "timestamp");
```
You need to use the `order_by` `key` parameter to specify the payload key. Then you can add other fields to control the ordering, such as `direction` and `start_from`:
```http
"order_by": {
"key": "timestamp",
"direction": "desc" // default is "asc"
"start_from": 123, // start from this value
}
```
```python
order_by=models.OrderBy(
key="timestamp",
direction="desc", # default is "asc"
start_from=123, # start from this value
)
```
```typescript
order_by: {
key: "timestamp",
direction: "desc", // default is "asc"
start_from: 123, // start from this value
}
```
```rust
order_by: Some(OrderBy {
key: "timestamp".to_string(),
direction: Some(Direction::Desc as i32), // default is Direction::Asc
start_from: Some(StartFrom {
value: Some(Value::Integer(123)),
}),
});
```
```java
import io.qdrant.client.grpc.Points.Direction;
import io.qdrant.client.grpc.Points.OrderBy;
import io.qdrant.client.grpc.Points.StartFrom;
OrderBy.newBuilder()
.setKey("timestamp")
.setDirection(Direction.Desc)
.setStartFrom(StartFrom.newBuilder()
.setInteger(123)
.build())
.build();
```
```csharp
using Qdrant.Client.Grpc;
new OrderBy
{
Key = "timestamp",
Direction = Direction.Desc,
StartFrom = 123
};
```
**Note:** for payloads with more than one value (such as arrays), the same point may show up more than once. Each point can appear as many times as the number of elements in the array. For example, if you have a point payload with a `timestamp` key, and the value for the key is an array of 3 elements, the same point will appear 3 times in the results, one for each timestamp.
<aside role="alert">When you use the <code>order_by</code> parameter, pagination is disabled.</aside>
When sorting is based on a non-unique value, it is not possible to rely on an ID offset. Thus, next_page_offset is not returned within the response. However, you can still do pagination by combining `"order_by": { "start_from": ... }` with a `{ "must_not": [{ "has_id": [...] }] }` filter.
## Counting points
_Available as of v0.8.4_
Sometimes it can be useful to know how many points fit the filter conditions without doing a real search.
Among others, for example, we can highlight the following scenarios:
- Evaluation of results size for faceted search
- Determining the number of pages for pagination
- Debugging the query execution speed
REST API ([Schema](https://api.qdrant.tech/master/api-reference/points/count-points)):
```http
POST /collections/{collection_name}/points/count
{
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
},
"exact": true
}
```
```python
client.count(
collection_name="{collection_name}",
count_filter=models.Filter(
must=[
models.FieldCondition(key="color", match=models.MatchValue(value="red")),
]
),
exact=True,
)
```
```typescript
client.count("{collection_name}", {
filter: {
must: [
{
key: "color",
match: {
value: "red",
},
},
],
},
exact: true,
});
```
```rust
use qdrant_client::qdrant::{Condition, CountPoints, Filter};
client
.count(&CountPoints {
collection_name: "{collection_name}".to_string(),
filter: Some(Filter::must([Condition::matches(
"color",
"red".to_string(),
)])),
exact: Some(true),
..Default::default()
})
.await?;
```
```java
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.grpc.Points.Filter;
client
.countAsync(
"{collection_name}",
Filter.newBuilder().addMust(matchKeyword("color", "red")).build(),
true)
.get();
```
```csharp
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.CountAsync(
collectionName: "{collection_name}",
filter: MatchKeyword("color", "red"),
exact: true
);
```
Returns number of counts matching given filtering conditions:
```json
{
"count": 3811
}
```
## Batch update
_Available as of v1.5.0_
You can batch multiple point update operations. This includes inserting,
updating and deleting points, vectors and payload.
A batch update request consists of a list of operations. These are executed in
order. These operations can be batched:
- [Upsert points](#upload-points): `upsert` or `UpsertOperation`
- [Delete points](#delete-points): `delete_points` or `DeleteOperation`
- [Update vectors](#update-vectors): `update_vectors` or `UpdateVectorsOperation`
- [Delete vectors](#delete-vectors): `delete_vectors` or `DeleteVectorsOperation`
- [Set payload](/documentation/concepts/payload/#set-payload): `set_payload` or `SetPayloadOperation`
- [Overwrite payload](/documentation/concepts/payload/#overwrite-payload): `overwrite_payload` or `OverwritePayload`
- [Delete payload](/documentation/concepts/payload/#delete-payload-keys): `delete_payload` or `DeletePayloadOperation`
- [Clear payload](/documentation/concepts/payload/#clear-payload): `clear_payload` or `ClearPayloadOperation`
The following example snippet makes use of all operations.
REST API ([Schema](https://api.qdrant.tech/master/api-reference/points/batch-update)):
```http
POST /collections/{collection_name}/points/batch
{
"operations": [
{
"upsert": {
"points": [
{
"id": 1,
"vector": [1.0, 2.0, 3.0, 4.0],
"payload": {}
}
]
}
},
{
"update_vectors": {
"points": [
{
"id": 1,
"vector": [1.0, 2.0, 3.0, 4.0]
}
]
}
},
{
"delete_vectors": {
"points": [1],
"vector": [""]
}
},
{
"overwrite_payload": {
"payload": {
"test_payload": "1"
},
"points": [1]
}
},
{
"set_payload": {
"payload": {
"test_payload_2": "2",
"test_payload_3": "3"
},
"points": [1]
}
},
{
"delete_payload": {
"keys": ["test_payload_2"],
"points": [1]
}
},
{
"clear_payload": {
"points": [1]
}
},
{"delete": {"points": [1]}}
]
}
```
```python
client.batch_update_points(
collection_name="{collection_name}",
update_operations=[
models.UpsertOperation(
upsert=models.PointsList(
points=[
models.PointStruct(
id=1,
vector=[1.0, 2.0, 3.0, 4.0],
payload={},
),
]
)
),
models.UpdateVectorsOperation(
update_vectors=models.UpdateVectors(
points=[
models.PointVectors(
id=1,
vector=[1.0, 2.0, 3.0, 4.0],
)
]
)
),
models.DeleteVectorsOperation(
delete_vectors=models.DeleteVectors(points=[1], vector=[""])
),
models.OverwritePayloadOperation(
overwrite_payload=models.SetPayload(
payload={"test_payload": 1},
points=[1],
)
),
models.SetPayloadOperation(
set_payload=models.SetPayload(
payload={
"test_payload_2": 2,
"test_payload_3": 3,
},
points=[1],
)
),
models.DeletePayloadOperation(
delete_payload=models.DeletePayload(keys=["test_payload_2"], points=[1])
),
models.ClearPayloadOperation(clear_payload=models.PointIdsList(points=[1])),
models.DeleteOperation(delete=models.PointIdsList(points=[1])),
],
)
```
```typescript
client.batchUpdate("{collection_name}", {
operations: [
{
upsert: {
points: [
{
id: 1,
vector: [1.0, 2.0, 3.0, 4.0],
payload: {},
},
],
},
},
{
update_vectors: {
points: [
{
id: 1,
vector: [1.0, 2.0, 3.0, 4.0],
},
],
},
},
{
delete_vectors: {
points: [1],
vector: [""],
},
},
{
overwrite_payload: {
payload: {
test_payload: 1,
},
points: [1],
},
},
{
set_payload: {
payload: {
test_payload_2: 2,
test_payload_3: 3,
},
points: [1],
},
},
{
delete_payload: {
keys: ["test_payload_2"],
points: [1],
},
},
{
clear_payload: {
points: [1],
},
},
{
delete: {
points: [1],
},
},
],
});
```
```rust
use std::collections::HashMap;
use qdrant_client::qdrant::{
points_selector::PointsSelectorOneOf,
points_update_operation::{
ClearPayload, DeletePayload, DeletePoints, DeleteVectors, Operation, PointStructList,
SetPayload, UpdateVectors,
},
PointStruct, PointVectors, PointsIdsList, PointsSelector, PointsUpdateOperation,
VectorsSelector,
};
use serde_json::json;
client
.batch_updates_blocking(
"{collection_name}",
&[
PointsUpdateOperation {
operation: Some(Operation::Upsert(PointStructList {
points: vec![PointStruct::new(
1,
vec![1.0, 2.0, 3.0, 4.0],
json!({}).try_into().unwrap(),
)],
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::UpdateVectors(UpdateVectors {
points: vec![PointVectors {
id: Some(1.into()),
vectors: Some(vec![1.0, 2.0, 3.0, 4.0].into()),
}],
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::DeleteVectors(DeleteVectors {
points_selector: Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(
PointsIdsList {
ids: vec![1.into()],
},
)),
}),
vectors: Some(VectorsSelector {
names: vec!["".into()],
}),
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::OverwritePayload(SetPayload {
points_selector: Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(
PointsIdsList {
ids: vec![1.into()],
},
)),
}),
payload: HashMap::from([("test_payload".to_string(), 1.into())]),
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::SetPayload(SetPayload {
points_selector: Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(
PointsIdsList {
ids: vec![1.into()],
},
)),
}),
payload: HashMap::from([
("test_payload_2".to_string(), 2.into()),
("test_payload_3".to_string(), 3.into()),
]),
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::DeletePayload(DeletePayload {
points_selector: Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(
PointsIdsList {
ids: vec![1.into()],
},
)),
}),
keys: vec!["test_payload_2".to_string()],
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::ClearPayload(ClearPayload {
points: Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(
PointsIdsList {
ids: vec![1.into()],
},
)),
}),
..Default::default()
})),
},
PointsUpdateOperation {
operation: Some(Operation::DeletePoints(DeletePoints {
points: Some(PointsSelector {
points_selector_one_of: Some(PointsSelectorOneOf::Points(
PointsIdsList {
ids: vec![1.into()],
},
)),
}),
..Default::default()
})),
},
],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.grpc.Points.PointStruct;
import io.qdrant.client.grpc.Points.PointVectors;
import io.qdrant.client.grpc.Points.PointsIdsList;
import io.qdrant.client.grpc.Points.PointsSelector;
import io.qdrant.client.grpc.Points.PointsUpdateOperation;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.ClearPayload;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.DeletePayload;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.DeletePoints;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.DeleteVectors;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.PointStructList;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.SetPayload;
import io.qdrant.client.grpc.Points.PointsUpdateOperation.UpdateVectors;
import io.qdrant.client.grpc.Points.VectorsSelector;
client
.batchUpdateAsync(
"{collection_name}",
List.of(
PointsUpdateOperation.newBuilder()
.setUpsert(
PointStructList.newBuilder()
.addPoints(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(1.0f, 2.0f, 3.0f, 4.0f))
.build())
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setUpdateVectors(
UpdateVectors.newBuilder()
.addPoints(
PointVectors.newBuilder()
.setId(id(1))
.setVectors(vectors(1.0f, 2.0f, 3.0f, 4.0f))
.build())
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setDeleteVectors(
DeleteVectors.newBuilder()
.setPointsSelector(
PointsSelector.newBuilder()
.setPoints(PointsIdsList.newBuilder().addIds(id(1)).build())
.build())
.setVectors(VectorsSelector.newBuilder().addNames("").build())
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setOverwritePayload(
SetPayload.newBuilder()
.setPointsSelector(
PointsSelector.newBuilder()
.setPoints(PointsIdsList.newBuilder().addIds(id(1)).build())
.build())
.putAllPayload(Map.of("test_payload", value(1)))
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setSetPayload(
SetPayload.newBuilder()
.setPointsSelector(
PointsSelector.newBuilder()
.setPoints(PointsIdsList.newBuilder().addIds(id(1)).build())
.build())
.putAllPayload(
Map.of("test_payload_2", value(2), "test_payload_3", value(3)))
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setDeletePayload(
DeletePayload.newBuilder()
.setPointsSelector(
PointsSelector.newBuilder()
.setPoints(PointsIdsList.newBuilder().addIds(id(1)).build())
.build())
.addKeys("test_payload_2")
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setClearPayload(
ClearPayload.newBuilder()
.setPoints(
PointsSelector.newBuilder()
.setPoints(PointsIdsList.newBuilder().addIds(id(1)).build())
.build())
.build())
.build(),
PointsUpdateOperation.newBuilder()
.setDeletePoints(
DeletePoints.newBuilder()
.setPoints(
PointsSelector.newBuilder()
.setPoints(PointsIdsList.newBuilder().addIds(id(1)).build())
.build())
.build())
.build()))
.get();
```
To batch many points with a single operation type, please use batching
functionality in that operation directly.
|
qdrant-landing/content/documentation/concepts/search.md | ---
title: Search
weight: 50
aliases:
- ../search
---
# Similarity search
Searching for the nearest vectors is at the core of many representational learning applications.
Modern neural networks are trained to transform objects into vectors so that objects close in the real world appear close in vector space.
It could be, for example, texts with similar meanings, visually similar pictures, or songs of the same genre.

## Metrics
There are many ways to estimate the similarity of vectors with each other.
In Qdrant terms, these ways are called metrics.
The choice of metric depends on vectors obtaining and, in particular, on the method of neural network encoder training.
Qdrant supports these most popular types of metrics:
* Dot product: `Dot` - https://en.wikipedia.org/wiki/Dot_product
* Cosine similarity: `Cosine` - https://en.wikipedia.org/wiki/Cosine_similarity
* Euclidean distance: `Euclid` - https://en.wikipedia.org/wiki/Euclidean_distance
* Manhattan distance: `Manhattan`* - https://en.wikipedia.org/wiki/Taxicab_geometry <i><sup>*Available as of v1.7</sup></i>
The most typical metric used in similarity learning models is the cosine metric.

Qdrant counts this metric in 2 steps, due to which a higher search speed is achieved.
The first step is to normalize the vector when adding it to the collection.
It happens only once for each vector.
The second step is the comparison of vectors.
In this case, it becomes equivalent to dot production - a very fast operation due to SIMD.
## Query planning
Depending on the filter used in the search - there are several possible scenarios for query execution.
Qdrant chooses one of the query execution options depending on the available indexes, the complexity of the conditions and the cardinality of the filtering result.
This process is called query planning.
The strategy selection process relies heavily on heuristics and can vary from release to release.
However, the general principles are:
* planning is performed for each segment independently (see [storage](../storage/) for more information about segments)
* prefer a full scan if the amount of points is below a threshold
* estimate the cardinality of a filtered result before selecting a strategy
* retrieve points using payload index (see [indexing](../indexing/)) if cardinality is below threshold
* use filterable vector index if the cardinality is above a threshold
You can adjust the threshold using a [configuration file](https://github.com/qdrant/qdrant/blob/master/config/config.yaml), as well as independently for each collection.
## Search API
Let's look at an example of a search query.
REST API - API Schema definition is available [here](https://api.qdrant.tech/master/api-reference/search/points)
```http
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(
value="London",
),
)
]
),
search_params=models.SearchParams(hnsw_ef=128, exact=False),
query_vector=[0.2, 0.1, 0.9, 0.7],
limit=3,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
filter: {
must: [
{
key: "city",
match: {
value: "London",
},
},
],
},
params: {
hnsw_ef: 128,
exact: false,
},
vector: [0.2, 0.1, 0.9, 0.7],
limit: 3,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{Condition, Filter, SearchParams, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
filter: Some(Filter::must([Condition::matches(
"city",
"London".to_string(),
)])),
params: Some(SearchParams {
hnsw_ef: Some(128),
exact: Some(false),
..Default::default()
}),
vector: vec![0.2, 0.1, 0.9, 0.7],
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.setFilter(Filter.newBuilder().addMust(matchKeyword("city", "London")).build())
.setParams(SearchParams.newBuilder().setExact(false).setHnswEf(128).build())
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
filter: MatchKeyword("city", "London"),
searchParams: new SearchParams { Exact = false, HnswEf = 128 },
limit: 3
);
```
In this example, we are looking for vectors similar to vector `[0.2, 0.1, 0.9, 0.7]`.
Parameter `limit` (or its alias - `top`) specifies the amount of most similar results we would like to retrieve.
Values under the key `params` specify custom parameters for the search.
Currently, it could be:
* `hnsw_ef` - value that specifies `ef` parameter of the HNSW algorithm.
* `exact` - option to not use the approximate search (ANN). If set to true, the search may run for a long as it performs a full scan to retrieve exact results.
* `indexed_only` - With this option you can disable the search in those segments where vector index is not built yet. This may be useful if you want to minimize the impact to the search performance whilst the collection is also being updated. Using this option may lead to a partial result if the collection is not fully indexed yet, consider using it only if eventual consistency is acceptable for your use case.
Since the `filter` parameter is specified, the search is performed only among those points that satisfy the filter condition.
See details of possible filters and their work in the [filtering](../filtering/) section.
Example result of this API would be
```json
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
```
The `result` contains ordered by `score` list of found point ids.
Note that payload and vector data is missing in these results by default.
See [payload and vector in the result](#payload-and-vector-in-the-result) on how
to include it.
*Available as of v0.10.0*
If the collection was created with multiple vectors, the name of the vector to use for searching should be provided:
```http
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=("image", [0.2, 0.1, 0.9, 0.7]),
limit=3,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: {
name: "image",
vector: [0.2, 0.1, 0.9, 0.7],
},
limit: 3,
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::SearchPoints};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
vector_name: Some("image".to_string()),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.setVectorName("image")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
vectorName: "image",
limit: 3
);
```
Search is processing only among vectors with the same name.
*Available as of v1.7.0*
If the collection was created with sparse vectors, the name of the sparse vector to use for searching should be provided:
You can still use payload filtering and other features of the search API with sparse vectors.
There are however important differences between dense and sparse vector search:
| Index| Sparse Query | Dense Query |
| --- | --- | --- |
| Scoring Metric | Default is `Dot product`, no need to specify it | `Distance` has supported metrics e.g. Dot, Cosine |
| Search Type | Always exact in Qdrant | HNSW is an approximate NN |
| Return Behaviour | Returns only vectors with non-zero values in the same indices as the query vector | Returns `limit` vectors |
In general, the speed of the search is proportional to the number of non-zero values in the query vector.
```http
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "text",
"vector": {
"indices": [6, 7],
"values": [1.0, 2.0]
}
},
"limit": 3
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=models.NamedSparseVector(
name="text",
vector=models.SparseVector(
indices=[1, 7],
values=[2.0, 1.0],
),
),
limit=3,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: {
name: "text",
vector: {
indices: [1, 7],
values: [2.0, 1.0]
},
},
limit: 3,
});
```
```rust
use qdrant_client::{client::QdrantClient, client::Vector, qdrant::SearchPoints};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
let sparse_vector: Vector = vec![(1, 2.0), (7, 1.0)].into();
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector_name: Some("text".to_string()),
sparse_indices: sparse_vector.indices,
vector: sparse_vector.data,
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.SearchPoints;
import io.qdrant.client.grpc.Points.SparseIndices;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.setVectorName("text")
.addAllVector(List.of(2.0f, 1.0f))
.setSparseIndices(SparseIndices.newBuilder().addAllData(List.of(1, 7)).build())
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 2.0f, 1.0f },
vectorName: "text",
limit: 3,
sparseIndices: new uint[] { 1, 7 }
);
```
### Filtering results by score
In addition to payload filtering, it might be useful to filter out results with a low similarity score.
For example, if you know the minimal acceptance score for your model and do not want any results which are less similar than the threshold.
In this case, you can use `score_threshold` parameter of the search query.
It will exclude all results with a score worse than the given.
<aside role="status">This parameter may exclude lower or higher scores depending on the used metric. For example, higher scores of Euclidean metric are considered more distant and, therefore, will be excluded.</aside>
### Payload and vector in the result
By default, retrieval methods do not return any stored information such as
payload and vectors. Additional parameters `with_vectors` and `with_payload`
alter this behavior.
Example:
```http
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
```
```python
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
with_vectors=True,
with_payload=True,
)
```
```typescript
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
with_vector: true,
with_payload: true,
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::SearchPoints};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
with_payload: Some(true.into()),
with_vectors: Some(true.into()),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.WithPayloadSelectorFactory.enable;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.WithVectorsSelectorFactory;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(enable(true))
.setWithVectors(WithVectorsSelectorFactory.enable(true))
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: true,
vectorsSelector: true,
limit: 3
);
```
You can use `with_payload` to scope to or filter a specific payload subset.
You can even specify an array of items to include, such as `city`,
`village`, and `town`:
```http
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": ["city", "village", "town"]
}
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
with_payload=["city", "village", "town"],
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
with_payload: ["city", "village", "town"],
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::SearchPoints};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
with_payload: Some(vec!["city", "village", "town"].into()),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.WithPayloadSelectorFactory.include;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(include(List.of("city", "village", "town")))
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: new WithPayloadSelector
{
Include = new PayloadIncludeSelector
{
Fields = { new string[] { "city", "village", "town" } }
}
},
limit: 3
);
```
Or use `include` or `exclude` explicitly. For example, to exclude `city`:
```http
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
with_payload=models.PayloadSelectorExclude(
exclude=["city"],
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
with_payload: {
exclude: ["city"],
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
with_payload_selector::SelectorOptions, PayloadExcludeSelector, SearchPoints,
WithPayloadSelector,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
with_payload: Some(WithPayloadSelector {
selector_options: Some(SelectorOptions::Exclude(PayloadExcludeSelector {
fields: vec!["city".to_string()],
})),
}),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.WithPayloadSelectorFactory.exclude;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(exclude(List.of("city")))
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: new WithPayloadSelector
{
Exclude = new PayloadExcludeSelector { Fields = { new string[] { "city" } } }
},
limit: 3
);
```
It is possible to target nested fields using a dot notation:
- `payload.nested_field` - for a nested field
- `payload.nested_array[].sub_field` - for projecting nested fields within an array
Accessing array elements by index is currently not supported.
## Batch search API
*Available as of v0.10.0*
The batch search API enables to perform multiple search requests via a single request.
Its semantic is straightforward, `n` batched search requests are equivalent to `n` singular search requests.
This approach has several advantages. Logically, fewer network connections are required which can be very beneficial on its own.
More importantly, batched requests will be efficiently processed via the query planner which can detect and optimize requests if they have the same `filter`.
This can have a great effect on latency for non trivial filters as the intermediary results can be shared among the request.
In order to use it, simply pack together your search requests. All the regular attributes of a search request are of course available.
```http
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
filter_ = models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(
value="London",
),
)
]
)
search_queries = [
models.SearchRequest(vector=[0.2, 0.1, 0.9, 0.7], filter=filter_, limit=3),
models.SearchRequest(vector=[0.5, 0.3, 0.2, 0.3], filter=filter_, limit=3),
]
client.search_batch(collection_name="{collection_name}", requests=search_queries)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
const filter = {
must: [
{
key: "city",
match: {
value: "London",
},
},
],
};
const searches = [
{
vector: [0.2, 0.1, 0.9, 0.7],
filter,
limit: 3,
},
{
vector: [0.5, 0.3, 0.2, 0.3],
filter,
limit: 3,
},
];
client.searchBatch("{collection_name}", {
searches,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{Condition, Filter, SearchBatchPoints, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
let filter = Filter::must([Condition::matches("city", "London".to_string())]);
let searches = vec![
SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
filter: Some(filter.clone()),
limit: 3,
..Default::default()
},
SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.5, 0.3, 0.2, 0.3],
filter: Some(filter),
limit: 3,
..Default::default()
},
];
client
.search_batch_points(&SearchBatchPoints {
collection_name: "{collection_name}".to_string(),
search_points: searches,
read_consistency: None,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
Filter filter = Filter.newBuilder().addMust(matchKeyword("city", "London")).build();
List<SearchPoints> searches =
List.of(
SearchPoints.newBuilder()
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setFilter(filter)
.setLimit(3)
.build(),
SearchPoints.newBuilder()
.addAllVector(List.of(0.5f, 0.3f, 0.2f, 0.3f))
.setFilter(filter)
.setLimit(3)
.build());
client.searchBatchAsync("{collection_name}", searches, null).get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
var filter = MatchKeyword("city", "London");
var searches = new List<SearchPoints>
{
new()
{
Vector = { new float[] { 0.2f, 0.1f, 0.9f, 0.7f } },
Filter = filter,
Limit = 3
},
new()
{
Vector = { new float[] { 0.5f, 0.3f, 0.2f, 0.3f } },
Filter = filter,
Limit = 3
}
};
await client.SearchBatchAsync(collectionName: "{collection_name}", searches: searches);
```
The result of this API contains one array per search requests.
```json
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
```
## Pagination
*Available as of v0.8.3*
Search and [recommendation](../explore/#recommendation-api) APIs allow to skip first results of the search and return only the result starting from some specified offset:
Example:
```http
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
with_vectors=True,
with_payload=True,
limit=10,
offset=100,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
with_vector: true,
with_payload: true,
limit: 10,
offset: 100,
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::SearchPoints};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
with_vectors: Some(true.into()),
with_payload: Some(true.into()),
limit: 10,
offset: Some(100),
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.WithPayloadSelectorFactory.enable;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.WithVectorsSelectorFactory;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(enable(true))
.setWithVectors(WithVectorsSelectorFactory.enable(true))
.setLimit(10)
.setOffset(100)
.build())
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
"{collection_name}",
new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: true,
vectorsSelector: true,
limit: 10,
offset: 100
);
```
Is equivalent to retrieving the 11th page with 10 records per page.
<aside role="alert">Large offset values may cause performance issues</aside>
Vector-based retrieval in general and HNSW index in particular, are not designed to be paginated.
It is impossible to retrieve Nth closest vector without retrieving the first N vectors first.
However, using the offset parameter saves the resources by reducing network traffic and the number of times the storage is accessed.
Using an `offset` parameter, will require to internally retrieve `offset + limit` points, but only access payload and vector from the storage those points which are going to be actually returned.
## Grouping API
*Available as of v1.2.0*
It is possible to group results by a certain field. This is useful when you have multiple points for the same item, and you want to avoid redundancy of the same item in the results.
For example, if you have a large document split into multiple chunks, and you want to search or [recommend](../explore/#recommendation-api) on a per-document basis, you can group the results by the document ID.
Consider having points with the following payloads:
```json
[
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a"
},
"vector": [0.91]
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"]
},
"vector": [0.8]
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a"
},
"vector": [0.2]
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123
},
"vector": [0.79]
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123
},
"vector": [0.75]
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10
},
"vector": [0.6]
}
]
```
With the ***groups*** API, you will be able to get the best *N* points for each document, assuming that the payload of the points contains the document ID. Of course there will be times where the best *N* points cannot be fulfilled due to lack of points or a big distance with respect to the query. In every case, the `group_size` is a best-effort parameter, akin to the `limit` parameter.
### Search groups
REST API ([Schema](https://api.qdrant.tech/master/api-reference/search/point-groups)):
```http
POST /collections/{collection_name}/points/search/groups
{
// Same as in the regular search API
"vector": [1.1],
// Grouping parameters
"group_by": "document_id", // Path of the field to group by
"limit": 4, // Max amount of groups
"group_size": 2, // Max amount of points per group
}
```
```python
client.search_groups(
collection_name="{collection_name}",
# Same as in the regular search() API
query_vector=[1.1],
# Grouping parameters
group_by="document_id", # Path of the field to group by
limit=4, # Max amount of groups
group_size=2, # Max amount of points per group
)
```
```typescript
client.searchPointGroups("{collection_name}", {
vector: [1.1],
group_by: "document_id",
limit: 4,
group_size: 2,
});
```
```rust
use qdrant_client::qdrant::SearchPointGroups;
client
.search_groups(&SearchPointGroups {
collection_name: "{collection_name}".to_string(),
vector: vec![1.1],
group_by: "document_id".to_string(),
limit: 4,
group_size: 2,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.grpc.Points.SearchPointGroups;
client
.searchGroupsAsync(
SearchPointGroups.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(1.1f))
.setGroupBy("document_id")
.setLimit(4)
.setGroupSize(2)
.build())
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.SearchGroupsAsync(
collectionName: "{collection_name}",
vector: new float[] { 1.1f },
groupBy: "document_id",
limit: 4,
groupSize: 2
);
```
The output of a ***groups*** call looks like this:
```json
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
```
The groups are ordered by the score of the top point in the group. Inside each group the points are sorted too.
If the `group_by` field of a point is an array (e.g. `"document_id": ["a", "b"]`), the point can be included in multiple groups (e.g. `"document_id": "a"` and `document_id: "b"`).
<aside role="status">This feature relies heavily on the `group_by` key provided. To improve performance, make sure to create a dedicated index for it.</aside>
**Limitations**:
* Only [keyword](../payload/#keyword) and [integer](../payload/#integer) payload values are supported for the `group_by` parameter. Payload values with other types will be ignored.
* At the moment, pagination is not enabled when using **groups**, so the `offset` parameter is not allowed.
### Lookup in groups
*Available as of v1.3.0*
Having multiple points for parts of the same item often introduces redundancy in the stored data. Which may be fine if the information shared by the points is small, but it can become a problem if the payload is large, because it multiplies the storage space needed to store the points by a factor of the amount of points we have per group.
One way of optimizing storage when using groups is to store the information shared by the points with the same group id in a single point in another collection. Then, when using the [**groups** API](#grouping-api), add the `with_lookup` parameter to bring the information from those points into each group.

This has the extra benefit of having a single point to update when the information shared by the points in a group changes.
For example, if you have a collection of documents, you may want to chunk them and store the points for the chunks in a separate collection, making sure that you store the point id from the document it belongs in the payload of the chunk point.
In this case, to bring the information from the documents into the chunks grouped by the document id, you can use the `with_lookup` parameter:
```http
POST /collections/chunks/points/search/groups
{
// Same as in the regular search API
"vector": [1.1],
// Grouping parameters
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Lookup parameters
"with_lookup": {
// Name of the collection to look up points in
"collection": "documents",
// Options for specifying what to bring from the payload
// of the looked up point, true by default
"with_payload": ["title", "text"],
// Options for specifying what to bring from the vector(s)
// of the looked up point, true by default
"with_vectors: false
}
}
```
```python
client.search_groups(
collection_name="chunks",
# Same as in the regular search() API
query_vector=[1.1],
# Grouping parameters
group_by="document_id", # Path of the field to group by
limit=2, # Max amount of groups
group_size=2, # Max amount of points per group
# Lookup parameters
with_lookup=models.WithLookup(
# Name of the collection to look up points in
collection="documents",
# Options for specifying what to bring from the payload
# of the looked up point, True by default
with_payload=["title", "text"],
# Options for specifying what to bring from the vector(s)
# of the looked up point, True by default
with_vectors=False,
),
)
```
```typescript
client.searchPointGroups("{collection_name}", {
vector: [1.1],
group_by: "document_id",
limit: 2,
group_size: 2,
with_lookup: {
collection: w,
with_payload: ["title", "text"],
with_vectors: false,
},
});
```
```rust
use qdrant_client::qdrant::{SearchPointGroups, WithLookup};
client
.search_groups(&SearchPointGroups {
collection_name: "{collection_name}".to_string(),
vector: vec![1.1],
group_by: "document_id".to_string(),
limit: 2,
group_size: 2,
with_lookup: Some(WithLookup {
collection: "documents".to_string(),
with_payload: Some(vec!["title", "text"].into()),
with_vectors: Some(false.into()),
}),
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.WithPayloadSelectorFactory.include;
import static io.qdrant.client.WithVectorsSelectorFactory.enable;
import io.qdrant.client.grpc.Points.SearchPointGroups;
import io.qdrant.client.grpc.Points.WithLookup;
client
.searchGroupsAsync(
SearchPointGroups.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(1.0f))
.setGroupBy("document_id")
.setLimit(2)
.setGroupSize(2)
.setWithLookup(
WithLookup.newBuilder()
.setCollection("documents")
.setWithPayload(include(List.of("title", "text")))
.setWithVectors(enable(false))
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchGroupsAsync(
collectionName: "{collection_name}",
vector: new float[] { 1.0f },
groupBy: "document_id",
limit: 2,
groupSize: 2,
withLookup: new WithLookup
{
Collection = "documents",
WithPayload = new WithPayloadSelector
{
Include = new PayloadIncludeSelector { Fields = { new string[] { "title", "text" } } }
},
WithVectors = false
}
);
```
For the `with_lookup` parameter, you can also use the shorthand `with_lookup="documents"` to bring the whole payload and vector(s) without explicitly specifying it.
The looked up result will show up under `lookup` in each group.
```json
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Document A",
"text": "This is document A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Document B",
"text": "This is document B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
```
Since the lookup is done by matching directly with the point id, any group id that is not an existing (and valid) point id in the lookup collection will be ignored, and the `lookup` field will be empty.
|
qdrant-landing/content/documentation/concepts/snapshots.md | ---
title: Snapshots
weight: 110
aliases:
- ../snapshots
---
# Snapshots
*Available as of v0.8.4*
Snapshots are `tar` archive files that contain data and configuration of a specific collection on a specific node at a specific time. In a distributed setup, when you have multiple nodes in your cluster, you must create snapshots for each node separately when dealing with a single collection.
This feature can be used to archive data or easily replicate an existing deployment. For disaster recovery, Qdrant Cloud users may prefer to use [Backups](/documentation/cloud/backups/) instead, which are physical disk-level copies of your data.
For a step-by-step guide on how to use snapshots, see our [tutorial](/documentation/tutorials/create-snapshot/).
## Store snapshots
The target directory used to store generated snapshots is controlled through the [configuration](../../guides/configuration/) or using the ENV variable: `QDRANT__STORAGE__SNAPSHOTS_PATH=./snapshots`.
You can set the snapshots storage directory from the [config.yaml](https://github.com/qdrant/qdrant/blob/master/config/config.yaml) file. If no value is given, default is `./snapshots`.
```yaml
storage:
# Specify where you want to store snapshots.
snapshots_path: ./snapshots
```
*Available as of v1.3.0*
While a snapshot is being created, temporary files are by default placed in the configured storage directory.
This location may have limited capacity or be on a slow network-attached disk. You may specify a separate location for temporary files:
```yaml
storage:
# Where to store temporary files
temp_path: /tmp
```
## Create snapshot
<aside role="status">If you work with a distributed deployment, you have to create snapshots for each node separately. A single snapshot will contain only the data stored on the node on which the snapshot was created.</aside>
To create a new snapshot for an existing collection:
```http
POST /collections/{collection_name}/snapshots
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.create_snapshot(collection_name="{collection_name}")
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createSnapshot("{collection_name}");
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client.create_snapshot("{collection_name}").await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.createSnapshotAsync("{collection_name}").get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreateSnapshotAsync("{collection_name}");
```
This is a synchronous operation for which a `tar` archive file will be generated into the `snapshot_path`.
### Delete snapshot
*Available as of v1.0.0*
```http
DELETE /collections/{collection_name}/snapshots/{snapshot_name}
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.delete_snapshot(
collection_name="{collection_name}", snapshot_name="{snapshot_name}"
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.deleteSnapshot("{collection_name}", "{snapshot_name}");
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client.delete_snapshot("{collection_name}", "{snapshot_name}").await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.deleteSnapshotAsync("{collection_name}", "{snapshot_name}").get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.DeleteSnapshotAsync(collectionName: "{collection_name}", snapshotName: "{snapshot_name}");
```
## List snapshot
List of snapshots for a collection:
```http
GET /collections/{collection_name}/snapshots
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.list_snapshots(collection_name="{collection_name}")
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.listSnapshots("{collection_name}");
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client.list_snapshots("{collection_name}").await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.listSnapshotAsync("{collection_name}").get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.ListSnapshotsAsync("{collection_name}");
```
## Retrieve snapshot
<aside role="status">Only available through the REST API for the time being.</aside>
To download a specified snapshot from a collection as a file:
```http
GET /collections/{collection_name}/snapshots/{snapshot_name}
```
```shell
curl 'http://{qdrant-url}:6333/collections/{collection_name}/snapshots/snapshot-2022-10-10.snapshot' \
-H 'api-key: ********' \
--output 'filename.snapshot'
```
## Restore snapshot
<aside role="status">Snapshots generated in one Qdrant cluster can only be restored to other Qdrant clusters that share the same minor version. For instance, a snapshot captured from a v1.4.1 cluster can only be restored to clusters running version v1.4.x, where x is equal to or greater than 1.</aside>
Snapshots can be restored in three possible ways:
1. [Recovering from a URL or local file](#recover-from-a-url-or-local-file) (useful for restoring a snapshot file that is on a remote server or already stored on the node)
3. [Recovering from an uploaded file](#recover-from-an-uploaded-file) (useful for migrating data to a new cluster)
3. [Recovering during start-up](#recover-during-start-up) (useful when running a self-hosted single-node Qdrant instance)
Regardless of the method used, Qdrant will extract the shard data from the snapshot and properly register shards in the cluster.
If there are other active replicas of the recovered shards in the cluster, Qdrant will replicate them to the newly recovered node by default to maintain data consistency.
### Recover from a URL or local file
*Available as of v0.11.3*
This method of recovery requires the snapshot file to be downloadable from a URL or exist as a local file on the node (like if you [created the snapshot](#create-snapshot) on this node previously). If instead you need to upload a snapshot file, see the next section.
To recover from a URL or local file use the [snapshot recovery endpoint](https://api.qdrant.tech/master/api-reference/snapshots/recover-from-snapshot). This endpoint accepts either a URL like `https://example.com` or a [file URI](https://en.wikipedia.org/wiki/File_URI_scheme) like `file:///tmp/snapshot-2022-10-10.snapshot`. If the target collection does not exist, it will be created.
```http
PUT /collections/{collection_name}/snapshots/recover
{
"location": "http://qdrant-node-1:6333/collections/{collection_name}/snapshots/snapshot-2022-10-10.shapshot"
}
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://qdrant-node-2:6333")
client.recover_snapshot(
"{collection_name}",
"http://qdrant-node-1:6333/collections/collection_name/snapshots/snapshot-2022-10-10.shapshot",
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.recoverSnapshot("{collection_name}", {
location: "http://qdrant-node-1:6333/collections/{collection_name}/snapshots/snapshot-2022-10-10.shapshot",
});
```
<aside role="status">When recovering from a URL, the URL must be reachable by the Qdrant node that you are restoring. In Qdrant Cloud, restoring via URL is not supported since all outbound traffic is blocked for security purposes. You may still restore via file URI or via an uploaded file.</aside>
### Recover from an uploaded file
The snapshot file can also be uploaded as a file and restored using the [recover from uploaded snapshot](https://api.qdrant.tech/master/api-reference/snapshots/recover-from-uploaded-snapshot). This endpoint accepts the raw snapshot data in the request body. If the target collection does not exist, it will be created.
```bash
curl -X POST 'http://{qdrant-url}:6333/collections/{collection_name}/snapshots/upload?priority=snapshot' \
-H 'api-key: ********' \
-H 'Content-Type:multipart/form-data' \
-F 'snapshot=@/path/to/snapshot-2022-10-10.shapshot'
```
This method is typically used to migrate data from one cluster to another, so we recommend setting the [priority](#snapshot-priority) to "snapshot" for that use-case.
### Recover during start-up
<aside role="alert">This method cannot be used in a multi-node deployment and cannot be used in Qdrant Cloud.</aside>
If you have a single-node deployment, you can recover any collection at start-up and it will be immediately available.
Restoring snapshots is done through the Qdrant CLI at start-up time via the `--snapshot` argument which accepts a list of pairs such as `<snapshot_file_path>:<target_collection_name>`
For example:
```bash
./qdrant --snapshot /snapshots/test-collection-archive.snapshot:test-collection --snapshot /snapshots/test-collection-archive.snapshot:test-copy-collection
```
The target collection **must** be absent otherwise the program will exit with an error.
If you wish instead to overwrite an existing collection, use the `--force_snapshot` flag with caution.
### Snapshot priority
When recovering a snapshot to a non-empty node, there may be conflicts between the snapshot data and the existing data. The "priority" setting controls how Qdrant handles these conflicts. The priority setting is important because different priorities can give very
different end results. The default priority may not be best for all situations.
The available snapshot recovery priorities are:
- `replica`: _(default)_ prefer existing data over the snapshot.
- `snapshot`: prefer snapshot data over existing data.
- `no_sync`: restore snapshot without any additional synchronization.
To recover a new collection from a snapshot, you need to set
the priority to `snapshot`. With `snapshot` priority, all data from the snapshot
will be recovered onto the cluster. With `replica` priority _(default)_, you'd
end up with an empty collection because the collection on the cluster did not
contain any points and that source was preferred.
`no_sync` is for specialized use cases and is not commonly used. It allows
managing shards and transferring shards between clusters manually without any
additional synchronization. Using it incorrectly will leave your cluster in a
broken state.
To recover from a URL, you specify an additional parameter in the request body:
```http
PUT /collections/{collection_name}/snapshots/recover
{
"location": "http://qdrant-node-1:6333/collections/{collection_name}/snapshots/snapshot-2022-10-10.shapshot",
"priority": "snapshot"
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://qdrant-node-2:6333")
client.recover_snapshot(
"{collection_name}",
"http://qdrant-node-1:6333/collections/{collection_name}/snapshots/snapshot-2022-10-10.shapshot",
priority=models.SnapshotPriority.SNAPSHOT,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.recoverSnapshot("{collection_name}", {
location: "http://qdrant-node-1:6333/collections/{collection_name}/snapshots/snapshot-2022-10-10.shapshot",
priority: "snapshot"
});
```
```bash
curl -X POST 'http://qdrant-node-1:6333/collections/{collection_name}/snapshots/upload?priority=snapshot' \
-H 'api-key: ********' \
-H 'Content-Type:multipart/form-data' \
-F 'snapshot=@/path/to/snapshot-2022-10-10.shapshot'
```
## Snapshots for the whole storage
*Available as of v0.8.5*
Sometimes it might be handy to create snapshot not just for a single collection, but for the whole storage, including collection aliases.
Qdrant provides a dedicated API for that as well. It is similar to collection-level snapshots, but does not require `collection_name`.
<aside role="alert">Full storage snapshots are only suitable for single-node deployments. <a href="/documentation/guides/distributed_deployment/">Distributed</a> mode is not supported as it doesn't contain the necessary files for that.</aside>
<aside role="status">Full storage snapshots can be created and downloaded from Qdrant Cloud, but you cannot restore a Qdrant Cloud cluster from a whole storage snapshot since that requires use of the Qdrant CLI. You can use <a href="/documentation/cloud/backups/">Backups</a> instead.</aside>
### Create full storage snapshot
```http
POST /snapshots
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.create_full_snapshot()
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createFullSnapshot();
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client.create_full_snapshot().await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.createFullSnapshotAsync().get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreateFullSnapshotAsync();
```
### Delete full storage snapshot
*Available as of v1.0.0*
```http
DELETE /snapshots/{snapshot_name}
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.delete_full_snapshot(snapshot_name="{snapshot_name}")
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.deleteFullSnapshot("{snapshot_name}");
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client.delete_full_snapshot("{snapshot_name}").await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.deleteFullSnapshotAsync("{snapshot_name}").get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.DeleteFullSnapshotAsync("{snapshot_name}");
```
### List full storage snapshots
```http
GET /snapshots
```
```python
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
client.list_full_snapshots()
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.listFullSnapshots();
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client.list_full_snapshots().await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.listFullSnapshotAsync().get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.ListFullSnapshotsAsync();
```
### Download full storage snapshot
<aside role="status">Only available through the REST API for the time being.</aside>
```http
GET /snapshots/{snapshot_name}
```
## Restore full storage snapshot
Restoring snapshots can only be done through the Qdrant CLI at startup time.
For example:
```bash
./qdrant --storage-snapshot /snapshots/full-snapshot-2022-07-18-11-20-51.snapshot
```
|
qdrant-landing/content/documentation/concepts/storage.md | ---
title: Storage
weight: 80
aliases:
- ../storage
---
# Storage
All data within one collection is divided into segments.
Each segment has its independent vector and payload storage as well as indexes.
Data stored in segments usually do not overlap.
However, storing the same point in different segments will not cause problems since the search contains a deduplication mechanism.
The segments consist of vector and payload storages, vector and payload [indexes](../indexing/), and id mapper, which stores the relationship between internal and external ids.
A segment can be `appendable` or `non-appendable` depending on the type of storage and index used.
You can freely add, delete and query data in the `appendable` segment.
With `non-appendable` segment can only read and delete data.
The configuration of the segments in the collection can be different and independent of one another, but at least one `appendable' segment must be present in a collection.
## Vector storage
Depending on the requirements of the application, Qdrant can use one of the data storage options.
The choice has to be made between the search speed and the size of the RAM used.
**In-memory storage** - Stores all vectors in RAM, has the highest speed since disk access is required only for persistence.
**Memmap storage** - Creates a virtual address space associated with the file on disk. [Wiki](https://en.wikipedia.org/wiki/Memory-mapped_file).
Mmapped files are not directly loaded into RAM. Instead, they use page cache to access the contents of the file.
This scheme allows flexible use of available memory. With sufficient RAM, it is almost as fast as in-memory storage.
### Configuring Memmap storage
There are two ways to configure the usage of memmap(also known as on-disk) storage:
- Set up `on_disk` option for the vectors in the collection create API:
*Available as of v1.2.0*
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine",
"on_disk": true
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(
size=768, distance=models.Distance.COSINE, on_disk=True
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
on_disk: true,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{vectors_config::Config, CreateCollection, Distance, VectorParams, VectorsConfig},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
on_disk: Some(true),
..Default::default()
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
"{collection_name}",
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.setOnDisk(true)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
"{collection_name}",
new VectorParams
{
Size = 768,
Distance = Distance.Cosine,
OnDisk = true
}
);
```
This will create a collection with all vectors immediately stored in memmap storage.
This is the recommended way, in case your Qdrant instance operates with fast disks and you are working with large collections.
- Set up `memmap_threshold_kb` option (deprecated). This option will set the threshold after which the segment will be converted to memmap storage.
There are two ways to do this:
1. You can set the threshold globally in the [configuration file](../../guides/configuration/). The parameter is called `memmap_threshold_kb`.
2. You can set the threshold for each collection separately during [creation](../collections/#create-collection) or [update](../collections/#update-collection-parameters).
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"optimizers_config": {
"memmap_threshold": 20000
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
optimizers_config=models.OptimizersConfigDiff(memmap_threshold=20000),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
optimizers_config: {
memmap_threshold: 20000,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
vectors_config::Config, CreateCollection, Distance, OptimizersConfigDiff, VectorParams,
VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
optimizers_config: Some(OptimizersConfigDiff {
memmap_threshold: Some(20000),
..Default::default()
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setOptimizersConfig(
OptimizersConfigDiff.newBuilder().setMemmapThreshold(20000).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
optimizersConfig: new OptimizersConfigDiff { MemmapThreshold = 20000 }
);
```
The rule of thumb to set the memmap threshold parameter is simple:
- if you have a balanced use scenario - set memmap threshold the same as `indexing_threshold` (default is 20000). In this case the optimizer will not make any extra runs and will optimize all thresholds at once.
- if you have a high write load and low RAM - set memmap threshold lower than `indexing_threshold` to e.g. 10000. In this case the optimizer will convert the segments to memmap storage first and will only apply indexing after that.
In addition, you can use memmap storage not only for vectors, but also for HNSW index.
To enable this, you need to set the `hnsw_config.on_disk` parameter to `true` during collection [creation](../collections/#create-a-collection) or [updating](../collections/#update-collection-parameters).
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"optimizers_config": {
"memmap_threshold": 20000
},
"hnsw_config": {
"on_disk": true
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
optimizers_config=models.OptimizersConfigDiff(memmap_threshold=20000),
hnsw_config=models.HnswConfigDiff(on_disk=True),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
optimizers_config: {
memmap_threshold: 20000,
},
hnsw_config: {
on_disk: true,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
vectors_config::Config, CreateCollection, Distance, HnswConfigDiff,
OptimizersConfigDiff, VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
optimizers_config: Some(OptimizersConfigDiff {
memmap_threshold: Some(20000),
..Default::default()
}),
hnsw_config: Some(HnswConfigDiff {
on_disk: Some(true),
..Default::default()
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.HnswConfigDiff;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setOptimizersConfig(
OptimizersConfigDiff.newBuilder().setMemmapThreshold(20000).build())
.setHnswConfig(HnswConfigDiff.newBuilder().setOnDisk(true).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
optimizersConfig: new OptimizersConfigDiff { MemmapThreshold = 20000 },
hnswConfig: new HnswConfigDiff { OnDisk = true }
);
```
## Payload storage
Qdrant supports two types of payload storages: InMemory and OnDisk.
InMemory payload storage is organized in the same way as in-memory vectors.
The payload data is loaded into RAM at service startup while disk and [RocksDB](https://rocksdb.org/) are used for persistence only.
This type of storage works quite fast, but it may require a lot of space to keep all the data in RAM, especially if the payload has large values attached - abstracts of text or even images.
In the case of large payload values, it might be better to use OnDisk payload storage.
This type of storage will read and write payload directly to RocksDB, so it won't require any significant amount of RAM to store.
The downside, however, is the access latency.
If you need to query vectors with some payload-based conditions - checking values stored on disk might take too much time.
In this scenario, we recommend creating a payload index for each field used in filtering conditions to avoid disk access.
Once you create the field index, Qdrant will preserve all values of the indexed field in RAM regardless of the payload storage type.
You can specify the desired type of payload storage with [configuration file](../../guides/configuration/) or with collection parameter `on_disk_payload` during [creation](../collections/#create-collection) of the collection.
## Versioning
To ensure data integrity, Qdrant performs all data changes in 2 stages.
In the first step, the data is written to the Write-ahead-log(WAL), which orders all operations and assigns them a sequential number.
Once a change has been added to the WAL, it will not be lost even if a power loss occurs.
Then the changes go into the segments.
Each segment stores the last version of the change applied to it as well as the version of each individual point.
If the new change has a sequential number less than the current version of the point, the updater will ignore the change.
This mechanism allows Qdrant to safely and efficiently restore the storage from the WAL in case of an abnormal shutdown.
|
qdrant-landing/content/documentation/embeddings/_index.md | ---
title: Embeddings
weight: 34
---
| Embeddings Providers |
| ----------------------------- |
| [Aleph Alpha](./aleph-alpha/) |
| [Bedrock](./bedrock/) |
| [Cohere](./cohere/) |
| [Gemini](./gemini/) |
| [Jina](./jina-emebddngs/) |
| [Mistral](./mistral/) |
| [Nomic](./nomic/) |
| [Nvidia](./nvidia/) |
| [OpenAI](./openai/) |
| [Prem AI](./premai/) |
| [Snowflake](./snowflake/) |
| [Upstage](./upstage/) |
| [Voyage AI](./voyage/) |
|
qdrant-landing/content/documentation/embeddings/aleph-alpha.md | ---
title: Aleph Alpha
weight: 900
aliases: [ ../integrations/aleph-alpha/ ]
---
Aleph Alpha is a multimodal and multilingual embeddings' provider. Their API allows creating the embeddings for text and images, both
in the same latent space. They maintain an [official Python client](https://github.com/Aleph-Alpha/aleph-alpha-client) that might be
installed with pip:
```bash
pip install aleph-alpha-client
```
There is both synchronous and asynchronous client available. Obtaining the embeddings for an image and storing it into Qdrant might
be done in the following way:
```python
import qdrant_client
from qdrant_client.models import Batch
from aleph_alpha_client import (
Prompt,
AsyncClient,
SemanticEmbeddingRequest,
SemanticRepresentation,
ImagePrompt
)
aa_token = "<< your_token >>"
model = "luminous-base"
qdrant_client = qdrant_client.QdrantClient()
async with AsyncClient(token=aa_token) as client:
prompt = ImagePrompt.from_file("./path/to/the/image.jpg")
prompt = Prompt.from_image(prompt)
query_params = {
"prompt": prompt,
"representation": SemanticRepresentation.Symmetric,
"compress_to_size": 128,
}
query_request = SemanticEmbeddingRequest(**query_params)
query_response = await client.semantic_embed(
request=query_request, model=model
)
qdrant_client.upsert(
collection_name="MyCollection",
points=Batch(
ids=[1],
vectors=[query_response.embedding],
)
)
```
If we wanted to create text embeddings with the same model, we wouldn't use `ImagePrompt.from_file`, but simply provide the input
text into the `Prompt.from_text` method.
|
qdrant-landing/content/documentation/embeddings/bedrock.md | ---
title: AWS Bedrock
weight: 1000
---
# Bedrock Embeddings
You can use [AWS Bedrock](https://aws.amazon.com/bedrock/) with Qdrant. AWS Bedrock supports multiple [embedding model providers](https://docs.aws.amazon.com/bedrock/latest/userguide/models-supported.html).
You'll need the following information from your AWS account:
- Region
- Access key ID
- Secret key
To configure your credentials, review the following AWS article: [How do I create an AWS access key](https://repost.aws/knowledge-center/create-access-key).
With the following code sample, you can generate embeddings using the [Titan Embeddings G1 - Text model](https://docs.aws.amazon.com/bedrock/latest/userguide/titan-embedding-models.html) which produces sentence embeddings of size 1536.
```python
# Install the required dependencies
# pip install boto3 qdrant_client
import json
import boto3
from qdrant_client import QdrantClient, models
session = boto3.Session()
bedrock_client = session.client(
"bedrock-runtime",
region_name="<YOUR_AWS_REGION>",
aws_access_key_id="<YOUR_AWS_ACCESS_KEY_ID>",
aws_secret_access_key="<YOUR_AWS_SECRET_KEY>",
)
qdrant_client = QdrantClient(url="http://localhost:6333")
qdrant_client.create_collection(
"{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
)
body = json.dumps({"inputText": "Some text to generate embeddings for"})
response = bedrock_client.invoke_model(
body=body,
modelId="amazon.titan-embed-text-v1",
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
qdrant_client.upsert(
"{collection_name}",
points=[models.PointStruct(id=1, vector=response_body["embedding"])],
)
```
```javascript
// Install the required dependencies
// npm install @aws-sdk/client-bedrock-runtime @qdrant/js-client-rest
import {
BedrockRuntimeClient,
InvokeModelCommand,
} from "@aws-sdk/client-bedrock-runtime";
import { QdrantClient } from '@qdrant/js-client-rest';
const main = async () => {
const bedrockClient = new BedrockRuntimeClient({
region: "<YOUR_AWS_REGION>",
credentials: {
accessKeyId: "<YOUR_AWS_ACCESS_KEY_ID>",,
secretAccessKey: "<YOUR_AWS_SECRET_KEY>",
},
});
const qdrantClient = new QdrantClient({ url: 'http://localhost:6333' });
await qdrantClient.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: 'Cosine',
}
});
const response = await bedrockClient.send(
new InvokeModelCommand({
modelId: "amazon.titan-embed-text-v1",
body: JSON.stringify({
inputText: "Some text to generate embeddings for",
}),
contentType: "application/json",
accept: "application/json",
})
);
const body = new TextDecoder().decode(response.body);
await qdrantClient.upsert("{collection_name}", {
points: [
{
id: 1,
vector: JSON.parse(body).embedding,
},
],
});
}
main();
```
|
qdrant-landing/content/documentation/embeddings/cohere.md | ---
title: Cohere
weight: 700
aliases: [ ../integrations/cohere/ ]
---
# Cohere
Qdrant is compatible with Cohere [co.embed API](https://docs.cohere.ai/reference/embed) and its official Python SDK that
might be installed as any other package:
```bash
pip install cohere
```
The embeddings returned by co.embed API might be used directly in the Qdrant client's calls:
```python
import cohere
import qdrant_client
from qdrant_client.models import Batch
cohere_client = cohere.Client("<< your_api_key >>")
qdrant_client = qdrant_client.QdrantClient()
qdrant_client.upsert(
collection_name="MyCollection",
points=Batch(
ids=[1],
vectors=cohere_client.embed(
model="large",
texts=["The best vector database"],
).embeddings,
),
)
```
If you are interested in seeing an end-to-end project created with co.embed API and Qdrant, please check out the
"[Question Answering as a Service with Cohere and Qdrant](/articles/qa-with-cohere-and-qdrant/)" article.
## Embed v3
Embed v3 is a new family of Cohere models, released in November 2023. The new models require passing an additional
parameter to the API call: `input_type`. It determines the type of task you want to use the embeddings for.
- `input_type="search_document"` - for documents to store in Qdrant
- `input_type="search_query"` - for search queries to find the most relevant documents
- `input_type="classification"` - for classification tasks
- `input_type="clustering"` - for text clustering
While implementing semantic search applications, such as RAG, you should use `input_type="search_document"` for the
indexed documents and `input_type="search_query"` for the search queries. The following example shows how to index
documents with the Embed v3 model:
```python
import cohere
import qdrant_client
from qdrant_client.models import Batch
cohere_client = cohere.Client("<< your_api_key >>")
client = qdrant_client.QdrantClient()
client.upsert(
collection_name="MyCollection",
points=Batch(
ids=[1],
vectors=cohere_client.embed(
model="embed-english-v3.0", # New Embed v3 model
input_type="search_document", # Input type for documents
texts=["Qdrant is the a vector database written in Rust"],
).embeddings,
),
)
```
Once the documents are indexed, you can search for the most relevant documents using the Embed v3 model:
```python
client.search(
collection_name="MyCollection",
query_vector=cohere_client.embed(
model="embed-english-v3.0", # New Embed v3 model
input_type="search_query", # Input type for search queries
texts=["The best vector database"],
).embeddings[0],
)
```
<aside role="status">
According to Cohere's documentation, all v3 models can use dot product, cosine similarity,
and Euclidean distance as the similarity metric, as all metrics return identical rankings.
</aside>
|
qdrant-landing/content/documentation/embeddings/gemini.md | ---
title: Gemini
weight: 700
---
| Time: 10 min | Level: Beginner | [](https://githubtocolab.com/qdrant/examples/blob/gemini-getting-started/gemini-getting-started/gemini-getting-started.ipynb) |
| --- | ----------- | ----------- |
# Gemini
Qdrant is compatible with Gemini Embedding Model API and its official Python SDK that can be installed as any other package:
Gemini is a new family of Google PaLM models, released in December 2023. The new embedding models succeed the previous Gecko Embedding Model.
In the latest models, an additional parameter, `task_type`, can be passed to the API call. This parameter serves to designate the intended purpose for the embeddings utilized.
The Embedding Model API supports various task types, outlined as follows:
1. `retrieval_query`: query in a search/retrieval setting
2. `retrieval_document`: document from the corpus being searched
3. `semantic_similarity`: semantic text similarity
4. `classification`: embeddings to be used for text classification
5. `clustering`: the generated embeddings will be used for clustering
6. `task_type_unspecified`: Unset value, which will default to one of the other values.
If you're building a semantic search application, such as RAG, you should use `task_type="retrieval_document"` for the indexed documents and `task_type="retrieval_query"` for the search queries.
The following example shows how to do this with Qdrant:
## Setup
```bash
pip install google-generativeai
```
Let's see how to use the Embedding Model API to embed a document for retrieval.
The following example shows how to embed a document with the `models/embedding-001` with the `retrieval_document` task type:
## Embedding a document
```python
import google.generativeai as gemini_client
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, PointStruct, VectorParams
collection_name = "example_collection"
GEMINI_API_KEY = "YOUR GEMINI API KEY" # add your key here
client = QdrantClient(url="http://localhost:6333")
gemini_client.configure(api_key=GEMINI_API_KEY)
texts = [
"Qdrant is a vector database that is compatible with Gemini.",
"Gemini is a new family of Google PaLM models, released in December 2023.",
]
results = [
gemini_client.embed_content(
model="models/embedding-001",
content=sentence,
task_type="retrieval_document",
title="Qdrant x Gemini",
)
for sentence in texts
]
```
## Creating Qdrant Points and Indexing documents with Qdrant
### Creating Qdrant Points
```python
points = [
PointStruct(
id=idx,
vector=response['embedding'],
payload={"text": text},
)
for idx, (response, text) in enumerate(zip(results, texts))
]
```
### Create Collection
```python
client.create_collection(collection_name, vectors_config=
VectorParams(
size=768,
distance=Distance.COSINE,
)
)
```
### Add these into the collection
```python
client.upsert(collection_name, points)
```
## Searching for documents with Qdrant
Once the documents are indexed, you can search for the most relevant documents using the same model with the `retrieval_query` task type:
```python
client.search(
collection_name=collection_name,
query_vector=gemini_client.embed_content(
model="models/embedding-001",
content="Is Qdrant compatible with Gemini?",
task_type="retrieval_query",
)["embedding"],
)
```
## Using Gemini Embedding Models with Binary Quantization
You can use Gemini Embedding Models with [Binary Quantization](/articles/binary-quantization/) - a technique that allows you to reduce the size of the embeddings by 32 times without losing the quality of the search results too much.
In this table, you can see the results of the search with the `models/embedding-001` model with Binary Quantization in comparison with the original model:
At an oversampling of 3 and a limit of 100, we've a 95% recall against the exact nearest neighbors with rescore enabled.
| Oversampling | | 1 | 1 | 2 | 2 | 3 | 3 |
|--------------|---------|----------|----------|----------|----------|----------|----------|
| | **Rescore** | False | True | False | True | False | True |
| **Limit** | | | | | | | |
| 10 | | 0.523333 | 0.831111 | 0.523333 | 0.915556 | 0.523333 | 0.950000 |
| 20 | | 0.510000 | 0.836667 | 0.510000 | 0.912222 | 0.510000 | 0.937778 |
| 50 | | 0.489111 | 0.841556 | 0.489111 | 0.913333 | 0.488444 | 0.947111 |
| 100 | | 0.485778 | 0.846556 | 0.485556 | 0.929000 | 0.486000 | **0.956333** |
That's it! You can now use Gemini Embedding Models with Qdrant!
|
qdrant-landing/content/documentation/embeddings/jina-embeddings.md | ---
title: Jina Embeddings
weight: 800
aliases:
- /documentation/embeddings/jina-emebddngs/
- ../integrations/jina-embeddings/
---
# Jina Embeddings
Qdrant can also easily work with [Jina embeddings](https://jina.ai/embeddings/) which allow for model input lengths of up to 8192 tokens.
To call their endpoint, all you need is an API key obtainable [here](https://jina.ai/embeddings/). By the way, our friends from **Jina AI** provided us with a code (**QDRANT**) that will grant you a **10% discount** if you plan to use Jina Embeddings in production.
```python
import qdrant_client
import requests
from qdrant_client.models import Distance, VectorParams, Batch
# Provide Jina API key and choose one of the available models.
# You can get a free trial key here: https://jina.ai/embeddings/
JINA_API_KEY = "jina_xxxxxxxxxxx"
MODEL = "jina-embeddings-v2-base-en" # or "jina-embeddings-v2-base-en"
EMBEDDING_SIZE = 768 # 512 for small variant
# Get embeddings from the API
url = "https://api.jina.ai/v1/embeddings"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {JINA_API_KEY}",
}
data = {
"input": ["Your text string goes here", "You can send multiple texts"],
"model": MODEL,
}
response = requests.post(url, headers=headers, json=data)
embeddings = [d["embedding"] for d in response.json()["data"]]
# Index the embeddings into Qdrant
client = qdrant_client.QdrantClient(":memory:")
client.create_collection(
collection_name="MyCollection",
vectors_config=VectorParams(size=EMBEDDING_SIZE, distance=Distance.DOT),
)
qdrant_client.upsert(
collection_name="MyCollection",
points=Batch(
ids=list(range(len(embeddings))),
vectors=embeddings,
),
)
```
|
qdrant-landing/content/documentation/embeddings/mistral.md | ---
title: Mistral
weight: 700
---
| Time: 10 min | Level: Beginner | [](https://githubtocolab.com/qdrant/examples/blob/mistral-getting-started/mistral-embed-getting-started/mistral_qdrant_getting_started.ipynb) |
| --- | ----------- | ----------- |
# Mistral
Qdrant is compatible with the new released Mistral Embed and its official Python SDK that can be installed as any other package:
## Setup
### Install the client
```bash
pip install mistralai
```
And then we set this up:
```python
from mistralai.client import MistralClient
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct, VectorParams, Distance
collection_name = "example_collection"
MISTRAL_API_KEY = "your_mistral_api_key"
client = QdrantClient(":memory:")
mistral_client = MistralClient(api_key=MISTRAL_API_KEY)
texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
Let's see how to use the Embedding Model API to embed a document for retrieval.
The following example shows how to embed a document with the `models/embedding-001` with the `retrieval_document` task type:
## Embedding a document
```python
result = mistral_client.embeddings(
model="mistral-embed",
input=texts,
)
```
The returned result has a data field with a key: `embedding`. The value of this key is a list of floats representing the embedding of the document.
### Converting this into Qdrant Points
```python
points = [
PointStruct(
id=idx,
vector=response.embedding,
payload={"text": text},
)
for idx, (response, text) in enumerate(zip(result.data, texts))
]
```
## Create a collection and Insert the documents
```python
client.create_collection(collection_name, vectors_config=VectorParams(
size=1024,
distance=Distance.COSINE,
)
)
client.upsert(collection_name, points)
```
## Searching for documents with Qdrant
Once the documents are indexed, you can search for the most relevant documents using the same model with the `retrieval_query` task type:
```python
client.search(
collection_name=collection_name,
query_vector=mistral_client.embeddings(
model="mistral-embed", input=["What is the best to use for vector search scaling?"]
).data[0].embedding,
)
```
## Using Mistral Embedding Models with Binary Quantization
You can use Mistral Embedding Models with [Binary Quantization](/articles/binary-quantization/) - a technique that allows you to reduce the size of the embeddings by 32 times without losing the quality of the search results too much.
At an oversampling of 3 and a limit of 100, we've a 95% recall against the exact nearest neighbors with rescore enabled.
| Oversampling | | 1 | 1 | 2 | 2 | 3 | 3 |
|--------------|---------|----------|----------|----------|----------|----------|--------------|
| | **Rescore** | False | True | False | True | False | True |
| **Limit** | | | | | | | |
| 10 | | 0.53444 | 0.857778 | 0.534444 | 0.918889 | 0.533333 | 0.941111 |
| 20 | | 0.508333 | 0.837778 | 0.508333 | 0.903889 | 0.508333 | 0.927778 |
| 50 | | 0.492222 | 0.834444 | 0.492222 | 0.903556 | 0.492889 | 0.940889 |
| 100 | | 0.499111 | 0.845444 | 0.498556 | 0.918333 | 0.497667 | **0.944556** |
That's it! You can now use Mistral Embedding Models with Qdrant!
|
qdrant-landing/content/documentation/embeddings/nomic.md | ---
title: "Nomic"
weight: 1100
---
# Nomic
The `nomic-embed-text-v1` model is an open source [8192 context length](https://github.com/nomic-ai/contrastors) text encoder.
While you can find it on the [Hugging Face Hub](https://huggingface.co/nomic-ai/nomic-embed-text-v1),
you may find it easier to obtain them through the [Nomic Text Embeddings](https://docs.nomic.ai/reference/endpoints/nomic-embed-text).
Once installed, you can configure it with the official Python client, FastEmbed or through direct HTTP requests.
<aside role="status">Using Nomic Embeddings via the Nomic API/SDK requires configuring the <a href="https://atlas.nomic.ai/cli-login">Nomic API token</a>.</aside>
You can use Nomic embeddings directly in Qdrant client calls. There is a difference in the way the embeddings
are obtained for documents and queries.
#### Upsert using [Nomic SDK](https://github.com/nomic-ai/nomic)
The `task_type` parameter defines the embeddings that you get.
For documents, set the `task_type` to `search_document`:
```python
from qdrant_client import QdrantClient, models
from nomic import embed
output = embed.text(
texts=["Qdrant is the best vector database!"],
model="nomic-embed-text-v1",
task_type="search_document",
)
client = QdrantClient()
client.upsert(
collection_name="my-collection",
points=models.Batch(
ids=[1],
vectors=output["embeddings"],
),
)
```
#### Upsert using [FastEmbed](https://github.com/qdrant/fastembed)
```python
from fastembed import TextEmbedding
from client import QdrantClient, models
model = TextEmbedding("nomic-ai/nomic-embed-text-v1")
output = model.embed(["Qdrant is the best vector database!"])
client = QdrantClient()
client.upsert(
collection_name="my-collection",
points=models.Batch(
ids=[1],
vectors=[embeddings.tolist() for embeddings in output],
),
)
```
#### Search using [Nomic SDK](https://github.com/nomic-ai/nomic)
To query the collection, set the `task_type` to `search_query`:
```python
output = embed.text(
texts=["What is the best vector database?"],
model="nomic-embed-text-v1",
task_type="search_query",
)
client.search(
collection_name="my-collection",
query_vector=output["embeddings"][0],
)
```
#### Search using [FastEmbed](https://github.com/qdrant/fastembed)
```python
output = next(model.embed("What is the best vector database?"))
client.search(
collection_name="my-collection",
query_vector=output.tolist(),
)
```
For more information, see the Nomic documentation on [Text embeddings](https://docs.nomic.ai/reference/endpoints/nomic-embed-text).
|
qdrant-landing/content/documentation/embeddings/nvidia.md | ---
title: Nvidia
weight: 1200
---
# Nvidia
Qdrant supports working with [Nvidia embeddings](https://build.nvidia.com/explore/retrieval).
You can generate an API key to authenticate the requests from the [Nvidia Playground](<https://build.nvidia.com/nvidia/embed-qa-4>).
### Setting up the Qdrant client and Nvidia session
```python
import requests
from qdrant_client import QdrantClient
NVIDIA_BASE_URL = "https://ai.api.nvidia.com/v1/retrieval/nvidia/embeddings"
NVIDIA_API_KEY = "<YOUR_API_KEY>"
nvidia_session = requests.Session()
client = QdrantClient(":memory:")
headers = {
"Authorization": f"Bearer {NVIDIA_API_KEY}",
"Accept": "application/json",
}
texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
```typescript
import { QdrantClient } from '@qdrant/js-client-rest';
const NVIDIA_BASE_URL = "https://ai.api.nvidia.com/v1/retrieval/nvidia/embeddings"
const NVIDIA_API_KEY = "<YOUR_API_KEY>"
const client = new QdrantClient({ url: 'http://localhost:6333' });
const headers = {
"Authorization": "Bearer " + NVIDIA_API_KEY,
"Accept": "application/json",
"Content-Type": "application/json"
}
const texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
The following example shows how to embed documents with the `embed-qa-4` model that generates sentence embeddings of size 1024.
### Embedding documents
```python
payload = {
"input": texts,
"input_type": "passage",
"model": "NV-Embed-QA",
}
response_body = nvidia_session.post(
NVIDIA_BASE_URL, headers=headers, json=payload
).json()
```
```typescript
let body = {
"input": texts,
"input_type": "passage",
"model": "NV-Embed-QA"
}
let response = await fetch(NVIDIA_BASE_URL, {
method: "POST",
body: JSON.stringify(body),
headers
});
let response_body = await response.json()
```
### Converting the model outputs to Qdrant points
```python
from qdrant_client.models import PointStruct
points = [
PointStruct(
id=idx,
vector=data["embedding"],
payload={"text": text},
)
for idx, (data, text) in enumerate(zip(response_body["data"], texts))
]
```
```typescript
let points = response_body.data.map((data, i) => {
return {
id: i,
vector: data.embedding,
payload: {
text: texts[i]
}
}
})
```
### Creating a collection to insert the documents
```python
from qdrant_client.models import VectorParams, Distance
collection_name = "example_collection"
client.create_collection(
collection_name,
vectors_config=VectorParams(
size=1024,
distance=Distance.COSINE,
),
)
client.upsert(collection_name, points)
```
```typescript
const COLLECTION_NAME = "example_collection"
await client.createCollection(COLLECTION_NAME, {
vectors: {
size: 1024,
distance: 'Cosine',
}
});
await client.upsert(COLLECTION_NAME, {
wait: true,
points
})
```
## Searching for documents with Qdrant
Once the documents are added, you can search for the most relevant documents.
```python
payload = {
"input": "What is the best to use for vector search scaling?",
"input_type": "query",
"model": "NV-Embed-QA",
}
response_body = nvidia_session.post(
NVIDIA_BASE_URL, headers=headers, json=payload
).json()
client.search(
collection_name=collection_name,
query_vector=response_body["data"][0]["embedding"],
)
```
```typescript
body = {
"input": "What is the best to use for vector search scaling?",
"input_type": "query",
"model": "NV-Embed-QA",
}
response = await fetch(NVIDIA_BASE_URL, {
method: "POST",
body: JSON.stringify(body),
headers
});
response_body = await response.json()
await client.search(COLLECTION_NAME, {
vector: response_body.data[0].embedding,
});
```
|
qdrant-landing/content/documentation/embeddings/openai.md | ---
title: OpenAI
weight: 800
aliases: [ ../integrations/openai/ ]
---
# OpenAI
Qdrant supports working with [OpenAI embeddings](https://platform.openai.com/docs/guides/embeddings/embeddings).
There is an official OpenAI Python package that simplifies obtaining them, and it can be installed with pip:
```bash
pip install openai
```
### Setting up the OpenAI and Qdrant clients
```python
import openai
import qdrant_client
openai_client = openai.Client(
api_key="<YOUR_API_KEY>"
)
client = qdrant_client.QdrantClient(":memory:")
texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
The following example shows how to embed a document with the `text-embedding-3-small` model that generates sentence embeddings of size 1536. You can find the list of all supported models [here](https://platform.openai.com/docs/models/embeddings).
### Embedding a document
```python
embedding_model = "text-embedding-3-small"
result = openai_client.embeddings.create(input=texts, model=embedding_model)
```
### Converting the model outputs to Qdrant points
```python
from qdrant_client.models import PointStruct
points = [
PointStruct(
id=idx,
vector=data.embedding,
payload={"text": text},
)
for idx, (data, text) in enumerate(zip(result.data, texts))
]
```
### Creating a collection to insert the documents
```python
from qdrant_client.models import VectorParams, Distance
collection_name = "example_collection"
client.create_collection(
collection_name,
vectors_config=VectorParams(
size=1536,
distance=Distance.COSINE,
),
)
client.upsert(collection_name, points)
```
## Searching for documents with Qdrant
Once the documents are indexed, you can search for the most relevant documents using the same model.
```python
client.search(
collection_name=collection_name,
query_vector=openai_client.embeddings.create(
input=["What is the best to use for vector search scaling?"],
model=embedding_model,
)
.data[0]
.embedding,
)
```
## Using OpenAI Embedding Models with Qdrant's Binary Quantization
You can use OpenAI embedding Models with [Binary Quantization](/articles/binary-quantization/) - a technique that allows you to reduce the size of the embeddings by 32 times without losing the quality of the search results too much.
|Method|Dimensionality|Test Dataset|Recall|Oversampling|
|-|-|-|-|-|
|OpenAI text-embedding-3-large|3072|[DBpedia 1M](https://huggingface.co/datasets/Qdrant/dbpedia-entities-openai3-text-embedding-3-large-3072-1M) | 0.9966|3x|
|OpenAI text-embedding-3-small|1536|[DBpedia 100K](https://huggingface.co/datasets/Qdrant/dbpedia-entities-openai3-text-embedding-3-small-1536-100K)| 0.9847|3x|
|OpenAI text-embedding-3-large|1536|[DBpedia 1M](https://huggingface.co/datasets/Qdrant/dbpedia-entities-openai3-text-embedding-3-large-1536-1M)| 0.9826|3x|
|OpenAI text-embedding-ada-002|1536|[DbPedia 1M](https://huggingface.co/datasets/KShivendu/dbpedia-entities-openai-1M) |0.98|4x|
|
qdrant-landing/content/documentation/embeddings/premai.md | ---
title: Prem AI
weight: 1600
---
# Prem AI
[PremAI](https://premai.io/) is a unified generative AI development platform for fine-tuning deploying, and monitoring AI models.
Qdrant is compatible with PremAI APIs.
### Installing the SDKs
```bash
pip install premai qdrant-client
```
To install the npm package:
```bash
npm install @premai/prem-sdk @qdrant/js-client-rest
```
### Import all required packages
```python
from premai import Prem
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
```
```typescript
import Prem from '@premai/prem-sdk';
import { QdrantClient } from '@qdrant/js-client-rest';
```
### Define all the constants
We need to define the project ID and the embedding model to use. You can learn more about obtaining these in the PremAI [docs](https://docs.premai.io/quick-start).
```python
PROJECT_ID = 123
EMBEDDING_MODEL = "text-embedding-3-large"
COLLECTION_NAME = "prem-collection-py"
QDRANT_SERVER_URL = "http://localhost:6333"
DOCUMENTS = [
"This is a sample python document",
"We will be using qdrant and premai python sdk"
]
```
```typescript
const PROJECT_ID = 123;
const EMBEDDING_MODEL = "text-embedding-3-large";
const COLLECTION_NAME = "prem-collection-js";
const SERVER_URL = "http://localhost:6333"
const DOCUMENTS = [
"This is a sample javascript document",
"We will be using qdrant and premai javascript sdk"
];
```
### Set up PremAI and Qdrant clients
```python
prem_client = Prem(api_key="xxxx-xxx-xxx")
qdrant_client = QdrantClient(url=QDRANT_SERVER_URL)
```
```typescript
const premaiClient = new Prem({
apiKey: "xxxx-xxx-xxx"
})
const qdrantClient = new QdrantClient({ url: SERVER_URL });
```
### Generating Embeddings
```python
from typing import Union, List
def get_embeddings(
project_id: int,
embedding_model: str,
documents: Union[str, List[str]]
) -> List[List[float]]:
"""
Helper function to get the embeddings from premai sdk
Args
project_id (int): The project id from prem saas platform.
embedding_model (str): The embedding model alias to choose
documents (Union[str, List[str]]): Single texts or list of texts to embed
Returns:
List[List[int]]: A list of list of integers that represents different
embeddings
"""
embeddings = []
documents = [documents] if isinstance(documents, str) else documents
for embedding in prem_client.embeddings.create(
project_id=project_id,
model=embedding_model,
input=documents
).data:
embeddings.append(embedding.embedding)
return embeddings
```
```typescript
async function getEmbeddings(projectID, embeddingModel, documents) {
const response = await premaiClient.embeddings.create({
project_id: projectID,
model: embeddingModel,
input: documents
});
return response;
}
```
### Converting Embeddings to Qdrant Points
```python
from qdrant_client.models import PointStruct
embeddings = get_embeddings(
project_id=PROJECT_ID,
embedding_model=EMBEDDING_MODEL,
documents=DOCUMENTS
)
points = [
PointStruct(
id=idx,
vector=embedding,
payload={"text": text},
) for idx, (embedding, text) in enumerate(zip(embeddings, DOCUMENTS))
]
```
```typescript
function convertToQdrantPoints(embeddings, texts) {
return embeddings.data.map((data, i) => {
return {
id: i,
vector: data.embedding,
payload: {
text: texts[i]
}
};
});
}
const embeddings = await getEmbeddings(PROJECT_ID, EMBEDDING_MODEL, DOCUMENTS);
const points = convertToQdrantPoints(embeddings, DOCUMENTS);
```
### Set up a Qdrant Collection
```python
qdrant_client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=3072, distance=Distance.DOT)
)
```
```typescript
await qdrantClient.createCollection(COLLECTION_NAME, {
vectors: {
size: 3072,
distance: 'Cosine'
}
})
```
### Insert Documents into the Collection
```python
doc_ids = list(range(len(embeddings)))
qdrant_client.upsert(
collection_name=COLLECTION_NAME,
points=points
)
```
```typescript
await qdrantClient.upsert(COLLECTION_NAME, {
wait: true,
points
});
```
### Perform a Search
```python
query = "what is the extension of python document"
query_embedding = get_embeddings(
project_id=PROJECT_ID,
embedding_model=EMBEDDING_MODEL,
documents=query
)
qdrant_client.search(collection_name=COLLECTION_NAME, query_vector=query_embedding[0])
```
```typescript
const query = "what is the extension of javascript document"
const query_embedding_response = await getEmbeddings(PROJECT_ID, EMBEDDING_MODEL, query)
await qdrantClient.search(COLLECTION_NAME, {
vector: query_embedding_response.data[0].embedding
});
```
|
qdrant-landing/content/documentation/embeddings/snowflake.md | ---
title: Snowflake Models
weight: 1500
---
# Snowflake
Qdrant supports working with [Snowflake](https://www.snowflake.com/blog/introducing-snowflake-arctic-embed-snowflakes-state-of-the-art-text-embedding-family-of-models/) text embedding models. You can find all the available models on [HuggingFace](https://huggingface.co/Snowflake).
### Setting up the Qdrant and Snowflake models
```python
from qdrant_client import QdrantClient
from fastembed import TextEmbedding
qclient = QdrantClient(":memory:")
embedding_model = TextEmbedding("snowflake/snowflake-arctic-embed-s")
texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
```typescript
import {QdrantClient} from '@qdrant/js-client-rest';
import { pipeline } from '@xenova/transformers';
const client = new QdrantClient({ url: 'http://localhost:6333' });
const extractor = await pipeline('feature-extraction', 'Snowflake/snowflake-arctic-embed-s');
const texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
The following example shows how to embed documents with the [`snowflake-arctic-embed-s`](https://huggingface.co/Snowflake/snowflake-arctic-embed-s) model that generates sentence embeddings of size 384.
### Embedding documents
```python
embeddings = embedding_model.embed(texts)
```
```typescript
const embeddings = await extractor(texts, { normalize: true, pooling: 'cls' });
```
### Converting the model outputs to Qdrant points
```python
from qdrant_client.models import PointStruct
points = [
PointStruct(
id=idx,
vector=embedding,
payload={"text": text},
)
for idx, (embedding, text) in enumerate(zip(embeddings, texts))
]
```
```typescript
let points = embeddings.tolist().map((embedding, i) => {
return {
id: i,
vector: embedding,
payload: {
text: texts[i]
}
}
});
```
### Creating a collection to insert the documents
```python
from qdrant_client.models import VectorParams, Distance
COLLECTION_NAME = "example_collection"
qclient.create_collection(
COLLECTION_NAME,
vectors_config=VectorParams(
size=384,
distance=Distance.COSINE,
),
)
qclient.upsert(COLLECTION_NAME, points)
```
```typescript
const COLLECTION_NAME = "example_collection"
await client.createCollection(COLLECTION_NAME, {
vectors: {
size: 384,
distance: 'Cosine',
}
});
await client.upsert(COLLECTION_NAME, {
wait: true,
points
});
```
### Searching for documents with Qdrant
Once the documents are added, you can search for the most relevant documents.
```python
query_embedding = next(embedding_model.query_embed("What is the best to use for vector search scaling?"))
qclient.search(
collection_name=COLLECTION_NAME,
query_vector=query_embedding,
)
```
```typescript
const query_embedding = await extractor("What is the best to use for vector search scaling?", {
normalize: true,
pooling: 'cls'
});
await client.search(COLLECTION_NAME, {
vector: query_embedding.tolist()[0],
});
```
|
qdrant-landing/content/documentation/embeddings/upstage.md | ---
title: Upstage
weight: 1700
---
# Upstage
Qdrant supports working with the Solar Embeddings API from [Upstage](https://upstage.ai/).
[Solar Embeddings](https://developers.upstage.ai/docs/apis/embeddings) API features dual models for user queries and document embedding, within a unified vector space, designed for performant text processing.
You can generate an API key to authenticate the requests from the [Upstage Console](<https://console.upstage.ai/api-keys>).
### Setting up the Qdrant client and Upstage session
```python
import requests
from qdrant_client import QdrantClient
UPSTAGE_BASE_URL = "https://api.upstage.ai/v1/solar/embeddings"
UPSTAGE_API_KEY = "<YOUR_API_KEY>"
upstage_session = requests.Session()
client = QdrantClient(url="http://localhost:6333")
headers = {
"Authorization": f"Bearer {UPSTAGE_API_KEY}",
"Accept": "application/json",
}
texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
```typescript
import { QdrantClient } from '@qdrant/js-client-rest';
const UPSTAGE_BASE_URL = "https://api.upstage.ai/v1/solar/embeddings"
const UPSTAGE_API_KEY = "<YOUR_API_KEY>"
const client = new QdrantClient({ url: 'http://localhost:6333' });
const headers = {
"Authorization": "Bearer " + UPSTAGE_API_KEY,
"Accept": "application/json",
"Content-Type": "application/json"
}
const texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
The following example shows how to embed documents with the recommended `solar-embedding-1-large-passage` and `solar-embedding-1-large-query` models that generates sentence embeddings of size 4096.
### Embedding documents
```python
body = {
"input": texts,
"model": "solar-embedding-1-large-passage",
}
response_body = upstage_session.post(
UPSTAGE_BASE_URL, headers=headers, json=body
).json()
```
```typescript
let body = {
"input": texts,
"model": "solar-embedding-1-large-passage",
}
let response = await fetch(UPSTAGE_BASE_URL, {
method: "POST",
body: JSON.stringify(body),
headers
});
let response_body = await response.json()
```
### Converting the model outputs to Qdrant points
```python
from qdrant_client.models import PointStruct
points = [
PointStruct(
id=idx,
vector=data["embedding"],
payload={"text": text},
)
for idx, (data, text) in enumerate(zip(response_body["data"], texts))
]
```
```typescript
let points = response_body.data.map((data, i) => {
return {
id: i,
vector: data.embedding,
payload: {
text: texts[i]
}
}
})
```
### Creating a collection to insert the documents
```python
from qdrant_client.models import VectorParams, Distance
collection_name = "example_collection"
client.create_collection(
collection_name,
vectors_config=VectorParams(
size=4096,
distance=Distance.COSINE,
),
)
client.upsert(collection_name, points)
```
```typescript
const COLLECTION_NAME = "example_collection"
await client.createCollection(COLLECTION_NAME, {
vectors: {
size: 4096,
distance: 'Cosine',
}
});
await client.upsert(COLLECTION_NAME, {
wait: true,
points
})
```
## Searching for documents with Qdrant
Once all the documents are added, you can search for the most relevant documents.
```python
body = {
"input": "What is the best to use for vector search scaling?",
"model": "solar-embedding-1-large-query",
}
response_body = upstage_session.post(
UPSTAGE_BASE_URL, headers=headers, json=body
).json()
client.search(
collection_name=collection_name,
query_vector=response_body["data"][0]["embedding"],
)
```
```typescript
body = {
"input": "What is the best to use for vector search scaling?",
"model": "solar-embedding-1-large-query",
}
response = await fetch(UPSTAGE_BASE_URL, {
method: "POST",
body: JSON.stringify(body),
headers
});
response_body = await response.json()
await client.search(COLLECTION_NAME, {
vector: response_body.data[0].embedding,
});
```
|
qdrant-landing/content/documentation/embeddings/voyage.md | ---
title: Voyage AI
weight: 1300
---
# Voyage AI
Qdrant supports working with [Voyage AI](https://voyageai.com/) embeddings. The supported models' list can be found [here](https://docs.voyageai.com/docs/embeddings).
You can generate an API key from the [Voyage AI dashboard](<https://dash.voyageai.com/>) to authenticate the requests.
### Setting up the Qdrant and Voyage clients
```python
from qdrant_client import QdrantClient
import voyageai
VOYAGE_API_KEY = "<YOUR_VOYAGEAI_API_KEY>"
qclient = QdrantClient(":memory:")
vclient = voyageai.Client(api_key=VOYAGE_API_KEY)
texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
```typescript
import {QdrantClient} from '@qdrant/js-client-rest';
const VOYAGEAI_BASE_URL = "https://api.voyageai.com/v1/embeddings"
const VOYAGEAI_API_KEY = "<YOUR_VOYAGEAI_API_KEY>"
const client = new QdrantClient({ url: 'http://localhost:6333' });
const headers = {
"Authorization": "Bearer " + VOYAGEAI_API_KEY,
"Content-Type": "application/json"
}
const texts = [
"Qdrant is the best vector search engine!",
"Loved by Enterprises and everyone building for low latency, high performance, and scale.",
]
```
The following example shows how to embed documents with the [`voyage-large-2`](https://docs.voyageai.com/docs/embeddings#model-choices) model that generates sentence embeddings of size 1536.
### Embedding documents
```python
response = vclient.embed(texts, model="voyage-large-2", input_type="document")
```
```typescript
let body = {
"input": texts,
"model": "voyage-large-2",
"input_type": "document",
}
let response = await fetch(VOYAGEAI_BASE_URL, {
method: "POST",
body: JSON.stringify(body),
headers
});
let response_body = await response.json();
```
### Converting the model outputs to Qdrant points
```python
from qdrant_client.models import PointStruct
points = [
PointStruct(
id=idx,
vector=embedding,
payload={"text": text},
)
for idx, (embedding, text) in enumerate(zip(response.embeddings, texts))
]
```
```typescript
let points = response_body.data.map((data, i) => {
return {
id: i,
vector: data.embedding,
payload: {
text: texts[i]
}
}
});
```
### Creating a collection to insert the documents
```python
from qdrant_client.models import VectorParams, Distance
COLLECTION_NAME = "example_collection"
qclient.create_collection(
COLLECTION_NAME,
vectors_config=VectorParams(
size=1536,
distance=Distance.COSINE,
),
)
qclient.upsert(COLLECTION_NAME, points)
```
```typescript
const COLLECTION_NAME = "example_collection"
await client.createCollection(COLLECTION_NAME, {
vectors: {
size: 1536,
distance: 'Cosine',
}
});
await client.upsert(COLLECTION_NAME, {
wait: true,
points
});
```
### Searching for documents with Qdrant
Once the documents are added, you can search for the most relevant documents.
```python
response = vclient.embed(
["What is the best to use for vector search scaling?"],
model="voyage-large-2",
input_type="query",
)
qclient.search(
collection_name=COLLECTION_NAME,
query_vector=response.embeddings[0],
)
```
```typescript
body = {
"input": ["What is the best to use for vector search scaling?"],
"model": "voyage-large-2",
"input_type": "query",
};
response = await fetch(VOYAGEAI_BASE_URL, {
method: "POST",
body: JSON.stringify(body),
headers
});
response_body = await response.json();
await client.search(COLLECTION_NAME, {
vector: response_body.data[0].embedding,
});
```
|
qdrant-landing/content/documentation/examples/_index.md | ---
title: Examples
weight: 35
---
# Examples
| End-to-End Code Samples | Description | Stack |
|---------------------------------------------------------------------------------|-------------------------------------------------------------------|---------------------------------------------|
| [Aleph Alpha Search](../examples/aleph-alpha-search/) | Build a multimodal search that combines text and image data. | Qdrant, Aleph Alpha |
| [Mighty Semantic Search](../examples/mighty/) | Build a simple semantic search with an on-demand NLP service. | Qdrant, Mighty |
| [Multitenancy with LlamaIndex](../examples/llama-index-multitenancy/) | Handle data coming from multiple users in LlamaIndex. | Qdrant, Python, LlamaIndex |
| [Implement custom connector for Cohere RAG](../examples/cohere-rag-connector/) | Bring data stored in Qdrant to Cohere RAG | Qdrant, Cohere, FastAPI |
| [Chatbot for Interactive Learning](../examples/rag-chatbot-red-hat-openshift-haystack/) | Build a Private RAG Chatbot for Interactive Learning | Qdrant, Haystack, OpenShift |
| [Information Extraction Engine](../examples/rag-chatbot-vultr-dspy-ollama/) | Build a Private RAG Information Extraction Engine | Qdrant, Vultr, DSPy, Ollama |
| [System for Employee Onboarding](../examples/natural-language-search-oracle-cloud-infrastructure-cohere-langchain/) | Build a RAG System for Employee Onboarding | Qdrant, Cohere, LangChain |
| [System for Contract Management](../examples/rag-contract-management-stackit-aleph-alpha/) | Build a Region-Specific RAG System for Contract Management | Qdrant, Aleph Alpha, STACKIT |
| [Question-Answering System for Customer Support](../examples/rag-customer-support-cohere-airbyte-aws/) | Build a RAG System for AI Customer Support | Qdrant, Cohere, Airbyte, AWS |
| [Hybrid Search on PDF Documents](../examples/hybrid-search-llamaindex-jinaai/) | Develop a Hybrid Search System for Product PDF Manuals | Qdrant, LlamaIndex, Jina AI
| [Blog-Reading RAG Chatbot](../examples/rag-chatbot-scaleway) | Develop a RAG-based Chatbot on Scaleway and with LangChain | Qdrant, LangChain, GPT-4o
| [Movie Recommendation System](../examples/recommendation-system-ovhcloud/) | Build a Movie Recommendation System with LlamaIndex and With JinaAI | Qdrant |
| [Qdrant on Databricks](../examples/databricks/) | Learn how to use Qdrant on Databricks using the Spark connector | Qdrant, Databricks, Apache Spark |
| [Qdrant with Airflow and Astronomer](../examples/qdrant-airflow-astronomer/) | Build a semantic querying system using Airflow and Astronomer | Qdrant, Airflow, Astronomer |
## Notebooks
Our Notebooks offer complex instructions that are supported with a throrough explanation. Follow along by trying out the code and get the most out of each example.
| Example | Description | Stack |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|----------------------------|
| [Intro to Semantic Search and Recommendations Systems](https://githubtocolab.com/qdrant/examples/blob/master/qdrant_101_getting_started/getting_started.ipynb) | Learn how to get started building semantic search and recommendation systems. | Qdrant |
| [Search and Recommend Newspaper Articles](https://githubtocolab.com/qdrant/examples/blob/master/qdrant_101_text_data/qdrant_and_text_data.ipynb) | Work with text data to develop a semantic search and a recommendation engine for news articles. | Qdrant |
| [Recommendation System for Songs](https://githubtocolab.com/qdrant/examples/blob/master/qdrant_101_audio_data/03_qdrant_101_audio.ipynb) | Use Qdrant to develop a music recommendation engine based on audio embeddings. | Qdrant |
| [Image Comparison System for Skin Conditions](https://colab.research.google.com/github/qdrant/examples/blob/master/qdrant_101_image_data/04_qdrant_101_cv.ipynb) | Use Qdrant to compare challenging images with labels representing different skin diseases. | Qdrant |
| [Question and Answer System with LlamaIndex](https://githubtocolab.com/qdrant/examples/blob/master/llama_index_recency/Qdrant%20and%20LlamaIndex%20%E2%80%94%20A%20new%20way%20to%20keep%20your%20Q%26A%20systems%20up-to-date.ipynb) | Combine Qdrant and LlamaIndex to create a self-updating Q&A system. | Qdrant, LlamaIndex, Cohere |
| [Extractive QA System](https://githubtocolab.com/qdrant/examples/blob/master/extractive_qa/extractive-question-answering.ipynb) | Extract answers directly from context to generate highly relevant answers. | Qdrant |
| [Ecommerce Reverse Image Search](https://githubtocolab.com/qdrant/examples/blob/master/ecommerce_reverse_image_search/ecommerce-reverse-image-search.ipynb) | Accept images as search queries to receive semantically appropriate answers. | Qdrant |
| [Basic RAG](https://githubtocolab.com/qdrant/examples/blob/master/rag-openai-qdrant/rag-openai-qdrant.ipynb) | Basic RAG pipeline with Qdrant and OpenAI SDKs. | OpenAI, Qdrant, FastEmbed |
## Data Transfer
| Example | Description | Stack |
|---------------------------------------------------------------------------------|-------------------------------------------------------------------|---------------------------------------------|
| [Pinecone to Qdrant Data Transfer](https://githubtocolab.com/qdrant/examples/blob/master/data-migration/from-pinecone-to-qdrant.ipynb) | Migrate your vector data from Pinecone to Qdrant. | Qdrant, Vector-io |
|
qdrant-landing/content/documentation/examples/aleph-alpha-search.md | ---
title: Aleph Alpha Search
weight: 16
aliases:
- /documentation/tutorials/aleph-alpha-search/
---
# Multimodal Semantic Search with Aleph Alpha
| Time: 30 min | Level: Beginner | | |
| --- | ----------- | ----------- |----------- |
This tutorial shows you how to run a proper multimodal semantic search system with a few lines of code, without the need to annotate the data or train your networks.
In most cases, semantic search is limited to homogenous data types for both documents and queries (text-text, image-image, audio-audio, etc.). With the recent growth of multimodal architectures, it is now possible to encode different data types into the same latent space. That opens up some great possibilities, as you can finally explore non-textual data, for example visual, with text queries.
In the past, this would require labelling every image with a description of what it presents. Right now, you can rely on vector embeddings, which can represent all
the inputs in the same space.
*Figure 1: Two examples of text-image pairs presenting a similar object, encoded by a multimodal network into the same
2D latent space. Both texts are examples of English [pangrams](https://en.wikipedia.org/wiki/Pangram).
https://deepai.org generated the images with pangrams used as input prompts.*

## Sample dataset
You will be using [COCO](https://cocodataset.org/), a large-scale object detection, segmentation, and captioning dataset. It provides
various splits, 330,000 images in total. For demonstration purposes, this tutorials uses the
[2017 validation split](http://images.cocodataset.org/zips/train2017.zip) that contains 5000 images from different
categories with total size about 19GB.
```terminal
wget http://images.cocodataset.org/zips/train2017.zip
```
## Prerequisites
There is no need to curate your datasets and train the models. [Aleph Alpha](https://www.aleph-alpha.com/), already has multimodality and multilinguality already built-in. There is an [official Python client](https://github.com/Aleph-Alpha/aleph-alpha-client) that simplifies the integration.
In order to enable the search capabilities, you need to build the search index to query on. For this example,
you are going to vectorize the images and store their embeddings along with the filenames. You can then return the most
similar files for given query.
There are two things you need to set up before you start:
1. You need to have a Qdrant instance running. If you want to launch it locally,
[Docker is the fastest way to do that](/documentation/quick_start/#installation).
2. You need to have a registered [Aleph Alpha account](https://app.aleph-alpha.com/).
3. Upon registration, create an API key (see: [API Tokens](https://app.aleph-alpha.com/profile)).
Now you can store the Aleph Alpha API key in a variable and choose the model your are going to use.
```python
aa_token = "<< your_token >>"
model = "luminous-base"
```
## Vectorize the dataset
In this example, images have been extracted and are stored in the `val2017` directory:
```python
from aleph_alpha_client import (
Prompt,
AsyncClient,
SemanticEmbeddingRequest,
SemanticRepresentation,
Image,
)
from glob import glob
ids, vectors, payloads = [], [], []
async with AsyncClient(token=aa_token) as aa_client:
for i, image_path in enumerate(glob("./val2017/*.jpg")):
# Convert the JPEG file into the embedding by calling
# Aleph Alpha API
prompt = Image.from_file(image_path)
prompt = Prompt.from_image(prompt)
query_params = {
"prompt": prompt,
"representation": SemanticRepresentation.Symmetric,
"compress_to_size": 128,
}
query_request = SemanticEmbeddingRequest(**query_params)
query_response = await aa_client.semantic_embed(request=query_request, model=model)
# Finally store the id, vector and the payload
ids.append(i)
vectors.append(query_response.embedding)
payloads.append({"filename": image_path})
```
## Load embeddings into Qdrant
Add all created embeddings, along with their ids and payloads into the `COCO` collection.
```python
import qdrant_client
from qdrant_client.models import Batch, VectorParams, Distance
client = qdrant_client.QdrantClient()
client.recreate_collection(
collection_name="COCO",
vectors_config=VectorParams(
size=len(vectors[0]),
distance=Distance.COSINE,
),
)
client.upsert(
collection_name="COCO",
points=Batch(
ids=ids,
vectors=vectors,
payloads=payloads,
),
)
```
## Query the database
The `luminous-base`, model can provide you the vectors for both texts and images, which means you can run both
text queries and reverse image search. Assume you want to find images similar to the one below:

With the following code snippet create its vector embedding and then perform the lookup in Qdrant:
```python
async with AsyncCliet(token=aa_token) as aa_client:
prompt = ImagePrompt.from_file("query.jpg")
prompt = Prompt.from_image(prompt)
query_params = {
"prompt": prompt,
"representation": SemanticRepresentation.Symmetric,
"compress_to_size": 128,
}
query_request = SemanticEmbeddingRequest(**query_params)
query_response = await aa_client.semantic_embed(request=query_request, model=model)
results = client.search(
collection_name="COCO",
query_vector=query_response.embedding,
limit=3,
)
print(results)
```
Here are the results:

**Note:** AlephAlpha models can provide embeddings for English, French, German, Italian
and Spanish. Your search is not only multimodal, but also multilingual, without any need for translations.
```python
text = "Surfing"
async with AsyncClient(token=aa_token) as aa_client:
query_params = {
"prompt": Prompt.from_text(text),
"representation": SemanticRepresentation.Symmetric,
"compres_to_size": 128,
}
query_request = SemanticEmbeddingRequest(**query_params)
query_response = await aa_client.semantic_embed(request=query_request, model=model)
results = client.search(
collection_name="COCO",
query_vector=query_response.embedding,
limit=3,
)
print(results)
```
Here are the top 3 results for “Surfing”:

|
qdrant-landing/content/documentation/examples/cohere-rag-connector.md | ---
title: Implement Cohere RAG connector
weight: 24
aliases:
- /documentation/tutorials/cohere-rag-connector/
---
# Implement custom connector for Cohere RAG
| Time: 45 min | Level: Intermediate | | |
|--------------|---------------------|-|----|
The usual approach to implementing Retrieval Augmented Generation requires users to build their prompts with the
relevant context the LLM may rely on, and manually sending them to the model. Cohere is quite unique here, as their
models can now speak to the external tools and extract meaningful data on their own. You can virtually connect any data
source and let the Cohere LLM know how to access it. Obviously, vector search goes well with LLMs, and enabling semantic
search over your data is a typical case.
Cohere RAG has lots of interesting features, such as inline citations, which help you to refer to the specific parts of
the documents used to generate the response.

*Source: https://docs.cohere.com/docs/retrieval-augmented-generation-rag*
The connectors have to implement a specific interface and expose the data source as HTTP REST API. Cohere documentation
[describes a general process of creating a connector](https://docs.cohere.com/docs/creating-and-deploying-a-connector).
This tutorial guides you step by step on building such a service around Qdrant.
## Qdrant connector
You probably already have some collections you would like to bring to the LLM. Maybe your pipeline was set up using some
of the popular libraries such as Langchain, Llama Index, or Haystack. Cohere connectors may implement even more complex
logic, e.g. hybrid search. In our case, we are going to start with a fresh Qdrant collection, index data using Cohere
Embed v3, build the connector, and finally connect it with the [Command-R model](https://txt.cohere.com/command-r/).
### Building the collection
First things first, let's build a collection and configure it for the Cohere `embed-multilingual-v3.0` model. It
produces 1024-dimensional embeddings, and we can choose any of the distance metrics available in Qdrant. Our connector
will act as a personal assistant of a software engineer, and it will expose our notes to suggest the priorities or
actions to perform.
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(
"https://my-cluster.cloud.qdrant.io:6333",
api_key="my-api-key",
)
client.create_collection(
collection_name="personal-notes",
vectors_config=models.VectorParams(
size=1024,
distance=models.Distance.DOT,
),
)
```
Our notes will be represented as simple JSON objects with a `title` and `text` of the specific note. The embeddings will
be created from the `text` field only.
```python
notes = [
{
"title": "Project Alpha Review",
"text": "Review the current progress of Project Alpha, focusing on the integration of the new API. Check for any compatibility issues with the existing system and document the steps needed to resolve them. Schedule a meeting with the development team to discuss the timeline and any potential roadblocks."
},
{
"title": "Learning Path Update",
"text": "Update the learning path document with the latest courses on React and Node.js from Pluralsight. Schedule at least 2 hours weekly to dedicate to these courses. Aim to complete the React course by the end of the month and the Node.js course by mid-next month."
},
{
"title": "Weekly Team Meeting Agenda",
"text": "Prepare the agenda for the weekly team meeting. Include the following topics: project updates, review of the sprint backlog, discussion on the new feature requests, and a brainstorming session for improving remote work practices. Send out the agenda and the Zoom link by Thursday afternoon."
},
{
"title": "Code Review Process Improvement",
"text": "Analyze the current code review process to identify inefficiencies. Consider adopting a new tool that integrates with our version control system. Explore options such as GitHub Actions for automating parts of the process. Draft a proposal with recommendations and share it with the team for feedback."
},
{
"title": "Cloud Migration Strategy",
"text": "Draft a plan for migrating our current on-premise infrastructure to the cloud. The plan should cover the selection of a cloud provider, cost analysis, and a phased migration approach. Identify critical applications for the first phase and any potential risks or challenges. Schedule a meeting with the IT department to discuss the plan."
},
{
"title": "Quarterly Goals Review",
"text": "Review the progress towards the quarterly goals. Update the documentation to reflect any completed objectives and outline steps for any remaining goals. Schedule individual meetings with team members to discuss their contributions and any support they might need to achieve their targets."
},
{
"title": "Personal Development Plan",
"text": "Reflect on the past quarter's achievements and areas for improvement. Update the personal development plan to include new technical skills to learn, certifications to pursue, and networking events to attend. Set realistic timelines and check-in points to monitor progress."
},
{
"title": "End-of-Year Performance Reviews",
"text": "Start preparing for the end-of-year performance reviews. Collect feedback from peers and managers, review project contributions, and document achievements. Consider areas for improvement and set goals for the next year. Schedule preliminary discussions with each team member to gather their self-assessments."
},
{
"title": "Technology Stack Evaluation",
"text": "Conduct an evaluation of our current technology stack to identify any outdated technologies or tools that could be replaced for better performance and productivity. Research emerging technologies that might benefit our projects. Prepare a report with findings and recommendations to present to the management team."
},
{
"title": "Team Building Event Planning",
"text": "Plan a team-building event for the next quarter. Consider activities that can be done remotely, such as virtual escape rooms or online game nights. Survey the team for their preferences and availability. Draft a budget proposal for the event and submit it for approval."
}
]
```
Storing the embeddings along with the metadata is fairly simple.
```python
import cohere
import uuid
cohere_client = cohere.Client(api_key="my-cohere-api-key")
response = cohere_client.embed(
texts=[
note.get("text")
for note in notes
],
model="embed-multilingual-v3.0",
input_type="search_document",
)
client.upload_points(
collection_name="personal-notes",
points=[
models.PointStruct(
id=uuid.uuid4().hex,
vector=embedding,
payload=note,
)
for note, embedding in zip(notes, response.embeddings)
]
)
```
Our collection is now ready to be searched over. In the real world, the set of notes would be changing over time, so the
ingestion process won't be as straightforward. This data is not yet exposed to the LLM, but we will build the connector
in the next step.
### Connector web service
[FastAPI](https://fastapi.tiangolo.com/) is a modern web framework and perfect a choice for a simple HTTP API. We are
going to use it for the purposes of our connector. There will be just one endpoint, as required by the model. It will
accept POST requests at the `/search` path. There is a single `query` parameter required. Let's define a corresponding
model.
```python
from pydantic import BaseModel
class SearchQuery(BaseModel):
query: str
```
RAG connector does not have to return the documents in any specific format. There are [some good practices to follow](https://docs.cohere.com/docs/creating-and-deploying-a-connector#configure-the-connection-between-the-connector-and-the-chat-api),
but Cohere models are quite flexible here. Results just have to be returned as JSON, with a list of objects in a
`results` property of the output. We will use the same document structure as we did for the Qdrant payloads, so there
is no conversion required. That requires two additional models to be created.
```python
from typing import List
class Document(BaseModel):
title: str
text: str
class SearchResults(BaseModel):
results: List[Document]
```
Once our model classes are ready, we can implement the logic that will get the query and provide the notes that are
relevant to it. Please note the LLM is not going to define the number of documents to be returned. That's completely
up to you how many of them you want to bring to the context.
There are two services we need to interact with - Qdrant server and Cohere API. FastAPI has a concept of a [dependency
injection](https://fastapi.tiangolo.com/tutorial/dependencies/#dependencies), and we will use it to provide both
clients into the implementation.
In case of queries, we need to set the `input_type` to `search_query` in the calls to Cohere API.
```python
from fastapi import FastAPI, Depends
from typing import Annotated
app = FastAPI()
def client() -> QdrantClient:
return QdrantClient(config.QDRANT_URL, api_key=config.QDRANT_API_KEY)
def cohere_client() -> cohere.Client:
return cohere.Client(api_key=config.COHERE_API_KEY)
@app.post("/search")
def search(
query: SearchQuery,
client: Annotated[QdrantClient, Depends(client)],
cohere_client: Annotated[cohere.Client, Depends(cohere_client)],
) -> SearchResults:
response = cohere_client.embed(
texts=[query.query],
model="embed-multilingual-v3.0",
input_type="search_query",
)
results = client.search(
collection_name="personal-notes",
query_vector=response.embeddings[0],
limit=2,
)
return SearchResults(
results=[
Document(**point.payload)
for point in results
]
)
```
Our app might be launched locally for the development purposes, given we have the `uvicorn` server installed:
```shell
uvicorn main:app
```
FastAPI exposes an interactive documentation at `http://localhost:8000/docs`, where we can test our endpoint. The
`/search` endpoint is available there.

We can interact with it and check the documents that will be returned for a specific query. For example, we want to know
recall what we are supposed to do regarding the infrastructure for your projects.
```shell
curl -X "POST" \
-H "Content-type: application/json" \
-d '{"query": "Is there anything I have to do regarding the project infrastructure?"}' \
"http://localhost:8000/search"
```
The output should look like following:
```json
{
"results": [
{
"title": "Cloud Migration Strategy",
"text": "Draft a plan for migrating our current on-premise infrastructure to the cloud. The plan should cover the selection of a cloud provider, cost analysis, and a phased migration approach. Identify critical applications for the first phase and any potential risks or challenges. Schedule a meeting with the IT department to discuss the plan."
},
{
"title": "Project Alpha Review",
"text": "Review the current progress of Project Alpha, focusing on the integration of the new API. Check for any compatibility issues with the existing system and document the steps needed to resolve them. Schedule a meeting with the development team to discuss the timeline and any potential roadblocks."
}
]
}
```
### Connecting to Command-R
Our web service is implemented, yet running only on our local machine. It has to be exposed to the public before
Command-R can interact with it. For a quick experiment, it might be enough to set up tunneling using services such as
[ngrok](https://ngrok.com/). We won't cover all the details in the tutorial, but their
[Quickstart](https://ngrok.com/docs/guides/getting-started/) is a great resource describing the process step-by-step.
Alternatively, you can also deploy the service with a public URL.
Once it's done, we can create the connector first, and then tell the model to use it, while interacting through the chat
API. Creating a connector is a single call to Cohere client:
```python
connector_response = cohere_client.connectors.create(
name="personal-notes",
url="https:/this-is-my-domain.app/search",
)
```
The `connector_response.connector` will be a descriptor, with `id` being one of the attributes. We'll use this
identifier for our interactions like this:
```python
response = cohere_client.chat(
message=(
"Is there anything I have to do regarding the project infrastructure? "
"Please mention the tasks briefly."
),
connectors=[
cohere.ChatConnector(id=connector_response.connector.id)
],
model="command-r",
)
```
We changed the `model` to `command-r`, as this is currently the best Cohere model available to public. The
`response.text` is the output of the model:
```text
Here are some of the tasks related to project infrastructure that you might have to perform:
- You need to draft a plan for migrating your on-premise infrastructure to the cloud and come up with a plan for the selection of a cloud provider, cost analysis, and a gradual migration approach.
- It's important to evaluate your current technology stack to identify any outdated technologies. You should also research emerging technologies and the benefits they could bring to your projects.
```
You only need to create a specific connector once! Please do not call `cohere_client.connectors.create` for every single
message you send to the `chat` method.
## Wrapping up
We have built a Cohere RAG connector that integrates with your existing knowledge base stored in Qdrant. We covered just
the basic flow, but in real world scenarios, you should also consider e.g. [building the authentication
system](https://docs.cohere.com/docs/connector-authentication) to prevent unauthorized access. |
qdrant-landing/content/documentation/examples/databricks.md | ---
title: Qdrant on Databricks
weight: 36
---
# Qdrant on Databricks
| Time: 30 min | Level: Intermediate | [Complete Notebook](https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/4750876096379825/93425612168199/6949977306828869/latest.html) |
| ------------ | ------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
[Databricks](https://www.databricks.com/) is a unified analytics platform for working with big data and AI. It's built around Apache Spark, a powerful open-source distributed computing system well-suited for processing large-scale datasets and performing complex analytics tasks.
Apache Spark is designed to scale horizontally, meaning it can handle expensive operations like generating vector embeddings by distributing computation across a cluster of machines. This scalability is crucial when dealing with large datasets.
In this example, we will demonstrate how to vectorize a dataset with dense and sparse embeddings using Qdrant's [FastEmbed](https://qdrant.github.io/fastembed/) library. We will then load this vectorized data into a Qdrant cluster using the [Qdrant Spark connector](/documentation/frameworks/spark/) on Databricks.
### Setting up a Databricks project
- Set up a **[Databricks cluster](https://docs.databricks.com/en/compute/configure.html)** following the official documentation guidelines.
- Install the **[Qdrant Spark connector](/documentation/frameworks/spark/)** as a library:
- Navigate to the `Libraries` section in your cluster dashboard.
- Click on `Install New` at the top-right to open the library installation modal.
- Search for `io.qdrant:spark:VERSION` in the Maven packages and click on `Install`.

- Create a new **[Databricks notebook](https://docs.databricks.com/en/notebooks/index.html)** on your cluster to begin working with your data and libraries.
### Download a dataset
- **Install the required dependencies:**
```python
%pip install fastembed datasets
```
- **Download the dataset:**
```python
from datasets import load_dataset
dataset_name = "tasksource/med"
dataset = load_dataset(dataset_name, split="train")
# We'll use the first 100 entries from this dataset and exclude some unused columns.
dataset = dataset.select(range(100)).remove_columns(["gold_label", "genre"])
```
- **Convert the dataset into a Spark dataframe:**
```python
dataset.to_parquet("/dbfs/pq.pq")
dataset_df = spark.read.parquet("file:/dbfs/pq.pq")
```
### Vectorizing the data
In this section, we'll be generating both dense and sparse vectors for our rows using [FastEmbed](https://qdrant.github.io/fastembed/). We'll create a user-defined function (UDF) to handle this step.
#### Creating the vectorization function
```python
from fastembed import TextEmbedding, SparseTextEmbedding
def vectorize(partition_data):
# Initialize dense and sparse models
dense_model = TextEmbedding(model_name="BAAI/bge-small-en-v1.5")
sparse_model = SparseTextEmbedding(model_name="prithivida/Splade_PP_en_v1")
for row in partition_data:
# Generate dense and sparse vectors
dense_vector = next(dense_model.embed(row.sentence1))
sparse_vector = next(sparse_model.embed(row.sentence2))
yield [
row.sentence1, # 1st column: original text
row.sentence2, # 2nd column: original text
dense_vector.tolist(), # 3rd column: dense vector
sparse_vector.indices.tolist(), # 4th column: sparse vector indices
sparse_vector.values.tolist(), # 5th column: sparse vector values
]
```
We're using the [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) model for dense embeddings and [prithivida/Splade_PP_en_v1](https://huggingface.co/prithivida/Splade_PP_en_v1) for sparse embeddings.
#### Applying the UDF on our dataframe
Next, let's apply our `vectorize` UDF on our Spark dataframe to generate embeddings.
```python
embeddings = dataset_df.rdd.mapPartitions(vectorize)
```
The `mapPartitions()` method returns a [Resilient Distributed Dataset (RDD)](https://www.databricks.com/glossary/what-is-rdd) which should then be converted back to a Spark dataframe.
#### Building the new Spark dataframe with the vectorized data
We'll now create a new Spark dataframe (`embeddings_df`) with the vectorized data using the specified schema.
```python
from pyspark.sql.types import StructType, StructField, StringType, ArrayType, FloatType, IntegerType
# Define the schema for the new dataframe
schema = StructType([
StructField("sentence1", StringType()),
StructField("sentence2", StringType()),
StructField("dense_vector", ArrayType(FloatType())),
StructField("sparse_vector_indices", ArrayType(IntegerType())),
StructField("sparse_vector_values", ArrayType(FloatType()))
])
# Create the new dataframe with the vectorized data
embeddings_df = spark.createDataFrame(data=embeddings, schema=schema)
```
### Uploading the data to Qdrant
- **Create a Qdrant collection:**
- [Follow the documentation](/documentation/concepts/collections/#create-a-collection) to create a collection with the appropriate configurations. Here's an example request to support both dense and sparse vectors:
```json
PUT /collections/{collection_name}
{
"vectors": {
"dense": {
"size": 384,
"distance": "Cosine"
}
},
"sparse_vectors": {
"sparse": {}
}
}
```
- **Upload the dataframe to Qdrant:**
```python
options = {
"qdrant_url": "<QDRANT_GRPC_URL>",
"api_key": "<QDRANT_API_KEY>",
"collection_name": "<QDRANT_COLLECTION_NAME>",
"vector_fields": "dense_vector",
"vector_names": "dense",
"sparse_vector_value_fields": "sparse_vector_values",
"sparse_vector_index_fields": "sparse_vector_indices",
"sparse_vector_names": "sparse",
"schema": embeddings_df.schema.json(),
}
embeddings_df.write.format("io.qdrant.spark.Qdrant").options(**options).mode(
"append"
).save()
```
<aside role="status">
<p>You can find the list of the Spark connector configuration options <a href="/documentation/frameworks/spark/#configuration-options" target="_blank">here</a>.</p>
</aside>
Ensure to replace the placeholder values (`<QDRANT_GRPC_URL>`, `<QDRANT_API_KEY>`, `<QDRANT_COLLECTION_NAME>`) with your actual values. If the `id_field` option is not specified, Qdrant Spark connector generates random UUIDs for each point.
The command output you should see is similar to:
```console
Command took 40.37 seconds -- by xxxxx90@xxxxxx.com at 4/17/2024, 12:13:28 PM on fastembed
```
### Conclusion
That wraps up our tutorial! Feel free to explore more functionalities and experiments with different models, parameters, and features available in Databricks, Spark, and Qdrant.
Happy data engineering!
|
qdrant-landing/content/documentation/examples/hybrid-search-llamaindex-jinaai.md | ---
title: Chat With Product PDF Manuals Using Hybrid Search
weight: 27
social_preview_image: /blog/hybrid-cloud-llamaindex/hybrid-cloud-llamaindex-tutorial.png
aliases:
- /documentation/tutorials/hybrid-search-llamaindex-jinaai/
---
# Chat With Product PDF Manuals Using Hybrid Search
| Time: 120 min | Level: Advanced | Output: [GitHub](https://github.com/infoslack/qdrant-example/blob/main/HC-demo/HC-DO-LlamaIndex-Jina-v2.ipynb) | [](https://githubtocolab.com/infoslack/qdrant-example/blob/main/HC-demo/HC-DO-LlamaIndex-Jina-v2.ipynb) |
| --- | ----------- | ----------- |----------- |
With the proliferation of digital manuals and the increasing demand for quick and accurate customer support, having a chatbot capable of efficiently parsing through complex PDF documents and delivering precise information can be a game-changer for any business.
In this tutorial, we'll walk you through the process of building a RAG-based chatbot, designed specifically to assist users with understanding the operation of various household appliances.
We'll cover the essential steps required to build your system, including data ingestion, natural language understanding, and response generation for customer support use cases.
## Components
- **Embeddings:** Jina Embeddings, served via the [Jina Embeddings API](https://jina.ai/embeddings/#apiform)
- **Database:** [Qdrant Hybrid Cloud](/documentation/hybrid-cloud/), deployed in a managed Kubernetes cluster on [DigitalOcean
(DOKS)](https://www.digitalocean.com/products/kubernetes)
- **LLM:** [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) language model on HuggingFace
- **Framework:** [LlamaIndex](https://www.llamaindex.ai/) for extended RAG functionality and [Hybrid Search support](https://docs.llamaindex.ai/en/stable/examples/vector_stores/qdrant_hybrid/).
- **Parser:** [LlamaParse](https://github.com/run-llama/llama_parse) as a way to parse complex documents with embedded objects such as tables and figures.

### Procedure
Retrieval Augmented Generation (RAG) combines search with language generation. An external information retrieval system is used to identify documents likely to provide information relevant to the user's query. These documents, along with the user's request, are then passed on to a text-generating language model, producing a natural response.
This method enables a language model to respond to questions and access information from a much larger set of documents than it could see otherwise. The language model only looks at a few relevant sections of the documents when generating responses, which also helps to reduce inexplicable errors.
##
[Service Managed Kubernetes](https://www.ovhcloud.com/en-in/public-cloud/kubernetes/), powered by OVH Public Cloud Instances, a leading European cloud provider. With OVHcloud Load Balancers and disks built in. OVHcloud Managed Kubernetes provides high availability, compliance, and CNCF conformance, allowing you to focus on your containerized software layers with total reversibility.
## Prerequisites
### Deploying Qdrant Hybrid Cloud on DigitalOcean
[DigitalOcean Kubernetes (DOKS)](https://www.digitalocean.com/products/kubernetes) is a managed Kubernetes service that lets you deploy Kubernetes clusters without the complexities of handling the control plane and containerized infrastructure. Clusters are compatible with standard Kubernetes toolchains and integrate natively with DigitalOcean Load Balancers and volumes.
1. To start using managed Kubernetes on DigitalOcean, follow the [platform-specific documentation](/documentation/hybrid-cloud/platform-deployment-options/#digital-ocean).
2. Once your Kubernetes clusters are up, [you can begin deploying Qdrant Hybrid Cloud](/documentation/hybrid-cloud/).
3. Once it's deployed, you should have a running Qdrant cluster with an API key.
### Development environment
Then, install all dependencies:
```python
!pip install -U \
llama-index \
llama-parse \
python-dotenv \
llama-index-embeddings-jinaai \
llama-index-llms-huggingface \
llama-index-vector-stores-qdrant \
"huggingface_hub[inference]" \
datasets
```
Set up secret key values on `.env` file:
```bash
JINAAI_API_KEY
HF_INFERENCE_API_KEY
LLAMA_CLOUD_API_KEY
QDRANT_HOST
QDRANT_API_KEY
```
Load all environment variables:
```python
import os
from dotenv import load_dotenv
load_dotenv('./.env')
```
## Implementation
### Connect Jina Embeddings and Mixtral LLM
LlamaIndex provides built-in support for the [Jina Embeddings API](https://jina.ai/embeddings/#apiform). To use it, you need to initialize the `JinaEmbedding` object with your API Key and model name.
For the LLM, you need wrap it in a subclass of `llama_index.llms.CustomLLM` to make it compatible with LlamaIndex.
```python
# connect embeddings
from llama_index.embeddings.jinaai import JinaEmbedding
jina_embedding_model = JinaEmbedding(
model="jina-embeddings-v2-base-en",
api_key=os.getenv("JINAAI_API_KEY"),
)
# connect LLM
from llama_index.llms.huggingface import HuggingFaceInferenceAPI
mixtral_llm = HuggingFaceInferenceAPI(
model_name = "mistralai/Mixtral-8x7B-Instruct-v0.1",
token=os.getenv("HF_INFERENCE_API_KEY"),
)
```
### Prepare data for RAG
This example will use household appliance manuals, which are generally available as PDF documents.
LlamaPar
In the `data` folder, we have three documents, and we will use it to extract the textual content from the PDF and use it as a knowledge base in a simple RAG.
The free LlamaIndex Cloud plan is sufficient for our example:
```python
import nest_asyncio
nest_asyncio.apply()
from llama_parse import LlamaParse
llamaparse_api_key = os.getenv("LLAMA_CLOUD_API_KEY")
llama_parse_documents = LlamaParse(api_key=llamaparse_api_key, result_type="markdown").load_data([
"data/DJ68-00682F_0.0.pdf",
"data/F500E_WF80F5E_03445F_EN.pdf",
"data/O_ME4000R_ME19R7041FS_AA_EN.pdf"
])
```
### Store data into Qdrant
The code below does the following:
- create a vector store with Qdrant client;
- get an embedding for each chunk using Jina Embeddings API;
- combines `sparse` and `dense` vectors for hybrid search;
- stores all data into Qdrant;
Hybrid search with Qdrant must be enabled from the beginning - we can simply set `enable_hybrid=True`.
```python
# By default llamaindex uses OpenAI models
# setting embed_model to Jina and llm model to Mixtral
from llama_index.core import Settings
Settings.embed_model = jina_embedding_model
Settings.llm = mixtral_llm
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(
url=os.getenv("QDRANT_HOST"),
api_key=os.getenv("QDRANT_API_KEY")
)
vector_store = QdrantVectorStore(
client=client, collection_name="demo", enable_hybrid=True, batch_size=20
)
Settings.chunk_size = 512
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents=llama_parse_documents,
storage_context=storage_context
)
```
### Prepare a prompt
Here we will create a custom prompt template. This prompt asks the LLM to use only the context information retrieved from Qdrant. When querying with hybrid mode, we can set `similarity_top_k` and `sparse_top_k` separately:
- `sparse_top_k` represents how many nodes will be retrieved from each dense and sparse query.
- `similarity_top_k` controls the final number of returned nodes. In the above setting, we end up with 10 nodes.
Then, we assemble the query engine using the prompt.
```python
from llama_index.core import PromptTemplate
qa_prompt_tmpl = (
"Context information is below.\n"
"-------------------------------"
"{context_str}\n"
"-------------------------------"
"Given the context information and not prior knowledge,"
"answer the query. Please be concise, and complete.\n"
"If the context does not contain an answer to the query,"
"respond with \"I don't know!\"."
"Query: {query_str}\n"
"Answer: "
)
qa_prompt = PromptTemplate(qa_prompt_tmpl)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import get_response_synthesizer
from llama_index.core import Settings
Settings.embed_model = jina_embedding_model
Settings.llm = mixtral_llm
# retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
sparse_top_k=12,
vector_store_query_mode="hybrid"
)
# response synthesizer
response_synthesizer = get_response_synthesizer(
llm=mixtral_llm,
text_qa_template=qa_prompt,
response_mode="compact",
)
# query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
```
## Run a test query
Now you can ask questions and receive answers based on the data:
**Question**
```python
result = query_engine.query("What temperature should I use for my laundry?")
print(result.response)
```
**Answer**
```text
The water temperature is set to 70 ˚C during the Eco Drum Clean cycle. You cannot change the water temperature. However, the temperature for other cycles is not specified in the context.
```
And that's it! Feel free to scale this up to as many documents and complex PDFs as you like. |
qdrant-landing/content/documentation/examples/llama-index-multitenancy.md | ---
title: Multitenancy with LlamaIndex
weight: 18
aliases:
- /documentation/tutorials/llama-index-multitenancy/
---
# Multitenancy with LlamaIndex
If you are building a service that serves vectors for many independent users, and you want to isolate their
data, the best practice is to use a single collection with payload-based partitioning. This approach is
called **multitenancy**. Our guide on the [Separate Partitions](/documentation/guides/multiple-partitions/) describes
how to set it up in general, but if you use [LlamaIndex](/documentation/integrations/llama-index/) as a
backend, you may prefer reading a more specific instruction. So here it is!
## Prerequisites
This tutorial assumes that you have already installed Qdrant and LlamaIndex. If you haven't, please run the
following commands:
```bash
pip install llama-index llama-index-vector-stores-qdrant
```
We are going to use a local Docker-based instance of Qdrant. If you want to use a remote instance, please
adjust the code accordingly. Here is how we can start a local instance:
```bash
docker run -d --name qdrant -p 6333:6333 -p 6334:6334 qdrant/qdrant:latest
```
## Setting up LlamaIndex pipeline
We are going to implement an end-to-end example of multitenant application using LlamaIndex. We'll be
indexing the documentation of different Python libraries, and we definitely don't want any users to see the
results coming from a library they are not interested in. In real case scenarios, this is even more dangerous,
as the documents may contain sensitive information.
### Creating vector store
[QdrantVectorStore](https://docs.llamaindex.ai/en/stable/examples/vector_stores/QdrantIndexDemo.html) is a
wrapper around Qdrant that provides all the necessary methods to work with your vector database in LlamaIndex.
Let's create a vector store for our collection. It requires setting a collection name and passing an instance
of `QdrantClient`.
```python
from qdrant_client import QdrantClient
from llama_index.vector_stores.qdrant import QdrantVectorStore
client = QdrantClient("http://localhost:6333")
vector_store = QdrantVectorStore(
collection_name="my_collection",
client=client,
)
```
### Defining chunking strategy and embedding model
Any semantic search application requires a way to convert text queries into vectors - an embedding model.
`ServiceContext` is a bundle of commonly used resources used during the indexing and querying stage in any
LlamaIndex application. We can also use it to set up an embedding model - in our case, a local
[BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5).
set up
```python
from llama_index.core import ServiceContext
service_context = ServiceContext.from_defaults(
embed_model="local:BAAI/bge-small-en-v1.5",
)
```
*Note*, in case you are using Large Language Model different from OpenAI's ChatGPT, you should specify
`llm` parameter for `ServiceContext`.
We can also control how our documents are split into chunks, or nodes using LLamaIndex's terminology.
The `SimpleNodeParser` splits documents into fixed length chunks with an overlap. The defaults are
reasonable, but we can also adjust them if we want to. Both values are defined in tokens.
```python
from llama_index.core.node_parser import SimpleNodeParser
node_parser = SimpleNodeParser.from_defaults(chunk_size=512, chunk_overlap=32)
```
Now we also need to inform the `ServiceContext` about our choices:
```python
service_context = ServiceContext.from_defaults(
embed_model="local:BAAI/bge-large-en-v1.5",
node_parser=node_parser,
)
```
Both embedding model and selected node parser will be implicitly used during the indexing and querying.
### Combining everything together
The last missing piece, before we can start indexing, is the `VectorStoreIndex`. It is a wrapper around
`VectorStore` that provides a convenient interface for indexing and querying. It also requires a
`ServiceContext` to be initialized.
```python
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store, service_context=service_context
)
```
## Indexing documents
No matter how our documents are generated, LlamaIndex will automatically split them into nodes, if
required, encode using selected embedding model, and then store in the vector store. Let's define
some documents manually and insert them into Qdrant collection. Our documents are going to have
a single metadata attribute - a library name they belong to.
```python
from llama_index.core.schema import Document
documents = [
Document(
text="LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models.",
metadata={
"library": "llama-index",
},
),
Document(
text="Qdrant is a vector database & vector similarity search engine.",
metadata={
"library": "qdrant",
},
),
]
```
Now we can index them using our `VectorStoreIndex`:
```python
for document in documents:
index.insert(document)
```
### Performance considerations
Our documents have been split into nodes, encoded using the embedding model, and stored in the vector
store. However, we don't want to allow our users to search for all the documents in the collection,
but only for the documents that belong to a library they are interested in. For that reason, we need
to set up the Qdrant [payload index](/documentation/concepts/indexing/#payload-index), so the search
is more efficient.
```python
from qdrant_client import models
client.create_payload_index(
collection_name="my_collection",
field_name="metadata.library",
field_type=models.PayloadSchemaType.KEYWORD,
)
```
The payload index is not the only thing we want to change. Since none of the search
queries will be executed on the whole collection, we can also change its configuration, so the HNSW
graph is not built globally. This is also done due to [performance reasons](/documentation/guides/multiple-partitions/#calibrate-performance).
**You should not be changing these parameters, if you know there will be some global search operations
done on the collection.**
```python
client.update_collection(
collection_name="my_collection",
hnsw_config=models.HnswConfigDiff(payload_m=16, m=0),
)
```
Once both operations are completed, we can start searching for our documents.
<aside role="status">These steps are done just once, when you index your first documents!</aside>
## Querying documents with constraints
Let's assume we are searching for some information about large language models, but are only allowed to
use Qdrant documentation. LlamaIndex has a concept of retrievers, responsible for finding the most
relevant nodes for a given query. Our `VectorStoreIndex` can be used as a retriever, with some additional
constraints - in our case value of the `library` metadata attribute.
```python
from llama_index.core.vector_stores.types import MetadataFilters, ExactMatchFilter
qdrant_retriever = index.as_retriever(
filters=MetadataFilters(
filters=[
ExactMatchFilter(
key="library",
value="qdrant",
)
]
)
)
nodes_with_scores = qdrant_retriever.retrieve("large language models")
for node in nodes_with_scores:
print(node.text, node.score)
# Output: Qdrant is a vector database & vector similarity search engine. 0.60551536
```
The description of Qdrant was the best match, even though it didn't mention large language models
at all. However, it was the only document that belonged to the `qdrant` library, so there was no
other choice. Let's try to search for something that is not present in the collection.
Let's define another retrieve, this time for the `llama-index` library:
```python
llama_index_retriever = index.as_retriever(
filters=MetadataFilters(
filters=[
ExactMatchFilter(
key="library",
value="llama-index",
)
]
)
)
nodes_with_scores = llama_index_retriever.retrieve("large language models")
for node in nodes_with_scores:
print(node.text, node.score)
# Output: LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models. 0.63576734
```
The results returned by both retrievers are different, due to the different constraints, so we implemented
a real multitenant search application!
|
qdrant-landing/content/documentation/examples/mighty.md | ---
title: "Inference with Mighty"
short_description: "Mighty offers a speedy scalable embedding, a perfect fit for the speedy scalable Qdrant search. Let's combine them!"
description: "We combine Mighty and Qdrant to create a semantic search service in Rust with just a few lines of code."
weight: 17
author: Andre Bogus
author_link: https://llogiq.github.io
date: 2023-06-01T11:24:20+01:00
aliases:
- /documentation/tutorials/mighty.md/
keywords:
- vector search
- embeddings
- mighty
- rust
- semantic search
---
# Semantic Search with Mighty and Qdrant
Much like Qdrant, the [Mighty](https://max.io/) inference server is written in Rust and promises to offer low latency and high scalability. This brief demo combines Mighty and Qdrant into a simple semantic search service that is efficient, affordable and easy to setup. We will use [Rust](https://rust-lang.org) and our [qdrant\_client crate](https://docs.rs/qdrant_client) for this integration.
## Initial setup
For Mighty, start up a [docker container](https://hub.docker.com/layers/maxdotio/mighty-sentence-transformers/0.9.9/images/sha256-0d92a89fbdc2c211d927f193c2d0d34470ecd963e8179798d8d391a4053f6caf?context=explore) with an open port 5050. Just loading the port in a window shows the following:
```json
{
"name": "sentence-transformers/all-MiniLM-L6-v2",
"architectures": [
"BertModel"
],
"model_type": "bert",
"max_position_embeddings": 512,
"labels": null,
"named_entities": null,
"image_size": null,
"source": "https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2"
}
```
Note that this uses the `MiniLM-L6-v2` model from Hugging Face. As per their website, the model "maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search". The distance measure to use is cosine similarity.
Verify that mighty works by calling `curl https://<address>:5050/sentence-transformer?q=hello+mighty`. This will give you a result like (formatted via `jq`):
```json
{
"outputs": [
[
-0.05019686743617058,
0.051746174693107605,
0.048117730766534805,
... (381 values skipped)
]
],
"shape": [
1,
384
],
"texts": [
"Hello mighty"
],
"took": 77
}
```
For Qdrant, follow our [cloud documentation](../../cloud/cloud-quick-start/) to spin up a [free tier](https://cloud.qdrant.io/). Make sure to retrieve an API key.
## Implement model API
For mighty, you will need a way to emit HTTP(S) requests. This version uses the [reqwest](https://docs.rs/reqwest) crate, so add the following to your `Cargo.toml`'s dependencies section:
```toml
[dependencies]
reqwest = { version = "0.11.18", default-features = false, features = ["json", "rustls-tls"] }
```
Mighty offers a variety of model APIs which will download and cache the model on first use. For semantic search, use the `sentence-transformer` API (as in the above `curl` command). The Rust code to make the call is:
```rust
use anyhow::anyhow;
use reqwest::Client;
use serde::Deserialize;
use serde_json::Value as JsonValue;
#[derive(Deserialize)]
struct EmbeddingsResponse {
pub outputs: Vec<Vec<f32>>,
}
pub async fn get_mighty_embedding(
client: &Client,
url: &str,
text: &str
) -> anyhow::Result<Vec<f32>> {
let response = client.get(url).query(&[("text", text)]).send().await?;
if !response.status().is_success() {
return Err(anyhow!(
"Mighty API returned status code {}",
response.status()
));
}
let embeddings: EmbeddingsResponse = response.json().await?;
// ignore multiple embeddings at the moment
embeddings.get(0).ok_or_else(|| anyhow!("mighty returned empty embedding"))
}
```
Note that mighty can return multiple embeddings (if the input is too long to fit the model, it is automatically split).
## Create embeddings and run a query
Use this code to create embeddings both for insertion and search. On the Qdrant side, take the embedding and run a query:
```rust
use anyhow::anyhow;
use qdrant_client::prelude::*;
pub const SEARCH_LIMIT: u64 = 5;
const COLLECTION_NAME: &str = "mighty";
pub async fn qdrant_search_embeddings(
qdrant_client: &QdrantClient,
vector: Vec<f32>,
) -> anyhow::Result<Vec<ScoredPoint>> {
qdrant_client
.search_points(&SearchPoints {
collection_name: COLLECTION_NAME.to_string(),
vector,
limit: SEARCH_LIMIT,
with_payload: Some(true.into()),
..Default::default()
})
.await
.map_err(|err| anyhow!("Failed to search Qdrant: {}", err))
}
```
You can convert the [`ScoredPoint`](https://docs.rs/qdrant-client/latest/qdrant_client/qdrant/struct.ScoredPoint.html)s to fit your desired output format. |
qdrant-landing/content/documentation/examples/natural-language-search-oracle-cloud-infrastructure-cohere-langchain.md | ---
title: RAG System for Employee Onboarding
weight: 30
social_preview_image: /blog/hybrid-cloud-oracle-cloud-infrastructure/hybrid-cloud-oracle-cloud-infrastructure-tutorial.png
aliases:
- /documentation/tutorials/natural-language-search-oracle-cloud-infrastructure-cohere-langchain/
---
# RAG System for Employee Onboarding
Public websites are a great way to share information with a wide audience. However, finding the right information can be
challenging, if you are not familiar with the website's structure or the terminology used. That's what the search bar is
for, but it is not always easy to formulate a query that will return the desired results, if you are not yet familiar
with the content. This is even more important in a corporate environment, and for the new employees, who are just
starting to learn the ropes, and don't even know how to ask the right questions yet. You may have even the best intranet
pages, but onboarding is more than just reading the documentation, it is about understanding the processes. Semantic
search can help with finding right resources easier, but wouldn't it be easier to just chat with the website, like you
would with a colleague?
Technological advancements have made it possible to interact with websites using natural language. This tutorial will
guide you through the process of integrating [Cohere](https://cohere.com/)'s language models with Qdrant to enable
natural language search on your documentation. We are going to use [LangChain](https://langchain.com/) as an
orchestrator. Everything will be hosted on [Oracle Cloud Infrastructure (OCI)](https://www.oracle.com/cloud/), so you
can scale your application as needed, and do not send your data to third parties. That is especially important when you
are working with confidential or sensitive data.
## Building up the application
Our application will consist of two main processes: indexing and searching. Langchain will glue everything together,
as we will use a few components, including Cohere and Qdrant, as well as some OCI services. Here is a high-level
overview of the architecture:

### Prerequisites
Before we dive into the implementation, make sure to set up all the necessary accounts and tools.
#### Libraries
We are going to use a few Python libraries. Of course, Langchain will be our main framework, but the Cohere models on
OCI are accessible via the [OCI SDK](https://docs.oracle.com/en-us/iaas/tools/python/2.125.1/). Let's install all the
necessary libraries:
```shell
pip install langchain oci qdrant-client langchainhub
```
#### Oracle Cloud
Our application will be fully running on Oracle Cloud Infrastructure (OCI). It's up to you to choose how you want to
deploy your application. Qdrant Hybrid Cloud will be running in your [Kubernetes cluster running on Oracle Cloud
(OKE)](https://www.oracle.com/cloud/cloud-native/container-engine-kubernetes/), so all the processes might be also
deployed there. You can get started with signing up for an account on [Oracle Cloud](https://signup.cloud.oracle.com/).
Cohere models are available on OCI as a part of the [Generative AI
Service](https://www.oracle.com/artificial-intelligence/generative-ai/generative-ai-service/). We need both the
[Generation models](https://docs.oracle.com/en-us/iaas/Content/generative-ai/use-playground-generate.htm) and the
[Embedding models](https://docs.oracle.com/en-us/iaas/Content/generative-ai/use-playground-embed.htm). Please follow the
linked tutorials to grasp the basics of using Cohere models there.
Accessing the models programmatically requires knowing the compartment OCID. Please refer to the [documentation that
describes how to find it](https://docs.oracle.com/en-us/iaas/Content/GSG/Tasks/contactingsupport_topic-Locating_Oracle_Cloud_Infrastructure_IDs.htm#Finding_the_OCID_of_a_Compartment).
For the further reference, we will assume that the compartment OCID is stored in the environment variable:
```shell
export COMPARTMENT_OCID="<your-compartment-ocid>"
```
```python
import os
os.environ["COMPARTMENT_OCID"] = "<your-compartment-ocid>"
```
#### Qdrant Hybrid Cloud
Qdrant Hybrid Cloud running on Oracle Cloud helps you build a solution without sending your data to external services. Our documentation provides a step-by-step guide on how to [deploy Qdrant Hybrid Cloud on Oracle
Cloud](/documentation/hybrid-cloud/platform-deployment-options/#oracle-cloud-infrastructure).
Qdrant will be running on a specific URL and access will be restricted by the API key. Make sure to store them both as environment variables as well:
```shell
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
```
*Optional:* Whenever you use LangChain, you can also [configure LangSmith](https://docs.smith.langchain.com/), which will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/).
```shell
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
```
Now you can get started:
```python
import os
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
```
Let's create the collection that will store the indexed documents. We will use the `qdrant-client` library, and our
collection will be named `oracle-cloud-website`. Our embedding model, `cohere.embed-english-v3.0`, produces embeddings
of size 1024, and we have to specify that when creating the collection.
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(
location=os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
client.create_collection(
collection_name="oracle-cloud-website",
vectors_config=models.VectorParams(
size=1024,
distance=models.Distance.COSINE,
),
)
```
### Indexing process
We have all the necessary tools set up, so let's start with the indexing process. We will use the Cohere Embedding
models to convert the text into vectors, and then store them in Qdrant. Langchain is integrated with OCI Generative AI
Service, so we can easily access the models.
Our dataset will be fairly simple, as it will consist of the questions and answers from the [Oracle Cloud Free Tier
FAQ page](https://www.oracle.com/cloud/free/faq/).

Questions and answers are presented in an HTML format, but we don't want to manually extract the text and adapt it for
each subpage. Instead, we will use the `WebBaseLoader` that just loads the HTML content from given URL and converts it
to text.
```python
from langchain_community.document_loaders.web_base import WebBaseLoader
loader = WebBaseLoader("https://www.oracle.com/cloud/free/faq/")
documents = loader.load()
```
Our `documents` is a list with just a single element, which is the text of the whole page. We need to split it into
meaningful parts, so we will use the `RecursiveCharacterTextSplitter` component. It will try to keep all paragraphs (and
then sentences, and then words) together as long as possible, as those would generically seem to be the strongest
semantically related pieces of text. The chunk size and overlap are both parameters that can be adjusted to fit the
specific use case.
```python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=100)
split_documents = splitter.split_documents(documents)
```
Our documents might be now indexed, but we need to convert them into vectors. Let's configure the embeddings so the
`cohere.embed-english-v3.0` is used. Not all the regions support the Generative AI Service, so we need to specify the
region where the models are stored. We will use the `us-chicago-1`, but please check the
[documentation](https://docs.oracle.com/en-us/iaas/Content/generative-ai/overview.htm#regions) for the most up-to-date
list of supported regions.
```python
from langchain_community.embeddings.oci_generative_ai import OCIGenAIEmbeddings
embeddings = OCIGenAIEmbeddings(
model_id="cohere.embed-english-v3.0",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=os.environ.get("COMPARTMENT_OCID"),
)
```
Now we can embed the documents and store them in Qdrant. We will create an instance of `Qdrant` and add the split
documents to the collection.
```python
from langchain.vectorstores.qdrant import Qdrant
qdrant = Qdrant(
client=client,
collection_name="oracle-cloud-website",
embeddings=embeddings,
)
qdrant.add_documents(split_documents, batch_size=20)
```
Our documents should be now indexed and ready for searching. Let's move to the next step.
### Speaking to the website
The intended method of interaction with the website is through the chatbot. Large Language Model, in our case [Cohere
Command](https://cohere.com/command), will be answering user's questions based on the relevant documents that Qdrant
will return using the question as a query. Our LLM is also hosted on OCI, so we can access it similarly to the embedding
model:
```python
from langchain_community.llms.oci_generative_ai import OCIGenAI
llm = OCIGenAI(
model_id="cohere.command",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=os.environ.get("COMPARTMENT_OCID"),
)
```
Connection to Qdrant might be established in the same way as we did during the indexing process. We can use it to create
a retrieval chain, which implements the question-answering process. The retrieval chain also requires an additional
chain that will combine retrieved documents before sending them to an LLM.
```python
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain import hub
retriever = qdrant.as_retriever()
combine_docs_chain = create_stuff_documents_chain(
llm=llm,
# Default prompt is loaded from the hub, but we can also modify it
prompt=hub.pull("langchain-ai/retrieval-qa-chat"),
)
retrieval_qa_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=combine_docs_chain,
)
response = retrieval_qa_chain.invoke({"input": "What is the Oracle Cloud Free Tier?"})
```
The output of the `.invoke` method is a dictionary-like structure with the query and answer, but we can also access the
source documents used to generate the response. This might be useful for debugging or for further processing.
```python
{
'input': 'What is the Oracle Cloud Free Tier?',
'context': [
Document(
page_content='* Free Tier is generally available in regions where commercial Oracle Cloud Infrastructure service is available. See the data regions page for detailed service availability (the exact regions available for Free Tier may differ during the sign-up process). The US$300 cloud credit is available in',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'c8cf98e0-4b88-4750-be42-4157495fed2c',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='Oracle Cloud Free Tier allows you to sign up for an Oracle Cloud account which provides a number of Always Free services and a Free Trial with US$300 of free credit to use on all eligible Oracle Cloud Infrastructure services for up to 30 days. The Always Free services are available for an unlimited',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'dc291430-ff7b-4181-944a-39f6e7a0de69',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='Oracle Cloud Free Tier does not include SLAs. Community support through our forums is available to all customers. Customers using only Always Free resources are not eligible for Oracle Support. Limited support is available for Oracle Cloud Free Tier with Free Trial credits. After you use all of',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': '9e831039-7ccc-47f7-9301-20dbddd2fc07',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='looking to test things before moving to cloud, a student wanting to learn, or an academic developing curriculum in the cloud, Oracle Cloud Free Tier enables you to learn, explore, build and test for free.',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'e2dc43e1-50ee-4678-8284-6df60a835cf5',
'_collection_name': 'oracle-cloud-website'
}
)
],
'answer': ' Oracle Cloud Free Tier is a subscription that gives you access to Always Free services and a Free Trial with $300 of credit that can be used on all eligible Oracle Cloud Infrastructure services for up to 30 days. \n\nThrough this Free Tier, you can learn, explore, build, and test for free. It is aimed at those who want to experiment with cloud services before making a commitment, as wellTheir use cases range from testing prior to cloud migration to learning and academic curriculum development. '
}
```
#### Other experiments
Asking the basic questions is just the beginning. What you want to avoid is a hallucination, where the model generates
an answer that is not based on the actual content. The default prompt of Langchain should already prevent this, but you
might still want to check it. Let's ask a question that is not directly answered on the FAQ page:
```python
response = retrieval_qa.invoke({
"input": "Is Oracle Generative AI Service included in the free tier?"
})
```
Output:
> Oracle Generative AI Services are not specifically mentioned as being available in the free tier. As per the text, the
> $300 free credit can be used on all eligible services for up to 30 days. To confirm if Oracle Generative AI Services
> are included in the free credit offer, it is best to check the official Oracle Cloud website or contact their support.
It seems that Cohere Command model could not find the exact answer in the provided documents, but it tried to interpret
the context and provide a reasonable answer, without making up the information. This is a good sign that the model is
not hallucinating in that case.
## Wrapping up
This tutorial has shown how to integrate Cohere's language models with Qdrant to enable natural language search on your
website. We have used Langchain as an orchestrator, and everything was hosted on Oracle Cloud Infrastructure (OCI).
Real world would require integrating this mechanism into your organization's systems, but we built a solid foundation
that can be further developed.
|
qdrant-landing/content/documentation/examples/qdrant-airflow-astronomer.md | ---
title: Semantic Querying with Airflow and Astronomer
weight: 36
---
# Semantic Querying with Airflow and Astronomer
| Time: 45 min | Level: Intermediate | | |
| ------------ | ------------------- | --- | --- |
In this tutorial, you will use Qdrant as a [provider](https://airflow.apache.org/docs/apache-airflow-providers-qdrant/stable/index.html) in [Apache Airflow](https://airflow.apache.org/), an open-source tool that lets you setup data-engineering workflows.
You will write the pipeline as a DAG (Directed Acyclic Graph) in Python. With this, you can leverage the powerful suite of Python's capabilities and libraries to achieve almost anything your data pipeline needs.
[Astronomer](https://www.astronomer.io/) is a managed platform that simplifies the process of developing and deploying Airflow projects via its easy-to-use CLI and extensive automation capabilities.
Airflow is useful when running operations in Qdrant based on data events or building parallel tasks for generating vector embeddings. By using Airflow, you can set up monitoring and alerts for your pipelines for full observability.
## Prerequisites
Please make sure you have the following ready:
- A running Qdrant instance. We'll be using a free instance from <https://cloud.qdrant.io>
- The Astronomer CLI. Find the installation instructions [here](https://docs.astronomer.io/astro/cli/install-cli).
- A [HuggingFace token](https://huggingface.co/docs/hub/en/security-tokens) to generate embeddings.
## Implementation
We'll be building a DAG that generates embeddings in parallel for our data corpus and performs semantic retrieval based on user input.
### Set up the project
The Astronomer CLI makes it very straightforward to set up the Airflow project:
```console
mkdir qdrant-airflow-tutorial && cd qdrant-airflow-tutorial
astro dev init
```
This command generates all of the project files you need to run Airflow locally. You can find a directory called `dags`, which is where we can place our Python DAG files.
To use Qdrant within Airflow, install the Qdrant Airflow provider by adding the following to the `requirements.txt` file
```text
apache-airflow-providers-qdrant==1.1.0
```
### Configure credentials
We can set up provider connections using the Airflow UI, environment variables or the `airflow_settings.yml` file.
Add the following to the `.env` file in the project. Replace the values as per your credentials.
```env
HUGGINGFACE_TOKEN="<YOUR_HUGGINGFACE_ACCESS_TOKEN>"
AIRFLOW_CONN_QDRANT_DEFAULT='{
"conn_type": "qdrant",
"host": "xyz-example.eu-central.aws.cloud.qdrant.io:6333",
"password": "<YOUR_QDRANT_API_KEY>"
}'
```
### Add the data corpus
Let's add some sample data to work with. Paste the following content into a file called `books.txt` file within the `include` directory.
```text
1 | To Kill a Mockingbird (1960) | fiction | Harper Lee's Pulitzer Prize-winning novel explores racial injustice and moral growth through the eyes of young Scout Finch in the Deep South.
2 | Harry Potter and the Sorcerer's Stone (1997) | fantasy | J.K. Rowling's magical tale follows Harry Potter as he discovers his wizarding heritage and attends Hogwarts School of Witchcraft and Wizardry.
3 | The Great Gatsby (1925) | fiction | F. Scott Fitzgerald's classic novel delves into the glitz, glamour, and moral decay of the Jazz Age through the eyes of narrator Nick Carraway and his enigmatic neighbour, Jay Gatsby.
4 | 1984 (1949) | dystopian | George Orwell's dystopian masterpiece paints a chilling picture of a totalitarian society where individuality is suppressed and the truth is manipulated by a powerful regime.
5 | The Catcher in the Rye (1951) | fiction | J.D. Salinger's iconic novel follows disillusioned teenager Holden Caulfield as he navigates the complexities of adulthood and society's expectations in post-World War II America.
6 | Pride and Prejudice (1813) | romance | Jane Austen's beloved novel revolves around the lively and independent Elizabeth Bennet as she navigates love, class, and societal expectations in Regency-era England.
7 | The Hobbit (1937) | fantasy | J.R.R. Tolkien's adventure follows Bilbo Baggins, a hobbit who embarks on a quest with a group of dwarves to reclaim their homeland from the dragon Smaug.
8 | The Lord of the Rings (1954-1955) | fantasy | J.R.R. Tolkien's epic fantasy trilogy follows the journey of Frodo Baggins to destroy the One Ring and defeat the Dark Lord Sauron in the land of Middle-earth.
9 | The Alchemist (1988) | fiction | Paulo Coelho's philosophical novel follows Santiago, an Andalusian shepherd boy, on a journey of self-discovery and spiritual awakening as he searches for a hidden treasure.
10 | The Da Vinci Code (2003) | mystery/thriller | Dan Brown's gripping thriller follows symbologist Robert Langdon as he unravels clues hidden in art and history while trying to solve a murder mystery with far-reaching implications.
```
Now, the hacking part - writing our Airflow DAG!
### Write the dag
We'll add the following content to a `books_recommend.py` file within the `dags` directory. Let's go over what it does for each task.
```python
import os
import requests
from airflow.decorators import dag, task
from airflow.models.baseoperator import chain
from airflow.models.param import Param
from airflow.providers.qdrant.hooks.qdrant import QdrantHook
from airflow.providers.qdrant.operators.qdrant import QdrantIngestOperator
from pendulum import datetime
from qdrant_client import models
QDRANT_CONNECTION_ID = "qdrant_default"
DATA_FILE_PATH = "include/books.txt"
COLLECTION_NAME = "airflow_tutorial_collection"
EMBEDDING_MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
EMBEDDING_DIMENSION = 384
SIMILARITY_METRIC = models.Distance.COSINE
def embed(text: str) -> list:
HUGGINFACE_URL = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{EMBEDDING_MODEL_ID}"
response = requests.post(
HUGGINFACE_URL,
headers={"Authorization": f"Bearer {os.getenv('HUGGINGFACE_TOKEN')}"},
json={"inputs": [text], "options": {"wait_for_model": True}},
)
return response.json()[0]
@dag(
dag_id="books_recommend",
start_date=datetime(2023, 10, 18),
schedule=None,
catchup=False,
params={"preference": Param("Something suspenseful and thrilling.", type="string")},
)
def recommend_book():
@task
def import_books(text_file_path: str) -> list:
data = []
with open(text_file_path, "r") as f:
for line in f:
_, title, genre, description = line.split("|")
data.append(
{
"title": title.strip(),
"genre": genre.strip(),
"description": description.strip(),
}
)
return data
@task
def init_collection():
hook = QdrantHook(conn_id=QDRANT_CONNECTION_ID)
hook.conn.recreate_collection(
COLLECTION_NAME,
vectors_config=models.VectorParams(
size=EMBEDDING_DIMENSION, distance=SIMILARITY_METRIC
),
)
@task
def embed_description(data: dict) -> list:
return embed(data["description"])
books = import_books(text_file_path=DATA_FILE_PATH)
embeddings = embed_description.expand(data=books)
qdrant_vector_ingest = QdrantIngestOperator(
conn_id=QDRANT_CONNECTION_ID,
task_id="qdrant_vector_ingest",
collection_name=COLLECTION_NAME,
payload=books,
vectors=embeddings,
)
@task
def embed_preference(**context) -> list:
user_mood = context["params"]["preference"]
response = embed(text=user_mood)
return response
@task
def search_qdrant(
preference_embedding: list,
) -> None:
hook = QdrantHook(conn_id=QDRANT_CONNECTION_ID)
result = hook.conn.search(
collection_name=COLLECTION_NAME,
query_vector=preference_embedding,
limit=1,
with_payload=True,
)
print("Book recommendation: " + result[0].payload["title"])
print("Description: " + result[0].payload["description"])
chain(
init_collection(),
qdrant_vector_ingest,
search_qdrant(embed_preference()),
)
recommend_book()
```
`import_books`: This task reads a text file containing information about the books (like title, genre, and description), and then returns the data as a list of dictionaries.
`init_collection`: This task initializes a collection in the Qdrant database, where we will store the vector representations of the book descriptions. The `recreate_collection()` deletes a collection first if it already exists. Trying to create a collection that already exists throws an error.
`embed_description`: This is a dynamic task that creates one mapped task instance for each book in the list. The task uses the `embed` function to generate vector embeddings for each description. To use a different embedding model, you can adjust the `EMBEDDING_MODEL_ID`, `EMBEDDING_DIMENSION` values.
`embed_user_preference`: Here, we take a user's input and convert it into a vector using the same pre-trained model used for the book descriptions.
`qdrant_vector_ingest`: This task ingests the book data into the Qdrant collection using the [QdrantIngestOperator](https://airflow.apache.org/docs/apache-airflow-providers-qdrant/1.0.0/), associating each book description with its corresponding vector embeddings.
`search_qdrant`: Finally, this task performs a search in the Qdrant database using the vectorized user preference. It finds the most relevant book in the collection based on vector similarity.
### Run the DAG
Head over to your terminal and run
```astro dev start```
A local Airflow container should spawn. You can now access the Airflow UI at <http://localhost:8080>. Visit our DAG by clicking on `books_recommend`.

Hit the PLAY button on the right to run the DAG. You'll be asked for input about your preference, with the default value already filled in.

After your DAG run completes, you should be able to see the output of your search in the logs of the `search_qdrant` task.

There you have it, an Airflow pipeline that interfaces with Qdrant! Feel free to fiddle around and explore Airflow. There are references below that might come in handy.
## Further reading
- [Introduction to Airflow](https://docs.astronomer.io/learn/intro-to-airflow)
- [Airflow Concepts](https://docs.astronomer.io/learn/category/airflow-concepts)
- [Airflow Reference](https://airflow.apache.org/docs/)
- [Astronomer Documentation](https://docs.astronomer.io/)
|
qdrant-landing/content/documentation/examples/rag-chatbot-red-hat-openshift-haystack.md | ---
title: Private Chatbot for Interactive Learning
weight: 23
social_preview_image: /blog/hybrid-cloud-red-hat-openshift/hybrid-cloud-red-hat-openshift-tutorial.png
aliases:
- /documentation/tutorials/rag-chatbot-red-hat-openshift-haystack/
---
# Private Chatbot for Interactive Learning
| Time: 120 min | Level: Advanced | |
| --- | ----------- | ----------- |----------- |
With chatbots, companies can scale their training programs to accommodate a large workforce, delivering consistent and standardized learning experiences across departments, locations, and time zones. Furthermore, having already completed their online training, corporate employees might want to refer back old course materials. Most of this information is proprietary to the company, and manually searching through an entire library of materials takes time. However, a chatbot built on this knowledge can respond in the blink of an eye.
With a simple RAG pipeline, you can build a private chatbot. In this tutorial, you will combine open source tools inside of a closed infrastructure and tie them together with a reliable framework. This custom solution lets you run a chatbot without public internet access. You will be able to keep sensitive data secure without compromising privacy.

**Figure 1:** The LLM and Qdrant Hybrid Cloud are containerized as separate services. Haystack combines them into a RAG pipeline and exposes the API via Hayhooks.
## Components
To maintain complete data isolation, we need to limit ourselves to open-source tools and use them in a private environment, such as [Red Hat OpenShift](https://www.redhat.com/en/technologies/cloud-computing/openshift). The pipeline will run internally and will be inaccessible from the internet.
- **Dataset:** [Red Hat Interactive Learning Portal](https://developers.redhat.com/learn), an online library of Red Hat course materials.
- **LLM:** `mistralai/Mistral-7B-Instruct-v0.1`, deployed as a standalone service on OpenShift.
- **Embedding Model:** `BAAI/bge-base-en-v1.5`, lightweight embedding model deployed from within the Haystack pipeline
with [FastEmbed](https://github.com/qdrant/fastembed)
- **Vector DB:** [Qdrant Hybrid Cloud](https://hybrid-cloud.qdrant.tech) running on OpenShift.
- **Framework:** [Haystack 2.x](https://haystack.deepset.ai/) to connect all and [Hayhooks](https://docs.haystack.deepset.ai/docs/hayhooks) to serve the app through HTTP endpoints.
### Procedure
The [Haystack](https://haystack.deepset.ai/) framework leverages two pipelines, which combine our components sequentially to process data.
1. The **Indexing Pipeline** will run offline in batches, when new data is added or updated.
2. The **Search Pipeline** will retrieve information from Qdrant and use an LLM to produce an answer.
> **Note:** We will define the pipelines in Python and then export them to YAML format, so that [Hayhooks](https://docs.haystack.deepset.ai/docs/hayhooks) can run them as a web service.
## Prerequisites
### Deploy the LLM to OpenShift
Follow the steps in [Chapter 6. Serving large language models](https://access.redhat.com/documentation/en-us/red_hat_openshift_ai_self-managed/2.5/html/working_on_data_science_projects/serving-large-language-models_serving-large-language-models#doc-wrapper). This will download the LLM from the [HuggingFace](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), and deploy it to OpenShift using a *single model serving platform*.
Your LLM service will have a URL, which you need to store as an environment variable.
```shell
export INFERENCE_ENDPOINT_URL="http://mistral-service.default.svc.cluster.local"
```
```python
import os
os.environ["INFERENCE_ENDPOINT_URL"] = "http://mistral-service.default.svc.cluster.local"
```
### Launch Qdrant Hybrid Cloud
Complete **How to Set Up Qdrant on Red Hat OpenShift**. When in Hybrid Cloud, your Qdrant instance is private and and its nodes run on the same OpenShift infrastructure as your other components.
Retrieve your Qdrant URL and API key and store them as environment variables:
```shell
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
```
```python
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
```
## Implementation
We will first create an indexing pipeline to add documents to the system.
Then, the search pipeline will retrieve relevant data from our documents.
After the pipelines are tested, we will export them to YAML files.
### Indexing pipeline
[Haystack 2.x](https://haystack.deepset.ai/) comes packed with a lot of useful components, from data fetching, through
HTML parsing, up to the vector storage. Before we start, there are a few Python packages that we need to install:
```shell
pip install haystack-ai \
qdrant-client \
qdrant-haystack \
fastembed-haystack
```
<aside role="status">
FastEmbed uses ONNX runtime and does not require a GPU for the embedding models while still providing a fast inference speed.
</aside>
Our environment is now ready, so we can jump right into the code. Let's define an empty pipeline and gradually add
components to it:
```python
from haystack import Pipeline
indexing_pipeline = Pipeline()
```
#### Data fetching and conversion
In this step, we will use Haystack's `LinkContentFetcher` to download course content from a list of URLs and store it in Qdrant for retrieval.
As we don't want to store raw HTML, this tool will extract text content from each webpage. Then, the fetcher will divide them into digestible chunks, since the documents might be pretty long.
Let's start with data fetching and text conversion:
```python
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
fetcher = LinkContentFetcher()
converter = HTMLToDocument()
indexing_pipeline.add_component("fetcher", fetcher)
indexing_pipeline.add_component("converter", converter)
```
Our pipeline knows there are two components, but they are not connected yet. We need to define the flow between them:
```python
indexing_pipeline.connect("fetcher.streams", "converter.sources")
```
Each component has a set of inputs and outputs which might be combined in a directed graph. The definitions of the
inputs and outputs are usually provided in the documentation of the component. The `LinkContentFetcher` has the
following parameters:

*Source: https://docs.haystack.deepset.ai/docs/linkcontentfetcher*
#### Chunking and creating the embeddings
We used `HTMLToDocument` to convert the HTML sources into `Document` instances of Haystack, which is a
base class containing some data to be queried. However, a single document might be too long to be processed by the
embedding model, and it also carries way too much information to make the search relevant.
Therefore, we need to split the document into smaller parts and convert them into embeddings. For this, we will use the
`DocumentSplitter` and `FastembedDocumentEmbedder` pointed to our `BAAI/bge-base-en-v1.5` model:
```python
from haystack.components.preprocessors import DocumentSplitter
from haystack_integrations.components.embedders.fastembed import FastembedDocumentEmbedder
splitter = DocumentSplitter(split_by="sentence", split_length=5, split_overlap=2)
embedder = FastembedDocumentEmbedder(model="BAAI/bge-base-en-v1.5")
embedder.warm_up()
indexing_pipeline.add_component("splitter", splitter)
indexing_pipeline.add_component("embedder", embedder)
indexing_pipeline.connect("converter.documents", "splitter.documents")
indexing_pipeline.connect("splitter.documents", "embedder.documents")
```
#### Writing data to Qdrant
The splitter will be producing chunks with a maximum length of 5 sentences, with an overlap of 2 sentences. Then, these
smaller portions will be converted into embeddings.
Finally, we need to store our embeddings in Qdrant.
```python
from haystack.utils import Secret
from haystack_integrations.document_stores.qdrant import QdrantDocumentStore
from haystack.components.writers import DocumentWriter
document_store = QdrantDocumentStore(
os.environ["QDRANT_URL"],
api_key=Secret.from_env_var("QDRANT_API_KEY"),
index="red-hat-learning",
return_embedding=True,
embedding_dim=768,
)
writer = DocumentWriter(document_store=document_store)
indexing_pipeline.add_component("writer", writer)
indexing_pipeline.connect("embedder.documents", "writer.documents")
```
Our pipeline is now complete. Haystack comes with a handy visualization of the pipeline, so you can see and verify the
connections between the components. It is displayed in the Jupyter notebook, but you can also export it to a file:
```python
indexing_pipeline.draw("indexing_pipeline.png")
```

#### Test the entire pipeline
We can finally run it on a list of URLs to index the content in Qdrant. We have a bunch of URLs to all the Red Hat
OpenShift Foundations course lessons, so let's use them:
```python
course_urls = [
"https://developers.redhat.com/learn/openshift/foundations-openshift",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:openshift-and-developer-sandbox",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:overview-web-console",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:use-terminal-window-within-red-hat-openshift-web-console",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:install-application-source-code-github-repository-using-openshift-web-console",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:install-application-linux-container-image-repository-using-openshift-web-console",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:install-application-linux-container-image-using-oc-cli-tool",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:install-application-source-code-using-oc-cli-tool",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:scale-applications-using-openshift-web-console",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:scale-applications-using-oc-cli-tool",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:work-databases-openshift-using-oc-cli-tool",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:work-databases-openshift-web-console",
"https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:view-performance-information-using-openshift-web-console",
]
indexing_pipeline.run(data={
"fetcher": {
"urls": course_urls,
}
})
```
The execution might take a while, as the model needs to process all the documents. After the process is finished, we
should have all the documents stored in Qdrant, ready for search. You should see a short summary of processed documents:
```shell
{'writer': {'documents_written': 381}}
```
### Search pipeline
Our documents are now indexed and ready for search. The next pipeline is a bit simpler, but we still need to define a
few components. Let's start again with an empty pipeline:
```python
search_pipeline = Pipeline()
```
Our second process takes user input, converts it into embeddings and then searches for the most relevant documents
using the query embedding. This might look familiar, but we arent working with `Document` instances
anymore, since the query only accepts raw text. Thus, some of the components will be different, especially the embedder,
as it has to accept a single string as an input and produce a single embedding as an output:
```python
from haystack_integrations.components.embedders.fastembed import FastembedTextEmbedder
from haystack_integrations.components.retrievers.qdrant import QdrantEmbeddingRetriever
query_embedder = FastembedTextEmbedder(model="BAAI/bge-base-en-v1.5")
query_embedder.warm_up()
retriever = QdrantEmbeddingRetriever(
document_store=document_store, # The same document store as the one used for indexing
top_k=3, # Number of documents to return
)
search_pipeline.add_component("query_embedder", query_embedder)
search_pipeline.add_component("retriever", retriever)
search_pipeline.connect("query_embedder.embedding", "retriever.query_embedding")
```
#### Run a test query
If our goal was to just retrieve the relevant documents, we could stop here. Let's try the current pipeline on a simple
query:
```python
query = "How to install an application using the OpenShift web console?"
search_pipeline.run(data={
"query_embedder": {
"text": query
}
})
```
We set the `top_k` parameter to 3, so the retriever should return the three most relevant documents. Your output should look like this:
```text
{
'retriever': {
'documents': [
Document(id=867b4aa4c37a91e72dc7ff452c47972c1a46a279a7531cd6af14169bcef1441b, content: 'Install a Node.js application from GitHub using the web console The following describes the steps r...', meta: {'content_type': 'text/html', 'source_id': 'f56e8f827dda86abe67c0ba3b4b11331d896e2d4f7b2b43c74d3ce973d07be0c', 'url': 'https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:work-databases-openshift-web-console'}, score: 0.9209432),
Document(id=0c74381c178597dd91335ebfde790d13bf5989b682d73bf5573c7734e6765af7, content: 'How to remove an application from OpenShift using the web console. In addition to providing the cap...', meta: {'content_type': 'text/html', 'source_id': '2a0759f3ce4a37d9f5c2af9c0ffcc80879077c102fb8e41e576e04833c9d24ce', 'url': 'https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:install-application-linux-container-image-repository-using-openshift-web-console'}, score: 0.9132109500000001),
Document(id=3e5f8923a34ab05611ef20783211e5543e880c709fd6534d9c1f63576edc4061, content: 'Path resource: Install an application from source code in a GitHub repository using the OpenShift w...', meta: {'content_type': 'text/html', 'source_id': 'a4c4cd62d07c0d9d240e3289d2a1cc0a3d1127ae70704529967f715601559089', 'url': 'https://developers.redhat.com/learning/learn:openshift:foundations-openshift/resource/resources:install-application-source-code-github-repository-using-openshift-web-console'}, score: 0.912748935)
]
}
}
```
#### Generating the answer
Retrieval should serve more than just documents. Therefore, we will need to use an LLM to generate exact answers to our question.
This is the final component of our second pipeline.
Haystack will create a prompt which adds your documents to the model's context.
```python
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.generators import HuggingFaceTGIGenerator
prompt_builder = PromptBuilder("""
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ query }}
""")
llm = HuggingFaceTGIGenerator(
model="mistralai/Mistral-7B-Instruct-v0.1",
url=os.environ["INFERENCE_ENDPOINT_URL"],
generation_kwargs={
"max_new_tokens": 1000, # Allow longer responses
},
)
search_pipeline.add_component("prompt_builder", prompt_builder)
search_pipeline.add_component("llm", llm)
search_pipeline.connect("retriever.documents", "prompt_builder.documents")
search_pipeline.connect("prompt_builder.prompt", "llm.prompt")
```
The `PromptBuilder` is a Jinja2 template that will be filled with the documents and the query. The
`HuggingFaceTGIGenerator` connects to the LLM service and generates the answer. Let's run the pipeline again:
```python
query = "How to install an application using the OpenShift web console?"
response = search_pipeline.run(data={
"query_embedder": {
"text": query
},
"prompt_builder": {
"query": query
},
})
```
The LLM may provide multiple replies, if asked to do so, so let's iterate over and print them out:
```python
for reply in response["llm"]["replies"]:
print(reply.strip())
```
In our case there is a single response, which should be the answer to the question:
```text
Answer: To install an application using the OpenShift web console, follow these steps:
1. Select +Add on the left side of the web console.
2. Identify the container image to install.
3. Using your web browser, navigate to the Developer Sandbox for Red Hat OpenShift and select Start your Sandbox for free.
4. Install an application from source code stored in a GitHub repository using the OpenShift web console.
```
Our final search pipeline might also be visualized, so we can see how the components are glued together:
```python
search_pipeline.draw("search_pipeline.png")
```

## Deployment
The pipelines are now ready, and we can export them to YAML. Hayhooks will use these files to run the
pipelines as HTTP endpoints. To do this, specify both file paths and your environment variables.
> Note: The indexing pipeline might be run inside your ETL tool, but search should be definitely exposed as an HTTP endpoint.
Let's run it on the local machine:
```shell
pip install hayhooks
```
First of all, we need to save the pipelines to the YAML file:
```python
with open("search-pipeline.yaml", "w") as fp:
search_pipeline.dump(fp)
```
And now we are able to run the Hayhooks service:
```shell
hayhooks run
```
The command should start the service on the default port, so you can access it at `http://localhost:1416`. The pipeline
is not deployed yet, but we can do it with just another command:
```shell
hayhooks deploy search-pipeline.yaml
```
Once it's finished, you should be able to see the OpenAPI documentation at
[http://localhost:1416/docs](http://localhost:1416/docs), and test the newly created endpoint.

Our search is now accessible through the HTTP endpoint, so we can integrate it with any other service. We can even
control the other parameters, like the number of documents to return:
```shell
curl -X 'POST' \
'http://localhost:1416/search-pipeline' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"llm": {
},
"prompt_builder": {
"query": "How can I remove an application?"
},
"query_embedder": {
"text": "How can I remove an application?"
},
"retriever": {
"top_k": 5
}
}'
```
The response should be similar to the one we got in the Python before:
```json
{
"llm": {
"replies": [
"\n\nAnswer: You can remove an application running in OpenShift by right-clicking on the circular graphic representing the application in Topology view and selecting the Delete Application text from the dialog that appears when you click the graphic’s outer ring. Alternatively, you can use the oc CLI tool to delete an installed application using the oc delete all command."
],
"meta": [
{
"model": "mistralai/Mistral-7B-Instruct-v0.1",
"index": 0,
"finish_reason": "eos_token",
"usage": {
"completion_tokens": 75,
"prompt_tokens": 642,
"total_tokens": 717
}
}
]
}
}
```
## Next steps
- In this example, [Red Hat OpenShift](https://www.redhat.com/en/technologies/cloud-computing/openshift) is the infrastructure of choice for proprietary chatbots. [Read more](https://access.redhat.com/documentation/en-us/red_hat_openshift_ai_self-managed/2.8) about how to host AI projects in their [extensive documentation](https://access.redhat.com/documentation/en-us/red_hat_openshift_ai_self-managed/2.8).
- [Haystack's documentation](https://docs.haystack.deepset.ai/docs/kubernetes) describes [how to deploy the Hayhooks service in a Kubernetes
environment](https://docs.haystack.deepset.ai/docs/kubernetes), so you can easily move it to your own OpenShift infrastructure.
- If you are just getting started and need more guidance on Qdrant, read the [quickstart](/documentation/quick-start/) or try out our [beginner tutorial](/documentation/tutorials/neural-search/). |
qdrant-landing/content/documentation/examples/rag-chatbot-scaleway.md | ---
title: Blog-Reading Chatbot with GPT-4o
weight: 35
social_preview_image: /blog/hybrid-cloud-scaleway/hybrid-cloud-scaleway-tutorial.png
aliases:
- /documentation/tutorials/rag-chatbot-scaleway/
---
# Blog-Reading Chatbot with GPT-4o
| Time: 90 min | Level: Advanced |[GitHub](https://github.com/qdrant/examples/blob/master/langchain-lcel-rag/Langchain-LCEL-RAG-Demo.ipynb)| |
|--------------|-----------------|--|----|
In this tutorial, you will build a RAG system that combines blog content ingestion with the capabilities of semantic search. **OpenAI's GPT-4o LLM** is powerful, but scaling its use requires us to supply context systematically.
RAG enhances the LLM's generation of answers by retrieving relevant documents to aid the question-answering process. This setup showcases the integration of advanced search and AI language processing to improve information retrieval and generation tasks.
A notebook for this tutorial is available on [GitHub](https://github.com/qdrant/examples/blob/master/langchain-lcel-rag/Langchain-LCEL-RAG-Demo.ipynb).
**Data Privacy and Sovereignty:** RAG applications often rely on sensitive or proprietary internal data. Running the entire stack within your own environment becomes crucial for maintaining control over this data. Qdrant Hybrid Cloud deployed on [Scaleway](https://www.scaleway.com/) addresses this need perfectly, offering a secure, scalable platform that still leverages the full potential of RAG. Scaleway offers serverless [Functions](https://www.scaleway.com/en/serverless-functions/) and serverless [Jobs](https://www.scaleway.com/en/serverless-jobs/), both of which are ideal for embedding creation in large-scale RAG cases.
## Components
- **Cloud Host:** [Scaleway on managed Kubernetes](https://www.scaleway.com/en/kubernetes-kapsule/) for compatibility with Qdrant Hybrid Cloud.
- **Vector Database:** Qdrant Hybrid Cloud as the vector search engine for retrieval.
- **LLM:** GPT-4o, developed by OpenAI is utilized as the generator for producing answers.
- **Framework:** [LangChain](https://www.langchain.com/) for extensive RAG capabilities.

> Langchain [supports a wide range of LLMs](https://python.langchain.com/docs/integrations/chat/), and GPT-4o is used as the main generator in this tutorial. You can easily swap it out for your preferred model that might be launched on your premises to complete the fully private setup. For the sake of simplicity, we used the OpenAI APIs, but LangChain makes the transition seamless.
## Deploying Qdrant Hybrid Cloud on Scaleway
[Scaleway Kapsule](https://www.scaleway.com/en/kubernetes-kapsule/) and [Kosmos](https://www.scaleway.com/en/kubernetes-kosmos/) are managed Kubernetes services from [Scaleway](https://www.scaleway.com/en/). They abstract away the complexities of managing and operating a Kubernetes cluster. The primary difference being, Kapsule clusters are composed solely of Scaleway Instances. Whereas, a Kosmos cluster is a managed multi-cloud Kubernetes engine that allows you to connect instances from any cloud provider to a single managed Control-Plane.
1. To start using managed Kubernetes on Scaleway, follow the [platform-specific documentation](/documentation/hybrid-cloud/platform-deployment-options/#scaleway).
2. Once your Kubernetes clusters are up, [you can begin deploying Qdrant Hybrid Cloud](/documentation/hybrid-cloud/).
## Prerequisites
To prepare the environment for working with Qdrant and related libraries, it's necessary to install all required Python packages. This can be done using Poetry, a tool for dependency management and packaging in Python. The code snippet imports various libraries essential for the tasks ahead, including `bs4` for parsing HTML and XML documents, `langchain` and its community extensions for working with language models and document loaders, and `Qdrant` for vector storage and retrieval. These imports lay the groundwork for utilizing Qdrant alongside other tools for natural language processing and machine learning tasks.
Qdrant will be running on a specific URL and access will be restricted by the API key. Make sure to store them both as environment variables as well:
```shell
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
```
*Optional:* Whenever you use LangChain, you can also [configure LangSmith](https://docs.smith.langchain.com/), which will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/).
```shell
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
```
Now you can get started:
```python
import getpass
import os
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_qdrant import Qdrant
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
```
Set up the OpenAI API key:
```python
os.environ["OPENAI_API_KEY"] = getpass.getpass()
```
Initialize the language model:
```python
llm = ChatOpenAI(model="gpt-4o")
```
It is here that we configure both the Embeddings and LLM. You can replace this with your own models using Ollama or other services. Scaleway has some great [L4 GPU Instances](https://www.scaleway.com/en/l4-gpu-instance/) you can use for compute here.
## Download and parse data
To begin working with blog post contents, the process involves loading and parsing the HTML content. This is achieved using `urllib` and `BeautifulSoup`, which are tools designed for such tasks. After the content is loaded and parsed, it is indexed using Qdrant, a powerful tool for managing and querying vector data. The code snippet demonstrates how to load, chunk, and index the contents of a blog post by specifying the URL of the blog and the specific HTML elements to parse. This step is crucial for preparing the data for further processing and analysis with Qdrant.
```python
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
```
### Chunking data
When dealing with large documents, such as a blog post exceeding 42,000 characters, it's crucial to manage the data efficiently for processing. Many models have a limited context window and struggle with long inputs, making it difficult to extract or find relevant information. To overcome this, the document is divided into smaller chunks. This approach enhances the model's ability to process and retrieve the most pertinent sections of the document effectively.
In this scenario, the document is split into chunks using the `RecursiveCharacterTextSplitter` with a specified chunk size and overlap. This method ensures that no critical information is lost between chunks. Following the splitting, these chunks are then indexed into Qdrant—a vector database for efficient similarity search and storage of embeddings. The `Qdrant.from_documents` function is utilized for indexing, with documents being the split chunks and embeddings generated through `OpenAIEmbeddings`. The entire process is facilitated within an in-memory database, signifying that the operations are performed without the need for persistent storage, and the collection is named "lilianweng" for reference.
This chunking and indexing strategy significantly improves the management and retrieval of information from large documents, making it a practical solution for handling extensive texts in data processing workflows.
```python
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Qdrant.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
collection_name="lilianweng",
url=os.environ["QDRANT_URL"],
api_key=os.environ["QDRANT_API_KEY"],
)
```
## Retrieve and generate content
The `vectorstore` is used as a retriever to fetch relevant documents based on vector similarity. The `hub.pull("rlm/rag-prompt")` function is used to pull a specific prompt from a repository, which is designed to work with retrieved documents and a question to generate a response.
The `format_docs` function formats the retrieved documents into a single string, preparing them for further processing. This formatted string, along with a question, is passed through a chain of operations. Firstly, the context (formatted documents) and the question are processed by the retriever and the prompt. Then, the result is fed into a large language model (`llm`) for content generation. Finally, the output is parsed into a string format using `StrOutputParser()`.
This chain of operations demonstrates a sophisticated approach to information retrieval and content generation, leveraging both the semantic understanding capabilities of vector search and the generative prowess of large language models.
Now, retrieve and generate data using relevant snippets from the blogL
```python
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
```
### Invoking the RAG Chain
```python
rag_chain.invoke("What is Task Decomposition?")
```
## Next steps:
We built a solid foundation for a simple chatbot, but there is still a lot to do. If you want to make the
system production-ready, you should consider implementing the mechanism into your existing stack. We recommend
Our vector database can easily be hosted on [Scaleway](https://www.scaleway.com/), our trusted [Qdrant Hybrid Cloud](/documentation/hybrid-cloud/) partner. This means that Qdrant can be run from your Scaleway region, but the database itself can still be managed from within Qdrant Cloud's interface. Both products have been tested for compatibility and scalability, and we recommend their [managed Kubernetes](https://www.scaleway.com/en/kubernetes-kapsule/) service.
Their French deployment regions e.g. France are excellent for network latency and data sovereignty. For hosted GPUs, try [rendering with L4 GPU instances](https://www.scaleway.com/en/l4-gpu-instance/).
If you have any questions, feel free to ask on our [Discord community](https://qdrant.to/discord).
|
qdrant-landing/content/documentation/examples/rag-chatbot-vultr-dspy-ollama.md | ---
title: Private RAG Information Extraction Engine
weight: 32
social_preview_image: /blog/hybrid-cloud-vultr/hybrid-cloud-vultr-tutorial.png
aliases:
- /documentation/tutorials/rag-chatbot-vultr-dspy-ollama/
---
# Private RAG Information Extraction Engine
| Time: 90 min | Level: Advanced | | |
|--------------|-----------------|--|----|
Handling private documents is a common task in many industries. Various businesses possess a large amount of
unstructured data stored as huge files that must be processed and analyzed. Industry reports, financial analysis, legal
documents, and many other documents are stored in PDF, Word, and other formats. Conversational chatbots built on top of
RAG pipelines are one of the viable solutions for finding the relevant answers in such documents. However, if we want to
extract structured information from these documents, and pass them to downstream systems, we need to use a different
approach.
Information extraction is a process of structuring unstructured data into a format that can be easily processed by
machines. In this tutorial, we will show you how to use [DSPy](https://dspy-docs.vercel.app/) to perform that process on
a set of documents. Assuming we cannot send our data to an external service, we will use [Ollama](https://ollama.com/)
to run our own LLM model on our premises, using [Vultr](https://www.vultr.com/) as a cloud provider. Qdrant, acting in
this setup as a knowledge base providing the relevant pieces of documents for a given query, will also be hosted in the
Hybrid Cloud mode on Vultr. The last missing piece, the DSPy application will be also running in the same environment.
If you work in a regulated industry, or just need to keep your data private, this tutorial is for you.

## Deploying Qdrant Hybrid Cloud on Vultr
All the services we are going to use in this tutorial will be running on [Vultr Kubernetes
Engine](https://www.vultr.com/kubernetes/). That gives us a lot of flexibility in terms of scaling and managing the resources. Vultr manages the control plane and worker nodes and provides integration with other managed services such as Load Balancers, Block Storage, and DNS.
1. To start using managed Kubernetes on Vultr, follow the [platform-specific documentation](/documentation/hybrid-cloud/platform-deployment-options/#vultr).
2. Once your Kubernetes clusters are up, [you can begin deploying Qdrant Hybrid Cloud](/documentation/hybrid-cloud/).
### Installing the necessary packages
We are going to need a couple of Python packages to run our application. They might be installed together with the
`dspy-ai` package and `qdrant` extra:
```shell
pip install dspy-ai[qdrant]
```
### Qdrant Hybrid Cloud
Our [documentation](/documentation/hybrid-cloud/) contains a comprehensive guide on how to set up Qdrant in the Hybrid Cloud mode on Vultr. Please follow it carefully to get your Qdrant instance up and running. Once it's done, we need to store the Qdrant URL and the API key in the environment variables. You can do it by running the following commands:
```shell
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
```
```python
import os
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
```
DSPy is framework we are going to use. It's integrated with Qdrant already, but it assumes you use
[FastEmbed](https://qdrant.github.io/fastembed/) to create the embeddings. DSPy does not provide a way to index the
data, but leaves this task to the user. We are going to create a collection on our own, and fill it with the embeddings
of our document chunks.
#### Data indexing
FastEmbed uses the `BAAI/bge-small-en` as the default embedding model. We are going to use it as well. Our collection
will be created automatically if we call the `.add` method on an existing `QdrantClient` instance. In this tutorial we
are not going to focus much on the document parsing, as there are plenty of tools that can help with that. The
[`unstructured`](https://github.com/Unstructured-IO/unstructured) library is one of the options you can launch on your
infrastructure. In our simplified example, we are going to use a list of strings as our documents. These are the
descriptions of the made up technical events. Each of them should contain the name of the event along with the location
and start and end dates.
```python
documents = [
"Taking place in San Francisco, USA, from the 10th to the 12th of June, 2024, the Global Developers Conference is the annual gathering spot for developers worldwide, offering insights into software engineering, web development, and mobile applications.",
"The AI Innovations Summit, scheduled for 15-17 September 2024 in London, UK, aims at professionals and researchers advancing artificial intelligence and machine learning.",
"Berlin, Germany will host the CyberSecurity World Conference between November 5th and 7th, 2024, serving as a key forum for cybersecurity professionals to exchange strategies and research on threat detection and mitigation.",
"Data Science Connect in New York City, USA, occurring from August 22nd to 24th, 2024, connects data scientists, analysts, and engineers to discuss data science's innovative methodologies, tools, and applications.",
"Set for July 14-16, 2024, in Tokyo, Japan, the Frontend Developers Fest invites developers to delve into the future of UI/UX design, web performance, and modern JavaScript frameworks.",
"The Blockchain Expo Global, happening May 20-22, 2024, in Dubai, UAE, focuses on blockchain technology's applications, opportunities, and challenges for entrepreneurs, developers, and investors.",
"Singapore's Cloud Computing Summit, scheduled for October 3-5, 2024, is where IT professionals and cloud experts will convene to discuss strategies, architectures, and cloud solutions.",
"The IoT World Forum, taking place in Barcelona, Spain from December 1st to 3rd, 2024, is the premier conference for those focused on the Internet of Things, from smart cities to IoT security.",
"Los Angeles, USA, will become the hub for game developers, designers, and enthusiasts at the Game Developers Arcade, running from April 18th to 20th, 2024, to showcase new games and discuss development tools.",
"The TechWomen Summit in Sydney, Australia, from March 8-10, 2024, aims to empower women in tech with workshops, keynotes, and networking opportunities.",
"Seoul, South Korea's Mobile Tech Conference, happening from September 29th to October 1st, 2024, will explore the future of mobile technology, including 5G networks and app development trends.",
"The Open Source Summit, to be held in Helsinki, Finland from August 11th to 13th, 2024, celebrates open source technologies and communities, offering insights into the latest software and collaboration techniques.",
"Vancouver, Canada will play host to the VR/AR Innovation Conference from June 20th to 22nd, 2024, focusing on the latest in virtual and augmented reality technologies.",
"Scheduled for May 5-7, 2024, in London, UK, the Fintech Leaders Forum brings together experts to discuss the future of finance, including innovations in blockchain, digital currencies, and payment technologies.",
"The Digital Marketing Summit, set for April 25-27, 2024, in New York City, USA, is designed for marketing professionals and strategists to discuss digital marketing and social media trends.",
"EcoTech Symposium in Paris, France, unfolds over 2024-10-09 to 2024-10-11, spotlighting sustainable technologies and green innovations for environmental scientists, tech entrepreneurs, and policy makers.",
"Set in Tokyo, Japan, from 16th to 18th May '24, the Robotic Innovations Conference showcases automation, robotics, and AI-driven solutions, appealing to enthusiasts and engineers.",
"The Software Architecture World Forum in Dublin, Ireland, occurring 22-24 Sept 2024, gathers software architects and IT managers to discuss modern architecture patterns.",
"Quantum Computing Summit, convening in Silicon Valley, USA from 2024/11/12 to 2024/11/14, is a rendezvous for exploring quantum computing advancements with physicists and technologists.",
"From March 3 to 5, 2024, the Global EdTech Conference in London, UK, discusses the intersection of education and technology, featuring e-learning and digital classrooms.",
"Bangalore, India's NextGen DevOps Days, from 28 to 30 August 2024, is a hotspot for IT professionals keen on the latest DevOps tools and innovations.",
"The UX/UI Design Conference, slated for April 21-23, 2024, in New York City, USA, invites discussions on the latest in user experience and interface design among designers and developers.",
"Big Data Analytics Summit, taking place 2024 July 10-12 in Amsterdam, Netherlands, brings together data professionals to delve into big data analysis and insights.",
"Toronto, Canada, will see the HealthTech Innovation Forum from June 8 to 10, '24, focusing on technology's impact on healthcare with professionals and innovators.",
"Blockchain for Business Summit, happening in Singapore from 2024-05-02 to 2024-05-04, focuses on blockchain's business applications, from finance to supply chain.",
"Las Vegas, USA hosts the Global Gaming Expo from October 18th to 20th, 2024, a premiere event for game developers, publishers, and enthusiasts.",
"The Renewable Energy Tech Conference in Copenhagen, Denmark, from 2024/09/05 to 2024/09/07, discusses renewable energy innovations and policies.",
"Set for 2024 Apr 9-11 in Boston, USA, the Artificial Intelligence in Healthcare Summit gathers healthcare professionals to discuss AI's healthcare applications.",
"Nordic Software Engineers Conference, happening in Stockholm, Sweden from June 15 to 17, 2024, focuses on software development in the Nordic region.",
"The International Space Exploration Symposium, scheduled in Houston, USA from 2024-08-05 to 2024-08-07, invites discussions on space exploration technologies and missions."
]
```
We'll be able to ask general questions, for example, about topics we are interested in or events happening in a specific
location, but expect the results to be returned in a structured format.

Indexing in Qdrant is a single call if we have the documents defined:
```python
client.add(
collection_name="document-parts",
documents=documents,
metadata=[{"document": document} for document in documents],
)
```
Our collection is ready to be queried. We can now move to the next step, which is setting up the Ollama model.
### Ollama on Vultr
Ollama is a great tool for running the LLM models on your own infrastructure. It's designed to be lightweight and easy
to use, and [an official Docker image](https://hub.docker.com/r/ollama/ollama) is available. We can use it to run Ollama
on our Vultr Kubernetes cluster. In case of LLMs we may have some special requirements, like a GPU, and Vultr provides
the [Vultr Kubernetes Engine for Cloud GPU](https://www.vultr.com/products/cloud-gpu/) so the model can be run on a
specialized machine. Please refer to the official documentation to get Ollama up and running within your environment.
Once it's done, we need to store the Ollama URL in the environment variable:
```shell
export OLLAMA_URL="https://ollama.example.com"
```
```python
os.environ["OLLAMA_URL"] = "https://ollama.example.com"
```
We will refer to this URL later on when configuring the Ollama model in our application.
#### Setting up the Large Language Model
We are going to use one of the lightweight LLMs available in Ollama, a `gemma:2b` model. It was developed by Google
DeepMind team and has 3B parameters. The [Ollama version](https://ollama.com/library/gemma:2b) uses 4-bit quantization.
Installing the model is as simple as running the following command on the machine where Ollama is running:
```shell
ollama run gemma:2b
```
Ollama models are also integrated with DSPy, so we can use them directly in our application.
## Implementing the information extraction pipeline
DSPy is a bit different from the other LLM frameworks. It's designed to optimize the prompts and weights of LMs in a
pipeline. It's a bit like a compiler for LMs: you write a pipeline in a high-level language, and DSPy generates the
prompts and weights for you. This means you can build complex systems without having to worry about the details of how
to prompt your LMs, as DSPy will do that for you. It is somehow similar to PyTorch but for LLMs.
First of all, we will define the Language Model we are going to use:
```python
import dspy
gemma_model = dspy.OllamaLocal(
model="gemma:2b",
base_url=os.environ.get("OLLAMA_URL"),
max_tokens=500,
)
```
Similarly, we have to define connection to our Qdrant Hybrid Cloud cluster:
```python
from dspy.retrieve.qdrant_rm import QdrantRM
from qdrant_client import QdrantClient, models
client = QdrantClient(
os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
qdrant_retriever = QdrantRM(
qdrant_collection_name="document-parts",
qdrant_client=client,
)
```
Finally, both components have to be configured in DSPy with a simple call to one of the functions:
```python
dspy.configure(lm=gemma_model, rm=qdrant_retriever)
```
### Application logic
There is a concept of signatures which defines input and output formats of the pipeline. We are going to define a simple
signature for the event:
```python
class Event(dspy.Signature):
description = dspy.InputField(
desc="Textual description of the event, including name, location and dates"
)
event_name = dspy.OutputField(desc="Name of the event")
location = dspy.OutputField(desc="Location of the event")
start_date = dspy.OutputField(desc="Start date of the event, YYYY-MM-DD")
end_date = dspy.OutputField(desc="End date of the event, YYYY-MM-DD")
```
It is designed to derive the structured information from the textual description of the event. Now, we can build our
module that will use it, along with Qdrant and Ollama model. Let's call it `EventExtractor`:
```python
class EventExtractor(dspy.Module):
def __init__(self):
super().__init__()
# Retrieve module to get relevant documents
self.retriever = dspy.Retrieve(k=3)
# Predict module for the created signature
self.predict = dspy.Predict(Event)
def forward(self, query: str):
# Retrieve the most relevant documents
results = self.retriever.forward(query)
# Try to extract events from the retrieved documents
events = []
for document in results.passages:
event = self.predict(description=document)
events.append(event)
return events
```
The logic is simple: we retrieve the most relevant documents from Qdrant, and then try to extract the structured
information from them using the `Event` signature. We can simply call it and see the results:
```python
extractor = EventExtractor()
extractor.forward("Blockchain events close to Europe")
```
Output:
```python
[
Prediction(
event_name='Event Name: Blockchain Expo Global',
location='Dubai, UAE',
start_date='2024-05-20',
end_date='2024-05-22'
),
Prediction(
event_name='Event Name: Blockchain for Business Summit',
location='Singapore',
start_date='2024-05-02',
end_date='2024-05-04'
),
Prediction(
event_name='Event Name: Open Source Summit',
location='Helsinki, Finland',
start_date='2024-08-11',
end_date='2024-08-13'
)
]
```
The task was solved successfully, even without any optimization. However, each of the events has the "Event Name: "
prefix that we might want to remove. DSPy allows optimizing the module, so we can improve the results. Optimization
might be done in different ways, and it's [well covered in the DSPy
documentation](https://dspy-docs.vercel.app/docs/building-blocks/optimizers).
We are not going to go through the optimization process in this tutorial. However, we encourage you to experiment with
it, as it might significantly improve the performance of your pipeline.
Created module might be easily stored on a specific path, and loaded later on:
```python
extractor.save("event_extractor")
```
To load, just create an instance of the module and call the `load` method:
```python
second_extractor = EventExtractor()
second_extractor.load("event_extractor")
```
This is especially useful when you optimize the module, as the optimized version might be stored and loaded later on
without redoing the optimization process each time you run the application.
### Deploying the extraction pipeline
Vultr gives us a lot of flexibility in terms of deploying the applications. Perfectly, we would use the Kubernetes
cluster we set up earlier to run it. The deployment is as simple as running any other Python application. This time we
don't need a GPU, as Ollama is already running on a separate machine, and DSPy just interacts with it.
## Wrapping up
In this tutorial, we showed you how to set up a private environment for information extraction using DSPy, Ollama, and
Qdrant. All the components might be securely hosted on the Vultr cloud, giving you full control over your data. |
qdrant-landing/content/documentation/examples/rag-contract-management-stackit-aleph-alpha.md | ---
title: Region-Specific Contract Management System
weight: 28
social_preview_image: /blog/hybrid-cloud-aleph-alpha/hybrid-cloud-aleph-alpha-tutorial.png
aliases:
- /documentation/tutorials/rag-contract-management-stackit-aleph-alpha/
---
# Region-Specific Contract Management System
| Time: 90 min | Level: Advanced | |
| --- | ----------- | ----------- |----------- |
Contract management benefits greatly from Retrieval Augmented Generation (RAG), streamlining the handling of lengthy business contract texts. With AI assistance, complex questions can be asked and well-informed answers generated, facilitating efficient document management. This proves invaluable for businesses with extensive relationships, like shipping companies, construction firms, and consulting practices. Access to such contracts is often restricted to authorized team members due to security and regulatory requirements, such as GDPR in Europe, necessitating secure storage practices.
Companies want their data to be kept and processed within specific geographical boundaries. For that reason, this RAG-centric tutorial focuses on dealing with a region-specific cloud provider. You will set up a contract management system using [Aleph Alpha's](https://aleph-alpha.com/) embeddings and LLM. You will host everything on [STACKIT](https://www.stackit.de/), a German business cloud provider. On this platform, you will run Qdrant Hybrid Cloud as well as the rest of your RAG application. This setup will ensure that your data is stored and processed in Germany.

## Components
A contract management platform is not a simple CLI tool, but an application that should be available to all team
members. It needs an interface to upload, search, and manage the documents. Ideally, the system should be
integrated with org's existing stack, and the permissions/access controls inherited from LDAP or Active
Directory.
> **Note:** In this tutorial, we are going to build a solid foundation for such a system. However, it is up to your organization's setup to implement the entire solution.
- **Dataset** - a collection of documents, using different formats, such as PDF or DOCx, scraped from internet
- **Asymmetric semantic embeddings** - [Aleph Alpha embedding](https://docs.aleph-alpha.com/api/semantic-embed/) to
convert the queries and the documents into vectors
- **Large Language Model** - the [Luminous-extended-control
model](https://docs.aleph-alpha.com/docs/introduction/model-card/), but you can play with a different one from the
Luminous family
- **Qdrant Hybrid Cloud** - a knowledge base to store the vectors and search over the documents
- **STACKIT** - a [German business cloud](https://www.stackit.de) to run the Qdrant Hybrid Cloud and the application
processes
We will implement the process of uploading the documents, converting them into vectors, and storing them in Qdrant.
Then, we will build a search interface to query the documents and get the answers. All that, assuming the user
interacts with the system with some set of permissions, and can only access the documents they are allowed to.
## Prerequisites
### Aleph Alpha account
Since you will be using Aleph Alpha's models, [sign up](https://app.aleph-alpha.com/signup) with their managed service and generate an API token in the [User Profile](https://app.aleph-alpha.com/profile). Once you have it ready, store it as an environment variable:
```shell
export ALEPH_ALPHA_API_KEY="<your-token>"
```
```python
import os
os.environ["ALEPH_ALPHA_API_KEY"] = "<your-token>"
```
### Qdrant Hybrid Cloud on STACKIT
Please refer to our documentation to see [how to deploy Qdrant Hybrid Cloud on
STACKIT](/documentation/hybrid-cloud/platform-deployment-options/#stackit). Once you finish the deployment, you will
have the API endpoint to interact with the Qdrant server. Let's store it in the environment variable as well:
```shell
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
```
```python
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
```
Qdrant will be running on a specific URL and access will be restricted by the API key. Make sure to store them both as environment variables as well:
*Optional:* Whenever you use LangChain, you can also [configure LangSmith](https://docs.smith.langchain.com/), which will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith [here](https://smith.langchain.com/).
```shell
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
```
## Implementation
To build the application, we can use the official SDKs of Aleph Alpha and Qdrant. However, to streamline the process
let's use [LangChain](https://python.langchain.com/docs/get_started/introduction). This framework is already integrated with both services, so we can focus our efforts on
developing business logic.
### Qdrant collection
Aleph Alpha embeddings are high dimensional vectors by default, with a dimensionality of `5120`. However, a pretty
unique feature of that model is that they might be compressed to a size of `128`, with a small drop in accuracy
performance (4-6%, according to the docs). Qdrant can store even the original vectors easily, and this sounds like a
good idea to enable [Binary Quantization](/documentation/guides/quantization/#binary-quantization) to save space and
make the retrieval faster. Let's create a collection with such settings:
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(
location=os.environ["QDRANT_URL"],
api_key=os.environ["QDRANT_API_KEY"],
)
client.create_collection(
collection_name="contracts",
vectors_config=models.VectorParams(
size=5120,
distance=models.Distance.COSINE,
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
)
)
),
)
```
We are going to use the `contracts` collection to store the vectors of the documents. The `always_ram` flag is set to
`True` to keep the quantized vectors in RAM, which will speed up the search process. We also wanted to restrict access
to the individual documents, so only users with the proper permissions can see them. In Qdrant that should be solved by
adding a payload field that defines who can access the document. We'll call this field `roles` and set it to an array
of strings with the roles that can access the document.
```python
client.create_payload_index(
collection_name="contracts",
field_name="metadata.roles",
field_schema=models.PayloadSchemaType.KEYWORD,
)
```
Since we use Langchain, the `roles` field is a nested field of the `metadata`, so we have to define it as
`metadata.roles`. The schema says that the field is a keyword, which means it is a string or an array of strings. We are
going to use the name of the customers as the roles, so the access control will be based on the customer name.
### Ingestion pipeline
Semantic search systems rely on high-quality data as their foundation. With the [unstructured integration of Langchain](https://python.langchain.com/docs/integrations/providers/unstructured), ingestion of various document formats like PDFs, Microsoft Word files, and PowerPoint presentations becomes effortless. However, it's crucial to split the text intelligently to avoid converting entire documents into vectors; instead, they should be divided into meaningful chunks. Subsequently, the extracted documents are converted into vectors using Aleph Alpha embeddings and stored in the Qdrant collection.
Let's start by defining the components and connecting them together:
```python
embeddings = AlephAlphaAsymmetricSemanticEmbedding(
model="luminous-base",
aleph_alpha_api_key=os.environ["ALEPH_ALPHA_API_KEY"],
normalize=True,
)
qdrant = Qdrant(
client=client,
collection_name="contracts",
embeddings=embeddings,
)
```
Now it's high time to index our documents. Each of the documents is a separate file, and we also have to know the
customer name to set the access control properly. There might be several roles for a single document, so let's keep them
in a list.
```python
documents = {
"data/Data-Processing-Agreement_STACKIT_Cloud_version-1.2.pdf": ["stackit"],
"data/langchain-terms-of-service.pdf": ["langchain"],
}
```
This is how the documents might look like:

Each has to be split into chunks first; there is no silver bullet. Our chunking algorithm will be simple and based on
recursive splitting, with the maximum chunk size of 500 characters and the overlap of 100 characters.
```python
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
)
```
Now we can iterate over the documents, split them into chunks, convert them into vectors with Aleph Alpha embedding
model, and store them in the Qdrant.
```python
from langchain_community.document_loaders.unstructured import UnstructuredFileLoader
for document_path, roles in documents.items():
document_loader = UnstructuredFileLoader(file_path=document_path)
# Unstructured loads each file into a single Document object
loaded_documents = document_loader.load()
for doc in loaded_documents:
doc.metadata["roles"] = roles
# Chunks will have the same metadata as the original document
document_chunks = text_splitter.split_documents(loaded_documents)
# Add the documents to the Qdrant collection
qdrant.add_documents(document_chunks, batch_size=20)
```
Our collection is filled with data, and we can start searching over it. In a real-world scenario, the ingestion process
should be automated and triggered by the new documents uploaded to the system. Since we already use Qdrant Hybrid Cloud
running on Kubernetes, we can easily deploy the ingestion pipeline as a job to the same environment. On STACKIT, you
probably use the [STACKIT Kubernetes Engine (SKE)](https://www.stackit.de/en/product/kubernetes/) and launch it in a
container. The [Compute Engine](https://www.stackit.de/en/product/stackit-compute-engine/) is also an option, but
everything depends on the specifics of your organization.
### Search application
Specialized Document Management Systems have a lot of features, but semantic search is not yet a standard. We are going
to build a simple search mechanism which could be possibly integrated with the existing system. The search process is
quite simple: we convert the query into a vector using the same Aleph Alpha model, and then search for the most similar
documents in the Qdrant collection. The access control is also applied, so the user can only see the documents they are
allowed to.
We start with creating an instance of the LLM of our choice, and set the maximum number of tokens to 200, as the default
value is 64, which might be too low for our purposes.
```python
from langchain.llms.aleph_alpha import AlephAlpha
llm = AlephAlpha(
model="luminous-extended-control",
aleph_alpha_api_key=os.environ["ALEPH_ALPHA_API_KEY"],
maximum_tokens=200,
)
```
Then, we can glue the components together and build the search process. `RetrievalQA` is a class that takes implements
the Question Retrieval process, with a specified retriever and Large Language Model. The instance of `Qdrant` might be
converted into a retriever, with additional filter that will be passed to the `similarity_search` method. The filter
is created as [in a regular Qdrant query](../../../documentation/concepts/filtering/), with the `roles` field set to the
user's roles.
```python
user_roles = ["stackit", "aleph-alpha"]
qdrant_retriever = qdrant.as_retriever(
search_kwargs={
"filter": models.Filter(
must=[
models.FieldCondition(
key="metadata.roles",
match=models.MatchAny(any=user_roles)
)
]
)
}
)
```
We set the user roles to `stackit` and `aleph-alpha`, so the user can see the documents that are accessible to these
customers, but not to the others. The final step is to create the `RetrievalQA` instance and use it to search over the
documents, with the custom prompt.
```python
from langchain.prompts import PromptTemplate
from langchain.chains.retrieval_qa.base import RetrievalQA
prompt_template = """
Question: {question}
Answer the question using the Source. If there's no answer, say "NO ANSWER IN TEXT".
Source: {context}
### Response:
"""
prompt = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
retrieval_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=qdrant_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt},
)
response = retrieval_qa.invoke({"query": "What are the rules of performing the audit?"})
print(response["result"])
```
Output:
```text
The rules for performing the audit are as follows:
1. The Customer must inform the Contractor in good time (usually at least two weeks in advance) about any and all circumstances related to the performance of the audit.
2. The Customer is entitled to perform one audit per calendar year. Any additional audits may be performed if agreed with the Contractor and are subject to reimbursement of expenses.
3. If the Customer engages a third party to perform the audit, the Customer must obtain the Contractor's consent and ensure that the confidentiality agreements with the third party are observed.
4. The Contractor may object to any third party deemed unsuitable.
```
There are some other parameters that might be tuned to optimize the search process. The `k` parameter defines how many
documents should be returned, but Langchain allows us also to control the retrieval process by choosing the type of the
search operation. The default is `similarity`, which is just vector search, but we can also use `mmr` which stands for
Maximal Marginal Relevance. It is a technique to diversify the search results, so the user gets the most relevant
documents, but also the most diverse ones. The `mmr` search is slower, but might be more user-friendly.
Our search application is ready, and we can deploy it to the same environment as the ingestion pipeline on STACKIT. The
same rules apply here, so you can use the SKE or the Compute Engine, depending on the specifics of your organization.
## Next steps
We built a solid foundation for the contract management system, but there is still a lot to do. If you want to make the
system production-ready, you should consider implementing the mechanism into your existing stack. If you have any
questions, feel free to ask on our [Discord community](https://qdrant.to/discord). |
qdrant-landing/content/documentation/examples/rag-customer-support-cohere-airbyte-aws.md | ---
title: Question-Answering System for AI Customer Support
weight: 26
social_preview_image: /blog/hybrid-cloud-airbyte/hybrid-cloud-airbyte-tutorial.png
aliases:
- /documentation/tutorials/rag-customer-support-cohere-airbyte-aws/
---
# Question-Answering System for AI Customer Support
| Time: 120 min | Level: Advanced | |
| --- | ----------- | ----------- |----------- |
Maintaining top-notch customer service is vital to business success. As your operation expands, so does the influx of customer queries. Many of these queries are repetitive, making automation a time-saving solution.
Your support team's expertise is typically kept private, but you can still use AI to automate responses securely.
In this tutorial we will setup a private AI service that answers customer support queries with high accuracy and effectiveness. By leveraging Cohere's powerful models (deployed to [AWS](https://cohere.com/deployment-options/aws)) with Qdrant Hybrid Cloud, you can create a fully private customer support system. Data synchronization, facilitated by [Airbyte](https://airbyte.com/), will complete the setup.

## System design
The history of past interactions with your customers is not a static dataset. It is constantly evolving, as new
questions are coming in. You probably have a ticketing system that stores all the interactions, or use a different way
to communicate with your customers. No matter what is the communication channel, you need to bring the correct answers
to the selected Large Language Model, and have an established way to do it in a continuous manner. Thus, we will build
an ingestion pipeline and then a Retrieval Augmented Generation application that will use the data.
- **Dataset:** a [set of Frequently Asked Questions from Qdrant
users](/documentation/faq/qdrant-fundamentals/) as an incrementally updated Excel sheet
- **Embedding model:** Cohere `embed-multilingual-v3.0`, to support different languages with the same pipeline
- **Knowledge base:** Qdrant, running in Hybrid Cloud mode
- **Ingestion pipeline:** [Airbyte](https://airbyte.com/), loading the data into Qdrant
- **Large Language Model:** Cohere [Command-R](https://docs.cohere.com/docs/command-r)
- **RAG:** Cohere [RAG](https://docs.cohere.com/docs/retrieval-augmented-generation-rag) using our knowledge base
through a custom connector
All the selected components are compatible with the [AWS](https://aws.amazon.com/) infrastructure. Thanks to Cohere models' availability, you can build a fully private customer support system completely isolates data within your infrastructure. Also, if you have AWS credits, you can now use them without spending additional money on the models or
semantic search layer.
### Data ingestion
Building a RAG starts with a well-curated dataset. In your specific case you may prefer loading the data directly from
a ticketing system, such as [Zendesk Support](https://airbyte.com/connectors/zendesk-support),
[Freshdesk](https://airbyte.com/connectors/freshdesk), or maybe integrate it with a shared inbox. However, in case of
customer questions quality over quantity is the key. There should be a conscious decision on what data to include in the
knowledge base, so we do not confuse the model with possibly irrelevant information. We'll assume there is an [Excel
sheet](https://docs.airbyte.com/integrations/sources/file) available over HTTP/FTP that Airbyte can access and load into
Qdrant in an incremental manner.
### Cohere <> Qdrant Connector for RAG
Cohere RAG relies on [connectors](https://docs.cohere.com/docs/connectors) which brings additional context to the model.
The connector is a web service that implements a specific interface, and exposes its data through HTTP API. With that
setup, the Large Language Model becomes responsible for communicating with the connectors, so building a prompt with the
context is not needed anymore.
### Answering bot
Finally, we want to automate the responses and send them automatically when we are sure that the model is confident
enough. Again, the way such an application should be created strongly depends on the system you are using within the
customer support team. If it exposes a way to set up a webhook whenever a new question is coming in, you can create a
web service and use it to automate the responses. In general, our bot should be created specifically for the platform
you use, so we'll just cover the general idea here and build a simple CLI tool.
## Prerequisites
### Cohere models on AWS
One of the possible ways to deploy Cohere models on AWS is to use AWS SageMaker. Cohere's website has [a detailed
guide on how to deploy the models in that way](https://docs.cohere.com/docs/amazon-sagemaker-setup-guide), so you can
follow the steps described there to set up your own instance.
### Qdrant Hybrid Cloud on AWS
Our documentation covers the deployment of Qdrant on AWS as a Hybrid Cloud Environment, so you can follow the steps described
there to set up your own instance. The deployment process is quite straightforward, and you can have your Qdrant cluster
up and running in a few minutes.
[//]: # (TODO: refer to the documentation on how to deploy Qdrant on AWS)
Once you perform all the steps, your Qdrant cluster should be running on a specific URL. You will need this URL and the
API key to interact with Qdrant, so let's store them both in the environment variables:
```shell
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
```
```python
import os
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
```
### Airbyte Open Source
Airbyte is an open-source data integration platform that helps you replicate your data in your warehouses, lakes, and
databases. You can install it on your infrastructure and use it to load the data into Qdrant. The installation process
for AWS EC2 is described in the [official documentation](https://docs.airbyte.com/deploying-airbyte/on-aws-ec2).
Please follow the instructions to set up your own instance.
#### Setting up the connection
Once you have an Airbyte up and running, you can configure the connection to load the data from the respective source
into Qdrant. The configuration will require setting up the source and destination connectors. In this tutorial we will
use the following connectors:
- **Source:** [File](https://docs.airbyte.com/integrations/sources/file) to load the data from an Excel sheet
- **Destination:** [Qdrant](https://docs.airbyte.com/integrations/destinations/qdrant) to load the data into Qdrant
Airbyte UI will guide you through the process of setting up the source and destination and connecting them. Here is how
the configuration of the source might look like:

Qdrant is our target destination, so we need to set up the connection to it. We need to specify which fields should be
included to generate the embeddings. In our case it makes complete sense to embed just the questions, as we are going
to look for similar questions asked in the past and provide the answers.

Once we have the destination set up, we can finally configure a connection. The connection will define the schedule
of the data synchronization.

Airbyte should now be ready to accept any data updates from the source and load them into Qdrant. You can monitor the
progress of the synchronization in the UI.
## RAG connector
One of our previous tutorials, guides you step-by-step on [implementing custom connector for Cohere
RAG](../cohere-rag-connector/) with Cohere Embed v3 and Qdrant. You can just point it to use your Hybrid Cloud
Qdrant instance running on AWS. Created connector might be deployed to Amazon Web Services in various ways, even in a
[Serverless](https://aws.amazon.com/serverless/) manner using [AWS
Lambda](https://aws.amazon.com/lambda/?c=ser&sec=srv).
In general, RAG connector has to expose a single endpoint that will accept POST requests with `query` parameter and
return the matching documents as JSON document with a specific structure. Our FastAPI implementation created [in the
related tutorial](../cohere-rag-connector/) is a perfect fit for this task. The only difference is that you
should point it to the Cohere models and Qdrant running on AWS infrastructure.
> Our connector is a lightweight web service that exposes a single endpoint and glues the Cohere embedding model with
> our Qdrant Hybrid Cloud instance. Thus, it perfectly fits the serverless architecture, requiring no additional
> infrastructure to run.
You can also run the connector as another service within your [Kubernetes cluster running on AWS
(EKS)](https://aws.amazon.com/eks/), or by launching an [EC2](https://aws.amazon.com/ec2/) compute instance. This step
is dependent on the way you deploy your other services, so we'll leave it to you to decide how to run the connector.
Eventually, the web service should be available under a specific URL, and it's a good practice to store it in the
environment variable, so the other services can easily access it.
```shell
export RAG_CONNECTOR_URL="https://rag-connector.example.com/search"
```
```python
os.environ["RAG_CONNECTOR_URL"] = "https://rag-connector.example.com/search"
```
## Customer interface
At this part we have all the data loaded into Qdrant, and the RAG connector is ready to serve the relevant context. The
last missing piece is the customer interface, that will call the Command model to create the answer. Such a system
should be built specifically for the platform you use and integrated into its workflow, but we will build the strong
foundation for it and show how to use it in a simple CLI tool.
> Our application does not have to connect to Qdrant anymore, as the model will connect to the RAG connector directly.
First of all, we have to create a connection to Cohere services through the Cohere SDK.
```python
import cohere
# Create a Cohere client pointing to the AWS instance
cohere_client = cohere.Client(...)
```
Next, our connector should be registered. **Please make sure to do it once, and store the id of the connector in the
environment variable or in any other way that will be accessible to the application.**
```python
import os
connector_response = cohere_client.connectors.create(
name="customer-support",
url=os.environ["RAG_CONNECTOR_URL"],
)
# The id returned by the API should be stored for future use
connector_id = connector_response.connector.id
```
Finally, we can create a prompt and get the answer from the model. Additionally, we define which of the connectors
should be used to provide the context, as we may have multiple connectors and want to use specific ones, depending on
some conditions. Let's start with asking a question.
```python
query = "Why Qdrant does not return my vectors?"
```
Now we can send the query to the model, get the response, and possibly send it back to the customer.
```python
response = cohere_client.chat(
message=query,
connectors=[
cohere.ChatConnector(id=connector_id),
],
model="command-r",
)
print(response.text)
```
The output should be the answer to the question, generated by the model, for example:
> Qdrant is set up by default to minimize network traffic and therefore doesn't return vectors in search results. However, you can make Qdrant return your vectors by setting the 'with_vector' parameter of the Search/Scroll function to true.
Customer support should not be fully automated, as some completely new issues might require human intervention. We
should play with prompt engineering and expect the model to provide the answer with a certain confidence level. If the
confidence is too low, we should not send the answer automatically but present it to the support team for review.
## Wrapping up
This tutorial shows how to build a fully private customer support system using Cohere models, Qdrant Hybrid Cloud, and
Airbyte, which runs on AWS infrastructure. You can ensure your data does not leave your premises and focus on providing
the best customer support experience without bothering your team with repetitive tasks.
|
qdrant-landing/content/documentation/examples/recommendation-system-ovhcloud.md | ---
title: Movie Recommendation System
weight: 34
social_preview_image: /blog/hybrid-cloud-ovhcloud/hybrid-cloud-ovhcloud-tutorial.png
aliases:
- /documentation/tutorials/recommendation-system-ovhcloud/
---
# Movie Recommendation System
| Time: 120 min | Level: Advanced | Output: [GitHub](https://github.com/infoslack/qdrant-example/blob/main/HC-demo/HC-OVH.ipynb) |
| --- | ----------- | ----------- |----------- |
In this tutorial, you will build a mechanism that recommends movies based on defined preferences. Vector databases like Qdrant are good for storing high-dimensional data, such as user and item embeddings. They can enable personalized recommendations by quickly retrieving similar entries based on advanced indexing techniques. In this specific case, we will use [sparse vectors](/articles/sparse-vectors/) to create an efficient and accurate recommendation system.
**Privacy and Sovereignty:** Since preference data is proprietary, it should be stored in a secure and controlled environment. Our vector database can easily be hosted on [OVHcloud](https://ovhcloud.com/), our trusted [Qdrant Hybrid Cloud](/documentation/hybrid-cloud/) partner. This means that Qdrant can be run from your OVHcloud region, but the database itself can still be managed from within Qdrant Cloud's interface. Both products have been tested for compatibility and scalability, and we recommend their [managed Kubernetes](https://www.ovhcloud.com/en/public-cloud/kubernetes/) service.
> To see the entire output, use our [notebook with complete instructions](https://github.com/infoslack/qdrant-example/blob/main/HC-demo/HC-OVH.ipynb).
## Components
- **Dataset:** The [MovieLens dataset](https://grouplens.org/datasets/movielens/) contains a list of movies and ratings given by users.
- **Cloud:** [OVHcloud](https://ovhcloud.com/), with managed Kubernetes.
- **Vector DB:** [Qdrant Hybrid Cloud](https://hybrid-cloud.qdrant.tech) running on [OVHcloud](https://ovhcloud.com/).
**Methodology:** We're adopting a collaborative filtering approach to construct a recommendation system from the dataset provided. Collaborative filtering works on the premise that if two users share similar tastes, they're likely to enjoy similar movies. Leveraging this concept, we'll identify users whose ratings align closely with ours, and explore the movies they liked but we haven't seen yet. To do this, we'll represent each user's ratings as a vector in a high-dimensional, sparse space. Using Qdrant, we'll index these vectors and search for users whose ratings vectors closely match ours. Ultimately, we will see which movies were enjoyed by users similar to us.

## Deploying Qdrant Hybrid Cloud on OVHcloud
[Service Managed Kubernetes](https://www.ovhcloud.com/en-in/public-cloud/kubernetes/), powered by OVH Public Cloud Instances, a leading European cloud provider. With OVHcloud Load Balancers and disks built in. OVHcloud Managed Kubernetes provides high availability, compliance, and CNCF conformance, allowing you to focus on your containerized software layers with total reversibility.
1. To start using managed Kubernetes on OVHcloud, follow the [platform-specific documentation](/documentation/hybrid-cloud/platform-deployment-options/#ovhcloud).
2. Once your Kubernetes clusters are up, [you can begin deploying Qdrant Hybrid Cloud](/documentation/hybrid-cloud/).
## Prerequisites
Download and unzip the MovieLens dataset:
```shell
mkdir -p data
wget https://files.grouplens.org/datasets/movielens/ml-1m.zip
unzip ml-1m.zip -d data
```
The necessary * libraries are installed using `pip`, including `pandas` for data manipulation, `qdrant-client` for interfacing with Qdrant, and `*-dotenv` for managing environment variables.
```python
!pip install -U \
pandas \
qdrant-client \
*-dotenv
```
The `.env` file is used to store sensitive information like the Qdrant host URL and API key securely.
```shell
QDRANT_HOST
QDRANT_API_KEY
```
Load all environment variables into the setup:
```python
import os
from dotenv import load_dotenv
load_dotenv('./.env')
```
## Implementation
Load the data from the MovieLens dataset into pandas DataFrames to facilitate data manipulation and analysis.
```python
from qdrant_client import QdrantClient, models
import pandas as pd
```
Load user data:
```python
users = pd.read_csv(
'data/ml-1m/users.dat',
sep='::',
names=['user_id', 'gender', 'age', 'occupation', 'zip'],
engine='*'
)
users.head()
```
Add movies:
```python
movies = pd.read_csv(
'data/ml-1m/movies.dat',
sep='::',
names=['movie_id', 'title', 'genres'],
engine='*',
encoding='latin-1'
)
movies.head()
```
Finally, add the ratings:
```python
ratings = pd.read_csv(
'data/ml-1m/ratings.dat',
sep='::',
names=['user_id', 'movie_id', 'rating', 'timestamp'],
engine='*'
)
ratings.head()
```
### Normalize the ratings
Sparse vectors can use advantage of negative values, so we can normalize ratings to have a mean of 0 and a standard deviation of 1. This normalization ensures that ratings are consistent and centered around zero, enabling accurate similarity calculations. In this scenario we can take into account movies that we don't like.
```python
ratings.rating = (ratings.rating - ratings.rating.mean()) / ratings.rating.std()
```
To get the results:
```python
ratings.head()
```
### Data preparation
Now you will transform user ratings into sparse vectors, where each vector represents ratings for different movies. This step prepares the data for indexing in Qdrant.
First, create a collection with configured sparse vectors. For sparse vectors, you don't need to specify the dimension, because it's extracted from the data automatically.
```python
from collections import defaultdict
user_sparse_vectors = defaultdict(lambda: {"values": [], "indices": []})
for row in ratings.itertuples():
user_sparse_vectors[row.user_id]["values"].append(row.rating)
user_sparse_vectors[row.user_id]["indices"].append(row.movie_id)
```
Connect to Qdrant and create a collection called **movielens**:
```python
client = QdrantClient(
url = os.getenv("QDRANT_HOST"),
api_key = os.getenv("QDRANT_API_KEY")
)
client.create_collection(
"movielens",
vectors_config={},
sparse_vectors_config={
"ratings": models.SparseVectorParams()
}
)
```
Upload user ratings to the **movielens** collection in Qdrant as sparse vectors, along with user metadata. This step populates the database with the necessary data for recommendation generation.
```python
def data_generator():
for user in users.itertuples():
yield models.PointStruct(
id=user.user_id,
vector={
"ratings": user_sparse_vectors[user.user_id]
},
payload=user._asdict()
)
client.upload_points(
"movielens",
data_generator()
)
```
## Recommendations
Personal movie ratings are specified, where positive ratings indicate likes and negative ratings indicate dislikes. These ratings serve as the basis for finding similar users with comparable tastes.
Personal ratings are converted into a sparse vector representation suitable for querying Qdrant. This vector represents the user's preferences across different movies.
Let's try to recommend something for ourselves:
```
1 = Like
-1 = dislike
```
```python
# Search with movies[movies.title.str.contains("Matrix", case=False)].
my_ratings = {
2571: 1, # Matrix
329: 1, # Star Trek
260: 1, # Star Wars
2288: -1, # The Thing
1: 1, # Toy Story
1721: -1, # Titanic
296: -1, # Pulp Fiction
356: 1, # Forrest Gump
2116: 1, # Lord of the Rings
1291: -1, # Indiana Jones
1036: -1 # Die Hard
}
inverse_ratings = {k: -v for k, v in my_ratings.items()}
def to_vector(ratings):
vector = models.SparseVector(
values=[],
indices=[]
)
for movie_id, rating in ratings.items():
vector.values.append(rating)
vector.indices.append(movie_id)
return vector
```
Query Qdrant to find users with similar tastes based on the provided personal ratings. The search returns a list of similar users along with their ratings, facilitating collaborative filtering.
```python
results = client.search(
"movielens",
query_vector=models.NamedSparseVector(
name="ratings",
vector=to_vector(my_ratings)
),
with_vectors=True, # We will use those to find new movies
limit=20
)
```
Movie scores are computed based on how frequently each movie appears in the ratings of similar users, weighted by their ratings. This step identifies popular movies among users with similar tastes. Calculate how frequently each movie is found in similar users' ratings
```python
def results_to_scores(results):
movie_scores = defaultdict(lambda: 0)
for user in results:
user_scores = user.vector['ratings']
for idx, rating in zip(user_scores.indices, user_scores.values):
if idx in my_ratings:
continue
movie_scores[idx] += rating
return movie_scores
```
The top-rated movies are sorted based on their scores and printed as recommendations for the user. These recommendations are tailored to the user's preferences and aligned with their tastes. Sort movies by score and print top five:
```python
movie_scores = results_to_scores(results)
top_movies = sorted(movie_scores.items(), key=lambda x: x[1], reverse=True)
for movie_id, score in top_movies[:5]:
print(movies[movies.movie_id == movie_id].title.values[0], score)
```
Result:
```text
Star Wars: Episode V - The Empire Strikes Back (1980) 20.02387858
Star Wars: Episode VI - Return of the Jedi (1983) 16.443184379999998
Princess Bride, The (1987) 15.840068229999996
Raiders of the Lost Ark (1981) 14.94489462
Sixth Sense, The (1999) 14.570322149999999
``` |
qdrant-landing/content/documentation/faq/_index.md | ---
title: FAQ
weight: 41
is_empty: true
--- |
qdrant-landing/content/documentation/faq/database-optimization.md | ---
title: Database Optimization
weight: 3
---
## Database Optimization Strategies
### How do I reduce memory usage?
The primary source of memory usage vector data. There are several ways to address that:
- Configure [Quantization](../../guides/quantization/) to reduce the memory usage of vectors.
- Configure on-disk vector storage
The choice of the approach depends on your requirements.
Read more about [configuring the optimal](../../tutorials/optimize/) use of Qdrant.
### How do you choose machine configuration?
There are two main scenarios of Qdrant usage in terms of resource consumption:
- **Performance-optimized** -- when you need to serve vector search as fast (many) as possible. In this case, you need to have as much vector data in RAM as possible. Use our [calculator](https://cloud.qdrant.io/calculator) to estimate the required RAM.
- **Storage-optimized** -- when you need to store many vectors and minimize costs by compromising some search speed. In this case, pay attention to the disk speed instead. More about it in the article about [Memory Consumption](../../../articles/memory-consumption/).
### I configured on-disk vector storage, but memory usage is still high. Why?
Firstly, memory usage metrics as reported by `top` or `htop` may be misleading. They are not showing the minimal amount of memory required to run the service.
If the RSS memory usage is 10 GB, it doesn't mean that it won't work on a machine with 8 GB of RAM.
Qdrant uses many techniques to reduce search latency, including caching disk data in RAM and preloading data from disk to RAM.
As a result, the Qdrant process might use more memory than the minimum required to run the service.
> Unused RAM is wasted RAM
If you want to limit the memory usage of the service, we recommend using [limits in Docker](https://docs.docker.com/config/containers/resource_constraints/#memory) or Kubernetes.
### My requests are very slow or time out. What should I do?
There are several possible reasons for that:
- **Using filters without payload index** -- If you're performing a search with a filter but you don't have a payload index, Qdrant will have to load whole payload data from disk to check the filtering condition. Ensure you have adequately configured [payload indexes](../../concepts/indexing/#payload-index).
- **Usage of on-disk vector storage with slow disks** -- If you're using on-disk vector storage, ensure you have fast enough disks. We recommend using local SSDs with at least 50k IOPS. Read more about the influence of the disk speed on the search latency in the article about [Memory Consumption](../../../articles/memory-consumption/).
- **Large limit or non-optimal query parameters** -- A large limit or offset might lead to significant performance degradation. Please pay close attention to the query/collection parameters that significantly diverge from the defaults. They might be the reason for the performance issues.
|
qdrant-landing/content/documentation/faq/qdrant-fundamentals.md | ---
title: Fundamentals
weight: 1
---
## Qdrant Fundamentals
### How many collections can I create?
As much as you want, but be aware that each collection requires additional resources.
It is _highly_ recommended not to create many small collections, as it will lead to significant resource consumption overhead.
We consider creating a collection for each user/dialog/document as an antipattern.
Please read more about collections, isolation, and multiple users in our [Multitenancy](../../tutorials/multiple-partitions/) tutorial.
### My search results contain vectors with null values. Why?
By default, Qdrant tries to minimize network traffic and doesn't return vectors in search results.
But you can force Qdrant to do so by setting the `with_vector` parameter of the Search/Scroll to `true`.
If you're still seeing `"vector": null` in your results, it might be that the vector you're passing is not in the correct format, or there's an issue with how you're calling the upsert method.
### How can I search without a vector?
You are likely looking for the [scroll](../../concepts/points/#scroll-points) method. It allows you to retrieve the records based on filters or even iterate over all the records in the collection.
### Does Qdrant support a full-text search or a hybrid search?
Qdrant is a vector search engine in the first place, and we only implement full-text support as long as it doesn't compromise the vector search use case.
That includes both the interface and the performance.
What Qdrant can do:
- Search with full-text filters
- Apply full-text filters to the vector search (i.e., perform vector search among the records with specific words or phrases)
- Do prefix search and semantic [search-as-you-type](../../../articles/search-as-you-type/)
- Sparse vectors, as used in [SPLADE](https://github.com/naver/splade) or similar models
What Qdrant plans to introduce in the future:
- ColBERT and other late-interaction models
- Fusion of the multiple searches
What Qdrant doesn't plan to support:
- BM25 or other non-vector-based retrieval or ranking functions
- Built-in ontologies or knowledge graphs
- Query analyzers and other NLP tools
Of course, you can always combine Qdrant with any specialized tool you need, including full-text search engines.
Read more about [our approach](../../../articles/hybrid-search/) to hybrid search.
### How do I upload a large number of vectors into a Qdrant collection?
Read about our recommendations in the [bulk upload](../../tutorials/bulk-upload/) tutorial.
### Can I only store quantized vectors and discard full precision vectors?
No, Qdrant requires full precision vectors for operations like reindexing, rescoring, etc.
## Qdrant Cloud
### Is it possible to scale down a Qdrant Cloud cluster?
In general, no. There's no way to scale down the underlying disk storage.
But in some cases, we might be able to help you with that through manual intervention, but it's not guaranteed.
## Versioning
### Do you support downgrades?
We do not support downgrading a cluster on any of our products. If you deploy a newer version of Qdrant, your
data is automatically migrated to the newer storage format. This migration is not reversible.
### How do I avoid issues when updating to the latest version?
We only guarantee compatibility if you update between consecutive versions. You would need to upgrade versions one at a time: `1.1 -> 1.2`, then `1.2 -> 1.3`, then `1.3 -> 1.4`.
### Do you guarantee compatibility across versions?
In case your version is older, we only guarantee compatibility between two consecutive minor versions. This also applies to client versions. Ensure your client version is never more than one minor version away from your cluster version.
While we will assist with break/fix troubleshooting of issues and errors specific to our products, Qdrant is not accountable for reviewing, writing (or rewriting), or debugging custom code.
|
qdrant-landing/content/documentation/frameworks/_index.md | ---
title: Frameworks
weight: 33
---
| Frameworks | Description |
| ------------------------------------- | ---------------------------------------------------------------------------------------------------- |
| [Airbyte](./airbyte/) | Data integration platform specialising in ELT pipelines. |
| [Airflow](./airflow/) | Platform designed for developing, scheduling, and monitoring batch-oriented workflows. |
| [AutoGen](./autogen/) | Framework from Microsoft building LLM applications using multiple conversational agents. |
| [Bubble](./bubble) | Development platform for application development with a no-code interface |
| [Canopy](./canopy/) | Framework from Pinecone for building RAG applications using LLMs and knowledge bases. |
| [Cheshire Cat](./cheshire-cat/) | Framework to create personalized AI assistants using custom data. |
| [DLT](./dlt/) | Python library to simplify data loading processes between several sources and destinations. |
| [DocArray](./docarray/) | Python library for managing data in multi-modal AI applications. |
| [DocsGPT](./docsgpt/) | Tool for ingesting documentation sources and enabling conversations and queries. |
| [DSPy](./dspy/) | Framework for algorithmically optimizing LM prompts and weights. |
| [Fifty-One](./fifty-one/) | Toolkit for building high-quality datasets and computer vision models. |
| [Fondant](./fondant/) | Framework for developing datasets, sharing reusable operations and data processing trees. |
| [Genkit](./genkit/) | Framework to build, deploy, and monitor production-ready AI-powered apps. |
| [Haystack](./haystack/) | LLM orchestration framework to build customizable, production-ready LLM applications. |
| [Langchain](./langchain/) | Python framework for building context-aware, reasoning applications using LLMs. |
| [Langchain-Go](./langchain-go/) | Go framework for building context-aware, reasoning applications using LLMs. |
| [Langchain4j](./langchain4j/) | Java framework for building context-aware, reasoning applications using LLMs. |
| [LlamaIndex](./llama-index/) | A data framework for building LLM applications with modular integrations. |
| [Make](./make/) | Cloud platform to build low-code workflows by integrating various software applications. |
| [MemGPT](./memgpt/) | System to build LLM agents with long term memory & custom tools |
| [MindsDB](./mindsdb/) | Platform to deploy, serve, and fine-tune models with numerous data source integrations. |
| [N8N](./n8n/) | Platform for node-based, low-code workflow automation. |
| [NiFi](./nifi/) | Data ingestion platform to manage data transfer between different sources and destination systems. |
| [OpenLIT](./openlit/) | Platform for OpenTelemetry-native Observability & Evals for LLMs and Vector Databases. |
| [OpenLLMetry](./openllmetry/) | Set of OpenTelemetry extensions to add Observability for your LLM application. |
| [Pandas-AI](./pandas-ai/) | Python library to query/visualize your data (CSV, XLSX, PostgreSQL, etc.) in natural language |
| [Pipedream](./pipedream/) | Platform for connecting apps and developing event-driven automations. |
| [PrivateGPT](./privategpt/) | Tool to ask questions about your documents using local LLMs emphasising privacy. |
| [Rivet](./rivet/) | A visual programming environment for building AI agents with LLMs. |
| [Semantic Router](./semantic-router/) | Python library to build a decision-making layer for AI applications using vector search. |
| [Spark](./spark/) | A unified analytics engine for large-scale data processing. |
| [Spring AI](./spring-ai/) | Java AI framework for building with Spring design principles such as portability and modular design. |
| [Testcontainers](./testcontainers/) | Set of frameworks for running containerized dependencies in tests. |
| [txtai](./txtai/) | Python library for semantic search, LLM orchestration and language model workflows. |
| [Unstructured](./unstructured/) | Python library with components for ingesting and pre-processing data from numerous sources. |
| [Vanna AI](./vanna-ai/) | Python RAG framework for SQL generation and querying. |
|
qdrant-landing/content/documentation/frameworks/airbyte.md | ---
title: Airbyte
weight: 1000
aliases: [ ../integrations/airbyte/ ]
---
# Airbyte
[Airbyte](https://airbyte.com/) is an open-source data integration platform that helps you replicate your data
between different systems. It has a [growing list of connectors](https://docs.airbyte.io/integrations) that can
be used to ingest data from multiple sources. Building data pipelines is also crucial for managing the data in
Qdrant, and Airbyte is a great tool for this purpose.
Airbyte may take care of the data ingestion from a selected source, while Qdrant will help you to build a search
engine on top of it. There are three supported modes of how the data can be ingested into Qdrant:
* **Full Refresh Sync**
* **Incremental - Append Sync**
* **Incremental - Append + Deduped**
You can read more about these modes in the [Airbyte documentation](https://docs.airbyte.io/integrations/destinations/qdrant).
## Prerequisites
Before you start, make sure you have the following:
1. Airbyte instance, either [Open Source](https://airbyte.com/solutions/airbyte-open-source),
[Self-Managed](https://airbyte.com/solutions/airbyte-enterprise), or [Cloud](https://airbyte.com/solutions/airbyte-cloud).
2. Running instance of Qdrant. It has to be accessible by URL from the machine where Airbyte is running.
You can follow the [installation guide](/documentation/guides/installation/) to set up Qdrant.
## Setting up Qdrant as a destination
Once you have a running instance of Airbyte, you can set up Qdrant as a destination directly in the UI.
Airbyte's Qdrant destination is connected with a single collection in Qdrant.

### Text processing
Airbyte has some built-in mechanisms to transform your texts into embeddings. You can choose how you want to
chunk your fields into pieces before calculating the embeddings, but also which fields should be used to
create the point payload.

### Embeddings
You can choose the model that will be used to calculate the embeddings. Currently, Airbyte supports multiple
models, including OpenAI and Cohere.

Using some precomputed embeddings from your data source is also possible. In this case, you can pass the field
name containing the embeddings and their dimensionality.

### Qdrant connection details
Finally, we can configure the target Qdrant instance and collection. In case you use the built-in authentication
mechanism, here is where you can pass the token.

Once you confirm creating the destination, Airbyte will test if a specified Qdrant cluster is accessible and
might be used as a destination.
## Setting up connection
Airbyte combines sources and destinations into a single entity called a connection. Once you have a destination
configured and a source, you can create a connection between them. It doesn't matter what source you use, as
long as Airbyte supports it. The process is pretty straightforward, but depends on the source you use.

## Further Reading
- [Airbyte documentation](https://docs.airbyte.com/understanding-airbyte/connections/).
- [Source Code](https://github.com/airbytehq/airbyte/tree/master/airbyte-integrations/connectors/destination-qdrant)
|
qdrant-landing/content/documentation/frameworks/airflow.md | ---
title: Apache Airflow
weight: 2100
---
# Apache Airflow
[Apache Airflow](https://airflow.apache.org/) is an open-source platform for authoring, scheduling and monitoring data and computing workflows. Airflow uses Python to create workflows that can be easily scheduled and monitored.
Qdrant is available as a [provider](https://airflow.apache.org/docs/apache-airflow-providers-qdrant/stable/index.html) in Airflow to interface with the database.
## Prerequisites
Before configuring Airflow, you need:
1. A Qdrant instance to connect to. You can set one up in our [installation guide](/documentation/guides/installation/).
2. A running Airflow instance. You can use their [Quick Start Guide](https://airflow.apache.org/docs/apache-airflow/stable/start.html).
## Setting up a connection
Open the `Admin-> Connections` section of the Airflow UI. Click the `Create` link to create a new [Qdrant connection](https://airflow.apache.org/docs/apache-airflow-providers-qdrant/stable/connections.html).

You can also set up a connection using [environment variables](https://airflow.apache.org/docs/apache-airflow/stable/howto/connection.html#environment-variables-connections) or an [external secret backend](https://airflow.apache.org/docs/apache-airflow/stable/security/secrets/secrets-backend/index.html).
## Qdrant hook
An Airflow hook is an abstraction of a specific API that allows Airflow to interact with an external system.
```python
from airflow.providers.qdrant.hooks.qdrant import QdrantHook
hook = QdrantHook(conn_id="qdrant_connection")
hook.verify_connection()
```
A [`qdrant_client#QdrantClient`](https://pypi.org/project/qdrant-client/) instance is available via `@property conn` of the `QdrantHook` instance for use within your Airflow workflows.
```python
from qdrant_client import models
hook.conn.count("<COLLECTION_NAME>")
hook.conn.upsert(
"<COLLECTION_NAME>",
points=[
models.PointStruct(id=32, vector=[0.32, 0.12, 0.123], payload={"color": "red"})
],
)
```
## Qdrant Ingest Operator
The Qdrant provider also provides a convenience operator for uploading data to a Qdrant collection that internally uses the Qdrant hook.
```python
from airflow.providers.qdrant.operators.qdrant import QdrantIngestOperator
vectors = [
[0.11, 0.22, 0.33, 0.44],
[0.55, 0.66, 0.77, 0.88],
[0.88, 0.11, 0.12, 0.13],
]
ids = [32, 21, "b626f6a9-b14d-4af9-b7c3-43d8deb719a6"]
payload = [{"meta": "data"}, {"meta": "data_2"}, {"meta": "data_3", "extra": "data"}]
QdrantIngestOperator(
conn_id="qdrant_connection",
task_id="qdrant_ingest",
collection_name="<COLLECTION_NAME>",
vectors=vectors,
ids=ids,
payload=payload,
)
```
## Reference
- 📦 [Provider package PyPI](https://pypi.org/project/apache-airflow-providers-qdrant/)
- 📚 [Provider docs](https://airflow.apache.org/docs/apache-airflow-providers-qdrant/stable/index.html)
- 📄 [Source Code](https://github.com/apache/airflow/tree/main/airflow/providers/qdrant)
|
qdrant-landing/content/documentation/frameworks/autogen.md | ---
title: Autogen
weight: 1200
aliases: [ ../integrations/autogen/ ]
---
# Microsoft Autogen
[AutoGen](https://github.com/microsoft/autogen) is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
- Multi-agent conversations: AutoGen agents can communicate with each other to solve tasks. This allows for more complex and sophisticated applications than would be possible with a single LLM.
- Customization: AutoGen agents can be customized to meet the specific needs of an application. This includes the ability to choose the LLMs to use, the types of human input to allow, and the tools to employ.
- Human participation: AutoGen seamlessly allows human participation. This means that humans can provide input and feedback to the agents as needed.
With the Autogen-Qdrant integration, you can use the `QdrantRetrieveUserProxyAgent` from autogen to build retrieval augmented generation(RAG) services with ease.
## Installation
```bash
pip install "pyautogen[retrievechat]" "qdrant_client[fastembed]"
```
## Usage
A demo application that generates code based on context w/o human feedback
#### Set your API Endpoint
The config_list_from_json function loads a list of configurations from an environment variable or a JSON file.
```python
from autogen import config_list_from_json
from autogen.agentchat.contrib.retrieve_assistant_agent import RetrieveAssistantAgent
from autogen.agentchat.contrib.qdrant_retrieve_user_proxy_agent import QdrantRetrieveUserProxyAgent
from qdrant_client import QdrantClient
config_list = config_list_from_json(
env_or_file="OAI_CONFIG_LIST",
file_location="."
)
```
It first looks for the environment variable "OAI_CONFIG_LIST" which needs to be a valid JSON string. If that variable is not found, it then looks for a JSON file named "OAI_CONFIG_LIST". The file structure sample can be found [here](https://github.com/microsoft/autogen/blob/main/OAI_CONFIG_LIST_sample).
#### Construct agents for RetrieveChat
We start by initializing the RetrieveAssistantAgent and QdrantRetrieveUserProxyAgent. The system message needs to be set to "You are a helpful assistant." for RetrieveAssistantAgent. The detailed instructions are given in the user message.
```python
# Print the generation steps
autogen.ChatCompletion.start_logging()
# 1. create a RetrieveAssistantAgent instance named "assistant"
assistant = RetrieveAssistantAgent(
name="assistant",
system_message="You are a helpful assistant.",
llm_config={
"request_timeout": 600,
"seed": 42,
"config_list": config_list,
},
)
# 2. create a QdrantRetrieveUserProxyAgent instance named "qdrantagent"
# By default, the human_input_mode is "ALWAYS", i.e. the agent will ask for human input at every step.
# `docs_path` is the path to the docs directory.
# `task` indicates the kind of task we're working on.
# `chunk_token_size` is the chunk token size for the retrieve chat.
# We use an in-memory QdrantClient instance here. Not recommended for production.
rag_proxy_agent = QdrantRetrieveUserProxyAgent(
name="qdrantagent",
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
retrieve_config={
"task": "code",
"docs_path": "./path/to/docs",
"chunk_token_size": 2000,
"model": config_list[0]["model"],
"client": QdrantClient(":memory:"),
"embedding_model": "BAAI/bge-small-en-v1.5",
},
)
```
#### Run the retriever service
```python
# Always reset the assistant before starting a new conversation.
assistant.reset()
# We use the ragproxyagent to generate a prompt to be sent to the assistant as the initial message.
# The assistant receives the message and generates a response. The response will be sent back to the ragproxyagent for processing.
# The conversation continues until the termination condition is met, in RetrieveChat, the termination condition when no human-in-loop is no code block detected.
# The query used below is for demonstration. It should usually be related to the docs made available to the agent
code_problem = "How can I use FLAML to perform a classification task?"
rag_proxy_agent.initiate_chat(assistant, problem=code_problem)
```
## Next steps
- Autogen [examples](https://microsoft.github.io/autogen/docs/Examples)
- AutoGen [documentation](https://microsoft.github.io/autogen/)
- [Source Code](https://github.com/microsoft/autogen/blob/main/autogen/agentchat/contrib/qdrant_retrieve_user_proxy_agent.py)
|
qdrant-landing/content/documentation/frameworks/bubble.md | ---
title: Bubble
weight: 3200
---
# Bubble
[Bubble](https://bubble.io/) is a software development platform that enables anyone to build and launch fully functional web applications without writing code.
You can use the [Qdrant Bubble plugin](https://bubble.io/plugin/qdrant-1716804374179x344999530386685950) to interface with Qdrant in your workflows.
## Prerequisites
1. A Qdrant instance to connect to. You can get a free cloud instance at [cloud.qdrant.io](https://cloud.qdrant.io/).
2. An account at [Bubble.io](https://bubble.io/) and an app set up.
## Setting up the plugin
Navigate to your app's workflows. Select `"Install more plugins actions"`.

You can now search for the Qdrant plugin and install it. Ensure all the categories are selected to perform a full search.

The Qdrant plugin can now be found in the installed plugins section of your workflow. Enter the API key of your Qdrant instance for authentication.

The plugin provides actions for upserting, searching, updating and deleting points from your Qdrant collection with dynamic and static values from your Bubble workflow.
## Further Reading
- [Bubble Academy](https://bubble.io/academy).
- [Bubble Manual](https://manual.bubble.io/)
|
qdrant-landing/content/documentation/frameworks/canopy.md | ---
title: Pinecone Canopy
weight: 2500
---
# Pinecone Canopy
[Canopy](https://github.com/pinecone-io/canopy) is an open-source framework and context engine to build chat assistants at scale.
Qdrant is supported as a knowledge base within Canopy for context retrieval and augmented generation.
## Usage
Install the SDK with the Qdrant extra as described in the [Canopy README](https://github.com/pinecone-io/canopy?tab=readme-ov-file#extras).
```bash
pip install canopy-sdk[qdrant]
```
### Creating a knowledge base
```python
from canopy.knowledge_base import QdrantKnowledgeBase
kb = QdrantKnowledgeBase(collection_name="<YOUR_COLLECTION_NAME>")
```
<aside role="status">The constructor accepts additional <a href="https://github.com/qdrant/qdrant-client/blob/eda201a1dbf1bbc67415f8437a5619f6f83e8ac6/qdrant_client/qdrant_client.py#L36-L61">options</a> to customize your connection to Qdrant.</aside>
To create a new Qdrant collection and connect it to the knowledge base, use the `create_canopy_collection` method:
```python
kb.create_canopy_collection()
```
You can always verify the connection to the collection with the `verify_index_connection` method:
```python
kb.verify_index_connection()
```
Learn more about customizing the knowledge base and its inner components [in the Canopy library](https://github.com/pinecone-io/canopy/blob/main/docs/library.md#understanding-knowledgebase-workings).
### Adding data to the knowledge base
To insert data into the knowledge base, you can create a list of documents and use the `upsert` method:
```python
from canopy.models.data_models import Document
documents = [
Document(
id="1",
text="U2 are an Irish rock band from Dublin, formed in 1976.",
source="https://en.wikipedia.org/wiki/U2",
),
Document(
id="2",
text="Arctic Monkeys are an English rock band formed in Sheffield in 2002.",
source="https://en.wikipedia.org/wiki/Arctic_Monkeys",
metadata={"my-key": "my-value"},
),
]
kb.upsert(documents)
```
### Querying the knowledge base
You can query the knowledge base with the `query` method to find the most similar documents to a given text:
```python
from canopy.models.data_models import Query
kb.query(
[
Query(text="Arctic Monkeys music genre"),
Query(
text="U2 music genre",
top_k=10,
metadata_filter={"key": "my-key", "match": {"value": "my-value"}},
),
]
)
```
## Further Reading
- [Introduction to Canopy](https://www.pinecone.io/blog/canopy-rag-framework/)
- [Canopy library reference](https://github.com/pinecone-io/canopy/blob/main/docs/library.md)
- [Source Code](https://github.com/pinecone-io/canopy/tree/main/src/canopy/knowledge_base/qdrant)
|
qdrant-landing/content/documentation/frameworks/cheshire-cat.md | ---
title: Cheshire Cat
weight: 600
aliases: [ ../integrations/cheshire-cat/ ]
---
# Cheshire Cat
[Cheshire Cat](https://cheshirecat.ai/) is an open-source framework that allows you to develop intelligent agents on top of many Large Language Models (LLM). You can develop your custom AI architecture to assist you in a wide range of tasks.

## Cheshire Cat and Qdrant
Cheshire Cat uses Qdrant as the default [Vector Memory](https://cheshire-cat-ai.github.io/docs/conceptual/memory/vector_memory/) for ingesting and retrieving documents.
```
# Decide host and port for your Cat. Default will be localhost:1865
CORE_HOST=localhost
CORE_PORT=1865
# Qdrant server
# QDRANT_HOST=localhost
# QDRANT_PORT=6333
```
Cheshire Cat takes great advantage of the following features of Qdrant:
* [Collection Aliases](../../concepts/collections/#collection-aliases) to manage the change from one embedder to another.
* [Quantization](../../guides/quantization/) to obtain a good balance between speed, memory usage and quality of the results.
* [Snapshots](../../concepts/snapshots/) to not miss any information.
* [Community](https://discord.com/invite/tdtYvXjC4h)

## How to use the Cheshire Cat
### Requirements
To run the Cheshire Cat, you need to have [Docker](https://docs.docker.com/engine/install/) and [docker-compose](https://docs.docker.com/compose/install/) already installed on your system.
```shell
docker run --rm -it -p 1865:80 ghcr.io/cheshire-cat-ai/core:latest
```
* Chat with the Cheshire Cat on [localhost:1865/admin](http://localhost:1865/admin).
* You can also interact via REST API and try out the endpoints on [localhost:1865/docs](http://localhost:1865/docs)
Check the [instructions on github](https://github.com/cheshire-cat-ai/core/blob/main/README.md) for a more comprehensive quick start.
### First configuration of the LLM
* Open the Admin Portal in your browser at [localhost:1865/admin](http://localhost:1865/admin).
* Configure the LLM in the `Settings` tab.
* If you don't explicitly choose it using `Settings` tab, the Embedder follows the LLM.
## Next steps
For more information, refer to the Cheshire Cat [documentation](https://cheshire-cat-ai.github.io/docs/) and [blog](https://cheshirecat.ai/blog/).
* [Getting started](https://cheshirecat.ai/hello-world/)
* [How the Cat works](https://cheshirecat.ai/how-the-cat-works/)
* [Write Your First Plugin](https://cheshirecat.ai/write-your-first-plugin/)
* [Cheshire Cat's use of Qdrant - Vector Space](https://cheshirecat.ai/dont-get-lost-in-vector-space/)
* [Cheshire Cat's use of Qdrant - Aliases](https://cheshirecat.ai/the-drunken-cat-effect/)
* [Discord Community](https://discord.com/invite/bHX5sNFCYU)
|
qdrant-landing/content/documentation/frameworks/dlt.md | ---
title: DLT
weight: 1300
aliases: [ ../integrations/dlt/ ]
---
# DLT(Data Load Tool)
[DLT](https://dlthub.com/) is an open-source library that you can add to your Python scripts to load data from various and often messy data sources into well-structured, live datasets.
With the DLT-Qdrant integration, you can now select Qdrant as a DLT destination to load data into.
**DLT Enables**
- Automated maintenance - with schema inference, alerts and short declarative code, maintenance becomes simple.
- Run it where Python runs - on Airflow, serverless functions, notebooks. Scales on micro and large infrastructure alike.
- User-friendly, declarative interface that removes knowledge obstacles for beginners while empowering senior professionals.
## Usage
To get started, install `dlt` with the `qdrant` extra.
```bash
pip install "dlt[qdrant]"
```
Configure the destination in the DLT secrets file. The file is located at `~/.dlt/secrets.toml` by default. Add the following section to the secrets file.
```toml
[destination.qdrant.credentials]
location = "https://your-qdrant-url"
api_key = "your-qdrant-api-key"
```
The location will default to `http://localhost:6333` and `api_key` is not defined - which are the defaults for a local Qdrant instance.
Find more information about DLT configurations [here](https://dlthub.com/docs/general-usage/credentials).
Define the source of the data.
```python
import dlt
from dlt.destinations.qdrant import qdrant_adapter
movies = [
{
"title": "Blade Runner",
"year": 1982,
"description": "The film is about a dystopian vision of the future that combines noir elements with sci-fi imagery."
},
{
"title": "Ghost in the Shell",
"year": 1995,
"description": "The film is about a cyborg policewoman and her partner who set out to find the main culprit behind brain hacking, the Puppet Master."
},
{
"title": "The Matrix",
"year": 1999,
"description": "The movie is set in the 22nd century and tells the story of a computer hacker who joins an underground group fighting the powerful computers that rule the earth."
}
]
```
<aside role="status">
A more comprehensive pipeline would load data from some API or use one of <a href="https://dlthub.com/docs/dlt-ecosystem/verified-sources">DLT's verified sources</a>.
</aside>
Define the pipeline.
```python
pipeline = dlt.pipeline(
pipeline_name="movies",
destination="qdrant",
dataset_name="movies_dataset",
)
```
Run the pipeline.
```python
info = pipeline.run(
qdrant_adapter(
movies,
embed=["title", "description"]
)
)
```
The data is now loaded into Qdrant.
To use vector search after the data has been loaded, you must specify which fields Qdrant needs to generate embeddings for. You do that by wrapping the data (or [DLT resource](https://dlthub.com/docs/general-usage/resource)) with the `qdrant_adapter` function.
## Write disposition
A DLT [write disposition](https://dlthub.com/docs/dlt-ecosystem/destinations/qdrant/#write-disposition) defines how the data should be written to the destination. All write dispositions are supported by the Qdrant destination.
## DLT Sync
Qdrant destination supports syncing of the [`DLT` state](https://dlthub.com/docs/general-usage/state#syncing-state-with-destination).
## Next steps
- The comprehensive Qdrant DLT destination documentation can be found [here](https://dlthub.com/docs/dlt-ecosystem/destinations/qdrant/).
- [Source Code](https://github.com/dlt-hub/dlt/tree/devel/dlt/destinations/impl/qdrant)
|
qdrant-landing/content/documentation/frameworks/docarray.md | ---
title: DocArray
weight: 300
aliases: [ ../integrations/docarray/ ]
---
# DocArray
You can use Qdrant natively in DocArray, where Qdrant serves as a high-performance document store to enable scalable vector search.
DocArray is a library from Jina AI for nested, unstructured data in transit, including text, image, audio, video, 3D mesh, etc.
It allows deep-learning engineers to efficiently process, embed, search, recommend, store, and transfer the data with a Pythonic API.
To install DocArray with Qdrant support, please do
```bash
pip install "docarray[qdrant]"
```
## Further Reading
- [DocArray documentations](https://docarray.jina.ai/advanced/document-store/qdrant/).
- [Source Code](https://github.com/docarray/docarray/blob/main/docarray/index/backends/qdrant.py)
|
qdrant-landing/content/documentation/frameworks/docsgpt.md | ---
title: DocsGPT
weight: 2600
---
# DocsGPT
[DocsGPT](https://docsgpt.arc53.com/) is an open-source documentation assistant that enables you to build conversational user experiences on top of your data.
Qdrant is supported as a vectorstore in DocsGPT to ingest and semantically retrieve documents.
## Configuration
Learn how to setup DocsGPT in their [Quickstart guide](https://docs.docsgpt.co.uk/Deploying/Quickstart).
You can configure DocsGPT with environment variables in a `.env` file.
To configure DocsGPT to use Qdrant as the vector store, set `VECTOR_STORE` to `"qdrant"`.
```bash
echo "VECTOR_STORE=qdrant" >> .env
```
DocsGPT includes a list of the Qdrant configuration options that you can set as environment variables [here](https://github.com/arc53/DocsGPT/blob/00dfb07b15602319bddb95089e3dab05fac56240/application/core/settings.py#L46-L59).
## Further reading
- [DocsGPT Reference](https://github.com/arc53/DocsGPT)
|
qdrant-landing/content/documentation/frameworks/dspy.md | ---
title: Stanford DSPy
weight: 1500
aliases: [ ../integrations/dspy/ ]
---
# Stanford DSPy
[DSPy](https://github.com/stanfordnlp/dspy) is the framework for solving advanced tasks with language models (LMs) and retrieval models (RMs). It unifies techniques for prompting and fine-tuning LMs — and approaches for reasoning, self-improvement, and augmentation with retrieval and tools.
- Provides composable and declarative modules for instructing LMs in a familiar Pythonic syntax.
- Introduces an automatic compiler that teaches LMs how to conduct the declarative steps in your program.
Qdrant can be used as a retrieval mechanism in the DSPy flow.
## Installation
For the Qdrant retrieval integration, include `dspy-ai` with the `qdrant` extra:
```bash
pip install dspy-ai[qdrant]
```
## Usage
We can configure `DSPy` settings to use the Qdrant retriever model like so:
```python
import dspy
from dspy.retrieve.qdrant_rm import QdrantRM
from qdrant_client import QdrantClient
turbo = dspy.OpenAI(model="gpt-3.5-turbo")
qdrant_client = QdrantClient() # Defaults to a local instance at http://localhost:6333/
qdrant_retriever_model = QdrantRM("collection-name", qdrant_client, k=3)
dspy.settings.configure(lm=turbo, rm=qdrant_retriever_model)
```
Using the retriever is pretty simple. The `dspy.Retrieve(k)` module will search for the top-k passages that match a given query.
```python
retrieve = dspy.Retrieve(k=3)
question = "Some question about my data"
topK_passages = retrieve(question).passages
print(f"Top {retrieve.k} passages for question: {question} \n", "\n")
for idx, passage in enumerate(topK_passages):
print(f"{idx+1}]", passage, "\n")
```
With Qdrant configured as the retriever for contexts, you can set up a DSPy module like so:
```python
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
...
def forward(self, question):
context = self.retrieve(question).passages
...
```
With the generic RAG blueprint now in place, you can add the many interactions offered by DSPy with context retrieval powered by Qdrant.
## Next steps
- Find DSPy usage docs and examples [here](https://github.com/stanfordnlp/dspy#4-documentation--tutorials).
- [Source Code](https://github.com/stanfordnlp/dspy/blob/main/dspy/retrieve/qdrant_rm.py)
|
qdrant-landing/content/documentation/frameworks/fifty-one.md | ---
title: FiftyOne
weight: 600
aliases: [ ../integrations/fifty-one ]
---
# FiftyOne
[FiftyOne](https://voxel51.com/) is an open-source toolkit designed to enhance computer vision workflows by optimizing dataset quality
and providing valuable insights about your models. FiftyOne 0.20, which includes a native integration with Qdrant, supporting workflows
like [image similarity search](https://docs.voxel51.com/user_guide/brain.html#image-similarity) and
[text search](https://docs.voxel51.com/user_guide/brain.html#text-similarity).
Qdrant helps FiftyOne to find the most similar images in the dataset using vector embeddings.
FiftyOne is available as a Python package that might be installed in the following way:
```bash
pip install fiftyone
```
Please check out the documentation of FiftyOne on [Qdrant integration](https://docs.voxel51.com/integrations/qdrant.html).
|
qdrant-landing/content/documentation/frameworks/fondant.md | ---
title: Fondant
weight: 1700
aliases: [ ../integrations/fondant/ ]
---
# Fondant
[Fondant](https://fondant.ai/en/stable/) is an open-source framework that aims to simplify and speed
up large-scale data processing by making containerized components reusable across pipelines and
execution environments. Benefit from built-in features such as autoscaling, data lineage, and
pipeline caching, and deploy to (managed) platforms such as Vertex AI, Sagemaker, and Kubeflow
Pipelines.
Fondant comes with a library of reusable components that you can leverage to compose your own
pipeline, including a Qdrant component for writing embeddings to Qdrant.
## Usage
<aside role="status">
A Qdrant collection has to be <a href="/documentation/concepts/collections/">created in advance</a>
</aside>
**A data load pipeline for RAG using Qdrant**.
A simple ingestion pipeline could look like the following:
```python
import pyarrow as pa
from fondant.pipeline import Pipeline
indexing_pipeline = Pipeline(
name="ingestion-pipeline",
description="Pipeline to prepare and process data for building a RAG solution",
base_path="./fondant-artifacts",
)
# An custom implemenation of a read component.
text = indexing_pipeline.read(
"path/to/data-source-component",
arguments={
# your custom arguments
}
)
chunks = text.apply(
"chunk_text",
arguments={
"chunk_size": 512,
"chunk_overlap": 32,
},
)
embeddings = chunks.apply(
"embed_text",
arguments={
"model_provider": "huggingface",
"model": "all-MiniLM-L6-v2",
},
)
embeddings.write(
"index_qdrant",
arguments={
"url": "http:localhost:6333",
"collection_name": "some-collection-name",
},
cache=False,
)
```
Once you have a pipeline, you can easily run it using the built-in CLI. Fondant allows
you to run the pipeline in production across different clouds.
The first component is a custom read module that needs to be implemented and cannot be used off the
shelf. A detailed tutorial on how to rebuild this
pipeline [is provided on GitHub](https://github.com/ml6team/fondant-usecase-RAG/tree/main).
## Next steps
More information about creating your own pipelines and components can be found in the [Fondant
documentation](https://fondant.ai/en/stable/).
|
qdrant-landing/content/documentation/frameworks/genkit.md | ---
title: Firebase Genkit
weight: 3400
---
# Firebase Genkit
[Genkit](https://firebase.google.com/products/genkit) is a framework to build, deploy, and monitor production-ready AI-powered apps.
You can build apps that generate custom content, use semantic search, handle unstructured inputs, answer questions with your business data, autonomously make decisions, orchestrate tool calls, and more.
You can use Qdrant for indexing/semantic retrieval of data in your Genkit applications via the [Qdrant-Genkit plugin](https://github.com/qdrant/qdrant-genkit).
Genkit currently supports server-side development in JavaScript/TypeScript (Node.js) with Go support in active development.
## Installation
```bash
npm i genkitx-qdrant
```
## Configuration
To use this plugin, specify it when you call `configureGenkit()`:
```js
import { qdrant } from 'genkitx-qdrant';
import { textEmbeddingGecko } from '@genkit-ai/vertexai';
export default configureGenkit({
plugins: [
qdrant([
{
clientParams: {
host: 'localhost',
port: 6333,
},
collectionName: 'some-collection',
embedder: textEmbeddingGecko,
},
]),
],
// ...
});
```
You'll need to specify a collection name, the embedding model you want to use and the Qdrant client parameters. In
addition, there are a few optional parameters:
- `embedderOptions`: Additional options to pass options to the embedder:
```js
embedderOptions: { taskType: 'RETRIEVAL_DOCUMENT' },
```
- `contentPayloadKey`: Name of the payload filed with the document content. Defaults to "content".
```js
contentPayloadKey: 'content';
```
- `metadataPayloadKey`: Name of the payload filed with the document metadata. Defaults to "metadata".
```js
metadataPayloadKey: 'metadata';
```
- `collectionCreateOptions`: [Additional options](<(https://qdrant.tech/documentation/concepts/collections/#create-a-collection)>) when creating the Qdrant collection.
## Usage
Import retriever and indexer references like so:
```js
import { qdrantIndexerRef, qdrantRetrieverRef } from 'genkitx-qdrant';
import { Document, index, retrieve } from '@genkit-ai/ai/retriever';
```
Then, pass the references to `retrieve()` and `index()`:
```js
// To specify an indexer:
export const qdrantIndexer = qdrantIndexerRef({
collectionName: 'some-collection',
displayName: 'Some Collection indexer',
});
await index({ indexer: qdrantIndexer, documents });
```
```js
// To specify a retriever:
export const qdrantRetriever = qdrantRetrieverRef({
collectionName: 'some-collection',
displayName: 'Some Collection Retriever',
});
let docs = await retrieve({ retriever: qdrantRetriever, query });
```
You can refer to [Retrieval-augmented generation](https://firebase.google.com/docs/genkit/rag) for a general
discussion on indexers and retrievers.
## Further Reading
- [Introduction to Genkit](https://firebase.google.com/docs/genkit)
- [Genkit Documentation](https://firebase.google.com/docs/genkit/get-started)
- [Source Code](https://github.com/qdrant/qdrant-genkit)
|
qdrant-landing/content/documentation/frameworks/haystack.md | ---
title: Haystack
weight: 400
aliases:
- ../integrations/haystack/
- /documentation/overview/integrations/haystack/
---
# Haystack
[Haystack](https://haystack.deepset.ai/) serves as a comprehensive NLP framework, offering a modular methodology for constructing
cutting-edge generative AI, QA, and semantic knowledge base search systems. A critical element in contemporary NLP systems is an
efficient database for storing and retrieving extensive text data. Vector databases excel in this role, as they house vector
representations of text and implement effective methods for swift retrieval. Thus, we are happy to announce the integration
with Haystack - `QdrantDocumentStore`. This document store is unique, as it is maintained externally by the Qdrant team.
The new document store comes as a separate package and can be updated independently of Haystack:
```bash
pip install qdrant-haystack
```
`QdrantDocumentStore` supports [all the configuration properties](/documentation/collections/#create-collection) available in
the Qdrant Python client. If you want to customize the default configuration of the collection used under the hood, you can
provide that settings when you create an instance of the `QdrantDocumentStore`. For example, if you'd like to enable the
Scalar Quantization, you'd make that in the following way:
```python
from qdrant_haystack.document_stores import QdrantDocumentStore
from qdrant_client import models
document_store = QdrantDocumentStore(
":memory:",
index="Document",
embedding_dim=512,
recreate_index=True,
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
quantile=0.99,
always_ram=True,
),
),
)
```
## Further Reading
- [Haystack Documentation](https://haystack.deepset.ai/integrations/qdrant-document-store)
- [Source Code](https://github.com/deepset-ai/haystack-core-integrations/tree/main/integrations/qdrant) |
qdrant-landing/content/documentation/frameworks/langchain-go.md | ---
title: Langchain Go
weight: 2120
---
# Langchain Go
[Langchain Go](https://tmc.github.io/langchaingo/docs/) is a framework for developing data-aware applications powered by language models in Go.
You can use Qdrant as a vector store in Langchain Go.
## Setup
Install the `langchain-go` project dependency
```bash
go get -u github.com/tmc/langchaingo
```
## Usage
Before you use the following code sample, customize the following values for your configuration:
- `YOUR_QDRANT_REST_URL`: If you've set up Qdrant using the [Quick Start](/documentation/quick-start/) guide,
set this value to `http://localhost:6333`.
- `YOUR_COLLECTION_NAME`: Use our [Collections](/documentation/concepts/collections/) guide to create or
list collections.
```go
import (
"fmt"
"log"
"github.com/tmc/langchaingo/embeddings"
"github.com/tmc/langchaingo/llms/openai"
"github.com/tmc/langchaingo/vectorstores"
"github.com/tmc/langchaingo/vectorstores/qdrant"
)
llm, err := openai.New()
if err != nil {
log.Fatal(err)
}
e, err := embeddings.NewEmbedder(llm)
if err != nil {
log.Fatal(err)
}
url, err := url.Parse("YOUR_QDRANT_REST_URL")
if err != nil {
log.Fatal(err)
}
store, err := qdrant.New(
qdrant.WithURL(*url),
qdrant.WithCollectionName("YOUR_COLLECTION_NAME"),
qdrant.WithEmbedder(e),
)
if err != nil {
log.Fatal(err)
}
```
## Further Reading
- You can find usage examples of Langchain Go [here](https://github.com/tmc/langchaingo/tree/main/examples).
- [Source Code](https://github.com/tmc/langchaingo/tree/main/vectorstores/qdrant)
|
qdrant-landing/content/documentation/frameworks/langchain.md | ---
title: Langchain
weight: 100
aliases:
- ../integrations/langchain/
- /documentation/overview/integrations/langchain/
---
# Langchain
Langchain is a library that makes developing Large Language Model-based applications much easier. It unifies the interfaces
to different libraries, including major embedding providers and Qdrant. Using Langchain, you can focus on the business value
instead of writing the boilerplate.
Langchain distributes their Qdrant integration in their community package. It might be installed with pip:
```bash
pip install langchain-community langchain-qdrant
```
Qdrant acts as a vector index that may store the embeddings with the documents used to generate them. There are various ways to use it, but calling `Qdrant.from_texts` or `Qdrant.from_documents` is probably the most straightforward way to get started:
```python
from langchain_qdrant import Qdrant
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
doc_store = Qdrant.from_texts(
texts, embeddings, url="<qdrant-url>", api_key="<qdrant-api-key>", collection_name="texts"
)
```
## Using an existing collection
To get an instance of `langchain_qdrant.Qdrant` without loading any new documents or texts, you can use the `Qdrant.from_existing_collection()` method.
```python
doc_store = Qdrant.from_existing_collection(
embeddings=embeddings,
collection_name="my_documents",
url="<qdrant-url>",
api_key="<qdrant-api-key>",
)
```
## Local mode
Python client allows you to run the same code in local mode without running the Qdrant server. That's great for testing things
out and debugging or if you plan to store just a small amount of vectors. The embeddings might be fully kept in memory or
persisted on disk.
### In-memory
For some testing scenarios and quick experiments, you may prefer to keep all the data in memory only, so it gets lost when the
client is destroyed - usually at the end of your script/notebook.
```python
qdrant = Qdrant.from_documents(
docs,
embeddings,
location=":memory:", # Local mode with in-memory storage only
collection_name="my_documents",
)
```
### On-disk storage
Local mode, without using the Qdrant server, may also store your vectors on disk so they’re persisted between runs.
```python
qdrant = Qdrant.from_documents(
docs,
embeddings,
path="/tmp/local_qdrant",
collection_name="my_documents",
)
```
### On-premise server deployment
No matter if you choose to launch Qdrant locally with [a Docker container](/documentation/guides/installation/), or
select a Kubernetes deployment with [the official Helm chart](https://github.com/qdrant/qdrant-helm), the way you're
going to connect to such an instance will be identical. You'll need to provide a URL pointing to the service.
```python
url = "<---qdrant url here --->"
qdrant = Qdrant.from_documents(
docs,
embeddings,
url,
prefer_grpc=True,
collection_name="my_documents",
)
```
## Next steps
If you'd like to know more about running Qdrant in a Langchain-based application, please read our article
[Question Answering with Langchain and Qdrant without boilerplate](/articles/langchain-integration/). Some more information
might also be found in the [Langchain documentation](https://python.langchain.com/docs/integrations/vectorstores/qdrant).
- [Source Code](https://github.com/langchain-ai/langchain/tree/master/libs%2Fpartners%2Fqdrant)
|
qdrant-landing/content/documentation/frameworks/langchain4j.md | ---
title: Langchain4J
weight: 2110
---
# LangChain for Java
LangChain for Java, also known as [Langchain4J](https://github.com/langchain4j/langchain4j), is a community port of [Langchain](https://www.langchain.com/) for building context-aware AI applications in Java
You can use Qdrant as a vector store in Langchain4J through the [`langchain4j-qdrant`](https://central.sonatype.com/artifact/dev.langchain4j/langchain4j-qdrant) module.
## Setup
Add the `langchain4j-qdrant` to your project dependencies.
```xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
<version>VERSION</version>
</dependency>
```
## Usage
Before you use the following code sample, customize the following values for your configuration:
- `YOUR_COLLECTION_NAME`: Use our [Collections](/documentation/concepts/collections/) guide to create or
list collections.
- `YOUR_HOST_URL`: Use the GRPC URL for your system. If you used the [Quick Start](/documentation/quick-start/) guide,
it may be http://localhost:6334. If you've deployed in the [Qdrant Cloud](/documentation/cloud/), you may have a
longer URL such as `https://example.location.cloud.qdrant.io:6334`.
- `YOUR_API_KEY`: Substitute the API key associated with your configuration.
```java
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.qdrant.QdrantEmbeddingStore;
EmbeddingStore<TextSegment> embeddingStore =
QdrantEmbeddingStore.builder()
// Ensure the collection is configured with the appropriate dimensions
// of the embedding model.
// Reference https://qdrant.tech/documentation/concepts/collections/
.collectionName("YOUR_COLLECTION_NAME")
.host("YOUR_HOST_URL")
// GRPC port of the Qdrant server
.port(6334)
.apiKey("YOUR_API_KEY")
.build();
```
`QdrantEmbeddingStore` supports all the semantic features of Langchain4J.
## Further Reading
- You can refer to the [Langchain4J examples](https://github.com/langchain4j/langchain4j-examples/) to get started.
- [Source Code](https://github.com/langchain4j/langchain4j/tree/main/langchain4j-qdrant)
|
qdrant-landing/content/documentation/frameworks/llama-index.md | ---
title: LlamaIndex
weight: 200
aliases:
- ../integrations/llama-index/
- /documentation/overview/integrations/llama-index/
---
# LlamaIndex
Llama Index acts as an interface between your external data and Large Language Models. So you can bring your
private data and augment LLMs with it. LlamaIndex simplifies data ingestion and indexing, integrating Qdrant as a vector index.
Installing Llama Index is straightforward if we use pip as a package manager. Qdrant is not installed by default, so we need to
install it separately. The integration of both tools also comes as another package.
```bash
pip install llama-index llama-index-vector-stores-qdrant
```
Llama Index requires providing an instance of `QdrantClient`, so it can interact with Qdrant server.
```python
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(
"<qdrant-url>",
api_key="<qdrant-api-key>", # For Qdrant Cloud, None for local instance
)
vector_store = QdrantVectorStore(client=client, collection_name="documents")
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
```
## Further Reading
- [LlamaIndex Documentation](https://docs.llamaindex.ai/en/stable/examples/vector_stores/QdrantIndexDemo/)
- [Example Notebook](https://colab.research.google.com/github/run-llama/llama_index/blob/main/docs/docs/examples/vector_stores/QdrantIndexDemo.ipynb)
- [Source Code](https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/vector_stores/llama-index-vector-stores-qdrant)
|
qdrant-landing/content/documentation/frameworks/make.md | ---
title: Make.com
weight: 1800
---
# Make.com
[Make](https://www.make.com/) is a platform for anyone to design, build, and automate anything—from tasks and workflows to apps and systems without code.
Find the comprehensive list of available Make apps [here](https://www.make.com/en/integrations).
Qdrant is available as an [app](https://www.make.com/en/integrations/qdrant) within Make to add to your scenarios.

## Prerequisites
Before you start, make sure you have the following:
1. A Qdrant instance to connect to. You can get free cloud instance [cloud.qdrant.io](https://cloud.qdrant.io/).
2. An account at Make.com. You can register yourself [here](https://www.make.com/en/register).
## Setting up a connection
Navigate to your scenario on the Make dashboard and select a Qdrant app module to start a connection.

You can now establish a connection to Qdrant using your [instance credentials](/documentation/cloud/authentication/).

## Modules
Modules represent actions that Make performs with an app.
The Qdrant Make app enables you to trigger the following app modules.

The modules support mapping to connect the data retrieved by one module to another module to perform the desired action. You can read more about the data processing options available for the modules in the [Make reference](https://www.make.com/en/help/modules).
## Next steps
- Find a list of Make workflow templates to connect with Qdrant [here](https://www.make.com/en/templates).
- Make scenario reference docs can be found [here](https://www.make.com/en/help/scenarios). |
qdrant-landing/content/documentation/frameworks/memgpt.md | ---
title: MemGPT
weight: 3200
---
# MemGPT
[MemGPT](https://memgpt.ai/) is a system that enables LLMs to manage their own memory and overcome limited context windows to
- Create perpetual chatbots that learn about you and change their personalities over time.
- Create perpetual chatbots that can interface with large data stores.
Qdrant is available as a storage backend in MemGPT for storing and semantically retrieving data.
## Usage
#### Installation
To install the required dependencies, install `pymemgpt` with the `qdrant` extra.
```sh
pip install 'pymemgpt[qdrant]'
```
You can configure MemGPT to use either a Qdrant server or an in-memory instance with the `memgpt configure` command.
#### Configuring the Qdrant server
When you run `memgpt configure`, go through the prompts as described in the [MemGPT configuration documentation](https://memgpt.readme.io/docs/config).
After you address several `memgpt` questions, you come to the following `memgpt` prompts:
```console
? Select storage backend for archival data: qdrant
? Select Qdrant backend: server
? Enter the Qdrant instance URI (Default: localhost:6333): https://xyz-example.eu-central.aws.cloud.qdrant.io
```
You can set an API key for authentication using the `QDRANT_API_KEY` environment variable.
#### Configuring an in-memory instance
```console
? Select storage backend for archival data: qdrant
? Select Qdrant backend: local
```
The data is persisted at the default MemGPT storage directory.
## Further Reading
- [MemGPT Examples][https://github.com/cpacker/MemGPT/tree/main/examples]
- [MemGPT Documentation](https://memgpt.readme.io/docs/index).
|
qdrant-landing/content/documentation/frameworks/mindsdb.md | ---
title: MindsDB
weight: 1100
aliases: [ ../integrations/mindsdb/ ]
---
# MindsDB
[MindsDB](https://mindsdb.com) is an AI automation platform for building AI/ML powered features and applications. It works by connecting any source of data with any AI/ML model or framework and automating how real-time data flows between them.
With the MindsDB-Qdrant integration, you can now select Qdrant as a database to load into and retrieve from with semantic search and filtering.
**MindsDB allows you to easily**:
- Connect to any store of data or end-user application.
- Pass data to an AI model from any store of data or end-user application.
- Plug the output of an AI model into any store of data or end-user application.
- Fully automate these workflows to build AI-powered features and applications
## Usage
To get started with Qdrant and MindsDB, the following syntax can be used.
```sql
CREATE DATABASE qdrant_test
WITH ENGINE = "qdrant",
PARAMETERS = {
"location": ":memory:",
"collection_config": {
"size": 386,
"distance": "Cosine"
}
}
```
The available arguments for instantiating Qdrant can be found [here](https://github.com/mindsdb/mindsdb/blob/23a509cb26bacae9cc22475497b8644e3f3e23c3/mindsdb/integrations/handlers/qdrant_handler/qdrant_handler.py#L408-L468).
## Creating a new table
- Qdrant options for creating a collection can be specified as `collection_config` in the `CREATE DATABASE` parameters.
- By default, UUIDs are set as collection IDs. You can provide your own IDs under the `id` column.
```sql
CREATE TABLE qdrant_test.test_table (
SELECT embeddings,'{"source": "bbc"}' as metadata FROM mysql_demo_db.test_embeddings
);
```
## Querying the database
#### Perform a full retrieval using the following syntax.
```sql
SELECT * FROM qdrant_test.test_table
```
By default, the `LIMIT` is set to 10 and the `OFFSET` is set to 0.
#### Perform a similarity search using your embeddings
<aside role="status">Qdrant supports <a href="/documentation/concepts/indexing/#payload-index">payload indexing</a> that vastly improves retrieval efficiency with filters and is highly recommended. Please note that this feature currently cannot be configured via MindsDB and must be set up separately if needed.</aside>
```sql
SELECT * FROM qdrant_test.test_table
WHERE search_vector = (select embeddings from mysql_demo_db.test_embeddings limit 1)
```
#### Perform a search using filters
```sql
SELECT * FROM qdrant_test.test_table
WHERE `metadata.source` = 'bbc';
```
#### Delete entries using IDs
```sql
DELETE FROM qtest.test_table_6
WHERE id = 2
```
#### Delete entries using filters
```sql
DELETE * FROM qdrant_test.test_table
WHERE `metadata.source` = 'bbc';
```
#### Drop a table
```sql
DROP TABLE qdrant_test.test_table;
```
## Next steps
- You can find more information pertaining to MindsDB and its datasources [here](https://docs.mindsdb.com/).
- [Source Code](https://github.com/mindsdb/mindsdb/tree/main/mindsdb/integrations/handlers/qdrant_handler)
|
qdrant-landing/content/documentation/frameworks/n8n.md | ---
title: N8N
weight: 2000
---
# N8N
[N8N](https://n8n.io/) is an automation platform that allows you to build flexible workflows focused on deep data integration.
Qdrant is available as a vectorstore node in N8N for building AI-powered functionality within your workflows.
## Prerequisites
1. A Qdrant instance to connect to. You can get a free cloud instance at [cloud.qdrant.io](https://cloud.qdrant.io/).
2. A running N8N instance. You can learn more about using the N8N cloud or self-hosting [here](https://docs.n8n.io/choose-n8n/).
## Setting up the vectorstore
Select the Qdrant vectorstore from the list of nodes in your workflow editor.

You can now configure the vectorstore node according to your workflow requirements. The configuration options reference can be found [here](https://docs.n8n.io/integrations/builtin/cluster-nodes/root-nodes/n8n-nodes-langchain.vectorstoreqdrant/#node-parameters).

Create a connection to Qdrant using your [instance credentials](/documentation/cloud/authentication/).

The vectorstore supports the following operations:
- Get Many - Get the top-ranked documents for a query.
- Insert documents - Add documents to the vectorstore.
- Retrieve documents - Retrieve documents for use with AI nodes.
## Further Reading
- N8N vectorstore [reference](https://docs.n8n.io/integrations/builtin/cluster-nodes/root-nodes/n8n-nodes-langchain.vectorstoreqdrant/).
- N8N AI-based workflows [reference](https://n8n.io/integrations/basic-llm-chain/).
- [Source Code](https://github.com/n8n-io/n8n/tree/master/packages/@n8n/nodes-langchain/nodes/vector_store/VectorStoreQdrant) |
qdrant-landing/content/documentation/frameworks/nifi.md | ---
title: Apache NiFi
weight: 3500
---
# Apache NiFi
[NiFi](https://nifi.apache.org/) is a real-time data ingestion platform, which can transfer and manage data transfer between numerous sources and destination systems. It supports many protocols and offers a web-based user interface for developing and monitoring data flows.
NiFi supports ingesting and querying data in Qdrant via its processor modules.
## Configuration

You can configure Qdrant NiFi processors with your Qdrant credentials, query/upload configurations. The processors offer 2 built-in embedding providers to encode data into vector embeddings - HuggingFace, OpenAI.
## Put Qdrant

The `Put Qdrant` processor can ingest NiFi [FlowFile](https://nifi.apache.org/docs/nifi-docs/html/nifi-in-depth.html#intro) data into a Qdrant collection.
## Query Qdrant

The `Query Qdrant` processor can perform a similarity search across a Qdrant collection and return a [FlowFile](https://nifi.apache.org/docs/nifi-docs/html/nifi-in-depth.html#intro) result.
## Further Reading
- [NiFi Documentation](https://nifi.apache.org/documentation/v2/).
- [Source Code](https://github.com/apache/nifi/tree/main/nifi-python-extensions/nifi-text-embeddings-module/src/main/python)
|
qdrant-landing/content/documentation/frameworks/openlit.md | ---
title: OpenLIT
weight: 3100
---
# OpenLIT
[OpenLIT](https://github.com/openlit/openlit) is an OpenTelemetry-native LLM Application Observability tool and includes OpenTelemetry auto-instrumentation to monitor Qdrant and provide insights to improve database operations and application performance.
This page assumes you're using `qdrant-client` version 1.7.3 or above.
## Usage
### Step 1: Install OpenLIT
Open your command line or terminal and run:
```bash
pip install openlit
```
### Step 2: Initialize OpenLIT in your Application
Integrating OpenLIT into LLM applications is straightforward with just **two lines of code**:
```python
import openlit
openlit.init()
```
OpenLIT directs the trace to your console by default. To forward telemetry data to an HTTP OTLP endpoint, configure the `otlp_endpoint` parameter or the `OTEL_EXPORTER_OTLP_ENDPOINT` environment variable.
For OpenTelemetry backends requiring authentication, use the `otlp_headers` parameter or the `OTEL_EXPORTER_OTLP_HEADERS` environment variable with the required values.
## Further Reading
With the LLM Observability data now being collected by OpenLIT, the next step is to visualize and analyze this data to get insights Qdrant's performance, behavior, and identify areas of improvement.
To begin exploring your LLM Application's performance data within the OpenLIT UI, please see the [Quickstart Guide](https://docs.openlit.io/latest/quickstart).
If you want to integrate and send the generated metrics and traces to your existing observability tools like Promethues+Jaeger, Grafana or more, refer to the [Official Documentation for OpenLIT Connections](https://docs.openlit.io/latest/connections/intro) for detailed instructions.
|
qdrant-landing/content/documentation/frameworks/openllmetry.md | ---
title: OpenLLMetry
weight: 2300
---
# OpenLLMetry
OpenLLMetry from [Traceloop](https://www.traceloop.com/) is a set of extensions built on top of [OpenTelemetry](https://opentelemetry.io/) that gives you complete observability over your LLM application.
OpenLLMetry supports instrumenting the `qdrant_client` Python library and exporting the traces to various observability platforms, as described in their [Integrations catalog](https://www.traceloop.com/docs/openllmetry/integrations/introduction#the-integrations-catalog).
This page assumes you're using `qdrant-client` version 1.7.3 or above.
## Usage
To set up OpenLLMetry, follow these steps:
1. Install the SDK:
```console
pip install traceloop-sdk
```
1. Instantiate the SDK:
```python
from traceloop.sdk import Traceloop
Traceloop.init()
```
You're now tracing your `qdrant_client` usage with OpenLLMetry!
## Without the SDK
Since Traceloop provides standard OpenTelemetry instrumentations, you can use them as standalone packages. To do so, follow these steps:
1. Install the package:
```console
pip install opentelemetry-instrumentation-qdrant
```
1. Instantiate the `QdrantInstrumentor`.
```python
from opentelemetry.instrumentation.qdrant import QdrantInstrumentor
QdrantInstrumentor().instrument()
```
## Further Reading
- 📚 OpenLLMetry [API reference](https://www.traceloop.com/docs/api-reference/introduction)
- 📄 [Source Code](https://github.com/traceloop/openllmetry/tree/main/packages/opentelemetry-instrumentation-qdrant)
|
qdrant-landing/content/documentation/frameworks/pandas-ai.md | ---
title: Pandas-AI
weight: 2900
---
# Pandas-AI
Pandas-AI is a Python library that uses a generative AI model to interpret natural language queries and translate them into Python code to interact with pandas data frames and return the final results to the user.
## Installation
```console
pip install pandasai[qdrant]
```
## Usage
You can begin a conversation by instantiating an `Agent` instance based on your Pandas data frame. The default Pandas-AI LLM requires an [API key](https://pandabi.ai).
You can find the list of all supported LLMs [here](https://docs.pandas-ai.com/en/latest/LLMs/llms/)
```python
import os
import pandas as pd
from pandasai import Agent
# Sample DataFrame
sales_by_country = pd.DataFrame(
{
"country": [
"United States",
"United Kingdom",
"France",
"Germany",
"Italy",
"Spain",
"Canada",
"Australia",
"Japan",
"China",
],
"sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000],
}
)
os.environ["PANDASAI_API_KEY"] = "YOUR_API_KEY"
agent = Agent(sales_by_country)
agent.chat("Which are the top 5 countries by sales?")
# OUTPUT: China, United States, Japan, Germany, Australia
```
## Qdrant support
You can train Pandas-AI to understand your data better and improve the quality of the results.
Qdrant can be configured as a vector store to ingest training data and retrieve semantically relevant content.
```python
from pandasai.ee.vectorstores.qdrant import Qdrant
qdrant = Qdrant(
collection_name="<SOME_COLLECTION>",
embedding_model="sentence-transformers/all-MiniLM-L6-v2",
url="http://localhost:6333",
grpc_port=6334,
prefer_grpc=True
)
agent = Agent(df, vector_store=qdrant)
# Train with custom information
agent.train(docs="The fiscal year starts in April")
# Train the q/a pairs of code snippets
query = "What are the total sales for the current fiscal year?"
response = """
import pandas as pd
df = dfs[0]
# Calculate the total sales for the current fiscal year
total_sales = df[df['date'] >= pd.to_datetime('today').replace(month=4, day=1)]['sales'].sum()
result = { "type": "number", "value": total_sales }
"""
agent.train(queries=[query], codes=[response])
# # The model will use the information provided in the training to generate a response
```
## Further reading
- [Getting Started with Pandas-AI](https://pandasai-docs.readthedocs.io/en/latest/getting-started/)
- [Pandas-AI Reference](https://pandasai-docs.readthedocs.io/en/latest/)
- [Source Code](https://github.com/Sinaptik-AI/pandas-ai/blob/main/pandasai/ee/vectorstores/qdrant.py)
|
qdrant-landing/content/documentation/frameworks/pipedream.md | ---
title: Pipedream
weight: 3300
---
# Pipedream
[Pipedream](https://pipedream.com/) is a development platform that allows developers to connect many different applications, data sources, and APIs in order to build automated cross-platform workflows. It also offers code-level control with Node.js, Python, Go, or Bash if required.
You can use the [Qdrant app](https://pipedream.com/apps/qdrant) in Pipedream to add vector search capabilities to your workflows.
## Prerequisites
1. A Qdrant instance to connect to. You can get a free cloud instance at [cloud.qdrant.io](https://cloud.qdrant.io/).
2. A [Pipedream project](https://pipedream.com/) to develop your workflows.
## Setting Up
Search for the Qdrant app in your workflow apps.

The Qdrant app offers extensible API interface and pre-built actions.

Select any of the actions of the app to set up a connection.

Configure connection with the credentials of your Qdrant instance.

You can verify your credentials using the "Test Connection" button.
Once a connection is set up, you can use the app to build workflows with the [2000+ apps supported by Pipedream](https://pipedream.com/apps/).
## Further Reading
- [Pipedream Documentation](https://pipedream.com/docs).
- [Qdrant Cloud Authentication](https://qdrant.tech/documentation/cloud/authentication/).
- [Source Code](https://github.com/PipedreamHQ/pipedream/tree/master/components/qdrant)
|
qdrant-landing/content/documentation/frameworks/privategpt.md | ---
title: PrivateGPT
weight: 1600
aliases: [ ../integrations/privategpt/ ]
---
# PrivateGPT
[PrivateGPT](https://docs.privategpt.dev/) is a production-ready AI project that allows you to inquire about your documents using Large Language Models (LLMs) with offline support.
PrivateGPT uses Qdrant as the default vectorstore for ingesting and retrieving documents.
## Configuration
Qdrant settings can be configured by setting values to the qdrant property in the `settings.yaml` file. By default, Qdrant tries to connect to an instance at http://localhost:3000.
Example:
```yaml
qdrant:
url: "https://xyz-example.eu-central.aws.cloud.qdrant.io:6333"
api_key: "<your-api-key>"
```
The available [configuration options](https://docs.privategpt.dev/manual/storage/vector-stores#qdrant-configuration) are:
| Field | Description |
|--------------|-------------|
| location | If `:memory:` - use in-memory Qdrant instance.<br>If `str` - use it as a `url` parameter.|
| url | Either host or str of `Optional[scheme], host, Optional[port], Optional[prefix]`.<br> Eg. `http://localhost:6333` |
| port | Port of the REST API interface. Default: `6333` |
| grpc_port | Port of the gRPC interface. Default: `6334` |
| prefer_grpc | If `true` - use gRPC interface whenever possible in custom methods. |
| https | If `true` - use HTTPS(SSL) protocol.|
| api_key | API key for authentication in Qdrant Cloud.|
| prefix | If set, add `prefix` to the REST URL path.<br>Example: `service/v1` will result in `http://localhost:6333/service/v1/{qdrant-endpoint}` for REST API.|
| timeout | Timeout for REST and gRPC API requests.<br>Default: 5.0 seconds for REST and unlimited for gRPC |
| host | Host name of Qdrant service. If url and host are not set, defaults to 'localhost'.|
| path | Persistence path for QdrantLocal. Eg. `local_data/private_gpt/qdrant`|
| force_disable_check_same_thread | Force disable check_same_thread for QdrantLocal sqlite connection.|
## Next steps
Find the PrivateGPT docs [here](https://docs.privategpt.dev/).
|
qdrant-landing/content/documentation/frameworks/rivet.md | ---
title: Ironclad Rivet
weight: 3100
---
# Ironclad Rivet
[Rivet](https://rivet.ironcladapp.com/) is an Integrated Development Environment (IDE) and library designed for creating AI agents using a visual, graph-based interface.
Qdrant is available as a [plugin](https://github.com/qdrant/rivet-plugin-qdrant) for building vector-search powered workflows in Rivet.
## Installation
- Open the plugins overlay at the top of the screen.
- Search for the official Qdrant plugin.
- Click the "Add" button to install it in your current project.

## Setting up the connection
You can configure your Qdrant instance credentials in the Rivet settings after installing the plugin.

Once you've configured your credentials, you can right-click on your workspace to add nodes from the plugin and get building!

## Further Reading
- Rivet [Tutorial](https://rivet.ironcladapp.com/docs/tutorial).
- Rivet [Documentation](https://rivet.ironcladapp.com/docs).
- Plugin [Source Code](https://github.com/qdrant/rivet-plugin-qdrant)
|
qdrant-landing/content/documentation/frameworks/semantic-router.md | ---
title: Semantic-Router
weight: 2700
---
# Semantic-Router
[Semantic-Router](https://www.aurelio.ai/semantic-router/) is a library to build decision-making layers for your LLMs and agents. It uses vector embeddings to make tool-use decisions rather than LLM generations, routing our requests using semantic meaning.
Qdrant is available as a supported index in Semantic-Router for you to ingest route data and perform retrievals.
## Installation
To use Semantic-Router with Qdrant, install the `qdrant` extra:
```console
pip install semantic-router[qdrant]
```
## Usage
Set up `QdrantIndex` with the appropriate configurations:
```python
from semantic_router.index import QdrantIndex
qdrant_index = QdrantIndex(
url="https://xyz-example.eu-central.aws.cloud.qdrant.io", api_key="<your-api-key>"
)
```
Once the Qdrant index is set up with the appropriate configurations, we can pass it to the `RouteLayer`.
```python
from semantic_router.layer import RouteLayer
RouteLayer(encoder=some_encoder, routes=some_routes, index=qdrant_index)
```
## Complete Example
<details>
<summary><b>Click to expand</b></summary>
```python
import os
from semantic_router import Route
from semantic_router.encoders import OpenAIEncoder
from semantic_router.index import QdrantIndex
from semantic_router.layer import RouteLayer
# we could use this as a guide for our chatbot to avoid political conversations
politics = Route(
name="politics value",
utterances=[
"isn't politics the best thing ever",
"why don't you tell me about your political opinions",
"don't you just love the president",
"they're going to destroy this country!",
"they will save the country!",
],
)
# this could be used as an indicator to our chatbot to switch to a more
# conversational prompt
chitchat = Route(
name="chitchat",
utterances=[
"how's the weather today?",
"how are things going?",
"lovely weather today",
"the weather is horrendous",
"let's go to the chippy",
],
)
# we place both of our decisions together into single list
routes = [politics, chitchat]
os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>"
encoder = OpenAIEncoder()
rl = RouteLayer(
encoder=encoder,
routes=routes,
index=QdrantIndex(location=":memory:"),
)
print(rl("What have you been upto?").name)
```
This returns:
```console
[Out]: 'chitchat'
```
</details>
## 📚 Further Reading
- Semantic-Router [Documentation](https://github.com/aurelio-labs/semantic-router/tree/main/docs)
- Semantic-Router [Video Course](https://www.aurelio.ai/course/semantic-router)
- [Source Code](https://github.com/aurelio-labs/semantic-router/blob/main/semantic_router/index/qdrant.py)
|
qdrant-landing/content/documentation/frameworks/spark.md | ---
title: Apache Spark
weight: 1400
aliases: [ ../integrations/spark/ ]
---
# Apache Spark
[Spark](https://spark.apache.org/) is a distributed computing framework designed for big data processing and analytics. The [Qdrant-Spark connector](https://github.com/qdrant/qdrant-spark) enables Qdrant to be a storage destination in Spark.
## Installation
You can set up the Qdrant-Spark Connector in a few different ways, depending on your preferences and requirements.
### GitHub Releases
The simplest way to get started is by downloading pre-packaged JAR file releases from the [GitHub releases page](https://github.com/qdrant/qdrant-spark/releases). These JAR files come with all the necessary dependencies.
### Building from Source
If you prefer to build the JAR from source, you'll need [JDK 8](https://www.azul.com/downloads/#zulu) and [Maven](https://maven.apache.org/) installed on your system. Once you have the prerequisites in place, navigate to the project's root directory and run the following command:
```bash
mvn package
```
This command will compile the source code and generate a fat JAR, which will be stored in the `target` directory by default.
### Maven Central
For use with Java and Scala projects, the package can be found [here](https://central.sonatype.com/artifact/io.qdrant/spark).
## Usage
Below, we'll walk through the steps of creating a Spark session with Qdrant support and loading data into Qdrant.
### Creating a single-node Spark session with Qdrant Support
To begin, import the necessary libraries and create a Spark session with Qdrant support:
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(
"spark.jars",
"spark-VERSION.jar", # Specify the downloaded JAR file
)
.master("local[*]")
.appName("qdrant")
.getOrCreate()
```
```scala
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder
.config("spark.jars", "spark-VERSION.jar") // Specify the downloaded JAR file
.master("local[*]")
.appName("qdrant")
.getOrCreate()
```
```java
import org.apache.spark.sql.SparkSession;
public class QdrantSparkJavaExample {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.config("spark.jars", "spark-VERSION.jar") // Specify the downloaded JAR file
.master("local[*]")
.appName("qdrant")
.getOrCreate();
}
}
```
### Loading data into Qdrant
<aside role="status">Before loading the data using this connector, a collection has to be <a href="/documentation/concepts/collections/#create-a-collection">created</a> in advance with the appropriate vector dimensions and configurations.</aside>
The connector supports ingesting multiple named/unnamed, dense/sparse vectors.
_Click each to expand._
<details>
<summary><b>Unnamed/Default vector</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", <QDRANT_GRPC_URL>)
.option("collection_name", <QDRANT_COLLECTION_NAME>)
.option("embedding_field", <EMBEDDING_FIELD_NAME>) # Expected to be a field of type ArrayType(FloatType)
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
</details>
<details>
<summary><b>Named vector</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", <QDRANT_GRPC_URL>)
.option("collection_name", <QDRANT_COLLECTION_NAME>)
.option("embedding_field", <EMBEDDING_FIELD_NAME>) # Expected to be a field of type ArrayType(FloatType)
.option("vector_name", <VECTOR_NAME>)
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
> #### NOTE
>
> The `embedding_field` and `vector_name` options are maintained for backward compatibility. It is recommended to use `vector_fields` and `vector_names` for named vectors as shown below.
</details>
<details>
<summary><b>Multiple named vectors</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("vector_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("vector_names", "<VECTOR_NAME>,<ANOTHER_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
</details>
<details>
<summary><b>Sparse vectors</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("sparse_vector_value_fields", "<COLUMN_NAME>")
.option("sparse_vector_index_fields", "<COLUMN_NAME>")
.option("sparse_vector_names", "<SPARSE_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
</details>
<details>
<summary><b>Multiple sparse vectors</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("sparse_vector_value_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_index_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_names", "<SPARSE_VECTOR_NAME>,<ANOTHER_SPARSE_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
</details>
<details>
<summary><b>Combination of named dense and sparse vectors</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("vector_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("vector_names", "<VECTOR_NAME>,<ANOTHER_VECTOR_NAME>")
.option("sparse_vector_value_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_index_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_names", "<SPARSE_VECTOR_NAME>,<ANOTHER_SPARSE_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
</details>
<details>
<summary><b>No vectors - Entire dataframe is stored as payload</b></summary>
```python
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
```
</details>
## Databricks
<aside role="status">
<p>Check out our <a href="/documentation/examples/databricks/" target="_blank">example</a> of using the Spark connector with Databricks.</p>
</aside>
You can use the `qdrant-spark` connector as a library in [Databricks](https://www.databricks.com/).
- Go to the `Libraries` section in your Databricks cluster dashboard.
- Select `Install New` to open the library installation modal.
- Search for `io.qdrant:spark:VERSION` in the Maven packages and click `Install`.

## Datatype Support
Qdrant supports all the Spark data types, and the appropriate data types are mapped based on the provided schema.
## Configuration Options
| Option | Description | Column DataType | Required |
| :--------------------------- | :------------------------------------------------------------------ | :---------------------------- | :------- |
| `qdrant_url` | GRPC URL of the Qdrant instance. Eg: <http://localhost:6334> | - | ✅ |
| `collection_name` | Name of the collection to write data into | - | ✅ |
| `schema` | JSON string of the dataframe schema | - | ✅ |
| `embedding_field` | Name of the column holding the embeddings | `ArrayType(FloatType)` | ❌ |
| `id_field` | Name of the column holding the point IDs. Default: Random UUID | `StringType` or `IntegerType` | ❌ |
| `batch_size` | Max size of the upload batch. Default: 64 | - | ❌ |
| `retries` | Number of upload retries. Default: 3 | - | ❌ |
| `api_key` | Qdrant API key for authentication | - | ❌ |
| `vector_name` | Name of the vector in the collection. | - | ❌ |
| `vector_fields` | Comma-separated names of columns holding the vectors. | `ArrayType(FloatType)` | ❌ |
| `vector_names` | Comma-separated names of vectors in the collection. | - | ❌ |
| `sparse_vector_index_fields` | Comma-separated names of columns holding the sparse vector indices. | `ArrayType(IntegerType)` | ❌ |
| `sparse_vector_value_fields` | Comma-separated names of columns holding the sparse vector values. | `ArrayType(FloatType)` | ❌ |
| `sparse_vector_names` | Comma-separated names of the sparse vectors in the collection. | - | ❌ |
| `shard_key_selector` | Comma-separated names of custom shard keys to use during upsert. | - | ❌ |
For more information, be sure to check out the [Qdrant-Spark GitHub repository](https://github.com/qdrant/qdrant-spark). The Apache Spark guide is available [here](https://spark.apache.org/docs/latest/quick-start.html). Happy data processing!
|
qdrant-landing/content/documentation/frameworks/spring-ai.md | ---
title: Spring AI
weight: 2200
---
# Spring AI
[Spring AI](https://docs.spring.io/spring-ai/reference/) is a Java framework that provides a [Spring-friendly](https://spring.io/) API and abstractions for developing AI applications.
Qdrant is available as supported vector database for use within your Spring AI projects.
## Installation
You can find the Spring AI installation instructions [here](https://docs.spring.io/spring-ai/reference/getting-started.html).
Add the Qdrant boot starter package.
```xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-qdrant-store-spring-boot-starter</artifactId>
</dependency>
```
## Usage
Configure Qdrant with Spring Boot’s `application.properties`.
```
spring.ai.vectorstore.qdrant.host=<host of your qdrant instance>
spring.ai.vectorstore.qdrant.port=<the GRPC port of your qdrant instance>
spring.ai.vectorstore.qdrant.api-key=<your api key>
spring.ai.vectorstore.qdrant.collection-name=<The name of the collection to use in Qdrant>
```
Learn more about these options in the [configuration reference](https://docs.spring.io/spring-ai/reference/api/vectordbs/qdrant.html#qdrant-vectorstore-properties).
Or you can set up the Qdrant vector store with the `QdrantVectorStoreConfig` options.
```java
@Bean
public QdrantVectorStoreConfig qdrantVectorStoreConfig() {
return QdrantVectorStoreConfig.builder()
.withHost("<QDRANT_HOSTNAME>")
.withPort(<QDRANT_GRPC_PORT>)
.withCollectionName("<QDRANT_COLLECTION_NAME>")
.withApiKey("<QDRANT_API_KEY>")
.build();
}
```
Build the vector store using the config and any of the support [Spring AI embedding providers](https://docs.spring.io/spring-ai/reference/api/embeddings.html#available-implementations).
```java
@Bean
public VectorStore vectorStore(QdrantVectorStoreConfig config, EmbeddingClient embeddingClient) {
return new QdrantVectorStore(config, embeddingClient);
}
```
You can now use the `VectorStore` instance backed by Qdrant as a vector store in the Spring AI APIs.
<aside role="status">If the collection is not <a href="/documentation/concepts/collections/#create-a-collection">created in advance</a>, <code>QdrantVectorStore</code> will attempt to create one using cosine similarity and the dimension of the configured <code>EmbeddingClient</code>.</aside>
## 📚 Further Reading
- Spring AI [Qdrant reference](https://docs.spring.io/spring-ai/reference/api/vectordbs/qdrant.html)
- Spring AI [API reference](https://docs.spring.io/spring-ai/reference/index.html)
- [Source Code](https://github.com/spring-projects/spring-ai/tree/main/vector-stores/spring-ai-qdrant)
|
qdrant-landing/content/documentation/frameworks/testcontainers.md | ---
title: Testcontainers
weight: 2700
---
# Testcontainers
Qdrant is available as a [Testcontainers module](https://testcontainers.com/modules/qdrant/) in multiple languages. It facilitates the spawning of a Qdrant instance for end-to-end testing.
As noted by [Testcontainers](https://testcontainers.com/), it "is an open source framework for providing throwaway, lightweight instances of databases, message brokers, web browsers, or just about anything that can run in a Docker container."
## Usage
```java
import org.testcontainers.qdrant.QdrantContainer;
QdrantContainer qdrantContainer = new QdrantContainer("qdrant/qdrant");
```
```go
import (
"github.com/testcontainers/testcontainers-go"
"github.com/testcontainers/testcontainers-go/modules/qdrant"
)
qdrantContainer, err := qdrant.RunContainer(ctx, testcontainers.WithImage("qdrant/qdrant"))
```
```typescript
import { QdrantContainer } from "@testcontainers/qdrant";
const qdrantContainer = await new QdrantContainer("qdrant/qdrant").start();
```
```python
from testcontainers.qdrant import QdrantContainer
qdrant_container = QdrantContainer("qdrant/qdrant").start()
```
Testcontainers modules provide options/methods to configure ENVs, volumes, and virtually everything you can configure in a Docker container.
## Further reading
- [Testcontainers Guides](https://testcontainers.com/guides/)
- [Testcontainers Qdrant Module](https://testcontainers.com/modules/qdrant/)
|
qdrant-landing/content/documentation/frameworks/txtai.md | ---
title: txtai
weight: 500
aliases: [ ../integrations/txtai/ ]
---
# txtai
Qdrant might be also used as an embedding backend in [txtai](https://neuml.github.io/txtai/) semantic applications.
txtai simplifies building AI-powered semantic search applications using Transformers. It leverages the neural embeddings and their
properties to encode high-dimensional data in a lower-dimensional space and allows to find similar objects based on their embeddings'
proximity.
Qdrant is not built-in txtai backend and requires installing an additional dependency:
```bash
pip install qdrant-txtai
```
The examples and some more information might be found in [qdrant-txtai repository](https://github.com/qdrant/qdrant-txtai).
|
qdrant-landing/content/documentation/frameworks/unstructured.md | ---
title: Unstructured
weight: 1900
---
# Unstructured
[Unstructured](https://unstructured.io/) is a library designed to help preprocess, structure unstructured text documents for downstream machine learning tasks.
Qdrant can be used as an ingestion destination in Unstructured.
## Setup
Install Unstructured with the `qdrant` extra.
```bash
pip install "unstructured[qdrant]"
```
## Usage
Depending on the use case you can prefer the command line or using it within your application.
### CLI
```bash
EMBEDDING_PROVIDER=${EMBEDDING_PROVIDER:-"langchain-huggingface"}
unstructured-ingest \
local \
--input-path example-docs/book-war-and-peace-1225p.txt \
--output-dir local-output-to-qdrant \
--strategy fast \
--chunk-elements \
--embedding-provider "$EMBEDDING_PROVIDER" \
--num-processes 2 \
--verbose \
qdrant \
--collection-name "test" \
--url "http://localhost:6333" \
--batch-size 80
```
For a full list of the options the CLI accepts, run `unstructured-ingest <upstream connector> qdrant --help`
### Programmatic usage
```python
from unstructured.ingest.connector.local import SimpleLocalConfig
from unstructured.ingest.connector.qdrant import (
QdrantWriteConfig,
SimpleQdrantConfig,
)
from unstructured.ingest.interfaces import (
ChunkingConfig,
EmbeddingConfig,
PartitionConfig,
ProcessorConfig,
ReadConfig,
)
from unstructured.ingest.runner import LocalRunner
from unstructured.ingest.runner.writers.base_writer import Writer
from unstructured.ingest.runner.writers.qdrant import QdrantWriter
def get_writer() -> Writer:
return QdrantWriter(
connector_config=SimpleQdrantConfig(
url="http://localhost:6333",
collection_name="test",
),
write_config=QdrantWriteConfig(batch_size=80),
)
if __name__ == "__main__":
writer = get_writer()
runner = LocalRunner(
processor_config=ProcessorConfig(
verbose=True,
output_dir="local-output-to-qdrant",
num_processes=2,
),
connector_config=SimpleLocalConfig(
input_path="example-docs/book-war-and-peace-1225p.txt",
),
read_config=ReadConfig(),
partition_config=PartitionConfig(),
chunking_config=ChunkingConfig(chunk_elements=True),
embedding_config=EmbeddingConfig(provider="langchain-huggingface"),
writer=writer,
writer_kwargs={},
)
runner.run()
```
## Next steps
- Unstructured API [reference](https://unstructured-io.github.io/unstructured/api.html).
- Qdrant ingestion destination [reference](https://unstructured-io.github.io/unstructured/ingest/destination_connectors/qdrant.html).
- [Source Code](https://github.com/Unstructured-IO/unstructured/blob/main/unstructured/ingest/connector/qdrant.py)
|
qdrant-landing/content/documentation/frameworks/vanna-ai.md | ---
title: Vanna.AI
weight: 3000
---
# Vanna.AI
[Vanna](https://vanna.ai/) is a Python package that uses retrieval augmentation to help you generate accurate SQL queries for your database using LLMs.
Vanna works in two easy steps - train a RAG "model" on your data, and then ask questions which will return SQL queries that can be set up to automatically run on your database.
Qdrant is available as a support vector store for ingesting and retrieving your RAG data.
## Installation
```console
pip install 'vanna[qdrant]'
```
## Setup
You can set up a Vanna agent using Qdrant as your vector store and any of the [LLMs supported by Vanna](https://vanna.ai/docs/postgres-openai-vanna-vannadb/).
We'll use OpenAI for demonstration.
```python
from vanna.openai import OpenAI_Chat
from vanna.qdrant import Qdrant_VectorStore
from qdrant_client import QdrantClient
class MyVanna(Qdrant, OpenAI_Chat):
def __init__(self, config=None):
Qdrant_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={
'client': QdrantClient(...),
'api_key': sk-...,
'model': gpt-4-...,
})
```
## Usage
Once a Vanna agent is instantiated, you can connect it to [any SQL database](https://vanna.ai/docs/FAQ/#can-i-use-this-with-my-sql-database) of your choosing.
For example, Postgres.
```python
vn.connect_to_postgres(host='my-host', dbname='my-dbname', user='my-user', password='my-password', port='my-port')
```
You can now train and begin querying your database with SQL.
```python
# You can add DDL statements that specify table names, column names, types, and potentially relationships
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
# You can add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines OTIF score as the percentage of orders that are delivered on time and in full")
# You can also add SQL queries to your training data. This is useful if you have some queries already laying around.
vn.train(sql="SELECT * FROM my-table WHERE name = 'John Doe'")
# You can remove training data if there's obsolete/incorrect information.
vn.remove_training_data(id='1-ddl')
# Whenever you ask a new question, Vanna will retrieve 10 most relevant pieces of training data and use it as part of the LLM prompt to generate the SQL.
vn.ask(question="<YOUR_QUESTION>")
```
## Further reading
- [Getting started with Vanna.AI](https://vanna.ai/docs/app/)
- [Vanna.AI documentation](https://vanna.ai/docs/)
- [Source Code](https://github.com/vanna-ai/vanna/tree/main/src/vanna/qdrant)
|
qdrant-landing/content/documentation/guides/_index.md | ---
title: Guides
weight: 22
# If the index.md file is empty, the link to the section will be hidden from the sidebar
is_empty: true
--- |
qdrant-landing/content/documentation/guides/administration.md | ---
title: Administration
weight: 10
aliases:
- ../administration
---
# Administration
Qdrant exposes administration tools which enable to modify at runtime the behavior of a qdrant instance without changing its configuration manually.
## Locking
A locking API enables users to restrict the possible operations on a qdrant process.
It is important to mention that:
- The configuration is not persistent therefore it is necessary to lock again following a restart.
- Locking applies to a single node only. It is necessary to call lock on all the desired nodes in a distributed deployment setup.
Lock request sample:
```http
POST /locks
{
"error_message": "write is forbidden",
"write": true
}
```
Write flags enables/disables write lock.
If the write lock is set to true, qdrant doesn't allow creating new collections or adding new data to the existing storage.
However, deletion operations or updates are not forbidden under the write lock.
This feature enables administrators to prevent a qdrant process from using more disk space while permitting users to search and delete unnecessary data.
You can optionally provide the error message that should be used for error responses to users.
## Recovery mode
*Available as of v1.2.0*
Recovery mode can help in situations where Qdrant fails to start repeatedly.
When starting in recovery mode, Qdrant only loads collection metadata to prevent
going out of memory. This allows you to resolve out of memory situations, for
example, by deleting a collection. After resolving Qdrant can be restarted
normally to continue operation.
In recovery mode, collection operations are limited to
[deleting](../../concepts/collections/#delete-collection) a
collection. That is because only collection metadata is loaded during recovery.
To enable recovery mode with the Qdrant Docker image you must set the
environment variable `QDRANT_ALLOW_RECOVERY_MODE=true`. The container will try
to start normally first, and restarts in recovery mode if initialisation fails
due to an out of memory error. This behavior is disabled by default.
If using a Qdrant binary, recovery mode can be enabled by setting a recovery
message in an environment variable, such as
`QDRANT__STORAGE__RECOVERY_MODE="My recovery message"`.
|
qdrant-landing/content/documentation/guides/common-errors.md | ---
title: Troubleshooting
weight: 170
aliases:
- ../tutorials/common-errors
- /documentation/troubleshooting/
---
# Solving common errors
## Too many files open (OS error 24)
Each collection segment needs some files to be open. At some point you may encounter the following errors in your server log:
```text
Error: Too many files open (OS error 24)
```
In such a case you may need to increase the limit of the open files. It might be done, for example, while you launch the Docker container:
```bash
docker run --ulimit nofile=10000:10000 qdrant/qdrant:latest
```
The command above will set both soft and hard limits to `10000`.
If you are not using Docker, the following command will change the limit for the current user session:
```bash
ulimit -n 10000
```
Please note, the command should be executed before you run Qdrant server.
## Can't open Collections meta Wal
When starting a Qdrant instance as part of a distributed deployment, you may
come across an error message similar to this:
```bash
Can't open Collections meta Wal: Os { code: 11, kind: WouldBlock, message: "Resource temporarily unavailable" }
```
It means that Qdrant cannot start because a collection cannot be loaded. Its
associated [WAL](../../concepts/storage/#versioning) files are currently
unavailable, likely because the same files are already being used by another
Qdrant instance.
Each node must have their own separate storage directory, volume or mount.
The formed cluster will take care of sharing all data with each node, putting it
all in the correct places for you. If using Kubernetes, each node must have
their own volume. If using Docker, each node must have their own storage mount
or volume. If using Qdrant directly, each node must have their own storage
directory.
|
qdrant-landing/content/documentation/guides/configuration.md | ---
title: Configuration
weight: 160
aliases:
- ../configuration
- /guides/configuration/
---
# Configuration
To change or correct Qdrant's behavior, default collection settings, and network interface parameters, you can use configuration files.
The default configuration file is located at [config/config.yaml](https://github.com/qdrant/qdrant/blob/master/config/config.yaml).
To change the default configuration, add a new configuration file and specify
the path with `--config-path path/to/custom_config.yaml`. If running in
production mode, you could also choose to overwrite `config/production.yaml`.
See [ordering](#order-and-priority) for details on how configurations are
loaded.
The [Installation](../installation/) guide contains examples of how to set up Qdrant with a custom configuration for the different deployment methods.
## Order and priority
*Effective as of v1.2.1*
Multiple configurations may be loaded on startup. All of them are merged into a
single effective configuration that is used by Qdrant.
Configurations are loaded in the following order, if present:
1. Embedded base configuration ([source](https://github.com/qdrant/qdrant/blob/master/config/config.yaml))
2. File `config/config.yaml`
3. File `config/{RUN_MODE}.yaml` (such as `config/production.yaml`)
4. File `config/local.yaml`
5. Config provided with `--config-path PATH` (if set)
6. [Environment variables](#environment-variables)
This list is from least to most significant. Properties in later configurations
will overwrite those loaded before it. For example, a property set with
`--config-path` will overwrite those in other files.
Most of these files are included by default in the Docker container. But it is
likely that they are absent on your local machine if you run the `qdrant` binary
manually.
If file 2 or 3 are not found, a warning is shown on startup.
If file 5 is provided but not found, an error is shown on startup.
Other supported configuration file formats and extensions include: `.toml`, `.json`, `.ini`.
## Environment variables
It is possible to set configuration properties using environment variables.
Environment variables are always the most significant and cannot be overwritten
(see [ordering](#order-and-priority)).
All environment variables are prefixed with `QDRANT__` and are separated with
`__`.
These variables:
```bash
QDRANT__LOG_LEVEL=INFO
QDRANT__SERVICE__HTTP_PORT=6333
QDRANT__SERVICE__ENABLE_TLS=1
QDRANT__TLS__CERT=./tls/cert.pem
QDRANT__TLS__CERT_TTL=3600
```
result in this configuration:
```yaml
log_level: INFO
service:
http_port: 6333
enable_tls: true
tls:
cert: ./tls/cert.pem
cert_ttl: 3600
```
To run Qdrant locally with a different HTTP port you could use:
```bash
QDRANT__SERVICE__HTTP_PORT=1234 ./qdrant
```
## Configuration file example
```yaml
log_level: INFO
storage:
# Where to store all the data
storage_path: ./storage
# Where to store snapshots
snapshots_path: ./snapshots
# Where to store temporary files
# If null, temporary snapshot are stored in: storage/snapshots_temp/
temp_path: null
# If true - point's payload will not be stored in memory.
# It will be read from the disk every time it is requested.
# This setting saves RAM by (slightly) increasing the response time.
# Note: those payload values that are involved in filtering and are indexed - remain in RAM.
on_disk_payload: true
# Maximum number of concurrent updates to shard replicas
# If `null` - maximum concurrency is used.
update_concurrency: null
# Write-ahead-log related configuration
wal:
# Size of a single WAL segment
wal_capacity_mb: 32
# Number of WAL segments to create ahead of actual data requirement
wal_segments_ahead: 0
# Normal node - receives all updates and answers all queries
node_type: "Normal"
# Listener node - receives all updates, but does not answer search/read queries
# Useful for setting up a dedicated backup node
# node_type: "Listener"
performance:
# Number of parallel threads used for search operations. If 0 - auto selection.
max_search_threads: 0
# Max total number of threads, which can be used for running optimization processes across all collections.
# Note: Each optimization thread will also use `max_indexing_threads` for index building.
# So total number of threads used for optimization will be `max_optimization_threads * max_indexing_threads`
max_optimization_threads: 1
# Prevent DDoS of too many concurrent updates in distributed mode.
# One external update usually triggers multiple internal updates, which breaks internal
# timings. For example, the health check timing and consensus timing.
# If null - auto selection.
update_rate_limit: null
optimizers:
# The minimal fraction of deleted vectors in a segment, required to perform segment optimization
deleted_threshold: 0.2
# The minimal number of vectors in a segment, required to perform segment optimization
vacuum_min_vector_number: 1000
# Target amount of segments optimizer will try to keep.
# Real amount of segments may vary depending on multiple parameters:
# - Amount of stored points
# - Current write RPS
#
# It is recommended to select default number of segments as a factor of the number of search threads,
# so that each segment would be handled evenly by one of the threads.
# If `default_segment_number = 0`, will be automatically selected by the number of available CPUs
default_segment_number: 0
# Do not create segments larger this size (in KiloBytes).
# Large segments might require disproportionately long indexation times,
# therefore it makes sense to limit the size of segments.
#
# If indexation speed have more priority for your - make this parameter lower.
# If search speed is more important - make this parameter higher.
# Note: 1Kb = 1 vector of size 256
# If not set, will be automatically selected considering the number of available CPUs.
max_segment_size_kb: null
# Maximum size (in KiloBytes) of vectors to store in-memory per segment.
# Segments larger than this threshold will be stored as read-only memmaped file.
# To enable memmap storage, lower the threshold
# Note: 1Kb = 1 vector of size 256
# To explicitly disable mmap optimization, set to `0`.
# If not set, will be disabled by default.
memmap_threshold_kb: null
# Maximum size (in KiloBytes) of vectors allowed for plain index.
# Default value based on https://github.com/google-research/google-research/blob/master/scann/docs/algorithms.md
# Note: 1Kb = 1 vector of size 256
# To explicitly disable vector indexing, set to `0`.
# If not set, the default value will be used.
indexing_threshold_kb: 20000
# Interval between forced flushes.
flush_interval_sec: 5
# Max number of threads, which can be used for optimization per collection.
# Note: Each optimization thread will also use `max_indexing_threads` for index building.
# So total number of threads used for optimization will be `max_optimization_threads * max_indexing_threads`
# If `max_optimization_threads = 0`, optimization will be disabled.
max_optimization_threads: 1
# Default parameters of HNSW Index. Could be overridden for each collection or named vector individually
hnsw_index:
# Number of edges per node in the index graph. Larger the value - more accurate the search, more space required.
m: 16
# Number of neighbours to consider during the index building. Larger the value - more accurate the search, more time required to build index.
ef_construct: 100
# Minimal size (in KiloBytes) of vectors for additional payload-based indexing.
# If payload chunk is smaller than `full_scan_threshold_kb` additional indexing won't be used -
# in this case full-scan search should be preferred by query planner and additional indexing is not required.
# Note: 1Kb = 1 vector of size 256
full_scan_threshold_kb: 10000
# Number of parallel threads used for background index building. If 0 - auto selection.
max_indexing_threads: 0
# Store HNSW index on disk. If set to false, index will be stored in RAM. Default: false
on_disk: false
# Custom M param for hnsw graph built for payload index. If not set, default M will be used.
payload_m: null
service:
# Maximum size of POST data in a single request in megabytes
max_request_size_mb: 32
# Number of parallel workers used for serving the api. If 0 - equal to the number of available cores.
# If missing - Same as storage.max_search_threads
max_workers: 0
# Host to bind the service on
host: 0.0.0.0
# HTTP(S) port to bind the service on
http_port: 6333
# gRPC port to bind the service on.
# If `null` - gRPC is disabled. Default: null
# Comment to disable gRPC:
grpc_port: 6334
# Enable CORS headers in REST API.
# If enabled, browsers would be allowed to query REST endpoints regardless of query origin.
# More info: https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
# Default: true
enable_cors: true
# Enable HTTPS for the REST and gRPC API
enable_tls: false
# Check user HTTPS client certificate against CA file specified in tls config
verify_https_client_certificate: false
# Set an api-key.
# If set, all requests must include a header with the api-key.
# example header: `api-key: <API-KEY>`
#
# If you enable this you should also enable TLS.
# (Either above or via an external service like nginx.)
# Sending an api-key over an unencrypted channel is insecure.
#
# Uncomment to enable.
# api_key: your_secret_api_key_here
# Set an api-key for read-only operations.
# If set, all requests must include a header with the api-key.
# example header: `api-key: <API-KEY>`
#
# If you enable this you should also enable TLS.
# (Either above or via an external service like nginx.)
# Sending an api-key over an unencrypted channel is insecure.
#
# Uncomment to enable.
# read_only_api_key: your_secret_read_only_api_key_here
cluster:
# Use `enabled: true` to run Qdrant in distributed deployment mode
enabled: false
# Configuration of the inter-cluster communication
p2p:
# Port for internal communication between peers
port: 6335
# Use TLS for communication between peers
enable_tls: false
# Configuration related to distributed consensus algorithm
consensus:
# How frequently peers should ping each other.
# Setting this parameter to lower value will allow consensus
# to detect disconnected nodes earlier, but too frequent
# tick period may create significant network and CPU overhead.
# We encourage you NOT to change this parameter unless you know what you are doing.
tick_period_ms: 100
# Set to true to prevent service from sending usage statistics to the developers.
# Read more: https://qdrant.tech/documentation/guides/telemetry
telemetry_disabled: false
# TLS configuration.
# Required if either service.enable_tls or cluster.p2p.enable_tls is true.
tls:
# Server certificate chain file
cert: ./tls/cert.pem
# Server private key file
key: ./tls/key.pem
# Certificate authority certificate file.
# This certificate will be used to validate the certificates
# presented by other nodes during inter-cluster communication.
#
# If verify_https_client_certificate is true, it will verify
# HTTPS client certificate
#
# Required if cluster.p2p.enable_tls is true.
ca_cert: ./tls/cacert.pem
# TTL in seconds to reload certificate from disk, useful for certificate rotations.
# Only works for HTTPS endpoints. Does not support gRPC (and intra-cluster communication).
# If `null` - TTL is disabled.
cert_ttl: 3600
```
## Validation
*Available since v1.1.1*
The configuration is validated on startup. If a configuration is loaded but
validation fails, a warning is logged. E.g.:
```text
WARN Settings configuration file has validation errors:
WARN - storage.optimizers.memmap_threshold: value 123 invalid, must be 1000 or larger
WARN - storage.hnsw_index.m: value 1 invalid, must be from 4 to 10000
```
The server will continue to operate. Any validation errors should be fixed as
soon as possible though to prevent problematic behavior. |
qdrant-landing/content/documentation/guides/distributed_deployment.md | ---
title: Distributed Deployment
weight: 100
aliases:
- ../distributed_deployment
- /guides/distributed_deployment
---
# Distributed deployment
Since version v0.8.0 Qdrant supports a distributed deployment mode.
In this mode, multiple Qdrant services communicate with each other to distribute the data across the peers to extend the storage capabilities and increase stability.
## How many Qdrant nodes should I run?
The ideal number of Qdrant nodes depends on how much you value cost-saving, resilience, and performance/scalability in relation to each other.
- **Prioritizing cost-saving**: If cost is most important to you, run a single Qdrant node. This is not recommended for production environments. Drawbacks:
- Resilience: Users will experience downtime during node restarts, and recovery is not possible unless you have backups or snapshots.
- Performance: Limited to the resources of a single server.
- **Prioritizing resilience**: If resilience is most important to you, run a Qdrant cluster with three or more nodes and two or more shard replicas. Clusters with three or more nodes and replication can perform all operations even while one node is down. Additionally, they gain performance benefits from load-balancing and they can recover from the permanent loss of one node without the need for backups or snapshots (but backups are still strongly recommended). This is most recommended for production environments. Drawbacks:
- Cost: Larger clusters are more costly than smaller clusters, which is the only drawback of this configuration.
- **Balancing cost, resilience, and performance**: Running a two-node Qdrant cluster with replicated shards allows the cluster to respond to most read/write requests even when one node is down, such as during maintenance events. Having two nodes also means greater performance than a single-node cluster while still being cheaper than a three-node cluster. Drawbacks:
- Resilience (uptime): The cluster cannot perform operations on collections when one node is down. Those operations require >50% of nodes to be running, so this is only possible in a 3+ node cluster. Since creating, editing, and deleting collections are usually rare operations, many users find this drawback to be negligible.
- Resilience (data integrity): If the data on one of the two nodes is permanently lost or corrupted, it cannot be recovered aside from snapshots or backups. Only 3+ node clusters can recover from the permanent loss of a single node since recovery operations require >50% of the cluster to be healthy.
- Cost: Replicating your shards requires storing two copies of your data.
- Performance: The maximum performance of a Qdrant cluster increases as you add more nodes.
In summary, single-node clusters are best for non-production workloads, replicated 3+ node clusters are the gold standard, and replicated 2-node clusters strike a good balance.
## Enabling distributed mode in self-hosted Qdrant
To enable distributed deployment - enable the cluster mode in the [configuration](../configuration/) or using the ENV variable: `QDRANT__CLUSTER__ENABLED=true`.
```yaml
cluster:
# Use `enabled: true` to run Qdrant in distributed deployment mode
enabled: true
# Configuration of the inter-cluster communication
p2p:
# Port for internal communication between peers
port: 6335
# Configuration related to distributed consensus algorithm
consensus:
# How frequently peers should ping each other.
# Setting this parameter to lower value will allow consensus
# to detect disconnected node earlier, but too frequent
# tick period may create significant network and CPU overhead.
# We encourage you NOT to change this parameter unless you know what you are doing.
tick_period_ms: 100
```
By default, Qdrant will use port `6335` for its internal communication.
All peers should be accessible on this port from within the cluster, but make sure to isolate this port from outside access, as it might be used to perform write operations.
Additionally, you must provide the `--uri` flag to the first peer so it can tell other nodes how it should be reached:
```bash
./qdrant --uri 'http://qdrant_node_1:6335'
```
Subsequent peers in a cluster must know at least one node of the existing cluster to synchronize through it with the rest of the cluster.
To do this, they need to be provided with a bootstrap URL:
```bash
./qdrant --bootstrap 'http://qdrant_node_1:6335'
```
The URL of the new peers themselves will be calculated automatically from the IP address of their request.
But it is also possible to provide them individually using the `--uri` argument.
```text
USAGE:
qdrant [OPTIONS]
OPTIONS:
--bootstrap <URI>
Uri of the peer to bootstrap from in case of multi-peer deployment. If not specified -
this peer will be considered as a first in a new deployment
--uri <URI>
Uri of this peer. Other peers should be able to reach it by this uri.
This value has to be supplied if this is the first peer in a new deployment.
In case this is not the first peer and it bootstraps the value is optional. If not
supplied then qdrant will take internal grpc port from config and derive the IP address
of this peer on bootstrap peer (receiving side)
```
After a successful synchronization you can observe the state of the cluster through the [REST API](https://api.qdrant.tech/master/api-reference/distributed/cluster-status):
```http
GET /cluster
```
Example result:
```json
{
"result": {
"status": "enabled",
"peer_id": 11532566549086892000,
"peers": {
"9834046559507417430": {
"uri": "http://172.18.0.3:6335/"
},
"11532566549086892528": {
"uri": "http://qdrant_node_1:6335/"
}
},
"raft_info": {
"term": 1,
"commit": 4,
"pending_operations": 1,
"leader": 11532566549086892000,
"role": "Leader"
}
},
"status": "ok",
"time": 5.731e-06
}
```
Note that enabling distributed mode does not automatically replicate your data. See the section on [making use of a new distributed Qdrant cluster](#making-use-of-a-new-distributed-qdrant-cluster) for the next steps.
## Enabling distributed mode in Qdrant Cloud
For best results, first ensure your cluster is running Qdrant v1.7.4 or higher. Older versions of Qdrant do support distributed mode, but improvements in v1.7.4 make distributed clusters more resilient during outages.
In the [Qdrant Cloud console](https://cloud.qdrant.io/), click "Scale Up" to increase your cluster size to >1. Qdrant Cloud configures the distributed mode settings automatically.
After the scale-up process completes, you will have a new empty node running alongside your existing node(s). To replicate data into this new empty node, see the next section.
## Making use of a new distributed Qdrant cluster
When you enable distributed mode and scale up to two or more nodes, your data does not move to the new node automatically; it starts out empty. To make use of your new empty node, do one of the following:
* Create a new replicated collection by setting the [replication_factor](#replication-factor) to 2 or more and setting the [number of shards](#choosing-the-right-number-of-shards) to a multiple of your number of nodes.
* If you have an existing collection which does not contain enough shards for each node, you must create a new collection as described in the previous bullet point.
* If you already have enough shards for each node and you merely need to replicate your data, follow the directions for [creating new shard replicas](#creating-new-shard-replicas).
* If you already have enough shards for each node and your data is already replicated, you can move data (without replicating it) onto the new node(s) by [moving shards](#moving-shards).
## Raft
Qdrant uses the [Raft](https://raft.github.io/) consensus protocol to maintain consistency regarding the cluster topology and the collections structure.
Operations on points, on the other hand, do not go through the consensus infrastructure.
Qdrant is not intended to have strong transaction guarantees, which allows it to perform point operations with low overhead.
In practice, it means that Qdrant does not guarantee atomic distributed updates but allows you to wait until the [operation is complete](../../concepts/points/#awaiting-result) to see the results of your writes.
Operations on collections, on the contrary, are part of the consensus which guarantees that all operations are durable and eventually executed by all nodes.
In practice it means that a majority of nodes agree on what operations should be applied before the service will perform them.
Practically, it means that if the cluster is in a transition state - either electing a new leader after a failure or starting up, the collection update operations will be denied.
You may use the cluster [REST API](https://api.qdrant.tech/master/api-reference/distributed/cluster-status) to check the state of the consensus.
## Sharding
A Collection in Qdrant is made of one or more shards.
A shard is an independent store of points which is able to perform all operations provided by collections.
There are two methods of distributing points across shards:
- **Automatic sharding**: Points are distributed among shards by using a [consistent hashing](https://en.wikipedia.org/wiki/Consistent_hashing) algorithm, so that shards are managing non-intersecting subsets of points. This is the default behavior.
- **User-defined sharding**: _Available as of v1.7.0_ - Each point is uploaded to a specific shard, so that operations can hit only the shard or shards they need. Even with this distribution, shards still ensure having non-intersecting subsets of points. [See more...](#user-defined-sharding)
Each node knows where all parts of the collection are stored through the [consensus protocol](./#raft), so when you send a search request to one Qdrant node, it automatically queries all other nodes to obtain the full search result.
### Choosing the right number of shards
When you create a collection, Qdrant splits the collection into `shard_number` shards. If left unset, `shard_number` is set to the number of nodes in your cluster when the collection was created. The `shard_number` cannot be changed without recreating the collection.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=300, distance=models.Distance.COSINE),
shard_number=6,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 300,
distance: "Cosine",
},
shard_number: 6,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{vectors_config::Config, CreateCollection, Distance, VectorParams, VectorsConfig},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".into(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 300,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
shard_number: Some(6),
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(300)
.setDistance(Distance.Cosine)
.build())
.build())
.setShardNumber(6)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 300, Distance = Distance.Cosine },
shardNumber: 6
);
```
To ensure all nodes in your cluster are evenly utilized, the number of shards must be a multiple of the number of nodes you are currently running in your cluster.
> Aside: Advanced use cases such as multitenancy may require an uneven distribution of shards. See [Multitenancy](/articles/multitenancy/).
We recommend creating at least 2 shards per node to allow future expansion without having to re-shard. Re-sharding should be avoided since it requires creating a new collection. In-place re-sharding is planned for a future version of Qdrant.
If you anticipate a lot of growth, we recommend 12 shards since you can expand from 1 node up to 2, 3, 6, and 12 nodes without having to re-shard. Having more than 12 shards in a small cluster may not be worth the performance overhead.
Shards are evenly distributed across all existing nodes when a collection is first created, but Qdrant does not automatically rebalance shards if your cluster size or replication factor changes (since this is an expensive operation on large clusters). See the next section for how to move shards after scaling operations.
### Moving shards
*Available as of v0.9.0*
Qdrant allows moving shards between nodes in the cluster and removing nodes from the cluster. This functionality unlocks the ability to dynamically scale the cluster size without downtime. It also allows you to upgrade or migrate nodes without downtime.
Qdrant provides the information regarding the current shard distribution in the cluster with the [Collection Cluster info API](https://api.qdrant.tech/master/api-reference/distributed/collection-cluster-info).
Use the [Update collection cluster setup API](https://api.qdrant.tech/master/api-reference/distributed/update-collection-cluster) to initiate the shard transfer:
```http
POST /collections/{collection_name}/cluster
{
"move_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995
}
}
```
<aside role="status">You likely want to select a specific <a href="#shard-transfer-method">shard transfer method</a> to get desired performance and guarantees.</aside>
After the transfer is initiated, the service will process it based on the used
[transfer method](#shard-transfer-method) keeping both shards in sync. Once the
transfer is completed, the old shard is deleted from the source node.
In case you want to downscale the cluster, you can move all shards away from a peer and then remove the peer using the [remove peer API](https://api.qdrant.tech/master/api-reference/distributed/remove-peer).
```http
DELETE /cluster/peer/{peer_id}
```
After that, Qdrant will exclude the node from the consensus, and the instance will be ready for shutdown.
### User-defined sharding
*Available as of v1.7.0*
Qdrant allows you to specify the shard for each point individually. This feature is useful if you want to control the shard placement of your data, so that operations can hit only the subset of shards they actually need. In big clusters, this can significantly improve the performance of operations that do not require the whole collection to be scanned.
A clear use-case for this feature is managing a multi-tenant collection, where each tenant (let it be a user or organization) is assumed to be segregated, so they can have their data stored in separate shards.
To enable user-defined sharding, set `sharding_method` to `custom` during collection creation:
```http
PUT /collections/{collection_name}
{
"shard_number": 1,
"sharding_method": "custom"
// ... other collection parameters
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
shard_number=1,
sharding_method=models.ShardingMethod.CUSTOM,
# ... other collection parameters
)
client.create_shard_key("{collection_name}", "{shard_key}")
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
shard_number: 1,
sharding_method: "custom",
// ... other collection parameters
});
client.createShardKey("{collection_name}", {
shard_key: "{shard_key}"
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{CreateCollection, ShardingMethod, shard_key::Key}
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".into(),
shard_number: Some(1),
sharding_method: Some(ShardingMethod::Custom),
// ... other collection parameters
..Default::default()
})
.await?;
client
.create_shard_key(
"{collection_name}",
&Key::Keyword("{shard_key".to_string()),
None,
None,
&[],
)
.await?;
```
```java
import static io.qdrant.client.ShardKeyFactory.shardKey;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.ShardingMethod;
import io.qdrant.client.grpc.Collections.CreateShardKey;
import io.qdrant.client.grpc.Collections.CreateShardKeyRequest;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
// ... other collection parameters
.setShardNumber(1)
.setShardingMethod(ShardingMethod.Custom)
.build())
.get();
client.createShardKeyAsync(CreateShardKeyRequest.newBuilder()
.setCollectionName("{collection_name}")
.setRequest(CreateShardKey.newBuilder()
.setShardKey(shardKey("{shard_key}"))
.build())
.build()).get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
// ... other collection parameters
shardNumber: 1,
shardingMethod: ShardingMethod.Custom
);
await client.CreateShardKeyAsync(
"{collection_name}",
new CreateShardKey { ShardKey = new ShardKey { Keyword = "{shard_key}", } }
);
```
In this mode, the `shard_number` means the number of shards per shard key, where points will be distributed evenly. For example, if you have 10 shard keys and a collection config with these settings:
```json
{
"shard_number": 1,
"sharding_method": "custom",
"replication_factor": 2
}
```
Then you will have `1 * 10 * 2 = 20` total physical shards in the collection.
Physical shards require a large amount of resources, so make sure your custom sharding key has a low cardinality.
For large cardinality keys, it is recommended to use [partition by payload](/documentation/guides/multiple-partitions/#partition-by-payload) instead.
To specify the shard for each point, you need to provide the `shard_key` field in the upsert request:
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1111,
"vector": [0.1, 0.2, 0.3]
},
]
"shard_key": "user_1"
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1111,
vector=[0.1, 0.2, 0.3],
),
],
shard_key_selector="user_1",
)
```
```typescript
client.upsertPoints("{collection_name}", {
points: [
{
id: 1111,
vector: [0.1, 0.2, 0.3],
},
],
shard_key: "user_1",
});
```
```rust
use qdrant_client::qdrant::{PointStruct, WriteOrdering, WriteOrderingType};
client
.upsert_points_blocking(
"{collection_name}",
Some(vec![shard_key::Key::String("user_1".into())]),
vec![
PointStruct::new(
1111,
vec![0.1, 0.2, 0.3],
Default::default(),
),
],
None,
)
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ShardKeySelectorFactory.shardKeySelector;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
import io.qdrant.client.grpc.Points.UpsertPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
UpsertPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllPoints(
List.of(
PointStruct.newBuilder()
.setId(id(111))
.setVectors(vectors(0.1f, 0.2f, 0.3f))
.build()))
.setShardKeySelector(shardKeySelector("user_1"))
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new() { Id = 111, Vectors = new[] { 0.1f, 0.2f, 0.3f } }
},
shardKeySelector: new ShardKeySelector { ShardKeys = { new List<ShardKey> { "user_id" } } }
);
```
<aside role="alert">
Using the same point ID across multiple shard keys is <strong>not supported<sup>*</sup></strong> and should be avoided.
</aside>
<sup>
<strong>*</strong> When using custom sharding, IDs are only enforced to be unique within a shard key. This means that you can have multiple points with the same ID, if they have different shard keys.
This is a limitation of the current implementation, and is an anti-pattern that should be avoided because it can create scenarios of points with the same ID to have different contents. In the future, we plan to add a global ID uniqueness check.
</sup>
Now you can target the operations to specific shard(s) by specifying the `shard_key` on any operation you do. Operations that do not specify the shard key will be executed on __all__ shards.
Another use-case would be to have shards that track the data chronologically, so that you can do more complex itineraries like uploading live data in one shard and archiving it once a certain age has passed.
<img src="/docs/sharding-per-day.png" alt="Sharding per day" width="500" height="600">
### Shard transfer method
*Available as of v1.7.0*
There are different methods for transferring a shard, such as moving or
replicating, to another node. Depending on what performance and guarantees you'd
like to have and how you'd like to manage your cluster, you likely want to
choose a specific method. Each method has its own pros and cons. Which is
fastest depends on the size and state of a shard.
Available shard transfer methods are:
- `stream_records`: _(default)_ transfer by streaming just its records to the target node in batches.
- `snapshot`: transfer including its index and quantized data by utilizing a [snapshot](../../concepts/snapshots/) automatically.
- `wal_delta`: _(auto recovery default)_ transfer by resolving [WAL] difference; the operations that were missed.
Each has pros, cons and specific requirements, some of which are:
| Method: | Stream records | Snapshot | WAL delta |
|:---|:---|:---|:---|
| **Version** | v0.8.0+ | v1.7.0+ | v1.8.0+ |
| **Target** | New/existing shard | New/existing shard | Existing shard |
| **Connectivity** | Internal gRPC API <small>(<abbr title="port">6335</abbr>)</small> | REST API <small>(<abbr title="port">6333</abbr>)</small><br>Internal gRPC API <small>(<abbr title="port">6335</abbr>)</small> | Internal gRPC API <small>(<abbr title="port">6335</abbr>)</small> |
| **HNSW index** | Doesn't transfer, will reindex on target. | Does transfer, immediately ready on target. | Doesn't transfer, may index on target. |
| **Quantization** | Doesn't transfer, will requantize on target. | Does transfer, immediately ready on target. | Doesn't transfer, may quantize on target. |
| **Ordering** | Unordered updates on target[^unordered] | Ordered updates on target[^ordered] | Ordered updates on target[^ordered] |
| **Disk space** | No extra required | Extra required for snapshot on both nodes | No extra required |
[^unordered]: Weak ordering for updates: All records are streamed to the target node in order.
New updates are received on the target node in parallel, while the transfer
of records is still happening. We therefore have `weak` ordering, regardless
of what [ordering](#write-ordering) is used for updates.
[^ordered]: Strong ordering for updates: A snapshot of the shard
is created, it is transferred and recovered on the target node. That ensures
the state of the shard is kept consistent. New updates are queued on the
source node, and transferred in order to the target node. Updates therefore
have the same [ordering](#write-ordering) as the user selects, making
`strong` ordering possible.
To select a shard transfer method, specify the `method` like:
```http
POST /collections/{collection_name}/cluster
{
"move_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995,
"method": "snapshot"
}
}
```
The `stream_records` transfer method is the simplest available. It simply
transfers all shard records in batches to the target node until it has
transferred all of them, keeping both shards in sync. It will also make sure the
transferred shard indexing process is keeping up before performing a final
switch. The method has two common disadvantages: 1. It does not transfer index
or quantization data, meaning that the shard has to be optimized again on the
new node, which can be very expensive. 2. The ordering guarantees are
`weak`[^unordered], which is not suitable for some applications. Because it is
so simple, it's also very robust, making it a reliable choice if the above cons
are acceptable in your use case. If your cluster is unstable and out of
resources, it's probably best to use the `stream_records` transfer method,
because it is unlikely to fail.
The `snapshot` transfer method utilizes [snapshots](../../concepts/snapshots/)
to transfer a shard. A snapshot is created automatically. It is then transferred
and restored on the target node. After this is done, the snapshot is removed
from both nodes. While the snapshot/transfer/restore operation is happening, the
source node queues up all new operations. All queued updates are then sent in
order to the target shard to bring it into the same state as the source. There
are two important benefits: 1. It transfers index and quantization data, so that
the shard does not have to be optimized again on the target node, making them
immediately available. This way, Qdrant ensures that there will be no
degradation in performance at the end of the transfer. Especially on large
shards, this can give a huge performance improvement. 2. The ordering guarantees
can be `strong`[^ordered], required for some applications.
The `wal_delta` transfer method only transfers the difference between two
shards. More specifically, it transfers all operations that were missed to the
target shard. The [WAL] of both shards is used to resolve this. There are two
benefits: 1. It will be very fast because it only transfers the difference
rather than all data. 2. The ordering guarantees can be `strong`[^ordered],
required for some applications. Two disadvantages are: 1. It can only be used to
transfer to a shard that already exists on the other node. 2. Applicability is
limited because the WALs normally don't hold more than 64MB of recent
operations. But that should be enough for a node that quickly restarts, to
upgrade for example. If a delta cannot be resolved, this method automatically
falls back to `stream_records` which equals transferring the full shard.
The `stream_records` method is currently used as default. This may change in the
future. As of Qdrant 1.9.0 `wal_delta` is used for automatic shard replications
to recover dead shards.
[WAL]: ../../concepts/storage/#versioning
## Replication
*Available as of v0.11.0*
Qdrant allows you to replicate shards between nodes in the cluster.
Shard replication increases the reliability of the cluster by keeping several copies of a shard spread across the cluster.
This ensures the availability of the data in case of node failures, except if all replicas are lost.
### Replication factor
When you create a collection, you can control how many shard replicas you'd like to store by changing the `replication_factor`. By default, `replication_factor` is set to "1", meaning no additional copy is maintained automatically. You can change that by setting the `replication_factor` when you create a collection.
Currently, the replication factor of a collection can only be configured at creation time.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2,
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=300, distance=models.Distance.COSINE),
shard_number=6,
replication_factor=2,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 300,
distance: "Cosine",
},
shard_number: 6,
replication_factor: 2,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{vectors_config::Config, CreateCollection, Distance, VectorParams, VectorsConfig},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".into(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 300,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
shard_number: Some(6),
replication_factor: Some(2),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(300)
.setDistance(Distance.Cosine)
.build())
.build())
.setShardNumber(6)
.setReplicationFactor(2)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 300, Distance = Distance.Cosine },
shardNumber: 6,
replicationFactor: 2
);
```
This code sample creates a collection with a total of 6 logical shards backed by a total of 12 physical shards.
Since a replication factor of "2" would require twice as much storage space, it is advised to make sure the hardware can host the additional shard replicas beforehand.
### Creating new shard replicas
It is possible to create or delete replicas manually on an existing collection using the [Update collection cluster setup API](https://api.qdrant.tech/master/api-reference/distributed/update-collection-cluster).
A replica can be added on a specific peer by specifying the peer from which to replicate.
```http
POST /collections/{collection_name}/cluster
{
"replicate_shard": {
"shard_id": 0,
"from_peer_id": 381894127,
"to_peer_id": 467122995
}
}
```
<aside role="status">You likely want to select a specific <a href="#shard-transfer-method">shard transfer method</a> to get desired performance and guarantees.</aside>
And a replica can be removed on a specific peer.
```http
POST /collections/{collection_name}/cluster
{
"drop_replica": {
"shard_id": 0,
"peer_id": 381894127
}
}
```
Keep in mind that a collection must contain at least one active replica of a shard.
### Error handling
Replicas can be in different states:
- Active: healthy and ready to serve traffic
- Dead: unhealthy and not ready to serve traffic
- Partial: currently under resynchronization before activation
A replica is marked as dead if it does not respond to internal healthchecks or if it fails to serve traffic.
A dead replica will not receive traffic from other peers and might require a manual intervention if it does not recover automatically.
This mechanism ensures data consistency and availability if a subset of the replicas fail during an update operation.
### Node Failure Recovery
Sometimes hardware malfunctions might render some nodes of the Qdrant cluster unrecoverable.
No system is immune to this.
But several recovery scenarios allow qdrant to stay available for requests and even avoid performance degradation.
Let's walk through them from best to worst.
**Recover with replicated collection**
If the number of failed nodes is less than the replication factor of the collection, then your cluster should still be able to perform read, search and update queries.
Now, if the failed node restarts, consensus will trigger the replication process to update the recovering node with the newest updates it has missed.
If the failed node never restarts, you can recover the lost shards if you have a 3+ node cluster. You cannot recover lost shards in smaller clusters because recovery operations go through [raft](#raft) which requires >50% of the nodes to be healthy.
**Recreate node with replicated collections**
If a node fails and it is impossible to recover it, you should exclude the dead node from the consensus and create an empty node.
To exclude failed nodes from the consensus, use [remove peer](https://api.qdrant.tech/master/api-reference/distributed/remove-peer) API.
Apply the `force` flag if necessary.
When you create a new node, make sure to attach it to the existing cluster by specifying `--bootstrap` CLI parameter with the URL of any of the running cluster nodes.
Once the new node is ready and synchronized with the cluster, you might want to ensure that the collection shards are replicated enough. Remember that Qdrant will not automatically balance shards since this is an expensive operation.
Use the [Replicate Shard Operation](https://api.qdrant.tech/master/api-reference/distributed/update-collection-cluster) to create another copy of the shard on the newly connected node.
It's worth mentioning that Qdrant only provides the necessary building blocks to create an automated failure recovery.
Building a completely automatic process of collection scaling would require control over the cluster machines themself.
Check out our [cloud solution](https://qdrant.to/cloud), where we made exactly that.
**Recover from snapshot**
If there are no copies of data in the cluster, it is still possible to recover from a snapshot.
Follow the same steps to detach failed node and create a new one in the cluster:
* To exclude failed nodes from the consensus, use [remove peer](https://api.qdrant.tech/master/api-reference/distributed/remove-peer) API. Apply the `force` flag if necessary.
* Create a new node, making sure to attach it to the existing cluster by specifying the `--bootstrap` CLI parameter with the URL of any of the running cluster nodes.
Snapshot recovery, used in single-node deployment, is different from cluster one.
Consensus manages all metadata about all collections and does not require snapshots to recover it.
But you can use snapshots to recover missing shards of the collections.
Use the [Collection Snapshot Recovery API](../../concepts/snapshots/#recover-in-cluster-deployment) to do it.
The service will download the specified snapshot of the collection and recover shards with data from it.
Once all shards of the collection are recovered, the collection will become operational again.
### Temporary node failure
If properly configured, running Qdrant in distributed mode can make your cluster resistant to outages when one node fails temporarily.
Here is how differently-configured Qdrant clusters respond:
* 1-node clusters: All operations time out or fail for up to a few minutes. It depends on how long it takes to restart and load data from disk.
* 2-node clusters where shards ARE NOT replicated: All operations will time out or fail for up to a few minutes. It depends on how long it takes to restart and load data from disk.
* 2-node clusters where all shards ARE replicated to both nodes: All requests except for operations on collections continue to work during the outage.
* 3+-node clusters where all shards are replicated to at least 2 nodes: All requests continue to work during the outage.
## Consistency guarantees
By default, Qdrant focuses on availability and maximum throughput of search operations.
For the majority of use cases, this is a preferable trade-off.
During the normal state of operation, it is possible to search and modify data from any peers in the cluster.
Before responding to the client, the peer handling the request dispatches all operations according to the current topology in order to keep the data synchronized across the cluster.
- reads are using a partial fan-out strategy to optimize latency and availability
- writes are executed in parallel on all active sharded replicas

However, in some cases, it is necessary to ensure additional guarantees during possible hardware instabilities, mass concurrent updates of same documents, etc.
Qdrant provides a few options to control consistency guarantees:
- `write_consistency_factor` - defines the number of replicas that must acknowledge a write operation before responding to the client. Increasing this value will make write operations tolerant to network partitions in the cluster, but will require a higher number of replicas to be active to perform write operations.
- Read `consistency` param, can be used with search and retrieve operations to ensure that the results obtained from all replicas are the same. If this option is used, Qdrant will perform the read operation on multiple replicas and resolve the result according to the selected strategy. This option is useful to avoid data inconsistency in case of concurrent updates of the same documents. This options is preferred if the update operations are frequent and the number of replicas is low.
- Write `ordering` param, can be used with update and delete operations to ensure that the operations are executed in the same order on all replicas. If this option is used, Qdrant will route the operation to the leader replica of the shard and wait for the response before responding to the client. This option is useful to avoid data inconsistency in case of concurrent updates of the same documents. This options is preferred if read operations are more frequent than update and if search performance is critical.
### Write consistency factor
The `write_consistency_factor` represents the number of replicas that must acknowledge a write operation before responding to the client. It is set to one by default.
It can be configured at the collection's creation time.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2,
"write_consistency_factor": 2,
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=300, distance=models.Distance.COSINE),
shard_number=6,
replication_factor=2,
write_consistency_factor=2,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 300,
distance: "Cosine",
},
shard_number: 6,
replication_factor: 2,
write_consistency_factor: 2,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{vectors_config::Config, CreateCollection, Distance, VectorParams, VectorsConfig},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".into(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 300,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
shard_number: Some(6),
replication_factor: Some(2),
write_consistency_factor: Some(2),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(300)
.setDistance(Distance.Cosine)
.build())
.build())
.setShardNumber(6)
.setReplicationFactor(2)
.setWriteConsistencyFactor(2)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 300, Distance = Distance.Cosine },
shardNumber: 6,
replicationFactor: 2,
writeConsistencyFactor: 2
);
```
Write operations will fail if the number of active replicas is less than the `write_consistency_factor`.
### Read consistency
Read `consistency` can be specified for most read requests and will ensure that the returned result
is consistent across cluster nodes.
- `all` will query all nodes and return points, which present on all of them
- `majority` will query all nodes and return points, which present on the majority of them
- `quorum` will query randomly selected majority of nodes and return points, which present on all of them
- `1`/`2`/`3`/etc - will query specified number of randomly selected nodes and return points which present on all of them
- default `consistency` is `1`
```http
POST /collections/{collection_name}/points/search?consistency=majority
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
```
```python
client.search(
collection_name="{collection_name}",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(
value="London",
),
)
]
),
search_params=models.SearchParams(hnsw_ef=128, exact=False),
query_vector=[0.2, 0.1, 0.9, 0.7],
limit=3,
consistency="majority",
)
```
```typescript
client.search("{collection_name}", {
filter: {
must: [{ key: "city", match: { value: "London" } }],
},
params: {
hnsw_ef: 128,
exact: false,
},
vector: [0.2, 0.1, 0.9, 0.7],
limit: 3,
consistency: "majority",
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
read_consistency::Value, Condition, Filter, ReadConsistency, ReadConsistencyType,
SearchParams, SearchPoints,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".into(),
filter: Some(Filter::must([Condition::matches(
"city",
"London".into(),
)])),
params: Some(SearchParams {
hnsw_ef: Some(128),
exact: Some(false),
..Default::default()
}),
vector: vec![0.2, 0.1, 0.9, 0.7],
limit: 3,
read_consistency: Some(ReadConsistency {
value: Some(Value::Type(ReadConsistencyType::Majority.into())),
}),
..Default::default()
})
.await?;
```
```java
import java.util.List;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.ReadConsistency;
import io.qdrant.client.grpc.Points.ReadConsistencyType;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.setFilter(Filter.newBuilder().addMust(matchKeyword("city", "London")).build())
.setParams(SearchParams.newBuilder().setHnswEf(128).setExact(true).build())
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setLimit(3)
.setReadConsistency(
ReadConsistency.newBuilder().setType(ReadConsistencyType.Majority).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
filter: MatchKeyword("city", "London"),
searchParams: new SearchParams { HnswEf = 128, Exact = true },
limit: 3,
readConsistency: new ReadConsistency { Type = ReadConsistencyType.Majority }
);
```
### Write ordering
Write `ordering` can be specified for any write request to serialize it through a single "leader" node,
which ensures that all write operations (issued with the same `ordering`) are performed and observed
sequentially.
- `weak` _(default)_ ordering does not provide any additional guarantees, so write operations can be freely reordered.
- `medium` ordering serializes all write operations through a dynamically elected leader, which might cause minor inconsistencies in case of leader change.
- `strong` ordering serializes all write operations through the permanent leader, which provides strong consistency, but write operations may be unavailable if the leader is down.
<aside role="status">Some <a href="#shard-transfer-method">shard transfer methods</a> may affect ordering guarantees.</aside>
```http
PUT /collections/{collection_name}/points?ordering=strong
{
"batch": {
"ids": [1, 2, 3],
"payloads": [
{"color": "red"},
{"color": "green"},
{"color": "blue"}
],
"vectors": [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9]
]
}
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=models.Batch(
ids=[1, 2, 3],
payloads=[
{"color": "red"},
{"color": "green"},
{"color": "blue"},
],
vectors=[
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9],
],
),
ordering=models.WriteOrdering.STRONG,
)
```
```typescript
client.upsert("{collection_name}", {
batch: {
ids: [1, 2, 3],
payloads: [{ color: "red" }, { color: "green" }, { color: "blue" }],
vectors: [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9],
],
},
ordering: "strong",
});
```
```rust
use qdrant_client::qdrant::{PointStruct, WriteOrdering, WriteOrderingType};
use serde_json::json;
client
.upsert_points_blocking(
"{collection_name}",
None,
vec![
PointStruct::new(
1,
vec![0.9, 0.1, 0.1],
json!({
"color": "red"
})
.try_into()
.unwrap(),
),
PointStruct::new(
2,
vec![0.1, 0.9, 0.1],
json!({
"color": "green"
})
.try_into()
.unwrap(),
),
PointStruct::new(
3,
vec![0.1, 0.1, 0.9],
json!({
"color": "blue"
})
.try_into()
.unwrap(),
),
],
Some(WriteOrdering {
r#type: WriteOrderingType::Strong.into(),
}),
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.ValueFactory.value;
import static io.qdrant.client.VectorsFactory.vectors;
import io.qdrant.client.grpc.Points.PointStruct;
import io.qdrant.client.grpc.Points.UpsertPoints;
import io.qdrant.client.grpc.Points.WriteOrdering;
import io.qdrant.client.grpc.Points.WriteOrderingType;
client
.upsertAsync(
UpsertPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllPoints(
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(0.9f, 0.1f, 0.1f))
.putAllPayload(Map.of("color", value("red")))
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(vectors(0.1f, 0.9f, 0.1f))
.putAllPayload(Map.of("color", value("green")))
.build(),
PointStruct.newBuilder()
.setId(id(3))
.setVectors(vectors(0.1f, 0.1f, 0.94f))
.putAllPayload(Map.of("color", value("blue")))
.build()))
.setOrdering(WriteOrdering.newBuilder().setType(WriteOrderingType.Strong).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new[] { 0.9f, 0.1f, 0.1f },
Payload = { ["city"] = "red" }
},
new()
{
Id = 2,
Vectors = new[] { 0.1f, 0.9f, 0.1f },
Payload = { ["city"] = "green" }
},
new()
{
Id = 3,
Vectors = new[] { 0.1f, 0.1f, 0.9f },
Payload = { ["city"] = "blue" }
}
},
ordering: WriteOrderingType.Strong
);
```
## Listener mode
<aside role="alert">This is an experimental feature, its behavior may change in the future.</aside>
In some cases it might be useful to have a Qdrant node that only accumulates data and does not participate in search operations.
There are several scenarios where this can be useful:
- Listener option can be used to store data in a separate node, which can be used for backup purposes or to store data for a long time.
- Listener node can be used to syncronize data into another region, while still performing search operations in the local region.
To enable listener mode, set `node_type` to `Listener` in the config file:
```yaml
storage:
node_type: "Listener"
```
Listener node will not participate in search operations, but will still accept write operations and will store the data in the local storage.
All shards, stored on the listener node, will be converted to the `Listener` state.
Additionally, all write requests sent to the listener node will be processed with `wait=false` option, which means that the write oprations will be considered successful once they are written to WAL.
This mechanism should allow to minimize upsert latency in case of parallel snapshotting.
## Consensus Checkpointing
Consensus checkpointing is a technique used in Raft to improve performance and simplify log management by periodically creating a consistent snapshot of the system state.
This snapshot represents a point in time where all nodes in the cluster have reached agreement on the state, and it can be used to truncate the log, reducing the amount of data that needs to be stored and transferred between nodes.
For example, if you attach a new node to the cluster, it should replay all the log entries to catch up with the current state.
In long-running clusters, this can take a long time, and the log can grow very large.
To prevent this, one can use a special checkpointing mechanism, that will truncate the log and create a snapshot of the current state.
To use this feature, simply call the `/cluster/recover` API on required node:
```http
POST /cluster/recover
```
This API can be triggered on any non-leader node, it will send a request to the current consensus leader to create a snapshot. The leader will in turn send the snapshot back to the requesting node for application.
In some cases, this API can be used to recover from an inconsistent cluster state by forcing a snapshot creation.
|
qdrant-landing/content/documentation/guides/installation.md | ---
title: Installation
weight: 10
aliases:
- ../install
- ../installation
---
## Installation requirements
The following sections describe the requirements for deploying Qdrant.
### CPU and memory
The CPU and RAM that you need depends on:
- Number of vectors
- Vector dimensions
- [Payloads](/documentation/concepts/payload/) and their indexes
- Storage
- Replication
- How you configure quantization
Our [Cloud Pricing Calculator](https://cloud.qdrant.io/calculator) can help you estimate required resources without payload or index data.
### Storage
For persistent storage, Qdrant requires block-level access to storage devices with a [POSIX-compatible file system](https://www.quobyte.com/storage-explained/posix-filesystem/). Network systems such as [iSCSI](https://en.wikipedia.org/wiki/ISCSI) that provide block-level access are also acceptable.
Qdrant won't work with [Network file systems](https://en.wikipedia.org/wiki/File_system#Network_file_systems) such as NFS, or [Object storage](https://en.wikipedia.org/wiki/Object_storage) systems such as S3.
If you offload vectors to a local disk, we recommend you use a solid-state (SSD or NVMe) drive.
### Networking
Each Qdrant instance requires three open ports:
* `6333` - For the HTTP API, for the [Monitoring](/documentation/guides/monitoring/) health and metrics endpoints
* `6334` - For the [gRPC](/documentation/interfaces/#grpc-interface) API
* `6335` - For [Distributed deployment](/documentation/guides/distributed_deployment/)
All Qdrant instances in a cluster must be able to:
- Communicate with each other over these ports
- Allow incoming connections to ports `6333` and `6334` from clients that use Qdrant.
### Security
The default configuration of Qdrant might not be secure enough for every situation. Please see [our security documentation](/documentation/guides/security/) for more information.
## Installation options
Qdrant can be installed in different ways depending on your needs:
For production, you can use our Qdrant Cloud to run Qdrant either fully managed in our infrastructure or with Hybrid Cloud in yours.
For testing or development setups, you can run the Qdrant container or as a binary executable.
If you want to run Qdrant in your own infrastructure, without any cloud connection, we recommend to install Qdrant in a Kubernetes cluster with our Helm chart, or to use our Qdrant Enterprise Operator
## Production
For production, we recommend that you configure Qdrant in the cloud, with Kubernetes, or with a Qdrant Enterprise Operator.
### Qdrant Cloud
You can set up production with the [Qdrant Cloud](https://qdrant.to/cloud), which provides fully managed Qdrant databases.
It provides horizontal and vertical scaling, one click installation and upgrades, monitoring, logging, as well as backup and disaster recovery. For more information, see the [Qdrant Cloud documentation](/documentation/cloud/).
### Kubernetes
You can use a ready-made [Helm Chart](https://helm.sh/docs/) to run Qdrant in your Kubernetes cluster:
```bash
helm repo add qdrant https://qdrant.to/helm
helm install qdrant qdrant/qdrant
```
For more information, see the [qdrant-helm](https://github.com/qdrant/qdrant-helm/tree/main/charts/qdrant) README.
### Qdrant Kubernetes Operator
We provide a Qdrant Enterprise Operator for Kubernetes installations. For more information, [use this form](https://qdrant.to/contact-us) to contact us.
### Docker and Docker Compose
Usually, we recommend to run Qdrant in Kubernetes, or use the Qdrant Cloud for production setups. This makes setting up highly available and scalable Qdrant clusters with backups and disaster recovery a lot easier.
However, you can also use Docker and Docker Compose to run Qdrant in production, by following the setup instructions in the [Docker](#docker) and [Docker Compose](#docker-compose) Development sections.
In addition, you have to make sure:
* To use a performant [persistent storage](#storage) for your data
* To configure the [security settings](/documentation/guides/security/) for your deployment
* To set up and configure Qdrant on multiple nodes for a highly available [distributed deployment](/documentation/guides/distributed_deployment/)
* To set up a load balancer for your Qdrant cluster
* To create a [backup and disaster recovery strategy](/documentation/concepts/snapshots/) for your data
* To integrate Qdrant with your [monitoring](/documentation/guides/monitoring/) and logging solutions
## Development
For development and testing, we recommend that you set up Qdrant in Docker. We also have different client libraries.
### Docker
The easiest way to start using Qdrant for testing or development is to run the Qdrant container image.
The latest versions are always available on [DockerHub](https://hub.docker.com/r/qdrant/qdrant/tags?page=1&ordering=last_updated).
Make sure that [Docker](https://docs.docker.com/engine/install/), [Podman](https://podman.io/docs/installation) or the container runtime of your choice is installed and running. The following instructions use Docker.
Pull the image:
```bash
docker pull qdrant/qdrant
```
In the following command, revise `$(pwd)/path/to/data` for your Docker configuration. Then use the updated command to run the container:
```bash
docker run -p 6333:6333 \
-v $(pwd)/path/to/data:/qdrant/storage \
qdrant/qdrant
```
With this command, you start a Qdrant instance with the default configuration.
It stores all data in the `./path/to/data` directory.
By default, Qdrant uses port 6333, so at [localhost:6333](http://localhost:6333) you should see the welcome message.
To change the Qdrant configuration, you can overwrite the production configuration:
```bash
docker run -p 6333:6333 \
-v $(pwd)/path/to/data:/qdrant/storage \
-v $(pwd)/path/to/custom_config.yaml:/qdrant/config/production.yaml \
qdrant/qdrant
```
Alternatively, you can use your own `custom_config.yaml` configuration file:
```bash
docker run -p 6333:6333 \
-v $(pwd)/path/to/data:/qdrant/storage \
-v $(pwd)/path/to/custom_config.yaml:/qdrant/config/custom_config.yaml \
qdrant/qdrant \
./qdrant --config-path config/custom_config.yaml
```
For more information, see the [Configuration](/documentation/guides/configuration/) documentation.
### Docker Compose
You can also use [Docker Compose](https://docs.docker.com/compose/) to run Qdrant.
Here is an example customized compose file for a single node Qdrant cluster:
```yaml
services:
qdrant:
image: qdrant/qdrant:latest
restart: always
container_name: qdrant
ports:
- 6333:6333
- 6334:6334
expose:
- 6333
- 6334
- 6335
configs:
- source: qdrant_config
target: /qdrant/config/production.yaml
volumes:
- ./qdrant_data:/qdrant/storage
configs:
qdrant_config:
content: |
log_level: INFO
```
<aside role="status">Proving the inline <code>content</code> in the <a href="https://docs.docker.com/compose/compose-file/08-configs/">configs top-level element</a> requires <a href="https://docs.docker.com/compose/release-notes/#2231">Docker Compose v2.23.1</a> or above. This functionality is supported starting <a href="https://docs.docker.com/engine/release-notes/25.0/#2500">Docker Engine v25.0.0</a> and <a href="https://docs.docker.com/desktop/release-notes/#4260">Docker Desktop v4.26.0</a> onwards.</aside>
### From source
Qdrant is written in Rust and can be compiled into a binary executable.
This installation method can be helpful if you want to compile Qdrant for a specific processor architecture or if you do not want to use Docker.
Before compiling, make sure that the necessary libraries and the [rust toolchain](https://www.rust-lang.org/tools/install) are installed.
The current list of required libraries can be found in the [Dockerfile](https://github.com/qdrant/qdrant/blob/master/Dockerfile).
Build Qdrant with Cargo:
```bash
cargo build --release --bin qdrant
```
After a successful build, you can find the binary in the following subdirectory `./target/release/qdrant`.
## Client libraries
In addition to the service, Qdrant provides a variety of client libraries for different programming languages. For a full list, see our [Client libraries](../../interfaces/#client-libraries) documentation.
|
qdrant-landing/content/documentation/guides/monitoring.md | ---
title: Monitoring
weight: 155
aliases:
- ../monitoring
---
# Monitoring
Qdrant exposes its metrics in [Prometheus](https://prometheus.io/docs/instrumenting/exposition_formats/#text-based-format)/[OpenMetrics](https://github.com/OpenObservability/OpenMetrics) format, so you can integrate them easily
with the compatible tools and monitor Qdrant with your own monitoring system. You can
use the `/metrics` endpoint and configure it as a scrape target.
Metrics endpoint: <http://localhost:6333/metrics>
The integration with Qdrant is easy to
[configure](https://prometheus.io/docs/prometheus/latest/getting_started/#configure-prometheus-to-monitor-the-sample-targets)
with Prometheus and Grafana.
## Monitoring multi-node clusters
When scraping metrics from multi-node Qdrant clusters, it is important to scrape from
each node individually instead of using a load-balanced URL. Otherwise, your metrics will appear inconsistent after each scrape.
## Monitoring in Qdrant Cloud
To scrape metrics from a Qdrant cluster running in Qdrant Cloud, note that an [API key](/documentation/cloud/authentication/) is required to access `/metrics`. Qdrant Cloud also supports supplying the API key as a [Bearer token](https://www.rfc-editor.org/rfc/rfc6750.html), which may be required by some providers.
## Exposed metrics
Each Qdrant server will expose the following metrics.
| Name | Type | Meaning |
|-------------------------------------|---------|---------------------------------------------------|
| app_info | counter | Information about Qdrant server |
| app_status_recovery_mode | counter | If Qdrant is currently started in recovery mode |
| collections_total | gauge | Number of collections |
| collections_vector_total | gauge | Total number of vectors in all collections |
| collections_full_total | gauge | Number of full collections |
| collections_aggregated_total | gauge | Number of aggregated collections |
| rest_responses_total | counter | Total number of responses through REST API |
| rest_responses_fail_total | counter | Total number of failed responses through REST API |
| rest_responses_avg_duration_seconds | gauge | Average response duration in REST API |
| rest_responses_min_duration_seconds | gauge | Minimum response duration in REST API |
| rest_responses_max_duration_seconds | gauge | Maximum response duration in REST API |
| grpc_responses_total | counter | Total number of responses through gRPC API |
| grpc_responses_fail_total | counter | Total number of failed responses through REST API |
| grpc_responses_avg_duration_seconds | gauge | Average response duration in gRPC API |
| grpc_responses_min_duration_seconds | gauge | Minimum response duration in gRPC API |
| grpc_responses_max_duration_seconds | gauge | Maximum response duration in gRPC API |
| cluster_enabled | gauge | Whether the cluster support is enabled |
### Cluster related metrics
There are also some metrics which are exposed in distributed mode only.
| Name | Type | Meaning |
|----------------------------------|---------|------------------------------------------------------------------------|
| cluster_peers_total | gauge | Total number of cluster peers |
| cluster_term | counter | Current cluster term |
| cluster_commit | counter | Index of last committed (finalized) operation cluster peer is aware of |
| cluster_pending_operations_total | gauge | Total number of pending operations for cluster peer |
| cluster_voter | gauge | Whether the cluster peer is a voter or learner |
## Kubernetes health endpoints
*Available as of v1.5.0*
Qdrant exposes three endpoints, namely
[`/healthz`](http://localhost:6333/healthz),
[`/livez`](http://localhost:6333/livez) and
[`/readyz`](http://localhost:6333/readyz), to indicate the current status of the
Qdrant server.
These currently provide the most basic status response, returning HTTP 200 if
Qdrant is started and ready to be used.
Regardless of whether an [API key](../security/#authentication) is configured,
the endpoints are always accessible.
You can read more about Kubernetes health endpoints
[here](https://kubernetes.io/docs/reference/using-api/health-checks/).
|
qdrant-landing/content/documentation/guides/multiple-partitions.md | ---
title: Multitenancy
weight: 12
aliases:
- ../tutorials/multiple-partitions
- /tutorials/multiple-partitions/
---
# Configure Multitenancy
**How many collections should you create?** In most cases, you should only use a single collection with payload-based partitioning. This approach is called multitenancy. It is efficient for most of users, but it requires additional configuration. This document will show you how to set it up.
**When should you create multiple collections?** When you have a limited number of users and you need isolation. This approach is flexible, but it may be more costly, since creating numerous collections may result in resource overhead. Also, you need to ensure that they do not affect each other in any way, including performance-wise.
## Partition by payload
When an instance is shared between multiple users, you may need to partition vectors by user. This is done so that each user can only access their own vectors and can't see the vectors of other users.
> ### NOTE
>
> The key doesn't necessarily need to be named `group_id`. You can choose a name that best suits your data structure and naming conventions.
1. Add a `group_id` field to each vector in the collection.
```http
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"payload": {"group_id": "user_1"},
"vector": [0.9, 0.1, 0.1]
},
{
"id": 2,
"payload": {"group_id": "user_1"},
"vector": [0.1, 0.9, 0.1]
},
{
"id": 3,
"payload": {"group_id": "user_2"},
"vector": [0.1, 0.1, 0.9]
},
]
}
```
```python
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
payload={"group_id": "user_1"},
vector=[0.9, 0.1, 0.1],
),
models.PointStruct(
id=2,
payload={"group_id": "user_1"},
vector=[0.1, 0.9, 0.1],
),
models.PointStruct(
id=3,
payload={"group_id": "user_2"},
vector=[0.1, 0.1, 0.9],
),
],
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.upsert("{collection_name}", {
points: [
{
id: 1,
payload: { group_id: "user_1" },
vector: [0.9, 0.1, 0.1],
},
{
id: 2,
payload: { group_id: "user_1" },
vector: [0.1, 0.9, 0.1],
},
{
id: 3,
payload: { group_id: "user_2" },
vector: [0.1, 0.1, 0.9],
},
],
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::PointStruct};
use serde_json::json;
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.upsert_points_blocking(
"{collection_name}".to_string(),
None,
vec![
PointStruct::new(
1,
vec![0.9, 0.1, 0.1],
json!(
{"group_id": "user_1"}
)
.try_into()
.unwrap(),
),
PointStruct::new(
2,
vec![0.1, 0.9, 0.1],
json!(
{"group_id": "user_1"}
)
.try_into()
.unwrap(),
),
PointStruct::new(
3,
vec![0.1, 0.1, 0.9],
json!(
{"group_id": "user_2"}
)
.try_into()
.unwrap(),
),
],
None,
)
.await?;
```
```java
import java.util.List;
import java.util.Map;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PointStruct;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(vectors(0.9f, 0.1f, 0.1f))
.putAllPayload(Map.of("group_id", value("user_1")))
.build(),
PointStruct.newBuilder()
.setId(id(2))
.setVectors(vectors(0.1f, 0.9f, 0.1f))
.putAllPayload(Map.of("group_id", value("user_1")))
.build(),
PointStruct.newBuilder()
.setId(id(3))
.setVectors(vectors(0.1f, 0.1f, 0.9f))
.putAllPayload(Map.of("group_id", value("user_2")))
.build()))
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new[] { 0.9f, 0.1f, 0.1f },
Payload = { ["group_id"] = "user_1" }
},
new()
{
Id = 2,
Vectors = new[] { 0.1f, 0.9f, 0.1f },
Payload = { ["group_id"] = "user_1" }
},
new()
{
Id = 3,
Vectors = new[] { 0.1f, 0.1f, 0.9f },
Payload = { ["group_id"] = "user_2" }
}
}
);
```
2. Use a filter along with `group_id` to filter vectors for each user.
```http
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "group_id",
"match": {
"value": "user_1"
}
}
]
},
"vector": [0.1, 0.1, 0.9],
"limit": 10
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="group_id",
match=models.MatchValue(
value="user_1",
),
)
]
),
query_vector=[0.1, 0.1, 0.9],
limit=10,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
filter: {
must: [{ key: "group_id", match: { value: "user_1" } }],
},
vector: [0.1, 0.1, 0.9],
limit: 10,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{Condition, Filter, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
filter: Some(Filter::must([Condition::matches(
"group_id",
"user_1".to_string(),
)])),
vector: vec![0.1, 0.1, 0.9],
limit: 10,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.setFilter(
Filter.newBuilder().addMust(matchKeyword("group_id", "user_1")).build())
.addAllVector(List.of(0.1f, 0.1f, 0.9f))
.setLimit(10)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.1f, 0.1f, 0.9f },
filter: MatchKeyword("group_id", "user_1"),
limit: 10
);
```
## Calibrate performance
The speed of indexation may become a bottleneck in this case, as each user's vector will be indexed into the same collection. To avoid this bottleneck, consider _bypassing the construction of a global vector index_ for the entire collection and building it only for individual groups instead.
By adopting this strategy, Qdrant will index vectors for each user independently, significantly accelerating the process.
To implement this approach, you should:
1. Set `payload_m` in the HNSW configuration to a non-zero value, such as 16.
2. Set `m` in hnsw config to 0. This will disable building global index for the whole collection.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"hnsw_config": {
"payload_m": 16,
"m": 0
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
hnsw_config=models.HnswConfigDiff(
payload_m=16,
m=0,
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
hnsw_config: {
payload_m: 16,
m: 0,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
vectors_config::Config, CreateCollection, Distance, HnswConfigDiff, VectorParams,
VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
hnsw_config: Some(HnswConfigDiff {
payload_m: Some(16),
m: Some(0),
..Default::default()
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.HnswConfigDiff;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setHnswConfig(HnswConfigDiff.newBuilder().setPayloadM(16).setM(0).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
hnswConfig: new HnswConfigDiff { PayloadM = 16, M = 0 }
);
```
3. Create keyword payload index for `group_id` field.
```http
PUT /collections/{collection_name}/index
{
"field_name": "group_id",
"field_schema": "keyword"
}
```
```python
client.create_payload_index(
collection_name="{collection_name}",
field_name="group_id",
field_schema=models.PayloadSchemaType.KEYWORD,
)
```
```typescript
client.createPayloadIndex("{collection_name}", {
field_name: "group_id",
field_schema: "keyword",
});
```
```rust
use qdrant_client::{client::QdrantClient, qdrant::FieldType};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_field_index(
"{collection_name}",
"group_id",
FieldType::Keyword,
None,
None,
)
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}", "group_id", PayloadSchsemaType.Keyword, null, null, null, null)
.get();
```
```csharp
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(collectionName: "{collection_name}", fieldName: "group_id");
```
## Limitations
One downside to this approach is that global requests (without the `group_id` filter) will be slower since they will necessitate scanning all groups to identify the nearest neighbors.
|
qdrant-landing/content/documentation/guides/optimize.md | ---
title: Optimize Resources
weight: 11
aliases:
- ../tutorials/optimize
---
# Optimize Qdrant
Different use cases have different requirements for balancing between memory, speed, and precision.
Qdrant is designed to be flexible and customizable so you can tune it to your needs.

Let's look deeper into each of those possible optimization scenarios.
## Prefer low memory footprint with high speed search
The main way to achieve high speed search with low memory footprint is to keep vectors on disk while at the same time minimizing the number of disk reads.
Vector quantization is one way to achieve this. Quantization converts vectors into a more compact representation, which can be stored in memory and used for search. With smaller vectors you can cache more in RAM and reduce the number of disk reads.
To configure in-memory quantization, with on-disk original vectors, you need to create a collection with the following configuration:
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine",
"on_disk": true
},
"quantization_config": {
"scalar": {
"type": "int8",
"always_ram": true
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
always_ram=True,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
on_disk: true,
},
quantization_config: {
scalar: {
type: "int8",
always_ram: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, CreateCollection, Distance,
OptimizersConfigDiff, QuantizationConfig, QuantizationType, ScalarQuantization,
VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
on_disk: Some(true),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Scalar(ScalarQuantization {
r#type: QuantizationType::Int8.into(),
always_ram: Some(true),
..Default::default()
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.QuantizationType;
import io.qdrant.client.grpc.Collections.ScalarQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.setOnDisk(true)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setScalar(
ScalarQuantization.newBuilder()
.setType(QuantizationType.Int8)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true },
quantizationConfig: new QuantizationConfig
{
Scalar = new ScalarQuantization { Type = QuantizationType.Int8, AlwaysRam = true }
}
);
```
`on_disk` will ensure that vectors will be stored on disk, while `always_ram` will ensure that quantized vectors will be stored in RAM.
Optionally, you can disable rescoring with search `params`, which will reduce the number of disk reads even further, but potentially slightly decrease the precision.
```http
POST /collections/{collection_name}/points/search
{
"params": {
"quantization": {
"rescore": false
}
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 10
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(rescore=False)
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
params: {
quantization: {
rescore: false,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{QuantizationSearchParams, SearchParams, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
params: Some(SearchParams {
quantization: Some(QuantizationSearchParams {
rescore: Some(false),
..Default::default()
}),
..Default::default()
}),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QuantizationSearchParams;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setQuantization(
QuantizationSearchParams.newBuilder().setRescore(false).build())
.build())
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Quantization = new QuantizationSearchParams { Rescore = false }
},
limit: 3
);
```
## Prefer high precision with low memory footprint
In case you need high precision, but don't have enough RAM to store vectors in memory, you can enable on-disk vectors and HNSW index.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine",
"on_disk": true
},
"hnsw_config": {
"on_disk": true
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True),
hnsw_config=models.HnswConfigDiff(on_disk=True),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
on_disk: true,
},
hnsw_config: {
on_disk: true,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
vectors_config::Config, CreateCollection, Distance, HnswConfigDiff, OptimizersConfigDiff,
VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
on_disk: Some(true),
..Default::default()
})),
}),
hnsw_config: Some(HnswConfigDiff {
on_disk: Some(true),
..Default::default()
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.HnswConfigDiff;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.setOnDisk(true)
.build())
.build())
.setHnswConfig(HnswConfigDiff.newBuilder().setOnDisk(true).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true},
hnswConfig: new HnswConfigDiff { OnDisk = true }
);
```
In this scenario you can increase the precision of the search by increasing the `ef` and `m` parameters of the HNSW index, even with limited RAM.
```json
...
"hnsw_config": {
"m": 64,
"ef_construct": 512,
"on_disk": true
}
...
```
The disk IOPS is a critical factor in this scenario, it will determine how fast you can perform search.
You can use [fio](https://gist.github.com/superboum/aaa45d305700a7873a8ebbab1abddf2b) to measure disk IOPS.
## Prefer high precision with high speed search
For high speed and high precision search it is critical to keep as much data in RAM as possible.
By default, Qdrant follows this approach, but you can tune it to your needs.
It is possible to achieve high search speed and tunable accuracy by applying quantization with re-scoring.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine",
"on_disk": true
},
"quantization_config": {
"scalar": {
"type": "int8",
"always_ram": true
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
always_ram=True,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
on_disk: true,
},
quantization_config: {
scalar: {
type: "int8",
always_ram: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, CreateCollection, Distance,
OptimizersConfigDiff, QuantizationConfig, QuantizationType, ScalarQuantization,
VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
on_disk: Some(true),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Scalar(ScalarQuantization {
r#type: QuantizationType::Int8.into(),
always_ram: Some(true),
..Default::default()
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.QuantizationType;
import io.qdrant.client.grpc.Collections.ScalarQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.setOnDisk(true)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setScalar(
ScalarQuantization.newBuilder()
.setType(QuantizationType.Int8)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true},
quantizationConfig: new QuantizationConfig
{
Scalar = new ScalarQuantization { Type = QuantizationType.Int8, AlwaysRam = true }
}
);
```
There are also some search-time parameters you can use to tune the search accuracy and speed:
```http
POST /collections/{collection_name}/points/search
{
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
search_params=models.SearchParams(hnsw_ef=128, exact=False),
query_vector=[0.2, 0.1, 0.9, 0.7],
limit=3,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
params: {
hnsw_ef: 128,
exact: false,
},
limit: 3,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{SearchParams, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
params: Some(SearchParams {
hnsw_ef: Some(128),
exact: Some(false),
..Default::default()
}),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(SearchParams.newBuilder().setHnswEf(128).setExact(false).build())
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams { HnswEf = 128, Exact = false },
limit: 3
);
```
- `hnsw_ef` - controls the number of neighbors to visit during search. The higher the value, the more accurate and slower the search will be. Recommended range is 32-512.
- `exact` - if set to `true`, will perform exact search, which will be slower, but more accurate. You can use it to compare results of the search with different `hnsw_ef` values versus the ground truth.
## Latency vs Throughput
- There are two main approaches to measure the speed of search:
- latency of the request - the time from the moment request is submitted to the moment a response is received
- throughput - the number of requests per second the system can handle
Those approaches are not mutually exclusive, but in some cases it might be preferable to optimize for one or another.
To prefer minimizing latency, you can set up Qdrant to use as many cores as possible for a single request\.
You can do this by setting the number of segments in the collection to be equal to the number of cores in the system. In this case, each segment will be processed in parallel, and the final result will be obtained faster.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"optimizers_config": {
"default_segment_number": 16
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
optimizers_config=models.OptimizersConfigDiff(default_segment_number=16),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
optimizers_config: {
default_segment_number: 16,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
vectors_config::Config, CreateCollection, Distance, OptimizersConfigDiff, VectorParams,
VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
optimizers_config: Some(OptimizersConfigDiff {
default_segment_number: Some(16),
..Default::default()
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setOptimizersConfig(
OptimizersConfigDiff.newBuilder().setDefaultSegmentNumber(16).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
optimizersConfig: new OptimizersConfigDiff { DefaultSegmentNumber = 16 }
);
```
To prefer throughput, you can set up Qdrant to use as many cores as possible for processing multiple requests in parallel.
To do that, you can configure qdrant to use minimal number of segments, which is usually 2.
Large segments benefit from the size of the index and overall smaller number of vector comparisons required to find the nearest neighbors. But at the same time require more time to build index.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"optimizers_config": {
"default_segment_number": 2
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
optimizers_config=models.OptimizersConfigDiff(default_segment_number=2),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
optimizers_config: {
default_segment_number: 2,
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
vectors_config::Config, CreateCollection, Distance, OptimizersConfigDiff, VectorParams,
VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
optimizers_config: Some(OptimizersConfigDiff {
default_segment_number: Some(2),
..Default::default()
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setOptimizersConfig(
OptimizersConfigDiff.newBuilder().setDefaultSegmentNumber(2).build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
optimizersConfig: new OptimizersConfigDiff { DefaultSegmentNumber = 2 }
);
``` |
qdrant-landing/content/documentation/guides/quantization.md | ---
title: Quantization
weight: 120
aliases:
- ../quantization
- /articles/dedicated-service/documentation/guides/quantization/
- /guides/quantization/
---
# Quantization
Quantization is an optional feature in Qdrant that enables efficient storage and search of high-dimensional vectors.
By transforming original vectors into a new representations, quantization compresses data while preserving close to original relative distances between vectors.
Different quantization methods have different mechanics and tradeoffs. We will cover them in this section.
Quantization is primarily used to reduce the memory footprint and accelerate the search process in high-dimensional vector spaces.
In the context of the Qdrant, quantization allows you to optimize the search engine for specific use cases, striking a balance between accuracy, storage efficiency, and search speed.
There are tradeoffs associated with quantization.
On the one hand, quantization allows for significant reductions in storage requirements and faster search times.
This can be particularly beneficial in large-scale applications where minimizing the use of resources is a top priority.
On the other hand, quantization introduces an approximation error, which can lead to a slight decrease in search quality.
The level of this tradeoff depends on the quantization method and its parameters, as well as the characteristics of the data.
## Scalar Quantization
*Available as of v1.1.0*
Scalar quantization, in the context of vector search engines, is a compression technique that compresses vectors by reducing the number of bits used to represent each vector component.
For instance, Qdrant uses 32-bit floating numbers to represent the original vector components. Scalar quantization allows you to reduce the number of bits used to 8.
In other words, Qdrant performs `float32 -> uint8` conversion for each vector component.
Effectively, this means that the amount of memory required to store a vector is reduced by a factor of 4.
In addition to reducing the memory footprint, scalar quantization also speeds up the search process.
Qdrant uses a special SIMD CPU instruction to perform fast vector comparison.
This instruction works with 8-bit integers, so the conversion to `uint8` allows Qdrant to perform the comparison faster.
The main drawback of scalar quantization is the loss of accuracy. The `float32 -> uint8` conversion introduces an error that can lead to a slight decrease in search quality.
However, this error is usually negligible, and tends to be less significant for high-dimensional vectors.
In our experiments, we found that the error introduced by scalar quantization is usually less than 1%.
However, this value depends on the data and the quantization parameters.
Please refer to the [Quantization Tips](#quantization-tips) section for more information on how to optimize the quantization parameters for your use case.
## Binary Quantization
*Available as of v1.5.0*
Binary quantization is an extreme case of scalar quantization.
This feature lets you represent each vector component as a single bit, effectively reducing the memory footprint by a **factor of 32**.
This is the fastest quantization method, since it lets you perform a vector comparison with a few CPU instructions.
Binary quantization can achieve up to a **40x** speedup compared to the original vectors.
However, binary quantization is only efficient for high-dimensional vectors and require a centered distribution of vector components.
At the moment, binary quantization shows good accuracy results with the following models:
- OpenAI `text-embedding-ada-002` - 1536d tested with [dbpedia dataset](https://huggingface.co/datasets/KShivendu/dbpedia-entities-openai-1M) achieving 0.98 recall@100 with 4x oversampling
- Cohere AI `embed-english-v2.0` - 4096d tested on [wikipedia embeddings](https://huggingface.co/datasets/nreimers/wikipedia-22-12-large/tree/main) - 0.98 recall@50 with 2x oversampling
Models with a lower dimensionality or a different distribution of vector components may require additional experiments to find the optimal quantization parameters.
We recommend using binary quantization only with rescoring enabled, as it can significantly improve the search quality
with just a minor performance impact.
Additionally, oversampling can be used to tune the tradeoff between search speed and search quality in the query time.
### Binary Quantization as Hamming Distance
The additional benefit of this method is that you can efficiently emulate Hamming distance with dot product.
Specifically, if original vectors contain `{-1, 1}` as possible values, then the dot product of two vectors is equal to the Hamming distance by simply replacing `-1` with `0` and `1` with `1`.
<!-- hidden section -->
<details>
<summary><b>Sample truth table</b></summary>
| Vector 1 | Vector 2 | Dot product |
|----------|----------|-------------|
| 1 | 1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| Vector 1 | Vector 2 | Hamming distance |
|----------|----------|------------------|
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
</details>
As you can see, both functions are equal up to a constant factor, which makes similarity search equivalent.
Binary quantization makes it efficient to compare vectors using this representation.
## Product Quantization
*Available as of v1.2.0*
Product quantization is a method of compressing vectors to minimize their memory usage by dividing them into
chunks and quantizing each segment individually.
Each chunk is approximated by a centroid index that represents the original vector component.
The positions of the centroids are determined through the utilization of a clustering algorithm such as k-means.
For now, Qdrant uses only 256 centroids, so each centroid index can be represented by a single byte.
Product quantization can compress by a more prominent factor than a scalar one.
But there are some tradeoffs. Product quantization distance calculations are not SIMD-friendly, so it is slower than scalar quantization.
Also, product quantization has a loss of accuracy, so it is recommended to use it only for high-dimensional vectors.
Please refer to the [Quantization Tips](#quantization-tips) section for more information on how to optimize the quantization parameters for your use case.
## How to choose the right quantization method
Here is a brief table of the pros and cons of each quantization method:
| Quantization method | Accuracy | Speed | Compression |
|---------------------|----------|--------------|-------------|
| Scalar | 0.99 | up to x2 | 4 |
| Product | 0.7 | 0.5 | up to 64 |
| Binary | 0.95* | up to x40 | 32 |
`*` - for compatible models
* **Binary Quantization** is the fastest method and the most memory-efficient, but it requires a centered distribution of vector components. It is recommended to use with tested models only.
* **Scalar Quantization** is the most universal method, as it provides a good balance between accuracy, speed, and compression. It is recommended as default quantization if binary quantization is not applicable.
* **Product Quantization** may provide a better compression ratio, but it has a significant loss of accuracy and is slower than scalar quantization. It is recommended if the memory footprint is the top priority and the search speed is not critical.
## Setting up Quantization in Qdrant
You can configure quantization for a collection by specifying the quantization parameters in the `quantization_config` section of the collection configuration.
Quantization will be automatically applied to all vectors during the indexation process.
Quantized vectors are stored alongside the original vectors in the collection, so you will still have access to the original vectors if you need them.
*Available as of v1.1.1*
The `quantization_config` can also be set on a per vector basis by specifying it in a named vector.
### Setting up Scalar Quantization
To enable scalar quantization, you need to specify the quantization parameters in the `quantization_config` section of the collection configuration.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"quantization_config": {
"scalar": {
"type": "int8",
"quantile": 0.99,
"always_ram": true
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
quantile=0.99,
always_ram=True,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
quantization_config: {
scalar: {
type: "int8",
quantile: 0.99,
always_ram: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, CreateCollection, Distance,
QuantizationConfig, QuantizationType, ScalarQuantization, VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Scalar(ScalarQuantization {
r#type: QuantizationType::Int8.into(),
quantile: Some(0.99),
always_ram: Some(true),
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.QuantizationType;
import io.qdrant.client.grpc.Collections.ScalarQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setScalar(
ScalarQuantization.newBuilder()
.setType(QuantizationType.Int8)
.setQuantile(0.99f)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Scalar = new ScalarQuantization
{
Type = QuantizationType.Int8,
Quantile = 0.99f,
AlwaysRam = true
}
}
);
```
There are 3 parameters that you can specify in the `quantization_config` section:
`type` - the type of the quantized vector components. Currently, Qdrant supports only `int8`.
`quantile` - the quantile of the quantized vector components.
The quantile is used to calculate the quantization bounds.
For instance, if you specify `0.99` as the quantile, 1% of extreme values will be excluded from the quantization bounds.
Using quantiles lower than `1.0` might be useful if there are outliers in your vector components.
This parameter only affects the resulting precision and not the memory footprint.
It might be worth tuning this parameter if you experience a significant decrease in search quality.
`always_ram` - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors.
However, in some setups you might want to keep quantized vectors in RAM to speed up the search process.
In this case, you can set `always_ram` to `true` to store quantized vectors in RAM.
### Setting up Binary Quantization
To enable binary quantization, you need to specify the quantization parameters in the `quantization_config` section of the collection configuration.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"binary": {
"always_ram": true
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: "Cosine",
},
quantization_config: {
binary: {
always_ram: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, BinaryQuantization,
CreateCollection, Distance, QuantizationConfig, VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 1536,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Binary(BinaryQuantization {
always_ram: Some(true),
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.BinaryQuantization;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(1536)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setBinary(BinaryQuantization.newBuilder().setAlwaysRam(true).build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 1536, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Binary = new BinaryQuantization { AlwaysRam = true }
}
);
```
`always_ram` - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors.
However, in some setups you might want to keep quantized vectors in RAM to speed up the search process.
In this case, you can set `always_ram` to `true` to store quantized vectors in RAM.
### Setting up Product Quantization
To enable product quantization, you need to specify the quantization parameters in the `quantization_config` section of the collection configuration.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"quantization_config": {
"product": {
"compression": "x16",
"always_ram": true
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
quantization_config=models.ProductQuantization(
product=models.ProductQuantizationConfig(
compression=models.CompressionRatio.X16,
always_ram=True,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
quantization_config: {
product: {
compression: "x16",
always_ram: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, CompressionRatio,
CreateCollection, Distance, ProductQuantization, QuantizationConfig, VectorParams,
VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Product(ProductQuantization {
compression: CompressionRatio::X16.into(),
always_ram: Some(true),
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CompressionRatio;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.ProductQuantization;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setProduct(
ProductQuantization.newBuilder()
.setCompression(CompressionRatio.x16)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Product = new ProductQuantization { Compression = CompressionRatio.X16, AlwaysRam = true }
}
);
```
There are two parameters that you can specify in the `quantization_config` section:
`compression` - compression ratio.
Compression ratio represents the size of the quantized vector in bytes divided by the size of the original vector in bytes.
In this case, the quantized vector will be 16 times smaller than the original vector.
`always_ram` - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors.
However, in some setups you might want to keep quantized vectors in RAM to speed up the search process. Then set `always_ram` to `true`.
### Searching with Quantization
Once you have configured quantization for a collection, you don't need to do anything extra to search with quantization.
Qdrant will automatically use quantized vectors if they are available.
However, there are a few options that you can use to control the search process:
```http
POST /collections/{collection_name}/points/search
{
"params": {
"quantization": {
"ignore": false,
"rescore": true,
"oversampling": 2.0
}
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 10
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
ignore=False,
rescore=True,
oversampling=2.0,
)
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
params: {
quantization: {
ignore: false,
rescore: true,
oversampling: 2.0,
},
},
limit: 10,
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{QuantizationSearchParams, SearchParams, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
params: Some(SearchParams {
quantization: Some(QuantizationSearchParams {
ignore: Some(false),
rescore: Some(true),
oversampling: Some(2.0),
..Default::default()
}),
..Default::default()
}),
limit: 10,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QuantizationSearchParams;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setQuantization(
QuantizationSearchParams.newBuilder()
.setIgnore(false)
.setRescore(true)
.setOversampling(2.0)
.build())
.build())
.setLimit(10)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Quantization = new QuantizationSearchParams
{
Ignore = false,
Rescore = true,
Oversampling = 2.0
}
},
limit: 10
);
```
`ignore` - Toggle whether to ignore quantized vectors during the search process. By default, Qdrant will use quantized vectors if they are available.
`rescore` - Having the original vectors available, Qdrant can re-evaluate top-k search results using the original vectors.
This can improve the search quality, but may slightly decrease the search speed, compared to the search without rescore.
It is recommended to disable rescore only if the original vectors are stored on a slow storage (e.g. HDD or network storage).
By default, rescore is enabled.
**Available as of v1.3.0**
`oversampling` - Defines how many extra vectors should be pre-selected using quantized index, and then re-scored using original vectors.
For example, if oversampling is 2.4 and limit is 100, then 240 vectors will be pre-selected using quantized index, and then top-100 will be returned after re-scoring.
Oversampling is useful if you want to tune the tradeoff between search speed and search quality in the query time.
## Quantization tips
#### Accuracy tuning
In this section, we will discuss how to tune the search precision.
The fastest way to understand the impact of quantization on the search quality is to compare the search results with and without quantization.
In order to disable quantization, you can set `ignore` to `true` in the search request:
```http
POST /collections/{collection_name}/points/search
{
"params": {
"quantization": {
"ignore": true
}
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 10
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
ignore=True,
)
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
params: {
quantization: {
ignore: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{QuantizationSearchParams, SearchParams, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
params: Some(SearchParams {
quantization: Some(QuantizationSearchParams {
ignore: Some(true),
..Default::default()
}),
..Default::default()
}),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QuantizationSearchParams;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setQuantization(
QuantizationSearchParams.newBuilder().setIgnore(true).build())
.build())
.setLimit(10)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Quantization = new QuantizationSearchParams { Ignore = true }
},
limit: 10
);
```
- **Adjust the quantile parameter**: The quantile parameter in scalar quantization determines the quantization bounds.
By setting it to a value lower than 1.0, you can exclude extreme values (outliers) from the quantization bounds.
For example, if you set the quantile to 0.99, 1% of the extreme values will be excluded.
By adjusting the quantile, you find an optimal value that will provide the best search quality for your collection.
- **Enable rescore**: Having the original vectors available, Qdrant can re-evaluate top-k search results using the original vectors. On large collections, this can improve the search quality, with just minor performance impact.
#### Memory and speed tuning
In this section, we will discuss how to tune the memory and speed of the search process with quantization.
There are 3 possible modes to place storage of vectors within the qdrant collection:
- **All in RAM** - all vector, original and quantized, are loaded and kept in RAM. This is the fastest mode, but requires a lot of RAM. Enabled by default.
- **Original on Disk, quantized in RAM** - this is a hybrid mode, allows to obtain a good balance between speed and memory usage. Recommended scenario if you are aiming to shrink the memory footprint while keeping the search speed.
This mode is enabled by setting `always_ram` to `true` in the quantization config while using memmap storage:
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine",
"on_disk": true
},
"quantization_config": {
"scalar": {
"type": "int8",
"always_ram": true
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
always_ram=True,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
on_disk: true,
},
quantization_config: {
scalar: {
type: "int8",
always_ram: true,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, CreateCollection, Distance,
OptimizersConfigDiff, QuantizationConfig, QuantizationType, ScalarQuantization,
VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
on_disk: Some(true),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Scalar(ScalarQuantization {
r#type: QuantizationType::Int8.into(),
always_ram: Some(true),
..Default::default()
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.QuantizationType;
import io.qdrant.client.grpc.Collections.ScalarQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.setOnDisk(true)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setScalar(
ScalarQuantization.newBuilder()
.setType(QuantizationType.Int8)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true},
quantizationConfig: new QuantizationConfig
{
Scalar = new ScalarQuantization { Type = QuantizationType.Int8, AlwaysRam = true }
}
);
```
In this scenario, the number of disk reads may play a significant role in the search speed.
In a system with high disk latency, the re-scoring step may become a bottleneck.
Consider disabling `rescore` to improve the search speed:
```http
POST /collections/{collection_name}/points/search
{
"params": {
"quantization": {
"rescore": false
}
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 10
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(rescore=False)
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.search("{collection_name}", {
vector: [0.2, 0.1, 0.9, 0.7],
params: {
quantization: {
rescore: false,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{QuantizationSearchParams, SearchParams, SearchPoints},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.search_points(&SearchPoints {
collection_name: "{collection_name}".to_string(),
vector: vec![0.2, 0.1, 0.9, 0.7],
params: Some(SearchParams {
quantization: Some(QuantizationSearchParams {
rescore: Some(false),
..Default::default()
}),
..Default::default()
}),
limit: 3,
..Default::default()
})
.await?;
```
```java
import java.util.List;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QuantizationSearchParams;
import io.qdrant.client.grpc.Points.SearchParams;
import io.qdrant.client.grpc.Points.SearchPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.searchAsync(
SearchPoints.newBuilder()
.setCollectionName("{collection_name}")
.addAllVector(List.of(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setQuantization(
QuantizationSearchParams.newBuilder().setRescore(false).build())
.build())
.setLimit(3)
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Quantization = new QuantizationSearchParams { Rescore = false }
},
limit: 3
);
```
- **All on Disk** - all vectors, original and quantized, are stored on disk. This mode allows to achieve the smallest memory footprint, but at the cost of the search speed.
It is recommended to use this mode if you have a large collection and fast storage (e.g. SSD or NVMe).
This mode is enabled by setting `always_ram` to `false` in the quantization config while using mmap storage:
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine",
"on_disk": true
},
"quantization_config": {
"scalar": {
"type": "int8",
"always_ram": false
}
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
always_ram=False,
),
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
on_disk: true,
},
quantization_config: {
scalar: {
type: "int8",
always_ram: false,
},
},
});
```
```rust
use qdrant_client::{
client::QdrantClient,
qdrant::{
quantization_config::Quantization, vectors_config::Config, CreateCollection, Distance,
OptimizersConfigDiff, QuantizationConfig, QuantizationType, ScalarQuantization,
VectorParams, VectorsConfig,
},
};
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: "{collection_name}".to_string(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 768,
distance: Distance::Cosine.into(),
on_disk: Some(true),
..Default::default()
})),
}),
quantization_config: Some(QuantizationConfig {
quantization: Some(Quantization::Scalar(ScalarQuantization {
r#type: QuantizationType::Int8.into(),
always_ram: Some(false),
..Default::default()
})),
}),
..Default::default()
})
.await?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.OptimizersConfigDiff;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.QuantizationType;
import io.qdrant.client.grpc.Collections.ScalarQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.setOnDisk(true)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setScalar(
ScalarQuantization.newBuilder()
.setType(QuantizationType.Int8)
.setAlwaysRam(false)
.build())
.build())
.build())
.get();
```
```csharp
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true},
quantizationConfig: new QuantizationConfig
{
Scalar = new ScalarQuantization { Type = QuantizationType.Int8, AlwaysRam = false }
}
);
``` |
qdrant-landing/content/documentation/guides/security.md | ---
title: Security
weight: 165
aliases:
- ../security
---
# Security
Please read this page carefully. Although there are various ways to secure your Qdrant instances, **they are unsecured by default**.
You need to enable security measures before production use. Otherwise, they are completely open to anyone
## Authentication
*Available as of v1.2.0*
Qdrant supports a simple form of client authentication using a static API key.
This can be used to secure your instance.
To enable API key based authentication in your own Qdrant instance you must
specify a key in the configuration:
```yaml
service:
# Set an api-key.
# If set, all requests must include a header with the api-key.
# example header: `api-key: <API-KEY>`
#
# If you enable this you should also enable TLS.
# (Either above or via an external service like nginx.)
# Sending an api-key over an unencrypted channel is insecure.
api_key: your_secret_api_key_here
```
Or alternatively, you can use the environment variable:
```bash
export QDRANT__SERVICE__API_KEY=your_secret_api_key_here
```
<aside role="alert"><a href="#tls">TLS</a> must be used to prevent leaking the API key over an unencrypted connection.</aside>
For using API key based authentication in Qdrant Cloud see the cloud
[Authentication](/documentation/cloud/authentication/)
section.
The API key then needs to be present in all REST or gRPC requests to your instance.
All official Qdrant clients for Python, Go, Rust, .NET and Java support the API key parameter.
<!---
Examples with clients
-->
```bash
curl \
-X GET https://localhost:6333 \
--header 'api-key: your_secret_api_key_here'
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(
url="https://localhost:6333",
api_key="your_secret_api_key_here",
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({
url: "http://localhost",
port: 6333,
apiKey: "your_secret_api_key_here",
});
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("https://xyz-example.eu-central.aws.cloud.qdrant.io:6334")
.with_api_key("<paste-your-api-key-here>")
.build()?;
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(
QdrantGrpcClient.newBuilder(
"xyz-example.eu-central.aws.cloud.qdrant.io",
6334,
true)
.withApiKey("<paste-your-api-key-here>")
.build());
```
```csharp
using Qdrant.Client;
var client = new QdrantClient(
host: "xyz-example.eu-central.aws.cloud.qdrant.io",
https: true,
apiKey: "<paste-your-api-key-here>"
);
```
<aside role="alert">Internal communication channels are <strong>never</strong> protected by an API key nor bearer tokens. Internal gRPC uses port 6335 by default if running in distributed mode. You must ensure that this port is not publicly reachable and can only be used for node communication. By default, this setting is disabled for Qdrant Cloud and the Qdrant Helm chart.</aside>
### Read-only API key
*Available as of v1.7.0*
In addition to the regular API key, Qdrant also supports a read-only API key.
This key can be used to access read-only operations on the instance.
```yaml
service:
read_only_api_key: your_secret_read_only_api_key_here
```
Or with the environment variable:
```bash
export QDRANT__SERVICE__READ_ONLY_API_KEY=your_secret_read_only_api_key_here
```
Both API keys can be used simultaneously.
### Granular access control with JWT
*Available as of v1.9.0*
For more complex cases, Qdrant supports granular access control with [JSON Web Tokens (JWT)](https://jwt.io/).
This allows you to have tokens, which allow restricited access to a specific parts of the stored data and build [Role-based access control (RBAC)](https://en.wikipedia.org/wiki/Role-based_access_control) on top of that.
In this way, you can define permissions for users and restrict access to sensitive endpoints.
To enable JWT-based authentication in your own Qdrant instance you need to specify the `api-key` and enable the `jwt_rbac` feature in the configuration:
```yaml
service:
api_key: you_secret_api_key_here
jwt_rbac: true
```
Or with the environment variables:
```bash
export QDRANT__SERVICE__API_KEY=your_secret_api_key_here
export QDRANT__SERVICE__JWT_RBAC=true
```
The `api_key` you set in the configuration will be used to encode and decode the JWTs, so –needless to say– keep it secure. If your `api_key` changes, all existing tokens will be invalid.
To use JWT-based authentication, you need to provide it as a bearer token in the `Authorization` header, or as an key in the `Api-Key` header of your requests.
```http
Authorization: Bearer <JWT>
// or
Api-Key: <JWT>
```
```python
from qdrant_client import QdrantClient
qdrant_client = QdrantClient(
"xyz-example.eu-central.aws.cloud.qdrant.io",
api_key="<JWT>",
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({
host: "xyz-example.eu-central.aws.cloud.qdrant.io",
apiKey: "<JWT>",
});
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("xyz-example.eu-central.aws.cloud.qdrant.io:6334")
.with_api_key("<JWT>")
.build()
.unwrap();
```
```java
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
QdrantClient client =
new QdrantClient(
QdrantGrpcClient.newBuilder(
"xyz-example.eu-central.aws.cloud.qdrant.io",
6334,
true)
.withApiKey("<JWT>")
.build());
```
```csharp
using Qdrant.Client;
var client = new QdrantClient(
host: "xyz-example.eu-central.aws.cloud.qdrant.io",
https: true,
apiKey: "<JWT>"
);
```
#### Generating JSON Web Tokens
Due to the nature of JWT, anyone who knows the `api_key` can generate tokens by using any of the existing libraries and tools, it is not necessary for them to have access to the Qdrant instance to generate them.
For convenience, we have added a JWT generation tool the Qdrant Web UI under the 🔑 tab, if you're using the default url, it will be at `http://localhost:6333/dashboard#/jwt`.
- **JWT Header** - Qdrant uses the `HS256` algorithm to decode the tokens.
```json
{
"alg": "HS256",
"typ": "JWT"
}
```
- **JWT Payload** - You can include any combination of the [parameters available](#jwt-configuration) in the payload. Keep reading for more info on each one.
```json
{
"exp": 1640995200, // Expiration time
"value_exists": ..., // Validate this token by looking for a point with a payload value
"access": "r", // Define the access level.
}
```
**Signing the token** - To confirm that the generated token is valid, it needs to be signed with the `api_key` you have set in the configuration.
That would mean, that someone who knows the `api_key` gives the authorization for the new token to be used in the Qdrant instance.
Qdrant can validate the signature, because it knows the `api_key` and can decode the token.
The process of token generation can be done on the client side offline, and doesn't require any communication with the Qdrant instance.
Here is an example of libraries that can be used to generate JWT tokens:
- Python: [PyJWT](https://pyjwt.readthedocs.io/en/stable/)
- JavaScript: [jsonwebtoken](https://www.npmjs.com/package/jsonwebtoken)
- Rust: [jsonwebtoken](https://crates.io/crates/jsonwebtoken)
#### JWT Configuration
These are the available options, or **claims** in the JWT lingo. You can use them in the JWT payload to define its functionality.
- **`exp`** - The expiration time of the token. This is a Unix timestamp in seconds. The token will be invalid after this time. The check for this claim includes a 30-second leeway to account for clock skew.
```json
{
"exp": 1640995200, // Expiration time
}
```
- **`value_exists`** - This is a claim that can be used to validate the token against the data stored in a collection. Structure of this claim is as follows:
```json
{
"value_exists": {
"collection": "my_validation_collection",
"matches": [
{ "key": "my_key", "value": "value_that_must_exist" }
],
},
}
```
If this claim is present, Qdrant will check if there is a point in the collection with the specified key-values. If it does, the token is valid.
This claim is especially useful if you want to have an ability to revoke tokens without changing the `api_key`.
Consider a case where you have a collection of users, and you want to revoke access to a specific user.
```json
{
"value_exists": {
"collection": "users",
"matches": [
{ "key": "user_id", "value": "andrey" },
{ "key": "role", "value": "manager" }
],
},
}
```
You can create a token with this claim, and when you want to revoke access, you can change the `role` of the user to something else, and the token will be invalid.
- **`access`** - This claim defines the [access level](#table-of-access) of the token. If this claim is present, Qdrant will check if the token has the required access level to perform the operation. If this claim is **not** present, **manage** access is assumed.
It can provide global access with `r` for read-only, or `m` for manage. For example:
```json
{
"access": "r"
}
```
It can also be specific to one or more collections. The `access` level for each collection is `r` for read-only, or `rw` for read-write, like this:
```json
{
"access": [
{
"collection": "my_collection",
"access": "rw"
}
]
}
```
You can also specify which subset of the collection the user is able to access by specifying a `payload` restriction that the points must have.
```json
{
"access": [
{
"collection": "my_collection",
"access": "r",
"payload": {
"user_id": "user_123456"
}
}
]
}
```
This `payload` claim will be used to implicitly filter the points in the collection. It will be equivalent to appending this filter to each request:
```json
{ "filter": { "must": [{ "key": "user_id", "match": { "value": "user_123456" } }] } }
```
### Table of access
Check out this table to see which actions are allowed or denied based on the access level.
This is also applicable to using api keys instead of tokens. In that case, `api_key` maps to **manage**, while `read_only_api_key` maps to **read-only**.
<div style="text-align: right"> <strong>Symbols:</strong> ✅ Allowed | ❌ Denied | 🟡 Allowed, but filtered </div>
| Action | manage | read-only | collection read-write | collection read-only | collection with payload claim (r / rw) |
|--------|--------|-----------|----------------------|-----------------------|------------------------------------|
| list collections | ✅ | ✅ | 🟡 | 🟡 | 🟡 |
| get collection info | ✅ | ✅ | ✅ | ✅ | ❌ |
| create collection | ✅ | ❌ | ❌ | ❌ | ❌ |
| delete collection | ✅ | ❌ | ❌ | ❌ | ❌ |
| update collection params | ✅ | ❌ | ❌ | ❌ | ❌ |
| get collection cluster info | ✅ | ✅ | ✅ | ✅ | ❌ |
| collection exists | ✅ | ✅ | ✅ | ✅ | ✅ |
| update collection cluster setup | ✅ | ❌ | ❌ | ❌ | ❌ |
| update aliases | ✅ | ❌ | ❌ | ❌ | ❌ |
| list collection aliases | ✅ | ✅ | 🟡 | 🟡 | 🟡 |
| list aliases | ✅ | ✅ | 🟡 | 🟡 | 🟡 |
| create shard key | ✅ | ❌ | ❌ | ❌ | ❌ |
| delete shard key | ✅ | ❌ | ❌ | ❌ | ❌ |
| create payload index | ✅ | ❌ | ✅ | ❌ | ❌ |
| delete payload index | ✅ | ❌ | ✅ | ❌ | ❌ |
| list collection snapshots | ✅ | ✅ | ✅ | ✅ | ❌ |
| create collection snapshot | ✅ | ❌ | ✅ | ❌ | ❌ |
| delete collection snapshot | ✅ | ❌ | ✅ | ❌ | ❌ |
| download collection snapshot | ✅ | ✅ | ✅ | ✅ | ❌ |
| upload collection snapshot | ✅ | ❌ | ❌ | ❌ | ❌ |
| recover collection snapshot | ✅ | ❌ | ❌ | ❌ | ❌ |
| list shard snapshots | ✅ | ✅ | ✅ | ✅ | ❌ |
| create shard snapshot | ✅ | ❌ | ✅ | ❌ | ❌ |
| delete shard snapshot | ✅ | ❌ | ✅ | ❌ | ❌ |
| download shard snapshot | ✅ | ✅ | ✅ | ✅ | ❌ |
| upload shard snapshot | ✅ | ❌ | ❌ | ❌ | ❌ |
| recover shard snapshot | ✅ | ❌ | ❌ | ❌ | ❌ |
| list full snapshots | ✅ | ✅ | ❌ | ❌ | ❌ |
| create full snapshot | ✅ | ❌ | ❌ | ❌ | ❌ |
| delete full snapshot | ✅ | ❌ | ❌ | ❌ | ❌ |
| download full snapshot | ✅ | ✅ | ❌ | ❌ | ❌ |
| get cluster info | ✅ | ✅ | ❌ | ❌ | ❌ |
| recover raft state | ✅ | ❌ | ❌ | ❌ | ❌ |
| delete peer | ✅ | ❌ | ❌ | ❌ | ❌ |
| get point | ✅ | ✅ | ✅ | ✅ | ❌ |
| get points | ✅ | ✅ | ✅ | ✅ | ❌ |
| upsert points | ✅ | ❌ | ✅ | ❌ | ❌ |
| update points batch | ✅ | ❌ | ✅ | ❌ | ❌ |
| delete points | ✅ | ❌ | ✅ | ❌ | ❌ / 🟡 |
| update vectors | ✅ | ❌ | ✅ | ❌ | ❌ |
| delete vectors | ✅ | ❌ | ✅ | ❌ | ❌ / 🟡 |
| set payload | ✅ | ❌ | ✅ | ❌ | ❌ |
| overwrite payload | ✅ | ❌ | ✅ | ❌ | ❌ |
| delete payload | ✅ | ❌ | ✅ | ❌ | ❌ |
| clear payload | ✅ | ❌ | ✅ | ❌ | ❌ |
| scroll points | ✅ | ✅ | ✅ | ✅ | 🟡 |
| search points | ✅ | ✅ | ✅ | ✅ | 🟡 |
| search groups | ✅ | ✅ | ✅ | ✅ | 🟡 |
| recommend points | ✅ | ✅ | ✅ | ✅ | ❌ |
| recommend groups | ✅ | ✅ | ✅ | ✅ | ❌ |
| discover points | ✅ | ✅ | ✅ | ✅ | ❌ |
| count points | ✅ | ✅ | ✅ | ✅ | 🟡 |
| version | ✅ | ✅ | ✅ | ✅ | ✅ |
| readyz, healthz, livez | ✅ | ✅ | ✅ | ✅ | ✅ |
| telemetry | ✅ | ✅ | ❌ | ❌ | ❌ |
| metrics | ✅ | ✅ | ❌ | ❌ | ❌ |
| update locks | ✅ | ❌ | ❌ | ❌ | ❌ |
| get locks | ✅ | ✅ | ❌ | ❌ | ❌ |
## TLS
*Available as of v1.2.0*
TLS for encrypted connections can be enabled on your Qdrant instance to secure
connections.
<aside role="alert">Connections are unencrypted by default. This allows sniffing and <a href="https://en.wikipedia.org/wiki/Man-in-the-middle_attack">MitM</a> attacks.</aside>
First make sure you have a certificate and private key for TLS, usually in
`.pem` format. On your local machine you may use
[mkcert](https://github.com/FiloSottile/mkcert#readme) to generate a self signed
certificate.
To enable TLS, set the following properties in the Qdrant configuration with the
correct paths and restart:
```yaml
service:
# Enable HTTPS for the REST and gRPC API
enable_tls: true
# TLS configuration.
# Required if either service.enable_tls or cluster.p2p.enable_tls is true.
tls:
# Server certificate chain file
cert: ./tls/cert.pem
# Server private key file
key: ./tls/key.pem
```
For internal communication when running cluster mode, TLS can be enabled with:
```yaml
cluster:
# Configuration of the inter-cluster communication
p2p:
# Use TLS for communication between peers
enable_tls: true
```
With TLS enabled, you must start using HTTPS connections. For example:
```bash
curl -X GET https://localhost:6333
```
```python
from qdrant_client import QdrantClient
client = QdrantClient(
url="https://localhost:6333",
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ url: "https://localhost", port: 6333 });
```
```rust
use qdrant_client::client::QdrantClient;
let client = QdrantClient::from_url("https://localhost:6334").build()?;
```
Certificate rotation is enabled with a default refresh time of one hour. This
reloads certificate files every hour while Qdrant is running. This way changed
certificates are picked up when they get updated externally. The refresh time
can be tuned by changing the `tls.cert_ttl` setting. You can leave this on, even
if you don't plan to update your certificates. Currently this is only supported
for the REST API.
Optionally, you can enable client certificate validation on the server against a
local certificate authority. Set the following properties and restart:
```yaml
service:
# Check user HTTPS client certificate against CA file specified in tls config
verify_https_client_certificate: false
# TLS configuration.
# Required if either service.enable_tls or cluster.p2p.enable_tls is true.
tls:
# Certificate authority certificate file.
# This certificate will be used to validate the certificates
# presented by other nodes during inter-cluster communication.
#
# If verify_https_client_certificate is true, it will verify
# HTTPS client certificate
#
# Required if cluster.p2p.enable_tls is true.
ca_cert: ./tls/cacert.pem
```
## Hardening
We recommend reducing the amount of permissions granted to Qdrant containers so that you can reduce the risk of exploitation. Here are some ways to reduce the permissions of a Qdrant container:
* Run Qdrant as a non-root user. This can help mitigate the risk of future container breakout vulnerabilities. Qdrant does not need the privileges of the root user for any purpose.
- You can use the image `qdrant/qdrant:<version>-unprivileged` instead of the default Qdrant image.
- You can use the flag `--user=1000:2000` when running [`docker run`](https://docs.docker.com/reference/cli/docker/container/run/).
- You can set [`user: 1000`](https://docs.docker.com/compose/compose-file/05-services/#user) when using Docker Compose.
- You can set [`runAsUser: 1000`](https://kubernetes.io/docs/tasks/configure-pod-container/security-context) when running in Kubernetes (our [Helm chart](https://github.com/qdrant/qdrant-helm) does this by default).
* Run Qdrant with a read-only root filesystem. This can help mitigate vulnerabilities that require the ability to modify system files, which is a permission Qdrant does not need. As long as the container uses mounted volumes for storage (`/qdrant/storage` and `/qdrant/snapshots` by default), Qdrant can continue to operate while being prevented from writing data outside of those volumes.
- You can use the flag `--read-only` when running [`docker run`](https://docs.docker.com/reference/cli/docker/container/run/).
- You can set [`read_only: true`](https://docs.docker.com/compose/compose-file/05-services/#read_only) when using Docker Compose.
- You can set [`readOnlyRootFilesystem: true`](https://kubernetes.io/docs/tasks/configure-pod-container/security-context) when running in Kubernetes (our [Helm chart](https://github.com/qdrant/qdrant-helm) does this by default).
There are other techniques for reducing the permissions such as dropping [Linux capabilities](https://www.man7.org/linux/man-pages/man7/capabilities.7.html) depending on your deployment method, but running as a non-root user with a read-only root file system are the two most important.
|
qdrant-landing/content/documentation/guides/telemetry.md | ---
title: Telemetry
weight: 150
aliases:
- ../telemetry
---
# Telemetry
Qdrant collects anonymized usage statistics from users in order to improve the engine.
You can [deactivate](#deactivate-telemetry) at any time, and any data that has already been collected can be [deleted on request](#request-information-deletion).
## Why do we collect telemetry?
We want to make Qdrant fast and reliable. To do this, we need to understand how it performs in real-world scenarios.
We do a lot of benchmarking internally, but it is impossible to cover all possible use cases, hardware, and configurations.
In order to identify bottlenecks and improve Qdrant, we need to collect information about how it is used.
Additionally, Qdrant uses a bunch of internal heuristics to optimize the performance.
To better set up parameters for these heuristics, we need to collect timings and counters of various pieces of code.
With this information, we can make Qdrant faster for everyone.
## What information is collected?
There are 3 types of information that we collect:
* System information - general information about the system, such as CPU, RAM, and disk type. As well as the configuration of the Qdrant instance.
* Performance - information about timings and counters of various pieces of code.
* Critical error reports - information about critical errors, such as backtraces, that occurred in Qdrant. This information would allow to identify problems nobody yet reported to us.
### We **never** collect the following information:
- User's IP address
- Any data that can be used to identify the user or the user's organization
- Any data, stored in the collections
- Any names of the collections
- Any URLs
## How do we anonymize data?
We understand that some users may be concerned about the privacy of their data.
That is why we make an extra effort to ensure your privacy.
There are several different techniques that we use to anonymize the data:
- We use a random UUID to identify instances. This UUID is generated on each startup and is not stored anywhere. There are no other ways to distinguish between different instances.
- We round all big numbers, so that the last digits are always 0. For example, if the number is 123456789, we will store 123456000.
- We replace all names with irreversibly hashed values. So no collection or field names will leak into the telemetry.
- All urls are hashed as well.
You can see exact version of anomymized collected data by accessing the [telemetry API](https://api.qdrant.tech/master/api-reference/service/telemetry) with `anonymize=true` parameter.
For example, <http://localhost:6333/telemetry?details_level=6&anonymize=true>
## Deactivate telemetry
You can deactivate telemetry by:
- setting the `QDRANT__TELEMETRY_DISABLED` environment variable to `true`
- setting the config option `telemetry_disabled` to `true` in the `config/production.yaml` or `config/config.yaml` files
- using cli option `--disable-telemetry`
Any of these options will prevent Qdrant from sending any telemetry data.
If you decide to deactivate telemetry, we kindly ask you to share your feedback with us in the [Discord community](https://qdrant.to/discord) or GitHub [discussions](https://github.com/qdrant/qdrant/discussions)
## Request information deletion
We provide an email address so that users can request the complete removal of their data from all of our tools.
To do so, send an email to privacy@qdrant.com containing the unique identifier generated for your Qdrant installation.
You can find this identifier in the telemetry API response (`"id"` field), or in the logs of your Qdrant instance.
Any questions regarding the management of the data we collect can also be sent to this email address.
|
qdrant-landing/content/documentation/hybrid-cloud/_index.md | ---
title: Hybrid Cloud
weight: 15
---
# Qdrant Hybrid Cloud
Seamlessly deploy and manage your vector database across diverse environments, ensuring performance, security, and cost efficiency for AI-driven applications.
[Qdrant Hybrid Cloud](/hybrid-cloud/) integrates Kubernetes clusters from any setting - cloud, on-premises, or edge - into a unified, enterprise-grade managed service.
You can use [Qdrant Cloud's UI](/documentation/cloud/create-cluster/) to create and manage your database clusters, while they still remain within your infrastructure. **All Qdrant databases will operate solely within your network, using your storage and compute resources.**
Qdrant Hybrid Cloud ensures data privacy, deployment flexibility, low latency, and delivers cost savings, elevating standards for vector search and AI applications.
**How it works:** When you onboard a Kubernetes cluster as a Hybrid Cloud Environment, you can deploy the Qdrant Kubernetes Operator and Cloud Agent into this cluster. These will manage Qdrant databases within your Kubernetes cluster and establish an outgoing connection to Qdrant Cloud at `cloud.qdrant.io` on port `443`. You can then benefit from the same cloud management features and transport telemetry as is available with any managed Qdrant Cloud cluster.
<aside role="status">Qdrant Cloud does not connect to the API of your Kubernetes cluster, cloud provider, or any other platform APIs.</aside>
**Setup instructions:** To begin using Qdrant Hybrid Cloud, [read our installation guide](/documentation/hybrid-cloud/hybrid-cloud-setup/).
## Hybrid Cloud architecture

## Upcoming roadmap items
We plan to introduce the following configuration options directly in the Qdrant Cloud Console in the future. If you need any of them beforehand, please contact our Support team.
* Node selectors
* Tolerations
* Affinities and anti-affinities
* Service types and annotations
* Ingresses
* Network policies
* Storage classes
* Volume snapshot classes
|
qdrant-landing/content/documentation/hybrid-cloud/hybrid-cloud-setup.md | ---
title: Hybrid Cloud setup
weight: 1
---
# Creating a Hybrid Cloud Environment
The following instruction set will show you how to properly setup a **Qdrant cluster** in your **Hybrid Cloud Environment**.
To learn how Hybrid Cloud works, [read the overview document](/documentation/hybrid-cloud/).
## Prerequisites
- **Kubernetes cluster:** To create a Hybrid Cloud Environment, you need a [standard compliant](https://www.cncf.io/training/certification/software-conformance/) Kubernetes cluster. You can run this cluster in any cloud, on-premise or edge environment, with distributions that range from AWS EKS to VMWare vSphere.
- **Storage:** For storage, you need to set up the Kubernetes cluster with a Container Storage Interface (CSI) driver that provides block storage. For vertical scaling, the CSI driver needs to support volume expansion. For backups and restores, the driver needs to support CSI snapshots and restores.
<aside role="status">Network storage systems like NFS or object storage systems such as S3 are not supported.</aside>
- **Permissions:** To install the Qdrant Kubernetes Operator you need to have `cluster-admin` access in your Kubernetes cluster.
- **Connection:** The Qdrant Kubernetes Operator in your cluster needs to be able to connect to Qdrant Cloud. It will create an outgoing connection to `cloud.qdrant.io` on port `443`.
- **Locations:** By default, the Qdrant Cloud Agent and Operator pulls Helm charts and container images from `registry.cloud.qdrant.io`. The Qdrant database container image is pulled from `docker.io`.
> **Note:** You can also mirror these images and charts into your own registry and pull them from there.
### Required artifacts
Container images:
- `docker.io/qdrant/qdrant`
- `registry.cloud.qdrant.io/qdrant/qdrant-cloud-agent`
- `registry.cloud.qdrant.io/qdrant/qdrant-operator`
- `registry.cloud.qdrant.io/qdrant/qdrant-cloud-cluster-manager`
- `registry.cloud.qdrant.io/qdrant/prometheus`
- `registry.cloud.qdrant.io/qdrant/prometheus-config-reloader`
- `registry.cloud.qdrant.io/qdrant/kube-state-metrics`
Open Containers Initiative (OCI) Helm charts:
- `registry.cloud.qdrant.io/qdrant-charts/qdrant-cloud-agent`
- `registry.cloud.qdrant.io/qdrant-charts/qdrant-operator`
- `registry.cloud.qdrant.io/qdrant-charts/prometheus`
## Installation
1. To set up Hybrid Cloud, open the Qdrant Cloud Console at [cloud.qdrant.io](https://cloud.qdrant.io). On the dashboard, select **Hybrid Cloud**.
2. Before creating your first Hybrid Cloud Environment, you have to provide billing information and accept the Hybrid Cloud license agreement. The installation wizard will guide you through the process.
> **Note:** You will only be charged for the Qdrant cluster you create in a Hybrid Cloud Environment, but not for the environment itself.
3. Now you can specify the following:
- **Name:** A name for the Hybrid Cloud Environment
- **Kubernetes Namespace:** The Kubernetes namespace for the operator and agent. Once you select a namespace, you can't change it.
4. You can then enter the YAML configuration for your Kubernetes operator. Qdrant supports a specific list of configuration options, as described in the [Qdrant Operator configuration](/documentation/hybrid-cloud/operator-configuration/) section.
5. (Optional) If you have special requirements for any of the following, activate the **Show advanced configuration** option:
- Proxy server
- Container registry URL for Qdrant Operator and Agent images. The default is <https://registry.cloud.qdrant.io/qdrant/>.
- Helm chart repository URL for the Qdrant Operator and Agent. The default is <oci://registry.cloud.qdrant.io/qdrant-charts>.
- CA certificate
- Log level for the operator and agent
6. Once complete, click **Create**.
> **Note:** All settings but the Kubernetes namespace can be changed later.
### Generate Installation Command
After creating your Hybrid Cloud, select **Generate Installation Command** to generate a script that you can run in your Kubernetes cluster which will perform the initial installation of the Kubernetes operator and agent. It will:
- Create the Kubernetes namespace
- Set up the necessary secrets with credentials to access the Qdrant container registry and the Qdrant Cloud API.
- Sign in to the Helm registry at `registry.cloud.qdrant.io`
- Install the Qdrant cloud agent and Kubernetes operator chart
You need this command only for the initial installation. After that, you can update the agent and operator using the Qdrant Cloud Console.
> **Note:** If you generate the installation command a second time, it will re-generate the included secrets and you will have to apply the command again to update them.
## Creating a Qdrant cluster
Once you have created a Hybrid Cloud Environment, you can create a Qdrant cluster in that enviroment. Use the same process to [Create a cluster](/documentation/cloud/create-cluster/). Make sure to select your Hybrid Cloud Environment as the target.
### Authentication at your Qdrant clusters
In Hybrid Cloud the authentication information is provided with Kubernetes secrets.
You can configure authentication for your Qdrant clusters in the "Configuration" section of the Qdrant Cluster detail page. There you can configure the Kubernetes secret name and key to be used as an API key and/or read-only API key.
One way to create a secret is with kubectl:
```shell
kubectl create secret generic qdrant-api-key --from-literal=api-key=your-secret-api-key
```
With this command the secret name would be `qdrant-api-key` and the key would be `api-key`.
If you want to retrieve the secret again, you can also use `kubectl`:
```shell
kubectl get secret qdrant-api-key -o jsonpath="{.data.api-key}" | base64 --decode
```
### Exposing Qdrant clusters to your client applications
You can expose your Qdrant clusters to your client applications using Kubernetes services and ingresses. By default, a `ClusterIP` service is created for each Qdrant cluster.
Within your Kubernetes cluster, you can access the Qdrant cluster using the service name and port:
```
http://qdrant-9a9f48c7-bb90-4fb2-816f-418a46a74b24.qdrant-namespace.svc:6333
```
This endpoint is also visible on the cluster detail page.
If you want to access the database from your local developer machine, you can use `kubectl port-forward` to forward the service port to your local machine:
```
kubectl -n qdrant-namespace port-forward service/qdrant-9a9f48c7-bb90-4fb2-816f-418a46a74b24 6333:6333
```
You can also expose the database outside the Kubernetes cluster with a `LoadBalancer` (if supported in your Kubernetes environment) or `NodePort` service or an ingress.
A simple Loadbalancer service could look like this:
```yaml
apiVersion: v1
kind: Service
metadata:
name: qdrant-9a9f48c7-bb90-4fb2-816f-418a46a74b24-lb
namespace: qdrant-namespace
spec:
type: LoadBalancer
ports:
- name: http
port: 6333
- name: grpc
port: 6334
selector:
app: qdrant
cluster-id: 9a9f48c7-bb90-4fb2-816f-418a46a74b24
```
An ingress could look like this:
```yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: qdrant-9a9f48c7-bb90-4fb2-816f-418a46a74b24
namespace: qdrant-namespace
spec:
rules:
- host: qdrant-9a9f48c7-bb90-4fb2-816f-418a46a74b24.your-domain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: qdrant-9a9f48c7-bb90-4fb2-816f-418a46a74b24
port:
number: 6333
```
Please refer to the Kubernetes, ingress controller and cloud provider documention for more details.
If you expose the database with such a way, you will be able to see this also reflected as an endpoint on the cluster detail page. And will see the Qdrant database dashboard link pointing to it.
## Deleting a Hybrid Cloud Environment
To delete a Hybrid Cloud Environment, first delete all Qdrant database clusters in it. Then you can delete the environment itself.
To clean up your Kubernetes cluster, after deleting the Hybrid Cloud Environment, you can use the following command:
```shell
helm -n the-qdrant-namespace delete qdrant-cloud-agent
helm -n the-qdrant-namespace delete qdrant-prometheus
helm -n the-qdrant-namespace delete qdrant-operator
kubectl -n the-qdrant-namespace patch HelmRelease.cd.qdrant.io qdrant-cloud-agent -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl -n the-qdrant-namespace patch HelmRelease.cd.qdrant.io qdrant-prometheus -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl -n the-qdrant-namespace patch HelmRelease.cd.qdrant.io qdrant-operator -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl -n the-qdrant-namespace patch HelmChart.cd.qdrant.io the-qdrant-namespace-qdrant-cloud-agent -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl -n the-qdrant-namespace patch HelmChart.cd.qdrant.io the-qdrant-namespace-qdrant-prometheus -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl -n the-qdrant-namespace patch HelmChart.cd.qdrant.io the-qdrant-namespace-qdrant-operator -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl -n the-qdrant-namespace patch HelmRepository.cd.qdrant.io qdrant-cloud -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl delete namespace the-qdrant-namespace
kubectl get crd -o name | grep qdrant | xargs -n 1 kubectl delete
```
|
qdrant-landing/content/documentation/hybrid-cloud/networking-logging-monitoring.md | ---
title: Networking, logging & monitoring
weight: 3
---
# Networking, logging & monitoring
## Configure network policies
For security reasons, each database cluster is secured with network policies. By default, database pods only allow egress traffic between each and allow ingress traffic to ports 6333 (rest) and 6334 (grpc) from within the Kubernetes cluster.
You can modify the default network policies in the Hybrid Cloud environment configuration:
```yaml
qdrant:
networkPolicies:
ingress:
- from:
- ipBlock:
cidr: 192.168.0.0/22
- podSelector:
matchLabels:
app: client-app
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: client-namespace
- podSelector:
matchLabels:
app: traefik
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
ports:
- port: 6333
protocol: TCP
- port: 6334
protocol: TCP
```
## Logging
You can access the logs with kubectl or the Kubernetes log management tool of your choice. For example:
```bash
kubectl -n qdrant-namespace logs -l app=qdrant,cluster-id=9a9f48c7-bb90-4fb2-816f-418a46a74b24
```
**Configuring log levels:** You can configure log levels for the databases individually in the configuration section of the Qdrant Cluster detail page. The log level for the **Qdrant Cloud Agent** and **Operator** can be set in the [Hybrid Cloud Environment configuration](/documentation/hybrid-cloud/operator-configuration/).
## Monitoring
The Qdrant Cloud console gives you access to basic metrics about CPU, memory and disk usage of your Qdrant clusters. You can also access Prometheus metrics endpoint of your Qdrant databases. Finally, you can use a Kubernetes workload monitoring tool of your choice to monitor your Qdrant clusters.
|
qdrant-landing/content/documentation/hybrid-cloud/operator-configuration.md | ---
title: Advanced Qdrant Operator configuration
weight: 2
---
# Advanced Qdrant Operator configuration
The Qdrant Operator has several configuration options, which can be configured in the advanced section of your Hybrid Cloud Environment.
The following YAML shows all configuration options with their default values:
```yaml
# Retention for the backup history of Qdrant clusters
backupHistoryRetentionDays: 2
# Timeout configuration for the Qdrant operator operations
operationTimeout: 7200 # 2 hours
handlerTimeout: 21600 # 6 hours
backupTimeout: 12600 # 3.5 hours
# Incremental backoff configuration for the Qdrant operator operations
backOff:
minDelay: 5
maxDelay: 300
increment: 5
# Cluster-manager configuration for a Qdrant cluster (experimental)
clusterManager:
image:
repository: qdrant/qdrant-cloud-cluster-manager
tag: 0.1.2
pullInterval: 10
logSize: 10
debug: false
# node_selector: {}
# tolerations: []
# Default ingress configuration for a Qdrant cluster
ingress:
enabled: false
provider: KubernetesIngress # or NginxIngress
# kubernetesIngress:
# ingressClassName: ""
# Default storage configuration for a Qdrant cluster
#storage:
# Default VolumeSnapshotClass for a Qdrant cluster
# snapshot_class: "csi-snapclass"
# Default StorageClass for a Qdrant cluster, uses cluster default StorageClass if not set
# default_storage_class_names:
# StorageClass for DB volumes
# db: ""
# StorageClass for snapshot volumes
# snapshots: ""
# Default scheduling configuration for a Qdrant cluster
#scheduling:
# default_topology_spread_constraints: []
# default_pod_disruption_budget: {}
qdrant:
# Default security context for Qdrant cluster
# securityContext:
# enabled: false
# user: ""
# fsGroup: ""
# group: ""
# Default Qdrant image configuration
# image:
# pull_secret: ""
# pull_policy: IfNotPresent
# repository: qdrant/qdrant
# Default Qdrant log_level
# log_level: INFO
# Default network policies to create for a qdrant cluster
networkPolicies:
ingress:
- ports:
- protocol: TCP
port: 6333
- protocol: TCP
port: 6334
# Allow DNS resolution from qdrant pods at Kubernetes internal DNS server
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
ports:
- protocol: UDP
port: 53
```
|
qdrant-landing/content/documentation/hybrid-cloud/platform-deployment-options.md | ---
title: Deployment platforms
weight: 4
---
# Platform Deployment Options
This page provides an overview of how to deploy Qdrant Hybrid Cloud on various managed Kubernetes platforms.
For a general list of prerequisites and installation steps, see our [Hybrid Cloud setup guide](/documentation/hybrid-cloud/hybrid-cloud-setup/).

## Akamai (Linode)
[The Linode Kubernetes Engine (LKE)](https://www.linode.com/products/kubernetes/) is a managed container orchestration engine built on top of Kubernetes. LKE enables you to quickly deploy and manage your containerized applications without needing to build (and maintain) your own Kubernetes cluster. All LKE instances are equipped with a fully managed control plane at no additional cost.
First, consult Linode's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on LKE**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Linode Kubernetes Engine
- [Getting Started with LKE](https://www.linode.com/docs/products/compute/kubernetes/get-started/)
- [LKE Guides](https://www.linode.com/docs/products/compute/kubernetes/guides/)
- [LKE API Reference](https://www.linode.com/docs/api/)
At the time of writing, Linode [does not support CSI Volume Snapshots](https://github.com/linode/linode-blockstorage-csi-driver/issues/107).

## Amazon Web Services (AWS)
[Amazon Elastic Kubernetes Service (Amazon EKS)](https://aws.amazon.com/eks/) is a managed service to run Kubernetes in the AWS cloud and on-premises data centers which can then be paired with Qdrant's hybrid cloud. With Amazon EKS, you can take advantage of all the performance, scale, reliability, and availability of AWS infrastructure, as well as integrations with AWS networking and security services.
First, consult AWS' managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on AWS**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Amazon Elastic Kubernetes Service
- [Getting Started with Amazon EKS](https://docs.aws.amazon.com/eks/)
- [Amazon EKS User Guide](https://docs.aws.amazon.com/eks/latest/userguide/what-is-eks.html)
- [Amazon EKS API Reference](https://docs.aws.amazon.com/eks/latest/APIReference/Welcome.html)
Your EKS cluster needs the EKS EBS CSI driver or a similar storage driver:
- [Amazon EBS CSI Driver](https://docs.aws.amazon.com/eks/latest/userguide/managing-ebs-csi.html)
To allow vertical scaling, you need a StorageClass with volume expansion enabled:
- [Amazon EBS CSI Volume Resizing](https://github.com/kubernetes-sigs/aws-ebs-csi-driver/blob/master/examples/kubernetes/resizing/README.md)
```yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "true"
name: ebs-sc
provisioner: ebs.csi.aws.com
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
```
To allow backups and restores, your EKS cluster needs the CSI snapshot controller:
- [Amazon EBS CSI Snapshot Controller](https://docs.aws.amazon.com/eks/latest/userguide/csi-snapshot-controller.html)
And you need to create a VolumeSnapshotClass:
```yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
deletionPolicy: Delete
driver: ebs.csi.aws.com
```

## Civo
[Civo Kubernetes](https://www.civo.com/kubernetes) is a robust, scalable, and managed Kubernetes service. Civo supplies a CNCF-compliant Kubernetes cluster and makes it easy to provide standard Kubernetes applications and containerized workloads. User-defined Kubernetes clusters can be created as self-service without complications using the Civo Portal.
First, consult Civo's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on Civo**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Civo Kubernetes
- [Getting Started with Civo Kubernetes](https://www.civo.com/docs/kubernetes)
- [Civo Tutorials](https://www.civo.com/learn)
- [Frequently Asked Questions on Civo](https://www.civo.com/docs/faq)
To allow backups and restores, you need to create a VolumeSnapshotClass:
```yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
deletionPolicy: Delete
driver: csi.civo.com
```

## Digital Ocean
[DigitalOcean Kubernetes (DOKS)](https://www.digitalocean.com/products/kubernetes) is a managed Kubernetes service that lets you deploy Kubernetes clusters without the complexities of handling the control plane and containerized infrastructure. Clusters are compatible with standard Kubernetes toolchains and integrate natively with DigitalOcean Load Balancers and volumes.
First, consult Digital Ocean's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on DigitalOcean**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on DigitalOcean Kubernetes
- [Getting Started with DOKS](https://docs.digitalocean.com/products/kubernetes/getting-started/quickstart/)
- [DOKS - How To Guides](https://docs.digitalocean.com/products/kubernetes/how-to/)
- [DOKS - Reference Manual](https://docs.digitalocean.com/products/kubernetes/reference/)

## Google Cloud Platform (GCP)
[Google Kubernetes Engine (GKE)](https://cloud.google.com/kubernetes-engine) is a managed Kubernetes service that you can use to deploy and operate containerized applications at scale using Google's infrastructure. GKE provides the operational power of Kubernetes while managing many of the underlying components, such as the control plane and nodes, for you.
First, consult GCP's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on GCP**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on the Google Kubernetes Engine
- [Getting Started with GKE](https://cloud.google.com/kubernetes-engine/docs/quickstart)
- [GKE Tutorials](https://cloud.google.com/kubernetes-engine/docs/tutorials)
- [GKE Documentation](https://cloud.google.com/kubernetes-engine/docs/)
To allow backups and restores, your GKE cluster needs the CSI VolumeSnapshot controller and class:
- [Google GKE Volume Snapshots](https://cloud.google.com/kubernetes-engine/docs/how-to/persistent-volumes/volume-snapshots)
```yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
deletionPolicy: Delete
driver: pd.csi.storage.gke.io
```

## Mircrosoft Azure
With [Azure Kubernetes Service (AKS)](https://azure.microsoft.com/en-in/products/kubernetes-service), you can start developing and deploying cloud-native apps in Azure, data centres, or at the edge. Get unified management and governance for on-premises, edge, and multi-cloud Kubernetes clusters. Interoperate with Azure security, identity, cost management, and migration services.
First, consult Azure's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on Azure**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Azure Kubernetes Service
- [Getting Started with AKS](https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-start-here)
- [AKS Documentation](https://learn.microsoft.com/en-in/azure/aks/)
- [Best Practices with AKS](https://learn.microsoft.com/en-in/azure/aks/best-practices)
To allow backups and restores, your AKS cluster needs the CSI VolumeSnapshot controller and class:
- [Azure AKS Volume Snapshots](https://learn.microsoft.com/en-us/azure/aks/azure-disk-csi#create-a-volume-snapshot)
```yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
deletionPolicy: Delete
driver: disk.csi.azure.com
```

## Oracle Cloud Infrastructure
[Oracle Cloud Infrastructure Container Engine for Kubernetes (OKE)](https://www.oracle.com/in/cloud/cloud-native/container-engine-kubernetes/) is a managed Kubernetes solution that enables you to deploy Kubernetes clusters while ensuring stable operations for both the control plane and the worker nodes through automatic scaling, upgrades, and security patching. Additionally, OKE offers a completely serverless Kubernetes experience with virtual nodes.
First, consult OCI's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on OCI**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on OCI Container Engine
- [Getting Started with OCI](https://docs.oracle.com/en-us/iaas/Content/ContEng/home.htm)
- [Frequently Asked Questions on OCI](https://www.oracle.com/in/cloud/cloud-native/container-engine-kubernetes/faq/)
- [OCI Product Updates](https://docs.oracle.com/en-us/iaas/releasenotes/services/conteng/)
To allow backups and restores, your OCI cluster needs the CSI VolumeSnapshot controller and class:
- [Prerequisites for Creating Volume Snapshots
](https://docs.oracle.com/en-us/iaas/Content/ContEng/Tasks/contengcreatingpersistentvolumeclaim_topic-Provisioning_PVCs_on_BV.htm#contengcreatingpersistentvolumeclaim_topic-Provisioning_PVCs_on_BV-PV_From_Snapshot_CSI__section_volume-snapshot-prerequisites)
```yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
deletionPolicy: Delete
driver: blockvolume.csi.oraclecloud.com
```

## OVHcloud
[Service Managed Kubernetes](https://www.ovhcloud.com/en-in/public-cloud/kubernetes/), powered by OVH Public Cloud Instances, a leading European cloud provider. With OVHcloud Load Balancers and disks built in. OVHcloud Managed Kubernetes provides high availability, compliance, and CNCF conformance, allowing you to focus on your containerized software layers with total reversibility.
First, consult OVHcloud's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on OVHcloud**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Service Managed Kubernetes by OVHcloud
- [Getting Started with OVH Managed Kubernetes](https://help.ovhcloud.com/csm/en-in-documentation-public-cloud-containers-orchestration-managed-kubernetes-k8s-getting-started)
- [OVH Managed Kubernetes Documentation](https://help.ovhcloud.com/csm/en-in-documentation-public-cloud-containers-orchestration-managed-kubernetes-k8s)
- [OVH Managed Kubernetes Tutorials](https://help.ovhcloud.com/csm/en-in-documentation-public-cloud-containers-orchestration-managed-kubernetes-k8s-tutorials)

## Red Hat OpenShift
[Red Hat OpenShift Kubernetes Engine](https://www.redhat.com/en/technologies/cloud-computing/openshift/kubernetes-engine) provides you with the basic functionality of Red Hat OpenShift. It offers a subset of the features that Red Hat OpenShift Container Platform offers, like full access to an enterprise-ready Kubernetes environment and an extensive compatibility test matrix with many of the software elements that you might use in your data centre.
First, consult Red Hat's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on Red Hat OpenShift**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on OpenShift Kubernetes Engine
- [Getting Started with Red Hat OpenShift Kubernetes](https://docs.openshift.com/container-platform/4.15/getting_started/kubernetes-overview.html)
- [Red Hat OpenShift Kubernetes Documentation](https://docs.openshift.com/container-platform/4.15/welcome/index.html)
- [Installing on Container Platforms](https://access.redhat.com/documentation/en-us/openshift_container_platform/4.5/html/installing/index)
Qdrant databases need a persistent storage solution. See [Openshift Storage Overview](https://docs.openshift.com/container-platform/4.15/storage/index.html).
To allow vertical scaling, you need a StorageClass with [volume expansion enabled](https://docs.openshift.com/container-platform/4.15/storage/expanding-persistent-volumes.html).
To allow backups and restores, your OpenShift cluster needs the [CSI snapshot controller](https://docs.openshift.com/container-platform/4.15/storage/container_storage_interface/persistent-storage-csi-snapshots.html), and you need to create a VolumeSnapshotClass.

## Scaleway
[Scaleway Kapsule](https://www.scaleway.com/en/kubernetes-kapsule/) and [Kosmos](https://www.scaleway.com/en/kubernetes-kosmos/) are managed Kubernetes services from [Scaleway](https://www.scaleway.com/en/). They abstract away the complexities of managing and operating a Kubernetes cluster. The primary difference being, Kapsule clusters are composed solely of Scaleway Instances. Whereas, a Kosmos cluster is a managed multi-cloud Kubernetes engine that allows you to connect instances from any cloud provider to a single managed Control-Plane.
First, consult Scaleway's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on Scaleway**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Scaleway Kubernetes
- [Getting Started with Scaleway Kubernetes](https://www.scaleway.com/en/docs/containers/kubernetes/quickstart/#how-to-add-a-scaleway-pool-to-a-kubernetes-cluster)
- [Scaleway Kubernetes Documentation](https://www.scaleway.com/en/docs/containers/kubernetes/)
- [Frequently Asked Questions on Scaleway Kubernetes](https://www.scaleway.com/en/docs/faq/kubernetes/)

## STACKIT
[STACKIT Kubernetes Engine (SKE)](https://www.stackit.de/en/product/kubernetes/) is a robust, scalable, and managed Kubernetes service. SKE supplies a CNCF-compliant Kubernetes cluster and makes it easy to provide standard Kubernetes applications and containerized workloads. User-defined Kubernetes clusters can be created as self-service without complications using the STACKIT Portal.
First, consult STACKIT's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on STACKIT**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on STACKIT Kubernetes Engine
- [Getting Started with SKE](https://docs.stackit.cloud/stackit/en/getting-started-ske-10125565.html)
- [SKE Tutorials](https://docs.stackit.cloud/stackit/en/tutorials-ske-66683162.html)
- [Frequently Asked Questions on SKE](https://docs.stackit.cloud/stackit/en/faq-known-issues-of-ske-28476393.html)
To allow backups and restores, you need to create a VolumeSnapshotClass:
```yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
deletionPolicy: Delete
driver: cinder.csi.openstack.org
```

## Vultr
[Vultr Kubernetes Engine (VKE)](https://www.vultr.com/kubernetes/) is a fully-managed product offering with predictable pricing that makes Kubernetes easy to use. Vultr manages the control plane and worker nodes and provides integration with other managed services such as Load Balancers, Block Storage, and DNS.
First, consult Vultr's managed Kubernetes instructions below. Then, **to set up Qdrant Hybrid Cloud on Vultr**, follow our [step-by-step documentation](/documentation/hybrid-cloud/hybrid-cloud-setup/).
### More on Vultr Kubernetes Engine
- [VKE Guide](https://docs.vultr.com/vultr-kubernetes-engine)
- [VKE Documentation](https://docs.vultr.com/)
- [Frequently Asked Questions on VKE](https://docs.vultr.com/vultr-kubernetes-engine#frequently-asked-questions)
At the time of writing, Vultr does not support CSI Volume Snapshots.

## Generic Kubernetes Support (on-premises, cloud, edge)
Qdrant Hybrid Cloud works with any Kubernetes cluster that meets the [standard compliance](https://www.cncf.io/training/certification/software-conformance/) requirements.
This includes for example:
- [VMWare Tanzu](https://tanzu.vmware.com/kubernetes-grid)
- [Red Hat OpenShift](https://www.openshift.com/)
- [SUSE Rancher](https://www.rancher.com/)
- [Canonical Kubernetes](https://ubuntu.com/kubernetes)
- [RKE](https://rancher.com/docs/rke/latest/en/)
- [RKE2](https://docs.rke2.io/)
- [K3s](https://k3s.io/)
Qdrant databases need persistent block storage. Most storage solutions provide a CSI driver that can be used with Kubernetes. See [CSI drivers](https://kubernetes-csi.github.io/docs/drivers.html) for more information.
To allow vertical scaling, you need a StorageClass with volume expansion enabled. See [Volume Expansion](https://kubernetes.io/docs/concepts/storage/storage-classes/#allow-volume-expansion) for more information.
To allow backups and restores, your CSI driver needs to support volume snapshots cluster needs the CSI VolumeSnapshot controller and class. See [CSI Volume Snapshots](https://kubernetes-csi.github.io/docs/snapshot-controller.html) for more information.
## Next Steps
Once you've got a Kubernetes cluster deployed on a platform of your choosing, you can begin setting up Qdrant Hybrid Cloud. Head to our Qdrant Hybrid Cloud [setup guide](/documentation/hybrid-cloud/hybrid-cloud-setup/) for instructions.
|
qdrant-landing/content/documentation/interfaces/_index.md | ---
title: Interfaces
weight: 11
aliases:
- /documentation/interfaces/
---
# Interfaces
Qdrant supports these "official" clients.
> **Note:** If you are using a language that is not listed here, you can use the REST API directly or generate a client for your language
using [OpenAPI](https://github.com/qdrant/qdrant/blob/master/docs/redoc/master/openapi.json)
or [protobuf](https://github.com/qdrant/qdrant/tree/master/lib/api/src/grpc/proto) definitions.
## Client Libraries
||Client Repository|Installation|Version|
|-|-|-|-|
|[](https://python-client.qdrant.tech/)|**[Python](https://github.com/qdrant/qdrant-client)** + **[(Client Docs)](https://python-client.qdrant.tech/)**|`pip install qdrant-client[fastembed]`|[Latest Release](https://github.com/qdrant/qdrant-client/releases)|
||**[JavaScript / Typescript](https://github.com/qdrant/qdrant-js)**|`npm install @qdrant/js-client-rest`|[Latest Release](https://github.com/qdrant/qdrant-js/releases)|
||**[Rust](https://github.com/qdrant/rust-client)**|`cargo add qdrant-client`|[Latest Release](https://github.com/qdrant/rust-client/releases)|
||**[Go](https://github.com/qdrant/go-client)**|`go get github.com/qdrant/go-client`|[Latest Release](https://github.com/qdrant/go-client)|
||**[.NET](https://github.com/qdrant/qdrant-dotnet)**|`dotnet add package Qdrant.Client`|[Latest Release](https://github.com/qdrant/qdrant-dotnet/releases)|
||**[Java](https://github.com/qdrant/java-client)**|[Available on Maven Central](https://central.sonatype.com/artifact/io.qdrant/client)|[Latest Release](https://github.com/qdrant/java-client/releases)|
## API Reference
All interaction with Qdrant takes place via the REST API. We recommend using REST API if you are using Qdrant for the first time or if you are working on a prototype.
| API | Documentation |
| -------- | ------------------------------------------------------------------------------------ |
| REST API | [OpenAPI Specification](https://api.qdrant.tech/api-reference) |
| gRPC API | [gRPC Documentation](https://github.com/qdrant/qdrant/blob/master/docs/grpc/docs.md) |
### gRPC Interface
The gRPC methods follow the same principles as REST. For each REST endpoint, there is a corresponding gRPC method.
As per the [configuration file](https://github.com/qdrant/qdrant/blob/master/config/config.yaml), the gRPC interface is available on the specified port.
```yaml
service:
grpc_port: 6334
```
<aside role="status">If you decide to use gRPC, you must expose the port when starting Qdrant.</aside>
Running the service inside of Docker will look like this:
```bash
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
```
**When to use gRPC:** The choice between gRPC and the REST API is a trade-off between convenience and speed. gRPC is a binary protocol and can be more challenging to debug. We recommend using gRPC if you are already familiar with Qdrant and are trying to optimize the performance of your application.
|
qdrant-landing/content/documentation/interfaces/web-ui.md | ---
title: Qdrant Web UI
weight: 1
aliases:
- /documentation/web-ui/
---
# Qdrant Web UI
You can manage both local and cloud Qdrant deployments through the Web UI.
If you've set up a deployment locally with the Qdrant [Quickstart](/documentation/quick-start/),
navigate to http://localhost:6333/dashboard.
If you've set up a deployment in a cloud cluster, find your Cluster URL in your
cloud dashboard, at https://cloud.qdrant.io. Add `:6333/dashboard` to the end
of the URL.
## Access the Web UI
Qdrant's Web UI is an intuitive and efficient graphic interface for your Qdrant Collections, REST API and data points.
In the **Console**, you may use the REST API to interact with Qdrant, while in **Collections**, you can manage all the collections and upload Snapshots.

### Qdrant Web UI features
In the Qdrant Web UI, you can:
- Run HTTP-based calls from the console
- List and search existing [collections](/documentation/concepts/collections/)
- Learn from our interactive tutorial
You can navigate to these options directly. For example, if you used our
[quick start](/documentation/quick-start/) to set up a cluster on localhost,
you can review our tutorial at http://localhost:6333/dashboard#/tutorial.
|
qdrant-landing/content/documentation/overview/_index.md | ---
title: What is Qdrant?
weight: 9
aliases:
- overview
---
# Introduction

Vector databases are a relatively new way for interacting with abstract data representations
derived from opaque machine learning models such as deep learning architectures. These
representations are often called vectors or embeddings and they are a compressed version of
the data used to train a machine learning model to accomplish a task like sentiment analysis,
speech recognition, object detection, and many others.
These new databases shine in many applications like [semantic search](https://en.wikipedia.org/wiki/Semantic_search)
and [recommendation systems](https://en.wikipedia.org/wiki/Recommender_system), and here, we'll
learn about one of the most popular and fastest growing vector databases in the market, [Qdrant](https://github.com/qdrant/qdrant).
## What is Qdrant?
[Qdrant](https://github.com/qdrant/qdrant) "is a vector similarity search engine that provides a production-ready
service with a convenient API to store, search, and manage points (i.e. vectors) with an additional
payload." You can think of the payloads as additional pieces of information that can help you
hone in on your search and also receive useful information that you can give to your users.
You can get started using Qdrant with the Python `qdrant-client`, by pulling the latest docker
image of `qdrant` and connecting to it locally, or by trying out [Qdrant's Cloud](https://cloud.qdrant.io/)
free tier option until you are ready to make the full switch.
With that out of the way, let's talk about what are vector databases.
## What Are Vector Databases?
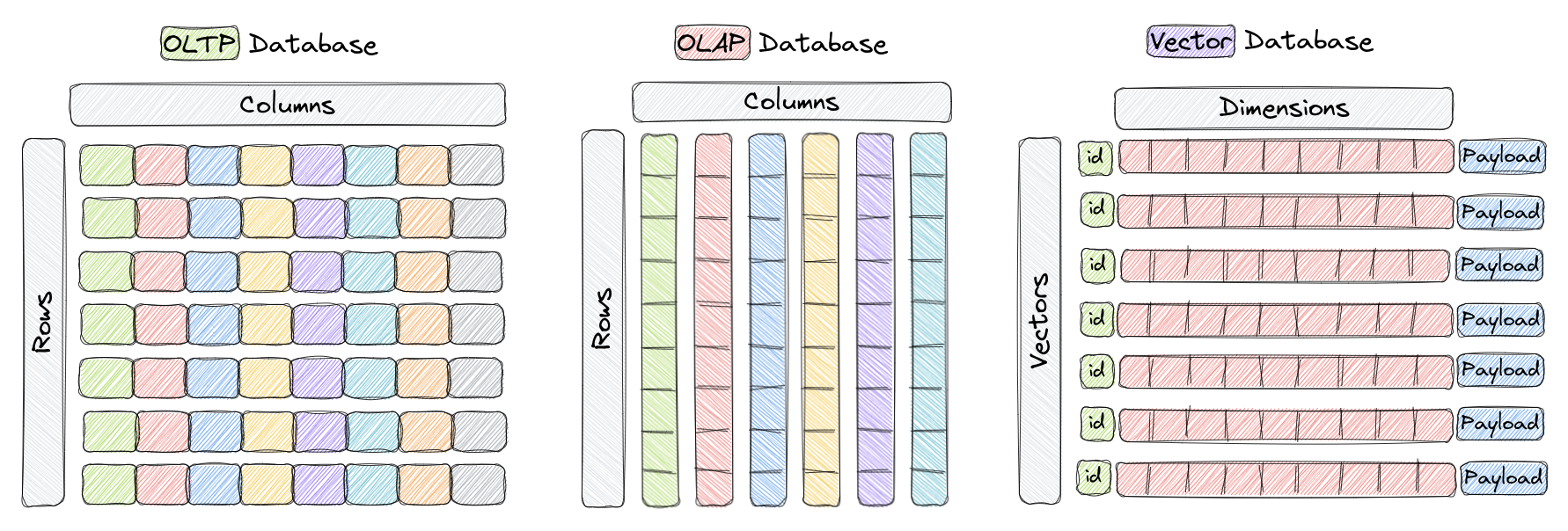
Vector databases are a type of database designed to store and query high-dimensional vectors
efficiently. In traditional [OLTP](https://www.ibm.com/topics/oltp) and [OLAP](https://www.ibm.com/topics/olap)
databases (as seen in the image above), data is organized in rows and columns (and these are
called **Tables**), and queries are performed based on the values in those columns. However,
in certain applications including image recognition, natural language processing, and recommendation
systems, data is often represented as vectors in a high-dimensional space, and these vectors, plus
an id and a payload, are the elements we store in something called a **Collection** a vector
database like Qdrant.
A vector in this context is a mathematical representation of an object or data point, where each
element of the vector corresponds to a specific feature or attribute of the object. For example,
in an image recognition system, a vector could represent an image, with each element of the vector
representing a pixel value or a descriptor/characteristic of that pixel. In a music recommendation
system, each vector would represent a song, and each element of the vector would represent a
characteristic song such as tempo, genre, lyrics, and so on.
Vector databases are optimized for **storing** and **querying** these high-dimensional vectors
efficiently, and they often using specialized data structures and indexing techniques such as
Hierarchical Navigable Small World (HNSW) -- which is used to implement Approximate Nearest
Neighbors -- and Product Quantization, among others. These databases enable fast similarity
and semantic search while allowing users to find vectors that are the closest to a given query
vector based on some distance metric. The most commonly used distance metrics are Euclidean
Distance, Cosine Similarity, and Dot Product, and these three are fully supported Qdrant.
Here's a quick overview of the three:
- [**Cosine Similarity**](https://en.wikipedia.org/wiki/Cosine_similarity) - Cosine similarity
is a way to measure how similar two things are. Think of it like a ruler that tells you how far
apart two points are, but instead of measuring distance, it measures how similar two things
are. It's often used with text to compare how similar two documents or sentences are to each
other. The output of the cosine similarity ranges from -1 to 1, where -1 means the two things
are completely dissimilar, and 1 means the two things are exactly the same. It's a straightforward
and effective way to compare two things!
- [**Dot Product**](https://en.wikipedia.org/wiki/Dot_product) - The dot product similarity
metric is another way of measuring how similar two things are, like cosine similarity. It's
often used in machine learning and data science when working with numbers. The dot product
similarity is calculated by multiplying the values in two sets of numbers, and then adding
up those products. The higher the sum, the more similar the two sets of numbers are. So, it's
like a scale that tells you how closely two sets of numbers match each other.
- [**Euclidean Distance**](https://en.wikipedia.org/wiki/Euclidean_distance) - Euclidean
distance is a way to measure the distance between two points in space, similar to how we
measure the distance between two places on a map. It's calculated by finding the square root
of the sum of the squared differences between the two points' coordinates. This distance metric
is commonly used in machine learning to measure how similar or dissimilar two data points are
or, in other words, to understand how far apart they are.
Now that we know what vector databases are and how they are structurally different than other
databases, let's go over why they are important.
## Why do we need Vector Databases?
Vector databases play a crucial role in various applications that require similarity search, such
as recommendation systems, content-based image retrieval, and personalized search. By taking
advantage of their efficient indexing and searching techniques, vector databases enable faster
and more accurate retrieval of unstructured data already represented as vectors, which can
help put in front of users the most relevant results to their queries.
In addition, other benefits of using vector databases include:
1. Efficient storage and indexing of high-dimensional data.
3. Ability to handle large-scale datasets with billions of data points.
4. Support for real-time analytics and queries.
5. Ability to handle vectors derived from complex data types such as images, videos, and natural language text.
6. Improved performance and reduced latency in machine learning and AI applications.
7. Reduced development and deployment time and cost compared to building a custom solution.
Keep in mind that the specific benefits of using a vector database may vary depending on the
use case of your organization and the features of the database you ultimately choose.
Let's now evaluate, at a high-level, the way Qdrant is architected.
## High-Level Overview of Qdrant's Architecture
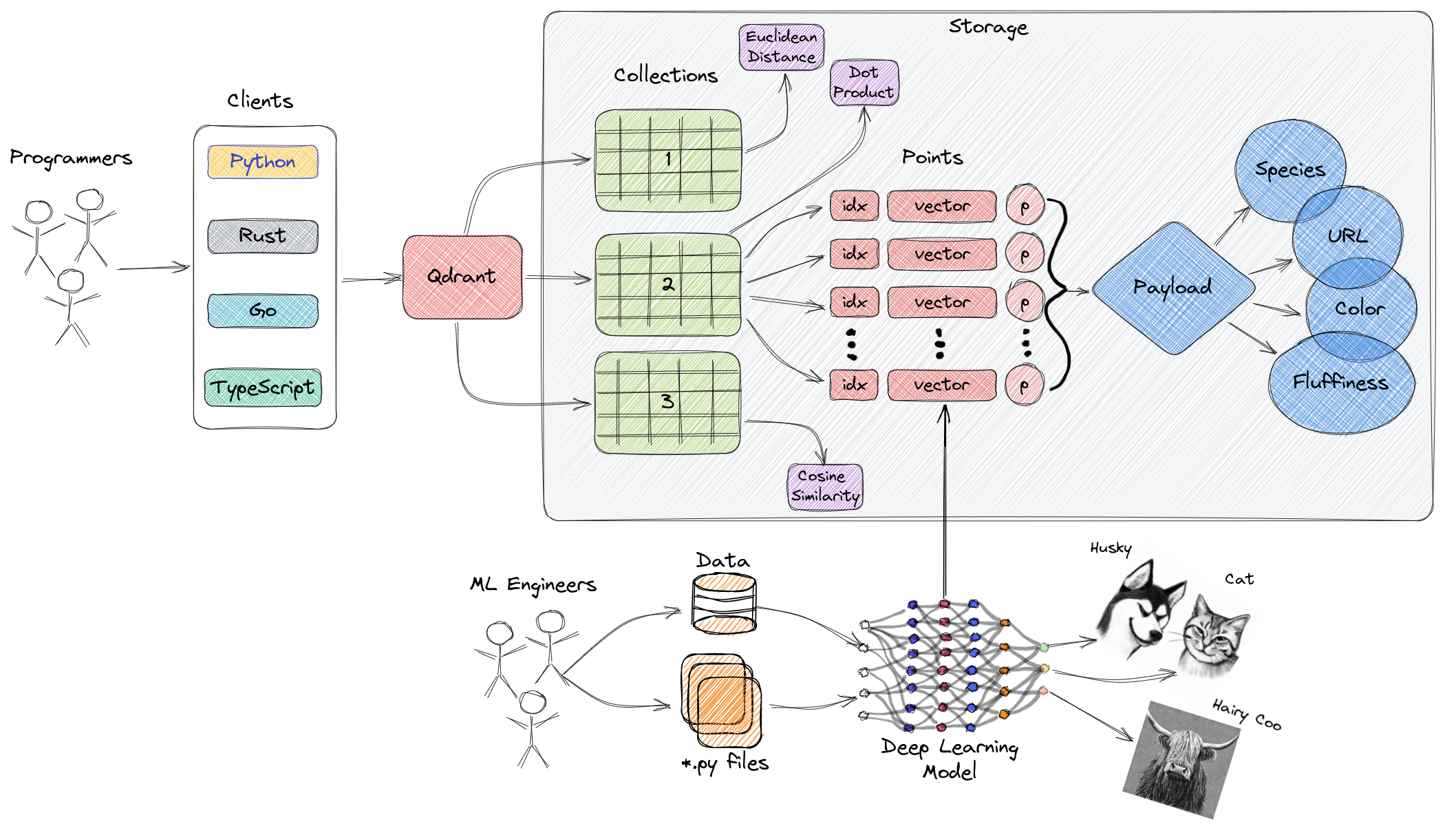
The diagram above represents a high-level overview of some of the main components of Qdrant. Here
are the terminologies you should get familiar with.
- [Collections](../concepts/collections/): A collection is a named set of points (vectors with a payload) among which you can search. The vector of each point within the same collection must have the same dimensionality and be compared by a single metric. [Named vectors](../concepts/collections/#collection-with-multiple-vectors) can be used to have multiple vectors in a single point, each of which can have their own dimensionality and metric requirements.
- [Distance Metrics](https://en.wikipedia.org/wiki/Metric_space): These are used to measure
similarities among vectors and they must be selected at the same time you are creating a
collection. The choice of metric depends on the way the vectors were obtained and, in particular,
on the neural network that will be used to encode new queries.
- [Points](../concepts/points/): The points are the central entity that
Qdrant operates with and they consist of a vector and an optional id and payload.
- id: a unique identifier for your vectors.
- Vector: a high-dimensional representation of data, for example, an image, a sound, a document, a video, etc.
- [Payload](../concepts/payload/): A payload is a JSON object with additional data you can add to a vector.
- [Storage](../concepts/storage/): Qdrant can use one of two options for
storage, **In-memory** storage (Stores all vectors in RAM, has the highest speed since disk
access is required only for persistence), or **Memmap** storage, (creates a virtual address
space associated with the file on disk).
- Clients: the programming languages you can use to connect to Qdrant.
## Next Steps
Now that you know more about vector databases and Qdrant, you are ready to get started with one
of our tutorials. If you've never used a vector database, go ahead and jump straight into
the **Getting Started** section. Conversely, if you are a seasoned developer in these
technology, jump to the section most relevant to your use case.
As you go through the tutorials, please let us know if any questions come up in our
[Discord channel here](https://qdrant.to/discord). 😎
|
qdrant-landing/content/documentation/overview/qdrant-alternatives.md | ---
title: Qdrant vs. Alternatives
weight: 2
aliases:
- /documentation/overview/qdrant-alternatives/overview/
---
# Comparing Qdrant with alternatives
If you are currently using other vector databases, we recommend you read this short guide. It breaks down the key differences between Qdrant and other similar products. This document should help you decide which product has the features and support you need.
Unfortunately, since Pinecone is not an open source product, we can't include it in our [benchmarks](/benchmarks/). However, we still recommend you use the [benchmark tool](/benchmarks/) while exploring Qdrant.
## Feature comparison
| Feature | Pinecone | Qdrant | Comments |
|-------------------------------------|-------------------------------|----------------------------------------------|----------------------------------------------------------|
| **Deployment Modes** | SaaS-only | Local, on-premise, Cloud | Qdrant offers more flexibility in deployment modes |
| **Supported Technologies** | Python, JavaScript/TypeScript | Python, JavaScript/TypeScript, Rust, Go | Qdrant supports a broader range of programming languages |
| **Performance** (e.g., query speed) | TnC Prohibit Benchmarking | [Benchmark result](/benchmarks/) | Compare performance metrics |
| **Pricing** | Starts at $70/mo | Free and Open Source, Cloud starts at $25/mo | Pricing as of May 2023 |
## Prototyping options
Qdrant offers multiple ways of deployment, including local mode, on-premise, and [Qdrant Cloud](https://cloud.qdrant.io/).
You can [get started with local mode quickly](/documentation/quick-start/) and without signing up for SaaS. With Pinecone you will have to connect your development environment to the cloud service just to test the product.
When it comes to SaaS, both Pinecone and [Qdrant Cloud](https://cloud.qdrant.io/) offer a free cloud tier to check out the services, and you don't have to give credit card details for either. Qdrant's free tier should be enough to keep around 1M of 768-dimensional vectors, but it may vary depending on the additional attributes stored with vectors. Pinecone's starter plan supports approximately 200k 768-dimensional embeddings and metadata, stored within a single index. With Qdrant Cloud, however, you can experiment with different models as you may create several collections or keep multiple vectors per each point. That means Qdrant Cloud allows you building several small demos, even on a free tier.
## Terminology
Although both tools serve similar purposes, there are some differences in the terms used. This dictionary may come
in handy during the transition.
| Pinecone | Qdrant | Comments |
|----------------|------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| **Index** | [**Collection**](../../concepts/collections/) | Pinecone's index is an organizational unit for storing and managing vectors of the same size. The index is tightly coupled with hardware (pods). Qdrant uses the collection to describe a similar concept, however, a single instance may handle multiple collections at once. |
| **Collection** | [**Snapshots**](../../concepts/snapshots/) | A collection in Pinecone is a static copy of an *index* that you cannot query, mostly used as some sort of backup. There is no direct analogy in Qdrant, but if you want to back your collection up, you may always create a more flexible [snapshot](../../concepts/snapshots/). |
| **Namespace** | [**Payload-based isolation**](../../guides/multiple-partitions/) / [**User-defined sharding**](../../guides/distributed_deployment/#user-defined-sharding) | Namespaces allow the partitioning of the vectors in an index into subsets. Qdrant provides multiple tools to ensure efficient data isolation within a collection. For fine-grained data segreation you can use payload-based approach to multitenancy, and use custom sharding at bigger scale |
| **Metadata** | [**Payload**](../../concepts/payload/) | Additional attributes describing a particular object, other than the embedding vector. Both engines support various data types, but Pinecone metadata is key-value, while Qdrant supports any JSON-like objects. |
| **Query** | [**Search**](../../concepts/search/) | Name of the method used to find the nearest neighbors for a given vector, possibly with some additional filters applied on top. |
| N/A | [**Scroll**](../../concepts/points/#scroll-points) | Pinecone does not offer a way to iterate through all the vectors in a particular index. Qdrant has a `scroll` method to get them all without using search. |
## Known limitations
1. Pinecone does not support arbitrary JSON metadata, but a flat structure with strings, numbers, booleans, or lists of strings used as values. Qdrant accepts any JSON object as a payload, even nested structures.
2. NULL values are not supported in Pinecone metadata but are handled properly by Qdrant.
3. The maximum size of Pinecone metadata is 40kb per vector.
4. Pinecone, unlike Qdrant, does not support geolocation and filtering based on geographical criteria.
5. Qdrant allows storing multiple vectors per point, and those might be of a different dimensionality. Pinecone doesn't support anything similar.
6. Vectors in Pinecone are mandatory for each point. Qdrant supports optional vectors.
It is worth mentioning, that **Pinecone will automatically create metadata indexes for all the fields**. Qdrant assumes you know
your data and your future queries best, so it's up to you to choose the fields to be indexed. Thus, **you need to explicitly define the payload indexes while using Qdrant**.
## Supported technologies
Both tools support various programming languages providing official SDKs.
| | Pinecone | Qdrant |
|---------------------------|----------------------|----------------------|
| **Python** | ✅ | ✅ |
| **JavaScript/TypeScript** | ✅ | ✅ |
| **Rust** | ❌ | ✅ |
| **Go** | ❌ | ✅ |
There are also various community-driven projects aimed to provide the support for the other languages, but those are not officially
maintained, thus not mentioned here. However, it is still possible to interact with both engines through the HTTP REST or gRPC API.
That makes it easy to integrate with any technology of your choice.
If you are a Python user, then both tools are well-integrated with the most popular libraries like [LangChain](/documentation/frameworks/langchain/), [LlamaIndex](/documentation/frameworks/llama-index/), [Haystack](/documentation/frameworks/haystack/), and more.
Using any of those libraries makes it easier to experiment with different vector databases, as the transition should be seamless.
## Planning to migrate?
> We strongly recommend you use [Qdrant Tools](https://github.com/NirantK/qdrant_tools) to migrate from Pinecone to Qdrant.
Migrating from Pinecone to Qdrant involves a series of well-planned steps to ensure that the transition is smooth and disruption-free. Here is a suggested migration plan:
1. Understanding Qdrant: It's important to first get a solid grasp of Qdrant, its functions, and its APIs. Take time to understand how to establish collections, add points, and query these collections.
2. Migration strategy: Create a comprehensive migration strategy, incorporating data migration (copying your vectors and associated metadata from Pinecone to Qdrant), feature migration (verifying the availability and setting up of features currently in use with Pinecone in Qdrant), and a contingency plan (should there be any unexpected issues).
3. Establishing a parallel Qdrant system: Set up a Qdrant system to run concurrently with your current Pinecone system. This step will let you begin testing Qdrant without disturbing your ongoing operations on Pinecone.
4. Data migration: Shift your vectors and metadata from Pinecone to Qdrant. The timeline for this step could vary, depending on the size of your data and Pinecone API's rate limitations.
5. Testing and transition: Following the data migration, thoroughly test the Qdrant system. Once you're assured of the Qdrant system's stability and performance, you can make the switch.
6. Monitoring and fine-tuning: After transitioning to Qdrant, maintain a close watch on its performance. It's key to continue refining the system for optimal results as needed.
## Next steps
1. If you aren't ready yet, [try out Qdrant locally](/documentation/quick-start/) or sign up for [Qdrant Cloud](https://cloud.qdrant.io/).
2. For more basic information on Qdrant read our [Overview](/documentation/overview/) section or learn more about Qdrant Cloud's [Free Tier](/documentation/cloud/).
3. If ready to migrate, please consult our [Comprehensive Guide](https://github.com/NirantK/qdrant_tools) for further details on migration steps.
|
qdrant-landing/content/documentation/overview/vector-search.md | ---
title: Vector Search Basics
weight: 1
social_preview_image: /docs/gettingstarted/vector-social.png
---
# Vector Search Basics
If you are still trying to figure out how vector search works, please read ahead. This document describes how vector search is used, covers Qdrant's place in the larger ecosystem, and outlines how you can use Qdrant to augment your existing projects.
For those who want to start writing code right away, visit our [Complete Beginners tutorial](/documentation/tutorials/search-beginners/) to build a search engine in 5-15 minutes.
## A Brief History of Search
Human memory is unreliable. Thus, as long as we have been trying to collect ‘knowledge’ in written form, we had to figure out how to search for relevant content without rereading the same books repeatedly. That’s why some brilliant minds introduced the inverted index. In the simplest form, it’s an appendix to a book, typically put at its end, with a list of the essential terms-and links to pages they occur at. Terms are put in alphabetical order. Back in the day, that was a manually crafted list requiring lots of effort to prepare. Once digitalization started, it became a lot easier, but still, we kept the same general principles. That worked, and still, it does.
If you are looking for a specific topic in a particular book, you can try to find a related phrase and quickly get to the correct page. Of course, assuming you know the proper term. If you don’t, you must try and fail several times or find somebody else to help you form the correct query.
{{< figure src=/docs/gettingstarted/inverted-index.png caption="A simplified version of the inverted index." >}}
Time passed, and we haven’t had much change in that area for quite a long time. But our textual data collection started to grow at a greater pace. So we also started building up many processes around those inverted indexes. For example, we allowed our users to provide many words and started splitting them into pieces. That allowed finding some documents which do not necessarily contain all the query words, but possibly part of them. We also started converting words into their root forms to cover more cases, removing stopwords, etc. Effectively we were becoming more and more user-friendly. Still, the idea behind the whole process is derived from the most straightforward keyword-based search known since the Middle Ages, with some tweaks.
{{< figure src=/docs/gettingstarted/tokenization.png caption="The process of tokenization with an additional stopwords removal and converstion to root form of a word." >}}
Technically speaking, we encode the documents and queries into so-called sparse vectors where each position has a corresponding word from the whole dictionary. If the input text contains a specific word, it gets a non-zero value at that position. But in reality, none of the texts will contain more than hundreds of different words. So the majority of vectors will have thousands of zeros and a few non-zero values. That’s why we call them sparse. And they might be already used to calculate some word-based similarity by finding the documents which have the biggest overlap.
{{< figure src=/docs/gettingstarted/query.png caption="An example of a query vectorized to sparse format." >}}
Sparse vectors have relatively **high dimensionality**; equal to the size of the dictionary. And the dictionary is obtained automatically from the input data. So if we have a vector, we are able to partially reconstruct the words used in the text that created that vector.
## The Tower of Babel
Every once in a while, when we discover new problems with inverted indexes, we come up with a new heuristic to tackle it, at least to some extent. Once we realized that people might describe the same concept with different words, we started building lists of synonyms to convert the query to a normalized form. But that won’t work for the cases we didn’t foresee. Still, we need to craft and maintain our dictionaries manually, so they can support the language that changes over time. Another difficult issue comes to light with multilingual scenarios. Old methods require setting up separate pipelines and keeping humans in the loop to maintain the quality.
{{< figure src=/docs/gettingstarted/babel.jpg caption="The Tower of Babel, Pieter Bruegel." >}}
## The Representation Revolution
The latest research in Machine Learning for NLP is heavily focused on training Deep Language Models. In this process, the neural network takes a large corpus of text as input and creates a mathematical representation of the words in the form of vectors. These vectors are created in such a way that words with similar meanings and occurring in similar contexts are grouped together and represented by similar vectors. And we can also take, for example, an average of all the word vectors to create the vector for a whole text (e.g query, sentence, or paragraph).

We can take those **dense vectors** produced by the network and use them as a **different data representation**. They are dense because neural networks will rarely produce zeros at any position. In contrary to sparse ones, they have a relatively low dimensionality — hundreds or a few thousand only. Unfortunately, if we want to have a look and understand the content of the document by looking at the vector it’s no longer possible. Dimensions are no longer representing the presence of specific words.
Dense vectors can capture the meaning, not the words used in a text. That being said, **Large Language Models can automatically handle synonyms**. Moreso, since those neural networks might have been trained with multilingual corpora, they translate the same sentence, written in different languages, to similar vector representations, also called **embeddings**. And we can compare them to find similar pieces of text by calculating the distance to other vectors in our database.
{{< figure src=/docs/gettingstarted/input.png caption="Input queries contain different words, but they are still converted into similar vector representations, because the neural encoder can capture the meaning of the sentences. That feature can capture synonyms but also different languages.." >}}
**Vector search** is a process of finding similar objects based on their embeddings similarity. The good thing is, you don’t have to design and train your neural network on your own. Many pre-trained models are available, either on **HuggingFace** or by using libraries like [SentenceTransformers](https://www.sbert.net/?ref=hackernoon.com). If you, however, prefer not to get your hands dirty with neural models, you can also create the embeddings with SaaS tools, like [co.embed API](https://docs.cohere.com/reference/embed?ref=hackernoon.com).
## Why Qdrant?
The challenge with vector search arises when we need to find similar documents in a big set of objects. If we want to find the closest examples, the naive approach would require calculating the distance to every document. That might work with dozens or even hundreds of examples but may become a bottleneck if we have more than that. When we work with relational data, we set up database indexes to speed things up and avoid full table scans. And the same is true for vector search. Qdrant is a fully-fledged vector database that speeds up the search process by using a graph-like structure to find the closest objects in sublinear time. So you don’t calculate the distance to every object from the database, but some candidates only.
{{< figure src=/docs/gettingstarted/vector-search.png caption="Vector search with Qdrant. Thanks to HNSW graph we are able to compare the distance to some of the objects from the database, not to all of them." >}}
While doing a semantic search at scale, because this is what we sometimes call the vector search done on texts, we need a specialized tool to do it effectively — a tool like Qdrant.
## Next Steps
Vector search is an exciting alternative to sparse methods. It solves the issues we had with the keyword-based search without needing to maintain lots of heuristics manually. It requires an additional component, a neural encoder, to convert text into vectors.
[**Tutorial 1 - Qdrant for Complete Beginners**](/documentation/tutorials/search-beginners/)
Despite its complicated background, vectors search is extraordinarily simple to set up. With Qdrant, you can have a search engine up-and-running in five minutes. Our [Complete Beginners tutorial](../../tutorials/search-beginners/) will show you how.
[**Tutorial 2 - Question and Answer System**](/articles/qa-with-cohere-and-qdrant/)
However, you can also choose SaaS tools to generate them and avoid building your model. Setting up a vector search project with Qdrant Cloud and Cohere co.embed API is fairly easy if you follow the [Question and Answer system tutorial](/articles/qa-with-cohere-and-qdrant/).
There is another exciting thing about vector search. You can search for any kind of data as long as there is a neural network that would vectorize your data type. Do you think about a reverse image search? That’s also possible with vector embeddings.
|
qdrant-landing/content/documentation/tutorials/_index.md | ---
title: Tutorials
weight: 23
# If the index.md file is empty, the link to the section will be hidden from the sidebar
is_empty: false
aliases:
- how-to
- tutorials
---
# Tutorials
These tutorials demonstrate different ways you can build vector search into your applications.
| Essential How-Tos | Description | Stack |
|---------------------------------------------------------------------------------|-------------------------------------------------------------------|---------------------------------------------|
| [Semantic Search for Beginners](../tutorials/search-beginners/) | Create a simple search engine locally in minutes. | Qdrant |
| [Simple Neural Search](../tutorials/neural-search/) | Build and deploy a neural search that browses startup data. | Qdrant, BERT, FastAPI |
| [Neural Search with FastEmbed](../tutorials/neural-search-fastembed/) | Build and deploy a neural search with our FastEmbed library. | Qdrant |
| [Bulk Upload Vectors](../tutorials/bulk-upload/) | Upload a large scale dataset. | Qdrant |
| [Asynchronous API](../tutorials/async-api/) | Communicate with Qdrant server asynchronously with Python SDK. | Qdrant, Python |
| [Create Dataset Snapshots](../tutorials/create-snapshot/) | Turn a dataset into a snapshot by exporting it from a collection. | Qdrant |
| [Load HuggingFace Dataset](../tutorials/huggingface-datasets/) | Load a Hugging Face dataset to Qdrant | Qdrant, Python, datasets |
| [Measure retrieval quality](../tutorials/retrieval-quality/) | Measure and fine-tune the retrieval quality | Qdrant, Python, datasets |
| [Use semantic search to navigate your codebase](../tutorials/code-search/) | Implement semantic search application for code search task | Qdrant, Python, sentence-transformers, Jina |
|
qdrant-landing/content/documentation/tutorials/async-api.md | ---
title: Asynchronous API
weight: 14
---
# Using Qdrant asynchronously
Asynchronous programming is being broadly adopted in the Python ecosystem. Tools such as FastAPI [have embraced this new
paradigm](https://fastapi.tiangolo.com/async/), but it is also becoming a standard for ML models served as SaaS. For example, the Cohere SDK
[provides an async client](https://github.com/cohere-ai/cohere-python/blob/856a4c3bd29e7a75fa66154b8ac9fcdf1e0745e0/src/cohere/client.py#L189) next to its synchronous counterpart.
Databases are often launched as separate services and are accessed via a network. All the interactions with them are IO-bound and can
be performed asynchronously so as not to waste time actively waiting for a server response. In Python, this is achieved by
using [`async/await`](https://docs.python.org/3/library/asyncio-task.html) syntax. That lets the interpreter switch to another task
while waiting for a response from the server.
## When to use async API
There is no need to use async API if the application you are writing will never support multiple users at once (e.g it is a script that runs once per day). However, if you are writing a web service that multiple users will use simultaneously, you shouldn't be
blocking the threads of the web server as it limits the number of concurrent requests it can handle. In this case, you should use
the async API.
Modern web frameworks like [FastAPI](https://fastapi.tiangolo.com/) and [Quart](https://quart.palletsprojects.com/en/latest/) support
async API out of the box. Mixing asynchronous code with an existing synchronous codebase might be a challenge. The `async/await` syntax
cannot be used in synchronous functions. On the other hand, calling an IO-bound operation synchronously in async code is considered
an antipattern. Therefore, if you build an async web service, exposed through an [ASGI](https://asgi.readthedocs.io/en/latest/) server,
you should use the async API for all the interactions with Qdrant.
<aside role="status">
All the async code has to be launched in an async context. Usually, it means you have to use <code>asyncio.run</code> or <code>asyncio.create_task</code> to run them.
Please refer to the <a href="https://docs.python.org/3/library/asyncio.html">asyncio documentation</a> for more details.
</aside>
### Using Qdrant asynchronously
The simplest way of running asynchronous code is to use define `async` function and use the `asyncio.run` in the following way to run it:
```python
from qdrant_client import models
import qdrant_client
import asyncio
async def main():
client = qdrant_client.AsyncQdrantClient("localhost")
# Create a collection
await client.create_collection(
collection_name="my_collection",
vectors_config=models.VectorParams(size=4, distance=models.Distance.COSINE),
)
# Insert a vector
await client.upsert(
collection_name="my_collection",
points=[
models.PointStruct(
id="5c56c793-69f3-4fbf-87e6-c4bf54c28c26",
payload={
"color": "red",
},
vector=[0.9, 0.1, 0.1, 0.5],
),
],
)
# Search for nearest neighbors
points = await client.search(
collection_name="my_collection",
query_vector=[0.9, 0.1, 0.1, 0.5],
limit=2,
)
# Your async code using AsyncQdrantClient might be put here
# ...
asyncio.run(main())
```
The `AsyncQdrantClient` provides the same methods as the synchronous counterpart `QdrantClient`. If you already have a synchronous
codebase, switching to async API is as simple as replacing `QdrantClient` with `AsyncQdrantClient` and adding `await` before each
method call.
<aside role="status">
Asynchronous client was introduced in <code>qdrant-client</code> version 1.6.1. If you are using an older version, you need to use autogenerated async clients directly.
</aside>
## Supported Python libraries
Qdrant integrates with numerous Python libraries. Until recently, only [Langchain](https://python.langchain.com) provided async Python API support.
Qdrant is the only vector database with full coverage of async API in Langchain. Their documentation [describes how to use
it](https://python.langchain.com/docs/modules/data_connection/vectorstores/#asynchronous-operations).
|
qdrant-landing/content/documentation/tutorials/bulk-upload.md | ---
title: Bulk Upload Vectors
weight: 13
---
# Bulk upload a large number of vectors
Uploading a large-scale dataset fast might be a challenge, but Qdrant has a few tricks to help you with that.
The first important detail about data uploading is that the bottleneck is usually located on the client side, not on the server side.
This means that if you are uploading a large dataset, you should prefer a high-performance client library.
We recommend using our [Rust client library](https://github.com/qdrant/rust-client) for this purpose, as it is the fastest client library available for Qdrant.
If you are not using Rust, you might want to consider parallelizing your upload process.
## Disable indexing during upload
In case you are doing an initial upload of a large dataset, you might want to disable indexing during upload.
It will enable to avoid unnecessary indexing of vectors, which will be overwritten by the next batch.
To disable indexing during upload, set `indexing_threshold` to `0`:
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"optimizers_config": {
"indexing_threshold": 0
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
optimizers_config=models.OptimizersConfigDiff(
indexing_threshold=0,
),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
optimizers_config: {
indexing_threshold: 0,
},
});
```
After upload is done, you can enable indexing by setting `indexing_threshold` to a desired value (default is 20000):
```http
PATCH /collections/{collection_name}
{
"optimizers_config": {
"indexing_threshold": 20000
}
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.update_collection(
collection_name="{collection_name}",
optimizer_config=models.OptimizersConfigDiff(indexing_threshold=20000),
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.updateCollection("{collection_name}", {
optimizers_config: {
indexing_threshold: 20000,
},
});
```
## Upload directly to disk
When the vectors you upload do not all fit in RAM, you likely want to use
[memmap](../../concepts/storage/#configuring-memmap-storage)
support.
During collection
[creation](../../concepts/collections/#create-collection),
memmaps may be enabled on a per-vector basis using the `on_disk` parameter. This
will store vector data directly on disk at all times. It is suitable for
ingesting a large amount of data, essential for the billion scale benchmark.
Using `memmap_threshold_kb` is not recommended in this case. It would require
the [optimizer](../../concepts/optimizer/) to constantly
transform in-memory segments into memmap segments on disk. This process is
slower, and the optimizer can be a bottleneck when ingesting a large amount of
data.
Read more about this in
[Configuring Memmap Storage](../../concepts/storage/#configuring-memmap-storage).
## Parallel upload into multiple shards
In Qdrant, each collection is split into shards. Each shard has a separate Write-Ahead-Log (WAL), which is responsible for ordering operations.
By creating multiple shards, you can parallelize upload of a large dataset. From 2 to 4 shards per one machine is a reasonable number.
```http
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"shard_number": 2
}
```
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
shard_number=2,
)
```
```typescript
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
shard_number: 2,
});
```
|
qdrant-landing/content/documentation/tutorials/code-search.md | ---
title: Semantic code search
weight: 22
---
# Use semantic search to navigate your codebase
| Time: 45 min | Level: Intermediate | [](https://colab.research.google.com/github/qdrant/examples/blob/master/code-search/code-search.ipynb) | |
|--------------|---------------------|--|----|
You too can enrich your applications with Qdrant semantic search. In this
tutorial, we describe how you can use Qdrant to navigate a codebase, to help
you find relevant code snippets. As an example, we will use the [Qdrant](https://github.com/qdrant/qdrant)
source code itself, which is mostly written in Rust.
<aside role="status">This tutorial might not work on code bases that are not disciplined or structured. For good code search, you may need to refactor the project first.</aside>
## The approach
We want to search codebases using natural semantic queries, and searching for
code based on similar logic. You can set up these tasks with embeddings:
1. General usage neural encoder for Natural Language Processing (NLP), in our case
`all-MiniLM-L6-v2` from the
[sentence-transformers](https://www.sbert.net/docs/pretrained_models.html) library.
2. Specialized embeddings for code-to-code similarity search. We use the
`jina-embeddings-v2-base-code` model.
To prepare our code for `all-MiniLM-L6-v2`, we preprocess the code to text that
more closely resembles natural language. The Jina embeddings model supports a
variety of standard programming languages, so there is no need to preprocess the
snippets. We can use the code as is.
NLP-based search is based on function signatures, but code search may return
smaller pieces, such as loops. So, if we receive a particular function signature
from the NLP model and part of its implementation from the code model, we merge
the results and highlight the overlap.
## Data preparation
Chunking the application sources into smaller parts is a non-trivial task. In
general, functions, class methods, structs, enums, and all the other language-specific
constructs are good candidates for chunks. They are big enough to
contain some meaningful information, but small enough to be processed by
embedding models with a limited context window. You can also use docstrings,
comments, and other metadata can be used to enrich the chunks with additional
information.

### Parsing the codebase
While our example uses Rust, you can use our approach with any other language.
You can parse code with a [Language Server Protocol](https://microsoft.github.io/language-server-protocol/) (**LSP**)
compatible tool. You can use an LSP to build a graph of the codebase, and then extract chunks.
We did our work with the [rust-analyzer](https://rust-analyzer.github.io/).
We exported the parsed codebase into the [LSIF](https://microsoft.github.io/language-server-protocol/specifications/lsif/0.4.0/specification/)
format, a standard for code intelligence data. Next, we used the LSIF data to
navigate the codebase and extract the chunks. For details, see our [code search
demo](https://github.com/qdrant/demo-code-search).
<aside role="status">
For other languages, you can use the same approach. There are
<a href="https://microsoft.github.io/language-server-protocol/implementors/servers/">plenty of implementations available
</a>.
</aside>
We then exported the chunks into JSON documents with not only the code itself,
but also context with the location of the code in the project. For example, see
the description of the `await_ready_for_timeout` function from the `IsReady`
struct in the `common` module:
```json
{
"name":"await_ready_for_timeout",
"signature":"fn await_ready_for_timeout (& self , timeout : Duration) -> bool",
"code_type":"Function",
"docstring":"= \" Return `true` if ready, `false` if timed out.\"",
"line":44,
"line_from":43,
"line_to":51,
"context":{
"module":"common",
"file_path":"lib/collection/src/common/is_ready.rs",
"file_name":"is_ready.rs",
"struct_name":"IsReady",
"snippet":" /// Return `true` if ready, `false` if timed out.\n pub fn await_ready_for_timeout(&self, timeout: Duration) -> bool {\n let mut is_ready = self.value.lock();\n if !*is_ready {\n !self.condvar.wait_for(&mut is_ready, timeout).timed_out()\n } else {\n true\n }\n }\n"
}
}
```
You can examine the Qdrant structures, parsed in JSON, in the [`structures.jsonl`
file](https://storage.googleapis.com/tutorial-attachments/code-search/structures.jsonl)
in our Google Cloud Storage bucket. Download it and use it as a source of data for our code search.
```shell
wget https://storage.googleapis.com/tutorial-attachments/code-search/structures.jsonl
```
Next, load the file and parse the lines into a list of dictionaries:
```python
import json
structures = []
with open("structures.jsonl", "r") as fp:
for i, row in enumerate(fp):
entry = json.loads(row)
structures.append(entry)
```
### Code to *natural language* conversion
Each programming language has its own syntax which is not a part of the natural
language. Thus, a general-purpose model probably does not understand the code
as is. We can, however, normalize the data by removing code specifics and
including additional context, such as module, class, function, and file name.
We took the following steps:
1. Extract the signature of the function, method, or other code construct.
2. Divide camel case and snake case names into separate words.
3. Take the docstring, comments, and other important metadata.
4. Build a sentence from the extracted data using a predefined template.
5. Remove the special characters and replace them with spaces.
As input, expect dictionaries with the same structure. Define a `textify`
function to do the conversion. We'll use an `inflection` library to convert
with different naming conventions.
```shell
pip install inflection
```
Once all dependencies are installed, we define the `textify` function:
```python
import inflection
import re
from typing import Dict, Any
def textify(chunk: Dict[str, Any]) -> str:
# Get rid of all the camel case / snake case
# - inflection.underscore changes the camel case to snake case
# - inflection.humanize converts the snake case to human readable form
name = inflection.humanize(inflection.underscore(chunk["name"]))
signature = inflection.humanize(inflection.underscore(chunk["signature"]))
# Check if docstring is provided
docstring = ""
if chunk["docstring"]:
docstring = f"that does {chunk['docstring']} "
# Extract the location of that snippet of code
context = (
f"module {chunk['context']['module']} "
f"file {chunk['context']['file_name']}"
)
if chunk["context"]["struct_name"]:
struct_name = inflection.humanize(
inflection.underscore(chunk["context"]["struct_name"])
)
context = f"defined in struct {struct_name} {context}"
# Combine all the bits and pieces together
text_representation = (
f"{chunk['code_type']} {name} "
f"{docstring}"
f"defined as {signature} "
f"{context}"
)
# Remove any special characters and concatenate the tokens
tokens = re.split(r"\W", text_representation)
tokens = filter(lambda x: x, tokens)
return " ".join(tokens)
```
Now we can use `textify` to convert all chunks into text representations:
```python
text_representations = list(map(textify, structures))
```
This is how the `await_ready_for_timeout` function description appears:
```text
Function Await ready for timeout that does Return true if ready false if timed out defined as Fn await ready for timeout self timeout duration bool defined in struct Is ready module common file is_ready rs
```
## Ingestion pipeline
Next, we build the code search engine to vectorizing data and set up a semantic
search mechanism for both embedding models.
### Natural language embeddings
We can encode text representations through the `all-MiniLM-L6-v2` model from
`sentence-transformers`. With the following command, we install `sentence-transformers`
with dependencies:
```shell
pip install sentence-transformers optimum onnx
```
Then we can use the model to encode the text representations:
```python
from sentence_transformers import SentenceTransformer
nlp_model = SentenceTransformer("all-MiniLM-L6-v2")
nlp_embeddings = nlp_model.encode(
text_representations, show_progress_bar=True,
)
```
### Code embeddings
The `jina-embeddings-v2-base-code` model is a good candidate for this task.
You can also get it from the `sentence-transformers` library, with conditions.
Visit [the model page](https://huggingface.co/jinaai/jina-embeddings-v2-base-code),
accept the rules, and generate the access token in your [account settings](https://huggingface.co/settings/tokens).
Once you have the token, you can use the model as follows:
```python
HF_TOKEN = "THIS_IS_YOUR_TOKEN"
# Extract the code snippets from the structures to a separate list
code_snippets = [
structure["context"]["snippet"] for structure in structures
]
code_model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-code",
token=HF_TOKEN,
trust_remote_code=True
)
code_model.max_seq_length = 8192 # increase the context length window
code_embeddings = code_model.encode(
code_snippets, batch_size=4, show_progress_bar=True,
)
```
Remember to set the `trust_remote_code` parameter to `True`. Otherwise, the
model does not produce meaningful vectors. Setting this parameter allows the
library to download and possibly launch some code on your machine, so be sure
to trust the source.
With both the natural language and code embeddings, we can store them in the
Qdrant collection.
### Building Qdrant collection
We use the `qdrant-client` library to interact with the Qdrant server. Let's
install that client:
```shell
pip install qdrant-client
```
Of course, we need a running Qdrant server for vector search. If you need one,
you can [use a local Docker container](/documentation/quick-start/)
or deploy it using the [Qdrant Cloud](https://cloud.qdrant.io/).
You can use either to follow this tutorial. Configure the connection parameters:
```python
QDRANT_URL = "https://my-cluster.cloud.qdrant.io:6333" # http://localhost:6333 for local instance
QDRANT_API_KEY = "THIS_IS_YOUR_API_KEY" # None for local instance
```
Then use the library to create a collection:
```python
from qdrant_client import QdrantClient, models
client = QdrantClient(QDRANT_URL, api_key=QDRANT_API_KEY)
client.create_collection(
"qdrant-sources",
vectors_config={
"text": models.VectorParams(
size=nlp_embeddings.shape[1],
distance=models.Distance.COSINE,
),
"code": models.VectorParams(
size=code_embeddings.shape[1],
distance=models.Distance.COSINE,
),
}
)
```
Our newly created collection is ready to accept the data. Let's upload the embeddings:
```python
import uuid
points = [
models.PointStruct(
id=uuid.uuid4().hex,
vector={
"text": text_embedding,
"code": code_embedding,
},
payload=structure,
)
for text_embedding, code_embedding, structure in zip(nlp_embeddings, code_embeddings, structures)
]
client.upload_points("qdrant-sources", points=points, batch_size=64)
```
The uploaded points are immediately available for search. Next, query the
collection to find relevant code snippets.
## Querying the codebase
We use one of the models to search the collection. Start with text embeddings.
Run the following query "*How do I count points in a collection?*". Review the
results.
<aside role="status">In these tables, we link to longer code excerpts from a
`file_name` in the `Qdrant` repository. The results are subject to change.
Fortunately, this model should continue to provide the results you need.</aside>
```python
query = "How do I count points in a collection?"
hits = client.search(
"qdrant-sources",
query_vector=(
"text", nlp_model.encode(query).tolist()
),
limit=5,
)
```
Now, review the results. The following table lists the module, the file name
and score. Each line includes a link to the signature, as a code block from
the file.
| module | file_name | score | signature |
|--------------------|---------------------|------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| toc | point_ops.rs | 0.59448624 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub async fn count`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/storage/src/content_manager/toc/point_ops.rs#L120) |
| operations | types.rs | 0.5493385 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub struct CountRequestInternal`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/collection/src/operations/types.rs#L831) |
| collection_manager | segments_updater.rs | 0.5121002 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub(crate) fn upsert_points<'a, T>`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/collection/src/collection_manager/segments_updater.rs#L339) |
| collection | point_ops.rs | 0.5063539 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub async fn count`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/collection/src/collection/point_ops.rs#L213) |
| map_index | mod.rs | 0.49973983 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn get_points_with_value_count<Q>`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/segment/src/index/field_index/map_index/mod.rs#L88) |
It seems we were able to find some relevant code structures. Let's try the same with the code embeddings:
```python
hits = client.search(
"qdrant-sources",
query_vector=(
"code", code_model.encode(query).tolist()
),
limit=5,
)
```
Output:
| module | file_name | score | signature |
|---------------|----------------------------|------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| field_index | geo_index.rs | 0.73278356 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/segment/src/index/field_index/geo_index.rs#L612) |
| numeric_index | mod.rs | 0.7254976 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/numeric_index/mod.rs#L322) |
| map_index | mod.rs | 0.7124739 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/map_index/mod.rs#L315) |
| map_index | mod.rs | 0.7124739 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/map_index/mod.rs#L429) |
| fixtures | payload_context_fixture.rs | 0.706204 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn total_point_count`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/fixtures/payload_context_fixture.rs#L122) |
While the scores retrieved by different models are not comparable, but we can
see that the results are different. Code and text embeddings can capture
different aspects of the codebase. We can use both models to query the collection
and then combine the results to get the most relevant code snippets, from a single batch request.
```python
results = client.search_batch(
"qdrant-sources",
requests=[
models.SearchRequest(
vector=models.NamedVector(
name="text",
vector=nlp_model.encode(query).tolist()
),
with_payload=True,
limit=5,
),
models.SearchRequest(
vector=models.NamedVector(
name="code",
vector=code_model.encode(query).tolist()
),
with_payload=True,
limit=5,
),
]
)
```
Output:
| module | file_name | score | signature |
|--------------------|----------------------------|------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| toc | point_ops.rs | 0.59448624 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub async fn count`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/storage/src/content_manager/toc/point_ops.rs#L120) |
| operations | types.rs | 0.5493385 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub struct CountRequestInternal`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/collection/src/operations/types.rs#L831) |
| collection_manager | segments_updater.rs | 0.5121002 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub(crate) fn upsert_points<'a, T>`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/collection/src/collection_manager/segments_updater.rs#L339) |
| collection | point_ops.rs | 0.5063539 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `pub async fn count`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/collection/src/collection/point_ops.rs#L213) |
| map_index | mod.rs | 0.49973983 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn get_points_with_value_count<Q>`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/segment/src/index/field_index/map_index/mod.rs#L88) |
| field_index | geo_index.rs | 0.73278356 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/segment/src/index/field_index/geo_index.rs#L612) |
| numeric_index | mod.rs | 0.7254976 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/numeric_index/mod.rs#L322) |
| map_index | mod.rs | 0.7124739 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/map_index/mod.rs#L315) |
| map_index | mod.rs | 0.7124739 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/map_index/mod.rs#L429) |
| fixtures | payload_context_fixture.rs | 0.706204 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn total_point_count`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/fixtures/payload_context_fixture.rs#L122) |
This is one example of how you can use different models and combine the results.
In a real-world scenario, you might run some reranking and deduplication, as
well as additional processing of the results.
### Code search demo
Our [Code search demo](https://code-search.qdrant.tech/) uses the following process:
1. The user sends a query.
1. Both models vectorize that query simultaneously. We get two different
vectors.
1. Both vectors are used in parallel to find relevant snippets. We expect
5 examples from the NLP search and 20 examples from the code search.
1. Once we retrieve results for both vectors, we merge them in one of the
following scenarios:
1. If both methods return different results, we prefer the results from
the general usage model (NLP).
1. If there is an overlap between the search results, we merge overlapping
snippets.
In the screenshot, we search for `flush of wal`. The result
shows relevant code, merged from both models. Note the highlighted
code in lines 621-629. It's where both models agree.

Now you see semantic code intelligence, in action.
### Grouping the results
You can improve the search results, by grouping them by payload properties.
In our case, we can group the results by the module. If we use code embeddings,
we can see multiple results from the `map_index` module. Let's group the
results and assume a single result per module:
```python
results = client.search_groups(
"qdrant-sources",
query_vector=(
"code", code_model.encode(query).tolist()
),
group_by="context.module",
limit=5,
group_size=1,
)
```
Output:
| module | file_name | score | signature |
|---------------|----------------------------|------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| field_index | geo_index.rs | 0.73278356 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/7aa164bd2dda1c0fc9bf3a0da42e656c95c2e52a/lib/segment/src/index/field_index/geo_index.rs#L612) |
| numeric_index | mod.rs | 0.7254976 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/numeric_index/mod.rs#L322) |
| map_index | mod.rs | 0.7124739 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn count_indexed_points`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/field_index/map_index/mod.rs#L315) |
| fixtures | payload_context_fixture.rs | 0.706204 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn total_point_count`](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/fixtures/payload_context_fixture.rs#L122) |
| hnsw_index | graph_links.rs | 0.6998417 | [<img src="/documentation/tutorials/code-search/github-mark.png" width="16" style="display: inline"> `fn num_points `](https://github.com/qdrant/qdrant/blob/3fbe1cae6cb7f51a0c5bb4b45cfe6749ac76ed59/lib/segment/src/index/hnsw_index/graph_links.rs#L477) |
With the grouping feature, we get more diverse results.
## Summary
This tutorial demonstrates how to use Qdrant to navigate a codebase. For an
end-to-end implementation, review the [code search
notebook](https://colab.research.google.com/github/qdrant/examples/blob/master/code-search/code-search.ipynb) and the
[code-search-demo](https://github.com/qdrant/demo-code-search). You can also check out [a running version of the code
search demo](https://code-search.qdrant.tech/) which exposes Qdrant codebase for search with a web interface.
|