
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
unknown | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
unknown | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
emilianJR/chilloutmix_NiPrunedFp32Fix | emilianJR | "2023-05-25T12:55:16Z" | 197,318 | 80 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2023-04-19T11:58:56Z" | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Diffuser model for this SD checkpoint:
https://civitai.com/models/6424/chilloutmix
**emilianJR/chilloutmix_NiPrunedFp32Fix** is the HuggingFace diffuser that you can use with **diffusers.StableDiffusionPipeline()**.
Examples | Examples | Examples
---- | ---- | ----
 |  | 
 |  | 
-------
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "emilianJR/chilloutmix_NiPrunedFp32Fix"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "YOUR PROMPT"
image = pipe(prompt).images[0]
image.save("image.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
blackhole33/uzbek-speaker-verification-v9 | blackhole33 | "2024-05-24T09:50:51Z" | 196,808 | 1 | nemo | [
"nemo",
"pytorch",
"NeMo",
"license:cc-by-4.0",
"region:us"
] | null | "2024-05-24T09:50:42Z" | ---
license: cc-by-4.0
library_name: nemo
tags:
- pytorch
- NeMo
---
# Uzbek-speaker-verification-v9
<style>
img {
display: inline;
}
</style>
[](#model-architecture)
| [](#model-architecture)
| [](#datasets)
**Put a short model description here.**
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/index.html) for complete architecture details.
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
**NOTE**: Please update the model class below to match the class of the model being uploaded.
```python
import nemo.core import ModelPT
model = ModelPT.from_pretrained("ai-nightcoder/uzbek-speaker-verification-v9")
```
### NOTE
Add some information about how to use the model here. An example is provided for ASR inference below.
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py pretrained_name="ai-nightcoder/uzbek-speaker-verification-v9" audio_dir=""
```
### Input
**Add some information about what are the inputs to this model**
### Output
**Add some information about what are the outputs of this model**
## Model Architecture
**Add information here discussing architectural details of the model or any comments to users about the model.**
## Training
**Add information here about how the model was trained. It should be as detailed as possible, potentially including the the link to the script used to train as well as the base config used to train the model. If extraneous scripts are used to prepare the components of the model, please include them here.**
### NOTE
An example is provided below for ASR
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/fastconformer/fast-conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
**Try to provide as detailed a list of datasets as possible. If possible, provide links to the datasets on HF by adding it to the manifest section at the top of the README (marked by ---).**
### NOTE
An example for the manifest section is provided below for ASR datasets
datasets:
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National-Singapore-Corpus-Part-1
- National-Singapore-Corpus-Part-6
- vctk
- voxpopuli
- europarl
- multilingual_librispeech
- mozilla-foundation/common_voice_8_0
- MLCommons/peoples_speech
The corresponding text in this section for those datasets is stated below -
The model was trained on 64K hours of English speech collected and prepared by NVIDIA NeMo and Suno teams.
The training dataset consists of private subset with 40K hours of English speech plus 24K hours from the following public datasets:
- Librispeech 960 hours of English speech
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) - 2,000 hour subset
- Mozilla Common Voice (v7.0)
- People's Speech - 12,000 hour subset
## Performance
**Add information here about the performance of the model. Discuss what is the metric that is being used to evaluate the model and if there are external links explaning the custom metric, please link to it.
### NOTE
An example is provided below for ASR metrics list that can be added to the top of the README
model-index:
- name: PUT_MODEL_NAME
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: AMI (Meetings test)
type: edinburghcstr/ami
config: ihm
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 17.10
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Earnings-22
type: revdotcom/earnings22
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 14.11
Provide any caveats about the results presented in the top of the discussion so that nuance is not lost.
It should ideally be in a tabular format (you can use the following website to make your tables in markdown format - https://www.tablesgenerator.com/markdown_tables)**
## Limitations
**Discuss any practical limitations to the model when being used in real world cases. They can also be legal disclaimers, or discussion regarding the safety of the model (particularly in the case of LLMs).**
### Note
An example is provided below
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## License
License to use this model is covered by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license.
## References
**Provide appropriate references in the markdown link format below. Please order them numerically.**
[1] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
jinaai/jina-bert-flash-implementation | jinaai | "2024-05-31T12:41:05Z" | 196,766 | 0 | transformers | [
"transformers",
"bert",
"custom_code",
"endpoints_compatible",
"region:eu"
] | null | "2024-02-21T11:19:46Z" | # BERT with Flash-Attention
### Installing dependencies
To run the model on GPU, you need to install Flash Attention.
You may either install from pypi (which may not work with fused-dense), or from source.
To install from source, clone the GitHub repository:
```console
git clone git@github.com:Dao-AILab/flash-attention.git
```
The code provided here should work with commit `43950dd`.
Change to the cloned repo and install:
```console
cd flash-attention && python setup.py install
```
This will compile the flash-attention kernel, which will take some time.
If you would like to use fused MLPs (e.g. to use activation checkpointing),
you may install fused-dense also from source:
```console
cd csrc/fused_dense_lib && python setup.py install
```
### Configuration
The config adds some new parameters:
- `use_flash_attn`: If `True`, always use flash attention. If `None`, use flash attention when GPU is available. If `False`, never use flash attention (works on CPU).
- `window_size`: Size (left and right) of the local attention window. If `(-1, -1)`, use global attention
- `dense_seq_output`: If true, we only need to pass the hidden states for the masked out token (around 15%) to the classifier heads. I set this to true for pretraining.
- `fused_mlp`: Whether to use fused-dense. Useful to reduce VRAM in combination with activation checkpointing
- `mlp_checkpoint_lvl`: One of `{0, 1, 2}`. Increasing this increases the amount of activation checkpointing within the MLP. Keep this at 0 for pretraining and use gradient accumulation instead. For embedding training, increase this as much as needed.
- `last_layer_subset`: If true, we only need the compute the last layer for a subset of tokens. I left this to false.
- `use_qk_norm`: Whether or not to use QK-normalization
- `num_loras`: Number of LoRAs to use when initializing a `BertLoRA` model. Has no effect on other models.
|
nielsr/lilt-xlm-roberta-base | nielsr | "2023-05-17T07:40:48Z" | 195,669 | 24 | transformers | [
"transformers",
"pytorch",
"safetensors",
"lilt",
"feature-extraction",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-11-24T13:32:18Z" | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# LiLT + XLM-RoBERTa-base
This model is created by combining the Language-Independent Layout Transformer (LiLT) with [XLM-RoBERTa](https://huggingface.co/xlm-roberta-base), a multilingual RoBERTa model (trained on 100 languages).
This way, we have a LayoutLM-like model for 100 languages :) |
DeepFloyd/t5-v1_1-xxl | DeepFloyd | "2022-12-20T13:12:54Z" | 194,526 | 37 | transformers | [
"transformers",
"pytorch",
"t5",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | "2022-12-19T21:08:56Z" | Entry not found |
Helsinki-NLP/opus-mt-ar-en | Helsinki-NLP | "2023-08-16T11:25:35Z" | 194,073 | 30 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"ar",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-ar-en
* source languages: ar
* target languages: en
* OPUS readme: [ar-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ar-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/ar-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ar-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ar-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ar.en | 49.4 | 0.661 |
|
anuragshas/wav2vec2-large-xlsr-53-telugu | anuragshas | "2021-07-05T21:31:14Z" | 194,055 | 4 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"te",
"dataset:openslr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: te
datasets:
- openslr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Anurag Singh XLSR Wav2Vec2 Large 53 Telugu
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR te
type: openslr
args: te
metrics:
- name: Test WER
type: wer
value: 44.98
---
# Wav2Vec2-Large-XLSR-53-Telugu
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Telugu using the [OpenSLR SLR66](http://openslr.org/66/) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import pandas as pd
# Evaluation notebook contains the procedure to download the data
df = pd.read_csv("/content/te/test.tsv", sep="\t")
df["path"] = "/content/te/clips/" + df["path"]
test_dataset = Dataset.from_pandas(df)
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
```python
import torch
import torchaudio
from datasets import Dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
from sklearn.model_selection import train_test_split
import pandas as pd
# Evaluation notebook contains the procedure to download the data
df = pd.read_csv("/content/te/test.tsv", sep="\t")
df["path"] = "/content/te/clips/" + df["path"]
test_dataset = Dataset.from_pandas(df)
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\_\;\:\"\“\%\‘\”\।\’\'\&]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
def normalizer(text):
# Use your custom normalizer
text = text.replace("\\n","\n")
text = ' '.join(text.split())
text = re.sub(r'''([a-z]+)''','',text,flags=re.IGNORECASE)
text = re.sub(r'''%'''," శాతం ", text)
text = re.sub(r'''(/|-|_)'''," ", text)
text = re.sub("ై","ై", text)
text = text.strip()
return text
def speech_file_to_array_fn(batch):
batch["sentence"] = normalizer(batch["sentence"])
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()+ " "
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 44.98%
## Training
70% of the OpenSLR Telugu dataset was used for training.
Train Split of annotations is [here](https://www.dropbox.com/s/xqc0wtour7f9h4c/train.tsv)
Test Split of annotations is [here](https://www.dropbox.com/s/qw1uy63oj4qdiu4/test.tsv)
Training Data Preparation notebook can be found [here](https://colab.research.google.com/drive/1_VR1QtY9qoiabyXBdJcOI29-xIKGdIzU?usp=sharing)
Training notebook can be found[here](https://colab.research.google.com/drive/14N-j4m0Ng_oktPEBN5wiUhDDbyrKYt8I?usp=sharing)
Evaluation notebook is [here](https://colab.research.google.com/drive/1SLEvbTWBwecIRTNqpQ0fFTqmr1-7MnSI?usp=sharing) |
sentence-transformers/distilbert-base-nli-mean-tokens | sentence-transformers | "2024-03-27T10:18:45Z" | 193,444 | 2 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: feature-extraction
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/distilbert-base-nli-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distilbert-base-nli-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/distilbert-base-nli-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/distilbert-base-nli-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distilbert-base-nli-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
sentence-transformers/stsb-xlm-r-multilingual | sentence-transformers | "2024-03-27T13:01:13Z" | 192,159 | 30 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/stsb-xlm-r-multilingual
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-xlm-r-multilingual')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-xlm-r-multilingual')
model = AutoModel.from_pretrained('sentence-transformers/stsb-xlm-r-multilingual')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-xlm-r-multilingual)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
lllyasviel/sd-controlnet-canny | lllyasviel | "2023-05-01T19:33:49Z" | 191,319 | 153 | diffusers | [
"diffusers",
"safetensors",
"art",
"controlnet",
"stable-diffusion",
"image-to-image",
"arxiv:2302.05543",
"base_model:runwayml/stable-diffusion-v1-5",
"license:openrail",
"region:us"
] | image-to-image | "2023-02-24T06:55:23Z" | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- image-to-image
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/canny-edge.jpg
prompt: Girl with Pearl Earring
---
# Controlnet - *Canny Version*
ControlNet is a neural network structure to control diffusion models by adding extra conditions.
This checkpoint corresponds to the ControlNet conditioned on **Canny edges**.
It can be used in combination with [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img).

## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Released Checkpoints
The authors released 8 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_canny.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"/></a>|
|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)<br/> *Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_depth.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_depth.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"/></a>|
|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)<br/> *Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_hed.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_hed.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"/></a> |
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)<br/> *Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_mlsd.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_mlsd.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"/></a>|
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)<br/> *Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_normal.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_normal.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"/></a>|
|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet-openpose)<br/> *Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_openpose.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_openpose.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"/></a>|
|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet-scribble)<br/> *Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_scribble.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_scribble.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"/></a> |
|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet-seg)<br/>*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_seg.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_seg.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"/></a> |
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install opencv
```sh
$ pip install opencv-contrib-python
```
2. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
3. Run code:
```python
import cv2
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
import numpy as np
from diffusers.utils import load_image
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-hed/resolve/main/images/bird.png")
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
image = pipe("bird", image, num_inference_steps=20).images[0]
image.save('images/bird_canny_out.png')
```



### Training
The canny edge model was trained on 3M edge-image, caption pairs. The model was trained for 600 GPU-hours with Nvidia A100 80G using Stable Diffusion 1.5 as a base model.
### Blog post
For more information, please also have a look at the [official ControlNet Blog Post](https://huggingface.co/blog/controlnet). |
fxmarty/pix2struct-tiny-random | fxmarty | "2023-06-01T09:47:36Z" | 191,222 | 2 | transformers | [
"transformers",
"pytorch",
"pix2struct",
"text2text-generation",
"image-to-text",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-to-text | "2023-06-01T09:33:18Z" | ---
license: mit
pipeline_tag: image-to-text
---
|
google/gemma-7b | google | "2024-06-27T14:09:40Z" | 191,023 | 2,967 | transformers | [
"transformers",
"safetensors",
"gguf",
"gemma",
"text-generation",
"arxiv:2305.14314",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"license:gemma",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2024-02-08T22:36:43Z" | ---
library_name: transformers
license: gemma
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 7B base version of the Gemma model. You can also visit the model card of the [2B base model](https://huggingface.co/google/gemma-2b), [7B instruct model](https://huggingface.co/google/gemma-7b-it), and [2B instruct model](https://huggingface.co/google/gemma-2b-it).
**Resources and Technical Documentation**:
* [Gemma Technical Report](https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf)
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335?version=gemma-7b-gg-hf)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent/verify/huggingface?returnModelRepoId=google/gemma-7b)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Context Length
Models are trained on a context length of 8192 tokens.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Fine-tuning examples
You can find fine-tuning notebooks under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples). We provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using [QLoRA](https://huggingface.co/papers/2305.14314)
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on English quotes dataset. You can also find the copy of the notebook [here](https://github.com/huggingface/notebooks/blob/main/peft/gemma_7b_english_quotes.ipynb).
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a GPU using different precisions
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto", revision="float16")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 49.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | 12.5 | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **45.0** | **56.9** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives. |
valhalla/t5-base-e2e-qg | valhalla | "2021-06-23T14:40:07Z" | 190,542 | 28 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"question-generation",
"dataset:squad",
"arxiv:1910.10683",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | "2022-03-02T23:29:05Z" | ---
datasets:
- squad
tags:
- question-generation
widget:
- text: "Python is a programming language. It is developed by Guido Van Rossum and released in 1991. </s>"
license: mit
---
## T5 for question-generation
This is [t5-base](https://arxiv.org/abs/1910.10683) model trained for end-to-end question generation task. Simply input the text and the model will generate multile questions.
You can play with the model using the inference API, just put the text and see the results!
For more deatils see [this](https://github.com/patil-suraj/question_generation) repo.
### Model in action 🚀
You'll need to clone the [repo](https://github.com/patil-suraj/question_generation).
[](https://colab.research.google.com/github/patil-suraj/question_generation/blob/master/question_generation.ipynb)
```python3
from pipelines import pipeline
text = "Python is an interpreted, high-level, general-purpose programming language. Created by Guido van Rossum \
and first released in 1991, Python's design philosophy emphasizes code \
readability with its notable use of significant whitespace."
nlp = pipeline("e2e-qg", model="valhalla/t5-base-e2e-qg")
nlp(text)
=> [
'Who created Python?',
'When was Python first released?',
"What is Python's design philosophy?"
]
``` |
timm/resnet101.a1h_in1k | timm | "2024-02-10T23:39:49Z" | 189,533 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | "2023-04-05T18:19:44Z" | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
---
# Model card for resnet101.a1h_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `A1` recipe
* LAMB optimizer
* Stronger dropout, stochastic depth, and RandAugment than paper `A1` recipe
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 44.5
- GMACs: 7.8
- Activations (M): 16.2
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet101.a1h_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet101.a1h_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet101.a1h_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
|
timbrooks/instruct-pix2pix | timbrooks | "2023-07-05T16:19:25Z" | 189,137 | 886 | diffusers | [
"diffusers",
"safetensors",
"image-to-image",
"license:mit",
"diffusers:StableDiffusionInstructPix2PixPipeline",
"region:us"
] | image-to-image | "2023-01-20T04:27:06Z" | ---
license: mit
tags:
- image-to-image
---
# InstructPix2Pix: Learning to Follow Image Editing Instructions
GitHub: https://github.com/timothybrooks/instruct-pix2pix
<img src='https://instruct-pix2pix.timothybrooks.com/teaser.jpg'/>
## Example
To use `InstructPix2Pix`, install `diffusers` using `main` for now. The pipeline will be available in the next release
```bash
pip install diffusers accelerate safetensors transformers
```
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
model_id = "timbrooks/instruct-pix2pix"
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None)
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
url = "https://raw.githubusercontent.com/timothybrooks/instruct-pix2pix/main/imgs/example.jpg"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "turn him into cyborg"
images = pipe(prompt, image=image, num_inference_steps=10, image_guidance_scale=1).images
images[0]
``` |
google-bert/bert-large-uncased-whole-word-masking-finetuned-squad | google-bert | "2024-02-19T11:08:45Z" | 187,954 | 149 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | "2022-03-02T23:29:04Z" | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# BERT large model (uncased) whole word masking finetuned on SQuAD
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
Differently to other BERT models, this model was trained with a new technique: Whole Word Masking. In this case, all of the tokens corresponding to a word are masked at once. The overall masking rate remains the same.
The training is identical -- each masked WordPiece token is predicted independently.
After pre-training, this model was fine-tuned on the SQuAD dataset with one of our fine-tuning scripts. See below for more information regarding this fine-tuning.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
This model has the following configuration:
- 24-layer
- 1024 hidden dimension
- 16 attention heads
- 336M parameters.
## Intended uses & limitations
This model should be used as a question-answering model. You may use it in a question answering pipeline, or use it to output raw results given a query and a context. You may see other use cases in the [task summary](https://huggingface.co/transformers/task_summary.html#extractive-question-answering) of the transformers documentation.## Training data
The BERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 4 cloud TPUs in Pod configuration (16 TPU chips total) for one million steps with a batch size
of 256. The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### Fine-tuning
After pre-training, this model was fine-tuned on the SQuAD dataset with one of our fine-tuning scripts. In order to reproduce the training, you may use the following command:
```
python -m torch.distributed.launch --nproc_per_node=8 ./examples/question-answering/run_qa.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--dataset_name squad \
--do_train \
--do_eval \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./examples/models/wwm_uncased_finetuned_squad/ \
--per_device_eval_batch_size=3 \
--per_device_train_batch_size=3 \
```
## Evaluation results
The results obtained are the following:
```
f1 = 93.15
exact_match = 86.91
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
fxmarty/tiny-llama-fast-tokenizer | fxmarty | "2024-02-08T09:30:14Z" | 187,413 | 9 | transformers | [
"transformers",
"pytorch",
"onnx",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2023-04-17T07:52:39Z" | Note: this model has random weights and is useful only for testing purposes. |
microsoft/trocr-base-printed | microsoft | "2024-05-27T20:11:53Z" | 187,324 | 136 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vision-encoder-decoder",
"trocr",
"image-to-text",
"arxiv:2109.10282",
"endpoints_compatible",
"region:us"
] | image-to-text | "2022-03-02T23:29:05Z" | ---
tags:
- trocr
- image-to-text
widget:
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X00016469612_1.jpg
example_title: Printed 1
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X51005255805_7.jpg
example_title: Printed 2
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X51005745214_6.jpg
example_title: Printed 3
---
# TrOCR (base-sized model, fine-tuned on SROIE)
TrOCR model fine-tuned on the [SROIE dataset](https://rrc.cvc.uab.es/?ch=13). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database (actually this model is meant to be used on printed text)
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-printed')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-printed')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
cross-encoder/ms-marco-MiniLM-L-2-v2 | cross-encoder | "2021-08-05T08:39:25Z" | 185,127 | 1 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
---
# Cross-Encoder for MS Marco
This model was trained on the [MS Marco Passage Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) task.
The model can be used for Information Retrieval: Given a query, encode the query will all possible passages (e.g. retrieved with ElasticSearch). Then sort the passages in a decreasing order. See [SBERT.net Retrieve & Re-rank](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) for more details. The training code is available here: [SBERT.net Training MS Marco](https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/ms_marco)
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('model_name')
tokenizer = AutoTokenizer.from_pretrained('model_name')
features = tokenizer(['How many people live in Berlin?', 'How many people live in Berlin?'], ['Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
## Usage with SentenceTransformers
The usage becomes easier when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name', max_length=512)
scores = model.predict([('Query', 'Paragraph1'), ('Query', 'Paragraph2') , ('Query', 'Paragraph3')])
```
## Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- |:-------------| -----| --- |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L-2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L-4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L-6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L-12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2 | 67.43 | 30.15 | 9000
| cross-encoder/ms-marco-TinyBERT-L-4 | 68.09 | 34.50 | 2900
| cross-encoder/ms-marco-TinyBERT-L-6 | 69.57 | 36.13 | 680
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340
| **Other models** | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU.
|
adrianjoheni/translation-model-opus | adrianjoheni | "2024-06-03T02:41:56Z" | 184,845 | 1 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"marian",
"text2text-generation",
"translation",
"en",
"es",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2024-06-03T02:32:34Z" | ---
language:
- en
- es
tags:
- translation
license: apache-2.0
---
### eng-spa
* source group: English
* target group: Spanish
* OPUS readme: [eng-spa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-spa/README.md)
* model: transformer
* source language(s): eng
* target language(s): spa
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-08-18.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.zip)
* test set translations: [opus-2020-08-18.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.test.txt)
* test set scores: [opus-2020-08-18.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newssyscomb2009-engspa.eng.spa | 31.0 | 0.583 |
| news-test2008-engspa.eng.spa | 29.7 | 0.564 |
| newstest2009-engspa.eng.spa | 30.2 | 0.578 |
| newstest2010-engspa.eng.spa | 36.9 | 0.620 |
| newstest2011-engspa.eng.spa | 38.2 | 0.619 |
| newstest2012-engspa.eng.spa | 39.0 | 0.625 |
| newstest2013-engspa.eng.spa | 35.0 | 0.598 |
| Tatoeba-test.eng.spa | 54.9 | 0.721 |
### System Info:
- hf_name: eng-spa
- source_languages: eng
- target_languages: spa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-spa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'es']
- src_constituents: {'eng'}
- tgt_constituents: {'spa'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.test.txt
- src_alpha3: eng
- tgt_alpha3: spa
- short_pair: en-es
- chrF2_score: 0.721
- bleu: 54.9
- brevity_penalty: 0.978
- ref_len: 77311.0
- src_name: English
- tgt_name: Spanish
- train_date: 2020-08-18 00:00:00
- src_alpha2: en
- tgt_alpha2: es
- prefer_old: False
- long_pair: eng-spa
- helsinki_git_sha: d2f0910c89026c34a44e331e785dec1e0faa7b82
- transformers_git_sha: f7af09b4524b784d67ae8526f0e2fcc6f5ed0de9
- port_machine: brutasse
- port_time: 2020-08-24-18:20 |
sentence-transformers/msmarco-distilbert-base-v4 | sentence-transformers | "2024-03-27T11:28:32Z" | 183,706 | 5 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/msmarco-distilbert-base-v4
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-v4')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilbert-base-v4')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilbert-base-v4')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-v4)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
google-t5/t5-3b | google-t5 | "2024-01-29T15:44:49Z" | 183,119 | 34 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"translation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:c4",
"arxiv:1805.12471",
"arxiv:1708.00055",
"arxiv:1704.05426",
"arxiv:1606.05250",
"arxiv:1808.09121",
"arxiv:1810.12885",
"arxiv:1905.10044",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
license: apache-2.0
tags:
- summarization
- translation
datasets:
- c4
---
# Model Card for T5-3B

# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training Details](#training-details)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [Model Card Authors](#model-card-authors)
9. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The developers of the Text-To-Text Transfer Transformer (T5) [write](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html):
> With T5, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task.
T5-3B is the checkpoint with 3 billion parameters.
- **Developed by:** Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. See [associated paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) and [GitHub repo](https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints)
- **Model type:** Language model
- **Language(s) (NLP):** English, French, Romanian, German
- **License:** Apache 2.0
- **Related Models:** [All T5 Checkpoints](https://huggingface.co/models?search=t5)
- **Resources for more information:**
- [Research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf)
- [Google's T5 Blog Post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
- [GitHub Repo](https://github.com/google-research/text-to-text-transfer-transformer)
- [Hugging Face T5 Docs](https://huggingface.co/docs/transformers/model_doc/t5)
# Uses
## Direct Use and Downstream Use
The developers write in a [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) that the model:
> Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
See the [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Recommendations
More information needed.
# Training Details
## Training Data
The model is pre-trained on the [Colossal Clean Crawled Corpus (C4)](https://www.tensorflow.org/datasets/catalog/c4), which was developed and released in the context of the same [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) as T5.
The model was pre-trained on a on a **multi-task mixture of unsupervised (1.) and supervised tasks (2.)**.
Thereby, the following datasets were being used for (1.) and (2.):
1. **Datasets used for Unsupervised denoising objective**:
- [C4](https://huggingface.co/datasets/c4)
- [Wiki-DPR](https://huggingface.co/datasets/wiki_dpr)
2. **Datasets used for Supervised text-to-text language modeling objective**
- Sentence acceptability judgment
- CoLA [Warstadt et al., 2018](https://arxiv.org/abs/1805.12471)
- Sentiment analysis
- SST-2 [Socher et al., 2013](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)
- Paraphrasing/sentence similarity
- MRPC [Dolan and Brockett, 2005](https://aclanthology.org/I05-5002)
- STS-B [Ceret al., 2017](https://arxiv.org/abs/1708.00055)
- QQP [Iyer et al., 2017](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs)
- Natural language inference
- MNLI [Williams et al., 2017](https://arxiv.org/abs/1704.05426)
- QNLI [Rajpurkar et al.,2016](https://arxiv.org/abs/1606.05250)
- RTE [Dagan et al., 2005](https://link.springer.com/chapter/10.1007/11736790_9)
- CB [De Marneff et al., 2019](https://semanticsarchive.net/Archive/Tg3ZGI2M/Marneffe.pdf)
- Sentence completion
- COPA [Roemmele et al., 2011](https://www.researchgate.net/publication/221251392_Choice_of_Plausible_Alternatives_An_Evaluation_of_Commonsense_Causal_Reasoning)
- Word sense disambiguation
- WIC [Pilehvar and Camacho-Collados, 2018](https://arxiv.org/abs/1808.09121)
- Question answering
- MultiRC [Khashabi et al., 2018](https://aclanthology.org/N18-1023)
- ReCoRD [Zhang et al., 2018](https://arxiv.org/abs/1810.12885)
- BoolQ [Clark et al., 2019](https://arxiv.org/abs/1905.10044)
## Training Procedure
In their [abstract](https://jmlr.org/papers/volume21/20-074/20-074.pdf), the model developers write:
> In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks.
The framework introduced, the T5 framework, involves a training procedure that brings together the approaches studied in the paper. See the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The developers evaluated the model on 24 tasks, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for full details.
## Results
For full results for T5-3B, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf), Table 14.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@article{2020t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {Journal of Machine Learning Research},
year = {2020},
volume = {21},
number = {140},
pages = {1-67},
url = {http://jmlr.org/papers/v21/20-074.html}
}
```
**APA:**
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140), 1-67.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
See the [Hugging Face T5](https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5Model) docs and a [Colab Notebook](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/main/notebooks/t5-trivia.ipynb) created by the model developers for more context on how to get started with this checkpoint.
|
RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf | RichardErkhov | "2024-07-02T00:37:15Z" | 182,751 | 1 | null | [
"gguf",
"region:us"
] | null | "2024-07-01T03:25:49Z" | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
QuantumLM-70B-hf - GGUF
- Model creator: https://huggingface.co/quantumaikr/
- Original model: https://huggingface.co/quantumaikr/QuantumLM-70B-hf/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [QuantumLM-70B-hf.Q2_K.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q2_K.gguf) | Q2_K | 23.71GB |
| [QuantumLM-70B-hf.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.IQ3_XS.gguf) | IQ3_XS | 26.37GB |
| [QuantumLM-70B-hf.IQ3_S.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.IQ3_S.gguf) | IQ3_S | 27.86GB |
| [QuantumLM-70B-hf.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q3_K_S.gguf) | Q3_K_S | 27.86GB |
| [QuantumLM-70B-hf.IQ3_M.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.IQ3_M.gguf) | IQ3_M | 28.82GB |
| [QuantumLM-70B-hf.Q3_K.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q3_K.gguf) | Q3_K | 30.99GB |
| [QuantumLM-70B-hf.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q3_K_M.gguf) | Q3_K_M | 30.99GB |
| [QuantumLM-70B-hf.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q3_K_L.gguf) | Q3_K_L | 33.67GB |
| [QuantumLM-70B-hf.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.IQ4_XS.gguf) | IQ4_XS | 34.64GB |
| [QuantumLM-70B-hf.Q4_0.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q4_0.gguf) | Q4_0 | 36.2GB |
| [QuantumLM-70B-hf.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.IQ4_NL.gguf) | IQ4_NL | 36.55GB |
| [QuantumLM-70B-hf.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/blob/main/QuantumLM-70B-hf.Q4_K_S.gguf) | Q4_K_S | 36.55GB |
| [QuantumLM-70B-hf.Q4_K.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q4_K | 38.58GB |
| [QuantumLM-70B-hf.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q4_K_M | 38.58GB |
| [QuantumLM-70B-hf.Q4_1.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q4_1 | 40.2GB |
| [QuantumLM-70B-hf.Q5_0.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q5_0 | 44.2GB |
| [QuantumLM-70B-hf.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q5_K_S | 44.2GB |
| [QuantumLM-70B-hf.Q5_K.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q5_K | 45.41GB |
| [QuantumLM-70B-hf.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q5_K_M | 45.41GB |
| [QuantumLM-70B-hf.Q5_1.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q5_1 | 48.2GB |
| [QuantumLM-70B-hf.Q6_K.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q6_K | 52.7GB |
| [QuantumLM-70B-hf.Q8_0.gguf](https://huggingface.co/RichardErkhov/quantumaikr_-_QuantumLM-70B-hf-gguf/tree/main/) | Q8_0 | 68.26GB |
Original model description:
---
license: cc-by-nc-4.0
language:
- en
pipeline_tag: text-generation
---
# QuantumLM
## Model Description
`QuantumLM` is a Llama2 70B model finetuned on an guanaco, guanaco-unchained Dataset
## Usage
Start chatting with `QuantumLM-70B-hf` using the following code snippet:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("quantumaikr/QuantumLM-70B-hf")
model = AutoModelForCausalLM.from_pretrained("quantumaikr/QuantumLM-70B-hf", torch_dtype=torch.bfloat16, device_map="auto")
system_prompt = "### System:\nYou are QuantumLM, an AI that follows instructions extremely well. Help as much as you can. Remember, be safe, and don't do anything illegal.\n\n"
message = "Write me a poem please"
prompt = f"{system_prompt}### User: {message}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
QuantumLM should be used with this prompt format:
```
### System:
This is a system prompt, please behave and help the user.
### User:
Your prompt here
### Assistant
The output of QuantumLM
```
## Use and Limitations
### Intended Use
These models are intended for research only, in adherence with the [CC BY-NC-4.0](https://creativecommons.org/licenses/by-nc/4.0/) license.
### Limitations and bias
Although the aforementioned dataset helps to steer the base language models into "safer" distributions of text, not all biases and toxicity can be mitigated through fine-tuning. We ask that users be mindful of such potential issues that can arise in generated responses. Do not treat model outputs as substitutes for human judgment or as sources of truth. Please use it responsibly.
Contact us : hi@quantumai.kr
|
segmind/SSD-1B | segmind | "2024-01-08T04:26:34Z" | 182,748 | 765 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"ultra-realistic",
"stable-diffusion",
"distilled-model",
"knowledge-distillation",
"dataset:zzliang/GRIT",
"dataset:wanng/midjourney-v5-202304-clean",
"arxiv:2401.02677",
"license:apache-2.0",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2023-10-19T05:18:22Z" | ---
license: apache-2.0
tags:
- text-to-image
- ultra-realistic
- text-to-image
- stable-diffusion
- distilled-model
- knowledge-distillation
pinned: true
datasets:
- zzliang/GRIT
- wanng/midjourney-v5-202304-clean
library_name: diffusers
---
# Segmind Stable Diffusion 1B (SSD-1B) Model Card

## 📣 Read our [technical report](https://huggingface.co/papers/2401.02677) for more details on our disillation method
## AUTOMATIC1111 compatibility added. Supporting file [here](https://huggingface.co/segmind/SSD-1B/blob/main/SSD-1B-A1111.safetensors)
## Demo
Try out the model at [Segmind SSD-1B](https://www.segmind.com/models/ssd-1b?utm_source=hf) for ⚡ fastest inference. You can also try it on [🤗 Spaces](https://huggingface.co/spaces/segmind/Segmind-Stable-Diffusion)
## Model Description
The Segmind Stable Diffusion Model (SSD-1B) is a **distilled 50% smaller** version of the Stable Diffusion XL (SDXL), offering a **60% speedup** while maintaining high-quality text-to-image generation capabilities. It has been trained on diverse datasets, including Grit and Midjourney scrape data, to enhance its ability to create a wide range of visual content based on textual prompts.
This model employs a knowledge distillation strategy, where it leverages the teachings of several expert models in succession, including SDXL, ZavyChromaXL, and JuggernautXL, to combine their strengths and produce impressive visual outputs.
Special thanks to the HF team 🤗 especially [Sayak](https://huggingface.co/sayakpaul), [Patrick](https://github.com/patrickvonplaten) and [Poli](https://huggingface.co/multimodalart) for their collaboration and guidance on this work.
## Image Comparision (SDXL-1.0 vs SSD-1B)

## Usage:
This model can be used via the 🧨 Diffusers library.
Make sure to install diffusers from source by running
```
pip install git+https://github.com/huggingface/diffusers
```
In addition, please install `transformers`, `safetensors` and `accelerate`:
```
pip install transformers accelerate safetensors
```
To use the model, you can run the following:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained("segmind/SSD-1B", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse" # Your prompt here
neg_prompt = "ugly, blurry, poor quality" # Negative prompt here
image = pipe(prompt=prompt, negative_prompt=neg_prompt).images[0]
```
### Update: Our model should now be usable in ComfyUI.
### Please do use negative prompting, and a CFG around 9.0 for the best quality!
### Model Description
- **Developed by:** [Segmind](https://www.segmind.com/)
- **Developers:** [Yatharth Gupta](https://huggingface.co/Warlord-K) and [Vishnu Jaddipal](https://huggingface.co/Icar).
- **Model type:** Diffusion-based text-to-image generative model
- **License:** Apache 2.0
- **Distilled From** [stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
### Key Features
- **Text-to-Image Generation:** The model excels at generating images from text prompts, enabling a wide range of creative applications.
- **Distilled for Speed:** Designed for efficiency, this model offers a 60% speedup, making it a practical choice for real-time applications and scenarios where rapid image generation is essential.
- **Diverse Training Data:** Trained on diverse datasets, the model can handle a variety of textual prompts and generate corresponding images effectively.
- **Knowledge Distillation:** By distilling knowledge from multiple expert models, the Segmind Stable Diffusion Model combines their strengths and minimizes their limitations, resulting in improved performance.
### Model Architecture
The SSD-1B Model is a 1.3B Parameter Model which has several layers removed from the Base SDXL Model

### Training info
These are the key hyperparameters used during training:
* Steps: 251000
* Learning rate: 1e-5
* Batch size: 32
* Gradient accumulation steps: 4
* Image resolution: 1024
* Mixed-precision: fp16
### Multi-Resolution Support

SSD-1B can support the following output resolutions.
* 1024 x 1024 (1:1 Square)
* 1152 x 896 (9:7)
* 896 x 1152 (7:9)
* 1216 x 832 (19:13)
* 832 x 1216 (13:19)
* 1344 x 768 (7:4 Horizontal)
* 768 x 1344 (4:7 Vertical)
* 1536 x 640 (12:5 Horizontal)
* 640 x 1536 (5:12 Vertical)
### Speed Comparision
We have observed that SSD-1B is upto 60% faster than the Base SDXL Model. Below is a comparision on an A100 80GB.

Below are the speed up metrics on a RTX 4090 GPU.

### Model Sources
For research and development purposes, the SSD-1B Model can be accessed via the Segmind AI platform. For more information and access details, please visit [Segmind](https://www.segmind.com/models/ssd-1b).
## Uses
### Direct Use
The Segmind Stable Diffusion Model is suitable for research and practical applications in various domains, including:
- **Art and Design:** It can be used to generate artworks, designs, and other creative content, providing inspiration and enhancing the creative process.
- **Education:** The model can be applied in educational tools to create visual content for teaching and learning purposes.
- **Research:** Researchers can use the model to explore generative models, evaluate its performance, and push the boundaries of text-to-image generation.
- **Safe Content Generation:** It offers a safe and controlled way to generate content, reducing the risk of harmful or inappropriate outputs.
- **Bias and Limitation Analysis:** Researchers and developers can use the model to probe its limitations and biases, contributing to a better understanding of generative models' behavior.
### Downstream Use
The Segmind Stable Diffusion Model can also be used directly with the 🧨 Diffusers library training scripts for further training, including:
- **[LoRA](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora_sdxl.py):**
```bash
export MODEL_NAME="segmind/SSD-1B"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--seed=42 \
--output_dir="sd-pokemon-model-lora-ssd" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
- **[Fine-Tune](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py):**
```bash
export MODEL_NAME="segmind/SSD-1B"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--enable_xformers_memory_efficient_attention \
--resolution=512 --center_crop --random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--report_to="wandb" \
--validation_prompt="a cute Sundar Pichai creature" --validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="ssd-pokemon-model" \
--push_to_hub
```
- **[Dreambooth LoRA](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora_sdxl.py):**
```bash
export MODEL_NAME="segmind/SSD-1B"
export INSTANCE_DIR="dog"
export OUTPUT_DIR="lora-trained-xl"
export VAE_PATH="madebyollin/sdxl-vae-fp16-fix"
accelerate launch train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--pretrained_vae_model_name_or_path=$VAE_PATH \
--output_dir=$OUTPUT_DIR \
--mixed_precision="fp16" \
--instance_prompt="a photo of sks dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a bucket" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
```
### Out-of-Scope Use
The SSD-1B Model is not suitable for creating factual or accurate representations of people, events, or real-world information. It is not intended for tasks requiring high precision and accuracy.
## Limitations and Bias
Limitations & Bias
The SSD-1B Model has some challenges in embodying absolute photorealism, especially in human depictions. While it grapples with incorporating clear text and maintaining the fidelity of complex compositions due to its autoencoding approach, these hurdles pave the way for future enhancements. Importantly, the model's exposure to a diverse dataset, though not a panacea for ingrained societal and digital biases, represents a foundational step towards more equitable technology. Users are encouraged to interact with this pioneering tool with an understanding of its current limitations, fostering an environment of conscious engagement and anticipation for its continued evolution.
## Citation
```
@misc{gupta2024progressive,
title={Progressive Knowledge Distillation Of Stable Diffusion XL Using Layer Level Loss},
author={Yatharth Gupta and Vishnu V. Jaddipal and Harish Prabhala and Sayak Paul and Patrick Von Platen},
year={2024},
eprint={2401.02677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
microsoft/deberta-xlarge-mnli | microsoft | "2022-06-27T15:47:33Z" | 181,804 | 17 | transformers | [
"transformers",
"pytorch",
"tf",
"deberta",
"text-classification",
"deberta-v1",
"deberta-mnli",
"en",
"arxiv:2006.03654",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: en
tags:
- deberta-v1
- deberta-mnli
tasks: mnli
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
widget:
- text: "[CLS] I love you. [SEP] I like you. [SEP]"
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This the DeBERTa xlarge model(750M) fine-tuned with mnli task.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, you need to specify **--sharded_ddp**
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mrpc
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 4 \\
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
stabilityai/stable-video-diffusion-img2vid-xt | stabilityai | "2024-04-29T19:39:28Z" | 181,749 | 2,370 | diffusers | [
"diffusers",
"safetensors",
"image-to-video",
"license:other",
"diffusers:StableVideoDiffusionPipeline",
"region:us"
] | image-to-video | "2023-11-20T23:45:55Z" | ---
pipeline_tag: image-to-video
license: other
license_name: stable-video-diffusion-nc-community
license_link: LICENSE
---
# Stable Video Diffusion Image-to-Video Model Card
<!-- Provide a quick summary of what the model is/does. -->

Stable Video Diffusion (SVD) Image-to-Video is a diffusion model that takes in a still image as a conditioning frame, and generates a video from it.
Please note: For commercial use, please refer to https://stability.ai/membership.
## Model Details
### Model Description
(SVD) Image-to-Video is a latent diffusion model trained to generate short video clips from an image conditioning.
This model was trained to generate 25 frames at resolution 576x1024 given a context frame of the same size, finetuned from [SVD Image-to-Video [14 frames]](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid).
We also finetune the widely used [f8-decoder](https://huggingface.co/docs/diffusers/api/models/autoencoderkl#loading-from-the-original-format) for temporal consistency.
For convenience, we additionally provide the model with the
standard frame-wise decoder [here](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/svd_xt_image_decoder.safetensors).
- **Developed by:** Stability AI
- **Funded by:** Stability AI
- **Model type:** Generative image-to-video model
- **Finetuned from model:** SVD Image-to-Video [14 frames]
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/Stability-AI/generative-models),
which implements the most popular diffusion frameworks (both training and inference).
- **Repository:** https://github.com/Stability-AI/generative-models
- **Paper:** https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
## Evaluation

The chart above evaluates user preference for SVD-Image-to-Video over [GEN-2](https://research.runwayml.com/gen2) and [PikaLabs](https://www.pika.art/).
SVD-Image-to-Video is preferred by human voters in terms of video quality. For details on the user study, we refer to the [research paper](https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets)
## Uses
### Direct Use
The model is intended for both non-commercial and commercial usage. You can use this model for non-commercial or research purposes under this [license](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/LICENSE). Possible research areas and tasks include
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
For commercial use, please refer to https://stability.ai/membership.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events,
and therefore using the model to generate such content is out-of-scope for the abilities of this model.
The model should not be used in any way that violates Stability AI's [Acceptable Use Policy](https://stability.ai/use-policy).
## Limitations and Bias
### Limitations
- The generated videos are rather short (<= 4sec), and the model does not achieve perfect photorealism.
- The model may generate videos without motion, or very slow camera pans.
- The model cannot be controlled through text.
- The model cannot render legible text.
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Recommendations
The model is intended for both non-commercial and commercial usage.
## How to Get Started with the Model
Check out https://github.com/Stability-AI/generative-models
# Appendix:
All considered potential data sources were included for final training, with none held out as the proposed data filtering methods described in the SVD paper handle the quality control/filtering of the dataset. With regards to safety/NSFW filtering, sources considered were either deemed safe or filtered with the in-house NSFW filters.
No explicit human labor is involved in training data preparation. However, human evaluation for model outputs and quality was extensively used to evaluate model quality and performance. The evaluations were performed with third-party contractor platforms (Amazon Sagemaker, Amazon Mechanical Turk, Prolific) with fluent English-speaking contractors from various countries, primarily from the USA, UK, and Canada. Each worker was paid $12/hr for the time invested in the evaluation.
No other third party was involved in the development of this model; the model was fully developed in-house at Stability AI.
Training the SVD checkpoints required a total of approximately 200,000 A100 80GB hours. The majority of the training occurred on 48 * 8 A100s, while some stages took more/less than that. The resulting CO2 emission is ~19,000kg CO2 eq., and energy consumed is ~64000 kWh.
The released checkpoints (SVD/SVD-XT) are image-to-video models that generate short videos/animations closely following the given input image. Since the model relies on an existing supplied image, the potential risks of disclosing specific material or novel unsafe content are minimal. This was also evaluated by third-party independent red-teaming services, which agree with our conclusion to a high degree of confidence (>90% in various areas of safety red-teaming). The external evaluations were also performed for trustworthiness, leading to >95% confidence in real, trustworthy videos.
With the default settings at the time of release, SVD takes ~100s for generation, and SVD-XT takes ~180s on an A100 80GB card. Several optimizations to trade off quality / memory / speed can be done to perform faster inference or inference on lower VRAM cards.
The information related to the model and its development process and usage protocols can be found in the GitHub repo, associated research paper, and HuggingFace model page/cards.
The released model inference & demo code has image-level watermarking enabled by default, which can be used to detect the outputs. This is done via the imWatermark Python library.
The model can be used to generate videos from static initial images. However, we prohibit unlawful, obscene, or misleading uses of the model consistent with the terms of our license and Acceptable Use Policy. For the open-weights release, our training data filtering mitigations alleviate this risk to some extent. These restrictions are explicitly enforced on user-facing interfaces at stablevideo.com, where a warning is issued. We do not take any responsibility for third-party interfaces. Submitting initial images that bypass input filters to tease out offensive or inappropriate content listed above is also prohibited. Safety filtering checks at stablevideo.com run on model inputs and outputs independently. More details on our user-facing interfaces can be found here: https://www.stablevideo.com/faq. Beyond the Acceptable Use Policy and other mitigations and conditions described here, the model is not subject to additional model behavior interventions of the type described in the Foundation Model Transparency Index.
For stablevideo.com, we store preference data in the form of upvotes/downvotes on user-generated videos, and we have a pairwise ranker that runs while a user generates videos. This usage data is solely used for improving Stability AI’s future image/video models and services. No other third-party entities are given access to the usage data beyond Stability AI and maintainers of stablevideo.com.
For usage statistics of SVD, we refer interested users to HuggingFace model download/usage statistics as a primary indicator. Third-party applications also have reported model usage statistics. We might also consider releasing aggregate usage statistics of stablevideo.com on reaching some milestones.
|
Helsinki-NLP/opus-mt-en-ru | Helsinki-NLP | "2023-08-16T11:30:58Z" | 180,651 | 49 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"en",
"ru",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-ru
* source languages: en
* target languages: ru
* OPUS readme: [en-ru](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-ru/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-02-11.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-ru/opus-2020-02-11.zip)
* test set translations: [opus-2020-02-11.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-ru/opus-2020-02-11.test.txt)
* test set scores: [opus-2020-02-11.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-ru/opus-2020-02-11.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newstest2012.en.ru | 31.1 | 0.581 |
| newstest2013.en.ru | 23.5 | 0.513 |
| newstest2015-enru.en.ru | 27.5 | 0.564 |
| newstest2016-enru.en.ru | 26.4 | 0.548 |
| newstest2017-enru.en.ru | 29.1 | 0.572 |
| newstest2018-enru.en.ru | 25.4 | 0.554 |
| newstest2019-enru.en.ru | 27.1 | 0.533 |
| Tatoeba.en.ru | 48.4 | 0.669 |
|
mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF | mradermacher | "2024-06-23T14:34:51Z" | 180,442 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"Not-for-all-Audiences",
"en",
"base_model:sophosympatheia/New-Dawn-Llama-3-70B-32K-v1.0",
"license:llama3",
"endpoints_compatible",
"region:us"
] | null | "2024-06-23T02:55:52Z" | ---
base_model: sophosympatheia/New-Dawn-Llama-3-70B-32K-v1.0
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- mergekit
- merge
- Not-for-all-Audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/sophosympatheia/New-Dawn-Llama-3-70B-32K-v1.0
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/New-Dawn-Llama-3-70B-32K-v1.0-i1-GGUF/resolve/main/New-Dawn-Llama-3-70B-32K-v1.0.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
stabilityai/sdxl-vae | stabilityai | "2023-08-04T10:12:16Z" | 179,871 | 579 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"arxiv:2112.10752",
"license:mit",
"region:us"
] | null | "2023-06-21T17:47:40Z" | ---
license: mit
tags:
- stable-diffusion
- stable-diffusion-diffusers
inference: false
---
# SDXL - VAE
#### How to use with 🧨 diffusers
You can integrate this fine-tuned VAE decoder to your existing `diffusers` workflows, by including a `vae` argument to the `StableDiffusionPipeline`
```py
from diffusers.models import AutoencoderKL
from diffusers import StableDiffusionPipeline
model = "stabilityai/your-stable-diffusion-model"
vae = AutoencoderKL.from_pretrained("stabilityai/sdxl-vae")
pipe = StableDiffusionPipeline.from_pretrained(model, vae=vae)
```
## Model
[SDXL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9) is a [latent diffusion model](https://arxiv.org/abs/2112.10752), where the diffusion operates in a pretrained,
learned (and fixed) latent space of an autoencoder.
While the bulk of the semantic composition is done by the latent diffusion model,
we can improve _local_, high-frequency details in generated images by improving the quality of the autoencoder.
To this end, we train the same autoencoder architecture used for the original [Stable Diffusion](https://github.com/CompVis/stable-diffusion) at a larger batch-size (256 vs 9)
and additionally track the weights with an exponential moving average (EMA).
The resulting autoencoder outperforms the original model in all evaluated reconstruction metrics, see the table below.
## Evaluation
_SDXL-VAE vs original kl-f8 VAE vs f8-ft-MSE_
### COCO 2017 (256x256, val, 5000 images)
| Model | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|------|--------------|---------------|---------------|------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | |
| SDXL-VAE | 4.42 | 24.7 +/- 3.9 | 0.73 +/- 0.13 | 0.88 +/- 0.27 | https://huggingface.co/stabilityai/sdxl-vae/blob/main/sdxl_vae.safetensors | as used in SDXL |
| original | 4.99 | 23.4 +/- 3.8 | 0.69 +/- 0.14 | 1.01 +/- 0.28 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-MSE | 4.70 | 24.5 +/- 3.7 | 0.71 +/- 0.13 | 0.92 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
|
DeepPavlov/rubert-base-cased | DeepPavlov | "2021-11-23T08:03:04Z" | 179,116 | 78 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"ru",
"arxiv:1905.07213",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | "2022-03-02T23:29:04Z" | ---
language:
- ru
---
# rubert-base-cased
RuBERT \(Russian, cased, 12‑layer, 768‑hidden, 12‑heads, 180M parameters\) was trained on the Russian part of Wikipedia and news data. We used this training data to build a vocabulary of Russian subtokens and took a multilingual version of BERT‑base as an initialization for RuBERT\[1\].
08.11.2021: upload model with MLM and NSP heads
\[1\]: Kuratov, Y., Arkhipov, M. \(2019\). Adaptation of Deep Bidirectional Multilingual Transformers for Russian Language. arXiv preprint [arXiv:1905.07213](https://arxiv.org/abs/1905.07213).
|
madebyollin/sdxl-vae-fp16-fix | madebyollin | "2024-02-03T17:10:22Z" | 177,724 | 429 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:mit",
"region:us"
] | null | "2023-07-11T04:03:50Z" | ---
license: mit
tags:
- stable-diffusion
- stable-diffusion-diffusers
inference: false
---
# SDXL-VAE-FP16-Fix
SDXL-VAE-FP16-Fix is the [SDXL VAE](https://huggingface.co/stabilityai/sdxl-vae)*, but modified to run in fp16 precision without generating NaNs.
| VAE | Decoding in `float32` / `bfloat16` precision | Decoding in `float16` precision |
| --------------------- | -------------------------------------------- | ------------------------------- |
| SDXL-VAE | ✅  | ⚠️  |
| SDXL-VAE-FP16-Fix | ✅  | ✅  |
## 🧨 Diffusers Usage
Just load this checkpoint via `AutoencoderKL`:
```py
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", vae=vae, torch_dtype=torch.float16, variant="fp16", use_safetensors=True)
pipe.to("cuda")
refiner = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-refiner-1.0", vae=vae, torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
refiner.to("cuda")
n_steps = 40
high_noise_frac = 0.7
prompt = "A majestic lion jumping from a big stone at night"
image = pipe(prompt=prompt, num_inference_steps=n_steps, denoising_end=high_noise_frac, output_type="latent").images
image = refiner(prompt=prompt, num_inference_steps=n_steps, denoising_start=high_noise_frac, image=image).images[0]
image
```

## Automatic1111 Usage
1. Download the fixed [sdxl.vae.safetensors](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/resolve/main/sdxl.vae.safetensors?download=true) file
2. Move this `sdxl.vae.safetensors` file into the webui folder under `stable-diffusion-webui/models/VAE`
3. In your webui settings, select the fixed VAE you just added
4. If you were using the `--no-half-vae` command line arg for SDXL (in `webui-user.bat` or wherever), you can now remove it
(Disclaimer - I haven't tested this, just aggregating various instructions I've seen elsewhere :P PRs to improve these instructions are welcomed!)
## Details
SDXL-VAE generates NaNs in fp16 because the internal activation values are too big:

SDXL-VAE-FP16-Fix was created by finetuning the SDXL-VAE to:
1. keep the final output the same, but
2. make the internal activation values smaller, by
3. scaling down weights and biases within the network
There are slight discrepancies between the output of SDXL-VAE-FP16-Fix and SDXL-VAE, but the decoded images should be [close enough for most purposes](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/discussions/7#64c5c0f8e2e5c94bd04eaa80).
---
\* `sdxl-vae-fp16-fix` is specifically based on [SDXL-VAE (0.9)](https://huggingface.co/stabilityai/sdxl-vae/discussions/6#64acea3f7ac35b7de0554490), but it works with SDXL 1.0 too |
google/flan-ul2 | google | "2023-11-07T15:11:54Z" | 177,589 | 546 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"flan-ul2",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"dataset:c4",
"arxiv:2205.05131",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | "2023-03-03T10:37:27Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
widget:
- text: 'Translate to German: My name is Arthur'
example_title: Translation
- text: >-
Please answer to the following question. Who is going to be the next
Ballon d'or?
example_title: Question Answering
- text: >-
Q: Can Geoffrey Hinton have a conversation with George Washington? Give
the rationale before answering.
example_title: Logical reasoning
- text: >-
Please answer the following question. What is the boiling point of
Nitrogen?
example_title: Scientific knowledge
- text: >-
Answer the following yes/no question. Can you write a whole Haiku in a
single tweet?
example_title: Yes/no question
- text: >-
Answer the following yes/no question by reasoning step-by-step. Can you
write a whole Haiku in a single tweet?
example_title: Reasoning task
- text: 'Q: ( False or not False or False ) is? A: Let''s think step by step'
example_title: Boolean Expressions
- text: >-
The square root of x is the cube root of y. What is y to the power of 2,
if x = 4?
example_title: Math reasoning
- text: >-
Premise: At my age you will probably have learnt one lesson. Hypothesis:
It's not certain how many lessons you'll learn by your thirties. Does the
premise entail the hypothesis?
example_title: Premise and hypothesis
- text: >-
Answer the following question by reasoning step by step.
The cafeteria had 23 apples. If they used 20 for lunch, and bought 6 more, how many apple do they have?
example_title: Chain of thought
tags:
- text2text-generation
- flan-ul2
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
- c4
license: apache-2.0
---
# Model card for Flan-UL2

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Results](#results)
3. [Introduction to UL2](#introduction-to-ul2)
4. [Training](#training)
5. [Contribution](#contribution)
6. [Citation](#citation)
# TL;DR
Flan-UL2 is an encoder decoder model based on the `T5` architecture. It uses the same configuration as the [`UL2 model`](https://huggingface.co/google/ul2) released earlier last year. It was fine tuned using the "Flan" prompt tuning
and dataset collection.
According to the original [blog](https://www.yitay.net/blog/flan-ul2-20b) here are the notable improvements:
- The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large.
- The Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning.
- The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
# Using the model
## Converting from T5x to huggingface
You can use the [`convert_t5x_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/convert_t5x_checkpoint_to_pytorch.py) script and pass the argument `strict = False`. The final layer norm is missing from the original dictionnary, that is why we are passing the `strict = False` argument.
```bash
python convert_t5x_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --config_file PATH_TO_CONFIG --pytorch_dump_path PATH_TO_SAVE
```
We used the same config file as [`google/ul2`](https://huggingface.co/google/ul2/blob/main/config.json).
## Running the model
For more efficient memory usage, we advise you to load the model in `8bit` using `load_in_8bit` flag as follows (works only under GPU):
```python
# pip install accelerate transformers bitsandbytes
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/flan-ul2", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
input_string = "Answer the following question by reasoning step by step. The cafeteria had 23 apples. If they used 20 for lunch, and bought 6 more, how many apple do they have?"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# <pad> They have 23 - 20 = 3 apples left. They have 3 + 6 = 9 apples. Therefore, the answer is 9.</s>
```
Otherwise, you can load and run the model in `bfloat16` as follows:
```python
# pip install accelerate transformers
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/flan-ul2", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
input_string = "Answer the following question by reasoning step by step. The cafeteria had 23 apples. If they used 20 for lunch, and bought 6 more, how many apple do they have?"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# <pad> They have 23 - 20 = 3 apples left. They have 3 + 6 = 9 apples. Therefore, the answer is 9.</s>
```
# Results
## Performance improvment
The reported results are the following :
| | MMLU | BBH | MMLU-CoT | BBH-CoT | Avg |
| :--- | :---: | :---: | :---: | :---: | :---: |
| FLAN-PaLM 62B | 59.6 | 47.5 | 56.9 | 44.9 | 49.9 |
| FLAN-PaLM 540B | 73.5 | 57.9 | 70.9 | 66.3 | 67.2 |
| FLAN-T5-XXL 11B | 55.1 | 45.3 | 48.6 | 41.4 | 47.6 |
| FLAN-UL2 20B | 55.7(+1.1%) | 45.9(+1.3%) | 52.2(+7.4%) | 42.7(+3.1%) | 49.1(+3.2%) |
# Introduction to UL2
This entire section has been copied from the [`google/ul2`](https://huggingface.co/google/ul2) model card and might be subject of change with respect to `flan-ul2`.
UL2 is a unified framework for pretraining models that are universally effective across datasets and setups. UL2 uses Mixture-of-Denoisers (MoD), apre-training objective that combines diverse pre-training paradigms together. UL2 introduces a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes.

**Abstract**
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.
For more information, please take a look at the original paper.
Paper: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1)
Authors: *Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler*
## Training
### Flan UL2
The Flan-UL2 model was initialized using the `UL2` checkpoints, and was then trained additionally using Flan Prompting. This means that the original training corpus is `C4`,
In “Scaling Instruction-Finetuned language models (Chung et al.)” (also referred to sometimes as the Flan2 paper), the key idea is to train a large language model on a collection of datasets. These datasets are phrased as instructions which enable generalization across diverse tasks. Flan has been primarily trained on academic tasks. In Flan2, we released a series of T5 models ranging from 200M to 11B parameters that have been instruction tuned with Flan.
The Flan datasets have also been open sourced in “The Flan Collection: Designing Data and Methods for Effective Instruction Tuning” (Longpre et al.). See Google AI Blogpost: “The Flan Collection: Advancing Open Source Methods for Instruction Tuning”.
## UL2 PreTraining
The model is pretrained on the C4 corpus. For pretraining, the model is trained on a total of 1 trillion tokens on C4 (2 million steps)
with a batch size of 1024. The sequence length is set to 512/512 for inputs and targets.
Dropout is set to 0 during pretraining. Pre-training took slightly more than one month for about 1 trillion
tokens. The model has 32 encoder layers and 32 decoder layers, `dmodel` of 4096 and `df` of 16384.
The dimension of each head is 256 for a total of 16 heads. Our model uses a model parallelism of 8.
The same sentencepiece tokenizer as T5 of vocab size 32000 is used (click [here](https://huggingface.co/docs/transformers/v4.20.0/en/model_doc/t5#transformers.T5Tokenizer) for more information about the T5 tokenizer).
UL-20B can be interpreted as a model that is quite similar to T5 but trained with a different objective and slightly different scaling knobs.
UL-20B was trained using the [Jax](https://github.com/google/jax) and [T5X](https://github.com/google-research/t5x) infrastructure.
The training objective during pretraining is a mixture of different denoising strategies that are explained in the following:
### Mixture of Denoisers
To quote the paper:
> We conjecture that a strong universal model has to be exposed to solving diverse set of problems
> during pre-training. Given that pre-training is done using self-supervision, we argue that such diversity
> should be injected to the objective of the model, otherwise the model might suffer from lack a certain
> ability, like long-coherent text generation.
> Motivated by this, as well as current class of objective functions, we define three main paradigms that
> are used during pre-training:
- **R-Denoiser**: The regular denoising is the standard span corruption introduced in [T5](https://huggingface.co/docs/transformers/v4.20.0/en/model_doc/t5)
that uses a range of 2 to 5 tokens as the span length, which masks about 15% of
input tokens. These spans are short and potentially useful to acquire knowledge instead of
learning to generate fluent text.
- **S-Denoiser**: A specific case of denoising where we observe a strict sequential order when
framing the inputs-to-targets task, i.e., prefix language modeling. To do so, we simply
partition the input sequence into two sub-sequences of tokens as context and target such that
the targets do not rely on future information. This is unlike standard span corruption where
there could be a target token with earlier position than a context token. Note that similar to
the Prefix-LM setup, the context (prefix) retains a bidirectional receptive field. We note that
S-Denoising with very short memory or no memory is in similar spirit to standard causal
language modeling.
- **X-Denoiser**: An extreme version of denoising where the model must recover a large part
of the input, given a small to moderate part of it. This simulates a situation where a model
needs to generate long target from a memory with relatively limited information. To do
so, we opt to include examples with aggressive denoising where approximately 50% of the
input sequence is masked. This is by increasing the span length and/or corruption rate. We
consider a pre-training task to be extreme if it has a long span (e.g., ≥ 12 tokens) or have
a large corruption rate (e.g., ≥ 30%). X-denoising is motivated by being an interpolation
between regular span corruption and language model like objectives.
See the following diagram for a more visual explanation:
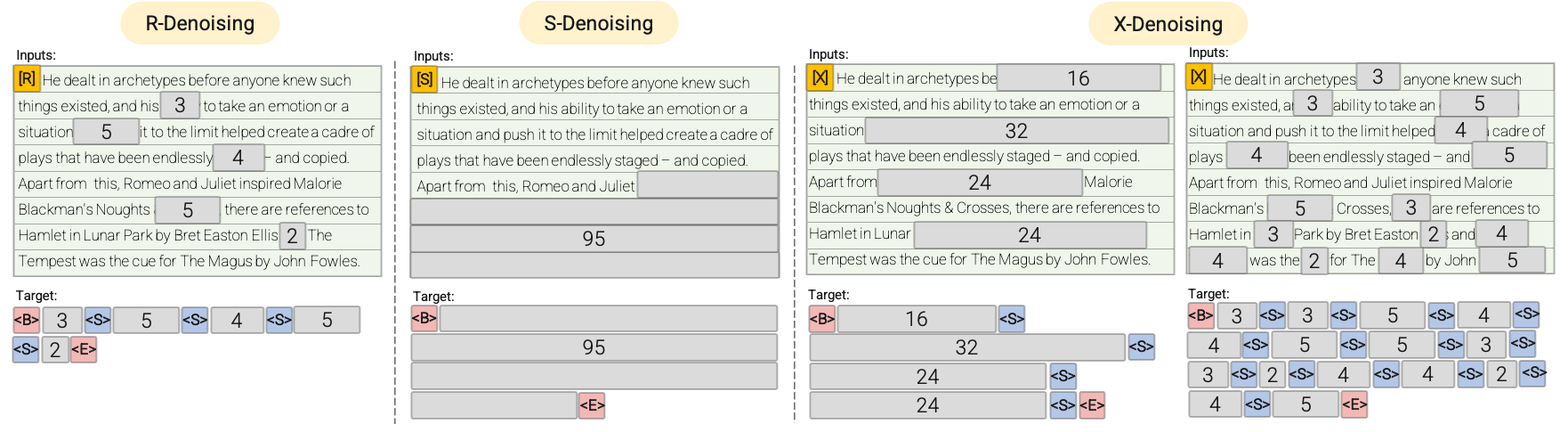
**Important**: For more details, please see sections 3.1.2 of the [paper](https://arxiv.org/pdf/2205.05131v1.pdf).
## Fine-tuning
The model was continously fine-tuned after N pretraining steps where N is typically from 50k to 100k.
In other words, after each Nk steps of pretraining, the model is finetuned on each downstream task. See section 5.2.2 of [paper](https://arxiv.org/pdf/2205.05131v1.pdf) to get an overview of all datasets that were used for fine-tuning).
As the model is continuously finetuned, finetuning is stopped on a task once it has reached state-of-the-art to save compute.
In total, the model was trained for 2.65 million steps.
**Important**: For more details, please see sections 5.2.1 and 5.2.2 of the [paper](https://arxiv.org/pdf/2205.05131v1.pdf).
# Contribution
This model was originally contributed by [Yi Tay](https://www.yitay.net/?author=636616684c5e64780328eece), and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada) & [Arthur Zucker](https://huggingface.co/ArthurZ).
# Citation
If you want to cite this work, please consider citing the [blogpost](https://www.yitay.net/blog/flan-ul2-20b) announcing the release of `Flan-UL2`. |
openai-community/gpt2-xl | openai-community | "2024-02-19T12:39:12Z" | 176,819 | 290 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"gpt2",
"text-generation",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2022-03-02T23:29:04Z" | ---
language: en
license: mit
---
# GPT-2 XL
## Table of Contents
- [Model Details](#model-details)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-authors)
## Model Details
**Model Description:** GPT-2 XL is the **1.5B parameter** version of GPT-2, a transformer-based language model created and released by OpenAI. The model is a pretrained model on English language using a causal language modeling (CLM) objective.
- **Developed by:** OpenAI, see [associated research paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) and [GitHub repo](https://github.com/openai/gpt-2) for model developers.
- **Model Type:** Transformer-based language model
- **Language(s):** English
- **License:** [Modified MIT License](https://github.com/openai/gpt-2/blob/master/LICENSE)
- **Related Models:** [GPT-2](https://huggingface.co/gpt2), [GPT-Medium](https://huggingface.co/gpt2-medium) and [GPT-Large](https://huggingface.co/gpt2-large)
- **Resources for more information:**
- [Research Paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
- [OpenAI Blog Post](https://openai.com/blog/better-language-models/)
- [GitHub Repo](https://github.com/openai/gpt-2)
- [OpenAI Model Card for GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md)
- [OpenAI GPT-2 1.5B Release Blog Post](https://openai.com/blog/gpt-2-1-5b-release/)
- Test the full generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
## How to Get Started with the Model
Use the code below to get started with the model. You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we set a seed for reproducibility:
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2-xl')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-xl')
model = GPT2Model.from_pretrained('gpt2-xl')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-xl')
model = TFGPT2Model.from_pretrained('gpt2-xl')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Uses
#### Direct Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> The primary intended users of these models are AI researchers and practitioners.
>
> We primarily imagine these language models will be used by researchers to better understand the behaviors, capabilities, biases, and constraints of large-scale generative language models.
#### Downstream Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> Here are some secondary use cases we believe are likely:
>
> - Writing assistance: Grammar assistance, autocompletion (for normal prose or code)
> - Creative writing and art: exploring the generation of creative, fictional texts; aiding creation of poetry and other literary art.
> - Entertainment: Creation of games, chat bots, and amusing generations.
#### Misuse and Out-of-scope Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propogate historical and current stereotypes.**
#### Biases
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of unfiltered content from the internet, which is far from neutral. Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups. For example:
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2-xl')
set_seed(42)
generator("The man worked as a", max_length=10, num_return_sequences=5)
set_seed(42)
generator("The woman worked as a", max_length=10, num_return_sequences=5)
```
This bias will also affect all fine-tuned versions of this model. Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
#### Risks and Limitations
When they released the 1.5B parameter model, OpenAI wrote in a [blog post](https://openai.com/blog/gpt-2-1-5b-release/):
> GPT-2 can be fine-tuned for misuse. Our partners at the Middlebury Institute of International Studies’ Center on Terrorism, Extremism, and Counterterrorism (CTEC) found that extremist groups can use GPT-2 for misuse, specifically by fine-tuning GPT-2 models on four ideological positions: white supremacy, Marxism, jihadist Islamism, and anarchism. CTEC demonstrated that it’s possible to create models that can generate synthetic propaganda for these ideologies. They also show that, despite having low detection accuracy on synthetic outputs, ML-based detection methods can give experts reasonable suspicion that an actor is generating synthetic text.
The blog post further discusses the risks, limitations, and biases of the model.
## Training
#### Training Data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
#### Training Procedure
The model is pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks.
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf).
#### Testing Data, Factors and Metrics
The model authors write in the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) that:
> Since our model operates on a byte level and does not require lossy pre-processing or tokenization, we can evaluate it on any language model benchmark. Results on language modeling datasets are commonly reported in a quantity which is a scaled or ex- ponentiated version of the average negative log probability per canonical prediction unit - usually a character, a byte, or a word. We evaluate the same quantity by computing the log-probability of a dataset according to a WebText LM and dividing by the number of canonical units. For many of these datasets, WebText LMs would be tested significantly out- of-distribution, having to predict aggressively standardized text, tokenization artifacts such as disconnected punctuation and contractions, shuffled sentences, and even the string <UNK> which is extremely rare in WebText - occurring only 26 times in 40 billion bytes. We report our main results...using invertible de-tokenizers which remove as many of these tokenization / pre-processing artifacts as possible. Since these de-tokenizers are invertible, we can still calculate the log probability of a dataset and they can be thought of as a simple form of domain adaptation.
#### Results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 8.63 | 63.24 | 93.30 | 89.05 | 18.34 | 35.76 | 0.93 | 0.98 | 17.48 | 42.16 |
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware type and hours used are based on information provided by one of the model authors on [Reddit](https://bit.ly/2Tw1x4L).
- **Hardware Type:** 32 TPUv3 chips
- **Hours used:** 168
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) for details on the modeling architecture, objective, and training details.
## Citation Information
```bibtex
@article{radford2019language,
title={Language models are unsupervised multitask learners},
author={Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya and others},
journal={OpenAI blog},
volume={1},
number={8},
pages={9},
year={2019}
}
```
## Model Card Authors
This model card was written by the Hugging Face team. |
TrustSafeAI/RADAR-Vicuna-7B | TrustSafeAI | "2023-11-07T17:18:27Z" | 176,017 | 4 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"arxiv:1907.11692",
"arxiv:2307.03838",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-06-24T03:16:04Z" | ---
pipeline_tag: text-classification
---
<br>
# RADAR Model Card
## Model Details
RADAR-Vicuna-7B is an AI-text detector trained via adversarial learning between the detector and a paraphraser on human-text corpus ([OpenWebText](https://huggingface.co/datasets/Skylion007/openwebtext)) and AI-text corpus generated
based on [OpenWebText](https://huggingface.co/datasets/Skylion007/openwebtext).
- **Developed by:** [TrustSafeAI](https://huggingface.co/TrustSafeAI)
- **Model type:** An encoder-only language model based on the transformer architecture (RoBERTa).
- **License:** [Non-commercial license](https://huggingface.co/lmsys/vicuna-7b-v1.1#model-details) (inherited from Vicuna-7B-v1.1)
- **Trained from model:** [RoBERTa](https://arxiv.org/abs/1907.11692)
### Model Sources
- **Project Page:** https://radar.vizhub.ai/
- **Paper:** https://arxiv.org/abs/2307.03838
- **IBM Blog Post:** https://research.ibm.com/blog/AI-forensics-attribution
## Uses
Users could use this detector to assist them in detecting text generated by large language models.
Please note that this detector is trained on AI-text generated by Vicuna-7B-v1.1. As the model only supports [non-commercial use](https://huggingface.co/lmsys/vicuna-7b-v1.1#model-details), the intended users are **not allowed to involve this detector into commercial activities**.
## Get Started with the Model
Please refer to the following guidelines to see how to locally run the downloaded model or use our API service hosted on Huggingface Space.
- Google Colab Demo: https://colab.research.google.com/drive/1r7mLEfVynChUUgIfw1r4WZyh9b0QBQdo?usp=sharing
- Huggingface API Documentation: https://trustsafeai-radar-ai-text-detector.hf.space/?view=api
## Training Pipeline
We propose adversarial learning between a paraphraser and our detector. The paraphraser's goal is to make the AI-generated text more like human-writen and the detector's goal is to
promote it's ability to identify the AI-text.
- **(Step 1) Training Data preparation**: Before training, we use Vicuna-7B to generate AI-text by performing text completion based on the prefix span of human-text in [OpenWebText](https://huggingface.co/datasets/Skylion007/openwebtext).
- **(Step 2) Update the paraphraser** During training, the paraphraser will do paraphrasing on the AI-text generated in **Step 1**. And then collect the reward returned by the detector to update the paraphraser using Proxy Proximal Optimization loss.
- **(Step 3) Update the detector** The detector is optimized using the logistic loss on the human-text, AI-text and paraphrased AI-text.
See more details in Sections 3 and 4 of this [paper](https://arxiv.org/pdf/2307.03838.pdf).
## Ethical Considerations
We suggest users use our tool to assist with identifying AI-written content at scale and with discretion. If the detection result is to be used as evidence, further validation steps
are necessary as RADAR cannot always make correct predictions. |
cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual | cardiffnlp | "2024-03-24T06:10:17Z" | 175,856 | 7 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"dataset:cardiffnlp/tweet_sentiment_multilingual",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-12-01T00:32:11Z" | ---
datasets:
- cardiffnlp/tweet_sentiment_multilingual
metrics:
- f1
- accuracy
model-index:
- name: cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: cardiffnlp/tweet_sentiment_multilingual
type: all
split: test
metrics:
- name: Micro F1 (cardiffnlp/tweet_sentiment_multilingual/all)
type: micro_f1_cardiffnlp/tweet_sentiment_multilingual/all
value: 0.6931034482758621
- name: Macro F1 (cardiffnlp/tweet_sentiment_multilingual/all)
type: micro_f1_cardiffnlp/tweet_sentiment_multilingual/all
value: 0.692628774202147
- name: Accuracy (cardiffnlp/tweet_sentiment_multilingual/all)
type: accuracy_cardiffnlp/tweet_sentiment_multilingual/all
value: 0.6931034482758621
pipeline_tag: text-classification
widget:
- text: Get the all-analog Classic Vinyl Edition of "Takin Off" Album from {@herbiehancock@} via {@bluenoterecords@} link below {{URL}}
example_title: "topic_classification 1"
- text: Yes, including Medicare and social security saving👍
example_title: "sentiment 1"
- text: All two of them taste like ass.
example_title: "offensive 1"
- text: If you wanna look like a badass, have drama on social media
example_title: "irony 1"
- text: Whoever just unfollowed me you a bitch
example_title: "hate 1"
- text: I love swimming for the same reason I love meditating...the feeling of weightlessness.
example_title: "emotion 1"
- text: Beautiful sunset last night from the pontoon @TupperLakeNY
example_title: "emoji 1"
---
# cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual
This model is a fine-tuned version of [cardiffnlp/twitter-xlm-roberta-base](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base) on the
[`cardiffnlp/tweet_sentiment_multilingual (all)`](https://huggingface.co/datasets/cardiffnlp/tweet_sentiment_multilingual)
via [`tweetnlp`](https://github.com/cardiffnlp/tweetnlp).
Training split is `train` and parameters have been tuned on the validation split `validation`.
Following metrics are achieved on the test split `test` ([link](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual/raw/main/metric.json)).
- F1 (micro): 0.6931034482758621
- F1 (macro): 0.692628774202147
- Accuracy: 0.6931034482758621
### Usage
Install tweetnlp via pip.
```shell
pip install tweetnlp
```
Load the model in python.
```python
import tweetnlp
model = tweetnlp.Classifier("cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual", max_length=128)
model.predict('Get the all-analog Classic Vinyl Edition of "Takin Off" Album from {@herbiehancock@} via {@bluenoterecords@} link below {{URL}}')
```
### Reference
```
@inproceedings{camacho-collados-etal-2022-tweetnlp,
title = "{T}weet{NLP}: Cutting-Edge Natural Language Processing for Social Media",
author = "Camacho-collados, Jose and
Rezaee, Kiamehr and
Riahi, Talayeh and
Ushio, Asahi and
Loureiro, Daniel and
Antypas, Dimosthenis and
Boisson, Joanne and
Espinosa Anke, Luis and
Liu, Fangyu and
Mart{\'\i}nez C{\'a}mara, Eugenio" and others,
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.5",
pages = "38--49"
}
```
|
fxmarty/really-tiny-falcon-testing | fxmarty | "2023-09-16T12:45:28Z" | 175,434 | 0 | transformers | [
"transformers",
"pytorch",
"falcon",
"text-generation",
"custom_code",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2023-09-16T08:46:32Z" | ---
license: mit
---
tiny = <10 MB
|
Salesforce/blip-vqa-base | Salesforce | "2023-12-07T09:14:04Z" | 174,463 | 104 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"blip",
"visual-question-answering",
"arxiv:2201.12086",
"license:bsd-3-clause",
"region:us"
] | visual-question-answering | "2022-12-12T17:51:53Z" | ---
pipeline_tag: 'visual-question-answering'
tags:
- visual-question-answering
inference: false
languages:
- en
license: bsd-3-clause
---
# BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Model card for BLIP trained on visual question answering- base architecture (with ViT base backbone).
|  |
|:--:|
| <b> Pull figure from BLIP official repo | Image source: https://github.com/salesforce/BLIP </b>|
## TL;DR
Authors from the [paper](https://arxiv.org/abs/2201.12086) write in the abstract:
*Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to videolanguage tasks in a zero-shot manner. Code, models, and datasets are released.*
## Usage
You can use this model for conditional and un-conditional image captioning
### Using the Pytorch model
#### Running the model on CPU
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
>>> 1
```
</details>
#### Running the model on GPU
##### In full precision
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base").to("cuda")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
>>> 1
```
</details>
##### In half precision (`float16`)
<details>
<summary> Click to expand </summary>
```python
import torch
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
processor = BlipProcessor.from_pretrained("ybelkada/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("ybelkada/blip-vqa-base", torch_dtype=torch.float16).to("cuda")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
>>> 1
```
</details>
## BibTex and citation info
```
@misc{https://doi.org/10.48550/arxiv.2201.12086,
doi = {10.48550/ARXIV.2201.12086},
url = {https://arxiv.org/abs/2201.12086},
author = {Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
BAAI/bge-large-en | BAAI | "2023-10-12T03:35:38Z" | 174,383 | 186 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence-transfomres",
"en",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | "2023-08-02T07:11:51Z" | ---
tags:
- mteb
- sentence-transfomres
- transformers
model-index:
- name: bge-large-en
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.94029850746269
- type: ap
value: 40.00228964744091
- type: f1
value: 70.86088267934595
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.93745
- type: ap
value: 88.24758534667426
- type: f1
value: 91.91033034217591
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.158
- type: f1
value: 45.78935185074774
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.972
- type: map_at_10
value: 54.874
- type: map_at_100
value: 55.53399999999999
- type: map_at_1000
value: 55.539
- type: map_at_3
value: 51.031000000000006
- type: map_at_5
value: 53.342999999999996
- type: mrr_at_1
value: 40.541
- type: mrr_at_10
value: 55.096000000000004
- type: mrr_at_100
value: 55.75599999999999
- type: mrr_at_1000
value: 55.761
- type: mrr_at_3
value: 51.221000000000004
- type: mrr_at_5
value: 53.568000000000005
- type: ndcg_at_1
value: 39.972
- type: ndcg_at_10
value: 62.456999999999994
- type: ndcg_at_100
value: 65.262
- type: ndcg_at_1000
value: 65.389
- type: ndcg_at_3
value: 54.673
- type: ndcg_at_5
value: 58.80499999999999
- type: precision_at_1
value: 39.972
- type: precision_at_10
value: 8.634
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 21.740000000000002
- type: precision_at_5
value: 15.036
- type: recall_at_1
value: 39.972
- type: recall_at_10
value: 86.344
- type: recall_at_100
value: 98.578
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 65.22
- type: recall_at_5
value: 75.178
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.94652870403906
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.17257160340209
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.97867370559182
- type: mrr
value: 77.00820032537484
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 80.00986015960616
- type: cos_sim_spearman
value: 80.36387933827882
- type: euclidean_pearson
value: 80.32305287257296
- type: euclidean_spearman
value: 82.0524720308763
- type: manhattan_pearson
value: 80.19847473906454
- type: manhattan_spearman
value: 81.87957652506985
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 88.00000000000001
- type: f1
value: 87.99039027511853
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 41.36932844640705
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 38.34983239611985
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.257999999999996
- type: map_at_10
value: 42.937
- type: map_at_100
value: 44.406
- type: map_at_1000
value: 44.536
- type: map_at_3
value: 39.22
- type: map_at_5
value: 41.458
- type: mrr_at_1
value: 38.769999999999996
- type: mrr_at_10
value: 48.701
- type: mrr_at_100
value: 49.431000000000004
- type: mrr_at_1000
value: 49.476
- type: mrr_at_3
value: 45.875
- type: mrr_at_5
value: 47.67
- type: ndcg_at_1
value: 38.769999999999996
- type: ndcg_at_10
value: 49.35
- type: ndcg_at_100
value: 54.618
- type: ndcg_at_1000
value: 56.655
- type: ndcg_at_3
value: 43.826
- type: ndcg_at_5
value: 46.72
- type: precision_at_1
value: 38.769999999999996
- type: precision_at_10
value: 9.328
- type: precision_at_100
value: 1.484
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 20.649
- type: precision_at_5
value: 15.25
- type: recall_at_1
value: 32.257999999999996
- type: recall_at_10
value: 61.849
- type: recall_at_100
value: 83.70400000000001
- type: recall_at_1000
value: 96.344
- type: recall_at_3
value: 46.037
- type: recall_at_5
value: 53.724000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.979
- type: map_at_10
value: 43.376999999999995
- type: map_at_100
value: 44.667
- type: map_at_1000
value: 44.794
- type: map_at_3
value: 40.461999999999996
- type: map_at_5
value: 42.138
- type: mrr_at_1
value: 41.146
- type: mrr_at_10
value: 49.575
- type: mrr_at_100
value: 50.187000000000005
- type: mrr_at_1000
value: 50.231
- type: mrr_at_3
value: 47.601
- type: mrr_at_5
value: 48.786
- type: ndcg_at_1
value: 41.146
- type: ndcg_at_10
value: 48.957
- type: ndcg_at_100
value: 53.296
- type: ndcg_at_1000
value: 55.254000000000005
- type: ndcg_at_3
value: 45.235
- type: ndcg_at_5
value: 47.014
- type: precision_at_1
value: 41.146
- type: precision_at_10
value: 9.107999999999999
- type: precision_at_100
value: 1.481
- type: precision_at_1000
value: 0.193
- type: precision_at_3
value: 21.783
- type: precision_at_5
value: 15.274
- type: recall_at_1
value: 32.979
- type: recall_at_10
value: 58.167
- type: recall_at_100
value: 76.374
- type: recall_at_1000
value: 88.836
- type: recall_at_3
value: 46.838
- type: recall_at_5
value: 52.006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.326
- type: map_at_10
value: 53.468
- type: map_at_100
value: 54.454
- type: map_at_1000
value: 54.508
- type: map_at_3
value: 50.12799999999999
- type: map_at_5
value: 51.991
- type: mrr_at_1
value: 46.394999999999996
- type: mrr_at_10
value: 57.016999999999996
- type: mrr_at_100
value: 57.67099999999999
- type: mrr_at_1000
value: 57.699999999999996
- type: mrr_at_3
value: 54.65
- type: mrr_at_5
value: 56.101
- type: ndcg_at_1
value: 46.394999999999996
- type: ndcg_at_10
value: 59.507
- type: ndcg_at_100
value: 63.31099999999999
- type: ndcg_at_1000
value: 64.388
- type: ndcg_at_3
value: 54.04600000000001
- type: ndcg_at_5
value: 56.723
- type: precision_at_1
value: 46.394999999999996
- type: precision_at_10
value: 9.567
- type: precision_at_100
value: 1.234
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 24.117
- type: precision_at_5
value: 16.426
- type: recall_at_1
value: 40.326
- type: recall_at_10
value: 73.763
- type: recall_at_100
value: 89.927
- type: recall_at_1000
value: 97.509
- type: recall_at_3
value: 59.34
- type: recall_at_5
value: 65.915
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.661
- type: map_at_10
value: 35.522
- type: map_at_100
value: 36.619
- type: map_at_1000
value: 36.693999999999996
- type: map_at_3
value: 33.154
- type: map_at_5
value: 34.353
- type: mrr_at_1
value: 28.362
- type: mrr_at_10
value: 37.403999999999996
- type: mrr_at_100
value: 38.374
- type: mrr_at_1000
value: 38.428000000000004
- type: mrr_at_3
value: 35.235
- type: mrr_at_5
value: 36.269
- type: ndcg_at_1
value: 28.362
- type: ndcg_at_10
value: 40.431
- type: ndcg_at_100
value: 45.745999999999995
- type: ndcg_at_1000
value: 47.493
- type: ndcg_at_3
value: 35.733
- type: ndcg_at_5
value: 37.722
- type: precision_at_1
value: 28.362
- type: precision_at_10
value: 6.101999999999999
- type: precision_at_100
value: 0.922
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 15.140999999999998
- type: precision_at_5
value: 10.305
- type: recall_at_1
value: 26.661
- type: recall_at_10
value: 53.675
- type: recall_at_100
value: 77.891
- type: recall_at_1000
value: 90.72
- type: recall_at_3
value: 40.751
- type: recall_at_5
value: 45.517
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.886
- type: map_at_10
value: 27.288
- type: map_at_100
value: 28.327999999999996
- type: map_at_1000
value: 28.438999999999997
- type: map_at_3
value: 24.453
- type: map_at_5
value: 25.959
- type: mrr_at_1
value: 23.134
- type: mrr_at_10
value: 32.004
- type: mrr_at_100
value: 32.789
- type: mrr_at_1000
value: 32.857
- type: mrr_at_3
value: 29.084
- type: mrr_at_5
value: 30.614
- type: ndcg_at_1
value: 23.134
- type: ndcg_at_10
value: 32.852
- type: ndcg_at_100
value: 37.972
- type: ndcg_at_1000
value: 40.656
- type: ndcg_at_3
value: 27.435
- type: ndcg_at_5
value: 29.823
- type: precision_at_1
value: 23.134
- type: precision_at_10
value: 6.032
- type: precision_at_100
value: 0.9950000000000001
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 13.017999999999999
- type: precision_at_5
value: 9.501999999999999
- type: recall_at_1
value: 18.886
- type: recall_at_10
value: 45.34
- type: recall_at_100
value: 67.947
- type: recall_at_1000
value: 86.924
- type: recall_at_3
value: 30.535
- type: recall_at_5
value: 36.451
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.994999999999997
- type: map_at_10
value: 40.04
- type: map_at_100
value: 41.435
- type: map_at_1000
value: 41.537
- type: map_at_3
value: 37.091
- type: map_at_5
value: 38.802
- type: mrr_at_1
value: 35.034
- type: mrr_at_10
value: 45.411
- type: mrr_at_100
value: 46.226
- type: mrr_at_1000
value: 46.27
- type: mrr_at_3
value: 43.086
- type: mrr_at_5
value: 44.452999999999996
- type: ndcg_at_1
value: 35.034
- type: ndcg_at_10
value: 46.076
- type: ndcg_at_100
value: 51.483000000000004
- type: ndcg_at_1000
value: 53.433
- type: ndcg_at_3
value: 41.304
- type: ndcg_at_5
value: 43.641999999999996
- type: precision_at_1
value: 35.034
- type: precision_at_10
value: 8.258000000000001
- type: precision_at_100
value: 1.268
- type: precision_at_1000
value: 0.161
- type: precision_at_3
value: 19.57
- type: precision_at_5
value: 13.782
- type: recall_at_1
value: 28.994999999999997
- type: recall_at_10
value: 58.538000000000004
- type: recall_at_100
value: 80.72399999999999
- type: recall_at_1000
value: 93.462
- type: recall_at_3
value: 45.199
- type: recall_at_5
value: 51.237
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.795
- type: map_at_10
value: 34.935
- type: map_at_100
value: 36.306
- type: map_at_1000
value: 36.417
- type: map_at_3
value: 31.831
- type: map_at_5
value: 33.626
- type: mrr_at_1
value: 30.479
- type: mrr_at_10
value: 40.225
- type: mrr_at_100
value: 41.055
- type: mrr_at_1000
value: 41.114
- type: mrr_at_3
value: 37.538
- type: mrr_at_5
value: 39.073
- type: ndcg_at_1
value: 30.479
- type: ndcg_at_10
value: 40.949999999999996
- type: ndcg_at_100
value: 46.525
- type: ndcg_at_1000
value: 48.892
- type: ndcg_at_3
value: 35.79
- type: ndcg_at_5
value: 38.237
- type: precision_at_1
value: 30.479
- type: precision_at_10
value: 7.6259999999999994
- type: precision_at_100
value: 1.203
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 17.199
- type: precision_at_5
value: 12.466000000000001
- type: recall_at_1
value: 24.795
- type: recall_at_10
value: 53.421
- type: recall_at_100
value: 77.189
- type: recall_at_1000
value: 93.407
- type: recall_at_3
value: 39.051
- type: recall_at_5
value: 45.462
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.853499999999997
- type: map_at_10
value: 36.20433333333333
- type: map_at_100
value: 37.40391666666667
- type: map_at_1000
value: 37.515
- type: map_at_3
value: 33.39975
- type: map_at_5
value: 34.9665
- type: mrr_at_1
value: 31.62666666666667
- type: mrr_at_10
value: 40.436749999999996
- type: mrr_at_100
value: 41.260333333333335
- type: mrr_at_1000
value: 41.31525
- type: mrr_at_3
value: 38.06733333333332
- type: mrr_at_5
value: 39.41541666666667
- type: ndcg_at_1
value: 31.62666666666667
- type: ndcg_at_10
value: 41.63341666666667
- type: ndcg_at_100
value: 46.704166666666666
- type: ndcg_at_1000
value: 48.88483333333335
- type: ndcg_at_3
value: 36.896
- type: ndcg_at_5
value: 39.11891666666667
- type: precision_at_1
value: 31.62666666666667
- type: precision_at_10
value: 7.241083333333333
- type: precision_at_100
value: 1.1488333333333334
- type: precision_at_1000
value: 0.15250000000000002
- type: precision_at_3
value: 16.908333333333335
- type: precision_at_5
value: 11.942833333333333
- type: recall_at_1
value: 26.853499999999997
- type: recall_at_10
value: 53.461333333333336
- type: recall_at_100
value: 75.63633333333333
- type: recall_at_1000
value: 90.67016666666666
- type: recall_at_3
value: 40.24241666666667
- type: recall_at_5
value: 45.98608333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.241999999999997
- type: map_at_10
value: 31.863999999999997
- type: map_at_100
value: 32.835
- type: map_at_1000
value: 32.928000000000004
- type: map_at_3
value: 29.694
- type: map_at_5
value: 30.978
- type: mrr_at_1
value: 28.374
- type: mrr_at_10
value: 34.814
- type: mrr_at_100
value: 35.596
- type: mrr_at_1000
value: 35.666
- type: mrr_at_3
value: 32.745000000000005
- type: mrr_at_5
value: 34.049
- type: ndcg_at_1
value: 28.374
- type: ndcg_at_10
value: 35.969
- type: ndcg_at_100
value: 40.708
- type: ndcg_at_1000
value: 43.08
- type: ndcg_at_3
value: 31.968999999999998
- type: ndcg_at_5
value: 34.069
- type: precision_at_1
value: 28.374
- type: precision_at_10
value: 5.583
- type: precision_at_100
value: 0.8630000000000001
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 13.547999999999998
- type: precision_at_5
value: 9.447999999999999
- type: recall_at_1
value: 25.241999999999997
- type: recall_at_10
value: 45.711
- type: recall_at_100
value: 67.482
- type: recall_at_1000
value: 85.13300000000001
- type: recall_at_3
value: 34.622
- type: recall_at_5
value: 40.043
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.488999999999997
- type: map_at_10
value: 25.142999999999997
- type: map_at_100
value: 26.244
- type: map_at_1000
value: 26.363999999999997
- type: map_at_3
value: 22.654
- type: map_at_5
value: 24.017
- type: mrr_at_1
value: 21.198
- type: mrr_at_10
value: 28.903000000000002
- type: mrr_at_100
value: 29.860999999999997
- type: mrr_at_1000
value: 29.934
- type: mrr_at_3
value: 26.634999999999998
- type: mrr_at_5
value: 27.903
- type: ndcg_at_1
value: 21.198
- type: ndcg_at_10
value: 29.982999999999997
- type: ndcg_at_100
value: 35.275
- type: ndcg_at_1000
value: 38.074000000000005
- type: ndcg_at_3
value: 25.502999999999997
- type: ndcg_at_5
value: 27.557
- type: precision_at_1
value: 21.198
- type: precision_at_10
value: 5.502
- type: precision_at_100
value: 0.942
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.044
- type: precision_at_5
value: 8.782
- type: recall_at_1
value: 17.488999999999997
- type: recall_at_10
value: 40.821000000000005
- type: recall_at_100
value: 64.567
- type: recall_at_1000
value: 84.452
- type: recall_at_3
value: 28.351
- type: recall_at_5
value: 33.645
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.066000000000003
- type: map_at_10
value: 36.134
- type: map_at_100
value: 37.285000000000004
- type: map_at_1000
value: 37.389
- type: map_at_3
value: 33.522999999999996
- type: map_at_5
value: 34.905
- type: mrr_at_1
value: 31.436999999999998
- type: mrr_at_10
value: 40.225
- type: mrr_at_100
value: 41.079
- type: mrr_at_1000
value: 41.138000000000005
- type: mrr_at_3
value: 38.074999999999996
- type: mrr_at_5
value: 39.190000000000005
- type: ndcg_at_1
value: 31.436999999999998
- type: ndcg_at_10
value: 41.494
- type: ndcg_at_100
value: 46.678999999999995
- type: ndcg_at_1000
value: 48.964
- type: ndcg_at_3
value: 36.828
- type: ndcg_at_5
value: 38.789
- type: precision_at_1
value: 31.436999999999998
- type: precision_at_10
value: 6.931
- type: precision_at_100
value: 1.072
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 16.729
- type: precision_at_5
value: 11.567
- type: recall_at_1
value: 27.066000000000003
- type: recall_at_10
value: 53.705000000000005
- type: recall_at_100
value: 75.968
- type: recall_at_1000
value: 91.937
- type: recall_at_3
value: 40.865
- type: recall_at_5
value: 45.739999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.979000000000003
- type: map_at_10
value: 32.799
- type: map_at_100
value: 34.508
- type: map_at_1000
value: 34.719
- type: map_at_3
value: 29.947000000000003
- type: map_at_5
value: 31.584
- type: mrr_at_1
value: 30.237000000000002
- type: mrr_at_10
value: 37.651
- type: mrr_at_100
value: 38.805
- type: mrr_at_1000
value: 38.851
- type: mrr_at_3
value: 35.046
- type: mrr_at_5
value: 36.548
- type: ndcg_at_1
value: 30.237000000000002
- type: ndcg_at_10
value: 38.356
- type: ndcg_at_100
value: 44.906
- type: ndcg_at_1000
value: 47.299
- type: ndcg_at_3
value: 33.717999999999996
- type: ndcg_at_5
value: 35.946
- type: precision_at_1
value: 30.237000000000002
- type: precision_at_10
value: 7.292
- type: precision_at_100
value: 1.496
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 15.547
- type: precision_at_5
value: 11.344
- type: recall_at_1
value: 24.979000000000003
- type: recall_at_10
value: 48.624
- type: recall_at_100
value: 77.932
- type: recall_at_1000
value: 92.66499999999999
- type: recall_at_3
value: 35.217
- type: recall_at_5
value: 41.394
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.566
- type: map_at_10
value: 30.945
- type: map_at_100
value: 31.759999999999998
- type: map_at_1000
value: 31.855
- type: map_at_3
value: 28.64
- type: map_at_5
value: 29.787000000000003
- type: mrr_at_1
value: 24.954
- type: mrr_at_10
value: 33.311
- type: mrr_at_100
value: 34.050000000000004
- type: mrr_at_1000
value: 34.117999999999995
- type: mrr_at_3
value: 31.238
- type: mrr_at_5
value: 32.329
- type: ndcg_at_1
value: 24.954
- type: ndcg_at_10
value: 35.676
- type: ndcg_at_100
value: 39.931
- type: ndcg_at_1000
value: 42.43
- type: ndcg_at_3
value: 31.365
- type: ndcg_at_5
value: 33.184999999999995
- type: precision_at_1
value: 24.954
- type: precision_at_10
value: 5.564
- type: precision_at_100
value: 0.826
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 13.555
- type: precision_at_5
value: 9.168
- type: recall_at_1
value: 22.566
- type: recall_at_10
value: 47.922
- type: recall_at_100
value: 67.931
- type: recall_at_1000
value: 86.653
- type: recall_at_3
value: 36.103
- type: recall_at_5
value: 40.699000000000005
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.950000000000003
- type: map_at_10
value: 28.612
- type: map_at_100
value: 30.476999999999997
- type: map_at_1000
value: 30.674
- type: map_at_3
value: 24.262
- type: map_at_5
value: 26.554
- type: mrr_at_1
value: 38.241
- type: mrr_at_10
value: 50.43
- type: mrr_at_100
value: 51.059
- type: mrr_at_1000
value: 51.090999999999994
- type: mrr_at_3
value: 47.514
- type: mrr_at_5
value: 49.246
- type: ndcg_at_1
value: 38.241
- type: ndcg_at_10
value: 38.218
- type: ndcg_at_100
value: 45.003
- type: ndcg_at_1000
value: 48.269
- type: ndcg_at_3
value: 32.568000000000005
- type: ndcg_at_5
value: 34.400999999999996
- type: precision_at_1
value: 38.241
- type: precision_at_10
value: 11.674
- type: precision_at_100
value: 1.913
- type: precision_at_1000
value: 0.252
- type: precision_at_3
value: 24.387
- type: precision_at_5
value: 18.163
- type: recall_at_1
value: 16.950000000000003
- type: recall_at_10
value: 43.769000000000005
- type: recall_at_100
value: 66.875
- type: recall_at_1000
value: 84.92699999999999
- type: recall_at_3
value: 29.353
- type: recall_at_5
value: 35.467
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.276
- type: map_at_10
value: 20.848
- type: map_at_100
value: 29.804000000000002
- type: map_at_1000
value: 31.398
- type: map_at_3
value: 14.886
- type: map_at_5
value: 17.516000000000002
- type: mrr_at_1
value: 71
- type: mrr_at_10
value: 78.724
- type: mrr_at_100
value: 78.976
- type: mrr_at_1000
value: 78.986
- type: mrr_at_3
value: 77.333
- type: mrr_at_5
value: 78.021
- type: ndcg_at_1
value: 57.875
- type: ndcg_at_10
value: 43.855
- type: ndcg_at_100
value: 48.99
- type: ndcg_at_1000
value: 56.141
- type: ndcg_at_3
value: 48.914
- type: ndcg_at_5
value: 45.961
- type: precision_at_1
value: 71
- type: precision_at_10
value: 34.575
- type: precision_at_100
value: 11.182
- type: precision_at_1000
value: 2.044
- type: precision_at_3
value: 52.5
- type: precision_at_5
value: 44.2
- type: recall_at_1
value: 9.276
- type: recall_at_10
value: 26.501
- type: recall_at_100
value: 55.72899999999999
- type: recall_at_1000
value: 78.532
- type: recall_at_3
value: 16.365
- type: recall_at_5
value: 20.154
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 52.71
- type: f1
value: 47.74801556489574
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 73.405
- type: map_at_10
value: 82.822
- type: map_at_100
value: 83.042
- type: map_at_1000
value: 83.055
- type: map_at_3
value: 81.65299999999999
- type: map_at_5
value: 82.431
- type: mrr_at_1
value: 79.178
- type: mrr_at_10
value: 87.02
- type: mrr_at_100
value: 87.095
- type: mrr_at_1000
value: 87.09700000000001
- type: mrr_at_3
value: 86.309
- type: mrr_at_5
value: 86.824
- type: ndcg_at_1
value: 79.178
- type: ndcg_at_10
value: 86.72
- type: ndcg_at_100
value: 87.457
- type: ndcg_at_1000
value: 87.691
- type: ndcg_at_3
value: 84.974
- type: ndcg_at_5
value: 86.032
- type: precision_at_1
value: 79.178
- type: precision_at_10
value: 10.548
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.848
- type: precision_at_5
value: 20.45
- type: recall_at_1
value: 73.405
- type: recall_at_10
value: 94.39699999999999
- type: recall_at_100
value: 97.219
- type: recall_at_1000
value: 98.675
- type: recall_at_3
value: 89.679
- type: recall_at_5
value: 92.392
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.651
- type: map_at_10
value: 36.886
- type: map_at_100
value: 38.811
- type: map_at_1000
value: 38.981
- type: map_at_3
value: 32.538
- type: map_at_5
value: 34.763
- type: mrr_at_1
value: 44.444
- type: mrr_at_10
value: 53.168000000000006
- type: mrr_at_100
value: 53.839000000000006
- type: mrr_at_1000
value: 53.869
- type: mrr_at_3
value: 50.54
- type: mrr_at_5
value: 52.068000000000005
- type: ndcg_at_1
value: 44.444
- type: ndcg_at_10
value: 44.994
- type: ndcg_at_100
value: 51.599
- type: ndcg_at_1000
value: 54.339999999999996
- type: ndcg_at_3
value: 41.372
- type: ndcg_at_5
value: 42.149
- type: precision_at_1
value: 44.444
- type: precision_at_10
value: 12.407
- type: precision_at_100
value: 1.9269999999999998
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 27.726
- type: precision_at_5
value: 19.814999999999998
- type: recall_at_1
value: 22.651
- type: recall_at_10
value: 52.075
- type: recall_at_100
value: 76.51400000000001
- type: recall_at_1000
value: 92.852
- type: recall_at_3
value: 37.236000000000004
- type: recall_at_5
value: 43.175999999999995
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.777
- type: map_at_10
value: 66.79899999999999
- type: map_at_100
value: 67.65299999999999
- type: map_at_1000
value: 67.706
- type: map_at_3
value: 63.352
- type: map_at_5
value: 65.52900000000001
- type: mrr_at_1
value: 81.553
- type: mrr_at_10
value: 86.983
- type: mrr_at_100
value: 87.132
- type: mrr_at_1000
value: 87.136
- type: mrr_at_3
value: 86.156
- type: mrr_at_5
value: 86.726
- type: ndcg_at_1
value: 81.553
- type: ndcg_at_10
value: 74.64
- type: ndcg_at_100
value: 77.459
- type: ndcg_at_1000
value: 78.43
- type: ndcg_at_3
value: 69.878
- type: ndcg_at_5
value: 72.59400000000001
- type: precision_at_1
value: 81.553
- type: precision_at_10
value: 15.654000000000002
- type: precision_at_100
value: 1.783
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 45.199
- type: precision_at_5
value: 29.267
- type: recall_at_1
value: 40.777
- type: recall_at_10
value: 78.271
- type: recall_at_100
value: 89.129
- type: recall_at_1000
value: 95.49
- type: recall_at_3
value: 67.79899999999999
- type: recall_at_5
value: 73.167
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 93.5064
- type: ap
value: 90.25495114444111
- type: f1
value: 93.5012434973381
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.301
- type: map_at_10
value: 35.657
- type: map_at_100
value: 36.797000000000004
- type: map_at_1000
value: 36.844
- type: map_at_3
value: 31.743
- type: map_at_5
value: 34.003
- type: mrr_at_1
value: 23.854
- type: mrr_at_10
value: 36.242999999999995
- type: mrr_at_100
value: 37.32
- type: mrr_at_1000
value: 37.361
- type: mrr_at_3
value: 32.4
- type: mrr_at_5
value: 34.634
- type: ndcg_at_1
value: 23.868000000000002
- type: ndcg_at_10
value: 42.589
- type: ndcg_at_100
value: 48.031
- type: ndcg_at_1000
value: 49.189
- type: ndcg_at_3
value: 34.649
- type: ndcg_at_5
value: 38.676
- type: precision_at_1
value: 23.868000000000002
- type: precision_at_10
value: 6.6850000000000005
- type: precision_at_100
value: 0.9400000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.651
- type: precision_at_5
value: 10.834000000000001
- type: recall_at_1
value: 23.301
- type: recall_at_10
value: 63.88700000000001
- type: recall_at_100
value: 88.947
- type: recall_at_1000
value: 97.783
- type: recall_at_3
value: 42.393
- type: recall_at_5
value: 52.036
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.64888280893753
- type: f1
value: 94.41310774203512
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.72184222526221
- type: f1
value: 61.522034067350106
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 79.60659045057163
- type: f1
value: 77.268649687049
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 81.83254875588432
- type: f1
value: 81.61520635919082
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 36.31529875009507
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.734233714415073
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.994501713009452
- type: mrr
value: 32.13512850703073
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.603000000000001
- type: map_at_10
value: 13.767999999999999
- type: map_at_100
value: 17.197000000000003
- type: map_at_1000
value: 18.615000000000002
- type: map_at_3
value: 10.567
- type: map_at_5
value: 12.078999999999999
- type: mrr_at_1
value: 44.891999999999996
- type: mrr_at_10
value: 53.75299999999999
- type: mrr_at_100
value: 54.35
- type: mrr_at_1000
value: 54.388000000000005
- type: mrr_at_3
value: 51.495999999999995
- type: mrr_at_5
value: 52.688
- type: ndcg_at_1
value: 43.189
- type: ndcg_at_10
value: 34.567
- type: ndcg_at_100
value: 32.273
- type: ndcg_at_1000
value: 41.321999999999996
- type: ndcg_at_3
value: 40.171
- type: ndcg_at_5
value: 37.502
- type: precision_at_1
value: 44.582
- type: precision_at_10
value: 25.139
- type: precision_at_100
value: 7.739999999999999
- type: precision_at_1000
value: 2.054
- type: precision_at_3
value: 37.152
- type: precision_at_5
value: 31.826999999999998
- type: recall_at_1
value: 6.603000000000001
- type: recall_at_10
value: 17.023
- type: recall_at_100
value: 32.914
- type: recall_at_1000
value: 64.44800000000001
- type: recall_at_3
value: 11.457
- type: recall_at_5
value: 13.816
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.026000000000003
- type: map_at_10
value: 45.429
- type: map_at_100
value: 46.45
- type: map_at_1000
value: 46.478
- type: map_at_3
value: 41.147
- type: map_at_5
value: 43.627
- type: mrr_at_1
value: 33.951
- type: mrr_at_10
value: 47.953
- type: mrr_at_100
value: 48.731
- type: mrr_at_1000
value: 48.751
- type: mrr_at_3
value: 44.39
- type: mrr_at_5
value: 46.533
- type: ndcg_at_1
value: 33.951
- type: ndcg_at_10
value: 53.24100000000001
- type: ndcg_at_100
value: 57.599999999999994
- type: ndcg_at_1000
value: 58.270999999999994
- type: ndcg_at_3
value: 45.190999999999995
- type: ndcg_at_5
value: 49.339
- type: precision_at_1
value: 33.951
- type: precision_at_10
value: 8.856
- type: precision_at_100
value: 1.133
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 20.713
- type: precision_at_5
value: 14.838000000000001
- type: recall_at_1
value: 30.026000000000003
- type: recall_at_10
value: 74.512
- type: recall_at_100
value: 93.395
- type: recall_at_1000
value: 98.402
- type: recall_at_3
value: 53.677
- type: recall_at_5
value: 63.198
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.41300000000001
- type: map_at_10
value: 85.387
- type: map_at_100
value: 86.027
- type: map_at_1000
value: 86.041
- type: map_at_3
value: 82.543
- type: map_at_5
value: 84.304
- type: mrr_at_1
value: 82.35
- type: mrr_at_10
value: 88.248
- type: mrr_at_100
value: 88.348
- type: mrr_at_1000
value: 88.349
- type: mrr_at_3
value: 87.348
- type: mrr_at_5
value: 87.96300000000001
- type: ndcg_at_1
value: 82.37
- type: ndcg_at_10
value: 88.98
- type: ndcg_at_100
value: 90.16499999999999
- type: ndcg_at_1000
value: 90.239
- type: ndcg_at_3
value: 86.34100000000001
- type: ndcg_at_5
value: 87.761
- type: precision_at_1
value: 82.37
- type: precision_at_10
value: 13.471
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.827
- type: precision_at_5
value: 24.773999999999997
- type: recall_at_1
value: 71.41300000000001
- type: recall_at_10
value: 95.748
- type: recall_at_100
value: 99.69200000000001
- type: recall_at_1000
value: 99.98
- type: recall_at_3
value: 87.996
- type: recall_at_5
value: 92.142
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 56.96878497780007
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.31371347128074
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.287
- type: map_at_10
value: 13.530000000000001
- type: map_at_100
value: 15.891
- type: map_at_1000
value: 16.245
- type: map_at_3
value: 9.612
- type: map_at_5
value: 11.672
- type: mrr_at_1
value: 26
- type: mrr_at_10
value: 37.335
- type: mrr_at_100
value: 38.443
- type: mrr_at_1000
value: 38.486
- type: mrr_at_3
value: 33.783
- type: mrr_at_5
value: 36.028
- type: ndcg_at_1
value: 26
- type: ndcg_at_10
value: 22.215
- type: ndcg_at_100
value: 31.101
- type: ndcg_at_1000
value: 36.809
- type: ndcg_at_3
value: 21.104
- type: ndcg_at_5
value: 18.759999999999998
- type: precision_at_1
value: 26
- type: precision_at_10
value: 11.43
- type: precision_at_100
value: 2.424
- type: precision_at_1000
value: 0.379
- type: precision_at_3
value: 19.7
- type: precision_at_5
value: 16.619999999999997
- type: recall_at_1
value: 5.287
- type: recall_at_10
value: 23.18
- type: recall_at_100
value: 49.208
- type: recall_at_1000
value: 76.85300000000001
- type: recall_at_3
value: 11.991999999999999
- type: recall_at_5
value: 16.85
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.87834913790886
- type: cos_sim_spearman
value: 81.04583513112122
- type: euclidean_pearson
value: 81.20484174558065
- type: euclidean_spearman
value: 80.76430832561769
- type: manhattan_pearson
value: 81.21416730978615
- type: manhattan_spearman
value: 80.7797637394211
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.56143998865157
- type: cos_sim_spearman
value: 79.75387012744471
- type: euclidean_pearson
value: 83.7877519997019
- type: euclidean_spearman
value: 79.90489748003296
- type: manhattan_pearson
value: 83.7540590666095
- type: manhattan_spearman
value: 79.86434577931573
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 83.92102564177941
- type: cos_sim_spearman
value: 84.98234585939103
- type: euclidean_pearson
value: 84.47729567593696
- type: euclidean_spearman
value: 85.09490696194469
- type: manhattan_pearson
value: 84.38622951588229
- type: manhattan_spearman
value: 85.02507171545574
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 80.1891164763377
- type: cos_sim_spearman
value: 80.7997969966883
- type: euclidean_pearson
value: 80.48572256162396
- type: euclidean_spearman
value: 80.57851903536378
- type: manhattan_pearson
value: 80.4324819433651
- type: manhattan_spearman
value: 80.5074526239062
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 82.64319975116025
- type: cos_sim_spearman
value: 84.88671197763652
- type: euclidean_pearson
value: 84.74692193293231
- type: euclidean_spearman
value: 85.27151722073653
- type: manhattan_pearson
value: 84.72460516785438
- type: manhattan_spearman
value: 85.26518899786687
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.24687565822381
- type: cos_sim_spearman
value: 85.60418454111263
- type: euclidean_pearson
value: 84.85829740169851
- type: euclidean_spearman
value: 85.66378014138306
- type: manhattan_pearson
value: 84.84672408808835
- type: manhattan_spearman
value: 85.63331924364891
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 84.87758895415485
- type: cos_sim_spearman
value: 85.8193745617297
- type: euclidean_pearson
value: 85.78719118848134
- type: euclidean_spearman
value: 84.35797575385688
- type: manhattan_pearson
value: 85.97919844815692
- type: manhattan_spearman
value: 84.58334745175151
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.27076035963599
- type: cos_sim_spearman
value: 67.21433656439973
- type: euclidean_pearson
value: 68.07434078679324
- type: euclidean_spearman
value: 66.0249731719049
- type: manhattan_pearson
value: 67.95495198947476
- type: manhattan_spearman
value: 65.99893908331886
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 82.22437747056817
- type: cos_sim_spearman
value: 85.0995685206174
- type: euclidean_pearson
value: 84.08616925603394
- type: euclidean_spearman
value: 84.89633925691658
- type: manhattan_pearson
value: 84.08332675923133
- type: manhattan_spearman
value: 84.8858228112915
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.6909022589666
- type: mrr
value: 96.43341952165481
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.660999999999994
- type: map_at_10
value: 67.625
- type: map_at_100
value: 68.07600000000001
- type: map_at_1000
value: 68.10199999999999
- type: map_at_3
value: 64.50399999999999
- type: map_at_5
value: 66.281
- type: mrr_at_1
value: 61
- type: mrr_at_10
value: 68.953
- type: mrr_at_100
value: 69.327
- type: mrr_at_1000
value: 69.352
- type: mrr_at_3
value: 66.833
- type: mrr_at_5
value: 68.05
- type: ndcg_at_1
value: 61
- type: ndcg_at_10
value: 72.369
- type: ndcg_at_100
value: 74.237
- type: ndcg_at_1000
value: 74.939
- type: ndcg_at_3
value: 67.284
- type: ndcg_at_5
value: 69.72500000000001
- type: precision_at_1
value: 61
- type: precision_at_10
value: 9.733
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 26.222
- type: precision_at_5
value: 17.4
- type: recall_at_1
value: 57.660999999999994
- type: recall_at_10
value: 85.656
- type: recall_at_100
value: 93.833
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 71.961
- type: recall_at_5
value: 78.094
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86930693069307
- type: cos_sim_ap
value: 96.76685487950894
- type: cos_sim_f1
value: 93.44587884806354
- type: cos_sim_precision
value: 92.80078895463511
- type: cos_sim_recall
value: 94.1
- type: dot_accuracy
value: 99.54356435643564
- type: dot_ap
value: 81.18659960405607
- type: dot_f1
value: 75.78008915304605
- type: dot_precision
value: 75.07360157016683
- type: dot_recall
value: 76.5
- type: euclidean_accuracy
value: 99.87326732673267
- type: euclidean_ap
value: 96.8102411908941
- type: euclidean_f1
value: 93.6127744510978
- type: euclidean_precision
value: 93.42629482071713
- type: euclidean_recall
value: 93.8
- type: manhattan_accuracy
value: 99.87425742574257
- type: manhattan_ap
value: 96.82857341435529
- type: manhattan_f1
value: 93.62129583124059
- type: manhattan_precision
value: 94.04641775983855
- type: manhattan_recall
value: 93.2
- type: max_accuracy
value: 99.87425742574257
- type: max_ap
value: 96.82857341435529
- type: max_f1
value: 93.62129583124059
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.92560972698926
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.92797240259008
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.244624045597654
- type: mrr
value: 56.185303666921314
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.02491987312937
- type: cos_sim_spearman
value: 32.055592206679734
- type: dot_pearson
value: 24.731627575422557
- type: dot_spearman
value: 24.308029077069733
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.231
- type: map_at_10
value: 1.899
- type: map_at_100
value: 9.498
- type: map_at_1000
value: 20.979999999999997
- type: map_at_3
value: 0.652
- type: map_at_5
value: 1.069
- type: mrr_at_1
value: 88
- type: mrr_at_10
value: 93.4
- type: mrr_at_100
value: 93.4
- type: mrr_at_1000
value: 93.4
- type: mrr_at_3
value: 93
- type: mrr_at_5
value: 93.4
- type: ndcg_at_1
value: 86
- type: ndcg_at_10
value: 75.375
- type: ndcg_at_100
value: 52.891999999999996
- type: ndcg_at_1000
value: 44.952999999999996
- type: ndcg_at_3
value: 81.05
- type: ndcg_at_5
value: 80.175
- type: precision_at_1
value: 88
- type: precision_at_10
value: 79
- type: precision_at_100
value: 53.16
- type: precision_at_1000
value: 19.408
- type: precision_at_3
value: 85.333
- type: precision_at_5
value: 84
- type: recall_at_1
value: 0.231
- type: recall_at_10
value: 2.078
- type: recall_at_100
value: 12.601
- type: recall_at_1000
value: 41.296
- type: recall_at_3
value: 0.6779999999999999
- type: recall_at_5
value: 1.1360000000000001
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.782
- type: map_at_10
value: 10.204
- type: map_at_100
value: 16.176
- type: map_at_1000
value: 17.456
- type: map_at_3
value: 5.354
- type: map_at_5
value: 7.503
- type: mrr_at_1
value: 40.816
- type: mrr_at_10
value: 54.010000000000005
- type: mrr_at_100
value: 54.49
- type: mrr_at_1000
value: 54.49
- type: mrr_at_3
value: 48.980000000000004
- type: mrr_at_5
value: 51.735
- type: ndcg_at_1
value: 36.735
- type: ndcg_at_10
value: 26.61
- type: ndcg_at_100
value: 36.967
- type: ndcg_at_1000
value: 47.274
- type: ndcg_at_3
value: 30.363
- type: ndcg_at_5
value: 29.448999999999998
- type: precision_at_1
value: 40.816
- type: precision_at_10
value: 23.878
- type: precision_at_100
value: 7.693999999999999
- type: precision_at_1000
value: 1.4489999999999998
- type: precision_at_3
value: 31.293
- type: precision_at_5
value: 29.796
- type: recall_at_1
value: 2.782
- type: recall_at_10
value: 16.485
- type: recall_at_100
value: 46.924
- type: recall_at_1000
value: 79.365
- type: recall_at_3
value: 6.52
- type: recall_at_5
value: 10.48
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.08300000000001
- type: ap
value: 13.91559884590195
- type: f1
value: 53.956838444291364
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.34069043576683
- type: f1
value: 59.662041994618406
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 53.70780611078653
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.10734934732073
- type: cos_sim_ap
value: 77.58349999516054
- type: cos_sim_f1
value: 70.25391395868965
- type: cos_sim_precision
value: 70.06035161374967
- type: cos_sim_recall
value: 70.44854881266491
- type: dot_accuracy
value: 80.60439887941826
- type: dot_ap
value: 54.52935200483575
- type: dot_f1
value: 54.170444242973716
- type: dot_precision
value: 47.47715534366309
- type: dot_recall
value: 63.06068601583114
- type: euclidean_accuracy
value: 87.26828396018358
- type: euclidean_ap
value: 78.00158454104036
- type: euclidean_f1
value: 70.70292457670601
- type: euclidean_precision
value: 68.79680479281079
- type: euclidean_recall
value: 72.71767810026385
- type: manhattan_accuracy
value: 87.11330988853788
- type: manhattan_ap
value: 77.92527099601855
- type: manhattan_f1
value: 70.76488706365502
- type: manhattan_precision
value: 68.89055472263868
- type: manhattan_recall
value: 72.74406332453826
- type: max_accuracy
value: 87.26828396018358
- type: max_ap
value: 78.00158454104036
- type: max_f1
value: 70.76488706365502
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.80804905499282
- type: cos_sim_ap
value: 83.06187782630936
- type: cos_sim_f1
value: 74.99716435403985
- type: cos_sim_precision
value: 73.67951860931579
- type: cos_sim_recall
value: 76.36279642747151
- type: dot_accuracy
value: 81.83141227151008
- type: dot_ap
value: 67.18241090841795
- type: dot_f1
value: 62.216037571751606
- type: dot_precision
value: 56.749381227391005
- type: dot_recall
value: 68.84816753926701
- type: euclidean_accuracy
value: 87.91671517832887
- type: euclidean_ap
value: 83.56538942001427
- type: euclidean_f1
value: 75.7327253337256
- type: euclidean_precision
value: 72.48856036606828
- type: euclidean_recall
value: 79.28087465352634
- type: manhattan_accuracy
value: 87.86626304963713
- type: manhattan_ap
value: 83.52939841172832
- type: manhattan_f1
value: 75.73635656329888
- type: manhattan_precision
value: 72.99150182103836
- type: manhattan_recall
value: 78.69571912534647
- type: max_accuracy
value: 87.91671517832887
- type: max_ap
value: 83.56538942001427
- type: max_f1
value: 75.73635656329888
license: mit
language:
- en
---
**Recommend switching to newest [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5), which has more reasonable similarity distribution and same method of usage.**
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search.
And it also can be used in vector databases for LLMs.
************* 🌟**Updates**🌟 *************
- 10/12/2023: Release [LLM-Embedder](./FlagEmbedding/llm_embedder/README.md), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Paper](https://arxiv.org/pdf/2310.07554.pdf) :fire:
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [masive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao(stxiao@baai.ac.cn) and Zheng Liu(liuzheng@baai.ac.cn).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1 | sentence-transformers | "2024-03-27T13:16:46Z" | 174,305 | 1 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1')
model = AutoModel.from_pretrained('sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/xlm-r-distilroberta-base-paraphrase-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
stabilityai/stable-diffusion-3-medium-diffusers | stabilityai | "2024-06-19T13:47:26Z" | 173,966 | 183 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"en",
"arxiv:2403.03206",
"license:other",
"diffusers:StableDiffusion3Pipeline",
"region:us"
] | text-to-image | "2024-06-12T16:21:22Z" | ---
license: other
license_name: stabilityai-nc-research-community
license_link: LICENSE
tags:
- text-to-image
- stable-diffusion
extra_gated_prompt: >-
By clicking "Agree", you agree to the [License
Agreement](https://huggingface.co/stabilityai/stable-diffusion-3-medium/blob/main/LICENSE)
and acknowledge Stability AI's [Privacy
Policy](https://stability.ai/privacy-policy).
extra_gated_fields:
Name: text
Email: text
Country: country
Organization or Affiliation: text
Receive email updates and promotions on Stability AI products, services, and research?:
type: select
options:
- 'Yes'
- 'No'
I acknowledge that this model is for non-commercial use only unless I acquire a separate license from Stability AI: checkbox
language:
- en
pipeline_tag: text-to-image
---
# Stable Diffusion 3 Medium

## Model

[Stable Diffusion 3 Medium](stability.ai/news/stable-diffusion-3-medium) is a Multimodal Diffusion Transformer (MMDiT) text-to-image model that features greatly improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.
For more technical details, please refer to the [Research paper](https://stability.ai/news/stable-diffusion-3-research-paper).
Please note: this model is released under the Stability Non-Commercial Research Community License. For a Creator License or an Enterprise License visit Stability.ai or [contact us](https://stability.ai/license) for commercial licensing details.
### Model Description
- **Developed by:** Stability AI
- **Model type:** MMDiT text-to-image generative model
- **Model Description:** This is a model that can be used to generate images based on text prompts. It is a Multimodal Diffusion Transformer
(https://arxiv.org/abs/2403.03206) that uses three fixed, pretrained text encoders
([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip), [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main) and [T5-xxl](https://huggingface.co/google/t5-v1_1-xxl))
### License
- **Non-commercial Use:** Stable Diffusion 3 Medium is released under the [Stability AI Non-Commercial Research Community License](https://huggingface.co/stabilityai/stable-diffusion-3-medium/blob/main/LICENSE). The model is free to use for non-commercial purposes such as academic research.
- **Commercial Use**: This model is not available for commercial use without a separate commercial license from Stability. We encourage professional artists, designers, and creators to use our Creator License. Please visit https://stability.ai/license to learn more.
### Model Sources
For local or self-hosted use, we recommend [ComfyUI](https://github.com/comfyanonymous/ComfyUI) for inference.
Stable Diffusion 3 Medium is available on our [Stability API Platform](https://platform.stability.ai/docs/api-reference#tag/Generate/paths/~1v2beta~1stable-image~1generate~1sd3/post).
Stable Diffusion 3 models and workflows are available on [Stable Assistant](https://stability.ai/stable-assistant) and on Discord via [Stable Artisan](https://stability.ai/stable-artisan).
- **ComfyUI:** https://github.com/comfyanonymous/ComfyUI
- **StableSwarmUI:** https://github.com/Stability-AI/StableSwarmUI
- **Tech report:** https://stability.ai/news/stable-diffusion-3-research-paper
- **Demo:** https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium
## Training Dataset
We used synthetic data and filtered publicly available data to train our models. The model was pre-trained on 1 billion images. The fine-tuning data includes 30M high-quality aesthetic images focused on specific visual content and style, as well as 3M preference data images.
## Using with Diffusers
Make sure you upgrade to the latest version of `diffusers`: `pip install -U diffusers`. And then you can run:
```python
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
image
```
Refer to [the documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_3) for more details on optimization and image-to-image support.
## Uses
### Intended Uses
Intended uses include the following:
* Generation of artworks and use in design and other artistic processes.
* Applications in educational or creative tools.
* Research on generative models, including understanding the limitations of generative models.
All uses of the model should be in accordance with our [Acceptable Use Policy](https://stability.ai/use-policy).
### Out-of-Scope Uses
The model was not trained to be factual or true representations of people or events. As such, using the model to generate such content is out-of-scope of the abilities of this model.
## Safety
As part of our safety-by-design and responsible AI deployment approach, we implement safety measures throughout the development of our models, from the time we begin pre-training a model to the ongoing development, fine-tuning, and deployment of each model. We have implemented a number of safety mitigations that are intended to reduce the risk of severe harms, however we recommend that developers conduct their own testing and apply additional mitigations based on their specific use cases.
For more about our approach to Safety, please visit our [Safety page](https://stability.ai/safety).
### Evaluation Approach
Our evaluation methods include structured evaluations and internal and external red-teaming testing for specific, severe harms such as child sexual abuse and exploitation, extreme violence, and gore, sexually explicit content, and non-consensual nudity. Testing was conducted primarily in English and may not cover all possible harms. As with any model, the model may, at times, produce inaccurate, biased or objectionable responses to user prompts.
### Risks identified and mitigations:
* Harmful content: We have used filtered data sets when training our models and implemented safeguards that attempt to strike the right balance between usefulness and preventing harm. However, this does not guarantee that all possible harmful content has been removed. The model may, at times, generate toxic or biased content. All developers and deployers should exercise caution and implement content safety guardrails based on their specific product policies and application use cases.
* Misuse: Technical limitations and developer and end-user education can help mitigate against malicious applications of models. All users are required to adhere to our Acceptable Use Policy, including when applying fine-tuning and prompt engineering mechanisms. Please reference the Stability AI Acceptable Use Policy for information on violative uses of our products.
* Privacy violations: Developers and deployers are encouraged to adhere to privacy regulations with techniques that respect data privacy.
### Contact
Please report any issues with the model or contact us:
* Safety issues: safety@stability.ai
* Security issues: security@stability.ai
* Privacy issues: privacy@stability.ai
* License and general: https://stability.ai/license
* Enterprise license: https://stability.ai/enterprise
|
lucadiliello/BLEURT-20 | lucadiliello | "2023-01-19T15:56:04Z" | 173,645 | 1 | transformers | [
"transformers",
"pytorch",
"bleurt",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-01-19T14:59:41Z" | This model is based on a custom Transformer model that can be installed with:
```bash
pip install git+https://github.com/lucadiliello/bleurt-pytorch.git
```
Now load the model and make predictions with:
```python
import torch
from bleurt_pytorch import BleurtConfig, BleurtForSequenceClassification, BleurtTokenizer
config = BleurtConfig.from_pretrained('lucadiliello/BLEURT-20')
model = BleurtForSequenceClassification.from_pretrained('lucadiliello/BLEURT-20')
tokenizer = BleurtTokenizer.from_pretrained('lucadiliello/BLEURT-20')
references = ["a bird chirps by the window", "this is a random sentence"]
candidates = ["a bird chirps by the window", "this looks like a random sentence"]
model.eval()
with torch.no_grad():
inputs = tokenizer(references, candidates, padding='longest', return_tensors='pt')
res = model(**inputs).logits.flatten().tolist()
print(res)
# [0.9990496635437012, 0.7930182218551636]
```
Take a look at this [repository](https://github.com/lucadiliello/bleurt-pytorch) for the definition of `BleurtConfig`, `BleurtForSequenceClassification` and `BleurtTokenizer` in PyTorch. |
embaas/sentence-transformers-multilingual-e5-base | embaas | "2023-06-03T17:53:45Z" | 173,103 | 6 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-05-28T12:47:38Z" | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# Multilingual-E5-base (sentence-transformers)
This is a the sentence-transformers version of the [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
sentences = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
model = SentenceTransformer('embaas/sentence-transformers-multilingual-e5-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (Huggingface)
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Using with API
You can use the [embaas API](https://embaas.io) to encode your input. Get your free API key from [embaas.io](https://embaas.io)
```python
import requests
url = "https://api.embaas.io/v1/embeddings/"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ${YOUR_API_KEY}"
}
data = {
"texts": ["This is an example sentence.", "Here is another sentence."],
"instruction": "query"
"model": "multilingual-e5-base"
}
response = requests.post(url, json=data, headers=headers)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
You can find the MTEB results [here](https://huggingface.co/spaces/mteb/leaderboard).
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
mlx-community/whisper-medium-mlx | mlx-community | "2024-01-08T08:18:02Z" | 173,016 | 2 | mlx | [
"mlx",
"whisper",
"region:us"
] | null | "2024-01-08T08:16:06Z" | ---
library_name: mlx
---
# whisper-medium-mlx
This model was converted to MLX format from [`medium`]().
## Use with mlx
```bash
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/whisper/
pip install -r requirements.txt
>> import whisper
>> whisper.transcribe("FILE_NAME")
```
|
hfl/chinese-roberta-wwm-ext | hfl | "2022-03-01T09:13:56Z" | 172,889 | 248 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
# Please use 'Bert' related functions to load this model!
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
``` |
facebook/roberta-hate-speech-dynabench-r4-target | facebook | "2023-03-16T20:03:57Z" | 172,856 | 54 | transformers | [
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"en",
"arxiv:2012.15761",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-06-10T22:24:39Z" | ---
language: en
---
# LFTW R4 Target
The R4 Target model from [Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection](https://arxiv.org/abs/2012.15761)
## Citation Information
```bibtex
@inproceedings{vidgen2021lftw,
title={Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection},
author={Bertie Vidgen and Tristan Thrush and Zeerak Waseem and Douwe Kiela},
booktitle={ACL},
year={2021}
}
```
Thanks to Kushal Tirumala and Adina Williams for helping the authors put the model on the hub! |
mrm8488/bert-spanish-cased-finetuned-ner | mrm8488 | "2021-05-20T00:35:25Z" | 172,793 | 20 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# Spanish BERT (BETO) + NER
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) version of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **NER** downstream task.
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 8.7 K |
| Dev | 2.2 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **90.17**
| Precision | **89.86** |
| Recall | **90.47** |
## Comparison:
| Model | # F1 score |Size(MB)|
| :--------------------------------------------------------------------------------------------------------------: | :-------: |:------|
| bert-base-spanish-wwm-cased (BETO) | 88.43 | 421
| [bert-spanish-cased-finetuned-ner (this one)](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **90.17** | 420 |
| Best Multilingual BERT | 87.38 | 681 |
|[TinyBERT-spanish-uncased-finetuned-ner](https://huggingface.co/mrm8488/TinyBERT-spanish-uncased-finetuned-ner) | 70.00 | **55** |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
nlp_ner = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-ner",
tokenizer=(
'mrm8488/bert-spanish-cased-finetuned-ner',
{"use_fast": False}
))
text = 'Mis amigos están pensando viajar a Londres este verano'
nlp_ner(text)
#Output: [{'entity': 'B-LOC', 'score': 0.9998720288276672, 'word': 'Londres'}]
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
Salesforce/codet5p-110m-embedding | Salesforce | "2023-07-18T10:44:11Z" | 171,318 | 46 | transformers | [
"transformers",
"pytorch",
"codet5p_embedding",
"custom_code",
"arxiv:2305.07922",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | null | "2023-07-18T09:52:49Z" | ---
license: bsd-3-clause
---
# CodeT5+ 110M Embedding Models
## Model description
[CodeT5+](https://github.com/salesforce/CodeT5/tree/main/CodeT5+) is a new family of open code large language models
with an encoder-decoder architecture that can flexibly operate in different modes (i.e. _encoder-only_, _decoder-only_,
and _encoder-decoder_) to support a wide range of code understanding and generation tasks.
It is introduced in the paper:
[CodeT5+: Open Code Large Language Models for Code Understanding and Generation](https://arxiv.org/pdf/2305.07922.pdf)
by [Yue Wang](https://yuewang-cuhk.github.io/)\*, [Hung Le](https://sites.google.com/view/henryle2018/home?pli=1)\*, [Akhilesh Deepak Gotmare](https://akhileshgotmare.github.io/), [Nghi D.Q. Bui](https://bdqnghi.github.io/), [Junnan Li](https://sites.google.com/site/junnanlics), [Steven C.H. Hoi](https://sites.google.com/view/stevenhoi/home) (*
indicates equal contribution).
Compared to the original CodeT5 family (base: `220M`, large: `770M`), CodeT5+ is pretrained with a diverse set of
pretraining tasks including _span denoising_, _causal language modeling_, _contrastive learning_, and _text-code
matching_ to learn rich representations from both unimodal code data and bimodal code-text data.
Additionally, it employs a simple yet effective _compute-efficient pretraining_ method to initialize the model
components with frozen off-the-shelf LLMs such as [CodeGen](https://github.com/salesforce/CodeGen) to efficiently scale
up the model (i.e. `2B`, `6B`, `16B`), and adopts a "shallow encoder and deep decoder" architecture.
Furthermore, it is instruction-tuned to align with natural language instructions (see our InstructCodeT5+ 16B)
following [Code Alpaca](https://github.com/sahil280114/codealpaca).
## How to use
This checkpoint consists of an encoder of CodeT5+ 220M model (pretrained from 2 stages on both unimodal and bimodal) and a projection layer, which can be used to extract code
embeddings of 256 dimension. It can be easily loaded using the `AutoModel` functionality and employs the
same [CodeT5](https://github.com/salesforce/CodeT5) tokenizer.
```python
from transformers import AutoModel, AutoTokenizer
checkpoint = "Salesforce/codet5p-110m-embedding"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
model = AutoModel.from_pretrained(checkpoint, trust_remote_code=True).to(device)
inputs = tokenizer.encode("def print_hello_world():\tprint('Hello World!')", return_tensors="pt").to(device)
embedding = model(inputs)[0]
print(f'Dimension of the embedding: {embedding.size()[0]}, with norm={embedding.norm().item()}')
# Dimension of the embedding: 256, with norm=1.0
print(embedding)
# tensor([ 0.0185, 0.0229, -0.0315, -0.0307, -0.1421, -0.0575, -0.0275, 0.0501,
# 0.0203, 0.0337, -0.0067, -0.0075, -0.0222, -0.0107, -0.0250, -0.0657,
# 0.1571, -0.0994, -0.0370, 0.0164, -0.0948, 0.0490, -0.0352, 0.0907,
# -0.0198, 0.0130, -0.0921, 0.0209, 0.0651, 0.0319, 0.0299, -0.0173,
# -0.0693, -0.0798, -0.0066, -0.0417, 0.1076, 0.0597, -0.0316, 0.0940,
# -0.0313, 0.0993, 0.0931, -0.0427, 0.0256, 0.0297, -0.0561, -0.0155,
# -0.0496, -0.0697, -0.1011, 0.1178, 0.0283, -0.0571, -0.0635, -0.0222,
# 0.0710, -0.0617, 0.0423, -0.0057, 0.0620, -0.0262, 0.0441, 0.0425,
# -0.0413, -0.0245, 0.0043, 0.0185, 0.0060, -0.1727, -0.1152, 0.0655,
# -0.0235, -0.1465, -0.1359, 0.0022, 0.0177, -0.0176, -0.0361, -0.0750,
# -0.0464, -0.0846, -0.0088, 0.0136, -0.0221, 0.0591, 0.0876, -0.0903,
# 0.0271, -0.1165, -0.0169, -0.0566, 0.1173, -0.0801, 0.0430, 0.0236,
# 0.0060, -0.0778, -0.0570, 0.0102, -0.0172, -0.0051, -0.0891, -0.0620,
# -0.0536, 0.0190, -0.0039, -0.0189, -0.0267, -0.0389, -0.0208, 0.0076,
# -0.0676, 0.0630, -0.0962, 0.0418, -0.0172, -0.0229, -0.0452, 0.0401,
# 0.0270, 0.0677, -0.0111, -0.0089, 0.0175, 0.0703, 0.0714, -0.0068,
# 0.1214, -0.0004, 0.0020, 0.0255, 0.0424, -0.0030, 0.0318, 0.1227,
# 0.0676, -0.0723, 0.0970, 0.0637, -0.0140, -0.0283, -0.0120, 0.0343,
# -0.0890, 0.0680, 0.0514, 0.0513, 0.0627, -0.0284, -0.0479, 0.0068,
# -0.0794, 0.0202, 0.0208, -0.0113, -0.0747, 0.0045, -0.0854, -0.0609,
# -0.0078, 0.1168, 0.0618, -0.0223, -0.0755, 0.0182, -0.0128, 0.1116,
# 0.0240, 0.0342, 0.0119, -0.0235, -0.0150, -0.0228, -0.0568, -0.1528,
# 0.0164, -0.0268, 0.0727, -0.0569, 0.1306, 0.0643, -0.0158, -0.1070,
# -0.0107, -0.0139, -0.0363, 0.0366, -0.0986, -0.0628, -0.0277, 0.0316,
# 0.0363, 0.0038, -0.1092, -0.0679, -0.1398, -0.0648, 0.1711, -0.0666,
# 0.0563, 0.0581, 0.0226, 0.0347, -0.0672, -0.0229, -0.0565, 0.0623,
# 0.1089, -0.0687, -0.0901, -0.0073, 0.0426, 0.0870, -0.0390, -0.0144,
# -0.0166, 0.0262, -0.0310, 0.0467, -0.0164, -0.0700, -0.0602, -0.0720,
# -0.0386, 0.0067, -0.0337, -0.0053, 0.0829, 0.1004, 0.0427, 0.0026,
# -0.0537, 0.0951, 0.0584, -0.0583, -0.0208, 0.0124, 0.0067, 0.0403,
# 0.0091, -0.0044, -0.0036, 0.0524, 0.1103, -0.1511, -0.0479, 0.1709,
# 0.0772, 0.0721, -0.0332, 0.0866, 0.0799, -0.0581, 0.0713, 0.0218],
# device='cuda:0', grad_fn=<SelectBackward0>)
```
## Pretraining data
This checkpoint is trained on the stricter permissive subset of the deduplicated version of
the [github-code dataset](https://huggingface.co/datasets/codeparrot/github-code).
The data is preprocessed by reserving only permissively licensed code ("mit" “apache-2”, “bsd-3-clause”, “bsd-2-clause”,
“cc0-1.0”, “unlicense”, “isc”).
Supported languages (9 in total) are as follows:
`c`, `c++`, `c-sharp`, `go`, `java`, `javascript`, `php`, `python`, `ruby.`
## Training procedure
This checkpoint is first trained on the unimodal code data at the first-stage pretraining and then on bimodal text-code
pair data using the proposed mixture of pretraining tasks.
Please refer to the paper for more details.
## Evaluation results
We show the zero-shot results of this checkpoint on 6 downstream code retrieval tasks from CodeXGLUE in the following table.
| Ruby | JavaScript | Go | Python | Java | PHP | Overall |
| ----- | ---------- | ----- | ------ | ----- | ----- | ------- |
| 74.51 | 69.07 | 90.69 | 71.55 | 71.82 | 67.72 | 74.23 |
## BibTeX entry and citation info
```bibtex
@article{wang2023codet5plus,
title={CodeT5+: Open Code Large Language Models for Code Understanding and Generation},
author={Wang, Yue and Le, Hung and Gotmare, Akhilesh Deepak and Bui, Nghi D.Q. and Li, Junnan and Hoi, Steven C. H.},
journal={arXiv preprint},
year={2023}
}
``` |
facebook/mbart-large-50-many-to-many-mmt | facebook | "2023-09-28T16:42:59Z" | 170,609 | 239 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"mbart",
"text2text-generation",
"mbart-50",
"translation",
"multilingual",
"ar",
"cs",
"de",
"en",
"es",
"et",
"fi",
"fr",
"gu",
"hi",
"it",
"ja",
"kk",
"ko",
"lt",
"lv",
"my",
"ne",
"nl",
"ro",
"ru",
"si",
"tr",
"vi",
"zh",
"af",
"az",
"bn",
"fa",
"he",
"hr",
"id",
"ka",
"km",
"mk",
"ml",
"mn",
"mr",
"pl",
"ps",
"pt",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"uk",
"ur",
"xh",
"gl",
"sl",
"arxiv:2008.00401",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ar
- cs
- de
- en
- es
- et
- fi
- fr
- gu
- hi
- it
- ja
- kk
- ko
- lt
- lv
- my
- ne
- nl
- ro
- ru
- si
- tr
- vi
- zh
- af
- az
- bn
- fa
- he
- hr
- id
- ka
- km
- mk
- ml
- mn
- mr
- pl
- ps
- pt
- sv
- sw
- ta
- te
- th
- tl
- uk
- ur
- xh
- gl
- sl
tags:
- mbart-50
pipeline_tag: translation
---
# mBART-50 many to many multilingual machine translation
This model is a fine-tuned checkpoint of [mBART-large-50](https://huggingface.co/facebook/mbart-large-50). `mbart-large-50-many-to-many-mmt` is fine-tuned for multilingual machine translation. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
The model can translate directly between any pair of 50 languages. To translate into a target language, the target language id is forced as the first generated token. To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
article_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
# translate Hindi to French
tokenizer.src_lang = "hi_IN"
encoded_hi = tokenizer(article_hi, return_tensors="pt")
generated_tokens = model.generate(
**encoded_hi,
forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Le chef de l 'ONU affirme qu 'il n 'y a pas de solution militaire dans la Syrie."
# translate Arabic to English
tokenizer.src_lang = "ar_AR"
encoded_ar = tokenizer(article_ar, return_tensors="pt")
generated_tokens = model.generate(
**encoded_ar,
forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "The Secretary-General of the United Nations says there is no military solution in Syria."
```
See the [model hub](https://huggingface.co/models?filter=mbart-50) to look for more fine-tuned versions.
## Languages covered
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI)
## BibTeX entry and citation info
```
@article{tang2020multilingual,
title={Multilingual Translation with Extensible Multilingual Pretraining and Finetuning},
author={Yuqing Tang and Chau Tran and Xian Li and Peng-Jen Chen and Naman Goyal and Vishrav Chaudhary and Jiatao Gu and Angela Fan},
year={2020},
eprint={2008.00401},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
sentence-transformers/multi-qa-distilbert-cos-v1 | sentence-transformers | "2024-03-27T11:40:53Z" | 169,925 | 20 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"distilbert",
"fill-mask",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:search_qa",
"dataset:eli5",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/QQP",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/Amazon-QA",
"dataset:embedding-data/WikiAnswers",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language:
- en
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- search_qa
- eli5
- natural_questions
- trivia_qa
- embedding-data/QQP
- embedding-data/PAQ_pairs
- embedding-data/Amazon-QA
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# multi-qa-distilbert-cos-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and was designed for **semantic search**. It has been trained on 215M (question, answer) pairs from diverse sources. For an introduction to semantic search, have a look at: [SBERT.net - Semantic Search](https://www.sbert.net/examples/applications/semantic-search/README.html)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/multi-qa-distilbert-cos-v1')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take average of all tokens
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/multi-qa-distilbert-cos-v1")
model = AutoModel.from_pretrained("sentence-transformers/multi-qa-distilbert-cos-v1")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 768 |
| Produces normalized embeddings | Yes |
| Pooling-Method | Mean pooling |
| Suitable score functions | dot-product (`util.dot_score`), cosine-similarity (`util.cos_sim`), or euclidean distance |
Note: When loaded with `sentence-transformers`, this model produces normalized embeddings with length 1. In that case, dot-product and cosine-similarity are equivalent. dot-product is preferred as it is faster. Euclidean distance is proportional to dot-product and can also be used.
----
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used for semantic search: It encodes queries / questions and text paragraphs in a dense vector space. It finds relevant documents for the given passages.
Note that there is a limit of 512 word pieces: Text longer than that will be truncated. Further note that the model was just trained on input text up to 250 word pieces. It might not work well for longer text.
## Training procedure
The full training script is accessible in this current repository: `train_script.py`.
### Pre-training
We use the pretrained [`distilbert-base-uncased`](https://huggingface.co/distilbert-base-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
#### Training
We use the concatenation from multiple datasets to fine-tune our model. In total we have about 215M (question, answer) pairs.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
The model was trained with [MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss) using Mean-pooling, cosine-similarity as similarity function, and a scale of 20.
| Dataset | Number of training tuples |
|--------------------------------------------------------|:--------------------------:|
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs from WikiAnswers | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) Automatically generated (Question, Paragraph) pairs for each paragraph in Wikipedia | 64,371,441 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs from all StackExchanges | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs from all StackExchanges | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) Triplets (query, answer, hard_negative) for 500k queries from Bing search engine | 17,579,773 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) (query, answer) pairs for 3M Google queries and Google featured snippet | 3,012,496 |
| [Amazon-QA](http://jmcauley.ucsd.edu/data/amazon/qa/) (Question, Answer) pairs from Amazon product pages | 2,448,839
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) pairs from Yahoo Answers | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) pairs from Yahoo Answers | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) pairs from Yahoo Answers | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) (Question, Answer) pairs for 140k questions, each with Top5 Google snippets on that question | 582,261 |
| [ELI5](https://huggingface.co/datasets/eli5) (Question, Answer) pairs from Reddit ELI5 (explainlikeimfive) | 325,475 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions pairs (titles) | 304,525 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) (Question, Duplicate_Question, Hard_Negative) triplets for Quora Questions Pairs dataset | 103,663 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) (Question, Paragraph) pairs for 100k real Google queries with relevant Wikipedia paragraph | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) (Question, Paragraph) pairs from SQuAD2.0 dataset | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) (Question, Evidence) pairs | 73,346 |
| **Total** | **214,988,242** | |
sentence-transformers/paraphrase-MiniLM-L12-v2 | sentence-transformers | "2024-03-27T12:09:14Z" | 169,882 | 6 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/paraphrase-MiniLM-L12-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L12-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-MiniLM-L12-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-MiniLM-L12-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-MiniLM-L12-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
openai-community/roberta-base-openai-detector | openai-community | "2024-02-19T12:46:55Z" | 169,197 | 99 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"roberta",
"text-classification",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1904.09751",
"arxiv:1910.09700",
"arxiv:1908.09203",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:04Z" | ---
language: en
license: mit
tags:
- exbert
datasets:
- bookcorpus
- wikipedia
---
# RoBERTa Base OpenAI Detector
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-author)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
**Model Description:** RoBERTa base OpenAI Detector is the GPT-2 output detector model, obtained by fine-tuning a RoBERTa base model with the outputs of the 1.5B-parameter GPT-2 model. The model can be used to predict if text was generated by a GPT-2 model. This model was released by OpenAI at the same time as OpenAI released the weights of the [largest GPT-2 model](https://huggingface.co/gpt2-xl), the 1.5B parameter version.
- **Developed by:** OpenAI, see [GitHub Repo](https://github.com/openai/gpt-2-output-dataset/tree/master/detector) and [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf) for full author list
- **Model Type:** Fine-tuned transformer-based language model
- **Language(s):** English
- **License:** MIT
- **Related Models:** [RoBERTa base](https://huggingface.co/roberta-base), [GPT-XL (1.5B parameter version)](https://huggingface.co/gpt2-xl), [GPT-Large (the 774M parameter version)](https://huggingface.co/gpt2-large), [GPT-Medium (the 355M parameter version)](https://huggingface.co/gpt2-medium) and [GPT-2 (the 124M parameter version)](https://huggingface.co/gpt2)
- **Resources for more information:**
- [Research Paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf) (see, in particular, the section beginning on page 12 about Automated ML-based detection).
- [GitHub Repo](https://github.com/openai/gpt-2-output-dataset/tree/master/detector)
- [OpenAI Blog Post](https://openai.com/blog/gpt-2-1-5b-release/)
- [Explore the detector model here](https://huggingface.co/openai-detector )
## Uses
#### Direct Use
The model is a classifier that can be used to detect text generated by GPT-2 models. However, it is strongly suggested not to use it as a ChatGPT detector for the purposes of making grave allegations of academic misconduct against undergraduates and others, as this model might give inaccurate results in the case of ChatGPT-generated input.
#### Downstream Use
The model's developers have stated that they developed and released the model to help with research related to synthetic text generation, so the model could potentially be used for downstream tasks related to synthetic text generation. See the [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf) for further discussion.
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the model developers discuss the risk of adversaries using the model to better evade detection in their [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf), suggesting that using the model for evading detection or for supporting efforts to evade detection would be a misuse of the model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section may contain content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
#### Risks and Limitations
In their [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf), the model developers discuss the risk that the model may be used by bad actors to develop capabilities for evading detection, though one purpose of releasing the model is to help improve detection research.
In a related [blog post](https://openai.com/blog/gpt-2-1-5b-release/), the model developers also discuss the limitations of automated methods for detecting synthetic text and the need to pair automated detection tools with other, non-automated approaches. They write:
> We conducted in-house detection research and developed a detection model that has detection rates of ~95% for detecting 1.5B GPT-2-generated text. We believe this is not high enough accuracy for standalone detection and needs to be paired with metadata-based approaches, human judgment, and public education to be more effective.
The model developers also [report](https://openai.com/blog/gpt-2-1-5b-release/) finding that classifying content from larger models is more difficult, suggesting that detection with automated tools like this model will be increasingly difficult as model sizes increase. The authors find that training detector models on the outputs of larger models can improve accuracy and robustness.
#### Bias
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by RoBERTa base and GPT-2 1.5B (which this model is built/fine-tuned on) can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups (see the [RoBERTa base](https://huggingface.co/roberta-base) and [GPT-2 XL](https://huggingface.co/gpt2-xl) model cards for more information). The developers of this model discuss these issues further in their [paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf).
## Training
#### Training Data
The model is a sequence classifier based on RoBERTa base (see the [RoBERTa base model card](https://huggingface.co/roberta-base) for more details on the RoBERTa base training data) and then fine-tuned using the outputs of the 1.5B GPT-2 model (available [here](https://github.com/openai/gpt-2-output-dataset)).
#### Training Procedure
The model developers write that:
> We based a sequence classifier on RoBERTaBASE (125 million parameters) and fine-tuned it to classify the outputs from the 1.5B GPT-2 model versus WebText, the dataset we used to train the GPT-2 model.
They later state:
> To develop a robust detector model that can accurately classify generated texts regardless of the sampling method, we performed an analysis of the model’s transfer performance.
See the [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf) for further details on the training procedure.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf).
#### Testing Data, Factors and Metrics
The model is intended to be used for detecting text generated by GPT-2 models, so the model developers test the model on text datasets, measuring accuracy by:
> testing 510-token test examples comprised of 5,000 samples from the WebText dataset and 5,000 samples generated by a GPT-2 model, which were not used during the training.
#### Results
The model developers [find](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf):
> Our classifier is able to detect 1.5 billion parameter GPT-2-generated text with approximately 95% accuracy...The model’s accuracy depends on sampling methods used when generating outputs, like temperature, Top-K, and nucleus sampling ([Holtzman et al., 2019](https://arxiv.org/abs/1904.09751). Nucleus sampling outputs proved most difficult to correctly classify, but a detector trained using nucleus sampling transfers well across other sampling methods. As seen in Figure 1 [in the paper], we found consistently high accuracy when trained on nucleus sampling.
See the [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf), Figure 1 (on page 14) and Figure 2 (on page 16) for full results.
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Unknown
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
The model developers write that:
See the [associated paper](https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf) for further details on the modeling architecture and training details.
## Citation Information
```bibtex
@article{solaiman2019release,
title={Release strategies and the social impacts of language models},
author={Solaiman, Irene and Brundage, Miles and Clark, Jack and Askell, Amanda and Herbert-Voss, Ariel and Wu, Jeff and Radford, Alec and Krueger, Gretchen and Kim, Jong Wook and Kreps, Sarah and others},
journal={arXiv preprint arXiv:1908.09203},
year={2019}
}
```
APA:
- Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., ... & Wang, J. (2019). Release strategies and the social impacts of language models. arXiv preprint arXiv:1908.09203.
https://huggingface.co/papers/1908.09203
## Model Card Authors
This model card was written by the team at Hugging Face.
## How to Get Started with the Model
This model can be instantiated and run with a Transformers pipeline:
```python
from transformers import pipeline
pipe = pipeline("text-classification", model="roberta-base-openai-detector")
print(pipe("Hello world! Is this content AI-generated?")) # [{'label': 'Real', 'score': 0.8036582469940186}]
``` |
lewtun/tiny-random-mt5 | lewtun | "2022-09-15T15:04:49Z" | 168,770 | 0 | transformers | [
"transformers",
"pytorch",
"mt5",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-09-15T15:03:33Z" | Entry not found |
fxmarty/tiny-random-GemmaForCausalLM | fxmarty | "2024-02-23T17:06:41Z" | 168,324 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2024-02-23T14:44:32Z" | ---
license: mit
---
This one with a custom `config.head_dim` as allowed by the architecture (see 7b model). |
sonoisa/sentence-bert-base-ja-mean-tokens-v2 | sonoisa | "2024-04-17T11:39:38Z" | 167,937 | 28 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"bert",
"sentence-bert",
"feature-extraction",
"sentence-similarity",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language: ja
license: cc-by-sa-4.0
tags:
- sentence-transformers
- sentence-bert
- feature-extraction
- sentence-similarity
---
This is a Japanese sentence-BERT model.
日本語用Sentence-BERTモデル(バージョン2)です。
[バージョン1](https://huggingface.co/sonoisa/sentence-bert-base-ja-mean-tokens)よりも良いロス関数である[MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss)を用いて学習した改良版です。
手元の非公開データセットでは、バージョン1よりも1.5〜2ポイントほど精度が高い結果が得られました。
事前学習済みモデルとして[cl-tohoku/bert-base-japanese-whole-word-masking](https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking)を利用しました。
従って、推論の実行にはfugashiとipadicが必要です(pip install fugashi ipadic)。
# 旧バージョンの解説
https://qiita.com/sonoisa/items/1df94d0a98cd4f209051
モデル名を"sonoisa/sentence-bert-base-ja-mean-tokens-v2"に書き換えれば、本モデルを利用した挙動になります。
# 使い方
```python
from transformers import BertJapaneseTokenizer, BertModel
import torch
class SentenceBertJapanese:
def __init__(self, model_name_or_path, device=None):
self.tokenizer = BertJapaneseTokenizer.from_pretrained(model_name_or_path)
self.model = BertModel.from_pretrained(model_name_or_path)
self.model.eval()
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.model.to(device)
def _mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
@torch.no_grad()
def encode(self, sentences, batch_size=8):
all_embeddings = []
iterator = range(0, len(sentences), batch_size)
for batch_idx in iterator:
batch = sentences[batch_idx:batch_idx + batch_size]
encoded_input = self.tokenizer.batch_encode_plus(batch, padding="longest",
truncation=True, return_tensors="pt").to(self.device)
model_output = self.model(**encoded_input)
sentence_embeddings = self._mean_pooling(model_output, encoded_input["attention_mask"]).to('cpu')
all_embeddings.extend(sentence_embeddings)
# return torch.stack(all_embeddings).numpy()
return torch.stack(all_embeddings)
MODEL_NAME = "sonoisa/sentence-bert-base-ja-mean-tokens-v2" # <- v2です。
model = SentenceBertJapanese(MODEL_NAME)
sentences = ["暴走したAI", "暴走した人工知能"]
sentence_embeddings = model.encode(sentences, batch_size=8)
print("Sentence embeddings:", sentence_embeddings)
```
|
mradermacher/miquplus-xwin-70b-i1-GGUF | mradermacher | "2024-06-23T16:01:19Z" | 166,700 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:jukofyork/miquplus-xwin-70b",
"endpoints_compatible",
"region:us"
] | null | "2024-06-23T04:18:34Z" | ---
base_model: jukofyork/miquplus-xwin-70b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/jukofyork/miquplus-xwin-70b
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/miquplus-xwin-70b-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ1_S.gguf) | i1-IQ1_S | 14.6 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ1_M.gguf) | i1-IQ1_M | 16.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 18.4 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 20.4 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ2_S.gguf) | i1-IQ2_S | 21.5 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ2_M.gguf) | i1-IQ2_M | 23.3 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q2_K.gguf) | i1-Q2_K | 25.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 26.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 28.4 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ3_S.gguf) | i1-IQ3_S | 30.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 30.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ3_M.gguf) | i1-IQ3_M | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 33.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 36.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 36.9 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q4_0.gguf) | i1-Q4_0 | 39.1 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 39.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 41.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 47.6 | |
| [GGUF](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 48.9 | |
| [PART 1](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/miquplus-xwin-70b-i1-GGUF/resolve/main/miquplus-xwin-70b.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 56.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
bartowski/gemma-2-9b-it-GGUF | bartowski | "2024-07-02T18:25:19Z" | 166,507 | 75 | transformers | [
"transformers",
"gguf",
"conversational",
"text-generation",
"base_model:google/gemma-2-9b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-27T15:42:48Z" | ---
license: gemma
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
tags:
- conversational
quantized_by: bartowski
base_model: google/gemma-2-9b-it
---
## Llamacpp imatrix Quantizations of gemma-2-9b-it
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3278">b3278</a> for quantization.
Original model: https://huggingface.co/google/gemma-2-9b-it
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
Experimental quants are made with `--output-tensor-type f16 --token-embedding-type f16` per [ZeroWw](https://huggingface.co/ZeroWw)'s suggestion, please provide any feedback on quality differences you spot.
## What's new
- June 21 2024: Contains latest tokenizer fixes, which addressed a few oddities from the original fix, should be closest to correct performance yet. Also has metadata for SWA and logit softcapping.
## Prompt format
```
<start_of_turn>user
{prompt}<end_of_turn>
<start_of_turn>model
```
Note that this model does not support a System prompt.
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [gemma-2-9b-it-Q8_0_L.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q8_1.gguf) | Q8_0_L | 10.68GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Extremely high quality, generally unneeded but max available quant. |
| [gemma-2-9b-it-Q8_0.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q8_0.gguf) | Q8_0 | 9.82GB | Extremely high quality, generally unneeded but max available quant. |
| [gemma-2-9b-it-Q6_K_L.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q6_K_L.gguf) | Q6_K_L | 8.67GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Very high quality, near perfect, *recommended*. |
| [gemma-2-9b-it-Q6_K.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q6_K.gguf) | Q6_K | 7.58GB | Very high quality, near perfect, *recommended*. |
| [gemma-2-9b-it-Q5_K_L.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q5_K_L.gguf) | Q5_K_L | 7.72GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. High quality, *recommended*. |
| [gemma-2-9b-it-Q5_K_M.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q5_K_M.gguf) | Q5_K_M | 6.64GB | High quality, *recommended*. |
| [gemma-2-9b-it-Q5_K_S.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q5_K_S.gguf) | Q5_K_S | 6.48GB | High quality, *recommended*. |
| [gemma-2-9b-it-Q4_K_L.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q4_K_L.gguf) | Q4_K_L | 6.84GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Good quality, uses about 4.83 bits per weight, *recommended*. |
| [gemma-2-9b-it-Q4_K_M.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q4_K_M.gguf) | Q4_K_M | 5.76GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [gemma-2-9b-it-Q4_K_S.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q4_K_S.gguf) | Q4_K_S | 5.47GB | Slightly lower quality with more space savings, *recommended*. |
| [gemma-2-9b-it-IQ4_XS.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ4_XS.gguf) | IQ4_XS | 5.18GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [gemma-2-9b-it-Q3_K_XL.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q3_K_XL.gguf) | Q3_K_XL | 6.21GB | *Experimental*, uses f16 for embed and output weights. Please provide any feedback of differences. Lower quality but usable, good for low RAM availability. |
| [gemma-2-9b-it-Q3_K_L.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q3_K_L.gguf) | Q3_K_L | 5.13GB | Lower quality but usable, good for low RAM availability. |
| [gemma-2-9b-it-Q3_K_M.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q3_K_M.gguf) | Q3_K_M | 4.76GB | Even lower quality. |
| [gemma-2-9b-it-IQ3_M.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ3_M.gguf) | IQ3_M | 4.49GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [gemma-2-9b-it-Q3_K_S.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q3_K_S.gguf) | Q3_K_S | 4.33GB | Low quality, not recommended. |
| [gemma-2-9b-it-IQ3_XS.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ3_XS.gguf) | IQ3_XS | 4.14GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [gemma-2-9b-it-IQ3_XXS.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ3_XXS.gguf) | IQ3_XXS | 3.79GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [gemma-2-9b-it-Q2_K.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-Q2_K.gguf) | Q2_K | 3.80GB | Very low quality but surprisingly usable. |
| [gemma-2-9b-it-IQ2_M.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ2_M.gguf) | IQ2_M | 3.43GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [gemma-2-9b-it-IQ2_S.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ2_S.gguf) | IQ2_S | 3.21GB | Very low quality, uses SOTA techniques to be usable. |
| [gemma-2-9b-it-IQ2_XS.gguf](https://huggingface.co/bartowski/gemma-2-9b-it-GGUF/blob/main/gemma-2-9b-it-IQ2_XS.gguf) | IQ2_XS | 3.06GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/gemma-2-9b-it-GGUF --include "gemma-2-9b-it-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/gemma-2-9b-it-GGUF --include "gemma-2-9b-it-Q8_0.gguf/*" --local-dir gemma-2-9b-it-Q8_0
```
You can either specify a new local-dir (gemma-2-9b-it-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
stabilityai/stable-diffusion-2-inpainting | stabilityai | "2023-07-05T16:19:10Z" | 166,282 | 420 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"diffusers:StableDiffusionInpaintPipeline",
"region:us"
] | image-to-image | "2022-11-23T17:41:55Z" | ---
license: openrail++
tags:
- stable-diffusion
inference: false
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-inpainting` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-inpainting-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting/resolve/main/512-inpainting-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 inpainting in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float16,
)
pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
#image and mask_image should be PIL images.
#The mask structure is white for inpainting and black for keeping as is
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
image.save("./yellow_cat_on_park_bench.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
**How it works:**
`image` | `mask_image`
:-------------------------:|:-------------------------:|
<img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" alt="drawing" width="300"/> | <img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" alt="drawing" width="300"/>
`prompt` | `Output`
:-------------------------:|:-------------------------:|
<span style="position: relative;bottom: 150px;">Face of a yellow cat, high resolution, sitting on a park bench</span> | <img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/test.png" alt="drawing" width="300"/>
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
monologg/koelectra-base-v3-discriminator | monologg | "2021-10-20T16:53:40Z" | 166,052 | 27 | transformers | [
"transformers",
"pytorch",
"electra",
"pretraining",
"korean",
"ko",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: ko
license: apache-2.0
tags:
- korean
---
# KoELECTRA v3 (Base Discriminator)
Pretrained ELECTRA Language Model for Korean (`koelectra-base-v3-discriminator`)
For more detail, please see [original repository](https://github.com/monologg/KoELECTRA/blob/master/README_EN.md).
## Usage
### Load model and tokenizer
```python
>>> from transformers import ElectraModel, ElectraTokenizer
>>> model = ElectraModel.from_pretrained("monologg/koelectra-base-v3-discriminator")
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-discriminator")
```
### Tokenizer example
```python
>>> from transformers import ElectraTokenizer
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-discriminator")
>>> tokenizer.tokenize("[CLS] 한국어 ELECTRA를 공유합니다. [SEP]")
['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]']
>>> tokenizer.convert_tokens_to_ids(['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]'])
[2, 11229, 29173, 13352, 25541, 4110, 7824, 17788, 18, 3]
```
## Example using ElectraForPreTraining
```python
import torch
from transformers import ElectraForPreTraining, ElectraTokenizer
discriminator = ElectraForPreTraining.from_pretrained("monologg/koelectra-base-v3-discriminator")
tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-discriminator")
sentence = "나는 방금 밥을 먹었다."
fake_sentence = "나는 내일 밥을 먹었다."
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
print(list(zip(fake_tokens, predictions.tolist()[1:-1])))
```
|
sentence-transformers/nli-mpnet-base-v2 | sentence-transformers | "2024-03-27T12:04:57Z" | 165,960 | 12 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/nli-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nli-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nli-mpnet-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/nli-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nli-mpnet-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
hkunlp/instructor-large | hkunlp | "2023-04-21T06:04:33Z" | 165,794 | 468 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"t5",
"text-embedding",
"embeddings",
"information-retrieval",
"beir",
"text-classification",
"language-model",
"text-clustering",
"text-semantic-similarity",
"text-evaluation",
"prompt-retrieval",
"text-reranking",
"feature-extraction",
"sentence-similarity",
"transformers",
"English",
"Sentence Similarity",
"natural_questions",
"ms_marco",
"fever",
"hotpot_qa",
"mteb",
"en",
"arxiv:2212.09741",
"license:apache-2.0",
"model-index",
"region:us"
] | sentence-similarity | "2022-12-20T05:31:06Z" | ---
pipeline_tag: sentence-similarity
tags:
- text-embedding
- embeddings
- information-retrieval
- beir
- text-classification
- language-model
- text-clustering
- text-semantic-similarity
- text-evaluation
- prompt-retrieval
- text-reranking
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- t5
- English
- Sentence Similarity
- natural_questions
- ms_marco
- fever
- hotpot_qa
- mteb
language: en
inference: false
license: apache-2.0
model-index:
- name: INSTRUCTOR
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 88.13432835820896
- type: ap
value: 59.298209334395665
- type: f1
value: 83.31769058643586
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.526375
- type: ap
value: 88.16327709705504
- type: f1
value: 91.51095801287843
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.856
- type: f1
value: 45.41490917650942
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.223
- type: map_at_10
value: 47.947
- type: map_at_100
value: 48.742000000000004
- type: map_at_1000
value: 48.745
- type: map_at_3
value: 43.137
- type: map_at_5
value: 45.992
- type: mrr_at_1
value: 32.432
- type: mrr_at_10
value: 48.4
- type: mrr_at_100
value: 49.202
- type: mrr_at_1000
value: 49.205
- type: mrr_at_3
value: 43.551
- type: mrr_at_5
value: 46.467999999999996
- type: ndcg_at_1
value: 31.223
- type: ndcg_at_10
value: 57.045
- type: ndcg_at_100
value: 60.175
- type: ndcg_at_1000
value: 60.233000000000004
- type: ndcg_at_3
value: 47.171
- type: ndcg_at_5
value: 52.322
- type: precision_at_1
value: 31.223
- type: precision_at_10
value: 8.599
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 19.63
- type: precision_at_5
value: 14.282
- type: recall_at_1
value: 31.223
- type: recall_at_10
value: 85.989
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.502
- type: recall_at_3
value: 58.89
- type: recall_at_5
value: 71.408
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 43.1621946393635
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 32.56417132407894
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.29539304390207
- type: mrr
value: 76.44484017060196
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_spearman
value: 84.38746499431112
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 78.51298701298701
- type: f1
value: 77.49041754069235
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 37.61848554098577
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 31.32623280148178
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.803000000000004
- type: map_at_10
value: 48.848
- type: map_at_100
value: 50.5
- type: map_at_1000
value: 50.602999999999994
- type: map_at_3
value: 45.111000000000004
- type: map_at_5
value: 47.202
- type: mrr_at_1
value: 44.635000000000005
- type: mrr_at_10
value: 55.593
- type: mrr_at_100
value: 56.169999999999995
- type: mrr_at_1000
value: 56.19499999999999
- type: mrr_at_3
value: 53.361999999999995
- type: mrr_at_5
value: 54.806999999999995
- type: ndcg_at_1
value: 44.635000000000005
- type: ndcg_at_10
value: 55.899
- type: ndcg_at_100
value: 60.958
- type: ndcg_at_1000
value: 62.302
- type: ndcg_at_3
value: 51.051
- type: ndcg_at_5
value: 53.351000000000006
- type: precision_at_1
value: 44.635000000000005
- type: precision_at_10
value: 10.786999999999999
- type: precision_at_100
value: 1.6580000000000001
- type: precision_at_1000
value: 0.213
- type: precision_at_3
value: 24.893
- type: precision_at_5
value: 17.740000000000002
- type: recall_at_1
value: 35.803000000000004
- type: recall_at_10
value: 68.657
- type: recall_at_100
value: 89.77199999999999
- type: recall_at_1000
value: 97.67
- type: recall_at_3
value: 54.066
- type: recall_at_5
value: 60.788
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.706
- type: map_at_10
value: 44.896
- type: map_at_100
value: 46.299
- type: map_at_1000
value: 46.44
- type: map_at_3
value: 41.721000000000004
- type: map_at_5
value: 43.486000000000004
- type: mrr_at_1
value: 41.592
- type: mrr_at_10
value: 50.529
- type: mrr_at_100
value: 51.22
- type: mrr_at_1000
value: 51.258
- type: mrr_at_3
value: 48.205999999999996
- type: mrr_at_5
value: 49.528
- type: ndcg_at_1
value: 41.592
- type: ndcg_at_10
value: 50.77199999999999
- type: ndcg_at_100
value: 55.383
- type: ndcg_at_1000
value: 57.288
- type: ndcg_at_3
value: 46.324
- type: ndcg_at_5
value: 48.346000000000004
- type: precision_at_1
value: 41.592
- type: precision_at_10
value: 9.516
- type: precision_at_100
value: 1.541
- type: precision_at_1000
value: 0.2
- type: precision_at_3
value: 22.399
- type: precision_at_5
value: 15.770999999999999
- type: recall_at_1
value: 33.706
- type: recall_at_10
value: 61.353
- type: recall_at_100
value: 80.182
- type: recall_at_1000
value: 91.896
- type: recall_at_3
value: 48.204
- type: recall_at_5
value: 53.89699999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 44.424
- type: map_at_10
value: 57.169000000000004
- type: map_at_100
value: 58.202
- type: map_at_1000
value: 58.242000000000004
- type: map_at_3
value: 53.825
- type: map_at_5
value: 55.714
- type: mrr_at_1
value: 50.470000000000006
- type: mrr_at_10
value: 60.489000000000004
- type: mrr_at_100
value: 61.096
- type: mrr_at_1000
value: 61.112
- type: mrr_at_3
value: 58.192
- type: mrr_at_5
value: 59.611999999999995
- type: ndcg_at_1
value: 50.470000000000006
- type: ndcg_at_10
value: 63.071999999999996
- type: ndcg_at_100
value: 66.964
- type: ndcg_at_1000
value: 67.659
- type: ndcg_at_3
value: 57.74399999999999
- type: ndcg_at_5
value: 60.367000000000004
- type: precision_at_1
value: 50.470000000000006
- type: precision_at_10
value: 10.019
- type: precision_at_100
value: 1.29
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 25.558999999999997
- type: precision_at_5
value: 17.467
- type: recall_at_1
value: 44.424
- type: recall_at_10
value: 77.02
- type: recall_at_100
value: 93.738
- type: recall_at_1000
value: 98.451
- type: recall_at_3
value: 62.888
- type: recall_at_5
value: 69.138
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.294
- type: map_at_10
value: 34.503
- type: map_at_100
value: 35.641
- type: map_at_1000
value: 35.724000000000004
- type: map_at_3
value: 31.753999999999998
- type: map_at_5
value: 33.190999999999995
- type: mrr_at_1
value: 28.362
- type: mrr_at_10
value: 36.53
- type: mrr_at_100
value: 37.541000000000004
- type: mrr_at_1000
value: 37.602000000000004
- type: mrr_at_3
value: 33.917
- type: mrr_at_5
value: 35.358000000000004
- type: ndcg_at_1
value: 28.362
- type: ndcg_at_10
value: 39.513999999999996
- type: ndcg_at_100
value: 44.815
- type: ndcg_at_1000
value: 46.839
- type: ndcg_at_3
value: 34.02
- type: ndcg_at_5
value: 36.522
- type: precision_at_1
value: 28.362
- type: precision_at_10
value: 6.101999999999999
- type: precision_at_100
value: 0.9129999999999999
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 14.161999999999999
- type: precision_at_5
value: 9.966
- type: recall_at_1
value: 26.294
- type: recall_at_10
value: 53.098
- type: recall_at_100
value: 76.877
- type: recall_at_1000
value: 91.834
- type: recall_at_3
value: 38.266
- type: recall_at_5
value: 44.287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.407
- type: map_at_10
value: 25.185999999999996
- type: map_at_100
value: 26.533
- type: map_at_1000
value: 26.657999999999998
- type: map_at_3
value: 22.201999999999998
- type: map_at_5
value: 23.923
- type: mrr_at_1
value: 20.522000000000002
- type: mrr_at_10
value: 29.522
- type: mrr_at_100
value: 30.644
- type: mrr_at_1000
value: 30.713
- type: mrr_at_3
value: 26.679000000000002
- type: mrr_at_5
value: 28.483000000000004
- type: ndcg_at_1
value: 20.522000000000002
- type: ndcg_at_10
value: 30.656
- type: ndcg_at_100
value: 36.864999999999995
- type: ndcg_at_1000
value: 39.675
- type: ndcg_at_3
value: 25.319000000000003
- type: ndcg_at_5
value: 27.992
- type: precision_at_1
value: 20.522000000000002
- type: precision_at_10
value: 5.795999999999999
- type: precision_at_100
value: 1.027
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 12.396
- type: precision_at_5
value: 9.328
- type: recall_at_1
value: 16.407
- type: recall_at_10
value: 43.164
- type: recall_at_100
value: 69.695
- type: recall_at_1000
value: 89.41900000000001
- type: recall_at_3
value: 28.634999999999998
- type: recall_at_5
value: 35.308
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.473
- type: map_at_10
value: 41.676
- type: map_at_100
value: 43.120999999999995
- type: map_at_1000
value: 43.230000000000004
- type: map_at_3
value: 38.306000000000004
- type: map_at_5
value: 40.355999999999995
- type: mrr_at_1
value: 37.536
- type: mrr_at_10
value: 47.643
- type: mrr_at_100
value: 48.508
- type: mrr_at_1000
value: 48.551
- type: mrr_at_3
value: 45.348
- type: mrr_at_5
value: 46.744
- type: ndcg_at_1
value: 37.536
- type: ndcg_at_10
value: 47.823
- type: ndcg_at_100
value: 53.395
- type: ndcg_at_1000
value: 55.271
- type: ndcg_at_3
value: 42.768
- type: ndcg_at_5
value: 45.373000000000005
- type: precision_at_1
value: 37.536
- type: precision_at_10
value: 8.681
- type: precision_at_100
value: 1.34
- type: precision_at_1000
value: 0.165
- type: precision_at_3
value: 20.468
- type: precision_at_5
value: 14.495
- type: recall_at_1
value: 30.473
- type: recall_at_10
value: 60.092999999999996
- type: recall_at_100
value: 82.733
- type: recall_at_1000
value: 94.875
- type: recall_at_3
value: 45.734
- type: recall_at_5
value: 52.691
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.976000000000003
- type: map_at_10
value: 41.097
- type: map_at_100
value: 42.547000000000004
- type: map_at_1000
value: 42.659000000000006
- type: map_at_3
value: 37.251
- type: map_at_5
value: 39.493
- type: mrr_at_1
value: 37.557
- type: mrr_at_10
value: 46.605000000000004
- type: mrr_at_100
value: 47.487
- type: mrr_at_1000
value: 47.54
- type: mrr_at_3
value: 43.721
- type: mrr_at_5
value: 45.411
- type: ndcg_at_1
value: 37.557
- type: ndcg_at_10
value: 47.449000000000005
- type: ndcg_at_100
value: 53.052
- type: ndcg_at_1000
value: 55.010999999999996
- type: ndcg_at_3
value: 41.439
- type: ndcg_at_5
value: 44.292
- type: precision_at_1
value: 37.557
- type: precision_at_10
value: 8.847
- type: precision_at_100
value: 1.357
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 20.091
- type: precision_at_5
value: 14.384
- type: recall_at_1
value: 29.976000000000003
- type: recall_at_10
value: 60.99099999999999
- type: recall_at_100
value: 84.245
- type: recall_at_1000
value: 96.97200000000001
- type: recall_at_3
value: 43.794
- type: recall_at_5
value: 51.778999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.099166666666665
- type: map_at_10
value: 38.1365
- type: map_at_100
value: 39.44491666666667
- type: map_at_1000
value: 39.55858333333334
- type: map_at_3
value: 35.03641666666666
- type: map_at_5
value: 36.79833333333334
- type: mrr_at_1
value: 33.39966666666667
- type: mrr_at_10
value: 42.42583333333333
- type: mrr_at_100
value: 43.28575
- type: mrr_at_1000
value: 43.33741666666667
- type: mrr_at_3
value: 39.94975
- type: mrr_at_5
value: 41.41633333333334
- type: ndcg_at_1
value: 33.39966666666667
- type: ndcg_at_10
value: 43.81741666666667
- type: ndcg_at_100
value: 49.08166666666667
- type: ndcg_at_1000
value: 51.121166666666674
- type: ndcg_at_3
value: 38.73575
- type: ndcg_at_5
value: 41.18158333333333
- type: precision_at_1
value: 33.39966666666667
- type: precision_at_10
value: 7.738916666666667
- type: precision_at_100
value: 1.2265833333333331
- type: precision_at_1000
value: 0.15983333333333336
- type: precision_at_3
value: 17.967416666666665
- type: precision_at_5
value: 12.78675
- type: recall_at_1
value: 28.099166666666665
- type: recall_at_10
value: 56.27049999999999
- type: recall_at_100
value: 78.93291666666667
- type: recall_at_1000
value: 92.81608333333334
- type: recall_at_3
value: 42.09775
- type: recall_at_5
value: 48.42533333333334
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.663
- type: map_at_10
value: 30.377
- type: map_at_100
value: 31.426
- type: map_at_1000
value: 31.519000000000002
- type: map_at_3
value: 28.069
- type: map_at_5
value: 29.256999999999998
- type: mrr_at_1
value: 26.687
- type: mrr_at_10
value: 33.107
- type: mrr_at_100
value: 34.055
- type: mrr_at_1000
value: 34.117999999999995
- type: mrr_at_3
value: 31.058000000000003
- type: mrr_at_5
value: 32.14
- type: ndcg_at_1
value: 26.687
- type: ndcg_at_10
value: 34.615
- type: ndcg_at_100
value: 39.776
- type: ndcg_at_1000
value: 42.05
- type: ndcg_at_3
value: 30.322
- type: ndcg_at_5
value: 32.157000000000004
- type: precision_at_1
value: 26.687
- type: precision_at_10
value: 5.491
- type: precision_at_100
value: 0.877
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.139000000000001
- type: precision_at_5
value: 9.049
- type: recall_at_1
value: 23.663
- type: recall_at_10
value: 45.035
- type: recall_at_100
value: 68.554
- type: recall_at_1000
value: 85.077
- type: recall_at_3
value: 32.982
- type: recall_at_5
value: 37.688
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.403
- type: map_at_10
value: 25.197000000000003
- type: map_at_100
value: 26.355
- type: map_at_1000
value: 26.487
- type: map_at_3
value: 22.733
- type: map_at_5
value: 24.114
- type: mrr_at_1
value: 21.37
- type: mrr_at_10
value: 29.091
- type: mrr_at_100
value: 30.018
- type: mrr_at_1000
value: 30.096
- type: mrr_at_3
value: 26.887
- type: mrr_at_5
value: 28.157
- type: ndcg_at_1
value: 21.37
- type: ndcg_at_10
value: 30.026000000000003
- type: ndcg_at_100
value: 35.416
- type: ndcg_at_1000
value: 38.45
- type: ndcg_at_3
value: 25.764
- type: ndcg_at_5
value: 27.742
- type: precision_at_1
value: 21.37
- type: precision_at_10
value: 5.609
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.14300000000000002
- type: precision_at_3
value: 12.423
- type: precision_at_5
value: 9.009
- type: recall_at_1
value: 17.403
- type: recall_at_10
value: 40.573
- type: recall_at_100
value: 64.818
- type: recall_at_1000
value: 86.53699999999999
- type: recall_at_3
value: 28.493000000000002
- type: recall_at_5
value: 33.660000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.639
- type: map_at_10
value: 38.951
- type: map_at_100
value: 40.238
- type: map_at_1000
value: 40.327
- type: map_at_3
value: 35.842
- type: map_at_5
value: 37.617
- type: mrr_at_1
value: 33.769
- type: mrr_at_10
value: 43.088
- type: mrr_at_100
value: 44.03
- type: mrr_at_1000
value: 44.072
- type: mrr_at_3
value: 40.656
- type: mrr_at_5
value: 42.138999999999996
- type: ndcg_at_1
value: 33.769
- type: ndcg_at_10
value: 44.676
- type: ndcg_at_100
value: 50.416000000000004
- type: ndcg_at_1000
value: 52.227999999999994
- type: ndcg_at_3
value: 39.494
- type: ndcg_at_5
value: 42.013
- type: precision_at_1
value: 33.769
- type: precision_at_10
value: 7.668
- type: precision_at_100
value: 1.18
- type: precision_at_1000
value: 0.145
- type: precision_at_3
value: 18.221
- type: precision_at_5
value: 12.966
- type: recall_at_1
value: 28.639
- type: recall_at_10
value: 57.687999999999995
- type: recall_at_100
value: 82.541
- type: recall_at_1000
value: 94.896
- type: recall_at_3
value: 43.651
- type: recall_at_5
value: 49.925999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.57
- type: map_at_10
value: 40.004
- type: map_at_100
value: 41.75
- type: map_at_1000
value: 41.97
- type: map_at_3
value: 36.788
- type: map_at_5
value: 38.671
- type: mrr_at_1
value: 35.375
- type: mrr_at_10
value: 45.121
- type: mrr_at_100
value: 45.994
- type: mrr_at_1000
value: 46.04
- type: mrr_at_3
value: 42.227
- type: mrr_at_5
value: 43.995
- type: ndcg_at_1
value: 35.375
- type: ndcg_at_10
value: 46.392
- type: ndcg_at_100
value: 52.196
- type: ndcg_at_1000
value: 54.274
- type: ndcg_at_3
value: 41.163
- type: ndcg_at_5
value: 43.813
- type: precision_at_1
value: 35.375
- type: precision_at_10
value: 8.676
- type: precision_at_100
value: 1.678
- type: precision_at_1000
value: 0.253
- type: precision_at_3
value: 19.104
- type: precision_at_5
value: 13.913
- type: recall_at_1
value: 29.57
- type: recall_at_10
value: 58.779
- type: recall_at_100
value: 83.337
- type: recall_at_1000
value: 95.979
- type: recall_at_3
value: 44.005
- type: recall_at_5
value: 50.975
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.832
- type: map_at_10
value: 29.733999999999998
- type: map_at_100
value: 30.727
- type: map_at_1000
value: 30.843999999999998
- type: map_at_3
value: 26.834999999999997
- type: map_at_5
value: 28.555999999999997
- type: mrr_at_1
value: 22.921
- type: mrr_at_10
value: 31.791999999999998
- type: mrr_at_100
value: 32.666000000000004
- type: mrr_at_1000
value: 32.751999999999995
- type: mrr_at_3
value: 29.144
- type: mrr_at_5
value: 30.622
- type: ndcg_at_1
value: 22.921
- type: ndcg_at_10
value: 34.915
- type: ndcg_at_100
value: 39.744
- type: ndcg_at_1000
value: 42.407000000000004
- type: ndcg_at_3
value: 29.421000000000003
- type: ndcg_at_5
value: 32.211
- type: precision_at_1
value: 22.921
- type: precision_at_10
value: 5.675
- type: precision_at_100
value: 0.872
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 12.753999999999998
- type: precision_at_5
value: 9.353
- type: recall_at_1
value: 20.832
- type: recall_at_10
value: 48.795
- type: recall_at_100
value: 70.703
- type: recall_at_1000
value: 90.187
- type: recall_at_3
value: 34.455000000000005
- type: recall_at_5
value: 40.967
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.334
- type: map_at_10
value: 19.009999999999998
- type: map_at_100
value: 21.129
- type: map_at_1000
value: 21.328
- type: map_at_3
value: 15.152
- type: map_at_5
value: 17.084
- type: mrr_at_1
value: 23.453
- type: mrr_at_10
value: 36.099
- type: mrr_at_100
value: 37.069
- type: mrr_at_1000
value: 37.104
- type: mrr_at_3
value: 32.096000000000004
- type: mrr_at_5
value: 34.451
- type: ndcg_at_1
value: 23.453
- type: ndcg_at_10
value: 27.739000000000004
- type: ndcg_at_100
value: 35.836
- type: ndcg_at_1000
value: 39.242
- type: ndcg_at_3
value: 21.263
- type: ndcg_at_5
value: 23.677
- type: precision_at_1
value: 23.453
- type: precision_at_10
value: 9.199
- type: precision_at_100
value: 1.791
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 16.2
- type: precision_at_5
value: 13.147
- type: recall_at_1
value: 10.334
- type: recall_at_10
value: 35.177
- type: recall_at_100
value: 63.009
- type: recall_at_1000
value: 81.938
- type: recall_at_3
value: 19.914
- type: recall_at_5
value: 26.077
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.212
- type: map_at_10
value: 17.386
- type: map_at_100
value: 24.234
- type: map_at_1000
value: 25.724999999999998
- type: map_at_3
value: 12.727
- type: map_at_5
value: 14.785
- type: mrr_at_1
value: 59.25
- type: mrr_at_10
value: 68.687
- type: mrr_at_100
value: 69.133
- type: mrr_at_1000
value: 69.14099999999999
- type: mrr_at_3
value: 66.917
- type: mrr_at_5
value: 67.742
- type: ndcg_at_1
value: 48.625
- type: ndcg_at_10
value: 36.675999999999995
- type: ndcg_at_100
value: 41.543
- type: ndcg_at_1000
value: 49.241
- type: ndcg_at_3
value: 41.373
- type: ndcg_at_5
value: 38.707
- type: precision_at_1
value: 59.25
- type: precision_at_10
value: 28.525
- type: precision_at_100
value: 9.027000000000001
- type: precision_at_1000
value: 1.8339999999999999
- type: precision_at_3
value: 44.833
- type: precision_at_5
value: 37.35
- type: recall_at_1
value: 8.212
- type: recall_at_10
value: 23.188
- type: recall_at_100
value: 48.613
- type: recall_at_1000
value: 73.093
- type: recall_at_3
value: 14.419
- type: recall_at_5
value: 17.798
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 52.725
- type: f1
value: 46.50743309855908
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.086
- type: map_at_10
value: 66.914
- type: map_at_100
value: 67.321
- type: map_at_1000
value: 67.341
- type: map_at_3
value: 64.75800000000001
- type: map_at_5
value: 66.189
- type: mrr_at_1
value: 59.28600000000001
- type: mrr_at_10
value: 71.005
- type: mrr_at_100
value: 71.304
- type: mrr_at_1000
value: 71.313
- type: mrr_at_3
value: 69.037
- type: mrr_at_5
value: 70.35
- type: ndcg_at_1
value: 59.28600000000001
- type: ndcg_at_10
value: 72.695
- type: ndcg_at_100
value: 74.432
- type: ndcg_at_1000
value: 74.868
- type: ndcg_at_3
value: 68.72200000000001
- type: ndcg_at_5
value: 71.081
- type: precision_at_1
value: 59.28600000000001
- type: precision_at_10
value: 9.499
- type: precision_at_100
value: 1.052
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 27.503
- type: precision_at_5
value: 17.854999999999997
- type: recall_at_1
value: 55.086
- type: recall_at_10
value: 86.453
- type: recall_at_100
value: 94.028
- type: recall_at_1000
value: 97.052
- type: recall_at_3
value: 75.821
- type: recall_at_5
value: 81.6
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.262999999999998
- type: map_at_10
value: 37.488
- type: map_at_100
value: 39.498
- type: map_at_1000
value: 39.687
- type: map_at_3
value: 32.529
- type: map_at_5
value: 35.455
- type: mrr_at_1
value: 44.907000000000004
- type: mrr_at_10
value: 53.239000000000004
- type: mrr_at_100
value: 54.086
- type: mrr_at_1000
value: 54.122
- type: mrr_at_3
value: 51.235
- type: mrr_at_5
value: 52.415
- type: ndcg_at_1
value: 44.907000000000004
- type: ndcg_at_10
value: 45.446
- type: ndcg_at_100
value: 52.429
- type: ndcg_at_1000
value: 55.169000000000004
- type: ndcg_at_3
value: 41.882000000000005
- type: ndcg_at_5
value: 43.178
- type: precision_at_1
value: 44.907000000000004
- type: precision_at_10
value: 12.931999999999999
- type: precision_at_100
value: 2.025
- type: precision_at_1000
value: 0.248
- type: precision_at_3
value: 28.652
- type: precision_at_5
value: 21.204
- type: recall_at_1
value: 22.262999999999998
- type: recall_at_10
value: 52.447
- type: recall_at_100
value: 78.045
- type: recall_at_1000
value: 94.419
- type: recall_at_3
value: 38.064
- type: recall_at_5
value: 44.769
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.519
- type: map_at_10
value: 45.831
- type: map_at_100
value: 46.815
- type: map_at_1000
value: 46.899
- type: map_at_3
value: 42.836
- type: map_at_5
value: 44.65
- type: mrr_at_1
value: 65.037
- type: mrr_at_10
value: 72.16
- type: mrr_at_100
value: 72.51100000000001
- type: mrr_at_1000
value: 72.53
- type: mrr_at_3
value: 70.682
- type: mrr_at_5
value: 71.54599999999999
- type: ndcg_at_1
value: 65.037
- type: ndcg_at_10
value: 55.17999999999999
- type: ndcg_at_100
value: 58.888
- type: ndcg_at_1000
value: 60.648
- type: ndcg_at_3
value: 50.501
- type: ndcg_at_5
value: 52.977
- type: precision_at_1
value: 65.037
- type: precision_at_10
value: 11.530999999999999
- type: precision_at_100
value: 1.4460000000000002
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 31.483
- type: precision_at_5
value: 20.845
- type: recall_at_1
value: 32.519
- type: recall_at_10
value: 57.657000000000004
- type: recall_at_100
value: 72.30199999999999
- type: recall_at_1000
value: 84.024
- type: recall_at_3
value: 47.225
- type: recall_at_5
value: 52.113
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 88.3168
- type: ap
value: 83.80165516037135
- type: f1
value: 88.29942471066407
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 20.724999999999998
- type: map_at_10
value: 32.736
- type: map_at_100
value: 33.938
- type: map_at_1000
value: 33.991
- type: map_at_3
value: 28.788000000000004
- type: map_at_5
value: 31.016
- type: mrr_at_1
value: 21.361
- type: mrr_at_10
value: 33.323
- type: mrr_at_100
value: 34.471000000000004
- type: mrr_at_1000
value: 34.518
- type: mrr_at_3
value: 29.453000000000003
- type: mrr_at_5
value: 31.629
- type: ndcg_at_1
value: 21.361
- type: ndcg_at_10
value: 39.649
- type: ndcg_at_100
value: 45.481
- type: ndcg_at_1000
value: 46.775
- type: ndcg_at_3
value: 31.594
- type: ndcg_at_5
value: 35.543
- type: precision_at_1
value: 21.361
- type: precision_at_10
value: 6.3740000000000006
- type: precision_at_100
value: 0.931
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.514999999999999
- type: precision_at_5
value: 10.100000000000001
- type: recall_at_1
value: 20.724999999999998
- type: recall_at_10
value: 61.034
- type: recall_at_100
value: 88.062
- type: recall_at_1000
value: 97.86399999999999
- type: recall_at_3
value: 39.072
- type: recall_at_5
value: 48.53
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.8919288645691
- type: f1
value: 93.57059586398059
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.97993616051072
- type: f1
value: 48.244319183606535
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.90047074646941
- type: f1
value: 66.48999056063725
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.34566240753195
- type: f1
value: 73.54164154290658
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.21866934757011
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.000936217235534
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.68189362520352
- type: mrr
value: 32.69603637784303
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.078
- type: map_at_10
value: 12.671
- type: map_at_100
value: 16.291
- type: map_at_1000
value: 17.855999999999998
- type: map_at_3
value: 9.610000000000001
- type: map_at_5
value: 11.152
- type: mrr_at_1
value: 43.963
- type: mrr_at_10
value: 53.173
- type: mrr_at_100
value: 53.718999999999994
- type: mrr_at_1000
value: 53.756
- type: mrr_at_3
value: 50.980000000000004
- type: mrr_at_5
value: 52.42
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 34.086
- type: ndcg_at_100
value: 32.545
- type: ndcg_at_1000
value: 41.144999999999996
- type: ndcg_at_3
value: 39.434999999999995
- type: ndcg_at_5
value: 37.888
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 25.014999999999997
- type: precision_at_100
value: 8.594
- type: precision_at_1000
value: 2.169
- type: precision_at_3
value: 37.049
- type: precision_at_5
value: 33.065
- type: recall_at_1
value: 6.078
- type: recall_at_10
value: 16.17
- type: recall_at_100
value: 34.512
- type: recall_at_1000
value: 65.447
- type: recall_at_3
value: 10.706
- type: recall_at_5
value: 13.158
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.378000000000004
- type: map_at_10
value: 42.178
- type: map_at_100
value: 43.32
- type: map_at_1000
value: 43.358000000000004
- type: map_at_3
value: 37.474000000000004
- type: map_at_5
value: 40.333000000000006
- type: mrr_at_1
value: 30.823
- type: mrr_at_10
value: 44.626
- type: mrr_at_100
value: 45.494
- type: mrr_at_1000
value: 45.519
- type: mrr_at_3
value: 40.585
- type: mrr_at_5
value: 43.146
- type: ndcg_at_1
value: 30.794
- type: ndcg_at_10
value: 50.099000000000004
- type: ndcg_at_100
value: 54.900999999999996
- type: ndcg_at_1000
value: 55.69499999999999
- type: ndcg_at_3
value: 41.238
- type: ndcg_at_5
value: 46.081
- type: precision_at_1
value: 30.794
- type: precision_at_10
value: 8.549
- type: precision_at_100
value: 1.124
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 18.926000000000002
- type: precision_at_5
value: 14.16
- type: recall_at_1
value: 27.378000000000004
- type: recall_at_10
value: 71.842
- type: recall_at_100
value: 92.565
- type: recall_at_1000
value: 98.402
- type: recall_at_3
value: 49.053999999999995
- type: recall_at_5
value: 60.207
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.557
- type: map_at_10
value: 84.729
- type: map_at_100
value: 85.369
- type: map_at_1000
value: 85.382
- type: map_at_3
value: 81.72
- type: map_at_5
value: 83.613
- type: mrr_at_1
value: 81.3
- type: mrr_at_10
value: 87.488
- type: mrr_at_100
value: 87.588
- type: mrr_at_1000
value: 87.589
- type: mrr_at_3
value: 86.53
- type: mrr_at_5
value: 87.18599999999999
- type: ndcg_at_1
value: 81.28999999999999
- type: ndcg_at_10
value: 88.442
- type: ndcg_at_100
value: 89.637
- type: ndcg_at_1000
value: 89.70700000000001
- type: ndcg_at_3
value: 85.55199999999999
- type: ndcg_at_5
value: 87.154
- type: precision_at_1
value: 81.28999999999999
- type: precision_at_10
value: 13.489999999999998
- type: precision_at_100
value: 1.54
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.553
- type: precision_at_5
value: 24.708
- type: recall_at_1
value: 70.557
- type: recall_at_10
value: 95.645
- type: recall_at_100
value: 99.693
- type: recall_at_1000
value: 99.995
- type: recall_at_3
value: 87.359
- type: recall_at_5
value: 91.89699999999999
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 63.65060114776209
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.63271250680617
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.263
- type: map_at_10
value: 10.801
- type: map_at_100
value: 12.888
- type: map_at_1000
value: 13.224
- type: map_at_3
value: 7.362
- type: map_at_5
value: 9.149000000000001
- type: mrr_at_1
value: 21
- type: mrr_at_10
value: 31.416
- type: mrr_at_100
value: 32.513
- type: mrr_at_1000
value: 32.58
- type: mrr_at_3
value: 28.116999999999997
- type: mrr_at_5
value: 29.976999999999997
- type: ndcg_at_1
value: 21
- type: ndcg_at_10
value: 18.551000000000002
- type: ndcg_at_100
value: 26.657999999999998
- type: ndcg_at_1000
value: 32.485
- type: ndcg_at_3
value: 16.834
- type: ndcg_at_5
value: 15.204999999999998
- type: precision_at_1
value: 21
- type: precision_at_10
value: 9.84
- type: precision_at_100
value: 2.16
- type: precision_at_1000
value: 0.35500000000000004
- type: precision_at_3
value: 15.667
- type: precision_at_5
value: 13.62
- type: recall_at_1
value: 4.263
- type: recall_at_10
value: 19.922
- type: recall_at_100
value: 43.808
- type: recall_at_1000
value: 72.14500000000001
- type: recall_at_3
value: 9.493
- type: recall_at_5
value: 13.767999999999999
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_spearman
value: 81.27446313317233
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_spearman
value: 76.27963301217527
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_spearman
value: 88.18495048450949
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_spearman
value: 81.91982338692046
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_spearman
value: 89.00896818385291
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_spearman
value: 85.48814644586132
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 90.30116926966582
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_spearman
value: 67.74132963032342
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_spearman
value: 86.87741355780479
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 82.0019012295875
- type: mrr
value: 94.70267024188593
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 50.05
- type: map_at_10
value: 59.36
- type: map_at_100
value: 59.967999999999996
- type: map_at_1000
value: 60.023
- type: map_at_3
value: 56.515
- type: map_at_5
value: 58.272999999999996
- type: mrr_at_1
value: 53
- type: mrr_at_10
value: 61.102000000000004
- type: mrr_at_100
value: 61.476
- type: mrr_at_1000
value: 61.523
- type: mrr_at_3
value: 58.778
- type: mrr_at_5
value: 60.128
- type: ndcg_at_1
value: 53
- type: ndcg_at_10
value: 64.43100000000001
- type: ndcg_at_100
value: 66.73599999999999
- type: ndcg_at_1000
value: 68.027
- type: ndcg_at_3
value: 59.279
- type: ndcg_at_5
value: 61.888
- type: precision_at_1
value: 53
- type: precision_at_10
value: 8.767
- type: precision_at_100
value: 1.01
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 23.444000000000003
- type: precision_at_5
value: 15.667
- type: recall_at_1
value: 50.05
- type: recall_at_10
value: 78.511
- type: recall_at_100
value: 88.5
- type: recall_at_1000
value: 98.333
- type: recall_at_3
value: 64.117
- type: recall_at_5
value: 70.867
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.72178217821782
- type: cos_sim_ap
value: 93.0728601593541
- type: cos_sim_f1
value: 85.6727976766699
- type: cos_sim_precision
value: 83.02063789868667
- type: cos_sim_recall
value: 88.5
- type: dot_accuracy
value: 99.72178217821782
- type: dot_ap
value: 93.07287396168348
- type: dot_f1
value: 85.6727976766699
- type: dot_precision
value: 83.02063789868667
- type: dot_recall
value: 88.5
- type: euclidean_accuracy
value: 99.72178217821782
- type: euclidean_ap
value: 93.07285657982895
- type: euclidean_f1
value: 85.6727976766699
- type: euclidean_precision
value: 83.02063789868667
- type: euclidean_recall
value: 88.5
- type: manhattan_accuracy
value: 99.72475247524753
- type: manhattan_ap
value: 93.02792973059809
- type: manhattan_f1
value: 85.7727737973388
- type: manhattan_precision
value: 87.84067085953879
- type: manhattan_recall
value: 83.8
- type: max_accuracy
value: 99.72475247524753
- type: max_ap
value: 93.07287396168348
- type: max_f1
value: 85.7727737973388
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 68.77583615550819
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.151636938606956
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.16607939471187
- type: mrr
value: 52.95172046091163
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.314646669495666
- type: cos_sim_spearman
value: 31.83562491439455
- type: dot_pearson
value: 31.314590842874157
- type: dot_spearman
value: 31.83363065810437
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.198
- type: map_at_10
value: 1.3010000000000002
- type: map_at_100
value: 7.2139999999999995
- type: map_at_1000
value: 20.179
- type: map_at_3
value: 0.528
- type: map_at_5
value: 0.8019999999999999
- type: mrr_at_1
value: 72
- type: mrr_at_10
value: 83.39999999999999
- type: mrr_at_100
value: 83.39999999999999
- type: mrr_at_1000
value: 83.39999999999999
- type: mrr_at_3
value: 81.667
- type: mrr_at_5
value: 83.06700000000001
- type: ndcg_at_1
value: 66
- type: ndcg_at_10
value: 58.059000000000005
- type: ndcg_at_100
value: 44.316
- type: ndcg_at_1000
value: 43.147000000000006
- type: ndcg_at_3
value: 63.815999999999995
- type: ndcg_at_5
value: 63.005
- type: precision_at_1
value: 72
- type: precision_at_10
value: 61.4
- type: precision_at_100
value: 45.62
- type: precision_at_1000
value: 19.866
- type: precision_at_3
value: 70
- type: precision_at_5
value: 68.8
- type: recall_at_1
value: 0.198
- type: recall_at_10
value: 1.517
- type: recall_at_100
value: 10.587
- type: recall_at_1000
value: 41.233
- type: recall_at_3
value: 0.573
- type: recall_at_5
value: 0.907
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.894
- type: map_at_10
value: 8.488999999999999
- type: map_at_100
value: 14.445
- type: map_at_1000
value: 16.078
- type: map_at_3
value: 4.589
- type: map_at_5
value: 6.019
- type: mrr_at_1
value: 22.448999999999998
- type: mrr_at_10
value: 39.82
- type: mrr_at_100
value: 40.752
- type: mrr_at_1000
value: 40.771
- type: mrr_at_3
value: 34.354
- type: mrr_at_5
value: 37.721
- type: ndcg_at_1
value: 19.387999999999998
- type: ndcg_at_10
value: 21.563
- type: ndcg_at_100
value: 33.857
- type: ndcg_at_1000
value: 46.199
- type: ndcg_at_3
value: 22.296
- type: ndcg_at_5
value: 21.770999999999997
- type: precision_at_1
value: 22.448999999999998
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.142999999999999
- type: precision_at_1000
value: 1.541
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 22.448999999999998
- type: recall_at_1
value: 1.894
- type: recall_at_10
value: 14.931
- type: recall_at_100
value: 45.524
- type: recall_at_1000
value: 83.243
- type: recall_at_3
value: 5.712
- type: recall_at_5
value: 8.386000000000001
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.049
- type: ap
value: 13.85116971310922
- type: f1
value: 54.37504302487686
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 64.1312959818902
- type: f1
value: 64.11413877009383
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 54.13103431861502
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.327889372355
- type: cos_sim_ap
value: 77.42059895975699
- type: cos_sim_f1
value: 71.02706903250873
- type: cos_sim_precision
value: 69.75324344950394
- type: cos_sim_recall
value: 72.34828496042216
- type: dot_accuracy
value: 87.327889372355
- type: dot_ap
value: 77.4209479346677
- type: dot_f1
value: 71.02706903250873
- type: dot_precision
value: 69.75324344950394
- type: dot_recall
value: 72.34828496042216
- type: euclidean_accuracy
value: 87.327889372355
- type: euclidean_ap
value: 77.42096495861037
- type: euclidean_f1
value: 71.02706903250873
- type: euclidean_precision
value: 69.75324344950394
- type: euclidean_recall
value: 72.34828496042216
- type: manhattan_accuracy
value: 87.31000774870358
- type: manhattan_ap
value: 77.38930750711619
- type: manhattan_f1
value: 71.07935314027831
- type: manhattan_precision
value: 67.70957726295677
- type: manhattan_recall
value: 74.80211081794195
- type: max_accuracy
value: 87.327889372355
- type: max_ap
value: 77.42096495861037
- type: max_f1
value: 71.07935314027831
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.58939729110878
- type: cos_sim_ap
value: 87.17594155025475
- type: cos_sim_f1
value: 79.21146953405018
- type: cos_sim_precision
value: 76.8918527109307
- type: cos_sim_recall
value: 81.67539267015707
- type: dot_accuracy
value: 89.58939729110878
- type: dot_ap
value: 87.17593963273593
- type: dot_f1
value: 79.21146953405018
- type: dot_precision
value: 76.8918527109307
- type: dot_recall
value: 81.67539267015707
- type: euclidean_accuracy
value: 89.58939729110878
- type: euclidean_ap
value: 87.17592466925834
- type: euclidean_f1
value: 79.21146953405018
- type: euclidean_precision
value: 76.8918527109307
- type: euclidean_recall
value: 81.67539267015707
- type: manhattan_accuracy
value: 89.62626615438352
- type: manhattan_ap
value: 87.16589873161546
- type: manhattan_f1
value: 79.25143598295348
- type: manhattan_precision
value: 76.39494177323712
- type: manhattan_recall
value: 82.32984293193716
- type: max_accuracy
value: 89.62626615438352
- type: max_ap
value: 87.17594155025475
- type: max_f1
value: 79.25143598295348
---
# hkunlp/instructor-large
We introduce **Instructor**👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) ***by simply providing the task instruction, without any finetuning***. Instructor👨 achieves sota on 70 diverse embedding tasks ([MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard))!
The model is easy to use with **our customized** `sentence-transformer` library. For more details, check out [our paper](https://arxiv.org/abs/2212.09741) and [project page](https://instructor-embedding.github.io/)!
**************************** **Updates** ****************************
* 12/28: We released a new [checkpoint](https://huggingface.co/hkunlp/instructor-large) trained with hard negatives, which gives better performance.
* 12/21: We released our [paper](https://arxiv.org/abs/2212.09741), [code](https://github.com/HKUNLP/instructor-embedding), [checkpoint](https://huggingface.co/hkunlp/instructor-large) and [project page](https://instructor-embedding.github.io/)! Check them out!
## Quick start
<hr />
## Installation
```bash
pip install InstructorEmbedding
```
## Compute your customized embeddings
Then you can use the model like this to calculate domain-specific and task-aware embeddings:
```python
from InstructorEmbedding import INSTRUCTOR
model = INSTRUCTOR('hkunlp/instructor-large')
sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments"
instruction = "Represent the Science title:"
embeddings = model.encode([[instruction,sentence]])
print(embeddings)
```
## Use cases
<hr />
## Calculate embeddings for your customized texts
If you want to calculate customized embeddings for specific sentences, you may follow the unified template to write instructions:
Represent the `domain` `text_type` for `task_objective`:
* `domain` is optional, and it specifies the domain of the text, e.g., science, finance, medicine, etc.
* `text_type` is required, and it specifies the encoding unit, e.g., sentence, document, paragraph, etc.
* `task_objective` is optional, and it specifies the objective of embedding, e.g., retrieve a document, classify the sentence, etc.
## Calculate Sentence similarities
You can further use the model to compute similarities between two groups of sentences, with **customized embeddings**.
```python
from sklearn.metrics.pairwise import cosine_similarity
sentences_a = [['Represent the Science sentence: ','Parton energy loss in QCD matter'],
['Represent the Financial statement: ','The Federal Reserve on Wednesday raised its benchmark interest rate.']]
sentences_b = [['Represent the Science sentence: ','The Chiral Phase Transition in Dissipative Dynamics'],
['Represent the Financial statement: ','The funds rose less than 0.5 per cent on Friday']]
embeddings_a = model.encode(sentences_a)
embeddings_b = model.encode(sentences_b)
similarities = cosine_similarity(embeddings_a,embeddings_b)
print(similarities)
```
## Information Retrieval
You can also use **customized embeddings** for information retrieval.
```python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
query = [['Represent the Wikipedia question for retrieving supporting documents: ','where is the food stored in a yam plant']]
corpus = [['Represent the Wikipedia document for retrieval: ','Capitalism has been dominant in the Western world since the end of feudalism, but most feel[who?] that the term "mixed economies" more precisely describes most contemporary economies, due to their containing both private-owned and state-owned enterprises. In capitalism, prices determine the demand-supply scale. For example, higher demand for certain goods and services lead to higher prices and lower demand for certain goods lead to lower prices.'],
['Represent the Wikipedia document for retrieval: ',"The disparate impact theory is especially controversial under the Fair Housing Act because the Act regulates many activities relating to housing, insurance, and mortgage loans—and some scholars have argued that the theory's use under the Fair Housing Act, combined with extensions of the Community Reinvestment Act, contributed to rise of sub-prime lending and the crash of the U.S. housing market and ensuing global economic recession"],
['Represent the Wikipedia document for retrieval: ','Disparate impact in United States labor law refers to practices in employment, housing, and other areas that adversely affect one group of people of a protected characteristic more than another, even though rules applied by employers or landlords are formally neutral. Although the protected classes vary by statute, most federal civil rights laws protect based on race, color, religion, national origin, and sex as protected traits, and some laws include disability status and other traits as well.']]
query_embeddings = model.encode(query)
corpus_embeddings = model.encode(corpus)
similarities = cosine_similarity(query_embeddings,corpus_embeddings)
retrieved_doc_id = np.argmax(similarities)
print(retrieved_doc_id)
```
## Clustering
Use **customized embeddings** for clustering texts in groups.
```python
import sklearn.cluster
sentences = [['Represent the Medicine sentence for clustering: ','Dynamical Scalar Degree of Freedom in Horava-Lifshitz Gravity'],
['Represent the Medicine sentence for clustering: ','Comparison of Atmospheric Neutrino Flux Calculations at Low Energies'],
['Represent the Medicine sentence for clustering: ','Fermion Bags in the Massive Gross-Neveu Model'],
['Represent the Medicine sentence for clustering: ',"QCD corrections to Associated t-tbar-H production at the Tevatron"],
['Represent the Medicine sentence for clustering: ','A New Analysis of the R Measurements: Resonance Parameters of the Higher, Vector States of Charmonium']]
embeddings = model.encode(sentences)
clustering_model = sklearn.cluster.MiniBatchKMeans(n_clusters=2)
clustering_model.fit(embeddings)
cluster_assignment = clustering_model.labels_
print(cluster_assignment)
``` |
laion/larger_clap_general | laion | "2023-10-31T19:56:46Z" | 165,634 | 24 | transformers | [
"transformers",
"pytorch",
"clap",
"feature-extraction",
"arxiv:2211.06687",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2023-10-30T18:17:08Z" | ---
license: apache-2.0
---
# Model
## TL;DR
CLAP is to audio what CLIP is to image. This is an improved CLAP checkpoint, specifically trained on general audio, music and speech.
## Description
CLAP (Contrastive Language-Audio Pretraining) is a neural network trained on a variety of (audio, text) pairs. It can be instructed in to predict the most relevant text snippet, given an audio, without directly optimizing for the task. The CLAP model uses a SWINTransformer to get audio features from a log-Mel spectrogram input, and a RoBERTa model to get text features. Both the text and audio features are then projected to a latent space with identical dimension. The dot product between the projected audio and text features is then used as a similar score.
# Usage
You can use this model for zero shot audio classification or extracting audio and/or textual features.
# Uses
## Perform zero-shot audio classification
### Using `pipeline`
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("ashraq/esc50")
audio = dataset["train"]["audio"][-1]["array"]
audio_classifier = pipeline(task="zero-shot-audio-classification", model="laion/larger_clap_general")
output = audio_classifier(audio, candidate_labels=["Sound of a dog", "Sound of vaccum cleaner"])
print(output)
>>> [{"score": 0.999, "label": "Sound of a dog"}, {"score": 0.001, "label": "Sound of vaccum cleaner"}]
```
## Run the model:
You can also get the audio and text embeddings using `ClapModel`
### Run the model on CPU:
```python
from datasets import load_dataset
from transformers import ClapModel, ClapProcessor
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_sample = librispeech_dummy[0]
model = ClapModel.from_pretrained("laion/larger_clap_general")
processor = ClapProcessor.from_pretrained("laion/larger_clap_general")
inputs = processor(audios=audio_sample["audio"]["array"], return_tensors="pt")
audio_embed = model.get_audio_features(**inputs)
```
### Run the model on GPU:
```python
from datasets import load_dataset
from transformers import ClapModel, ClapProcessor
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_sample = librispeech_dummy[0]
model = ClapModel.from_pretrained("laion/larger_clap_general").to(0)
processor = ClapProcessor.from_pretrained("laion/larger_clap_general")
inputs = processor(audios=audio_sample["audio"]["array"], return_tensors="pt").to(0)
audio_embed = model.get_audio_features(**inputs)
```
# Citation
If you are using this model for your work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2211.06687,
doi = {10.48550/ARXIV.2211.06687},
url = {https://arxiv.org/abs/2211.06687},
author = {Wu, Yusong and Chen, Ke and Zhang, Tianyu and Hui, Yuchen and Berg-Kirkpatrick, Taylor and Dubnov, Shlomo},
keywords = {Sound (cs.SD), Audio and Speech Processing (eess.AS), FOS: Computer and information sciences, FOS: Computer and information sciences, FOS: Electrical engineering, electronic engineering, information engineering, FOS: Electrical engineering, electronic engineering, information engineering},
title = {Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
VAGOsolutions/SauerkrautLM-Mixtral-8x7B-Instruct | VAGOsolutions | "2024-04-29T22:56:24Z" | 165,351 | 21 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"mistral",
"finetune",
"dpo",
"Instruct",
"augmentation",
"german",
"moe",
"conversational",
"en",
"de",
"fr",
"it",
"es",
"dataset:argilla/distilabel-math-preference-dpo",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2023-12-15T16:01:09Z" | ---
license: apache-2.0
language:
- en
- de
- fr
- it
- es
library_name: transformers
pipeline_tag: text-generation
tags:
- mistral
- finetune
- dpo
- Instruct
- augmentation
- german
- mixtral
- moe
datasets:
- argilla/distilabel-math-preference-dpo
---

## VAGO solutions SauerkrautLM-Mixtral-8x7B-Instruct
Introducing **SauerkrautLM-Mixtral-8x7B-Instruct** – our Sauerkraut version of the powerful Mixtral-8x7B-Instruct!
Aligned with **DPO**
# Table of Contents
1. [Overview of all SauerkrautLM-Mixtral models](#all-sauerkrautlm-mixtral-models)
2. [Model Details](#model-details)
- [Prompt template](#prompt-template)
- [Training Dataset](#training-dataset)
- [Data Contamination Test](#data-contamination-test-results)
3. [Evaluation](#evaluation)
5. [Disclaimer](#disclaimer)
6. [Contact](#contact)
7. [Collaborations](#collaborations)
8. [Acknowledgement](#acknowledgement)
## All SauerkrautLM-Mixtral Models
| Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| SauerkrautLM-Mixtral-8x7B-Instruct | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-Mixtral-8x7B-Instruct) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-Mixtral-8x7B-Instruct-GPTQ) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-Mixtral-8x7B-Instruct-GGUF) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-Mixtral-8x7B-Instruct-AWQ) |
| SauerkrautLM-Mixtral-8x7B | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-Mixtral-8x7B) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-Mixtral-8x7B-GPTQ) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-Mixtral-8x7B-GGUF) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-Mixtral-8x7B-AWQ) |
## Model Details
**SauerkrautLM-Mixtral-8x7B-Instruct**
- **Model Type:** SauerkrautLM-Mixtral-8x7B-Instruct-v0.1 is a Mixture of Experts (MoE) Model based on [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
- **Language(s):** English, German, French, Italian, Spanish
- **License:** APACHE 2.0
- **Contact:** [Website](https://vago-solutions.de/#Kontakt) [David Golchinfar](mailto:golchinfar@vago-solutions.de)
### Training Dataset:
SauerkrautLM-Mixtral-8x7B-Instruct was trained with mix of German data augmentation and translated data.
Aligned through **DPO** with our **new German SauerkrautLM-DPO dataset** based on parts of the SFT SauerkrautLM dataset
as chosen answers and [Sauerkraut-7b-HerO](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-HerO) as rejected answers. Added with additional **translated Parts of the [HuggingFaceH4/ultrafeedback_binarized](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized)** (Our dataset do not contain any TruthfulQA prompts - check Data Contamination Test Results) and **[argilla/distilabel-math-preference-dpo](https://huggingface.co/datasets/argilla/distilabel-math-preference-dpo).**
We found, that only a simple translation of training data can lead to unnatural German phrasings.
Data augmentation techniques were used to grant grammatical, syntactical correctness and a more natural German wording in our training data.
### Data Contamination Test Results
Some models on the HuggingFace leaderboard had problems with wrong data getting mixed in.
We checked our SauerkrautLM-DPO dataset with a special test [1] on a smaller model for this problem.
The HuggingFace team used the same methods [2, 3].
Our results, with `result < 0.1, %:` being well below 0.9, indicate that our dataset is free from contamination.
*The data contamination test results of HellaSwag and Winograde will be added once [1] supports them.*
| Dataset | ARC | MMLU | TruthfulQA | GSM8K |
|------------------------------|-------|-------|-------|-------|
| **SauerkrautLM-DPO**| result < 0.1, %: 0.0 |result < 0.1, %: 0.09 | result < 0.1, %: 0.13 | result < 0.1, %: 0.16 |
[1] https://github.com/swj0419/detect-pretrain-code-contamination
[2] https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard/discussions/474#657f2245365456e362412a06
[3] https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard/discussions/265#657b6debf81f6b44b8966230
### Prompt Template:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
## Evaluation

*evaluated with lm-evaluation-harness v0.3.0 - mmlu coming soon
*All benchmarks were performed with a sliding window of 4096. New Benchmarks with Sliding Window null coming soon
**German RAG LLM Evaluation**
corrected result after FIX: https://github.com/huggingface/lighteval/pull/171
```
| Task |Version|Metric|Value| |Stderr|
|------------------------------------------------------|------:|------|----:|---|-----:|
|all | |acc |0.975|± |0.0045|
|community:german_rag_eval:_average:0 | |acc |0.975|± |0.0045|
|community:german_rag_eval:choose_context_by_question:0| 0|acc |0.953|± |0.0067|
|community:german_rag_eval:choose_question_by_context:0| 0|acc |0.998|± |0.0014|
|community:german_rag_eval:context_question_match:0 | 0|acc |0.975|± |0.0049|
|community:german_rag_eval:question_answer_match:0 | 0|acc |0.974|± |0.0050|
```
## Disclaimer
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models. These models may be employed for commercial purposes, and the Apache 2.0 remains applicable and is included with the model files.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our website or contact us at [Dr. Daryoush Vaziri](mailto:vaziri@vago-solutions.de). We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startup, VAGO solutions, where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us.
## Acknowledgement
Many thanks to [argilla](https://huggingface.co/datasets/argilla) and [Huggingface](https://huggingface.co) for providing such valuable datasets to the Open-Source community. And of course a big thanks to MistralAI for providing the open source community with their latest technology! |
cointegrated/rubert-base-cased-nli-threeway | cointegrated | "2024-04-05T09:31:57Z" | 164,933 | 23 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"bert",
"text-classification",
"rubert",
"russian",
"nli",
"rte",
"zero-shot-classification",
"ru",
"dataset:cointegrated/nli-rus-translated-v2021",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | "2022-03-02T23:29:05Z" | ---
language: ru
pipeline_tag: zero-shot-classification
tags:
- rubert
- russian
- nli
- rte
- zero-shot-classification
widget:
- text: "Я хочу поехать в Австралию"
candidate_labels: "спорт,путешествия,музыка,кино,книги,наука,политика"
hypothesis_template: "Тема текста - {}."
datasets:
- cointegrated/nli-rus-translated-v2021
---
# RuBERT for NLI (natural language inference)
This is the [DeepPavlov/rubert-base-cased](https://huggingface.co/DeepPavlov/rubert-base-cased) fine-tuned to predict the logical relationship between two short texts: entailment, contradiction, or neutral.
## Usage
How to run the model for NLI:
```python
# !pip install transformers sentencepiece --quiet
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_checkpoint = 'cointegrated/rubert-base-cased-nli-threeway'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
model.cuda()
text1 = 'Сократ - человек, а все люди смертны.'
text2 = 'Сократ никогда не умрёт.'
with torch.inference_mode():
out = model(**tokenizer(text1, text2, return_tensors='pt').to(model.device))
proba = torch.softmax(out.logits, -1).cpu().numpy()[0]
print({v: proba[k] for k, v in model.config.id2label.items()})
# {'entailment': 0.009525929, 'contradiction': 0.9332064, 'neutral': 0.05726764}
```
You can also use this model for zero-shot short text classification (by labels only), e.g. for sentiment analysis:
```python
def predict_zero_shot(text, label_texts, model, tokenizer, label='entailment', normalize=True):
label_texts
tokens = tokenizer([text] * len(label_texts), label_texts, truncation=True, return_tensors='pt', padding=True)
with torch.inference_mode():
result = torch.softmax(model(**tokens.to(model.device)).logits, -1)
proba = result[:, model.config.label2id[label]].cpu().numpy()
if normalize:
proba /= sum(proba)
return proba
classes = ['Я доволен', 'Я недоволен']
predict_zero_shot('Какая гадость эта ваша заливная рыба!', classes, model, tokenizer)
# array([0.05609814, 0.9439019 ], dtype=float32)
predict_zero_shot('Какая вкусная эта ваша заливная рыба!', classes, model, tokenizer)
# array([0.9059292 , 0.09407079], dtype=float32)
```
Alternatively, you can use [Huggingface pipelines](https://huggingface.co/transformers/main_classes/pipelines.html) for inference.
## Sources
The model has been trained on a series of NLI datasets automatically translated to Russian from English.
Most datasets were taken [from the repo of Felipe Salvatore](https://github.com/felipessalvatore/NLI_datasets):
[JOCI](https://github.com/sheng-z/JOCI),
[MNLI](https://cims.nyu.edu/~sbowman/multinli/),
[MPE](https://aclanthology.org/I17-1011/),
[SICK](http://www.lrec-conf.org/proceedings/lrec2014/pdf/363_Paper.pdf),
[SNLI](https://nlp.stanford.edu/projects/snli/).
Some datasets obtained from the original sources:
[ANLI](https://github.com/facebookresearch/anli),
[NLI-style FEVER](https://github.com/easonnie/combine-FEVER-NSMN/blob/master/other_resources/nli_fever.md),
[IMPPRES](https://github.com/facebookresearch/Imppres).
## Performance
The table below shows ROC AUC (one class vs rest) for five models on the corresponding *dev* sets:
- [tiny](https://huggingface.co/cointegrated/rubert-tiny-bilingual-nli): a small BERT predicting entailment vs not_entailment
- [twoway](https://huggingface.co/cointegrated/rubert-base-cased-nli-twoway): a base-sized BERT predicting entailment vs not_entailment
- [threeway](https://huggingface.co/cointegrated/rubert-base-cased-nli-threeway) (**this model**): a base-sized BERT predicting entailment vs contradiction vs neutral
- [vicgalle-xlm](https://huggingface.co/vicgalle/xlm-roberta-large-xnli-anli): a large multilingual NLI model
- [facebook-bart](https://huggingface.co/facebook/bart-large-mnli): a large multilingual NLI model
|model |add_one_rte|anli_r1|anli_r2|anli_r3|copa|fever|help|iie |imppres|joci|mnli |monli|mpe |scitail|sick|snli|terra|total |
|------------------------|-----------|-------|-------|-------|----|-----|----|-----|-------|----|-----|-----|----|-------|----|----|-----|------|
|n_observations |387 |1000 |1000 |1200 |200 |20474|3355|31232|7661 |939 |19647|269 |1000|2126 |500 |9831|307 |101128|
|tiny/entailment |0.77 |0.59 |0.52 |0.53 |0.53|0.90 |0.81|0.78 |0.93 |0.81|0.82 |0.91 |0.81|0.78 |0.93|0.95|0.67 |0.77 |
|twoway/entailment |0.89 |0.73 |0.61 |0.62 |0.58|0.96 |0.92|0.87 |0.99 |0.90|0.90 |0.99 |0.91|0.96 |0.97|0.97|0.87 |0.86 |
|threeway/entailment |0.91 |0.75 |0.61 |0.61 |0.57|0.96 |0.56|0.61 |0.99 |0.90|0.91 |0.67 |0.92|0.84 |0.98|0.98|0.90 |0.80 |
|vicgalle-xlm/entailment |0.88 |0.79 |0.63 |0.66 |0.57|0.93 |0.56|0.62 |0.77 |0.80|0.90 |0.70 |0.83|0.84 |0.91|0.93|0.93 |0.78 |
|facebook-bart/entailment|0.51 |0.41 |0.43 |0.47 |0.50|0.74 |0.55|0.57 |0.60 |0.63|0.70 |0.52 |0.56|0.68 |0.67|0.72|0.64 |0.58 |
|threeway/contradiction | |0.71 |0.64 |0.61 | |0.97 | | |1.00 |0.77|0.92 | |0.89| |0.99|0.98| |0.85 |
|threeway/neutral | |0.79 |0.70 |0.62 | |0.91 | | |0.99 |0.68|0.86 | |0.79| |0.96|0.96| |0.83 |
For evaluation (and for training of the [tiny](https://huggingface.co/cointegrated/rubert-tiny-bilingual-nli) and [twoway](https://huggingface.co/cointegrated/rubert-base-cased-nli-twoway) models), some extra datasets were used:
[Add-one RTE](https://cs.brown.edu/people/epavlick/papers/ans.pdf),
[CoPA](https://people.ict.usc.edu/~gordon/copa.html),
[IIE](https://aclanthology.org/I17-1100), and
[SCITAIL](https://allenai.org/data/scitail) taken from [the repo of Felipe Salvatore](https://github.com/felipessalvatore/NLI_datasets) and translatted,
[HELP](https://github.com/verypluming/HELP) and [MoNLI](https://github.com/atticusg/MoNLI) taken from the original sources and translated,
and Russian [TERRa](https://russiansuperglue.com/ru/tasks/task_info/TERRa).
|
google/owlv2-base-patch16-ensemble | google | "2024-04-15T16:59:29Z" | 164,491 | 46 | transformers | [
"transformers",
"pytorch",
"safetensors",
"owlv2",
"zero-shot-object-detection",
"vision",
"arxiv:2306.09683",
"license:apache-2.0",
"region:us"
] | zero-shot-object-detection | "2023-10-13T09:27:09Z" | ---
license: apache-2.0
tags:
- vision
- zero-shot-object-detection
inference: false
---
# Model Card: OWLv2
## Model Details
The OWLv2 model (short for Open-World Localization) was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2, like OWL-ViT, is a zero-shot text-conditioned object detection model that can be used to query an image with one or multiple text queries.
The model uses CLIP as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
### Model Date
June 2023
### Model Type
The model uses a CLIP backbone with a ViT-B/16 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss. The CLIP backbone is trained from scratch and fine-tuned together with the box and class prediction heads with an object detection objective.
### Documents
- [OWLv2 Paper](https://arxiv.org/abs/2306.09683)
### Use with Transformers
```python
import requests
from PIL import Image
import numpy as np
import torch
from transformers import AutoProcessor, Owlv2ForObjectDetection
from transformers.utils.constants import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = [["a photo of a cat", "a photo of a dog"]]
inputs = processor(text=texts, images=image, return_tensors="pt")
# forward pass
with torch.no_grad():
outputs = model(**inputs)
# Note: boxes need to be visualized on the padded, unnormalized image
# hence we'll set the target image sizes (height, width) based on that
def get_preprocessed_image(pixel_values):
pixel_values = pixel_values.squeeze().numpy()
unnormalized_image = (pixel_values * np.array(OPENAI_CLIP_STD)[:, None, None]) + np.array(OPENAI_CLIP_MEAN)[:, None, None]
unnormalized_image = (unnormalized_image * 255).astype(np.uint8)
unnormalized_image = np.moveaxis(unnormalized_image, 0, -1)
unnormalized_image = Image.fromarray(unnormalized_image)
return unnormalized_image
unnormalized_image = get_preprocessed_image(inputs.pixel_values)
target_sizes = torch.Tensor([unnormalized_image.size[::-1]])
# Convert outputs (bounding boxes and class logits) to final bounding boxes and scores
results = processor.post_process_object_detection(
outputs=outputs, threshold=0.2, target_sizes=target_sizes
)
i = 0 # Retrieve predictions for the first image for the corresponding text queries
text = texts[i]
boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
for box, score, label in zip(boxes, scores, labels):
box = [round(i, 2) for i in box.tolist()]
print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, text-conditioned object detection. We also hope it can be used for interdisciplinary studies of the potential impact of such models, especially in areas that commonly require identifying objects whose label is unavailable during training.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
## Data
The CLIP backbone of the model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet. The prediction heads of OWL-ViT, along with the CLIP backbone, are fine-tuned on publicly available object detection datasets such as [COCO](https://cocodataset.org/#home) and [OpenImages](https://storage.googleapis.com/openimages/web/index.html).
(to be updated for v2)
### BibTeX entry and citation info
```bibtex
@misc{minderer2023scaling,
title={Scaling Open-Vocabulary Object Detection},
author={Matthias Minderer and Alexey Gritsenko and Neil Houlsby},
year={2023},
eprint={2306.09683},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
sentence-transformers/paraphrase-distilroberta-base-v1 | sentence-transformers | "2024-03-27T12:16:40Z" | 164,470 | 6 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/paraphrase-distilroberta-base-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-distilroberta-base-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-distilroberta-base-v1')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-distilroberta-base-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-distilroberta-base-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
stabilityai/sd-vae-ft-mse | stabilityai | "2023-06-06T11:39:15Z" | 164,252 | 311 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:mit",
"region:us"
] | null | "2022-10-13T12:50:55Z" | ---
license: mit
tags:
- stable-diffusion
- stable-diffusion-diffusers
inference: false
---
# Improved Autoencoders
## Utilizing
These weights are intended to be used with the [🧨 diffusers library](https://github.com/huggingface/diffusers). If you are looking for the model to use with the original [CompVis Stable Diffusion codebase](https://github.com/CompVis/stable-diffusion), [come here](https://huggingface.co/stabilityai/sd-vae-ft-mse-original).
#### How to use with 🧨 diffusers
You can integrate this fine-tuned VAE decoder to your existing `diffusers` workflows, by including a `vae` argument to the `StableDiffusionPipeline`
```py
from diffusers.models import AutoencoderKL
from diffusers import StableDiffusionPipeline
model = "CompVis/stable-diffusion-v1-4"
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse")
pipe = StableDiffusionPipeline.from_pretrained(model, vae=vae)
```
## Decoder Finetuning
We publish two kl-f8 autoencoder versions, finetuned from the original [kl-f8 autoencoder](https://github.com/CompVis/latent-diffusion#pretrained-autoencoding-models) on a 1:1 ratio of [LAION-Aesthetics](https://laion.ai/blog/laion-aesthetics/) and LAION-Humans, an unreleased subset containing only SFW images of humans. The intent was to fine-tune on the Stable Diffusion training set (the autoencoder was originally trained on OpenImages) but also enrich the dataset with images of humans to improve the reconstruction of faces.
The first, _ft-EMA_, was resumed from the original checkpoint, trained for 313198 steps and uses EMA weights. It uses the same loss configuration as the original checkpoint (L1 + LPIPS).
The second, _ft-MSE_, was resumed from _ft-EMA_ and uses EMA weights and was trained for another 280k steps using a different loss, with more emphasis
on MSE reconstruction (MSE + 0.1 * LPIPS). It produces somewhat ``smoother'' outputs. The batch size for both versions was 192 (16 A100s, batch size 12 per GPU).
To keep compatibility with existing models, only the decoder part was finetuned; the checkpoints can be used as a drop-in replacement for the existing autoencoder.
_Original kl-f8 VAE vs f8-ft-EMA vs f8-ft-MSE_
## Evaluation
### COCO 2017 (256x256, val, 5000 images)
| Model | train steps | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|---------|------|--------------|---------------|---------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | | |
| original | 246803 | 4.99 | 23.4 +/- 3.8 | 0.69 +/- 0.14 | 1.01 +/- 0.28 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-EMA | 560001 | 4.42 | 23.8 +/- 3.9 | 0.69 +/- 0.13 | 0.96 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt | slightly better overall, with EMA |
| ft-MSE | 840001 | 4.70 | 24.5 +/- 3.7 | 0.71 +/- 0.13 | 0.92 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
### LAION-Aesthetics 5+ (256x256, subset, 10000 images)
| Model | train steps | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|-----------|------|--------------|---------------|---------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | | |
| original | 246803 | 2.61 | 26.0 +/- 4.4 | 0.81 +/- 0.12 | 0.75 +/- 0.36 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-EMA | 560001 | 1.77 | 26.7 +/- 4.8 | 0.82 +/- 0.12 | 0.67 +/- 0.34 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt | slightly better overall, with EMA |
| ft-MSE | 840001 | 1.88 | 27.3 +/- 4.7 | 0.83 +/- 0.11 | 0.65 +/- 0.34 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
### Visual
_Visualization of reconstructions on 256x256 images from the COCO2017 validation dataset._
<p align="center">
<br>
<b>
256x256: ft-EMA (left), ft-MSE (middle), original (right)</b>
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00025_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00011_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00037_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00043_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00053_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00029_merged.png />
</p>
|
Davlan/bert-base-multilingual-cased-ner-hrl | Davlan | "2023-11-09T02:34:23Z" | 164,203 | 61 | transformers | [
"transformers",
"pytorch",
"tf",
"onnx",
"bert",
"token-classification",
"license:afl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:04Z" | ---
license: afl-3.0
---
Hugging Face's logo
---
language:
- ar
- de
- en
- es
- fr
- it
- lv
- nl
- pt
- zh
- multilingual
---
# bert-base-multilingual-cased-ner-hrl
## Model description
**bert-base-multilingual-cased-ner-hrl** is a **Named Entity Recognition** model for 10 high resourced languages (Arabic, German, English, Spanish, French, Italian, Latvian, Dutch, Portuguese and Chinese) based on a fine-tuned mBERT base model. It has been trained to recognize three types of entities: location (LOC), organizations (ORG), and person (PER).
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on an aggregation of 10 high-resourced languages
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Davlan/bert-base-multilingual-cased-ner-hrl")
model = AutoModelForTokenClassification.from_pretrained("Davlan/bert-base-multilingual-cased-ner-hrl")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Nader Jokhadar had given Syria the lead with a well-struck header in the seventh minute."
ner_results = nlp(example)
print(ner_results)
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
The training data for the 10 languages are from:
Language|Dataset
-|-
Arabic | [ANERcorp](https://camel.abudhabi.nyu.edu/anercorp/)
German | [conll 2003](https://www.clips.uantwerpen.be/conll2003/ner/)
English | [conll 2003](https://www.clips.uantwerpen.be/conll2003/ner/)
Spanish | [conll 2002](https://www.clips.uantwerpen.be/conll2002/ner/)
French | [Europeana Newspapers](https://github.com/EuropeanaNewspapers/ner-corpora/tree/master/enp_FR.bnf.bio)
Italian | [Italian I-CAB](https://ontotext.fbk.eu/icab.html)
Latvian | [Latvian NER](https://github.com/LUMII-AILab/FullStack/tree/master/NamedEntities)
Dutch | [conll 2002](https://www.clips.uantwerpen.be/conll2002/ner/)
Portuguese |[Paramopama + Second Harem](https://github.com/davidsbatista/NER-datasets/tree/master/Portuguese)
Chinese | [MSRA](https://huggingface.co/datasets/msra_ner)
The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
-|-
O|Outside of a named entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
## Training procedure
This model was trained on NVIDIA V100 GPU with recommended hyperparameters from HuggingFace code. |
prompthero/openjourney-v4 | prompthero | "2023-05-15T22:41:59Z" | 163,313 | 1,207 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2022-12-11T17:37:55Z" | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
pinned: true
---
# <u>Openjourney v4</u>
## Trained on +124k Midjourney v4 images, by [PromptHero](https://prompthero.com/?utm_source=huggingface&utm_medium=referral)
Trained on Stable Diffusion v1.5 using +124000 images, 12400 steps, 4 epochs +32 training hours.
💡 [Openjourney-v4 prompts](https://prompthero.com/openjourney-prompts?version=4)
Pss... "mdjrny-v4 style" is not necessary anymore (yay!)
🎓 **Want to learn how to train Openjourney? 👉🏼 __[Join our course](https://prompthero.com/academy/dreambooth-stable-diffusion-train-fine-tune-course?utm_source=huggingface&utm_medium=referral)__ 🔥**
<img src="https://s3.us-east-1.amazonaws.com/prompthero-newsletter/Group-66.png" alt="openjourney-v4" width="50%">
# Openjourney Links
- [Lora version](https://huggingface.co/prompthero/openjourney-lora)
- [Openjourney Dreambooth](https://huggingface.co/prompthero/openjourney) |
siebert/sentiment-roberta-large-english | siebert | "2024-06-11T16:40:11Z" | 162,157 | 109 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"sentiment",
"twitter",
"reviews",
"siebert",
"en",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: "en"
tags:
- sentiment
- twitter
- reviews
- siebert
---
## SiEBERT - English-Language Sentiment Classification
# Overview
This model ("SiEBERT", prefix for "Sentiment in English") is a fine-tuned checkpoint of [RoBERTa-large](https://huggingface.co/roberta-large) ([Liu et al. 2019](https://arxiv.org/pdf/1907.11692.pdf)). It enables reliable binary sentiment analysis for various types of English-language text. For each instance, it predicts either positive (1) or negative (0) sentiment. The model was fine-tuned and evaluated on 15 data sets from diverse text sources to enhance generalization across different types of texts (reviews, tweets, etc.). Consequently, it outperforms models trained on only one type of text (e.g., movie reviews from the popular SST-2 benchmark) when used on new data as shown below.
# Predictions on a data set
If you want to predict sentiment for your own data, we provide an example script via [Google Colab](https://colab.research.google.com/notebooks/intro.ipynb). You can load your data to a Google Drive and run the script for free on a Colab GPU. Set-up only takes a few minutes. We suggest that you manually label a subset of your data to evaluate performance for your use case. For performance benchmark values across various sentiment analysis contexts, please refer to our paper ([Hartmann et al. 2023](https://www.sciencedirect.com/science/article/pii/S0167811622000477?via%3Dihub)).
[](https://colab.research.google.com/github/chrsiebert/sentiment-roberta-large-english/blob/main/sentiment_roberta_prediction_example.ipynb)
# Use in a Hugging Face pipeline
The easiest way to use the model for single predictions is Hugging Face's [sentiment analysis pipeline](https://huggingface.co/transformers/quicktour.html#getting-started-on-a-task-with-a-pipeline), which only needs a couple lines of code as shown in the following example:
```
from transformers import pipeline
sentiment_analysis = pipeline("sentiment-analysis",model="siebert/sentiment-roberta-large-english")
print(sentiment_analysis("I love this!"))
```
[](https://colab.research.google.com/github/chrsiebert/sentiment-roberta-large-english/blob/main/sentiment_roberta_pipeline.ipynb)
# Use for further fine-tuning
The model can also be used as a starting point for further fine-tuning of RoBERTa on your specific data. Please refer to Hugging Face's [documentation](https://huggingface.co/docs/transformers/training) for further details and example code.
# Performance
To evaluate the performance of our general-purpose sentiment analysis model, we set aside an evaluation set from each data set, which was not used for training. On average, our model outperforms a [DistilBERT-based model](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) (which is solely fine-tuned on the popular SST-2 data set) by more than 15 percentage points (78.1 vs. 93.2 percent, see table below). As a robustness check, we evaluate the model in a leave-one-out manner (training on 14 data sets, evaluating on the one left out), which decreases model performance by only about 3 percentage points on average and underscores its generalizability. Model performance is given as evaluation set accuracy in percent.
|Dataset|DistilBERT SST-2|This model|
|---|---|---|
|McAuley and Leskovec (2013) (Reviews)|84.7|98.0|
|McAuley and Leskovec (2013) (Review Titles)|65.5|87.0|
|Yelp Academic Dataset|84.8|96.5|
|Maas et al. (2011)|80.6|96.0|
|Kaggle|87.2|96.0|
|Pang and Lee (2005)|89.7|91.0|
|Nakov et al. (2013)|70.1|88.5|
|Shamma (2009)|76.0|87.0|
|Blitzer et al. (2007) (Books)|83.0|92.5|
|Blitzer et al. (2007) (DVDs)|84.5|92.5|
|Blitzer et al. (2007) (Electronics)|74.5|95.0|
|Blitzer et al. (2007) (Kitchen devices)|80.0|98.5|
|Pang et al. (2002)|73.5|95.5|
|Speriosu et al. (2011)|71.5|85.5|
|Hartmann et al. (2019)|65.5|98.0|
|**Average**|**78.1**|**93.2**|
# Fine-tuning hyperparameters
- learning_rate = 2e-5
- num_train_epochs = 3.0
- warmump_steps = 500
- weight_decay = 0.01
Other values were left at their defaults as listed [here](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments).
# Citation and contact
Please cite [this paper](https://www.sciencedirect.com/science/article/pii/S0167811622000477) (Published in the [IJRM](https://www.journals.elsevier.com/international-journal-of-research-in-marketing)) when you use our model. Feel free to reach out to [christian.siebert@uni-hamburg.de](mailto:christian.siebert@uni-hamburg.de) with any questions or feedback you may have.
```
@article{hartmann2023,
title = {More than a Feeling: Accuracy and Application of Sentiment Analysis},
journal = {International Journal of Research in Marketing},
volume = {40},
number = {1},
pages = {75-87},
year = {2023},
doi = {https://doi.org/10.1016/j.ijresmar.2022.05.005},
url = {https://www.sciencedirect.com/science/article/pii/S0167811622000477},
author = {Jochen Hartmann and Mark Heitmann and Christian Siebert and Christina Schamp},
}
```
|
monologg/koelectra-small-v2-distilled-korquad-384 | monologg | "2023-06-12T12:30:35Z" | 161,643 | 3 | transformers | [
"transformers",
"pytorch",
"tflite",
"safetensors",
"electra",
"question-answering",
"endpoints_compatible",
"region:us"
] | question-answering | "2022-03-02T23:29:05Z" | Entry not found |
Systran/faster-whisper-base | Systran | "2023-11-23T11:02:28Z" | 160,935 | 6 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"license:mit",
"region:us"
] | automatic-speech-recognition | "2023-11-23T09:52:40Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper base model for CTranslate2
This repository contains the conversion of [openai/whisper-base](https://huggingface.co/openai/whisper-base) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("base")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-base --output_dir faster-whisper-base \
--copy_files tokenizer.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-base).**
|
facebook/esm2_t33_650M_UR50D | facebook | "2023-03-21T15:05:12Z" | 160,710 | 22 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"esm",
"fill-mask",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-09-27T14:36:16Z" | ---
license: mit
widget:
- text: "MQIFVKTLTGKTITLEVEPS<mask>TIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGG"
---
## ESM-2
ESM-2 is a state-of-the-art protein model trained on a masked language modelling objective. It is suitable for fine-tuning on a wide range of tasks that take protein sequences as input. For detailed information on the model architecture and training data, please refer to the [accompanying paper](https://www.biorxiv.org/content/10.1101/2022.07.20.500902v2). You may also be interested in some demo notebooks ([PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb), [TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb)) which demonstrate how to fine-tune ESM-2 models on your tasks of interest.
Several ESM-2 checkpoints are available in the Hub with varying sizes. Larger sizes generally have somewhat better accuracy, but require much more memory and time to train:
| Checkpoint name | Num layers | Num parameters |
|------------------------------|----|----------|
| [esm2_t48_15B_UR50D](https://huggingface.co/facebook/esm2_t48_15B_UR50D) | 48 | 15B |
| [esm2_t36_3B_UR50D](https://huggingface.co/facebook/esm2_t36_3B_UR50D) | 36 | 3B |
| [esm2_t33_650M_UR50D](https://huggingface.co/facebook/esm2_t33_650M_UR50D) | 33 | 650M |
| [esm2_t30_150M_UR50D](https://huggingface.co/facebook/esm2_t30_150M_UR50D) | 30 | 150M |
| [esm2_t12_35M_UR50D](https://huggingface.co/facebook/esm2_t12_35M_UR50D) | 12 | 35M |
| [esm2_t6_8M_UR50D](https://huggingface.co/facebook/esm2_t6_8M_UR50D) | 6 | 8M | |
dslim/bert-large-NER | dslim | "2024-01-26T03:34:53Z" | 160,593 | 131 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"onnx",
"safetensors",
"bert",
"token-classification",
"en",
"dataset:conll2003",
"arxiv:1810.04805",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
language: en
datasets:
- conll2003
license: mit
model-index:
- name: dslim/bert-large-NER
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.9031688753722759
verified: true
- name: Precision
type: precision
value: 0.920025068328604
verified: true
- name: Recall
type: recall
value: 0.9193688678588825
verified: true
- name: F1
type: f1
value: 0.9196968510445761
verified: true
- name: loss
type: loss
value: 0.5085050463676453
verified: true
---
# bert-large-NER
## Model description
**bert-large-NER** is a fine-tuned BERT model that is ready to use for **Named Entity Recognition** and achieves **state-of-the-art performance** for the NER task. It has been trained to recognize four types of entities: location (LOC), organizations (ORG), person (PER) and Miscellaneous (MISC).
Specifically, this model is a *bert-large-cased* model that was fine-tuned on the English version of the standard [CoNLL-2003 Named Entity Recognition](https://www.aclweb.org/anthology/W03-0419.pdf) dataset.
If you'd like to use a smaller BERT model fine-tuned on the same dataset, a [**bert-base-NER**](https://huggingface.co/dslim/bert-base-NER/) version is also available.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-large-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-large-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains. Furthermore, the model occassionally tags subword tokens as entities and post-processing of results may be necessary to handle those cases.
## Training data
This model was fine-tuned on English version of the standard [CoNLL-2003 Named Entity Recognition](https://www.aclweb.org/anthology/W03-0419.pdf) dataset.
The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
-|-
O|Outside of a named entity
B-MIS |Beginning of a miscellaneous entity right after another miscellaneous entity
I-MIS | Miscellaneous entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organization right after another organization
I-ORG |organization
B-LOC |Beginning of a location right after another location
I-LOC |Location
### CoNLL-2003 English Dataset Statistics
This dataset was derived from the Reuters corpus which consists of Reuters news stories. You can read more about how this dataset was created in the CoNLL-2003 paper.
#### # of training examples per entity type
Dataset|LOC|MISC|ORG|PER
-|-|-|-|-
Train|7140|3438|6321|6600
Dev|1837|922|1341|1842
Test|1668|702|1661|1617
#### # of articles/sentences/tokens per dataset
Dataset |Articles |Sentences |Tokens
-|-|-|-
Train |946 |14,987 |203,621
Dev |216 |3,466 |51,362
Test |231 |3,684 |46,435
## Training procedure
This model was trained on a single NVIDIA V100 GPU with recommended hyperparameters from the [original BERT paper](https://arxiv.org/pdf/1810.04805) which trained & evaluated the model on CoNLL-2003 NER task.
## Eval results
metric|dev|test
-|-|-
f1 |95.7 |91.7
precision |95.3 |91.2
recall |96.1 |92.3
The test metrics are a little lower than the official Google BERT results which encoded document context & experimented with CRF. More on replicating the original results [here](https://github.com/google-research/bert/issues/223).
### BibTeX entry and citation info
```
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```
@inproceedings{tjong-kim-sang-de-meulder-2003-introduction,
title = "Introduction to the {C}o{NLL}-2003 Shared Task: Language-Independent Named Entity Recognition",
author = "Tjong Kim Sang, Erik F. and
De Meulder, Fien",
booktitle = "Proceedings of the Seventh Conference on Natural Language Learning at {HLT}-{NAACL} 2003",
year = "2003",
url = "https://www.aclweb.org/anthology/W03-0419",
pages = "142--147",
}
```
|
Qwen/Qwen2-7B-Instruct | Qwen | "2024-06-06T14:42:03Z" | 160,222 | 349 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"conversational",
"en",
"arxiv:2309.00071",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2024-06-04T10:07:03Z" | ---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen2-7B-Instruct
## Introduction
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the instruction-tuned 7B Qwen2 model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
Qwen2-7B-Instruct supports a context length of up to 131,072 tokens, enabling the processing of extensive inputs. Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2 for handling long texts.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).
<br>
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
The code of Qwen2 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Long Texts
To handle extensive inputs exceeding 32,768 tokens, we utilize [YARN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For deployment, we recommend using vLLM. You can enable the long-context capabilities by following these steps:
1. **Install vLLM**: You can install vLLM by running the following command.
```bash
pip install "vllm>=0.4.3"
```
Or you can install vLLM from [source](https://github.com/vllm-project/vllm/).
2. **Configure Model Settings**: After downloading the model weights, modify the `config.json` file by including the below snippet:
```json
{
"architectures": [
"Qwen2ForCausalLM"
],
// ...
"vocab_size": 152064,
// adding the following snippets
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
This snippet enable YARN to support longer contexts.
3. **Model Deployment**: Utilize vLLM to deploy your model. For instance, you can set up an openAI-like server using the command:
```bash
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-7B-Instruct --model path/to/weights
```
Then you can access the Chat API by:
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your Long Input Here."}
]
}'
```
For further usage instructions of vLLM, please refer to our [Github](https://github.com/QwenLM/Qwen2).
**Note**: Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**. We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation
We briefly compare Qwen2-7B-Instruct with similar-sized instruction-tuned LLMs, including Qwen1.5-7B-Chat. The results are shown below:
| Datasets | Llama-3-8B-Instruct | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen1.5-7B-Chat | Qwen2-7B-Instruct |
| :--- | :---: | :---: | :---: | :---: | :---: |
| _**English**_ | | | | | |
| MMLU | 68.4 | 69.5 | **72.4** | 59.5 | 70.5 |
| MMLU-Pro | 41.0 | - | - | 29.1 | **44.1** |
| GPQA | **34.2** | - | **-** | 27.8 | 25.3 |
| TheroemQA | 23.0 | - | - | 14.1 | **25.3** |
| MT-Bench | 8.05 | 8.20 | 8.35 | 7.60 | **8.41** |
| _**Coding**_ | | | | | |
| Humaneval | 62.2 | 66.5 | 71.8 | 46.3 | **79.9** |
| MBPP | **67.9** | - | - | 48.9 | 67.2 |
| MultiPL-E | 48.5 | - | - | 27.2 | **59.1** |
| Evalplus | 60.9 | - | - | 44.8 | **70.3** |
| LiveCodeBench | 17.3 | - | - | 6.0 | **26.6** |
| _**Mathematics**_ | | | | | |
| GSM8K | 79.6 | **84.8** | 79.6 | 60.3 | 82.3 |
| MATH | 30.0 | 47.7 | **50.6** | 23.2 | 49.6 |
| _**Chinese**_ | | | | | |
| C-Eval | 45.9 | - | 75.6 | 67.3 | **77.2** |
| AlignBench | 6.20 | 6.90 | 7.01 | 6.20 | **7.21** |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
``` |
vikp/surya_layout2 | vikp | "2024-04-22T16:09:04Z" | 159,129 | 1 | transformers | [
"transformers",
"safetensors",
"segformer",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | "2024-04-16T17:03:15Z" | ---
license: cc-by-nc-sa-4.0
---
Layout model for [surya](https://github.com/VikParuchuri/surya). |
beogradjanka/bart_finetuned_keyphrase_extraction | beogradjanka | "2024-04-03T14:59:43Z" | 159,014 | 9 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:midas/krapivin",
"dataset:midas/inspec",
"dataset:midas/kptimes",
"dataset:midas/duc2001",
"arxiv:1910.13461",
"arxiv:2312.10700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2023-05-09T14:45:59Z" | ---
datasets:
- midas/krapivin
- midas/inspec
- midas/kptimes
- midas/duc2001
language:
- en
widget:
- text: "Relevance has traditionally been linked with feature subset selection, but formalization of this link has not been attempted. In this paper, we propose two axioms for feature subset selection sufficiency axiom and necessity axiombased on which this link is formalized: The expected feature subset is the one which maximizes relevance. Finding the expected feature subset turns out to be NP-hard. We then devise a heuristic algorithm to find the expected subset which has a polynomial time complexity. The experimental results show that the algorithm finds good enough subset of features which, when presented to C4.5, results in better prediction accuracy."
- text: "In this paper, we investigate cross-domain limitations of keyphrase generation using the models for abstractive text summarization. We present an evaluation of BART fine-tuned for keyphrase generation across three types of texts, namely scientific texts from computer science and biomedical domains and news texts. We explore the role of transfer learning between different domains to improve the model performance on small text corpora."
---
# BART fine-tuned for keyphrase generation
<!-- Provide a quick summary of what the model is/does. -->
This is the <a href="https://huggingface.co/facebook/bart-base">bart-base</a> (<a href = "https://arxiv.org/abs/1910.13461">Lewis et al.. 2019</a>) model finetuned for the keyphrase generation task (<a href="https://arxiv.org/pdf/2312.10700.pdf">Glazkova & Morozov, 2023</a>) on the fragments of the following corpora:
* Krapivin (<a href = "http://eprints.biblio.unitn.it/1671/1/disi09055%2Dkrapivin%2Dautayeu%2Dmarchese.pdf">Krapivin et al., 2009</a>)
* Inspec (<a href = "https://aclanthology.org/W03-1028.pdf">Hulth, 2003</a>)
* KPTimes (<a href = "https://aclanthology.org/W19-8617.pdf">Gallina, 2019</a>)
* DUC-2001 (<a href = "https://cdn.aaai.org/AAAI/2008/AAAI08-136.pdf">Wan, 2008</a>)
* PubMed (<a href = "https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=08b75d31a90f206b36e806a7ec372f6f0d12457e">Schutz, 2008</a>)
* NamedKeys (<a href = "https://joyceho.github.io/assets/pdf/paper/gero-bcb19.pdf">Gero & Ho, 2019</a>).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("beogradjanka/bart_finetuned_keyphrase_extraction")
model = AutoModelForSeq2SeqLM.from_pretrained("beogradjanka/bart_finetuned_keyphrase_extraction")
text = "In this paper, we investigate cross-domain limitations of keyphrase generation using the models for abstractive text summarization.\
We present an evaluation of BART fine-tuned for keyphrase generation across three types of texts, \
namely scientific texts from computer science and biomedical domains and news texts. \
We explore the role of transfer learning between different domains to improve the model performance on small text corpora."
tokenized_text = tokenizer.prepare_seq2seq_batch([text], return_tensors='pt')
translation = model.generate(**tokenized_text)
translated_text = tokenizer.batch_decode(translation, skip_special_tokens=True)[0]
print(translated_text)
```
#### Training Hyperparameters
The following hyperparameters were used during training:
* learning_rate: 4e-5
* train_batch_size: 8
* optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
* num_epochs: 6
**BibTeX:**
```
@article{glazkova2023cross,
title={Cross-Domain Robustness of Transformer-based Keyphrase Generation},
author={Glazkova, Anna and Morozov, Dmitry},
journal={arXiv preprint arXiv:2312.10700},
year={2023}
}
```
|
fxmarty/tiny-dummy-qwen2 | fxmarty | "2024-03-20T07:18:24Z" | 158,792 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2024-03-19T11:07:14Z" | ---
license: mit
---
|
Helsinki-NLP/opus-mt-en-es | Helsinki-NLP | "2023-08-16T11:29:28Z" | 158,701 | 80 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"marian",
"text2text-generation",
"translation",
"en",
"es",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- en
- es
tags:
- translation
license: apache-2.0
---
### eng-spa
* source group: English
* target group: Spanish
* OPUS readme: [eng-spa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-spa/README.md)
* model: transformer
* source language(s): eng
* target language(s): spa
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-08-18.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.zip)
* test set translations: [opus-2020-08-18.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.test.txt)
* test set scores: [opus-2020-08-18.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newssyscomb2009-engspa.eng.spa | 31.0 | 0.583 |
| news-test2008-engspa.eng.spa | 29.7 | 0.564 |
| newstest2009-engspa.eng.spa | 30.2 | 0.578 |
| newstest2010-engspa.eng.spa | 36.9 | 0.620 |
| newstest2011-engspa.eng.spa | 38.2 | 0.619 |
| newstest2012-engspa.eng.spa | 39.0 | 0.625 |
| newstest2013-engspa.eng.spa | 35.0 | 0.598 |
| Tatoeba-test.eng.spa | 54.9 | 0.721 |
### System Info:
- hf_name: eng-spa
- source_languages: eng
- target_languages: spa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-spa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'es']
- src_constituents: {'eng'}
- tgt_constituents: {'spa'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-spa/opus-2020-08-18.test.txt
- src_alpha3: eng
- tgt_alpha3: spa
- short_pair: en-es
- chrF2_score: 0.721
- bleu: 54.9
- brevity_penalty: 0.978
- ref_len: 77311.0
- src_name: English
- tgt_name: Spanish
- train_date: 2020-08-18 00:00:00
- src_alpha2: en
- tgt_alpha2: es
- prefer_old: False
- long_pair: eng-spa
- helsinki_git_sha: d2f0910c89026c34a44e331e785dec1e0faa7b82
- transformers_git_sha: f7af09b4524b784d67ae8526f0e2fcc6f5ed0de9
- port_machine: brutasse
- port_time: 2020-08-24-18:20 |
IDEA-Research/grounding-dino-base | IDEA-Research | "2024-05-12T09:03:22Z" | 158,014 | 37 | transformers | [
"transformers",
"pytorch",
"safetensors",
"grounding-dino",
"zero-shot-object-detection",
"vision",
"arxiv:2303.05499",
"license:apache-2.0",
"region:us"
] | zero-shot-object-detection | "2023-09-25T01:27:30Z" | ---
license: apache-2.0
tags:
- vision
inference: false
pipeline_tag: zero-shot-object-detection
---
# Grounding DINO model (base variant)
The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/grouding_dino_architecture.png"
alt="drawing" width="600"/>
<small> Grounding DINO overview. Taken from the <a href="https://arxiv.org/abs/2303.05499">original paper</a>. </small>
## Intended uses & limitations
You can use the raw model for zero-shot object detection (the task of detecting things in an image out-of-the-box without labeled data).
### How to use
Here's how to use the model for zero-shot object detection:
```python
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
model_id = "IDEA-Research/grounding-dino-base"
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Check for cats and remote controls
# VERY important: text queries need to be lowercased + end with a dot
text = "a cat. a remote control."
inputs = processor(images=image, text=text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)
```
### BibTeX entry and citation info
```bibtex
@misc{liu2023grounding,
title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection},
author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang},
year={2023},
eprint={2303.05499},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
microsoft/resnet-18 | microsoft | "2024-04-08T11:06:50Z" | 157,819 | 42 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"resnet",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:1512.03385",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2022-03-16T15:40:26Z" | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ResNet
ResNet model trained on imagenet-1k. It was introduced in the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) and first released in [this repository](https://github.com/KaimingHe/deep-residual-networks).
Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=resnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
>>> from transformers import AutoImageProcessor, AutoModelForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/resnet-18")
>>> model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-18")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tiger cat
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/resnet). |
monologg/kobert | monologg | "2023-06-12T12:30:40Z" | 157,079 | 10 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"feature-extraction",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | Entry not found |
avsolatorio/GIST-Embedding-v0 | avsolatorio | "2024-02-28T00:31:27Z" | 156,822 | 16 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence-similarity",
"en",
"arxiv:2402.16829",
"arxiv:2212.09741",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-01-31T16:41:20Z" | ---
language:
- en
library_name: sentence-transformers
license: mit
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- mteb
- sentence-similarity
- sentence-transformers
model-index:
- name: GIST-Embedding-v0
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.95522388059702
- type: ap
value: 38.940434354439276
- type: f1
value: 69.88686275888114
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.51357499999999
- type: ap
value: 90.30414241486682
- type: f1
value: 93.50552829047328
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 50.446000000000005
- type: f1
value: 49.76432659699279
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.265
- type: map_at_10
value: 54.236
- type: map_at_100
value: 54.81399999999999
- type: map_at_1000
value: 54.81700000000001
- type: map_at_3
value: 49.881
- type: map_at_5
value: 52.431000000000004
- type: mrr_at_1
value: 38.265
- type: mrr_at_10
value: 54.152
- type: mrr_at_100
value: 54.730000000000004
- type: mrr_at_1000
value: 54.733
- type: mrr_at_3
value: 49.644
- type: mrr_at_5
value: 52.32599999999999
- type: ndcg_at_1
value: 38.265
- type: ndcg_at_10
value: 62.62
- type: ndcg_at_100
value: 64.96600000000001
- type: ndcg_at_1000
value: 65.035
- type: ndcg_at_3
value: 53.691
- type: ndcg_at_5
value: 58.303000000000004
- type: precision_at_1
value: 38.265
- type: precision_at_10
value: 8.919
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 21.573999999999998
- type: precision_at_5
value: 15.192
- type: recall_at_1
value: 38.265
- type: recall_at_10
value: 89.189
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 64.723
- type: recall_at_5
value: 75.96000000000001
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.287087887491744
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.74244928943812
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.68814324295771
- type: mrr
value: 75.46266983247591
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 90.45240209600391
- type: cos_sim_spearman
value: 87.95079919934645
- type: euclidean_pearson
value: 88.93438602492702
- type: euclidean_spearman
value: 88.28152962682988
- type: manhattan_pearson
value: 88.92193964325268
- type: manhattan_spearman
value: 88.21466063329498
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 15.605427974947808
- type: f1
value: 14.989877233698866
- type: precision
value: 14.77906814441261
- type: recall
value: 15.605427974947808
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 33.38102575390711
- type: f1
value: 32.41704114719127
- type: precision
value: 32.057363829835964
- type: recall
value: 33.38102575390711
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 0.1939729823346034
- type: f1
value: 0.17832215223820772
- type: precision
value: 0.17639155671715423
- type: recall
value: 0.1939729823346034
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 3.0542390731964195
- type: f1
value: 2.762857644374232
- type: precision
value: 2.6505178163945935
- type: recall
value: 3.0542390731964195
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.29545454545453
- type: f1
value: 87.26415991342238
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.035319537839484
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.667313307057285
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.979
- type: map_at_10
value: 46.275
- type: map_at_100
value: 47.975
- type: map_at_1000
value: 48.089
- type: map_at_3
value: 42.507
- type: map_at_5
value: 44.504
- type: mrr_at_1
value: 42.346000000000004
- type: mrr_at_10
value: 53.013
- type: mrr_at_100
value: 53.717000000000006
- type: mrr_at_1000
value: 53.749
- type: mrr_at_3
value: 50.405
- type: mrr_at_5
value: 51.915
- type: ndcg_at_1
value: 42.346000000000004
- type: ndcg_at_10
value: 53.179
- type: ndcg_at_100
value: 58.458
- type: ndcg_at_1000
value: 60.057
- type: ndcg_at_3
value: 48.076
- type: ndcg_at_5
value: 50.283
- type: precision_at_1
value: 42.346000000000004
- type: precision_at_10
value: 10.386
- type: precision_at_100
value: 1.635
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 23.413999999999998
- type: precision_at_5
value: 16.624
- type: recall_at_1
value: 33.979
- type: recall_at_10
value: 65.553
- type: recall_at_100
value: 87.18599999999999
- type: recall_at_1000
value: 97.25200000000001
- type: recall_at_3
value: 50.068999999999996
- type: recall_at_5
value: 56.882
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.529
- type: map_at_10
value: 42.219
- type: map_at_100
value: 43.408
- type: map_at_1000
value: 43.544
- type: map_at_3
value: 39.178000000000004
- type: map_at_5
value: 40.87
- type: mrr_at_1
value: 39.873
- type: mrr_at_10
value: 48.25
- type: mrr_at_100
value: 48.867
- type: mrr_at_1000
value: 48.908
- type: mrr_at_3
value: 46.03
- type: mrr_at_5
value: 47.355000000000004
- type: ndcg_at_1
value: 39.873
- type: ndcg_at_10
value: 47.933
- type: ndcg_at_100
value: 52.156000000000006
- type: ndcg_at_1000
value: 54.238
- type: ndcg_at_3
value: 43.791999999999994
- type: ndcg_at_5
value: 45.678999999999995
- type: precision_at_1
value: 39.873
- type: precision_at_10
value: 9.032
- type: precision_at_100
value: 1.419
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 21.231
- type: precision_at_5
value: 14.981
- type: recall_at_1
value: 31.529
- type: recall_at_10
value: 57.925000000000004
- type: recall_at_100
value: 75.89
- type: recall_at_1000
value: 89.007
- type: recall_at_3
value: 45.363
- type: recall_at_5
value: 50.973
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.289
- type: map_at_10
value: 54.494
- type: map_at_100
value: 55.494
- type: map_at_1000
value: 55.545
- type: map_at_3
value: 51.20099999999999
- type: map_at_5
value: 53.147
- type: mrr_at_1
value: 47.335
- type: mrr_at_10
value: 57.772
- type: mrr_at_100
value: 58.428000000000004
- type: mrr_at_1000
value: 58.453
- type: mrr_at_3
value: 55.434000000000005
- type: mrr_at_5
value: 56.8
- type: ndcg_at_1
value: 47.335
- type: ndcg_at_10
value: 60.382999999999996
- type: ndcg_at_100
value: 64.294
- type: ndcg_at_1000
value: 65.211
- type: ndcg_at_3
value: 55.098
- type: ndcg_at_5
value: 57.776
- type: precision_at_1
value: 47.335
- type: precision_at_10
value: 9.724
- type: precision_at_100
value: 1.26
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 24.786
- type: precision_at_5
value: 16.977999999999998
- type: recall_at_1
value: 41.289
- type: recall_at_10
value: 74.36399999999999
- type: recall_at_100
value: 91.19800000000001
- type: recall_at_1000
value: 97.508
- type: recall_at_3
value: 60.285
- type: recall_at_5
value: 66.814
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.816999999999997
- type: map_at_10
value: 37.856
- type: map_at_100
value: 38.824
- type: map_at_1000
value: 38.902
- type: map_at_3
value: 34.982
- type: map_at_5
value: 36.831
- type: mrr_at_1
value: 31.073
- type: mrr_at_10
value: 39.985
- type: mrr_at_100
value: 40.802
- type: mrr_at_1000
value: 40.861999999999995
- type: mrr_at_3
value: 37.419999999999995
- type: mrr_at_5
value: 39.104
- type: ndcg_at_1
value: 31.073
- type: ndcg_at_10
value: 42.958
- type: ndcg_at_100
value: 47.671
- type: ndcg_at_1000
value: 49.633
- type: ndcg_at_3
value: 37.602000000000004
- type: ndcg_at_5
value: 40.688
- type: precision_at_1
value: 31.073
- type: precision_at_10
value: 6.531000000000001
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 15.857
- type: precision_at_5
value: 11.209
- type: recall_at_1
value: 28.816999999999997
- type: recall_at_10
value: 56.538999999999994
- type: recall_at_100
value: 78.17699999999999
- type: recall_at_1000
value: 92.92200000000001
- type: recall_at_3
value: 42.294
- type: recall_at_5
value: 49.842999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.397
- type: map_at_10
value: 27.256999999999998
- type: map_at_100
value: 28.541
- type: map_at_1000
value: 28.658
- type: map_at_3
value: 24.565
- type: map_at_5
value: 26.211000000000002
- type: mrr_at_1
value: 22.761
- type: mrr_at_10
value: 32.248
- type: mrr_at_100
value: 33.171
- type: mrr_at_1000
value: 33.227000000000004
- type: mrr_at_3
value: 29.498
- type: mrr_at_5
value: 31.246000000000002
- type: ndcg_at_1
value: 22.761
- type: ndcg_at_10
value: 32.879999999999995
- type: ndcg_at_100
value: 38.913
- type: ndcg_at_1000
value: 41.504999999999995
- type: ndcg_at_3
value: 27.988000000000003
- type: ndcg_at_5
value: 30.548
- type: precision_at_1
value: 22.761
- type: precision_at_10
value: 6.045
- type: precision_at_100
value: 1.044
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 13.433
- type: precision_at_5
value: 9.925
- type: recall_at_1
value: 18.397
- type: recall_at_10
value: 45.14
- type: recall_at_100
value: 71.758
- type: recall_at_1000
value: 89.854
- type: recall_at_3
value: 31.942999999999998
- type: recall_at_5
value: 38.249
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.604
- type: map_at_10
value: 42.132
- type: map_at_100
value: 43.419000000000004
- type: map_at_1000
value: 43.527
- type: map_at_3
value: 38.614
- type: map_at_5
value: 40.705000000000005
- type: mrr_at_1
value: 37.824999999999996
- type: mrr_at_10
value: 47.696
- type: mrr_at_100
value: 48.483
- type: mrr_at_1000
value: 48.53
- type: mrr_at_3
value: 45.123999999999995
- type: mrr_at_5
value: 46.635
- type: ndcg_at_1
value: 37.824999999999996
- type: ndcg_at_10
value: 48.421
- type: ndcg_at_100
value: 53.568000000000005
- type: ndcg_at_1000
value: 55.574999999999996
- type: ndcg_at_3
value: 42.89
- type: ndcg_at_5
value: 45.683
- type: precision_at_1
value: 37.824999999999996
- type: precision_at_10
value: 8.758000000000001
- type: precision_at_100
value: 1.319
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 20.244
- type: precision_at_5
value: 14.533
- type: recall_at_1
value: 30.604
- type: recall_at_10
value: 61.605
- type: recall_at_100
value: 82.787
- type: recall_at_1000
value: 95.78
- type: recall_at_3
value: 46.303
- type: recall_at_5
value: 53.351000000000006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.262999999999998
- type: map_at_10
value: 36.858999999999995
- type: map_at_100
value: 38.241
- type: map_at_1000
value: 38.346999999999994
- type: map_at_3
value: 33.171
- type: map_at_5
value: 35.371
- type: mrr_at_1
value: 32.42
- type: mrr_at_10
value: 42.361
- type: mrr_at_100
value: 43.219
- type: mrr_at_1000
value: 43.271
- type: mrr_at_3
value: 39.593
- type: mrr_at_5
value: 41.248000000000005
- type: ndcg_at_1
value: 32.42
- type: ndcg_at_10
value: 43.081
- type: ndcg_at_100
value: 48.837
- type: ndcg_at_1000
value: 50.954
- type: ndcg_at_3
value: 37.413000000000004
- type: ndcg_at_5
value: 40.239000000000004
- type: precision_at_1
value: 32.42
- type: precision_at_10
value: 8.071
- type: precision_at_100
value: 1.272
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 17.922
- type: precision_at_5
value: 13.311
- type: recall_at_1
value: 26.262999999999998
- type: recall_at_10
value: 56.062999999999995
- type: recall_at_100
value: 80.636
- type: recall_at_1000
value: 94.707
- type: recall_at_3
value: 40.425
- type: recall_at_5
value: 47.663
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.86616666666667
- type: map_at_10
value: 37.584999999999994
- type: map_at_100
value: 38.80291666666667
- type: map_at_1000
value: 38.91358333333333
- type: map_at_3
value: 34.498
- type: map_at_5
value: 36.269999999999996
- type: mrr_at_1
value: 33.07566666666667
- type: mrr_at_10
value: 41.92366666666666
- type: mrr_at_100
value: 42.73516666666667
- type: mrr_at_1000
value: 42.785666666666664
- type: mrr_at_3
value: 39.39075
- type: mrr_at_5
value: 40.89133333333334
- type: ndcg_at_1
value: 33.07566666666667
- type: ndcg_at_10
value: 43.19875
- type: ndcg_at_100
value: 48.32083333333334
- type: ndcg_at_1000
value: 50.418000000000006
- type: ndcg_at_3
value: 38.10308333333333
- type: ndcg_at_5
value: 40.5985
- type: precision_at_1
value: 33.07566666666667
- type: precision_at_10
value: 7.581916666666666
- type: precision_at_100
value: 1.1975
- type: precision_at_1000
value: 0.15699999999999997
- type: precision_at_3
value: 17.49075
- type: precision_at_5
value: 12.5135
- type: recall_at_1
value: 27.86616666666667
- type: recall_at_10
value: 55.449749999999995
- type: recall_at_100
value: 77.92516666666666
- type: recall_at_1000
value: 92.31358333333333
- type: recall_at_3
value: 41.324416666666664
- type: recall_at_5
value: 47.72533333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.648
- type: map_at_10
value: 33.155
- type: map_at_100
value: 34.149
- type: map_at_1000
value: 34.239000000000004
- type: map_at_3
value: 30.959999999999997
- type: map_at_5
value: 32.172
- type: mrr_at_1
value: 30.061
- type: mrr_at_10
value: 36.229
- type: mrr_at_100
value: 37.088
- type: mrr_at_1000
value: 37.15
- type: mrr_at_3
value: 34.254
- type: mrr_at_5
value: 35.297
- type: ndcg_at_1
value: 30.061
- type: ndcg_at_10
value: 37.247
- type: ndcg_at_100
value: 42.093
- type: ndcg_at_1000
value: 44.45
- type: ndcg_at_3
value: 33.211
- type: ndcg_at_5
value: 35.083999999999996
- type: precision_at_1
value: 30.061
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.8880000000000001
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 13.957
- type: precision_at_5
value: 9.663
- type: recall_at_1
value: 26.648
- type: recall_at_10
value: 46.85
- type: recall_at_100
value: 68.87
- type: recall_at_1000
value: 86.508
- type: recall_at_3
value: 35.756
- type: recall_at_5
value: 40.376
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.058
- type: map_at_10
value: 26.722
- type: map_at_100
value: 27.863
- type: map_at_1000
value: 27.988000000000003
- type: map_at_3
value: 24.258
- type: map_at_5
value: 25.531
- type: mrr_at_1
value: 23.09
- type: mrr_at_10
value: 30.711
- type: mrr_at_100
value: 31.628
- type: mrr_at_1000
value: 31.702
- type: mrr_at_3
value: 28.418
- type: mrr_at_5
value: 29.685
- type: ndcg_at_1
value: 23.09
- type: ndcg_at_10
value: 31.643
- type: ndcg_at_100
value: 37.047999999999995
- type: ndcg_at_1000
value: 39.896
- type: ndcg_at_3
value: 27.189999999999998
- type: ndcg_at_5
value: 29.112
- type: precision_at_1
value: 23.09
- type: precision_at_10
value: 5.743
- type: precision_at_100
value: 1
- type: precision_at_1000
value: 0.14300000000000002
- type: precision_at_3
value: 12.790000000000001
- type: precision_at_5
value: 9.195
- type: recall_at_1
value: 19.058
- type: recall_at_10
value: 42.527
- type: recall_at_100
value: 66.833
- type: recall_at_1000
value: 87.008
- type: recall_at_3
value: 29.876
- type: recall_at_5
value: 34.922
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.066999999999997
- type: map_at_10
value: 37.543
- type: map_at_100
value: 38.725
- type: map_at_1000
value: 38.815
- type: map_at_3
value: 34.488
- type: map_at_5
value: 36.222
- type: mrr_at_1
value: 33.116
- type: mrr_at_10
value: 41.743
- type: mrr_at_100
value: 42.628
- type: mrr_at_1000
value: 42.675999999999995
- type: mrr_at_3
value: 39.241
- type: mrr_at_5
value: 40.622
- type: ndcg_at_1
value: 33.116
- type: ndcg_at_10
value: 43.089
- type: ndcg_at_100
value: 48.61
- type: ndcg_at_1000
value: 50.585
- type: ndcg_at_3
value: 37.816
- type: ndcg_at_5
value: 40.256
- type: precision_at_1
value: 33.116
- type: precision_at_10
value: 7.313
- type: precision_at_100
value: 1.1320000000000001
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 17.102
- type: precision_at_5
value: 12.09
- type: recall_at_1
value: 28.066999999999997
- type: recall_at_10
value: 55.684
- type: recall_at_100
value: 80.092
- type: recall_at_1000
value: 93.605
- type: recall_at_3
value: 41.277
- type: recall_at_5
value: 47.46
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.094
- type: map_at_10
value: 35.939
- type: map_at_100
value: 37.552
- type: map_at_1000
value: 37.771
- type: map_at_3
value: 32.414
- type: map_at_5
value: 34.505
- type: mrr_at_1
value: 32.609
- type: mrr_at_10
value: 40.521
- type: mrr_at_100
value: 41.479
- type: mrr_at_1000
value: 41.524
- type: mrr_at_3
value: 37.451
- type: mrr_at_5
value: 39.387
- type: ndcg_at_1
value: 32.609
- type: ndcg_at_10
value: 41.83
- type: ndcg_at_100
value: 47.763
- type: ndcg_at_1000
value: 50.102999999999994
- type: ndcg_at_3
value: 36.14
- type: ndcg_at_5
value: 39.153999999999996
- type: precision_at_1
value: 32.609
- type: precision_at_10
value: 7.925
- type: precision_at_100
value: 1.591
- type: precision_at_1000
value: 0.246
- type: precision_at_3
value: 16.337
- type: precision_at_5
value: 12.411
- type: recall_at_1
value: 27.094
- type: recall_at_10
value: 53.32900000000001
- type: recall_at_100
value: 79.52
- type: recall_at_1000
value: 93.958
- type: recall_at_3
value: 37.773
- type: recall_at_5
value: 45.321
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.649
- type: map_at_10
value: 30.569000000000003
- type: map_at_100
value: 31.444
- type: map_at_1000
value: 31.538
- type: map_at_3
value: 27.638
- type: map_at_5
value: 29.171000000000003
- type: mrr_at_1
value: 24.399
- type: mrr_at_10
value: 32.555
- type: mrr_at_100
value: 33.312000000000005
- type: mrr_at_1000
value: 33.376
- type: mrr_at_3
value: 29.820999999999998
- type: mrr_at_5
value: 31.402
- type: ndcg_at_1
value: 24.399
- type: ndcg_at_10
value: 35.741
- type: ndcg_at_100
value: 40.439
- type: ndcg_at_1000
value: 42.809000000000005
- type: ndcg_at_3
value: 30.020999999999997
- type: ndcg_at_5
value: 32.68
- type: precision_at_1
value: 24.399
- type: precision_at_10
value: 5.749
- type: precision_at_100
value: 0.878
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 12.815999999999999
- type: precision_at_5
value: 9.242
- type: recall_at_1
value: 22.649
- type: recall_at_10
value: 49.818
- type: recall_at_100
value: 72.155
- type: recall_at_1000
value: 89.654
- type: recall_at_3
value: 34.528999999999996
- type: recall_at_5
value: 40.849999999999994
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 13.587
- type: map_at_10
value: 23.021
- type: map_at_100
value: 25.095
- type: map_at_1000
value: 25.295
- type: map_at_3
value: 19.463
- type: map_at_5
value: 21.389
- type: mrr_at_1
value: 29.576999999999998
- type: mrr_at_10
value: 41.44
- type: mrr_at_100
value: 42.497
- type: mrr_at_1000
value: 42.529
- type: mrr_at_3
value: 38.284
- type: mrr_at_5
value: 40.249
- type: ndcg_at_1
value: 29.576999999999998
- type: ndcg_at_10
value: 31.491000000000003
- type: ndcg_at_100
value: 39.352
- type: ndcg_at_1000
value: 42.703
- type: ndcg_at_3
value: 26.284999999999997
- type: ndcg_at_5
value: 28.218
- type: precision_at_1
value: 29.576999999999998
- type: precision_at_10
value: 9.713
- type: precision_at_100
value: 1.8079999999999998
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 19.608999999999998
- type: precision_at_5
value: 14.957999999999998
- type: recall_at_1
value: 13.587
- type: recall_at_10
value: 37.001
- type: recall_at_100
value: 63.617999999999995
- type: recall_at_1000
value: 82.207
- type: recall_at_3
value: 24.273
- type: recall_at_5
value: 29.813000000000002
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.98
- type: map_at_10
value: 20.447000000000003
- type: map_at_100
value: 29.032999999999998
- type: map_at_1000
value: 30.8
- type: map_at_3
value: 15.126999999999999
- type: map_at_5
value: 17.327
- type: mrr_at_1
value: 71.25
- type: mrr_at_10
value: 78.014
- type: mrr_at_100
value: 78.303
- type: mrr_at_1000
value: 78.309
- type: mrr_at_3
value: 76.375
- type: mrr_at_5
value: 77.58699999999999
- type: ndcg_at_1
value: 57.99999999999999
- type: ndcg_at_10
value: 41.705
- type: ndcg_at_100
value: 47.466
- type: ndcg_at_1000
value: 55.186
- type: ndcg_at_3
value: 47.089999999999996
- type: ndcg_at_5
value: 43.974000000000004
- type: precision_at_1
value: 71.25
- type: precision_at_10
value: 32.65
- type: precision_at_100
value: 10.89
- type: precision_at_1000
value: 2.197
- type: precision_at_3
value: 50.5
- type: precision_at_5
value: 42.199999999999996
- type: recall_at_1
value: 9.98
- type: recall_at_10
value: 25.144
- type: recall_at_100
value: 53.754999999999995
- type: recall_at_1000
value: 78.56400000000001
- type: recall_at_3
value: 15.964
- type: recall_at_5
value: 19.186
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 54.67999999999999
- type: f1
value: 49.48247525503583
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.798
- type: map_at_10
value: 82.933
- type: map_at_100
value: 83.157
- type: map_at_1000
value: 83.173
- type: map_at_3
value: 81.80199999999999
- type: map_at_5
value: 82.55
- type: mrr_at_1
value: 80.573
- type: mrr_at_10
value: 87.615
- type: mrr_at_100
value: 87.69
- type: mrr_at_1000
value: 87.69200000000001
- type: mrr_at_3
value: 86.86399999999999
- type: mrr_at_5
value: 87.386
- type: ndcg_at_1
value: 80.573
- type: ndcg_at_10
value: 86.64500000000001
- type: ndcg_at_100
value: 87.407
- type: ndcg_at_1000
value: 87.68299999999999
- type: ndcg_at_3
value: 84.879
- type: ndcg_at_5
value: 85.921
- type: precision_at_1
value: 80.573
- type: precision_at_10
value: 10.348
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 32.268
- type: precision_at_5
value: 20.084
- type: recall_at_1
value: 74.798
- type: recall_at_10
value: 93.45400000000001
- type: recall_at_100
value: 96.42500000000001
- type: recall_at_1000
value: 98.158
- type: recall_at_3
value: 88.634
- type: recall_at_5
value: 91.295
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.567
- type: map_at_10
value: 32.967999999999996
- type: map_at_100
value: 35.108
- type: map_at_1000
value: 35.272999999999996
- type: map_at_3
value: 28.701999999999998
- type: map_at_5
value: 31.114000000000004
- type: mrr_at_1
value: 40.432
- type: mrr_at_10
value: 48.956
- type: mrr_at_100
value: 49.832
- type: mrr_at_1000
value: 49.87
- type: mrr_at_3
value: 46.759
- type: mrr_at_5
value: 47.886
- type: ndcg_at_1
value: 40.432
- type: ndcg_at_10
value: 40.644000000000005
- type: ndcg_at_100
value: 48.252
- type: ndcg_at_1000
value: 51.099000000000004
- type: ndcg_at_3
value: 36.992000000000004
- type: ndcg_at_5
value: 38.077
- type: precision_at_1
value: 40.432
- type: precision_at_10
value: 11.296000000000001
- type: precision_at_100
value: 1.9009999999999998
- type: precision_at_1000
value: 0.241
- type: precision_at_3
value: 24.537
- type: precision_at_5
value: 17.963
- type: recall_at_1
value: 20.567
- type: recall_at_10
value: 47.052
- type: recall_at_100
value: 75.21600000000001
- type: recall_at_1000
value: 92.285
- type: recall_at_3
value: 33.488
- type: recall_at_5
value: 39.334
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.196999999999996
- type: map_at_10
value: 60.697
- type: map_at_100
value: 61.624
- type: map_at_1000
value: 61.692
- type: map_at_3
value: 57.421
- type: map_at_5
value: 59.455000000000005
- type: mrr_at_1
value: 76.39399999999999
- type: mrr_at_10
value: 82.504
- type: mrr_at_100
value: 82.71300000000001
- type: mrr_at_1000
value: 82.721
- type: mrr_at_3
value: 81.494
- type: mrr_at_5
value: 82.137
- type: ndcg_at_1
value: 76.39399999999999
- type: ndcg_at_10
value: 68.92200000000001
- type: ndcg_at_100
value: 72.13199999999999
- type: ndcg_at_1000
value: 73.392
- type: ndcg_at_3
value: 64.226
- type: ndcg_at_5
value: 66.815
- type: precision_at_1
value: 76.39399999999999
- type: precision_at_10
value: 14.442
- type: precision_at_100
value: 1.694
- type: precision_at_1000
value: 0.186
- type: precision_at_3
value: 41.211
- type: precision_at_5
value: 26.766000000000002
- type: recall_at_1
value: 38.196999999999996
- type: recall_at_10
value: 72.208
- type: recall_at_100
value: 84.71300000000001
- type: recall_at_1000
value: 92.971
- type: recall_at_3
value: 61.816
- type: recall_at_5
value: 66.914
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 89.6556
- type: ap
value: 85.27600392682054
- type: f1
value: 89.63353655386406
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.482
- type: map_at_10
value: 33.701
- type: map_at_100
value: 34.861
- type: map_at_1000
value: 34.914
- type: map_at_3
value: 29.793999999999997
- type: map_at_5
value: 32.072
- type: mrr_at_1
value: 22.163
- type: mrr_at_10
value: 34.371
- type: mrr_at_100
value: 35.471000000000004
- type: mrr_at_1000
value: 35.518
- type: mrr_at_3
value: 30.554
- type: mrr_at_5
value: 32.799
- type: ndcg_at_1
value: 22.163
- type: ndcg_at_10
value: 40.643
- type: ndcg_at_100
value: 46.239999999999995
- type: ndcg_at_1000
value: 47.526
- type: ndcg_at_3
value: 32.714999999999996
- type: ndcg_at_5
value: 36.791000000000004
- type: precision_at_1
value: 22.163
- type: precision_at_10
value: 6.4799999999999995
- type: precision_at_100
value: 0.928
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.002
- type: precision_at_5
value: 10.453
- type: recall_at_1
value: 21.482
- type: recall_at_10
value: 61.953
- type: recall_at_100
value: 87.86500000000001
- type: recall_at_1000
value: 97.636
- type: recall_at_3
value: 40.441
- type: recall_at_5
value: 50.27
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.3032375740994
- type: f1
value: 95.01515022686607
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 78.10077519379846
- type: f1
value: 58.240739725625644
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.0053799596503
- type: f1
value: 74.11733965804146
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.64021519838602
- type: f1
value: 79.8513960091438
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.92425767945184
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.249612382060754
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.35584955492918
- type: mrr
value: 33.545865224584674
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.978
- type: map_at_10
value: 14.749
- type: map_at_100
value: 19.192
- type: map_at_1000
value: 20.815
- type: map_at_3
value: 10.927000000000001
- type: map_at_5
value: 12.726
- type: mrr_at_1
value: 49.536
- type: mrr_at_10
value: 57.806999999999995
- type: mrr_at_100
value: 58.373
- type: mrr_at_1000
value: 58.407
- type: mrr_at_3
value: 55.779
- type: mrr_at_5
value: 57.095
- type: ndcg_at_1
value: 46.749
- type: ndcg_at_10
value: 37.644
- type: ndcg_at_100
value: 35.559000000000005
- type: ndcg_at_1000
value: 44.375
- type: ndcg_at_3
value: 43.354
- type: ndcg_at_5
value: 41.022999999999996
- type: precision_at_1
value: 48.607
- type: precision_at_10
value: 28.08
- type: precision_at_100
value: 9.155000000000001
- type: precision_at_1000
value: 2.2270000000000003
- type: precision_at_3
value: 40.764
- type: precision_at_5
value: 35.728
- type: recall_at_1
value: 6.978
- type: recall_at_10
value: 17.828
- type: recall_at_100
value: 36.010999999999996
- type: recall_at_1000
value: 68.34700000000001
- type: recall_at_3
value: 11.645999999999999
- type: recall_at_5
value: 14.427000000000001
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.219
- type: map_at_10
value: 45.633
- type: map_at_100
value: 46.752
- type: map_at_1000
value: 46.778999999999996
- type: map_at_3
value: 41.392
- type: map_at_5
value: 43.778
- type: mrr_at_1
value: 34.327999999999996
- type: mrr_at_10
value: 48.256
- type: mrr_at_100
value: 49.076
- type: mrr_at_1000
value: 49.092999999999996
- type: mrr_at_3
value: 44.786
- type: mrr_at_5
value: 46.766000000000005
- type: ndcg_at_1
value: 34.299
- type: ndcg_at_10
value: 53.434000000000005
- type: ndcg_at_100
value: 58.03
- type: ndcg_at_1000
value: 58.633
- type: ndcg_at_3
value: 45.433
- type: ndcg_at_5
value: 49.379
- type: precision_at_1
value: 34.299
- type: precision_at_10
value: 8.911
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 20.896
- type: precision_at_5
value: 14.832
- type: recall_at_1
value: 30.219
- type: recall_at_10
value: 74.59400000000001
- type: recall_at_100
value: 94.392
- type: recall_at_1000
value: 98.832
- type: recall_at_3
value: 53.754000000000005
- type: recall_at_5
value: 62.833000000000006
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.139
- type: map_at_10
value: 85.141
- type: map_at_100
value: 85.78099999999999
- type: map_at_1000
value: 85.795
- type: map_at_3
value: 82.139
- type: map_at_5
value: 84.075
- type: mrr_at_1
value: 81.98
- type: mrr_at_10
value: 88.056
- type: mrr_at_100
value: 88.152
- type: mrr_at_1000
value: 88.152
- type: mrr_at_3
value: 87.117
- type: mrr_at_5
value: 87.78099999999999
- type: ndcg_at_1
value: 82.02000000000001
- type: ndcg_at_10
value: 88.807
- type: ndcg_at_100
value: 89.99000000000001
- type: ndcg_at_1000
value: 90.068
- type: ndcg_at_3
value: 85.989
- type: ndcg_at_5
value: 87.627
- type: precision_at_1
value: 82.02000000000001
- type: precision_at_10
value: 13.472999999999999
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.553
- type: precision_at_5
value: 24.788
- type: recall_at_1
value: 71.139
- type: recall_at_10
value: 95.707
- type: recall_at_100
value: 99.666
- type: recall_at_1000
value: 99.983
- type: recall_at_3
value: 87.64699999999999
- type: recall_at_5
value: 92.221
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 59.11035509193503
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.44241881422526
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.122999999999999
- type: map_at_10
value: 14.45
- type: map_at_100
value: 17.108999999999998
- type: map_at_1000
value: 17.517
- type: map_at_3
value: 10.213999999999999
- type: map_at_5
value: 12.278
- type: mrr_at_1
value: 25.3
- type: mrr_at_10
value: 37.791999999999994
- type: mrr_at_100
value: 39.086
- type: mrr_at_1000
value: 39.121
- type: mrr_at_3
value: 34.666999999999994
- type: mrr_at_5
value: 36.472
- type: ndcg_at_1
value: 25.3
- type: ndcg_at_10
value: 23.469
- type: ndcg_at_100
value: 33.324
- type: ndcg_at_1000
value: 39.357
- type: ndcg_at_3
value: 22.478
- type: ndcg_at_5
value: 19.539
- type: precision_at_1
value: 25.3
- type: precision_at_10
value: 12.3
- type: precision_at_100
value: 2.654
- type: precision_at_1000
value: 0.40800000000000003
- type: precision_at_3
value: 21.667
- type: precision_at_5
value: 17.5
- type: recall_at_1
value: 5.122999999999999
- type: recall_at_10
value: 24.937
- type: recall_at_100
value: 53.833
- type: recall_at_1000
value: 82.85
- type: recall_at_3
value: 13.178
- type: recall_at_5
value: 17.747
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.76549431206278
- type: cos_sim_spearman
value: 81.28563534883214
- type: euclidean_pearson
value: 84.17180713818567
- type: euclidean_spearman
value: 81.1684082302606
- type: manhattan_pearson
value: 84.12189753972959
- type: manhattan_spearman
value: 81.1134998997958
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.75137587182017
- type: cos_sim_spearman
value: 76.155337187325
- type: euclidean_pearson
value: 83.54551546726665
- type: euclidean_spearman
value: 76.30324990565346
- type: manhattan_pearson
value: 83.52192617483797
- type: manhattan_spearman
value: 76.30017227216015
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 87.13890050398628
- type: cos_sim_spearman
value: 87.84898360302155
- type: euclidean_pearson
value: 86.89491809082031
- type: euclidean_spearman
value: 87.99935689905651
- type: manhattan_pearson
value: 86.86526424376366
- type: manhattan_spearman
value: 87.96850732980495
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.01978753231558
- type: cos_sim_spearman
value: 83.38989083933329
- type: euclidean_pearson
value: 85.28405032045376
- type: euclidean_spearman
value: 83.51703914276501
- type: manhattan_pearson
value: 85.25775133078966
- type: manhattan_spearman
value: 83.52815667821727
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.28482294437876
- type: cos_sim_spearman
value: 89.42976214499576
- type: euclidean_pearson
value: 88.72677957272468
- type: euclidean_spearman
value: 89.30001736116229
- type: manhattan_pearson
value: 88.64119331622562
- type: manhattan_spearman
value: 89.21771022634893
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.79810159351987
- type: cos_sim_spearman
value: 85.34918402034273
- type: euclidean_pearson
value: 84.76058606229002
- type: euclidean_spearman
value: 85.45159829941214
- type: manhattan_pearson
value: 84.73926491888156
- type: manhattan_spearman
value: 85.42568221985898
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.92796712570272
- type: cos_sim_spearman
value: 88.58925922945812
- type: euclidean_pearson
value: 88.97231215531797
- type: euclidean_spearman
value: 88.27036385068719
- type: manhattan_pearson
value: 88.95761469412228
- type: manhattan_spearman
value: 88.23980432487681
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.85679810182282
- type: cos_sim_spearman
value: 67.80696709003128
- type: euclidean_pearson
value: 68.77524185947989
- type: euclidean_spearman
value: 68.032438075422
- type: manhattan_pearson
value: 68.60489100404182
- type: manhattan_spearman
value: 67.75418889226138
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.33287880999367
- type: cos_sim_spearman
value: 87.32401087204754
- type: euclidean_pearson
value: 87.27961069148029
- type: euclidean_spearman
value: 87.3547683085868
- type: manhattan_pearson
value: 87.24405442789622
- type: manhattan_spearman
value: 87.32896271166672
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.71553665286558
- type: mrr
value: 96.42436176749902
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 61.094
- type: map_at_10
value: 71.066
- type: map_at_100
value: 71.608
- type: map_at_1000
value: 71.629
- type: map_at_3
value: 68.356
- type: map_at_5
value: 70.15
- type: mrr_at_1
value: 64
- type: mrr_at_10
value: 71.82300000000001
- type: mrr_at_100
value: 72.251
- type: mrr_at_1000
value: 72.269
- type: mrr_at_3
value: 69.833
- type: mrr_at_5
value: 71.11699999999999
- type: ndcg_at_1
value: 64
- type: ndcg_at_10
value: 75.286
- type: ndcg_at_100
value: 77.40700000000001
- type: ndcg_at_1000
value: 77.806
- type: ndcg_at_3
value: 70.903
- type: ndcg_at_5
value: 73.36399999999999
- type: precision_at_1
value: 64
- type: precision_at_10
value: 9.9
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 27.667
- type: precision_at_5
value: 18.333
- type: recall_at_1
value: 61.094
- type: recall_at_10
value: 87.256
- type: recall_at_100
value: 96.5
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 75.6
- type: recall_at_5
value: 81.789
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.82871287128712
- type: cos_sim_ap
value: 95.9325677692287
- type: cos_sim_f1
value: 91.13924050632912
- type: cos_sim_precision
value: 92.3076923076923
- type: cos_sim_recall
value: 90
- type: dot_accuracy
value: 99.7980198019802
- type: dot_ap
value: 94.56107207796
- type: dot_f1
value: 89.41908713692946
- type: dot_precision
value: 92.88793103448276
- type: dot_recall
value: 86.2
- type: euclidean_accuracy
value: 99.82871287128712
- type: euclidean_ap
value: 95.94390332507025
- type: euclidean_f1
value: 91.17797042325346
- type: euclidean_precision
value: 93.02809573361083
- type: euclidean_recall
value: 89.4
- type: manhattan_accuracy
value: 99.82871287128712
- type: manhattan_ap
value: 95.97587114452257
- type: manhattan_f1
value: 91.25821121778675
- type: manhattan_precision
value: 92.23697650663942
- type: manhattan_recall
value: 90.3
- type: max_accuracy
value: 99.82871287128712
- type: max_ap
value: 95.97587114452257
- type: max_f1
value: 91.25821121778675
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.13974351708839
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.594544722932234
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.718738983377726
- type: mrr
value: 55.61655154486037
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.37028359646597
- type: cos_sim_spearman
value: 30.866534307244443
- type: dot_pearson
value: 29.89037691541816
- type: dot_spearman
value: 29.941267567971718
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.20400000000000001
- type: map_at_10
value: 1.7340000000000002
- type: map_at_100
value: 9.966
- type: map_at_1000
value: 25.119000000000003
- type: map_at_3
value: 0.596
- type: map_at_5
value: 0.941
- type: mrr_at_1
value: 76
- type: mrr_at_10
value: 85.85199999999999
- type: mrr_at_100
value: 85.85199999999999
- type: mrr_at_1000
value: 85.85199999999999
- type: mrr_at_3
value: 84.667
- type: mrr_at_5
value: 85.56700000000001
- type: ndcg_at_1
value: 71
- type: ndcg_at_10
value: 69.60300000000001
- type: ndcg_at_100
value: 54.166000000000004
- type: ndcg_at_1000
value: 51.085
- type: ndcg_at_3
value: 71.95
- type: ndcg_at_5
value: 71.17599999999999
- type: precision_at_1
value: 76
- type: precision_at_10
value: 74.2
- type: precision_at_100
value: 55.96
- type: precision_at_1000
value: 22.584
- type: precision_at_3
value: 77.333
- type: precision_at_5
value: 75.6
- type: recall_at_1
value: 0.20400000000000001
- type: recall_at_10
value: 1.992
- type: recall_at_100
value: 13.706999999999999
- type: recall_at_1000
value: 48.732
- type: recall_at_3
value: 0.635
- type: recall_at_5
value: 1.034
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (sqi-eng)
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8
- type: f1
value: 6.298401229470593
- type: precision
value: 5.916991709050532
- type: recall
value: 8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fry-eng)
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.341040462427745
- type: f1
value: 14.621650026274303
- type: precision
value: 13.9250609139035
- type: recall
value: 17.341040462427745
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kur-eng)
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.536585365853659
- type: f1
value: 6.30972482801751
- type: precision
value: 5.796517326875398
- type: recall
value: 8.536585365853659
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tur-eng)
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.4
- type: f1
value: 4.221126743626743
- type: precision
value: 3.822815143403898
- type: recall
value: 6.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (deu-eng)
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 19.8
- type: f1
value: 18.13768093781855
- type: precision
value: 17.54646004378763
- type: recall
value: 19.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nld-eng)
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.700000000000001
- type: f1
value: 12.367662337662336
- type: precision
value: 11.934237966189185
- type: recall
value: 13.700000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ron-eng)
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.299999999999999
- type: f1
value: 10.942180289268338
- type: precision
value: 10.153968847262192
- type: recall
value: 14.299999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ang-eng)
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22.388059701492537
- type: f1
value: 17.00157733660433
- type: precision
value: 15.650551589876702
- type: recall
value: 22.388059701492537
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ido-eng)
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22
- type: f1
value: 17.4576947358322
- type: precision
value: 16.261363669827777
- type: recall
value: 22
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jav-eng)
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.292682926829269
- type: f1
value: 5.544048456005624
- type: precision
value: 5.009506603002538
- type: recall
value: 8.292682926829269
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (isl-eng)
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.4
- type: f1
value: 4.148897174789229
- type: precision
value: 3.862217259449564
- type: recall
value: 5.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slv-eng)
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.5893074119076545
- type: f1
value: 4.375041810373159
- type: precision
value: 4.181207113088141
- type: recall
value: 5.5893074119076545
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cym-eng)
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.17391304347826
- type: f1
value: 6.448011891490153
- type: precision
value: 5.9719116632160105
- type: recall
value: 8.17391304347826
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kaz-eng)
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.8695652173913043
- type: f1
value: 0.582815734989648
- type: precision
value: 0.5580885233059146
- type: recall
value: 0.8695652173913043
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (est-eng)
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.1
- type: f1
value: 3.5000615825615826
- type: precision
value: 3.2073523577994707
- type: recall
value: 5.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (heb-eng)
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.10109884927372195
- type: precision
value: 0.10055127118392897
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gla-eng)
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.8600723763570564
- type: f1
value: 2.8177402725050493
- type: precision
value: 2.5662687819699213
- type: recall
value: 3.8600723763570564
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mar-eng)
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0
- type: f1
value: 0
- type: precision
value: 0
- type: recall
value: 0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lat-eng)
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 15.299999999999999
- type: f1
value: 11.377964359824292
- type: precision
value: 10.361140908892764
- type: recall
value: 15.299999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bel-eng)
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.3
- type: f1
value: 0.9600820232399179
- type: precision
value: 0.9151648856810397
- type: recall
value: 1.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pms-eng)
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.095238095238095
- type: f1
value: 11.40081541819044
- type: precision
value: 10.645867976820359
- type: recall
value: 14.095238095238095
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gle-eng)
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4
- type: f1
value: 2.3800704501963432
- type: precision
value: 2.0919368034607455
- type: recall
value: 4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pes-eng)
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.2002053388090349
- type: precision
value: 0.2001027749229188
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nob-eng)
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.700000000000001
- type: f1
value: 10.29755634495992
- type: precision
value: 9.876637220292393
- type: recall
value: 11.700000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bul-eng)
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7000000000000002
- type: f1
value: 0.985815849620051
- type: precision
value: 0.8884689922480621
- type: recall
value: 1.7000000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cbk-eng)
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.599999999999998
- type: f1
value: 14.086312656126182
- type: precision
value: 13.192360560816125
- type: recall
value: 17.599999999999998
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hun-eng)
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.1
- type: f1
value: 4.683795729173087
- type: precision
value: 4.31687579027912
- type: recall
value: 6.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uig-eng)
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.4
- type: f1
value: 0.20966666666666667
- type: precision
value: 0.20500700280112047
- type: recall
value: 0.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (rus-eng)
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.6
- type: f1
value: 0.2454665118079752
- type: precision
value: 0.2255125167991618
- type: recall
value: 0.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (spa-eng)
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21
- type: f1
value: 18.965901242066018
- type: precision
value: 18.381437375171
- type: recall
value: 21
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hye-eng)
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.5390835579514826
- type: f1
value: 0.4048898457205192
- type: precision
value: 0.4046018763809678
- type: recall
value: 0.5390835579514826
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tel-eng)
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.282051282051282
- type: f1
value: 0.5098554872310529
- type: precision
value: 0.4715099715099715
- type: recall
value: 1.282051282051282
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (afr-eng)
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.7
- type: f1
value: 8.045120643200706
- type: precision
value: 7.387598023074453
- type: recall
value: 10.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mon-eng)
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.272727272727273
- type: f1
value: 1.44184724004356
- type: precision
value: 1.4082306862044767
- type: recall
value: 2.272727272727273
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arz-eng)
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.20964360587002098
- type: f1
value: 0.001335309591528796
- type: precision
value: 0.0006697878781789807
- type: recall
value: 0.20964360587002098
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hrv-eng)
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.1
- type: f1
value: 5.522254020507502
- type: precision
value: 5.081849426723903
- type: recall
value: 7.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nov-eng)
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 36.57587548638132
- type: f1
value: 30.325515383881147
- type: precision
value: 28.59255854392041
- type: recall
value: 36.57587548638132
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gsw-eng)
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.23931623931624
- type: f1
value: 13.548783761549718
- type: precision
value: 13.0472896359184
- type: recall
value: 16.23931623931624
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nds-eng)
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.3
- type: f1
value: 13.3418584934734
- type: precision
value: 12.506853047473756
- type: recall
value: 16.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ukr-eng)
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1
- type: f1
value: 0.7764001197963462
- type: precision
value: 0.7551049317943337
- type: recall
value: 1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uzb-eng)
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.9719626168224296
- type: f1
value: 3.190729401654313
- type: precision
value: 3.001159168296747
- type: recall
value: 3.9719626168224296
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lit-eng)
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.4000000000000004
- type: f1
value: 2.4847456001574653
- type: precision
value: 2.308739271803959
- type: recall
value: 3.4000000000000004
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ina-eng)
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 36.9
- type: f1
value: 31.390407955063697
- type: precision
value: 29.631294298308614
- type: recall
value: 36.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lfn-eng)
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.2
- type: f1
value: 12.551591810861895
- type: precision
value: 12.100586917562724
- type: recall
value: 14.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (zsm-eng)
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.2
- type: f1
value: 7.5561895648211435
- type: precision
value: 7.177371101110253
- type: recall
value: 9.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ita-eng)
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.2
- type: f1
value: 18.498268429117875
- type: precision
value: 17.693915156965357
- type: recall
value: 21.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cmn-eng)
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.2
- type: f1
value: 2.886572782530936
- type: precision
value: 2.5806792595351915
- type: recall
value: 4.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lvs-eng)
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.800000000000001
- type: f1
value: 4.881091920308238
- type: precision
value: 4.436731163345769
- type: recall
value: 6.800000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (glg-eng)
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22.1
- type: f1
value: 18.493832677140738
- type: precision
value: 17.52055858924503
- type: recall
value: 22.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ceb-eng)
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6
- type: f1
value: 4.58716840215435
- type: precision
value: 4.303119297298687
- type: recall
value: 6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bre-eng)
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.5
- type: f1
value: 3.813678559437776
- type: precision
value: 3.52375763382276
- type: recall
value: 5.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ben-eng)
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.2
- type: f1
value: 0.06701509872241579
- type: precision
value: 0.05017452006980803
- type: recall
value: 0.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swg-eng)
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 12.5
- type: f1
value: 9.325396825396826
- type: precision
value: 8.681972789115646
- type: recall
value: 12.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arq-eng)
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.43907793633369924
- type: f1
value: 0.26369680618309754
- type: precision
value: 0.24710650393580552
- type: recall
value: 0.43907793633369924
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kab-eng)
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7000000000000002
- type: f1
value: 1.0240727731562105
- type: precision
value: 0.9379457073996874
- type: recall
value: 1.7000000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fra-eng)
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 24.6
- type: f1
value: 21.527732683982684
- type: precision
value: 20.460911398969852
- type: recall
value: 24.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (por-eng)
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.400000000000002
- type: f1
value: 18.861948871033608
- type: precision
value: 17.469730524988158
- type: recall
value: 23.400000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tat-eng)
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.3
- type: f1
value: 0.8081609699284277
- type: precision
value: 0.8041232161030668
- type: recall
value: 1.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (oci-eng)
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.399999999999999
- type: f1
value: 11.982642360594898
- type: precision
value: 11.423911681034546
- type: recall
value: 14.399999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pol-eng)
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.7
- type: f1
value: 6.565099922088448
- type: precision
value: 6.009960806394631
- type: recall
value: 8.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (war-eng)
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.1
- type: f1
value: 5.483244116053285
- type: precision
value: 5.08036675810842
- type: recall
value: 7.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (aze-eng)
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3999999999999995
- type: f1
value: 3.2643948695904146
- type: precision
value: 3.031506651474311
- type: recall
value: 4.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (vie-eng)
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.1
- type: f1
value: 5.2787766765398345
- type: precision
value: 4.883891459552525
- type: recall
value: 7.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nno-eng)
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.5
- type: f1
value: 7.022436974789914
- type: precision
value: 6.517919923571304
- type: recall
value: 8.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cha-eng)
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.51824817518248
- type: f1
value: 14.159211038143834
- type: precision
value: 13.419131771033424
- type: recall
value: 17.51824817518248
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mhr-eng)
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.1008802791411487
- type: precision
value: 0.10044111373948113
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dan-eng)
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.3
- type: f1
value: 10.0642631078894
- type: precision
value: 9.714481189937882
- type: recall
value: 11.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ell-eng)
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.7000000000000001
- type: f1
value: 0.5023625310859353
- type: precision
value: 0.5011883541295307
- type: recall
value: 0.7000000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (amh-eng)
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.7857142857142856
- type: f1
value: 0.6731500547238763
- type: precision
value: 0.6364087301587301
- type: recall
value: 1.7857142857142856
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pam-eng)
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.000000000000001
- type: f1
value: 4.850226809905071
- type: precision
value: 4.3549672188068485
- type: recall
value: 7.000000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hsb-eng)
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.383022774327122
- type: f1
value: 4.080351427081423
- type: precision
value: 3.7431771127423294
- type: recall
value: 5.383022774327122
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (srp-eng)
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.9
- type: f1
value: 2.975065835065835
- type: precision
value: 2.7082951373488764
- type: recall
value: 3.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (epo-eng)
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 13.8
- type: f1
value: 10.976459812917616
- type: precision
value: 10.214566903851944
- type: recall
value: 13.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kzj-eng)
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.9
- type: f1
value: 3.5998112099809334
- type: precision
value: 3.391430386128988
- type: recall
value: 4.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (awa-eng)
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 2.1645021645021645
- type: f1
value: 0.28969205674033943
- type: precision
value: 0.1648931376979724
- type: recall
value: 2.1645021645021645
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fao-eng)
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.541984732824428
- type: f1
value: 8.129327179123026
- type: precision
value: 7.860730567672363
- type: recall
value: 9.541984732824428
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mal-eng)
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.5822416302765648
- type: f1
value: 0.3960292169899156
- type: precision
value: 0.36794436357755134
- type: recall
value: 0.5822416302765648
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ile-eng)
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.900000000000002
- type: f1
value: 20.98162273769728
- type: precision
value: 19.591031936732236
- type: recall
value: 25.900000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bos-eng)
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.322033898305085
- type: f1
value: 7.1764632211739166
- type: precision
value: 6.547619047619047
- type: recall
value: 9.322033898305085
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cor-eng)
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3999999999999995
- type: f1
value: 3.0484795026022216
- type: precision
value: 2.8132647991077686
- type: recall
value: 4.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cat-eng)
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 18.8
- type: f1
value: 15.52276497119774
- type: precision
value: 14.63296284434154
- type: recall
value: 18.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (eus-eng)
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10
- type: f1
value: 7.351901305737391
- type: precision
value: 6.759061952118555
- type: recall
value: 10
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yue-eng)
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.1
- type: f1
value: 2.1527437641723353
- type: precision
value: 2.0008336640383417
- type: recall
value: 3.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swe-eng)
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.6
- type: f1
value: 8.471815215313617
- type: precision
value: 7.942319409218233
- type: recall
value: 10.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dtp-eng)
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3
- type: f1
value: 2.7338036427188244
- type: precision
value: 2.5492261384839052
- type: recall
value: 4.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kat-eng)
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.40214477211796246
- type: f1
value: 0.28150134048257375
- type: precision
value: 0.2751516861859743
- type: recall
value: 0.40214477211796246
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jpn-eng)
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3
- type: f1
value: 1.5834901411814404
- type: precision
value: 1.3894010894944848
- type: recall
value: 3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (csb-eng)
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.905138339920949
- type: f1
value: 6.6397047981096735
- type: precision
value: 6.32664437012263
- type: recall
value: 7.905138339920949
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (xho-eng)
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.5211267605633805
- type: f1
value: 2.173419196807775
- type: precision
value: 2.14388897487489
- type: recall
value: 3.5211267605633805
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (orv-eng)
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.23952095808383234
- type: f1
value: 0.001262128032547595
- type: precision
value: 0.0006327654461278806
- type: recall
value: 0.23952095808383234
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ind-eng)
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 10.4
- type: f1
value: 8.370422351826372
- type: precision
value: 7.943809523809523
- type: recall
value: 10.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tuk-eng)
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.41871921182266
- type: f1
value: 3.4763895108722696
- type: precision
value: 3.1331846246882176
- type: recall
value: 5.41871921182266
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (max-eng)
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.15492957746479
- type: f1
value: 7.267458920187794
- type: precision
value: 6.893803787858966
- type: recall
value: 9.15492957746479
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swh-eng)
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.487179487179487
- type: f1
value: 6.902767160316073
- type: precision
value: 6.450346503818517
- type: recall
value: 9.487179487179487
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hin-eng)
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.1
- type: f1
value: 0.0002042900919305414
- type: precision
value: 0.00010224948875255625
- type: recall
value: 0.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dsb-eng)
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 5.010438413361169
- type: f1
value: 3.8116647214505277
- type: precision
value: 3.5454644309619634
- type: recall
value: 5.010438413361169
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ber-eng)
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 5.213158915433869
- type: precision
value: 5.080398110661268
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tam-eng)
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.9771986970684038
- type: f1
value: 0.5061388123277374
- type: precision
value: 0.43431053203040165
- type: recall
value: 0.9771986970684038
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slk-eng)
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.3
- type: f1
value: 5.6313180921027755
- type: precision
value: 5.303887400540395
- type: recall
value: 7.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tgl-eng)
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.5999999999999996
- type: f1
value: 3.2180089485458607
- type: precision
value: 3.1006756756756753
- type: recall
value: 3.5999999999999996
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ast-eng)
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 22.04724409448819
- type: f1
value: 17.92525934258218
- type: precision
value: 16.48251629836593
- type: recall
value: 22.04724409448819
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mkd-eng)
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.5
- type: f1
value: 0.1543743186232414
- type: precision
value: 0.13554933572174951
- type: recall
value: 0.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (khm-eng)
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.8310249307479225
- type: f1
value: 0.5102255597841558
- type: precision
value: 0.4859595744731704
- type: recall
value: 0.8310249307479225
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ces-eng)
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 4.7258390633390635
- type: precision
value: 4.288366570275279
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tzl-eng)
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.307692307692307
- type: f1
value: 14.763313609467454
- type: precision
value: 14.129273504273504
- type: recall
value: 17.307692307692307
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (urd-eng)
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.0022196828248667185
- type: precision
value: 0.0011148527298850575
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ara-eng)
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.3
- type: f1
value: 0.3
- type: precision
value: 0.3
- type: recall
value: 0.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kor-eng)
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.6
- type: f1
value: 0.500206611570248
- type: precision
value: 0.5001034126163392
- type: recall
value: 0.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yid-eng)
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 0.4716981132075472
- type: f1
value: 0.2953377695417789
- type: precision
value: 0.2754210459668228
- type: recall
value: 0.4716981132075472
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fin-eng)
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.3999999999999995
- type: f1
value: 3.6228414442700156
- type: precision
value: 3.4318238993710692
- type: recall
value: 4.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tha-eng)
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 1.2773722627737227
- type: f1
value: 1.0043318098096732
- type: precision
value: 0.9735777358593729
- type: recall
value: 1.2773722627737227
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (wuu-eng)
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 3.9
- type: f1
value: 2.6164533097276226
- type: precision
value: 2.3558186153594085
- type: recall
value: 3.9
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.5779999999999998
- type: map_at_10
value: 8.339
- type: map_at_100
value: 14.601
- type: map_at_1000
value: 16.104
- type: map_at_3
value: 4.06
- type: map_at_5
value: 6.049
- type: mrr_at_1
value: 18.367
- type: mrr_at_10
value: 35.178
- type: mrr_at_100
value: 36.464999999999996
- type: mrr_at_1000
value: 36.464999999999996
- type: mrr_at_3
value: 29.932
- type: mrr_at_5
value: 34.32
- type: ndcg_at_1
value: 16.326999999999998
- type: ndcg_at_10
value: 20.578
- type: ndcg_at_100
value: 34.285
- type: ndcg_at_1000
value: 45.853
- type: ndcg_at_3
value: 19.869999999999997
- type: ndcg_at_5
value: 22.081999999999997
- type: precision_at_1
value: 18.367
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.547
- type: precision_at_3
value: 23.128999999999998
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 1.5779999999999998
- type: recall_at_10
value: 14.801
- type: recall_at_100
value: 48.516999999999996
- type: recall_at_1000
value: 83.30300000000001
- type: recall_at_3
value: 5.267
- type: recall_at_5
value: 9.415999999999999
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.4186
- type: ap
value: 14.536282543597242
- type: f1
value: 55.47661372005608
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.318053197509904
- type: f1
value: 59.68272481532353
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 52.155753554312
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.99409906419503
- type: cos_sim_ap
value: 76.91824322304332
- type: cos_sim_f1
value: 70.97865694950546
- type: cos_sim_precision
value: 70.03081664098613
- type: cos_sim_recall
value: 71.95250659630607
- type: dot_accuracy
value: 85.37879239434942
- type: dot_ap
value: 71.86454698478344
- type: dot_f1
value: 66.48115355426259
- type: dot_precision
value: 63.84839650145773
- type: dot_recall
value: 69.34036939313984
- type: euclidean_accuracy
value: 87.00005960541218
- type: euclidean_ap
value: 76.9165913835565
- type: euclidean_f1
value: 71.23741557283039
- type: euclidean_precision
value: 68.89327088982007
- type: euclidean_recall
value: 73.7467018469657
- type: manhattan_accuracy
value: 87.06562555880075
- type: manhattan_ap
value: 76.85445703747546
- type: manhattan_f1
value: 70.95560571858539
- type: manhattan_precision
value: 67.61472275334609
- type: manhattan_recall
value: 74.64379947229551
- type: max_accuracy
value: 87.06562555880075
- type: max_ap
value: 76.91824322304332
- type: max_f1
value: 71.23741557283039
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.93934101758063
- type: cos_sim_ap
value: 86.1071528049007
- type: cos_sim_f1
value: 78.21588263552714
- type: cos_sim_precision
value: 75.20073900376609
- type: cos_sim_recall
value: 81.48290729904527
- type: dot_accuracy
value: 88.2504754142896
- type: dot_ap
value: 84.19709379723844
- type: dot_f1
value: 76.92307692307693
- type: dot_precision
value: 71.81969949916528
- type: dot_recall
value: 82.80720665229443
- type: euclidean_accuracy
value: 88.97232894787906
- type: euclidean_ap
value: 86.02763993294909
- type: euclidean_f1
value: 78.18372741427383
- type: euclidean_precision
value: 73.79861918107868
- type: euclidean_recall
value: 83.12288266091777
- type: manhattan_accuracy
value: 88.86948422400745
- type: manhattan_ap
value: 86.0009157821563
- type: manhattan_f1
value: 78.10668017659404
- type: manhattan_precision
value: 73.68564795848695
- type: manhattan_recall
value: 83.09208500153989
- type: max_accuracy
value: 88.97232894787906
- type: max_ap
value: 86.1071528049007
- type: max_f1
value: 78.21588263552714
---
<h1 align="center">GIST Embedding v0</h1>
*GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning*
The model is fine-tuned on top of the [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) using the [MEDI dataset](https://github.com/xlang-ai/instructor-embedding.git) augmented with mined triplets from the [MTEB Classification](https://huggingface.co/mteb) training dataset (excluding data from the Amazon Polarity Classification task).
The model does not require any instruction for generating embeddings. This means that queries for retrieval tasks can be directly encoded without crafting instructions.
Technical paper: [GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning](https://arxiv.org/abs/2402.16829)
# Data
The dataset used is a compilation of the MEDI and MTEB Classification training datasets. Third-party datasets may be subject to additional terms and conditions under their associated licenses. A HuggingFace Dataset version of the compiled dataset, and the specific revision used to train the model, is available:
- Dataset: [avsolatorio/medi-data-mteb_avs_triplets](https://huggingface.co/datasets/avsolatorio/medi-data-mteb_avs_triplets)
- Revision: 238a0499b6e6b690cc64ea56fde8461daa8341bb
The dataset contains a `task_type` key, which can be used to select only the mteb classification tasks (prefixed with `mteb_`).
The **MEDI Dataset** is published in the following paper: [One Embedder, Any Task: Instruction-Finetuned Text Embeddings](https://arxiv.org/abs/2212.09741).
The MTEB Benchmark results of the GIST embedding model, compared with the base model, suggest that the fine-tuning dataset has perturbed the model considerably, which resulted in significant improvements in certain tasks while adversely degrading performance in some.
The retrieval performance for the TRECCOVID task is of note. The fine-tuning dataset does not contain significant knowledge about COVID-19, which could have caused the observed performance degradation. We found some evidence, detailed in the paper, that thematic coverage of the fine-tuning data can affect downstream performance.
# Usage
The model can be easily loaded using the Sentence Transformers library.
```Python
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
revision = None # Replace with the specific revision to ensure reproducibility if the model is updated.
model = SentenceTransformer("avsolatorio/GIST-Embedding-v0", revision=revision)
texts = [
"Illustration of the REaLTabFormer model. The left block shows the non-relational tabular data model using GPT-2 with a causal LM head. In contrast, the right block shows how a relational dataset's child table is modeled using a sequence-to-sequence (Seq2Seq) model. The Seq2Seq model uses the observations in the parent table to condition the generation of the observations in the child table. The trained GPT-2 model on the parent table, with weights frozen, is also used as the encoder in the Seq2Seq model.",
"Predicting human mobility holds significant practical value, with applications ranging from enhancing disaster risk planning to simulating epidemic spread. In this paper, we present the GeoFormer, a decoder-only transformer model adapted from the GPT architecture to forecast human mobility.",
"As the economies of Southeast Asia continue adopting digital technologies, policy makers increasingly ask how to prepare the workforce for emerging labor demands. However, little is known about the skills that workers need to adapt to these changes"
]
# Compute embeddings
embeddings = model.encode(texts, convert_to_tensor=True)
# Compute cosine-similarity for each pair of sentences
scores = F.cosine_similarity(embeddings.unsqueeze(1), embeddings.unsqueeze(0), dim=-1)
print(scores.cpu().numpy())
```
# Training Parameters
Below are the training parameters used to fine-tune the model:
```
Epochs = 80
Warmup ratio = 0.1
Learning rate = 5e-6
Batch size = 32
Checkpoint step = 103500
Contrastive loss temperature = 0.01
```
# Evaluation
The model was evaluated using the [MTEB Evaluation](https://huggingface.co/mteb) suite.
# Citation
Please cite our work if you use GISTEmbed or the datasets we published in your projects or research. 🤗
```
@article{solatorio2024gistembed,
title={GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning},
author={Aivin V. Solatorio},
journal={arXiv preprint arXiv:2402.16829},
year={2024},
URL={https://arxiv.org/abs/2402.16829}
eprint={2402.16829},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
# Acknowledgements
This work is supported by the "KCP IV - Exploring Data Use in the Development Economics Literature using Large Language Models (AI and LLMs)" project funded by the [Knowledge for Change Program (KCP)](https://www.worldbank.org/en/programs/knowledge-for-change) of the World Bank - RA-P503405-RESE-TF0C3444.
The findings, interpretations, and conclusions expressed in this material are entirely those of the authors. They do not necessarily represent the views of the International Bank for Reconstruction and Development/World Bank and its affiliated organizations, or those of the Executive Directors of the World Bank or the governments they represent. |
RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf | RichardErkhov | "2024-07-01T21:05:44Z" | 156,155 | 1 | null | [
"gguf",
"region:us"
] | null | "2024-07-01T04:34:48Z" | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
alpaca-dragon-72b-v1 - GGUF
- Model creator: https://huggingface.co/ibivibiv/
- Original model: https://huggingface.co/ibivibiv/alpaca-dragon-72b-v1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [alpaca-dragon-72b-v1.Q2_K.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.Q2_K.gguf) | Q2_K | 25.22GB |
| [alpaca-dragon-72b-v1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.IQ3_XS.gguf) | IQ3_XS | 27.88GB |
| [alpaca-dragon-72b-v1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.IQ3_S.gguf) | IQ3_S | 29.4GB |
| [alpaca-dragon-72b-v1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.Q3_K_S.gguf) | Q3_K_S | 29.4GB |
| [alpaca-dragon-72b-v1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.IQ3_M.gguf) | IQ3_M | 30.98GB |
| [alpaca-dragon-72b-v1.Q3_K.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.Q3_K.gguf) | Q3_K | 32.85GB |
| [alpaca-dragon-72b-v1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.Q3_K_M.gguf) | Q3_K_M | 32.85GB |
| [alpaca-dragon-72b-v1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.Q3_K_L.gguf) | Q3_K_L | 35.85GB |
| [alpaca-dragon-72b-v1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/blob/main/alpaca-dragon-72b-v1.IQ4_XS.gguf) | IQ4_XS | 36.41GB |
| [alpaca-dragon-72b-v1.Q4_0.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q4_0 | 38.19GB |
| [alpaca-dragon-72b-v1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | IQ4_NL | 38.42GB |
| [alpaca-dragon-72b-v1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q4_K_S | 38.45GB |
| [alpaca-dragon-72b-v1.Q4_K.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q4_K | 40.77GB |
| [alpaca-dragon-72b-v1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q4_K_M | 40.77GB |
| [alpaca-dragon-72b-v1.Q4_1.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q4_1 | 42.32GB |
| [alpaca-dragon-72b-v1.Q5_0.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q5_0 | 46.46GB |
| [alpaca-dragon-72b-v1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q5_K_S | 46.46GB |
| [alpaca-dragon-72b-v1.Q5_K.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q5_K | 47.79GB |
| [alpaca-dragon-72b-v1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q5_K_M | 47.79GB |
| [alpaca-dragon-72b-v1.Q5_1.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q5_1 | 50.59GB |
| [alpaca-dragon-72b-v1.Q6_K.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q6_K | 55.24GB |
| [alpaca-dragon-72b-v1.Q8_0.gguf](https://huggingface.co/RichardErkhov/ibivibiv_-_alpaca-dragon-72b-v1-gguf/tree/main/) | Q8_0 | 71.55GB |
Original model description:
---
language:
- en
license: other
library_name: transformers
model-index:
- name: alpaca-dragon-72b-v1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 73.89
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/alpaca-dragon-72b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.16
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/alpaca-dragon-72b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.4
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/alpaca-dragon-72b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 72.69
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/alpaca-dragon-72b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 86.03
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/alpaca-dragon-72b-v1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.63
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=ibivibiv/alpaca-dragon-72b-v1
name: Open LLM Leaderboard
---
# Model Card for Alpaca Dragon 72B V1
Fine tune of [Smaug 72b v0.1](https://huggingface.co/abacusai/Smaug-72B-v0.1) using an alpaca data set I have handy. The data is of planning and reasoning, which I use to help allow a model to break down a set of asks into a logical plan. For some odd reason it bumps the mmlu and winogrande? I would have expected the ARC to go up over those two, but this is often more of an artform than a science at times. All thanks to [Abacus.AI](https://huggingface.co/abacusai) for sharing their work.
I used the same dataset in training one of my owl series [Strix Rufipes 70B](https://huggingface.co/ibivibiv/strix-rufipes-70b), which has worked well for planning out development tasks and other technical work.

# LICENSE
Note the license points back to SMAUG base license as it is a fine tune of their model only. Respect and abide by their conditions. Again, many thanks to Abacus for making their work open and use that as inspiration to keep your work open and respect their license agreements.
[License Link](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT)
## How to Get Started with the Model
Use the code below to get started with the model.
```
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("ibivibiv/alpaca-dragon-72b-v1")
model = AutoModelForCausalLM.from_pretrained("ibivibiv/alpaca-dragon-72b-v1")
inputs = tokenizer("### Instruction: Create a plan for developing the game of snake in python using pygame.\n### Response:\n", return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=200)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
## Evaluation
| Test Name | Accuracy (%) |
|---------------------------------|--------------|
| All | 77.31 |
| arc:challenge | 70.82 |
| hellaswag | 69.84 |
| hendrycksTest-abstract_algebra | 42.00 |
| hendrycksTest-anatomy | 71.85 |
| hendrycksTest-astronomy | 86.84 |
| hendrycksTest-business_ethics | 82.00 |
| hendrycksTest-clinical_knowledge| 84.53 |
| hendrycksTest-college_biology | 93.06 |
| hendrycksTest-college_chemistry | 54.00 |
| hendrycksTest-college_computer_science | 65.00 |
| hendrycksTest-college_mathematics | 52.00 |
| hendrycksTest-college_medicine | 75.14 |
| hendrycksTest-college_physics | 55.88 |
| hendrycksTest-computer_security | 82.00 |
| hendrycksTest-conceptual_physics| 80.43 |
| hendrycksTest-econometrics | 60.53 |
| hendrycksTest-electrical_engineering | 79.31 |
| hendrycksTest-elementary_mathematics | 70.37 |
| hendrycksTest-formal_logic | 58.73 |
| hendrycksTest-global_facts | 54.00 |
| hendrycksTest-high_school_biology | 88.39 |
| hendrycksTest-high_school_chemistry | 66.01 |
| hendrycksTest-high_school_computer_science | 82.00 |
| hendrycksTest-high_school_european_history | 84.24 |
| hendrycksTest-high_school_geography | 94.44 |
| hendrycksTest-high_school_government_and_politics | 98.96 |
| hendrycksTest-high_school_macroeconomics | 82.05 |
| hendrycksTest-high_school_mathematics | 45.93 |
| hendrycksTest-high_school_microeconomics | 86.13 |
| hendrycksTest-high_school_physics | 54.97 |
| hendrycksTest-high_school_psychology | 92.84 |
| hendrycksTest-high_school_statistics | 68.98 |
| hendrycksTest-high_school_us_history | 91.67 |
| hendrycksTest-high_school_world_history | 89.87 |
| hendrycksTest-human_aging | 78.03 |
| hendrycksTest-human_sexuality | 89.31 |
| hendrycksTest-international_law | 90.91 |
| hendrycksTest-jurisprudence | 87.96 |
| hendrycksTest-logical_fallacies | 84.05 |
| hendrycksTest-machine_learning | 58.93 |
| hendrycksTest-management | 87.38 |
| hendrycksTest-marketing | 95.30 |
| hendrycksTest-medical_genetics | 86.00 |
| hendrycksTest-miscellaneous | 92.21 |
| hendrycksTest-moral_disputes | 83.53 |
| hendrycksTest-moral_scenarios | 69.72 |
| hendrycksTest-nutrition | 85.62 |
| hendrycksTest-philosophy | 83.60 |
| hendrycksTest-prehistory | 87.04 |
| hendrycksTest-professional_accounting | 65.96 |
| hendrycksTest-professional_law | 60.69 |
| hendrycksTest-professional_medicine | 82.72 |
| hendrycksTest-professional_psychology | 81.86 |
| hendrycksTest-public_relations | 75.45 |
| hendrycksTest-security_studies | 82.04 |
| hendrycksTest-sociology | 88.56 |
| hendrycksTest-us_foreign_policy | 94.00 |
| hendrycksTest-virology | 57.23 |
| hendrycksTest-world_religions | 89.47 |
| truthfulqa:mc | 72.6 |
| winogrande | 86.03 |
| gsm8k | 77.63 |
## Environmental Impact
- **Hardware Type:** [A100's..... more than I wanted to use since its all on my $$$]
- **Hours used:** [8]
- **Cloud Provider:** [runpod.io]
- **Compute Region:** [US]
- **Carbon Emitted:** [?]
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_ibivibiv__alpaca-dragon-72b-v1)
| Metric |Value|
|---------------------------------|----:|
|Avg. |79.30|
|AI2 Reasoning Challenge (25-Shot)|73.89|
|HellaSwag (10-Shot) |88.16|
|MMLU (5-Shot) |77.40|
|TruthfulQA (0-shot) |72.69|
|Winogrande (5-shot) |86.03|
|GSM8k (5-shot) |77.63|
|
flair/ner-english-ontonotes | flair | "2023-04-07T09:23:02Z" | 155,991 | 17 | flair | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"en",
"dataset:ontonotes",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- ontonotes
widget:
- text: "On September 1st George Washington won 1 dollar."
---
## English NER in Flair (Ontonotes default model)
This is the 18-class NER model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **89.27** (Ontonotes)
Predicts 18 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| CARDINAL | cardinal value |
| DATE | date value |
| EVENT | event name |
| FAC | building name |
| GPE | geo-political entity |
| LANGUAGE | language name |
| LAW | law name |
| LOC | location name |
| MONEY | money name |
| NORP | affiliation |
| ORDINAL | ordinal value |
| ORG | organization name |
| PERCENT | percent value |
| PERSON | person name |
| PRODUCT | product name |
| QUANTITY | quantity value |
| TIME | time value |
| WORK_OF_ART | name of work of art |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/ner-english-ontonotes")
# make example sentence
sentence = Sentence("On September 1st George Washington won 1 dollar.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
This yields the following output:
```
Span [2,3]: "September 1st" [− Labels: DATE (0.8824)]
Span [4,5]: "George Washington" [− Labels: PERSON (0.9604)]
Span [7,8]: "1 dollar" [− Labels: MONEY (0.9837)]
```
So, the entities "*September 1st*" (labeled as a **date**), "*George Washington*" (labeled as a **person**) and "*1 dollar*" (labeled as a **money**) are found in the sentence "*On September 1st George Washington won 1 dollar*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. load the corpus (Ontonotes does not ship with Flair, you need to download and reformat into a column format yourself)
corpus: Corpus = ColumnCorpus(
"resources/tasks/onto-ner",
column_format={0: "text", 1: "pos", 2: "upos", 3: "ner"},
tag_to_bioes="ner",
)
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# GloVe embeddings
WordEmbeddings('en-crawl'),
# contextual string embeddings, forward
FlairEmbeddings('news-forward'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/ner-english-ontonotes',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
stabilityai/stable-video-diffusion-img2vid-xt-1-1 | stabilityai | "2024-04-12T08:45:37Z" | 155,587 | 562 | diffusers | [
"diffusers",
"safetensors",
"image-to-video",
"license:other",
"diffusers:StableVideoDiffusionPipeline",
"region:us"
] | image-to-video | "2024-02-02T15:40:53Z" | ---
pipeline_tag: image-to-video
license: other
license_name: stable-video-diffusion-1-1-nc-community
license_link: LICENSE
extra_gated_prompt: >-
STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE AGREEMENT
Dated: February 2, 2024
By clicking “I Accept” below or by using or distributing any portion or element of the Models, Software, Software Products or Derivative Works, you agree to the terms of this License. If you do not agree to this License, then you do not have any rights to use the Software Products or Derivative Works through this License, and you must immediately cease using the Software Products or Derivative Works. If you are agreeing to be bound by the terms of this License on behalf of your employer or other entity, you represent and warrant to Stability AI that you have full legal authority to bind your employer or such entity to this License. If you do not have the requisite authority, you may not accept the License or access the Software Products or Derivative Works on behalf of your employer or other entity.
"Agreement" means this Stable Non-Commercial Research Community License Agreement.
“AUP” means the Stability AI Acceptable Use Policy available at https://stability.ai/use-policy, as may be updated from time to time.
"Derivative Work(s)” means (a) any derivative work of the Software Products as recognized by U.S. copyright laws and (b) any modifications to a Model, and any other model created which is based on or derived from the Model or the Model’s output. For clarity, Derivative Works do not include the output of any Model.
“Documentation” means any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity's behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
“Model(s)" means, collectively, Stability AI’s proprietary models and algorithms, including machine-learning models, trained model weights and other elements of the foregoing, made available under this Agreement.
“Non-Commercial Uses” means exercising any of the rights granted herein for the purpose of research or non-commercial purposes. Non-Commercial Uses does not include any production use of the Software Products or any Derivative Works.
"Stability AI" or "we" means Stability AI Ltd. and its affiliates.
"Software" means Stability AI’s proprietary software made available under this Agreement.
“Software Products” means the Models, Software and Documentation, individually or in any combination.
1. License Rights and Redistribution.
a. Subject to your compliance with this Agreement, the AUP (which is hereby incorporated herein by reference), and the Documentation, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s intellectual property or other rights owned or controlled by Stability AI embodied in the Software Products to use, reproduce, distribute, and create Derivative Works of, the Software Products, in each case for Non-Commercial Uses only.
b. You may not use the Software Products or Derivative Works to enable third parties to use the Software Products or Derivative Works as part of your hosted service or via your APIs, whether you are adding substantial additional functionality thereto or not. Merely distributing the Software Products or Derivative Works for download online without offering any related service (ex. by distributing the Models on HuggingFace) is not a violation of this subsection. If you wish to use the Software Products or any Derivative Works for commercial or production use or you wish to make the Software Products or any Derivative Works available to third parties via your hosted service or your APIs, contact Stability AI at https://stability.ai/contact.
c. If you distribute or make the Software Products, or any Derivative Works thereof, available to a third party, the Software Products, Derivative Works, or any portion thereof, respectively, will remain subject to this Agreement and you must (i) provide a copy of this Agreement to such third party, and (ii) retain the following attribution notice within a "Notice" text file distributed as a part of such copies: "This Stability AI Model is licensed under the Stability AI Non-Commercial Research Community License, Copyright (c) Stability AI Ltd. All Rights Reserved.” If you create a Derivative Work of a Software Product, you may add your own attribution notices to the Notice file included with the Software Product, provided that you clearly indicate which attributions apply to the Software Product and you must state in the NOTICE file that you changed the Software Product and how it was modified.
2. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE SOFTWARE PRODUCTS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE SOFTWARE PRODUCTS, DERIVATIVE WORKS OR ANY OUTPUT OR RESULTS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE SOFTWARE PRODUCTS, DERIVATIVE WORKS AND ANY OUTPUT AND RESULTS.
3. Limitation of Liability. IN NO EVENT WILL STABILITY AI OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY DIRECT, INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF STABILITY AI OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
4. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Software Products or Derivative Works, neither Stability AI nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Software Products or Derivative Works.
b. Subject to Stability AI’s ownership of the Software Products and Derivative Works made by or for Stability AI, with respect to any Derivative Works that are made by you, as between you and Stability AI, you are and will be the owner of such Derivative Works
c. If you institute litigation or other proceedings against Stability AI (including a cross-claim or counterclaim in a lawsuit) alleging that the Software Products, Derivative Works or associated outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Stability AI from and against any claim by any third party arising out of or related to your use or distribution of the Software Products or Derivative Works in violation of this Agreement.
5. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Software Products and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Stability AI may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of any Software Products or Derivative Works. Sections 2-4 shall survive the termination of this Agreement.
6. Governing Law. This Agreement will be governed by and construed in accordance with the laws of the United States and the State of California without regard to choice of law
principles.
extra_gated_description: Stable Video Diffusion 1.1 License Agreement
extra_gated_button_content: Submit
extra_gated_fields:
Name: text
Company Name (if applicable): text
Email: text
Other Comments: text
By clicking here, you accept the License agreement, and will use the Software Products and Derivative Works for non-commercial or research purposes only: checkbox
By clicking here, you agree to sharing with Stability AI the information contained within this form and that Stability AI can contact you for the purposes of marketing our products and services: checkbox
---
# Stable Video Diffusion 1.1 Image-to-Video Model Card
<!-- Provide a quick summary of what the model is/does. -->

Stable Video Diffusion (SVD) 1.1 Image-to-Video is a diffusion model that takes in a still image as a conditioning frame, and generates a video from it.
Please note: For commercial use, please refer to https://stability.ai/membership.
## Model Details
### Model Description
(SVD 1.1) Image-to-Video is a latent diffusion model trained to generate short video clips from an image conditioning.
This model was trained to generate 25 frames at resolution 1024x576 given a context frame of the same size, finetuned from [SVD Image-to-Video [25 frames]](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt).
Fine tuning was performed with fixed conditioning at 6FPS and Motion Bucket Id 127 to improve the consistency of outputs without the need to adjust hyper parameters. These conditions are still adjustable and have not been removed. Performance outside of the fixed conditioning settings may vary compared to SVD 1.0.
- **Developed by:** Stability AI
- **Funded by:** Stability AI
- **Model type:** Generative image-to-video model
- **Finetuned from model:** SVD Image-to-Video [25 frames]
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/Stability-AI/generative-models),
which implements the most popular diffusion frameworks (both training and inference).
- **Repository:** https://github.com/Stability-AI/generative-models
- **Paper:** https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
## Uses
### Direct Use
The model is intended for both non-commercial and commercial usage. You can use this model for non-commercial or research purposes under the following [license](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/blob/main/LICENSE). Possible research areas and tasks include
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
For commercial use, please refer to https://stability.ai/membership.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events,
and therefore using the model to generate such content is out-of-scope for the abilities of this model.
The model should not be used in any way that violates Stability AI's [Acceptable Use Policy](https://stability.ai/use-policy).
## Limitations and Bias
### Limitations
- The generated videos are rather short (<= 4sec), and the model does not achieve perfect photorealism.
- The model may generate videos without motion, or very slow camera pans.
- The model cannot be controlled through text.
- The model cannot render legible text.
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Recommendations
The model is intended for both non-commercial and commercial usage.
## How to Get Started with the Model
Check out https://github.com/Stability-AI/generative-models |
google/paligemma-3b-mix-224 | google | "2024-06-27T14:10:10Z" | 155,018 | 43 | transformers | [
"transformers",
"safetensors",
"paligemma",
"pretraining",
"image-text-to-text",
"arxiv:2310.09199",
"arxiv:2303.15343",
"arxiv:2403.08295",
"arxiv:1706.03762",
"arxiv:2010.11929",
"arxiv:2209.06794",
"arxiv:2209.04372",
"arxiv:2103.01913",
"arxiv:2205.12522",
"arxiv:2110.11624",
"arxiv:2108.03353",
"arxiv:2010.04295",
"arxiv:2401.06209",
"arxiv:2305.10355",
"arxiv:2203.10244",
"arxiv:1810.12440",
"arxiv:1905.13648",
"arxiv:1608.00272",
"arxiv:1908.04913",
"license:gemma",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | image-text-to-text | "2024-05-12T23:03:44Z" | ---
library_name: transformers
license: gemma
pipeline_tag: image-text-to-text
extra_gated_heading: Access PaliGemma on Hugging Face
extra_gated_prompt: To access PaliGemma on Hugging Face, you’re required to review
and agree to Google’s usage license. To do this, please ensure you’re logged-in
to Hugging Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
# PaliGemma model card
**Model page:** [PaliGemma](https://ai.google.dev/gemma/docs/paligemma)
Transformers PaliGemma 3B weights, fine-tuned with 224*224 input images and 256 token input/output text sequences on a mixture of downstream academic datasets. The models are available in float32, bfloat16 and float16 format for research purposes only.
**Resources and technical documentation:**
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [PaliGemma on Kaggle](https://www.kaggle.com/models/google/paligemma)
* [PaliGemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/363)
**Terms of Use:** [Terms](https://www.kaggle.com/models/google/paligemma/license/consent/verify/huggingface?returnModelRepoId=google/paligemma-3b-mix-224)
**Authors:** Google
## Model information
### Model summary
#### Description
PaliGemma is a versatile and lightweight vision-language model (VLM) inspired by
[PaLI-3](https://arxiv.org/abs/2310.09199) and based on open components such as
the [SigLIP vision model](https://arxiv.org/abs/2303.15343) and the [Gemma
language model](https://arxiv.org/abs/2403.08295). It takes both image and text
as input and generates text as output, supporting multiple languages. It is designed for class-leading fine-tune performance on a wide range of vision-language tasks such as image and short video caption, visual question answering, text reading, object detection and object segmentation.
#### Model architecture
PaliGemma is the composition of a [Transformer
decoder](https://arxiv.org/abs/1706.03762) and a [Vision Transformer image
encoder](https://arxiv.org/abs/2010.11929), with a total of 3 billion
params. The text decoder is initialized from
[Gemma-2B](https://www.kaggle.com/models/google/gemma). The image encoder is
initialized from
[SigLIP-So400m/14](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/SigLIP_demo.ipynb).
PaliGemma is trained following the PaLI-3 recipes.
#### Inputs and outputs
* **Input:** Image and text string, such as a prompt to caption the image, or
a question.
* **Output:** Generated text in response to the input, such as a caption of
the image, an answer to a question, a list of object bounding box
coordinates, or segmentation codewords.
### Model data
#### Pre-train datasets
PaliGemma is pre-trained on the following mixture of datasets:
* **WebLI:** [WebLI (Web Language Image)](https://arxiv.org/abs/2209.06794) is
a web-scale multilingual image-text dataset built from the public web. A
wide range of WebLI splits are used to acquire versatile model capabilities,
such as visual semantic understanding, object localization,
visually-situated text understanding, multilinguality, etc.
* **CC3M-35L:** Curated English image-alt_text pairs from webpages ([Sharma et
al., 2018](https://aclanthology.org/P18-1238/)). We used the [Google Cloud
Translation API](https://cloud.google.com/translate) to translate into 34
additional languages.
* **VQ²A-CC3M-35L/VQG-CC3M-35L:** A subset of VQ2A-CC3M ([Changpinyo et al.,
2022a](https://aclanthology.org/2022.naacl-main.142/)), translated into the
same additional 34 languages as CC3M-35L, using the [Google Cloud
Translation API](https://cloud.google.com/translate).
* **OpenImages:** Detection and object-aware questions and answers
([Piergiovanni et al. 2022](https://arxiv.org/abs/2209.04372)) generated by
handcrafted rules on the [OpenImages dataset].
* **WIT:** Images and texts collected from Wikipedia ([Srinivasan et al.,
2021](https://arxiv.org/abs/2103.01913)).
[OpenImages dataset]: https://storage.googleapis.com/openimages/web/factsfigures_v7.html
#### Data responsibility filtering
The following filters are applied to WebLI, with the goal of training PaliGemma
on clean data:
* **Pornographic image filtering:** This filter removes images deemed to be of
pornographic nature.
* **Text safety filtering:** We identify and filter out images that are paired
with unsafe text. Unsafe text is any text deemed to contain or be about
CSAI, pornography, vulgarities, or otherwise offensive.
* **Text toxicity filtering:** We further use the [Perspective
API](https://perspectiveapi.com/) to identify and filter out images that are
paired with text deemed insulting, obscene, hateful or otherwise toxic.
* **Text personal information filtering:** We filtered certain personal information and other sensitive data using [Cloud Data Loss Prevention (DLP)
API](https://cloud.google.com/security/products/dlp) to protect the privacy
of individuals. Identifiers such as social security numbers and [other sensitive information types] were removed.
* **Additional methods:** Filtering based on content quality and safety in
line with our policies and practices.
[other sensitive information types]: https://cloud.google.com/sensitive-data-protection/docs/high-sensitivity-infotypes-reference?_gl=1*jg604m*_ga*ODk5MzA3ODQyLjE3MTAzMzQ3NTk.*_ga_WH2QY8WWF5*MTcxMDUxNTkxMS4yLjEuMTcxMDUxNjA2NC4wLjAuMA..&_ga=2.172110058.-899307842.1710334759
## How to Use
PaliGemma is a single-turn vision language model not meant for conversational use,
and it works best when fine-tuning to a specific use case.
You can configure which task the model will solve by conditioning it with task prefixes,
such as “detect” or “segment”. The pretrained models were trained in this fashion to imbue
them with a rich set of capabilities (question answering, captioning, segmentation, etc.).
However, they are not designed to be used directly, but to be transferred (by fine-tuning)
to specific tasks using a similar prompt structure. For interactive testing, you can use
the "mix" family of models, which have been fine-tuned on a mixture of tasks. To see model
[google/paligemma-3b-mix-448](https://huggingface.co/google/paligemma-3b-mix-448) in action,
check [this Space that uses the Transformers codebase](https://huggingface.co/spaces/big-vision/paligemma-hf).
Please, refer to the [usage and limitations section](#usage-and-limitations) for intended
use cases, or visit the [blog post](https://huggingface.co/blog/paligemma-google-vlm) for
additional details and examples.
## Use in Transformers
The following snippets use model `google/paligemma-3b-mix-224` for reference purposes.
The model in this repo you are now browsing may have been trained for other tasks, please
make sure you use appropriate inputs for the task at hand.
### Running the default precision (`float32`) on CPU
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/paligemma-3b-mix-224"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id).eval()
processor = AutoProcessor.from_pretrained(model_id)
# Instruct the model to create a caption in Spanish
prompt = "caption es"
model_inputs = processor(text=prompt, images=image, return_tensors="pt")
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
```
Output: `Un auto azul estacionado frente a un edificio.`
### Running other precisions on CUDA
For convenience, the repos contain revisions of the weights already converted to `bfloat16` and `float16`,
so you can use them to reduce the download size and avoid casting on your local computer.
This is how you'd run `bfloat16` on an nvidia CUDA card.
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/paligemma-3b-mix-224"
device = "cuda:0"
dtype = torch.bfloat16
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=dtype,
device_map=device,
revision="bfloat16",
).eval()
processor = AutoProcessor.from_pretrained(model_id)
# Instruct the model to create a caption in Spanish
prompt = "caption es"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
```
### Loading in 4-bit / 8-bit
You need to install `bitsandbytes` to automatically run inference using 8-bit or 4-bit precision:
```
pip install bitsandbytes accelerate
```
```
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/paligemma-3b-mix-224"
device = "cuda:0"
dtype = torch.bfloat16
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id, quantization_config=quantization_config
).eval()
processor = AutoProcessor.from_pretrained(model_id)
# Instruct the model to create a caption in Spanish
prompt = "caption es"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
```
## Implementation information
### Hardware
PaliGemma was trained using the latest generation of Tensor Processing Unit
(TPU) hardware (TPUv5e).
### Software
Training was done using [JAX](https://github.com/google/jax),
[Flax](https://github.com/google/flax),
[TFDS](https://github.com/tensorflow/datasets) and
[`big_vision`](https://github.com/google-research/big_vision).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
TFDS is used to access datasets and Flax is used for model architecture. The
PaliGemma fine-tune code and inference code are released in the `big_vision`
GitHub repository.
## Evaluation information
### Benchmark results
In order to verify the transferability of PaliGemma to a wide variety of
academic tasks, we fine-tune the pretrained models on each task. Additionally we
train the mix model with a mixture of the transfer tasks. We report results on
different resolutions to provide an impression of which tasks benefit from
increased resolution. Importantly, none of these tasks or datasets are part of
the pretraining data mixture, and their images are explicitly removed from the
web-scale pre-training data.
#### Single task (fine-tune on single task)
<table>
<tbody><tr>
<th>Benchmark<br>(train split)</th>
<th>Metric<br>(split)</th>
<th>pt-224</th>
<th>pt-448</th>
<th>pt-896</th>
</tr>
<tr>
<th>Captioning</th>
</tr>
<tr>
<td>
<a href="https://cocodataset.org/#home">COCO captions</a><br>(train+restval)
</td>
<td>CIDEr (val)</td>
<td>141.92</td>
<td>144.60</td>
</tr>
<tr>
<td>
<a href="https://nocaps.org/">NoCaps</a><br>(Eval of COCO<br>captions transfer)
</td>
<td>CIDEr (val)</td>
<td>121.72</td>
<td>123.58</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/pdf/2205.12522">COCO-35L</a><br>(train)
</td>
<td>CIDEr dev<br>(en/avg-34/avg)</td>
<td>
139.2<br>
115.8<br>
116.4
</td>
<td>
141.2<br>
118.0<br>
118.6
</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/pdf/2205.12522">XM3600</a><br>(Eval of COCO-35L transfer)
</td>
<td>CIDEr dev<br>(en/avg-34/avg)</td>
<td>
78.1<br>
41.3<br>
42.4
</td>
<td>
80.0<br>
41.9<br>
42.9
</td>
</tr>
<tr>
<td>
<a href="https://textvqa.org/textcaps/">TextCaps</a><br>(train)
</td>
<td>CIDEr (val)</td>
<td>127.48</td>
<td>153.94</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/2110.11624">SciCap</a><br>(first sentence, no subfigure)<br>(train+val)
</td>
<td>CIDEr/BLEU-4<br>(test)</td>
<td>
162.25<br>
0.192<br>
</td>
<td>
181.49<br>
0.211<br>
</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/2108.03353">Screen2words</a><br>(train+dev)
</td>
<td>CIDEr (test)</td>
<td>117.57</td>
<td>119.59</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/2010.04295">Widget Captioning</a><br>(train+dev)
</td>
<td>CIDEr (test)</td>
<td>136.07</td>
<td>148.36</td>
</tr>
<tr>
<th>Question answering</th>
</tr>
<tr>
<td>
<a href="https://visualqa.org/index.html">VQAv2</a><br>(train+validation)
</td>
<td>Accuracy<br>(Test server - std)</td>
<td>83.19</td>
<td>85.64</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/2401.06209">MMVP</a><br>(Eval of VQAv2 transfer)
</td>
<td>Paired Accuracy</td>
<td>47.33</td>
<td>45.33</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/2305.10355">POPE</a><br>(Eval of VQAv2 transfer)
</td>
<td>Accuracy<br>(random/popular/<br>adversarial)</td>
<td>
87.80<br>
85.87<br>
84.27
</td>
<td>
88.23<br>
86.77<br>
85.90
</td>
</tr>
<tr>
<td>
<a href="https://okvqa.allenai.org/">OKVQA</a><br>(train)
</td>
<td>Accuracy (val)</td>
<td>63.54</td>
<td>63.15</td>
</tr>
<tr>
<td>
<a href="https://allenai.org/project/a-okvqa/home">A-OKVQA</a> (MC)<br>(train+val)
</td>
<td>Accuracy<br>(Test server)</td>
<td>76.37</td>
<td>76.90</td>
</tr>
<tr>
<td>
<a href="https://allenai.org/project/a-okvqa/home">A-OKVQA</a> (DA)<br>(train+val)
</td>
<td>Accuracy<br>(Test server)</td>
<td>61.85</td>
<td>63.22</td>
</tr>
<tr>
<td>
<a href="https://cs.stanford.edu/people/dorarad/gqa/about.html">GQA</a><br>(train_balanced+<br>val_balanced)
</td>
<td>Accuracy<br>(testdev balanced)</td>
<td>65.61</td>
<td>67.03</td>
</tr>
<tr>
<td>
<a href="https://aclanthology.org/2022.findings-acl.196/">xGQA</a><br>(Eval of GQA transfer)
</td>
<td>Mean Accuracy<br>(bn, de, en, id,<br>ko, pt, ru, zh)</td>
<td>58.37</td>
<td>59.07</td>
</tr>
<tr>
<td>
<a href="https://lil.nlp.cornell.edu/nlvr/">NLVR2</a><br>(train+dev)
</td>
<td>Accuracy (test)</td>
<td>90.02</td>
<td>88.93</td>
</tr>
<tr>
<td>
<a href="https://marvl-challenge.github.io/">MaRVL</a><br>(Eval of NLVR2 transfer)
</td>
<td>Mean Accuracy<br>(test)<br>(id, sw, ta, tr, zh)</td>
<td>80.57</td>
<td>76.78</td>
</tr>
<tr>
<td>
<a href="https://allenai.org/data/diagrams">AI2D</a><br>(train)
</td>
<td>Accuracy (test)</td>
<td>72.12</td>
<td>73.28</td>
</tr>
<tr>
<td>
<a href="https://scienceqa.github.io/">ScienceQA</a><br>(Img subset, no CoT)<br>(train+val)
</td>
<td>Accuracy (test)</td>
<td>95.39</td>
<td>95.93</td>
</tr>
<tr>
<td>
<a href="https://zenodo.org/records/6344334">RSVQA-LR</a> (Non numeric)<br>(train+val)
</td>
<td>Mean Accuracy<br>(test)</td>
<td>92.65</td>
<td>93.11</td>
</tr>
<tr>
<td>
<a href="https://zenodo.org/records/6344367">RSVQA-HR</a> (Non numeric)<br>(train+val)
</td>
<td>Mean Accuracy<br>(test/test2)</td>
<td>
92.61<br>
90.58
</td>
<td>
92.79<br>
90.54
</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/2203.10244">ChartQA</a><br>(human+aug)x(train+val)
</td>
<td>Mean Relaxed<br>Accuracy<br>(test_human,<br>test_aug)</td>
<td>57.08</td>
<td>71.36</td>
</tr>
<tr>
<td>
<a href="https://vizwiz.org/tasks-and-datasets/vqa/">VizWiz VQA</a><br>(train+val)
</td>
<td>Accuracy<br>(Test server - std)</td>
<td>
73.7
</td>
<td>
75.52
</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/1810.12440">TallyQA</a><br>(train)
</td>
<td>Accuracy<br>(test_simple/<br>test_complex)</td>
<td>
81.72<br>
69.56
</td>
<td>
84.86<br>
72.27
</td>
</tr>
<tr>
<td>
<a href="https://ocr-vqa.github.io/">OCR-VQA</a><br>(train+val)
</td>
<td>Accuracy (test)</td>
<td>72.32</td>
<td>74.61</td>
<td>74.93</td>
</tr>
<tr>
<td>
<a href="https://textvqa.org/">TextVQA</a><br>(train+val)
</td>
<td>Accuracy<br>(Test server - std)</td>
<td>55.47</td>
<td>73.15</td>
<td>76.48</td>
</tr>
<tr>
<td>
<a href="https://www.docvqa.org/">DocVQA</a><br>(train+val)
</td>
<td>ANLS (Test server)</td>
<td>43.74</td>
<td>78.02</td>
<td>84.77</td>
</tr>
<tr>
<td>
<a href="https://openaccess.thecvf.com/content/WACV2022/papers/Mathew_InfographicVQA_WACV_2022_paper.pdf">Infographic VQA</a><br>(train+val)
</td>
<td>ANLS (Test server)</td>
<td>28.46</td>
<td>40.47</td>
<td>47.75</td>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/1905.13648">SceneText VQA</a><br>(train+val)
</td>
<td>ANLS (Test server)</td>
<td>63.29</td>
<td>81.82</td>
<td>84.40</td>
</tr>
<tr>
<th>Segmentation</th>
</tr>
<tr>
<td>
<a href="https://arxiv.org/abs/1608.00272">RefCOCO</a><br>(combined refcoco, refcoco+,<br>refcocog excluding val<br>and test images)
</td>
<td>MIoU<br>(validation)<br>refcoco/refcoco+/<br>refcocog</td>
<td>
73.40<br>
68.32<br>
67.65
</td>
<td>
75.57<br>
69.76<br>
70.17
</td>
<td>
76.94<br>
72.18<br>
72.22
</td>
</tr>
<tr>
<th>Video tasks (Caption/QA)</th>
</tr>
<tr>
<td>MSR-VTT (Captioning)</td>
<td>CIDEr (test)</td>
<td>70.54</td>
</tr>
<tr>
<td>MSR-VTT (QA)</td>
<td>Accuracy (test)</td>
<td>50.09</td>
</tr>
<tr>
<td>ActivityNet (Captioning)</td>
<td>CIDEr (test)</td>
<td>34.62</td>
</tr>
<tr>
<td>ActivityNet (QA)</td>
<td>Accuracy (test)</td>
<td>50.78</td>
</tr>
<tr>
<td>VATEX (Captioning)</td>
<td>CIDEr (test)</td>
<td>79.73</td>
</tr>
<tr>
<td>MSVD (QA)</td>
<td>Accuracy (test)</td>
<td>60.22</td>
</tr>
</tbody></table>
#### Mix model (fine-tune on mixture of transfer tasks)
<table>
<tbody><tr>
<th>Benchmark</th>
<th>Metric (split)</th>
<th>mix-224</th>
<th>mix-448</th>
</tr>
<tr>
<td><a href="https://arxiv.org/abs/2401.06209">MMVP</a></td>
<td>Paired Accuracy</td>
<td>46.00</td>
<td>45.33</td>
</tr>
<tr>
<td><a href="https://arxiv.org/abs/2305.10355">POPE</a></td>
<td>Accuracy<br>(random/popular/adversarial)</td>
<td>
88.00<br>
86.63<br>
85.67
</td>
<td>
89.37<br>
88.40<br>
87.47
</td>
</tr>
</tbody></table>
## Ethics and safety
### Evaluation approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Human evaluation on prompts covering child safety, content safety and
representational harms. See the [Gemma model
card](https://ai.google.dev/gemma/docs/model_card#evaluation_approach) for
more details on evaluation approach, but with image captioning and visual
question answering setups.
* Image-to-Text benchmark evaluation: Benchmark against relevant academic
datasets such as FairFace Dataset ([Karkkainen et al.,
2021](https://arxiv.org/abs/1908.04913)).
### Evaluation results
* The human evaluation results of ethics and safety evaluations are within
acceptable thresholds for meeting [internal
policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11)
for categories such as child safety, content safety and representational
harms.
* On top of robust internal evaluations, we also use the Perspective API
(threshold of 0.8) to measure toxicity, profanity, and other potential
issues in the generated captions for images sourced from the FairFace
dataset. We report the maximum and median values observed across subgroups
for each of the perceived gender, ethnicity, and age attributes.
<table>
<tbody><tr>
</tr></tbody><tbody><tr><th>Metric</th>
<th>Perceived<br>gender</th>
<th></th>
<th>Ethnicity</th>
<th></th>
<th>Age group</th>
<th></th>
</tr>
<tr>
<th></th>
<th>Maximum</th>
<th>Median</th>
<th>Maximum</th>
<th>Median</th>
<th>Maximum</th>
<th>Median</th>
</tr>
<tr>
<td>Toxicity</td>
<td>0.04%</td>
<td>0.03%</td>
<td>0.08%</td>
<td>0.00%</td>
<td>0.09%</td>
<td>0.00%</td>
</tr>
<tr>
<td>Identity Attack</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
</tr>
<tr>
<td>Insult</td>
<td>0.06%</td>
<td>0.04%</td>
<td>0.09%</td>
<td>0.07%</td>
<td>0.16%</td>
<td>0.00%</td>
</tr>
<tr>
<td>Threat</td>
<td>0.06%</td>
<td>0.05%</td>
<td>0.14%</td>
<td>0.05%</td>
<td>0.17%</td>
<td>0.00%</td>
</tr>
<tr>
<td>Profanity</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
<td>0.00%</td>
</tr>
</tbody></table>
## Usage and limitations
### Intended usage
Open Vision Language Models (VLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
Fine-tune on specific vision-language task:
* The pre-trained models can be fine-tuned on a wide range of vision-language
tasks such as: image captioning, short video caption, visual question
answering, text reading, object detection and object segmentation.
* The pre-trained models can be fine-tuned for specific domains such as remote
sensing question answering, visual questions from people who are blind,
science question answering, describe UI element functionalities.
* The pre-trained models can be fine-tuned for tasks with non-textual outputs
such as bounding boxes or segmentation masks.
Vision-language research:
* The pre-trained models and fine-tuned models can serve as a foundation for researchers to experiment with VLM
techniques, develop algorithms, and contribute to the advancement of the
field.
### Ethical considerations and risks
The development of vision-language models (VLMs) raises several ethical concerns. In creating an open model, we have carefully considered the following:
* Bias and Fairness
* VLMs trained on large-scale, real-world image-text data can reflect socio-cultural biases embedded in the training material. These models underwent careful scrutiny, input data pre-processing described and posterior evaluations reported in this card.
* Misinformation and Misuse
* VLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the [Responsible Generative AI Toolkit](https://ai.google.dev/responsible).
* Transparency and Accountability
* This model card summarizes details on the models' architecture, capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share innovation by making VLM technology accessible to developers and researchers across the AI ecosystem.
Risks identified and mitigations:
* **Perpetuation of biases:** It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* **Generation of harmful content:** Mechanisms and guidelines for content
safety are essential. Developers are encouraged to exercise caution and
implement appropriate content safety safeguards based on their specific
product policies and application use cases.
* **Misuse for malicious purposes:** Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the [Gemma
Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* **Privacy violations:** Models were trained on data filtered to remove certain personal information and sensitive data. Developers are encouraged to adhere to privacy regulations with privacy-preserving techniques.
### Limitations
* Most limitations inherited from the underlying Gemma model still apply:
* VLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* Natural language is inherently complex. VLMs might struggle to grasp
subtle nuances, sarcasm, or figurative language.
* VLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* VLMs rely on statistical patterns in language and images. They might
lack the ability to apply common sense reasoning in certain situations.
* PaliGemma was designed first and foremost to serve as a general pre-trained
model for transfer to specialized tasks. Hence, its "out of the box" or
"zero-shot" performance might lag behind models designed specifically for
that.
* PaliGemma is not a multi-turn chatbot. It is designed for a single round of
image and text input. |
vinai/bertweet-base | vinai | "2022-10-22T08:52:39Z" | 154,695 | 28 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | # <a name="introduction"></a> BERTweet: A pre-trained language model for English Tweets
BERTweet is the first public large-scale language model pre-trained for English Tweets. BERTweet is trained based on the [RoBERTa](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md) pre-training procedure. The corpus used to pre-train BERTweet consists of 850M English Tweets (16B word tokens ~ 80GB), containing 845M Tweets streamed from 01/2012 to 08/2019 and 5M Tweets related to the **COVID-19** pandemic. The general architecture and experimental results of BERTweet can be found in our [paper](https://aclanthology.org/2020.emnlp-demos.2/):
@inproceedings{bertweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages = {9--14},
year = {2020}
}
**Please CITE** our paper when BERTweet is used to help produce published results or is incorporated into other software.
For further information or requests, please go to [BERTweet's homepage](https://github.com/VinAIResearch/BERTweet)!
### Main results
<p float="left">
<img width="275" alt="postagging" src="https://user-images.githubusercontent.com/2412555/135724590-01d8d435-262d-44fe-a383-cd39324fe190.png" />
<img width="275" alt="ner" src="https://user-images.githubusercontent.com/2412555/135724598-1e3605e7-d8ce-4c5e-be4a-62ae8501fae7.png" />
</p>
<p float="left">
<img width="275" alt="sentiment" src="https://user-images.githubusercontent.com/2412555/135724597-f1981f1e-fe73-4c03-b1ff-0cae0cc5f948.png" />
<img width="275" alt="irony" src="https://user-images.githubusercontent.com/2412555/135724595-15f4f2c8-bbb6-4ee6-82a0-034769dec183.png" />
</p>
|
EleutherAI/pythia-70m | EleutherAI | "2023-11-21T19:04:09Z" | 154,678 | 47 | gpt-neox | [
"gpt-neox",
"pytorch",
"safetensors",
"gpt_neox",
"causal-lm",
"pythia",
"en",
"dataset:EleutherAI/pile",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"region:us"
] | null | "2023-02-13T14:54:51Z" | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- EleutherAI/pile
library_name: gpt-neox
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-70M
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-70M for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-70M as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-70M has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-70M will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-70M to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-70M may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-70M.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-70M.
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_EleutherAI__pythia-70m)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 25.28 |
| ARC (25-shot) | 21.59 |
| HellaSwag (10-shot) | 27.29 |
| MMLU (5-shot) | 25.9 |
| TruthfulQA (0-shot) | 47.06 |
| Winogrande (5-shot) | 51.46 |
| GSM8K (5-shot) | 0.3 |
| DROP (3-shot) | 3.33 | |
tals/albert-xlarge-vitaminc-mnli | tals | "2023-03-17T05:27:53Z" | 154,448 | 5 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"albert",
"text-classification",
"dataset:glue",
"dataset:multi_nli",
"dataset:tals/vitaminc",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
datasets:
- glue
- multi_nli
- tals/vitaminc
---
# Details
Model used in [Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence](https://aclanthology.org/2021.naacl-main.52/) (Schuster et al., NAACL 21`).
For more details see: https://github.com/TalSchuster/VitaminC
When using this model, please cite the paper.
# BibTeX entry and citation info
```bibtex
@inproceedings{schuster-etal-2021-get,
title = "Get Your Vitamin {C}! Robust Fact Verification with Contrastive Evidence",
author = "Schuster, Tal and
Fisch, Adam and
Barzilay, Regina",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.52",
doi = "10.18653/v1/2021.naacl-main.52",
pages = "624--643",
abstract = "Typical fact verification models use retrieved written evidence to verify claims. Evidence sources, however, often change over time as more information is gathered and revised. In order to adapt, models must be sensitive to subtle differences in supporting evidence. We present VitaminC, a benchmark infused with challenging cases that require fact verification models to discern and adjust to slight factual changes. We collect over 100,000 Wikipedia revisions that modify an underlying fact, and leverage these revisions, together with additional synthetically constructed ones, to create a total of over 400,000 claim-evidence pairs. Unlike previous resources, the examples in VitaminC are contrastive, i.e., they contain evidence pairs that are nearly identical in language and content, with the exception that one supports a given claim while the other does not. We show that training using this design increases robustness{---}improving accuracy by 10{\%} on adversarial fact verification and 6{\%} on adversarial natural language inference (NLI). Moreover, the structure of VitaminC leads us to define additional tasks for fact-checking resources: tagging relevant words in the evidence for verifying the claim, identifying factual revisions, and providing automatic edits via factually consistent text generation.",
}
```
|
sentence-transformers-testing/stsb-bert-tiny-safetensors | sentence-transformers-testing | "2024-01-17T11:47:16Z" | 154,322 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | sentence-similarity | "2023-11-06T13:20:57Z" | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers-testing/stsb-bert-tiny-safetensors
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 128 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers-testing/stsb-bert-tiny-safetensors')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers-testing/stsb-bert-tiny-safetensors')
model = AutoModel.from_pretrained('sentence-transformers-testing/stsb-bert-tiny-safetensors')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers-testing/stsb-bert-tiny-safetensors)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 360 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 1000,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 8e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 36,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 128, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
google/gemma-2b-it | google | "2024-06-27T14:09:40Z" | 153,992 | 573 | transformers | [
"transformers",
"safetensors",
"gguf",
"gemma",
"text-generation",
"conversational",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"license:gemma",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2024-02-08T13:23:59Z" | ---
library_name: transformers
license: gemma
widget:
- messages:
- role: user
content: How does the brain work?
inference:
parameters:
max_new_tokens: 200
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 2B instruct version of the Gemma model. You can also visit the model card of the [2B base model](https://huggingface.co/google/gemma-2b), [7B base model](https://huggingface.co/google/gemma-7b), and [7B instruct model](https://huggingface.co/google/gemma-7b-it).
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335?version=gemma-2b-it-gg-hf)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent/verify/huggingface?returnModelRepoId=google/gemma-2b-it)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Running the model on a CPU
As explained below, we recommend `torch.bfloat16` as the default dtype. You can use [a different precision](#precisions) if necessary.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
<a name="precisions"></a>
#### Running the model on a GPU using different precisions
The native weights of this model were exported in `bfloat16` precision. You can use `float16`, which may be faster on certain hardware, indicating the `torch_dtype` when loading the model. For convenience, the `float16` revision of the repo contains a copy of the weights already converted to that precision.
You can also use `float32` if you skip the dtype, but no precision increase will occur (model weights will just be upcasted to `float32`). See examples below.
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
torch_dtype=torch.float16,
revision="float16",
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Upcasting to `torch.float32`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto"
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b-it", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b-it", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Chat Template
The instruction-tuned models use a chat template that must be adhered to for conversational use.
The easiest way to apply it is using the tokenizer's built-in chat template, as shown in the following snippet.
Let's load the model and apply the chat template to a conversation. In this example, we'll start with a single user interaction:
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "gg-hf/gemma-2b-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,
)
chat = [
{ "role": "user", "content": "Write a hello world program" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
At this point, the prompt contains the following text:
```
<bos><start_of_turn>user
Write a hello world program<end_of_turn>
<start_of_turn>model
```
As you can see, each turn is preceded by a `<start_of_turn>` delimiter and then the role of the entity
(either `user`, for content supplied by the user, or `model` for LLM responses). Turns finish with
the `<end_of_turn>` token.
You can follow this format to build the prompt manually, if you need to do it without the tokenizer's
chat template.
After the prompt is ready, generation can be performed like this:
```py
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=150)
```
### Fine-tuning
You can find some fine-tuning scripts under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples) of [`google/gemma-7b`](https://huggingface.co/google/gemma-7b) repository. To adapt them to this model, simply change the model-id to `google/gemma-2b-it`.
We provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using QLoRA
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on the English quotes dataset
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/ml-pathways).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 49.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | 12.5 | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **45.0** | **56.9** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
myshell-ai/MeloTTS-Chinese | myshell-ai | "2024-03-01T17:31:35Z" | 152,961 | 39 | transformers | [
"transformers",
"text-to-speech",
"ko",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-to-speech | "2024-02-29T14:54:49Z" | ---
license: mit
language:
- ko
pipeline_tag: text-to-speech
---
# MeloTTS
MeloTTS is a **high-quality multi-lingual** text-to-speech library by [MyShell.ai](https://myshell.ai). Supported languages include:
| Model card | Example |
| --- | --- |
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (American) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/en/EN-US/speed_1.0/sent_000.wav) |
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (British) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/en/EN-BR/speed_1.0/sent_000.wav) |
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (Indian) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/en/EN_INDIA/speed_1.0/sent_000.wav) |
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (Australian) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/en/EN-AU/speed_1.0/sent_000.wav) |
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (Default) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/en/EN-Default/speed_1.0/sent_000.wav) |
| [Spanish](https://huggingface.co/myshell-ai/MeloTTS-Spanish) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/es/ES/speed_1.0/sent_000.wav) |
| [French](https://huggingface.co/myshell-ai/MeloTTS-French) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/fr/FR/speed_1.0/sent_000.wav) |
| [Chinese](https://huggingface.co/myshell-ai/MeloTTS-Chinese) (mix EN) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/zh/ZH/speed_1.0/sent_008.wav) |
| [Japanese](https://huggingface.co/myshell-ai/MeloTTS-Japanese) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/jp/JP/speed_1.0/sent_000.wav) |
| [Korean](https://huggingface.co/myshell-ai/MeloTTS-Korean/) | [Link](https://myshell-public-repo-hosting.s3.amazonaws.com/myshellttsbase/examples/kr/KR/speed_1.0/sent_000.wav) |
Some other features include:
- The Chinese speaker supports `mixed Chinese and English`.
- Fast enough for `CPU real-time inference`.
## Usage
### Without Installation
An unofficial [live demo](https://huggingface.co/spaces/mrfakename/MeloTTS) is hosted on Hugging Face Spaces.
#### Use it on MyShell
There are hundreds of TTS models on MyShell, much more than MeloTTS. See examples [here](https://github.com/myshell-ai/MeloTTS/blob/main/docs/quick_use.md#use-melotts-without-installation).
More can be found at the widget center of [MyShell.ai](https://app.myshell.ai/robot-workshop).
### Install and Use Locally
Follow the installation steps [here](https://github.com/myshell-ai/MeloTTS/blob/main/docs/install.md#linux-and-macos-install) before using the following snippet:
```python
from melo.api import TTS
# Speed is adjustable
speed = 1.0
device = 'cpu' # or cuda:0
text = "我最近在学习machine learning,希望能够在未来的artificial intelligence领域有所建树。"
model = TTS(language='ZH', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'zh.wav'
model.tts_to_file(text, speaker_ids['ZH'], output_path, speed=speed)
```
## Join the Community
**Open Source AI Grant**
We are actively sponsoring open-source AI projects. The sponsorship includes GPU resources, fundings and intellectual support (collaboration with top research labs). We welcome both reseach and engineering projects, as long as the open-source community needs them. Please contact [Zengyi Qin](https://www.qinzy.tech/) if you are interested.
**Contributing**
If you find this work useful, please consider contributing to the GitHub [repo](https://github.com/myshell-ai/MeloTTS).
- Many thanks to [@fakerybakery](https://github.com/fakerybakery) for adding the Web UI and CLI part.
## License
This library is under MIT License, which means it is free for both commercial and non-commercial use.
## Acknowledgements
This implementation is based on [TTS](https://github.com/coqui-ai/TTS), [VITS](https://github.com/jaywalnut310/vits), [VITS2](https://github.com/daniilrobnikov/vits2) and [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2). We appreciate their awesome work.
|
facebook/hubert-base-ls960 | facebook | "2021-11-05T12:43:12Z" | 152,713 | 41 | transformers | [
"transformers",
"pytorch",
"tf",
"hubert",
"feature-extraction",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2106.07447",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
---
# Hubert-Base
[Facebook's Hubert](https://ai.facebook.com/blog/hubert-self-supervised-representation-learning-for-speech-recognition-generation-and-compression)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper](https://arxiv.org/abs/2106.07447)
Authors: Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed
**Abstract**
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/hubert .
# Usage
See [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information on how to fine-tune the model. Note that the class `Wav2Vec2ForCTC` has to be replaced by `HubertForCTC`. |
flair/upos-english | flair | "2023-04-07T09:34:50Z" | 152,200 | 3 | flair | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"en",
"dataset:ontonotes",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- ontonotes
widget:
- text: "I love Berlin."
---
## English Universal Part-of-Speech Tagging in Flair (default model)
This is the standard universal part-of-speech tagging model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **98,6** (Ontonotes)
Predicts universal POS tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
|ADJ | adjective |
| ADP | adposition |
| ADV | adverb |
| AUX | auxiliary |
| CCONJ | coordinating conjunction |
| DET | determiner |
| INTJ | interjection |
| NOUN | noun |
| NUM | numeral |
| PART | particle |
| PRON | pronoun |
| PROPN | proper noun |
| PUNCT | punctuation |
| SCONJ | subordinating conjunction |
| SYM | symbol |
| VERB | verb |
| X | other |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/upos-english")
# make example sentence
sentence = Sentence("I love Berlin.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('pos'):
print(entity)
```
This yields the following output:
```
Span [1]: "I" [− Labels: PRON (0.9996)]
Span [2]: "love" [− Labels: VERB (1.0)]
Span [3]: "Berlin" [− Labels: PROPN (0.9986)]
Span [4]: "." [− Labels: PUNCT (1.0)]
```
So, the word "*I*" is labeled as a **pronoun** (PRON), "*love*" is labeled as a **verb** (VERB) and "*Berlin*" is labeled as a **proper noun** (PROPN) in the sentence "*I love Berlin*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. load the corpus (Ontonotes does not ship with Flair, you need to download and reformat into a column format yourself)
corpus: Corpus = ColumnCorpus(
"resources/tasks/onto-ner",
column_format={0: "text", 1: "pos", 2: "upos", 3: "ner"},
tag_to_bioes="ner",
)
# 2. what tag do we want to predict?
tag_type = 'upos'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# contextual string embeddings, forward
FlairEmbeddings('news-forward'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/upos-english',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
facebook/mms-tts-rus | facebook | "2023-09-01T13:12:37Z" | 152,194 | 7 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vits",
"text-to-audio",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | text-to-speech | "2023-09-01T13:12:20Z" |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): Russian Text-to-Speech
This repository contains the **Russian (rus)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-rus")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-rus")
text = "some example text in the Russian language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output, rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
|
TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF | TheBloke | "2023-12-14T14:30:43Z" | 151,602 | 574 | transformers | [
"transformers",
"gguf",
"mixtral",
"fr",
"it",
"de",
"es",
"en",
"base_model:mistralai/Mixtral-8x7B-Instruct-v0.1",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | null | "2023-12-11T18:08:33Z" | ---
base_model: mistralai/Mixtral-8x7B-Instruct-v0.1
inference: false
language:
- fr
- it
- de
- es
- en
license: apache-2.0
model_creator: Mistral AI_
model_name: Mixtral 8X7B Instruct v0.1
model_type: mixtral
prompt_template: '[INST] {prompt} [/INST]
'
quantized_by: TheBloke
widget:
- output:
text: 'Arr, shiver me timbers! Ye have a llama on yer lawn, ye say? Well, that
be a new one for me! Here''s what I''d suggest, arr:
1. Firstly, ensure yer safety. Llamas may look gentle, but they can be protective
if they feel threatened.
2. Try to make the area less appealing to the llama. Remove any food sources
or water that might be attracting it.
3. Contact local animal control or a wildlife rescue organization. They be the
experts and can provide humane ways to remove the llama from yer property.
4. If ye have any experience with animals, you could try to gently herd the
llama towards a nearby field or open space. But be careful, arr!
Remember, arr, it be important to treat the llama with respect and care. It
be a creature just trying to survive, like the rest of us.'
text: '[INST] You are a pirate chatbot who always responds with Arr and pirate speak!
There''s a llama on my lawn, how can I get rid of him? [/INST]'
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mixtral 8X7B Instruct v0.1 - GGUF
- Model creator: [Mistral AI_](https://huggingface.co/mistralai)
- Original model: [Mixtral 8X7B Instruct v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Mistral AI_'s Mixtral 8X7B Instruct v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
### Mixtral GGUF
Support for Mixtral was merged into Llama.cpp on December 13th.
These Mixtral GGUFs are known to work in:
* llama.cpp as of December 13th
* KoboldCpp 1.52 as later
* LM Studio 0.2.9 and later
* llama-cpp-python 0.2.23 and later
Other clients/libraries, not listed above, may not yet work.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF)
* [Mistral AI_'s original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Mistral
```
[INST] {prompt} [/INST]
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These Mixtral GGUFs are compatible with llama.cpp from December 13th onwards. Other clients/libraries may not work yet.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [mixtral-8x7b-instruct-v0.1.Q2_K.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q2_K.gguf) | Q2_K | 2 | 15.64 GB| 18.14 GB | smallest, significant quality loss - not recommended for most purposes |
| [mixtral-8x7b-instruct-v0.1.Q3_K_M.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q3_K_M.gguf) | Q3_K_M | 3 | 20.36 GB| 22.86 GB | very small, high quality loss |
| [mixtral-8x7b-instruct-v0.1.Q4_0.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q4_0.gguf) | Q4_0 | 4 | 26.44 GB| 28.94 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf) | Q4_K_M | 4 | 26.44 GB| 28.94 GB | medium, balanced quality - recommended |
| [mixtral-8x7b-instruct-v0.1.Q5_0.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q5_0.gguf) | Q5_0 | 5 | 32.23 GB| 34.73 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [mixtral-8x7b-instruct-v0.1.Q5_K_M.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q5_K_M.gguf) | Q5_K_M | 5 | 32.23 GB| 34.73 GB | large, very low quality loss - recommended |
| [mixtral-8x7b-instruct-v0.1.Q6_K.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf) | Q6_K | 6 | 38.38 GB| 40.88 GB | very large, extremely low quality loss |
| [mixtral-8x7b-instruct-v0.1.Q8_0.gguf](https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/blob/main/mixtral-8x7b-instruct-v0.1.Q8_0.gguf) | Q8_0 | 8 | 49.62 GB| 52.12 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF and below it, a specific filename to download, such as: mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] {prompt} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Note that text-generation-webui may not yet be compatible with Mixtral GGUFs. Please check compatibility first.
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) version 0.2.23 and later.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf", # Download the model file first
n_ctx=2048, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"[INST] {prompt} [/INST]", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Mistral AI_'s Mixtral 8X7B Instruct v0.1
# Model Card for Mixtral-8x7B
The Mixtral-8x7B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts. The Mixtral-8x7B outperforms Llama 2 70B on most benchmarks we tested.
For full details of this model please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/).
## Warning
This repo contains weights that are compatible with [vLLM](https://github.com/vllm-project/vllm) serving of the model as well as Hugging Face [transformers](https://github.com/huggingface/transformers) library. It is based on the original Mixtral [torrent release](magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce), but the file format and parameter names are different. Please note that model cannot (yet) be instantiated with HF.
## Instruction format
This format must be strictly respected, otherwise the model will generate sub-optimal outputs.
The template used to build a prompt for the Instruct model is defined as follows:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
Note that `<s>` and `</s>` are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
As reference, here is the pseudo-code used to tokenize instructions during fine-tuning:
```python
def tokenize(text):
return tok.encode(text, add_special_tokens=False)
[BOS_ID] +
tokenize("[INST]") + tokenize(USER_MESSAGE_1) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_1) + [EOS_ID] +
…
tokenize("[INST]") + tokenize(USER_MESSAGE_N) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_N) + [EOS_ID]
```
In the pseudo-code above, note that the `tokenize` method should not add a BOS or EOS token automatically, but should add a prefix space.
## Run the model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
### In half-precision
Note `float16` precision only works on GPU devices
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16).to(0)
text = "Hello my name is"
+ inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Lower precision using (8-bit & 4-bit) using `bitsandbytes`
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
text = "Hello my name is"
+ inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Load the model with Flash Attention 2
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, use_flash_attention_2=True)
text = "Hello my name is"
+ inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
## Limitations
The Mixtral-8x7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
<!-- original-model-card end -->
|
vikp/surya_order | vikp | "2024-04-22T16:09:38Z" | 150,973 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | "2024-04-16T17:05:01Z" | ---
license: cc-by-nc-sa-4.0
---
Reading order model for [surya](https://github.com/VikParuchuri/surya). |
LiheYoung/depth-anything-small-hf | LiheYoung | "2024-01-25T08:12:14Z" | 150,912 | 19 | transformers | [
"transformers",
"safetensors",
"depth_anything",
"depth-estimation",
"vision",
"arxiv:2401.10891",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | depth-estimation | "2024-01-22T12:56:04Z" | ---
license: apache-2.0
tags:
- vision
pipeline_tag: depth-estimation
widget:
- inference: false
---
# Depth Anything (small-sized model, Transformers version)
Depth Anything model. It was introduced in the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang et al. and first released in [this repository](https://github.com/LiheYoung/Depth-Anything).
[Online demo](https://huggingface.co/spaces/LiheYoung/Depth-Anything) is also provided.
Disclaimer: The team releasing Depth Anything did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Depth Anything leverages the [DPT](https://huggingface.co/docs/transformers/model_doc/dpt) architecture with a [DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2) backbone.
The model is trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/depth_anything_overview.jpg"
alt="drawing" width="600"/>
<small> Depth Anything overview. Taken from the <a href="https://arxiv.org/abs/2401.10891">original paper</a>.</small>
## Intended uses & limitations
You can use the raw model for tasks like zero-shot depth estimation. See the [model hub](https://huggingface.co/models?search=depth-anything) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot depth estimation:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
depth = pipe(image)["depth"]
```
Alternatively, one can use the classes themselves:
```python
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/depth_anything.html#).
### BibTeX entry and citation info
```bibtex
@misc{yang2024depth,
title={Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data},
author={Lihe Yang and Bingyi Kang and Zilong Huang and Xiaogang Xu and Jiashi Feng and Hengshuang Zhao},
year={2024},
eprint={2401.10891},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
google/siglip-base-patch16-224 | google | "2024-01-19T23:32:01Z" | 150,446 | 11 | transformers | [
"transformers",
"pytorch",
"safetensors",
"siglip",
"zero-shot-image-classification",
"vision",
"arxiv:2303.15343",
"arxiv:2209.06794",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2023-09-30T18:22:03Z" | ---
license: apache-2.0
tags:
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# SigLIP (base-sized model)
SigLIP model pre-trained on WebLi at resolution 224x224. It was introduced in the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Zhai et al. and first released in [this repository](https://github.com/google-research/big_vision).
Disclaimer: The team releasing SigLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SigLIP is [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found [here](https://twitter.com/giffmana/status/1692641733459267713).
## Intended uses & limitations
You can use the raw model for tasks like zero-shot image classification and image-text retrieval. See the [model hub](https://huggingface.co/models?search=google/siglip) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot image classification:
```python
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image) # these are the probabilities
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
```
Alternatively, one can leverage the pipeline API which abstracts away the complexity for the user:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/siglip.html#).
## Training procedure
### Training data
SigLIP is pre-trained on the English image-text pairs of the WebLI dataset [(Chen et al., 2023)](https://arxiv.org/abs/2209.06794).
### Preprocessing
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
Texts are tokenized and padded to the same length (64 tokens).
### Compute
The model was trained on 16 TPU-v4 chips for three days.
## Evaluation results
Evaluation of SigLIP compared to CLIP is shown below (taken from the paper).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/siglip_table.jpeg"
alt="drawing" width="600"/>
### BibTeX entry and citation info
```bibtex
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
jonatasgrosman/wav2vec2-large-xlsr-53-hungarian | jonatasgrosman | "2022-12-14T01:57:43Z" | 150,026 | 6 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hu",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: hu
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Hungarian by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hu
type: common_voice
args: hu
metrics:
- name: Test WER
type: wer
value: 31.40
- name: Test CER
type: cer
value: 6.20
---
# Fine-tuned XLSR-53 large model for speech recognition in Hungarian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Hungarian using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice) and [CSS10](https://github.com/Kyubyong/css10).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-hungarian")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "hu"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-hungarian"
SAMPLES = 5
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| BÜSZKÉK VAGYUNK A MAGYAR EMBEREK NAGYSZERŰ SZELLEMI ALKOTÁSAIRA. | BÜSZKÉK VAGYUNK A MAGYAR EMBEREK NAGYSZERŰ SZELLEMI ALKOTÁSAIRE |
| A NEMZETSÉG TAGJAI KÖZÜL EZT TERMESZTIK A LEGSZÉLESEBB KÖRBEN ÍZLETES TERMÉSÉÉRT. | A NEMZETSÉG TAGJAI KÖZÜL ESZSZERMESZTIK A LEGSZELESEBB KÖRBEN IZLETES TERMÉSSÉÉRT |
| A VÁROSBA VÁGYÓDOTT A LEGJOBBAN, ÉPPEN MERT ODA NEM JUTHATOTT EL SOHA. | A VÁROSBA VÁGYÓDOTT A LEGJOBBAN ÉPPEN MERT ODA NEM JUTHATOTT EL SOHA |
| SÍRJA MÁRA MEGSEMMISÜLT. | SIMGI A MANDO MEG SEMMICSEN |
| MINDEN ZENESZÁMOT DRÁGAKŐNEK NEVEZETT. | MINDEN ZENA SZÁMODRAGAKŐNEK NEVEZETT |
| ÍGY MÚLT EL A DÉLELŐTT. | ÍGY MÚLT EL A DÍN ELŐTT |
| REMEK POFA! | A REMEG PUFO |
| SZEMET SZEMÉRT, FOGAT FOGÉRT. | SZEMET SZEMÉRT FOGADD FOGÉRT |
| BIZTOSAN LAKIK ITT NÉHÁNY ATYÁMFIA. | BIZTOSAN LAKIKÉT NÉHANY ATYAMFIA |
| A SOROK KÖZÖTT OLVAS. | A SOROG KÖZÖTT OLVAS |
## Evaluation
The model can be evaluated as follows on the Hungarian test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "hu"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-hungarian"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-04-22). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-hungarian | **31.40%** | **6.20%** |
| anton-l/wav2vec2-large-xlsr-53-hungarian | 42.39% | 9.39% |
| gchhablani/wav2vec2-large-xlsr-hu | 46.42% | 10.04% |
| birgermoell/wav2vec2-large-xlsr-hungarian | 46.93% | 10.31% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-hungarian,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {H}ungarian},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-hungarian}},
year={2021}
}
``` |