
title
stringlengths 1
290
| body
stringlengths 0
228k
⌀ | html_url
stringlengths 46
51
| comments
sequence | pull_request
dict | number
int64 1
5.59k
| is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|
Support cloud storage in load_dataset | Would be nice to be able to do
```python
data_files=["s3://..."]
storage_options = {...}
load_dataset(..., data_files=data_files, storage_options=storage_options)
```
or even
```python
load_dataset("gs://...")
```
The idea would be to use `fsspec` as in `download_and_prepare` and `save_to_disk`.
This has been requested several times already. Some users want to use their data from private cloud storage to train models
related:
https://github.com/huggingface/datasets/issues/3490
https://github.com/huggingface/datasets/issues/5244
[forum](https://discuss.huggingface.co/t/how-to-use-s3-path-with-load-dataset-with-streaming-true/25739/2) | https://github.com/huggingface/datasets/issues/5281 | [
"Or for example an archive on GitHub releases! Before I added support for JXL (locally only, PR still pending) I was considering hosting my files on GitHub instead...",
"+1 to this. I would like to use 'audiofolder' with a data_dir that's on S3, for example. I don't want to upload my dataset to the Hub, but I would find all the fingerprinting/caching features useful.",
"Adding to the conversation, Dask also uses `fsspec` for this feature.\r\n\r\n[Dask: How to connect to remote data](https://docs.dask.org/en/stable/how-to/connect-to-remote-data.html)\r\n\r\nHappy to help on this feature :D ",
"+1 to this feature request since I think it also tackles my use-case. I am collaborating with a team, working with a loading script which takes some time to generate the dataset artifacts. It would be very handy to use this as a cloud cache to avoid duplicating the effort. \r\n\r\nCurrently we could use `builder.download_and_prepare(path_to_cloud_storage, storage_options, ...)` to cache the artifacts to cloud storage, but then `builder.as_dataset()` yields `NotImplementedError: Loading a dataset cached in SomeCloudFileSystem is not supported`",
"Makes sense ! If you want to load locally a dataset that you download_and_prepared on a cloud storage, you would use `load_dataset(path_to_cloud_storage)` indeed. It would download the data from the cloud storage, cache them locally, and return a `Dataset`.",
"It seems currently the `cached_path` function handles all URLs by `get_from_cache` that only supports `ftp` and `http(s)` here:\r\nhttps://github.com/huggingface/datasets/blob/b5672a956d5de864e6f5550e493527d962d6ae55/src/datasets/utils/file_utils.py#L181\r\n\r\nI guess one can add another condition that handles `s3://` or `gs://` URLs via `fsspec` here.",
"I could use this functionality, so I put together a PR using @kyamagu's suggestion to use `fsspec` in `datasets.utils.file_utils`\r\n\r\nhttps://github.com/huggingface/datasets/pull/5580",
"Thanks @dwyatte for adding support for fsspec urls !\r\n\r\nLet me just reopen this since the original issue is not fully resolved - we still need to support storage options and update `load_dataset`",
"I'm not yet understanding how to use https://github.com/huggingface/datasets/pull/5580 in order to use `load_dataset(data_files=\"s3://...\")`. Any help/example would be much appreciated :) thanks! ",
"It's still not officially supported x) But you can try to update `request_etag` in `file_utils.py` to use `fsspec_head` instead of `http_head`. It is responsible of getting the ETags of the remote files for caching. This change may do the trick for S3 urls"
] | null | 5,281 | false |
Import error | https://github.com/huggingface/datasets/blob/cd3d8e637cfab62d352a3f4e5e60e96597b5f0e9/src/datasets/__init__.py#L28
Hy,
I have error at the above line. I have python version 3.8.13, the message says I need python>=3.7, which is True, but I think the if statement not working properly (or the message wrong) | https://github.com/huggingface/datasets/issues/5280 | [
"Hi ! Can you \r\n```python\r\nimport platform\r\nprint(platform.python_version())\r\n```\r\nto see that it returns ?",
"Hi,\n\n3.8.13\n\nGet Outlook for Android<https://aka.ms/AAb9ysg>\n________________________________\nFrom: Quentin Lhoest ***@***.***>\nSent: Tuesday, November 22, 2022 2:37:02 PM\nTo: huggingface/datasets ***@***.***>\nCc: feketedavid1012 ***@***.***>; Author ***@***.***>\nSubject: Re: [huggingface/datasets] Import error (Issue #5280)\n\n\nHi ! Can you\n\nimport platform\nprint(platform.python_version())\n\nto see that it returns ?\n\n—\nReply to this email directly, view it on GitHub<https://github.com/huggingface/datasets/issues/5280#issuecomment-1323691385>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AJW7F5YGG32W6WABYC25NJTWJTD75ANCNFSM6AAAAAASHZJ2AU>.\nYou are receiving this because you authored the thread.Message ID: ***@***.***>\n",
"Then it should work as expected if you use the same python when using `datasets`\r\n\r\nPlease make sure you're running your code in the right environment",
"It's the right environment. But in if statement I have\n\"3.8.13\" < 3.7\nAnd in the error message is Python>=3.7 which is true in my case (3.8.13 is greater then 3.7), so I don't understand my python should be below the 3.7 which case the if statement is right, but the message is wrong, or above 3.7 which case if statement is wrong, error message is right.\n\nGet Outlook for Android<https://aka.ms/AAb9ysg>\n________________________________\nFrom: Quentin Lhoest ***@***.***>\nSent: Tuesday, November 22, 2022 2:41:43 PM\nTo: huggingface/datasets ***@***.***>\nCc: feketedavid1012 ***@***.***>; Author ***@***.***>\nSubject: Re: [huggingface/datasets] Import error (Issue #5280)\n\n\nThen it should work as expected if you use the same python when using datasets\n\nPlease make sure you're running your code in the right environment\n\n—\nReply to this email directly, view it on GitHub<https://github.com/huggingface/datasets/issues/5280#issuecomment-1323697094>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AJW7F54JURTAJJWWDO2QGI3WJTERPANCNFSM6AAAAAASHZJ2AU>.\nYou are receiving this because you authored the thread.Message ID: ***@***.***>\n",
"If you're having an error then you're not running your code in the right environment."
] | null | 5,280 | false |
Warn about checksums | It takes a lot of time on big datasets to compute the checksums, we should at least add a warning to notify the user about this step. I also mentioned how to disable it, and added a tqdm bar (delay=5 seconds)
cc @ola13 | https://github.com/huggingface/datasets/pull/5279 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I'm also in favor of disabling this by default - it's kinda impractical",
"Great, thanks for the quick turnaround on this!"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5279",
"html_url": "https://github.com/huggingface/datasets/pull/5279",
"diff_url": "https://github.com/huggingface/datasets/pull/5279.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5279.patch",
"merged_at": "2022-11-23T09:47:01"
} | 5,279 | true |
load_dataset does not read jsonl metadata file properly | ### Describe the bug
Hi, I'm following [this page](https://huggingface.co/docs/datasets/image_dataset) to create a dataset of images and captions via an image folder and a metadata.json file, but I can't seem to get the dataloader to recognize the "text" column. It just spits out "image" and "label" as features.
Below is code to reproduce my exact example/problem.
### Steps to reproduce the bug
```ruby
dataset_link="19Unu89Ih_kP6zsE7f9Mkw8dy3NwHopRF"
id = dataset_link
output = 'Godardv01.zip'
gdown.download(id=id, output=output, quiet=False)
ds = load_dataset("imagefolder", data_dir="/kaggle/working/Volumes/TOSHIBA/Godard_imgs/Volumes/TOSHIBA/Godard_imgs/Full/train", split="train", drop_labels=False)
print(ds)
```
### Expected behavior
I would expect that it returned "image" and "text" columns from the code above.
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 5.0.0
- Pandas version: 1.3.5 | https://github.com/huggingface/datasets/issues/5278 | [
"Can you try to remove \"drop_labels=false\" ? It may force the loader to infer the labels instead of reading the metadata",
"Hi, thanks for responding. I tried that, but it does not change anything.",
"Can you try updating `datasets` ? Metadata support was added in `datasets` 2.4",
"Probably the issue, will report back asap!",
"Okay, now it seems to actually load the metadata and create the train_split, but it still says only returns \"image\" and \"label\", which is always 0 since all images are from same folder",
"> Can you try updating `datasets` ? Metadata support was added in `datasets` 2.4\r\n\r\nUpdate: This was the issue."
] | null | 5,278 | false |
Remove YAML integer keys from class_label metadata | Fix partially #5275. | https://github.com/huggingface/datasets/pull/5277 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Also note that this approach is valid when metadata keys are str, but also if they are int.\r\n- This will be helpful for any community dataset using old integer keys in their metadata",
"perfect !"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5277",
"html_url": "https://github.com/huggingface/datasets/pull/5277",
"diff_url": "https://github.com/huggingface/datasets/pull/5277.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5277.patch",
"merged_at": "2022-11-22T13:55:49"
} | 5,277 | true |
Bug in downloading common_voice data and snall chunk of it to one's own hub | ### Describe the bug
I'm trying to load the common voice dataset. Currently there is no implementation to download just par tof the data, and I need just one part of it, without downloading the entire dataset
Help please?

### Steps to reproduce the bug
So here is what I have done:
1. Download common_voice data
2. Trim part of it and publish it to my own repo.
3. Download data from my own repo, but am getting this error.
### Expected behavior
There shouldn't be an error in downloading part of the data and publishing it to one's own repo
### Environment info
common_voice 11 | https://github.com/huggingface/datasets/issues/5276 | [
"Sounds like one of the file is not a valid one, can you make sure you uploaded valid mp3 files ?",
"Well I just sharded the original commonVoice dataset and pushed a small chunk of it in a private rep\n\nWhat did go wrong?\n\nHolen Sie sich Outlook für iOS<https://aka.ms/o0ukef>\n________________________________\nVon: Quentin Lhoest ***@***.***>\nGesendet: Tuesday, November 22, 2022 3:03:40 PM\nAn: huggingface/datasets ***@***.***>\nCc: capsabogdan ***@***.***>; Author ***@***.***>\nBetreff: Re: [huggingface/datasets] Bug in downloading common_voice data and snall chunk of it to one's own hub (Issue #5276)\n\n\nSounds like one of the file is not a valid one, can you make sure you uploaded valid mp3 files ?\n\n—\nReply to this email directly, view it on GitHub<https://github.com/huggingface/datasets/issues/5276#issuecomment-1323727434>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/ALSIFOAPAL2V4TBJTSPMAULWJTHDZANCNFSM6AAAAAASHQJ63U>.\nYou are receiving this because you authored the thread.Message ID: ***@***.***>\n",
"It should be all good then !\r\nCould you share a link to your repository for me to investigate what went wrong ?",
"https://huggingface.co/datasets/DTU54DL/common-voice-test16k\n\nAm Di., 22. Nov. 2022 um 16:43 Uhr schrieb Quentin Lhoest <\n***@***.***>:\n\n> It should be all good then !\n> Could you share a link to your repository for me to investigate what went\n> wrong ?\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5276#issuecomment-1323876682>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOEUJRZWXAM7DYA5VJDWJTS3NANCNFSM6AAAAAASHQJ63U>\n> .\n> You are receiving this because you authored the thread.Message ID:\n> ***@***.***>\n>\n",
"I see ! This is a bug with MP3 files.\r\n\r\nWhen we store audio data in parquet, we store the bytes and the file name. From the file name extension we know if it's a WAV, an MP3 or else. But here it looks like the paths are all None.\r\n\r\nIt looks like it comes from here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/7feeb5648a63b6135a8259dedc3b1e19185ee4c7/src/datasets/features/audio.py#L212\r\n\r\nCc @polinaeterna maybe we should simply put the file name instead of None values ?",
"@lhoestq I remember we wanted to avoid storing redundant data but maybe it's not that crucial indeed to store one more string value. \r\nOr we can store paths only for mp3s, considering that for other formats we don't have such a problem with reading from bytes without format specified. ",
"It doesn't cost much to always store the file name IMO",
"thanks for the help!\n\ncan I do anything on my side? we are doing a DL project and we need the\ndata really quick.\n\nthanks\nbogdan\n\n> Message ID: ***@***.***>\n>\n",
"I opened a pull requests here: https://github.com/huggingface/datasets/pull/5285, we'll do a new release soon with this fix.\r\n\r\nOtherwise if you're really in a hurry you can install `datasets` from this PR",
"[image: image.png]\n\n> Message ID: ***@***.***>\n>\n",
"any idea on what's going wrong here?\n\nthanks\n\nAm So., 27. Nov. 2022 um 13:53 Uhr schrieb Bogdan Capsa <\n***@***.***>:\n\n> [image: image.png]\n>\n>> Message ID: ***@***.***>\n>>\n>\n",
"hi @capsabogdan! \r\ncould you please share more specifically what problem do you have now?",
"I have attached this screenshot above . can u pls help? So can not pip from pull request\r\n\r\n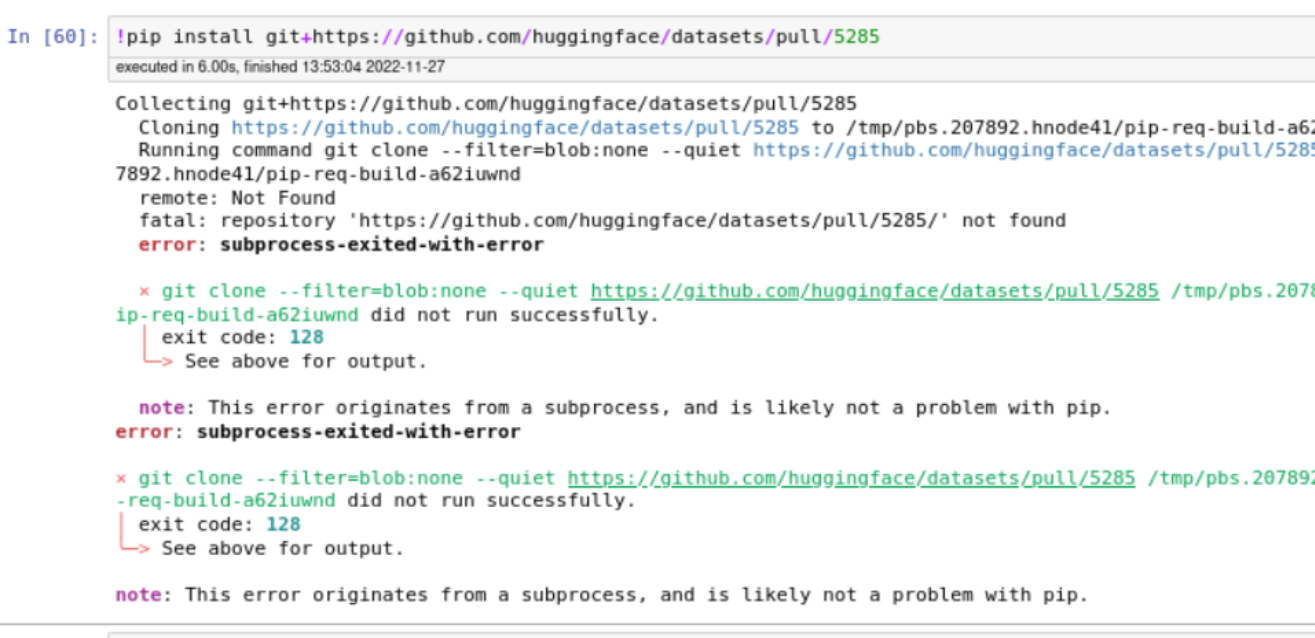\r\n",
"The pull request has been merged on `main`.\r\nYou can install `datasets` from `main` using\r\n```\r\npip install git+https://github.com/huggingface/datasets.git\r\n```",
"I've tried to load this dataset DTU54DL/common-voice-test16k, but am\ngetting the same error.\n\nSo the bug fix will fix only if I upload a new dataset, or also loading\npreviously uploaded datasets?\n\nthanks\n\nAm Mo., 28. Nov. 2022 um 19:51 Uhr schrieb Quentin Lhoest <\n***@***.***>:\n\n> The pull request has been merged on main.\n> You can install datasets from main using\n>\n> pip install git+https://github.com/huggingface/datasets.git\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5276#issuecomment-1329587334>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOCNYYIGHM2EX3ZIO6DWKT5MXANCNFSM6AAAAAASHQJ63U>\n> .\n> You are receiving this because you were mentioned.Message ID:\n> ***@***.***>\n>\n",
"> So the bug fix will fix only if I upload a new dataset, or also loading\r\npreviously uploaded datasets?\r\n\r\nYou have to reupload the dataset, sorry for the inconvenience",
"thank you so much for the help! works like a charm!\n\nAm Di., 29. Nov. 2022 um 12:15 Uhr schrieb Quentin Lhoest <\n***@***.***>:\n\n> So the bug fix will fix only if I upload a new dataset, or also loading\n> previously uploaded datasets?\n>\n> You have to reupload the dataset, sorry for the inconvenience\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5276#issuecomment-1330468393>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOBKEFZO57BAKY4IGW3WKXQUZANCNFSM6AAAAAASHQJ63U>\n> .\n> You are receiving this because you were mentioned.Message ID:\n> ***@***.***>\n>\n"
] | null | 5,276 | false |
YAML integer keys are not preserved Hub server-side | After an internal discussion (https://github.com/huggingface/moon-landing/issues/4563):
- YAML integer keys are not preserved server-side: they are transformed to strings
- See for example this Hub PR: https://huggingface.co/datasets/acronym_identification/discussions/1/files
- Original:
```yaml
class_label:
names:
0: B-long
1: B-short
```
- Returned by the server:
```yaml
class_label:
names:
'0': B-long
'1': B-short
```
- They are planning to enforce only string keys
- Other projects already use interger-transformed-to string keys: e.g. `transformers` models `id2label`: https://huggingface.co/roberta-large-mnli/blob/main/config.json
```yaml
"id2label": {
"0": "CONTRADICTION",
"1": "NEUTRAL",
"2": "ENTAILMENT"
}
```
On the other hand, at `datasets` we are currently using YAML integer keys for `dataset_info` `class_label`.
Please note (thanks @lhoestq for pointing out) that previous versions (2.6 and 2.7) of `datasets` need being patched:
```python
In [18]: Features._from_yaml_list([{'dtype': {'class_label': {'names': {'0': 'neg', '1': 'pos'}}}, 'name': 'label'}])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-18-974f07eea526> in <module>
----> 1 Features._from_yaml_list(ry)
~/Desktop/hf/nlp/src/datasets/features/features.py in _from_yaml_list(cls, yaml_data)
1743 raise TypeError(f"Expected a dict or a list but got {type(obj)}: {obj}")
1744
-> 1745 return cls.from_dict(from_yaml_inner(yaml_data))
1746
1747 def encode_example(self, example):
~/Desktop/hf/nlp/src/datasets/features/features.py in from_yaml_inner(obj)
1739 elif isinstance(obj, list):
1740 names = [_feature.pop("name") for _feature in obj]
-> 1741 return {name: from_yaml_inner(_feature) for name, _feature in zip(names, obj)}
1742 else:
1743 raise TypeError(f"Expected a dict or a list but got {type(obj)}: {obj}")
~/Desktop/hf/nlp/src/datasets/features/features.py in <dictcomp>(.0)
1739 elif isinstance(obj, list):
1740 names = [_feature.pop("name") for _feature in obj]
-> 1741 return {name: from_yaml_inner(_feature) for name, _feature in zip(names, obj)}
1742 else:
1743 raise TypeError(f"Expected a dict or a list but got {type(obj)}: {obj}")
~/Desktop/hf/nlp/src/datasets/features/features.py in from_yaml_inner(obj)
1734 return {"_type": snakecase_to_camelcase(obj["dtype"])}
1735 else:
-> 1736 return from_yaml_inner(obj["dtype"])
1737 else:
1738 return {"_type": snakecase_to_camelcase(_type), **unsimplify(obj)[_type]}
~/Desktop/hf/nlp/src/datasets/features/features.py in from_yaml_inner(obj)
1736 return from_yaml_inner(obj["dtype"])
1737 else:
-> 1738 return {"_type": snakecase_to_camelcase(_type), **unsimplify(obj)[_type]}
1739 elif isinstance(obj, list):
1740 names = [_feature.pop("name") for _feature in obj]
~/Desktop/hf/nlp/src/datasets/features/features.py in unsimplify(feature)
1704 if isinstance(feature.get("class_label"), dict) and isinstance(feature["class_label"].get("names"), dict):
1705 label_ids = sorted(feature["class_label"]["names"])
-> 1706 if label_ids and label_ids != list(range(label_ids[-1] + 1)):
1707 raise ValueError(
1708 f"ClassLabel expected a value for all label ids [0:{label_ids[-1] + 1}] but some ids are missing."
TypeError: can only concatenate str (not "int") to str
```
TODO:
- [x] Remove YAML integer keys from `dataset_info` metadata
- [x] Make a patch release for affected `datasets` versions: 2.6 and 2.7
- [x] Communicate on the fix
- [x] Wait for adoption
- [x] Bulk edit the Hub to fix this in all canonical datasets | https://github.com/huggingface/datasets/issues/5275 | [
"@huggingface/datasets if you agree, I can make the bulk edit on the Hub to fix integer keys into strings.",
"Ok for me, and we can merge (internal) https://github.com/huggingface/moon-landing/pull/4609",
"FYI there are still 2k+ weekly users on `datasets` 2.6.1 which doesn't support the string label format for class labels. And among those, some are using datasets with class labels like imdb (60 users), conllpp (40), msra_ner (40), peoples_daily_enr (40), weibo_ner (30), conll2003 (20), etc. And renaming to string would break these users code.",
"but isn't `datasets 2.6.1` downloading files from the Hub with the corresponding tag? I thought we had something like this before",
"We're using `main` as models do. Some datasets need to be updated from time to time, e.g. when a link to download the data is dead.\r\n\r\nBut yea a year ago we had those tags, we just ended up not using them",
"I opened https://github.com/huggingface/datasets/issues/5406 to communicate on this. Let me know what you think, and if it sounds good to you I can pin this issue",
"So, is it OK to make the bulk edit on the Hub now or should we wait longer? If the latter, how long?",
"I think we can do it. If you want to be extra cautious you can do it for all datasets except imdb and conllpp for now which are actively used by 2.6.1 users. For those two we can keep the YAML like this for some more time, or alternatively use the old dataset_infos.json file",
"The bulk edit of canonical datasets (except imdb and conllpp) is running. \r\n\r\nSee e.g.: https://huggingface.co/datasets/acronym_identification/discussions/3\r\n\r\nEDITED: \r\nDone, except for \"universal_morphologies\", where I get\r\n```\r\nHTTPError: 413 Client Error: Payload Too Large for url: https://huggingface.co/api/validate-yaml\r\n```\r\n\r\nAlso not done for the datasets missing matadata \"dataset_info\":\r\n- mc4: https://huggingface.co/datasets/mc4/discussions/3\r\n- the_pile: https://huggingface.co/datasets/the_pile/discussions/6\r\n- timit_asr: https://huggingface.co/datasets/timit_asr/discussions/1",
"Thank you !",
"@lhoestq, there are 6 community datasets with YAML integer keys in their `dataset_info` `class_label`:\r\n- indonlp/indonlu\r\n- rcds/swiss_judgment_prediction\r\n- Jean-Baptiste/wikiner_fr\r\n- Bingsu/Cat_and_Dog\r\n- taskydata/tasky_or_not\r\n- RCC-MSU/collection3\r\n\r\nMaybe we could open a PR on them as well?",
"Let's do this then:\r\n\r\n- [x] [indonlp/indonlu](https://huggingface.co/datasets/indonlp/indonlu/discussions/3)\r\n- [x] rcds/swiss_judgment_prediction\r\n- [x] Jean-Baptiste/wikiner_fr\r\n- [x] Bingsu/Cat_and_Dog -> merged\r\n- [x] taskydata/tasky_or_not (was already using quotes)\r\n- [x] RCC-MSU/collection3\r\n\r\nEDIT: all done :)",
"@lhoestq I was not asking you to do it, but asking if you agree me to do it... :man_facepalming: \r\nAs I self-assigned this issue... :sweat_smile: "
] | null | 5,275 | false |
load_dataset possibly broken for gated datasets? | ### Describe the bug
When trying to download the [winoground dataset](https://huggingface.co/datasets/facebook/winoground), I get this error unless I roll back the version of huggingface-hub:
```
[/usr/local/lib/python3.7/dist-packages/huggingface_hub/utils/_validators.py](https://localhost:8080/#) in validate_repo_id(repo_id)
165 if repo_id.count("/") > 1:
166 raise HFValidationError(
--> 167 "Repo id must be in the form 'repo_name' or 'namespace/repo_name':"
168 f" '{repo_id}'. Use `repo_type` argument if needed."
169 )
HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': 'datasets/facebook/winoground'. Use `repo_type` argument if needed
```
### Steps to reproduce the bug
Install requirements:
```
pip install transformers
pip install datasets
# It works if you uncomment the following line, rolling back huggingface hub:
# pip install huggingface-hub==0.10.1
```
Then:
```
from datasets import load_dataset
auth_token = "" # Replace with an auth token, which you can get from your huggingface account: Profile -> Settings -> Access Tokens -> New Token
winoground = load_dataset("facebook/winoground", use_auth_token=auth_token)["test"]
```
### Expected behavior
Downloading of the datset
### Environment info
Just a google colab; see here: https://colab.research.google.com/drive/15wwOSte2CjTazdnCWYUm2VPlFbk2NGc0?usp=sharing | https://github.com/huggingface/datasets/issues/5274 | [
"@BradleyHsu",
"Btw, thanks very much for finding the hub rollback temporary fix and bringing the issue to our attention @KhoomeiK!",
"I see the same issue when calling `load_dataset('poloclub/diffusiondb', 'large_random_1k')` with `datasets==2.7.1` and `huggingface-hub=0.11.0`. No issue with `datasets=2.6.1` and `huggingface_hub==0.10.1`.\r\n\r\nhttps://github.com/poloclub/diffusiondb/issues/7",
"I fixed my issue by specifying `repo_type` in `hf_hub_url()`. https://github.com/poloclub/diffusiondb/commit/9eb91c79aaca98b0515a0ce45778b8af65b84652\r\n\r\nI opened a PR on the Winoground's repo: https://huggingface.co/datasets/facebook/winoground/discussions/2",
"This is a bug in the script, indeed. The most robust fix is to use a relative path instead of `hf_hub_url`, which does not depend on `huggingface_hub`'s version 🙂. I've opened a PR here: https://huggingface.co/datasets/facebook/winoground/discussions/3.",
"Awesome, big thanks to both @xiaohk and @mariosasko!"
] | null | 5,274 | false |
download_mode="force_redownload" does not refresh cached dataset | ### Describe the bug
`load_datasets` does not refresh dataset when features are imported from external file, even with `download_mode="force_redownload"`. The bug is not limited to nested fields, however it is more likely to occur with nested fields.
### Steps to reproduce the bug
To reproduce the bug 3 files are needed: `dataset.py` (contains dataset loading script), `schema.py` (contains features of dataset) and `main.py` (to run `load_datasets`)
`dataset.py`
```python
import datasets
from schema import features
class NewDataset(datasets.GeneratorBasedBuilder):
def _info(self):
return datasets.DatasetInfo(
features=features
)
def _split_generators(self, dl_manager):
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN
)
]
def _generate_examples(self):
data = [
{"id": 0, "nested": []},
{"id": 1, "nested": []}
]
for key, example in enumerate(data):
yield key, example
```
`schema.py`
```python
import datasets
features = datasets.Features(
{
"id": datasets.Value("int32"),
"nested": [
{"text": datasets.Value("string")}
]
}
)
```
`main.py`
```python
import datasets
a = datasets.load_dataset("dataset.py")
print(a["train"].info.features)
```
Now if `main.py` is run it prints the following correct output: `{'id': Value(dtype='int32', id=None), 'nested': [{'text': Value(dtype='string', id=None)}]}`. However, if f.e. the label of the feature "text" is changed to something else, f.e. to
`schema.py`
```python
import datasets
features = datasets.Features(
{
"id": datasets.Value("int32"),
"nested": [
{"textfoo": datasets.Value("string")}
]
}
)
```
`main.py` still prints `{'id': Value(dtype='int32', id=None), 'nested': [{'text': Value(dtype='string', id=None)}]}`, even if run with `download_mode="force_redownload"`. The only fix is to delete the folder in the cache.
### Expected behavior
The cached dataset is deleted and refreshed when using `load_datasets` with `download_mode="force_redownload"`.
### Environment info
- `datasets` version: 2.7.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.9
- PyArrow version: 10.0.0
- Pandas version: 1.3.5 | https://github.com/huggingface/datasets/issues/5273 | [] | null | 5,273 | false |
Use pyarrow Tensor dtype | ### Feature request
I was going the discussion of converting tensors to lists.
Is there a way to leverage pyarrow's Tensors for nested arrays / embeddings?
For example:
```python
import pyarrow as pa
import numpy as np
x = np.array([[2, 2, 4], [4, 5, 100]], np.int32)
pa.Tensor.from_numpy(x, dim_names=["dim1","dim2"])
```
[Apache docs](https://arrow.apache.org/docs/python/generated/pyarrow.Tensor.html)
Maybe this belongs into the pyarrow features / repo.
### Motivation
Working with big data, we need to make sure to use the best data structures and IO out there
### Your contribution
Can try to a PR if code changes necessary | https://github.com/huggingface/datasets/issues/5272 | [
"Hi ! We're using the Arrow format for the datasets, and PyArrow tensors are not part of the Arrow format AFAIK:\r\n\r\n> There is no direct support in the arrow columnar format to store Tensors as column values.\r\n\r\nsource: https://github.com/apache/arrow/issues/4802#issuecomment-508494694",
"@wesm @rok its been around three years. any updates, regarding dataset arrow tensor support? 🙏 I know you must be very busy, would appreciate to learn what is the state of art. I saw the PR is still open [#8510](https://github.com/apache/arrow/pull/8510)",
"Hey @franz101 & @lhoestq!\r\nThere is a plan and a PR to create an [ExtensionArray of Tensors](https://github.com/apache/arrow/pull/8510) of equal sizes as well as a plan to do the same for Tensors of different sizes [ARROW-8714](https://issues.apache.org/jira/browse/ARROW-8714).",
"The work stalled a little because it was not clear where TensorArray would live. However Arrow community recently agreed to make a [well-known-extension-type document](https://lists.apache.org/thread/sxd5fhc42hb6svs79t3fd79gkqj83pfh) and I would like https://github.com/apache/arrow/pull/8510 to land there and add an implementation to C++/Python + another language. Is that something you would find beneficial to you?",
"that is a great update, thank you.\r\nit looks like this feature would benefit datasets implementation of [ArrayExtensionArray](https://github.com/huggingface/datasets/blob/9f2ff14673cac1f1ad56d80221a793f5938b68c7/src/datasets/features/features.py#L585-L641). Is that correct @eladsegal @lhoestq?\r\n\r\n",
"TensorArray sounds great ! Looking forward to it :)\r\n\r\nWe've had our own ExtensionArray for fixed shape tensors for a while now, hoping to see something more standardized by the arrow community.\r\n\r\nAlso super interested in the extension array for tensors of different sizes cc @mariosasko "
] | null | 5,272 | false |
Fix #5269 | ```
$ datasets-cli convert --datasets_directory <TAB>
datasets_directory
benchmarks/ docs/ metrics/ notebooks/ src/ templates/ tests/ utils/
```
| https://github.com/huggingface/datasets/pull/5271 | [
"See <https://github.com/huggingface/datasets/issues/5269>"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5271",
"html_url": "https://github.com/huggingface/datasets/pull/5271",
"diff_url": "https://github.com/huggingface/datasets/pull/5271.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5271.patch",
"merged_at": null
} | 5,271 | true |
When len(_URLS) > 16, download will hang | ### Describe the bug
```python
In [9]: dataset = load_dataset('Freed-Wu/kodak', split='test')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.53k/2.53k [00:00<00:00, 1.88MB/s]
[11/19/22 22:16:21] WARNING Using custom data configuration default builder.py:379
Downloading and preparing dataset kodak/default to /home/wzy/.cache/huggingface/datasets/Freed-Wu___kodak/default/0.0.1/bd1cc3434212e3e654f7e16ad618f8a1470b5982b086c91b1d6bc7187183c6e9...
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 531k/531k [00:02<00:00, 239kB/s]
#10: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.06s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 534k/534k [00:02<00:00, 193kB/s]
#14: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.37s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 692k/692k [00:02<00:00, 269kB/s]
#12: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.44s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 566k/566k [00:02<00:00, 210kB/s]
#5: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.53s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 613k/613k [00:02<00:00, 235kB/s]
#13: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.53s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 786k/786k [00:02<00:00, 342kB/s]
#3: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.60s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 619k/619k [00:02<00:00, 254kB/s]
#4: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.68s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 737k/737k [00:02<00:00, 271kB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 788k/788k [00:02<00:00, 285kB/s]
#6: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 5.04s/obj]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 618k/618k [00:04<00:00, 153kB/s]
#0: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.69s/obj]
^CProcess ForkPoolWorker-47:
Process ForkPoolWorker-46:
Process ForkPoolWorker-36:
Process ForkPoolWorker-38:██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 5.04s/obj]
Process ForkPoolWorker-37:
Process ForkPoolWorker-45:
Process ForkPoolWorker-39:
Process ForkPoolWorker-43:
Process ForkPoolWorker-33:
Process ForkPoolWorker-18:
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
KeyboardInterrupt
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
KeyboardInterrupt
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
KeyboardInterrupt
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
KeyboardInterrupt
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/queues.py", line 365, in get
res = self._reader.recv_bytes()
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
KeyboardInterrupt
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
File "/usr/lib/python3.10/multiprocessing/connection.py", line 221, in recv_bytes
buf = self._recv_bytes(maxlength)
KeyboardInterrupt
KeyboardInterrupt
File "/usr/lib/python3.10/multiprocessing/connection.py", line 419, in _recv_bytes
buf = self._recv(4)
File "/usr/lib/python3.10/multiprocessing/connection.py", line 384, in _recv
chunk = read(handle, remaining)
KeyboardInterrupt
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 114, in worker
task = get()
File "/usr/lib/python3.10/multiprocessing/queues.py", line 364, in get
with self._rlock:
File "/usr/lib/python3.10/multiprocessing/synchronize.py", line 95, in __enter__
return self._semlock.__enter__()
KeyboardInterrupt
Process ForkPoolWorker-20:
Process ForkPoolWorker-44:
Process ForkPoolWorker-22:
Traceback (most recent call last):
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection
sock.connect(sa)
ConnectionRefusedError: [Errno 111] Connection refused
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/usr/lib/python3.10/multiprocessing/pool.py", line 48, in mapstar
return list(map(*args))
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/lib/python3.10/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 298, in cached_path
output_path = get_from_cache(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 561, in get_from_cache
response = http_head(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 476, in http_head
response = _request_with_retry(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 405, in _request_with_retry
response = requests.request(method=method.upper(), url=url, timeout=timeout, **params)
File "/usr/lib/python3.10/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/adapters.py", line 489, in send
resp = conn.urlopen(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 386, in _make_request
self._validate_conn(conn)
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1042, in _validate_conn
conn.connect()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 358, in connect
self.sock = conn = self._new_conn()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection
sock.connect(sa)
KeyboardInterrupt
#1: 0%| | 0/2 [03:00<?, ?obj/s]
Traceback (most recent call last):
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/usr/lib/python3.10/multiprocessing/pool.py", line 48, in mapstar
return list(map(*args))
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/lib/python3.10/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 298, in cached_path
output_path = get_from_cache(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 659, in get_from_cache
http_get(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 442, in http_get
response = _request_with_retry(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 405, in _request_with_retry
response = requests.request(method=method.upper(), url=url, timeout=timeout, **params)
File "/usr/lib/python3.10/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/adapters.py", line 489, in send
resp = conn.urlopen(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 386, in _make_request
self._validate_conn(conn)
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1042, in _validate_conn
conn.connect()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 358, in connect
self.sock = conn = self._new_conn()
File "/usr/lib/python3.10/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "/usr/lib/python3.10/multiprocessing/pool.py", line 48, in mapstar
return list(map(*args))
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 72, in create_connection
for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/socket.py", line 955, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/lib/python3.10/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
KeyboardInterrupt
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 298, in cached_path
output_path = get_from_cache(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 561, in get_from_cache
response = http_head(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 476, in http_head
response = _request_with_retry(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 405, in _request_with_retry
response = requests.request(method=method.upper(), url=url, timeout=timeout, **params)
File "/usr/lib/python3.10/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/adapters.py", line 489, in send
resp = conn.urlopen(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 386, in _make_request
self._validate_conn(conn)
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1042, in _validate_conn
conn.connect()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 358, in connect
self.sock = conn = self._new_conn()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 72, in create_connection
for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
File "/usr/lib/python3.10/socket.py", line 955, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
KeyboardInterrupt
#3: 0%| | 0/2 [03:00<?, ?obj/s]
#11: 0%| | 0/1 [00:49<?, ?obj/s]
Traceback (most recent call last):
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection
sock.connect(sa)
ConnectionRefusedError: [Errno 111] Connection refused
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/usr/lib/python3.10/multiprocessing/pool.py", line 48, in mapstar
return list(map(*args))
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/lib/python3.10/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 298, in cached_path
output_path = get_from_cache(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 561, in get_from_cache
response = http_head(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 476, in http_head
response = _request_with_retry(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 405, in _request_with_retry
response = requests.request(method=method.upper(), url=url, timeout=timeout, **params)
File "/usr/lib/python3.10/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 723, in send
history = [resp for resp in gen]
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 723, in <listcomp>
history = [resp for resp in gen]
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 266, in resolve_redirects
resp = self.send(
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/adapters.py", line 489, in send
resp = conn.urlopen(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 386, in _make_request
self._validate_conn(conn)
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1042, in _validate_conn
conn.connect()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 358, in connect
self.sock = conn = self._new_conn()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 85, in create_connection
sock.connect(sa)
KeyboardInterrupt
#5: 0%| | 0/1 [03:00<?, ?obj/s]
KeyboardInterrupt
Process ForkPoolWorker-42:
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.10/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/usr/lib/python3.10/multiprocessing/pool.py", line 48, in mapstar
return list(map(*args))
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 215, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/usr/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/lib/python3.10/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 298, in cached_path
output_path = get_from_cache(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 561, in get_from_cache
response = http_head(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 476, in http_head
response = _request_with_retry(
File "/usr/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 405, in _request_with_retry
response = requests.request(method=method.upper(), url=url, timeout=timeout, **params)
File "/usr/lib/python3.10/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/usr/lib/python3.10/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/usr/lib/python3.10/site-packages/requests/adapters.py", line 489, in send
resp = conn.urlopen(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 386, in _make_request
self._validate_conn(conn)
File "/usr/lib/python3.10/site-packages/urllib3/connectionpool.py", line 1042, in _validate_conn
conn.connect()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 358, in connect
self.sock = conn = self._new_conn()
File "/usr/lib/python3.10/site-packages/urllib3/connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "/usr/lib/python3.10/site-packages/urllib3/util/connection.py", line 72, in create_connection
for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
File "/usr/lib/python3.10/socket.py", line 955, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
KeyboardInterrupt
#9: 0%| | 0/1 [00:51<?, ?obj/s]
```
### Steps to reproduce the bug
```python
"""Kodak.
Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
import datasets
NUMBER = 17
_DESCRIPTION = """\
The pictures below link to lossless, true color (24 bits per pixel, aka "full
color") images. It is my understanding they have been released by the Eastman
Kodak Company for unrestricted usage. Many sites use them as a standard test
suite for compression testing, etc. Prior to this site, they were only
available in the Sun Raster format via ftp. This meant that the images could
not be previewed before downloading. Since their release, however, the lossless
PNG format has been incorporated into all the major browsers. Since PNG
supports 24-bit lossless color (which GIF and JPEG do not), it is now possible
to offer this browser-friendly access to the images.
"""
_HOMEPAGE = "https://r0k.us/graphics/kodak/"
_LICENSE = "GPLv3"
_URLS = [
f"https://github.com/MohamedBakrAli/Kodak-Lossless-True-Color-Image-Suite/raw/master/PhotoCD_PCD0992/{i}.png"
for i in range(1, 1 + NUMBER)
]
class Kodak(datasets.GeneratorBasedBuilder):
"""Kodak datasets."""
VERSION = datasets.Version("0.0.1")
def _info(self):
features = datasets.Features(
{
"image": datasets.Image(),
}
)
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=features,
homepage=_HOMEPAGE,
license=_LICENSE,
)
def _split_generators(self, dl_manager):
"""Return SplitGenerators."""
file_paths = dl_manager.download_and_extract(_URLS)
return [
datasets.SplitGenerator(
name=datasets.Split.TEST,
gen_kwargs={
"file_paths": file_paths,
},
),
]
def _generate_examples(self, file_paths):
"""Yield examples."""
for file_path in file_paths:
yield file_path, {"image": file_path}
```
### Expected behavior
When `len(_URLS) < 16`, it works.
```python
In [3]: dataset = load_dataset('Freed-Wu/kodak', split='test')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.53k/2.53k [00:00<00:00, 3.02MB/s]
[11/19/22 22:04:28] WARNING Using custom data configuration default builder.py:379
Downloading and preparing dataset kodak/default to /home/wzy/.cache/huggingface/datasets/Freed-Wu___kodak/default/0.0.1/d26017602a592b5bfa7e008127cdf9dec5af220c9068005f1b4eda036031f475...
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 593k/593k [00:00<00:00, 2.88MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 621k/621k [00:03<00:00, 166kB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 531k/531k [00:01<00:00, 366kB/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 16/16 [00:13<00:00, 1.18it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 16/16 [00:00<00:00, 3832.38it/s]
Dataset kodak downloaded and prepared to /home/wzy/.cache/huggingface/datasets/Freed-Wu___kodak/default/0.0.1/d26017602a592b5bfa7e008127cdf9dec5af220c9068005f1b4eda036031f475. Subsequent calls will reuse this data.
```
### Environment info
- `datasets` version: 2.7.0
- Platform: Linux-6.0.8-arch1-1-x86_64-with-glibc2.36
- Python version: 3.10.8
- PyArrow version: 9.0.0
- Pandas version: 1.4.4 | https://github.com/huggingface/datasets/issues/5270 | [
"It can fix the bug temporarily.\r\n```python\r\nfrom datasets import DownloadConfig\r\nconfig = DownloadConfig(num_proc=8)\r\nIn [5]: dataset = load_dataset('Freed-Wu/kodak', split='test', download_config=config)\r\nDownloading and preparing dataset kodak/default to /home/wzy/.cache/huggingface/datasets/Freed-Wu___kodak/default/0.0.1/6cf51f2b3d686d24a33fe86945f9e16802def212325f9345cf3cbb1b9f5f4a57...\r\nDownloading data files #4: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.39obj/s]\r\nDownloading data files #2: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.38obj/s]\r\nDownloading data files #3: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.13obj/s]\r\nDownloading data files #7: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.09obj/s]\r\nDownloading data files #5: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.08obj/s]\r\nDownloading data files #0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.08obj/s]\r\nDownloading data files #1: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:10<00:00, 3.36s/obj]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 492k/492k [00:01<00:00, 253kB/s]\r\nDownloading data files #6: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:13<00:00, 4.63s/obj]\r\nExtracting data files #0: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1407.17obj/s]\r\nExtracting data files #1: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1325.91obj/s]\r\nExtracting data files #3: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1524.46obj/s]\r\nExtracting data files #2: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1404.66obj/s]\r\nExtracting data files #4: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1538.63obj/s]\r\nExtracting data files #6: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1711.73obj/s]\r\nExtracting data files #7: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 2144.33obj/s]\r\nExtracting data files #5: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1964.85obj/s]\r\nDataset kodak downloaded and prepared to /home/wzy/.cache/huggingface/datasets/Freed-Wu___kodak/default/0.0.1/6cf51f2b3d686d24a33fe86945f9e16802def212325f9345cf3cbb1b9f5f4a57. Subsequent calls will reuse this data.\r\n```",
"Thanks for reporting ! This sounds like an issue with python multiprocessing. If we switch to multithreading for the downloads it should be much more robust - let me know if this is something you'd like to contribute, I'd be happy to help and give you some pointers",
"> an issue with python multiprocessing\r\n\r\nIf it is an issue with multiprocessing, should we report it to upstream?",
"Debugging this would require quite some work in my opinion, and I've often failed to make reproducible examples, since it's pretty correlated to one's environment + hardware. So I wouldn't spend too much time on this unless we manage to reproduce this on another machine consistently.\r\n\r\nInstead I'd encourage a more pragmatic fix that is: not create tons of processes (on regular machines it may slow things down anyway), and instead use multithreading by default.",
"I am not expert of python. I hear about python has GIL, which result in multi processing is worse than multi threading. So I am not sure if this change makes sense?\r\n\r\nAnd if this is a bug of multi processing, why not report to upstream and let them fix? And even if change it to multi threading, how can we make sure it can truly fix this problem?",
"Just my 2c. No offense.",
"> Just my 2c. No offense.\r\n\r\nsure np ^^\r\n\r\n> I hear about python has GIL, which result in multi processing is worse than multi threading. So I am not sure if this change makes sense?\r\n\r\nHere the bottleneck speed is the bandwidth used to download the files. When downloading, the GIL is released, so multithreading gives the same speed as multiprocessing.\r\n\r\n> And if this is a bug of multi processing, why not report to upstream and let them fix?\r\n\r\nUsually to fix a bug it's important to be able to reproduce it. This way you can share it, experiment with it, and then make sure it's fixed. Here I'm afraid it's not easy to reproduce. Though I think that spawning too many processes for your machine can lead to this kind of issues.\r\n\r\n> And even if change it to multi threading, how can we make sure it can truly fix this problem?\r\n\r\nMultithreading is more robust in python because IIRC there are less locks involved which are often the cause of code hanging for no reason."
] | null | 5,270 | false |
Shell completions | ### Feature request
Like <https://github.com/huggingface/huggingface_hub/issues/1197>, datasets-cli maybe need it, too.
### Motivation
See above.
### Your contribution
Maybe. | https://github.com/huggingface/datasets/issues/5269 | [
"I don't think we need completion on the datasets-cli, since we're mainly developing huggingface-cli",
"I see."
] | null | 5,269 | false |
Sharded save_to_disk + multiprocessing | Added `num_shards=` and `num_proc=` to `save_to_disk()`
EDIT: also added `max_shard_size=` to `save_to_disk()`, and also `num_shards=` to `push_to_hub`
I also:
- deprecated the fs parameter in favor of storage_options (for consistency with the rest of the lib) in save_to_disk and load_from_disk
- always embed the image/audio data in arrow when doing `save_to_disk`
- added a tqdm bar in `save_to_disk`
- Use the MockFileSystem in tests for `save_to_disk` and `load_from_disk`
- removed the unused integration tests with S3, since we can now test with `mockfs` instead of `s3fs`
TODO:
- [x] implem save_to_disk for dataset dict
- [x] save_to_disk for dataset dict tests
- [x] deprecate fs in dataset dict load_from_disk as well
- [x] update docs
Close #5263
Close https://github.com/huggingface/datasets/issues/4196
Close https://github.com/huggingface/datasets/issues/4351 | https://github.com/huggingface/datasets/pull/5268 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Added both num_shards and max_shard_size in push_to_hub/save_to_disk. Will take care of updating the tests later",
"It's ready for a final review @mariosasko and @albertvillanova, let me know what you think :)",
"Took your comments into account, and also changed `iflatmap_unordered` to take an iterable of kwargs to make the code more redable :)"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5268",
"html_url": "https://github.com/huggingface/datasets/pull/5268",
"diff_url": "https://github.com/huggingface/datasets/pull/5268.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5268.patch",
"merged_at": "2022-12-14T18:22:58"
} | 5,268 | true |
Fix `max_shard_size` docs | null | https://github.com/huggingface/datasets/pull/5267 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5267",
"html_url": "https://github.com/huggingface/datasets/pull/5267",
"diff_url": "https://github.com/huggingface/datasets/pull/5267.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5267.patch",
"merged_at": "2022-11-18T17:25:26"
} | 5,267 | true |
Specify arguments as keywords in librosa.reshape to avoid future errors | Fixes a warning and future deprecation from `librosa.reshape`:
```
FutureWarning: Pass orig_sr=16000, target_sr=48000 as keyword args. From version 0.10 passing these as positional arguments will result in an error
array = librosa.resample(array, sampling_rate, self.sampling_rate, res_type="kaiser_best")
``` | https://github.com/huggingface/datasets/pull/5266 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5266",
"html_url": "https://github.com/huggingface/datasets/pull/5266",
"diff_url": "https://github.com/huggingface/datasets/pull/5266.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5266.patch",
"merged_at": "2022-11-21T15:41:57"
} | 5,266 | true |
Get an IterableDataset from a map-style Dataset | This is useful to leverage iterable datasets specific features like:
- fast approximate shuffling
- lazy map, filter etc.
Iterating over the resulting iterable dataset should be at least as fast at iterating over the map-style dataset.
Here are some ideas regarding the API:
```python
# 1.
# - consistency with load_dataset(..., streaming=True)
# - gives intuition that map/filter/etc. are done on-the-fly
ids = ds.stream()
# 2.
# - more explicit on the output type
# - but maybe sounds like a conversion tool rather than a step in a processing pipeline
ids = ds.as_iterable_dataset()
``` | https://github.com/huggingface/datasets/issues/5265 | [
"I think `stream` could be misleading since the data is not being streamed from remote endpoints (one could think that's the case when they see `load_dataset` followed by `stream`). Hence, I prefer the second option.\r\n\r\nPS: When we resolve https://github.com/huggingface/datasets/issues/4542, we could add `as_tf_dataset` to the API for consistency and deprecate `to_tf_dataset`."
] | null | 5,265 | false |
`datasets` can't read a Parquet file in Python 3.9.13 | ### Describe the bug
I have an error when trying to load this [dataset](https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj) (it's private but I can add you to the bigcode org). `datasets` can't read one of the parquet files in the Java subset
```python
from datasets import load_dataset
ds = load_dataset("bigcode/the-stack-dedup-pjj", data_dir="data/java", split="train", revision="v1.1.a1", use_auth_token=True)
````
```
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.
```
It seems to be an issue with new Python versions, Because it works in these two environements:
```
- `datasets` version: 2.6.1
- Platform: Linux-5.4.0-131-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
```
```
- `datasets` version: 2.6.1
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.12
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
```
But not in this:
```
- `datasets` version: 2.6.1
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
```
### Steps to reproduce the bug
Load the dataset in python 3.9.13
### Expected behavior
Load the dataset without the pyarrow error.
### Environment info
```
- `datasets` version: 2.6.1
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.3.4
``` | https://github.com/huggingface/datasets/issues/5264 | [
"Could you share the full stack trace please ?\r\n\r\n\r\nCan you also try running this code ? It can be useful to determine if the issue comes from `datasets` or `fsspec` (streaming) or `pyarrow` (parquet reading):\r\n```python\r\nds = load_dataset(\"parquet\", data_files=a_parquet_file_url, use_auth_token=True)\r\n```",
"Here's the full trace\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/loubna_huggingface_co/load.py\", line 15, in <module>\r\n ds_all = load_dataset(\"bigcode/the-stack-dedup-pjj\", data_dir=\"data/java\",use_auth_token=True, split=\"train\", revision=\"v1.1.a1\")\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1742, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 814, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 905, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 1502, in _prepare_split\r\n for key, table in logging.tqdm(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py\", line 1195, in __iter__\r\n for obj in iterable:\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py\", line 67, in _generate_tables\r\n parquet_file = pq.ParquetFile(f)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/parquet/__init__.py\", line 286, in __init__\r\n self.reader.open(\r\n File \"pyarrow/_parquet.pyx\", line 1227, in pyarrow._parquet.ParquetReader.open\r\n File \"pyarrow/error.pxi\", line 100, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.\r\n```\r\n\r\nwhen running\r\n```python\r\nds = load_dataset(\"parquet\", data_files=\"https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/blob/v1.1.a1/data/java/data_0000.parquet\", use_auth_token=True)\r\n```\r\nI get 401 error, but that's the case for the python subset too which I can load properly\r\n```\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1719, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1497, in load_dataset_builder\r\n dataset_module = dataset_module_factory(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1134, in dataset_module_factory\r\n return PackagedDatasetModuleFactory(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 707, in get_module\r\n data_files = DataFilesDict.from_local_or_remote(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 795, in from_local_or_remote\r\n DataFilesList.from_local_or_remote(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 764, in from_local_or_remote\r\n origin_metadata = _get_origin_metadata_locally_or_by_urls(data_files, use_auth_token=use_auth_token)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 710, in _get_origin_metadata_locally_or_by_urls\r\n return thread_map(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/contrib/concurrent.py\", line 94, in thread_map\r\n return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/contrib/concurrent.py\", line 76, in _executor_map\r\n return list(tqdm_class(ex.map(fn, *iterables, **map_args), **kwargs))\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py\", line 1183, in __iter__\r\n for obj in iterable:\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/_base.py\", line 609, in result_iterator\r\n yield fs.pop().result()\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/_base.py\", line 446, in result\r\n return self.__get_result()\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/_base.py\", line 391, in __get_result\r\n raise self._exception\r\n File \"/opt/conda/envs/venv/lib/python3.9/concurrent/futures/thread.py\", line 58, in run\r\n result = self.fn(*self.args, **self.kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/data_files.py\", line 701, in _get_single_origin_metadata_locally_or_by_urls\r\n return (request_etag(data_file, use_auth_token=use_auth_token),)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 411, in request_etag\r\n response.raise_for_status()\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/requests/models.py\", line 960, in raise_for_status\r\n raise HTTPError(http_error_msg, response=self)\r\nrequests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/blob/v1.1.a1/data/python/data_0000.parquet```",
"Can you check you used the right token ? You shouldn't get a 401 using your token",
"I checked it’s the right token, when loading the full dataset I get the error after data extraction so I can access the files. \r\n```\r\nDownloading and preparing dataset parquet/bigcode--the-stack-dedup-pjj to /home/loubna_huggingface_co/.cache/huggingface/datasets/bigcode___parquet/bigcode--the-stack-dedup-pjj-872ffac7f4bb46ca/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...\r\nDownloading data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 22.38it/s]\r\nExtracting data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 49.91it/s]\r\nTraceback (most recent call last):\r\n File \"/home/loubna_huggingface_co/load_ds.py\", line 5, in <module>\r\n ds = load_dataset(\"bigcode/the-stack-dedup-pjj\", data_dir=\"data/java\", use_auth_token=True,split=\"train\", revision=\"v1.1.a1\")\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py\", line 1742, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 814, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 905, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py\", line 1502, in _prepare_split\r\n for key, table in logging.tqdm(\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py\", line 1195, in __iter__\r\n for obj in iterable:\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py\", line 67, in _generate_tables\r\n parquet_file = pq.ParquetFile(f)\r\n File \"/opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/parquet/__init__.py\", line 286, in __init__\r\n self.reader.open(\r\n File \"pyarrow/_parquet.pyx\", line 1227, in pyarrow._parquet.ParquetReader.open\r\n File \"pyarrow/error.pxi\", line 100, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.\r\n```\r\nCould it be that I'm using a wrong url, I just copied it from the address bar",
"The URL is wrong indeed, the right one is the one with \"resolve\" (the one you get when clicking on \"download\")- otherwise you try to download an html page ;)\r\n```\r\nhttps://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/resolve/v1.1.a1/data/java/data_0000.parquet\r\n```",
"Ah thanks! So I tried it with the first parquet file and it works, is there a way to know which parquet file was causing the issue since there are a lot of shards?",
"I think you have to try them all :/\r\n\r\nAlternatively you can add a try/catch in `parquet.py` in `datasets` to raise the name of the file that fails at doing `parquet_file = pq.ParquetFile(f)` when you run your initial code\r\n```python\r\nload_dataset(\"bigcode/the-stack-dedup-pjj\", data_dir=\"data/java\", split=\"train\", revision=\"v1.1.a1\", use_auth_token=True)\r\n```\r\nbut it will still iterate on all the files until it fails",
"Ok I will do that",
"I did find the file, and I get the same error as before \r\n```\r\nDownloading data files: 100%|███████████████████| 1/1 [00:00<00:00, 8160.12it/s]\r\nExtracting data files: 100%|████████████████████| 1/1 [00:00<00:00, 1447.81it/s]\r\n \r\n---------------------------------------------------------------------------\r\nArrowInvalid Traceback (most recent call last)\r\nInput In [22], in <cell line: 7>()\r\n 4 data_features = (data[\"train\"].features)\r\n 6 url = \"/home/loubna_huggingface_co/.cache/huggingface/datasets/downloads/93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7\"\r\n----> 7 data = load_dataset(\"parquet\", \r\n 8 data_files=url,\r\n 9 split=\"train\",\r\n 10 features=data_features,\r\n 11 use_auth_token=True)\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/load.py:1742, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)\r\n 1739 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES\r\n 1741 # Download and prepare data\r\n-> 1742 builder_instance.download_and_prepare(\r\n 1743 download_config=download_config,\r\n 1744 download_mode=download_mode,\r\n 1745 ignore_verifications=ignore_verifications,\r\n 1746 try_from_hf_gcs=try_from_hf_gcs,\r\n 1747 use_auth_token=use_auth_token,\r\n 1748 )\r\n 1750 # Build dataset for splits\r\n 1751 keep_in_memory = (\r\n 1752 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)\r\n 1753 )\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py:814, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, storage_options, **download_and_prepare_kwargs)\r\n 808 if not downloaded_from_gcs:\r\n 809 prepare_split_kwargs = {\r\n 810 \"file_format\": file_format,\r\n 811 \"max_shard_size\": max_shard_size,\r\n 812 **download_and_prepare_kwargs,\r\n 813 }\r\n--> 814 self._download_and_prepare(\r\n 815 dl_manager=dl_manager,\r\n 816 verify_infos=verify_infos,\r\n 817 **prepare_split_kwargs,\r\n 818 **download_and_prepare_kwargs,\r\n 819 )\r\n 820 # Sync info\r\n 821 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py:905, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 901 split_dict.add(split_generator.split_info)\r\n 903 try:\r\n 904 # Prepare split will record examples associated to the split\r\n--> 905 self._prepare_split(split_generator, **prepare_split_kwargs)\r\n 906 except OSError as e:\r\n 907 raise OSError(\r\n 908 \"Cannot find data file. \"\r\n 909 + (self.manual_download_instructions or \"\")\r\n 910 + \"\\nOriginal error:\\n\"\r\n 911 + str(e)\r\n 912 ) from None\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/builder.py:1502, in ArrowBasedBuilder._prepare_split(self, split_generator, file_format, max_shard_size)\r\n 1500 total_num_examples, total_num_bytes = 0, 0\r\n 1501 try:\r\n-> 1502 for key, table in logging.tqdm(\r\n 1503 generator,\r\n 1504 unit=\" tables\",\r\n 1505 leave=False,\r\n 1506 disable=not logging.is_progress_bar_enabled(),\r\n 1507 ):\r\n 1508 if max_shard_size is not None and writer._num_bytes > max_shard_size:\r\n 1509 num_examples, num_bytes = writer.finalize()\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/tqdm/std.py:1195, in tqdm.__iter__(self)\r\n 1192 time = self._time\r\n 1194 try:\r\n-> 1195 for obj in iterable:\r\n 1196 yield obj\r\n 1197 # Update and possibly print the progressbar.\r\n 1198 # Note: does not call self.update(1) for speed optimisation.\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py:67, in Parquet._generate_tables(self, files)\r\n 65 for file_idx, file in enumerate(itertools.chain.from_iterable(files)):\r\n 66 with open(file, \"rb\") as f:\r\n---> 67 parquet_file = pq.ParquetFile(f)\r\n 68 try:\r\n 69 for batch_idx, record_batch in enumerate(\r\n 70 parquet_file.iter_batches(batch_size=self.config.batch_size, columns=self.config.columns)\r\n 71 ):\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/parquet/__init__.py:286, in ParquetFile.__init__(self, source, metadata, common_metadata, read_dictionary, memory_map, buffer_size, pre_buffer, coerce_int96_timestamp_unit, decryption_properties, thrift_string_size_limit, thrift_container_size_limit)\r\n 280 def __init__(self, source, *, metadata=None, common_metadata=None,\r\n 281 read_dictionary=None, memory_map=False, buffer_size=0,\r\n 282 pre_buffer=False, coerce_int96_timestamp_unit=None,\r\n 283 decryption_properties=None, thrift_string_size_limit=None,\r\n 284 thrift_container_size_limit=None):\r\n 285 self.reader = ParquetReader()\r\n--> 286 self.reader.open(\r\n 287 source, use_memory_map=memory_map,\r\n 288 buffer_size=buffer_size, pre_buffer=pre_buffer,\r\n 289 read_dictionary=read_dictionary, metadata=metadata,\r\n 290 coerce_int96_timestamp_unit=coerce_int96_timestamp_unit,\r\n 291 decryption_properties=decryption_properties,\r\n 292 thrift_string_size_limit=thrift_string_size_limit,\r\n 293 thrift_container_size_limit=thrift_container_size_limit,\r\n 294 )\r\n 295 self.common_metadata = common_metadata\r\n 296 self._nested_paths_by_prefix = self._build_nested_paths()\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/_parquet.pyx:1227, in pyarrow._parquet.ParquetReader.open()\r\n\r\nFile /opt/conda/envs/venv/lib/python3.9/site-packages/pyarrow/error.pxi:100, in pyarrow.lib.check_status()\r\n\r\nArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.\r\n```",
"Can you check the JSON file associated to `/home/loubna_huggingface_co/.cache/huggingface/datasets/downloads/93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7` ? In the JSON file we can know from where it was downloaded\r\n\r\nYou can find it at `/home/loubna_huggingface_co/.cache/huggingface/datasets/downloads/93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7.json`",
"It's this file `https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj/resolve/f48656daa9f3a3607dacf8b57a65810a6a7a7f73/data/java/data_0022.parquet` loading it gives the same error",
"I'm able to load it properly using\r\n```python\r\nds = load_dataset(\"parquet\", data_files=a_parquet_file_url, use_auth_token=token)\r\n```\r\n\r\nMy guess is that your download was corrupted. Please delete `93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7` and `93431bc4380de07de8b0ab533666cb5a6120cbe266779e0a63c86bf7717475d7.json` locally and try again",
"That worked, thanks! But I thought if something went wrong with a download `datasets` creates new cache for all the files, that's not the case? (at some point I even changed dataset versions so it was still using that cache?)",
"Cool !\r\n\r\n> But I thought if something went wrong with a download datasets creates new cache for all the files\r\n\r\nWe don't perform integrity verifications if we don't know in advance the hash of the file to download.\r\n\r\n> at some point I even changed dataset versions so it was still using that cache?\r\n\r\n`datasets` caches the files by URL and ETag. If the content of a file changes, then the ETag changes and so it redownloads the file",
"I see, thank you!\r\n"
] | null | 5,264 | false |
Save a dataset in a determined number of shards | This is useful to distribute the shards to training nodes.
This can be implemented in `save_to_disk` and can also leverage multiprocessing to speed up the process | https://github.com/huggingface/datasets/issues/5263 | [] | null | 5,263 | false |
AttributeError: 'Value' object has no attribute 'names' | Hello
I'm trying to build a model for custom token classification
I already followed the token classification course on huggingface
while adapting the code to my work, this message occures :
'Value' object has no attribute 'names'
Here's my code:
`raw_datasets`
generates
DatasetDict({
train: Dataset({
features: ['isDisf', 'pos', 'tokens', 'id'],
num_rows: 14
})
})
`raw_datasets["train"][3]["isDisf"]`
generates
['B_RM', 'I_RM', 'I_RM', 'B_RP', 'I_RP', 'O', 'O']
`dis_feature = raw_datasets["train"].features["isDisf"]
dis_feature`
generates
Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)
and
`label_names = dis_feature.feature.names
label_names`
generates
AttributeError Traceback (most recent call last)
[<ipython-input-28-972fd54a869a>](https://localhost:8080/#) in <module>
----> 1 label_names = dis_feature.feature.names
2 label_names
AttributeError: 'Value' object has
AttributeError: 'Value' object has no attribute 'names'
Thank you for your help | https://github.com/huggingface/datasets/issues/5262 | [
"Hi ! It looks like your \"isDif\" column is a Sequence of Value(\"string\"), not a Sequence of ClassLabel.\r\n\r\nYou can convert your Value(\"string\") feature type to a ClassLabel feature type this way:\r\n```python\r\nfrom datasets import ClassLabel, Sequence\r\n\r\n# provide the label_names yourself\r\nlabel_names = [...]\r\n# OR get them from the dataset\r\nlabel_names = sorted(set(label for labels in raw_datasets[\"train\"][\"isDif\"] for label in labels))\r\n\r\n# Cast to ClassLabel\r\nraw_datasets = raw_datasets.cast_column(\"isDif\", Sequence(ClassLabel(names=label_names)))\r\n```\r\n",
"thank you \r\nit works 💯 "
] | null | 5,262 | false |
Add PubTables-1M | ### Name
PubTables-1M
### Paper
https://openaccess.thecvf.com/content/CVPR2022/html/Smock_PubTables-1M_Towards_Comprehensive_Table_Extraction_From_Unstructured_Documents_CVPR_2022_paper.html
### Data
https://github.com/microsoft/table-transformer
### Motivation
Table Transformer is now available in 🤗 Transformer, and it was trained on PubTables-1M. It's a large dataset for table extraction and structure recognition in unstructured documents. | https://github.com/huggingface/datasets/issues/5261 | [
"cc @albertvillanova the author would like to add this dataset to the hub: https://github.com/microsoft/table-transformer/issues/68#issuecomment-1319114621. Could you help him out?"
] | null | 5,261 | false |
consumer-finance-complaints dataset not loading | ### Describe the bug
Error during dataset loading
### Steps to reproduce the bug
```
>>> import datasets
>>> cf_raw = datasets.load_dataset("consumer-finance-complaints")
Downloading builder script: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8.42k/8.42k [00:00<00:00, 3.33MB/s]
Downloading metadata: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5.60k/5.60k [00:00<00:00, 2.90MB/s]
Downloading readme: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 16.6k/16.6k [00:00<00:00, 510kB/s]
Downloading and preparing dataset consumer-finance-complaints/default to /root/.cache/huggingface/datasets/consumer-finance-complaints/default/0.0.0/30e483d37fb4b25bb98cad1bfd2dc48f6ed6d1f3371eb4568c625a61d1a79b69...
Downloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 511M/511M [00:04<00:00, 103MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/skunk-pod-storage-lee-2emartie-40ibm-2ecom-pvc/anaconda3/envs/datasets/lib/python3.8/site-packages/datasets/load.py", line 1741, in load_dataset
builder_instance.download_and_prepare(
File "/skunk-pod-storage-lee-2emartie-40ibm-2ecom-pvc/anaconda3/envs/datasets/lib/python3.8/site-packages/datasets/builder.py", line 822, in download_and_prepare
self._download_and_prepare(
File "/skunk-pod-storage-lee-2emartie-40ibm-2ecom-pvc/anaconda3/envs/datasets/lib/python3.8/site-packages/datasets/builder.py", line 1555, in _download_and_prepare
super()._download_and_prepare(
File "/skunk-pod-storage-lee-2emartie-40ibm-2ecom-pvc/anaconda3/envs/datasets/lib/python3.8/site-packages/datasets/builder.py", line 931, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/skunk-pod-storage-lee-2emartie-40ibm-2ecom-pvc/anaconda3/envs/datasets/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=1605177353, num_examples=2455765, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='train', num_bytes=2043641693, num_examples=3079747, shard_lengths=[721000, 656000, 788000, 846000, 68747], dataset_name='consumer-finance-complaints')}]
```
### Expected behavior
dataset should load
### Environment info
>>> datasets.__version__
'2.7.0'
Python 3.8.10
"Ubuntu 20.04.4 LTS" | https://github.com/huggingface/datasets/issues/5260 | [
"Thanks for reporting, @adiprasad.\r\n\r\nWe are having a look at it.",
"I have opened an issue in that dataset Community tab on the Hub: https://huggingface.co/datasets/consumer-finance-complaints/discussions/1\r\n\r\nPlease note that in the meantime, you can load the dataset by passing `ignore_verifications=True`:\r\n```python\r\n>>> ds = load_dataset(\"consumer-finance-complaints\", ignore_verifications=True)\r\n>>> ds\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['Date Received', 'Product', 'Sub Product', 'Issue', 'Sub Issue', 'Complaint Text', 'Company Public Response', 'Company', 'State', 'Zip Code', 'Tags', 'Consumer Consent Provided', 'Submitted via', 'Date Sent To Company', 'Company Response To Consumer', 'Timely Response', 'Consumer Disputed', 'Complaint ID'],\r\n num_rows: 3079747\r\n })\r\n})\r\n```",
"PR fixing this issue: https://huggingface.co/datasets/consumer-finance-complaints/discussions/2"
] | null | 5,260 | false |
datasets 2.7 introduces sharding error | ### Describe the bug
dataset fails to load with runtime error
`RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_files has length 46
- key data has length 0
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.`
### Steps to reproduce the bug
With datasets[audio] 2.7 loaded, and logged into hugging face,
`data = datasets.load_dataset('sil-ai/bloom-speech', 'bis', use_auth_token=True)`
creates the error.
Full stack trace:
```---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
[<ipython-input-7-8cb9ca0f79f0>](https://localhost:8080/#) in <module>
----> 1 data = datasets.load_dataset('sil-ai/bloom-speech', 'bis', use_auth_token=True)
5 frames
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
1745 try_from_hf_gcs=try_from_hf_gcs,
1746 use_auth_token=use_auth_token,
-> 1747 num_proc=num_proc,
1748 )
1749
[/usr/local/lib/python3.7/dist-packages/datasets/builder.py](https://localhost:8080/#) in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
824 verify_infos=verify_infos,
825 **prepare_split_kwargs,
--> 826 **download_and_prepare_kwargs,
827 )
828 # Sync info
[/usr/local/lib/python3.7/dist-packages/datasets/builder.py](https://localhost:8080/#) in _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
1554 def _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs):
1555 super()._download_and_prepare(
-> 1556 dl_manager, verify_infos, check_duplicate_keys=verify_infos, **prepare_splits_kwargs
1557 )
1558
[/usr/local/lib/python3.7/dist-packages/datasets/builder.py](https://localhost:8080/#) in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
911 try:
912 # Prepare split will record examples associated to the split
--> 913 self._prepare_split(split_generator, **prepare_split_kwargs)
914 except OSError as e:
915 raise OSError(
[/usr/local/lib/python3.7/dist-packages/datasets/builder.py](https://localhost:8080/#) in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
1362 fpath = path_join(self._output_dir, fname)
1363
-> 1364 num_input_shards = _number_of_shards_in_gen_kwargs(split_generator.gen_kwargs)
1365 if num_input_shards <= 1 and num_proc is not None:
1366 logger.warning(
[/usr/local/lib/python3.7/dist-packages/datasets/utils/sharding.py](https://localhost:8080/#) in _number_of_shards_in_gen_kwargs(gen_kwargs)
16 + "\n".join(f"\t- key {key} has length {length}" for key, length in lists_lengths.items())
17 + "\nTo fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, "
---> 18 + "and use tuples otherwise. In the end there should only be one single list, or several lists with the same length."
19 )
20 )
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_files has length 46
- key data has length 0
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.```
### Expected behavior
the dataset loads in datasets version 2.6.1 and should load with datasets 2.7
### Environment info
- `datasets` version: 2.7.0
- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.15
- PyArrow version: 6.0.1
- Pandas version: 1.3.5 | https://github.com/huggingface/datasets/issues/5259 | [
"I notice a comment in the code says:\r\n`Having lists of different sizes makes sharding ambigious, raise an error in this case until we decide how to define sharding without ambiguity for users` \r\n \r\n ... which suggests this update was pushed knowing that it might break some things. But, it didn't seem to have a useful error message of an argument that could be passed to avoid the error.",
"Sorry for the inconvenience, I opened a PR in your repo to fix this: https://huggingface.co/datasets/sil-ai/bloom-speech/discussions/2\r\n\r\nBasically we've always considered lists in `gen_kwargs` to be a shard list that we can split and pass into different workers to generate the dataset (e.g. if you pass `num_proc=` in `load_dataset()` to generate the dataset in parallel), but it was documented only recently",
"@lhoestq Thanks for the help. It looks like that took care of it."
] | null | 5,259 | false |
Restore order of split names in dataset_info for canonical datasets | After a bulk edit of canonical datasets to create the YAML `dataset_info` metadata, the split names were accidentally sorted alphabetically. See for example:
- https://huggingface.co/datasets/bc2gm_corpus/commit/2384629484401ecf4bb77cd808816719c424e57c
Note that this order is the one appearing in the preview of the datasets.
I'm making a bulk edit to align the order of the splits appearing in the metadata info with the order appearing in the loading script.
Related to:
- #5202 | https://github.com/huggingface/datasets/issues/5258 | [
"The bulk edit is running...\r\n\r\nSee for example: \r\n- A single config: https://huggingface.co/datasets/acronym_identification/discussions/2\r\n- Multiple configs: https://huggingface.co/datasets/babi_qa/discussions/1",
"TODO: Add \"dataset_info\" YAML metadata to:\r\n- [x] \"chr_en\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card\r\n - Fixing PR: https://huggingface.co/datasets/chr_en/discussions/1 \r\n- [x] \"conll2000\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [x] \"crime_and_punish\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [x] \"dart\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [x] \"iwslt2017\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [ ] \"mc4\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card\r\n- [ ] \"the_pile\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card\r\n- [ ] \"timit_asr\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card",
"The bulk edit is finished."
] | null | 5,258 | false |
remove an unused statement | remove the unused statement: `input_pairs = list(zip())` | https://github.com/huggingface/datasets/pull/5257 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5257",
"html_url": "https://github.com/huggingface/datasets/pull/5257",
"diff_url": "https://github.com/huggingface/datasets/pull/5257.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5257.patch",
"merged_at": "2022-11-18T11:04:08"
} | 5,257 | true |
fix wrong print | print `encoded_dataset.column_names` not `dataset.column_names` | https://github.com/huggingface/datasets/pull/5256 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5256",
"html_url": "https://github.com/huggingface/datasets/pull/5256",
"diff_url": "https://github.com/huggingface/datasets/pull/5256.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5256.patch",
"merged_at": "2022-11-18T11:05:32"
} | 5,256 | true |
Add a Depth Estimation dataset - DIODE / NYUDepth / KITTI | ### Name
NYUDepth
### Paper
http://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
### Data
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
### Motivation
Depth estimation is an important problem in computer vision. We have a couple of Depth Estimation models on Hub as well:
* [GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)
* [DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
Would be nice to have a dataset for depth estimation. These datasets usually have three things: input image, depth map image, and depth mask (validity mask to indicate if a reading for a pixel is valid or not). Since we already have [semantic segmentation datasets on the Hub](https://huggingface.co/datasets?task_categories=task_categories:image-segmentation&sort=downloads), I don't think we need any extended utilities to support this addition.
Having this dataset would also allow us to author data preprocessing guides for depth estimation, particularly like the ones we have for other tasks ([example](https://huggingface.co/docs/datasets/image_classification)).
Ccing @osanseviero @nateraw @NielsRogge
Happy to work on adding it. | https://github.com/huggingface/datasets/issues/5255 | [
"Also cc @mariosasko and @lhoestq ",
"Cool ! Let us know if you have questions or if we can help :)\r\n\r\nI guess we'll also have to create the NYU CS Department on the Hub ?",
"> I guess we'll also have to create the NYU CS Department on the Hub ?\r\n\r\nYes, you're right! Let me add it to my profile first, and then we can transfer. Meanwhile, if it's recommended to loop the dataset author in here, let me know. \r\n\r\nAlso, the NYU Depth dataset seems big. Any example scripts for creating image datasets that I could refer? ",
"You can check the imagenet-1k one.\r\n\r\nPS: If the licenses allows it, it'b be nice to host the dataset as sharded TAR archives (like imagenet-1k) instead of the ZIP format they use:\r\n- it will make streaming much faster\r\n- ZIP compression is not well suited for images\r\n- it will allow parallel processing of the dataset (you can pass a subset of shards to each worker)\r\n\r\n> if it's recommended to loop the dataset author in here, let me know.\r\n\r\nIt's recommended indeed, you can send them an email once you have the dataset ready and invite them to the org on the Hub",
"> You can check the imagenet-1k one.\r\n\r\nWhere can I find the script? Are you referring to https://huggingface.co/docs/datasets/image_process ? Or is there anything more specific? ",
"You can find it here: https://huggingface.co/datasets/imagenet-1k/blob/main/imagenet-1k.py",
"Update: started working on it here: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2. \r\n\r\nI am facing an issue and I have detailed it here: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/discussions/1\r\n\r\nEdit: The issue is gone. \r\n\r\nHowever, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive? \r\n\r\n@lhoestq \r\n\r\n",
"A Colab Notebook demonstrating the dataset loading part: \r\n\r\nhttps://colab.research.google.com/gist/sayakpaul/aa0958c8d4ad8518d52a78f28044d871/scratchpad.ipynb\r\n\r\n@osanseviero @lhoestq \r\n\r\nI will work on a notebook to work with the dataset including data visualization.",
"@osanseviero @lhoestq things seem to work fine with the current version of the dataset [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2). Here's a notebook I developed to help with visualization: https://colab.research.google.com/drive/1K3ZU8XUPRDOYD38MQS9nreQXJYitlKSW?usp=sharing. \r\n\r\n@lhoestq I need your help with the following:\r\n\r\n> However, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive?\r\n\r\n@osanseviero @lhoestq question for you:\r\n\r\nWhere should we host the dataset? I think hosting it under hf.co/datasets (that is HF is the org) is fine as we have ImageNet-1k hosted similarly. We could then reach out to Diana Wofk (author of [Fast Depth](https://github.com/dwofk/fast-depth) and the owner of the repo on which TFDS NYU Depth V2 is based) for a review. WDYT? ",
"> However, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive?\r\n\r\nFirst you can separate the train data and the validation data.\r\n\r\nThen since the dataset is quite big, you can even shard the train split and the validation split in multiple TAR archives. Something around 16 archives for train and 4 for validation would be fine for example.\r\n\r\nAlso no need to gzip the TAR archives, the images are already compressed in png or jpeg.",
"> Then since the dataset is quite big, you can even shard the train split and the validation split in multiple TAR archives. Something around 16 archives for train and 4 for validation would be fine for example.\r\n\r\nYes, I got you. But this process seems to be manual and should be tailored for the given dataset. Do you have any script that you used to create the ImageNet-1k shards? \r\n\r\n> Also no need to gzip the TAR archives, the images are already compressed in png or jpeg.\r\n\r\nI was not going to do that. Not sure what brought it up. ",
"> Yes, I got you. But this process seems to be manual and should be tailored for the given dataset. Do you have any script that you used to create the ImageNet-1k shards?\r\n\r\nI don't, but I agree it'd be nice to have a script for that !\r\n\r\n> I was not going to do that. Not sure what brought it up.\r\n\r\nThe original dataset is gzipped for some reason",
"Oh, I am using this URL for the download: https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py#L24. ",
"> Where should we host the dataset? I think hosting it under hf.co/datasets (that is HF is the org) is fine as we have ImageNet-1k hosted similarly.\r\n\r\nMaybe you can create an org for NYU Courant (this is the institute of the lab of the main author of the dataset if I'm not mistaken), and invite the authors to join.\r\n\r\nWe don't add datasets without namespace anymore",
"Updates: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/discussions/5\r\n\r\nThe entire process (preparing multiple archives, preparing data loading script, etc.) was fun and engaging, thanks to the documentation. I believe we could work on a small blog post that would work as a reference for the future contributors following this path. What say? \r\n\r\nCc: @lhoestq @osanseviero ",
"> I believe we could work on a small blog post that would work as a reference for the future contributors following this path. What say?\r\n\r\n@polinaeterna already mentioned it would be nice to present this process for audio (it's exactly the same), I believe it can be useful to many people",
"Cool. Let's work on that after the NYU Depth Dataset is fully in on Hub (under the appropriate org). 🤗",
"@lhoestq need to discuss something while I am adding the dataset card to https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/. \r\n\r\nAs per [Papers With Code](https://paperswithcode.com/dataset/nyuv2), NYU Depth v2 is used for many different tasks:\r\n\r\n* Monocular depth estimation\r\n* Depth estimation \r\n* Semantic segmentation\r\n* Plane instance segmentation \r\n* ...\r\n\r\nSo, while writing the supported task part of the dataset card, should we focus on all these? IMO, we could focus on just depth estimation and semantic segmentation for now since we have supported models for these two. WDYT?\r\n\r\nAlso, I am getting: \r\n\r\n\r\n```\r\nremote: Your push was accepted, but with warnings:\r\nremote: - Warning: The task_ids \"depth-estimation\" is not in the official list: acceptability-classification, entity-linking-classification, fact-checking, intent-classification, multi-class-classification, multi-label-classification, multi-input-text-classification, natural-language-inference, semantic-similarity-classification, sentiment-classification, topic-classification, semantic-similarity-scoring, sentiment-scoring, sentiment-analysis, hate-speech-detection, text-scoring, named-entity-recognition, part-of-speech, parsing, lemmatization, word-sense-disambiguation, coreference-resolution, extractive-qa, open-domain-qa, closed-domain-qa, news-articles-summarization, news-articles-headline-generation, dialogue-generation, dialogue-modeling, language-modeling, text-simplification, explanation-generation, abstractive-qa, open-domain-abstractive-qa, closed-domain-qa, open-book-qa, closed-book-qa, slot-filling, masked-language-modeling, keyword-spotting, speaker-identification, audio-intent-classification, audio-emotion-recognition, audio-language-identification, multi-label-image-classification, multi-class-image-classification, face-detection, vehicle-detection, instance-segmentation, semantic-segmentation, panoptic-segmentation, image-captioning, grasping, task-planning, tabular-multi-class-classification, tabular-multi-label-classification, tabular-single-column-regression, rdf-to-text, multiple-choice-qa, multiple-choice-coreference-resolution, document-retrieval, utterance-retrieval, entity-linking-retrieval, fact-checking-retrieval, univariate-time-series-forecasting, multivariate-time-series-forecasting, visual-question-answering, document-question-answering\r\nremote: ----------------------------------------------------------\r\nremote: Please find the documentation at:\r\nremote: https://huggingface.co/docs/hub/model-cards#model-card-metadata\r\n```\r\n\r\nWhat should be the plan of action for this?\r\n\r\nCc: @osanseviero \r\n\r\n",
"> What should be the plan of action for this?\r\n\r\nWhen you merged https://github.com/huggingface/hub-docs/pull/488, there is a JS Interfaces GitHub Actions workflow that runs https://github.com/huggingface/hub-docs/actions/workflows/js-interfaces-tests.yml. It has a step called [export-task scripts](https://github.com/huggingface/hub-docs/actions/runs/3622479064/jobs/6107238948) which exports an interface you can use in `dataset`. If you look at the logs, it prints out a map. This map can replace https://github.com/huggingface/datasets/blob/main/src/datasets/utils/resources/tasks.json (tasks.json was generated with this script), which should add depth estimation\r\n",
"Thanks @osanseviero. \r\n\r\nhttps://github.com/huggingface/datasets/pull/5335",
"Closing the issue as the dataset has been successfully added: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2"
] | null | 5,255 | false |
typo | null | https://github.com/huggingface/datasets/pull/5254 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5254",
"html_url": "https://github.com/huggingface/datasets/pull/5254",
"diff_url": "https://github.com/huggingface/datasets/pull/5254.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5254.patch",
"merged_at": "2022-11-18T10:53:45"
} | 5,254 | true |
typo | null | https://github.com/huggingface/datasets/pull/5253 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5253",
"html_url": "https://github.com/huggingface/datasets/pull/5253",
"diff_url": "https://github.com/huggingface/datasets/pull/5253.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5253.patch",
"merged_at": "2022-11-18T10:53:10"
} | 5,253 | true |
Support for decoding Image/Audio types in map when format type is not default one | Add support for decoding the `Image`/`Audio` types in `map` for the formats (Numpy, TF, Jax, PyTorch) other than the default one (Python).
Additional improvements:
* make `Dataset`'s "iter" API cleaner by removing `_iter` and replacing `_iter_batches` with `iter(batch_size)` (also implemented for `IterableDataset`)
* iterate over arrow tables in `map` to avoid `_getitem` calls, which are much slower than `__iter__`/`iter(batch_size)`, when the `format_type` is not Python
* fix `_iter_batches` (now named `iter`) when `drop_last_batch=True` and `pyarrow<=8.0.0` is installed
* lazily extract and decode arrow data in the default format
TODO:
* [x] update the `iter` benchmark in the docs (the `BeamBuilder` cannot load the preprocessed datasets from our bucket, so wait for this to be fixed (cc @lhoestq))
Fix https://github.com/huggingface/datasets/issues/3992, fix https://github.com/huggingface/datasets/issues/3756 | https://github.com/huggingface/datasets/pull/5252 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5252). All of your documentation changes will be reflected on that endpoint.",
"Yes, if the image column is the first in the batch keys, it will decode the images because it reads the actual values. We could avoid this by checking the batch type, and if it's `LazyDict`, `num_examples` is equal to `len(batch.pa_table)`, which doesn't lead to decoding.",
"Good idea. This can be done in a subsequent PR btw, since it's out of scope of the original goal of this PR",
"Just fixed a small bug where it would show the pyarrow 10 warning about None -> empty lists conversions even with an Array2D with no nulls",
"Fixed another bug when your map function returns a mix of LazyDict or regular dict and added some tests"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5252",
"html_url": "https://github.com/huggingface/datasets/pull/5252",
"diff_url": "https://github.com/huggingface/datasets/pull/5252.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5252.patch",
"merged_at": "2022-12-13T16:59:04"
} | 5,252 | true |
Docs are not generated after latest release | After the latest `datasets` release version 0.7.0, the docs were not generated.
As we have changed the release procedure (so that now we do not push directly to main branch), maybe we should also change the corresponding GitHub action:
https://github.com/huggingface/datasets/blob/edf1902f954c5568daadebcd8754bdad44b02a85/.github/workflows/build_documentation.yml#L3-L8
Related to:
- #5250
CC: @mishig25 | https://github.com/huggingface/datasets/issues/5251 | [
"After a discussion with @mishig25:\r\n- He said that this action should be triggered if we call our release branch according to the regex `v*-release`, as transformers does\r\n- I said that our procedure is different: our release branch is *temporary* and it is deleted just after the release PR is merged to main\r\n - Indeed the release tag is not yet created when we make the release PR (not event when this is merged to main), but when we make the Release itself.\r\n\r\nI was thinking that maybe we could change the triggering event: use `release` instead of `push`.\r\n\r\nWhat do you think, @huggingface/datasets?",
"Why is it an issue if our branch is temporary ?",
"He says not; but the branch has no tag yet; does the doc building require the tag? Or just the version number in `__init__.py` or setup.py?",
"It uses `module.__version__` (i.e. the one defined in `__init__.py`) - no need to have a tag\r\n\r\nhttps://github.com/huggingface/doc-builder/blob/81575cf081964c30ea5fd39450f4820db963f18e/src/doc_builder/commands/build.py#L69",
"Thanks, @lhoestq.\r\n\r\n@mishig25 has manually forced the generation of the docs, that are live for 2.7.0 version: https://huggingface.co/docs/datasets/v2.7.0/en/index ",
"Cool ! this can be closed then ?",
"I was waiting for #5250 to be merged to close this.",
"just to confirm, is there anything I need to do from my side ? Or is everything good here ?"
] | null | 5,251 | false |
Change release procedure to use only pull requests | This PR changes the release procedure so that:
- it only make changes to main branch via pull requests
- it is no longer necessary to directly commit/push to main branch
Close #5251.
| https://github.com/huggingface/datasets/pull/5250 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5250). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5250). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5250). All of your documentation changes will be reflected on that endpoint.",
"Little recap:\r\n- The release-conda GH action was properly triggered by push-tag event: therefore I guess this event is also created when we publish a release and create a tag within it (as it is the case in the new procedure)\r\n - However, the package was only uploaded to huggingface channel and not to conda-forge channel\r\n - [x] Why? Need to address this.\r\n - Reply by @lhoestq: https://github.com/huggingface/datasets/pull/5250#discussion_r1025047531\r\n - We only maintain the huggingface channel\r\n - The conda-forge channel is maintained by the community; the 2.7.0 has been finally added as well to this channel \r\n- The generate-documentation GH action will be triggered by the push-to-branch event if we align the name of the release branch with the expected regex `v*-release`\r\n - [x] The naming has been aligned in the new procedure\r\n - [ ] Question: why do we have different triggering events for generate-doc and release-conda? Maybe we could set the same for both: either push-tag (when publishing the release), or push-to-branch\r\n - I think it will be better to use the push-tag event because in the new release procedure this happens later (when we publish the release), once we have already tested that everything works using the test-PyPI; on the contrary, the push-to-branch event happens before, even before opening the release PR: we could see afterwards that there is an issue, and cancel the Pull Request, but the docs and conda-package will already be published.\r\n- For the naming of the dev-version branch/PR, instead of having a complicated version naming, I'm proposing:\r\n - Using always the same branch name `dev-version`\r\n - Just include a step to delete this branch locally if it exists: `git branch -D dev-version`\r\n - The remote version will not exist because it is deleted once the PR is merged\r\n - This approach is approved by @lhoestq: https://github.com/huggingface/datasets/pull/5250#discussion_r1025048300",
"Just one question to be addressed: why do we have different triggering events for generate-doc and release-conda? Maybe we could set the same for both: either push-tag (when publishing the release), or push-to-branch\r\n\r\nI think it will be better to use the push-tag event because in the new release procedure this happens later (when we publish the release), once we have already tested that everything works using the test-PyPI; on the contrary, the push-to-branch event happens before, even before opening the release PR: we could see afterwards that there is an issue, and cancel the Pull Request, but the docs and conda-package will already be published.\r\n\r\nWe could even use the release-published event instead: [8694901](https://github.com/huggingface/datasets/pull/5250/commits/86949013c9dc59a07b55fad5b78104b8a03f60cd)\r\n",
"@lhoestq now that we have push-tag event for both build_documentation and release-conda, we have no constraint on the naming of the release branch:\r\n- we could name it simpler: maybe as you suggested above: https://github.com/huggingface/datasets/pull/5250#discussion_r1024119018\r\n `release-VERSION` instead of `vVERSION-release` (we do not use the prefix \"v\" anywhere in our repo)"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5250",
"html_url": "https://github.com/huggingface/datasets/pull/5250",
"diff_url": "https://github.com/huggingface/datasets/pull/5250.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5250.patch",
"merged_at": "2022-11-22T16:27:48"
} | 5,250 | true |
Protect the main branch from inadvertent direct pushes | We have decided to implement a protection mechanism in this repository, so that nobody (not even administrators) can inadvertently push accidentally directly to the main branch.
See context here:
- d7c942228b8dcf4de64b00a3053dce59b335f618
To do:
- [x] Protect main branch
- Settings > Branches > Branch protection rules > main > Edit
- [x] Check: Do not allow bypassing the above settings
- The above settings will apply to administrators and custom roles with the "bypass branch protections" permission.
- [x] Additionally, uncheck: Require approvals [under "Require a pull request before merging", which was already checked]
- Before, we could exceptionally merge a non-approved PR, using Administrator bypass
- Now that Administrator bypass is no longer possible, we would always need an approval to be able to merge; and pull request authors cannot approve their own pull requests. This could be an inconvenient in some exceptional circumstances when an urgent fix is needed
- Nevertheless, although it is no longer enforced, it is strongly recommended to merge PRs only if they have at least one approval
- [ ] #5250
- So that direct pushes to main branch are no longer necessary | https://github.com/huggingface/datasets/issues/5249 | [] | null | 5,249 | false |
Complete doc migration | Reverts huggingface/datasets#5214
Everything is handled on the doc-builder side now 😊 | https://github.com/huggingface/datasets/pull/5248 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5248). All of your documentation changes will be reflected on that endpoint.",
"Thanks for the fix @mishig25.\r\n\r\nI guess this is the reason why the docs are not generated for the latest release version 2.7.0? https://huggingface.co/docs/datasets/index "
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5248",
"html_url": "https://github.com/huggingface/datasets/pull/5248",
"diff_url": "https://github.com/huggingface/datasets/pull/5248.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5248.patch",
"merged_at": "2022-11-16T10:41:10"
} | 5,248 | true |
Set dev version | null | https://github.com/huggingface/datasets/pull/5247 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5247). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5247",
"html_url": "https://github.com/huggingface/datasets/pull/5247",
"diff_url": "https://github.com/huggingface/datasets/pull/5247.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5247.patch",
"merged_at": "2022-11-16T10:17:50"
} | 5,247 | true |
Release: 2.7.0 | null | https://github.com/huggingface/datasets/pull/5246 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5246",
"html_url": "https://github.com/huggingface/datasets/pull/5246",
"diff_url": "https://github.com/huggingface/datasets/pull/5246.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5246.patch",
"merged_at": "2022-11-16T09:37:03"
} | 5,246 | true |
Unable to rename columns in streaming dataset | ### Describe the bug
Trying to rename column in a streaming datasets, destroys the features object.
### Steps to reproduce the bug
The following code illustrates the error:
```
from datasets import load_dataset
dataset = load_dataset('mc4', 'en', streaming=True, split='train')
dataset.info.features
# {'text': Value(dtype='string', id=None), 'timestamp': Value(dtype='string', id=None), 'url': Value(dtype='string', id=None)}
dataset = dataset.rename_column("text", "content")
dataset.info.features
# This returned object is now None!
```
### Expected behavior
This should just alter the renamed column.
### Environment info
datasets 2.6.1 | https://github.com/huggingface/datasets/issues/5245 | [
"Hi @peregilk this bug is directly related to https://github.com/huggingface/datasets/issues/3888, and still not fixed... But I'll try to have a look!",
"Thanks @alvarobartt. It is great if you are able to fix it, but when reading the explanation it seems like it is possible to work around it.\r\n\r\nWe also tried keeping the 'info.features' and then adding a modified version back after the remove/rename. Unforutunately that leads to a dataset that is not possible to iterate over.",
"So if you iterate over the `IterableDataset` as `next(iter(ds))` and then run `rename_columns` when checking that data it will work, but in the end, it's just renaming the column one example/batch at a time, not renaming the column name for all the entries in the dataset, which is the ideal.",
"@alvarobartt Thanks. My use case was that I wanted to do multiple things, ie removing all unnecessary columns, renaming some valid columns, and then using cast (in my case checking if the audio is not 16K and casting it). It is just convenient to look into the info.features between each of these operations. Alternatively, I will just plan ahead...;) To me it seems like all the operations are working.\r\n\r\nThanks for the advice. It was very useful.",
"If we know the features before renaming, then we know the features after renaming, so we can pass the new features to the returned dataset in `rename_column` indeed ! If anyone is interested in contributing, feel free to open a PR and I'd be happy to help / give some pointers :)",
"Sure @lhoestq thanks! I’ll try to work on that",
"#self-assign"
] | null | 5,245 | false |
Allow dataset streaming from private a private source when loading a dataset with a dataset loading script | ### Feature request
Add arguments to the function _get_authentication_headers_for_url_ like custom_endpoint and custom_token in order to add flexibility when downloading files from a private source.
It should also be possible to provide these arguments from the dataset loading script, maybe giving them to the dl_manager
### Motivation
It is possible to share a dataset hosted on another platform by writing a dataset loading script. It works perfectly for publicly available resources.
For resources that require authentication, you can provide a [download_custom](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadManager) method to the download_manager.
Unfortunately, this function doesn't work with **dataset streaming**.
A solution so as to allow dataset streaming from private sources would be a more flexible _get_authentication_headers_for_url_ function.
### Your contribution
Would you be interested in this improvement ?
If so I could provide a PR. I've got something working locally, but it's not very clean, I'd need some guidance regarding integration. | https://github.com/huggingface/datasets/issues/5244 | [
"Hi ! What kind of private source ? We're exploring adding support for cloud storage and URIs like s3://, gs:// etc. with authentication in the download manager",
"Hello! It's a google cloud storage, so gs://, but I'm using it with https.\r\nBeing able to provide a file system like [here](https://huggingface.co/docs/datasets/main/filesystems#load-serialized-datasets) would be even more practical indeed.\r\nI've found a quite complicated workaround which consists of monkey patching all of the functions in streaming_download_manager.py to use my own _get_authentication_headers_for_url_ . \r\n\r\nA support for this use case would be greatly appreciated!\r\n\r\nFor reference my _get_authentication_headers_for_url_ looks like this:\r\n```\r\nimport os\r\nfrom typing import Optional, Union\r\n\r\nfrom datasets import config\r\nfrom huggingface_hub import HfFolder\r\nfrom gcsfs.credentials import GoogleCredentials\r\n\r\nDEFAULT_PROJECT = os.environ.get(\"GCSFS_DEFAULT_PROJECT\", \"\")\r\naccess = \"full_control\"\r\ngcs_token = os.environ.get(\"GCS_TOKEN\")\r\n\r\n\r\ndef get_authentication_headers_for_url(url: str, use_auth_token: Optional[Union[str, bool]] = None) -> dict:\r\n \"\"\"Handle the HF authentication\"\"\"\r\n headers = {}\r\n if url.startswith(config.HF_ENDPOINT):\r\n if use_auth_token is False:\r\n token = None\r\n elif isinstance(use_auth_token, str):\r\n token = use_auth_token\r\n else:\r\n token = HfFolder.get_token()\r\n elif url.startswith(\"https://storage.googleapis.com\"):\r\n credentials = GoogleCredentials(DEFAULT_PROJECT, access, gcs_token)\r\n credentials.maybe_refresh()\r\n token = credentials.credentials.token\r\n else:\r\n token = None\r\n if token:\r\n headers[\"authorization\"] = f\"Bearer {token}\"\r\n return headers\r\n```",
"I would be a big fan of this feature! @Hubert-Bonisseur if this doesn't become a supported feature, would you mind sharing your code? Thanks!",
"> I would be a big fan of this feature! @Hubert-Bonisseur if this doesn't become a supported feature, would you mind sharing your code? Thanks!\r\n\r\nI published it here:\r\nhttps://github.com/Hubert-Bonisseur/private-dataset-hub\r\n\r\nI modified the names of a lot of functions for privacy and I don't have time to test it again so you may get import errors, but you have the code. The custom_load_dataset is the function you are interested in I think.\r\n\r\nIt relies a lot on patching, if you find a better way to do this, I'd be interested.",
"Given the amount of patching it does, this is likely to break at one point. I'd encourage you to wait for a proper support in `datasets` directly if you can wait."
] | null | 5,244 | false |
Download only split data | ### Feature request
Is it possible to download only the data that I am requesting and not the entire dataset? I run out of disk spaceas it seems to download the entire dataset, instead of only the part needed.
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="test",
cache_dir="cache/path...",
use_auth_token=True,
download_config=DownloadConfig(delete_extracted='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')
)
### Motivation
efficiency improvement
### Your contribution
n/a | https://github.com/huggingface/datasets/issues/5243 | [
"Hi @capsabogdan! Unfortunately, it's hard to implement because quite often datasets data is being hosted in a single archive for all splits :( So we have to download the whole archive to split it into splits. This is the case for CommonVoice too. \r\n\r\nHowever, for cases when data is distributed in separate archives ащк different splits I suppose it can (and will) be implemented someday. \r\n\r\n\r\nBtw for quick check of the dataset you can use [streaming](https://huggingface.co/docs/datasets/stream):\r\n```python\r\ncv = load_dataset(\"mozilla-foundation/common_voice_11_0\", \"en\", split=\"test\", streaming=True)\r\ncv = iter(cv)\r\nprint(next(cv))\r\n\r\n>> {'client_id': 'a07b17f8234ded5e847443ea6f423cef745cbbc7537fb637d58326000aa751e829a21c4fd0a35fc17fb833aa7e95ebafce5efd19beeb8d843887b85e4eb35f5b',\r\n>> 'path': None,\r\n>> 'audio': {'path': 'cv-corpus-11.0-2022-09-21/en/clips/common_voice_en_100363.mp3',\r\n>> 'array': array([ 0.0000000e+00, 1.1748125e-14, 1.5450088e-14, ...,\r\n>> 1.3011958e-06, -6.3548953e-08, -9.9098514e-08], dtype=float32),\r\n>> ...}\r\n\r\n```",
"thank you for the answer but am not sure if this will not be helpful, as we\nneed maybe just 10% of the datasets for some experiment\n\ncan we get just a portion of the dataset with stream?\n\n\nis there really no solution? :(\n\nAm Di., 15. Nov. 2022 um 16:55 Uhr schrieb Polina Kazakova <\n***@***.***>:\n\n> Hi @capsabogdan <https://github.com/capsabogdan>! Unfortunately, it's\n> hard to implement because quite often datasets data is being hosted in a\n> single archive for all splits :( So we have to download the whole archive\n> to split it into splits. This is the case for CommonVoice too.\n>\n> However, for cases when data is distributed in separate archives in\n> different splits I suppose it can be implemented someday.\n>\n> Btw for quick check of the dataset you can use streaming\n> <https://huggingface.co/docs/datasets/stream>:\n>\n> cv = load_dataset(\"mozilla-foundation/common_voice_11_0\", \"en\", split=\"test\", streaming=True)cv = iter(cv)print(next(cv))\n> >> {'client_id': 'a07b17f8234ded5e847443ea6f423cef745cbbc7537fb637d58326000aa751e829a21c4fd0a35fc17fb833aa7e95ebafce5efd19beeb8d843887b85e4eb35f5b',>> 'path': None,>> 'audio': {'path': 'cv-corpus-11.0-2022-09-21/en/clips/common_voice_en_100363.mp3',>> 'array': array([ 0.0000000e+00, 1.1748125e-14, 1.5450088e-14, ...,>> 1.3011958e-06, -6.3548953e-08, -9.9098514e-08], dtype=float32),>> ...}\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5243#issuecomment-1315512887>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOC3JYRCTH54OBRUJULWIOW6PANCNFSM6AAAAAASAYO2LY>\n> .\n> You are receiving this because you were mentioned.Message ID:\n> ***@***.***>\n>\n",
"maybe it would be nice if you guys ould do some sort of shard before\nloading the dataset, so users can download just chunks of data :)\n\nI think this would be very helpful\n\nAm Di., 15. Nov. 2022 um 19:24 Uhr schrieb Bogdan Capsa <\n***@***.***>:\n\n> thank you for the answer but am not sure if this will not be helpful, as\n> we need maybe just 10% of the datasets for some experiment\n>\n> can we get just a portion of the dataset with stream?\n>\n>\n> is there really no solution? :(\n>\n> Am Di., 15. Nov. 2022 um 16:55 Uhr schrieb Polina Kazakova <\n> ***@***.***>:\n>\n>> Hi @capsabogdan <https://github.com/capsabogdan>! Unfortunately, it's\n>> hard to implement because quite often datasets data is being hosted in a\n>> single archive for all splits :( So we have to download the whole archive\n>> to split it into splits. This is the case for CommonVoice too.\n>>\n>> However, for cases when data is distributed in separate archives in\n>> different splits I suppose it can be implemented someday.\n>>\n>> Btw for quick check of the dataset you can use streaming\n>> <https://huggingface.co/docs/datasets/stream>:\n>>\n>> cv = load_dataset(\"mozilla-foundation/common_voice_11_0\", \"en\", split=\"test\", streaming=True)cv = iter(cv)print(next(cv))\n>> >> {'client_id': 'a07b17f8234ded5e847443ea6f423cef745cbbc7537fb637d58326000aa751e829a21c4fd0a35fc17fb833aa7e95ebafce5efd19beeb8d843887b85e4eb35f5b',>> 'path': None,>> 'audio': {'path': 'cv-corpus-11.0-2022-09-21/en/clips/common_voice_en_100363.mp3',>> 'array': array([ 0.0000000e+00, 1.1748125e-14, 1.5450088e-14, ...,>> 1.3011958e-06, -6.3548953e-08, -9.9098514e-08], dtype=float32),>> ...}\n>>\n>> —\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/datasets/issues/5243#issuecomment-1315512887>,\n>> or unsubscribe\n>> <https://github.com/notifications/unsubscribe-auth/ALSIFOC3JYRCTH54OBRUJULWIOW6PANCNFSM6AAAAAASAYO2LY>\n>> .\n>> You are receiving this because you were mentioned.Message ID:\n>> ***@***.***>\n>>\n>\n",
"+1 on this feature request - I am running into the same problem, where I only need the test set for a dataset that has a huge training set"
] | null | 5,243 | false |
Failed Data Processing upon upload with zip file full of images | I went to autotrain and under image classification arrived where it was time to prepare my dataset. Screenshot below

I chose the method 2 option. I have a csv file with two columns. ~23,000 files.
I uploaded this and chose the image_relpath, and target columns.
The image uploader said that I could only upload 10,000 singular images at a time so the 2nd option was to zip the images up and upload a zip archive which I did.
That all uploaded.
Now I have the message below. It appears the zip archive does just uncompress on the Hugging Face end?
What am I missing here?

| https://github.com/huggingface/datasets/issues/5242 | [
"cc @abhishekkrthakur @SBrandeis "
] | null | 5,242 | false |
Support hfh rc version | otherwise the code doesn't work for hfh 0.11.0rc0
following #5237 | https://github.com/huggingface/datasets/pull/5241 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5241",
"html_url": "https://github.com/huggingface/datasets/pull/5241",
"diff_url": "https://github.com/huggingface/datasets/pull/5241.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5241.patch",
"merged_at": "2022-11-15T16:09:31"
} | 5,241 | true |
Cleaner error tracebacks for dataset script errors | Make the traceback of the errors raised in `_generate_examples` cleaner for easier debugging. Additionally, initialize the `writer` in the for-loop to avoid the `ValueError` from `ArrowWriter.finalize` raised in the `finally` block when no examples are yielded before the `_generate_examples` error.
<details>
<summary>
The full traceback of the "SQLAlchemy ImportError" error that gets printed with these changes:
</summary>
```bash
ImportError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _prepare_split_single(self, arg)
1759 _time = time.time()
-> 1760 for _, table in generator:
1761 # Only initialize the writer when we have the first record (to avoid having to do the clean-up if an error occurs before that)
9 frames
/usr/local/lib/python3.7/dist-packages/datasets/packaged_modules/sql/sql.py in _generate_tables(self)
112 sql_reader = pd.read_sql(
--> 113 self.config.sql, self.config.con, chunksize=chunksize, **self.config.pd_read_sql_kwargs
114 )
/usr/local/lib/python3.7/dist-packages/pandas/io/sql.py in read_sql(sql, con, index_col, coerce_float, params, parse_dates, columns, chunksize)
598 """
--> 599 pandas_sql = pandasSQL_builder(con)
600
/usr/local/lib/python3.7/dist-packages/pandas/io/sql.py in pandasSQL_builder(con, schema, meta, is_cursor)
789 elif isinstance(con, str):
--> 790 raise ImportError("Using URI string without sqlalchemy installed.")
791 else:
ImportError: Using URI string without sqlalchemy installed.
The above exception was the direct cause of the following exception:
DatasetGenerationError Traceback (most recent call last)
<ipython-input-4-5af11af4737b> in <module>
----> 1 ds = Dataset.from_sql('''SELECT * from states WHERE state=="New York";''', "sqlite:///us_covid_data.db")
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in from_sql(sql, con, features, cache_dir, keep_in_memory, **kwargs)
1152 cache_dir=cache_dir,
1153 keep_in_memory=keep_in_memory,
-> 1154 **kwargs,
1155 ).read()
1156
/usr/local/lib/python3.7/dist-packages/datasets/io/sql.py in read(self)
47 # try_from_hf_gcs=try_from_hf_gcs,
48 base_path=base_path,
---> 49 use_auth_token=use_auth_token,
50 )
51
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
825 verify_infos=verify_infos,
826 **prepare_split_kwargs,
--> 827 **download_and_prepare_kwargs,
828 )
829 # Sync info
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
912 try:
913 # Prepare split will record examples associated to the split
--> 914 self._prepare_split(split_generator, **prepare_split_kwargs)
915 except OSError as e:
916 raise OSError(
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _prepare_split(self, split_generator, file_format, num_proc, max_shard_size)
1652 job_id = 0
1653 for job_id, done, content in self._prepare_split_single(
-> 1654 {"gen_kwargs": gen_kwargs, "job_id": job_id, **_prepare_split_args}
1655 ):
1656 if done:
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _prepare_split_single(self, arg)
1789 raise DatasetGenerationError(
1790 f"An error occured while generating the dataset"
-> 1791 ) from e
1792 finally:
1793 yield job_id, False, num_examples_progress_update
DatasetGenerationError: An error occurred while generating the dataset
```
</details>
PS: I've also considered raising the error as follows:
```python
tb = sys.exc_info()[2]
raise DatasetGenerationError(f"An error occurred while generating the dataset: {type(e).__name__}: {e}").with_traceback(tb) from None # this raises the DatasetGenerationError with "e"'s traceback
```
But it seems like "from e" is now the [preferred](https://docs.python.org/3/library/exceptions.html#BaseException.with_traceback) way to chain exceptions.
Fix https://github.com/huggingface/datasets/issues/5186
cc @nateraw
| https://github.com/huggingface/datasets/pull/5240 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq Good catch! This currently leads to an AttributeError (due to `writer` being None) on this line:\r\nhttps://github.com/huggingface/datasets/blob/fed1628d49a91f9ae259ddf6edbb252c7972d9a3/src/datasets/builder.py#L1552\r\n"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5240",
"html_url": "https://github.com/huggingface/datasets/pull/5240",
"diff_url": "https://github.com/huggingface/datasets/pull/5240.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5240.patch",
"merged_at": "2022-11-15T18:24:38"
} | 5,240 | true |
Add num_proc to from_csv/generator/json/parquet/text | Allow multiprocessing to from_* methods | https://github.com/huggingface/datasets/pull/5239 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5239). All of your documentation changes will be reflected on that endpoint.",
"I ended up moving `num_proc` to `AbstractDatasetReader.__init__` :)\r\n\r\nLet me know if it sounds good to you now"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5239",
"html_url": "https://github.com/huggingface/datasets/pull/5239",
"diff_url": "https://github.com/huggingface/datasets/pull/5239.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5239.patch",
"merged_at": "2022-12-06T15:39:09"
} | 5,239 | true |
Make `Version` hashable | Add `__hash__` to the `Version` class to make it hashable (and remove the unneeded methods), as `Version("0.0.0")` is the default value of `BuilderConfig.version` and the default fields of a dataclass need to be hashable in Python 3.11.
Fix https://github.com/huggingface/datasets/issues/5230 | https://github.com/huggingface/datasets/pull/5238 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5238",
"html_url": "https://github.com/huggingface/datasets/pull/5238",
"diff_url": "https://github.com/huggingface/datasets/pull/5238.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5238.patch",
"merged_at": "2022-11-14T15:27:35"
} | 5,238 | true |
Encode path only for old versions of hfh | Next version of `huggingface-hub` 0.11 does encode the `path`, and we don't want to encode twice | https://github.com/huggingface/datasets/pull/5237 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5237",
"html_url": "https://github.com/huggingface/datasets/pull/5237",
"diff_url": "https://github.com/huggingface/datasets/pull/5237.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5237.patch",
"merged_at": "2022-11-14T17:35:59"
} | 5,237 | true |
Handle ArrowNotImplementedError caused by try_type being Image or Audio in cast | Handle the `ArrowNotImplementedError` thrown when `try_type` is `Image` or `Audio` and the input array cannot be converted to their storage formats.
Reproducer:
```python
from datasets import Dataset
from PIL import Image
import requests
ds = Dataset.from_dict({"image": [Image.open(requests.get("https://upload.wikimedia.org/wikipedia/commons/e/e9/Felis_silvestris_silvestris_small_gradual_decrease_of_quality.png", stream=True).raw)]})
ds.map(lambda x: {"image": True}) # ArrowNotImplementedError
```
PS: This could also be fixed by raising `TypeError` in `{Image, Audio}.cast_storage` for unsupported types instead of passing the array to `array_cast.` | https://github.com/huggingface/datasets/pull/5236 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Not sure how we can have a test that is relevant for this though - feel free to add one if you have ideas\r\n\r\nYes, this was my reasoning for not adding a test. This change is pretty simple, so I think it's OK not to have a test for it."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5236",
"html_url": "https://github.com/huggingface/datasets/pull/5236",
"diff_url": "https://github.com/huggingface/datasets/pull/5236.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5236.patch",
"merged_at": "2022-11-14T16:01:48"
} | 5,236 | true |
Pin `typer` version in tests to <0.5 to fix Windows CI | Otherwise `click` fails on Windows:
```
Traceback (most recent call last):
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\spacy\__main__.py", line 4, in <module>
setup_cli()
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\spacy\cli\_util.py", line 71, in setup_cli
command(prog_name=COMMAND)
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\click\core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\typer\core.py", line 785, in main
**extra,
File "C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\typer\core.py", line 190, in _main
args = click.utils._expand_args(args)
AttributeError: module 'click.utils' has no attribute '_expand_args'
```
See https://github.com/tiangolo/typer/issues/427 | https://github.com/huggingface/datasets/pull/5235 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5235",
"html_url": "https://github.com/huggingface/datasets/pull/5235",
"diff_url": "https://github.com/huggingface/datasets/pull/5235.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5235.patch",
"merged_at": "2022-11-14T13:41:12"
} | 5,235 | true |
fix: dataset path should be absolute | cache_file_name depends on dataset's path.
A simple way where this could cause a problem:
```
import os
import datasets
def add_prefix(example):
example["text"] = "Review: " + example["text"]
return example
ds = datasets.load_from_disk("a/relative/path")
os.chdir("/tmp")
ds_1 = ds.map(add_prefix)
```
while it may feel that the `chdir` is quite constructed, there are many scenarios when the current working dir can/will change... | https://github.com/huggingface/datasets/pull/5234 | [
"Good catch thanks ! Have you tried to use the absolue path in `MemoryMappedTable.__init__` in `table.py`?\r\n\r\nI think it can fix issues with relative paths at more levels than just fixing it `load_from_disk`. If it works I think it would be a more robust fix to this issue",
"@lhoestq right, that actually fixed it indeed. I've pushed the changes (one-liner). lemme know if there's anything else you need for this fix",
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5234",
"html_url": "https://github.com/huggingface/datasets/pull/5234",
"diff_url": "https://github.com/huggingface/datasets/pull/5234.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5234.patch",
"merged_at": "2022-12-07T23:46:34"
} | 5,234 | true |
Fix shards in IterableDataset.from_generator | Allow to define a sharded iterable dataset | https://github.com/huggingface/datasets/pull/5233 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5233",
"html_url": "https://github.com/huggingface/datasets/pull/5233",
"diff_url": "https://github.com/huggingface/datasets/pull/5233.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5233.patch",
"merged_at": "2022-11-14T14:13:22"
} | 5,233 | true |
Incompatible dill versions in datasets 2.6.1 | ### Describe the bug
datasets version 2.6.1 has a dependency on dill<0.3.6. This causes a conflict with dill>=0.3.6 used by multiprocess dependency in datasets 2.6.1
This issue is already fixed in https://github.com/huggingface/datasets/pull/5166/files, but not yet been released. Please release a new version of the datasets library to fix this.
### Steps to reproduce the bug
1. Create requirements.in with only dependency being datasets (or datasets[s3])
2. Run pip-compile
3. The output is as follows:
```
Could not find a version that matches dill<0.3.6,>=0.3.6 (from datasets[s3]==2.6.1->-r requirements.in (line 1))
Tried: 0.2, 0.2, 0.2.1, 0.2.1, 0.2.2, 0.2.2, 0.2.3, 0.2.3, 0.2.4, 0.2.4, 0.2.5, 0.2.5, 0.2.6, 0.2.7, 0.2.7.1, 0.2.8, 0.2.8.1, 0.2.8.2, 0.2.9, 0.3.0, 0.3.1, 0.3.1.1, 0.3.2, 0.3.3, 0.3.3, 0.3.4, 0.3.4, 0.3.5, 0.3.5, 0.3.5.1, 0.3.5.1, 0.3.6, 0.3.6
Skipped pre-versions: 0.1a1, 0.2a1, 0.2a1, 0.2b1, 0.2b1
There are incompatible versions in the resolved dependencies:
dill<0.3.6 (from datasets[s3]==2.6.1->-r requirements.in (line 1))
dill>=0.3.6 (from multiprocess==0.70.14->datasets[s3]==2.6.1->-r requirements.in (line 1))
```
### Expected behavior
pip-compile produces requirements.txt without any conflicts
### Environment info
datasets version 2.6.1 | https://github.com/huggingface/datasets/issues/5232 | [
"Thanks for reporting, @vinaykakade.\r\n\r\nWe are discussing about making a release early this week.\r\n\r\nPlease note that in the meantime, in your specific case (as we also pointed out here: https://github.com/huggingface/datasets/issues/5162#issuecomment-1291720293), you can circumvent the issue by pinning `multiprocess` to 0.70.13 version (instead of using latest 0.70.14).\r\n\r\nDuplicate of:\r\n- https://github.com/huggingface/datasets/issues/5162",
"You can also make `pip-compile` work by using the backtracking resolver (instead of the legacy one): https://pip-tools.readthedocs.io/en/latest/#a-note-on-resolvers\r\n```\r\npip-compile --resolver=backtracking requirements.in\r\n```\r\nThis resolver will automatically use `multiprocess` 0.70.13 version.\r\n"
] | null | 5,232 | false |
Using `set_format(type='torch', columns=columns)` makes Array2D/3D columns stop formatting correctly | I have a Dataset with two Features defined as follows:
```
'image': Array3D(dtype="int64", shape=(3, 224, 224)),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
```
On said dataset, if I `dataset.set_format(type='torch')` and then use the dataset in a dataloader, these columns are correctly cast to Tensors of (batch_size, 3, 224, 244) for example.
However, if I `dataset.set_format(type='torch', columns=['image', 'bbox'])` these columns are cast to Lists of tensors and miss the batch size completely (the 3 dimension is the list length).
I'm currently digging through datasets formatting code to try and find out why, but was curious if someone knew an immediate solution for this. | https://github.com/huggingface/datasets/issues/5231 | [
"In case others find this, the problem was not with set_format, but my usages of `to_pandas()` and `from_pandas()` which I was using during dataset splitting; somewhere in the chain of converting to and from pandas the `Array2D/Array3D` types get converted to series of `Sequence()` types"
] | null | 5,231 | false |
dataclasses error when importing the library in python 3.11 | ### Describe the bug
When I import datasets using python 3.11 the dataclasses standard library raises the following error:
`ValueError: mutable default <class 'datasets.utils.version.Version'> for field version is not allowed: use default_factory`
When I tried to import the library using the following jupyter notebook:
```
%%bash
# create python 3.11 conda env
conda create --yes --quiet -n myenv -c conda-forge python=3.11
# activate is
source activate myenv
# install pyarrow
/opt/conda/envs/myenv/bin/python -m pip install --quiet --extra-index-url https://pypi.fury.io/arrow-nightlies/ \
--prefer-binary --pre pyarrow
# install datasets
/opt/conda/envs/myenv/bin/python -m pip install --quiet datasets
```
```
# create a python file that only imports datasets
with open("import_datasets.py", 'w') as f:
f.write("import datasets")
# run it with the env
!/opt/conda/envs/myenv/bin/python import_datasets.py
```
I get the following error:
```
Traceback (most recent call last):
File "/kaggle/working/import_datasets.py", line 1, in <module>
import datasets
File "/opt/conda/envs/myenv/lib/python3.11/site-packages/datasets/__init__.py", line 45, in <module>
from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
File "/opt/conda/envs/myenv/lib/python3.11/site-packages/datasets/builder.py", line 91, in <module>
@dataclass
^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 1221, in dataclass
return wrap(cls)
^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 1211, in wrap
return _process_class(cls, init, repr, eq, order, unsafe_hash,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 959, in _process_class
cls_fields.append(_get_field(cls, name, type, kw_only))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/envs/myenv/lib/python3.11/dataclasses.py", line 816, in _get_field
raise ValueError(f'mutable default {type(f.default)} for field '
ValueError: mutable default <class 'datasets.utils.version.Version'> for field version is not allowed: use default_factory
```
This is probably due to one of the following changes in the [dataclasses standard library](https://docs.python.org/3/library/dataclasses.html) in version 3.11:
1. Changed in version 3.11: Instead of looking for and disallowing objects of type list, dict, or set, unhashable objects are now not allowed as default values. Unhashability is used to approximate mutability.
2. fields may optionally specify a default value, using normal Python syntax:
```
@dataclass
class C:
a: int # 'a' has no default value
b: int = 0 # assign a default value for 'b'
In this example, both a and b will be included in the added __init__() method, which will be defined as:
def __init__(self, a: int, b: int = 0):
```
3. Changed in version 3.11: If a field name is already included in the __slots__ of a base class, it will not be included in the generated __slots__ to prevent [overriding them](https://docs.python.org/3/reference/datamodel.html#datamodel-note-slots). Therefore, do not use __slots__ to retrieve the field names of a dataclass. Use [fields()](https://docs.python.org/3/library/dataclasses.html#dataclasses.fields) instead. To be able to determine inherited slots, base class __slots__ may be any iterable, but not an iterator.
4. weakref_slot: If true (the default is False), add a slot named “__weakref__”, which is required to make an instance weakref-able. It is an error to specify weakref_slot=True without also specifying slots=True.
[TypeError](https://docs.python.org/3/library/exceptions.html#TypeError) will be raised if a field without a default value follows a field with a default value. This is true whether this occurs in a single class, or as a result of class inheritance.
### Steps to reproduce the bug
Steps to reproduce the behavior:
1. go to [the notebook in kaggle](https://www.kaggle.com/yonikremer/repreducing-issue)
2. rub both of the cells
### Expected behavior
I'm expecting no issues.
This error should not occur.
### Environment info
kaggle kernels, with default settings:
pin to original environment, no accelerator. | https://github.com/huggingface/datasets/issues/5230 | [
"I opened [this issue](https://github.com/python/cpython/issues/99401).\r\nPython's maintainers say that the issue is caused by [this change](https://docs.python.org/3.11/whatsnew/3.11.html#dataclasses).\r\nI believe adding a `__hash__` method to `datasets.utils.version.Version` should solve (at least partially) this issue.",
"Has this been fixed? I am running into this issue now. \r\n\r\nIf this has been fixed, could have a new release with this?\r\n"
] | null | 5,230 | false |
Type error when calling `map` over dataset containing 0-d tensors | ### Describe the bug
0-dimensional tensors in a dataset lead to `TypeError: iteration over a 0-d array` when calling `map`. It is easy to generate such tensors by using `.with_format("...")` on the whole dataset.
### Steps to reproduce the bug
```
ds = datasets.Dataset.from_list([{"a": 1}, {"a": 1}]).with_format("torch")
ds.map(None)
```
### Expected behavior
Getting back `ds` without errors.
### Environment info
Python 3.10.8
datasets 2.6.
torch 1.13.0 | https://github.com/huggingface/datasets/issues/5229 | [
"Hi! \r\n\r\nWe could address this by calling `.item()` on such tensors to extract the value, but this would lose us the type, which could lead to storing the generated dataset in a suboptimal format. Considering this, I think the only proper fix would be implementing support for 0-D tensors on Apache Arrow's side (Arrow is the underlying format we use to store datasets on disk/in memory). WDYT @lhoestq?",
"I think we can just convert the item to a numpy typed scalar using `.numpy()` ?\r\n\r\nFor example this works:\r\n```python\r\nimport numpy as np\r\nimport pyarrow as pa\r\n\r\nassert pa.array([np.float64(1.0)]).type == pa.float64()\r\nassert pa.array([np.float32(1.0)]).type == pa.float32()\r\nassert pa.array([np.int32(1)]).type == pa.int32()\r\nassert pa.array([np.int64(1)]).type == pa.int64()\r\n```\r\n\r\nAnd therefore it would work the same as for PyTorch N-D Tensors: convert to Numpy Array to keep the type in `_cast_to_python_objects`, then convert to Arrow"
] | null | 5,229 | false |
Loading a dataset from the hub fails if you happen to have a folder of the same name | ### Describe the bug
I'm not 100% sure this should be considered a bug, but it was certainly annoying to figure out the cause of. And perhaps I am just missing a specific argument needed to avoid this conflict. Basically I had a situation where multiple workers were downloading different parts of the glue dataset and then training on them. Additionally, they were writing their checkpoints to a folder called `glue`. This meant that once one worker had created the `glue` folder to write checkpoints to, the next worker to try to load a glue dataset would fail as shown in the minimal repro below. I'm not sure what the solution would be since I'm not super familiar with the `datasets` code, but I would expect `load_dataset` to not crash just because i have a local folder with the same name as a dataset from the hub.
### Steps to reproduce the bug
```
In [1]: import datasets
In [2]: rte = datasets.load_dataset('glue', 'rte')
Downloading and preparing dataset glue/rte to /Users/danielking/.cache/huggingface/datasets/glue/rte/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad...
Downloading data: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 697k/697k [00:00<00:00, 6.08MB/s]
Dataset glue downloaded and prepared to /Users/danielking/.cache/huggingface/datasets/glue/rte/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad. Subsequent calls will reuse this data.
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 773.81it/s]
In [3]: import os
In [4]: os.mkdir('glue')
In [5]: rte = datasets.load_dataset('glue', 'rte')
---------------------------------------------------------------------------
EmptyDatasetError Traceback (most recent call last)
<ipython-input-5-0d6b9ad8bbd0> in <cell line: 1>()
----> 1 rte = datasets.load_dataset('glue', 'rte')
~/miniconda3/envs/composer/lib/python3.9/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1717
1718 # Create a dataset builder
-> 1719 builder_instance = load_dataset_builder(
1720 path=path,
1721 name=name,
~/miniconda3/envs/composer/lib/python3.9/site-packages/datasets/load.py in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, use_auth_token, **config_kwargs)
1495 download_config = download_config.copy() if download_config else DownloadConfig()
1496 download_config.use_auth_token = use_auth_token
-> 1497 dataset_module = dataset_module_factory(
1498 path,
1499 revision=revision,
~/miniconda3/envs/composer/lib/python3.9/site-packages/datasets/load.py in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, **download_kwargs)
1152 ).get_module()
1153 elif os.path.isdir(path):
-> 1154 return LocalDatasetModuleFactoryWithoutScript(
1155 path, data_dir=data_dir, data_files=data_files, download_mode=download_mode
1156 ).get_module()
~/miniconda3/envs/composer/lib/python3.9/site-packages/datasets/load.py in get_module(self)
624 base_path = os.path.join(self.path, self.data_dir) if self.data_dir else self.path
625 patterns = (
--> 626 sanitize_patterns(self.data_files) if self.data_files is not None else get_data_patterns_locally(base_path)
627 )
628 data_files = DataFilesDict.from_local_or_remote(
~/miniconda3/envs/composer/lib/python3.9/site-packages/datasets/data_files.py in get_data_patterns_locally(base_path)
458 return _get_data_files_patterns(resolver)
459 except FileNotFoundError:
--> 460 raise EmptyDatasetError(f"The directory at {base_path} doesn't contain any data files") from None
461
462
EmptyDatasetError: The directory at glue doesn't contain any data files
```
### Expected behavior
Dataset is still able to be loaded from the hub even if I have a local folder with the same name.
### Environment info
datasets version: 2.6.1 | https://github.com/huggingface/datasets/issues/5228 | [
"`load_dataset` first checks for a local directory before checking for the Hub.\r\n\r\nTo make it explicit that it has to fetch the Hub, we could support the `hffs` syntax:\r\n```python\r\nload_dataset(\"hf://datasets/glue\")\r\n```\r\n\r\nwould that work for you ? Also cc @mariosasko who's leading the `hffs` project",
"yeah, that would be a fine solution."
] | null | 5,228 | false |
datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files | ### Describe the bug
From these lines:
from datasets import list_datasets, load_dataset
dataset = load_dataset("wikisql","binary")
I get error message:
datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files
And yet the 'wikisql' is reported to exist via the list_datasets().
Any help appreciated.
### Steps to reproduce the bug
From these lines:
from datasets import list_datasets, load_dataset
dataset = load_dataset("wikisql","binary")
I get error message:
datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files
And yet the 'wikisql' is reported to exist via the list_datasets().
Any help appreciated.
### Expected behavior
Dataset should load. This same code used to work.
### Environment info
Mac OS | https://github.com/huggingface/datasets/issues/5227 | [
"Fixed. Please close."
] | null | 5,227 | false |
Q: Memory release when removing the column? | ### Describe the bug
How do I release memory when I use methods like `.remove_columns()` or `clear()` in notebooks?
```python
from datasets import load_dataset
common_voice = load_dataset("mozilla-foundation/common_voice_11_0", "ja", use_auth_token=True)
# check memory -> RAM Used (GB): 0.704 / Total (GB) 33.670
common_voice = common_voice.remove_columns(column_names=common_voice.column_names['train'])
common_voice.clear()
# check memory -> RAM Used (GB): 0.705 / Total (GB) 33.670
```
I tried `gc.collect()` but did not help
### Steps to reproduce the bug
1. load dataset
2. remove all the columns
3. check memory is reduced or not
[link to reproduce](https://www.kaggle.com/code/bayartsogtya/huggingface-dataset-memory-issue/notebook?scriptVersionId=110630567)
### Expected behavior
Memory released when I remove the column
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | https://github.com/huggingface/datasets/issues/5226 | [
"Hi ! Datasets are memory mapped from your disk, i.e. they're not loaded in RAM. This is possible thanks to the Arrow data format.\r\n\r\nTherefore the column you remove is not in RAM, so removing it doesn't cause the RAM to decrease.",
"Thanks for the explanation! @lhoestq \r\nI wonder since it is memory mapped, can we reduce or remove this memory map?",
"Yes you can `del common_voice` for example or wait for it to be garbage collected"
] | null | 5,226 | false |
Add video feature | ### Feature request
Add a `Video` feature to the library so folks can include videos in their datasets.
### Motivation
Being able to load Video data would be quite helpful. However, there are some challenges when it comes to videos:
1. Videos, unlike images, can end up being extremely large files
2. Often times when training video models, you need to do some very specific sampling. Videos might end up needing to be broken down into X number of clips used for training/inference
3. Videos have an additional audio stream, which must be accounted for
4. The feature needs to be able to encode/decode videos (with right video settings) from bytes.
### Your contribution
I did work on this a while back in [this (now closed) PR](https://github.com/huggingface/datasets/pull/4532). It used a library I made called [encoded_video](https://github.com/nateraw/encoded-video), which is basically the utils from [pytorchvideo](https://github.com/facebookresearch/pytorchvideo), but without the `torch` dep. It included the ability to read/write from bytes, as we need to do here. We don't want to be using a sketchy library that I made as a dependency in this repo, though.
Would love to use this issue as a place to:
- brainstorm ideas on how to do this right
- list ways/examples to work around it for now
CC @sayakpaul @mariosasko @fcakyon | https://github.com/huggingface/datasets/issues/5225 | [
"@NielsRogge @rwightman may have additional requirements regarding this feature.\r\n\r\nWhen adding a new (decodable) type, the hardest part is choosing the right decoding library. What I mean by \"right\" here is that it has all the features we need and is easy to install (with GPU support?).\r\n\r\nSome candidates/options:\r\n* [`decord`](https://github.com/dmlc/decord): no longer [maintained](https://github.com/dmlc/decord/issues/214), not trivial to install with GPU support\r\n* [`pyAV`](https://github.com/PyAV-Org/PyAV): used for CPU decoding in `torchvision`, GPU decoding not supported if I'm not mistaken, otherwise the best candidate probably\r\n* [`video_reader`](https://github.com/pytorch/vision/blob/de350bc01ad2193ea2888f0ce8a6a346d3cba5a9/torchvision/csrc/io/video_reader/video_reader.cpp): used for GPU decoding in `torchvision`, depends on `torch'\r\n* OpenCV: uses `ffmpeg` for video decoding under the hood\r\n* ...\r\n\r\nAnd the last resort is building our own library, which is the most flexible solution but also requires the most work.\r\n\r\nPS: I'm adding a link to an article that compares various video decoding libraries: https://towardsdatascience.com/lightning-fast-video-reading-in-python-c1438771c4e6",
"@mariosasko is GPU decoding a hard requirement here? Do we really need it? (I don't know)\r\n\r\nSomething to consider with `decord` is that it doesn't (AFAIK) support writing videos, so you'd still need something else for that. also I've noticed [issues](https://github.com/dmlc/decord/issues/242) with decord's ability to decode stereo audio streams along side the video (which you don't run into with PyAV).\r\n\r\n---\r\n\r\nI think PyAV should be able to do the job just fine to start. If we write the video io utilities as their own functions, we can hot swap them later if we find/write a different solution that's faster/better.",
"Video is still a bit of a mess, but I'd say pyAV is likely the best approach (or supporting all three via pytorchvideo, but that adds a middle man dependency).\r\n\r\nBeing able to decode on the GPU, into memory that could be passed off to a Tensor in whatever framework is being used would be the dream, I don't think there is any interop of that nature working right now. Number of decoder instances per GPU is limited so it's not clear if balancing load btw GPU decoders and CPUs would be needed in say large scale video training.\r\n\r\nAny of these solutions is less than ideal due to the nature of video, having a simple Python interface video / start -> end results in lots of extra memory (you need to decode whole range of the clips into a buffer before using anything). Any scalable video system would be streaming on the fly (issuing frames via callbacks as soon as the stream is far enough along to have re-ordered the frames and synced audio+video+other metadata (sensors, CC, etc).\r\n\r\n",
"For standalone usage, decoding on GPU could be ideal but isn't async processing of inputs on CPUs while letting the accelerator busy for training the de-facto? Of course, I am aware of other advanced mechanisms such as CPU offloading, but I think my point is conveyed. ",
"Here's a minimal implementation of the helper functions we'd need from PyAV, a lot of which I borrowed from `pytorchvideo`, stripping out the `torch` specific stuff:\r\n\r\n[](https://colab.research.google.com/gist/nateraw/c327cb6ff6b074e6ddc8068d19c0367d/pyav-io.ipynb)\r\n \r\nIt's not too much code...@mariosasko we could probably just maintain these helper fns within the `datasets` library, right? ",
"Also wanted to note I added a PR for video classification in `transformers` here, which uses `decord`. It's still open...should we make a decision now to align the libraries we are using between `datasets` and `transformers`? (CC @Narsil )\r\n\r\nhttps://github.com/huggingface/transformers/pull/20151",
"Fully agree on at least trying to unite things.\r\n\r\nMaking clear function boundaries to help us change dependency if needed seems like a good idea since there doesn't seem to be a clear winner.\r\n\r\nI also happen to like directly calling ffmpeg. For some reason it was a lot faster than pyav. "
] | null | 5,225 | false |
Seems to freeze when loading audio dataset with wav files from local folder | ### Describe the bug
I'm following the instructions in [https://huggingface.co/docs/datasets/audio_load#audiofolder-with-metadata](url) to be able to load a dataset from a local folder.
I have everything into a folder, into a train folder and then the audios and csv. When I try to load the dataset and run from terminal, seems to work but then freezes with no apparent reason.
The metadata.csv file contains a few columns but the important ones, `file_name` with the filename and `transcription` with the transcription are okay.
The audios are `.wav` files, I don't know if that might be the problem (I will proceed to try to change them all to `.mp3` and try again).
### Steps to reproduce the bug
The code I'm using:
```python
from datasets import load_dataset
dataset = load_dataset("audiofolder", data_dir="../archive/Dataset")
dataset[0]["audio"]
```
The output I obtain:
```
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 311135.43it/s]
Using custom data configuration default-38d4546ffd010f3e
Downloading and preparing dataset audiofolder/default to /Users/mine/.cache/huggingface/datasets/audiofolder/default-38d4546ffd010f3e/0.0.0/6cbdd16f8688354c63b4e2a36e1585d05de285023ee6443ffd71c4182055c0fc...
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 166467.72it/s]
Using custom data configuration default-38d4546ffd010f3e
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 187772.74it/s]
Using custom data configuration default-38d4546ffd010f3e
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 59623.71it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 138090.55it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 106065.64it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 56036.38it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 74004.24it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 162343.45it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 101881.23it/s]
Using custom data configuration default-38d4546ffd010f3e
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 60145.67it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 80890.02it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 54036.67it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 95851.09it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 155897.00it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 137656.96it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 131230.81it/s]
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
```
And then here it just freezes and nothing more happens.
### Expected behavior
Load the dataset.
### Environment info
Datasets version:
datasets 2.6.1 pypi_0 pypi
| https://github.com/huggingface/datasets/issues/5224 | [
"I just tried to do the same but changing the `.wav` files to `.mp3` files and that doesn't fix it.",
"I don't know if anyone will ever read this but I've tried to upload the same dataset with google colab and the output seems more clarifying. I didn't specify the train/test split so the dataset wasn't fully uploaded (or that is what I understood, might be wrong!!).\r\n\r\nNow, including the `drop_metadata` flag I can load the dataset normally (at least with colab notebook):\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"audiofolder\", data_dir=\"../archive/Dataset\", , drop_metadata=True)\r\n```\r\n\r\nI'll close the issue."
] | null | 5,224 | false |
Add SQL guide | This PR adapts @nateraw's awesome SQL notebook as a guide for the docs! | https://github.com/huggingface/datasets/pull/5223 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5223). All of your documentation changes will be reflected on that endpoint.",
"I think we may want more content on this page that's not SQL related. Some of that content probably already lives in the main `load` docs page, but might be bad to remove major things like csv/pandas from there...WDYT we should do @lhoestq ?",
"Maybe the main load page can only show one example and redirect to this page for more details ?\r\n\r\nWe can do the same for pandas stuff: have one example in load, and redirect to this page for more details",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5223). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5223",
"html_url": "https://github.com/huggingface/datasets/pull/5223",
"diff_url": "https://github.com/huggingface/datasets/pull/5223.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5223.patch",
"merged_at": "2022-11-15T17:40:21"
} | 5,223 | true |
HuggingFace website is incorrectly reporting that my datasets are pickled | ### Describe the bug
HuggingFace is incorrectly reporting that my datasets are pickled. They are not picked, they are simple ZIP files containing PNG images.
Hopefully this is the right location to report this bug.
### Steps to reproduce the bug
Inspect my dataset respository here: https://huggingface.co/datasets/ProGamerGov/StableDiffusion-v1-5-Regularization-Images
### Expected behavior
They should not be reported as being pickled.
### Environment info
N/A | https://github.com/huggingface/datasets/issues/5222 | [
"cc @McPatate maybe you know what's happening ?",
"Yes I think I know what is happening. We check in zips for pickles, and the UI must display the pickle jar when a scan has an associated list of imports, even when empty.\r\n~I'll fix ASAP !~",
"> I'll fix ASAP !\r\n\r\nActually I'd rather leave it like that for now, as it indicates that we checked for pickles and nothing dangerous appeared :)",
"Closing the issue with the typical \"feature not a bug\" "
] | null | 5,222 | false |
Cannot push | ### Describe the bug
I am facing the issue when I try to push the tar.gz file around 11G to HUB.
```
(venv) ╭─laptop@laptop ~/PersonalProjects/data/ulaanbal_v0 ‹main●›
╰─$ du -sh *
4.0K README.md
13G data
516K test.jsonl
18M train.jsonl
4.0K ulaanbal_v0.py
11G ulaanbal_v0.tar.gz
452K validation.jsonl
(venv) ╭─laptop@laptop~/PersonalProjects/data/ulaanbal_v0 ‹main●›
╰─$ git add ulaanbal_v0.tar.gz && git commit -m 'large version'
(venv) ╭─laptop@laptop ~/PersonalProjects/data/ulaanbal_v0 ‹main●›
╰─$ git push
EOFoading LFS objects: 0% (0/1), 0 B | 0 B/s
Uploading LFS objects: 0% (0/1), 0 B | 0 B/s, done.
error: failed to push some refs to 'https://huggingface.co/datasets/bayartsogt/ulaanbal_v0'
```
I have already tried pushing a small version of this and it was working fine. So my guess it is probably because of the big file.
Following I run before the commit:
```
╰─$ git lfs install
╰─$ huggingface-cli lfs-enable-largefiles .
```
### Steps to reproduce the bug
Create a private dataset on huggingface and push 12G tar.gz file
### Expected behavior
To be pushed with no issue
### Environment info
- `datasets` version: 2.6.1
- Platform: Darwin-21.6.0-x86_64-i386-64bit
- Python version: 3.7.11
- PyArrow version: 10.0.0
- Pandas version: 1.3.5
| https://github.com/huggingface/datasets/issues/5221 | [
"Did you run `huggingface-cli lfs-enable-largefiles` before committing or before adding ? Maybe you can try before adding\r\n\r\nAnyway I'd encourage you to split your data into several TAR archives if possible, this way the dataset can loaded faster using multiprocessing (by giving each process a subset of shards to process)",
"@lhoestq \r\nThanks for the help!\r\n> Maybe you can try before adding\r\n\r\nIt did not help\r\n\r\nBut I totally got your point about split into multiple TAR archives. It really helped!"
] | null | 5,221 | false |
Implicit type conversion of lists in to_pandas | ### Describe the bug
```
ds = Dataset.from_list([{'a':[1,2,3]}])
ds.to_pandas().a.values[0]
```
Results in `array([1, 2, 3])` -- a rather unexpected conversion of types which made downstream tools expecting lists not happy.
### Steps to reproduce the bug
See snippet
### Expected behavior
Keep the original type
### Environment info
datasets 2.6.1
python 3.8.10 | https://github.com/huggingface/datasets/issues/5220 | [
"I think this behavior comes from PyArrow:\r\n```python\r\nimport pyarrow as pa\r\nt = pa.table({\"a\": [[0]]})\r\nt.to_pandas().a.values[0]\r\n# array([0])\r\n```\r\n\r\nI believe this has to do with zero-copy: you can get a pandas DataFrame without copying the buffers from arrow, and therefore end up with numpy arrays.",
"That's interesting, I guess not much to do here then."
] | null | 5,220 | false |
Delta Tables usage using Datasets Library | ### Feature request
Adding compatibility of Datasets library with Delta Format. Elevating the utilities of Datasets library from Machine Learning Scope to Data Engineering Scope as well.
### Motivation
We know datasets library can absorb csv, json, parquet, etc. file formats but it would be great if Datasets library could work with Delta Tables (with delta format) as it has different features such as time travelling, layout optimization, query performance, aids in Data Engineering.
This will help and enhance Datasets library from Machine Learning utility to Data Engineering utilities and expand horizons thereafter. I am totally using Datasets library in all my usecases and as my role expands so does the work, compatibility with Datasets library is something I don't want to lose.
### Your contribution
Would love to work on this feature, even if this has to picked up from scratch, including design paradigms and patterns.
I have basic idea about Delta Live Tables, would brush it easily for this feature. | https://github.com/huggingface/datasets/issues/5219 | [
"Hi ! Interesting :) Can you provide concrete examples of cases where it can be useful ?",
"Few example blogs and posts that might help on this - \r\n\r\n1. https://hevodata.com/learn/databricks-delta-tables/\r\n2. https://docs.databricks.com/delta/index.html\r\n\r\nBasically, we are looking at utility of Datasets library with Delta Lake Tables.\r\n",
"`datasets` can already read/write from parquet from/to a cloud storage using fsspec, if I understand correctly it's should be possible to load parquet files as delat lake tables no ? :) Or is there someting missing ?",
"@lhoestq Per my understanding, delta lake table is a bunch of paruqet files together with the meta to support ACID. For example file 1 contains v0.1 of record A while file 2 contains v0.2 of record A. I am assuming the Hugging face dataset would delegate the read/write delta table to 3rd party lib, maybe pyarrow. Correct me if I was wrong @reichenbch \r\n\r\nAnd I am assuming, people are asking the versioning of Hugging face datasets. But I am assuming Hugging face delegate this function to github and it is not the key requirement for Public Data set. It actually the key function of ML Ops, I am not sure whether hugging face would like expand to that area."
] | null | 5,219 | false |
Delta Tables usage using Datasets Library | ### Feature request
Adding compatibility of Datasets library with Delta Format. Elevating the utilities of Datasets library from Machine Learning Scope to Data Engineering Scope as well.
### Motivation
We know datasets library can absorb csv, json, parquet, etc. file formats but it would be great if Datasets library could work with Delta Tables (with delta format) as it has different features such as time travelling, layout optimization, query performance, aids in Data Engineering.
This will help and enhance Datasets library from Machine Learning utility to Data Engineering utilities and expand horizons thereafter. I am totally using Datasets library in all my usecases and as my role expands so does the work, compatibility with Datasets library is something I don't want to lose.
### Your contribution
Would love to work on this feature, even if this has to picked up from scratch, including design paradigms and patterns.
I have basic idea about Delta Live Tables, would brush it easily for this feature. | https://github.com/huggingface/datasets/issues/5218 | [] | null | 5,218 | false |
Reword E2E training and inference tips in the vision guides | Reference: https://github.com/huggingface/datasets/pull/5188#discussion_r1012148730 | https://github.com/huggingface/datasets/pull/5217 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5217",
"html_url": "https://github.com/huggingface/datasets/pull/5217",
"diff_url": "https://github.com/huggingface/datasets/pull/5217.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5217.patch",
"merged_at": "2022-11-10T01:36:08"
} | 5,217 | true |
save_elasticsearch_index | Hi,
I am new to Dataset and elasticsearch. I was wondering is there any equivalent approach to save elasticsearch index as of save_faiss_index locally for later use, to remove the need to re-index a dataset? | https://github.com/huggingface/datasets/issues/5216 | [
"Hi ! I think there exist tools to dump and reload an index in your elastic search but I'm not super familiar with it.\r\n\r\nAnyway after reloading an index in elastic search you can call `ds.load_elasticsearch_index` which will connect the index to the dataset without re-indexing"
] | null | 5,216 | false |
Update github pr docs actions | null | https://github.com/huggingface/datasets/pull/5214 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5214). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5214",
"html_url": "https://github.com/huggingface/datasets/pull/5214",
"diff_url": "https://github.com/huggingface/datasets/pull/5214.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5214.patch",
"merged_at": "2022-11-08T15:39:57"
} | 5,214 | true |
Add support for different configs with `push_to_hub` | will solve #5151
@lhoestq @albertvillanova @mariosasko
This is still a super draft so please ignore code issues but I want to discuss some conceptually important things.
I suggest a way to do `.push_to_hub("repo_id", "config_name")` with pushing parquet files to directories named as `config_name` (inside `data/` dir as it is now), for example:
```
data
|__config-v1
train-00000-00002-...-.parquet
train-00001-00002-...-.parquet
...
|__config-v2
....
```
When loading a dataset, I parse these configs from repository data files (only for `"data/{split}-[0-9][0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9]*.*"` pattern that is used for parquet datasets pushed with `.push_to_hub`).
Therefore,
- when user tries to load a dataset that has configs parsed from data files dir names without providing a config (like `load_dataset("repo")` instead of `load_dataset("repo", "config-v1")`) - raise error and asks for config - to be aligned with how it works in datasets with scripts.
- for backward compatibility: if user tries to `.push_to_hub(""repo", "config_name")` to an existing parquet repo with no configurations (all parquet files are directly in `data/` dir) - raise error. My initial idea was to raise a warning and move these files to another dir with name (config) like "default" or smth but in a PR and suggest user to merge it on the Hub. But there is no support for renaming (moving) files via `HfApi` yet so it would require deleting and pushing again if I understand it right.
This parsing approach can be extended to other Hub packaged modules, and to local packaged modules and other data files patterns
(except for cases when splits are in dir names `KEYWORDS_IN_DIR_NAME_BASE_PATTERNS` because we allow for arbitrary depth of directory hierarchy).
Do you think it's reasonable? Not sure how to provide flexibility (and backward compatibility) to not parsing configs and load all the data in a single config as it is now.
I also thought about getting information about configs from Readme.md `dataset_info` ([example](https://huggingface.co/datasets/polinaeterna/test_push_two_configs/blob/main/README.md)). But that way we
are dependent on if it exists. It is created automatically with `.push_to_hub` but what if it is
accidentally deleted or smth).
Also, what I don't like is that this parsing is a part of Module/DataFiles logic, not Builder's one, which is not aligned with datasets with custom scripts. But I don't know to implement the second approach in current library's logic.
What do you think about this all? Am I missing smth?
TODO:
- [ ] save cache in the same dir for configs of the same datasets
- [ ] fix verification errors
- [ ] correctly update `dataset_infos.json` too
- [ ] ...
| https://github.com/huggingface/datasets/pull/5213 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5213). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5213). All of your documentation changes will be reflected on that endpoint.",
"Nice thanks !\r\n\r\nWould it be possible to have the new folders at the same level as \"data\" ? This way they're all separated\r\n```\r\n├─ config-v1/\r\n│ ├── train-00000-00002-...-.parquet\r\n│ └── train-00001-00002-...-.parquet\r\n└ config-v2/\r\n ├── train-00000-00002-...-.parquet\r\n └── train-00001-00002-...-.parquet\r\n```\r\nand if you don't provide a config name, it goes in a folder named \"default\" instead, that would be loaded by default.\r\n\r\nWe could also write in the YAML something like\r\n```yaml\r\nconfigs:\r\n- name: config-v1\r\n data_dir: config-v1\r\n- name: config-v2\r\n data_dir: config-v2\r\n```\r\nand loading `config-v1` would be equivalent to run `load_dataset(ds_name, \"config-v1\", data_dir=\"config-v1\")`\r\n\r\nDo you think it would make sense ?\r\n\r\nFor backward compatibility we can just keep the \"data/*\" pattern. It's ok to expect users to have an updated version of `datasets` to be able to load datasets with configurations.",
"@lhoestq thank you for the feedback! i'll reflect on this on Moday, my mind just melted because of the fever.\r\n\r\n@mariosasko @albertvillanova what do you think?",
"Thanks for addressing this, @polinaeterna. It is good:\r\n- we support configs for datasets without scripts\r\n- we align the behavior to datasets with scripts as much as possible\r\n\r\nMaybe adding some tests will help clarify what is the expected behavior...",
"After some discussion with @lhoestq we decided that it's better to rely on metadata file than on data files patterns. \r\n\r\nSo we decided to introduce a new field to yaml (like `configs` or smth like that) that would contain arbitrary configs kwargs to be passed to loader, including `data_dir` and `data_files`. \r\nThis is more aligned with datasets with custom scripts where we explicitly write all the supported configs and config parameters in the code and is extendable to all packaged modules.\r\nThis would solve https://github.com/huggingface/datasets/issues/5209\r\n\r\n(@lhoestq was right 21 days ago, this is a more general solution idk why i ignored this...)",
"closed in favor of https://github.com/huggingface/datasets/pull/5331"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5213",
"html_url": "https://github.com/huggingface/datasets/pull/5213",
"diff_url": "https://github.com/huggingface/datasets/pull/5213.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5213.patch",
"merged_at": null
} | 5,213 | true |
Fix CI require_beam maximum compatible dill version | A previous commit to main branch introduced an additional requirement on maximum compatible `dill` version with `apache-beam` in our CI `require_beam`:
- d7c942228b8dcf4de64b00a3053dce59b335f618
- ec222b220b79f10c8d7b015769f0999b15959feb
This PR fixes the maximum compatible `dill` version with `apache-beam`, which is <0.3.2 (and not 0.3.6): https://github.com/apache/beam/blob/v2.42.0/sdks/python/setup.py#L219 | https://github.com/huggingface/datasets/pull/5212 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5212). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5212",
"html_url": "https://github.com/huggingface/datasets/pull/5212",
"diff_url": "https://github.com/huggingface/datasets/pull/5212.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5212.patch",
"merged_at": "2022-11-15T06:32:26"
} | 5,212 | true |
Update Overview.ipynb google colab | - removed metrics stuff
- added image example
- added audio example (with ffmpeg instructions)
- updated the "add a new dataset" section | https://github.com/huggingface/datasets/pull/5211 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"WDYT @albertvillanova ?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5211). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5211",
"html_url": "https://github.com/huggingface/datasets/pull/5211",
"diff_url": "https://github.com/huggingface/datasets/pull/5211.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5211.patch",
"merged_at": "2022-11-29T15:54:17"
} | 5,211 | true |
Tweak readme | Tweaked some paragraphs mentioning the modalities we support + added a paragraph on security | https://github.com/huggingface/datasets/pull/5210 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Nit: We should also update the `Disclaimers` section to let the dataset owners know they should use Hub discussions rather than GH issues for removal requests/updates",
"Updated the disclaimers section, thanks !\r\n\r\nDoes it sound good to you @albertvillanova ?"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5210",
"html_url": "https://github.com/huggingface/datasets/pull/5210",
"diff_url": "https://github.com/huggingface/datasets/pull/5210.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5210.patch",
"merged_at": "2022-11-24T11:26:16"
} | 5,210 | true |
Implement ability to define splits in metadata section of dataset card | ### Feature request
If you go here: https://huggingface.co/datasets/inria-soda/tabular-benchmark/tree/main you will see bunch of folders that has various CSV files. I’d like dataset viewer to show these files instead of only one dataset like it currently does. (and also people to be able to load them as splits instead of loading through `data_files`)
e.g GLUE has various splits on viewer but it’s too overkill to ask people to implement loading script, so it would be better to let them define these in the README file instead.
Also pinging @polinaeterna @lhoestq @adrinjalali
| https://github.com/huggingface/datasets/issues/5209 | [
"@merveenoyan Do you want different files to be splits or configurations?\r\n\r\nFrom [what you specified in `Readme.md`](https://huggingface.co/datasets/inria-soda/tabular-benchmark/commit/fb4575853772c62a20203bdd6cc0202f5db4ce4e) I hypothesize that you want to have 4 **configs** corresponding to directories: `\"clf_cat\", \"clf_num\", \"reg_cat\", \"reg_num\"`. And inside each config you require to have as many splits as there are `csv` files\r\nso if you run \r\n```python\r\nload_dataset(\"inria-soda/tabular-benchmark\", \"clf_cat\", split=\"compass\")\r\n```\r\nyou will generate the data only from `compass.csv` file.\r\nIn this case, running `load_dataset(\"inria-soda/tabular-benchmark\", \"clf_cat\"`) without split parameter will return `DatasetDict` object with `\"KDDCup09_upselling\", \"cat_compass\", \"cat_covertype\", ... \"road_safety\"` keys (which values are splits - `Dataset` objects)\r\n\r\n**or**\r\ndo you want each file to be a separate config? Like:\r\n```python\r\nload_dataset(\"inria-soda/tabular-benchmark\", \"clf_cat_compass\") # returns DatasetDict with a single \"train\" split\r\n```\r\n**or**\r\nmaybe smth completely different? :smile: \r\n\r\nAnyway, now I have an impression that this is probably rather a matter of automatically inferring configs from repository structure rather than providing parameters in metadata yaml.\r\n",
"@polinaeterna I want the latter where you can think of every CSV file as a config, like MNLI from GLUE.",
"@merveenoyan @lhoestq I see two solutions to this case. \r\n1. Parse configurations automatically from directories names. That is, if you have data structure like:\r\n```\r\ntabular-benchmark\r\n └─clf_cat_compass\r\n └─compass.csv\r\n └─clf_cat_cat_covertype\r\n └─covertype.csv\r\n ...\r\n └─reg_cat_house_sales\r\n └─house_sales.csv\r\n```\r\nyou'll get \"clf_cat_compass\", \"clf_cat_cat_covertype\", ... \"reg_cat_house_sales\" configurations that would contain **only files from corresponding directories**. \r\n**\\+** this is a requested change and needed in general and would solve other problems, see https://github.com/huggingface/datasets/issues/4578, would also help with https://github.com/huggingface/datasets/pull/5213 which I'm working on currently\r\n**\\+** would allow users to do just `load_dataset(“inria-soda/tabular-benchmark”, “clf_cat_compass”)`, no `data_files` param required\r\n**\\-** in this specific case it would require restructuring of the data - putting each file in a directory named as a config name (to me personally it doesn't seem to be a big deal) \r\n\r\n2. More or less what we discussed before - add support for manually specifying parameters in the metadata. We can add new metadata yaml field (say, `\"custom_configs_info\"`), so that we can provide smth like:\r\n```yaml\r\n---\r\n...\r\ndataset_info:\r\n ... \r\ncustom_configs_info:\r\n- config_name: reg_cat_house_sales\r\n data_files:\r\n - reg_cat/house_sales.csv\r\n- config_name: clf_cat_compass\r\n data_files:\r\n - clf_cat/compass.csv\r\n...\r\n---\r\n```\r\n**\\+** Would be useful not only for tabular data and not only for `data_files` parameter - any packaged dataset’s viewer can be customized to use specific, non-default parameters. @merveenoyan do you maybe have any other examples/use cases in mind where you want to provide any specific parameters to the viewer? \r\n**\\-** I'm not sure here but assume that it might require changes in interaction with the viewer on the hub side - to parse these configurations, as they not default configurations (not in `BUILDER_CONFIGS` list). cc @severo But probably this can be solved on the `datasets` side too.\r\n\r\nOverall, I would start from implementing the first solution since it's related to what I'm doing now and is super useful for `datasets` in general. And then if we agree that having more flexibility in providing parameters to the viewer is required, I can implement the second one. Let me know what you think :) ",
"> We can add new metadata yaml field (say, \"custom_configs_info\"), so that we can provide smth like:\r\n\r\nLove it ! Some other ideas to name the \"custom_configs_info\" field: \"configs\", \"parameters\", \"config_args\", \"configurations\"\r\n\r\n> it might require changes in interaction with the viewer on the hub side - to parse these configurations, as they not default configurations (not in BUILDER_CONFIGS list)\r\n\r\nIf we update the `get_dataset_config_names()` function in `datasets` in inspect.py we should be fine - that's what the viewer is using\r\n\r\n> Overall, I would start from implementing the first solution since it's related to what I'm doing now and is super useful for datasets in general. And then if we agree that having more flexibility in providing parameters to the viewer is required, I can implement the second one. Let me know what you think :)\r\n\r\nActually I feel like the second solution includes the first use case you mentioned. If you implement the second solution, then users would just have to add a few lines of YAML and their directories would be considered configurations no ? Maybe there's no need to implement two different logics to do the same thing",
"is there any update on this? 🕵🏻",
"@merveenoyan I haven't started working on this yet, working on adding configs to packaged datasets instead: https://github.com/huggingface/datasets/pull/5213 because this both would allow you to solve your issue and is a frequently requested feature.\r\n\r\nadding arbitrary parameters to yaml would be my next task i think!",
"@merveenoyan ignore my comment above, I'm switching to this task now :D",
"I want to be able to create folders in a model."
] | null | 5,209 | false |
Refactor CI hub fixtures to use monkeypatch instead of patch | Minor refactoring of CI to use `pytest` `monkeypatch` instead of `unittest` `patch`. | https://github.com/huggingface/datasets/pull/5208 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5208",
"html_url": "https://github.com/huggingface/datasets/pull/5208",
"diff_url": "https://github.com/huggingface/datasets/pull/5208.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5208.patch",
"merged_at": "2022-11-08T06:49:17"
} | 5,208 | true |
Connection error of the HuggingFace's dataset Hub due to SSLError with proxy | ### Describe the bug
It's weird. I could not normally connect the dataset Hub of HuggingFace due to a SSLError in my office.
Even when I try to connect using my company's proxy address (e.g., http_proxy and https_proxy),
I'm getting the SSLError issue. What should I do to download the datanet stored in HuggingFace normally?
I welcome any comments. I think those comments will be helpful to me.
* Dataset address - https://huggingface.co/datasets/moyix/debian_csrc/viewer/moyix--debian_csrc
* Log message
```
............ OMISSION ..............
Traceback (most recent call last):
File "/data/home/geunsik-lim/qtlab/./transformers/examples/pytorch/language-modeling/run_clm.py", line 587, in <module>
main()
File "/data/home/geunsik-lim/qtlab/./transformers/examples/pytorch/language-modeling/run_clm.py", line 278, in main
raw_datasets = load_dataset(
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1719, in load_dataset
builder_instance = load_dataset_builder(
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1497, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1222, in dataset_module_factory
raise e1 from None
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1179, in dataset_module_factory
raise ConnectionError(f"Couldn't reach '{path}' on the Hub ({type(e).__name__})")
ConnectionError: Couldn't reach 'moyix/debian_csrc' on the Hub (SSLError)
[2022-11-07 15:23:38,476] [INFO] [launch.py:318:sigkill_handler] Killing subprocess 6760
[2022-11-07 15:23:38,476] [ERROR] [launch.py:324:sigkill_handler] ['/home/geunsik-lim/anaconda3/envs/deepspeed/bin/python', '-u', './transformers/examples/pytorch/language-modeling/run_clm.py', '--local_rank=0', '--model_name_or_path=Salesforce/codegen-350M-multi', '--per_device_train_batch_size=1', '--learning_rate', '2e-5', '--num_train_epochs', '1', '--output_dir=./codegen-350M-finetuned', '--overwrite_output_dir', '--dataset_name', 'moyix/debian_csrc', '--cache_dir', '/data/home/geunsik-lim/.cache', '--tokenizer_name', 'Salesforce/codegen-350M-multi', '--block_size', '2048', '--gradient_accumulation_steps', '32', '--do_train', '--fp16', '--deepspeed', 'ds_config_zero2.json'] exits with return code = 1
real 0m7.742s
user 0m4.930s
```
### Steps to reproduce the bug
Steps to reproduce this behavior.
```
(deepspeed) geunsik-lim@ai02:~/qtlab$ ./test_debian_csrc_dataset.py
Traceback (most recent call last):
File "/data/home/geunsik-lim/qtlab/./test_debian_csrc_dataset.py", line 6, in <module>
dataset = load_dataset("moyix/debian_csrc")
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1719, in load_dataset
builder_instance = load_dataset_builder(
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1497, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1222, in dataset_module_factory
raise e1 from None
File "/home/geunsik-lim/anaconda3/envs/deepspeed/lib/python3.10/site-packages/datasets/load.py", line 1179, in dataset_module_factory
raise ConnectionError(f"Couldn't reach '{path}' on the Hub ({type(e).__name__})")
ConnectionError: Couldn't reach 'moyix/debian_csrc' on the Hub (SSLError)
(deepspeed) geunsik-lim@ai02:~/qtlab$
(deepspeed) geunsik-lim@ai02:~/qtlab$
(deepspeed) geunsik-lim@ai02:~/qtlab$
(deepspeed) geunsik-lim@ai02:~/qtlab$ cat ./test_debian_csrc_dataset.py
#!/usr/bin/env python
from datasets import load_dataset
dataset = load_dataset("moyix/debian_csrc")
```
1. Adde proxy address of a company in /etc/profile
2. Download dataset with load_dataset() function of datasets package that is provided by HuggingFace.
3. In this case, the address would be "moyix--debian_csrc".
4. I get the "`ConnectionError: Couldn't reach 'moyix/debian_csrc' on the Hub (SSLError`)" error message.
### Expected behavior
* error message:
ConnectionError: Couldn't reach 'moyix/debian_csrc' on the Hub (SSLError)
### Environment info
* software version information:
```
(deepspeed) geunsik-lim@ai02:~$
(deepspeed) geunsik-lim@ai02:~$ conda list -f pytorch
# packages in environment at /home/geunsik-lim/anaconda3/envs/deepspeed:
#
# Name Version Build Channel
pytorch 1.13.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
(deepspeed) geunsik-lim@ai02:~$ conda list -f python
# packages in environment at /home/geunsik-lim/anaconda3/envs/deepspeed:
#
# Name Version Build Channel
python 3.10.6 haa1d7c7_1
(deepspeed) geunsik-lim@ai02:~$ conda list -f datasets
# packages in environment at /home/geunsik-lim/anaconda3/envs/deepspeed:
#
# Name Version Build Channel
datasets 2.6.1 py_0 huggingface
(deepspeed) geunsik-lim@ai02:~$ uname -a
Linux ai02 5.4.0-131-generic #147-Ubuntu SMP Fri Oct 14 17:07:22 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
(deepspeed) geunsik-lim@ai02:~$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=20.04
DISTRIB_CODENAME=focal
DISTRIB_DESCRIPTION="Ubuntu 20.04.5 LTS"
``` | https://github.com/huggingface/datasets/issues/5207 | [
"Hi ! It looks like an issue with your python environment, can you make sure you're able to run GET requests to https://huggingface.co using `requests` in python ?",
"\r\nThanks for your reply. Does this mean that I have to use the `do_dataset `function and the `requests `function to download the dataset from the company's proxy environment?\r\n\r\n\r\n* Reference: \r\n```\r\n### How to load this dataset directly with the [datasets](https://github.com/huggingface/datasets) library\r\n\r\n\r\n* https://huggingface.co/datasets/moyix/debian_csrc\r\n\r\n\r\n* \r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"moyix/debian_csrc\")\r\n\r\n\r\n\r\n### Or just clone the dataset repo\r\n\r\n\r\ngit lfs install\r\ngit clone https://huggingface.co/datasets/moyix/debian_csrc\r\n# if you want to clone without large files – just their pointers\r\n# prepend your git clone with the following env var:\r\nGIT_LFS_SKIP_SMUDGE=1\r\n```",
"You can use `requests` to see if downloading a file from the Hugging Face Hub works. If so, then `datasets` should work as well. If not, then you have to find another way using an internet connection that works"
] | null | 5,207 | false |
Use logging instead of printing to console | ### Describe the bug
Some logs ([here](https://github.com/huggingface/datasets/blob/4a6e1fe2735505efc7e3a3dbd3e1835da0702575/src/datasets/builder.py#L778), [here](https://github.com/huggingface/datasets/blob/4a6e1fe2735505efc7e3a3dbd3e1835da0702575/src/datasets/builder.py#L786), and [here](https://github.com/huggingface/datasets/blob/4a6e1fe2735505efc7e3a3dbd3e1835da0702575/src/datasets/builder.py#L830)) generated by the `DatasetBuilder` are printed to the console instead of passed to `datasets` logger.
### Steps to reproduce the bug
```python
>> import datasets
>> datasets.load_dataset("some-dataset")
Downloading and preparing dataset csv/data to <path>...
Downloading data files: 100%|██████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 7729.06it/s]
Extracting data files: 100%|████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 527.23it/s]
Dataset csv downloaded and prepared to <path>. Subsequent calls will reuse this data.
```
### Expected behavior
The logs should not be printed to the console directly but passed to the logger so that the user can redirect them wherever he wants.
### Environment info
- `datasets` version: 2.6.1
- Platform: macOS-13.0-x86_64-i386-64bit
- Python version: 3.9.15
- PyArrow version: 10.0.0
- Pandas version: 1.5.1 | https://github.com/huggingface/datasets/issues/5206 | [
"Actually upon closer inspection, it is documented in the code that this behavior is intentional, so I'll close this."
] | null | 5,206 | false |
Add missing `DownloadConfig.use_auth_token` value | This PR solves https://github.com/huggingface/datasets/issues/5204
Now the `token` is propagated so that `DownloadConfig.use_auth_token` value is set before trying to download private files from existing datasets in the Hub. | https://github.com/huggingface/datasets/pull/5205 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5205",
"html_url": "https://github.com/huggingface/datasets/pull/5205",
"diff_url": "https://github.com/huggingface/datasets/pull/5205.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5205.patch",
"merged_at": "2022-11-07T16:20:24"
} | 5,205 | true |
`push_to_hub` not propagating `token` through `DownloadConfig` | ### Describe the bug
When trying to upload a new 🤗 Dataset to the Hub via Python, and providing the `token` as a parameter to the `Dataset.push_to_hub` function, it just works for the first time, assuming that the dataset didn't exist before.
But when trying to run `Dataset.push_to_hub` again over the same dataset, instead of updating it, it throws a `ConnectionError` when trying to retrieve the `README.md` that may contain some metadata about the dataset, so as to also update it, but since the `token` is not propagated, the `DownloadConfig` provided to the `datasets.utils.file_utils.get_from_cache` function doesn't contain the `use_auth_token` value set to `token`, it's just using the default one which is None/False.
So on, when uploading a dataset via Python with `push_to_hub` with the `token` as a parameter with the HuggingFace API Token as value, it can just be uploaded when the dataset is new, otherwise it fails with to `ConnectionError` due to the `token` not being propagated as `use_auth_token`.
### Steps to reproduce the bug
Let's create a new dataset in our HF account via Python as:
```python
from datasets import Dataset
data = {"a": [1, 2, 3], "b": [4, 5, 6]}
ds = Dataset.from_dict(data)
ds.push_to_hub(repo_id=<HF_USERNAME>/<HF_DATASET>, private=private, token=<HF_TOKEN_HERE>)
```
When we create the `Dataset` for the first time it works and there are no issues, but when trying to actually upload a new version of the same dataset (same name under the same username), we encounter the following issue:
```python
from datasets import Dataset
data = {"a": [1, 2, 3], "b": [4, 5, 6]}
ds = Dataset.from_dict(data)
ds.push_to_hub(repo_id=<HF_USERNAME>/<HF_DATASET>, private=private, token=<HF_TOKEN_HERE>)
>>> ConnectionError: Couldn't reach https://huggingface.co/datasets/alvarobartt/demo/resolve/main/README.md (ConnectionError('Unauthorized for URL https://huggingface.co/datasets/<HF_USERNAME>/<HF_DATASET>/resolve/main/README.md. Please use the parameter `use_auth_token=True` after logging in with `huggingface-cli login`'))
```
### Expected behavior
Ideally, the `token` parameter provided to `push_to_hub` should be propagated and used to download the `README.md` when trying to update a `Dataset`, instead of throwing that exception, so that the authentication can be done directly through code without running `huggingface-cli login`as mentioned at https://huggingface.co/docs/datasets/upload_dataset#upload-with-python.
### Environment info
- `datasets` version: 2.6.1
- Platform: macOS-13.0-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 10.0.0
- Pandas version: 1.5.1 | https://github.com/huggingface/datasets/issues/5204 | [
"#self-assign",
"@lhoestq can you close this issue as part of the recent #5205 merge? Thanks 🤗 ",
"Thank you :)"
] | null | 5,204 | false |
Update canonical links to Hub links | This PR updates some of the canonical dataset links to their corresponding links on the Hub; closes #5200. | https://github.com/huggingface/datasets/pull/5203 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5203",
"html_url": "https://github.com/huggingface/datasets/pull/5203",
"diff_url": "https://github.com/huggingface/datasets/pull/5203.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5203.patch",
"merged_at": "2022-11-07T18:40:19"
} | 5,203 | true |
CI fails after bulk edit of canonical datasets | ```
______ test_get_dataset_config_info[paws-labeled_final-expected_splits2] _______
[gw0] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
path = 'paws', config_name = 'labeled_final'
expected_splits = ['train', 'test', 'validation']
@pytest.mark.parametrize(
"path, config_name, expected_splits",
[
("squad", "plain_text", ["train", "validation"]),
("dalle-mini/wit", "dalle-mini--wit", ["train"]),
("paws", "labeled_final", ["train", "test", "validation"]),
],
)
def test_get_dataset_config_info(path, config_name, expected_splits):
info = get_dataset_config_info(path, config_name=config_name)
assert info.config_name == config_name
> assert list(info.splits.keys()) == expected_splits
E AssertionError: assert ['test', 'tra... 'validation'] == ['train', 'te... 'validation']
E At index 0 diff: 'test' != 'train'
E Full diff:
E - ['train', 'test', 'validation']
E + ['test', 'train', 'validation']
tests/test_inspect.py:45: AssertionError
_ test_get_dataset_info[paws-expected_configs2-expected_splits_in_first_config2] _
[gw0] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
path = 'paws'
expected_configs = ['labeled_final', 'labeled_swap', 'unlabeled_final']
expected_splits_in_first_config = ['train', 'test', 'validation']
@pytest.mark.parametrize(
"path, expected_configs, expected_splits_in_first_config",
[
("squad", ["plain_text"], ["train", "validation"]),
("dalle-mini/wit", ["dalle-mini--wit"], ["train"]),
("paws", ["labeled_final", "labeled_swap", "unlabeled_final"], ["train", "test", "validation"]),
],
)
def test_get_dataset_info(path, expected_configs, expected_splits_in_first_config):
infos = get_dataset_infos(path)
assert list(infos.keys()) == expected_configs
expected_config = expected_configs[0]
assert expected_config in infos
info = infos[expected_config]
assert info.config_name == expected_config
> assert list(info.splits.keys()) == expected_splits_in_first_config
E AssertionError: assert ['test', 'tra... 'validation'] == ['train', 'te... 'validation']
E At index 0 diff: 'test' != 'train'
E Full diff:
E - ['train', 'test', 'validation']
E + ['test', 'train', 'validation']
tests/test_inspect.py:90: AssertionError
______ test_get_dataset_split_names[paws-labeled_final-expected_splits2] _______
[gw0] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
path = 'paws', expected_config = 'labeled_final'
expected_splits = ['train', 'test', 'validation']
@pytest.mark.parametrize(
"path, expected_config, expected_splits",
[
("squad", "plain_text", ["train", "validation"]),
("dalle-mini/wit", "dalle-mini--wit", ["train"]),
("paws", "labeled_final", ["train", "test", "validation"]),
],
)
def test_get_dataset_split_names(path, expected_config, expected_splits):
infos = get_dataset_infos(path)
assert expected_config in infos
info = infos[expected_config]
assert info.config_name == expected_config
> assert list(info.splits.keys()) == expected_splits
E AssertionError: assert ['test', 'tra... 'validation'] == ['train', 'te... 'validation']
E At index 0 diff: 'test' != 'train'
E Full diff:
E - ['train', 'test', 'validation']
E + ['test', 'train', 'validation']
``` | https://github.com/huggingface/datasets/issues/5202 | [
"Fixed by: https://huggingface.co/datasets/paws/discussions/1"
] | null | 5,202 | false |
Do not sort splits in dataset info | I suggest not to sort splits by their names in dataset_info in README so that they are displayed in the order specified in the loading script. Otherwise `test` split is displayed first, see this repo: https://huggingface.co/datasets/paws
What do you think?
But I added sorting in tests to fix CI (for the same dataset). | https://github.com/huggingface/datasets/pull/5201 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"It would be coherent with https://github.com/huggingface/datasets-server/issues/614#issuecomment-1290534153",
"I think we started working on this issue nearly at the same time... :sweat_smile: \r\n- CI was fixed with this: https://huggingface.co/datasets/paws/discussions/1\r\n\r\nRelated issue:\r\n- #5202",
"@albertvillanova yeah I noticed it right after the PR :smile: thank you! the fix of the dataset info yaml fixes tests on CI, but in general order of splits in yaml influences the order in which they are displayed in the viewer, if I understand it correctly. So I suggest not to sort splits in yaml initially to avoid this for other datasets in the future. I think [this change](https://github.com/huggingface/datasets/pull/5201/files#diff-198ba4fdf2f94cb3e1aba8a0170a43b08d4ab5636d682374321c5a383a8be24dR571) should work for it. \r\n\r\nChanges to tests here maybe can be reverted considering that order in yaml now corresponds to the one in tests, thanks to your change in the dataset info.",
"Hehe, @polinaeterna, we make comments nearly at the same time as well... :laughing: "
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5201",
"html_url": "https://github.com/huggingface/datasets/pull/5201",
"diff_url": "https://github.com/huggingface/datasets/pull/5201.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5201.patch",
"merged_at": "2022-11-04T14:45:09"
} | 5,201 | true |
Some links to canonical datasets in the docs are outdated | As we don't have canonical datasets in the github repo anymore, some old links to them doesn't work. I don't know how many of them are there, I found link to SuperGlue here: https://huggingface.co/docs/datasets/dataset_script#multiple-configurations, probably there are more of them. These links should be replaced by links to the corresponding datasets on the Hub. | https://github.com/huggingface/datasets/issues/5200 | [
"Thanks for catching this, I can go through the docs and replace the links to their corresponding datasets on the Hub!"
] | null | 5,200 | false |
Deprecate dummy data generation command | Deprecate the `dummy_data` CLI command. | https://github.com/huggingface/datasets/pull/5199 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5199",
"html_url": "https://github.com/huggingface/datasets/pull/5199",
"diff_url": "https://github.com/huggingface/datasets/pull/5199.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5199.patch",
"merged_at": "2022-11-04T13:59:47"
} | 5,199 | true |
Add note about the name of a dataset script | Add note that a dataset script should has the same name as a repo/dir, a bit related to this issue https://github.com/huggingface/datasets/issues/5193
also fixed two minor issues in audio docs (broken links) | https://github.com/huggingface/datasets/pull/5198 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5198",
"html_url": "https://github.com/huggingface/datasets/pull/5198",
"diff_url": "https://github.com/huggingface/datasets/pull/5198.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5198.patch",
"merged_at": "2022-11-04T12:46:01"
} | 5,198 | true |
[zstd] Use max window log size | ZstdDecompressor has a parameter `max_window_size` to limit max memory usage when decompressing zstd files. The default `max_window_size` is not enough when files are compressed by `zstd --ultra` flags.
Change `max_window_size` to the zstd's max window size. NOTE, the `zstd.WINDOWLOG_MAX` is the log_2 value of the max window size. | https://github.com/huggingface/datasets/pull/5197 | [
"@albertvillanova Please take a review.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5197). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5197",
"html_url": "https://github.com/huggingface/datasets/pull/5197",
"diff_url": "https://github.com/huggingface/datasets/pull/5197.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5197.patch",
"merged_at": null
} | 5,197 | true |
Use hfh hf_hub_url function | Small refactoring to use `hf_hub_url` function from `huggingface_hub`.
This PR also creates the `hub` module that will contain all `huggingface_hub` functionalities relevant to `datasets`.
This is a necessary stage before implementing the use of the `hfh` caching system (which uses its `hf_hub_url` under the hood).
EDIT:
~~Finally, we use our `config.HUB_DATASETS_URL` when using `hfh.hf_hub_url`~~
There is a breaking change: the `hfh` `hf_hub_url` function uses
- `hfh` `HUGGINGFACE_CO_URL_TEMPLATE` URL template, different from the `datasets` `config.HUB_DATASETS_URL`
- also, `hfh` `DEFAULT_REVISION`, instead of `datasets` `config.HUB_DEFAULT_VERSION` | https://github.com/huggingface/datasets/pull/5196 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5196). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq I think we should first agree if `datasets` can introduce the breaking change of ignoring `config.HUB_DATASETS_URL`: some users may have override this.\r\n\r\nIf so, I then would suggest to initiate a deprecation cycle.",
"After a discussion with the rest of the datasets team, we agreed we can introduce the breaking change of ignoring `config.HUB_DATASETS_URL`: this will have minimal impact, only for **private Hubs**. We will address eventual possible impacts in the future.\r\n\r\nAdditionally, we also ignore `config.HUB_DEFAULT_VERSION`.\r\n\r\nSee explanation in this PR description: https://github.com/huggingface/datasets/pull/5196#issue-1434401646",
"I'm trying to upgrade datasets to 2.7.0 in https://github.com/huggingface/datasets-server, and the tests fail due to this change. I think it's a breaking change (that was not listed in https://github.com/huggingface/datasets/releases/tag/2.7.0) since code that previously worked (by setting `datasets.config.HUB_DATASETS_URL = CI_HUB_DATASETS_URL` for example) does not work anymore.\r\n\r\nI'm not sure what is the correct way to set up the tests; besides setting the env var \"HF_ENDPOINT\" before launching the tests (which, I think, is not a good way to do: the tests should not depend on the environment).",
"OK, I re-read this thread, and https://github.com/huggingface/datasets/pull/5196#issuecomment-1307430175 explicitely states that `config.HUB_DATASETS_URL` (as well as `config.HUB_DEFAULT_VERSION`) is now ignored. I was expecting the breaking changes to be listed in the release notes: https://github.com/huggingface/datasets/releases/tag/2.7.0.",
"> I'm not sure what is the correct way to set up the tests; besides setting the env var \"HF_ENDPOINT\" before launching the tests (which, I think, is not a good way to do: the tests should not depend on the environment).\r\n\r\nI think the current workaround of settings an env variable before launching the tests is \"not so bad\" when considering the fact that env variables are evaluated at import time in `huggingface_hub` (and most probable `datasets` as well). I think that when refactoring this in huggingface_hub (https://github.com/huggingface/huggingface_hub/issues/1172) I'll opt for instantiating a `Settings` object (or `Constants`) that contains all the settings variables. This way it will not be possible to import attributes individually + tests would be easier. As I see it, it would be similar to [what `Pydantic` does](https://pydantic-docs.helpmanual.io/usage/settings/) even though we most probably don't want Pydantic as a root dependency just for that. ",
"You can use fixtures in your tests:\r\n```python\r\nCI_HUB_ENDPOINT = \"https://hub-ci.huggingface.co\"\r\nCI_HUB_DATASETS_URL = CI_HUB_ENDPOINT + \"/datasets/{repo_id}/resolve/{revision}/{path}\"\r\nCI_HFH_HUGGINGFACE_CO_URL_TEMPLATE = CI_HUB_ENDPOINT + \"/{repo_id}/resolve/{revision}/{filename}\"\r\n\r\n@pytest.fixture\r\ndef ci_hfh_hf_hub_url(monkeypatch):\r\n monkeypatch.setattr(\r\n \"huggingface_hub.file_download.HUGGINGFACE_CO_URL_TEMPLATE\", CI_HFH_HUGGINGFACE_CO_URL_TEMPLATE\r\n )\r\n\r\n@pytest.fixture\r\ndef ci_hub_config(monkeypatch):\r\n monkeypatch.setattr(\"datasets.config.HF_ENDPOINT\", CI_HUB_ENDPOINT)\r\n monkeypatch.setattr(\"datasets.config.HUB_DATASETS_URL\", CI_HUB_DATASETS_URL)\r\n```\r\n\r\nand use `@pytest.fixture(autouse=True)` if you want to always use the CI endpoints.\r\n\r\nAnd when `huggingface-hub` and `datasets` change the way we can set the endpoint, we'll just need to update the fixtures.\r\nI think ultimately you'll only have to change the `huggingface-hub` endpoint settings\r\n",
"OK.\r\n\r\nIn fact, in datasets-server we set `config.HUB_DATASETS_URL` (https://github.com/huggingface/datasets-server/blob/35a30dbcd687b26db1f02502ea8305f70c064473/workers/splits/src/splits/config.py#L26) at config time, before starting the workers. It's not an issue with how to launch the tests, but with the app in itself.\r\n\r\nI understand that for now, the only way to fix this is to setup `HF_ENDPOINT` in the env when launching the app (currently, we set the endpoint with `COMMON_HF_ENDPOINT`, a custom env var I set to be sure not to have side-effects)",
"> You can use fixtures in your tests:\r\n\r\nThanks, used in https://github.com/huggingface/datasets-server/pull/644."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5196",
"html_url": "https://github.com/huggingface/datasets/pull/5196",
"diff_url": "https://github.com/huggingface/datasets/pull/5196.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5196.patch",
"merged_at": "2022-11-09T07:15:12"
} | 5,196 | true |
[wip testing docs] | null | https://github.com/huggingface/datasets/pull/5195 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5195). All of your documentation changes will be reflected on that endpoint."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5195",
"html_url": "https://github.com/huggingface/datasets/pull/5195",
"diff_url": "https://github.com/huggingface/datasets/pull/5195.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5195.patch",
"merged_at": null
} | 5,195 | true |
Fix docs about dataset_info in YAML | This PR fixes some misalignment in the docs after we transferred the dataset_info from `dataset_infos.json` to YAML in the dataset card:
- #4926
Related to:
- #5193 | https://github.com/huggingface/datasets/pull/5194 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5194",
"html_url": "https://github.com/huggingface/datasets/pull/5194",
"diff_url": "https://github.com/huggingface/datasets/pull/5194.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5194.patch",
"merged_at": "2022-11-03T13:29:21"
} | 5,194 | true |
"One or several metadata. were found, but not in the same directory or in a parent directory" | ### Describe the bug
When loading my own dataset, on loading it I get an error.
Here is my dataset link: https://huggingface.co/datasets/corentinm7/MyoQuant-SDH-Data
And the error after loading with:
```python
from datasets import load_dataset
load_dataset("corentinm7/MyoQuant-SDH-Data")
```
```python
Downloading readme: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.34k/3.34k [00:00<00:00, 4.45MB/s]
Using custom data configuration SDH_16k-53e7301a92ab0025
Downloading and preparing dataset None/SDH_16k to /home/corentin/.cache/huggingface/datasets/corentinm7___imagefolder/SDH_16k-53e7301a92ab0025/0.0.0/37fbb85cc714a338bea574ac6c7d0b5be5aff46c1862c1989b20e0771199e93f...
Downloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.28M/3.28M [00:00<00:00, 4.31MB/s]
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.75s/it]
Downloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.13G/1.13G [00:15<00:00, 74.3MB/s]
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:16<00:00, 16.09s/it]
Extracting data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:13<00:00, 13.16s/it]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/datasets/load.py", line 1742, in load_dataset
builder_instance.download_and_prepare(
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/datasets/builder.py", line 814, in download_and_prepare
self._download_and_prepare(
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/datasets/builder.py", line 1423, in _download_and_prepare
super()._download_and_prepare(
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/datasets/builder.py", line 905, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/datasets/builder.py", line 1374, in _prepare_split
for key, record in logging.tqdm(
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/home/corentin/code-project/hugging_face_play/.venv/lib/python3.10/site-packages/datasets/packaged_modules/folder_based_builder/folder_based_builder.py", line 394, in _generate_examples
raise ValueError(
ValueError: One or several metadata. were found, but not in the same directory or in a parent directory of /home/corentin/.cache/huggingface/datasets/downloads/extracted/60c4aa8d4da3065bb3d310de4373dffd73bd4dc331aedcb4ee867febe4fdb7cd/validation/sick/2_CG_SDH_TAM_Bin1cKO_ko_pla_4_1640.tif.
```
However the test command is working fine. ```datasets-cli test hugging_face_play/ds_test/SDH_16k.py --save_info --all_configs --force_redownload```
```
Using custom data configuration SDH_16k
Testing builder 'SDH_16k' (1/1)
Downloading and preparing dataset sdh_16k/SDH_16k to /home/corentin/.cache/huggingface/datasets/sdh_16k/SDH_16k/1.0.0/21b584239a638aeeda33cba1ac2ca4869d48e4b4f20fb22274d5a5ddc487659d...
Downloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.13G/1.13G [00:14<00:00, 76.5MB/s]
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:15<00:00, 15.66s/it]
Downloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.28M/3.28M [00:02<00:00, 1.44MB/s]
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:03<00:00, 3.21s/it]
Downloading data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 11586.48it/s]
Extracting data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:13<00:00, 13.42s/it]
Dataset sdh_16k downloaded and prepared to /home/corentin/.cache/huggingface/datasets/sdh_16k/SDH_16k/1.0.0/21b584239a638aeeda33cba1ac2ca4869d48e4b4f20fb22274d5a5ddc487659d. Subsequent calls will reuse this data.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 605.27it/s]
Dataset card saved at hugging_face_play/ds_test/README.md
Test successful.
```
### Steps to reproduce the bug
Simply run on python
```python
from datasets import load_dataset
load_dataset("corentinm7/MyoQuant-SDH-Data")
```
### Expected behavior
As the test command worked, this error should not appear
### Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.10.16.3-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.6
- PyArrow version: 10.0.0
- Pandas version: 1.5.1
| https://github.com/huggingface/datasets/issues/5193 | [
"Also unrelated but still: https://huggingface.co/docs/datasets/image_dataset#generate-the-dataset\r\n```If your loading script passed the test, you should now have a dataset_infos.json file in your dataset folder.```\r\nIt's not the case anymore as it's now in the readme.md, it was confusing to me",
"And here is my data loader script: https://huggingface.co/datasets/corentinm7/MyoQuant-SDH-Data/blob/main/SDH_16k.py\r\nI have one file archive to download that contains the images for all splits and one `metadata.jsonl` to download that contains the informations about what image goes into what split.",
"Hi @lambda-science! It seems that your repo is recognized as a packaged module [ImageFolder](https://huggingface.co/docs/datasets/main/en/image_dataset#imagefolder), not as a dataset with the custom loading script, because loader looks for a script that has the same name as the dataset repo. So please try to rename your script to `MyoQuant-SDH-Data.py`, this should help.",
"> Hi @lambda-science! It seems that your repo is recognized as a packaged module [ImageFolder](https://huggingface.co/docs/datasets/main/en/image_dataset#imagefolder), not as a dataset with the custom loading script, because loader looks for a script that has the same name as the dataset repo. So please try to rename your script to `MyoQuant-SDH-Data.py`, this should help.\r\n\r\nHi !\r\n\r\nThank you for your answer. That was... embarrassingly easy, sorry for this issue, everything is fixed now ! \r\n\r\nHave a nice day ! :)",
"@lambda-science that's not embarrassing at all! it's actually not clear from the documentation that the script should have the same name, so thank you for the issue, we'll add this information to the docs :) "
] | null | 5,193 | false |
Drop labels in Image and Audio folders if files are on different levels in directory or if there is only one label | Will close https://github.com/huggingface/datasets/issues/5153
Drop labels by default (`drop_labels=None`) when:
* there are files on different levels of directory hierarchy by checking their path depth
* all files are in the same directory (=only one label was inferred)
First one fixes cases like this:
```
repo
image3.jpg
image4.jpg
data
image1.jpg
image2.jpg
```
Second one fixes cases like this:
```
repo
image1.jpg
image2.jpg
image3.jpg
```
This is mostly to fix the viewer for people who just drop images in the Hub interface into the root dir.
I added tests for both of the cases on local and remote files. **I also changed data files for old test on drop_labels** (`test_generate_examples_drop_labels`). The files I provide to `test_generate_examples_drop_labels` now has "canonical" classification structure (two dirs) in order not to change the logic of the test (=not to check these two cases addressed in the PR).
| https://github.com/huggingface/datasets/pull/5192 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"> Nit: maybe we can use the count_path_segments function from this file for counting (updated with your logic to make it faster).\r\n\r\n@mariosasko just to make sure I understood you correctly - are you okay with this change? (actually `os.path.normpath` is redundant here as paths from `data_files` should be already normalized but just in case)\r\nhttps://github.com/huggingface/datasets/pull/5192/files#diff-1f09f7a178211f7539b1499b64b69793bd53b30c8b7b34cfcc5835e25d31929fR33\r\nIf you are, we can merge.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5192). All of your documentation changes will be reflected on that endpoint.",
"awesome ! :D"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5192",
"html_url": "https://github.com/huggingface/datasets/pull/5192",
"diff_url": "https://github.com/huggingface/datasets/pull/5192.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5192.patch",
"merged_at": "2022-11-15T16:31:07"
} | 5,192 | true |
Make torch.Tensor and spacy models cacheable | Override `Pickler.save` to implement deterministic reduction (lazily registered; inspired by https://github.com/uqfoundation/dill/blob/master/dill/_dill.py#L343) functions for `torch.Tensor` and spaCy models.
Fix https://github.com/huggingface/datasets/issues/5170, fix https://github.com/huggingface/datasets/issues/3178
| https://github.com/huggingface/datasets/pull/5191 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5191",
"html_url": "https://github.com/huggingface/datasets/pull/5191",
"diff_url": "https://github.com/huggingface/datasets/pull/5191.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5191.patch",
"merged_at": "2022-11-02T17:18:42"
} | 5,191 | true |
`path` is `None` when downloading a custom audio dataset from the Hub | ### Describe the bug
I've created an [audio dataset](https://huggingface.co/datasets/lewtun/audio-test-push) using the `audiofolder` feature desribed in the [docs](https://huggingface.co/docs/datasets/audio_dataset#audiofolder) and then pushed it to the Hub.
Locally, I can see the `audio.path` feature is of the expected form `path/to/data_dir`, but when I download the dataset from the Hub, I see `audio.path` is `None`
Here's an example:
```python
from datasets import load_dataset
ds = load_dataset("lewtun/audio-test-push")
ds["train"][0]
# {
# "audio": {
# "path": None, <-- Is this expected?
# "array": array(
# [
# 3.97140226e-07,
# 7.30310290e-07,
# 7.56406735e-07,
# ...,
# -1.19636677e-01,
# -1.16811886e-01,
# -1.12441722e-01,
# ]
# ),
# "sampling_rate": 44100,
# },
# "song_id": 0,
# "genre_id": 0,
# "genre": "Electronic",
# }
```
Is this expected behaviour? If yes, feel free to close this issue as it's not a true bug then :)
### Steps to reproduce the bug
1. Create an audio dataset with the `audiofolder` feature
2. Push the dataset to the Hub with `push_to_hub()`
3. Download the Hub dataset and inspect the `audio.path` feature
### Expected behavior
`audio.path` points to the file associated with the audio data
### Environment info
- `datasets` version: 2.6.2.dev0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.1 | https://github.com/huggingface/datasets/issues/5190 | [
"Hi! Yes, this is expected behavior - we do this as a security measure to not leak local paths (this info would be useless on other users' machines anyways) and only push audio bytes. \r\n"
] | null | 5,190 | false |
Reduce friction in tabular dataset workflow by eliminating having splits when dataset is loaded | ### Feature request
Sorry for cryptic name but I'd like to explain using code itself. When I want to load a specific dataset from a repository (for instance, this: https://huggingface.co/datasets/inria-soda/tabular-benchmark)
```python
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-benchmark", data_files=["reg_cat/house_sales.csv"], streaming=True)
print(next(iter(dataset["train"])))
```
`datasets` library is essentially designed for people who'd like to use benchmark datasets on various modalities to fine-tune their models, and these benchmark datasets usually have pre-defined train and test splits. However, for tabular workflows, having train and test splits usually ends up model overfitting to validation split so usually the users would like to do validation techniques like `StratifiedKFoldCrossValidation` or when they tune for hyperparameters they do `GridSearchCrossValidation` so often the behavior is to create their own splits. Even [in this paper](https://hal.archives-ouvertes.fr/hal-03723551) a benchmark is introduced but the split is done by authors.
It's a bit confusing for average tabular user to try and load a dataset and see `"train"` so it would be nice if we would not load dataset into a split called `train `by default.
```diff
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-benchmark", data_files=["reg_cat/house_sales.csv"], streaming=True)
-print(next(iter(dataset["train"])))
+print(next(iter(dataset)))
```
### Motivation
I explained it above 😅
### Your contribution
I think this is quite a big change that seems small (e.g. how to determine datasets that will not be load to train split?), it's best if we discuss first! | https://github.com/huggingface/datasets/issues/5189 | [
"I have to admit I'm not a fan of this idea, as this would result in a non-consistent behavior between tabular and non-tabular datasets, which is confusing if done without the context you provided. Instead, we could consider returning a `Dataset` object rather than `DatasetDict` if there is only one split in the generated dataset. But then again, I think this lib is a bit too old to make such changes. @lhoestq @albertvillanova WDYT?\r\n\r\n",
"We can brainstorm here to see how we could make it happen ? And then depending on the options we see if it's a change we can do.\r\n\r\nI'm starting with a first reasoning\r\n\r\nCurrently not passing `split=` in `load_dataset` means \"return a dict with each split\".\r\n\r\nNow what would happen if a dataset has no split ? Ideally it should return one Dataset. And passing `split=` would have no sense. So depending on the dataset content, not passing `split=` should return a dict or a Dataset. In particular, those two cases should work:\r\n```python\r\n# case 1: dataset without split\r\nds = load_dataset(\"dataset_without_split\")\r\nds[0], ds[\"column_name\"], list(ds) # we want this\r\n\r\n# case 2: dataset with splits\r\nds = load_dataset(\"dataset_with_splits\")\r\nds[\"train\"] # this works and can't be changed\r\nds = load_dataset(\"dataset_with_splits\", split=\"train\")\r\nds[0], ds[\"column_name\"], list(ds) # this works and can't be changed\r\n```\r\n\r\nI can see several ideas:\r\n1. allowing `load_dataset` to return a different object based on the dataset content - either a Dataset or a DatasetDict\r\n - we can update `get_dataset_split_names` to return None or a list if users want to know in advance what object will be returned. They can also use `isinstance` _a posteriori_\r\n - but in this case we expect users to be careful when loading datasets and always to extra steps to check if they got a Dataset or DatasetDict\r\n2. merge Dataset and DatasetDict objects\r\n - they already share many functions: map, filter, push_to_hub etc.\r\n - we can define `ds[0]` to be the first item of the first split, and consider that the uses accesses rows from the full table of all the splits concatenated\r\n - however there is a collision when doing `ds[\"column_name\"]` or `ds[\"train\"]` that we need to address: the first returns a list, while the other returns a Dataset.\r\n\r\nWhat are your opinions on those two ideas ? Do you have other ideas in mind ?",
"I like the first idea more (concatenating splits doesn't seem useful, no?). This is a significant breaking change, so I think we should do a poll (or something similar) to gather more info on the actual \"expected behavior\" and wait for Datasets 3.0 if we decide to implement it.\r\n\r\nPS: @thomwolf also suggested the same thing a while ago (https://github.com/huggingface/datasets/issues/743#issuecomment-746074641).",
"I think it's an interesting improvement to the user experience for a case that comes often (no split) so I would definitively support it.\r\n\r\nI would be more in favor of option 2 rather than returning various types of objects from load_dataset and handling carefully the possible collisions indeed",
"Related: if a dataset only has one split, we don't show the splits select control in the dataset viewer on the Hub, eg. compare https://huggingface.co/datasets/hf-internal-testing/fixtures_image_utils/viewer/image/test with https://huggingface.co/datasets/glue/viewer/mnli/test.\r\n\r\nSee https://github.com/huggingface/moon-landing/pull/3858 for more details (internal)",
"I feel like the second idea is a bit more overkill. \r\n@severo I would say it's a bit irrelevant to the problem we have but is a separate problem @polinaeterna is solving at the moment. 😅 (also discussed on slack)",
"OK, sorry for polluting the thread. The relation I saw with the dataset viewer is that from a UX point of view, we hide the concepts of split and configuration whenever possible -> this issue feels like doing the same in the datasets library.",
"I would agree that returning different types based on the content of the dataset might be confusing.\r\n\r\nWe can do something similar to what `fetch_*` or `load_*` from `sklearn.datasets` do, which is to have an arg which changes the type of the returned type. For instance, `load_iris` would return a dict, but `load_iris(..., return_X_y=True)` would return a tuple.\r\n\r\nHere we can have a similar arg such as `return_X` which would then only return a single `DataSet` or an array.",
"> I feel like the second idea is a bit more overkill.\r\n\r\nOverkill in what sense ?\r\n\r\n> Here we can have a similar arg such as return_X which would then only return a single DataSet or an array.\r\n\r\nRight now one can already pass `split=\"all\"` to get one `Dataset` object with all the data in it (unsplit). We could also have something like `return_all=True` so make the API clearer.\r\n\r\n> I would be more in favor of option 2 rather than returning various types of objects from load_dataset and handling carefully the possible collisions indeed\r\n\r\nI think it would be ok to handle the collision by allowing both `ds[\"train\"]` and `ds[\"column_name\"]` (and maybe adding something like `ds.splits` for those who want to iterate over the splits or add new ones)",
"Would it make sense to remove the notion of \"split\" in `load_dataset`? I feel a lof of it comes from the want to have some sort of group of more or less similar dataset. \"train\"/\"test\"/\"validation\" are the traditional ones, but there are some datasets that have much more splits.\r\n\r\nWould it make sense to force `load_dataset` to only load a single `Dataset` object, and fail if it doesn't point to one. And have another method that's like `load_dataset_group_info` that can return a very arbitrary info class (Dict, List whatever), but you need to pass individual infos to `load_dataset` to run anything? Typically I don't think `DatasetDict.map` is really that helpful, but that's my personal opinion. This would help make things more readable (typically knowing if an object is a `Dataset` or a `DatasetDict`)",
"> Would it make sense to remove the notion of \"split\" in load_dataset?\r\n\r\nI think we need to keep it - though in practice people can name the splits whatever they want anyway.\r\n\r\n> Would it make sense to force load_dataset to only load a single Dataset object, and fail if it doesn't point to one.\r\n\r\nWe need to keep backward compatibility ideally - in particular the load_dataset + ds[\"train\"] one",
"> I think we need to keep it - though in practice people can name the splits whatever they want anyway.\r\n\r\nIt was my understanding that the whole issue was that `load_dataset` returned multiple types of objects.\r\n\r\n> We need to keep backward compatibility ideally - in particular the load_dataset + ds[\"train\"] one\r\n\r\nYeah sorry I meant ideally. One can always start developing `load_dataset_v2` can deprecate the first one and remove it in the longer term.",
"> It was my understanding that the whole issue was that load_dataset returned multiple types of objects.\r\n\r\nYes indeed, but we still want to keep a way to load the train/val/test/whatever splits alone ;)",
"@thomasw21's solution is good but it will break backwards compatibility. 😅",
"Started to experiment with merging Dataset and DatasetDict. My plan is to define the splits of a Dataset in Dataset.info.splits (already exists, but never used). A Dataset would then be the concatenation of its splits if they exist.\r\n\r\nNot sure yet this is the way to go. My plan is to play with it and see and share it with you, so we can see if it makes sense from a UX point of view.",
"So just to make sure that I understand the current direction, people will have to be extra careful when handling splits right?\r\nImagine \"potato\" a dataset containing train/validation split:\r\n```\r\nload_dataset(\"potato\") # returns the concatenation of all the splits\r\n```\r\nPreviously the design would force you to choose a split (it would raise otherwise), or manually concat them if you really wanted to play with concatenated splits. Now it would potentially run without raising for a bit of time until you figure out that you've been training on both train and validation split.\r\n\r\nWould it make sense to use a dataset specific default instead of using the concatenation, typically \"potato\" dataset's default would be train?\r\n```\r\nload_dataset(\"potato\") # returns \"train\" split\r\nload_dataset(\"potato\", split=\"train\") # returns \"train\" split\r\nload_dataset(\"potato\", split=\"validation\") # returns \"validation\" split\r\nconcatenate_datasets([load_dataset(\"potato\", split=\"train\"), load_dataset(\"potato\", split=\"validation\")]) # returns concatenation\r\n```",
"> load_dataset(\"potato\") # returns \"train\" split\r\n\r\nTo avoid a breaking change we need to be able to do `load_dataset(\"potato\")[\"validation\"]` as well.\r\n\r\nIn that case I'd wonder where the validation split comes from, since the rows of the dataset wouldn't contain the validation split according to your example. That's why I'm more in favor of concatenating.\r\n\r\nA dataset is one table, that optionally has some split info about subsets (e.g. for training an evaluation)\r\n\r\nThis also allows anyone to re-split the dataset the way they want if they're not happy with the default:\r\n\r\n```python\r\nds = load_dataset(\"potato\").train_test_split(test_size=0.2)\r\ntrain_ds = ds[\"train\"]\r\ntest_ds = ds[\"test\"]\r\n```",
"Just thinking about this, we could just have `to_dataframe()` as `load_dataset(\"blah\").to_dataframe()` to get the whole dataset, and not change anything else.",
"I have a first implementation of option 2 (merging Dataset and DatasetDict) in this PR: https://github.com/huggingface/datasets/pull/5301/\r\n\r\nFeel free to play with it if you're interested, and let me know what you think. In this PR, a dataset is one table that optionally has some split info about subsets.",
"@adrinjalali we already have [to_pandas](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_pandas) AFAIK that essentially does the same thing (for a dataset, not for a dataset dict), I was wondering if it makes sense to have this as I don't know portion of people who load non-tabular datasets into dataframes. @lhoestq I saw your PR and it will break a lot of things imo, WDYT of this option? ",
"> we already have [to_pandas](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_pandas) AFAIK that essentially does the same thing (for a dataset, not for a dataset dict)\r\n\r\nyes correct :)\r\n\r\n> I saw your PR and it will break a lot of things imo\r\n\r\nDo you have concrete examples you can share ?\r\n\r\n> WDYT of this option?\r\n\r\nThe to_dataframe option ? I think it not enough, since you'd still get a `DatasetDict({\"train\": Dataset()})` if you load a dataset with no splits (e.g. one CSV), and this doesn't really make sense.\r\n\r\nNote that in the PR I opened you can do\r\n```python\r\nds = load_dataset(\"dataset_with_just_one_csv\") # Dataset type\r\ndf = load_dataset(\"dataset_with_just_one_csv\").to_pandas() # DataFrame type\r\n```",
"@lhoestq no I think @adrinjalali and I meant when user calls `to_dataframe` if there's only train split in `DatasetDict` we could directly load that into dataframe. This might cause a confusion given there's to_pandas but I think it's more intuitive and least breaking change. (given people -who use `datasets` for tabular workflows- will eventually call `to_pandas` anyway) ",
"So in that case it would be fine to still end up with a dataset dict with a \"train\" split ?",
"yeah what I mean is this:\r\n\r\n```py\r\ndataset = load_dataset(\"blah\")\r\n\r\n# deal with a split of the dataset\r\ntrain = dataset[\"train\"]\r\ntrain_df = dataset[\"train\"].to_dataframe()\r\n\r\n# deal with the whole dataset\r\ndataset_df = dataset.to_dataframe()\r\n```\r\n\r\nSo we do two things to improve tabular experience:\r\n- allow datasets to have a single split\r\n- add `to_dataframe` to the root dict level so that users can simply call `df = load_dataset(\"blah\").to_dataframe()` and have it in their `pandas.DataFrame` object.",
"Ok ! Note that we already have `Dataset.to_pandas()` so for consistency I'd call it `DatasetDict.to_pandas()` as well, does it sound good to you ? This is something we can add pretty easily",
"yeah that sounds perfect @lhoestq !",
"> So just to make sure that I understand the current direction, people will have to be extra careful when handling splits right?\r\n\r\nWe can raise an error if someone does `load_dataset(...)[0]` if the dataset is made of several splits, and return the first example if there's one or zero splits (i.e. when it's not ambiguous). Had this idea from the dicussions in #5312 WDYT @thomasw21 ?",
"> We can raise an error if someone does load_dataset(...)[0] if the dataset is made of several splits,\r\n\r\nBut then how is that different to have the distinction between DatasetDict and Dataset then? Is it just that \"default behaviour when there are no splits or single split, it returns directly the split when there's no ambiguity\".\r\n\r\nAlso I was wondering how the concatenation could have heavy impacts when running mapping functions/filtering in batch? Typically can batch be somehow mixed?",
"> But then how is that different to have the distinction between DatasetDict and Dataset then?\r\n\r\nBecause it doesn't make sense to be able to do `example = ds[0]` or `examples = list(ds)` on a class named `DatasetDict` of type `Dict[str, Dataset]`.\r\n\r\n> Also I was wondering how the concatenation could have heavy impacts when running mapping functions/filtering in batch? Typically can batch be somehow mixed?\r\n\r\nNo, we run each function on each split separated",
"> Because it doesn't make sense to be able to do example = ds[0] or examples = list(ds) on a class named DatasetDict of type Dict[str, Dataset].\r\n\r\nHum but you're still going to raise an exception in both those cases with your current change no? (actually list(ds) would return the name of the splits no?)\r\n\r\n> No, we run each function on each split separated\r\n\r\nNice!"
] | null | 5,189 | false |
add: segmentation guide. | Closes #5181
I have opened a PR on Hub (https://huggingface.co/datasets/huggingface/documentation-images/discussions/5) to include the images in our central Hub repository. Once the PR is merged I will edit the image links.
I have also prepared a [Colab Notebook](https://colab.research.google.com/drive/1BMDCfOTBnyshoME5RSxn5iQy-TWeFbOA?usp=sharing) in case anyone wants to play.
- [x] Replace the image links | https://github.com/huggingface/datasets/pull/5188 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks @osanseviero. Am I good to merge? ",
"I would wait for a second approval just in case :) ",
"Sure :) ",
"Merging since the images have been pushed as LFS files ([PR](https://huggingface.co/datasets/huggingface/documentation-images/discussions/8)). "
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5188",
"html_url": "https://github.com/huggingface/datasets/pull/5188",
"diff_url": "https://github.com/huggingface/datasets/pull/5188.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5188.patch",
"merged_at": "2022-11-04T18:23:34"
} | 5,188 | true |
chore: add notebook links to img cls and obj det. | Closes https://github.com/huggingface/datasets/issues/5182 | https://github.com/huggingface/datasets/pull/5187 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@nateraw I guess the failing test is unrelated. ",
"@sayakpaul Yea failures are unrelated. ",
"Alright. Will wait for @osanseviero's take and then merge. ",
"FYI @stevhliu ",
"@osanseviero @stevhliu @nateraw thank you for your comments. Acted on them.",
"Thanks! Can I merge? Or should we wait for approvals from the others?",
"Since @stevhliu approved as well, I think you're good to go",
"Alright!\r\n\r\nMerging as a Member for the first time 🫀"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5187",
"html_url": "https://github.com/huggingface/datasets/pull/5187",
"diff_url": "https://github.com/huggingface/datasets/pull/5187.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5187.patch",
"merged_at": "2022-11-03T01:49:56"
} | 5,187 | true |
Incorrect error message when Dataset.from_sql fails and sqlalchemy not installed | ### Describe the bug
When calling `Dataset.from_sql` (in my case, with sqlite3), it fails with a message ```ValueError: Please pass `features` or at least one example when writing data``` when I don't have `sqlalchemy` installed.
### Steps to reproduce the bug
Make a new sqlite db with `sqlite3` and `pandas` from a remote [URL](https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-states.csv).
```python
import sqlite3
import pandas as pd
from datasets import Dataset
conn = sqlite3.connect('us_covid_data.db')
df = pd.read_csv('https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-states.csv')
df.to_sql('states', conn, if_exists='replace')
```
Then if you try to query this DB like this:
```python
ds = Dataset.from_sql('''SELECT * from states WHERE state=="New York";''', "sqlite:///us_covid_data.db")
```
You run into the error I described above:
```ValueError: Please pass `features` or at least one example when writing data```
However, if you try to pass features, as the error suggests, then you get an error that tells you the underlying problem...
```python
from datasets import Dataset, Features, Value
features = Features({
'date': Value('date32'),
'label': Value('string'),
'fips': Value('int32'),
'cases': Value('int32'),
'deaths': Value('int32')
})
ds = Dataset.from_sql(
'''SELECT * from states WHERE state=="New York";''',
"sqlite:///us_covid_data.db",
features=features
)
```
Which results in the actual underlying error: `ImportError: Using URI string without sqlalchemy installed.`
### Expected behavior
Instead of `ValueError` about needing to pass features, we should provide the actual underlying error about not having SQLAlchemy installed when it isn't found in the environment.
### Environment info
- `datasets` version: 2.6.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.10
- PyArrow version: 10.0.0
- Pandas version: 1.2.5 | https://github.com/huggingface/datasets/issues/5186 | [
"Hi! The first `Dataset.from_sql` call also outputs the \"ImportError: Using URI string without sqlalchemy installed.\" message, but you also get \"During handling of the above exception another exception occurred: ...\" after which the ValueError is printed. I agree that this behavior makes it easy to miss the original error. \r\n\r\nI think we can improve this by not throwing the writer's ValueError if the error from a dataset script is already being handled to make debugging easier. @lhoestq @albertvillanova wdyt?",
"Yup ! Alternatively the error can be raised in sql.py before generating the examples ? In `_info` for example",
"yea @lhoestq that would probably be good. The 2nd error is useless if the 1st error is the real reason it failed. "
] | null | 5,186 | false |
Allow passing a subset of output features to Dataset.map | ### Feature request
Currently, map does one of two things to the features (if I'm not mistaken):
* when you do not pass features, types are assumed to be equal to the input if they can be cast, and inferred otherwise
* when you pass a full specification of features, output features are set to this
However, sometimes you want to just pass some of the output types, particularly when the first of these modes makes an incorrect type. This currently crashes.
### Motivation
To give a little background: this problem appears in converting labels to ids, where the labels happen to be floats rather than strings
Consider the following use of map to convert from float to int
```python
data = Dataset.from_dict({'y':[1.0,2.0,3.0]})
mapped = data.map(lambda r: {'y': int(r['y'])})
mapped['y'] # is floats, not ints
```
The result is a float again, since after the mapping operation it forces the old datatypes back on the data.
Passing `features=Features({"y": Value(dtype="int64")})` to map works in principle, but then extending it a little to e.g.
```python
def format_data(r):
return {**tokenizer(r["text"]), "y": int(r["y"])}
data = Dataset.from_dict({"y": [1.0, 2.0, 3.0], "text": ["one", "two", "three"]})
mapped = data.map(
format_data,
features=Features({'y': Value(dtype="int64")}),
remove_columns=["text"],
)
```
Results in a crash in dataset internals, as it expects either all or no output features to be specified.
Of course one can pass a full feature specification, but this becomes tokenizer specific and very awkward.
### Your contribution
I've looked at `write_batch` and particularly `col_type = features[col] if features else None`, but checking for `col in features` here makes it fail elsewhere, but the structure makes it hard to understand how and why. I do not think I would have the time myself to get to the bottom of this anytime soon. | https://github.com/huggingface/datasets/issues/5185 | [] | null | 5,185 | false |
Loading an external dataset in a format similar to conll2003 | I'm trying to load a custom dataset in a Dataset object, it's similar to conll2003 but with 2 columns only (word entity), I used the following script:
features = datasets.Features(
{"tokens": datasets.Sequence(datasets.Value("string")),
"ner_tags": datasets.Sequence(
datasets.features.ClassLabel(
names=["B-PER", .... etc.]))}
)
from datasets import Dataset
INPUT_COLUMNS = "tokens ner_tags".split(" ")
def read_conll(file):
#all_labels = []
example = {col: [] for col in INPUT_COLUMNS}
idx = 0
with open(file) as f:
for line in f:
if line:
if line.startswith("-DOCSTART-") and example["tokens"] != []:
print(idx, example)
yield idx, example
idx += 1
example = {col: [] for col in INPUT_COLUMNS}
elif line == "\n" or (line.startswith("-DOCSTART-") and example["tokens"] == []):
continue
else:
row_cols = line.split(" ")
for i, col in enumerate(example):
example[col] = row_cols[i].rstrip()
dset = Dataset.from_generator(read_conll, gen_kwargs={"file": "/content/new_train.txt"}, features = features)
The following error happened:
[/usr/local/lib/python3.7/dist-packages/datasets/utils/py_utils.py](https://localhost:8080/#) in <genexpr>(.0)
285 for key in unique_values(itertools.chain(*dicts)): # set merge all keys
286 # Will raise KeyError if the dict don't have the same keys
--> 287 yield key, tuple(d[key] for d in dicts)
288
TypeError: tuple indices must be integers or slices, not str
What does this mean and what should I modify? | https://github.com/huggingface/datasets/issues/5183 | [] | null | 5,183 | false |
Add notebook / other resource links to the task-specific data loading guides | Does it make sense to include links to notebooks / scripts that show how to use a dataset for training / fine-tuning a model?
For example, here in [https://huggingface.co/docs/datasets/image_classification] we could include a mention of https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb.
Applies to https://huggingface.co/docs/datasets/object_detection as well.
Cc: @osanseviero @nateraw | https://github.com/huggingface/datasets/issues/5182 | [
"Yea this would be great! We would need an object detection tutorial notebook too if it doesn't already exist there. ",
"There is one: https://huggingface.co/docs/datasets/object_detection.\r\n\r\nI will start the work. "
] | null | 5,182 | false |
Add a guide for semantic segmentation | Currently, we have these guides for object detection and image classification:
* https://huggingface.co/docs/datasets/object_detection
* https://huggingface.co/docs/datasets/image_classification
I am proposing adding a similar guide for semantic segmentation.
I am happy to contribute a PR for it.
Cc: @osanseviero @nateraw | https://github.com/huggingface/datasets/issues/5181 | [
"Sure this sounds great! Would this be pure torchvision, albumentations, or something else?",
"I am considering `torchvision` and `albumentations`. Also [works with TensorFlow](https://github.com/deep-diver/segformer-tf-transformers/blob/main/notebooks/TFSegFormer_Finetune.ipynb). \r\n\r\nI am assigning the issue to myself then. "
] | null | 5,181 | false |
An example or recommendations for creating large image datasets? | I know that Apache Beam and `datasets` have [some connector utilities](https://huggingface.co/docs/datasets/beam). But it's a little unclear what we mean by "But if you want to run your own Beam pipeline with Dataflow, here is how:". What does that pipeline do?
As a user, I was wondering if we have this support for creating large image datasets. If so, we should mention that [here](https://huggingface.co/docs/datasets/image_dataset).
Cc @lhoestq | https://github.com/huggingface/datasets/issues/5180 | [
"The beam utilities allow to prepare a dataset as parquet in your cloud storage. From my perspective this CLI is not super easy to use, but we've been working on a new python API to prepare a dataset in your cloud storage:\r\n```python\r\nfrom datasets import load_dataset_builder\r\n\r\nbuilder = load_dataset_builder(\"c4\", \"en\")\r\nbuilder.download_and_prepapre(\"s3://my-bucket/c4\", file_format=\"parquet\")\r\n```\r\n\r\nAnd to use Beam you can do:\r\n```python\r\nbeam_runner = ... # one of \"SparkRunner\", \"DataFlowRunner\", \"DirectRunner\", etc.\r\nbeam_options = ...\r\n\r\nbuilder.download_and_prepapre(\r\n \"s3://my-bucket/c4\",\r\n file_format=\"parquet\",\r\n beam_runner=beam_runner,\r\n beam_options=beam_options\r\n)\r\n```\r\n\r\nThough Beam can be used ONLY if there is a dataset script based on the `BeamBasedBuilder` right now - it doesn't work on an arbitrary dataset (see [wikipedia.py](https://huggingface.co/datasets/wikipedia/blob/main/wikipedia.py) for example).",
"Thanks! \r\n\r\nWould be nice to have something similar for creating large image datasets. "
] | null | 5,180 | false |