
anchor
stringlengths 159
16.8k
| positive
stringlengths 184
16.2k
| negative
stringlengths 167
16.2k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Check it out on GitHub!
The machine learning and web app segments are split into 2 different branches. Make sure to switch to these branches to see the source code! You can view the repository [here](https://github.com/SuddenlyBananas/be-right-back/).
## Inspiration
Inspired in part by the Black Mirror episode of the same title (though we had similar thoughts before we made the connection).
## What it does
The goal of the project is to be able to talk to a neural net simulation of your Facebook friends you've had conversations with. It uses a standard base model and customizes it based on message upload input. However, we ran into some struggles that prevented the full achievement of this goal.
The user downloads their message history data and uploads it to the site. Then, they can theoretically ask the bot to emulate one of their friends and the bot customizes the neural net model to fit the friend in question.
## How we built it
Tensor Flow for the machine learning aspect, Node JS and HTML5 for the data-managing website, Python for data scraping. Users can interact with the data through a Facebook Messenger Chat Bot.
## Challenges we ran into
AWS wouldn't let us rent a GPU-based E2 instance, and Azure didn't show anything for us either. Thus, training took much longer than expected.
In fact, we had to run back to an apartment at 5 AM to try to run it on a desktop with a GPU... which didn't end up working (as we found out when we got back half an hour after starting the training set).
The Facebook API proved to be more complex than expected, especially negotiating the 2 different user IDs assigned to Facebook and Messenger user accounts.
## Accomplishments that we're proud of
Getting a mostly functional machine learning model that can be interacted with live via a Facebook Messenger Chat Bot.
## What we learned
Communication between many different components of the app; specifically the machine learning server, data parsing script, web server, and Facebook app.
## What's next for Be Right Back
We would like to fully realize the goals of this project by training the model on a bigger data set and allowing more customization to specific users. | ## Inspiration
Globally, one in ten people do not know how to interpret their feelings. There's a huge global shift towards sadness and depression. At the same time, AI models like Dall-E and Stable Diffusion are creating beautiful works of art, completely automatically. Our team saw the opportunity to leverage AI image models and the emerging industry of Brain Computer Interfaces (BCIs) to create works of art from brainwaves: enabling people to learn more about themselves and
## What it does
A user puts on a Brain Computer Interface (BCI) and logs in to the app. As they work in front of front of their computer or go throughout their day, the user's brainwaves are measured. These differing brainwaves are interpreted as indicative of different moods, for which key words are then fed into the Stable Diffusion model. The model produces several pieces, which are sent back to the user through the web platform.
## How we built it
We created this project using Python for the backend, and Flask, HTML, and CSS for the frontend. We made use of a BCI library available to us to process and interpret brainwaves, as well as Google OAuth for sign-ins. We made use of an OpenBCI Ganglion interface provided by one of our group members to measure brainwaves.
## Challenges we ran into
We faced a series of challenges throughout the Hackathon, which is perhaps the essential route of all Hackathons. Initially, we had struggles setting up the electrodes on the BCI to ensure that they were receptive enough, as well as working our way around the Twitter API. Later, we had trouble integrating our Python backend with the React frontend, so we decided to move to a Flask frontend. It was our team's first ever hackathon and first in-person hackathon, so we definitely had our struggles with time management and aligning on priorities.
## Accomplishments that we're proud of
We're proud to have built a functioning product, especially with our limited experience programming and operating under a time constraint. We're especially happy that we had the opportunity to use hardware in our hack, as it provides a unique aspect to our solution.
## What we learned
Our team had our first experience with a 'real' hackathon, working under a time constraint to come up with a functioning solution, which is a valuable lesson in and of itself. We learned the importance of time management throughout the hackathon, as well as the importance of a storyboard and a plan of action going into the event. We gained exposure to various new technologies and APIs, including React, Flask, Twitter API and OAuth2.0.
## What's next for BrAInstorm
We're currently building a 'Be Real' like social media plattform, where people will be able to post the art they generated on a daily basis to their peers. We're also planning integrating a brain2music feature, where users can not only see how they feel, but what it sounds like as well | ## Inspiration
One thing the pandemic has taught us was the severity of mental health and how crucial it is to have someone to talk to during hardships. We believe in using technology to create a solution that addresses mental health, a global issue of utmost importance in today's world. As high school students, we constantly face stress and emotional challenges that significantly impact our lives. We often want help to get out of a hard situation, however; the help we receive, such as a therapist and a list of non-profit help lines, isn't usually the help that we want such as someone to talk to.
## What it does
My-AI is a chatbox that has a one-on-one conversation with the user in a way that is comforting and helpful by providing emotional support and advice. Maiya, the AI chatbot, assesses the user's messages and feelings to generate a human-like response so the user feels as if they are talking to another human, more so to a friend; a friend without bias and judgement. The entire conversation is not saved and so deleted once the user finishes the conversation.
## How we built it
We prototyped on Figma and then developed the front end with React. Our backend was created using Java Script to made the node server, which is responsible for calling the API.
## Challenges we ran into
Our team ran into many problems as it was one of the first hackathons that most of our team members attended. In terms of front-end development, none of our team members had experience in React so building a website within a time constraint was a learning curve. Other problems we faced in the backend were issues with the API as it would not respond sometimes, the accuracy was off, and wasn't doing what we needed it to do. Finally, we had trouble connecting the back end to the front end.
## Accomplishments that we're proud of
One thing our whole team is most proud of is our skillset improvement in React. All members experienced using React for the first time so navigating an issue for us helped us grasp a better understanding of it. We are also extremely proud of the fine-tuning of the API to meet our project's demands.
## What we learned
We mainly enhanced our skills in React and how to implement and fine-time an API.
## What's next for My-AI
The more Maya is trained with people and different experiences obtained through the chat box, the more accurate the support is. | winning |
## Inspiration
In a world where time is money, the traditional process of expense reporting is a glaring inefficiency in corporate workflows. Inspired by the staggering statistics from the Global Business Travel Association—highlighting that the average expense report takes 20 minutes to complete and costs companies $58, coupled with a high error rate—our team set out to revolutionize this outdated system. Our goal was to harness the power of artificial intelligence to create a solution that not only saves time and money but also brings a new level of simplicity and accuracy to expense management. Thus, ExpenseAI was born.
## What we Learned
For half of our team, this was our first hackathon, so it was a major learning experience for us. We learned a lot about close collaboration across our team to ensure successful implementation. We also learned the value of simplicity and efficiency. We made sure that our project reinforces the value of a simple, intuitive user interface that minimizes the effort required from the user to submit expense reports. We learned about the importance of stress testing our program to identify pain points and areas for enhancement, particularly in understanding user expectations for automation and interaction with the system. Lastly, we learned about optimizing for speed using techniques like preprocessing.
## How We Built It
* ExpenseAI was built on an array of cutting-edge AI technologies.
We used LangChain, an open-source framework, in Python to create the AI agent
* We use GPT4-Vision for converting images to high-quality text descriptions, and OpenAI’s Whisper for reliably converting audio to text.
* We then fed these text inputs into GPT4 to generate the expense reports. A major issue we encountered was that, despite adding a system message and spending hours on prompt engineering, GPT4 was unable to consistently output an expense report with most of the details provided in the prompt and the user’s contact info. We combined the little real-world expense report data we found with our own synthetic dataset, and used this result with ElasticSearch’s vector database and OpenAI’s embeddings in Retrieval Augmented Generation with GPT4. Specifically, we use Fast API to host our LangChain agent so we can call it from the frontend. We also made some optimizations for speed such as preprocessing. This resulted in a much higher quality and more consistent output.
* We used Streamlit for the frontend, largely due to its beautiful design and ease of use.
* We used Firebase’s Firestore as the backend to store user data and expense reports, allowing easy communication between the client and manager side of the application.
* We then wrote our own Autoencoder anomaly detection model trained on our vector database of existing, synthetic, and our own expense report data. This model then accepts or rejects a report that appears in the manager’s dashboard, updating the database too so the change is reflected in the client side.
## Challenges we Faced
We encountered many challenges while making this model. Here are some of them.
* Streamlit’s model depends on running the entirety of a file from top to bottom whenever something on the screen is updated. This had massive downsides, such as not having a cookie manager, so we needed to include many workarounds to get the effects we wanted.
* We had a massive issue where our API was rerunning all of our preprocessing issue each time it was called, leading to slow response times. We eventually fixed this using FastAPI’s methods.
* Prompt engineering became a challenge as mentioned previously, so we eventually used RAG to improve outputs. | ## Inspiration
In this modern times, we thought of re-creating a fun and interactive Indian tourism website which will attract more tourists towards the "Incredible India". All the states are unique and have their individual websites for tourism. Many tourists are not aware about it so it inspired us to build ***"Explore India with us"*** the all-in-one guide.
## What it does
**Explore India with us** provides a unified platform as a guide for tourists coming to India. India is a big and diverse country which has 28 states and 8 union territories. All of them have their own tourism sites. With our website, travelers can get travel information of any state in just one place. We also have embedded an interactive chat-bot which will guide the travelers during their visit in India like road trips, famous attractions, facts, history etc., and make their India journey remarkable.
## How we built it
The main attraction of the website is DialogFlow powered chat-bot assistant. We have trained our chat-bot agent with many queries regarding travelling in India, for instance, the chat-bot can tell you tourist attractions in Gujarat, suggest road-trips, tell you brief history about Indian subcontinent etc., and many more. **NOTE:** The chat-bot is still under training phase. The beautiful UI is built with pure HTML and CSS with smooth animations.
## Challenges we ran into
DialogFlow was a completely new platform for us. We learned and we built the chat-bot for our website during this hackathon period, which was an exciting challenge we took and completed!!
## Accomplishments that we're proud of
Keeping in mind the **"Make in India"** campaign, we are proud of having built this site to boost tourism.
## What we learned
We initially had no idea how to make a chat-bot. We watched YouTube tutorials and analyzing the docs on DialogFlow and we built this amazing chat-bot from scratch. We also explored the Beta version features of DialogFlow Messenger and integrated it with our project.
## What's next for Explore India With Us
Our future plans are to train the chat-bot to handle all types of user queries and give best end-user response. | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :) | losing |
## Inspiration
I was inspired to make this device while sitting in physics class. I really felt compelled to make something that I learned inside the classroom and apply my education to something practical. Growing up I always remembered playing with magnetic kits and loved the feeling of repulsion between magnets.
## What it does
There is a base layer of small magnets all taped together so the North pole is facing up. There are hall effect devices to measure the variances in magnetic field that is created by the user's magnet attached to their finger. This allows the device to track the user's finger and determine how they are interacting with the magnetic field pointing up.
## How I built it
It is build using the intel edison. Each hall effect device is either on or off depending if there is a magnetic field pointing down through the face of the black plate. This determines where the user's finger is. From there the analog data is sent via serial port to the processing program on the computer that demonstrates that it works. That just takes the data and maps the motion of the object.
## Challenges I ran into
There are many challenges I faced. Two of them dealt with just the hardware. I bought the wrong type of sensors. These are threshold sensors which means they are either on or off instead of linear sensors that give a voltage proportional to the strength of magnetic field around it. This would allow the device to be more accurate. The other one deals with having alot of very small worn out magnets. I had to find a way to tape and hold them all together because they are in an unstable configuration to create an almost uniform magnetic field on the base. Another problem I ran into was dealing with the edison, I was planning on just controlling the mouse to show that it works but the mouse library only works with the arduino leonardo. I had to come up with a way to transfer the data to another program, which is how i came up dealing with serial ports and initially tried mapping it into a Unity game.
## Accomplishments that I'm proud of
I am proud of creating a hardware hack that I believe is practical. I used this device as a way to prove the concept of creating a more interactive environment for the user with a sense of touch rather than things like the kinect and leap motion that track your motion but it is just in thin air without any real interaction. Some areas this concept can be useful in is in learning environment or helping people in physical therapy learning to do things again after a tragedy, since it is always better to learn with a sense of touch.
## What I learned
I had a grand vision of this project from thinking about it before hand and I thought it was going to theoretically work out great! I learned how to adapt to many changes and overcoming them with limited time and resources. I also learned alot about dealing with serial data and how the intel edison works on a machine level.
## What's next for Tactile Leap Motion
Creating a better prototype with better hardware(stronger magnets and more accurate sensors) | ## Inspiration
They say we’re simply a reflection of the five closest people to us. It’s so easy to get comfortable in our own echo chambers, lost in opinions that seem so real because they’re all around us. But sometimes we can’t look at life as a bigger picture unless we take a step back and empathize with people we don’t normally talk about.
7cups, a site where I volunteered to talk to anonymous strangers about their lives, helped me do that. BubblePop was inspired to do the same.
## What it does
BubblePop presents you with a series of opinions.
Chocolate is life; Psychopaths are simply less socially inhibited; The US should implement a junk food tax.
Swipe up, down, left, or right - your choice.
Once done, you’re connected with your furthest neighbor - a stranger who answered the most differently from you.
Meet up and say hello!
On a more serious note, recently with the advent of social media oligarchies, fake news, and extremist groups, division of opinion has received a reputation as the enemy of societal progress. This shouldn't be the case, though.
We create a place where people can anonymously proclaim their opinions on various articles regarding pressing issues. Then, we match people with differing opinions and encourage them to meet and discuss in a productive fashion. We hope to foster a diverse yet highly empathetic community.
## How I built it
* Firebase Realtime Database - Opinion bank storage, profile storage, and partner matching state storage-
* Twilio - Effortless peer to peer calling
* Code and iOS - main platform
## Challenges I ran into
First: Our team was quite unprepared for iOs since only one teammate had briefly worked with the platform and we only had two and a half Macs out of the four of us. Nevertheless, we learned iOs literally overnight and pulled through on the project.
Second: I wish I paid more attention in university math classes. For one of the first times in my life, I was required to think mathematically about a computer science problem. The goal was to transform the longitude and latitude coordinates of myself and my match, as well as my current compass direction, into a two-dimensional vector of how I should move to quickly reach my match. Unfortunately, after my teammate and I stressed for over six hours on this issue, reading mathematical formulas again and again while questioning whether we actually understood any of it, we finally settled on a semi-satisfactory compromise. In other words, we hacked it.
## Accomplishments that I'm proud of
Half the things stated above.
## What I learned
How iOS works, how iOS doesn’t work, and how iOS sometimes works.
## What's next for BubblePop | ## Inspiration
As a dedicated language learner for over two years, I faced the challenge of finding conversation partners during my first year. Working as a Food Service and Customer Service Worker allowed me to practice and learn real-life conversational skills. This experience inspired me to create a project that helps others learn practical language skills. My personal projects often focus on teaching, and this one aims to provide learners with the tools and opportunities to engage in meaningful conversations and master the language effectively.
## What it does
The app allows users to simulate conversations with diverse characters and different locations in their target language, creating an immersive learning experience. With an interactive, game-like UI, learning becomes fun and engaging. Additionally, the app features a chat window for real-time practice, enhancing conversational skills and making language acquisition more enjoyable and effective.
## How I built it
I used NextJS for the fullstack development of the app. For the style of the elements, I used TailwindCSS. For creating game-like menu, I first created an Isometric Tilemap in Godot and exported the map I created as an image. In Figma, I imported the Image and added the characters and Labels of the locations and exported it as an SVG file. I then converted the SVG file to something useable as a component in NextJS. Since the file is imported as an SVG, I can easily access the components which makes adding onClick functions for each character possible. I used the React useContext function to allow changing of the character in the chat possible. I used Groq and their LLM model for the character AI. I used the NextJS API routing system to fetch the response from the Groq API.
## What's next for LanguageRPG.AI
Allow users to upload pdf files and translate it allowing research papers, business papers, and legal documents accessible for people.
Allow users to hover on each character to show what they mean making learning a language easier. | partial |
**Made by Ella Smith (ella#4637) & Akram Hannoufa (ak\_hannou#7596) -- Team #15**
*Domain: <https://www.birtha.online/>*
## Inspiration
Conversations with friends and family about the difficulty of finding the right birth control pill on the first try.
## What it does
Determines the brand of hormonal contraceptive pill most likely to work for you using data gathered from drugs.com. Data includes: User Reviews, Drug Interactions, and Drug Effectiveness.
## How we built it
The front-end was built using HTML, CSS, JS, and Bootstrap. The data was scraped from drugs.com using Beautiful Soup web-scraper.
## Challenges we ran into
Having no experience in web-dev made this a particularly interesting learning experience. Determining how we would connect the scraped data to the front-end was challenging, as well as building a fully functional multi-page form proved to be difficult.
## Accomplishments that we're proud of
We are proud of the UI design, given it is our first attempt at web development. We are also proud of setting up a logic system that provides variability in the generated results. Additionally, figuring out how to web scrape was very rewarding.
## What we learned
We learned how to use version control software, specifically Git and GitHub. We also learned the basics of Bootstrap and developing a functional front-end using HTML, CSS, and JS.
## What's next for birtha
Giving more detailed and accurate results to the user by further parsing and analyzing the written user reviews. We would also like to add some more data sources to give even more complete results to the user. | ## Inspiration
Donut was originally inspired by a viral story about dmdm hydantoin, a chemical preservative used in hair products rumoured to be toxic and lead to hair loss. This started a broader discussion about commercial products in general and the plethora of chemical substances and ingredients we blindly use and consume on a daily basis. We wanted to remove these veils that can impact the health of the community and encourage people to be more informed consumers.
## What it does
Donut uses computer vision to read the labels off packaging through a camera. After acquiring this data, it displays all the ingredients in a list and uses sentiment analysis to determine the general safety of each ingredient. Users can click into each ingredient to learn more and read related articles that we recommend in order to make more educated purchases.
## How we built it
## Challenges we ran into
Front end development was a challenge since it was something our team was inexperienced with, but there’s no better place to learn than at a hackathon! Fighting away the sleepiness was another hurdle too.
## Accomplishments that we're proud of
We got more done than we imagined with a 3 person team :)
Michael is proud that he was very productive with the backend code :D
Grace is proud that she wrote any code at all as a designer o\_o
Denny is proud to have learned more about HTTP requests and worked with both the front and backend :0
## What we learned
We could be benefitted from a more well-balanced team (befriend some front end devs!). Sleep is important. Have snacks at the ready.
## What's next for Donut Eat This
Features that we would love to implement next would be a way to upload photos from a user’s album and a way to view recent scans. | ## Inspiration
According to the WHO, drug donation today is encountering serious waste in terms of both labor and medical products due to disorganized, massive amount of charity. 80% or donated drugs arrive unsolicited, unexpected, and most notably, unsorted. 62% come with labels in foreign languages that locals cannot decipher. Meanwhile, in other areas, drug cleanup fails to be completed appropriately and cause serious threats to the environment. Dr.Pill was then devised to simplify the medicinal identification process so people, ranging from those simply curious about the pills lying around in the cabinet to those in dire need of quick medical assortment, could utilize the current medical resources for efficiently and sustain-ably.
## What it does
Dr.Phil uses image recognition to instantly identify medicinal pills, from over-the-counter to prescribed counterparts. Functional and consumption information after industry research was carefully selected among many from drugbank database, so contrary to traditional pill identifiers, Dr.Pill could provide much clearer and easier-to-follow insights. It also offers translation for international adoption, especially concerning the influence language barrier can build amidst drug donation.
## How I built it
We created a server using node.js and separately wrote python scripts to use the machine learning APIs (Google OCR, IBM Watson, Translator), then we executed the scripts within the node.js server and rendered the results on frontend templates.
## Challenges I ran into
Fetching data from drugbank and drugs.com was a challenging experience. Certain important drug-related information such as storage methods were inaccessibly as well.
## Accomplishments that I'm proud of
We are proud to have given an attempt towards the life-sciences field for the first time. It was quite different and the topic was very rewarding.
## What I learned
We fortified our experience on using computer vision APIs.
## What's next for Dr.Pill
We hope to add advanced details such as storage details, actual dosages, and voice-interaction functionalities.
Improvement in UX would be another viable integration with better readability of details. | winning |
## Inspiration
Social media has revolutionized the way of life. As avid promotes of diversity and inclusion, we felt that visually impaired people have limited access to social media. Therefore, we wanted to build something meaningful with the hope of improving the way of their lives.
## What it does?
Herddit is an Alexa skill that allows users especially who are visually impaired to access Reddit by reading posts, comments as well as describing images, gifs and videos using Microsoft Vision API.
## How we built it?
We built this Alexa skill using Python. Our team made use of Reddit API to extract data and Microsoft Vision API to process images. In addition, we made use of AWS as our backend platform.
## Challenges we ran into
One of the challenges that we ran into was working python as every member of our team has little python experience.
## Accomplishments that we're proud of
Learning how to work with different APIs.
## What we learned
Don't ever use replace all to rename variables
## What's next for HERDDIT
Increase robustness by allowing users to create posts and comment on posts. Interact with more social media apps such as Instagram, Facebook and Twitter. | ## Inspiration
1.3 billion People have some sort of vision impairment. They face difficulties in simple day to day task like reading, recognizing faces, objects, etc. Despite the huge number surprisingly there are only a few devices in the market to aid them, which can be hard on the pocket (5000$ - 10000$!!). These devices essentially just magnify the images and only help those with mild to moderate impairment. There is no product in circulation for those who are completely blind.
## What it does
The Third Eye brings a plethora of features at just 5% the cost. We set our minds to come up with a device that provides much more than just a sense of sight and most importantly is affordable to all. We see this product as an edge cutting technology for futuristic development of Assistive technologies.
## Feature List
**Guidance** - ***Uses haptic feedback to navigate the user to the room they choose avoiding all obstacles***. In fact, it's a soothing robotic head massage guiding you through the obstacles around you. Believe me, you're going to love it.
**Home Automation** - ***Provides full control over all house appliances***. With our device, you can just call out **Alexa** or even using the mobile app and tell it to switch off those appliances directly from the bed now.
**Face Recognition** - Recognize friends (even their emotions (P.S: Thanks to **Cloud Vision's** accurate facial recognitions!). Found someone new? Don't worry, on your command, we register their face in our database to ensure the next meeting is no more anonymous and awkward!
**Event Description** - ***Describes the activity taking place***. A group of people waving somewhere and you still not sure what's going on next to you? Fear not, we have made this device very much alive as this specific feature gives speech feedback describing the scenic beauty around you. [Thanks to **Microsoft Azure API**]
**Read Up** - You don't need to spend some extra bucks for blind based products like braille devices. Whether it be general printed text or a handwritten note. With the help of **Google Cloud Vision**, we got you covered from both ends. **Read up** not only decodes the text from the image but using **Google text to speech**, we also convert the decoded data into a speech so that the blind person won't face any difficulty reading any kind of books or notes they want.
**Object Locator** - Okay, so whether we are blind or not, we all have this bad habit of misplacing things. Even with the two eyes, sometimes it's too much pain to find the misplaced things in our rooms. And so, we have added the feature of locating most generic objects within the camera frame with its approximate location. You can either ask for a specific object which you're looking for or just get the feedback of all the objects **Google Cloud Vision** has found for you.
**Text-a-Friend** - In the world full of virtuality and social media, we can be pushed back if we don't have access to the fully connected online world. Typing could be difficult at times if you have vision issues and so using **Twilio API** now you can easily send text messages to saved contacts.
**SOS** - Okay, so I am in an emergency, but I can't find and trigger the SOS feature!? Again, thanks to the **Twilio** messaging and phone call services, with the help of our image and sensor data, now any blind person can ***Quickly intimate the authorities of the emergency along with their GPS location***. (This includes auto-detection of hazards too)
**EZ Shoppe** - It's not an easy job for a blind person to access ATMs or perform monetary transactions independently. And so, taking this into consideration, with the help of superbly designed **Capital One Hackathon API**, we have created a **server-based blockchain** transaction system which adds ease to your shopping without being worried about anything. Currently, the server integrated module supports **customer addition, account addition, person to person transactions, merchant transactions, balance check and info, withdrawals and secure payment to vendors**. No need of worrying about individual items, just with one QR scan, your entire shopping list is generated along with the vendor information and the total billing amount.
**What's up Doc** - Monitoring heart pulse rate and using online datasets, we devised a machine learning algorithm and classified labels which tells about the person's health. These labels include: "Athletic", "Excellent", 'Good", "Above Average", "Average", "Below Average" and "Poor". The function takes age, heart rate, and gender as an argument and performs the computation to provide you with the best current condition of your heart pulse rate.
\*All features above can be triggered from Phone via voice, Alexa echo dot and even the wearable itself.
\*\*Output information is relayed via headphones and Alexa.
## How we built it
Retrofit Devices (NodeMCU) fit behind switchboards and allow them to be controlled remotely.
The **RSSI guidance uses Wi-Fi signal intensity** to triangulate its position. Ultrasonic sensor and camera detects obstacles (**OpenCV**) and runs Left and Right haptic motors according to closeness to device and position of the obstacle.
We used **dlib computer vision library** to record and extract features to perform **facial recognition**.
**Microsoft Azure Cloud services** takes a series of images to describe the activity taking place.
We used **Optical Character Recognition (Google Cloud)** for Text To Speech Output.
We used **Google Cloud Vision** which classifies and locates the object.
**Twilio API** sends the alert using GPS from Phone when a hazard is detected by the **Google Cloud Vision API**.
QR Scanner scans the QR Code and uses **Capital One API** to make secure and fast transactions in a **BlockChain Network**.
Pulse Sensor data is taken and sent to the server where it is analysed using ML models from **AWS SageMaker** to make the health predictions.
## Challenges we ran into
Making individual modules was a bit easier but integrating them all together into one hardware (Raspberry Pi) and getting them to work was something really challenging to us.
## Accomplishments that we're proud of
The number of features we successfully integrated to prototype level.
## What we learned
We learned to trust in ourselves and our teammates and that when we do that there's nothing we can't accomplish.
## What's next for The Third Eye
Adding a personal assistant to up the game and so much more.
Every person has potential they deserve to unleash; we pledge to level the playfield by taking this initiative forward and strongly urge you to help us in this undertaking. | ## Inspiration
The idea was to help people who are blind, to be able to discretely gather context during social interactions and general day-to-day activities
## What it does
The glasses take a picture and analyze them using Microsoft, Google, and IBM Watson's Vision Recognition APIs and try to understand what is happening. They then form a sentence and let the user know. There's also a neural network at play that discerns between the two dens and can tell who is in the frame
## How I built it
We took a RPi Camera and increased the length of the cable. We then made a hole in our lens of the glasses and fit it in there. We added a touch sensor to discretely control the camera as well.
## Challenges I ran into
The biggest challenge we ran into was Natural Language Processing, as in trying to parse together a human-sounding sentence that describes the scene.
## What I learned
I learnt a lot about the different vision APIs out there and creating/trainingyour own Neural Network.
## What's next for Let Me See
We want to further improve our analysis and reduce our analyzing time. | partial |
## Inspiration
Sometimes we will wake up in the morning and realize that we want to go for a short jog but don't want to be out for too long. Therefore it would be helpful to know how long the route is so we can anticipate the time we would spend. Google Maps does have a feature where we can input various destinations and find their total distance, but this typically requires a precise address where a runner would not necessarily care for.
## What it does
The user selects a general loop around which they want to run, and the Map will "snap" that path to the closest adjacent roads. At the click of a button, they will also be able to find the total distance of their route. If mistakes were made in generating the route, they can easily clear it and restart.
## How I built it
We used Google Cloud, particularly Maps and integrated that into Javascript. We looked through documentation to find strategies in determining the device location and route planning strategies through sample code in the API. We built on top of them to generate desirable polylines and calculate distances as accurately as possible. Additionally, we used web development (HTML and CSS) to build a simple yet attractive interface for the software.
## Challenges I ran into
A more practical use of this type of application is obviously a mobile application for easy access to . We spent countless hours trying to learn Java and work with Android Studio, but the complexity of all the libraries and features made it extremely difficult to work with. As a result, we transitioned over to a desktop web server, as we were slightly more comfortable working with Javascript. Within the web app, we spent a lot of time trying to implement polylines and snapping them to roads properly.
## Accomplishments that I'm proud of
We were able to make polylines work out, which was the most difficult and core part of our hack.
## What I learned
Always look for documentation and search for answers online. Javascript has a lot of resources to learn and use, and is very flexible to use. We definitely improved my knowledge of web development through this hack.
## What's next for Run Master
We are going to automate a method to have the user *input* a distance and the application with generate a suggested loop. It is much more difficult but will definitely be a very useful feature! | ## Inspiration
NutriLens was inspired by the growing emphasis on health and wellness, and the challenge many people face in understanding the nutritional content of their meals, especially when dining out or trying new dishes. The idea was to leverage technology to provide instant access to detailed nutritional information, making it easier for individuals to make informed dietary choices.
## What it does
NutriLens is an augmented reality (AR) spectacle system that:
* Provides real-time macro tracking by identifying ingredients and estimating portion sizes.
* Offers recipe suggestions based on available ingredients.
* Displays nutritional information directly in the user's field of view.
## How we built it
* AR technology integrated into spectacles for hands-free operation.
* AI-powered image recognition to identify food items and ingredients.
* Integration with the USDA Food Data Central API for retrieving nutritional information.
* A backend connection to for processing input and generating recommendations.
* AR UI menus for displaying information and interacting with the system.
## Challenges we ran into
* Developing accurate food recognition algorithms for a wide variety of ingredients and dishes.
* Creating an intuitive AR user interface that doesn't obstruct the user's view.
* Ensuring real-time performance for instant feedback and information display.
## Accomplishments that we're proud of
* Successfully integrating AR technology with nutritional analysis for a seamless user experience.
* Developing a system that provides instant, accurate nutritional information in real-time.
* Creating a multi-functional tool that assists users throughout the entire cooking process.
* Designing an innovative solution to promote healthier eating habits and informed dietary choices.
## What we learned
* The importance of user-centered design in creating wearable technology.
* The complexities of integrating multiple technologies (AR, AI, image recognition) into a single system.
* The value of real-time data processing and display in enhancing user experience.
* The potential of AR in revolutionizing everyday tasks like cooking and meal planning.
## What's next for NutriLens
* Expanding the food recognition database to cover a wider range of cuisines and ingredients.
* Implementing personalized dietary recommendations based on user preferences and health goals.
* Developing social features to allow users to share recipes and cooking experiences.
* Exploring partnerships with nutrition apps and food delivery services for enhanced functionality.
* Refining the AR interface for even more seamless integration into the cooking process.
* Conducting user studies to gather feedback and improve the overall experience. | ## Inspiration
EV vehicles are environment friendly and yet it does not receive the recognition it deserves. Even today we do not find many users driving electric vehicles and we believe this must change. Our project aims to provide EV users with a travel route showcasing optimal (and functioning) charging stations to enhance the use of Electric Vehicles by resolving a major concern, range anxiety. We also believe that this will inherently promote the usage of electric vehicles amongst other technological advancements in the car industry.
## What it does
The primary aim of our project is to display the **ideal route** to the user for the electric vehicle to take along with the **optimal (and functional) charging stations** using markers based on the source and destination.
## How we built it
Primarily, in the backend, we integrated two APIs. The **first API** call is used to fetch the longitude as well as latitude coordinates of the start and destination addresses while the **second API** was used to locate stations within a **specific radius** along the journey route. This computation required the start and destination addresses leading to the display of the ideal route containing optimal (and functioning) charging points along the way. Along with CSS, the frontend utilizes **Leaflet (SDK/API)** to render the map which not only recommends the ideal route showing the source, destination, and optimal charging stations as markers but also provides a **side panel** displaying route details and turn-by-turn directions.
## Challenges we ran into
* Most of the APIs available to help develop our application were paid
* We found a **scarcity of reliable data sources** for EV charging stations
* It was difficult to understand the documentation for the Maps API
* Java Script
## Accomplishments that we're proud of
* We developed a **fully functioning app in < 24 hours**
* Understood as well as **integrated 3 APIs**
## What we learned
* Team work makes the dream work: we not only played off each others strengths but also individually tried things that are out of our comfort zone
* How Ford works (from the workshop) as well as more about EVs and charging stations
* We learnt about new APIs
* If we have a strong will to learn and develop something new, we can no matter how hard it is; We just have to keep at it
## What's next for ChargeRoute Navigator: Enhancing the EV Journey
* **Profile** | User Account: Display the user's profile picture or account details
* **Accessibility** features (e.g., alternative text)
* **Autocomplete** Suggestions: Provide autocomplete suggestions as users type, utilizing geolocation services for accuracy
* **Details on Clicking the Charging Station (on map)**: Provide additional information about each charging station, such as charging speed, availability, and user ratings
* **Save Routes**: Allow users to save frequently used routes for quick access.
* **Traffic Information (integration with GMaps API)**: Integrate real-time traffic data to optimize routes
* **User feedback** about (charging station recommendations and experience) to improve user experience | losing |
## Inspiration
Osu! players often use drawing tablets instead of a normal mouse and keyboard setup because a tablet gives more precision than a mouse can provide. These tablets also provide a better way to input to devices. Overuse of conventional keyboards and mice can lead to carpal tunnel syndrome, and can be difficult to use for those that have specific disabilities. Tablet pens can provide an alternate form of HID, and have better ergonomics reducing the risk of carpal tunnel. Digital artists usually draw on these digital input tablets, as mice do not provide the control over the input as needed by artists. However, tablets can often come at a high cost of entry, and are not easy to bring around.
## What it does
Limestone is an alternate form of tablet input, allowing you to input using a normal pen and using computer vision for the rest. That way, you can use any flat surface as your tablet
## How we built it
Limestone is built on top of the neural network library mediapipe from google. mediapipe hands provide a pretrained network that returns the 3D position of 21 joints in any hands detected in a photo. This provides a lot of useful data, which we could probably use to find the direction each finger points in and derive the endpoint of the pen in the photo. To safe myself some work, I created a second neural network that takes in the joint data from mediapipe and derive the 2D endpoint of the pen. This second network is extremely simple, since all the complex image processing has already been done. I used 2 1D convolutional layers and 4 hidden dense layers for this second network. I was only able to create about 40 entries in a dataset after some experimentation with the formatting, but I found a way to generate fairly accurate datasets with some work.
## Dataset Creation
I created a small python script that marks small dots on your screen for accurate spacing. I could the place my pen on the dot, take a photo, and enter in the coordinate of the point as the label.
## Challenges we ran into
It took a while to tune the hyperparameters of the network. Fortunately, due to the small size it was not too hard to get it into a configuration that could train and improve. However, it doesn't perform as well as I would like it to but due to time constraints I couldn't experiment further. The mean average error loss of the final model trained for 1000 epochs was around 0.0015
Unfortunately, the model was very overtrained. The dataset was o where near large enough. Adding noise probably could have helped to reduce overtraining, but I doubt by much. There just wasn't anywhere enough data, but the framework is there.
## Whats Next
If this project is to be continued, the model architecture would have to be tuned much more, and the dataset expanded to at least a few hundred entries. Adding noise would also definitely help with the variance of the dataset. There is still a lot of work to be done on limestone, but the current code at least provides some structure and a proof of concept. | # Stegano
## End-to-end steganalysis and steganography tool
#### Demo at <https://stanleyzheng.tech>
Please see the video before reading documentation, as the video is more brief: <https://youtu.be/47eLlklIG-Q>
A technicality, GitHub user RonanAlmeida ghosted our group after committing react template code, which has been removed in its entirety.
### What is steganalysis and steganography?
Steganography is the practice of concealing a message within a file, usually an image. It can be done one of 3 ways, JMiPOD, UNIWARD, or UERD. These are beyond the scope of this hackathon, but each algorithm must have its own unique bruteforce tools and methods, contributing to the massive compute required to crack it.
Steganoanalysis is the opposite of steganography; either detecting or breaking/decoding steganographs. Think of it like cryptanalysis and cryptography.
### Inspiration
We read an article about the use of steganography in Al Qaeda, notably by Osama Bin Laden[1]. The concept was interesting. The advantage of steganography over cryptography alone is that the intended secret message does not attract attention to itself as an object of scrutiny. Plainly visible encrypted messages, no matter how unbreakable they are, arouse interest.
Another curious case was its use by Russian spies, who communicated in plain sight through images uploaded to public websites hiding steganographed messages.[2]
Finally, we were utterly shocked by how difficult these steganographs were to decode - 2 images sent to the FBI claiming to hold a plan to bomb 11 airliners took a year to decode. [3] We thought to each other, "If this is such a widespread and powerful technique, why are there so few modern solutions?"
Therefore, we were inspired to do this project to deploy a model to streamline steganalysis; also to educate others on stegography and steganalysis, two underappreciated areas.
### What it does
Our app is split into 3 parts. Firstly, we provide users a way to encode their images with a steganography technique called least significant bit, or LSB. It's a quick and simple way to encode a message into an image.
This is followed by our decoder, which decodes PNG's downloaded from our LSB steganograph encoder. In this image, our decoder can be seen decoding a previoustly steganographed image:

Finally, we have a model (learn more about the model itself in the section below) which classifies an image into 4 categories: unstegographed, MiPOD, UNIWARD, or UERD. You can input an image into the encoder, then save it, and input the encoded and original images into the model, and they will be distinguished from each other. In this image, we are inferencing our model on the image we decoded earlier, and it is correctly identified as stegographed.

### How I built it (very technical machine learning)
We used data from a previous Kaggle competition, [ALASKA2 Image Steganalysis](https://www.kaggle.com/c/alaska2-image-steganalysis). This dataset presented a large problem in its massive size, of 305 000 512x512 images, or about 30gb. I first tried training on it with my local GPU alone, but at over 40 hours for an Efficientnet b3 model, it wasn't within our timeline for this hackathon. I ended up running this model on dual Tesla V100's with mixed precision, bringing the training time to about 10 hours. We then inferred on the train set and distilled a second model, an Efficientnet b1 (a smaller, faster model). This was trained on the RTX3090.
The entire training pipeline was built with PyTorch and optimized with a number of small optimizations and tricks I used in previous Kaggle competitions.
Top solutions in the Kaggle competition use techniques that marginally increase score while hugely increasing inference time, such as test time augmentation (TTA) or ensembling. In the interest of scalibility and low latency, we used neither of these. These are by no means the most optimized hyperparameters, but with only a single fold, we didn't have good enough cross validation, or enough time, to tune them more. Considering we achieved 95% of the performance of the State of the Art with a tiny fraction of the compute power needed due to our use of mixed precision and lack of TTA and ensembling, I'm very proud.
One aspect of this entire pipeline I found very interesting was the metric. The metric is a weighted area under receiver operating characteristic (AUROC, often abbreviated as AUC), biased towards the true positive rate and against the false positive rate. This way, as few unstegographed images are mislabelled as possible.
### What I learned
I learned about a ton of resources I would have never learned otherwise. I've used GCP for cloud GPU instances, but never for hosting, and was super suprised by the utility; I will definitely be using it more in the future.
I also learned about stenography and steganalysis; these were fields I knew very little about, but was very interested in, and this hackathon proved to be the perfect place to learn more and implement ideas.
### What's next for Stegano - end-to-end steganlaysis tool
We put a ton of time into the Steganalysis aspect of our project, expecting there to be a simple steganography library in python to be easy to use. We found 2 libraries, one of which had not been updated for 5 years; ultimantely we chose stegano[4], the namesake for our project. We'd love to create our own module, adding more algorithms for steganography and incorporating audio data and models.
Scaling to larger models is also something we would love to do - Efficientnet b1 offered us the best mix of performance and speed at this time, but further research into the new NFNet models or others could yeild significant performance uplifts on the modelling side, but many GPU hours are needed.
## References
1. <https://www.wired.com/2001/02/bin-laden-steganography-master/>
2. <https://www.wired.com/2010/06/alleged-spies-hid-secret-messages-on-public-websites/>
3. <https://www.giac.org/paper/gsec/3494/steganography-age-terrorism/102620>
4. <https://pypi.org/project/stegano/> | ## Inspiration
There are over 1.3 billion people in the world who live with some form of vision impairment. Often, retrieving small objects, especially off the ground, can be tedious for those without complete seeing ability. We wanted to create a solution for those people where technology can not only advise them, but physically guide their muscles in their daily life interacting with the world.
## What it does
ForeSight was meant to be as intuitive as possible in assisting people with their daily lives. This means tapping into people's sense of touch and guiding their muscles without the user having to think about it. ForeSight straps on the user's forearm and detects objects nearby. If the user begins to reach the object to grab it, ForeSight emits multidimensional vibrations in the armband which guide the muscles to move in the direction of the object to grab it without the user seeing its exact location.
## How we built it
This project involved multiple different disciplines and leveraged our entire team's past experience. We used a Logitech C615 camera and ran two different deep learning algorithms, specifically convolutional neural networks, to detect the object. One CNN was using the Tensorflow platform and served as our offline solution. Our other object detection algorithm uses AWS Sagemaker recorded significantly better results, but only works with an Internet connection. Thus, we use a two-sided approach where we used Tensorflow if no or weak connection was available and AWS Sagemaker if there was a suitable connection. The object detection and processing component can be done on any computer; specifically, a single-board computer like the NVIDIA Jetson Nano is a great choice. From there, we powered an ESP32 that drove the 14 different vibration motors that provided the haptic feedback in the armband. To supply power to the motors, we used transistor arrays to use power from an external Lithium-Ion battery. From a software side, we implemented an algorithm that accurately selected and set the right strength level of all the vibration motors. We used an approach that calculates the angular difference between the center of the object and the center of the frame as well as the distance between them to calculate the given vibration motors' strength. We also built a piece of simulation software that draws a circular histogram and graphs the usage of each vibration motor at any given time.
## Challenges we ran into
One of the major challenges we ran into was the capability of Deep Learning algorithms on the market. We had the impression that CNN could work like a “black box” and have nearly-perfect accuracy. However, this is not the case, and we experienced several glitches and inaccuracies. It then became our job to prevent these glitches from reaching the user’s experience.
Another challenge we ran into was fitting all of the hardware onto an armband without overwhelming the user. Especially on a body part as used as an arm, users prioritize movement and lack of weight on their devices. Therefore, we aimed to provide a device that is light and small.
## Accomplishments that we're proud of
We’re very proud that we were able to create a project that solves a true problem that a large population faces. In addition, we're proud that the project works and can't wait to take it further!
Specifically, we're particularly happy with the user experience of the project. The vibration motors work very well for influencing movement in the arms without involving too much thought or effort from the user.
## What we learned
We all learned how to implement a project that has mechanical, electrical, and software components and how to pack it seamlessly into one product.
From a more technical side, we gained more experience with Tensorflow and AWS. Also, working with various single board computers taught us a lot about how to use these in our projects.
## What's next for ForeSight
We’re looking forward to building our version 2 by ironing out some bugs and making the mechanical design more approachable. In addition, we’re looking at new features like facial recognition and voice control. | winning |
## Inspiration
Our inspiration for Synthify stemmed from our experiences as students and researchers at the University of Pennsylvania. We noticed significant limitations in traditional survey platforms, particularly in terms of representation, sample size, and cost. This inspired us to develop a solution that could address these challenges and revolutionize the process of data collection for human-centric research.
## What it does
Synthify is a platform that generates artificially intelligent personas to synthetically complete surveys for human data-centric research. Researchers can create accounts, design surveys, and recruit personas based on demographics such as age, race, and location. The platform utilizes custom large language models to automatically complete surveys, providing researchers with structured data outputs.
## How we built it
We built Synthify by integrating custom large language models into the platform and developing features for user authentication, survey design, and persona recruitment. We utilized technologies such as Python, JavaScript, and various machine learning libraries to create a seamless user experience and ensure the accuracy of synthetic data generation.
## Challenges we ran into
One of the main challenges we encountered was developing a reliable method for generating synthetic data that closely mimics real data. Additionally, integrating large language models and ensuring their efficient functioning within the platform presented technical hurdles that we had to overcome.
## Accomplishments that we're proud of
We are proud to have successfully built all core features of Synthify and to be piloting studies with researchers at prestigious institutions such as the Wharton School and the Annenberg School of Communication. Furthermore, securing funding and support from organizations like Microsoft for Startups and the Wharton School has been a significant accomplishment for us.
## What we learned
Through our journey with Synthify, we have learned the importance of addressing key issues in survey design and the potential of synthetic data in human-centric research. Additionally, we have gained valuable insights into user needs and preferences, driving our continuous improvement efforts.
## What's next for Synthify
Moving forward, we plan to enhance Synthify with additional features such as synthetic interviews and social media interactions. Furthermore, we aim to expand our partnerships with academic institutions and research organizations to broaden the application of synthetic data across various industries. Ultimately, we envision Synthify as a pioneering solution in data creation for research and innovation. | ## Inspiration
We have all experienced a massive shift in workplace dynamics over the past 4 months, which will likely become the new precedent for the foreseeable future. One of the largest hurdles of working from home is the lack of social interaction with coworkers, and missed opportunities to meet new people and network among those outside of your direct team. We aim to tackle this issue head on, and make connecting with new people around the office an easy and habitual occurence.
## What it does
Our project integrates directly with slack and uses advanced recommender systems hosted in Azure ML services to match similar individuals within the office. Every week, a new match is made within slack, and employees will have an easy opportunity to schedule a virtual coffee chat and get to know someone new.
## How I built it
The focus of our tech stack for this app has been to experiment with platform based services. In other words, we wanted to use platform service providers such as Autocode and Azure to maintain our infrastructure, and deployment steps, while we focused on making the actual features of each endpoint.
As for the actual implementation steps, our frontend is contained in Slack. We used the Slack api extensively in conjunction with the Autocode platform, using everything from group creation, question and answering and user retrieval.
The Autocode platform is then linked with airtable, which acted as a simple database. Autocode performed numerous operations in regards to airtable, such as fetching, and inserting entries to the table.
Finally, the brain of our hack is the logic, and ML component. All of which is based in Azure. To start with, we hosted a recommendation engine inside Azure Machine Learning Services, we trained the model, and hyperparameterized it via the Azure machine learning studio, which streamlined the process. Then, we served our trained model via Azure web services, making it available as a normal http API. We also built the backend with scalability in mind, knowing that in the future for large companies/user base, we would need to move off airtable. We also knew that for larger companies there would likely be high traffic. Hence, to ensure scalability we decided to use Azure serverless functions to act as a gateway, to direct incoming traffic, and to also allow easy access to any azure services we may add to our app in the future.
## Accomplishments that I'm proud of
The thing that we were most proud of was the fact that we reached all of our initial expectations, and beyond with regards to the product build. Additionally, our platform is entirely based on API as a service, and contains almost zero infrastructure code allowing for easy implementation and a lightweight build, while also demonstrating the power of PaaS, showcased via Autocode and Azure. At the end of the two days we were left with a deployable product, that had gone through end to end testing and was ready for production. Given the limited time for development, we were very pleased with our performance and the resulting project we built. We were especially proud when we tested the service, and found that the recommender system worked extremely well in matching compatible people together.
## What I learned
Working on this project has helped each one of us gain soft skills and technical skills. Some of us had no prior experience with technologies on our stack and working together helped to share the knowledge like the use of autocode and recommender algorithms. The guidance provided through HackThe6ix gave us all insights to the big and great world of cloud computing with two of the world's largest cloud computing service onsite at the hackathon. Apart from technical skills, leveraging the skill of team work and communication was something we all benefitted from, and something we will definitely need in the future.
## What's next for ViChat
We hope to integrate with other workplace messaging platforms in the future such as Microsoft teams to bring our service to as many offices and employees as we can! | ## FLEX [Freelancing Linking Expertise Xchange]
## Inspiration
Freelancers deserve a platform where they can fully showcase their skills, without worrying about high fees or delayed payments. Companies need fast, reliable access to talent with specific expertise to complete jobs efficiently. "FLEX" bridges the gap, enabling recruiters to instantly find top candidates through AI-powered conversations, ensuring the right fit, right away.
## What it does
Clients talk to our AI, explaining the type of candidate they need and any specific skills they're looking for. As they speak, the AI highlights important keywords and asks any more factors that they would need with the candidate. This data is then analyzed and parsed through our vast database of Freelancers or the best matching candidates. The AI then talks back to the recruiter, showing the top candidates based on the recruiter’s requirements. Once the recruiter picks the right candidate, they can create a smart contract that’s securely stored and managed on the blockchain for transparent payments and agreements.
## How we built it
We built starting with the Frontend using **Next.JS**, and deployed the entire application on **Terraform** for seamless scalability. For voice interaction, we integrated **Deepgram** to generate human-like voice and process recruiter inputs, which are then handled by **Fetch.ai**'s agents. These agents work in tandem: one agent interacts with **Flask** to analyze keywords from the recruiter's speech, another queries the **SingleStore** database, and the third handles communication with **Deepgram**.
Using SingleStore's real-time data analysis and Full-Text Search, we find the best candidates based on factors provided by the client. For secure transactions, we utilized **SUI** blockchain, creating an agreement object once the recruiter posts a job. When a freelancer is selected and both parties reach an agreement, the object gets updated, and escrowed funds are released upon task completion—all through Smart Contracts developed in **Move**. We also used Flask and **Express.js** to manage backend and routing efficiently.
## Challenges we ran into
We faced challenges integrating Fetch.ai agents for the first time, particularly with getting smooth communication between them. Learning Move for SUI and connecting smart contracts with the frontend also proved tricky. Setting up reliable Speech to Text was tough, as we struggled to control when voice input should stop. Despite these hurdles, we persevered and successfully developed this full stack application.
## Accomplishments that we're proud of
We’re proud to have built a fully finished application while learning and implementing new technologies here at CalHacks. Successfully integrating blockchain and AI into a cohesive solution was a major achievement, especially given how cutting-edge both are. It’s exciting to create something that leverages the potential of these rapidly emerging technologies.
## What we learned
We learned how to work with a range of new technologies, including SUI for blockchain transactions, Fetch.ai for agent communication, and SingleStore for real-time data analysis. We also gained experience with Deepgram for voice AI integration.
## What's next for FLEX
Next, we plan to implement DAOs for conflict resolution, allowing decentralized governance to handle disputes between freelancers and clients. We also aim to launch on the SUI mainnet and conduct thorough testing to ensure scalability and performance. | losing |
## Inspiration
**Reddit card threads and Minji's brother's military service**
We know these two things sound a little funny together, but trust us, they formulated an idea. Our group was discussing the multiple threads on Reddit related to sending sick and unfortunate children cards through the mail to cheer them up. We thought there must be an easier, more efficient way to accomplish this. Our group also began to chat about Minji's brother, who served in the Republic of Korea Armed Forces. We talked about his limited Internet access, and how he tried to efficiently manage communication with those who supported him. Light bulb! Why not make a website dedicated to combining everyone's love and support in one convenient place?
## What it does
**Videos and photos and text, oh my!**
A little bit of love can go a long way with Cheerluck. Our user interface is very simple and intuitive (and responsive), so audiences of all ages can post and enjoy the website with little to no hassle. The theme is simple, bright, and lighthearted to create a cheerful experience for the user. Past the aesthetic, the functionality of the website is creating personal pages for those in stressful or undesirable times, such as patients, soldiers, those in the Peace Corps, and so on. Once a user has created a page for someone, people are welcome to either (a) create a text post, (b) upload photos, or (c) use their webcam/phone camera to record a video greeting to post. The Disqus and Ziggeo APIs allow for moderation of content. These posts would all be appended to the user's page, where someone can give them the link to view whenever they want as a great source of love, cheer and comfort. For example, if this had existed when Jihoon was in the military, he could've used his limited internet time more efficiently by visiting this one page where his family and friends were updating him on their lives at once. This visual scrapbook can put a smile on anyone's face, young or old, on desktop or mobile!
## How we built it
• HTML, CSS, Javascript, JQuery, Node.js, Bootstrap (worked off of a theme)
• APIs: Ziggeo (videos), Disqus (commenting/photos)
• Hosted on Heroku using our domain.com name
• Also, Affinity Photo and Affinity Designer were used to create graphic design elements
## Challenges we ran into
**36 hours: Not as long as you’d think**
When this idea first came about, we got a little carried away with the functionality we wanted to add. Our main challenge was racing the clock. Debugging took up a lot of time, as well as researching documentation on how to effectively put all of these pieces together. We left some important elements out, but are overall proud of what have to present based on our prior knowledge!
## Accomplishments that we're proud of
Our group is interested in web development, but all of us have little to no knowledge of it. So, we decided to take on the challenge of tackling one this weekend! We were very excited to test out different APIs to make our site functional, and work with different frameworks that all the cool kids talk about. Given the amount of time, we're proud that we have a presentable website that can definitely be built upon in the future. This challenge was more difficult than we thought it would be, but we’re proud of what we accomplished and will use this as a big learning experience going forward.
## What we learned
• A couple of us knew very basic ideas of HTML, CSS, Bootstrap, node.js, and Heroku. We learned how they interact with each other and come together in order to publish a website.
• How to integrate APIs to help our web app be functional
• How to troubleshoot problems related to hosting the website
• How to use the nifty features of Bootstrap (columns! So wonderful!)
• How to host a website on an actual .com domain (thanks domain.com!)
## What's next for Cheerluck
We hope to expand upon this project at some point; there’s a lot of features that can be added, and this could become a full-fledged web app someday. There are definitely a lot of security worries for something that is as open as this, so we’d hope to add filters to make approving posts easier. Users could view all pages and search for causes they’d like to spread cheer to. We would also like to add the ability to make a page public or private. If we’re feeling really fancy, we’d love to make each page customizable to a certain degree, such as different colored buttons.
There will always be people in difficult situations who need support from loved ones, young and old, and this accessible, simple solution could be an appealing platform for anyone with internet access. | Inspiration
We decided to try the Best Civic Hack challenge with YHack & Yale Code4Good -- the collaboration with the New Haven/León Sister City Project. The purpose of this project is to both fundraise money, and raise awareness about the impact of greenhouse gases through technology.
What it does
The Carbon Fund Bot is a Facebook messenger chat agent based on the Yale Community Carbon Fund calculator. It ensues a friendly conversation with the user - estimating the amount of carbon emission from the last trip according to the source and destination of travel as well as the mode of transport used. It serves the purpose to raise money equivalent to the amount of carbon emission - thus donating the same to a worthy organization and raising awareness about the harm to the environment.
How we built it
We built the messenger chatbot with Node.js and Heroku. Firstly, we created a new messenger app from the facebook developers page. We used a facebook webhook for enabling communication between facebook users and the node.js application. To persist user information, we also used MongoDB (mLabs). According to the user's response, an appropriate response was generated. An API was used to calculate the distance between two endpoints (either areial or road distance) and their carbon emission units were computed using it.
Challenges we ran into
There was a steep curve for us learning Node.js and using callbacks in general. We spent a lot of time figuring out how to design the models, and how a user would interact with the system. Natural Language Processing was also a problem.
Accomplishments that we're proud of
We were able to integrate the easy to use and friendly Facebook Messenger through the API with the objective of working towards a social cause through this idea
What's next
Using Api.Ai for better NLP is on the cards. Using the logged journeys of users can be mined and can be used to gain valuable insights into carbon consumption. | ## Inspiration ✨
Seeing friends' lives being ruined through **unhealthy** attachment to video games. Struggling with regulating your emotions properly is one of the **biggest** negative effects of video games.
## What it does 🍎
YourHP is a webapp/discord bot designed to improve the mental health of gamers. By using ML and AI, when specific emotion spikes are detected, voice recordings are queued *accordingly*. When the sensor detects anger, calming reassurance is played. When happy, encouragement is given, to keep it up, etc.
The discord bot is an additional fun feature that sends messages with the same intention to improve mental health. It sends advice, motivation, and gifs when commands are sent by users.
## How we built it 🔧
Our entire web app is made using Javascript, CSS, and HTML. For our facial emotion detection, we used a javascript library built using TensorFlow API called FaceApi.js. Emotions are detected by what patterns can be found on the face such as eyebrow direction, mouth shape, and head tilt. We used their probability value to determine the emotional level and played voice lines accordingly.
The timer is a simple build that alerts users when they should take breaks from gaming and sends sound clips when the timer is up. It uses Javascript, CSS, and HTML.
## Challenges we ran into 🚧
Capturing images in JavaScript, making the discord bot, and hosting on GitHub pages, were all challenges we faced. We were constantly thinking of more ideas as we built our original project which led us to face time limitations and was not able to produce some of the more unique features to our webapp. This project was also difficult as we were fairly new to a lot of the tools we used. Before this Hackathon, we didn't know much about tensorflow, domain names, and discord bots.
## Accomplishments that we're proud of 🏆
We're proud to have finished this product to the best of our abilities. We were able to make the most out of our circumstances and adapt to our skills when obstacles were faced. Despite being sleep deprived, we still managed to persevere and almost kept up with our planned schedule.
## What we learned 🧠
We learned many priceless lessons, about new technology, teamwork, and dedication. Most importantly, we learned about failure, and redirection. Throughout the last few days, we were humbled and pushed to our limits. Many of our ideas were ambitious and unsuccessful, allowing us to be redirected into new doors and opening our minds to other possibilities that worked better.
## Future ⏭️
YourHP will continue to develop on our search for a new way to combat mental health caused by video games. Technological improvements to our systems such as speech to text can also greatly raise the efficiency of our product and towards reaching our goals! | partial |
TBD, still a work in progress
## Inspiration
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Dodge The React | ## Inspiration
Queriamos hacer una pagina interactiva la cual llamara la atencion de las personas jovenes de esta manera logrando mantenerlos durante mucho tiempo siendo leales a la familia de marcas Qualtias
## What it does
Lo que hace es
## How we built it
## Challenges we ran into
Al no tener un experiencia previa con el diseño de paginas web encontramos problemas al momento de querer imaginar el como se veria nuestra pagina.
## Accomplishments that we're proud of
Nos sentimos orgullosos de haber logrado un diseño con el cual nos senitmos orgullosos y logramos implementar las ideas que teniamos en mente.
## What we learned
Aprendimos mucho sobre diseño de paginas y de como implmentar diferentes tipos de infraestructuras y de como conectarlas.
## What's next for QualtiaPlay
Seguiremos tratando de mejorar nuestra idea para futuros proyectos y de mayor eficiencia | ## Inspiration
Growing up, our team members struggled with gaming addictions and how games affected our mind. Solutions that could help detect, document, and provide solutions for how games affected our mental health were poorly designed and few and far between. We Created this app as an aide for our own struggles, and with the hope that it could help others who share the same struggles as we did. Building on top of that though, we also wanted to increase our performance in competitive games and taste more of that sweet, sweet victory, Managing your temper and mood is a large contributor to competitive game performance.
## What it does
Shoebill is a web application that tracks, detects, documents and provides solutions to gaming addiction. It's analytics are able to track your mental stability, mood and emotions while you game. It can help you discover trends in your temperament and learn what kind of gamer you are. Using Shoebill, we can learn what tilts you the most — and optimize and grow as a competitive gamer.
## How is it built
React.js is the main framework on which we built our web application, supported by a Flask Python backend. We integrated Hume’s API to detect emotions related to game addiction and rage behaviour. We also tried integrating the Zepp watch to get user's health data for analysis.
## Challenges we ran into
Navigating the React.js framework was a challenge for us as most of our team was unfamiliar with the framework. Integrating Flask with React was also difficult, as these two frameworks are implemented fairly differently when together versus when separately implemented.
More, initially, we experimented with pure HTML and CSS for the frontend, but then realized that React JS files would make the web app more dynamic and easier to integrate, so we had to switch halfway. We also had to pivot to Vite, since we ran into root bugs with the deprecated Create React App framework we initially used.
Also, navigating through the APIs were more difficult than usual due to unclear documentation. Notably, since there are so many hackers in the same venue, the provided wifi speed was exceptionally slow which decelerated our progress.
## Accomplishments that we're proud of
Despite the challenges, our APIs have seamlessly integrated and in the last few hours we were able to piece together the backend and frontend - that were once only working separately - and make it a functioning web app. Our logo is also sleek and minimalistic, reflecting the professional nature of Shoebill. Equally important, we've formed stronger bonds with our teammates through collaboration and support, reaching for success together.
## What we learned
We were able to learn how React.js and Flask worked together, and understand the fundamental functionalities of Git. We also learned the importance of optimizing our ideation phase.
We learned that frequent contributions to GitHub is vital, in that it is a fundamental aspect of project management and version control. Furthermore, we understand the significance of collaboration among team members, especially constant and effective communication. Lastly, we gained a deeper understanding of API integration.
## What's next for Shoebill
Moving forward, we wish to integrate 3D graph visualizations with dynamic elements. We want to evolve from the hackathon project into a fully-fledged product, involving: the incorporation of user profiles, an integrated Discord bot, and extracting more health data from the Zepp watch (such as blood oxygen levels). | partial |
## Inspiration
We looked at some of the sponsored prizes for some ideas as to what our hackathon project could be about, and we noticed that TELUS would be sponsoring a prize for a mental health related project. We thought that this would be an excellent idea, especially so due to the current situation. Because of the global pandemic, people have been more socially isolated than before. Many students in particular have been struggling with online schooling, which further takes a toll on their mental health. In general, mental health is a bigger issue than ever before, which is why we thought that creating a project about it would be appropriate. With all of that in mind, we decided that creating some sort of application to promote positivity hopefully create some inspiration and order in everyone's lives during these uncertain times would be our overall goal.
## What it does
Ponder is an app which allows the user to write journal entries about whatever they're grateful for. This prompted self reflection is meant to have the user try to stay optimistic and see the bright side of whatever situation they may be in. It also provides inspiring quotes and stories for the user to read, which can hopefully motivate the user in some way to self-improve. Lastly, there is also a to-do list function, which is meant to help keep the user on task and focused, and allow them to finish whatever work they may need to do before they fall behind and create more stress for themselves.
## How we built it
We built the frontend using React Native, using Expo CLI. Most of the project was frontend related, so most of it was made using React Native. We had a bit of backend in the project as well, which was done using SQLite.
## Challenges we ran into
One major challenge we ran into was the fact that most of us had no experience using React Native, and most of our project ended up using React Native. Because of this, we had to learn on the fly and figure things out, which slowed down the development process. Another challenge was time zone differences, which caused some time conflicts and inconveniences.
## Accomplishments that we're proud of
Overall, we are proud that we were able to develop Ponder to the extent that we did, especially considering most of us had no experience using React Native. We are proud of our app's front end design, and the project idea is something that we're proud of as well, since we were able to think of features that we hadn't ever seen in any other app which we could try and implement.
## What we learned
Many of us learned how to use React Native this weekend, and for most of us, it was our first hackathon. We learned what it's like being under time pressure and trying to collaborate and work towards a goal, and we learned about the challenges but also how rewarding such an experience could be.
## What's next for Ponder
Next for Ponder, with more time, we could add even more features, such as things for tracking mood. We could also improve some functionality of some of the existing features, given a bit more time. | # TranslateMe: Breaking Language Barriers, One Text at a Time
## Inspiration
Living in a diverse and interconnected world, our team of three has always been fascinated by the power of technology to bring people together, regardless of language barriers. As students who come from an immigrant background we understand the struggles of not being able to communicate with others who do not speak the same language. We noticed that language often stood in the way of these intercultural connections, hindering meaningful interactions to create a space where language isembraced. This inspired us to create TranslateMe, an app that makes it effortless for people to communicate across languages seamlessly.
## What We Learned
Building TranslateMe was a remarkable journey that taught us valuable lessons as a team. Here are some key takeaways:
**Effective Collaboration**: Working as a team, we learned the importance of effective collaboration. Each of us had unique skills and expertise, and we leveraged these strengths to build a well-rounded application.
**API Integration**: We gained a deep understanding of how to integrate third-party APIs into our project. In this case, we utilized Twilio's communications API for handling text messages and Google Translate API for language translation.
**Node.js Mastery**: We honed our Node.js skills throughout this project. Working with asynchronous operations and callbacks to handle communication between APIs and user interactions was challenging but rewarding.
**User-Centric Design**: We learned the importance of user-centric design. Making TranslateMe user-friendly and intuitive was crucial to ensure that anyone, regardless of their technical expertise, could benefit from it.
**Handling Errors and Edge Cases**: Dealing with potential errors and unexpected edge cases was a significant learning experience. We implemented error handling strategies to provide a smooth user experience even when things didn't go as planned.
## How We Built TranslateMe
# Technologies Used
**Twilio API**: We used Twilio's communication API to send and receive text messages. This allowed users to send messages in their preferred language.
**Google Translate API**: To perform the actual translation, we integrated the Google Translate API, which supports a wide range of languages.
**Node.js**: The backend of TranslateMe was built using Node.js, providing a robust and scalable foundation for the application.
## The Development Process
**Planning and Design**: We started by outlining the app's architecture, user flows, and wireframes. This helped us clarify the project's scope and user experience.
**Setting Up Twilio**: We set up a Twilio account and configured it to handle incoming and outgoing text messages. Twilio's documentation was incredibly helpful in this process.
**Implementing Translation Logic**: Using the Google Translate API, we developed the core functionality of translating incoming messages into the user's chosen language.
**Building the Frontend**: With the backend in place, we created a user-friendly frontend that allowed users to choose languages and see translated messages.
**Testing and Debugging**: Rigorous testing was essential to ensure that TranslateMe worked seamlessly. We focused on both functional and user experience testing.
**Deployment**: We deployed the application to a twilio server to make it as accessible as possible.
## Challenges Faced
While creating TranslateMe, we encountered several challenges:
**Limited by Trial Version**: The Twilio API didn't allow unauthorized phone-numbers to text back to a twilio in the trial version so we had to jump through a few hoops to get that working.
**Language Detection**: Some users might not specify their preferred language, so we needed to implement language detection to provide a seamless experience.
**NPM** version conflicts: When using the different APIs we ran into some npm versioning issues that took longer than we would have liked to complete.
## Conclusion
TranslateMe has been a fulfilling project that allowed our team to combine our passion for technology with a desire to break down language barriers. Two out of three of us are international students so we are painfully aware of the barriers presented by the lack of knowing a language. We're excited to see how TranslateMe helps people connect and communicate across languages, fostering greater understanding and unity in our diverse world. | ## Inspiration
Our inspiration comes from many of our own experiences with dealing with mental health and self-care, as well as from those around us. We know what it's like to lose track of self-care, especially in our current environment, and wanted to create a digital companion that could help us in our journey of understanding our thoughts and feelings. We were inspired to create an easily accessible space where users could feel safe in confiding in their mood and check-in to see how they're feeling, but also receive encouraging messages throughout the day.
## What it does
Carepanion allows users an easily accessible space to check-in on their own wellbeing and gently brings awareness to self-care activities using encouraging push notifications. With Carepanion, users are able to check-in with their personal companion and log their wellbeing and self-care for the day, such as their mood, water and medication consumption, amount of exercise and amount of sleep. Users are also able to view their activity for each day and visualize the different states of their wellbeing during different periods of time. Because it is especially easy for people to neglect their own basic needs when going through a difficult time, Carepanion sends periodic notifications to the user with messages of encouragement and assurance as well as gentle reminders for the user to take care of themselves and to check-in.
## How we built it
We built our project through the collective use of Figma, React Native, Expo and Git. We first used Figma to prototype and wireframe our application. We then developed our project in Javascript using React Native and the Expo platform. For version control we used Git and Github.
## Challenges we ran into
Some challenges we ran into included transferring our React knowledge into React Native knowledge, as well as handling package managers with Node.js. With most of our team having working knowledge of React.js but being completely new to React Native, we found that while some of the features of React were easily interchangeable with React Native, some features were not, and we had a tricky time figuring out which ones did and didn't. One example of this is passing props; we spent a lot of time researching ways to pass props in React Native. We also had difficult time in resolving the package files in our application using Node.js, as our team members all used different versions of Node. This meant that some packages were not compatible with certain versions of Node, and some members had difficulty installing specific packages in the application. Luckily, we figured out that if we all upgraded our versions, we were able to successfully install everything. Ultimately, we were able to overcome our challenges and learn a lot from the experience.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to produce an application from ground up, from the design process to a working prototype. We are excited that we got to learn a new style of development, as most of us were new to mobile development. We are also proud that we were able to pick up a new framework, React Native & Expo, and create an application from it, despite not having previous experience.
## What we learned
Most of our team was new to React Native, mobile development, as well as UI/UX design. We wanted to challenge ourselves by creating a functioning mobile app from beginning to end, starting with the UI/UX design and finishing with a full-fledged application. During this process, we learned a lot about the design and development process, as well as our capabilities in creating an application within a short time frame.
We began by learning how to use Figma to develop design prototypes that would later help us in determining the overall look and feel of our app, as well as the different screens the user would experience and the components that they would have to interact with. We learned about UX, and how to design a flow that would give the user the smoothest experience. Then, we learned how basics of React Native, and integrated our knowledge of React into the learning process. We were able to pick it up quickly, and use the framework in conjunction with Expo (a platform for creating mobile apps) to create a working prototype of our idea.
## What's next for Carepanion
While we were nearing the end of work on this project during the allotted hackathon time, we thought of several ways we could expand and add to Carepanion that we did not have enough time to get to. In the future, we plan on continuing to develop the UI and functionality, ideas include customizable check-in and calendar options, expanding the bank of messages and notifications, personalizing the messages further, and allowing for customization of the colours of the app for a more visually pleasing and calming experience for users. | losing |
## Inspiration
A couple weeks ago, a friend was hospitalized for taking Advil–she accidentally took 27 pills, which is nearly 5 times the maximum daily amount. Apparently, when asked why, she responded that thats just what she always had done and how her parents have told her to take Advil. The maximum Advil you are supposed to take is 6 per day, before it becomes a hazard to your stomach.
#### PillAR is your personal augmented reality pill/medicine tracker.
It can be difficult to remember when to take your medications, especially when there are countless different restrictions for each different medicine. For people that depend on their medication to live normally, remembering and knowing when it is okay to take their medication is a difficult challenge. Many drugs have very specific restrictions (eg. no more than one pill every 8 hours, 3 max per day, take with food or water), which can be hard to keep track of. PillAR helps you keep track of when you take your medicine and how much you take to keep you safe by not over or under dosing.
We also saw a need for a medicine tracker due to the aging population and the number of people who have many different medications that they need to take. According to health studies in the U.S., 23.1% of people take three or more medications in a 30 day period and 11.9% take 5 or more. That is over 75 million U.S. citizens that could use PillAR to keep track of their numerous medicines.
## How we built it
We created an iOS app in Swift using ARKit. We collect data on the pill bottles from the iphone camera and passed it to the Google Vision API. From there we receive the name of drug, which our app then forwards to a Python web scraping backend that we built. This web scraper collects usage and administration information for the medications we examine, since this information is not available in any accessible api or queryable database. We then use this information in the app to keep track of pill usage and power the core functionality of the app.
## Accomplishments that we're proud of
This is our first time creating an app using Apple's ARKit. We also did a lot of research to find a suitable website to scrape medication dosage information from and then had to process that information to make it easier to understand.
## What's next for PillAR
In the future, we hope to be able to get more accurate medication information for each specific bottle (such as pill size). We would like to improve the bottle recognition capabilities, by maybe writing our own classifiers or training a data set. We would also like to add features like notifications to remind you of good times to take pills to keep you even healthier. | ## Inspiration
How many times have you forgotten to take your medication and damned yourself for it? It has happened to us all, with different consequences. Indeed, missing out on a single pill can, for some of us, throw an entire treatment process out the window. Being able to keep track of our prescriptions is key in healthcare, this is why we decided to create PillsOnTime.
## What it does
PillsOnTime allows you to load your prescription information, including the daily dosage and refills, as well as reminders in your local phone calendar, simply by taking a quick photo or uploading one from the library. The app takes care of the rest!
## How we built it
We built the app with react native and expo using firebase for authentication. We used the built in expo module to access the devices camera and store the image locally. We then used the Google Cloud Vision API to extract the text from the photo. We used this data to then create a (semi-accurate) algorithm which can identify key information about the prescription/medication to be added to your calendar. Finally the event was added to the phones calendar with the built in expo module.
## Challenges we ran into
As our team has a diverse array of experiences, the same can be said about the challenges that each encountered. Some had to get accustomed to new platforms in order to design an application in less than a day, while figuring out how to build an algorithm that will efficiently analyze data from prescription labels. None of us had worked with machine learning before and it took a while for us to process the incredibly large amount of data that the API gives back to you. Also working with the permissions of writing to someones calendar was also time consuming.
## Accomplishments that we're proud of
Just going into this challenge, we faced a lot of problems that we managed to overcome, whether it was getting used to unfamiliar platforms or figuring out the design of our app.
We ended up with a result rather satisfying given the time constraints & we learned quite a lot.
## What we learned
None of us had worked with ML before but we all realized that it isn't as hard as we thought!! We will definitely be exploring more similar API's that google has to offer.
## What's next for PillsOnTime
We would like to refine the algorithm to create calendar events with more accuracy | ## Inspiration
When you are prescribed medication by a Doctor, it is crucial that you complete the dosage cycle in order to ensure that you recover fully and quickly. Unfortunately forgetting to take your medication is something that we have all done. Failing to run the full course of medicine often results in a delayed recovery and leads to more suffering through the painful and annoying symptoms of illness. This has inspired us to create Re-Pill. With Re-Pill, you can automatically generate scheduling and reminders to take you medicine by simply uploading a photo of your prescription.
## What it does
A user uploads an image of their prescription which is then processed by image to text algorithms that extract the details of the medication. Data such as the name of the medication, its dosage, and total tablets is stored and presented to the user. The application synchronizes with google calendar and automatically sets reminders for taking pills into the user's schedule based on the dosage instructions on the prescription. The user can view their medication details at any time by logging into Re-Pill.
## How we built it
We built the application using the Python web framework Flask. Simple endpoints were created for login, registration, and viewing of the user's medication. User data is stored in Google Cloud's Firestore. Images are uploaded and sent to a processing endpoint through a HTTP Request which delivers the medication information. Reminders are set using the Google Calendar API.
## Challenges we ran into
We initially struggled to figure out the right tech-stack to use for building the app. We struggled with Android development before settling for a web-app. One big challenge we faced was to merge all the different part of our application into one smoothly running product. Another challenge was finding a method to inform/notify the user of his/her medication time through a web-based application.
## Accomplishments that we're proud of
There are a couple of things that we are proud of. One of them is how well our team was able to communicate with one another. All team members knew what the other members were working on and the work was divided in such a manner that all teammates worked on the projects using his/her strengths. One important accomplishment is that we were able to overcome a huge time constraint and come up with a prototype of an idea that has potential to change people's lives.
## What we learned
We learned how to set up and leverage Google API's, manage non-relational databases and process image to text using various python libraries.
## What's next for Re-Pill
The next steps for Re-Pill would be to move to a mobile environment and explore useful features that we can implement. Building a mobile application would make it easier for the user to stay connected with the schedules and upload prescription images at a click of a button using the built in camera. Some features we hope to explore are creating automated activities, such as routine appointment bookings with the family doctor and monitoring dietary considerations with regards to stronger medications that might conflict with a patients diet. | winning |
## Inspiration
The beginnings of this idea came from long road trips. When driving having good
visibility is very important. When driving into the sun, the sun visor never seemed
to be able to actually cover the sun. When driving at night, the headlights of
oncoming cars made for a few moments of dangerous low visibility. Why isn't there
a better solution for these things? We decided to see if we could make one, and
discovered a wide range of applications for this technology, going far beyond
simply blocking light.
## What it does
EyeHUD is able to track objects on opposite sides of a transparent LCD screen in order to
render graphics on the screen relative to all of the objects it is tracking. i.e. Depending on where the observer and the object of interest are located on the each side of the screen, the location of the graphical renderings are adjusted
Our basic demonstration is based on our original goal of blocking light. When sitting
in front of the screen, eyeHUD uses facial recognition to track the position of
the users eyes. It also tracks the location of a bright flash light on the opposite side
of the screen with a second camera. It then calculates the exact position to render a dot on the screen
that completely blocks the flash light from the view of the user no matter where
the user moves their head, or where the flash light moves. By tracking both objects
in 3D space it can calculate the line that connects the two objects and then where
that line intersects the monitor to find the exact position it needs to render graphics
for the particular application.
## How we built it
We found an LCD monitor that had a broken backlight. Removing the case and the backlight
from the monitor left us with just the glass and liquid crystal part of the display.
Although this part of the monitor is not completely transparent, a bright light would
shine through it easily. Unfortunately we couldn't source a fully transparent display
but we were able to use what we had lying around. The camera on a laptop and a small webcam
gave us the ability to track objects on both sides of the screen.
On the software side we used OpenCV's haar cascade classifier in python to perform facial recognition.
Once the facial recognition is done we must locate the users eyes in their face in pixel space for
the user camera, and locate the light with the other camera in its own pixel space. We then wrote
an algorithm that was able to translate the two separate pixel spaces into real 3D space, calculate
the line that connects the object and the user, finds the intersection of this line and the monitor,
then finally translates this position into pixel space on the monitor in order to render a dot.
## Challenges we ran Into
First we needed to determine a set of equations that would allow us to translate between the three separate
pixel spaces and real space. It was important not only to be able to calculate this transformation, but
we also needed to be able to calibrate the position and the angular resolution of the cameras. This meant
that when we found our equations we needed to identify the linearly independent parts of the equation to figure
out which parameters actually needed to be calibrated.
Coming up with a calibration procedure was a bit of a challenge. There were a number of calibration parameters
that we needed to constrain by making some measurements. We eventually solved this by having the monitor render
a dot on the screen in a random position. Then the user would move their head until the dot completely blocked the
light on the far side of the monitor. We then had the computer record the positions in pixel space of all three objects.
This then told the computer that these three pixel space points correspond to a straight line in real space.
This provided one data point. We then repeated this process several times (enough to constrain all of the degrees of freedom
in the system). After we had a number of data points we performed a chi-squared fit to the line defined by these points
in the multidimensional calibration space. The parameters of the best fit line determined our calibration parameters to use
in the transformation algorithm.
This calibration procedure took us a while to perfect but we were very happy with the speed and accuracy we were able to calibrate at.
Another difficulty was getting accurate tracking on the bright light on the far side of the monitor. The web cam we were
using was cheap and we had almost no access to the settings like aperture and exposure which made it so the light would
easily saturate the CCD in the camera. Because the light was saturating and the camera was trying to adjust its own exposure,
other lights in the room were also saturating the CCD and so even bright spots on the white walls were being tracked as well.
We eventually solved this problem by reusing the radial diffuser that was on the backlight of the monitor we took apart.
This made any bright spots on the walls diffused well under the threshold for tracking. Even after this we had a bit of trouble
locating the exact center of the light as we were still getting a bit of glare from the light on the camera lens. We were
able to solve this problem by applying a gaussian convolution to the raw video before trying any tracking. This allowed us
to accurately locate the center of the light.
## Accomplishments that we are proud of
The fact that our tracking display worked at all we felt was a huge accomplishments. Every stage of this project felt like a
huge victory. We started with a broken LCD monitor and two white boards full of math. Reaching a well working final product
was extremely exciting for all of us.
## What we learned
None of our group had any experience with facial recognition or the OpenCV library. This was a great opportunity to dig into
a part of machine learning that we had not used before and build something fun with it.
## What's next for eyeHUD
Expanding the scope of applicability.
* Infrared detection for pedestrians and wildlife in night time conditions
* Displaying information on objects of interest
* Police information via license plate recognition
Transition to a fully transparent display and more sophisticated cameras.
General optimization of software. | ## Inspiration
I've always been fascinated by the complexities of UX design, and this project was an opportunity to explore an interesting mode of interaction. I drew inspiration from the futuristic UIs that movies have to offer, such as Minority Report's gesture-based OS or Iron Man's heads-up display, Jarvis.
## What it does
Each window in your desktop is rendered on a separate piece of paper, creating a tangible version of your everyday computer. It is fully featured desktop, with specific shortcuts for window management.
## How I built it
The hardware is combination of a projector and a webcam. The camera tracks the position of the sheets of paper, on which the projector renders the corresponding window. An OpenCV backend does the heavy lifting, calculating the appropriate translation and warping to apply.
## Challenges I ran into
The projector was initially difficulty to setup, since it has a fairly long focusing distance. Also, the engine that tracks the pieces of paper was incredibly unreliable under certain lighting conditions, which made it difficult to calibrate the device.
## Accomplishments that I'm proud of
I'm glad to have been able to produce a functional product, that could possibly be developed into a commercial one. Furthermore, I believe I've managed to put an innovative spin to one of the oldest concepts in the history of computers: the desktop.
## What I learned
I learned lots about computer vision, and especially on how to do on-the-fly image manipulation. | ## Inspiration
The original idea was to create an alarm clock that could aim at the ~~victim's~~ sleeping person's face and shoot water instead of playing a sound to wake-up.
Obviously, nobody carries around peristaltic pumps at hackathons so the water squirting part had to be removed, but the idea of getting a plateform that could aim at a person't face remained.
## What it does
It simply tries to always keep a webcam pointed directly at the largest face in it's field of view.
## How I built it
The brain is a Raspberry Pi model 3 with a webcam attachment that streams raw pictures to Microsoft Cognitive Services. The cloud API then identifies the faces (if any) in the picture and gives a coordinate in pixel of the position of the face.
These coordinates are then converted to an offset (in pixel) from the current position.
This offset (in X and Y but only X is used) is then transmitted to the Arduino that's in control of the stepper motor. This is done by encoding the data as a JSON string, sending it over the serial connection between the Pi and the Arduino and parsing the string on the Arduino. A translation is done to get an actual number of steps. The translation isn't necessarily precise, as the algorithm will naturally converge towards the center of the face.
## Challenges I ran into
Building the enclosure was a lot harder than what I believed initially. It was impossible to build it with two axis of freedom. A compromise was reached by having only the assembly rotate on the X axis (it can pan but not tilt.)
Acrylic panels were used. This was sub-optimal as we had no proper equipment to drill into acrylic to secure screws correctly. Furthermore, the shape of the stepper-motors made it very hard to secure anything to their rotating axis. This is the reason the tilt feature had to be abandoned.
Proper tooling *and expertise* could have fixed these issues.
## Accomplishments that I'm proud of
Stepping out of my confort zone by making a project that depends on areas of expertise I am not familiar with (physical fabrication).
## What I learned
It's easier to write software than to build *real* stuff. There is no "fast iterations" in hardware.
It was also my first time using epoxy resin as well as laser cuted acrylic. These two materials are interesting to work with and are a good alternative to using thin wood as I was used to before. It's incredibly faster to glue than wood and the laser cutting of the acrylic allows for a precision that's hard to match with wood.
It was a lot easier than what I imagined working with the electronics, as driver and library support was already existing and the pieces of equipment as well as the libraries where well documented.
## What's next for FaceTracker
Re-do the enclosure with appropriate materials and proper engineering.
Switch to OpenCV for image recognition as using a cloud service incurs too much latency.
Refine the algorithm to take advantage of the reduced latency.
Add tilt capabilities to the project. | winning |
## Inspiration Behind DejaVu 🌍
The inspiration behind DejaVu is deeply rooted in our fascination with the human experience and the power of memories. We've all had those moments where we felt a memory on the tip of our tongues but couldn't quite grasp it, like a fleeting dream slipping through our fingers. These fragments of the past hold immense value, as they connect us to our personal history, our emotions, and the people who have been a part of our journey. 🌟✨
We embarked on the journey to create DejaVu with the vision of bridging the gap between the past and the present, between what's remembered and what's forgotten. Our goal was to harness the magic of technology and innovation to make these elusive memories accessible once more. We wanted to give people the power to rediscover the treasures hidden within their own minds, to relive those special moments as if they were happening all over again, and to cherish the emotions they evoke. 🚀🔮
The spark that ignited DejaVu came from a profound understanding that our memories are not just records of the past; they are the essence of our identity. We wanted to empower individuals to be the architects of their own narratives, allowing them to revisit their life's most meaningful chapters. With DejaVu, we set out to create a tool that could turn the faint whispers of forgotten memories into vibrant, tangible experiences, filling our lives with the warmth of nostalgia and the joy of reconnection. 🧠🔑
## How We Built DejaVu 🛠️
It all starts with the hardware component. There is a video/audio-recording Python script running on a laptop, to which a webcam is connected. This webcam is connected to the user's hat, which they wear on their head and it records video. Once the video recording is stopped, the video is uploaded to a storage bucket on Google Cloud. 🎥☁️
The video is retrieved by the backend, which can then be processed. Vector embeddings are generated for both the audio and the video so that semantic search features can be integrated into our Python-based software. After that, the resulting vectors can be leveraged to deliver content to the front-end through a Flask microservice. Through the Cohere API, we were able to vectorize audio and contextual descriptions, as well as summarize all results on the client side. 🖥️🚀
Our front-end, which was created using Next.js and hosted on Vercel, features a landing page and a search page. On the search page, a user can search a query for a memory which they are attempting to recall. After that, the query text is sent to the backend through a request, and the necessary information relating to the location of this memory is sent back to the frontend. After this occurs, the video where this memory occurs is displayed on the screen and allows the user to get rid of the ominous feeling of déjà vu. 🔎🌟
## Challenges We Overcame at DejaVu 🚧
🧩 Overcoming Hardware Difficulties 🛠️
One of the significant challenges we encountered during the creation of DejaVu was finding the right hardware to support our project. Initially, we explored using AdHawk glasses, which unfortunately removed existing functionality critical to our project's success. Additionally, we found that the Raspberry Pi, while versatile, didn't possess the computing power required for our memory time machine. To overcome these hardware limitations, we had to pivot and develop Python scripts for our laptops, ensuring we had the necessary processing capacity to bring DejaVu to life. This adaptation proved to be a critical step in ensuring the project's success. 🚫💻
📱 Navigating the Complex World of Vector Embedding 🌐
Another formidable challenge we faced was in the realm of vector embedding. This intricate process, essential for capturing and understanding the essence of memories, presented difficulties throughout our development journey. We had to work diligently to fine-tune and optimize the vector embedding techniques to ensure the highest quality results. Overcoming this challenge required a deep understanding of the underlying technology and relentless dedication to refining the process. Ultimately, our commitment to tackling this complexity paid off, as it is a crucial component of DejaVu's effectiveness. 🔍📈
🌐 Connecting App Components and Cloud Hosting with Google Cloud 🔗
Integrating the various components of the DejaVu app and ensuring seamless cloud hosting were additional challenges we had to surmount. This involved intricate work to connect user interfaces, databases, and the cloud infrastructure with Google Cloud services. The complexity of this task required meticulous planning and execution to create a cohesive and robust platform. We overcame these challenges by leveraging the expertise of our team and dedicating considerable effort to ensure that all aspects of the app worked harmoniously, providing users with a smooth and reliable experience. 📱☁️
## Accomplishments We Celebrate at DejaVu 🏆
🚀 Navigating the Hardware-Software Connection Challenge 🔌
One of the most significant hurdles we faced during the creation of DejaVu was connecting hardware and software seamlessly. The integration of our memory time machine with the physical devices and sensors posed complex challenges. It required a delicate balance of engineering and software development expertise to ensure that the hardware effectively communicated with our software platform. Overcoming this challenge was essential to make DejaVu a user-friendly and reliable tool for capturing and reliving memories, and our team's dedication paid off in achieving this intricate connection. 💻🤝
🕵️♂️ Mastering Semantic Search Complexity 🧠
Another formidable challenge we encountered was the implementation of semantic search. Enabling DejaVu to understand the context and meaning behind users' search queries proved to be a significant undertaking. Achieving this required advanced natural language processing and machine learning techniques. We had to develop intricate algorithms to decipher the nuances of human language, ensuring that DejaVu could provide relevant results even for complex or abstract queries. This challenge was a testament to our commitment to delivering a cutting-edge memory time machine that truly understands and serves its users. 📚🔍
🔗 Cloud Hosting and Cross-Component Integration 🌐
Integrating the various components of the DejaVu app and hosting data on Google Cloud presented a multifaceted challenge. Creating a seamless connection between user interfaces, databases, and cloud infrastructure demanded meticulous planning and execution. Ensuring that the app operated smoothly and efficiently, even as it scaled, required careful design and architecture. We dedicated considerable effort to overcome this challenge, leveraging the robust capabilities of Google Cloud to provide users with a reliable and responsive platform for preserving and reliving their cherished memories. 📱☁️
## Lessons Learned from DejaVu's Journey 📚
💻 Innate Hardware Limitations 🚀
One of the most significant lessons we've gleaned from creating DejaVu is the importance of understanding hardware capabilities. We initially explored using Arduinos and Raspberry Pi's for certain aspects of our project, but we soon realized their innate limitations. These compact and versatile devices have their place in many projects, but for a memory-intensive and complex application like DejaVu, they proved to be improbable choices. 🤖🔌
📝 Planning Before Executing 🤯
A crucial takeaway from our journey of creating DejaVu was the significance of meticulous planning for user flow before diving into coding. There were instances where we rushed into development without a comprehensive understanding of how users would interact with our platform. This led to poor systems design, resulting in unnecessary complications and setbacks. We learned that a well-thought-out user flow and system architecture are fundamental to the success of any project, helping to streamline development and enhance user experience. 🚀🌟
🤖 Less Technology is More Progress💡
Another valuable lesson revolved around the concept that complex systems can often be simplified by reducing the number of technologies in use. At one point, we experimented with a CockroachDB serverless database, hoping to achieve certain functionalities. However, we soon realized that this introduced unnecessary complexity and redundancy into our architecture. Simplifying our technology stack and focusing on essential components allowed us to improve efficiency and maintain a more straightforward and robust system. 🗃️🧩
## The Future of DejaVu: Where Innovation Thrives! 💫
🧩 Facial Recognition and Video Sorting 📸
With our eyes set on the future, DejaVu is poised to bring even more remarkable features to life. This feature will play a pivotal role in enhancing the user experience. Our ongoing development efforts will allow DejaVu to recognize individuals in your video archives, making it easier than ever to locate and relive moments featuring specific people. This breakthrough in technology will enable users to effortlessly organize their memories, unlocking a new level of convenience and personalization. 🤳📽️
🎁 Sharing Memories In-App 📲
Imagine being able to send a cherished memory video from one user to another, all within the DejaVu platform. Whether it's a heartfelt message, a funny moment, or a shared experience, this feature will foster deeper connections between users, making it easy to celebrate and relive memories together, regardless of physical distance. DejaVu aims to be more than just a memory tool; it's a platform for creating and sharing meaningful experiences. 💌👥
💻 Integrating BCI (Brain-Computer Interface) Technology 🧠
This exciting frontier will open up possibilities for users to interact with their memories in entirely new ways. Imagine being able to navigate and interact with your memory archives using only your thoughts. This integration could revolutionize the way we access and relive memories, making it a truly immersive and personal experience. The future of DejaVu is all about pushing boundaries and providing users with innovative tools to make their memories more accessible and meaningful. 🌐🤯 | ## Inspiration
It's easy to zone off in online meetings/lectures, and it's difficult to rewind without losing focus at the moment. It could also be disrespectful to others if you expose the fact that you weren't paying attention. Wouldn't it be nice if we can just quickly skim through a list of keywords to immediately see what happened?
## What it does
Rewind is an intelligent, collaborative and interactive web canvas with built in voice chat that maintains a list of live-updated keywords that summarize the voice chat history. You can see timestamps of the keywords and click on them to reveal the actual transcribed text.
## How we built it
Communications: WebRTC, WebSockets, HTTPS
We used WebRTC, a peer-to-peer protocol to connect the users though a voice channel, and we used websockets to update the web pages dynamically, so the users would get instant feedback for others actions. Additionally, a web server is used to maintain stateful information.
For summarization and live transcript generation, we used Google Cloud APIs, including natural language processing as well as voice recognition.
Audio transcription and summary: Google Cloud Speech (live transcription) and natural language APIs (for summarization)
## Challenges we ran into
There are many challenges that we ran into when we tried to bring this project to reality. For the backend development, one of the most challenging problems was getting WebRTC to work on both the backend and the frontend. We spent more than 18 hours on it to come to a working prototype. In addition, the frontend development was also full of challenges. The design and implementation of the canvas involved many trial and errors and the history rewinding page was also time-consuming. Overall, most components of the project took the combined effort of everyone on the team and we have learned a lot from this experience.
## Accomplishments that we're proud of
Despite all the challenges we ran into, we were able to have a working product with many different features. Although the final product is by no means perfect, we had fun working on it utilizing every bit of intelligence we had. We were proud to have learned many new tools and get through all the bugs!
## What we learned
For the backend, the main thing we learned was how to use WebRTC, which includes client negotiations and management. We also learned how to use Google Cloud Platform in a Python backend and integrate it with the websockets. As for the frontend, we learned to use various javascript elements to help develop interactive client webapp. We also learned event delegation in javascript to help with an essential component of the history page of the frontend.
## What's next for Rewind
We imagined a mini dashboard that also shows other live-updated information, such as the sentiment, summary of the entire meeting, as well as the ability to examine information on a particular user. | ## Inspiration
This year's theme of Nostalgia reminded us of our childhoods, reading stories and being so immersed in them. As a result, we created Mememto as a way for us to collectively look back on the past from the retelling of it through thrilling and exciting stories.
## What it does
We created a web application that asks users to input an image, date, and brief description of the memory associated with the provided image. Doing so, users are then given a generated story full of emotions, allowing them to relive the past in a unique and comforting way. Users are also able to connect with others on the platform and even create groups with each other.
## How we built it
Thanks to Taipy and Cohere, we were able to bring this application to life. Taipy supplied both the necessary front-end and back-end components. Additionally, Cohere enabled story generation through natural language processing (NLP) via their POST chat endpoint (<https://api.cohere.ai/v1/chat>).
## Challenges we ran into
Mastering Taipy presented a significant challenge. Due to its novelty, we encountered difficulty freely styling, constrained by its syntax. Setting up virtual environments also posed challenges initially, but ultimately, we successfully learned the proper setup.
## Accomplishments that we're proud of
* We were able to build a web application that functions
* We were able to use Taipy and Cohere to build a functional application
## What we learned
* We were able to learn a lot about the Taipy library, Cohere, and Figma
## What's next for Memento
* Adding login and sign-up
* Improving front-end design
* Adding image processing, able to identify entities within user given image and using that information, along with the brief description of the photo, to produce a more accurate story that resonates with the user
* Saving and storing data | winning |
## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call. | ## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages. | ## Inspiration
As hopeful entrepreneurs who are also interested in venture capital, we are constantly faced with the challenge of determining how a startup or a business we are interested in grows. Using historical data about companies that are now IPO, we saw that we could examine the growth of prior companies that achieved similar initial growth and use this data to get a rough idea of how well a new business idea or startup would thrive.
## What it does
This tool uses cutting-edge machine learning techniques to map historical data in company earning reports, analyze sentiment from news articles, and gather information about the company's funding rounds. Using the k-means clustering algorithm, it groups together companies with similar quantitative measures, allowing VCs to predict the growth of startups that they are evaluating by looking at prior companies that achieved similar early-stage growth and are likely to see similar long-term growth.
## How we built it
We used multiple web-scraping tools, written in Python, to grab data about thousands of startups and established companies. After filtering down this list of companies by year and industry and running sentiment analyses on hundreds of articles about these startups, we built a model using the k-means clustering algorithm, written with the Tensorflow and scikit-learn libraries. For any startup that we wish to evaluate, we can now use the results of our model to determine the startups that are most similar in terms of early-stage growth and press, factors which are potentially useful for a VC to determine a startup's long term growth. Finally, we built a web application to host and display the results of our algorithm.
## Challenges we ran into
The major challenge we ran into was figuring out what data would be relevant four our k-means clustering algorithm. We wanted to use information that Vcs and investors would use to make investment decisions such as gross profit and margin, previous funding, and operation costs. We also needed to perform a lot of data cleaning in order to reduce the size of the Crunchbase dataset.
## Accomplishments that we're proud of
Our team is most proud of successfully building a tool with the potential to significantly change the way in which VCs analyze, view, and invest in startups. Within a very short frame of time, our team was able to put together an end-to-end pipeline for web scraping, sentiment analysis, and clustering, achieving much of our initial ambitious goal. Beyond just being a cool project, however, this project came together with the addition of a well-accessible frontend, allowing us to visualize and display our results in an easily digestable format.
## What we learned
This project required us to learn about and build multiple frameworks for web scraping, which, prior to this project, we had very limited experience with. We had to learn to deal with websites that had information in multiple different formats and that had noisy data. Additionally, prior to this project, we had limited experience with the k-means clustering algorithm and had to quickly learn how to implement it with multiple variables and hundreds of datapoints. However, most importantly, this project gave us the confidence to pursue projects in which there was a lot of uncertainty and we had to figure out our way as we went along.
## What's next for Speculon
We hope to expand our dataset significantly. As of now, we were limited by companies that had gone IPO and whatever we could find publicly available on Crunchbase and Google Finance. However, with more access to private datasets, we can easily improve our model's accuracy and reliability and make it a very practical tool for real-life investors and VCs. | winning |
## Inspiration
Genomic data is unique in that it is both incredibly personal and near impossible to change. Companies that store genomic data for analysis are vulnerable to data breaches, both traditional direct breaches and indirectly revealing insights into their data via the AI tools they develop.
## What it does
DPAncestry is a platform that uses state-the-the-art local differential privacy algorithms to securely process genomic data while maintaining individual privacy. By adding a layer of obfuscation to the data, DPAncestry ensures that sensitive information remains confidential, even when analyzed for ancestral insights. While many top companies and organizations such as Google, Microsoft, Apple, and the U.S. Census Bureau have already adapted differentially privacy in their models, our platform is, to our knowledge, the first to pioneer this idea for the genetic testing sphere.
To learn more about the research we referenced while developing our platform, check out: <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9073402/>
## How we built it
DPAncestry leverages local differential privacy (DP) algorithms, which work by adding controlled noise to individual data points before any analysis occurs. This approach ensures that the true values are obscured, but useful aggregate information can still be derived. We built our platform based on the methods detailed in the paper we cited, which provides a comprehensive framework for implementing differential privacy in genomic data analysis.
## Challenges we ran into
One of the major challenges we faced was choosing a focus for the project that utilizes this advanced technology while still being impactful. Additionally, we had to carefully select the most suitable differential privacy algorithm that balances privacy with data utility, ensuring meaningful insights without compromising individual privacy.
Our project additionally required parsing through academic research papers on privacy algorithms, which presented a substantial challenge for converting to a concrete implementation.
## Accomplishments that we're proud of
We are proud of successfully integrating local differential privacy into a user-friendly platform that can handle data as complex as genomic data. It provides a simple, powerful and most significantly, anonymous service for ancestry determination. We also linked an LLM model, Anthropic’s Claude, which guides the user to interpreting their genomics results, and help understanding the privacy mechanisms behind the model.
## What we learned
Throughout the development of DPAncestry, we gained a deeper understanding of the intricacies of differential privacy and how it can protect personally identifiable information. We also learned about the challenges of balancing privacy and data utility, and the importance of user trust in handling sensitive information.
## What's next for DPAncestry
Once our project acquires additional investment, we aspire to accelerate our company into the first DP genetic testing company. We’ll develop our platform into a more cohesive product for seamless usage.
Another proposition deliberated by the team was selling our software to genetics testing companies like 23andMe, to recover share prices after their major 2023 data leak, which leaked the sensitive data of over 6 million clients. | ## Inspiration
81% of Americans today feel a lack of control over their own data. Customers today can’t trust that companies won’t store or use their data maliciously, nor can they trust data communication channels. However, many companies need access to user data to offer extensive proprietary analyses. This results in seemingly clashing objectives: how can we get access to state-of-the-art proprietary models without having to fork over our data to companies?
What if we can have our cake and eat it too?
## What it does
We use end-to-end encryption offered by The @ Company to encrypt user data and include a digital signature before we send it over an insecure communication channel. Using public-key cryptography, the server can verify the digital signature and decrypt user data after receiving it. This prevents any malicious third party from accessing the data through exploiting communications between IoT devices.
In order to prevent companies from having access to user data, we use a method known as Fully Homomorphic Encryption (FHE) to perform operations on encrypted user data without needing to decrypt it first. Therefore, we encrypt data on the user-side, send over the encrypted data to the server, the server performs operations on the encrypted data without decrypting it, then sends the result in ciphertext back to the user. Thus, we achieve access to state-of-the-art models saved on cloud servers without having to give up user data in plaintext to potentially untrustworthy companies.
## How we built it
We used Flutter as our frontend, and trained two different machine learning algorithms in the backend. From our frontend, we encrypt our user data with FHE, and send it over an encrypted channel using services provided by The @ Company. Our backend runs a simple convolutional neural network (CNN) over the encrypted data *without* decrypting it, and sends the encrypted result back. Finally, the application decrypts the result, and displays it to the user.
## Challenges we ran into
Currently, existing FHE schemes can only provide linear operators. However, nonlinearities are crucial to implementing any sort of convolutional neural networks (CNN’s). After doing [some research](https://arxiv.org/pdf/2106.07229.pdf), we initially decided to use polynomial approximations of nonlinear functions, but at the cost of greatly increasing inference error (on CIFAR-10, the approximation models produced an accuracy of 77.5% vs. ~95% on state-of-the-art models).
Again, can we have our cake and eat it too? Yes we can! We employ a scheme inspired by [the latest FHE research](https://priml-workshop.github.io/priml2019/papers/PriML2019_paper_28.pdf) that compresses high-resolution images and leverages Taylor series expansion of smooth ReLU with novel min-max normalization to bound error to approximately 3% off state-of-the-art, with cleverly formulated low-rank approximations.
This scheme solves the dual problem of heavily reducing communication overhead in other FHE schemes when faced with number of pixels growing quadratically as edge length increases.
## Accomplishments that we're proud of
Not only did we get a demo up and running in a day, we also learned encryption algorithms from scratch and was able to implement it in our project idea. In addition to the technical application details that we had to implement, we also had to read different research papers, test out different models and algorithms, and integrate them into our project.
## What we learned
### Homomorphic Functions
Homomorphic functions are a structure-preserving map between two algebraic structures of the same type. This means that given a function on the plaintext space, we can find a function on the encrypted ciphertext space that would result in the same respective outputs.
For example, if we are given two messages m1 and m2, then homomorphism in addition states that encrypting m1 and m2 and then adding them together is the same as encrypting the sum of m1 and m2.
### Fully Homomorphic Encryption
Fully homomorphic encryption uses homomorphic functions to ensure that data is stored in a trustworthy space. The user first encrypts their data, sends the encrypted data to a server, then the server performs computations on the encrypted data using homomorphic functions, and sends the result back to the user. Once decrypted by the user, the user will have their desired result.
The benefits of FHE is that there is no need for trusted third parties to get proprietary data analysis. The user doesn’t have to trust the server with their data to get their results. In addition, it eliminates the tradeoff between data usability and privacy, as there is no need to mask or drop any features to preserve data privacy.
## What's next for CypherAI
In our project, we demonstrated two use cases for our product in different company settles: home monitoring for security cameras, and healthcare systems. In the future, we are looking forward to expanding this beyond to other companies! | # Project Incognito: The Mirror of Your Digital Footprint 🕵️♂️
### "With great power comes great responsibility." - A glimpse into the abyss of personal data accessibility. 🔍
---
## Overview 📝
**Incognito** is not just a project; it's a wake-up call 🚨. Inspired by the unnerving concept of identity access in the anime "Death Note," we developed a system that reflects the chilling ease with which personal information can be extracted from a mere photograph.
**Our Mission:** To simulate the startling reality of data vulnerability and empower individuals with the knowledge to protect their digital identity. 🛡️
## How It Works 🧩
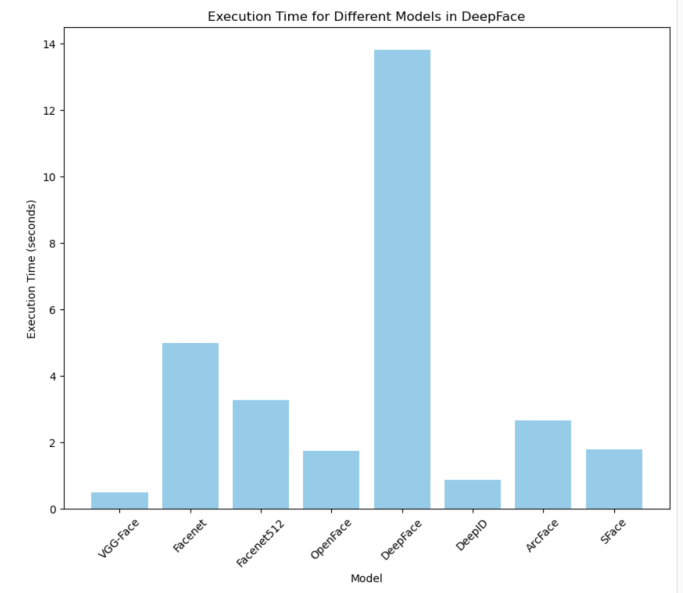
1. **The Photo**: The journey into your digital persona begins with a snapshot. Your face is the key. 📸
2. **The Intel Dev Cloud Processing**: This image is processed through sophisticated algorithms on the Intel Dev Cloud. ☁️
3. **DeepFace Validation**: Our DeepFace model, handpicked for its superior performance, compares your image against our AWS-stored database. 🤖
4. **LinkedIn and Identity Confirmation**: Names associated with your facial features are cross-referenced with top LinkedIn profiles using DeepFace's `verify` functionality. 🔗
5. **Together AI's JSON Magic**: A JSON packed with Personally Identifiable Information (PII) is conjured, setting the stage for the next act. ✨
6. **Melissa's Insight**: Presenting the Melissa API with the Personator endpoint that divulges deeper details - addresses, income, spouse and offspring names, all from the initial data seed. 👩💼
7. **Together AI Summarization**: The raw data, now a narrative of your digital footprint, is summarized for impact. 📊
8. **Data Privacy Rights**: In applicable jurisdictions, you have the option to demand data removal.🔗🛠️
9. **JUSTICE!!**: This in the end is powered by Fetch AI and the chaining it provides. ⛓️
---

## The Darker Side 🌘
Our research ventured into the shadows, retrieving public data of individuals tagged as 'judges' on Slack. But fear not, for we tread lightly and ethically, using only data from consenting participants (our team :') ). 👥
## The Even Darker Side 🌑
What we've uncovered is merely the tip of the iceberg. Time-bound, we've scratched the surface of available data. Imagine the potential depths. We present this to stir awareness, not fear. 🧊
## The Beacon of Hope 🏮
Our core ethos is solution-centric. We've abstained from exploiting judge data or misusing PII. Instead, we're expanding to trace the origin of data points, fostering transparency and control. ✨
---
## Closing Thoughts 💡
Incognito stands as a testament and a solution to the digital age's paradox of accessibility. It's a reminder and a resource, urging vigilance and offering tools for data sovereignty. 🌐
--- | partial |
# My Eyes
Helping dyslectics read by using vision and text-to-speech.
## Mission Statement
Dyslexia is a reading disability that affects 5% of the population. Individuals with dyslexia have difficulty decoding written word with speed and accuracy. To help those afflicted with dyslexia, many schools in BC provide additional reading classes. But even with reading strategies, it can take quite a bit of concentration and effort to comprehend text.
Listening to an audio book is more convenient than reading a physical one. There are text-to-speech services which can read off digital text on your tablet or computer. However, there aren't any easily accessible services which offer reading off physical text.
Our mission was to provide an easily accessible service that could read off physical text. Our MOBILE app at 104.131.142.126:3000 or eye-speak.org allows you to take a picture of any text and play it back. The site's UI was designed for those with dyslexia in mind. The site fonts and color scheme were purposely chosen to be as easily read as possible.
This site attempts to provide an easy free service for those with reading disabilities.
## Getting Started
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes.
### Installing
Create a file called '.env' and a folder called 'uploads' in the root folder
Append API keys from [IBM Watson](https://www.ibm.com/watson/services/text-to-speech/)
Append API keys from Google Cloud Vision
1. [Select or create a Cloud Platform project](https://console.cloud.google.com/project)
2. [Enable billing for your project](https://support.google.com/cloud/answer/6293499#enable-billing)
3. [Enable the Google Cloud Vision API API](https://console.cloud.google.com/flows/enableapi?apiid=vision.googleapis.com)
4. [Set up authentication with a service account so you can access the API from your local workstation](https://cloud.google.com/docs/authentication/getting-started)
.env should look like this when you're done:
```
USERNAME=<watson_username>
PASSWORD=<watson_password>
GOOGLE_APPLICATION_CREDENTIALS=<path_to_json_file>
```
Install dependencies and start the program:
```
npm install
npm start
```
Take a picture of some text and and press play to activate text-to-speech.
## Built With
* [Cloud Vision API](https://cloud.google.com/vision/) - Used to read text from images
* [Watson Text to Speech](https://console.bluemix.net/catalog/services/text-to-speech) - Used to read text from images to speech
## Authors
* **Zachary Anderson** - *Frontend* - [ZachaRuba](https://github.com/ZachaRuba)
* **Håvard Estensen** - *Google Cloud Vision* - [estensen](https://github.com/estensen)
* **Kristian Jensen** - *Backend, IBM Watson* - [HoboKristian](https://github.com/HoboKristian)
* **Charissa Sukontasukkul** - *Design*
* **Josh Vocal** - *Frontend* - [joshvocal](https://github.com/joshvocal) | ## Inspiration
We wanted to tackle a problem that impacts a large demographic of people. After research, we learned that 1 in 10 people suffer from dyslexia and 5-20% of people suffer from dysgraphia. These neurological disorders go undiagnosed or misdiagnosed often leading to these individuals constantly struggling to read and write which is an integral part of your education. With such learning disabilities, learning a new language would be quite frustrating and filled with struggles. Thus, we decided to create an application like Duolingo that helps make the learning process easier and more catered toward individuals.
## What it does
ReadRight offers interactive language lessons but with a unique twist. It reads out the prompt to the user as opposed to it being displayed on the screen for the user to read themselves and process. Then once the user repeats the word or phrase, the application processes their pronunciation with the use of AI and gives them a score for their accuracy. This way individuals with reading and writing disabilities can still hone their skills in a new language.
## How we built it
We built the frontend UI using React, Javascript, HTML and CSS.
For the Backend, we used Node.js and Express.js. We made use of Google Cloud's speech-to-text API. We also utilized Cohere's API to generate text using their LLM.
Finally, for user authentication, we made use of Firebase.
## Challenges we faced + What we learned
When you first open our web app, our homepage consists of a lot of information on our app and our target audience. From there the user needs to log in to their account. User authentication is where we faced our first major challenge. Third-party integration took us significant time to test and debug.
Secondly, we struggled with the generation of prompts for the user to repeat and using AI to implement that.
## Accomplishments that we're proud of
This was the first time for many of our members to be integrating AI into an application that we are developing so that was a very rewarding experience especially since AI is the new big thing in the world of technology and it is here to stay.
We are also proud of the fact that we are developing an application for individuals with learning disabilities as we strongly believe that everyone has the right to education and their abilities should not discourage them from trying to learn new things.
## What's next for ReadRight
As of now, ReadRight has the basics of the English language for users to study and get prompts from but we hope to integrate more languages and expand into a more widely used application. Additionally, we hope to integrate more features such as voice-activated commands so that it is easier for the user to navigate the application itself. Also, for better voice recognition, we should | ## Inspiration
Currently, Zoom only offers live closed captioning when a human transcriber manually transcribes a meeting. We believe that users would benefit greatly from closed captions in *every* meeting, so we created Cloud Caption.
## What it does
Cloud Caption receives live system audio from a Zoom meeting or other video conference platform and translate this audio in real time to closed captioning that is displayed in a floating window. This window can be positioned on top of the Zoom meeting and it is translucent, so it will never get in the way.
## How we built it
Cloud Caption uses the Google Cloud Speech-to-Text API to automatically transcribe the audio streamed from Zoom or another video conferencing app.
## Challenges we ran into
We went through a few iterations before we were able to get Cloud Caption working. First, we started with a browser-based app that would embed Zoom, but we discovered that the Google Cloud framework isn't compatible in browser-based environments. We then pivoted to an Electron-based desktop app, but the experimental web APIs that we needed did not work. Finally, we implemented a Python-based desktop app that uses a third-party program like [Loopback](https://rogueamoeba.com/loopback/) to route the audio.
## Accomplishments that we're proud of
We are proud of our ability to think and adapt quickly and collaborate efficiently during this remote event. We're also proud that our app is a genuinely useful accessibility tool for anyone who is deaf or hard-of-hearing, encouraging all students and learners to collaborate in real time despite any personal challenges they may face. Cloud Caption is also useful for students who aren't auditory learners and prefer to learn information by reading.
Finally, we're proud of the relative ease-of-use of the application. Users only need to have Loopback (or another audio-routing program) installed on their computer in order to receive real time video speech-to-text transcription, instead of being forced to wait and re-watch a video conference later with closed captioning embedded.
## What we learned
Our team learned that specifying, controlling, and linking audio input and output sources can be an incredibly difficult task with poor support from browser and framework vendors. We also came to appreciate the values of building with accessibility as a major goal throughout the design and development process. Accessibility can often be overlooked in applications and projects of every size, so all of us have learned to prioritize developing with inclusivity in mind for our projects moving forward.
## What's next for Cloud Caption
Our next step is to integrate audio routing so that users won't need a third-party program. We would also like to explore further applications of our closed captioning application in other business or corporate uses cases for HR or training purposes, especially targeting those users who may be deaf or hard-of-hearing. | winning |
## Inspiration
Our inspiration is the multiple travelling salesman problem, in which multiple salesmen are required to visit a given number of destinations once and return while minimizing travel cost. This problem occurs in many subjects but is prominent in logistics. It is essential that goods and services are delivered to customers at the the right time, at the right place and at a low cost, with the use of multiple assets. Solving this problem would result in improved quality of service to customers and cost reductions to service providers.
## What it does
Our project generates delivery routes for a given number of mail trucks. We receive a list of all recipients along with their physical locations. These recipients are assigned to trucks based on their locations. The sequence of delivery for each truck is then optimized to minimize each of their travel times, factoring in road conditions such as traffic and weather.
## How we built it
Our project generates delivery routes by simplifying the multiple travelling salesman problem into multiple instances of the single travelling salesman problem.
1 - Data Preperation. The list of addresses is converted into latitude and longitude GPS coordinates. The travel times between locations is acquired for and to each other location using the google maps API.
2 - Assignment of recipients based on physical location. We use KMeans clustering to group recipients based on their proximity to each other. Each truck has their own set of recipients. This step simplifies the problem from multiple travelling sales to multiple instances of single travelling salesman, for each truck.
3 - Individual route sequencing. We use the metropolis algorithm to optimize the sequence of recipients for each truck. For each truck, an initial random route is generated, followed by subsequent trial routes. The difference in route lengths are computed and the trial route is either accepted or rejected based on optimization parameters.
4 - Visualization. We use folium to visualize the locations of recipients, grouping and assignment of recipients and finally the route calculated for each truck.
## Challenges we ran into
Our two main challenges were:
1 - Our algorithm has inherent limitations that can make it unwieldy. It does converge onto optimal routes but it can be time consuming and computationally intensive
2 - Our algorithm relies on the assumption that going from point A to point B has the same travel time as from point B to point A. This is true if the path was a straight line and both ways have the same speed. However, in reality, going from point A to point B may take longer than the other way, such as different roads and speed limits. To overcome this limitation, we used the greater time requirement for our algorithm.
## Accomplishments that we're proud of
We put together a working solution for the multiple travelling salesman problem that can be applied on real world logistics problems. This problem is considered NP hard; as it is a generalization of the single travelling salesman which is also NP hard because the number of viable routes grows exponentially as more destinations are added. Overall, implementing a solution for this problem, to the level of a minimum viable product under tight time constraints was a non-trivial task.
## What we learned
We improved our knowledge on optimization for complex problems, as well as integrating mathematical solutions with APIs and visualization tools.
## What's next for ShipPy
ShipPy may be in a usable state but it can use more work. The individual route sequencing can be computationally intensive so that represents an area of improvement. For real time data, we used google maps API for travel time estimate, but this is all done prior to departure of the mail trucks. It may be possible to implement a solution that can adjust mail trucks' routes in real time should unforeseeable changes in road conditions occur. | ## Inspiration
Let’s face it: getting your groceries is hard. As students, we’re constantly looking for food that is healthy, convenient, and cheap. With so many choices for where to shop and what to get, it’s hard to find the best way to get your groceries. Our product makes it easy. It helps you plan your grocery trip, helping you save time and money.
## What it does
Our product takes your list of grocery items and searches an automatically generated database of deals and prices at numerous stores. We collect this data by collecting prices from both grocery store websites directly as well as couponing websites.
We show you the best way to purchase items from stores nearby your postal code, choosing the best deals per item, and algorithmically determining a fast way to make your grocery run to these stores. We help you shorten your grocery trip by allowing you to filter which stores you want to visit, and suggesting ways to balance trip time with savings. This helps you reach a balance that is fast and affordable.
For your convenience, we offer an alternative option where you could get your grocery orders delivered from several different stores by ordering online.
Finally, as a bonus, we offer AI generated suggestions for recipes you can cook, because you might not know exactly what you want right away. Also, as students, it is incredibly helpful to have a thorough recipe ready to go right away.
## How we built it
On the frontend, we used **JavaScript** with **React, Vite, and TailwindCSS**. On the backend, we made a server using **Python and FastAPI**.
In order to collect grocery information quickly and accurately, we used **Cloudscraper** (Python) and **Puppeteer** (Node.js). We processed data using handcrafted text searching. To find the items that most relate to what the user desires, we experimented with **Cohere's semantic search**, but found that an implementation of the **Levenshtein distance string algorithm** works best for this case, largely since the user only provides one to two-word grocery item entries.
To determine the best travel paths, we combined the **Google Maps API** with our own path-finding code. We determine the path using a **greedy algorithm**. This algorithm, though heuristic in nature, still gives us a reasonably accurate result without exhausting resources and time on simulating many different possibilities.
To process user payments, we used the **Paybilt API** to accept Interac E-transfers. Sometimes, it is more convenient for us to just have the items delivered than to go out and buy it ourselves.
To provide automatically generated recipes, we used **OpenAI’s GPT API**.
## Challenges we ran into
Everything.
Firstly, as Waterloo students, we are facing midterms next week. Throughout this weekend, it has been essential to balance working on our project with our mental health, rest, and last-minute study.
Collaborating in a team of four was a challenge. We had to decide on a project idea, scope, and expectations, and get working on it immediately. Maximizing our productivity was difficult when some tasks depended on others. We also faced a number of challenges with merging our Git commits; we tended to overwrite one anothers’ code, and bugs resulted. We all had to learn new technologies, techniques, and ideas to make it all happen.
Of course, we also faced a fair number of technical roadblocks working with code and APIs. However, with reading documentation, speaking with sponsors/mentors, and admittedly a few workarounds, we solved them.
## Accomplishments that we’re proud of
We felt that we put forth a very effective prototype given the time and resource constraints. This is an app that we ourselves can start using right away for our own purposes.
## What we learned
Perhaps most of our learning came from the process of going from an idea to a fully working prototype. We learned to work efficiently even when we didn’t know what we were doing, or when we were tired at 2 am. We had to develop a team dynamic in less than two days, understanding how best to communicate and work together quickly, resolving our literal and metaphorical merge conflicts. We persisted towards our goal, and we were successful.
Additionally, we were able to learn about technologies in software development. We incorporated location and map data, web scraping, payments, and large language models into our product.
## What’s next for our project
We’re very proud that, although still rough, our product is functional. We don’t have any specific plans, but we’re considering further work on it. Obviously, we will use it to save time in our own daily lives. | ## Inspiration
We wanted to build a sustainable project which gave us the idea to plant crops on a farmland in a way that would give the farmer the maximum profit. The program also accounts for crop rotation which means that the land gets time to replenish its nutrients and increase the quality of the soil.
## What it does
It does many things, It first checks what crops can be grown in that area or land depending on the weather of the area, the soil, the nutrients in the soil, the amount of precipitation, and much more information that we have got from the APIs that we have used in the project. It then forms a plan which accounts for the crop rotation process. This helps the land regain its lost nutrients while increasing the profits that the farmer is getting from his or her land. This means that without stopping the process of harvesting we are regaining the lost nutrients. It also gives the farmer daily updates on the weather in that area so that he can be prepared for severe weather.
## How we built it
For most of the backend of the program, we used Python.
For the front end of the website, we used HTML. To format the website we used CSS. we have also used Javascript for formates and to connect Python to HTML.
We used the API of Twilio in order to send daily messages to the user in order to help the user be ready for severe weather conditions.
## Challenges we ran into
The biggest challenge that we faced during the making of this project was the connection of the Python code with the HTML code. so that the website can display crop rotation patterns after executing the Python back end script.
## Accomplishments that we're proud of
While making this each of us in the group has accomplished a lot of things. This project as a whole was a great learning experience for all of us. We got to know a lot of things about the different APIs that we have used throughout the project. We also accomplished making predictions on which crops can be grown in an area depending on the weather of the area in the past years and what would be the best crop rotation patterns. On the whole, it was cool to see how the project went from data collection to processing to finally presentation.
## What we learned
We have learned a lot of things in the course of this hackathon. We learned team management and time management, Moreover, we got hands on experience in Machine Learning. We got to implement Linear Regression, Random decision trees, SVM models. Finally, using APIs became second nature to us because of the number of them we had to use to pull data.
## What's next for ECO-HARVEST
For now, the data we have is only limited to the United States, in the future we plan to increase it to the whole world and also increase our accuracy in predicting which crops can be grown in the area. Using the crops that we can grow in the area we want to give better crop rotation models so that the soil will gain its lost nutrients faster. We also plan to give better and more informative daily messages to the user in the future. | partial |
## Inspiration
In today's world, Public Speaking is one of the greatest skills any individual can have. From pitching at a hackathon to simply conversing with friends, being able to speak clearly, be passionate and modulate your voice are key features of any great speech. To tackle this problem of becoming a better public speaker, we created Talky.
## What it does
It helps you improve your speaking skills by giving you suggestions based on what you said to the phone. Once you finish presenting your speech to the app, an audio file of the speech will be sent to a flask server running on Heroku. The server will analyze the audio file by examining pauses, loudness, accuracy and how fast user spoke. In addition, the server will do a comparative analysis with the past data stored in Firebase. Then the server will return the performance of the speech.The app also provides the community functionality which allows the user to check out other people’s audio files and view community speeches.
## How we built it
We used Firebase to store the users’ speech data. Having past data will allow the server to do a comparative analysis and inform the users if they have improved or not.
The Flask server uses similar Audio python libraries to extract meaning patterns: Speech Recognition library to extract the words, Pydub to detect silences and Soundfile to find the length of the audio file.
On the iOS side, we used Alamofire to make the Http request to our server to send data and retrieve a response.
## Challenges we ran into
Everyone on our team was unfamiliar with the properties of audio, so discovering the nuances of wavelengths in particular and the information it provides was challenging and integral part of our project.
## Accomplishments that we're proud of
We successfully recognize the speeches and extract parameters from the sound file to perform the analysis.
We successfully provide the users with an interactive bot-like UI.
We successfully bridge the IOS to the Flask server and perform efficient connections.
## What we learned
We learned how to upload audio file properly and process them using python libraries.
We learned to utilize Azure voice recognition to perform operations from speech to text.
We learned the fluent UI design using dynamic table views.
We learned how to analyze the audio files from different perspectives and given an overall judgment to the performance of the speech.
## What's next for Talky
We added the community functionality while it is still basic. In the future, we can expand this functionality and add more social aspects to the existing app.
Also, the current version is focused on only the audio file. In the future, we can add the video files to enrich the post libraries and support video analyze which will be promising. | ## Inspiration
Many people feel unconfident, shy, and/or awkward doing interview speaking. It can be challenging for them to know how to improve and what aspects are key to better performance. With Talkology, they will be able to practice in a rather private setting while receiving relatively objective speaking feedback based on numerical analysis instead of individual opinions. We hope this helps more students and general job seekers become more confident and comfortable, crack their behavioral interviews, and land that dream offer!
## What it does
* Gives users interview questions (behavioural, future expansion to questions specific to the job/industry)
* Performs quantitative analysis of users’ responses using speech-to-text & linguistic software package praat to study acoustic features of their speech
* Displays performance metrics with suggestions in a user-friendly, interactive dashboard
## How we built it
* React/JavaScript for the frontend dashboard and Flask/Python for backend server and requests
* My-voice-analysis package for voice analysis in Python
* AssemblyAI APIs for speech-to-text and sentiment analysis
* MediaStream Recording API to get user’s voice recordings
* Figma for the interactive display and prototyping
## Challenges we ran into
We went through many conversations to reach this idea and as a result, only started hacking around 8AM on Saturday. On top of this time constraint layer, we also lacked experience in frontend and full stack development. Many of us had to spend a lot of our time debugging with package setup, server errors, and for some of us even M1-chip specific problems.
## Accomplishments that we're proud of
This was Aidan’s first full-stack application ever. Though we started developing kind of late in the event, we were able to pull most of the pieces together within a day of time on Saturday. We really believe that this product (and/or future versions of it) will help other people with not only their job search process but also daily communication as well. The friendships we made along the way is also definitely something we cherish and feel grateful about <3
## What we learned
* Aidan: Basics of React and Flask
* Spark: Introduction to Git and full-stack development with sprinkles of life advice
* Cathleen: Deeper dive into Flask and React and structural induction
* Helen: Better understanding of API calls & language models and managing many different parts of a product at once
## What's next for Talkology
We hope to integrate computer vision approaches by collecting video recordings (rather than just audio) to perform analysis on hand gestures, overall posture, and body language. We also want to extend our language analysis to explore novel models aimed at performing tone analysis on live speech. Apart from our analysis methods, we hope to improve our question bank to be more than just behavioural questions and better cater to each user's specific job demands. Lastly, there are general loose ends that could be easily tied up to make the project more cohesive, such as integrating the live voice recording functionality and optimizing some remaining components of the interactive dashboard. | ## Inspiration
Since we are a group of students, we have been seeing our peers losing motivation for school due to un-engaging lectures. Young adults are more stressed due to added responsibilities of taking care of younger siblings at home and supporting their family financially. Thus, students who have more responsibilities due to the pandemic miss a lot of classes, and they clearly don't have a lot of time to re-watch a one-hour lecture that they've missed.
This was me, during the earlier months of the pandemic. By having to work extra hours due to the financial impacts of the Coronavirus, alongside the inaccessibility of the internet when being outside, I missed the most important classes to finish my requirements for my degree.
That's where the inspiration of this project came from. I personally know people in different fields facing the same issue, and with my team, I wanted to help them out.
## What it does
By taking an audio file as the input, we use the Google Cloud API's function to turn the audio into text. We then analyze that text to determine the main topics by word frequency which we display to the user. We then display all sentences containing words with the highest frequency to the user.
## How we built it
First, we laid out the wireframe on Figma; after further discussion, the dev team went on working on the backend while the design team worked on the high-fidelity prototype.
After the high-fidelity prototype was handed off to the developers, the dev team then built the frontend aspect of our product to allow the user to select audios which they want to condense.
## Challenges we ran into
While building the backend, we ran into numerous bugs when developing algorithms to detect the main topics of the audio converted text. After resolving that issue, we had to figure out how to use the Google Cloud API to convert the audio files into text to pass into our processing algorithms. Finally, we had to find a way to connect our website to our backend containing our text-processing algorithms.
## Accomplishments that we're proud of
Our team figured out to convert speech to text and to display the output of our text processing algorithms to the user. Our team is also proud of creating a website that displays what our product does, acting as a portfolio of our product.
## What we learned
We learned how to utilize APIs, develop algorithms to process our text using patterns, debugging our code while learning under a time limit with new teammates.
## What's next for Xalta
* Integration with Zoom and Canvas for a more seamless user experience
* A desktop/mobile native app for stability | partial |
Our inspiration began with a simple observation: food insecurity being an issue especially in marginalized communities. We were inspired by the idea that small, sustainable changes in food habits can lead to significant improvements in food security. A study found that adopting sustainable food practices can reduce household food costs by up to 30%. (Source: University of British Columbia). We wanted to create a tool that not only provides ingredients to recipes but also empowers users to make better food choices while minimizing waste.
Throughout this project, we discovered how education plays a crucial role in helping individuals make informed decisions about their food. Additionally, we gained hands-on experience in developing a chatbot and creating a user-friendly web interface, which developed our understanding of web development and user interaction.
To bring our idea to life, we utilized a tech stack that includes Python with Flask for the backend, allowing us to handle user interactions efficiently. For the chatbot functionality, we integrated natural language processing (NLP) libraries that enable our bot to understand user queries and provide relevant responses. The front end was built using HTML, CSS, and JavaScript to create an interactive and visually appealing user experience.
One of the main challenges we encountered was making sure that the chatbot could provide accurate and helpful information. We spent significant time refining the algorithms to enhance its understanding of user inputs. Additionally, designing an engaging and intuitive user interface required multiple iterations and feedback sessions. We also faced time constraints during the hackathon, which pushed us to prioritize features.
Overall, this project was an excellent learning experience that strengthened our commitment to addressing food insecurity through innovative technology. We are excited about the potential impact of BiteWISE in helping individuals make sustainable food choices. | ## Inspiration
As we brainstormed areas we could work in for our project, we began to look for inconveniences in each of our lives that we could tackle. One of our teammates unfortunately has a lot of dietary restrictions due to allergies, and as we watched him finding organizers to check ingredients and straining to read the microscopic text on processed foods' packaging, we realized that this was an everyday issue that we could help to resolve, and that the issue is not limited to just our teammate. Thus, we sought to find a way to make his and others' lives easier and simplify the way they check for allergens.
## What it does
Our project scans food items' ingredients lists and identifies allergens within the ingredients list to ensure that a given food item is safe for consumption, as well as putting the tool in a user-friendly web app.
## How we built it
We divided responsibilities and made sure each of us was on the same page when completing our individual parts. Some of us worked on the backend, with initializing databases and creating the script to process camera inputs, and some of us worked on frontend development, striving to create an easy-to-navigate platform for people to use.
## Challenges we ran into
One major challenge we ran into was time management. As newer programmers to hackathons, the pace of the project development was a bit of a shock going into the work. Additionally, there were various incompatibilities between softwares that we ran into, causing a variety of setbacks that ultimately led to most of the issues with the final product.
## Accomplishments that we're proud of
We are very proud of the fact that the tool is functional. Even though the product is certainly far from what we wanted to end up with, we are happy that we were able to at least approach a state of completion.
## What we learned
In the end, our project was a part of the grander learning experience each of us went through. The stress of completing all intended functionality and the difficulties of working under difficult, tiring conditions was a combination that challenged us all, and from those challenges we were able to learn strategies to mitigate such obstacles in the future.
## What's next for foodsense
We hope to be able to finally complete the web app in the way we originally intended. A big regret was definitely that we were not able to execute our plan as we originally meant to, so future development is definitely in the future of the website. | ## Inspiration
We wanted to build a sustainable project which gave us the idea to plant crops on a farmland in a way that would give the farmer the maximum profit. The program also accounts for crop rotation which means that the land gets time to replenish its nutrients and increase the quality of the soil.
## What it does
It does many things, It first checks what crops can be grown in that area or land depending on the weather of the area, the soil, the nutrients in the soil, the amount of precipitation, and much more information that we have got from the APIs that we have used in the project. It then forms a plan which accounts for the crop rotation process. This helps the land regain its lost nutrients while increasing the profits that the farmer is getting from his or her land. This means that without stopping the process of harvesting we are regaining the lost nutrients. It also gives the farmer daily updates on the weather in that area so that he can be prepared for severe weather.
## How we built it
For most of the backend of the program, we used Python.
For the front end of the website, we used HTML. To format the website we used CSS. we have also used Javascript for formates and to connect Python to HTML.
We used the API of Twilio in order to send daily messages to the user in order to help the user be ready for severe weather conditions.
## Challenges we ran into
The biggest challenge that we faced during the making of this project was the connection of the Python code with the HTML code. so that the website can display crop rotation patterns after executing the Python back end script.
## Accomplishments that we're proud of
While making this each of us in the group has accomplished a lot of things. This project as a whole was a great learning experience for all of us. We got to know a lot of things about the different APIs that we have used throughout the project. We also accomplished making predictions on which crops can be grown in an area depending on the weather of the area in the past years and what would be the best crop rotation patterns. On the whole, it was cool to see how the project went from data collection to processing to finally presentation.
## What we learned
We have learned a lot of things in the course of this hackathon. We learned team management and time management, Moreover, we got hands on experience in Machine Learning. We got to implement Linear Regression, Random decision trees, SVM models. Finally, using APIs became second nature to us because of the number of them we had to use to pull data.
## What's next for ECO-HARVEST
For now, the data we have is only limited to the United States, in the future we plan to increase it to the whole world and also increase our accuracy in predicting which crops can be grown in the area. Using the crops that we can grow in the area we want to give better crop rotation models so that the soil will gain its lost nutrients faster. We also plan to give better and more informative daily messages to the user in the future. | losing |
## What it does
Khaledifier replaces all quotes and images around the internet with pictures and quotes of DJ Khaled!
## How we built it
Chrome web app written in JS interacts with live web pages to make changes.
The app sends a quote to a server which tokenizes words into types using NLP
This server then makes a call to an Azure Machine Learning API that has been trained on DJ Khaled quotes to return the closest matching one.
## Challenges we ran into
Keeping the server running with older Python packages and for free proved to be a bit of a challenge | ## Inspiration
There is a growing number of people sharing gardens in Montreal. As a lot of people share apartment buildings, it is indeed more convenient to share gardens than to have their own.
## What it does
With that in mind, we decided to create a smart garden platform that is meant to make sharing gardens as fast, intuitive, and community friendly as possible.
## How I built it
We use a plethora of sensors that are connected to a Raspberry Pi. Sensors range from temperature to light-sensitivity, with one sensor even detecting humidity levels. Through this, we're able to collect data from the sensors and post it on a google sheet, using the Google Drive API.
Once the data is posted on the google sheet, we use a python script to retrieve the 3 latest values and make an average of those values. This allows us to detect a change and send a flag to other parts of our algorithm.
For the user, it is very simple. They simply have to text a number dedicated to a certain garden. This will allow them to create an account and to receive alerts if a plant needs attention.
This part is done through the Twilio API and python scripts that are triggered when the user sends an SMS to the dedicated cell-phone number.
We even thought about implementing credit and verification systems that allow active users to gain points over time. These points are earned once the user decides to take action in the garden after receiving a notification from the Twilio API. The points can be redeemed through the app via Interac transfer or by simply keeping the plant once it is fully grown. In order to verify that the user actually takes action in the garden, we use a visual recognition software that runs the Azure API. Through a very simple system of QR codes, the user can scan its QR code to verify his identity. | ## Inspiration
**Read something, do something.** We constantly encounter articles about social and political problems affecting communities all over the world – mass incarceration, the climate emergency, attacks on women's reproductive rights, and countless others. Many people are concerned or outraged by reading about these problems, but don't know how to directly take action to reduce harm and fight for systemic change. **We want to connect users to events, organizations, and communities so they may take action on the issues they care about, based on the articles they are viewing**
## What it does
The Act Now Chrome extension analyzes articles the user is reading. If the article is relevant to a social or political issue or cause, it will display a banner linking the user to an opportunity to directly take action or connect with an organization working to address the issue. For example, someone reading an article about the climate crisis might be prompted with a link to information about the Sunrise Movement's efforts to fight for political action to address the emergency. Someone reading about laws restricting women's reproductive rights might be linked to opportunities to volunteer for Planned Parenthood.
## How we built it
We built the Chrome extension by using a background.js and content.js file to dynamically render a ReactJS app onto any webpage the API identified to contain topics of interest. We built the REST API back end in Python using Django and Django REST Framework. Our API is hosted on Heroku, the chrome app is published in "developer mode" on the chrome app store and consumes this API. We used bitbucket to collaborate with one another and held meetings every 2 - 3 hours to reconvene and engage in discourse about progress or challenges we encountered to keep our team productive.
## Challenges we ran into
Our initial attempts to use sophisticated NLP methods to measure the relevance of an article to a given organization or opportunity for action were not very successful. A simpler method based on keywords turned out to be much more accurate.
Passing messages to the back-end REST API from the Chrome extension was somewhat tedious as well, especially because the API had to be consumed before the react app was initialized. This resulted in the use of chrome's messaging system and numerous javascript promises.
## Accomplishments that we're proud of
In just one weekend, **we've prototyped a versatile platform that could help motivate and connect thousands of people to take action toward positive social change**. We hope that by connecting people to relevant communities and organizations, based off their viewing of various social topics, that the anxiety, outrage or even mere preoccupation cultivated by such readings may manifest into productive action and encourage people to be better allies and advocates for communities experiencing harm and oppression.
## What we learned
Although some of us had basic experience with Django and building simple Chrome extensions, this project provided new challenges and technologies to learn for all of us. Integrating the Django backend with Heroku and the ReactJS frontend was challenging, along with writing a versatile web scraper to extract article content from any site.
## What's next for Act Now
We plan to create a web interface where organizations and communities can post events, meetups, and actions to our database so that they may be suggested to Act Now users. This update will not only make our applicaiton more dynamic but will further stimulate connection by introducing a completely new group of people to the application: the event hosters. This update would also include spatial and temporal information thus making it easier for users to connect with local organizations and communities. | winning |
## Inspiration
As students with busy lives, it's difficult to remember to water your plants especially when you're constantly thinking about more important matters. So as solution we thought it would be best to have an app that centralizes, monitors, and notifies users on the health of your plants.
## What it does
The system is setup with 2 main components hardware and software. On the hardware side, we have multiple sensors placed around the plant that provide input on various parameters (i.e. moisture, temperature, etc.). Once extracted, the data is then relayed to an online database (in our case Google Firebase) where it's then taken from our front end system; an android app. The app currently allows user authentication and the ability to add and delete plants.
## How we built it
**The Hardware**:
The Hardware setup for this hack was reiterated multiple times through the hacking phase due to setbacks of the hardware given. Originally we planned on using the Dragonboard 410c as a central hub for all the sensory input before transmitting it via wifi. However, the Dragonboard taken by the hardware lab had a corrupted version of windows iot which meant we had to flash the entire device before starting. After flashing, we learned that dragonboards (and raspberry Pi's) lack the support for analog input meaning the circuit required some sort of ADC (analog to digital converter). Afterwards, we decided to use the ESP-8266 wifi boards to send data as it better reflected the form factor of a realistic prototype and because the board itself supports analog input. In addition we used an Arduino UNO to power the moisture sensor because it required 5V and the esp outputs 3.3V (Arduino acts as a 5v regulator).
**The Software**:
The app was made in Android studios and was built with user interaction in mind by having users authenticate themselves and add their corresponding plants which in the future would each have sensors. The app is built with scalability in mind as it uses Google Firebase for user authentication, sensor datalogging,
## Challenges we ran into
The lack of support for the Dragonboard left us with many setbacks; endless boot cycles, lack of IO support, flashing multiple OSs on the device. What put us off the most was having people tell us not to use it because of its difficultly. However, we still wanted to incorporate in some way.
## Accomplishments that we're proud of
* Flashing the Dragonboard and booting it with Windows IOT core
* a working hardware/software setup that tracks the life of a plant using sensory input.
## What we learned
* learned how to program the dragonboard (in both linux and windows)
* learning how to incorporate Firebase into our hack
## What's next for Dew Drop
* Take it to the garden world where users can track multiple plants at once and even support a self watering system | ## 💡 Inspiration
From farmers' protest around the world, subsidies to keep agriculture afloat, to the regular use of pesticides that kills organisms and pollutes the environment, the agriculture industry has an issue in optimizing resources. So, we want to make technology that would efficiently manage a farm through AI fully automated to reduce human energy costs. Not only that, but we would also open crowdfunding for farm plants as a form of an environmental investment that rewards you with money and carbon credits offset.
## 💻 What it does
Drone:
The drone communicates with the ground sensors which include, UV, pest vision detection, humidity sensor, CO2 sensor, and more. Based on this data then the drone would execute a cloud command to solve it. For example, if it detects a pest, it will call the second drone with the pest spray. Or if its lacking water, it would command the pump using wifi to pump the water, creating an efficient fully automated cycle that reduces resources as it's based on need.
Farmer’s Dashboard:
View the latest data on your plant from its growth, pest status, watering status, fertilizing status, etc. Open your farm for crowdfunding, in terms of land share for extra money. Harvest money would be split based on that share.
Plant Adopter:
Adopt a plan and see how much carbon offset it did in real time until harvest. Other than collecting carbon points you could also potentially get a capital gain from the selling of the harvest. Have a less worry investment by being able to check on it anytime you want with extra data such as height when it’s last sprayed, etc.
On Field Sensor Array and horticulture system:
Collects various information about the plants using a custom built sensor array, and then automatically adjusts lighting, heat, irrigation and fertilization accordingly. The sensor data is stored on cockroachdb using an onramping function deployed on Google Cloud which also hosts the pest detection and weed detection machine learning models.
## 🔨 How we built it:
* Hardware Setup:
SoC Hub: Raspberry PI
Sensor MCU: Arduino Mega 2560
Actuation MCU Arduino UNO R3
Temperature (outdoor/indoor): SHT40, CCS811, MR115A2
Humidity: SHT40
Barometric Pressure: MR115A2
Soil Temperature: Adafruit Stemma Soil Sensing Module
Soil Moisture: Adafruit Stemma Soil Sensing Module
Carbon Dioxide Emitted/Absorbed: CCS811
UV Index/incident: VEML6070
Ventilation Control: SG90 Mini Servo
Lighting: AdaFruit NeoPixel Strip x8
Irrigation Pump: EK1893 3-5V Submersible Pump
\*Drones: DJI TELLO RoboMaster TT
\*Database: CockroachDB
\*Cloud: Google Cloud Services
\*Machine Learning (for pest and weed detection): Cloud Vision, AutoML
Design: Figma
Arduino, Google Vision Cloud, Raspberry pi, Drones, Cockroach DB, etc
We trained ML models for pest (saddleback caterpillar,true armyworm) and weed detection using images dataset from "ipmimages". We used google cloud Auto ML to train our model.
## 📖 What we learned
This is the first time some of us have coded a drone, so it’s an amazing experience to be able to automate the code like that. It is also a struggle to find a solution that can be realistically implemented in a business sense. | ## Inspiration
We wanted to create a proof-of-concept for a potentially useful device that could be used commercially and at a large scale. We ultimately designed to focus on the agricultural industry as we feel that there's a lot of innovation possible in this space.
## What it does
The PowerPlant uses sensors to detect whether a plant is receiving enough water. If it's not, then it sends a signal to water the plant. While our proof of concept doesn't actually receive the signal to pour water (we quite like having working laptops), it would be extremely easy to enable this feature.
All data detected by the sensor is sent to a webserver, where users can view the current and historical data from the sensors. The user is also told whether the plant is currently being automatically watered.
## How I built it
The hardware is built on an Arduino 101, with dampness detectors being used to detect the state of the soil. We run custom scripts on the Arduino to display basic info on an LCD screen. Data is sent to the websever via a program called Gobetwino, and our JavaScript frontend reads this data and displays it to the user.
## Challenges I ran into
After choosing our hardware, we discovered that MLH didn't have an adapter to connect it to a network. This meant we had to work around this issue by writing text files directly to the server using Gobetwino. This was an imperfect solution that caused some other problems, but it worked well enough to make a demoable product.
We also had quite a lot of problems with Chart.js. There's some undocumented quirks to it that we had to deal with - for example, data isn't plotted on the chart unless a label for it is set.
## Accomplishments that I'm proud of
For most of us, this was the first time we'd ever created a hardware hack (and competed in a hackathon in general), so managing to create something demoable is amazing. One of our team members even managed to learn the basics of web development from scratch.
## What I learned
As a team we learned a lot this weekend - everything from how to make hardware communicate with software, the basics of developing with Arduino and how to use the Charts.js library. Two of our team member's first language isn't English, so managing to achieve this is incredible.
## What's next for PowerPlant
We think that the technology used in this prototype could have great real world applications. It's almost certainly possible to build a more stable self-contained unit that could be used commercially. | partial |
## Inspiration
After our initial hack failed, and with only 12 hours of time remaining, we decided to create a proof-of-concept that was achievable in the time remaining. As Twilio was a sponsor, we had the idea of using SMS to control a video game. We created Hackermon to demonstrate how this technology has potential, and as a proof-of-concept of more practical uses.
## What it does
Controlled entirely via SMS, two players can select a knockoff Pokemon and fight each other, with the ability to block or attack. The game is turn based, and has checks to ensure the person texting the API is the correct person, so cheating is effectively impossible.
## How we built it
The backend is built with Node.js and Express.js, with SMS controls made possible with Twilio's API. The frontend is built in HTML, CSS, JavaScript and jQuery and uses AJAX to constantly poll the backend for updates.
## Challenges we ran into
Sleep deprivation was a major challenge that affected us. Trying to focus on learning a new API and developing with a new framework was very challenging after being awake for 22 hours. However, having to prototype something so rapidly was very rewarding - we had to carefully prioritise and cut features in order to create a demoable product in time.
## What we learned
Our initial idea for a project involved using Facebook's Instant Game API. We discovered that many of Facebook's APIs aren't as documented as we expected, and some of their post-Cambridge Analytica security features can cause major unexpected issues.
This was the first time we'd ever used the Twilio API, and it was great to learn how powerful the platform is. Initially, we'd never had to handle getting requests from the backend to the frontend in Node.js before, so managing to get this to work consistently was amazing - even though we know it's not done in the most efficient way.
## What's next for Hackermon
While the game itself is only a basic proof-of-concept, the mechanic of using SMS to control a game has many applications. For example, a quiz webapp used in university classes could accept inputs via SMS rather than requiring students to download a clunky and badly designed app. | # INSPIRATION
Never before than now, existed something which can teach out about managing your money the right way practically. Our team REVA brings FinLearn, not another budgeting app.
Money has been one thing around which everyone’s life revolves. Yet, no one teaches us how to manage it effectively. As much as earning money is not easy, so is managing it. As a student, when you start to live alone, take a student loan, or plans to study abroad, all this becomes a pain for you if you don’t understand how to manage your personal finances. We faced this problem ourselves and eventually educated ourselves. Hence, we bring a solution for all.
Finlearn is a fin-ed mobile application that can teach you about money management in a practical way. You can set practical finance goals for yourself and learn while achieving them. Now, learning personal finances is easier than ever with FinLearn,
# WHAT IT DOES
Finlearn is a fin-ed-based mobile application that can teach you about money and finances in a practical way. You can set practical finance goals for yourself and learn while achieving them. Now, learning personal finances is easier than ever with FinLearn.
It has features like Financial Learning Track, Goal Streaks, Reward-Based Learning Management, News Feed for all the latest cool information in the business world.
# HOW WE BUILT IT
* We built the mobile application on Flutter Framework and designed it on Figma.
* It consists of Learning and Goal Tracker APIs built with Flask and Cosmos DB
* The learning track has a voice-based feature too built with Azure text-to-speech cognitive services.
* Our Budget Diary feature helps you to record all your daily expenses into major categories which can be visualized over time and can help in forecasting your future expenses.
* These recorded expenses aid in managing your financial goals in the app.
* The rewards-based learning system unlocks more learning paths to you as you complete your goal.
# CHALLENGES WE RAN INTO
Building this project in such a short time was quite a challenge. Building logic for the whole reward-based learning was not easy. Yet we were able to pull it off. Integrating APIs by using proper data/error handling and maintaining the sleek UI along with great performance was a tricky task. Making reusable/extractable snippets of Widgets helped a lot to overcome this challenge.
# ACCOMPLISHMENTS WE ARE PROUD OF
We are proud of the efforts that we put in and pulled off the entire application within 1.5 days. Only from an idea to building an entire beautiful application is more than enough to make us feel content. The whole Learning Track we made is the charm of the application.
# WHAT’S NEXT
FinLearn would have a lot of other things in the future. Our first agenda would be to build a community feature for the students on our app. Building a learning community is gonna give it an edge.
# Credits
Veideo editing: Aaditya VK | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | partial |
## Inspiration
Having grown up in developing countries, our team understands that there are many people who simply cannot afford to visit doctors frequently (distance, money, etc.), even when regular check-ups are required. This brings forth the problem - patients in developing countries often have the money to buy medicine but not enough money to visit the doctor every time. Not only does this disparity lead to lower mortality rates for citizens and children but makes it difficult to seek help when you truly need it.
Our team aims to bridge that gap and provide patients with the healthcare they deserve by implementing "Pillar" stations in settings of need.
## What it does
Patients visit the pillar stations for at least one of three purposes:
1. Update doctor with medical symptoms
2. Get updates from doctors regarding their past symptoms and progress
3. Get medicine prescribed by doctors
For the first purpose, patients activate the Pillar stations (Amazon Echo) and are called on a secure, private line to discuss symptoms and describe how they've been feeling. Pillar's algorithm processes that audio and summarizes it through machine learning APIs and sends it to the remote doctor in batches. Our reason for choosing phone calls is to increase privacy, accessibility and feasibility. The summarized information which includes sentiment analysis, key word detection and entity identification is stored in the doctor's dashboard and the doctor can update fields as required such as new notes, medicine to dispense, specific instructions etc. The purpose of this action is to inform the doctor of any updates so the doctor is briefed and well-prepared to speak to the patient next time they visit the village. There are also emergency update features that allow the doctor to still be connected with patients he sees less often.
For the second purpose, patients receive updates and diagnosis from the doctor regarding the symptoms they explained during their last Pillar visit. This diagnosis is not based purely on a patient's described symptoms, it is an aggregation of in-person checkups and collected data on the patient that can be sent at any time. This mitigates the worry and uncertainty patients may have of not knowing whether their symptoms are trivial or severe. Most importantly it provides a sense of connection and comfort knowing knowledgable guidance is always by their side.
Finally, for the third purpose, patients receive medicine prescribed by doctors instantly (given the Pillar station has been loaded). This prevents patients' conditions from worsening early-on. The hardware dispenses exactly the prescribed amount while also reciting instructions from the doctor and sends SMS notifications along with it. The Pillar prototype dispenses one type of pill but there is evident potential for more complicated systems.
## How we built it
We built this project using a number of different software and hardware programs that were seamlessly integrated to provide maximum accessibility and feasibility. To begin, the entry point to the Pillar stations is through a complex **Voiceflow** schema connected to **Amazon Echo** that connects to our servers to process what patients describe and need. Voiceflow gives us the ability to easily make API calls and integrate voice, something we believe is more accessible than text or writing for the less-educated populations of developing countries. The audio is summarized by **Meaning Cloud API** and a custom algorithm and is sent to the Doctor's dashboard to evaluate. The dashboard uses **MongoDB Altas** to store patients' information, it allows for high scalability and flexibility for our document oriented model. The front-end of the the dashboard is built using jQuery, HTML5, CSS (Bootstrap) and JavaScript. It provides a visual model for doctors to easily analyze patient data. Doctors can also provide updates and prescriptions for the customer through the dashboard. The Pillar station can dispense prescription pills through the use of **Arduino** (programmed with C). The pill dispense mechanism is triggered through a Voiceflow trigger and a Python script that polls for that trigger. This makes sense for areas with weak wi-fi. Finally, everything is connected through a **Flask** server which creates a host of endpoints and is deployed on **Heroku** for other components to communicate. Another key aspect is that patients can also be reminded of periodic visits to local Pillar stations using **Avaya's SMS & Call Transcription** services. Again, for individuals surviving more than living, often appointments and prescriptions are forgotten.
Through this low-cost and convenient service, we hope to create a world of more accessible healthcare for everyone.
## Challenges and What We Learned
* Hardware issues, we had a lot of difficulties getting the Raspberry Pi to work with the SD card. We are proud that we resolved this hardware issue by switching to Arduino. This was a risk but our problem solving abilities endured.
* The heavy theme of voice throughout our hack was new to most of the team and was a hurdle at first to adapt to non-text data analysis
* For all of us, we also found it to be a huge learning curve to connect both hardware and software for this project. We are proud that we got the project to work after hours on end of Google searches, Stack Overflow Forums and YouTube tutorials.
## What's next for Pillar
* We originally integrated Amazon Web Services (Facial Recognition) login for our project but did not have enough time to polish it. For added security reasons, we would polish and implement this feature in the future. This would also be used to provide annotated and analyzed images for doctors to go with symptom descriptions.
* We also wanted to visualize a lot of the patient's information in their profile dashboard to demonstrate change over time and save that information to the database
* Hardware improvements are boundless and complex pill dispensary systems would be the end goal | ## Inspiration
In India, there are a lot of cases of corruption in the medicine industry. Medicines are generally expensive and not accessible to people from financially backward households. As a result, there are many unnecessary deaths caused by lack of proper treatment. People who buy the medicines at high costs are generally caught in debt traps and face a lifetime of discomfort. Every year, the government spends 95 million CAD on medicines from private medical stores to provide it to ration shops in rural areas that sell it for cheap prices to poor people. However, private medical store owners bribe government hospital doctors to prescribe medicines which can only be found in private stores, thus causing a loss for the government and creating debt traps for the people.
## What it does
Every medicine has an alternative to it. This is measure by the salts present in it. Our app provides a list of alternative medicines to every medicine prescribed by doctors to give patients a variety to choose from and go to ration stores who might have the alternative at cheaper prices. This information is retrieved from the data sets of medicines by the Medical Authority of India.
## How we built it
We built the front end using Swift, Figma and Illustrator. For the backend, we used Google firebase and SQL for collecting information about medicines from official sources. We also used the Google Maps API and the Google Translate API to track the location of the patient and provide information in his own language/dialect.
## Challenges we ran into
## Accomplishments that we're proud of
We are proud of coming up with an idea that solves problems for both the government and the patients by solving corruption. We are also proud of our ability to think of and create such an elaborate product in a restricted time frame.
## What's next for Value-Med
If we had more time, we would have integrated Voiceflow as well for people who did not know how to read so that they could receive voice commands for navigating the application. | ## Inspiration
While we were brainstorming for ideas, we realized that two of our teammates are international students from India also from the University of Waterloo. Their inspiration to create this project was based on what they had seen in real life. Noticing how impactful access to proper healthcare can be, and how much this depends on your socioeconomic status, we decided on creating a healthcare kiosk that can be used by people in developing nations. By designing interface that focuses heavily on images; it can be understood by those that are illiterate as is the case in many developing nations, or can bypass language barriers. This application is the perfect combination of all of our interests; and allows us to use tech for social good by improving accessibility in the healthcare industry.
## What it does
Our service, Medi-Stand is targeted towards residents of regions who will have the opportunity to monitor their health through regular self administered check-ups. By creating healthy citizens, Medi-Stand has the potential to curb the spread of infectious diseases before they become a bane to the society and build a more productive society. Health care reforms are becoming more and more necessary for third world nations to progress economically and move towards developed economies that place greater emphasis on human capital. We have also included supply-side policies and government injections through the integration of systems that have the ability to streamline this process through the creation of a database and eliminating all paper-work thus making the entire process more streamlined for both- patients and the doctors. This service will be available to patients through kiosks present near local communities to save their time and keep their health in check. By creating a profile the first time you use this system in a government run healthcare facility, users can create a profile and upload health data that is currently on paper or in emails all over the interwebs. By inputting this information for the first time manually into the database, we can access it later using the system we’ve developed. Overtime, the data can be inputted automatically using sensors on the Kiosk and by the doctor during consultations; but this depends on 100% compliance.
## How I built it
In terms of the UX/UI, this was designed using Sketch. By beginning with the creation of mock ups on various sheets of paper, 2 members of the team brainstormed customer requirements for a healthcare system of this magnitude and what features we would be able to implement in a short period of time. After hours of deliberation and finding ways to present this, we decided to create a simple interface with 6 different screens that a user would be faced with. After choosing basic icons, a font that could be understood by those with dyslexia, and accessible colours (ie those that can be understood even by the colour blind); we had successfully created a user interface that could be easily understood by a large population.
In terms of developing the backend, we wanted to create the doctor’s side of the app so that they could access patient information. IT was written in XCode and connects to Firebase database which connects to the patient’s information and simply displays this visually on an IPhone emulator. The database entries were fetched in Json notation, using requests.
In terms of using the Arduino hardware, we used Grove temperature sensor V1.2 along with a Grove base shield to read the values from the sensor and display it on the screen. The device has a detectable range of -40 to 150 C and has an accuracy of ±1.5 C.
## Challenges I ran into
When designing the product, one of the challenges we chose to tackle was an accessibility challenge. We had trouble understanding how we can turn a healthcare product more accessible. Oftentimes, healthcare products exist from the doctor side and the patients simply take home their prescription and hold the doctors to an unnecessarily high level of expectations. We wanted to allow both sides of this interaction to understand what was happening, which is where the app came in. After speaking to our teammates, they made it clear that many of the people from lower income households in a developing nation such as India are not able to access hospitals due to the high costs; and cannot use other sources to obtain this information due to accessibility issues. I spent lots of time researching how to make this a user friendly app and what principles other designers had incorporated into their apps to make it accessible. By doing so, we lost lots of time focusing more on accessibility than overall design. Though we adhered to the challenge requirements, this may have come at the loss of a more positive user experience.
## Accomplishments that I'm proud of
For half the team, this was their first Hackathon. Having never experienced the thrill of designing a product from start to finish, being able to turn an idea into more than just a set of wireframes was an amazing accomplishment that the entire team is proud of.
We are extremely happy with the UX/UI that we were able to create given that this is only our second time using Sketch; especially the fact that we learned how to link and use transactions to create a live demo. In terms of the backend, this was our first time developing an iOS app, and the fact that we were able to create a fully functioning app that could demo on our phones was a pretty great feat!
## What I learned
We learned the basics of front-end and back-end development as well as how to make designs more accessible.
## What's next for MediStand
Integrate the various features of this prototype.
How can we make this a global hack?
MediStand is a private company that can begin to sell its software to the governments (as these are the people who focus on providing healthcare)
Finding more ways to make this product more accessible | partial |
## Inspiration
As international students, we often have to navigate around a lot of roadblocks when it comes to receiving money from back home for our tuition.
Cross-border payments are gaining momentum with so many emerging markets. In 2021, the top five recipient countries for remittance inflows in current USD were India (89 billion), Mexico (54 billion), China (53 billion), the Philippines (37 billion), and Egypt (32 billion). The United States was the largest source country for remittances in 2020, followed by the United Arab Emirates, Saudi Arabia, and Switzerland.
However, Cross-border payments face 5 main challenges: cost, security, time, liquidity & transparency.
* Cost: Cross-border payments are typically costly due to costs involved such as currency exchange costs, intermediary charges, and regulatory costs.
-Time: most international payments take anything between 2-5 days.
-Security: The rate of fraud in cross-border payments is comparatively higher than in domestic payments because it's much more difficult to track once it crosses the border.
* Standardization: Different countries tend to follow a different set of rules & formats which make cross-border payments even more difficult & complicated at times.
* Liquidity: Most cross-border payments work on the pre-funding of accounts to settle payments; hence it becomes important to ensure adequate liquidity in correspondent bank accounts to meet payment obligations within cut-off deadlines.
## What it does
Cashflow is a solution to all of the problems above. It provides a secure method to transfer money overseas. It uses the checkbook.io API to verify users' bank information, and check for liquidity, and with features such as KYC, it ensures security in enabling instant payments. Further, it uses another API to convert the currencies using accurate, non-inflated rates.
Sending money:
Our system requests a few pieces of information from you, which pertain to the recipient. After having added your bank details to your profile, you will be able to send money through the platform.
The recipient will receive an email message, through which they can deposit into their account in multiple ways.
Requesting money:
By requesting money from a sender, an invoice is generated to them. They can choose to send money back through multiple methods, which include credit and debit card payments.
## How we built it
We built it using HTML, CSS, and JavaScript. We also used the Checkbook.io API and exchange rate API.
## Challenges we ran into
Neither of us is familiar with backend technologies or react. Mihir has never worked with JS before and I haven't worked on many web dev projects in the last 2 years, so we had to engage in a lot of learning and refreshing of knowledge as we built the project which took a lot of time.
## Accomplishments that we're proud of
We learned a lot and built the whole web app as we were continuously learning. Mihir learned JavaScript from scratch and coded in it for the whole project all under 36 hours.
## What we learned
We learned how to integrate APIs in building web apps, JavaScript, and a lot of web dev.
## What's next for CashFlow
We were having a couple of bugs that we couldn't fix, we plan to work on those in the near future. | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | ## Inspiration
As budding musicians, we've had our fair share of struggles with obtaining sheet music for pieces that we wanted to learn how to play. Sometimes the sheet music was hidden behind a paywall and sometimes, the sheet music didn't exist online. Our goal with OsKey is to increase accessibility to sheet music to allow musicians to work on their craft without worrying about obtaining the sheet music.
## What it does
OsKey takes in audio recordings (MP3s), breaks it down to the individual notes, and uses machine learning to identify each distinct note. Then OsKey formats this into a list which is pushed to a database. Within that database, OsKey takes the notes and turn them into a beautiful visualization of the sheet music.
## How we built it
We trained OsKey on a database of music notes and songs to boost its accuracy in recognizing the notes. We then converted the notes it found into lists which we pushed to a database. Within this database, we took these notes and converted them into visualizations of how the notes should look on sheet music.
## Challenges we ran into
Some of the challenges included accessing and cleaning the dataset, lack of documentation for CreateML files, managing the dataset, and visualizing the data. Apart from this, we learned a lot through this challenge and had tons of fun.
## Accomplishments that we're proud of
We were able to rapidly gain new technical ground in Firebase, CreateML, ReactJS, and more. Along with this, we were retrospectively proud of persevering throughout the night (a little caffeine goes a long way) and being able to work as a coherent unit to finish this project.
## What we learned
We learned that there are always multiple approaches to the same problem, that we can have fun no matter what, and that we should ALWAYS set up our technical environment before we start a hackathon again.
## What's next for OsKey
Refine the classification model, expand into more instruments (trumpet, alto sax, etc), and be able to offer a versatile tool to both burgeoning and advanced musicians. | winning |
# 🍅 NutriSnap
### NutriSnap is an intuitive nutrition tracker that seamlessly integrates into your daily life.
## Inspiration
Every time you go to a restaurant, its highly likely that you see someone taking a picture of their food before they eat it. We wanted to create a seamless way for people to keep track of their nutritional intake, minimizing the obstacles required to be aware of the food you consume. Building on the idea that people already often take pictures of the food they eat, we decided to utilize something as simple as one's camera app to keep track of their daily nutritional intake.
## What it does
NutriSnap analyzes pictures of food to detect its nutritional value. After simply scanning a picture of food, it summarizes all its nutritional information and displays it to the user, while also adding it to a log of all consumed food so people have more insight on all the food they consume. NutriSnap has two fundamental features:
* scan UPC codes on purchased items and fetch its nutritional information
* detect food from an image using a public ML food-classification API and estimate its nutritional information
This information is summarized and displayed to the user in a clean and concise manner, taking their recommended daily intake values into account. Furthermore, it is added to a log of all consumed food items so the user can always access a history of their nutritional intake.
## How we built it
The app uses React Native for its frontend and a Python Django API for its backend. If the app detects a UPC code in the photo, it retrieves nutritional information from a [UPC food nutrition API](https://world.openfoodfacts.org) and summarizes its data in a clean and concise manner. If the app fails to detect a UPC code in the photo, it forwards the photo to its Django backend, which proceeds to classify all the food in the image using another [open API](https://www.logmeal.es). All collected nutritional data is forwarded to the [OpenAI API](https://platform.openai.com/docs/guides/text-generation/json-mode) to summarize nutritional information of the food item, and to provide the item with a nutrition rating betwween 1 and 10. This data is displayed to the user, and also added to their log of consumed food.
## What's next for NutriSnap
As a standalone app, NutriSnap is still pretty inconvenient to integrate into your daily life. One amazing update would be to make the API more independent of the frontend, allowing people to sync their Google Photos library so NutriSnap automatically detects and summarizes all consumed food without the need for any manual user input. | ## Inspiration
While there are several applications that use OCR to read receipts, few take the leap towards informing consumers on their purchase decisions. We decided to capitalize on this gap: we currently provide information to customers about the healthiness of the food they purchase at grocery stores by analyzing receipts. In order to encourage healthy eating, we are also donating a portion of the total value of healthy food to a food-related non-profit charity in the United States or abroad.
## What it does
Our application uses Optical Character Recognition (OCR) to capture items and their respective prices on scanned receipts. We then parse through these words and numbers using an advanced Natural Language Processing (NLP) algorithm to match grocery items with its nutritional values from a database. By analyzing the amount of calories, fats, saturates, sugars, and sodium in each of these grocery items, we determine if the food is relatively healthy or unhealthy. Then, we calculate the amount of money spent on healthy and unhealthy foods, and donate a portion of the total healthy values to a food-related charity. In the future, we plan to run analytics on receipts from other industries, including retail, clothing, wellness, and education to provide additional information on personal spending habits.
## How We Built It
We use AWS Textract and Instabase API for OCR to analyze the words and prices in receipts. After parsing out the purchases and prices in Python, we used Levenshtein distance optimization for text classification to associate grocery purchases with nutritional information from an online database. Our algorithm utilizes Pandas to sort nutritional facts of food and determine if grocery items are healthy or unhealthy by calculating a “healthiness” factor based on calories, fats, saturates, sugars, and sodium. Ultimately, we output the amount of money spent in a given month on healthy and unhealthy food.
## Challenges We Ran Into
Our product relies heavily on utilizing the capabilities of OCR APIs such as Instabase and AWS Textract to parse the receipts that we use as our dataset. While both of these APIs have been developed on finely-tuned algorithms, the accuracy of parsing from OCR was lower than desired due to abbreviations for items on receipts, brand names, and low resolution images. As a result, we were forced to dedicate a significant amount of time to augment abbreviations of words, and then match them to a large nutritional dataset.
## Accomplishments That We're Proud Of
Project Horus has the capability to utilize powerful APIs from both Instabase or AWS to solve the complex OCR problem of receipt parsing. By diversifying our software, we were able to glean useful information and higher accuracy from both services to further strengthen the project itself, which leaves us with a unique dual capability.
We are exceptionally satisfied with our solution’s food health classification. While our algorithm does not always identify the exact same food item on the receipt due to truncation and OCR inaccuracy, it still matches items to substitutes with similar nutritional information.
## What We Learned
Through this project, the team gained experience with developing on APIS from Amazon Web Services. We found Amazon Textract extremely powerful and integral to our work of reading receipts. We were also exposed to the power of natural language processing, and its applications in bringing ML solutions to everyday life. Finally, we learned about combining multiple algorithms in a sequential order to solve complex problems. This placed an emphasis on modularity, communication, and documentation.
## The Future Of Project Horus
We plan on using our application and algorithm to provide analytics on receipts from outside of the grocery industry, including the clothing, technology, wellness, education industries to improve spending decisions among the average consumers. Additionally, this technology can be applied to manage the finances of startups and analyze the spending of small businesses in their early stages. Finally, we can improve the individual components of our model to increase accuracy, particularly text classification. | ## Inspiration
## What it does
## How we built it
## Challenges we ran into
The connections between the front end and backend
## Accomplishments that we're proud of
Worked out a neural network model to predict the chance of the user getting a certain disease
## What we learned
Connection between API
## What's next for AI health consultant | winning |
## Inspiration
Although there are limitless technologies that connect people from around the world, language barriers still stand as an unbreakable wall blocking communication between people who speak different languages. We want to eliminate language barriers so that everyone can talk with anyone. We saw a gap in real-time translation apps and thus decided to create HelloWorld, a program to translate languages in real-time in-person and on the Internet.
## What it does
HelloWorld is a real-time translator that allows users to communicate in the languages of their choice. HelloWorld allows quick, real-time, easy user-to-user communication in 50+ languages.
HelloWorld translates your language into another language with two optional outputs: speaker output for in-person communication or microphone output for virtual communication.
To translate into another language, HelloWorld receives the user’s microphone input and outputs the translated sentence into a speaker, headset, video call, or other audio output.
## How we built it
We were able to smoothly transition from inputted speech to translated speech in four steps: we first convert the recorded speech to text, translate that text, then convert the text to speech. Finally, we output the translated audio to the appropriate output stream. We handle all of these transitions with a **multithreaded PyQt** frontend, utilizing a **virtual audio cable**.
The initial speech-to-text process uses the **speech\_recognition Python library**. The key to this part of the program is making sure that the input stream the program is listening to is not the actual system input stream -- this is because we must avoid overlapping our translated output and the original inputted speech. Our solution to this problem is outlined below. We record the audio input phrase-by-phrase to ensure that the text reads naturally.
After converting the speech input to text, we translate the text using the **googletrans library** which communicates with the **Google Translate API**. The Google Translate API supports translation between a vast array of languages, which is optimal for our implementation as we want as broad a user base as possible, working toward our goal of maximizing interlanguage communication around the globe.
The final process of text-to-speech was accomplished with the **gTTS Google text-to-speech function**, using the Python library pyttsx3. To play the translated speech back to the user, we sent the translated speech out to the default audio output. If we need to send the translated speech to an *application*, we send it to a **virtual output device**.
## Challenges we ran into
One of the initial obstacles we encountered was the need for the application to interact with two separate input streams. One input stream is used to capture the user's voice, and another input stream is utilized for pipelining the translated audio into the target application. We achieved this by using both a physical input (microphone) and a virtual input (software emulated input). Another challenge we encountered was the utilization of multithreading to create a smooth real-time experience, as the application uses several threads to run the front end, listen to the user's speech, translate it, and send the translated speech into the virtual stream.
## Accomplishments that we're proud of
We are proud that we could create a finished product and expand on our idea more than what we had originally planned. We are happy with how the translation turned out given our challenges. Additionally, we feel like this has a real world application that millions of people world-wide could benefit from. Overall, we are most proud of what we learned!
## What we learned
We learned two major things while building this project. Firstly, we learned how to use multithreading in Python. Secondly, we learned about interfacing various audio input/output devices on Mac/Windows devices to make everything runs smoothly. This was our team's first project in this sphere, so it was a great learning experience for all of us, as we picked up vast new knowledge and skills regarding how apps like ours are implemented.
## What's next for HelloWorld
The first thing to improve in HelloWorld is the latency: the time between speaking and the translator outputting the translated audio. It currently takes a few seconds, making for a slightly awkward turnaround period without speech. To make the app more natural and seamless, the first thing to do is cut down this interval. Second, we’d like to improve the consistency of the translation, optimizing its accuracy. Finally, we would like to make HelloWorld deliverable on more devices (e.g., mobile) to widen the pool of potential users and make the app more accessible. Implementing HelloWorld as a web app could also make strides in this direction. | ## Inspiration
Since the beginning of the COVID-19 pandemic, WFH and online school has fatigued us all. As remote learners ourselves, our team wanted to create a hack that could help digital workers and students improve mental and physical health. While brainstorming for solutions, our team realized that we often forget to take breaks from staring at our screens and sitting for prolonged periods of time. We also identified "Zoom fatigue" as a common problem among remote workers and students. As such, we decided to create a wellness widget for desktops.
## What it does
HealthSimple is a desktop widget that delivers motivation messages, as well as reminders for hydration and physical activity. Users have the option to select which category of messages they would like to receive (ie: motivation, hydration, activity). They can also decide the time intervals at which messages are delivered. For example, if you wish to be reminded to take breaks from your desk every half hour, you would select "activity" as your category and enter "30" as your time interval. HealthSimple will then deliver an activity message, which can range from a posture reminder to an exercise suggestion, every 30 minutes.
## How we built it
Our team used Python as our programming language. Within Python, we used the Plyer library to access the features of the hardware and because it is platform-independent. For the GUI, we used the Tkinter and PIL libraries.
## Challenges we ran into
The main challenge that we ran into was trying to ensure that while the notifications ran in the background, the user would still be able to interact with the main GUI. To do this, our team learned the differences between threading and multiprocessing, both of which allow for different parts of the program run concurrently. We eventually decided to use threading because multiprocessing uses different memory space while threading uses the same. Figuring out how to run notifications while also keeping the main GUI interactive and then learning how to implement threading in Python was challenging.
## Accomplishments that we're proud of
Our team met each other only on the first day of the hackathon. We're proud that we were able to collaborate effectively in a virtual environment despite having had no experience working together before. Most of us were also hackathon newbies yet we were still able to complete our hack and pitch in less than 36 hours!
## What's next for HealthSimple
There are several other features that HealthSimple is hoping to implement, including a Pomodoro timer. As WFH becomes increasingly prevalent, it's important that the modern worker is equipped with tools that keep them happy, healthy, and productive. We would also love to test HealthSimple with prospective users, and iterate on their feedback to improve user flow, functionality, and product design. | ## Inspiration
Many of us have a hard time preparing for interviews, presentations, and any other social situation. We wanted to sit down and have a real talk... with ourselves.
## What it does
The app will analyse your speech, hand gestures, and facial expressions and give you both real-time feedback as well as a complete rundown of your results after you're done.
## How We built it
We used Flask for the backend and used OpenCV, TensorFlow, and Google Cloud speech to text API to perform all of the background analyses. In the frontend, we used ReactJS and Formidable's Victory library to display real-time data visualisations.
## Challenges we ran into
We had some difficulties on the backend integrating both video and voice together using multi-threading. We also ran into some issues with populating real-time data into our dashboard to display the results correctly in real-time.
## Accomplishments that we're proud of
We were able to build a complete package that we believe is purposeful and gives users real feedback that is applicable to real life. We also managed to finish the app slightly ahead of schedule, giving us time to regroup and add some finishing touches.
## What we learned
We learned that planning ahead is very effective because we had a very smooth experience for a majority of the hackathon since we knew exactly what we had to do from the start.
## What's next for RealTalk
We'd like to transform the app into an actual service where people could log in and save their presentations so they can look at past recordings and results, and track their progress over time. We'd also like to implement a feature in the future where users could post their presentations online for real feedback from other users. Finally, we'd also like to re-implement the communication endpoints with websockets so we can push data directly to the client rather than spamming requests to the server.
Tracks movement of hands and face to provide real-time analysis on expressions and body-language.
 | losing |
## Inspiration
All of our team members have a passion for music and play or have played instruments. Oftentimes, we would find ourselves in a desperate hunt for the corresponding piece of sheet music to a melody we had stuck in our heads. Our search often leads nowhere as there is virtually no text to sheet music search engines. Moreover, audio to video searches were often unreliable, especially without a proper instrument on your hands.
Thus, we decided to create Musescribe, a music search engine that allows you to find sheet music to snippets of melodies that you remember.
## What it does
1. **Capture Your Melody:** Simply input the notes you have in mind using our intuitive interface that works similarly to how Lilypond, a text based music engraver takes in inputs.
2. **Magic of Music Recognition:** Musescribe pattern matches the melody you've provided, no matter how simple or complex it may be.
3. **Find Your Music:** Within moments, Musescribe scours our database of sheet music, matching your melody to a wide array of musical compositions.
## How we built it
Overall, we created a project that can process user queries containing LilyPond-style musical notation, translate them into MIDI values and durations, and store and retrieve musical scores using a graph database. There are 5 main parts to our project:
1. Query Language with LilyPond Notation:
We defined a query language for processing musical notation using LilyPond notation. This query language allows users to input musical notations, including pitch, accidentals, and octaves, and we parse these inputs into note values and durations.
2. Kuzu Database:
We used the Kuzu database to store and manage music-related data. Kuzu is a graph database that we used to model our musical data, including songs, parts, and notes.
3. Importing Scores:
We created a function called import\_score that takes a musical score object (in a standard format, MusicXML) and imports it into our Kuzu database. This function creates nodes and relationships in the database to represent songs, parts, and notes.
4. Database Schema Setup:
We defined the schema for our Kuzu database, including node types such as "Song," "Part," and "Note," and the relationships between them.
5. Processing and Storing Musical Data:
Our code processes and stores musical data in a structured way, allowing for efficient querying and retrieval of musical information based on user input.
## Challenges we ran into
1. Figuring out how to represent melodies into a text
2. Implementing grammar for our query engine
## Accomplishments that we're proud of
Using Kuzu to elegantly find sequences of notes was satisfying especially since learning the Cypher query language took much effort.
## What we learned
1. Learned to use Kuzu database
2. Learned to write cypher query language
3. Learned to represent musical notes in strings
## What's next for Musescript
1. Integrate more music into the Musescript database:
It’s difficult to find large amounts of openly accessible sheet music on the internet. In order to fully test and exemplify the reliability of our search engine, we need to work with a greater amount of data from various genres of music.
2. Add more functionality that incorporates musical elements beyond melodies:
We hope to add search functionality for rhythms, time signatures, chord progressions, and more. This will ideally make searches more refined. Lilypond-style inputs do support the writing of the above elements in a text-based manner. | ## Inspiration: Music theory classes reveal that there are many rules to follow when composing sheet music that may be easily forgotten.
## What it does: Scans sheet music, represented in XML format, for parallel fifths, eighths, in order to prevent aural issues.
## How we built it: Python
## Challenges I ran into: Keeping track of some of the math
## Accomplishments that I'm proud of: Parsing XML successfully and having fun in New Haven
## What I learned: How XML files represent data and how to interact with them.
## What's next for Wolo: WOLOWOLO! | ## Inspiration
The idea arose from the current political climate. At a time where there is so much information floating around, and it is hard for people to even define what a fact is, it seemed integral to provide context to users during speeches.
## What it does
The program first translates speech in audio into text. It then analyzes the text for relevant topics for listeners, and cross references that with a database of related facts. In the end, it will, in real time, show viewers/listeners a stream of relevant facts related to what is said in the program.
## How we built it
We built a natural language processing pipeline that begins with a speech to text translation of a YouTube video through Rev APIs. We then utilize custom unsupervised learning networks and a graph search algorithm for NLP inspired by PageRank to parse the context and categories discussed in different portions of a video. These categories are then used to query a variety of different endpoints and APIs, including custom data extraction API's we built with Mathematica's cloud platform, to collect data relevant to the speech's context. This information is processed on a Flask server that serves as a REST API for an Angular frontend. The frontend takes in YouTube URL's and creates custom annotations and generates relevant data to augment the viewing experience of a video.
## Challenges we ran into
None of the team members were very familiar with Mathematica or advanced language processing. Thus, time was spent learning the language and how to accurately parse data, give the huge amount of unfiltered information out there.
## Accomplishments that we're proud of
We are proud that we made a product that can help people become more informed in their everyday life, and hopefully give deeper insight into their opinions. The general NLP pipeline and the technologies we have built can be scaled to work with other data sources, allowing for better and broader annotation of video and audio sources.
## What we learned
We learned from our challenges. We learned how to work around the constraints of a lack of a dataset that we could use for supervised learning and text categorization by developing a nice model for unsupervised text categorization. We also explored Mathematica's cloud frameworks for building custom API's.
## What's next for Nemo
The two big things necessary to expand on Nemo are larger data base references and better determination of topics mentioned and "facts." Ideally this could then be expanded for a person to use on any audio they want context for, whether it be a presentation or a debate or just a conversation. | losing |
## Inspiration
Over 70 million people around the world use sign language as their native form of communication. 70 million voices who were unable to be fully recognized in today’s society. This disparity inspired our team to develop a program that will allow for real-time translation of sign language into a text display monitor. Allowing for more inclusivity among those who do not know sign language to be able to communicate with a new community by breaking down language barriers.
## What it does
It translates sign language into text in real-time processing.
## How we built it
We set the environment by installing different packages (Open cv, mediapipe, scikit-learn), and set a webcam.
-Data preparation: We collected data for our ML model by capturing a few sign language letters through the webcam that takes the whole image frame to collect it into different categories to classify the letters.
-Data processing: We use the media pipe computer vision inference to capture the hand gestures to localize the landmarks of your fingers.
-Train/ Test model: We trained our model to detect the matches between the trained images and hand landmarks captured in real time.
## Challenges we ran into
The challenges we ran into first began with our team struggling to come up with a topic to develop. Then we ran into the issue of developing a program to integrate our sign language detection code with the hardware due to our laptop lacking the ability to effectively process the magnitude of our code.
## Accomplishments that we're proud of
The accomplishment that we are most proud of is that we were able to implement hardware in our project as well as Machine Learning with a focus on computer vision.
## What we learned
At the beginning of our project, our team was inexperienced with developing machine learning coding. However, through our extensive research on machine learning, we were able to expand our knowledge in under 36 hrs to develop a fully working program. | ## **1st Place!**
## Inspiration
Sign language is a universal language which allows many individuals to exercise their intellect through common communication. Many people around the world suffer from hearing loss and from mutism that needs sign language to communicate. Even those who do not experience these conditions may still require the use of sign language for certain circumstances. We plan to expand our company to be known worldwide to fill the lack of a virtual sign language learning tool that is accessible to everyone, everywhere, for free.
## What it does
Here at SignSpeak, we create an encouraging learning environment that provides computer vision sign language tests to track progression and to perfect sign language skills. The UI is built around simplicity and useability. We have provided a teaching system that works by engaging the user in lessons, then partaking in a progression test. The lessons will include the material that will be tested during the lesson quiz. Once the user has completed the lesson, they will be redirected to the quiz which can result in either a failure or success. Consequently, successfully completing the quiz will congratulate the user and direct them to the proceeding lesson, however, failure will result in the user having to retake the lesson. The user will retake the lesson until they are successful during the quiz to proceed to the following lesson.
## How we built it
We built SignSpeak on react with next.js. For our sign recognition, we used TensorFlow with a media pipe model to detect points on the hand which were then compared with preassigned gestures.
## Challenges we ran into
We ran into multiple roadblocks mainly regarding our misunderstandings of Next.js.
## Accomplishments that we're proud of
We are proud that we managed to come up with so many ideas in such little time.
## What we learned
Throughout the event, we participated in many workshops and created many connections. We engaged in many conversations that involved certain bugs and issues that others were having and learned from their experience using javascript and react. Additionally, throughout the workshops, we learned about the blockchain and entrepreneurship connections to coding for the overall benefit of the hackathon.
## What's next for SignSpeak
SignSpeak is seeking to continue services for teaching people to learn sign language. For future use, we plan to implement a suggestion box for our users to communicate with us about problems with our program so that we can work quickly to fix them. Additionally, we will collaborate and improve companies that cater to phone audible navigation for blind people. | ## Inspiration
We wanted to promote an easy learning system to introduce verbal individuals to the basics of American Sign Language. Often people in the non-verbal community are restricted by the lack of understanding outside of the community. Our team wants to break down these barriers and create a fun, interactive, and visual environment for users. In addition, our team wanted to replicate a 3D model of how to position the hand as videos often do not convey sufficient information.
## What it does
**Step 1** Create a Machine Learning Model To Interpret the Hand Gestures
This step provides the foundation for the project. Using OpenCV, our team was able to create datasets for each of the ASL alphabet hand positions. Based on the model trained using Tensorflow and Google Cloud Storage, a video datastream is started, interpreted and the letter is identified.
**Step 2** 3D Model of the Hand
The Arduino UNO starts a series of servo motors to activate the 3D hand model. The user can input the desired letter and the 3D printed robotic hand can then interpret this (using the model from step 1) to display the desired hand position. Data is transferred through the SPI Bus and is powered by a 9V battery for ease of transportation.
## How I built it
Languages: Python, C++
Platforms: TensorFlow, Fusion 360, OpenCV, UiPath
Hardware: 4 servo motors, Arduino UNO
Parts: 3D-printed
## Challenges I ran into
1. Raspberry Pi Camera would overheat and not connect leading us to remove the Telus IoT connectivity from our final project
2. Issues with incompatibilities with Mac and OpenCV and UiPath
3. Issues with lighting and lack of variety in training data leading to less accurate results.
## Accomplishments that I'm proud of
* Able to design and integrate the hardware with software and apply it to a mechanical application.
* Create data, train and deploy a working machine learning model
## What I learned
How to integrate simple low resource hardware systems with complex Machine Learning Algorithms.
## What's next for ASL Hand Bot
* expand beyond letters into words
* create a more dynamic user interface
* expand the dataset and models to incorporate more | winning |
## Inspiration
Have you ever wanted to search something, but aren't connected to the internet? Data plans too expensive, but you really need to figure something out online quick? Us too, and that's why we created an application that allows you to search the internet without being connected.
## What it does
Text your search queries to (705) 710-3709, and the application will text back the results of your query.
Not happy with the first result? Specify a result using the `--result [number]` flag.
Want to save the URL to view your result when you are connected to the internet? Send your query with `--url` to get the url of your result.
Send `--help` to see a list of all the commands.
## How we built it
Built on a **Nodejs** backend, we leverage **Twilio** to send and receive text messages. When receiving a text message, we send this information using **RapidAPI**'s **Bing Search API**.
Our backend is **dockerized** and deployed continuously using **GitHub Actions** onto a **Google Cloud Run** server. Additionally, we make use of **Google Cloud's Secret Manager** to not expose our API Keys to the public.
Internally, we use a domain registered with **domain.com** to point our text messages to our server.
## Challenges we ran into
Our team is very inexperienced with Google Cloud, Docker and GitHub Actions so it was a challenge needing to deploy our app to the internet. We recognized that without deploying, we would could not allow anybody to demo our application.
* There was a lot of configuration with permissions, and service accounts that had a learning curve. Accessing our secrets from our backend, and ensuring that the backend is authenticated to access the secrets was a huge challenge.
We also have varying levels of skill with JavaScript. It was a challenge trying to understand each other's code and collaborating efficiently to get this done.
## Accomplishments that we're proud of
We honestly think that this is a really cool application. It's very practical, and we can't find any solutions like this that exist right now. There was not a moment where we dreaded working on this project.
This is the most well planned project that we've all made for a hackathon. We were always aware how our individual tasks contribute to the to project as a whole. When we felt that we were making an important part of the code, we would pair program together which accelerated our understanding.
Continuously deploying is awesome! Not having to click buttons to deploy our app was really cool, and it really made our testing in production a lot easier. It also reduced a lot of potential user errors when deploying.
## What we learned
Planning is very important in the early stages of a project. We could not have collaborated so well together, and separated the modules that we were coding the way we did without planning.
Hackathons are much more enjoyable when you get a full night sleep :D.
## What's next for NoData
In the future, we would love to use AI to better suit the search results of the client. Some search results have a very large scope right now.
We would also like to have more time to write some tests and have better error handling. | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | ## Inspiration
You don't have Internet connection, but you want to use Bing anyway cuz you're a hopeless Internet addict.
Or you want to find cheap hotel deals. HotlineBing can help.
## What it does
Allows you to use Bing via text messaging, search for hotel deals using natural language (that's right no prompts) using HP-HavenOnDemand Extract Entity API
## How I built it
Nodejs, Express, HP-HavenOnDemand, BrainTree API, Bing API, PriceLine API
## Challenges I ran into
Twilio Voice API requires an upgraded account so this is not really a hotline (\*sighs Drake), general asynchronous JS flow conflicts with our expectation of how our app should flow, integrating Braintree API is also hard given the nature of our hack
## Accomplishments that I'm proud of
Get some functionality working
## What I learned
JS is a pain to work with
## What's next for HotlineBing
More polished version: improve natural language processing, allow for more dynamic workflow, send Drake gifs via MMS?? | winning |
## Inspiration
When you find a game you enjoy, the last thing you want is to be banned from it. Don't Ban Us is a tool users can leverage to make sure their language is always appropriate to their opponents and never is the reason why they get blocked! We built this project from our shared experience of playing games and realizing the importance of fair and respectful interactions within the gaming community.
Our mission is to promote a positive gaming environment where players can enjoy their favorite games without fear of being banned due to offensive language or behavior. With Don't Ban Us, we aim to foster a sense of camaraderie among gamers while upholding the principles of fair play and sportsmanship.
## What it does
Don't Ban Us is a plugin that gamers can install on their machines and apply to games of any shape and size. When users open the chat in a game and type a rude or toxic message, Don't Ban Us will replace their text with more game-friendly phrases that still insult their opponents. Roast other people in the chat without fear of losing game privileges! Don't Ban Us is supportive of positive chat messages and allows those to pass through unfiltered.
**Before:** My grandmother plays League better than you, you stupid loser.
**After:** Your League skills must come from your grandmother, because they sure don't come from you!
## How we built it
Don't Ban Us is built atop Electron. With powerful features like built-in macros, system tray, and end-to-end connection, it gave clarity to the road ahead. When users press certain inputs, we intercept these and process them through functions, then use a robot-type feature that lets us override the text users have in their chat boxes.
The backend is built with Python! We used the nltk (Natural Language Toolkit) for sentiment analysis on user messages to detect Negative phrases. Once a message is determined to be rude, we use GPT's API to rephrase the sentence into kinder yet still insulting text.
## Challenges we ran into
We ran into some recursive issues with registering key binds! For example, we had some cases where we needed to register keys to trigger our backend script, unregister them so we could use those keys to type text, and then reregister them again to be ready for the next time a user clicked it. We also experienced challenges with connecting Electron to our Python backend as it's not very well documented. Since we are building Don't Ban Us for fast-moving game environments, we realized the importance of optimizing our tool's performance so we worked to save trained models and quicken our GPT calls.
## Accomplishments that we're proud of
We were proud of the first time that we saw our tool run end-to-end! It was exciting to watch the backend calls get triggered after we typed an insulting message and see the automated typing complete as the message was replaced. We were very satisfied to have successfully overcome our merge conflicts and connect the backend and frontend of our project!
## What we learned
Our team has been able to try out working with new frameworks and libraries that we haven't experienced before, from the GPT API, to nltk, to Electron.
## What's next for Don't Ban Us
We envision Don't Ban Us to be the future of standardized chat moderation across platforms ranging from gameplay to social media. Currently, it censors rude/profane chat messages but we have explored extensions of the tool to filter sensitive information (think credit card numbers, addresses, phone numbers, and ages) and adapt to prevent racial slurs on popular platforms. Our goal is to provide chat moderation features to games of all sizes (established ones with large development teams as well as smaller projects with fewer technical resources). | ## Inspiration
We wanted a low-anxiety tool to boost our public speaking skills. With an ever-accelerating shift of communication away from face-to-face and towards pretty much just memes, it's becoming difficult for younger generations to express themselves or articulate an argument without a screen as a proxy.
## What does it do?
DebateABot is a web-app that allows the user to pick a topic and make their point, while arguing against our chat bot.
## How did we build it?
Our website is boot-strapped with Javascript/JQuery and HTML5. The user can talk to our web app which used NLP to convert speech to text, and sends the text to our server, which was built with PHP and background written in python. We perform key-word matching and search result ranking using the indico API, after which we run Sentiment Analysis on the text. The counter-argument, as a string, is sent back to the web app and is read aloud to the user using the Mozilla Web Speech API
## Some challenges we ran into
First off, trying to use the Watson APIs and the Azure APIs lead to a lot of initial difficulties trying to get set up and get access. Early on we also wanted to use our Amazon Echo that we have, but reached a point where it wasn't realistic to use AWS and Alexa skills for what we wanted to do. A common theme amongst other challenges has simply been sleep deprivation; staying up past 3am is a sure-fire way to exponentiate your rate of errors and bugs. The last significant difficulty is the bane of most software projects, and ours is no exception- integration.
## Accomplishments that we're proud of
The first time that we got our voice input to print out on the screen, in our own program, was a big moment. We also kicked ass as a team! This was the first hackathon EVER for two of our team members, and everyone had a role to play, and was able to be fully involved in developing our hack. Also, we just had a lot of fun together. Spirits were kept high throughout the 36 hours, and we lasted a whole day before swearing at our chat bot. To our surprise, instead of echoing out our exclaimed profanity, the Web Speech API read aloud "eff-asterix-asterix-asterix you, chat bot!" It took 5 minutes of straight laughing before we could get back to work.
## What we learned
The Mozilla Web Speech API does not swear! So don't get any ideas when you're talking to our innocent chat bot...
## What's next for DebateABot?
While DebateABot isn't likely to evolve into the singularity, it definitely has the potential to become a lot smarter. The immediate next step is to port the project over to be usable with Amazon Echo or Google Home, which eliminates the need for a screen, making the conversation more realistic. After that, it's a question of taking DebateABot and applying it to something important to YOU. Whether that's a way to practice for a Model UN or practice your thesis defence, it's just a matter of collecting more data.
<https://www.youtube.com/watch?v=klXpGybSi3A> | ## Inspiration
After conducting extensive internal and external market research, our team discovered that customer experience is one of the biggest challenges the insurance industry faces. With the rapid increase in digitalization, **customers are seeking faster and higher quality services** where they can find answers, personalize their products and manage their policies instantly online.
## What it does
**Insur-AI** is a fully functional chatbot that mimics the role of an insurance broker through human-like conversation and provides an accurate insurance quote within minutes!
## You can check out a working version of our website on: insur-AI.tech
## How we built it
We used **ReactJS**, **Bootstrap** along with some basic **HTML & CSS** for our project! Some of the design elements were created using Photoshop and Canva.
.
## Accomplishments that we're proud of
Creation of a full personalized report of an **Intact** insurance premium estimate including graphical analysis of price, ways to reduce insurance premium costs, in a matter of minutes!
## What's next for Insur-Al
One of the things we could work on is the integration of Insur-AI into <https://www.intact.ca/> , so prospective customers can have a quick and easy way to get a home insurance quote! Moreover, the idea of a chatbot can be expanded into other kinds of insurance as well, allowing insurance companies to reach a broader customer base.
**NOTE:** There have been some domain issues due to configuration errors. If insur-AI.tech does not work, please try a (slightly) older copy here: aryamans.me/insur-AI
<https://www.youtube.com/watch?v=YEU5eBp_Um4&feature=youtu.be> | partial |
## 🌠 Inspiration
For our Hack the North project, one of our main goal was to experiment with Unity and game development. More importantly, however, we were simply excited to be able to work with each other! As a group of four, we are in the same program, but in completely different sets. Bonded by a love of cats (sorry, cats), a drive to learn, and a summer-time meet up with board games, we decided to build Cats In Space.
## 🌌 What it does
Cats In Space is a single-player 2D tower defense game set in space. It's intention was to create a safe space for our team to experiment with Unity and C# for the very first time as growing developers! 🌱
*No cats were harmed in the process of this production and we do not mean to offend any cats.*
## 🚀 How we built it
Using Unity and C# and a lot of Googling.
## 🌍 Challenges we ran into
As with any learning process, there were a lot of unknowns for our team when we dove into Unity. The first hiccup we ran into right off the bat was figuring out how to use Git with Unity! We ended up settling with trying out Unity's Collaboration feature, which helped us easily Publish and see each other's changes.
In addition to this particular detail, we also ran into challenges debugging our code, solving the mysteries of the disappearing Sprites, and constructing a map. Although a lot of this took time, we made sure to push through and simply had the goal to wrap up a minimal, finished game.
## 💫Accomplishments that we're proud of
There were certainly times when it seemed like there was a long road ahead of us to completion for this game, but we are really proud of the fact that we were able to wrap our game up with fun components and a great experience going through trials and errors together as a team.
## 🛰 What we learned
We learned that sometimes, hackathons can be a chance to not only challenge yourself to take home prizes, but just to learn. It can be a great chance for you and your friends to dial back and enjoy the learning process together.
## ✨ What's next for Cats In Space
Our project can be grown to be a more developed game; however, most of the developers really wanted this to be our first foray into development on Unity overall. It is not our intention to continue building upon this game. That being said, we can see some future changes that we can implement better including:
* a better balanced Catmmando to Enemy gameplay
* increase the Catmmando variety 🐱🚀
* a more customized build with an improved UI
* adjust the shooting range of our Catmmandos
* include areas where players cannot station Catmmandos
## 👩🏻🚀 Extra Credits
* Cosmic Lilac Tiles by Petricake Games
* Mini Magick Shoot design by XYEzawr
* Code references and adaptation from ZeveonHD
* Music from PlayOnLoop: "Geek Club", "Cactus Land", & "Chubby Cat" | ## Inspiration
I was inspired by a bug infestation in my house.
## What it does
You play as a farmer, and water a plant to make it grow while being attacked by insects. You win when the plant grows large enough.
## How we built it
We built this game through Unity, and coded in C#
## Challenges we ran into
Our largest issue was dealing with the health system. Connecting the player with the Unity UI was tricky, as UI was coded separately from all the game mechanics. We learned to use static variables to carry over important info such as health to update the UI.
## Accomplishments that we're proud of
We are proud of the experience our teammates earned. 3 of our members were new to Unity, and not only were they able to learn material quickly, they were able to contribute new ideas, such as designing and implementing sprites into the game.
Our greatest challenge was managing work. What components and lines of code could I separate between teammates in order to help them understand Unity within the timeframe of 3 days? And how could the work they complete be implemented within the main program the game will be ran in? We managed to separate work based on prefabs, which are objects in unity such as pests and growing plants. Each of us took a prefab to work on and combined them all into a scene for our game. From doing so we did not need to use extra programs to collaborate, and simplify the work process.
## What we learned
We learned how to connect various small systems, such as movement controls and UI, design and implement art and work as a team.
## What's next for Plant Defense
Plant defense will have an increased map size, as well as several platforms and different enemies to allow the player to experiment and theorize unique ways to win. | ## Inspiration
Our mission is to foster a **culture of understanding**. A culture where people of diverse backgrounds get to truly *connect* with each other. But, how can we reduce the barriers that exists today and make the world more inclusive?
Our solution is to bridge the communication gap of **people with different races and cultures** and **people of different physical abilities**.
## What we built
In 36 hours, we created a mixed reality app that allows everyone in the conversation to communicate using their most comfortable method:
You want to communicate using your mother tongue?
Your friend wants to communicate using sign language?
Your aunt is hard of hearing and she wants to communicate without that back-and-forth frustration?
Our app enables everyone to do that.
## How we built it
VRbind takes in speech and coverts it into text using Bing Speech API. Internally, that text is then translated into your mother tongue language using Google Translate API, and given out as speech back to the user through the built-in speaker on Oculus Rift. Additionally, we also provide a platform where the user can communicate using sign language. This is detected using the leap motion controller and interpreted as an English text. Similarly, the text is then translated into your mother tongue language and given out as speech to Oculus Rift.
## Challenges we ran into
We are running our program in Unity, therefore the challenge is in converting all our APIs into C#.
## Accomplishments that we are proud of
We are proud that we were able complete with all the essential feature that we intended to implement and troubleshoot the problems that we had successfully throughout the competition.
## What we learned
We learn how to code in C# as well as how to select, implement, and integrate different APIs onto the unity platform.
## What's next for VRbind
Facial, voice, and body language emotional analysis of the person that you are speaking with. | losing |
## Inspiration
While discussing potential ideas, Robin had to leave the call because of a fire alarm in his dorm — due to burning eggs in the dorm's kitchen. We saw potential for an easier and safer way to cook eggs.
## What it does
Eggsy makes cooking eggs easy. Simply place your egg in the machine, customize the settings on your phone, and get a fully-cooked egg in minutes. Eggsy is a great, healthy, quick food option that you can cook from anywhere!
## How we built it
The egg cracking and cooking are handled by a EZCracker egg cracker and hot plate, respectively. Servo motors control these devices and manage the movement of the egg within the machine. The servos are controlled by a Sparkfun Redboard, which is connected to a Raspberry Pi 3 running the back-end server. This server connects to the iOS app and web interface.
## Challenges we ran into
One of the most difficult challenges was managing all the resources that we needed in order to build the project. This included gaining access to a 3D printer, finding a reliable way to apply a force to crack an egg, and the tools to put it all together. Despite these issues, we are happy with what we were able to hack together in such a short period time with limited resources!
## Accomplishments that we're proud of
Creating a robust interface between hardware and software. We wanted the user to have multiple ways to interact with the device (the app, voice (Siri), quick actions, the web app) and the hardware to work reliably no matter how the user prefers to interact. We are proud of our ability to take a challenging project head-on, and get as much done as we possibly could.
## What we learned
Hardware is hard. Solid architecture is important, especially when connecting many pieces together in order to create a cohesive experience.
## What's next for Eggsy
We think Eggsy has a lot of potential, and many people we have demo'd to have really liked the idea. We would like to add additional egg-cooking options, including scrambled and hardboiled eggs. While Eggsy still a prototype, it's definitely possible to build a smaller, more reliable model in the future to market to consumers. | SmartArm is our submission to UofTHacks 2018.
SmartArm uses Microsoft Cognitive Services, namely the Computer Vision API and Text to Speech API. We designed and rapid prototyped a prosthetic hand model, and embedded a Raspberry PI modular camera on to it. There are servo motors attached to each digit of the hand, powered by an Arduino Uno. The camera feeds image frames to the Analyze.py script, in which objects in the frame are recognzied against Microsoft's pretrained model. Based on the shape of the object, the arduino issues the optimal grasp to hold the identified object.
The SmartArm is a revolutionary step in prosthetics. Because it is completley 3D printed apart form the circuitry, it is meant to be a more cost-friendly and efficient method for amputees and those with congenital defects to gain access to fully functional prosthetics. | ## Inspiration
We wanted to find an application for the Watson ML APIs that was both relatively novel and relatively adaptable. We initially tried to use a series of APIs in order to assess relations between keywords, entities, and sentiments to determine bias in news media, but quickly determined that due to the length and diversity of news articles, as well as a lack of a way to sort articles based on 'quality,' it was infeasible. However, we did determine that it would be much more feasible and applicable to assess social media comments, which already have easily accessible metrics for perceived quality, (upvotes/likes/retweets), short strings, which would allow for a much better way to both produce a working model of sentimental analysis and make useful sense of the data that we produced.
We ended up choosing to select posts from reddit, and analyze what keywords and entities they encompassed, incorporating upvote data, top comments, and body text. In doing so, we created a system that produced data on trending topics in a selective basis, picking from one or a combination of subreddits, which allows for granular topic control, providing sets of similar data points (posts), that also had scope for application on other text-heavy social media websites.
## What it does
Baker Street Analytica is a prototype framework for in-depth analysis of subreddit trends and opinions. We created a GUI for selecting data sets [subreddit(s), number of posts collected, number of comments assessed], we produced a user-friendly graphical output that can be easily interpreted to understand the collective consciousness of a subforum. This framework, while currently plugged into the PRAW (Python Reddit API Wrapper) tool for Reddit, can easily be reworked to take input from Twitter and/or other forum style websites.
## How we built it
We started by tinkering with Watson's Natural Language Understanding API, to try and figure out how it interpreted text and divided it into keywords and entities. From there on, we decided on a website to gather our data from, and ended up picking reddit due to its numerous and specific sub-forums, which closely group similar posts and its python API, which allowed us to use one powerful language that became modular due to its ease of understanding and use. From there on, we decided to first output the data we gathered as text, separating keywords/entities, and how positively, and negatively they were perceived. While we gained adequate results, which we kept in as a debugging tool, we still believed that there was a better way to represent them. As such, we went on to first develop a graphical tool to produce a graph of the intensity of the negative and positive sentiments of each keyword and entity. From there, we then decided to improve the user-friendlyness of our script and produce a 'webpage' that allowed for easy input of subreddits, number of posts to be assessed, number of comments, and number of keywords/entities to be chosen.
## Challenges we ran into
After we completed the initial task of implementing a barebones NLU keywords algorithm, we decided to attempt graphical representations of the data. We had some trouble finding a good graph type to represent both positive and negative feedback without convoluting the data. We eventually settled on a bar graph that extended both into the negative as well as the positive end. Then, we struggled to embed the graph into the front-end interface that we were developing. We started by using a Dash implementation, which run a new server and opened a new page for each new graph. We eventually had to switch to a Plot.ly implementation, which involved rewriting our entire graph implementation to embed our graph to the same page as our form.
## What's next for Baker Street Analytica
Sometimes it becomes quite hard to interpret the data outputs, particularly when they return non-sequitur keywords and entities. Certainly, improvements to the accuracy and contextualization of results would vastly increase the utility of this application. | partial |
## Inspiration
RoomRival drew inspiration from the desire to revolutionize indoor gaming experiences. We wanted to create an innovative and dynamic platform that transforms ordinary spaces into competitive battlegrounds, bringing people together through technology, strategy, and social interaction while integrating the website with MappedIn API.
## What it does
RoomRival is a fast-paced indoor game where players strategically claim rooms using QR codes (corresponds to each room), and tries to claim as many as possible. Players are able to steal rooms that have already been claimed by other players. The real-time leaderboard shows the ranking of players and the points they have gained. In addition, the real-time map also shows the room status of the map - whether a room is claimed (the claimed room is coloured according to the players colour) or not claimed.
## How we built it
Crafting RoomRival involved using React for dynamic UI, Socket.io for real-time communication, JavaScript for versatile functionality, QR-Scanner for efficient room claiming once a player scans, Node.js for a robust backend, and MappedIn for precise mapping and visualization. This comprehensive tech stack allowed us to seamlessly integrate innovative features, overcoming challenges and delivering an immersive indoor gaming experience.
## Challenges we ran into
Getting Socket.io up and running was tough, and we struggled with creating a real-time mapping system using MappedIn. Hosting and making the website work on phones posed some challenges, as well as making sure the dynamic look of the website worked well with the technical stuff behind it. Overcoming these issues needed us to work together and stick to making RoomRival awesome.
## Accomplishments that we're proud of
We find satisfaction in successfully blending technology and real-world gaming, transforming RoomRival into an engaging and dynamic platform that captivates players. Our accomplishment lies in creating an immersive gaming experience that seamlessly fuses innovation with entertainment.
## What we learned
Optimizing QR functionality with React, real-time communication with Socket.io, and backend operations with Node.js were integral lessons. Challenges in setting up Socket.io and real-time mapping with MappedIn, along with hosting dynamics, provided valuable insights. These learnings contributed to the successful creation of RoomRival.
## What's next for RoomRival
RoomRival's future includes ongoing refinement, feature enhancements, and expanding the gaming community. We aim to introduce new challenges and expanding the map to not just UBC campus but anywhere the user wants, as well as explore opportunities for partnerships to continually elevate the RoomRival experience. | ## Inspiration
As first-year students, we have experienced the difficulties of navigating our way around our new home. We wanted to facilitate the transition to university by helping students learn more about their university campus.
## What it does
A social media app for students to share daily images of their campus and earn points by accurately guessing the locations of their friend's image. After guessing, students can explore the location in full with detailed maps, including within university buildings.
## How we built it
Mapped-in SDK was used to display user locations in relation to surrounding buildings and help identify different campus areas. Reactjs was used as a mobile website as the SDK was unavailable for mobile. Express and Node for backend, and MongoDB Atlas serves as the backend for flexible datatypes.
## Challenges we ran into
* Developing in an unfamiliar framework (React) after learning that Android Studio was not feasible
* Bypassing CORS permissions when accessing the user's camera
## Accomplishments that we're proud of
* Using a new SDK purposely to address an issue that was relevant to our team
* Going through the development process, and gaining a range of experiences over a short period of time
## What we learned
* Planning time effectively and redirecting our goals accordingly
* How to learn by collaborating with team members to SDK experts, as well as reading documentation.
* Our tech stack
## What's next for LooGuessr
* creating more social elements, such as a global leaderboard/tournaments to increase engagement beyond first years
* considering freemium components, such as extra guesses, 360-view, and interpersonal wagers
* showcasing 360-picture view by stitching together a video recording from the user
* addressing privacy concerns with image face blur and an option for delaying showing the image | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps out the WiFi landscape of the world. That information is sent to a central server and combined with location and WiFi data from all users of the app. The server then processes the data and generates heatmaps of WiFi signal strength to send back to the end user. Because of our architecture these heatmaps are real time, updating dynamically as the WiFi strength changes.
## How we built it
We split up the work into three parts: mobile, cloud, and visualization and had each member of our team work on a part. For the mobile component, we quickly built an MVP iOS app that could collect and push data to the server and iteratively improved our locationing methodology. For the cloud, we set up a Firebase Realtime Database (NoSQL) to allow for large amounts of data throughput. For the visualization, we took the points we received and used gaussian kernel density estimation to generate interpretable heatmaps.
## Challenges we ran into
Engineering an algorithm to determine the location of the client was significantly more difficult than expected. Initially, we wanted to use accelerometer data, and use GPS as well to calibrate the data, but excessive noise in the resulting data prevented us from using it effectively and from proceeding with this approach. We ran into even more issues when we used a device with less accurate sensors like an Android phone.
## Accomplishments that we're proud of
We are particularly proud of getting accurate paths travelled from the phones. We initially tried to use double integrator dynamics on top of oriented accelerometer readings, correcting for errors with GPS. However, we quickly realized that without prohibitively expensive filtering, the data from the accelerometer was useless and that GPS did not function well indoors due to the walls affecting the time-of-flight measurements. Instead, we used a built in pedometer framework to estimate distance travelled (this used a lot of advanced on-device signal processing) and combined this with the average heading (calculated using a magnetometer) to get meter-level accurate distances.
## What we learned
Locationing is hard! Especially indoors or over short distances.
Firebase’s realtime database was extremely easy to use and very performant
Distributing the data processing between the server and client is a balance worth playing with
## What's next for Hotspot
Next, we’d like to expand our work on the iOS side and create a sister application for Android (currently in the works). We’d also like to overlay our heatmap on Google maps.
There are also many interesting things you can do with a WiFi heatmap. Given some user settings, we could automatically switch from WiFi to data when the WiFi signal strength is about to get too poor. We could also use this app to find optimal placements for routers. Finally, we could use the application in disaster scenarios to on-the-fly compute areas with internet access still up or produce approximate population heatmaps. | partial |
## Inspiration
Each of our group members have been affected by Type 2 Diabetes as it runs in our families. From personal experience, we understand that diabetes can be a demanding condition to manage and affect our lives in many ways. Everyone wants to have the best possible quality of life. It just feels good to be satisfied and happy. However, there is another reason, as well. Just as diabetes can affect your quality of life, your quality of life can affect your diabetes. This notion inspired our application: Sugr Rush, a mobile application for identification of Type 2 diabetes and voice-enabled workout routines to prevent further severity of the condition.
## What it does
Sugr Rush is a mobile application which identifies whether a female individual has Type 2 diabetes or not. It suggests workout routines with voice-enabled dialogue to guide patients through specified level workouts as per their health conditions related to diabetes. The application has a physician/doctor login and patient login.
1. On the patient side, the individual can request a diagnosis from their doctor at their clinic on the interface.
2. On the doctor side, the physician can login to his/her database and select new diagnoses to complete as per health care records.
a) The doctor fills out patient information on the input parameters pertaining to Type 2 diabetes.
b) The interface will output whether the individual is at low risk or high risk for Type 2 Diabetes.
c) Information gets relayed to patient side
3. On the patient side, the individual views diagnosis and obtains workout routines tailored to their specific level of severity for diabetes.
a) Voice-enabled workouts help the individual complete routines based on their frequency and time preferences
b) Individuals may keep track of their workouts on interface and request updated diagnosis from doctor after completion of workouts in a set duration of time.
## How we built it
The model is built using python’s machine learning libraries (tensorflow, Keras) by incorporating deep neural networks to predict whether a patient has type 2 diabetes or not. The model uses the K-fold Cross Validation(CV) technique by dividing the data into folds and ensuring that each fold is used as a testing set at some point. The data set consists of some medical distinct variables, such as pregnancy record, BMI, insulin level, age, glucose concentration, diastolic blood pressure, triceps skin fold thickness, diabetes pedigree function etc. The data set has 768 patient’s data where all the patients are female and at least 21 years old.
The front-end application interface was built on Sketch and Android Studio with the server hosted on the Internet. In addition, the voice-enabled, NLP technology was integrated with Dialogflow, an API on Google Cloud.
## Challenges we ran into
* Coming up with a solid idea that we are all passionate about
* Connectivity issues related to integrating functionality of the back-end, front-end and speech into one application
* Dialogflow challenges with voice integration
* Learning curve in understanding new languages from scratch (JavaScript)
## Accomplishments that we're proud of and what we learned
1. Learning more about the implications of Type 2 Diabetes
2. Working with the Dialogflow API for the first time
3. Communication between an application and a server hosted on the internet
4. Leveraging our skill-sets while learning new skills (whether it's a new coding language or constructing an interface)
## What's next for Sugr Rush
1. Applying the solution across different demographics (males, children, individuals across different populations around the world)
2. Learning to diagnosis more specific problems related to diabetes (identification of Type 1 vs. Type 2, early detection, and hearing loss prevention from diabetes)
3. Integrating a communication network between doctor-side and patient-side for other conditions outside of diabetes on the application itself | ## Inspiration
Everyone is bound to run into the same problem: you can't decide what to wear! Plus, the weather is constantly changing, meaning you can never comfortably weather the same outfits all year round. Our team seeks to change that by creating an application that inspires people to look into new styles based on the local weather.
## What it does
WeatherWear is a weather forecast application that helps the user to "Get Inspired!" on outfit ideas based on the current day's forecast.
## How we built it
We used the OpenWeather API to collect data about current and future forecasts at the user’s location. When the user opens the application, they are prompted with a message asking for permission to use their location. Upon granting access, their longitude and latitude are used to pinpoint their location. The API then provides the program with the forecast data of their region in 3-hour intervals, for the next 5 days. From here, the weather temperature in Kelvin is converted into celsius (which can also be changed to Fahrenheit). Then, the is whether ID is given found in order to present a corresponding icon based on weather conditions (e.g. cloudy, snowing, rainy, etc.). Finally, the data is then analyzed to present to the user appropriate outfit ideas.
## Challenges we ran into
The main challenge we ran into was displaying the proper data from the API to our webpage. The API that we used gave us a wider quantity of information than needed. To combat this, we experimented with different methods in order to take exclusively the key pieces of information.
## Accomplishments that we're proud of
As a team, we can proudly say that learning how to use an API for the first time was a significant accomplishment for our project. In addition, we were also quite satisfied with how the aesthetics and design of the application had turned out.
## What we learned
Going into this hackathon, all of our team members had only had experience with the basics of JavaScript, HTML, and CSS. As such, a majority of the code was learned whilst developing the application. Furthermore, we learned what APIs are and how to integrate them using JavaScript.
## What's next for Working Weather App
Our next step to improve WeatherWear is to get the images through a browsing tool. We would use a separate tool in order to browse sites like Pinterest and gather a greater range of content. Theoretically, the user would be able to continuously refresh the page for their next piece of outfit inspiration. | ## Inspiration
Disasters can strike quickly and without notice. Most people are unprepared for situations such as earthquakes which occur with alarming frequency along the Pacific Rim. When wifi and cell service are unavailable, medical aid, food, water, and shelter struggle to be shared as the community can only communicate and connect in person.
## What it does
In disaster situations, Rebuild allows users to share and receive information about nearby resources and dangers by placing icons on a map. Rebuild uses a mesh network to automatically transfer data between nearby devices, ensuring that users have the most recent information in their area. What makes Rebuild a unique and effective app is that it does not require WIFI to share and receive data.
## How we built it
We built it with Android and the Nearby Connections API, a built-in Android library which manages the
## Challenges we ran into
The main challenges we faced while making this project were updating the device location so that the markers are placed accurately, and establishing a reliable mesh-network connection between the app users. While these features still aren't perfect, after a long night we managed to reach something we are satisfied with.
## Accomplishments that we're proud of
WORKING MESH NETWORK! (If you heard the scream of joy last night I apologize.)
## What we learned
## What's next for Rebuild | losing |
## Inspiration
The motivation behind creating catPhish arises from the unfortunate reality that many non-tech-savvy individuals often fall victim to phishing scams. These scams can result in innocent people losing nearly their entire life savings due to these deceptive tactics employed by cybercriminals. By leveraging both AI technology and various APIs, this tool aims to empower users to identify and prevent potential threats. It serves as a vital resource in helping users recognize whether a website is reputable and trusted, thereby contributing in the prevention of financial and personal data loss.
## What it does
catPhish integrates multiple APIs, including the OpenAI API, to combat phishing schemes effectively. Designed as a user friendly Chrome extension, catPhish unites various services into a single tool. With just a simple click, users can diminish their doubts or avoid potential mistakes, making it an accessible solution for users of all levels of technical expertise.
## How we built it
CatPhish was developed using React for the user interface visible in the browser, while Python and JavaScript were employed for the backend operations. We integrated various tools to enhance its effectiveness in combating phishing attempts. These tools include the Google Safe Browsing API, which alerts users about potentially harmful websites, virus total, Exerra Anti-Phish, which specializes in detecting phishing threats. In addition, we incorporated OpenAI to leverage advanced technology for identifying malicious websites. To assess the credibility of websites, we employed the IP Quality Score tool, which evaluates factors like risk level. For managing user authentication and data storage, we relied on Firebase, a comprehensive platform that facilitates secure user authentication and data management. By combining these components, CatPhish emerges as a sturdy solution for safeguarding users against online scams, offering enhanced security and peace of mind during web browsing.
## Challenges we ran into
Throughout the development process, we came across various permissions and security related challenges essential to the project. Issues such as CORS (Cross-Origin Resource Sharing) and web-related security hurdles posed a significant amount of obstacles. While there were no straightforward solutions to these challenges, we adopted a proactive approach to address them effectively. One of the strategies we employed involved leveraging Python's Flask CORS to navigate around permission issues arising from cross origin requests. This allowed us to facilitate communication between different domains. Additionally, we encountered security issues such as unauthorized routing, however through careful analysis, we patched up these vulnerabilities to ensure the integrity and security of the application. Despite the complexity of the challenges, our team remained resilient and resourceful, allowing us to overcome them through critical thinking and innovative problem solving techniques. One noteworthy challenge we faced was the limitation of React browser routing within Chrome extensions. We discovered that traditional routing methods didn't work as expected within this environment, which allowed us to explore alternative solutions. Through research and experimentation, we learned about MemoryBrowsing, one of React's components. Implementing this approach enabled us to get around the limitations of Chrome's native routing restrictions.
## Accomplishments that we're proud of
We take great pride in our ability to successfully integrate several functionalities into a single project, despite facing several complexities and challenges along the way. Our team's collaborative effort, resilience, and support for one another have been extremely resourceful in overcoming obstacles and achieving our goals. By leveraging our expertise and working closely together, we were able to navigate through many technical issues, implement sophisticated features, and deliver a solid solution that addresses the critical need for enhanced security against phishing attacks. We take pride in the teamwork and trust among our team members.
## What we learned
Our journey with this project has been an extremely profound learning experience for all of us. As a team, it was our first venture into building a browser extension, which provided valuable insights into the complexity of extension development. We navigated through the process, gaining a deeper understanding of extension architecture and functionality. One of the significant learning points was integrating Python with TypeScript to facilitate communication between different parts of the project. This required us to manage API requests and data fetching efficiently, enhancing our skills in backend/frontend integration. Furthermore, diving into routing mechanisms within the extension environment expanded our knowledge base, with some team members developing a stronger grasp of routing concepts and implementation. The use of Tailwind CSS for styling purposes presented another learning opportunity. We explored its features and capabilities, improving our skills in responsive design and UI development. Understanding how extensions operate and interact with web browsers was another enlightening aspect of the project as it actually differed from how a web application operates. It provided practical insights into the inner workings of browser extensions and their functionalities. Additionally, our hands-on experience with Firebase empowered us to practice database implementation. Leveraging Firebase's user friendly interface, we gained experience in managing and storing data securely. The project also afforded us the chance to integrate multiple APIs using both Python and JavaScript, strengthening our understanding of API integration. Implementing these APIs within the React framework, coupled with TypeScript, improved our ability to build sturdy and scalable applications. Overall, our journey with this project has been marked by continuous learning and growth, furnishing us with valuable skills and insights that will undoubtedly benefit us in future endeavors.
## What's next for catPhish
What's next for CatPhish
The future holds exciting possibilities for CatPhish as we continue to enhance its capabilities and expand some of its offerings. One of our key objectives is to integrate additional trusted APIs to increase its phishing detection capabilities further. By leveraging a huge range of API services, we aim to further CatPhish's ability to identify and raduce phishing threats. We were also exploring the development of a proprietary machine learning model trained specifically on phishing attempts. This dedicated model will allow CatPhish to evolve and adapt to emerging phishing techniques. As the cybersecurity realm grows, on the other hand, cybercriminals are using effective and advanced skills such as MiTM (Man In the Middle) Attacks through advanced use of phishing pages and such. In addition to refining our machine learning capabilities, we plan to enhance the functionality of the OpenAI API chat GPT bot. By using advanced features such as web browsing using Bing and expanding its conversational abilities, we see ourselves creating a more comprehensive and intuitive user experience. | ## Inspiration
We were inspired to make this educational, musical composition game by the need for virtual learning aid now more than ever. Another large inspiration for this website was the coding software/game Scratch. Similar to scratch, Lil’ Play and Music Making allows users to drag and add different components to their own composition.
## Features
Lil’ Play and Music Making allows users to start creating their own music. They can choose from various pre-recorded melodies and beat, or upload their own recordings. Users can create their profile with just a username and password. Then, from the music they created, they can save it into different playlists of their choice. Moreover, users can add their favourite songs into their favourites list, so they can easily listen to their top choices. Creating and listening to music by yourself is boring. Therefore, Lil’ Play and Music Making has a unique feature that allows artists to share their music. If they like other artists’ music, they can save it to their own favourites’ list and listen to it all day. It’s a great platform to not only make your own music but also share and hear from many other creative people as well!
## Goal
Our website seeks to provide children a way to express themselves musically without needing any musical knowledge. We want to allow children to create a piece of music they can call their own with the prewritten resource we provide. If the child is reaching the limits of what our pre-recorded samples can create, they have the option to upload their own recordings, making the creative possibilities and application endless.
## What's next for Children’s composition game
With the Lil’ play and music maker website we hope to make music accessible to all and boost the creativity of the youngest generation. | ## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | losing |
## Inspiration
The need for faster and more reliable emergency communication in remote areas inspired the creation of FRED (Fire & Rescue Emergency Dispatch). Whether due to natural disasters, accidents in isolated locations, or a lack of cellular network coverage, emergencies in remote areas often result in delayed response times and first-responders rarely getting the full picture of the emergency at hand. We wanted to bridge this gap by leveraging cutting-edge satellite communication technology to create a reliable, individualized, and automated emergency dispatch system. Our goal was to create a tool that could enhance the quality of information transmitted between users and emergency responders, ensuring swift, better informed rescue operations on a case-by-case basis.
## What it does
FRED is an innovative emergency response system designed for remote areas with limited or no cellular coverage. Using satellite capabilities, an agentic system, and a basic chain of thought FRED allows users to call for help from virtually any location. What sets FRED apart is its ability to transmit critical data to emergency responders, including GPS coordinates, detailed captions of the images taken at the site of the emergency, and voice recordings of the situation. Once this information is collected, the system processes it to help responders assess the situation quickly. FRED streamlines emergency communication in situations where every second matters, offering precise, real-time data that can save lives.
## How we built it
FRED is composed of three main components: a mobile application, a transmitter, and a backend data processing system.
```
1. Mobile Application: The mobile app is designed to be lightweight and user-friendly. It collects critical data from the user, including their GPS location, images of the scene, and voice recordings.
2. Transmitter: The app sends this data to the transmitter, which consists of a Raspberry Pi integrated with Skylo’s Satellite/Cellular combo board. The Raspberry Pi performs some local data processing, such as image transcription, to optimize the data size before sending it to the backend. This minimizes the amount of data transmitted via satellite, allowing for faster communication.
3. Backend: The backend receives the data, performs further processing using a multi-agent system, and routes it to the appropriate emergency responders. The backend system is designed to handle multiple inputs and prioritize critical situations, ensuring responders get the information they need without delay.
4. Frontend: We built a simple front-end to display the dispatch notifications as well as the source of the SOS message on a live-map feed.
```
## Challenges we ran into
One major challenge was managing image data transmission via satellite. Initially, we underestimated the limitations on data size, which led to our satellite server rejecting the images. Since transmitting images was essential to our product, we needed a quick and efficient solution. To overcome this, we implemented a lightweight machine learning model on the Raspberry Pi that transcribes the images into text descriptions. This drastically reduced the data size while still conveying critical visual information to emergency responders. This solution enabled us to meet satellite data constraints and ensure the smooth transmission of essential data.
## Accomplishments that we’re proud of
We are proud of how our team successfully integrated several complex components—mobile application, hardware, and AI powered backend—into a functional product. Seeing the workflow from data collection to emergency dispatch in action was a gratifying moment for all of us. Each part of the project could stand alone, showcasing the rapid pace and scalability of our development process. Most importantly, we are proud to have built a tool that has the potential to save lives in real-world emergency scenarios, fulfilling our goal of using technology to make a positive impact.
## What we learned
Throughout the development of FRED, we gained valuable experience working with the Raspberry Pi and integrating hardware with the power of Large Language Models to build advanced IOT system. We also learned about the importance of optimizing data transmission in systems with hardware and bandwidth constraints, especially in critical applications like emergency services. Moreover, this project highlighted the power of building modular systems that function independently, akin to a microservice architecture. This approach allowed us to test each component separately and ensure that the system as a whole worked seamlessly.
## What’s next for FRED
Looking ahead, we plan to refine the image transmission process and improve the accuracy and efficiency of our data processing. Our immediate goal is to ensure that image data is captioned with more technical details and that transmission is seamless and reliable, overcoming the constraints we faced during development. In the long term, we aim to connect FRED directly to local emergency departments, allowing us to test the system in real-world scenarios. By establishing communication channels between FRED and official emergency dispatch systems, we can ensure that our product delivers its intended value—saving lives in critical situations. | ## What it does
MemoryLane is an app designed to support individuals coping with dementia by aiding in the recall of daily tasks, medication schedules, and essential dates.
The app personalizes memories through its reminisce panel, providing a contextualized experience for users. Additionally, MemoryLane ensures timely reminders through WhatsApp, facilitating adherence to daily living routines such as medication administration and appointment attendance.
## How we built it
The back end was developed using Flask and Python and MongoDB. Next.js was employed for the app's front-end development. Additionally, the app integrates the Google Cloud speech-to-text API to process audio messages from users, converting them into commands for execution. It also utilizes the InfoBip SDK for caregivers to establish timely messaging reminders through a calendar within the application.
## Challenges we ran into
An initial hurdle we encountered involved selecting a front-end framework for the app. We transitioned from React to Next due to the seamless integration of styling provided by Next, a decision that proved to be efficient and time-saving. The subsequent challenge revolved around ensuring the functionality of text messaging.
## Accomplishments that we're proud of
The accomplishments we have achieved thus far are truly significant milestones for us. We had the opportunity to explore and learn new technologies that were previously unfamiliar to us. The integration of voice recognition, text messaging, and the development of an easily accessible interface tailored to our audience is what fills us with pride.
## What's next for Memory Lane
We aim for MemoryLane to incorporate additional accessibility features and support integration with other systems for implementing activities that offer memory exercises. Additionally, we envision MemoryLane forming partnerships with existing systems dedicated to supporting individuals with dementia. Recognizing the importance of overcoming organizational language barriers in healthcare systems, we advocate for the formal use of interoperability within the reminder aspect of the application. This integration aims to provide caregivers with a seamless means of receiving the latest health updates, eliminating any friction in accessing essential information. | ## Inspiration
• Saw a need for mental health service provision in Amazon Alexa
## What it does
• Created Amazon Alexa skill in Node.js to enable Alexa to empathize with and help a user who is feeling low
• Capabilities include: probing user for the cause of low mood, playing soothing music, reciting inspirational quote
## How we built it
• Created Amazon Alexa skill in Node.js using Amazon Web Services (AWS) and Lambda Function
## Challenges we ran into
• Accessing the web via Alexa, making sample utterances all-encompassing, how to work with Node.js
## Accomplishments that we're proud of
• Made a stable Alexa skill that is useful and extendable
## What we learned
• Node.js, How to use Amazon Web Services
## What's next for Alexa Baymax
• Add resources to Alexa Baymax (if the user has academic issues, can provide links to helpful websites), and emergency contact information, tailor playlist to user's taste and needs, may commercialize by adding an option for the user to book therapy/massage/counseling session | winning |
## Inspiration
## When selecting a course, it can be difficult to find and know exactly which professor is teaching what course during the selection of courses. With our software, we make it easy to find courses and see which professor is best based on ratings on ratemyprofessor. You can also find the required textbooks for the course.
## How we built it
We built the back-end web scraping algorithm using Python and Selenium/Beautiful Soup packages. The front end was built using HTML/CSS.
## Challenges we ran into
There were a lot of errors and possible changes of content that can cause our program to crash. Combining both the front end and back end to make functional software was also a struggle.
## Accomplishments that we're proud of
We are proud that we at least got something to work and can happily post this on devpost as our first Hackathon project!
## What we learned
We learned how to style in HTML/CSS and efficiently use Beautiful Soup as well as Selenium to scrap data from the web and run bots.
## What's next for Western University Course Lookup
We will be updating our software regularly and plan to have an official domain for it very soon. | ## Inspiration
The *horrible* course selection and searching experience provided in the current Princeton registrar website.
## What it does
Select courses based on a query (day, section, professor, title, course code... anything!).
## How we built it
Scrap information using python, store as a JSON file. Handle query by a python interpreter. And put it on a website.
## Challenges we ran into
We tried our best, but we are still unable to connect the python query handler with the website we built.
## Accomplishments that we're proud of
We are beginners who have almost never touched front-end and web stuff. We are proud of what we've got and the effort we've put into it.
## What we learned
Front-end stuff: HTML/CSS
How to build a website.
How to scrap information from online and store it as JSON.
## What's next for TigerCourse
Although we are not able to finish it within the given time, we will work on it as our future project. Our vision is to combine student information with course information, so we can see who else are taking this course and what are those people's emails. We plan to extract information from the TigerBook API. Trust us. The missing thing here is just the front-end stuff. | ## Inspiration
Course selection is an exciting but frustrating time to be a Princeton student. While you can look at all the cool classes that the university has to offer, it is challenging to aggregate a full list of prerequisites and borderline impossible to find what courses each of them leads to in the future. We recently encountered this problem when building our schedules for next fall. The amount of searching and cross-referencing that we had to do was overwhelming, and to this day, we are not exactly sure whether our schedules are valid or if there will be hidden conflicts moving forward. So we built TigerMap to address this common issue among students.
## What it does
TigerMap compiles scraped course data from the Princeton Registrar into a traversable graph where every class comes with a clear set of prerequisites and unlocked classes. A user can search for a specific class code using a search bar and then browse through its prereqs and unlocks, going down different course paths and efficiently exploring the options available to them.
## How we built it
We used React (frontend), Python (middle tier), and a MongoDB database (backend). Prior to creating the application itself, we spent several hours scraping the Registrar's website, extracting information, and building the course graph. We then implemented the graph in Python and had it connect to a MongoDB database that stores course data like names and descriptions. The prereqs and unlocks that are found through various graph traversal algorithms, and the results are sent to the frontend to be displayed in a clear and accessible manner.
## Challenges we ran into
Data collection and processing was by far the biggest challenge for TigerMap. It was difficult to scrape the Registrar pages given that they are rendered by JavaScript, and once we had the pages downloaded, we had to go through a tedious process of extracting the necessary information and creating our course graph. The prerequisites for courses is not written in a consistent manner across the Registrar's pages, so we had to develop robust methods of extracting data. Our main concern was ensuring that we would get a graph that completely covered all of Princeton's courses and was not missing any references between classes. To accomplish this, we used classes from both the Fall and Spring 21-22 semesters, and we can proudly say that, apart from a handful of rare occurrences, we achieved full course coverage and consistency within our graph.
## Accomplishments that we're proud of
We are extremely proud of how fast and elegant our solution turned out to be. TigerMap definitely satisifes all of our objectives for the project, is user-friendly, and gives accurate results for nearly all Princeton courses. The amount of time and stress that TigerMap can save is immeasurable.
## What we learned
* Graph algorithms
* The full stack development process
* Databases
* Web-scraping
* Data cleaning and processing techniques
## What's next for TigerMap
We would like to improve our data collection pipeline, tie up some loose ends, and release TigerMap for the Princeton community to enjoy!
## Track
Education
## Discord
Leo Stepanewk - nwker#3994
Aaliyah Sayed - aaligator#1793 | losing |
## We want to change the way you donate to people/causes. All to often people donate to causes and have no clue where that money goes or who will actually be effected by it. Donerlife would change the way people view donating. We tell the stories of the people who you will be effecting and the doctors who need the money to help. We did the KPCB’s challange which was to figure out a way to optimize donating and support doctors who need funds to help in third world countries. Not only will you get background on the doctor that they money will be going to but also you would be able to track the person in needs progress. This brings a voice to people in need.
## What it does
Doctors post pictures of their patients, and input data about each specific person’s problems/need for help
People who wants to help, registers on the app and creates an account
Person scrolls through cases, and decides to help a specific person out
Person decides to donate, and presses donate button
Person is directed to payment method
Person is offered push notifications regarding that specific patient (be notified on any posts with patient’s name)
## How I built it
We built an IOS app with swift. The frontend is built with Sketch
## Challenges I ran into
Really making sure the importance of the app got across also making sure the told the doctors and patients story correctly.
## Accomplishments that I'm proud of
I'm proud to say I felt like we could actually help people in need. It makes me feel good that people might want to donate after hearing all the insiprational stories for the patients.
## What I learned
Swift is super hard .
## What's next for DonerLife
Getting on the app store!! | ## Inspiration
I’m an Engineering Physics student—so I learn a lot about engineering, math, and physics. I know that fields in STEM are sometimes thought of as being “cold”, and not as “human”, in a sense, as a field like, say, history.
Aside from struggling with understanding concepts at times, I struggle with my overall wellbeing. Something that’s helped has been relating the STEM concepts I’ve been learning to my own life. It makes STEM human, it brings me comfort, and it helps me remember/understand the content I'm learning. I thought it might help other people feel less alone, learn about STEM concepts, and make STEM feel more relatable—and that’s where mylifeastoldbystem.com came from.
## What it does
This is a website where people can view, like, and submit user’s submissions, all of which relate STEM concepts to real life. Right now there are four example posts: an S, a T, an E, and an M. Read through the posts for an explanation!
You can see who submitted the post, and you can see how many likes the post has gotten. You can “like” it as many times as you want, similar to Medium claps—the idea behind this was so that people could spread as much love for STEM as they like, so I didn’t want to put any restrictions on it. There is also Facebook liking functionality for further social media reach.
Submitted entries would be reviewed manually before being turned into a submission on the site.
## How I built it
I wanted to do something completely full-stack.
**Text:** identified concepts and wrote the copy
**Design:** Adobe Photoshop and Illustrator
**Front-End:** HTML/CSS, JavaScript (no frameworks; more on that later...)
**Loading in data:** loaded in XML file on page load
**Back-End:** attempts included.....
* PHP/MySQL
* Node.js and Express
* using XAMPP? AMPPS? phpmyadmin??
* YDN-DB
* this was frustrating because I really wanted to set up a backend :(
* ended up embedding Facebook liking system
## Challenges I ran into
I had a commitment earlier in the day, so I had to start hacking late—so I decided to work on my own. Taking care of the entire project from start to finish was fun, but it was a lot of work.
I tried getting a ton of things started—Angular, React, many, many node modules, MySQL, PHP (I'm 100% sure my PHP is somehow configured improperly)...every time I installed something, the command couldn't be found. I couldn't figure out how to configure my system, and after spending 10 hours trying to get something going, I decided to just put in a Facebook like button.
## Accomplishments that I'm proud of
* Finishing the designs
* building the website from scratch
* Got core functionality working
* The form does email validation
## What I learned
* ran things on localhost!! python -m SimpleHTTPServer worked for me and it was so exciting!
* some CSS transitions
* circular incrementation
* tried practicing some different design styles
* I need to ask someone how to deal with my computer so that I can actually use PHP/MySQL/React/Angular/Browserify/Express/everything I tried to get going...............
## What's next for my life as told by STEM
* Figure out what's wrong with how I'm using my terminal so I can set up a backend for real! | ## Inspiration
We were inspired by Katie's 3-month hospital stay as a child when she had a difficult-to-diagnose condition. During that time, she remembers being bored and scared -- there was nothing fun to do and no one to talk to. We also looked into the larger problem and realized that 10-15% of kids in hospitals develop PTSD from their experience (not their injury) and 20-25% in ICUs develop PTSD.
## What it does
The AR iOS app we created presents educational, gamification aspects to make the hospital experience more bearable for elementary-aged children. These features include:
* An **augmented reality game system** with **educational medical questions** that pop up based on image recognition of given hospital objects. For example, if the child points the phone at an MRI machine, a basic quiz question about MRIs will pop-up.
* If the child chooses the correct answer in these quizzes, they see a sparkly animation indicating that they earned **gems**. These gems go towards their total gem count.
* Each time they earn enough gems, kids **level-up**. On their profile, they can see a progress bar of how many total levels they've conquered.
* Upon leveling up, children are presented with an **emotional check-in**. We do sentiment analysis on their response and **parents receive a text message** of their child's input and an analysis of the strongest emotion portrayed in the text.
* Kids can also view a **leaderboard of gem rankings** within their hospital. This social aspect helps connect kids in the hospital in a fun way as they compete to see who can earn the most gems.
## How we built it
We used **Xcode** to make the UI-heavy screens of the app. We used **Unity** with **Augmented Reality** for the gamification and learning aspect. The **iOS app (with Unity embedded)** calls a **Firebase Realtime Database** to get the user’s progress and score as well as push new data. We also use **IBM Watson** to analyze the child input for sentiment and the **Twilio API** to send updates to the parents. The backend, which communicates with the **Swift** and **C# code** is written in **Python** using the **Flask** microframework. We deployed this Flask app using **Heroku**.
## Accomplishments that we're proud of
We are proud of getting all the components to work together in our app, given our use of multiple APIs and development platforms. In particular, we are proud of getting our flask backend to work with each component.
## What's next for HealthHunt AR
In the future, we would like to add more game features like more questions, detecting real-life objects in addition to images, and adding safety measures like GPS tracking. We would also like to add an ALERT button for if the child needs assistance. Other cool extensions include a chatbot for learning medical facts, a QR code scavenger hunt, and better social interactions. To enhance the quality of our quizzes, we would interview doctors and teachers to create the best educational content. | losing |
## Inspiration
When it comes to finding solutions to global issues, we often feel helpless: making us feel as if our small impact will not help the bigger picture. Climate change is a critical concern of our age; however, the extent of this matter often reaches beyond what one person can do....or so we think!
Inspired by the feeling of "not much we can do", we created *eatco*. *Eatco* allows the user to gain live updates and learn how their usage of the platform helps fight climate change. This allows us to not only present users with a medium to make an impact but also helps spread information about how mother nature can heal.
## What it does
While *eatco* is centered around providing an eco-friendly alternative lifestyle, we narrowed our approach to something everyone loves and can apt to; food! Other than the plenty of health benefits of adopting a vegetarian diet — such as lowering cholesterol intake and protecting against cardiovascular diseases — having a meatless diet also allows you to reduce greenhouse gas emissions which contribute to 60% of our climate crisis. Providing users with a vegetarian (or vegan!) alternative to their favourite foods, *eatco* aims to use small wins to create a big impact on the issue of global warming. Moreover, with an option to connect their *eatco* account with Spotify we engage our users and make them love the cooking process even more by using their personal song choices, mixed with the flavours of our recipe, to create a personalized playlist for every recipe.
## How we built it
For the front-end component of the website, we created our web-app pages in React and used HTML5 with CSS3 to style the site. There are three main pages the site routes to: the main app, and the login and register page. The login pages utilized a minimalist aesthetic with a CSS style sheet integrated into an HTML file while the recipe pages used React for the database. Because we wanted to keep the user experience cohesive and reduce the delay with rendering different pages through the backend, the main app — recipe searching and viewing — occurs on one page. We also wanted to reduce the wait time for fetching search results so rather than rendering a new page and searching again for the same query we use React to hide and render the appropriate components. We built the backend using the Flask framework. The required functionalities were implemented using specific libraries in python as well as certain APIs. For example, our web search API utilized the googlesearch and beautifulsoup4 libraries to access search results for vegetarian alternatives and return relevant data using web scraping. We also made use of Spotify Web API to access metadata about the user’s favourite artists and tracks to generate a personalized playlist based on the recipe being made. Lastly, we used a mongoDB database to store and access user-specific information such as their username, trees saved, recipes viewed, etc. We made multiple GET and POST requests to update the user’s info, i.e. saved recipes and recipes viewed, as well as making use of our web scraping API that retrieves recipe search results using the recipe query users submit.
## Challenges we ran into
In terms of the front-end, we should have considered implementing Routing earlier because when it came to doing so afterward, it would be too complicated to split up the main app page into different routes; this however ended up working out alright as we decided to keep the main page on one main component. Moreover, integrating animation transitions with React was something we hadn’t done and if we had more time we would’ve liked to add it in. Finally, only one of us working on the front-end was familiar with React so balancing what was familiar (HTML) and being able to integrate it into the React workflow took some time. Implementing the backend, particularly the spotify playlist feature, was quite tedious since some aspects of the spotify web API were not as well explained in online resources and hence, we had to rely solely on documentation. Furthermore, having web scraping and APIs in our project meant that we had to parse a lot of dictionaries and lists, making sure that all our keys were exactly correct. Additionally, since dictionaries in Python can have single quotes, when converting these to JSONs we had many issues with not having them be double quotes. The JSONs for the recipes also often had quotation marks in the title, so we had to carefully replace these before the recipes were themselves returned. Later, we also ran into issues with rate limiting which made it difficult to consistently test our application as it would send too many requests in a small period of time. As a result, we had to increase the pause interval between requests when testing which made it a slow and time consuming process. Integrating the Spotify API calls on the backend with the frontend proved quite difficult. This involved making sure that the authentication and redirects were done properly. We first planned to do this with a popup that called back to the original recipe page, but with the enormous amount of complexity of this task, we switched to have the playlist open in a separate page.
## Accomplishments that we're proud of
Besides our main idea of allowing users to create a better carbon footprint for themselves, we are proud of accomplishing our Spotify integration. Using the Spotify API and metadata was something none of the team had worked with before and we're glad we learned the new skill because it adds great character to the site. We all love music and being able to use metadata for personalized playlists satisfied our inner musical geek and the integration turned out great so we're really happy with the feature. Along with our vast recipe database this far, we are also proud of our integration! Creating a full-stack database application can be tough and putting together all of our different parts was quite hard, especially as it's something we have limited experience with; hence, we're really proud of our service layer for that. Finally, this was the first time our front-end developers used React for a hackathon; hence, using it in a time and resource constraint environment for the first time and managing to do it as well as we did is also one of our greatest accomplishments.
## What we learned
This hackathon was a great learning experience for all of us because everyone delved into a tool that they'd never used before! As a group, one of the main things we learned was the importance of a good git workflow because it allows all team members to have a medium to collaborate efficiently by combing individual parts. Moreover, we also learned about Spotify embedding which not only gave *eatco* a great feature but also provided us with exposure to metadata and API tools. Moreover, we also learned more about creating a component hierarchy and routing on the front end. Another new tool that we used in the back-end was learning how to perform database operations on a cloud-based MongoDB Atlas database from a python script using the pymongo API. This allowed us to complete our recipe database which was the biggest functionality in *eatco*.
## What's next for Eatco
Our team is proud of what *eatco* stands for and we want to continue this project beyond the scope of this hackathon and join the fight against climate change. We truly believe in this cause and feel eatco has the power to bring meaningful change; thus, we plan to improve the site further and release it as a web platform and a mobile application. Before making *eatco* available for users publically we want to add more functionality and further improve the database and present the user with a more accurate update of their carbon footprint. In addition to making our recipe database bigger, we also want to focus on enhancing the front-end for a better user experience. Furthermore, we also hope to include features such as connecting to maps (if the user doesn't have a certain ingredient, they will be directed to the nearest facility where that item can be found), and better use of the Spotify metadata to generate even better playlists. Lastly, we also want to add a saved water feature to also contribute into the global water crisis because eating green also helps cut back on wasteful water consumption! We firmly believe that *eatco* can go beyond the range of the last 36 hours and make impactful change on our planet; hence, we want to share with the world how global issues don't always need huge corporate or public support to be solved, but one person can also make a difference. | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | ## Inspiration
We have all heard about the nutrition and health issues from those who surround us. Yes, adult obesity has plateaued since 2003, but it's at an extremely high rate. Two out of three U.S. adults are overweight or obese. If we look at diabetes, it's prevalent in 25.9% americans over 65. That's 11.8 million people! Those are the most common instances, let's not forget about people affected by high blood pressure, allergies, digestive or eating disorders—the list goes on. We've created a user friendly platform that utilizes Alexa to help users create healthy recipes tailored to their dietary restrictions. The voice interaction allows for a broad range of ages to learn how to use our platform. On top of that, we provide a hands free environment to ease multitasking and users are more inclined to follow the diet since it’s simple and quick to use.
## How we built it
The backend is built with Flask on Python, with the server containerized and deployed on AWS served over nginx and wsgi. We also built this with scale in mind as this should be able to scale to many millions of users, and by containerizing the server with docker and hosting it on AWS, scaling it horizontally is as easy as scaling it vertically, with a few clicks on the AWS dev console.
The front end is powered by bootstrap and Jinja (JavaScript Framework) that interfaces with a mySQL database on AWS through Flask’s object relational mapping.
All in all, Ramsay is a product built on sweat, pressure, lack of sleep and <3
## Challenges we ran into
The deployment pipeline for alexa is extremely cumbersome due to the fact that alexa has a separate dev console and debugging has to be done on the page. The way lambda handles code change is also extremely inefficient. It has taken a big toll on the development cycle and caused a lot of frustrating debugging times..
It was also very time consuming for us to manually scrape all the recipe and ingredients data from the web, because there no open source recipe API that satisfies our needs. Many of them are either costly or had rate limit restrictions on the endpoints for the free tier, which we are not content with because we wanted to provide a wide range of recipe selection for the user.
Scraping different sites gave us a lot of dirty data that required a lot of work to make it usable. We ended up using NLTK to employ noun and entity extraction to get meaningful data from a sea of garbage.
## Accomplishments that we're proud of
We managed to build out a Alexa/Lambda deployment pipeline that utilizes AWS S3 buckets and sshfs. The local source files are mounted on a remote S3 bucket that syncs with the Lambda server, enabling the developer to skip over the hassle of manually uploading the files to the lambda console everytime there is a change in the codebase.
We also built up a very comprehensive recipe database with over 10000 recipes and 3000 ingredients that allows the user to have tons of selection.
This is also the first Alexa app that we made that has a well thought out user experience and it works surprisingly well. For once Alexa is not super confused every time a user ask a question.
## What we learned:
We learnt how to web scrape implementing NLTK and BeautifulSoup python libraries. This was essential to create of database containing information about ingredients and recipe steps as well. We also became more proficient in using git and SQL. We are now git sergeants and SQL soldiers.
## What's next for Ramsay:
Make up for the sleep that we missed out on over the weekend :') | winning |
## Inspiration
We wanted to create a green solution to the growing problem of hospital wait times
## What it does
Replaces outdated pagers with 2-way communication
## How we built it
A python server interacts with the clients and mediates a list of staff and patients
## Challenges we ran into
Many resources did not work as intended, many obscure bugs had to be removed
## Accomplishments that we're proud of
Creating a functional communication platform in the allotted time
## What we learned
How to effectively use git version control to manage a project with multiple contributors
## What's next for GreenComm
Further improvements to UI and functionality | ### Inspiration
Have you ever found yourself wandering in a foreign land, eyes wide with wonder, yet feeling that pang of curiosity about the stories behind the unfamiliar sights and sounds? That's exactly where we found ourselves. All four of us share a deep love for travel and an insatiable curiosity about the diverse cultures, breathtaking scenery, and intriguing items we encounter abroad. It sparked an idea: why not create a travel companion that not only shares our journey but enhances it? Enter our brainchild, a fusion of VR and AI designed to be your personal travel buddy. Imagine having a friend who can instantly transcribe signs in foreign languages, identify any object from monuments to local flora, and guide you through the most bewildering of environments. That's what we set out to build—a gateway to a richer, more informed travel experience.
### What it does
Picture this: you're standing before a captivating monument, curiosity bubbling up. With our VR travel assistant, simply speak your question, and it springs into action. This clever buddy captures your voice, processes your command, and zooms in on the object of your interest in the video feed. Using cutting-edge image search, it fetches information about just what you're gazing at. Wondering about that unusual plant or historic site? Ask away, and you'll have your answer. It's like having a local guide, historian, and botanist all rolled into one, accessible with just a glance and a word.
### How we built it
We initiated our project by integrating Unity with the Meta XR SDK to bring our VR concept to life. The core of our system, a server engineered with Python and FastAPI, was designed to perform the critical tasks, enhanced by AI capabilities for efficient processing. We leveraged Google Lens via the SERP API for superior image recognition and OpenAI's Whisper for precise voice transcription. Our approach was refined by adopting techniques from a Meta research paper, enabling us to accurately crop images to highlight specific objects. This method ensured that queries were efficiently directed to the appropriate AI model for quick and reliable answers. To ensure a smooth operation, we encapsulated our system within Docker and established connectivity to our VR app through ngrok, facilitating instantaneous communication via websockets and the SocketIO library.

### Challenges we ran into
None of us had much or any experience with both Unity3D and developing VR applications so there were many challenges in learning how to use the Meta XR SDK and how to build a VR app in general. Additionally, Meta imposed a major restriction that added to the complexity of the application: we could not capture the passthrough video feed through any third-party screen recording software. This meant we had to, in the last few hours of the hackathon, create a new server in our network that would capture the casted video feed from the headset (which had no API) and then send it to the backend. This was a major challenge and we are proud to have overcome it.
### Accomplishments that we're proud of
From web developers to VR innovators, we've journeyed into uncharted territories, crafting a VR application that's not just functional but truly enriching for the travel-hungry soul. Our creation stands as a beacon of what's possible, painting a future where smart glasses serve as your personal AI-powered travel guides, making every journey an enlightening exploration.
### What we learned
The journey was as rewarding as the destination. We mastered the integration of Meta Quest 2s and 3s with Unity, weaving through the intricacies of Meta XR SDKs. Our adventure taught us to make HTTP calls within Unity, transform screenshots into Base64 strings, and leverage Google Cloud for image hosting, culminating in real-time object identification through Google Lens. Every challenge was a lesson, turning us from novices into seasoned navigators of VR development and AI integration. | ## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created completely by its users - a program where anyone could rate how well these “hubs” were following COVID-19 safety protocol.
## What it does
Our app allows for users to search a “hub” using a Google Map API, and write a review by rating prompted questions on a scale of 1 to 5 regarding how well the location enforces public health guidelines. Future visitors can then see these reviews and add their own, contributing to a collective safety rating.
## How I built it
We collaborated using Github and Android Studio, and incorporated both a Google Maps API as well integrated Firebase API.
## Challenges I ran into
Our group unfortunately faced a number of unprecedented challenges, including losing a team member mid-hack due to an emergency situation, working with 3 different timezones, and additional technical difficulties. However, we pushed through and came up with a final product we are all very passionate about and proud of!
## Accomplishments that I'm proud of
We are proud of how well we collaborated through adversity, and having never met each other in person before. We were able to tackle a prevalent social issue and come up with a plausible solution that could help bring our communities together, worldwide, similar to how our diverse team was brought together through this opportunity.
## What I learned
Our team brought a wide range of different skill sets to the table, and we were able to learn lots from each other because of our various experiences. From a technical perspective, we improved on our Java and android development fluency. From a team perspective, we improved on our ability to compromise and adapt to unforeseen situations. For 3 of us, this was our first ever hackathon and we feel very lucky to have found such kind and patient teammates that we could learn a lot from. The amount of knowledge they shared in the past 24 hours is insane.
## What's next for SafeHubs
Our next steps for SafeHubs include personalizing user experience through creating profiles, and integrating it into our community. We want SafeHubs to be a new way of staying connected (virtually) to look out for each other and keep our neighbours safe during the pandemic. | losing |
## Inspiration
We were inspired by the demo from Myo's website that the device could recognize various hand gestures and translate into computer input. The computer technologies are changing every day and the way we interact with computers also need to be changed. Just think about that when our wearables could understand us and help us input the command into computers and that totally got us started this project.
## What it does
Multiple users with Myo Armbands can collaborate on the same remote white board and combine result could be displayed at the same time in different location.
## How we built it
At first, we build a simple web application that prints the frames of data captured from Myo using the MyoJS framework, later we decided to implement a backend server that its job is to manage, delegate and synchronize the Myo data stream coming from our Myo Web Client, we have used **Microsoft Azure** to host the server and it worked really well. We are able to achieve maximum throughput of 600 eps (events per second). Because we have broken the barrier that 1 myo control one computer, we are able to use multiple Myo data streams to control the same canvas on a remote computer running our blackboard demo software. The rest of the time we have invested in debugging the application, increase its stability and creating tools that help us mange the 3 Myos we have borrowed. We have created a very simple iOS/Android application using **Ionic frameworks** that shows the data stream of all Myos on the server and its EMG graph. We also made a connection counter using **Beaglebone**, it has a 7-segment display will show how many Myos is currently connected.
## Challenges we ran into
* It's not easy to get meaningful data from the Myo Armband SDK.
* Data are sent to a centralized server which could be limited by internet condition
## Accomplishments that we're proud of
* Myo could only connect to one computer via Bluetooth but we broke the barrier that we could use Myo to send command across the globe
* We have successfully came up with a demo to show that it's possible to interact with others on the same digital workspace without using the traditional computer input (keyboard/mouse).
## What we learned
* There are still works to do to optimize the data collection
* Myo need to improve the SDK to be more developer friendly
## What's next for Wasabi Myo
If we had more time, we would love to take this project to the next level, by enabling gesture controls and simple collaboration software, the current Wasabi Myo is a proof-of-concept project that we have spent a lot of time to create, so there are still a lot of features planned for Wasabi Myo. | ## Inspiration
As ECE students, we have sat through classes that expect us to come in knowing how to prototype and how to use electrical components. However, students who never experienced working with ICs, resistors, or breadboards have struggled through a class where they need to learn how everything works during lab and it can be incredibly overwhelming. (ECE is an acronym for "Electrical and Computer Engineering".)
## What it does
Our game "wires." is an interactive tutorial, almost like an Introduction to ECE Practical Skills. The tutorial is a survey of basic electrical tools that a student should know how to use not only for classes, but also in the industry. Each task goes over a different topic and the student can only move onto the next task after completely the current task correctly.
## How we built it
We built the tutorial in Unity to use with an Oculus Rift and an Xbox Controller.
## Challenges we ran into
We worked with the Myo Armband to integrate with the Oculus Rift for hand gesture-based movement in the Tutorial. However, when testing the responsiveness of the Myo Armband with different people and Spotify hand-gestures,we found that the Myo Armband would at least detect 1 gesture correctly every ~50 gestures for those with thicker arms but would not recognize gestures from those with thinner arms at all. This could have been either a stability issue of the Myo Armband on thinner arms or due to the average gesture profile used in testing. In the end, we used a Xbox controller.
We also attempted to code a script that would allow for object movement and recognition of contact of objects in order to see if the student completed the task correctly. We thought of a solution that would require for creation of Collider Bodies to detect proximity of wires and pins relative to each other; touching would be recognized as successful contact. Another challenge we ran into was how to use Ray Cast and draw wires from hole to hole of the breadboard. We looked up a tutorial and then got one of the companies to help us figure out what exactly they were doing in the tutorial. However, writing the code for that was harder than we thought. We do not have that much experience in OOP, so to try and use a Ray Cast and index through pixels was harder than we thought. We spent many hours trying to figure out the code, and in the end we just ran out of time.
## Accomplishments that we're proud of
We figured out how to code in C#. We originally were going to use JavaScript, but we wanted a challenge and use an actual OOP language. We could have used packages to import all settings, but we wanted to focus on both the graphics and the logic behind this project. Instead of using packages, we started from scratch and had a lot of fun with learning about all that Unity has to offer.
We also figured out how to move the camera relative to an object in the project for later integration with movement of other objects. This involved testing for a while with the Xbox controller, instead of just looking at the screen.
## What we learned
This was our first time using Unity and the Oculus Rift, and coding in C#. All of us had diverse previous experiences, but as a team we were able to put together what ever knowledge we had and support each other. Our goal was to learn the most we could and put together a really beautiful hack. What we actually learned was that there will always be challenges to overcome, but working in a team provides the mental and knowledge support greatly needed to succeed. We really liked how open the atmosphere was at CalHacks regarding help. At one point, we walked around and kept asking people if they knew Unity so they could help, and we learned that it is always okay to ask.
## What's next for wires.
Our next immediate steps would be to both understand accurate and precise object movement and implement a solution for the Correctness Algorithm that would allow the user to move onto the end scene of a task. | ## Inspiration
WristPass was inspired by the fact that NFC is usually only authenticated using fingerprints. If your fingerprint is compromised, there is nothing you can do to change your fingerprint. We wanted to build a similarly intuitive technology that would allow users to change their unique ids at the push of a button. We envisioned it to be simple and not require many extra accessories which is exactly what we created.
## What it does
WristPass is a wearable Electro-Biometric transmission device and companion app for secure and reconfigurable personal identification with our universal receivers. Make purchases with a single touch. Check into events without worrying about forgetting tickets. Unlock doors by simply touching the handle.
## How we built it
WristPass was built using several different means of creation due to there being multiple parts to the projects. The WristPass itself was fabricated using various electronic components. The companion app uses Swift to transmit and display data to and from your device. The app also plugs into our back end to grab user data and information. Finally our receiving plates are able to handle the data in any way they want after the correct signal has been decoded. From here we demoed the unlocking of a door, a check in at a concert, and paying for a meal at your local subway shop.
## Challenges we ran into
By far the largest challenge we ran into was properly receiving and transcoding the user’s encoded information. We could reliably transmit data from our device using an alternating current, but it became a much larger ordeal when we had to reliably detect these incoming signals and process the information stored within. In the end we were able to both send and receive information.
## Accomplishments that we're proud of
1. Actually being able to transmit data using an alternating current
2. Building a successful coupling capacitor
3. The vast application of the product and how it can be expanded to so many different endpoints
## What we learned
1. We learned how to do capacitive coupling and decode signals transmitted from it.
2. We learned how to create a RESTful API using MongoDB, Spring and a Linode Instance.
3. We became more familiarized with new APIs including: Nexmo, Lyft, Capital One’s Nessie.
4. And a LOT of physics!
## What's next for WristPass
1. We plan on improving security of the device.
2. We plan to integrate Bluetooth in our serial communications to pair it with our companion iOS app.
3. Develop for android and create a web UI.
4. Partner with various companies to create an electro-biometric device ecosystem. | losing |
## Inspiration
Our good friend's uncle was involved in a nearly-fatal injury. This led to him becoming deaf-blind at a very young age, without many ways to communicate with others. To help people like our friend's uncle, we decided to create HapticSpeak, a communication tool that transcends traditional barriers. As we have witnessed the challenges faced by deaf-blind individuals first hand, we were determined to bring help to these people.
## What it does
Our project HapticSpeak can take a users voice, and then converts the voice to text. The text is then converted to morse code. At this point, the morse code is sent to an arduino using the bluetooth module, where the arduino will decode the morse code into it's haptic feedback equivalents, allowing for the deafblind indivudals to understand what the user's said.
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for HapticSpeak | ## Inspiration
News frequently reports on vehicle crashes and accidents, with one statistic highlighting the prevalence of heavy truck accidents caused by driver fatigue. Truck drivers endure long hours on the road, delivering shipments nationwide, contributing to the tiredness that can lead to accidents. According to the National Transportation Safety Board, nearly 40% of heavy truck accidents originate from fatigue. In response, we pushed to develop a system capable of monitoring both facial expressions and heartbeats to detect early signs of fatigue among drivers.
## What it does
Our web app boasts two features aimed at improving driver safety: one harnesses computer vision technology to track the driver's face, effectively detecting signs of drowsiness, while the other streams the driver's heartbeat in real-time, providing an additional layer of drowsiness detection. Accessible through our web app is a dedicated page for viewing the webcam feed, which ideally can be monitored via personal devices like smartphones. Should the webcam detect the driver falling asleep, it triggers an alert with flashing lights and a sound to awaken the driver. Additionally, our dashboard feature enables managers to monitor their drivers and their respective drowsiness levels. We've incorporated a graphing feature within the dashboard that dynamically turns red when a selected driver's drowsiness level drops below the acceptable threshold, providing a clear visual indication of potential fatigue.
## How we built it
By combining Reflex and TerraAPI, as well as a companion mobile app in Swift, we were able to create a solution all within our ecosystem. The TerraAPI provided the crucial heartrate data in real time, which we livestreamed through a webhook that our Reflex website could read. The Reflex website also contains a manager-style dashboard for viewing several truckers and collect their unique data all at the same time. As a demo for future mobile usage, we also included a facial recognition and landmarking model to detect drowsiness and alert the user if they are falling asleep. The Swift app also provided additional information such as the heartrate in real time and establishing the connection to the webhook from the wearable device.
## Challenges we ran into
In order to construct the complex data flow of our project, we had to learn several new technologies along the way. It started with developing on a new wearable device with limited documentation and support only through a Swift iOS app, which none of us had experience with. With Reflex, we also encountered some bugs, which all had workarounds, and the difficulties that come with developing any website.
## Accomplishments that we're proud of
We're proud of being able to integrate such complex technologies and orchestrate them in a seamless way. At times, we were afraid that our product wouldn't come together since all the components depended on each other and we needed to complete all of them. However, our team made everything work in the end.
## What we learned
Many of the technologies we worked with during TreeHacks were new and had a large learning curve in order to build our end goal. Along this journey, our team picked up valuable skills in Swift, Python, computer vision, web development, and how to work on 2 hours of sleep.
## What's next for TruckrZzz
We hope to broaden our target audience and not only apply these technologies for truck drivers, but also every day drivers that might need some extra assistance staying awake on the road. | ## Inspiration
I was inspired to make Sign Speak when I read about a barista at Star Bucks who learned sign language to make a frequent customer feel even more welcome at Star Bucks. While I may not have the determination to learn ASL, I can sure as hell engineer a way for people who use sign language to be heard!
## What it does
Sign Speak is comprised of two main components. 1: The Arduino based glove that feeds data through bluetooth low energy while a person is signing. 2: The iPhone app is collecting the data send over bluetooth and proceeds to feed it into a special machine learning algorithm (SVM) and helps to determine the sign that the person is making. The iPhone then uses it's speaker to speak up what the person signed.
## How I built it
I first breadboarded my entire circuit to ensure that everything was in tip top shape. From there, I went on to establish the connection between my Arduino and iPhone application, and limit the flex sensors to a readable value of 0-100. After that I learned how to solder and created the circuits that I needed. Unfortunately, it got fried, and I had to restart... So I re-soldered everything, fit it into an NES Power Glove, and went on to work on the machine learning algorithm. Unfortunately due to the nature of machine learning, a lot of data was needed, and I did not have the hours to train the glove to learn every ASL letter. So I decided on 4 important letters to me. H-A-C-K.
## Challenges I ran into
Machine learning was definitely a challenge for me having used it only a few times before. I was given help by a friend
not attending PennApps, Nathan Flurry aka McFlurry. Another challenge was losing all of my hardware mid way through. Luckily a PennApps volunteer/organizer found out that they had more Arduino Micros, that had not been listed before and saved my project.
## Accomplishments that I'm proud of
I am very proud to have made Sign Speak over the past 36 hours on a 1 man team. It was a daunting task but I think I was able to execute a successful hack!
## What I learned
I learned a great deal about Arduino hardware and how to solder, as well as Arduino and iOS interfacing.
## What's next for Sign Speak
I hope to create a more refined version of Sign Speak, one with an accelerometer/gyroscope that will allow me to not only identify letters, but also words/gestures. | partial |
## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | ## Inspiration
Disasters can strike quickly and without notice. Most people are unprepared for situations such as earthquakes which occur with alarming frequency along the Pacific Rim. When wifi and cell service are unavailable, medical aid, food, water, and shelter struggle to be shared as the community can only communicate and connect in person.
## What it does
In disaster situations, Rebuild allows users to share and receive information about nearby resources and dangers by placing icons on a map. Rebuild uses a mesh network to automatically transfer data between nearby devices, ensuring that users have the most recent information in their area. What makes Rebuild a unique and effective app is that it does not require WIFI to share and receive data.
## How we built it
We built it with Android and the Nearby Connections API, a built-in Android library which manages the
## Challenges we ran into
The main challenges we faced while making this project were updating the device location so that the markers are placed accurately, and establishing a reliable mesh-network connection between the app users. While these features still aren't perfect, after a long night we managed to reach something we are satisfied with.
## Accomplishments that we're proud of
WORKING MESH NETWORK! (If you heard the scream of joy last night I apologize.)
## What we learned
## What's next for Rebuild | ## Inspiration
In response to the recent sexual assault cases on campus, we decided that there was a pressing need to create an app that would be a means for people to seek help from those around them, mitigating the bystander effect at the same time.
## What it does
Our cross-platform app allows users to send out a distress signal to others within close proximity (up to a five mile radius), and conversely, allows individuals to respond to such SOS calls. Users can include a brief description of their distress signal call, as well as an "Intensity Rating" to describe the enormity of their current situation.
## How we built it
We used Django as a server-side framework and hosted it using Heroku. React Native was chosen as the user interface platform due to its cross-platform abilities. We all shared the load of front end and back end development, along with feature spec writing and UX design.
## Challenges we ran into
Some of us had no experience working with React Native/Expo, so we ran into quite a few challenges with getting acclimated to the programming language. Additionally, deploying the server-side code onto an actual server, as well as deploying the application bundles as standalone apps on iOS and Android, caused us to spend significant amounts of time to figure out how to deploy everything properly.
## Accomplishments that we're proud of
This was the very first hackathon for the two of us (but surely, won’t be the last!). And, as a team, we built a full cross-platform MVP from the ground up in under 36 hours while learning the technologies used to create it.
## What we learned
We learned technical skills (React Native), as well as more soft skills (working as a team, coordinating tasks among members, incorporating all of our ideas/brainstorming, etc.).
## What's next for SOSed Up
Adding functionality to always send alerts to specific individuals (e.g. family, close friends) is high on the list of immediate things to add. | winning |
## Inspiration
We take our inspiration from our everyday lives. As avid travellers, we often run into places with foreign languages and need help with translations. As avid learners, we're always eager to add more words to our bank of knowledge. As children of immigrant parents, we know how difficult it is to grasp a new language and how comforting it is to hear the voice in your native tongue. LingoVision was born with these inspirations and these inspirations were born from our experiences.
## What it does
LingoVision uses AdHawk MindLink's eye-tracking glasses to capture foreign words or sentences as pictures when given a signal (double blink). Those sentences are played back in an audio translation (either using an earpiece, or out loud with a speaker) in your preferred language of choice. Additionally, LingoVision stores all of the old photos and translations for future review and study.
## How we built it
We used the AdHawk MindLink eye-tracking classes to map the user's point of view, and detect where exactly in that space they're focusing on. From there, we used Google's Cloud Vision API to perform OCR and construct bounding boxes around text. We developed a custom algorithm to infer what text the user is most likely looking at, based on the vector projected from the glasses, and the available bounding boxes from CV analysis.
After that, we pipe the text output into the DeepL translator API to a language of the users choice. Finally, the output is sent to Google's text to speech service to be delivered to the user.
We use Firebase Cloud Firestore to keep track of global settings, such as output language, and also a log of translation events for future reference.
## Challenges we ran into
* Getting the eye-tracker to be properly calibrated (it was always a bit off than our view)
* Using a Mac, when the officially supported platforms are Windows and Linux (yay virtualization!)
## Accomplishments that we're proud of
* Hearing the first audio playback of a translation was exciting
* Seeing the system work completely hands free while walking around the event venue was super cool!
## What we learned
* we learned about how to work within the limitations of the eye tracker
## What's next for LingoVision
One of the next steps in our plan for LingoVision is to develop a dictionary for individual words. Since we're all about encouraging learning, we want to our users to see definitions of individual words and add them in a dictionary.
Another goal is to eliminate the need to be tethered to a computer. Computers are the currently used due to ease of development and software constraints. If a user is able to simply use eye tracking glasses with their cell phone, usability would improve significantly. | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | ## Inspiration
There are thousands of people worldwide who suffer from conditions that make it difficult for them to both understand speech and also speak for themselves. According to the Journal of Deaf Studies and Deaf Education, the loss of a personal form of expression (through speech) has the capability to impact their (affected individuals') internal stress and lead to detachment. One of our main goals in this project was to solve this problem, by developing a tool that would a step forward in the effort to make it seamless for everyone to communicate. By exclusively utilizing mouth movements to predict speech, we can introduce a unique modality for communication.
While developing this tool, we also realized how helpful it would be to ourselves in daily usage, as well. In areas of commotion, and while hands are busy, the ability to simply use natural lip-reading in front of a camera to transcribe text would make it much easier to communicate.
## What it does
**The Speakinto.space website-based hack has two functions: first and foremost, it is able to 'lip-read' a stream from the user (discarding audio) and transcribe to text; and secondly, it is capable of mimicking one's speech patterns to generate accurate vocal recordings of user-inputted text with very little latency.**
## How we built it
We have a Flask server running on an AWS server (Thanks for the free credit, AWS!), which is connected to a Machine Learning model running on the server, with a frontend made with HTML and MaterializeCSS. This was trained to transcribe people mouthing words, using the millions of words in LRW and LSR datasets (from the BBC and TED). This algorithm's integration is the centerpiece of our hack. We then used the HTML MediaRecorder to take 8-second clips of video to initially implement the video-to-mouthing-words function on the website, using a direct application of the machine learning model.
We then later added an encoder model, to translate audio into an embedding containing vocal information, and then a decoder, to convert the embeddings to speech. To convert the text in the first function to speech output, we use the Google Text-to-Speech API, and this would be the main point of future development of the technology, in having noiseless calls.
## Challenges we ran into
The machine learning model was quite difficult to create, and required a large amount of testing (and caffeine) to finally result in a model that was fairly accurate for visual analysis (72%). The process of preprocessing the data, and formatting such a large amount of data to train the algorithm was the area which took the most time, but it was extremely rewarding when we finally saw our model begin to train.
## Accomplishments that we're proud of
Our final product is much more than any of us expected, especially the ability to which it seemed like it was an impossibility when we first started. We are very proud of the optimizations that were necessary to run the webpage fast enough to be viable in an actual use scenario.
## What we learned
The development of such a wide array of computing concepts, from web development, to statistical analysis, to the development and optimization of ML models, was an amazing learning experience over the last two days. We all learned so much from each other, as each one of us brought special expertise to our team.
## What's next for speaking.space
As a standalone site, it has its use cases, but the use cases are limited due to the requirement to navigate to the page. The next steps are to integrate it in with other services, such as Facebook Messenger or Google Keyboard, to make it available when it is needed just as conveniently as its inspiration. | winning |
# About the Project 🐇
HopChat was born out of a need to simplify digital communication and eliminate the all-too-common miscommunications that occur when people cannot speak face-to-face. Our journey from conception to realization taught us about the complexity of language, the subtleties of human emotion, and the transformative power of technology in communication.
## Inspiration 🐇
We drew inspiration from our collective exasperation with the frequent miscommunications that plague text-based conversations. It's easy for messages to be misread and intentions to be misconstrued. HopChat is our response to this challenge: an application designed to facilitate understanding and bring clarity to digital dialogues.
## What it does 🐇
HopChat is an intelligent messaging app that enhances digital conversations by ensuring clarity and emotional context? It offers:
* **Reply Suggestions:** Context-sensitive responses that adapt to the tone and content of the conversation.
* **Mood/Emotion Interpretations:** Real-time sentiment analysis to help understand the underlying feelings in messages.
* **Summarization:** Boiling down lengthy conversations to their essential points.
These features work in concert to prevent miscommunication and enrich digital interactions.
## How we built it 🐇
Our team developed HopChat using cutting-edge NLP techniques to analyze and understand text. We built the front-end interface with a focus on simplicity and user experience. The frontend is made with vite, react, and tailwind (and css LOL). The backend is powered by gemini, which is proxied through a US server. We iterated on our designs and algorithms through continuous testing and feedback.
## Challenges we ran into 🐇
Crafting an algorithm that could accurately gauge the mood and tone of text was a significant challenge due to the subtlety and variety of human emotions. Balancing personalization with privacy was also a delicate task, requiring meticulous design to protect user data.
Another problem is that gemini is not yet available in Canada due to geo-restrictions. Therefore, we needed to proxy each request and stream data through a proxy server hosted in USA. This means that the features may not be 100% stable, if any connection problems happen in between.
Our team also consisted of mostly backend developers and competitive programmers, we tried to learn our tech stack as much as possible, so the code style may not be industry standard, but we are proud in making something that actually works!
We were incredibly ambitious and had many features in mind, but were only able to implement a few of them.
## Accomplishments that we're proud of 🐇
We are proud of HopChat's capability to reduce misunderstandings in digital communication significantly. The positive impact on our beta testers' daily interactions and the high engagement rates are testaments to our success. We are also proud of our backend's sophistication, which can handle a variety of languages and dialects.
## What we learned 🐇
This project deepened our understanding of NLP and AI, especially in interpreting human emotions through text. We learned that good design is more than aesthetics; it's about creating intuitive and efficient user experiences. Team collaboration was key to our success, reinforcing the idea that diverse perspectives can lead to innovative solutions.
## What's next for HopChat 🐇
The future of HopChat is filled with exciting enhancements and expansions. Our roadmap includes:
* **Broader Language Support:** Introducing more language options for our real-time translation feature to ensure no one is left out of the conversation.
* **Enhanced AI:** Continuous improvements in our AI to provide even sharper mood interpretations and more personalized reply suggestions.
* **Text-to-Voice and Voice-to-Text:** Implementing accessibility features that allow users to communicate in the way that's most comfortable for them, whether that's speaking or typing.
* **Confidential Modes:** Developing secure communication modes for sensitive conversations, ensuring privacy and discretion for our users.
* **Platform Integrations:** Expanding HopChat's functionality across various social media and professional platforms for a seamless communication experience.
* **Professional Use Case Development:** Tailoring HopChat's features for specific industries, such as customer support and mental health services, to foster clear, empathetic, and efficient digital interactions.
* **Reminders:** Intelligent prompts to follow up on important messages that you may have forgotten.
* **Translation Languages:** Real-time translation for a wide array of languages, breaking down language barriers in communication.
These advancements are designed to position HopChat as a leader in the messaging app space, not just for casual conversations, but as an essential tool for businesses and individuals who require the utmost in communication precision and reliability. | ## Inspiration
During these times of Covid-19 it has been more difficult to meet up with experts in their fields due to the associated danger of meeting up in an office. Even with this, the need of advice from those who have mastered their respective fields has not reduced. For some, there has been an increase of need of financial assistance due to suddenly being found out of a job. While others may find themselves feeling a lot more stressed and lost due to being alone and away from others due to isolation and want to have easier access to mental health assistance. This inspired us to build QuickConnect where connectivity is created among people who needs help and who are ready to help.
## What it does
It is like a social media platform where two types of user are observed - regular users who are looking to share thoughts and looking for help from professionals and service providers who provide service like financial budgeting plan for students, improving mental health, provide treatment as a doctor, helping other students as a student and earn money. People can create post, hit Like or create comments on other posts. But if the comment is a negative one then the system detects that using Natural Language Processing and Sentiment Analysis technique and prevents the comment from posting. It also has a Real Time chatting feature where users and service providers can chat and make a conversation in real time.
## How we built it
The application is based on two servers. First server was set up using Node.js and Express.js where the APIs are developed and logics are implemented. This is the backend server. Natural Language Processing and Sentiment Analysis part has also been setup on this server. Whenever there is a negative comment, the system reads the comment, corrects the spelling of each word where necessary, does the sentiment analysis and returns a score for the entire comment. Any value less than 0 is considered as a negative comment and in that case, the user is informed about it and the comment is not posted. This helps to stop spread negativity. Another Front End App was created using Vue JS and this is the user interface or the client application. APIs were created in Backend server and data was fetched from Front End. We also made use of the Socket.io for the real time chat experience and this was needed to be implemented on both the front end and the back end. APIs are called from front end app using Axios. When a user is logged in, the information is stored in the localStorage of the browser and that is used for making further http requests. In this way, communication was established between the front end and the back end application.
## Challenges we ran into
We faced the following challenges:
* Connecting the front-end to backend
* Seamless connections between users for Socket.io (networking)
* We tried to implement CockroachDB but ran into too many troubles for us to continue wasting time on it
* Due to shortage of time, we could not use database. Instead we created variables in the back end side and used those to store information temporarily.
## Accomplishments that we're proud of
In this short period of time, we were able to develop an entire web based application having two servers front end and back end, implementing Natural Language Processing and Sentiment Analysis, Real Time chat feature integration using Socket.io and absolute teamwork.
## What we learned
From QuickConnect, we learned:
* Sockets and networking
* Gained deeper understanding of Vue for our frontend team and nodeJs for our backend team
* Server/client-side integration
* Data handling/data collection
* Dividing tasks among team members and strong teamwork
## What's next for QuickConnect
We plan to add video chat feature and payment integration using which payment can be done. Implementing token based security is also in the priority list that will help to do secure data communication. | ## Inspiration ⛹️♂️
Regularly courts are getting many cases and currently, it is becoming challenging to prioritize those cases. There are about 73,000 cases pending before the Supreme Court and about 44 million in all the courts of India. Cases that have been in the courts for more than 30 years, as of January 2021. A software/algorithm should be developed for prioritizing and allocations of dates to the cases based on the following parameters:
* Time of filing of chargesheet
* Severity of the crime and sections involved
* Last hearing date
* Degree of responsibility of the alleged perpetrators.
To provide a solution to this problem, we thought of a system to prioritize the cases, considering various real-life factors using an efficient machine learning algorithm.
That's how we came up with **"e-Adalat"** ("digital law court" in English), e-Court Management System.
## What it does?
e-Adalat is a platform (website) that prioritizes court cases and suggests the priority order to the judges in which these cases should be heard so that no pending cases will be there and no case is left pending for long periods of time. Judges and Lawyers can create their profiles and manage complete information of all the cases, a lawyer can file a case along with all the info in the portal whereas a judge can view the suggested priority of the cases to be held in court using the ML model, the cases would be automatically assigned to the judge based on their location. The judge and the lawyer can view the status of all the cases and edit them.
## How we built it?
While some of the team members were working on the front-end, the other members started creating a dummy dataset and analyzing the best machine learning algorithm, after testing a lot of algorithms we reached to the conclusion that random forest regression is the best for the current scenario, after developing the frontend and creating the Machine Learning model, we started working on the backend functionality of the portal using Node.js as the runtime environment with express.js for the backend logic and routes, this mainly involved authorization of judges and lawyers, linking the Machine Learning model with backend and storing info in database and fetching the information while the model is running.
Once, The backend was linked with the Machine Learning model, we started integrating the backend and ML model with the frontend, and that's how we created e-Adalat.
## Challenges we ran into
We searched online for various datasets but were not able to find a dataset that matched our requirements and as we were not much familiar with creating a dataset, we learned how to do that and then created a dataset.
Later on, we also ran this data through various Machine Learning algorithms to get the best result. We also faced some problems while linking the ML model with the backend and building the Web Packs but we were able to overcome that problem by surfing through the web and running various tests.
## Accomplishments that we're proud of
The fact that our offline exams were going on and still we managed to create a full-fledged portal in such a tight schedule that can handle multiple judges and lawyers, prioritize cases and handle all of the information securely from scratch in a short time is a feat that we are proud of, while also at the same time diversifying our Tech-Stacks and learning how to use Machine Learning Algorithms in real-time integrated neatly into our platform!
## What we learned
While building this project, we learned many new things, and to name a few, we learned how to create datasets, and test different machine learning algorithms. Apart from technical aspects we also learned a lot about Law And Legislation and how courts work in a professional environment as our project was primarily focused on law and order, we as a team needed to have an idea about how cases are prioritized in courts currently and what are the existing gaps in this system.
Being in a team and working under such a strict deadline along with having exams at the same time, we learned time management while also being under pressure.
## What's next for e-Adalat
### We have a series of steps planned next for our platform :
* Improve UI/UX and make the website more intuitive and easy to use for judges and lawyers.
* Increase the scope of profile management to different judicial advisors.
* Case tracking for judges and lawyers.
* Filtering of cases and assignment on the basis of different types of judges.
* Increasing the accuracy of our existing Machine Learning model.
## Discord Usernames:
* Shivam Dargan - Shivam#4488
* Aman Kumar - 1Man#9977
* Nikhil Bakshi - nikhilbakshi#8994
* Bakul Gupta - Bakul Gupta#5727 | losing |
## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages. | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | ## Inspiration
We thought Adhawk's eye tracking technology was super cool, so we wanted to leverage it in a VR game. However, since Adhawk currently only has a Unity SDK, we thought we would demonstrate a way to build eye-tracking VR games for the web using WebVR.
## Our first game
You, a mad scientist, want to be able to be in two places at once. So, like any mad scientist, you develop cloning technology that allows you to inhabit your clone's body. But the authorities come in and arrest you and your clone for violating scientific ethics. Now, you and your clone are being held in two separate prison cells. Luckily, it seems like you should be able to escape by taking control of your clone. But, you can only take control of your clone by **blinking**. Seemed like a good idea at the time of developing the cloning technology, but it *might* prove to be a little annoying. Blink to change between you and your clone to solve puzzles in both prison cells and break out of prison together!
## How we built it
We extracted the blinking data from the Adhawk Quest 2 headset using the Adhawk Python SDK and routed it into a Three.js app that renders the rooms in VR.
## Challenges we ran into
Setting up the Quest 2 headset to even display WebVR data took a lot longer than expected.
## Accomplishments that we're proud of
Combining the Adhawk sensor data with the Quest 2 headset and WebVR to tell a story we could experience and explore!
## What we learned
Coming up with an idea is probably the hardest part of a hackathon. During the ideation process, we learned a lot about the applications of eye tracking in both VR and non-VR settings. Coming up with game mechanics specific to eye tracking input had our creative juices flowing; we really wanted to use eye tracking as its own special gameplay elements and not just as a substitute to other input methods (for example, keyboard or mouse).
And VR game development is a whole other beast.
## What's next for eye♥webvr
We want to continue developing our game to add more eye tracking functionality to make the world more realistic, such as being able to fixate on objects to be able to read them, receive hints, and "notice" things that you would normally miss if you didn't take a second glance. | winning |
## Inspiration
Battleship was a popular game and we want to use our skills to translate the idea of the game to code.
## What it does
This code will create a 10 x 10 board with 5 hidden enemy submarines. The user will enter both the row and column coordinates. if there is a submarine at that coordinate, a sunk message will appear and the the sign "#" will be at the coordinate. If there is no submarine at that coordinate, the board will show a number that tells the user how far the distance is the submarine located.
## How we built it
We mainly used C++ to create the game and used web development languages for the frond-end.
## Challenges we ran into
We had a hard time trying to connect the back-end to the front-end.
## What's next for Battlemarines
Hopefully figure out ways to connect the website to the game itself. | ## Inspiration
We found that even there are so many resources to learn to code, but all of them fall into one of two categories: they are either in a generic course and grade structure, or are oversimplified to fit a high-level mould. We thought the ideal learning environment would be an interactive experience where players have to learn to code, not for a grade or score, but to progress an already interactive game. The code the students learn is actual Python script, but it guided with the help of an interactive tutorial.
## What it does
This code models a "dinosaur game" structure where players have to jump over obstacles. However, as the player experiences more and more difficult obstacles through the level progression, they are encouraged to automate the character behavior with the use of Python commands. Players can code the behavior for the given level, telling the player to "jump when the obstacles is 10 pixels away" with workable Python script. The game covers the basic concepts behind integers, loops, and boolean statements.
## How we built it
We began with a Pygame template and created a game akin to the "Dinosaur game" of Google Chrome. We then integrated a text editor that allows quick and dirty compilation of Python code into the visually appealing format of the game. Furthermore, we implemented a file structure for all educators to customize their own programming lessons and custom functions to target specific concepts, such as for loops and while loops.
## Challenges we ran into
We had most trouble with troubleshooting an idea that is both educational and fun. Finding that halfway point pushed both our creativity and technical abilities. While there were some ideas that had heavily utilizing AI and VR, we knew that we could not code that up in 36 hours. The idea we settled on still challenged us, but was something we thought was accomplishable. We also had difficulty with the graphics side of the project as that is something that we do not actively focus on learning through standard CS courses in school.
## Accomplishments that we're proud of
We were most proud of the code incorporation feature. We had many different approaches for incorporating the user input into the game, that finding one that worked proved to be very difficult. We considered making pre-written code snippets that the game would compare to the user input or creating a pseudocode system that could interpret the user's intentions. The idea we settled upon, the most graceful, was a method through which the user input is directly input into the character behavior instantiation, meaning that the user code is directly what is running the character--no proxies or comparison strings. We are proud of the cleanliness and truthfulness this hold with our mission statement--giving the user the most hand-ons and accurate coding experience.
## What we learned
We learned so much about game design and the implementation of computer science skills we learned in the classroom. We also learned a lot about education, through both introspection into ourselves as well as some research articles we found about how best to teach concepts and drill practice.
## What's next for The Code Runner
The next steps for Code Runner would be adding more concepts covered through the game functionality. We were hoping to cover while-loops and other Python elements that we thought were crucial building blocks for anyone working with code. We were also hoping to add some gravity features where obstacles can jump with realistic believability. | ## Inspiration:
Millions of active software developers use GitHub for managing their software development, however, our team believes that there is a lack of incentive and engagement factor within the platform. As users on GitHub, we are aware of this problem and want to apply a twist that can open doors to a new innovative experience. In addition, we were having thoughts on how we could make GitHub more accessible such as looking into language barriers which we ultimately believed wouldn't be that useful and creative. Our offical final project was inspired by how we would apply something to GitHub but instead llooking into youth going into CS. Combining these ideas together, our team ended up coming up with the idea of DevDuels.
## What It Does:
Introducing DevDuels! A video game located on a website that's goal is making GitHub more entertaining to users. One of our target audiences is the rising younger generation that may struggle with learning to code or enter the coding world due to complications such as lack of motivation or lack of resources found. Keeping in mind the high rate of video gamers in the youth, we created a game that hopes to introduce users to the world of coding (how to improve, open sources, troubleshooting) with a competitive aspect leaving users wanting to use our website beyond the first time. We've applied this to our 3 major features which include our immediate AI feedback to code, Duo Battles, and leaderboard.
In more depth about our features, our AI feedback looks at the given code and analyses it. Very shortly after, it provides a rating out of 10 and comments on what it's good and bad about the code such as the code syntax and conventions.
## How We Built It:
The web app is built using Next.js as the framework. HTML, Tailwind CSS, and JS were the main languages used in the project’s production. We used MongoDB in order to store information such as the user account info, scores, and commits which were pulled from the Github API using octokit. Langchain API was utilised in order to help rate the commit code that users sent to the website while also providing its rationale for said rankings.
## Challenges We Ran Into
The first roadblock our team experienced occurred during ideation. Though we generated multiple problem-solution ideas, our main issue was that the ideas either were too common in hackathons, had little ‘wow’ factor that could captivate judges, or were simply too difficult to implement given the time allotted and team member skillset.
While working on the project in specific, we struggled a lot with getting MongoDB to work alongside the other technologies we wished to utilise (Lanchain, Github API). The frequent problems with getting the backend to work quickly diminished team morale as well. Despite these shortcomings, we consistently worked on our project down to the last minute to produce this final result.
## Accomplishments that We're Proud of:
Our proudest accomplishment is being able to produce a functional game following the ideas we’ve brainstormed. When we were building this project, the more we coded, the less optimistic we got in completing it. This was largely attributed to the sheer amount of error messages and lack of progression we were observing for an extended period of time. Our team was incredibly lucky to have members with such high perseverance which allowed us to continue working on, resolving issues and rewriting code until features worked as intended.
## What We Learned:
DevDuels was the first step into the world hackathons for many of our team members. As such, there was so much learning throughout this project’s production. During the design and ideation process, our members learned a lot about website UI design and Figma. Additionally, we learned HTML, CSS, and JS (Next.js) in building the web app itself. Some members learned APIs such as Langchain while others explored Github API (octokit). All the new hackers navigated the Github website and Git itself (push, pull, merch, branch , etc.)
## What's Next for DevDuels:
DevDuels has a lot of potential to grow and make it more engaging for users. This can be through more additional features added to the game such as weekly / daily goals that users can complete, ability to create accounts, and advance from just a pair connecting with one another in Duo Battles.
Within these 36 hours, we worked hard to work on the main features we believed were the best. These features can be improved with more time and thought put into it. There can be small to large changes ranging from configuring our backend and fixing our user interface. | losing |
## Inspiration
StuddyBuddy originated from 4 students at the University of British Columbia that felt a need for prioritizing mental and physical health while regaining control over the technology that surrounds us. It was inspired by our own struggles during online school and the lack of productivity tools that actually worked for our demographic. We created a personalized productivity tool as a Google Chrome extension that is customizable, aesthetic, and efficient using a healthy reward system.
## What it does
StuddyBuddy is a Google Chrome extension that is a simple productivity tool that is customizable, aesthetic, and efficient through a healthy reward system. An assortment of animals cheer you on, tracks your progress, and helps control screen time.
Components include: Timer, Break Time, Rounds, Time Remaining, Progress Bar, Start button, Animated Animal, and a StuddyBuddy!
## How we built it
We used three programming languages in the development of this chrome extension: CSS, JavaScript, and HTML. We also used several coding technologies such as GitHub and Visual Studio Code. This project was a huge learning curve and we took advantage of the resources available to us including youtube videos, online code sharing platforms, and of course, the wonderful NW Hacks mentors.
We began by researching the basics of how to design a chrome extension and watched more tutorials to include the functionality we were looking for. As with most programmers, we also did a lot of trial and error to consistently test out our design and catch small bugs early, as opposed to solving larger issues at the end.
## Challenges we ran into
Considering this was our first hackathon with no technical experience outside of the classroom, it was definitely difficult figuring out where to start with the project in terms of the code. We overcame this problem by talking to a mentor about how to approach the project. He advised that we first create a plan of all the components we need to code before we actually start working.
It was definitely a challenge to learn HTML, CSS, and JavaScript on the fly as we built, rather than having that knowledge beforehand. I don’t think we necessarily “overcame” this challenge, but we more so embraced it as a learning opportunity and saw this as a chance to push our ability to learn quickly and effectively.
Lastly, we underestimated the complexity of our initial idea; when we realized how complex it really was, we began to feel overwhelmed/lost. Instead of sitting in our frustration, we proactively decided to commit to making a minimum viable product. We accepted the fact that things don’t always go as planned and quickly iterated our vision for the product.
## Accomplishments that we're proud of
Our team is proud of our willingness to take risks and learn throughout this project. There were many times we felt underqualified or not experienced enough, yet instead of giving up, we reached out for support from mentors and sought resources to help us. On the design side, we are proud of the creativity and originality of our designs. We believe these have the perfect balance of cute and motivation to help students stay productive while studying but remind them to take healthy breaks. On the development side, we are proud of our self-learning ability and desire to figure things out on our own if possible. As a whole, our team is very proud of our collaboration and communication. Each team member contributed many ideas to the final product and we worked well together to create a final solution for an issue we all sometimes struggle with.
## What we learned
This hackathon was definitely a huge learning curve for our group! We learned new coding languages (CSS, JavaScript, HTML), code sharing technology (GitHub), how to use code editors (Visual Studio Code), and the terminal. We learned how a hackathon works and we were surprised to learn how many coding languages are required for one project! We also learned about ourselves in this project, like our new passion for creating cute animations and designs. We even learned how to use discord!
## What's next for StuddyBuddy
In the future, we hope to add more animals and personalization settings, such as unlocking more options through rewards and garden growing. Further additions could be:
Music: automatically plays once a certain time limit is reached (animals dance)
Breathe: screen displays flower that slowly expands and compresses several times to mimic deep breathing patterns (and animal breathes along)
Stretch: follow an animal on screen stretching
Fitness: do some low-intesity exercise like jumping jacks / plank / sit-ups (animals follow)
Connect: text some friends/family to say hi (animals text)
Gratitude: write down three things you are grateful for in this moment (into the browser textbox?)
Meditate: plays a short meditation recording (led by the animal)
Water: drink a cup of water (with the animal)
Eat: get a healthy snack (the animals give suggestions)
Walk: go for a short outdoor walk tracked by your phone (animal walks around screen)
Tidy: take a before and after picture of a small area of your room (animal dusts the screen)
As well, adding shareable insights of time studying, break time, and completed tasks will add a social aspect! Having friends to keep you accountable on your goals and self care tasks will improve the efficiency of our extension. Finally, scaling up for different platforms like iOS or android. | ## Inspiration
Every student has experienced the difficulties that arise with a sudden transition to an online learning medium. With a multitude of assignments, midterms, extra-curriculars, etc, time is of the essence. We strived to create a solution that enables any individual to be able to focus on their productivity through the power of automation.
## What it does
**ProSistant** is an easy-to-download Google Chrome extension that will be available to any individual through the Google Chrome Webstore. This productivity assistant's main purpose is to ensure that the student is able to stay on track throughout the week by reducing the stress of having to remember deadlines and tasks while promoting a positive working environment.
## How we built it
Through Google Chrome's developer mode, we unpacked a load package that consisted of all of our HTML, CSS and JavaScript files. HTML was used to give the content of the extension its structure, CSS a presentation language created to style the appearance of content—using, for example, fonts or colours. JavaScript was the functionality workhorse of the extension, powered and enhanced by Google's developer extension API.
## Challenges we ran into
Although the development of the HTML and CSS code went relatively smoothly, the user interface that was working perfectly through the HTML interface failed to build when the Chrome extension was loaded. This was a major setback in the design process as there were many contradicting sources about the way to fix this. However, through repeated experimentation and fully diversifying in the behaviour of JavaScript, we were able to overcome this obstacle and build a Chrome extension that encompassed the interface that we wished for the user to interact with.
## Accomplishments that we're proud of
All three of us were new to web development, and we were able to maintain a positive working environment while demonstrating our ability to pick up on new techniques in a fast and efficient manner. We are proud of our ability to implement unique features that we are confident will be of service for any student through the use of programming languages that, coming into this weekend, were foreign to us.
## What we learned
We fully emersed ourselves in the hackathon environment and learned to trust one another when it came to implementing unique features that would eventually come together for the final product. We learned how to optimize HTML and CSS code to make visually appealing interfaces, and essential JavaScript code to increase user interactivity.
## What's next for ProSistant
The potential for **ProSistant** is abundant. Our team will continue to roll out newer versions to implement even more productivity-related features and further improve the user interface. | # anonybuddy
## What it does
In times of hardship, sometimes you just need someone to talk to. *anonybuddy* is a web app designed to provide support to addicts and others in recovery in a personal yet anonymous way. "Clients" can reach out when they feel overwhelmed or fear relapse, and volunteers will support them over text.
## Inspiration
When recovering addicts are struggling, the typical route is to call a hotline or attend a support group. This can be an issue for those who worry about shame and stigma, or are simply unable to make it to in-person meetings.
Existing addiction and other mental-health centred apps primarily focus on self-help, self-guided therapy, behaviour tracking, and automated reminders to stay on target. These are useful tools, but they don't provide the human connection and immediate feedback that a human sponsor provides. We wanted to create a solution that would offer that support.
We were inspired by the app "Be My Eyes" that connects sighted volunteers with blind or visually impaired people with vision-related tasks such as reading labels.
With this in mind, we built a web app that would anonymously connect users ("clients"), to human volunteers ("buddies") in a one-on-one chat room. This way, they can find motivation, solace, and comfort without worry of revealing their identity.
## How we built it
*anonybuddy* is a React web app with a Google Firebase backend and styled components done in HTML, CSS and Bootstrap. We went through a lengthy ideation and design phase at the beginning of development in order to ensure our plans were solid. As we developed, we had to downsize and rethink our approach due to time constraints, but worked to ensure that we had a working minimum viable product by the end.
## Challenges we had
Our main challenges were in our project implementation and inexperience with React. Our original plan was to build HTML and CSS web pages and integrate them with Firebase and React for the backend. Issues forced us to switch direction and build everything with React, which then brought up other difficulties due to our inexperience. We also ran into some communication struggles within our team, as multiple people were working on the same thing in different ways. One big issue was how to integrate all the pieces we individually worked on together.
## What we learned
**Communicate!** One of the most important things we'll be taking away from this project is the importance to have frequent check-ins with the team. This will prevent overlap, highlight concerns earlier, and leave more time to solve problems. Other than that, we think it's important to limit the use of new technologies in a hackathon. Learning a new tool is great, but it is a short time window and it's probably best to stick to one new thing and integrate it with what we already know.
Also, taking the time to make good pitch plans, slides, and Devposts is well worth the effort.
## What's next for anonybuddy
If we continued this project into the future, we would like to port it to a mobile app in order to let people connect to buddies more conveniently. We'd also love to incorporate Google's natural language processing API so that clients could type in their situation and get better matches. If our app were in production, we would like to ensure that mental health professionals were also on call to assist the volunteers and intervene in potentially dangerous situations. | losing |
# Nexus, **Empowering Voices, Creating Connections**.
## Inspiration
The inspiration for our project, Nexus, comes from our experience as individuals with unique interests and challenges. Often, it isn't easy to meet others with these interests or who can relate to our challenges through traditional social media platforms.
With Nexus, people can effortlessly meet and converse with others who share these common interests and challenges, creating a vibrant community of like-minded individuals.
Our aim is to foster meaningful connections and empower our users to explore, engage, and grow together in a space that truly understands and values their uniqueness.
## What it Does
In Nexus, we empower our users to tailor their conversational experience. You have the flexibility to choose how you want to connect with others. Whether you prefer one-on-one interactions for more intimate conversations or want to participate in group discussions, our application Nexus has got you covered.
We allow users to either get matched with a single person, fostering deeper connections, or join one of the many voice chats to speak in a group setting, promoting diverse discussions and the opportunity to engage with a broader community. With Nexus, the power to connect is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tool:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* DaisyUI for animations and UI components
* 100ms live for real-time audio communication
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel perfect icons
* Vite for simplified building and fast dev server
* Convex for vector search over our database
* React-router for client-side navigation
* Convex for real-time server and end-to-end type safety
* 100ms for real-time audio infrastructure and client SDK
* MLH for our free .tech domain
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used Convex and 100ms, it took a lot of research and heads-down coding to get Nexus working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Nexus.
* Working with **very** poor internet throughout the duration of the hackathon, we estimate it cost us multiple hours of development time.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Nexus.
* Learning a ton of new technologies we would have never come across without Cal Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
* Integrating 100ms well enough to experience bullet-proof audio communication.
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Nexus
* Make Nexus rooms only open at a cadence, ideally twice each day, formalizing the "meeting" aspect for users.
* Allow users to favorite or persist their favorite matches to possibly re-connect in the future.
* Create more options for users within rooms to interact with not just their own audio and voice but other users as well.
* Establishing a more sophisticated and bullet-proof matchmaking service and algorithm.
## 🚀 Contributors 🚀
| | | | |
| --- | --- | --- | --- |
| [Jeff Huang](https://github.com/solderq35) | [Derek Williams](https://github.com/derek-williams00) | [Tom Nyuma](https://github.com/Nyumat) | [Sankalp Patil](https://github.com/Sankalpsp21) | | ## Inspiration
We wanted to watch videos together as a social activity during the pandemic but were unable as many platforms were hard to use or unstable. Therefore our team decided to create a platform that met our needs in terms of usability and functionality.
## What it does
Bubbles allow people to create viewing rooms and invite their rooms to watch synchronized videos. Viewers no longer have to conduct countdowns on their play buttons or have a separate chat while watching!
## How I built it
Our web app uses React for the frontend and interfaces with our Node.js REST API in the backend. The core of our app uses the Solace PubSub+ and the MQTT protocol to coordinate events such as video play/pause, a new member joining your bubble, and instant text messaging. Users broadcast events with the topic being their bubble room code, so only other people in the same room receive these events.
## Challenges I ran into
* Collaborating in a remote environment: we were in a discord call for the whole weekend, using Miro for whiteboarding, etc.
* Our teammates came from various technical backgrounds, and we all had a chance to learn a lot about the technologies we used and how to build a web app
* The project was so much fun we forgot to sleep and hacking was more difficult the next day
## Accomplishments that I'm proud of
The majority of our team was inexperienced in the technologies used. Our team is very proud that our product was challenging and was completed by the end of the hackathon.
## What I learned
We learned how to build a web app ground up, beginning with the design in Figma to the final deployment to GitHub and Heroku. We learned about React component lifecycle, asynchronous operation, React routers with a NodeJS backend, and how to interface all of this with a Solace PubSub+ Event Broker. But also, we learned how to collaborate and be productive together while still having a blast
## What's next for Bubbles
We will develop additional features regarding Bubbles. This includes seek syncing, user join messages and custom privilege for individuals. | ## Inspiration
Our inspiration was our experience as university students at the University of Waterloo. During the pandemic, most of our lectures were held online. This resulted in us having several hours of lectures to watch each day. Many of our peers would put videos at 2x speed to get through all the lectures, but we found that this could result in us missing certain details. We wanted to build a website that could help students get through long lectures quickly.
## What it does
Using our website, you can paste the link to most audio and video file types. The website will take the link and provide you with the transcript of the audio/video you sent as well as a summary of that content. The summary includes a title for the audio/video, the synopsis, and the main takeaway.
We chose to include the transcript, because the AI can miss details that you may want to make note of. The transcript allows you to quickly skim through the lecture without needing to watch the entire video. Also, a transcript doesn't include the pauses that happen during a normal lecture, accelerating how fast you can skim!
## How we built it
To start, we created wireframes using Figma. Once we decided on a general layout, we built the website using HTML, CSS, Sass, Bootstrap, and JavaScript. The AssemblyAI Speech-to-Text API handles the processing of the video/audio and returns the information required for the transcript and summary. All files are hosted in our [GitHub repository](https://github.com/ctanamas/HackTheNorth). We deployed our website using Netlify and purchased our domain name from Domain.com. The logo was created in Canva.
## Challenges we ran into
Early on we struggled with learning how to properly use the API. We were not experienced with APIs, and as a result, we found it difficult to get the correct response from the API. Often times when we tried testing our code, we simply got an error from the API. We also struggled with learning how to secure our website while using an API. Learning how to hide the secret key when using an API was something we had never dealt with before.
## Accomplishments that we're proud of
We are proud to have a working demo of our product! We are also proud of the fact that we were able to incorporate an API into our project and make something that we will actually use in our studies! We hope other students can use our product as well!
## What we learned
We learned about how an API works. We learned about how to properly set up a request and how to process the response and incorporate it into our website. We also learned about the process of deploying a website from GitHub. Being able to take plain files and create a website that we can access on any browser was a big step forward for us!
## What's next for notetaker
In the future, we want to add an extension to our summary feature by creating a worksheet for the user as well. The worksheet would replace key words in the summary with blanks to allow the user to test themselves on how well they know the topic. We also wanted to include relevant images to the summary study guide, but were unsure on how that could be done. We want to make our website the ultimate study tool for students on a tight schedule. | winning |
# 🎓 **Inspiration**
Entering our **junior year**, we realized we were unprepared for **college applications**. Over the last couple of weeks, we scrambled to find professors to work with to possibly land a research internship. There was one big problem though: **we had no idea which professors we wanted to contact**. This naturally led us to our newest product, **"ScholarFlow"**. With our website, we assure you that finding professors and research papers that interest you will feel **effortless**, like **flowing down a stream**. 🌊
# 💡 **What it Does**
Similar to the popular dating app **Tinder**, we provide you with **hundreds of research articles** and papers, and you choose whether to approve or discard them by **swiping right or left**. Our **recommendation system** will then provide you with what we think might interest you. Additionally, you can talk to our chatbot, **"Scholar Chat"** 🤖. This chatbot allows you to ask specific questions like, "What are some **Machine Learning** papers?". Both the recommendation system and chatbot will provide you with **links, names, colleges, and descriptions**, giving you all the information you need to find your next internship and accelerate your career 🚀.
# 🛠️ **How We Built It**
While half of our team worked on **REST API endpoints** and **front-end development**, the rest worked on **scraping Google Scholar** for data on published papers. The website was built using **HTML/CSS/JS** with the **Bulma** CSS framework. We used **Flask** to create API endpoints for JSON-based communication between the server and the front end.
To process the data, we used **sentence-transformers from HuggingFace** to vectorize everything. Afterward, we performed **calculations on the vectors** to find the optimal vector for the highest accuracy in recommendations. **MongoDB Vector Search** was key to retrieving documents at lightning speed, which helped provide context to the **Cerebras Llama3 LLM** 🧠. The query is summarized, keywords are extracted, and top-k similar documents are retrieved from the vector database. We then combined context with some **prompt engineering** to create a seamless and **human-like interaction** with the LLM.
# 🚧 **Challenges We Ran Into**
The biggest challenge we faced was gathering data from **Google Scholar** due to their servers blocking requests from automated bots 🤖⛔. It took several hours of debugging and thinking to obtain a large enough dataset. Another challenge was collaboration – **LiveShare from Visual Studio Code** would frequently disconnect, making teamwork difficult. Many tasks were dependent on one another, so we often had to wait for one person to finish before another could begin. However, we overcame these obstacles and created something we're **truly proud of**! 💪
# 🏆 **Accomplishments That We're Proud Of**
We’re most proud of the **chatbot**, both in its front and backend implementations. What amazed us the most was how **accurately** the **Llama3** model understood the context and delivered relevant answers. We could even ask follow-up questions and receive **blazing-fast responses**, thanks to **Cerebras** 🏅.
# 📚 **What We Learned**
The most important lesson was learning how to **work together as a team**. Despite the challenges, we **pushed each other to the limit** to reach our goal and finish the project. On the technical side, we learned how to use **Bulma** and **Vector Search** from MongoDB. But the most valuable lesson was using **Cerebras** – the speed and accuracy were simply incredible! **Cerebras is the future of LLMs**, and we can't wait to use it in future projects. 🚀
# 🔮 **What's Next for ScholarFlow**
Currently, our data is **limited**. In the future, we’re excited to **expand our dataset by collaborating with Google Scholar** to gain even more information for our platform. Additionally, we have plans to develop an **iOS app** 📱 so people can discover new professors on the go! | ## Inspiration
No one likes being stranded at late hours in an unknown place with unreliable transit as the only safe, affordable option to get home. Between paying for an expensive taxi ride yourself, or sharing a taxi with random street goers, the current options aren't looking great. WeGo aims to streamline taxi ride sharing, creating a safe, efficient and affordable option.
## What it does
WeGo connects you with people around with similar destinations who are also looking to share a taxi. The application aims to reduce taxi costs by splitting rides, improve taxi efficiency by intelligently routing taxi routes and improve sustainability by encouraging ride sharing.
### User Process
1. User logs in to the app/web
2. Nearby riders requesting rides are shown
3. The user then may choose to "request" a ride, by entering a destination.
4. Once the system finds a suitable group of people within close proximity, the user will be send the taxi pickup and rider information. (Taxi request is initiated)
5. User hops on the taxi, along with other members of the application!
## How we built it
The user begins by logging in through their web browser (ReactJS) or mobile device (Android). Through API calls to our NodeJS backend, our system analyzes outstanding requests and intelligently groups people together based on location, user ratings & similar destination - all in real time.
## Challenges we ran into
A big hurdle we faced was the complexity of our ride analysis algorithm. To create the most cost efficient solution for the user, we wanted to always try to fill up taxi cars completely. This, along with scaling up our system to support multiple locations with high taxi request traffic was definitely a challenge for our team.
## Accomplishments that we're proud of
Looking back on our work over the 24 hours, our team is really excited about a few things about WeGo. First, the fact that we're encouraging sustainability on a city-wide scale is something really important to us. With the future leaning towards autonomous vehicles & taxis, having a similar system like WeGo in place we see as something necessary for the future.
On the technical side, we're really excited to have a single, robust backend that can serve our multiple front end apps. We see this as something necessary for mass adoption of any product, especially for solving a problem like ours.
## What we learned
Our team members definitely learned quite a few things over the last 24 hours at nwHacks! (Both technical and non-technical!)
Working under a time crunch, we really had to rethink how we managed our time to ensure we were always working efficiently and working towards our goal. Coming from different backgrounds, team members learned new technical skills such as interfacing with the Google Maps API, using Node.JS on the backend or developing native mobile apps with Android Studio. Through all of this, we all learned the persistence is key when solving a new problem outside of your comfort zone. (Sometimes you need to throw everything and the kitchen sink at the problem at hand!)
## What's next for WeGo
The team wants to look at improving the overall user experience with better UI, figure out better tools for specificially what we're looking for, and add improved taxi & payment integration services. | # 🔥🧠 FlaimBrain: The Future of Academic Excellence
[API Endpoint Documentation](https://documenter.getpostman.com/view/16996416/2s9YR6ZYu6)
Every student embarks on a unique academic journey, filled with challenges that span from comprehending feedback on assignments to acing exams. Recognizing knowledge gaps is one thing, but bridging them effectively? That's a monumental task. Enter **FlaimBrain**—your personalized AI-powered academic mentor, tailored to support every student's individual learning curve. 🚀
## 🤖 FlaimBrain At A Glance
FlaimBrain transcends the capabilities of standard chatbots. By allowing users to upload and scan files, this intelligent bot lends its expertise in summarizing notes, crafting flashcards, proposing study guides, and devising mock assessments—all based on the material you provide. It's not just about providing feedback; it's about aligning that feedback with a student's unique learning trajectory. This ensures that FlaimBrain doesn't just assist; it revolutionizes the way students engage with their academic materials.
## 🔧 Our Journey in Crafting FlaimBrain
Our elegant frontend is the fusion of TypeScript and React.js, while the true genius—our backend—capitalizes on the strengths of Langchain, Flask, MongoDB, and the impressive capabilities of the GPT-4 model. Yet, our journey was not without its fair share of challenges. With MongoDB's recent foray into cloud vector databases on MongoDB Atlas in June 2023, we found ourselves in unfamiliar waters. Sparse examples and limited resources paired with potential systemic issues with MongoDB during our hackathon period kept us on our toes. But as every challenge brought a new learning curve, it also fueled our determination to persevere.
## 🏆 From Novices to Innovators
Our proudest moment? Watching our backend team, primarily composed of newbies, conquer formidable challenges. We embarked on a whirlwind journey: from building APIs, mastering MongoDB databases, integrating AI technologies, to experimenting with Google Cloud Vision and myriad Python libraries. Delving headfirst into the vast universe of artificial intelligence, LangChain, OpenAI, and LLMs became not just a task but an exhilarating adventure!
## 📚 Our Academic Endeavour
Our journey mirrored the academic process. We became students, soaking up knowledge from Cohere's LLMU. The art of vector database management, Flask API endpoint creation, and strategic system design became our syllabus. And as we grew, so did our expertise in React and the effective deployment of ChatGPT 4, from browsing to DALL-E integration.
## 🚀 The Future Beckons
As we gaze into FlaimBrain's future, the horizon promises further innovation. We envision incorporating memory-enhancing features, much like those of ChatGPT, into LangChain. And with plans to broaden our file compatibility spectrum, FlaimBrain is poised to become an indispensable companion in every student's academic voyage.
Join us as we redefine learning. With FlaimBrain, students aren't just studying—they're thriving. 📖🤝 | partial |
## Inspiration
Communication is key -- in all aspects of life. Yet, a fear of public speaking is *the* most common phobia, affecting more than 75% of people according to [surveys](https://www.supportivecareaba.com/statistics/fear-of-public-speaking-statistics#:%7E:text=Glossophobia%2C%20the%20fear%20of%20public,the%20population%20experiences%20severe%20glossophobia.). Exacerbated by the lack of social interaction during quarantine, both children and adults struggle with conveying their emotions, especially in front of large crowds.
Often, speakers are so overwhelmed by the nerves of being on-stage that they’re unable to concentrate on effective, emotional delivery, decreasing the impact of their message. What if you had a personalized speech coach and the opportunity for focused practice on emotional delivery, so that not even the worst of stage-fright could phase you? That’s where SpeakEazy comes in, providing personalized feedback about speakers’ emotional delivery.
Yet, even beyond public speaking applications, our tool could help people practice and refine their delivery of important and sensitive personal conversations.
As a group of people who love communication and love helping people learn and improve their skills, the idea for this project emerged naturally.
## What it does
SpeakEazy allows users to record themselves speaking and get feedback on the emotions they demonstrated while speaking. After users are done recording, we present users with their results, including the top 5 emotions they displayed.
We also feed their speech transcript and time-stamped data to Chat-GPT to provide intelligent, personalized, qualitative feedback to help them better understand the quantitative expression-data.
By allowing users to practice their speaking with immediate feedback, SpeakEazy allows users to refine their speaking style, identify weak points and hone in on those areas. Additionally, while the LLM can suggest certain emotions that the user should be emphasizing based on the context of their speech, by presenting the complete expression data, we allow users to identify whether or not the emotions they are expressing are intentional or not.
## How we built it
We used WebSocket to stream a user's video + audio recording real time to Hume AI's Expression Measurement API.
We also used Chat-GPT's API to create a chat-bot that would enable the user to ask for more detailed feedback on their speaking.
## Challenges we ran into
We faced many challenges, especially when trying to integrate Expression Management API and the LLM prompts into our app. While we were able to connect our app to Hume AI, our WebSocket kept closing immediately after connecting.
## Accomplishments that we're proud of
We implemented Hume on SpeakEazy which allows for real-time empathic interpretations of facial expressions, tone, and spoken language. This helps public speakers gauge if they are effectively communicating the right emotions to their audience. Additionally, we built a media stream to capture hand gestures and eye contact to pass this information to ChatGPT. This integration allows ChatGPT to generate personalized feedback for the speaker and improve their public speaking abilities.
## What we learned
We’ve learned many technical and project-management skills through this project. We also realized the importance of developing with an end-goal in mind, synthesizing different collaboration styles, and the joy of building new connections.
## What's next for SpeakEazy
In order to more effectively support users on their journey to overcoming the fear of public speaking, SpeakEazy could incorporate analysis of hand-gestures and non-verbal body language, which are both integral to public speaking and communication more broadly. Additionally, as more complex dynamics emerge when communication is bi-directional, we’re also considering creating a debate-agent that enables two users to record a debate and receive feedback personalized to each user.
We could also see SpeakEazy being integrated into a broader educational ecosystem that leverages game-based learning methods to promote the love of learning among students. | ## Description
Recycletron is an AI-powered tool designed to classify trash instantly as recyclable or non-recyclable. It empowers users to make informed decisions about waste disposal, ensuring recyclables don’t end up in landfills. Recycletron is scalable globally, working seamlessly for individuals, businesses, and governments alike. By integrating gamification and educational features, Recycletron not only promotes proper waste management but also makes it engaging and rewarding for users. Whether you’re a global corporation, a developing nation, or simply looking to teach children the value of sustainability, Recycletron is here to help.
## How we built it
* Meta’s detectron2 object identification model
* Flask for backend implementation
* HTML, Javascript for frontend
“Detectron2 is Facebook AI Research's next generation library that provides state-of-the-art detection and segmentation algorithms. It is the successor of Detectron and maskrcnn-benchmark. It supports a number of computer vision research projects and production applications in Facebook.” - From Meta/Facebook GitHub README.md.
Object identification is a class of novel computer vision algorithms that uses advanced methods to find multiple objects within one image. This contrasts with traditional image classification techniques that can only put one label on an image. It does this by first learning how to “split” an image into multiple possible regions where images could exist, and then runs a Convolutional Neural Network, Swin Transformer, or other computer vision models across each region individually. Detectron2 is a library that allows users to test multiple advanced methods, already trained on enormous data of everyday household objects.
For more specifics, feel free to check out Detectron2’s detailed documentation.
## Challenges we ran into
The largest challenge was finding a class of models that would fit our use case, and being able to understand it well enough to use it. Traditional Convolutional Neural Networks would work okay, but our vision was to have a model that could take a pile of waste and determine what is recyclable and what is not; after all, in households and in recycling factories, where we hope to deploy this technology to facilitate the recycling process and incentivize individuals to recycle, there aren’t usually ways to individually separate each waste material into its own individual picture to then classify. We were able to find object identifying networks, but there are many versions, including YOLO models, R-CNN, and Weak Supervised Segmentation, and finding a codebase that had prepackaged models as well as useable modules was tough.
We also ran into challenges when we finally looked to deploy our model. Though these models are extraordinarily fast, they used lots of memory which made it tough to deploy these models through virtual servers. Since we didn't have advanced GPUs, we had to push these models through our cpus, which made them a lot slower and harder to host. We got around this by hosting our backend on one computer, pushing all the calculations from there before sending it back to the frontend for the user to view.
## Accomplishments that we're proud of
We're proud of getting a model connected to a frontend service and able to run fast inference on any image given by a user. For many of us, this is our first time working with AI models, and object identification is an exciting field still undergoing development. We're excited to have been a small part of it.
## What's next for Recycletron
We wanted to make Recycletron more gamified, so that users could log in, upload images, and be rewarded for recycling and also adding to our database of recycled items. We added a basic framework for username, password, and score storage but in the future we would like to fully develop this into a sort of game.
While deploying our model, we struggled with finding a way to host the network. Virtual machines would get overloaded with their low memory, and our computers did not have GPUs, sometimes making inference slow, especially in real-time. In the future we'd like to get a small server with a GPU to have a centralized place for users.
There are more advanced object identification models trained on over 20,000 different objects and ready-to-go. An example is the Detic model created by Facebook, which is much more robust than Detectron2. However, these models were too heavy for us to use for inference | ## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front of a mirror could work, but it does not live up to the real environment of a public speaker. As a result, public speaking is dreaded not only for the act itself, but also because it's *difficult to feel ready*. If there was an efficient way of ensuring you aced a presentation, the negative connotation associated with them would no longer exist . That is why we have created Speech Simulator, a VR web application used for practice public speaking. With it, we hope to alleviate the stress that comes with speaking in front of others.
## What it does
Speech Simulator is an easy to use VR web application. Simply login with discord, import your script into the site from any device, then put on your VR headset to enter a 3D classroom, a common location for public speaking. From there, you are able to practice speaking. Behind the user is a board containing your script, split into slides, emulating a real powerpoint styled presentation. Once you have run through your script, you may exit VR, where you will find results based on the application's recording of your presentation. From your talking speed to how many filler words said, Speech Simulator will provide you with stats based on your performance as well as a summary on what you did well and how you can improve. Presentations can be attempted again and are saved onto our database. Additionally, any adjustments to the presentation templates can be made using our editing feature.
## How we built it
Our project was created primarily using the T3 stack. The stack uses **Next.js** as our full-stack React framework. The frontend uses **React** and **Tailwind CSS** for component state and styling. The backend utilizes **NextAuth.js** for login and user authentication and **Prisma** as our ORM. The whole application was type safe ensured using **tRPC**, **Zod**, and **TypeScript**. For the VR aspect of our project, we used **React Three Fiber** for rendering **Three.js** objects in, **React XR**, and **React Speech Recognition** for transcribing speech to text. The server is hosted on Vercel and the database on **CockroachDB**.
## Challenges we ran into
Despite completing, there were numerous challenges that we ran into during the hackathon. The largest problem was the connection between the web app on computer and the VR headset. As both were two separate web clients, it was very challenging to communicate our sites' workflow between the two devices. For example, if a user finished their presentation in VR and wanted to view the results on their computer, how would this be accomplished without the user manually refreshing the page? After discussion between using web-sockets or polling, we went with polling + a queuing system, which allowed each respective client to know what to display. We decided to use polling because it enables a severless deploy and concluded that we did not have enough time to setup websockets. Another challenge we had run into was the 3D configuration on the application. As none of us have had real experience with 3D web applications, it was a very daunting task to try and work with meshes and various geometry. However, after a lot of trial and error, we were able to manage a VR solution for our application.
## What we learned
This hackathon provided us with a great amount of experience and lessons. Although each of us learned a lot on the technological aspect of this hackathon, there were many other takeaways during this weekend. As this was most of our group's first 24 hour hackathon, we were able to learn to manage our time effectively in a day's span. With a small time limit and semi large project, this hackathon also improved our communication skills and overall coherence of our team. However, we did not just learn from our own experiences, but also from others. Viewing everyone's creations gave us insight on what makes a project meaningful, and we gained a lot from looking at other hacker's projects and their presentations. Overall, this event provided us with an invaluable set of new skills and perspective.
## What's next for VR Speech Simulator
There are a ton of ways that we believe can improve Speech Simulator. The first and potentially most important change is the appearance of our VR setting. As this was our first project involving 3D rendering, we had difficulty adding colour to our classroom. This reduced the immersion that we originally hoped for, so improving our 3D environment would allow the user to more accurately practice. Furthermore, as public speaking infers speaking in front of others, large improvements can be made by adding human models into VR. On the other hand, we also believe that we can improve Speech Simulator by adding more functionality to the feedback it provides to the user. From hand gestures to tone of voice, there are so many ways of differentiating the quality of a presentation that could be added to our application. In the future, we hope to add these new features and further elevate Speech Simulator. | losing |
## Inspiration
Having experienced a language barrier firsthand, witnessing its effects in family, and reflecting on equity in services inspired our team to create a resource to help Canadian newcomers navigate their new home.
Newt aims to reduce one of the most stressful aspects of the immigrant experience by promoting more equitable access to services.
## What it does
We believe that everyone deserves equal access to health, financial, legal, and other services. Newt displays ratings on how well businesses can accommodate a user's first language, allowing newcomers to make more informed choices based on their needs.
When searching for a particular services, we use a map to display several options and their ratings for the user's first language. Users can then contact businesses by writing a message in their language of choice. Newt automatically translates the message and sends a text to the business provider containing the original and translated message as well as the user's contact information and preferred language of correspondence.
## How we built it
Frontend: React, Typescript
Backend: Python, Flask, PostgreSQL, Infobip API, Yelp API, Google Translate, Docker
## Challenges we ran into
Representing location data within our relational database was challenging. It would not be feasible to store every possible location that users might search for within the database. We needed to find a balance between sourcing data from the Yelp API and updating the database using the results without creating unnecessary duplicates.
## What we learned
We learned to display location data through an interactive map. To do so, we learned about react-leaflet to embed maps on React webpages. In the backend, we learned to use Infobip by reviewing related documentation, experimenting with test data, and with the help of Hack Western's sponsors. Lastly, we challenged ourselves to write unit tests for our backend functions and integrate testing within GitHub Actions to ensure every code contribution was safe.
## What's next for Newts
* Further support for translating the frontend display in each user's first language.
* Expanding backend data sources beyond the Yelp API and including other data sources more specific to user queries | ## Inspiration
* Everyone and their dog have a big idea for the next hit app but most people lack the skills or resources to build them.
* Having used some commercial app-building and prototyping tools in the past, we consider them inefficient as they don't reflect what the app is actually going to look like until it is run on a real device.
## What it does
Appception allows you to build mobile apps on your iPhone through a simple drag and drop interface. While building your app, it is always running and it has its own behaviors and states. With Appception, anyone can build apps that use the device's sensors, persist and retrieve data locally or remotely, and interact with third party services. If you are pursuing more complex development, with just a tap of a button, we'll generate the source code of your app and send it you.
## How we built it
We built Appception with React Native, a new open-source framework by Facebook for building mobile cross platform native apps using JavaScript.
Using Redux, a predictable state container JavaScript library, we can handle the state of the user created app.
We designed a software architecture that allowed us to effectively isolate the states of the app builder and the user generated app, within the same iOS app. (hence App-ception)
Appception communicates with a server application in order to deliver a generated app to the user.
## Challenges I ran into
We ran into a lot of challenges with creating barriers, keeping the building app and the dynamic app separate, while at the same time expanding the possible functionality that a user can build.
## Accomplishments that I'm proud of
We're proud to have built a proof of concept app that, if deployed at scale will lower the barrier of entry for people to build apps that create value for their users.
Everyone, including your grandma can build the dumb ideas that never got built because uber for cats actually isn’t a good idea.
## What I learned
Today we all learned React Native. Although some of us were familiar before hand, creating an app with JavaScript was a whole new experience for some others.
## What's next for Appception
Expanding the range of apps that you can build with Appception by providing more draggable components and integrations.
Integrate deployment facilities within the Appception iPhone app to allow users to ship the app to beta users and push updates directly to their devices instantly. | ## Inspiration for this Project
Canada is a beautiful country, with lots of places for people to visit, ranging from natural scenery, to the wide range of delicacies, and culture. With large variety, comes a natural sense of indecisiveness, and confusion. So we decided to make an application to help people, narrow down their choices. This way you can make an easy decision as well as take someone with you, because why experience it on your own, when you can share it with someone special, right?
## What it does
Our project, basically takes the Google Maps API, and using its data, you're able to search and see the ratings and reviews, for activities, and spots that you may experience with someone special... (specifically "date spots"). This allows you to get the outside opinion of others, in just a few clicks; as well as leave your own, to help others !
## How we built it
Splitting our squad of four hackers, we decided to do a front-end, and back-end split. Where we had two of our members, using JavaScript, and their expertise, to iterate and create specific algorithms, and features for our project. They used the Google Maps API, to create a search feature, that autofills locations, as well as a map, and a display that shows the images of the place you want to go to. They also compiled code for the ratings, review, and even a log in system. So you can have a personal experience. This all while the front-end team, developed the website, and themes. Using PUG, a template engine that compiles to HTML, and simplifies the syntax for more efficient, and easy to read programs. The front-end development duo, used CSS to style, and html, to display the website that you have in front of you for convenient accessibility.
## Challenges we ran into
Being comprised of mostly newbie hackers, we ran into a lot of challenges, and obstacles to tackle. Even just getting started, we started running into slight problems and complications, as we were deciding on how to split roles, two of our members were much more experienced with coding, and we could either put the more experienced members on back-end to create more advanced features, or have the two more beginner members, to do back-end, and leave the others to do front-end for an easier time. Instead, we decided to take on the challenge, to allow the more advanced coders to do back-end, so we could seriously create a cool and impactful project, while the two others would learn, to create and apply front-end developments to our code. This seemingly simple challenge, really took us for a run, as the front-end developers ended up spending several hours just learning how to format and code in HTML, CSS, while using pug, but eventually we were able to scrape something up (after about 8 hours lol). Our seemingly crazy, and almost goofy idea, started to become more realistic, as our back-end duo finished and started implementing our new features into our website.
## Accomplishments that we're proud of
Nearing the end of this project, we had completed a lot of our learning, and gained a sense of fluency in a lot of the new languages, and obstacles we had to overcome. This left us with a sense of achievement, and comfort, as despite our struggles, we had something to show for it. Also, this being most of our first hackathon, we're happy we managed to dish out a unique idea, and successfully work on it too (as well as being able to stay awake for to complete it).
## What we learned
Honestly, this was really a journey for all of us, we learned many new things, from teamwork skills, to even new programming languages, and techniques. Some of the highlights being, the front-end developers learning how to code in HTML and CSS completely from scratch, in the span of 6 hours, and the back-end developers learning about the Google Maps API, and how to operate through it, and implement it (also starting from nothing).
## What's next for Rate My Date
The next step for Rate My Date, would be to further polish the code, and make sure that there are no bugs, as it was a pretty ambitious project for 24 hours. We were all very excited to be making this idea come true, and are looking forward to its future changes, and potential. | partial |
## Inspiration
How cool would it be to be able to listen to different parts of a song and actually see them play while learning about instruments that you have never heard before!
## What it does
Quintessence provides a totally immersive experience of music through virtual reality. You can choose what parts of the music you want to hear/mute and see the effect of your choice; you can also learn about instruments simply by playing with it in combination with other instruments; you can give instructions to the musicians with voice control!
## How we built it
We used Unity for our project, working with C# in terms of the programming language. It runs on a mobile device through Google Cardboard.
## Challenges we ran into
Calculations of angles and positions in 3D are very tricky! In addition, it is extremely hard to implement version control with unity due to the incredibly large size of the project which cannot be synced on Github. Precision in voice accuracy was also a challenge we ran into.
## Accomplishments that we're proud of
User Interface/Experience!
## What we learned
How to use Unity for the first time for all of us and how to use C# for the first time for the majority of us.
## What's next for Quintessence
To enlarge our music repertoire and further give users the opportunity to compose and try out different combinations of instruments on their own. | ## Inspiration
The inspiration for this project was drawn from the daily experiences of our team members. As post-secondary students, we often make purchases for our peers for convenience, yet forget to follow up. This can lead to disagreements and accountability issues. Thus, we came up with the idea of CashDat, to alleviate this commonly faced issue. People will no longer have to remind their friends about paying them back! With the available API’s, we realized that we could create an application to directly tackle this problem.
## What it does
CashDat is an application available on the iOS platform that allows users to keep track of who owes them money, as well as who they owe money to. Users are able to scan their receipts, divide the costs with other people, and send requests for e-transfer.
## How we built it
We used Xcode to program a multi-view app and implement all the screens/features necessary.
We used Python and Optical Character Recognition (OCR) built inside Google Cloud Vision API to implement text extraction using AI on the cloud. This was used specifically to draw item names and prices from the scanned receipts.
We used Google Firebase to store user login information, receipt images, as well as recorded transactions and transaction details.
Figma was utilized to design the front-end mobile interface that users interact with. The application itself was primarily developed with Swift with focus on iOS support.
## Challenges we ran into
We found that we had a lot of great ideas for utilizing sponsor APIs, but due to time constraints we were unable to fully implement them.
The main challenge was incorporating the Request Money option with the Interac API into our application and Swift code. We found that since the API was in BETA made it difficult to implement it onto an IOS app. We certainly hope to work on the implementation of the Interac API as it is a crucial part of our product.
## Accomplishments that we're proud of
Overall, our team was able to develop a functioning application and were able to use new APIs provided by sponsors. We used modern design elements and integrated that with the software.
## What we learned
We learned about implementing different APIs and overall IOS development. We also had very little experience with flask backend deployment process. This proved to be quite difficult at first, but we learned about setting up environment variables and off-site server setup.
## What's next for CashDat
We see a great opportunity for the further development of CashDat as it helps streamline the process of current payment methods. We plan on continuing to develop this application to further optimize user experience. | ## Inspiration
We often found ourselves stuck at the start of the design process, not knowing where to begin or how to turn our ideas into something real. In large organisations these issues are not only inconvenient and costly, but also slow down development. That is why we created ConArt AI to make it easier. It helps teams get their ideas out quickly and turn them into something real without all the confusion.
## What it does
ConArt AI is a gamified design application that helps artists and teams brainstorm ideas faster in the early stages of a project. Teams come together in a shared space where each person has to create a quick sketch and provide a prompt before the timer runs out. The sketches are then turned into images and everyone votes on their team's design where points are given from 1 to 5. This process encourages fast and fun brainstorming while helping teams quickly move from ideas to concepts. It makes collaboration more engaging and helps speed up the creative process.
## How we built it
We built ConArt AI using React for the frontend to create a smooth and responsive interface that allows for real-time collaboration. On the backend, we used Convex to handle game logic and state management, ensuring seamless communication between players during the sketching, voting, and scoring phases.
For the image generation, we integrated the Replicate API, which utilises AI models like ControlNet with Stable Diffusion to transform the sketches and prompts into full-fledged concept images. These API calls are managed through Convex actions, allowing for real-time updates and feedback loops.
The entire project is hosted on Vercel, which is officially supported by Convex, ensuring fast deployment and scaling. Convex especially enabled us to have a serverless experience which allowed us to not worry about extra infrastructure and focus more on the functions of our app. The combination of these technologies allows ConArt AI to deliver a gamified, collaborative experience.
## Challenges we ran into
We faced several challenges while building ConArt AI. One of the key issues was with routing in production, where we had to troubleshoot differences between development and live environments. We also encountered challenges in managing server vs. client-side actions, particularly ensuring smooth, real-time updates. Additionally, we had some difficulties with responsive design, ensuring the app looked and worked well across different devices and screen sizes. These challenges pushed us to refine our approach and improve the overall performance of the application.
## Accomplishments that we're proud of
We’re incredibly proud of several key accomplishments from this hackathon.
Nikhil: Learned how to use a new service like Convex during the hackathon, adapting quickly to integrate it into our project.
Ben: Instead of just showcasing a local demo, he managed to finish and fully deploy the project by the end of the hackathon, which is a huge achievement.
Shireen: Completed the UI/UX design of a website in under 36 hours for the first time, while also planning our pitch and brand identity, all during her first hackathon.
Ryushen: He worked on building React components and the frontend, ensuring the UI/UX looked pretty, while also helping to craft an awesome pitch.
Overall, we’re most proud of how well we worked as a team. Every person filled their role and brought the project to completion, and we’re happy to have made new friends along the way!
## What we learned
We learned how to effectively use Convex by studying its documentation, which helped us manage real-time state and game logic for features like live sketching, voting, and scoring. We also learned how to trigger external API calls, like image generation with Replicate, through Convex actions, making the integration of AI seamless. On top of that, we improved our collaboration as a team, dividing tasks efficiently and troubleshooting together, which was key to building ConArt AI successfully.
## What's next for ConArt AI
We plan to incorporate user profiles in order to let users personalise their experience and track their creative contributions over time. We will also be adding a feature to save concept art, allowing teams to store and revisit their designs for future reference or iteration. These updates will enhance collaboration and creativity, making ConArt AI even more valuable for artists and teams working on long-term projects. | losing |
## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandemic. The respondents also stated that some motivations included a loss of disposable time (due to an increase in workload from online learning), tight spending budgets, and fear of exposure to covid-19.
While developing our product strategy, we realized that a significant pain point in grocery shopping is the process of price-checking between different stores. This process would either require the user to visit each store (in-person and/or online) and check the inventory and manually price check. Consolidated platforms to help with grocery list generation and payment do not exist in the market today - as such, we decided to explore this idea.
**What does G.e.o.r.g.e stand for? : Grocery Examiner Organizer Registrator Generator (for) Everyone**
## What it does
The high-level workflow can be broken down into three major components:
1: Python (flask) and Firebase backend
2: React frontend
3: Stripe API integration
Our backend flask server is responsible for web scraping and generating semantic, usable JSON code for each product item, which is passed through to our React frontend.
Our React frontend acts as the hub for tangible user-product interactions. Users are given the option to search for grocery products, add them to a grocery list, generate the cheapest possible list, compare prices between stores, and make a direct payment for their groceries through the Stripe API.
## How we built it
We started our product development process with brainstorming various topics we would be interested in working on. Once we decided to proceed with our payment service application. We drew up designs as well as prototyped using Figma, then proceeded to implement the front end designs with React. Our backend uses Flask to handle Stripe API requests as well as web scraping. We also used Firebase to handle user authentication and storage of user data.
## Challenges we ran into
Once we had finished coming up with our problem scope, one of the first challenges we ran into was finding a reliable way to obtain grocery store information. There are no readily available APIs to access price data for grocery stores so we decided to do our own web scraping. This lead to complications with slower server response since some grocery stores have dynamically generated websites, causing some query results to be slower than desired. Due to the limited price availability of some grocery stores, we decided to pivot our focus towards e-commerce and online grocery vendors, which would allow us to flesh out our end-to-end workflow.
## Accomplishments that we're proud of
Some of the websites we had to scrape had lots of information to comb through and we are proud of how we could pick up new skills in Beautiful Soup and Selenium to automate that process! We are also proud of completing the ideation process with an application that included even more features than our original designs. Also, we were scrambling at the end to finish integrating the Stripe API, but it feels incredibly rewarding to be able to utilize real money with our app.
## What we learned
We picked up skills such as web scraping to automate the process of parsing through large data sets. Web scraping dynamically generated websites can also lead to slow server response times that are generally undesirable. It also became apparent to us that we should have set up virtual environments for flask applications so that team members do not have to reinstall every dependency. Last but not least, deciding to integrate a new API at 3am will make you want to pull out your hair, but at least we now know that it can be done :’)
## What's next for G.e.o.r.g.e.
Our next steps with G.e.o.r.g.e. would be to improve the overall user experience of the application by standardizing our UI components and UX workflows with Ecommerce industry standards. In the future, our goal is to work directly with more vendors to gain quicker access to price data, as well as creating more seamless payment solutions. | ## Inspiration
We recognized how much time meal planning can cause, especially for busy young professionals and students who have little experience cooking. We wanted to provide an easy way to buy healthy, sustainable meals for the week, without compromising the budget or harming the environment.
## What it does
Similar to services like "Hello Fresh", this is a webapp for finding recipes and delivering the ingredients to your house. This is where the similarities end, however. Instead of shipping the ingredients to you directly, our app makes use of local grocery delivery services, such as the one provided by Loblaws. The advantages to this are two-fold: first, it helps keep the price down, as your main fee is for the groceries themselves, instead of paying large amounts in fees to a meal kit company. Second, this is more eco-friendly. Meal kit companies traditionally repackage the ingredients in house into single-use plastic packaging, before shipping it to the user, along with large coolers and ice packs which mostly are never re-used. Our app adds no additional packaging beyond that the groceries initially come in.
## How We built it
We made a web app, with the client side code written using React. The server was written in python using Flask, and was hosted on the cloud using Google App Engine. We used MongoDB Atlas, also hosted on Google Cloud.
On the server, we used the Spoonacular API to search for recipes, and Instacart for the grocery delivery.
## Challenges we ran into
The Instacart API is not publicly available, and there are no public API's for grocery delivery, so we had to reverse engineer this API to allow us to add things to the cart. The Spoonacular API was down for about 4 hours on Saturday evening, during which time we almost entirely switched over to a less functional API, before it came back online and we switched back.
## Accomplishments that we're proud of
Created a functional prototype capable of facilitating the order of recipes through Instacart. Learning new skills, like Flask, Google Cloud and for some of the team React.
## What we've learned
How to reverse engineer an API, using Python as a web server with Flask, Google Cloud, new API's, MongoDB
## What's next for Fiscal Fresh
Add additional functionality on the client side, such as browsing by popular recipes | ## Inspiration
Because of covid-19 and the holiday season, we are getting increasingly guilty over the carbon footprint caused by our online shopping. This is not a coincidence, Amazon along contributed over 55.17 million tonnes of CO2 in 2019 alone, the equivalent of 13 coal power plants.
We have seen many carbon footprint calculators that aim to measure individual carbon pollution. However, the pure mass of carbon footprint too abstract and has little meaning to average consumers. After calculating footprints, we would feel guilty about our carbon consumption caused by our lifestyles, and maybe, maybe donate once to offset the guilt inside us.
The problem is, climate change cannot be eliminated by a single contribution because it's a continuous process, so we thought to gamefy carbon footprint to cultivate engagement, encourage donations, and raise awareness over the long term.
## What it does
We build a google chrome extension to track the user’s amazon purchases and determine the carbon footprint of the product using all available variables scraped from the page, including product type, weight, distance, and shipping options in real-time. We set up Google Firebase to store user’s account information and purchase history and created a gaming system to track user progressions, achievements, and pet status in the backend.
## How we built it
We created the front end using React.js, developed our web scraper using javascript to extract amazon information, and Netlify for deploying the website. We developed the back end in Python using Flask, storing our data on Firestore, calculating shipping distance using Google's distance-matrix API, and hosting on Google Cloud Platform. For the user authentication system, we used the SHA-256 hashes and salts to store passwords securely on the cloud.
## Challenges we ran into
This is our first time developing a web app application for most of us because we have our background in Mechatronics Engineering and Computer Engineering.
## Accomplishments that we're proud of
We are very proud that we are able to accomplish an app of this magnitude, as well as its potential impact on social good by reducing Carbon Footprint emission.
## What we learned
We learned about utilizing the google cloud platform, integrating the front end and back end to make a complete webapp.
## What's next for Purrtector
Our mission is to build tools to gamify our fight against climate change, cultivate user engagement, and make it fun to save the world. We see ourselves as a non-profit and we would welcome collaboration from third parties to offer additional perks and discounts to our users for reducing carbon emission by unlocking designated achievements with their pet similar. This would bring in additional incentives towards a carbon-neutral lifetime on top of emotional attachments to their pet.
## Domain.com Link
<https://purrtector.space> Note: We weren't able to register this via domain.com due to the site errors but Sean said we could have this domain considered. | winning |
## Team
* Sunho Kim [@sunho](https://github.com/sunho) : Frontend, Backend, UI/UX Design, Database
* Brandon Hung [@qilin2](https://www.github.com/qilin2): Frontend, UI/UX Design
* Wei Quan Lai [@LaiWeiQuan](https://github.com/LaiWeiQuan) & Eren Saglam [@ghostpyy](https://github.com/ghostpyy): CockroachDB Database, Backend.
## Inspiration
Inspired by [Scratch Programming](https://scratch.mit.edu/developers).
During this summer break, we volunteered as a coding tutor for elementary kids. We realized the kids enjoy learning scratch more than python. Python was too dull and wordy for them, they like scratch more as it’s more colourful and easily visualized. With C being one of the hardest programming languages, we decided to make a C to scratch translator, so that it will be easily visualized and understood.
## What it does
C and C++ programming language is especially challenging language to learn as a beginner. Compared to higher languages like python and javascript, they have more tricky concepts such as pointers that makes the language not really approachable. What we built is a real time bi-translator between scratch-like block language and c/c++ which allows students to toy around with text and block code simultaneously. This enables students to learn complicated programming languages like c/c++ more hands-on, intuitive way.
## How we built it
We used c parser written in javascript to get C AST and implemented a DFS style conversion from C AST to our own blocking language tree representation. We implemented reverse conversion from blocking language tree to C code so that bi-translation works perfectly. We got a virtual machine for our own block coding language which makes the simulation of variables and expression interpretation more low-level. It allows to implement visualization of control structure and variables changes more easily. We also used CockroachDB which also uses Google Cloud to implement code sharing function. CockroachDB fitted into this purpose since it could be used to visualize the traffic of share real time using this software.
## Challenges we ran into
#### **Brandon**
I was mainly responsible for the frontend, which is the UI / UX Design. With only two weeks of ReactJS knowledge, I faced various difficulties. For example, I didn't know how to use onClick = () => , const [active, setActive], classes and ids in .css, html syntaxes like div tag, importing .tsx files into App.jsx to be used. All of these difficulties taught me how ReactJS works in the industry and how it's programmed to develop an industry-ready website.
#### **Eren and Wei Quan**
We had to look throught and figure out a lot of libraries and choose the best one to be able to compile the code. In addition, we had hard time setting up CockroachDB as it is a relatively new database platform and there is not a lot of materials and tutorials online to guide us. However, after settling the set up, we found out that CockroachDB actually provides sufficient sample code on github which makes it easier to implement the Database.
#### **Sunho**
It took a lot of time and work to get some converage of c ast patterns. We put all nighters to implement every one of patterns and traversals that we needed.
Thank you
[PowerPoint](https://docs.google.com/presentation/d/1M8hGexV4LJ8D3bOm5D_e8hCjvt31cTHusOutigX_EwM/edit?usp=sharing) | ## Inspiration
Throughout the history of programming there has always been a barrier between humans and computers in terms of understanding on another. For example, there is no one simple way which we can both communicate but rather there are so called programming languages which we can understand and then the binary language which the computer understands. While it is close to impossible to eliminate that right now, we want to use the middle ground of the Assembly Language in order to educate prorgammers on how the computer attempts to understand us.
## What it does
When programmers develop code and press run, they just see an output dialog with their result. Through An Asm Reality, we allow users to develop code and understand how the computer converts that into Asm (assembly language) by allowing users to enter a virtual world using an Oculus Rift. In this world, they are able to see two different windows, one with the the code they have written and one with the assembly language the computer has generated. From there they are able to press on text in one area and see what it relates to in the other window. As well as that, a brief description of each area will pop up as the user views specific lines of code enlightening even the most advanced programmers on how assembly language decodes actual written code.
## How I built it
This was built using Unity which allowed for the creation of the virual world. Along with that languages such as Python and C# were used. Lastly we used the Oculus Rift and Leap Motion to bring this idea into our reality.
## Challenges I ran into
Our group was very unfamiliar with assembly language and therefore being able to understand how to convert programmed code into assembly language was a huge barrier as this type of reverse engineering has very limited resources and thus it came down to having to do tons of readings.
## Accomplishments that I'm proud of
We are proud of the fact that we were able to use Oculus Rift for the first time for all of the group members and sufficiently program the device using Unity.
## What I learned
Through this adventure we learned: how to interpret assembly language (or at least the basics of it), how to use linux (gcc and gdp), how to program scripts in C#, how to send information through a network in order to transfer files effortlessly, and lastly we learned how to work with the Unity environment along with Leap-Motion.
## What's next for An Asm Reality
We plan to make this application more complex where individuals are able to using multiple languages apart from C and visualize the assembly version of the code. Also we plan on making the UI more user friendly and more informative to allow others to educate themselves in a more interesting manner. | ## Inspiration
We've noticed that many educators draw common structures on boards, just to erase them and redraw them in common ways to portray something. Imagine your CS teacher drawing an array to show you how bubble sort works, and erasing elements for every swap. This learning experience can be optimized with AI.
## What It Does
Our software recognizes digits drawn and digitizes the information. If you draw a list of numbers, it'll recognize it as an array and let you visualize bubble sort automatically. If you draw a pair of axes, it'll recognize this and let you write an equation that it will automatically graph.
The voice assisted list operator allows one to execute the most commonly used list operation, "append" through voice alone. A typical use case would be a professor free to roam around the classroom and incorporate a more intimate learning experience, since edits need no longer be made by hand.
## How We Built It
The digits are recognized using a neural network trained on the MNIST hand written digits data set. Our code scans the canvas to find digits written in one continuous stroke, puts bounding boxes on them and cuts them out, shrinks them to run through the neural network, and outputs the digit and location info to the results canvas.
For the voice driven list operator, the backend server's written in Node.js/Express.js. It accepts voice commands through Bixby and sends them to Almond, which stores and updates the list in a remote server, and also in the web user interface.
## Challenges We Ran Into
* The canvas was difficult to work with using JavaScript
* It is unbelievably hard to test voice-driven applications amidst a room full of noisy hackers haha
## Accomplishments that We're Proud Of
* Our software can accurately recognize digits and digitize the info!
## What We Learned
* Almond's, like, *really* cool
* Speech recognition has a long way to go, but is also quite impressive in its current form.
## What's Next for Super Smart Board
* Recognizing trees and visualizing search algorithms
* Recognizing structures commonly found in humanities classes and implementing operations for them
* Leveraging Almond's unique capabilities to facilitate operations like inserting at a specific index and expanding uses to data structures besides lists
* More robust error handling, in case the voice command is misinterpreted (as it often is)
* Generating code to represent the changes made alongside the visual data structure representation | losing |
### Excuse Us for submitting a 5-minute video, as we couldn't cover all the features in the given time frame.
## Inspiration
Due to the ongoing pandemic, there has been an increased use of technology. Both noticed that it was very easy to get distracted and lose track of ongoing tasks.
## What it does
Social media, shopping, videos, games...these apps and websites are scientifically engineered to keep you hooked and coming back. The cost to your productivity, ability to focus, and general well-being can be staggering. ATLMUSE gives you control over them thus improving your quality of life.
## How we built it
To build this app we integrated technologies such as Google Cloud Firebase and discord RTC.
## Challenges we ran into
While building the app to fetch the active title we used a package named active win however we ran into an error while packing it with electron builder. We figured the active win package was causing the error and had to switch to Electron Active Window. Secondly, we had to give admin privileges to the app, as it was necessary for features such as blocking/redirecting websites that needed elevated privileges.
## Accomplishments that we're proud of
To begin with, we are proud that we learned how to integrate Firebase into our project and create prototypes with Figma. Secondly, our collaborating skills improved as time progressed.
## What we learned
We learned how to work with Figma, Google Cloud Firebase Firestore, and Google Cloud Firebase Authentication.
## What's next for ATLMUSE
We plan on adding features such as
* Day Planner
* Habit tracker
* Todo list
* Project Planner | ## Inspiration
We’ve noticed that it’s often difficult to form intentional and lasting relationships when life moves so quickly. This issue has only been compounded by the pandemic, as students spend more time than ever isolated from others. As social media is increasingly making the world feel more “digital”, we wanted to provide a means for users to develop tangible and meaningful connections. Last week, I received an email from my residential college inviting students to sign up for a “buddy program” where they would be matched with other students with similar interests to go for walks, to the gym, or for a meal. The program garnered considerable interest, and we were inspired to expand upon the Google Forms setup to a more full-fledged social platform.
## What it does
We built a social network that abstracts away the tediousness of scheduling and reduces the “activation energy” required to reach out to those you want to connect with. Scheduling a meeting with someone on your friend’s feed is only a few taps away. Our scheduling matching algorithm automatically determines the top best times for the meeting based on the inputted availabilities of both parties. Furthermore, forming meaningful connections is a process, we plan to provide data-driven reminders and activity suggestions to keep the ball rolling after an initial meeting.
## How we built it
We built the app for mobile, using react-native to leverage cross-platform support. We used redux for state management and firebase for user authentication.
## Challenges we ran into
Getting the environment (emulators, dependencies, firebase) configured was tricky because of the many different setup methods. Also, getting the state management with Redux setup was challenging given all the boilerplate needed.
## Accomplishments that we're proud of
We are proud of the cohesive and cleanliness of our design. Furthermore, the structure of state management with redux drastically improved maintainability and scalability for data to be passed around the app seamlessly.
## What we learned
We learned how to create an end-to-end app in flutter, wireframe in Figma, and use API’s like firebase authentication and dependencies like React-redux.
## What's next for tiMe
Further flesh out the post-meeting followups for maintaining connections and relationships | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | losing |
## Inspiration
IoT devices are extremely useful; however, they come at a high price. A key example of this is a smart fridge, which can cost thousands of dollars. Although many people can't afford this type of luxury, they can still greatly benefit from it. A smart fridge can eliminate food waste by keeping an inventory of your food and its freshness. If you don't know what to do with leftover food, a smart fridge can suggest recipes that use what you have in your fridge. This can easily expand to guiding your food consumption and shopping choices.
## What it does
FridgeSight offers a cheap, practical solution for those not ready to invest in a smart fridge. It can mount on any existing fridge as a touch interface and camera. By logging what you put in, take out, and use from your fridge, FridgeSight can deliver the very same benefits that smart fridges provide. It scans barcodes of packaged products and classifies produce and other unprocessed foods. FridgeSight's companion mobile app displays your food inventory, gives shopping suggestions based on your past behavior, and offers recipes that utilize what you currently have.
## How we built it
The IoT device is powered by Android Things with a Raspberry Pi 3. A camera and touchscreen display serve as peripherals for the user. FridgeSight scans UPC barcodes in front of it with the Google Mobile Vision API and cross references them with the UPCItemdb API in order to get the product's name and image. It also can classify produce and other unpackaged products with the Google Cloud Vision API. From there, the IoT device uploads this data to its Hasura backend.
FridgeSight's mobile app is built with Expo and React Native, allowing it to dynamically display information from Hasura. Besides using the data to display inventory and log absences, it pulls from the Food2Fork API in order to suggest recipes. Together, the IoT device and mobile app have the capability to exceed the functionality of a modern smart fridge.
## Challenges we ran into
Android Things provides a flexible environment for an IoT device. However, we had difficulty with initial configuration. At the very start, we had to reflash the device with an older OS because the latest version wasn't able to connect to WiFi networks. Our setup would also experience power issues, where the camera took too much power and shut down the entire system. In order to avoid this, we had to convert from video streaming to repeated image captures. In general, there was little documentation on communicating with the Raspberry Pi camera.
## Accomplishments that we're proud of
Concurring with Android Things's philosophy, we are proud of giving accessibility to previously unaffordable IoT devices. We're also proud of integrating a multitude of APIs across different fields in order to solve this issue.
## What we learned
This was our first time programming with Android Things, Expo, Hasura, and Google Cloud - platforms that we are excited to use in the future.
## What's next for FridgeSight
We've only scratched the surface for what the FridgeSight technology is capable of. Our current system, without any hardware modifications, can notify you when food is about to expire or hasn't been touched recently. Based on your activity, it can conveniently analyze your diet and provide healthier eating suggestions. FridgeSight can also be used for cabinets and other kitchen inventories. In the future, a large FridgeSight community would be able to push the platform with crowd-trained neural networks, easily surpassing standalone IoT kitchenware. There is a lot of potential in FridgeSight, and we hope to use PennApps as a way forward. | ## Inspiration
An individual living in Canada wastes approximately 183 kilograms of solid food per year. This equates to $35 billion worth of food. A study that asked why so much food is wasted illustrated that about 57% thought that their food goes bad too quickly, while another 44% of people say the food is past the expiration date.
## What it does
LetsEat is an assistant that comprises of the server, app and the google home mini that reminds users of food that is going to expire soon and encourages them to cook it in a meal before it goes bad.
## How we built it
We used a variety of leading technologies including firebase for database and cloud functions and Google Assistant API with Dialogueflow. On the mobile side, we have the system of effortlessly uploading the receipts using Microsoft cognitive services optical character recognition (OCR). The Android app is writen using RxKotlin, RxAndroid, Retrofit on a MVP architecture.
## Challenges we ran into
One of the biggest challenges that we ran into was fleshing out our idea. Every time we thought we solved an issue in our concept, another one appeared. We iterated over our system design, app design, Google Action conversation design, integration design, over and over again for around 6 hours into the event. During development, we faced the learning curve of Firebase Cloud Functions, setting up Google Actions using DialogueFlow, and setting up socket connections.
## What we learned
We learned a lot more about how voice user interaction design worked. | ## Inspiration
Have you ever been in a situation where you forgot what's in your fridge while you go shopping for groceries? Well, worry no more, because with Grocery Vision, you can quickly see what's currently in your fridge and what groceries you need to buy!
## What it does
Every time when a fridge door opens and closes, images are taken of the items available in the fridge. Using image recognition, a list of items available and missing in the fridge is generated and provided to the user in an app.
## How we built it
* Light sensor: Senses when the fridge light is on or off, which is when the contents of the fridge might change
* M5Cam: Takes images of the items in the fridge
* Google Cloud Vision API: Recognizes items in the fridge and stores the list in the cloud
* Domain.com: The user can see the list in an app (<http://groceryvision.tech/>)
## Challenges we ran into
The biggest challenge is definitely getting the hardware to set up. Some of the hardware equipment ran out, so we had to come up with alternative replacements.
## Accomplishments that we're proud of
Getting the Cloud Vision API to produce a list of items in an image.
## What we learned
* How to overcome the challenge of successfully setting up hardware
* How to set up APIs using Google Cloud
## What's next for Grocery Vision
* Sort the food items into different categories
* Connect the different components of the project together | winning |
## Inspiration
Osu! players often use drawing tablets instead of a normal mouse and keyboard setup because a tablet gives more precision than a mouse can provide. These tablets also provide a better way to input to devices. Overuse of conventional keyboards and mice can lead to carpal tunnel syndrome, and can be difficult to use for those that have specific disabilities. Tablet pens can provide an alternate form of HID, and have better ergonomics reducing the risk of carpal tunnel. Digital artists usually draw on these digital input tablets, as mice do not provide the control over the input as needed by artists. However, tablets can often come at a high cost of entry, and are not easy to bring around.
## What it does
Limestone is an alternate form of tablet input, allowing you to input using a normal pen and using computer vision for the rest. That way, you can use any flat surface as your tablet
## How we built it
Limestone is built on top of the neural network library mediapipe from google. mediapipe hands provide a pretrained network that returns the 3D position of 21 joints in any hands detected in a photo. This provides a lot of useful data, which we could probably use to find the direction each finger points in and derive the endpoint of the pen in the photo. To safe myself some work, I created a second neural network that takes in the joint data from mediapipe and derive the 2D endpoint of the pen. This second network is extremely simple, since all the complex image processing has already been done. I used 2 1D convolutional layers and 4 hidden dense layers for this second network. I was only able to create about 40 entries in a dataset after some experimentation with the formatting, but I found a way to generate fairly accurate datasets with some work.
## Dataset Creation
I created a small python script that marks small dots on your screen for accurate spacing. I could the place my pen on the dot, take a photo, and enter in the coordinate of the point as the label.
## Challenges we ran into
It took a while to tune the hyperparameters of the network. Fortunately, due to the small size it was not too hard to get it into a configuration that could train and improve. However, it doesn't perform as well as I would like it to but due to time constraints I couldn't experiment further. The mean average error loss of the final model trained for 1000 epochs was around 0.0015
Unfortunately, the model was very overtrained. The dataset was o where near large enough. Adding noise probably could have helped to reduce overtraining, but I doubt by much. There just wasn't anywhere enough data, but the framework is there.
## Whats Next
If this project is to be continued, the model architecture would have to be tuned much more, and the dataset expanded to at least a few hundred entries. Adding noise would also definitely help with the variance of the dataset. There is still a lot of work to be done on limestone, but the current code at least provides some structure and a proof of concept. | ## Inspiration
It’s insane how the majority of the U.S. still looks like **endless freeways and suburban sprawl.** The majority of Americans can’t get a cup of coffee or go to the grocery store without a car.
What would America look like with cleaner air, walkable cities, green spaces, and effective routing from place to place that builds on infrastructure for active transport and micro mobility? This is the question we answer, and show, to urban planners, at an extremely granular street level.
Compared to most of Europe and Asia (where there are public transportation options, human-scale streets, and dense neighborhoods) the United States is light-years away ... but urban planners don’t have the tools right now to easily assess a specific area’s walkability.
**Here's why this is an urgent problem:** Current tools for urban planners don’t provide *location-specific information* —they only provide arbitrary, high-level data overviews over a 50-mile or so radius about population density. Even though consumers see new tools, like Google Maps’ area busyness bars, it is only bits and pieces of all the data an urban planner needs, like data on bike paths, bus stops, and the relationships between traffic and pedestrians.
As a result, there’s very few actionable improvements that urban planners can make. Moreover, because cities are physical spaces, planners cannot easily visualize what an improvement (e.g. adding a bike/bus lane, parks, open spaces) would look like in the existing context of that specific road. Many urban planners don’t have the resources or capability to fully immerse themselves in a new city, live like a resident, and understand the problems that residents face on a daily basis that prevent them from accessing public transport, active commutes, or even safe outdoor spaces.
There’s also been a significant rise in micro-mobility—usage of e-bikes (e.g. CityBike rental services) and scooters (especially on college campuses) are growing. Research studies have shown that access to public transport, safe walking areas, and micro mobility all contribute to greater access of opportunity and successful mixed income neighborhoods, which can raise entire generations out of poverty. To continue this movement and translate this into economic mobility, we have to ensure urban developers are **making space for car-alternatives** in their city planning. This means bike lanes, bus stops, plaza’s, well-lit sidewalks, and green space in the city.
These reasons are why our team created CityGO—a tool that helps urban planners understand their region’s walkability scores down to the **granular street intersection level** and **instantly visualize what a street would look like if it was actually walkable** using Open AI's CLIP and DALL-E image generation tools (e.g. “What would the street in front of Painted Ladies look like if there were 2 bike lanes installed?)”
We are extremely intentional about the unseen effects of walkability on social structures, the environments, and public health and we are ecstatic to see the results: 1.Car-alternatives provide economic mobility as they give Americans alternatives to purchasing and maintaining cars that are cumbersome, unreliable, and extremely costly to maintain in dense urban areas. Having lower upfront costs also enables handicapped people, people that can’t drive, and extremely young/old people to have the same access to opportunity and continue living high quality lives. This disproportionately benefits people in poverty, as children with access to public transport or farther walking routes also gain access to better education, food sources, and can meet friends/share the resources of other neighborhoods which can have the **huge** impact of pulling communities out of poverty.
Placing bicycle lanes and barriers that protect cyclists from side traffic will encourage people to utilize micro mobility and active transport options. This is not possible if urban planners don’t know where existing transport is or even recognize the outsized impact of increased bike lanes.
Finally, it’s no surprise that transportation as a sector alone leads to 27% of carbon emissions (US EPA) and is a massive safety issue that all citizens face everyday. Our country’s dependence on cars has been leading to deeper issues that affect basic safety, climate change, and economic mobility. The faster that we take steps to mitigate this dependence, the more sustainable our lifestyles and Earth can be.
## What it does
TLDR:
1) Map that pulls together data on car traffic and congestion, pedestrian foot traffic, and bike parking opportunities. Heat maps that represent the density of foot traffic and location-specific interactive markers.
2) Google Map Street View API enables urban planners to see and move through live imagery of their site.
3) OpenAI CLIP and DALL-E are used to incorporate an uploaded image (taken from StreetView) and descriptor text embeddings to accurately provide a **hyper location-specific augmented image**.
The exact street venues that are unwalkable in a city are extremely difficult to pinpoint. There’s an insane amount of data that you have to consolidate to get a cohesive image of a city’s walkability state at every point—from car traffic congestion, pedestrian foot traffic, bike parking, and more.
Because cohesive data collection is extremely important to produce a well-nuanced understanding of a place’s walkability, our team incorporated a mix of geoJSON data formats and vector tiles (specific to MapBox API). There was a significant amount of unexpected “data wrangling” that came from this project since multiple formats from various sources had to be integrated with existing mapping software—however, it was a great exposure to real issues data analysts and urban planners have when trying to work with data.
There are three primary layers to our mapping software: traffic congestion, pedestrian traffic, and bicycle parking.
In order to get the exact traffic congestion per street, avenue, and boulevard in San Francisco, we utilized a data layer in MapBox API. We specified all possible locations within SF and made requests for geoJSON data that is represented through each Marker. Green stands for low congestion, yellow stands for average congestion, and red stands for high congestion. This data layer was classified as a vector tile in MapBox API.
Consolidating pedestrian foot traffic data was an interesting task to handle since this data is heavily locked in enterprise software tools. There are existing open source data sets that are posted by regional governments, but none of them are specific enough that they can produce 20+ or so heat maps of high foot traffic areas in a 15 mile radius. Thus, we utilized Best Time API to index for a diverse range of locations (e.g. restaurants, bars, activities, tourist spots, etc.) so our heat maps would not be biased towards a certain style of venue to capture information relevant to all audiences. We then cross-validated that data with Walk Score (the most trusted site for gaining walkability scores on specific addresses). We then ranked these areas and rendered heat maps on MapBox to showcase density.
San Francisco’s government open sources extremely useful data on all of the locations for bike parking installed in the past few years. We ensured that the data has been well maintained and preserved its quality over the past few years so we don’t over/underrepresent certain areas more than others. This was enforced by recent updates in the past 2 months that deemed the data accurate, so we added the geographic data as a new layer on our app. Each bike parking spot installed by the SF government is represented by a little bike icon on the map!
**The most valuable feature** is the user can navigate to any location and prompt CityGo to produce a hyper realistic augmented image resembling that location with added infrastructure improvements to make the area more walkable. Seeing the StreetView of that location, which you can move around and see real time information, and being able to envision the end product is the final bridge to an urban developer’s planning process, ensuring that walkability is within our near future.
## How we built it
We utilized the React framework to organize our project’s state variables, components, and state transfer. We also used it to build custom components, like the one that conditionally renders a live panoramic street view of the given location or render information retrieved from various data entry points.
To create the map on the left, our team used MapBox’s API to style the map and integrate the heat map visualizations with existing data sources. In order to create the markers that corresponded to specific geometric coordinates, we utilized Mapbox GL JS (their specific Javascript library) and third-party React libraries.
To create the Google Maps Panoramic Street View, we integrated our backend geometric coordinates to Google Maps’ API so there could be an individual rendering of each location. We supplemented this with third party React libraries for better error handling, feasibility, and visual appeal. The panoramic street view was extremely important for us to include this because urban planners need context on spatial configurations to develop designs that integrate well into the existing communities.
We created a custom function and used the required HTTP route (in PHP) to grab data from the Walk Score API with our JSON server so it could provide specific Walkability Scores for every marker in our map.
Text Generation from OpenAI’s text completion API was used to produce location-specific suggestions on walkability. Whatever marker a user clicked, the address was plugged in as a variable to a prompt that lists out 5 suggestions that are specific to that place within a 500-feet radius. This process opened us to the difficulties and rewarding aspects of prompt engineering, enabling us to get more actionable and location-specific than the generic alternative.
Additionally, we give the user the option to generate a potential view of the area with optimal walkability conditions using a variety of OpenAI models. We have created our own API using the Flask API development framework for Google Street View analysis and optimal scene generation.
**Here’s how we were able to get true image generation to work:** When the user prompts the website for a more walkable version of the current location, we grab an image of the Google Street View and implement our own architecture using OpenAI contrastive language-image pre-training (CLIP) image and text encoders to encode both the image and a variety of potential descriptions describing the traffic, use of public transport, and pedestrian walkways present within the image. The outputted embeddings for both the image and the bodies of text were then compared with each other using scaled cosine similarity to output similarity scores. We then tag the image with the necessary descriptors, like classifiers,—this is our way of making the system understand the semantic meaning behind the image and prompt potential changes based on very specific street views (e.g. the Painted Ladies in San Francisco might have a high walkability score via the Walk Score API, but could potentially need larger sidewalks to further improve transport and the ability to travel in that region of SF). This is significantly more accurate than simply using DALL-E’s set image generation parameters with an unspecific prompt based purely on the walkability score because we are incorporating both the uploaded image for context and descriptor text embeddings to accurately provide a hyper location-specific augmented image.
A descriptive prompt is constructed from this semantic image analysis and fed into DALLE, a diffusion based image generation model conditioned on textual descriptors. The resulting images are higher quality, as they preserve structural integrity to resemble the real world, and effectively implement the necessary changes to make specific locations optimal for travel.
We used Tailwind CSS to style our components.
## Challenges we ran into
There were existing data bottlenecks, especially with getting accurate, granular, pedestrian foot traffic data.
The main challenge we ran into was integrating the necessary Open AI models + API routes. Creating a fast, seamless pipeline that provided the user with as much mobility and autonomy as possible required that we make use of not just the Walk Score API, but also map and geographical information from maps + google street view.
Processing both image and textual information pushed us to explore using the CLIP pre-trained text and image encoders to create semantically rich embeddings which can be used to relate ideas and objects present within the image to textual descriptions.
## Accomplishments that we're proud of
We could have done just normal image generation but we were able to detect car, people, and public transit concentration existing in an image, assign that to a numerical score, and then match that with a hyper-specific prompt that was generating an image based off of that information. This enabled us to make our own metrics for a given scene; we wonder how this model can be used in the real world to speed up or completely automate the data collection pipeline for local governments.
## What we learned and what's next for CityGO
Utilizing multiple data formats and sources to cohesively show up in the map + provide accurate suggestions for walkability improvement was important to us because data is the backbone for this idea. Properly processing the right pieces of data at the right step in the system process and presenting the proper results to the user was of utmost importance. We definitely learned a lot about keeping data lightweight, easily transferring between third-party softwares, and finding relationships between different types of data to synthesize a proper output.
We also learned quite a bit by implementing Open AI’s CLIP image and text encoders for semantic tagging of images with specific textual descriptions describing car, public transit, and people/people crosswalk concentrations. It was important for us to plan out a system architecture that effectively utilized advanced technologies for a seamless end-to-end pipeline. We learned about how information abstraction (i.e. converting between images and text and finding relationships between them via embeddings) can play to our advantage and utilizing different artificially intelligent models for intermediate processing.
In the future, we plan on integrating a better visualization tool to produce more realistic renders and introduce an inpainting feature so that users have the freedom to select a specific view on street view and be given recommendations + implement very specific changes incrementally. We hope that this will allow urban planners to more effectively implement design changes to urban spaces by receiving an immediate visual + seeing how a specific change seamlessly integrates with the rest of the environment.
Additionally we hope to do a neural radiance field (NERF) integration with the produced “optimal” scenes to give the user the freedom to navigate through the environment within the NERF to visualize the change (e.g. adding a bike lane or expanding a sidewalk or shifting the build site for a building). A potential virtual reality platform would provide an immersive experience for urban planners to effectively receive AI-powered layout recommendations and instantly visualize them.
Our ultimate goal is to integrate an asset library and use NERF-based 3D asset generation to allow planners to generate realistic and interactive 3D renders of locations with AI-assisted changes to improve walkability. One end-to-end pipeline for visualizing an area, identifying potential changes, visualizing said changes using image generation + 3D scene editing/construction, and quickly iterating through different design cycles to create an optimal solution for a specific locations’ walkability as efficiently as possible! | ## Inspiration
Pac-Man and Flappy Bird are two of the most famous retro games of the past 100 years. We decided to recreate these games, but with a twist. These games were integral parts of our childhood, and it was great to put our technical skills to use in a project that was both challenging and fun.
## What it does
Our games are a recreation of Pac-Man and Flappy Bird but without the use of a keyboard. The player uses his/her hand to direct the Pac-Man either top, down, left, or right. The player then opens and closes his/her hands into a fist to represent the jumping of the bird. The user scores are displayed on the screen and a frontend application displays the score leaderboards for the respective games.
## How we built it
Our project connects various facets of programming and math. We used primarily **Python** as our programming language. We utilized **Django** as a backend that includes **CRUD** functionality for user data. **Taipy** was used for the frontend, which provided incredibly easy to use and beautiful designs. PyGame was used for the general game logic using **OOP** and computer vision libraries like **OpenCV/Tensorflow/Mediapipe** were used together to handle hand gesture recognition.
## Challenges we ran into 😈
We faced many challenges both large and small.
One large and expected challenge was training a **Convolutional Neural Network** that would accurately detect hand signs. We initially implemented a ML solution that trained on thousands of images of our own hand using Google Teachable Machines but we were disappointed by the speed and accuracy of the model when using it to run our games. Fortunately, we were able to implement a completely new technique using hand landmark detection and linear algebra techniques to optimize our network solution. This let us find the direction of the finger for player direction and the distance of landmark points from the mean point on the hand to detect whether the hand was open or closed.
To handle the issue where we could not get consistent results depending on how far the hand was from the camera, we divided our distance between the total distance between the top of our finger and our wrist to ensure consistent accuracy in our inference.
The other major challenge was about optimizing for efficiency, mainly for the Pac-Man game. In order to move the Pac-Man, we had to translate the predicted hand signal from the Neural Network to PyGame. We tried many approaches to do so. One was using Django **REST** Framework to make a POST request for every hand sign recognized by the ML model. Another was for the ML model to write the predicted hand signal to another file, which would be read by **PyGame**. However, these approaches were slow and resulted in high latency and thus slow results on the GUI. To solve these issues, we utilized concurrent programming by implementing **multithreading**. Thanks to this, we were able to simultaneously run the game and ML model with great efficiency.
## Accomplishments that we're proud of
We were all able to learn from each other and expand upon our interests. For example, we often learn complex math in school, but we were able to find real life use cases for linear algebra to determine the direction of our finger which we are quite happy about.
## What we learned
We each learned varying things, whether it is learning about the intuition behind a neural network, the way to make API requests, and learning the intricacies of version control using Git.
## What's next for Telekinesis
Perhaps expanding upon the complexity of the game. | winning |
## Inspiration
How often are you in the position where CPR is needed? If that was to ever happen would you be ready? If you’re not part of the 18% of Canadians trained in CPR then how would you respond? You would most definitely call 911. Depending on where you are it may be too late for the individuals involved But for a moment imagine that in that very same building was a health care professional or an individual trained in CPR. An individual who was alerted through an app that not only pings out their location to a series of individuals trained in CPR but also alerted emergency services about their whereabouts and situation. That’s where Ribbon, A app designed to just that comes into play.
## What it does
Ribbons purpose is to locate CPR certified individuals within a certain range and direct them to individuals in need of CPR, this alongside a call to emergency services will help improve the mean time needed before care is delivered.
## How we built it
The web app was built entirely in HTML, CSS and JS with a PHP with MariaDB backend with the intent of being desktop and mobile friendly while remaining lightweight.
## Challenges we ran into
A big challenge when developing Ribbon was tackling the issue of creating a database that could both notify individuals and call 911 all with the push of a button, due to sensitive nature of emergency calls, it was challenging to test the services on real scale
## Accomplishments that we're proud of
Our stop animation video made on a whiteboard.
## What we learned
Hackathons are exhausting.
## What's next for Ribbon
Plans for an automated recognition system to verify CPR certificates as well as mapping builds to get locations on a certain floor of a building. | CalPal is a tool that uses computer vision and optical character recognition to detect details from an event poster and autopopulate a calendar event. Users open up app to a snapchat-like camera viewer and can take a picture or upload an existing photo. The Google Vision API helps to parse the image, which the app processes to determine critical information such as the title, location, and time of the event depicted on the poster. This information is used to automatically populate a calendar entry which is added to the user's calendar. We hope this will make it easier than ever to add and keep track of events you are interested in. | ## Inspiration
The pandemic has ruined our collective health. Since its onset, rates of depression amongst teens and adults alike have risen to unprecedented levels. In a world where we are told for our own safety to keep distance from those who we cherish, how do we maintain these relationships and with it, our wellbeing?
These problems were the inspiration for our solution – Dance Party. What better way to connect with loved ones, promote physical and mental health, then with a little dance and song? Join us as we use cutting edge technologies to build a brighter future, together.
## What it does
Dance Party is a web application for anyone who is looking to have some fun dancing with friends. It is a cause for good times and good laughs. There is also a little bit of competition for when things get serious. The application is super user-friendly. Once you launch Dance Party and join with the same meeting ID, you can immediately pick a “Dance Leader” to lead the dance and your favorite songs, and then the fun begins. The ‘Dance Leader” leads the choreography and the rest of the group has to match what the “Dance Leader” is doing. You get accumulated points based on how closely you are following the routine in real time. At the end of the time limit, you get to see how you placed amongst your friends, and do it all over again!
## How we built it
### PoseNet Training Model
We utilized a TensorFlow.js machine learning extension, called PoseNet, to generate the rigid body skeletons of the people in Dance Party. PoseNet can take a picture of individuals and return the data points in the form of x and y coordinates of the 17 major body parts. Using this data, we ran our scoring algorithm to match closeness of the users’ pose to the host’s post. Moreover, to ensure best performance of PoseNet, we performed cross-validation by running the model through various simulated trials and fine-tuned the hyperparameters to ensure the highest average confidence scores.
### Similarity Score and Scoring Algorithm
For the scoring algorithm, we had to compare the rigid body skeletons of the client and the host. We superimposed and normalized each of the body parts through linear algebra, more specifically, through a linear transformation and a favorable change of basis, ensuring that we accounted for potential inversion of the camera and varying lengths of body parts. Once we had each body part superimposed, we simply compared the difference in degrees of each of the skeleton lines and generated a similarity score from 0 to 1. This frame by frame aggregate of score is then used to generate the closest match within a time range, and a score is then given to users who were the closest to the host’s dance moves. To factor in the issue of time lag between the host performing a move and the client copying the move, we cached the last 25 frames of data and used them to get a max score between the different poses. This allowed us to still credit the client, even if they were half a second behind in trying to copy the dance move.
### Frontend
To build the frontend of our app we used React as several of our group members had heard a lot of the hype around it but had yet to try it. We used React to build the room selection page where users can enter in a room ID and username, as well as the Dance Room layout. We utilized webRTC for the group streaming of video, assisted by the Agora API, which handled a lot of the low level work necessary to handle group calling - including built in functionality, such as the video routing between different networks. We then intercepted the video stream and passed it to the PoseNet TensorFlow Model which handled single pose detection. In every Dance Room, there is one host and many participants. Hosts have access to additional settings, having the control to start and pause the Dance Game and the ability to reset the score of all members. If we had more time, we would have liked to flesh this out and create mini games that the host could choose for their room.
## Challenges we ran into
One of the biggest challenges we ran into was in our implementation of Sockets. Sockets are a really powerful way to provide real time updates between a client (website) and the server. However, we were faced with a lot of debugging ‘finicky’ situations where our server was not correctly identifying who was trying to connect to it. It turned out to be a result of a 5 second default timeout value that Socket.Io had and the process-intensive task of pose detection. Recognizing this bug was one of the big ‘euphoria’ moments for the project.
## Accomplishments that we're proud of
We’re super proud of our Similarity Score algorithm that we made from scratch. We were a little nervous when putting all of our pieces together, as things always work differently than they theoretically do, but we were pleasantly surprised when we first began testing to see that it worked at a high level of accuracy even at a basepoint, before fine tuning it. It is always great when things you conceptualize in your head come to fruition, and this project is a prime example of that. Going in, we knew this idea was going to be tough to implement, but after two all-nighters and a lot of confidence in each other, we were able to transform our imaginations to reality.
## What we learned
We learned how to use websockets in conjunction with react to provide real time updates to all connected users in a given socket room. Additionally, we learned the greater lesson of the power of future planning. Our development process would have been a lot more smoother, if planned out, using diagrams and all, how parts would mesh together.
## What's next for Dance Party
* Add Youtube/external dance routine functionality
+ The core functionality exists, it would be well within the realm of reason to add a YouTube stream and use our detection and similarity algorithms on it.
* Improve performance
* Host publically | losing |
## Inspiration
In today's age, people have become more and more divisive on their opinions. We've found that discussion nowadays can just result in people shouting instead of trying to understand each other.
## What it does
**Change my Mind** helps to alleviate this problem. Our app is designed to help you find people to discuss a variety of different topics. They can range from silly scenarios to more serious situations. (Eg. Is a Hot Dog a sandwich? Is mass surveillance needed?)
Once you've picked a topic and your opinion of it, you'll be matched with a user with the opposing opinion and put into a chat room. You'll have 10 mins to chat with this person and hopefully discover your similarities and differences in perspective.
After the chat is over, you ask you to rate the maturity level of the person you interacted with. This metric allows us to increase the success rate of future discussions as both users matched will have reputations for maturity.
## How we built it
**Tech Stack**
* Front-end/UI
+ Flutter and dart
+ Adobe XD
* Backend
+ Firebase
- Cloud Firestore
- Cloud Storage
- Firebase Authentication
**Details**
* Front end was built after developing UI mockups/designs
* Heavy use of advanced widgets and animations throughout the app
* Creation of multiple widgets that are reused around the app
* Backend uses gmail authentication with firebase.
* Topics for debate are uploaded using node.js to cloud firestore and are displayed in the app using specific firebase packages.
* Images are stored in firebase storage to keep the source files together.
## Challenges we ran into
* Initially connecting Firebase to the front-end
* Managing state while implementing multiple complicated animations
* Designing backend and mapping users with each other and allowing them to chat.
## Accomplishments that we're proud of
* The user interface we made and animations on the screens
* Sign up and login using Firebase Authentication
* Saving user info into Firestore and storing images in Firebase storage
* Creation of beautiful widgets.
## What we're learned
* Deeper dive into State Management in flutter
* How to make UI/UX with fonts and colour palates
* Learned how to use Cloud functions in Google Cloud Platform
* Built on top of our knowledge of Firestore.
## What's next for Change My Mind
* More topics and User settings
* Implementing ML to match users based on maturity and other metrics
* Potential Monetization of the app, premium analysis on user conversations
* Clean up the Coooooode! Better implementation of state management specifically implementation of provide or BLOC. | ## Inspiration
There are millions of people around the world who have a physical or learning disability which makes creating visual presentations extremely difficult. They may be visually impaired, suffer from ADHD or have disabilities like Parkinsons. For these people, being unable to create presentations isn’t just a hassle. It’s a barrier to learning, a reason for feeling left out, or a career disadvantage in the workplace. That’s why we created **Pitch.ai.**
## What it does
Pitch.ai is a web app which creates visual presentations for you as you present. Once you open the web app, just start talking! Pitch.ai will listen to what you say and in real-time and generate a slide deck based on the content of your speech, just as if you had a slideshow prepared in advance.
## How we built it
We used a **React** client combined with a **Flask** server to make our API calls. To continuously listen for audio to convert to text, we used a react library called “react-speech-recognition”. Then, we designed an algorithm to detect pauses in the speech in order to separate sentences, which would be sent to the Flask server.
The Flask server would then use multithreading in order to make several API calls simultaneously. Firstly, the **Monkeylearn** API is used to find the most relevant keyword in the sentence. Then, the keyword is sent to **SerpAPI** in order to find an image to add to the presentation. At the same time, an API call is sent to OpenAPI’s GPT-3 in order to generate a caption to put on the slide. The caption, keyword and image of a single slide deck are all combined into an object to be sent back to the client.
## Challenges we ran into
* Learning how to make dynamic websites
* Optimizing audio processing time
* Increasing efficiency of server
## Accomplishments that we're proud of
* Made an aesthetic user interface
* Distributing work efficiently
* Good organization and integration of many APIs
## What we learned
* Multithreading
* How to use continuous audio input
* How to use React hooks, Animations, Figma
## What's next for Pitch.ai
* Faster and more accurate picture, keyword and caption generation
* "Presentation mode”
* Integrate a database to save your generated presentation
* Customizable templates for slide structure, color, etc.
* Build our own web scraping API to find images | ## Inspiration
Many of us had class sessions in which the teacher pulled out whiteboards or chalkboards and used them as a tool for teaching. These made classes very interactive and engaging. With the switch to virtual teaching, class interactivity has been harder. Usually a teacher just shares their screen and talks, and students can ask questions in the chat. We wanted to build something to bring back this childhood memory for students now and help classes be more engaging and encourage more students to attend, especially in the younger grades.
## What it does
Our application creates an environment where teachers can engage students through the use of virtual whiteboards. There will be two available views, the teacher’s view and the student’s view. Each view will have a canvas that the corresponding user can draw on. The difference between the views is that the teacher’s view contains a list of all the students’ canvases while the students can only view the teacher’s canvas in addition to their own.
An example use case for our application would be in a math class where the teacher can put a math problem on their canvas and students could show their work and solution on their own canvas. The teacher can then verify that the students are reaching the solution properly and can help students if they see that they are struggling.
Students can follow along and when they want the teacher’s attention, click on the I’m Done button to notify the teacher. Teachers can see their boards and mark up anything they would want to. Teachers can also put students in groups and those students can share a whiteboard together to collaborate.
## How we built it
* **Backend:** We used Socket.IO to handle the real-time update of the whiteboard. We also have a Firebase database to store the user accounts and details.
* **Frontend:** We used React to create the application and Socket.IO to connect it to the backend.
* **DevOps:** The server is hosted on Google App Engine and the frontend website is hosted on Firebase and redirected to Domain.com.
## Challenges we ran into
Understanding and planning an architecture for the application. We went back and forth about if we needed a database or could handle all the information through Socket.IO. Displaying multiple canvases while maintaining the functionality was also an issue we faced.
## Accomplishments that we're proud of
We successfully were able to display multiple canvases while maintaining the drawing functionality. This was also the first time we used Socket.IO and were successfully able to use it in our project.
## What we learned
This was the first time we used Socket.IO to handle realtime database connections. We also learned how to create mouse strokes on a canvas in React.
## What's next for Lecturely
This product can be useful even past digital schooling as it can save schools money as they would not have to purchase supplies. Thus it could benefit from building out more features.
Currently, Lecturely doesn’t support audio but it would be on our roadmap. Thus, classes would still need to have another software also running to handle the audio communication. | winning |
## Inspiration
As lane-keep assist and adaptive cruise control features are becoming more available in commercial vehicles, we wanted to explore the potential of a dedicated collision avoidance system
## What it does
We've created an adaptive, small-scale collision avoidance system that leverages Apple's AR technology to detect an oncoming vehicle in the system's field of view and respond appropriately, by braking, slowing down, and/or turning
## How we built it
Using Swift and ARKit, we built an image-detecting app which was uploaded to an iOS device. The app was used to recognize a principal other vehicle (POV), get its position and velocity, and send data (corresponding to a certain driving mode) to an HTTP endpoint on Autocode. This data was then parsed and sent to an Arduino control board for actuating the motors of the automated vehicle
## Challenges we ran into
One of the main challenges was transferring data from an iOS app/device to Arduino. We were able to solve this by hosting a web server on Autocode and transferring data via HTTP requests. Although this allowed us to fetch the data and transmit it via Bluetooth to the Arduino, latency was still an issue and led us to adjust the danger zones in the automated vehicle's field of view accordingly
## Accomplishments that we're proud of
Our team was all-around unfamiliar with Swift and iOS development. Learning the Swift syntax and how to use ARKit's image detection feature in a day was definitely a proud moment. We used a variety of technologies in the project and finding a way to interface with all of them and have real-time data transfer between the mobile app and the car was another highlight!
## What we learned
We learned about Swift and more generally about what goes into developing an iOS app. Working with ARKit has inspired us to build more AR apps in the future
## What's next for Anti-Bumper Car - A Collision Avoidance System
Specifically for this project, solving an issue related to file IO and reducing latency would be the next step in providing a more reliable collision avoiding system. Hopefully one day this project can be expanded to a real-life system and help drivers stay safe on the road | ## Inspiration
As OEMs(Original equipment manufacturers) and consumers keep putting on brighter and brighter lights, this can be blinding for oncoming traffic. Along with the fatigue and difficulty judging distance, it becomes increasingly harder to drive safely at night. Having an extra pair of night vision would be essential to protect your eyes and that's where the NCAR comes into play. The Nighttime Collision Avoidance Response system provides those extra sets of eyes via an infrared camera that uses machine learning to classify obstacles in the road that are detected and projects light to indicate obstacles in the road and allows safe driving regardless of the time of day.
## What it does
* NCAR provides users with an affordable wearable tech that ensures driver safety at night
* With its machine learning model, it can detect when humans are on the road when it is pitch black
* The NCAR alerts users of obstacles on the road by projecting a beam of light onto the windshield using the OLED Display
* If the user’s headlights fail, the infrared camera can act as a powerful backup light
## How we built it
* Machine Learning Model: Tensorflow API
* Python Libraries: OpenCV, PyGame
* Hardware: (Raspberry Pi 4B), 1 inch OLED display, Infrared Camera
## Challenges we ran into
* Training machine learning model with limited training data
* Infrared camera breaking down, we had to use old footage of the ml model
## Accomplishments that we're proud of
* Implementing a model that can detect human obstacles from 5-7 meters from the camera
* building a portable design that can be implemented on any car
## What we learned
* Learned how to code different hardware sensors together
* Building a Tensorflow model on a Raspberry PI
* Collaborating with people with different backgrounds, skills and experiences
## What's next for NCAR: Nighttime Collision Avoidance System
* Building a more custom training model that can detect and calculate the distances of the obstacles to the user
* A more sophisticated system of alerting users of obstacles on the path that is easy to maneuver
* Be able to adjust the OLED screen with a 3d printer to display light in a more noticeable way | ## Inspiration
Car theft is a serious issue that has affected many people in the GTA. Car theft incidents have gone up 60% since 2021. That means thousands of cars are getting stolen PER WEEK, and right in front from their driveway. This problem is affecting middle class communities, most evidently at Markham, Ontario. This issue inspired us to create a tracking app and device that would prevent your car from being stolen, while keeping your friend’s car safe as well.
## What it does
We built two components in this project. A hardware security system and an app that connects to it.
In the app you can choose to turn on/off the hardware system by clicking lock/unlock inside the app. When on, the hardware component will use ultrasonic sensors to detect motion. If motion is detected, the hardware will start buzzing and will connect to Twilio to immediately send an SMS message to your phone. As while the app has many more user-friendly features including location tracking for the car and the option to add additional cars.
## How we built it
We built the front-end design with figma. This was our first time using it and it took some Youtube videos to get used to the software, but in the end we were happy with our builds. The hardware system incorporated an arduino yun that connected and made SMS text messages through twilio’s api system. As well, the arduino required C code for all the SMS calls, LED lights, and buzzer. The hardware also included some wiring and ultrasonic sensors for detection. We finally wanted to produce an even better product so we used CAD designs to expand upon our original hardware designs. Overall, we are extremely pleased with our final product.
## Business Aspect of SeCARity
As for the business side of things, we believe that this product can be easily marketable and attract many consumers. These types of products are in high demand currently as they solve an issue our society is currently facing. The market for this will be big and as this product holds hardware parts that can be bought for cheap, meaning that the product will be reasonably priced.
## Challenges we ran into
We had some trouble coming up with an idea, and specifically one that would allow our project to be different from other GPS tracker devices. We also ran into the issue of certain areas of our project not functioning the way we had ideally planned, so we had to use quick problem solving to think of an alternative solution. Our project went through many iterations to come up with a final product.
There were many challenges we ran into on Figma, especially regarding technical aspects. The most challenging aspect in this would’ve been the implementation of the design.
Finally, the virtual hacking part was difficult at times to communicate with each other, but we persisted and were able to work around this.
## Accomplishments that we're proud of
We are extremely proud of the polished CAD version of the more complex and specific and detailed car tracker. We are very proud of the app and all the designs. Furthermore, we were really happy with the hardware system and the 3-D printed model casing to cover it.
## What we learned
We learned how to use Figma and as well an Arduino Yun. We never used this model of an Arduino and it was definitely something really cool. As it had wifi capabilities, it was pretty fun to play around with and implement new creations to this type of model. As for Figma, we learned how to navigate around the application and create designs.
## What's next for SeCARity
-Using OpenCV to add camera detection
-Adding a laser detection hardware system
-Ability to connect with local authorities | winning |
## Inspiration
Politicians make a lot of money. Like, a lot. After a thorough analysis of how politicians apply their skill sets to faithfully "serve the general public", we realized that there's a hidden skill that many of them possess. It is a skill that hasn't been in the spotlight for some time. It is the skill which allowed US senator, Richard Burr, to sell 95% of his holdings in his retirement account just before a downturn in the market (thus avoiding $80,000 in losses and generating a profit upwards of $100k). This same skill allowed several senators like Spencer Bachus who had access to top secret meetings discussing the 2008 stock market crash and it's inevitably to heavily short the market just before the crash, generating a 200% per 1% drop in the NASDAQ. So, we decided that... senators know best! Our project is about outsider trading, which essentially means an outsider (you) get to trade! It allows you to track and copy the live trades of whatever politician you like.
## Why the idea works and what problem is solves
We have a term called "recognition by ignition", a simple set of words that describe how this unconventional approach works. Our system has the ability to, by virtue of the data that is available to it, prioritize the activity of Senators previously engaged in suspicious trading activities. When these Senators make a big move, everyone following them receives a message via our InfoBip integration, and knows, temporarily acting as a catalyst for changes in the value of that stock, at best just enough to draw the scrutiny of financial institutions, essentially serving as an extra layer of safety checks while consistently being a trustworthy platform to trade on, ensured by wallet management and transactions through Circle integration.
## What it does
Outsider trading gets the trading data of a large set of politicians, showing you their trading history and allowing you to select one or more politicians to follow. After depositing an amount into outsider trading, our tool either lets you manually assess the presented data and invest wherever you want, or automatically follow the actions of the politicians that you have followed. Sp. when they invest in stock x, our tools proportionally invest for you in the same stock. When they pull out of stock y, your bot will pull out of that stock too! This latter feature can be simulated or followed through with actual funds to track the portfolio performance of a certain senator.
## How we built it
We built our web app using ReactJS for the front end connected to a snappy Node.js backend, and a MySQL server hosted on RDS. Thanks in part to the STOCK act of 2012, most trading data for US senators has to be made public information, so we used the BeautifulSoup library to Web Scrape and collect our data.
## Challenges we ran into
Naturally, 36 hours (realistically less) of coding, would involve tense sessions of figuring out how to do certain things. We saw the direct value that the services offered by InfoBip and Circle could have on our project so we got to work implementing that and as expected had to traverse a learning curve with implementing the APIs, this job was however made easier because of the presence of mentors and good documentation online that allowed us to integrate an SMS notification system and a system that sets up crypto wallets for any user that signs up.
Collaborating effectively is one of the most important parts of a hackathon, so we as a team learnt a lot more about effective and efficient version control measures and how to communicate and divide roles and work in a software focused development environment.
## Accomplishments that we're proud of
* A complete front-end for the project was finished in due time
* A fully functional back-end and database system to support our front-end
* InfoBip integration to set up effective communication with the customer. Our web-app automatically sends an SMS when a senator you are following makes a trade.
* Crypto wallets for payment, implemented with Circle!
* A well designed and effective database hosted on an RDS instance
## What we learned
While working on this project we had to push ourselves outside of all of our comfort zones. Going into this project none of us knew how to web scrape, set up crypto wallets, create SMS/email notification systems, or work with RDS instances. Although some of these features may be bare bones, we are leaving this project with new knowledge and confidence in these areas. We learnt how to effectively work and scale a full stack web-app, and got invaluable experience on how to collaborate and version control as a team.
## What's next for Outsider Trading
This is only the beginning for us, there's a lot more to come!
* Increased InfoBip integration with features like:
1) Weekly summary email of your portfolio (We have investment data and financial data on Circle that can simply be summarized with the API we use to make charts on the portfolio page and then attach that through Infobip through the email.
2) SMS 2.0 features can be used to directly allow the user to invest from their messaging app of choice
* Improved statistical summaries of your own trades and those of each senator with models trained on trading datasets that can detect the likelihood of foul play in the market.
* Zapier integration with InfoBip to post updates about senator trades regularly to a live Twitter (X) page.
* An iOS and android native app, featuring all of our current features an more. | 

## Inspiration
We wanted to truly create a well-rounded platform for learning investing where transparency and collaboration is of utmost importance. With the growing influence of social media on the stock market, we wanted to create a tool where it will auto generate a list of recommended stocks based on its popularity. This feature is called Stock-R (coz it 'Stalks' the social media....get it?)
## What it does
This is an all in one platform where a user can find all the necessary stock market related resources (websites, videos, articles, podcasts, simulators etc) under a single roof. New investors can also learn from other more experienced investors in the platform through the use of the chatrooms or public stories. The Stock-R feature uses Natural Language processing and sentiment analysis to generate a list of popular and most talked about stocks on twitter and reddit.
## How we built it
We built this project using the MERN stack. The frontend is created using React. NodeJs and Express was used for the server and the Database was hosted on the cloud using MongoDB Atlas. We used various Google cloud APIs such as Google authentication, Cloud Natural Language for the sentiment analysis, and the app engine for deployment.
For the stock sentiment analysis, we used the Reddit and Twitter API to parse their respective social media platforms for instances where a stock/company was mentioned that instance was given a sentiment value via the IBM Watson Tone Analyzer.
For Reddit, popular subreddits such as r/wallstreetbets and r/pennystocks were parsed for the top 100 submissions. Each submission's title was compared to a list of 3600 stock tickers for a mention, and if found, then the submission's comment section was passed through the Tone Analyzer. Each comment was assigned a sentiment rating, the goal being to garner an average sentiment for the parent stock on a given day.
## Challenges we ran into
In terms of the Chat application interface, the integration between this application and main dashboard hub was a major issue as it was necessary to pull forward the users credentials without having them to re-login to their account. This issue was resolved by producing a new chat application which didn't require the need of credentials, and just a username for the chatroom. We deployed this chat application independent of the main platform with a microservices architecture.
On the back-end sentiment analysis, we ran into the issue of efficiently storing the comments parsed for each stock as the program iterated over hundreds of posts, commonly collecting further data on an already parsed stock. This issue was resolved by locally generating an average sentiment for each post and assigning that to a dictionary key-value pair. If a sentiment score was generated for multiple posts, the average were added to the existing value.
## Accomplishments that we're proud of
## What we learned
A few of the components that we were able to learn and touch base one were:
* REST APIs
* Reddit API
* React
* NodeJs
* Google-Cloud
* IBM Watson Tone Analyzer
-Web Sockets using Socket.io
-Google App Engine
## What's next for Stockhub
## Registered Domains:
-stockhub.online
-stockitup.online
-REST-api-inpeace.tech
-letslearntogether.online
## Beginner Hackers
This was the first Hackathon for 3/4 Hackers in our team
## Demo
The apply is fully functional and deployed using the custom domain. Please feel free to try it out and let us know if you have any questions.
<http://www.stockhub.online/> | ## Inspiration
As a beginner team at HackMIT, the various options and big-name sponsors were daunting. We really struggled with hashing out a solid idea that would be feasible in the time that we had. As the clock kept ticking, we were running out of time quickly. And then it hit us. Our hackathon idea is to generate hackathon ideas.
## What it does
The user interacts with our HackPal in order to generate hackathon project ideas based on their preferences (e.g. what track they chose for their project, what technologies to use, what is the end goal of the project).
## How we built it
We used HTML, JS and CSS for our website. For the data collection, we used BeautifulSoup to scrape information off of Devpost in order to store ideas into our database that we would later generate ideas from using natural language processors.
## Challenges we ran into
We wanted to narrow down AI-generated hackathon project results by referencing existing hackathon projects, so we had to learn how to configure a chatbot and scrape data through Python (BeautifulSoup).
## Accomplishments that we're proud of
We were able to utilize existing AI software and innovate upon that to provide more specific results for hackathon projects. Also, for most of us, this is our very first hackathon and being able to execute a project that would have a real world impact and assist others is something we are proud of.
## What we learned
Front-end development, AI and NLP programs, problem-solving, teamwork
## What's next
We are planning to implement a feature that suggests to the user how they can actually start their project. We also plan on connecting the multiple parts of backend with our frontend. | partial |
## Inspiration
I read a paper on an app named fingerIO that would use active Sonar and two microphones to trilaterate(length based triangulation) to map where a hand moved. I thought that if you just had the source attempting to identify itself you could take it a step further.
## What it does
It will track in 3D space a phone emitting a designed series of chirps 13 times second. These chirps are inaudible to humans.
## How we built it
We used 3 laptops and and IPhone. We put the coordinates of the laptops and the phones starting position and then began playing the chips at regular intervals. we used this to calculate how far the phone was from each laptop, and then trilaterate the position. We would then plot this in 3D in matplotlib.
## Challenges we ran into
The clock speed of each of the computers is slightly different. Because sound travels at 340 meters per second a drift of less than milliseconds would make it impossible to track. We ended up hard coding in a 0.0000044 second adjusted period of chirps to compensate for this.
## Accomplishments that we're proud of
That it actually worked! Also that we overcame so many obstacles to make something that has never been made before.
## What we learned
We learned a lot about how sonar systems are designed and how to cross-correlate input signals containing random white noise with known signals. We also learned how to use many of the elements in scipy like fourier transforms, frequency modulated chirps, and efficient array operations.
## What's next for Trimaran
I would like to use the complex portion of the fourier transform to identify the phase offset and get distance readings more accurate than even the 96000 Hz sound input rate from our microphones could find. Also, it would be cool to add this to a VR headset like google glass so you could move around in the VR space instead of just moving your head to look around. | ## Inspiration
One of our team members, Nicky, has a significant amount of trouble hearing (subtle) noises! The name behind our application, Tricone, was first canned because of the triangular, hat-like shape of our hardware contraption, which resembled a tricorn. Later, we changed the name to Tricone because of the three types of cones that we have in our retinas -- red, green, and blue -- which represent the color in our world.
## What it does
Tricone is an AR mobile application that uses the direction and location of sounds to provide real-time visualization in order to help people who have trouble with hearing be able to detect their surroundings. The application displays the camera screen with dots, which represent the location and intensity of sounds nearby, and updates as the camera feed is updated as the user moves around.
## How we built it
First thing, we began building through installing Android Studio onto our laptops and then downloading Flutter SDK and the Dart language for the IDE. Then once we fully developed our idea and process, we rented an Arduino 101, 15 Digi-Key components (jumper wires, sound sensors and a soldering kit and iron), and an Adafruit Bluefruit BLE (Bluetooth Low Energy) Breakout wireless protocol. The next day, we wired our components to the Arduino so that the sound sensors formed an equilateral triangle with a 20cm side length each by measuring 120° between the sensors and so that we could establish connectivity between the Arduino with the mobile app.
Our mission was to be able to translate sound waves into identifiable objects based on their location and direction. We determined that we would need hardware components, such as a microcontroller with sensors that had powerful microphones to distinguish between nearby sounds. Then we worked on implementing Bluetooth to connect with our Flutter-based mobile application, which would receive the data from the three sound sensors and convert it into graphics that would appear on the screen of the mobile app. Using Augmented Reality, the mobile application would be able to display the location and intensity of the sounds as according to the camera's directionality.
### Theoretical research and findings behind sound triangulation
In general, sound localization of a sound source is a non-trivial topic to grasp and even produce in such a short amount of time allotted in a hackathon. At first, I was trying to understand how such a process could be replicated and found a plethora of research papers that were insightful and related to this difficult problem. The first topic I found related to sound localization through a single microphone: monaural capturing. Another had used two microphones, but both experiments dealt with ambiguity of the direction of a sound source that could be anywhere in the 2D plane. That is the use of three microphones was settled on for our hackathon project since ambiguity of direction would be lifted with a third microphone in place.
Essentially, we decided to utilize three microphones to localize sound by using each microphone as an edge to an equilateral triangle centered at the origin with a radius of 20. The key here is that the placement of the microphones is non-collinear as a linear placement would still bring ambiguity to a sound that could be behind the mics. The mics would then capture the sound pressure from the sound source and quantify it for determining the location of the source later on. Here, we took the sound pressure from each mic because there is an inverse relationship between sound pressure and distance from an incoming sound, making it quite useful. By creating a linear system from the equations of circles from the three mics as their locations are already known and deriving each mic’s distance to the source as radii, we were able to use Gaussian elimination method to find an identity matrix and its solution as the source’s location. This is how we triangulated the location: the sound source assuming that there is only one location where the three circles mentioned previously can intersect and the position of the mics are always in a triangular formation. This method of formulation was based on the limitations posed by the hardware available and knowledge of higher-level algorithms.
Another way of visualizing the intersection of the three circles is a geometrical image with radical lines, where the intersection of all those lines is the radical center. However, in this specific case, the radical center is simply the intersection based on the previous assumption of one possible intersection with a triangular positioning at the origin. The figure below generalizes this description.
## Challenges we ran into
A significant chunk of time was spent dealing with technical hurdles, since many of us didn't come in with a lot of experience with Flutter and Dart, so we dealt with minor software issues and program bugs. We also had to research a lot of documentation and read plenty of Stack Overflow to understand the science behind our complex idea of detecting direction and distance of sound from our hardware. in order to solve issues we ran into or just to learn how to implement things. Problems with integrating our mobile application with the hardware provided, given the limited range of plugins that Flutter supported, made development tricky and towards the end, we decided to pivot and change technologies to a web application.
We also faced problems more-so on the trivial side, such as not being able to compile our Flutter app for several hours due to Gradle synchronization problems within Android Studio, and other problems that related to the connectivity between the Arduino BLE and our mobile application.
As an alternative, we created a web application to process HTTP requests to substitute Bluetooth connectivity through Google Hosting, which would make web API calls with the technology and host a PWA-based (Progressive Website Application) app and still be compatible for mobile app usage.
## Accomplishments that we're proud of
We are proud of coming up and following through on a multifaceted project idea! We divvied up the work to focus on four key areas: hardware, mobile app AR functionality, network connectivity, and front-end design. Our team as a whole worked incredibly hard on making this a success. Some of our most memorable milestones were: 1) being able to successfully control a smartphone to connect to the Arduino via Bluetooth, and 2) finalizing a theoretical formula for sound triangulation based on mathematical research!
## What we learned
Especially because all of us had little to no prior experience in at least one of the technologies we used, we were all able to learn about how we are able to connect software with hardware, and also conceptualize complex algorithms to make the technology possible. Additionally, we found the importance of pinpointing and outlining the technologies we would use for the hackathon project before immediately jumping into them, as we later determined midway into the day that we would have had more resources if we had selected other frameworks.
However, we all had a pleasant experience taking on a major challenge at HackHarvard, and this learning experience was extremely exciting in terms of what we were able to do within the weekend and the complexity of combining technologies together for widespread applications.
## What's next for TRICONE
Our application and hardware connectivity has significant room to grow; initially, the idea was to have a standalone mobile application that could be easily used as a handheld. At our current prototyping stage, we rely substantially on hardware to be able to produce accurate results. We believe that a mobile application or AR apparatus (ex. HoloLens) is still the end goal, albeit requiring a significant upfront budget for research in technology and funding.
In future work, the method of localization can be improved by increasing the number of microphones to increase accuracy with higher-level algorithms, such as beamforming methods or Multiple Signal Classification (MUSIC), to closely fine-precise the source location. Additionally, in research, fast Fourier Transformations to turn captured sound into a domain of frequencies along with differences in time delays are often used that would be interesting to substitute the comparatively primitive method used originally in this project. We would like to implement an outlier removal method/algorithm that would exclude unrelated sound to ensure localization can still be determined without interruption. Retrospectively, we learned that math is strongly connected in real-world situations and that it can quantify/represent sound that is invisible to the naked eye. | ## Team
Sam Blouir
Pat Baptiste
## Inspiration
Seeing the challenges of blind people navigating, especially in new areas and being inspired by someone who wanted to remain blind anonymously
## What it does
Uses computer vision to find nearby objects in the vicinity of the wearer and sends information (X,Y coordinates, depth, and size) to the wearer in real-time so they can enjoy walking
## How I built it
Python, C, C++, OpenCV, and an Arduino
## Challenges I ran into
Performance and creating disparity maps from stereo cameras with significantly different video output qualities
## Accomplishments that I'm proud of
It works!
## What I learned
We learned lots about using Python, OpenCV, an Arduino, and integrating all of these to create a hardware hack
## What's next for Good Vibrations
Better depth-sensing and miniaturization! | losing |
## Inspiration
Our inspiration has and will always be to empower various communities with tech. In this project, we attempted to build a product that can
by used by anyone and everyone to have some fun with their old photos and experience them differently, using mainly auditory sense.
Imagine you had an old photo of your backyard from when you were 5 but you don't remember what it sounded like back then, that's a feeling
we are trying to bring back and inject some life into your photos.
## What it does
The project ReAlive adds realistic sounding audio to any photo you want, trying to recreate what it would have been like back at the time
of the photo. We take image as an input and return a video that is basically the same image and an audio overalyed. Now this audio is
smartly synthesized by extracting information from your image and creating a mapping with our sound dataset.
## How we built it
Our project is a web-app built using Flask, FastAPI and basic CSS. It provides a simple input for an image and displays the video after
processing it on our backend. Our backend tech-stack is Tensorflow, Pytorch and Pydub to mix audio, with the audio data sitting on Google
Cloud storage and Deep Learning models deployed on Google Cloud in containers. Our first task was to extract information from the image and
then create a key-map with our sound dataset. Past that we smartly mixed the various audio files into one to make it sound realistic and
paint a complete picture of the scene.
## Challenges we ran into
Firstly, figuring out the depth and distance calculation for monochannel images using CNN and OpenCV was a challengin task.
Next, applying this to sound intensity mapping ran us into few challenges. And finally, deploying and API latency was a factor we had to deal with and optimize.
## Accomplishments that we're proud of
Building and finishing the project in 36 hours!!!
## What we learned
We learned that building proof-of-concepts in two days is a really uphill task. A lot of things went our way but some didn’t, we made it at the end and our key learnings were:
Creating a refreshing experience for a user takes a lot of research and having insufficient data is not great
## What's next for ReAlive
Image animation and fluidity with augmented sound and augmented reality. | ## Inspiration
Inspired by the fintech challenge. We wanted to explore possible ways large-scale social trends could influence the market.
## What it does
Sentigrade is constantly listening to tweets and analyzing the sentiments of messages about different companies. Over time, it builds up an idea of which companies are viewed positively, and which negatively.
Sentigrade also shows historical stock data, allowing users to look for potential relations.
## How we built it
A service constantly updates the database with information from the real-time Twitter message stream. It performs sentiment analysis and aggregates the result over fixed intervals.
The web backend, written in Flask, pulls Twitter data from the database and stock data from Yahoo Finance. The frontend is a simple jQuery/Bootstrap page to display the results in an informative, nice-looking way.
## Challenges we ran into
We originally intended to use arbitrary lists of items, retrieving every message from Twitter. However, this functionality was not available. Also, the stock data retrieval proved messy, though it worked well in the end.
## Accomplishments that we're proud of
Finishing the project ahead of schedule and getting to really flesh out the details.
## What we learned
Web development is scary to start with since you don't know where to begin, but once you hash out all the details, everything comes through.
## What's next for Sentigrade
Sentiment history. Actionable insights, possibly. Per-user settings for filtering, etc. | ## Inspiration
There are millions of people around the world who have a physical or learning disability which makes creating visual presentations extremely difficult. They may be visually impaired, suffer from ADHD or have disabilities like Parkinsons. For these people, being unable to create presentations isn’t just a hassle. It’s a barrier to learning, a reason for feeling left out, or a career disadvantage in the workplace. That’s why we created **Pitch.ai.**
## What it does
Pitch.ai is a web app which creates visual presentations for you as you present. Once you open the web app, just start talking! Pitch.ai will listen to what you say and in real-time and generate a slide deck based on the content of your speech, just as if you had a slideshow prepared in advance.
## How we built it
We used a **React** client combined with a **Flask** server to make our API calls. To continuously listen for audio to convert to text, we used a react library called “react-speech-recognition”. Then, we designed an algorithm to detect pauses in the speech in order to separate sentences, which would be sent to the Flask server.
The Flask server would then use multithreading in order to make several API calls simultaneously. Firstly, the **Monkeylearn** API is used to find the most relevant keyword in the sentence. Then, the keyword is sent to **SerpAPI** in order to find an image to add to the presentation. At the same time, an API call is sent to OpenAPI’s GPT-3 in order to generate a caption to put on the slide. The caption, keyword and image of a single slide deck are all combined into an object to be sent back to the client.
## Challenges we ran into
* Learning how to make dynamic websites
* Optimizing audio processing time
* Increasing efficiency of server
## Accomplishments that we're proud of
* Made an aesthetic user interface
* Distributing work efficiently
* Good organization and integration of many APIs
## What we learned
* Multithreading
* How to use continuous audio input
* How to use React hooks, Animations, Figma
## What's next for Pitch.ai
* Faster and more accurate picture, keyword and caption generation
* "Presentation mode”
* Integrate a database to save your generated presentation
* Customizable templates for slide structure, color, etc.
* Build our own web scraping API to find images | partial |
## Inspiration
It's easy to zone off in online meetings/lectures, and it's difficult to rewind without losing focus at the moment. It could also be disrespectful to others if you expose the fact that you weren't paying attention. Wouldn't it be nice if we can just quickly skim through a list of keywords to immediately see what happened?
## What it does
Rewind is an intelligent, collaborative and interactive web canvas with built in voice chat that maintains a list of live-updated keywords that summarize the voice chat history. You can see timestamps of the keywords and click on them to reveal the actual transcribed text.
## How we built it
Communications: WebRTC, WebSockets, HTTPS
We used WebRTC, a peer-to-peer protocol to connect the users though a voice channel, and we used websockets to update the web pages dynamically, so the users would get instant feedback for others actions. Additionally, a web server is used to maintain stateful information.
For summarization and live transcript generation, we used Google Cloud APIs, including natural language processing as well as voice recognition.
Audio transcription and summary: Google Cloud Speech (live transcription) and natural language APIs (for summarization)
## Challenges we ran into
There are many challenges that we ran into when we tried to bring this project to reality. For the backend development, one of the most challenging problems was getting WebRTC to work on both the backend and the frontend. We spent more than 18 hours on it to come to a working prototype. In addition, the frontend development was also full of challenges. The design and implementation of the canvas involved many trial and errors and the history rewinding page was also time-consuming. Overall, most components of the project took the combined effort of everyone on the team and we have learned a lot from this experience.
## Accomplishments that we're proud of
Despite all the challenges we ran into, we were able to have a working product with many different features. Although the final product is by no means perfect, we had fun working on it utilizing every bit of intelligence we had. We were proud to have learned many new tools and get through all the bugs!
## What we learned
For the backend, the main thing we learned was how to use WebRTC, which includes client negotiations and management. We also learned how to use Google Cloud Platform in a Python backend and integrate it with the websockets. As for the frontend, we learned to use various javascript elements to help develop interactive client webapp. We also learned event delegation in javascript to help with an essential component of the history page of the frontend.
## What's next for Rewind
We imagined a mini dashboard that also shows other live-updated information, such as the sentiment, summary of the entire meeting, as well as the ability to examine information on a particular user. | ## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | Business Write-up:
## 💡 Inspiration
A genuine problem faced by millions of people every day. There was not enough awareness and useful tools for navigating the confusing terrain of online agreements. Big tech companies often collect and store large amounts of user data, which users consent to unknowingly.
## 📃 What it does
Condenses thousands of lines in agreement forms into the few concise lines containing key points. Customizes the points according to the user's preferences and suggests alternative services that may provide more user-friendly policies. We have included additional tools to aid with accessibility factors such as text-speech, translation and pre-loaded terms and conditions.
## 🛠 How we built it
**Frontend:** The frontend of our website was built with HTML, CSS, JavaScript, ReactJS, and Vue. We also used Bootstrap, Tailwind CSS, and Bulma for styling.
**Backend:** The backend of our website was built with Python Flask, Firebase for authentication and SQLite databases.
**Machine Learning:** We used NLTK and HuggingFace to train our Natural Language Processing models.
**Branding, UI, design, and Video:** We designed our website using Figma and edited our demo video using Adobe After Effects.
## 🛑 Challenges we ran into
* The short time frame was a challenge since all of our team members had other commitments over the weekend. As a result, we were unable to spend as much time on the project as we had hoped to.
* We also were not able to model the “perfect” summarizer, nevertheless, we had tested about a dozen different varieties. So, we had to create a custom solution in this short time frame.
* Additionally, we had to spend countless hours debugging the front-end framework to get our website up and running.
## 🏆 Accomplishments that we're proud of
* Creating a custom summarization model in a short time span.
* Designing and prototyping websites in various frameworks while the clock was ticking.
## 🧠 What we learned
* Throughout the ups and downs of our journey, we learned that…
* It is important to utilize the team’s strengths when in a time crunch.
* Time management is key. Having a clear plan on how to distribute tasks from the start helps maximize what we can do in the given time-frame.
* Begin with a minimum viable product and expand on it.
* Flask, Vue, Firebase
## 🤔 What's next for Argon
* We plan to create a Chrome extension to allow easier and more efficient access to our service. We also hope to work with professionals in the area...
* Chrome extension; this will be extremely useful as users would not need to copy & paste or upload a file, but could instead let the extension scan the page.
* Working with professionals in the area to make further improvements. | winning |
## Inspiration
We've all had that experience with our parents and grandparents asking us for help with the computer or smartphone, especially being at home in the pandemic with most meetings being virtual. This brought to mind the technological barriers between us and the older generation, as well as more so with lower socioeconomic groups who may not have access to the same privileges we have. Thus we got to thinking how can we increase accessibility of technology, and an idea is that people would need immediate help and would prefer an interface where they can talk to someone, but also more comprehensive educational materials are available to learn the technologies. Since what older people generally ask is 'can you help me with [insert technological issue]', the idea of CanYouHelpWith.Tech website was born.
## What it does
Our website has 4 main functions:
1. offer immediate tech support through search options to narrow your problem and video call and chat with our volunteers 24/7,
2. provide free live and recorded educational workshops to the general public,
3. become a volunteer and
4. make a donation.
## How we built it
Prototyping:
Figma
Website:
* React web app
* Node.js
* JavaScript, CSS, HTML
* Google Calendar API
* Goggle Auth2 User login
* Google Speech to text API that utilizes ML
* Twilio API
* Heroku Deployment
* Domain.com for a custom domain
## Challenges we ran into
The biggest challenge was that most of our teammates haven’t used the technologies such as React, Twilio and Google Authorization before, so we had to learn these as we used them. As expected, some errors also came up when running the code, which we discussed and worked through together to solve. Another issue that came up was with typescript files interfering with the javascript files, but this was resolved by removing the typescript.
## Accomplishments that we're proud of
* Built a mostly functional website!
* Learned React and Twilio
* Utilized features of Google Calendar, Google Speech to text and Twilio video call and chat
## What we learned
* How to build a website
* New Technologies: React, Twilio, Google technologies API
* How to merge conflicts with Git
## What's next for CanYouHelpWithMy.Tech
* Text-to-speech to aid those with vision issues
* Continue fixing bugs
* Optimize/update UI
* Recruit volunteers
* Advertising | >
> Domain.com domain: IDE-asy.com
>
>
>
## Inspiration
Software engineering and development have always been subject to change over the years. With new tools, frameworks, and languages being announced every year, it can be challenging for new developers or students to keep up with the new trends the technological industry has to offer. Creativity and project inspiration should not be limited by syntactic and programming knowledge. Quick Code allows ideas to come to life no matter the developer's experience, breaking the coding barrier to entry allowing everyone equal access to express their ideas in code.
## What it does
Quick Code allowed users to code simply with high level voice commands. The user can speak in pseudo code and our platform will interpret the audio command and generate the corresponding javascript code snippet in the web-based IDE.
## How we built it
We used React for the frontend, and the recorder.js API for the user voice input. We used runkit for the in-browser IDE. We used Python and Microsoft Azure for the backend, we used Microsoft Azure to process user input with the cognitive speech services modules and provide syntactic translation for the frontend’s IDE.
## Challenges we ran into
>
> "Before this hackathon I would usually deal with the back-end, however, for this project I challenged myself to experience a different role. I worked on the front end using react, as I do not have much experience with either react or Javascript, and so I put myself through the learning curve. It didn't help that this hacakthon was only 24 hours, however, I did it. I did my part on the front-end and I now have another language to add on my resume.
> The main Challenge that I dealt with was the fact that many of the Voice reg" *-Iyad*
>
>
> "Working with blobs, and voice data in JavaScript was entirely new to me." *-Isaac*
>
>
> "Initial integration of the Speech to Text model was a challenge at first, and further recognition of user audio was an obstacle. However with the aid of recorder.js and Python Flask, we able to properly implement the Azure model." *-Amir*
>
>
> "I have never worked with Microsoft Azure before this hackathon, but decided to embrace challenge and change for this project. Utilizing python to hit API endpoints was unfamiliar to me at first, however with extended effort and exploration my team and I were able to implement the model into our hack. Now with a better understanding of Microsoft Azure, I feel much more confident working with these services and will continue to pursue further education beyond this project." *-Kris*
>
>
>
## Accomplishments that we're proud of
>
> "We had a few problems working with recorder.js as it used many outdated modules, as a result we had to ask many mentors to help us get the code running. Though they could not figure it out, after hours of research and trying, I was able to successfully implement recorder.js and have the output exactly as we needed. I am very proud of the fact that I was able to finish it and not have to compromise any data." *-Iyad*
>
>
> "Being able to use Node and recorder.js to send user audio files to our back-end and getting the formatted code from Microsoft Azure's speech recognition model was the biggest feat we accomplished." *-Isaac*
>
>
> "Generating and integrating the Microsoft Azure Speech to Text model in our back-end was a great accomplishment for our project. It allowed us to parse user's pseudo code into properly formatted code to provide to our website's IDE." *-Amir*
>
>
> "Being able to properly integrate and interact with the Microsoft Azure's Speech to Text model was a great accomplishment!" *-Kris*
>
>
>
## What we learned
>
> "I learned how to connect the backend to a react app, and how to work with the Voice recognition and recording modules in react. I also worked a bit with Python when trying to debug some problems in sending the voice recordings to Azure’s servers." *-Iyad*
>
>
> "I was introduced to Python and learned how to properly interact with Microsoft's cognitive service models." *-Isaac*
>
>
> "This hackathon introduced me to Microsoft Azure's Speech to Text model and Azure web app. It was a unique experience integrating a flask app with Azure cognitive services. The challenging part was to make the Speaker Recognition to work; which unfortunately, seems to be in preview/beta mode and not functioning properly. However, I'm quite happy with how the integration worked with the Speach2Text cognitive models and I ended up creating a neat api for our app." *-Amir*
>
>
> "The biggest thing I learned was how to generate, call and integrate with Microsoft azure's cognitive services. Although it was a challenge at first, learning how to integrate Microsoft's models into our hack was an amazing learning experience. " *-Kris*
>
>
>
## What's next for QuickCode
We plan on continuing development and making this product available on the market. We first hope to include more functionality within Javascript, then extending to support other languages. From here, we want to integrate a group development environment, where users can work on files and projects together (version control). During the hackathon we also planned to have voice recognition to recognize and highlight which user is inputting (speaking) which code. | ## Inspiration
Digitized conversations have given the hearing impaired and other persons with disabilities the ability to better communicate with others despite the barriers in place as a result of their disabilities. Through our app, we hope to build towards a solution where we can extend the effects of technological development to aid those with hearing disabilities to communicate with others in real life.
## What it does
Co:herent is (currently) a webapp which allows the hearing impaired to streamline their conversations with others by providing them sentence or phrase suggestions given the context of a conversation. We use Co:here's NLP text generation API in order to achieve this and in order to provide more accurate results we give the API context from the conversation as well as using prompt engineering in order to better tune the model. The other (non hearing impaired) person is able to communicate with the webapp naturally through speech-to-text inputs and text-to-speech functionalities are put in place in order to better facilitate the flow of the conversation.
## How we built it
We built the entire app using Next.js with the Co:here API, React Speech Recognition API, and React Speech Kit API.
## Challenges we ran into
* Coming up with an idea
* Learning Next.js as we go as this is all of our first time using it
* Calling APIs are difficult without a backend through a server side rendered framework such as Next.js
* Coordinating and designating tasks in order to be efficient and minimize code conflicts
* .env and SSR compatibility issues
## Accomplishments that we're proud of
Creating a fully functional app without cutting corners or deviating from the original plan despite various minor setbacks.
## What we learned
We were able to learn a lot about Next.js as well as the various APIs through our first time using them.
## What's next for Co:herent
* Better tuning the NLP model to generate better/more personal responses as well as storing and maintaining more information on the user through user profiles and database integrations
* Better tuning of the TTS, as well as giving users the choice to select from a menu of possible voices
* Possibility of alternative forms of input for those who may be physically impaired (such as in cases of cerebral palsy)
* Mobile support
* Better UI | partial |
## Inspiration
Many students rely on scholarships to attend college. As students in different universities, the team understands the impact of scholarships on people's college experiences. When scholarships fall through, it can be difficult for students who cannot attend college without them. In situations like these, they have to depend on existing crowdfunding websites such as GoFundMe. However, platforms like GoFundMe are not necessarily the most reliable solution as there is no way of verifying student status and the success of the campaign depends on social media reach. That is why we designed ScholarSource: an easy way for people to donate to college students in need!
## What it does
ScholarSource harnesses the power of blockchain technology to enhance transparency, security, and trust in the crowdfunding process. Here's how it works:
Transparent Funding Process: ScholarSource utilizes blockchain to create an immutable and transparent ledger of all transactions and donations. Every step of the funding process, from the initial donation to the final disbursement, is recorded on the blockchain, ensuring transparency and accountability.
Verified Student Profiles: ScholarSource employs blockchain-based identity verification mechanisms to authenticate student profiles. This process ensures that only eligible students with a genuine need for funding can participate in the platform, minimizing the risk of fraudulent campaigns.
Smart Contracts for Funding Conditions: Smart contracts, powered by blockchain technology, are used on ScholarSource to establish and enforce funding conditions. These self-executing contracts automatically trigger the release of funds when predetermined criteria are met, such as project milestones or the achievement of specific research outcomes. This feature provides donors with assurance that their contributions will be used appropriately and incentivizes students to deliver on their promised objectives.
Immutable Project Documentation: Students can securely upload project documentation, research papers, and progress reports onto the blockchain. This ensures the integrity and immutability of their work, providing a reliable record of their accomplishments and facilitating the evaluation process for potential donors.
Decentralized Funding: ScholarSource operates on a decentralized network, powered by blockchain technology. This decentralization eliminates the need for intermediaries, reduces transaction costs, and allows for global participation. Students can receive funding from donors around the world, expanding their opportunities for financial support.
Community Governance: ScholarSource incorporates community governance mechanisms, where participants have a say in platform policies and decision-making processes. Through decentralized voting systems, stakeholders can collectively shape the direction and development of the platform, fostering a sense of ownership and inclusivity.
## How we built it
We used React and Nextjs for the front end. We also integrated with ThirdWeb's SDK that provided authentication with wallets like Metamask. Furthermore, we built a smart contract in order to manage the crowdfunding for recipients and scholars.
## Challenges we ran into
We had trouble integrating with MetaMask and Third Web after writing the solidity contract. The reason was that our configuration was throwing errors, but we had to configure the HTTP/HTTPS link,
## Accomplishments that we're proud of
Our team is proud of building a full end-to-end platform that incorporates the very essence of blockchain technology. We are very excited that we are learning a lot about blockchain technology and connecting with students at UPenn.
## What we learned
* Aleo
* Blockchain
* Solidity
* React and Nextjs
* UI/UX Design
* Thirdweb integration
## What's next for ScholarSource
We are looking to expand to other blockchains and incorporate multiple blockchains like Aleo. We are also looking to onboard users as we continue to expand and new features. | ### Inspiration
The way research is funded is harmful to science — researchers seeking science funding can be big losers in the equality and diversity game. We need a fresh ethos to change this.
### What it does
Connexsci is a grant funding platform that generates exposure to undervalued and independent research through graph-based analytics. We've built a proprietary graph representation across 250k research papers that allows for indexing central nodes with highest value-driving research. Our grant marketplace allows users to leverage these graph analytics and make informed decisions on scientific public funding, a power which is currently concentrated in a select few government organizations. Additionally, we employ quadratic funding, a fundraising model that democratizes impact of contributions that has seen mainstream success through <https://gitcoin.co/>.
### How we built it
To gain unique insights on graph representations of research papers, we leveraged Cohere's NLP suite. More specifically, we used Cohere's generate functionality for entity extraction and fine-tuned their small language model with our custom research paper dataset for text embeddings. We created self-supervised training examples where we fine-tuned Cohere's model using extracted key topics given abstracts using entity extraction. These training examples were then used to fine-tune a small language model for our text embeddings.
Node prediction was achieved via a mix of document-wise cosine similarity, and other adjacency matrices that held rich information regarding authors, journals, and domains.
For our funding model, we created a modified version of the Quadratic Funding model. Unlike the typical quadratic funding systems, if the subsidy pool is not big enough to make the full required payment to every project, we can divide the subsidies proportionately by whatever constant makes the total add up to the subsidy pool's budget. For a given scenario, for example, a project dominated the leaderboard with an absolute advantage. The team then gives away up to 50% of their matching pool distribution so that every other project can have a share from the round, and after that we can see an increase of submissions.
The model is then implemented to our Bounty platform where organizers/investors can set a "goal" or bounty for a certain group/topic to be encouraged to research in a specific area of academia. In turn, this allows more researchers of unpopular topics to be noticed by society, as well as allow for advancements in the unpopular fields.
### Challenges we ran into
The entire dataset broke down in the middle of the night! Cohere also gave trouble with semantic search, making it hard to train our exploration model.
### Accomplishments that we're proud of
Parsing 250K+ publications and breaking it down to the top 150 most influential models. Parsing all ML outputs on to a dynamic knowledge graph. Building an explorable knowledge graph that interacts with the bounty backend.
### What's next for Connex
Integrating models directly on the page, instead of through smaller microservices. | ## Inspiration
As students of Berkeley, we value websites like Gofundme in providing anyone with the opportunity to spend money on causes they believe in. One problem we realized however is that the goodwill and trust of the public could be taken advantage of because there is a lack of strict accountability when it comes to the way the fundraised money is spent. From here, we noticed a similar trend among crowdsourced funding efforts in general -- whether it be funding for social causes or funding for investors. Investors wanting to take a leap of faith in a cause that catches their eye may be discouraged to invest for fear of losing all their money — whether from being scammed or from an irresponsible usage of money — while genuine parties who need money may be skipped. We wanted to make an application that solves this problem by giving the crowd control and transparency over the money that they provide.
## What it does
Guaranteed Good focuses on the operations of NPOs that need financial support with building technologies for their organization. Anybody can view the NPO's history and choose to provide cryptocurrency to help the NPO fund their project. However, the organization is forced to allocate and spend this money legitimately via smart contracts; every time they want to use a portion of their money pool and hire a freelancer to contribute to their project, they must notify all their investors who will decide whether or not to approve of this expenditure. Only if a majority of investors approve can the NPO actually use the money, and only in the way specified.
## How we built it
To enable the smart contract feature of our application, we used Solidity for some of our backend infrastructures.
We programmed the frontend in React, Next, and Tailwind.
## Challenges we ran into
None of us had previous experience with Solidity or blockchain technologies so there was a steep learning curve when trying to familiarize ourselves with implementing smart contracts and working with blockchain. It was difficult to get started and we had a lot of confusion with setup and dependencies management.
The second thing that stumped us was adapting to using Solidity as a backend language. Since the language is a bit more niche than other more commonly used backend languages, there was less of an abundance of resources to teach us how to integrate our React frontend with our Solidity backend. Luckily, we found out that Solidity can integrate with the Next.js framework, so we set out to learn and implement Next.
## Accomplishments that we're proud of
We're all proud of the amount of deep diving that we did to familiarize ourselves with blockchain in a short amount of time! We thought it would be a risky move since we weren't sure if we would be able to actually learn and complete a blockchain-centered application, but we wanted to try anyway since we really liked our idea. Although we are by no mean experts in blockchain now, it was fun spending time and learning a lot about this technology. We were also really satisfied when we were able to pull together a functioning full-stack application by the end of 24 hours.
In addition, with so many moving components in our application, it was especially important to make our website intuitive and simple for users to navigate. Thus, we spent time coming up with a streamlined and aesthetic design for our application and implementing it in react. Additionally, none of us really had design experience so we tried our best to quickly learn Figma and simple design principles and were surprised when it didn't come out as totally awkward-looking.
## What we learned
* New technologies such as blockchain, Solidity, Figma design, and Next
* How to communicate smart contract data from Solidity using Next and Node
* To appreciate the amount of careful planning and frontend design necessary for a good web application with many functionalities
## What's next for Guaranteed Good
**Dashboard**
* Currently GuarenteedGood has a user dashboard that is bare bones. With more time, we wanted to be able to offer analytics on how the project was going, graphs, and process more information from the user.
**Optimizing Runtime**
* With a lot of projects and user information to load, it takes a bit longer than we like to run the website. We want to integrate lazy loading, optimize images, and website caching.
**Matching Freelancer users**
* Allowing Freelancers to post and edit their profiles to their job board, and accept or reject job offers | winning |
## Inspiration
All of us have gone through the painstaking and difficult process of onboarding as interns and making sense of huge repositories with many layers of folders and files. We hoped to shorten this or remove it completely through the use of Code Flow.
## What it does
Code Flow exists to speed up onboarding and make code easy to understand for non-technical people such as Project Managers and Business Analysts. Once the user has uploaded the repo, it has 2 main features. First, it can visualize the entire repo by showing how different folders and files are connected and providing a brief summary of each file and folder. It can also visualize a file by showing how the different functions are connected for a more technical user. The second feature is a specialized chatbot that allows you to ask questions about the entire project as a whole or even specific files. For example, "Which file do I need to change to implement this new feature?"
## How we built it
We used React to build the front end. Any folders uploaded by the user through the UI are stored using MongoDB. The backend is built using Python-Flask. If the user chooses a visualization, we first summarize what every file and folder does and display that in a graph data structure using the library pyvis. We analyze whether files are connected in the graph based on an algorithm that checks features such as the functions imported, etc. For the file-level visualization, we analyze the file's code using an AST and figure out which functions are interacting with each other. Finally for the chatbot, when the user asks a question we first use Cohere's embeddings to check the similarity of the question with the description we generated for the files. After narrowing down the correct file, we use its code to answer the question using Cohere generate.
## Challenges we ran into
We struggled a lot with narrowing down which file to use to answer the user's questions. We initially thought to simply use Cohere generate to reply with the correct file but knew that it isn't specialized for that purpose. We decided to use embeddings and then had to figure out how to use those numbers to actually get a valid result. We also struggled with getting all of our tech stacks to work as we used React, MongoDB and Flask. Making the API calls seamless proved to be very difficult.
## Accomplishments that we're proud of
This was our first time using Cohere's embeddings feature and accurately analyzing the result to match the best file. We are also proud of being able to combine various different stacks and have a working application.
## What we learned
We learned a lot about NLP, how embeddings work, and what they can be used for. In addition, we learned how to problem solve and step out of our comfort zones to test new technologies.
## What's next for Code Flow
We plan on adding annotations for key sections of the code, possibly using a new UI so that the user can quickly understand important parts without wasting time. | ## Inspiration
During my last internship, I worked on an aging product with numerous security vulnerabilities, but identifying and fixing these issues was a major challenge. One of my key projects was to implement CodeQL scanning to better locate vulnerabilities. While setting up CodeQL wasn't overly complex, it became repetitive as I had to manually configure it for every repository, identifying languages and creating YAML files. Fixing the issues proved even more difficult as many of the vulnerabilities were obscure, requiring extensive research and troubleshooting. With that experience in mind, I wanted to create a tool that could automate this process, making code security more accessible and ultimately improving internet safety
## What it does
AutoLock automates the security of your GitHub repositories. First, you select a repository and hit install, which triggers a pull request with a GitHub Actions configuration to scan for vulnerabilities and perform AI-driven analysis. Next, you select which vulnerabilities to fix, and AutoLock opens another pull request with the necessary code modifications to address the issues.
## How I built it
I built AutoLock using Svelte for the frontend and Go for the backend. The backend leverages the Gin framework and Gorm ORM for smooth API interactions, while the frontend is powered by Svelte and styled using Flowbite.
## Challenges we ran into
One of the biggest challenges was navigating GitHub's app permissions. Understanding which permissions were needed and ensuring the app was correctly installed for both the user and their repositories took some time. Initially, I struggled to figure out why I couldn't access the repos even with the right permissions.
## Accomplishments that we're proud of
I'm incredibly proud of the scope of this project, especially since I developed it solo. The user interface is one of the best I've ever created—responsive, modern, and dynamic—all of which were challenges for me in the past. I'm also proud of the growth I experienced working with Go, as I had very little experience with it when I started.
## What we learned
While the unstable CalHacks WiFi made deployment tricky (basically impossible, terraform kept failing due to network issues 😅), I gained valuable knowledge about working with frontend component libraries, Go's Gin framework, and Gorm ORM. I also learned a lot about integrating with third-party services and navigating the complexities of their APIs.
## What's next for AutoLock
I see huge potential for AutoLock as a startup. There's a growing need for automated code security tools, and I believe AutoLock's ability to simplify the process could make it highly successful and beneficial for developers across the web. | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | partial |
## Inspiration 🔥
While on the way to CalHacks, we drove past a fire in Oakland Hills that had started just a few hours prior, meters away from I-580. Over the weekend, the fire quickly spread and ended up burning an area of 15 acres, damaging 2 homes and prompting 500 households to evacuate. This served as a harsh reminder that wildfires can and will start anywhere as long as few environmental conditions are met, and can have devastating effects on lives, property, and the environment.
*The following statistics are from the year 2020[1].*
**People:** Wildfires killed over 30 people in our home state of California. The pollution is set to shave off a year of life expectancy of CA residents in our most polluted counties if the trend continues.
**Property:** We sustained $19b in economic losses due to property damage.
**Environment:** Wildfires have made a significant impact on climate change. It was estimated that the smoke from CA wildfires made up 30% of the state’s greenhouse gas emissions. UChicago also found that “a single year of wildfire emissions is close to double emissions reductions achieved over 16 years.”
Right now (as of 10/20, 9:00AM): According to Cal Fire, there are 7 active wildfires that have scorched a total of approx. 120,000 acres.
[[1] - news.chicago.edu](https://news.uchicago.edu/story/wildfires-are-erasing-californias-climate-gains-research-shows)
## Our Solution: Canary 🐦🚨
Canary is an early wildfire detection system powered by an extensible, low-power, low-cost, low-maintenance sensor network solution. Each sensor in the network is placed in strategic locations in remote forest areas and records environmental data such as temperature and air quality, both of which can be used to detect fires. This data is forwarded through a WiFi link to a centrally-located satellite gateway computer. The gateway computer leverages a Monogoto Satellite NTN (graciously provided by Skylo) and receives all of the incoming sensor data from its local network, which is then relayed to a geostationary satellite. Back on Earth, we have a ground station dashboard that would be used by forest rangers and fire departments that receives the real-time sensor feed. Based on the locations and density of the sensors, we can effectively detect and localize a fire before it gets out of control.
## What Sets Canary Apart 💡
Current satellite-based solutions include Google’s FireSat and NASA’s GOES satellite network. These systems rely on high-quality **imagery** to localize the fires, quite literally a ‘top-down’ approach. Google claims it can detect a fire the size of a classroom and notify emergency services in 20 minutes on average, while GOES reports a latency of 3 hours or more. We believe these existing solutions are not effective enough to prevent the disasters that constantly disrupt the lives of California residents as the fires get too big or the latency is too high before we are able to do anything about it. To address these concerns, we propose our ‘bottom-up’ approach, where we can deploy sensor networks on a single forest or area level and then extend them with more sensors and gateway computers as needed.
## Technology Details 🖥️
Each node in the network is equipped with an Arduino 101 that reads from a Grove temperature sensor. This is wired to an ESP8266 that has a WiFi module to forward the sensor data to the central gateway computer wirelessly. The gateway computer, using the Monogoto board, relays all of the sensor data to the geostationary satellite. On the ground, we have a UDP server running in Google Cloud that receives packets from the satellite and is hooked up to a Streamlit dashboard for data visualization.
## Challenges and Lessons 🗻
There were two main challenges to this project.
**Hardware limitations:** Our team as a whole is not very experienced with hardware, and setting everything up and getting the different components to talk to each other was difficult. We went through 3 Raspberry Pis, a couple Arduinos, different types of sensors, and even had to fashion our own voltage divider before arriving at the final product. Although it was disheartening at times to deal with these constant failures, knowing that we persevered and stepped out of our comfort zones is fulfilling.
**Satellite communications:** The communication proved to be tricky due to inconsistent timing between sending and receiving the packages. We went through various socket ids and ports to see if there were any patterns to the delays. Through our thorough documentation of steps taken, we were eventually able to recognize a pattern in when the packages were being sent and modify our code accordingly.
## What’s Next for Canary 🛰️
As we get access to better sensors and gain more experience working with hardware components (especially PCB design), the reliability of our systems will improve. We ran into a fair amount of obstacles with the Monogoto board in particular, but as it was announced as a development kit only a week ago, we have full faith that it will only get better in the future. Our vision is to see Canary used by park services and fire departments in the most remote areas of our beautiful forest landscapes in which our satellite-powered sensor network can overcome the limitations of cellular communication and existing fire detection solutions. | ## Inspiration
The California wildfires have proven how deadly fires can be; the mere smoke from fireworks can set ablaze hundreds of acres. What starts as a few sparks can easily become the ignition for a fire capable of destroying homes and habitats. California is just one example; fires can be just as dangerous in other parts of the world, even if not as often.
Approximately 300,000 were affected by fires and 14 million people were affected by floods last year in the US alone. These numbers will continue to rise, due to issues such as climate change.
Preventative equipment and forecasting is only half of the solution; the other half is education. People should be able to navigate any situation they may encounter. However, there are inherent shortcomings in the traditional teaching approach, and our game -S.O.S. - looks to bridge that gap by mixing fun and education.
## What it does
S.O.S. is a first-person story mode game that allows the player to choose between two scenarios: a home fire, or a flooded car. Players will be presented with multiple options designed to either help get the player out of the situation unscathed or impede their escape. For example, players may choose between breaking open car windows in a flood or waiting inside for help, based on their experience and knowledge.
Through trial and error and "bulletin boards" of info gathered from national institutions, players will be able to learn about fire and flood safety. We hope to make learning safety rules fun and engaging, straying from conventional teaching methods to create an overall pleasant experience and ultimately, save lives.
## How we built it
The game was built using C#, Unity, and Blender. Some open resource models were downloaded and, if needed, textured in Blender. These models were then imported into Unity, which was then laid out using ProBuilder and ProGrids. Afterward, C# code was written using the built-in Visual Studio IDE of Unity.
## Challenges we ran into
Some challenges we ran into include learning how to use Unity and code in C# as well as texture models in Blender and Unity itself. We ran into problems such as models not having the right textures or the wrong UV maps, so one of our biggest challenges was troubleshooting all of these problems. Furthermore, the C# code proved to be a challenge, especially with buttons and the physics component of Unity. Time was the biggest challenge of all, forcing us to cut down on our initial idea.
## Accomplishments that we're proud of
There are many accomplishments we as a team are proud of in this hackathon. Overall, our group has become much more adept with 3D software and coding.
## What we learned
We expanded our knowledge of making games in Unity, coding in C#, and modeling in Blender.
## What's next for SOS; Saving Our Souls
Next, we plan to improve the appearance of our game. The maps, lighting, and animation could use some work. Furthermore, more scenarios can be added, such as a Covid-19 scenario which we had initially planned. | ## Inspiration
Gamified social enterprise
## What it does
Free walking tour on your mobile device
## How I built it
Initially made a web app, after idea testing went with pure end user experience on mobile native.
## Challenges I ran into
Navigating Android Studio (Beginner) - registering with auth while adding to the realtime database simultaneously while still getting the correct UID.
Uploading it to this 35mb size limit submission. Couldn't get the APK out in time :P (not fully functional anyways)
## Accomplishments that I'm proud of
Idea testing
## What I learned
People don't like stickers
## What's next for stampii
A bit more market research, try and launch? | winning |
## Inspiration
1.3 billion People have some sort of vision impairment. They face difficulties in simple day to day task like reading, recognizing faces, objects, etc. Despite the huge number surprisingly there are only a few devices in the market to aid them, which can be hard on the pocket (5000$ - 10000$!!). These devices essentially just magnify the images and only help those with mild to moderate impairment. There is no product in circulation for those who are completely blind.
## What it does
The Third Eye brings a plethora of features at just 5% the cost. We set our minds to come up with a device that provides much more than just a sense of sight and most importantly is affordable to all. We see this product as an edge cutting technology for futuristic development of Assistive technologies.
## Feature List
**Guidance** - ***Uses haptic feedback to navigate the user to the room they choose avoiding all obstacles***. In fact, it's a soothing robotic head massage guiding you through the obstacles around you. Believe me, you're going to love it.
**Home Automation** - ***Provides full control over all house appliances***. With our device, you can just call out **Alexa** or even using the mobile app and tell it to switch off those appliances directly from the bed now.
**Face Recognition** - Recognize friends (even their emotions (P.S: Thanks to **Cloud Vision's** accurate facial recognitions!). Found someone new? Don't worry, on your command, we register their face in our database to ensure the next meeting is no more anonymous and awkward!
**Event Description** - ***Describes the activity taking place***. A group of people waving somewhere and you still not sure what's going on next to you? Fear not, we have made this device very much alive as this specific feature gives speech feedback describing the scenic beauty around you. [Thanks to **Microsoft Azure API**]
**Read Up** - You don't need to spend some extra bucks for blind based products like braille devices. Whether it be general printed text or a handwritten note. With the help of **Google Cloud Vision**, we got you covered from both ends. **Read up** not only decodes the text from the image but using **Google text to speech**, we also convert the decoded data into a speech so that the blind person won't face any difficulty reading any kind of books or notes they want.
**Object Locator** - Okay, so whether we are blind or not, we all have this bad habit of misplacing things. Even with the two eyes, sometimes it's too much pain to find the misplaced things in our rooms. And so, we have added the feature of locating most generic objects within the camera frame with its approximate location. You can either ask for a specific object which you're looking for or just get the feedback of all the objects **Google Cloud Vision** has found for you.
**Text-a-Friend** - In the world full of virtuality and social media, we can be pushed back if we don't have access to the fully connected online world. Typing could be difficult at times if you have vision issues and so using **Twilio API** now you can easily send text messages to saved contacts.
**SOS** - Okay, so I am in an emergency, but I can't find and trigger the SOS feature!? Again, thanks to the **Twilio** messaging and phone call services, with the help of our image and sensor data, now any blind person can ***Quickly intimate the authorities of the emergency along with their GPS location***. (This includes auto-detection of hazards too)
**EZ Shoppe** - It's not an easy job for a blind person to access ATMs or perform monetary transactions independently. And so, taking this into consideration, with the help of superbly designed **Capital One Hackathon API**, we have created a **server-based blockchain** transaction system which adds ease to your shopping without being worried about anything. Currently, the server integrated module supports **customer addition, account addition, person to person transactions, merchant transactions, balance check and info, withdrawals and secure payment to vendors**. No need of worrying about individual items, just with one QR scan, your entire shopping list is generated along with the vendor information and the total billing amount.
**What's up Doc** - Monitoring heart pulse rate and using online datasets, we devised a machine learning algorithm and classified labels which tells about the person's health. These labels include: "Athletic", "Excellent", 'Good", "Above Average", "Average", "Below Average" and "Poor". The function takes age, heart rate, and gender as an argument and performs the computation to provide you with the best current condition of your heart pulse rate.
\*All features above can be triggered from Phone via voice, Alexa echo dot and even the wearable itself.
\*\*Output information is relayed via headphones and Alexa.
## How we built it
Retrofit Devices (NodeMCU) fit behind switchboards and allow them to be controlled remotely.
The **RSSI guidance uses Wi-Fi signal intensity** to triangulate its position. Ultrasonic sensor and camera detects obstacles (**OpenCV**) and runs Left and Right haptic motors according to closeness to device and position of the obstacle.
We used **dlib computer vision library** to record and extract features to perform **facial recognition**.
**Microsoft Azure Cloud services** takes a series of images to describe the activity taking place.
We used **Optical Character Recognition (Google Cloud)** for Text To Speech Output.
We used **Google Cloud Vision** which classifies and locates the object.
**Twilio API** sends the alert using GPS from Phone when a hazard is detected by the **Google Cloud Vision API**.
QR Scanner scans the QR Code and uses **Capital One API** to make secure and fast transactions in a **BlockChain Network**.
Pulse Sensor data is taken and sent to the server where it is analysed using ML models from **AWS SageMaker** to make the health predictions.
## Challenges we ran into
Making individual modules was a bit easier but integrating them all together into one hardware (Raspberry Pi) and getting them to work was something really challenging to us.
## Accomplishments that we're proud of
The number of features we successfully integrated to prototype level.
## What we learned
We learned to trust in ourselves and our teammates and that when we do that there's nothing we can't accomplish.
## What's next for The Third Eye
Adding a personal assistant to up the game and so much more.
Every person has potential they deserve to unleash; we pledge to level the playfield by taking this initiative forward and strongly urge you to help us in this undertaking. | ## Inspiration
Students are often put into a position where they do not have the time nor experience to effectively budget their finances. This unfortunately leads to many students falling into debt, and having a difficult time keeping up with their finances. That's where wiSpend comes to the rescue! Our objective is to allow students to make healthy financial choices and be aware of their spending behaviours.
## What it does
wiSpend is an Android application that analyses financial transactions of students and creates a predictive model of spending patterns. Our application requires no effort from the user to input their own information, as all bank transaction data is synced in real-time to the application. Our advanced financial analytics allow us to create effective budget plans tailored to each user, and to provide financial advice to help students stay on budget.
## How I built it
wiSpend is build using an Android application that makes REST requests to our hosted Flask server. This server periodically creates requests to the Plaid API to obtain financial information and processes the data. Plaid API allows us to access major financial institutions' users' banking data, including transactions, balances, assets & liabilities, and much more. We focused on analysing the credit and debit transaction data, and applied statistical analytics techniques in order to identify trends from the transaction data. Based on the analysed results, the server will determine what financial advice in form of a notification to send to the user at any given point of time.
## Challenges I ran into
Integration and creating our data processing algorithm.
## Accomplishments that I'm proud of
This was the first time we as a group successfully brought all our individual work on the project and successfully integrated them together! This is a huge accomplishment for us as the integration part is usually the blocking factor from a successful hackathon project.
## What I learned
Interfacing the Android and Web server was a huge challenge but it allowed us as developers to find clever solutions by overcoming encountered roadblocks and thereby developing our own skills.
## What's next for wiSpend
Our first next feature would be to build a sophist acted budgeting app to assist users in their budgeting needs. We also plan on creating a mobile UI that can provide even more insights to users in form of charts, graphs, and infographics, as well as further developing our web platform to create a seamless experience across devices. | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | partial |
## Inspiration
gitpizza was inspired by a late night development push and a bout of hunger. What if you could order a pizza without having to leave the comfort of your terminal?
## What it does
gitpizza is a CLI based on git which allows you to create a number of pizzas (branches), add toppings (files), configure your address and delivery info, and push your order straight to Pizza Hut.
## How I built it
Python is bread and butter of gitpizza, parsing the provided arguments and using selenium to automatically navigate through the Pizza Hut website.
## Challenges I ran into
Pizza Hut's website is mostly created with angular, meaning selenium would retrieve a barebones HTML page and it would later be dynamically populated with JavaScript. But selenium didn't see these changes, so finding elements by ids and such was impossible. That, along with the generic names and lack of ids in general on the website meant that my only solution was the physically move the mouse and click on pixel-perfect positions to add toppings and place the user's order.
## Accomplishments that I'm proud of
Just the amount of commands that gitpizza supports. `gitpizza init` to start a new order, `gitpizza checkout -b new-pizza` to create a second pizza, `gitpizza add --left pepperoni` to add pepperoni to only the left half of your pizza, and `gitpizza diff` to see the differences between each side of your pizza. Visit [the repository](https://github.com/Microsquad/gitpizza) for the full list of commands | ## Inspiration
There are very small but impactful ways to be eco-conscious 🌱 in your daily life, like using reusable bags, shopping at thrift stores, or carpooling. We know one thing for certain; people love rewards ✨. So we thought, how can we reward people for eco-conscious behaviour such as taking the bus or shopping at sustainable businesses?
We wanted a way to make eco-consciousness simple, cost-effective, rewarding, and accessible to everyone.
## What it does
Ecodes rewards you for every sustainable decision you make. Some examples are: shopping at sustainable partner businesses, taking the local transit, and eating at sustainable restaurants. Simply scanning an Ecode at these locations will allow you to claim EcoPoints that can be converted into discounts, coupons or gift cards to eco-conscious businesses. Ecodes also sends users text-based reminders when acting sustainably is especially convenient (ex. take the bus when the weather is unsafe for driving). Furthermore, sustainable businesses also get free advertising, so it's a win-win for both parties! See the demo [here](https://drive.google.com/file/d/1suT7tPila3rz4PSmoyl42G5gyAwrC_vu/view?usp=sharing).
## How we built it
We initially prototyped UI/UX using Figma, then built onto a React-Native frontend and a Flask backend. QR codes were generated for each business via python and detected using a camera access feature created in React-Native. We then moved on to use the OpenWeatherMaps API and the Twilio API in the backend to send users text-based eco-friendly reminders.
## Challenges we ran into
Implementing camera access into the app and actually scanning specific QR codes that corresponded to a unique business and number of EcoPoints was a challenge. We had to add these technical features to the front-end seamlessly without much effort from the user but also have it function correctly. But after all, there's nothing a little documentation can't solve! In the end, we were able to debug our code and successfully implement this key feature.
## Accomplishments that we're proud of
**Kemi** is proud that she learned how to implement new features such as camera access in React Native. 😙
**Akanksha** is proud that she learnt Flask and interfacing with Google Maps APIs in python. 😁
**Vaisnavi** is proud that she was able to generate multiple QR codes in python, each with a unique function. 😝
**Anna** is proud to create the logistics behind the project and learnt about frontend and backend development. 😎
Everyone was super open to working together as a team and helping one another out. As as a team, we learnt a lot from each other in a short amount of time, and the effort was worth it!
## What we learned
We took the challenge to learn new skills outside of our comfort zone, learning how to add impressive features to an app such as camera access, QR code scanning, counter updates, and aesthetic UI. Our final hack turned out to be better than we anticipated, and inspired us to develop impactful and immensely capable apps in the future :)
## What's next for Ecodes
Probably adding a location feature to send users text-based reminders to the user, informing them that an Ecode is nearby. We can use the Geolocation Google Maps API and Twilio API to implement this. Additionally, we hope to add a carpooling feature which enables users to earn points together by carpooling with one another!! | ## Inspiration
## What it does
## How we built it
* Notion API
* Send data to notion to display on dashboard of issues
* Using Zapier to assign nurses
## Challenges we ran into
* working with Notion API
## Accomplishments that we're proud of
* Getting database functions with Notion's API to work
## What we learned
## What's next for Jira4Hospitals
* coded front end
* integration with netlify | partial |
## Inspiration: As per the Stats provided by Annual Disability Statistics Compendium, 19,344,883 civilian veterans ages 18 years and over live in the community in 2013, of which 5,522,589 were individuals with disabilities . DAV - Disabled American Veterans organization has spent about $ 61.8 million to buy and operate vehicles to act as a transit service for veterans but the reach of this program is limited.
Following these stats we wanted to support Veterans with something more feasible and efficient.
## What it does: It is a web application that will serve as a common platform between DAV and Uber. Instead of spending a huge amount on buying cars the DAV instead pay Uber and Uber will then provide free rides to veterans. Any veteran can register with his Veteran ID and SSN. During the application process our Portal matches the details with DAV to prevent non-veterans from using this service. After registration, Veterans can request rides on our website, that uses Uber API and can commute free.
## How we built it: We used the following technologies:
Uber API ,Google Maps, Directions, and Geocoding APIs, WAMP as local server.
Boot-Strap to create website, php-MyAdmin to maintain SQL database and webpages are designed using HTML, CSS, Javascript, Python script etc.
## Challenges we ran into: Using Uber API effectively, by parsing through data and code to make javascript files that use the API endpoints. Also, Uber API has problematic network/server permission issues.
Another challenge was to figure out the misuse of this service by non-veterans. To save that, we created a dummy Database, where each Veteran-ID is associated with corresponding 4 digits SSN. The pair is matched when user registers for free Uber rides. For real-time application, the same data can be provided by DAV and that can be used to authenticate a Veteran.
## Accomplishments that we're proud of: Finishing the project well in time, almost 4 hours before. From a team of strangers, brainstorming ideas for hours and then have a finished product in less than 24 hours.
## What we learned: We learnt to use third party APIs and gained more experience in web-development.
## What's next for VeTransit: We plan to launch a smartphone app that will be developed for the same service.
It will also include Speech recognition. We will display location services for nearby hospitals and medical facilities based on veteran’s needs. Using APIs of online job providers, veterans will receive data on jobs.
To access the website, Please register as user first.
During that process, It will ask Veteran-ID and four digits of SSN.
The pair should match for successful registration.
Please use one of the following key pairs from our Dummy Data, to do that:
VET00104 0659
VET00105 0705
VET00106 0931
VET00107 0978
VET00108 0307
VET00109 0674 | ## Inspiration
A study recently done in the UK learned that 69% of people above the age of 65 lack the IT skills needed to use the internet. Our world's largest resource for information, communication, and so much more is shut off to such a large population. We realized that we can leverage artificial intelligence to simplify completing online tasks for senior citizens or people with disabilities. Thus, we decided to build a voice-powered web agent that can execute user requests (such as booking a flight or ordering an iPad).
## What it does
The first part of Companion is a conversation between the user and a voice AI agent in which the agent understands the user's request and asks follow up questions for specific details. After this call, the web agent generates a plan of attack and executes the task by navigating the to the appropriate website and typing in relevant search details/clicking buttons. While the agent is navigating the web, we stream the agent's actions to the user in real time, allowing the user to monitor how it is browsing/using the web. In addition, each user request is stored in a Pinecone database, to the agent has context about similar past user requests/preferences. The user can also see the live state of the web agent navigation on the app.
## How we built it
We developed Companion using a combination of modern web technologies and tools to create an accessible and user-friendly experience:
For the frontend, we used React, providing a responsive and interactive user interface. We utilized components for input fields, buttons, and real-time feedback to enhance usability as well as integrated VAPI, a voice recognition API, to enable voice commands, making it easier for users with accessibility needs. For the Backend we used Flask to handle API requests and manage the server-side logic. For web automation tasks we leveraged Selenium, allowing the agent to navigate websites and perform actions like filling forms and clicking buttons. We stored user interactions in a Pinecone database to maintain context and improve future interactions by learning user preferences over time, and the user can also view past flows. We hosted the application on a local server during development, with plans for cloud deployment to ensure scalability and accessibility. Thus, Companion can effectively assist users in navigating the web, particularly benefiting seniors and individuals with disabilities.
## Challenges we ran into
We ran into difficulties getting the agent to accurately complete each task. Getting it to take the right steps and always execute the task efficiently was a hard but fun problem. It was also challenging to prompt the voice agent such to effectively communicate with the user and understand their request.
## Accomplishments that we're proud of
Building a complete, end-to-end agentic flow that is able to navigate the web in real time. We think that this project is socially impactful and can make a difference for those with accessibility needs.
## What we learned
The small things that can make or break an AI agent such as the way we display memory, how we ask it to reflect, and what supplemental info we give it (images, annotations, etc.)
## What's next for Companion
Making it work without CSS selectors; training a model to highlight all the places the computer can click because certain buttons can be unreachable for Companion. | ## Inspiration
As university students and soon to be graduates, we understand the financial strain that comes along with being a student, especially in terms of commuting. Carpooling has been a long existing method of getting to a desired destination, but there are very few driving platforms that make the experience better for the carpool driver. Additionally, by encouraging more people to choose carpooling at a way of commuting, we hope to work towards more sustainable cities.
## What it does
FaceLyft is a web app that includes features that allow drivers to lock or unlock their car from their device, as well as request payments from riders through facial recognition. Facial recognition is also implemented as an account verification to make signing into your account secure yet effortless.
## How we built it
We used IBM Watson Visual Recognition as a way to recognize users from a live image; After which they can request money from riders in the carpool by taking a picture of them and calling our API that leverages the Interac E-transfer API. We utilized Firebase from the Google Cloud Platform and the SmartCar API to control the car. We built our own API using stdlib which collects information from Interac, IBM Watson, Firebase and SmartCar API's.
## Challenges we ran into
IBM Facial Recognition software isn't quite perfect and doesn't always accurately recognize the person in the images we send it. There were also many challenges that came up as we began to integrate several APIs together to build our own API in Standard Library. This was particularly tough when considering the flow for authenticating the SmartCar as it required a redirection of the url.
## Accomplishments that we're proud of
We successfully got all of our APIs to work together! (SmartCar API, Firebase, Watson, StdLib,Google Maps, and our own Standard Library layer). Other tough feats we accomplished was the entire webcam to image to API flow that wasn't trivial to design or implement.
## What's next for FaceLyft
While creating FaceLyft, we created a security API for requesting for payment via visual recognition. We believe that this API can be used in so many more scenarios than carpooling and hope we can expand this API into different user cases. | partial |
## Inspiration
Falls are the leading cause of injury and death among seniors in the US and cost over $60 billion in medical expenses every year. With every one in four seniors in the US experiencing a fall each year, attempts at prevention are badly needed and are currently implemented through careful monitoring and caregiving. However, in the age of COVID-19 (and even before), remote caregiving has been a difficult and time-consuming process: caregivers must either rely on updates given by the senior themselves or monitor a video camera or other device 24/7. Tracking day-to-day health and progress is nearly impossible, and maintaining and improving strength and mobility presents unique challenges.
Having personally experienced this exhausting process in the past, our team decided to create an all-in-one tool that helps prevent such devastating falls from happening and makes remote caregivers' lives easier.
## What it does
NoFall enables smart ambient activity monitoring, proactive risk assessments, a mobile alert system, and a web interface to tie everything together.
### **Ambient activity monitoring**
NoFall continuously watches and updates caregivers with the condition of their patient through an online dashboard. The activity section of the dashboard provides the following information:
* Current action: sitting, standing, not in area, fallen, etc.
* How many times the patient drank water and took their medicine
* Graph of activity throughout the day, annotated with key events
* Histogram of stand-ups per hour
* Daily activity goals and progress score
* Alerts for key events
### **Proactive risk assessment**
Using the powerful tools offered by Google Cloud, a proactive risk assessment can be activated with a simple voice query to a smart speaker like Google Home. When starting an assessment, our algorithms begin analyzing the user's movements against a standardized medical testing protocol for screening a patient's risk of falling. The screening consists of two tasks:
1. Timed Up-and-Go (TUG) test. The user is asked to sit up from a chair and walk 10 feet. The user is timed, and the timer stops when 10 feet has been walked. If the user completes this task in over 12 seconds, the user is said to be of at a high risk of falling.
2. 30-second Chair Stand test: The user is asked to stand up and sit down on a chair repeatedly, as fast as they can, for 30 seconds. If the user not is able to sit down more than 12 times (for females) and 14 times (for males), they are considered to be at a high risk of falling.
The videos of the tests are recorded and can be rewatched on the dashboard. The caregiver can also view the results of tests in the dashboard in a graph as a function of time.
### **Mobile alert system**
When the user is in a fallen state, a warning message is displayed in the dashboard and texted using SMS to the assigned caregiver's phone.
## How we built it
### **Frontend**
The frontend was built using React and styled using TailwindCSS. All data is updated from Firestore in real time using listeners, and new activity and assessment goals are also instantly saved to the cloud.
Alerts are also instantly delivered to the web dashboard and caretakers' phones using IFTTT's SMS Action.
We created voice assistant functionality through Amazon Alexa skills and Google home routines. A voice command triggers an IFTTT webhook, which posts to our Flask backend API and starts risk assessments.
### **Backend**
**Model determination and validation**
To determine the pose of the user, we utilized Google's MediaPipe library in Python. We decided to use the BlazePose model, which is lightweight and can run on real-time security camera footage. The BlazePose model is able to determine the pixel location of 33 landmarks of the body, corresponding to the hips, shoulders, arms, face, etc. given a 2D picture of interest. We connected the real-time streaming from the security camera footage to continuously feed frames into the BlazePose model. Our testing confirmed the ability of the model to determine landmarks despite occlusion and different angles, which would be commonplace when used on real security camera footage.
**Ambient sitting, standing, and falling detection**
To determine if the user is sitting or standing, we calculated the angle that the knees make with the hips and set a threshold, where angles (measured from the horizontal) less than that number are considered sitting. To account for the angle where the user is directly facing the camera, we also determined the ratio of the hip-to knee length to the hip-to-shoulder length, reasoning that the 2D landmarks of the knees would be closer to the body when the user is sitting. To determine the fallen status, we determined if the center of the shoulders and the center of the knees made an angle less than 45 degrees for over 20 frames at once. If the legs made an angle greater than a certain threshold (close to 90 degrees), we considered the user to be standing. Lastly, if there was no detection of landmarks, we considered the status to be unknown (the user may have left the room/area). Because of the different possible angles of the camera, we also determined the perspective of the camera based on the convergence of straight lines (the straight lines are determined by a Hough transformation algorithm). The convergence can indicate how angled the camera is, and the thresholds for the ratio of lengths can be mathematically transformed accordingly.
**Proactive risk assessment analysis**
To analyze timed up-and-go tests, we first determined if the user is able to change his or her status from sitting to standing, and then determined the distance the user has traveled by determining the speed from finite difference calculation of the velocity from the previous frame. The pixel distance was then transformed based on the distance between the user's eyes and the height of the user (which is pre-entered in our website) to determine the real-world distance the user has traveled. Once the user reaches 10 meters cumulative distance traveled, the timer stops and is reported to the server.
To analyze 30-second chair stand tests, the number of transitions between sitting and standing were counted. Once 30 seconds has been reached, the number of times the user sat down is half of the number of transitions, and the data is sent to the server.
## Challenges we ran into
* Figuring out port forwarding with barebones IP camera, then streaming the video to the world wide web for consumption by our model.
* Calibrating the tests (time limits, excessive movements) to follow the standards outlined by research. We had to come up with a way to mitigate random errors that could trigger fast changes in sitting and standing.
* Converting recorded videos to a web-compatible format. The videos saved by python's video recording package was only compatible with saving .avi videos, which was not compatible with the web. We had to use scripted ffmpeg to dynamically convert the videos into .mp4
* Live streaming the processed Python video to the front end required processing frames with ffmpeg and a custom streaming endpoint.
* Determination of a model that works on realtime security camera data: we tried Openpose, Posenet, tf-pose-estimation, and other models, but finally we found that MediaPipe was the only model that could fit our needs
## Accomplishments that we're proud of
* Making the model ignore the noisy background, bad quality video stream, dim lighting
* Fluid communication from backend to frontend with live updating data
* Great team communication and separation of tasks
## What we learned
* How to use IoT to simplify and streamline end-user processes.
* How to use computer vision models to analyze pose and velocity from a reference length
* How to display data in accessible, engaging, and intuitive formats
## What's next for NoFall
We're proud of all the features we have implemented with NoFall and are eager to implement more. In the future, we hope to generalize to more camera angles (such as a bird's-eye view), support lower-light and infrared ambient activity tracking, enable obstacle detection, monitor for signs of other conditions (heart attack, stroke, etc.) and detect more therapeutic tasks, such as daily cognitive puzzles for fighting dementia. | ## \*\* Internet of Things 4 Diabetic Patient Care \*\*
## The Story Behind Our Device
One team member, from his foot doctor, heard of a story of a diabetic patient who almost lost his foot due to an untreated foot infection after stepping on a foreign object. Another team member came across a competitive shooter who had his lower leg amputated after an untreated foot ulcer resulted in gangrene.
A symptom in diabetic patients is diabetic nephropathy which results in loss of sensation in the extremities. This means a cut or a blister on a foot often goes unnoticed and untreated.
Occasionally, these small cuts or blisters don't heal properly due to poor blood circulation, which exacerbates the problem and leads to further complications. These further complications can result in serious infection and possibly amputation.
We decided to make a device that helped combat this problem. We invented IoT4DPC, a device that detects abnormal muscle activity caused by either stepping on potentially dangerous objects or caused by inflammation due to swelling.
## The technology behind it
A muscle sensor attaches to the Nucleo-L496ZG board that feeds data to a Azure IoT Hub. The IoT Hub, through Trillo, can notify the patient (or a physician, depending on the situation) via SMS that a problem has occurred, and the patient needs to get their feet checked or come in to see the doctor.
## Challenges
While the team was successful in prototyping data aquisition with an Arduino, we were unable to build a working prototype with the Nucleo board. We also came across serious hurdles with uploading any sensible data to the Azure IoTHub.
## What we did accomplish
We were able to set up an Azure IoT Hub and connect the Nucleo board to send JSON packages. We were also able to aquire test data in an excel file via the Arduino | ## Inspiration
Poor Economics by Abhijit Banerjee and Esther Duflo
## What it does
Uses blockchain technology to build a consumer-centric peer-to-peer insurance system.
## How I built it
Solidity, Flask, React, MongoDB
## Challenges I ran into
Deploying solidity, integrating solidity contracts with the flask web app.
## Accomplishments that I'm proud of
Everything.
## What I learned
Solidity, building a web framework.
## What's next for DisasterVibes
Continuing to build this for other applications. Improve oracle making it more algorithmic, implement AI algorithms and such. | winning |
## Inspiration
Our inspiration came from our first year in University, as we all lived without our parents for the first time. We had to cook and buy groceries for ourselves while trying to manage the school on top of that. More often than not, we found that the food in our fridge or pantries would go bad, while we spent money on food from fast-food restaurants. In the end, we were all eating unhealthy food while spending a ton of money and wasting way too much food.
## What it does
iFridge helps you keep track of all the food you have at home. It has a built-in database of expiration dates of certain foods. Each food has a "type of food", "days to expire", "quantity", and "name" attribute. This helps the user sort their fridge items based on what they are looking for. It is also able to find recipes that match your ingredients or the foods that will expire first. It has a shopping list where you can see the food you have in a horizontal scroll. The vertical scroll on the page will show what you need to buy in a checklist format. The shopping list feature helps the user while they are shopping for groceries. No more wondering whether or not you have the ingredients for a recipe you just searched up, everything is all in one place. When the user checks a food off the list, it will ask for the quantity of the food and input it automatically into your fridge. Lastly, our input has a camera feature that allows the user scan their food into their fridge. The user can manually input it as well, however, we thought that providing a scanning function would be better.
## How we built it
We built our project using flutter dart. We built-in login authentication with the use of Firebase Authentication and connected each user's food to the Cloud Firestore database. We used google photo API to take pictures for our input and scan the items in the photo into the app.
## Challenges we ran into
A challenge we ran into was working with dart streams specifically so that the stream only read the current user data and added only to the current user's database. Also learning about the different Widgets, Event Loops, Futures and Async that's unique to flutter and that are new concepts was challenging but lots of fun!
Another challenge we ran into was keeping track of whether the user was logged in or not. Depending on if there is an account active, the app must display different widgets to accommodate the needs of the user. This required the use of Streams to track the activity of the user.
We weren't familiar with git either. So, in the beginning, a lot of work was lost because of merging problems.
## Accomplishments that we're proud of
We are so proud to have a physical app that allows users create accounts and input data. This was our first time using databases (we never heard of firebase before today) and our first time using flutter. We’ve never even used github before to push and pull files. The google photo API was an enormous challenge as this was also a first for us.
## What we learned
We learned a lot about flutter dart and how it works, how to implement google photo APIs, and how to access and rewrite information in a database.
## What's next for iFridge
There are many features that we want to implement. This includes a healthy eating tracker that helps the user analyze what food categories they need more of. Eventually, the recipes can also cater to the likes and dislikes of the user. We also want to implement a feature that allows the user to add all the ingredients they need (ones that aren't already in their fridge) into their shopping cart. Overall we want to make our app user friendly. We don't want to over-complicate the environment, however, we want our design to be efficient and accomplish any needs of the user. | ## Inspiration
Each year, over approximately 1.3 billion tonnes of produced food is wasted ever year, a startling statistic that we found to be truly unacceptable, especially for the 21st century. The impacts of such waste are wide spread, ranging from the millions of starving individuals around the world that could in theory have been fed with this food to the progression of global warming caused by the greenhouse gases released as a result of emissions from decaying food waste. Ultimately, the problem at hand was one that we wanted to fix using an application, which led us precisely to the idea of Cibus, an application that helps the common householder manage the food in their fridge with ease and minimize waste throughout the year.
## What it does
Essentially, our app works in two ways. First, the app uses image processing to take pictures of receipts and extract the information from it that we then further process in order to identify the food purchased and the amount of time till that particular food item will expire. This information is collectively stored in a dictionary that is specific to each user on the app. The second thing our app does is sort through the list of food items that a user has in their home and prioritize the foods that are closest to expiry. With this prioritized list, the app then suggests recipes that maximize the use of food that is about to expire so that as little of it goes to waste as possible once the user makes the recipes using the ingredients that are about to expire in their home.
## How we built it
We essentially split the project into front end and back end work. On the front end, we used iOS development in order to create the design for the app and sent requests to the back end for information that would create the information that needed to be displayed on the app itself. Then, on the backend, we used flask as well as Cloud9 for a development environment in order to compose the code necessary to help the app run. We incorporated image processing APIs as well as a recipe API in order to help our app accomplish the goals we set out for it. Furthermore, we were able to code our app such that individual accounts can be created within it and most of the functionalities of it were implemented here. We used Google Cloud Vision for OCR and Microsoft Azure for cognitive processing in order to implement a spell check in our app.
## Challenges we ran into
A lot of the challenges initially derived from identifying the scope of the program and how far we wanted to take the app. Ultimately, we were able to decide on an end goal and we began programming. Along the way, many road blocks occurred including how to integrate the backend seamlessly into the front end and more importantly, how to integrate the image processing API into the app. Our first attempts at the image processing API did not end as well as the API only allowed for one website to be searched at a time for at a time, when more were required to find instances of all of the food items necessary to plug into the app. We then turned to Google Cloud Vision, which worked well with the app and allowed us to identify the writing on receipts.
## Accomplishments that we're proud of
We are proud to report that the app works and that a user can accurately upload information onto the app and generate recipes that correspond to the items that are about to expire the soonest. Ultimately, we worked together well throughout the weekend and are proud of the final product.
## What we learned
We learnt that integrating image processing can be harder than initially expected, but manageable. Additionally, we learned how to program an app from front to back in a manner that blends harmoniously such that the app itself is solid on the interface and in calling information.
## What's next for Cibus
There remain a lot of functionalities that can be further optimized within the app, like number of foods with corresponding expiry dates in the database. Furthermore, we would in the future like the user to be able to take a picture of a food item and have it automatically upload the information on it to the app. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | losing |
## Inspiration
We recognized that many individuals are keen on embracing journaling as a habit, but hurdles like the "all or nothing" mindset often hinder their progress. The pressure to write extensively or perfectly every time can be overwhelming, deterring potential journalers. Consistency poses another challenge, with life's busy rhythm making it hard to maintain a daily writing routine. The common issue of forgetting to journal compounds the struggle, as people find it difficult to integrate this practice seamlessly into their day. Furthermore, the blank page can be intimidating, leaving many uncertain about what to write and causing them to abandon the idea altogether. In addressing these barriers, our aim with **Pawndr** is to make journaling an inviting, effortless, and supportive experience for everyone, encouraging a sustainable habit that fits naturally into daily life.
## What it does
**Pawndr** is a journaling app that connects with you through text and voice. You will receive conversational prompts delivered to their phone, sparking meaningful reflections wherever you are and making journaling more accessible and fun. Simply reply to our friendly messages with your thoughts or responses to our prompts, and watch your personal journey unfold. Your memories are safely stored, easy accessible through our web app, and beautifully organized. **Pawndr** is able to transform your daily moments into a rich tapestry of self-discovery.
## How we built it
The front-end was built using react.js. We built the backend using FastAPI, and used MongoDB as our database. We deployed our web application and API to a Google Cloud VM using nginx and uvicorn. We utilized Infobip to build our primary user interaction method. Finally, we made use of OpenAI's GPT 3 and Whisper APIs to power organic journaling conversations.
## Challenges we ran into
Our user stories required us to use 10 digit phone numbers for SMS messaging via Infobip. However, Canadian regulations blocked any live messages we sent using the Infobip API. Unfortunately, this was a niche problem that the sponsor reps could not help us with (we still really appreciate all of their help and support!! <3), so we pivoted to a WhatsApp interface instead.
## Accomplishments that we're proud of
We are proud of being able to quickly problem-solve and pivot to a WhatsApp interface upon the SMS difficulties. We are also proud of being able to integrate our project into an end-to-end working demo, allowing hackathon participants to experience our project vision.
## What we learned
We learned how to deploy a web app to a cloud VM using nginx. We also learned how to use Infobip to interface with WhatsApp business and SMS. We learned about the various benefits of journaling, the common barriers to journaling, and how to make journaling rewarding, effortless, and accessible to users.
## What's next for Pawndr
We want to implement more channels to allow our users to use any platform of their choice to journal with us (SMS, Messenger, WhatsApp, WeChat, etc.). We also hope to have more comprehensive sentiment analysis visualization, including plots of mood trends over time. | View the SlideDeck for this project at: [slides](https://docs.google.com/presentation/d/1G1M9v0Vk2-tAhulnirHIsoivKq3WK7E2tx3RZW12Zas/edit?usp=sharing)
## Inspiration / Why
It is no surprise that mental health has been a prevailing issue in modern society. 16.2 million adults in the US and 300 million people in the world have depression according to the World Health Organization. Nearly 50 percent of all people diagnosed with depression are also diagnosed with anxiety. Furthermore, anxiety and depression rates are a rising issue among the teenage and adolescent population. About 20 percent of all teens experience depression before they reach adulthood, and only 30 percent of depressed teens are being treated for it.
To help battle for mental well-being within this space, we created DearAI. Since many teenagers do not actively seek out support for potential mental health issues (either due to financial or personal reasons), we want to find a way to inform teens about their emotions using machine learning and NLP and recommend to them activities designed to improve their well-being.
## Our Product:
To help us achieve this goal, we wanted to create an app that integrated journaling, a great way for users to input and track their emotions over time. Journaling has been shown to reduce stress, improve immune function, boost mood, and strengthen emotional functions. Journaling apps already exist, however, our app performs sentiment analysis on the user entries to help users be aware of and keep track of their emotions over time.
Furthermore, every time a user inputs an entry, we want to recommend the user something that will lighten up their day if they are having a bad day, or something that will keep their day strong if they are having a good day. As a result, if the natural language processing results return a negative sentiment like fear or sadness, we will recommend a variety of prescriptions from meditation, which has shown to decrease anxiety and depression, to cat videos on Youtube. We currently also recommend dining options and can expand these recommendations to other activities such as outdoors activities (i.e. hiking, climbing) or movies.
**We want to improve the mental well-being and lifestyle of our users through machine learning and journaling.This is why we created DearAI.**
## Implementation / How
Research has found that ML/AI can detect the emotions of a user better than the user themself can. As a result, we leveraged the power of IBM Watson’s NLP algorithms to extract the sentiments within a user’s textual journal entries. With the user’s emotions now quantified, DearAI then makes recommendations to either improve or strengthen the user’s current state of mind. The program makes a series of requests to various API endpoints, and we explored many APIs including Yelp, Spotify, OMDb, and Youtube. Their databases have been integrated and this has allowed us to curate the content of the recommendation based on the user’s specific emotion, because not all forms of entertainment are relevant to all emotions.
For example, the detection of sadness could result in recommendations ranging from guided meditation to comedy. Each journal entry is also saved so that users can monitor the development of their emotions over time.
## Future
There are a considerable amount of features that we did not have the opportunity to implement that we believe would have improved the app experience. In the future, we would like to include video and audio recording so that the user can feel more natural speaking their thoughts and also so that we can use computer vision analysis on the video to help us more accurately determine users’ emotions. Also, we would like to integrate a recommendation system via reinforcement learning by having the user input whether our recommendations improved their mood or not, so that we can more accurately prescribe recommendations as well. Lastly, we can also expand the APIs we use to allow for more recommendations. | # Journally - A journal entry a day. All through text.
## Welcome to Journally! Where we restore our memories one journal, one day at a time.
## Inspiration and What it Does
With everyone returning to their busy lives of work, commuting, school, and other commitments, people need an opportunity to restore their peace of mind. Journalling has been shown to improve mental health and can help restore memories, so that you don't get too caught up in the minutiae of life and can instead appreciate the big picture. *Journally* encourages you to quickly and easily record a daily journal entry - it's all done through text!
*Journally* sends you a daily text message reminder and then you simply reply back with whatever you want to record about your day. Your journal entries are available to view through the Journally website later, for whenever you want to take a walk down memory lane.
## Challenges and Major Accomplishments
This was the first full-stack project that either of us has completed, so there was definitely a lot of learning involved. In particular, integrating the many different servers was difficult -- Python Flask for sending and receiving text messages via the Twilio messaging API, a MySQL database, and the Node.js webserver. With so many complex parts, we were very proud of our ability to get it all running in under 24 hours! Moreover, we realized that this project was quite a bit for two people to complete. We weren't able to get everything to work perfectly, but at least we have a working product!
## What we learned
It was our first time working with API routings in Node.js and interacting with databases, so we learned a lot from that! We also learned how to work with Twilio's API using Flask. We had lots of fun sending ourselves a ton of test SMS messages.
## How we built it
* **Twilio** to send our registered users *daily* messages to Journal!
* Secure `MySQL` database to to store user registration info and their Journally entries
* `Flask` to *send* SMS from a user database of phone numbers
* `Flask` to *receive* SMS and store the user's Journallys into the database
* `Node.JS` for server routings, user registration on site, and storing user data into the database
* `Express.js` backend to host Journally
## Next Steps:
* allow simple markups like bolds in texts
* allow user to rate their day on a scale
* sort by scale feature
* Feel free to contribute!! Let's Journally together
# Check out our GitHub repo:
[GitHub](https://github.com/natalievolk/UofTHacks) | winning |
## Inspiration
Ironman
## What it does
Move and control mouse cursor
## How I built it
Using a Microsoft Kinect for Xbox360
## Challenges I ran into
Is getting the code to compile
## Accomplishments that I'm proud of
It works
## What I learned
Many things
## What's next for The Gesture Pointer
Implement the rest of the functionality of a real mouse (i.e. left button, scroll, click) | ## Inspiration
Throughout history, we've invented better and better ways of interfacing with machines. The **mouse**, the **VirtualBoy**, the **nub mouse thing** on ThinkPads. But we weren't satisfied with the current state of input devices. As computers become more and more personal and more and more a part of our daily lives, we need better, **more efficient** ways of interacting with them. One of the biggest inefficiencies in modern desktop computing is moving your hands from the keyboard to the track pad. So we got rid of that. Yup. Really.
Introducing **asdfghjkl** , a revolution in computer-human interface design patterns, by team "Keyboard as Trackpad".
[http://asdfghjkl.co](http://www.asdfghjkl.co)
## What it does
Hold down the *Control* key and run your finger across the keyboard. Watch as the mouse follows your commands. Marvel at the time you saved.
Hold down the *Shift* key and run your finger across the keyboard. Watch as the page scrolls under your command. Marvel at the time you saved.
## Challenges I ran into
Using my computer.
## Accomplishments that I'm proud of
Using my computer.
## What I learned
How to better use my computer.
## How I built it
After getting the MVP working, I exclusively used **asdfghjkl** for navigation and input while developing the app.
It's built in Swift 2.0 (for the easy C interoperability) and partially Obj-C for certain functions.
## What's next for **asdfghjkl**
Apple partnership is in the works. NASA partnership is going smoothly; soon the inhabitants of the ISS will be able to get more done, easier, thanks to mandatory **asdfghjkl** usage.
## Info
The correct way to pronounce **asdfghjkl** is "asdfghjkl". Please don't get it wrong. Additionally, the only way to type **asdfghjkl** is by sliding your finger across the entire home row. Just don't hold *Control*, or your mouse will fly to the right! | ## Inspiration
The inspiration for this project was a group-wide understanding that trying to scroll through a feed while your hands are dirty or in use is near impossible. We wanted to create a computer program to allow us to scroll through windows without coming into contact with the computer, for eating, chores, or any other time when you do not want to touch your computer. This idea evolved into moving the cursor around the screen and interacting with a computer window hands-free, making boring tasks, such as chores, more interesting and fun.
## What it does
HandsFree allows users to control their computer without touching it. By tilting their head, moving their nose, or opening their mouth, the user can control scrolling, clicking, and cursor movement. This allows users to use their device while doing other things with their hands, such as doing chores around the house. Because HandsFree gives users complete **touchless** control, they’re able to scroll through social media, like posts, and do other tasks on their device, even when their hands are full.
## How we built it
We used a DLib face feature tracking model to compare some parts of the face with others when the face moves around.
To determine whether the user was staring at the screen, we compared the distance from the edge of the left eye and the left edge of the face to the edge of the right eye and the right edge of the face. We noticed that one of the distances was noticeably bigger than the other when the user has a tilted head. Once the distance of one side was larger by a certain amount, the scroll feature was disabled, and the user would get a message saying "not looking at camera."
To determine which way and when to scroll the page, we compared the left edge of the face with the face's right edge. When the right edge was significantly higher than the left edge, then the page would scroll up. When the left edge was significantly higher than the right edge, the page would scroll down. If both edges had around the same Y coordinate, the page wouldn't scroll at all.
To determine the cursor movement, we tracked the tip of the nose. We created an adjustable bounding box in the center of the users' face (based on the average values of the edges of the face). Whenever the nose left the box, the cursor would move at a constant speed in the nose's position relative to the center.
To determine a click, we compared the top lip Y coordinate to the bottom lip Y coordinate. Whenever they moved apart by a certain distance, a click was activated.
To reset the program, the user can look away from the camera, so the user can't track a face anymore. This will reset the cursor to the middle of the screen.
For the GUI, we used Tkinter module, an interface to the Tk GUI toolkit in python, to generate the application's front-end interface. The tutorial site was built using simple HTML & CSS.
## Challenges we ran into
We ran into several problems while working on this project. For example, we had trouble developing a system of judging whether a face has changed enough to move the cursor or scroll through the screen, calibrating the system and movements for different faces, and users not telling whether their faces were balanced. It took a lot of time looking into various mathematical relationships between the different points of someone's face. Next, to handle the calibration, we ran large numbers of tests, using different faces, distances from the screen, and the face's angle to a screen. To counter the last challenge, we added a box feature to the window displaying the user's face to visualize the distance they need to move to move the cursor. We used the calibrating tests to come up with default values for this box, but we made customizable constants so users can set their boxes according to their preferences. Users can also customize the scroll speed and mouse movement speed to their own liking.
## Accomplishments that we're proud of
We are proud that we could create a finished product and expand on our idea *more* than what we had originally planned. Additionally, this project worked much better than expected and using it felt like a super power.
## What we learned
We learned how to use facial recognition libraries in Python, how they work, and how they’re implemented. For some of us, this was our first experience with OpenCV, so it was interesting to create something new on the spot. Additionally, we learned how to use many new python libraries, and some of us learned about Python class structures.
## What's next for HandsFree
The next step is getting this software on mobile. Of course, most users use social media on their phones, so porting this over to Android and iOS is the natural next step. This would reach a much wider audience, and allow for users to use this service across many different devices. Additionally, implementing this technology as a Chrome extension would make HandsFree more widely accessible. | losing |
## Inspiration
* My inspiration for this project is the tendency of medical facilities such as hospitals lacking in terms of technology, with this virtual automated HospQueue app, we will be saving more lives by saving more time for healthcare workers to focus on the more important tasks.
* Also amidst the global pandemic, managing the crowd has been one of the prime challenges of the government and various institutions. That is where HospQueue comes to the rescue. HospQueue is a webapp that allows you to join a queue virtually which leads to no gathering hence lesser people in hospitals that enables health workers to have the essentials handy.
* During the pandemic, we have all witnessed how patients in need have to wait in lines to get themselves treated. This led to people violating social distancing guidelines and giving the opportunity for the virus to spread further.
* I had an idea to implement HospQueue that would help hospitals to manage and check-in incoming patients smoothly.
## What it does
It saves time for healthcare workers as it takes away a task that is usually time-consuming. On HospQueue, you can check into your hospital on the app instead of in person. Essentially, you either don’t go to the hospital until it is your turn, or you stay into the car until you are next in line. This will not only make the check-in process for all hospitals easier and more convenient and safe but will also allow health care workers to focus on saving more people.
## How I built it
The frontend part was built using HTML and CSS. The backend was built using Flask and Postgresql as the database.
## Challenges I ran into
Some challenges I ran into were completing the database queries required for the system. I also had trouble with making the queue list work effectively. Hosting the website on Heroku was quite a challenge as well.
## Accomplishments that I'm proud of
I am glad to have implemented the idea of HospQueue that I thought of at the beginning of the hackathon. I made the real-time fetching and updating of the database successful.
## What I learned
* I learned how to fetch and update the database in real time.
* I learned how to deploy an app on Heroku using Heroku's Postgresql database.
## What's next for HospQueue
HospQueue will add and register hospitals so it is easier to manage. I also hope to integrate AI to make it easier for people to log in, maybe by simply scanning a QR code. Finally, I will also create a separate interface in which doctors can log in and see all the people in line instead of having to pull it from the program. | ## Inspiration
With the increase in Covid-19 cases, the healthcare sector has experienced a shortage of PPE supplies. Many hospitals have turned to the public for donations. However, people who are willing to donate may not know what items are needed, which hospitals need it urgently, or even how to donate.
## What it does
Corona Helping Hands is a real-time website that sources data directly from hospitals and ranks their needs based on bed capacity and urgency of necessary items. An interested donor can visit the website and see the hospitals in their area that are accepting donations, what specific items, and how to donate.
## How we built it
We built the donation web application using:
1) HTML/ CSS/ Bootstrap (Frontend Web Development)
2) Flask (Backend Web Development)
3) Python (Back-End Language)
## Challenges we ran into
We ran into issues getting integrating our map with the HTML page. Taking data and displaying it on the web application was not easy at first, but we were able to pull it off at the end.
## Accomplishments that we're proud of
None of us had a lot of experience in frontend web development, so that was challenging for all of us. However, we were able to complete a web application by the end of this hackathon which we are all proud of. We are also proud of creating a platform that can help users help hospitals in need and give them an easy way to figure out how to donate.
## What we learned
This was most of our first times working with web development, so we learned a lot on that aspect of the project. We also learned how to integrate an API with our project to show real-time data.
## What's next for Corona Helping Hands
We hope to further improve our web application by integrating data from across the nation. We would also like to further improve on the UI/UX of the app to enhance the user experience. | ## Inspiration
Inspired by the triangle challenge that suggests a more efficient way to communicate between patients, clinicians, doctors, and hospital records. We want to find a way to use Google vision APIs to scan patients' information and automatically update medical history and clinic wait lists.
## What it does
Uses APIs to scan documents such as OHIP and SIN cards in order to save patient information on a platform that also hosts hospital information, medical history of the patient (including hospital visits, prescriptions, etc.), and opportunities for doctors to manually update and add information on any patient in a place any other doctor can also access in the future when working with the patient in question.
## How I built it
Splitting the work up into a web app and a database, we used HTML, CSS, and Bootstrap to design the web app and MySQL to create a database of patients (their personal and medical information) and hospitals. We also began using Git to combine the components but that wasn't seen to the end.
## Challenges I ran into
Finding a way to transfer MySQL information to the web app was the most difficult part and the reason we couldn't finish in time. It also hindered our ability to begin the vision APIs.
## Accomplishments that I'm proud of
We had a teammate who attended his first hackathon this weekend and he learned a lot about building web apps!!
## What I learned
I learned how to use MySQL and how hard it is to use it with Node.JS (a mistake)
## What's next for Healthie
Get that ish running | partial |
## Inspiration
We wanted to build a sustainable project which gave us the idea to plant crops on a farmland in a way that would give the farmer the maximum profit. The program also accounts for crop rotation which means that the land gets time to replenish its nutrients and increase the quality of the soil.
## What it does
It does many things, It first checks what crops can be grown in that area or land depending on the weather of the area, the soil, the nutrients in the soil, the amount of precipitation, and much more information that we have got from the APIs that we have used in the project. It then forms a plan which accounts for the crop rotation process. This helps the land regain its lost nutrients while increasing the profits that the farmer is getting from his or her land. This means that without stopping the process of harvesting we are regaining the lost nutrients. It also gives the farmer daily updates on the weather in that area so that he can be prepared for severe weather.
## How we built it
For most of the backend of the program, we used Python.
For the front end of the website, we used HTML. To format the website we used CSS. we have also used Javascript for formates and to connect Python to HTML.
We used the API of Twilio in order to send daily messages to the user in order to help the user be ready for severe weather conditions.
## Challenges we ran into
The biggest challenge that we faced during the making of this project was the connection of the Python code with the HTML code. so that the website can display crop rotation patterns after executing the Python back end script.
## Accomplishments that we're proud of
While making this each of us in the group has accomplished a lot of things. This project as a whole was a great learning experience for all of us. We got to know a lot of things about the different APIs that we have used throughout the project. We also accomplished making predictions on which crops can be grown in an area depending on the weather of the area in the past years and what would be the best crop rotation patterns. On the whole, it was cool to see how the project went from data collection to processing to finally presentation.
## What we learned
We have learned a lot of things in the course of this hackathon. We learned team management and time management, Moreover, we got hands on experience in Machine Learning. We got to implement Linear Regression, Random decision trees, SVM models. Finally, using APIs became second nature to us because of the number of them we had to use to pull data.
## What's next for ECO-HARVEST
For now, the data we have is only limited to the United States, in the future we plan to increase it to the whole world and also increase our accuracy in predicting which crops can be grown in the area. Using the crops that we can grow in the area we want to give better crop rotation models so that the soil will gain its lost nutrients faster. We also plan to give better and more informative daily messages to the user in the future. | The Book Reading Bot (brb) programmatically flips through physical books, and using TTS reads the pages aloud. There are also options to download the pdf or audiobook.
I read an article on [The Spectator](http://columbiaspectator.com/) how some low-income students cannot afford textbooks, and actually spend time at the library manually scanning the books on their phones. I realized this was a perfect opportunity for technology to help people and eliminate repetitive tasks. All you do is click start on the web app and the software and hardware do the rest!
Another use case is for young children who do not know how to read yet. Using brb, they can read Dr. Seuss alone! As kids nowadays spend too much time on the television, I hope this might lure kids back to children books.
On a high level technical overview, the web app (bootstrap) sends an image to a flask server which uses ocr and tts. | ## Inspiration
Countries around the world suffer from famines due to irregular crop yields, and third-world countries are the most susceptible. Poor farming practices, including having low genetic variation, makes them susceptible to disease and widespread wipeouts of farms. We wanted to create a solution.
## What it does
We simulated randomly generated images that will be used to train the model for higher accuracy. It can detect if a potato leaf has blight(disease). Furthermore, it displays predictions for efficacy of antimicrobial peptides(cure) using bioinformatics.
## How we built it
We incorporated deep-learning classification and RFC algorithms to support our analytics and visualizations of our models.
## Challenges we ran into
This is everyone's first hackathon in our group, so we were very clueless in the beginning.
Trying to connect our models into a flask server to embed into our website was deemed very difficult.
## Accomplishments that we're proud of
The technologies are stuff we had to learn and implement in the past 24 hours. We're very proud of, we combined all of our past experiences to make something unique and interesting.
## What we learned
Bill - I was introduced to and learned how to make a website using html, javascript, and css.
Lee - I learned how to incorporate bio with data science to create analytics while having no prior coding experience.
Arvin - I learned deep-learning algorithms and how to classify images with AI.
## What's next for Disease in Plant Leaves / Antimicrobial Peptides
We plan to scale our application to include other plant leaves. Our algorithm can be tried with different plant data sets and should work the same. Therefore our prediction in antimicrobial peptides will be accurate for all cases. | winning |
## Inspiration
It currently costs the US $1.5 billion per year to run street lights. We thought that there had to be a way to reduce that cost and save electricity
## What it does
Smart City Lights is creating a smart street light that
## How we built it
We used TRCT 5000 ir sensors to detect the presence of activity. Each sensor were addressable and when a sensor was triggered, it would communicate in MQTT to another micro controller and update associated
## Challenges we ran into
We had a major block in progress when we had communication issues between our python code and arduino
## Accomplishments that we're proud of
Everyone's commitment to completing the work
## What we learned
Teamwork is key to success
## What's next for Smart City Lights
Data analytics as well as optimizing the process of processing addresses. | ## Inspiration
The Arduino community provides a full eco-system of developing systems, and I saw the potential in using hardware, IOT and cloud-integration to provide a unique solution for streamlining processes for business.
## What it does
The web-app provides the workflow for a one-stop place to manage hundreds of different sensors by incorporating intelligence to each utility provided by the Arduino REST API. Imagine a health-care company that would need to manage all its heart-rate sensors and derive insights quickly and continuously on patient data. Or picture a way for a business to manage customer device location parameters by inputting customized conditions on the data or parameters. Or a way for a child to control her robot-controlled coffee machine from school. This app provides many different possibilities for use-cases.
## How we built it
I connected iPhones to the Arduino cloud, and built a web-app with NodeJS that uses the Arduino IOT API to connect to the cloud, and connected MongoDB to make the app more efficient and scalable. I followed the CRM architecture to build the app, and implemented the best practices to keep scalability in mind, since it is the main focus of the app.
## Challenges we ran into
A lot of the problems faced were naturally in the web application, and it required a lot of time.
## Accomplishments that we're proud of
I are proud of the app and its usefulness in different contexts. This is a creative solution that could have real world uses if the intelligence is implemented carefully.
## What we learned
I learned a LOT about web development, database management and API integration.
## What's next for OrangeBanana
Provided we have more time, we would implement more sensors and more use-cases for handling each of these. | ## Inspiration
For the last 2^6 years, compilers have struggled with business models and monetization... but no more! With LLVZen you get the dual benefits of an added revenue stream, and an incentive for customers to simplify their code.
How does this magical mystery tool work? I'm so glad you asked. LLVZen hooks into the LLVM compiler toolchain and detects when one of your ~~idiots~~ clients tries to compile a program with more than 5 functions. It pops up with a friendly error message and nulls out the results of all future function calls. Clients are then sternly requested to place money in an LLVM tip jar to continue compilation.
What kinds of problems would this solve?
**[THIS!](http://quellish.tumblr.com/post/126712999812/how-on-earth-the-facebook-ios-application-is-so)**
How do I install this gem?
Well, good question... ~~~watch this space~~~ | partial |
## Inspiration
Let's face it: Museums, parks, and exhibits need some work in this digital era. Why lean over to read a small plaque when you can get a summary and details by tagging exhibits with a portable device?
There is a solution for this of course: NFC tags are a fun modern technology, and they could be used to help people appreciate both modern and historic masterpieces. Also there's one on your chest right now!
## The Plan
Whenever a tour group, such as a student body, visits a museum, they can streamline their activities with our technology. When a member visits an exhibit, they can scan an NFC tag to get detailed information and receive a virtual collectible based on the artifact. The goal is to facilitate interaction amongst the museum patrons for collective appreciation of the culture. At any time, the members (or, as an option, group leaders only) will have access to a live slack feed of the interactions, keeping track of each other's whereabouts and learning.
## How it Works
When a user tags an exhibit with their device, the Android mobile app (built in Java) will send a request to the StdLib service (built in Node.js) that registers the action in our MongoDB database, and adds a public notification to the real-time feed on slack.
## The Hurdles and the Outcome
Our entire team was green to every technology we used, but our extensive experience and relentless dedication let us persevere. Along the way, we gained experience with deployment oriented web service development, and will put it towards our numerous future projects. Due to our work, we believe this technology could be a substantial improvement to the museum industry.
## Extensions
Our product can be easily tailored for ecotourism, business conferences, and even larger scale explorations (such as cities and campus). In addition, we are building extensions for geotags, collectibles, and information trading. | ## Inspiration
The impact of COVID-19 has had lasting effects on the way we interact and socialize with each other. Even when engulfed by bustling crowds and crowded classrooms, it can be hard to find our friends and the comfort of not being alone. Too many times have we grabbed lunch, coffee, or boba alone only to find out later that there was someone who was right next to us!
Inspired by our undevised use of Apple's FindMy feature, we wanted to create a cross-device platform that's actually designed for promoting interaction and social health!
## What it does
Bump! is a geolocation-based social networking platform that encourages and streamlines day-to-day interactions.
**The Map**
On the home map, you can see all your friends around you! By tapping on their icon, you can message them or even better, Bump! them.
If texting is like talking, you can think of a Bump! as a friendly wave. Just a friendly Bump! to let your friends know that you're there!
Your bestie cramming for a midterm at Mofitt? Bump! them for good luck!
Your roommate in the classroom above you? Bump! them to help them stay awake!
Your crush waiting in line for a boba? Make that two bobas! Bump! them.
**Built-in Chat**
Of course, Bump! comes with a built-in messaging chat feature!
**Add Your Friends**
Add your friends to allow them to see your location! Your unique settings and friends list are tied to the account that you register and log in with.
## How we built it
Using React Native and JavaScript, Bump! is built for both IOS and Android. For the Backend, we used MongoDB and Node.js. The project consisted of four major and distinct components.
**Geolocation Map**
For our geolocation map, we used the expo's geolocation library, which allowed us to cross-match the positional data of all the user's friends.
**User Authentication**
The user authentication proceeds was built using additional packages such as Passport.js, Jotai, and Bcrypt.js. Essentially, we wanted to store new users through registration and verify old users through login by searching them up in MongoDB, hashing and salting their password for registration using Bcrypt.js, and comparing their password hash to the existing hash in the database for login. We also used Passport.js to create Json Web Tokens, and Jotai to store user ID data globally in the front end.
**Routing and Web Sockets**
To keep track of user location data, friend lists, conversation logs, and notifications, we used MongoDB as our database and a node.js backend to save and access data from the database. While this worked for the majority of our use cases, using HTTP protocols for instant messaging proved to be too slow and clunky so we made the design choice to include WebSockets for client-client communication. Our architecture involved using the server as a WebSocket host that would receive all client communication but would filter messages so they would only be delivered to the intended recipient.
**Navigation and User Interface**:
For our UI, we wanted to focus on simplicity, cleanliness, and neutral aesthetics. After all, we felt that the Bump! the experience was really about the time spent with friends rather than on the app, so designed the UX such that Bump! is really easy to use.
## Challenges we ran into
To begin, package management and setup were fairly challenging. Since we've never done mobile development before, having to learn how to debug, structure, and develop our code was definitely tedious. In our project, we initially programmed our frontend and backend completely separately; integrating them both and working out the moving parts was really difficult and required everyone to teach each other how their part worked.
When building the instant messaging feature, we ran into several design hurdles; HTTP requests are only half-duplex, as they are designed with client initiation in mind. Thus, there is no elegant method for server-initiated client communication. Another challenge was that the server needed to act as the host for all WebSocket communication, resulting in the need to selectively filter and send received messages.
## Accomplishments that we're proud of
We're particularly proud of Bump! because we came in with limited or no mobile app development experience (in fact, this was the first hackathon for half the team). This project was definitely a huge learning experience for us; not only did we have to grind through tutorials, youtube videos, and a Stack Overflowing of tears, we also had to learn how to efficiently work together as a team. Moreover, we're also proud that we were not only able to build something that would make a positive impact in theory but a platform that we see ourselves actually using on a day-to-day basis. Lastly, despite setbacks and complications, we're super happy that we developed an end product that resembled our initial design.
## What we learned
In this project, we really had an opportunity to dive headfirst in mobile app development; specifically, learning all about React Native, JavaScript, and the unique challenges of implementing backend on mobile devices. We also learned how to delegate tasks more efficiently, and we also learned to give some big respect to front-end engineers!
## What's next for Bump!
**Deployment!**
We definitely plan on using the app with our extended friends, so the biggest next step for Bump! is polishing the rough edges and getting it on App Stores. To get Bump! production-ready, we're going to robustify the backend, as well as clean up the frontend for a smoother look.
**More Features!**
We also want to add some more functionality to Bump! Here are some of the ideas we had, let us know if there's any we missed!
* Adding friends with QR-code scanning
* Bump! leaderboards
* Status updates
* Siri! "Hey Siri, bump Emma!" | ## Inspiration
Over the past few years, the art of learning has been slowly reduced to a chore rather than something people look forward to. Perhaps it was a factor of the pandemic, or maybe it is indicative of a dwindling education system. However, we believe that learning should be an exciting journey and have a simple to follow path.
## What it does
As a result, we created TagTeam, a web application that uses natural language processing and optical character recognition libraries to tag users’ notes with whatever they write about, whether it be math, physics, or even history and then suggest further relevant readings.
## How we built it
The program pipeline works as follows:
Our flask backend stores and retrieves documents from a MongoDB atlas cluster to perform operations such as JWT authentication and object relational modelling
We interact with the google cloud vision and pipe the data from it to the Cohere and OpenAI APIs to do some cool NLP stuff
Then our React frontend simply fetches and posts data accordingly using Axios
Going in more depth about the APIs we used:
The google cloud vision API used confidence level based OCR to parse a base64 encoded image into a simple string
That string is then corrected using Cohere’s text correction model, and is then passed through two more xlarge model layers to classify and generate tags for the image
Finally, the corrected string is also asynchronously piped to the openAI davinci-003 model to give recommendation based on the content.
## Challenges we ran into
For majority of the team, this was our first hackathon and for some was even our first time trying web development. Resultantly, coordinating and delegating tasks was hard due to everyone's difference pace of completion. Also, Google Cloud authentication is a nightmare. Also, BSON data is a nightmare to work with. Also staying up until the next day was a nightmare.
## Accomplishments that we're proud of
"Completing" the project and overcoming whatever obstacles stood in our way.
## What we learned
A bit of everything, from how to design a REST API to how to manage stateful applications.
## What's next for TagTeam
We are planning on further polishing this app to be suitable for mass use and adding features we unfortunately did not have time to add, such as recommending courses/books and a friend system. | winning |
## Inspiration
In light of the election, we wanted to bring together the community by presenting political perspectives that are often ignored (by the polarized sides).
## What it does
It allows people to explore different political perspectives by first gathering data on their personal political perspective then presenting links to sources that may be novel to them or that may be used to extend their own ideas. The website demo (2nd link) is functional. Only abortion is functional at the moment. Enjoy (ALSO, the website AWS does NOT have Java pre-installed, which took up a lot of time for us to figure out. In fact, we went overtime BECAUSE Java wasn't installed).
## How we built it
We built it by analyzing texts through ConTEXT and parsing the data (one person focused on this), which would be taken in by a Java program to analyze the data. This would then be presented on html/css/javascript layout.
## Challenges we ran into
We initially wanted to work with RestFB and friend lists, but as a result of API update, we are no longer able to access too much information from Facebook. From there, we moved onto this current project
## Accomplishments that we're proud of
Three out of the four of us have not completed a hackathon before, so it was truly a rewarding experience to learn languages that we have never used before.
## What we learned
How to make pretty things from HTML/CSS/JavaScript, using ConTEXT, etc.
## What's next for Swing
Think of cool projects for the future, possibly think about using some hardware. | ## Inspiration
An informed electorate is as vital as the ballot itself in facilitating a true democracy. In this day and age, it is not a lack of information but rather an excess that threatens to take power away from the people. Finding the time to research all 19 Democratic nominee hopefuls to make a truly informed decision is a challenge for most, and out of convenience, many voters tend to rely on just a handful of major media outlets as the source of truth. This monopoly on information gives mass media considerable ability to project its biases onto the public opinion. The solution to this problem presents an opportunity to utilize technology for social good.
## What it does
InforME returns power to the people by leveraging Google Cloud’s Natural Language API to detect systematic biases across a large volume of articles pertinent to the 2020 Presidential Election from 8 major media sources, including ABC, CNN, Fox, Washington Post, and Associated Press. We accomplish this by scraping relevant and recent articles from a variety of online sources and using the Google Cloud NLP API to perform sentiment analysis on them. We then aggregate individual entity sentiments and statistical measures of linguistic salience in order to synthesize our data in a meaningful and convenient format for understanding and comparing the individual biases major media outlets hold towards or against each candidate.
## How we built it and Challenges we ran into
One of the many challenges we faced is learning the new technology. We dedicated ourselves to learning multiple GCP technologies throughout HackMIT from calling GCP API to serverless deployment. We employed Google NLP API to make sense of our huge data set scraped from major news outlets, Firebase real-time database to log data, and finally GCP App Engine for deployments of our web apps. Coming into the hackathon with little experience with GCP, we found the learning curve to be steep yet rewarding. This immersion in GCP technology renders us a deeper understanding of how different components of GCP work together, and how much potential GCP has for contributing to social good.
Another challenge we faced is how to represent the data in a visually meaningful way. Though we were able to generate a lot of insightful technical data, we chose to represent the data in a straightforward, easy-to-understand way without losing information or precision. It’s undoubtedly challenging to find the perfect balance between technicality and aesthetics, and our front-end design tackles this task of using technology for social good in an accessible way without compromising the complexity of current politics. Just as there’s no simple solution to current social problems, there’s no perfect way to contribute to social good. Despite this, InforME is an attempt to return power to the people, providing for a more just distribution of information and better informed electorate, a gateway to a society where information is open and accessible.
## What's next for InforME
Despite our progress, there is room for improvement. First, we can allow users to filter results by dates to better represent data in a more specific time range. We can also identify pressing issues or hot topics associated with each candidate via entity sentiment analysis. Moreover, with enough data, we can also build a graph of relationships between each candidates to better serve our audience. | ## Inspiration
We thought it would be nice if, for example, while working in the Computer Science building, you could send out a little post asking for help from people around you.
Also, it would also enable greater interconnectivity between people at an event without needing to subscribe to anything.
## What it does
Users create posts that are then attached to their location, complete with a picture and a description. Other people can then view it two ways.
**1)** On a map, with markers indicating the location of the post that can be tapped on for more detail.
**2)** As a live feed, with the details of all the posts that are in your current location.
The posts don't last long, however, and only posts within a certain radius are visible to you.
## How we built it
Individual pages were built using HTML, CSS and JS, which would then interact with a server built using Node.js and Express.js. The database, which used cockroachDB, was hosted with Amazon Web Services. We used PHP to upload images onto a separate private server. Finally, the app was packaged using Apache Cordova to be runnable on the phone. Heroku allowed us to upload the Node.js portion on the cloud.
## Challenges we ran into
Setting up and using CockroachDB was difficult because we were unfamiliar with it. We were also not used to using so many technologies at once. | losing |
## Inspiration
As victims, bystanders and perpetrators of cyberbullying, we felt it was necessary to focus our efforts this weekend on combating an issue that impacts 1 in 5 Canadian teens. As technology continues to advance, children are being exposed to vulgarities online at a much younger age than before.
## What it does
**Prof**(ani)**ty** searches through any webpage a child may access, censors black-listed words and replaces them with an appropriate emoji. This easy to install chrome extension is accessible for all institutional settings or even applicable home devices.
## How we built it
We built a Google chrome extension using JavaScript (JQuery), HTML, and CSS. We also used regular expressions to detect and replace profanities on webpages. The UI was developed with Sketch.
## Challenges we ran into
Every member of our team was a first-time hacker, with little web development experience. We learned how to use JavaScript and Sketch on the fly. We’re incredibly grateful for the mentors who supported us and guided us while we developed these new skills (shout out to Kush from Hootsuite)!
## Accomplishments that we're proud of
Learning how to make beautiful webpages.
Parsing specific keywords from HTML elements.
Learning how to use JavaScript, HTML, CSS and Sketch for the first time.
## What we learned
The manifest.json file is not to be messed with.
## What's next for PROFTY
Expand the size of our black-list.
Increase robustness so it parses pop-up messages as well, such as live-stream comments. | ## Inspiration
Fashion has always been a world that seemed far away from tech. We want to bridge this gap with "StyleList", which understands your fashion within a few swipes and makes personalized suggestions for your daily outfits. When you and I visit the Nordstorm website, we see the exact same product page. But we could have completely different styles and preferences. With Machine Intelligence, StyleList makes it convenient for people to figure out what they want to wear (you simply swipe!) and it also allows people to discover a trend that they favor!
## What it does
With StyleList, you don’t have to scroll through hundreds of images and filters and search on so many different websites to compare the clothes. Rather, you can enjoy a personalized shopping experience with a simple movement from your fingertip (a swipe!). StyleList shows you a few clothing items at a time. Like it? Swipe left. No? Swipe right! StyleList will learn your style and show you similar clothes to the ones you favored so you won't need to waste your time filtering clothes. If you find something you love and want to own, just click “Buy” and you’ll have access to the purchase page.
## How I built it
We use a web scrapper to get the clothing items information from Nordstrom.ca and then feed these data into our backend. Our backend is a Machine Learning model trained on the bank of keywords and it provides next items after a swipe based on the cosine similarities between the next items and the liked items. The interaction with the clothing items and the swipes is on our React frontend.
## Accomplishments that I'm proud of
Good teamwork! Connecting the backend, frontend and database took us more time than we expected but now we have a full stack project completed. (starting from scratch 36 hours ago!)
## What's next for StyleList
In the next steps, we want to help people who wonders "what should I wear today" in the morning with a simple one click page, where they fill in the weather and plan for the day then StyleList will provide a suggested outfit from head to toe! | <https://docs.google.com/presentation/d/17jLxtiNIFxF41xbQ_rubA5ijnvBGJ1RSAMUSMkTO91U/edit?usp=sharing>
## Inspiration
We became inspired after realizing the complexity of bias in media and the implicant bias people have when writing articles. We began the project by recognizing four major issues with bias in media:
* Media companies are motivated to create biased articles to attract attention
* Individuals introduce implicit biases unintentionally in their writing.
* People can waste time reading articles without knowing the biases contained within those articles beforehand.
* No standard API despite recent advances in natural language processing and cloud computing.
## What it does
To address the issues we identified, we began by creating a general-purpose API to identify the degree and sources of bias in long-form text input. We then tried to build several tools around the API to demonstrate what can be done, in hopes of encouraging others.
Sway helps identify bias in the media by providing a chrome extension. The extension provides a degree of bias and the cause of the bias (if any exists) for any website, all with the click of a button. Sway also offers a writing editor to identify bias in the text. Lastly, Sway offers a search interface to conduct research on unbiased resources. The search interface utilizes Google search and our bias detection to rank websites according to credibility.
## How we built it
We decided to build two microservices, along with a Chrome extension. We built the Chrome extension in HTML/CSS, and Javascript. The web platforms were built in React and Python. Our API for performing the text analysis was written in Python.
## Challenges we ran into
We had trouble finding training data to properly classify particles. As we overcame this issue the training data didn't give us the outputs we expected so we had to spend additional time fine-tuning our model. The biggest challenge we ran into was creating endpoints to properly connect the frontend and backend. The endpoints had to be rewritten as we had to narrow down the scope of some features and we decided to scale-up other features.
## Accomplishments that we're proud of
We built out three different platforms in a day! Sway also works extremely well and we're very happy with the performance. We had planned to only build the chrome extension but picked up good momentum and were able to add the two other platforms over the weekend!
## What's next for Sway
We want to market and develop our algorithm further to the point where we could commercially deploy it. One thing that's required to do is add significantly more training data! We would like to keep adding more features to our core product. We would like to provide more helpful insights to users, such as numerical scores across multiple categories of bias. | winning |
## Inspiration
Companies lack insight into their users, audiences, and marketing funnel.
This is an issue I've run into on many separate occasions. Specifically,
* while doing cold marketing outbound, need better insight onto key variables of successful outreach
* while writing a blog, I have no idea who reads it
* while triaging inbound, which users do I prioritize
Given a list of user emails, Cognito scrapes the internet finding public information about users and the companies they work at. With this corpus of unstructured data, Cognito allows you to extract any relevant piece of information across users. An unordered collection of text and images becomes structured data relevant to you.
## A Few Example Use Cases
* Startups going to market need to identify where their power users are and their defining attributes. We allow them to ask questions about their users, helping them define their niche and better focus outbound marketing.
* SaaS platforms such as Modal have trouble with abuse. They want to ensure people joining are not going to abuse it. We provide more data points to make better judgments such as taking into account how senior of a developer a user is and the types of companies they used to work at.
* VCs such as YC have emails from a bunch of prospective founders and highly talented individuals. Cognito would allow them to ask key questions such as what companies are people flocking to work at and who are the highest potential people in my network.
* Content creators such as authors on Substack looking to monetize their work have a much more compelling case when coming to advertisers with a good grasp on who their audience is.
## What it does
Given a list of user emails, we crawl the web, gather a corpus of relevant text data, and allow companies/creators/influencers/marketers to ask any question about their users/audience.
We store these data points and allow for advanced querying in natural language.
[video demo](https://www.loom.com/share/1c13be37e0f8419c81aa731c7b3085f0)
## How we built it
we orchestrated 3 ML models across 7 different tasks in 30 hours
* search results person info extraction
* custom field generation from scraped data
* company website details extraction
* facial recognition for age and gender
* NoSQL query generation from natural language
* crunchbase company summary extraction
* email extraction
This culminated in a full-stack web app with batch processing via async pubsub messaging. Deployed on GCP using Cloud Run, Cloud Functions, Cloud Storage, PubSub, Programmable Search, and Cloud Build.
## What we learned
* how to be really creative about scraping
* batch processing paradigms
* prompt engineering techniques
## What's next for Cognito
1. predictive modeling and classification using scraped data points
2. scrape more data
3. more advanced queries
4. proactive alerts
[video demo](https://www.loom.com/share/1c13be37e0f8419c81aa731c7b3085f0) | # see our presentation [here](https://docs.google.com/presentation/d/1AWFR0UEZ3NBi8W04uCgkNGMovDwHm_xRZ-3Zk3TC8-E/edit?usp=sharing)
## Inspiration
Without purchasing hardware, there are few ways to have contact-free interactions with your computer.
To make such technologies accessible to everyone, we created one of the first touch-less hardware-less means of computer control by employing machine learning and gesture analysis algorithms. Additionally, we wanted to make it as accessible as possible in order to reach a wide demographic of users and developers.
## What it does
Puppet uses machine learning technology such as k-means clustering in order to distinguish between different hand signs. Then, it interprets the hand-signs into computer inputs such as keys or mouse movements to allow the user to have full control without a physical keyboard or mouse.
## How we built it
Using OpenCV in order to capture the user's camera input and media-pipe to parse hand data, we could capture the relevant features of a user's hand. Once these features are extracted, they are fed into the k-means clustering algorithm (built with Sci-Kit Learn) to distinguish between different types of hand gestures. The hand gestures are then translated into specific computer commands which pair together AppleScript and PyAutoGUI to provide the user with the Puppet experience.
## Challenges we ran into
One major issue that we ran into was that in the first iteration of our k-means clustering algorithm the clusters were colliding. We fed into the model the distance of each on your hand from your wrist, and designed it to return the revenant gesture. Though we considered changing this to a coordinate-based system, we settled on changing the hand gestures to be more distinct with our current distance system. This was ultimately the best solution because it allowed us to keep a small model while increasing accuracy.
Mapping a finger position on camera to a point for the cursor on the screen was not as easy as expected. Because of inaccuracies in the hand detection among other things, the mouse was at first very shaky. Additionally, it was nearly impossible to reach the edges of the screen because your finger would not be detected near the edge of the camera's frame. In our Puppet implementation, we constantly *pursue* the desired cursor position instead of directly *tracking it* with the camera. Also, we scaled our coordinate system so it required less hand movement in order to reach the screen's edge.
## Accomplishments that we're proud of
We are proud of the gesture recognition model and motion algorithms we designed. We also take pride in the organization and execution of this project in such a short time.
## What we learned
A lot was discovered about the difficulties of utilizing hand gestures. From a data perspective, many of the gestures look very similar and it took us time to develop specific transformations, models and algorithms to parse our data into individual hand motions / signs.
Also, our team members possess diverse and separate skillsets in machine learning, mathematics and computer science. We can proudly say it required nearly all three of us to overcome any major issue presented. Because of this, we all leave here with a more advanced skillset in each of these areas and better continuity as a team.
## What's next for Puppet
Right now, Puppet can control presentations, the web, and your keyboard. In the future, puppet could control much more.
* Opportunities in education: Puppet provides a more interactive experience for controlling computers. This feature can be potentially utilized in elementary school classrooms to give kids hands-on learning with maps, science labs, and language.
* Opportunities in video games: As Puppet advances, it could provide game developers a way to create games wear the user interacts without a controller. Unlike technologies such as XBOX Kinect, it would require no additional hardware.
* Opportunities in virtual reality: Cheaper VR alternatives such as Google Cardboard could be paired with
Puppet to create a premium VR experience with at-home technology. This could be used in both examples described above.
* Opportunities in hospitals / public areas: People have been especially careful about avoiding germs lately. With Puppet, you won't need to touch any keyboard and mice shared by many doctors, providing a more sanitary way to use computers. | ## Inspiration
Going into UofThacks, we really wanted to work on a security/privacy related hack, and eventually brainstormed an idea for a location surveilling system based on MAC addresses in WiFi packets that seemed to fit the bill.
## What it does
Big Brother consists of a number (currently three) of Raspberry Pis, each with two network adapters, one of which is connected to the University of Toronto's student WiFi, and one of which is set to monitor mode and used by the Kismet packet sniffer to scan for as many 802.11 packets as possible. Packet data is set to a central Kismet server running on a VPS, which combines all the packet data into a single sqlite database.
A straightforward webapp can then be used to comb through the data, narrowing in on particular individuals (see images). Kismet reports the specific RPi that picked up each packet, which can be mapped to a location description (eg. Galbraith building lobby, Sanford Fleming Building Pit, etc.). This enables people's location to be tracked over time based on packets intercepted from their devices.
There are a variety of possible applications for Big Brother, from surveillance for law enforcement purposes, to location based targeted advertising. Our main goal in building it was to raise awareness of the fact that tracking individuals based on wireless devices they carry around is a relatively simple process, and doesn't require any of the target's devices to be compromised.
## Challenges we ran into
Getting the extra USB WiFi adapters to work comprised the bulk of the pain involved in this project, it was a long arduous process.
## What we learned
Just use Kali Linux, it has the WiFi dongle drivers pre-installed. | winning |
## Inspiration
This project was inspired by my love of walking. We all need more outdoor time, but people often feel like walking is pointless unless they have somewhere to go. I have fond memories of spending hours walking around just to play Pokemon Go, so I wanted to create something that would give people a reason to go somewhere new. I envision friends and family sending mystery locations to their loved ones with a secret message, picture, or video that will be revealed when they arrive. You could send them to a historical landmark, a beautiful park, or just like a neat rock you saw somewhere. The possibilities are endless!
## What it does
You want to go out for a walk, but where to? SparkWalk offers users their choice of exciting "mystery walks". Given a secret location, the app tells you which direction to go and roughly how long it will take. When you get close to your destination, the app welcomes you with a message. For now, SparkWalk has just a few preset messages and locations, but the ability for users to add their own and share them with others is coming soon.
## How we built it
SparkWalk was created using Expo for React Native. The map and location functionalities were implemented using the react-native-maps, expo-location, and geolib libraries.
## Challenges we ran into
Styling components for different devices is always tricky! Unfortunately, I didn't have time to ensure the styling works on every device, but it works well on at least one iOS and one Android device that I tested it on.
## Accomplishments that we're proud of
This is my first time using geolocation and integrating a map, so I'm proud that I was able to make it work.
## What we learned
I've learned a lot more about how to work with React Native, especially using state and effect hooks.
## What's next for SparkWalk
Next, I plan to add user authentication and the ability to add friends and send locations to each other. Users will be able to store messages for their friends that are tied to specific locations. I'll add a backend server and a database to host saved locations and messages. I also want to add reward cards for visiting locations that can be saved to the user's profile and reviewed later. Eventually, I'll publish the app so anyone can use it! | ## Inspiration
Social interaction with peers is harder than ever in our world today where everything is online. We wanted to create a setting that will mimic organic encounters the same way as if they would occur in real life -- in the very same places that you’re familiar with.
## What it does
Traverse a map of your familiar environment with an avatar, and experience random encounters like you would in real life! A Zoom call will initiate when two people bump into each other.
## Use Cases
Many students entering their first year at university have noted the difficulty in finding new friends because few people stick around after zoom classes, and with cameras off, it’s hard to even put a name to the face. And it's not just first years too - everybody is feeling the [impact](https://www.mcgill.ca/newsroom/channels/news/social-isolation-causing-psychological-distress-among-university-students-324910).
Our solution helps students meet potential new friends and reunite with old ones in a one-on-one setting in an environment reminiscent of the actual school campus.
Another place where organic communication is vital is in the workplace. [Studies](https://pyrus.com/en/blog/how-spontaneity-can-boost-productivity) have shown that random spontaneous meetings between co-workers can help to inspire new ideas and facilitate connections. With indefinite work from home, this simply doesn't happen anymore. Again, Bump fills this gap of organic conversation between co-workers by creating random happenstances for interaction - you can find out which of your co-workers also likes to hang out in the (virtual) coffee room!
## How we built it
Webapp built with Vue.js for the main structure, firebase backend
Video conferencing integrated with Zoom Web SDK. Original artwork was created with Illustrator and Procreate.
## Major Challenges
Major challenges included implementing the character-map interaction and implementing the queueing process for meetups based on which area of the map each person’s character was in across all instances of the Bump client. In the prototype, queueing is achieved by writing the user id of the waiting client in documents located at area-specific paths in the database and continuously polling for a partner, and dequeuing once that partner is found. This will be replaced with a more elegant implementation down the line.
## What's next for bump
* Auto-map generation: give our app the functionality to create a map with zones just by uploading a map or floor plan (using OCR and image recognition technologies)
* Porting it over to mobile: change arrow key input to touch for apps
* Schedule mode: automatically move your avatar around on the map, following your course schedule. This makes it more likely to bump into classmates in the gap between classes.
## Notes
This demo is a sample of BUMP for a single community - UBC. In the future, we plan on adding the ability for users to be part of multiple communities. Since our login authentication uses email addresses, these communities can be kept secure by only allowing @ubc.ca emails into the UBC community, for example. This ensures that you aren’t just meeting random strangers on the Internet - rather, you’re meeting the same people you would have met in person if COVID wasn’t around. | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | partial |
## Inspiration
As post secondary students, our mental health is directly affected. Constantly being overwhelmed with large amounts of work causes us to stress over these large loads, in turn resulting in our efforts and productivity to also decrease. A common occurrence we as students continuously endure is this notion that there is a relationship and cycle between mental health and productivity; when we are unproductive, it results in us stressing, which further results in unproductivity.
## What it does
Moodivity is a web application that improves productivity for users while guiding users to be more in tune with their mental health, as well as aware of their own mental well-being.
Users can create a profile, setting daily goals for themselves, and different activities linked to the work they will be doing. They can then start their daily work, timing themselves as they do so. Once they are finished for the day, they are prompted to record an audio log to reflect on the work done in the day.
These logs are transcribed and analyzed using powerful Machine Learning models, and saved to the database so that users can reflect later on days they did better, or worse, and how their sentiment reflected that.
## How we built it
***Backend and Frontend connected through REST API***
**Frontend**
* React
+ UI framework the application was written in
* JavaScript
+ Language the frontend was written in
* Redux
+ Library used for state management in React
* Redux-Sagas
+ Library used for asynchronous requests and complex state management
**Backend**
* Django
+ Backend framework the application was written in
* Python
+ Language the backend was written in
* Django Rest Framework
+ built in library to connect backend to frontend
* Google Cloud API
+ Speech To Text API for audio transcription
+ NLP Sentiment Analysis for mood analysis of transcription
+ Google Cloud Storage to store audio files recorded by users
**Database**
* PostgreSQL
+ used for data storage of Users, Logs, Profiles, etc.
## Challenges we ran into
Creating a full-stack application from the ground up was a huge challenge. In fact, we were almost unable to accomplish this. Luckily, with lots of motivation and some mentorship, we are comfortable with naming our application *full-stack*.
Additionally, many of our issues were niche and didn't have much documentation. For example, we spent a lot of time on figuring out how to send audio through HTTP requests and manipulating the request to be interpreted by Google-Cloud's APIs.
## Accomplishments that we're proud of
Many of our team members are unfamiliar with Django let alone Python. Being able to interact with the Google-Cloud APIs is an amazing accomplishment considering where we started from.
## What we learned
* How to integrate Google-Cloud's API into a full-stack application.
* Sending audio files over HTTP and interpreting them in Python.
* Using NLP to analyze text
* Transcribing audio through powerful Machine Learning Models
## What's next for Moodivity
The Moodivity team really wanted to implement visual statistics like graphs and calendars to really drive home visual trends between productivity and mental health. In a distant future, we would love to add a mobile app to make our tool more easily accessible for day to day use. Furthermore, the idea of email push notifications can make being productive and tracking mental health even easier. | ## Inspiration
During modern times, the idea underlying a facemask is simple--if more people wear them, less people will get sick. And while it holds true, this is an oversimplification: the number of lives saved is dependent not only on the quantity, but also on the quality of the masks which people wear (as evidenced by recent research by the CDC). However, due to an insufficient supply of N95 masks, healthcare workers are forced to wear cloth or surgical masks which both leak from the sides, increasing the risk of infection, and are arduous to breathe through for extended physical exertion.
## What it does
Maskus is the first mask bracket and fitter in one - custom-fitted and printed using accessible technology. It is designed to improve the baseline quality of facemasks around the world, with its first and most pressing use is for healthcare workers. The user starts taking a picture of their face through their computer/smartphone camera. We then generate an accurate 3D representation of the user's face and design a tight-fitting 3D printable mask bracket specifically tailored to the user's face contours. Within seconds, we can render the user's custom mask onto the user's face in augmented reality in realtime. The user can then either download their custom mask in a format ready for 3D printing, or set up software to print the mask automatically. We also have an Arduino Nano that alerts the user if the mask is secured properly, or letting them now it needs to be readjusted.
## How we built it
After the user visits the Maskus website, our React frontend sends a POST request to a Python Flask backend. The server receives the image, decodes it, and feeds it into a state of the art machine learning 3D face reconstruction model (3DDFA). The resultant 3D face model then goes through some preprocessing, which compresses the 3D data to improve performance. Another script then extracts the user's face contour/outline from the 3D model and builds a custom mask bracket with programmable CAD software. On the web app, the user gets to see both their own 3D face mesh as well as an AR rendering of the custom fitted mask onto their face (using React and three.js). Lastly, this data is saved to a standard 3D printing file format (.obj) and returned to the user so they can print it wherever they like. In terms of our hardware, the mask's alert system comprises of an Arduino Nano with a piezo buzzer and two push buttons (left and right side of face) wired in series. In order to get the push buttons to engage when the mask is worn, we created custom 3D parts that create a larger area for the buttons to be pushed.
## Challenges we ran into
This project was touched many disciplines, and posed many difficulties. We were determined to provide the user with the ability to see how their mask would fit them in real time using AR. In order to do this, we needed a way to visualize 3D models in the web. This proved difficult due to many misleading resources and weak documentation. Simple things (like figuring out how to get a 3D model to stop rotating) took much longer than they should have, simply because the frameworks were obfuscated. AR was also very difficult to implement, particularly due to the fact that it is a new technology and the existing frameworks for it are not yet mature. Our project is one of the first we've seen placing 3D models (not images) onto user faces.
## Accomplishments that we're proud of
From the machine learning side of the project, 3D face reconstruction is a very difficult problem. Luckily, our team was able to succesfully implement and use the 3DDFA state of the art machine learning model for face reconstruction. Installing and configuring the neccessary Python packages and virtual environments posed a challenge at the start, but we were able to quickly overcome this and get a working machine learning pipeline. Being able to solve this problem early on in the hackathon gave our team more time to focus on other problems, such as web 3D model visualization and constructing the facemask from our 3D face model.
## What we learned
Amusingly, during this project we found that things which were supposed to be difficult turned out to be easy to implement and, conversely, the easy parts turned out to be hard. Things like front end design and integrating web frameworks turned out to be some of the most challenging parts of the project, whereas things like machine learning were easier than expected. A takeaway is that the feasibility of quickly building a project should be based not only on the difficulty of the task, but also on the quality of existing resources which can be used to build it. Good frameworks make implementing difficult projects much easier.
## What's next for Maskus
Aside from refactoring the code and improving webpage design, we see several things for the project going forward. Perhaps the biggest points is developing a reliable algorithm to extract the facemask outline from a 3D face model. The one the group currently has works most of the time, but serves as the bottleneck of the system in terms of facial recognition accuracy. The UI design can be improved as well. Lastly, threeJS was found to be a pain, especially when trying to integrate it with React. It would be worth exploring simpler JavaScript frameworks. We would also love to add more functionality to the Arduino in the future, making it a 'smarter' mask. We hope to add sensors like AQS (Air Quality Sensor), creating alerts if the mask has been worn too long and needs to be replaced, and status LEDs in order to visually tell your mask is secure.
In terms of future growth, Markus can comfortably be deployed as a web app and used by healthcare workers around the world in order to decrease risk of COVID transmission. It is a low cost solution designed to work with existing masks and improve upon them. Opening up the software to open source contribution is a potential way to grow, and we hope it would lead to very fast progress. | ## Inspiration
Ever Ubered/Lyfted from your college campus to the airport for break? And how many of those times were you alone? Every school break, thousands of college kids flock to the airports all at the same time. But they don't know who else to coordinate sharing Uber, Lyft, and other carpooling services with.
## What it does
This web app resolves the problem by matching users with similar flight times, so that they can coordinate Ubering or Lyfting together to the airport (or wherever else they'd like). This can reduce the cost by more than half for each person!!
Step 1. Give Your Travel Plans:
Provide Migrate with the day you plan to fly out of an airport near campus, as well as the earliest and latest times in the day you can leave.
Step 2. Merge and Coordinate:
Migrate will alert you whenever another student has an overlapping shared ride with you. When at most 6 people match, a groupchat will start and you can take it from there! You can also view all existing trips on the website.
## How we built it
This app was built using Google Cloud Services. We integrated Google App Engine and Facebook login to get accounts up and running.
## Challenges we ran into
Our greatest challenge was by-far setting up the database. We were unfamiliar with Google's version of relational databases and how to represent them, so the learning curve was sharp. Eventually we got the bare bone application working, but with the sacrifice of missing styling. And that's because we're a team of two!
## Accomplishments that we're proud of
We're happy that we conquered the technologies we sought out to use (besides Facebook). Neither of us had used Bootstrap before, despite writing other websites from scratch. And we now feel comfortable just-starting a web app using Google Cloud Platform
## What we learned
How to learn at a Hackathon
## What's next for yhack2017
Three words: Rocket ship sharing | partial |
## Inspiration
Currently the insurance claims process is quite labour intensive. A person has to investigate the car to approve or deny a claim, and so we aim to make the alleviate this cumbersome process smooth and easy for the policy holders.
## What it does
Quick Quote is a proof-of-concept tool for visually evaluating images of auto accidents and classifying the level of damage and estimated insurance payout.
## How we built it
The frontend is built with just static HTML, CSS and Javascript. We used Materialize css to achieve some of our UI mocks created in Figma. Conveniently we have also created our own "state machine" to make our web-app more responsive.
## Challenges we ran into
>
> I've never done any machine learning before, let alone trying to create a model for a hackthon project. I definitely took a quite a bit of time to understand some of the concepts in this field. *-Jerry*
>
>
>
## Accomplishments that we're proud of
>
> This is my 9th hackathon and I'm honestly quite proud that I'm still learning something new at every hackathon that I've attended thus far. *-Jerry*
>
>
>
## What we learned
>
> Attempting to do a challenge with very little description of what the challenge actually is asking for is like a toddler a man stranded on an island. *-Jerry*
>
>
>
## What's next for Quick Quote
Things that are on our roadmap to improve Quick Quote:
* Apply google analytics to track user's movement and collect feedbacks to enhance our UI.
* Enhance our neural network model to enrich our knowledge base.
* Train our data with more evalution to give more depth
* Includes ads (mostly auto companies ads). | ## Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
## What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
## How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions.
After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
## Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
## What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time.
On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
## What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward. | ## Inspiration
One of the biggest problems we constantly have faced when interacting with insurance companies lies in the process of filing and receiving insurance claims. When one of our team members got into a huge traffic accident (luckily everyone was safe), they had to wait over 5 weeks before they got their claim back for their damaged vehicle. After hearing this, we knew we had to pursue a fix for this extremely lengthy claim process.
## What it does
Autosurance is meant to integrate into an auto insurance firm's claim process. Typically, there are three very time-consuming steps in filing for and receiving a claim. This process is automated effortlessly with Autosurance, where you can file for a claim, have it verified, and get your money back to you--way faster.
## How we built it
Our machine learning solutions were solely created using AWS SageMaker, which provided a really convenient way to train and create an endpoint for our two models; one of which is for crash verification (image classification), and the other which is for cost analysis (regression). These endpoints were linked to our software's backend using AWS Lambda, an extremely convenient gateway connecting AWS and our website. Our CRUD operations run on a Flask server which acts as an intermediary between our AWS S3 buckets and our ReactJS front-end.
## Challenges we ran into
We faced a lot of problems setting up AWS Sagemaker and getting Lambda to work, as all of us were extremely new to AWS. However, with help from the awesome mentors, we managed to get all the machine learning to work with our back-end. Since our project has such a diverse stack, consisting of AWS (Sagemaker, Lambda, S3), Flask, and ReactJS, it was also quite a challenge to integrate all of these components and get them to work with each other.
## Accomplishments that we're proud of
We're really happy that we ~~managed to get decent sleep~~ were able to create an interesting solution to such a far-reaching problem and had *tons* of fun.
## What we learned
We learned tons about using AWS, and are really happy that we were able to make something useful with it. All of us also got some great first-hand experience in developing a full tech stack for a functioning app.
## What's next for Autosurance
We want to have Autosurance integrate into a current insurance platform's web or mobile service, to be able to perform its intended use: to make filing and receiving claims, really frickin' fast. | winning |
## Inspiration
We wanted to create a simple GUI for data visualization
## What it does
SalesView is a data visualization tool. Users can post their data, see graphical analysis and statistics.
## How I built it
Firebase Real Time Database, React, Node.js, Google Maps API, Heroku
## Challenges I ran into
Connecting firebase to the app, optimizing data parsing to reduce render time.
## Accomplishments that I'm proud of
## What I learned
Learn how to use firebase realtime database. Google maps API
## What's next for SalesView | ## Inspiration
Fannie Mae, the largest provider of financing for mortgage lenders, faces a daunting task of micromanaging nearly every house in the country. One problem they have is the need to maintain a house property to certain standards when it is foreclosed so that its value does not depreciate significantly; a house that is not inhabited constantly needs maintenance to make sure the lawn is cut, A/C and heating are working, utilities are intact, etc.
## What it doies
Our team built a mobile app and web app that help simplify the task of maintaining houses. The mobile app is used by house inspectors, who would use the app to take pictures of and write descriptions for various parts of the house. For example, if an inspector discovered that the bathtub was leaking on the second floor, he would take a picture of the scene, and write a brief description of the problem. The app would then take the picture and description, and load it into a database, which can be accessed later by both the mobile and web apps. On the web side, pictures and descriptions for each part of the house can be accessed. Furthermore, the web app features an interface that displays the repair status for each section of the house, whether it needs repair, is currently being repaired, or is in good condition; users can make repair requests on the website.
## How I built it
We used an Angular framework to construct the web app, with Firebase API to upload and download images and information, and a bit of bootstrap to enhance aesthetics. For the mobile side, we used Swift to build the iOS app and Firebase to upload and download images and information.
## Challenges I ran into
Since this was the first time any of us had used Firebase Storage, learning the API and even getting basic functions to work was difficult. In addition, making sure the right information was being uploaded, and in turn, the correct information downloaded and parsed was also difficult, since we were not familiar with Firebase. We also ran into a lot of Javascript issues, not only because it was our first time using Angular, but also that we were not familiar with many aspects of Javascript, such as scope and closure issues, as well as asynchronous and synchronous calls.
## Accomplishments that I'm proud of
We are happy that we were able to accomplish our original goal of providing a mobile and web app that work together to provide information about various parts of the house, and give companies like Fannie Mae the ability to micromanage a large number of houses in a simple and compact way.
## What I learned
The team members that worked on the mobile app learned a great deal of formatting data, and grabbing and uploading files onto Firebase. The team members that worked on the web app increased proficiency in Javascript and Angular. Everybody learned a good amount in the side of the Firebase (mobile, web) that they had to work in.
# What's next for House Maed
As Fannie Mae is looking to eventually deploy an app like House Maed in the future to make their management of house properties more efficient, we hope our app provides inspiration and is a guide for how such an app can be developed. | # Community Watch
## Inspiration
There are a lot of issues when investing in real estate, mainly associated with the research process. Including having to search multiple websites to find relevant information, information being hidden behind paywalls and lack of enjoyable user experience. This all sucks the job out of investing.
## What it does
Community Watch fixes those issues by providing an interactive user friendly web app where all the most relevant data real estate agents need to know is displayed. With the ability to save and explore different communities using the interactive map tool, it makes finding the right community to buy real estate more enjoyable.
## How we built it
The app was built using ReactJS and implemented the Google Maps APIs. A geojson file of Toronto’s communities was used to draw the various Polygons and compare with our processed data. ChartJS was also used to display the historical price charts and sales data.
The data pipeline is built with python pandas to aggregate and sort data. The ML component that outputs safety, transportation and education index is done using a CNN with TF.keras. Most of the data we sourced was from Federal open data sources including:
[Break and Enters](https://data.torontopolice.on.ca/datasets/break-and-enter-2014-to-2019/data)
[Theft](https://data.torontopolice.on.ca/datasets/theft-over-2014-to-2019)
[Robbery](https://data.torontopolice.on.ca/datasets/robbery-2014-to-2019/data)
## Challenges we ran into
There was virtually never the exact data we needed, so we used Machine learning to predict those values using the open sourced data we had combined with some web scraping for target values.
Also, we had our first experience with Google Maps API and there were very few docs on the API implementation in React. We needed to check numerous different 3rd party tutorials and try various ways to implement the API. Once we overcame that, we were able to smoothly integrate our other components.
## Accomplishments that we're proud of
We are proud that we came together and built a full project despite the barrier of not being able to work in-person. It was difficult to start moving at first, but ultimately we were able to communicate better and work cohesively to build this.
## What we learned
We learned that there is a lot of open-sourced data online that we can use in future projects. A large part of this was learning how to search for data and how to find accurate and relevant datasets that pertain to our idea.
## What's next for Community Watch
Automate the entire data pipeline and move the backend onto a program such as FireBase. This would clean up the code on the front end and further smoothen out the user experience.
We also would like to continue finding data in other regions such as Richmond HIll and Markham and implement all the data together. | partial |
## Inspiration
Many students rely on scholarships to attend college. As students in different universities, the team understands the impact of scholarships on people's college experiences. When scholarships fall through, it can be difficult for students who cannot attend college without them. In situations like these, they have to depend on existing crowdfunding websites such as GoFundMe. However, platforms like GoFundMe are not necessarily the most reliable solution as there is no way of verifying student status and the success of the campaign depends on social media reach. That is why we designed ScholarSource: an easy way for people to donate to college students in need!
## What it does
ScholarSource harnesses the power of blockchain technology to enhance transparency, security, and trust in the crowdfunding process. Here's how it works:
Transparent Funding Process: ScholarSource utilizes blockchain to create an immutable and transparent ledger of all transactions and donations. Every step of the funding process, from the initial donation to the final disbursement, is recorded on the blockchain, ensuring transparency and accountability.
Verified Student Profiles: ScholarSource employs blockchain-based identity verification mechanisms to authenticate student profiles. This process ensures that only eligible students with a genuine need for funding can participate in the platform, minimizing the risk of fraudulent campaigns.
Smart Contracts for Funding Conditions: Smart contracts, powered by blockchain technology, are used on ScholarSource to establish and enforce funding conditions. These self-executing contracts automatically trigger the release of funds when predetermined criteria are met, such as project milestones or the achievement of specific research outcomes. This feature provides donors with assurance that their contributions will be used appropriately and incentivizes students to deliver on their promised objectives.
Immutable Project Documentation: Students can securely upload project documentation, research papers, and progress reports onto the blockchain. This ensures the integrity and immutability of their work, providing a reliable record of their accomplishments and facilitating the evaluation process for potential donors.
Decentralized Funding: ScholarSource operates on a decentralized network, powered by blockchain technology. This decentralization eliminates the need for intermediaries, reduces transaction costs, and allows for global participation. Students can receive funding from donors around the world, expanding their opportunities for financial support.
Community Governance: ScholarSource incorporates community governance mechanisms, where participants have a say in platform policies and decision-making processes. Through decentralized voting systems, stakeholders can collectively shape the direction and development of the platform, fostering a sense of ownership and inclusivity.
## How we built it
We used React and Nextjs for the front end. We also integrated with ThirdWeb's SDK that provided authentication with wallets like Metamask. Furthermore, we built a smart contract in order to manage the crowdfunding for recipients and scholars.
## Challenges we ran into
We had trouble integrating with MetaMask and Third Web after writing the solidity contract. The reason was that our configuration was throwing errors, but we had to configure the HTTP/HTTPS link,
## Accomplishments that we're proud of
Our team is proud of building a full end-to-end platform that incorporates the very essence of blockchain technology. We are very excited that we are learning a lot about blockchain technology and connecting with students at UPenn.
## What we learned
* Aleo
* Blockchain
* Solidity
* React and Nextjs
* UI/UX Design
* Thirdweb integration
## What's next for ScholarSource
We are looking to expand to other blockchains and incorporate multiple blockchains like Aleo. We are also looking to onboard users as we continue to expand and new features. | ## Inspiration
Blockchain has created new opportunities for financial empowerment and decentralized finance (DeFi), but it also introduces several new considerations. Despite its potential for equitability, malicious actors can currently take advantage of it to launder money and fund criminal activities. There has been a recent wave of effort to introduce regulations for crypto, but the ease of money laundering proves to be a serious challenge for regulatory bodies like the Canadian Revenue Agency. Recognizing these dangers, we aimed to tackle this issue through BlockXism!
## What it does
BlockXism is an attempt at placing more transparency in the blockchain ecosystem, through a simple verification system. It consists of (1) a self-authenticating service, (2) a ledger of verified users, and (3) rules for how verified and unverified users interact. Users can "verify" themselves by giving proof of identity to our self-authenticating service, which stores their encrypted identity on-chain. A ledger of verified users keeps track of which addresses have been verified, without giving away personal information. Finally, users will lose verification status if they make transactions with an unverified address, preventing suspicious funds from ever entering the verified economy. Importantly, verified users will remain anonymous as long as they are in good standing. Otherwise, such as if they transact with an unverified user, a regulatory body (like the CRA) will gain permission to view their identity (as determined by a smart contract).
Through this system, we create a verified market, where suspicious funds cannot enter the verified economy while flagging suspicious activity. With the addition of a legislation piece (e.g. requiring banks and stores to be verified and only transact with verified users), BlockXism creates a safer and more regulated crypto ecosystem, while maintaining benefits like blockchain’s decentralization, absence of a middleman, and anonymity.
## How we built it
BlockXism is built on a smart contract written in Solidity, which manages the ledger. For our self-authenticating service, we incorporated Circle wallets, which we plan to integrate into a self-sovereign identification system. We simulated the chain locally using Ganache and Metamask. On the application side, we used a combination of React, Tailwind, and ethers.js for the frontend and Express and MongoDB for our backend.
## Challenges we ran into
A challenge we faced was overcoming the constraints when connecting the different tools with one another, meaning we often ran into issues with our fetch requests. For instance, we realized you can only call MetaMask from the frontend, so we had to find an alternative for the backend. Additionally, there were multiple issues with versioning in our local test chain, leading to inconsistent behaviour and some very strange bugs.
## Accomplishments that we're proud of
Since most of our team had limited exposure to blockchain prior to this hackathon, we are proud to have quickly learned about the technologies used in a crypto ecosystem. We are also proud to have built a fully working full-stack web3 MVP with many of the features we originally planned to incorporate.
## What we learned
Firstly, from researching cryptocurrency transactions and fraud prevention on the blockchain, we learned about the advantages and challenges at the intersection of blockchain and finance. We also learned how to simulate how users interact with one another blockchain, such as through peer-to-peer verification and making secure transactions using Circle wallets. Furthermore, we learned how to write smart contracts and implement them with a web application.
## What's next for BlockXism
We plan to use IPFS instead of using MongoDB to better maintain decentralization. For our self-sovereign identity service, we want to incorporate an API to recognize valid proof of ID, and potentially move the logic into another smart contract. Finally, we plan on having a chain scraper to automatically recognize unverified transactions and edit the ledger accordingly. | ## Inspiration
We always keep on losing remotes and cannot find the right one at the right time. We thought to eliminate this problem completely by creating a universal smart remote that can control all devices
## What it does
It identifies the device it is being pointed at changes the controls on the display accordingly. It adapts to user's preferences and style.
## How we built it
We scraped the internet for thousands of images of devices and annotated these devices. Then we trained the neural net on an AWS server to get our weight files. Created a flask server that handles the requests and processing. A raspberry pi (client) is our remote with the camera module that communicates with the flask server.
## Challenges we ran into
Emitting IR signals using a raspberry pi. It was very difficult to emit the IR rays at the desired frequency and time duration to control a device.
## Accomplishments that we're proud of
We scraped the web, annotated the images and trained a neural net in a short span of time.
## What we learned
We learned a lot about YOLO (You Only Look Once) and Darkflow. Additionally, we spent a lot of time working on the hardware that gave us a good insight into how a remote is supposed to be designed.
## What's next for OneCtrl
We plan to train it more on a wider range of devices with a larger set of images to make our net robust and accurate. | winning |
PulsePoint represents a significant stride in healthcare technology, leveraging the security and efficiency of blockchain to enhance the way medical records are managed and shared across healthcare providers. By creating a centralized Electronic Medical Record (EMR) system, PulsePoint addresses a longstanding issue in healthcare: the cumbersome process of transferring patient records between clinics and healthcare providers. Here's a deeper dive into its components, achievements, lessons learned, and future directions:
Inspiration
The inspiration behind PulsePoint stemmed from the critical need to streamline the management and sharing of medical records in the healthcare industry. The traditional methods of handling EMRs are often fraught with inefficiencies, including delays in record transfers, risks of data breaches, and difficulties in maintaining up-to-date patient information across different healthcare systems. PulsePoint aims to solve these issues by providing a secure, blockchain-based platform that empowers patients with control over their medical data, enabling seamless transfers with just a click.
What It Does
PulsePoint revolutionizes the way EMRs are managed by utilizing blockchain technology to ensure the integrity, security, and portability of medical records. Patients can easily grant access to their medical history to any participating clinic, significantly reducing the administrative burden on healthcare providers and improving the overall patient care experience. This system not only facilitates quicker access to patient data but also enhances data privacy and security, critical components in healthcare.
How We Built It
The development of PulsePoint involved a modified MERN stack (MongoDB, Express.js, React.js, Node.js), incorporating additional technologies such as Auth0 for authentication services and OpenAI's API for an AI-powered assistant. The use of Auth0 allowed for secure and scalable user authentication, while OpenAI's API provided an intelligent assistant feature to help users navigate their medical records and the platform more efficiently. The integration of blockchain technology was a pivotal part of the project, ensuring that all data transactions on the platform are secure and immutable.
Challenges We Ran Into
One of the significant challenges faced during the development was setting up the blockchain service. The team encountered difficulties in integrating blockchain to securely manage the EMRs, which required extensive research and troubleshooting. Another challenge was devising a robust solution for document upload and storage that met the necessary standards for security and privacy compliance.
Accomplishments That We're Proud Of
Despite the challenges, the team successfully developed a functional and secure platform that addresses many of the inefficiencies present in traditional EMR systems. The ability to securely transfer patient records across clinics with ease represents a major achievement in healthcare technology. Furthermore, the team's increased proficiency in React.js and a deeper understanding of blockchain services are significant accomplishments that will benefit future projects.
What We Learned
The development process of PulsePoint was a learning journey, particularly in enhancing the team's skills in React.js and blockchain technology. The project provided valuable insights into the complexities of healthcare data management and the potential of blockchain to address these challenges. It also highlighted the importance of user-friendly design and robust security measures in developing healthcare applications.
What's Next for PulsePoint
Looking ahead, PulsePoint aims to expand its network by onboarding more clinics and healthcare providers, thereby increasing the platform's utility and accessibility for patients nationwide. Future developments will focus on enhancing the platform's AI capabilities to offer more personalized and intelligent features for users, such as health insights and recommendations. Additionally, the team plans to explore the integration of advanced blockchain technologies to further improve data security and interoperability between different healthcare systems.
By continuously evolving and adapting to the needs of the healthcare industry, PulsePoint is poised to become a cornerstone in the digital transformation of healthcare, making patient data management more secure, efficient, and patient-centric. | ## Inspiration
We were inspired by the topic of UofTHacks X theme **Exploration**. The game itself requires **players to explore** all the clues inside the rooms. We also want **"explore" ourselves** in UofTHacks X. Since our team does not have experience in game development, we also witness our 24-hour-accomplishment in this new area.
We were inspired by **Metaverse** AND **Virtual Reality (VR)**. We believe that Metaverse will be the next generation of the Internet. Metaverse is a collective virtual sharing space. Metaverse is formed by a combination of physical reality, augmented reality (AR), and virtual reality (VR) to enable users to interact virtually. VR is widely used in game development. Therefore, we decided to design a VR game.
## What it does
Escape room is a first-person, multiplayer VR game that allows users to discover clues, solve puzzles, and accomplish tasks in rooms in order to accomplish a specific goal in a limited amount of time.
## How we built it
We found the 3D models, and animations from the Unity asserts store and import the models to different scenes in our project. We used **Unity** as our development platform and used **GitHub** to manage our project. In order to allow multiplay in our game, we used the **photon engine**. For our VR development, we used the **OpenXR** plug-in in Unity.
## Challenges we ran into
One of the challenges we ran into was setting up the VR devices. We used **Valve Index** as our VR devices. As Valve Index only supports DisplayPort output, but our laptop only supports HDMI input. We spent lots of time looking for the adapter and could not find one. After asking for university laptops, and friends, we found a DisplayPort input-supportive device.
Another challenge we have is that we are not experienced in game development. And we start our project by script. However, we find awesome tutorials on YouTube and learn game development in a short period of time.
## Accomplishments that we're proud of
We are proud of allowing multiplayer in our game, we learned the photon engine within one hour and applied it in our project. We are also proud of creating a VR game using the OpenXR toolkit with no previous experience in game development.
## What we learned
We learned about Unity and C# from YouTube. We also learned the photon engine that allows multiuser play in our game. Moreover, we learned the OpenXR plug-in for our VR development. To better manage our project, we also learned more about GitHub.
## What's next for Escape Room
We want to allow users to self-design their rooms and create puzzles by themselves.
We plan to design more puzzles in our game.
We also want to improve the overall user experience by allowing our game runs smoothly. | ## Inspiration
Suppose we go out for a run early in the morning without our wallet and cellphone, our service enables banking systems to use facial recognition as a means of payment enabling us to go cashless and cardless.
## What it does
It uses deep neural networks in the back end to detect faces at point of sale terminals and match them with those stored in the banking systems database and lets the customer purchase a product from a verified seller almost instantaneously. In addition, it allows a bill to be divided between customers using recognition of multiple faces. It works in a very non-invasive manner and hence makes life easier for everyone.
## How we built it
Used dlib as the deep learning framework for face detection and recognition, along with Flask for the web API and plain JS on the front end. The front end uses AJAX to communicate with the back end server. All requests are encrypted using SSL (self-signed for the hackathon).
## Challenges we ran into
We attempted to incorporate gesture recognition into the service, but it would cause delays in the transaction due to extensive training/inference based on hand features. This is a feature to be developed in the future, and has the potential to distinguish and popularize our unique service
## Accomplishments that we're proud of
Within 24 hours, we are able to pull up a demo for payment using facial recognition simply by having the customer stand in front of the camera using real-time image streaming. We were also able to enable payment splitting by detection of multiple faces.
## What we learned
We learned to set realistic goals and pivot in the right times. There were points where we thought we wouldn't be able to build anything but we persevered through it to build a minimum viable product. Our lesson of the day would therefore be to never give up and always keep trying -- that is the only reason we could get our demo working by the end of the 24 hour period.
## What's next for GazePay
We plan on associating this service with bank accounts from institutions such as Scotiabank. This will allow users to also see their bank balance after payment, and help us expand our project to include facial recognition ATMs, gesture detection, and voice-enabled payment/ATMs for them to be more accessible and secure for Scotiabank's clients. | losing |
## Inspiration
asdasd
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for Test Project | ## Inspiration
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for EduBate
World domination | ## Inspiration
When we thought about tackling the pandemic, it was clear to us that we'd have to **think outside the box**. The concept of a hardware device to enforce social distancing quickly came to mind, and thus we decided to create the SDE device.
## What it does
We utilized an ultra-sonic sensor to detect bodies within 2m of the user, and relay that data to the Arduino. If we detect a body within 2m, the buzzer and speaker go off, and a display notifies others that they are not obeying social distancing procedures and should relocate.
## How we built it
We started by creating a wiring diagram for the hardware internals using [Circuito](circuito.io). This also provided us some starter code including the libraries and tester code for the hardware components.
We then had part of the team start the assembly of the circuit and troubleshoot the components while the other focused on getting the CAD model of the casing designed for 3D printing.
Once this was all completed, we printed the device and tested it for any bugs in the system.
## Challenges we ran into
We initially wanted to make an Android partner application to log the incidence rate of individuals/objects within 2m via Bluetooth but quickly found this to be a challenge as the team was split geographically, and we did not have Bluetooth components to attach to our Arduino model. The development of the Android application also proved difficult, as no one on our team had experience developing Android applications in a Bluetooth environment.
## Accomplishments that we're proud of
Effectively troubleshooting the SDE device and getting a functional prototype finished.
## What we learned
Hardware debugging skills, how hard it is to make an Android app if you have no previous experience, and project management skills for distanced hardware projects.
## What's next for Social Distancing Enforcement (SDE)
Develop the Android application, add Bluetooth functionality, and decrease the size of the SDE device to a more usable size. | losing |
## Inspiration
With the new normal and digitalization of every sector we came to realise that there are mostly blogs available on the internet on Autism and felt that the Autism community was somewhere sidelined with having barely any resources or softwares which could help the parents and therapists continue their therapies virtually and still had to depend on traditional means of crafts etc to develop puzzles for children to teach life skills . On more surfing around the internet, we realised the gravity of the situation when there was only one website which had educational games teaching autistic kids eye contact etc. which had also discontinued because of technical glitches.The severity of the situation alongside the fact that 1 in 54 children have autism inspired us to use technology to create tools catering to the needs of the children, parents and people associated with autism. Spreading awareness about Autism through our project has been the major driving force.
## What it does
Walk with me is a working prototype aimed at incorporating technology into the traditional tools used in teaching people with autism basic life skills. The project is coded in colour blue and has the puzzle logo which are symbolic to autism and have been incorporated with the aim to spread awareness.
The project has three distinct highlights aimed at trying to cover people who are on different levels of the autism spectrum.
Special Educators use traditional means of making adaptive books to teach life skills like brushing teeth etc and to reduce the cumbersome work load in making work system using hand crafts, we decided to design prototype centralizing to the people with autism by keeping them simple so that with one click of mouse, the child can easily navigate through the steps and learn new skills making the work easier for both the educators and children.
The website in itself is a compact platform providing knowledge of Autism and spreading awareness about it through blogs ,videos etc as well as linking the features together including the game prototype and bot.
The discord bot linked with the website is a tool for non verbal autistic people (approx 30-40% people on spectrum are non verbal) who can use the text input to interact with the bot. The bot provides positive reinforcements to the user which in return helps in uplifting the mood of the user as well as increasing confidence and preaching self worth through phrases like “You can do it.” ,“You are the best.” etc. It also has quotations from personalities like Rumi etc.
## How we built it
Our project is an amalgamation of the following things-
Discord Bot- Python
Front End -HTML/CSS
- Bootstrap
- Java script
Back End - php
Educational Game Prototype -Google Slides
## Challenges we ran into
1)We faced a lot of system and softwares problems while the frontend of the website was being created due to which we had to redo the whole front end.
2)We had one of our teammate leave us just after the start of the Hack due to some unforeseen circumstances, which made our schedule more scrambled but we managed to finish our project .
3) It took us some time and help from the mentors to figure out a way to present the idea of the game in form of a prototype but we managed to make the best use of google slides in prototyping our idea.
## Accomplishments that we're proud of
We now know the use of HTML/CSS,using sandbox,bootstrap,template editing and shuffling in an intermediate level as well as learning how to create games/short animations using google slides.
We are proud of how we were able to come together as a team since we had never met each other prior but were still able to work together in a collaborative and healthy environment.
## What we learned
The research phase of the hack was an eye opening experience for us all as a team especially learning about Autism and how an autistic person spends his/her daily routine especially the tools and techniques used in teaching an autistic child life skills. We also realised that apart from numerous blogs on autism, there isn't much out there in terms of softwares or educational games etc. catering to the needs of autistic people etc which motivated us to take this project in the hackathon.
On the technical forefront, working on the project has taught us how to manage our time while simultaneously collaborating with each other and making quick decisions as well as learning new technical hacks like extensions etc which enables us to code in real time.
## What's next for Walk With Me
Post the hackathon, converting the prototype for the educational games into actual games using platforms like unity is on our to-do list. Considering the lack of educational games built catering to autistic people, we are planning to improve our prototype and turn it into educational games teaching people with autism basic life skills helping them with their journey into being independent.
We also plan on improving the discord bot as well as text to speech functionality keeping in mind the non verbal children on the autism spectrum and helping them communicate through technology.We plan on making the security of our website as well as the discord so as to make sure there is no breach or unparliamentary action in our environment and to ensure the environment runs as a safe,civil and learning platform.
Alongside this we look forward to adding more functionality to the website and making it dynamic with good quality content and incorporating a better tech stack like react into it. We also plan on improving the content of the website in terms of resources etc like sharing the journey of people who are on the spectrum, sharing books written by people having autism ,sessions and conferences catering to autism etc.
We hope to even develop an app version of the website , incorporate an inbuilt chat feature for a peer to peer interaction or peer to admin interaction as well as develop more advanced,secure admin records with the database.
2) WCAG
We plan to integrate and follow the WCAG 2.0(WEB ACCESSIBILITY GUIDELINES) which are :
1)Provides content not prone to have seizures
2)Content should be substituted with pictures for better understanding
3)Sentence should not be cluttered
4)Font needs to be large and legible
5)Content present needs to be verified such that it is not prone to seizures.
Overall we have a lot to look forward to in terms of our Hack. | ## Inspiration
Our inspiration were are friends who have Autism and also hearing the keynote speaker talk about her brother who is Autistic.
## What it does
Assist ASD is an application made for people with autism, their caretakers and behavioral therapists. Our mobile application allows people with autism to understand social signals through image/facial recognition. In addition, the care takers are able to track their receiver in order to know events like when entering and leaving home, sleeping schedules and physical activity. Care takers not only track these events, but have measures for recording notes based ABC assessment. Lastly, all information and data is then pushed to the behavioral therapist who is able to view the metrics and data analytics in order to make more informed decisions for their patients.
## How I built it
Using AGILE/SCRUM planning, we built it using technologies based on scope. After planning the project, we incorporated google's cloud service and facial recognition along with Microsoft's sentimental analytics. We incorporated Neura's API in order to get updates on the autistic person's movements such as physical activity, sleeping activity and entering or leaving designated points. We used Qualtrics in order to display data analytics of all behaviors tracked.
## Challenges I ran into
We ran into API issues with Microsoft services. Initially it was a very confusing setup because they only had code for objective C. However, after playing around with the curl and python aspect it became useful. We also had an interesting adventure of scoping our project more precisely and cutting out possible technologies that we could use.
## Accomplishments that I'm proud of
Well, we see our application having a big impact on the ASD community.
## What I learned
More about the problem space of ASD and new technologies and capabilities for applications.
## What's next for Assist ASD
We will user interview behavioral therapist to make sure we are solving and implementing the right features. | ## Inspiration
One of our team members underwent speech therapy as a child, and the therapy helped him gain a sense of independence and self-esteem. In fact, over 7 million Americans, ranging from children with gene-related diseases to adults who suffer from stroke, go through some sort of speech impairment. We wanted to create a solution that could help amplify the effects of in-person treatment by giving families a way to practice at home. We also wanted to make speech therapy accessible to everyone who cannot afford the cost or time to seek institutional help.
## What it does
BeHeard makes speech therapy interactive, insightful, and fun. We present a hybrid text and voice assistant visual interface that guides patients through voice exercises. First, we have them say sentences designed to exercise specific nerves and muscles in the mouth. We use deep learning to identify mishaps and disorders on a word-by-word basis, and show users where exactly they could use more practice. Then, we lead patients through mouth exercises that target those neural pathways. They imitate a sound and mouth shape, and we use deep computer vision to display the desired lip shape directly on their mouth. Finally, when they are able to hold the position for a few seconds, we celebrate their improvement by showing them wearing fun augmented-reality masks in the browser.
## How we built it
* On the frontend, we used Flask, Bootstrap, Houndify and JavaScript/css/html to build our UI. We used Houndify extensively to navigate around our site and process speech during exercises.
* On the backend, we used two Flask servers that split the processing load, with one running the server IO with the frontend and the other running the machine learning.
* On our algorithms side, we used deep\_disfluency to identify speech irregularities and filler words and used the IBM Watson speech-to-text (STT) API for a more raw, fine-resolution transcription.
* We used the tensorflow.js deep learning library to extract 19 points representing the mouth of a face. With exhaustive vector analysis, we determined the correct mouth shape for pronouncing basic vowels and gave real-time guidance for lip movements. To increase motivation for the user to practice, we even incorporated AR to draw the desired lip shapes on users mouths, and rewards them with fun masks when they get it right!
## Challenges we ran into
* It was quite challenging to smoothly incorporate voice our platform for navigation, while also being sensitive to the fact that our users may have trouble with voice AI. We help those who are still improving gain competence and feel at ease by creating a chat bubble interface that reads messages to users, and also accepts text and clicks.
* We also ran into issues finding the balance between getting noisy, unreliable STT transcriptions and transcriptions that autocorrected our users’ mistakes. We ended up employing a balance of the Houndify and Watson APIs. We also adapted a dynamic programming solution to the Longest Common Subsequence problem to create the most accurate and intuitive visualization of our users’ mistakes.
## Accomplishments that we are proud of
We’re proud of being one of the first easily-accessible digital solutions that we know of that both conducts interactive speech therapy, while also deeply analyzing our users speech to show them insights. We’re also really excited to have created a really pleasant and intuitive user experience given our time constraints.
We’re also proud to have implemented a speech practice program that involves mouth shape detection and correction that customizes the AR mouth goals to every user’s facial dimensions.
## What we learned
We learned a lot about the strength of the speech therapy community, and the patients who inspire us to persist in this hackathon. We’ve also learned about the fundamental challenges of detecting anomalous speech, and the need for more NLP research to strengthen the technology in this field.
We learned how to work with facial recognition systems in interactive settings. All the vector calculations and geometric analyses to make detection more accurate and guidance systems look more natural was a challenging but a great learning experience.
## What's next for Be Heard
We have demonstrated how technology can be used to effectively assist speech therapy by building a prototype of a working solution. From here, we will first develop more models to determine stutters and mistakes in speech by diving into audio and language related algorithms and machine learning techniques. It will be used to diagnose the problems for users on a more personal level. We will then develop an in-house facial recognition system to obtain more points representing the human mouth. We would then gain the ability to feature more types of pronunciation practices and more sophisticated lip guidance. | partial |
## Inspiration
A week or so ago, Nyle DiMarco, the model/actor/deaf activist, visited my school and enlightened our students about how his experience as a deaf person was in shows like Dancing with the Stars (where he danced without hearing the music) and America's Next Top Model. Many people on those sets and in the cast could not use American Sign Language (ASL) to communicate with him, and so he had no idea what was going on at times.
## What it does
SpeakAR listens to speech around the user and translates it into a language the user can understand. Especially for deaf users, the visual ASL translations are helpful because that is often their native language.

## How we built it
We utilized Unity's built-in dictation recognizer API to convert spoken word into text. Then, using a combination of gifs and 3D-modeled hands, we translated that text into ASL. The scripts were written in C#.
## Challenges we ran into
The Microsoft HoloLens requires very specific development tools, and because we had never used the laptops we brought to develop for it before, we had to start setting everything up from scratch. One of our laptops could not "Build" properly at all, so all four of us were stuck using only one laptop. Our original idea of implementing facial recognition could not work due to technical challenges, so we actually had to start over with a **completely new** idea at 5:30PM on Saturday night. The time constraint as well as the technical restrictions on Unity3D reduced the number of features/quality of features we could include in the app.
## Accomplishments that we're proud of
This was our first time developing with the HoloLens at a hackathon. We were completely new to using GIFs in Unity and displaying it in the Hololens. We are proud of overcoming our technical challenges and adapting the idea to suit the technology.
## What we learned
Make sure you have a laptop (with the proper software installed) that's compatible with the device you want to build for.
## What's next for SpeakAR
In the future, we hope to implement reverse communication to enable those fluent in ASL to sign in front of the HoloLens and automatically translate their movements into speech. We also want to include foreign language translation so it provides more value to **deaf and hearing** users. The overall quality and speed of translations can also be improved greatly. | ## The problem it solves :
During these tough times when humanity is struggling to survive, **it is essential to maintain social distancing and proper hygiene.** As a big crowd now is approaching the **vaccination centres**, it is obvious that there will be overcrowding.
This project implements virtual queues which will ensure social distancing and allow people to stand separate instead of crowding near the counter or the reception site which is a evolving necessity in covid settings!
**“ With Quelix, you can just scan the OR code, enter the virtual world of queues and wait for your turn to arrive. Timely notifications will keep the user updated about his position in the Queue.”**
## Key-Features
* **Just scan the OR code!**
* **Enter the virtual world of queues and wait for your turn to arrive.**
* **Timely notifications/sound alerts will keep the user updated about his position/Time Left in the Queue.**
* **Automated Check-in Authentication System for Following the Queue.**
* **Admin Can Pause the Queue.**
* **Admin now have the power to remove anyone from the queue**
* Reduces Crowding to Great Extent.
* Efficient Operation with Minimum Cost/No additional hardware Required
* Completely Contactless
## Challenges we ran into :
* Simultaneous Synchronisation of admin & queue members with instant Updates.
* Implementing Queue Data structure in MongoDB
* Building OTP API just from scratch using Flask.
```
while(quelix.on):
if covid_cases.slope<0:
print(True)
>>> True
```
[Github repo](https://github.com/Dart9000/Quelix2.0)
[OTP-API-repo](https://github.com/Dart9000/OTP-flask-API)
[Deployment](https://quelix.herokuapp.com/) | ## Inspiration
Other educational games like [OhMyGit](https://ohmygit.org/).
Some gameplay aspects of a popular rhythm game: Friday Night Funkin'
## What it does
Players will be able to select a topic to battle in and enter a pop-quiz style battle where getting correct answers attacks your opponent and getting incorrect ones allow the opponent to attack you.
Ideally, the game would have fun animations and visual cues to show the user was correct or not, these effects mainly in seeing the player attack the enemy or vice versa if the answer was incorrect.
## How we built it
Using the Unity game engine.
## Challenges we ran into
Team members we're quite busy over the weekend, and a lack of knowledge in Unity.
## Accomplishments that we're proud of
The main gameplay mechanic is mostly refined, and we were able to complete it in essentially a day's work with 2 people.
## What we learned
Some unique Unity mechanics and planning is key to put out a project this quickly.
## What's next for Saturday Evening Studyin'
Adding the other question types specified in our design (listed in the README.md), adding animations to the actual battle, adding character dialogue and depth.
One of the original ideas that were too complex to implement in this short amount of time is for 2 human players to battle each other, where the battle is turn-based and players can select the difficulty of question to determine the damage they can deal, with some questions having a margin of error for partial correctness to deal a fraction of the normal amount. | winning |
## DEMO WITHOUT PRESENTATION
## **this app would typically be running in a public space**
[demo without presentation (judges please watch the demo with the presentation)](https://youtu.be/qNmGr1GJNrE)
## Inspiration
We spent **hours** thinking about what to create for our hackathon submission. Every idea that we had already existed. These first hours went by quickly and our hopes of finding an idea that we loved were dwindling. The idea that eventually became **CovidEye** started as an app that would run in the background of your phone and track the type and amount of coughs throughout the day, however we discovered a successful app that already does this. About an hour after this idea was pitched **@Green-Robot-Dev-Studios (Nick)** pitched a variation of this app that would run on a security camera or in the web and track the coughs of people in stores (anonymously). A light bulb immediately lit over all of our heads as this would help prevent covid-19 outbreaks, collect data, and is accessible to everyone (it can run on your laptop as opposed to a security camera).
## What it does
**CovidEye** tracks a tally of coughs and face touches live and graphs it for you.**CovidEye** allows you to pass in any video feed to monitor for COVID-19 symptoms within the area covered by the camera. The app monitors the feed for anyone that coughs or touches their face. **\_For demoing purposes, we are using a webcam, but this could easily be replaced with a security camera. Our logic can even handle multiple events by different people simultaneously. \_**
## How we built it
We used an AI called PoseNet built by Tensorflow. The data outputted by this AI is passed through through some clever detection logic. Also, this data can be passed on to the government as an indicator of where symptomatic people are going. We used Firebase as the backend to persist the tally count. We created a simple A.P.I. to connect Firebase and our ReactJS frontend.
## Challenges we ran into
* We spent about 3 hours connecting the AI count to Firebase and patching it into the react state.
* Tweaking the pose detection logic took a lot of trial and error
* Deploying a built react app (we had never done that before and had a lot of difficulty resulting in the need to change code within our application)
* Optimizing the A.I. garbage collection (chrome would freeze)
* Optimizing the graph (Too much for chrome to handle with the local A.I.)
## Accomplishments that we're proud of
* **All 3 of us** We are very proud that we thought of and built something that could really make a difference in this time of COVID-19, directly and with statistics. We are also proud that this app is accessible to everyone as many small businesses are not able to afford security cameras.
* **@Alex-Walsh (Alex)** I've never touched any form of A.I/M.L. before so this was a massive learning experience for me. I'm also proud to have competed in my first hackathon.
* **@Green-Robot-Dev-Studios (Nick)** I'm very proud that we were able to create an A.I. as accurate as it in is the time frame
* **@Khalid Filali (Khalid)** I'm proud to have pushed my ReactJS skills to the next level and competed in my first hackathon.
## What we learned
* Posenet
* ChartJS
* A.I. basics
* ReactJS Hooks
## What's next for CovidEye
-**Refining** : with a more enhanced dataset our accuracy would greatly increase
* Solace PubSub, we didn't have enough time but we wanted to create live notifications that would go to multiple people when there is excessive coughing.
* Individual Tally's instead of 1 tally for each person (we didn't have enough time)
* Accounts (we didn't have enough time) | ## Inspiration
Businesses have been hit hard with COVID-19 as they try to survive consecutive lockdowns and restrictions alongside logistical uncertainties. This includes challenges that entail dealing with certain people who disobey building occupancy limits and regulations, irregular foot traffic, and dealing with lower profits while trying to meet operational expenses.
## What it does
With 2020 Vision, businesses can add a live video stream from the entrance of the building where the app can analyze and track the number/flow of people and enforce a lock upon the maximum occupancy. Data is collected on the foot traffic for the business which is visualized in the dashboard. This data is also used to calculate various metrics like avg entrance/hour, avg exit/hour, avg people/week, avg capacity, customer density, and people in & out. This helps business owners to make decisions for when and how long to operate during the day or week.
## How we built it
A React web app was built to display a dashboard of visualized data metrics with Chart.JS. The web app also displays a live video feed that has been processed by OpenCV for detecting movements of people frame by frame. It keeps track of the number of people inside the building and enables a lock signal for when it has exceeded maximum occupancy. The React web app and OpenCV API are both socket clients that transmit and receive data to/from the NodeJS socket server.
Furthermore on the computer vision, the object detection is designed with Single Shot Detector, which identifies the object(s) in a video frame. This is built alongside a MobileNet architecture which is a Deep Neural Network built to perform on devices with lower memory and processing/computing power like smartphones and IP cameras. Centroid tracker is used for object tracking by calculating the center of the bounding box of an object. A detected object (a customer) is uniquely identified and tracked over the following frames and is utilized to calculate number of people inside, and people leaving/entering. The detected object has a directional vector which gauges their movement for leaving or entering. The machine-learning algorithm also identifies a physical threshold that represents the line of entry/exit point.
## Challenges we ran into
Fixing broken modules and package dependencies in order to establish a socket client/server connection. Dealing with everybody's individual schedule and coordinating the team in an online remote environment. Figuring out how to send real-time data from socket connections. Difficulties with data collection for creating useful logistical metrics and sending video inputs to a computer vision model that is less resource intensive for our web architecture. Issues for deploying computer vision model onto AWS Cloud9 within EC2 instance.
## Accomplishments that we're proud of
Clean and easy-to-use UI, effectively setting up web architecture alongside socket connections for real-time data handling, creating an end-to-end solution, deploying a computer vision model seamlessly integrated in the web architecture.
## What we learned
OpenCV/SSD/MobileNet/Centroid Tracker for implementing a computer vision API, Chart.JS for data visualization, Socket.IO for real-time data handling in clients/server.
## What's next for 2020 Vision
Integrating IoT for smart-locking systems to further modularize the software for varying businesses. | ## Inspiration
According to a 2015 study in the American Journal of Infection Control, people touch their faces more than 20 times an hour on average. More concerningly, about 44% of the time involves contact with mucous membranes (e.g. eyes, nose, mouth).
With the onset of the COVID-19 pandemic ravaging our population (with more than 300 million current cases according to the WHO), it's vital that we take preventative steps wherever possible to curb the spread of the virus. Health care professionals are urging us to refrain from touching these mucous membranes of ours as these parts of our face essentially act as pathways to the throat and lungs.
## What it does
Our multi-platform application (a python application, and a hardware wearable) acts to make users aware of the frequency they are touching their faces in order for them to consciously avoid doing so in the future. The web app and python script work by detecting whenever the user's hands reach the vicinity of the user's face and tallies the total number of touches over a span of time. It presents the user with their rate of face touches, images of them touching their faces, and compares their rate with a **global average**!
## How we built it
The base of the application (the hands tracking) was built using OpenCV and tkinter to create an intuitive interface for users. The database integration used CockroachDB to persist user login records and their face touching counts. The website was developed in React to showcase our products. The wearable schematic was written up using Fritzing and the code developed on Arduino IDE. By means of a tilt switch, the onboard microcontroller can detect when a user's hand is in an upright position, which typically only occurs when the hand is reaching up to touch the face. The device alerts the wearer via the buzzing of a vibratory motor/buzzer and the flashing of an LED. The emotion detection analysis component was built using the Google Cloud Vision API.
## Challenges we ran into
After deciding to use opencv and deep vision to determine with live footage if a user was touching their face, we came to the unfortunate conclusion that there isn't a lot of high quality trained algorithms for detecting hands, given the variability of what a hand looks like (open, closed, pointed, etc.).
In addition to this, the CockroachDB documentation was out of date/inconsistent which caused the actual implementation to differ from the documentation examples and a lot of debugging.
## Accomplishments that we're proud of
Despite developing on three different OSes we managed to get our application to work on every platform. We are also proud of the multifaceted nature of our product which covers a variety of use cases. Despite being two projects we still managed to finish on time.
To work around the original idea of detecting overlap between hands detected and faces, we opted to detect for eyes visible and determine whether an eye was covered due to hand contact.
## What we learned
We learned how to use CockroachDB and how it differs from other DBMSes we have used in the past, such as MongoDB and MySQL.
We learned about deep vision, how to utilize opencv with python to detect certain elements from a live web camera, and how intricate the process for generating Haar-cascade models are.
## What's next for Hands Off
Our next steps would be to increase the accuracy of Hands Off to account for specific edge cases (ex. touching hair/glasses/etc.) to ensure false touches aren't reported. As well, to make the application more accessible to users, we would want to port the application to a web app so that it is easily accessible to everyone. Our use of CockroachDB will help with scaling in the future. With our newfound familliarity with opencv, we would like to train our own models to have a more precise and accurate deep vision algorithm that is much better suited to our project's goals. | losing |
## Inspiration
Trump's statements include some of the most outrageous things said recently, so we wanted to see whether someone could distinguish between a fake statement and something Trump would say.
## What it does
We generated statements using markov chains (<https://en.wikipedia.org/wiki/Markov_chain>) that are based off of the things trump actually says. To show how difficult it is to distinguish between the machine generated text and the real stuff he says, we made a web app to test whether someone could determine which was the machine generated text (Drumpf) and which was the real Trump speech.
## How we built it
python+regex for parsing Trump's statementsurrent tools you use to find & apply to jobs?
html/css/js frontend
azure and aws for backend/hosting
## Challenges we ran into
Machine learning is hard. We tried to use recurrent neural networks at first for speech but realized we didn't have a large enough data set, so we switched to markov chains which don't need as much training data, but also have less variance in what is generated.
We actually spent a bit of time getting <https://github.com/jcjohnson/torch-rnn> up and running, but then figured out it was actually pretty bad as we had a pretty small data set (<100kB at that point)
Eventually got to 200kB and we were half-satisfied with the results, so we took the good ones and put it up on our web app.
## Accomplishments that we're proud of
First hackathon we've done where our front end looks good in addition to having a decent backend.
regex was interesting.
## What we learned
bootstrap/javascript/python to generate markov chains
## What's next for MakeTrumpTrumpAgain
scrape trump's twitter and add it
get enough data to use a neural network
dynamically generate drumpf statements
If you want to read all the machine generated text that we deemed acceptable to release to the public, open up your javascript console, open up main.js. Line 4599 is where the hilarity starts. | We have the best app, the best. A tremendous app. People come from all over the world to tell us how great our app is. Believe us, we know apps.
With Trump Speech Simulator, write a tweet in Donald Trump's voice and our app will magically stitch a video of Trump speaking the words you wrote. Poof!
President Trump often holds long rallies with his followers, where he makes speeches that are then uploaded on Youtube and feature detailed subtitles. We realized that we could parse these subtitles to isolate individual words. We used ffmpeg to slice rally videos and then intelligently stitch them back together. | ## Inspiration
I like looking at things. I do not enjoy bad quality videos . I do not enjoy waiting. My CPU is a lazy fool. He just lays there like a drunkard on new years eve. My poor router has a heart attack every other day so I can stream the latest Kylie Jenner video blog post, or has the kids these days call it, a 'vlog' post.
CPU isn't being effectively leveraged to improve video quality. Deep learning methods are in their own world, concerned more with accuracy than applications. We decided to develop a machine learning application to enhance resolution while developing our models in such a way that they can effective run without 10,000 GPUs.
## What it does
We reduce your streaming bill. We let you stream Kylie's vlog in high definition. We connect first world medical resources to developing nations. We make convert an unrecognizeable figure in a cop's body cam to a human being. We improve video resolution.
## How I built it
Wow. So lots of stuff.
Web scraping youtube videos for datasets of 144, 240, 360, 480 pixels. Error catching, thread timeouts, yada, yada. Data is the most import part of machine learning, and no one cares in the slightest. So I'll move on.
## ML stuff now. Where the challenges begin
We tried research papers. Super Resolution Generative Adversarial Model [link](https://arxiv.org/abs/1609.04802). SRGAN with an attention layer [link](https://arxiv.org/pdf/1812.04821.pdf). These were so bad. The models were to large to hold in our laptop, much less in real time. The model's weights alone consisted of over 16GB. And yeah, they get pretty good accuracy. That's the result of training a million residual layers (actually *only* 80 layers) for months on GPU clusters. We did not have the time or resources to build anything similar to these papers. We did not follow onward with this path.
We instead looked to our own experience. Our team had previously analyzed the connection between image recognition and natural language processing and their shared relationship to high dimensional spaces [see here](https://arxiv.org/abs/1809.05286). We took these learnings and built a model that minimized the root mean squared error as it upscaled from 240 to 480 px.
However, we quickly hit a wall, as this pixel based loss consistently left the upscaled output with blurry edges. In order to address these edges, we used our model as the Generator in a Generative Adversarial Network. However, our generator was too powerful, and the discriminator was lost.
We decided then to leverage the work of the researchers before us in order to build this application for the people. We loaded a pretrained VGG network and leveraged its image embeddings as preprocessing for our discriminator. Leveraging this pretrained model, we were able to effectively iron out the blurry edges while still minimizing mean squared error.
Now model built. We then worked at 4 AM to build an application that can convert videos into high resolution.
## Accomplishments that I'm proud of
Building it good.
## What I learned
Balanced approaches and leveraging past learning
## What's next for Crystallize
Real time stream-enhance app. | partial |
Discord:
* spicedGG#1470
* jeremy#1472

## 💡 Inspiration
As healthcare is continuing to be more interconnected and advanced, patients and healthcare resources will always have to worry about data breaches and the misuses of private information. While healthcare facilities move their databases to third-party providers (Amazon, Google, Microsoft), patients become further distanced from accessing their own medical record history, and the complete infrastructure of healthcare networks are significantly at risk and threatened by malicious actors. Even a single damaging attack on a centralized storage solution can end up revealing much sensitive and revealing data.
To combat this risk, we created Patientport as a decentralized and secure solution for patients to easily view the requests for their medical records and take action on them.
## 💻 What it does
Patientport is a decentralized, secure, and open medical record solution. It is built on the Ethereum blockchain and securely stores all of your medical record requests, responses, and exchanges through smart contracts. Your medical data is encrypted and stored on the blockchain.
By accessing the powerful web application online through <patientport.tech>, the patient can gain access to all these features.
First, on the website, the patient authenticates to the blockchain via MetaMask, and provides the contract address that was provided to them from their primary care provider.
Once they complete these two steps, a user has the ability to view all requests made about their medical record by viewing their “patientport” smart contract that is stored on the blockchain.
For demo purposes, the instance of the Ethereum blockchain that the application connects to is hosted locally.
However, anyone can compile and deploy the smart contracts on the Ethereum mainnet and connect to our web app.
## ⚙️ How we built it
| | |
| --- | --- |
| **Application** | **Purpose** |
| React, React Router, Chakra UI
| Front-end web application
|
| Ethers, Solidity, MetaMask
| Blockchain, Smart contracts
|
| Netlify
| Hosting
|
| Figma, undraw.co
| Design
|
## 🧠 Challenges we ran into
* Implementation of blockchain and smart contracts was very difficult, especially since the web3.js API was incompatible with the latest version of react, so we had to switch to a new, unfamiliar library, ethers.
* We ran into many bugs and unfamiliar behavior when coding the smart contracts with Solidity due to our lack of experience with it.
* Despite our goals and aspirations for the project, we had to settle to build a viable product quickly within the timeframe.
## 🏅 Accomplishments that we're proud of
* Implementing a working and functioning prototype of our idea
* Designing and developing a minimalist and clean user interface through a new UI library and reusable components with a integrated design
* Working closely with Solidity and MetaMask to make an application that interfaces directly with the Ethereum blockchain
* Creating and deploying smart contracts that communicate with each other and store patient data securely
## 📖 What we learned
* How to work with the blockchain and smart contracts to make decentralized transactions that can accurately record and encrypt/decrypt transactions
* How to work together and collaborate with developers in a remote environment via Github
* How to use React to develop a fully-featured web application that users can access and interact with
## 🚀 What's next for patientport
* Implementing more features, data, and information into patientport via a more robust smart contract and blockchain connections
* Developing a solution for medical professionals to handle their patients’ data with patientport through a simplified interface of the blockchain wallet | ## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that there had to be a better way and that we would create that better way, which brings us to EZ-Med!
## What it does
This web app changes the logistics involved when visiting people in the hospital. Some of our primary features include a home page with a variety of patient updates that give the patient's current status based on recent logs from the doctors and nurses. The next page is the resources page, which is meant to connect the family with the medical team assigned to your loved one and provide resources for any grief or hardships associated with having a loved one in the hospital. The map page shows the user how to navigate to the patient they are trying to visit and then back to the parking lot after their visit since we know that these small details can be frustrating during a hospital visit. Lastly, we have a patient update and login screen, where they both run on a database we set and populate the information to the patient updates screen and validate the login data.
## How we built it
We built this web app using a variety of technologies. We used React to create the web app and MongoDB for the backend/database component of the app. We then decided to utilize the MappedIn SDK to integrate our map service seamlessly into the project.
## Challenges we ran into
We ran into many challenges during this hackathon, but we learned a lot through the struggle. Our first challenge was trying to use React Native. We tried this for hours, but after much confusion among redirect challenges, we had to completely change course around halfway in :( In the end, we learnt a lot about the React development process, came out of this event much more experienced, and built the best product possible in the time we had left.
## Accomplishments that we're proud of
We're proud that we could pivot after much struggle with React. We are also proud that we decided to explore the area of healthcare, which none of us had ever interacted with in a programming setting.
## What we learned
We learned a lot about React and MongoDB, two frameworks we had minimal experience with before this hackathon. We also learned about the value of playing around with different frameworks before committing to using them for an entire hackathon, haha!
## What's next for EZ-Med
The next step for EZ-Med is to iron out all the bugs and have it fully functioning. | Team channel #43
Team discord users - Sarim Zia #0673,
Elly #2476,
(ASK),
rusticolus #4817,
Names -
Vamiq,
Elly,
Sarim,
Shahbaaz
## Inspiration
When brainstorming an idea, we concentrated on problems that affected a large population and that mattered to us. Topics such as homelessness, food waste and a clean environment came up while in discussion. FULLER was able to incorporate all our ideas and ended up being a multifaceted solution that was able to help support the community.
## What it does
FULLER connects charities and shelters to local restaurants with uneaten food and unused groceries. As food prices begin to increase along with homelessness and unemployment we decided to create FULLER. Our website serves as a communication platform between both parties. A scheduled pick-up time is inputted by restaurants and charities are able to easily access a listing of restaurants with available food or groceries for contactless pick-up later in the week.
## How we built it
We used React.js to create our website, coding in HTML, CSS, JS, mongodb, bcrypt, node.js, mern, express.js . We also used a backend database.
## Challenges we ran into
A challenge that we ran into was communication of the how the code was organized. This led to setbacks as we had to fix up the code which sometimes required us to rewrite lines.
## Accomplishments that we're proud of
We are proud that we were able to finish the website. Half our team had no prior experience with HTML, CSS or React, despite this, we were able to create a fair outline of our website. We are also proud that we were able to come up with a viable solution to help out our community that is potentially implementable.
## What we learned
We learned that when collaborating on a project it is important to communicate, more specifically on how the code is organized. As previously mentioned we had trouble editing and running the code which caused major setbacks.
In addition to this, two team members were able to learn HTML, CSS, and JS over the weekend.
## What's next for us
We would want to create more pages in the website to have it fully functional as well as clean up the Front-end of our project. Moreover, we would also like to look into how to implement the project to help out those in need in our community. | winning |
## Inspiration
One of our own member's worry about his puppy inspired us to create this project, so he could keep an eye on him.
## What it does
Our app essentially monitors your dog(s) and determines their mood/emotional state based on their sound and body language, and optionally notifies the owner about any changes in it. Specifically, if the dog becomes agitated for any reasons, manages to escape wherever they are supposed to be, or if they fall asleep or wake up.
## How we built it
We built the behavioral detection using OpenCV and TensorFlow with a publicly available neural network. The notification system utilizes the Twilio API to notify owners via SMS. The app's user interface was created using JavaScript, CSS, and HTML.
## Challenges we ran into
We found it difficult to identify the emotional state of the dog using only a camera feed. Designing and writing a clean and efficient UI that worked with both desktop and mobile platforms was also challenging.
## Accomplishments that we're proud of
Our largest achievement was determining whether the dog was agitated, sleeping, or had just escaped using computer vision. We are also very proud of our UI design.
## What we learned
We learned some more about utilizing computer vision and neural networks.
## What's next for PupTrack
KittyTrack, possibly
Improving the detection, so it is more useful for our team member | ## Inspiration
Our inspiration for this project was to develop a new approach to how animal shelter networks function, and how the nationwide animal care and shelter systems can be improved to function more efficiently, and cost effectively. In particular, we sought out to develop a program that will help care for animals, find facilities capable of providing the care needed for a particular animal, and eradicate the use of euthanization to quell shelter overpopulation.
## What it does
Our program retrieves input data from various shelters, estimates the capacity limit of these shelters, determines which shelters are currently at capacity, or operating above capacity, and optimizes the transfer or animals capable of being moved to new facilities in the cheapest way possible. In particular, the process of optimizing transfers to different facilities based on which facilities are overpopulated was the particular goal of our hack. Our algorithm moves animals from high-population shelters to low-population shelters, while using google maps data to find the optimal routes between any two facilities. Optimization of routes takes into account the cost of traveling to a different facility, and the cost of moving any given number of animals to that facility through cost estimations. Finally, upon determining optimal transfer routes between facilities in our network, our algorithm plots the locations of a map, giving visual representations of how using this optimization scheme will redistribute the animal population over multiple shelters.
## How we built it
We built our program using a python infrastructure with json API calls and data manipulation. In particular, we used python to make json API calls to rescue groups and google maps, stored the returned json data, and used python to interpret and analyze this data. Since there are no publicly available datasets containing shelter data, we used rescue groups to generate our own test data sets to run through our program. Our program takes this data, and optimizes how to organize and distribute animals based on this data.
## Challenges we ran into
The lack of publicly available data for use was particularly difficult since we needed to generate our own datasets in order to test our system. This problem made us particularly aware of the need to generate a program that can function as a nationwide data acquisition program for shelters to input and share their animal information with neighboring shelters. Since our team didn't have significant experience working on many parts of this project, the entire process was a learning experience.
## Accomplishments that we're proud of
We're particularly proud of the time we managed to commit to building this program, given the level of experience we had going into this project as our first hackathon. Our algorithm operates efficiently, using as much information as we were able to incorporate from our limited dataset, and constraints on how we were able to access the data we had compiled. Since our algorithm can find the optimal position to send animals that are at risk due to their location in an overpopulated shelter, our program offers a solution to efficiently redistribute animals at the lowest cost, in order to prevent euthanization of animals, which was our primary goal behind this project.
## What we learned
Aside from technical skills learned in the process of working on this project, we all learned how to work as a team on a large software project while under a strict time constraint. This was particularly important since we only began working on the project on the afternoon of the second day of the hackathon. In terms of technical skills, we all learned a lot about using APIs, json calls in python, and learning python much farther in depth than any of us previously had experience in. Additionally, this hackathon was the first time one of our team members had ever coded, and by the end of the project she had written the entire front end of the project and data visualization process.
## What's next for Everybody Lives
We had a lot of other ideas that we came up with as a result of this project that we wanted to implement, but did not have the time nor resources available to work on. Specifically, there are numerous areas we would like to improve upon and we conceptualized numerous solutions to issues present in today's shelter management and systems. Overall, we envisioned a software program used by shelters across the country in order to streamline the data acquisition process, and share this data between shelters in order to coordinate animal transfers, and resource sharing to better serve animals at any shelter. The data acquisition process could be improved by developing an easy to use mobile or desktop app that allows to easily input information on new shelter arrivals which immediately is added to a nationally available dataset, which can be used to optimize transfers, resource sharing, and population distribution. Another potential contribution to our program would be to develop a type of transportation and ride-share system that would allow people traveling various distances to transport animals from shelter to shelter such that animals more suited to particular climates and regions would be likely to be adopted in these regions. This feature would be similar to an Uber pool system. Lastly, the most prominent method of improving our program would be to develop a more robust algorithm to run the optimization process, that incorporates more information on every animal, and makes more detailed optimization decisions based on larger input data sets. Additionally, a machine learning mechanism could be implemented in the algorithm in order to learn what situations warrant an animal transfer, from the perspective of the shelter, rather than only basing transfers on data alone. This would make the algorithm grow, learn and become more robust over time. | ## Inspiration
Every year, millions of people suffer from concussions without even realizing it. We wanted to tackle this problem by offering a simple solution that could be used by everyone to offer these people proper care.
## What it does
Harnessing computer vision and NLP, we have developed a tool that can administer a concussion test in under 2 minutes. It can be easily done anywhere using just a smartphone. The test consists of multiple cognitive tasks in order to get a complete assessment of the situation.
## How we built it
The application consists of a react-native app that can be installed on both iOS and Android devices. The app communicates with our servers, running a complex neural network model, which analyzes the user's pupils. It is then passed through a computer vision algorithm written in opencv. Next, there is a reaction game built in react-native to test reflexes. A speech analysis tool that uses the Google Cloud Platform's API is also used. Finally, there is a questionnaire regarding the symptoms of a user's concussion.
## Challenges we ran into
It was very complicated to get a proper segmentation of the pupil because of how small it is. We also ran into some minor Google Cloud bugs.
## Accomplishments that we're proud of
We are very proud of our handmade opencv algorithm. We also love how intuitive our UI looks.
## What we learned
It was Antonio's first time using react-native and Alex's first time using torch.
## What's next for BrainBud
By obtaining a bigger data set of pupils, we could improve the accuracy of the algorithm. | winning |
## Inspiration
Moodly's cause -- fostering positive mental health -- is one very close to my own heart. I struggled with my own mental health over the last year, finding that I wasn't the best at figuring out how I was feeling before it started to impact my day. When I eventually took up journaling, I realized that I could get a feel of my emotional state on a previous day by just reading through my account of it. My verbiage, the events I focused on, the passivity of my voice, it all painted a clear picture of how I was doing.
And that got me thinking.
Did it just have to be through introspection that these patterns could be meaningful? And from that question, Moodly was born.
## What it Does
Moodly is a live audio journal that provides real-time analysis on mood and underlying emotional states. Talk to it while you fold your laundry, walk to class -- however you want to use it. Just talk, about anything you like, and Moodly will process your speech patterns, visualizing useful metrics through a friendly graphical interface.
Moodly was built specifically as an assistive tool for people with mental health disabilities. When your whole day can start to spiral from a small pattern of negative thoughts and feelings, it's extremely important to stay in touch with your emotional state. Moodly allows the user to do exactly that, in an effort-free form factor that feels like the furthest thing from an evaluation.
## How I built it
Moodly is a Python script that combines Rev.ai's speech-to-text software and IBM's Watson tonal analysis suite to provide an accurate and thorough assessment of a speaker's style and content. First, an audio stream is created using PyAudio. Then, that stream is connected via a web socket to Rev.ai's web API to generate a transcript of the session. That transcript is fed via REST API to IBM's Watson analysis, and the interpreted data is displayed using a custom-built graphical interface utilizing the Zelle python library.
## Challenges I ran into
Moodly has multiple processes running at very distinct time scales, so synchronizing all of the processes into a single, smooth user experience was a challenge and a half.
## Accomplishments that I'm proud of
I'm super proud of the graphical interface! This was my first time plotting anything that wasn't a simple line graph in Python, and I really love how the end result came out -- intuitive, clean, and attention-grabbing.
## What I learned
First and foremost: AI is awesome! But more importantly, I learned to ywork efficiently -- without a team, I didn't have time to get bogged down, especially when every library used was a first time for me.
## What's next for Moodly
I'd love to consider more data patterns in order to create more useful and higher-level emotional classifications. | ## Inspiration
As students who undergo a lot of stress throughout the year, we are often out of touch with our emotions and it can sometimes be difficult to tell how we are feeling throughout the day. There are days when we might be unsure of how we are really feeling based on our self-talk. Do I feel down, happy, sad, etc? We decided to develop a journal app that interprets the entries we write and quantitatively tracks our mood. This allows us to be more aware of our mental well-being at all times.
## What it does
mood.io takes your daily journal entries and returns a "mood" score for that specific day. This is calculated using Google Cloud's ML Natural Language API, which is then translated into a line graph that tracks your moods over time. The Natural Language API also identifies important subject matter in each entry, known as "entities", which mood.io displays using attractive data visualization tools. This allows you to aim for improvement in your mental health and identify issues you might have in your daily lives.
## How I built it
For our prototype, we built a web app using the Flask framework within Python, which helped with routing and rendering our HTML based homepage. We used Bootstrap to help with the front-end UI look. We also used the Google Cloud Natural Language Processing API to analyze sentiment values and provide the entity data. The data was shown using the matplotlib library within Python.
A concept of our final product was created using Figma and is attached to this submission.
## Challenges I ran into
Our very first challenge was installing python and getting it properly set up so that we didn’t have any errors. When trying to run a simple program.
We then ran into challenges in trying to understand how to interact with the Google Cloud API and how to get it set up and running with Python. After talking to some Google sponsors and mentors, we managed to get it set up properly and work with the code.
Another issue was getting a graph to display properly and making a pretty data visualization, we had tried many different applications to generate graphs but we had issues with each of them until we found one that worked.
Additionally no one in our team had a lack of experience in front end development so making the site look nice and display properly was another issue.
## Accomplishments that I'm proud of
Used a WDM for decision making process process.
Cool idea!
Real results!
Learning to use python.
Getting an api to work.
Getting a graph to display properly.
We are proud of the progress we were able to achieve through our first Hackathon experience. Thanks to all the mentors and sponsors that assisted us in our journey
## What I learned
How to program in Python, interact with an API, make a data visualization, how to build a web app from scratch, how to use Google Cloud and its various computing services
## What's next for mood.io
Add users so you can add close friends and family and track their moods.
Adding the entities feature on our prototype
Further improving our UI experience | # better.me, AI Journaling
## Project Description
better.me is an AI journaling tool that helps you analyze your emotions and provide you with smart recommendations for your well being. We used NLP emotion analytics to process text data and incorporated a suicidal prevention algorithm that will help you make better informed decisions about your mental health.
## Motivation
Poor mental health is a growing pandemic that is still being stigmatized. Even after spending $5 Billion in federal investments for mental health, 1.3 million adults attempted suicide and 1.1 million plans to commit suicide.
>
> Our mission is to provide a private environment to help people analyze their emotions and receive mental health support.
>
>
>
## MVP Product Features Overview
| Features | Description |
| --- | --- |
| Personal Journal | Better Me is a personal AI-powered journal where users can write daily notes reflecting on their life's progress. |
| NLP Emotion Analytics | With the help of natural language process, Better Me will classify the user's emotional situation and keep a track of the data. |
| Smart Recommendations | It uses this monitored data to suggest appropriate mental health resources to the users and also provides them with suitable data analytics. |
| Suicide Prevention | In order to take a step forward towards suicide prevention, it also incorporates a suicidal text detection algorithm that triggers a preventive measure . |
## How we built it
We used Google T5 NLP model for emotional recognition and categorizing emotions. We trained data set with deep learning to develop a fine tuned BERT model to prevent suicide. We also implemented our own algorithm to make resource recommendations to users based on their emotional changes, and also did some data analytics. Due to time restraints and a member's absence, we had to change from React.js plus Firebase stack to Streamlit, a python library design framework.
## Challenges
Initially, we tried creating a dashboard using full-stack web development, however, it proved to be quite a challenging task with the little amount of time we had. We decided to shift our focus to quickly prototyping using a lightweight tool, and streamlit was the ideal choice for our needs. While deploying our suicide prevention algorithm on Google Cloud Function, we had trouble deploying due to memory availability constraints.
## Accomplishments
We are proud that we came up with such a novel idea that could be useful to innumerable people suffering from mental health issues, or those who are like to stay reserved with themselves or in a confused state about their mental well-being, just by writing about their daily lives. We are also proud of incorporating a suicide prevention algorithm, which could be life-saving for many.
## Roadmap
| Future Implementations | Description |
| --- | --- |
| Firebase Back End Architecture | We hope to design a scalable backend which accommodates for the users needs. |
| AI Mental Health Chat bot | Provide on the spot, mental health support using Dialogflow AI chat bot. |
| Connect with Therapists | Elevate data analytical features to connect and report to personal therapists. |
| Scaling Up | Fund our project and develop this project with scalable front and back end. |
| Languages Support | Support multiple languages, including French, Mandarin, and Spanish. | | losing |
## Inspiration
* Videos exist in just 1 language
* In this era of MOOCs, students, professionals would like to learn from videos in their own language without depending on the language of the video
* Even though subtitles are available, it becomes difficult to focus on the content of the video and the subtitles shown at the botton of the video
* It is really dificult to find the right videos because of badly titled content and lack of detailed description
## What it does
Feature 1: Translates a video to any language and processes the video to retrieve essential information from the video
Feature 2: Efficiently indexes the processed information for quick search and retrieval
Feature 3: Provides User friendly interface to search, upload, view and translate them to any language
Feature 4: Get access to the translated videos on any device including mobile phones, tablets and laptops
Feature 5: Enables users to seach for videos based on people, objects and entities occurring in the video
## How we built it
Technologies:
* Python (Flask) + AngularJS : We built our application using Python for backend and used AngularJS for frontend
* Microsoft Azure Blob Storage : User uploads video on the page. This video gets uploaded to Microsoft’s Blob Storage
* Microsoft Video Indexer : Simultaneously, the video is uploaded to Microsoft’s Video indexer to convert the audio in the video to text and get relevant tags in the video such as if there is a red car in the video, it adds one of the relevant tags as red
* Microsoft Cosmos Database (MongoDB) : MongoDB is used to store details such as tags and input language
* Microsoft Text to Speech Translator : The text is translated to an audio in the lamnguage mentioned by the user
* Microsoft Email Service : An email is sent once the video is ready to be viewed
Use Case 1: User Uploads Video -> Audio is extracted and converted to text format -> Relevant tags associated with the video is discovered and entered into MongoDB collection
Use Case 2: User selects video to be translated -> Text file for the video is translated to speech format in the relevant language -> Video and new audio is merged to produce video in the relevant language -> Email is sent to the user once the video is ready
## Challenges we ran into
* No API which provides direct speech to speech translation : We found Microsoft’s API to convert speech to text and text to speech conversion.
* Search - To find videos based on keywords/objects found in the video
## Accomplishments that we’re proud of
* Synced speech with the video with right amount of pause. There is no algorithm that exists as of now which syncs audio with video properly.
## What we learned
* Learned to deal with complex audio and video structures
* Learned to use Azure technologies and Cognitive Services
* Learned to efficiently index and search for large text data
## What’s next for InstaTranslate
* Translate videos of longer length.
* Better sync with translated audio and video
* Add emotions to the translated speech
* Here’s the elevator pitch
There is abundance of knowledge on the web in the form of videos and a large majority of the population can not make the most of it because of language barriers. We aim to reduce that by providing an instant way to translate videos to any language of your choice which will be available instantaneously. Also, sometimes, it is really dificult to find the right videos because of badly titled content and lack of detailed description. We use latest advancements in AI and Machine Learning to extract the main entities in the video and index them so that there is an efficient way to store them and thus allow users to access most relevant contents efficiently and instantaneously.
new messages | ## Inspiration
The idea arose from the current political climate. At a time where there is so much information floating around, and it is hard for people to even define what a fact is, it seemed integral to provide context to users during speeches.
## What it does
The program first translates speech in audio into text. It then analyzes the text for relevant topics for listeners, and cross references that with a database of related facts. In the end, it will, in real time, show viewers/listeners a stream of relevant facts related to what is said in the program.
## How we built it
We built a natural language processing pipeline that begins with a speech to text translation of a YouTube video through Rev APIs. We then utilize custom unsupervised learning networks and a graph search algorithm for NLP inspired by PageRank to parse the context and categories discussed in different portions of a video. These categories are then used to query a variety of different endpoints and APIs, including custom data extraction API's we built with Mathematica's cloud platform, to collect data relevant to the speech's context. This information is processed on a Flask server that serves as a REST API for an Angular frontend. The frontend takes in YouTube URL's and creates custom annotations and generates relevant data to augment the viewing experience of a video.
## Challenges we ran into
None of the team members were very familiar with Mathematica or advanced language processing. Thus, time was spent learning the language and how to accurately parse data, give the huge amount of unfiltered information out there.
## Accomplishments that we're proud of
We are proud that we made a product that can help people become more informed in their everyday life, and hopefully give deeper insight into their opinions. The general NLP pipeline and the technologies we have built can be scaled to work with other data sources, allowing for better and broader annotation of video and audio sources.
## What we learned
We learned from our challenges. We learned how to work around the constraints of a lack of a dataset that we could use for supervised learning and text categorization by developing a nice model for unsupervised text categorization. We also explored Mathematica's cloud frameworks for building custom API's.
## What's next for Nemo
The two big things necessary to expand on Nemo are larger data base references and better determination of topics mentioned and "facts." Ideally this could then be expanded for a person to use on any audio they want context for, whether it be a presentation or a debate or just a conversation. | ## What it does
Danstrument lets you video call your friends and create music together using only your actions. You can start a call which generates a code that your friend can use to join.
## How we built it
We used Node.js to create our web app which employs WebRTC to allow video calling between devices. Movements are tracked with pose estimation from tensorflow and then vector calculations are done to trigger audio files.
## Challenges we ran into
Connecting different devices with WebRTC over an unsecured site proved to be very difficult. We also wanted to have continuous sound but found that libraries that could accomplish this caused too many problems so we chose to work with discrete sound bites instead.
## What's next for Danstrument
Annoying everyone around us. | partial |
Copyright 2018 The Social-Engineer Firewall (SEF)
Written by Christopher Ngo, Jennifer Zou, Kyle O'Brien, and Omri Gabay.
Founded Treehacks 2018, Stanford University.
## Inspiration
No matter how secure your code is, the biggest cybersecurity vulnerability is the human vector. It takes very little to exploit an end-user with social engineering, yet the consequences are severe.
Practically every platform, from banking to social media, to email and corporate data, implements some form of self-service password reset feature based on security questions to authenticate the account “owner.”
Most people wouldn’t think twice to talk about their favourite pet or first car, yet such sensitive information is all that stands between a social engineer and total control of all your private accounts.
## What it does
The Social-Engineer Firewall (SEF) aims to protect us from these threats. Upon activation, SEF actively monitors for known attack signatures with voice to speech transcription courtesy of SoundHound’s Houndify engine. SEF is the world’s first solution to protect the OSI Level 8 (end-user/human) from social engineer attacks.
## How it was built
SEF is a Web Application written in React-Native deployed on Microsoft Azure with node.js. iOS and Android app versions are powered by Expo. Real-time audio monitoring is powered by the Houndify SDK API.
## Todo List
Complete development of TensorFlow model
## Development challenges
Our lack of experience with new technologies provided us with many learning opportunities. | ## Inspiration
Have you ever met someone, but forgot their name right afterwards?
Our inspiration for INFU comes from our own struggles to remember every detail of every conversation. We all deal with moments of embarrassment or disconnection when failing to remember someone’s name or details of past conversations.
We know these challenges are not unique to us, but actually common across various social and professional settings. INFU was born to bridge the gap between our human limitations and the potential for enhanced interpersonal connections—ensuring no details or interactions are lost to memory again.
## What it does
By attaching a camera and microphone to a user, we can record different conversations with people by transcribing the audio and categorizing using facial recognition. With this, we can upload these details onto a database and have it summarised by an AI and displayed on our website and custom wrist wearable.
## How we built it
There are three main parts to the project. The first part is the hardware which includes all the wearable components. The second part includes face recognition and speech-to-text processing that receives camera and microphone input from the user's iPhone. The third part is storing, modifying, and retrieving data of people's faces, names, and conversations from our database.
The hardware comprises an ESP-32, an OLED screen, and two wires that act as touch buttons. These touch buttons act as record and stop recording buttons which turn on and off the face recognition and microphone. Data is sent wirelessly via Bluetooth to the laptop which processes the face recognition and speech data. Once a person's name and your conversation with them are extracted from the current data or prior data from the database, the laptop sends that data to the wearable and displays it using the OLED screen.
The laptop acts as the control center. It runs a backend Python script that takes in data from the wearable via Bluetooth and iPhone via WiFi. The Python Face Recognition library then detects the speaker's face and takes a picture. Speech data is subsequently extracted from the microphone using the Google Cloud Speech to Text API which is then parsed through the OpenAI API, allowing us to obtain the person's name and the discussion the user had with that person. This data gets sent to the wearable and the cloud database along with a picture of the person's face labeled with their name. Therefore, if the user meets the person again, their name and last conversation summary can be extracted from the database and displayed on the wearable for the user to see.
## Accomplishments that we're proud of
* Creating an end product with a complex tech stack despite various setbacks
* Having a working demo
* Organizing and working efficiently as a team to complete this project over the weekend
* Combining and integrating hardware, software, and AI into a project
## What's next for Infu
* Further optimizing our hardware
* Develop our own ML model to enhance speech-to-text accuracy to account for different accents, speech mannerisms, languages
* Integrate more advanced NLP techniques to refine conversational transcripts
* Improve user experience by employing personalization and privacy features | ## Inspiration
JAGT Move originally came forth as an idea after one of our members injured himself trying to perform a basic exercise move he wasn't used to. The project has pivoted around over time, but the idea of applying new technologies to help people perform poses has remained.
## What it does
The project compares positional information between the user and their reference exercise footage using pose recognition (ML) in order to give them metrics and advice which will help them perform better (either as a clinical tool, or for everyday use).
## How we built it
* Android frontend based of TensorFlow Lite Posenet application
* NodeJS backend to retrieve the metrics, process it and provide the error of each body part to the website for visual presentation.
* A React website showing the live analysis with details to which parts of your body were out of sync.
## Challenges we ran into
* Only starting model available for Android project used Kotlin, which our mobile dev. had to learn on the fly
* Server errors like "post method too voluminous", and a bunch of other we had to work around
* Tons of difficult back-end calculations
* Work with more complex sets of data (human shapes) in an ML context
## What's next for JAGT Move
Expand the service, specialize the application for medical use further, expand on the convenience of use of the app for the general public, and much more! It's time to get JAGT! | winning |